Hallo,
ich habe im Moment ein mir unerklärliches Problem und zwar geht es um
eine zeitkritische Ausgabe von Daten. Dazu mal folgender Code-Ausschnitt
welcher drei Byte ausgibt:
void LED_Ausgabe()
{
int8_t i;
char tmp ;
unsigned char R,G,B;
R = 255;
G = 0;
B = 0;
for (i=0;i<8;i++)
{
tmp = G>>(7-i);
G -= tmp<<(7-i);
if (tmp == 1)
L_High(); //Gibt ein logisches high-Bit aus
else
L_Low(); ////Gibt ein logisches low-Bit aus
}
Diese Schleife gibts danach noch zwei Mal für G und B.
In dieser Konstellation funktioniert auch alles d.h. es dauert 1,25usec
um 1 Bit auszugeben (so wie gewünscht).
Wenn ich den Code jedoch folgendermaßen anpasse (die RGB Werte werden
übergaben anstatt sie innerhalb der Funktion fest zu definieren):
void LED_Ausgabe(unsigned char R, unsigned char G, unsigned char B)
{
int8_t i;
char tmp ;
for (i=0;i<8;i++)
{
tmp = G>>(7-i);
G -= tmp<<(7-i);
if (tmp == 1)
L_High();
else
L_Low();
}
dann benötigt der Prozessor sehr viel länger pro Bit (zwischen 2 und
10usec).
Ich arbeite mit einem atmega8 @ 8Mhz und externem Quarz. Die Compiler
Optimierung steht „optimize most“
Hat irgendwer eine Idee wie das zustande kommt bzw. wie ich das Problem
lösen kann?
Mit freundlichen Grüßen
Was glaubst du was das hier für ein Forum ist? Robert Lembke und sein Rateteam?
was machst du überhaupt hier?
tmp = G>>(7-i);
G -= tmp<<(7-i);
irgenwie sieht es mir sehr umständlihc aus und es ist extrem langsam auf
einem atmel.
Was ist das ziel davon?
außerdem handelst du dir Probleme mit deinem temp ein, weil es char ist
und damit signed und nicht unsigned.
Anstatt sinnlose Kritik zu äußern hättest du auch sagen können was dir an Informationen fehlt, dann könnte ich diese nachliefern. Ich bin noch recht unerfahren was µC programmiereung angeht und habe den Text nach besten wissen verfasst. MfG.
Peter II schrieb: > as machst du überhaupt hier? > > tmp = G>>(7-i); > G -= tmp<<(7-i); Das tmp signed ist habe ich eben auch gemerkt, macht allerdings keinen Unterschied. Was ich da mache: Ich gehe das Byte Bit für Bit duch und entscheide jenachdem ob das aktuelle Bite eine Null oder eine Eins ist welche der beiden Funktionen (L_High oder L_Low)aufgerufen wird.
Im 1. Fall sind R,G,B Konstanten und der Compiler kann deine Berechnungen wegoptimieren. Im 2. Fall halt nicht mehr.
Jan schrieb: > Ich gehe das Byte Bit für Bit duch und entscheide jenachdem ob das > aktuelle Bite eine Null oder eine Eins ist welche der beiden Funktionen > (L_High oder L_Low)aufgerufen wird. irgenwie ist mir das zu hoch wie du es gemacht hast. besser ist es auf jeden Fall so: for (i=0;i<8;i++) { if ( i & 1 ) L_High(); else L_Low(); i = i >> 1; } eventuell noch umdrehen, ich verstehe ja bei deim code nicht mal wie rum die bits ausgeben werden.
Peter II schrieb: > for (i=0;i<8;i++) > { > if ( i & 1 ) > L_High(); > else > L_Low(); > i = i >> 1; > } muss natürlich anders sein
1 | for (i=0;i<8;i++) |
2 | {
|
3 | if ( G & 1 ) |
4 | L_High(); |
5 | else
|
6 | L_Low(); |
7 | |
8 | G = G >> 1; |
9 | }
|
void LED_Ausgabe(unsigned char R, unsigned char G, unsigned char B)
{
int8_t i;
for (i = 0; i < 8; i++)
{
if ((G & (0x80 >> i)) != 0)
L_High();
else
L_Low();
}
}
Helfender schrieb: > void LED_Ausgabe(unsigned char R, unsigned char G, unsigned char B) > { > int8_t i; > for (i = 0; i < 8; i++) > { > if ((G & (0x80 >> i)) != 0) > L_High(); > else > L_Low(); > } > } genauso schlecht, 0x80 >> i sollte man auf einem atmel vermeiden, weil es es nicht in hardware kann. Hier baut der compiler selber wieder eine schleife ein.
Danke schonmal für eure Verbesserungsvorschläge, allerdings habe ich immernoch mein Timigproblem. Volker schrieb: > Im 1. Fall sind R,G,B Konstanten und der Compiler kann deine > Berechnungen wegoptimieren. Im 2. Fall halt nicht mehr. So ungefähr habe ich mir das auch gedacht allerdings keine Lösung gefunden. Ist es denn irgendwie möglich die Variable zu übergeben und diese dann zu einer Konstanten werden zu lassen ? MfG.
Jan schrieb: > So ungefähr habe ich mir das auch gedacht allerdings keine Lösung > gefunden. Ist es denn irgendwie möglich die Variable zu übergeben und > diese dann zu einer Konstanten werden zu lassen ? dafür müsste man mehr von dem Programm sehen, vermutlich lieg das Problem wo anders. Der code von mir oben braucht keine µs zum ausführen.
Hallo Jan. Jan schrieb: > In dieser Konstellation funktioniert auch alles d.h. es dauert 1,25usec > um 1 Bit auszugeben (so wie gewünscht). [...] > dann benötigt der Prozessor sehr viel länger pro Bit (zwischen 2 und > 10usec). > > Ich arbeite mit einem atmega8 @ 8Mhz und externem Quarz. Die Compiler > Optimierung steht „optimize most“ Das riecht nach WS2811/WS2812? Mache Dir mal klar, dass 800kHz (1.25µS/bit) bei einem Takt von 8MHz bedeutet, dass Du 10 Zyklen pro Bit zur Verfügung hast. Also maximal 10 Assembler-Instruktionen. Schon alleine ein Funktionsaufruf ohne Argumente braucht davon 5 oder 6. In dem Rest muss dann noch festgestellt werden welches Bit wie ausgegeben werden muss. Will sagen: Du musst da hand-getuneden Assembler hernehmen, wenn Du wissen willst dass das Timing funktioniert. Und selbst dann wird es extrem knifflig. Such mal nach WS2811 oder WS2812 im Forum, da kannst Du verschiedene Ansätze dazu begutachten. Viele Grüße, Simon
Sprungtabelle?
void ( * LED_Ausgabe_x ( ) ) [] = {
LED_Ausgabe_0,
LED_Ausgabe_1,
LED_Ausgabe_2,
LED_Ausgabe_3,
...
LED_Ausgabe_255
};
void LED_Ausgabe(unsigned char R, unsigned char G, unsigned char B)
{
LED_Ausgabe_x[R]();
}
void LED_Ausgabe_0()
{
L_Low(); ////Gibt ein logisches low-Bit aus
L_Low(); ////Gibt ein logisches low-Bit aus
L_Low(); ////Gibt ein logisches low-Bit aus
L_Low(); ////Gibt ein logisches low-Bit aus
L_Low(); ////Gibt ein logisches low-Bit aus
L_Low(); ////Gibt ein logisches low-Bit aus
L_Low(); ////Gibt ein logisches low-Bit aus
L_Low(); ////Gibt ein logisches low-Bit aus
}
usw.
Braucht aber viel Platz...
Wenn Du es so machen willst, schreibst Dir am besten ein
Programm, was den Source Code erzeugt...
Ist deine L_Low/L_High schnell genug? Inline?
Vielleicht auch LED_Ausgabe inline?
Was ist mit den G und B Werten? Werden die hintereinander
ausgegeben? Oder müssen die zur gleichen Zeit raus?
Simon Budig schrieb: > Das riecht nach WS2811/WS2812? Genau darum geht es ;) Hier mal der Code der L_High Funktion: void L_High() { PORTC |= 0b00000001; asm volatile ("nop"); asm volatile ("nop"); asm volatile ("nop"); asm volatile ("nop"); PORTC &=~ 0b00000001; asm volatile ("nop"); asm volatile ("nop"); } Mir ist bewusst das dass mit dem "asm volatile ("nop");" nicht das gelbe vom Ei ist allerdings funktioniert es vom Prinzip her. Im Anhang nochmal zwei Bilder. Bild 1 ist mit dem Code von Peter II mit übergebenen RGB Werten (Timigs stimmen nicht). Bild 2 ist auch mit dem selben Code allerdings mit Konstaten Werten (hier funktioniert alles)
Exakte Bit Timinigs über Software stabil hinzubekommen ist extrem schwierig. Da darf es nicht mal einen Interrupt geben, sonst passt das schon nicht mehr. Wenn du das weiterhin per SW machen willst solltest du den µC controller wechseln. Ist diese Frequenz mit 1.25µS Bit Takt gesetzt, dann solltest du einen µC mit so rund 80 MHz anpeilen um da hinzukommen. Also ein Cortex M oder sowas in die Richtung. Ich würde allerdings eher eine HW Lösung hier sehen. 3 Schieberegister mit Latch mit gemeinsamen BitTakt. Nach jeweils 8 Bit legst du das Byte als ganzes ins Schieberegister, und von dort wird es Bitweise raus geschoben.
Angehängte Dateien:
-

Timings.JPG
75 KB
{kind=link}
{kind=link}
Ja eine Hardwarelösung wäre mir auch am liebsten. Im Anhang ist ein Bild wie die Ausgangssignale aussehen müssen. Ich habe leider keinen Ansatz oder auch nur eine Idee wie ich das mit Schieberegistern realisieren soll. Gibts da eventuell ein Link wo soetwas erklärt ist ? MfG.
Geht es vielleicht mit SPI? CLK mit 4 MHz, jeweils 8 Bits einfüllen alle 500 kHz. Wenn der uC eine FIFO hat, dann vielleicht sogar x mal 8 Bits auf einmal. Für eine zu sendende 0 oder 1 werden 10 Bits benötigt. Für eine zu sendende 0: 2 x H, 8 x L Für eine zu sendende 1: 5 x H, 5 x L Die SPI Hardware sorgt dann dafür, dass die Bits zur richtigen Zeit gesendet werden.
Hi, man kann das Timing auch bei 8Mhz relativ genau hinbekommen. Allerdings hat mit für das High-speed Protokoll des WS2811/2812 nur 3 bis 5 Taktzyklen Zeit, das Signal auf hi und low zu setzen. Mit ein wenig inline-Assembler ist das kein unlösbares Problem. Wie schon woanders gepostet (Beitrag "Lightweight WS2811/WS2812 Library"), setzte ich mich auch gerade mit diesem Problem auseinander. Mir ist dabei aufgefallen, dass der AVR-GCC teilweise wenig nachvollziehbare Optimierungen macht. z.B. wird für unterschiedliche AVRs ohne verständliche Gründe ganz anderer Code erzeugt, der mehr oder weniger Taktzyklen benötigt.
Helfender schrieb: > Geht es vielleicht mit SPI? Im Forus gibt es eine Lösung mit PWM: Beitrag "AVR ASM ws2811 / ws2812 Ansteuerung mit FastPWM". Diese funktioniert aber wohl nur mit 16Mhz. Wie Markus in seiner Dokumentation schreibt, benötigt diese Lösung auf den kleineren AVR aber trotzdem 100% der CPU Zeit und benötigt zusätzliche noch peripherie. Eine Bitbang-Lösung ist daher wohl einfacher. Auf XMEGA sieht es wohl anders aus.
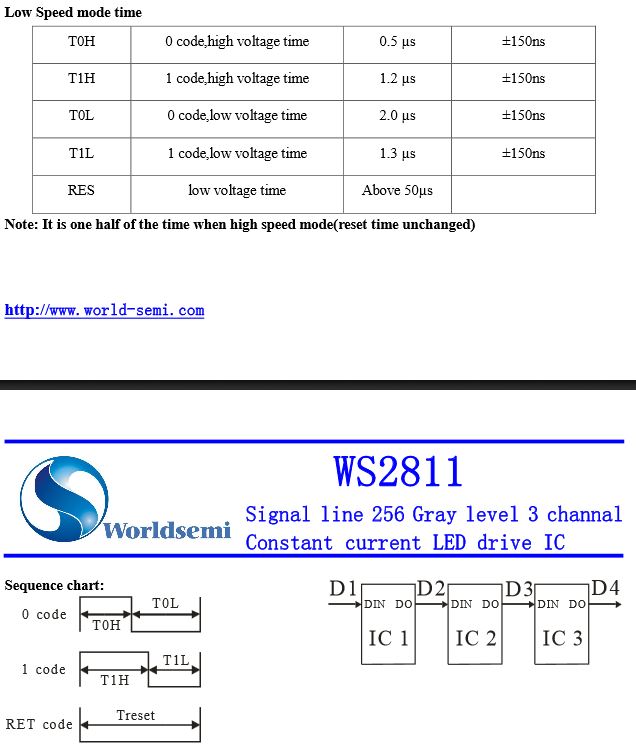
Jan schrieb: > L_High(); //Gibt ein logisches high-Bit aus > L_Low(); ////Gibt ein logisches low-Bit aus Was machst du denn in den beiden Funktionen ? Ich gehen mal davon aus das deine Übertragung so nicht funktionieren wird. Das Interface des Chip ist ein PWM interface. Das heißt du brauchst einen festen Datentakt von 400 KHz. Die Information wird dann über den dutycycle übertragen. Die "0" hat dabei den dutycycle 20 % ( 0,5µs highphase) Die "1" hat dabei den dutycycle ~50 % ( 1,2µs highpahse) Mit anderen Worten du hast für die "0" genau 0,5 µs +- 150ns Zeit zwischen Pin auf High und Pin auf Low. Also ich kenne da nur eine µc Familie die sowas packt. Das sind die TMS 570 von TI, und zwar die Varianten die den HET ( HighEndTimer) Baustein drin haben. HET ist ein Programmierbarer Timer der unabhängig vom µC Core arbeitet und das mit einer Auflösung bis über 60 MHz. Die Datenausgabe würde dann über diesen HET laufen. Helfender schrieb: > Geht es vielleicht mit SPI? Nein geht nicht, da man bei SPI den Dutycycle nicht manipulieren kann.
>Also ich kenne da nur eine µc Familie die sowas packt. Das sind die TMS >570 von TI, und zwar die Varianten die den HET ( HighEndTimer) Baustein >drin haben. >Wenn du das weiterhin per SW machen willst solltest du den µC controller >wechseln. Ist diese Frequenz mit 1.25µS Bit Takt gesetzt, dann solltest du >einen µC mit so rund 80 MHz anpeilen um da hinzukommen. Also ein Cortex M >oder sowas in die Richtung. Und ich dachte immer das Microntroller die letzte Bastion der laufzeitoptimierten Software wären? Das klingt mir doch sehr nach einer "PC" Lösung... :)
Ralph schrieb: > Helfender schrieb: >> Geht es vielleicht mit SPI? > > Nein geht nicht, da man bei SPI den Dutycycle nicht manipulieren kann. Doch mittels SPI klappt es ;) Man kann einfach z.B 3 Einsen (750us)gefolgt von 2 Nullen (500us)ausgeben um die logische 1 darzustellen. Dafür muss die SPI Frequenz 4Mhz betragen, ist also mit meinen 8Mhz Prozessortakt möglich. MfG.
Hast Du mal folgendes probiert?
// für low --> high
tmp = 1;
for (i=0;i<8;i++)
{
if ( G & tmp )
L_High();
else
L_Low();
tmp = tmp << 1;
}
// oder für high --> low
tmp = 128;
for (i=0;i<8;i++)
{
if ( G & tmp )
L_High();
else
L_Low();
tmp = tmp >> 1;
}
Ist nicht so viel geschubse. Du kannst tmp auch für die anderen Dinger
benutzen. Also eine "Große" Schleife und nur am Ende Schiebung.
Jan schrieb: > Man kann einfach z.B 3 Einsen (750us)gefolgt von 2 Nullen > (500us)ausgeben um die logische 1 darzustellen. Nein passt nicht. "0" ist 2µs zu 0.5µs : Also brauchst du 10 Bit ; 2 Bit High dann 8 Bit Low "1" ist 1,2 µs zu 1,3 µsec Dann brauchst du 5 Bit high, dann 5 Bit Low Das Problem ist aber, das zwischen den Datenbits kein Abstand sein darf. Also muss sofort nach der LowPhase das nächste Bit, der SPi Übertragung kommen, ohne Zeitversatz. Ansonsten passt das Low timing nicht, eventuell gibt es auch ein Reset des Interface. Aber stimmt soweit, das SPI dürfte die einzige Chance sein das mit einem 8 MHz µC hinzubekommen. Die Frage ist nur was der µC nebenbei noch machen kann wenn die SPI in dem Tempo nachgeladen werden muss. Es bring ja auch nichts wenn der µC mit dem Treiben der LED's schon zu 100 % ausgelastet ist. Das hat man dann zwar geschafft, aber im Endeffekt auch nichts gekonnt.
>Es bring ja auch nichts wenn der µC mit dem Treiben der LED's schon zu >100 % ausgelastet ist. >Das hat man dann zwar geschafft, aber im Endeffekt auch nichts gekonnt. Die LEDs halten den Status bis zum nächsten Update. Wenn man z.B. nur mit 30Hz updated hat die CPU noch eine Menge "Freizeit", je nach anzahl der LEDs im String.
Ralph schrieb: > Aber stimmt soweit, das SPI dürfte die einzige Chance sein das mit einem > 8 MHz µC hinzubekommen. In Assembler ist das mit 8 Mhz ein Klacks. Da dürfte das sogar mit 4 Mhz funktionieren.
Einige Tips:
> while (datlen--) {
besser: while (--len), da er das Zero-Flag direkt (=ohne einen Compare)
auswerten kann. Len muss vorher um eins korrigiert werden.
Bei der Loop: der Counter kann entfallen, wenn die Mask mit dafür
verwendet wird:
mask=0x80;
do {if (data & mask) Pin = low; else Pin = high;} while((mask>>=1)!=0);
Ich würde aber tatsächlich Unrolling machen:
if(data&0x80) Pin = low; else Pin = high;
if(data&0x40) Pin = low; else Pin = high;
if(data&0x20) Pin = low; else Pin = high;
if(data&0x10) Pin = low; else Pin = high;
if(data&0x08) Pin = low; else Pin = high;
if(data&0x04) Pin = low; else Pin = high;
if(data&0x02) Pin = low; else Pin = high;
if(data&0x01) Pin = low; else Pin = high;
high und low sind vertauscht, richtig ist:
mask=0x80;
do {if (data & mask) Pin = high; else Pin = low;} while((mask>>=1)!=0);
Ich würde aber tatsächlich Unrolling machen:
if(data&0x80) Pin = high; else Pin = low;
if(data&0x40) Pin = high; else Pin = low;
if(data&0x20) Pin = high; else Pin = low;
if(data&0x10) Pin = high; else Pin = low;
if(data&0x08) Pin = high; else Pin = low;
if(data&0x04) Pin = high; else Pin = low;
if(data&0x02) Pin = high; else Pin = low;
if(data&0x01) Pin = high; else Pin = low;
Ok, ich habe mich doch selbst daran gewagt - und siehe da, es funktioniert auch mit 4Mhz auf einem ATtiny 10! Allerdings weicht das Timing deutlich von der Spezifikation ab. Ob das unter kritischeren Bedinungen auch noch zuverlässig funktioniert, wage ich anzuzweifeln.
1 | /* |
2 | Timing optimized for 4Mhz tinyAVR with reduced core. |
3 | (ATtiny 4/5/9/10/20/40) |
4 | |
5 | 2013/08/14 - cpldcpu@gmail.com |
6 | |
7 | The main difference is a reduced instruction timing for cbi and sbi |
8 | with 1 cycle instead of 2 for normal AVR. |
9 | |
10 | The total length of each bit is 1.25µs (5 cycles @ 4Mhz) |
11 | * At 0µs the dataline is pulled high. (cycle 0+1) |
12 | * To send a zero the dataline is pulled low after 0.5µs (spec: 0.375µs) (2+1=3 cycles). |
13 | * To send a one the dataline is pulled low after 0.75µs (spec: 0.5µs) (3+1=4 cycles). |
14 | |
15 | The timing of this implementation is significantly off, however it seems to |
16 | work empirically. Not recommended for actual use. |
17 | |
18 | Final timing: |
19 | * 8 cycles for bits 7-1 |
20 | * 13 cycles for bit 0 |
21 | */ |
22 | |
23 | |
24 | void ws2812_sendarray_4Mhz_rc(uint8_t *data,uint16_t datlen) |
25 | {
|
26 | uint8_t curbyte,ctr; |
27 | |
28 | if (!datlen) return; |
29 | |
30 | asm volatile( |
31 | "olop%=:ld %1,Z+ \n\t" |
32 | " ldi %0,8 \n\t" |
33 | |
34 | "ilop%=: \n\t" |
35 | " sbi %2, %3 \n\t" // 1 |
36 | " sbrs %1,7 \n\t" // 2 |
37 | " cbi %2, %3 \n\t" // 3 |
38 | " cbi %2, %3 \n\t" // 4 |
39 | " lsl %1 \n\t" // 5 |
40 | " dec %0 \n\t" // 6 |
41 | |
42 | " brne ilop%= \n\t" // 8 |
43 | |
44 | " dec %5 \n\t" |
45 | " brne olop%= \n\t" |
46 | |
47 | : "=&d" (ctr), "=&d" (curbyte) |
48 | : "I" (ws2812_port), "I" (ws2812_pin), "z" (data), "r" (datlen) |
49 | ); |
50 | } |
Ok, mit loop unrolling geht es bei 4Mhz auch mit korrektem Timing. Die Frage ist nur: Warum sollte man den AVR mit 4Mhz betreiben? :)
Tim . schrieb: > Die Frage ist nur: Warum sollte man den AVR mit 4Mhz betreiben? :) Wenn ich mal den Smiley geflissentlich übersehe, dann fallen mir 2 Antworten ein: 1. Wegen der geringeren Stromaufnahme 2. Evtl. ist die Versorgungsspannung nur 1,8V
Besserwisser schrieb: > Einige Tips: >> while (datlen--) { > besser: while (--len), da er das Zero-Flag direkt (=ohne einen Compare) > auswerten kann. Len muss vorher um eins korrigiert werden. Ein besserer Tip: Optimierungen aus der Computersteinzeit, aus "urban legends" , "ham wer immer schon so gemacht" oder "ich hab da mal was gehört" einfach sein lassen, statt dessen den erzeugten Assemblercode anschauen und danach entscheiden. Die Zeiten der seligen Z80, 6502 etc. sind lange vorbei, und aktuelle C-Compiler optimieren so etwas durchaus zuverlässig. Abgesehen davon wäre der Tip sowieso Unsinn, da in beiden Fällen auf 0 geprüft wird, was ja angeblich dank Zero-Flag scheller gehen soll.. Oliver
Simon Budig schrieb: > Du musst da hand-getuneden Assembler hernehmen, wenn Du > wissen willst dass das Timing funktioniert. Und selbst dann wird es > extrem knifflig. Nö. Nimm einfach einen neueren AVR (ATmega88) mit UART im SPI-Mode. Durch den Sende-Puffer kann man beliebige Datenmuster lückenlos ausgeben.
Lothar Miller schrieb: > Tim . schrieb: >> Die Frage ist nur: Warum sollte man den AVR mit 4Mhz betreiben? :) > Wenn ich mal den Smiley geflissentlich übersehe, dann fallen mir 2 > Antworten ein: > 1. Wegen der geringeren Stromaufnahme > 2. Evtl. ist die Versorgungsspannung nur 1,8V Ja, nur was hilft einem das, wenn man den AVR nutzt um damit RGB-Leds anzusteuern, die mit 5V betrieben werden und pro Stück bis zu 60mA ziehen? Allgemein hast Du natürlich recht...
Besserwisser schrieb: > Einige Tips: > >> while (datlen--) { > besser: while (--len), da er das Zero-Flag direkt (=ohne einen Compare) > auswerten kann. Len muss vorher um eins korrigiert werden. > Probiere das 'mal mit AVR-GCC aus. Du wirst Dich wundern..
Tim . schrieb: > Ok, mit loop unrolling geht es bei 4Mhz auch mit korrektem Timing. Es geht auch ohne - auch wenn es ein bisschen knifflig wurde. Besonders der Trick mit dem ori, welches den Zähler zurücksetzt, gleichzeitig das Zero-Flag löscht und kein Einfluss auf das Carry-Flag nimmt, war nicht leicht zu finden.
1 | void ws2812_sendarray_4Mhz(uint8_t *ptr, uint16_t len) |
2 | {
|
3 | if (!len) |
4 | return; |
5 | |
6 | uint8_t lo_pin = WS2812_PIN; |
7 | uint8_t hi_pin = lo_pin; |
8 | lo_pin &= ~(1<<WS2812_PIN_NUM); |
9 | hi_pin |= 1<<WS2812_PIN_NUM; |
10 | |
11 | uint16_t end_ptr = (uint16_t)ptr + len; |
12 | |
13 | uint8_t bit_counter = 7; |
14 | |
15 | asm volatile( |
16 | " ld __tmp_reg__, %a[ptr]+ \n\t" |
17 | " rjmp start \n\t" |
18 | "loop: \n\t" |
19 | " out %[PORT], %[lo_pin] \n\t" |
20 | " lsl __tmp_reg__ \n\t" |
21 | " cp %A[ptr], %A[end_ptr] \n\t" |
22 | " cpc %B[ptr], %B[end_ptr] \n\t" |
23 | " dec %[bit_counter] \n\t" |
24 | "start: \n\t" |
25 | " out %[PORT], %[hi_pin] \n\t" |
26 | " sbrs __tmp_reg__, 7 \n\t" |
27 | " out %[PORT], %[lo_pin] \n\t" |
28 | " brne loop \n\t" |
29 | " ori %[bit_counter], 7 \n\t" |
30 | " out %[PORT], %[lo_pin] \n\t" |
31 | " ld __tmp_reg__, %a[ptr]+ \n\t" |
32 | " brlo start \n\t" |
33 | |
34 | : [bit_counter] "+d" (bit_counter) |
35 | : [lo_pin] "r" (lo_pin), [hi_pin] "r" (hi_pin), [ptr] "e" (ptr), [end_ptr] "r" (end_ptr), [PORT] "M" (_SFR_IO_ADDR (WS2812_PORT)) |
36 | );
|
37 | }
|
Wenn in dem Code nun kein Fehler steckt, kann man mit ihm bis zu 2^16-1 Bytes schicken. Ich habe es nur im Simulator testen können, da ich diese Leds nicht besitze.
Hi "fallobst", Du hast die Herausforderung angenommen - super! :) Die Tricks gefallen mir sehr gut. Ich habe den code ausprobiert. Leider blieb die LED schwarz Bei der Durchsicht des Codes sind mir zwei Sachen aufgefallen: * Die Schleife benötigt 10 Zyklen. Bei 4Mhz sind nur 5 erlaubt. Insbesondere ist das timing für die "1" zu lang. (Mein Beispiel war für einen Attiny10, auf dem CBI/SBI nur 1 zyklus benötigen) * Das Z-Flag ist am Anfang in einem undefinierten Zustand, daher ist die Ausführung des ersten "BRNE loop" zufällig. CLZ eingefügt -> und siehe da, es läuft. Obwohl das Timing etwas daneben liegt, scheint es immer noch zu funktionieren.
Tim . schrieb: > * Die Schleife benötigt 10 Zyklen. Bei 4Mhz sind nur 5 erlaubt. Stimmt. Mir ist erst jetzt aufgefallen, dass die angehängte Tabelle nur Low-Speed zeigt. Daher dürfte mein Code die Spezifikationen bei 8 Mhz einhalten. Bei 4 Mhz dürfte das wirklich nur mit ausgerollten Schleifen zu schaffen sein. > Insbesondere ist das timing für die "1" zu lang. (Mein Beispiel war für > einen Attiny10, auf dem CBI/SBI nur 1 zyklus benötigen) -> out benötigt auch nur einen Zyklus. > * Das Z-Flag ist am Anfang in einem undefinierten Zustand, daher ist die > Ausführung des ersten "BRNE loop" zufällig. > CLZ eingefügt -> und siehe da, es läuft. Obwohl das Timing etwas daneben > liegt, scheint es immer noch zu funktionieren. Das habe ich tatsächlich vergessen, danke.
1 | void ws2812_sendarray_8Mhz(uint8_t *ptr, uint16_t len) |
2 | {
|
3 | if (!len) |
4 | return; |
5 | |
6 | uint8_t lo_pin = WS2812_PIN; |
7 | uint8_t hi_pin = lo_pin; |
8 | lo_pin &= ~(1<<WS2812_PIN_NUM); |
9 | hi_pin |= 1<<WS2812_PIN_NUM; |
10 | |
11 | uint16_t end_ptr = (uint16_t)ptr + len; |
12 | |
13 | uint8_t bit_counter = 8; |
14 | |
15 | asm volatile( |
16 | " ld __tmp_reg__, %a[ptr]+ \n\t" |
17 | " rjmp init \n\t" |
18 | "loop: \n\t" |
19 | " out %[PORT], %[lo_pin] \n\t" |
20 | " lsl __tmp_reg__ \n\t" |
21 | " cp %A[ptr], %A[end_ptr] \n\t" |
22 | " cpc %B[ptr], %B[end_ptr] \n\t" |
23 | "init: \n\t" |
24 | " dec %[bit_counter] \n\t" |
25 | "start: \n\t" |
26 | " out %[PORT], %[hi_pin] \n\t" |
27 | " sbrs __tmp_reg__, 7 \n\t" |
28 | " out %[PORT], %[lo_pin] \n\t" |
29 | " brne loop \n\t" |
30 | " ori %[bit_counter], 7 \n\t" |
31 | " out %[PORT], %[lo_pin] \n\t" |
32 | " ld __tmp_reg__, %a[ptr]+ \n\t" |
33 | " brlo start \n\t" |
34 | |
35 | : [bit_counter] "+d" (bit_counter) |
36 | : [lo_pin] "r" (lo_pin), [hi_pin] "r" (hi_pin), [ptr] "e" (ptr), [end_ptr] "r" (end_ptr), [PORT] "M" (_SFR_IO_ADDR (WS2812_PORT)) |
37 | );
|
38 | }
|
Ach ja, hier der ausgerollte Code. Funktioniert nur auf den reduced core AVR, da SBI/CBI auf den "großen" AVRs 2 zyklen benötigt. Mit "out" würde es aber gehen.
1 | /*
|
2 | Timing optimized for 4Mhz tinyAVR with reduced core.
|
3 | (ATtiny 4/5/9/10/20/40)
|
4 |
|
5 | 2013/04/08 - cpldcpu@gmail.com
|
6 |
|
7 | The main difference is a reduced instruction timing for cbi and sbi
|
8 | with 1 cycle instead of 2.
|
9 | |
10 | The total length of each bit is 1.25µs (5 cycles @ 4Mhz)
|
11 | * At 0µs the dataline is pulled high. (cycle 0+1)
|
12 | * To send a zero the dataline is pulled low after 0.5µs (spec: 0.375µs) (2+1=3 cycles).
|
13 | * To send a one the dataline is pulled low after 0.75µs (spec: 0.625µs) (3+1=4 cycles).
|
14 | |
15 | The timing of this implementation is slightly off, however it seems to
|
16 | work empirically. Not recommended for actual use.
|
17 |
|
18 |
|
19 | Final timing:
|
20 | * 5 cycles for bits 7-1
|
21 | * 8 cycles for bit 0
|
22 | */
|
23 | |
24 | |
25 | void ws2812_sendarray_4Mhz_rc_unrolled(uint8_t *data,uint16_t datlen) |
26 | {
|
27 | uint8_t curbyte,ctr; |
28 | |
29 | if (!datlen) return; |
30 | |
31 | asm volatile( |
32 | "olop%=:ld %1,Z+ \n\t" |
33 | |
34 | "ilop%=: \n\t" |
35 | " sbi %2, %3 \n\t" // 1 |
36 | " sbrs %1,7 \n\t" // 2 |
37 | " cbi %2, %3 \n\t" // 3 |
38 | " cbi %2, %3 \n\t" // 4 |
39 | " nop \n\t" // 5 |
40 | |
41 | " sbi %2, %3 \n\t" // 1 |
42 | " sbrs %1,6 \n\t" // 2 |
43 | " cbi %2, %3 \n\t" // 3 |
44 | " cbi %2, %3 \n\t" // 4 |
45 | " nop \n\t" // 5 |
46 | |
47 | " sbi %2, %3 \n\t" // 1 |
48 | " sbrs %1,5 \n\t" // 2 |
49 | " cbi %2, %3 \n\t" // 3 |
50 | " cbi %2, %3 \n\t" // 4 |
51 | " nop \n\t" // 5 |
52 | |
53 | " sbi %2, %3 \n\t" // 1 |
54 | " sbrs %1,4 \n\t" // 2 |
55 | " cbi %2, %3 \n\t" // 3 |
56 | " cbi %2, %3 \n\t" // 4 |
57 | " nop \n\t" // 5 |
58 | |
59 | " sbi %2, %3 \n\t" // 1 |
60 | " sbrs %1,3 \n\t" // 2 |
61 | " cbi %2, %3 \n\t" // 3 |
62 | " cbi %2, %3 \n\t" // 4 |
63 | " nop \n\t" // 5 |
64 | |
65 | " sbi %2, %3 \n\t" // 1 |
66 | " sbrs %1,2 \n\t" // 2 |
67 | " cbi %2, %3 \n\t" // 3 |
68 | " cbi %2, %3 \n\t" // 4 |
69 | " nop \n\t" // 5 |
70 | |
71 | " sbi %2, %3 \n\t" // 1 |
72 | " sbrs %1,1 \n\t" // 2 |
73 | " cbi %2, %3 \n\t" // 3 |
74 | " cbi %2, %3 \n\t" // 4 |
75 | " dec %5 \n\t" // 5 |
76 | |
77 | " sbi %2, %3 \n\t" // 1 |
78 | " sbrs %1,0 \n\t" // 2 |
79 | " cbi %2, %3 \n\t" // 3 |
80 | " cbi %2, %3 \n\t" // 4 |
81 | |
82 | " brne olop%= \n\t" // 6 |
83 | |
84 | : "=&d" (ctr), "=&d" (curbyte) |
85 | : "I" (ws2812_port), "I" (ws2812_pin), "z" (data), "r" (datlen) |
86 | );
|
87 | }
|
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.