Hallo zusammen! Meine neue Aufgabe ist so eine Art Interface-Board zu entwerfen für die Verbindung zwischen: - auf einer Seite sind mehrere SPI-fähige Bausteine (ADC, DAC, Sensoren; bis zu ca. 8 Stk.) die parallel (also gleichzeitig) beschrieben/gelesen werden - auf der anderen Seite ist ein Board, welches die Daten per LVDS empfangen soll Die LVDS-Übertragung soll die Daten der parallelen SPI-Ports "serialisieren" sozusagen, also wenn 8 SPI-Module ihre Daten gleichzeitig mit einer Rate von 2 MBit/s schicken, sollen die Daten mit mindestens achtfacher Rate,also 16 MBit/s per LVDS gesendet werden. Als Möglichkeiten sehe ich bis jetzt: 1. Einen schnellen µC mit 8 SPI-Schnittstellen (gibts von TI z.B.) nehmen (dann kann man ja fast gleichzeitig mit 8 SPI-Bausteinen kommunizieren, oder?) Und die Daten mit einer anderen Schnittstelle des Controllers (welche wäre da geeignet?) mittels LVDS-Treiber an die andere Seite übertragen 2. Einen FPGA/CPLD nehmen, die ja LVDS schon unterstützen (Treiber enfallen) und die parallele Kommunikation mit 8 SPI-Modulen kann ja bei genügen IOs problemlos programmiert werden 3. Gibt es vielleicht so eine Art ASICs speziell für so etwas (so wie es für Profibus von Profichip gibt (SPI --> Profibus) Ich bitte euch um die Bewertung der genannten Möglichkeiten oder um die Anregungen, wie das anders gelöst werden könnte. Vielen Dank im Voraus!!!
Angehängte Dateien:
-

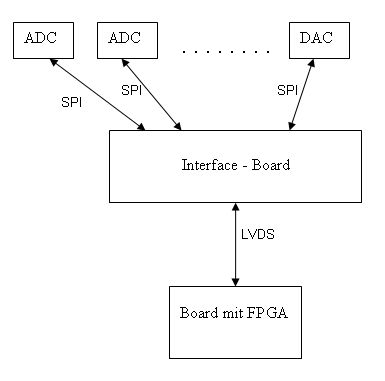
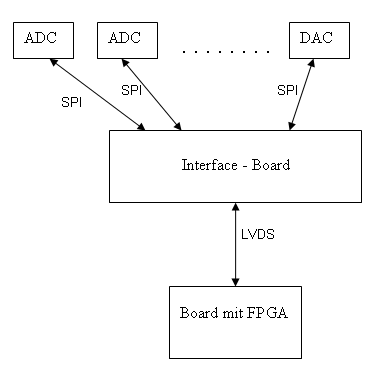
blockbild.gif
3,9 KB
{kind=link}
Ach ja, hier wäre noch so ein Blockschaltbild des beschriebenen Aufbaus zur besseren Verständlichkeit!
@ noips (Gast) >1. Einen schnellen µC mit 8 SPI-Schnittstellen (gibts von TI z.B.) >nehmen (dann kann man ja fast gleichzeitig mit 8 SPI-Bausteinen Naja, kann man machen, wird aber ggf. eng. Ausserdem ist man auf wenige, spezielle ICs eingeschränkt. >2. Einen FPGA/CPLD nehmen, Würde ich so machen. > die ja LVDS schon unterstützen (Treiber enfallen) Der Treiber ist vollkommen nebensächlich. Ob der im FPGA steckt oder nicht interessiert nicht. >3. Gibt es vielleicht so eine Art ASICs speziell für so etwas (so wie es >für Profibus von Profichip gibt (SPI --> Profibus) AFAIK nein. MFG Falk
Falk Brunner schrieb: >> die ja LVDS schon unterstützen (Treiber enfallen) > > Der Treiber ist vollkommen nebensächlich. Ob der im FPGA steckt oder > nicht interessiert nicht. Warum das? Ich habe gemein, bei der Lösung mit Controller wären dann ja auch noch LVDS-Treiber nötig. Bei der Lösung mit FPGA entfallen die Treiber, weil die Signale ja schon aus dem Baustein differentiell ausgegeben werden können. Was aus meiner Situation heraus gegen FPGA spricht, ist dass es für mich ein ziemlich unbekannter Bereich ist und mehr Einarbeitung erfordert.
@ noips (Gast) >> Der Treiber ist vollkommen nebensächlich. Ob der im FPGA steckt oder >> nicht interessiert nicht. >Warum das? Weil das einfach ein IC wie ein MAX485 oder so ist. Den schließt man an, fertig. > Ich habe gemein, bei der Lösung mit Controller wären dann ja >auch noch LVDS-Treiber nötig. Ja und? Wo ist das Problem. IC anschließen, fertig. > Bei der Lösung mit FPGA entfallen die >Treiber, weil die Signale ja schon aus dem Baustein differentiell >ausgegeben werden können. Bei den läppischen Datenraten mit ein paar Mbit/s ist das vollkommen egal. >Was aus meiner Situation heraus gegen FPGA spricht, ist dass es für mich >ein ziemlich unbekannter Bereich ist und mehr Einarbeitung erfordert. Tja, there aint no thing as free lunch. MFG Falk
Falk Brunner schrieb: > Tja, there aint no thing as free lunch. Ich kann zwar etwas Englisch, aber das hier verstehe ich nicht!
noips schrieb: > Falk Brunner schrieb: >> Tja, there aint no thing as free lunch. > Ich kann zwar etwas Englisch, aber das hier verstehe ich nicht! Im Leben gibt es nichts umsonst/geschenkt...
Gibt es denn µC von Atmel, die unabhängige 8 SPI-Schnittstellen haben? Habe bis jetzt nichts gefunden.
@noips (Gast)
>Gibt es denn µC von Atmel, die unabhängige 8 SPI-Schnittstellen haben?
Nöö, das braucht auch keiner.
MfG
Falk
Also einer ist eindeutig für die Lösung mit FPGA/CPLD. Sind die anderen auch klar dafür? Oder sagt jemand, mit einem geeigneten Controller könnte man das Problem auch nicht weniger sinnvoll lösen?
Oder kennt jemand einen alternativen dritten Weg, der nicht weniger sinnvoll wäre? Ich wäre für Vorschläge sehr dankbar!
@ FPGA Anfänger (Gast) >Oder kennt jemand einen alternativen dritten Weg, der nicht weniger >sinnvoll wäre? Ich wäre für Vorschläge sehr dankbar! Warum schließt du die SPI-ICs nicht direkt an das FPGA an? Klar, braucht mehr IOs, aber die Logik braucht im FPGA keinen nennenswerten Platz. Wie lang soll die LVDS-Verbindung sein? MfG Falk
> Warum schließt du die SPI-ICs nicht direkt an das FPGA an? Meine Sache ist nur das Interface-Board. Alles andere ist nicht von mir entwickelt. Das Konzept wurde mir vorgegeben. Das FPGA Board ist vereinfacht dargestellt. In der Tat ist das ein Board mit zusätzlich einem DSP und noch einigem mehr. Das FPGA darauf hat schon genug andere Sachen zu tun. Darum wurde nur eine Schnittstelle vorgesehen (evtl. auch SPI aber eine genügend schnelle, damit die "serialisierten" Daten von allen SPI-ICs in Echtzeit sozusagen angenommen werden. Die einzelnen SPI-ICs sind aber relativ langsam (1-5MBit/s) darum sollen sie gleichzeitig und nicht nacheinander angesprochen werden. Die LVDS-Verbindung geht über ein paar Stecker und ein Stück Backplane-Board, ich schätze 10-20cm insgesamt. Soll aber sicher sein, trotz höherer Datenrate (evtl. bis 40 MBit/s), darum differentiell. Es liegt aber noch nicht entgültig fest mit dem LVDS.
@ FPGA Anfänger (Gast) >Backplane-Board, ich schätze 10-20cm insgesamt. Soll aber sicher sein, >trotz höherer Datenrate (evtl. bis 40 MBit/s), darum differentiell. Für 20cm und 40 Mbit/s tut es stinknormales 3,3V CMOS locker. MfG Falk
>Für 20cm und 40 Mbit/s tut es stinknormales 3,3V CMOS locker.
Also du würdest sagen einfach SPI nehmen, ohne jegliche Treiber, und
verbinden?
Wie störungsfest ist die Sache dann? Es sind ja auch anderen Sachen im
selben Gehäuse, zum Teil auch optogekoppelte 24V Ein- und Ausgänge die
zur beliebigen Zeit schalten können.
@ FPGA Anfänger (Gast) >Also du würdest sagen einfach SPI nehmen, ohne jegliche Treiber, und >verbinden? Ja. Entscheidend ist das Layout, siehe Wellenwiderstand. >Wie störungsfest ist die Sache dann? Ziemlich. > Es sind ja auch anderen Sachen im >selben Gehäuse, zum Teil auch optogekoppelte 24V Ein- und Ausgänge die >zur beliebigen Zeit schalten können. Ist zu 90% eine Frage des richtigen Layouts. MfG Falk
Da es wohl eher auf die Verwendung eines FPGA/CPLD hinaus läuft, mache ich im Bereich "FPGA, VHDL & Co." einen neuen Beitrag mit dem Titel "Bitte um Check meiner FPGA-Auswahl für ein Interface-Board" auf. Ich bitte euch, meine Überlegungen zu der FPGA-Auswahl dort zu prüfen und bitte um Bewertung. Vielen Dank für die Hilfe in diesem Beitrag!!
Übrigens, wie macht man hier ein Link zu einem Beitrag. Sowas habe ich hier schon oft gesehen. Das wollte ich an dieser Stelle machen. Wie zu Artikeln gelinkt wird, ist beschrieben, aber nicht, wie zu Beiträgen gelinkt wird. Muss man dafür angemeldet sein?
> Übrigens, wie macht man hier ein Link zu einem Beitrag. Einfach den Link aus der Browser-Adresszeile herkopieren. Und dann gehts im Beitrag "Bitte um Check meiner FPGA-Auswahl für ein Interface-Board" weiter... > Muss man dafür angemeldet sein? Nein.
Anderer Ansatz. Alle SPI slaves hintereinander Schalten und dann mit einer SPI Schnittstelle vom Interface board durchtakten. Damit sind schon mal alle Slaves synchron mit immer der gleichen Reihenfolge und der Datenstrom für die externe LVDS ist auch schon komplett.
Ralph schrieb: > nderer Ansatz. > Alle SPI slaves hintereinander Schalten und dann mit einer SPI > Schnittstelle vom Interface board durchtakten. > Damit sind schon mal alle Slaves synchron mit immer der gleichen > Reihenfolge und der Datenstrom für die externe LVDS ist auch schon > komplett. Aber die Slaves senden ja dann nacheinander und nicht gleichzeitig. Das muss bei zumindest einigen Signalen schneller gehen.
noips schrieb: > Aber die Slaves senden ja dann nacheinander und nicht gleichzeitig. Das > muss bei zumindest einigen Signalen schneller gehen. Hallo, das war mir schon klar, dass hier der Hauptknackpunkt liegt. SPI ist Master-Slave, wenn also deine 8 externen schneller sein müssen als die zentrale SPI-Schnittstelle, brauchst du 8 Master, die asynchron untereinander und zur Zentrale arbeiten, und musst alles zwischenspeichern. Die zentrale SPI muss damit zurechtkommen, dass sie keine unmittelbare Antwort bekommt, weil sie ja erst die Abfrage weiterreichen muss (es sei denn, alle Abfragen sind von vornherein fixiert). Du wirst noch viel Spass mit dieser Aufgabe haben. Einfach geht es nur wie (von Ralph) vorgeschlagen wenn zentrale und externe SPIs gleich schnell und synchron laufen, aber dann brauchst die die ganze Schaltung nicht, weil SPI ja sowieso mehrere Slaves ansprechen kann. Gruss Reinhard
Reinhard Kern schrieb: > wenn also deine 8 externen schneller sein müssen als die > zentrale SPI-Schnittstelle, brauchst du 8 Master, die asynchron > untereinander und zur Zentrale arbeiten, und musst alles > zwischenspeichern. Entweder verstehe ich dich nicht oder aber hast du das geplannte Prinzip der Schaltung nicht verstanden. Die 8 externen müssen nicht schneller als die zentrale SPI (die mit LVDS in der Skizze) sein. Umgekehrt muss die zentrale SPI 8 Mal schneller sein, als die einzelne externe, und zwar damit sie in der gleich langer Zeit, in welcher die externen ihre Daten parallel liefern, all diese Daten wegschicken kann.
Ich glaube Reinhard Kern meint, dass die Slaves insgesamt eine höhere
Datenrate brauchen als eine ("externe") SPI liefern kann.
Wäre dem nicht so könnte man sich das Design auch schenken...
Shuzz schrieb: > Ich glaube Reinhard Kern meint, dass die Slaves insgesamt eine höhere > Datenrate brauchen als eine ("externe") SPI liefern kann. > Wäre dem nicht so könnte man sich das Design auch schenken... Es tut mir leid, aber irgendwie kapiere ich nichts. Ich brauche es etwas ausführlicher, tut mir leid.
noips schrieb: > Es tut mir leid, aber irgendwie kapiere ich nichts. Ich brauche es etwas > ausführlicher, tut mir leid. Hallo, habe ich vielleicht missverständlich formuliert, aber das Problem besteht: die 8 externen SPIs können nicht mit dem gleichen Takt arbeiten wie die Zentrale, das behauptest du jedenfalls glaubwürdig selbst, wegen des nötigen Durchsatzes. SPI arbeitet aber, jedenfalls soweit mir bekannt, rein als Master/Slave, d.h. die Masterseite sendet was und erwartet eine Antwort darauf. Wegen der verschiedenen Geschwindigkeit kann aber eine Masteranfrage der Zentrale nicht direkt "durchgeschaltet" werden und die Antwort auch nicht. Also muss die Platine, von der hier die Rede ist, die Anfrage zwischenspeichern und anschliessend selbst als Master an die externe SPI weitergeben, die Antwort ebenfalls zwischenspeichern und an die Zentrale zurückgeben - da tritt aber ein Problem auf, denn diese Verzögerungen sind selbstverständlich nicht tolerabel, eigentlich müsste also die Zentrale inzwischen mit der nächsten Abfrage weitergemacht haben. Ich sehe aber nicht, wie sie dann die verpätet eintreffende Antwort der ersten Anfrage zuordnen soll. Durch die notwendige Geschwindigkeitsumsetzung trifft ja eine externe Antwort immer erst nach der nächsten oder übernächsten zentralen Anfrage ein. Verzichtet man auf die Taktumsetzung, müssten die externen SPIs schneller sein als bisher vorgesehen, aber vor allem kann man dann die SPIs direkt miteinander verbinden und braucht die ganze Platine nicht. Gruss Reinhard
OK, jetzt verstehe ich was du gemeint hast. Das geht schon tiefer ins Detail. Nun, die Slaves sind größtenteils AD-Wandler. Soweit ich das ganze vestehe, werden die beim Start konfiguriert und wandeln dann gleichzeitig mit einer bestimmten Sample-Rate und schicken die Daten in festem Zeitraster an das Interface-Board. Dieses "komprimiert" die, zeitlich gesehen, und schickt an die Zentrale. Ich glaube, dass hast du gemeint mit: Reinhard Kern schrieb: > (es sei denn, alle Abfragen sind von vornherein > fixiert). Natürlich wird das Ganze nicht wirklich so funktionieren, als wäre die Zentrale direkt und parallel mit den Slaves verbunden, aber die Kommunikation mit den Slaves läuft doch viel schneller ab, als wenn die Slaves mit ihrer langsameren Datenrate nacheinander über eine Schnittstelle senden würden.
Die AD-Wandler mit SPI die ich so kenne erwarten immer ein Configurationswort für die nächste Wandlung und senden, während sie die Config empfangen, das Resultat der letzten Wandlung.
Sven H. schrieb: > ... senden, während sie die > Config empfangen, das Resultat der letzten Wandlung. Hallo, in dem Fall kann man die Sache vereinfachen, indem man der Zentrale ein falsches Resultat als sofortige Antwort unterschiebt - nämlich das der vorletzten statt der letzten Wandlung. Das dürfte praktisch keine Rolle spielen, aber eben nur in genau diesem Anwendungsfall. Ich gehe dabei davon aus, dass Config für einen bestimmten Wandler immer gleich ist. Gruss Reinhard
noips schrieb: > ... Nun, die Slaves sind größtenteils AD-Wandler. Soweit ich das > ganze vestehe, werden die beim Start konfiguriert und wandeln dann > gleichzeitig mit einer bestimmten Sample-Rate und schicken die Daten in > festem Zeitraster an das Interface-Board. Hallo, das ist wahrscheinlich der grundlegende Fehler (jedenfalls nach meiner Kenntnis) in der bisherigen Planung. Bei SPI senden Slaves niemals etwas von sich aus, sie antworten nur auf eine Masteranfrage. Gruss Reinhard
Wie gesagt, das Konzept wurde mir vorgegeben und ich muss mich um die Umsetzung kümmern, nicht darum ob es so geht oder nicht. Dann wird es wohl sinnvoll sein. Aber ich sehe schon, ich muss mir eine genauere Vorstellung bilden, wie das denn gedacht ist.
Sven H. schrieb: > Die AD-Wandler mit SPI die ich so kenne erwarten immer ein > Configurationswort für die nächste Wandlung und senden, während sie die > Config empfangen, das Resultat der letzten Wandlung. Reinhard Kern schrieb: > das ist wahrscheinlich der grundlegende Fehler (jedenfalls nach meiner > Kenntnis) in der bisherigen Planung. Bei SPI senden Slaves niemals etwas > von sich aus, sie antworten nur auf eine Masteranfrage. Ich habe das jetzt ausführlich durchdacht. Ich sehe keinen grundlegenden Fehler, der das Prinzip (Serialisierung der Daten von mehreren SPI-Schnittstellen zur schnellen Übertragung über eine zentrale SPI-Schnittstelle) in Frage stellt. Ich würde sagen, auch wenn die Slaves nur auf eine Anfrage antworten, die zuerst von der Zentrale an das Interface und dann an die Slaves geschickt wird, wird der erwünschte Datendurchsatz erreicht. Allerdings ist die Übertragund um 2-3 SPI-Zyklen verzögert (SPI-Zyklen der langsamen SPIs).
noips schrieb: > Ich habe das jetzt ausführlich durchdacht. Ich sehe keinen grundlegenden > Fehler, der das Prinzip (Serialisierung der Daten von mehreren > SPI-Schnittstellen zur schnellen Übertragung über eine zentrale > SPI-Schnittstelle) in Frage stellt. Ich würde sagen, auch wenn die > Slaves nur auf eine Anfrage antworten, die zuerst von der Zentrale an > das Interface und dann an die Slaves geschickt wird, wird der erwünschte > Datendurchsatz erreicht. Allerdings ist die Übertragund um 2-3 > SPI-Zyklen verzögert (SPI-Zyklen der langsamen SPIs). Hallo, vorab, ich habe nicht gesagt geht nicht, sondern dass es sehr anspruchsvoll wird. Zu deiner aktuellen Idee: du leitest also die zentrale Anfrage weiter, sobald sie angefangen hat, nur mit dem langsameren externen Takt. Kein Problem. Die Antwort kannst du allerdings erst zurück weiterleiten, wenn sie vollständig ist, weil du jetzt ja auf schnelleren Takt umsetzen musst. Mittleres Problem. Aber wieso soll die Übertragungszeit damit kürzer werden als die Summe der externen SPI-Transaktionen??? Ich würde mal behaupten, das ist sogar langsamer als die externen SPIs einfach aneinanderzuhängen, was ja wie inzwischen mehrfach erwähnt ohne jeden Aufwand und ohne Wandlerplatine geht. Dass dir das so "befohlen" wurde, ist ein technisch völlig wertloses Argument. Gruss Reinhard
Reinhard Kern schrieb: > Aber wieso soll die Übertragungszeit damit > kürzer werden als die Summe der externen SPI-Transaktionen??? Weil die Übertragung zwischen Interface-Board und den Slaves gleichzeitig abläuft. Ich habe jetzt so ein Timing-Diagram der SPI-Übertragung erstellt (Anhang). Es soll den zeitlichen Verlauf der Signale darstellen. Ganz oben ist die Übertragung zwischen Zentrale und Interface-Board, bezeichnet mit Main SPI. Darunter sind untereinander die Daten zwischen Interface und Slaves SPI1 bis SPI8. Ein Zyklus der Main SPI ist um Faktor 8 kürzer als ein Slave-SPI-Zyklus. Zum Kennzeichnen habe ich folgende Abkürzung verwendet: C x.y dabei steht C für Abfrage der Zentrale (Command) x zeigt die Nummer der Abfrage y zeigt, an welchen Slave die Abfrage gerichtet ist z.B. C1.5 bedeutet - erste Abfrage an Slave 5 A x.y A steht für Antwort, x.y so wie bei Abfragen (siehe oben) z.B. A 2.3 bedeutet - die Antwort des Slaves 3 an die zweite Abfrage Das Diagramm zeit eine Möglichkeit, die zentrale Abfrage, ihre Weiterleitung an die Slaves und die Übetragung der Antwort an die Zentrale zeitlich anzuordnen. MOSI und MISO sind hier zusammengefasst. So erfolgt z.B. während einem Zyklus das Abholen der Antwort und die Übermittlung der nächsten Abfrage gleichzeitig, dann sind die Abkürzungen mit einem Schrägstrich im Diagramm eingetragen (z.B. C2.1/A1.1) Zuerst werden alle 8 Anfragen an das Interface geschickt, dazu ist ein langsamerer SPI-Zyklus nötig, die Slave warten. Im nächsten Zyklus werden alle acht Abfragen gleichzeitig an die Slaves geschickt. Im dritten Zyklus werden von den Slaves gleichzeitig die Antworten auf die erste Abfrage abgeholt und zugleich jeweils zweite Abfrage geschickt (zweite Abfrage für alle 8 Slaves wurde vom Interface im 2. Zyklus empfangen). Im vierten Zyklus werden alle 8 Antworten der Slaves auf die erste Abfrage an die Zentrale zurückgeschickt. Im fünften Zyklus bekommt die Zentrale die Slaves-Antworten auf die zweite Abfrage und so weiter. Somit kommen die Antworten von allen Slaves auf einmal um 3 Zyklen verzögert. Und jetzt ein Vergleich mit der Übertragung bei aneinander angehängten Slaves direkt an die Zentrale ohne Interface-Board. Die Antwort auf die erste Abfrage kommt in diesem Fall nach 2 SPI-Zyklen ( 1. Zyklus - Abfrage senden, 2. Zyklus - Antwort holen/nächste Abfrage senden). Die Antworten auf die weiteren Abfragen benötigen dann jeweils nur ein Zyklus, weil die Abfrage im vorigen Zyklus geschickt wurde, während die letzte Antwort agbeholt wurde. Das heißt z.B. dass für 10 Abfragen aller Slaves 8 + 8 x 10 = 88 Zyklen nötig wären. Dagegen mit Interface-Board sind dafür, wie oben beschrieben, nur 13 Zyklen nötig. Es ist zwar keine Verachtfachung der Rate, aber wenn wir die Zahl der Abfragen immer größer werden lassen, wird eine Verachtfachung erreicht. Wenn ich da einen Denkfehler habe, würde ich mich über die Hinweise freuen.
Vielleicht mag noch jemand das Timing-Diagramm ansehen und seine Sicht sagen, ob es so geht oder nicht! Würde mich freuen!
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.