Bei Thalia gibt es jetzt einen "Hörstift" TING, einen etwas dickeren elektronischen Stift mit Akku und USB-Anschluß. Durch Antippen einer Stelle auf einer Buchseite wird ein passendes Geräusch/ Musik/Sprache abgespielt. Die Bücher müssen natürlich speziell darauf vorbereitet sein, und die zum Buch passenden Daten müssen auf den Stift über das Internet geladen werden. Wie erkennt der Stift was er abspielen soll. Es ist keine sichtbare Markierung auf den Seiten, und die Öffnung des Stifts ist ca. 2mm. Ist da eine Mini-Cam drin oder wie funktioniert das genau?
Hans H. schrieb: > Wie erkennt der Stift was er abspielen soll. Es ist keine sichtbare > Markierung auf den Seiten, und die Öffnung des Stifts ist ca. 2mm. > > Ist da eine Mini-Cam drin oder wie funktioniert das genau? Ich vermute, dass das eine optische Erkennung ist. Bei genauerem Hinsehen, sieht man auf den gedruckten Seiten ein graues Punktraster in dem die Position auf der Seite codiert sein könnte, ähnlich wie bei diesen "smarten" Stiften zum Erfassen von handschriftlichen Sachen via Computer. Viele Grüße, Simon
So funktioniert der TING Hörstift Im Hörstift verbirgt sich eine einmalige Technologie. Mit dem Sensor an der Stiftspitze wird ein Code auf den Buchseiten ausgelesen. Man muss nur den TING Hörstift über “unsichtbare” eingedruckte Markierungen gleiten lassen. Dieser geht in seinen Index, spielt die passende Datei über den integrierten Lautsprecher (oder über den Kopfhörerausgang) ab und Bilder, Wörter, Sätze oder Kapitel werden zum Leben erweckt. Auf diesem Weg werden die Inhalte durch Audioinformationen, wie Hintergrundberichte, Geräusche oder Musik ergänzt. Die Audioinhalte können später kostenlos beliebig aktualisiert werden. Die Audiodateien werden ganz einfach via USB-Kabel aus dem Internet auf den TING Hörstift geladen. Er ist unabhängig von stationären Abspielgeräten und durch seine kleine “Größe” auch unterwegs ein treuer Begleiter. Wer möchte, kann den TING Hörstift sogar für seine eigenen MP3 Musikdateien nutzen. Gute Übersicht verschafft dabei eine auf dem Hörstift installierte Software, welche Infos über geladene Buchtitel, sowie mp3-Dateien gibt.
Danke erstmal für die Hinweise, Niemand, weißt Du mehr über die Art der unsichtbaren Markierungen? Die Erkennung muß ja recht preiswert realisierbar sein, und sicher unter verschiedenen Umgebungslichtbedingungen funktionieren. Wie das mit dem Abspielen funktioniert ist mir schon klar, es geht speziell um die sichere Erkennung der Stelle auf der Buchseite. Denn wenn Kind auf Kuh tippt und das Audio eines Schweins abgespielt würde hätte Kind nicht viel Freude ;-)
Niemand hat einfach nur den Werbetext des Herstellers kopiert :)
Ein Sensor 160x160 Pixel ist derzeit Massenware, da in jeder Maus eingebaut und entsprechend günstig.
Noch günstiger wird es, wenn ein Infrarot Druckfarbe verwendet wird, dann reduziert sich das ganze auf eine ir-diode.
Ich schrieb: > Noch günstiger wird es, wenn ein Infrarot Druckfarbe verwendet wird, > dann reduziert sich das ganze auf eine ir-diode. Toll, mit roter Druckfarbe reicht dann eine rote LED, oder?
Von Ravensburger gibt es TipToi fuer Kinder, das aehnlich aufgebaut ist. In einem anderen Forum hatte ichgelesen, dass das mit "Digitalem Papier" funktioniert. http://de.wikipedia.org/wiki/Digitales_Papier Dann wahrscheinlich mit Kamera im Stift und Druck evt. auch mit IR oder UV Farbe. Ich habe da mal ein Bild 'geklaut'.

Der ideale Stift für Agenten.
Könnte ein Raster aus IR-Druckfarbe o.ä. auf der Seite sein schätze ich. Bei Farblaser-Druckern macht man das ja mit gelben Punkten auf der Seite, so kriegt man die Seriennummer heimlich mit aufs papier gedruckt.
Die gleiche Frage hab ich mir auch gestellt als ich das Ding im Laden meiner Mutter gesehen habe. Die Handykamera zeigt auf jeden Fall wildes IR geblinke von zwei kleinen LEDs links und rechts von etwas was sehr wahrscheinlich eine kleine Kamera ist. Aber ich war auch sehr überrascht, das ding ist sehr tollerant was Entfernung und lage angeht, man kann den Stift sowohl etwa 1cm über das Papier halten, als auch direkt drauf, oder schräg. Auch funktioniert er sobald man das "Symbol" gerade so seitlich abdeckt, man muss den Stift also nicht 100%ig mittig halten. Wenn ich ein (teil-)defektes Exemplar in die Finger bekomme werd ich das ding mal genauer untersuchen!
Ich habe mir so ein Ding mal genauer angesehen. Der Stift enthält eine Infrarotbeleuchtung und eine Kamera. Der "Code" steckt im normalen Druckraster. Wenn man sehr genau hinschaut, z.B. mit einer Lupe, fällt die Regelmäßigkeit auf. Auch "weiße" Flächen sind mit dem feinen Punktmuster überzogen. Sieht aus wie ein DataMatrix Code.
Hat man da nicht eine hohe Ausschussquote beim Druck? Wenn ich mir den normalen Buchdruck ansehe, gibts da ja immer mal winzige Punkte oder im Schfriftbild winzige Lücken. Oder ist das auf Glossy gedruckt?
Ich schrieb: > Ein Sensor 160x160 Pixel ist derzeit Massenware, da in jeder Maus > eingebaut > und entsprechend günstig. Welcher denn? Die ganzen von Avago haben doch nur 30x30.
Dominique Görsch schrieb: > Hat man da nicht eine hohe Ausschussquote beim Druck? Wenn ich mir den > normalen Buchdruck ansehe, gibts da ja immer mal winzige Punkte oder im > Schfriftbild winzige Lücken. Oder ist das auf Glossy gedruckt? Naja, die Markierungen sind sehr klein und auf einer begrenzten Fläche überall gleich. Wenn eine davon mal abweicht, stört das kaum. Außerdem sind die Codes sicherlich mittels Prüfsumme abgesichert.
http://www.himmer.de/en/news/als-die-bücher-sprechen-lernten_g2647ig9.html hier wird ganz gut beschrieben, wie ting funktioniert und wo's her kommt.
ja, die Punkte um die Bilder bzw Begriffe kann man erkennen ich habe mich auch gefragt wie das ding funktioniert. Im Bücherladen war so eins ausgestellt zum testen, bei einem anderen Buch wurden jedoch falsche datein abgespielt... also noch nicht ausgereift die Technik
@ Tim: Auf dem Umschlag des Buches muss man das Buch zuerst aktivieren, damit der Hörstift weiß, welche Dateien er wiedergeben soll. Bei der ersten Aktivierung des Buches auf dem Stift müssen die entsprechenden Dateien aus dem Internet heruntergeladen werden. Die Dateien, die sich auf dem Stift befinden, lassen sich über eine mitgelieferte Software verwalten, funktioniert ähnlich wie beim iPod. Grüße
Anscheinend gibt es bisher keinen besseren Artikel zu diesem Thema. Danke für die obigen weiterführenden Beiträge. Zusätzlich zum oben gesagten möchte ich hier ein Dokument anfügen, aus dem man weitere technische Details zur Frage entnehmen kann: http://www.ting.eu/portals/h1676517/downloads/infos/TING_aus_QuarkXPress.pdf Das Dokument gibt Anleitung zur Herstellung eines Buch mit gängigen DTP-Programmen. Aus diesem Dokument ist m.E. ersichtlich, dass pro Buch etwa 50.000 Codes verfügbar sind. Meine Spekulation ist, dass die Codes 1 bis 15.000 zur Codierung von Buchtiteln reserviert sind. Da die Anzahl den Code 64.999 ist, liegt die Annahme nahe, dass dies der binären Zahl 2 hoch 16 abgeleitet ist. Das entspricht einem logischen Raster von 4x4. Wahrscheinlich ist das physische Raster aus Redundanzgründen höher, und das Abtastraster der Kamera noch höher. Weiter oben wurde bemerkt, dass der Stift falsche Resultate liefert, wenn der Code des Buche vorher nicht korrekt erfasst wurde. Das wird aus dem dadurch erklärt und hat nichts mit "technischer Reife" zu tun, sondern ist einzig eine Systembegrenzung. Um das zu vermeiden, müsste man das Raster um 13 bit erweitern Codierung. Das im Stift verankerte Dateisystem würde dadurch verkompliziert, bei Lesefehlern käme es eventuell zu Dateifragmenten aus anderen Büchern oder Fehlermeldungen ... Mein Vorschlag wäre, dass nach "Untätigkeit" des Stiftes erneut das Einscannen des Buchtitels gefordert wird, oder "Lesen Sie noch das Buch XXX - wenn nicht ..." Ich möchte hiermit die Elektronik-Kollegen ermuntern, das Ding doch mal außeinanderzunehmen, um die wohl eingebaute Kamera zu analysieren.
http://www.srs-management.de/ allerdings sind das selber nur Lizenznehmer die eine Softwarelösung obendrauf setzen. Das Prinzip ist immer das gleiche, eine Matrix aus Pixeln die durch eine Sub-Matrix aus Pixeln die Position innerhalb der Gesamtmatrix eindeutig errechnen kann. Die Kamera muß also aus der großen Matrix nur ein Pixelbereich von zb: 4x4 Pixeln sehen und kann dann die Position innerhalb der großen Matrix bestimmen. Die große Matrix umfasst mehrere m²-Papieroberfläche. Das Entscheidende daran ist diese Positionsbestimmung und darin liegt das Patent. Gruß hagen
Hi, ich habe gerade mal einen TipToi Stift auseinandergenommen. Die verwenden die Technologie und den Imageprozessor von http://www.sonix.com.tw/sonix/home.do Zusätzlich ist ein ASIC von http://www.chomptech.com/ drauf, der USB, Flash-Interface, und MP3-Decoding macht. Chomptech bietet komplette Stifte wie den Tiptoi nur in anderen Gehäusen an, so dass die Vermutun nahe liegt, dass Ravensburger bei denen Fertigen läßt. Gruß Thomas
Hallo zusammen, muss da nochmal 'ne blöde Frage einwerfen: Meint ihr man kann sich den Stift kaufen und die Codes selber generieren? Mache grade 'n Buch über Dialekte, bei dem die Hörproben ganz wichtig wären und da hab ich von dem Stift gehört. Was meint ihr?
Würde mich auch interessieren, ob man sowas selbst erstellen kann. Leider kommt man nur als Verlagspartner in den Download-Bereich, wo man die Codes zum Platzieren runterladen kann. Zusätzlich bräuchte man ja auch noch eine Möglichkeit, die entsprechenden Audiodateien den Codes zuzuordnen und man müsste wissen, wie die Audio-Daten samt Zuordnung auf dem Stift gespeichert werden müssen... alles offenbar nicht fürs selber machen ausgelegt. :) Hat da jemand mehr Infos zu den verwendeten Matritzen? Die müsste man sich ja theoretisch auch selbst erstellen können. Kathrin, es gibt noch den Anybook Reader, der nach dem gleichen Prinzip funktioniert, aber mit codierten Stickern und Aufnahme direkt auf den Stift. Das wäre für den Hausgebrauch vielleicht die einfachste Möglichkeit.
Das beiliegende Dokument des Herstellers (www.himmer.de) bringt evtl etwas Licht ins Dunkel. Insgesamt scheint das System durchaus für Eigenproduktionen geeignet, sofern ein sehr guter Farbdrucker (Laser?) vorhanden ist und der Hersteller seinen Codepool entsprechend öffnen würde. Danach sieht es jedoch bisher nicht aus.
Hallo Bytemixer, vielen Dank für das Dokument. Sehr interessant... momentan versuche ich gerade, die Codes zu entschlüsseln. Weit bin ich aber noch nicht gekommen. Es ist eine 4x4 Matrix (wie jemand oben schonmal vermutet hatte), aber welche Anordnung der Druckpunkte für welche Nummer steht, hab ich noch nicht raus..
Für Selbermacher ist wohl der (teurere) AnyBook Stift die richtige Wahl. http://de.franklineurope.com/news/anybook-der-audiodigitale-vorlesestift-von-franklin/
Es geht ja auch ein bisschen um die Herausforderung.. ;)
Hallo Marc, es ist mir gelungen, eine Hand voll Beispielcodes aufzutreiben. Siehe Anhang. Der Code sollte dem jeweiligen Dateinamen entsprechen. Viel Erfolg.
@M.B.: Der Franklin hat leider erhebliche Nachteile. Unter anderem lassen sich keine Daten von und zum Gerät übertragen. Man muss daher alles mit dem (schlechten) integrierten Mikrofon aufzeichnen und im Falle eines Defekts ist alle Mühe komplett für die Hose und man muss von vorn anfangen. Ein Anschluß für Kopfhörer fehlt außerdem auch.
Bytemixer schrieb: > Hallo Marc, > > es ist mir gelungen, eine Hand voll Beispielcodes aufzutreiben. Siehe > Anhang. Der Code sollte dem jeweiligen Dateinamen entsprechen. > > Viel Erfolg. Hallo Bytemixer, wow, vielen Dank. Bin mal gespannt, ob man daraus was schließen kann. Beim ersten drüberschauen war es jedenfalls noch nicht offensichtlich. ;) Wo nehmt ihr eigentlich diese Sachen immer her? Ohne die zusammengetragenen Infos aus diesem Thread wäre ich wohl noch am Anfang.. :)
Marc F. schrieb: > Wo nehmt ihr eigentlich diese Sachen immer her? Ohne die > zusammengetragenen Infos aus diesem Thread wäre ich wohl noch am > Anfang.. :) Gezielte Recherche und intelligentes Raten. Viele Informationen sind "frei" verfügbar, wenn man nur richtig sucht.
Einige der Dokumente finde ich inzwischen auch, NACHDEM ich weiß, wonach ich suchen muss. ;) Die Beispielcodes z.B. finde ich aber auch so noch nicht. Die waren übrigens wirklich sehr hilfreich. Die Codestruktur habe ich damit zu 94% verstanden. Die letzten 6% machen mir aber schwer zu schaffen. ;) Momentan liegt das Ganze auch erstmal auf Eis. Ich habe ca. 150 funktionierende Codes erstellen können (was für meine privaten Projekte locker ausreichen würde), aber da auch das Dateiformat mir noch ein großes Rätsel aufgibt (leider ein sehr entscheidendes), nützen die mir nicht viel. Achja, und der Digitaldruck ist längst nicht so zuverlässig wie die gedruckten Bücher, man muss manchmal etwas länger auf den Codes rumreiben, bis sie erkannt werden.. :) Fazit: Nicht wirklich zum Selbermachen geeignet, selbst mit offiziellen Codes und Software hätte man wohl Mühe, gut funktionierende Codes auch auszudrucken.
Ja hi, klingt ja schon mal nicht schlecht! Ich würde mich freuen, wenn Du Deine Erkenntnisse zur Codestruktur kurz zusammenfassen und mit uns teilen könntest. Die von Dir erstellten 150 Codes wären sicher auch für andere Anwender von Interesse, genau wie ein Bericht darüber, wie Du beim Drucken vorgegangen bist (Druckerart, -hersteller und -modell, Farben, Fehlschläge etc etc). Vielen Dank!
Marc F. schrieb: > Achja, und der Digitaldruck ist längst nicht so zuverlässig > wie die gedruckten Bücher, man muss manchmal etwas länger auf den Codes > rumreiben, bis sie erkannt werden.. :) Hast Du mit einem Laserdrucker oder mit einem Tintenstrahler probiert? Ich vermute, dass die Kamera überwiegend im infraroten Spektrum aktiv ist und da könnte das einen Unterschied machen... Grüße, Simon
Simon Budig schrieb: > Hast Du mit einem Laserdrucker oder mit einem Tintenstrahler probiert? Ich habe einen Laserdrucker benutzt. Einen Tintenstrahler habe ich hier leider nicht zur Verfügung. Bzgl. Austausch der Informationen: Ich habe nichts dagegen, möchte es aber ungern öffentlich tun. Wen es interessiert, dem kann ich aber gern meine Erkenntnisse (und Codes) per Privatnachricht oder Mail zukommen lassen.
bzgl Verbreitung: Wofür gibt es denn anonyme Sharehoster, kostenloses T-Online WebDAV und Strato Highdrives :-) Oder Du lädst Dein Archiv einfach auf den Server des Herstellers :-P Ich habe hier aktuell keinen Account. Ein Zusammenhang was mit meinen je nach Betrachtungswinkel etwas grenzwertigen Recherchemethoden darf gern vermutet werden.
Bytemixer schrieb: > bzgl Verbreitung: > > Wofür gibt es denn anonyme Sharehoster, kostenloses T-Online WebDAV und > Strato Highdrives :-) Njargh, irgendwer muss ja auch noch den Link veröffentlichen. Was bei dem aktuellen Rechtssprechungsklima ja auch nicht unbedingt risikofrei ist. Grüße, Simon
wenn das ganze patentiert ist, dann sind die Patentseiten doch öffentlich zugänglich. Darin muss ja auch alles nachvollziebar erklärt sein. zB: http://www.freepatentsonline.com/ http://www.patentserver.de/Patentserver/Navigation/Patentschutz/patentrecherche,did=196684.html usw. auf diese Weise habe ich Schaltungsdetails zu Geräten erhalten, deren Unterlagen sonst nicht zugänglich wären. Vielleicht ist das ein Anstz.
Es gibt tatsächlich ein Patent was danach klingt. Aber leider ist das zugehörige PDF komplett auf chinesisch ?-) http://www.freepatentsonline.com/WO2012071745A1.html
Hi Bytemixer, anbei die Ergebnisse meiner Code-Analyse. Ist noch nicht 100%, aber mit dem Teilen dieser Infos können andere auch besser mitraten. The Analyzer
Hi Analyzer, schön aufbereitet. Ich hatte so eine PDF auch mal gebastelt, aber ab sofort würde ich nur noch auf deine verweisen. ;) Das Paritäts-Bit ist übrigens inzwischen entschlüsselt (nicht von mir). Das aktuelle Problem ist die Zuordnung Zahlenwert -> Code-Nr. Die Abweichung ist nämlich leider nicht konstant 4103. Der Null-Code z.B. hat den Zahlenwert 4. Ich hänge mal die Liste der ersten 100 Codes an (in der Reihenfolge eigentlicher Code-Wert : TING-Code), vielleicht erkennt ja jemand ein Muster...
Marc schrieb: > Das Paritäts-Bit ist übrigens inzwischen entschlüsselt Genau. Wenn man von den 9 Informationstragenden Symbolen das obere linke als "Prüfsymbol" auffasst, dann kann man dessen Wert folgendermaßen bestimmen (dabei ist "raw" der rohe 16-bit Zahlenwert wie er sich durch die decodierten Symbole ergibt):
1 | check = (((raw >> 2) ^ (raw >> 8) ^ (raw >> 12) ^ (raw >> 14)) & 0x01) << 1 |
2 | check |= (((raw >> 0) ^ (raw >> 4) ^ (raw >> 6) ^ (raw >> 10)) & 0x01) << 0 |
Es ist also im Prinzip eine verXORung ausgewählter Bits - lustigerweise immer nur die geraden Bits, warum auch immer. > Das aktuelle Problem ist die Zuordnung Zahlenwert -> Code-Nr. Die > Abweichung ist nämlich leider nicht konstant 4103. Da stehe ich nach wie vor völlig auf dem Schlauch. Ich bin inzwischen etwas abgelenkt worden und habe versucht, eine Methode zu erfinden um möglichst schnell möglichst viele Codes zu scannen, so dass man via "cloud" von interessierten Leuten möglichst viele Codes scannt. Es sind viele große zusammenhängende Bereiche, so dass man mit einem cleveren Ansatz mit moderatem Aufwand eine Analyse machen könnte. Das ärgerlichste ist immer, die Zahlen zu erfassen, die der Stift vorliest. Ich habe damit rumexperimentiert, die "Ziffern"-mp3s auf dem Stift durch DTMF-Töne zu ersetzen und die dann vom Computer erkennen zu lassen. Allerdings ist die Soundqualität bei meinem Setup relativ unterirdisch und mein hingehackter Detektor nicht besonders robust. Deswegen ist das noch nicht in einem guten Zustand... Nunja, jetzt muss mich erstmal wieder die Motivation packen um das wieder aufzugreifen :) Viele Grüße (vom Chaos Communication Congress) Simon
Hallo zusammen, ich bin beeindruckt von euren Beiträgen! Uns beschäftigt gerade eine ähnliche (aber hoffentlich nicht so komplizierte) Frage: Nachdem Ihr den Ting und den Tiptoi ja quasi schon vollens auseinandergenommen habt, Kann man eigentlich mit dem Ting Stift irgendwie die Tiptoi Sachen benutzen (durch sw austausch oder so), oder arbeiten die dann doch auf zu unterschiedlicher weise? Vielen Dank Sandra
Hi Sandra, ich weiß nur, dass beide Systeme die gleichen Codes verwenden, d.h. ein Ting-Stift wird auch die Codes in einem Tiptoi Buch erkennen, aber keine oder die falschen Texte vorlesen. :) Bücher werden sich wohl nicht so einfach austauschen lassen, da hätten die Hersteller sicher was gegen...
Marc schrieb: > ich weiß nur, dass beide Systeme die gleichen Codes verwenden, d.h. ein > Ting-Stift wird auch die Codes in einem Tiptoi Buch erkennen Ich glaube das stimmt nur bedingt. Ja, es wird das gleiche System (OID) verwendet, aber es gibt noch diverse Codierungsbits (von den 4x4 Punkten sind 7 immer identisch, wohl aber für TING/Tiptoi unterschiedlich, d.h. die Stifte können die Systeme auseinanderhalten. Insbesonders werden die Codes für den einen keine Aktion bei dem anderen auslösen. Viele Grüße, Simon
Simon Budig schrieb: > Ich habe damit rumexperimentiert, die "Ziffern"-mp3s auf dem > Stift durch DTMF-Töne zu ersetzen und die dann vom Computer erkennen zu > lassen. Hi Simon, heißt das, dass du es geschafft hast, die "Ziffern"-mp3s per Codeerkennung abzuspielen? Wenn ja, welchen Zahlenwerten/Codenummern sind sie denn zugeordnet? Oder hast du sogar grad eine PDF oder ähnliches mit den korrespondierenden Codestellen für die "Ziffern"-mp3s? Viele liebe Grüße
Sebi schrieb: > heißt das, dass du es geschafft hast, die "Ziffern"-mp3s per > Codeerkennung abzuspielen? Wenn ja, welchen Zahlenwerten/Codenummern > sind sie denn zugeordnet? Du kannst in den Config-Dateien auf dem Stift in einen Debug-Modus schalten, wo dann alle codes numerisch vorgelesen werden. Ich habe die Details gerade nicht parat, aber der Config-Eintrag war ziemlich selbsterklärend... Viele Grüße, Simon
In der SETTINGS.ini: testpen=no in testpen=yes ändern :)
Danke für eure Tipps mit dem Debug Modus :-) So kann ich jetzt immerhin 9 mp3's abspielen (der Code für 0 wird irgendwie nicht erkannt). Einer der nächsten Schritte wäre jetzt wohl das Disassemblieren dieser ".ouf"-Dateien. Aber hier begibt man sich wohl sehr schnell in rechtliche Grauzone :-( Die Stifterkennung hat bei mir übrigens super funktioniert! Zum Originalbuch war kein Unterschied in der Erkennungsqualität zu erkennen! Hierzu habe ich das obige PDF mit den 100 Beispielcodes in eine 1200-dpi-CMYK-tif Datei konvertiert. Aus irgend einem Grund hatte der tif-Ausdruck eine bessere Qualität als der pdf-Ausdruck. Das Gerät war ein hochwertiger Farblaser-Drucker, die Druckeigenschaften waren auf maximale Auflösung und Qualität gestellt. Vllt hat das Papier ja auch eine Rolle gespielt, qualitativ hochwertiges Papier nimmt ja feinauflösende Ausdrucke besser auf.
Sebi schrieb: > So kann ich jetzt immerhin 9 mp3's abspielen (der Code für 0 wird > irgendwie nicht erkannt). Meine Vermutung ist, dass der beim Aussprechen dem Eliminieren der führenden Nullen zum Opfer fällt... :) Viele Grüße, Simon
Angehängte Dateien:
-

tiptoi_ausschnitt.png
13 KB

Simon Budig schrieb: > Marc schrieb: >> Das Paritäts-Bit ist übrigens inzwischen entschlüsselt > > Genau. Wenn man von den 9 Informationstragenden Symbolen das obere linke > als "Prüfsymbol" auffasst, dann kann man dessen Wert folgendermaßen > bestimmen (dabei ist "raw" der rohe 16-bit Zahlenwert wie er sich durch > die decodierten Symbole ergibt): Hi, danke an alle für die interessanten Beiträge. Die Beispielcodes von Simon konnte ich soweit nachvollziehen. Jetzt wollte ich das mal an dem Ausschnitt aus dem Tiptoi-Buch prüfen, der oben geposted wurde (siehe angehängtes Bild). Ich würde das decodieren als 0 1 1 3 3 3 3 2 1 Berechne ich dann aber davon (von 01 01 11 11 11 11 10 01) das Prüfsymbol mit dem Verfahren von oben, kommt bei mir 2 heraus statt 0. Habe ich irgendwo einen Fehler gemacht? Oder bezog sich das auf den Ting-Stift und beim Tiptoi ist das Verfahren anders? Gruß, Thomas
Thomas schrieb: > Oder bezog sich das auf den > Ting-Stift und beim Tiptoi ist das Verfahren anders? Davon gehe ich aus. Ich bin schon überrascht, dass das "fixe" Muster anscheinend das gleiche ist. Für Tiptoi müsste man wohl mal anfangen Daten zu sammeln - und mal einen Debug-Modus finden :) Das überlasse ich aber gerne jemand anders :) Grüße, Simon
Ok, danke für die Info. Ich werde da leider nicht viel beitragen können. Aber ich melde mich, wenn es was zu berichten gibt. Gruß, Thomas
Hallo, bei uns in der Familie gibt es auch einen Tiptoi Stift und es würde mich auch sehr interessieren, wie man eigene "Spiele" (.gme-Datei) dafür basteln kann. Ich hab immerhin schon geschaft, eine .mp3-Datei im Debug Modus abzuspielen. Leider ist der Debug-Modus chinesisch... (DEBUG-MODUS: Einschalte-Taste und Lautstärke-runter-Taste gedrückt halten, Navigation mit Lautstärke rauf/runter) Mit einem Chinesisch-Wörterbuch hab ich einige Zahlen erkannt. Jedoch wäre es interessanter, eine eigene .gme-Datei zu basteln. Es gibt ja schon eine Software dafür ( http://elearningblog.phst.at/wp-content/uploads/2012/06/20120626_Skofitsch_Tiptoi.pdf ), die aber nicht öffentlich verfügbar ist sondern nur im Rahmen einer Projektarbeit entstanden ist... lG, David
Ich bin nicht sicher, ob ich die Frage richtig verstehe... Wenn du meinst, "Wie kann ich mit dem Anybook Stift Ting Bücher mit den dazugehörigen Audiodaten verwenden?", ist die Antwort wohl "gar nicht". Wenn du meinst, "Wie kann ich mit meinem Anybook Stift Ting-Bücher neu vertonen?" weiß ich die Antwort nicht. Der Anybook Stift verwendet wohl grundsätzlich die gleiche Codierung wie der Ting Stift, aber ob die Codes wirklich kompatibel sind, käme auf einen Versuch an. WENN der Anybook Stift die Ting-Codes verarbeiten kann, könnte man damit wohl ein Ting-Buch neu vertonen. Aber das funktioniert dann genauso wie mit den Anybook Stickern, nur dass man eben die Codes im Ting-Buch verwendet. Also verstehe ich die Frage wohl doch nicht richtig... :)
Hallo
>>>Wenn du meinst, "Wie kann ich mit dem Anybook Stift Ting Bücher mit den
dazugehörigen Audiodaten verwenden?", ist die Antwort wohl "gar
nicht".<<<
--
Danke für Deine Antwort. So war meine Frage gemeint.
Grund meiner Frage: Ich versuche aus den vorherigen Beiträgen zu
verstehen wie man Ting Stifte mit Tiptoi Audiodaten codieren kann.
Ich habe einen Aybook stift und dachte es geht mit dem Stift auch. Wäre
echt praktisch.
Langsam kapier ich.. ...jetzt verstehe ich dass das umcodieren von ting auf tiptoy oder anybook wirklich nicht geht. Wäre aber ne gute Herausforderung da irgendwie rein zu kommen.
Ich habe mir mal die OUF Dateien angeschaut (unter http://forum.ubuntuusers.de/topic/synchronisation-von-ting-dem-hoerstift-von-bro/?#post-5480292 steht beschrieben, wie man problemlos an die Dateien kommt). Würde gerne selbst Fotobücher mit Audiokommentar o.ä. machen können. Möchte hier nur kurz meine Fortschritte teilen: - Zu Beginn der Datei scheint eine Art "Tabelle" zu kommen. Vermutlich die Zuordnung Datei <-> Code. HEX: 00 00 00 01 00 könnte als Trenner fungieren. Allerdings erkenne ich keine fortlaufende Nummerierung à la 15001, 15002, ... Vor dieser "Tabelle" stehen zusätzlich noch einige nicht identifizierbare Bytes (keine fixe Länge). - Anschließend kommen scheinbar direkt aneinander gehängt die MP3 Dateien. Ich konnte mühelos Teile der Datei herauskopieren und via VLC wiedergeben. Wenn man nach TEXT: TAG oder TEXT: ID3 sucht, findet man recht leicht den Anfang der Dateien.
Hi, ich hatte mich auch schon mal mit dem Dateiformat beschäftigt. Vielleicht weisst du das alles auch schon, aber hier ist, was ich herausgefunden hatte.. :) In den ersten 10 Bytes der Datei stehen folgende Infos (in dieser Reihenfolge): 1.) Start der Zuordnungstabelle (in bytes) 2.) unbekannt 3.) erster verwendeter Code (vermutlich immer 15001) 4.) letzter verwendeter Code 5.) Gesamtanzahl der verwendeten Codes 6.) Nummer des Buchs 7.-10.) sind mir leider ein Rätsel Die Zuordnungstabelle hast du ja auch schon entdeckt, das "00000001" sehe ich bisher auch nur als Trenner (bzw. könnte hier auch etwas stehen bei Büchern mit interaktiven Inhalten, Spielen etc., bei denen nicht nur Audiodaten abgespielt werden.) Von den beiden Blöcken jeweils davor kann ich zumindest den zweiten eindeutig bestimmen: das ist wohl immer die Länge der Audiodatei in Bytes. Ich habe ein paar Stichproben gemacht und es hat immer gepasst. Der erste Block ist mir leider ein komplettes Rätsel. Entweder ist das die verschlüsselte Position der Audiodatei oder es ist vielleicht eine Prüfsumme. Oder ganz was anderes. ;) Ich hoffe, das hilft irgendwie weiter... wäre doch schön, wenn wir das doch noch mal hinbekommen würden. :)
Ich habe mal ein bisschen weiter geforscht... Der Kopf einer jeden Datei besteht aus mindestens 8 Blöcken à 4 Bytes (d.h. 32 Bit Blöcke; der Chip im Stift nutzt sicherlich 32 Bit); der Header kann aber scheinbar auch länger sein. Meine Gedanken zu den ersten Blöcken: Block 0: Start der Tabelle Block 2: Erster Code (wobei ich in einer Datei auch 15000 gefunden habe) Block 3: Letzter Code Block 4: Tabellenlänge, Anzahl der Codes o.ä.; Allerdings muss dies weder der Differenz von Block 2 und 3 entsprechen, noch der tatsächlichen Tabellenlänge. Block 5: Buch ID Ich habe mal eine kleine Toolbox geschrieben, um die Analyse zu erleichtern... Siehe Anhang. Gut zum Analysieren eignen sich meiner Meinung nach (u.a.) die Bücher 00029 und 05041. In 00029 befindet sich ab dem 10. Block ein YouTube Link. In Block 8 und 9 stehen 15124 und 15125, wobei in Block 3 15123 steht... Meine weiteren Erkenntnisse: - Tabelleneinträge mit den tatsächlichen Startpositionen zu xor'en liefert kein offensichtliches Muster. - Die Einträge in der ersten Spalte nicht aufsteigend sein, trotzdem liefert die mp3 Extraktion (interactive.find_mp3_data) brauchbare Ergebnisse (versucht anhand der zweiten Spalte die die Länge der mp3 Blöcke zu finden). - Die Einträge in der ersten Tabellenspalte scheinen immer auf 0x******00 zu enden. - Die Einträge der ersten Spalte sind teilweise größer als die Datei lang ist. - Die Tabelle enthält manchmal Zeilen mit 0x00000000 0x00000000 0x00000000. - In manchen Dateien geht die "automatische" mp3 Erkennung ziemlich schief. Ich vermute mal, dass da Skripte eingebunden sind.
<spekulier> Könnte die Tabelle eine Zustandsmaschine sein? Beispielsweise gibts im TipToi-Buch Stellen, die unterschiedliche MP3s abspielen je nachdem ob man vorher das Auge, die Glühbirne oder den Würfel angeclickt hat. Zu diesen Symbolen müsste es dann mehrere Einträge geben. Ein Tabelleneintrag müsste dann das getippte Symbol, das zu spielende Audio und die ID oder Adresse des Folgezustands beinhalten. Mit Sonder-Werten könnte das Ende der Übergänge eines Zustands markiert werden. Einige Features ("Finde alle 10 Mäuse auf der Seite", "Tippe nacheinander die 10 gehörten Dinge an") erfordern m.E., dass Register gesetzt bzw abgefragt werden können, denn sonst wird die Anzahl der möglichen Zustände unnötig hoch. Wenn dafür ein paar Bits bei den Codes abgeknapst wurden, könnte das die Werte erklären die hinter dem Dateiende liegen. </spekulier>
robot schrieb: > <spekulier> > Könnte die Tabelle eine Zustandsmaschine sein? > </spekulier> Sogar mehr als eine reine Zustandsmaschine: es gibt auch bei dem Ting ein Art "Skriptsprache"[*]. Ich bin aber noch nicht dazu gekommen, das Dateiformat zu reverse-engineeren. Nuja, irgendwann... :) Grüße, Simon
Ihr seid nicht allein mit dekodieren. Auf http://www.quadrierer.de/geekythinking/blog/?itemid=368 gibts ne kleine Diskussion zu Tip-Toi. Die ergebnisse und ein bisschen Code gibts auf https://github.com/entropia/tip-toi-reveng Wir haben das Datenformat für die Tip-Toi-Bücher soweit entschlüsselt das sman die OGG-Dateien extrahieren kann. Als nächstes muss man wohl den Zustandsautomaten bzw. das Skript dekodieren – jede Hilfeist willkommen!
Der Programmcode für die Normalen Modi (Wissen, Entdecken) ist entschlüsselt. Fehlen nur noch die Spiele!
Angehängte Dateien:
-

bauernhof-start.png
6,9 KB -

strassenverkehr-start.png
14 KB


Thomas schrieb: > Ich würde das decodieren als > 0 1 1 > 3 3 3 > 3 2 1 > Berechne ich dann aber davon (von 01 01 11 11 11 11 10 01) das > Prüfsymbol mit dem Verfahren von oben, kommt bei mir 2 heraus statt 0. > Habe ich irgendwo einen Fehler gemacht? Oder bezog sich das auf den > Ting-Stift und beim Tiptoi ist das Verfahren anders? Simon Budig schrieb: > Davon gehe ich aus. Ich bin schon überrascht, dass das "fixe" Muster > anscheinend das gleiche ist. Hallo zusammen, bei mir hat es bisher immer gepasst, wenn ich die "TING-Prüfziffer" nochmal per XOR mit 2 verknüpfe, also: checksum = (((dec >> 2) ^ (dec >> 8) ^ (dec >> 12) ^ (dec >> 14)) & 0x01) << 1; checksum |= (((dec) ^ (dec >> 4) ^ (dec >> 6) ^ (dec >> 10)) & 0x01); checksum ^= 0x02; Ich habe das dann mal quick and dirty in HTML/Javascript gegossen: http://upload.querysave.de/code.html (oder hier: https://github.com/entropia/tip-toi-reveng/pull/32) Falls ihr Codes habt, bei denen das nicht passt oder sonst etwas mit der Seite nicht stimmt, bitte hier posten (oder direkt bei Github dran rumfummeln)... ;-) Marc schrieb: > Das aktuelle Problem ist die Zuordnung Zahlenwert -> Code-Nr. Die > Abweichung ist nämlich leider nicht konstant 4103. Der Null-Code z.B. > hat den Zahlenwert 4. Ich hänge mal die Liste der ersten 100 Codes an > (in der Reihenfolge eigentlicher Code-Wert : TING-Code), vielleicht > erkennt ja jemand ein Muster... Zumindest für 1 (Bauernhof = 5 dezimal) und 5 (Sicher im Straßenverkehr = 15 dezimal)stimmt das mit Tiptoi überein. Weitere Codes in dem Zahlenbereich habe ich leider nicht.
Hallo Tobias, ein super Tool, danke! Ich habe sechs Stichproben aus dem Tiptoi Bauernhof probiert, und es hat bei allen gestimmt. Gruß, Thomas
Thomas schrieb: > Ich habe sechs Stichproben aus dem Tiptoi > Bauernhof probiert, und es hat bei allen gestimmt. Das klingt doch schon mal gut. Ich habe jetzt noch ergänzt, dass zwei Grafiken (PNG) erzeugt werden (per Mod-Rewrite und php - liefere ich bei Gelegenheit noch nach). Eine DPI-Angabe habe ich jetzt noch nicht mit aufgenommen, sollte aber machbar sein. Mit 600*600 DPI ist der Ausdruck zwar gut mit dem Auge zu erkennen, aber für den Stift zu riesig. 1200*1200 scheint zu stimmen, aber da steigt mein Drucker aus, so dass ich das Muster auch nicht mehr klar erkennen kann.
Jetzt muss ich doch mal blöd fragen: Hat es jetzt schon jeman geschafft, was selbst auszurucken was dann vom TING oder TipToi-Stift erkannt wurde? Oder wurde es nur theoretisch verstanden und die nötige Druckqualität erreicht mal zu hause nicht ohne weiteres?
Kann mir mal jemand erklären was man bei libtiptoi.c beachten muss, wenn man Dateien im GME-File ersetzen will? Ich habe es unter linux kompiliert, extrahieren der Dateien geht. Wenn ich aber die Sateien ersetzen möchte, kommt immer "Speicherzugriffsfehler (Speicherabzug geschrieben)" und ich erhalte keinen Output. Der Fehler tritt wohl in der routine addAudioFiles auf. Mehr konnte ich bisher noch nicht herausfinden. - Wie müssen da genau die Aufrufparameter aussehen - Kann ich einfach bei den exportieren Files die Dateien austauschen und dann libtiptoui mit dem Parameter n aufrufen? - Wass muss man sonst noch beachten?
Joachim Breitner schrieb: > Jetzt muss ich doch mal blöd fragen: Hat es jetzt schon jeman geschafft, > was selbst auszurucken was dann vom TING oder TipToi-Stift erkannt > wurde? Oder wurde es nur theoretisch verstanden und die nötige > Druckqualität erreicht mal zu hause nicht ohne weiteres? Ich habe TING-Codes auf einem Laser-Drucker ausgedruckt und erfolgreich im Test-Modus eingelesen. Es war aber fiddelig: Die Codes brauchten gerne mehrere Anläufe bis sie erkannt wurden und die Erkennungsqualität hing massiv von den Druckparametern ab (Tonerdichte, evtl. kleine Skalierungen). Die Codes in ein farbiges Bild einzubetten habe ich nicht probiert. Viele Grüße, Simon
Hi, Ich habe die gleichen Erfahrungen gemacht, dass die Codes auf einem Laserdrucker gedruckt nur schwer lesbar waren. In meinem Fall hat es geholfen, die einzelnen Punkte größer zu machen. Also statt nur einem Pixel habe ich vier gezeichnet (evtl. sogar 9, weiß nicht mehr genau). So war die Erkennung ziemlich gut, nur mit vereinzelten Aussetzern. Die Codes in Bilder einzubetten habe ich auch nicht versucht. Ich denke, das wird nicht gehen, allenfalls auf sehr hellen Farben. Die echten Ting Bücher benutzen dafür eine spezielle Tinte, die sogar auf schwarz noch erkannt wird. Gruß, Marc
Ich habe beim Codegenerator noch ergänzt, dass bei einem Klick auf die Bilder in einem neuen Fenster/Tab ein passendes Code-PNG mit 4096*4096 Pixeln und 1200*1200 DPI erstellt wird. Klingt deutlich größer, als es dann ausgedruckt wirklich ist. Als Beispiel die 11 (dezimal) = Tiptoi 5 = Bauernhof-Einschaltzeichen: http://upload.querysave.de/tiptoi_100000011_64.png Mit einem Samsung CLP-300 ist es - wie erwähnt - zu verwaschen. Ich habe mich an die 4 Pixel aus dem Code-PDF gehalten. Bei Gelegenheit versuche ich es dann mal mit 9 Pixeln...
Also das austauschen der Dateien hab ich hinbekommen. Man muss r verwenden und nicht n . Wer lesen kann ist klar im Vorteil. Zum Drucken : ja das würde mich auch interessieren, ob das bei jemanden geklappt hat. Ich hab's bis jetzt nicht hinbekommen. Ich meine gelesen zu haben, dass eine Tinte verwendet wird, die Graphit Partikel enthält . Ich glaube das ist entweder in einem der Patente gestanden oder auf der Webseite des oid Herstellers. Das konnte der Grund sein, warum es in den Büchern auch auf dunklem Hintergrund funktioniert. Das wird natürlich zu Hause schwierig. Die Auflösung ist das nächste Problem . Der Stift erkennt im Abstand von etwa 0-4mm .
Na, wenns mit den Laserdruckern schon ein bisschen klappt, dann ist das doch ganz ermutigend. Wer so ein Gerät sein eigen nennt kann ja mal ein bisschen experimentieren. Vielleicht akzeptiert der Stift ja auch ein etwas größeres Raster (was sich vielleicht genauer drucken lässt). Oder vielleicht hilft es die Pixel größer zu machen, oder mit Subpixeln zu arbeiten (also statt ein Pixel komplett eine Reihe zu verschieben, nur die Hälfte der Deckkraft verschieben)....
In der Anleitung zur Erstellung der Bücher wird explizit darauf hingewiesen, dass die OID-Codes nicht in der Größe geändert werden dürfen. Das größere Raster dürfe also vermutlich wirklich nur minimal größer sein. Vielleicht könnte man mal versuchen, testweise mit einer konkaven Vorsatzlinse zu arbeiten?
Was wäre, wenn man mal ein Foto ausarbeiten, auf dem die Codes in verschiedenen Größen drauf sind. Man könnte auch verschiedene Papiersorten bzw. matt/glänzend probieren ... Ein Fotobuch mit OID auszustatten wäre im Endeffekt recht cool ... LG Wopi
Hi, hat sich schon mal jemand Gedanken über den ersten Teil der Decodierung gemacht, d.h. den Weg vom Graustufenbild bis zu den decodierten neun Symbolen? Meiner Meinung nach unterteilt man das am besten in drei Schritte: 1. Aus dem Graustufenbild eine Liste mit den 2D-Koordinaten der im Bild enthaltenen Punkte bekommen. 2. Liste der Punkte-Koordinaten so in eine Matrix eintragen, dass benachbarte Matrix-Einträge benachbarten Punkten entsprechen. Die Matrix bildet also das Punkt-Raster ab. Dabei muss natürlich die Drehung des Rasters erkannt werden. Man könnte auch sagen, man muss die Nachbarschaftsbeziehungen zwischen den Punkten herstellen, vielleicht in einen Graphen umsetzen. 3. Symbol-Erkennung, d.h. decodieren der zwei Bits aus der Verschiebung jedes Symbols. Die Punkte 1 und 3 sehe ich im Moment als nicht so schwierig an, Punkt 2 ist aber gar nicht so einfach wie ich dachte. Die Verschiebung der informationstragenden Punkte vom regelmäßigen Raster ist doch relativ groß. Ich gehe am Anfang mal von einer Perspektive direkt von oben aus. (Der Tiptoi-Stift muss zusätzlich ja noch mit perspektivischer Verzerrung zurechtkommen, wenn der Stift schräg aufgesetzt wird.) Hat da jemand Ideen dazu? Gruß, Thomas
Übrigens, ich hab kürzlich die erste personalisierte GME-Datei verschenkt: http://www.joachim-breitner.de/blog/archives/641-Personalisierte-Tip-Toi-Datei-als-Geschenk.html
Hallo, Habe mir gerade einen Stift bei Ebay gekauft. Ich möchte mir gerne Codes mit meinem Laserdrucker drucken und damit dann verschiedene Sounds abspielen lassen. Habe mir hier alles durchgelesen, leider weiß ich nicht wie ich anfNgen soll? Es gibt einen codegenerator? Wenn ich verschiedene Codes erstelle, wie weiß der Stift welchen Code er abspielen soll? Hat jemand schon geschafft, Codes erfolgreich auszudrucken? Bitte um Antwort und Hilfe! Danke!
Hier ist mein aktueller Fortschritt: Es ist nur ein kurzes Handyvideo, aber ich denke, ihr könnt seh'n, was alles geht. http://youtu.be/KC97F4PfNhk
Hallo Pronwan, sehr schön! Kannst du ein wenig mehr erzählen? Wie hast du die Code erzeugt, und wie aufs Bild gepackt? Wie hast du die gme-Dateien erzeugt? Bin gespannt! Joachim
Ich stelle demnächst ein Tutorial Video online. Viele Grüße
Moderne Welt, alle machen Video-Tutorials, niemand schreibt mehr schöne Texte... Werds mir anschauen wenn ich 30 Minuten Ruhe am Stück habe, aber schon mal vielen Dank!
Hi, danke fürs Tutorial. Hab jetzt nur mal kurz reinschauen können, wüsste aber gern, ob das "TING" im Titel so richtig ist. Denn tiptoi und Ting nutzen zwar das gleiche System, sind aber nicht kompatibel... :) Im Video sehe ich da immer nur den tiptoi Stift... Gruß, Marc
Hallo Marc, lediglich die Codes werden beim TING anders generiert. Ansonsten sollte alles 100% identisch sein. Im Code-Generator kannst du einfach TING statt tiptoi anklicken, fertig. Hallo Joachim, da ist wohl was dran :-) Beruflich habe ich immer zu viel schreiben müssen, sodass ich privat meist Videos mache, hehe. Natürlich kann ich auch gerne einen Erklärungstext als PDF machen, wenn du ihn irgendwo einpflegen möchtest. Viele Grüße!
Großartig! Mal schauen, ob ich heute Zeit finde, das PHP-Script für dein Raster anzupassen... :-)
DAS wäre natürlich was :-) das händische ändern ist doch recht aufwändig, hehe. Viele Grüße!
Ich habe das Script eben überarbeitet. Passt das jetzt? Beispiel: http://upload.querysave.de/tiptoic_100001032_1.png
Angehängte Dateien:
-

Image6.jpg
9,9 KB
Der hellblaue 2x2 Rasterpunkt (versetzter Punkt in linker Spalte) müsste noch um 1 px nach rechts verschoben werden. Ansonsten sieht das gut aus. Brauchbar ist der Code natürlich nur in komplett schwarz-weiss :-) Vielen Dank und super Tool!
Ok - dann sollte es jetzt passen. http://upload.querysave.de/tiptoic_100001032_1.png => farbig, 1x1 http://upload.querysave.de/tiptoi_100001032_2.png => s/w, 2x2
Ich wollte allen hier Beteiligten mal ein großes Lob und meinen Dank aussprechen! Meine Kinder lieben ihr TipToi und mich hat schon immer interessiert wie die Technik dahinter funktioniert. Dass das Ding jetzt schon zu so großen Teilen reverse-engineered ist hätte ich nicht gedacht. Vor allem das tttool und das Tutorial Video haben mir wirklich weitergeholfen. Sehr gute Arbeit, vielen Dank!!! :)
Super Video-Tutorial! Es gibt übrigens inzwischen auch ein spezielles GME, mit welchem die OIDs auf Englisch bzw. Deutsch angesagt werden. (bei Interesse Details per PM) Wo auf der Ravensburger-Seite kann ich das in deinem Video ab 4:52 gezeigte "Konzeptblatt" finden?
Super Sache, weiter so. Gibt es schon eine Seite für die Hardware? Ich habe hier nämlich Stifte mit unterschiedlicher Speicherausstattung. Das kann sehr nervig sein wenn man viele Bücher hat. Die passen nicht alle drauf. Meine Kinder haben schon einen Internen Lautsprecher gehimmelt(getauscht gegen ein Köpfhörerstöpsel), und die erste Hohlspitze ist so runtergeschmirgelt das ich neu justieren musste damit der Kamerafokus wieder stimmt. Sonst noch jemand Technische Probleme gehabt?
Björn, die Navigationsleiste kannst du hier herunterladen: http://www.ravensburger.de/content/wcm/mediadata/PDF/01_Kinder/tiptoicode_Navigationsleiste.pdf
So, Video angeschaut. Klasse Arbeit! Sieht ja richtig gut aus, das Cars-Spiel. Hat mich auch gefreut dass mein tttool so gut weg kommt, und sogar als intuitiv bezeichnet wird. Hat sich wohl gelohnt dass ich für Windows eine fertige exe bereitgestellt hab. Danke! Bugs hast du wohl keine gefunden? Wenn du aus Büchern generierte YAML-Dateien als Vorlage nimmst hast du das vielleicht nicht gesehen, aber die Soundfiles müssen keine Zahlen als Namen haben, denen kannst du ruhig sprechende Namen geben – siehe https://github.com/entropia/tip-toi-reveng/blob/master/example.yaml und das zugehörige example-Verzeichnis. Hast du vor deine Werke irgendwo hochzuladen? Vielleicht will jemand dein Spiel auch seinen Kindern geben, oder es zumindest als Vorlage nehmen (dann am Besten mit den Corel Draw und .yaml-Dateien)? Jetzt bräuchte man noch ein Plug für Corel Draw oder Gimp oder was auch immer dass diese Punkt-Codes generiert. Ich würde wohl am ehesten eine Ebene pro Code anlegen, die das ganze Bild mit dem Code überdeckt, und sie dann mit einer Ebenenmaske auf den gewünschten Bereich eingeschränkt.
> Sonst noch jemand Technische Probleme gehabt? Ich nicht, aber der Lautsprecher lässt sich wohl tauschen: http://husmanns.ch/?page_id=7
Super Danke für den Link mit dem Lautsprecher. Der Ohrstöpsel ist schon arg leise ;)
Für eine Veröffentlichung müsste ich mich nochmal genau mit dem Patent auseinandersetzen und die Rechte prüfen. Denn eine Urheberrechtsverletzung muss nicht unbedingt sein :-)
Hallo, erstmal einen riesen Respekt für das revese-engineering. Ich wollte mich heute auch mal an die Sachen mit dem tttool machen, doch leider bekomme ich es unter Linux nicht kompiliert. Hier die Fehlermeldung:
1 | ghc -O -with-rtsopts=-K100M tttool.hs |
2 | |
3 | tttool.hs:1:42: |
4 | Warning: -XRecursiveDo is deprecated: use -XDoRec or pragma {-# LANGUAGE DoRec #-} instead
|
5 | [1 of 1] Compiling Main ( tttool.hs, tttool.o ) |
6 | |
7 | tttool.hs:144:47: |
8 | Couldn't match expected type `bytestring-0.9.2.1:Data.ByteString.Lazy.Internal.ByteString' |
9 | with actual type `BC.ByteString' |
10 | In the first argument of `Br.fromLazyByteString', namely `bs' |
11 | In the first argument of `tell', namely |
12 | `(Br.fromLazyByteString bs)' |
13 | In the first argument of `(>>)', namely |
14 | `tell (Br.fromLazyByteString bs)' |
15 | |
16 | tttool.hs:182:5: |
17 | No instance for (MonadWriter Br.Builder m0) |
18 | arising from a use of `tell' |
19 | Possible fix: |
20 | add an instance declaration for (MonadWriter Br.Builder m0) |
21 | In the expression: tell |
22 | In a stmt of a 'do' block: |
23 | tell |
24 | $ (Br.fromLazyByteString (B.replicate (fromIntegral (to - now)) 0)) |
25 | In the second argument of `($)', namely |
26 | `do { now <- get;
|
27 | when (now > to) |
28 | $ do { fail
|
29 | $ printf "Cannot seek to 0x%08X, already at 0x%08X" to now }; |
30 | tell |
31 | $ (Br.fromLazyByteString |
32 | (B.replicate (fromIntegral (to - now)) 0)); |
33 | modify (+ (to - now)) }' |
34 | |
35 | tttool.hs:182:36: |
36 | Couldn't match expected type `bytestring-0.9.2.1:Data.ByteString.Lazy.Internal.ByteString' |
37 | with actual type `BC.ByteString' |
38 | In the return type of a call of `B.replicate' |
39 | In the first argument of `Br.fromLazyByteString', namely |
40 | `(B.replicate (fromIntegral (to - now)) 0)' |
41 | In the second argument of `($)', namely |
42 | `(Br.fromLazyByteString (B.replicate (fromIntegral (to - now)) 0))' |
43 | |
44 | tttool.hs:194:23: |
45 | Couldn't match expected type `BC.ByteString' |
46 | with actual type `bytestring-0.9.2.1:Data.ByteString.Lazy.Internal.ByteString' |
47 | In the expression: |
48 | Br.toLazyByteString $ execWriter (evalStateT act 0) |
49 | In an equation for `runSPut': |
50 | runSPut (SPutM act) |
51 | = Br.toLazyByteString $ execWriter (evalStateT act 0) |
52 | |
53 | tttool.hs:333:40: |
54 | Couldn't match expected type `bytestring-0.9.2.1:Data.ByteString.Lazy.Internal.ByteString' |
55 | with actual type `BC.ByteString' |
56 | In the return type of a call of `BC.drop' |
57 | In the second argument of `G.runGetState', namely |
58 | `(BC.drop (fromIntegral offset) bytes)' |
59 | In the expression: |
60 | G.runGetState act (BC.drop (fromIntegral offset) bytes) 0 |
61 | |
62 | tttool.hs:405:13: |
63 | Couldn't match expected type `BC.ByteString' |
64 | with actual type `bytestring-0.9.2.1:Data.ByteString.Lazy.Internal.ByteString' |
65 | Expected type: SGet BC.ByteString |
66 | Actual type: SGet |
67 | bytestring-0.9.2.1:Data.ByteString.Lazy.Internal.ByteString |
68 | In the expression: liftGet $ G.getLazyByteString (fromIntegral n) |
69 | In an equation for `getBS': |
70 | getBS n = liftGet $ G.getLazyByteString (fromIntegral n) |
71 | |
72 | tttool.hs:1059:80: |
73 | Couldn't match expected type `bytestring-0.9.2.1:Data.ByteString.Lazy.Internal.ByteString' |
74 | with actual type `BC.ByteString' |
75 | In the second argument of `G.runGet', namely `bytes' |
76 | In the first argument of `(==)', namely |
77 | `G.runGet (G.skip (fromIntegral o) >> G.getWord16le) bytes' |
78 | In the second argument of `(&&)', namely |
79 | `G.runGet (G.skip (fromIntegral o) >> G.getWord16le) bytes == 0' |
80 | |
81 | tttool.hs:1148:31: |
82 | Couldn't match expected type `bytestring-0.9.2.1:Data.ByteString.Lazy.Internal.ByteString' |
83 | with actual type `BC.ByteString' |
84 | In the first argument of `Br.fromLazyByteString', namely `bytes' |
85 | In the first argument of `Br.append', namely |
86 | `Br.fromLazyByteString bytes' |
87 | In the second argument of `($)', namely |
88 | `Br.fromLazyByteString bytes `Br.append` Br.putWord32le checksum' |
89 | make: *** [tttool] Fehler 1 |
Da ich bis jetzt noch nie etwas mit Haskell gemacht habe, bräuchte ich hier noch etwas hilfe. Fehlt evtl. ncoh ein Paket ? Vielen Dank, Gruß, Michael
Lass uns das auf https://github.com/entropia/tip-toi-reveng/issues/ besprechen, sonst wird das Forum hier mit Zeug zugemüllt was nicht alle interessiert. Mach einfach ein Ticket auf. (Auf den ersten Blick scheinen irgendwelche Versionen nicht zu stimmen)
So, die Windowsversion funktioniert und ich hab schon ein paar GME Dateien etwas "persönlicher" gestaltet. Jetzt ist aber das Problem, dass man dann immer die selbst erstellte Version hat und man nur durch umkopieren auf dem Stift die Original Version hat. Jetzt kam mir die Idee, das ich der selbst erstellten GME einen neuen Namen gebe und nur ein eigenes Startsymbol ausdrucke, dass dann diese GME lädt. Nun zu meinem Problem.... Wo ist festgelegt, Weilchen GME DAtei bei dem entsprechenden Anschaltzeichen geladen wird? Ist es überhaupt möglich, zwei GME Dateien mit identischen OID auf dem Stift zu haben ? Gruß, Michael
> Wo ist festgelegt, Weilchen GME DAtei bei dem entsprechenden Anschaltzeichen geladen wird? Das ist das Feld "product-id: 1" in der yaml-Datei, aus der du die GME-Datei baust. > Ist es überhaupt möglich, zwei GME Dateien mit identischen OID auf dem Stift zu haben ? Ja, solange sie unterschiedliche Start-Codes haben klappt das.
Joachim Breitner schrieb: > Das ist das Feld "product-id: 1" in der yaml-Datei, aus der du die > GME-Datei baust Das werde ich mal testen. Noch eine grundsätzliche Frage... Woher weiß der Stift, ob die Passende GME Datei zum Anschaltzeichen vorhanden ist? Wird da beim start ein Scan über alle GME Datein gemacht? Gruß, Michael
Michael A. schrieb: > Noch eine grundsätzliche Frage... > Woher weiß der Stift, ob die Passende GME Datei zum Anschaltzeichen > vorhanden ist? > > Wird da beim start ein Scan über alle GME Datein gemacht? wir kennen den Code des Stiftes nicht (wäre ein nettes Projekt für jemand der ARM-Assembly lesen kann), aber ich gehe davon aus dass es genau so ist wie du es beschreibst.
Hi, wenn ich an das Video von Pronwan denke, wie ist das mit dem TING-Stift? Was lässt sich übertragen? Nur die Drucktechnik? Oder auch die Software? Oder anders gefragt: Verwenden die TING-Stifte auch .gme-Dateien, oder haben die komplett andere Firmware. Gruß, Joachim
Hallo Joachim, beim Tingstift ist die Endung ouf kann mann von dem tingserver runterladen: zb: http://system.ting.eu/book-files/get/id/5005/area/en/type/archive/ ich hab auch mal meine log datei von meinem Stift angehängt, da sind sämtliche downloadlinks von meinen bereits gekauften Büchern drinn. Sind immer Beschreibungstextfile; Bildfile; und das große ouf file was wohl vergleichbar mit dem gme file ist. Wäre cool wenn du das fileformat auch mit deinem ttt tool unterstützen könntest. Da würden meine Kids staunen wenn Sie auf einmal selbst aus den Büchern singen würden :-)
Martin K schrieb: > Wäre cool wenn du das fileformat auch mit deinem ttt tool unterstützen > könntest. > Da würden meine Kids staunen wenn Sie auf einmal selbst aus den Büchern > singen würden :-) hab mal kurz reingeschaut. Identisch sind sie schon mal nicht... Und anders als die GME-Dateien wohl auch nicht „verschlüsselt“: Ich sehe da im Hexdump MP3-Tags und hinweise auf den MP3-Kodierer LAME3.97. Naja, werde das erstmal anderen überlassen :-)
Joachim Breitner schrieb: > Naja, werde das erstmal anderen überlassen :-) Sehe ich das richtig, dass es bisher noch keine Bemühungen gibt, das OUF-Format zu "entschlüsseln"? Wenn das so ist, werde ich mir das mal genauer anschauen...
Hi Dirk, Bemühungen gab es da schon (siehe weiter oben), aber ein paar entscheidende Details fehlten leider noch. Wäre schön, wenn sich mal wieder jemand damit beschäftigt und vielleicht doch noch was rausbekommt. Mir fehlt leider inzwischen die Zeit, aber ich fürchte, ich war auch am Ende meiner eingeschränkten Kenntnisse angekommen.. :)
Marc schrieb: > Bemühungen gab es da schon (siehe weiter oben) Danke, ich dachte erst, die Beiträge ab 21.10.2013 13:09 ff würden sich auf das Tiptoi-Format beziehen. Jetzt habe ich aber erkannt, das das mit meinen OUF-Dateien übereinstimmt. Mal schauen, wieviel Zeit ich dafür habe...
Jetzt will ich mir die Dateien auch noch einmal anschauen. Dazu würde ich gerne die Python-Script interactive.py, helper.py und ouf.py laufen lassen - habe aber von Pythohn keine Ahnung. Wie kann ich denn z.B. print_head(ouf_file) oder find_mp3_data(ouf_file) aus interactive.py aufrufen? Möchte es nicht nochmal in C o.ä. programmieren :-(
Angehängte Dateien:
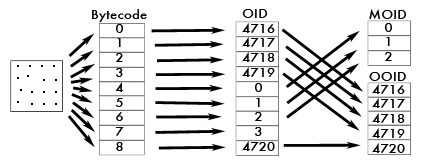
Mein Sohn hat vor kurzem einen Tiptoi Stift geschenkt bekommen, und natürlich denkt der Papa sofort darüber nach, was man mit dem Ding so alles anstellen kann. Ich habe festgestellt, daß in diesem Forum schon unglaublich viel über die Tiptoi Technik herausgefunden wurde (DANKE!) Allerdings ist es nicht ganz einfach gewesen, die ganzen Puzzleteile zusammenzusetzen, daher hier eine kurze Zusammenfassung Wissensstand Tiptoi OID ======================================= Tiptoi Codes sind gedruckte 4x4 Punkte Matrizen mit einer Größe von 0,1 x 0,1 mm. TipToi Matrizen bestehen aus 7 Punkten zur Ausrichtung, 8 Informationspunkten (welche je 4 Werte annehmen können), sowie einem Paritätspunkt. Die nutzbare Information einer Matrix liegt somit bei 16 bit. Tiptoi Matrizen können eindeutig als Bytecode dargestellt werden, welcher einer Zahl von 0 bis 65536 entspricht. Die 2 bit Parität wird durch eine bekannte bitshift-xor Operation erzeugt. Aus jedem Tiptoi Bytecode wird durch eine bisher unbekannte, bijektive Funktion jeweils eine Tiptoi OID erzeugt. Fortlaufende Bytecodes werden in zwei, in sich fortlaufende, aber miteinander vermischte Wertbereiche übersetzt, ein Wertbereich von 4716 bis 65535, ein Wertbereich von 0 bis 4715. Tiptoi Media-OID's (OID 0 bis OID 4715) werden verwendet um Bücher, Figuren, Spiele etc. auszuwählen. M-OID's werden normalerweise hinter dem Anschaltzeichen gedruckt. Jeder M-OID ist jeweils eine .gme Datei am Stift zugeordnet, die durch das scannen der M-OID geladen wird. Wenn eine M-OID angewählt wird, zu welcher keine .gme Datei am Stift gespeichert ist, folgt die Meldung „Laden Sie erst die passende Audiodatei auf den Stift“ Tiptoi Objekt-OID's (OID 4716 bis OID 65535) werden verwendet um Aktionen auszulösen. Das Verhalten bei scannen der jeweiligen O-OID wird in der .gme Datei beschrieben. Wenn zu einer O-OID kein passender Eintrag in der aktuell geladenen .gme Datei existiert, vermutet die Software, daß ein anderes Buch gescannt wurde und es erfolgt die Meldung „berühren Sie zunächst das Anschaltzeichen“ Bytecode2oid: ============= Die Funktion bytecode2oid() ist bisher nicht veröffentlicht worden. Ich vermute, daß es sich um eine bitshift-xor Funktion handelt, ähnlich wie die Paritätsfunktion, allerdings reichen meine Kenntnisse nicht, diese zu entschlüsseln. Ich habe daher aus allen bisher veröffentlichten Bytecode/OID Paaren eine XLS Liste mit ca. 1600 OID's erstellt, davon ca. 100 M-OID's. Das sollte reichen, um eigene TipToi Dokumente zu erstellen.
Hallo Alexander H, klasse Recherche. Vor allem die Trennung von MOID und OOID ist mir neu. Das müsste am besten auch auf https://github.com/entropia/tip-toi-reveng festgehalten werden. Ich würde mich über einen Pull-Request freuen, kann es aber auch bei Gelegenheit selbst dort einpflegen. Vielleicht können wir die Tabelle auch dem tttool beibringen, das würde dem Benutzer einiges vereinfachen. Gruß, Joachim
Hallo Joachim! Danke für Dein Feedback. Die Aufteilung in MOID und und OOID ist tatsächlich neu, elegant, stammt von mir und ist (nach neuester Kenntnis und zumindest teilweise) falsch... Ich habe die OIDs, welche von Ravensburger bis dato verwendet werden, ausgewertet (Liste anbei) und bin zu einigen Schlüssen gekommen, denen ich noch weiter nachgehen möchte: Aussage 1: Alle bisher von Ravensburger verwendeten MOIDs sind eindeutig und fortlaufend von 1 bis 72. Einzelne Medien existieren aber nur in einzelnen Sprachen. Aussage 2: Die kleinste, regulär verwendete OOID ist 1001 (z.B. "Strassenverkehr") Aussage 3: In manchen .gme Dateien existiert ein „"main table" Eintrag für jene OOID, die deren MOID entspricht. (z.B. "Mein grosses Bilderlexikon", OOID ab 30 dann FF bis 14001) Schluß: Meine Aussage: "OIDs von 0 bis 4716 dienen immer der Medienauswahl" kann nicht aufrecht erhalten werden. Hypothese A: Die höchst-mögliche MOID ist kleiner als 1001. Hypothese B: Die höchst-mögliche MOID ist größer als 1001 (z.B. 4715) aber eine eventuell angelegte OOID mit niedrigerer Nummer übersteuert das Verhalten "Medien abrufen" Hypothese C (gewagt): Es existiert eine (interne) Sprungtabelle im TipToi Stift, in der einige (MOIDs) auf Ladeskripts verweisen (Lade Datei mit dieser MOID oder spiele Jingle „"Datei fehlt"), andere auf Abspielskripts verweisen (spiele Jingle "Anschaltzeichen berühren"). Vor dem laden wird die original Sprungtabelle wieder hergestellt, dann mit den Sprungpunkten der neuen geladenen Datei überschrieben. Mein persönliches Todo: => Bytecodes für OID >1000 und <4716 durch probieren finden (MOID kommen meist geballt vor, guter Startpunkt ist nach Bytecode 16384). Dann testen, ob der TipToi Stift mit "Datei fehlt" (Hinweis auf MOID) oder "Anschaltzeichen berühren" (Hinweis auf OOID) reagiert. => Prüfen, ob Medien bei denen die MOID als OOID angelegt ist (30, 33, 34, 42, 65, 69), auf das erste Lesen des Anschaltzeichens anderes reagiert, als beim zweiten mal (Hinweis auf überschreiben der MOID Funktion durch eine OOID) => Prüfen ob es möglich ist, in einer eigenen .gme Datei beliebige MOIDs als OOID zu definieren und so deren „Medium laden“ Funktion zu überschreiben (deaktivieren!?!) (Was da so alles möglich wäre, wenn es eine Autostart .gme gäbe...) Lg, Alexander
Hallo zusammen, Joachim hat dem FABLAB Karlsruhe (www.fablab-karlsruhe.de) zugesagt, im Januar einen Workshop zu dem hier diskutierten Thema abzuhalten. Die Zusammenfassung zum Workshop sieht wie folgt aus: Mit dem Tip-Toi-Stift von Ravensburger werden Bücher, Puzzles, Spiele und sogar Tierfiguren zum Leben erweckt. Das Prinzip ist einfach: Eine kleine Kamera in der Spitze des Stiftes erkennt ein feines Muster aus schwarzen Punkten auf den Buchseiten und reagiert entsprechend. Dabei steckt die ganze Logik im Stift bzw. in der Datei zum Buch, die man vorher runterlädt und auf den Stift kopiert. Die Bücher selbst enthalten keine Technik. Dem geneigten Bastler juckt es da doch in den Fingern, selbst Hand anzulegen und eigene Bücher zu gestalten. Und tatsächlich: Ein guter, haushaltsüblicher Laserdrucker kann die Muster mit den nötigen Details erstellen, und das Format der Dateien wurde weitgehend entschlüsselt. Und so werden wir im Workshop selber unser eigenes Tip-Toi-Bild mit den optischen Codes versehen und diese drucken sowie die zugehörige Datei Programmieren. Mitzubringen sind, nach Möglichkeit: - Ein Laptop mit Linux, Windows oder MacOS - Ein Bildverarbeitungsprogramm, z.B. GIMP - Einen Tip-Toi-Stift (sofern die lieben Kleinen ihn hergeben) Ein klein wenig Erfahrung mit der Bildverarbeitung wäre hilfreich, Programmierkenntnisse sind nicht zwingend nötig. Wer schon ein Bild oder eine Zeichnung hat, die er verarbeiten will, darf diese gern (als Bild-Datei) mitbringen. Schwarze oder sehr dunkle Flächen sollten dabei vermieden werden. Aktuell haben wir gerade eine Doodle-Umfrage gestartet, um den optimalen Termin zu ermitteln. Wer also in der Umgebung von Karlsruhe wohnt oder wem der Weg nicht zu weit ist, ist gerne eingeladen teilzunehmen. http://doodle.com/ps2eirs7t7y4w5nx Sobald der Termin steht, werden wir das auch hier nochmals bekanntgeben. Gruß Wolfgang
Hallo, der Termin des Workshops steht! Am Samstag, dem 31. Januar wird Joachim ab 15:00 bei uns im FABLAB Karlsruhe e.V. zu Gast sein. Wer bei dem kostenlosen Workshop mitmachen möchte, wird um eine formlose Anmeldung per E-Mail gebeten: Wolfgang.Kraft@fablab-karlsruhe.de
Hello everyone! You have done a great job. Thanks. Maybe somebody already disassembled his pen and knows what main chips are there? I mean the first and the second generation. Are the main chips different or the same? Best wishes.
Hi, die letzten zwei Tage hat der Tiptoi-Stift bei unseren Weihnachtsbescherungen eine zentrale Rolle gespielt; genaueres auf meinem Blog: https://www.joachim-breitner.de/blog/666-Geschenke_mit_dem_Tiptoi-Stift_verteilen Außerdem habe ich eine Mailingliste für Tiptoi-Bastler eingerichtet, auf der man sich über solche Basteleien und das tttool austauschen kann: https://lists.nomeata.de/mailman/listinfo/tiptoi Frohe Weihnachten, Joachim
Hi, das Überschreiben von M-OIDs funktioniert IIRC nicht. Desweiteren meine ich mich zu erinnern, dass irgendwo mal die Information stand, dass rund 15000 Codes in einem Buch möglich seien. Demnach sind die restlichen die M-OIDs. Das würde grob zu der Theorie der 1000 möglichen M-OIDs passen. Das liesse sich bestimmt durch etwas Disassemblieren herausfinden. Uli
Angehängte Dateien:
-

OIDs600.png
74 KB
{kind=link}
{kind=link}
{kind=link}
Hallo, ich fange seit gestern ebenfalls mit dem Basteln von TipToi-Büchern an und habe ein wenig an der Auflösung rumprobiert (mein Drucker kann nur 600dpi). Die vom tttool generierten OIDs werden vom Stift auch in der Auflösung 600dpi erkannt. Mein Interpolationsverfahren beim Kleinrechnen war "Pixelwiederholung (harte Kanten)". Siehe oids600.png :) Tanja
mal dumm gefragt (ich habe nicht den gesmaten Thread durchgelesen): kann es sein, daß die teilweisen schlechten Lese-Ergebnisse etwas damit zu tun haben, daß die meisten (Laser-)Farb-Drucker automatisch einen Identcode mit ausdrucken, der sich mit dem Ting-Code irgendwie in die Quere kommt? http://de.wikipedia.org/wiki/Machine_Identification_Code#mediaviewer/File:HP_Color_Laserjet_3700_schutz_g.jpg
{kind=link}
Hallo Tanja, > ich fange seit gestern ebenfalls mit dem Basteln von TipToi-Büchern an > und habe ein wenig an der Auflösung rumprobiert (mein Drucker kann nur > 600dpi). > > Die vom tttool generierten OIDs werden vom Stift auch in der Auflösung > 600dpi erkannt. Mein Interpolationsverfahren beim Kleinrechnen war > "Pixelwiederholung (harte Kanten)". > Siehe oids600.png gut zu wissen! Ist das ein Laserdrucker gewesen? Andererseits: Die Drucker mit denen ich gearbeitet habe haben offiziell auch 600dpi... und am Ende ist es vermutlich nicht arg wichtig, ob man es vorm Drucken skaliert oder obs der Drucker selbst macht. > kann es sein, daß die teilweisen schlechten Lese-Ergebnisse etwas damit > zu tun haben, daß die meisten (Laser-)Farb-Drucker automatisch einen > Identcode mit ausdrucken, der sich mit dem Ting-Code irgendwie in die > Quere kommt? Würde ich stark bezweifeln. Unter der Lupe sieht man ja gut was gedruckt wird und was nicht. Und die hellen gelben Punkte würden kaum stören.
Wenn man das Reduzieren auf 600dpi dem Druckertreiber (oder dem Automatismus des Grafikprogramms) überlässt, kann folgendes passieren: 1. Klappt (mein Tiptoi hat aber gerade mal 2 von 10 OIDs erkannt). 2. Die Abstände innerhalb des 4*4 Musters sind verändert, daher wird der OID unlesbar. 3. Saubere Kanten werden zu "grauem Brei"; der OID ist unlesbar. Daher lieber selber richtig reduzieren :) Mein Drucker ist übrigens ein Farblaser (Kyocera). Viel Erfolg allen anderen Mitbastlern, Tanja
Vor Jahren hat der Chaos Computer Club herausgefunden, dass viele Drucker einen einamligen Id-code mit auf das Papier drucken. Das sind wenige Pixel, die über den ganzen Druckbereich (seite) verteilt werden. Angeblich nur um Geldfälscher die Geld mit Farblaserdruckern kopieren, zu entlarven.
> Daher lieber selber richtig reduzieren :) Na gut. Werds bei Gelegenheit in tttool einbauen: https://github.com/entropia/tip-toi-reveng/issues/68
Vielen Dank für das hervorragende tttool! Auch der Druck funktioniert gut. Ich habe erfolgreich Bilder mit Code (also nur ein Druckdurchgang) auf einem Farblaser ausgedruckt. Die Erkennung funktioniert auch bei dunklen Farben sehr gut: Bin wie folgt vorgegangen: -Code auf 600DPI Schwarz/Weiß Bitmap reduziert. (Drucker hat nur 600DPI) -Fotos/Bilder In Photoshop in CMYK umgerechnet. Hierbei manuell festgelegt, dass für den Schwarzaufbau nur CMY verwendet wird. Im Foto sind also keinen schwarzern Pixel vorhanden. Als CMYK Bild speichern. (Wenn dem Drucker die Umwandlung der RGB Bildes in die CMYK Druckfarben überlassen wird, wird für dunkle Farben immer etwas Schwarz verwendet, was die Erkennung der Codes stört) -In Indesign (Arbeitsfarbraum CMYK) das CMYK Bild plazieren und die S/W Bitmap mit dem code darüberlegen. -Auf einem Postscript Farblaserdrucker (meiner war Magicolor 4750) ohne weiteres Farbmanagement als CMYK drucken. -Fertig!
Na, wenn ihr alle mit 600dpi druckt, dann kann das tttool das jetzt auch, einfach "tttool -d 600 123-127" angeben.
Wenn ich fragen darf, wie ist es möglich zu drucken Ting stift Code? Tttool ist wunderbar aber es druckt nur für Tiptoi. Danke.
Halo Zusammen und allen ein gutes neues Jahr.
Ich bin auch auf der Recherche, wie ich meinen kleinen (7+5 J.)
den Stift , vor allem der Großen in der Schule (beim Rechnen mit den
Zauberminis oder den RechenFlusel)
oder die ich beim Geocachen (Erstellung von MultiCaches, oder virtuellen
Caches) verwenden kann.
Daher habe ich nun begonnen die Mission im Lesedschungel zu analysieren
(mit bestem Dank an Joachim für die hervorragende Leistung für das
tttool).
Ich habe zwar eine Fachinformatikerausbildung, aber in den Fächern
Mikrocontroller/Programmierung war ich keine Leuchte. Daher hoffe ich
auf reges
Feedback für meine Fragen, denn diese habe ich nun nach langem Suchen:
1. ) Wie verwende ich die yaml-Informationen zu den Subgames (tttool
games)?
2. ) Hat jemand eine Idee, wie ich das mit "gehe nun zu Punkt_A und
dann zu Punkt_B gehe aber dabei nicht über die Punkte_x _y und z_"
in einer Yaml-Datei realisiere?
3. ) Habe ich nur einen HP-Tintendrucker (OfficeJet 4620) der
anscheinend
die Punkte nicht klar genug druckt.
Kennt jemand die weitere Einstellungen (entweder zu klein/zu Groß)?
4. ) Welche Nummer muss ich beim Erstellen er OID's im tttool eingeben,
dass der Stift diese erkennt (habe 'Mission im Lesedschungel,
Product-Id=27, Scripts for OIDs from 5679 to 12838;
6841/7160 are disabled.)?
Lieben Dank, st_germain
Hallo Zusammen und allen ein gutes neues Jahr.
Ich bin auch auf der Recherche, wie ich meinen kleinen (7+5 J.)
den Stift , vor allem der Großen in der Schule (beim Rechnen mit den
Zauberminis oder den RechenFlusel)
oder die ich beim Geocachen (Erstellung von MultiCaches, oder virtuellen
Caches) verwenden kann.
Daher habe ich nun begonnen die Mission im Lesedschungel zu analysieren
(mit bestem Dank an Joachim für die hervorragende Leistung für das
tttool).
Ich habe zwar eine Fachinformatikerausbildung, aber in den Fächern
Mikrocontroller/Programmierung war ich keine Leuchte. Daher hoffe ich
auf reges
Feedback für meine Fragen, denn diese habe ich nun nach langem Suchen:
1. ) Wie verwende ich die yaml-Informationen zu den Subgames (tttool
games)?
2. ) Hat jemand eine Idee, wie ich das mit "gehe nun zu Punkt_A und
dann zu Punkt_B gehe aber dabei nicht über die Punkte_x _y und z_"
in einer Yaml-Datei realisiere?
3. ) Habe ich nur einen HP-Tintendrucker (OfficeJet 4620) der
anscheinend
die Punkte nicht klar genug druckt.
Kennt jemand die weitere Einstellungen (entweder zu klein/zu Groß)?
4. ) Welche Nummer muss ich beim Erstellen er OID's im tttool eingeben,
dass der Stift diese erkennt (habe 'Mission im Lesedschungel,
Product-Id=27, Scripts for OIDs from 5679 to 12838;
6841/7160 are disabled.)?
Lieben Dank, st_germain
Hi st_germain, 1. leider sind die "Spiele" (im Sinne der GME-Datei) noch nicht komplett verstanden, und auch nicht alles verstandene ist im tttool umgesetzt. Aber das ist weniger schlimm als es scheint, wenn man eh sein eigenes Ding machen will: Mit den vorhandenen Register-Abfrage und -Rechenbefehlen kann man seine eigene Spiellogik umsetzen! 2. Du nimmst ein Register her, was das Aktuelle „Ziel“ festlegt. Etwa $1 == 0 am Anfang, $1 == 1 wenn man zu B gehen muss, $1 == 2 wenn man zu C gehe muss. Bei den Code für B steht dann z.B. 6002: - $1 == 1? $1 := 2 P(gut_so) P(jetzt_zu_C) - $1 < 1? P(das_war_zu_voreilig) - $1 > 2? P(hier warst du schon) 3. Sorry, da musst du selber noch etwas Probieren. Vielleicht klappts mit 600dpi besser? 4. Wenn du das Labyrinth umprogrammieren willst: Genau diese: product-id: 27, und dann von 5679 aufwärts für die einzelnen Skripte. Im Zweifel mit dem Debug-Modus vorlesen lassen, welcher Code hinter etwas im Buch steht.
Diese Technologie ist von Anoto aus Lund in Schweden, die haben 100e patente auf ein Papier mit Rasteraufdruck mit spezieller IR-Tinte. Habe damit viel Erfahrung und habe alles Reverse-Engineered :)
●● pit ●● schrieb: > Habe > damit viel Erfahrung und habe alles Reverse-Engineered :) Und wo kann man es lesen?
●● pit ●● schrieb: > Diese Technologie ist von Anoto aus Lund in Schweden, die haben 100e > patente auf ein Papier mit Rasteraufdruck mit spezieller IR-Tinte. Habe > damit viel Erfahrung und habe alles Reverse-Engineered :) Das hat aber mit dem TING/Tiptoi-System nicht wirklich was zu tun, wenn ich das alles richtig verstehe... außer, dass in beiden Fällen ein Stift ein Raster abtastet, sehe ich keine Gemeinsamkeiten.
Schwer vorstellbar, das es eine andere Technologie ist, außer Patente sind bereits abgelaufen oder so was. Jedenfalls, so weit ich das mit limitierten patentrechtlichen Kenntnissen via Google Patents erfassen kann, ist fast alles im Kontext optische Abtastung von "Raster auf Papier" für fast jede Anwendung zigfach von Anoto patentiert.
Hallo Zusammen, kennt Ihr schon das: https://books.google.de/books?id=xr5mqyeBUrQC&pg=PA74&lpg=PA74&dq=tiptoi+firmware&source=bl&ots=_qy1jaiefQ&sig=LtA403-5b3L9GNEampoz7AfBK8I&hl=de&sa=X&ei=2fSvVI3eJMm3PKWHgIgB&ved=0CEAQ6AEwBTgU#v=onepage&q=tiptoi%20firmware&f=false Hier wird auf der den Seiten 72 bis 75 die TipToi Hardware näher beschrieben ...
Wie sieht es eigentlich mit Lizenz-Rechten aus ? Darf ich ein selbstgedrucktes Buch verkaufen ???
> Wie sieht es eigentlich mit Lizenz-Rechten aus ? > Darf ich ein selbstgedrucktes Buch verkaufen ??? Vermutlich nicht. Da stecken ein paar Patente drin, die du vermutlich verletzen würdest. Aber so genau will ich das glaub gar nicht wissen :-]
st germain schrieb: > Hier wird auf der den Seiten 72 bis 75 die TipToi Hardware näher > beschrieben ... Naja, diese Informationen sind nicht wirklich neu und auch nicht hilfreich. Wer seinen TipToi schonmal aufgemacht hat (z.B. um einen defekten Lautsprecher zu ersetzen), kann problemlos sehen, welche Bauteile enthalten sind.
hallo zusammen, es freut mich dass schon soviel dokumentiert wurde und tttool entstanden ist (muss ich noch ausprobieren). bin aus "saisonalen gruenden" hier gelandet. bin gerade dabei die paar Anhaenge mit Code/Punktemuster hier aus dem Forum zu drucken, um zu sehen was der Stift so erkennt. Ich mache mir Gedanken wie ich selber aktive Bilder machen kann, fuer meine 2 neugiereigen maedels (2 J. u. 3 J.). Irgendwie habe ich hier den Eindruck dass versucht wird "einzelne" Punktcodes (resp. "clusters" von Punktcodes) an gezielte Stellen zu drucken. Beim begutachten des mir vorliegenden tiptoi Bauernhofbuches mittels Lupe, stelle ich fest dass die Buchseiten voll "bis ueber den Rand bepunktmustert" sind. Also muesste der Weg doch sein, aehnlich wie Wasserzeichen (aber Stiftlesetauglich) seitenfuellend Punktmuster zu generieren, welche von den Werten her wie ein Koordinatensystem ueber alle Seiten hinweg gehen. Jede "Daumennagelgrosse" (sodass <64k davon reichen) Zone jeder Seite ist dann eindeutig lokalisierbar. Dies kommt nun auf alle Seiten "ueberlagert" gedruckt. (bin nicht von der Bildbearbeitenden noch von der Druckenden Branche, man verzeihe mir den ev. holprigen Jargon) Nun kann man dank dem Debug-mode (tttool) alle Hotspots/Interessanten Zonen inventarisieren und den passenden YAML Code dazuschreiben, um die zugehoerigen Audiodateien zu "verorten" (natuerlich inkl. der ev. Ablauflogik). Mache ich mit meinen dargelegten Gedanken ueberlegungsfehler? Ich sehe auch Nachteile; - die "lokalisierung" ist diskretisiert, also weist die kleinstmoegliche lokalisierbare Zone eine Mindestgroesse auf und die uebergaenge von Zone zu Zone sind durche das Zonenraster vorgegeben - ev. sind "Standard Hintergrundgeraeusche" nicht moeglich oder muehsam in YAML zu codieren Mir scheint es jedenfalls im Ueberblick so einfacher, als bestimmte Punktmuster einzeln ueber die Seiten zu plazieren. Modifikationen der Zuordnung sind auch nach dem Druck noch moeglich. 73 de HB9ocq
Hallo Stephan, > Beim begutachten des mir vorliegenden tiptoi Bauernhofbuches mittels > Lupe, stelle ich fest dass die Buchseiten voll "bis ueber den Rand > bepunktmustert" sind. richtig. Das liegt aber daran dass die auch in die inaktiven Bereiche einen Null-Code drucken, damit das Buch gleichmäßig grauer wird – sonst würden die aktiven Bereiche wohl eher auffallen. Trotzdem bin ich mir sicher dass die Muster wirklich den Formen angepasst sind. Das heißt natürlich nicht dass die Idee einer „Universalseite“ nicht brauchbar wäre... Aber das würde auch heißen dass man bei einem aktiven Bereich, der mehrere Daumennägel umfasst, die zugehörigen Programme im GME-File zig-mal duplizieren muss. Eventuell sprengt man damit irgendwelche Resourcenbeschränkungen des Formats oder des Stiftes.
Ich sehe gerade dass ich da wohl ein paar mal nicht eingeloggt war, und auch noch das Autoren-Feld mit dem Titel-Feld verwechselt hab. „Autor: Tiptoistift als Christikindhelfer (Gast)“ bin ich :-)
Tiptoistift als Christikindhelfer schrieb: > Aber das würde auch heißen dass man bei einem aktiven > Bereich, der mehrere Daumennägel umfasst, die zugehörigen Programme im > GME-File zig-mal duplizieren muss. Hallo Zusammen, das passt aus meiner Sicht zusammen zu dem TipToi-Stift. Auch wäre es einfacher Sprünge und Wiederholungen zu adressieren. So wird das bestimmt mit dem Handschrifterkennung-Stift (irgendwo auf youtube gesehen) gemacht... Auch erkennst das tttool von Dir ja auch schon Duplikate "Audio table repeated twice". Dies könnte auch die Game-Struktur erklären, oder sehe ich das falsch? tttool.exe info ".\media\027\00522 - Mission im Lesedschungel\20120118\Mission im Lesedschungel.gme" Product ID: 0x0000001B Raw XOR value: 0x0000002E Magic XOR value: 0xD9 Comment: CHOMPTECH DATA FORMAT CopyRight 2009 Ver2.10.0901 Date: 20120118 Number of registers: 1 Initial registers: [1] Initial sounds: [[768,769]] Scripts for OIDs from 5679 to 12838; 6841/7160 are disabled. Audio Table entries: 770 Audio table repeated twice Checksum found 0xC1A64BA3, calculated 0xC1A64BA3 St_germain
Hallo, ich habe diese Diskussion aufmerksam verfolgt, doch leider die Lösung für mein Problem so direkt nicht entnehmen können: Mein Sohn bekam zu Weihnachten ein Ting-Kinderliederbuch. Doch der Singsang, der über den Ting-Stift kommt ist grauenhaft schlecht. Ich wollte die Datei, welche die Lieder enthält, editieren, und die Lieder austauschen. Mit Audacity kann man sämtliche Sound-Dateien aus der *.ouf-Datei anhören, aber das Rückspeichern geht wohl sicher nicht. Ich fragte bei dem Ting-Service, doch bekam ich die Nachricht, ich könne die (*.ouf-) Dateien nicht ändern .. Leider bin ich nicht so sehr fit im dieser speziellen Computer-Anwendung. Vielleicht steht hier irgendwo schon die Lösung, und ich habe sie nicht erkannt .. Ich nutze Linux Miint 17.1 (Rebecca)
Hallo, leider bezieht sich das meiste hier auf den TipToi Stift. Das Dateiformat des Ting-Stiftes ist noch nicht vollständig bekannt, daher stimmt die Aussage, dass es nicht geht, zur Zeit leider noch.. :)
.. Und mit einem Hex-Editor die entsprechenden Titel löschen, oder gleich durch eigene MP3-Titel überspielen? Das müßte doch gehen, mindestens, wenn die gesamte Dateilänge nicht verändert wird? Nur: wie finde ich definitiv den Anfang und das Ende eines MP3-Titels? Der Vorspann kann mir wahrscheinlich egal sein, da dieser wahrscheinlich wohl nur einen Pointer setzt, und nicht weiß, wie der Titel eigentlich klingen muß.
Hallo Wolfgang, wenn es funktioniert wie beim Tiptoi-Stift, dann findest du irgendwo eine 32-bit-Zahl, die genau die Position der MP3-Daten in der Datei anzeigt. Die direkt darauf folgende 32-bit-Zahl ist die Länge der MP3-Daten – damit weißt du wass du austauschen darfst. Also: * Anfang der MP3-Datei suchen (gar nicht so einfach bei MP3-Leider) * Die Position in der Datei notieren. * Diesen Wert weiter vorne suchen. * Schauen was direkt danach notieren. * MP3-Datei austauschen.
Hallo Leute, Tingeltangel präsentiert das MyTingBook-Tool mit dem sich eigene Ting-Bücher erstellen lassen. https://tingeltangel12.wordpress.com/ (Es gibt auch ein paar Infos zum ous-Dateiformat) Viel Spass Euer Tingeltangel
Hi Tingeltangel, schön, dass sich nochmal jemand dem Ting-Stift angenommen hat. :) Konnte das Tool leider noch nicht testen, aber die Infos auf der Webseite fand ich schon sehr spannend. Es hat mir auch gezeigt, dass es die richtige Entscheidung war, das Dateiformat nicht weiter zu untersuchen... wie die Positionen der mp3s innerhalb der Datei errechnet werden, verstehe ich nicht mal ansatzweise. ;) Ist das ein gängiges Verfahren, das da verwendet wird, oder wie findet man das raus? Einen Zusammenhang zwischen Ting-Id und Code-Id scheint es also tatsächlich nicht zu geben? Ich hatte schon mal vermutet, dass es einfach eine Art Lookup-Tabelle im Stift gibt, um es uns schwerer zu machen, aber hatte zu wenig funktionierende Codes, um da weiter zu forschen. :) Tolle Arbeit auf jeden Fall! Und vielen Dank fürs zur Verfügung stellen. Ich hoffe, ich komme bald mal zum Testen. :) Gruß, Marc
Hallo zusammen, bin gerade durch Freunde auf den TING-Stift aufmerksam geworden. Danke für das bisher Geleistete! :-) Die noch unklare Zuordnung TING-ID zu Code-ID beschäftigt mich. Ich möchte hier einen Denkanstoß liefern, da mir selbst aktuelle leider die Zeit fehlt, den Ansatz weiter zu prüfen: Beim Einlesen ist mir aufgefallen, dass die aktuell angewendete Übersetzung der Punktmatrix-Codes bekannterweise nicht direkt die TING-ID liefert. Ist also die aktuelle Interpretation fehlerhaft, weil wir z.B. von einer falschen Byteorder ausgehen? Denkbar ist alles bis hin zu einem nichtlinearen Muster. Vielleicht kann damit der notwendige LUT-Schritt ganz entfallen bzw. lässt sich dann eine allgemeingültige Transformationsfunktion extrahieren. IMHO ist dieser (für uns aktuell notwendige) Transformationsschritt ursprünglich nicht vorgesehen. Zumindest finde ich keinen Grund für eine solche Implementierung.
Hallo, ich wollte die deutschsprahigen Übersetzungen aus dem 'Wir lernen Englisch' TipToi-Buch durch österreichischen Dialekt ersetzen (sozusagen als Motivation, damit das Buch wieder hergenommen wird). Nach dem ich die Oggs neu aufgenommen habe und die Gme ohne Fehlermeldung erzeugt worden ist, ist hatte sie nur noch 13 statt 37MB und die ganzen Übersetzungen waren weg. Habe dann als Test die Gme aus der Yaml mit originalen Ogg-Dateien erzeugt aber diese hatte dann auch nur 13MB und auch dort fehlten die deutschen Übersetzungen. In der Yaml-Datei sind aber auch die deutschen Oggs zugeordnet. Was mache ich denn falsch? Grüßle, David
Hi David, das tttool versteht nicht alle Funktionen einer GME-Datei. Insbesondere Spiele und Binärprogramme werden nicht unterstützt. Wenn also die Übersetzungen nicht über „normale“ Felder angesprochen werden, sondern über Spiele, dann kann tttool diese Sachen nicht mehr zusammenbauen. Allerdings schreibst du dass die Dateien in der YAML-Datei erwähnt werden. Dann sollte das also eigentlich nicht das Problem sein... Magst du deine Frage nochmal auf der tttool-Mailingliste https://lists.nomeata.de/mailman/listinfo/tiptoi stellen? Vielleicht kann dir dort jemand weiterhelfen. Gruß, Joachim
Hallo Joachim, werde ich gleich machen. Mit besten Dank für die prompte Antwort, David
> Allerdings schreibst du dass die Dateien in der YAML-Datei erwähnt > werden. Dann sollte das also eigentlich nicht das Problem sein... Hallo Joachim, ich hatte nach den falschen Nummern in der Yaml-Datei gesucht: die deutschsprachigen Dateien werden da nicht erwähnt. Sorry. Dann hat es wohl (leider) geklärt. Danke nochmals, David
Hallo, Ich will für meine Kids nur zusätzliche (eigene) Lieder auf den TipToi-Stift laden um ihn als 'mp3-player' zu verwenden. Gibt es dazu Erfahrungen/Hints? Muss ich mich dafür mit den ganzen Codes herumschlagen oder können die mp3/ogg Dateien einfach in gme übersetzt werden? lg Howil
Hallo howil, hallo miteinander, > Ich will für meine Kids nur zusätzliche (eigene) Lieder auf den > TipToi-Stift laden um ihn als 'mp3-player' zu verwenden. Gibt es dazu > Erfahrungen/Hints? > Muss ich mich dafür mit den ganzen Codes herumschlagen oder können die > mp3/ogg Dateien einfach in gme übersetzt werden? Den gleichen Wunsch hatte auch ich, als der TipToi Stift bei uns kurz vor Weihnachten ins Haus kam. Ich habe über Weihnachten ein kleines GUI geschrieben, das die bekannten Tools integriert und mit dem man mp3 und ogg Dateien sehr schnell und einfach in den TipToi Stift laden kann: https://github.com/sidiandi/ttaudio Den ersten Release gibt es hier: https://github.com/sidiandi/ttaudio/releases/download/v0.1.6/ttaudio-0.1.6.msi Viel Spaß damit, Andreas
Hallo, danke für das sehr interessante Informationen. Auch wenn hier jetzt schon fast 1Jahr ruhe ist greif ich es doch noch mal auf. Da meine Tochter auch einen solchen Tiptoi-Stift bekommen hat, habe ich mich mal ein wenig belesen was so alles möglich ist. Leider verzweifel ich einfach beim drucken des Codes. Ich bin Step-by-Step dieser (http://tttool.entropia.de/) Anleitung gefolgt. Das klappt auch so weit ganz gut, nur an der Stelle wo Steht das die Codes ausgedruckt 10x10cm sein sollen, bin ich am verzweifeln. Egal ob im 600 oder 1200dpi erzeuge, es werden immer nur 3x3cm Kästchen gedruckt. Daher auch keine Chance für den Stift was zu erkennen. Kann mir jemand sagen was ich evt. falsch mache? Ich habe es mit PhotoShop und IfranView versucht. Hat vielleicht jemand eine PS-Datei, mit einem Test-Code, bei der alle Einstellungen (vom Programm her) schon getätigt sind, damit ich mal sehen kann was anders gemacht wurde. Oder einfach nur ein paar Tipps würden es auch schon tun. Leider besitze ich auch nur einen Epson XP-510 (Tintenstrahldrucker), bei dem eine manuelle Einstellung nicht wirklich machbar ist (zumindest hab ich noch keine gefunden). lg Pielo @sidiandi das Tool ttaudio gibt es wohl nicht mehr?
> Das klappt auch so weit ganz gut, nur an der Stelle wo Steht > das die Codes ausgedruckt 10x10cm sein sollen, bin ich am verzweifeln. > Egal ob im 600 oder 1200dpi erzeuge, es werden immer nur 3x3cm Kästchen > gedruckt. Das liegt an einer neuen Version des tttool. 3cm×3cm ist korrekt. Da ist die Webseite nicht mehr aktuell, das schau ich mir gleich an. Aktivere Diskussionen zum tttool findet hier stat: https://lists.nomeata.de/mailman/listinfo/tiptoi > @sidiandi das Tool ttaudio gibt es wohl nicht mehr? Doch: https://github.com/sidiandi/ttaudio Frohe Weihnachten, Joachim
Robert M. schrieb: > Ich habe es mit > IfranView versucht. Mit IrfanView sollte es funktionieren. Da kann im Druckfenster jede gewünschte Grösse eingestellt werden.
Joachim Breitner schrieb: >> @sidiandi das Tool ttaudio gibt es wohl nicht mehr? > > Doch: https://github.com/sidiandi/ttaudio Danke für die hilfreichen Antworten Auch wenn ich mich jetzt vielleicht etwas doof anstelle, aber wie Starte ich ttaudio? Oder anders gefragt, kann ich das Tool mit Win starten, oder ist das ein Linux Tool?
Robert M. schrieb: > Auch wenn ich mich jetzt vielleicht etwas doof anstelle, aber wie Starte > ich ttaudio? Oder anders gefragt, kann ich das Tool mit Win starten, > oder ist das ein Linux Tool? Hast du die `MSI`-Datei von https://github.com/sidiandi/ttaudio/releases installiert? Mehr weiß ich auch nicht, benutze kein Windows :-)
Joachim Breitner schrieb: > Robert M. schrieb: > Auch wenn ich mich jetzt vielleicht etwas doof anstelle, aber wie Starte > ich ttaudio? Oder anders gefragt, kann ich das Tool mit Win starten, > oder ist das ein Linux Tool? > > Hast du die `MSI`-Datei von https://github.com/sidiandi/ttaudio/releases > installiert? Mehr weiß ich auch nicht, benutze kein Windows :-) Genau die hatte ich. Der Installer hat aber ohne was zu sagen einfach auf C: installiert. (Muss man erstmal wissen ?) Muss jetzt nur noch den Druck hinbekommen, bzw die Drucker aus dem Bekanntenkreis alle austesten. Irgendeiner muss es doch hinbekommen...
Hat schon jemand versucht, die OIDs (per Photoshop) über "normale" Digitalfotos zu legen und dann Abzüge davon im Fotolabor machen zu lassen?
Hallo, das ist echt total faszinierend. Hätte jemand Lust und Zeit ein Material für den Unterricht für mich mit der TinG Funktion zu erstellen? Ich würde es auch vergüten. Einfach melden. Danke!
Karo (gast) schrieb: > Einfach melden. Danke! Du Held! Dann müßtest du halt auch mal irgend eine Kontakt-Adresse angeben, oder wie soll sonst die Meldung erfolgen?
FABLAB Karlsruhe (Wolfgang Kraft) schrieb: > mitmachen Wegstaben V. schrieb: > Karo (gast) schrieb: > Einfach melden. Danke! > > Du Held! > Dann müßtest du halt auch mal irgend eine Kontakt-Adresse angeben, oder > wie soll sonst die Meldung erfolgen! ??? Sorry, meine E Mail ist Karo-pereira@gmx.de Danke ?
Beitrag #4926302 wurde von einem Moderator gelöscht.
Beitrag #4926303 wurde von einem Moderator gelöscht.
Martin B. schrieb: > Hat schon jemand versucht, die OIDs (per Photoshop) über "normale" > Digitalfotos zu legen und dann Abzüge davon im Fotolabor machen zu > lassen? Immner noch keine Erfahrungen? Die üblichen Drogeriemärkte bieten Photodrucke ja im Centbereich. Ich habe keinen (Farb-)Drucker zu Hause. Es wäre sehr ärgerlich, wenn ich mit dem ganzen Software-Kram anfange und Stunden investiere, um dann später feststelle, dass es nicht funktioniert. :( tttool konnte ich unter debian jessie übrigens erfolgreich bauen. ttmp32gme ist allerdings eine sehr harte Nuss: Perl-Monster sondergleichen! Habe tausend Module mit cpan / cpanm nachinstalliert. Einige musste ich forcen, weil Tests fehlschlugen. An "Music::Tag::MP3" bin ich leider gescheitert. Selbst mit Forcen klappt es nicht. ttmp32gme.pl sagt immer noch, dass es fehlt :( Ist mir leider zu hoch: Mit debian jessie kriege ich es zumindest nicht hin. Bleibt nur der Windoof-Rechner meiner Frau. Aber bevor ich dort wieder bei Null anfange, würde ich gerne wissen, ob es überhaupt Sinn macht mit dem DM-, Rossmann- oder Müller-Druckservice.
Hinweis für alle, die sich bis hier durchgelesen haben: Superseite zum Ting-Stift, unbdedingt beachten: https://www.ting-el-tangel.de/ Gruß Bernhard
Gibt es für den Tiptoi (mit Aufnahmefunktion) auch eine settings.ini
o.ä. bzw. eine andere Möglichkeit, die Standardlautstärke einzustellen?
Ich möchte die Aufnahmefunktion ("Create") für ein Fotoalbum nutzen,
dort aber keine Pinguine o.ä. mit vorgegebenen Texten aufkleben.
Eigentlich brauche ich dort nur einen Play button, die Aufnahmecodes
können separat sein.
Was ist "games / finishplaylists" ("Stickerbogen_Starterset",
product-id: 133)?
In https://tttool.readthedocs.io/de/latest/yaml-referenz.html leider
nicht dokumentiert.
Scripts für Aufnahme und Wiedergabe unterscheiden sich offenbar nicht.
Wie ist die Zuordnung zu den Sounds? Scheint auf
https://github.com/entropia/tip-toi-reveng/wiki/REC-file-format nicht
abschließend geklärt zu sein.
Z.B. hängt der Pinguin mit RecSlot0005.rec zusammen (Aufnahme: OID 9964,
Abspielen: OID 9965).
Ah: in Reihenfolge der OIDs, d.h. die niedrigste bekommt
RecSlot0001.rec.
Bei der Katze (RecSlot0003.rec) kommt nach dem Abspielen (9959) der
Aufnahme (9958) noch Stickerbogen_Starterset_37.ogg ("Das war ein
zauberhafter Zungenbrecher") oder 18 (Applaus) ungefragt hinterher.
finishplaylists hat 5 Listen, aber 18 und 37 sind nicht in derselben,
und haben auch nicht den Index 3 (Katze).
Kann dir nicht weiterhelfen, aber lese die Mailingliste [1] mit, wo sich die Profis rum treiben und ähnliche Probleme gelöst werden: Also Email an tiptoi@lists.nomeata.de und unter [1] abonnieren falls du mit lesen willst. ;) LG Georg [1] https://lists.nomeata.de/mailman/listinfo/tiptoi
Danke für den Tipp. https://lists.nomeata.de/archive/tiptoi/2020/002359.html hat alle OIDs und Zuordnungen von der Musterseite ("236699"). Nützt aber nicht viel, wenn die entsprechenden script-Befehle nicht bekannt sind. Es funktioniert auch nicht "export" gefolgt von "assemble". Die resultierende gme ist etwas kleiner. Keiner der Codes ergibt eine Reaktion. Da muss man tiefer einsteigen: https://github.com/entropia/tip-toi-reveng/wiki/GME-Format
Beitrag #6973506 wurde von einem Moderator gelöscht.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.