In einer von mir kreierten Programmiersprache gibt es die
"Schleife mit Hineinsprung" anstelle der while-Schleife.
Kennt jemand sonst eine Sprache mit dieser Struktur?
Beitrag "Re: 8bit-Computing mit FPGA"
In C ist das eine Do-While-Schleife mit eine Goto für den Sprung ins
Innere der Schleife. Wenn man will, kann man mit ein paar Makros den
Goto kaschieren und das Ganze wie eine "echte" Kontrollstruktur aussehen
lassen.
Wenn man die Anweisungen etwas umstellt, kann man auch eine
Endlos-Schleife mit bedingtem Break verwenden. Das ist der Weg, wie so
etwas üblicherweise realisiert wird.
Josef G. schrieb:> In einer von mir kreierten Programmiersprache gibt es die> "Schleife mit Hineinsprung" anstelle der while-Schleife.
Das erinnert mich an den Vorschlag, komplementär zum GO TO-Befehl
noch einen COME FROM-Befehl zu implementieren.
> Kennt jemand sonst eine Sprache mit dieser Struktur?
BASIC.
Yalu X. schrieb:> Wenn man die Anweisungen etwas umstellt, kann man auch eine> Endlos-Schleife mit bedingtem Break verwenden. Das ist der> Weg, wie so etwas üblicherweise realisiert wird.
Sofern der Compiler das nicht optimiert und eine Schleife mit
Hineinsprung daraus macht, hätte diese Lösung allerdings den
Nachteil, dass bei jedem Durchlauf 2 Sprünge ausgeführt oder
Sprungbedingungen getestet werden müssen: der unbedingte
Rücksprung am Schluss und ein bedingter Sprung für break.
Meine Eingangsfrage war so gemeint, ob es eine solche Struktur
in irgendeiner Sprache fertig gibt. Dass man sie mit anderen
Strukturen nachbilden kann ist klar, und wenn man GOTO zulässt
sowieso. Die Antwort auf die Frage lautet nach den bisherigen
Reaktionen: Es gibt keine solche Sprache.
@Josef G. (bome) Benutzerseite
>In meiner Sprache gibt es kein GOTO, und die Blockstruktur>ist streng und kann nicht durchbrochen werden.
Das beschreibt dein (Kommunikations)dilema ziemlich gut!
@ Jörg Wunsch (dl8dtl) (Moderator) Benutzerseite
>Das erinnert mich an den Vorschlag, komplementär zum GO TO-Befehl>noch einen COME FROM-Befehl zu implementieren.
Naja, im weitesten Sinne wäre das die Sprungmarke einer ISR ;-)
Josef G. schrieb:
> Sofern der Compiler das nicht optimiert und eine Schleife mit> Hineinsprung daraus macht, hätte diese Lösung allerdings den> Nachteil, dass bei jedem Durchlauf 2 Sprünge ausgeführt oder> Sprungbedingungen getestet werden müssen: der unbedingte> Rücksprung am Schluss und ein bedingter Sprung für break.
Neue Programmiersprachen werden entworfen, um den Programmierer – und
nicht den Compiler – in seiner Arbeit zu unterstützen. Werden bestimmte
Konstrukte nicht zufriedenstellend optimiert, wird deswegen am Compiler
Hand angelegt, nicht an der Programmiersprache.
Josef G. schrieb:> Meine Eingangsfrage war so gemeint, ob es eine solche Struktur> in irgendeiner Sprache fertig gibt.
Nicht dass ich wüsste.
In deiner neuen Kontrollstruktur steht derjenige Teil des
Schleifenrumpfs, der zuerst ausgeführt wird, nach dem Teil, der
danach ausgeführt wird. Dadurch wird die tatsächliche
Ausführungsreihenfolge verschleiert.
Das Konstrukt nimmt also dem Compiler minimal Arbeit ab, belastet aber
auf der anderen Seite den Programmierer, nicht nur, weil er dafür
"vekehrt" herum denken muss, sondern auch, weil er für diesen
zweifelhaften Fortschritt erst eine neue Sprache lernen muss, seinen
bestehenden Code ggf. umschreiben muss usw.
Das ist aber nicht das Ziel moderner Programmiersprachen.
Yalu X. schrieb:> belastet aber auf der anderen Seite den Programmierer,> nicht nur, weil er dafür "vekehrt" herum denken muss,
Das ist nicht richtig. Der Code steht in der Reihenfolge da,
wie er ausgeführt wird, der Abbruch erfolgt am Ende. Nur beim
Starten der Schleife wird einmalig ein Abschnitt am Anfang
übersprungen. Und das ist kein Problem für den Programmierer,
denn es steht ja am Anfang explizit da: L.JP, JP für"jump".
Jörg Wunsch schrieb:> Das erinnert mich an den Vorschlag, komplementär zum GO TO-Befehl> noch einen COME FROM-Befehl zu implementieren.
der nicht so unsinnig ist wie es scheint.
Am PC1500 hatte ich relokatiblen Assemblercode einige Unterprogramme im
Eeprom geschrieben.
Branch war leicht möglich da mein Ziel bekannte Byte vorher oder zurück
lag, goto jsr jump sub routine schied ja aus wegen relokatibel.
Aber wie zurück kommen wenn ich nicht weiss woher ich kam ?
Deswegen musste ich tricky den PC (Programmcounter) auslesen auf den
erst mal auf den Stack packen und diesen so manipulieren das er in
meiner Unterroutine passend richtig liegt für ein RET (return jump)
Josef G. schrieb:> Yalu X. schrieb:>> belastet aber auf der anderen Seite den Programmierer,>> nicht nur, weil er dafür "vekehrt" herum denken muss,>> Das ist nicht richtig. Der Code steht in der Reihenfolge da,> wie er ausgeführt wird, der Abbruch erfolgt am Ende. Nur beim> Starten der Schleife wird einmalig ein Abschnitt am Anfang> übersprungen.
Kann es sein, dass du ein Programm tatsächlich in der Richtung liest,
wie du es hier beschreibst, nämlich von hinten nach vorne bzw. vom Ende
zum Start? Dann ist dein neues Konstrukt für dich genau richtig ;-)
Bei den meisten Leuten ist das aber anders herum. Sie fragen sich: Was
macht das Programm als erstes, was folgt danach?
Josef G. schrieb:> Nur beim> Starten der Schleife wird einmalig ein Abschnitt am Anfang> übersprungen.
Ich überleg jetzt schon eine ganze Weile.
Wahrscheinlich hatte ich in all den Jahren durchaus schon mal den Fall,
der von deiner "Schleife mit Hineinsprung" abgedeckt wird. Aber im
Moment fällt mir kein Beispiel aus den letzten Jahren ein, bei dem ich
das mal gebraucht hätte.
In normalem C wäre das ja im Grunde (wenn ich das richtig verstanden
habe)
1
xyz;
2
3
while(Abbruchbedingung){
4
abc;
5
xyz;
6
}
wobei xyz bzw. abc für irgendwelche nicht triviale Codeteile stehen.
Solange die Codeteile nicht zu komplex sind, könnte man das auch so
schreiben
1
for(xyz;Abbruchbedingung;xyz)
2
abc;
ich finde allerdings die erste Variante mit dem while trotzdem besser.
Nur. Das ist gar nicht der springende Punkt. Ich bin jetzt sicher nicht
der repräsentative Programmierer, der das Mass aller Dinge darstellt.
Trotzdem. Mir fällt ad hoc kein reales Beispiel aus den letzten Jahren
ein und ich bilde mir ein, vom Code der letzten Jahre noch so einiges im
Gedächtnis parat zu haben. So häufig dürfte der Fall also nicht sein.
Das erinnert mich irgendwie an 'Duffs Device'. Das ist ein netter
kleiner Trick, aber ausser auf tiefster Treiberebene braucht das Ding im
Grude genommen kein Mensch. Und selbst da ist zweifelhaft ob man das
Loop-Unrolling nicht doch besser dem Compiler überlassen sollte.
Da offenbar kaum jemand den im Eröffnungsbeitrag verlinkten
Beitrag im Nachbarforum anschaut, hier eine Kopie:
> *L.JP / springt zu *HERE> oper1> oper2> *HERE> oper3> oper4 / weist VAR einen Wert zu> *RP.Z VAR / springt zu oper1 falls VAR = zero> In C würde man hier eine function definieren, welche> oper3/4 ausführt und den Rückgabewert VAR erhält.> Und man würde eine while-Schleife verwenden, welche> oper1/2 ausführt, solange die function Null liefert.> Die Schleife mit Hineinsprung erfüllt den gleichen> Zweck auf einfachere Weise. Die Hochsprache braucht dann> auch nicht das Konstrukt einer function mit Rückgabewert,> sondern es reichen einfache Unterprogramme, bei welchen> alle Übergabe-Parameter gleichberechtigt sind.
Ergänzend hierzu noch der Hinweis auf obigen Beitrag:
Josef G. schrieb:> Yalu X. schrieb:>> Wenn man die Anweisungen etwas umstellt, kann man auch eine>> Endlos-Schleife mit bedingtem Break verwenden. Das ist der>> Weg, wie so etwas üblicherweise realisiert wird.>> Sofern der Compiler das nicht optimiert und eine Schleife mit> Hineinsprung daraus macht, hätte diese Lösung allerdings den> Nachteil, dass bei jedem Durchlauf 2 Sprünge ausgeführt oder> Sprungbedingungen getestet werden müssen: der unbedingte> Rücksprung am Schluss und ein bedingter Sprung für break.
Josef G. schrieb:>> Die Schleife mit Hineinsprung erfüllt den gleichen>> Zweck auf einfachere Weise.
Das ist doch gar nicht der springende Punkt.
Der springende Punkt ist, dass diese Form der Schleife so selten
vorkommt, dass es sich überhaupt nicht lohnt, dafür ein extra
Sprachkonstrukt aufzusetzen.
Du tust so, als ob das ein enorm drängendes Problem wäre.
Das ist es nicht.
Deshalb bricht hier auch keiner in Jubelstürme aus.
(Allerdings: warst du nicht der Typ, der einen eigenen Zeichensatz
vorgeschlagen hat, der für Hex-Ziffern eigene Zeichen benutzt?
Selbiges: Du schlägst eine Lösung für etwas vor, was überhaupt kein
Problem ist)
Karl Heinz schrieb:> Der springende Punkt ist, dass diese> Form der Schleife so selten vorkommt
Wie ich im Eröffnungsbeitrag geschrieben habe, gibt es diese
Schleife bei meiner Sprache nicht zusätzlich zur while-Schleife,
sondern anstelle der while-Schleife. Deshalb kommt sie häufig
vor. Und die hier beschriebenen Vorteile kommen dann hinzu.
Jörg Wunsch schrieb:> Das erinnert mich an den Vorschlag, komplementär zum GO TO-Befehl> noch einen COME FROM-Befehl zu implementieren.
Ein COMEFROM käme wohl noch am ehesten dem EXCEPT eines TRY/EXCEPT
Konstrukts nahe.
Josef G. schrieb:> In einer von mir kreierten Programmiersprache gibt es die> "Schleife mit Hineinsprung" anstelle der while-Schleife.
Das erinnert mich ein wenig an den hier:
Ein Betrunkener tastet sich irritiert ständig um eine Litfassäule herum.
Nach etwa 10 Runden sinkt er resigniert in sich zusammen und murmelt:
"Verdammt! Eingesperrt!"
Und genau das kann passiert bei dieser Hineinsprung-Schleife auch: es
ist eine Frage der Sichtweise. Man stülpt sie einfach um und hat einen
definierten Anfang, mittendrin einen Absprung und sonst eine einfache
Schleife...
@ Karl Heinz (kbuchegg) (Moderator)
>Das ist doch gar nicht der springende Punkt.
In der Tat.
>(Allerdings: warst du nicht der Typ, der einen eigenen Zeichensatz>vorgeschlagen hat, der für Hex-Ziffern eigene Zeichen benutzt?>Selbiges: Du schlägst eine Lösung für etwas vor, was überhaupt kein>Problem ist)
Du hast es erfasst.
Ich verweise auf
Beitrag "wer kann sich noch an den hex-zeichensatz erinnern?"
Wie sieht eigentlich diese neue Programmiersprache insgesamt aus? Gibt
es da eine Spezifikation oder Beispielprogramme?
Gibt es neben der Schleife mit "Hineinsprung" noch weitere Features, die
sie von bestehenden Sprachen unterscheiden?
Noch etwas zum Thema Schleifenoptimierung: Der GCC dreht alle Schleifen
– egal, ob for, while, do-while oder endlos mit break – so hin, dass die
Abbruchbedingung am Ende liegt. Man muss sich darum als Programmierer
also keine Gedanken machen.
Yalu X. schrieb:> Gibt es da eine Spezifikation oder Beispielprogramme?
Siehe meine Benutzerseite, da ist meine Website zu finden. Die Sprache
wird beschrieben auf der Seite SYS-doku. Zum Testen auf Linux-PC gibt
es ein Emulationsprogramm des 8bit-Rechners, und Beispielprogramme.
> weitere Features, die sie von bestehenden Sprachen unterscheiden?
Die Sprache ist angepasst an die Hardware des 8bit-Rechners. Sie stellt
Variablen und Strukturelemente (zB. Schleifen) bereit, enthält selber
aber nur ganz wenige Routinen (zB. Inkrementieren/Dekrementieren). Der
Hauptteil der Routinen wird von den 8 Steckkarten geliefert.
Ein Schwachpunkt der Sprache: Sie kennt keine Ausdrücke. Stattdessen
gibt es "Mikrooperationen", welche ebenfalls von den Steckkarten
geliefert werden. Statt VAR1 = VAR2 + VAR3 würde es zB. heissen
GET VAR2 ADD VAR3 STO VAR1 je nach Steckkarten-Software.
Der Compiler erzeugt keinen Maschinencode, sondern einen Code,
welcher interpretativ von der CPU abgearbeitet wird. Sofern die
Steckkarten-Software dafür ausgelegt ist, kann man die Zahl der
Taktzyklen für alle Programmteile exakt berechnen.
Josef G. schrieb:> Die Sprache ist angepasst an die Hardware des 8bit-Rechners.Josef G. schrieb:> Ein Schwachpunkt der Sprache: Sie kennt keine Ausdrücke. Stattdessen> gibt es "Mikrooperationen", welche ebenfalls von den Steckkarten> geliefert werden. Statt VAR1 = VAR2 + VAR3 würde es zB. heissen> GET VAR2 ADD VAR3 STO VAR1 je nach Steckkarten-Software.Josef G. schrieb:> In der im ROM eingebauten Hochsprache des Gesamtsystems> wird nach gleichem Muster die "Schleife mit Hineinsprung"> zur Realisierung von while-Schleifen verwendet.
Jetzt bleibt nur noch die Frage, was man unter einer Hochsprache
versteht.
Kleiner Hinweis für alle, die sich dem COME-FROM-Thema mit einer
gewissen Ernsthaftigkeit genähert haben: Seht Euch mal die Spezifikation
zu INTERCAL an, das ist die Sprache, aus der das Konstrukt stammt. So
was kommt heraus, wenn ein paar wirklich kluge Leute wie ESR eine
Spaßsprache entwickeln - kein Vergleich zu diesen kreuzlangweiligen
Turingmaschinen-Emulatoren mit pseudolustigen Symbolen wie brainfuck,
Ook!, Whitespace etc.
http://catb.org/esr/intercal/http://catb.org/esr/intercal/ick.htm
Klaus Wachtler schrieb:> Jetzt bleibt nur noch die Frage, was man unter einer Hochsprache> versteht.
Dieses Ding, was Josef im Nachbarthread
Beitrag "Re: 8bit-Computing mit FPGA" (1)
unbeirrt anpreist, obwohl es keiner haben will, ist jedenfalls keine
Hochsprache. Ich würde es "kryptischen Assembler" nennen, wobei die
Betonung auf kryptisch liegt.
Seine Mnemonics bieten dem Leser leider überhaupt keine Eselsbrücken an,
um Assoziationen zu bereits bekannten Befehlen zu ziehen. Kurz: Es ist
für mich genauso unlesbar wie chinesisch.
(1) Link zeigt den vollständigen Befehlssatz.
Josef G. schrieb:> Jörg Wunsch schrieb:>> BASIC.>> In meiner Sprache gibt es kein GOTO, und die Blockstruktur> ist streng und kann nicht durchbrochen werden.
Blöcke?
dazu ne Frage..
gibt es diese "Schleife mit Hineinspringen" jetzt eigentlich shon oder
ist das noch eher theoretsich?
der syntax lässt ja mal keine "blöcke" erkennen, verschachteln scheint
mir unmöglich..
Robert L. schrieb:> oder ist das noch eher theoretsich?
Es gibt eine fertige Implementierung auf meinem 8bit-Rechner
> der syntax lässt ja mal keine "blöcke" erkennen,
Der Bereich zwischen *L.JP und *HERE zählt als ein Block,
ebenso der Bereich zwischen *HERE und *RP.Z
> verschachteln scheint mir unmöglich..
Doch, ist natürlich möglich.
Frank M. schrieb:> ist jedenfalls keine Hochsprache.
Was du verlinkt hast ist die Tabelle der Assembler-
Mnemonics und hat mit der Hochsprache nichts zu tun.
@Josef G. (bome) Benutzerseite
>> ist jedenfalls keine Hochsprache.>Was du verlinkt hast ist die Tabelle der Assembler->Mnemonics und hat mit der Hochsprache nichts zu tun.
Was du da fabriziert hast ist eher eine Art Anti-Logikpuzzle und hat mit
einem ANWENDBAREN Mikrorechnersystem nichts zu tun. :-0
Josef G. schrieb:> Frank M. schrieb:>> ist jedenfalls keine Hochsprache.>> Was du verlinkt hast ist die Tabelle der Assembler-> Mnemonics und hat mit der Hochsprache nichts zu tun.
Die Verwechslungsgefahr zwischen den Assemblerm-Mnemonics und den
Hochsprachenschlüsselwörtern kommt aber auch nicht ganz von ungefähr:
*L.JP und *RP.Z sind Hochsprache, die nicht viel anders aussehenden
Befehle LZ.A und S.RP sind Assembler.
Beim folgenden Code dachte ich auch erst, dass das ja nur der vom
Compiler aus der Hininspringschleife generierte Assemblercode sein kann:
> *L.JP / springt zu *HERE> oper1> oper2> *HERE> oper3> oper4 / weist VAR einen Wert zu> *RP.Z VAR / springt zu oper1 falls VAR = zero
Ist es aber nicht, wie ich inzwischen gelernt habe.
Ich habe auch schon versucht, die Dokmentation auf deiner Webseite zu
verstehen. Bei den einzelnen Seiten (home, CPU-doku, SYS-doku, Emul und
Hawa) schmeißt du aber schon in den ersten 10 Zeilen mit Bergiffen und
Konzepten um dich, dass ich dachte, ich müsste erst eine andere Seite
durcharbeiten, um die Grundlagen zu verstehen. Dieses Problem hatte ich
aber auf jeder der fünf Seiten, so dass sich sozusagen eine
fünfschwänzige Katze jeweils fünffach in ihre fünf Schwänze biss.
Deine Hochsprache (oder das, was ich meine, dass sie es ist) erinnert
mich stark an die Assemblersprache der IBM/360-Computer und deren
Nachfolger. Auch dort gab es (gegen Aufpreis, versteht sich) ein
Makropaket für die strukturierte Programmierung (If-Else, verschiedene
Schleifenkonstrukte, Switch-Case usw.). Mit diesem Assembler wurde nicht
nur hardwarenah (Treiber u.ä.) programmiert, er wurde tatsächlich wie
eine Hochsprache für kaufmännische Software (als Alternative zu Cobol)
eingesetzt.
Mittlerweile sind aber viele Jahrzehnte vergangen, und die Software-
entwicklungsmethoden haben sich völlig verändert. Eingefleischte IBMler
nutzen aber immer noch ihren Assembler und verwenden – ähnlich wie auch
du – sogar ihren eigenen Zeichensatz (EBCDIC). Erst vor kurzem hatten
wir eine amüsante Diskussion, in der dieses Thema aufkam:
Beitrag "Was hat es mit den 'trigraphs' aufsich"
Kann es vielleicht sein, dass du bei IBM beschäftigt bist oder warst?
Es gibt in der Tat eine Eins-zu-Eins-Entsprechung zwischen
dem Quelltext und dem erzeugten Code. Und dies ermöglicht
es, durch Addieren von Ausführungszeiten die Dauer von
Programmteilen zu berechnen. Ob es dafür einmal eine
ernsthafte Anwendung geben wird, wird man sehen.
Josef G. schrieb:> Ob es dafür einmal eine> ernsthafte Anwendung geben wird, wird man sehen.
Da sich offensichtlich niemand damit beschäftigen will, wird sich die
Verbereitung und damit die Anwendung in Grenzen halten. Vermutlich sind
die Grenzen gleichzeitig durch deine eigenen 4 Wände definiert...
Oo
Manuel X. schrieb:> Vermutlich sind> die Grenzen gleichzeitig durch deine eigenen 4 Wände definiert...
Was ja nicht eine ernsthafte Anwendung ausschließt....
Yalu X. schrieb:> Mittlerweile sind aber viele Jahrzehnte vergangen, und die> Software-entwicklungsmethoden haben sich völlig verändert.> Kann es vielleicht sein,
Richtig ist, dass ich schon etwas älter bin und mir
vieles an den modernen Entwicklungen nicht gefällt.
Josef G. schrieb:> Richtig ist, dass ich schon etwas älter bin und mir> vieles an den modernen Entwicklungen nicht gefällt.
Ich bin auch nicht mehr der Jüngste, und auch mir gefällt vieles an den
modernen Entwicklungen nicht.
Aber wie alt musst du sein, dass du die Infixschreibweise arithmetischer
Ausdrücke (wie bspw. y = m * x + b) in einer höheren Programmiersprache
als "moderne Entwicklung" empfindest?
Diese Entwicklung hat immerhin schon vor deutlich über einem halben
Jahrhundert stattgefunden ;-)
Josef G. schrieb:> Siehe meine Benutzerseite, da ist meine Website zu finden. Die Sprache> wird beschrieben auf der Seite SYS-doku.
Diese Chaosseiten sind eine Strafe - unklar ist mir eigentlich nur, was
man ausgefressen haben muss, um dazu verdonnert zu werden, diesen
Krempel zu lesen.
Josef, du tätest wirklich gut daran, dir endlich die Grundlagen der
Informatik anzueignen, statt immer wieder Anfänge aus den 1960er Jahren
"neu" zu "erfinden".
Wenn du dir unbedingt mit Reto-Technologien einen Namen machen willst,
musst du eine nehmen, was wenigstens ein paar Tausend Jahre alt ist und
heute nicht mehr gebräuchlich ist, z.B. das Herstellen von
Steinzeitwerkzeugen und -waffen.
Yalu X. schrieb:> Ausdrücke (wie bspw. y = m * x + b) in einer höheren Programmiersprache
Ausdrücke lehne ich keineswegs ab. Ich habe selber geschrieben
Josef G. schrieb:> Ein Schwachpunkt der Sprache: Sie kennt keine Ausdrücke.
Bei der von mir gewählten Methode, anstelle von Ausdrücken Folgen
von "Mikrooperationen" zu verwenden, hat der Programmierer die volle
Kontrolle über den tatsächlich ausgeführten Code, und die Dauer lässt
sich einfach berechnen, wenn die Dauer der einzelnen Mikrooperationen
bekannt ist. Andererseits werden diese Folgen recht schnell sehr
umfangreich, insbesondere bei Verwendung von Arrays.
Denkbar wäre, dass es irgendwann so etwas wie einen Präprozessor gibt,
der Ausdrücke im Quelltext in Folgen von Mikrooperationen umwandelt.
Josef G. schrieb:> Bei der von mir gewählten Methode, anstelle von Ausdrücken Folgen> von "Mikrooperationen" zu verwenden, hat der Programmierer die volle> Kontrolle über den tatsächlich ausgeführten Code,
"Real programmers write Microcode. Assembler is a high level language."
Josef G. schrieb:> Denkbar wäre, dass es irgendwann so etwas wie einen Präprozessor gibt,> der Ausdrücke im Quelltext in Folgen von Mikrooperationen umwandelt.
Manche Leute nennen das einen "Compiler". ;-)
A. K. schrieb:> Josef G. schrieb:>> Denkbar wäre, dass es irgendwann so etwas wie einen Präprozessor gibt,>> der Ausdrücke im Quelltext in Folgen von Mikrooperationen umwandelt.>> Manche Leute nennen das einen "Compiler". ;-)
Nein. Der Präprozessor würde Text in Text umwandeln. Meine Aussage
war hier missverständlich, da ich Mikrooperationen geschrieben habe,
aber die Text-Kürzel gemeint waren, welche für die Mikrooperationen
stehen und vom Compiler durch die Mikrooperationen ersetzt werden.
Josef G. schrieb:> Der Compiler erzeugt keinen Maschinencode, sondern einen Code,> welcher interpretativ von der CPU abgearbeitet wird.
Die "Mikrooperationen" sind keine CPU-Operationen, sondern
Elemente des vom Compiler erzeugten (Zwischen-)Codes.
Die Bezeichnung Compiler ist zB. auch bei der Sprache Java
üblich, wo es ebenfalls einen solchen Zwischencode gibt.
Falls jemand sich grundsätzlich für das System interessiert,
aber die Dokumentation für unverständlich hält:
Vielleicht würde es helfen, erst einmal mittels des Emulations-
Programms sich die Quelltexte der Beispielprogramme anzuschauen
und die Programme zu testen. Insbesondere das erste (emtext_a)
würde ich empfehlen.
Josef G. schrieb:> Insbesondere das erste (emtext_a)> würde ich empfehlen.
Also ich kriege da nur eine Datei mit lauter Zahlen, nischt mit
'Quelltext'.
Für mich sieht das ganze wieder mal nach 'Habe Gerät, suche Anwendung'
aus. Da ist Assembler auf dem 8051 richtig entspannend gegen das, was
ich da auf deiner Webseite gelesen habe. Wer soll sich denn da
durchfinden?
Dann doch lieber richtige Herausforderungen wie 'CP/M auf dem 8048' oder
'Gleitkommaberechnung mit Diodenmatrix' :-P
Richtig interessant finde ich auch sowas hier:
http://www.vaxman.de/my_machines/hitachi/240/240.html
Matthias Sch. schrieb:> Also ich kriege da nur eine Datei mit lauter Zahlen,
Man braucht das Emulationsprogramm, um den Text anzuschauen.
> Für mich sieht das ganze wieder mal nach 'Habe Gerät,> suche Anwendung' aus.
Ist richtig, hab ich nie bestritten.
Josef G. schrieb:> Nein. Der Präprozessor würde Text in Text umwandeln.
Es gab C++ - Compiler, die C++ - Code in C übersetzten. Transpiler
übersetzen Code einer Sprach in welchen einer anderen.
Ich würde sagen, dass das gemeinsame Kriterium von Compilern der Aufbau
eines Syntax-Baumes ist, aus dem anschließend das Endprodukt erzeugt
wird.
Ob das Text, Binärcode, oder sonstwas ist, ist dabei egal.
https://de.wikipedia.org/wiki/Compiler#Einordnung_verschiedener_Compiler-Arten
Josef G. schrieb:> Vielleicht würde es helfen, erst einmal mittels des Emulations-> Programms sich die Quelltexte der Beispielprogramme anzuschauen> und die Programme zu testen. Insbesondere das erste (emtext_a)> würde ich empfehlen.
Dazu müsstest du erst mal deine elende "Dokumentation" in ein halbwegs
verdauliches und übersichtliches Format bringen. So wie sie im Moment
ist, ist sie nur für Masochisten und Buchhalter geeignet.
Josef G. schrieb:> Vielleicht könnte ja mal jemand, der meint, die Dokumentation> sei unverständlich, mir eine konkrete Stelle nennen, wo etwas> unverständlich ist.
Im Allgemeinen:
Zuerst einmal wirkt deine Dokumentation so, als ob du während deiner
Entwicklung, die für dich wesentlichen Teile in reine Textdateien
geschrieben hast, und diese nun 1:1 auf deinen Server hochgeladen hast.
Die gesamte Dokumentation erfüllt sicherlich den Zweck für dich als
persönliche Referenz, ist aber völlig ungeeignet um neue Menschen für
dein System zu begeistern. Also erschlage den interessierten Leser nicht
gleich mit Fakten, sondern nimm ihn bei der Hand, und zeige Schritt für
Schritt, was er mit dem System anstellen kann. In der jetzigen Form,
muss man die komplette Seite mehrfach lesen um irgendwie einen Einstieg
zu finden.
Konkret:
Als interessierter Leser klicke ich erstmal auf "SYS-doku", weil ich
dahinter die Systemdokumentation vermute. Der erste Abschnitt lautet:
> Die Zuordnung der Adressregister zu einer memory-page erfolgt> durch 2bit-Latches MP,MX,MY,MZ , und es gibt Austauschregister> NP,NX,NY,NZ . Das CPU-Signal B# tauscht M#-N# (#= P,X,Y,Z).
Interessiert mich das? Nein! Was spräche dagegen, z.B. deinen Emulator
zu zeigen, wie man diesen bedient, und ein einfaches Programm zum laufen
kriegt? Schau dir mal Programmierlehrbücher an, und wie diese aufgebaut
sind. Wo finde ich eine gegliederte Darstellung? Das ganze ist ein
einziger Fließtext ohne Struktur.
Zum Webdesign:
Es spricht nichts gegen puristisches Webdesign. Aber Links und Bilder
gibt es schon ne Weile, und diese kann und sollte man benutzen.
Josef G. schrieb:> Matthias Sch. schrieb:>> Also ich kriege da nur eine Datei mit lauter Zahlen,>> Man braucht das Emulationsprogramm, um den Text anzuschauen.
Das z.B. ist etwas, das Interessierte schon mal abschreckt - was für ein
Emulationsprogramm, und wieso kann man einen Quelltext nicht, wie bei
jedem anderen System seit Urzeiten, im Klartext lesen? Die Token (oder
was auch immer da drin steht) interessieren mich am Anfang doch gar
nicht und 'Quelltext' ist für mich eben genau das - Text, der als Quelle
für einen wie auch immer gearteten Compiler, Assembler, Tokenizer oder
Interpreter dient, der dann irgendwann Maschinencode erzeugt.
Und wenn ich mir einen Eindruck von einem Rechnersystem verschaffen
will, dann schau ich mir gerne auch mal den Assemblertext (oder wie auch
immer das bei dir heisst) an. Dumm eben auch, wenn man vor einem Rechner
mit z.B. Windows oder Mac OS sitzt, dann kriegt man den Emulationator
nicht mal ohne Verrenkungen zum Laufen.
Du könntest also ganz einfach mal eines der Programme umschnurzeln und
als Klartext auf die Webseite setzen.
Nächster Punkt: Du redest zwar von irgendwelche Steckkarten und
Programmen dadrauf, aber mir ist der Sinn des Ganzen nicht klargeworden.
Sind das Option ROMs wie bei einem Apple ][ oder IBM PC oder was ist der
Sinn dahinter? Du hast dich in Flipflops,Register und
Signalbezeichnungen verstrickt, aber vergessen, einem Typen wie mir zu
erklären, warum und wofür du das überhaupt machst.
Das war z.B. einer der grossen Vorzüge beim IBM PC oder dem o.a. Apple
][. Ein offenes System, das jeder nachvollziehen konnte, mit Unterlagen,
und einem einfach zu verstehenden System aus Erweiterungen und der
Möglichkeit, mal eben selber eine Karte zu stricken und die durch den
Rechner anzusprechen.
Gut, in den Zeiten von PCI-Express und USB ist das ein wenig schwieriger
geworden, aber immer noch vollständig dokumentiert und nachvollziehbar.
Matthias Sch. schrieb:> Nächster Punkt: Du redest zwar von irgendwelche Steckkarten und> Programmen dadrauf, aber mir ist der Sinn des Ganzen nicht klargeworden.> Sind das Option ROMs wie bei einem Apple ][ oder IBM PC oder was ist der> Sinn dahinter?>> Das war z.B. einer der grossen Vorzüge beim IBM PC oder dem o.a. Apple> ][. Ein offenes System, das jeder nachvollziehen konnte, mit Unterlagen,> und einem einfach zu verstehenden System aus Erweiterungen und der> Möglichkeit, mal eben selber eine Karte zu stricken und die durch den> Rechner anzusprechen.
Genauso ist auch mein Rechner konzipiert.
Beim AppleII belegte jeder Steckplatz 256 Byte (oder waren es 512).
Die Adressbereiche waren übereinander angeordnet. Hat man bei einer
Karte den Steckplatz gewechselt, haben sich die Adressen geändert.
Mir hat das nicht gefallen. Und die Kommandos an die Karte wurden
mittels PRINT zeichenweise an die Karte gesendet.
Bei meinem System hat jede Karte volle 64KByte zur Verfügung. Die
Namen der Karten-Kommandos werden bereits beim Compilieren durch
Nummern ersetzt. Es gibt sauber definierte Schnittstellen für den
Aufruf der Kommandos und des "Formelinterpreters", so habe ich das
auf der Karte befindliche Programm genannt, welches die oben
genannten Folgen von "Mikrooperationen" ausführt. Auf die Karten
wird über die Steckplatz-Nummer zugegriffen, das erfolgt indirekt
über eine Ersetzungstabelle. Wenn man eine Karte in einen anderen
Steckplatz steckt, muss man nur diese Tabelle ändern.
@ Josef G. (bome) Benutzerseite
>> Das war z.B. einer der grossen Vorzüge beim IBM PC oder dem o.a. Apple>> ][. Ein offenes System, das jeder nachvollziehen konnte, mit Unterlagen,>> und einem einfach zu verstehenden System aus Erweiterungen und der>> Möglichkeit, mal eben selber eine Karte zu stricken und die durch den>> Rechner anzusprechen.>Genauso ist auch mein Rechner konzipiert.
Meinst DU! Nur mit dem "kleinen" Unterschied, dass Apple II und Ur-PC
locker 35 Jahre her sind, damals ein Novum waren, innerhalb kürzester
Zeit Massen von Leuten begeisterten und die Erbauer zu reichen Leuten
gemacht haben. Aber was rede ich hier über Nebensächlichkeiten.
Facepalm
ich find es ja (wirklich!) beeindruckend, wenn jemand eine CPU (ganzen
Rechner?) selber entwickelt.. (ich könnte das nicht)
ist eben so, als baute man eine Balliste oder ein Katapult (das machen
auch noch viele Leute aus Spaß/Nostalgie, und nicht weil man heute noch
einen nutzen davon hätte..)
zum Thema (schleife mit Hirneinspringen)
bin ich grundsätzlich der Meinung, dass du dich hier in irgend einem
(total unwichtigen) Detail verrennst.. ob man das hat, oder nicht ist
doch egal..
mich würde immer noch interessieren, wie solch eine Schleife
verschachtelt ausschaut (und zwar in realem code, nicht skizziert...)
kannst da mal an Screenshot machen?
Falls jemand wirklich glaube, der Typ von schleife wäre sinnvoll, könnte
man seine Zeit doch auch damit verbringen das bei z.b. FreePascal oder
GCC (in einem Fork) einzubauen.. und herzeigen wie toll man damit
tägliche Probleme lösen kann..
das mit den Steckkarten errinnert mich an den GameBoy/C64 usw.
warum es wichtig sein sollte, dass man (anhand vom Code) abzählen kann,
wieviele takte ein bestimmtes programm jetzt genau braucht, kapier ich
übrigens nicht..
ps. auch interessant ist, dass die Homepage die ausschaut als wäre sie
mit der Scheinmaschine geschrieben wurde, mit iWeb erstellt wurde ...
Robert L. schrieb:> mich würde immer noch interessieren, wie solch eine Schleife> verschachtelt ausschaut (und zwar in realem code, nicht skizziert...)> kannst da mal an Screenshot machen?
Habe also ein Beispiel erstellt, wo sowohl zwischen L.JP und HERE
als auch zwischen HERE und RP.x eine weitere Schleife mit Hinein-
sprung steht. Siehe part1.png und part2.png, darunter nochmal im
Ganzen. run.png zeigt den Ablauf beim Compilieren und Testen.
Das Programm liest zwei Zahlen ein, wobei davor ?? ausgegeben wird.
Die Eingabe wird wiederholt, falls die zweite Zahl Null ist. Bei
den Wiederholungen wird zusätzlich ein zweites ?? ausgegeben.
Wenn anschließend die erste Zahl größer ist als 7, erfolgt Abbruch,
andernfalls wird diese Zahl ausgegeben und in derselben Zeile bis
Null dekrementiert und es geht wieder zur Eingabe.
Das Programm dient ausschließlich dazu, die Verschachtelbarkeit
der Schleife mit Hineinsprung zu demonstrieren. Niemand würde
sonst ein Programm so schreiben.
Eine Hochsprache ist das ja nicht gerade...
Wer programmiert heutzutage noch ernsthaft Assembler? Höchstens Bastler
und Nostalgiker.
Josef G. schrieb:> In meiner Sprache gibt es kein GOTO, und die Blockstruktur> ist streng und kann nicht durchbrochen werden.
Wozu man einem Assembler eine "strenge Blockstruktur" aufbrummen muss,
erschließt sich mir nicht.
Warum man die "strenge Blockstruktur" anschließend wieder mit so einer
komischen Konstruktion, wie dem "Hineinsprung" durchlöchern muss, schon
zweimal nicht.
Das ganze ist doch nur reine Beschäftigungstherapie.
Ich kenne aus den 1970ern noch ein Sprachkonstrukt, das ich seither
nicht wieder gesehen habe und das ich wirklich interessant finde:
Das Betriebssystem MCP der Borroughs 1700er-Serie wurde in einer Sprache
namens SDL (System Development Language) programmiert. Das war eine
echte Hochsprache (ohne Fließkomma-Arithmetik!) mit folgendem
Schleifenkonstrukt:
1
do outerloop forever /* unendliche Schleife! */
2
...
3
...
4
do innerloop forever
5
...
6
...
7
undo outerloop
8
...
9
end
10
...
11
...
12
end
- Die Schleifennamen (hier: outerloop, innerloop) waren optional und
frei wählbar
- undo entspricht dem break in C
- undo ohne Label beendet die Schleife, in der undo steht
- undo mit Label beendet die gelabelte Schleife
SDL hatte kein goto und mit dem undo hatte man einen Sprung, der
keine "Sauereien" zuließ und die Schleifenrücksprünge aus geschachtelten
Schleifen sehr bequem und sicher machte.
Uhu Uhuhu schrieb:> Warum man die "strenge Blockstruktur" anschließend wieder mit so einer> komischen Konstruktion, wie dem "Hineinsprung" durchlöchern muss,
Die wird nicht durchlöchert.
L.JP .. HERE .. RP.x ist genauso ein Block mit zwei Unterblöcken,
wie dies bei if .. else .. end-else der Fall ist.
Uhu Uhuhu schrieb:> Wozu man einem Assembler eine "strenge Blockstruktur" aufbrummen muss,> erschließt sich mir nicht.
Wenn man schon in Assembler programmiert, dann kann das sehr wohl Sinn
ergeben. Ganz besonders dann, wenn man nichts anderes zur Verfügung hat
oder Hochsprachen generell ablehnt (haben wir hier ja so einen oder zwei
im Forum).
> Warum man die "strenge Blockstruktur" anschließend wieder mit so einer> komischen Konstruktion, wie dem "Hineinsprung" durchlöchern muss, schon> zweimal nicht.
Ist doch langweilig, immer bloss den gleichen Strukturen von anno Algol
nachzueifern.
In meiner Sprache gibt es den Datentyp "Databox". Es gibt den
Mechanismus des "Ausleihens", wobei Variable, welche zuvor keinen
Wert haben (reine Zeiger sind), innerhalb der Databox ihren Wert
zugewiesen bekommen. Die Werte müssen danach wieder "zurückgegeben"
werden, bevor die Databox nicht mehr existiert, andernfalls würden
die Werte in undefinierten Bereichen des RAM liegen und Schreib-
zugriffe könnten Unheil anrichten. (Das hat Ähnlichkeit mit üblichen
Konstruktionen wie "with record do", wo die Elemente des records
innerhalb dieses Blocks verfügbar sind.) Der Compiler garantiert,
dass das Zurückgeben innerhalb desselben Blocks erfolgt wie das
Ausleihen. Genau zu diesem Zweck wird die Blockstruktur benötigt,
und da darf es auch kein Herausspringen aus Schleifen geben.
Uhu Uhuhu schrieb:> Ich kenne aus den 1970ern noch ein Sprachkonstrukt, das ich seither> nicht wieder gesehen habe und das ich wirklich interessant finde:
PL/I:
Uhu Uhuhu schrieb:> A. K. schrieb:>> PL/I:>> Das war etwa dieselbe Zeit...
Beispiele aus jüngerer Zeit:
In Java gibt es ähnlich wie in PL/I labeled Loops:
1
outerloop:
2
for(x=0;x<10;x++){
3
for(y=0;y<10;y++){
4
if(condition(x,y))
5
breakouterloop;
6
}
7
}
Ähnlich geht es auch in Javascript, Ada, Perl, Fortran 90 (und neuer),
Go, Swift und sicher noch etlichen weiteren Sprachen.
In PHP gibt es
1
breakn;
wobei n angibt, wieviele der verschachtelten Schleifen verlassen werden
sollen. Dabei entspricht break 1 einem break ohne Argument.
In Python und Rust wurde so ein Konstrukt vorgeschlagen, dann aber
abgewiesen.
Die Hineinspringschleife von Josef ist im Vergleich dazu schon etwas
Besonderes :)
Yalu X. schrieb:> In Java gibt es ähnlich wie in PL/I labeled Loops:
Diese "Wenn Prädikat dann Abbrechen-Befehl"-Konstruktionen kann man
direkter so schreiben:
1
found=false;
2
for(x=0;x<10&&!found;x++)
3
for(y=0;y<10&&!found;y++)
4
found=test(x,y);
5
6
if(found)
7
use(x,y);
Man sieht sofort in den Schleifenbedingungen dass sie frühzeitig (bei
erfolgreicher Suche) abgebrochen werden und man brauch das "found" in
der Regel sowieso später, da man wissen möchte ob die Suche erfolgreich
war oder nicht.
Die Alternative die Schleifenvariablen 'x' und 'y' nach der Suche erneut
auf gültige Werte zu testen, ist viel zu fehleranfällig.
Das "use(x, y)" in die Schleife packen und und danach sofort abbrechen,
ist noch viel unübersichtlicher, da die beiden Schritte "erst mal
suchen" und "wenn gefunden dann benutzen", ineinander verschachtelt
werden und somit der Programmfluss schlecht ersichtlich ist.
@ Unbekannt Unbekannt (unbekannter)
>Diese "Wenn Prädikat dann Abbrechen-Befehl"-Konstruktionen kann man>direkter so schreiben:
Endlich mal jemand mit Durchblick und klarer Ansage! Diese Diskussion
ist sowas von hirnrissig! Mental gesunde Menschem müssen und sollten
sich NICHT mit diese Josefschen Konstrukt beschäftigen, es sein denn,
ihnen ist an der Nichtaufrechterhaltung ihrer mentalen Gesundheit
gelegen.
Unbekannt Unbekannt schrieb:> Man sieht sofort in den Schleifenbedingungen dass sie frühzeitig (bei> erfolgreicher Suche) abgebrochen werden und man brauch das "found" in> der Regel sowieso später, da man wissen möchte ob die Suche erfolgreich> war oder nicht.
Deshalb ja auch der geliebte wie verhasste C Klassiker:
Noch ein kleines Beispiel aus dem Kuriositätenkabinett:
In Fortran sind Unterprogramme mit mehreren Einstiegspunkten möglich.
Das folgende Beispiel zeigt eine Zählfunktion, die entweder aufgerufen
als
icounter()
dann wird der aktuelle Inhalt der internen Zählvariable icnt
zurückgegeben und diese inkrementiert, oder als
icounterinit(istart)
dann wird zusätzlich icnt auf einen neuen Startwert gesetzt:
1
program test
2
print *, icounter()
3
print *, icounter()
4
print *, icounterinit(100)
5
print *, icounter()
6
print *, icounter()
7
end
8
9
function icounterinit(istart)
10
data icnt /0/
11
icnt = istart
12
entry icounter()
13
icounter = icnt
14
icnt = icnt + 1
15
end
Ausgabe:
1
0
2
1
3
100
4
101
5
102
Mit diesem Konstrukt kann man bspw. einen Zufallszahlengenerator
ohne die Verwendung einer globalen Statusvariable realisieren.
Yalu X. schrieb:> Ähnlich geht es auch in Javascript, Ada, Perl, Fortran 90 (und neuer),> Go, Swift und sicher noch etlichen weiteren Sprachen.
Aha, dann bin ich also durch jahrzehntelanges C-Programmieren
verdorben... Ist halt doch eigentlich eine Scheiß-Sprache :-(
> In PHP gibt es> break n;>> wobei n angibt, wieviele der verschachtelten Schleifen verlassen werden> sollen. Dabei entspricht break 1 einem break ohne Argument.
Dass die PHP-Fritzen einen Trick finden werden, der die gute Idee wieder
in einen Mist umwandelt, den man lieber nicht will, war zu erwarten...
Yalu X. schrieb:> In Fortran sind Unterprogramme mit mehreren Einstiegspunkten möglich.
Soll das jetzt etwa eine Anregung für Josef sein?
Marten W. schrieb:> Auch wenns OT ist, in C# kann man so etwas ähnliches mittels yield> machen.
Auch wieder nur eine halbherzige Flickschusterei. Es ist erstaunlich,
wie "schwach" viele der verbreiteten Programmiersprachen entworfen
wurden. Teils historisch bedingt, teils weil man auf allen Hochzeiten
tanzen möchte.
Sei's drum. Das "yield"-Konzept ist den mehr als 50 Jahren alten
"Koroutinen" entliehen:
http://en.wikipedia.org/wiki/Coroutine
Gratulation.
Ich dachte ich hätte schon vieles gesehen aber so was hab ich auch noch
nie gesehen. Mit Ausnahme vielleicht von meiner ersten Begegnung mit APL
ist es mir seit Jahrzehnten nicht mehr passiert, dass ich in angeblichem
Quelltext nicht das Geringste verstehe. Noch nicht mal ansatzweise
Da sag noch mal einer, C wäre kryptisch.
Erinnert entfernt an manchen frühen Assemblercode, oder irgendwelche
Drucker- oder Job-Controls.
Frühe Assembler waren mitunter ähnlich kryptisch:
http://en.wikipedia.org/wiki/COMPASS/Sample_Code
Karl Heinz schrieb:> Gratulation.>> Ich dachte ich hätte schon vieles gesehen aber so was hab ich auch noch> nie gesehen. Mit Ausnahme vielleicht von meiner ersten Begegnung mit APL> ist es mir seit Jahrzehnten nicht mehr passiert, dass ich in angeblichem> Quelltext nicht das Geringste verstehe. Noch nicht mal ansatzweise> Da sag noch mal einer, C wäre kryptisch.
Das ist doch ganz einfach. Josefs Code ist absolut intuitiv und auch für
den Nicht-Eingeweihten komplett lesbar!
Ich erklärs Dir:
> *PGM DEMO
Wir beginnen ein Programm namens "DEMO". Beachte die Großbuchstaben.
Kleinbuchstaben sind nicht erlaubt. Warum? Josef benutzt immer noch
einen 5-Bit-Lochkartenstanzer.
> *CON STRG -??
Einer der einfachsten Befehle: Schreibe auf die Console. Das "-??" ist
ein geheimer Code für die Ausgabe von:
HALLO KARL HEINZ, HEUTE IST MITTWOCH, DER 29. OKTOBER,
WIR HABEN 12:37 UND EINE ZIMMERTEMPERATUR VON 22 GRAD.
MORGEN WIRD ES REGNEN UND KALT.
BITTE GIB NUN ZWEI ZAHLEN EIN:
Wohlgemerkt: Nur Großbuchstaben. Daran müsste Josef nochmal arbeiten.
> *AUT AA. /00 BB. /00
AUT steht für AUTOMATISCHE EINGABE VON ZAHLEN. Hier nennt Josef diese
AA. und BB, beide vorbelegt mit 00. Das "/" vor den Zahlen 00 soll nur
den geneigten Leser verwirren: Es handelt sich NICHT um eine Division
durch Null! Merken!
> *BEGN
Wir beginnen endlich - nach der Eingabe von 2 Zahlen - mit der
Abarbeitung des Programms. Das Kürzel BEGN statt BEGINN ist besonders
pfiffig. Josef spart damit Vokale, macht das Programm kompakter und für
NSA-Mitarbeiter schwieriger. Das ist ABSICHT!
> *L.JP
Oh, jetzt kommts richtig heftig: Das L steht für LOOP, das wissen nur
die wirklich eingeweihten! Aber macht nichts, ich habe dies nach
nächtelangem Einsatz von 1024-Bit-Key-Entschlüsselungsroutinen auf
einer alten Cray im Münchener Museum ganz klar herausgefunden! Und JP
steht selbstverständlich
JAM POT, achnee JUMP. Wir springen also jetzt mit Lichtgeschwindigkeit
in eine Schleife..... festhaaaaaaalten!
> 1LFEED
Eine der einfachsten Anweisungen überhaupt. Wörtlich übersetzt heisst
das
Mach ein Line Feed
Warum Josef hier FEED komplett ausschreibt, ist mir absolut rätselhaft.
Er hätte es auch mit Q abkürzen können, um der Programmiersprache noch
etwas mehr Transparenz zu geben. Denn
1 LQ
wäre viel viel verständlicher gewesen, oder nicht? Wenn man nun noch die
Transponierung von L nach I vornimmt, steht da
1 IQ
welches klar die Intelligenz dieses phänomenalen Programms ausdrücken
soll.
Aber wir schweifen ab... zurück zum Code:
> *L.JP
Tja, kennen wir schon: Wir springen in die innere Schleife. Weitere
Kommentare sind hier überflüssig.
> 1ADDLOC /01
DAAAAAS ist der absolut Knüller! Wir addieren auf die erste Variable
(wegen der 1 vor ADDLOC, gemeint ist also AA) eine 1.
> =DECR AA.
Und hier dekrementieren wir wieder AA. Und jetzt das verblüffendste: Der
Wert von AA ist danach wieder ABSOLUT IDENTISCH mit der eingegebenen
Zahl!!!!!11111
> *HERE
Das HERE steht selbstverständlich nicht für HERE, also "hier", sondern
für "da", also THERE! Hier müsste der Compiler eigentlich mit einem
Syntax-Error aussteigen. Aber Josef hat vorgesorgt. Bei einem
Syntax-Error googelt der Compiler automatisch nach der Bedeutung des
Wortes, um dann den Sinn einfach umzudrehen! Das ist GENIAL!!!! So
werden Programmierfehler automatisch korrigiert!
> 1PRINTN /08 AA.
Tja, PRINTN ist wirklich ziemlich geschwätzig. PT hätte mir ja besser
gefallen. Aber was passiert hier? Ganz einfach: Die Zahl AA wird
gedruckt - und zwas auf die Console. Und Hurra! Das Programm gibt exakt
die Zahl wieder aus, die der User vorher eingegeben hat! Das ist
Wahnsinn! Ein Programm, welches die Gedanken des Anwenders lesen (und
sicher auch verstehen!) kann!
Die /08 sind klar? Nein? Ganz einfach: "Formatiere die Ausgabe
rechtsbündig auf 8 Stellen.". Wenn Josef linksbündig meint, dann
schreibt er "08/", wenn er zentrieren will, dann "/08/". Echt pfiffig.
> *RP.S AA.
Okay, das ist auf den ersten Blick ziemlich verwirrend hier, aber ist
für den Experten sofort klar: Das ist ein einfacher NOP. Kennt ja jeder.
Das genialische: Man kann bei Josefs Rechner dem NOP ein Argument
mitgeben! Jawoll! Es sollen hier also soviele NOPs gemacht werden, wie
AA als Zahl bedeutet.
> 1LFEED
Mittlerweile ist die Console nicht mehr busy und kann endlich eine neue
Zeile ausgeben. Ist sinnig, sonst steht der Druckerkopf von Josefs
Teletype-Terminal noch hinter der ausgegebenen Zahl und versperrt den
Blick auf diese.
> *HERE
Nochmal: DA! Guck DA! Also THERE!
> 1SETLOC /f0
Oh, jetzt wird Josefs Programm prozessor-spezifisch. Das heißt soviel
wie:
LOKALISIERE DEN VERDAMMTEN F0-BUG AUF DIESER CPU!
Damit beugt Josef einem Fehler von INTEL vor, welcher das Programm ohne
diese Vorsichtsmaßnahme zum Crash bringen könnte. Aber noch ist Josefs
Rechner nicht auf INTEL-Rechner portiert. GUT SO!
> *L.JP
Springe in Schleife...
>> 1PRINTS /02 STRG
Jetzt wird nochmal der Begrüßunssting gedruckt, also eigentlich den von
oben:
HALLO KARL HEINZ, HEUTE IST MITTWOCH, DER 29. OKTOBER,
WIR HABEN 12:37 UND EINE ZIMMERTEMPERATUR VON 22 GRAD.
MORGEN WIRD ES REGNEN UND KALT.
Durch die Formatierung /02 wird daraus aber:
HA
Hier hat Josef sich geirrt. Es muss sich um einen Tippfehler handeln,
denn es hätte /03 heißen müssen. Nur dann würde diese Message auch einen
Sinn ergeben:
HAL
Ja, es handelt sich um HAL aus "Odyssee 2001"! Das Rätsel ist gelüftet!
Josef wars!
> *HERE> 1PRINTS /00 STRG> 1INPUTN /08 AA.> 1INPUTN /0c BB.> 1LFEED> *RP.Z BB.
Diese Befehle habe ich oben schon erklärt, daher überspringe ich das.
> 1 oGET AA. oAND /f8 oSTO BB.
Das ist wieder ganz intuitiv. frei übersetzt:
SCHNAPPE DIR AA UND SPEICHERE DAS IN BB
Ja. Jetzt hat der Rechner die Gedanken des Users von AA nach BB kopiert
und für die Ewigkeit gespeichert...
> *RP.Z BB.
Kennen wir auch schon: Das war der NOP. Bevor wir also gleich das
Programm beeenden, ärgern wir den Rechner nochmal mit unsinnigen
Befehlen. Und das gleich BB-mal!
> *RETN
Kennt jeder: RETURN. Fragt sich nur wohin? Aber das werden wir dann in
der nächsten Stunde erklären.... brzzzz krrrrchs....
Karl Heinz schrieb:> Josef G. schrieb:>>> *PGM DEMO> jede Menge Zeugs entfernt>> *RETN>>> Gratulation.
Auch von mir beste Wünsche. Ich habe selten so etwas fehlerträchtiges
und unlesbares gesehen. Trotz Franks ausgezeichneter Erklärung der
einzelnen Programmteile bin ich jetzt froh, mir keinerlei Emulazionator
für dieses ulkige Kauderwelsch geladen/kompiliert/eingetreten zu haben.
Vielen Dank, Frank, das du so viel deiner Zeit geopfert hast -
andererseits schade drum...
Da ist ja selbst TMS320 Assembler eine wahre Wohltat gegen:
Frank M. schrieb:> Karl Heinz schrieb:>> *CON STRG -??
Es wird eine String-Konstante mit Wert "??" vereinbart.
>> *AUT AA. /00 BB. /00
Es werden die 1-Byte-Variablen AA. und BB. vereinbart. AUT steht für
Automatische Installation auf Stack A beim Starten des Programms.
>> 1ADDLOC /01
Erhöht den Positionszeiger für die Ein/Ausgabe.
>> =DECR AA.>> Und hier dekrementieren wir wieder AA. Und jetzt das> verblüffendste: Der Wert von AA ist danach wieder ABSOLUT> IDENTISCH mit der eingegebenen Zahl!!!!!11111
Dekrementieren ist richtig, "wieder" ist falsch. Der Wert ist
danach nicht identisch. Aber weil das =DECR beim erstenmal
übersprungen wird, wird zuerst die unveränderte Zahl ausgegeben.
>> *HERE>> Das HERE steht selbstverständlich nicht für HERE, also "hier",> sondern für "da", also THERE!
Der Unterschied von here und there im Englischen ist mir durchaus
klar. Aber here sieht besser aus als there, und ganz falsch ist es
auch nicht, wenn man es nicht liest als "jump here", was tatsächlich
falsch wäre, sondern als "hier ist das Sprungziel".
>> *RP.S AA.>> Das ist ein einfacher NOP.
Repeat falls AA. "set", also "not zero".
>> 1SETLOC /f0
Setze Positionszeiger.
>> *RP.Z BB.>> Kennen wir auch schon: Das war der NOP.
Repeat falls BB. zero.
>> *RETN>> Kennt jeder: RETURN. Fragt sich nur wohin?
In diesem Fall in die Kommandozeile. Es wäre aber auch möglich,
das Programm aus einem anderen Programm heraus aufzurufen.
Alle Operationen 1xxxx sind nicht Teil der Sprache selber,
sondern Teil der Software der Test-Steckkarte in Steckplatz 1.
Eigenschaft der Sprache ist es aber, wie diese Operationen
beim Compilieren eingebunden und bei der Programm-Ausführung
aufgerufen werden.
Uhu Uhuhu schrieb:> Frank M. schrieb:>> Josef benutzt immer noch einen 5-Bit-Lochkartenstanzer.>> Sollte er etwa seinem Hex-Code untreu geworden sein?
Er hat einen speziellen Lochkartenstanzer dafür:
Er kann eckige und runde Löcher stanzen. Damit vervielfachen sich die 5
Bits von (2^5 = 32) auf 5 Trits (3^5 Möglichkeiten = 243)!
Und schon hat er Großbuchstaben, Ziffern und Punkte. Das reicht - auch
für Hex-code. Der Rest ist zukünftigen Erweiterungen vorbehalten ;-)
> Er kann eckige und runde Löcher stanzen. Damit vervielfachen sich die 5> Bits von (2^5 = 32) auf 5 Trits (3^5 Möglichkeiten = 243)!
Um noch etwas genauer zu werden:
Er kann die Basis über die Anzahl der Ecken einstellen.
Die runden Löcher sind ganz einfach eckige Löcher mit sehr vielen Ecken.
Somit hat er den Quanten-Computer erfunden.
Mit der Differenzial- und der Integralrechnung kann dann noch bestimmt
werden, wieviele Zyklen das Programm benötigt, um den Programmierer in
die Klapse einzuliefern, nach dem er es fertiggestellt hat. ;-DDD
Frank M. (ukw) schrieb:
>> *AUT AA. /00 BB. /00> AUT steht für AUTOMATISCHE EINGABE VON ZAHLEN. Hier nennt Josef diese> AA. und BB, beide vorbelegt mit 00. Das "/" vor den Zahlen 00 soll nur> den geneigten Leser verwirren: Es handelt sich NICHT um eine Division> durch Null! Merken!
Ich wollte schon fragen, ob das eine Zeile aus Josef's Fahrzeugschein
ist. Sah mir ganz danach aus. Aber jetzt wo du das aufgeklärt hast ...
(nicht böse gemeint Josef, bezüglich deiner Codierungen lebst du
anscheinend wohl in deiner eigenen unzugänglichen Welt ;))
g. c. schrieb:> (nicht böse gemeint Josef, bezüglich deiner Codierungen lebst du> anscheinend wohl in deiner eigenen unzugänglichen Welt ;))
Ist in C ja auch nicht viel anders, wenn man es genau nimmt.
>Ist in C ja auch nicht viel anders, wenn man es genau nimmt.
Ähmm... Hochsprachen wurden ja wohl ursprünglich entwickelt, um sich die
Arbeit zu erleichtern und nicht zu erschweren, damit man sich weniger um
den ganzen Kram auf Bit-Ebene kümmern muss usw. (d.h. im Vordergrund
steht nur das Problem, das mit möglichst wenig Aufwand gelöst werden
soll), um die Lesbarkeit und Wiederverwendbarkeit des Codes zu
verbessern.
Seine kryptischen Konstrukte sind aber schwer durchzublicken.
Das sieht eher nach korruptem Assembler aus. Assembler ist sogar
einfacher zu lesen...
Achja... Eine anständige Dokumentation ist ja wohl das wichtigste, wenn
man vom Nutzen überzeugen möchte.
Ansonsten, wieso sollte ich z.B. von C/C++
umsteigen, wenn damit sowieso schon fast alles möglich ist?
Ein Vorteil der Technik ist natürlich, dass solche Programme auf
beliebigem System ablaufen können (portabilität).
Ein großer Nachteil ist, dass der erzeugte Zwischencode eben nicht nativ
ist, man für den Ablauf eines solchen Programms also unbedingt ein
Betriebssystem braucht, welches nur sehr schwer bspw. auf einen
Mikrocontroller wg. zu kleinen Speichern zu bekommen ist.
Weiterer Nachteil: Ausführungszeit ist größer als bei nativem Code.
Karl Heinz schrieb:> In normalem C wäre das ja im Grunde (wenn ich das richtig verstanden> habe)>
1
>xyz;
2
>
3
>while(Abbruchbedingung){
4
>abc;
5
>xyz;
6
>}
7
>
>> wobei xyz bzw. abc für irgendwelche nicht triviale Codeteile stehen.>> Solange die Codeteile nicht zu komplex sind, könnte man das auch so> schreiben>
1
>for(xyz;Abbruchbedingung;xyz)
2
>abc;
3
>
> ich finde allerdings die erste Variante mit dem while trotzdem besser.
oder halt
1
while(xyz,bedingung)
2
{
3
abc;
4
}
falls xyz nicht zu complex ist. Wenn schon, dann könnte man das noch
in einer Funktion stecken, die die Auswertung der Bedingung
zurückliefert:
1
while(xyz_funktion())
2
{
3
abc;
4
}
Aber meist reicht deine erste Variante, und ein guter Compiler
wird das schon optimieren.
Eric B. schrieb:> Wenn schon, dann könnte man das noch in einer Funktion> stecken, die die Auswertung der Bedingung zurückliefert
Ist auch genau das, was ich geschrieben hatte:
Josef G. schrieb:>> *L.JP / springt zu *HERE>> oper1>> oper2>> *HERE>> oper3>> oper4 / weist VAR einen Wert zu>> *RP.Z VAR / springt zu oper1 falls VAR = zero>>> In C würde man hier eine function definieren, welche>> oper3/4 ausführt und den Rückgabewert VAR erhält.>> Und man würde eine while-Schleife verwenden, welche>> oper1/2 ausführt, solange die function Null liefert.
Danke Frank!
Josef schrub
> *RP.S AA.> Repeat falls AA. "set", also "not zero".> *RP.Z BB.> Repeat falls BB. zero.
Ja, das ist natürlich intuitiv. S ist das Gegenteil von Z, so wie 'set'
das Gegenteil von 'zero' ist.
Josef, Josef. Ich denke, es wird dir immer ein unlösbares Rätsel
bleiben, warum du einfach nicht den Durchbruch schaffst.
Nicht das es mich wirklich interessiert.
Aber
manche Zeilen fangen mit einem '*' an, manche mit einer 1, eine ist
dabei, die mit einem = anfängt.
Hat das irgendwas zu bedeuten, zb das die einen Zeilen nur Montags
gelten und die anderen nur in Monaten mit 'R'? Oder kann man die erste
Spalte einer Zeile nach Gutdünken verwenden?
Es sieht ja fast so aus, als ob alle Zeilen, die irgendwas mit
Flusskontrolle zu tun haben, mit einem '*' ingeleitet werden, während
alle 'normalen' Anweisungen mit einer '1' beginnen, mit Ausnahme des '='
im DEC. Da wird das = wohl anzeigen, dass das Ergebnis wieder im selben
Register abgelegt werden soll (was nebenbei bemerkt eigentlich recht
normal wäre, sonst würde man ja auch einen SUB benutzen).
Aber diese Erklärung scheint mir in Anbetracht der restlichen
Komplexität als etwas zu banal. Es wäre zwar logisch, denn eigentlich
braucht diese Sonderzeichen in Wirklichkeit kein Mensch, daher wäre das
ein gefundenes Fressen für Josef, aber irgendwie auch wieder zu
naheliegend. Da muss noch mehr dahinter stecken.
Karl Heinz schrieb:> Es sieht ja fast so aus, als ob alle Zeilen, die irgendwas mit> Flusskontrolle zu tun haben, mit einem '*' ingeleitet werden, während> alle 'normalen' Anweisungen mit einer '1' beginnen, mit Ausnahme des '='> im DEC. Da wird das = wohl anzeigen, dass das Ergebnis wieder im selben> Register abgelegt werden soll (was nebenbei bemerkt eigentlich recht> normal wäre, sonst würde man ja auch einen SUB benutzen).
Ja, genau so habe ich es mir auch erklärt. Ich weiß - genauso wie Du -
überhaupt nicht, was diese zusätzliche Redundanz für einen Zweck hat.
Ich glaube nicht, dass Abweichungen - wie zum Beispiel
=LFEED
statt
1LFEED
oder
=RP.S AA.
statt
*RP.S AA.
irgendwie einen Sinn ergeben. Diese Zeichen vor jedem Befehl sind
irgendwie hyperfluid.
Aber vielleicht ist die Erklärung ganz einfach: Wenn schon kryptisch,
dann richtig!
P.S.
Meine Vermutung: Josefs Parser ist wahrscheinlich ziemlich einfach
gestrickt. Diese Sonderzeichen unterstützen diesen wohl bei der
Erkennung.
Karl Heinz schrieb:> Es sieht ja fast so aus, als ob alle Zeilen, die irgendwas mit> Flusskontrolle zu tun haben, mit einem '*' ingeleitet werden,
Genauso ist es.
> während alle 'normalen' Anweisungen mit einer '1' beginnen,> mit Ausnahme des '=' im DEC.
Die mit 1 beginnenden Anweisungen werden von der Test-Steckkarte
in Steckplatz 1 ausgeführt. Die mit = beginnenden Anweisungen
sind interner Bestandteil der Sprache.
Josef G. schrieb:> Alle Operationen 1xxxx sind nicht Teil der Sprache selber,> sondern Teil der Software der Test-Steckkarte in Steckplatz 1.> Eigenschaft der Sprache ist es aber, wie diese Operationen> beim Compilieren eingebunden und bei der Programm-Ausführung> aufgerufen werden.
Frank M. schrieb:> Meine Vermutung: Josefs Parser ist wahrscheinlich ziemlich einfach> gestrickt. Diese Sonderzeichen unterstützen diesen wohl bei der> Erkennung.
Richtig.
Bei den von den Steckkarten ausgeführten Anweisungen kommt als
weiterer Vorteil hinzu, dass Namens-Konflikte vermieden werden.
Josef G. schrieb:> Die mit 1 beginnenden Anweisungen werden von der Test-Steckkarte> in Steckplatz 1 ausgeführt. Die mit = beginnenden Anweisungen> sind interner Bestandteil der Sprache.
Das heisst, wenn ich de "Test-Steckkarte" in "Steckplatz 2" stecke, muss
ich mein Programm neu schreiben und compilieren? o_O
Josef G. schrieb:> Die mit 1 beginnenden Anweisungen werden von der Test-Steckkarte> in Steckplatz 1 ausgeführt.
D.h.: wenn du deine Steckkarten mischst, läuft das Programm nicht mehr.
Das ist eine echte Innovation, nach der Heere von Informatikern seit 60
Jahren gesucht haben, aber nie fündig wurden.
Josef G. schrieb:> Frank M. schrieb:>> Meine Vermutung: Josefs Parser ist wahrscheinlich ziemlich einfach>> gestrickt. Diese Sonderzeichen unterstützen diesen wohl bei der>> Erkennung.>> Richtig.
Es gibt von Nikolaus Wirth ein kleines Büchlein über Compilerbau. Das
ist auch für Nicht-Informatiker verständlich. Ich würde dir den Erwerb
und das Durcharbeiten desselben extremst ans Herz legen.
Eric B. schrieb:> Das heisst, wenn ich de "Test-Steckkarte" in "Steckplatz 2" stecke, muss> ich mein Programm neu schreiben und compilieren? o_O
Nein.
Josef G. schrieb:> Auf die Karten> wird über die Steckplatz-Nummer zugegriffen, das erfolgt indirekt> über eine Ersetzungstabelle. Wenn man eine Karte in einen anderen> Steckplatz steckt, muss man nur diese Tabelle ändern.
Ergänzend gibt es ein Kommando zur Vertauschung von
Steckplatz-Nummern in fertig kompilierten Programmen.
Uhu Uhuhu schrieb:> Josef G. schrieb:>> Die mit 1 beginnenden Anweisungen werden von der Test-Steckkarte>> in Steckplatz 1 ausgeführt.>> D.h.: wenn du deine Steckkarten mischst, läuft das Programm nicht mehr.>> Das ist eine echte Innovation, nach der Heere von Informatikern seit 60> Jahren gesucht haben, aber nie fündig wurden.
Allerdings. Das ist mal was Neues.
Normalerweise versucht man ja um jeden Preis, so einen Zustand zu
vermeiden.
Wie weiter oben schon mal wer geschrieben hat: Wenn schon komplex, dann
richtig komplex.
A. K. schrieb:> Yacc gibts seit 1975. ;-)
Ja, hat mir schon früher immer viel Spaß gemacht, mit yacc einen Parser
zu bauen. Leider ist yacc aber für User, die weniger bis gar nicht mit
unixoiden Systemen arbeiten, ziemlich unbekannt.
Mittlerweile bin ich davon aber weg und habe meine eigenen Libs, um
Sprachen zu entwickeln und diese zu parsen.
Fall jemand denkt, Compiler müssten unbedingt riesige und komplexe
Gebilde sein: Im Anhang ein einfacher Compiler für Z80 und ein
Beispielprogramm, Quelle und Resultat. Die Sprache erinnert eher an
einen strukturierten Assembler, aber das war Absicht und ist hier im
Thread ja auch nicht anders.
Frank M. schrieb:> Ja, hat mir schon früher immer viel Spaß gemacht, mit yacc einen Parser> zu bauen. […]>> Mittlerweile bin ich davon aber weg
Yacc und Bison sind mittlerweile ziemlich aus der Mode gekommen. Um sie
für nichtriviale Dinge benutzen zu können, muss man wissen, wie ein
LALR-Parser-funktioniert und wie er durch den Parsergenerator erzeugt
wird. Nur dann können die Fehlermeldungen richtig gedeutet und die
angezeigten Konflikte in ihrer Relevanz bewertet werden.
Wenn jemand aber so viel Wissen in sich vereint, ist es für ihn ein
Leichtes, einen Parser von Hand zu schreiben (ggf. unter Zuhilfenahme
einer entsprechenden Bibliothek). Das mag zwar etwas mehr Tipparbeit
bedeuten als wenn ein Generator zum Einsatz kommt. Da ein Compiler aber
nicht nur aus dem Parser besteht, sondern der Parser nur einen kleinen
Teil des Ganzen ausmacht, fällt dieser Mehraufwand praktisch überhaupt
nicht ins Gewicht und wird durch die größere Flexibilität, die man mit
einem handgeschrieben Parser hat, mehr als wett gemacht.
Yalu X. schrieb:> Da ein Compiler aber> nicht nur aus dem Parser besteht, sondern der Parser nur einen kleinen> Teil des Ganzen ausmacht,
Mein vorhin gezeigter Compiler besteht praktisch nur aus dem Parser. ;-)
Der Code kommt direkt aus dem Parser raus, keine Zwischendarstellung.
Mehr als dieses eine File gibts nicht, das ist der ganze Compiler.
Sicher, für ernsthafte und grosse Compiler ist das nicht unbedingt der
beste Weg. Aber für einfache kleine Dinge ist das ungemein praktisch. So
hatte ich auch mal einen Dekoder für Intel/Microsoft-Objektfiles gebaut,
und einen Encoder in Yacc dazu, der den Output des Dekoders wieder zu
einem Objektfile zusammen baute. Um solche Files in Textform einfach
modifizieren zu können.
A. K. schrieb:> Mein vorhin gezeigter Compiler besteht praktisch nur aus dem Parser. ;-)
und
> Aber für einfache kleine Dinge ist das ungemein praktisch.
Zweimal Zustimmung :)
Für die kleinen Dinge, wo auch die Übersetzungsgeschwindigkeit nicht die
große Rolle spielt, kann man sich auch mal Pyparsing anschauen:
http://pyparsing.wikispaces.com/
Wenn man es ernsthaft benutzen möchte, sollte man aber das auf der
Webseite angepriesene Buch kaufen. Die Online-Dokumentation ist eher
als ergänzende Referenz dazu zu sehen.
Edit:
Nein, man muss es nicht kaufen (ist auch gar nicht so leicht irgendwo zu
bekommen). Hier kann man es online lesen oder herunterladen:
http://it-ebooks.info/book/245/
Yalu X. schrieb:> Yacc und Bison sind mittlerweile ziemlich aus der Mode gekommen. Um sie> für nichtriviale Dinge benutzen zu können, muss man wissen, wie ein> LALR-Parser-funktioniert und wie er durch den Parsergenerator erzeugt> wird. Nur dann können die Fehlermeldungen richtig gedeutet und die> angezeigten Konflikte in ihrer Relevanz bewertet werden.
Was ich an Yacc nie mochte, ist genau dieser LALR Parser. Ich hatte
damit immer Schwierigkeiten in der Grammatik-Definition. Ok, das mag
auch an meiner Ausbildung liegen, in der wir im Compilerbau uns nur auf
LL(1) Parser konzentriert haben. Von daher war ich es gewohnt, bereits
die Grammatik auf LL(1) Verhalten zu trimmen, was ich ehrlich gesagt nie
als Nachteil empfand.
Gerade mit Yacc hatte ich bei den wenigen Versuchen auch immer das
Problem, dass ich die Statemachine als sehr schwierig zu debuggen
empfand. Etwas, das mir bei einem rekursiven Abstieg überhaupt keine
Probleme machte.
Von daher wurde dann der COCO zu meinem Lieblings Parser Generator. Auch
wenn es den meines Wissens auch als tabellenbasierenden Parser gibt,
bevorzuge ich trotzdem die Variante, die einen rekursiven Abstieg
erzeugt. Im Debuggen ist das meiner Meinung nach immer noch unschlagbar
einfach, wenn man sich wieder mal in der Grammatik einen Hund
reingehauen hat.
> nicht ins Gewicht und wird durch die größere Flexibilität, die man mit> einem handgeschrieben Parser hat, mehr als wett gemacht.
Da ich sowieso auch per Hand einen rekursiven Abstieg schreiben würde,
lass ich mir diese Arbeit gerne von einem Generator abnehmen :-)
Der macht dann nicht die vielen kleinen Fehlerchen, die ich selbst bei
sorgfältigstem Arbeiten einbauen würde (wieder mal ein nextSym Aufruf
versemmelt, so was kann einem den ganzen Tag versauen :-)
Karl Heinz schrieb:> Ok, das mag> auch an meiner Ausbildung liegen, in der wir im Compilerbau uns nur auf> LL(1) Parser konzentriert haben.
Das ist ja auch die verkehrte Reihenfolge ;-). Ich hatte mich dank
entsprechendem Bedarf zuerst mit Compiler und Yacc beschäftigt. Die
Vorlesung "Compilerbau" folgte später.
PS: Das war in den 80ern. Da war die Auswahl solcher Werkzeuge noch
etwas kleiner als heute. Auch der PLZ Compiler entstand damals, wie man
unschwer am K&R Code erkennen kann. Es liegt in der Natur der Sache,
dass über die Jahrzehnte bessere Werkzeuge entstehen.
Yalu X. schrieb:> Noch etwas zum Thema Schleifenoptimierung: Der GCC dreht alle Schleifen> – egal, ob for, while, do-while oder endlos mit break – so hin, dass die> Abbruchbedingung am Ende liegt. Man muss sich darum als Programmierer> also keine Gedanken machen.
Jede while-Schleife ist also in Wahrheit eine Schleife mit Hineinsprung.
Dies wird lediglich vor dem Programmierer verborgen.
Josef G. schrieb:> Jede while-Schleife ist also in Wahrheit eine Schleife mit Hineinsprung.
Nein. "Hinein" im Sinne von "Nicht an den Anfang" wird in eine
while-Schleife nicht.
@Josef G. (bome) Benutzerseite
>Jede while-Schleife ist also in Wahrheit eine Schleife mit Hineinsprung.>Dies wird lediglich vor dem Programmierer verborgen.
Nö. Es wird nur vor dem Schleifeneintritt die Laufbedingung geprüft.
Deine Diskussion ist eine Endlosschleife ohne Heraussprung, komplementär
zu deiner erfundenen Schleife mit Hineinsprung.
Yalu X. schrieb:> Noch etwas zum Thema Schleifenoptimierung: Der GCC dreht alle Schleifen> – egal, ob for, while, do-while oder endlos mit break – so hin, dass die> Abbruchbedingung am Ende liegt. Man muss sich darum als Programmierer> also keine Gedanken machen.
Rein Interessehalber: Das habe ich jetzt schon mehrfach gelesen.
Andererseits hat einer meiner Profs behauptet, es würde einen
Unterschied machen (dass der möglicherweise auf dem Stand der 80er
stehen geblieben ist, schließe ich ausdrücklich nicht aus).
Hat jemand eine vertrauenswürdige Quelle oder sogar ein Schnipsel
Beispielcode mit zugehörigem Auszug aus der Ausgabe des Compilers,
wodurch das bestätigt wird?
Leider bin ich mit Google nicht fündig geworden und konnte auch selbst
kein aussagekräfgiges Beispiel herbeizaubern. Letzteres liegt aber
wahrscheinlich daran, dass meine Assembler-Kenntinsse auf dem Stand "ich
weiß was es ist" sind...
Dass es in der Praxis zu 99,99% irrelevant ist, ist mir auch klar. Aber
besagter Prof hat dazu auch eine Prüfungsfrage gestellt und ist voll
davon überzeugt, deswegen interessier es mich eben doch ;-)
Andreas P. schrieb:> Hat jemand eine vertrauenswürdige Quelle oder sogar ein Schnipsel> Beispielcode mit zugehörigem Auszug aus der Ausgabe des Compilers,> wodurch das bestätigt wird?
Kannst du nicht einfach selbst ein Stück Code compilieren?
Nimm doch eine einfache Kopierschleife:
1
void
2
memorycopy(char*dst,constchar*src,unsignedinti)
3
{
4
for(unsignedj=0;j<i;j++){
5
*dst++=*src++;
6
}
7
}
Compiliert auf dem Host (amd64) mit -Os gibt das:
1
.file "copy.c"
2
.text
3
.globl memorycopy
4
.type memorycopy, @function
5
memorycopy:
6
.LFB0:
7
.cfi_startproc
8
xorl %eax, %eax
9
.L2:
10
cmpl %eax, %edx
11
jbe .L5
12
movb (%rsi,%rax), %cl
13
movb %cl, (%rdi,%rax)
14
incq %rax
15
jmp .L2
16
.L5:
17
ret
18
.cfi_endproc
19
.LFE0:
20
.size memorycopy, .-memorycopy
21
.ident "GCC: (Ubuntu 4.8.2-19ubuntu1) 4.8.2"
22
.section .note.GNU-stack,"",@progbits
Der Schleifentest befindet sich hier am Anfang der Schleife, beim
Erreichen des Schleifenendes wird zu .L5 rausgesprungen, am Ende
der Schleife wird zum Test nach .L2 zurückgesprungen.
Gleicher Code mit dem AVR-GCC compiliert:
1
.file "copy.c"
2
__SP_H__ = 0x3e
3
__SP_L__ = 0x3d
4
__SREG__ = 0x3f
5
__tmp_reg__ = 0
6
__zero_reg__ = 1
7
.text
8
.global memorycopy
9
.type memorycopy, @function
10
memorycopy:
11
/* prologue: function */
12
/* frame size = 0 */
13
/* stack size = 0 */
14
.L__stack_usage = 0
15
mov r30,r22
16
mov r31,r23
17
add r20,r24
18
adc r21,r25
19
rjmp .L2
20
.L3:
21
ld r18,Z+
22
mov r26,r24
23
mov r27,r25
24
st X+,r18
25
mov r24,r26
26
mov r25,r27
27
.L2:
28
cp r24,r20
29
cpc r25,r21
30
brne .L3
31
/* epilogue start */
32
ret
33
.size memorycopy, .-memorycopy
34
.ident "GCC: (GNU) 4.7.2"
Hier wird zuerst (bedingungslos) zum Schleifentest am Ende der Schleife
nach .L2 gesprungen, bei negativem Test dann zurück zum Anfang nach .L3.
Bleibt sich völlig gleich, was der Compiler genau draus macht.
Jörg Wunsch schrieb:> Kannst du nicht einfach selbst ein Stück Code compilieren?
Erst mal danke für deine Antwort! Das heißt, das ganze ist absolut vom
Compiler abhängig und eine Aussage von wegen "das eine ist besser" ist
scheinbar sinnlos, ohne die Toolchain und deren Einstellung sehr genau
zu kennen (und anzugeben)...
Das Problem, das ich habe ist folgendes:
Aus diesem Code mit for()
1
intmain(void)
2
{
3
intb=0;
4
for(inti=1;i<10;i*2)
5
{
6
asmvolatile("nop");
7
b++;
8
}
9
}
macht Atmel Studio folgendes:
1
000000c4 <main>:
2
int main(void)
3
{
4
int b=0;
5
for (int i=1; i<10; i*2)
6
{
7
asm volatile ("nop");
8
c4: 00 00 nop
9
c6: fe cf rjmp .-4 ; 0xc4 <main>
und aus dem Beispiel mit while() hier:
1
intmain(void)
2
{
3
intb=0;
4
inti=1;
5
while(i<10)
6
{
7
i=i*2;
8
asmvolatile("nop");
9
b++;
10
}
11
}
wird das hier:
1
000000c4 <main>:
2
3
4
#include <avr/io.h>
5
6
int main(void)
7
{
8
c4: 84 e0 ldi r24, 0x04 ; 4
9
c6: 90 e0 ldi r25, 0x00 ; 0
10
int b=0;
11
int i=1;
12
while(i<10)
13
{
14
i=i*2;
15
asm volatile ("nop");
16
c8: 00 00 nop
17
ca: 01 97 sbiw r24, 0x01 ; 1
18
19
int main(void)
20
{
21
int b=0;
22
int i=1;
23
while(i<10)
24
cc: 00 97 sbiw r24, 0x00 ; 0
25
ce: e1 f7 brne .-8 ; 0xc8 <main+0x4>
26
{
27
i=i*2;
28
asm volatile ("nop");
29
b++;
30
}
31
d0: 80 e0 ldi r24, 0x00 ; 0
32
d2: 90 e0 ldi r25, 0x00 ; 0
33
d4: 08 95 ret
Also für meine (in Assembler ungeübten) Augen ein komplett anderer und
vor Allem deutlich umfangreierer Code...also macht es scheinbar doch
einen Unterschied?
Oder spielt mir hier die Optimierung des Compilers einen Streich?
Insbesondere verwirrt mich die doppelte main-Schleife beim Beispiel mit
while() (und nein, mir ist nicht beim kopieren ein Fehler unterlaufen
;-) ) Beide Beispiele sind mit absolut gleichen Einstellungen
gleichzeitig kompiliert worden.
Jörg Wunsch schrieb:> Hier wird zuerst (bedingungslos) zum Schleifentest am Ende der Schleife> nach .L2 gesprungen, bei negativem Test dann zurück zum Anfang nach .L3.
Das bestätigt meine Aussage:
Josef G. schrieb:> Jede while-Schleife ist also in Wahrheit eine Schleife mit Hineinsprung.> Dies wird lediglich vor dem Programmierer verborgen.
Andreas P. schrieb:> Also für meine (in Assembler ungeübten) Augen ein komplett anderer und> vor Allem deutlich umfangreierer Code.
Klar, wenn der Quellcode was anderes tut … Hast du dir mal die
Warnungen angesehen? Da sollte drin stehen:
1
foo.c: In function ‘main’:
2
foo.c:4:5: warning: statement with no effect [-Wunused-value]
Dein „b * 2“ in der for-Schleife ist das, was er damit meint: das
ist eine sinnlose Operation.
Vermutlich meintest du entweder „b *= 2“ oder „b = b * 2“.
Josef G. schrieb:> Das bestätigt meine Aussage:
Aber nur, weil du dein selektives Wahrnehmungsfilter eingeschaltet
hast. Ansonsten wäre dir aufgefallen, dass der völlig gleiche
Sourcecode selbst vom nahezu gleichen Compiler (GCC 4.7 vs. 4.8) nur
für eine andere Zielarchitektur halt genau andersherum compiliert
wird: erst der Test, dann die Schleife.
Aus Sicht der Programmiersprache ist dein Konstrukt also absolut
überflüssig, da er nichts anderes als die normale while-Schleife
darstellt, die man halt verschieden in Maschinencode umsetzen kann.
Auch eine dritte Variante ist noch drin, wenn man nämlich auf
maximale Geschwindigkeit optimieren lässt. Dann wird der Test auf
vorzeitigen Schleifenabbruch vorgezogen und ein zweiter Test am
Ende der Schleife eingebaut. Hier das Beispiel mit dem AVR-GCC:
Jörg Wunsch schrieb:>> Also für meine (in Assembler ungeübten) Augen ein komplett anderer und>> vor Allem deutlich umfangreierer Code.>> Klar, wenn der Quellcode was anderes tut … Hast du dir mal die> Warnungen angesehen? Da sollte drin stehen:> foo.c: In function ‘main’:> foo.c:4:5: warning: statement with no effect [-Wunused-value]>> Dein „b * 2“ in der for-Schleife ist das, was er damit meint: das> ist eine sinnlose Operation.>> Vermutlich meintest du entweder „b *= 2“ oder „b = b * 2“.
Kopf --> Tisch
Du hast ja so was von recht (obwohl du mit b das i meinst).
Sorry, mein Fehler! Wenns keine Probleme zwischen Tastatur und Stuhl
gibt, kommt tatsächlich genau der gleiche Asm-Code raus ;-)
Übrigens auch wenn man es über do-while, for-break und while-break
realisiert.
Danke für deine Hilfe und vy 73!
Andreas P. schrieb:> (dass der möglicherweise auf dem Stand der 80er> stehen geblieben ist, schließe ich ausdrücklich nicht aus).
Diesen Trick hatte man schon in der 80ern drauf. Weils eine der
einfachsten Übungen ist. Komplexer wird es eher heute wieder, weil das
Verhalten der Prozessoren und deren Sprünge viel komplexer geworden ist.
Jörg Wunsch schrieb:> Aus Sicht der Programmiersprache ist dein Konstrukt also absolut> überflüssig, da er nichts anderes als die normale while-Schleife> darstellt, die man halt verschieden in Maschinencode umsetzen kann.
Das Konstrukt wäre überflüssig, wenn die Sprache zusätzlich
while-Schleifen bietet. Es ist jedoch nicht überflüssig, wenn
es keine while-Schleifen gibt und diese durch eben dieses
Konstrukt ersetzt werden.
Und gegenüber while-Schleifen hat das Konstrukt den Vorteil,
dass man bereits im Quelltext unmittelbar den erzeugten Code
vor sich sieht und keine Optimierung erforderlich ist.
Ausserdem hat es den Vorteil, dass die Ermittlung der
Abbruchbedingung beliebig kompliziert sein kann. Es muss
lediglich die Zielmarke *HERE des Hineinsprungs entsprechend
weit genug vor dem bedingten Rückwärtssprung liegen.
Bei der while-Schleife müsste man in so einem Fall die
Ermittlung der Abbruchbedingung in eine function packen,
deren Rückgabewert dann abgefragt wird. Oder man muss
eine Endlosschleife mit bedingtem break verwenden,
was der Philosophie der while-Schleife zuwiderläuft.
Jörg Wunsch schrieb:> Der Schleifentest befindet sich hier am Anfang der Schleife, beim> Erreichen des Schleifenendes wird zu .L5 rausgesprungen, am Ende> der Schleife wird zum Test nach .L2 zurückgesprungen.
Wobei das am -Os hängt. Bei -O1 gibts eine dritte Version:
if (condition) do ... while (condition)
Also keine eingesprungene Schleife, sondern eine vermiedene Schleife.
testl %edx, %edx
je .L1
movl $0, %eax
.L3:
movzbl (%rsi,%rax), %ecx
movb %cl, (%rdi,%rax)
addq $1, %rax
cmpl %eax, %edx
ja .L3
.L1:
Josef G. schrieb:> Das Konstrukt wäre überflüssig, wenn die Sprache zusätzlich> while-Schleifen bietet. Es ist jedoch nicht überflüssig, wenn> es keine while-Schleifen gibt und diese durch eben dieses> Konstrukt ersetzt werden.
OK.
> Und gegenüber while-Schleifen hat das Konstrukt den Vorteil,> dass man bereits im Quelltext unmittelbar den erzeugten Code> vor sich sieht und keine Optimierung erforderlich ist.
Das ist kein Vorteil, sondern deutet darauf hin, dass du eher eine
Art „Hochsprach-Assembler“ im Blick hast denn einen vernünftigen
Compiler. Letzterer sollte immer sinnvoll optimieren können,
und siehe oben, ob nun der Schleifentest am Anfang oder am Ende
oder auf beiden Seiten erfolgt, kann von Fall zu Fall unterschiedlich
optimiert werden.
Aus Sicht des Programmierers wäre es mir wichtig, dass die
Programmiersprache sich einigermaßen so verhält wie die bereits
existierenden Sprachen (POLA - principle of least astonishment).
> Ausserdem hat es den Vorteil, dass die Ermittlung der> Abbruchbedingung beliebig kompliziert sein kann.
Inwiefern sollte das bei existierenden while-Schleifen nicht der
Fall sein?
Aber lassen wir das: keiner außer dir versteht deine etwas verworren
anmutenden Gedankengänge, während Millionen von Programmierern es
bislang geschafft haben, mit klassischen while-Schleifen ohne
große Diskussionen ihr Ziel zu erreichen.
A. K. schrieb:> Wobei das am -Os hängt. Bei -O1 gibts eine dritte Version:
Ja, das ist die, die er auch bie -O3 dann noch nimmt.
Josef G. schrieb:> Und gegenüber while-Schleifen hat das Konstrukt den Vorteil,> dass man bereits im Quelltext unmittelbar den erzeugten Code> vor sich sieht und keine Optimierung erforderlich ist.
Du verkaufst also einen Mangel (Sprache bietet keine while-Schleife) als
einen Vorteil? Das erinnert mich an Versicherungsvertreter.
Eine höhere Programmiersprache bietet eine Abstraktionsebene an. Genau
das ist der Sinn einer höheren Programmiersprache. Dem Programmierer
kann es im allgemeinen vollkommen wurscht sein, wie der Compiler das
umsetzt. Hauptsache, er macht es korrekt und effizient.
Und jetzt lassen wir uns nochmal Deinen Satz auf der Zunge zergehen:
> Und gegenüber while-Schleifen hat das Konstrukt den Vorteil,> dass man bereits im Quelltext unmittelbar den erzeugten Code> vor sich sieht und keine Optimierung erforderlich ist.
Der einzige Programmierer, der "unmittelbar den erzeugten Code vor sich
sieht", ist ein Assembler-Programmierer. Deine "Sprache" bietet also
keine Abstraktionsebene an. Und das soll ein "Vorteil" sein?
Oder noch besser im Umkehrschluss:
Alle Sprachen, die dem Programmierer Dein "Konstrukt" nicht zur
Verfügung stellen, stellen einen Rückschritt dar?
Josefs Version der eingesprungenen Schleife:
while condition
statement2
entry:
statement1
end while
Äquivalente Version in vielen Programmiersprachen:
while true
statement1
if condition false
exit while
statement2
end while
Wie der Compiler das in Code umsetzt ist sowieso seine Sache, d.h. aus
dem Quellcode der zweiten Version kann ein an die erste Version
erinnernder Maschinencode werden, oder es kann streckenweise conditional
execution genutzt werden.
Die zweiten Version hat den Vorzug, dass nicht einen Block rein, sondern
aus ihm raus gesprungen wird. Das ist an vielen Stellen angenehmer,
beispielsweise bei Variablen lokal zum Block (*) und bei exception
handling.
Optisch vermeidet man in der zweiten den Spaghetticode-Eindruck der
ersten Version, deren Statements anfangs in umgekehrter Reihenfolge
ausgeführt werden. Ein Compiler würde in der heute üblichen
Datenflussanalyse die erste Version deshalb ohnehin intern umdrehen
müssen.
*: Mit lokaler Variable, wird das dann so geschrieben:
while condition
statement2(i) // was ist i? Kenn ich nicht!
entry:
declare i as integer = 1
i = 2
end while
oder so:
while condition
declare i as integer = 1 // wird i hier initialisiert?
statement2(i) // Aufruf ist mit i=2 oder i=1?
entry: // wird i hier initialisiert?
i = 2
end while
oder wie?
Eingesprungene Blöcke sind Mist. Die C Syntax von switch statements ist
es auch.
A. K. schrieb:> beispielsweise bei Variablen lokal zum Block (*)
Gibt es in meiner Sprache nicht.
Gegf. müsste die Variablen-Vereinbarung nach *HERE erfolgen.
> Spaghetticode-Eindruck
Wenn die Schleife mit Hineinsprung auf dich wie Spaghetticode
wirkt, ist das rein subjektiv und nur eine Frage der Gewöhnung.
Tatsächlich hat es mit Spaghetticode nichts zu tun.
Josef G. schrieb:>> Warum man die "strenge Blockstruktur" anschließend wieder mit so einer>> komischen Konstruktion, wie dem "Hineinsprung" durchlöchern muss,>> Die wird nicht durchlöchert.> L.JP .. HERE .. RP.x ist genauso ein Block mit zwei Unterblöcken,> wie dies bei if .. else .. end-else der Fall ist.
Josef G. schrieb:> Wenn die Schleife mit Hineinsprung auf dich wie Spaghetticode> wirkt, ist das rein subjektiv und nur eine Frage der Gewöhnung.
Totschlagargument: kann man immer behaupten. „Für mich sieht das
alles schön aus, muss also dein Problem sein.“
Wie ich schon schrieb: mach' deine Sprache, wenn du sie unbedingt so
brauchst. Alles andere scheint dich ja nur dann zu interessieren,
wenn es irgendwie deiner Argumentation hilfreich ist, also als
externe Selbstbestätigung.
Jörg Wunsch schrieb:> Aus Sicht des Programmierers wäre es mir wichtig, dass die> Programmiersprache sich einigermaßen so verhält wie die bereits> existierenden Sprachen (POLA - principle of least astonishment).
naja, es gibt auch Programmierer, die wünschen sich POFUC (Principle Of
FUrthest from C).
A. K. schrieb:> Josefs Version der eingesprungenen Schleife:> while condition> statement2> entry:> statement1> end while
Abgesehenen davon, dass die Schlüsselworte bei mir anders sind:
Die Verwirrung entsteht durch die von dir gewählte Bezeichnung
statement2 statement1. Ich würde es so schreiben:
1
*L.JP
2
statement1
3
*HERE
4
statement2
5
RP.c
In der Schleife wird jeweils statement1 & statement2 ausgeführt,
zuletzt statement2. Nur beim ersten Durchlauf wird statement1
übersprungen.
Wenn man diese Vorstellung verinnerlicht hat, wirkt alles
ganz natürlich. Wie schon geschrieben: reine Gewöhnungssache.
Jörg Wunsch schrieb:>> Ausserdem hat es den Vorteil, dass die Ermittlung der>> Abbruchbedingung beliebig kompliziert sein kann.>> Inwiefern sollte das bei existierenden while-Schleifen> nicht der Fall sein?
Es ist jedenfalls nicht so einfach wie
bei der Schleife mit Hineinsprung.
Josef G. schrieb:> Es ist jedenfalls nicht so einfach wie> bei der Schleife mit Hineinsprung.
Kann ich nicht nachvollziehen. Ich kann zwischen den beiden oben
gezeigten Varianten keinen Unterschied erkennen, was die Komplexität der
Abbruchbedingung angeht.
Josef G. schrieb:> Wenn man diese Vorstellung verinnerlicht hat, wirkt alles> ganz natürlich. Wie schon geschrieben: reine Gewöhnungssache.
Ich fand es auch mal völlig natürlich, das bei -1+2 am Ende -3
rauskommt, und 1/3 zu 3 wird. Ersteres finde ich auch heute noch
logischer und konsequenter als den ganzen Zirkus mit der operator
precedence.
A. K. schrieb:> Kann ich nicht nachvollziehen.Josef G. schrieb:> Ausserdem hat es den Vorteil, dass die Ermittlung der> Abbruchbedingung beliebig kompliziert sein kann. Es muss> lediglich die Zielmarke *HERE des Hineinsprungs entsprechend> weit genug vor dem bedingten Rückwärtssprung liegen.>> Bei der while-Schleife müsste man in so einem Fall die> Ermittlung der Abbruchbedingung in eine function packen,> deren Rückgabewert dann abgefragt wird. Oder man muss> eine Endlosschleife mit bedingtem break verwenden,> was der Philosophie der while-Schleife zuwiderläuft.
A. K. schrieb:> Ich bezog mich die zu deiner Methode äquivalente Version in> Beitrag "Re: Gibt es eine Programmiersprache mit diesem Schleifentyp?".A. K. schrieb:> Äquivalente Version in vielen Programmiersprachen:> while true> statement1> if condition false> exit while> statement2> end while
Ich vermute, gemeint war das:
> while true> statement1> if condition=false exit> statement2> end while
also eine Endlosschleife mit bedingtem break.
Da gilt meine Aussage
> eine Endlosschleife mit bedingtem break verwenden,> was der Philosophie der while-Schleife zuwiderläuft.
Ist sicher kein starkes Argument, aber immerhin, es ist ein Argument.
Bei einfacher Abbruchbedingung schreibt man
while(??){...}
Wenn die Ermittlung der Abbruchbedingung
eine lange Befehlsfolge beinhaltet, schreibt man
while(1){Befehlsfolge; if(??) break; ...}
Man hat also zwei verschiedene Strukturen,
je nach Komplexität der Abbruchbedingung.
Bei der Schleife mit Hineinsprung hat man beide Male dieselbe
Struktur, nur die Marke *HERE steht unterschiedlich weit
vom bedingen Rückwärtssprung entfernt.
Josef G. schrieb:> Wenn die Ermittlung der Abbruchbedingung> eine lange Befehlsfolge beinhaltet, schreibt man>> while(1){Befehlsfolge; if(??) break; ...}
Warum denn das?
Alles, was du im "if" schreiben kannst, kannst du auch im "while"
als Bedingung schreiben.
Klar kann es aus Gründen der Übersichtlichkeit Sinn haben, dass man
für die Bedingung eine (inline-)Funktion schreibt, aber ansonsten
kann man gerade in C beliebig komplexe Ausdrücke als Steuerung von
"if" oder "while" konstruieren.
Du legst dir tausendundein Argument zurecht für einen Konstrukt, den
nur du haben willst, und den du nun unbedingt allen anderen als
Vorteil deines aufgebohrten Assemblers verkaufen willst.
Aufgebohrte Assembler gab es auch schon vor 40 Jahren, PL/M zum
Bleistift. Sie haben sich nicht wirklich durchgesetzt.
Jörg Wunsch schrieb:>> Und gegenüber while-Schleifen hat das Konstrukt den Vorteil,>> dass man bereits im Quelltext unmittelbar den erzeugten Code>> vor sich sieht und keine Optimierung erforderlich ist.>> Das ist kein Vorteil, sondern deutet darauf hin, dass du eher eine
Es hat sogar einen praktischen Vorteil: Ein Programmierer,
der sich das Compilat anschauen will um es zu überprüfen,
findet sich schneller zurecht.
Jörg Wunsch schrieb:> Alles, was du im "if" schreiben kannst, kannst du auch im "while"> als Bedingung schreiben.
So etwas? while(Befehlsfolge; ??){...}
Wusste ich nicht, dass das geht.
@ Jörg Wunsch (dl8dtl) (Moderator) Benutzerseite
>Wie ich schon schrieb: mach' deine Sprache, wenn du sie unbedingt so>brauchst. Alles andere scheint dich ja nur dann zu interessieren,>wenn es irgendwie deiner Argumentation hilfreich ist, also als>externe Selbstbestätigung.
Genau. Darum sind wir HIER und JETZT Zeuge der Geburt einer neuen
Sprache.
https://www.youtube.com/watch?v=XrzRH2I5Mpo
E (wie Ego), created by Josef G.
(Über G. dürfen hier und jetzt pupertäre Witzchen gemacht werden ;-)
Josef G. schrieb:> Wusste ich nicht, dass das geht.
Du kennst C nicht, insbesondere den Komma-Operator.
Jetzt verrätst du mir aber, warum man so einen Kram unbedingt
vor der ersten Iteration der Schleife ernsthaft braucht. In allen
anderen Fällen kann man ja deine „Befehlsfolge“ problemlos ans Ende
der Schleife schreiben, ohne dass sie beim ersten Mal mit abgearbeitet
werden muss.
Josef G. schrieb:> Es hat sogar einen praktischen Vorteil: Ein Programmierer,> der sich das Compilat anschauen will um es zu überprüfen,> findet sich schneller zurecht.
Nur, weil dein Compiler zu blöd ist zum optimieren.
Bei einem optimierenden Compiler erkennt man völlig unabhängig von
solchen Schleifenkonstrukten im Maschinencode niemals mehr 1:1 den
Quellcode.
Aus dem Alter, in dem man das Compilat „überprüfen“ muss, sind wir
sowieso schon lange raus.
Jörg Wunsch schrieb:> Josef G. schrieb:>> Wenn die Ermittlung der Abbruchbedingung>> eine lange Befehlsfolge beinhaltet, schreibt man>>>> while(1){Befehlsfolge; if(??) break; ...}>> Warum denn das?> ... kannst du auch im "while" als Bedingung schreiben.Jörg Wunsch schrieb:> Du kennst C nicht, insbesondere den Komma-Operator.
Wenn aber "Befehlsfolge" keine einfache Folge ist,
sondern selber Verzweigungen/Schleifen beinhaltet?
Sogar wenn es ginge, das in den runden Klammern der Struktur
1
while(..., ..., ??){...}
unterzubringen, würde man das sicher nicht so machen, sondern
1
while(1){"Befehlsfolge"; if(??) break; ...}
verwenden. Und dann gilt mein Argument wieder:
Josef G. schrieb:> Bei einfacher Abbruchbedingung schreibt man> while(??){...}>> Wenn die Ermittlung der Abbruchbedingung> eine lange Befehlsfolge beinhaltet, schreibt man> while(1){Befehlsfolge; if(??) break; ...}>> Man hat also zwei verschiedene Strukturen,> je nach Komplexität der Abbruchbedingung.>> Bei der Schleife mit Hineinsprung hat man beide Male dieselbe> Struktur, nur die Marke *HERE steht unterschiedlich weit> vom bedingen Rückwärtssprung entfernt.
Jörg Wunsch schrieb:> Nur, weil dein Compiler zu blöd ist zum optimieren.
Dafür läuft er aber auch auf einem 8bit-Rechner
und benötigt nicht die Ressourcen eines PC.
Josef G. schrieb:> Dafür läuft er aber auch auf einem 8bit-Rechner> und benötigt nicht die Ressourcen eines PC.
Das ist sicherlich reizvoll. Gewesen. Vor dreißig Jahren. Auch wenn das
Programmieren von 8-Bit-Systemen nach wie vor sinn- und reizvoll ist,
das auf 8-Bit-Systemen zu tun ist Masochismus. Brauchbare
Texteditoren, brauchbare Ein- und Ausgabesysteme, Dateisysteme, die auch
Dateinamen verarbeiten können (statt auf wenige Zeichen Länge
beschränkte Kürzel) ... all das sind Gründe, die Programmiererei auf
einem etwas zeitgenössischeren System zu veranstalten.
Ich habe auch noch meinen ersten selbst zusammengelöteten 8-Bit-Rechner
herumstehen, der wird demnächst mal abgestaubt und zum 30. seiner
Inbetriebnahme auch mal wieder eingeschaltet, eine Zeitlang bewundert
und dann wieder ausgeschaltet. Obwohl der unter anderem einen
Pascal-Compiler im ROM hat, und so ziemlich den schicksten aller
8-Bit-Prozessoren verwendet (6809).
Rufus Τ. Firefly schrieb:> Josef G. schrieb:>> Dafür läuft er aber auch auf einem 8bit-Rechner>> und benötigt nicht die Ressourcen eines PC.>> Das ist sicherlich reizvoll. Gewesen. Vor dreißig Jahren.
Abgesehen davon.
Auch vor 30 Jahren gab es schon C-Compiler die problemlos und sauber auf
den damaligen 8 Bit Rechnern liefen.
Nur weil heutige IDE Megabyteweise Dinge mitbringen, bedeutet das ja
nicht, dass das immer so sein muss. Ein C Compiler ist kein besonders
umfangreiches Programm. Der gcc hat es natürlich schwerer, weil er so
gebaut ist, dass er von den kleinsten bis zu den größten Maschinen mit
unterschiedlichen Architekturen klar kommen muss. D.h. alles muss sehr
allgemein gehalten sein.
> Sogar wenn es ginge, das in den runden Klammern der Struktur>> while(..., ..., ??){...}> unterzubringen, würde man das sicher nicht so machen, sondern>> while(1){"Befehlsfolge"; if(??) break; ...}> verwenden. Und dann gilt mein Argument wieder:
Klar. Man kann natürlich immer damit argumentieren, dass die gröbsten
Schweinereien in einer Sprache nicht so einfach möglich sind. Die
Erfahrung zeigt aber, dass irgendwer immer einen Weg findet :-)
Um das klar zu sagen: Wenn du das willst, dann hast du die ganze
Entwicklung der strukturierten Programmierung und was man aus den
letzten 80 Jahren Programmierung gelernt hat, ganz einfach verschlafen.
Der Trend ging nicht grundlos in die Richtung, dass man derartige
Schweinereien gezielt abstellen will.
Die Praxis zeigt nämlich auch, dass genau diese Schweinereien es nicht
sind, mit denen man aus einem Programm Speed herausholt. Ausser
natürlich in sinnlosen Demos. Aber in realen Programmen sind diese Dinge
nicht der Bottleneck.
Ich finde die Schleife mit Hineinsprung durchaus interessant. Aber es
ist jetzt nichts, was ich mir unbedingt zu Weihnachten wünschen würde.
Karl Heinz schrieb:> Auch vor 30 Jahren gab es schon C-Compiler die problemlos und sauber auf> den damaligen 8 Bit Rechnern liefen.
Und vor 30 Jahren gab es auch längst 32-Bit 68000 Systeme, die sich weit
besser als Host für Compiler eigneten.
Karl Heinz schrieb:> Auch vor 30 Jahren gab es schon C-Compiler die problemlos und sauber auf> den damaligen 8 Bit Rechnern liefen.
Insbesondere gab es schon Turbo-Pascal, welches gar nicht mal so
schlecht optimiert hat und auch keine derartig verrenkten syntaktischen
Konstrukte benötigte, wie Josef sie hier anzetteln will.
Josef G. schrieb:> Und dann gilt mein Argument wieder:
… für das du bislang immer noch den Anwendungsfall schuldig geblieben
bist. Du theoretisierst da um irgendwas herum. Wo zum Geier braucht
man derartig kompliziert gestaltete Abbruchbedingungen, die man dann
auch noch unbedingt vor dem ersten Abarbeiten der Schleife
durchlaufen muss? Alles andere in deinen komplizierten Abläufen kann
man ja immer noch ganz normal ans Ende der Schleife setzen:
1
while(!abbruchbedingung){
2
tuwas();
3
komplizierte_vorbereitung_der_abbruchbedingung;
4
}
Ich würde mal sagen, in den allermeisten Fällen müsste man selbst
bei derzeitigen C-Programmen die Abbruchbedingung noch nichtmal
vor dem ersten Schleifendurchlauf testen, weil von der Umgebung her
klar ist, dass beim Eintritt in die Schleife auf jeden Fall was zu
tun ist. Es würde dann eine do{}while-Schleife genügen.
Rufus Τ. Firefly schrieb:> Und das lief in den ersten Inkarnationen sogar auf 8-Bit-Systemen
Und zwar verdammt gut, trotz wenig RAM. Klar, grossartig optimiert hat
der Compiler nicht, aber gegenüber den vorher üblichen Compilern, wie
UCSD-Pascal mit interpretierem Bytecode, oder den dicken FORTRAN und
PL/I Dingern war die Zeit zwischen Quellcodeänderung und Ausführung
angenehm kurz.
Nur: Muss man das heute auch noch so machen? Schon in der Anfangszeit
fand professionelle Entwicklung für 8-Bit Systeme unterhalb der CP/M
Klasse auf Minicomputern statt, bevor die PCs deren Rolle übernahmen.
@ A. K. (prx)
>Nur: Muss man das heute auch noch so machen? Schon in der Anfangszeit>fand professionelle Entwicklung für 8-Bit Systeme unterhalb der CP/M>Klasse auf Minicomputern statt, bevor die PCs deren Rolle übernahmen.
Hat nicht auch Bill Gates so angefangen? Auf dem Rechner der Uni für die
"Homecomputer" was programmiert. Da gab dann Ärger.
@Jörg Wunsch (dl8dtl) (Moderator) Benutzerseite
>> Und dann gilt mein Argument wieder:>… für das du bislang immer noch den Anwendungsfall schuldig geblieben>bist. Du theoretisierst da um irgendwas herum.
Jörg, die "kennst" den Josef doch schon seit Jahren. Immer noch nicht
verstanden, wie es um ihn steht?
Beitrag "Re: wer kann sich noch an den hex-zeichensatz erinnern?"
Jörg Wunsch schrieb:> für das du bislang immer noch den Anwendungsfall schuldig geblieben
Eine Zahl SELECT soll eingelesen werden, wozu mehrere Aktionen nötig
sind (Linefeed, Ausgabe von Benutzer-Info und Eingabe-Maske, ...).
Hat die Zahl einen Wert 0..3, dann soll dadurch eine von vier Aktionen
ausgewählt werden, welche dann auszuführen sind, und es soll eine neue
Zahl SELECT eingelesen werden und so fort. Falls aber SELECT den Wert
4 oder größer hat, soll abgebrochen werden.
Man hat eine Schleife mit Hineinsprung: Nach dem *HERE stehen die
Eingabe der Zahl SELECT und die unterstützenden Aktionen, dann
der Rückwärtssprung falls SELECT nicht größer als 3. Vor dem
*HERE stehen in einer CASE-Struktur die vier Aktionen,
welche durch SELECT ausgewählt werden.
Josef G. schrieb:> Man hat eine Schleife mit Hineinsprung
Nein. Hat man nicht. Die Schleife kann auch bei Deiner Anforderung ganz
vorne, also an ihrem Anfang begonnen werden.
In c-artigem Pseudocode
Jörg Wunsch schrieb:> Dass ja seine tolle Erfindung dann doch bloß wieder flüssiger als> Wasser ist. ;-)
Nu, das wär doch wirklich was.
Suprafluidität - eine völlig reibungslos funktionierende IT.
Josef G. schrieb:> Es gibt in der Tat eine Eins-zu-Eins-Entsprechung zwischen> dem Quelltext und dem erzeugten Code. Und dies ermöglicht> es, durch Addieren von Ausführungszeiten die Dauer von> Programmteilen zu berechnen. Ob es dafür einmal eine> ernsthafte Anwendung geben wird, wird man sehen.Robert L. schrieb:> warum es wichtig sein sollte, dass man (anhand vom Code) abzählen kann,> wieviele takte ein bestimmtes programm jetzt genau braucht, kapier ich> übrigens nicht..
Offenbar gibt es doch Leute, die für so etwas eine Anwendung haben.
Beitrag "Funktion mit gleichbleibender Ausführungszeit"
>die für so etwas eine Anwendung haben.
nein, die GLAUBEN für so etwas eine Anwendung zu haben!
dort wurde (wie so oft) gefragt, wie man eine vermeintliche Lösung für
ein Problem umsetzten kann
das PROBLEM ansich aber nicht dargelegt: ob es diese "Lösung" also
überhaupt braucht, oder die beste ist weiß keiner..
Geht auch in "C", sogar ohne explizites "goto":
switch (einsprung) while (bedingung) {
case EINSPRUNG_1:
case EINSPRUNG_2:
case EINSPRUNG_3:
// Tu' irgendwas mit "bedingung"
}
Sage niemandem dass Du das von mir hast!
Fuer soetwas wird man in jedem Review bei lebendigem Leibe verbrannt ;)
Josef G. schrieb:> In einer von mir kreierten Programmiersprache gibt es die> "Schleife mit Hineinsprung" anstelle der while-Schleife.>> Kennt jemand sonst eine Sprache mit dieser Struktur?>> Beitrag "Re: 8bit-Computing mit FPGA"
Helmut S. schrieb:> Sage niemandem dass Du das von mir hast!> Fuer soetwas wird man in jedem Review bei lebendigem Leibe verbrannt ;)
Ich sage auch niemandem, daß du es von Duff's Device abgeschaut hast :-)
https://en.wikipedia.org/wiki/Duff%27s_device
Klaus W. schrieb:> https://en.wikipedia.org/wiki/Duff%27s_device
Habe jetzt den Wikipedia-Artikel doch noch einigermaßen verstanden.
Es geht darum, bei Zähl-Schleifen die Zahl der Durchläufe und damit
die Zahl der bedingten Rückwärtssprünge, welche Zeit kosten, auf
einen Bruchteil zu reduzieren, indem man den Schleifenkern mehrere
Male (zB. achtmal) untereinander schreibt und den Startwert des zu
dekrementierenden Zählers durch einen Bruchteil (zB. ein Achtel)
des ursprünglichen Wertes ersetzt. Falls der ursprüngliche Wert
nicht durch acht teilbar ist, springt man zu Beginn in die
Schleife zu einer der Kopien des Schleifenkerns.
Zwar nicht auf Hochsprachen-Ebene aber bei Assembler-Programmierung
wird dieses Problem bei meiner CPU auf andere Weise gelöst. Hier
als Beispiel ein Code zur Blockverschiebung (S = Schleifenzähler):
1
S.RP Setze Schleifenstartadresse auf den GTMX-Befehl
2
GTMX Lade (X) in den Akku
3
STMY Speichere Akku in (Y)
4
IX0 Inkrementiere X
5
R.IY Falls S nicht Null ist:
6
Dekrementiere S, Inkrementiere Y, Sprung zum Start
Der kombinierte Befehl R.IY dauert nicht länger als ein einfaches
Inkrementieren IY0. Damit entfällt der Anreiz, Schleifendurchläufe
zusammenzufassen durch mehrmaliges Hinschreiben des Schleifenkerns.
Zu diesem und anderen Aspekten der CPU siehe auch
Beitrag "Re: 8bit-Computing mit FPGA"
Ohne jetzt den wie üblich wirren Thread durchgelesen zu haben, habe ich
den Eindruck, dass hier "Repeat [Anweisungen] Until [Bedingung]"
wiederentdeckt wurde. Bekannt aus bspw. PASCAL.
Lukas T. schrieb:> Ohne jetzt den wie üblich wirren Thread durchgelesen zu haben, habe> ich den Eindruck, dass hier "Repeat [Anweisungen] Until [Bedingung]"> wiederentdeckt wurde. Bekannt aus bspw. PASCAL.
Der Eindruck ist falsch.
In dem Thread geht es um die "Schleife mit Hineinsprung",
welche while-Schleifen ersetzt und darüber hinaus mehr kann.
In meinen letzten zwei Beiträgen geht es um etwas anderes:
Bei Zählschleifen, welche bestehen aus dem Schleifenkern und dem
Zählvorgang mit bedingtem Rückwärtssprung, verlängert sich die Dauer
einer Ausführung des Schleifenkerns um die Dauer des Zählvorgangs mit
Rückwärtssprung. Wenn man den Schleifenkern zweimal hinschreibt und
die Zahl der Schleifendurchläufe halbiert, ist pro Ausführung des
Schleifenkerns nur noch die halbe Dauer eines Zählvorgangs mit
Rückwärtssprung anzurechnen, es geht also schneller. Dadurch ergibt
sich für den Programmierer ein Konflikt zwischen Geschwindigkeit
einerseits und Codelänge/Einfachheit andererseits.
Sofern im Schleifenkern ein Adressregister inkrementiert oder
dekrementiert wird, wird bei meiner CPU dieser Konflikt vermieden
durch kombinierte Befehle, welche ein Adressregister inkrementieren
oder dekrementieren und gleichzeitig den Zählvorgang mit bedingtem
Rückwärtssprung ausführen, und welche nicht länger dauern als das
Inkrementieren/Dekrementieren des Adressregisters allein.
>Dadurch ergibt>sich für den Programmierer ein Konflikt zwischen Geschwindigkeit>einerseits und Codelänge/Einfachheit andererseits.
eigentlich nicht: es ist ein "Problem" des Compilers...
für den Programmier ist der Code ja der selbe, egal ob der Compiler
jetzt auf geschwindigkeit oder größe optimiert..
(es steht auch in dem WIKI artikel zu Duff's Device, dass das aufgrund
von modernen comilern nicht mehr/kaum notwendig ist..)
ausserdem sind heutige CPU so extrem schnell, dass es in 99,999% der
Fälle nicht notwendig ist sich über sowas überhaupt gedaken machen zu
müssen
und in den restlichen 0.0001% wird man zuerstmal eine schnellere CPU
(und vorallem keine 8bit CPU) verwenden.. und DANN erste anfangen mühsam
code zu optimieren... (siehe stm32 für ein paar $..)
>und welche nicht länger dauern als das>Inkrementieren/Dekrementieren des Adressregisters allein.
liegt aber vielleicht daran dass dein "inkremtenieren alleine" zu
langsam ist, und nicht dass das kombinierte so schnell ist ;-)
ausserdem: wenn du dir anschaust, welche optimierungen "aktuelle" CPU
(seit Jahrezehnten) gerade bei bedingten sprüngen machen, ist nicht mal
sicher, ob mehrmaliges hinschreiben, schneller ist als normale
schleife...
Robert L. schrieb:> ausserdem: wenn du dir anschaust, welche optimierungen "aktuelle" CPU> (seit Jahrezehnten) gerade bei bedingten sprüngen machen, ist nicht mal> sicher, ob mehrmaliges hinschreiben, schneller ist als normale> schleife...
Wer sich dafür interessiert, was in CPUs heute abgeht, der kann man hier
reinschnuppern: http://www.realworldtech.com/sandy-bridge/
Leider versteckt David Kanter seine sehr guten Analysen mittlerweile im
unbezahlbaren Microprocessor Report.
In Matlab hätte ich jahrelang diesen Schleifentyp gern gehabt. Ich hatte
ein "kleines" Dynamik-FEM-Programm, das ungefähr so aussah:
1
Preprocessing
2
Initialization
3
Step-Postprocess
4
5
for( ... )
6
Step-Calculation
7
Step-Postprocess
8
end for
Das Problem war, daß Matlab nur call by value beherrscht, und da die
Übergabe von Matrices > 1GB (sparse) viel zu langsam gewesen wäre,
mußten die einzelnen Schritte in der Hauptschleife ausgeschrieben
werden, d.h. die beiden Blocks "Step-Prostprocess" waren 1:1-Textkopien
des Quelltextes. Sehr lästig.
Da hätte man den Einsprung in eine Schleife gut gebrauchen können. Das
ist aber eher das gegenteilige Extrem, was Programmgröße und
Programmiersprache (Hochsprache) angeht.
Robert L. schrieb:> wenn du dir anschaust, welche optimierungen "aktuelle" CPU> (seit Jahrezehnten) gerade bei bedingten sprüngen machen
Zudem werden auch die Compiler immer schlauer und nutzen diese Features
der aktuellen Prozessoren meist besser als man dies durch explizite
Programmierung (sei es in Assembler oder durch neue Sprachkonstrukte wie
der "Josef-G.-Schleife") kann.
Schon vor ca. 20 Jahren war der C-Compiler für den TMS320C30 (DSP von
TI) in der Lage, eine Schleife komplett umzustellen, um damit Features
des Prozessors wie bspw. die Multiply/Accumulate (parallele Addition/
Multiplikation) und Single-Instruction-Repeat (Wiederholung einer
Einzeinstruktion ohne Schleifen-Overhead) nutzen zu können.
Beispiel Skalarprodukt:
So schreibt man den Code üblicherweise hin:
1
doubledot(doublex[],doubley[],intn){
2
doublesum;
3
inti;
4
5
sum=0.0;
6
for(i=0;i<n;i++)
7
sum+=x[i]*y[i];
8
9
returnsum;
10
}
Er ist zwar leicht schreib- und lesbar, hat aber den Nachteil, dass die
Addition in der Schleife vom Ergebnis der Multiplikation abhängt,
weswegen diese beiden Operationen nicht parallel ausgeführt werden
können.
Der Compiler erzeugt daraus Code, der äquivalent zu diesem ist:
1
doubledotopt(doublex[],doubley[],intn){
2
doublesum,prod;
3
inti;
4
5
sum=0.0;
6
prod=x[0]*y[0];
7
for(i=1;i<n;i++){
8
sum+=prod;
9
prod=x[i]*y[i];
10
}
11
sum+=prod;
12
13
returnsum;
14
}
Durch die Umstellung der Operationen innerhalb der Schleife können sie
jetzt parallel ausgeführt werden. Die erste Multiplikation und die
letzte Addition der gesamten Berechnung werden außerhalb der Schleife
ausgeführt, weswegen die Schleife statt n nur n-1 Durchläufe hat.
Das alles bastelt der Compiler ohne Zutun des Programmierers so hin mit
dem Ergebnis, dass die Berechnung statt 5n+1 nur n+2 Maschinenzyklen
dauert. Das ist eine Geschwindigkeitssteigerung um den Faktor 5, ohne
dass dafür neuartige Schleifenkonstrukte vonnöten wären.
Und die Compiler sind seither nicht schlechter, sonden noch viel besser
geworden
Josef G. schrieb:> Wenn man den Schleifenkern zweimal hinschreibt und die Zahl der> Schleifendurchläufe halbiert, ist pro Ausführung des Schleifenkerns> nur noch die halbe Dauer eines Zählvorgangs mit Rückwärtssprung> anzurechnen, es geht also schneller.
Loop-Unrolling wäre im obigen Beispiel sogar kontraproduktiv, da dadurch
ein Schleifen-Overhead entstünde, der vorher nicht vorhanden war. Und
auf Prozessoren, wo es tatsächlich einen Nutzen bringt, überlässt man es
sinnvollerweise meist ebenfalls dem Compiler, so dass man damit nicht
den Quellcode verunstalten muss.
Walter T. schrieb:> Preprocessing> Initialization> Step-Postprocess>> for( ... )> Step-Calculation> Step-Postprocess> end for>> Das Problem war, daß Matlab nur call by value beherrscht, und da die> Übergabe von Matrices > 1GB (sparse) viel zu langsam gewesen wäre,> mußten die einzelnen Schritte in der Hauptschleife ausgeschrieben> werden, d.h. die beiden Blocks "Step-Prostprocess" waren 1:1-Textkopien> des Quelltextes. Sehr lästig.
Matlab hat doch eine Break-Anweisung.Warum also nicht so:
A. K. schrieb:> Leider versteckt David Kanter seine sehr guten Analysen mittlerweile im> unbezahlbaren Microprocessor Report.
Der wird doch nicht etwa hier bei Joseph abschreiben?
Yalu X. schrieb:> Matlab hat doch eine Break-Anweisung.Warum also nicht so:
Die klassische Antwort: "Ja, aber." Matlab war damals (ich mache diesen
Kram leider nicht mehr) extrem viel schneller, wenn es vorher die Anzahl
der Schleifendurchläufe kannte. Sprich: Eine einfache for-Schleife mit
konstantem Initialsierungsvektor war deutlich schneller als eine
while-Schleife oder wenn in der Schleife "break" oder
"continue"-Anweisungen vorhanden waren.
Einen Tod muß man halt immer sterben.
Walter T. schrieb:> Yalu X. schrieb:>> Matlab hat doch eine Break-Anweisung.Warum also nicht so:>> Die klassische Antwort: "Ja, aber." Matlab war damals (ich mache diesen> Kram leider nicht mehr) extrem viel schneller, wenn es vorher die Anzahl> der Schleifendurchläufe kannte.
Macht sich der Schleifen-Overhead auch dann noch bemerkbar, wenn
innerhalb der Schleife
Walter T. schrieb:> Matrices > 1GB
verarbeitet werden? So lahm wird doch selbst der Matlab-Intepreter nkaum
sein, oder?
Yalu X. schrieb:> Macht sich der Schleifen-Overhead auch dann noch bemerkbar, wenn> innerhalb der Schleife>> Walter T. schrieb:>> Matrices > 1GB>> verarbeitet werden? So lahm wird doch selbst der Matlab-Intepreter nkaum> sein, oder?
So lahm ist der Interpreter gar nicht. Im Vergleich zu
Fortran-Programmen von mittelmäßig darin begabten Ingenieuren (da
schließe ich mich ein) ist er sogar ziemlich fix. Ich nehme an, daß er
einfach deutlich besser parallelisieren kann, wenn er schon vorher die
Anzahl der Schleifenläufe kennt.
Robert L. schrieb:>>und welche nicht länger dauern als das>>Inkrementieren/Dekrementieren des Adressregisters allein.>> liegt aber vielleicht daran dass dein "inkremtenieren alleine" zu> langsam ist, und nicht dass das kombinierte so schnell ist ;-)
Bei meiner CPU dauern alle Operationen 1 oder 2 oder 3 "Vollzyklen",
wobei ein Vollzyklus aus den Halbzyklen tA und tB besteht.
Das Inkrementieren/Dekrementieren eines Adressregisters
dauert 1 Vollzyklus, ebenso die kombinierten Befehle.
Beim Inkrementieren eines Adressregisters wird bei tA das
Adressregister in ein Hilfsregister übertragen, an dessen
Ausgang ein Inkrementiernetz hängt. Bei tB wird der Ausgang
des Inkrementiernetzes in das Adressregister geschrieben.
Gleichzeitig wird bei tA der Programmzähler P auf dem Adressbus
ausgegeben und der nächste OpCode in ein Eingangs-Pufferregister
geladen. Bei tB wird er dann in das für das folgende tA zuständige
OpCode-Register übertragen. Ebenfalls gleichzeitig wird bei tA
der Programmzähler P in ein Hilfsregister übertragen, an dessen
Ausgang ein Inkrementiernetz hängt, bei tB wird das Ergebnis
in den Programmzähler geschrieben.
Bei den kombinierten Befehlen wird, sofern der Schleifenzähler
nicht Null ist, bei tA statt P die Schleifenstartadresse R auf dem
Adressbus ausgegeben zum Einlesen des nächsten OpCodes, und in das
Hilfsregister, an dessen Ausgang das Inkrementiernetz hängt, wird
ebenfalls R statt P übertragen. Das Ergebnis kommt wieder nach P.
Bei den kombinierten Befehlen wird gleichzeitig bei tA der
Schleifenzähler S in ein Hilfsregister übertragen, an dessen
Ausgang ein Dekrementiernetz hängt. Bei tB wird das Ergebnis
in S gespeichert, falls S vorher nicht Null war.
Man sieht, dass wirklich alles parallel ausgeführt wird und
nicht länger dauert als das Inkrementieren des Adressregisters
allein. Das Inkrementieren des Adressregisters wird auch nicht
künstlich verlängert, um gleiche Dauer wie bei den kombinierten
Befehlen zu erreichen.
Würde man das CPU-Konzept grundlegend ändern und die Hilfsregister
einsparen und statt tA/tB nur eine Phase haben, könnte man das auf
alle genannten parallel ablaufenden Vorgänge anwenden, und die
gleiche Dauer von kombinierten Befehlen und einfachem
Inkrementieren würde weiter gelten.
Josef G. schrieb:> Das Inkrementieren/Dekrementieren eines Adressregisters> dauert 1 Vollzyklus, ebenso die kombinierten Befehle.
nein...
wenn ich das jetzt richtig verstanden habe, ist dein "kominierter
Befehl" kein echter "bedingter Sprung" ..
der würde nämlich eine Zieladresse beinhalten..
(im nahen und sehr nahen Umfeld)
http://www.mathemainzel.info/files/x86asmref.html#jne
du hingegen hast hier Arbeit auf 2 Befehle aufgeteilt (S.RP und R.IY)
d.h. man muss fairerweise auch die Zeit von beiden addieren..
ist mir aber soweiso unklar, wie man hiermit verschachtelte schleifen
programmierne kann ..
p.s. schön dass du alle anderen Ausführungen ignoriert hast und nur auf
das Antwortest was dir lieb ist..
Robert L. schrieb:> du hingegen hast hier Arbeit auf 2 Befehle aufgeteilt (S.RP und R.IY)> d.h. man muss fairerweise auch die Zeit von beiden addieren..
Nein, man muss die Zeiten nicht addieren. Das S.RP steht
ausserhalb der Schleife und wird nur 1-mal ausgeführt.
> ist mir aber soweiso unklar, wie man hiermit verschachtelte schleifen> programmierne kann ..
Das ist in der Tat nicht möglich. Der schnelle Rückwärtssprung ist
nur für die innerste Schleife gedacht, für äussere Schleifen muss
man bedingte Rückwärtssprünge ( B.xx nn ) mit expliziter Angabe
der Sprungdistanz nn verwenden. Bei dieser äusseren Schleife
ist aber die Dauer des Rückwärtssprungs vernachlässigbar
gegenüber der Gesamtdauer der inneren Schleife.
Angeregt durch diesen aktuellen Thread
Beitrag "goto verpönt - was dann nehmen?"
möchte ich hiermit nochmal einen Versuch machen,
für meine Programmiersprache zu werben.
Es gibt in dieser Sprache kein goto, kein break, kein continue,
und in jedem Programm oder Unterprogramm genau 1 return,
nämlich am Ende des Programms oder Unterprogramms.
Die Strukturelemente sind folgende:
1
Bedingte Anweisung: IF.c ... ENDF
2
Verzweigung: IF.c ... ELSE ... ENDE
3
Case-Struktur: CASE /nn ... NEXT /nn ... LAST
4
Do-while-Schleife: LOOP ... RP.c
5
While-Schleife: L.JP ... HERE ... RP.c
c steht hier für die Sprungbedingung, nn steht für eine Zahl
fallend bis 00, NEXT /nn ist entsprechend mehrmals anzugeben.
RP.c steht für wiederhole falls c.
Ebenso wie IF.c ... ELSE ... ENDE zählt die
Schleife mit Hineinsprung L.JP ... HERE ... RP.c als ein
Block mit zwei Unterblöcken, die strenge Blockstruktur
wird durch den Hineinsprung nicht durchbrochen.
Unterprogramme: Es gibt keine functions mit Rückgabewert,
sondern nur einfache Unterprogramme, bei welchen alle Parameter
gleichberechtigt sind. Es werden ausschließlich Zeiger übergeben.
http://www.mikrocontroller.net/articles/8bit-Computer:_bo8h
Josef G. schrieb:> Angeregt durch diesen aktuellen Thread> Beitrag "goto verpönnt - was dann nehmen?"> möchte ich hiermit nochmal einen Versuch machen,> für meine Programmiersprache zu werben.
Du willst doch nicht etwa Kurt die Schau stehlen?
Josef G. schrieb:> Unterprogramme: Es gibt keine functions mit Rückgabewert,> sondern nur einfache Unterprogramme, bei welchen alle Parameter> gleichberechtigt sind.
Reiner Masochismus bringt mich dazu, Dich zu fragen, was das sein soll.
Rufus Τ. F. schrieb:> was das sein soll.
Beim Aufrufen werden nach dem Namen des Unterprogramms die Namen
der Parameter aufgelistet. Das Unterprogramm kann die Parameter
lesen und beschreiben, sofern der betreffende Variablentyp das zu-
lässt. Damit kann jeder Parameter auch für die Rückgabe verwendet
werden. Einen speziellen Rückgabe-Parameter gibt es nicht.
Rufus Τ. F. schrieb:> Reiner Masochismus bringt mich dazu, Dich zu fragen, was das sein soll.
Vereinfacht den Compiler. Sowohl in der so sehr einfachen Syntax, als
auch bei der Umsetzung in Code. Verschachtelte Aufrufe kann es damit
nicht geben, so dass man sich keine andere Ausrede überlegen muss,
weshalb man sie nicht zulässt. Und dass sein Sinn für Ästhetik deutlich
anders entwickelt ist, als bei jedem anderen, wissen wir bereits.
A. K. schrieb:> Verschachtelte Aufrufe kann es damit nicht geben,
Bin zwar nicht ganz sicher, was damit gemeint ist, aber, nur
damit es keine Missverständnisse gibt: Unterprogramme können
selbstverständlich ihrerseits andere Unterprogramme aufrufen.
Josef G. schrieb:> Bin zwar nicht ganz sicher, was damit gemeint ist,
Ja, das war etwas undeutlich ausgedrückt. In diesem Fall meine ich einen
Funktionsaufruf als Argument eines Unterprogrammaufrufs. Also sowas wie
call foobar (1, sin(0.5))
statt
temp = sin(0.5)
call foobar (1, temp)
oder bei dir sinngemäss wohl
call sin (0,5, temp)
call foobar (1, temp)
falls du Konstanten als Argumente überhaupt zulässt.
Josef G. schrieb:> Beim Aufrufen werden nach dem Namen des Unterprogramms die Namen> der Parameter aufgelistet. Das Unterprogramm kann die Parameter> lesen und beschreiben, sofern der betreffende Variablentyp das zu-> lässt.
Toll. Und was ist daran jetzt besonders, abgesehen davon, daß man beim
Betrachten des Aufrufs eines "Unterprogrammes" nicht sieht, welche
Parameter verändert werden können (ohne sich das "Unterprogramm" näher
anzusehen)?
Praktisch jede andere Programmiersprache kennt das auch - in Pascal
nennt sich das "call by reference", in C verwendet man Pointer auf die
Argumente, und in C++ kann man das auch machen, oder die dafür
vorgesehenen Referenzen verwenden.
Bei C/C++ und der Verwendung von Pointern kann man auch ohne Betrachtung
der aufgerufenen Funktion (bzw. ihres Prototypen) erkennen, welche der
Parameter verändert werden könnten und welche nicht - wo kein Pointer
übergeben wird, kann auch nichts verändert werden.
Oh, und man hat in all diesen Programmiersprachen auch die Möglichkeit,
einen expliziten Rückgabewert zu verwenden, was z.B. zum Zurückgeben
von Fehlercodes sinnvoll sein kann.
Bei der "ich schreib' hier mal zehn Parameter hin"-Methode muss man
jedes mal erneut vereinbaren, welcher davon ein etwaiger Fehlercode sein
könnte.
Nein, ich vermag keinen einzigen Vorteil zu erkennen.
Es ist oft genug grad andersrum, d.h. es gibt einen gewisse Neigung,
mehrere Returnobjekte zuzulassen, nicht nur eines. Entweder, indem man
Klassenobjekte als Returnwert verwendet (wie in C++), oder indem die
Sprache ganz offizell mehrere Returnobjekte zulässt (wie etwa Go).
Ein klassisches Beispiel dafür ist eine Funktion, die neben dem
eigentlichen Returnwert auch noch mitteilen muss, ob sie überhaupt einen
gültigen Wert produzieren konnte. Damit entsteht ein Paar aus dem Wert
selbst und einem Error-Flag.
Natürlich kann man das auch per Referenz-Parameter implementieren.
Leider bewegt man sich damit allzu leicht von übersichtlicherer
funktionaler Programmierung mit seiteneffektfreien Funktionen weg und
die Programme werden zudem auch länger.
Hinzu kommt, dass Objekte in Registern weit besser aufgehoben sind als
im Speicher, was die Rechenleistung angeht. Übergabe von Werten in
Registern ist daher sehr viel effizienter als die Übergabe von Werten im
Speicher und deren Speicheradressen in Registern. Das gilt
gleichermassen für Parameter wie für Returnobjekte.
Es gibt Programmiersprachen, die Parameter in "in", "out" und "inout"
unterscheiden. Bei "in" und "out" kommt man dem Prinzip nach ganz gut
ohne Speicheradresse aus und "out" Parameter liessen sich auch als
Returnobjekte darstellen.
Ob Grunde bewegt man sich mit dem konsequenten Verzicht auf call by
value also zurück in 50er Jahre, die Zeit der Entstehung von FORTRAN.
Eine Zeit, in der Register sehr aufwändig und daher selten waren.
>möchte ich hiermit nochmal einen Versuch machen,>für meine Programmiersprache zu werben.
die nur auf einer 8-bit CPU funktioniert, die es nicht mal gibt..
na viel glück..
Rufus Τ. F. schrieb:> Nein, ich vermag keinen einzigen Vorteil zu erkennen.
Die Anwendung des Prinzips Minimalismus hat immerhin
den Vorteil, dass die Sprache leichter zu erlernen
wäre, wenn es denn jemand versuchen würde.
Rufus Τ. F. schrieb:> Da ist nichts minimalistisches.> Eine Programmiersprache wie C ist minimalistisch,
Also diese Antwort versteh ich nun wirklich nicht.
Ausgangspunkt waren meine Aussagen:
Josef G. schrieb:> Unterprogramme: Es gibt keine functions mit Rückgabewert,> Es werden ausschließlich Zeiger übergeben.
In meiner Sprache gibt es also nur eine Sorte von Parametern.
In C gibt es mehrere Sorten. Da ist es doch offensichtlich, dass
in dieser Hinsicht meine Sprache minimalistischer ist als C.
nur weil was minimalistisch ist, ist es nicht automatisch einfacher..
Schach Regeln sind sehr einfach.. ist deshalb Schach spielen einfach?
gerade in/out/var/const parameter machen vieles einfacher
gäbs das nicht, müsste man es eben in die doku schreiben..
(nur lesen leider die meisten Compiler die doku nicht, und können somit
auch nichts überprüfen..)
Josef G. schrieb:> Da ist es doch offensichtlich, dass> in dieser Hinsicht meine Sprache minimalistischer ist als C.
Auf den Nutzen bezogen hast du wohl recht.
Hau noch mindestens 10 Jahre drauf. Vor 50 Jahren gab es FORTRAN, Lisp,
Algol, APL, COBOL, BASIC, PL/I, BCPL(*), ... Alle lesbarer. ;-)
*: aka "Before C Programming Language". Für B langts noch nicht ganz.
Der Fairness halber sollte man ASM als Vergleich heranziehen - damit
wurde seinerzeit noch sehr viel gemacht.
Das alles ändert aber nichts an der Lächerlichkeit, ein Projekt wie
dieses hier heutzutage als Ultima Ratio anzupreisen.
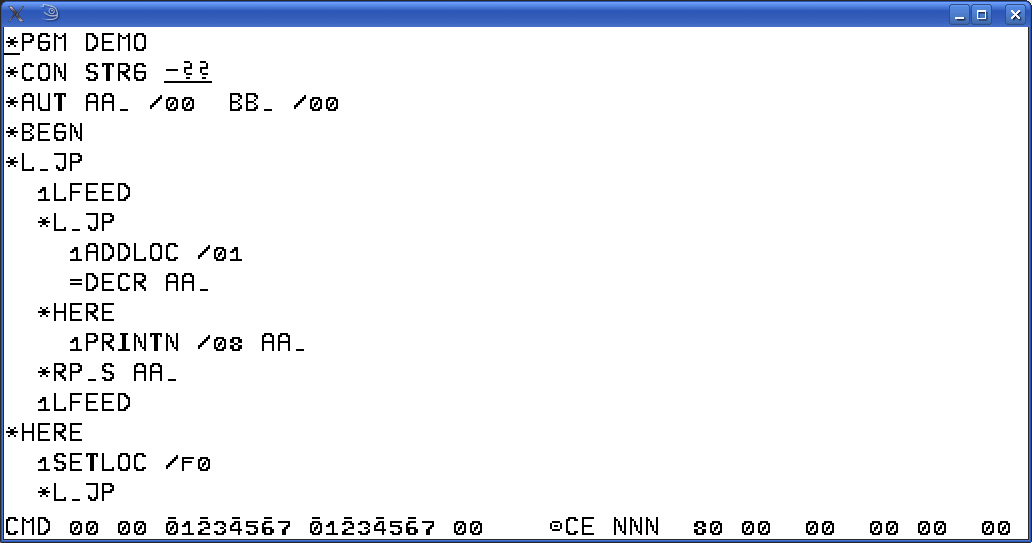
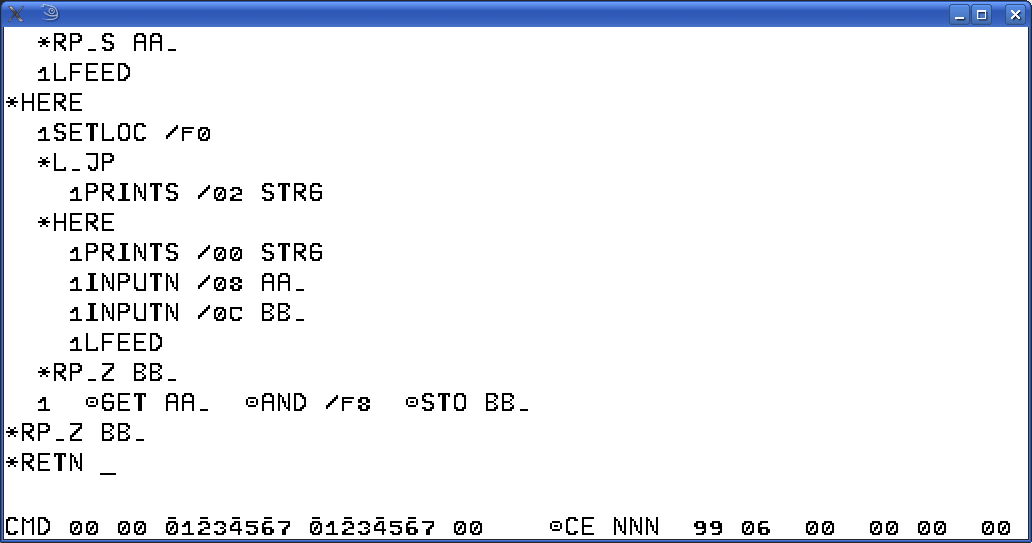
{kind=link}