Hier habe ich begonnen, mich in die VHDL-Grundlagen mit einem MACHX02
board einzuarbeiten:
Beitrag "Re: VHDL Grundlagen"
Interessanter als das Blinken von LEDs finde ich aber die Tonerzeugung.
Hier habe ich mal ein Beispiel für die Erzeugung eines 440Hz Tons
ersellt:
1
libraryieee;
2
useIEEE.STD_LOGIC_1164.ALL;
3
useIEEE.NUMERIC_STD.ALL;
4
5
LIBRARYlattice;
6
USElattice.components.all;
7
8
entitysquareToneis
9
Port(
10
speaker:bufferSTD_LOGIC
11
);
12
endsquareTone;
13
14
architectureBehavioralofsquareToneis
15
16
signalc:integerrange0to60455:=0;-- 440Hz bei 53.2MHz fosc
chris schrieb:> Hier habe ich mal ein Beispiel für die Erzeugung eines 440Hz Tons> ersellt:> if ( c < 60455) then
Und schon den klassischen "off-by-one" Fehler hinbekommen. Denn dein
Zähler zählt nicht 60455 Schritte, sondern 60456, weil er 0 auch noch
mitzählt. Natürlich ist der Fehler hier nicht relevant, aber mal
angenommen, der Zähler sollte in einem anderen Fall 6 Schritte zählen,
würde aber 7 machen:
> if ( c < 6) then
:-o
> Wie würde man das schreiben, wenn man den Teilerfaktor in VHDL berechnen> lassen will?
Naja, halt ausrechnen wie du es auch von Hand auf einem Blattl Papier
machst...
1
constantprescalerinteger:=53200000/(2*440)-1;-- minus 1 wegen des off-by-one
Lothar M. schrieb:>> if ( c < 60455) then> Und schon den klassischen "off-by-one" Fehler hinbekommen. Denn dein> Zähler zählt nicht 60455 Schritte, sondern 60456, weil er 0 auch noch> mitzählt.
Also mit der Bedingung "KLEINER ALS" tritt dieser Fehler eigentlich
nicht auf. Normalerweisde vergleicht man auf "UNGLEICH" dann liegt man
eins daneben. Vergleich auf GLEICH oder UNGLEICH wird oft vewendet weil
es halt weniger LUTs als KLEINER oder GRÖSSER benötigt.
Andi
Nach nochmaliger Überlegung ziehe ich meinen Einwand hiermit zurück ;)
Der Fehler ist natürlich der gleiche wie bei einer UNGLEICH Bedingung.
Lothar hatte also recht!
Andi
chris schrieb:> Auch wenn ich jetzt etwas Zeit gebraucht habe, weil in der Vorlage ein> Doppelpunkt gefehlt hat
Ja, dieser Prozess wird "Lernen" genannt... ;-)
> Als nächste werde ich versuchen, einen minimaltistischen Step-Sequenzer> zu programmieren.
Da kannst du mal dort spicken:
http://www.lothar-miller.de/s9y/archives/61-Lauflicht.html
Allerdings erscheint es sinnvoll, in deinem Fall das "Tonfolgearrray"
als Integer anzulegen, denn der Zähler ist ja auch ein Integer. Dann
vergleicht sich das einfacher...
Na klar ;-)
Ich habe mich absichtlich nicht an der "Zweiklang Diskussion" beteiligt,
weil es mir zu trivial erschien. Zwei DDS-Generatoren und gut ist.
Außerdem viel das Wort "BASCOM".
Mal sehen ... vielleicht wäre es ein minimalistischer Zweiklanggenerator
auf dem FPGA ein gute Übung. Zur Erhöhung der Schwierigkeit ohne
externen Mischer für die zwei Kanäle.
Da ja nicht jeder ein MACHX02 FPGA hat, hier mein erster Versuch, den
Takgenerator vom restlichen Tongenerator zu trennen. Die beiden
Komponenten werden über das TopLevel File verbunden.
Ein wenig ungünstig könnte eventuell sein, dass die Frequenzkonstante im
Tongenerator fest kodiert ist.
Wie mache ich das am besten variabel?
Seltsam, warum laden die Leute das Top-Level-Diagramm für das MACHX02
herunter, aber nicht den Tongenerator?
Egal ..
Eine ziemlich gute Verbesserung für das "Klangerlebnis" wäre der Einsatz
von Hüllkurvengeneratoren für das An- und Abschwellen der Lautstärke.
Damit klingen dann die Töne viel natürlicher. Man kann z.B. Glockentöne
damit erzeugen.
Der SID aus dem C64 wäre hier ein gutes Beispiel. Ich hänge mal das
Schema an.
Gibt es einen fertigen Hüllkurvengenerator in VHDL?
Andi schrieb:> Vergleich auf GLEICH oder UNGLEICH wird oft vewendet weil es halt> weniger LUTs als KLEINER oder GRÖSSER benötigt.
Auch dazu ein kleiner Denkanstoß im
Beitrag "Re: Warum ist hier weniger los als."
Fazit: man sollte das für einen gegebenen Fall ruhig ab&an mal
ausprobieren...
Ich bin ja erstaunt, was für Kleinode sich hier im MC-Netz so finden
lassen.
Witzigerweise höre ich genau diesen Gong vom benachbarten Rathaus jeden
Morgen. Scheint wohl ein SAB0600 verbaut ;-)
Damit es die Leute ausprobieren können, hänge ich das Top-Level Design
für das MACHX02 board hier mal an.
Zum Test habe ich einfach direkt einen Piezo Lautpsrecher mit ~2K
Vorwiderstand angeschlossen.
Der 2.te und 3.te Ton klingt etwas übersteuert.
>Auch dazu ein kleiner Denkanstoß im
Sehr interessant. Ich hätte auch gedacht, dass ein '=' weniger Resourcen
als ein '<' verbraucht. Nach der Aussage im anderen Thread braucht aber
das '=' mehr.
Hier habe ich einen einfachen FPGA-Synthesizer entdeckt:
http://www.instructables.com/id/8-Step-FPGA-Sequencer-and-Synthesizer/
Das Design ist leider in Veriolog und eher sehr einfach gehalten, weil
es nur Rechtecktöne macht. Dafür kann man über die Schalter am Board mit
den Tonfolgen spielen. Ich poste das mal als Inspiration:
https://youtu.be/zJfWnLn4zno
Vielleicht ist es trotzdem gut, mal zu sehen, was andere so machen.
Im Moment verusche ich gerade einen Tongenerator mit veränderlicher
Amplitude zu entwerfen. Wenn ich das geschafft habe, kann ich die
Ausgangssignale mehrere Genereatoren addieren und dann über PWM
ausgeben.
Das ist mein erster Versuch. Er scheint aber immer bei einer Frequenz
hängen zu bleiben:
1
libraryieee;
2
useIEEE.STD_LOGIC_1164.ALL;
3
useIEEE.NUMERIC_STD.ALL;
4
5
entitynoteToneGeneratoris
6
port(
7
clk:inSTD_LOGIC;
8
noteIn:inSTD_LOGIC_VECTOR(2downto0);
9
amplitude:inSTD_LOGIC_VECTOR(7downto0);
10
waveOut:outSTD_LOGIC_VECTOR(7downto0)
11
);
12
endnoteToneGenerator;
13
14
architectureBehavioralofnoteToneGeneratoris
15
16
constantNOTE_C4:integer:=53200000/(2*262)-1;
17
constantNOTE_D4:integer:=53200000/(2*294)-1;
18
constantNOTE_E4:integer:=53200000/(2*330)-1;
19
constantNOTE_F4:integer:=53200000/(2*349)-1;
20
constantNOTE_G4:integer:=53200000/(2*392)-1;
21
constantNOTE_A4:integer:=53200000/(2*440)-1;
22
constantNOTE_H4:integer:=53200000/(2*494)-1;
23
constantNOTE_C5:integer:=53200000/(2*523)-1;
24
25
constantMINFREQUENCY:integer:=10;-- Hz
26
signalprescaler:integerrange0to53200000/(2*MINFREQUENCY)-1:=53200000/(2*MINFREQUENCY)-1;-- bei 53.2MHz fosc
Um in den Tönen genau(er) zu werden, sollte man den prescaler etwas
verkleinern und die Töne auf wenigstens 0,1% genau stimmen. Genau
gerechnet ist das Optimum für den höchsten Ton bei einem Scaler nahe
Wurzel (Taktfrequenz) zu finden.
Ansonsten empfiehlt es sich, um starre Teiler zu machen und die
Primärfrequenzen zum weiteren Teilen hochfrequent genug zu erzeugen:
Die Teiler für 7 Haupttöne (weisse Tasten) wären:
24, 27, 30, 32, 36, 40, 45 (gemäß dieser Überlegung):
Beitrag "Re: Zweiklang Ton erzeugen"
Für die jetzige Ausbaustufe der Tonerzeugung in diesem Thread wird das
wahrscheinlich eher keine Rolle spielen.
Damit man den Unterschied beim Abspielen der Tonleiter hört, brauch man
wahrscheinlich ein absolutes Gehör.
Aber ich werde Deinen Vorschlag mal im Hinterkopf behalten, vielleicht
erreicht dieser Thread ja noch die Stufe, wo es wichtig wird.
Hier die neueste Kreation um zwei Töne gleichzeiig zu spielen.
Im MelodyPlayer musste ich für das Mischen von zwei Tönen
STD_LOGIC_VECTOR in Integer und zurück verwandeln, damit ich die Werte
addieren konnte. Das finde ich etwas umständlich.
Gespielt werden Zweiklänge, deren musikalische Qualität durch meine
begrenzten musikalischen Kenntnisse bedingt ist ;-)
Vielleicht will sich da mal ein Musiker drann wagen ...
chris schrieb:> Im MelodyPlayer musste ich für das Mischen von zwei Tönen> STD_LOGIC_VECTOR in Integer und zurück verwandeln, damit ich die Werte> addieren konnte. Das finde ich etwas umständlich.
Du kannst auch (un-)signed Vektoren addieren.
Was dir da allerdings passieren wird, ist dass dich der Synthesizer zu
Recht abwatscht, weil die Addition zweier 8 Bit Vektoren einen 9 Bit
Vektor gibt.
Und wenn du an geeigneter Stelle statt std_logic Vektoren gleich
unsigned Vektoren verwendest, dann musst du überhaupt gar nichts
konvertieren:
1
system_pwmValue<=wave1+wave2;
Fazit: nicht VHDL an sich ist umständlich und geschwätzig. Es wird dazu
gemacht... ;-)
chris schrieb:> außerdem viel das Wort "BASCOM".
Ich kaufe ein "F" :-)
chris schrieb:> Ich bin ja erstaunt, was für Kleinode sich hier im MC-Netz so finden> lassen.
Recht einfach gehalten. Eher nicht anzunehmen, dass das klingt, wie der
Original-CHIP. Der war übrigens damals sehr berühmt und vielfach
verbaut.
In den 80ern war der an jeder 5. Hausklingel zu hören.
> https://www.mikrocontroller.net/attachment/highlight/158318> Recht einfach gehalten. Eher nicht anzunehmen, dass das klingt, wie der> Original-CHIP.
Ich finde es aber trotzdem gut gemacht, weil es zeigt, dass man mit so
einem kurzen Code schon mehr als nur simples Rechteckgefiepse erzeugen
kann.
Lothar Miller schrieb
> Und wenn du an geeigneter Stelle statt std_logic> Vektoren gleich unsigned Vektoren verwendest,> dann musst du überhaupt gar nichts konvertieren:
Bis jetzt habe ich als Ports für die Submodule STD_LOGIC_VECTOR
verwendet. Kann man auch einfach "Integer" verwenden? Dann könnte ja
einiger Schreibaufwand weg fallen.
Hier habe ich noch eine VHDL-ADSR entdeckt und nach einigem Probieren
hat das Einbinden auch funktioniert:
https://github.com/hanshuebner/rekonstrukt/blob/master/vhdl/adsr.vhd
Hier der Zweitongenerator mit ADSR.
Der Aufbau ist dabei folgender
top_MACHX02
+ top_sub_melodyPlayer
++ noteTonegenerator
++ adsr
++ pwmDac
top_MACHX02 ist wieder nur die Anbindung für das MACHX02 und darunter
liegt gleich top_sub_melodyPlayer der die Notentabellen beinhaltet und
die Glue-Logik.
Mach mal ein Tonbeispiel rein, damit wir hören, wie das klingt.
Auch zu dem SAB köknnte man mal was posten. Kaum anzunehmen, dass der
Code dem Original nahekommt.
>Mach mal ein Tonbeispiel rein, damit wir hören, wie das klingt.
Im Moment habe ich ja nur den Piezo als Lautsprecher angeschlossen, von
daher ist das im Moment noch weniger beeindruckend.
>Auch zu dem SAB köknnte man mal was posten. Kaum anzunehmen, dass der>Code dem Original nahekommt.
Naja, das FPGA hat ein paar Transistoren mehr als der Chip, der
vermutlich aus den 80er Jahren stammt.
Der erste Ton des Codes SAB0600 klingt realtiv gut, die anderen bei
meinem Piezo-Versuchsaufbau etwas überssteuert.
Ich vermute, dass das von der Mixer-Implementierung von Lothar kommt.
Kaum anzunehmen. Der Mixer, mixt nämlich gar nicht, sondern muxt! Es ist
ein Multiplexer und zwar ein Inklusivmuxer. Wenn ein Signal dominant
anliegt, wird der Ton nicht gemuxt. Das kann so nicht funktionieren.
Die Tonwellen müssen addiert und dann in eine PWM übersetzt werden. Oder
man muss die drei Töne sehr schnell multiplexen, also die drei PWM-Bits
parallel arbeiten lassen und dann am Pin schnell umschalten. Kriegste
halt nur ein Drittel der PWM- Frequenz hin.
Besser wäre es sicher, drei Ausgangspins zu nehmen und die über
Widerstände auf einen Summenpunkt arbeiten zu lassen. Allerdings kannst
Du dann auch gleich den PWM-Wert über 2 Pins und einen R2R-Wandler
ausgeben: Der wert wäre ja maximal 3.
Warum nimmst Du eigentlich überhaupt ein PWM? Nimm einen R2R-Wandler mit
5 Widerständen und 5 Bit. Das sind 32 Stufen bei Taktfrequenz.
Anschließend ein träges RC-filter auf 10kHz Grenzfrequenz.
E. M. schrieb:> Das kann so nicht funktionieren.
Und sie dreht sich doch... ;-)
E. M. schrieb:> Eher nicht anzunehmen, dass das klingt, wie der Original-CHIP
Probiers aus: ein Laie kann das kaum auseinander halten.
chris schrieb:> Der erste Ton des Codes SAB0600 klingt realtiv gut, die anderen bei> meinem Piezo-Versuchsaufbau etwas überssteuert. Ich vermute, dass das> von der Mixer-Implementierung von Lothar kommt.
Hier im Beitrag "Re: Zweiklang Ton erzeugen - direkte Ausgabe per PWM" sind die
Hintergründe dieser "Mischung" etwas erläutert. Letztlich ist es
natürlich so, dass wenn 1 Ausgang schon die volle Amplitude bringt, eine
Mischung verzerren muss, weil sie ja rein rechnerisch schon nicht
funktionieren kann.
Man müsste also tatsächlich den Mischer etwas aufwändiger gestalten, so
dass jeder Ton maximal 1/3 der Maximalamplitude beisteuern kann.
Lothar M. schrieb:> E. M. schrieb:>> Das kann so nicht funktionieren.> Und sie dreht sich doch... ;-)
Rauskommen tut da was, klar, aber eine Mischer ist das nicht so
wirklich. Daher schrieb Ich Muxer, denn das ist, was da passiert: Durch
das gleichzeitige Aktivsein zweier Wellen, wird die PWM-Welle getoggelt
und damit werden deren Rechtecke gefaltet. Es entstehen also die
typischen Mischprodukte, allerdings ist der Filter nicht dafür
ausgelegt.
Ich fände einen echten Mischer, also ein Rotieren der Pins praktikabler.
Es muss natürlich dafür gesorgt werden, dass die PMMs eine Mitte
produzieren und sich nicht eine 0 nach unten durchsetzt. Das würde zu
einigen Verzerrungen führen denke Ich.
Auf diese Weise kann man übrigens zwei PWM Steuerungen ineinanderfahren
um das Signal zu übergeben: Beispiel Ineinanderlaufenden
Lauflichtleisten.
Gerade habe ich mir das Original angehört:
https://www.youtube.com/watch?v=RF9SGqEax8o
Für mich klingt der zweite und dritte Ton dort auch übersteuert.
Wenn man genau hinhört, vermindert sich die Amplitude beim letzten Ton
stufenweise.
Ursprünglich dachte ich, der SAB0600 sei eher ein analoges Design, aber
es scheint wohl eher digital zu sein. Beim analogen Design wäre es für
die FPGA Implementation schwierig gewesen, den Ton gut zu emulieren.
Deshalb klingt die FPGA Version dem Original schon sehr ähnlich.
Was wäre eigentlich ein geeigentes, sehr kleines FPGA dafür?
chris schrieb:> Welches CPLD?
Das, das 18V aushält.
> Gibt es eines mit 8 Pins
Nimm eines im QFP 64 und schneide die nicht benötigten 56 Pins ab...
> welches passen würde?
Hochkant vielleicht? ;-)
Liegt vermutlich am Mikrophon am Laptop. Mit den Ohren klingt es für
mich fast wie das Original.
Vielleicht gibt es auch eine Interferenz von hochfrequenten Tönen aus
meinem MP3-Verstärker-Lautsprecher mit dem Mikrophon in einem Bereich,
den ich nicht mehr hören kann ...
chris schrieb:> Liegt vermutlich am Mikrophon am Laptop. Mit den Ohren klingt es für> mich fast wie das Original.
Nun ja, abgesehen davon, dass es mehrere Originale gibt, würde Ich
sagen, dass es sich vom YT schon stark unterscheidet. Vollkommen andere
Schwebungen und die Tonhöhen sind auch nicht richtig stimmig.
Man muss sich halt fragen, was man will: Einen einfachen Klang bekommt
man aus ein paar Zählern raus, eine wirklich echte Emulation eines
Analogshcaltkreises, um ihn weitgehend echt abzubilden, wie ein SAB oder
SID et. al. wird so oder so schwierig. Auch die Teile solcher Chips, die
Digitalteile sind, unterliegen etlichen Effekten der Analogwelt - vor
allem, weil da in Sachen Versorgung und Präzision kostenoptimiert
designed wurde. Das gilt auch für elektronische Musikinstrumente: Bei
vielen Klangerzeugern der 80er und 90er schlägt sich ein schwaches
Netzteil, eine unzureichende Entkopplung, Übersprechen, einfache
nichtlineare Verstärker und sonstige Verzerrungen nieder.
>Nun ja, abgesehen davon, dass es mehrere Originale gibt, würde Ich>sagen, dass es sich vom YT schon stark unterscheidet.
Das liegt bestimmt an Deinen über lange Jahre mit 96kHz geschulten Ohren
:-)
Im Anhang noch das VHDL-Beispiel mit ADSR von oben mit einem lüfterlosen
Laptop aufgenommen. Da scheinen die Störgeräusche etwas niedriger.
Witzig an dem Beispiel: Obwohl nicht so absichtlich programmiert, ändert
sich die Tonart des "Refrains" immer ein wenig. Damit klingt es
praktischerweise weniger monoton.
Aber, aber .. es klingt doch irgendwie ungewöhnlich, nicht?
Du kannst ja die 5 Töne mal auf Deinen professionellen Anlagen laufen
lassen.
Es sind zwei Spuren parallel, schnelles Attack, landsameres Decay und
Rechtecksignal ..
Ansonsten: ich glaube, hier ist gar nicht so das
Musik-Synthesizer-Forum, das Zip-File mit dem Code wurde nur 1 x runter
geladen.
chris schrieb:> Ansonsten: ich glaube, hier ist gar nicht so das> Musik-Synthesizer-Forum, das Zip-File mit dem Code wurde nur 1 x runter> geladen.
Das ist wohl so, wobei das in meinem Fall daran liegt, dass Ich
insgesamt sehr wenig Bedarf an VHDL für Audioerzeugung habe, weil meine
Platte damit schon voll ist :-)
Mir fehlt eigentlich nur eine richtig gute Trompetenemulation.
Mal eine Frage, an diejenigen, die sich ein wenig mit der
Audiosignalerzeugung auskennen:
Reicht ein Sinus mit 8Bit Zeitauflösung wie der von Lothar aus, um einen
guten Klang zu erhalten?:
http://www.lothar-miller.de/s9y/archives/37-DDFS-mit-BROM.html
chris schrieb:> Reicht ein Sinus mit 8Bit Zeitauflösung wie der von Lothar aus, um> einen guten Klang zu erhalten?
Definiere "gut".
Der Rauschabstand ist schon mal nur 48dB, das ist auf jeden Fall
"retro".
Wenn du solche "old school" Sounds erzeugen willst, dann ist der Klang
gut.
> Reicht ein Sinus mit 8Bit Zeitauflösung wie der von Lothar aus
Über welchen Frequenzbereich? Mit welchem Filter?
>Definiere "gut".
Die Grenze, bei der ein ca.35 jähriger Erwachsener die nächst höhere
Auflösungsstufe eines Sinus sowohl bei der Zeit als auch bei der
Amplitudenquantisierung bei einer Frequenz von 440Hz und einer
Samplingfrequenz von 48kHz nicht mehr von der vorigen unterscheiden
kann.
Präzise genug?
Lothar M. schrieb:> chris schrieb:>> Reicht ein Sinus mit 8Bit Zeitauflösung wie der von Lothar aus, um>> einen guten Klang zu erhalten?> Der Rauschabstand ist schon mal nur 48dB, das ist auf jeden Fall> "retro".> Wenn du solche "old school" Sounds erzeugen willst, dann ist der Klang> gut.
Der "Retrosound" kommt ja durch Quantisierung der Amplitude
(harmonisches Spektrum mit binären FAktoren) und die Sprünge gemäß der
Auflösung der Phase bei ungeraden Frequenzen zustande, die sich in einer
Faltung äussern.
Vor allem die neuen Spiegelfrequenzen sind es, die den Ton machen, wobei
da auch die Filter der Klangerzeuger-Chips eine große Rolle spielen, was
die daraus machen. 48dB Güte wären gfs schon zu gut, wenn man die
Frequenz passt und man es auch eine Sinuserzeugung anlegt.
8 Bit als Quelle sind auch generell nicht unbedingt ein Hindernis. Man
kann das ja intern auch interpolieren und hochsetzen, filtern und
vorverarbeiten.
Es kommt halt darauf an, wieviel man speichern und wie viel man
prozessieren möchte: Je einfacher man Auslesen und Ausgeben will, desto
breiter muss die Tabelle sein.
Meine Synths arbeiten z.B. mit 18 Bit Auflösung in der Phase für die
höchste Frequenz, allein netto ohne Interpolation, dithering etc. Die
Synthesegleichungen und Tabellen liefern 24 Bit Daten aus 18 Bit Phase.
Der Phasenakku hat dann jeweils mindestens 36 Bits für alle
Manipulationen wie Verzerrung, Faltung und Vibrato. Damit ist das
wirklich wie analog und es gibt keine Artefakte. Da Ich sowohl bei der
Phase als auch der Auflösung in Echtzeit parametrisch dezimieren kann,
lässt sich der Qualitätsverlust direkt anhören, bez zumindest messen.
Weniger als 12-14 Bit Phasenauflösung sollte man für eine breitbandige
DDS nicht haben, bei komplizierten Wellenformen entsprechend mehr.
>> Reicht ein Sinus mit 8Bit Zeitauflösung wie der von Lothar aus> Über welchen Frequenzbereich? Mit welchem Filter?
Genau das ist die Frage. Man kann aus einem 1-Bit-Rechteck einen Sinus
modellieren, wenn man genügend gut filtert. Je tiefer die Frequenz,
desto besser ist das Signal. Effektiv wird das natürlich nur durch eine
Modulation.
Dazu ist auch bereits genug hier geschrieben worden, siehe PDM, DSD.
Als Richtwert kann man sagen, dass man mit einem FPGA direkt auf einem
Pin ohne große Verrenkungen ein 16-Bit-Audio nur mit einem guten
analogen AA-Filter hinbekommt. Nimmt man dagegen nur ein einfaches
RC-Filter, muss das der Modulator berücksichtigen und es muss
ausgemessen sein, bzw justiert werden, oder die Qualität ist schlechter.
Wenn man sich auf das untere Spektrum konzentriert, reicht die Qualität
immerhin bei einem mittelmäßigen 24dB-Filter auf z.B. 400Hz, um Bässe
auszugeben und sauber in der Phase zu führen, d.h. man kann Subwoofer,
die i.d.R. unter 80Hz arbeiten, ohne Qualitätsverlust betreiben.
> So sieht das aktuell gemessen nach einem RC-TP mit 100Ohm,100nF aus.
Wenn man jetzt nicht 1 Bit, sondern 8 hat, ist man statistisch zwischen
Faktor 8 und Wurzel 8 besser, je nachdem, welchen Aspekt des Klangs man
betrachtet. Das Problem ist aber, die Bits sauber rauszubekommen. Ohne
DAC wird das nichts, oder man braucht eine optimierte Ansteuerung für
ein R2R-Filter, das kalibiert wird. Damit wiederum hauen manche 32 Bit
raus und übertreffen auch 24-Bit-Delta-Sigma-Wandler.
Von daher ist entweder ein richtiger DAC mit voller Auflösung oder 1-Bit
Audio zu bevorzugen, weil alles, was man im FPGA an Tricks und
Vorverarbeitung macht, mathematisch perfekt läuft.
Das Problem ist dann nur, es auf einen Lautsprecher zu bekommen. Heute
arbeiten fast alle Stufen digital, die kann man aber so direkt nicht mit
200MHz ansteuern, weil sie nicht mehr als 500kHz vertragen. Die
500W-Leistungsteile eher nur 200kHz.
Da muss man dann einen schlauen Filter/Modulator einsetzen, um diesen
Faktor 1000 gut runter zu bekommen - und zwar einen sehr schlauen, der
auch für den Analogteil des Amps mitdenkt :-)
>Meine Synths arbeiten z.B. mit 18 Bit Auflösung in der Phase für die>höchste Frequenz, allein netto ohne Interpolation, dithering etc. Die>Synthesegleichungen und Tabellen liefern 24 Bit Daten aus 18 Bit Phase.>Der Phasenakku hat dann jeweils mindestens 36 Bits für alle>Manipulationen wie Verzerrung, Faltung und Vibrato. Damit ist das>wirklich wie analog und es gibt keine Artefakte. Da Ich sowohl bei der>Phase als auch der Auflösung in Echtzeit parametrisch dezimieren kann,>lässt sich der Qualitätsverlust direkt anhören, bez zumindest messen.>Weniger als 12-14 Bit Phasenauflösung sollte man für eine breitbandige>DDS nicht haben, bei komplizierten Wellenformen entsprechend mehr.
Danke für die Hinweise, das sind doch mal gute Anhaltspunkte.
Für den Sinus würde das also im kleinsten Fall 12 Bit, also 4096
Abtastwerte anstatt der 2056 Abtastwerte im Moment, d.h. Faktor 16
mehr.
Wo das gerade als "zuletzt geänderter Beitrag" über die Liste schwirrt,
habe Ich es mir angehört und muss doch ernsthaft fragen, wozu man da ein
dickes FPGA benötigt. Solche Sachen lassen sich mit einfachsten
Schaltungen machen und nicht zuletzt mit einem Microcontroller. Woher
kommt eigentlich die Wut mit grösstmöglichem Einsatz kleinstmögliche
Ergebnisse zu schaffen?
In der Zeit wo man umständlich einen FPGA programmiert , wäre mit einem
Controller der 8-Bit-2-Euro-Klasse 10mal mehr zu machen. Mehr als
Spielerei kommt da nicht bei raus.
>Wo das gerade als "zuletzt geänderter Beitrag" über die Liste schwirrt,>habe Ich es mir angehört und muss doch ernsthaft fragen, wozu man da ein>dickes FPGA benötigt.
Wo steht denn geschrieben, dass man dafür ein dickes FPGA benötigt?
Hier mal ein wenig der Versuch, die Auslastung durch meinen
2-Oscillator-Synthesizer abzuschätzen.
Im Floorplan sieht es so aus, als wenn etwas ein Fünftel des FPGAs
benutzt ist. Das scheint mir ganz gut zu der Anzahl der Slices von 15%
zu passen.
1
Design Summary:
2
Number of registers: 394 out of 7209 (5%)
3
PFU registers: 394 out of 6864 (6%)
4
PIO registers: 0 out of 345 (0%)
5
Number of SLICEs: 503 out of 3432 (15%)
6
SLICEs as Logic/ROM: 503 out of 3432 (15%)
7
SLICEs as RAM: 0 out of 2574 (0%)
8
SLICEs as Carry: 355 out of 3432 (10%)
9
Number of LUT4s: 1001 out of 6864 (15%)
10
Number used as logic LUTs: 291
11
Number used as distributed RAM: 0
12
Number used as ripple logic: 710
13
Number used as shift registers: 0
14
Number of PIO sites used: 14 + 4(JTAG) out of 115 (16%)
15
Number of block RAMs: 2 out of 26 (8%)
Für die Sinus-Rom-Tabellen nutzt der Synthesizer wohl den eingebauten
Speicher. Einen davon habe ich angeklickt. Man sieht die grünen
Verbindungslinien.
Das jetzige Design müsste als für ca. 10 Oscillatoren reichen. Weil das
compilieren aber so lange dauert, lasse ich es mal bei dem Versuch mit 2
Oscillatoren bewenden.
chris schrieb:> Wo steht denn geschrieben, dass man dafür ein dickes FPGA benötigt?FPGAs sind immer ineffizient in der Nutzung der Chipfläche und wenn man
etwas mit einem kleinen Controller machen kann, ist das das Mittel der
Wahl. Das mag jetzt Philosophie sein, aber uns wurde beigebracht,
Lösungen mit den geringsten Mitteln zu bauen und daruf richtet sich der
Blick bi Entwicklungen in der Industrie. Heute ist es aber wohl üblich,
erst einmal mit MATLAB ein Systemmodell zu bauen, dann die Umsetzung
automatisiert erledigen zu lassen (man kann es ja selber nicht) und dann
sehr viel Gedöhns für wenig Inhalt zu haben. Dann aber gleich ein Video
machen und ab nach Youtube, damit es nach richtig viel aussieht.
>floor plan
Bist Du eigentlich wirklich der Überzeugung, dass ein floor plan eine
Aussage für einen Leser macht, wenn er das design tool nicht zu Hand
hat? Ich erkenne da nur Farbkleckse. :-)
So schlecht ist das jetzt gar nicht. Meine ersten PLD-Versuche klangen
ähnlich. Ich finde es sogar lustig, klingt irgendwie nach 80-er Jahre
Telespiel. Allerdings sind "unmusikalische" 9 Töne pro Wiederholung
verbaut und so hat es keinen Rhythmus. Habe es mal durch meinen
FPGA-Sampler gejagt: Reloop bei 300, 400 und 700ms.
Jetzt brauchen wir noch einen Rauschgenerator fürs Schlagzeug.
>So schlecht ist das jetzt gar nicht.
Upss, das hätte ich ja jetzt fast nicht wieder erkannt. Nach dem
Durchlauf durch Deinen "Looper" klingt das tatsächlich um einiges besser
als mein Original.
> Meine ersten PLD-Versuche klangen ähnlich.> Ich finde es sogar lustig, klingt irgendwie nach 80-er Jahre>Telespiel.
Das hat ich tatsächlich auch etwas erstaunt. Eigentlich hätte ich
gedacht, dass der typische 8Bit Sound aus den 80ern durch die
Quantisierung und die kleinen Abtastraten verursacht waren. Deshalb habe
ich ja nach der notwenigen Auflösung für den Sinus gefragt.
Der jetzt eingebaute hat 1024 Steps und 16 Bit. Die Artifakte hört man
immer noch ein wenig, aber ich hatte das Gefühl, sie liegen auf einem
erträglichen Maß. Aber trotz dieser Maßnahme klingt es immer noch fast
wie C64. Das Problem war dort also nicht die Auflösung, sondern die
Struktur der Tongenerierung ( wenig Generatoren ).
>Allerdings sind "unmusikalische" 9 Töne pro Wiederholung>verbaut und so hat es keinen Rhythmus.
Upps .. nein ... ich habe mich verzählt und es ist mir akkustisch nicht
aufgefallen.
Gibt's nicht so was wie den 3/3 Takt oder 9/9 Takt. Sollte man ihn
erfinden? Wahrscheinlich muss sich das Gehör an die neue Taktform nur
lange genug gewöhnen, wie in meinen Experimenten oder bei Heavy Metall
;-)
>Habe es mal durch meinen>FPGA-Sampler gejagt: Reloop bei 300, 400 und 700ms.
Klingt gut. Ich nehme an, "FPGA-sampler" bedeutet in dem Fall "Echo" bei
300,400 und 700ms.
>Jetzt brauchen wir noch einen Rauschgenerator fürs Schlagzeug.
Am Ende in meinem Stück ist der "Knall". Den hast Du "ausgefadet".
Eigentlich ist das ein Rauschgenerator.
Wie sollte die Melodie organisiert sein: 8 Takte auf den zwei Kanälen
und beim jeweils 8.ten der zusätliche Rauschgenerator als Schlagzeug?
Die ADSR dafür A=0 D=200ms ?
Ich verlinke noch die interessante Melody hier, damit sie nicht verloren
geht:
Beitrag "Re: So schön können Pointer-Fehler sein"
Edi. M. (Firma: Industrie 1.0) (elektromeister)
>FPGAs sind immer ineffizient in der Nutzung der Chipfläche und wenn man>etwas mit einem kleinen Controller machen kann, ist das das Mittel der>Wahl. Das mag jetzt Philosophie sein, aber uns wurde beigebracht,>Lösungen mit den geringsten Mitteln zu bauen und daruf richtet sich der>Blick bi Entwicklungen in der Industrie.
Dem aufmerksamen Leser dürfte die Thread-Überschrift nicht entgangen
sein.
Es geht hier um Grundlagen und Übungsprojekte, nicht um die industrielle
Entwicklung eines "Tonerzeugers".
Tatsächlich kann man das bisher erreichte locker mit einem günstigen
Mikrocontroller erzeugen, der sich auch noch viel einfacher
programmieren lässt ( Was ich schon in verschiedensten Ausführungsformen
gemacht habe ).
Ich wollte aber u.a. mal sehen, wie z.B. ein im FPGA implementierte
Sigma-Delta-Wandler in der Praxis klingt. Und mein selbst gebauter 1.ter
Ordnung läuft mit 50MHz, das ist auf einem MC eher nicht machbar.
Und wenn man wirklich an die professionellen Grenzen des musikalisch
Machbaren wie Jürgen geht, dann wird man wohl auch ein FPGA brauchen,
schätze ich.
Außerdem gibt es noch ein Argument für die FPGA-Grundlagen zur
Tonerzeugung: Es macht schlicht mehr Spaß als das ziemlich ausgetretene
LED-geblinke welches normalerweise in Anfängerübungen gemacht wird.
chris schrieb:> Ich wollte aber u.a. mal sehen, wie z.B. ein im FPGA implementierte> Sigma-Delta-Wandler in der Praxis klingt.
Dort ist standardmäßig zunächst überhaupt nichts implementiert, wie Du
aber sicher wießt, das wirst Du selbst tun müssen wodurch das Ergebnis
von deinem Ansatz abhängig sein dürfte. Und ob ein Wandler "klingt"
darüber hat jeder Audiotyp seine eigene Meinung. Dem grundsätzlichen
Sinne nach sollen Analog-Digital-Wandler für sich gesehen eigentlich
überhaupt garnicht klingen, sondern nur wandeln unf gut ist.
> Außerdem gibt es noch ein Argument für die FPGA-Grundlagen zur> Tonerzeugung: Es macht schlicht mehr Spaß als das ziemlich ausgetretene> LED-geblinke welches normalerweise in Anfängerübungen gemacht wird.
Da ist natürlich etwas dran. Irgendwas musst Du schliesslich bauen. Man
hätte aber auch darüber nachdenken können, irgendetwas mit encryptic zu
machen, um Codes zu knacken, also etwas, wo richtig Bandbreite benötigt
wird und der Einsatz eines FPGA mehr gerechtfertigt ist, als beim
langsamen Audio.
Als Denkanstoss böte sich noch an:
Beitrag "Ideen für interresante FPGA Projekte"
Und besonders das hier:
Beitrag "Ideen für FPGA-Projekte?"
chris schrieb:> Das hat ich tatsächlich auch etwas erstaunt. Eigentlich hätte ich> gedacht, dass der typische 8Bit Sound aus den 80ern durch die> Quantisierung und die kleinen Abtastraten verursacht waren.
Da waren ja noch analoge Filter drin, die Signale waren schon "rund".
Die Stufen tauchen da eher als Oberwellenanteil auf. Da gibt es auch
noch viele Aspekte. Unter anderem waren die Frequenzen nicht exakt auf
der Skala, hatten aber bei einfachen Tongeneratoren aber immer dieselbe
Frequenz. Damit falten sich die Oberwellen unterschiedlicher Töne
ineinander und löschen sich gegenseitig aus, wenn mehrere Stimmen
beteiligt sind.
> Gibt's nicht so was wie den 3/3 Takt oder 9/9 Takt.
3/4 und 5/4 sind üblich.
Die anderen Takteinstellungen braucht man nur für die Echos auf dem
jeweils 3. und 7. Takt als Auftakt. Viele Drumboxen machen davon
Gebrauch.
> Sollte man ihn erfinden?
Auf geht's :-)
chris schrieb:> Ich habe mich absichtlich nicht an der "Zweiklang Diskussion" beteiligt,> weil es mir zu trivial erschien. Zwei DDS-Generatoren und gut ist.
Was ist denn an Deiner hier vorgestellten Schaltung anderes drinne, als
ein DDS-Generator? Ist Dir klar, was Du baust?
chris schrieb:> Seltsam, warum laden die Leute das Top-Level-Diagramm für das MACHX02> herunter, aber nicht den Tongenerator?
Vermutlich, weil sie von dem Tongenerator erschlagen sind und die Masse
an VHDL nicht verstehen.
Im Ernst: Nichts an dem Thema hat wirklich etwas mit FPGAs zu tun. Als
Software für einen DSP oder MCU sähe es in C ganz genau so aus. 1:1 ztu
übersetzen. Das sind eher Musikfragen, wie Töne abgespielt werden
müssen.
> Der SID aus dem C64 wäre hier ein gutes Beispiel. Ich hänge mal das> Schema an.
Das wäre schon eher eine Aufgabe für einen FPGA, besonders die Filter.
Da könntest Du Dir Sporen verdienen, einen solchen Baustein
nachzukonstruieren.
> Gibt es einen fertigen Hüllkurvengenerator in VHDL?
Der sollte recht einfach in einer state machine zu machen sein.
FPGA macht nur dann einen Sinn, wenn es ohne nicht geht, wie bei dem
Bauwerk hier:
http://www.keyboardpartner.de/hammond/hoax.htm
Lieber Weltbester FPGA-Pongo,
würde es Dir etwas ausmachen, einen Thread vorher durchzulesen, bevor Du
ihn kommentierst?
>Ist Dir klar, was Du baust?
Eine VHDL Übung um mich ein wenig an den Syntax und die Strukturen zu
gewöhnen. Ich dachte, ich hätte das verständlich genug beschrieben:
Beitrag "Re: VHDL Grundlagen Tonerzeugung">FPGA macht nur dann einen Sinn, wenn es ohne nicht geht,> wie bei dem Bauwerk hier:>http://www.keyboardpartner.de/hammond/hoax.htm
Ob dem Mann wohl klar war, welche Bedeutung "Hoax" üblicherweise hat?
chris schrieb:> Ob dem Mann wohl klar war, welche Bedeutung "Hoax" üblicherweise hat?
Es ist "ihm" klar geworden und "er2 hat seine Bezeichnung inzwischen
geändert. Die Bezeichnung ändert jedoch nichts an der Qualität des
Gerätes.
chris schrieb:> Ich wollte aber u.a. mal sehen, wie z.B. ein im FPGA implementierte> Sigma-Delta-Wandler in der Praxis klingt. Und mein selbst gebauter 1.ter> Ordnung läuft mit 50MHz,
Das hier wäre noch lesenswert dazu PulsdichtemodulationWeltbester FPGA-Pongo schrieb:> chris schrieb:>> Der SID aus dem C64 wäre hier ein gutes Beispiel. Ich hänge mal das>> Schema an.> Das wäre schon eher eine Aufgabe für einen FPGA, besonders die Filter.> Da könntest Du Dir Sporen verdienen, einen solchen Baustein> nachzukonstruieren.
Gibt es schon einige unter anderem den hier:
http://www.fpgasid.de
Anders, als meine Emulation, gibt es den sogar im Formfaktor zu dem
MOS-Chip - ist also direkt einzusetzen. Was der in Sachen Authentizität
kann, weiß Ich nicht, bei dem SID ist es nur so, dass viele Emulatoren
einfach das Datenblatt nachbauen und vergessen, dass der Klang zu 80%
durch die Effekte der Analogtechnik in den Ding gemacht werden.
>Gibt es schon einige unter anderem den hier:>http://www.fpgasid.de
Ja, SID Realisierungen gibt es einige.
Hier z.B. mit dem Papillo:
https://www.youtube.com/watch?v=_34yHrEZC-E&feature=youtu.be
Gibt es eigentlich Unterlagen über die Filter des Original-SID ? Ich
habe da noch nichts gefunden.
Interessant ist auch, was man mit Mikrocontrollern alles so an
Synthesizern machen kann.
Hier Beispiele mit dem Axoloti ( STM32F4 ):
http://www.axoloti.com/examples/
Falls ich nichts übersehen habe, ist in den obigen SID-Links auch keine
genaue Beschreibung der Filter. Ich vermute zur damaligen Zeit sind es
"switched capacitor" Filter.
Gerade sehe ich, dass es hier einen Beitrag zu Schlagzeugtönen gibt:
Beitrag "Drum-Computer in VHDL"
Ich dachte eine Base-Drum besteht im wesentlichen aus einem
tief-frequenten Sinus.
chris schrieb:> Falls ich nichts übersehen habe, ist in den obigen SID-Links auch keine> genaue Beschreibung der Filter. Ich vermute zur damaligen Zeit sind es> "switched capacitor" Filter.
Gut möglich. Leider habe Ich auch keine genauen Info. Ich habe das nach
Gehör nachgebaut:
http://www.96khz.org/htm/sidemulation.htm
(unten auf der Seite ist ein Soundbeispiel)
> Ich dachte eine Base-Drum besteht im wesentlichen aus einem> tief-frequenten Sinus.
Ja, die Base-Drum, da ist sie wieder:-)
Bei der Antwort muss Ich etwas ausholen:
Die base line, also die (Rythmus-)basis in einem Mix wird häufig durch
eine bass drum, also das Instrument Basstrommel realisiert, weswegen
manche Produzenten (auch Ich) - von einer base drum sprechen. Viele
Deutsche sprechen es aber auch nur falsch aus (Herr Bohlen z.B.), weil
sie die Amis nicht richtig verstehen.
Das darf man aber nicht verwechseln:
Gerade in der elektronischen Musik macht der Begriff base drum Sinn,
weil es in der Tat die Rythmusspur ist, die musikalisch wichtig ist und
die auch als erste aufgesetzt wird. Diese ist allerdings meist nur eine
künstliche kick drum, d.h. ein atonaler Knall, wie bei einem
Überschalldüsenjet, der gefiltert wird, d.h. es entsteht ein
Frequenzgemisch mit vorwiegend Oberwellen. Die Grundwelle, die man
erhält passt in das kurze Sample auch nicht richtig rein, sondern
entsteht in erster Linie durch die Hüllkurve. So machen es auch viele
Drum-Computer. Der Ton ist also funktionell ein "base* sound, aber nicht
hauptsächlich im Bassbereich.
Im Techno verwendet man aber auch gerne auf- oder absteigende Frequenzen
und die werden in der Tat aus Sinus-Sweeps gebildet. Im Trance verwendet
man wiederum ruhige tiefe Töne, die aus modulierten Sinüssen bestehen
wobei die drum in den Hintergrund tritt, also der Schlag auf 1 und 3
leiser ist, als der Bass auf 2 und 4.
In der akustischen Musik mit einer realen Basstrommel sind das auch
weitgehend stabile Sinusfrequenzen, die bei den großen Swing-Orchestern
auch lange auslaufen. Bei den großen Orchesterpauken kann man die
Tonhöhe sogar mit einem Fußpedal stimmen.
In der Rockmusik ist wegen der oft benutzten Felldämmung der Ton oft so
kurz, dass auch dort kaum ein Sinus richtig erkennbar ist und sich mit
der Hülllurve mischt. Das sind dann bass drums, aber funktionell gesehen
oft keine base drums, weil das Schlagzeug bei dieser Musik nicht die
Rolle spielt und oft erst im Nachhinein aufgenommen und dazugesetzt
werden. Besonders bei schlecht spielenden Rockmusikern :-) Dort ist oft
die Bassgitarre die "base line", weil sie starke Akzente setzt und den
Rythmus bestimmt.
Wenn Du das nachvollziehen möchtest, brauchst Du Sinusgeneratoren,
Rauschgeneratoren und Hüllkurvengeneratoren, die alle in den Parametern
über die Zeit steuerbar sind und entsprechend eingestellt werden, weil
strenge exakte Sinuswellen nicht gut klingen und auch realitätsfern
sind.
Eine einfache Methode, das in DrumComputern zu mischen wäre, den
Bassanteil komplett rauszulassen und nur den atonalen Knack ab 300Hz zu
benutzen, um dann einen tonalen, zur Musik passenden Klang
draufzusetzen. Dann ist der Bass stimmbar. Das gleiche macht man mit den
Toms.
klingt alles sehr sehr spannend, aber irgendwie ist es schade, das so
viele Entwickler beginnen, mit solchen FPGA Musik zu machen und wir dann
nie etwas Sinnvolles zu hören bekommen. Offensichtlich geht da Vielen
nach den ersten Schritten die Luft aus.
carlo schrieb:> Offensichtlich geht da Vielen> nach den ersten Schritten die Luft aus.
oder sie hatten zu keinem Zeitpunkt ein Interesse etwas auf die Beine zu
stellen:
chris schrieb:> Edi. M. (Firma: Industrie 1.0) (elektromeister)>>Lösungen mit den geringsten Mitteln zu bauen und daruf richtet sich der>>Blick bi Entwicklungen in der Industrie.>> Dem aufmerksamen Leser dürfte die Thread-Überschrift nicht entgangen> sein. Es geht hier um Grundlagen und Übungsprojekte, nicht> um die industrielle Entwicklung eines "Tonerzeugers".
Als Teilzeit-VHDL-Benutzer werfe Ich frech die Frage in den Raum, worin
sich denn die Tonerzeugung bei FPGAs und CPUs überhaupt unterscheiden
soll. Einen Frequenzgenerator baut man immer gleich. Womit das
ausgerechnet wird, dürfte herzlich egal sein.
>Als Teilzeit-VHDL-Benutzer werfe Ich frech die Frage in den Raum, worin>sich denn die Tonerzeugung bei FPGAs und CPUs überhaupt unterscheiden>soll.
Lies mal den Thread hier durch, da wird darüber diskutiert.
Lothar M. schrieb:> carlo schrieb:>> wir dann nie etwas Sinnvolles zu hören bekommen.> Sieh dir mal dort die Demos an:
Interessant, nur sehe Ich dort weder irgendwelchen Code noch erblicke
Ich Klänge, die man auf übliche Weise mit Samples nicht auch erzeugen
könnte, wenn nicht besser.
Carlo schrieb:> noch erblicke Ich Klänge, die man auf übliche Weise mit Samples nicht> auch erzeugen könnte, wenn nicht besser.
War das eine implizite Forderung? Ich konnte nur die Forderung nach
"etwas Sinnvollem" erkennen. Und für meine Ohren klingt das ziemlich
sinnvoll.
> noch erblicke Ich Klänge, die man auf übliche Weise mit Samples nicht> auch erzeugen könnte, wenn nicht besser.
Wenn du wenigstens "Synthesizer" statt "Sampler" geschrieben hättest.
Und natürlich kannst du mit Samples sogar Dinge erzeugen, die du selbst
mit paralleler Rechenarbeit nicht in Echtzeit hinbekommst. Denn zur Not
rechnest du das Sample eben zehntausend mal langsamer aus und spielst es
hinterher in Echtzeit ab.
Edi M. schrieb:> Als Teilzeit-VHDL-Benutzer werfe Ich frech die Frage in den Raum, worin> sich denn die Tonerzeugung bei FPGAs und CPUs überhaupt unterscheiden> soll. Einen Frequenzgenerator baut man immer gleich. Womit das> ausgerechnet wird, dürfte herzlich egal sein.
Na in der Geschwindigkeit, vor allem wegen Parallelverarbeitung. Einen
DDS Oszillator kann das FPGA in einem Takt berechnen, im nächsten
berechnet es z.B die Pulsweite, während dem der DDS Block schon den 2.
Oszillator berechnet. Durch solches Pipelining benötigst du pro
berechneter Stimme im besten Fall nur einen Takt, was dann sehr hohe
Abtastfrequenzen oder extrem viele Stimmen ermöglicht.
CPUs können halt nur eins nach dem anderen und benötigen mehrere
Instruktionen für jede Funktion.
Carlo schrieb:> Interessant, nur sehe Ich dort weder irgendwelchen Code noch erblicke> Ich Klänge, die man auf übliche Weise mit Samples nicht auch erzeugen> könnte, wenn nicht besser.
Das ändert sich aber sofort, wenn du durch Drehen von Knöpfen die Klänge
verändern können willst. Und wenn nicht jeder angeschlagene Ton exakt
gleich klingen soll. Eine in Echtzeit berechnete Synthese klingt einfach
viel lebendiger.
Andi
Andi schrieb:> Edi M. schrieb:>> worin>> sich denn die Tonerzeugung bei FPGAs und CPUs überhaupt unterscheiden>> soll. Einen Frequenzgenerator baut man immer gleich. Womit das>> ausgerechnet wird, dürfte herzlich egal sein.>> Na in der Geschwindigkeit, vor allem wegen Parallelverarbeitung.
Die Möglichkeit, in FPGAs Dinge gleichzeitig zu tun ist mir sehr wohl
geläufig. Darum ging es mir aber nicht. Denn so, wie Du es darstellst,
liefe es nur auf mehr Quantität hinaus. Das kann es aber nicht sein,
denn mit ausreichend DSP-Power kann jeder am Ende Dasselbe tun, nur mit
geringeren Kosten.
C-Code ist allemal einfacher, als VHDL-Code, im günstigsten Fall gleich.
"Gleich" ist aber noch kein Vorteil.
> Eine in Echtzeit berechnete Synthese klingt einfach> viel lebendiger.
Ach, wieso sollte sie das? Die Mathematik dahin müsste eine anderen
sein. Oder sind wir jetzt wieder bei der Esotherik angelangt? FPGA =
Hardware = besser?
chris schrieb:> Lies mal den Thread hier durch, da wird darüber diskutiert.
Du möchtest uns jetzt aber nicht verklickern, dass ausgerechnet dieser
von dir ins Leben gerufene Artikelstrang die gesamte Bandbreite der
Tonerzeugung in VHDL abdeckt, oder?
Um dem Thema noch eine andere ergänzende "Note" zu geben:
In unterschiedlichen Artikeln im gesamten Internet, liest man seit
Jahren immer wieder über die angebliche mathematische Nachbildung realer
Instrumente mit Microprozessoren und manchmal auch FPGAs. Abgesehen von
einigen wenigen Produkten, ist da aber so gut wie nie etwas
herausgekommen, was durchschlagenden Erfolg gehabt hätte und die
einzigen Geräte, die Ich kenne sind auf DSP-Basis. Z.B. liefert eine
Recherche ein V-Piano der Firma Roland zutage. Für Gitarristen gibt es
einen AMP-Modellierer. Warum nehmen die keine FPGA?
Auf FPGA basieren nur neu aufgemachte Nachbauten alter Analogelektronik
wie TB303 und ähnliche und die werden in den Musikgruppen allenthalben
verrissen. Scheint nicht so zu klappen mit dem Physical Modelling.
Autor: Carlo (Gast)
>Interessant, nur sehe Ich dort weder irgendwelchen Code noch erblicke>Ich Klänge, die man auf übliche Weise mit Samples nicht auch erzeugen>könnte, wenn nicht besser.
Die Wavetable-Synthese wird für Produktion von digitalen Sounds schon
lange verwendet.
Der Commodore Amiga war berühmt dafür:
https://www.youtube.com/watch?v=6tNizdyx-DE
Hier im Mikrocontrollernetz gibt es den 17-Stimmigen
Wavetable-Synthesizer auf einem Atmega:
Beitrag "Re: 17 Kanal Avr Synthesizer in Asm"
Die teuren E-Pianos nutzen gesammpelte Aufnahmen von teuren Klavieren
und Flügeln, die mit unterschiedlichen Tastenanschlägen aufgenommen
wurden. Ich meine es nennt sich "microtonal synthesis" .
Der Nachteil der Wavetablesynthes ist, dass man die Sounds nicht in der
Breite wie mit dem abgebildeten Modularsynthesier ändern kann.
Autor: Edi M. (Firma: Solides Industrieunternehmen) (elektromeister)
>In unterschiedlichen Artikeln im gesamten Internet, liest man seit>Jahren immer wieder über die angebliche mathematische Nachbildung realer>Instrumente mit Microprozessoren und manchmal auch FPGAs.
Bei Musik und Musikinstrumenten wird oft auf Details und Feinheiten Wert
gelegt.
Das kann sich zum Beispiel in der Liebe zu vergoldeten, gekühlten
Lautsprecherkabeln für den besseren Klang äüßern.
Viele finden auch den Röhrenklang gut, was sich zur Zeit in Artikeln zur
oben abgebildeten NuTube Röhre zeigt.
Manche schwören auch auf 24 statt 16 Bit Audio weil's besser klingt.
Professionelle Musiker müssen sich erst langen an ein bestimmtes
Instrument gewöhnen, bis sich den gewünschten Klang erzeugen können.
Und so ist es: Einiges in der Musik mag esoterisch sein, bei vielem aber
kommt es auf das genaue hinhören an.
Und so haben die FPGA-Synthesizer von Jürgen sicherlich andere
klangliche Eigenschaften als ein PC-Programm.
Das selbe gilt für's physical Modelling: Die erzeugen Sounds sind andere
als Wavetable-synthetisierte.
Wenn Ich mir das alles hier so zu Gmüte führe, dann wäre es nun die
Aufage, einen Commodore 64 ins FAPG zu befördern und dann die gute alte
8Bit Software laufen zu lassen.
Richtig?
chris schrieb:> Die Wavetable-Synthese wird für Produktion von digitalen Sounds schon> lange verwendet.
Ich denke, hier wird das Wort Wavetable-Synthese falsch verwendet. Du
meinst sicherlich Sample-Playing? Nun, Wavetable-Synthese ist etwas
komplett anderes:
https://en.wikipedia.org/wiki/Wavetable_synthesis
(s Abschnitt "Confusion with sample-based synthesis (S&S) and Digital
Wave Synthesis")
PS Das oben zitierte Projekt macht auch keine Wavetable-Synthesis wenn
ich das richtig sehe, und der Amiga auch nicht.
Der neue Peak von Novation setzt ebenfalls auf FPGAs fuer die
Sound-Erzeugung - einige Tester haben sich das mit dem Oskar angesehen,
und die Wellenformen sind natuerlich super hochaufloesend:
https://global.novationmusic.com/peak-explained
Edi M. schrieb:> Warum nehmen die keine FPGA?
Vielleicht, weil die Entwickler dort solche Bausteine (noch) nicht
können/kennen und ihnen die bisherigen DSPs ausreichen?
Allerdings haben gerade die Musikinstrumentenentwickler immer schon
gerne ASICs gebastelt, die sich für den Massenmarkt dann ja anstatt
FPGAs durchaus lohnen. Wenn das Keyboard nicht großartig erweiterbar
oder updatebar sein muss, dann nehme ich natürlich ein ASIC, auch wenn
das Design evtl. vorher im FPGA erprobt wurde...
Dass die Entwickler FPGAs nicht kennen, ist eher nicht anzunehmen. Eher
schon scheint mir da die Flucht nach vorne angetreten worden zu sein um
etwas zu bringen, was es noch nicht gab. Dabei schießen einige wohl am
Ziel vorbei:
Wenn Ich das hier zu dem Peak lese:
Each of Peak’s eight voices has an independent oversampling
digital-to-analogue converter (DAC). These DAC’s are oversampling at
over 24MHz (24 million times per second), using a simple RC
(resistor-capacitor) filter on their output in the analogue domain. In
itself this is not new technology, but their integration inside the FPGA
has enabled their design to be extended to enable optimum waveform
synthesis. Because other virtual synths use discrete ‘off the shelf’ DAC
chips, which are restricted to running at sample rates of either 48kHz
or perhaps 96kHz, they often have aliasing issues, especially when
synthesising higher frequencies. Peak’s ability to generate waveforms at
the oversampling frequency — up to 512 times the traditional
rate — ensures that Peak’s waveforms are pure at all frequencies, free
from digital artifacts no matter how aggressively the pitch is
modulated.
Das heisst sie bauen im FPGA einen DA-Wandler nach und nutzen jeweils
24MHz 1-Bit Audio Daten. Wirklich sehr innovativ. Dieses Konzept ist
bereits an anderen Geräten der HIFI-Szene ausprobiert worden und
gescheitert.
Jeder kann sich ausrechnen, wie stark ein RC-Filter dieser Bauart dämpft
und wie gut damit 24000 Hz darszustellen sind. Das ist gerade mal ein
Faktor 1000, also 3 Dekaden.
Esotherik pur!
Ich glaube eher, dass die Nutzer von FPGAs die Signalverarbeitung nicht
verstanden haben. Diese Erzeugung von Audiodaten ist ja kein Hexenwerk
sondern reiht sich nahtlos in die Landschaft ein. Wenn einfache
Signalgeneratoren bis 500kHz super genau mit DSPs und DACs arbeiten,
kann das mit FPGAs nicht angehen. Jedenfalls nicht so!
Ich bin raus,,,
Wer es sich antun möchte:
Beitrag "Re: 1Bit Audio als Alternative zu PWM"
Wie man den Ausführungen gleich mehrerer Autoren dort entnehmen kann,
ist das 1-Bit-Audio nicht oder kaum besser und erfordert sehr präzise
Schaltungen. Es wäre mir neu, daß jemand das in einem PPGA besser
hinbekomt, als es die Chiphersteller der DACs können.
Michael Wessel (michael_w738)
>Ich denke, hier wird das Wort Wavetable-Synthese falsch verwendet. Du>meinst sicherlich Sample-Playing? Nun, Wavetable-Synthese ist etwas>komplett anderes:>https://en.wikipedia.org/wiki/Wavetable_synthesis
Meiner Meinung nach verwenden viele Leute den Begriff genau so wie ich,
auch wenn es nach der Wikipedia-Definition einen kleinen Unterschied zum
korrekten Begriff der "sample-based_synthesis" gibt:
https://en.wikipedia.org/wiki/Sample-based_synthesis
Aber über die Ähnlichkeit beider Begriffe wird im Wikipedia-Artikel ja
diskutiert.
>PS Das oben zitierte Projekt macht auch keine Wavetable-Synthesis wenn>ich das richtig sehe, und der Amiga auch nicht.
Mit dem Amiga wurde sehr wohl die "sample based synthesis" gemacht:
"Der Ultimate Soundtracker war der erste Tracker für den Amiga und wurde
1987 von Karsten Obarski programmiert.[9][10][11][12] Das Gesamtkonzept,
Samples mit einem zeitlich gerasterten und numerisch gesteuerten
Sequenzer auszugeben"
https://de.wikipedia.org/wiki/Tracker_(Musik)
( siehe: Geschichte )
>Each of Peak’s eight voices has an independent oversampling>digital-to-analogue converter (DAC). These DAC’s are oversampling at>over 24MHz (24 million times per second), using a simple RC>(resistor-capacitor) filter on their output in the analogue domain.
Vielleicht liegt es auch daran, dass sich ein RC-Tiefpass so einfach und
ohne Aufwand an ein FPGA anschließen lässt und man es unter
Werbeaspekten gut verkaufen kann.
Auf manchen der chinesischen Spartan-6 Boards befindet sich eine
Audiobuchse. Die Hardware dahinter: sie haben einfach zwei FPGA
Anschlüsse über zwei Widerstände an die Buchse angeschlossen. Das nenne
ich mal "ungefiltert".
Mein Bastelaufbau-DAC läuft übrigens mit 50MHz :-P
Wobei meine Intention im Moment nicht die ist, mit echten AudioDacs
mithalten zu wollen.
chris schrieb:> Mit dem Amiga wurde sehr wohl die "sample based synthesis" gemacht:> Das Gesamtkonzept,> Samples mit einem zeitlich gerasterten und numerisch gesteuerten> Sequenzer auszugeben"
Dann war das vielleicht der erste Computer, der das konnte, aber als
Musikinstrument gab es das schon vorher. Z.B. konnte mein
Casio-Synthesizer Samples abspielen. Man konnte sie nur nicht selber
sampeln, jedenfalls nicht "online". Man konnte aber die ROMs austauschen
und vorher extern programmieren. Das konnten einige Geräte damals.
Klassische Sampler mit RAM gab es auch schon vorher.
> Vielleicht liegt es auch daran, dass sich ein RC-Tiefpass so einfach und> ohne Aufwand an ein FPGA anschließen lässt und man es unter> Werbeaspekten gut verkaufen kann.
Das scheint mir auch so. Einfache RC-Tiefpass-DACs werden normalerweise
nur dort angewendet, wo es gilt, PINs zu sparen und ein paar analoge
Zeigerinstrumente zu treiben.
Michael W. schrieb:> einige Tester haben sich das mit dem Oskar angesehen,> und die Wellenformen sind natuerlich super hochaufloesend:
Das möchte Ich mal sehen, wie es gelingt, mit einem 10-Bit-Oszilloskop
die Qualität von Audio nachzumessen. Das benötigt nämlich mindestens 16
Bit und auch da befinden sich hinter den digitalen Ausgängen immer noch
Tiefpassfilter höherer Ordnung, welche das Signal stark glätten.
Ich kann mir weder vorstellen, wie es möglich sein soll, mit einem
simplen RC-Filter einen wirklich glatten Sinus zu erzeugen, noch - wie
man das so einfach nachmessen könnte.
Als kleine Gedankenstütze könnte dieser Gesprächsverlauf dienen:
Beitrag "Funktionsweise PWM"
Wenn die höchste zu übertragene Frequenz im FPGA-Synthesizer bei 20kHz
liegt, dann stünden tasächlich nur 3 Dekaden zur Verfügung für den
Filter. Mit einem einfachen Filter sind maximal 60dB machbar. Unter
Berücksichtigung der Abstände in Stopp und Passband zu der Nutz- und der
Taktfrequenz wäre nur eine Dekade wirklich nutzbar. Aus meiner Sicht
müsste es eher so gebaut sein, daß der Filter bei z.B. 30kHz liegt und
deutlich höherer Ordnung ist, z.B. 5.Ordnung. Dann wären es 100dB bei
300kHz. Bei einem Ultraschallsystem benutzen wir 384kHz Abtastrate. Die
Anforderung liegt bei 95dB (16Bit) und wird so leicht übertroffen.
Bei einem 1-Bit-Wandler müsste dann noch berücksichtigt werden, daß der
mehr Rauschen hat, als ein 16 Bit-Wandler.
chris schrieb:>>PS Das oben zitierte Projekt macht auch keine Wavetable-Synthesis wenn>>ich das richtig sehe, und der Amiga auch nicht.>> Mit dem Amiga wurde sehr wohl die "sample based synthesis" gemacht:> "Der Ultimate Soundtracker war der erste Tracker für den Amiga und wurde> 1987 von Karsten Obarski programmiert.[9][10][11][12] Das Gesamtkonzept,> Samples mit einem zeitlich gerasterten und numerisch gesteuerten> Sequenzer auszugeben"> https://de.wikipedia.org/wiki/Tracker_(Musik)> ( siehe: Geschichte )
Du hast nicht verstanden, was Wave Table Synthese ist... Du sprichst vom
Sample-Playing. Ich habe den SoundTracker selbst jahrelang auf dem Amiga
verwendet, das ist ein Sample-Player. Keine Wavetable Synthese. Einfach
mal nachlesen was das ist.
Carlo schrieb:> Michael W. schrieb:>> einige Tester haben sich das mit dem Oskar angesehen,>> und die Wellenformen sind natuerlich super hochaufloesend:> Das möchte Ich mal sehen, wie es gelingt, mit einem 10-Bit-Oszilloskop> die Qualität von Audio nachzumessen. Das benötigt nämlich mindestens 16> Bit und auch da befinden sich hinter den digitalen Ausgängen immer noch> Tiefpassfilter höherer Ordnung, welche das Signal stark glätten.
Ja, kannst DU Dir ja mal bei YouTube ansehen. Die haben glaube ich ein
analoges Oszi verwendet. Ich habe bei meinem BIllig-Synthesizer
(DAC-basiert) allerdings auch nie irgendwelche Artefakte o.ae. mit
meinem Equipment ausmachen koennen. Aber ich habe ja auch keine
vergoldeten und freon-gekuehlten AUdiokabel :-)
Carlo schrieb:> chris schrieb:>> Mit dem Amiga wurde sehr wohl die "sample based synthesis" gemacht:>> Das Gesamtkonzept,>> Samples mit einem zeitlich gerasterten und numerisch gesteuerten>> Sequenzer auszugeben">> Dann war das vielleicht der erste Computer, der das konnte, aber als
Eher nicht - hier fruehe sample-basierte Spraechsynthese auf der IBM 704
https://www.youtube.com/watch?v=ebK4wX76RZ4
Wir nähern uns immer mehr dem Thema "Tonerzeugung" und entfernen uns vom
FPGA, wie Ich sehe :-)
Um den Expertenstreit zur "wave table" - "synthesis" oder vielleicht
besser "wave" - "table synthesis" abzukürzen:
In der Tat ist der Mechanismus, wie ihn Wolfgang Palm einsetzt,
wesentlich mehr, als das, was die meisten darunter verstehen. Vor allem
der Denkansatz ist ja schon ein anderer. Dass am Ende im einfachsten
Fall "nur" Samples (oder generische) Wellenformen abgespielt werden,
bleibt davon unberührt.
Das Prinzip unterscheidet sich vom reinen Abspielen der Wellen z.B.
dadurch, dass die Wellenformen kontinuierlich ausgetauscht werden und
das auch dynamisch. Ich weiß nicht 100% wie weit der PPG da ging, aber
wenn man z.B. die Einsprungpositionen ändert (was bei generischen Wellen
beliebig gut geht) erhält man eine Mischung aus Phasenmodulation und
Frequenzmodulation, die sich den Wellenspektren auffalten. D.h. es
entstehen Mischprodukte. Das ist z.B. ein Punkt, wo ein FPGA ganz andere
Möglichkeiten hat, als eine Software, weil besonders bei längeren
Samples die Abtastfrequenz real geändert werden kann um die
Tabellenpositionen anzuspringen. Sowas mache Ich z.B. in meinem Morpher.
Ich bin gerade dabei das genauer zu recherchieren, weil Ich in einer
Musikgruppe auf einen Hinweis auf ein angeblich inzwischen bestehendes
Patent diesbezüglich gestoßen bin.
Ohne da jetzt in die Details zu gehen, nur soviel: Da geht noch mehr!
Zu dem Hinweis in der Wikipedia: Die Soundblasterkarten und andere
Begleiter betreiben zwar auch ein Morphing, allerdings rein auf der
Amplitudenebene, d.h. die Wellenformen werden parallel abgespielt und
gemischt, wörtlich "gelayert". Dies Art der Klangänderung ist viel
stärker limitiert.
Mit einer WTS, bei der Ich die Nulldurchgänge berücksichtige, kann Ich
dynamische Sweeps erzeugen, die wirklich (im Rahmen der Granularität der
Welle) kontinuierlich und rein sind. Und da scheiden sich die Geister:
Die PPG hatte eine sehr stark limitierte Auflösung und produziert beim
Durchgang immer Faltungsspektren. Diese sind letztlich auch für den
Klang verantwortlich.
Michael W. schrieb:> Ich habe bei meinem BIllig-Synthesizer> (DAC-basiert) allerdings auch nie irgendwelche Artefakte o.ae. mit> meinem Equipment ausmachen koennen.
Das ist auch nicht so einfach. Man muss zunächst mal definieren, was
denn das Ziel ist und wie gut es durch eine Synthese erreicht wird. Bei
einem starren Dauersinus ist das mit einer selektiven und feinen FFT gut
zu messen, was an Oberwellen enthalten ist. Auch mit analogen Filtern
kann man das.
Richtig deutlich wird der Vergleich mit einem mathematischen Sinus, den
man vom Original abzieht, wobei dort schnell massive Amplituden- und
Phasenfehler auftreten, die in der Praxis unbedeutend sind, weil man es
dem Sinus selber nicht ansehen (und nicht anhören!) kann.
Die subjektive Qualität der einfachen, hergebrachten Tonerzeugung ist
damit der objektiven oft weit voraus, was bedeutet, dass man durch
technisch qualitativ bessere Wellensynthese noch lange keine bessere
Klangsynthese hat. Man hat allerdings eine bessere Kontrolle über das,
was in Filtern passiert und wie es im Zusammenspiel mit anderen Tönen
und deren Oberwellen wirkt.
Wie gut die Wellensynthese des genannten Novation Synthies jetzt ist,
kann Ich von hieraus nicht beurteilen, erlaube mir aber einige
Anmerkungen zu den Aussagen auf deren Webseite:
Wie wir in diesem Thema schon erörtert haben, ist der Vorteil der
DSD-Daten gegenüber der heute üblichen 192kHz-Technik marginal:
Beitrag "Wie DSD512 erzeugen?"
Von daher ist die Aussage, dass der permanente "oversampled audio
stream" weniger Artefakte mache, der Form nach stimmig, hat aber IMO
kein Gewicht. Spätestens bei 192kHz braucht man Spezialausstattung, um
Unterschiede zu messen. Das heißt auf Deutsch: Man kann ein analoges
Signal in der realen Welt mit Delta-Sigma (und nichts anderes macht
deren DAC) erfassen und sie getrost in 192kHz24Bit speichern (und nichts
anderes machen die Studio-DACs),
Folglich ist es um so leichter möglich, auf 192kHz zu generieren und es
damit auszugeben.
Jürgen S. schrieb:> Die PPG hatte eine sehr stark limitierte Auflösung und produziert beim> Durchgang immer Faltungsspektren. Diese sind letztlich auch für den> Klang verantwortlich.
Und der metallische Sound und die Wavetable Artefakte, Aliasing etc.
sind genau das, wofuer einige Leute heute noch > 1000 EUR fuer eine
gebrauchte Waldorf Microwave 1 (natuerlich mit analogen Curtis Filtern
;-) ) ausgeben... ist halt ein legendaeres Sammlerstueck.
I wuenschte, Waldorf wuerde die Microwave 1 im Original-Design (bitte
keine Verbesserungen an Sample Rate o.ae.!) neu auflegen. Das waere so
ein Verkaufsschlager.
Und weiter gehts:
Nichtsdestotrotz macht es Sinn, digitale Nachbildungen von Elektronik
(und das dürften die genannten Oszillatoren in dem Novation-Synthesizer
ja sein) mit deutlich höherer Raten laufen zu lassen, weil diese selbst
Fehler und Artefakte produzieren, wenn sie nicht analytisch sondern
numerisch arbeiten. Dort muss auch Rauschen und Filterung rein, um das
Weglaufen von Integralen etc klein zu halten. Weg bekommt man die nicht,
weil die Schaltung am Ende immer diskret rechnet und der Realität
wegläuft, aber es reicht, wenn ein genügend gutes Ergebnis erzielt wird.
Richtig ist deren Aussage, dass man solche hoch aufgelösten Rechnungen
detaillierter beeinflussen kann sie sie sich damit "analoger" dem
Modulator verhalten, der auf sie wirkt, sei es eine Spannung oder eine
Knopfbewegung. (Nett, dass Ich heute, 15 Jahre nachdem Ich meinen ersten
FPGA-Oszillator mit genau solchen Begründungen gebaut habe, nunmehr von
offizieller Seite davon Bestätigung bekomme :-)
Weniger folgen kann Ich jedoch der Darstellung und Überlegung, dass man
diese superfein gerechneten Schwingungen auch mit einem DSD-ähnlichen
DAC ausgeben muss, noch dazu mit einem händisch im FPGA realisierten.
Ich tue dies in meinem aktuellen board nur für Bassfrequenzen, sowie
intern zur Weiterverarbeitung und gehe für die Ausgabe ins Analoge den
Weg, dass Ich filtere und auf z.B. 96kHz sample. Bei der Synthese der
Klänge habe Ich nämlich anders als bei der Tonaufnahme, kein AA-Filter
am Eingang sondern bin ideal. Dasselbe sehe Ich beim idealen Samplen von
generischen Töne, die keine unerwünschten Oberwellen (alias) haben -
eben wegen des Filters. Dieser wiederum läuft allerdings auf 768kHz und
auch die kann Ich jedem SV-Experten begründen.
Edi M. schrieb:> Dass die Entwickler FPGAs nicht kennen, ist eher nicht anzunehmen. Eher> schon scheint mir da die Flucht nach vorne angetreten worden zu sein um> etwas zu bringen, was es noch nicht gab.
Man darf nicht vergessen, dass es sich hierbei um Consumer-Technik
handelt und der Markt für elektronische Instrumente nicht mehr der ist,
der es einmal war. Die Produzenten haben die Studios und Racks mit
Synthies, Romplern und Samplern vollgestopft und nur der, mit einem
neuen modernen Sound, den andere nicht haben, hat da Chancen. Das gilt
auch für Musiker.
> Das heisst sie bauen im FPGA einen DA-Wandler nach und nutzen jeweils> 24MHz 1-Bit Audio Daten. Wirklich sehr innovativ. Dieses Konzept ist> bereits an anderen Geräten der HIFI-Szene ausprobiert worden und> gescheitert.
Man muss jetzt unterscheiden, ob man von Kleinsignal- oder
Großsignaltechnik spricht. Bei der 1-Bit-Audio-Thematik war ja das
Problem, dass man angefangen hat, Leistung über die Kabel zu schicken
(Auto) oder einen digitalen Datenstrom zu Aktivlautsprechern zu
transportieren (Digitalmonitore). In der Anfangszeit waren das DSD64 als
64x44,1kHz und das entsprach in der Tat nur einem 16-Bit Audio. Oft war
es schlechter, weil es Jitter unterworfen war und nicht gut verarbeitet
wurde. Das ist heute anders. Die Datenströme werden gepuffert, digital
rekonstruiert und in SW gewandelt, um sie auszugeben. Auch
leistungstechnisch wird das inzwischen gemacht: Siehe digitale
Endstufen.
> Ich glaube eher, dass die Nutzer von FPGAs die Signalverarbeitung nicht> verstanden haben. Diese Erzeugung von Audiodaten ist ja kein Hexenwerk> sondern reiht sich nahtlos in die Landschaft ein. Wenn einfache> Signalgeneratoren bis 500kHz super genau mit DSPs und DACs arbeiten,> kann das mit FPGAs nicht angehen. Jedenfalls nicht so!
Für das Abspielen ja, aber wie oben beschrieben, sind Samples einfacher
zu modulieren, wenn man auf höheren Auflösungen arbeitet. Besonders bei
der Echtzeitsynthese im Zeitbereich.
Ob es sich lohnt und ob es wirtschaftlich ist, ist eine andere Frage.
Michael W. schrieb:> Und der metallische Sound und die Wavetable Artefakte, Aliasing etc.> sind genau das, wofuer einige Leute heute noch > 1000 EUR fuer eine> gebrauchte Waldorf Microwave 1 (natuerlich mit analogen Curtis Filtern> ;-) ) ausgeben... ist halt ein legendaeres Sammlerstueck.
Das ist wahr. Auch die Waldorf-Synthies erzielen hohe Preise. Das ist
aber auf den Kultstatus zurückzuführen und was den Klang angeht, auf
Prägung. Viele Menschen sind mit diesen Plastikklängen aufgewachsen und
finden sie schön. Wenn man umgekehrt heute die Klangqualität anlernen
und ihnen dann eine alte Microwave hinlegen würde, täten sie keinen
Fuffi dafür hinlegen.
Und es gibt noch einen Punkt: Die Geräte haben einfach ein flair! Wenn
man daran herumschraubt, hat man Musikgeschichte in der Hand und diese
Stimmung überträgt sich auf den Musiker! Elektroproduzenten der alten
Schule sind daher auch dann kreativ, wenn sie an ihrem Synthie
herumschrauben. Daher hängen Viele ja auch noch an ihren analogen
Synthies.
Auch manche Rolandgeräte passen in diese Schiene: Klang mies und
verpatzt aber optisch einfach eine Wucht. Die TB 303 und der JX 305 sind
solche Teile.
Jürgen S. schrieb:> Edi M. schrieb:>> Dass die Entwickler FPGAs nicht kennen, ist eher nicht anzunehmen. Eher>> schon scheint mir da die Flucht nach vorne angetreten worden zu sein um>> etwas zu bringen, was es noch nicht gab.> Man darf nicht vergessen, dass es sich hierbei um Consumer-Technik> handelt und der Markt für elektronische Instrumente nicht mehr der ist,> der es einmal war.
Ob es sich um Consumer- oder andere Technikbereiche handelt, kann
eigentlich kaum reelvant sein. Es ist einzig wichtig, ob für eine
Anwendung ein FPGA benötigt wird oder nicht. Und bisher habe Ich
niemanden gefunden, der mir gezeigt hat, dass man für etwas einen FPGA
nehmen muss, und das mit DSPs nicht ganz genau so machbar wäre und das
günstiger.
Edi M. schrieb:> Und bisher habe Ich> niemanden gefunden, der mir gezeigt hat, dass man für etwas einen FPGA> nehmen muss, und das mit DSPs nicht ganz genau so machbar wäre und das> günstiger.
DSP ist tot. Bzw. DSP lebt als Multiplizierer im FPGA weiter. Oder als
FPU im Cortex-M4. Die Lücke zwischen FPGA und Mikrocontroller ist
inzwischen ziemlich klein geworden. Desweiteren werden die µController
immer leistungsfähiger und greifen die FPGAs von unten an.
Es wäre schön, wenn Du mir ein paar aktuelle DSP-Evaluationboards
verlinkst, damit ich deren Leistungsfähigkeit einschätzen kann.
Dann kann ich Dir -- bei Bedarf -- auch ein paar FPGA-Boards verlinken.
Duke
Andi schrieb:> Eine in Echtzeit berechnete Synthese klingt einfach> viel lebendiger.
Was ist denn bei Dir "Echtzeit"? Audiosamples arbeiten im Bereich von
200...300kHz, wenn es um industrielle Anwendungen wie Ultraschall geht,
ansonsten darunter. Wie langsam sollte ein Prozessor sein, nicht alle
paar us ein Sample zu berechnen? Es ist lediglich erforderlich, die
Zeit, um ein Sample = x us vorzuschieben und dann die Gleichungen für
diese Zeit zu rechnen. Am Ende geht es nur um die Rechenleistung und die
ist bei Signalprozessoren immer günstiger einzukaufen.
Duke Scarring schrieb:> DSP ist tot.
Und warum arbeiten dann nahezu alle elektronischen Musikinstrumente mit
solchen Signalprozessoren? Selbst für Videoverarbeitung sind die schnell
und leistungsfähig genug.
Carlo schrieb:> Wie langsam sollte ein Prozessor sein, nicht alle> paar us ein Sample zu berechnen? Es ist lediglich erforderlich, die> Zeit, um ein Sample = x us vorzuschieben und dann die Gleichungen für> diese Zeit zu rechnen. Am Ende geht es nur um die Rechenleistung und die> ist bei Signalprozessoren immer günstiger einzukaufen.
Bei einem polyphonen Synthesizer willst du eben diese Gleichnungen nicht
nur einmal in der Abtastzeit berechnen, sondern vielleicht 100 mal um
100 Stimmen zu erhalten. FPGAs können da vieles parallel machen, was
DSPs Befehl für Befehl berechnen müssen.
Ich bezweifle, dass ein Synthesizer mit Signalprozessoren immer
günstiger ist als einer mit FPGAs. Erstens gibt es heute sehr günstige
FPGAs die leistungsfähig genug sind (ECP5-12 mit 28 DSP Blocks für 5€).
Zweitens kannst im FPGA vieles integrieren, was beim DSP zusätzliche ICs
erfordert (Steuerprozessor, Memory Kontroller, DACs).
Aber für tot halte ich DSPs auch nicht, die Hersteller machen heute
DSPs, die für eine spezifische Anwendung optimiert sind, und da sind sie
dann natürlich schon die effektivste Lösung.
Andi
Duke Scarring schrieb:> DSP ist tot. Bzw. DSP lebt als Multiplizierer im FPGA weiter.
Dir ist schon bewusst, dass Ich mit "DSP" einen ausgewachsenen Prozessor
mit FPU-Unterstützung etc meine und nicht nur einen Multiplizierer?
Nö, war mir nicht bewusst. Ich stelle mir unter DSP einen dedizierten
Chip vor, sowas wie die TMS320-Serie. Diesbezüglich sind mir keine
Neuentwicklungen bekannt.
Die "signal processing"-Funktionen wandern als FPUs in die Prozessoren
und Controller und sind seit Jahren als "multipy & add" im FPGA als
Hardmacro verfügbar.
Ergo: Als Chip ist DSP tot, aber die Funktionalität ist allgegenwärtig
und wird auch zunehmend eingesetzt.
Duke
Andi schrieb:> Bei einem polyphonen Synthesizer willst du eben diese Gleichnungen nicht> nur einmal in der Abtastzeit berechnen, sondern vielleicht 100 mal um> 100 Stimmen zu erhalten.
Übliche Synthesizer sind 128-stimmig polyphon. Wie machen die das?
Vielleicht, weil sie mit 300MHz arbeiten und 50 Schritte je Sample und
Kanal dafür Zeit haben?
Duke Scarring schrieb:> Nö, war mir nicht bewusst. Ich stelle mir unter DSP einen dedizierten> Chip vor, sowas wie die TMS320-Serie. Diesbezüglich sind mir keine> Neuentwicklungen bekannt.
Was ist denn mit XMOS? Haben die nicht sowas im Programm? Oder liefern
die nur Cores die wiederum woanders eingebaut werden?
Carlo schrieb:> Es ist lediglich erforderlich, die> Zeit, um ein Sample = x us vorzuschieben und dann die Gleichungen für> diese Zeit zu rechnen.
Das ist der Knackpunkt! Sobald die Gleichungen komplizierter werden (und
bei physikalischer Modellierung von Musikinstrumenten, Nichtlinearitäten
und der Verwendung von Energiespeichern mit Verlusten, ist das sehr
schnell der Fall) gibt es keine analytische Lösung mehr!
Das geht dann nur noch über numerische Simulation und Integration und
dabei wirken die kumulierenden Fehler, die durch die partiellen
Annäherungen entstehen, weil mit dem Differenzenquotient gearbeitet
wird, wo der Differenzialquotient nötig gewesen wäre. Damit sind sowohl
equidistante, wie auch nicht-equidistante Berechnungen, die man
ansonsten einfach und sehr präzise durch Iteration (wie bei MATLAB,
Simulink oder pSPICE) durchführen kann, stark von der Auflösung der
Vektoren und der Zeit abhängig.
Von der Rechengenauigkeit ist man bei den 64-Bit-Systemen inzwischen
ausreichend genau, um effektiv zu sein, damit geht es einzig um die
zeitliche Auflösung.
Um einen einfachen Oszillator mit genügend guter Annäherung an die
Realität, also einer Abweichung von vielleicht 1 Promille in Frequenz
und Amplitude gegenüber der Realität nachbilden zu können, braucht man
schon eine Überabtastung von wenigstens einem Faktor 10.000, wenn man
ohne große Korrekturen oder Tricks einfach vorwärts rechnen will.
Mit einem 200MHz FPGA komme Ich da auf eine Frequenz von 20kHz und komme
damit gerade so audiomäßig hin.
Rechnungen, die die Realität nachbilden möchten, um z.B. etwas zu
überwachen und auf der Basis von Messwerten das Verhalten einer
Elektronik oder einer Physik abschätzen möchten, müssen auch in der Tat
so genau formuliert werden.
Bei der Audio-Synthese kann man es sich natürlich erlauben, etwas
ungenauer zu sein, weil die Parameter, mit denen ein Klang eingestellt
wird, erstens willkürlich sind und zweitens auch nur auf 10/12 Bit genau
vorliegen. Damit reicht eine geringere Überabtastung. Die Frequenz ist
dann zwar nicht exakt dem, was es streng mathematisch wäre, ist aber in
sich deterministisch, d.h. ein aperiodisch auslaufender Oszillator
produziert einen guten Sinus und läuft ungefähr mit der eingestellten
Dämpfung aus.
Erfahrungsgemäß braucht man aber wenigstens eine 10-fache Abtastung,
damit noch ein artefaktarmer Sinus rauskommt und nicht durch
Rechenfehler nennenswertes digitales Rauschen herauskommt. Bei sonst
gleicher Rechentiefe und -aufwand verliert man bei der numerischen
Methode so durchschnittlich einen Faktor 20 gegenüber einer analytischen
Synthese.
Michael W. schrieb:> Und der metallische Sound und die Wavetable Artefakte, Aliasing etc.> sind genau das, wofuer einige Leute heute noch > 1000 EUR fuer eine> gebrauchte Waldorf Microwave 1 (natuerlich mit analogen Curtis Filtern> ;-) ) ausgeben... ist halt ein legendaeres Sammlerstueck.
Hallo Michael, da stimme Ich voll zu. Ich probiere auch gerade wieder
eine Microwave abzubekommen, aber die Preise sind astronomisch! Steht in
keinem Verhältnis zur Leistung. Die werden gesammelt und gehortet, weil
sie cool aussehen. Das ist ärgerlich für mich, weil Ich noch unzählige
Setups dafür habe, aber kein Gerät mehr. Das alles nachzustricken, ist
mühsam. Allerdings bin Ich nicht bereit, 1200,- hinzulegen (dafür ging
heute einer in der Bucht weg) wenn ein aktueller Blofeld ein Drittel
kostet und das Dreifache tut.
> I wuenschte, Waldorf wuerde die Microwave 1 im Original-Design (bitte> keine Verbesserungen an Sample Rate o.ae.!) neu auflegen. Das waere so> ein Verkaufsschlager.
Das glaube Ich auch! Ich hatte auch mal an Waldorf geschrieben und das
angeregt, aber dort sieht man die Zukunft eher in der Software und der
Modularebene. Mir scheint auch, dass die heutige Entwicklung in eine
andere Richtung geht. Ansonsten gilt das hier gesagte:
Beitrag "Re: "Schrecklicher" Synthi - wie funktioniert das?"
>Carlo schrieb:>> Es ist lediglich erforderlich, die>> Zeit, um ein Sample = x us vorzuschieben und dann die Gleichungen für>> diese Zeit zu rechnen.>Das ist der Knackpunkt! Sobald die Gleichungen komplizierter werden (und>bei physikalischer Modellierung von Musikinstrumenten, Nichtlinearitäten>und der Verwendung von Energiespeichern mit Verlusten, ist das sehr>schnell der Fall) gibt es keine analytische Lösung mehr!
Schon bei gemischt analog/digitalen Schaltungen dürfte es schwierig
werden, diese in Software nachzubilden.
Man versuche nur, die Klarheit, Direktheit und Unmittelbarkeit des
folgenden Stücks digital zu simulieren ;-) :
Beitrag "Re: Tonleiter mit acht Tönen herstellen"
Mein Verdacht: Überlicherweise versucht man die eintönige
Unzulänglichkeit der digitalen Klangerzeugung durch Hall zu überpinseln:
https://www.youtube.com/watch?v=DoUH5gkX8uY
:-)
Markus privat schrieb:> wenn ein aktueller Blofeld ein Drittel> kostet und das Dreifache tut.
Kann man mit dem nicht die Klänge der Microwave nachstellen?
Andi schrieb:> Ich bezweifle, dass ein Synthesizer mit Signalprozessoren immer> günstiger ist als einer mit FPGAs. Erstens gibt es heute sehr günstige> FPGAs die leistungsfähig genug sind (ECP5-12 mit 28 DSP Blocks für 5€).> Zweitens kannst im FPGA vieles integrieren, was beim DSP zusätzliche ICs> erfordert (Steuerprozessor, Memory Kontroller, DACs).
Diese zusätlzichen Sachen bekommst Du aber in einen kleinen FPGA nicht
hinein. Wegen Tempo und wegen Fläche nicht. Ein FPGA, der groß genug
ist, das zu beherrbergen kostet ungleich mehr. Trotzdem hat er noch
nicht mehr Fläche für Musikfunktion.
Rechnest Du aber nur die Musikerzeugungsfunktion in Fläche um bist Du
beim DSP immer billiger. Schau Dir mal die ADSPs und die AudioLibs drum
herum an. Kann auch über PureData angesteuert werden.
Das machst du im FPGA erst einmal nicht so einfach nach.
Rolf S. schrieb:> Rechnest Du aber nur die Musikerzeugungsfunktion in Fläche um bist Du> beim DSP immer billiger.
Eigentlich müsste man sich nur die Gitarreneffektgeräte und Prozessoren
genauer anschauen, um zu wissen, was günstiger ist. Die Hersteller
solcher Geräte arbeiten mit Signalprozessoren und kleinen
Microcontrollern. Ich kenne keinen einzigen Bodentreter, der einen FPGA
benutzt. Die fressen viel zu viel Strom, manchen EMI und sind zu warm.
Für eine Tonerzeugung braucht es auch keinen FPGA. Die einfachsen
AVR-Controller sind heute schnell genug, um mehrere Tonfolgen und Klänge
zu berechnen.
Beitrag "17 Kanal Avr Synthesizer in Asm"Beitrag "AVR Synthesizer Konzept"
Andi F. schrieb:> Eigentlich müsste man sich nur die Gitarreneffektgeräte und Prozessoren> genauer anschauen, um zu wissen, was günstiger ist. Die Hersteller> solcher Geräte arbeiten mit Signalprozessoren und kleinen> Microcontrollern.
Das meinte ich. Solche Gerätchen liegen bei Endvebraucherpreisen von
50,- bis 150,-. Mehr ist da kaum drin. Zu den Preisen muss die
Elektronik 10,- bis 50,- kostet und da ist nicht viel Platz für mehr,
als einen 3,- euro Controller.
chris schrieb:> Schon bei gemischt analog/digitalen Schaltungen dürfte es schwierig> werden, diese in Software nachzubilden.
Nachbilden kann man alles. Aber berechnen?
Meine Uni hat solche Analysen schon. Ist heute Ausbildungsstandard.
http://www.vvz.ethz.ch/lerneinheitPre.do?semkez=2017W&lerneinheitId=116630&lang=en
Rolf S. schrieb:> Das meinte ich. Solche Gerätchen liegen bei Endverbraucherpreisen von> 50,- bis 150,-. Mehr ist da kaum drin. Zu den Preisen muss die> Elektronik 10,- bis 50,- kostet und da ist nicht viel Platz für mehr,> als einen 3,- euro Controller.
Man kriegt auch einen 6,- Euro-Controller rein :-)
Meine Guit-Box kostete nebenbei 899,-. Da ist ein richtig dicker DSP
drin. Die Elektronik schätze ich auf deutlich über 100,- HSK.
FPGAs scheinen aktuell sehr in Mode, um Töne zu erzeugen. In Zeiten, in
denen kleine Controllerchen nur noch ein paar Euro kosten, echt
interessant.
Kleine Anmerkung hierzu:
Rolf S. schrieb:> Rechnest Du aber nur die Musikerzeugungsfunktion in Fläche um bist Du> beim DSP immer billiger. Schau Dir mal die ADSPs und die AudioLibs drum> herum an. Kann auch über PureData angesteuert werden.
Mit PureData bekommt man nicht nur den Code sondern auch das framework
um Audio zu prozessieren. Das suche ich bei VHDL vergeblich. Beim Thema
Video gibt es einiges. Aber Audio?
Elbi schrieb:> In Zeiten, in> denen kleine Controllerchen nur noch ein paar Euro kosten, echt> interessant.
Sind eventuell ähnliche vintage und purelogic Ideen wie beim Thema
Cassette und Schallplatte. Alt = Gut, Hardware besser, als Software.
Momentan baut Behringer alte Moogs in Analog nach.
Markus privat schrieb:> an Waldorf geschrieben und das> angeregt, aber dort sieht man die Zukunft eher in der Software und der> Modularebene.
Die werden wissen, was sie tun, weil sie den Markt täglich vor Augen
haben.
Zynq-Entwickler schrieb:> Momentan baut Behringer alte Moogs in Analog nach.
Aber mit mäßigem Erfolg. Wie man liest, haben sie aus insolventen
Firmen, welche Rechte an Smith'schem und andere Leuz Denken hatten, die
Rechte aufgekauft. Ferner haben sie angeblich Chips aus Restbeständen
aufgekauft und freie nachproduziert.
Herausgekommen sind aber bisher nur sehr billige Kopien der Originale.
Im Fall des Model "D" (man beachte den Namen) wird ihnen von den Nutzern
zwar eine hohe Stimmstabilität bescheinigt, diese ist aber eben nicht
was, was richtige Musiker mit ihrem echten Model von D- Smith hatten.
J. S. schrieb:> Auch manche Rolandgeräte passen in diese Schiene:
Die modernen Roland-Synthies sind auch nicht mehr das, was sie mal
waren.
Mit der Maid-of-Orleneans-Version auf einer Fantom wären OMD kaum
berühmt geworden.
https://www.youtube.com/watch?v=UtOXmAGzCiw
Im Orginal sind die Synth-Strings und v.a. der Choralklang nur gewaltig.
Einfach unübertrefflich. Ich kann das schon nachvollziehen, dass nicht
wenige Musiker aus Prinzips keine modernen Synthesizer und vor allem
keine Digital-Synthesizer spielen mögen.
Rolf S. schrieb:> wird ihnen von den Nutzern> zwar eine hohe Stimmstabilität bescheinigt
Nicht einmal das:
https://www.keyboards.de/equipment/behringer-model-d-minimoog-clone-im-test/
Das ist ein grundsätzlicher Nachteil der analogen Technik. Was benötigt
würde, wäre eine Symbiose der Qualität der analogen Technik und der
Genauigkeit der digitalen Technologie.
> was, was richtige Musiker mit ihrem echten Model von D- Smith hatten.
war auch die Haptik. Da kann der Model D nicht mithalten. Der ist eine
verkleinerte optische Kopie. Eine Tröte für 299,-. Made in China.
Edi M. schrieb:> Und bisher habe Ich> niemanden gefunden, der mir gezeigt hat, dass man für etwas einen FPGA> nehmen muss, und das mit DSPs nicht ganz genau so machbar wäre und das> günstiger.
DSP-Power in UCs oder Intel-Kernen ist definitiv günstiger, das stimmt.
Aber es gibt eben neben der Problematik der Rechenleistung auch das
Thema IO-Bandbreite, Speicherbandbreite und Signalgeneration. Mit einem
FPGA hast Du die Möglichkeit ....
Aber schon das Thema Rechenleistung hat einige Limits:
https://www.xilinx.com/support/answers/59893.html
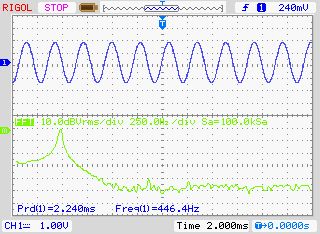


{kind=link}