Hallo, ich wollte mal fragen, ob sich schon jemand mit dem LPC810 beschäftigt hat? Inzwischen sind wohl erste Samples lieferbar. z.I.: Es handelt sich um einen Cortex-M0 im 8Pin DIP-Gehäuse. http://www.nxp.com/products/microcontrollers/cortex_m0_m0/LPC810M021FN8.html Dank eingebautem Bootloader sollte er sich wohl ähnlich einfach wie der LPC1114 programmmieren lassen http://vilaca.eu/lpc1114/
Dann berichte mal fleißig!!! Daran bin sicher nicht nur ich interessiert. Interessant dürften auch die neuen Infineons werden.
Angehängte Dateien:
-

lpc810.jpg
110 KB

Da ist er. Außer Blinky läuft aber noch nicht viel. Der Code scheint deutlich größer als beim AVR zu werden. Die 4kb kann man also nicht mit 4kb beim AVR vergleichen..
Angehängte Dateien:
-

Simon_says.jpg
47 KB

Hi, ich bin auch an einem kleinen Projekt mit LPC810 dran. Das mit dem Code kann ich bestätigen. Könnte aber auch am CodeRed Compiler (GNU) liegen... Würde mich mal interessieren, ob es mit einem kommerziellen Compiler z.B. IAR deutlich kompakter wird. Ein anderes Problem bei meinem Projekt war die Verwendung des Reset-Pins als GPIO. Ich hatte damit einen Haufen Ärger, da der Bootloader dann nicht mehr richtig funktioniert und auch das Programm nicht mehr sauber startet. Ich habe es deshalb erstmal aufgegeben, den Reset-Pin zu nutzen. Auch scheint das Switchmatrix-Tool von NXP etwas buggy zu sein. Es wird z.B. immer der Reset-Pin als GPIO konfiguriert (auch wenn er mit Switchmatrix als Reset deklariert wurde). Im Moment kämpfe ich gerade mit dem SCT, den ich für eine Soundausgabe (Beeper) nutzen möchte... Wenn da noich jemand einen Tip oder Samplecode hat, wäre ich dankbar..
Wo hast Du denn Deinen LPC810 her? Ich habe das Board "gewonnen", hätte aber auch gerne einzelne Devices.
Kann mir jemand mal den Sinn eines 32 Bitters im DIL8 erklären bzw. Wo man sowas wirklich ernsthaft einsetzen könnte? Ernstgemeinte Frage!
Der Sinn für NXP besteht ganz konkret darin, mittels einer Softwarekompatiblen und Migrationsfähigen Plattform den 8 Bittern von Atmel und Microchip das Wasser abzugraben. Auf Kosten- und Energieseite haben 8 Bitter bei den aktuellen Halbleiterprozessen keinen Vorteil mehr. Die Entwicklung zu ARM im Low-End liegt klar auf der Hand.
Ich habe erst letzte Woche ein winziges Projekt 300 Byte mit nem Tiny13 gemacht. Dauer ca 2h. Mit nem Cortex wäre das sicher mehr geworden
Mehr Bytes vielleicht, aber in 4K hätte es wohl gepasst. Wäre es auch mehr Zeit geworden, wenn du mit den LPCs schon viel gemacht hast, aber noch nichts mit AVRs? Denn darum geht es: das ganze Spektrum abzudecken. Auch nach unten.
Ich weiß nicht wie es bei einem LPC ist, aber wenn ich mit nem STM4F4 sehe, was es da an Overhead gibt, finde ich das gerade bei kleinen Projekten unnütz. Bei größeren Projekten is dieser ganze Kram wiederum sehr hilfreich. Muss man evtl abwägen... Grundsätzlich finde ich 32Bit gut, aber für winzprojekte im DIL8 finde ich es absoluten Overkill, solange mir jemand tatsächlich ein Projekt nennt, wo hier 32Bit mehr Sinn machen als 8. unabhängig von den sowieso gleichen kosten...
A. K. schrieb: > Mehr Bytes vielleicht, Warum eigentlich? Die Thumb-Instruktionen sind auch fast alle 16bit groß wie beim AVR, behandeln dafür aber gleich 4fach so große Variablen... Beispiel: 32bit-Addition ist beim M0 eine 16bit-breite Instruktion (die auch noch auf Wunsch einen Shift durchführen kann), beim AVR 4 16bit-Instruktionen (+ 1 16bit-Instruktion pro Shift-Bit).
Das ergibt nicht mehr und nicht weniger Sinn, als 8051er mit 1/2 MB Programmgrösse (gibts wohl). Man macht es nicht, weil es aus Hardwaresicht optimal ist, sondern weil es aus Rerrourcensicht sinnvoll ist - Manpower und Entwicklungsumgebung eingeschlossen.
Dr. Sommer schrieb: > Warum eigentlich? Allein schon, weil die Initialisierung vermutlich komplexer ist. Ausserdem sind bei solchen Zwergprogrammen Bit-I/O und I/O-Registerzugriff signifikant, und da ist der Unterschied markant.
A. K. schrieb: > Allein schon, weil die Initialisierung vermutlich komplexer ist. Welche Initialisierung? Der Core ist sofort bereit C Code auszuführen. Höchstens das Laden der .data Sections, aber die ist beim AVR eher 4x so groß (und so langsam).
Dr. Sommer schrieb: > Warum eigentlich? Ausserdem sind bei solchen Zwergprogrammen Bit-I/O und I/O-Registerzugriff signifikant, und da ist der Unterschied markant. Portbit setzen: AVR 2 Bytes, CM0 12-14.
Dr. Sommer schrieb: > Welche Initialisierung? Der Core ist sofort bereit C Code auszuführen. Fertig initialisierte Stackpointer inklusive? Kenne diesen LPC nicht, aber üblicherweise muss man bei den Cortexen schon ein bissel was vorneweg machen. Zwecks Familienähnlichkeit werden auch die I/O-Module erheblich komplexer ausfallen. Ausserdem programmiert man die nicht in Assembler, und die bestehenden Entwicklungssysteme für ARMs sind vom Overhead her sicherlich nicht schon durchweg auf solche Zwerge optimiert.
A. K. schrieb: > Ausserdem sind bei solchen Zwergprogrammen Bit-I/O und > I/O-Registerzugriff signifikant, und da ist der Unterschied markant. > Portbit setzen: AVR 2 Bytes, CM0 12-14. Das stimmt sogar... Bei sukzessiven Zugriffen auf das selbe Register wirds aber etwas besser. Gäbe es einen Compiler der das Bit Banding vom ARM unterstützen würde ging's wohl in 6 bytes. Der Vorteil ist allerdings - es kann 4 GB an I/O Registern geben, bei einigen AVR's (ATmega*8 wimre?) läuft der I/O Adress Space über, was die Sache dort so ineffizient wie beim ARM macht. A. K. schrieb: > Fertig initialisierte Stackpointer inklusive? Ja. Nur die FPU muss man ggf. aktivieren (4 Instruktionen). A. K. schrieb: > Kenne diesen LPC nicht, > aber üblicherweise muss man bei den Cortexen schon ein bissel was > vorneweg machen. Für den Cortex Core an sich nicht; je nach Controller muss man aber Clocks initialisieren... (Nachteil: Codesize, Vorteil: unverfusbar) > Zwecks Familienähnlichkeit werden auch die I/O-Module > erheblich komplexer ausfallen. Ja, die sind aber auch wesentlich mächtiger dann... A. K. schrieb: > Ausserdem programmiert man die nicht in Assembler, Die Optimierungen, die Compiler machen können zur perfekten Ausnutzung der Pipeline etc. könnte man ja auch kaum von Hand schaffen. > und die bestehenden > Entwicklungssysteme für ARMs sind vom Overhead her sicherlich nicht > schon durchweg auf solche Zwerge optimiert. Zumindest beim GCC geht das schon ziemlich gut.
Dr. Sommer schrieb: > Gäbe es einen Compiler der das Bit Banding vom > ARM unterstützen würde ging's wohl in 6 bytes. Der Cortex M0 hat kein Bitbanding. Der CM0+ optional. > Zumindest beim GCC geht das schon ziemlich gut. Es sei denn zu ziehst unversehens die Newlib mit rein. Bei Freeware-Entwicklungsumgebungen passiert das schnell mal.
Dr. Sommer schrieb: > (Nachteil: Codesize, Vorteil: unverfusbar) Doch, sowas in der Richtung geht auch, zumindest bei manchen. Mindestens ältere LPC2000 konnte man mit einer falsch programmierten PLL in den Halbleiterhimmel schiessen. Andere haben sich bei versehentlichem Zugriff auf undokumentierte Flash-Register zerlegt. Und manche kann man versehentlich zusperren und den Schlüssel wegwerfen - das rettende HVP gibts nicht.
A. K. schrieb: > Der Cortex M0 hat kein Bitbanding. Der CM0+ optional. Okay, die größeren haben das... A. K. schrieb: > Es sei denn zu ziehst unversehens die Newlib mit rein. Bei > Freeware-Entwicklungsumgebungen passiert das schnell mal. Stimmt, man muss eben aufpassen was man tut, nicht einfach mal fröhlich printf und scanf benutzen :) A. K. schrieb: > Doch, sowas in der Richtung geht auch, zumindest bei manchen. Okay mit denen kenn ich mich weniger aus, bei den STM32 zB kann man schwer durch falsche Programmierung was kaputtmachen (dafür aber durch falsche Beschaltung)
@cpldcpu Ich habe einfach mal bei einem Distri (Arrow) nach Mustern gefragt. Ein paar Wochen spaeter hatte ich dann 10 Muster. (Ok ich kenne ein paar Leute von Arrow)
Bei dem Code kräuseln sich schon manchmal die Fußnägel. Untiges Beispiel Resettet das GPIO-Modul. Dazu muss ein Bit gelöscht und danach wieder gesetzt werden. -Os und -O3 erzeugen den gleichen Code.
1 | 44:../src/gpio.c **** LPC_SYSCON->PRESETCTRL &= ~(1 << 10); |
2 | 38 .loc 1 44 0 |
3 | 39 000c 5968 ldr r1, [r3, #4] |
4 | 40 000e 054A ldr r2, .L2+4 |
5 | 41 0010 0A40 and r2, r1 |
6 | 42 0012 5A60 str r2, [r3, #4] |
7 | 45:../src/gpio.c **** LPC_SYSCON->PRESETCTRL |= (1 << 10); |
8 | 43 .loc 1 45 0 |
9 | 44 0014 5968 ldr r1, [r3, #4] |
10 | 45 0016 8022 mov r2, #128 |
11 | 46 0018 D200 lsl r2, r2, #3 |
12 | 47 001a 0A43 orr r2, r1 |
13 | 48 001c 5A60 str r2, [r3, #4] |
14 | |
15 | 54 0020 00800440 .word 1074036736 |
16 | 55 0024 FFFBFFFF .word -1025 |
Ergebnis: 9 Befehle, 2x32 bit Konstanten = 26 Bytes. Fairerweise muss man aber sagen, dass die Zugriff auf die GPIO-Pins etwas effizienter sind.
Immerhin - blinky ist jetzt bei 332 bytes. Das ist immer noch mehr als auf einem AVR, dafür sind die Sprungtabellen aufgrund der größeren Komplexität des ARMs aber auch deutlich größer.
Falls es jemanden interessiert: Ich habe mich heute damit beschäftigt die LPC810 Software zu verkleinern. Die Ergebnisse sind inzwischen im semioffiziellen Repository. https://github.com/microbuilder/LPC810_CodeBase/pull/3 CMSIS begeistert nicht gerade...
Tim . schrieb: > Bei dem Code kräuseln sich schon manchmal die Fußnägel. Untiges Beispiel > Resettet das GPIO-Modul. Dazu muss ein Bit gelöscht und danach wieder > gesetzt werden. -Os und -O3 erzeugen den gleichen Code. Okay, für einzelne Bits ists ohne Bitbanding tatsächlich unschön... Der AVR kann das aber nur aufgrund dank SBI/CBI besser, mit den bekannten Einschränkungen... Die Cortex sind wohl doch besser für größere Dateneinheiten gemacht :-) Man versucht diesem Problem eher mit einfach mehr Flash & MHz zu begegnen, was wohl etwas einfacher als die "direkten" SBI/CBI ist...
>dafür sind die Sprungtabellen aufgrund der größeren >Komplexität des ARMs Die Sprungtabellen-Grösse hat aber nichts mit der "Komplexität" zu tun, sondern nur mit der Weite der Sprungziele. >Die Cortex sind wohl doch besser für größere >Dateneinheiten gemacht :-) Ja, bis sageundschreibe 4kB (12ADRbits), denn nur das passt als IMM-ofs in den OPcode. >Man versucht diesem Problem eher mit einfach >mehr Flash & MHz zu begegnen,........ denn sonst müsste man ja (nach nur 3 Jahrzehnten) die CPU (bzw den Bef.satz) ändern.
MCUA schrieb: >>Die Cortex sind wohl doch besser für größere >>Dateneinheiten gemacht :-) > Ja, bis sageundschreibe 4kB (12ADRbits), denn nur das passt als IMM-ofs > in den OPcode. Das ist aber Absicht, um die kurzen 16bit-Opcodes zu behalten - wie willst du 32bit-Adressen in 16bit-Opcodes packen?? Wenn man 32bit-Adressen laden will, verwendet man eben seperate Konstanten. >>Man versucht diesem Problem eher mit einfach >>mehr Flash & MHz zu begegnen,........ > denn sonst müsste man ja (nach nur 3 Jahrzehnten) die CPU (bzw den > Bef.satz) ändern. Eher etwas einbauen, das in die RISC + Load-Store-Architektur vom ARM überhaupt nicht hineinpasst... Eine entsprechende Instruktion dafür wäre wohl genauso langsam wie die Folge der Einzelinstruktionen.
Dr. Sommer schrieb: > Das ist aber Absicht, um die kurzen 16bit-Opcodes zu behalten - wie > willst du 32bit-Adressen in 16bit-Opcodes packen?? Lass mal. RISC mag er nicht so, er will seine Renesas verkaufen. ;-)
>Eher etwas einbauen, das in die RISC + Load-Store-Architektur vom ARM >überhaupt nicht hineinpasst... Eine entsprechende Instruktion dafür wäre Für die GPIO-Register hat man das über die Peripherie getan. Für GPIO gibt es getrennte Addressen zum setzten und Löschen von Bits. Damit simuliert man die CBI und SBI-Befehle des AVR. Da diese über einen Speziellen Bus angesprochen werden, werden Zugriffe auf die GPIO-Bereiche auf Cortex-M0+ normalerweise auch in einem Taktzyklus ausgeführt. Allerdings macht das die I/O Zugriff nicht schneller, sondern nur genau so schnell wie beim AVR. Die kleinen Cortex-M0 erreichen auch nur 30Mhz. Für I/O-Intensive Anwendungen ergibt sich noch kein klarer Vorteil.
Tim . schrieb: > Da diese über einen Speziellen Bus angesprochen werden Speziell ist er nicht, nur näher dran am Core und schneller.
>Das ist aber Absicht, um die kurzen 16bit-Opcodes zu behalten Ja, vor 30 Jahren. >Für die GPIO-Register hat man das über die Peripherie getan...... Besser als nichts, aber auch das geht in Wirklichkeit nicht mit 1 Befehl.
MCUA schrieb: >>Das ist aber Absicht, um die kurzen 16bit-Opcodes zu behalten > Ja, vor 30 Jahren. Vor 30 Jahren war die VAX en vogue. Nicht grad der Prototyp einer Load/Store-RISC. Die fristeten damals ein noch ziemlich verstecktes Leben.
>>Für die GPIO-Register hat man das über die Peripherie getan...... >Besser als nichts, aber auch das geht in Wirklichkeit nicht mit 1 >Befehl. Zum Halten der Basisaddressen und Bitmasken findet sich schon immer ein Register. Übrigens benötigen SBI und CBI auf den klassischen AVR auch 2 Zyklen...
Super. Ich bin gerade auf Wikipedia auf dieses kleine Detail gestossen, welches im User manual fehlt: >Flash sizes of 4 8 16 KB general purpose, zero wait-state up to 20 MHz, >one wait-state up to 30 MHz. Da fast alle Befehle nur einen Taktzyklus benötigen, wird die Geschwindigkeit mit einem Waitstate fast halbiert. D.h. 24Mhz CPU-Clock entsprechen ungefähr 12Mhz. Interessant...
Tim . schrieb: > Da fast alle Befehle nur einen Taktzyklus benötigen, wird die > Geschwindigkeit mit einem Waitstate fast halbiert. D.h. 24Mhz CPU-Clock > entsprechen ungefähr 12Mhz. Interessant... Nur bei Branches die aus dem aktuell im Cache verfügbaren Code heraus springen - "linearer" Code wird praktisch mit der angegebenen Taktfrequenz abgearbeitet. Und falls einem das nicht reicht kann man den Code immer noch in den RAM kopieren...
>Nur bei Branches die aus dem aktuell im Cache verfügbaren Code heraus >springen - "linearer" Code wird praktisch mit der angegebenen Nur wie groß ist der Cache? Im User Manual taucht das Wort "Cache" nicht auf. "Linearer" code ist ja eigentlich gerade das, was eine schlechte Cache-Ausnutzung erzeugt. Besser sind Schleifen.
Tim . schrieb: > Nur wie groß ist der Cache? Im User Manual taucht das Wort "Cache" nicht > auf. Da "Cache" nicht marketingwirksam ist, nennt das jeder Hersteller anders; bei ST sieht das so aus: "The proprietary Adaptive real-time (ART) memory accelerator is optimized for STM32 industry-standard ARM® Cortex-M4F processors. It balances the inherent performance advantage of the ARM Cortex-M4F over Flash memory technologies, which normally requires the processor to wait for the Flash memory at higher operating frequencies. To release the processor full performance, the accelerator implements an instruction prefetch queue and branch cache which increases program execution speed from the 128-bit Flash memory. Based on CoreMark benchmark, the performance achieved thanks to the ART accelerator is equivalent to 0 wait state program execution from Flash memory at a CPU frequency up to 168 MHz." Müsste man für den LPC mal raussuchen. > "Linearer" code ist ja eigentlich gerade das, was eine schlechte > Cache-Ausnutzung erzeugt. Besser sind Schleifen. Okay das ist noch besser. Ich meinte jetzt Code der wild durch die Gegend springt. Hängt aber auch von der Cache-Strategie ab...
Hi, den ART kannte ich. Ich bezweifle nur, dass man einem 4kb Cortex-M0+ viel Cache spendiert. Wenn überhaupt, dann würde ich nur einen loop-buffer erwarten. Ich habe mal an den NXP-Support geschrieben. Inzwischen habe ich herausgefunden, das msn die Waitstates bei 20 MHz manuell auf 0 setzen kann. Damit wird der LPC810 immerhin schneller als ein AVR. Warum das im CMSIS nicht erfolgt, ist mir ein Rätsel.
Tim . schrieb: > Inzwischen habe ich herausgefunden, das msn die Waitstates bei 20 MHz > manuell auf 0 setzen kann. Damit wird der LPC810 immerhin schneller als > ein AVR. Warum das im CMSIS nicht erfolgt, ist mir ein Rätsel. Weil die CMSIS sich nur auf den Cortex Core bezieht, und das Zeug mit den Waitstates/Cache spezifisch für den Hersteller des ganzen Controllers ist (wie eben der ART für STMicroelectronics).
Dr. Sommer schrieb: > Weil die CMSIS sich nur auf den Cortex Core bezieht, und das Zeug mit > den Waitstates/Cache spezifisch für den Hersteller des ganzen > Controllers ist (wie eben der ART für STMicroelectronics). Dazu passt dann aber nicht, dass das Clocksystem initilialisiert wird... Überhaupt: Ich dachte CMSIS stellt gerade den Softwarelayer zur Peripherie bereit?
Tim . schrieb: > Dazu passt dann aber nicht, dass das Clocksystem initilialisiert wird... Wird es nicht, das macht die Hardware Library des µC-Herstellers. > Überhaupt: Ich dachte CMSIS stellt gerade den Softwarelayer zur > Peripherie bereit? Nein, nur zum Core. Für die Peripherie ist der µC-Hersteller zuständig.
Jetzt bin ich etwas verwirrt. Der Hersteller muss CMSIS natürlich an seine Peripherie anpassen, das Softwareinterface ist aber schon standardisiert?
1 | * @file: system_LPC8xx.h |
2 | * @purpose: CMSIS Cortex-M0+ Device Peripheral Access Layer Header File |
3 | * for the NXP LPC8xx Device Series |
4 | * @version: V1.0 |
5 | * @date: 16. Aug. 2012 |
6 | *----------------------------------------------------------------------------
|
7 | |
8 | /**
|
9 | * Initialize the system
|
10 | *
|
11 | * @param none
|
12 | * @return none
|
13 | *
|
14 | * @brief Setup the microcontroller system.
|
15 | * Initialize the System and update the SystemCoreClock variable.
|
16 | */
|
17 | extern void SystemInit (void); |
18 | |
19 | /**
|
20 | * Update SystemCoreClock variable
|
21 | *
|
22 | * @param none
|
23 | * @return none
|
24 | *
|
25 | * @brief Updates the SystemCoreClock with current core Clock
|
26 | * retrieved from cpu registers.
|
27 | */
|
28 | extern void SystemCoreClockUpdate (void); |
Tim . schrieb: > Jetzt bin ich etwas verwirrt. Der Hersteller muss CMSIS natürlich an > seine Peripherie anpassen, das Softwareinterface ist aber schon > standardisiert? Hm okay, ich hab die Begriffe etwas verdreht. Die CMSIS ist einerseits die µC-unabhängige library zum Zugriff auf den Core (zB NVIC und sachen wie __enable_irq) und andererseits der "Standard" wie das API der Library der Hersteller drumherum auszusehen hat. ST nennt seinen Teil dann "Standard Periphal Library", und nur der unabhängige Teil für den Core CMSIS (der auch getrennt vom drumherum existieren kann). Wenn NXP das anders macht ists wohl auch richtig. Das mit dem Clocksystem ist dann der herstellerspezifische Teil (und nicht die "eigentliche CMSIS")... :-)
Angehängte Dateien:
-

CMSIS_CORE_Files_user.png
5,5 KB
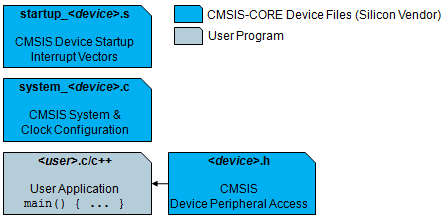
Ich habe gerade dieses Bild in der CMSIS-Dokumentation gefunden. Anscheinend ist das Clocksystem eine Ausnahme. Jetzt kann man natürlich philosophieren, ob die (Clockabhängige) Konfiguration der Waitstates auch zur Initilialisierung des Clocksystems gehören...
Bei einem so kleinen Controller würde ich mir die ganzen Lib's der Hersteller noch viel weniger antun als bei den größeren Cortexen. Fakt ist doch eins, es wird jetzt erst mal die Tür aufgemacht für 32bit Cortexe in ganz kleinen Gehäusen. Es geht nicht darum ein paar Byte Flash zu sparen oder um ein paar Prozent Performanze. Wenn man sich in eine Entwicklungsumgebung für Cortex Mx eingearbeitet hat und stolpert nicht mehr über jeden Stein will man nicht mehr zurück zu AVR oder PIC. Da liegen im Handling Welten dazwischen. Es ist nicht die Frage ob es nötig ist. Wenn ich eine Entwicklung mit Cortex M3/M4 mache, die ein paar Monate Zeit kostet und dann wird mal schnell ein MC für eine primitive Sache benötigt wo sieht man sich dann um? Wenn es etwas gibt was mir nicht wieder einen Break im Kopf abringt, dann benutze ich das in meiner gewohnten Entwicklungsumgebung. Dass die Teile preislich mithalten können haben wir ja schon festgestellt.
temp schrieb: > Dass die Teile preislich > mithalten können haben wir ja schon festgestellt. Können sie nicht. Gerade die kleinener Avrs sind günstiger (bspw. Atmega48 oder Attiny24). Und fang nicht mit einem Vergleich mit reichelt oder ebay an. Da sind sie meistens teuer.
Also wenn ich das richtig interpretiere, gibt es hier noch einige hundert kostenlose LPC800-Mini-Kits: http://www.element14.com/community/docs/DOC-54622/l/we-have-500-lpc800-mini-kits-to-giveaway
Hi Tim, ich habe das Board auch "gewonnen", aber ausser der Benachrichtung nichts erhalten. Von wem hast Du das gewonnene Board bekommen ? Direkt von NXP oder einem Disti? Andreas
Das Board kam direkt von NXP aus Indien(?). Hat nach erhalt der Nachricht ca. 14 Tage gedauert.
>"The proprietary Adaptive real-time (ART) memory accelerator is >optimized for STM32 industry-standard...... Nicht erwähnt -habs schon öfter erwähnt- haben die, dass der 4 Takte braucht, bis er Werte liefern kann. Das beginnt nach jedem Sprung, Branch usw von neuem! Und complett linearer Code -habs schon öfter erwähnt- gibt es bei Steuerungen usw faktisch nicht. Also grift das Dingen sehr oft überhaupt nicht. NXP hat bei manchen CM3's was ähnliches. (das Zeugs müsste denkich mal in den entspr. Artikel rein) >Jetzt kann man natürlich >philosophieren, ob die (Clockabhängige) Konfiguration der Waitstates >auch zur Initilialisierung des Clocksystems gehören... Nö. kamm man nicht. Befehle, die nicht im Cache sind brauchen länger.
MCUA schrieb: >>Jetzt kann man natürlich >>philosophieren, ob die (Clockabhängige) Konfiguration der Waitstates >>auch zur Initilialisierung des Clocksystems gehören... > Nö. kamm man nicht. Befehle, die nicht im Cache sind brauchen länger. Die Waitstates bestimmen die Zyklenzeiten des Flash-Zugriffs. Default sind 1+1 Zyklen. Wenn man beim LPC810 die Waitstates nicht "per Hand" auf 0 stellt, wird die MCU unnötig langsam.
lpc21isp (ab Version 1.91) sollte jetzt auch mit dem LPC8xx zurecht kommen. Die Version ist hier erhältlich: 1) Yahoo-Gruppe (Registrierung nötig, wegen Spam-Vermeidung) http://tech.groups.yahoo.com/group/lpc21isp/files/Beta%20versions/ Sie liegt dort als lpc21isp_191.zip (fast ganz unten auf der Seite) 2) github https://github.com/capiman/lpc21isp 3) Sourceforge http://sourceforge.net/projects/lpc21isp/ Feedback erwünscht!
Dumme frage: Wo ist der Vorteil gegenüber der Programmierung über den seriellen Bootloader?
So mein kleines Projekt mit LPC810 ist jetzt online: http://www.hwhardsoft.de/deutsch/projekte/simon-says/ Software und Schaltplan können unter dem Link oben heruntergeladen werden... Als Compiler habe ich das LPCXpresso genutzt. Programmiert wurde via Bootloader mit Flashmagic. Debugging per brenn-und-renn!
Hat jemand schon mal einen jlink zum Programmieren benutzt? ich habe es erfolglos probiert. Segger schreibt zwar dass der LPC810 supported wird, dazu passt aber folgendes nicht: http://forum.segger.com/index.php?page=Thread&threadID=1464 Deshalb die Frage, gibts Erfahrungen?
Naja bei JLink oder einem anderen JTAG Debugger stellt sich bei einem Controller mit nur 8 Pins also maximal 6 nutzbaren GPIO schon die Frage nach dem Sinn... Es bleibt ja dann nix mehr für die Applikation übrig.
HWHardSoft schrieb: > Naja bei JLink oder einem anderen JTAG Debugger stellt sich bei einem > Controller mit nur 8 Pins also maximal 6 nutzbaren GPIO schon die Frage > nach dem Sinn... Es bleibt ja dann nix mehr für die Applikation übrig. Es sprach niemand von JTAG. Für SWD sind genau 2 Leitungen + Masse nötig. Bleiben also 4 übrig. Ob das Sinn macht oder nicht kann nur der Beantworten der es macht...
Ich habe mich in den letzten Wochen damit beschäftigt, die LPC810 Codebase zu optimieren. Inzwischen ist der Overhead so klein, dass man in den 4kb tatsächlich sinnvolle Programme unterbringen kann. Außerdem hat sich nach Diskussion mit dem NXP support gezeigt, dass bei 30Mhz auch zero waitstate-Zugriff auf das Flash möglich ist. Damit erreicht der LPC810 mit dem internen Oszillator ca. 30 MIPS und ist damit selbst bei 8 bit Arithmetik ca 50% schneller als der ATtiny 85. Alle änderungen sind inzwischen im Repository von microbuilder: https://github.com/microbuilder/LPC810_CodeBase
Angehängte Dateien:
-

LPC810_ws2812.jpg
150 KB

Mein LPC810 kann inzwischen WS2812 LED-Strips ansteuern. Die Strips scheinen 3.3V kompatibel zu sein. Momentan wird die Ansteuerung per Bit-Banging umgesetzt, ich hoffe allerdings dafür den State Configurable Timer (SCT) einsetzen zu können. Hat mit dem schon jemand erfolgreich etwas gemacht?
NXP ist nicht alleine auf dem Markt: eben den hier gesehen: http://www.st.com/web/catalog/mmc/FM141/SC1169/SS1574/LN1826/PF258968 TSSOP20 mit 0,65-Pitch würde ich noch als Bastlerfreundlich bezeichnen. Im Vergleich zum LPC hat der - 12 Bit ADC mit 1µs Sampletime - 48 MHz - DMA dafür - ist ein Cortex-M0 und kein M0+ - kein Analogcomparator - kein Switch-Matrix-Feature, nur reguläre Alternate Functions. In wie weit die Switch-Matrix wirklich besser ist muß ich mir aber noch im Detail anschauen Auch wenn "Active" dran steht ist das Ding noch nicht draußen. Es gibt auch noch kein Reference Manual. Dauert also noch ein wenig für den echten Vergleich. Preislich sagt ST 0.425 US$ @ 10000. Beim schon erhältlichen STM32F050G4U6 werden 0.8 US$ @ 10000 angegeben, Mouser verlangt für 10 Stück dann 1,61 EUR. Es besteht also gute Hoffnung daß das Teil auch in kleineren Stückzahlen unter 1 EUR landet.
Gerd E. schrieb: > NXP ist nicht alleine auf dem Markt: > > eben den hier gesehen: > http://www.st.com/web/catalog/mmc/FM141/SC1169/SS1574/LN1826/PF258968 > > TSSOP20 mit 0,65-Pitch würde ich noch als Bastlerfreundlich bezeichnen. Nett! Ähnlich ist auch der XMC1000 von Infineon. Die gibt es auch im TSSOP-Gehäuse und unter in 1€ Stückzahlen. Im DIP Gehäuse ist NXP allerdings im Moment außer Konkurrenz. >Im Vergleich zum LPC hat der >- 12 Bit ADC mit 1µs Sampletime >- 48 MHz >- DMA >The Flash memory access time is adjusted to the fHCLK frequency (0 wait >state from 0 to 24 MHz and 1 wait state above 24 MHz) Sieht so aus, als wenn bei 48MHz ein wait state benötigt wird. Damit relativiert sich die Geschwindigkeit wieder... DMA ist allerdings ein nettes Feature, welches NXP und Infineon nicht haben. Der SCT im LPC81X ist prinzipiell auch noch ein interessantes Feature. Allerdings scheint es schwierig, ihn wirklich auszunutzen.
Tim . schrieb: >>The Flash memory access time is adjusted to the fHCLK frequency (0 wait >state > from 0 to 24 MHz and 1 wait state above 24 MHz) > > Sieht so aus, als wenn bei 48MHz ein wait state benötigt wird. Damit > relativiert sich die Geschwindigkeit wieder... Stimmt. In wie weit hängt allerdings davon ab was die für Prefetch-Technik eingebaut haben. Das steht im Detail normalerweise im Reference Manual, das ist aber noch nicht draußen... Wenn Du aber z.B. schnellere PWM machen willst sind die 48 MHz natürlich schon praktisch.
Gerd E. schrieb: > Stimmt. In wie weit hängt allerdings davon ab was die für > Prefetch-Technik eingebaut haben. Das steht im Detail normalerweise im > Reference Manual, das ist aber noch nicht draußen... Bei den ST32F05x ist der Prefetch-Buffer 3x4 Bytes groß. Ich gehe davon aus, dass es beim ST32F03x identisch ist. Das hilft nur bei sehr kleinen Schleifen... > Wenn Du aber z.B. schnellere PWM machen willst sind die 48 MHz natürlich > schon praktisch. Normalerweise kann der Takt für die Peripherie getrennt vom Core eingestellt werden?
Tim . schrieb: >> Wenn Du aber z.B. schnellere PWM machen willst sind die 48 MHz natürlich >> schon praktisch. > > Normalerweise kann der Takt für die Peripherie getrennt vom Core > eingestellt werden? Ok, ich muss mich da korrigieren. Beim LPC810 wird nur der USART-Takt direkt von der Main CLK abgeleitet (Warum auch immer?). Die übrige Peripherie wird entsprechend der CPU getaktet.
Hallo, eine Frage: Ich habe dieses Mini-Kit und einen USB Adapter zum programmieren. Wie schließe ich das richtig an? Muss das Mini-Kit selbst am USB-Port hängen? Ich hatte VCC vom Board und dem Adapter zusammen geschlossen und beide an USB gesteckt, aber dann hats den Programmieradapter gehimmelt.
lpc schrieb: > am USB-Port hängen? Ich hatte VCC vom Board und dem Adapter zusammen > geschlossen und beide an USB gesteckt, aber dann hats den > Programmieradapter gehimmelt. Tja, gut dass die USB-RS232 Adapter fast nix kosten. Wenn Du die Stromversogung vom RS232 nimmst, bleibt der USB-Anschluss am Mini-Kit unbenutzt. Du musst nur folgende Leitungen verbinden: Adapet - Mini Kit 5V - VCC GND - GND RXD - RXD TXD - TXD Den Rest einfach offen lassen. Bei mir tut es ein billigster PL2303-HX RS232 Adapter.
Ich hatte was von 3,3V gelesen. Und RxD/TxD sind nicht gekreuzt?
Auf dem Board ist ein Spannungsregler. Wenn R2 eingebaut ist, nimmt das Board 5V. Und nerin, RxD und TxD nicht kreuzen.
Habe einen Silicon Labs CP210x und versuche mit dem Tool Flash Magic eine Verbindung herzustellen. Bisher kein Erfolg.
lpc schrieb: > Habe einen Silicon Labs CP210x und versuche mit dem Tool Flash Magic > eine Verbindung herzustellen. Bisher kein Erfolg. Und die bist sicher, dass der LPC810 auch im ISP mode ist? (Reset Button muss vor dem ISP-Button losgelassen werden)
Habe es gerade mit einem CP2102 probiert - kein Problem. Es funktioniert auch mit beiden PL23032-HX die ich habe, von denen einer wahrscheinlich eine Fälschung ist...
Sorry, hab noch null Erfahrung mit dem Teil. Jetzt klappt es :) Danke
NXP hat gerade eine Promotion laufen, bei der man das LPC800-MAX Board für 1€ bekommt: http://www.nxp.com/campaigns/lpc800-go/lpc800-max
Sieht aber aus, als bekommt man nur einen Gutschein, den man dann bei Embedded Artists einlösen kann? Wenn ich richtig gesehen habe, dann fallen Versandkosten in Höhe von 22.20 Euro bzw. 7.60 Euro an... (zumindest, wenn man das LPC812MAX, nicht das LPC810MAX auswählt, LPC810MAX habe ich auf die schnelle nicht gefunden)
Ingo schrieb: > den man dann bei Embedded Artists einlösen kann? > Wenn ich richtig gesehen habe, dann fallen Versandkosten > in Höhe von 22.20 Euro bzw. 7.60 Euro an... > (zumindest, wenn man das LPC812MAX, nicht das LPC810MAX auswählt, > LPC810MAX habe ich auf die schnelle nicht gefunden) Keine Ahnung, vielleicht sind die Versandkosten auch im Gutschein enthalten? 7.6EUR sind jetzt aber nicht so viel. Die wollen die Boards halt nicht kostenlos weggeben, damit die nicht bei Leuten Schrank verstauben, die sie nur genommen haben, weil sie kostenlos waren.
Hat sich einer das bestellt und kann sagen, was es wirklich unter dem Strich gekostet hat?
Die Versandkosten sind im Gutschein enthalten, man muss also nur 1€ zahlen. Allerdings hat es ewig gedauert, bis NXP mir den Gutschein zugesendet hat. Anscheinend wird manuell geprüft.
Angehängte Dateien:
-

top.png
24 KB -

bottom.png
16 KB
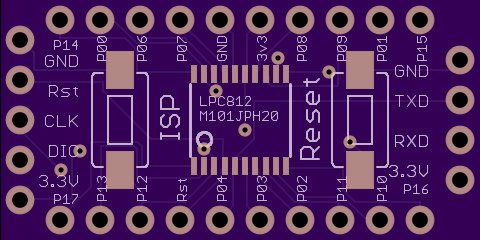
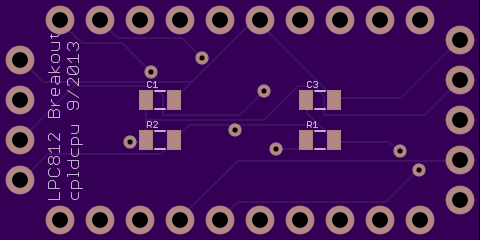
Die LPC812 sind übrigens inzwischen bei Mouser erhältlich. Ich habe für den LPC812M101JPH20 (TSSOP20) ein Break-Out board mit seriellen und SWD Eingang entworfen. Siehe Anhang. Hat dazu noch jemand Ideen?
Eagle Library für alle LPC800 Controller: https://github.com/cpldcpu/LPC812breakout/tree/master/Eagle%20Library
Tim . schrieb: > Die Versandkosten sind im Gutschein enthalten, man muss also nur 1€ > zahlen. + 25% Steuern = 1,25 Euro Versand mit UPS. > Allerdings hat es ewig gedauert, bis NXP mir den Gutschein zugesendet > hat. Das stimmt, ich habe ca. 2 Wochen auf den Gutschein gewartet. Dann geht es schnell: am 30.09. bei embeddedartists bestellt, eben ausgepackt.
Dr. Sommer schrieb: > Gäbe es einen Compiler der das Bit Banding vom > ARM unterstützen würde ging's wohl in 6 bytes. Hätte der Hund nicht geschissen, hätte er den Hasen sicher gefangen... > Der Vorteil ist > allerdings - es kann 4 GB an I/O Registern geben Das ist ja mal 'n extrem häufig benötigtes Feature. Insbesondere im Bereich kleiner µC-Anwendungen... > bei einigen AVR's > (ATmega*8 wimre?) läuft der I/O Adress Space über Ja, das stimmt. Allerdings bemüht sich Atmel, die Register, auf die ein besonders schneller Zugriff wünschenswert ist, im IO-Space zu halten. Gut, das klappt natürlich nicht für jeden Anwendungsfall. > was die Sache dort so > ineffizient wie beim ARM macht. Noch lange nicht. Zwei Ticks statt einem und vier Bytes Code statt zwei. Und damit immer noch wesentlich effizienter als ARM.
@c-hater: Was willst Du uns damit sagen? 1. Nur mal so 2. Der AVR ist tot, es lebe der AVR Falls 2.: Es gibt genügend Leute, die sich aufgrund der Preisentwicklung im 32bit Bereich überhaupt nicht mehr mit 8bit beschäftigen. Wozu auch. Es macht in diesem Fall Sinn, auch bei kleinen Anwendungen bei 32bit zu bleiben. Krampfhaftes Festhalten an Technologien des 20. Jahrhunderts ist eigentlich nur dann angeraten, wenn Altlasten zu pflegen sind. (Falls sich jemand am Begriff "Sinn machen" anstelle "Sinn haben" stört, ich bleibe dabei)
...und er ist endlich lieferbar: http://de.mouser.com/ProductDetail/NXP/LPC810M021FN8FP/?qs=%2fha2pyFaduiGKlE7K%252bl%2foWBWRr%2fRA2onCtWBuDOEGkw%3d Direkte links zu Mouser funktionieren nicht?!?
Tim schrieb: > ...und er ist endlich lieferbar: War auch schon vorher lieferbar, allerdings in Rev. 2A mit Analogteil ohne Stromversorgung :-) http://www.lpcware.com/content/forum/lpc-mini-kit-analog-comparator-howto Das ist jetzt Rev. 4C wo das hoffentlich funktioniert, brauche das dringend.
> > War auch schon vorher lieferbar, allerdings in Rev. 2A mit Analogteil > ohne Stromversorgung :-) ... und als Sample. Lustig, da haben sie wohl vergessen ein Pad zu bonden? Der DIE wird auf jeden Fall der gleiche wie bei den anderen LPC800 Familienmitgliedern sein.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.