Hallo zusammen, bin ein Kind der 88er und etwas altmodisch. Kurze Frage. In den alten Zeiten haben Computer/Rechner/Terminals/Fernschreiber/.../.... noch 8 Bit Zeichensätze verwendet und tun dies auch heute noch. Z.B. habe ich in den 90ern noch MS-DOS 6.22 verwendet und mir über mögliche Probleme keine Gedanken gemacht. Andere verwendeten Commodore, wieder andere BBC, ZX ... Apple ... RISC OS ... different UNIX ... Ich schreibe, lese, höre und spreche diese Sprache sowie Englisch (Yes, I Do write, read, understand and speak English). Was ist z.B. mit jugoslawischen Sprachen (kroatisch, serbisch, ... , .... , ...) oder vietnamesisch? Pure English depends on Latin letters but German requires Öö Ää Üü ß ... Or French/Turkish Çç ... Spanish Ññ ... Polish ł .. Ist es Möglich einen neuen Zeichensatz ohne die diakritischen Zeichen zu erstellen? Ist it possible to create a new codepage Without all the diacritic marks? And use an overlay instead? Ich dachte an einen Zeichensatz für alle Systeme verschiedener Marken basierend auf Bitmap/Raster font/Zeichen. Mit 70er/80er Kompatiblität. Grüße Marcel
Würde dir ein schwarzweiß bmp eines Monospace Font, Aussehen ähnlich MS-Font "System" helfen? mfg mf
Marcel Z. schrieb: > In den alten Zeiten haben > Computer/Rechner/Terminals/Fernschreiber/.../.... noch 8 Bit > Zeichensätze verwendet 8-Bit ist doch schon modern. ASCII ist 7-Bit, Fernschreiber haben den Baudot-Code (5-Bit) verwendet. Marcel Z. schrieb: > MS-DOS 6.22 verwendet und mir über mögliche Probleme keine Gedanken > gemacht. Solange man die richtige Codepage verwendet hat, ging das. Marcel Z. schrieb: > Ich dachte an einen Zeichensatz für alle Systeme verschiedener Marken > basierend auf Bitmap/Raster font/Zeichen. Verwechselst Du gerade Zeichensätze und Fonts?
Marcel Z. schrieb: > Without all the diacritic marks? Ei sink sis is wrong oversetted. Ich hätte gesagt es wäre "diacritic characters". Not? Mir stellt sich die Frage, wozu. Und wie. Es gibt nicht ohne Grund UTF und Unicode. Das lag ja nicht daran das man nicht gewollt hätte bis ins Jahr 9999 mit 8 Bit auszukommen. Es geht einfach nicht. Ja ok, logisch kannst du natürlich einen ".."-Charakter bauen und den auf ein "A" überlagern um ein "Ä" zu bekommen. Wie beschreibst du das dann mit 8 Bit? Brauchst du dann 2 Bytes? Oh mist... Und nicht zu vergessen: Batchdateien unter Windows haben immer noch Probleme mit den Umlauten. Obwohl auf der exakt selben Maschine geschrieben und getestet, mit Windows 11, das ja eigentlich gar kein DOS mehr hat. Dennoch ist die Codepage des Windows-Editors und der Eingabeaufforderung verschieden, obwohl beide Umlaute können. Noch eine Codepage mehr macht's nicht besser.
:
Bearbeitet durch User
Hmmm schrieb: > Marcel Z. schrieb: >> In den alten Zeiten haben >> Computer/Rechner/Terminals/Fernschreiber/.../.... noch 8 Bit >> Zeichensätze verwendet > > 8-Bit ist doch schon modern. ASCII ist 7-Bit, Fernschreiber haben den > Baudot-Code (5-Bit) verwendet. > Hatten die Lochstreifen nicht 5 Löcher?
BirnKichler S. schrieb: > Hatten die Lochstreifen nicht 5 Löcher? Nur die vom Fernschreiber (zuzüglich natürlich der Taktspur mit den etwas kleineren Löchern). Die Lochstreifen von Computern hatten 8 Spuren.
Jens M. schrieb: > Dennoch ist die Codepage des Windows-Editors und der Eingabeaufforderung > verschieden, obwohl beide Umlaute können. Mit chcp 1252 und TrueType Schriftsätzen in der "DOS"-Box sollten beide daselbe verstehen.
Genau die richtigen Antworten !! Vielen Dank. Ich dachte jetzt allerdings eher an "handelsübliche" Geräte mit legacy Kompatiblität. Also richtig, ich meine einen Zeichensatz inkl. Schriftzeichen (code page AND Bitmap font). Ich persönlich habe keinen Bedarf an "anderen" Schriften wie Kyrillische, Semitische oder Indische oder weitere japanische/chinesisch/.../.../... UTF ist zu dick!!! Die Betriebssysteme werden immer aufgeblähter ... Eine Schande !!!
Marcel Z. schrieb: > UTF ist zu dick!!! Unsinn! Alles was im 7-Bit ASCII vorhanden ist, ist IDENTISCH in UTF-8. Nur Sprachspezifisches und Sonderzeichen brauchen 2, selten 3, sehr,sehr selten 4 Zeichen.
Marcel Z. schrieb: > Also richtig, ich meine einen Zeichensatz inkl. Schriftzeichen (code > page AND Bitmap font). Der modernste gängige 8-Bit-Zeichensatz hierzulande ist ISO-8859-15 (leicht erweiterter ISO-8859-1, insbesondere mit Euro-Symbol). Die Windows-Codepage 1252 entspricht im wesentlichen ISO-8859-1, mit ein paar Erweiterungen, die wiederum nicht mit -15 kompatibel sind. Marcel Z. schrieb: > UTF ist zu dick!!! A propos "zu dick", der übliche einzelne Punkt am Satzende hätte (auch mit UTF-8) nur ein Byte gebraucht.
Genau, nur an Bajt! Lajdar könnän Ämozijonän hija nich' ausgädrukkt wärdän. Ich schreibe von "pure latin" mit overlay, DOS-kompatibel (MS,IBM,DR- und Free). Für ALLE Sprachen ...
Muss an mir liegen aber ich habe keine Ahnung was dieser Clown will oder meint. Ich bekomme Kopfschmerzen vom lesen seiner Beiträge.
Cyblord -. schrieb: > Muss an mir liegen aber ich habe keine Ahnung was [...] oder meint. vielleicht eine Neuauflage vom hex-Zeichensatzcomputeruniversalweltverbesseungsdingsbums?
Ich kümmere mich nicht um Codepages, da ich eine Kugelkopf-Maschine verwende. Damit ist blitzschnell der Kugelkopf gewechselt. Siehe: https://de.wikipedia.org/wiki/Schreibmaschinen-Kugelkopf
Angehängte Dateien:
-

zeichen.gif
12 KB -

zeichen2.gif
24 KB
{kind=link}
{kind=link}
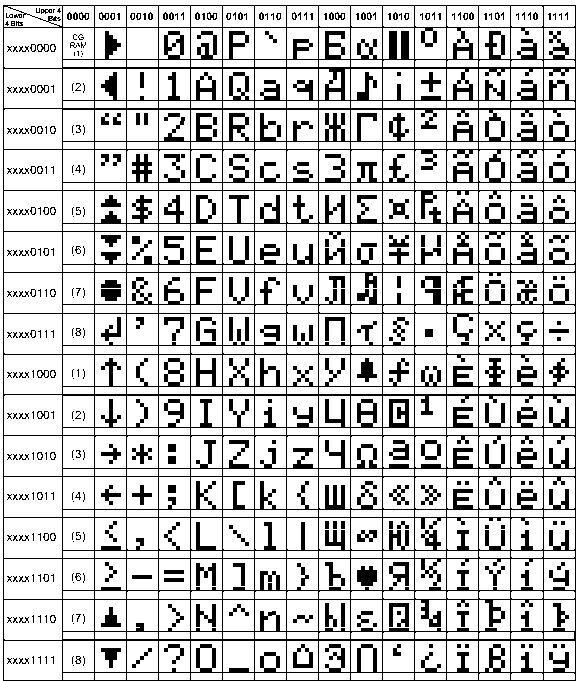
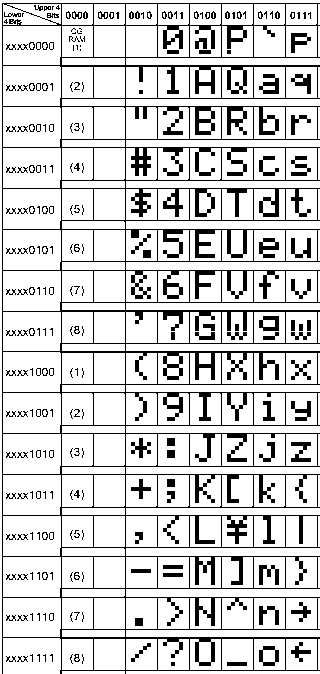
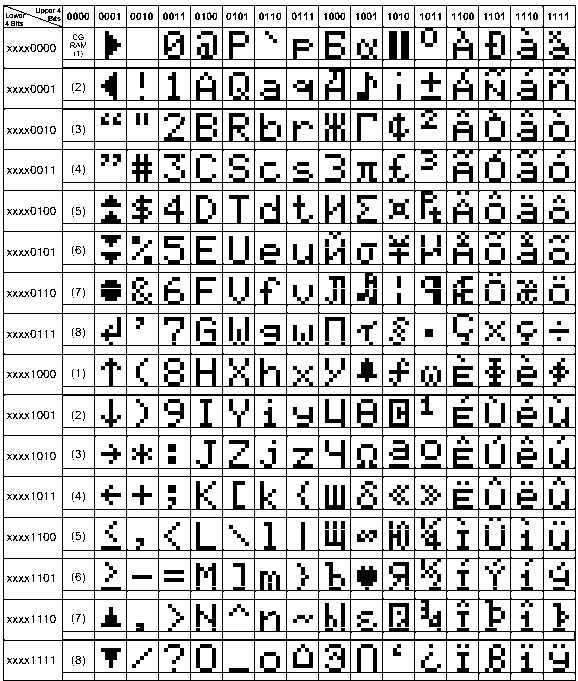
Marcel Z. schrieb: > Ist es Möglich einen neuen Zeichensatz ohne die diakritischen Zeichen zu > erstellen? > > Ich dachte an einen Zeichensatz für alle Systeme verschiedener Marken > basierend auf Bitmap/Raster font/Zeichen. Alle Systeme verschiedener Marken, also diese: Marcel Z. schrieb: > Andere verwendeten Commodore, wieder andere BBC, > ZX ... Apple ... RISC OS ... different UNIX ... Sicher nicht, jedes nutzte ihren 8-bit Zeichensatz mit Sonderzeichen vollständig aus. Selbst wenn es nur um Schrift geht und man alle Graphikzeichen weglässt hat man dann vielleicht einen Zeichensatz, mit dem alle geschriebenen Texte von all diesen Systemen abbildbar wären, aber erstens nur nach Umkodierung und zweitens was will man damit ? Oben findest du den Zeichensatz der HD44780. Dein jetziger Rechner hat Unicode und damit einen Zeichensatz für alle Sprachen, ebenso wie der Browser. 他知道所有迹象 རྟགས་ཐམས་ཅད་མཁྱེན། Ол шупту демдектерни билир
:
Bearbeitet durch User
Beitrag #8019070 wurde von einem Moderator gelöscht.
Hmmm schrieb: > Marcel Z. schrieb: >> UTF ist zu dick!!! > > A propos "zu dick", der übliche einzelne Punkt am Satzende hätte (auch > mit UTF-8) nur ein Byte gebraucht. "Multiple exclamation marks are a sure sign of a diseased mind." (Terry Pratchett, Eric)
Beitrag #8019079 wurde von einem Moderator gelöscht.
Beitrag #8019100 wurde von einem Moderator gelöscht.
Ja dea Foierfogel auf'm zmaatfoon feawendett utf-8 ... Mich interessieren "andere" Zeichensätze wie Arabisch, Kyrillisch, Japanisch usw. NICHT. Die sollten optional und nachinstallierbar sein. Lass uns nur mal an MS-DOS 6.22 denken ... Welche Codepage muss ich verwenden, um Deutsch, Französisch, Spanisch, Katalanisch, Portugiesisch, Nordisch (Schwedisch/Norwegisch-Booksmal/-Rikamal) Polnisch, Kroatisch/Serbisch/Bosnisch, Türkisch, Kurdisch zu verwenden? Ich will kein UTF-8. Es geht mir um "legacy" Systeme, die noch am Netz hängen, bzw wieder angeschlossen werden sollen. MacOS9 oder Windows ME, DOS, ....
Marcel Z. schrieb: > Ich will kein UTF-8. > > Es geht mir um "legacy" Systeme, die noch am Netz hängen, bzw wieder > angeschlossen werden sollen. MacOS9 oder Windows ME, DOS, .... Dann nimm halt die, die dort vorhanden sind. Welche Codepage zu welcher Sprache passt, lässt sich mit wenig Aufwand finden – war ja nie ein Geheimnis. Zu deiner falschen Vorstellung von UTF-8 hatte Norbert ja schon was geschrieben.
:
Bearbeitet durch User
Marcel Z. schrieb: > Ja dea Foierfogel auf'm zmaatfoon feawendett utf-8 ... Aus welchem Kindergarten bist Du denn ausgebrochen? Marcel Z. schrieb: > Lass uns nur mal an MS-DOS 6.22 denken ... Welche Codepage muss ich > verwenden, um Deutsch, Französisch, Spanisch, Katalanisch, > Portugiesisch, Nordisch (Schwedisch/Norwegisch-Booksmal/-Rikamal) > Polnisch, Kroatisch/Serbisch/Bosnisch, Türkisch, Kurdisch zu verwenden? Wenn Du glaubst, das für die Liste eine reicht, bist Du ziemlich naiv. Such Dir was aus: https://en.wikipedia.org/wiki/Category:DOS_code_pages Danach leuchtet Dir vielleicht ein, warum man auf die Idee mit UTF-8 (bzw. Unicode allgemein) gekommen ist. Marcel Z. schrieb: > Es geht mir um "legacy" Systeme, die noch am Netz hängen, bzw wieder > angeschlossen werden sollen. Sicher, dass es Dir nicht bloss ums Trollen geht? Frisch angemeldet, "Kind der 88er" (Was soll das sein?), weder Kompetenz noch Eigeninitiative, Babysprache...
Marcel Z. schrieb: > Welche Codepage muss ich > verwenden, um Deutsch, Französisch, Spanisch, Katalanisch, > Portugiesisch, Nordisch (Schwedisch/Norwegisch-Booksmal/-Rikamal) > Polnisch, Kroatisch/Serbisch/Bosnisch, Türkisch, Kurdisch zu verwenden? Dafür kannst du keine Codepage verwenden, weil es keine gibt (auch nicht geben kann) [1] die diese Zeichenvorräte alle hat. > Ich will kein UTF-8. Tja. Keine Arme, keine Kekse! Genau um das Problem der zu geringen Anzahl an Sonderzeichen bei klassischen Code Pages [1] zu lösen, hat man Unicode und die Transportcodierung UTF-8 erfunden. Wenn das dem Herren nicht genehm ist, kann er ja immer noch eine Sonderlockenperücke erfinden. [1] eine klassische Code Page mit 8-Bit Zeichencodierung, wo die Codes 0..127 schon vergeben sind, erlaubt bis zu 128 zusätzliche Zeichen. Das reicht, um alle westeuropäischen Zeichen einzuschließen. Aber schon für ganz Europa braucht man 4 Stück davon (latin-1 .. latin-4 aka ISO 8859-1 .. 4). Türkisch und Keltisch brauchen noch zwei weitere.
Hmmm schrieb: > Aus welchem Kindergarten bist Du denn ausgebrochen? Er hat sehr ernsthafte Probleme. Mal schreibt er zweisprachig parallel, dann wieder sowas. Ich hoffe er bekommt die Hilfe die er braucht. Und dabei meine ich sicher keine Zeichensätze.
Cyblord -. schrieb: > ich habe keine Ahnung was dieser Clown will oder meint. weich gebettet in Unicode hat er keine Ahnung mehr von den Computern mit nur Großbuchstaben und erinnert sich vage an die Zeit der Code-Pages. Und wie alles Nostalgische waren auch die so simpel und hinterwäldlerisch, dass er es nicht nur in einem Nachmittag vollständig erforschen, sondern auch virtuos damit brillieren kann.
Bruno V. schrieb: > weich gebettet in Unicode hat er keine Ahnung mehr von den Computern mit > nur Großbuchstaben und erinnert sich vage an die Zeit der Code-Pages. Unser "Cyblord" fällt zwar des öfteren durch verschiedenes auf, aber das halte ich für eine irrige Unterstellung. Da muss ich den glatt vor Dir in Schutz nehmen.
Bruno V. schrieb: > wen? Den, den Du da gerade zitiert hast, Dich in Deinem Beitrag offensichtlich auf ihn beziehend.
Harald K. schrieb: > Den, den Du da gerade zitiert hast, Dich in Deinem Beitrag > offensichtlich auf ihn beziehend. Sorry, nein. Ja, ich weiß, manche verwenden "er" statt "Du", aber ich bin da altmodisch. Mein Satz ergäbe auch keinen Sinn, wenn ich Cyblord meinen würde.
Bruno V. schrieb: > Mein Satz ergäbe auch keinen Sinn, wenn ich Cyblord > meinen würde. Du meinst also, Dich auf den Threadstarter zu beziehen? Der aber ist nicht "weich gebettet in Unicode", denn er hat noch nicht mal utf-8 begriffen. Der soll einfach EBCDIC verwenden. Oder sich mit "bome" kurzschließen, dem Typen mit den speziellen Glyphen für hexadezimale Zahlen (oder unlesbare 7-Segment-Darstellungen).
Harald K. schrieb: > Der aber ist > nicht "weich gebettet in Unicode", denn er hat noch nicht mal utf-8 > begriffen. Naja, deshalb weich gebettet. Er kann Umlaute&Co hier und anderswo verwenden ohne sich darüber Gedanken zu machen. In dieser komfortablen Position unterschätzt er die Komplexität aber auch die Probleme der Codepages und verkennt den Nutzen von utf-8 selbst in kleinsten embedded-Systemen.
:
Bearbeitet durch User
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.