Ich möchte einen monophonen FM (PM) Synthesizer auf einem FPGA implementieren und frage mich, welche "Größe" gebraucht wird, also wie viele Logikzellen. Es geht um 4 numerisch gesteuerte Sinusoszillatoren, 4 Butterworthfilter, zwei 4x4 Matrizen für Modulation und einen recht komplexen LFO der ca. nochmal den selben Umfang hat. Reicht dafür ein Xilinx Spartan-3AN Starter Kit aus oder nicht? Ich hab noch keine Erfahrung damit und kann die erforderliche Menge an Logikzellen nicht einschätzen. Vielen Dank. Olaf PS. Mit welcher Samplingfrequenz kann auf dem Xilinx Spartan-3AN Starter Kit der DAC betrieben werden?
Spontan würde ich befürchten dass du da an die Grenzen stößt... Digitale FM braucht schon ordentliche Abtastraten und Genauigkeiten um vernünftig zu klingen, ensprechend groß werden Oszillatoren und Recheneinheiten...
Olaf Hilgenfeld schrieb: > Reicht dafür ein Xilinx Spartan-3AN Starter Kit aus oder nicht? Ich würde sagen: ja. Allerdings kommt es schon ein wenig auf deine Ansprüche auf die Rechengenauigkeit an. Es macht ja durchaus einen Unterschied, ob du alles mit 8 Bit oder mit 32 Bit berechnest... Und dann ist das Interface zur Aussenwelt auch nicht uninteressant. Woher kommen die Rechenwerte (welcher Ton soll berechnet werden)? > Es geht um 4 numerisch gesteuerte Sinusoszillatoren, 4 Butterworthfilter Ein Filter hinter einem Sinusoszillator ist eigentlich ziemlich witzlos... > Ich hab noch keine Erfahrung damit und kann die erforderliche Menge an > Logikzellen nicht einschätzen. Das geht auch mit Erfahrung nicht sooo einfach. Am einfachsten ist es, eine Komponente zu beschreiben, zu synthetisieren und dann zu schauen, wieviel Platz benötigt wird... ;-)
> Reicht dafür ein Xilinx Spartan-3AN Starter Kit aus oder nicht? Das habe ich auch benutzt. http://www.dossmatik.de/cordic/cordic_flyer.pdf PS. Mit welcher Samplingfrequenz kann auf dem Xilinx Spartan-3AN Starter Kit der DAC betrieben werden? Ich habe den VGA-Port missbraucht.
Olaf Hilgenfeld schrieb: > Es geht um 4 numerisch gesteuerte Sinusoszillatoren, > 4 Butterworthfilter, > Ich hab noch keine Erfahrung damit Dann ist ein IIR-Filter (dazu gehört auch der Butterworth) nicht das, womit du anfangen solltest. Ich habe sowieso den Eindruck, dass du ein analoges Design einfach digital nach bilden willst. Jede Domäne (analog oder digital) hat ihre Vorteile, rekursive oder IIR-Filter sind nicht gerade die Domäne der digitalen Signalverarbeitung. Da braucht es eine Menge Erfahrung und Simulationswerkzeuge. In digitalen Systemen setzt man lieber FIR-Filter ein, die gibt es in der analogen Welt gar nicht. Tom
Mit einem S3AN wirst Du nicht viel einbauen können. Je nach Güte Deiner Filter und Präzision der FM sprengt dein Projekt auch einen kleinen Virtex. Spartan 3A DSP 1800 ginge wohl.
> Es geht um 4 numerisch gesteuerte Sinusoszillatoren, Warum betreibst Du nicht DDS? Geht im FPGA am einfachsten und bei einem mittelgroßen FPGA hat man auch genug Platz. Dann schaffst du bequem auch mehrere Kanäle gleichzeitig und mit genügend hoher Auflösung. Mit 120MHz FPGA Takt kannst Du Samplefrequenzen von 96k mit Faktor 128 auflösen (inklusive phase dithering!) und bequem auf effektiv 18bit Phasen / Amplitudengenauigkeit kommen. Das reicht dann für 8 Kanäle. Besonders Vibratoeffekte sind da wesentlich sauberer und feiner abzubilden. >Butterworthfilter Da gibt es zweckmäßigeres in der digital domain.
Ich denke mal das ist ohne weiteres möglich. http://www.fpga.synth.net/pmwiki/pmwiki.php?n=FPGASynth.8vFM-2x4 Klingt sehr interessant.
-die filter hinter den sinusoszillatoren sind antialias-filter (lopass 25kHz, steilflankig). damit bekommt man digitale fm praktisch aliasfrei und kann extrem stark modulieren. mit dem nachbilden analoger synthese hat das nichts zu tun. -das ganze soll in 32bit berechnet werden obwohl sicher 16- oder gar 12bit interessant wären... "rekursive oder IIR-Filter sind nicht gerade die Domäne der digitalen Signalverarbeitung." -ist es denn nicht möglich schaltungsinhärentes feedback zu synthetisieren (also rekursion)? hat der Spartan 3A DSP 1800 ad/da wandler? "Mit 120MHz FPGA Takt kannst Du Samplefrequenzen von 96k mit Faktor 128 auflösen" -meinst du, man kann bei 96kHz DA-wandlung intern 128-fach oversampeln? sowas schwebte mir vor, also gut, wenn es ginge...
>"rekursive oder IIR-Filter sind nicht gerade die Domäne der digitalen >Signalverarbeitung." >-ist es denn nicht möglich schaltungsinhärentes feedback zu >synthetisieren (also rekursion)? Also IIR Filter in VHDL zu realisieren ist im Prinzip nicht das Thema. Es kommt halt auf das Design an. In meinem Audio-Projekt werden IIR-Filter als "Opcode" in dem abzuarbeitenden Programm ausgeführt. Dahinter verbirgt sich eine Statemachine die ein Rechenwerk schaltet/bedient, welche u.a. die IIR-Filter durchrechnet. Bei 80MHz Systemtakt lassen sich bei 48Khz etwa 20 Filter durchrechnen (ich musste die Multiplikation seriell ausführen, da es vom Place&Route her immer Probleme gab).
Olaf, nein- auch der Spartan DSP hat keine AD-Wandler. Du bekommst aber EVAL-Boards mit den meisten FPGAs, die schon Wandler drauf haben. Die Frage ist, wie gut die sind. Zu Deiner anderen Frage: Es geht hier nicht wirklich um oversampling, sondern um phasenorientiertes Mehrfachabtasten der DDS-Tabelle und quasi "Tunnelung" der diskreten Sprünge. Das scheint aber Dein Erfahrungspektrum etwas zu sprengen ;-) Bei einer DDS wird - anders, als beim z.B. CORDIC - der Sinuswert nicht iterativ berechnet, sondern direkt digital aus einem RAM geholt. Die Genauigkeit steht und fällt mit der Größe der Tabelle. Amplitude und Phase sind ja beide gerastert. Bei so geringen Frequenzen wie im Audiobereich, kann man die Tabelle mehrfach mit leicht veränderter Phase abtasten und aufaddieren, um so die Rundungsfehler und Quantisierungen zu mindern. Für meinen FPGA-SYN verwende ich z.B. ein RAM mit 64kB, allein für die Sinustabelle (16 Bit Sinus x 1024) -> 26 Bit brutto vor den Filtern und etwa >22 Bit SFDR bei 192kHz Abtastung. >die filter hinter den sinusoszillatoren sind antialias-filter > (lopass 25kHz, steilflankig). Kommt auf die Abtastfrequenz an. Mitunter sind weniger steile Filter bei genügend headromm besser, da weniger verzerrend.
Olaf Hilgenfeld schrieb: > "rekursive oder IIR-Filter sind nicht gerade die Domäne der digitalen > Signalverarbeitung." > -ist es denn nicht möglich schaltungsinhärentes feedback zu > synthetisieren (also rekursion)? Natürlich ist das möglich Olaf Hilgenfeld schrieb: > -die filter hinter den sinusoszillatoren sind antialias-filter (lopass > 25kHz, steilflankig). damit bekommt man digitale fm praktisch aliasfrei > und kann extrem stark modulieren. Xilinx hat in seinem Coregenerator einen DDS, der erzeugt dir schon einen sauberen Sinus, der hat bei uns bisher immer ausgereicht. Dort war er der lokale Oszillaor für eine DDC. FM haben wir damit noch nicht gemacht. > mit dem nachbilden analoger synthese hat das nichts zu tun. > -das ganze soll in 32bit berechnet werden obwohl sicher 16- oder gar > 12bit interessant wären... Die Multiplizierer im Spartan sind 18x18 Bit, mit dem Coregen kannst du dir einen 32x32 Bit Multiplizierer generieren der entweder 1 Mult + 805 LUTs oder 4 Mult + 124 LUTs benötigt. (Angaben für normalen Spartan, kein DSP) Nach der Multiplikation hast du 64 Bits. Was machst du mit den 32 übrigen Bits, hier musst du Runden > "rekursive oder IIR-Filter sind nicht gerade die Domäne der digitalen > Signalverarbeitung." > -ist es denn nicht möglich schaltungsinhärentes feedback zu > synthetisieren (also rekursion)? Natürlich kannst du eine Recheneinheit mit Rückführung beschreiben, aber du musst dir Gedanken um die Rundung machen. Üblicherweise simuliert man soetwas vorher. Damit man nicht ein Haufen Zeit bei der Implementierung vertrödelt hat, um später festzustellen, dass die Rundungsfehler zu groß sind. Rundungsfehler können einen IIR-Filter instabil machen. Man sieht es schon daran, das die Pole nach Rundung der Koeffizienten nach außen wandern. Tom
J. S. schrieb: "Es geht hier nicht wirklich um oversampling, sondern um phasenorientiertes Mehrfachabtasten der DDS-Tabelle und quasi "Tunnelung" der diskreten Sprünge." Es geht tatsächlich um oversampling im Sinne einer deutlich höheren Samplingrate als für Audio eigentlich notwendig. Frequenzmodulation ist nicht bandlimitiert, d.h. bei sehr hohem Modulationsindex treten schnell Frequenzen im Megahertzbereich auf, selbst wenn Carrier und Modulator im unteren Audiobereich liegen. Da kommt dann der Headroom ins Spiel, den Du ansprichst. Je größer der ist, desto geringer die Amplitude der Frequenzalia von jenseites der Nyquistfrequenz. Diese Amplituden sind ebenfalls deutlich von der Steilheit des Filters abhängig. Die Nichtlinearitäten rund um die Grenzfrequenz sind da relativ wurscht. Ich würde zur Sinusberechnung wahrscheinlich Chebyshev-Polynome verwenden...
>doch over sampling Bei dem Stichwort "oversampling" ging ich davon aus, daß solche Dinge wie Wandlerüberabtasung gemeint waren, daher habe ich das etwas verneint. Die DDS in der Phase zu modulieren, um eine höhrere Auflösung und weniger Artefakte zu generieren ist doch noch etwas anderers. Es kommt mehr einem Verrauschen der Phase gleich, somit liegt die Amplitude dieser Modulation im Bereich von ca +/- einem Abtastschritt der DDS. Das muss man von der Modulation trennen, die im Zuge der FM verwendet wird / werden soll. Richtig ist, daß hier theoretisch extreme Frequenzen in den Spektren auftreten können, aber diese werden ja durch das AA-filter vor der Abtastung "genullt". Mit einem diskreten Filter überschaubarer Größe bekommt man das genügend gut hin, daß die AA-Effekte, die über bleiben, im Bereich der Genauigkeit der DDS liegen. >Xilinx hat in seinem Coregenerator einen DDS, der erzeugt dir >schon einen sauberen Sinus Naja, einen relativ sauberen, der noch Filterbedürftig ist. Die Phasen kann man auch nicht beliebig fein einstellen und der CoreGen tut letztlich nichts, als "manuell" einen Sinus berechnen und ihn in RAMs stopfen. :-) Das mache ich dann lieber selber! Dann bekomme ich auch RAMs mit den benötigten Längen 2hochN-1 und 2hochN+1 gefüllt, was der DDS nicht kann.
Danke erstmal, für die umfassenden Antworten. Ich bin wie gesagt gerade in der Phase wo ich mir Gedanken mache, was ich genau an Hardware brauche. Dazu Folgendes: Wie gut lässt sich Gleitkommaarithmetik implementieren? Sind da Boards mit DSP besser geeignet? Ich habe den Synthesizer in PD (PureData) programmiert und dafür einen Controller gebaut (ca. 100 Potis, Fader und Knöpfe). Die Software will ich nun in ein FPGA "portieren" für ein Standalone-Gerät. Ich will die an sich recht einfache Mathematik mit hohen Abtastraten und Feedbackmöglichkeiten (Modulationsmatrix) betreiben. Olaf
Was erzeugt denn Pure Data für einen output??
PureData erzeugt in meinem Falle Audio über die Soundkarte (den Output einen Synthesizers halt). An sich kann es aber jede erdenklichen Daten an alles schicken, was Du an den Rechner angeschlossen kriegst... Olaf
Habe mir das auch mal angesehen - hört sich interessant an, aber bei mir kam da nur eine komische Konsole. Ist das aufwändig? Erzeugt Pure Data ein eigenes Format? Oder läuft das Ding einfach nur und man muss bei der Erzeugung von C oder VHDL selber alles übersetzen?
PD "erzeugt" kein Format. Du kannst damit speziell signalverarbeitende Schaltungen/Algorithmen/Methoden sehr leicht entwickeln, da du keine einzige Zeile Programmcode schreibst, sondern building blocks mit "Kabeln" miteinander verbindest. Das lässt sich erstens sehr leicht debuggen. Zweitens kannst du praktisch parallel arbeitende Strukturen erzeugen, indem du einfach nebeneinanderlegst was du willst... Sehr anschaulich und lehrreich. Nach C bzw. VHDL musst du natürlich selbst übersetzen, aber du musst in diesen Umgebungen nichts mehr entwickeln und rumexperimentieren, da der Algorithmus schon steht. Schau dir mal ein paar Beispiele an; könnte sich lohnen. Olaf
Angehängte Dateien:
-

pseudosinus.gif
8 KB
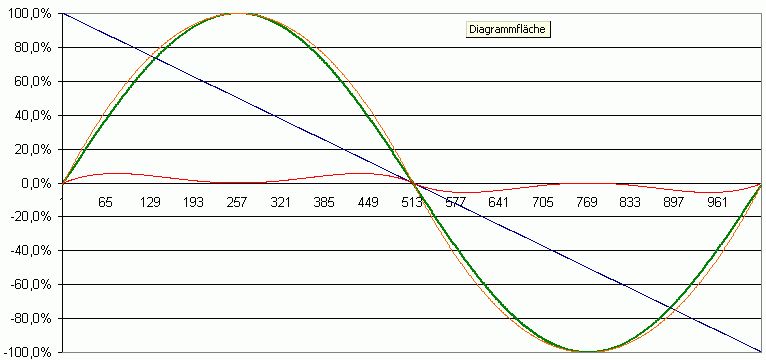
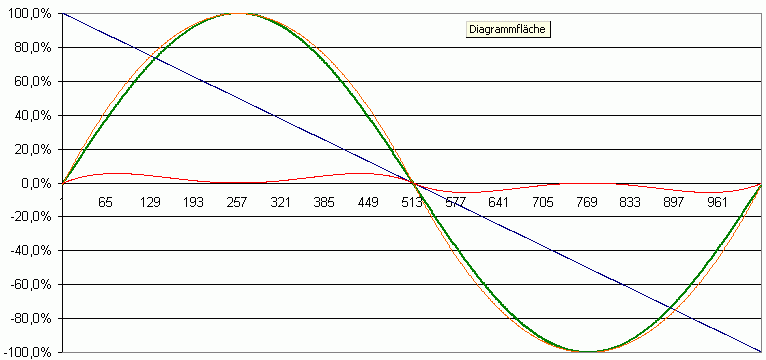
Ein Tipp: Bevor Du Dir Gedanken über einen tauglichen Sinusgenerator machst und auf DDS oder Interpolation + kommst... Ich habe in meinem einfachen Musiksynthies in den 80ern immer eine generische Funktion für den Sinus verwendet, die den realen Schwingungsfall von z.B. Gitarren und Harfen sogar noch etwas näher kommt, als der mathematische Sinus. Du rechnest einfach Y= 4 x p * (1 - abs(p)) mit p = Phase von 0 bis 1.0. Das geht bei kleinen Bitbreiten in VHDL in 1-2 Schritten. Die Funktion weicht maximal 6% vom Endwert ab und die Fehler (rote Kurve) sind nicht digitales Rauschen, sondern harmonische Oberwellen. Du erhälst so einen wesentlich musikalischeren Sinus, als mit DDS und aufwändiger Filterung.
welche kurve ist denn da der sinus und welche die nachbildung? sieht eigentlich nicht schlecht aus.
Die grüne ist der Sinus und der Orange das "fake". :-) Im Prinzip entspricht das einfach der Potenzreihenentwicklung für den Sinus. Man kann die natürlich auch weiterführen, um den Sinus mathematisch zu verbessern, aber ein reiner Sinus ist eben recht unmusikalisch und Tongeneratoren, die schon Oberwellen haben, sind interessanter zu filtern. In ähnlicher Weise bekommt man auch eine einfache Funktion für die halbe Frequenz einer Welle: Man integriert den Halbwellenbogen und gelangt zu einer S-Funktion, die man nach unten auf die Achse verschieben und stückweise verwenden kann: Y= k * ( x*x/2 - x*x*x/3 ) + b Diese Funktion kann man sowohl für die Generation von Wellen, als auch als nachgeschaltetes Effektgerät verwenden - hier als Zumischung eines Untertons.
Hi, hab etwas ähnliches vor. ich möchte ein surround konzept, dass in PD (PureData) bereits existiert, auf einem Spartan 3AN StarterKit synthetisieren. der grund für den fpga einsatz ist, dass multichannel audio dsp auf dem rechner zu große latenzen produziert. selbst in echtzeitumgebung mit rme hdsp 5296 soundkarte (auch ein spartan 3 fpga). signal verlauf soll sein: pc-RME Karte -> adat-I2S -> dediziertes PureData -> I2S-adat -> pc-RME Karte kann das Spartan3AN StarterKit überhaupt I2S? könnte an der stelle c-to-verilog eine lösung sein, oder wäre das zu ineffizient? gruß Ck
> kann das Spartan3AN StarterKit überhaupt I2S? Ein Interface hat das per se nicht drauf, aber mn kann das natürlich implementieren. Falls ihr von dem S3A-Starterkit sprecht: Das hat den 50er drauf und da geht wenig rein. Sehr wenig. DAS hier ist das richtige board derzeit: http://cgi.ebay.de/FPGA-Altera-Cyclone-EP1C6-NIOSII-FULL-Devlopment-Board-/220736567863?pt=LH_DefaultDomain_77&hash=item3364ecba37 39,- Euro und ne Menge drauf.
Sensormann schrieb: >> kann das Spartan3AN StarterKit überhaupt I2S? > Ein Interface hat das per se nicht drauf, aber mn kann das natürlich > implementieren. Falls ihr von dem S3A-Starterkit sprecht: Das hat den > 50er drauf und da geht wenig rein. Sehr wenig. > > DAS hier ist das richtige board derzeit: > > http://cgi.ebay.de/FPGA-Altera-Cyclone-EP1C6-NIOSII-FULL-Devlopment-Board-/220736567863?pt=LH_DefaultDomain_77&hash=item3364ecba37 > > 39,- Euro und ne Menge drauf. also ich würde lieber das nehmen, das fpga ist ~4 mal so groß http://www.terasic.com.tw/cgi-bin/page/archive.pl?Language=English&CategoryNo=56&No=364
hi, danke für den hinweis. leider kommen die alteras nicht in frage, da ich für andere projekte ne bestimmte intellectual property benötige, die ich bislang nur bei xilinx gefunden habe (IEEE 802.1AVB (Audio Video Bridging)). jemand vielleicht einen erfahrungsbericht wie gut c-to-verilog funktioniert? kann man damit komplexe programme "so einfach" von c nach verilog übersetzen?
Christoph K. schrieb: > jemand vielleicht einen erfahrungsbericht wie gut c-to-verilog > funktioniert? Nein, keine Ahnung. Wo gibt es das zu kaufen und für wieviel Geld? > kann man damit komplexe programme "so einfach" von c nach > verilog übersetzen? Wahrscheinlich nicht, sonst wäre ich schon arbeitslos und müßte mir was anderes suchen... Duke
>kann das Spartan3AN StarterKit überhaupt I2S? I2S ist doch nur ein Protokoll bzw Bitstrom. Und wenn ein FPGA das nicht hinbekommt .... Aber keine sorge. I2S kann man ohne Probleme in VHDL implementieren. Sonst würde mein Audio-Projekt nicht auch schon seit 4 Jahren vor sich hindümpeln und tuten (wenn ichs denn mal wieder Anschließe bzw mich damit wieder beschäftige)
> Nein, keine Ahnung. Wo gibt es das zu kaufen und für wieviel Geld? für umme... www.c-to-verilog.com oder aber nach VHDL auch FPAGC oder SHARK worauf muss ich achten, wenn ich ein c "programm", eher ein algorithmus, nach VHDL übersetzen will? kennt jemand ein tutorial? habe vorkenntnisse in fpga synthese und VHDL... aber auch nicht mehr es soll möglichst schnell gehen ^^ Gruß Ck
> www.c-to-verilog.com Uiui das macht ja aus 10 Zeilen C-Code (deren Standard Beispiel) grob 1000 Zeilen supi toll übersichtlichen Verilog Code ;)
1 | ... |
2 | i_exitcond8___0___ <= (i_cloned37___0___ == (32)); |
3 | i_reduced_and27238 <= ((((((1)) & (((i_cloned___0___) >> ((24)))))) + ((((1)) & (((i_cloned___0___) >> ((23))))))))+((((((1)) & (((i_cloned___0___) >> ((4)))))) + ((((1)) & (((i_cloned___0___) >> ((3)))))))); |
4 | i_reduced_and27242 <= ((((((1)) & (((i_cloned___0___) >> ((16)))))) + ((((1)) & (((i_cloned___0___) >> ((15))))))))+((((((1)) & (((i_cloned___0___) >> ((26)))))) + ((((1)) & (((i_cloned___0___) >> ((25)))))))); |
5 | i_reduced_and27246 <= ((((((1)) & (((i_cloned___0___) >> ((18)))))) + ((((1)) & (((i_cloned___0___) >> ((17))))))))+((((((1)) & (((i_cloned___0___) >> ((14)))))) + ((((1)) & (((i_cloned___0___) >> ((13)))))))); |
6 | i_reduced_and27250 <= ((((((1)) & (((i_cloned___0___) >> ((28)))))) + ((((1)) & (((i_cloned___0___) >> ((27))))))))+((((((1)) & (((i_cloned___0___) >> ((30)))))) + ((((1)) & (((i_cloned___0___) >> ((29)))))))); |
7 | ... |
Den Code mit Testmuster testen und synthetisieren und mit den richtigen Randbedingungen durch P&R jagen, und wenn etwas verneuftiges dabei herauskommt und die FPGA Groesse nicht explodiert, dann waere die Aufgae erledigt. Aber 1000 Zeilen Code versprechen etwas anderes...
Schock lass nach. Vollkommen untauglich. Dann doch bitte die C-Strukturen direkt in einen schnellen Softcore setzen. Was als Software gebaut ist, wird eh nicht schnell und strukturell so gebaut, dass es eine gute HW gibt.
Update zur Machbarkeit eines (Audio-) FM-Synthesizers in Hardware: Beitrag "Drum-Computer in VHDL" Yes we can :-) ----------------- Falls der TE noch liest: Effektiver sollte das Ganze in einem DSP zu machen sein, wenn es mit float gerechnet werden soll, aber bei den von Dir beschriebenen Bandbreiten (MHz) ist das FPGA ein Muss. Für eine technische App habe ich in einem Spartan einen Modulator laufen, der komplex einen Datenstrom von 5MHz auf 200MHz aufmoduliert. Um Bandbreite zu gewinnen, mache ich das Mehrfachparallel, d.h. es werden 4(8) Sin/Cos-Paare in einem Schritt verarbeitet.
Jürgen S. schrieb: > Für meinen FPGA-SYN verwende ich z.B. ein RAM mit 64kB Du schwendest hoffentlich keine 64kB RAM, nur um einen Sinus zu produzieren. Warum nimmst Du keinen CORDIC? Christoph K. schrieb: > ich möchte ein surround konzept, dass in PD (PureData) bereits > existiert, auf einem Spartan 3AN StarterKit synthetisieren. Könntest Du das bitte etwas näher erläutern, wie das mit PureData funktioniert? Soweit ich mich nun da hindurchgeklickt habe, ist das nur einen Art Simulink zum Simulieren. Wird da auch Code erzeugt? Oder wie gelangst Du zum VHDL?
Mr. Zulu schrieb: > Christoph K. schrieb: > >> ich möchte ein surround konzept, dass in PD (PureData) bereits >> existiert, auf einem Spartan 3AN StarterKit synthetisieren. > Könntest Du das bitte etwas näher erläutern, wie das mit PureData > funktioniert? Gerade gestern wurde eine neuer Internetservice eingerichtet. Er richtet sich speziell an Personen, die in der Audio- und Videotechnik unerfahren sind und sich über Möglichkeiten informieren wollen, komplexe Synthesizer in FM-Technik zu implementieren und nicht wissen, was PureData ist. Der hierfür eingerichtete Service heisst Guhgel. Man geht auf die Guhgelseite und tipp sein Suchwort ein: http://puredata.info/
Lothar Miller schrieb: >> Es geht um 4 numerisch gesteuerte Sinusoszillatoren, 4 Butterworthfilter > > Ein Filter hinter einem Sinusoszillator ist eigentlich ziemlich > > witzlos... Warum? DDS-Sinüsse sind nicht die Besten und ein Filter kann helfen, das zu verbesseren.
TippGeber schrieb: > Man geht auf die Guhgelseite und tipp sein Suchwort ein: > http://puredata.info/ Wer die Frage hat, braucht für den Spott nicht zu sorgen, ich weiss. Aber Dein link liefert wenig zum Thema und sagt inbesondere nichts darüber aus, wie Christian das macht. Leider scheint er aber nicht mehr aktiv, genausowenig, wie die anderen Synthesizeringenieure, die bisher beigetragen haben. Alle verschwunden? > Synthesizer in FM-Technik zu implementieren Fragen wir doch mal so: Warum überhaupt FM-Technik? Meiner Recherche nach hat sich Yamaha seinerzeit die Rechte an der Technik gesichert um (als einziger ?) Musiksynthesizer zu bauen. Was ist der Vorteil? Warum nicht einfach klassischer Sinus und dann deduktive Synthese, wie es immer genannt und realisiert wird? Zur Grundfragestellung: Wozu muss man einen FPGA hernehmen, um einen solchen Synthesizer zu erzeugen? Die Frequenzen erstrecken sich bis maximal 15kHz? Modulationen dieser Art müsste jeder Mikrorechner hinbekommen, direkte Synthese erst Recht. Zumal ich bei Rene's Projekt zu erkennen glaube, dass der dort verwendete FPGA auch nur zyklisch rechnet, wie ein Microprocessor und nicht Parallel wie ein FPGA.
Mr. Zulu schrieb: >Jürgen Schuhmacher schrieb: >> Für meinen FPGA-SYN verwende ich z.B. ein RAM mit 64kB > Du schwendest hoffentlich keine 64kB RAM, nur um einen Sinus zu > produzieren. Warum nimmst Du keinen CORDIC? Weil ich den Sinus in dieser erwähnten FPGA-Version sehr genau erzeugen möchte, was seinen Grund in einer nachgeschalteten Oberwellensynthese hat, die ich mittels einer analytischen Rechnung vollziehe, wie ich es bei meinem LaPlace-Generator beschrieben habe. Damit das vernünftig funktioniert, muss der Sinus sehr oberwellenarm sein, d.h. ich muss ihn entweder sehr genau berechnen und/oder interpolieren. Meinen Erfahrungen mit diesem Thema zufolge ist es einfacher, eine kleinere Tabelle zu nehmen, diese zu interpolieren und per Filterung zu glätten. Ein Cordic liefe auf eine vergleichsweise grosse Tiefe hinaus, die nicht nur richtig viel Latenz bringt, die ich bei meiner Architektur nicht gebrauchen kann, weil ich im pipeline Betrieb viele andere Werte deselben prozessierten Kanals registerintensiv mitschleppen müsste, sondern auch noch viel Platz braucht, was in den kleinen FPGAs recht relevant ist. Mit "Platz" sind hierbei konkret DSPs und Register gemeint. Die Vorbelegung im RAM macht da durchaus Sinn. Bei den boards, die ich für meine Musik-Synthesizer verwende, ist meist ein externes RAM drauf. Beim kleinen Altera sind es wenigstens 64MB, da machen 0,1% "Verschwendung" nicht viel aus :-) Daher gehe ich sogar noch einen Schritt weiter und hinterlege für die Synthesizer, die ich mit einem echten Sinus ausstatten möchte, inzwischen eine 256k lange und 32Bit breite Tabelle mit je 16 Bit für den Sinus und einem Komplement für den Cosinus. Damit habe ich die Steigung für die Interpolation direkt parat und brauche nicht zweimal zu lesen - komme also auf entsprechende Bandbreiten und Genauigkeiten. Mr. Zulu schrieb: > Fragen wir doch mal so: Warum überhaupt FM-Technik? Meiner Recherche > nach hat sich Yamaha seinerzeit die Rechte an der Technik gesichert um > (als einziger ?) Musiksynthesizer zu bauen. Was ist der Vorteil? Tja, gute Frage. Yamaha nutzt seit Mitte der 90er die AWM-Synthese, also eine Mischung aus Wavetable und Filter. Dasselbe findet man auch bei Korg. Welche patentrechtlichen Themen da eine Rolle spielen, kann ich nicht sagen. Rein technisch sehe ich keine qualitativen Vorteile oder Aspekte, die die FM in der Musik prädestinieren. In der HF-Technik ist das was anderes! Reine FM-Synthese kenne ich eigentlich auch nur von den EMU-Chips, die auf den Soundblasterkarten verbaut worden und auch die arbeiten seit über 20 Jahren auch mit Wavetable -> Soundfonts!
Frage an Olaf und Christoph: Habt ihr das realisiert? Ich möchte etwas Ähnliches für Videodaten / SDR bauen. Die Modulationsfrequenzen liegen im Bereich bis 30 MHz. Ich würde es gerne mit einem FPGA realisieren, das mit einer freien Webversion zu bearbeiten ist. Wäre da der Spartan oder der Cyclone besser? Ich brauche bis zu 200 MHz Trägerfrequenz und insgesamt 8 Kanäle mit komplexer Rechung.
high tec ing schrieb: > Frage an Olaf und Christoph: Habt ihr das realisiert? Ich möchte etwas > Ähnliches für Videodaten / SDR bauen. Die Modulationsfrequenzen liegen > im Bereich bis 30 MHz. Ich würde es gerne mit einem FPGA realisieren, > das mit einer freien Webversion zu bearbeiten ist. Wäre da der Spartan > oder der Cyclone besser? > > Ich brauche bis zu 200 MHz Trägerfrequenz und insgesamt 8 Kanäle mit > komplexer Rechung. Also wenn du 200MHz raushauen willst dann musst du größer 400MHz arbeiten. Abtasttheorem!!! Das wird mit beiden Bausteinen nichts gescheites. Besser ist die 30MHz Modulation im FPGA zu erzeugen und extern auf die Trägerfrequenz zu modulieren, Wenn du AM modulieren willst.
René D. schrieb: > Besser ist die 30MHz Modulation im FPGA zu erzeugen und extern auf die > > Trägerfrequenz zu modulieren, Wenn du AM modulieren willst. also ich bräuchte 200MHz als Träger und eine Frequenz von 0 ... 30MHz draufmoduliert, aber FM. Die Randbedingungen der 400 MHz ist mir da aber nicht klar.
Wo hast du dein Ing her? high tec ing http://de.wikipedia.org/wiki/Nyquist-Shannon-Abtasttheorem f_abtast > 2*f_max Dein FPGA gibt abgetastete Werte aus.
Achso, das meinst Du - ich bezog mich erstmal auf die digitale domain. Was die Ausgabe angeht, muss ich mir Gedanken machen. Gfs reichen die 400 MHz gar nicht. Der Träger bleibt ja bei 200 , aber die 30 MHz sind ja variabel - können also auch 29,994 sein.
> 400 MHz gar nicht. Der Träger bleibt ja bei 200 , aber die 30 MHz sind > ja variabel - können also auch 29,994 sein. 0,006/30=0,0002 Dann musst du alles auf 1/5000 alles genau bauen.
ok, wären dann 200 MHz x 5000 = 1000 GHz, da sehe ich mich mal nach geeigneten FPGAs um. Jetzt aber im Ernst: Das kann es ja wohl nicht sein. Meines Erachtens reicht es, die 200 MHz mit den 0...30 MHz zu mischen, weil dann nur 230 MHz rauskommen können. Oder täusche ich mich da? Ok, beim Audio sind es 48kHz die z.B. mit einer Tonfrequenz von sagen wir 1kHz gemischt werden. Da könnte man auch argumentieren, dass es auch 999,1 Hz sein könnten und damit 48kHz / 1/10000 = 500 MHz gebraucht werden. Ist dem so? Oder beschränkt man sich da auf die echten Tonhöhen mit den 1/12tel Sprüngen? Bei den DDS Chips kann man die Frequenz zum modulieren voreinstellen, die Genauigkeit beträgt wenigstens 16 Bit. Intern laufen die z.B. mit 2 GHz, damit muss es ja gehen. Oder geht das nur grob?
high tec ing schrieb: > ok, wären dann 200 MHz x 5000 = 1000 GHz, da sehe ich mich mal nach > geeigneten FPGAs um. > > Jetzt aber im Ernst: Das kann es ja wohl nicht sein. Meines Erachtens > reicht es, die 200 MHz mit den 0...30 MHz zu mischen, weil dann nur 230 > MHz rauskommen können. Oder täusche ich mich da? > Sagte ich bereits. FM geht auch mit Mischen. >Besser ist die 30MHz Modulation im FPGA zu erzeugen und extern auf die >Trägerfrequenz zu modulieren, Wenn du AM modulieren willst.
ok, dann schaue ich mal und melde mich wieder, wenn ich was habe. Danke.
Ich habe in den vergangenen Tagen mit den IO-Delays herum experimentiert und denke, dass ich damit arbeiten kann. Ich bekomme den Takt damit sicher genau genug hin, um das Signal ausreichen fein modulieren zu können. Laut Spezi sind 50ps einstellbar, bei den angestrebten 200MHz = 5ns sind es Faktor 1 zu 100. Der Empfänger wird so und so filtern, um die Frequenz wiederherzustellen. Ich muss mir noch noch überlegen, wie ich das an das Ziel übertrage.
high tec ing schrieb: > ok, wären dann 200 MHz x 5000 = 1000 GHz, da sehe ich mich mal nach > geeigneten FPGAs um. Eine Möglichkeit wäre, 10.000 FPGAs parallel zu schalten und diese mit jeweils 100 MHz zu betreiben. :-) Das wäre dann die erste SDR-Platine mit Starkstromanschluss. Die geschätzten 50kW liessen sich mit einigen wenigen 3-Phasen Leitungen versorgen. Mal zurück zur Realität: high tec ing schrieb: > Ok, beim Audio sind es 48kHz die z.B. mit einer Tonfrequenz von sagen > wir 1kHz gemischt werden. Da könnte man auch argumentieren, dass es auch > 999,1 Hz sein könnten und damit 48kHz / 1/10000 = 500 MHz gebraucht > werden. Ist dem so? Oder beschränkt man sich da auf die echten Tonhöhen > mit den 1/12tel Sprüngen? Ich glaube, hier liegt noch ein grundsätzliches Problem beim Verständnis der digitalen Signalrepräsentation vor. Die digitalisierten Werte, werden nicht diskret unterteilt oder in der Zeitachse skaliert, wenn man Frequenzmodulation betreibt. Auch beim Audio wird ein Vibrato nicht durch das Verschieben der Frequenzachse realisiert, wenn man mal von einem aktiven Entjittern durch Taktmanipulation absieht. Zwar kann man z.B. die Gesangspur einer Studioaufnahme mit Vibrato versehen, indem man den normalen Datanstom ausgibt und den Takt mit einem Verschiebeverfahren mit Schwingungen beaufschlagt, wie ich das hier getan habe : http://www.96khz.org/oldpages/frequencyshifter2.htm ... und umgekehrt verjitterte Aufnahmen von Bändern mit Gleichlaufschwankungen bei der Digitalisierung durch passende Steuerung des AD-Wandlers kompensieren, praktisch wird die Modulation aber in die Amplitudenachse abgebildet. Die Zeitpunkte der Abtastung bleiben konstant, es ändern sich nur die Werte, die im digitalen Datenstrom auftauchen. Sie entsprechen derjenigen analogen Welle, die durch die Modulation verkürzt oder verlängert würde. Dass dies so funktioniert liegt an dem Umstand, dass nach der Rekonstruktion mit dem AA-Filter wieder eine kontinuierliche Wellenform entsteht, wenn die abgebildeten Frequenzen unterhalb der Nyquistfrequenz liegen. Es reicht also, die beiden Wellen zu multiplizieren, um den mathematisch exakten Datenstrom zu bekommen. Soweit die Theorie. Praktisch sieht es etwas anders aus, weil man den idealen Filter für diese Rekonstruktion nicht bauen kann, bzw. nicht genügend gut, um die Zielfrequenz und die Abtastfrequenz komplett zu trennen, bzw. soäter mal die Trägerfrequenz zu entfernen. Deshalb arbeitet man mit möglichst hoher Abtastrate, um das Signal zu repräsentieren, weil die Filterprobleme dann geringer werden. Beim Audio sind es z.B. 192kHz, um Oberwellen bis real 12kHz-15kHz noch sehr gut hinzubekommen. Der Faktor 10 ist da schon ziemlich gut und reicht bei entsprechenden Filtern auch einigermassen für die angestrebte Genauigkeit von 16+ aufwärts. Wie gut die 230 MHz fürs SDR nachher analog aussehen, hängt somit vom DA-Wandler und dem nachgeschalteten realen Filter ab. Üblicherweise haben derartige analoge Filter einige Macken, die man digital vorkompensieren kann, so wie der anloge Filter seinerseits die Schwächen digitaler Filters beheben hilft. Die Frage ist, ob die überhaupt analog benötigt werden oder erst noch weiterverarbeitet werden sollen. Unter der Annahme der späteren korrekten AA-Rekonstruktion (das ist der Grundtenor bei all diesen Überlegungen) ist der Datanstrom soweit erstmal clean, solange er in der digitalen Domain bleibt. Klar ist natürlich, dass man sich mit jeder rundung der Phase und der Amplitude ein Rauschen einfängt, dass später zutage treten wrid. Was man natürlich tun kann, ist die Trägerfrequenz, die Abtastfrequenz und die Filter aufeinander abzustimmen. So sollte ein digitales Filter bezüglich der Dämpfung im Sperrbereich für die Trägerfrequenz idealerweise eine Null haben, weil diese dann komplett verschwindet - des weiteren empfehlen sich sinnvolle Konstellationen von Trägerfrequenz und festen Modulationsfrequenz, also möglichst ein Ganzzahlverhältnis, sodass die entstehnde Schwebung eine kurze Periodendauer hat und zudem noch zur Integraltiefe des Filters passt, wenn machbar. Speziell bei DDSen ist es ja so, dass bei bestimmten Frequenzen eine sehr niederfrequente Schwebung entsteht, die sich dann im Endsignal abbildet. Dies lässt sich durch eine Variation der Tabellenlänge kompensieren, die zu einer ungeraden Anzahl von Durchläufen per Perdiode führt. die Schwebung ist dann auch einige Peridoen beschränkt, schwingt also hochfrequent und wird durch ein Filter besser gedämpft. Nochmal zum Beispiel des Audio und der Tonhöhen bei der DDS: Ein Vibrato wird einfach dadurch erzeugt, indem man die Phase schneller oder langsamer addiert und somit frühere oder spätere Amplitudenwerte ausgit. Die Abtastrate bleibt gleich. Eine Interpolation ist nicht unbedingt nötig, wenn der Fehler im Bereich der Auflösung von Y bleibt. Sie ist aber dann sehr hilfreich, wenn man mit zu kleinen Tabellen arbeiten muss. Daher kann man auch für diesen Frequenzbereich mit FPGAs direkt modulieren und mit parallelen Methoden auch noch um einige Stufen oberhalb der Taktfrequenz. Beitrag "Re: Rechnen im FPGA, wenn Daten schneller, als der Takt" > Welche Abtastfrequenz muss ich dann haben? Ich nehme mal an, dass in Deinem Beispiel die 200 der Träger sein soll und die 30MHz irgendwann (verarbeitet, dezimiert) ausgegeben / -gewertet werden sollen. Massgeblich ist daher die Representation der 200 in der Abtastfrequenz und der oberhead zu den 30 MHz. Ich würde ich einen steilen TP sehen, der mit 2x300 MHz Taktfrequenz (6x Ft) gefahren wird und eine GF von 300/8 MHz hat mit Nullstelle bei 200MHz. Mit etwas Gefummel geht es auch mit der 5 fachen Frequenz - darunter wird es ein bissl "wackelig". Mit der Einschätzung hinsichtlich der Spartanfrage gebe ich daher René recht: Das wird aufwändig. Du bräuchtest 4 Rechenstränge mit je 150 MHz, das können die noch einigermassen. Sowas ist eine Aufgabe für Virtex und Stratix.
Hallo, ich möchte auch gerne was mit FM machen :-) Ich habe verstanden, dass hier nicht die Tonhöhe des zu modulierenden Tones die Trägerfrequenz verschiebt, sondern nur die Amplitude. Jetzt bekomme ich ein analoges Sognal (Audio) an einem 8-Bit ADC rein ins FPGA und möchte damit die Trägerfrequenz ändern. Gemacht wird das einfach mit einem Zähler bei dem das höchste Bit dann auf die Antenne gegeben wird. Wenn ich also Trägerfrequenz von 100MHz haben will, muss an der Antenne 1010101010 ankommen und eine "10" Folge darf 10ns Dauern, also der Zähler muss mit mindestens 200MHz zählen. Wenn jetzt bei dem 8-Bit Wert die Nulllinie bei 127 liegt, dann muss ich also den Zähler so gestalten, dass jedes Mal wenn 127 addiert wird die Grundfrequenz unverändert rauskommt, also wenn ich z.B. einen 7-Bit Zähler nehme würde das passen - Aber der Rest passt natürlich noch nicht. Es gibt dann vermutlich ein "Band" also wieweit die Frequenz verändert werden darf maximal für das Minimum und das Maximum der Amplitude. Wie sind da die Werte? Diese brauche ich vermutlich um den Zähler richtig einzustellen damit das Radio das am Ende auch empfangen kann. Bin ich auf einem grob richtigen Weg oder habe ich krasse Fehler drinnen? Vielen Dank!
Hier: http://hamsterworks.co.nz/mediawiki/index.php/FM_SOS Geht es um 75kHz nach oben und nach unten von der Mitte aus, also 150kHz Breite - ist das korrekt so oder wird was Anderes empfohlen?
Nach der Carson-Formel liegen 99% der Leistung einer FM innerhalb 2*Fmod + 2*Fhub, daher ist ein Stereo-Rundfunksignal 2*75 kHz + 2*57 kHz breit.
Danke! Also kann ich auch locker 200kHz Breite nehmen. Warum hat der in dem Beispiel 320MHz für eine Frequenz von 91MHz verwendet? Ich meine ja der Takt muss schon deutlich schneller sein weil man ja so die unterschiedlichen Abstände erzeugt aber gibt es da ein unteres Limit? Wenn ich 100MHz erreichen will, gibt es da einen minimalen Takt am Accu?
Nach dem Nyquist-Theorem müssen mindestens 2 Punkte pro Periode ausgegeben werden für eine eindeutige Definition. Mehr ist besser.
2 Punkte reichen nie und nimmer bei der DDS. Wenn das was werden soll braucht man erfahrungsgemäß einen Faktor 10 in der Abtastung. Mit FPGAs ist da auch irgendwann Schluss. Die 91 sind ein Kundstgiff: Durch die Verstimmung tastet der Träger die aufmodulierte Frequenz irgendwann komplett ab.
Ich komme nochmals zurück auf mein Problem mit den +/-30 MHz. Brächte es etwas auf 100MHz Trägerfrequenz herunterzugehen? Juergen S. schrieb: > Auch beim Audio wird ein Vibrato nicht durch das Verschieben der > Frequenzachse realisiert ... Danke für Deine Erklärungen. Eine Frage hätte ich noch. Du schreibst: > Unter der Annahme der späteren korrekten AA-Rekonstruktion, > ist der Datenstrom soweit erstmal clean, solange er in der > digitalen Domain bleibt. D.h. solange ich digital bleibe, reicht die doppelte Abtastfrequenz?
Wie ist das mit dem Accumulator und dem Takt mit dem ich addiere? wenn ich einen 8-Bit Accu habe und in jedem Takt 128 dazuaddiere, dann kippt in jedem Takt das höchste Bit. Wenn ich das jetzt etwas, und zwar nur minimal, verschieben will, dann addiere ich etwas kleinere oder leicht größere Werte. Aber dann kippt das höchste Bit trotzdem fast immer bei jedem Takt und nur ganz selten sieht es anders aus. Bei einem 4-Bit Accu zu dem ich immer 8 addiere erhalte ich am höchsten Bit: 01010101010101 addiere ich aber jetzt 9: 01010101101 ... Ich erhalte also nicht einen konstant minmal größeren Abstand zwischen 1 und 0 zeitlich, sondern nur ganz selten. Also müsste ich mit einer deutlich höheren Frequend wie der die ich am Ende verschieben will addieren. Aber wieso geht das mit 91MHz und 320MHz? Sooo viel großer ist das doch auch nicht?
high tec ing schrieb: > D.h. solange ich digital bleibe, reicht die doppelte Abtastfrequenz? In der Theorie ja. In der Betrachtungswelt der idealen SV reicht ein infinitisimales Plus der Abtastfrequenz zu deren Representation. Du bekommst aber damit eine Schwebung, die weggefiltert werden müsste. Rein mathematisch geht das wunderbar, weil die Schwebung aus Frequenzen besteht, die mit einem idealen AA-Filter verschwinden. Der Umstand, dass es diesen nicht gibt, ist der Grund der Überabtastung.
Gustl Buheitel schrieb: > wenn ich einen 8-Bit Accu habe und in jedem Takt 128 dazuaddiere, dann > kippt in jedem Takt das höchste Bit. Dann bist Du genau an der theoretischen Betriebsgrenze der DDS mit 50% Abtastfrequenz. Und Du bist unter Zuhilfennahme der o.g. Darstellung bezüglich der Nichtidealität realer Filter bereits deutlich ÜBER der praktischen Betriebsfrequenz von DDS-en. > Ich erhalte also nicht einen konstant minmal größeren Abstand zwischen > 1 und 0 zeitlich, sondern nur ganz selten. Das ist der der DDS-Methodik eigenen Jitter, der auch als digitales Phasenrauschen bezeichnet wird. Deine Tabelle / Syntheseeinheit muss in Verbindung mit dem Phasenvektor genügend groß sein, damit dieser Effekt verschwindet, respektive im AA-Filter genügend gedämpft wird. Stelle Dir die Laplace-Transformation dieses Phasenrundungssprunges dar, genauer das dazu generierte dy/dx in Deiner DDS-Tabelle und überlege, wie dieser Impuls im Filter gedämpft wird.
Jürgen Schuhmacher schrieb: > Rein technisch sehe ich keine qualitativen Vorteile oder > Aspekte, die die FM in der Musik prädestinieren. Hmm, rechnen wir doch mal ganz einfach mal. Für "Wavetable-Synthese" muss man die Quelle samplen. Bei mindestens 20 kHz Abtastrate und 0.1 Sekunden (man kann ja Schleifen machen) sind das schon 2000 Abtastwerte die Du speichern musst. Das sind mindestens 1000 Bytes... für jeden Klang! Das war in den 1980gern ziemlich viel Speicher. So ein typisches Keyboard hätte viele Kilobytes an Speicher gebraucht. Bei der FM-Synthese musst Du hingegen nur sehr wenige Parameter speichern, und diese Parameter kannst Du vom Nutzer einstellbar machen. Sprich der Benutzer kann relativ einfach neue Klänge erstellen, und die sind so klein, dass er die Parameter abschreiben kann. Die FM-Synthese ist eine der Möglichkeiten mit sehr wenig Speicher sehr interessante Klänge zu erzeugen.
@ Jürgen Schuhmacher: Das ist mir schon klar, ich möchte aber eine Frequenz von um die 91MHz erreichen und kann meinen 4C Spartan 3 nur mit 275MHz takten. Das erstaunliche: Es funktioniert trotzdem und ich kann mit einem normalen Radio im ganzen Garten die Musik hören die ich auf den AD Wandler gegeben habe. Das finde ich ist das eigentlich komische, also obwohl mein Zähler, also das oberste Bit fast immer mit der gleichen Frequenz kippt und nur ganz selten einen Takt länger bleibt oder einen früher kippt reicht das anscheinend aus um es mit dem Radio zu empfangen. Klingt noch dazu erstaunlich gut.
@Gustel Kann schon hinkommen. Die 275MHz sind gegenüber der 91MHz ja auch um einiges höher, als nur Faktor 2. Mit einem guten steilflankigen Filter kann man bis zu 40% Nutzfrequenz erzielen, wenn man einen Sinus herstellen will - je nach Güteanspruch. Bei der FM braucht man noch etwas "Hub" - passt so in etwa. Was für einen Filter verwendest Du? Deine Antenne, wie immer sie aussehen mag, dürfte einen Resonanzschwingkreis bilden und eine entsprechende Filterwirkung haben. Wie ist das inzwischen eigentlich rechtlich? Eigene Radiosender zu bauen war doch immer verboten? @Christian Mit Blick auf das Thema RAM hast Du freilich Recht, wobei ich die FM Synthese eher mit der klassischen Synthesizertechnik der additiven/deduktiven Synthese vergleichen würde und da braucht(e) man auch nur ein wenig RAM für die Parameter. Die wavetable-Synthese kam einiges später, ja, allerdings haben wir sie ja nun, von daher war der Nutzen der FM aus musikalischer Sicht ab da begrenzt. Musikalisch ist WTS flexibler, denn das, was mit FM Operatoren und virtueller Synthesetechnik möglich ist, kann ja auch auf das WAVE angewendet werden. Nahezu alle WT-basierten Synthies und Keyboards haben entsprechende Manipulationsmöglichkeiten intus, z.b. KORG - teilweise sogar auch die Yamaha. Habe noch eines dieser Viecher von 1990 (PSR) hier rumliegen.
Rechtlich darf man mit 50nW senden, das ist nicht viel und ich bin mit einem Pin samt Leiterbahn und ohne Antenne vermutlich schon deutlich drüber. Filter verwende ich auch nicht und mir ist immer noch unklar was das mit einem Sinus zu tun hat. Also: Ich habe einen Zähler, 32 Bit. Und zu dem Addiere ich in jedem Takt eine Zahl. Bei FM verschiebt man ja etwas die Frequenz, also addiere ich einen etwas höheren Wert wenn die Frequenz schneller und einen niedrigeren Wert, wenn die Frequenz langsamer werden soll. Also komplett ohne Sinus oder so. Auf die Antenne wird in jedem Takt das höchstwertige Bit des Zählers gegeben. Immer noch kein Sinus. Der Zähler ist lang im Vergleich zur maximalen Wertänderung den ich addiere. Also sagen wir mal als Beispiel bei der Mittenfrequenz kippt das obere Bit bei jedem 4. Takt. Jetzt will ich die Frequenz minimal erhöhen, also addiere ich einen leicht höheren Wert. Was passiert? Das Bit kippt immer noch bei jedem 4. Takt bis auf wenige Ausnahmen, denn manchmal kippt es einen Takt früher, aber extrem selten. Aus einem 000111000111000111000111000111000111000111000111000111000111000111000111 wird ein 000111000111000111000111000111000111000111001110001110001110001110001110 Ich habe das jetzt nicht simuliert, werde das aber noch machen. Die änderung ist jedenfalls nur extrem selten und ich verstehe einfach nicht wie das Radio das erkennen soll.
Aha, nun verstehe ich das. Du gibts den Phasenvektor selbst aus, bzw dessen höchstes Bit. Damit pulst Du mit einem Rechteck auf Deine Pseudoantenne, so wie beim PWM. Üblicherweise würdest Du anhand des Phasenvektors in eine Sinustabelle schauen und diesen Wert per DAC ausgeben. Ich würde sagen, dass Deine Anordnung, also die Leiterbahnwiderstände + parasitäre Kapazitäten + Leiterbahn-Induktivität einen Schwing-Kreis bilden, bzw eine Dämpfung darstellen, die dann etwas halbwegs sinusförmiges überträgt. Die Oberwellen, die im Rechteck stecken, werden stärker gedämpft und beeinflussen zudem den Empfänger nicht. Das Ganze geht aber schon ziemlich in Richtung Störsender :D
Das komische ist halt, dass es richtig gut klingt und mit dem Radio zu empfangen ist. Und zwar obwohl die "Wellen" fast immer gleich lang sind und sich nur extrem selten minimal unterscheiden.
Im Prinzip tust Du ja hiermit: ************************************************************* Ich habe einen Zähler, 32 Bit. Und zu dem Addiere ich in jedem Takt eine Zahl. Bei FM verschiebt man ja etwas die Frequenz, also addiere ich einen etwas höheren Wert wenn die Frequenz schneller und einen niedrigeren Wert, wenn die Frequenz langsamer werden soll. ************************************************************** ... durchaus das Richtige, siehe meine Anmerkungen weiter oben zum Thema Vibrato. Das ist ja eine FM. Nur so, wie Du es hier realisierst und ausgibst, produzierst Du eine Menge Jitter und unproduktive Oberwellen, die nicht zum Nutzsignal beitragen und nur stören. Damit brauchst Du viel mehr Leistung. Das Ziel wäre dagegen, möglichst schmalbandig und schwach zu senden und nicht, das ganze Band in der Siedlung zu verseuchen ;-)
Ach so weil es ein Rechteck und kein Sinus ist ... hm, muss ich mir wohl mal einen schnellen DAC kaufen oder den VGA Anschluss verwenden :-D Keine Angst ich sende hier nicht ununterbrochen, nur zum Testen ab und zu ein paar wenige Minuten und auch nur "Aqua - Barbie Girl".
Rene B. schrieb: > Aber keine sorge. I2S kann man ohne Probleme in VHDL implementieren. > Sonst würde mein Audio-Projekt nicht auch schon seit 4 Jahren vor sich > hindümpeln und tuten Wozu hast Du bei Deiner Lösung überhaupt I2S implementiert? Welche Chips benutzt Du diesbezpflich? Oder ist am Ende doch I2C gemeint? - Wenn ich die Artikel hier so lese, kommt mir nämlich der Verdacht. Gustl Buheitel schrieb: > Keine Angst ich sende hier nicht ununterbrochen, nur zum Testen ab und > zu ein paar wenige Minuten Auch die sind nicht ohne, wenn jemand dadurch gestört wird. > und auch nur "Aqua - Barbie Girl". Das ist wohl sicherlich das grösste Verbrechen an der Geschichte :-)
Herr Hilgenfeld scheint hier nicht mehr mitzulesen. Sicher ist der FM-Synthesizer schon fertig und dudelt bereits eifrig, sofern es überhaupt ein Musiksynthesizer gewesen sein sollte, davon steht nämlich nichts. Falls doch, würden mich mal Konzepte interessieren
FPGA-Vollprofi schrieb im Beitrag #3370438: > Sicher ist der FM-Synthesizer schon fertig und dudelt bereits eifrig, Sehr wahrscheinlich, wenn man in Betracht zieht, dass das Thema schon über 3 Jahre alt ist :-) > sofern es überhaupt ein Musiksynthesizer gewesen sein sollte Auch sehr wahrscheinlich, denn: Olaf Hilgenfeld schrieb: > Ich möchte einen monophonen FM (PM) Synthesizer auf einem FPGA "phon" -> "laut" = hörbar. Wäre aber auch nicht unbedingt relevant, ob der für Musik oder was anderes genutzt wird, weil FM ist FM. Jürgen S. schrieb: > möglichst ein Ganzzahlverhältnis, sodass die entstehnde Schwebung eine > kurze Periodendauer hat und zudem noch zur Integraltiefe des Filters > passt, wenn machbar Was ist bei Dir die Integraltiefe?
Definitionssache. Aus sicht der Mathematik ist es erstmal eine Länge. Wenn ma Filter aber Parallel baut, ist das Prozessieren zweidimensional. Daher gibt es quasi eine Länge (in der Zeitachse) und eine Tiefe (in der pipeline-Achse). Kann man natürlich so und so interpetieren. :-)
Rene B. schrieb: > Ich denke mal das ist ohne weiteres möglich. > > http://www.fpga.synth.net/pmwiki/pmwiki.php?n=FPGASynth.8vFM-2x4 > > Klingt sehr interessant. Ist das wirklich ein FM-Synthesizer wie der TO es meinte, bzw. ist es ein FM-Synthesizer, wie er in Musiksynthesizern Anwendung findet? Ich habe das Gegenteiliges dazu gefunden und auch der Betreiber der Seite schreibt dazu: "Please note that I understand that this type of synthesizer, though commonly referred to as "FM" is in fact not a frequency modulated system. Instead, it is a phase modulated or "PM" system." Also ein Phasenmodulator?
http://de.wikipedia.org/wiki/FM-Synthese beantwortet eigentlich beide Fragen, vor allem auch die nach den FM-Musiksynthesizern: Obwohl der DX7 damit für viele Anwender zum Synonym der FM-Technik wurde, arbeitet er genaugenommen gar nicht mit diesem Verfahren. Zum Einsatz kommt hier hingegen die verwandte Phasenmodulation, die mathematisch über eine Integration funktioniert.
Ich greife das Thema aus aktuellem Anlass Beitrag "FM-Synthesizer Analyse" nochmals auf und beziehe mich auf die Frage von Olaf ganz oben: Wie bekommt man es gehandhabt, die hohen auftretenden Oberwellen mit dem System abzubilden? Gehe ich die Beiträge durch, dann müsste die Frage wohl nicht lauten "FPGA Größe ausreichend", sondern eher "FPGA-Taktfrequenz ausreichend ?" Offenbar ist es doch ein Problem, die FM-Frequenzen genau genug zu berechnen: Als Beispiel einen 2kHz Sinus mit 200Hz Modulationsfrequenz. Der Träger läge dann doch wohl bei 400kHz. Abgebildet in einem 400MHz-FPGA reicht das für 1000 Punkte Auflösung des Sinus. Sind das genug?
> Als Beispiel einen 2kHz Sinus mit 200Hz Modulationsfrequenz. > Der Träger läge dann doch wohl bei 400kHz. Wo da irgendwelche Träger liegen, bestimmt der Modulationsgrad. Weitere Ausführungen erspare ich mir wegen Fledderei alter Beiträge.
Ich sehe keine Fledderei sondern ein Fortsetzen einer offenen Frage.
Nach meinem Verständnis ist die höchst auftretende Oberwelle bei
maximalem Modulationsgrad eben jeder Wert, der sich aus dem Produkt der
beiden Frequenzen ergibt. Wir multiplizieren ja ("mischen") statt nur zu
addieren.
Gretel schrieb: > Wo da irgendwelche Träger liegen, bestimmt der Modulationsgrad. Ich stelle mir eine Sinus-Wertetabelle vor. Da gibt es eine Leseadresse. Der 2kHz Sinus wird erzeugt indem durch diese Wertetabelle durchgegangen wird. Dabei hängt es von der Anzahl der Punkte in der Wertetabelle und der Schrittweite ab mit der ich die Leseadresse je Abtastwert (= Zeiteinheit Lesetakt) erhöhe welche Frequenz da raus kommt. Wenn ich eine Sinustabelle mit 16k Abtastwerten einer Sinusperiode habe, dann muss ich diese 16k Werte in 500us durchlaufen um einen 2kHz Sinus zu erzeugen. Wenn wirklich alle Werte ausgegeben werden sollen bedeutet das also 16k Schritte, 500us/16k=30.25ns der Takt liegt also bei grob 32,765 MHz mit dem aus dieser Tabelle gelesen wird. Aber man könnte ja auch die Schrittweite ändern und nicht jeden Tabellenwert ausgeben. Z. B. Kann man auch einen Lesetakt von 1 MHz verwenden. Dann muss die Leseadresse in jedem Takt im Schnitt um 32,765 erhöht werden um wieder den 2kHz Sinus zu erzeugen. Jetzt soll moduliert werden und das bedeutet das Modulationssignal bestimmt die Schrittweite für die Leseadresse. Das kann man jetzt so bauen, dass es von 0 bis zu einem Maximalwert geht. Man kann es aber auch so bauen, dass es bei einem Wert größer 0 beginnt. Ist eben die Frage wie das Signal moduliert werden soll. Von 0Hz bis 2kHz oder von z. B. 1kHz bis 3kHz oder von 0Hz bis 4kHz oder nur in einem kleinen Bereich von 1.9kHz bis 2.1kHz? Je nachdem welchen Takt man zur Verfügung hat und welche Schritteilten man braucht ergibt sich dann ein Wertebereich für die "Geschwindigkeit" - also für den Wert den man in jedem Takt zur Leseadresse addieren muss.
Gustl B. schrieb: > Jetzt soll moduliert werden und das bedeutet das Modulationssignal > bestimmt die Schrittweite für die Leseadresse. Ich bin nicht so sicher, ob das funktioniert. Dieses Verfahren, dass du beschreibst, ist DDS und nutzt eigentlich einen Filter, um aus den digitalen Daten einen Sinus zu machen. Der hat eine Grenzfrequenz, die zur maximalen Tonfrequenz passt. Einfach den Pointer noch zu variieren, bringt Frequenzen, die nicht (gut) durch den Filter gehen.
Naja, also wie ich DDS kenne nimmt man nur ein MSB von einem Akku auf den man draufaddiert. Das MSB wackelt also mit einer Frequenz. Zumindest im zeitlichen Mittel. Das muss man dann noch zu einem Sinus filtern. Aber man kann natürlich auch die ersten z.B. 14 Bits des Akkus als Adresse für eine Sinustabelle nehmen.
Ich setzte hier mal ein Link zur Frage der benötigten Auflösung des Sinus: Beitrag "Re: VHDL Grundlagen Tonerzeugung"
Signalverarbeiter schrieb: > Wir multiplizieren ja ("mischen") statt nur zu > addieren. Nicht notwendigerweise. Zwar entsteht eine FM-Modulation, wenn man die Amplitudenwerte multipliziert, aber eben auch eine Amplitudenschwebung. Eine reine FM-Modulation hat eine konstante Amplitude und wirkt nur auf die Phase. Gustl B. schrieb: > Ich stelle mir eine Sinus-Wertetabelle vor. Mit DDS geht das in der Tat und es gibt die oben erwähnten Effekte. Das gilt aber nur, wenn man in Echtzeit im Zeitbereich moduliert, also so, wie du es beschreibst, am Phasenvektor ganzzahlig manipuliert. Dann addieren sich beide Fehler. Vermeiden kann man das, indem mit entsprechender Auflösung / analytisch gearbeitet wird. Das ist dann gänzlich losgelöst von der Taktfrequenz und geht auch mit 48kHz Audioabtastung. Die entstehende Grenzfrequenz muss natürlich mit Blick auf Nyquist im Auge behalten werden.
Naja, kommt drauf an was begrenzt. Speicher ist oft viel auf dem Board. Muss nicht schnell sein. Also kann man eine sehr große Wertetabelle nehmen. Je mehr Punkte in der Sinustabelle, desto kleiner wird der Fehler. Da kann man also einmal eine 32M Punkte Tabelle rechnen und das beim Start ins RAM laden. Selbst viele FPGA Bastlerboards haben zwar ein kleines FPGA, aber viel RAM.
Gustl B. schrieb: > Selbst viele FPGA Bastlerboards haben zwar ein kleines FPGA, aber viel > RAM. Aber nur externes SDRAM oder DDR-RAM. Sinus in BRAM-Tabellen machen im FPGA nur Sinn, wenn man sie mehrfach nutzt, für z.B. mehrkanalige pipelined Synthese in eben jenen Musiksynthesizern, wo man die hohe Bandbreite nutzen kann. Für eine einkanalige DDS lässt sich der Sinus auch mit einem CORDIC rechnen. Da ist RAM zu teuer :-) CORDIC hat über dies den Vorteil, der bei vertretbarem Aufwand und Latzen höhereren Genauigkeit. Sinus-Tabellen müssen interpoliert werden, sollen sie was taugen.
Weiß ich nicht. Wenn das FPGA sehr klein ist und trotzdem viel externes RAM hat, dann kann man da sehr feine Wertetabellen hinlegen. Bei den im Audiobereich üblichen Abtastraten kommt man auch bei SDRAM locker ohne Bursts aus. Ich kann das schlecht abschätzen, bin aber der Meinung, dass mit zunehmender Länge der Wertetabelle der Fehler immer kleiner wird. Irgendwo gibt es dann vielleicht einen Punkt ab dem externer Speicher der sowieso da ist auf vielen Platinen sinnvoller ist als intern Logik mit Cordic zu verbraten. Ich habe aber auch noch nie cordic gemacht und weiß nicht wie genau das wird.
Musikalische FM Synthese hat nicht viel mit der analogen FM zu tun, bei der man ein Nutzsignal auf eine Trägerfrequenz aufmoduliert. Die musikalische FM ist, wie schon gesagt, eigentlich eine Phasenmodulation. Modulator und Trägerfrequenz sind beide im Audiobereich und meist nahe an einem ganzzahligen Verhältnis, wie 1:1, 2:1, 3:1 usw. Der Modulator verzerrt eigentlich nur die Phase des Trägers, so dass neue, vom Sinus abweichende, Wellenformen entstehen, die musikalisch interessant klingen. Das Mischerprodukt z.B. spielt da keine Rolle, das ganze wird ja sowieso nur mit der Audioabtastfrequenz berechnet, so hohe Frequenzen können da gar nicht entstehen, und sind für das Ergebnis auch nicht gewünscht. Es ist also sinnlos das möglichst genau und im Mega- oder Gigahertz Bereich berechnen zu wollen. Die Güte des Sinus ist ebenfalls nicht sehr relevant. Dieser wird ja sowieso verzerrt durch die Modulationen. Musiksynthese ist etwas anderes als Messtechnik. Höchste Genauigkeit klingt eher langweilig und oft sind es gerade die Unsauberkeiten, die ein Instrument interessant machen.
Andi schrieb: > Das Mischerprodukt z.B. spielt da keine Rolle, das ganze wird ja sowieso > nur mit der Audioabtastfrequenz berechnet, so hohe Frequenzen können da > gar nicht entstehen, Entstehen tun die schon, aber sie werden nicht abgebildet und wenn, dann falsch, wegen eben der zu geringen Abtastfrequenz, würde ich sagen. Ich nehme an, die Mischprpdukte der Trägerfrequenz werden vorher rausgefiltert, oder müssen gefiltert werden.
Angehängte Dateien:
-

DDFS_16.png
41 KB -

DDFS_24.png
39 KB
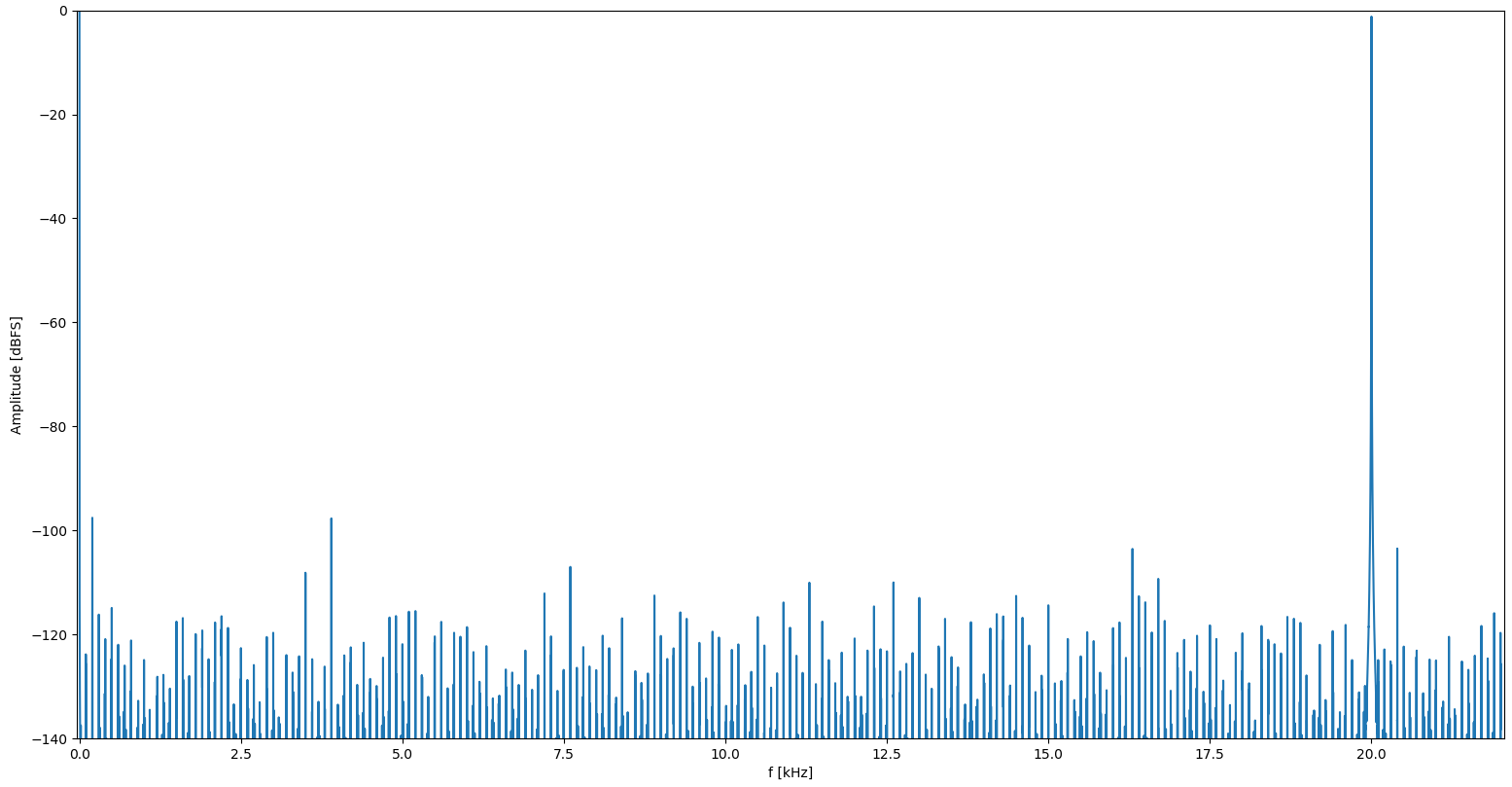
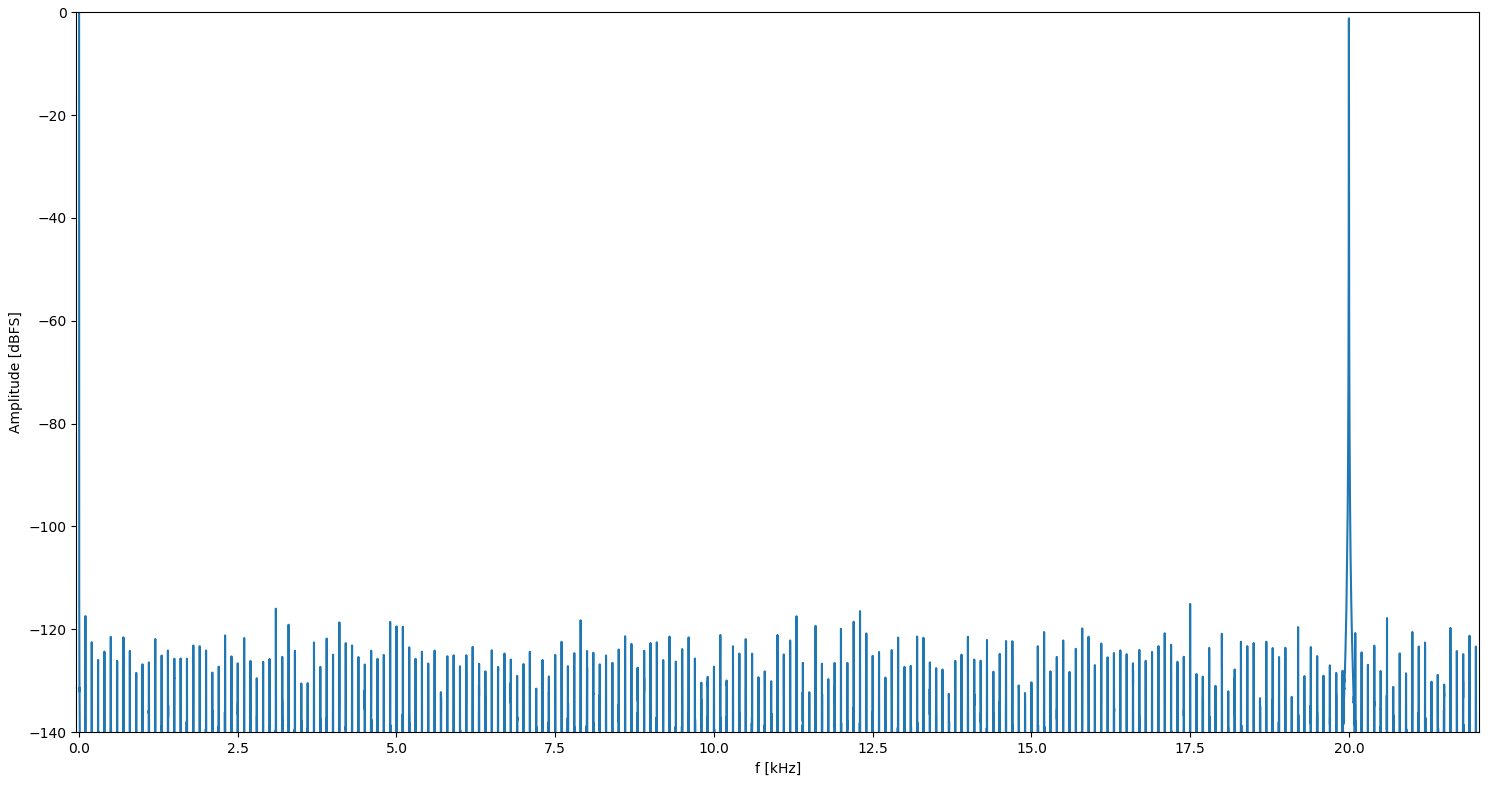
Wie gut muss ein Signal für Audio eigentlich sein oder was ist das üblich? Ich habe jetzt mal Signale erzeugt und eine FFT rechnen lassen. Mit einer Sinus-Wertetabelle von 2**16 Werten a 16 Bit (= 128kByte) sieht das noch nicht irre schön aus, aber wenn ich 2**24 Werte verwende (=32 MBytes) sieht das schon deutlich besser aus. Der Akku sind jeweils 32 Bits und eben einmal die 16 MSBs und einmal die 24 MSBs die Leseadresse. Edit: Virtuelle Abtsatrate sind 44.1 kHz und ohne Tiefpassfilter dahinter.
Angehängte Dateien:
-

DDFS_16.png
34 KB -

DDFS_24.png
38 KB
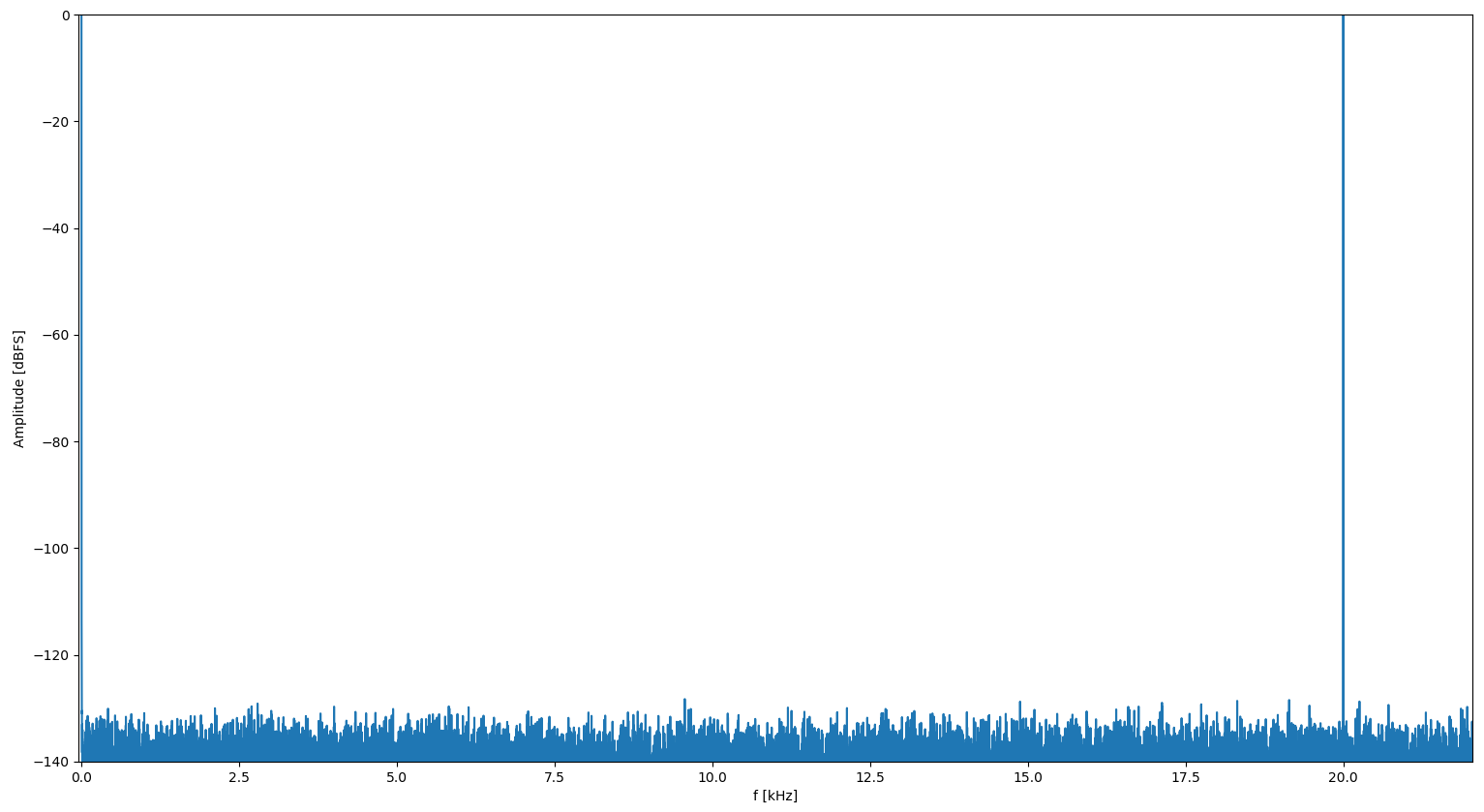
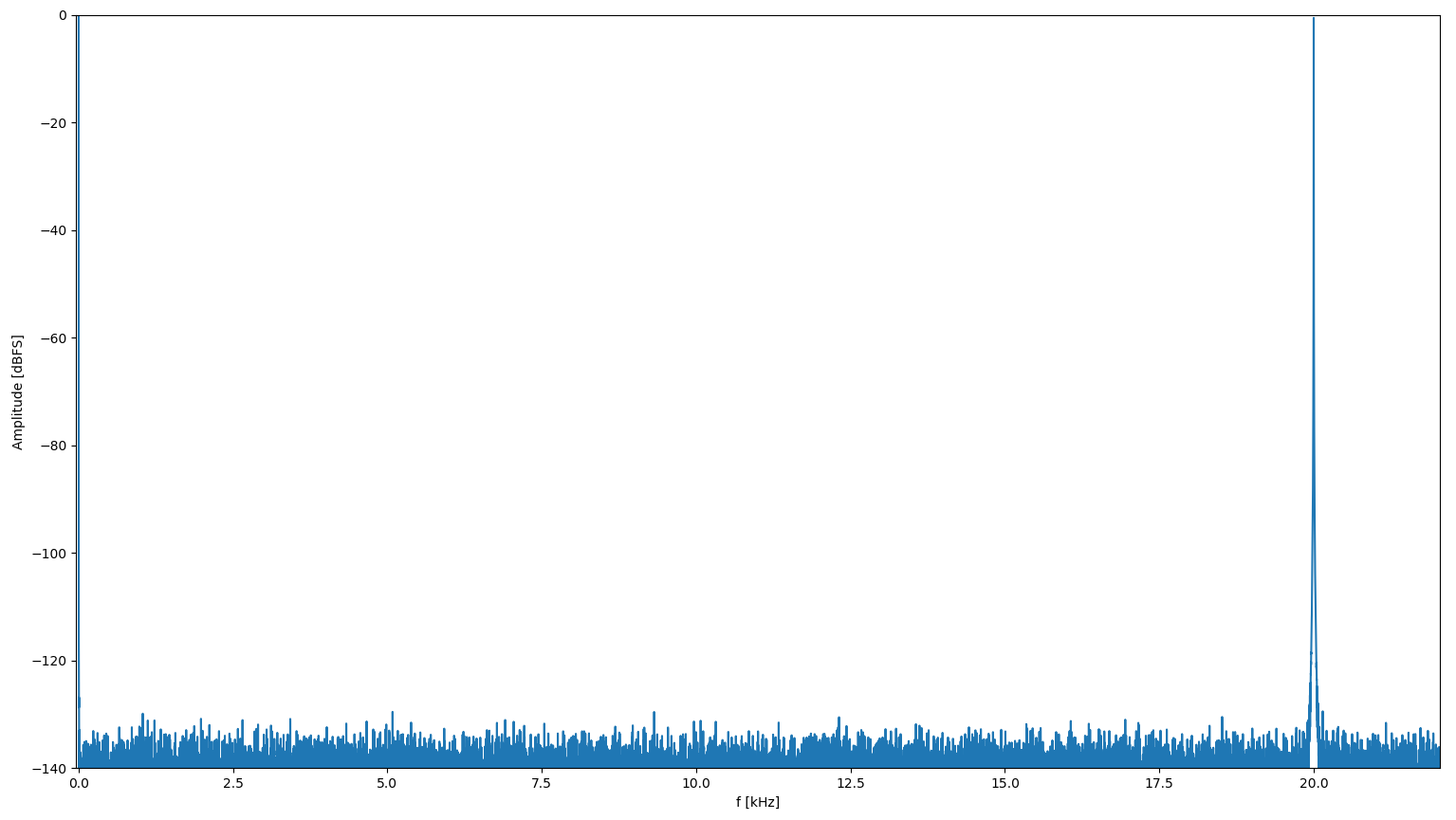
Irgendwie seltsam. Wenn ich statt 20.0 kHz 20.001 kHz einstelle sieht es deutlich anders aus. Vorallem ist bei der mit der nur 2**16 Werte langen Sinustabelle der Peak im FFT deutlich schmaler. Komisch ...
Das ist nicht wirklich komisch sondern Resultat der unpassenden Frequenzen. Je nach dem, wie die DDS Tabelle durchlaufen wird, gibt es Harmonische im Spektrum. Deshalb ist DDS bei Audiofachleuten auch so "beliebt".
Gustl B. schrieb: > Wie gut muss ein Signal für Audio eigentlich sein oder was ist das > üblich? > > Ich habe jetzt mal Signale erzeugt und eine FFT rechnen lassen. > Mit einer Sinus-Wertetabelle von 2**16 Werten a 16 Bit ... Wie gut so ein Sinus (oder andere Wellenformen) sein müssen, hängt davon ab, wie die Synthese funktioniert. Ein 20 kHz Sinus mit CD Qualität macht einfach keinen Sinn, wenn du bedenkst, dass dahinter mindestens noch ein Hüllkurve für die Amplitude folgt, die den Störabstand um Grössenordnungen verbessert. Ausserdem sind am resultierenden Klang ja viele Sinusse pro Stimme und dann auch noch viele Stimmen beteiligt. Der gute alte PPG Wave 2.2 Synthesizer benutzte 20 Bit DDS, mit 7 MSB für die Wellentabelle, also 128 Werte, und die mit 8 Bits aufgelöst. Da folgte allerdings auch noch ein Filter dahinter.
Andi schrieb: > Der gute alte PPG Wave 2.2 Synthesizer benutzte 20 Bit DDS, mit 7 MSB > für die Wellentabelle, also 128 Werte, Woher kommen diese Infos? Ich finde 7 Bit ein wenig arg klein, da die Wellenformen nicht einmal Sinus waren sondern doch irgendwas mit Oberwellen. Wie willst du das vernünftig abbilden?
Audiomann schrieb: > Woher kommen diese Infos? Internet Recherche: z.B. hier: http://www.ppg.synth.net/wave22/ > Ich finde 7 Bit ein wenig arg klein, da die Wellenformen nicht einmal > Sinus waren sondern doch irgendwas mit Oberwellen. Wie willst du das > vernünftig abbilden? Wenn du ein 1kHz Signal mit 44.1 kHz abtastest hast du gerade mal 44 Werte pro Periode. Aber natürlich sind 128 Samples pro Wellenform etwas wenig, vor allem für Bassklänge. Da werden dann die gleichen Werte mehrfach wiederholt, was einer tieferen Abtastfrequenz entspricht. Das gute Filter des PPG macht das wieder wett.
Andi schrieb: > Wenn du ein 1kHz Signal mit 44.1 kHz abtastest hast du gerade mal 44 > Werte pro Periode. Das wäre noch kein Problem. Selbst nur 4 Werte wären noch prima. Das Problem ist, dass es meistens 44 Werte sind und alle paar Nase lang nur 43 bzw beim sampeln 45. Das ergibt einen Phasensprung mit 1/44tel der Frequenz und die hängt voll im Audiospektrum samt ihrer Oberwellen. Das ist alles andere, als musikalisch sinnvoll, siehe auch meine Ausführungen hier: http://www.96khz.org/oldpages/limitsofdds.htm Zu einem Sinus kommt dann immer noch ein unmusikalisches Rechteck hinzu - bzw das ist dann Teil des Klangs:-) > Aber natürlich sind 128 Samples pro Wellenform etwas wenig, vor allem > für Bassklänge. Die sind sogar weniger das Problem, weil man das durch Phasen-Dither leicht überwinden kann, siehe Dithering > Das gute Filter des PPG macht das wieder wett. Mit einem Filter allein kommt man dem nicht bei. Man braucht das Dithering. Ist bekannt, ob die PGP das macht? Ich denke, die Schwierigkeit sind schon die hohen Töne, vor allem bei steilflankigen Signalkomponenten. Beides wird aber etwas entschärft, wenn man Vibrato in den Stimmen benutzt.
Angehängte Dateien:
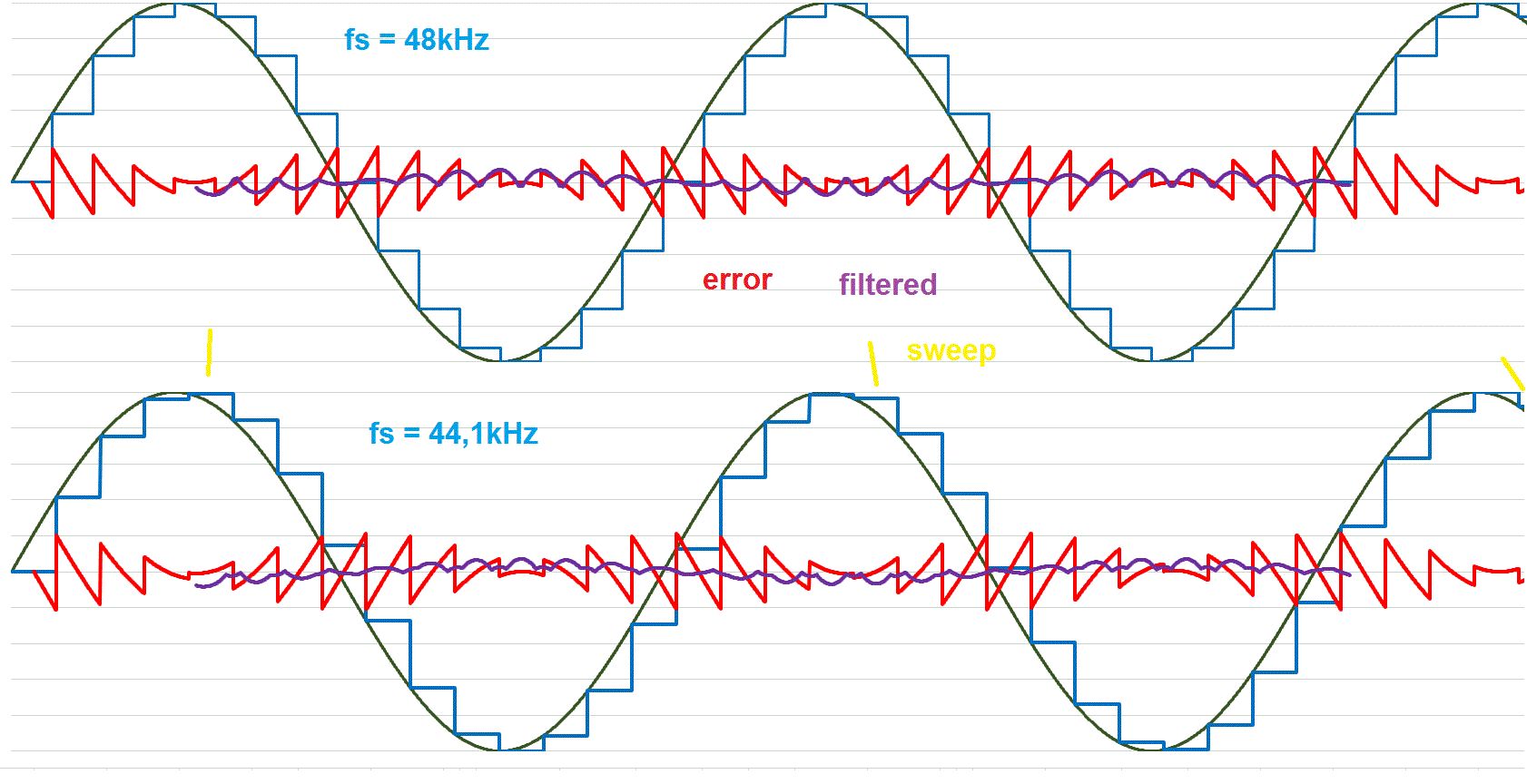
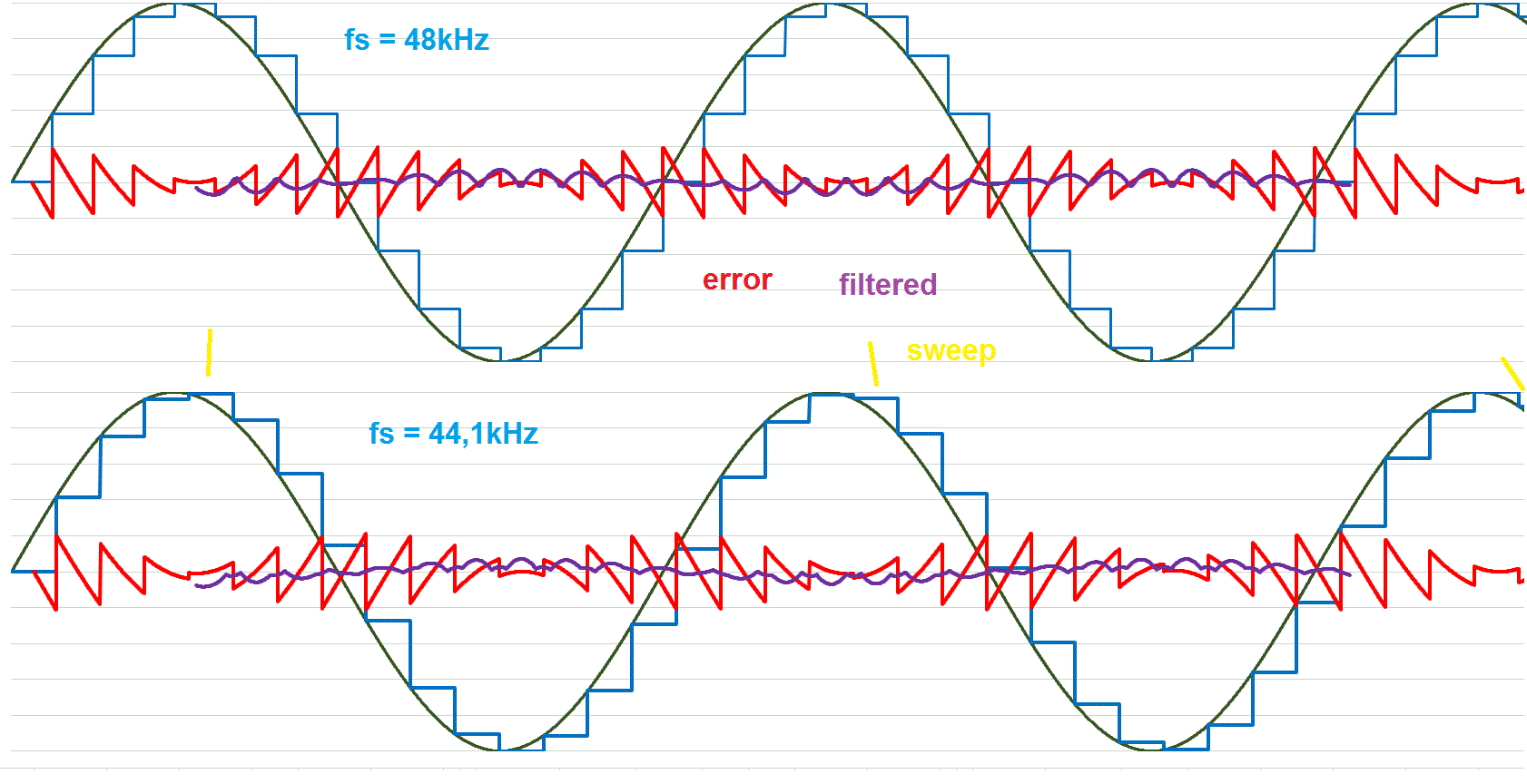
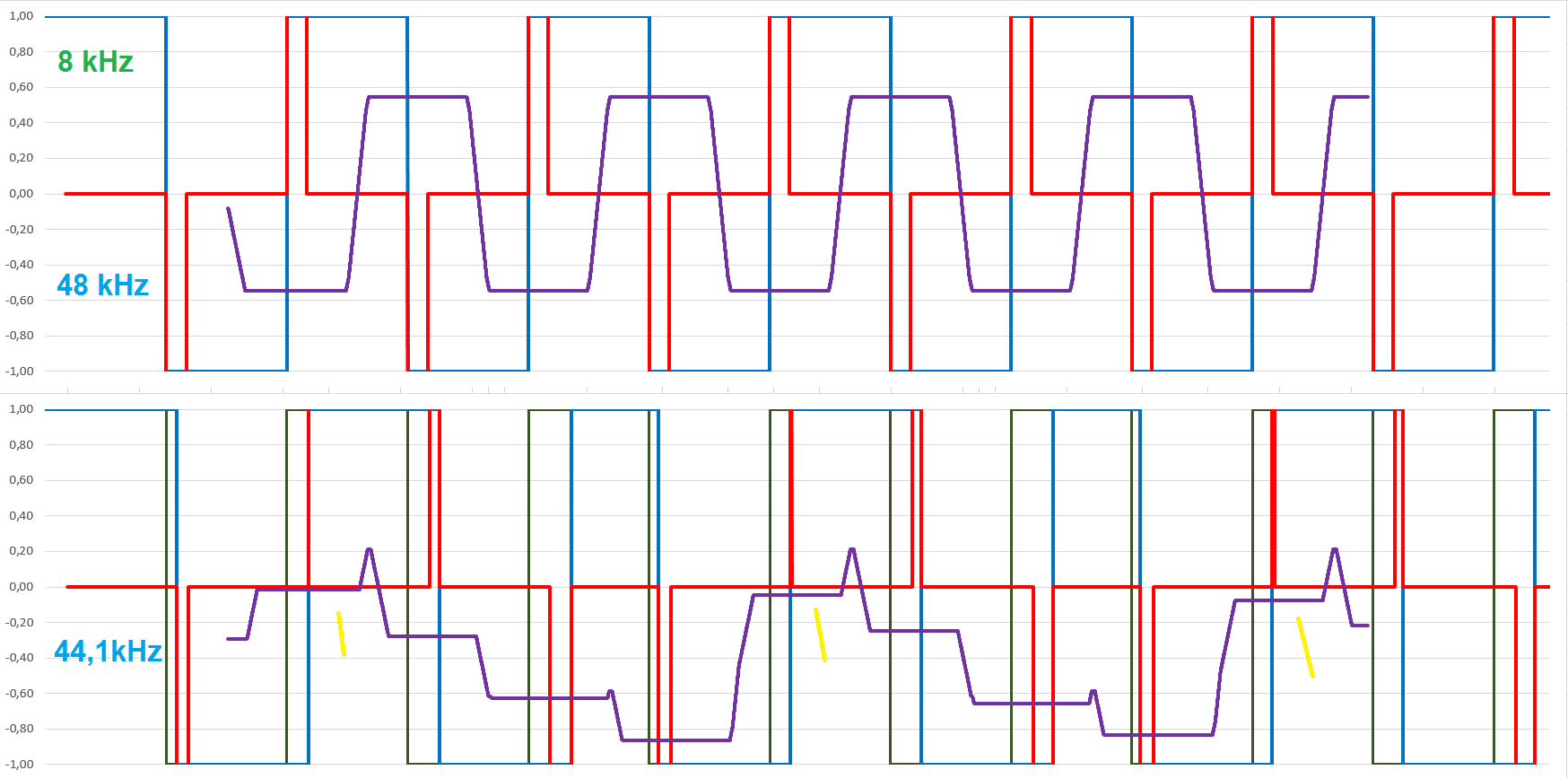
Anbei dazu ein Vergleich von Sinus und Rechteck bei 48kHz und 44,1kHz. Für ein 3kHz und 8kHz Signal, die beide perfekt durch die 48kHz abgebildet werden können. Das "Fehlersignal" in rot, das aus Differenzbildung von "Ideal" zu "Gesampelt" gebildet wird, läuft in das Rekonstruktionsfilter (hier ideal angenommen) und wird so gut wie möglich eliminiert, was zur violetten Kurve führt. (Diese ist in der Darstellung bei Sinus um Faktor 10 vergrössert, beim Rechteck nur um Faktor 5, weil der Fehler viel größer ist.) Sinus 48: Übrig bleibt neben dem hochfrequenten "Gezitter" auch eine geringe niederfrequente Schwingung infolge des Phasenverschiebung vom Filter, was aber nur optischer Natur in dieser Darstellung ist. Praktisch ohne Bedeutung. Sinus 44,1: Ähnliches Bild aber etwas mehr Schwebung (im Bild nicht gut sichtbar, aber simulierbar). Rechteck 48: Perfekte Abbildung bis auf Phasenversatz. Das nicht weggefilterte Signal ist ebenfalls ein perfektes Rechteck, praktisch wird es flankenverschliffen sein, hat aber keine Schwebung. Rechteck 44,1: Starke Schwebung auf der halben Frequenz. Die Plateaus (gelbe Marker) verschieben sich dabei über den Verlauf des Tons auch noch und zwar mit einer sehr niedrigen Frequenz, was zu einem hörbaren Klirren / Rattern führt. Bei den Rechtecken sind die Amplitudenfehler absolut erheblich größer. Schaut und hört man sich das in der Praxis an, dann versteht man schnell die Limits der digitalen Klangsynthese und das Problem ist grundsätzlich nicht lösbar, auch nicht durch eine analytische Berechnung der Rechtecks i.A. einer Phase mit float. Man bekommt zwar die Zeitpunkte exakt heraus, muss dann aber auf die Rasterung der Samplerate übersetzen, um ein Rechteck zu bilden. Das gilt mithin auch für die FM-Synthese. Sobald eine Wellenform ins Spiel kommt, die in der Folgestufe verwendet wird, hat man das Granularitätsthema.
Ich benutze seit längerer Zeit einen einfachen FM-Synthesizer auf einem ARM4 (Goom), der eine Wertetabelle von 256 * 16bit für eine volle Sinus-Periode besitzt. Effektiv sogar nur die Hälfte davon, der Rest wird gespiegelt. Jedenfalls reicht das in meinen Augen aus.
Angehängte Dateien:
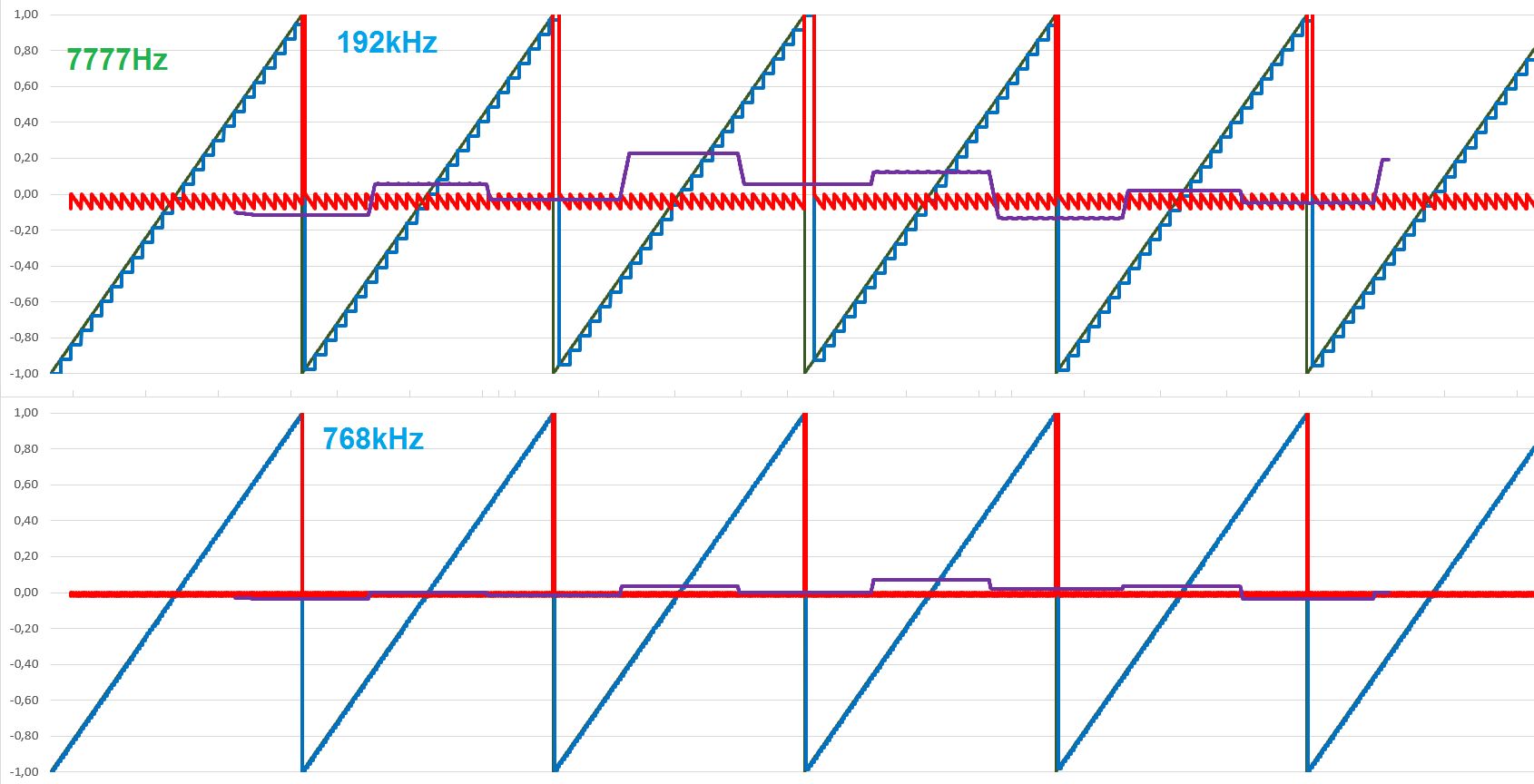
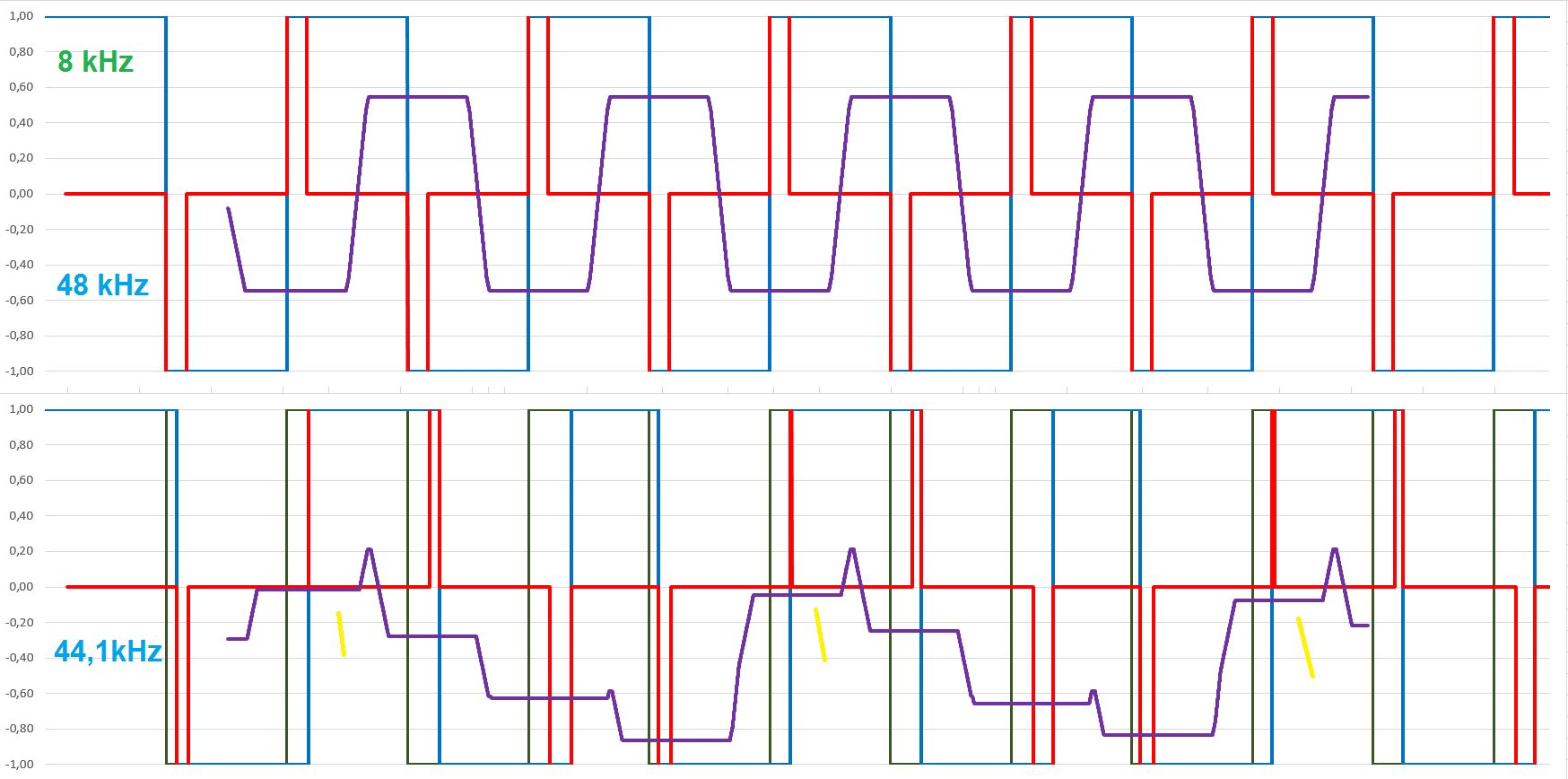
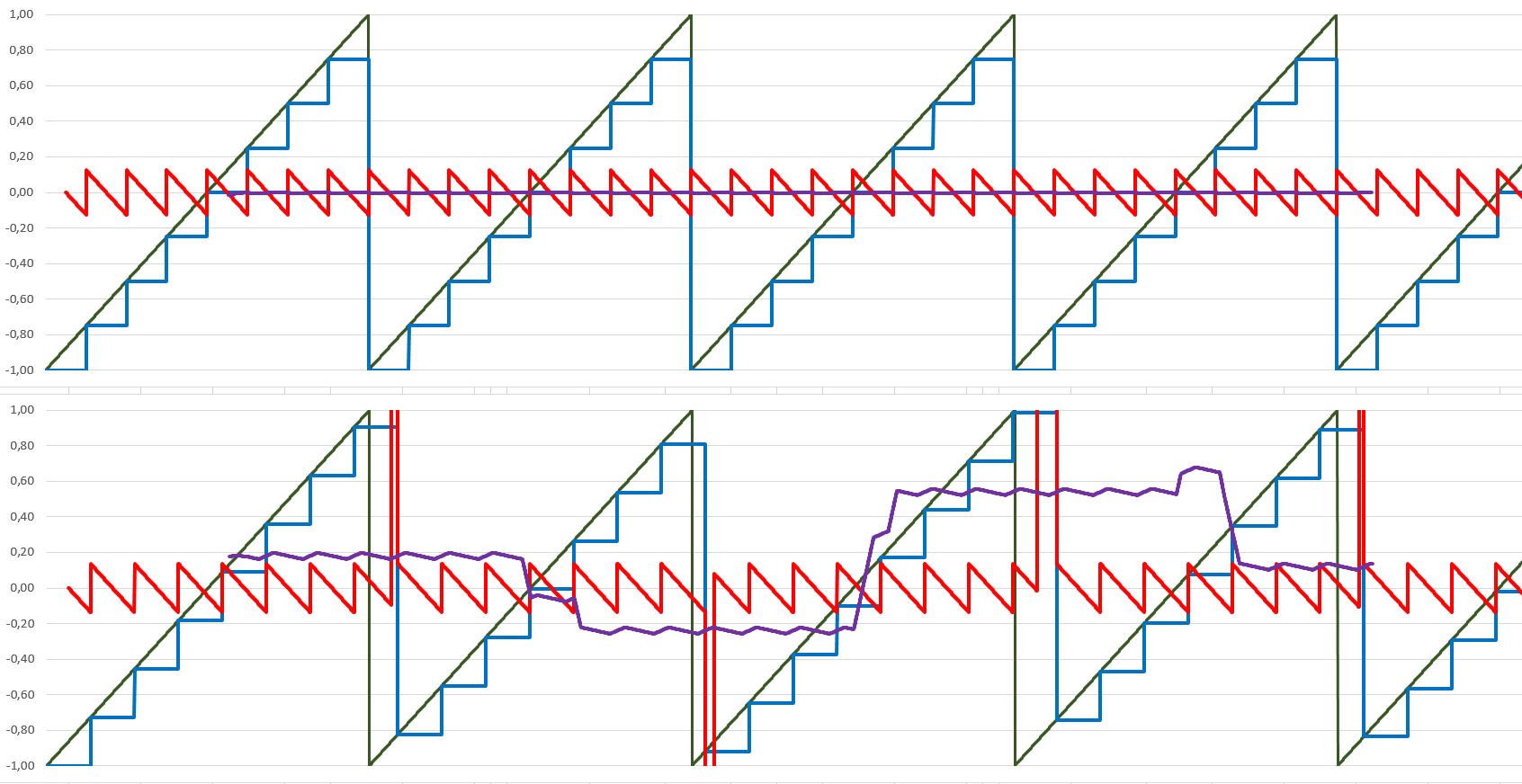
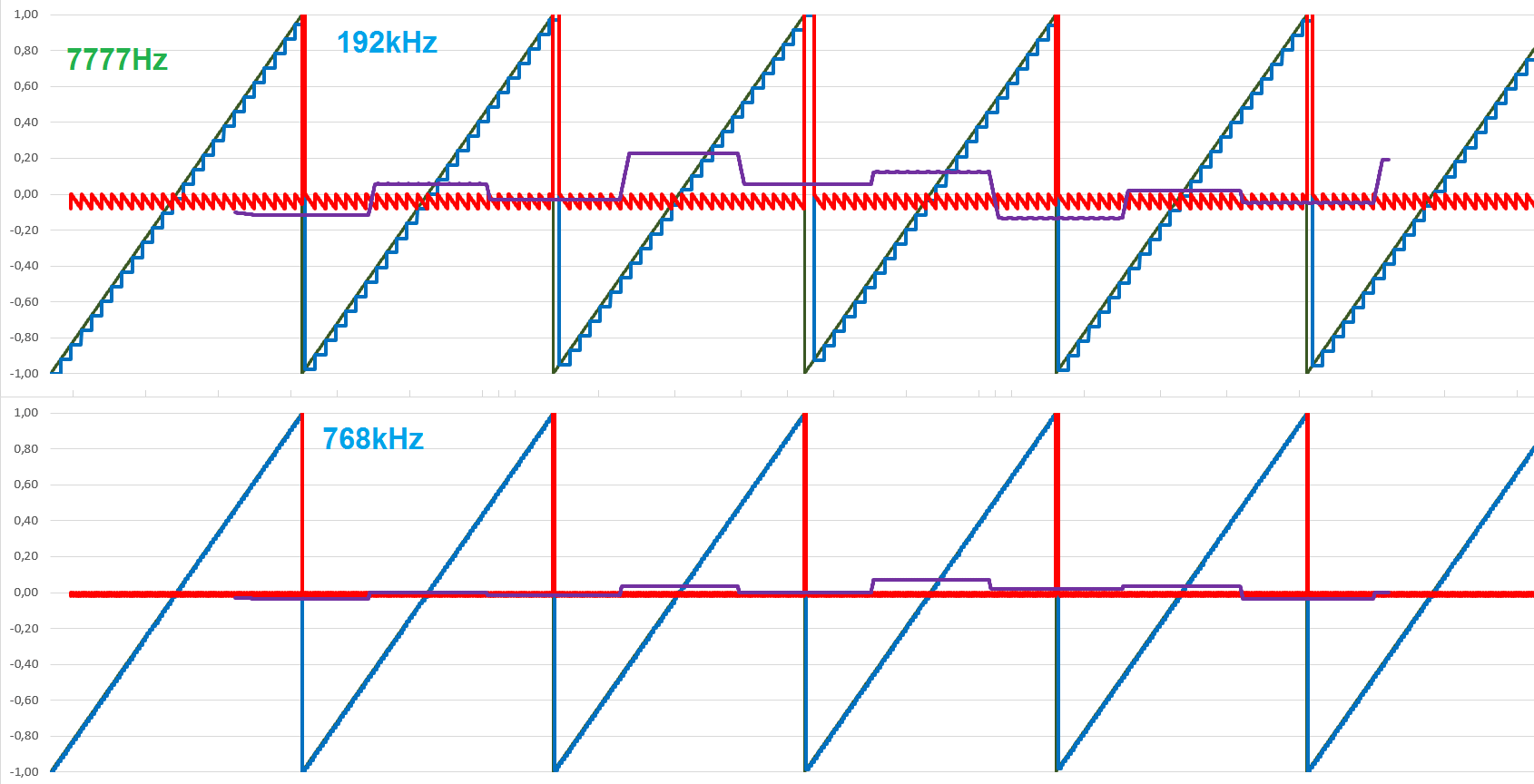
Die Sache kann nur durch eine grundsätzlich erhöhte zeitliche Auflösung = Abtastrate reduziert werden. Man kann sich schon rein gefühlsmäßig ausrechnen, wie gering der Fehler z.B. in einem 768kHz System ist. Beim Dreieck wird es besonders evident: Nur, wenn die Rate perfekt passt (Bild Links oben, 6kHz in 48kHz) kriegt man einen sauberen Ton. Unpassende Abtastung erzeugt einen mehr oder weniger lauten rechteckigen Unterton (Bild links unten, 44kHz). Die Störtöne bestehen immer auch in einer niederfrequenten Schwebung. Beides ist bei höheren Raten stark reduziert. Auch mit 192kHz hat man bei der krummen Sollfrequenz von 7,777kHz immer noch eine sichtbare Schwebung und minimale Reste der hochfrequenzen Abtastfehlers, den der Filter bearbeiten muss. Diese sind allerdings erheblich kleiner (Fehler in der Grafik um Faktor 4 vergrössert, gegenüber oben). Bei 768kHz sind auch diese Reset praktisch erledigt.
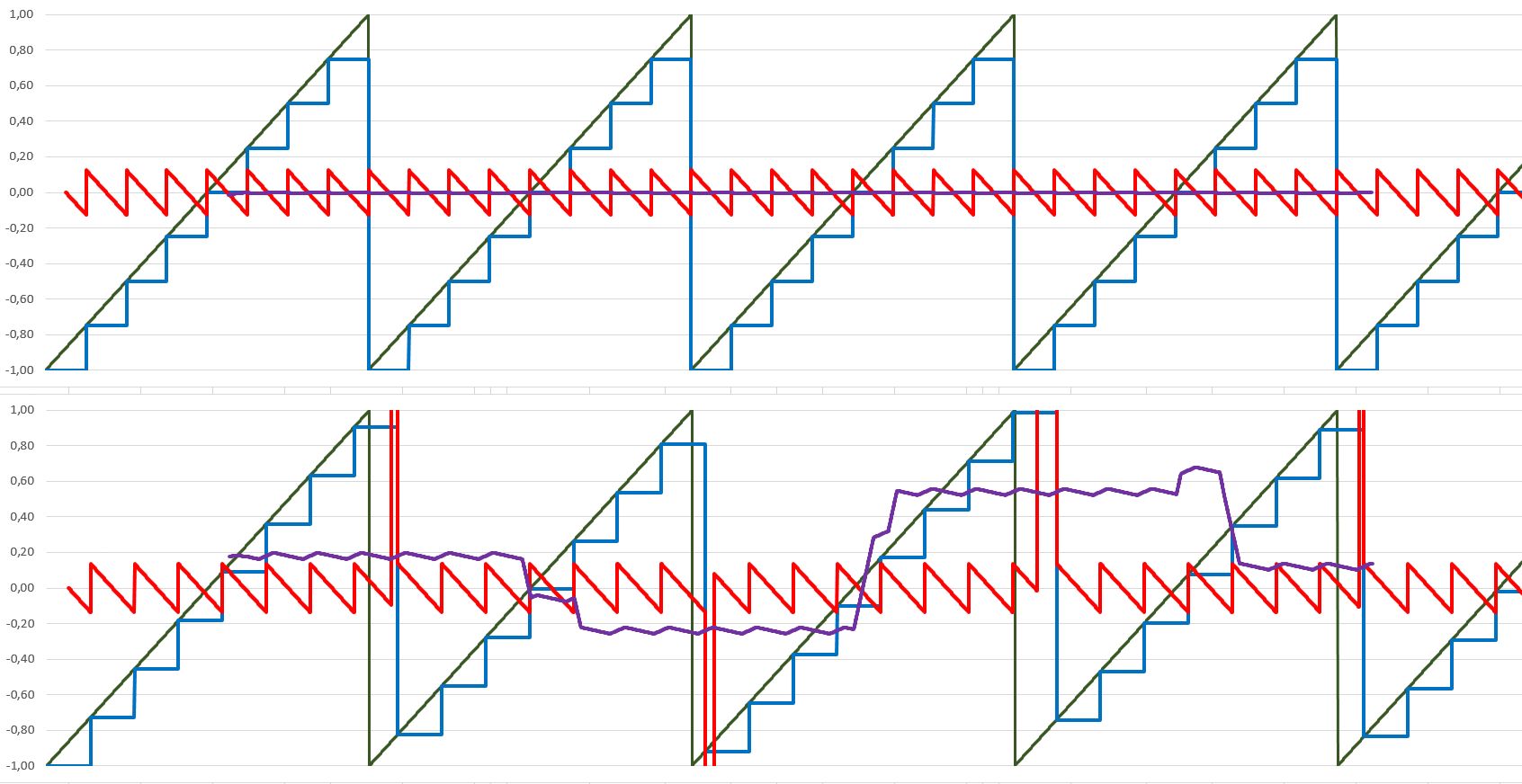
synth schrieb: > Effektiv sogar nur die Hälfte davon, der Rest > wird gespiegelt. Man braucht ja sogar nur ein Viertel, wenn man es voll symmetrisch macht, aber die Auflösung bleibt trotzdem bei 256. >Jedenfalls reicht das in meinen Augen aus. Mit den Augen ist das so eine Sache. Ich habe damals auch Simulationen zur FM gemacht und eine so geringe Auflösung ist allenfalls dazu nötig, die Technik der 90er nachzustellen, nicht aber saubere Sounds zu produzieren. An meiner Pyratone kann ich das ja auch leicht nachstellen, indem die Vektoren gerundet werden und der Klang verändert sich massiv, wenn man von 24 Bit über 20 auf 16 und darunter runter geht. Die Ergebnisse haben kaum mehr etwas miteinander zu tun. Wenn man solche Systeme nicht fürs Tonerzeugen, sondern andere messtechnische Anwendungen baut, muss man so ziemlich maximal bauen. Da waren oft die standardmäßigen MULs im Xilinx-FPGA mit 25x18Bit zu knapp.
>An meiner Pyratone kann ich das ja auch leicht nachstellen, >indem die Vektoren gerundet werden und der Klang verändert sich massiv, >wenn man von 24 Bit über 20 auf 16 und darunter runter geht. Die >Ergebnisse haben kaum mehr etwas miteinander zu tun. Wie wär's mit zwei Soundsamples im Vergleich? Sonst ist das alles so theoretisch.
Angehängte Dateien:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
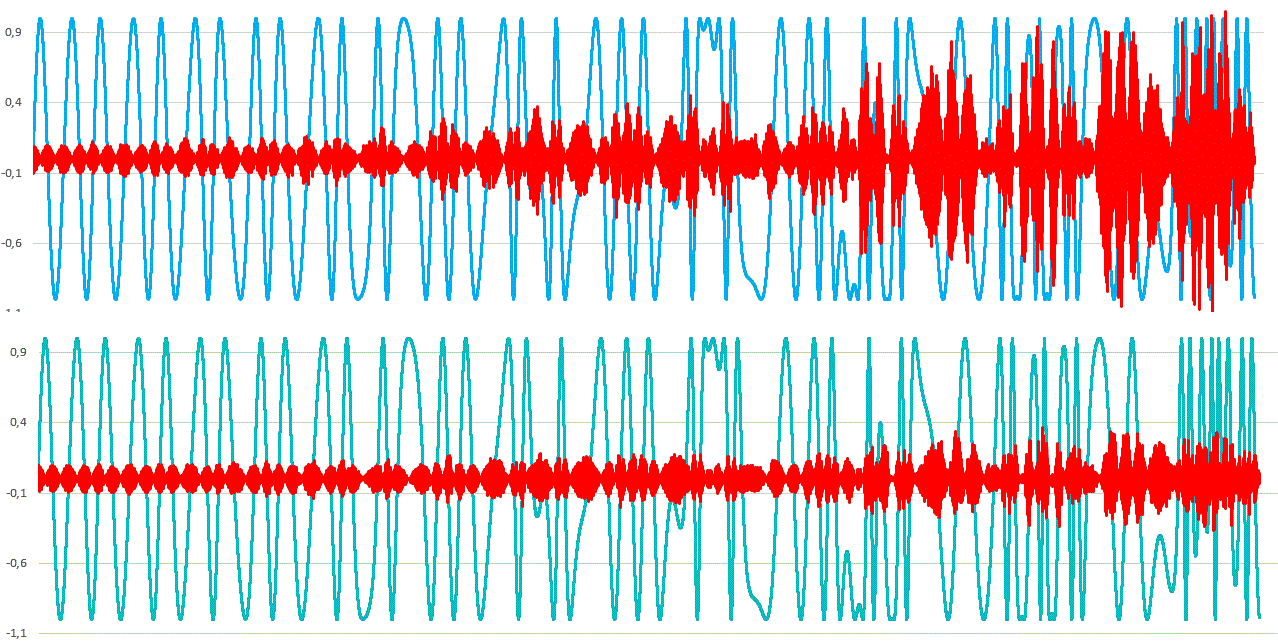
Nun nochmal konkret zur FM-Modulation: 3 Frequenzen mit der Konstellation 133 : 377 : 733 Die jeweils folgende Stufe wird mit der davor steigend von 0 ... PI/2 moduliert Rundung aller 3 Phasen auf 256 Stufen = 8 Bit, Amplitude ungerundet in real Der Fehler in rot ist um Faktor 50 verstärkt. Liegt also im Bereich von 2% des Signals und zwar gerade da, wo die FM interessant wird. In der darunter liegenden Grafik sind die frühen Stufen höher aufgelöst (meine Empfehlung). Konkret 1024 : 512 : 256 -> <1% Fehler Eine Auflösung von wenigstens 16,15,14 Bit ist nötig, um auf einen Fehler von unter 0,1% zu kommen. Das wäre für Sinus akzeptabel. Für Rechteck braucht es entsprechend mehr. Das gilt auch für mehrere Stufen/Tiefe. Christoph M. schrieb: > Wie wär's mit zwei Soundsamples im Vergleich? Sonst ist das alles so > theoretisch. Kommt.
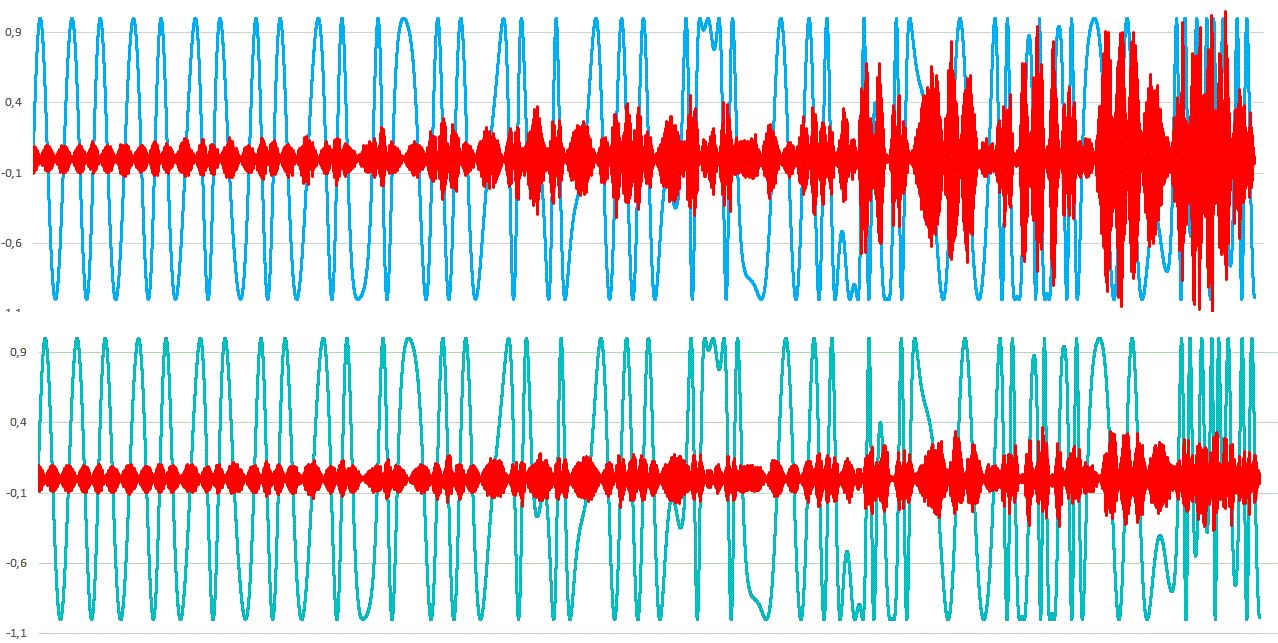
So ein Beispiel meines FPGA FM Synth-Moduls (4 OPs). http://www.96khz.org/htm/fmsynthesis2.htm 3 Töne mit voller Auflösung und einmal mit Bitbegrenzung auf 10, also faktisch Tabellen mit 1024 Einträgen. Der Klang wird durch die Codierung noch etwas verändert, aber man kann den Unterschied schon hören, meine ich. Die hintere Sequenz hat unpassende Obertöne drin, die besonders den Filter zum Nachschwingen anregen. Der Ton ist unsauberer. Bei einzelnen Tönen ist es weniger störend, aber bei Akkorden tödlich. Wie es im einzelnen klingt hängt natürlich sehr von den Einstellungen ab. Ein reiner Sinuston mit wenig Modulation ist logischerweise eher unauffällig.
>Der Klang wird durch die Codierung noch etwas verändert
Danke für das Beispiel. Ich habe es mir jetzt mehrfach angehört. Auf dem
Laptop höre ich keinen Unterschied. Auf den großen Boxen könnte ich mir
einbilden, etwas zu hören.
Vielleicht kann es mal jemand mit besseren Ohren bzw. Anlage
kommentieren.
Christoph M. schrieb: > Auf den großen Boxen könnte ich mir > einbilden, etwas zu hören. Für mich scheppert es "a bizzli", besonders auch am Ende des Klangs. Andi schrieb: > Ein 20 kHz Sinus mit CD Qualität macht einfach keinen Sinn, wenn du > bedenkst, dass dahinter mindestens noch ein Hüllkurve für die Amplitude > folgt, die den Störabstand um Grössenordnungen verbessert. Was meinst du damit?
Moin, Signalverarbeiter schrieb: > sondern eher > > "FPGA-Taktfrequenz ausreichend ?" Zwar nicht mehr brandaktuell, aber damit's nicht verschuett' geht, hier mal ein wenigzeiler, mit dem in C ein bisschen FM-synthetisiert werden kann...
1 | /* compile with:
|
2 | |
3 | gcc -Wall -O2 bla.c -lm
|
4 | |
5 | play raw file with:
|
6 | |
7 | ./a.out | mplayer -rawaudio samplesize=2:channels=1:rate=48000 -demuxer rawaudio -
|
8 | |
9 | */
|
10 | |
11 | #include <stdio.h> |
12 | #include <math.h> |
13 | |
14 | |
15 | float fm1(float inp) { |
16 | // pure sine, no FM:
|
17 | // return cos(inp + 0.0 *cos(inp/2) + 0.0 * cos(inp/4));
|
18 | |
19 | // play around with the coefficents:
|
20 | return cos(inp + 5.5 *cos(inp*0.01) + 0.5 * cos(inp*3.0)); |
21 | }
|
22 | |
23 | int main() { |
24 | unsigned int i,j; |
25 | int sample; |
26 | int envelope; |
27 | float pitch[]={1.0, 1.25882104989, 1.49830707688,2.0}; |
28 | for (j=0;j<sizeof(pitch)/sizeof(float);j++) { |
29 | for (i=0;i<48000*1;i++) { |
30 | envelope = 20000*exp(-(i/40000.0)); |
31 | sample = envelope*fm1((i*pitch[j])/100.0*M_PI); |
32 | printf("%c%c",sample%256,sample/256); |
33 | }
|
34 | }
|
35 | return 0; |
36 | }
|
Also die "Taktfrequenz" ist die Samplefrequenz; jetzt waer' halt noch die Frage, wieweit man den Sinus in Tabellenform eindampfen kann, bis es anders klingt. Gruss WK
Dergute W. schrieb: > Also die "Taktfrequenz" ist die Samplefrequenz; jetzt waer' halt noch > die Frage, wieweit man den Sinus in Tabellenform eindampfen kann, bis es > anders klingt. Für diese Zwecke gab es eine spezielle Transformation, mit der die Tabelle reduziert werden konnte. Ich komme jetzt nicht mehr auf den Namen. Man musste die oberen und unteren Bits cutten und nur die in die Tabelle stecken. Die mittleren 4 waren unerheblich. Allerdings frage ich mich, ob das überhaupt nötig ist, bei heutigen RAM-Reserven. Ich glaube eigentlich, dass ein FM-Synth sehr genaue Sinuswellen braucht. Die lassen sich aber über Taylor einfacher ermitteln, denke ich. https://www.pjrc.com/high-precision-sine-wave-synthesis-using-taylor-series/
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.