Halloo Angenommen, ich schreiben Bytes über SPI zu einem Slave. Der Master (hier der µC) schreibt byteweise in ein SPI-Datenregister und setzt danach ein Tx-Request. Dann sollten doch mit dem SCK-Takt über die MISO und MOSI Leitungen die Bits weitergeschoben werden. Frage ist nun: Zu dem Zeitpunkt, nachdem das Byte in das SPI-Register geschrieben wurde, wer kümmert sich um die Übertragung via SCK? Wird das über einen Bypass erledigt oder muss die MCU direkt ran? Ich will, dass die MCU so wenig wie nötig mit der SPI Sache belastet wird, denn dann bleiben andere Anwendungen in der Zeit der Übertragung hinterher.
Nein, das macht ein Zaehler. Nach 8 takten ist das register leer. Dann wird ein Intterrupt ausgeloest, falls zugelassen
> das Byte in das SPI-Register >geschrieben wurde, wer kümmert sich um die Übertragung via SCK? Hä? Was? Du solltest dir zuerst mal in aller Ruhe eine SPI Verbindung in einem Datenblatt ansehen. Wie ist das verschaltet, was passiert dort, was muss die Software machen..
ich kenn SPI. Nur wollte ich mal weiter ins Detail. Aber es scheint als wenn nach Setzen des TxReq-Bit sich die CPU von der Sache abwenden kann und anderes machen kann. Bis eben ein INT auftritt. Oder mann wartet nach Start der Übertragung im Poll-Verfahren auf SPIF-Bit.
...das unterscheidet einen Microcontroller von einem schnöden Microprozessor. Der uController hat auch Funktionsgruppen in Hardware drin, die bestimmte Aufgaben autonom erledigen...
SPI kennen, heisst das Detail kennen. Interrupts lohnen sich bei den maximalen transferraten uebigens kaum. Bei Clk/2 vergehen 16 clocks, wenn man da in der interruptrouting etwas pusht und popt ist die Zeit auch schon um.
Nullpainter wrote:
> Bei Clk/2 vergehen 16 clocks,
Ich hab mal irgendwo gelesen, dass es genaugenommen 18 Clocks sind, bis
das nächste Byte wieder ins Register geladen werden darf.
Trotz allem geb ich dir Recht ;) Ich hab auch bei meinen
SD-Karten-Fullspeed-sources (Clk/2) keine Interruptgesteuerte SPI
Schnittstelle. Das lohnt sich einfach nicht. Die paar takte kann man
eben auch warten.
Absolut gesehen sind das bei 20MHz weniger als eine µS.
Bei mir hat die Zeitbetrachtung folgenden Grund: Ich sende dem ENC28J60-Baustein über SPI @ 8MHz genau 122 Byte Stack-Daten. (42+80 UDP) Bei dieser SPI-Geschwindigkeit wird also 1 MegaByte/s übertragen. Oder anders: 1 Byte/µs Auf meine 122 Byte wären das dann 122µs an Zeit die vergehe würde, bis der Datenstrom im ENC ist. Am Oszi mess ich aber: 380µs. Ist der Rest alles Warte-Zeit? Ich hab schon überlegt via DMA die Daten in das SPI-Register zu schieben. Ich weis nicht ob das Abhilfe schafft.
Zeig' doch mal den Code, wie du die Daten reinschaufelst. 1 MiB/s erreichst du natürlich nur, wenn das SPI im Dauerbetrieb taktet und das ist ja nicht möglich. Das Register zu laden benötigt ja auch etwas Zeit. Mehr als das Dreifache der Zeit ist allerdings schon etwas extrem.
Das beste ist, du guckst dir während der Übertragung die SCK Leitung auf nem Oszi an. Am besten als Triggerung den Beginn (oder kurz vorher) der Übertragung des ersten Bytes. zB mit CS=Low, oder per extra Pin. Dort siehst du sofort, wie "effektiv" deine Übertragung ist. Also wie groß die Pausen zwischen den Bytes sind... Somit siehst du, obs am Programm zwischen den ausgaben (zB Daten aus RAM.. holen) liegt, oder obs am Programmeinsprung.. liegt...
Wenn man's nicht in ASM macht kann schon was an Zeit verplemepert werden. Wenn mn zB Wartet bis das SPI fertig ist, und dann erst das byte holengeht, mit Arrayindexrechnung und so, ist einiges moeglich. Ich wuerd diesen Ladeprozess mal im simulator laufen lassen, oder falls das nicht geht, am Objekt selbst mit einem puls an einem Debugpin jeweils.
@ Horst (Gast) >Aber es scheint als wenn nach Setzen des TxReq-Bit sich die CPU von der >Sache abwenden kann und anderes machen kann. Bis eben ein INT auftritt. Ja. Das Generieren von SCK und rausschieben der Bits macht das SPI-Modul allein. >Oder mann wartet nach Start der Übertragung im Poll-Verfahren auf >SPIF-Bit. Genau. Sinnvollereise wird man erst dan nächste Datenbyte laden und dann pollen. MFG Falk
Angehängte Dateien:
-

Bild3.png
540 KB
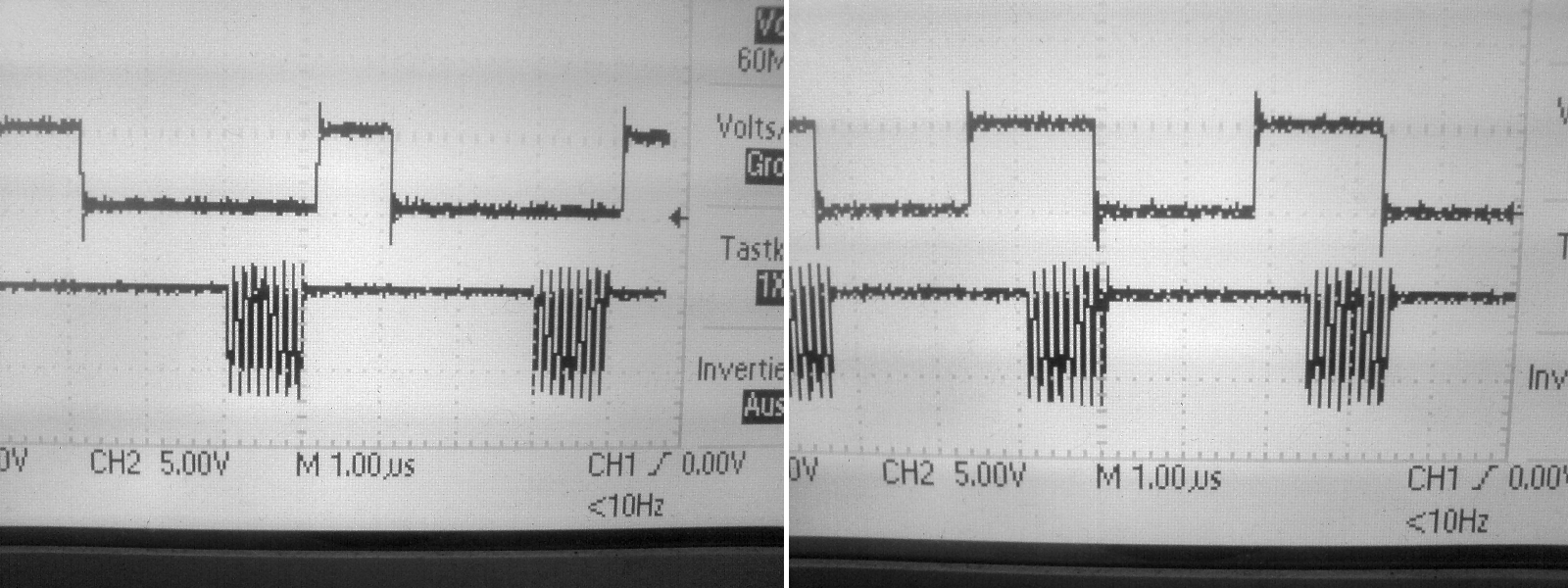
Hallo, so jetzt gehts weiter.. ich habe also mal das SCK Signal über den gesamten Vorgang aufgenommen. Es ist also deutlich zu sehen: Lücken zwischen den Bytes. 90% der Daten sind mein Stack der übertragen wird. Die Funktion zum Schreiben des Stack ist die folgende:
1 | void enc28j60WriteBuffer(uint16_t len, uint8_t* data) // Länge (Byte), Startadresse Data |
2 | {
|
3 | // assert CS
|
4 | ENC28J60_CONTROL_PORT &= ~(1<<ENC28J60_CONTROL_CS); |
5 | // issue write command
|
6 | SPDR = ENC28J60_WRITE_BUF_MEM; |
7 | while(!(SPSR & (1<<SPIF))); |
8 | while(len--) |
9 | {
|
10 | // write data
|
11 | SPDR = *data++; |
12 | while(!(SPSR & (1<<SPIF))); |
13 | }
|
14 | // release CS
|
15 | ENC28J60_CONTROL_PORT |= (1<<ENC28J60_CONTROL_CS); |
16 | }
|
Der Code ist vielermals im Netz zu finden, ich habe den eben auch genommen. Die Daten werden per Zeiger zugewiesen, was doch schon sehr zügig sein sollte. Hier konnte ich dann mit einem Debug-Pin die Wartezeiten feststellen. Für das erste Bild gilt:
1 | while(len--) |
2 | {
|
3 | // write data
|
4 | SPDR = *data++; |
5 | PORTC = 1; |
6 | while(!(SPSR & (1<<SPIF))); |
7 | PORTC = 0; |
8 | }
|
Hier ist also die Poll-Zeit des SPIF-Bit aufgezeichnet. Für das zweite Bild:
1 | while(len--) |
2 | {
|
3 | // write data
|
4 | PORTC = 1; |
5 | SPDR = *data++; |
6 | PORTC = 0; |
7 | while(!(SPSR & (1<<SPIF))); |
8 | }
|
Hier also das Schreiben eines Bytes in das SPI Register. Aber wieso inklusive SCK-Taktung? Ich denke mal die Warte-Zeit auf das SPIF kann ich nicht verringern. Beim Transferieren der Daten in das SPI-Datenregister jedoch müsste doch was machbar sein. Evtl. DMA?
Die COdes wurden wohl nicht korrekt übertragen. Nochmal: Das PORTC-Bit0 ist der Debug Pin. Für das erste Bild gilt:
1 | while(len--) |
2 | {
|
3 | // write data
|
4 | SPDR = *data++; |
5 | PORTC = 1; |
6 | while(!(SPSR & (1<<SPIF))); |
7 | PORTC = 0; |
8 | }
|
Für das zweite Bild:
1 | while(len--) |
2 | {
|
3 | // write data
|
4 | PORTC = 1; |
5 | SPDR = *data++; |
6 | PORTC = 0; |
7 | while(!(SPSR & (1<<SPIF))); |
8 | }
|
Horst wrote: > Ich denke mal die Warte-Zeit auf das SPIF kann ich nicht verringern. > Beim Transferieren der Daten in das SPI-Datenregister jedoch müsste doch > was machbar sein. Evtl. DMA? Hm, auf welcher Optimierungsstufe ist das kompiliert? Hast du eventuell mal Assembler-code von der Write-Funktion? Komisch, dass das laden und inkrementieren so "lange" braucht. Wobei das so lange ja garnicht ist ;) Wenn ich mich nicht irre handelt es sich doch um einen 8-Bit AVR, die haben doch garkeine DMA Unterstützung.
richtig, dort gibts kein DMA. Der AVR dient nur zum Testen. EIgentlich läuft der Code auf einem Fujitsu 32-Bit. Dort sieht das aber alles sehr ähnlich aus.
@ Horst (Gast) >ich habe also mal das SCK Signal über den gesamten Vorgang aufgenommen. >Es ist also deutlich zu sehen: Lücken zwischen den Bytes. Yep. >void enc28j60WriteBuffer(uint16_t len, uint8_t* data) // Länge (Byte), Startadresse Data >{ > // assert CS > ENC28J60_CONTROL_PORT &= ~(1<<ENC28J60_CONTROL_CS); > // issue write command > SPDR = ENC28J60_WRITE_BUF_MEM; > while(!(SPSR & (1<<SPIF))); > while(len--) > { > // write data > SPDR = *data++; > while(!(SPSR & (1<<SPIF))); > } > // release CS > ENC28J60_CONTROL_PORT |= (1<<ENC28J60_CONTROL_CS); >} >Der Code ist vielermals im Netz zu finden, ich habe den eben auch >genommen. Die Daten werden per Zeiger zugewiesen, was doch schon sehr >zügig sein sollte. Naja, hier wird man wohl um Assembler nicht rumkommen. Der Trick ist, während die alte Übertragung läuft schon die neuen Daten zu holen. In C ist es nicht sehr einfach zu garantieren, dass der Compiler das nicht in die flasche Richtung optimiert. Versuch mal das. void enc28j60WriteBuffer(uint16_t len, uint8_t* data) // Länge (Byte), Startadresse Data { uint8_t tmp; // assert CS ENC28J60_CONTROL_PORT &= ~(1<<ENC28J60_CONTROL_CS); // issue write command SPDR = ENC28J60_WRITE_BUF_MEM; while(!(SPSR & (1<<SPIF))); while(len--) { // write data tmp = *data++; while(!(SPSR & (1<<SPIF))); SPDR = tmp; } // release CS ENC28J60_CONTROL_PORT |= (1<<ENC28J60_CONTROL_CS); } >Ich denke mal die Warte-Zeit auf das SPIF kann ich nicht verringern. Kaum, das SPI-Interface muss ja die Daten erstmal übertragen, bevor neue reingeschrieben werden können. >Beim Transferieren der Daten in das SPI-Datenregister jedoch müsste doch >was machbar sein. Evtl. DMA? Assembler + Knoff Hoff! MFG Falk
interessante Links! Danke mit einer Optimierung O1 konnte ich eben 40% Zeitersparnis erreichen :-) DIe anderen Optimierungen brachten dann nichts mehr. @Falk, guter Tipp. Aber erscheint dann am while zu hängen da die Bedingung bein ersten Mal wohl nicht erfpllt ist.
Hast nochmal nen Oszillogramm? :-) PS: Assembler-code wäre vielleicht auch nicht uninteressant.
Mir ist es mal gelungen, 24Bytes innerhalb einer ext. Int. ISR herauszutakten. Das ganze hat für den kompletten Aufruf(einsprung+push), Bearbung und Beenden(pop) etwa 35Mikrosekunden gedauert. Das Ganze auf nem mega128@16MHz.
jo kommt... hier schon mal die Optimierungen im Vergleich: o0 und o1
hab mal diesen Code Beitrag "Re: SPI Codetuning" benutzt, und Optimierung Stufe 1 eingestellt. Da wurden die 122 Byte in 152µs übertragen. (1,2µs pro Byte) Das ist doch schon eine Steigerung. Die Lücken sind auch deutlich kleiner.
Die Frage ist, ob man überhaupt Pollen sollte... while(!(SPSR & (1<<SPIF))); 17c: 77 9b sbis 0x0e, 7 17e: fe cf rjmp .-4 Oben drüber ist das "out". Wenn ich richtig gezählt habe, dann fällt der 16. Takt danach direkt auf das sbis. Da erst mit dem 17. Takt die Transmission beendet ist, wird nicht übersprungen und der rjmp wird ausgeführt. Dann dauert es nochmal 4 Takte, bis man aus der Schleife draußen ist, da rjmp=2 + aktives_sbis=2. Wenn man jedoch einfach 16 Takte durch nops verliert (oder Platzsparender rjmp +0), dann wäre man eigentlich genau richtig im Timing. Die zweite Frage ist, ob das auch so hinhaut. Hat das jemand mal ausprobiert oder willst du das mal ausprobieren Horst?
@Dave du wolltest bestimmt nen anderen Ausschnitt zeigen, den deiner ist uninteresant. Alles in der while muss betrachtet werden.
>Die zweite Frage ist, ob das auch so hinhaut. Hat das jemand mal >ausprobiert oder willst du das mal ausprobieren Horst? Ja, hab ich. das geht. Hab aber statt der nops immer einen temp.ausgabepuffer geladen und andere dinge gemacht. und das ganze komplett ohne schleife..
@ Matthias L. (lippy) >Hab aber statt der nops immer einen temp.ausgabepuffer geladen und >andere dinge gemacht. und das ganze komplett ohne schleife.. Ohne Schleife? Wie willst du da variable Datenblöcke übertragen? MfG Falk
>>illst du da variable Datenblöcke
Bei meinen Programm ging es immer um exakt 24Datenbytes.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.