Hallo, ich hab eine Shake Hands Implementierung realisiert. Dabei benutze ich 2 ATMega 16, einen als Master, einen als Slave. allerdings erreiche ich zwischen 2 Atmenga16 gerademal 90kbyte/sekunde. ich hatte mir etwas mehr vorgestellt. ISt eine Interrupt gesteuerte Methode schneller? ich benutze den schnellsten SPI clock (fCLK/4). Ausserdem moechte ich auf dauer mehr als einen Slave benutzen. Ich denke da an 5 oder mehr im Daisy Chain modus. das problem ist jetzt aber erstmal die langsame uebertragung.
Das Problem der Master Slave SPI zwischen controllern ist dass der Slave nicht gleich schnell wie der Master kann. Auch wenn er koennte. Es sollte ein FIFO mit sagen wir 64 byte fuer den Empfaenger da sein. Sind aber nicht. Es gibt beinm Slave einen Interrupt, und dann muss man das Byte holen. Sonst ist das naechste auch schon da. Meines Erachtens ist SPI mangels Buffern nicht geeignet fuer schnelle controller/controller kommunikation. Falls es doch schnell sein sollte, koennte man eine Schieberegister/Buffer-Architektur in einem CPLD bauen. Fuer erhoehte Anforderungen gibt's das schon : Serdes. 32bit parallel, der clock von 25MHz vor hoch-ge-PLL't auf 860MHz oder so und dann hat man PCI auf LVDS. Auf der anderen Seite wieder runter. Was dazwischen gibt's leider nicht standardmaessig.
@ Kaplan >ich hab eine Shake Hands Implementierung realisiert. Dabei benutze ich 2 >ATMega 16, einen als Master, einen als Slave. >allerdings erreiche ich zwischen 2 Atmenga16 gerademal 90kbyte/sekunde. >ISt eine Interrupt gesteuerte Methode schneller? Ich denke eher langsamer. Denn wenn für jedes Byte der Interrupt aufgerufen werden muss, beschäftigt sich der AVR zu 90% mit Overhead. Bei fCLK/4 SPI-takt dauert die Übertragung eines Bytes gerade mal 32 Takte. In dieser Zeit kann der Sendende AVR schom mal das nächste Byte bereitstellen (lesen über Pointer ais dem SRAM) und noch bissel warten. Der Empfänger kann das zuletzt empfangene Byte speichern. Damit sollte man schon recht nah an die theoretisch mögliche Grenze von 500kB/s rankommen. Abr wie gesagt OHNE Interrupt. >Ausserdem moechte ich auf dauer mehr als einen Slave benutzen. Ich denke >da an 5 oder mehr im Daisy Chain modus. Daisy Chain bei SPI? @ Kornfisch >Byte holen. Sonst ist das naechste auch schon da. Meines Erachtens ist >SPI mangels Buffern nicht geeignet fuer schnelle controller/controller >kommunikation. Falls es doch schnell sein sollte, koennte man eine Naja mal langsam. Bei 16 MHz sind das immerhin 4 Mbit/s, schlappe 500 kB/s. WENN man es richtig macht! Geht hier eben nicht wie beim UART, wo man jedes Byte per Interrupt abholen kann. Manachmal sind schnöde Polling-Schleifen halt doch besser als Interupts. ;-) MfG Falk
dann ist meine schallmauer wohl schon bei 100kbyte/s erreicht. denn ich mach ja nicht mehr ausser nur in das register zu schreiben und zu lesen. ausserdem ist mir nur die datenuebertragung von mehreren SLAVES zum MASTER wichtig. gibts da alternativen. Meine SLAVES sammeln analogdaten und filtern diese. dann werden nur die fuer mich sinnvollen an den MASTER uebertragen. und das moeglichst schnell!!!
>ich benutze den schnellsten SPI clock (fCLK/4).
Ist er das wirklich ?
// SPI2X=1; //Double speed for SPI = 8MHz @16MHz Clock
SPSR=0x01;
War natürlich Quatsch :( Der Slave kann nur fclk/4. Bitte löschen bevor falsches verbreitet wird.
@ Kaplan >dann ist meine schallmauer wohl schon bei 100kbyte/s erreicht. denn ich >mach ja nicht mehr ausser nur in das register zu schreiben und zu lesen. Zeig mal deinen Quelltext. >ausserdem ist mir nur die datenuebertragung von mehreren SLAVES zum >MASTER wichtig. gibts da alternativen. SPI ist schon so ziemlich das schnellste, was man sich denken kann. Es sei denn, du kanns/willst viele IOs "opfern" und die Daten parallel übertragen. Da könnte man noch etwas Zeit rausholen. MfG Falk
Hallo Falk,
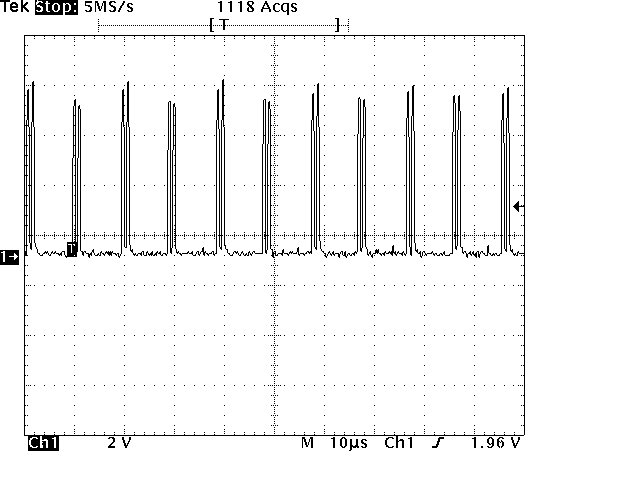
im Anhang noch die Osziaufnahme dazu. 1 byte alle ca 7 us ergeben 139
kbyte pro sekunde. Mit Shakehands sind nur noch 97.66kbyte/s. allerdings
kann ich dort von fehlerfreier uebertragung vom Slave zum Master
ausgehen.
das ziel ist von mehreren Slaves in kurzer zeit die daten zu einem
Master zu bringen.
[c]
#ifndef F_CPU
#define F_CPU 16000000UL
#endif
#include <avr/io.h>
#include <avr/interrupt.h>
#include <avr/delay.h>
#include <avr/pgmspace.h>
#include <inttypes.h>
#include <string.h>
#include "uart.h" // communication with serial interface
#define UART_BAUD_RATE 56000
#define MASTER 1
//overwrite PortB with SPI
#define DD_SS PB4
#define DD_MOSI PB5
#define DD_MISO PB6
#define DD_SCK PB7
#define DDR_SPI DDRB
char receivebyte=0x00;
char receivebyte2=0x00;
void SPI_MasterInit(void) {
// Set MOSI SCKK and SS as output, all others input
DDR_SPI = (1<<DD_MOSI)|(1<<DD_SCK)|(1<<DD_SS);
//Set SS as output (SS= PB4)
//DDRB|=(1<<PB4);
//Enable SPI, Master, set clock rated fclk/4
SPCR = (1<<SPE) | (1<<MSTR) ;
}
void SPI_SlaveInit(void)
{
//Set MISO output, all others input
DDR_SPI = (1<<DD_MISO);
//Enable SPI
SPCR = (1<<SPE);
}
char SPI_SlaveReceiveTransmit(char cData){
SPDR=cData;
//wait for reception complete
while (!(SPSR & (1<<SPIF)));
//return data register
return SPDR;
}
char SPI_MasterTransmitReceive (char cData){
//Start Transmission
SPDR = cData;
//wait for transmission complete
while (!(SPSR & (1<<SPIF)));
return SPDR;
}
int main(){
if (MASTER==1) {
sei();
//initialize UART and set baudrate
uart_init( UART_BAUD_SELECT(UART_BAUD_RATE,F_CPU) ); char
countvar=0;
SPI_MasterInit();
while (1) {
PORTB &= ~(1<<DD_SS);
//receivebyte=SPI_MasterTransmitReceive(0xF1);
receivebyte=SPI_MasterTransmitReceive(countvar);
countvar+=1;
PORTB |= (1<<DD_SS);
if (receivebyte != receivebyte2) {
uart_putc(receivebyte);
uart_putc(receivebyte2);
uart_putc(receivebyte-receivebyte2);
uart_putc(0xAA);
}
receivebyte2=receivebyte+1;
}
}
//SLAVE
else {
sei();
//initialize UART and set baudrate
uart_init( UART_BAUD_SELECT(UART_BAUD_RATE,F_CPU) );
char countvar=0;
SPI_SlaveInit();
while (1){
while (!(PINB & (1<<DD_SS)));
receivebyte=SPI_SlaveReceiveTransmit(countvar);
countvar+=1;
}
}
}
[\c]
Kaplan wrote: > Hallo Falk, > im Anhang noch die Osziaufnahme dazu. Anhang fehlt.
Angehängte Dateien:
-

SPI_ShakeHands_max.png
2,3 KB
hier noch die shakehands loesung plus bild im anhang. SlaveBusy ist die
ShakeHands leitung :)
wer das verwenden will sollte gleichen ground bei beiden
Mikrocontrollern verwenden...
[c]
#define SLAVE_BUSY PINB3
#define DD_SLAVE_BUSY PB3
// Input influences SPI CLK: 0 = fCLK/4, 1 = fCLK/16, 2=fCLK/64,
2=fCLK/128
void SPI_MasterInit(char clockselect) {
// Set MOSI SCKK and SS as output, all others input
DDR_SPI = (1<<DD_MOSI)|(1<<DD_SCK)|(1<<DD_SS);
//Enable SPI, Master, set clock rated fclk/16
SPCR = (1<<SPE) | (1<<MSTR) | (clockselect);
// ~SS ist high, somit disable
PORTB |= (1<<SLAVESELECT); // set SS high
while (PINB & (1<<SLAVE_BUSY));//warte auf busy low
while (!(PINB & (1<<SLAVE_BUSY)));//warte auf busy high
}
// cData is a byte to send via SPI,returns a byte that has been received
synchronously
char SPI_MasterTR(char cData){
PORTB &= ~(1<<SLAVESELECT); // set SS low
while (PINB & (1<<SLAVE_BUSY));//warte auf busy low
SPDR = cData;
//wait for transmission complete. this is not necessary but clears
SPIF bit.
while (!(SPSR & (1<<SPIF)));
//wait for slave, till transmission is finished
while (!(PINB & (1<<SLAVE_BUSY)));//warte auf busy high
//Pulling high slave select
PORTB |= (1<<SLAVESELECT);
return SPDR;
}
void SPI_SlaveInit(void)
{
//Set MISO and SLAVE_BUSY as output, all others input
//DD_SLAVE_BUSY = PB3 to show status to Master
DDR_SPI = (1<<DD_MISO) | (1<<DD_SLAVE_BUSY);
//Enable SPI
SPCR = (1<<SPE);
//SET Slave to busy
//PORTB|=(1<<SLAVE_BUSY);
}
//cData is a byte send to Master
char SPI_SlaveTR(char cData){
while (PINB & (1<<SLAVESELECT)); //warte auf SS low
SPDR = cData;
PORTB &= ~(1<<SLAVE_BUSY); //setze SLAVE BUSY low
while (!(SPSR & (1<<SPIF))); //warte auf SPIF
PORTB |= (1<<SLAVE_BUSY); //setze SLAVE BUSY high
return SPDR;
}
int main(){
sei();
if (MASTER==1) {
uart_puts("MASTER|");
SPI_MasterInit(0x00);
while (1) {
receivebyte = SPI_MasterTR(0x12);
}
}
else {
uart_puts("SLAVE|");
while (!(PINB & (1<<SLAVESELECT)));//warte auf SS high
//SET SLAVE BUSY as output
DDRB |= (1<<SLAVE_BUSY);
PORTB &= ~(1<<SLAVE_BUSY); //set busy low
_delay_ms(1);
PORTB |= (1<<SLAVE_BUSY); // set BUSY high
while (1) {
SPI_SlaveInit();
receivebyte = SPI_SlaveTR(0x34);
}
}
}
Angehängte Dateien:
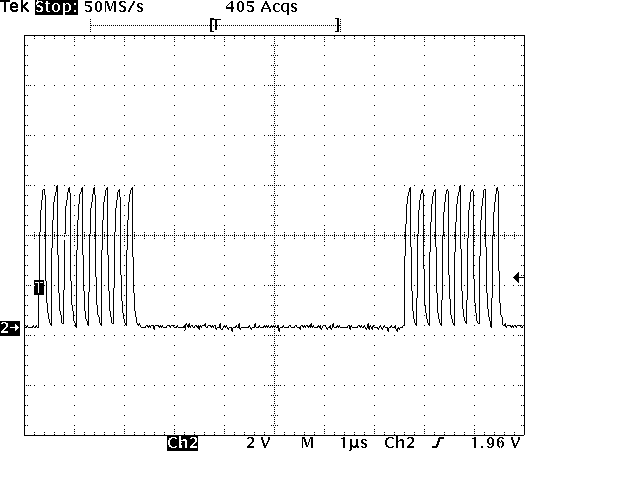
hier noch der anhang der gefehlt hat...
dennoch bin ich am ueberlegen ob ein Interrupt gesteuerte SPI kommunikation nicht schneller wäre... denn die while schleifen sind doch irgendwie lahm. dass ich während einer while schleife nichts machen kann, stört mich nicht. aber das der slave so zeitkritisch arbeiten muss ist schon hart. mit interrupts kenn ich mich nicht so aus aber wenn ich die leitungen SS und SLAVE_Busy als externe interrupts verwende, könnte ich doch unter umständen einsparen oder? falls der code oben sich beschleunigen lässt bin ich auch dankbar.
mit SPI habe ich noch nichts gemacht. ein interrupt braucht ein paar takte um überhaupt zum code zu kommen. es sind ja ein unterroutinen-aufruf und ein sprung in den code. beides braucht zeit.
Dein C-Compiler wird auch einen gewissen (wenn auch kleinen) Overhead erzeugen, z.B. wenn Du Funktionen aufrufst, Werte zurückgibst, zuweist usw. Du kannst ja mal versuchen, z.B. den Inhalt von "SPI_SlaveReceiveTransmit" direkt in die aufrufende Programmstruktur 'reinzuschreiben. Das sollte schneller gehen als ein Funktionsaufruf, schon weil Du die Zeit einsparen solltest, cData in SPDR zu speichern und beim Rücksprung das Funktionsergebnis zu lesen. (ok, es kommt auch nicht unwesentlich auf den Compiler an). Das sieht dann aus wie "mit Absicht schlechterer Programmierstil, dafür schnellerer". Oder wenn es schnellstmöglich sein soll, in Assembler: loop1: sbis spsr,spif rjmp loop1
@ Kaplan >dennoch bin ich am ueberlegen ob ein Interrupt gesteuerte SPI >kommunikation nicht schneller wäre... denn die while schleifen sind doch Nein, wäre sie nicht. >irgendwie lahm. dass ich während einer while schleife nichts machen Wieso lahm? Was soll der Interrupt da schneller machen? Und wieso machst du vor jeder Überttragung eines Bytes einen SPI_SlaveInit()? Das ist Unsinn und kostet haufenweise Zeit. >kann, stört mich nicht. >aber das der slave so zeitkritisch arbeiten muss ist schon hart. mit Wieso? Den AVR interessiert das nicht. Ober er nun NOPs ausführt oder sinnvolle Operationen ist ihm egal. >falls der code oben sich beschleunigen lässt bin ich auch dankbar. Lässt er. @ Carsten Pietsch >Dein C-Compiler wird auch einen gewissen (wenn auch kleinen) Overhead >erzeugen, z.B. wenn Du Funktionen aufrufst, Werte zurückgibst, zuweist >usw. >Du kannst ja mal versuchen, z.B. den Inhalt von >"SPI_SlaveReceiveTransmit" direkt in die aufrufende Programmstruktur >'reinzuschreiben. Das sollte schneller gehen als ein Funktionsaufruf, Kann amn einfacher und sauberer, indem man die Funktionen als inline definiert. Das spart das Übergeben der Parameter udn den Aufruf per call. >Absicht schlechterer Programmierstil, dafür schnellerer". Oder wenn es >schnellstmöglich sein soll, in Assembler: Naja, man kann auch in C noch EINIGES an Geschwindigkeit rausholen. Zunächst mal nicht dauern einen SPI_SlaveInit() beim Senden machen. Einfach nur das, was wirklich notwendig ist. Nämlich das RX bzw. TX complete Flag pollen und Daten rauschreiben. Und nicht bei jedem Byte ein Handshake mit dem Master machen. Das braucht mehr Zeit als der eigentliche Transfer! Den Handshake braucht man nur um die Übertragung einzuleiten. Dann wird eine feste Anzahl Bytes übertragen, mit maximaler Geschwindigkeit. Und das wars dann auch. Und wieso gibt die SENDEroutine die gesendeten Daten wieder zurück? Das ist sinnlos und Zeitverschwendung! Ich würde es ungefähr so machen. Vom Master geht jeweils eine Leitung zu den jeweiligen Slaves (Slave Select). Alle Slaves werdem über eine gemeinsame Leitung (nenn ich mal ACK) in Richtung Master verbunden (Die Ausgänge müssen dann als Open Drain betrieben werden, sonst gibts Kurzschlüsse). Der jeweils selektierte Slave erkennt erstmal, dass er angesprochen wird, schreibt das erste Byte in sein SPI Datenregister und zieht ACK auf LOW als Zeichen dafür, dass es nun losgehen kann. Und das sollte auch der Master erkennt ACK=LOW und generiert nun N Datentransfers (N = Anzahl der Bytes). Und das so schnell wie möglich. Der Trick dabei ist, dass eben NICHT für jedes Byte ein Handshakezyklus gemacht wird wie er im Datenblatt beschrieben ist, das ist auch irgendwie Nonsense. Der Master muss nach Erkennen von SPIF ein minimale Zeit warten, die auch der Slave braucht, um SPIF zu erkennen und neue Daten ins Register zu schreiben. Das kann man eigentlich ausrechnen und per konstantem Delay realisieren. Das sollte um einiges schneller sein als die bisherige Lösung. MfG Falk P.S. Atmel hätte dem SPI mal lieber noch einen Puffer für die Senderichtung spendiert, die paar Quadratmicrometer hätten den Preis nicht nennenswert beeinflusst, die Funktionalität jedoch WESENTLICH verbessert. P.P.S. Das Problem ist hier ein exakt definiertes Timing, welches von Compiler zu Compiler und vor allem in Abhängigkeit der Optimierungsstufe schwanken kann. Assembler ist hier besser.
@FALK: vielen dank fuer deine rege Anteilmahme Falk wrote: > Und wieso machst du vor jeder Überttragung eines Bytes einen > SPI_SlaveInit()? Das ist Unsinn und kostet haufenweise Zeit. nun ich hab da wohl was falsch in der SPI doku verstanden: "NOTE: IN SLAVE Mode, the SOI logic will be reset once the SS pin is brought high...." da hab ich gedacht ich muss neu initialisieren. aber man lern ja nie aus :) > Naja, man kann auch in C noch EINIGES an Geschwindigkeit rausholen. > Zunächst mal nicht dauern einen SPI_SlaveInit() beim Senden machen. > Einfach nur das, was wirklich notwendig ist. Nämlich das RX bzw. TX > complete Flag pollen und Daten rauschreiben. Und nicht bei jedem Byte > ein Handshake mit dem Master machen. Das braucht mehr Zeit als der > eigentliche Transfer! Den Handshake braucht man nur um die Übertragung > einzuleiten. Dann wird eine feste Anzahl Bytes übertragen, mit maximaler > Geschwindigkeit. Und das wars dann auch. Und wieso gibt die SENDEroutine > die gesendeten Daten wieder zurück? Das ist sinnlos und > Zeitverschwendung! also nur handshake bei der einleitung. der slave sagt dann wieviel er zu versenden hat und der Master stellt entsprechende anzahl an dummybytes zur verfuegung. soweit so gut. Die senderoutine gibt die daten zurueck, da es sich um die EMPFANGENEN DATEN handelt. sowohl master als auch slave senden und empfangen. zugegeben: ich brauch nur die richtung vom slave zum master. in diesem fall ist es wirklich zeitverschwendung. > Ich würde es ungefähr so machen. Vom Master geht jeweils eine Leitung zu > den jeweiligen Slaves (Slave Select). > Alle Slaves werdem über eine gemeinsame Leitung (nenn ich mal ACK) in > Richtung Master verbunden (Die Ausgänge müssen dann als Open Drain > betrieben werden, sonst gibts Kurzschlüsse). > Der jeweils selektierte Slave erkennt erstmal, dass er angesprochen > wird, schreibt das erste Byte in sein SPI Datenregister und zieht ACK > auf LOW als Zeichen dafür, dass es nun losgehen kann. Und das sollte > auch der Master erkennt ACK=LOW und generiert nun N Datentransfers (N = > Anzahl der Bytes). Und das so schnell wie möglich. Der Trick dabei ist, > dass eben NICHT für jedes Byte ein Handshakezyklus gemacht wird wie er > im Datenblatt beschrieben ist, das ist auch irgendwie Nonsense. Der > Master muss nach Erkennen von SPIF ein minimale Zeit warten, die auch > der Slave braucht, um SPIF zu erkennen und neue Daten ins Register zu > schreiben. Das kann man eigentlich ausrechnen und per konstantem Delay > realisieren. Das sollte um einiges schneller sein als die bisherige > Lösung. Das werd ich heute mal versuchen. vom prinzip her klar. wo ich das problem sehe ist diese "minimale zeit" die abgewartet werden muss. denn der slave muss ja eben rechtzeitig die daten ins register packen, sonst kommt mist dabei raus > P.P.S. Das Problem ist hier ein exakt definiertes Timing, welches von > Compiler zu Compiler und vor allem in Abhängigkeit der Optimierungsstufe > schwanken kann. Assembler ist hier besser. Am liebsten wuerd ich das natuerlich machen. aber ich hab nicht so viel ahnung von assembler... aber das kann ja noch kommen. Vielen dank auf jeden fall!!!
hallo leute ich bin Anfänger von atmega16,ich brauche dringend hilfe und zwar: Es handelet sich um ein steurbares Pendel.Die Aufhängung des Pendel wird durch einen Winkelgeber gebildet.der eine analoge spannung ausgibt Am andere aluminiunstange befindet sich ein Elektromotor.: in abhängigkeit von Drehzahl nimmt das pendel ein gleichgewischtslage an. wie stellt ihr das vor? das ding habe ich noch nicht gebaut.brauch noch ideen(Literatur (link))?
@Mario. Nasser findest Du es gut, einen völlig themenfremden Thread zu hijacken ? Mach selber einen auf ! Abgesehen davon habe ich ein Pendel noch nie drehen sehen, es pendelt (schwingt) halt. Eine Drehzahlmessung dürfte daher ziemlich sinnfrei sein. Peter
So da bin ich nochmal. Bezueglich SPI Kommunikation hab ich nochmal etwas herum gespielt. Vorallem die "OPTIMIZATION" des compilers umzustellen hat einiges an geschwindigkeit gebracht. So konnte ich von 195 kbyte/s auf 260 kbyte/s das ganze beschleunigen. Gemessen bei 9 uebertragenene Byte, wobei das erste byte nur zu Shakehands Zweck genutzt wird. Dort sagt der Slave dem master wieviele byte er uebertragen moechte. im gemessenen fall 8 byte. so ergeben sich 9 datenbyte mit 8 nutzdatenbyte in ca 30 microsekunden. mfg Patrick Kaplan
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.