Hallo Zusammen,
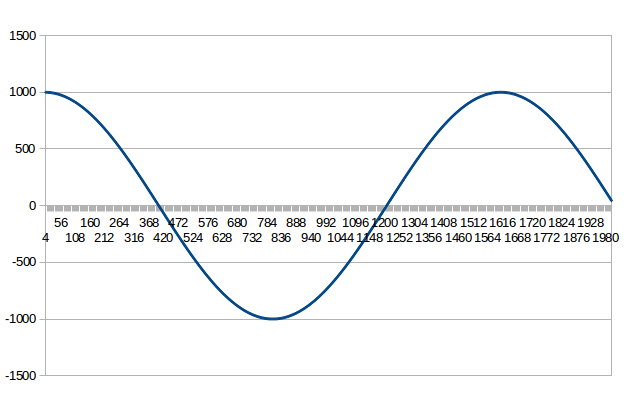
vor einiger Zeit habe ich mit der Berechnung eines Feder-Masse-Pendels
experimentiert. Nachdem ich die Gleichungen minimiert hatte, bin ich auf
den Algorithmus zur Erzeugung einer Sinus-Schwinung gestoßen.
1
#define KONST -10
2
3
voidloop(){
4
5
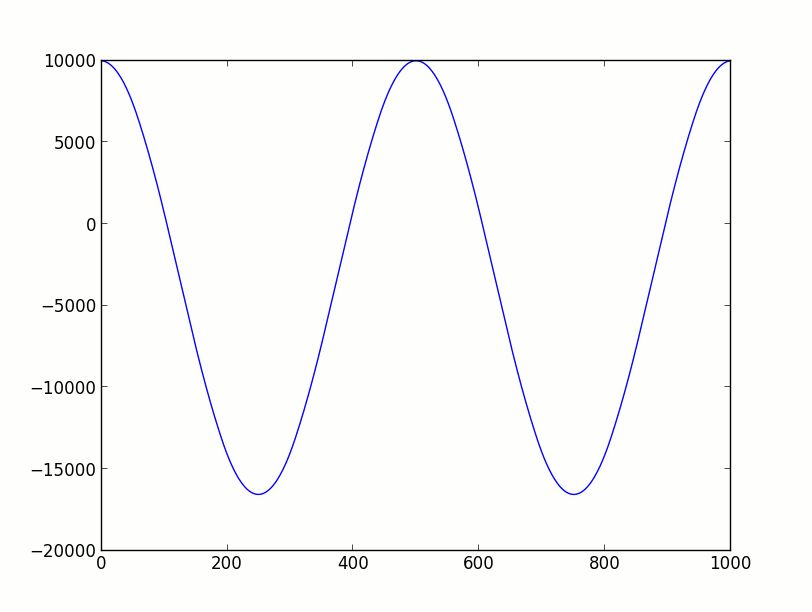
int32_ts=10000;// initial excursion ( mass position ) of the spring
6
int32_tv=0;// velocity
7
int32_tds=0;// delta excursion
8
int32_tdv=0;// delta velocity
9
10
while(1)
11
{
12
//********** sine wave generation *************
13
dv=(s*KONST)/65536;// update delta velocity
14
ds=v+dv;// update delta position
15
v=v+dv;// update velocity
16
s=s+ds;// update excursion
17
//*********************************************
18
19
writeDAC(s);// write sin wave to DAC
20
}
21
}
Vielleicht kann ihn jemand gebrauchen ;-)
Die Division lässt sich durch geeignete Schiebeoperationen ersetzen. Man
muss allerdings das Vorzeichen beachten.
Die Konstante lässt sich innerhalb bestimmter Grenzen variieren, um die
Frequenz zu ändern. Im Beispiel habe ich eine sehr niedrige Frequenz
gewählt, dammit der Vorteil gegenüber Tabellen zur Geltung kommt.
Hi chris,
das ist ein echt spannendes Thema. Zu optimierten diskreten Oszillatoren
gibt es hier einen ziemlich guten Artikel:
http://www.claysturner.com/dsp/2nd_OSC_paper.pdf
Deine Implementation scheint Amplitudenfehler zu akkumulieren.
./. schrieb:> Das geht mit der Hilberttransformation viel einfacher.
soso...
> http://www.claysturner.com/dsp/2nd_OSC_paper.pdf
Das ist ja ein ziemlich interessantes Paper, Danke :-)
Vom Aufwand her scheint meine Implementierung in Richtung Biquad aus dem
Paper zu gehen. Lustig ist die Beschreibung dazu:
> The biquad oscillator was one of the> first discrete oscillators to see use in> signal processing applications. I recall> an application patent issued in the> 1980s that used this oscillator for> generating call progress tones used in> telephony. I found this interesting> since François Viète discovered the> trigonometric recurrence relation (1)> long before; his result was published> in the year 1571! /
Die Implementierung des Biquad erfordert sogar noch etwas weniger
Aufwand, da nur eine Multiplikation und eine Addition benötigt wird.
Allerdings stellt sich immer die Frage nach der notwendigen Auflösung
des Koeffizienten und der Stabilität. Vielleicht hat von euch schon mal
jemand den Biquad in C getestet?
>Deine Implementation scheint Amplitudenfehler zu akkumulieren.
Wie meinst Du das? Hergeleitet habe ich das Verfahren über die Formeln
für ein Feder Masse-System
v=Geschwindigkeit
s=Ort
dv=Geschwindigkeitsdifferenz
ds=Wegdifferenz
Die Schwingung ist stabil, da sich die Werte nach 2 Zyklen immer exakt
wiederholen.
>Wie wirken sich numerische Fehler in Deinem Ansatz aus?
1
dv=(s*KONST)/65536;// update delta velocity
Das ist die Zeile, in der die Fehler entstehen. Durch die Division
entstehen Rundungsfehler. Umso kleiner die Konstante "KONST" desto
niedriger die Frequenz und desto größer die Rundungsfehler.
Die Auswirkungen: zusätzliche Frequenzen im Spektrum.
Es ist also besser, hohe Frequenzen zu erzeugen, weil dort die Fehler
kleiner sind. Andererseits: Nur bei tiefen Frequenzen kann das Verfahren
auf einem Mikrocontroller seine Vorteile ausspielen, weil das die langen
Sinustabellen spaaren würde.
Jo mei. Das ist eine numerische Näherungslösung für die kanonische
Differentialgleichung, zusammen mit der Vereinfachung sin(x) ~= x
(für kleine x)
Also 1. Semester Physik in einem technischen Studiengang. Oder wenn man
einen engagierten Physiklehrer hat, Leistungskurs Physik am Gymnasium.
XL
Seltsamer Code: Warum berechnest Du v+dv zweimal?
So wär's übrigens richtig:
1
a = (s*KONST)/65536;
2
v = v + a*dt;
3
s = s + v*dt;
mit dem konstanten Zeitintervall dt als Diskretisierungsschritt.
Explizites Euler-Einschrittverfahren nennt sich dieser Spaß übrigens.
>zusammen mit der Vereinfachung sin(x) ~= x (für kleine x)
Wie bitte? An welcher Stelle soll die denn stecken?
>Seltsamer Code: Warum berechnest Du v+dv zweimal?
Der Code ist für kleine Mikrocontroller wie den Attiny13 ohne
Multiplikationseinheit oder FPGAs gedacht. Dort geht es darum, möglichst
wenig oder gar keine Multiplikationen zu verwenden.
Beim Attiny13 geht es darum, mölichst wenig Rechenzeit zu verbrauchen.
Sparen kann man an der Anzhal und der Auflösung der Variablen und den
Rechenoperationen.
Diese Zeit beinhaltet in meinem Code die einzige Multiplikation:
1
dv=(s*KONST)/65536;
Die Division kann man sich auf folgende Weise, wenn man die Zeile
folgendermaßen ersetzt:
1
dv=s*KONST;
2
if(dv<0)
3
{
4
dv=-dv;
5
dv=dv>>16;
6
dv=-dv;
7
}
8
elsedv=dv>>16;
Wobei ich da noch auf eine elegantere Lösung hoffe.
>Hmm, laut python sieht es wie sinus aus:
Irgendwas geht da schief in Python, wenn ich mir die negative Amplitude
anschaue. Möglicherweise liegt es an der Typisierung.
chris_, das was bei deinem Algorithmus herauskommt, sieht doch nicht wie
ein Sinus, sondern wie ein Dreieck mit abgerundeten Spitzen aus. Der
Grund dafür liegt darin, dass dv=(s*KONST)/65536 in einem großen Bereich
(nämlich für |s| < 65536/10) gleich 0 ist. Damit ist v in diesem Bereich
konstant.
chris_ schrieb:> Irgendwas geht da schief in Python, wenn ich mir die negative Amplitude> anschaue.
Nicht nur das, auch die Frequenz ist eine völlig andere. Das liegt
daran, dass Python bei Integer-Divisionen das Ergebnis gegen -∞, C
hingegen gegen 0 rundet. Wenn man in Fatals Programm eine entsprechende
Fallunterscheidung einbaut, erhält man das gleiche Ergebnis wie bei dir.
Um die Qualität der Sinuserzeugung zu verbessern, musst du versuchen,
bei der Berechnung den vollen 32-Bit-Wertebereich zu nutzen. Im Moment
liegt das größte Zwischenergebnis gerade mal im Bereich ±100000, was nur
unwesentlich über den 16-Bit-Wertebereich hinausgeht und deswegen zu
großen Rundungsfehlern führt.
>Jo mei. Das ist eine numerische Näherungslösung für die kanonische>Differentialgleichung, zusammen mit der Vereinfachung sin(x) ~= x>(für kleine x)>>Also 1. Semester Physik in einem technischen Studiengang. Oder wenn man>einen engagierten Physiklehrer hat, Leistungskurs Physik am Gymnasium.
Jo mei, tatsächlich geht es in diesem Beitrag wahrscheinlich um die
Optimierung eines digitalen Berechnungsverfahrens bezüglich begrenzter
Hardwareresourcen einer Sinusschwingung.
Der Threadstarter hat vermutlich das Feder/Masse System nur erwähnt, um
die Grundlage darzustellen, mit der der Algortithmus entwickelt wurde.
Wichtig sind für den Algorithmus die Kenntnisse über Integerarithmektik,
Stabilitätskriterien digitaler Signalverarbeitungssysteme sowie
Kenntnisse über den Hardwareaufwand, der für die Realisierung von
Signalverarbeitungsalgorithmen notwendig ist.
Deine Kenntnisse der Schulphysik reichen jedenfalls nicht für die
Eintrittskarte zu einem vernünfigen Beitrag in dieser Diskussion.
Eher sind sie ein Hinweis auf den Dunning-Kruger-Effekt.
>chris_, das was bei deinem Algorithmus herauskommt, sieht doch nicht wie>ein Sinus, sondern wie ein Dreieck mit abgerundeten Spitzen aus.
Da hast Du natürlich recht, so sieht der Sinus eher wie ein Dreieck aus.
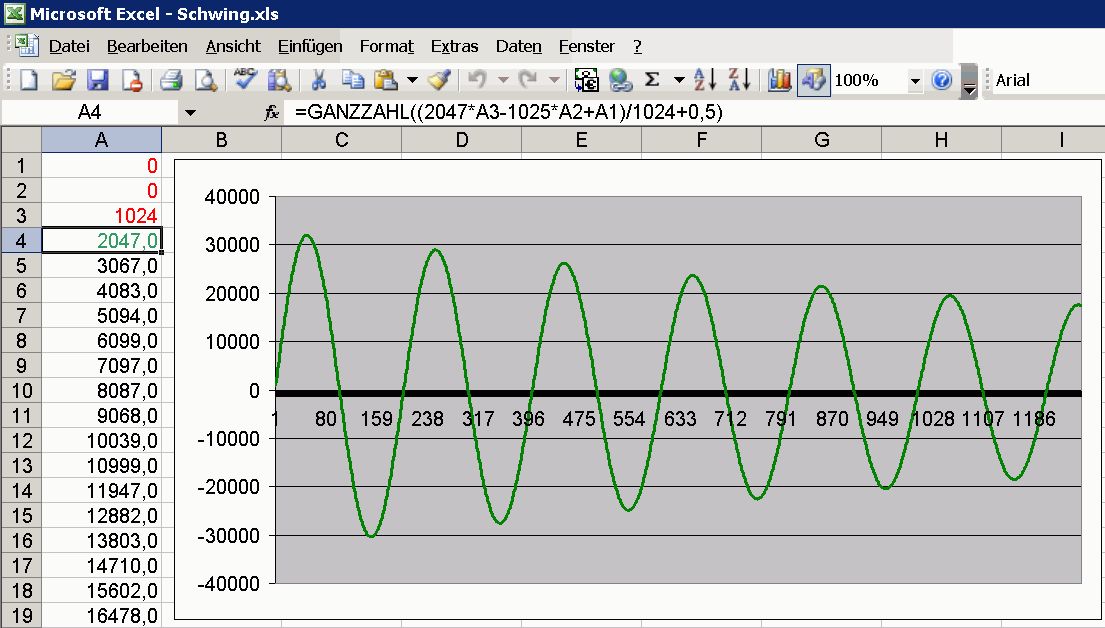
Deshalb habe ich den Wert jetzt mal auf 16Bit hochskaliert:
1
#define KONST 1
2
#define SCALE 0x10000L // scale for fractional number 16bit.16bit
3
#define AMPLITUDE 1000*SCALE
4
5
..
6
int32_ts=AMPLITUDE;// initial excursion ( mass position ) of the spring
7
8
loop()
9
{
10
11
w=(s*KONST)/SCALE;
12
q=q-w;
13
s=s+q;
14
15
writeDAC(s/SCALE);// write sin wave to DAC
16
}
17
..
Was besonders interessant ist: Mit der Wahl auf die Konstante 1
reduziert sich die Sinuserzeugung auf eine Subtraktion und eine
Addition.
Wie schnell das wohl auf einem AVR in Assembler läuft? Vielleicht gibt
es hier einen guten Assemblerprogrammierer, der das mal auf einem AVR
umsetzen möchte.
Im Anhang habe ich noch eine Version für den PC, damit die Daten in eine
Datei geschrieben werden.
>Das liegt daran, dass Python bei Integer-Divisionen das>Ergebnis gegen -∞, C hingegen gegen 0 rundet.
aww, wie gemein. Aber danke für die Erklärung, so konnte ich den Fehler
lösen:
Wenn man die Int-Division in python als float-division ausführt und das
Ergebnis wieder nach int wandelt sind die Ergebnisse wie eine
int-null-rundung auf dem AVR.
( gefunden hier:
http://stackoverflow.com/questions/19919387/in-python-what-is-a-good-way-to-round-towards-zero-in-integer-division
)
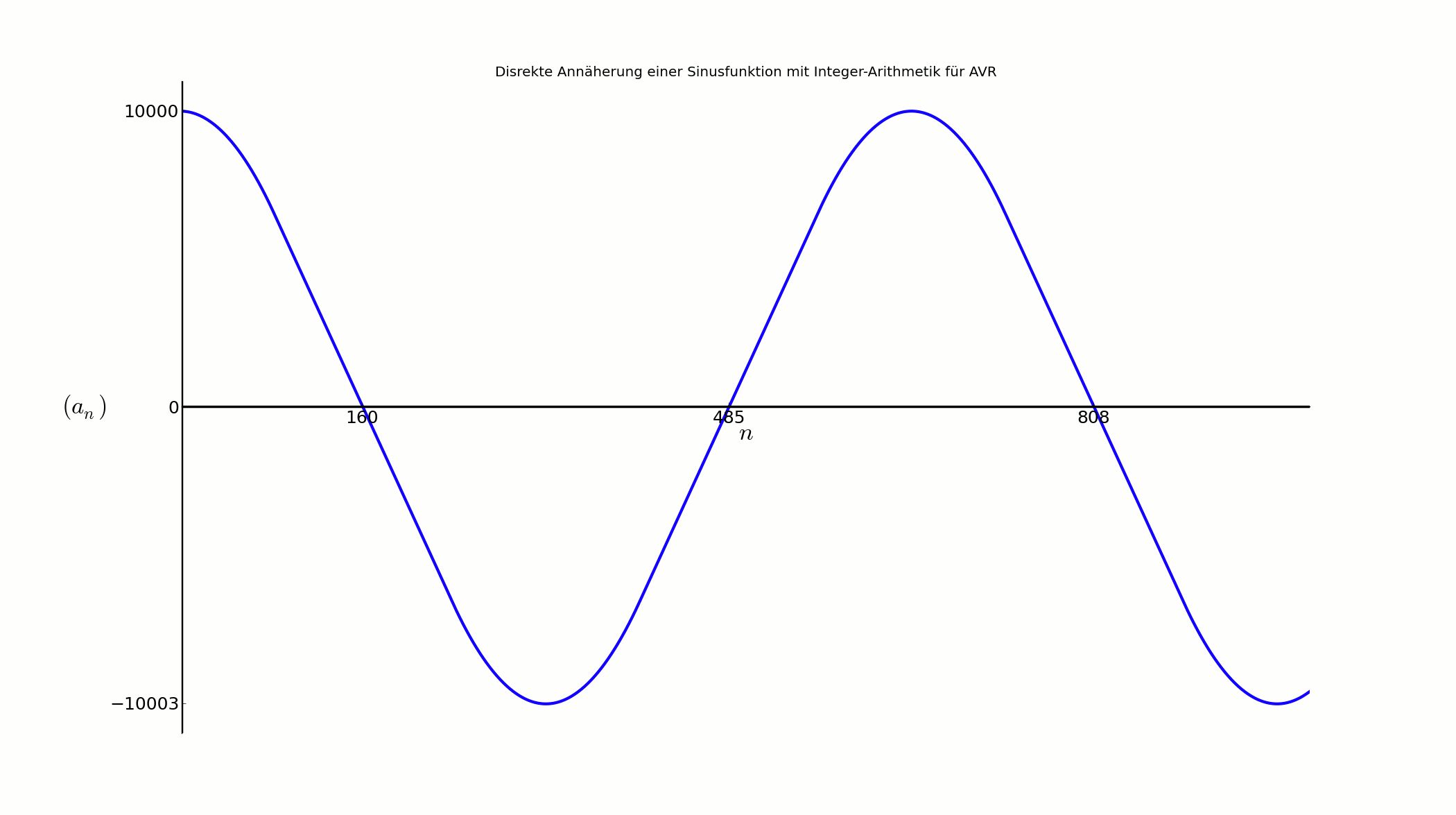
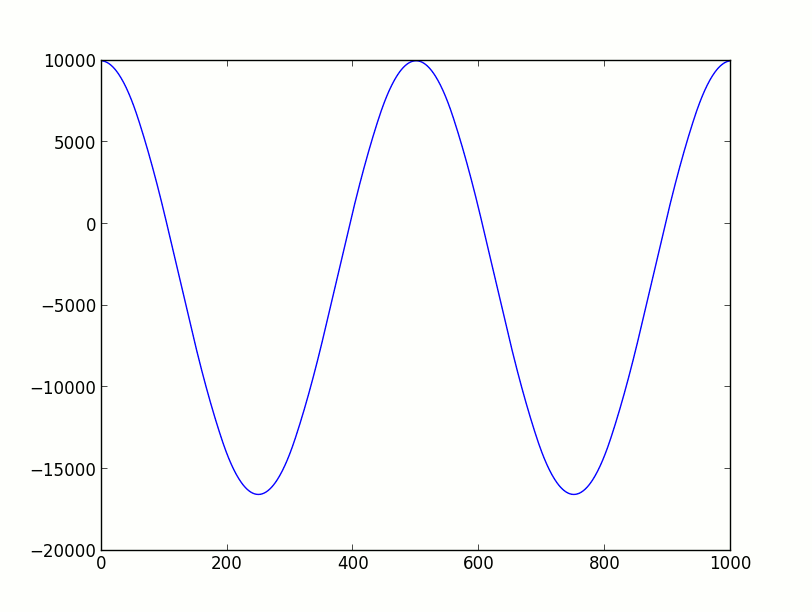
1
from matplotlib import pyplot as plt
2
dt=1
3
KONST=-10
4
s=10000
5
v=0
6
ds=0
7
dv=0
8
9
ADCvalues=[]
10
for i in range(1000):
11
# integerwerte als float-division und wieder cast zu int --> simuliert in python die integer-rundung nach 0
12
# wie im AVR (anstelle Rundung zu $-\infty$ wie es python mit ints normal macht)
13
a = int(float((s*KONST))/65536)
14
v = v + a*dt
15
s = s + v*dt
16
ADCvalues.append(s)
17
18
plt.plot(ADCvalues,color='blue',linewidth=3)
19
20
# x-achse in die mitte... http://scipy-lectures.github.io/intro/matplotlib/matplotlib.html#moving-spines
21
ax=plt.gca() # 'get current axis'
22
ax.spines['right'].set_color('none')
23
ax.spines['top'].set_color('none')
24
ax.xaxis.set_ticks_position('bottom')
25
ax.spines['bottom'].set_position(('data',0))
26
ax.yaxis.set_ticks_position('left')
27
ax.spines['left'].set_position(('data',0))
28
ax.xaxis.set_tick_params(labelsize=18)
29
ax.yaxis.set_tick_params(labelsize=18)
30
31
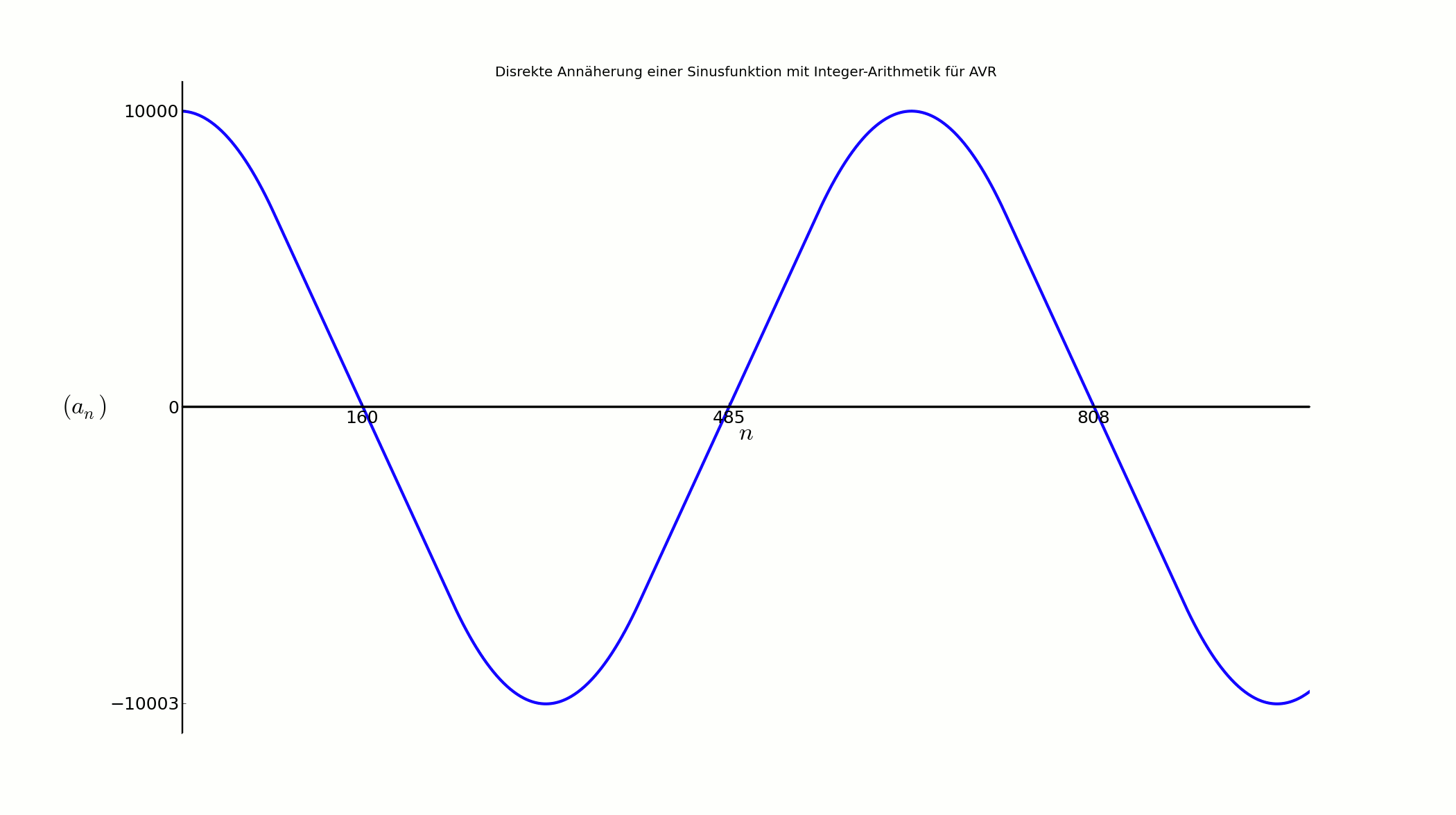
plt.title(u"Disrekte Annäherung einer Sinusfunktion mit Integer-Arithmetik für AVR")
32
33
#plt.ylim([-11000,11000])
34
plt.ylim(min(ADCvalues)*1.1, max(ADCvalues)*1.1)
35
36
cnt=0
37
nNull=[]
38
for i in ADCvalues:
39
if 0<=i<75: nNull.append(cnt)
40
cnt+=1
41
plt.xticks(nNull)
42
43
#plt.xticks([100*n for n in range(len(ADCvalues)/100)])
Die Gleichung hat noch 3 Multiplikationen. Vielleicht sollt man dt noch
auf 1 setzen, damit diese wegfallen.
1
a=int(float((s*KONST))/65536)
2
v=v+a*dt
3
s=s+v*dt
Dann fehlt nur noch die Formel für den Zusammenhang zwischen KONST und
der Abtatsfrequenz um die Sinusfrequenz zu berechnen.
>Wenn man die Int-Division in python als float-division ausführt und das>Ergebnis wieder nach int wandelt sind die Ergebnisse wie eine
So ähnlich habe ich es bei der Integerdivision mit Rechtsschieben
gemacht, weil dort genau der selbe Rundungsfehler auftritt, wenn man nur
schiebt:
chris_ schrieb:>> http://www.claysturner.com/dsp/2nd_OSC_paper.pdf> Das ist ja ein ziemlich interessantes Paper, Danke :-)>> Vom Aufwand her scheint meine Implementierung in Richtung Biquad aus dem> Paper zu gehen. Lustig ist die Beschreibung dazu:
Wenn man Deinen Ansatz in die vorgeschlagene Normalform bringt, kommt
man auf folgende Matrix:
mit
Die Determinante der Matrix ist 1, womit die Amplitude im Gegensatz zu
meiner ersten Vermutung stabil ist. Der Ansatz entspricht im
Wesentlichen dem, den Clay als "Reinsche" bezeichnet.
http://www.claysturner.com/dsp/digital_resonators.pdf (Ab Folie 59)
Dieser Ansatz ist numerisch etwas kritisch, da beiden Variablen
unterscheidliche Amplituden haben. Das ist auch in Deiner Herleitung zu
sehen, da Deine Geschwindigkeitsvariable insbesondere bei niedrigen
Frequenzen einen kleineren Wertebereich als die Amplitude hat.
Stabiler ist der "Magic-Circle" Ansatz. Dieser genertiert gleichzeitig
cosinus und sinus bei gleicher Amplitude.
Man kann sich diesen Ansatz leicht aus der diskreten Integration von sin
und cos herleiten. Kritisch ist hier aber, dass in der zweiten Zeile das
Ergebnis der ersten Berechnung genutzt wird. Wenn man hier nur a nutzt,
ist die Determinante nicht 1 und die Amplituden degradieren.
Dieser Ansatz benötigt zwar zwei Multiplikationen, ist aber schon bei 8
Bit Arithmetik erstaunlich stabil.
LostInMusic schrieb:> So wär's übrigens richtig:> a = (s*KONST)/65536;> v = v + a*dt;> s = s + v*d
Das ist auch nicht "richtig", sondern einfach ein komplett anderer
Ansatz.
>Wenn man Deinen Ansatz in die vorgeschlagene Normalform bringt, kommt>man auf folgende Matrix:
Wow, da hast Du Dich ja ganz schön reingehängt. Das muss ich noch mal
nachvollziehen.
>Stabiler ist der "Magic-Circle" Ansatz. Dieser genertiert gleichzeitig>cosinus und sinus bei gleicher Amplitude.
Das klingt auch sehr interessant. So einen Oszillator könnte man
vielleicht für den Görtzle-Algorithmus verwenden, falls man keine
Tabelle speichern kann. Wenn er mit 8Bit funktioniert, muss ich den auf
jeden Fall mal ausprobieren.
Jetzt habe ich in meinem Code oben
1
loop()
2
{
3
4
w=(s*KONST)/SCALE;
5
q=q-w;
6
s=s+q;
7
8
writeDAC(s/SCALE);// write sin wave to DAC
9
}
von der Multiplikation befreit.
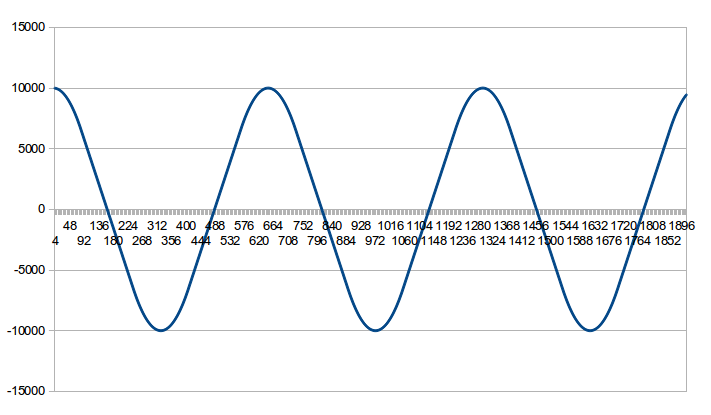
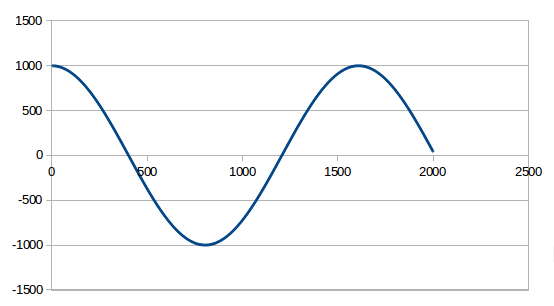
Heraus kommt dieser Generator, der nur aus einer Addition und einer
Subtraktion besteht:
1
#define SCALE 0x10000L // scale for fractional number 16bit.16bit
2
#define AMPLITUDE 1000*SCALE
3
4
voidloop(){
5
// attention: converting numbers with a union is machine
6
// and possibly compiler dependent
7
// this code runs on a Intel PC compiled with GCC
8
unionshifter{
9
int16_tpart[2];
10
int32_tvalue;
11
}sr;
12
13
sr.value=AMPLITUDE;// initial excursion ( mass position ) of the spring
14
int32_tq=0;
15
16
intn;
17
18
for(n=0;n<2000;n++)
19
{
20
21
//********** sine wave generation *************
22
q=q-sr.part[1];
23
sr.value=sr.value+q;
24
//*********************************************
25
26
writeDAC(sr.part[1]);// write sin wave to DAC
27
}
28
}
Ich finde es völlig faszinierend, dass daraus ein Sinus entsteht.
chris_ schrieb:> Das klingt auch sehr interessant. So einen Oszillator könnte man> vielleicht für den Görtzle-Algorithmus verwenden, falls man keine> Tabelle speichern kann. Wenn er mit 8Bit funktioniert, muss ich den auf> jeden Fall mal ausprobieren.
Genau für die Anwendung untersucht Clay Turner diese Oszillatoren ja.
Das geht auf jeden Fall.
chris_ schrieb:> Heraus kommt dieser Generator, der nur aus einer Addition und einer> Subtraktion besteht:
Das ist aber ein wenig geschummelt :) Die Multiplikation ist immer noch
da, Du hast sie nur durch einen Shift ersetzt. Dafür lässt sich jetzt
die Frequenz nicht mehr frei wählen.
>Dafür lässt sich jetzt
die Frequenz nicht mehr frei wählen.
Wobei Du aber in einem FPGA einfach nur die Taktfrequenz der Loop ändern
müsstest, um unterschiedliche Frequenzen zu erhalten.
Da die FPGAs ja ziemlich hohe Taktfrequenzen erlauben, wäre das
vielleicht ein nützliches Verfahren zur Erzeugung von Frequenzen im
Audiobereich.
chris_ schrieb:> Wobei Du aber in einem FPGA einfach nur die Taktfrequenz der Loop ändern> müsstest, um unterschiedliche Frequenzen zu erhalten.> Da die FPGAs ja ziemlich hohe Taktfrequenzen erlauben, wäre das> vielleicht ein nützliches Verfahren zur Erzeugung von Frequenzen im> Audiobereich.
Dazu benötigt man aber eine PLL, welche es auf FPGAs nur in sehr
begrenzter Stückzahl gibt und welche auch keine beliebige Auflösung
erlauben. Da ist es einfacher, eine Multiply-Accumulate-Einheit zu
verwenden, von denen es auf jedem modernen FPGA etliche gibt.
LostInMusic schrieb:> Explizites Euler-Einschrittverfahren nennt sich dieser Spaß übrigens.
Danke für diesen Beitrag. So isses. Alles alte Hüte.
Tim schrieb:> Dazu benötigt man aber eine PLL, welche es auf FPGAs nur in sehr> begrenzter Stückzahl gibt und welche auch keine beliebige Auflösung> erlauben. Da ist es einfacher, eine Multiply-Accumulate-Einheit zu> verwenden, von denen es auf jedem modernen FPGA etliche gibt.
Wobei anzumerken wäre, dass die Akumulation einige steps erfordert, bis
ein Sinus fertig ist und damit eine obere Grenzfrequenz vorgegeben ist.
Und das Ergebnis wird dann auch so ungenau und Fehleranfällig.
Grundsätzlich ist die Formel aber i.O. weil sie Fehler eher
wegkompensiert.
>> Explizites Euler-Einschrittverfahren nennt sich dieser Spaß übrigens.>Danke für diesen Beitrag. So isses. Alles alte Hüte.
Das klingt interssant. Kannst Du einen Link oder Literaturverweis
posten?
Bitte einen Link auf eine konkrete Umsetzung in Code.
>Was ist denn nicht gut an einer Tabelle ?
Eine Tabelle ist in vielen Fällen die beste Wahl. Eine lineare
Interpolation zwischen den Punkten kostet allerdings Rechenzeit. Ob und
wie viele Multiplikationen für eine Interpolation notwendig sind, weiß
ich im Moment nicht.
Der obige Algortihmus ist ein Spezialfall und für diesen vermutlich das
Optimum was Rechenzeit und Speicherverbrauch anbelangt. Wahrscheinlich
könnte man ihn am ehesten für FPGAs oder System mit wenig Speicher
geeignet sein in denen man auch nicht interpolieren kann.
chris_ schrieb:> wie viele Multiplikationen für eine Interpolation notwendig sind, weiß> ich im Moment nicht.
Eine :-) Y = m*b * a
Eine Interpolation bringt enorme Vorteile in der Einsparung der
Tabellengrösse. Man kann die Granularität der Tabellenlösungen aber auch
durch Phasen-Dither umgehen.
Generell besteht der Vorteil der DDS-Lösungen dadurch, dass die Frequenz
fest vorgegeben ist und die Fehler "nur" zu einem Jitter führen, während
sie bei selbstgesteuerten Sinusgeneratoren aufsummieren und die Frequenz
sowie die Phasenlage ändern. Die Wellen laufen also weg.
Gerade wird hier parallel etwas Ähnliches diskutiert:
Beitrag "Re: IIR-Filter als Sinusgenerator"
Jürgen Schuhmacher schrieb:> Generell besteht der Vorteil der DDS-Lösungen dadurch, dass die Frequenz> fest vorgegeben ist und die Fehler "nur" zu einem Jitter führen, während> sie bei selbstgesteuerten Sinusgeneratoren aufsummieren und die Frequenz> sowie die Phasenlage ändern. Die Wellen laufen also weg.
Das ist eine unnötig pauschalisierende Aussage. Der Fehler beider
Methoden lässt sich genau berechnen. Beim DDS entsteht ebenso ein
Frequenz/Phasenfehler, wenn die Auflösung des Akkumulators nicht
ausreicht.
>> wie viele Multiplikationen für eine Interpolation notwendig sind, weiß>> ich im Moment nicht.>Eine :-) Y = m*b * a
Lass uns y=mx + b sagen, das kennt man aus der Schule besser.
Die Frage wäre: woher bekommst du m ohne Rechenaufwand?
Und wie zerlegst Du den index x ohne Rechenaufwand?
Tim schrieb:> Das ist eine unnötig pauschalisierende Aussage.
Ok, ich hätte besser schreiben sollen: DDS ist bei gleichem Aufwand
genauer. Gerade die Auflösung der speichernden Variablen ist ein echter
Limiter.
> Beim DDS entsteht ebenso ein> Frequenz/Phasenfehler, wenn die Auflösung des Akkumulators nicht> ausreicht.
Richtig. Ich bin jetzt davon ausgegangen, dass die Auflösung des
Phasenvektors ausreichend gross ist, was ja mit wenigen Bits zu erzielen
ist.
chris_ schrieb:> Lass uns y=mx + b sagen, das kennt man aus der Schule besser.
Genehmigt :-)
> Die Frage wäre: woher bekommst du m ohne Rechenaufwand?
Bei den meisten technischen Aufgaben wird Sinus und Cosinus benötigt und
die hinterlegt man in der Tabelle oder liest sie zweifach ab. Dann ist
die Steigung inkusive.
> Und wie zerlegst Du den index x ohne Rechenaufwand?
Indem binär multipliziert wird. Der vordere Teil des Vektors ist die
Adresse für den lookup-Wert der Tabelle, der hintere Teil der X-Wert für
die Multiplikation.
Siehe oberes Bild:
http://www.96khz.org/oldpages/limitsofdds.htm
Das Problem der DDS ist also letzlich weniger die Phasenvektorlänge, als
die Tabellengrösse. Man kann es aber dithern und filtern, siehe unteres
Bild.
Hallo Jürgen,
um den Rechenaufwand einer Interpolation abzuschätzen und mit meinem
obgen Verfahren wäre es am besten, wenn Du ein Stück Code posten
könntest.
Dort können wir dann direkt sehen, wie viele Instruktionen gebraucht
werden. Das würde die Diskussion sehr vereinfachen.
Ich denke bei sehr rechenzeitkritischen Anwendungen ist eine allgemene
Diskussion schwierig, eine konkrete Implementierung führt hier eher zum
Ziel.
Gruß,
chris_
chris,
warum ist es eigentlich so wichtig, das "Dein" Verfahren "besser" ist?
Die Diskussion mutet teilweise schon etwas bizarr an. Alle hier
erwähnten Verfahren sind schon lange bekannt, gut dokumentiert und haben
Applikationsspezifische Vor- und Nachteile.
Viel interessanter ist es doch, alle Ansätze so weit zu verstehen dass
man selbst in der Lange ist den richtigen auszuwählen.
> Die Diskussion mutet teilweise schon etwas bizarr an. Alle hier> erwähnten Verfahren sind schon lange bekannt, gut dokumentiert und haben> Applikationsspezifische Vor- und Nachteile.
Deine Meinung teile ich nicht ganz. Es ist richtig, das die Verfahren
zur Sinusberechnung seit hunderten von Jahren bekannt sind. Aber in der
Technik kommt es auf die Art der Realisierung an. Insbesondere bei
rechenzeitkritischen Problemen bei denen einzelne Zyklen gezählt werden
müssen, ist der Realisierung entscheidend.
Das Prinzip der digitalen Filterung ist z.B. mathematisch schon lange
bekannt und trotzdem gibt es sehr teuere Bücher über deren Realisierung
in FPGAs und wie man dort möglichst viele Bits und Register spart. ( Da
könnte sicherlich Tim von weiter oben einige Literaturhinweise geben )
In diesen Büchern steckt das Wissen "wie etwas gemacht wird", dazu sind
einige Denkschritte nötig, um von den akademischen Grundlagen auf eine
praktikable Umsetzung zu kommen.
Nimm z.B. die ARM-Prozessoren: Zu der Zeit als die ersten
ARM-Prozessoren entwickelt wurden gab es schon viele andere Prozessoren
und auch die zur Umsetzung notwendige Boolsche-Logik. Auch die von
Neuman oder Harward Architektur waren schon da., aber der große Vorteil
des Prozessors war seine minimalistische Realisierung und die
Beantwortung der ganz praktischen Frage:
Wie bekomme ich mit möglichst wenig Transistoren einen schnellen 32 Bit
Prozessor.
Den Erfolg verdankt dieser Prozessor also nicht akademischen Grundlagen
sondern dem praktischen "Wie wird es gemacht".
> um den Rechenaufwand einer Interpolation abzuschätzen und mit meinem> obgen Verfahren wäre es am besten, wenn Du ein Stück Code posten> könntest.
Wenn Dir also das Problem aus akademischer Sicht zu trivial erscheint
und Du der Meinung bist, man kann den Code für die Interpolation in 10
Minuten hinschreiben, dann bitte ich Dich Dir die Zeit zu nehmen und den
Code hier zu posten.
Mich würde es freuen und ich könnte vielleicht etwas lernen. Auf jeden
Fall lässt dann der Vergleich der verschiedenen Verfahren und die
Aufwandsabschätzung auf sehr fundierter Basis durchführen.
>warum ist es eigentlich so wichtig, das "Dein" Verfahren "besser" ist?
Weil ich über Jahre hinweg immer wieder einmal an das Problem der
schnellen Sinusberechnung gedacht habe und mir irgendwann die Lösung
oben eingefallen ist. Jetzt möchte ich wissen, ob diese für ihren
Anwendungsfall wirklich optimal ist und ob es genau diese Realisierung
voher schon gab. Wenn ja, wäre ich sehr an dem Code oder einem Link
darauf interessiert.
Ausserdem finde ich es ganz gut, wenn aus diesem Thread eine gute
Methodenübersicht zur schnellen Sinusberechnung entsteht. Am besten mit
Code-Beispielen.
@Chris: Ich bezog mich bei meiner Sinusberechnung auf den FPGA-Fall. Was
ich für uCs noch anzubieten hätte, wäre diese Näherung:
http://www.96khz.org/oldpages/sinesynthesisdds.htm
(unterstes Bild)
Welches Verfahren zur Erzeugung eines Sinus generell das jeweils beste
ist, hängt von den Ansprüchen ab. Die iterative Methode /
Selbstschwingung von oben ist ja z.B. in der Bandbreite begrenzt und
setzt eine kontinuierliche äquidistante Berechnung voraus. Eine
Amplitudenänderung gelingt auch nur per Skalierung. Bei einem
vollständig parametrischen Oszillator habe ich auch ein natürliche
Dämpfung owie gleichzeitige Anpassung der Phase und der Amplitude, wenn
ich die Randbedingungen ändere.
Hier hätte ich nochmal was aus meinem Fundus: So ähnlich habe ich das
früher mit DSPs gemacht und später auch in FPGAs implementiert, dort
allerdings (da Integer) mit etwas höherer Auflösung und Dithering, weil
sonst der Sinus nicht sinusförmig (sondern am Ende dreieckig)
ausschwingt und auch nicht die Nullachse erreicht.
Frequenz und Dämpfung hängen hier zusammen, kann man aber auch aus
primären Parametern bilden. Meiner Erinnerung nach resultierte der
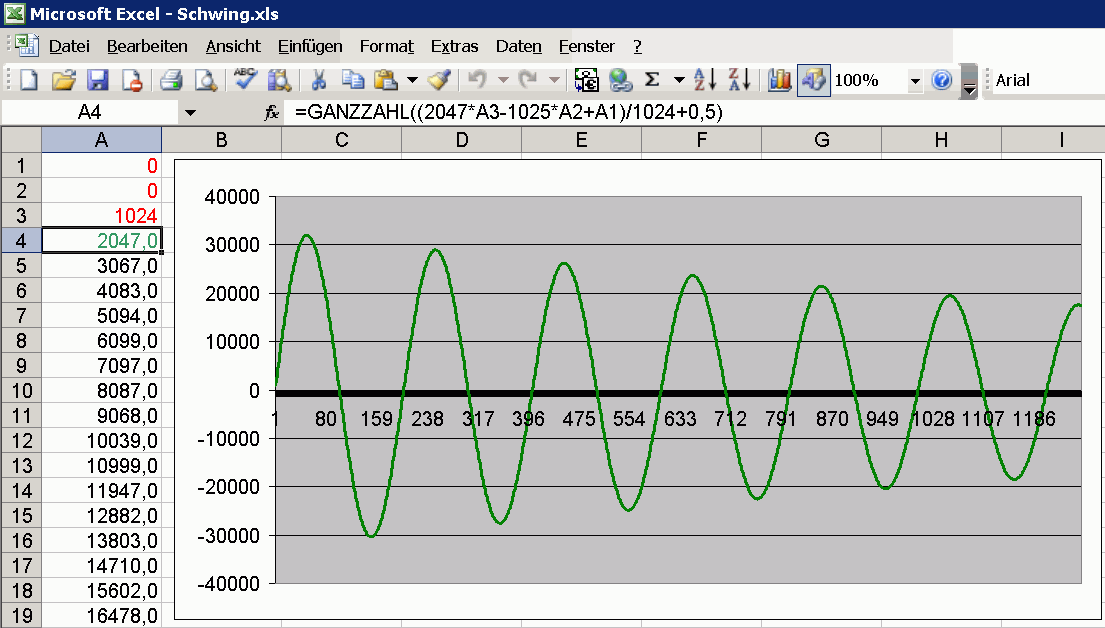
bestimmende Wert (oben 2047) aus der Vollausstuerung - Frequenz hoch 2.
Eine neue Welle schubst man durch Vorbelegung mit 0,0,Amplitude in den 3
Speicherzellen an oder aber überträgt aus einer anregenden Welle die
"Energie". So lässt sich z.B. die 3.Saite beim Klavier (Sustenuto)
modellieren.
Da ist kein Dithering drin. In einem späteren System habe ich das
angefügt. Wenn man das in Excel nachstellen will, muss man eine Spalte
vor ansetzen, die abwechselnd 1 und 0 addiert. Das kann man dann
beliebig steigern, wenn man eine 0,3,1,2 Folge nimmt. Muss nur skaliert
werden. Damit rauscht das Ausgangssignal, kommt aber praktisch auf den
Nullpunkt und die Rundungsfehler werden "rausgeschüttelt" um es bildlich
darzustellen.
chris_ schrieb:>>Eine kleine Änderung auf das Leapfrog-Verfahren sollte viel besser sein:>> Kannst Du das genauer erklären? Ich sehe keinen Unterschied.
Dieser Frage würde ich mich anschließen! Kann das jemand genauer
ausführen?
Im www.mikrocontroller.net/topic/91683 beschrieb ich zwei Verfahren zur
Sinuserzeugung:
Es gibt noch weitere Filter- und Generatormethoden: wurden z.B.
in DSP56F800FM.pdf (DSP56F800 Family Manual) beschrieben:
B.1.13.1 Double Integration Technique Vorteil: Amplitude konstant
B.1.13.2 Second Order Oscillator Vorteil: einfach, aber Amplitude von
der Frequenz abhängig.
Anderes Beispiel: Maxim AN3386
Signal processing with the MAXQ multiply-accumulate unit (MAC)
http://pdfserv.maxim-ic.com/en/an/AN3386.pdf
beschreibt die
- Sinusgenerierung nur mit Mul und Add (recursive digital
resonator) und
- Tonerkennung mittels Goertzel-Algorithmus
sehr anschaulich.
eProfi schrieb:> www.mikrocontroller.net/topic/91683
Das steht aber nur was vom "Audio 2 MIDI Converter bauen" - ar das
wirklich gemeint?
Hier wäre was zur Sinuserzeugung:
Beitrag "Re: Software-Synthesizer"
{kind=link}
{kind=link}
{kind=link}