Ich benötige die Sinus- und Cosinusfunktion in AVR-Assembler und dachte an den Cordic-Algorithmus, konnte aber keinen Code dazu finden. Ich habe jede Menge Implementierungen gefunden entweder für andere Prozessor-Familien oder in anderen Programmier-Sprachen, aber nichts in AVR-Assembler.
Ist es vollkommen aus der Mode gekommen ein Programm das man benoetigt auch selber zu schreiben? Olaf
Ist es vollkommen in Mode das Rad neu zu erfinden? Vielleicht tut's aber auch eine lookup table.
> Ist es vollkommen in Mode das Rad neu zu erfinden? Wenn Millionen Raeder am Wegesrand liegen dann nicht, aber leider liegen da nur kaputte Radkappen aus Plastik von Aldi im Alufelgenlook.... > Vielleicht tut's aber auch eine lookup table. Stimmt. Manchmal kann man so eine Radkappe doch verwenden. :-D Olaf
Eine Lookup-Table ist für meine Anwendung Speicherverschwendung. Wenn ich 10tel-Grad eingeben möchte brauche ich 900 Einträge. Bei ausreichender Genauigkeit sind das 1800 Byte. Mein Programm soll aber noch mehr machen, also bin ich mit Speicher geizig. Vielleicht möchte ich später auch auf 100tel Grad gehen, dann sieht es noch schlimmer aus. Rechenzeit spielt in meinem Fall übrigens keine so große Rolle. (Mark hat richtig erkannt: Ich möchte das Rad nicht neu erfinden. Olaf's Aussage steht nicht im Widerspruch dazu. Wenn für mich über diesen Thread keine Implementierung auffindbar ist, mache ich es natürlich selbst. Nicht ganz verstehe ich seine polemische Äußerung. Warum gibt es diese Forum überhaupt, wenn man nicht darüber Wissen austauschen möchte. Aber vielleicht habe ich Ihn ja falsch verstanden.)
Nachdem sich hier niemand mit einer Implementierung gemeldet hat, habe ich mich selbst daran versucht. Hier das erste Resultat für eine Sinus/Cosinusberechnung nach Cordic. Eingegeben wird der Winkel in 10tel Grad als 16-bit vorzeichenbehaftete Ganzzahl im Bereich -91 bis +91 Grad, also -910 bis +910. Als Ergebnis erhält man den Sinus und Cosinus als 16-bit vorzeichenbehaftete Ganzzahl. Ich hoffe jetzt auf reges Feedback zur Verbesserung des Codes. Hier zwei Ansatzpunkte: Gegenüber einer 16bit-Tabelle gibt es kleine Aproximationsfehler. Die meiste Zeit frisst der Barrel-Shifter, der beim AVR leider nicht in Hardware existiert und als Software-Schleife realisiert wurde. Etwas optimiert habe ich dadurch, dass ich bei Shifts größer 8 erst einmal ganze Register verschiebe.
Ich habe sowas auch mal angefangen, bin aber noch nicht weit gekommen. Der Barrel-shifter braucht den meisten Platz, das stimmt.
Was noch fehlt, ist unter anderem die Umrechnung auf den 180 Grad Konvergenzbereich. Zuerst muss ein DDS-Phasenakkumulator eine "Dreieckschwingung", also eine auf- und absteigende Treppe erzeugen, und am Ende muß man die Vorzeichen für Sinus und Cosinus passend dazufügen.
Hallo Christoph, danke für Deinen Code-Beitrag. Ist vom Prinzip ähnlich meiner Lösung. Einen Phasenakkumulator brauche ich nicht, da ich keine Signale erzeugen will, sondern nur den Sinus und Cosinus berechnen muss. Deshalb auch die andere Skalierung, damit man den Winkel dezimal eingeben kann. Dein Programm ist aber ein gutes Beispiel für den Phasenakkumulator. Hebe ich mir auf, wenn ich mal so etwas brauche. Der Barrel-Shifter braucht nicht nur viel Platz, sondern auch Zeit. Du könntest Deinen Code optimieren, wenn Du den Barrel-Shifter von mir verwenden würdest. Damit würde auch der Table-Lookup für den arctan einfacher. Größe und Laufzeit würden erheblich kürzer. - Ich sehe allerdings, dass Du die iterationen 8 bis 15 auskommentiert hast, dann relativiert sich das Ganze natürlich. Ich benötigte eine möglichst hohe Genauigkeit und brauche die 15 Iterationen, erwäge sogar auf 24bit-Arithmetik zu erweitern.
Ich wollte die Unterprogrammaufrufe vermeiden, das kostet jedesmal 7 oder 8 Takte, daher die Sprungtabelle. Der Artikel im Wiki war damals auch von mir begonnen worden. Ob der Phasenakkumulator so funktioniert weiß ich nicht. Eine ausführliche Beschreibung zum Cordic und Phasenakkumulator stammt aus einer leider gelöschten Seite: http://cnmat.cnmat.berkeley.edu/~norbert/cordic/node4.html die ich noch auf archive.org finden konnte, hier als PDF.
Ka Suh schrieb: > Nachdem sich hier niemand mit einer Implementierung gemeldet hat, habe > ich mich selbst daran versucht. Hier das erste Resultat für eine > Sinus/Cosinusberechnung nach Cordic. > > Ich hoffe jetzt auf reges Feedback zur Verbesserung des Codes. > > Hier zwei Ansatzpunkte: > > Gegenüber einer 16bit-Tabelle gibt es kleine Aproximationsfehler. > > Die meiste Zeit frisst der Barrel-Shifter, der beim AVR leider nicht in > Hardware existiert und als Software-Schleife realisiert wurde. Etwas > optimiert habe ich dadurch, dass ich bei Shifts größer 8 erst einmal > ganze Register verschiebe. Interessant wäre, das ganze so zu schreiben, daß es auf das avr-gcc ABI passt, d.h. daß man die Funktionen komfortabel von avr-gcc aus aufrufen und in C/C++ Programmen verwenden könnte. Dann enthält das Programm einen Fehler, von dem ich aber nicht weiß, ob er sich auf die Genauigkeit auswirkt. Es ist nämlich
Beispiel: wenn du 1 um 1 nach rechts schiebst, dann wird das 0. Aber wenn du -1 nach rechts schiebst, dann bleibt das -1. Egal, wie oft du eine negative Zahl nach rechts schiebst, sie wird nie 0. Es müsste also vor dem (Barrel-)Shift der Betrag genpmmen werden, und nach dem Shift für negative Zahlen das Vorzeichen wie der angepasst werden. Johann
Der Barrel-Shift lässt sich vielleicht durch explizite Fallunterscheidung beschleunigen, zumindest im Mittel:
1 | __tmp_reg__ = 0 |
2 | __zero_reg__ = 1 |
3 | .section .progmem.data,"a",@progbits |
4 | .size l.0, 16 |
5 | labels.0: |
6 | .word pm(.L.sh0) |
7 | .word pm(.L.sh1) |
8 | .word pm(.L.sh2) |
9 | .word pm(.L.sh3) |
10 | .word pm(.L.sh4) |
11 | .word pm(.L.sh5) |
12 | .word pm(.L.sh6) |
13 | .word pm(.L.sh7) |
14 | |
15 | .text |
16 | |
17 | ;; r25:r24 >>= r22 (unsigned) |
18 | ;; kaputt: r26, r27, r30, r31 |
19 | .global shift |
20 | shift: |
21 | cpi r22, 8 |
22 | brlo .less.than.8 |
23 | mov r24, r25 |
24 | clr r25 |
25 | sbrc r22,2 |
26 | swap r24 |
27 | sbrc r22,2 |
28 | andi r24, 0xf |
29 | sbrc r22,1 |
30 | lsr r24 |
31 | sbrc r22,1 |
32 | lsr r24 |
33 | sbrc r22,0 |
34 | lsr r24 |
35 | ret |
36 | |
37 | .less.than.8: |
38 | mov r30, r22 |
39 | lsl r30 |
40 | clr r31 |
41 | subi r30, lo8(-(labels.0)) |
42 | sbci r31, hi8(-(labels.0)) |
43 | |
44 | lpm r26, Z+ |
45 | lpm r27, Z |
46 | movw r30, r26 |
47 | ijmp |
48 | .L.sh7: |
49 | lsr r25 |
50 | ror r24 |
51 | .L.sh6: |
52 | lsr r25 |
53 | ror r24 |
54 | .L.sh5: |
55 | lsr r25 |
56 | ror r24 |
57 | .L.sh4: |
58 | lsr r25 |
59 | ror r24 |
60 | .L.sh3: |
61 | lsr r25 |
62 | ror r24 |
63 | .L.sh2: |
64 | lsr r25 |
65 | ror r24 |
66 | .L.sh1: |
67 | lsr r25 |
68 | ror r24 |
69 | .L.sh0: |
70 | ret |
Johann
auf Megas könnte man mit FMUL auch den Rechtsshift beschleunigen.
Ka Suh schrieb: > Nachdem sich hier niemand mit einer Implementierung gemeldet hat, habe > ich mich selbst daran versucht. Hier das erste Resultat für eine > Sinus/Cosinusberechnung nach Cordic. > > Eingegeben wird der Winkel in 10tel Grad als 16-bit vorzeichenbehaftete > Ganzzahl im Bereich -91 bis +91 Grad, also -910 bis +910. > Als Ergebnis erhält man den Sinus und Cosinus als 16-bit > vorzeichenbehaftete Ganzzahl. > > Ich hoffe jetzt auf reges Feedback zur Verbesserung des Codes. > > Hier zwei Ansatzpunkte: > > Gegenüber einer 16bit-Tabelle gibt es kleine Aproximationsfehler. > > Die meiste Zeit frisst der Barrel-Shifter, der beim AVR leider nicht in > Hardware existiert und als Software-Schleife realisiert wurde. Etwas > optimiert habe ich dadurch, dass ich bei Shifts größer 8 erst einmal > ganze Register verschiebe. Hast du mal ne Zeitmessung gemacht? Würd mich interessieren, wieviel Ticks die Berechnung braucht. Ich hab den CORDIC jetzt mit Multiplikation anstatt AShift implementiert, und der braucht pro Aufruf recht konstant ca. 690 Ticks inclusive Aufruf von C aus. Gemessen wirde auf der Hardware. Die Implementierung ist avr-gcc ABI-konform, und Eingabe und Ausgabe sind skalierbar. Die Eingabe muss in -sqrt(3)...sqrt(3) liegen. Das entsprich -99°...99° bzw. -1.1*Pi/2...1.1*Pi/2, und die Ausgabe ist auf 1.15 signed Q-Format. Ist wie gesagt über zwei Makros skalierbar: eins für den Bereich der Eingabe und einen für die Ausgabe. Welche Genauigkeiten sind erreichbar? Wenn man von 16 Schleifendurchläufen ausgeht und in jedem Durchlauf 1 Bit verliert, verliert man doch insgesamt 4 Bit an Genauigkeit wegen Rundungsfehlern, oder? Der Fehler scheint bei ca. 1-4 Incrementen zu liegen. Wenn Interesse an der Implementierung da ist und sie von der Geschwindigkeit her nicht ausser Konkurrenz ist, würde ich's aufhübschen und hier reinstellen. Codegröße ist 222 Bytes + 34 Bytes atan-Tabelle. Johann
Einige Verbesserungen: wenn CoTmp und SiTmp beide 0 sind kann die Iteration abgebrochen werden. Der Gain des CORDIC darf dann aber erst am Ende der Iteration berücksichtigt werden. Denn dieser ist ja abhängig von der Anzahl der Iterationen. Man sollte also bei dieser Beschleunigung eine weitere Tabelle mit max. 16 Einträgen haben um den Gain an die Iterationstiefe anzupassen. Mit wenigen Änderungen kann man Wurzel(X^2+Y^2) und ArcTan2(X, Y) ebenfalls mit dieser Funktion ausrechnen. Beides in einem Rutsch und sehr hilfreich wenn man zb. bei einer nicht kohärenten IQ Demodulation den Betrag und die Phase des demodulierten Signales ausrechnen möchte. Statt über den Angle zu gehen wird man dann die Y Koordiante abfragen. Gruß Hagen
Angehängte Dateien:
-

cordic-kreis.png
19 KB

Hagen Re schrieb: > Einige Verbesserungen: > wenn CoTmp und SiTmp beide 0 sind kann die Iteration abgebrochen werden. Lohnt das? Dürfte selten der Fall sein das, und im Mittel die Abfrage mehr kosten als sie bringt. Momentan scheint eher die Genauigkeit ein Problem zu sein, und ich bin mir nicht sicher, ob ich das fmul-Zeug richtig verstanden hab und immer korrekt runde. Anbei eine Grafik. Die roten Punkte sind vom PC berechnet. Die schwarzen kommen vom AVR und sind darübergemalt (rechts einer weniger als vom PC). Die Schrittweite ist 0.25°, also 0.00436, im Bereich -91°...91°. Sieht aus als wär damit die Auflösung am Ende der Fahnenstange, oder ich hab was Grunsätzliches verpeilt... Johann
Angehängte Dateien:
-

cordic-kreis2.png
12 KB

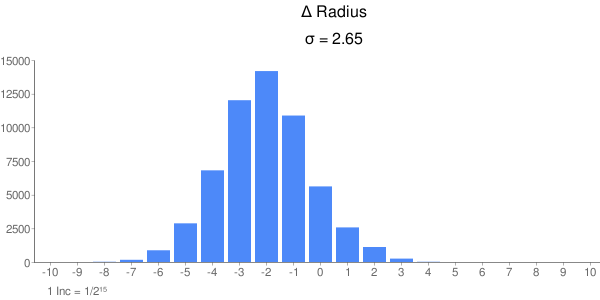
Hier noch der Kreis selbst, mit einer Schrittweite von 0.01°, wieder kommen die Daten direkt vom AVR. Der Abstand zweier Pixel auf dem Kreisrand entspricht bei der Bildauflösung ca. 0.036°. Sieht sauber aus und ohne Ausreisser. Der Genauigkeitsverlust ist nicht in der r-Komponente sondern in phi. Die Ausgaberoutine auf AVR bringt natürlich auch nen Rundungsfehler, aber der dürfte deutlich unter dem des Cordic liegen, nämlich bei einem Inkrement bzw 1/32768 ~ 0.00003. Fehler darin würde man auch in r sehen, nicht nur in phi. Johann
>Lohnt das? Dürfte selten der Fall sein das, und im Mittel die Abfrage >mehr kosten als sie bringt. Kannst einfach ausrechnen. Die Iterationsanzahl hängt von der Bitgröße der beiden Operanden X,Y ab. Bei zb. X,Y=8 = 2^3 also 3 Bits und somit minimal 3 Iterationen nötig. Ausgehend von 16Bit Wertebereich sind es also Iterationen, Wahrscheinlichkeit 2=0.003% 3=0.006% 4=0.012% 5=0.024% 6=0.048% 7=0.097% 8=0.195% 9=0.390% 10=0.781% 11=1.562% 12=3.125% 13=6.25% 14=12.5% 15=25% 16=50% Das ist aber nur die Bitwahrscheinlichkeit, also wenn man annimmt das gleichverteilt alle möglichen bis zu 16Bit Werte vorkommen. Ich würde erstmal versuchen den Algo. wenn möglich mit immer gleichbleibender Taktanzahl zu programieren, da man so das Gesamtsytem besser vorhesagbar macht. Erst wenn es auf den letzten Takt ankäme würde ich in diese Richtung weiter entwickeln. Meistens wird man dann eher eine Funktion bauen die mit konstanten Winkeln etc.pp. arbeitet. Interssanter wäre da schon die Möglichkeit die Rechtsshifts durch Linksshifts austauschen zu können. Linksshift sind bei einfacher MUL noch besser zu optimieren als Rechtsshifts. Grundsätzlich geht das sogar auch. Man kann zahlentheoretsich den Rechtsshift per Multipikation als Linksshift bauen. Angenommen man wollte 3 Bits Rechtsshiften dann kann man auch X << (8-3) / 2^8 rechnen. Dh. man multipliziert mit 2^(8-3) und verwirft das unterste Byte der Multiplikation. Für kleine Shifts ist die Multiplikation langsammer aber alles an Shift mit größer 1 oder 2 wird durch die Multipikation in jedem Fall schneller. Für diesen Trick müsstest du die Zählervariable einfach von 15 nach 0 runterzählen lassen, würde ich mal so aus dem Stegreif sagen. Gruß Hagen
Hagen Re schrieb: > Interssanter wäre da schon die Möglichkeit die Rechtsshifts durch > Linksshifts austauschen zu können. Linksshift sind bei einfacher MUL > noch besser zu optimieren als Rechtsshifts. Grundsätzlich geht das sogar > auch. Man kann zahlentheoretsich den Rechtsshift per Multipikation als > Linksshift bauen. Angenommen man wollte 3 Bits Rechtsshiften dann kann > man auch X << (8-3) / 2^8 rechnen. Dh. man multipliziert mit 2^(8-3) und > verwirft das unterste Byte der Multiplikation. Für kleine Shifts ist die > Multiplikation langsammer aber alles an Shift mit größer 1 oder 2 wird > durch die Multipikation in jedem Fall schneller. Für diesen Trick > müsstest du die Zählervariable einfach von 15 nach 0 runterzählen > lassen, würde ich mal so aus dem Stegreif sagen. Ja, so mach ich das. Mit der Fallunterscheidung ob es mehr oder weniger als 8 Bits zu schieben sind. Bin jetzt bei 550 Ticks und 268 Bytes. Immerhin um 20% schneller als meine erste Version :-)) Geht also voran... Johann
Da ich nur in Assembler programmiere, habe ich bisher keine Ahnung von avr-gcc ABI-Konformität, bin aber daran interessiert in Zukunft nach Möglichkeit konformen Assembler-Code zu erstellen. Kann mir jemand helfen und einen Link zu einer einfachen Anleitung oder Spezifikation nennen oder kurz die Konformitätsregeln beschreiben? (Ich benutze AVR-Studio) Gruß Ka
Hallo Johann Zu Deinen Fragen vom 28.06.2009 12:06: Mein Code vom 06.2009 benötigt konstant 886 Takte und 70 Worte. Da ich mit 16bit signed arbeite genügen genau 15 Iterationen. Enthalten ist die Skalierung des Eingangswertes. Ich orientiere mich bei den Angaben an den Applicationnotes von Atmel, d.h. ohne Aufruf und return. Meine Optimierungsschwerpunkt lag eher auf minimaler Wortzahl und konstante, vom eingegeben Winkel unabhängige Taktzahl. Trotzdem habe ich eine einfache Takt-Optimierung am Barrelshifter vorgenommen, da sie bei geringer Größenerhöhung doch einiges an Geschwindigkeit brachte. Bei Shifts >= 8 wird erst über mov ein ganzes Byte verschoben und der dann die restlichen Shifts ausgeführt. Lässt man diese nämlich weg, kommt man auf 1261 Takte bei 63 Worten. Zieht man beim optimierten Code die Skalierung des Eingabewertes ab und verzichtet auf konstante Abarbeitungszeit kommt man auf 60 Worte und schwankende Taktzahl (beobachtet: 854-873 Takte) Du macht aber 16 Iterationen, stimmt dass? Dann bist Du mit Deinen derzeit 550 Ticks konkurrenzlos besser. bei mir wären es 976 Ticks. Der Größenverlust von 268 Bytes bei Dir zu 120 Bytes bei mir ist dafür durchaus tragbar. Kurzum, Johann, ich wäre an Deinem Code interessiert, kannst Du Ihn hier veröffentlichen, auch wenn noch vorläufig. Gruß Ka
Ka Suh schrieb: > Da ich nur in Assembler programmiere, habe ich bisher keine Ahnung von > avr-gcc ABI-Konformität, bin aber daran interessiert in Zukunft nach > Möglichkeit konformen Assembler-Code zu erstellen. Kann mir jemand > helfen und einen Link zu einer einfachen Anleitung oder Spezifikation > nennen oder kurz die Konformitätsregeln beschreiben? http://www.rn-wissen.de/index.php/Avr-gcc/Interna#Registerverwendung http://avr-libc.nongnu.org/user-manual/FAQ.html#faq_reg_usage Johann
Hallo Johann, danke für die Info. Ergänzende Frage: wie wird in meinem Fall der return-Wert gebildet, wenn Sinus und Cosinus zusammen zurückgegeben werden sollen, damit es mit gcc kompatibel ist? Aus den Beschreibungen ist mir nicht klar, wie Arrays oder Strukturen zurückgegeben werden? Ich hätte jetzt einfach den Sinus in r25:r24 gepackt und den cosinus in r22:r23. Geht das? Ka
Ka Suh schrieb: > Hallo Johann, > > danke für die Info. Ergänzende Frage: wie wird in meinem Fall der > return-Wert gebildet, wenn Sinus und Cosinus zusammen zurückgegeben > werden sollen, damit es mit gcc kompatibel ist? Aus den Beschreibungen > ist mir nicht klar, wie Arrays oder Strukturen zurückgegeben werden? Ich > hätte jetzt einfach den Sinus in r25:r24 gepackt und den cosinus in > r22:r23. Geht das? Ja, genau dort gebe ich sie auch zurück. Passend zum Assembler-Modul gibt's dann nen Header mit den Prototypen für die Funktionen, damit (avr-)gcc weiß, wie die Funktionen aufzurufen sind. Als Returnwert
1 | #include <stdint.h> |
2 | |
3 | typedef struct |
4 | {
|
5 | uint16_t cos; |
6 | uint16_t sin; |
7 | } __attribute__((packed)) cossin_t; |
Dann wird cos in r23:r22 und sin in r25:24 übergeben. Ka Suh schrieb: > Du macht aber 16 Iterationen, stimmt dass? Dann bist Du mit Deinen > derzeit 550 Ticks konkurrenzlos besser. bei mir wären es 976 Ticks. Der > Größenverlust von 268 Bytes > bei Dir zu 120 Bytes bei mir ist dafür durchaus tragbar. Mir ging es eher um Geschwindigkeit; nicht bis aufs Messer, aber in 500 Ticks sind schon Weltreiche aufgestiegen und wieder zerfallen... > Kurzum, Johann, ich wäre an Deinem Code interessiert, kannst Du Ihn hier > veröffentlichen, auch wenn noch vorläufig. Vorher muss ich noch die Arithmetik testen. Zum Shift ist der Abstand der Multplikation nie größer als 1 LSB, was plausibel ist. Muss aber noch gegen die Standard-Multiplikation testen, weil natürlich auch die Präzision so hoch wie unter den Umständen möglich sein soll. Möglicherweise vertögle ich bei den fmul* irgendwo ein LSB, bin aber noch nicht sicher. Bis dahen gibt's also kein Code. Johann
So, hier ist der Code. -- Code: 278 Bytes -- Ticks: weniger als 560 -- Eingabe in (-sqrt3, sqrt3), das entspricht -99°...99° -- Ausgabe als signed 1.15 Q-Format Johann
Angehängte Dateien:
-

cordic-err-phi.png
4,2 KB
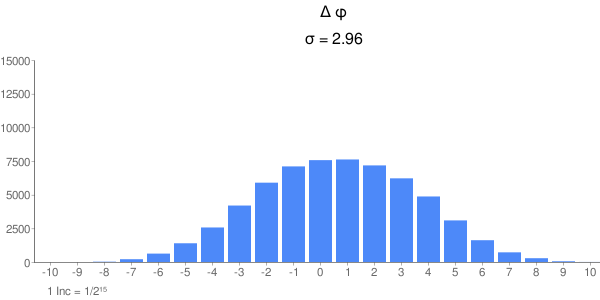
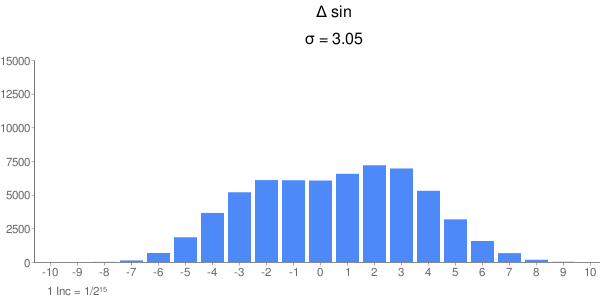
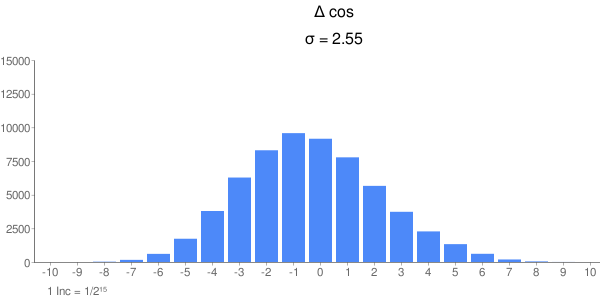
...und für den Winkel Die Fehler sind wie zu erwarten gut Normalverteilt in einem Intervall von ca 16 Inkrementen. Das ist auch zu erwarten bei 16 Iterationschritten und Fehlerfortpflanzung. Aus der Reihe fällt der Sinus; der Fehler schein aus der Summe zweier Gauß-Glocken zu bestehen. Ich weiß aber nicht, wie die 2 Komponenten zustandekommen oder wie man die Kurve schmäler (d.h. die Standardabweichung kleiner) bekommt. Vielleicht findet ja jemand nen Rundungsfehler im Algorithmus, wobei erstaunt, daß das Phänomen nur den Sinus betrifft. Johann
Zu Beginn kann man noch ausnutzen, daß sin=0 ist:
1 | cordic: |
2 | ;; end prolog |
3 | movw _phi, R24 |
4 | clr _zero |
5 | ;; Z = cordic_atan_tab[] |
6 | ldi r30, lo8 (cordic_atan_tab) |
7 | ldi r31, hi8 (cordic_atan_tab) |
8 | ;; cos = 1 / CORDIC_GAIN |
9 | lpm _cos, z+ |
10 | lpm _cos+1, z+ |
11 | |
12 | ldi _pow2, 0x80 |
13 | |
14 | ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; |
15 | ;; Shift = 0 |
16 | movw _sin, _cos |
17 | |
18 | tst _phi+1 |
19 | ;; phi >= 0: sin = 0+cos |
20 | brpl .L_phi_pos_1_7 |
21 | |
22 | ;; phi < 0 : sin = 0-cos |
23 | com _sin+1 |
24 | neg _sin |
25 | sbci _sin+1, -1 |
26 | rjmp .L_phi_neg_1_7 |
Hallo Johann, kleine Nebenfrage. Ich benutze AVRstudio und programmiere nur in Assembler. Die Syntax, die Du verwendest, insbesondere Sprungadressen, Makros, Precompiler-Direktive etc. versteht mein Compiler nicht. Ich kann zwar den Code anpassen, aber ist das der richtige Weg? Gruß Ka
Ka Suh schrieb: > Hallo Johann, > > kleine Nebenfrage. Ich benutze AVRstudio und programmiere nur in > Assembler. Die Syntax, die Du verwendest, insbesondere Sprungadressen, > Makros, Precompiler-Direktive etc. versteht mein Compiler nicht. Ich > kann zwar den Code anpassen, aber ist das der richtige Weg? Kann man machen. Fast einfacher ist es da, den Code aus nem Disassemble raus neu zu erzeugen. Du kannst einfach die Kommandozeile wie in cordic-demo.c ausführen und ein Disassembler erstellen. AVR-Tools gibt's frei und kostenlos. Ich verwende den GNU-Assembler. Zum einen ist der "mächtiger" als der Atmel-Assembler, zum zweiten arbeitet der als AVR-Tool mit Linker und Compiler zusammen und erzeugt richtige Objekte in elf32-avr gegen die man linken kann. Damit kann man gegen andere Objekte in elf32-avr linken, egel ob sie aus einer Assembler-Quelle kommen, aus C, aus C++, AVR-Ada, ... und Biblioteken erstellen, ... Johann
Ich hab Sinus und Cosinus mal per linearer Interpolation implementiert. Der Code ist mit 300 Bytes zwar größer als Cordic, dafür ist er mit 60 Ticks für Sinus bzw. 74 Ticks für Cosinus (incl. CALL+RET) deutlich schneller als CORDIC. Ebenfalls besser ist die Genauigkeit sowie eigenschaften wie Monotonie (CORDIC-Ausgaben sind idR "verrauscht" und nicht monoton). http://www.mikrocontroller.net/articles/AVR_Arithmetik/Sinus_und_Cosinus_%28Lineare_Interpolation%29 Johann
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.