Die ersten CPUs wie 6502 und Z80 hatten keine Hardware Multiplizierer. Wie viel Aufwand war es, Hardwaremultiplizierer auf in den CPUs zu implementieren? Gibt es irgendwo Chipbilder, wo man den Flächenverbrauch des Multiplizierers sehen kann?
Angehängte Dateien:
-

Multiplier.png
48 KB
> Die ersten CPUs wie 6502 und Z80 hatten keine Hardware Multiplizierer. Auch die späteren CPU nicht, Hardware-Multiplizier erschienen mit DSP's auf dem Markt. > Wie viel Aufwand war es, Hardwaremultiplizierer auf in den CPUs zu > implementieren? Man braucht halt n X m Full-Adder, steht so in jeder Literatur zum Thema Computerarchitektur. Für nen Full-Adder kann man bis zu 28 Transistoren rechnen und so ne poplige 8 bit CPU kommt mit weniger als 10000 Transistoren aus. > Gibt es irgendwo Chipbilder, wo man den Flächenverbrauch des > Multiplizierers sehen kann? Es ist nicht nur die Fläche wichtig, sondern auch die Durchlaufzeit, die Datenverarbeitung soll ja beim Signal-processing in Echtzeit laufen.
:
Bearbeitet durch User
Bradward B. schrieb: >> Die ersten CPUs wie 6502 und Z80 hatten keine Hardware Multiplizierer. > > Auch die späteren CPU nicht, Hardware-Multiplizier erschienen mit DSP's > auf dem Markt. Nu ja, 6809 (1978, zwei Jahre "neuer" als der Z80) konnte schon 8x8=16Bit. Der 68000 (von 1979) hatten schon 16x16=32Bit. Der 68020 sogar 32x32=64Bit. "The 6809 included one of the earliest dedicated hardware multipliers. It takes 8-bit numbers in the A and B accumulators and produces a 16-bit result in A:B, known collectively as D" - https://en.wikipedia.org/wiki/Motorola_6809 Intel hat sich mit dem 8086 (1978) noch etwas schwerer damit getan: - https://www.righto.com/2023/03/8086-multiplication-microcode.html Mit den späteren DSP kam eher das Thema Floatpoint und Rechnen in einem Taktzyklus auf.
Irgend W. schrieb: > Nu ja, 6809 (1978, zwei Jahre "neuer" als der Z80) konnte schon > 8x8=16Bit. > Der 68000 (von 1979) hatten schon 16x16=32Bit. Der 68020 sogar > 32x32=64Bit. Jetzt geht es halt um die Frage, wie viel Resourcen dafür verbraucht wurden. Die Atmega Serie hat ja einen Single Cycle 8x8 Multiplizierer mit 16 Bit Ergebnis. Kann man den auf dem Chip-Foto erkennen? Die modernen Arm Prozessoren haben aber schon 32x32 Multiplizierer oder die STM32F4 Serie vermutlich schon Float Multiplierer. Wobei es auch ARM Prozessoren ohne Multiplizierer gibt. Der Transisotorcount für einen Float-Multiplizierer dürfte schon ziemlich groß sein. Mein Annahme ist, dass ein Multiplizierer viel Transistoren und viel Fläche verbraucht.
> Der Transisotorcount für einen > Float-Multiplizierer dürfte schon ziemlich groß sein. Es kommt auch noch drauf an ob der Hardware-Multiplizierer in einem Taktzyklus zum Ergebnis kommt oder ob der eine State Machine hat die mehrere Zyklen braucht bis das Ergebnis da ist.
Die Begründung heisst "Amdahl's Gesetz", Frei formuliert, um einen Algo zu beschleunigen, beschleunige die Teiloperationen die am häufigsten vorkommen/abgearbeitet werden. Im Signalprocessing wird viel multipliziert (Vektorprodukte bei der Filterung, FFT), also hat da ein Multiplizierer oft und viel zu tun. Also wird ein Hardwaremultiplizier hier die Gesamtausführung erheblich beschleunigen. Bei Algo's ohne Multiplikation wie GUI-Fensterschieben eher nicht, also wird man für GUI-Fensterschieb-CPU's eher einen Cache implmentieren, der allen Befehlen nützt als einen Hardwareblock der nur eine "Exoten-Operationen" beschleunigt. Man hat so eine Beschleunigung auch lange als Aufrüstoption angeboten, hiess dann FPU-Coprozessor und so eine FPU war nicht selten komplexer und verbriet mehr Strom als die CPU. >> Der Transisotorcount für einen >> Float-Multiplizierer dürfte schon ziemlich groß sein. >Es kommt auch noch drauf an ob der Hardware-Multiplizierer in einem >Taktzyklus zum Ergebnis kommt oder ob der eine State Machine hat die >mehrere Zyklen braucht bis das Ergebnis da ist. Eigentlich geht man immer davon aus, das ein "Hardware-Multiplizierer" in einem Takt durch ist. (So wie ein Barrel-shifter) Wobei dann eben das Problem ist, das der "kritische Pfad" im Multiplizierer" liegt und dieser ohnehin die maximale Taktfrequenz bestimmt. Bei Float kommen zusätzliche Operationen wie "Normalisierung vor Multiplikation" hinzu. Und viel wird in ROM-Tabellen gemacht, in die sich auch mal ein "Fehler" einschleichen kann (https://de.wikipedia.org/wiki/Pentium-FDIV-Bug).
Es ist scheinbar gar nicht so einfach, die Geschwindigkeit für eine float Multiplikation für einen STM32F4 heraus zu bekommen. Es kursieren Zahlen von 3 Zyklen bis 6 Zyklen. Wie lange braucht so ein Ding die Berechnung des Float-Skalarprodukts mit Vektorlänge 1000? Gibt es einen Prozessor mit 1000 Multiplizieren, der das in einem Zyklus kann?
:
Bearbeitet durch User
Irgend W. schrieb: > Nu ja, 6809 (1978, zwei Jahre "neuer" als der Z80) konnte schon > 8x8=16Bit Aber nicht in Hardware, sondern als Mikrocode, braucht also mehrere Takte, bit für bit. Das reduziert den Hardwareaufwand beträchtlich, nicht mehr n x m full adder.
Christoph M. schrieb: > Mein Annahme ist, dass ein Multiplizierer viel Transistoren und viel > Fläche verbraucht. Ein 8x8 Multiplizierer auf einem der frühen Mikroprozessoren hat ziemlich sicher mehr Fläche verbraucht, als ein 32x32 Multiplizierer auf einem modernen Arm Controller. Bradward B. schrieb: > Bei Float kommen zusätzliche Operationen wie "Normalisierung vor > Multiplikation" hinzu. Und viel wird in ROM-Tabellen gemacht, in die > sich auch mal ein "Fehler" einschleichen kann Das ist ein QS-Problem und hat nichts mit dem Prinzip zu tun. Allenfalls fällt eine fehlerhafte Makrozelle eher auf als ein fehlerhafter Wert in einer Tabelle.
:
Bearbeitet durch User
Christoph M. schrieb: > Irgend W. schrieb: >> Nu ja, 6809 (1978, zwei Jahre "neuer" als der Z80) konnte schon >> 8x8=16Bit. >> Der 68000 (von 1979) hatten schon 16x16=32Bit. Der 68020 sogar >> 32x32=64Bit. > > Jetzt geht es halt um die Frage, wie viel Resourcen dafür verbraucht > wurden. Die Microvax II (mit einem 78032-CPU) war eine der ersten 32-Bit-Rechner, die als ein einziger Chip (+ Huehnerfutter) gefertigt wurde. Wenn Du ein bischen den Chip angucken willst, gucke auf die Richies Seite: https://www.richis-lab.de/cpu04.htm Die CPU hatte natuerlich Hardware-Multiplikation fuer 32-Bit-Integer (MUL{B,W,L}) und auch DIV{B,W,L}), allerdings schon sehr frueh im Microcode. Das ist nur fuer Integers, Floats wurden mit der 78032-CPU in Software emuliert. DEC entwickelte dann eine Floating-Point-Unit (DEC78132), die im wesentlichen A*x + B (Polynome) rechnen konnte. Ein Photo bei Richie: https://www.richis-lab.de/cpu05.htm Wenn Du ein bischen Einsicht in die Rechenkraft der Disco-Zeit hast, empfehle ich Dir das Heftchen vom DTJ (Digital Technical Journal), March 1986: https://vmssoftware.com/docs/dtj-v01-02-mar1986.pdf Sind natuerlich die Ideen der '80-er Jahre, ein Teil ist noch gueltig.
Christoph M. schrieb: > Mein Annahme ist, dass ein Multiplizierer viel Transistoren und viel > Fläche verbraucht. Das hängt von verschiedenen Faktoren ab. Am Anfang gibt es erstmal nur 4 Rechenregeln.. Dann ist noch die Frage, welche Bitbreiten man haben möchte, ein Übertragbit braucht man wohl auch, oder ob seriell oder parallel abgewickelt wird, wieviel Zwischenregister man wohl braucht, und und und. Man kann aber klein anfangen, wenn es um ein Grundverständnis geht. Thomas W. schrieb: > die Ideen der '80-er Jahre Sehr schöne Links oben - ich dachte auch so, so ein etwas älteres Beuth Digitaltechnik-Buch könnte auch hilfreich sein.
Wenn man sich den Aufwand, und die Umsetzung eines Single-Cycle- Multiplizierers heute ansehen will, könnte man auch einfach für einen FPGA ohne Hardwaremultiplizierer, ein VHDL-Fragment, das Signale multipliziert, synthetisieren lassen. Die Belegung sieht man dann im Floorplanner und die Umsetzung in den Logikplänen. Aber Vorsicht! Der Multiplizierer arbeitet tatsächlich asynchron! Sonst wäre er ja auch kein Single-Cycle-Multiplizierer. ☺ Versucht man ihn asynchron zu benutzen, wird der FPGA nach einigen Sekunden thermisch das Handtuch werfen, und einen Reset durchführen. Auf einem Cyclone I erreicht man ca. 2-3 ns für einen per Synthese erzeugten 32x32 bit Multiplizierer. Wenn ich mich richtig erinnere... Christoph M. schrieb: > Gibt es einen Prozessor mit 1000 Multiplizieren, der das in einem Zyklus > kann? Ei gewiss. Nennt sich FPGA. 1000 Multiplikationsblöcke werden aber schon recht teuer.
:
Bearbeitet durch User
Danke für euren sehr interessanten Beiträge (insbesondere die Links von Thomas). Da werde ich wohl noch einiges genauer analysieren müssen. Cartman E. schrieb: > Ei gewiss. Nennt sich FPGA. > 1000 Multiplikationsblöcke werden aber schon recht teuer. Ein Artix 7 XC7A200T hat aber nur 740 25x18Bit Multiplizierer und kein Float.
Es gibt meiner Erinnerung nach einige Die-Shots von DSPs wie 56k bei Zeptobars und Konsorten, wo man die Multipliziererketten gut identifizieren kann. Speaking of FPGA: Es sind auch ein paar interessante Architekturen die Jahre aufgekommen, u.a. auch die Gatemate-CPE-Arrangements, mit denen man nette kaskadierte Multiplier direkt im Logik-Gewebe inferieren kann und so einige Flaschenhälse wie bei klassischen DSP48-Routings zumindest in der Theorie nicht so schnell auftreten. Wie weit das inzwischen produktiv nutzbar ist, kann ich aber nicht sagen.
Christoph M. schrieb: > Danke für euren sehr interessanten Beiträge (insbesondere die Links von > Thomas). Da werde ich wohl noch einiges genauer analysieren müssen. > > Cartman E. schrieb: >> Ei gewiss. Nennt sich FPGA. >> 1000 Multiplikationsblöcke werden aber schon recht teuer. > > Ein Artix 7 XC7A200T hat aber nur 740 25x18Bit Multiplizierer und kein > Float. Wenn dir der zu klein ist: Dann wirst du wohl noch ein paar $$$ drauflegen müssen.
Bei den größeren CPUs kann man die einzelnen Multiplizierer überhaupt nicht mehr sehen, aber im NPU Block dieses Ryzen-AI-300 werden wohl einige drinn stecken. https://static.tweaktown.com/news/9/9/99633_43_check-out-this-beautiful-die-shot-of-amds-new-ryzen-ai-300-strix-point-apu_full.jpg
:
Bearbeitet durch User
Christoph M. schrieb: > Es ist scheinbar gar nicht so einfach, die Geschwindigkeit für eine > float Multiplikation für einen STM32F4 heraus zu bekommen. Es kursieren > Zahlen von 3 Zyklen bis 6 Zyklen. Gerade einmal mit nem RP2350 und Thumb-Assembler getestet. S0 und S1 mit 1 + 1 ÷ (1<<23) geladen. (1,000000119209289550781250, kleinster Wert größer als 1) In einer 2²⁴ Schleife:
1 | loop: |
2 | vmul s1, s1, s0 |
3 | sub r0, #1 |
4 | bne loop |
Ergibt 4 Taktzyklen pro Schleife. Bei 1 Zyklus für sub und 2 Zyklen für bne bleiben 1 Zyklus für Multiplikation. Nachtrag Gleiches Assembler Programm braucht auf einem STM32F407 8 Taktzyklen pro Schleife. Bei 1 Zyklus für sub und 2 Zyklen für bne bleiben 5 Zyklen für Multiplikation.
:
Bearbeitet durch User
Multiplikation und Division sind heute auch noch wichtig, im wesentlich im Bereich der Kryptographie. Es sind auch verschiedene Algorithmen entwickelt wurden um grosse Binaer-Zahlen zu multiplizieren (am Ende geht es um sehr schlaue Shift-Operationen). Was zu lesen: John L. Hennessy, David A. Patterson: Computer Architecture, A Quantitative Approach, sixth Edition, Morgan Kaufmann Publisher, 2019, 1527p. Insbesondere Seiten J-48 und weiter. M.Morris Mano, Computer System Architecture, Third Edition, 1992, 524p. Page 343ff.
…und ein Nachtrag zum STM32F407: Bei geschickter Assembler-Programmierung, WORD alignment anstelle von HALFWORD trotz Thumb und bei Benutzung alternativ wechselnder Sx Register, kann man die vmul auf 2 Zyklen reduzieren. Aber nur wenn es der Algorithmus hergibt und er sich entsprechend anpassen lässt. Beim RP2350 bleibt's bei einem Zyklus. Schneller geht's nicht, verdammt. ;-)
Norbert schrieb: > Beim RP2350 bleibt's bei einem Zyklus. > Schneller geht's nicht, verdammt. ;-) Der x86 schafft um die 64 Multiplikationen pro Takt ;-)
Udo K. schrieb: > Der x86 schafft um die 64 Multiplikationen pro Takt ;-) Jetzt wo du's sagst, der RP2350 kann natürlich zwei pro Zyklus. Einen pro Kern und FPU. ;-)
Der Arm M4 braucht einen Takt für Multiply-Accumulate. Aber das Programm muss im schnellen RAM sein (TCM) sein, sonst limitiert das Flash.
Norbert schrieb: > Jetzt wo du's sagst, der RP2350 kann natürlich zwei pro Zyklus. Einen > pro Kern und FPU. ;-) Wenn man die Kerne noch mitnimmt, dann schafft der x86 1024 8 Bit (oder 256 32 Bit) Multiplikationen und Additionen pro Takt (oder war da noch ein Faktor 2 weil ein Kern 2 AVX Einheiten hat?) ;-) Aber eine GPU schafft mehr.
:
Bearbeitet durch User
Bradward B. schrieb: > Man braucht halt n X m Full-Adder, Es gibt jedoch auch effizientere Strukturen.
:
Bearbeitet durch User
Udo K. schrieb: > Der Arm M4 braucht einen Takt für Multiply-Accumulate. Aber das > Programm muss im schnellen RAM sein (TCM) sein, sonst limitiert das > Flash. Das lief/läuft natürlich im RAM. Aber es mag sein (wimre) dass der F4 zwei unterschiedliche RAM Bereiche hat (spielt zumindest bei DMA eine Rolle)
Thomas W. schrieb: > Multiplikation und Division sind heute auch noch wichtig sehen die heutigen Schüler nicht so
Norbert schrieb: > Gerade einmal mit nem RP2350 und Thumb-Assembler getestet. Essentiel für DSP Anwendungen (unter die auch die KI fällt) sind die MAC Operationen. Beim STM32F4 sollte es dazu die Assemblerbefehle MLA und VFMA geben. Ob der RP2350 das auch hat, weiß ich nicht.
(prx) A. K. schrieb: > Bradward B. schrieb: >> Man braucht halt n X m Full-Adder, > > Es gibt jedoch auch effizientere Strukturen. Welche?
Christoph M. schrieb: > Ob der RP2350 das auch hat, weiß ich nicht. Na klar hat er die, das sind zwei M33 Kerne.
Christoph M. schrieb: >> Es gibt jedoch auch effizientere Strukturen. > > Welche? https://en.wikipedia.org/wiki/Carry-save_adder https://en.wikipedia.org/wiki/Wallace_tree https://en.wikipedia.org/wiki/Dadda_multiplier
Christoph M. schrieb: > Gibt es irgendwo Chipbilder, wo man den Flächenverbrauch des > Multiplizierers sehen kann? https://archive.org/details/eti-1986-01/page/n2/mode/1up
Christoph M. schrieb: > (prx) A. K. schrieb: >> Bradward B. schrieb: >>> Man braucht halt n X m Full-Adder, >> >> Es gibt jedoch auch effizientere Strukturen. > > Welche? zusaetzlich: https://en.wikipedia.org/wiki/Booth%27s_multiplication_algorithm
Thomas W. schrieb: > Die Microvax II (mit einem 78032-CPU) war eine der ersten > 32-Bit-Rechner, die als ein einziger Chip (+ Huehnerfutter) gefertigt > wurde. Wenn Du ein bischen den Chip angucken willst, gucke auf die > Richies Seite: https://www.richis-lab.de/cpu04.htm > > Die CPU hatte natuerlich Hardware-Multiplikation fuer 32-Bit-Integer > (MUL{B,W,L}) und auch DIV{B,W,L}), allerdings schon sehr frueh im > Microcode. Wie man an den Bildern sehr schön sehen hat das µ-Code-Rom bei den alten Gurken sehr viel Platz verbraucht. Jim Keller (https://de.wikipedia.org/wiki/Jim_Keller) hat in einem Interview erzählt das der Platzverbrauch der µ-Code-Roms auch ein Grund für die Entwicklung von RISC-CPUs war. Heute fällt das kaum noch ins Gewicht.
G. K. schrieb: > Wie man an den Bildern sehr schön sehen hat das µ-Code-Rom bei den alten > Gurken sehr viel Platz verbraucht. Jo, die gesamte ALU ist, im Vergleich zum Rest, schon recht klein. Darin jetzt noch einzelne Funktionen finden, schwierig...? - https://www.cpcwiki.eu/index.php?title=Motorola_68000#Block_Diagram Bei den "neueren" stopft man auf den Platz eher schon mehrere vollständige CPU-Core: - https://www.reddit.com/r/Amd/comments/giik5t/llano_die_floor_plan_looking_back_at_amds_second/#lightbox - https://www.reddit.com/r/Amd/comments/jqjg8e/quick_zen3_die_shot_annotations_die_shot_from/?tl=de#lightbox
G. K. schrieb: > das der Platzverbrauch der µ-Code-Roms auch ein Grund > für die Entwicklung von RISC-CPUs war. Wobei die VAX-Architektur in ihrer Komplexität allerdings auch extrem von Microcode abhing. Von der VAX inspirierte µP-Architekturen wie NS 32K und NEC V60/70 waren ähnlich komplex und es erging ihnen nicht besser.
:
Bearbeitet durch User
Irgend W. schrieb: > Der 68000 (von 1979) hatten schon 16x16=32Bit. Allerdings lief das bitweise sequentiell als shift/add ab, wie man mühelos der Befehlslaufzeit entnehmen kann. Unter einem Hardware-Multiplizierer verstehe ich Kombinatorik.
:
Bearbeitet durch User
Christoph M. schrieb: > Der Transisotorcount für einen > Float-Multiplizierer dürfte schon ziemlich groß sein. Wobei kombinatorische Multiplizierer auf sehr hohe Transistordichte optimierbar sind, weil aus sehr regelmässigen Strukturen dicht an dicht bestehend, wie man dies auch bei Caches findet. Steuerlogik ist weit weniger dicht, auch Busstrukturen benötigen viel Platz.
:
Bearbeitet durch User
Bradward B. schrieb: > Eigentlich geht man immer davon aus, das ein "Hardware-Multiplizierer" > in einem Takt durch ist. (So wie ein Barrel-shifter) Nein. > Problem ist, das der "kritische Pfad" im Multiplizierer" liegt und > dieser ohnehin die maximale Taktfrequenz bestimmt. Es dürfen schon mehrere Takte sein, eben um nicht die Taktrate zu bremsen. Wobei man die Kombinatorik dann ggf in mehrere Teile aufdröselt, die man als Pipeline anspricht. Dann braucht eine Multiplikation zwar mehrere Takte, kann aber pro Takt ein Ergebnis liefert. Oder man implementiert die Kombinatorik als Teilwort-Multiplikation und addiert die Teilergebnisse zusammen.
Norbert schrieb: > Ergibt 4 Taktzyklen pro Schleife. Tests dieser Art sollte man etwas anders aufbauen. Besonders jedoch bei CPUs hoher Komplexität und innerer Parallelität. - Keine kleine Schleife mit einer Multiplikation, sondern etliche Multiplikationen hintereinander, so dass ein zeitlicher Aufwand der Schleife verschwindet. - Zwei Varianten, eine mit Abhängigkeit der Multiplikationen untereinander, indem also der Folgebefehl vom Ergebnis abhängt. Und eine mit nicht voneinander abhängigen Multiplikationen. Damit entschlüsselt man mögliches Pipelining.
:
Bearbeitet durch User
Christoph M. schrieb: > Die ersten CPUs wie 6502 und Z80 hatten keine Hardware Multiplizierer. Nicht doch - schaffen manche heutigen Cores zwar 64 parallele 8-Bit Multiplikationen in einer Vektor-Operation, beherrschte auch die olle 6502 bereits 8 parallele 1-Bit Multiplikationen. Und berechnete das sogar in einem Taktzyklus, während die Z80 dank ihrer 4-Bit ALU deutlich beschränkter war. :)
:
Bearbeitet durch User
(prx) A. K. schrieb: > - Zwei Varianten, eine mit Abhängigkeit der Multiplikationen > untereinander, indem also der Folgebefehl vom Ergebnis abhängt. Und eine > mit nicht voneinander abhängigen Multiplikationen. Damit entschlüsselt > man mögliches Pipelining. Und heute ist es noch etwas komplexer, siehe hier: https://www.agner.org/optimize/instruction_tables.pdf Und bei ARM kommt auch noch das lustige aufteilen bei immediate Adressierung hinzu: (Was aber durchaus in der Spekulation zeitmässig verschwinden kann)
1 | int a(int num) {
|
2 | return num * 0xfedc; |
3 | } |
4 | int b(int num) {
|
5 | return num * 0xffeeddccbbaa; |
6 | } |
7 | |
8 | a(int): |
9 | movw r3, #65244 |
10 | mul r0, r3, r0 |
11 | bx lr |
12 | b(int): |
13 | movw r3, #48042 |
14 | movt r3, 56780 |
15 | mul r0, r3, r0 |
16 | bx lr |
via https://godbolt.org/
:
Bearbeitet durch User
Angehängte Dateien:
-

PipeMultCutSet.jpg
170 KB

>> Eigentlich geht man immer davon aus, das ein "Hardware-Multiplizierer" >> in einem Takt durch ist. (So wie ein Barrel-shifter) > > Nein. > >> Problem ist, das der "kritische Pfad" im Multiplizierer" liegt und >> dieser ohnehin die maximale Taktfrequenz bestimmt. > > Es dürfen schon mehrere Takte sein, eben um nicht die Taktrate zu > bremsen. Wobei man die Kombinatorik dann ggf in mehrere Teile > aufdröselt, die man als Pipeline anspricht. Dann braucht eine > Multiplikation zwar mehrere Takte, kann aber pro Takt ein Ergebnis > liefert. Oder man implementiert die Kombinatorik als > Teilwort-Multiplikation und addiert die Teilergebnisse zusammen. Ich seh schon, hier gibt es keine einheitliche Begrifflichkeit, Takt, Maschinenzyklus, alles querbeet. Latenz und Durchsatzrate wurden noch garnicht erwähnt und der TO klemmt immer noch "auf Fläche" als einzige Metrik des Resourcenbedarfs fest. Anbei eine Seite aus Pirsch: "Architekturen der digitalen Signalverarbeitung" v. 1996 einen kleinen Einblick auf die Komplexität des Multipliziererbaus zu geben. Steht alles in der BVibliothek, muß man sich nur besorgen. Auch oder gerade beim Pipelining liegt nach jedem Takt ein neues Produkt aus dem Hardware-Multiplizierer als Ergebnis vor. Ohne Pipeling auch, aber da muss wegen der vielen Gatterlaufzeiten hintereinander die Taktperiode verlängern werden, was den Durchsatz (prozessierte Daten pro Zeiteinheit) verringert. Wobei es dem TO nicht nützt 1000 Multiplikationen auf einmal zu erledigene, wenn er es nicht schafft die 2000 Faktoren auch in jedem Takt zu dem Multipliziereingängen zu schaffen. Falls sein System überhaupt einen solchen Input schafft (wieviel Pins hat ein STM32 ?). Und Float ist nicht gleich Float, inzwischen sollte sich doch auch bei den KI-Fussvolk die Erkenntniss durchgesetzt haben, das es nicht 128 Bit Gewichte sein müßen sindern das es auch gern wenige bits sein können: Accomplish more by doing less: * https://www.heise.de/news/Gleitkommazahlen-im-Machine-Learning-Weniger-ist-mehr-fuer-Intel-Nvidia-und-ARM-7264714.html
:
Bearbeitet durch User
Bradward B. schrieb: > Und Float ist nicht gleich Float, inzwischen sollte sich doch auch bei > den KI-Fussvolk die Erkenntniss durchgesetzt haben, das es nicht 128 Bit > Gewichte sein müßen sindern das es auch gern wenige bits sein können: > Accomplish more by doing less: > > * > https://www.heise.de/news/Gleitkommazahlen-im-Machine-Learning-Weniger-ist-mehr-fuer-Intel-Nvidia-und-ARM-7264714.html Da ist unser naseweiser Chatbot aber nicht ganz auf dem neuesten Stand. Nvidia ist das längst bei FP4 angelangt, siehe GB300 (unten): https://www.nvidia.com/en-us/data-center/gb300-nvl72/
Die NVIDIA RTX5060 wird mit 614 AI TOPs angegeben. Da die Berechnungen im wesentlichen aus MAC-Operationen bestehen dürften (also einer Multiplikation mit Addition) stellt sich die Frage, ob die 614TOPs nur 312 Multiplikation/Sec beinhalten.
(prx) A. K. schrieb: > - Keine kleine Schleife mit einer Multiplikation, sondern etliche > Multiplikationen hintereinander, so dass ein zeitlicher Aufwand der > Schleife verschwindet. Jetzt rate mal wie ich die Tests gemacht habe? ;-) 1,2,3,4,6,8,12,16 VMUL Befehle hintereinander in der Schleife. Genau da kann man so einiges an den zuerst nicht proportional steigenden Zyklenzeiten ablesen. Man muss übrigens auch noch die S-Register beachten. Immer die gleichen für eine repetitive Berechnung ergibt durchaus andere Werte als eine alternierende Benutzung.
> https://www.heise.de/news/Gleitkommazahlen-im-Machine-Learning-Weniger-ist-mehr-fuer-Intel-Nvidia-und-ARM-7264714.html > > Da ist unser naseweiser Chatbot aber nicht ganz auf dem neuesten Stand. > Nvidia ist das längst bei FP4 angelangt, siehe GB300 (unten): Und für welche Operandenbreite hat sich der TO entschieden ? Grad für KI wäre FP0 ideal. SCNR
Christoph M. schrieb: > Die NVIDIA RTX5060 wird mit 614 AI TOPs angegeben. Da die Berechnungen > im wesentlichen aus MAC-Operationen bestehen dürften (also einer > Multiplikation mit Addition) stellt sich die Frage, ob die 614TOPs nur > 312 Multiplikation/Sec beinhalten. Du hast das T=Tera vergessen, aber ja. Bei sagen wir mal 2,5GHz sind das dann 312.000.000.000.000 MULs / 2.500.000.000 Hz = 124.800 parallele Multiplikationen pro Takt. Wahrscheinlich 4Bit. Oben wurde der Ryzen 300 Strix AI genannt, der 32 Einheiten zu je 512 MACs hat, also 16.384 parallele Multiplikationen kann. Allerdings 8bit
Markus K. schrieb: > Christoph M. schrieb: >> Die NVIDIA RTX5060 wird mit 614 AI TOPs angegeben. Da die Berechnungen >> im wesentlichen aus MAC-Operationen bestehen dürften (also einer >> Multiplikation mit Addition) stellt sich die Frage, ob die 614TOPs nur >> 312 Multiplikation/Sec beinhalten. > > Du hast das T=Tera vergessen, aber ja. > Bei sagen wir mal 2,5GHz sind das dann 312.000.000.000.000 MULs / > 2.500.000.000 Hz = 124.800 parallele Multiplikationen pro Takt. > Wahrscheinlich 4Bit. > > Oben wurde der Ryzen 300 Strix AI genannt, der 32 Einheiten zu je 512 > MACs hat, also 16.384 parallele Multiplikationen kann. Allerdings 8bit Rechnen die KI-Bros nicht mittlerweile (zu mindestens teilweise) mit INTs?
G. K. schrieb: > Markus K. schrieb: >> Bei sagen wir mal 2,5GHz sind das dann 312.000.000.000.000 MULs / >> 2.500.000.000 Hz = 124.800 parallele Multiplikationen pro Takt. >> Wahrscheinlich 4Bit. >> >> Oben wurde der Ryzen 300 Strix AI genannt, der 32 Einheiten zu je 512 >> MACs hat, also 16.384 parallele Multiplikationen kann. Allerdings 8bit > > Rechnen die KI-Bros nicht mittlerweile (zu mindestens teilweise) mit > INTs? Was meinst Du mit "INTs"? Integer? Klar, OPS sind zwar ganz allgemein Operationen, aber wenn man float meint, dann nennt man das traditionell FLOPS. Es sind also Integer Operationen. Wobei die RTX50xx glaub auch fp4 kann.
:
Bearbeitet durch User
Angehängte Dateien:
-

BlackwellFormats.png
51 KB

Markus K. schrieb: > Wobei die RTX50xx glaub auch > fp4 kann. Sie kann .. und noch einige mehr (Blackwell Architektur).
Christoph M. schrieb: > Markus K. schrieb: >> Wobei die RTX50xx glaub auch >> fp4 kann. > > Sie kann .. und noch einige mehr (Blackwell Architektur). Für möglichst große Zahlen muss das Format ja möglichst klein sein.
Angehängte Dateien:
-

8x8Multiplizierer.png
240 KB

Bezüglich des Transistorcounts kann man heutzutage auch einfach Perplexity fragen, weiß allerdings nie genau ob die Angaben stimmen. Für einen 8x8 Multiplizierer werden 500-2000 Transistoren angegeben, was deutlich von dieser Antwort hier abweicht: Bradward B. schrieb: > Man braucht halt n X m Full-Adder, steht so in jeder Literatur zum > Thema Computerarchitektur. Für nen Full-Adder kann man bis zu 28 > Transistoren rechnen und so ne poplige 8 bit CPU kommt mit weniger als > 10000 Transistoren aus.
Irgend W. schrieb: > Nu ja, 6809 (1978, zwei Jahre "neuer" als der Z80) konnte schon > 8x8=16Bit. Allerdings handelte es sich dabei nicht um einen kombinatorischen Multiplizierer. Auch nicht ausschließlich um Microcode auf Basis einer klassischen ALU. Sondern nutzt Hardware zur Optimierung der klassischen iterativen shift/add-Methode unter Verwendung der ALU. Der Befehl benötigte dazu passende 11 Takte. Der Aufwand war also vergleichsweise gering.
:
Bearbeitet durch User
Angehängte Dateien:
-

SynapseI.PNG
39 KB
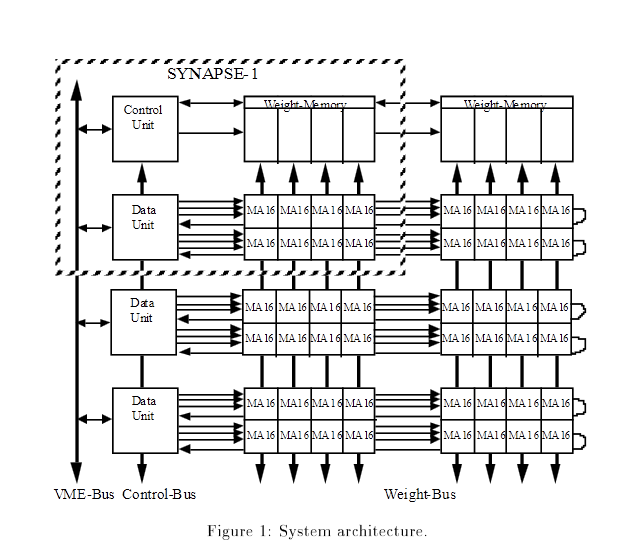
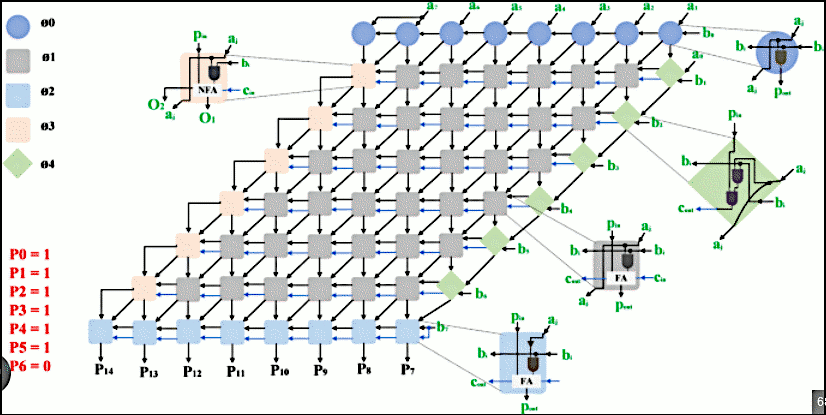
> Für einen 8x8 Multiplizierer werden 500-2000 Transistoren angegeben, was > deutlich von dieser Antwort hier abweicht: >> Man braucht halt n X m Full-Adder, steht so in jeder Literatur zum >> Thema Computerarchitektur. Für nen Full-Adder kann man bis zu 28 >> Transistoren rechnen und so ne poplige 8 bit CPU kommt mit weniger als >> 10000 Transistoren aus. Eigentlich keinerlei Abweichung, weil 8*8*28 = 1792 und damit wie erwartbar im oberen Bereich des genannten Intervalls, "deutliche Abweichung" ist was anderes. Mal zum Vergleich, für ne 32bit ALU in der Toshiba TC170G Macorcell-Bibliothek aus den Neunzigern wird ein Gate count von maximal 1090 angegeben. Und für ein Gate rechnet man bspw. vier Komplementärtransistoren. So ein Multiplizier-array ist schon groß, aber nicht riesig. Der Flächenbedarf skaliert zwar etwa quadratisch mit der Operanden-bitbreite, was aber nach Moore's Gesetz (alle 18 bis 24 Monate Verdopplung des Transistorcounts)) über die Jahre kein Problem für die Halbleiterindustrie ist. https://de.wikipedia.org/wiki/Mooresches_Gesetz Und die zusätzlichen Transistoren werden eher zur Beschleunigung aller Operationen eingesetzt, nicht nur der Multiplikation, also L1-Caches, Vorhersage-Logic, Speicherverwaltung (MMU), ... und irgendwann ploppt man mehrere Cores unter ein CPU-packages. BTW: dedizierte ASIC zur Ermittlung des Vectorproduktes mit der Gewichtsmatrix gabs schon in den Neunzigern (siehe Architektur mit MA16-Blöcke im Anhang), es sei an den Neurocomputer Synapse-I erinnert. https://madoc.bib.uni-mannheim.de/810/1/TR-95-011.pdf Aber ausser dem direkten Umfeld von Prof. Ulrich Ramacher wenig bekannt, obwohl einzelne Exemplare an Universitäten standen.
:
Bearbeitet durch User
Christoph M. schrieb: > Bezüglich des Transistorcounts kann man heutzutage auch einfach > Perplexity fragen, weiß allerdings nie genau ob die Angaben stimmen. Dann muss man das halt nachprüfen. Die KIs geben teilweise Quellen von selber an, manchmal muss man sie ausdrücklich darum bitten. In Deinem Screenshot kann man sehen, dass Quellen angegeben wurden. Da ich natürlich nicht auf die Links in Deinem Screenshot klicken kann, habe ich dazu ChatGPT gefragt und es hat mir u.a. Quellen dafür gegeben, dass ein Fulladder 28 Transistoren hat (das wurde oben schon gesagt), dass ein D-Flip-Flop 20 Transistoren hat (braucht man, wenn man Ergebnis in mehreren Takten rechnen will) und er spuckt insbesondere dieses Paper aus: https://www.researchgate.net/profile/Vikas-Singla-2/publication/306125496_Performance_Analysis_of_Different_8x8_Bit_CMOS_Multiplier_using_65nm_Technology/links/57ed2ed708aea9385439c67e/Performance-Analysis-of-Different-8x8-Bit-CMOS-Multiplier-using-65nm-Technology.pdf
Thomas W. schrieb: > Wenn Du ein bischen Einsicht in die Rechenkraft der Disco-Zeit hast, > empfehle ich Dir das Heftchen vom DTJ (Digital Technical Journal), March > 1986: https://vmssoftware.com/docs/dtj-v01-02-mar1986.pdf Interessant: Im Wikipediaeintrag wird die Mikrovax mit 2 SMD Chips gezeigt. https://de.wikipedia.org/wiki/MicroVAX_78032 In der Zeit (1985) gab es meines Wissens nach SMD so gut wie gar nicht.
Christoph M. schrieb: > Es ist scheinbar gar nicht so einfach, die Geschwindigkeit für eine > float Multiplikation für einen STM32F4 heraus zu bekommen. Es kursieren > Zahlen von 3 Zyklen bis 6 Zyklen. Im Cortex-M4 technical reference manual sind die Takte für alle Instruktionen aufgelistet. Bei "vmul.f32" steht 1 Takt. Der Rest wird Verzögerung durch Speicherzugriff sein, insbesondere für die Instruktion selbst. Wenn der Eingabewert für vmul unmittelbar zuvor noch berechnet oder aus dem Speicher geladen wird, oder der Ausgabewert direkt danach weiter verarbeitet wird, wird es wohl noch Pipeline-Stalls geben die weitere Takte hinzufügen.
Christoph M. schrieb: > Interessant: Im Wikipediaeintrag wird die Mikrovax mit 2 SMD Chips > gezeigt. > https://de.wikipedia.org/wiki/MicroVAX_78032 > In der Zeit (1985) gab es meines Wissens nach SMD so gut wie gar nicht. SMD gabs schon in den 1960ern.
Niklas G. schrieb: > Im Cortex-M4 technical reference manual sind die Takte für alle > Instruktionen aufgelistet. Bei "vmul.f32" steht 1 Takt. Ja. Freistehend. Denn sie brauchen einen zusätzlichen Zylus wenn das Ergebnis danach benutzt wird.
Norbert schrieb: > Denn sie brauchen einen zusätzlichen Zylus wenn das Ergebnis danach > benutzt wird. Wie gesagt... Daher sollte man direkt nach das "vmul" was anderes hinein schieben, wie z.B. Schleifenzähler verarbeiten und erst später das vmul-Ergebnis verwenden.
Niklas G. schrieb: > Norbert schrieb: >> Denn sie brauchen einen zusätzlichen Zylus wenn das Ergebnis danach >> benutzt wird. > > Wie gesagt... Daher sollte man direkt nach das "vmul" was anderes hinein > schieben, wie z.B. Schleifenzähler verarbeiten und erst später das > vmul-Ergebnis verwenden. Wenn's der Algorithmus hergibt. Hatte ich aber weiter oben schon geschrieben. Bei geschicktem Verweben der Instruktionen kann man die benötigte Anzahl Zyklen minimieren. Aber nur wenn's der Algorithmus hergibt.
Norbert schrieb: > Bei geschicktem Verweben der Instruktionen kann man die benötigte Anzahl > Zyklen minimieren. Aber nur wenn's der Algorithmus hergibt. Ist ja bei allen Instruktionen so. Die Zahl im TRM ist eben das Minimum, welches man aber prinzipiell schon erreichen können müsste, aber eben nicht immer.
Niklas G. schrieb: > Ist ja bei allen Instruktionen so. Ähm, das ist bei allen FPU add,sub,mul,div so. Aber eben (in dieser Weise) nur dort. Bei INT add,sub,mul,div zB. tritt dies nicht auf.
Norbert schrieb: > Bei INT add,sub,mul,div zB. tritt dies nicht auf. Okay, ich hätte jetzt gedacht dass die auch Pipelining verwenden und man da ebenfalls die Instruktionen umsortieren sollte - was Compiler ja auch machen.
Angehängte Dateien:

{kind=link}
>> Bei INT add,sub,mul,div zB. tritt dies nicht auf. > > Okay, ich hätte jetzt gedacht dass die auch Pipelining verwenden und man > da ebenfalls die Instruktionen umsortieren sollte - was Compiler ja auch > machen. Sollte man sich nicht drauf verlassen, grad bei DSP besser die optimierten libs des herstellers verwenden. Schon bei DSP's gibt es Tricks die darausf beruhten, das noch der alte Wert im Register stand, den man eigentlich mit dem vorherigen Befehl überschrieben hat. https://www.ti.com/lit/an/spra481/spra481.pdf?ts=1777038408661
Niklas G. schrieb: > Okay, ich hätte jetzt gedacht dass die auch Pipelining verwenden und man > da ebenfalls die Instruktionen umsortieren sollte - was Compiler ja auch > machen. Alle Werte mit dem Cortex-M33 internen cyclecounter gemessen. r0=0,r2=2,r4=4 vorbesetzt Auf der Assembler-Ebene sieht das so aus:
1 | mul r0, r0 ;@ 2 (2) |
2 | mul r0, r0 ;@ 4 (2) |
3 | mul r0, r0 ;@ 6 (2) |
4 | mul r0, r0 ;@ 8 (2) |
5 | |
6 | add r0, r0, r0 ;@ 9 (1) |
7 | add r0, r0, r0 ;@ 10 (1) |
8 | add r0, r0, r0 ;@ 11 (1) |
9 | add r0, r0, r0 ;@ 12 (1) |
10 | |
11 | mul r0, r0 ;@ 14 (2) |
12 | add r0, r0, r0 ;@ 15 (1) |
13 | mul r0, r0 ;@ 17 (2) |
14 | add r0, r0, r0 ;@ 18 (1) |
15 | mul r0, r0 ;@ 20 (2) |
16 | add r0, r0, r0 ;@ 21 (1) |
17 | mul r0, r0 ;@ 23 (2) |
18 | add r0, r0, r0 ;@ 24 (1) |
19 | |
20 | udiv r0, r4, r2 ;@ 29 (5) |
21 | mul r0, r2 ;@ 31 (2) |
22 | udiv r0, r4, r2 ;@ 36 (5) |
23 | mul r0, r2 ;@ 38 (2) |
24 | udiv r0, r4, r2 ;@ 43 (5) |
25 | mul r0, r2 ;@ 45 (2) |
26 | udiv r0, r4, r2 ;@ 50 (5) |
27 | mul r0, r2 ;@ 52 (2) |
28 | |
29 | udiv r0, r4, r2 ;@ 57 (5) |
30 | add r0, r0, r0 ;@ 58 (1) |
31 | udiv r0, r4, r2 ;@ 63 (5) |
32 | add r0, r0, r0 ;@ 64 (1) |
Norbert schrieb: > Auf der Assembler-Ebene sieht das so aus: Ich glaube entscheident ist, wie lange ein Sinc-Tiefpass mit z.B. 1024 Koeffizienten braucht. https://de.wikipedia.org/wiki/Idealer_Tiefpass
Christoph M. schrieb: > Ich glaube entscheident ist, wie lange ein Sinc-Tiefpass mit z.B. 1024 > Koeffizienten braucht. Wenn das entscheidend ist, dann mach mal. Arm-Assembler ist kostenlos. Bin gespannt auf die Scores.
Endlich mal ein Bild mit dem Flächenverbrauch eines Mutliplizierers auf einem Chip. Der Platzverbrauch gegenüber der Alu ist enorm: https://www.richis-lab.de/images/GraKa_S3/05x25.jpg Von https://www.richis-lab.de/GraKa05.htm https://de.wikipedia.org/wiki/Sega_Virtua_Processor
{kind=link}
> Endlich mal ein Bild mit dem Flächenverbrauch eines Mutliplizierers auf > einem Chip. Der Platzverbrauch gegenüber der Alu ist enorm: Nö, eher erwartbar. für ne 32b alu braucht man zwar einmal (2x16) ⨷ (2x16) und für ne MUL das halbe 32 mal verjüngend zulaufend, aber in den beispiel ist das flächenmässig etwa gleich. IMHO sieht man aber recht gut, das der kritische Pfad vom IN zu OUT im MUL recht lang ist. Das deutet eher auf eine 16bit statt eine 32 bit architektur hin, der MUL liefert 32b Result aus 16b Input und die ALU akkumuliert und skaliert runter. Sind halt 90er Jahre. Kommt natürlich auch auf die Entwurfsmethodik an, Full Custom ist halt hinsichtlich fläche besser als Gate-Array o.ä.
:
Bearbeitet durch User
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.