Hier gibts ja viele Meinungen zu C++, aber wenn man es selber probieren
will, gibt es große Hürden.
Es gibt kein verstehbares Lehrbuch und wenn man sich anderen Code
ansieht, dann ist der riesen groß und unübersichtlich und geht überhaupt
nicht auf MC-spezifische Abläufe ein (IO-Zugriffe, Statemaschine usw.).
Vielleicht kann ja mal ein C++ Guru mir etwas auf die Sprünge helfen.
In C wird ja für jeden Quark eine Funktion benötigt, was nicht besonders
gut lesbar ist.
In C++ könnte man Zuweisungen nehmen, wenn man nur wüßte, wie man das
implementiert.
Z.B. mal ganz einfach das Setzen von Ausgängen und Entprellen von
Eingängen.
Ich möchte gerne folgendes erreichen:
1
LED0=KEY0.state;// an solange Taste gedrückt
2
LED1.toggle=KEY1.press// wechsel bei jeder Drückflanke
3
LED2.off=KEY2.press_short;// kurz drücken - aus
4
LED2.on=KEY2.press_long;// lang drücken - an
Geht sowas in C++ und wie könnte eine Implementierung aussehen?
Besonders interessant wäre die Entprellung portweise parallel und nur
das Auswerten der Tasten einzeln. Also irgendwie, jede Taste ist Teil
der Klasse entprelle_port, die wiederum für mehre 8Bit-Ports verwendet
werden kann. Z.B. 16 Tasten an 2 Ports.
Irgendwie scheinst du merkwürdige Vorstellungen von C++ zu haben.
Deine Beispiel ist doch nonsense.
Grade bei OOP (was man ja meist will wenn man C++ nimmt) hast du eher
mehr Funktionen weil du Datenkapselung via getter/setter machst.
Wenn man PORT/PINs als Template-Parameter übergeben kann:
Evtl. ein Konstrukt wie:
Entpreller<PINA> KEY0;
Entpreller<PINB> KEY1;
die Entpreller-Klasse enthält dann die Counter etc.
Zum Zugriff dann:
if (KEY0.press.BUTTON1) ...
if (KEY1.long_press.BUTTON4) ...
(mit press/long-Press einfach als Bitfields)
Im Timer muss dann
KEY0.update();
KEY1.update();
aufgerufen werden.
Durch inlining sollte fast dasselbe wie in deinem genialen C-Entpreller
herauskommen...
Die Features von C++ sind hauptsächlich zur Strukturierung & Abstraktion
von Daten, Verwaltung von Speicher gedacht. Sie erlauben nicht magisch
eine parallele Verarbeitung, wie du sie durch diese Zeilen
Peter Dannegger schrieb:> LED0 = KEY0.state; // an solange Taste gedrückt> LED1.toggle = KEY1.press // wechsel bei jeder Drückflanke> LED2.off = KEY2.press_short; // kurz drücken - aus> LED2.on = KEY2.press_long; // lang drücken - an
andeutest. Das sieht mehr nach VHDL oder modellbasierter Programmierung
ala Simulink als nach einer imperativen Sprache wie C(++) aus. Sicher,
man könnte Objekte LED0 und KEY0 so anlegen, dass jede dieser
Anweisungen ein Objekt erzeugt das die angedeutete Funktion erfüllt,
sich in eine Liste einträgt und dann von einem Timer-Interrupt o.ä.
verarbeitet wird. Aber parallele deklarative Verarbeitung dieser Art ist
nicht gerade C++' Kernkompetenz, und es ist fraglich ob man das so
will... Was viel eher in die imperative Struktur von C(++) passt wäre
vielleicht so etwas:
1
voidTIM1_IRQ(){
2
LED0.state=KEY0.state;
3
if(KEY1.state)
4
LED1.state=!LED1.state;
5
if(KEY2.pressedTime>=1000)
6
LED2.state=true;
7
elseif(KEY2.pressedTime>=100)
8
LED2.state=false;
9
}
Mark Brandis schrieb:> Nahezu alles, was man in C machen kann, kann man auch in C++> machen.> Naja, so gut wie alles. 99 Prozent.
Aber auch in Brainfuck. Warum verwendet niemand Brainfuck? Es ist
supereinfach zu lernen, verwenden und implementieren.
cyblord ---- schrieb:> Deine Beispiel ist doch nonsense.
Ich denke aber, es wird klar, was es machen soll.
Ich will mir nicht überall merken müssen, welche Led, Taste an welchem
Port hängt und welche Polarität und welche Aktion.
Ich will das einmal und nur an einer einzigen Stelle angeben müssen und
fürderhin kümmert sich C++ darum, das entsprechend aufzulösen.
C kann das ja nicht, da kann ich schreiben:
1
PORTC|=1<<PB7;
und es meckert in keinster Weise.
Wenn meine Aufruf-Syntax falsch ist, dann bitte korrigieren.
Leider nicht.
C++ wird wie C Zeile für Zeile abgearbeitet. Um die dauer des
Tastendrucks festzustellen benötigt man auch hier eine ISR oder
zumindest eine periodische Schleife.
Der größte Vorteil von C++ ist das Daten und Funktionen zusammen als ein
Objekt gespeichert werden. Man spart sich also viele Parameterübergaben
oder globale Variablen. Wenn das ganze dann noch als "static" definiert
ist, dann erzeugt ein aktueller C++ Compiler Code der genau so schnell
ausgeführt wird wie der C Code...
Eine Klasse ist im einfachsten Fall sozusagen eine struct mit Methoden
drinnen (das kann man auch wirklich so verwenden, wenn man möchte).
Jede Variable die dann den Typ diesen Typ hat wird dann einfach Objekt
genannt...
Es gibt natürlich die ganzen netten Sachen von Objektorientierter
Programmierung, wie Vererbung, Polymorphismus usw... Ob man die im
embedded Bereich sinnvoll verwenden kann hängt sehr stark von der
Anwendung ab.
Im allgemeinen kann man aber viel portableren und wiederverwertbaren
Code schreiben wie in C.
Was mit persönlich an C++ im Embedded Bereich sehr gefällt sind die
Generics (bei C++ Templates genannt). Damit kann man einen großteil der
statischen DEFINES in einem typeischen C Programm weg bringen und das
ganze dazu noch kapseln.
z.B. hab ich Filterklassen als Template realisiert denen man bei der
Instantierung nur die Ordnung und die Charakteristik mitgibt. Der vom
Compiler erzeugte Code ist dann exakt genau so schnell wie C code. Der
Vorteil ist das man mit einer Zeile einen neuen Filter hat - ganz ohne
Code Duplication, globale Variablen, Precompiler DEFINES usw... sauber
halt.
Es geht natürlich auch mit C genau so gut. Nur halt umständlicher und
nicht so sauber, aber für nicht C++ affine Programmier halt dafür viel
verständlicher...
Liebe Grüße,
Sepp
Den Syntax welchen du zu errecihen versuchst ist standard C++. Sowas ist
möglich per "property" implementierung und z.B. Teil von der Borland C++
Spracherweiterung. Normales C++ bietet sowas nicht ohne höheren Aufwand.
Hier müsstest du für jeden Member eine subklasse schreiben und den
"=-Operator" überladen. Möglich ist das, schön aber nicht.
Zu lesen in deiner Fragestellung ist ebenfalls, dass dir sowohl
Programmier- als auch Systemkenntnisse fehlen, um mit OOP überhaupt
etwas zu erreichen.
Dann wüsstest du, dass der Syntaktische Zucker eigentlich keinene
Overhead im Code erzeugt und wie dein gewünschter Syntax auch am PC zu
implementieren wäre -> denn der Unterschied == 0.
Peter Dannegger schrieb:> Ich denke aber, es wird klar, was es machen soll.> Ich will mir nicht überall merken müssen, welche Led, Taste an welchem> Port hängt und welche Polarität und welche Aktion.> Ich will das einmal und nur an einer einzigen Stelle angeben müssen und> fürderhin kümmert sich C++ darum, das entsprechend aufzulösen.
dafür macht man sein in paar makros.
sieht mir mir so aus.
#define LED_ROT_PORT PORTD
#define_LED_ROT_PIN PIN1
#define LOD_ROT_INVERT 1
#define TASTER_EIN_PORT PORTD
#define_TASTER_EIN_PIN PIN2
#define TASTER_EIN_INVERT 0
im code kann ich dann über ein paar makros einfach
EIN( LED_ROT );
oder
if ( IS_ON( TASTER_EIN ) ) ..
schreiben. Dafür braucht man doch kein C++.
Peter Dannegger schrieb:> Ich will das einmal und nur an einer einzigen Stelle angeben müssen und> fürderhin kümmert sich C++ darum, das entsprechend aufzulösen.
Na das ist ja was völlig anderes. Das ist kein Problem (Beispiel
anhand STM32F4):
Sepp schrieb:> Um die dauer des> Tastendrucks festzustellen benötigt man auch hier eine ISR
Das ist klar.
Es ging mir auch haupsächlich darum, wie ich in der Mainloop die
Ereignisse auswerten kann und wie ich die Klassen definieren muß.
Z.B. ich definiere eine Klasse LED und ein Klasse KEY und darin alle
Aktionen und Initialisierungen dafür. Die Aktionen benutze ich dann in
der Mainloop.
Schön wäre es noch, wenn die Klasse automatisch den passenden
Interrupthandler aktiviert.
Füge ich eine neue Taste der Klasse KEY hinzu, wird geprüft, ob deren
Port bereits entprellt wird und wenn es ein neuer Port ist, wird der
Code dafür hinzugefügt.
Peter Dannegger schrieb:> Geht sowas in C++ und wie könnte eine Implementierung aussehen?
Gehen wird sowas schon, aber man muß sicher eine Weile darüber
nachdenken, damit es sinnvoll wird.
Für deine Zuweisungen könnte ich mir vorstellen, daß Funktionsobjekte
zugewiesen werden, und die operator=() entsprechend überschrieben
werden.
Die Funktionsobjekte können dann ggf. mit Parametern wie Frequenzen,
Parameter zum Entprellen etc. manipuliert werden.
(Ein paar Konstanten zu definieren werden dafür nicht reichen, weil du
offenbar erreichen willst, daß nach der Zuweisung noch irgendwas im
Hintergrund weiterläuft).
Für einen kleinen AVR ist das vielleicht etwas viel Code, aber für einen
dickeren atmega oder einen ARM sollte das machbar sein.
Wird dann sicher nicht jeden Puristen überzeugen (siehe den paralellen
Thread mit dem C++-Geprügel), aber könnte nett aussehen.
Wenn es dich dann noch juckt, könnte ich übernächstes WE ein Grundgerüst
als Vorschlag machen - macht bestimmt Spaß.
FH-Student schrieb:> cyblord ---- schrieb:>> via getter/setter machst>> Alt aber nach wie vor aktuell:>> http://www.javaworld.com/article/2073723/core-java/why-getter-and-setter-methods-are-evil.html
Der Tag mag kommen an dem FH-Studenten mir Nachhilfe in
Programmierkonzepten erteilen, aber heute ist das sicher noch nicht ;-)
Die Bedenken sind in der Tat alt und wohl bekannt. Und auch korrekt.
Trotzdem erhält man im OOP Umfeld Daten mittels Funktionen und übergibt
Daten mittels Funktionen.(Das man dies nicht durch sture getter/setter
sondern auf höherer Abstraktionsebene machen sollte, das stimmt
natürlich).
Was ich damit eigentlich nur sagen wollte, dass eben bei OOP eher MEHR
Funktionsaufrufe im Code stehen als bei reinem C. Peter meinte ja das
Gegenteil.
Auschnitt aus der Luna Beschreibung:
"Luna ... bietet im Gegensatz zu einfacheren Basic-Sprachen, wie z.Bsp.
BASCOM, wesentlich komplexere Möglichkeiten auf technischer Augenhöhe
mit Pascal, Modula und C/C++."
http://avr.myluna.de/doku.php?id=de:about
Vielleicht ist das ja was für den TO?
Ich meine, die Syntax "name.action" schon recht häufig gesehen zu haben.
Wichtiger ist mir aber, daß ich Schreibarbeit und damit
Fehlerträchtigkeit spare.
In plain C muß ich zu jeder LED auch das Richtungsbit definieren, bzw.
zu jeder Taste das Pullup-Bit.
Daher dachte ich, wenn ich eine Klasse definiere und darin die LED als
Member, wird für jedes Member automatisch die Initialisierung mit
aufgerufen.
Und wenn ich im Main eine Member-Aktion mache, wird der entsprechende
Code der Klasse ausgeführt.
Damit sollte exakt der gleiche Code entstehen, wie in plain C, also kein
Mehrverbrauch.
cyblord ---- schrieb:> Was ich damit eigentlich nur sagen wollte, dass eben bei OOP eher MEHR> Funktionsaufrufe im Code stehen als bei reinem C.
Im Quelltext lassen sich aber viele Funktionsaufrufe verstecken.
Copy-Construktoren, conversion-operatoren, andere overloads,
destruktoren, ...
Peter Dannegger schrieb:> In plain C muß ich zu jeder LED auch das Richtungsbit definieren, bzw.> zu jeder Taste das Pullup-Bit.> Daher dachte ich, wenn ich eine Klasse definiere und darin die LED als> Member, wird für jedes Member automatisch die Initialisierung mit> aufgerufen.
Woher soll die Klasse denn wissen, wie du es eingestellt haben willst,
wenn du das nicht explizit hinschreibst?
@ Peter Dannegger (peda)
>Ich meine, die Syntax "name.action" schon recht häufig gesehen zu haben.>Wichtiger ist mir aber, daß ich Schreibarbeit und damit>Fehlerträchtigkeit spare.
Vielleicht ist dann Arduino dar Richtige für dich?
SCNR
Falk
Ich denke hier versteht gerade niemand niemanden. Ich kann das Ziel im
OP noch nicht so ganz deuten und vor allem kommt es mir so vor, dass in
den Folgeposts was ganz anderes gemeint ist. Hier besteht
Aufkärungsbedarf!
Rolf Magnus schrieb:> Woher soll die Klasse denn wissen, wie du es eingestellt haben willst,> wenn du das nicht explizit hinschreibst?
Ich hatte gedacht, daß eine Klasse Code enthalten kann, der dann für
jedes Member aufgerufen wird.
Ich habe also ein Objekt vom Typ LED und dafür definiere ich die
Initialisierungen und Aktionen in der Klasse LED als Code.
BastiDerBastler schrieb:> Ich kann das Ziel im> OP noch nicht so ganz deuten
Ich möchte z.B. LEDs und Tasten als Objekte behandeln und dafür nur
bestimmte Aktionen zulassen bzw. vorbelegen.
Es kann sein, daß OOP primär was völlig anderes im Sinn hat, aber ich
hatte den Eindruck, daß es mit C++ möglich wäre.
Peter Dannegger schrieb:> Z.B. ich definiere eine Klasse LED und ein Klasse KEY und darin alle> Aktionen und Initialisierungen dafür.
Das kannst du natürlich schon
1
classLED
2
{
3
public:
4
LED(volatileuint8_t*Port,uint8_tBit)
5
:Port_(Port),Bit_(Bit)
6
{DDR_From_Port(Port)|=(1<<Bit_);}
7
8
voidOn(){Port_&=~(1<<Bit_);}
9
voidOff(){Port_|=(1<<Bit_);}
10
11
private:
12
volatileuint8_t*constPort_;
13
constuint8_tBit_;
14
};
15
16
17
intmain()
18
{
19
LEDErrorLed(PORTB,PB0);
20
21
ErrorLed.On();
22
ErrorLed.Off();
23
}
Mit den Tasten ist das dann nicht mehr ganz so einfach. Da müsste es
wohl einen übergeordneten Koordinator geben, der sich um den Timer bzw.
die ISR kümmert und die KEY Objekte da einschleust.
> Füge ich eine neue Taste der Klasse KEY hinzu
Du hast da eine Konzeptdiskrepanz. Eine Klasse ist der Bauplan. Die KEY
Klasse beschreibt daher eine Taste. Erst eine übergeordnete Klasse,
nennen wir sie mal Keyboard, hat dann die Fähigkeit mehere Keys zu
verwalten. Klassen willst du nicht wirklich ändern, nur weil du in
deiner Anwendung mehrere Objekte davon hast.
Hallo Peter,
Peter Dannegger schrieb:> Daher dachte ich, wenn ich eine Klasse definiere und darin die LED als> Member, wird für jedes Member automatisch die Initialisierung mit> aufgerufen.> Und wenn ich im Main eine Member-Aktion mache, wird der entsprechende> Code der Klasse ausgeführt.> Damit sollte exakt der gleiche Code entstehen, wie in plain C, also kein> Mehrverbrauch.
das macht man auch so. Etwas Mehrverbrauch entsteht je nach Compiler.
(schon alleine, da jedes Bit jeder LED einzeln initialisiert wird)
In C++ würde ich das mit Templates umsetzen. Jede LED bekommt damit eine
eigene Klasse. Dann braucht man keine Variable die Pin und Port
speichert und entsprechend viel RAM belegt.
Led<PortA, 7> Led_gruen;
Led_gruen.An(); // oder mit Operatorüberladung Led_gruen = true;
Die Template Parameter verhalten sich ähnlich wie ein Macro, werden also
beim Compilieren in den Quellcode eingefügt. Den Rest macht die
Optimierung.
Wenn du jetzt einen ganzen Port entprellen möchtest und einzeln
auslesen:
Male ein Diagramm, was für Objekte du hast und was diese tun sollen. Das
ist OOP und hat nichts mit C++ zu tun. C++ macht es dir nur einfacher ;)
Grüße Felix
FelixW schrieb:> In C++ würde ich das mit Templates umsetzen. Jede LED bekommt damit eine> eigene Klasse. Dann braucht man keine Variable die Pin und Port> speichert und entsprechend viel RAM belegt.
Wenn man alles const macht, kann man darauf spekulieren, dass das alles
wieder wegoptimiert wird.
Ganz im Gegenteil würde ich als einen der Bausteine eines C++ Frameworks
ein Template ansehen, welches die Kombination Port+Pin kapselt. Das wäre
so ziemlich die unterste Ebene und wäre recht nützlich um genau diese
Einheit an andere Klassen weiterzugeben, wie zb ein LCD, dem man
mitteilt auf welchen 'Anschlüssen' seine Steuerleitungen sitzen. So
wenig ich mich mit der Arduino Philosophie der durchnummerierten
Anschlüsse auch anfreunden kann, eines muss man doch zugeben: diese
Nummerierung vereinfacht vieles.
Peter Dannegger schrieb:>> class LED>> Danke, das sieht schon sehr gut aus.> Wo gibt es das DDR_From_Port()?
Das hab ich gerade eben erst erfunden :-)
Und es ist das leidige Problem, zuverlässig aus der Portangabe die DDR
Adresse zu ermitteln.
Wie ich an Felix auch schon geschrieben habe. Ich denke ein wirklich
nicht unwesentlicher Punkt wäre es, für diese Low-Level Sachen ein gut
aufgebautes Framework zu haben, welches diese ganzen Port, Pin, DDR
Sachen sauber kapselt OHNE dabei Codemässig stark aufzutragen. Gedanken
hab ich mir dazu allerdings noch nie gemacht, so dass ich da auch nichts
aus dem Ärmel schütteln kann.
Karl Heinz schrieb:> Ganz im Gegenteil würde ich als einen der Bausteine eines C++ Frameworks> ein Template ansehen, welches die Kombination Port+Pin kapselt.rechtgeb
Aber ein Framework ist Schritt n+1 ... Peter erst einmal anfangen
lassen.
@Karl Heinz,
das mit der Wegoptimierung der const Variablen habe ich noch nicht
ausprobiert, spekulieren will ich nicht. Ich verstehe davon zu wenig
wie/was der Compiler optimieren kann.
Grüße Felix
Karl Heinz schrieb:> Das hab ich gerade eben erst erfunden :-)
Vielleicht sollte man nur A,B,C usw. übergeben und dann PORT##A, DDR##A,
PIN##A draus basteln.
FelixW schrieb:> Karl Heinz schrieb:>> Ganz im Gegenteil würde ich als einen der Bausteine eines C++ Frameworks>> ein Template ansehen, welches die Kombination Port+Pin kapselt.>> *rechtgeb*>> Aber ein Framework ist Schritt n+1 ...
Ja, ok. Ersetz Framework durch einen anderen Begriff. Der passt wirklich
nicht besonders.
Man bräuchte eine einfache Möglichkeit einen physikalischen Pin in
seinen Eigenschaften zu beschreiben. Welches Port Register? Welches
DDR-Register? Welches Bit?
Klar kann man einem Pin Template zb das DDR Register mitgeben. Aber das
find ich persönlich recht unelegant. Im besten Fall sag ich dem Teil
einfach nur "Am Port B, und dort das Bit x" und damit muss bereits alles
klar sein.
Edit:
Ich würde das gerne So benutzen können
1
intmain()
2
Pin<PortB,3>LedPin;
3
LEDErrorLed(LedPin);
oder dann natürlich auch
1
intmain()
2
{
3
LEDErrorLed(Pin<PortB,3>);
wird klar, wo ich gerne hin möchte?
Mir gehts momentan nur darum, der LED zu beschreiben, wo ihr Anschluss
liegt. Und in dieser Beschreibung soll alles enthalten sein, so dass ich
die Pin Klasse auch um das korrekte DDR Register befragen kann.
Hallo Peter,
ich bin mir nicht ganz sicher, ob ich Dich richtig verstehe, aber ich
meine, Du hast da ein Verständnisproblem:
- Du könntest eine Klasse led_t anlegen.
1
classlet_t{...};
- Und könntest eine Instanz der Klasse anlegen.
1
let_tLED4;// Hängt an Port2.6
Aber:
Um den Port2.6 zu bedienen, muss in die Instanz (!!!) "LED4" das
Wissen hinein, dass diese LED an Port2.6 hängt. Dieses Wissen kannst Du
nicht von vornherein in "led_t" hineinpacken, denn sonst würde "led_t"
ja nur für den Port2.6 funktionieren.
Dies wäre z.B. so möglich:
>> wird klar, wo ich gerne hin möchte?> Mir gehts momentan nur darum, der LED zu beschreiben, wo ihr Anschluss> liegt. Und in dieser Beschreibung soll alles enthalten sein, so dass ich> die Pin Klasse auch um das korrekte DDR Register befragen kann.
Dann könnte die LED Klasse wiederrum so aussehen
1
classLED
2
{
3
public;
4
LED(constPin&pin)
5
:pin_(pin)
6
{pin_.DDr()|=pin_.bitmask()}
7
8
voidOn(){pin_.port()|=pin_.bitmask();}
9
voidOff(){pin_.port()&=~pin.bitmask();}
10
11
private:
12
constPinpin_;
13
};
oder überhaupt gleich das Setzen bzw. Löschen in das Pin Template
verfrachten
1
classLED
2
{
3
public;
4
LED(constPin&pin)
5
:pin_(pin)
6
{pin_.toOutput();}
7
8
voidOn(){pin_.setZero();}
9
voidOff(){pin_.setOne();}
10
11
private:
12
constPinpin_;
13
};
insbesonders letzteres sieht doch schon recht ordentlich aus.
Edit: hab noch ein paar const bzw. die Referenz im Argument nachgetragen
Auweia.. Angriff der C++ Fetischisten Teil II. Da kann ich einfach nicht
anders als meinen Senf dazu geben.
Also erst einmal zur Entzauberung: C++ und OPP ist mit Sicherheit nicht
schwerer als C oder gar Assembler zu programmieren. Im Gegenteil. Aber
offensichtlich diesem Mythos erlegen glauben einige dieses
Sprachkonstruckt nun für alles verwenden zu müssen ob’s nun Sinn macht,
oder nicht. Ist ja im Prinzip auch legitim. Am Ende kommt eh Assembler
bzw. Maschinencode heraus. Die einen können den selber Programmieren und
beeinflussen wie er was macht, die anderen schreiben lieber vorher
Romane und überlassen die Arbeit letzten Endes denen die den Compiler
programmiert haben.
Die Verwendung von C++ auf kleinen µC ist meiner Meinung nach aber
Nonsens –und ich schreibe Nonsens und nicht Verbrechen- weil es
keinerlei Vorteil bringt. Es sei man glaubt die Mär vom kompakteren und
schnelleren Code. Dies kann aber eigentlich nur ein Grenzdebiler
glauben. Hinzu kommt bei den ausgewiesenen Hochsprachen mit starker
Abstrahierung dass der ganze Misst nicht mehr vernünftig zu debuggen
ist. Und das muss jeder der hardwarenah programmiert eben tun und damit
meine ich nicht den eigenen Prozessor im Focus habend, sondern die immer
wieder neue und unbekannte periphere HW mit der ein µC Entwickler zu tun
hat und der vor der Aufgabe steht anhand eines Datenblattes seinen Code
anzupassen.
Ich Entwickle seit über 10 Jahren für OSX und iOS und davor für Windows.
Für solche Systeme führt fast kein Weg an C++ bzw. den
Weiterentwicklungen C“#“ und „Objectice C“ vorbei. Hier stellt quasi OOP
mit all seinen Vorteilen und den >>bereits vorhandenen<< mächtigen und
kaum zu überschauenden Klassen und Schnittstellen die einzige
Möglichkeit dar überhaupt noch mit einem so komplexen System zu
kommunizieren und dessen Funktionen zu verwenden. Dafür ist diese
Sprache das einzige Mittel.
Gäbe es für alle Mikrocontroller und jede aktuelle mögliche periphere
Hardware frei verfügbare und funktionierende Klassen und einem Compiler
der C++ fehlerfrei unterstützt zuzüglich einer funktionierenden
Möglichkeit adäquat zu debuggen dann sähe die Sache für den einen oder
anderen Fall möglicherweise etwas anders aus. Denn dann wäre wie bei
den „Hochbetriebssystemen“, OOP eine Erleichterung und würde seine
eigentliche Stärke ausspielen. Das tut es aber nicht und wird es
vermutlich nie geben. Aus vielen verschiedenen und offensichtlichen
Gründen. Und unter den gegebenen Voraussetzungen ist C++ ein Hemmschuh.
Weil das erstellen, Testen und optimieren der Klassen erst einmal
einfach wahnsinnig viel Mehrarbeit ist.
Kleine Ausnahme: Die kleine Auswahl an „Arduino Kontrollern für die
einige pfiffige ein paar nützliche Kassen geschrieben haben, damit auch
Kid’s und Künstler programmieren können. Sketch LED Blinken: 1KB, Sketch
ADC einlesen und UART ausgeben 4KB, weiter auf die Performance muss ich
an dieser stelle wohl kaum eingehen.
Wer also zur Selbstbestätigung seiner intellektuellen Omnipotenz
trotzdem gerne C++ benutzt um kleine µC zu programmieren, dem wünsche
ich einfach viel Freude an seiner Arbeit oder wie in den meisten Fällen
hier an seinem Hobby. Es reicht ja auch oft einfach den C++ Compiler zu
benutzen und trotzdem plain C zu schreiben. Mutti merkt’s nicht.
Thomas Holmes schrieb:> Da kann ich einfach nicht> anders als meinen Senf dazu geben.
Danke, wäre aber nicht nötig gewesen - es hilft leider nicht, die Frage
zu beantworten.
Peter Dannegger ist wohl alt genug, zu wissen warum er seine Frage
stellt.
Da kann man doch wirklich nicht meckern!
Edit:
Für alle Nörgler: Natürlich bleibt das nicht so. Die einzelnen Klassen
kommen natürlich in ihre Header Files, etc.
Im Endeffekt schreibt man dann nur
Peter Dannegger schrieb:> Geht sowas in C++ und wie könnte eine Implementierung aussehen?
Ich vermute, Du bist definitiv auf C++ festgelegt?
Ansonsten könnte man - völlig unabhängig von der
Implementierungssrache - gewisse Anleihen bei der
SPS-Technik aufnehmen.
Ich denke, man muss PeDa nicht wirklich in Dingen Softwaretechniken
beraten. Der hat mehr als genug auf dem Kasten, um das selbst
einschätzen zu können.
Wenn PeDa nach C++ und seinen Möglichkeiten fragt, dann nur aus einem
Grund: weil er genau wie wir alle in der Situation ist, dass es
bestimmte Fehler in der AVR Programmierung gibt, die einfach nur lästig
sind. Die Kombination aus Register und zugehörigem Bit für eine
bestimmte Funktionalität ist einfach eine fehleranfällige Sache. Je
weiter man die aus der Anwendungsprogrammierung rauskriegt, umso besser.
Auch ist das zusammenkopieren von Codeschnipseln in einem neuen Projekt
eine lästige Arbeit. Auch wenn die PeDa Entprellung in 5 Minuten
eingebaut ist, so ist es doch eine manuelle Arbeit und als solche
fehleranfällig.
PeDa geht es sicher nicht um Code-Techniken sondern darum, wie er sich
in der Entwicklung das Leben leichter machen kann, indem er die
Programmiersprache soweit ausreizt, dass sie ihm Fehlerfälle nach
Möglichkeit abfangen kann. Und sei es nur, dass er die falsche Pinnummer
an eine Funktion übergibt.
Karl Heinz schrieb:> Ich denke, man muss PeDa nicht wirklich in Dingen> Softwaretechniken> beraten. Der hat mehr als genug auf dem Kasten, um das selbst> einschätzen zu können.> Wenn PeDa nach C++ und seinen Möglichkeiten fragt, dann nur aus einem> Grund: weil er genau wie wir alle in der Situation ist, dass es> bestimmte Fehler in der AVR Programmierung gibt, die einfach nur lästig> sind. Die Kombination aus Register und zugehörigem Bit für eine> bestimmte Funktionalität ist einfach eine fehleranfällige Sache. Je> weiter man die aus der Anwendungsprogrammierung rauskriegt, umso besser.> Auch ist das zusammenkopieren von Codeschnipseln in einem neuen Projekt> eine lästige Arbeit. Auch wenn die PeDa Entprellung in 5 Minuten> eingebaut ist, so ist es doch eine manuelle Arbeit und als solche> fehleranfällig.> PeDa geht es sicher nicht um Code-Techniken sondern darum, wie er sich> in der Entwicklung das Leben leichter machen kann, indem er die> Programmiersprache soweit ausreizt, dass sie ihm Fehlerfälle nach> Möglichkeit abfangen kann. Und sei es nur, dass er die falsche Pinnummer> an eine Funktion übergibt.kopfkratz
Also wenn er seine Entprellung in C++ umsetzen möchte sollte er das
ganze nicht nur kapseln sondern auch z.B. mit überladenen Operatoren
arbeiten und für den Fehlerfall eine Exception werfen.
Um die Deklaration der Hardware kommt man damit allerdings nicht herum.
Da wäre ein Ansatz sich in einem .h File genormte Spezifikationen zu
setzen, so wie das ja im AVR-GCC auch gemacht wird.
Die Kardinalfrage ist halt ob es einen Sinn ergibt bei kleinen µCs mit
wenig Ressourcen C++ einzusetzen und sich damit einige Byte oder
Kilobyte an "Overhead" einzuhandeln.
Von der teilweisen schlechten Umsetzung der jeweiligen Compiler mal
abgesehen ...
Karl Heinz schrieb:>> Wo gibt es das DDR_From_Port()?>> Das hab ich gerade eben erst erfunden :-)> Und es ist das leidige Problem, zuverlässig aus der Portangabe die DDR> Adresse zu ermitteln.
Gab es da nicht von Atmel zu den AVR-Typen xml-Files, die die
beschreiben, aus denen dann die Include-Files für C und Assembler
generiert werden? Das könnte man doch für C++ genauso machen.
Thomas Holmes (Firma: CIA) (apostel13) schrieb:
>Kleine Ausnahme: Die kleine Auswahl an „Arduino Kontrollern für die>einige pfiffige ein paar nützliche Kassen geschrieben haben, damit auch>Kid’s und Künstler programmieren können. Sketch LED Blinken: 1KB, Sketch>ADC einlesen und UART ausgeben 4KB, weiter auf die Performance muss ich>an dieser stelle wohl kaum eingehen.
Na dann guck Dir mal diese Lib an
http://sensorium.github.io/Mozzi/
mir scheint die Realisierung in C++ ganz nützlich. Performant ist es auf
jeden Fall programmiert. Auiosignalerzeugung auf einem 8Bit Controller
ist nicht so einfach.
Klaus Wachtler schrieb:> Peter Dannegger ist wohl alt genug, zu wissen warum er seine Frage> stellt.
An Rande:
Seine Frage im übrigen hat mich sehr erfreut. Zum einen weil sie etwas
über C++ aussagt und zum anderen natürlich weil es bald auch endlich
eine Endprellungsversion in C++ gibt, nachdem diese in Assembler und C
ja bereits schon jedem zur Verfügung steht.
Wobei es das eigentlich schon gibt. Die Arduinogemeinde hat etliche
Button Klassen hervorgebracht. Eineige mit und einige ohne Entprellung.
Karl Heinz schrieb:> Ich denke, man muss PeDa nicht wirklich in Dingen Softwaretechniken> beraten. Der hat mehr als genug auf dem Kasten, um das selbst> einschätzen zu können.> Wenn PeDa nach C++ und seinen Möglichkeiten fragt, dann nur aus einem> Grund:
Offensichtlich hat er sogar einen Pressesprecher. Alle Achtung!
:-)
Heiliger Bimbam schrieb:> Ist Euch die Programmierung in den gängigen Sprachen noch nicht> kompliziert genug?
Karl Heinz hat das ganz richtig erkannt, es geht mir vorrangig darum,
das Programmieren einfacher und sicherer zu machen.
Z.B. stört mich auch beim plain C, daß es keine Typprüfung für Enums
gibt. Man kann ganz leicht ein Enum in der falschen Statemaschine
verwenden und der Compiler lacht sich ins Fäustchen.
Und wie es aussieht, erzeugt C++ keinen Overhead, wenn die Argumente
schon zur Compilezeit bekannt sind.
Sind sie es nicht, dann hat man auch unter plain C mit Macros oder
Inlinefunktionen den Overhead.
Und C++ ist ja schon im AVR-GCC includiert, man braucht also an der
Programmierumgebung nichts zu ändern. Einfach nur *.c nach *.C
umbenennen.
Karl Heinz schrieb:> Ich werd verrückt.> Ich hab mal einfach was zusammengebraut.> Siehe Cpp-File.
Wow. Das schaut wirklich so aus, als könnte man auf die Weise ein
"Arduino in Gut" basteln.
Für eine effiziente LCD-Lib bräuchte man als Grundlage noch ein
"Multi-Bit-GPIO" für den Datenbus mit integrierter Maskierung, und ggfs
__builtin_avr_insert_bits zum Umsortieren der Datenleitungen.
Dann ein paar ähnliche (aber umfangreichere) Konstrukte für TWI, SPI,
UART usw.
Für Timer (eine der ganz großen Arduino-Schwachstellen IMHO) fällt mir
grad keine vernünftige Lösung ohne Virtuelle Methoden etc. ein. Evtl
kriegt man mit Templates was gebastelt?
Für Tastenentprellung könnte vmtl. das atomic/locking ein Problem
werden?
Karl Heinz schrieb:> Ich hab mal einfach was zusammengebraut.
Ich hab' mal meine port.h angehängt. Verwendet wird's ungefähr so:
1
#include"port.h"
2
3
typedefPin<PortB,PB0>PinLED;
4
typedefPin<PortD,PD3>PinTaste;
5
6
intmain()
7
{
8
PinTaste::SetPullUp();
9
if(PinTaste::IsSet())
10
PinLED::Set();
11
}
Nachteil meiner Implementierung: Sie verwendet reinterpret_cast<>, um
von der Port-Adresse eine Integer-Konstante für ein Template-Argument zu
machen, was der GCC nur gnadenhalber als Konstante interpretiert; streng
genommen ist es nicht C++-konform.
Ich habe davor auch mit deiner Variante gespielt, da habe ich aber
attribute((force_inline)) benötigt, um GCC das Inlinen schmackhaft zu
machen.
Könnte der unterschiedliche Datentyp durch das Template nicht evtl zum
Problem werden?
Wenn ich z.B an meine LCD Klasse die Pins als Objekte übergebe, wie
könnte man das dann einheitlich definieren?
Interface?
tictactoe schrieb:> Ich habe davor auch mit deiner Variante gespielt, da habe ich aber> attribute((force_inline)) benötigt, um GCC das Inlinen schmackhaft zu> machen.
Das was mich am allermeisten verblüfft hat. Ich hatte eigentlich damit
gerechnet, dass ich da noch ein paar const mit einbauen müsste.
Zumindest hatte ich damit gerechnet, in der Hauptschleife irgendeine
in-or-out Sequenz zu sehen. Das da direkt ein sbi bzw. cbi auftaucht,
damit hab ich nicht gerechnet.
Aber in deinem Header File hab ich mir noch ein paar andere Dinge
abgeschaut, bei denen ich mir auf die Stirne klopfe und mir denke: Mann,
so simpel und ich komm nicht drauf.
> Für eine effiziente LCD-Lib bräuchte man als Grundlage noch ein> "Multi-Bit-GPIO" für den Datenbus mit integrierter Maskierung,> und ggfs __builtin_avr_insert_bits zum Umsortieren der Datenleitungen
Ich hatte in Gedanken schon mit einer Nibble Klasse gespielt. Aber noch
ist mir nicht klar, wie ich die Fälle "Alle 4 Leitungen schön
regelmässig angeordnet" versus "komplettes Durcheinander" im Code so
trennen kann (je nach Konstruktor Aufruf), dass dann nur der Code Teil
übrig bleibt, der wirklich gebraucht wird. P-Fleury hat zwar eine Lösung
in Form einer #ifdef Origie, aber so richtig happy bin ich damit nicht.
Das müsste auch eleganter gehen.
C+++ schrieb:> Für Timer (eine der ganz großen Arduino-Schwachstellen IMHO) fällt mir> grad keine vernünftige Lösung ohne Virtuelle Methoden etc. ein. Evtl> kriegt man mit Templates was gebastelt?
Da hab ich auch noch keine Idee dazu. Mit virtuellen Funktionen könnt
ich (für mich) sogar leben. Da bin ich nicht mehr der Takt-Zähler.
Templates, denke ich, werden dir da nicht helfen. Denn Timer leben
davon, dass ich Funktionalität in die ISR einbringen kann. Das können ja
auch mehrere Funktionale Einheiten sein. Gleichzeitig in der ISR
entprellen und eine Uhr treiben, wobei Entpreller und Uhr
unterschiedliche Klassen sind - ich seh da keinen anderen Ausweg als
virtuelle Funktionen.
Nop schrieb:> Könnte der unterschiedliche Datentyp durch das Template nicht evtl zum> Problem werden?> Wenn ich z.B an meine LCD Klasse die Pins als Objekte übergebe, wie> könnte man das dann einheitlich definieren?> Interface?
Du definierst deine Klasse als Template:
template<class CLOCK_PIN, class DATA_PIN>
class LCD { ... };
Eine Klasse macht man sich ja, weil man irgendwelchen State behalten
will. In der LCD-Klasse wäre z.B. eine Cursor-Position als State
geeignet. Aber die Pins sind kein State: Die werden sich in deiner
Anwendung nie nicht ändern und sind deshalb als (konstante)
Template-Argumente geeignet.
tictactoe schrieb:> Nop schrieb:>> Könnte der unterschiedliche Datentyp durch das Template nicht evtl zum>> Problem werden?>> Wenn ich z.B an meine LCD Klasse die Pins als Objekte übergebe, wie>> könnte man das dann einheitlich definieren?>> Interface?>> Du definierst deine Klasse als Template:>> template<class CLOCK_PIN, class DATA_PIN>> class LCD { ... };
Ich seh schon.
Ich muss auf meine alten Tage doch noch lernen mit Templates umzugehen.
Bisher hab ich mich ja erfolgreich davor gedrückt.
Hm, ich sehe schon( :-) )... die Template Geschichte reicht sich dann
immer weiter hoch.
Aber für die Nibbel Geschichte von K.H. ist ja ein Template optimal.
Warum tut man sich das denn eigentlich an? Warum erdenkt man sich
kompliziert zu lesende C++ Gebilde für etwas was andere Sprachen viel
einfacher und damit im Lernaufwand schneller lösen können? Warum nicht
gleich mit einer speziell zugeschnittenen Sprache wie hier
http://avr.myluna.de/doku.php?id=de:features
sich genau den Teil der Objektorientiertheit herauspicken, den es auch
wirklich braucht?
Wozu muss man die Dinge nur immer unnötig verkomplizieren?
Verkomplizierung bringt neue Fehleranfälligkeit durch
Verständnisprobleme bei unnötig komplizierten Ausdrücken.
Warum also macht man das? Um sich anschließend selbst zu beweihräuchern?
ICH kann C++ SOGAR auf MC und DU dümpelst mit deiner "schlichten Sprache
für JEDERMANN" nur im allgemeinen Fahrwasser? Ich bin "die Elite", DU
hingegen bist "der Depp", der nur das kann, was jeder andere gut lernen
und damit umsetzen kann?
Wo ist der wirkliche MEHRWERT? Ist das Endergebnis wirklich besser?
Lohnt der Aufwand wirklich?
Karl Heinz schrieb:> Templates, denke ich, werden dir da nicht helfen. Denn Timer leben> davon, dass ich Funktionalität in die ISR einbringen kann. Das können ja> auch mehrere Funktionale Einheiten sein. Gleichzeitig in der ISR> entprellen und eine Uhr treiben, wobei Entpreller und Uhr> unterschiedliche Klassen sind - ich seh da keinen anderen Ausweg als> virtuelle Funktionen.
Wie machst du dem Interrupt-Handler eine variable Anzahl von Clienten
bekannt? Hmm... Halt! Variable Anzahl? Die gibt's bestimmt nicht, denn
du hast nur eine konstante Anzahl von Tastern und Uhren an deinem
Controller hängen.
Dann können wir also z.B. einen Array mit Pointern auf die Clienten
anlegen, damit wir die virtuelle Handler-Funktione aufrufen können.
Vielleicht so:
1
staticconstOVF_Handler*OVF_clients[]={
2
&uhr,
3
&taste1,
4
&taste2
5
};
6
ISR(TIMER0_OVF_vect){
7
for(autoclient:OVF_clients)
8
client->OVF_vect();
9
}
Aber das kriegt man auch mit Template-Metaprogramming hin (Stichwort
Parameter Packs). (Wie genau, müsste ich mir erst überlegen -- bin noch
nicht so geübt darin.) Sieht auf der User-Seite dann ungefähr so aus:
clients();// operator(), ruft OVF_vect() von den Clients mittels Meta-Programming-"Schleife" auf
4
}
Und schon sind wir die Pointer los, und OVF_vect() in den Clients
braucht nicht mehr virtuell sein; die Clients müssen nicht einmal eine
gemeinsame Basisklasse haben, solange sie eine Funktion OVF_vect()
implementieren.
Thomas Holmes schrieb:> Also erst einmal zur Entzauberung: C++ und OPP ist mit Sicherheit nicht> schwerer als C oder gar Assembler zu programmieren. Im Gegenteil.
So? Ich denke, schlechter Code ist schnell geschrieben, gerade bei der
Komplexität, die C++ bietet. Gerade durch die Bandbreite an Stilmitteln
wird's doch kompliziert — angefangen von der saumäßig lahmen RTTI, über
die reine Behandlung statisch typisierter Objekte bis hin zur
effizienten, aber gruselig lesbaren, template-Ebene: man sollte schon
wissen, was man tut. Was Karlheinz und Peter hier diskutieren ist die
Verwendung der Sprache für effizientest möglichen Code, der trotzdem die
Grundlage für halbwegs objektorientierte Ansätze sein kann. Gerade auch
durch Metaprogrammierung mit templates sollte einiges drin sein.
Die Implementierung von Karlheinz ist super: sie erzeugt relativ
selbsterklärenden und gut lesbaren Code und ist effizient.
> Die Verwendung von C++ auf kleinen µC ist meiner Meinung nach aber> Nonsens –und ich schreibe Nonsens und nicht Verbrechen- weil es> keinerlei Vorteil bringt.
Für wen bringt es keine Vorteile? So üblen Code produzieren die Compiler
gar nicht - auf kleinen ARMs würde ich überhaupt keinen Asm mehr
anfassen, noch nicht mal für NEON der Cortexe oder so, sondern pauschal
nicht. Und auf AVR — wenn es eine libC++ gibt, die Arduino-like Dinge
kapselt, dann halte ich es mit Don Knuth, der vor vorschnellen
Optimierungen warnt. Man kann auch mit C Grütze schreiben und
softwaretechnischen Unsinn, der einzeln effektiv, aber im Gesamtsystem
uneffizient ist.
> Es sei man glaubt die Mär vom kompakteren und> schnelleren Code. Dies kann aber eigentlich nur ein Grenzdebiler> glauben. Hinzu kommt bei den ausgewiesenen Hochsprachen mit starker> Abstrahierung dass der ganze Misst nicht mehr vernünftig zu debuggen> ist.
Persönlich bin ich ein großer Fan von Abstraktion, eben weil sie
Portabilität bzw. Testbarkeit von Einzelkomponenten ermöglicht und somit
Debugging eigentlich im Vorfeld vermeiden kann. Natürlich werden auch
Fehler versteckt, das liegt in der Natur der Sache. Abstraktion lässt
aber Optionen offen: nämlich Komponenten zu bauen, die z.B. besonders
performant (z.B. Karlheinz Code-Demo) oder auch gut wiederverwendbar
sind. Wenn man halt das volle Programm haben will, sowohl Performanz als
auch Wiederverwendbarkeit, muss man auch entsprechend viel Zeit
investieren. Was aber leider nicht immer vermittelbar ist, weil C++ ja
angeblich so pille-palle ist und bloß durch die reine Verwendung die
Time-To-Market reduziert.
Und das muss jeder der hardwarenah programmiert eben tun und damit
> meine ich nicht den eigenen Prozessor im Focus habend, sondern die immer> wieder neue und unbekannte periphere HW mit der ein µC Entwickler zu tun> hat und der vor der Aufgabe steht anhand eines Datenblattes seinen Code> anzupassen.
Sollte doch genauso möglich sein. Ich persönlich mag C auch (besonders
c99), weil es mit vergleichsweise wenig Sprachumfang sehr effizient ist.
In der einfachsten Denke fasst C++ halt gewisse Sachen einfach durch ein
Schlüsselwort zusammen. In C machste 'ne struct mit Funktionspointern,
in C++ isses 'ne Klasse. Der umgekehrte Weg - Klassen mit C-Strukturen
darstellen - ist imho auch nicht verkehrt, das würde auch eine Art
Programmierung gegen Schnittstellen sein. In C++ ist das halt gleich
durch die Syntax von 'class' mit dabei, was dir eine vtable erzeugen
kann.
> Ich Entwickle seit über 10 Jahren für OSX und iOS und davor für Windows.> Für solche Systeme führt fast kein Weg an C++ bzw. den> Weiterentwicklungen C“#“ und „Objectice C“ vorbei. Hier stellt quasi OOP> mit all seinen Vorteilen und den >>bereits vorhandenen<< mächtigen und> kaum zu überschauenden Klassen und Schnittstellen die einzige> Möglichkeit dar überhaupt noch mit einem so komplexen System zu> kommunizieren und dessen Funktionen zu verwenden. Dafür ist diese> Sprache das einzige Mittel.
Polymorphie hat Vorteile, hat aber auch Nachteile. Für die Modellierung
ist sie schön, wenn sie richtig angewandt wird. Ich hab sie auch selber
schon oft genug selber falsch angewendet - sei es durch unbekannte oder
zu flexible Requirements / Constraints und sicher auch einfach durch
manchmal ungeschickte Platzierung.
> Gäbe es für alle Mikrocontroller und jede aktuelle mögliche periphere> Hardware frei verfügbare und funktionierende Klassen und einem Compiler> der C++ fehlerfrei unterstützt zuzüglich einer funktionierenden> Möglichkeit adäquat zu debuggen dann sähe die Sache für den einen oder> anderen Fall möglicherweise etwas anders aus. Denn dann wäre wie bei> den „Hochbetriebssystemen“, OOP eine Erleichterung und würde seine> eigentliche Stärke ausspielen. Das tut es aber nicht und wird es> vermutlich nie geben. Aus vielen verschiedenen und offensichtlichen> Gründen. Und unter den gegebenen Voraussetzungen ist C++ ein Hemmschuh.
Im Zweifelsfall sollte auch der sportliche Aspekt gelten: einfach mal
gucken, wie gut es im Endeffekt wirklich funktioniert.
Leute, der Thread heißt:
"C++ auf einem MC, wie geht das?"
Könnt ihr das philosophieren nicht auf den andren heute gestarteten
Laber Thread verschieben?
>Ich möchte gerne folgendes erreichen:> LED0 = KEY0.state; // an solange Taste gedrückt> LED1.toggle = KEY1.press // wechsel bei jeder Drückflanke> LED2.off = KEY2.press_short; // kurz drücken - aus> LED2.on = KEY2.press_long; // lang drücken - an
Man könnte ein Konzept verwenden, welches bei Java oder C# übliche ist.
Dort gibt es die sogenannten "Listener" also Zuhörer, die bei einer
Ereigniserzeuger eingetragen werden. In Java würden die KEYs übrigens
"Button" heißen.
Ich wandle das Prinzip aus Java etwas ab, damit es auf einfache Weise
zum Tastenproblem passt.
Es geht hier mittlerweile auch darum möglichst guten Code zu erzeugen
;-)
Im Normalfall weiß man zur Compilezeit wieviele Tasten angeschlossen
sind.
Eine dynamische Erzeugung ist somit überflüssig!
tictactoe schrieb:> Dann können wir also z.B. einen Array mit Pointern auf die Clienten> anlegen, damit wir die virtuelle Handler-Funktione aufrufen können.> Vielleicht so> ...> Aber das kriegt man auch mit Template-Metaprogramming hin
Ich muss hier nochmal nachhaken. Mein Post ist eine Werbung für
Template-Metaprogramming. Man muss hier aber einen Schritt zurück machen
und noch mal die Ausgangssituation betrachten. Gerade weil man auf einem
µC keine dynamischen Listen von (Uhren, Tastern...) hat, könnte man
Template-Metaprogramming verwenden (weil alle teilnehmenden Klassen zur
Compile-Zeit bekannt sind). Aber aus dem selben Grund kann man genau so
gut auch schreiben:
1
ISR(TIMER0_OVF_vect){
2
uhr.OVF_vect();
3
taste1.OVF_vect();
4
taste2.OVF_vect();
5
}
Wozu also das ganze Gedöns um virtuelle Funktionen (braucht man bei
dieser Form nicht) und Template-Metaprogramming? Hab' ich was an den
Anforderungen nicht verstanden?
tictactoe schrieb:> Wozu also das ganze Gedöns um virtuelle Funktionen (braucht man bei> dieser Form nicht) und Template-Metaprogramming? Hab' ich was an den> Anforderungen nicht verstanden?
Das sehe ich auch so. So schön die ganze Template Geschichte auch ist,
man kann kaum richtig einschätzen was der Compiler am Ende wirklich
daraus macht. Wenn man dann aber erst im Assemblerlisting rumkramen muss
um die Qualität der Umsetzung zu beurteilen wir es lästig und fraglich.
Noch dazu bei einem Interrupt. Dann ist die traditionelle Variante:
>> Wozu also das ganze Gedöns um virtuelle Funktionen (braucht man bei>> dieser Form nicht) und Template-Metaprogramming? Hab' ich was an den>> Anforderungen nicht verstanden?
Vermutlich: Damit sich ein Instanziiertes Template selbständig irgendwie
automatisch am Timer registrieren kann.
Also
1
#include<IRPM>
2
3
...
4
5
intmain(){
6
IRMPreceiver<Pin<PORTB,3>>;
7
8
while(1){
9
if(receiver.gotCode()){....}
10
}
11
}
Ohne dass man selber in der ISR ein "receiver.poll()" Aufrufen müsste...
Geht ziemlich in die Richtung von "Flow-Based Programming", oder nicht?
(http://en.wikipedia.org/wiki/Flow-based_programming)
Den Gedanken mag ich sehr, aber mir fiel nie eine vernünftige
Ausdrucksweise in C/C++ ein, dem dem PROGRAMMIERER nützt und noch
irgendwie effizient ist. Da bräuchte man eigentlich eine höhere Sprache,
die das dann beispielsweise in C übersetzt... Mit all den Nachteilen die
man sich da einhandelt.
Ich dachte mir, ich könnte eine C++11 alternative zu <avr/io.h>
schreiben, aber ich schaffe es nicht, dass am Schluss ein sbi dabei
rauskommt. Warum will avr-gcc 4.8.2 hier nicht stärker optimieren?
Was ich erwartet habe:
1
PORTA |= 1;
2
3a: 70 9a sbi 0x0e, 0 ; 14
Was immer herauskommt, egal welche Optimierungseinstellung:
Peter Dannegger schrieb:> Man kann ganz leicht ein Enum in der falschen Statemaschine> verwenden und der Compiler lacht sich ins Fäustchen.
Das umgeht man entweder dadurch, dass man die Sichtbarkeit
einschränkt, indem man die Enumeration (meistens Typdefinition +
Enumeration) nur in dem C-File hinzufügt, in dem auch die Funktion
steckt, die das Enum nutzen soll/darf
oder
mittels Defines nur die notwendigen Enums aus einem Header-File
inkludiert (ifdef ichbin's, dann include nur meinen relevanten Code).
Da wäre z.B. der Tipp sich mal den MID Innovator anzusehen
bezüglich SA/SD/Implementierung.
http://www.mid.de/
Der erledigt dann z.B. die Sichtbarkeit von Handles automatisch.
Peter Danneger schrieb:
>Ich möchte gerne folgendes erreichen:> LED0 = KEY0.state; // an solange Taste gedrückt> LED1.toggle = KEY1.press // wechsel bei jeder Drückflanke> LED2.off = KEY2.press_short; // kurz drücken - aus> LED2.on = KEY2.press_long; // lang drücken - an
Hallo Peter,
da mich das Thema auch ein wenig interessiert, habe ich ein wenig Code
geschrieben. Mir geht es eher um die "Architektur" des Programms,
deshalb habe ich der Einfachheit halber einen Arduino verwendet mit
seinen langsamen Libs verwendet und die Sachen nicht
Geschwindigkeitsoptimiert. Der Arduino liegt hier meistens herum und ich
muss nicht erste ein Steckbrett mit MCU aufbauen.
Da das Prinzip der Listener sich auf den PCs durchgesetzt hat, habe ich
dieses implementiert.
So weit ich weiß, hast Du hier im Forum irgenwo eine sehr gute
Entprellroutine für MCs geschrieben, die sehr viel Anklang findet.
Dein Code ist überlicherweise kurz, klar und gut, deshalb mögen die
langen Funktionsnamen im folgenden Beispiel etwas abschreckend sein,
aber ich versuche selbst erklärenden Code zu produzieren und die
Funktionsnamen für sich sprechen zu lassen.
Dr. Sommer schrieb:> Aber auch in Brainfuck. Warum verwendet niemand Brainfuck? Es ist> supereinfach zu lernen, verwenden und implementieren.
Habe mir das mal angeguckt - ich hätte fast gekotzt.
Daniel A. schrieb:> aber ich schaffe es nicht, dass am Schluss ein sbi dabei> rauskommt.
Dann nimm doch einfach Asm ;-)
Ret schrieb:> Wo ist der wirkliche MEHRWERT? Ist das Endergebnis wirklich besser?> Lohnt der Aufwand wirklich?
Auf diese alberne Frage gibts HIER doch keine Antwort. Da sind andere
Dinge wirklich wichtiger!
>Jetzt kann man da nur LEDs anschließen und das "new" dort ist wohl>unnötig... Für PRESSED etc. besser enum oder enum class...
Hmm, man kann LEDs und Taster anschließen. Ich dachte, das sei die
Aufgabe. Peter hatte ja ganz am Anfang dieses Threads den "Beispielcode"
gepostet, der in C++ umgesetzt werden soll.
Peter Dannegger schrieb:> Hier gibts ja viele Meinungen zu C++, aber wenn man es selber probieren> will, gibt es große Hürden.Peter Dannegger schrieb:> Besonders interessant wäre die Entprellung portweise parallel und nur> das Auswerten der Tasten einzeln.
Peter, ich verstehe dich wirklich nicht. Was soll das bloß?
Also erstens, wozu über C++ nachdenken? Um für einen µC eine Firmware zu
schreiben, nimmt man sinnvollerweise etwas, das dem Teil angemessen ist
und das man kriegen kann und bezahlen kann und womit man selber auch
zurecht kommt. Das läuft zumeist auf simples C hinaus, wobwi allerdings
einige Compiler auch genausogut C++ verstehen.
Wo sind deine Hürden?
Ich sehe das so, daß viele Leute einfach völlig unstrukturiert an ihre
Probleme herangehen und einfach brüllen "Ich brauche jetzt&hier eine
Entprellung meiner 7 Tasten, aber PRONTO!" anstatt sich irgend einen
Gedanken über eine Strukturierung ihrer Firmware zu machen.
Dazu hätte gehört, zwischen quasi einer Anwendung und quasi einem Satz
echter Hardwaretreiber zu unterscheiden, wo das geeignete Abfragen und
Behandeln von solchen Dingen wie Tasten, Drehgebern, Endlagenschaltern
und so weiter sauber und gekapselt und sicher für's System stattfindet.
An solchen Niederungen ist das, was manche unter C++ verstehen wollen,
einfach fehl am Platz.
Peter Dannegger schrieb:> LED1.toggle = KEY1.press
Eben. So ein Gedanke (wenn man das denn so nennen will) ist sowas von
strunzfalsch, daß mir dafür die geeigneten Worte fehlen. Stattdessen
sieht das sinnvollerweise eher so aus:
1. Keytreiber stellt fest, daß KEY1 immer noch ununterbrochen gedrückt
ist, obwohl die Repetierzeit vorbei ist, also ruft er den Eventhandler
auf mit AddEvent(Key1_pressed)
2. Die zentrale Eventverwaltung der Firmware arbeitet die aufgelaufenen
Events ab und wird dann auch "Key1_pressed" an die zuständigen Teile der
Anwendung weiterreichen.
3. Ein Programmteil im Anwendungsbereich der Firmware kriegt diesen
Event ab und tut daraufhin, was er tun soll, z.B. die Heizung
abschalten. Das signalisiert er dann mit der zuständigen Signallampe,
indem er LED1 ausschaltet. Das macht er direkt im zuständigen Port, weil
sowas eine nebeneffektfreie Aktion ist.
Wo siehst du da bloß einen Ansatzpunkt, um Tasten per C++ zu entprellen?
W.S.
>Peter, ich verstehe dich wirklich nicht.
Da liegt wahrscheinlich Dein Problem.
Peter kennt sich mit Treibern zur Tastenentprellung ziemlich gut aus:
http://www.mikrocontroller.net/articles/Entprellung#Timer-Verfahren_.28nach_Peter_Dannegger.29
Ich denke hier geht es eher um die Frage: wie kann die Methoden und
Techniken die C++ und die Objektorientierung bieten auch für eine
Tastenentprellung auf einem MC nutzen.
Daniel A. schrieb:> aber ich schaffe es nicht, dass am Schluss ein sbi dabei> rauskommt. Warum will avr-gcc 4.8.2 hier nicht stärker optimieren?
Ich habe es jetzt herausgefunden, es war mein Fehler: Als ich die
Adressen der Ports aus <avr/iotn48.h> abgeschrieben habe, habe ich
übersehen, dass makro _SFR_IO8 einen offset von 0x20 hinzugefügt hat.
Dadurch hatte gcc die falsche Adresse und konnte kein sbi benutzen.
Im Anhang sind alle geänderten Dateien. Jetzt verwendet gcc immer ein
sbi, und wenn ich das aus dem C++ code generierte hexfile mit dem
hexfile aus folgendem C-Code vergleiche, sind diese Identisch!
Peter Dannegger schrieb:> Sepp schrieb:>> Um die dauer des>> Tastendrucks festzustellen benötigt man auch hier eine ISR>> Das ist klar.> Es ging mir auch haupsächlich darum, wie ich in der Mainloop die> Ereignisse auswerten kann und wie ich die Klassen definieren muß.>> Z.B. ich definiere eine Klasse LED und ein Klasse KEY und darin alle> Aktionen und Initialisierungen dafür. Die Aktionen benutze ich dann in> der Mainloop.> Schön wäre es noch, wenn die Klasse automatisch den passenden> Interrupthandler aktiviert.> Füge ich eine neue Taste der Klasse KEY hinzu, wird geprüft, ob deren> Port bereits entprellt wird und wenn es ein neuer Port ist, wird der> Code dafür hinzugefügt.
Ich finde die Stossrichtung diese Dinge mal objektorientiert zu
betrachten hervorragend und lese neugierig mit.
Mir gehen dazu ein paar Gedanken durch den Kopf, die ich Euch einfach
mal so hinwerfen wollte:
Was Pin, Key und Debounce angeht sind das für mich aus einer
Datenmodell-Perspektive 3 verschiedene Dinge.
Pin ist die "physikalische Schicht", die Hardware.
Key ist ist ein Device, das am Pin hängt.
Debounce ist ein Service, die die beiden verbindet.
Desweiteren ist Debounce nicht 1:1 mit Pin oder Key verbunden, sondern
ist ein "Service", der mehrere Pins abfragt und als Key an die
Applikation liefert, also:
Pin \ / Key
Pin +-- Debounce-Service -- + Key
Pin / \ Key
Wahlweise können Keys dann an Pins hängen, wenn die Hardware-entprellt
sind, also müsste die Key-Klasse mit beidem umgehen können.
Der Debounce-Service wäre also eine Klasse, die im Interrupt hängt,
einen oder mehrere Ports bedient (könnte sogar selbst wissen, wann es
das tun muss) und mehreren Keys als Input dient.
Keys haben also eine Referenz auf ein Bit des Debounce-Objekts, das
einen Port bedient und alternativ eine direkte Referenz auf ein Pin.
Weiters sollte m.E. ein Key nicht mit einer LED verbunden sein,
zumindest nicht 1:1. Denn üblicherweise ist der Zweck eines Keypress
nicht, eine LED zu schalten, sondern die LED ist ein Signal für einen
Zustand des Systems.
Also wäre der primäre Vorgang mit einem Keypress einen Vorgang im System
auszulösen, eine Zustandsänderung. Und die Zustandsänderung ist mit der
LED verknüpft.
Angenommen also, dass ein bestimmter Zustand eine richtige Statemachine
in einen anderen Zustand bringt, dann müsste die LED mit der
Statemachine verbunden sein und bei erreichen eines bestimmten State
geschaltet werden. Und zwar am besten nicht explizit mit "LED.on()",
sondern implizit durch die State Machine, weil die LED mit dem State
verknüpft ist.
Moin !
Ich finde den OOP Gedanken sehr schick.
Aktuell habe ich mal wieder ein Projekt bei dem :
- Ein digitales Signal vermessen wird. (Pulsdauer und Startzeitpunkt)
- Die Daten durch eine simple Berechnung gehen.
- Und am entsprechenden Pin wieder digital zappeln muss.
Das ganze ist vierfach vorhanden.
Die Daten liegen alle in einem Struct.daten1, Struct.daten2 ...
Die "Vermessprozedur" sowie die "Ausgabe" werden mit ihrem
entsprechenden Pointern aufgerufen.
Dabei wird auch ein Pointer auf den entsprechenden Port übergeben.
(nicht sehr schick)
Das schreit doch förmlich nach OOP !?
Die Frage ist jetzt nur wie weit treibe ich den Spuck.
Für meine Problemstellung würde ich folgende Klassen benötigen :
GPIO - Digitale Ein und Ausgabe.
SENSOR - Vermessen des Signal und Trigger für Startzeitpunkt
CALCULATOR - Signal für die Ausgabe berechnen
AKTOR - Gibt bei Trigger von SENSOR die berechnete Pulslänge aus.
Obiges könnte man aber auch zu GPIO und EINSPRITZDING zusammenfassen.
Vielleicht wäre es auch sinnvoll wenn GPIO den PORT erbt.
Bestimmte PORT haben etwas mit GPIO, UART, SPI etc zu tun.
Aber SPI und UART müssten auch auf GPIO zugriff haben.
In echtem guten OOP müsste ich das doch nachbilden ?
Aber klar ist doch das verschiedene GPIO an SENSOR und AKTOR übergeben
werden.
Für mein Problem reicht ein einfaches GPIO.
Macht man es gescheit wirds ne dicke Kuh.
Ich denke ich baue das Programm nochmal in C++ und OOP nach.
Mal schauen was rauskommt...
F. Fo (foldi) schrieb:
Dr. Sommer schrieb:
>> Aber auch in Brainfuck. Warum verwendet niemand Brainfuck? Es ist>> supereinfach zu lernen, verwenden und implementieren.> Habe mir das mal angeguckt - ich hätte fast gekotzt.
Da kann ich dich voll verstehen! Denn mir geht es genau nicht anders.
Wer so einen hingekotzten Zeichensalat (ich hab extra nochmal
nachgeschaut) wie Brainfuck ernsthaft als Programmiersprache empfiehlt,
verarscht entweder seine Mitdiskutanten oder hat schlicht nicht alle
Tassen im Schrank. Langsam nähren sich in mir die Anzeichen, dass ich
solche Leute künftig an anderer Stelle nicht mehr für voll nehmen
sollte. Und wenn mir der gleiche Herr demnächst dann seine C++
Template-Orgien schmackhaft unter die Nase reiben will, denke ich mir
darauf, "hab Nachsicht mit ihm! Das ist einer, der auf Brainfuck steht.
Von dem kann einfach nichts Brauchbares oder Gescheites kommen".
So kann man sich seine Glaubwürdigkeit hier auf einen Schlag verspielen.
Aber vielleicht passt auch alles gut zusammen. Wer auf Brainfuck steht,
der findet manche Brainfuck-Ausdrücke, die in Form von C++ so anfallen,
eben auch "geil" und ergötzt sich daran. Nur verschont bitte die noch
normal gebliebenen Landsleute unter uns damit, die einfach in
vertretbarem Aufwand, LESBAREN UND WARTBAREN CODE programmieren möchten,
ob für den PC oder für µC, ob in C, Assembler, Pascal (Delphi, Lazarus),
LunaAVR, Processing oder einem modernen BASIC-Dialekt.
Esoterische Hirnkrampf-Programmiersprachen sind was für Leute, die zu
viel gelangweilte Freizeit zur Verfügung haben, konsumtechnologisch
total übersättigt sind, fortwährend nach einem neuen Kick suchen und in
ihrem Umfeld schließlich durch zu viel nerdiges Hipster-Verhalten
anderen chronisch auf die Hutschnur gehen. Einfach künftig mal die
Klappe halten und lieber anderen zuhören ist der erste Schritt zur
Heilung. ECHTE Hilfe anbieten ist dann Schritt Nr. 2 usw. Brainfuck
braucht es dazu nicht.
Hier wird jetzt viel geschrieben, a la "geht nicht", "ist nicht anders
vom Aufwand", "ist zu langsam und zu viel overhead". Andere sagen dann
wieder, "geht doch" ...
Mal anders gefragt: Wer von euch programmiert seine µC's mit C++ und was
sind das für Programme?
Wenn jemand wie Peda an sowas denkt und das für eine gute Idee hält, wo
er doch so ein C Spezi ist, dann ist das sicher mal ein berechtigter
Gedanke.
Die einzige wirklich (für mich) brauchbare Aussage habe ich hier
gelesen:
Sepp schrieb:> Was mit persönlich an C++ im Embedded Bereich sehr gefällt sind die> Generics (bei C++ Templates genannt). Damit kann man einen großteil der> statischen DEFINES in einem typeischen C Programm weg bringen und das> ganze dazu noch kapseln.>> z.B. hab ich Filterklassen als Template realisiert denen man bei der> Instantierung nur die Ordnung und die Charakteristik mitgibt. Der vom> Compiler erzeugte Code ist dann exakt genau so schnell wie C code. Der> Vorteil ist das man mit einer Zeile einen neuen Filter hat - ganz ohne> Code Duplication, globale Variablen, Precompiler DEFINES usw... sauber> halt.>> Es geht natürlich auch mit C genau so gut. Nur halt umständlicher und> nicht so sauber, aber für nicht C++ affine Programmier halt dafür viel> verständlicher...
Und genau darum geht es doch.
Conny G. schrieb:> Ich finde die Stossrichtung diese Dinge mal objektorientiert zu> betrachten hervorragendThomas W. schrieb:> Ich finde den OOP Gedanken sehr schick.
Viele (die meisten) Programmierer würden wohl unterschreiben, daß man
die Dinge möglichst einfach halten sollte, verfallen aber dann doch dem
intellektuellen Reiz, das OOP Prinzip Problemstellungen jedweder Art
überzustülpen. Die OOP Sichtweise hat offensichtlich geradezu was
Ideologisches, dem sich manche nicht mehr entziehen können. Wenn
Peter Dannegger schrieb:> Ich möchte gerne folgendes erreichen: LED0 = KEY0.state; //> an solange Taste gedrückt> LED1.toggle = KEY1.press // wechsel bei jeder Drückflanke> LED2.off = KEY2.press_short; // kurz drücken - aus> LED2.on = KEY2.press_long; // lang drücken - an
würde man doch nur
- in einem zyklischen Timerinterrupt vorhandene Keys ein paarmal
abfragen und einen über mehrere Zyklen festgestellten gleichen Zustand
als aktuellen für Key X zuweisen (Entprellung)
- mit dem Wechsel des aktuellen Zustands von Key1 LED1 toggeln
- mit den über im selbigen Timerinterrupt feststellbaren verschieden
langen Key2-ON Statusperioden LED2 aus- und einschalten.
Was zum Teufel muß einen reiten, über die Codierung dieser klar
begrenzte Funktionalität hinaus Gedankenakrobatik mit
unterschiedlichsten OOP Konstrukten zu betreiben?
Moby schrieb:> Was zum Teufel muß einen reiten, über die Codierung dieser klar> begrenzte Funktionalität hinaus Gedankenakrobatik mit> unterschiedlichsten OOP Konstrukten zu betreiben?
Auch wenn ich wenig Hoffnung habe, daß du es irgendwann einsehen willst,
noch ein Versuch: es gibt auch Programme, die über Pinwackeln
hinausgehen.
Ein Programm kann durchaus mehrere Ebenen haben, die man intelektuell zu
erfassen hat (siehe z.B. OSI - 7 Schichten, oder Anwendung - USB-Stack -
HW-Ansteuerung).
Wer in einem Programm ab einer gewissen Komplexität (a) Code, der die
Logik eines Webservers abbildet, mit (b) Code, der IO-Pins setzt,
vermatscht, programmiert ziemlichen Mist.
Das ist Pfusch und keine SW-Entwicklung.
Insofern ist es durchaus sinnvoll, Sachen, die nicht zusammengehören,
auseinander zu ziehen.
Assembler ist jetzt halt geeignet, Prozessorbefehle auszudrücken.
Wenn das Programm aus nicht wesentlich mehr besteht, ist das vollkommen
in Ordnung. Deine "klar begrenzte Funktionalität" ist aber nicht immer
die ganze Welt, sondern hier nur ein Beispiel.
Mit ABS und ESP nur in Assembler geschrieben würde ich mich nicht
anfreunden wollen, wenn jemand irgendwas unstrukturiert hinrotzt.
Für die darüber liegenden Ebenen gibt es einfach bessere Sprachen.
Ob das jetzt C++ ist oder was anderes, steht wieder auf einem anderen
Blatt.
Die ursprüngliche Frage geht jetzt halt nun dahin, wo die Grenze
sinnvollerweise zu ziehen ist und wie man sie gestalten könnte.
Daß du die Frage nicht verstanden hast, weiß inzwischen jeder. Belass es
doch einfach dabei, bevor es noch peinlicher wird.
Mag sein, daß du nur Probleme hast, bei denen deine Arbeitsweise passt.
Mag auch sein daß deine Probleme nicht zu dieser Arbeitsweise passen, du
aber totzdem so arbeitest. Das tut hier aber alles nichts zur Sache.
Hier geht es darum, wie man es auch anders machen könnte.
Also für Leute, die auch mal etwas weiter schauen wollen...
PSOC geht ja so ein bisschen den Weg Hardware von eigentlichem Code zu
trennen. Die Hardware zeichnet man, stellt dort alles ein was so ein Pin
soll und den Rest in Software.
Was ich hier überhaupt nicht verstehe und für mich wieder zeigt wie
viele hier mehr reden als wirklich machen, da doch immer mehr die
Cortexe bevorzugt werden, mit ihren viel höheren Geschwindigkeiten und
mehr Speicher, wieso dann nicht auch gleich die Programmiersprache mit
wechseln?
Auf jeden Fall habe ich schon mal wieder das C++ Buch aus dem Regal
genommen.
Klaus Wachtler schrieb:> sondern hier nur ein Beispiel
Nein nein Klaus- nicht "nur" ein Beispiel.
Wohin man auch schaut wenn man es denn konkret tut: Überall dieselben
"Beispiele"! Und nein, wir reden hier nicht von einem Webserver oder
einem ausladenden SAP-Programm, sondern ganz konkreten
Peter Dannegger schrieb:> MC-spezifische Abläufe ... (IO-Zugriffe, Statemaschine usw.)
Die liegen allermeistens immer noch unter
Klaus Wachtler schrieb:> Programm ab einer gewissen Komplexität
was Du hier offensichtlich meinst.
Klaus Wachtler schrieb:> es gibt auch Programme, die über Pinwackeln> hinausgehen.
Tatsächlich?
Dann weißt Du aber auch, daß sich vielschichtigere Programme beileibe
nicht nur mit OOP-Zauberspuk, sondern ganz klassisch über ein
Interruptsystem realisieren lassen. Das hat nämlich meist den Vorteil,
kürzer, schneller, punktgenauer und übersichtlicher zu sein. Man nutze
nur die Ressourcen seines Controllers, dann klappt es vielleicht auch
mit der Reduktion vermeintlich nötiger Ebenen.
F. Fo schrieb:> wieder das C++ Buch aus dem Regal
Oh da oben stehen bei mir auch noch welche...
Leider haben sie bislang nur Zeit gekostet, fürs E-Hobby aber nix
gebracht ;-(
Bei soviel Kritik an der Idee muss ich doch nochmal was dazu schreiben.
Mit einer mutigen Vision entstehen oft hervorragende Dinge.
Wenn man sich vorab denkt "wer braucht das?", dann wird man sich nie auf
den Weg machen eine neue Kategorie von Lösung zu erforschen.
Schaut "node.js" - da hab ich mir vor ein paar Jahren gedacht - so ein
Quatsch, wer braucht Javascript auf dem Server.
Und inzwischen ist es signifikant populär und ich hab selber node.js für
ein Projekt am Laufen, weil es das nur so gibt. Hätte ich nicht gedacht.
Oder Java vor 20 Jahren - "wer braucht eine hardwareunabhängige
Programmiersprache für Geräte??". Ich arbeite fast nur noch mit Java.
D.h. das Argument "braucht man nicht, wenn ..." (oder "Hammer immer
schon so gemacht") ist kein Innovationstreiber :-)
(V.a. was soll denn das bringen, diejenigen, die diese Idee verfolgen
Niederzuargumentieren und Ihnen den Mut zu nehmen? Innovation bremsen?)
Irgendein Wahnsinniger (oder eine Gruppe von Wahnsinnigen) muss einfach
damit voran machen und die anderen überzeugen.
Wem's nicht gefällt der braucht ja nicht mitmachen.
Es gibt sicher auch einen großen Unterschied zwischen
Hobby-Eletronikern, die moderat viele Dinge umsetzen, deren Komplexität
meist begrenzt bleibt und die auch nur wenig Zeit haben sich mit der
"Schönheit" der Lösung zu beschäftigen, und beruflichen
Mikroprozessor-Lösungs-Entwicklern, die ihre Softwarearbeit skalierbar
gestalten wollen.
Und aus der Ecke scheint PeDas Frage zu kommen:
zuviele Lösungen, die alle in sich die Gefahr tragen mal einen Pin im
Code zu verwechseln etc.
Wenn man das und weitere Komplexität hübsch in OOP einpacken kann,
sodass die Definition der Objekte bereits Fehler verhindert (strenge
Typisierung) und das Ganze einfach übersichtlich macht (Kapselung), dann
ist viel Debug-Zeit erspart und es wird auch pflegbarer und teamfähiger.
Jetzt Schluss mit Infragestellung von PeDas Frage und weiter an der
Lösung!!
Conny G. schrieb:> Erinnerung, dass dies kein Ideologie-Thread ist, sondern die konkrete> Frage von PeDa, ob und wie man seine Fragestellung in C++ lösen kann.
Reichen die bisherigen Beiträge denn WIRKLICH nicht aus, diese Frage
final geklärt zu haben???
Nein?
Dann gebe ich hier mal zwei Antworten unterschiedlicher Art:
1. die Flapsige: Nimm einen C++ Compiler und gib ihm die bisherigen C
Quellen zum Übersetzen. Dann kann man sich rühmen, C++ benutzt zu haben.
2. die Eigentliche: Setze dich hin und versuche zu allererst, deine
Gedanken zu strukturieren. Genau DAS hat nämlich an der eigentlichen
Fragestellung gefehlt. Im Grunde ist es nämich scheissegal, welche
Programmiersprache man zum Erstellen seiner µC Firmware benutzt,
stattdessen ist es nur wichtig, wie man die gewünschte Funktionalität
strukturiert. Ob man da als Geradeausprogrammierer alle Ebenen der
Firmware durcheinanderschmeißt und partout sowas wie Peter anvisiert:
Peter Dannegger schrieb:> Ich möchte gerne folgendes erreichen:> LED0 = KEY0.state; // an solange Taste gedrückt> LED1.toggle = KEY1.press // wechsel bei jeder Drückflanke> LED2.off = KEY2.press_short; // kurz drücken - aus> LED2.on = KEY2.press_long; // lang drücken - an
oder ob man sich Gedanken über sinnvolle Hardwarekapselung - verbunden
mit einer firmwareinternen HAL macht, hängt eben davon ab, ob man
gewillt ist, zu allererst mal seine Gedanken zu strukturieren.
Apropos HAL: Damit meine ich NICHT solche eher blödsinnigen
Möchtegern-Kapselungen wie PortX.SetzeBit(2), sondern was Echtes, also
derart, daß die konkrete Hardware im Interface zum übergeordneten
Programm überhaupt nicht mehr auftaucht. Wer jetzt schreit "Ich brauche
aber PortX und dort Bit 2 in meiner Routine!", hat den Sinn einer HAL
nicht verstanden und seine Firmware schlichtweg falsch oder garnicht
strukturiert.
Fazit: Peters Vorstellung, so etwa wie das oben Zitierte in C++
formulieren zu wollen, ist m.E. inhaltlich nicht sinnvoll. Deswegen
mein Rat, so etwas bleiben zu lassen und stattdessen das gesamte Thema
völlig anders anzugehen:
Tastaturtreiber --> Events --> Eventverteilung im System --> eigentliche
Funktionalroutinen --> Signalisierungsroutinen.
W.S.
W.S. schrieb:> sondern was Echtes, also> derart, daß die konkrete Hardware im Interface zum übergeordneten> Programm überhaupt nicht mehr auftaucht.
Ich glaube das ist ja sein Ziel. So habe ich das verstanden.
Wenn du das schon gemacht hast, dann stelle doch mal hier was vor!
Also ich hab die letzten Tage mal weiter drüber nachgedacht. Es gibts ja
letztlich 2 Ebenen, die man zu betrachten hat.
1) Low-Level. Also das, was man sieht wenn man in die
Peripherie-Treiber-Schicht reinschaut. Hier ist wohl kaum mit
OOP-Techniken irgendetwas zu gewinnen.
2) High-Level. Also das, was man mit dem Low-Level-Teil macht. Hier
hängt es doch sehr stark von der Applikation ab, wie man ihn umsetzt.
Wenn man riesige dynamische Gebilde hat, kommt vielleicht OOP in Frage,
C++ könnte einen hier unterstützen. Vielleicht aber auch nicht.
Ich habe mich dieses Wochenende nun mal zum Spaß auf Part 1
konzentriert, und wie C++ hier vielleicht für übersichtlicheren Code
sorgen kann. Meine Zielhardware ist STM32F4 und was mich immer gestört
hat, waren die Textwände, die die Register initialisieren. Ich habe mir
deshalb den GPIO-Teil herausgesucht, weil der wohl das erste ist, womit
man in Berührung kommt. Herausgekommen ist eine Template-"Bibliothek",
die folgendes zulässt:
Ich bitte die Formatierung zu entschuldigen, für das Forum währen ein
paar Newlines vielleicht praktischer.
Ziele waren mit absteigender Priorität:
1) Der User-Code soll nur noch das beinhalten, was von Belang ist.
Nämlich was die Pins bedeuten, und wie sie eingestellt werden sollen.
2) Vertretbarer Template-Aufwand
3) Qualität des Ausgespuckten Assembler-Codes
Die einzelnen Configure-Aufrufe erzeugen mit -O3 so ziemlich perfekten
Assembler-Code mit meiner Toolchain. Allerdings ist es natürlich so,
dass sie nur innerhalb des Aufrufs Registerzugriffe zusammenlegen
können. Wer das Optimum für seine Plattform und seine Applikation
herausbekommen will, muss in solchen Aspekten aber sowieso von der
Modularisierung Abstand nehmen, weil die einzelnen Teile eben Ressourcen
auf Hardwareebene teilen. Hier wäre eine externe Applikation hilfreich,
der man sagt was man wie verwendet und die dann (meinetwegen auch ASM-)
Code generiert, der die optimale Initialisierung durchführt. Gibt's
sowas schon für AVR/STM32?
Ich weiß nicht, ob ich die entstandene Bibliothek jetzt weiterpflege und
verwende, aber ich hatte auf jeden Fall große Freude, das zu entwickeln
;) Ich finde, der User-Code braucht den Vergleich mit dem ihm
entsprechenden STM-Hal-Code/Direkten Registerzugriffen nicht zu
fürchten.
Ich habe außerdem ein Amulett mit +500 Widesrtand auf Troll, also spart
es euch gleich ;)
Ich denke man sollte erstmal wissen man man möchte.
Wie weit will man abstrahieren ?
Die Pins von unseren Kontrollern sind doch nicht nur GPIOs sondern auch
UART, SPI, I2C, ADC...
Das muss doch von Anfang an bedacht werden.
Für eine Tastenentprellung macht es doch Sinn wenn wenn dem
"Entprellobjekt" ein oder mehrere, vorher initialisiertes, "GPIO
Objekte" übergeben wird.
Über die Läuft der Zugriff.
Jetzt braucht es immer noch einen Timer bei dem eine entsprechende
Methode registriert ist.
Für sowas kenne ich nur SIGNAL und SLOT aus QT.
IMHO werden die durch dem MOC in CallBacks umgewandelt.
Wie würde es sinnvollerweise bei UART, SPI, I2C ADC aussehen ?
Tastenentprellung ist eine reine Softwaresache sowie
Software UART, Software SPI, Software I2C.
Allerdings wird das bei den Hardware Features schon schwieriger.
Immerhin muss sich das entsprechende Objekt die GPIOs "reservieren".
Dazu muss es jemanden geben der die Eigenschaften der Pins und Ports
kennt.
Das weiss das GPIO Objekt nicht, denn dessen Klasse ist ein allgemeines
Objekt.
Bei der Instanziierung muss ihm das erst beigebracht werden.
1
GPIOgpioLED(portA,Pinnummer5,Datenrichtung,...);
2
LEDled(&gpioLED);
3
4
led.on();
5
led.off();
6
led.Blink(500ms);
7
...
Bei meinen Programmen versuche ich stark zwischen der "Logik" und dem
ansprechen der Hardware zu trennen.
Leider kann man das in meinem Beispiel noch nicht so gut sehen.
(sehr heiss gestrickt, eigentlich alles passiert in der ISR)
Bei anderen (fertigen) Projekten würde jetzt hal.h separat inkludiert
und nur auf die bekannten (sozusagen public) Funktionen zugegriffen
werden können.
Somit habe ich eine starke Trennung von der Hardwareansteuerung und der
eigentlichen Programmlogik bzw. hier beim Impulse verlängern.
Aber ich muss für jedes neue Projekt so eine hal.h schreiben.
Das nimmt einen grossteil meiner "Programmierzeit" in Anspruch.
Auch das riesen Struct kostet Zeit.
Für jedes Einspritzventile und jeden Eingang muss ich das "HAL" Struct
händisch erweitern, initialiseren...
Bei einer OOP Umsetzung, würde ich mir erhoffen, nur die GPIOs an die
Injektor und "Sensing" Objekte zu übergeben.
...und noch irgendwie die Sensing mit dem entsprechenden Injektor Objekt
zu "verheiraten" und beim Timer zu registrieren.
Es wäre für mich dann ein bisschen "egaler" wieviele Zylinder ich
befeuern muss.
Auch wird es entsprechend aufgeräumter.
Bei Änderungen muss ich, wenn ich es richtig erdenke, an weniger Stellen
nachbessern.
Stimmt das nicht ?
Fuer das High-Level Design der OOP gibt es UML.
Ich habe versucht mein Programm weiter oben in ein Diagramm zu fassen.
Bitte entschuldigt die etwas duerftige Qualitaet, es ist auf dem Pad
handgezeichnet.
Thomas W. (wagneth) schrieb
>Jetzt braucht es immer noch einen Timer bei dem eine entsprechende Methode
registriert ist.
Den Timer habe ich oben der Einfacheit halber durch eine While-Schleife
realisiert.
1
while(1)
2
{
3
key1.update();
4
key2.update();
5
key3.update();
6
7
delay(100);
8
}
Man koennte natuerlich auch eine richtige Timerklasse bauen, das haette
das Beispielprogramm unnoetig verkompliziert.
Chris,
ja das funktioniert.
Im Prinzip ist das EventDriven.
Ich möchte aber nicht im MainLoop warten.
Zumal die Laufzeiten/Verzögerung abhängig von den Laufzeiten sind.
In meiner ISR ist wenigstens der Start der Verarbeitung zu einem fixen
Zeitpunkt gegeben.
Irgendwie muss ein Automatismus her bei dem man einen Handler
registrieren kann...
>Es muss doch irgendwie ein GPIO Objekt o.ä. an Dein Key Objekt übergeben>werden, oder ?
Ich weiß noch nicht so recht. Der ursprüngliche Vorschlag von Peter war
ja, dass ein Key-Object in die Informationen über den Pin schon hat.
In meiner Umsetzung oben wäre das die Zeile mit
uint8_t keyPin;
1
#define PRESSED 0
2
#define TOOGLE 1
3
#define SHORTLONG 2
4
5
classKey{
6
public:
7
uint8_tkeyPin;
8
Led*oneLed;
9
uint8_taction;
10
uint8_toldKey;
11
uint8_tkeyToogleState;
12
13
Key(){
14
keyToogleState=0;
15
};
16
17
Key(uint8_tp){
18
keyPin=p;
19
pinMode(keyPin,INPUT);
20
21
keyToogleState=0;
22
};
23
24
voidaddKeyPressedListener(Led*led){
25
oneLed=led;
26
action=PRESSED;
27
};
28
voidaddKeyToogleListener(Led*led){
29
oneLed=led;
30
action=TOOGLE;
31
};
32
voidaddShortLongListener(Led*led){
33
oneLed=led;
34
action=SHORTLONG;
35
};
36
37
voidupdate()
38
{
39
uint8_tk=digitalRead(keyPin);
40
if(k!=oldKey)keyToogleState=!keyToogleState;
41
oldKey=k;
42
43
switch(action)
44
{
45
casePRESSED:{
46
oneLed->set(k);
47
};break;
48
49
caseTOOGLE:{
50
oneLed->set(keyToogleState);
51
};break;
52
53
caseSHORTLONG:{
54
55
};break;
56
default:{}break;
57
}
58
59
};
60
};
Wenn ich es richtig verstehe, möchtest Du das Konzept etwas erweitern
d.h. dem Key-Objekt verschiedene Quellen zuordnen können anstatt nur
IO-Pins.
Thomas W. schrieb
>ja das funktioniert.>Im Prinzip ist das EventDriven.>Ich möchte aber nicht im MainLoop warten.>Zumal die Laufzeiten/Verzögerung abhängig von den Laufzeiten sind.>In meiner ISR ist wenigstens der Start der Verarbeitung zu einem fixen>Zeitpunkt gegeben.
Eine While(1)-Loop in Main war auf die Schnelle so am einfachsten zu
realisieren. Man könnte die Key.update() Funktionen auch in die
ISR-hängen.
1
ISR...
2
{
3
key1.update();
4
key2.update();
5
key3.update();
6
}
Ich persönlich bin ein Fan von Interrupt-freien Programmen, weil sich
Interrupts auch gerne mal "verklemmen" wenn man beim Programmieren nicht
aufpasst.
Lange Zeit war die OOP für mich ein Buch mit sieben Siegeln, weil ich
noch aus der Zeit der Homecomputer Ära stamme. Dass ich es nicht
verstanden habe hat mich aber so geärgert, dass ich mich intensiver
damit befasst habe und einige Programme damit geschrieben habe. Um so
länger man es tut, um so klarer wird die Philosophie der OOP.
Zunächst muss ich sagen: wer es wirklich lernen will, sollte nicht mit
C++ sondern eher mit Python anfangen. Damit verschont man sich von den
ganzen Fehlern die C++ als zusätzliches Feature anbietet.
In der OOP gibt es das Prinzip, dass eine Klasse einer anderen eine
Nachricht schicken kann. Ich habe mich lange Zeit gefragt: Wie muss man
das konkret programmieren? Wie kann ein Klasse einer anderen eine
Nachricht schicken.
Oben im Beispielprogramm kann man das sehr gut sehen. In der Klasse Key
ist ein Leerpointer für eine LED eingebaut. Man muss einen Key
initialisieren, in dem man dem Key den Pointer auf eine LED mitgibt.
Danach kennt der Key die LED und kann ihr jetzt "Nachrichten" senden,
indem er einfach eine Funktion in der LED aufruft.
Peter Dannegger schrieb:> Schön wäre es noch, wenn die Klasse automatisch den passenden> Interrupthandler aktiviert.
Auf Plattformen wie AVR und CMSIS sind die Namen der Interrupt-Handler
in C Konvention fest vorgegeben und leiten sich von Devicenamen wie
UART0 ab. Zudem benötigt eine Handler als Teil einer Klasseninstanz den
Pointer auf diese Instanz.
Die Zuordnung eines vom Entwicklungsssytem vorgegebenen Handlers zur
passenden Funktion einer Instanz muss also unweigerlich von Hand
erfolgen, als Wrapper-Funktion um den eigentlichen Handler, mit den
Namen des Handlers. Darin wird dann über den Pointer auf die Instanz der
eigentliche Handler aufgerufen, beispielhaft:
extern "C" {
void UART0_Receive_Buffer_Full(void) // offizieller Name
{
UART0object->Receive_Buffer_Full(); // C++ member funktion
}
}
chris_ schrieb:> Ich persönlich bin ein Fan von Interrupt-freien Programmen
Ein wesentliches Feature von MC einfach mal über Board werfen? Naja.
Wenn man auf den Stromverbrauch achten muss, kommt man um Interrupts
nicht herum. Und auch sonst nützen und vereinfachen die mehr, als das
man sie vermeiden müsste.
A. K. schrieb:> Peter Dannegger schrieb:>> Schön wäre es noch, wenn die Klasse automatisch den passenden>> Interrupthandler aktiviert.>> Auf Plattformen wie AVR und CMSIS sind die Namen der Interrupt-Handler> in C Konvention fest vorgegeben und leiten sich von Devicenamen wie> UART0 ab. Zudem benötigt eine Handler als Teil einer Klasseninstanz den> Pointer auf diese Instanz.>> Die Zuordnung eines vom Entwicklungsssytem vorgegebenen Handlers zur> passenden Funktion einer Instanz muss also unweigerlich von Hand> erfolgen, als Wrapper-Funktion um den eigentlichen Handler, mit den> Namen des Handlers. Darin wird dann über den Pointer auf die Instanz der> eigentliche Handler aufgerufen, beispielhaft:>> extern "C" {> void UART0_Receive_Buffer_Full(void) // offizieller Name> {> UART0object->Receive_Buffer_Full(); // C++ member funktion> }> }
Je nachdem wie spendabel man mit Taktzyklen im Int sein möchte könnte es
über eine Int-Handler Registry erfolgen.
Es gibt ein Objekt "IntDispatcher" das den Keys bekannt ist und sie
registrieren sich dort mit "intDispatcher.register(&intHandler)".
Und der eigentliche Interrupt ruft grundsätzlich
intDispatcher->Timer0OvfInt() auf, der sich dann um seine Kunden
kümmert.
Alternativ gibt es eine IntTimer0OvfHandler-Basisklasse von der Klassen
wie die Key-Klasse erben und automatisch einen Handler für den Int
haben, der dann mit aufgerufen wird.
chris_ schrieb:>>Ein wesentliches Feature von MC einfach mal über Board werfen?>> Guck mal, hier gibt es einen sehr innovativen Controller ganz ohne> Interrupts:> http://www.parallax.com/microcontrollers/propeller
Ja, der löst den Bedarf an Ints alternativ mit 8 Cores, d.h. statt
Interrupts die den laufenden Code unterbrechen kann ein Core gemütlich
auf ein Ereignis warten. Finde den auch sehr cool.
Conny G. schrieb:> Ja, der löst den Bedarf an Ints alternativ mit 8 Cores, d.h. statt> Interrupts die den laufenden Code unterbrechen kann ein Core gemütlich> auf ein Ereignis warten. Finde den auch sehr cool.
XMOS ist ähnlich, aber weit besser konstruiert.
Sowas ist aus meiner Sicht tödlich. Funktionen in einer ISR aufrufen,
ist ja schon in C verpönt. Unter günstigen Umständen macht der Compiler
da ein paar wenige Instruktionen draus, wenn er die Funktion kennt! Aber
bestimmt nicht, wenn die Funktion - irgenwo weit weg - in einer anderen
Datei als Methode einer Klasse deklariert wurde.
'key1.update();' sieht ja wenigstens noch wie ein Funktionsaufruf aus.
Aber bei 'Beleuchtung.Led1 = an' können sich jede Menge Funktionsaufrufe
dahinter verbergen.
Ralf G. schrieb:> Funktionen in einer ISR aufrufen, ist ja schon in C verpönt.
Ach? Warum? Weil das dir vertraute Interrupt-System keine Priorisierung
kennt, somit kein Interrupt länger als 10 Takte dauern darf?
Das:
Conny G. schrieb:> Alternativ gibt es eine IntTimer0OvfHandler-Basisklasse von der Klassen> wie die Key-Klasse erben und automatisch einen Handler für den Int> haben, der dann mit aufgerufen wird.
läuft dann auf sowas:
Conny G. schrieb:> Es gibt ein Objekt "IntDispatcher" das den Keys bekannt ist und sie> registrieren sich dort mit "intDispatcher.register(&intHandler)".> Und der eigentliche Interrupt ruft grundsätzlich> intDispatcher->Timer0OvfInt() auf, der sich dann um seine Kunden> kümmert.
hinaus, da die ISR nicht an eine Klasse gebunden werden kann. Also wenn,
dann nur mit Tricks (Funktionszeiger). (Vielleicht auch nur in der
jetzigen Konstellation?)
Wenn sich jetzt eine Klasse (über Ihre Basisklasse) sozusagen bei der
Timer-ISR anmeldet, um von ihr später mal benachrichtigt zu werden, wenn
'was anliegt', dann muss das ja in einer Liste vermerkt werden. Die
Liste wird in der ISR dann abgearbeitet. Wenn's gut läuft, reicht das
vielleicht, der benachrichtigten Klasse nur einen Wert zu übergeben.
Ohne Funktionsaufruf! Wenn nicht, ...
Billig ist's auf jeden Fall nicht (Speicher/ Rechenzeit).
A. K. schrieb:> Ach? Warum? Weil das dir vertraute Interrupt-System keine Priorisierung> kennt, somit kein Interrupt länger als 10 Takte dauern darf?
Vielleicht. Kann sein.
Nur irgenwann ist trotzdem Schicht im Schacht.
Bei 'C++ auf einem MC, wie geht das?' denke ich nicht an 'Einen' (jeder
sucht sich seinen raus und alle reden aneinander vorbei) sondern an
'Alle' im Sinne von universell.
Ralf G. schrieb:> Billig ist's auf jeden Fall nicht (Speicher/ Rechenzeit).
Deshalb schrieb ich auch, je nachdem wie spendabel man für Komfort sein
will.
Am Ende ist das manuelle Mappen von ISR nach Methode auch akzeptabel.
Wenn man will könnte man es in einen Mechanismus packen.
Dann läuft man aber wiederum Gefahr in die
Arduino-Vollkasko-Bequemlichkeit zu kommen, die dann richtig viel
Resourcen kosten kann.
D.h. der Knackpunkt an einer cleveren OOP-Implementation muss sein:
Strukturierung und Fehlervermeidung, nicht alleine Komfort.
Und da wäre diese Vorgehensweise (Automatismus für ISRs) schon an oder
vielleicht sogar schon über der Grenze des Sinnvollen.
Denn über die genaue ISR-Architektur muss man sich als Entwickler
unbedingt Gedanken machen, das ist gefährlich, wenn ein Framework einem
suggeriert es sei alles easy.
A. K. (prx) schrieb:
Conny G. schrieb:
>> Ja, der löst den Bedarf an Ints alternativ mit 8 Cores, d.h. statt>> Interrupts die den laufenden Code unterbrechen kann ein Core gemütlich>> auf ein Ereignis warten. Finde den auch sehr cool.> XMOS ist ähnlich, aber weit besser konstruiert.
Alle Jahre wieder, siehe auch Abdul's Frage: "Was wurde aus .."
Beitrag "XMOS jemand?"
;)
Finde die Diskussion auch interessant.
Ich würde bis hierher mal festhalten:
OOP mittels C++ auf Mikrocontrollern geht und macht Sinn. Dass es die
Fehlerquellen reduzieren und leserlichen Code produzieren kann bei
gleichzeitig geringerer Einarbeitungszeit sieht man am Beispiel des
Arduino (hier blende ich mal die typischen Anfängerfragen aus, die nicht
dem Arduino-System verschuldet sind sondern schlichtweg aus Unwissen
oder Faulheit des Fragenstellers resultieren).
Die Probleme der Arduino-Libs (Laufzeit, Ressourcen) könnte man lösen,
wenn man sich mal hinsetzt und gründlich Gedanken macht. Das Beispiel
oben mit dem Portsetzen (was in einem sbi resultiert) beweist dies.
Ret schrieb:> A. K. (prx) schrieb:> Conny G. schrieb:>>> Ja, der löst den Bedarf an Ints alternativ mit 8 Cores, d.h. statt>>> Interrupts die den laufenden Code unterbrechen kann ein Core gemütlich>>> auf ein Ereignis warten. Finde den auch sehr cool.>> XMOS ist ähnlich, aber weit besser konstruiert.>> Alle Jahre wieder, siehe auch Abdul's Frage: "Was wurde aus .."> Beitrag "XMOS jemand?"> ;)
Danke für die Inspiration, hab mir grad ein StartKit bestellt. Habe
gerade eine Aufgabenstellung, wo der Propeller eigentlich gut passen
würde, aber genau dort seine Schwäche hat (RAM-Daten-Transfer zwischen
COGS).
Mal gespannt, ob das mit dem Xmos besser ist.
chris_ schrieb:> Guck mal, hier gibt es einen sehr innovativen Controller ganz ohne> Interrupts:> http://www.parallax.com/microcontrollers/propeller
okay, aber das ist nun nicht gerade ein Feld-Wald-und-Wiesen
Controller...
Auf anderen Controllern habe ich überlicherweise nur einen Core, und
entweder ich polle andauernd alle I/Os oder ich benutze IRQs.
Klar, der Propeller hat eine sehr spezielle Architektur. Bei anderen
Prozessoren gibt es viele Anwendungsfälle, in denen Interrupts
unerlässlich sind wie z.B. Treiber mit Buffer für die serielle
Schnittstelle.
Ich meine zu erkennen, dass das Beispiel von SisyAvr oben auch keine
Interrupts benutzt.
Hier sieht man, dass sie in der Basisklasse vordefinierte
Timerfunktionen haben, die sie bei Bedarf überschreiben:
http://www.avr-cpp.de/doku.php?id=timer
@Chris:
...und wo ist in Deinem Bildchen der Controller ?
(damit meine ich seine Pins)
Abstrahiert hat man doch folgendes Szenarion :
- Entprellroutine muss regelmässig aufgerufen werden.
- Entprellroutine muss irgendwo was machen, vielleicht Dein MyObjekt...
- MyObjekt triggert das LED Object. Dieses Entscheidet was am GPIO
passieren soll.
- GPIO Object ist das unterste Bindeglied.
Das Einzige was pollt ist die Entprellroutine.
Weil sie es muss.
Alle anderen Objecte arbeiten event getriggert.
Kürzer geht es nicht.
In Deinem Bild sehen sich auch noch irgendwie
LED und Entprellung / KEY.
Wofür ? Das wäre wieder komplexität.
Ich denke es ist so wie es oben BastiDerBastler beschrieben hat:
>1) Low-Level. Also das, was man sieht wenn man in die>Peripherie-Treiber-Schicht reinschaut. Hier ist wohl kaum mit>OOP-Techniken irgendetwas zu gewinnen.>>2) High-Level. Also das, was man mit dem Low-Level-Teil macht. Hier>hängt es doch sehr stark von der Applikation ab, wie man ihn umsetzt.>Wenn man riesige dynamische Gebilde hat, kommt vielleicht OOP in Frage,>C++ könnte einen hier unterstützen. Vielleicht aber auch nicht.
Ich wollte mich mit Punkt 2 beschäftigen, oben wurden ja schon ziemlich
effiziente Methoden der Hardwareabstraktion gefunden.
Thomas W. schrieb
>...und wo ist in Deinem Bildchen der Controller ?>(damit meine ich seine Pins)
Zugegebenermaßen ist mein Bildchen dahingehend etwas irreführend, weil
ich ja in Wirklichkeit gar keine Klasse habe, die sich Main nennt. Es
ist einfach die Main-Loop des Arduino:
1
voidloop(){
2
3
Ledled1(12);// led on x
4
Ledled2(13);
5
Ledled3(11);
6
7
Keykey1(4);
8
Keykey2(5);
9
Keykey3(6);
10
11
key1.addKeyPressedListener(&led1);
12
key2.addKeyToogleListener(&led2);
13
key3.addShortLongListener(&led3);
14
15
16
while(1)
17
{
18
key1.update();
19
key2.update();
20
key3.update();
21
22
delay(100);
23
Serial.println(key2.keyToogleState);
24
}
25
}
Wie man sieht, werden die LEDs und KEYs in der "loop" angelegt.
Deshalb verwende ich auch das die "Komposition" in meiner Handzeichnung,
weil die LEDs und KEYs mit der Erzeugung der Main-Loop entstehen:
http://wiki.adolf-reichwein-schule.de/images/8/8f/Uml-assoziationen03.png
Für das Bekanntmachen der LEDs bei den Tastern verwende ich die
Aggregation, weil beide unabhängig von einander existieren.
>Abstrahiert hat man doch folgendes Szenarion :>- Entprellroutine muss regelmässig aufgerufen werden.
Das stimmt. In meinem Programm passiert das durch Key.update(), weil die
Entprellroutinen direkt im Key implementiert sind ( bzw. nur ansatzweise
implementiert sind, weil ich zu faul war und dachte das wäre
ersichtlich) . Wenn Du es lieber hast, könnten wir die Entprellroutinen
raus ziehen. Ich bin mir aber noch nicht sicher, ob das wirklich viel
bringt. Ich gehe davon aus, dass wir die Taste entprellen wollen und
nicht die serielle Schnittstelle.
Chris,
genau deswegen würde ich als LowLevel einen GPIO, SPIHardware, SPI oder
sonstwas Objekt an die nächste Instanz übergeben.
Der Trick ist doch das Du mit jedem Verschiedenen BitWackelTeil, z.b.
die LED, jedes mal das Portgewackel neu erfinden musst.
Wiederverwertbarkeit von Code ist doch auch eine Forderung an OOP.
Man kann den Handler ja auch in der ISR manuell eintragen oder
man baut ein Wrapper Objekt.
Savr oder Dein Link von oben machen das doch eigentlich schon ganz net
vor.
Wobei ich bei letzterem nicht so genau weiss wie es mit der Abstraktion
aussieht.
Bei einem LC Display musst Du gleich mehrere Pins an das Objekt
weitergeben,
man müsste das Bitgewackel wieder selbst anfassen.
Wenn es aber auf das Timing ankommt muss die nächst höhere Instanz ran.
Sehe ich das Richtig,
unbenutzte und überladene Mehtoden werden nicht mitgelinkt ?
Es wird nur das mitgelinkt, was referenziert wird. Zumindest in
optimierten Builds. Wenn eine Funktion überall ge-inlined wird, wird
auch sie nicht ins Image übernommen.
>Der Trick ist doch das Du mit jedem Verschiedenen BitWackelTeil, z.b. die LED,
jedes mal das >Portgewackel neu erfinden musst.
>Wiederverwertbarkeit von Code ist doch auch eine Forderung an OOP.
Ok, mache doch mal 4-5 konkrete Beispiele. So in der Art
"wird eine Taste gedrueckt, soll eine Led leuchten" .
Dann koenen wir darueber nachdenken, wie das umzusetzen waere.
Muss denn hinter jeder Aktion gleich eine Reaktion stehen? Die Aktionen
werden ja meist in einer ISR abgerufen und dort ist meist eh keine Zeit
um groß etwas zu rechnen, etc. Also wird in der Regel eine Flag gesetzt
oder Daten in einen Buffer geschrieben Und das ganze dann im
Hauptprogramm abgearbeitet. Ob die LED jetzt nach 1µS oder nach 50ms
leuchtet ist in der Regel egal und wird sowieso nicht wahrgenommen.
Wichtiger als OOP bis auf das letzte Bit des Controllers runter zu
bringen ist doch eine einheitliche Basis, auf der man aufbauen kann. Vom
Programmablauf ähneln sich ja die meisten Programme ja mehr oder
weniger:
- Hardware initialisieren, Systemtimer starten. In den ISR Daten in
einen Buffer schreiben und eine Flag für das Hauptprogramm setzten. Im
Hauptprogramm wird sich wenn nichts mehr zu tun ist, schlafen gelegt.
Für ein Setze_Bit braucht es noch keine Klasse, aber es wird wohl in
sehr vielen Verwendung finden. Deswegen wäre der Erste schritt eine Art
Betriebssystem zu schreiben, das definierte Funktionen zur Verfügung
stellt und die Hardware entsprechend initialisiert. Also Systemtimer,
UART, I/O,... nach defines o.ä. initialisiert. Letztenendes Alles was
direkten Zugriff auf die Hardware hat muss bereitgestellt werden.
Auf diesen Grundfunktionen können dann alle anderen Funktionen aufbauen,
ob eine Softuart Klasse, Tastenentprellen,... alle haben die gleichen
Hardwareschnittstellen und greifen auf die gleichen Funktionen zu.
Dadurch wird auch schon eine gewisse Wiederverwentbarkeit des Codes
ermöglicht. Auf einem Neuen Controller müssen halt nur genau diese
Grundfunktionen bereit gestellt werden. Aber eine Initialisierung der
Hardware ist ja so oder so nötig.
Und mal nebenbei erwähnt, bei euren Beispielen mit dem Hinzufügen zu den
ISR habt ihr einen entscheidenden Punkt vergessen, die häufigkeit des
aufrufens, nicht jede Funktion muss in jeder Timer ISR aufgerufen
werden. Ich würde sogar noch einen Schritt weiter gehen und einen Offset
einplanen damit man z.B. eine funktion nur in geraden und eine andere
Funktion nur in ungeraden Timer ISRs aufrufen kann und somit die Last
verteilung beeinflussen.
>Der Trick ist doch das Du mit jedem Verschiedenen BitWackelTeil, z.b. die LED,>jedes mal das >Portgewackel neu erfinden musst.>Wiederverwertbarkeit von Code ist doch auch eine Forderung an OOP.
Noch besser wird's, wenn zig verschiedene Klassen auf die Klasse
BitWackel aufbauen. Die brauchen dann für eine neue Wackelart nur eine
dafür vorgesehene Implementierung, d.h. statt WackelAVR ein WackelARM,
und schon Funktionieren sie auf der neuen Kiste. Zwar nur theoretisch,
aber das ist mehr als "gar nicht". Und wenn man sich beim Wackelart
Design nicht zu blöd angestellt hat, dann spielt auch die Realität mit.
Ich behaupte wir haben hier nicht nur blinkende LEDs,
in meinem nicht OOP Beispiel wird ein Signal in 100µs Schritten
abgetastet und auch wieder ausgegeben.
In der Interrupt.h wird doch der ISR Handler per Makro und
Funktionszeiger gebaut.
Das müsste doch auch mit einer Methode gehen.
Ahh ein Methodenzeiger !
So könnte man vielleicht den Wrapper los werden.
...und jetzt noch die virtuelle Handler Methode der Basis Timerklasse in
der Implementierung damit überschreiben.
Schon hat man seine eigene Timerklasse in der man in den Handler
eintragen kann was man will.
---
Eine meiner Forderungen wäre das dass Ansprechen der Hardware gekapselt
von der anderen Programmlogik ist.
Dabei würde es doch schon reichen wenn man
den Buchegger aufbläst
Beitrag "Re: C++ auf einem MC, wie geht das?"
Seine pin Klasse kann auch das DDR zum auslesen setzen...
Nach dem Stil noch die Hardwarefeatures (spi,uart...) aufgesetzt und Gut
ists.
Thomas W. schrieb:> In der Interrupt.h wird doch der ISR Handler per Makro und> Funktionszeiger gebaut.> Das müsste doch auch mit einer Methode gehen.> Ahh ein Methodenzeiger !> So könnte man vielleicht den Wrapper los werden.
Ein Memberfunktion-pointer ist aber anders als ein funktionspointer. Der
aufruf erfordert zwingend das dazugehörige object. Man müsste also eine
templateclasse nehmen, den pointer auf eine darin enthaltene statische
metode holen, welche die als templateparameter übergebene funktion auf
das ebenfalls als templateparameter übergebenen objekt aufruft.
Daniel A. schrieb:> Man müsste also eine> templateclasse nehmen, den pointer auf eine darin enthaltene statische> metode holen, welche die als templateparameter übergebene funktion auf> das ebenfalls als templateparameter übergebenen objekt aufruft.
Mit Pointern kommt man nicht weiter, wenn die Sprung/Vektorleiste für
Interrupt-Handler direkt feste Namen entsprechend C Namenskonvention
anspringt. Da müsste man schon CMSIS oder die avr-libc über Bord werfen
und eine ziemlich eigene Methode für die Vektorleiste erfinden.
Krempelt man jedoch nicht alles um, dann müsste man bei diesem Prinzip
der statischen Methode einen auf Linker-Ebene frei wählbaren
Funktionsnamen verpassen können (irgendein GCC Attribut?) und den dem
Template übergeben können. Geht das?
Bei ARM7/9 Prozessoren hat man es leichter, denn da hat man 32-Bit Werte
beliebiger Konvention in Registern des Interrupt-Controllers und könnte
sogar an Stelle einer Funktionsadresse einen Pointer auf einen Pointer
auf eine Memberfunktion dort reinschreiben.
Ich habe mal einige ideen dazu gesammelt:
* Vieleicht kann man da mit dem gcc alias attribut was drehen
* Mit extern c kann das name mangeling deaktiviert werden. Vileicht
kann man gcc ja eien ensprechend benannten funktionszeiger unterjubeln?
* Man macht ein Makro, welches erst die memberfunktion als inline
deklariert, dann in einem extern block das isr makro benutzt, in der isr
die memberfunktion aufruft, und danach die memberfunktion definiert.
Einen konkretes Anwendungsszenario hinzuschreiben, scheint gar nicht so
einfach ....
Seis drumm, im Anhang ein Bild zur Pinklasse. Wahrscheinlich ist es gut
OutPin und Innpin abzuleiten, dann kann man gleich dir
Richtungsinitialisierung einbauen.
chris_ schrieb:> Einen konkretes Anwendungsszenario hinzuschreiben, scheint gar nicht so> einfach ....> Seis drumm, im Anhang ein Bild zur Pinklasse. Wahrscheinlich ist es gut> OutPin und Innpin abzuleiten, dann kann man gleich dir> Richtungsinitialisierung einbauen.
Könnte man so noch weiter untergliedern, in die Funktion des jeweiligen
Pins.
Jetzt wären wir wieder beim Konkreten: wie soll eine Tri-State Klasse
verwendet werden? Ich habe auch schon darüber nachgedacht, mir ist aber
nichts eingefallen.
Man könnte es aber auch fast so belassen, wie es Karl-Heinz oben gemacht
hat:
http://www.mikrocontroller.net/attachment/237464/PinTest.cpp
Dem Pin eine Funktion toOutput mitgeben, mit dem er auf Output gestellt
wird. Meiner Meinung nach fehlt dort aber die Funktion toInput, bei der
das DDR wieder auf Input umgestellt werden kann. Außerdem sollte das Pin
in der Inittialisierung auf "input" gestellt werden.
Die Idee mit dem Methodenaufruf für die ISR geht nicht weil der ISR
Vector vom Linker aufgelöst wird ?
Dachte immer das wäre ein reinrassiger Funktionszeiger.
Die sind mehr als nur ein Jump auf Assemblerebene ?
(Kontext etc...)
---
Denke für Polling wird das so funktionieren.
Beim PinChange Interrupt kehrt sich die Richtung um.
In meinem nicht OOP Beispiel ist (wird wenn der entsprechende Solver*
eingebaut ist) alles nebenläufig sein.
Das könnte sich am ende beissen.
Hier wird immer eine ganze Kette aufgerufen.
Oder verrenne ich mich gerade ?
* : Der Solver wird eine multiplikative und additive "korrektur"
einbringen. Abgetastet wird mit dem ISR Takt, genauso die Ausgabe.
Gerechnet wird im Solver. (MainLoop)
PS: Hängt wohl an "meiner Betriebsart" das ich aus den vorhandenen
Modell immer alle pins Zyklisch setze, auch wenn sich nichts verändert
hat.
Diese ganzen Klassen hören sich erstmal toll an, vor allem wenn man den
Gedanken weiterspinnt und sich UART, LCD und SPI Klassen anlegt. Eine
LCD Klasse erhält noch die benötigten Pins mit übergeben (per Template
oder im Konstruktor).
Aber wie würde man vorgehen, wenn es von einer internen Hardware mehrere
Instanzen gäbe, Beispiel UART?
Ich müsste entweder das komplette Registersetup per Template/Konstruktor
übergeben, oder ich halte für jede Instanz eine eine Liste im RAM vor.
Bei letzterem bin ich mir aber nicht sicher wie effizient der Compiler
dann die Zugriffe umsetzen kann...
Man könnte die Pins und die Hardware (z.B. lcd) auch mit einem kabel
verbinden. Man hat dann irgendwo die classe lcd, und irgendwo die klasse
wire. Die klasse wire wird dann in einem eigenen file mit den pins
(welche eine eigene classe haben) und der Hardware ( classe lcd_xyz)
instanziert. Dadurch kann man dann ganz einfach auf unterschiedlichen
hardwareconfigurationen unterschiedliche verbindungen definieren.
Naja,
ich denke man sollte schon die verschiedenen Schichten stark trennen.
Niedrige schicht: GPIO, SPI, TWI --- Direkte Hardwaremanipulation.
Höhe Schicht : LCD, Schiebergister --- Übersetzt Datenstrom,
Anforderungen in LowLevel Ebene.
Höchste Schicht : Anwendung/Solver die auf die über die unteren
schichten auf die Hardware zugreifen. --- komplette höhere Logik,
Denke darunter versteht man einen Hardware Abstration Layer.
Karl Heinz schrieb:> Ich denke ein wirklich> nicht unwesentlicher Punkt wäre es, für diese Low-Level Sachen ein gut> aufgebautes Framework zu haben, welches diese ganzen Port, Pin, DDR> Sachen sauber kapselt OHNE dabei Codemässig stark aufzutragen.
Ich hab' da mal was probiert... (Siehe Anhang.)
So eine Pin-Klasse trägt überhaupt nicht auf. Das alles reduziert sich
auf ein paar Befehle.
Jetzt habe ich aber ein Problem als Hobby-Programmierer! Wenn ich nun
versuche von 'mcPin' eine Klasse 'mcKey' abzuleiten, dann fängt der
Compiler an, liederlich zu arbeiten ;-) Auf einmal wird nichts mehr
ge-inlined.
Was brauch' ich jetzt für Zaubersprüche, um dem Compiler auf die Sprünge
zu helfen?
Hallo Karl Heinz,
Karl Heinz schrieb:> Das hab ich gerade eben erst erfunden :-)> Und es ist das leidige Problem, zuverlässig aus der Portangabe die DDR> Adresse zu ermitteln.
Warum die Information nicht einfach mitnehmen? Der Optimizier will sich
ja auch nicht langweilen.
Da sind jetzt schon ein paar C++-Features (Klassen, Vererbung, Überladen
von Operatoren) drin, die das (IMHO) am Ende deutlich les- und wartbarer
machen als den entsprechenden C-Code. Und das ist meines Erachtens dann
auch das eigentliche Ziel von C++: den Code besser zu strukturieren und
dessen Wartbarkeit und Wiederverwendbarkeit zu erhöhen.
Nebenbei habe ich den Code mal mit avr-c++ -O3 übersetzt, mit avr-strip
bearbytet, jeweils einmal mit überladenem "="-Operator und einmal ohne
(und dafür [1]) in der main()-Loop. Ergebnis: in beiden Fällen ist das
Kompilat 524 Bytes groß (-mmcu=atmega328).
Um einmal zu schauen, wie groß das Kompilat ist, wenn ich genau dieselbe
Funktionalität in C implementiere, habe ich den Code aus [2] benutzt und
mit denselben Compilereinstellungen mit avr-gcc übersetzt.
Wie soll ich sagen: auf meinem Kubuntu 14.04 LTS mit avr-gcc 4.8.2 ist
auch das C-Kompilat exakt 524 Bytes groß, genau wie mit C++. Übrigens
dasselbe, wenn ich die unnötige Zeile weglasse. Scheint ja wirklich ein
böses Zeug mit einem riesigen Overhead zu sein, dieses C++. Oder so. ;-)
Wie dem auch sei: als jemand, der seine Brötchen als UNIX-Guru verdient
und daher nicht täglich Codezeilen wie "DDRB &= ~(1 << PB0)" sieht,
finde ich die C++-Variante viel les- und wartbarer als die Version in C.
Just my centz,
Karl
[1] Code:
1
if(btnPin.isHigh()){
2
ledPin.setHigh();
3
}else{
4
ledPin.setLow();
5
}
[2] Code:
1
#include<avr/io.h>
2
3
intmain(){
4
5
DDRD|=(1<<PD0);// set OUTPUT
6
DDRB&=~(1<<PB0);// unnecessary: is already an INPUT
Hallo Peter,
Peter Dannegger schrieb:> Heiliger Bimbam schrieb:>> Ist Euch die Programmierung in den gängigen Sprachen noch nicht>> kompliziert genug?>> Karl Heinz hat das ganz richtig erkannt, es geht mir vorrangig darum,> das Programmieren einfacher und sicherer zu machen.
Genau dafür ist C++ ein enorm leistungsfähiges Werkzeug. Leider werfen
die meisten, die hier Beiträge verfassen, die Konzepte wild
durcheinander und scheinen C++ nicht wirklich verstanden zu haben.
> Und C++ ist ja schon im AVR-GCC includiert, man braucht also an der> Programmierumgebung nichts zu ändern. Einfach nur *.c nach *.C> umbenennen.
Besser ".cpp" und ".hpp", dann kommen auch die Windowsleute besser klar.
Liebe Grüße,
Karl
PS: danke für Deine Libraries!
Hi Ticktacktoe,
tictactoe schrieb:> tictactoe schrieb:>> Dann können wir also z.B. einen Array mit Pointern auf die Clienten>> anlegen, damit wir die virtuelle Handler-Funktione aufrufen können.>> Vielleicht so>> ...>> Aber das kriegt man auch mit Template-Metaprogramming hin>> Ich muss hier nochmal nachhaken. Mein Post ist eine Werbung für> Template-Metaprogramming. Man muss hier aber einen Schritt zurück machen> und noch mal die Ausgangssituation betrachten. Gerade weil man auf einem> µC keine dynamischen Listen von (Uhren, Tastern...) hat, könnte man> Template-Metaprogramming verwenden (weil alle teilnehmenden Klassen zur> Compile-Zeit bekannt sind). Aber aus dem selben Grund kann man genau so> gut auch schreiben:>
1
ISR(TIMER0_OVF_vect){
2
>uhr.OVF_vect();
3
>taste1.OVF_vect();
4
>taste2.OVF_vect();
5
>}
6
>
> Wozu also das ganze Gedöns um virtuelle Funktionen (braucht man bei> dieser Form nicht) und Template-Metaprogramming? Hab' ich was an den> Anforderungen nicht verstanden?
Nein, die Anforderungen sind nicht das Problem. Das Problem ist ein ganz
anderes, viel tiefgreifenderes.
Du (und Karl Heinz und viele andere hier im Thread) habt den Sinn von
Klassen, Instanzen und vor allem Templates einfach noch nicht richtig
verstanden. Ein Template-Parameter ist ein Datentyp und wird übergeben,
damit dieselbe Operation mit verschiedenen Datentypen ausgeführt werden
kann.
Liebe Grüße,
Karl
Ret schrieb:> F. Fo (foldi) schrieb:>> Dr. Sommer schrieb:>>> Aber auch in Brainfuck. Warum verwendet niemand Brainfuck? Es ist>>> supereinfach zu lernen, verwenden und implementieren.>>> Habe mir das mal angeguckt - ich hätte fast gekotzt.>> Da kann ich dich voll verstehen! Denn mir geht es genau nicht anders.> Wer so einen hingekotzten Zeichensalat (ich hab extra nochmal> nachgeschaut) wie Brainfuck ernsthaft als Programmiersprache empfiehlt,> verarscht entweder seine Mitdiskutanten oder hat schlicht nicht alle> Tassen im Schrank. Langsam nähren sich in mir die Anzeichen, dass ich> solche Leute künftig an anderer Stelle nicht mehr für voll nehmen> sollte. Und wenn mir der gleiche Herr demnächst dann seine C++> Template-Orgien schmackhaft unter die Nase reiben will, denke ich mir> darauf, "hab Nachsicht mit ihm! Das ist einer, der auf Brainfuck steht.> Von dem kann einfach nichts Brauchbares oder Gescheites kommen".>> So kann man sich seine Glaubwürdigkeit hier auf einen Schlag verspielen.> Aber vielleicht passt auch alles gut zusammen. Wer auf Brainfuck steht,
Man kann das hier abkürzen: wer auf Brainfuck steht, ist brainfucked.
Wer auf Mikrocontrollern C++-Templateprogrammierung einsetzen will,
braucht aber auch gute Gründe. ;-)
Beste Grüße,
Karl
Karl Käfer schrieb:> verstanden. Ein Template-Parameter ist ein Datentyp und wird übergeben,> damit dieselbe Operation mit verschiedenen Datentypen ausgeführt werden> kann.
Das ist praktisch das Konstrukt, das in Java "generics" heißt?
Hallo Conny,
Conny G. schrieb:> Karl Käfer schrieb:>> verstanden. Ein Template-Parameter ist ein Datentyp und wird übergeben,>> damit dieselbe Operation mit verschiedenen Datentypen ausgeführt werden>> kann.>> Das ist praktisch das Konstrukt, das in Java "generics" heißt?
Ja, genau das.
Liebe Grüße,
Karl
Karl Käfer schrieb:> Du (und Karl Heinz und viele andere hier im Thread) habt den Sinn von> Klassen, Instanzen und vor allem Templates einfach noch nicht richtig> verstanden. Ein Template-Parameter ist ein Datentyp und wird übergeben,> damit dieselbe Operation mit verschiedenen Datentypen ausgeführt werden> kann.
Nananana..
Also ich sag's mal so: Wenn die Features einer Programmiersprache so
extrem schwer zu begreifen sind, daß "Du (und Karl Heinz und viele
andere hier im Thread)" es trotz deiner vielen Worte noch immer nicht
begriffen haben, dann taugt diese Programmiersprache nix. Schließlich
soll sie ja dem geneigten Programmierer das Leben erleichtern und ihn
nicht veranlassen, sich das Hirn zermartern zu müssen.
Aber mal konkret: Klassen sind Typen und um damit was anfangen zu
können, muß man Daten so eines Types erschaffen, auch Instanziieren
genannt. Sowas ist ganz generell eine softwareinterne Angelegenheit.
Du kannst keinen Port instanziieren, denn der ist schlichtweg da, ganz
einfach in der zugrundeliegenden Hardware DA. Du kannst mit all dem
Klassengedöns lediglich die Hardware in eine zusätzliche Softwareschicht
einwickeln - und diese Schicht kannst du dann instanziieren nach
Belieben.
Blöd ist nur, daß du je nach Hardware innerhalb der Methoden deiner
Klasse in ganz erheblichen Fallunterscheidungen ersticken wirst.
Versuche z.B. mal die Pins eines gewöhnlichen ARM Controllers
einzurichten. Ei wo ist denn nun der Satz von 2 oder 4 Bits innerhalb
eines der 9 PINSEL Register, der für das gesuchte Pin zuständig ist? Und
hat dieser Eintrag überhaupt was zu sagen, wenn an anderer Stelle ein
Peripheriecore aktiviert ist, der diesen Pin von sch aus belegt?
Mit so einem simplen AVR als Beispiel sieht die Welt noch einfach aus,
aber wollen wir hier über akademische Bleistift-Geraderückerei reden
oder über reale Dinge aus der Praxis? Vielleicht sollte man sowas ganz
am Anfang eines Threads mal klar festlegen.
Aber bei der o.g. Wrapperei geht der tiefere Sinn verloren, denn du hast
in der Hardware niemals mehrere gleichartige Objekte, die aus Sicht des
übergeordneten Programms gleichbehandelt werden können. Immerhin hat
(eigentlich) jedes verdammte Pin am Käfer seine besondere Bedeutung und
seine Funktionalität, die es von allen anderen unterscheidet. Das Pin
für das Zünden der Bombe hat wirklich eine ganz andere Behandlung
verdient als das Pin zum Einschalten der Displaybeleuchtung.
Abgesehen davon halte ich so eine Pseudo-Vereinfachung wie
if(btnPin.isHigh())
ledPin.setHigh();
else
ledPin.setLow();
für unzureichenden Mumpitz. Es wird in jedem Falle ein Unterprogramm
aufgerufen und ehe man irgendwelche allumfassenden Wrapper-Klassen
erfindet, wäre es leichter und klarer, selbiges mit ganz simplen
gewöhnlichen Unterprogrammen zu erledigen.
Das würde dann ENDLICH die eigentlich angstrebte Abstraktion bringen:
if (StartKnopfGedrueckt())
{ BeleuchtungEin();
if (GangEingelegt() || !BremseGedrueckt())
beep(); //
else
StarteMotor();
}
else
{ ZuendungAus();
BeleuchtungAus();
}
Siehste: Hier wird nicht mit popligen Bit High oder Bit Low
herumgefummelt, denn jemand, der draufschaut, weiß nicht, welchem
eigentlichen Systemzustand "btnPin.isHigh()" entspricht. Und was man mit
"ledPin.setLow()" anrichtet, steht auch nicht dabei. Sowas ist also ein
ausgesprochen mickriger Abstraktionslevel, der letztlich herzlich unnütz
ist.
W.S.
@WS:
Ich vermute ich verstehe Dich recht gut.
Das was Du beschreibst setzte ich so um.
Allerdings lasse ich in einer Timer ISR alle Ausgänge immer wieder neu
setzten.
Die eigentlichen Zustände stehen in einem grossen Struct.
Die Setter/Getter Funktionen greifen nur auf das Struct und /oder
bereiten dinge vor.
Dabei kommt sowas heraus wie : setMotor(Motor1,Zeit_in_Timertakte);
Im Logikteil Zustandsautomat Hauptschleife sieht das recht gut aus.
Mein obiges Beispiel ist unfertig und hat noch keine Setter/Getter,
aber der Grundsätzliche aufbau ist sichtbar.
Du kannst Dir sicherlich vorstellen wie sich (prozeduraler Ansatz) die
ISR aufbläht, unübersichtlich wird.
Tiefere Änderungen sind schmerzhaft !
Derzeit habe ich einen Kunden der ständig das Lastenheft ändert.
Ich glaube ich habe die ISR und Setter/Getter schon mindestens 100 mal
angeändert.
Das Projekt verschlingt mittlerweile 6kb flash, ohne Mathmatik.
Was meinst Du wieviel schreiberei sowas in prozedural ersetzen könnte ?
{
GPIOPWMGEN motor1PWM(GPIO::GPIO(PORTB,4));
GPIOPWMGEN motor2PWM(GPIO::GPIO(PORTB,6));
GPIOPWMGEN motor3PWM(GPIO::GPIO(PORTB,9));
motor1PWM.setPWM(PẀM1);
motor2PWM.setPWM(PWM2);
motor3PWM.setPWM(PWM3);
....
}
ISR (TIMER)
{
motor1PWM.handler();
motor2PWM.handler();
motor3PWM.handler();
}
Dafür braucht man aber auch eine GPIO, PWM, SPI... irgendwas Klasse.
Danach baut man die "höhere" Logik ein.
Andere Baustelle, oder ?
Hallo W.S.,
W.S. schrieb:> Also ich sag's mal so: Wenn die Features einer Programmiersprache so> extrem schwer zu begreifen sind, daß "Du (und Karl Heinz und viele> andere hier im Thread)" es trotz deiner vielen Worte noch immer nicht> begriffen haben, dann taugt diese Programmiersprache nix. Schließlich> soll sie ja dem geneigten Programmierer das Leben erleichtern und ihn> nicht veranlassen, sich das Hirn zermartern zu müssen.
Tja, das ist so eine Sache mit dem Verständnis: entweder man hat es,
oder man hat es eben nicht. Daß schon C enorm komplex ist, siehst Du
schon an den vielen Fragen und Fehlern, die hier ständig aufschlagen --
und die bisweilen sogar sehr erfahrenen C-Entwicklern passieren. Was
hattest Du denn erwartet, was herauskommt, wenn man eine komplizierte
Sprache wie C um ein komplexes Paradigma wie die Objektorientierung
erweitert? Diese Komplexität ist der Preis für die Mächtigkeit, und wenn
Du von diesen vielen neuen Features überfordert bist, spricht das nicht
unbedingt gegen die Features. Dies gilt insbesondere, da es sich bei dem
Besagten um eines handelt, das ausschließlich der Bequemlichkeit des
Entwicklers dient und somit zur besseren Wart- und Wiederverwendbarkeit
des Code beiträgt.
Du mußt das Feature ja nicht benutzen und kannst Dir gerne und jederzeit
Deine eigenen Klassen für vector_int, vector_long, vector_float und so
weiter schreiben. Ich hingegen bevorzuge eindeutig das Standard-Template
std::vector<T> und kann damit genau dieselben vector-Klassen automatisch
erzeugen lassen, die Du Dir mühselig und fehlerträchtig von Hand
zusammen basteln müßtest.
Und wenn Du Deine Aussagen einmal zuende denkst, endest Du irgendwann
bei Programmiersprachen, die dem intellektuellen Niveau solcher,
hüstel, "Argumentationen", entsprechen: Niki the robot, BASIC und
Scratch. ;-)
> Aber mal konkret: Klassen sind Typen und um damit was anfangen zu> können, muß man Daten so eines Types erschaffen, auch Instanziieren> genannt. Sowas ist ganz generell eine softwareinterne Angelegenheit.
Gut erkannt.
> Du kannst keinen Port instanziieren, denn der ist schlichtweg da, ganz> einfach in der zugrundeliegenden Hardware DA.
Ja, und nein. Ja, der Port im Sinne der zugrundeliegenden Hardware ist
bereits vorhanden, aber seine softwaretechnische Abstraktion natürlich
nicht. Oder verzichtest Du auf <avr/io.h> und programmierst direkt gegen
die Registeradressen? Auch die #defines sind letztlich Abstraktionen,
welche die Lesbarkeit und die Verständlichkeit erhöhen sollen.
Aber richtig: ein Port ist jedenfalls kein Datentyp, und seine Adresse
ist auch keiner. Genau deswegen sind, wie ich schon sagte, Templates
hier schlicht und ergreifend deplatziert und nicht das Mittel der Wahl.
Daß Du dieses Feature mißverstehst, spricht immer noch nicht gegen das
Feature, sondern nur gegen Dein Verständnis davon. Nicht schlimm: wie
wir gerade erst gesehen haben, befindest Du Dich da in sehr guter
Gesellschaft.
> Blöd ist nur, daß du je nach Hardware innerhalb der Methoden deiner> Klasse in ganz erheblichen Fallunterscheidungen ersticken wirst.> Versuche z.B. mal die Pins eines gewöhnlichen ARM Controllers> einzurichten. Ei wo ist denn nun der Satz von 2 oder 4 Bits innerhalb> eines der 9 PINSEL Register, der für das gesuchte Pin zuständig ist? Und> hat dieser Eintrag überhaupt was zu sagen, wenn an anderer Stelle ein> Peripheriecore aktiviert ist, der diesen Pin von sch aus belegt?
Du benutzt die AVR-Header für ARM-Controller? Erzähl mehr davon, das
klingt zwar wenig zielführend, dafür aber sehr interessant. Nein, im
Ernst: wer sagt, daß man für AVRs, PICs und ARMs dieselben Klassen,
dieselbe Abstraktion verwenden muß? Das ist nur Deine ganz persönliche,
naive, wenn nicht sogar böswillige Unterstellung.
Tatsächlich könnte man jedoch für ARMs, AVRs und andere Controller immer
dieselbe Schnittstelle verwenden. Was die Methode Pin::setHigh() macht,
läßt sich hinter einer simplen Abstraktionsschicht verbergen, ähnlich
wie avr/io.h die richtigen Adressen für DDRB, PINB und PORTB des
betreffenden Controllers einbindet -- je nachdem, was avr-gcc als "mmcu"
bekommt.
> Mit so einem simplen AVR als Beispiel sieht die Welt noch einfach aus,> aber wollen wir hier über akademische Bleistift-Geraderückerei reden> oder über reale Dinge aus der Praxis? Vielleicht sollte man sowas ganz> am Anfang eines Threads mal klar festlegen.
In diesem Fall sind die akademische und die praktische Betrachtung
absolut deckungsgleich: Templates übergeben Datentypen an generische
Klassen und Funktionen, Punkt. Templates sind kein alternativer
Mechanismus zur Übergabe von Variablen, Punkt. Ob Du das praktisch,
theoretisch, oder akademisch betrachtest, ist egal, es kommt immer
dasselbe dabei heraus: Templates sind hier nicht das richtige Feature,
ganz einfach.
> Aber bei der o.g. Wrapperei geht der tiefere Sinn verloren, denn du hast> in der Hardware niemals mehrere gleichartige Objekte, die aus Sicht des> übergeordneten Programms gleichbehandelt werden können. Immerhin hat> (eigentlich) jedes verdammte Pin am Käfer seine besondere Bedeutung und> seine Funktionalität, die es von allen anderen unterscheidet. Das Pin> für das Zünden der Bombe hat wirklich eine ganz andere Behandlung> verdient als das Pin zum Einschalten der Displaybeleuchtung.
Letzten Endes ist ihre Funktionalität aber exakt dieselbe: High heißt
"$Peripherie einschalten", Low bedeutet "$Periperhie ausschalten" -- und
zwar völlig ungeachtet ob $Peripherie nun der Initialzünder der Bombe
oder die Displaybeleuchtung ist. Und wenn ich in meinem Programm die
Instanz des Bomben-Pins "zuender" und die Instanz des Display-Pins
"beleuchtung" nenne, ist das am Ende schon ziemlich deutlich.
> Abgesehen davon halte ich so eine Pseudo-Vereinfachung wie>> if(btnPin.isHigh())> ledPin.setHigh();> else> ledPin.setLow();>> für unzureichenden Mumpitz.
Nein. Der Mumpitz ist nur, was Du daraus zusammenkonstruierst, um krude
Thesen zu belegen. Was ich hier gemacht habe, ist eine Verallgemeinerung
der Hardware, hier die von Input- und Output-Pins. Das sagt natürlich
noch nichts darüber, was an den Input- und Output-Pins hängt, welchen
Zuständen der daran hängenden Peripherie-Hardware isHigh() und isLow()
entsprechen, und was setHigh() und setLow() am ledPin bewirken. Das
gehört aber ganz woanders hin und ist für jedes Projekt unterschiedlich:
in einem Projekt schalte ich eine LED gegen GND, dann schaltet setHigh()
die LED ein, und in einem anderen Projekt schalte ich die LED gegen Vcc,
dann schaltet setHigh() die LED aus. Deswegen kann ich nicht
allgemeingültig eine Klasse LED festlegen, weil ich nicht
allgemeingültig sagen kann, ob on() den Pin jetzt High oder Low setzen
muß.
> Es wird in jedem Falle ein Unterprogramm aufgerufen
Nö, der Optimizer macht genau dasselbe wie beim Direktzugriff auf die
Register. Aber während Du eine sehr konkrete Funktionalität für ein ganz
bestimmtes Projekt mit einer definierten Peripherie-Hardware zeigst,
ging es bei mir um eine allgemeine Abstraktion der uC-Hardware statt um
eine singuläre, projektspezifische Hardwarebeschreibung der Peripherie.
Um also aus meiner Abstraktion des Mikrocontrollers ein richtiges
Projekt mit einer bestimmten Peripherie-Hardware zu machen, braucht es
noch einen weiteren Layer: nämlich eine Abstraktion der
Peripherie-Hardware -- die allerdings prima auf Basis meiner
uC-Abstraktion erfolgen kann.
> und ehe man irgendwelche allumfassenden Wrapper-Klassen> erfindet, wäre es leichter und klarer, selbiges mit ganz simplen> gewöhnlichen Unterprogrammen zu erledigen.> Das würde dann ENDLICH die eigentlich angstrebte Abstraktion bringen:> if (StartKnopfGedrueckt())> { BeleuchtungEin();> if (GangEingelegt() || !BremseGedrueckt())> beep(); //> else> StarteMotor();> }> else> { ZuendungAus();> BeleuchtungAus();> }
Ja, Du kannst Dir natürlich für jeden Kram eine eigene Funktion basteln,
genau wie ich mir meine Klasse. Von der Konsistenz ("StarteMotor()" und
"ZuendungAus()"?) Deines Beispielcode einmal abgesehen: was hindert mich
daran, das mit Klassen zu abstrahieren? Ach ja: nichts.
1
if(startknopf.gedrueckt()){
2
beleuchtung.ein();
3
if(gang.eingelegt()||!bremse.gedrueckt()){
4
beep();//
5
}else{
6
motor.ein();
7
}
8
}else{
9
motor.aus();
10
beleuchtung.aus();
11
}
> Siehste: Hier wird nicht mit popligen Bit High oder Bit Low> herumgefummelt, denn jemand, der draufschaut, weiß nicht, welchem> eigentlichen Systemzustand "btnPin.isHigh()" entspricht.
Vergleiche meinen Code mit Deinem. Merkst Du was? Zum Beispiel für die
Instanzen motor und beleuchtung oder für die Instanzen startknopf und
bremse? Na? Genau:
So läßt sich auf der Basis meiner Klassen eine einfache, lesbare und
trotzdem sehr flexible Abstraktion der Peripherie-Hardware durchführen.
Der Code in der Hauptschleife ist ähnlich wie Deiner, nur konsistenter,
lesbarer -- und ohne den logischen Fehler den Du gemacht hast. Diese
Abstraktionsschicht ist sehr leicht, absolut projektspezifisch und trägt
auch im Maschinencode nicht auf: das optimierte Kompilat ist nach
avr-strip 536 Bytes groß. Und jetzt? Fällt Dir auch mal was Sachliches,
Konstruktives und vielleicht sogar Kluges zum Thema ein?
Liebe Grüße,
Karl
@Karl:
Das finde ich ein gutes Beispiel.
Werden mehrere Motoren verwendet, dann wird der Vorteil von
Objektorientierung besonders deutlich:
EinAus motorLinks = EinAus(&DDRB, &PORTB, &PINB, PB1);
EinAus motorRechts = EinAus(&DDRB, &PORTB, &PINB, PB2);
...
motorLinks.ein();
motorRechts.ein();
Natürlich geht es auch so:
StarteMotorlinks();
StarteMotorRechts();
oder:
StarteMotor(pMotorParameterLinks);
StarteMotor(pMotorParameterRechts);
Aber dafür darf ich mein komplettes Programm ändern - überall, wo bisher
StarteMotor() stand.
Spätestens, wenn die Motorsteuerung komplexer wird, weil z.B. der Choke
in Abhängigkeit von der Temperatur etc. gezogen werden muß: beim
objektorientierten Ansatz ändert sich nur die Klasse Motor, im gesamten
restlichen Programm wird der Code nicht angefasst.
Ich habe lange "normales" C programmiert. Nachdem ich auf C++
umgestiegen bin, habe ich dann gemerkt, daß viele Probleme, die ich
früher mühsam von Hand mit structs etc. gelöst habe, in C++ sehr einfach
und logisch lösbar sind. Und in den allermeisten Fällen ohne negative
Auswirkungen auf Performance und Codegröße.
Viele Grüße,
Stefan
... macht nach Adam Riese maximal schnelle 32 Bytes (+ ein paar für die
Beep-Routine) bei viel weniger Schreibaufwand, mindestens genauso
übersichtlich und ohne sich das Hirn mit komplexen Programmausdrücken
aufreiben zu müssen. Hier fehlt in Asm lediglich, einem Ausdruck wie
portb,0 ein passendes Alias geben zu können. Und jetzt?
Moby schrieb:> Und jetzt?
Und jetzt bitte eine Antwort auf die Frage des TO.
Nur am Rande: er hatte nicht gefragt, ob und wie man ein Bit in
Assembler setzen kann.
Moby: Bei Deinem Quelltext muss ich dem Programmfluss folgen um zu
sehen, wo und wie die Schleifen oder die Fallunterscheidungen liegen.
Daher habe ich länger benötigt um zu verstehen, was geschieht.
Mal abgesehen davon, daß der TO nach C++ gefragt hat, ist es einfach nur
peinlich, Peter Danegger etwas über Assembler erzählen zu wollen.
Gruß, Stefan
Moby schrieb:> Und jetzt?
Der Assemblerbrei ist ja wohl auch keine Schmeicheleinheit für die
Augen. Ob das nun 32Byte oder das 10fache ist spielt keine Rolle. Aus so
was wird nie wartbarer Code.
Moby schrieb im Beitrag #3910701:
> Ich denke, diese wenigen Zeilen werden keinen der doch so komplex denken> könnenden C++ Programmierer überfordern ;-)
Schön provokant, aber in der Sache kein zusätzlicher Gedankeninhalt.
Nächster Versuch!
Das lieber Lässt Du mal besser weg.
Sowohl Peter Danegger, als auch Klaus, und genauso ich haben sicher
schon wesentlich mehr in Assembler gearbeitet und sind mittlerweile ein
paar Softwaregenerationen weiter als Du.
Stefan
Moby schrieb:> Und jetzt?
Und jetzt portierst Du den Assembler-Code auf zwölf verschiedene
Mikroprozessoren mit unterschiedlichen Befehlssätzen. Viel Spaß dabei!
:-)
Ganz unrecht hat moby aber auch nicht. Gut bei seinem code fehlt die
initialisierung. Also lasst es 100 zu 500 byte code sein. Das is ne
Menge für ein und dieselbe Aufgabe.
Lesbarer wäre der Code mit kommentaren, ist also auch nicht so schlimm.
Und offtopic ist es auch nicht, da ihr immer argumentiert, es gibt
keinen overhead.
Also wo kommen die ca400 bytes her? Hier wäre das asm file nicht
schlecht. Evtl fehlende optimierungen?
Vom code sieht das c++ ja nicht schlecht aus, wobei ich dem pin noch nen
startwert mitgeben würde beim initialisieren.
Auch wurde ich dem outputpin gleich an und aus als Funktion geben und
noch nen inveroutoutpin einbauen.
Moby schrieb im Beitrag #3910841:
> Ist das etwa alles?> Ich meine zum eigentlichen Thema?
Jetzt folgst Du vollends dem normalen Trollschema. Du trägst nichts bei
außer einer (möglichst feinfühligen) Provokation und dann drehen wir uns
wieder auf einer Metaebene im Kreis, also lassen wir's einfach bleiben!
Robin E. schrieb:> Ganz unrecht hat moby aber auch nicht. Gut bei seinem code fehlt die> initialisierung. Also lasst es 100 zu 500 byte code sein. Das is ne> Menge für ein und dieselbe Aufgabe.
Was auch immer der Autor dort oben mit seiner Bibliothek gemacht hat, es
war offenbar nicht gut, oder aber der entsprechende Compiler ist extrem
schlecht, wenn es zu solchen Unterschieden kommt. Ja, Startup kostet ein
bissl was, C-Runtime-Init vielleicht auch (aber nicht so viel,
wahrscheinlich hat er keine minimal-Runtime ausgewählt). So sollte aber
nicht dermaßen viel Overhead entstehen. Wenn man im Stande ist, den
Startup-Code zu verändern, entfällt es dann auch gänzlich. Vielleicht
ist der AVR-gcc aber auch einfach schlecht, würde mich nicht
überraschen.
Moby schrieb im Beitrag #3910701:
> Tja Klaus, zur Frage C++ auf MC gehört immer auch die Frage der> Sinnhaftigkeit.
Wie wärs wenn du mal über die Sinnhaftigkeit deiner Beiträge denkst,
anstatt hier ständig ungefragt deine Ansichten zu C und C++ zu
verbreiten. Im Forum müsste es jetzt jeder wissen. Gibt es dir nicht mal
langsam zu denken, wenn kein Anderer deine Meinung teilt und dir schon
etliche Leute (die auch noch beruflich mit µCs zutun haben) dagegen
argumentieren? Dazu kommt dann noch dass du von C++ (und anscheinend C)
keine Ahnung hast, es aber dennoch erbittert bekämpfst. Ganz ehrlich, du
erinnerst mich an irgendwelche fanatischen Missionare, die meinen den
einzig wahren Glauben verbreiten zu müssen.
Moby schrieb:> . macht nach Adam Riese maximal schnelle 32 Bytes (+ ein paar für die> Beep-Routine) bei viel weniger Schreibaufwand, mindestens genauso> übersichtlich und ohne sich das Hirn mit komplexen Programmausdrücken> aufreiben zu müssen. Hier fehlt in Asm lediglich, einem Ausdruck wie> portb,0 ein passendes Alias geben zu können. Und jetzt?
Auf den Punkt gebracht. Zumindest für diese Aufgabe. Natürlich
programmiere auch ich keine LAN Anbindung in Assembler. Wobei man da
schon den klassischen MC verlässt. Der Kluge Entwickler passt sein
Sprachwerkzeug der Anforderung an und micht C u. assembler und da wo er
komplexe nicht zeitkritische Aufgaben hat und den entsprechenden
Speicher zur Verfügung meinetwegen auch C++.
TriHexagon schrieb:> die meinen den> einzig wahren Glauben verbreiten zu müssen
Nun, das Asm-Beispiel bezeugt keinen Glauben, sondern schlicht Fakten.
Auch wenn sie manchem OOP-Gläubigen nicht in den Kram passen ;-)
Paladium schrieb:> Auf den Punkt gebracht. Zumindest für diese Aufgabe.
Für viele weitere genauso ;-)
Moby schrieb im Beitrag #3910701:
> Tja Klaus, zur Frage C++ auf MC gehört immer auch die Frage der> Sinnhaftigkeit
Sicher nicht. Peters Frage war klar - nach Assemblerlösungen wurde nicht
gefragt.
Wenn Du diese Frage stellen willst, mach bitte Deinen eigenen Thread
dazu auf.
Danke.
Hallo Moby,
Moby schrieb:> Und jetzt?
Irgendwie habe ich trotz intensiver Bemühungen noch nicht verstanden,
welche Relevanz das denn für eine Diskussion haben sollte, bei der es um
C++ (und damit: um les-, wart- und wiederverwendbaren Code) auf
Mikrocontrollern geht.
Trotzdem vielen Dank für Deinen "Beitrag".
Liebe Grüße,
Karl
Ich hatte ja schon mal hier die PSoC angeführt. Da wird der Hardwareteil
als Schaltung dargestellt und auch die Funktionen, die ein Pin ausüben
soll wird dort in der graphischen Ansicht eingestellt.
Dahinter muss sich doch im Prinzip solch ein Konzept verbergen.
Eine einmal klar getrennte Hardware, wohl möglich noch für eine ganze
Gruppe von µC's, die dann den eigentlich wichtigen Code wartbarer und
austauschbar macht, das wäre doch wünschenswert.
das war ein spannender und sehr detaillierter Vortrag zum Für und Wider
C++
http://www.ese-kongress.de/paper/presentation/id/309
die für mich wichtigste Botschaft war: C und C++ Lösungen miteinander
vergleichen, zum Beispiel bezüglich Speicherplatz und Laufzeit, läuft
oft auf den Vergleich von Äpfeln und Birnen hinaus. Er hat sehr das
schön an Beispielen nachgewiesen die sich eben erst auf den zweiten
Blick erschließen. So hat er eine C-Lösung für einen Up- und
Down-Counter einmal klassisch und einmal objektorientiert vorgestellt
und auseinandergepflückt. Quintessenz war dabei die geschickt gebaute
Klasse war nur 3% größer aber dafür 20% schneller :-o zudem war die
OO-Lösung noch Typsicher und hat automatisch verhindert dass die Counter
durch Anwendungsentwickler falsch benutzt werden konnten.
Dann hat er die C-Lösung vorgestellt die tatsächlich äquivalente
Eigenschaften hatte und die war um einiges fetter und langsamer als die
C++ Lösung da es eben durch den Programmierer und nicht auf
Compilerebene gelöst wurde.
Vielleicht ist der Vortrag ja mal im Download verfügbar.
Gruß J.
Aber der vergleicht ja nur C mit C++. Für eingeschworene ASM'er beides
das gleiche Teufelszeug. Gefundene Ironie bitte behalten!
Ansonst, die Zusammenfassung bringt's auf den Punkt: mehr Features ohne
extra Kosten.
Bastler schrieb:> die Zusammenfassung bringt's auf den Punkt: mehr Features ohne> extra Kosten.
So habe ich das bisher auch gesehen. Auf einem PC programmiere ich ja
auch in C++ oder C#. Vor allem Templates sind genial.
Aber mit den IDEs, die ich für µCs benutze, hat das nie richtig
funktioniert. Der Compiler für den MSP430 unterstützt keine Templates
und bem Atmel Studio und CooCox funktioniert es bei mir (noch?) nicht,
beim Debuggen mit Breakpoints in die Instanz-Variablen zu schauen.
Welche IDEs benutzt Ihr für C++ und klappt dort das Debugging?
Karl Käfer schrieb:> habe ich trotz intensiver Bemühungen noch nicht verstanden
Das hast Du bestimmt ganz genau verstanden.
Aber was sollst Du bei diesen offensichtlichen Unterschieden nun auch
sagen.
Also verstecke Dich ruhig weiter hinter der völlig irrealistischen
Moderatoren-Richtlinie, stets konstant und punktgenau beim Thema zu
bleiben.
Um es dann (wie könnte es auch anders sein) selber nicht so genau zu
nehmen.
Johannes R. B. schrieb:> Dann hat er die C-Lösung vorgestellt die tatsächlich äquivalente> Eigenschaften hatte und die war um einiges fetter und langsamer als die> C++ Lösung da es eben durch den Programmierer und nicht auf> Compilerebene gelöst wurde.
Solange man den Quelltext solcher grandiosen Beispiele nicht sehen kann,
glaube ich solchen Leuten kein einziges Wort. Das ist ganz genau so wie
bei Vertretern irgendeiner Ware, die sehr schön zeigen können, daß
allein mit IHRER Ware der wahre Fortschritt einhergeht und alle anderen
bloß Stümper sind. Frei nach Churchill.. glaube ich nur der Statistik,
die ich eigenhändig gefälscht habe.
W.S.
@ Moby + W.S.: Hört doch mal mit Eurem kleigeistigen Krieg auf.
Folgende Frage finde ich im Zusammenhang "wie geht das?" viel
spannender.
Torsten C. schrieb:> Welche IDEs benutzt Ihr für C++ und klappt dort das Debugging?
Bei mir geht das eben leider noch nicht so schön, wie in der Theorie.
Oder hat der TO Peter das Problem vielleicht gar nicht? Ich will ja
nicht den Thread kapern.
@Karl Käfer: Kannst Du den Header vielleicht irgendwo hochladen, würde
das gerne mal auf meine Plattform -> sinngemäß <- portieren.
@all: EinAus(&DDRB, &PORTB, &PINB, PB1);
Warum sind beim Atmel 4 Werte vonnöten um einen Pin zu steuern? Was ist
DDRB und was unterscheidet es von PORTB, was bedeutet PINB und warum
beinhaltet dann PB1 nochmal das B? Ich bin da lieder außenstehender :(
BastiDerBastler schrieb:> Warum sind beim Atmel 4 Werte vonnöten um einen Pin zu steuern? Was ist> DDRB und was unterscheidet es von PORTB, was bedeutet PINB und warum> beinhaltet dann PB1 nochmal das B? Ich bin da lieder außenstehender :(
DDRB = Portpins I/O Definition Register
PORTB = Port-Output Register
PINB = Port-Input Register
PB1 = Port B Bit 1
BastiDerBastler schrieb:> Also würde im Prinzip auch PB1 genügen, DDRB, PORTB, PINB ließen sich> daraus ableiten?
So wie ich das verstehe enthält Px0 - Px7 nur die Bitnummer 0-7 für x=
Port A,B,C..., woraus sich natürlich nicht die verschiedenen I/O
Locations der drei zu einem Port x gehörigen Register DDRx,PORTx,PINx
ableiten lassen sondern explizit anzugeben sind.
Ich versuche gerade die Snippets aus dem Artikel (erstes Beispiel) :
http://www.mikrocontroller.net/articles/AVR_Interrupt_Routinen_mit_C%2B%2B
einzubauen.
Ich C++ Neuling, kann da mal jemand drübersehen ?
Die Timer0 Klasse wird in der Main.cpp abgeleitet.
Sollte das so funktionieren ???
Gibt es einen besseren weg ?
BastiDerBastler schrieb:> Also würde im Prinzip auch PB1 genügen, DDRB, PORTB, PINB ließen sich> daraus ableiten?
Nein.
Ein Port besteht hier aus einem Byte, bzw. 8 Pit. Zu einem Port gehören
drei Register, jeweils 1 Byte bzw. 8 Bit groß:
DDRx = Pins als Eingönge oder Ausgänge einstellen
PORTx = Für Ausgang-Pins ihr Wert, also An oder Aus
PINx = Für Eingangs-Pins ihr Wert, also An oder Aus
Und nun musst Du noch die Bitnummer Deines Ports wissen. Die steht in
Pxn.
chris schrieb:> Meiner Meinung nach wäre aber ein ZIP-File sinnvoller
Meiner Meinung ist die "Codeansicht" zumindest bei den .cpp ganz nett,
die ginge bei zip verloren.
@ Thomas W: Welche IDE benutzt Du?
Eclipse CDT mit dem AVR GCC Plugin.
Habe misst gebaut.
Wenn man MyTimer instanziiert passiert das hier :
Timer.cpp:(.text._ZN6Timer0C2Ev+0x2): undefined reference to
`Timer0::timerInterrupt::ownerTimer'
Das muss jetzt aber bis morgen warten.
Im nachhinein finde ich den Anhang auch extrem unübersichtlich.
BastiDerBastler schrieb:> @Karl Käfer: Kannst Du den Header vielleicht irgendwo hochladen, würde> das gerne mal auf meine Plattform -> sinngemäß <- portieren.
Der Header ist der Code für die Klassen Pin, InputPin und OutputPin aus
meinem vorherigen Beispiel.
HTH,
Karl
Soo,
also ich habe den Code hier mal so hingefrickelt in meiner Bibliothek.
Wollte jetzt kein Getriebe von einem Pin ableiten lassen usw.
(Komposition wäre da eindeutig besser).
Vielleicht sollte man die Dinge auch nicht "pin" nennen, sondern
"pin_ref", schließlich referenziert das ja nur einen real existierenden
Pin.
Mit den ".configure" bin ich noch nicht zufrieden, aber input_pin,
output_pin wären falsch, weil der Zustand des realen Pins ja nicht an
die Referenz gebunden ist.
"pb<3>" usw. sind "statische" Pin-Referenzen, die man auch verwenden
könnte, aber da der Beispielcode oben ja Laufzeit-Werte genommen hat,
habe ich das hier ebenso gemacht.
[cpp]
void playground()
{
using namespace gpio;
pin motor = pb<3>();
pin beleuchtung = pb<2>();
pin startknopf = pd<1>();
pin bremse = pd<2>();
pin gang = pd<3>();
motor.configure(inout());
beleuchtung.configure(inout());
startknopf.configure(input);
bremse.configure(input);
gang.configure(input);
while(1) {
if(startknopf.get()) {
beleuchtung.set();
if(gang.get() && !bremse.get()) {
// beep
} else {
motor.set();
}
} else {
motor.reset();
beleuchtung.reset();
}
}
}
[/cpp]
Der Schleifenanteil nimmt genau 32 Byte Code ein. Die Konfiguration
nimmt mehr ein, weil das ja ->Laufzeitabhängig<- in einigen Fällen
maskierte read-modify-write auf mehrere Register bedeutet (in meinem
Fall: STM32F4). Wären die Pins festverdrahtet, würden die Masken von
meinen Templates entsprechend zusammengelegt und ausgerechnet, für
entsprechend weniger Schreiboperationen.
Karl Käfer schrieb:> Tja, das ist so eine Sache mit dem Verständnis: entweder man hat es,> oder man hat es eben nicht. Daß schon C enorm komplex ist, siehst Du> schon an den vielen Fragen und Fehlern, die hier ständig aufschlagen --> und die bisweilen sogar sehr erfahrenen C-Entwicklern passieren. Was> hattest Du denn erwartet, was herauskommt, wenn man eine komplizierte> Sprache wie C um ein komplexes Paradigma wie die Objektorientierung> erweitert?
Der Volksmund sagt "getroffene Hunde bellen". Da hast du in einem
ellenlangen Beitrag versucht, deine seltsamen Ansichten zu untermauern -
und hast doch nur geschrieben, daß du kein Verständnis für echte
Abstraktionen hast. Du hast nicht begriffen, daß das Abstrahieren der
Hardware auf ein bloßes Wrappen a la Port123.SetBit9.high oder so
einfach nur ein viel zu mickriger Denkansatz ist.
Was also sollen solche billigen Dinge wie:
pin motor = pb<3>();
und
motor.configure(inout());
denn zum Verbessern der Situation innerhalb der Firmware beitragen? Es
ist eben ganau DAS, was ich schon schrieb: ein viel zu mickriger
Denkansatz - geschrieben eben nur zu dem Zweck, hier eine krampfhafte OO
Anwendung mittels C++ zu posten. Von einem echten HW-Treiber bzw. einer
echten HAL ist sowas meilenweit entfernt.
Aber mal zum oben zitierten: C ist überhaupt nicht komplex. C ist
lediglich kompliziert, weil es zu einem ganz erheblichen Teil auf
Konstruktionsfehlern beruht, die wiederum per Dekret a la Ordre de Mufti
wieder ausgebügelt wurden. Ich spare mir mal die Details, das hatten wir
schon anderweitig.
Wenn man eine komplexe UND unkomplizierte Sprache (wie Pascal) erweitert
(um "ein komplexes Paradigma wie die Objektorientierung"), dann bleibt
das dank Weitsicht der Leute, die das taten, auch leicht les- und
verstehbar. Es geht also. Und man kann sogar mehrere Konstruktoren
haben und nicht bloß einen einzigen mickrigen Konstruktor wi bei C++.
W.S.
W.S. schrieb:> Und man kann sogar mehrere Konstruktoren> haben und nicht bloß einen einzigen mickrigen Konstruktor wi bei C++.
Und wo hast du die Weisheit her, dass C++ keine überladenen
Konstruktoren unterstützt?
W.S. schrieb:> Aber mal zum oben zitierten: C ist überhaupt nicht komplex. C ist> lediglich kompliziert, weil es zu einem ganz erheblichen Teil auf> Konstruktionsfehlern beruht, die wiederum per Dekret a la Ordre de Mufti> wieder ausgebügelt wurden. Ich spare mir mal die Details, das hatten wir> schon anderweitig.
Wo soll den C kompliziert sein? Natürlich sind da ein paar grobe
Schnitzer, aber welche Sprache ist perfekt?
C ist eine richtige pragmatische Systemprogrammiersprache, die dazu
entwickelt wurde portable Betriebssysteme entwickeln zu können (z.B.
Unix). Was Anfängern immer wieder aus der Bahn wirft, sind solche Dinge
wie z.B., dass ein Stringliteral ein const char* Zeiger zurück gibt und
dass ein String nicht durch ein = Operator kopiert werden kann. Was ist
daran kompliziert? Da stolpert halt ein ungedultiger Anfänger drüber.
Viele Eigenschaften von C erscheinen erstmal merkwürdig und eigensinnig
(wie z.B. die automatische Initialisierung von Variablen), wenn man aber
die Hintergründe erforscht, dann ist es eigentlich immer logisch und
eingängig.
@W.S: Wie sieht denn Dein architektonischer High-Level Code aus, wenn Du
solche Basis-sachen wie wiederbelegbare Pin-Referenzen und sowas nicht
irgendwo wegkapselst? Der muss dann ja durchsetzt sein von
Low-Level-Kram, der auf der Ebene gar nix zu suchen hat...
Hallo Basti,
BastiDerBastler schrieb:> also ich habe den Code hier mal so hingefrickelt in meiner Bibliothek.
Da wäre es natürlich schön, die Bibliothek einmal zu sehen. ;-)
> Wollte jetzt kein Getriebe von einem Pin ableiten lassen usw.> (Komposition wäre da eindeutig besser).
Ja, in einer realen Welt, in der ein Getriebe mehr Informationen hergibt
als nur, ob ein Gang eingelegt ist, wäre das möglicherweise sinnvoll. In
diesem Beispiel ist es allerdings unnötig.
> Vielleicht sollte man die Dinge auch nicht "pin" nennen, sondern> "pin_ref", schließlich referenziert das ja nur einen real existierenden> Pin.
Nein, sorry, es referenziert den Pin nicht, sondern repräsentiert
ihn. Die Klasse "Pin" ist eine allgemeingültige Software-Repräsentation
aller Hardware-Pins, und eine konkrete Instanz der Klasse "Pin"
repräsentiert dann einen konkreten Hardware-Pin in der Software.
> "pb<3>" usw. sind "statische" Pin-Referenzen, die man auch verwenden> könnte, aber da der Beispielcode oben ja Laufzeit-Werte genommen hat,> habe ich das hier ebenso gemacht.
Bitte verzeih', aber "pb<3>" ist Unfug und jeder ordentliche Compiler
sollte Dir das mit einer deutlichen Fehlermeldung um die Ohren hauen.
Du sitzt -- wie auch andere hier -- einem grundsätzlichen Mißverständnis
bezüglich des C++-Sprachfeature Templates auf. Template-Programmierung
ist ein Mechanismus, um einer generischen Klasse oder Funktion einen
Datentyp zu übergeben, nicht einen Wert. Die "3" in "pb<3>" ist aber
kein Typ, sondern ein Wert (genauer: eine Konstante) vom Typ Integer.
"pb(3)" und "pb<int>" ergeben einen Sinn, "pb<3>" tut es nicht.
Ein Beispiel:
Die Klasse "Templateklasse" kann ich jetzt mit verschiedenen Datentypen
verwenden, beispielsweise mit einem "int" und einem "string". Daraus
erzeugt der Compiler dann eine Klasse "Templateklasse" für Integers, und
eine Klasse "Templateklasse" für Strings.
Die Wikipedia hat eine ganz gute Erklärung zu Templates in C++:
http://de.wikipedia.org/wiki/Template_%28Programmierung%29
HTH und liebe Grüße,
Karl
Hallo W,
W.S. schrieb:> Der Volksmund sagt "getroffene Hunde bellen".
Bitte entschuldige, daß ich versucht habe, Deinen Horizont zu erweitern.
Offensichtlich hast Du daran gar kein Interesse.
> Was also sollen solche billigen Dinge wie:>> pin motor = pb<3>();> und> motor.configure(inout());
Was das soll, kann ich Dir auch nicht sagen -- nur, daß es fehlerhaft
ist und von einem guten Compiler mit einem Fehler quittiert werden
sollte. g++ und clang++ tun das jedenfalls.
Und wenn Du mit mir diskutieren willst, dann solltest Du Dich auf meine
Beispiele beziehen. Daß Du Dir stattdessen ein fehlerhaftes Beispiel von
Basti heraussuchen mußt, um es dann mir unter die Nase zu reiben, zeigt
mir allerdings, daß Du zu einer sachlichen Diskussion entweder nicht
fähig bist, oder kein Interesse daran hast.
> Und man kann sogar mehrere Konstruktoren> haben und nicht bloß einen einzigen mickrigen Konstruktor wi bei C++.
Natürlich geht das auch bei C++. Das zeigt, daß Du hier die ganze Zeit
über Dinge redest, von denen Du offenbar keine Ahnung hast. Schade.
Liebe Grüße,
Karl
Oh, lustig: das ist natürlich ein Fehler und wurde von mir nur in den
Code geschrieben um zu sehen, ob g++ und clang++ dabei für Fehler
ausgeben. Sie tun es jedenfalls. Ansonsten ist diese Zeile Unfug und zu
ignorieren.
Liebe Grüße,
Karl
Hallo Peter,
Peter L. schrieb:> Hast du deinen Link auch mal selber gelesen?
Ja, natürlich.
> http://de.wikipedia.org/wiki/Template_%28Programmierung%29#Nichttyp-Parameter
Und das hat hier welche Relevanz? Für die Übergabe einer Pinnummer sind
Nichttypparameter jedenfalls Unsinn -- und wer so weit ist, daß er
solche Parameter braucht, der hat Templates weit genug verstanden, um
das gar nicht erst versuchen zu wollen. Tipp: Nichttyp-Parameter sind
Template-Parameter, also Parameter für Templates statt für Instanzen.
Liebe Grüße,
Karl
> Ansonsten ist diese Zeile Unfug und zu ignorieren.
Konstanten als Parameter sind eine grundlage der C++ Metaprogrammierung.
> Nichttyp-Parameter sind> Template-Parameter, also Parameter für Templates statt für Instanzen.
Sehr richtig. Und da typen keinen Speicherplaz belegen, im gegensatz zu
instanzen, und man Templateclassen nicht instanzieren muss, um auf
dessen statische Variablen zuzugreifen, kann man damit viel Ram und
Rechenzeit sparen.
C++ Metaprogramming kann ich nur emphelen:
http://de.m.wikipedia.org/wiki/C%2B%2B-Metaprogrammierung
Im funktionierenden Beispiel, das ich ganz weit oben mal Postete (Beide
beiträge beachten), habe ich änliches gemacht. 0 bytes Overhead! Aber
leider niemand, der den code kommentierte...
Daniel A. schrieb:> C++ Metaprogramming kann ich nur emphelen:
Das ist wirklich cool. :-) Mache ich auch!
Torsten C. schrieb:> Aber mit den diversen IDEs, die ich für µCs benutze, hat es nie> richtig funktioniert … beim Debuggen mit Breakpoints in die> Instanz-Variablen zu schauen.
Aber mit welcher IDE geht das auch für µCs in der Praxis?
Was nützt all Eure Theorie? Bei Visual Studio .net für Windows wäre das
alles kein Problem. Aber hier geht es doch um "C++ auf einem MC", oder?
Karl Käfer:
Ich nehm's Dir nicht übel, weil ich sehe, dass Du Dich ernsthaft damit
auseinandersetzt. Ich möchte meinen Quellcode hier nicht unbedingt
breittreten, würde ihn Dir aber auf irgendeinem Weg zur Verfügung
stellen. Ich glaube einschätzen zu können, dass das meiste darin Dir
vielleicht etwas zu abgefahren ist (gemeint als: der Problematik nicht
angemessen, nicht über Deinen Verstand, hehe).
Soviel: das pb<3>() dort, dient dem Konstruktor von "pin" nur als
Information ("pb<3>" ist ein typ-alias für "static_pin<1,3>"), das
temporäre Objekt selber ist irrelevant (und wird vom Compiler dann
geschluckt).
Ich könnte aber auch pb<3>::set() schreiben, nur wäre das halt zur
Compile-Zeit festverdrahtet. Ich finde das so eigentlich ziemlich
ausdrucksstark.
Templates sind halt nicht nur über Typen parametrierbar, aber das haben
meine Vorredner ja schon dargelegt.
Karl Käfer:
Noch zu der Referenz-Sache, das habe ich versäumt.
1
int a;
2
int b;
3
4
a = 1;
5
b = 2;
6
7
assert(a != b); // unabhängige Objekte
8
9
int c;
10
int& d = c;
11
int& e = c;
12
13
d = 4;
14
e = 2;
15
16
assert( d == e ); // Referenzen auf ein Objekt
17
18
pin f = pb<3>();
19
pin g = pb<3>();
20
21
f.set();
22
g.reset();
23
24
assert( f.get() == g.get() ); // ????
Was man da als Objekt der Klasse "pin" hat, besitzt für mich eindeutig
Referenzcharakter (bis auf, dass man diese Referenz im Gegensatz zu
C++-Referenzen neu setzen kann).
Hallo Peter,
Peter L. schrieb:> template <int pin>> struct pb{> void set(){> ptr = (int*)0xDEADBEEF + pin;> *ptr = 0x1;> };>> pb<1337> a;> a.set();>> Sowas ist erlaubt.
Die Frage ist ja nicht, ob es erlaubt ist, sondern, ob es sinnvoll ist.
> Also husch nochmal paar template tutorials durcharbeiten.
;-)
Liebe Grüße,
Karl
Hallo Daniel,
Daniel A. schrieb:> Sehr richtig. Und da typen keinen Speicherplaz belegen, im gegensatz zu> instanzen, und man Templateclassen nicht instanzieren muss, um auf> dessen statische Variablen zuzugreifen, kann man damit viel Ram und> Rechenzeit sparen.
Na klar. Aber bei der Initialisierung eines Hardware-Pins mit
1
OutputPinledPin(&DDRB,&PORTB,&PINB,PB0);
sind DDRB, PORTB und PINB keine Variablen, also keine Instanzen,
sondern Konstante.
> Im funktionierenden Beispiel, das ich ganz weit oben mal Postete (Beide> beiträge beachten), habe ich änliches gemacht. 0 bytes Overhead! Aber> leider niemand, der den code kommentierte...
Da schaue ich gerne hinein. Aber möchtest Du Dir vielleicht auch einmal
meine Code-Beispiele in [1] und [2] anschauen? Viel Spaß!
Liebe Grüße,
Karl
[1] Beitrag "Re: C++ auf einem MC, wie geht das?"
[2] Beitrag "Re: C++ auf einem MC, wie geht das?"
Hallo Basti,
BastiDerBastler schrieb:> Ich nehm's Dir nicht übel, weil ich sehe, dass Du Dich ernsthaft damit> auseinandersetzt. Ich möchte meinen Quellcode hier nicht unbedingt> breittreten, würde ihn Dir aber auf irgendeinem Weg zur Verfügung> stellen.
Die E-Mail-Adresse karl@lukenukem.de sollte funktionieren. Dein Code ist
bei mir in guten Händen.
> Ich glaube einschätzen zu können, dass das meiste darin Dir> vielleicht etwas zu abgefahren ist (gemeint als: der Problematik nicht> angemessen, nicht über Deinen Verstand, hehe).
Ob ein Code dem Problem angemessen ist, liegt doch immer am Problem. ;-)
> Soviel: das pb<3>() dort, dient dem Konstruktor von "pin" nur als> Information ("pb<3>" ist ein typ-alias für "static_pin<1,3>"), das> temporäre Objekt selber ist irrelevant (und wird vom Compiler dann> geschluckt).> Ich könnte aber auch pb<3>::set() schreiben, nur wäre das halt zur> Compile-Zeit festverdrahtet. Ich finde das so eigentlich ziemlich> ausdrucksstark.
Ok, dann habe ich Deine Kenntnisse offensichtlich flahsc eingeschätzt
und muß um Verzeihung bitten.
Liebe Grüße,
Karl
Weil ich immer wieder meine Zeit mit solchen Mist verschwende, möchte
ich nun auch endlich mal 'ne ordentliche HAL-API haben.
STM32CubeMX erstellt leider auch kein C++. Außerdem wird der STM32F103
noch nicht unterstützt und gerade mit dem arbeite ich hauptsächlich,
weil es den bei aliexpress für weniger als 2€ gibt.
Das "xpcc project" ^^ ist ja schon ziemlich dicht dran. Aber es gibt
immer was, was einem nicht gefällt. Zum Beispiel könnte der USART
zumindest beim TX auch den DMA-Controller nutzen, statt nur Interrupts:
http://xpcc.kreatives-chaos.com/api/classxpcc_1_1stm32_1_1_usart_hal1.html
Ausgezeichnet finde ich die Präsentation von Scott Meyers zu "Effective
C++ in an Embedded Environment". Anbei ein Beispiel, wie man ein
Peripherie-Register in c++ darstellen könnte. Auf den folgenden Slides
werden viele Details besprochen und Alternativen zu dem Thema
besprochen.
Bei uns im Wiki gib's ja noch nicht allzuviel zu dem Thema:
http://www.mikrocontroller.net/articles/Kategorie:C%2B%2B
Was ich bisher so an Quellen gefunden habe, sammle ich gerade unter:
https://notizblog.wordpress.com/%C2%B5c-programmierung-mit-c/
Dort ist auch ein Link zum PDF-Dokument von Scott Meyers.
Hat schon jemand die Sourcen vom "xpcc project" ausprobiert? Sind diese
eine gute Basis, um darauf aufzubauen?
Macht es Sinn, unser gesammeltes Wissen in einem eigenen Wiki-Artikel zu
sammeln?
[ScoMe01] Slide 169 sagt:
> “A fundamental design goal is that design violations> should not compile.”
Jawohl! :-) Also auch, wenn PCLK1 oder PCLK2 verwechselt werden? Oder
wenn es einen Konklikt beim DMA-Kanal gibt?
Torsten C. schrieb:> Zum Beispiel könnte der USART zumindest beim TX auch> den DMA-Controller nutzen, statt nur Interrupts.
Ich habe daher mal ganz einfach angefangen, mit dem USART.
Versteht jemand in diesem Zusammenhang diese drei Dinge?
http://xpcc.kreatives-chaos.com/api/classxpcc_1_1stm32_1_1_uart_base.html
1. Ist "uint32_t baudrate" eine gute Idee, oder sollte das eher
ein float sein?
2. Warum wird "sabclk" als Parameter übergeben und kein Pointer auf
PCLK1 oder PCLK2 genutzt (rot im 2. Bild)?
3. Wie stellt man sicher, dass ein DMA-Kanal immer nur einmal verwendet
wird, also z.B. SPI2_RX nicht von USART1_TX überschrieben wird?
Beides zusammen geht nicht (1. Bild).
Torsten C. schrieb:> Ausgezeichnet finde ich die Präsentation von Scott Meyers zu> "Effective C++ in an Embedded Environment". … Dort ist auch> ein Link zum PDF-Dokument von Scott Meyers.
@Peter Dannegger (peda): Ist Deine Frage "C++ auf einem MC, wie geht
das?" damit beantwortet? Es ist so still geworden hier!
Torsten C. schrieb:> Es ist so still geworden hier!
Das muß nun nicht wirklich verwundern.
C++ auf kleinen Controllern ist und bleibt eine Schnapsidee.
So wie ich PeDa einschätzte hat er sich nur von diesem Scheißartikel
ausgeklinkt.
Durch die ganzen Möchtegern ASMler kommt doch hier sowieso nichts dabei
rum.
Wie die kleinen Kinder.
Grüße Frank
Jens schrieb:> Torsten C. schrieb:>> Macht es Sinn, unser gesammeltes Wissen in einem eigenen Wiki-Artikel zu>> sammeln?> Ja. Unbedingt.Frank schrieb:> kommt doch hier sowieso nichts dabei rum.
Es müsste schon eine "kritische Masse" an Leuten geben, die Ihr Wissen
zusammentun und sich von "Möchtegern ASMlern" ^^ nicht stören lassen,
also die Trolle nicht füttern.
Falls dies ein "Scheißartikel" ^^ ist und Interesse besteht, könnte man
ja einen neuen aufmachen.
Torsten C. versteht das nicht falsch mit dem Scheißartikel. Ich bin
absoluter Befürworter einer abstrakten objektorientierten Programmierung
und das auch auf uC.
Ich nutzte dies in meinem beruflichen Alltag zu 95%.
In 5% gibt es Bereiche, die in ASM programmiert werden, dann aber wieder
in einem einheitlichen Interface gekapselt werden.
Wobei es in diesem Artikel leider gar nicht um das "warum", sondern um
das "wie" gehen sollte, so war ja auch die eigentlich gestellt
Frage...deshalb Scheißartikel!
Frank schrieb:> sondern um> das "wie" gehen sollte, so war ja auch die eigentlich gestellt> Frage
Ja. Über das "warum" wurde schon genug debattiert. Wer's nicht machen
will, kann die Klappe halten, weil seine Posts ignoriert werden. Alles
heiße Luft!
Ich habe für das Dokument von "Scott Meyers"^^ bestimmt ein paar Stunden
gebraucht, um alles zu verstehen, aber das "wie" ist hier schon fast
umfassend erklärt.
Zusammen mit den Beispielen aus dem "xpcc project" hat man eigentlich
schon fast alles, was man braucht.
Was nur noch fehlt, sind ein paar Leute, mit dem man Fragen, Vor- und
Nachteile verschiedener Implementierungen usw. diskutieren kann. Da
kommt hier wohl leider keine kritische Masse zustande. :-(
Torsten C. schrieb:> Da kommt hier wohl leider keine kritische Masse zustande. :-(
Na warum wohl? Stell Dir mal diese Frage!
Vielleicht, weil es mehr als
Torsten C. schrieb:> ein paar Stunden (ge)braucht, um alles zu verstehen,
für ein auf kleinen Controllern letztlich zweifelhaftes Ergebnis?
Au sder ursprünglichen Frage:
Peter Dannegger schrieb:> ... MC-spezifische Abläufe ...
Das können kleine oder größere MC sein, wir leben im Jahr 2015.
Moby AVR schrieb im Beitrag #3972786:
> ... für ein auf kleinen Controllern ...
Es gibt nicht nur deine attiny-Welt.
Also geh doch bitte wieder in den Sandkasten, du hast genug genervt.
Klaus Wachtler schrieb:> Es gibt nicht nur deine attiny-Welt.
Richtig. Da wären auch noch die Megas. Und die XMegas erst...
> Also geh doch bitte wieder in den Sandkasten
Was Du "Sandkasten" nennst, damit ist das Meiste hier problemlos lösbar.
Da muß es nicht auf Biegen und Brechen die Großbaustelle sein ;-)
@Moderator: Geht das (siehe unten)?
Frank schrieb:> Wie die kleinen Kinder.
Was leider mal wieder bewiesen wurde. :-(
Füttert keine Trolle!
Klaus Wachtler schrieb:> Masse könnte ich beisteuern, aber ist wohl das falsche Forum hier.
Das klingt doch gut. Einfach diejenigen, die den Sinn diskutieren wollen
ignorieren ist aber produktiver, egal in welchem Forum.
Welches Forum wäre besser?
Wir könnten hier ja auch einen neuen Thread aufmachen und mit den Mods
sprechen, dass dann die gemeldeten Troll-Posts gelöscht werden. Dann
wird nur über das "wie" diskutiert und nicht das "warum".
Ausgangsbasis?
* eine Kurzfassung von dem hier? http://wp.me/PCum-qm
* andere Vorschläge?
Torsten C. schrieb:> Wir könnten hier ja auch einen neuen Thread aufmachen> wird nur über das "wie" diskutiert und nicht das "warum".
Ob das daran was ändert:
Torsten C. schrieb:> Es ist so still geworden hier!
???
Hilft doch nicht, der Frage nach dem Sinn und Zweck konsequent
auszuweichen...
Torsten C. schrieb:> Wir könnten hier ja auch einen neuen Thread aufmachen und mit den Mods> sprechen, dass dann die gemeldeten Troll-Posts gelöscht werden. Dann> wird nur über das "wie" diskutiert und nicht das "warum".
Ich würde mich dafür interessieren.
Ich denke, Ziel sollte es sein, eine Sammlung von Klassen zur Verfügung
zu stellen um von der Hardware eines ATmega abstrahieren zu können.
Angefangen mit der oft Diskutierten Pin-Klasse. Man müsste beweisen dass
diese Klasse keinen zusätzlichen Overhead verursacht. Davon ausgehend
könnte man dann weitere Klassen nach ähnlichem Schema anlegen (UART,
Timer, ...)
Torsten C. schrieb:> @Moderator: Geht das (siehe unten)?
Nein. Bleib mal bei einem Thread.
Wenn du einen Wiki-Artikel schreiben willst, dann musst du ihn allgemein
halten und möglichst unabhängig von Controllerfamilien (so, wie die
Überschrift gewählt ist). Kann man sicher machen, aber dürfte viel
Arbeit werden.
Mir scheint, was du willst, ist eher ein Projekt, welches für ein oder
zwei ganz konkrete Controller(familien) die Abstraktion implementiert.
Sowie du das versuchst, auf viele Familien auszuweiten, geht das schnell
ins Uferlose.
Für Projekte wiederum gibt es hier die Möglichkeit, einen SVN-Server
zu hosten sowie das in "Projekte & Code" zu posten.
Um ein wenig auf den Ursprungspost zurückzukommen. Der Aussage: "Es gibt
kein verstehbares Lehrbuch" widerspreche ich zum Teil.
Grundsätzlich lässt sich C++ auf Embedded-Systemen wunderbar einsetzen,
FALLS man ein umfassendes Verständnis der Sprachmittel hat. Und das in
einem sehr viel grösseren Umfang als es bei C der Fall wäre. C++ birgt
gerade durch den höheren Abstraktionsgrad die Gefahr dass banalste
Statements zu Resourcen- oder Laufzeitfressern werden.
Für einen sauberen Spracheinstieg empfehle ich die Bücher C++ Primer (S.
Lippman) und Principles and Practice Using C++ (B. Stroutsrup). Beide
müsste es auch in deutsch geben, falls das beim Lesen leichter fällt.
Hat man C++ im Grundsatz auf dem Kasten kommt die absolute
Pflichtlektüre:
Industrial Strength C++ (Nyquist)
Spätestens jetzt hat man genug Wissen um z.b. dynamische
Speichverwaltung zu umgehen wo es nicht unbedingt notwendig ist.
Nur wer genau weiss was ein C++-Ausdruck auf dem Target zu Folge hat
sollte darüber nachdenken C++ auf MCUs einzusetzen.
Darf ich das hier noch mal schnell unterstreichen?:
Matthias schrieb:> Grundsätzlich lässt sich C++ auf Embedded-Systemen wunderbar einsetzen,> FALLS man ein umfassendes Verständnis der Sprachmittel hat.Matthias schrieb:> Nur wer genau weiss was ein C++-Ausdruck auf dem Target zu Folge hat> sollte darüber nachdenken C++ auf MCUs einzusetzen.
Jörg Wunsch schrieb:> Mir scheint, was du willst, ist eher ein Projekt, welches für ein oder> zwei ganz konkrete Controller(familien) die Abstraktion implementiert.
Ja, denn einerseits sind wir hier vielleicht eine Handvoll Leute, die
zusammen was machen wollen, da wird man sich sicher schnell auf eine
Untermenge einigen, damit das Projekt nicht ins Uferlose geht.
Ich kenne den AVR zwar auch gut, mache meine neuen Projekte aber mit
STM32F1xx und STM32F4xx. Auf den STM32Fxxx läge bei mir daher der Focus.
Ben schrieb:> … um von der Hardware eines ATmega abstrahieren zu können
Der ATmega darf natürlich nicht fehlen. Vielleicht reicht es auch, mit
diesen Beiden anzufangen, um sich nicht zu verzetteln.
Beim Infineon XMC4500 ist z.B. wieder alles ganz anders. Der
interessiert mich zwar auch, aber da würde ich erstmal nur einen Blick
drauf werfen, damit sich die Bibliotheken später ohne komplette
Umstrukturierung erweitern lassen.
Und der MSP430-Compiler von TI unterstützt z.B. eh keine Templates.
> Für Projekte wiederum gibt es hier die Möglichkeit, einen SVN-Server> zu hosten sowie das in "Projekte & Code" zu posten.
Ich habe bisher Github genutzt, viele finden das einfacher. Ich selbst
habe mir noch keine Meinung gebildet.
Legt jemand auf den µC.net-SVN-Server Wert? Oder soll ich auf Github ein
Git für dieses Projekt anlegen?
Wie soll das Projekt (das Git, die Wiki-Seite, das SVN-Repository)
heißen? "EmbeddedCpp" oder ist das zu kurz?
Jörg Wunsch schrieb:> Bleib mal bei einem Thread.
OK, Gern. Langfristig, wenn das Ziel klar ist und wir uns einig sind,
kann ich mir aber auch einen Thread in "Projekte & Code" vorstellen.
Fazit bisher:
¯¯¯¯¯¯¯¯¯¯¯¯¯
3 Personen:
¯¯¯¯¯¯¯¯¯¯¯
* Klaus Wachtler (mfgkw)
* Ben (Gast)
* Torsten C. (torsten_c)
2 Targets:
¯¯¯¯¯¯¯¯¯¯
* STM32-ARMs
* ATMega-AVRs
Erste Zwischenziele
¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯
* Pin-Klasse
* weitere Klassen (UART, Timer, SPI, DMA, ...)
… also so wie Ben schieb^^. Allerdings würde ich beim STM32 auch schon
mit Takt-System anfangen, da ich ohne diesen Teil den Rest gar nicht
vernünftig testen und einsetzen könnte.
Auch sowas wie <std::bitset> für Embedded fände ich z.B. interessant,
das nutze ich gerade für das WordClock-Projekt in Java
(java.util.BitSet).
Wenn was nicht paßt oder falsch verstanden wurde: Bitte einfach richtig
stellen, ich will niemandem was unterstellen und niemandem übergehen!
> Torsten C. schrieb:> Angefangen mit der oft Diskutierten Pin-Klasse. Man müsste beweisen dass> diese Klasse keinen zusätzlichen Overhead verursacht.> Moby schrieb> im Beitrag #3910583:> auto_control ... Assembler code ...
Angeregt durch diesen Thread habe ich mich auch mit dem Problem
beschäftigt ...
Der beiliegende Code ist die Umsetzung von Mobys Assembler Program in
C++.
Der vom AtmelStudio 6,2.1153 erzeugte Code ist nicht schlechter wie der
handgeschriebene von Moby.
Verbrauch 28 Byte Flash und 0 Byte Ram !
00000034 <main>:
34: bb 9a sbi 0x17, 3 ; 23 port motor init
36: bc 9a sbi 0x17, 4 ; 23 port beleuchtung init
while:
;startknopf gedrückt ?
38: b0 9b sbis 0x16, 0 ; 22
;nein jmp startknopf nicht gedrückt
3a: 07 c0 rjmp .+14 ; 0x4a <__SREG__+0xb>
; ja
3c: c4 9a sbi 0x18, 4 ; 24 beleuchtung ein
; gang eingelegt ?
3e: b1 9b sbis 0x16, 1 ; 22
; nein jmp while
40: fb cf rjmp .-10 ; 0x38 <main+0x4>
;ja
;bremse nicht angezogen ?
42: b2 99 sbic 0x16, 2 ; 22
;nein Jmp while
44: f9 cf rjmp .-14 ; 0x38 <main+0x4>
;ja
; bremse nicht angezogen und gang eingelegt
46: c3 9a sbi 0x18, 3 ; 24 motor ein
; jmp while
48: f7 cf rjmp .-18 ; 0x38 <main+0x4>
; startknopf nicht gedrückt :
4a: c3 98 cbi 0x18, 3 ; 24 motor aus
4c: c4 98 cbi 0x18, 4 ; 24 beleuchtung aus
; jmp while
4e: f4 cf rjmp .-24 ; 0x38 <main+0x4>
Das Prinzip lässt sich auf alle MC für die ein C++ Compiler gibt und die
über SFR Register verfügen anwenden.
Man braucht man auch nicht das DDR bit mit einer Extra Methode/ Funktion
setzen, wie bei anderen Implemetierungen die mir bisher begegnet sind,
das macht bei mir der Konstrukor der Ein/Ausgabe Klasse.
Hans-Georg Lehnard schrieb:> auf alle MC für die ein C++ Compiler gibt und die> über SFR Register verfügen
"SfrRegAccess" sagt mir jetzt noch nichts und spontan habe ich dazu auch
nix in Google gefunden. Ich hatte das mal so ausprobiert wie in
Modeling_a_Control_Register.png ^^. Da benötigte ich kein
"SfrRegAccess::…".
Vielleicht ist das im Hintergrund das Gleiche?
Torsten C. schrieb:> Hans-Georg Lehnard schrieb:>> auf alle MC für die ein C++ Compiler gibt und die>> über SFR Register verfügen>> "SfrRegAccess" sagt mir jetzt noch nichts und spontan habe ich dazu auch> nix in Google gefunden. Ich hatte das mal so ausprobiert wie in> Modeling_a_Control_Register.png ^^. Da benötigte ich kein> "SfrRegAccess::…".>> Vielleicht ist das im Hintergrund das Gleiche?
Hallo Thorsten
SfrRegisterAccess ist einfach eine Template Klasse die den generellen
Zugriff auf SFR-Register kapselt.
Du übergibst die Register Adresse und das bit das manipuliert werden
soll.
Und dabei ist es egal ob es ein "port" register oder z.B. ein timer ctrl
Register ist.
Du kannst auch darüber nichts in Google finden weil der Code bisher
meine Festplatte nicht verlassen hatte :)
Hans-Georg Lehnard schrieb:> Angeregt durch diesen Thread habe ich mich auch mit dem Problem> beschäftigt ...
Deine Lösung mit den Templates (Metaprogrammierung) gefällt mir deutlich
besser als die mit preprocessor:
https://github.com/roboterclubaachen/xpcc/blob/da4cbb9f6dddaa0df8eaf0a13b95293360fd20f0/src/xpcc/architecture/platform/avr/xmega/gpio.hpp
Wie seht Ihr das mit den Bezeichern für die Methoden:
* Get()
* IsSet()
* IsNotSet()
Das sind zwar Kleinigkeiten, aber falls es hier schnell einen Konsens
gibt, kann man's ja gleich richtig machen, dann hat man später weniger
Arbeit. Vorschlag:
* get()
* isSet()
Welchen Vorteil siehst Du in "IsNotSet()"? Ein "!isSet()" ist doch auch
gut lesbar. Oder Ist das für Dich besser Lesbar? Das ist ja eine
Geschmacksfrage. Trotzdem können wir uns vielleicht einig werden. Ich
möchte nur den Grund verstehen, weil sich das Thema ja an allen anderen
Stellen wiederholt.
Hans-Georg Lehnard schrieb:> SfrRegisterAccess ist einfach eine Template Klasse die den generellen> Zugriff auf SFR-Register kapselt
Ah, cool. Magst Du das Template auch mal posten?
Hallo,
nachdem ich die Diskussion im November hier schon einmal gesehen hatte
bin ich heute erneut auf diesen Thread gestossen.
Seit zwei Jahren bin ich Mitentwickler der hier schon ein paar Mal
zitierten xpcc Programmbibliothek.
Falls ihr euch bei dieser für den aktuellen Entwicklungscode
interessiert, sind folgende Links gültig:
* Doku: http://develop.xpcc.io/
* API: http://develop.xpcc.io/api/
* Code: https://github.com/roboterclubaachen/xpcc
* Mailingliste [Englisch]:
http://mailman.rwth-aachen.de/mailman/listinfo/xpcc-dev
Falls ihr eine eigene C++ Mikrocontroller Bibliothek von Grund auf neu
schreiben wollt, kann ich das gut nachvollziehen. Denn nur so kann man
von Anfang an auf Performance optimieren und alle Designentscheidungen
selbst treffen.
Torsten C. schrieb:> Zusammen mit den Beispielen aus dem "xpcc project" hat man eigentlich> schon fast alles, was man braucht.
Sollte aber Interesse bestehen statt (oder auch vor) einer
Eigenentwicklung sich die xpcc Library anzusehen könnte ich euch dazu
eure Fragen beantworten. Entweder hier im Forum (vielleicht am besten
als eigener Thread?) oder auf Englisch auf der Mailingliste.
Wenn ihr das ganze ausprobieren wollt könnt ihr das unter Linux nativ
tun:
http://develop.xpcc.io/install/linux.html
Für Windows Benutzer empfehlen wir unsere Virtuelle Maschine mit Vagrant
zu benutzen:
https://github.com/roboterclubaachen/xpcc#use-our-virtual-machine
An Hardware empfehle ich euch entweder das STM32F4 oder das STM32F3
Discovery Board oder einen Arduino UNO (für AVR) da es dafür die am
besten getesteten Examples gibt.
Vielleicht kann ich euch ja etwas weiterhelfen.
eKiwi
eKiwi schrieb:> Sollte aber Interesse bestehen … sich die xpcc Library anzusehen> könnte ich euch dazu eure Fragen beantworten.
Cool! :-) Ich muss jetzt erstmal viel lesen und verstehen, um die
richtigen Fragen zu stellen. Danke vielmals für das Angebot, darauf
werde wohl nicht nur ich allein zurückkommen. :-)
Hans-Georg Lehnard schrieb:> was mir bisher im Internet zu dem Thema über den Weg gelaufen ist> und wie dabei IO Pins angesprochen werden ..
Boah! Viel Stoff zum Lesen und Vergleichen, danke. :-) Aber bevor man
das Rad neu erfindet, muss man sich das alles erstmal anschauen!
Torsten C. schrieb:> Hans-Georg Lehnard schrieb:>> SfrRegisterAccess ist einfach eine Template Klasse die den generellen>> Zugriff auf SFR-Register kapselt>> Ah, cool. Magst Du das Template auch mal posten?
Ist doch alles dabei ...
Das ist kein Template sondern einfach eine normal C++ Klasse.
Weil aber alle Methoden dieser Klasse static sind gibt es davon keine
Instanz oder Objekt. SfrRegisterAccess ist einfach ein namespace.
deshalb ja auch SfrRegisterAccess::Get( ..
und nicht SfrRegisterAccess.Get(
Torsten C. schrieb:> Aber bevor man das Rad neu erfindet, muss man sich das alles erstmal> anschauen!
Ich will keine allgemeine Library schreiben, für mich ist das eine reine
private Machbarkeitsstudie und Auffrischung meiner C++ Kentnisse.
Mit dem Code wollte ich hauptsächlich zeigen, das C++ auch auf ATTiny
Sinn machen kann.
Hallo Moby,
Moby AVR schrieb im Beitrag #3971437:
> C++ auf kleinen Controllern ist und bleibt eine Schnapsidee.
Das kannst Du gerne noch hundertmal behaupten, aber wird dadurch kein
bisschen richtiger. C++ ist auch auf dem Mikrocontroller eine prima
Sache, um den Code besser zu strukturieren und zu modularisieren, und
damit sowohl die Wartbarkeit als auch die Wiederverwendbarkeit des Code
zu erhöhen.
Daß Du diesen Mehrwert nicht erkennst, spricht nicht gegen den Mehrwert,
sondern nur gegen Deine Fähigkeiten zur Erkenntnis -- zumal Du grob die
Hälfte der Diskussion offenbar nicht gelesen oder nicht verstanden hast.
Liebe Grüße,
Karl
Hallo Ben,
Ben schrieb:> Ich denke, Ziel sollte es sein, eine Sammlung von Klassen zur Verfügung> zu stellen um von der Hardware eines ATmega abstrahieren zu können.>> Angefangen mit der oft Diskutierten Pin-Klasse. Man müsste beweisen dass> diese Klasse keinen zusätzlichen Overhead verursacht. Davon ausgehend> könnte man dann weitere Klassen nach ähnlichem Schema anlegen (UART,> Timer, ...)
Schau bitte mal etwas weiter oben, da habe ich ganz genau solche
Pin-Klassen gepostet, die, wie gewünscht, keinen Overhead gegenüber
funktional gleichen C-Programmen erzeugen, alles hübsch getestet mit dem
GCC und mit Angaben von Kompilatsgrößen. Vielleicht ist das ein Ansatz,
auf den man aufbauen kann.
HTH,
Karl
Hi Torsten,
Torsten C. schrieb:> Fazit bisher:> ¯¯¯¯¯¯¯¯¯¯¯¯¯> 3 Personen:> ¯¯¯¯¯¯¯¯¯¯¯> * Klaus Wachtler (mfgkw)> * Ben (Gast)> * Torsten C. (torsten_c)
Da würde ich mich auch gerne beteiligen.
LG,
Karl
besser als die vielen "#define"^^:
Falls man "ins Uferlose" will, hier eine ToDo-Liste ;-)
http://mikrocontroller.bplaced.net/wordpress/?page_id=744Hans-Georg Lehnard schrieb:> Ich will keine allgemeine Library schreiben
OK, vielleicht macht ja jemand anders mit. Das hatte ich falsch
verstanden.
Gibt es irgendwo eine geeignete Struktur, die man übernehmen sollte?
Ansonsten hier eine Diskussionsgrundlage:
Hallo Torsten,
Torsten C. schrieb:> Deine Lösung mit den Templates (Metaprogrammierung) gefällt mir deutlich> besser als die mit preprocessor:
Ich verstehe immer noch nicht, warum so viele Leute geradezu krampfhaft
was mit Templates machen wollen. Was soll das nutzen?
Liebe Grüße,
Karl
Karl Käfer schrieb:> Da würde ich mich auch gerne beteiligen.Karl Käfer schrieb:> Was soll das nutzen?
Hmmm. Wenn Du Dich beteiligen willst, solltest Du über die Frage "Was
soll das nutzen?" doch schon hinweg sein, oder? Es wurde alles schon
gesagt: Z.B. Wartbarkeit, Übersichtlichkeit und Wiederverwendbarkeit von
Code.
Torsten C. schrieb:> [ScoMe01] Slide 169 sagt:>> “A fundamental design goal is that design violations>> should not compile.”
Das funktioniert mit #define statt enum {…} halt nicht so gut.
Hallo Torsten,
Torsten C. schrieb:> Karl Käfer schrieb:>> Was soll das nutzen?>> Hmmm. Wenn Du Dich beteiligen willst, solltest Du über die Frage "Was> soll das nutzen?" doch schon hinweg sein, oder? Es wurde alles schon> gesagt: Z.B. Wartbarkeit, Übersichtlichkeit und Wiederverwendbarkeit von> Code.>> Torsten C. schrieb:>> [ScoMe01] Slide 169 sagt:>>> “A fundamental design goal is that design violations>>> should not compile.”>> Das funktioniert mit #define statt enum {…} halt nicht so gut.
Meine Frage bezieht sich explizit auf Templates -- und zwar nicht im
Vergleich mit #defines und enums, sondern im Vergleich mit klasssischen
C++-Klassen. Wozu? Was soll das? "Weil man es kann" ja ist kein
Argument, und "weil man damit zeigen kann, was für ein toller
C++-Experte man ist" ... och, nö. ;-)
Templates machen die Sache (im Mikrocontroller-Umfelt mit seinen
meistens stark limitierten Ressourcen) nur komplizierter und
unübersichtlicher, weil man sich jedes Mal überlegen muß, was der
Compiler daraus macht -- und wenn man dabei nicht sehr, sehr sorgfältig
vorgeht (oder einen blöden Compiler hat), kann das den Code ohne jede
Not deutlich vergrößern. Um diese Kosten wieder einzuspielen, müßte die
Template-Programmierung auf Mikrocontrollern einen Nutzen haben, der die
Kosten deutlich übersteigt. Welcher Nutzen sollte das sein? Ich habe
diese Frage schon mehrmals gestellt, auch hier, aber bisher konnte oder
wollte sie mir niemand sinnvoll beantworten.
Da auch Du jetzt als Erstes nach Templates rufst, frage ich Dich: was
ist der praktische Nutzen von Template-Metaprogrammierung für
Mikrocontroller? Was versprichst Du Dir davon?
Liebe Grüße,
Karl
Karl Käfer schrieb:> Hi Torsten,>> Torsten C. schrieb:>> Fazit bisher:>> ¯¯¯¯¯¯¯¯¯¯¯¯¯>> 3 Personen:>> ¯¯¯¯¯¯¯¯¯¯¯>> * Klaus Wachtler (mfgkw)>> * Ben (Gast)>> * Torsten C. (torsten_c)>> Da würde ich mich auch gerne beteiligen.>> LG,> Karl
Wäre interessiert trollfrei mitzulesen, leider nicht viel Zeit
beizutragen. Die Diskussion um den Sinn nervt mich auch, ich finde das
Thema sehr spannend.
Karl Käfer schrieb:> was ist der praktische Nutzen von Template-Metaprogrammierung für> Mikrocontroller?
Wie ist Deine Frage gemeint:
a) Wozu ein Codegenerator?
b) Wo ist der Vorteil von C++-Templates gegenüber Alternativen?
Das ist wie ein Serienbrief: Du kannst einen Brief 100x schreiben und
von Hand die Adresse und Anrede tauschen oder z.B. mit Excel und Word
einen Serienbrief erstellen.
Statt Template-Metaprogrammierung geht auch ein anderer Codegenerator
z.B. mit XSLT, aber dann hat man mehr Tools in der Toolkette und mehr
Schnittstellen.
Da es in C++ keine "partial class" wie in C# gibt, ist die
Template-Metaprogrammierung vergleichsweise einfacher als die
Alternativen.
Meiner Meinung nach ein gutes und konkretes Beispiel für den Nutzen von
Templates auf dem uC.
Festkommazahlen mit C++
Beitrag "Festkommazahlen mit C++"
Conny G. schrieb:> Wäre interessiert trollfrei mitzulesen, leider nicht viel Zeit …
Das geht mir auch so, im Postkasten:
> [µC.net] Neuer Beitrag in "C++ auf einem MC, wie geht das?"
Und wieder nur ein Troll-Post.
Irgendwann kommt ein neuer Beitrag in "Projekte & Code", da grenzen wir
im Ausgangspost genau das Thema ab (auch was nicht zum Thema gehört) und
melden alle gemeinsam die Off-Topic-Posts mit "Beitrag melden" an den
Moderator. Irgendwann ebbt das Problem dann ab.
@Jörg Wunsch: Wäre das OK?
Die Formulierung des neuen Ausgangsposts in "Projekte & Code" würde ich
hier zur Diskussion stellen, bevor ihn jemand anlegt.
Am besten verweisen wir dort noch auf einen anderen Thread um die
"sonstigen Fragen" zu kanalisieren und damit der Plan noch besser
funktioniert. Können wir als Verweis diesen Thread hier nehmen?
Karl Käfer schrieb:> Ich verstehe immer noch nicht, warum so viele Leute geradezu krampfhaft> was mit Templates machen wollen. Was soll das nutzen?>
Hallo Karl,
wenn du Programme für einen dicken ARM mit viel (externen) MB Ram
Speicher schreibst und auch noch Linux darauf läuft brauchst du dir über
die Feinheiten der Template Programmierung keine Gedanken machen. Du
benutzt normale OOP Klassen und dazu vielleicht noch STD oder BOOST
Libs.
Das ist aber nur die eine Seite der embedded Programmierung. Auf der
anderen Seite hast du z.B einen ATtiny mit 128 Byte RAM und da spielt es
schon eine Rolle diesen Speicher effizient zu nutzen und dafür sind die
Meta-Templates eben geeigneter. Das hat nichts mit Angeberei oder
krampfhaft zu tun.
;)
Hans-Georg Lehnard schrieb:> und da spielt es> schon eine Rolle diesen Speicher effizient zu nutzen und dafür sind die> Meta-Templates eben geeigneter.
Gute Ergänzung, Danke. :-) Bei Vererbung (Interfaces, Polymorphie)
werden "Virtuelle Methoden-Tabellen" (VMTs) angelegt und dann greift
das Argument: C++ ist langsamer und Ressourcen-fressend. VMTs lassen
sich mit automatischer Code-Generierung umgehen, wenn die genaue Klasse
bereits zur Entwurfszeit feststeht und nicht erst zur Laufzeit ermittelt
werden muss.
Torsten C. schrieb:> Bei Vererbung (Interfaces, Polymorphie) werden "Virtuelle> Methoden-Tabellen" (VMTs) angelegt
Falsch, bei Vererbung werden keine VMTs angelegt, und Interfaces
existieren in c++ nicht.
VMTs gibt es, wenn man man eine Classe instanziert, die virtuelle
Methoden besitzt. Die anwendung von Polymorphie ist dafür nicht
erforderlich.
> Falsch, bei Vererbung werden keine VMTs angelegt, und Interfaces> existieren in c++ nicht.
Auch falsch, ein Interface ist ein Konzept der OOP und ein Spezialfall
der Mehrfachvererbung. C++ kennt das, auch wenn es das Schlüsselwort
"interface" nicht gibt.
> VMTs gibt es, wenn man man eine Classe instanziert, die virtuelle> Methoden besitzt. Die anwendung von Polymorphie ist dafür nicht> erforderlich.
Wieder falsch. VMTs gibt es nur wenn eine Klasse instanziert wird die
von einer anderen Klasse mit virtuellen Methoden geerbt hat.
Und auch nur dann wenn (virtuelle) Methoden über einen Pointer auf die
Basisklasse aufgerufen werden: Polymorphie.
Wenn dein Compiler es in anderen Fällen tut, schalte die Optimierung ein
oder schreib einen Bugreport.
Danke für die Klarstellungen. So "Übergenau" sind meine Worte oft nicht.
Stefan schrieb:> Und auch nur dann wenn (virtuelle) Methoden über einen Pointer auf die> Basisklasse aufgerufen werden …
Bevor das zur akademischen Wortklauberei wird, viel wichtiger: Was muss
man tun, damit virtuelle Methoden in der Embedded-SW garantiert nicht
über einen Pointer auf die Basisklasse aufgerufen werden?
Ich dachte, das ist immer dann der Fall, wenn die Klasse bereits zur
Entwurfszeit genau feststeht und nicht erst zur Laufzeit ermittelt
werden muss. Oder?
Um auch meinen Senf dazu geben zu wollen - etwas zu C++ auf dem MC.
Ich stimme in einigen Punkten der Meinung eines Vorschreibers bei, dass
C++ auf einem MC keinen wirklichen Vorteil gegenüber C bringt.
Ich hatte sowas auch mal probiert und musste entnervt aufgeben denn
mangels verfügbarer Libraries muss man einfach zu viel Arbeit
investieren um keine besseren Ergebnisse zu erhalten. Meine Motivation
mal C++ auf einem MC zu probieren war zur prüfen, ob der Vorteil der
Übersichtlichkeit der per Klassendefinitionen gekapselten Instanzen und
Variablen zu lasten anderer Nachteile geht. Mir gefällt die
übersichtliche Art der Darstellung. Leider ist kaum eine Handfeste
Unterstützung vorhanden. Der Grund dafür ist der Mange an Vorteilen und
dass wurde ja auch mehrfach erwähnt. Man kann es auch mit einer anderen
Art der Deklaration schaffen, Ordnung in den Quellen zu halten.
C++ ist auf kleinen System nicht wirklich hilfreich und macht eigentlich
nur Mehrarbeit.
DD4DA schrieb:> Leider ist kaum eine Handfeste Unterstützung vorhanden.
Das geht mir genau so. Aus diesem Grund hatte ich die Hoffnung, dass wir
hier gemeinsam einen guten Leitfaden oder wenigstens eine gute Basis für
eine Bibliothek erschaffen können.
PS zu "So 'Übergenau' sind meine Worte oft nicht."^^: Viele
UML-Programme für C++ nutzen m.E. "Lollipop-Notation", wenn eine Klasse
nur aus virtuellen Methoden besteht. Und dann gib's immer VMTs. Ist das
so nun richtig?
Karl Käfer schrieb:> was ist der praktische Nutzen von Template-Metaprogrammierung> für Mikrocontroller?
Waren die Antworten verständlich und überzeugend? In einem Wiki-Artikel
müsste das nämlich wohl auch erwähnt werden.
Hallo Hans-Georg,
Hans-Georg Lehnard schrieb:> wenn du Programme für einen dicken ARM mit viel (externen) MB Ram> Speicher schreibst und auch noch Linux darauf läuft brauchst du dir über> die Feinheiten der Template Programmierung keine Gedanken machen. Du> benutzt normale OOP Klassen und dazu vielleicht noch STD oder BOOST> Libs.
Wenn ich Programme für Linux schreibe, benutze ich diverse
Skriptsprachen; meistens Python. C++ verwende ich nur dann, wenn die zu
viele Ressourcen verbrauchen. Dabei kann ich da dann auch die STL und
die Boost-Libraries verwenden, denn dort mache ich mir vergleichsweise
wenig Gedanken über den Speicherverbrauch. Nur, wenn mein Programm dann
immer noch nicht mit den verfügbaren Ressourcen auskommt, fange ich an
zu optimieren. Knuth wußte schon '74: "premature optimization is the
root of all evil". ;-)
> Das ist aber nur die eine Seite der embedded Programmierung. Auf der> anderen Seite hast du z.B einen ATtiny mit 128 Byte RAM und da spielt es> schon eine Rolle diesen Speicher effizient zu nutzen und dafür sind die> Meta-Templates eben geeigneter.
Ich habe mir Deinen Code oben angeschaut, übersetzt, und sehe immer noch
keinerlei Vorteil darin, dabei Templates zu einzusetzen. Mein Code in
Beitrag "Re: C++ auf einem MC, wie geht das?" (ganz unten) erzeugt
beinah genau dasselbe .lss; das Kompilat ist nur sechs Byte größer, weil
meine Klasse auch die Input-Pins initialisiert. (Daß Du das nicht
machst, würde übrigens zu einem Fehler führen, wenn Du denselben Pin
später als Input nutzen willst.)
Insofern spart die Template-Programmierung keinen Speicher zur Laufzeit,
weder RAM noch Programmgröße. In einigen Situationen spart sie
Quellcode, etwa bei der verlinkten Fließkommaberechnung. Bei den
Pin-Klassen sparen Templates aber nichtmal Quellcode -- Dein und mein
Quelltext haben genau gleich viele Zeilen Code (ohne "InoutPin").
Versteht mich bitte nicht falsch: ich habe nichts gegen Templates und
nutze sie dort, wo sie echte Vorteile haben, sehr gerne. Aber für das
Beispiel von Moby bieten Templates keinerlei Vorteil -- sein Assembler
lustigerweise übrigens auch nicht. Dafür ist mein Quellcode einfacher,
was sowohl der Wiederverwendbarkeit als auch der Wartbarkeit zugute, und
auch Anfängern sicherlich entgegenkommt.
Bisher sehe ich also immer noch keinen Vorteil, dafür aber eine Reihe
weicher, aber doch signifikanter Nachteile. Wenn jemand ein besseres
Beispiel hat, lasse ich mich aber jederzeit gerne überzeugen.
Liebe Grüße,
Karl
PS: Der Einfachheit halber habe ich Deinen und meinen Code nochmal in
ein Zip-Archiv gepackt und angehängt.
Karl Käfer schrieb:> Meine Frage bezieht sich explizit auf Templates -- und zwar nicht im> Vergleich mit #defines und enums, sondern im Vergleich mit klasssischen> C++-Klassen.
Ich glaube, genau hier reden wir aneinander vorbei.
Wie sind denn "DDRB" und "PORTB" bei Dir definiert?
Ich bereits schrieb:> RCC_APB1PeriphClockCmd(RCC_APB2Periph_SPI1, ENABLE);> Was stimmt da nicht? Richtig, es muss heißen:> RCC_APB2PeriphClockCmd(RCC_APB2Periph_SPI1, ENABLE);
Um sowas ^^ geht es im Satz von Scott Meyers: ^^
> “A fundamental design goal is that design violations> should not compile.”
Können bei Deinen "DDRB" und "PORTB" solche Verwechslungen vom Compiler
erkannt werden? Bei Templates und Enums werden sie erkannt!
Lass doch. Als asm guru hat Moby sich in den letzten Posts auch nicht
gerade empfohlen, von daher sollte man den Worten auch nicht übermäßig
Gewicht geben.
Die c++ Diskussion ist jedenfalls fachlich nicht so ganz banal würde ich
sagen (Ich kann jedenfalls nicht lückenlos folgen) und wenn dann weder
bei asm noch oop intimeres Wissen da ist, sind doch Kommentare einfach
zu ignorieren.
Es ist, auch in diesem thread, immer eine schwierige Aufgabe für sich
festzustellen wessen Wort Gewicht haben soll und wessen Wort nur wichtig
klingt.
Jeder fortgeschrittene Amateur oder Profi weiß was Moby meinen mag. Und
jedem macht auch mal eine asm Knösterei Spaß - ganz bestimmt.
Jeder fortgeschrittene Amatuer wird aber auch ab gewissen Projekten
interessiert sein, effizientere Werkzeuge zu haben. Moby kann aber
mangels derzeitigen Wissen oder einfach aus Verweigerung, Erfahrung und
Weitsicht halt nicht immer nachvollziehen, worüber die anderen reden.
Warum er das nicht einsieht oder den anderen glaubt weiß ich auch nciht.
Hier reden keine PC Programmierer, die bei Adobe Arbeiten und Ressourcen
aus dem Fenster schmeissen, noch Script Kiddies.
Warum streiten
edit: Wenn es dir hilft, Moby, sieh doch die oop Überlegungen als
intellektuelle Herausforderung an. Wühl dich rein und lass dich von den
anderen durch Fragen mit an Bord holen. So will ich es machen als jemand
der nur asm/c Erfahrung hat.
Und hier ist ein Beispiel ..
Nachdem ich die Atmel defines rausgeschmissen habe kann ich alle Namen
neu und sauber vergeben.
weiteres Templates z.B. in bordX.h
typedef Pin <PORTA, bit0> PA0;
...
typedef Pin <PORTA, bit7> PA7;
Damit kann ich im Anwendungscode schreiben:
DigitalInput<PA0> taster1;
Wenn es einen PIN bei diesen MCU Typ nicht gibt oder er auf der Platine
nicht verdrahtet ist kann ich ihn einfach auskommentieren und der
Compiler bringt einen Fehler wenn mein Anwendungscode ihn benutzt.
weitere Möglichkeit wäre ..
anstelle der Pin namen aus dem Datenblatt
typedef Pin <PORTA, bitX> PAX;
könnte ich dann auch
typedef Pin <PORTA, bit6> LCD_WR; in avr_board1.h
typedef Pin <PORTC, bit2> LCD_WR; in avr_board2.h
oder auch
typedef Pin <PORTA, bit31> LCD_WR; in arm_board1.h
definieren
Bevor Diskussionen jetzt hier aufkommen PORTA und bit31 sind Datentypen
und natürlich beim ARM anders wie bei einem AVR definiert aber der
Compiler ist nicht doof und instanziiert das richtige Template anhand
vom Datentyp.
Im Anwendungscode muss dann nur das richtige Board includet werden der
eigendliche Code bleibt gleich.
#include avr_bord1.h oder avr_bord2.h oder arm_board1.h
DigitalOutput<LCD_WR> lcd_wr;
usw ...
Moby schrieb im Beitrag #3975867:
> Karl Käfer schrieb:>> C++ ist auch auf dem Mikrocontroller eine prima>> Sache, um den Code besser zu strukturieren und zu modularisieren,>> Na eher eine prima Sache, um Code und Schreibbedarf aufzublähen, mit> allerlei Gedankenakrobatik im Ganzen zu verkomplizieren und...>
Mein lieber Moby,
ich bin zwar ein frischgebackener Rentner aber scheinbar im Kopf doch
noch etwas flexibler wie du ;)
Mein C++ Code von deinem Beispiel ist weder im Code noch im
Schreibbedarf grösser aber viel verständlicher.
Ich habe in meinem beruflichen Leben so viel Code-Reviews mitgemacht und
da wärst du mit deinem Assembler gewurschtel wieder nach Hause geschickt
worden. Aber wenn du damit zufrieden bist und nichts mehr dazu lernen
willst ....
Bitteschön ...
Hans-Georg Lehnard schrieb:> Im Anwendungscode muss dann nur das richtige Board includet werden der> eigendliche Code bleibt gleich.
Genau so hätte ich es auch gern. :-) Danke!
Das ist ein weiteres "fundamental design goal"!
PS:
Das wäre doch schon mal eine Basis für ein Projekt "µC.net C++".
Wollen wir eins gemeinsames Projekt starten?
Zwei "design goals" hätten wir schon, wir brauchen noch einen Namen. Da
muss ich nochmal die Mods nerven => nächster Beitrag.
Jörg Wunsch schrieb:> Für Projekte wiederum gibt es hier die Möglichkeit, einen SVN-Server> zu hosten sowie das in "Projekte & Code" zu posten.
Wir haben m.E. inzwischen zwei "Design-Ziele" ^^ und könnten damit
langsam starten.
Vorausgesetzt, wir haben auch noch ein gemeinsames Projektziel …
Eine C ++ Bibliothek mit folgenden Design-Zielen : …
… brauchen wir noch einen Projekt-Namen.
@Moderator: Darf der Name einen Bezug zum "mikrocontroller.net" haben,
oder bedarf es da eines "Genehmigungsprozesses" oder gibt es
Namensrechtliche Probleme?
Der Name sollte auch als Namespace ein gültiger Bezeichner sein, hier
zwei Links dazu:
http://stackoverflow.com/questions/228783/what-are-the-rules-about-using-an-underscore-in-a-c-identifier#228797http://www.cplusplus.com/doc/tutorial/variables/#identifiers
Um mal einen Stein ins Wasser zu werfen, über den weitestgehenden Antrag
muss immer zuerst abgestimmt werden: ;-)
* "uCnet" als Namespace
* "µC.net C++ Bibliothek" als Projektbezeichnung
Es kann gern auch eine "Nummer kleiner" sein! Die Antwort ist nicht
dringend, ich wollte nur, dass die Frage nicht übersehen wird.
… oder ist englisch (µC.net C++ library") besser? Aber im
"embdev.net/forum/" gibt's ja gar kein Forum "projects & code".
Ich fände Deutsch besser. Klassen, Variablen, Funktionen sollten
trotzdem in Englisch sein. Über die Sprache der Kommentare könnte man
sich noch streiten.
Wer will µC.net SVN und wer will github?
Hi Torsten,
Torsten C. schrieb:> * "uCnet" als Namespace> * "µC.net C++ Bibliothek" als Projektbezeichnung
Ich würde das "net" herauslassen, wegen der Verwechslungsgefahr mit
.N(j)ET und der bekannten Klagefreudigkeit des Herstellers.
LG,
Karl
> das relativieren würde, sofern es funktioniert.
Das funktioniert prima, probier's aus.
> Der output scheint ja derselbe zu sein, weswegen von dieser Seite ja> nichts gegen Templates spricht.
Aber eben auch nichts dafür. Und Templates sind, wie erwähnt, eine recht
komplexe Angelegenheit, die Anfänger regelmäßig überfordert. Warum denn
Komplexität einbauen, ohne Not und ohne Vorteil?
Wozu Kosten und Einstiegshürden steigern, wenn kein Nutzen erkennbar
ist? Das kann man machen, wenn man der einzige Nutzer ist und das aus
eigenem Interesse macht. Aber bei einem Softwareprojekt, das sich auch
an andere richtet, muß der Wurm dem Fisch schmecken und nicht dem
Angler.
Liebe Grüße,
Karl
Hi Torsten,
Torsten C. schrieb:> Karl Käfer schrieb:>> Meine Frage bezieht sich explizit auf Templates -- und zwar nicht im>> Vergleich mit #defines und enums, sondern im Vergleich mit klasssischen>> C++-Klassen.>> Ich glaube, genau hier reden wir aneinander vorbei.
Möglich.
> Wie sind denn "DDRB" und "PORTB" bei Dir definiert?
Wie in avr/io.h.
> Ich bereits schrieb:>> RCC_APB1PeriphClockCmd(RCC_APB2Periph_SPI1, ENABLE);>> Was stimmt da nicht? Richtig, es muss heißen:>> RCC_APB2PeriphClockCmd(RCC_APB2Periph_SPI1, ENABLE);>> Um sowas ^^ geht es im Satz von Scott Meyers: ^^>> “A fundamental design goal is that design violations>> should not compile.”>> Können bei Deinen "DDRB" und "PORTB" solche Verwechslungen vom Compiler> erkannt werden?
Nö, aber ich halte das für einen logischen Fehler.
> Bei Templates und Enums werden sie erkannt!
Klingt spannend, wie stellst Du Dir das denn vor?
Liebe Grüße,
Karl
Karl Käfer schrieb:> Klingt spannend, wie stellst Du Dir das denn vor?
Nicht ich. Du hast gestern selbst die demo.h in
der "Code.zip" ^^ geposted.
Hast Du Dir die überhaupt angeschaut?
1
template<classregs,PINpin>
PIN ist ein Enum.
Karl Käfer schrieb im Beitrag #3976273:
> können wir diesen "Herrn" nicht einfach alle ignorieren?
Off-Topic (also alles was nix bringt) zu ignorieren ist eine gute Idee.
Sich beim Ignorieren an einer Person statt am Thema zu orientieren ist
keine gute Idee.
Torsten C. schrieb:> Können bei Deinen "DDRB" und "PORTB" solche Verwechslungen vom Compiler> erkannt werden? Bei Templates und Enums werden sie erkannt!
Geht auch in C bei AVRs, siehe
Beitrag "Re: AVR-Register als Bitfields"
Stichwort: "Registersichere Bitfields"
Das Projekt hatte ich mal angefangen, dann aber aus Zeitgründen liegen
gelassen. Vielleicht sollte ich das mal wieder aufnehmen.,..
Ist es nicht möglich alle hier gestellten Forderungen unter einen Hut zu
bringen?
Also ich versuche das hier mal zusammenzufassen:
* “A fundamental design goal is that design violations should not
compile.”
* Genauso effektiv wie ein Zugriff in C (Speicherbedarf, Laufzeit)
* Möglichst leicht zu durchschauende, alt bekannte Sprachkonstrukte,
evtl. verzicht auf Templates
Mir wäre ein Zugriff der Art:
1
EinAus beleuchtung = EinAus(PORT_B, P4);
am liebsten.
Ich bin jetzt nicht so der C++ Experte, das sollte sich doch aber zu
realisieren lassen.
Gruß
Stefan
Frank M. schrieb:> Geht auch in C bei AVRs,
Nur bei AVRs oder allgemeinin C?
Ein C-Compiler kann doch gar keine Typsicherheit festestellen. Dem ist
doch egal, zu welchem Enum-Typ ein Enumerator gehört. Ich hab mir das
Thema "Registersicher" fünfmal durchgelesen und nicht verstanden, was Du
meinst.
Falls Du meinst, dass man das Problem mit "RCC_APB1PeriphClockCmd" ^^
auch in C (nicht C++) lösen kann, bin ich gespannt!
Torsten C. schrieb:> Ein C-Compiler kann doch gar keine Typsicherheit festestellen. Dem ist> doch egal, zu welchem Enum-Typ ein Enumerator gehört.
Ein C compiler kann das nicht aber ein C++11 Compiler kann das.
Der g++ im Atmel Studio 6.2 kann C++11 Sytax , wenn du das compilerflag
-std=c++11 setzt.
Beispiel:
enum class bit8_mask_t : uint8_t
{
bit0 = 0x01U,
bit1 = 0x02U,
bit2 = 0x04U,
bit3 = 0x08U,
bit4 = 0x10U,
bit5 = 0x20U,
bit6 = 0x40U,
bit7 = 0x80U
};
enum class bit16_mask_t: uint16_t
{
bit0 = 0x0001U,
bit1 = 0x0002U,
bit2 = 0x0004U,
bit3 = 0x0008U,
bit4 = 0x0010U,
bit5 = 0x0020U,
bit6 = 0x0040U,
bit7 = 0x0080U,
bit8 = 0x0100U,
bit9 = 0x0200U,
bit10 = 0x0400U,
bit11 = 0x0800U,
bit12 = 0x1000U,
bit13 = 0x2000U,
bit14 = 0x4000U,
bit15 = 0x8000U
};
Torsten C. schrieb:> Ein C-Compiler kann doch gar keine Typsicherheit festestellen. Dem ist> doch egal, zu welchem Enum-Typ ein Enumerator gehört. Ich hab mir das> Thema "Registersicher" fünfmal durchgelesen und nicht verstanden, was Du> meinst.
z.B.
Torsten C. schrieb:> Nur bei AVRs oder allgemeinin C?
Kannst Du natürlich auch auf andere µCs ausweichen.
> Ein C-Compiler kann doch gar keine Typsicherheit festestellen. Dem ist> doch egal, zu welchem Enum-Typ ein Enumerator gehört. Ich hab mir das> Thema "Registersicher" fünfmal durchgelesen und nicht verstanden, was Du> meinst.
Der Compiler stellt sicher, dass Du WGM01 ausschließlich in TCCR0A
setzen kannst und nicht in einem anderen Register. Da diese Bits gerne
mal von AVR zu AVR in andere Register wechseln, weil Atmel das Spaß
macht, gibt/gab es schon immer dieses Problem - gerade bei der
Portierung von einem µC auf einen anderen.
In der klassischen Schreibweise
TCCR0A |= (1<<WGM01);
frisst der Compiler auch dieses:
TCCR0B |= (1<<WGM01);
Das ist aber ein Fehler, denn (meistens) sitzt das Bit WGM01 in TCCR0A
und nicht in TCCR0B.
Mit "registersicheren Bitfields" kannst Du einfach schreiben:
BFM_WGM01 = 1;
und Du musst überhaupt gar nicht wissen, in welchem Register das Bit
überhaupt steckt. Das macht dann der Compiler.
> Falls Du meinst, dass man das Problem mit "RCC_APB1PeriphClockCmd" ^^> auch in C (nicht C++) lösen kann, bin ich gespannt!
Hm, das ist eine Funktion... Da müsste es aber einen analogen Weg geben.
Hans-Georg Lehnard schrieb:> Ein C compiler kann das nicht aber ein C++11 Compiler kann das.
Ach so, na denn ist´s klar. Du hattest aber geschrieben "Geht auch in C
bei AVRs". Und wollte nicht in meinem Kopf! Geht also auch in C++ bei
AVRs!
Dann meinen wir das Gleiche und Du hast nochmal
schöne Beispiele gepostet. ;-)
Torsten C. schrieb:> Ach so, na denn ist´s klar. Du hattest aber geschrieben "Geht auch in C> bei AVRs". Und wollte nicht in meinem Kopf! Geht also auch in C++ bei> AVRs!
Du velwechserst grad zwei Postings von unterschiedlichen Leuten!
Torsten C. schrieb:> Wie sind denn "DDRB" und "PORTB" bei Dir definiert? …> Um sowas ^^ geht es im Satz von Scott Meyers: ^^>> “A fundamental design goal is that design violations>> should not compile.”> Können bei Deinen "DDRB" und "PORTB" solche Verwechslungen vom Compiler> erkannt werden? Bei Templates und Enums werden sie erkannt!Darauf Karl Käfer schrieb:>> Wie sind denn "DDRB" und "PORTB" bei Dir definiert?> Wie in avr/io.h.
Also mit #define und nicht mit enum!
Frank M. schrieb:> Torsten C. schrieb:>> … Bei Templates und Enums werden sie erkannt!> Geht auch in C bei AVRs,
Also: Typsichere enums, damit Verwechslungen vom Compiler erkannt
werden, gehen auch "in C bei AVRs"^^?! Nein, aber mit C++. Das ist ja
nun geklärt.
Michael Reinelt schrieb:> Du verwechserst grad zwei Postings von unterschiedlichen Leuten!
Sorry, falls ich was verwechselt haben sollte. Was meinst Du?
Ich frage Karl den Käfer nochmal …
… wie ich schrieb:> Waren die Antworten verständlich und überzeugend? In einem Wiki-Art…
Danke fürs Aufräumen. Das hat mir viel verplemperte Zeit gespart! :-)
> Beitrag #3975867 wurde von einem Moderator gelöscht.> Beitrag #3975873 wurde von einem Moderator gelöscht.> Beitrag #3976273 wurde von einem Moderator gelöscht.> Beitrag #3976354 wurde von einem Moderator gelöscht.> Beitrag #3976354 wurde von einem Moderator gelöscht.> Beitrag #3976413 wurde von einem Moderator gelöscht.> Beitrag #3976471 wurde von einem Moderator gelöscht.> Beitrag #3976507 wurde von einem Moderator gelöscht.> Beitrag #3976530 wurde von einem Moderator gelöscht.> Beitrag #3976878 wurde von einem Moderator gelöscht.> Beitrag #3976908 wurde von einem Moderator gelöscht.
Um das nach den ganzen OT-Beiträgen nochmal in Erinnerung rufen:
Torsten C. schrieb:> Wer will µC.net-SVN und wer will GitHub?Karl Käfer schrieb:> Torsten C. schrieb:>> * "uCnet" als Namespace>> * "µC.net C++ Bibliothek" als Projektbezeichnung> Ich würde das "net" herauslassen …
Also wie genau? Nur "uC"? Neee …
Torsten C. schrieb:> Frank M. schrieb:>> Torsten C. schrieb:>>> … Bei Templates und Enums werden sie erkannt!>> Geht auch in C bei AVRs,>> Also: Typsichere enums, damit Verwechslungen vom Compiler erkannt> werden, gehen auch "in C bei AVRs"^^?! Nein, aber mit C++. Das ist ja> nun geklärt.
Gewöhne Dir bitte an, genauer zu lesen. (Hatte ich Dir das nicht schon
einmal empfohlen?)
Du schriebst:
> Können bei Deinen "DDRB" und "PORTB" solche Verwechslungen vom Compiler> erkannt werden? Bei Templates und Enums werden sie erkannt!
Ich antwortete:
> Geht auch in C bei AVRs [...]
Ich habe also geschrieben, dass man Verwechselungen bzgl. DDRB und PORTB
auch in C sicher abfangen kann und Dir einen Link geliefert, der Dir
erklärt, wie das geht. Und sogar anschaulicher: Nämlich mit TCCR0A und
WGM01. Ich habe NICHT geschrieben, dass man das über enums und
Templates "in C" machen kann.
Oben hast Du das unvollständig zitiert. Und wahrscheinlich genauso
unvollständig beim Lesen in Dich aufgenommen. Aber daran gewöhne ich
mich langsam...
Wer mal ein (meiner Meinung nach) einigermaßen gelungenes Beispiel
nutzen, bzw. als Basis für eigene Libraries darauf aufbauen möchte, kann
sich ja mal SAVR anschauen.
https://code.google.com/p/savr/
Frank M. schrieb:> Oben hast Du das unvollständig zitiert. Und wahrscheinlich genauso> unvollständig beim Lesen in Dich aufgenommen.
Genau! Ich habe so zitiert, wie ich es aufgenommen hatte. Nobody is
perfect! Sorry und danke für die Klarstellung.
PS:
Frank M. schrieb:> Gewöhne Dir bitte an, genauer zu lesen.
Und in meinem Zeugnis steht dann …
Ich kann versichern: Ich bin stets bemüht! Sorry nochmal!
Nils Friess schrieb
>Wer mal ein (meiner Meinung nach) einigermaßen gelungenes Beispiel>nutzen, bzw. als Basis für eigene Libraries darauf aufbauen möchte, kann>sich ja mal SAVR anschauen.>https://code.google.com/p/savr/
Die original Arduino Funktionen-API ist für alle Mikrocontrollertypen
gleich. Vor kurzem habe ich eine Programm 1:1 auf einem Arduino UNO mit
Atmega und einem Arduino DUE mit ARM-SAM83x laufen lassen.
Die oben gezeigte Lib ist zwar schön, aber leider auf Atmegas begrenzt.
Wenn man sich die Beiträge im MC-Netz so ansieht, würde ich sagen, die
ARM-Beiträge überwiegen bald.
Ich fände eine Lib mit verschiedenen Abstraktionsschichten gut. Direkte
Porbbezeichnunge wie PORTB und PB7 sind für die Portabilität nicht so
gut.
Beitrag "BIOS für Mikrocontroller"
Sollte nicht erst einmal geklärt werden, was das Ziel des ganzen ist,
bevor man mit Templates, Klassen, assembler oder was auch immer um sich
wirft.
Der Gedanke hinter diesem Vorhaben ist doch, eine einheitliche
Schnittstelle zwischen der Software und verschiedener Hardware
verschiedener Mikrocontrollertypen zu ermöglichen.
Als Beispiel würde ich hier eine HD44780 LCD library nennen. Sie besteht
letztenendes nur aus Warten und I/O Pins setzen. Da sie eigentlich nur
daraus besteht, muss sie auch für jeden Controller fast komplett neu
geschrieben werden. Ein einheitlicher Standard, wie man
Controller-unabhängig wartet und einen gpio Pin setzt, fehlt.
Ein weiteres Beispiel wäre ein PID-Regler, letzten Endes wird nur ein
Ist- und Sollwert eingelesen, und ein Stellwert ausgegeben. Also
get_ADC, set_DAC bzw set_PWM.
Man sollte sich also erst einmal einigen, was wird alles Benötigt, bevor
man sich auf eine Syntax versteift, die später nicht mehr eingehalten
wird.
Hier würde ich auch nicht all zu komplexe Funktionen einbauen, sondern
recht einfache funktionen, die immer wieder kommen definieren.
Zum Beispiel würde ich folgendes Vorschlagen:
- startupcode
- gpio_einlesen
- gpio_setzen
- adc_einlesen
- dac_setzen
- delay
- pwm erzeugen
- timer der alle X ms bestimme funktionen abarbeitet
- uart, SPI, I²C/TWI, RS485
- ...
Mit diesen Paar Funktionen liesen sich schon allerhand Aufgaben Lösen
und das Hardwareunabhängig. Für einen neuen Controller nur eine andere
Library Laden, die Pins abändern und den Rest übernimmt der Compiler.
Sofern die Library vorhanden ist.
Dann die ganzen Funktionen über eine Configdatei einstellen und fertig.
Torsten C. schrieb:> Zum UART habe ich genug Input, aber beim Zustandasautomat könntet Ihr> mir helfen…
android.util.JsonReader sagt:
> beginArray() / endArray()> beginObject() / endObject()> …
org.xml.sax sagt:
> startDocument()> startElement() / endElement()> …
So ein Ereignis-gesteuertes Interface ist für µCs mit wenig RAM
(512..2048 Bytes) m.E. die einzige Möglichkeit, um Daten in einem
Zustandsautomaten schnell parsen zu können.
Da ich über den UART http-GET und http-POST bekomme, muss ich die
UART-API auch so ähnlich wie oben umsetzen.
Hat jemand einen Vorschlag? Gibt's das schon? Vielleicht erfinde ich ja
gerade ras Rad neu.
http://en.wikipedia.org/wiki/Reinventing_the_wheel
Grober Entwurf:
> startLine() / endLine()> startIPD() / endIPD()> startEcho() / endEcho()
… oder so ähnlich. ("IPD" = InPutData)
Peter Dannegger schrieb:> Ich möchte gerne folgendes erreichen: LED0 = KEY0.state; //> an solange Taste gedrückt> LED1.toggle = KEY1.press // wechsel bei jeder Drückflanke> LED2.off = KEY2.press_short; // kurz drücken - aus> LED2.on = KEY2.press_long; // lang drücken - an>> Geht sowas in C++ und wie könnte eine Implementierung aussehen?>> Besonders interessant wäre die Entprellung portweise parallel und nur> das Auswerten der Tasten einzeln. Also irgendwie, jede Taste ist Teil> der Klasse entprelle_port, die wiederum für mehre 8Bit-Ports verwendet> werden kann. Z.B. 16 Tasten an 2 Ports.
hier wird soetwas ähnliches realisiert.
http://avr-cpp.de/doku.php?id=grafische_programmierung_mit_der_uml#zustaende
jan schrieb:> Peter Dannegger schrieb:>> Ich möchte gerne folgendes erreichen: LED0 = KEY0.state; //>> hier wird soetwas ähnliches realisiert.> http://avr-cpp.de/doku.php?id=grafische_programmie...
PScC geht ja wohl einen ähnlichen Weg und, man darf es kaum aussprechen,
Arduino letztlich auch.
Wenn ich mir allerdings das Beispiel aus deinem Link ansehe, dann sind
mir die paar Zeilen C dann doch angenehmer. Zumindest was dieses
Beispiel betrifft.
@Thorsten:
>> delay(ms); delayMicroseconds(us)>>Ist das Dein Ernst?
Das Zeug kommt aus der Arduino-Welt. Und da gibt es mehrere Tasks. daher
kann da durchaus was anderes parallel laufen.
Gruß, Stefan
Vielleicht hat es sich noch nicht durchgesetzt, weil man darüber nicht
ungestört diskutieren darf. Bitte alle die schon jetzt überzeugt sich,
daß es sich um "iwerzwerches Ziegs" handelt, wie man in meiner Heimat
sagen würde, einfach wegschauen. Und bitte nix mehr schreiben!
Stefan schrieb:> Das Zeug kommt aus der Arduino-Welt. Und da gibt es mehrere Tasks. daher> kann da durchaus was anderes parallel laufen.
Ich lerne immer gern dazu.
> the use of delay() in a sketch has significant drawbacks …, so in> effect, it brings most other activity to a halt.http://arduino.cc/en/pmwiki.php?n=Reference/Delay
Gibt es noch ein anderes delay?
In "Efficiently implementing objects" ist eine gute Erklärung, wann vom
Compiler "virtual method tables" (VMTs) im "class instance record" (CIR)
angelegt werden und wann nicht:
* http://www.toves.org/books/oops/index.html
* http://www.cburch.com/cs/230/test/re/index.html
Leider lässt sich für eine Bibliothek, die für mehrere Toolketten
geeignet sein soll, nicht immer genau sagen, ob vom Comiler eine VMT
angelegt wird oder nicht. :-(
Hier das Beispiel:
1
Containerbag=newSuitcase(100);
2
bag.add(10);
> A compiler might look at this code and determine that, when the> add method is being called, bag is of necessity a Suitcase. Thus,> it could generate code to call Suitcase's add method directly,> without reference to the VMT to which bag refers.
Frage: Macht eine Bibliothek, die für mehrere Toolketten geeignet sein
soll, dann überhaupt Sinn?
Torsten C. schrieb:> aber beim Zustandasautomat könntet Ihr mir helfen: …> "switch/case" finde ich doof: …
… denn performanter als "switch/case" ist es, wenn jeder Zustand eine
Klasse (Instanz) ist oder Funktionen (function-pointer) sind!
Und wir wollen in C++ ja nicht schlechter sein als in C!
Daraufhin jan schrieb:> hier wird soetwas ähnliches realisiert.http://avr-cpp.de/doku.php?id=grafische_programmierung_mit_der_uml#zustaende
Ein Grafischer Editor für Zustandasautomaten. Cool! Bei meinem ersten
Versuch damit kam aber auch "switch/case" raus.
Schade. :-(
Eine Demoversion von SiSy läuft übrigens 70 Tage.
Ich bin ja kein C++-Profi und bei mir fallen die Groschen auch nur
pfennigweise. Aber weil die Frage "Wozu Templates?" vielleicht (Käfer
Karl?) noch nicht hinreichend beantwortet ist:
Man nutzt Vererbung ja oft, um Gemeinsamkeiten einmal in einer
Basis-Klasse festzulegen. Falls dadurch VMTs entstehen (was ja nicht
immer vorhersehbat ist^^), wird der C++-Code ineffizienter. Ich brauche
aber höchste Effizienz (Zustandasautomat in einer ISR, s.u.)! Daher kann
ich auch kein "switch/case"^^ im Zustandasautomaten gebrauchen.
Mit Templates können Gemeinsamkeiten und Unterschiede aber auch ohne
Vererbung definiert werden, also immer ohne VMTs, unabhängig von der
Toolkette. Ist das vielleicht die Begründung, warum Templates bei
Embedded C++ so wichtig sind?
BTW: Das OOP Konzept "Containment" ist übrigens auch noch eine
Alternative, um VMTs zu vermeiden:
http://www.codeproject.com/Articles/24948/Three-Ways-To-Extend-A-Class
PS zu "höchste Effizienz"^^:
Ich möchte die Ansätze für die neue "µC.Cet C++-Bibliothek" auf einem
ATTiny1634 erstmalig nutzen, weil ich damit gerade mein aktuelles
Projekt umsetze. Der ATTiny1634 hat 1KB RAM und ich muss HTTP-Requests
direkt in der ISR bearbeiten, damit ich den RX-Puffer klein halten kann.
"bearbeiten" heißt dabei parsen und wie bei "JsonReader" oder "sax"^^
entsprechende Ereignisse auslösen, z.B.
• NextChar(),
• EndOfLine(),
• NumCharsReached() oder
• TimeOut().
Diese Ereignisse müssen von einem effizienten Zustandasautomaten
ausgewertet werden, denn der Zustandasautomat läuft in einer ISR!
PPS @Modertor: Wie sollen wir uns verhalten?
Ich habe 3978837#3978829 eben gemeldet. War das gewünscht?
Moby schrieb im Beitrag #3978856:
> Am besten wie ein Mann der Widerspruch ertragen kann
Mit Widerspruch habe ich kein Problem! Dass es mir um die überflüssigen
> "[µC.net] Neuer Beitrag in "C++ auf einem MC, wie geht das?"
geht, hatte ich ja geschrieben!
350418#3978856 und 350418#3978862 können von mir aus gelöscht werden;
wenn Moby kein Gast wäre, hätte ich natürlich 'ne PN geschrieben.
Torsten C. schrieb:> Dass es mir um die überflüssigen>> "[µC.net] Neuer Beitrag in "C++ auf einem MC, wie geht das?"> geht,
Nö.
Torsten C. schrieb:> #3978829 eben gemeldet
... war ja wohl mein Beitrag, der hier ständig wegzensiert wird.
Torsten C. schrieb:> "höchste Effizienz"^^:> Ich möchte die Ansätze für die neue "µC.Cet C++-Bibliothek" auf einem> ATTiny1634 erstmalig nutzen, weil ich damit gerade mein aktuelles> Projekt umsetze.
Respekt. Da hast Du Dir was vorgenommen. Gutes Gelingen.
So^^ denke ich gerade, einen Zustandsautomaten für die UART-ISR
umzusetzen. Das wäre noch ohne Templates. Mal sehen, wann ich
wirklich Templates brauche.
PS: Moby schrieb:> war ja wohl mein Beitrag
… und meinen eigenen hatte ich auch aufgeführt.
Moby schrieb:> Respekt. Da hast Du Dir was vorgenommen. Gutes Gelingen.
Danke. Falls Du Recht haben solltest und Embedded C++ wirklich Mist sein
sollte, dann würde mir diese Erkenntnis auch nützlich sein. Aber mir
ist das noch nicht klar!
PS: Ich muss mir noch den asm-Code anschauen. Falls diese
Mehrfach-Vererbung eine VMT erzeugt, probiere ich mal "Containment"^^
aus. Oder kann das jemand vorhersagen?
Hi Torsten,
Torsten C. schrieb:> Karl Käfer schrieb:>> Torsten C. schrieb:>>> * "uCnet" als Namespace>>> * "µC.net C++ Bibliothek" als Projektbezeichnung>> Ich würde das "net" herauslassen …>> Also wie genau? Nur "uC"? Neee …
uC++?
LG,
Karl
Hi Torsten,
Torsten C. schrieb:> Ich bin ja kein C++-Profi und bei mir fallen die Groschen auch nur> pfennigweise. Aber weil die Frage "Wozu Templates?" vielleicht (Käfer> Karl?) noch nicht hinreichend beantwortet ist:
Bin (wieder) hier. Sorry, hin und wieder wünscht sich mein Arbeitgeber
doch tatsächlich, daß ich auch mal das tue, wofür er mich bezahlt.
Ich bin zwar immer noch nicht überzeugt, aber die Mehrheit scheint wohl
Templates zu bevorzugen und dem muß ich mich als guter Demokrat beugen.
Aber sagt am Ende nicht, ich hätte nicht davor gewarnt! ;-)
Wie dem auch sei: laßt und doch vielleicht einfach mal zusammentragen,
welche Hardware-Plattformen wir unterstützen wollen. Sicherlich AVRs,
offensichtlich auch ARMs. Was ist mit PICs, PIC32 und MCP430?
Wenn wir die gewünschten Plattformen zusammengetragen und entschieden
haben, sollten wir deren Gemeinsamkeiten und Unterschiede im Detail
herausarbeiten. Erst dann können wir uns sinnvolle Gedanken über
High-Level-APIs und die darunter liegenden Abstraktionsschichten für die
konkrete Hardware aussehen können. Bei einem GPIO-Pin ist das ja simpel,
aber spätestens bei den leicht unterschiedlichen Timer-Funktionalitäten
verschiedener AVRs könnte das schon spannend genug werden.
Liebe Grüße,
Karl
Torsten C. schrieb:> Der Name sollte auch als Namespace ein gültiger Bezeichner sein, hier> zwei Links dazu …Daraufhin Karl Käfer schrieb:> uC++?
Nee, "+" ist ein unerlaubtes Zeichen. Das geht nur in der
"Projektbezeichnung". Du hattest das "net" aber auch im Namespace nicht
haben wollen.
Karl Käfer schrieb:> aber die Mehrheit scheint wohl Templates zu bevorzugen
Mal sehen, wie weit ich ohne komme. Ich versuche es erstmal ohne.
Karl Käfer schrieb:> Was ist mit PICs, PIC32 und MCP430?Dazu Jörg bereits schrieb:> Sowie du das versuchst, auf viele Familien auszuweiten, geht das schnell> ins Uferlose.Zum MSP430 ich schrieb:> Und der MSP430-Compiler von TI unterstützt z.B. eh keine Templates.
Daher sollten wir mit dem MSP430 auch erstmal abwarten.
Falls sich jemand berufen fühlt, das ganze aus der Sicht der PICs oder
anderer µCs zu machen, habe ich natürlich überhaupt nix dagegen.
Hi,
ich finde, das ist ein sehr spannender Thread hier. Danke für die
vielen wertvollen Gedanken!
Bitte entschuldigt, dass ich Torstens Beitrag so zerstückelt zitiere.
Aber da sind eigentlich zwei Punkte drin, auf die ich separat eingehen
möchte: Dass Vererbung nicht immer ein guter Weg für Code Reuse ist. Und
dass Templates helfen können, Polymorphismus ("Vererbung") zur Compile
Zeit aufzulösen.
Torsten C. schrieb:> Man nutzt Vererbung ja oft, um Gemeinsamkeiten einmal in einer> Basis-Klasse festzulegen. [...]> BTW: Das OOP Konzept "Containment" ist übrigens auch noch eine> Alternative, um VMTs zu vermeiden:>> http://www.codeproject.com/Articles/24948/Three-Ways-To-Extend-A-Class
Ich denke, dass der Gedanke "durch Vererbung kann ich Code wieder
verwenden" einer der größeren Irrtümer im Verständnis von
Objektorientierung ist -- völlig unabhängig von C++. Wahrscheinlich ist
das der "is-a" Sprechweise geschuldet ("Eine Katze ist ein Tier").
Vermutlich wäre es besser, wenn man darüber nachdenken würde, ob eine
Komponente wie eine andere behandelt werden kann. Beim Bespiel Katze vs.
Tier funktioniert das gut, denn man kann eine Katze ganz offensichtlich
wie ein Tier behandeln.
Erst gestern hatte ich eine spannende Diskussion mit einem Kollegen zu
dem Thema. Er brachte das Beispiel "Kreis vs. Ellipse" ein und meinte,
dass ein Kreis aus mathematischer Sicht im Prinzip eine Spezalisierung
einer Ellipse sei. Ich versteh nicht so viel von Mathe, aber wenn man
sich "Quadrat vs. Rechteck" anschaut, dann ist's genauso anschaulich:
Ein Quadrat ist ja nichts als ein Rechteck, das gleich lang wie breit
ist. Man könnte also zunächst verleitet sein, eine Quadrat-Klasse von
einer Rechteck-Klasse abzuleiten und z.B. die Funktion zum Berechnen der
Fläche in der Basisklasse lassen. Man handelt sich dann aber relativ
schnell Probleme ein, wenn man über die Attribute (Länge, Breite)
nachdenkt. Wie stellt man im Quadrat sicher, dass sie immer gleich sind?
Und warum sollte die Klasse, welche die Seitenlänge von Rechtecken
abstrakt behandelt, plötzlich wissen, dass Länge und Breite immer gleich
sein müssen?
Man erkennt hier sofort, dass die "is-a" Denkweise nicht so optimal ist.
Denkt man stattdessen darüber nach, ob ein Quadrat wie ein Rechteck
behandelt werden kann, dann ist's schnell klar, dass dem nicht so ist.
Der Ausweg aus der Situation ist Objekt-Komposition, wie in dem
verlinkten Artikel beschrieben. Lässt man sich auf den Gedanken ein,
dass ein Quadrat-Objekt halt ein Rechteck "hat", dann verschwinden
plötzlich auch viele andere Probleme. Das Quadrat exportiert das eine
Attribut "Kantenlänge" und sorgt halt dafür, dass das Rechteck immer mit
Länge=Breite aufgesetzt wird. Die Methode zum Ausrechnen der Fläche wird
dann einfach vom Quadrat an das Rechteck "durchgereicht" -- übrigens
ohne "virtual" Deklaration und damit garantiert ohne Vtables/VMT.
Torsten C. schrieb:> [...] Falls dadurch VMTs entstehen (was ja nicht> immer vorhersehbat ist^^), wird der C++-Code ineffizienter. Ich brauche> aber höchste Effizienz (Zustandasautomat in einer ISR, s.u.)! Daher kann> ich auch kein "switch/case"^^ im Zustandasautomaten gebrauchen.>> Mit Templates können Gemeinsamkeiten und Unterschiede aber auch ohne> Vererbung definiert werden, also immer ohne VMTs, unabhängig von der> Toolkette. Ist das vielleicht die Begründung, warum Templates bei> Embedded C++ so wichtig sind?>
Siehe oben. Wenn Du vtables/VMT garantiert vermeiden willst, dann musst
Du auf "virtual" Deklarationen verzichten. Falls Du dennoch
Polymorphismus (im Sinne mehrerer Implementierungen eines Interfaces)
brauchst/willst, dann können Dir Templates helfen. Das Stichwort heisst
"Compile Time Polymorphism" bzw. "Static Polymorphism", siehe z.B.
dieser Wikipedia Artikel:
http://en.wikipedia.org/wiki/Template_metaprogramming#Static_polymorphism
Ob das jetzt speziell für Embedded Code wichtig ist, kann ich nicht
beurteilen. Aber es bietet sich halt immer dann an, wenn eigentlich
schon zur Compile-Zeit feststeht, welche konkrete Implementierung eines
Interfaces verwendet werden soll. Gerade das ist aber nicht ungewöhnlich
für Mikrocontroller-Projekte ;-)
Hi Torsten,
>> the use of delay() in a sketch has significant drawbacks …, so in>> effect, it brings most other activity to a halt.> http://arduino.cc/en/pmwiki.php?n=Reference/Delay>> Gibt es noch ein anderes delay?
Sorry, Du hast Recht. Ich glaube, ich habe da Arduino und Scratch
verwechselt. Die laufen beide bei meinen Kindern auf dem Rechner.
Viele Grüße, Stefan
Lieber Torsten C. du hast jetzt zwar diesen Thread erobert ;) ...
Aber die Ursprungsfrage von Peter war nicht: wie erstelle ich eine C++
Library für uC. Also sollte dein Lib Peters Frage beantworten können.
@peda
Bist du noch dabei und hast du was aus diesem Thread mitnehmen können
oder hat sich die Frage erledigt ?
Ich denke auch man sollte einen neuen Thread aufmachen indem dann das
was und wie diskutiert werden kann.
Im ersten Post sollte klar auf die erhofften Vorteile eingegeben werden
und klar gestellt werden, dass das warum draußen bleiben soll.
Es geht ja letzten Endes darum eine einfache, performante,
fehlerverhindernde und Controller unabhängige Schnittstelle für
Standardfunktionen, die in jeden Projekt benötigt werden zu liefern.
So weit richtig?
Jetzt ist doch die wichtigste frage das was soll alles enthalten sein.
Und da hilft es mMn. wenig, Code Beispiele zu Posten.
@Stefan: Ja ich kenne arduino. Aber es ist schon sehr Controller
abhängig und ist stark eingeschränkt, bei der Verwendung von Pins.
Servus!
Torsten C. schrieb:>> Und der MSP430-Compiler von TI unterstützt z.B. eh keine Templates.>> Daher sollten wir mit dem MSP430 auch erstmal abwarten.
Bin mir gerade nicht sicher, daheim hab ich mspgcc oder msp430-gcc und
damit kann ich C++11 schreiben. Structs, die einen Port beschreiben (wie
heißen die Ports / Register für I2C, SPI, UART, ...) kann er auch
wunderbar als Template an die Implementierung weitergeben.
Wenn man typedefs benutzt, behält man auch halbwegs den Überblick,
welchen Typ man da gerade benutzt :)
Hab letztens auch zu dem Thema noch einen Talk "gelesen" :), da ich
letztes Jahr leider nicht hingehen konnte...
http://meetingcpp.de/tl_files/2014/talks/objects%20-%20no%20thanks.pdf
Grüße,
Ronny
Hans-Georg Lehnard schrieb:> Aber die Ursprungsfrage von Peter war nicht: wie erstelle ich eine C++> Library für uC.
Seine Frage war eigentlich genau das. Im Ursprungsposting ist der
einzige Satz, der als Frage formuliert ist, folgender:
Peter Dannegger schrieb:> Geht sowas in C++ und wie könnte eine Implementierung aussehen?
Unter "sowas" hat er sich mangels C++-Erfahrung die Lib zugegebenermaßen
noch etwas anders vorgestellt.
Rolf Magnus schrieb:> Hans-Georg Lehnard schrieb:>> Aber die Ursprungsfrage von Peter war nicht: wie erstelle ich eine C++>> Library für uC.>> Seine Frage war eigentlich genau das. Im Ursprungsposting ist der> einzige Satz, der als Frage formuliert ist, folgender:>> Peter Dannegger schrieb:>> Geht sowas in C++ und wie könnte eine Implementierung aussehen?>> Unter "sowas" hat er sich mangels C++-Erfahrung die Lib zugegebenermaßen> noch etwas anders vorgestellt.
Hm ...
Du meinst Peter, hat mangels C++ Erfahrung die falsche Frage gestellt
und eigendlich wollte er eine komplette Lib möglichst für alle
erhältlichen MC haben ?.
Das sehe ich nicht so ...
Hans-Georg Lehnard schrieb:> Du meinst Peter, hat mangels C++ Erfahrung die falsche Frage gestellt> und eigendlich wollte er eine komplette Lib möglichst für alle> erhältlichen MC haben ?.
Wieso falsche Frage?
> Das sehe ich nicht so ...
Ich auch nicht. Das war aber auch nicht das, was ich gesagt hab.
Er wollte wissen, wie man eine C++-Bibliothek speziell für µCs macht und
wie die aussehen könnte. Genau darüber wird gerade diskutiert. Er hat
sie sich eben mangels der C++-Erfahrung vom Design her etwas anders
vorgestellt, als die jetzt diskutierten Ideen.
Seine Frage zielte auch nicht auf einen ganz spezifischen Typ ab,
sondern allgemein auf µCs.
Philip S. schrieb:> ich finde, das ist ein sehr spannender Thread hier.
Und er wurde Durch Deinen Beitrag sehr bereichert. Danke für die
Hinweise, Stichwörter und Klarstellumgen. :-)
Philip S. schrieb:> Das Stichwort heisst "Compile Time Polymorphism" bzw. "Static> Polymorphism"
Das ist es! Genau das habe ich gebraucht! Ich hatte schon angefangen,
mit non-static member function pointers (MFPs)eine Art Polymorphie zu
basteln:
http://www.codeproject.com/Articles/7150/Member-Function-Pointers-and-the-Fastest-Possible
Vielleicht sind diese MFPs ja trotzdem noch zu was gut.
robin schrieb:> Ich denke auch man sollte einen neuen Thread aufmachen indem dann das> was und wie diskutiert werden kann.Dazu Jörg Wunsch bereits schrieb:> Nein. Bleib mal bei einem Thread.> Für Projekte wiederum gibt es hier die Möglichkeit, einen SVN-Server> zu hosten sowie das in "Projekte & Code" zu posten.
@robin: Wie meinst Du das? Möchtest Du jetzt schon einen neuen Thread in
"Projekte & Code" aufmachen oder noch einen weiteren neuen davor, indem
dann z.B. das "was" (…ist das Projektziel) und das "wie" (…arbeiten wir
zusammen) geklärt wird?
Den neuen Thread in "Projekte & Code" kann jeder selbst aufmachen, ich
bin hier kein "Projektleiter" und wollte den Thread auch nicht
"erobern". Ich will nur mal in die Pötte kommen.
Falls wir uns auf einen Namen einigen, würde auch ich den neuen Thread
in "Projekte & Code" aufmachen.
Stefan schrieb:> Auch falsch, ein Interface ist ein Konzept der OOP und ein Spezialfall> der Mehrfachvererbung. C++ kennt das, auch wenn es das Schlüsselwort> "interface" nicht gibt.
Die Vererbung muss gar nicht "mehrfach" sein. Wichtig ist, dass die
virtuellen Methoden "pure virtual" sein müssen, also mit " = 0":
http://www.learncpp.com/cpp-tutorial/126-pure-virtual-functions-abstract-base-classes-and-interface-classes/
Rolf Magnus schrieb:> Hans-Georg Lehnard schrieb:>> Du meinst Peter, hat mangels C++ Erfahrung die falsche Frage gestellt>> und eigendlich wollte er eine komplette Lib möglichst für alle>> erhältlichen MC haben ?.>> Wieso falsche Frage?>>> Das sehe ich nicht so ...>> Ich auch nicht. Das war aber auch nicht das, was ich gesagt hab.> Er wollte wissen, wie man eine C++-Bibliothek speziell für µCs macht und> wie die aussehen könnte. Genau darüber wird gerade diskutiert. Er hat> sie sich eben mangels der C++-Erfahrung vom Design her etwas anders> vorgestellt, als die jetzt diskutierten Ideen.> Seine Frage zielte auch nicht auf einen ganz spezifischen Typ ab,> sondern allgemein auf µCs.
Nö, seine Frage war wie kann ich folgendes in C++ lösen bzw. wie kann
ich das in C++ lernen ( in Assembler oder C schreibt er dir das im
Schlaf):
a. schalte Led solange Taste gedrückt
b. toggle Led bei jeder (positiven) Drückflanke
c. led aus wenn taster kurz gedrückt
d. led an wenn taster lang gedrückt
und ich füge noch dazu:
e. led blinkt schnell ( 1/2 sec) wenn taster kurz (<500ms) gedrückt
f. led blinkt normal(1 sec) wenn taster normal(500 ..1500ms) gedrückt
g. led blink langsam(2 sec) wenn taster lang( >1500ms) gedrückt
usw.
Und darauf ist die Antwort:
"Das kannst du mit unserer neuen uC++ Lib irgenwann mal machen"
genauso gut wie 42 oder schau in die gelbe Seiten ;)
Natürlich kann man alles in eine Lib verpacken.
Schau dir doch mal alle bekannten Libs in dieser Richtung an, da ist
keine dabei die Peters Frage konkret und nachvollziehbar beantwortet.
Die Diskussion hier: wie müsste eine LIB aussehen, was müsste sie
beinhalten und wie kann sie effektiv implementiert werden ist mit
Sicherheit sinnvoll und nützlich aber sie beantwortet die ursprünglichen
Fragen nicht. Mehr wollte ich mit meinem Post nicht sagen ...
> weiterhin schrieb peda>In C wird ja für jeden Quark eine Funktion benötigt, was nicht besonders>gut lesbar ist.>In C++ könnte man Zuweisungen nehmen, wenn man nur wüßte, wie man das>implementiert.
Da fragt er doch eher nach Überladung vom = operator und nicht nach
einer LIB.
Hans-Georg Lehnard schrieb:> Lieber Torsten C. du hast jetzt zwar diesen Thread erobert ;) ...
Lieber Hans-Georg,
der Eindruck mag entstehen und falls ich in Zukunft noch 'ne spezielle
Frage zu meinen "Zustandsautomaten für die UART-ISR" ^^ habe, werde ich
sie auch in einem separaten Thread stellen, denn "erobern" wollte ich
den Thread nicht. Ich bleibe in Zukunft beim Zustandsautomaten für
Taster!
Hans-Georg Lehnard schrieb:> Und darauf ist die Antwort:> "Das kannst du mit unserer neuen uC++ Lib irgenwann mal machen"
Die Diskussion um eine "neue uC++ Lib" ist ja nur Vorbereitung auf einen
neuen Thread in "P&C" und behandelt - bis auf den Namen und die Liste
der zu unterstützenden µC-Familien - genau auch das gefragte Thema "wie
kann man 'folgendes' (effizient) in C++ lösen":
Zu "Taster kurz gedrückt" und "Taster lang gedrückt" hatte Jan auf den
Zustandsautomaten verwiesen:
http://avr-cpp.de/lib/exe/detail.php?id=grafische_programmierung_mit_der_uml&cache=cache&media=smbutton.jpg
Hier heißt das nur anders: "OnHold", "OnBtnUp" und "OnClick".
Zum Thema "effizient in C++ lösen" ist meine Anmerkung (nun weiß ich
ja, wie das heißt): "Compile Time Polymorphism", "Static Polymorphism"
oder "Member Function Pointers" sind effizienter als "switch/case" wie
bei Jans SiSy.
Aber wie ich nun den Zustandsautomaten am besten umsetzen soll? Ich bin
immer noch am lesen und probieren, wie ich das übersichtlich, flexibel,
ohne "switch/case" und µC-tauglich ohne VMTs machen könnte.
Die Antwort wird die Gleiche sein, egal ob für die UART-ISR oder für
Taster.
>Aber wie ich nun den Zustandsautomaten am besten umsetzen soll? Ich bin>immer noch am lesen und probieren, wie ich das übersichtlich, flexibel,>ohne "switch/case" und µC-tauglich
Was stört dich an switch/case? Als Alternative sehe ich nur If/else oder
im schlimmsten Fall so wie es Rational Rhapsody macht: mit "goto" (
wohlgemerkt in C ).
Allerdings könnte die "goto" Variante tatsächlich die schnellste sein.
Dr. Sommer schrieb:> Mark Brandis schrieb:>> Nahezu alles, was man in C machen kann, kann man auch in C++>> machen.>> Naja, so gut wie alles. 99 Prozent.> Aber auch in Brainfuck. Warum verwendet niemand Brainfuck? Es ist> supereinfach zu lernen, verwenden und implementieren.
Give me five - Patsch!
Der war gut :-)
Ich habe auch spasseshalber mal ein bisschen mit Brainfuck
experimentiert.
Vielleicht interessiert ja mal das "Hello World":
http://de.wikipedia.org/wiki/Brainfuck
oder das:
http://de.wikipedia.org/wiki/Esoterische_Programmiersprache
Cyblord ---- schrieb:> Der Tag mag kommen an dem FH-Studenten mir Nachhilfe in> Programmierkonzepten erteilen, aber heute ist das sicher noch nicht ;-)
Ein feiner, umgänglicher und bescheidener Herr, dieser Cyblord
Hallo Thorsten,
mein Post war ja auch mit einem Augenzwinkern versehen ...
Hast du dir schonmal die Umsetzung von state transition tables mit
Templates angesehen ?
http://aristeia.com/TalkNotes/C++_Embedded_Deutsch.pdf
Ab Seite 114/folie244.
http://www.boost.org/doc/libs/1_55_0/libs/msm/doc/HTML/ch03s02.html
Das ist für mich die übersichtlichste Art wie man state machines im
Quellcode darstellen kann.
Google findet noch mehr dazu.
Das Problem Taste entprellen, kurz, lang, mittel gedrückt und überhaupt
timing im allgemeinen wird eine state machine alleine nicht lösen. Dazu
wirst du wahrscheinlich auch ein mini OS mit SytemTimer und evtl Task
Verwaltung brauchen. Du brauchst auf jeden Fall eine "call back"
Funktion in deinen IO Ports die du beliebig auf PinChange oder Timer
Callback konfigurieren kannst. Die CPU mit delay() schlafen legen ist
eine schlechte Idee für eine MC lib. Und bei Batterie betriebenen
Anwendungen kommt noch der Sleep Modus, den viele MC beherschen und der
sich überall einmischt dazu.
Deshalb ist meine Meinung, das eine allgemeine uCpp Lib (Vorschlag für
den Namen) nur Teilaspekte der Möglichkeiten heutiger MC modellieren
kann. Das bedeutet, entweder sie ist: unvollständig, wird nie fertig,
ist flexibel erweiterbar. Den letzten Punkt halte ich im Moment (noch)
nicht für realisierbar.
Anhang Buchtips fals jemand ein WIKI zum Thema aufmachen möchte:
David Abrahams, Aleksey Gurtovoy :
C++ Template Metaprogramming: Concepts, Tools, and Techniques from Boost
and Beyond
Scott Meyers :
Effective C++
Effective Modern C++
Effective C++ in an Embedded Environment
David Vandevoorde, Nicolai M. Josuttis :
C++ templates : The complete Guide
Christopher Michael Kormanyos
Real Time C++
Mob** schrieb im Beitrag #3980904:
> wie immer das gleiche ...
Es lebte einst ein kleiner Moby in seiner Assembler Welt und diese Welt
war eine Scheibe. In dieser Welt leben immer weniger Menschen, weil sie
lernten über den Tellerand zu schauen und sie merkten es gibt auch noch
Scheibe++.
Nun sitzt er einsam da und jammert, aber keiner hört ihm zu ...
Galileo Galilei benannte später Scheibe++ in Kugel um.
Wenn das Zensur ist, ist dann die Abwesenheit von Zensur jeder
Nervensäge ausgeliefert zu sein? Wir haben verstanden, nicht jeder will
den Algorithmus in lesbar vor sich liegen haben, mancher will lieber
Registerdispatcher spielen. Das macht besonders bei Änderungen richtig
Spaß.
Ich beschäftige mich gerade mit Assembler (wenn ich denn mal Zeit habe)
und sicher ist das für manche Sachen oder als inline ne gute Sache, aber
komplexe Sachen damit machen?
Da blickst du selbst nach drei Jahren nicht mehr durch, wenn du was
ändern willst.
F. Fo schrieb:> Ich beschäftige mich gerade mit Assembler (wenn ich denn mal Zeit habe)> und sicher ist das für manche Sachen oder als inline ne gute Sache, aber> komplexe Sachen damit machen?> Da blickst du selbst nach drei Jahren nicht mehr durch, wenn du was> ändern willst.
Hallo Foldi,
spätestens wenn du deinen Assembler code auf einen anderen MC und/oder
auf einen anderen Assembler Hersteller übertragen willst wirst du merken
das das nicht so einfach geht. Versuch einfach mal Keil oder IAR
Assembler auf Gnu Assembler oder dein AVR Assembler Code auf PIC zu
portieren dann wirst du sehen, warum die Assembler Welten alles
Scheibenwelten sind ...
Das gilt auch für inline Assembler in C.
Trotzdem wirst du Assembler Code verstehen lernen müssen, weil C erst
bei main anfängt und C davon ausgeht das statische Variablen bis dahin
initialisiert sind. Sinnvoll ist es auch wenn Interrupt Vektoren oder
das Ende von main, wenn du die while(1) vergessen hast, nicht ins
Nirwana zeigen. Der Prozessor startet aber schon viel früher bei einer
bestimmten Adresse ( oft Adresse 0, muss aber nicht so sein ). Für
Startup code oder Bootloader wirst du immer Assembler brauchen.
Bastler schrieb:> mancher will lieber> Registerdispatcher spielen. Das macht besonders bei Änderungen richtig> Spaß.F. Fo schrieb:> ber> komplexe Sachen damit machen?> Da blickst du selbst nach drei Jahren nicht mehr durch,
Da fehlts Euch a bisserl an Systematik... In Asm baut man mit der Zeit
aus kleinen Bausteinen größere, und daraus durchaus auch komplexe
Funktionen. Ohne freilich an Flexibilität, Size, Speed und totaler
Codecontrolle zu verlieren. Den Rest übernimmt eine durchdachte
Dokumentation.
Hans-Georg Lehnard schrieb:> wenn du deinen Assembler code auf einen anderen MC und/oder> auf einen anderen Assembler Hersteller übertragen willst
Sogesehen ist Asm natürlich schon eine kleine Scheibe. Wählt man seinen
Controller aber geschickt (AVR), sorgt gerade das effiziente Asm dafür,
daß man dabei lange lange bleiben kann und sich die Notwendigkeit eines
Wechsels gar nicht ergibt. "Größere Teller" bedeuten dann nur noch
unnützen Mehraufwand.
Hans-Georg Lehnard schrieb:> Trotzdem wirst du Assembler Code verstehen lernen müssen,> Für> Startup code oder Bootloader wirst du immer Assembler brauchen
Na wenigstens eine Spur von Einsicht ;-)
Moby schrieb:> Hans-Georg Lehnard schrieb:>> Trotzdem wirst du Assembler Code verstehen lernen müssen,>> Für>> Startup code oder Bootloader wirst du immer Assembler brauchen>> Na wenigstens eine Spur von Einsicht ;-)
Das hat nichts mit Einsicht zu tun sodern mit dem Wissen das es außer
Faustkeil auch Hammer und sogar Elektrowerkzeuge gibt, die einem das
Leben erleichtern. Und diese Wissen hatte ich schon zu 8080 Zeiten wo
ich sogar den Assembler selber gespielt habe weil Assembler und Code
über Lochstreifen einlesen keinen wirklichen Spass gemacht hat. Oder
sogar noch früher wo ich meine Selbstbau "Computer" mit 74181 mit dem
Lötkolben (Dioden auf Lochraster-Rom) programmiert habe.
Geh dich doch einfach mal bewerben und erzähle dort ich kann nur
Assembler und kleine avr und deine ganzen anderen Floskeln ...
Hans-Georg Lehnard schrieb:> Geh dich doch einfach mal bewerben...
Der Hobbybastler ist zum Glück frei in seiner Entscheidung und kann sich
auf das wirklich notwendige beschränken. ;-)
Zu Floskeln zähle ich Vergleiche mit Hammer, Faustkeil, Code mit
Lochstreifen einlesen usw.
Hans-Georg Lehnard schrieb:> Hallo Foldi,> spätestens wenn du deinen Assembler code auf einen anderen MC und/oder> auf einen anderen Assembler Hersteller übertragen willst wirst du merken> das das nicht so einfach geht.
Hans Georg, ich will das auch nicht lernen um hinterher in ASM zu
programmieren, sondern eher um die Funktionsweise und die Abläufe im µC
noch besser verstehen zu können.
Mein endgültiges Ziel ist (wenn ich noch alt genug werde) sowieso C++ zu
lernen und zu programmieren.
Aber ich bin auch nicht so ein typischer "Fanboy".
Genauso, um bei vorgenannten Beispielen zu bleiben, nehme ich bei der
Arbeit einen Hammer, wenn ich mit dem Hammer am leichtesten oder am
besten zum Ziel komme. Einen 17ner Schlüssel für die 10ner Schraube.
Ich bin auch nicht der Verfechter eines bestimmten Mikrocontrollers und
kann ehrlich gesagt auch da die Glaubenskriege nicht verstehen. Zumal in
ein paar Jahren wieder was ganz neues hip sein kann.
Hans-Georg Lehnard schrieb:> Hast du dir schonmal die Umsetzung von state transition tables mit> Templates angesehen ?> http://aristeia.com/TalkNotes/C++_Embedded_Deutsch.pdf> Ab Seite 114/folie244.
Cool, das verkauft Scott in Englisch für US$24,95!
http://www.artima.com/shop/effective_cpp_in_an_embedded_environmentHans-Georg Lehnard schrieb:> Scott Meyers: … Effective C++ in an Embedded Environment
Gut, dass ich mir nicht das "Effective C++…" [ScoMe01]^^ gekauft habe,
das ist zu 90% das Gleiche!
Die Templates gefallen mir grundsätzlich, weil sie so klar gegliedert
sind, also leicht zu verstehen und zu pflegen. Ich hatte sie schom mal
gesehen, aber irgendwie sind sie in Vergessenheit geraten. Danke für den
Hinweis!
Mich würde mal interessieren, wie der Code nach einer "template
expansion" aussieht. Dann hätte Käfer Karl auch 'ne variante ohne
Templates. ;-)
Mit "-fdump-rtl-all" kann man ja schon etwas davon sehen, ist aber
unübersichtlich. Vielleicht kennt jemand was besseres dafür?
Hans-Georg Lehnard schrieb:> http://www.boost.org/doc/libs/1_55_0/libs/msm/doc/HTML/ch03s02.html
Ob die BOOST-Version wohl ohne new(), also ohne dynamic memory
allocation auskommt?
Gerade das finde ich beim AVR nämlich gut: Normalerweise hat der gar
keine new()-Operator:
http://www.avrfreaks.net/forum/avr-c-micro-how?name=PNphpBB2&file=viewtopic&t=59453jan schrieb:> Ohne switch/case If/else einfach ein array von Funktionszeiger in C
Genau, weil´s schneller geht als mit enums. Die nächste Funktion ist ja
schon klar, wenn man die int-Variable "state" auf den nächsten Wert
setzt.
Warum soll man dann später nochmal ein "switch (state)" mit einem Haufen
case-Anweisungen bauen???
Ich habe es nach viel Schweissarbeit endlich geschafft, einen kleinen
Zustandsautomaten sogar mit Typ-Sicheren Funktionszeigern (Delegates) zu
implementieren, ohne Templates, erstmal noch "geradeaus":
Das ist Option 4: pointer to member functions (fastest solution) aus:
http://stackoverflow.com/questions/9568150/what-is-a-c-delegate
Es gibt drei Zeiger-Typen:
Die "SM_RX_ISRs" sind verschiedene ISRs für den "USART0_RX_vect", also
so:
1
ISR(USART0_RX_vect){
2
// vectors are located in flash rom
3
(sM_RX_ISRs.*USART_RX_ISR)();
4
// TODO: In ASM würde man nur springen und würde den Funktionsaufruf vermeiden.
5
}
Und der Zustandsautomat (kleiner Web-Server), reagiert nur auf diese
Interrupps und löst je nach eintretender Bedingung ein "SM_ErrEvent"
oder ein "SM_OkEvent" aus, um damit den nächsten Zustandsübergang zu
erreichen.
Da die Ereignisse (ohne swich/case/…) sehr schnell bearbeitet werden,
kann der Automat hoffentlich komplett in der ISR laufen.
Hans-Georg Lehnard schrieb:> mein Post war ja auch mit einem Augenzwinkern versehen ...
Hab´ ich gesehen, alles im grünen Bereich! Aber ich muss mal meckern:
Es nervt, wenn man hier im Thread mal was sucht und zwischen den ganzen
"lustigen" Posts nix wieder findet ("da war doch mal ..."). Bald sind
wir auf Seite 3 und dann geht das Hin-und-her-Geblättere los.
"Es lebte einst ein kleiner Moby in seiner Assembler Welt …" usw. war
zwar ganz lustig, aber vielleicht kannst auch Du versuchen, den Thread
übersichtlicher zu halten.
chris_ schrieb:> Allerdings könnte die "goto" Variante tatsächlich die schnellste sein.chris_ schrieb:> Meiner Meinung nach kann man die Funktiosnzeiger aber auch als> versteckte Art des "goto" betrachten:
Was Du immer mit Deinem GoTo willst, musst Du mir mal erklären!
Torsten C. schrieb:> Warum soll man dann später nochmal ein "switch (state)" mit einem Haufen> case-Anweisungen bauen???
Mit "später nochmal" meine ich: Irgendwann, wenn das nächste Ereignis
(Spalte "Event") eintritt. Dann wird halt ggf. nach der "Guard"
geschaut, eine "Action" ausgeführt und der Zeiger auf eine Tabelle mit
denjenigen Reihen ("a_row/_row") gesetzt, deren "Start" in der "Target"
stehen.
Du hast dann pro Zustand eine Unter-Tabelle mit je einem
Funktionszeiger in C pro Event.
Wo ist da Dein GoTo?
F. Fo schrieb:> Ich bin auch nicht der Verfechter eines bestimmten Mikrocontrollers und> kann ehrlich gesagt auch da die Glaubenskriege nicht verstehen. Zumal in> ein paar Jahren wieder was ganz neues hip sein kann.
Der einzige Glaubenskrieger hier ist Moby.
Ein "verstecktes" Goto ist nicht schlimm. Jedes Bedingung, jede
Schleife, jeder Funktions- oder Methodenaufruf ist ein "verstecktes"
Goto.
Die spannende Frage ist, wie organisiert man in einer Sprache oder
System all die "versteckten" Gotos so dass man sich nicht im Chaos
verirrt.
chris_ schrieb:> 3.ter Codeblock:
Ach mit "yield", das kannte ich bis eben noch gar nicht:
http://www.cplusplus.com/reference/thread/this_thread/yield/
OK, bei Multi-Threading kann man das auch mit GoTo machen, nun habe ich
es verstanden.
Aber ob das auf einem µC Sinn macht? Interessante Fragestellung!
Falls ja, Multi-Threading wäre 'ne feine Sache und ein echter Pluspunkt
für die Einfachheit der Programmierung, gerade bei Zustandsautomaten.
Aus Erfahrung mit Multi-Threading-Programmierung mit C# unter Windows
kann ich jedoch berichten, dass sich solche Programme manchmal schwer
debuggen lassen.
Hans-Georg Lehnard schrieb:> Der einzige Glaubenskrieger hier ist Moby.
Man sollte die Dinge möglichst einfach halten.
Das Motto "Keep it simple" ist keine Glaubensfrage , sondern eine Gebot
rationaler Vernunft.
Oder wie sagte schon der große Karl der Käfer:
"Warum denn Komplexität einbauen, ohne Not und ohne Vorteil?
Wozu Kosten und Einstiegshürden steigern wenn kein Nutzen erkennbar?"
Meine "rationale Vernuft" sagt mir: es gibt auch andere Architekturen.
Ich hab nämlich in den letzten 35 Jahren schon einige erlebt. Das Motto
"keep it simple" kenne ich zur Genüge von der Arbeit. Aber da gibt es
immer 2 Seiten. Für den einen ist simple: nur eine Architektur (und nur
so einfache Sachen, daß ASM reicht). Für andere ist es: eine
Beschreibung der Lösung eines (gerne auch komplexeren) Problems,
unabhängig von der Zielarchitektur. Wie ich schon weiter oben
geschrieben hab: das Register-Dispatchen überlasse ich gern dem GCC.
Moby AVR schrieb im Beitrag #3982637:
> Wozu Kosten und Einstiegshürden steigern wenn kein Nutzen erkennbar?"
Weil du keinen Nutzen siehst, gibt es keinen? Sag mal erleuchteter Moby
welche Erfahrungen kannst du den mit C und C++ vorweisen, dass du das
beurteilen kannst? Bin ja mal gespannt.
Nebenbei schon mal gemerkt dass es hier nicht um ASM vs. irgendwas geht?
Wobei hier auch noch nicht viel von seinem ASM zu sehen war.
Außerdem, Moby, darfst du nicht ständig deinen Namen im Thread ändern.
Das verbieten die Forenregeln.
TriHexagon schrieb:> Nebenbei schon mal gemerkt dass es hier nicht um ASM vs. irgendwas geht?
So ist es.
Ich bitte deswegen darum, wieder zum Thema zurückzukehren:
Peter Dannegger schrieb:> LED0 = KEY0.state; // an solange Taste gedrückt> LED1.toggle = KEY1.press // wechsel bei jeder Drückflanke> LED2.off = KEY2.press_short; // kurz drücken - aus> LED2.on = KEY2.press_long; // lang drücken - an> Geht sowas in C++ und wie könnte eine Implementierung aussehen?
Das interessiert nämlich wirklich einige - unter anderem mich.
Wenn jemand anderes diskutieren möchte,kann er dazu gerne einen eigenen
Thread eröffnen.
Danke.
Chris D. schrieb:> Das interessiert nämlich wirklich einige - unter anderem mich.
Man könnte sich ein "Port-System" überlegen, und mit einem überladendem
Assignment-Operator einen Input-Port an einen Output-Port "binden".
Chris D. schrieb im Beitrag #3982854
> Das interessiert nämlich wirklich einige - unter anderem mich.
Nun existiert der Thread schon seit November und die versammelte C++
Expertenrunde hat auf die von Peter D. skizzierten Trivialaufgaben immer
noch keine Antwort gefunden? Was sagt uns das bitteschön?
Moby schrieb:> Nun existiert der Thread schon seit November und die versammelte C++> Expertenrunde hat auf die von Peter D. skizzierten Trivialaufgaben immer> noch keine Antwort gefunden? Was sagt uns das bitteschön?
Dass es so trivial wohl doch nicht ist. Zumindest dann nicht, wenn es
eine für verschieden(st)e Mikrocontroller funktionierende Lösung werden
soll.
Mark Brandis schrieb:> Dass es so trivial wohl doch nicht ist
... diese Probleme mit C++ lösen zu wollen!
Was für ein Gestolper und Gewürge. Was für ein Kampf mit dessen
wildwüchsigen Sprachkonstrukten schon bei diesen MC-Programm
Grundfunktionalitäten ;-(
Moby schrieb:> ... diese Probleme mit C++ lösen zu wollen!
Naja, wenn Du meinst, dass Du mit Assembler eine plattformübergreifende
Lösung schaffen kannst, dann stelle sie mal vor und beantworte Peters
ursprüngliche Frage.
Achja, Du kannst ja gar nicht mit Assembler plattformübergreifende
Programm-Bibliotheken schreiben. Was willst Du dann hier in diesem
Thread?
Moby schrieb:> Mark Brandis schrieb:>> Dass es so trivial wohl doch nicht ist>> ... diese Probleme mit C++ lösen zu wollen!> Was für ein Gestolper und Gewürge. Was für ein Kampf mit dessen> wildwüchsigen Sprachkonstrukten schon bei diesen MC-Programm> Grundfunktionalitäten ;-(
Das unterscheidet jemanden, der sich damit auseinandergesetzt hat, von
einem Laien: er weiss, dass trivial aussehende Probleme eben nicht
trivial sind.
Hast Du auch Konstruktives zur Fragestellung des OPs beizutragen,
nämlich Vorschläge zur Implementierung in C++, beizutragen?
Wenn nicht, dann halte Dich hier bitte einfach zurück.
Ist doch eigentlich nicht schwer: Ich weiss nicht viel von C++ -> also
schreibe ich nichts dazu.
Sieh mal - selbst ich schaffe das: ich habe auch schon Jahre nicht mehr
in C++ gearbeitet - also lese ich hier erstmal nur mit und versuche zu
lernen.
Bau Du weiter Deine IP-Stacks, Web-Server und und Grafikbibliotheken in
Assembler - ist doch ok.
Leute, die plattformübegreifend arbeiten müssen, interessiert aber eine
effiziente Lösung dieses Problems.
Also: bitte zur Sache "Implementierung in C++" oder schweigen.
P.S.: Und hör bitte auf, hier mit mehreren Nicks aufzutreten - das ist
Kindergartenniveau.
Hi foldi,
F. Fo schrieb:> Eigentlich geht die ganze Diskussion, mal von Moby abgesehen, nur um> das, was Arduino macht.> Dahinter verbirgt sich C++.
Dahinter verbirgt sich eine Art C++, die dafür gemacht und optimiert
wurde, von absoluten Anfängern und Nichttechnikern benutzt zu werden.
Die Arduino-Entwickler haben überall Sicherheitsnetze eingebaut und
versuchen da, jeden irgendwie denkbaren und undenkbaren Fehler
abzufangen. Das ist ihnen zwar recht gut gelungen, aber leider auch
nicht sonderlich effizient.
Ich habe mir die oben erwähnte und verlinkte xpcc-Bibliothek einmal
näher angeschaut. Das scheint mir eher was für fortgeschrittene,
effizienz- und ressourcenorientierte Entwickler zu sein als die
Arduino-Bibliotheken.
Liebe Grüße,
Karl
Natürlich ist das Problem nicht trivial, aber das merkt man erst wenn
man sich damit beschäftigt und nicht nur jammert.
Die Idee: "Hurra, wir machen ein Projekt daraus und entwickeln gemeinsam
eine Lib" halte ich auch aus diesem Grunde für ein wenig blauäugig.
Blauäugig in dem Sinne das das Projekt irgendwann mal fertig wird.
Ich bin aber überzeugt, das es prinzipiell geht und auch effektiv auf
einem Tiny mit 2k Flash und 128Byte Ram laufen kann.
Denn: "Der Weg ist das Ziel" und "viele Wege führen ins ROM (Flash)".
Frank M. schrieb:> Moby schrieb:>> ... diese Probleme mit C++ lösen zu wollen!>> Naja, wenn Du meinst, dass Du mit Assembler eine plattformübergreifende> Lösung schaffen kannst, dann stelle sie mal vor und beantworte Peters> ursprüngliche Frage.>> Achja, Du kannst ja gar nicht mit Assembler plattformübergreifende> Programm-Bibliotheken schreiben. Was willst Du dann hier in diesem> Thread?
Moby,
kannst Du jetzt mal aufhören mit Deinem unproduktiven Gestänkere, bitte.
Chris D. schrieb:> Hast Du auch Konstruktives zur Fragestellung des OPs beizutragen,> nämlich Vorschläge zur Implementierung in C++, beizutragen?
Der Hinweis, zum Einschlagen des Nagel besser einen einfachen Hammer zu
verwenden ist sowas von konstruktiv...
Chris D. schrieb:> trivial aussehende Probleme eben nicht trivial sind
... denn die von Peter D. skizzierten Problemchen SIND u.a. in Asm
trivial zu lösen.
Chris D. schrieb:> das ist> Kindergartenniveau:
Richtig Herr Moderator. Nämlich inhaltlich mißliebige Beiträge in
blanker Willkür zu löschen.
Conny G. schrieb:> unproduktiven Gestänkere
Klar. Die konsequente Nachfrage nach Sinn und Zweck kann manchmal schon
sehr nerven. Nun schaun mer mal, ob von diesem Thread mehr als heiße
Luft bleibt. Wie eine einfache Lösung in hochgradig abstrakten C++
controllerübergreifend vielfältige Hardwaredifferenzen überbrücken soll
wird hier bestimmt bald aufgedeckt! Ich warte ab und bin gespannt!
Moby schrieb:> Chris D. schrieb:>> trivial aussehende Probleme eben nicht trivial sind>> ... denn die von Peter D. skizzierten Problemchen SIND u.a. in Asm> trivial zu lösen.
Im Threadtitel fragt er, wie er das in C++ lösen kann, nicht in ASM
oder?
>> Chris D. schrieb:>> das ist>> Kindergartenniveau:>> Richtig Herr Moderator. Nämlich inhaltlich mißliebige Beiträge in> blanker Willkür zu löschen.
Deine Beiträge nerven und gehen am Thema vollständig vorbei. Es geht
nicht darum, ob ASM oder C++ besser ist, sondern wie das in C++ geht.
>> Conny G. schrieb:>> unproduktiven Gestänkere
Da kann ich nur beipflichten.
>> Klar. Die konsequente Nachfrage nach Sinn und Zweck kann manchmal schon> sehr nerven. Nun schaun mer mal, ob von diesem Thread mehr als heiße> Luft bleibt. Wie eine einfache Lösung in hochgradig abstrakten C++> controllerübergreifend vielfältige Hardwaredifferenzen überbrücken soll> wird hier bestimmt bald aufgedeckt! Ich warte ab und bin gespannt!
Solange du das nicht in ASM vorweisen kannst, ist deine Kritik irgendwie
unangebracht. Es geht hier auch nicht um ASM.
Und ehrlich gesagt glänzt du vollständig durch Inkompetenz.
Und bitte halte dich raus. Wenn es dir nicht paßt, dass hier C++
verwendet werden soll, dann halt doch einfach die Finger still oder hast
du im Ernst den Eindruck, dass deine Texte hier jemand lesen möchte?
DANKE.
900ss
Moby schrieb:> ... denn die von Peter D. skizzierten Problemchen SIND u.a. in Asm> trivial zu lösen.
Es geht hier aber nicht um Assembler, sondern um C++.
Ist das so schwer zu verstehen?
> Chris D. schrieb:>> das ist>> Kindergartenniveau:>> Richtig Herr Moderator. Nämlich inhaltlich mißliebige Beiträge in> blanker Willkür zu löschen.
Ersetze "mißliebig" durch "permanent offtopic", dann passt es exakt.
> Ich warte ab und bin gespannt!
Dein Wort in Gottes Ohr. Ich glaube ja nicht dran.
TriHexagon schrieb:> Moby AVR schrieb im Beitrag #3982637:>> Wozu Kosten und Einstiegshürden steigern wenn kein Nutzen erkennbar?">> Weil du keinen Nutzen siehst, gibt es keinen? Sag mal erleuchteter Moby> welche Erfahrungen kannst du den mit C und C++ vorweisen, dass du das> beurteilen kannst? Bin ja mal gespannt.
Die Frage hast du mir immer noch nicht beantwortet.
Moby schrieb:> Chris D. schrieb:>> trivial aussehende Probleme eben nicht trivial sind>> ... denn die von Peter D. skizzierten Problemchen SIND u.a. in Asm> trivial zu lösen.
Dann zeig doch mal.
Moby schrieb:> Chris D. schrieb:>> das ist>> Kindergartenniveau:>> Richtig Herr Moderator. Nämlich inhaltlich mißliebige Beiträge in> blanker Willkür zu löschen.
Ich verstehe immer noch nicht was du hier willst. Mit deinem getrolle
störst du diese Diskussion, insofern ist es die Pflicht eines
Moderators, deinen Müll zu entsorgen.
Moin,
Ihr habt ja jetzt viel geredet, wo gibt es denn eine
Referenz-Implementierung von den ganzen Vorschlägen, die hier genannt
wurden?
Hat da jemand schon ein GitHub/BitBucket/Sourceforge Repository
angelegt, wo man die ganzen Ideen mal sammeln und kompilieren kann?
Dann könnte man sich nämlich einfach mal den vom C++-Compiler
generierten ASM anschauen, und dann entscheiden, ob es da überhaupt
Overhead gibt und wenn ja, ob er bzgl. der gewonnenen Abstraktion
vertretbar ist.
Den Erkenntnisgewinn könnte man ja dann auch mal dokumentieren, sodass
man dann darauf aufbauend sinnvolle Entscheidungen treffen könnte.
Grüße,
DualZähler
Hi
>Hast Du auch Konstruktives zur Fragestellung des OPs beizutragen,>nämlich Vorschläge zur Implementierung in C++, beizutragen?
Peter hatte eine einfache Frage gestellt. Da aber nicht wirklich etwas
gekommen ist hat er sich schon seit Ende November nicht mehr beteiligt.
Warum wohl? Es war, im Sinne des OT, nie nach einer Platform
übergreifenden Lösung gefragt. Also haben hier fast alle nicht zur
Fragestellung des OPs beigetragen. War eher eine Art der
Selbstbeweiräucherung.
MfG Spess
spess53 schrieb:> Peter hatte eine einfache Frage gestellt. Da aber nicht wirklich etwas> gekommen ist hat er sich schon seit Ende November nicht mehr beteiligt.> Warum wohl? Es war, im Sinne des OT, nie nach einer Platform> übergreifenden Lösung gefragt.
Das stimmt. Ausserdem halte ich eine "plattformübergreifende Lösung" für
ein Unterfangen, dass sehr viel Arbeit bedeutet, bei dem das Ziel in so
weiter Ferne liegt, dass - wenn eine Lösung denn irgendwann existieren
sollte - die Hardware dafür dann gar nicht mehr existieren wird.
Kurz: ich halte diesen Anspruch für ein Fass ohne Boden.
Die Arduinos haben sich auf wenige ausgesuchte Hardware konzentriert.
Und schon da musste man auf Kosten von Effizienz Abstriche machen. Was
hier aber besprochen wurde, geht viel weiter... und hat mit Peters
einfachen Frage wirklich nichts mehr zu tun.
Karl Käfer schrieb:> Die Arduino-Entwickler haben überall Sicherheitsnetze eingebaut und> versuchen da, jeden irgendwie denkbaren und undenkbaren Fehler> abzufangen.
Und das machen sie teilweise zur Laufzeit. :-(
Wenn möglich, sollte ja schon zur Entwurfszeit sicher sein, dass bei
einem illegalen Code möglichst der Compiler oder wenigstens der Linker
meckert ("fundamental design goal: design violations should not
compile"^^).
Um zum Ursprung zurück zu kommen:
Eine Lösung mit new(); (also dynamic memory) wollen wir PeDa sicher
nicht empfehlen. Ich habe aber keine Idee, wie man folgende "design
violation" ohne Konstruktor und ohne Laufzeit-Prüfungen geschickter
absichern könnte:
http://xpcc.io/api/group__gpio.html#details sagt:
> When you use the pins directly outside any device driver class you have> to remember to initialize them first. Call configure(), setInput() or> setOutput() before the first use, otherwise the result is undefined and> most likely not what you expect!
Können wir behaupten "das geht auch gar nicht" oder habe ich was
übersehen?
Hallo Thorsten,
ich verstehe nicht wo jetzt das new() herkommt.
Objekte kann man doch auch statisch anlegen.
Auch hier wird ein/einer der CTors/DTors ausgefühert,
entweder implizit (z.b. der StandardKonstruktor) oder explizit.
Es gibt ja seit C++11 static_assert mit der man einiges zur Compilezeit
überprüfen kann. Dazu constexpr funktionen um den Compiler Sachen
berechnen zu lassen. Zusammen mit Templates (die Arduino leider , aber
verständlicherweise nicht nutzt) kann man sehr viel festlegen und
überprüfen bevor ausführbarer Code entsteht.
Torsten C. schrieb:>> Eine Lösung mit new(); (also dynamic memory) wollen wir PeDa sicher> nicht empfehlen. Ich habe aber keine Idee, wie man folgende "design> violation" ohne Konstruktor und ohne Laufzeit-Prüfungen geschickter> absichern könnte:>> http://xpcc.io/api/group__gpio.html#details sagt:>> When you use the pins directly outside any device driver class you have>> to remember to initialize them first. Call configure(), setInput() or>> setOutput() before the first use, otherwise the result is undefined and>> most likely not what you expect!>> Können wir behaupten "das geht auch gar nicht" oder habe ich was> übersehen?
Hallo Thorsten,
du kannst nicht verhindern, das jemand code dazu linkt, der nativ direkt
auf die Register zugreift und sie verändert. Du kannst auch nicht
verhindern, das jemand deinen Pin Ausgangspegel mit eine Strippe
verändert.
Der moderne (c++11) Compiler hat die Fähigkeit zu erkennen was während
der Compilierzeit konstant ist und zu optimieren und das nutzt man ganz
gezielt aus. Du musst unterscheiden was "lebt" nur während der
Compilierzeit und was landet im object File, wird gelinkt, und während
der Laufzeit ausgeführt. Während der Compilierzeit gibt es keine Objekte
oder Variable nur Konstante.
Ich habe auch immer gedacht ich kann C++ und was soll das alles mit dem
C++11 das brauch ich doch nie aber genau hier für die Embedded
Programmierung kann man es sehr gut gebrauchen. Der Nachteil ist, es ist
nicht leicht verständlich und für Anfänger in C++ völlig ungeeignet. Die
Compiler Fehlermeldungen sind alles andere als verständlich und debuggen
im single-step lässt sich das erst recht nicht.
Hier wir so oft geschrieben, ich programmiere in Assembler weil ich
verstehen will was mein MC genau macht. Ich programmiere mit
Meta-Templates weil ich verstehen will, was mein Compiler genau macht.
Naja, ich versuchs halt und lerne täglich dazu ;)
frischling schrieb:> Kannst Du mir erklären wo ich gerade hänge?
Ja, Objekte kann man statisch anlegen und dabei gleich initialisieren.
❶ Zu dem Fehler ("vergessen von configure()…"):
Man sollte für GPIO-OUTPUT also einen ctor (constructor) mit "direction"
als Parameter erstellen und keinen ctor ohne Parameter, um den Fehler
auszuschließen, Richtig?
Oder gibt es vielleicht einen Grund, warum die das nicht so gemacht
haben?
❷ Das Port-Register z.B. soll ja als const definiert sein, damit zur
Entwurfszeit schon alle Werte feststehen, und C++ nicht langsamer wird
als C.
Oder gerade ich hänge irgendwo?
Und das geht in einem ctor m.E. nicht. Sonst meldet
der Compiler:
> Der Ausdruck muss ein änderbarer lvalue sein.> L-Wert gibt ein const-Objekt an
Ich komme aus der Java und C#-Welt und blicke da noch nicht ganz durch.
Scelumbro schrieb:> Es gibt ja seit C++11 static_assert mit der man einiges zur Compilezeit> überprüfen kann. Dazu constexpr funktionen …
Danke für den Hinweis. :-) Schaue ich mir an!
Hans-Georg Lehnard schrieb:> Ich habe auch immer gedacht ich kann C++ und was soll das alles mit dem> C++11 das brauch ich doch nie aber genau hier für die Embedded> Programmierung kann man es sehr gut gebrauchen. Der Nachteil ist, es ist> nicht leicht verständlich und für Anfänger in C++ völlig ungeeignet.
OK, dann muss mal geklärt werden, wie wir hier "C++ auf einem MC, wie
geht das?" beantworten: Ist C++11 gefragt oder nicht?
Eben deshalb, weil man C++11 für die Embedded Programmierung sehr gut
gebrauchen kann, hätte ich kein Intersse an Lösungen ohne "11".
Lieber versuche ich es mit "11" und muss dann halt auch noch viel dazu
lernen.
PS: Cooles Tutorial:
http://www.codeproject.com/Articles/257589/An-Idiots-Guide-to-Cplusplus-Templates-Part
Torsten C. schrieb:> Ich komme aus der Java und C#-Welt und blicke da noch nicht ganz durch.
Generic Methods (vergleichbar mit C++-Templates) gibts auch in Java ;-)
Torsten C. schrieb:>> OK, dann muss mal geklärt werden, wie wir hier "C++ auf einem MC, wie> geht das?" beantworten: Ist C++11 gefragt oder nicht?>
Hallo Thorsten,
Ich habe nicht geschrieben das es "nur" in C++11 geht es geht auch mit
früheren Versionen ! Nur werden mit der 11er ein paar Sachen einfacher.
Du hast wie Scelumbro schon schrieb die static_assert und vor allen
Dingen varadic templates. Dazu noch auto , constexpr usw ...
Du kannst dir nicht einfach isoliert ein paar Goodies herauspicken,
sondern du musst verstehen: wann, wie und warum man code auf die
Compilezeit verschieben kann und er zu Laufzeit nicht mehr auftaucht,
sondern vom Compiler durch Konstanten ersetzt wurde.
Torsten C. schrieb im Beitrag #3985508:
> Genau das ist es. Bis auf das "Warum" ist das auch ziemlich klar.>> Peter L. schrieb:template <int pin>> struct pb{> void set(){> ptr = (int*)0xDEADBEEF + pin;> *ptr = 0x1;> }> };> pb<1337> a;> a.set();> Sowas ist erlaubt.>> Aber ptr* sollte doch zur Compilezeit bereits feststehen. Ich habe noch> nicht kapiert, wie das geht.
Im Idealfall wird der ganze code doch noch geinlinet und ist dann nicht
kaum mehr als als ein einzige Assemblerinstruktion, die an die Adresse
0xDEADBEEF+1337 die Zahl 0x1 schreibt. In C++ würde man wohl statt
(int*)0xDEADBEEF + pin ein reinterpret_cast<int *>(0xDEADBEEF + pin);
stehen.
Torsten C. schrieb:> Man sollte für GPIO-OUTPUT also einen ctor (constructor) mit "direction"> als Parameter erstellen und keinen ctor ohne Parameter, um den Fehler> auszuschließen, Richtig?>> Oder gibt es vielleicht einen Grund, warum die das nicht so gemacht> haben?
Also in xpcc erstellt man keine Instanz um einen Gpio benutzen zu
können. Stattdessen wird sichergestellt, dass alle Pins, die beim
benutzten Controller verfügbar sind, als Klassen mit rein statischen
Methoden zur Verfügung stehen.[0] Daher gibt es auch keinen Konstruktor.
Die Entscheidung gegen Instanzen kommt daher, dass es mit Instanzen
nicht so einfach ist, zu sehen, was der Compiler inlinen kann und was
nicht. Statische Methoden verhalten sich dagegen fast wie C Funktionen.
Ausserdem macht die Entscheidung für statische Klassen den Einsatz von
Compilezeit Polimorphismus einfach.[1] Es ist nämlich nicht trivial
(oder vielleicht sogar unmöglich) einem Template eine Instanz zu
übergeben. Sehrwohl ist es aber bei Templates vorgesehen Klassen zu
übergeben.
Wenn nun also für jeden Gpio eine Instanz erstellt wird, dann wäre der
"normale" Ansatz eine Gpio Basisklasse mit als "virtual" deklarierten
Funktionen anzulegen z.B.:
1
class
2
AbstractGpio
3
{
4
public:
5
virtualvoidset()=0;
6
virtualvoidreset()=0;
7
virtualboolread()=0;
8
}
9
10
class
11
GpioA0:publicAbstractGpio
12
{
13
public:
14
GpioA0(...){...}
15
16
voidset(){GPIOA->BSRRL=(1<<0);}
17
voidreset(){GPIOA->BSRRH=(1<<0);}
18
boolread(){returnGPIOA->IDR&(1<<0);}
19
}
Dann kann man einer Klasse, welche Pins benutzen muss, Pointer auf
AbstractGpio Instanzen übergeben und darüber die Pins ansprechen. Also
der Standard Laufzeitpolymorphismus.
Hierbei wird aber jegliches Inlinen durch den Compiler verhindert (denn
die Bindung Pin zu Klasse findet ja erst zur Laufzeit statt) und
ausserdem v-tables erzeugt. D.h. es gib einen Overhead.
Dieser wird durch den oben erwähnten Compilezeit Polymorphismus
verhindert. Mit dem Nachteil, dass beim Compilezeit Polymorphismus nur
statische Konstrukte unterstützt werden. Mit einer
Laufzeitpolymorphismus Lösung kann man dagegen die Pins während der
Laufzeit wechseln.
1
i2c.setScl(&gpioB0Instance);
Das ist nichts was man normalerweise auf einem Mikrocontroller machen
möchte, aber doch ein Feature, dass manche User, die von der PC
Programmierung her kommen erwarten und das z.B. bei Arduino mit der
Adressierung von Pins über Integer realisiert wird.
eKiwi
PS: Natürlich kann man, statt für jeden Gpio eine eigene Klasse
anzulegen, das ganze, wie weiter oben in diesem Thread schon erwähnt
wurde, mit Hilfe von Template lösen. Ich habe das aber hier nicht
beachtet, damit die Beispiele einfacher werden. Nur weil xpcc die Gpio
Klassen mit jinja2 Templates erzeugt, heist das nicht, dass es der beste
Weg ist. C++ Templates haben unter anderem den Vorteil, dass sie keine
grossen Anforderungen an die Buildumgebung stellen.
[0]
Für diejenigen, die es interessiert ein paar Details am Beispiel des
stm32f407vg:
1. Für unsere unterstützten Controller gibt es eine XML Beschreibung
z.B.:
https://github.com/roboterclubaachen/xpcc/blob/develop/src/xpcc/architecture/platform/devices/stm32/stm32f405_407_415_417-i_r_v_z-e_g.xml
2. Mit deren Hilfe werden für jeden verfügbaren (also auch gebondeten)
Pin drei Klassen erzeugt: z.B. GpioA0, GpioOutputA0, GpioInputA0
Das Headerfiletemplate (jinja2) dazu sieht so aus:
https://github.com/roboterclubaachen/xpcc/blob/develop/src/xpcc/architecture/platform/driver/gpio/stm32/gpio.hpp.in
[1]
Als Beispiel eignet sich unser Software I2C Treiber:
https://github.com/roboterclubaachen/xpcc/blob/develop/src/xpcc/architecture/platform/driver/i2c/generic/i2c_master.hpp
@Scelumbro: Habe ich zu spät gemerkt, sorry, danke.
Es zwei da zwei unterschiedliche Ansätze.
Bei dem Code von Peter L. kommt "kaum mehr als als ein einzige
Assemblerinstruktion"^^ raus, wenn set() als "inline" optimiert wird. Ob
es was bringen würde, set() in die .h als "inline set() {… zu schreiben,
ist ein separates Thema, kommt später!
^^ Das wäre der eine Ansatz.
Aber es gibt sicherlich auch komplexere Funktionen, die für die
Beantwortung der Ausgangfrage erforderlich sind, bei denen "inline" wohl
keinen Sinn mehr macht:
1
LED2.on=KEY2.press_long;// lang drücken - an
Hier gibt es ja z.B. kein
1
KEY2.setLongPressTime();
Als ich eben schrieb: "Das Port-Register z.B. soll ja als const
definiert sein", hatte ich ein schlechtes Beispiel. Vielleicht ist die
LongPressTime ein besseres.
Angenommen, die longPressTime soll zur Compilezeit bereits feststehen.
Die "longPressTime "sollte in diesem Fall doch im ROM stehen, oder?
Würde man dem OP für 3 Tasten mit unterschiedlichen Zeiten (5s/6s/7s)
empfehlen, dass er per Template 3 verschiedene Klassen erzeugt, also:
1
LPKey<5,1337>key1;
2
LPKey<6,1338>key2;
3
LPKey<7,1339>key3;
Und der Timer, der jeweils benutzt werden soll, muss ja auch
parametrierbar sein, also => ein weiterer Template-Parameter. Wer weiss,
was noch alles dazu kommt!
Das gibt einen Haufen Templates für Karl den Käfer ;-)
Irgendwann kommt man an den Punkt, wo man einen Parameter gern als
Objekt-Eigenschaft definieren würde
Als const (so, wie oben):…
1
MyObjectobj1(ParameterdesCTor);
… geht das aber nicht, und damit steht die Zahl dann im RAM und wird zur
Laufzeit ständig dynamisch ausgelesen, wenn man sich nicht auf die
Compiler-Optimierung verlassen will.
Aber vielleicht machen const Eigenschaften auch keinen Sinn und man muss
- wenn man den Parameter nicht als Template-Parameter übergibt - halt
damit leben, dass der Parameter zur Laufzeit bei jedem Funktionsaufruf
ausgewertet wird.
Frank M. schrieb:> Generic Methods (vergleichbar mit C++-Templates) gibts auch in Java ;-)
Das war anders gemeint: Wenn z.B. die "LongPressTime" zur Compilezeit
bereits fest steht, ist ein setLongPressTime() kontraproduktiv. In Java
habe ich mir über "ROMable" nie Gedanken gemacht, das ist da auch
unüblich und das Thema ist für mich Neuland.
Torsten C. schrieb:> Man sollte für GPIO-OUTPUT also einen ctor (constructor) mit "direction"> als Parameter erstellen und keinen ctor ohne Parameter, um den Fehler> auszuschließen, Richtig?
Dazu ist mir noch ein Problem, unabhängig von Instanz/Klasse etc.
eingefallen:
Falls ihr die Gpios alle statisch Instanzieren wollt wie hier:
frischling schrieb:> class MyObject> {> // MyStuff> MyObject (Paramter, liste);> }>> MyObject obj1(Parameter des CTor);
Dann ist nicht immer garantiert in welcher Reihenfolge die CTors
aufgerufen werden. (in einer compile unit mit gcc so weit ich weis
schon, aber sobald das mehr als ein .cpp file wird, wird es
komplizierter)
Das kann zu ungewollten "glitches" führen, falls der eine Pin zu frueh
nach Masse oder VCC zieht, obwohl man eigentlich erst noch etwas anderes
initialisieren muss.
> Peter L. schrieb:template <int pin>> struct pb{> void set(){> ptr = (int*)0xDEADBEEF + pin;> *ptr = 0x1;> }> };> pb<1337> a;> a.set();> Sowas ist erlaubt.
Ein ziemlich ungeschicktes Beispiel ...
Das Template ist überflüssig, du kannst Pin gleich als Parameter
übergeben.
Und warum eine Speicheradresse erst als pointer definieren dann
dereferenzieren ...
Und wenn nicht irgendwo im Programm später mal auf diese Addresse lesend
zugegriffen wird, was z.B bei DDR-Degister oft der Fall ist, optimiert
der Compiler alles weg, weil volatile fehlt.
Hallo eKiwi, Deine Antwort sehe ich erst jetzt, sehr gute Erklärung! :-)
eKiwi schrieb:> Wenn nun also für jeden Gpio eine Instanz erstellt wird, dann wäre der> "normale" Ansatz eine Gpio Basisklasse mit als "virtual" deklarierten> Funktionen anzulegen
Beim GPIO habe ich ein blödes Beispiel gewählt. Die longPressTime ist
hoffentlich besser:
Warum virtual? Da sitzt genau mein Klemmer:
Wenn sich nur die Daten unterscheiden, aber die Funktionen immer gleich
sind, müssen die Funktionen doch nicht virtuell sein.
Trotzdem sollen die Daten im ROM liegen. Wahrscheinlich ist das ganz
einfach und ich habe Tomaten auf den Augen.
eKiwi schrieb:> Natürlich kann man, statt für jeden Gpio eine eigene Klasse> anzulegen, das ganze, wie weiter oben in diesem Thread schon erwähnt> wurde, mit Hilfe von Template lösen.
So "Natürlich" war das bis eben für mich nicht, aber dann scheint das
wohl der einzige gangbare Weg für "enbedded" zu sein, um "vergessen von
configure()…"^^ usw. zur Compilezeit zu detektieren.
Hans-Georg Lehnard schrieb:> Das Template ist überflüssig, du kannst Pin gleich als Parameter> übergeben.
Als Parameter an wen? Aktuell als Parameter an das Template. Das ist bis
auf vergessene volatile und den Umweg über ptr* doch ganz nett für
inline.
Meinst Du vielleicht als Parameter an einen constructor (ctor)? Dann
wären wir wieder bei einer Instanz (also nicht static). Wäre der ptr
dann noch ROMable? Ich wüsste nicht, wie.
Torsten C. schrieb:> Als const (so, wie oben):…MyObject obj1(Parameter des CTor);… geht das> aber nicht, und damit steht die Zahl dann im RAM und wird zur> Laufzeit ständig dynamisch ausgelesen, wenn man sich nicht auf die> Compiler-Optimierung verlassen will.
Vielleicht habe ich das falsch verstanden, aber es gibt ja auch
constexpr constructoren.
Torsten C. schrieb:> [...] wenn man sich nicht auf die> Compiler-Optimierung verlassen will.
In diesem Fällen hilft man dem Compiler zwar mit const/constexpr und
template Geschichten auf die Sprünge. Aber letztendlich haben zumindest
die GCC Programmierer auch schon ganze Arbeit geleistet, nicht unnötig
Konstanten aus dem RAM zu holen. Wenn du ihnen nicht traust, dann schau
mal ins lss. Ich war bei meinen template experimenten mit dem AVR-GCC
auch immer wieder erstaunt zu was komplexe konstruktionen dann
letztendlich zusammenschrumpfen.
Torsten C. schrieb:> Und der Timer, der jeweils benutzt werden soll, muss ja auch> parametrierbar sein, also => ein weiterer Template-Parameter. Wer weiss,> was noch alles dazu kommt!
Du kannst ja für die Timer eine eigene Klasse anlegen.
Zusätzlich gibt es ja noch Sachen wie using mit der man durch Aliase in
das entstehende Chaos aus eckigen Klammern wieder Ruhe bringen kann.
Torsten C. schrieb:> Hallo eKiwi, Deine Antwort sehe ich erst jetzt
PS: Ich willte damut sagen: Ich hatte inzwischen den Beitrag mit
"longPressTime" geschrieben, der ging über Kreuz. Gesehen?
Scelumbro schrieb:> aber es gibt ja auch constexpr constructoren
Ups, ja. Hatte ich vorhin gelesen, kannte ich vorher nicht, muss ich mir
anschauen und geht nur in C++11. Letzteres wäre für mich -wie gesagt -
OK.
Scelumbro schrieb:> Du kannst ja für die Timer eine eigene Klasse anlegen.
OK, wenn der Compiler merkt, dass die zu verwendende Timer-Instanz zur
Compilezeit bereits feststeht (constexpr??), könnte man das tun. Ob ich
verstanden habe, wie man das programmiert, weiss ich erst, wenn ich es
ausprobiert habe.
Scelumbro schrieb:> Zusätzlich gibt es ja noch Sachen wie using
Auch ein guter Tipp. Danke. :-)
Torsten C. schrieb:> Beim GPIO habe ich ein blödes Beispiel gewählt. Die longPressTime ist> hoffentlich besser:
Naja, das ganze sind doch erst einmal verschiedene Baustellen:
Bei den Gpios will man für jeden eine eigene Klasse haben, da eben nicht
die Daten sondern der zu erzeugende Code unterschiedlich ist.
Also zumindest wenn man das so wie oben z.B. von Micha erwähnt wurde
macht. Das hat den Vorteil, dass eine Instanz der Klasse keine Daten
enthält und daher praktisch eine Grösse von 0 hat.
Micha schrieb:> @ Karl Käfer> Um deinen Vergleich noch anzusprechen: ich persönlich> findeDigitalOutput<PORT_B,P4> beleuchtung;> DigitalInput<PORT_B,P0> startknopf;
Zugegeben hatte ich die Loesung von Karl vergessen:
Karl Käfer schrieb:> #include <avr/io.h>>> class Pin {> public:> volatile uint8_t* ddr;> volatile uint8_t* port;> volatile uint8_t* pin;> uint8_t num;>> Pin(volatile uint8_t* ddr, volatile uint8_t* port,> volatile uint8_t* pin, uint8_t num):> ddr(ddr), port(port), pin(pin), num(num)> {}> };>> class InputPin : public Pin {> public:> InputPin(volatile uint8_t* ddr, volatile uint8_t* port,> volatile uint8_t* pin, uint8_t num):> Pin(ddr, port, pin, num) {> *this->ddr &= ~(1 << this->num);> }> int isHigh(void) { return (*this->pin & (1 << this->num)); };> int isLow(void) { return !((*this->pin & (1 << this->num))); };> };>> class OutputPin : public Pin {> public:> OutputPin(volatile uint8_t* ddr, volatile uint8_t* port,> volatile uint8_t* pin, uint8_t num):> Pin(ddr, port, pin, num) {> *this->ddr |= (1 << this->num);> }> void setHigh(void) { *this->port |= (1 << this->num); };> void setLow(void) { *this->port &= ~(1 << this->num); };> void operator=(bool const &parm) {> if(parm) { this->setHigh(); }> else { this->setLow(); }> }> };>> int main(void) {>> OutputPin ledPin (&DDRD, &PORTD, &PIND, PD0);> InputPin btnPin (&DDRB, &PORTB, &PINB, PB0);>> while(1) {> //...> ledPin.setHigh();> ledPin.setLow();> ledPin = btnPin.isHigh();> }> }
Hier hast du wirklich eine Pin Klasse, bei der die Instanzen jeweils
andere Daten erhalten. Hierauf treffen dann meine oben gemachten
Kommentare nicht ganz zu. Mich würde aber noch interessieren wie weit
man das ganze treiben kann, bis der Compiler Speicherplatz für ddr,
port, pin und num anlegt. An sich aber auf jeden Fall ein interessanter
Ansatz.
> Warum virtual? Da sitzt genau mein Klemmer:>> Wenn sich nur die Daten unterscheiden, aber die Funktionen immer gleich> sind, müssen die Funktionen doch nicht virtuell sein.
Genau. Aber spätestens wenn du eine Funktion hast, die nicht direkt
einen Pointer auf einen Pin benutzt, sondern einen Pointer, der ein
Member der Klasse, zu der diese Methode gehört, ist, dann wird - nach
meinem Verständnis - doch Speicher für die Datenmember des Pins angelegt
werden muessen, da zur Compilezeit nicht bekannt ist, welcher Pin genau
angesprochen wird.
z.B.
1
class
2
SoftwareI2C
3
{
4
public:
5
SoftwareI2C(Pin*Scl,Pin*Sda):scl(Scl),sda(Sda){}
6
7
voidrun()
8
{
9
// hier ist voraussichtlich zur Compilezeit nicht bekannt,
10
// welcher pin das ist, also kann das nicht in einen simplen
11
// ASM Befehl übersetzt werden
12
// wahrscheinlich wird das eine function call an die Pin::set
13
// Methode mit der Adresse in this->scl als Argument erzeugen
14
// wobei in dieser Methode dann aus den Daten an dieser Adresse
15
// das Register berechnet wird
16
// an dieser Stelle sollte man sich aber wohl wirklich
17
// mal den ASM Code ansehen
18
// vielleicht habt ihr ja etwas cooles gefunden und das
19
// ganze wird wegoptimiert (da gcc schlauer ist als ich denke)
20
this->scl->set();
21
}
22
23
private:
24
Pin*scl;
25
Pin*sda;
26
27
}
> Trotzdem sollen die Daten im ROM liegen. Wahrscheinlich ist das ganz> einfach und ich habe Tomaten auf den Augen.
Dazu kann ich die bereits oben zitierten Folien empfehlen, dort steht
ganz gut, wann etwas ins ROM kommt und wann nicht:
http://aristeia.com/TalkNotes/C++_Embedded_Deutsch.pdf
eKiwi schrieb:> Mich würde aber noch interessieren wie weit> man das ganze treiben kann, bis der Compiler Speicherplatz für ddr,> port, pin und num anlegt.
... sobald man die Ports/ Pins 'richtig' verwenden will. Z.B. in einer
LCD-Klasse, die Funktionen für die Ausgabe enthält und der man dann so
ein paar Port-/ Pinobjekte übergibt. Dann hat sich's auch mit den
schnellen IO-Zugriffen erledigt.
> An sich aber auf jeden Fall ein interessanter Ansatz.
Besser ist das mit Templates, da sieht der Compiler alles. Ich habe
allerdings noch keinen Einfall, wie man solche Objekte universell in
andere Objekte einbinden kann (ohne diese <>-Klammerlisten).
Ralf G. schrieb:> Besser ist das mit Templates, da sieht der Compiler alles.
Da muss ich dir zustimmen. Deshalb benutzt xpcc ja auch generierte
Klassen für die Gpio Pins. Ich wollte jetzt nur einen neuen Ansatz nicht
sofort ausschliessen.
Ralf G. schrieb:> Ich habe> allerdings noch keinen Einfall, wie man solche Objekte universell in> andere Objekte einbinden kann (ohne diese <>-Klammerlisten).
Wenn man universelle Klassen schreiben möchte muss man sich dann, früher
oder später zwischen Lauf- und Compilezeitpolymorphismus (aka das Ding
mit den <>-Klammerlisten) entscheiden. Bei den Gpio Pins war es in xpcc
unsere Designentscheidung das über einen Compilezeitpolymorphismus zu
lösen, da das ansteuern von Pins möglichst ohne Overhead funktionieren
sollte.
So kann niemand auf die Idee kommen dafür direkt in die Register zu
schreiben. Dies ist leider bei viel zu vielen Arduino Libraries der
Fall, die dadurch nicht portabel sind. Deshalb konnten sich imho die ARM
basierenden Arduinos nie richtig durchsetzen.
@Scelumbro + Hans-Georg: Danke und sorry, ich habe jetzt endlich das
faszinierende Kapitel zu constexpr gelesen:
http://www.cprogramming.com/c++11/c++11-compile-time-processing-with-constexpr.htmlTorsten C. schrieb:> Wäre der ptr dann noch ROMable? Ich wüsste nicht, wie.
Nun weiss ich wie! Das geht per constexpr wunderbar. Ich hab's gerade
mit avr GCC 4.7.2 probiert. Das löst meinen Knoten im Kopf! :-)
Alex Allain sagt dort:
> In fact, the only compiler version I know of that fully> supports constexpr is GCC 4.7.
Hmmm, die Aussage ist doch hoffentlich schon etwas älter, oder?
eKiwi schrieb:> Ralf G. schrieb:>> Ich habe>> allerdings noch keinen Einfall, wie man solche Objekte universell in>> andere Objekte einbinden kann (ohne diese <>-Klammerlisten).>> Wenn man universelle Klassen schreiben möchte muss man sich dann, früher> oder später zwischen Lauf- und Compilezeitpolymorphismus (aka das Ding> mit den <>-Klammerlisten) entscheiden.
Mit constexpr ist m.E. auch die Variante von Karl Käfer ROMable. Zur
Frage, ob der Compiler Speicherplatz für ddr, port, pin und num anlegt.
Bei
1
constuint8_tnum;
sicherlich nicht. Die Eigenschaften ddr, port und pin kann man doch
sicher auch const machen.
Nun habe ich nur noch ein Problem mit Instanzen statt Templates: Kann
man irgendwie verhindern, dass ein Pin doppelt instanziiert wird? Ich
kenne dafür nur Singletons. Sollte man versuchen, Singletons umzusetzen?
Ralf G. schrieb:> eKiwi schrieb:>> Mich würde aber noch interessieren wie weit>> man das ganze treiben kann, bis der Compiler Speicherplatz für ddr,>> port, pin und num anlegt.
Das brauch er nicht, weil es den Speicher dafür schon gibt, das sind die
SFR Register und die sind fix im RAM.
Beispiel: PORTA P7 und PORTA P4
Der Compiler kennt natürlich das nicht, du musst ihm irgenwie sagen
Register PORTA.ddr gibt es schon und das liegt an der Speicheradresse XX
und P7 ist das bit7 in diesem Register.
Für PORTA P4 gibt es kein neues PORTA.ddr P4 liegt an der gleichen
Adresse und ist nur ein anderes Bit.
Hans-Georg Lehnard schrieb:> weil es den Speicher dafür schon gibt
Aber nicht für "uint8_t num", aber da gingen unsere Beiträge über
Kreuz^^, ist also auch kein Problem.
Torsten C. schrieb:>> Nun weiss ich wie! Das geht per constexpr wunderbar. Ich hab's gerade> mit avr GCC 4.7.2 probiert. Das löst meinen Knoten im Kopf! :-)>> Alex Allain sagt dort:>> In fact, the only compiler version I know of that fully>> supports constexpr is GCC 4.7.>> Hmmm, die Aussage ist doch hoffentlich schon etwas älter, oder?>
Der Aktuelle Compiler im Atmel bei mir (4.8.1) ist nicht 100% C++11
kompatibel. Vor allen Dingen die C++11 Libs fehlen.
Bisher ist mir nur aufgefallen, das "auto" mit Vorsicht zu geniessen
ist.
> Mit constexpr ist m.E. auch die Variante von Karl Käfer ROMable. Zur> Frage, ob der Compiler Speicherplatz für ddr, port, pin und num anlegt.> Bei>
1
constuint8_tnum;
> sicherlich nicht. Die Eigenschaften ddr, port und pin kann man doch> sicher auch const machen.
Nochmal: ddr, port, pin usw. müssen Ram Speicher haben sonst könnte man
ja nichts ändern! Aber den gibt es schon im SFR Bereich vom Ram, du must
es dem Compiler nur erzählen.
> Nun habe ich nur noch ein Problem mit Instanzen statt Templates:
Der Begriff Instanz ist hier mehrdeutig. Templates werden immer
instanziiert, leben aber nur im (PC)Arbeitsspeicher vom (Cross)Compiler.
Das was du meinst sind Objektinstanzen einer Klasse die während der
Laufzeit im Speicher vom Target MC leben.
> Kann man irgendwie verhindern, dass ein Pin doppelt instanziiert wird?
Wenn die erste (template) Instanz für den Compiler konstant ist und die
2. versucht diese Konstante zu überschreiben sollte er eine
Fehlermeldung bringen. Hab ich aber noch nicht probiert.
> Ich kenne dafür nur Singletons.
Ja, ja die kleine wunderbare Welt der Java Programmierer ;)
ich hatte mal das Verknügen meinen Java Kollegen Thread Synchronisierung
bei zu bringen ... Braucht man doch bei Java alles nicht hör ich gerade
...
Aber nur wenn alle Threads in der gleichen VM leben.
Ein Embedded Programierer würde dafür eher pro Port ein Byte reservieren
und dort ein Bit für jeden belegten Pin setzen.
Hans-Georg Lehnard schrieb:> Das was du meinst sind Objektinstanzen einer Klasse die während der> Laufzeit im Speicher vom Target MC leben.
Genau, aber mein Problem^^ ist, wie man bei dieser Art der Modellierung
eine doppelte instanziierung vermeiden kann. Ansonsten finde ich den
Ansatz von Karl Käfer erstmal optimal. Mal sehen, was die Praxis sagt.
Im o.g. Port-Beispiel ist das vielleicht nicht so schlimm. Aber zwei
RingBuffer auf einen und den selben UART wären z.B. doof.
Hans-Georg Lehnard schrieb:> Nochmal: ddr, port, pin usw. müssen Ram Speicher haben sonst könnte man> ja nichts ändern!
Ach. Aber die Adressen (Zeiger!!) ddr, port und pin sollen doch konstant
also ROMable sein und nicht im RAM liegen. Oder? Nix ändern können fände
ich doof. ;-) :-p
1
volatileuint8_t*ddr;
2
volatileuint8_t*port;
3
volatileuint8_t*pin;
Warum eigentlich drei getrennte Pointer? Einen einzigen fände ich
übersichtlicher.
Ich bin gerade mit dem UART am basteln, da reicht ein ein einziger
USART_t*:
Torsten C. schrieb:>> Ach. Aber die Adressen (Zeiger!!) ddr, port und pin sollen doch konstant> also ROMable sein und nicht im RAM liegen. Oder?
Der Compiler macht aus dem ganzen Theather was du veranstaltest um ein
Bit im Register zu setzen und um ihm das schonend beizubringen ganz
schnöde den Assembler Befehl z.B. "sbi 0x17, 3" und das wars.
0x17 ist dein Zeiger und 3 ist der Pin aber direkt codiert in einem
Assembler Befehl.
Look mam no pointer ;)
Hans-Georg Lehnard schrieb:> Der Compiler macht aus dem ganzen Theather was du veranstaltest um ein> Bit im Register zu setzen und um ihm das schonend beizubringen ganz> schnöde den Assembler Befehl z.B. "sbi 0x17, 3" und das wars.
Das wäre cool! :-) Aber welches Theater?
eKiwi schrieb:
1
classPin{
2
public:
3
volatileuint8_t*ddr;
4
volatileuint8_t*port;
5
volatileuint8_t*pin;
6
uint8_tnum;
7
};
Also kann auch mal jemand schreiben, dass sich das während der Laufzeit
ändert:
1
Pinichbinmaldiesmaldas(ddr,port,pin,num);
2
ichbinmaldiesmaldas.port=&einanderer;// ???
Ich meine, die Pointer müssen konstant sein, damit der Compiler da
wirklich zuverlässig z.B. "sbi 0x17, 3" draus macht und nicht nur
zufällig je nach Compiler-Optimizing-Level.
Aber vielleicht weiss es jemand besser? Ich lerne gern dazu!
Also, falls ein "const" nötig ist, ich musste gerade selber mal googeln:
Bradley Jones sagt:
1
constchar*myPtr=&char_A;// pointer to a constant character. You cannot use this pointer to change the value being pointed to
2
char*constmyPtr=&char_A;// constant pointer to a character. The location stored in the pointer cannot change
3
constchar*constmyPtr=&char_A;// pointer to a character where both the pointer value and the value being pointed at will not change.
Torsten C. schrieb:> Ich meine, die Pointer müssen konstant sein, damit der Compiler da> wirklich z.B. "sbi 0x17, 3" draus macht, aber vielleicht weiss es> jemand besser? Ich lerne gern dazu!
- Die Pointer müssen nicht konstant sein!
- DDRx, PORTx, PINx sind keine Pointer
- man kann einen Zeiger darauf definieren
- wenn der Compiler die Chance hat zu erkennen, dass dieser Pointer
immer nur auf eine Adresse zeigt, dann optimiert er das!
- Wenn ein Pointer auf verschiedene Objekte 'gestellt' wird, kann der
Compiler selbstverständlich nicht optimieren, weil im 'sbi'-Befehl die
Adresse direkt codiert ist.
- ...
Ralf G. schrieb:> Torsten C. schrieb:>> Ich meine, die Pointer müssen konstant sein, damit der Compiler da>> wirklich z.B. "sbi 0x17, 3" draus macht, aber vielleicht weiss es>> jemand besser? Ich lerne gern dazu!>> - Die Pointer müssen nicht konstant sein!> - DDRx, PORTx, PINx sind keine Pointer> - man kann einen Zeiger darauf definieren> - wenn der Compiler die Chance hat zu erkennen, dass dieser Pointer> immer nur auf eine Adresse zeigt, dann optimiert er das!> - Wenn ein Pointer auf verschiedene Objekte 'gestellt' wird, kann der> Compiler selbstverständlich nicht optimieren, weil im 'sbi'-Befehl die> Adresse direkt codiert ist.> - ...
Das hat aber weniger mit Pointern zu tun, das liegt daran das sbi nur
auf bit-addressable Speicherbereiche und nicht im gesammten
adressierbaren Speicher funktioniert.
Ralf G. schrieb:> DDRx, PORTx, PINx sind keine Pointer
Und wozu ist der Stern in "public: volatile uint8_t* ddr;"^^?
Oder hast Du einen Vorschlag, wie man das ohne Pointer macht? Dann würde
hier nicht so eine ellenlange Debatte entstehen.
Ralf G. schrieb:> - wenn der Compiler die Chance hat zu erkennen, dass dieser Pointer> immer nur auf eine Adresse zeigt, dann optimiert er das!
Das kann er aber m.E. nur bei "private". Selbst bei "protected" könnte
in einem anderen .cpp noch eine abgeleitete Klasse sein, die die Adresse
verändert. Dagegen würde "final" helfen.
Aber falls das auch ohne Pointer geht, wozu dann das ganze Theather?
Lieber Ralf und lieber Hans-Georg, dann posted doch bitte einfach eine
Alternative zu dem Vorschlag von Karl Käfer.
Ralf G. schrieb:> - wenn der Compiler die Chance hat zu erkennen, dass dieser Pointer> immer nur auf eine Adresse zeigt, dann optimiert er das!
Ich habe gelesen, dass das von Compiler zu Compiler unterschiedlich ist.
Es mag sein, dass das nicht stimmt. Was stört Dich daran, das mit
"const" bzw. "constexpr" abzusichern?
Torsten C. schrieb:> eKiwi schrieb:class Pin {> public:> volatile uint8_t* ddr; …
PS: Da habe ich eine Zeile verschluckt. Den Vorschlag hat zwar eKiwi
zitiert, aber er kommt von Karl Käfer aus Beitrag #3902529. Sorry.
Vorteil des Vorschlags:
* Ohne diese <>-Klammerlisten^^
Torsten C. schrieb:> Also kann auch mal jemand schreiben, dass sich das während der Laufzeit> ändert:>
1
Pinichbinmaldiesmaldas(ddr,port,pin,num);
2
>ichbinmaldiesmaldas.port=&einanderer;// ???
>
Prinipiell hast du recht und das musst du verhindern. C++ erzeugt bei
Klassen automatisch einen Copy Constructor und einen Destructor.
Die beiden sollte man "leer" überschreiben und als privat deklarieren
dann ist das sicher.
Und vergiss nicht von allem was C++ kann ist nur ein Teil für die
embedded Programmierung geeignet sonst hast du deinen mühsam gespaarten
Speicher schnell, durch eine lib die automatisch dazugelinkt wird,
wieder zunichte gemacht.
Sorry .. das ist ja ein gnu Linker und der linkt natürlich nicht dazu
sondern dagegen ;)
Hans-Georg Lehnard schrieb:> sonst hast du deinen mühsam gespaarten> Speicher schnell, durch eine lib die automatisch dazugelinkt wird,> wieder zunichte gemacht.
… wie z.B. bei GoTo ^^ mit "boost::thread". ;-)
Einige der "header-only Boost libraries" gibt es ja wohl auch für den
AVR, aber natürlich ohne boost::thread.
Ich wage mich da mit meinem ATtiny1634
ganz bestimmt nicht ran:
http://academic.cleardefinition.com/2012/09/21/using-c-on-the-arduino-a-mainstream-c-standard-library-port-for-the-avr/
Oder hat damit etwa schon mal jemand gute Erfahrungen gemacht?
Trotzdem nochmal: Falls jemand einen Vorschlag hat, wie man "class
Pin"^^ ohne Pointer machen könnte, das wäre dann noch eleganter.
Torsten C. schrieb:> Ralf G. schrieb:>> DDRx, PORTx, PINx sind keine Pointer>> Und wozu ist der Stern in "public: volatile uint8_t* ddr;"^^?>> Oder hast Du einen Vorschlag, wie man das ohne Pointer macht?
Wenn man hier auch folgendes verwenden kann:
1
volatileuint8_t*constddr;
Sind auch referenzen möglich:
1
volatileuint8_t&ddr;
PS: In dem Bespiel, welches ich ganz weit oben Postete, habe ich dafür
Referenzen verwendet.
kopfkratz
Also nochmal langsam und zum mitmeisseln (oder wird das mit ß
geschrieben ?) ...
Man muß die Abstraktionsstufen im Auge behalten.
Entweder man definert eine vorgegebene Struktur die immer die gleichen
Variablen nutzt aber für jeden µC entsprechend angepaßt ist (so wie ich
das schon erwähnt habe).
Oder man geht den Weg der Vererbung und muß dann für jeden µC die
passende Basisklasse schreiben ebenfalls wie im obigen Fall.
Der Weg über Templates ist der meiner Meinung nach sinnvollste und
flexibelste, denn dann spart man sich die Vererbung bzw. Einbindung
verschiedener Definitionen.
Damit kommt man aber von einer Basisdefinition des µCs auch nicht herum.
Von der Compilerseite könnte man das auch im makefile erledigen bzw.
beim linken.
Torsten C. schrieb:> Falls jemand einen Vorschlag hat, wie man "class> Pin"^^ ohne Pointer machen könnte, das wäre dann noch eleganter.
???
Na so:
Beitrag "Re: C++ auf einem MC, wie geht das?"
Die Registeradressen würde man allerdings über die Port-Adresse
ermitteln lassen. Den Rest macht der Compiler. Der kann das.
Vorteil:
- geht für alle AVRs einheitlich.
- es sind automatisch auch die mit im Boot, wo die Register nicht im
IO-Bereich liegen.
Ralf G. schrieb:> Ich habe> allerdings noch keinen Einfall, wie man solche Objekte universell in> andere Objekte einbinden kann (ohne diese <>-Klammerlisten).
Da wird man wohl nicht drum herumkommen...
Daniel A. schrieb:> Wenn man hier auch folgendes verwenden kann:
^^ Das alles sind Beispiele, wie sie schon seit Jahren immer einmal,
hier im µC-net vorgeschlagen/ diskutiert werden. Ob Pointer, Referenzen,
'const' oder nicht 'const'...
Ist egal. Kann man so machen. Macht man auch so! Wenn man weiß und das
toleriert, dass da nur direkte Zugriffe draus werden, wenn der Compiler
den kompletten Code sehen kann.
Hallo Torsten,
Torsten C. schrieb:> Nun habe ich nur noch ein Problem mit Instanzen statt Templates: Kann> man irgendwie verhindern, dass ein Pin doppelt instanziiert wird? Ich> kenne dafür nur Singletons. Sollte man versuchen, Singletons umzusetzen?
Ach, Torsten... Jedes Mal, wenn Du etwas idiotensicher machen willst,
dann kommt die Natur und erfindet bessere Idioten.
Kurz gesagt: Man kann nicht verhindern, daß Idioten idiotische Sachen
tun. Das ist auch nicht die Aufgabe einer Bibliothek. Was dabei heraus
kommt, wenn Du es versuchst, siehst Du an den Arduino-Libraries:
funktioniert zwar, ist aber ein riesiger Source- und Codebloat. Und
trotzdem gibt es genug Idioten, die idiotische Sachen damit machen --
schau mal in dieses Forum! ;-)
Mit dem Anspruch, jeden noch so bescheuerten Fehler mit Compiler- und
Sprachmitteln abzufangen, stehst Du Dir daher einerseits selbst im Weg,
andererseits verhinderst Du wahrscheinlich exotische Dinge, die wir uns
vielleicht nur nicht vorstellen können, die aber trotzdem sinnvoll sind.
Es ist nicht Deine Aufgabe, die Anwender Deiner Bibliothek zu
bevormunden, und darauf läuft die ganze Sache letztendlich hinaus (ja,
ich weiß, das ist nicht Deine Intention, aber "gut gemeint" ist
bekanntlich die kleine Schwester von "schlecht gemacht"). Wenn Anwender
idiotische Sachen machen wollen, ist das ihr gutes Recht. Etliche gute
Ideen und Produkte sind aus etwas entstanden, das andere zuvor als
sinnlos, idiotisch abgetan haben.
Ich schlage daher vor, daß wir diesen Quatsch endlich lassen und uns
darum kümmern, ordentlichen, funktionierenden Code zu schreiben -- und
zwar auch auf die Gefahr hin, daß Idioten nun einmal idiotische Sachen
damit tun.
Liebe Grüße,
Karl
>> Warum eigentlich drei getrennte Pointer? Einen einzigen fände ich
übersichtlicher.
Weil die Hardware der AVRs das nun einmal so abbildet. Ansonsten gibt es
in dem von mir geposteten Code ein sehr übersichtliches Makro, das
trotzdem für alle aktuellen und zukünftigen AVRs korrekt funktioniert.
Liebe Grüße,
Karl
Hallo Hans-Georg,
Hans-Georg Lehnard schrieb:> Ich habe auch immer gedacht ich kann C++ und was soll das alles mit dem> C++11 das brauch ich doch nie aber genau hier für die Embedded> Programmierung kann man es sehr gut gebrauchen. Der Nachteil ist, es ist> nicht leicht verständlich und für Anfänger in C++ völlig ungeeignet. Die> Compiler Fehlermeldungen sind alles andere als verständlich und debuggen> im single-step lässt sich das erst recht nicht.
Für PC-Programme nutze ich mittlerweile statt des g++ den LLVM-Compiler
mit dem clang++-Frontend. Das wird genauso aufgerufen wie der g++ (mit
denselben Optionen und Schaltern), gibt aber sehr viel bessere
Fehlermeldungen aus und erzeugt in oft auch besseren (iSv. kleineren
oder schnelleren) Code.
HTH,
Karl
Hallo Torsten,
Torsten C. schrieb:> Ich meine, die Pointer müssen konstant sein, damit der Compiler da> wirklich zuverlässig z.B. "sbi 0x17, 3" draus macht und nicht nur> zufällig je nach Compiler-Optimizing-Level.
Guckstu avr/io.h: DDRD, PIND, PORTB und PB4 sind Konstanten!
HTH,
Karl
Hi Torsten,
Torsten C. schrieb:> Ralf G. schrieb:>> DDRx, PORTx, PINx sind keine Pointer>> Und wozu ist der Stern in "public: volatile uint8_t* ddr;"^^?
Rein technisch betrachtet ist ein Pointer (Zeiger) etwas, das auf einen
bestimmten Speicherbereich zeigt -- meistens ist das eine Variable, hier
aber eben nicht! Dieser Zeiger hier zeigt auf einen festen
Speicherbereich, nämlich ein Register, bei dem der Inhalt des
Speicherbereichs volatil, der Zeiger auf den Speicherbereich hingegen
konstant ist. Insofern ist das aus Sicht der Programmiersprache ein
konstanter Pointer auf etwas Verändliches, und gleichzeitig aus Sicht
der Hardware eine Registeradresse.
Liebe Grüße,
Karl
kopfkratzer schrieb:> *kopfkratz*> Also nochmal langsam und zum mitmeisseln (oder wird das mit ß> geschrieben ?) ...
Es geht etwas wirr durcheinander, aber wie soll man das verhindern ..
> Man muß die Abstraktionsstufen im Auge behalten.> Entweder man definert eine vorgegebene Struktur die immer die gleichen> Variablen nutzt aber für jeden µC entsprechend angepaßt ist (so wie ich> das schon erwähnt habe).> Oder man geht den Weg der Vererbung und muß dann für jeden µC die> passende Basisklasse schreiben ebenfalls wie im obigen Fall.> Der Weg über Templates ist der meiner Meinung nach sinnvollste und> flexibelste, denn dann spart man sich die Vererbung bzw. Einbindung> verschiedener Definitionen.> Damit kommt man aber von einer Basisdefinition des µCs auch nicht herum.> Von der Compilerseite könnte man das auch im makefile erledigen bzw.> beim linken.
Wenn wir das auf den "speziellen" Fall 8Bit,AVR,SFR und Port reduzieren
geht es einfach darum ein paar 8-bit Register zusammen zu fassen und sie
für jeden Port als konstant definieren.
Konstante haben aber die Eigenschaft, das sie sofort initialisiert
werden müssen, und deshalb kommen Konstruktoren nicht in Frage.
Es sind und bleiben aber immer Konstante die nur verschieden
initialisiert werden.
Beispiel:
const int x = 4711;
const int y = 4712;
würdest du da auch y von x erben lassen ?
Karl Käfer schrieb:> Hallo Hans-Georg,> Für PC-Programme nutze ich mittlerweile statt des g++ den LLVM-Compiler> mit dem clang++-Frontend. Das wird genauso aufgerufen wie der g++ (mit> denselben Optionen und Schaltern), gibt aber sehr viel bessere> Fehlermeldungen aus und erzeugt in oft auch besseren (iSv. kleineren> oder schnelleren) Code.>
Der gibt bei Template Fehlern sehr viel bessere Fehlermeldungen aus ?
Das würde mich sehr wundern.
Karl Käfer schrieb:>> Guckstu avr/io.h: DDRD, PIND, PORTB und PB4 sind Konstanten!>
Das sind Preprocessor Definitionen und die kümmern sich nicht um
Namespaces und kollidieren mit allem möglichen, deshalb in C++ eher
ungeeignet. Dafür gibt es const und constexpr.
Für #ifdef sind sie in Ordnung aber mehr nicht.
Hans-Georg Lehnard schrieb:> Konstante haben aber die Eigenschaft, das sie sofort initialisiert> werden müssen
Das stimmt, ist ein echter Vorteil (keine ironie)
> und deshalb kommen Konstruktoren nicht in Frage
Falsch, konstruktoren haben eine Initializer list! Das geht!
Daniel A. schrieb:> Hans-Georg Lehnard schrieb:>> Konstante haben aber die Eigenschaft, das sie sofort initialisiert>> werden müssen> Das stimmt, ist ein echter Vorteil (keine ironie)>> und deshalb kommen Konstruktoren nicht in Frage> Falsch, konstruktoren haben eine Initializer list! Das geht!
Hast Recht und mit constexpr Konstruktoren gehts auch.
Hans-Georg Lehnard schrieb:> Hast Recht und mit constexpr Konstruktoren gehts auch.
Genau das meinte ich oben mit "Das geht per constexpr wunderbar. Ich
hab's gerade mit avr GCC 4.7.2 probiert."
Cool, dann sind wir uns einig?
Ich frage mich jetzt gerade, ob und ggf. worüber eine weitere Diskussion
hier noch Sinn macht. Das ganze ist ja etwas "abstrus", weil sich der OP
PeDa ofenbar aus dem Thread zurück gezogen hat, und wir hier ein Stück
weit eine "Phantom-Diskussion" führen.
Ich habe dabei viel gelernt und habe hoffentlich hier und da auch
nützliche Beiträge geleistet.
Zum Thema uCpp Frank M. schrieb:> Ausserdem halte ich eine "plattformübergreifende Lösung" für> ein Unterfangen, dass sehr viel Arbeit bedeutet, bei dem das Ziel in so> weiter Ferne liegt, dass - wenn eine Lösung denn irgendwann existieren> sollte - die Hardware dafür dann gar nicht mehr existieren wird.> Kurz: ich halte diesen Anspruch für ein Fass ohne Boden.
Das mag - je nach Anspruch - darauf hinaus laufen und eine Fortführung
des Themas wäre in diesem Thread wahrscheinlich falsch platziert.
Gibt es Einsprüche? ;-)
TriHexagon schrieb:>> Chris D. schrieb:>>> trivial aussehende Probleme eben nicht trivial sind>>>> ... denn die von Peter D. skizzierten Problemchen SIND u.a. in Asm>> trivial zu lösen.>> Dann zeig doch mal.
Mach ich gerne noch wenn Bedarf besteht- obwohl solcherlei Trivialitäten
nun wirklich jeder mittelmäßige Asm-Progger hinbekommt. Denn man gewinnt
ja fast den Eindruck, daß manche C++ Experten vor dem Herrn scheinbar
gar keinen Schimmer mehr davon haben, wie die einfachste Problemlösung
für
LED0 = KEY0.state; // an solange Taste gedrückt
LED1.toggle = KEY1.press // wechsel bei jeder Drückflanke
LED2.off = KEY2.press_short; // kurz drücken - aus
LED2.on = KEY2.press_long; // lang drücken - an
ausschaut.
Torsten C. schrieb:> Ich habe dabei viel gelernt und habe hoffentlich hier und da auch> nützliche Beiträge geleistet.
Das von Peter D. gesuchte fehlt immer noch: Wie mit C++ eine einfache
Lösung obiger Anweisungen gelingt.
Torsten C. schrieb:> Das mag - je nach Anspruch - darauf hinaus laufen und eine Fortführung> des Themas wäre in diesem Thread wahrscheinlich falsch platziert.
Also Kapitulation auf der ganzen Linie. Wie zu erwarten, sind die
hochtrabenden Bemühungen an der Komplexität der Sprache erstickt.
Torsten C. schrieb:> Hans-Georg Lehnard schrieb:>> Hast Recht und mit constexpr Konstruktoren gehts auch.>> Genau das meinte ich oben mit "Das geht per constexpr wunderbar. Ich> hab's gerade mit avr GCC 4.7.2 probiert.">> Cool, dann sind wir uns einig?>
Ich hatte damit nie Probleme ;)
> Ich frage mich jetzt gerade, ob und ggf. worüber eine weitere Diskussion> hier noch Sinn macht. Das ganze ist ja etwas "abstrus", weil sich der OP> PeDa ofenbar aus dem Thread zurück gezogen hat, und wir hier ein Stück> weit eine "Phantom-Diskussion" führen.>
Die Diskussion finde ich weder "Phantom" noch "abstrus" eher etwas
offtopic, weil von der ursprünglichen Frage eines Praktikers durch viele
theoretische Beiträge nicht viel übrig geblieben ist ...
Das ist jetzt nicht abwertetend gemeint.
> Ich habe dabei viel gelernt und habe hoffentlich hier und da auch> nützliche Beiträge geleistet.>
So sehe ich das auch.
> Zum Thema uCpp Frank M. schrieb:>> Ausserdem halte ich eine "plattformübergreifende Lösung" für>> ein Unterfangen, dass sehr viel Arbeit bedeutet, bei dem das Ziel in so>> weiter Ferne liegt, dass - wenn eine Lösung denn irgendwann existieren>> sollte - die Hardware dafür dann gar nicht mehr existieren wird.>> Kurz: ich halte diesen Anspruch für ein Fass ohne Boden.>> Das mag - je nach Anspruch - darauf hinaus laufen und eine Fortführung> des Themas wäre in diesem Thread wahrscheinlich falsch platziert.>
Das mag nicht nur das ist garantiert so.
> Gibt es Einsprüche? ;-)
Gegen die Einstellung einer Lib Entwicklung aus den genannten Gründen
gibt es nichts zu sagen. Es wäre ähnlich xpcc geworden, da kann man das
auch gleich benutzen wenn man will.
Das Thema an sich ist für mich noch nicht erledigt aber da kann ich auch
alleine weiter im stillen Kämmerlein werkeln.
Den Thread kann man, meiner Meinung nach, aber offen lassen !.
Bastler schrieb:> Noch hab ich keine ASM-Lösung schimmern sehen.
Ist auch besser so, es geht hier um etwas anderes als Rechthaberei mit
ASM.
Macht doch für sowas einen anderen Thread auf!
Das war doch nur die Antwort auf "ihr seit wegen der Sprache immer noch
nicht fertig". Wollte sagen "der Einzeller aber auch nicht". Sonst: ich
kenne ASM. Viele verschiedene. Und will das deshalb nicht mehr selber
machen. So nun warte ich wieder gespannt auf C++?
Hallo Hans-Georg,
Hans-Georg Lehnard schrieb:> Karl Käfer schrieb:>>>> Guckstu avr/io.h: DDRD, PIND, PORTB und PB4 sind Konstanten!>>> Das sind Preprocessor Definitionen
Das sind Präprozessor-Makros für Präprozessor-Makros, die dann letzten
Endes in Konstanten aufgelöst werden. Das Makro "DDRB" wird in
avr/iotn13.h durch "_SFR_IO8(0x17)" ersetzt. "_SFR_IO8(io_addr)"
wiederum ist ein Makro für "((io_addr) + __SFR_OFFSET)", und da in
diesem Falle io_addr (0x17) und __SFR_OFFSET (je nach AVR-Architektur
0x00 oder 0x20) bekannte Konstanten sind, ist das Ergebnis dieser
Addition eine Konstante, die der Compiler zur Compilezeit berechnet --
genau wie wenn Du "int a = 3 + 4" in Deinen C-Code schreibst.
Es ist ein wenig verkürzt, zugegeben -- aber im Ergebnis stehen diese
genannten Präprozessor-Makros also für Konstanten, die zur Compilezeit
bekannt sind, ohne den Compiler explizit darauf hinweisen zu müssen.
> und die kümmern sich nicht um Namespaces und kollidieren mit allem> möglichen, deshalb in C++ eher ungeeignet. Dafür gibt es const und> constexpr.
Irgendwie wirst Du konstante Registeraddressen halt mit symbolischen und
verständlichen Namen versehen müssen. Mir erscheinen Bezeichner wie DDRD
und Co. da schon deswegen sinnvoll, weil sie so auch in den
Datenblättern der MCUs verwendet werden. Wenn Du eine bessere Lösung
kennst, die ebenso wenig kostet und ebenso verständlich ist: sehr gerne,
her damit. ;-)
Liebe Grüße,
Karl
Ausgangspunkt:
Beitrag "Re: C++ auf einem MC, wie geht das?"Karl Käfer schrieb:> eine Konstante, die der Compiler zur Compilezeit berechnet
Und die berechneten Werte werden in dem Code aus Deinem o.g. Beitrag im
ctor der "class Pin" den folgenden Pointern zugewiesen:
1
volatileuint8_t*constddr;
2
volatileuint8_t*constport;
3
volatileuint8_t*constpin;
Wie man sieht: Die gewohnten Namen sind wiedererkennbar!
Ich habe nur ein "const" ergänzt, wegen "ichbinmaldiesmaldas"^^.
Ich dachte, das wäre geklärt.
Man könnte dem ctor die Makros "DDRB" usw. übergeben oder die Adressen
anders berechnen. Bei "anders" muss man - je nach Methode - "constexpr"
benutzen, bei enums^^ wäre man sogar typsicher. Beides geht.
U. a. Weil #define nicht typsicher ist, sind z.B. in C# mit #define
keine Wert-Zuweisungen mehr möglich, sondern nur noch "bedingte
compilierung".
Wenn Dir das egal ist, nimm Macros.
Hans-Georg Lehnard schrieb:> Das Thema an sich ist für mich noch nicht erledigt aber da kann ich auch> alleine weiter im stillen Kämmerlein werkeln.
Zur Frage des OP fehlen m.E. nur noch ein "Zustandsautomat" und ein
"Timer".
Ein Timer wäre ja einfach 'ne weitere Klasse, die ohne template<> nach
dem gleichen Schema wie "class Pin"^^ aufgesetzt wird.
Ralf G. schrieb:> Ralf G. schrieb:>> Ich habe>> allerdings noch keinen Einfall, wie man solche Objekte universell in>> andere Objekte einbinden kann (ohne diese <>-Klammerlisten).> Da wird man wohl nicht drum herumkommen...
Das man um "diese <>-Klammerlisten" herum kommt, falls mann will,
wurde ja an "class Pin" von Karl Käfer gezeigt, oder sind da noch Fragen
offen?
Hans-Georg Lehnard schrieb:> weil von der ursprünglichen Frage eines Praktikers durch viele> theoretische Beiträge nicht viel übrig geblieben ist ...
Meinst Du z.B. die theoretischen Beiträge um den Zustandsautomaten?
Wollen wir uns dazu auch noch auf ein gemeinsames Ergebnis einigen?
Ich kann dazu erstmal wenig sagen, weil ich erstmal die einfache
Delegates^^-Variante ohne <>-Klammerlisten umgesetzt habe und die
Variante mit Templates "Boost_sm.png"^^ erst noch ausprobieren müsste.
Hallo Karl,
wir wollen schon das gleiche .. "sprechende Namen"
Beispiel:
in avrio.h
#define PINA _SFR_IO8(0x19)
#define DDRA _SFR_IO8(0x1A)
#define PORTA _SFR_IO8(0x1B)
#define PINB _SFR_IO8(0x16)
#define DDRB _SFR_IO8(0x17)
#define PORTB _SFR_IO8(0x18)
#define PINC _SFR_IO8(0x13)
#define DDRC _SFR_IO8(0x14)
#define PORTC _SFR_IO8(0x15)
#define PIND _SFR_IO8(0x10)
#define DDRD _SFR_IO8(0x11)
#define PORTD _SFR_IO8(0x12)
usw.
Und ich fasse die Port Register einmalig in einer Struktur zusammen und
weil es auch Ports mit einem weiteren Register für pull up gibt habe ich
2 Typen definiert
struct AvrPortRegsTyp1 {
uint8_t in; // PINx input register
uint8_t dir; // DDRx input register
uint8_t out; // DATAx output register
};
struct AvrPortRegsTyp2 {
uint8_t in; // PINx input register
uint8_t dir; // DDRx direction register
uint8_t out; // DATAx output register
uint8_t pue; // PUEx pull up enable
};
Und definiere dann meine Ports als Konstante .
#ifdef _AVR_ATmega16_
constexpr AvrPortRegsTyp1 PORTA = {0x19,0x1A,0x1B};
constexpr AvrPortRegsTyp1 PORTB = {0x16,0x17,0x18};
constexpr AvrPortRegsTyp1 PORTC = {0x13,0x14,0x15};
constexpr AvrPortRegsTyp1 PORTD = {0x10,0x11,0x12};
#endif // _AVR_ATmega16_
#ifdef _AVR_ATtiny1634_
constexpr AvrPortRegsTyp2 PORTA = {0x0F,0x10,0x11,0x12};
constexpr AvrPortRegsTyp2 PORTB = {0x0B,0x0C,0x0D,0x0E};
constexpr AvrPortRegsTyp2 PORTC = {0x07,0x08,0x09,0x0A};
#endif // _AVR_ATtiny1634_
Der Unterschied ist aber mein PORTA definiert den Kompletten Port und
nicht nur ein Register und das gefällt mir besser und ich halte es für
stimmiger. Das lässt sich auch auf alle anderen "Module" wie USART,
TIMER usw. anwenden.
Würde ich nun avrio.h davor includen, würden meine Definitionen durch
den Preprocessor verändert werden, weil die in avrio.h als Macro
definiert sind.
Ich kann das auch nicht verhindern indem ich mein Code in einen
Namespace packe. Das wollte ich damit sagen, mehr nicht ...
Torsten C. schrieb:> Bei "anders" muss man - je nach Methode - "constexpr" benutzen
Auch mit dem Risiko weiterer "vieler theoretischer Beiträge"^^: Mich
würde mal interessieren, wie weit man das treiben kann. Vielleicht
könnte man in einer constexpr-Funktion sogar eine XML-Datei abfragen,
z.B. so ein jinja2-Headerfiletemplate^^. ;-)
OK, dann dauert das Compilieren ewig, war doof. Aber es würde zeigen,
was alles möglich wäre, wenn man constexpr-Funktionen statt #define
benutzt.
Hans-Georg Lehnard schrieb:> constexpr AvrPortRegsTyp2 PORTC = {0x07,0x08,0x09,0x0A};> … und das gefällt mir besser und ich halte es für stimmiger.
Mir auch / ich auch. Cool, Deine Arrays! :-) Genau so werde ich das in
Zukunft machen!
Eventuell als Übergang erstmal, indem ich die Start-Adressen aus avrio.h
hole. Hauptsache der Editor kennt die nicht und die ollen Macros werden
nicht dauernd vorgeschlagen , also z.B. "DDR0", wenn ich "DD" tippe!
Beim STM32 heißt die .h anders, aber das Prinzip ist das Gleiche.
Hans-Georg Lehnard schrieb:> Den Thread kann man, meiner Meinung nach, aber offen lassen!
Ja! Ich will weiter lernen! :-)
Torsten C. schrieb:>> Zur Frage des OP fehlen m.E. nur noch ein "Zustandsautomat" und ein> "Timer".>> Ein Timer wäre ja einfach 'ne weitere Klasse, die ohne template<> nach> dem gleichen Schema wie "class Pin"^^ aufgesetzt wird.>
Das sehe ich nicht ganz so ;)
Einen Zustandsautomaten kann man einsetzen aber ob der so effektiv ist
wie Pedas entprellroutine würd ich jetzt nicht unterschreiben. Und wie
kommt die Zeit in dein IO Port ? Da brauchst du eine Callback Funktion
entweder direkt aus der ISR aufgerufen oder besser über eine Klasse
SystemTimer die einen Hardware Timer verwaltet.
Dann wäre es schön, wenn der Pin sich beim SystemTimer anmelden könnte
und dabei noch sagen in welchem Intervall er gerne einen Rückruf hätte.
Vielleicht sogar während der Laufzeit umschaltbar.
Aha, höre ich dich sagen: Das ist eine Aufgabe für das Observer Pattern.
Richtig aber dann bitte in einer Embedded Version ;)
Dann Brauchst du Klassen für Tasten:
SimpleButton // taste gedrückt ja/nein
EdgeButton // Taste seit der letzten Abfrage neu gedrückt
TimedButton // Taste kurz, mittel, lang gedrückt.
Und jetzt noch eine Super Led, die alles kann // ein, aus, schnell,
langsam blinken.
Die IO Ports über die wir bisher geschrieben haben geben das nicht her.
Damit wäre für mich Pedas Frage beantwortet ;)
main
{
SimpleButton simplBtn(PORTA,P1);
EdgeButton edgeBtn(PORTA,P2);
TimedButton timedBtn(PORTA,P3);
// led ist default aus
SuperLed led1(PORTA,P4);
SuperLed led2(PORTA,P5);
SuperLed led3(PORTA,P6);
while(1) {
led1 = simplBtn // Led Ein wenn gedrückt
led2 = edgeBtn // Led togelt bei jedem Tastendruck
led3 = timedBtn // kurz gedrückt led aus, mittel gedrückt led
// blinkt schnell, lang gedrückt led blinkt
langsam
}
}
Und dann schaun wir mal in welchen MC das noch rein passt ;)
Mit dem automatischen hochzählen der Register und nur das erste
definieren wäre ich vorsichtig. Falls Atmel aud die Idee kommt, bei der
nächsten Umstellung auf einen anderen Produktionsprozess und mit einer
Maskenrevision die Reihenfolge ändert hast du verloren. Alles schon
vorgekommen !
Hans-Georg Lehnard schrieb:> Mit dem automatischen hochzählen der Register und nur das erste> definieren wäre ich vorsichtig.
Mit Startadresse meinte ich die Startadresse für die structs
"AvrPortRegsTyp1"^^ oder "AvrPortRegsTyp2". Sorry, also nicht "genau
so"^^, sondern "so ähnlch". Danke für den Hinweis!
Es könnte dann je ein Array mit UARTs, ein Array mit Timern eins mit
DMA-Kanälen usw. geben. Ich muss das in der Praxis ausprobieren, das
kann ich mir im Moment nicht 100% vorstellen.
Vielleicht wird's 'ne eigene Klasse, wo alle UARTs, Timer, DMA-Kanäle
usw. in einer static const drin sind. Diese Klasse wird ja dann nur zur
Compile-Zeit von constexpr-Funktionen gebraucht, landet also nicht im
µC.
Hallo Torsten,
Torsten C. schrieb:> Und die berechneten Werte werden in dem Code aus Deinem o.g. Beitrag im> ctor der "class Pin" den folgenden Pointern zugewiesen:>>
1
volatileuint8_t*constddr;
2
>volatileuint8_t*constport;
3
>volatileuint8_t*constpin;
Pointer, Zeiger, Adressen... nenn' es wie Du willst. Tatsache ist, daß
Du Deinem Compiler irgendwie sagen mußt, daß die Variable keine Variable
im herkömmlichen Sinne, sondern die Adresse eines Registers ist, auf das
er nur über ebendiese hart codierte, konstante Adresse zugreifen kann.
> Ich habe nur ein "const" ergänzt, wegen "ichbinmaldiesmaldas"^^.
Die Fehler, die das verhindert, erscheinen mir ziemlich hypothetisch, so
daß der echte, praktische Nutzen sich IMHO in Grenzen hält. Aber es ist
ein wenig eleganter und offensichtlicher (Lesbarkeit!) und kostet
nichts, insofern habe ich die Änderung in mein "typedef _Register"
übernommen.
> Man könnte dem ctor die Makros "DDRB" usw. übergeben oder die Adressen> anders berechnen. Bei "anders" muss man - je nach Methode - "constexpr"> benutzen, bei enums^^ wäre man sogar typsicher. Beides geht.
Ja. Man kann auch das Rad neu erfinden und sich dann in den Fuß
schießen, das geht auch. Die Frage ist aber doch, ob das auch klug ist.
;-)
Solche Konstanten werden in der Regel nur ein Mal verwendet, nämlich,
wenn eine Instanz von Pin erzeugt wird. Wenn Du das anders machen
willst, wirst Du nicht umhin kommen, eigene Libraries für verschiedene
AVRs zu schreiben und sie dauerhaft zu pflegen. Ob sich der Aufwand
dafür lohnt, um Fehlern vorzubeugen, die bei näherem Hinsehen a) relativ
unwahrscheinlich und b) ausgesprochen leicht zu finden sind, sei
dahingestellt.
Aber unter dem Stichwort der Wiederverwendbarkeit halte ich es für eine
bessere Idee, hier einfach die bereits vorhandenen Makros aus der
AVR-Libc zu benutzen. Die wird nämlich dankenswerterweise von anderen
erstellt und gepflegt, und solange es keine gravierenden Nachteile
bedingt, nehme ich diese großzügige Schenkung ausgesprochen gerne an.
Faulheit ist laut Larry Wall schließlich eine der Kardinaltugenden guter
Programmierer. ;-)
Liebe Grüße,
Karl
Karl Käfer schrieb:> Die Fehler, die das verhindert, erscheinen mir ziemlich hypothetisch
Es geht nicht um Fehler, sondern um "final und private"^^. Eigentlich
egal, denn Du hast die Änderung ja bereits übernommen.
Karl Käfer schrieb:> Die Frage ist aber doch, ob das auch klug ist.
Über Geschmacksfragen kann man nicht streiten. Mich stören die
Vorschläge vom Editor^^ und die Verschmutzung des globalen
"Namensraums", wenn ich das so nennen darf.
Karl Käfer schrieb:> unter dem Stichwort der Wiederverwendbarkeit halte ich es für eine> bessere Idee, hier einfach die bereits vorhandenen Makros aus der> AVR-Libc zu benutzen
Ja, das sehe ich genau so. Entweder man holt sich die Startadressen der
struct-Pointer (z.B. auf AvrPortRegsTyp1^^) aus der AVR-Libc oder
bastelt eine automatische Konvertierung in Klassen mit "static
constexpr".
Karl Käfer schrieb:>> Solche Konstanten werden in der Regel nur ein Mal verwendet, nämlich,> wenn eine Instanz von Pin erzeugt wird. Wenn Du das anders machen> willst, wirst Du nicht umhin kommen, eigene Libraries für verschiedene> AVRs zu schreiben und sie dauerhaft zu pflegen. Ob sich der Aufwand> dafür lohnt, um Fehlern vorzubeugen, die bei näherem Hinsehen a) relativ> unwahrscheinlich und b) ausgesprochen leicht zu finden sind, sei> dahingestellt.>> Aber unter dem Stichwort der Wiederverwendbarkeit halte ich es für eine> bessere Idee, hier einfach die bereits vorhandenen Makros aus der> AVR-Libc zu benutzen. Die wird nämlich dankenswerterweise von anderen> erstellt und gepflegt, und solange es keine gravierenden Nachteile> bedingt, nehme ich diese großzügige Schenkung ausgesprochen gerne an.> Faulheit ist laut Larry Wall schließlich eine der Kardinaltugenden guter> Programmierer. ;-)>
Hallo Karl,
natürlich hast du recht aber bei den AVR ist es nicht so schlimm,
denn die mitgelieferten xml Files parsen und in einem passenden Format
speichern dürfte eine der leichteren Übungen sein ;)
Torsten C. schrieb:> Und die berechneten Werte werden in dem Code aus Deinem o.g. Beitrag im> ctor der "class Pin" den folgenden Pointern zugewiesen:> volatile uint8_t * const ddr;> volatile uint8_t * const port;> volatile uint8_t * const pin;> Wie man sieht: Die gewohnten Namen sind wiedererkennbar!
Es resultiert daraus aber nur kurzer Code mit Direktzugriff auf die
Ports (z.B. 'sbi'/ 'cbi') in den aufgeführten Minimalbeispielen, wo
alles in einer Datei steht!
Torsten C. schrieb:> Das man um "diese <>-Klammerlisten" herum kommt, falls mann will,> wurde ja an "class Pin" von Karl Käfer gezeigt, oder sind da noch Fragen> offen?
siehe oben.
Hans-Georg Lehnard schrieb:> Mit dem automatischen hochzählen der Register und nur das erste> definieren wäre ich vorsichtig. Falls Atmel aud die Idee kommt, bei der> nächsten Umstellung auf einen anderen Produktionsprozess und mit einer> Maskenrevision die Reihenfolge ändert hast du verloren. Alles schon> vorgekommen !
Das gibt's schon!
Deshalb:
<komt morgen>
Ralf G. schrieb:> Es resultiert daraus aber nur kurzer Code mit Direktzugriff auf die> Ports (z.B. 'sbi'/ 'cbi') in den aufgeführten Minimalbeispielen, wo> alles in einer Datei steht!
Das verstehe ich nicht. Die Anzahl der Dateien doch egal, mit "const",
"private" oder "final". Hast Du die Beiträge ^^ gelesen?
Ohne "const", "private" oder "final" wären 'sbi' oder 'cbi' nicht
wirklich sicher, da hättest Du Recht, genau deshalb ja "const".
Torsten C. schrieb:> Hans-Georg Lehnard schrieb:>> Mit dem automatischen hochzählen der Register und nur das erste>> definieren wäre ich vorsichtig.>> Mit Startadresse meinte ich die Startadresse für die structs> "AvrPortRegsTyp1"^^ oder "AvrPortRegsTyp2". Sorry, also nicht "genau> so"^^, sondern "so ähnlch". Danke für den Hinweis!>> Es könnte dann je ein Array mit UARTs, ein Array mit Timern eins mit> DMA-Kanälen usw. geben. Ich muss das in der Praxis ausprobieren, das> kann ich mir im Moment nicht 100% vorstellen.>> Vielleicht wird's 'ne eigene Klasse, wo alle UARTs, Timer, DMA-Kanäle> usw. in einer static const drin sind. Diese Klasse wird ja dann nur zur> Compile-Zeit von constexpr-Funktionen gebraucht, landet also nicht im> µC.
Denk nicht so kompliziert;)
Eine Uart ist nur eine Ausprägung einer AVR USART die muss nicht immer
eine Uart sein sondern kann SPI und I2C sein oder sonst was sein.
Oder du hast eine Software Uart zusätzlich. Oder eine UART mit 9 bit
Protokoll usw. da kommst du mit deinen Arrays nicht mehr hinterher ;)
So jetzt bin ich mal wieder ruhig ... ,)
Hans-Georg Lehnard schrieb:> Eine Uart ist nur eine Ausprägung einer AVR USART die muss nicht immer> eine Uart sein sondern kann SPI und I2C sein oder sonst was sein.> Oder du hast eine Software Uart zusätzlich.
Und dann müsste ein SPI-ctor oder I2C-ctor statt eines UART-ctors
aufgerufen werden. So lange die Methoden-Bezeichner identisch sind, geht
das ohne Vererbung flexibel. Passt! Oder?
BTW, blöde Frage:
Woran erkennt der Compiler, dass 'sbi' oder 'cbi' anwendbar sind? Oder
geht das bei allen Adressen im RAM?
Torsten C. schrieb:> Woran erkennt der Compiler, dass 'sbi' oder 'cbi' anwendbar sind? Oder> geht das bei allen Adressen im RAM?
Da kann ich ja jetzt mal fragen: "Hast du das Datenblatt gelesen?" :-(
Genau darum geht es die ganze Zeit. Effizienter Code. Mit Zeigern und
virtuellen Funktionen um sich schmeißen, kann jeder!
Ralf G. schrieb:> Da kann ich ja jetzt mal fragen: "Hast du das Datenblatt gelesen?"
Das ist lange her! Ich hatte nur grob in Erinnerung, dass das nicht
überall im RAM geht, daher die Frage, ob wir was übersehen haben.
Ich hätte auch morgen nachlesen und danach posten können. Sorry, es war
ja auch nur "by the way". Aber vielleicht wichtig, wie Du selbst sagst.
Hallo Hans-Georg,
Hans-Georg Lehnard schrieb:> wir wollen schon das gleiche .. "sprechende Namen"> [...]> struct AvrPortRegsTyp1 {> uint8_t in; // PINx input register> uint8_t dir; // DDRx input register> uint8_t out; // DATAx output register> };> [...]> Und definiere dann meine Ports als Konstante .>> #ifdef __AVR_ATmega16__> constexpr AvrPortRegsTyp1 PORTA = {0x19,0x1A,0x1B};> #endif // __AVR_ATmega16__> [...]> Der Unterschied ist aber mein PORTA definiert den Kompletten Port und> nicht nur ein Register und das gefällt mir besser und ich halte es für> stimmiger.
Das ist wohl Geschmackssache, aber die Idee gefällt mir. Aber dann
müssten wir die Definitionen für alle möglichen AVRs a) erstellen und b)
zukünftig pflegen... hm.
Liebe Grüße,
Karl
Karl Käfer schrieb:> Aber dann müssten wir die Definitionen für alle möglichen AVRs> a) erstellen und> b) zukünftig pflegen... hm.
Wie gesagt: Entweder in einer constexpr-Funktion (kompliziert aber sehr
dynamisch) die .xml- oder .h-Dateien parsen oder ein Script basteln:
"eine der leichteren Übungen"^^.
Letzteres muss ja nur einmal pro "Update" ausgeführt werden und das
Ergebnis könnte einer einmal in Github aktualisieren.
Weitere Ideen? Favorit?
Torsten C. schrieb:> Sorry.
Ja, Okay.
Dann mal als Zusammenfassung:
'const' ist deine eigene Absichtserklärung, den Wert (Zeiger/
Variable) nie zu verändern. Der Compiler tritt dir dafür in... (du weißt
schon). Wie der Compiler das intern umsetzt, ist sein Bier.
Die 'Daten' für den Port (DDRx, PORTx, PINx) in eine Klasse zu packen
ist erstmal sinnvoll. Jetzt kommt es darauf an wie. Zeiger, Referenzen,
gerne auch 'const'... ist völlig egal. Sobald das Projekt über mehrere
Module geht, ist es nicht mehr zu erkennen, dass es sich um Zeiger auf
den IO-Bereich handelt. Der Compiler macht 'ganz normale'
Speicherzugriffe daraus. Normalerweise macht das nichts. Dauert es eben
ein paar Takte länger. Jetzt ist aber die Frage: 'Geht das trotzdem
anders?' Da bieten sich möglicherweise! Templates an. Da sehe ich
allerdings die Grenze: Wenn man jetzt mit den IO_Pin-Klassen
weiterarbeiten will, müsste man den ganzen '<>-Rattenschwanz' mitnehmen.
Das gefällt mir nicht!!! Ich hab trotzdem mal was probiert. Stichwort
'virtuelle Funktion'. Gefällt mir auch nicht!!!: zusätzlicher
RAM-Verbrauch, zusätzlicher ROM-Verbrauch, Geschwindigkeitsvorteil
gegenüber Zeigern mit 'normalen Speicherzugriffen' sehr zweifelhaft!
Eigentlich wollte ich mal noch ein paar andere Varianten vor der
Veröffentlichung probieren, aber ich stell's heute schon mal ein:
Ralf G. schrieb:> Vielleicht hat ein Profi 'ne bessere Idee.
Ich bin kein "Profi", aber falls das niemand vor mir macht, werde ich
gelegentlich folgendes mal mit verschiedenen Compilern analysieren:
Ralf G. schrieb:> Zeiger, Referenzen, gerne auch 'const'... ist völlig egal
Ich bin fest davon überzeugt, dass sich ein "const" nicht anders
auswirkt als ein #define. Das steht jedenfalls überall im I-Net. Daher
bin ich davon ausgegangen, dass das nicht völlig egal ist. Ohne
"const", "final" oder "private" (^^gelesen?) hättest Du mit Sicherheit
Recht und sobald das Projekt über mehrere Module ginge, könnte der
Compiler 'ganz normale' Speicherzugriffe daraus machen. Aber ich würde
mich (wie mehrfach gesagt^^) nicht darauf verlassen, dass er das nie
tut, daher "const", "final" oder "private".
Hallo Hans-Georg,
Hans-Georg Lehnard schrieb:> natürlich hast du recht aber bei den AVR ist es nicht so schlimm,> denn die mitgelieferten xml Files parsen und in einem passenden Format> speichern dürfte eine der leichteren Übungen sein ;)
Mitgelieferte XML Files... huch. Habe gerade mal einen Download von
Atmel Studio angeworfen, sowas hab' ich hier nämlich nicht -- ich habe
auch das Betrübssystem nicht, auf dem das läuft. Mal schauen, ob ich das
irgendwie entpackt bekomme, sonst muß ich mir morgen eine Wegwerf-VM
machen.
Gute Nacht,
Karl
Karl Käfer schrieb:> sowas hab' ich hier nämlich nicht
Kenne ich auch nicht, hatte mich auf Hans-Georg bezogen: Kläre uns mal
auf!
xpcc hätte die XML-Files und .h kann man zur Not auch selbst parsen. Für
XML gäbe es halt fertige Parser, das wäre bequemer; das ist aber am Ende
"Conchita", wie die Ösis sagen, also "Wurst"!
Karl Käfer schrieb:> Gute Nacht
Danke, wünsche ich Dir auch!
@ekiwi,
Super Sache, die ihr da macht.
@Peter Danneger
Peter Dannegger schrieb:> Ich möchte gerne folgendes erreichen: LED0 = KEY0.state; //> an solange Taste gedrückt> LED1.toggle = KEY1.press // wechsel bei jeder Drückflanke> LED2.off = KEY2.press_short; // kurz drücken - aus> LED2.on = KEY2.press_long; // lang drücken - an
Ersetze einfache
LED1.off
mit
LED1::setOutput(xpcc::Gpio::Low);
;-)
Die Syntax LED1.off beruht irgendwie auf der Annahme, daß man SFR mit
struct abstrahiert hat. Ist aber nur eine Vorstufe der
Objektorientierung. Interessant wird es erst, wenn Funktionen
dazukommen.
frischling schrieb:> Objekte kann man doch auch statisch anlegen.
Hmmm, muss man das eigentlich tun?
noreply@noreply.com schrieb:> LED1::setOutput(xpcc::Gpio::Low);
Die Variante hatten wir noch gar nicht, also ohne was statisch bzw.
als Klassen-Instanz mit const-Pointern anzulegen. Oder?
Das würde vllt. mein Singleton^^-Problem lösen, aber das blicke ich
heute N8 nicht mehr.
Torsten C. schrieb:> Es könnte dann je ein Array mit UARTs, ein Array mit Timern eins mit> DMA-Kanälen usw. geben.
Hmm... meinst du in etwa so, wie Atmel das bei den Cortex-Controlllern
gemacht hat?
Torsten C. schrieb:> noreply@noreply.com schrieb:>> LED1::setOutput(xpcc::Gpio::Low);>> Die Variante hatten wir noch gar nicht, also ohne was statisch bzw. als> Klassen-Instanz mit const-Pointern anzulegen. Oder?
Meinst du ohne Instanzierung? Das gabs in meinem Beispiel ganz weit oben
schoneinmal. Schaut sich das denn wirklich niemand an???
Daniel A. schrieb:> Schaut sich das denn wirklich niemand an???
Nein, hier geht es durcheinander wie Kraut und Rüben es dreht sich alles
im Kreis aber alle machen mit. Aber wie willst du das Online mit den
verschieden Kentnissen und Interessen lösen ?
Hans-Georg Lehnard schrieb:> Nein, hier geht es durcheinander wie Kraut und Rüben es dreht sich alles> im Kreis aber alle machen mit.
Gute Zusammenfassung. Es ist für den stillen Mitleser sehr unterhaltsam,
zu sehen, wie einige aneinander komplett vorbeireden und sich überhaupt
nicht richtig konzentrieren auf das, was der andere gerade geschrieben
bzw. schon als Lösung aufgezeigt hat.
> Aber wie willst du das Online mit den verschieden Kentnissen und> Interessen lösen ?
So jedenfalls nicht. Das sag ich Dir aus eigener Erfahrung.
Mein Vorschlag als Denkanstoß:
- Machs erstmal alleine oder schließ Dich mit einem oder maximal
zwei Leuten, die Ahnung von der Materie haben, per Mail kurz.
- Erstelle (allein oder in der kleinen Gruppe) ein Konzept, was
Hand und Fuß hat.
- Erstelle erste Ansätze von Lösungen als nachvollziehbare
Prototypen.
- Stelle das Konzept, den Prototyp und den Weg zur
Vorgehensweise hier vor.
- Gewinne damit andere, die genau diesen Weg mitgehen wollen
und lass Dir vor allem nicht mehr reinquatschen, dass man es
auch auf tausend anderen Wegen machen könnte.
- Setze dann mit den anderen im Team dieses Ziel um.
Ich habe einige (auch größere) Open-Source-Projekte aus dem Boden
gestampft und dann online mit bis zu 70 Leuten im Team umgesetzt und
gepflegt - viele Jahre lang. Ich sag Dir: Es geht nur so wie oben
beschrieben. Einer muss voranschreiten und die Richtung vorgeben.
Hans-Georg Lehnard schrieb:> Aber wie willst du das Online mit den verschieden Kentnissen und> Interessen lösen ?
1) Die Interessen gruppieren und die Gruppen in Github projekte
aufteilen.
2) Die github projekte unter eine Lizenz wie z.B. MIT stellen, damit
alle voneinander kopieren können.
3) Die vor und nachteile der verschiedenen Umsetzungen im bezug auf die
Kriterien Komplexität, Performance, Usabillity, Erweiterbarkeit, etc.
diskutieren
4) Erfahrungen für zukünftige projekte nutzen/Lieblingslib verwenden
Frank M. schrieb:> - Machs erstmal alleine oder schließ Dich mit einem oder maximal> zwei Leuten, die Ahnung von der Materie haben, per Mail kurz.>
Lieber Frank,
auch du hast nicht alles gelesen ;)
Thorsten will ein Projekt ich nicht.
Für mich stellt sich eher die Frage:
Wie kann jemand, ohne spezielle Kenstnisse über die Feinheitem von
C++(11) und Meta-Templates, diesen Thread lesen und was davon mitnehmen.
Dieser Thread motiviert doch nicht Cpp einzusetzen !!
Sondern jeder Leser denkt doch: "Alles viel zu kompliziert, nichts für
mich" ich mach weiter wie bisher.
Peda hat nach einer verständlichen Anleitung gefragt und das ist dieser
Thead mit Sicherheit, bisher jedenfalls, nicht.
Hans-Georg Lehnard schrieb:> Lieber Frank,> auch du hast nicht alles gelesen ;)
Ja, weil mich das Thema nur am Rande interessiert. Eine solche C++-Lib
ist für mich nicht lebensnotwendig, auch wenn ich ihr eine gewisse
Attraktivität nicht absprechen könnte ;-)
> Thorsten will ein Projekt ich nicht.
(BTW: Lass mal das 'h' aus Torstens Namen raus. Das irritiert mich doch
jedesmal sehr und ich denke: "Nanu, noch einer, der mitmischt?")
Okay, ich wusste nicht bzw. habe bisher nicht herauslesen können, dass
Du das Projekt gar nicht willst ;-)
Aber egal. Die oben von mir genannten Punkte sind nicht personenbezogen.
Kann man auf jeden übertragen. Ich muss aber dann noch einen Punkt
hinzufügen:
- Man muss als Vordenker von der Materie jede Menge Ahnung haben.
> Für mich stellt sich eher die Frage:>> Wie kann jemand, ohne spezielle Kenstnisse über die Feinheitem von> C++(11) und Meta-Templates, diesen Thread lesen und was davon mitnehmen.
Man kann nur Fetzen davon mitnehmen. Wenn man nicht täglich mit C++
arbeitet, sollte man erstmal die Basis lernen, bevor man sich auf die
Details von C++(11) stürzt. Sonst kommt einem viel als total neu und
aufregend vor, was tatsächlich schon ein alter Hut ist - siehe
C++-Templates im allgemeinen.
> Dieser Thread motiviert doch nicht Cpp einzusetzen !!> Sondern jeder Leser denkt doch: "Alles viel zu kompliziert, nichts für> mich" ich mach weiter wie bisher.
Eben. Das liegt in der Natur der Sache - sprich an der Natur eines
Forums. Wenn jemand einen Thread eröffnet, dann tragen 10% der Mitleser
etwas zum Thema bei, 30% versuchen, es Dir auszureden, weil man es
anders und viel besser machen könnte, weitere 30% haben es überhaupt
nicht verstanden und der Rest amüsiert sich nur über die Typen, die da
aufeinander losquasseln.
> Peda hat nach einer verständlichen Anleitung gefragt und das ist dieser> Thead mit Sicherheit, bisher jedenfalls, nicht.
Es gibt halt Leute, die finden zunächst die Fragestellung spannend und
versuchen dann, schon mal weiter zu denken. Sie kommen dann irgendwann
auf die geniale Idee, dass dieses Problem (und weitere zweitausend
ähnlich gelagerte Fälle) nur mit einem revolutionären Rundumschlag zu
lösen ist. Alsbald kommt man von Hölzchen auf Stöckchen, hat längst die
zugrundeliegende Frage bzw. Aufgabenstellung verdrängt und verkrümelt
sich in Details von Randproblemen, die plötzlich in den Vordergrund
drängen.
Danach werden dann die Prioritäten verschoben und man begeistert sich
plötzlich nur noch für diese Detailprobleme, die jetzt erstmal absoluten
Vorrang haben, weil sie so enorm spannend sind. Man mag sich nun fragen:
"Was soll das?"
Die Antwort ist einfach: Gar nichts. Irgendwann findet derjenige
"geniale Geist" ein komplett anderes Gebiet spannender ("z.B. wie
bekomme ich Bananen wieder gerade?") und das Thema und alle bisher dazu
erstellten Gedanken und Ideen werden einfach in den Orkus gespült. Und
so hangelt man sich von einer Aufgabe zur nächsten durchs Leben - ohne
irgend etwas tatsächlich fertigzustellen.
Ich gebe Dir abschließend nur einen Rat: Wenn Du dieses Projekt gar
nicht willst, dann lass es einfach. Gespräche mit Blinden über Farben
sind nicht zielführend.
Hallo Frank M,
ich zitiere mich jetzt mal selbst ;)
Ich will keine allgemeine Library schreiben, für mich ist das eine reine
private Machbarkeitsstudie und Auffrischung meiner C++ Kentnisse.
Ansonsten sehe ich das genau so wie du.
Manchmal habe ich den Eindruck, solche Foren sind reine
Selbsthifegruppen von "Nerds" ;)
Karl Käfer schrieb:> Ach, Torsten... Jedes Mal, wenn Du etwas idiotensicher machen willst,> dann kommt die Natur und erfindet bessere Idioten.
Danke für den "Gegenwind" in den darauf folgenden Argumenten. In der
Industrie werden ja auch noch solche code-review-tools eingesetzt:
http://en.wikipedia.org/wiki/List_of_tools_for_static_code_analysis#C.2FC.2B.2B
Wenn man wollte, käme man damit wahrscheinlich sogar weiter, als sich
auf compiler- oder Linker-Fehler allein zu verlassen.
Ich bin eigentlich ganz froh, wenn ich mir darüber im Moment nicht auch
noch Gedanken machen muss.
Frank M. schrieb:> Gespräche mit Blinden über Farben sind nicht zielführend.
Ich hoffe, dass ich nicht mit blind gemeint bin. Ich lerne aus den
Gesprächen sehr viel.
Frank M. schrieb:> - Man muss als Vordenker von der Materie jede Menge Ahnung haben.Hans-Georg Lehnard schrieb:> Torsten will ein Projekt ich nicht.
Das ist nicht ganz falsch, denn da steht ja nicht "Torsten will ein
Projekt starten", denn für einen einen "Vordenker" reicht meine
Erfahrung mit C++ noch nicht.
Ich hätte schon gern irgendwann eine Bibliothek für AVR und ARM
gemeinsam und mit C++. Ich habe hier viele interessante Denkanstöße
bekommen, die ich erstmal ausprobieren muss, um weiter zu kommen.
Ich muss jetzt z.B. mal ausprobieren, ob sich bei "Containment" bzw.
"Objekt-Komposition" (siehe "Quadrat vs. Rechteck"^^) die neue Klasse
auch problemlos statisch anlegen lässt, wenn man nur mit const arbeitet
und im ctor alle Pointer der gesamten Komposition initialisieren will.
Torsten C. schrieb:> Frank M. schrieb:>> Gespräche mit Blinden über Farben sind nicht zielführend.>> Ich hoffe, dass ich nicht mit blind gemeint bin.
Du kannst ganz beruhigt sein. Ich habe mich lediglich allgemein über
Forum-Threads und deren dynamische Entwicklung geäußert. Das Ende war
lediglich ein Fazit, bzw. eine Lehre, die ich schon vor langer Zeit
erfahren musste.
Ob sich da jemand einen Schuh anzieht oder anziehen will, ist seine
alleinige Sache.
Frank M. schrieb:> Ob sich da jemand einen Schuh anzieht oder anziehen will, ist seine> alleinige Sache.
Und Deine "Checkliste" ist dabei sehr hilfreich. :-)
Hans-Georg Lehnard schrieb:
1
while(1){
2
led1=simplBtn// Led Ein wenn gedrückt
3
led2=edgeBtn// Led togelt bei jedem Tastendruck
4
led3=timedBtn// kurz gedrückt led aus, mittel gedrückt led
5
// blinkt schnell, lang gedrückt led blinkt
6
}
Wenn das mit Objekt-Komposition^^ klappt, würde ich eine "fest
verdrahtete" und eine dynamische Variante anlegen, wo die Zuweisung
direkt in der Klasse passiert und nicht in einer While-Schleife.
>led3=timedBtn// kurz gedrückt led aus, mittel gedrückt led
5
>// blinkt schnell, lang gedrückt led blinkt
6
>}
>> Wenn das mit Objekt-Komposition^^ klappt, würde ich eine "fest> verdrahtete" und eine dynamische Variante anlegen, wo die Zuweisung> direkt in der Klasse passiert und nicht in einer While-Schleife.
Ach Torsten,
diese while Schleife ist doch dein "Hauptpramm" in einer embedded
Anwendung.
Hans-Georg Lehnard schrieb:> Ach Torsten, diese while Schleife ist doch dein "Hauptpramm" …
Ach Hans-Georg, das ist mir doch klar!
Aber was willst Du uns damit sagen?
Torsten C. schrieb:> Hans-Georg Lehnard schrieb:>> Ach Torsten, diese while Schleife ist doch dein "Hauptpramm" …>> Ach Hans-Georg, das ist mir doch klar!>> Aber was willst Du uns damit sagen?
Torsten schrieb :
> wo die Zuweisung direkt in der Klasse passiert und nicht> in einer While-Schleife.
Eher was wolltest du uns damit sagen ?
Es gibt bereits eine weitverbreitete, erfolgreiche und halbwegs
Plattform unabhängige C++ Library für uC: Arduino.
Und die zeigt meines Erachtens bestens warum so ein Projekt für eine
breite Zielgruppe fast unmöglich ist:
- Für Anfänger kann es nicht einfach und idiotensicher genug sein,
Performance ist Zweitrangig
- ASM Programmierer wollen sowieso jedes Bit selbst kontrollieren, und
bekommen einen Herzkasper für jede unnötige Anweisung die der Compiler
generiert
- Erfahrene uC Programmierer würden schon gerne jedes noch so spezielle
Feature ihres ZieluC ausnutzen und genau darüber wissen, was das
Framework so in den Registern anstellt.
- Reine C Programmierer können sich mit einfacher Objektorientierung
noch anfreundne, aber spitze Klammern kennen die nur aus Operatoren für
Vergleich und Shift.
- Gute C++ Programmierer könnten sicherlich ein Lib aufstellen, die mit
so Sachen wie Objektorientierung, Templates, Metaprogrammierung einen
hocheffizienten Code erstellt, aber für keine der vorgenannten Gruppen
noch zugänglich wäre, weil sie in spitzen Klammern und völlig
unverständlichen Compilerfehlermeldungen ertrinken.
(Das ist jetzt alles etwas zugespitzt)
Arduino hat sich deswegen einzig und allein auf die erste Gruppe
konzentriert und sehr großen Erfolg gehabt. Und alle anderen Gruppen
schimpfen über ineffizienten, langsamen, großen Code der viele
Besonderheiten der Zielplattform versteckt oder überhaupt nicht
zugänglich macht.
vielleicht hab ich das problem nicht verstanden, aber beim programmieren
meines quadrocopters habe ich überlegt, ob luna, c, oder c++ .
als er in c dann geflogen ist, habe ich ein uml gezeichnet, und das dann
in c++ mit modellierten klassen umgeschrieben. fliegt natürlich genauso
;-)
laufzeitmessungen haben ergeben, daß der c++ - code wenige % länger
rechnet als der reine c-code, und im experiment dieser genauso lange wie
der in luna geschriebene.
die entwicklung scheint mir aber in c++ (klassenorientiert) überlegen,
z.b. die nutzung von mehreren objekten der gleichen klasse (z.b.
signalfilter) scheint mir für "nicht profis" wie mich in c++
übersichtlicher.
Hallo Hans-Georg,
Hans-Georg Lehnard schrieb:> Nein, hier geht es durcheinander wie Kraut und Rüben es dreht sich alles> im Kreis aber alle machen mit. Aber wie willst du das Online mit den> verschieden Kentnissen und Interessen lösen ?
Um das Ganze womöglich wieder in etwas geordnetere Bahnen zu lenken --
und nicht zuletzt, weil konkreter Code IMHO immer noch die beste
Grundlage für diese Diskussion ist -- hier meine aktuelle Pin.hpp. Dem
geneigten Betrachter wird auffallen, daß:
- die Member-Variablen der Basisklasse jetzt nicht mehr "public",
sondern "protected" sind
- der Typ "_Register" jetzt mit dem Typ-Modifizierer "const" versehen
ist, wie angekündigt
- die Klasse "InputPin" jetzt Funktionen zum Setzen und Löschen des
Pullup-Widerstandes hat
- der Konstruktor der Klasse "InputPin" einen optionalen Parameter zum
Setzen der Pullups besitzt
- der Klasse "OutputPin" die Methode "toggle()" hinzugefügt wurde, die
den Pin durch das Schreiben auf das Register PIN umschaltet und
- daß die Klasse "InoutPin" zwar wieder enthalten, aber noch nicht um
die gerade genannten Funktionen ergänzt worden ist. Hier könnte es sein,
daß eine Art "Sicherheitsabfrage" sinnvoll ist, um zum Beispiel zu
verhindern, daß der Nutzer die Methode "toggle()" aufruft obwohl der Pin
gerade als Input konfiguriert ist. Andererseits würde das den Code
größer machen und die Frage aufwerfen, wie ein solcher Fehler abgefangen
und / oder darauf reagiert werden kann.
Bezüglich des "toggle()"-Verhaltens ist anzumerken, daß "PIN" im Prinzip
ein Input-Register ist, bei dem man üblicherweise nicht erwarten würde,
daß man darauf schreiben kann. Neuere AVRs erlauben es allerdings, durch
Schreiben auf dieses Register ein Umschalten mit nur einem
Maschinenbefehl durchzuführen; bei älteren AVRs soll das IIRC nicht
gehen. Wenn jemandem bekannt ist, bei welchen AVRs das geht und bei
welchen nicht, möge er sich bitte melden. Dann würde ich dort über
"#ifdef __AVR_ARCH__" Code einbauen wollen, der abhängig von der
AVR-Architektur den korrekten Code einfügt.
Der Bequemlichkeit halber habe ich die Datei einmal zum Download
angefügt und poste sie zusätzlich noch einmal:
1
#ifndef _PIN_HPP
2
#define _PIN_HPP 1
3
4
#include<avr/io.h>
5
6
/** expands PINDEF(B, 0) to &DDRB, &PORTB, &PINB, PB0
7
* example:
8
* OutputPin ledPin ( PINDEF(B, 0) );
9
* expands to:
10
* OutputPin ledPin (&DDRB, &PORTB, &PINB, PB0);
11
*/
12
#define PINDEF(X,Y) &DDR##X,&PORT##X,&PIN##X,Y
13
14
15
typedefvolatileuint8_t*const_Register;
16
17
18
classPin{/** base class for a pin */
19
protected:
20
_Registerddr;
21
_Registerport;
22
_Registerpin;
23
uint8_tnum;
24
25
public:
26
/** constructor
27
* @param ddr DDRn register address of pin (eg. &DDRB)
Hallo Scelumbro,
Scelumbro schrieb:> Es gibt bereits eine weitverbreitete, erfolgreiche und halbwegs> Plattform unabhängige C++ Library für uC: Arduino.> Und die zeigt meines Erachtens bestens warum so ein Projekt für eine> breite Zielgruppe fast unmöglich ist:> - Für Anfänger kann es nicht einfach und idiotensicher genug sein,> Performance ist Zweitrangig> - ASM Programmierer wollen sowieso jedes Bit selbst kontrollieren, und> bekommen einen Herzkasper für jede unnötige Anweisung die der Compiler> generiert> - Erfahrene uC Programmierer würden schon gerne jedes noch so spezielle> Feature ihres ZieluC ausnutzen und genau darüber wissen, was das> Framework so in den Registern anstellt.> - Reine C Programmierer können sich mit einfacher Objektorientierung> noch anfreundne, aber spitze Klammern kennen die nur aus Operatoren für> Vergleich und Shift.> - Gute C++ Programmierer könnten sicherlich ein Lib aufstellen, die mit> so Sachen wie Objektorientierung, Templates, Metaprogrammierung einen> hocheffizienten Code erstellt, aber für keine der vorgenannten Gruppen> noch zugänglich wäre, weil sie in spitzen Klammern und völlig> unverständlichen Compilerfehlermeldungen ertrinken.> (Das ist jetzt alles etwas zugespitzt)
Das ist alles sehr richtig, was Du schreibst, vielen Dank. Aus den von
Dir so treffend formulierten Gründen würde ich eine Bibliothek
bevorzugen, die auf der AVR-Libc aufbaut -- damit die erfahrenen
uC-Entwickler einerseits immer noch alle Features ihres Ziel-uC
ausnutzen können, wo das notwendig ist, andererseits aber ansonsten den
Komfort von C++ nutzen können. Zudem soll das Ganze idealerweise schlank
und effizient, trotzdem auch noch für weniger erfahrene C++-Entwickler
zugänglich bleiben.
Höre ich da jemanden "eierlegende Wollmilchsau" sagen? Mag sein. Aber
die von mir eben gepostete Pin-Bibliothek zeigt IMHO, daß die Ziele
zumindest für diese triviale Funktionalität durchaus vereinbar sind. Ich
persönlich bin gespannt, ob das auch bei nichttrivialen Funktionalitäten
so bleibt.
> Arduino hat sich deswegen einzig und allein auf die erste Gruppe> konzentriert und sehr großen Erfolg gehabt. Und alle anderen Gruppen> schimpfen über ineffizienten, langsamen, großen Code der viele> Besonderheiten der Zielplattform versteckt oder überhaupt nicht> zugänglich macht.
...und kreiden den wegen der Anfängerfreundlichkeit entstandenen Bloat
dann leider C++ an.
Liebe Grüße,
Karl
>Es gibt bereits eine weitverbreitete, erfolgreiche und halbwegs>Plattform unabhängige C++ Library für uC: Arduino.>Und die zeigt meines Erachtens bestens warum so ein Projekt für eine>breite Zielgruppe fast unmöglich ist:>- Für Anfänger kann es nicht einfach und idiotensicher genug sein,>Performance ist Zweitrangig
Die Arduino LIB ist gar nicht so schlecht. Wie ich schon weiter oben
erwähnt habe, kann man damit den selben Code auf AVR und ARM laufen
lassen.
Im Gegensatz zu diesem Thread hier haben die Arduino Entwickler
irgendwann angefangen, Code auszuliefern, obwohl er noch nicht perfekt
war. Wie aber in diesem Thread gezeigt, kann man bei geschickter C++
Programmierung auch die Pin-Zugriffsfunktionen wie digitalWrite hoch
performant machen. Man könnte die Erkenntnisse dieses Threads also
durchaus verwenden, um die Arduino LIB zu optimieren. Es macht dabei
durchaus Sinn, bei den gleichen Funktionsnamen zu bleiben und kein neuen
zu erfinden. Das Netz ist voll von HELP-Files und Beispielen für die
Befehle und Programme. Das ist ein Dokumentations und Erklärungsaufwand,
der mit einer neuen, anderen Lib nur sehr schwer zu verbessern ist. Man
darf die LIB auch durchaus erweitern, wenn einem die Funktionen nicht
reichen. Auch dafür gibt es viele Beispiele im Netz.
Es gibt von der iX-Developer (Heise) ein Sonderheft "Embedded Software".
Dort ein Artikel "Schlanke Embedded-Entwicklung mit Small-C++".
Der beschreibt Anhand eines kleinen Beispiels für AVR, wie man trotz C++
den Code klein hält. Also es wird an einem kleinem Beispiel von C zu C++
entwickelt und gezeigt, wie sich die Codegröße ändert.
Vielleicht interessiert es ja den TO oder auch sonst jemand.
Gruß Joachim
Karl Käfer schrieb:> Um das Ganze womöglich wieder in etwas geordnetere Bahnen zu lenken --> und nicht zuletzt, weil konkreter Code IMHO immer noch die beste> Grundlage für diese Diskussion ist -- hier meine aktuelle Pin.hpp.
Danke!
Ich verstehe aber noch nicht, wie man deine Klassen weiter nutzen soll.
Folgendes Beispiel adaptiert von
Beitrag "Re: C++ auf einem MC, wie geht das?":
Deine Pin Klasse ist doch leer. Welche Methoden soll LCD da denn
benutzen?
Also um klar zu sein: Du hast NIE eine automatische virtuelle Vererbung.
Du must schon explizit `virtual` hinschreiben damit der Compiler das
auch macht.
Nur dann weiß der Compiler was er überhaupt aufrufen kann und soll.
DualZähler schrieb:> Deine Pin Klasse ist doch leer. Welche Methoden soll LCD da denn> benutzen?> Also um klar zu sein: Du hast NIE eine automatische virtuelle Vererbung.> Du must schon explizit `virtual` hinschreiben damit der Compiler das> auch macht.
Ich denke, wir sind uns einig, dass zumindest in Hardware-nahen
Bibliotheken (Pin, UART, Device-Treiber wie z.B. für NRF24L01+, ...)
VMTs ('virtual') ein "no-go" sind.
Mit einer "Objekt-Komposition" (siehe "Quadrat vs. Rechteck"^^) macht
man das dann z.B. so:
1
classMeinPinMitMethoden{
2
InputPinpin;
3
OutputPinled;
4
Timertimer;
5
// Weitere Member (Methoden, Zustandsautomaten, ...)
6
};
Oder?
@Hans-Georg: Ich meinte, dass man irgendwie in dieser Richtung weiter
denken müsste und nicht mit "led3 = timedBtn" in der MainLoop. Wozu soll
denn andauernd diese Zuweisung wiederholt werden?
Es muss eine Art "Ereignis" ausgewertet werden, wenn ein Timer abläuft,
eine Taste gedrückt oder losgelassen wird. Also ein Callback, Delegat
oder Event-Handler, ... aufgerufen werden.
Torsten C. schrieb:> Wenn das mit Objekt-Komposition^^ klappt, würde ich eine "fest> verdrahtete" und eine dynamische Variante anlegen
Jo, geht beides, der Compiler hatte nix zu meckern:
festverdrahtet wie oben oder:
1
classMeinPinMitMethoden{
2
InputPin*constpin;// festverdrahtet
3
OutputPin*constled;// festverdrahtet
4
Timer*consttimer;// festverdrahtet
5
// Weitere Member (Methoden, Zustandsautomaten, ...)
6
};
dynamisch:
1
classMeinPinMitMethoden{
2
InputPin*pin;// dynamisch
3
OutputPin*led;// dynamisch
4
Timer*timer;// dynamisch
5
// Weitere Member (Methoden, Zustandsautomaten, ...)
Karl Käfer schrieb:> Um das Ganze womöglich wieder in etwas geordnetere Bahnen zu lenken --> und nicht zuletzt, weil konkreter Code IMHO immer noch die beste> Grundlage für diese Diskussion ist ...:
Um mal eine Alternative zu zeigen, die schon länger bei mir rumliegt:
Die main() kompiliert, wird zu zwei sbi und einem Sprung für die
while(1).
Letztendlich mag das für GPIOs ganz gut funktionieren. Wie aber bildet
man plattformübergreifend Timer, serielle Schnittstellen und
insbesondere die ISRs ab?
Überhaupt die zusammenarbeit von ISR mit C++ bereitet mir noch
Kopfzerbrechen.
Hallo Torsten,
ich geh jeztz mal davon aus, das wie beide der Meinung sind, der LED
Zustand soll sich jedesmal ändern wen sich an einer Taste was ändert.
Da hast du praktisch mehrere Möglichkeiten, eine davon ist in der
Hauptschleife die Taste zu pollen, genau das habe ich gemacht.
Du könntest für die Buttons auch z.B. Pin Change Interrupt nehmen aber
wie erfährt dann die jeweilige Led davon das sich etwas geändert hat. Da
musst du dann Listen pflegen welche LED hängt an welchem Button.
Meine "Design Entscheidung" an dieser Stelle war:
Led schau doch selber nach ob sich was geändert hat ;)
Und ich gebe ihr in der Hauptschleife genug Möglichkeit das auch zu tun.
Was man dem geposteten (Pseudo) Code nicht direkt ansieht ist folgendes:
Die SuperLed hat überladene Zuweisungsoperatoren(=), für jeden
Button(Typ) und der ruft GetState() vom jeweiligen Button(Objekt) auf.
Das sollte keine "Vorschrift" sein wie man etwas implementiert sondern
ich habe nur Peters Pseudo Code etwas umgeschrieben ... ;)
Peter Dannegger schrieb:> In C++ könnte man Zuweisungen nehmen, wenn man nur wüßte, wie man das> implementiert.>
1
>LED0=KEY0.state;// an solange Taste gedrückt
2
>LED1.toggle=KEY1.press// wechsel bei jeder Drückflanke
3
>LED2.off=KEY2.press_short;// kurz drücken - aus
4
>LED2.on=KEY2.press_long;// lang drücken - an
5
>
>
Also Peter, wenn du noch mit liest .. es geht ;)
Torsten C. schrieb:> nicht mit "led3 = timedBtn" in der MainLoop. Wozu soll denn andauernd> diese Zuweisung wiederholt werden?>> Es muss eine Art "Ereignis" ausgewertet werden
Diese Designentscheidung sollte dem User überlassen werden. Die lib kann
ja templates für events und eventQueues bereirstellen, und die
verwendung bleibt dem user überlassen.
Gleiches denke ich auch über ALLE ISRs: Templates und Makros für default
ISRs, welche der nutzer nutzen könnte, aber nicht muss. Man macht dazu
dan ein "best practice guid". Darin empfielt man dann das anlegen
Conroller und Layoutspezifischer headerfiles, mit
controllerunspezifischen .cpp files:
1
// Platine1Conf.hpp
2
#include<ucpp> // includiere lib
3
namespacehardware{
4
namespaceLED{
5
staticconstucpp::Port<0>::Pin<0>status;// declariere status led
6
staticconstucpp::Port<0>::Pin<1>error;// declariere error led
7
}
8
inlinevoidinit(){
9
LED::status.setOutput();
10
LED::error.setOutput();
11
}
12
}
13
14
// Main.cpp
15
#include CONFIG_FILE // includire config abhängig von macro
Scelumbro schrieb:> Überhaupt die zusammenarbeit von ISR mit C++ bereitet mir noch> Kopfzerbrechen.
Auf einem STM32F4 Discovery Board habe ich das so gelöst:
Also im Prinzip nicht anders als es in C gemacht würde: Die betroffenen
Methoden aus dem Interrupt-Handler direkt aufrufen. Der Unterschied ist
halt, dass man dazu die betreffenden Objekte erreichbar machen muss --
hier eben als globale Objekte.
In C++ bedeutet das allerdings, dass man sich um das Initialisieren der
statischen Objekte -- bzw. die Reihenfolge davon -- Gedanken machen
muss. Ich habe das Problem umschifft, in dem ich eben nur in einer
einzigen .cpp Datei im Projekt statische Objekte anlege.
Eine Zeit lang habe ich darüber nachgedacht, so etwas wie einen
Interrupt Handler zu modellieren. Das hätte dann bedeutet, dass sich die
Objekte, die den Interrupt behandeln wollen, beim Handler hätten
registrieren müssen. Ich habe keine Lösung gefunden, wie man das ohne
virtual Deklarationen hin kriegt. Und meinen Anspruch, dass sich die am
Interrupt interessierten Objekte schon zur Compile-Zeit auf den
Interrupt "registrieren" müssen, den wollte ich nicht aufgeben.
Und jetzt noch der unvollständige, unausgegore und wahrscheinlich
fehlerhafter Code
aber ich denke das Prinzip der Operator Überladung wird für nicht C++
Spezialisten auch klar und darum gehts ...
typedef enum
{
off,
on,
toggle,
fast_blink,
normal_blink,
slow_blink
} SUPER_LED_STATE;
Und nun die verschiedenen überladenen Operatoren
bool SuperLed::operator = (const bool value )
{
if( value)
led_State = on;
else
led_State = off;
return value;
}
Damit geht:
led = false/true;
und:
led1 = led2 = led3 = false/true;
// und das gleiche für SUPER_LED_STATE
EXT_LED_STATE SuperLed::operator = (const SUPER_LED_STATE state )
{
led_State = state;
return state;
}
Damit geht:
led = fast_blink;
und:
led1 = led2 = led3 = slow_blink;
const DigitalInput& SuperLed::operator = ( const DigitalInput& inp )
{
bool value = inp.GetInput(); // liefert nur true/false
if( value)
led_State = on;
else
led_State = off;
return inp;
}
// Ich denke ab hier macht Verkettung keinen Sinn mehr deshalb void
// Wenn man verkettung möchte muss man die Referenz auf den Button
zurückgeben
void SuperLed::operator = ( const SimpleButton& sib )
{
// liefert nur true/false
bool value = inp.GetInput();
if( value)
led_State = on;
else
led_State = off;
}
void SuperLed::operator = ( const EdgeButton& edb )
{
// liefert no_edge_detect, edge_detect
EDGE_BTN_STATE value = edb.GetInput();
if( edge_detect){
// toggle habe ich als einen eigenen state definiert, damit wenn der
blink callback noch aktiv ist er nicht ausgewertet wird
led_state = toggle;
this.Toggle();
// jetz müssen wir aber dem Edge Button irgendwie mitteilen das wir die
Flanke ausgewertet haben
// er sich auf no_edge_detect setzen soll und warten bis der Benutzer
die Taste neu gedrückt hat.
edb.Release();
}
}
void SuperLed::operator = ( const TimedButton& tib )
{
TIMED_BTN_STATE value = tib.GetState();
switch (value)
{
case not_pressed :
// nix machen;
break;
case short_pressed :
led_state = off;
break;
case normal_pressed :
led_state = fast_blink;
break;
case long_pressed :
led_state = slow_blink;
break;
}
}
Ich würde so weit gehen und die LED, den Taster und die Verbindung
zwischen beiden in separate Klassen einbauen.
Die LED ist ein GPIO_output, der Taster ein GPIO_input und beide werden
über einen "Logikbaustein" (der nichts mit der Hardware zu tun hat)
verbunden.
Soll das Ganze ein Blinklicht werden, dann muss sich eben dieser
Logikbaustein darum kümmern, dass er in jeder x-ten Timer-ISR aufgerufen
wird und entsprechend die LED blinken lässt.
Damit er das tun kann, wird im bei der Erstellung der Output, Input und
der entsprechende Timer übergeben und die Klasse bzw der Compiler
kümmert sich um den Rest.
Achim schrieb:> Ich würde so weit gehen und die LED, den Taster und die Verbindung> zwischen beiden in separate Klassen einbauen.>> Die LED ist ein GPIO_output, der Taster ein GPIO_input und beide werden> über einen "Logikbaustein" (der nichts mit der Hardware zu tun hat)> verbunden.>> Soll das Ganze ein Blinklicht werden, dann muss sich eben dieser> Logikbaustein darum kümmern, dass er in jeder x-ten Timer-ISR aufgerufen> wird und entsprechend die LED blinken lässt.>> Damit er das tun kann, wird im bei der Erstellung der Output, Input und> der entsprechende Timer übergeben und die Klasse bzw der Compiler> kümmert sich um den Rest.
Hallo Achim,
das kann jeder machen wie er will. Und du siehst ja wie die Meinungen
hier manchmal auseinander gehen. Es gibt hier kein falsch oder richtig.
Aber wenn du eine Lib für die Allgemeinheit schreiben willst solltest du
das wie Daniel schon schrieb dem Anwender deiner Lib überlassen.
Achim schrieb:> Ich würde so weit gehen und die LED, den Taster und die Verbindung> zwischen beiden in separate Klassen einbauen. …> Soll das Ganze ein Blinklicht werden, dann muss sich eben dieser> Logikbaustein darum kümmern, dass er in jeder x-ten Timer-ISR aufgerufen> wird
Den gleichen Gedanken hatte ich bei MeinPinMitMethoden^^.
Hans-Georg Lehnard schrieb:> wenn du eine Lib für die Allgemeinheit schreiben willst solltest du> das wie Daniel schon schrieb dem Anwender deiner Lib überlassen.
Bei MeinPinMitMethoden^^ hatte ich das nicht explitit erwähnt: Genau so
war das gedacht. Es war ein Versuch einer Antwort auf das,
was DualZähler schrieb:> Deine Pin Klasse ist doch leer. Welche Methoden soll LCD da denn> benutzen?
Die Antwort wäre: Die Klasse stellt nur Basis-Methoden zur Verfügung.
Das "drumherum" passiert dann durch abgeleitete Klassen (vorzugsweise
ohne 'virtual') oder Kompositionen.
Nicht nur, dass jeder Progammierer "seinen eigenen Dickkopf" hat (das
ist gar nicht böse gemeint, jeder hat halt so seine Erfahrungen).
Auch wenn man Objektmodelle verschiedener Projekte mehreren erfahrenen
Programmierern zum Review gibt, wird ein Konsesns von der Applikation
und den individuellen Randbedingungen abhängig sein, also nicht
unbedingt für alle Projekte gleich aussehen.
chris_ schrieb:> Man könnte die Erkenntnisse dieses Threads also> durchaus verwenden, um die Arduino LIB zu optimieren. Es macht dabei> durchaus Sinn, bei den gleichen Funktionsnamen zu bleiben und kein neuen> zu erfinden.
Den Gedanken finde ich sehr attaktiv, …
1. weil man damit - wie gesagt - bereits den selben Code
auf AVR und ARM laufen lassen kann und
2. weil vielen die Benennungen der Klassen und Methoden geläufig sind.
Ich habe noch nie mit der Arduino LIB gearbeitet, also bisher alls "zu
Fuß" selbst gemacht.
@All, die die Arduino LIBs kennen:
Könnte man den "riesigen Source- und Codebloat"^^ sinngemäß mit
#ifdef DEBUG / #else / #endif
ausblenden?
Oder ist das gesamte Objektmodell zu unflexibel aufgesetzt?
Hallo DualZähler,
DualZähler schrieb:> Ich verstehe aber noch nicht, wie man deine Klassen weiter nutzen soll.> Folgendes Beispiel adaptiert von> Beitrag "Re: C++ auf einem MC, wie geht das?"
Der Code in dem verlinkten Beitrag ist von Ralf und hat mit meinem
nichts zu tun.
> Deine Pin Klasse ist doch leer. Welche Methoden soll LCD da denn> benutzen?
Aber nein, meine Klasse "Pin" ist keineswegs leer, sondern sie enthält
die vier Datenfelder "ddr", "port", "pin" und "num", die übrigens bei
mir nur "protected" statt wie bei Ralf "private" sind.
Die Klasse "Pin" ist deswegen bei mir nur eine Basisklasse für die
Klassen "InputPin", "OutputPin" und "InoutPin" mit entsprechenden
Funktionen.
> Also um klar zu sein: Du hast NIE eine automatische virtuelle Vererbung.> Du must schon explizit `virtual` hinschreiben damit der Compiler das> auch macht.
Virtuelle Vererbung würde ich gerne vermeiden, weil der Compiler dann
mit hoher Wahrscheinlichkeit virtual method tables (VMTs) anlegt, die
jedoch relativ viel Speicher kosten.
> Nur dann weiß der Compiler was er überhaupt aufrufen kann und soll.
Wie gesagt: die Kind-Klassen "xxxPin" enthalten entsprechende
Funktionen, mit denen Du einen Eingabe-Pin lesen und einen Ausgabe-Pin
high oder low setzen kannst. Ich habe Dir meine Datei "main.cpp"
angehängt, die ein in diesem Thread gewünschtes Beispiel implementiert
und meine Klassen nutzt.
Liebe Grüße,
Karl
Karl Käfer schrieb:> Virtuelle Vererbung würde ich gerne vermeiden,
ich auch :-)
> weil der Compiler dann> mit hoher Wahrscheinlichkeit virtual method tables (VMTs) anlegt, die> jedoch relativ viel Speicher kosten.
Bei meinen Versuchen immer. Deshalb sollte das ein Beispiel sein, wie
man es nicht macht. Es werden nicht nur die 'benötigten' Funktionen
eingetragen, sondern auch für die nicht benutzten, für die auch noch
Code erzeugt wird.
Obwohl...
Man könnte mal sehen, was der LTO dazu sagt...
Edit:
... der schlägt bei meinem Test noch zwei Bytes drauf.
Hallo,
weitere Überlegungen zum Thema brachten mich auf die Idee, auf einer
noch tieferen Ebene anzusetzen und zunächst einmal etwas für die
komfortablere Manipulation einzelner Register zu implementieren. Denn
was ich vor allem nicht mag, ist die häßliche Syntax zur Bitmanipulation
in C/C++. Da kann ich ja gleich in Perl programmieren... ;-)
Also habe ich zunächst einmal Template-Funktionen zur Manipulation und
Abfrage von Bits in 8- und 16-Bit-Registern geschrieben, welche sich in
"Reg.hpp" finden. Danach habe ich die Pin-Klassen in "Pin.hpp" an diese
Register-Implementierung angepaßt. Die "main.cpp" ist unverändert, alle
Dateien sind angehängt. Wenn ich diese Dateien mit "avr-g++
-mmcu=atmega32 -Os" übersetze und das Kompilat mit avr-strip(1)
bearbeite, ist das Ergebnis gemäß avr-size(1) exakt 130 Byte groß.
Damit jetzt nicht gleich wieder so ein besonders kluger Mensch aufpoppt
und uns erklärt, daß C++ ein riesiger Codebloat und furchtbar
ineffizient wäre, habe ich dieselbe Funktionalität noch einmal in C
umgesetzt. Und siehe da: mit denselben Compilereinstellungen und
avr-strip(1) bearbeitet, hat der resultierende Code einen Umfang von 148
Byte, unabhängig davon, ob ich den C-Code mit avr-g++ oder avr-gcc
übersetze.
Kurz gesagt: die C++-Implementierung ist über 12% kleiner als die in C.
Wer das selbst überprüfen möchte, findet auch die "main.c" im Anhang.
Liebe Grüße,
Karl
Karl Käfer schrieb:>> Damit jetzt nicht gleich wieder so ein besonders kluger Mensch aufpoppt> und uns erklärt, daß C++ ein riesiger Codebloat und furchtbar> ineffizient wäre, habe ich dieselbe Funktionalität noch einmal in C> umgesetzt. Und siehe da: mit denselben Compilereinstellungen und> avr-strip(1) bearbeitet, hat der resultierende Code einen Umfang von 148> Byte, unabhängig davon, ob ich den C-Code mit avr-g++ oder avr-gcc> übersetze.>
Hallo Karl,
ich lasse normal dem Compiler ein leeres main übersetzen und schau mir
an wieviel Code erzeugt wird. Das ist von MC Typ abhängig, liegt
hauptsächlich an der ISR Tabelle die mal grösser oder kleiner ist und ob
static variable initialisiert werden. Das wird auch bei normalem C so
gemacht.
Dann include ich meine templates und dann sollte sich der code nicht
vergrössern sonst schleppt die Implementation irgendwas mit. Zum Schluss
lege ich in main variable an die meine Templates instanziieren und
vergleiche die code grösse mit dem leeren main.
Wenn du noch kleineren code haben willst, musst du den Startup code auch
noch selber schreiben. Das ist aber auch kein Hexenwerk.
@Karl Käfer
Was mir die größten Sorgen macht, dass man sich zwar bei den
Minimalbeispielen an der geringen Codegröße erfreuen kann. Aber der
Bereich 'hardware abstraction' ist doch im richtigen Leben viel
umfangreicher und wird deshalb schön übersichtlich in Module verteilt.
Ich hab' das mal auseinandergepflückt (siehe Anhang). Für eine
ordentliche Code-Größe hat es sich dann mit 'AVR-Studio aufmachen -
Projekt anlegen - Dateien einfügen - Compilern' erledigt!
> kann das sein, dass hier noch das return rein muss?
Noch eine Anmerkung zu dieser Schreibweise (1 << bit).
Das hat Atmel so eingeführt und jeder macht es.
Ich finde es hässlich, und wenn man mehrere Bits maskiert wird es auch
nicht schöner .. aber das ist meine private Meinung dazu.
Aber ..
wenn du in deiner funktion shiftest kannst du ihr keine maske wo mehrere
bits gleichzeitig gesetzt sind mehr übergeben. Vorschlag: direkt die
bitmaske und keine pin nummer übergeben.
und noch was lustiges ..
enum {
bit0 = 1,
bit1 = 1<<1,
...
bit30 = 1<<30, // bis hierhin alles OK
bit31 = 1<<31 // Compiler sagt Fehler !!
und warum ? weil enums 32Bit aber signed und nicht unsigned sind und du
multiplizierts dann bei dem 31sten schieben nicht mehr mit 2 sondern
schiebst die 1 in das Vorzeichen. Übrigends auch Array indices sind
signed und können negativ sein.
Bei den C++11 enums kannst du den darunterliegenden Datentyp uint32_t
angeben und dann geht es wieder ...
Hans-Georg Lehnard schrieb:> Noch eine Anmerkung zu dieser Schreibweise (1 << bit).> Das hat Atmel so eingeführt und jeder macht es.
Das glaub ich jetzt wieder nicht, dass Atmel das erfunden hat...
> Ich finde es hässlich, und wenn man mehrere Bits maskiert wird es auch> nicht schöner ..
Wie lautet dein Gegenvorschlag? (in C, ohne ++)
Ich finde das sehr praktisch, weil man in einer zeile alle Bits angeben
kann, und sofort erkennt welches Bit 1 und welches 0 ist:
Michael Reinelt schrieb:> Wie würdest du das gerne "schöner" codieren?
Über Geschmack kann man nicht streiten. Andere (lassen wir Atmel/STM/...
mal weg), definieren z.B. sinngemäß:
1
staticconstintFOC0A=(1<<0);
2
staticconstintFOC0B=(1<<1);
3
staticconstintWGM00=(1<<2);
4
staticconstintWGM01=(1<<3);
5
staticconstintWGM02=(1<<4);
6
staticconstintCS00=(1<<5);
7
staticconstintCS01=(1<<6);
8
staticconstintCS02=(1<<7);
... oder fassen mehrere Bits zusammen. Z.B. in den MSP430-Bibliotheken
ist das so.
Michael Reinelt schrieb:> Ich finde das sehr praktisch, weil man in einer zeile alle Bits angeben> kann, und sofort erkennt welches Bit 1 und welches 0 ist:
Ich find's sogar schön, Bits zusammenzufassen...
1
TCCR0B=(0<<FOC0A)|(0<<FOC0B)|(0<<WGM02)|(0b010<<CS00);// 3Bits für CS0n
Torsten C. schrieb:> Michael Reinelt schrieb:>> Wie würdest du das gerne "schöner" codieren?>> Über Geschmack kann man nicht streiten. Andere (lassen wir Atmel/STM/...> mal weg), definieren z.B. sinngemäß:>> [c]static const int FOC0A = (1<<0);> static const int FOC0B = (1<<1);> static const int WGM00 = (1<<2);
...
> ... oder fassen mehrere Bits zusammen. Z.B. in den MSP430-Bibliotheken> ist das so.
Beantwortet aber meine Frage nicht: Wie schreibst du, dass du WGM00 auf
0 setzte, WGM01 auf 1 und WGM02 auf 0? So dass auch erkennbar ist dass
WGM00 und WGM02 auf 0?
Michael Reinelt schrieb:> Hans-Georg Lehnard schrieb:>> Noch eine Anmerkung zu dieser Schreibweise (1 << bit).>> Das hat Atmel so eingeführt und jeder macht es.> Das glaub ich jetzt wieder nicht, dass Atmel das erfunden hat...>>> Ich finde es hässlich, und wenn man mehrere Bits maskiert wird es auch>> nicht schöner ..>> Wie würdest du das gerne "schöner" codieren? (in C, ohne ++)
ich mach das gerne so ..
typedef enum {
PA0 = 0x01u,
PA1 = 0x02u,
PA2 = 0x04u,
PA3 = 0x08u,
PA4 = 0x10u,
PA5 = 0x20u,
PA6 = 0x40u,
PA7 = 0x80u
}PORTA_BITS;
typedef enum {
PB0 = 0x01u,
PB1 = 0x02u,
PB2 = 0x04u,
PB3 = 0x08u,
PB4 = 0x10u,
PB5 = 0x20u,
PB6 = 0x40u,
PB7 = 0x80u
}PORTB_BITS;
Dann ist dem Compiler auch klar, das ich unsigned meine ...
(1<<5) ist für den Compiler signed int, 0x20u nicht.
Es liegt vielleicht daran, das ich mit Binärzahlen aufgewachsen bin und
wenn ich mit Leuten von der PD11 diskutierte immer im Kopf zwischen
oktal und hex hin und her umrechnen musste aber das ist wie gesagt reine
Geschmacksache;
Und wenn ich das in C++ als Datentypen für Templates nehme.
DigitalInput<PORT_A, PB> gibt dann ein Compiler Fehler.
Hans-Georg Lehnard schrieb:> ich mach das gerne so ..
Beantwortet auch nciht meine Frage. Wie codierst du mein obiges
Beispiel? So dass sofort erkennbar ist, dass ein gewisses bit gesetzt
wird, aber auf 0?
Hallo Hans-Georg,
Hans-Georg Lehnard schrieb:> ich lasse normal dem Compiler ein leeres main übersetzen und schau mir> an wieviel Code erzeugt wird.
Schon klar, aber ich bin faul und mir geht es aber nur um eine schnelle
Vergleichbarkeit. Darum übersetze ich die verschiedenen Quellcodes
einfach immer für dasselbe Ziel und vergleiche die Größen der Kompilate,
das muß für einfache Betrachtungen genügen.
> Wenn du noch kleineren code haben willst, musst du den Startup code auch> noch selber schreiben. Das ist aber auch kein Hexenwerk.
Das ist kein Hexenwerk, aber ich bin wie gesagt faul und mir geht es
hier ausschließlich um den Vergleich verschiedener Quellcodes. Darum
gehe ich einfach davon aus, daß der Startcode für dasselbe Ziel immer
derselbe und damit immer gleich groß ist.
Liebe Grüße,
Karl
Michael Reinelt schrieb:> Hans-Georg Lehnard schrieb:>> ich mach das gerne so ..>> Beantwortet auch nciht meine Frage. Wie codierst du mein obiges> Beispiel? So dass sofort erkennbar ist, dass ein gewisses bit gesetzt> wird, aber auf 0?
Michael,
es ist ganz einfach bei << muss ich denken bei bits in hex codieren
nicht .. ich will niemand überzeugen. Und bei Nullen nehm ich & und
nicht | und wenn ich selber was definiere immer in positiver Logik.
Hallo Ralf,
Ralf G. schrieb:> Was mir die größten Sorgen macht, dass man sich zwar bei den> Minimalbeispielen an der geringen Codegröße erfreuen kann. Aber der> Bereich 'hardware abstraction' ist doch im richtigen Leben viel> umfangreicher und wird deshalb schön übersichtlich in Module verteilt.> Ich hab' das mal auseinandergepflückt (siehe Anhang). Für eine> ordentliche Code-Größe hat es sich dann mit 'AVR-Studio aufmachen -> Projekt anlegen - Dateien einfügen - Compilern' erledigt!
Das wundert mich nicht, denn der Optimizer des GCC arbeitet nun einmal
nur auf den einzelnen Übersetzungseinheiten. Deswegen kann er den Code
nicht mehr anständig optimieren, sobald Du ihn über mehrere Einheiten
verteilst und diese einzeln übersetzt. [1] Die kleine Codegröße meiner
Kompilate baut jedoch darauf, daß der Optimizer erkennt, daß es sich bei
meinen Klassen in Wahrheit nur um Sammlungen von Konstanten handelt, so
daß er diese elegant von dannen optimieren kann. ;-)
Nun gibt es IMHO drei Gründe, Code auf verschiedene
Übersetzungseinheiten zu verteilen. Erstens dient das dazu, daß bei
Änderungen an einer Einheit nur diese neu übersetzt werden muß, und bei
unveränderten Einheiten nur die bereits vorhandene Objektdatei dazu
gelinkt werden muß. Bei größeren Projekten spart das Übersetzungs- und
damit Entwicklungszeit, aber bei in der Regel sehr kleinen
Mikrocontroller-Projekten hält sich der praktische Nutzen dessen wohl in
Grenzen.
Zweitens kann man, wenn man kommerzielle Bibliotheken entwickelt, diese
als Headerdateien mit vorkompilierten Objektdateien ausliefern, also
ohne mehr von seinem Quellcode offenzulegen als die Headerdateien. Das
ist bei einem OpenSource-Projekt wie diesem hier wohl eher unerwünscht,
denn da geht es ja gerade um die Weitergabe des Quellcodes.
Und letztlich dient das drittens auch der Übersichtlichkeit, und dieses
Argument sticht natürlich auch hier. Aber um dieses Ziel zu erreichen,
müssen wir die Übersetzungseinheiten nicht einzeln übersetzen und dann
zusammenlinken, sondern es reicht vollkommen aus, erst den Präprozessor
über "#include"-Direktiven die Drecksarbeit machen zu lassen. Damit hast
Du den Code übersichtlich auf mehrere Dateien verteilt, aber sie werden
trotzdem zusammen als eine Übersetzungsarbeit übersetzt und optimiert.
Da spielt dann wieder die überschaubare Größe von uC-Projekten hinein.
Ja, ich weiß, das ist nicht die gängige Praxis aus dem Lehrbuch. Aber
ich vertrete die Ansicht, daß sowohl gängige Praktiken als auch
Empfehlungen aus Lehrbüchern nicht in Stein gemeißelt sind und durchaus
auch schon mal ignoriert werden dürfen, wenn es, wie hier, gute Gründe
dafür gibt.
Liebe Grüße,
Karl
[1] Das ist, am Rande bemerkt, einer der Gründe dafür, daß ich bei
PC-Projekten den LLVM/clang++ nutze, der über mehrere Einheiten hinweg
optimieren kann, wenngleich er bei einzelnen Einheiten etwas weniger gut
optimiert.
Karl Käfer schrieb:> Aber um dieses Ziel zu erreichen,> müssen wir die Übersetzungseinheiten nicht einzeln übersetzen und dann> zusammenlinken, sondern es reicht vollkommen aus, erst den Präprozessor> über "#include"-Direktiven die Drecksarbeit machen zu lassen.
OOUuuh.
Ob du damit durchkommst? ;-)
>> kann das sein, dass hier noch das return rein muss?>> Noch eine Anmerkung zu dieser Schreibweise (1 << bit).>> Das hat Atmel so eingeführt und jeder macht es.
So sehen Bitoperationen in C nun einmal aus, da ist Atmel unschuldig.
> Ich finde es hässlich, und wenn man mehrere Bits maskiert wird es auch> nicht schöner .. aber das ist meine private Meinung dazu.>> Aber ..>> wenn du in deiner funktion shiftest kannst du ihr keine maske wo mehrere> bits gleichzeitig gesetzt sind mehr übergeben. Vorschlag: direkt die> bitmaske und keine pin nummer übergeben.
Die aktuelle Version meiner "Reg.hpp" und "Pin.hpp" hat -- schon aus
Gründen der Wiedererkennbarkeit -- die Funktionstemplates "_set()" in
"_sbi()", "_clr()" in "_cbi()" und "_get()" in "_gbi()" umbenannt, und
dazu die neuen Funktion "_sms()" und "_cms()", denen man eine komplette
Maske übergeben kann. Dir Funktionen "_set()" und "_get()" arbeiten nun
auf dem kompletten Register.
Liebe Grüße,
Karl
PS: Liebe Moderatoren / Betreiber, es wäre schön, wenn auch .hpp-Dateien
eine Codeansicht bekommen könnten. Besten Dank!
Michael Reinelt schrieb:> Wie schreibst du, dass du WGM00 auf> 0 setzte, WGM01 auf 1 und WGM02 auf 0? So dass auch erkennbar ist dass> WGM00 und WGM02 auf 0?
Entweder so wie oben gesagt, mit &=~ statt |= oder eben durch das
Zusammenfassen von mehreren Bits, wie in msp430x552x.h^^:
Hallo Ralf,
Ralf G. schrieb:> Karl Käfer schrieb:>> Aber um dieses Ziel zu erreichen,>> müssen wir die Übersetzungseinheiten nicht einzeln übersetzen und dann>> zusammenlinken, sondern es reicht vollkommen aus, erst den Präprozessor>> über "#include"-Direktiven die Drecksarbeit machen zu lassen.>> OOUuuh.> Ob du damit durchkommst? ;-)
Werden wir sehen, ich lasse mich gerne überraschen. ;-) Denn wenn ich
nicht damit durchkomme, müßte es doch bessere Argumente dagegen als
meines dafür geben. Da bin ich sehr gespannt, eventuell habe ich ja
etwas übersehen.
Liebe Grüße,
Karl
Karl Käfer schrieb:> Die kleine Codegröße meiner> Kompilate baut jedoch darauf, daß der Optimizer erkennt, daß es sich bei> meinen Klassen in Wahrheit nur um Sammlungen von Konstanten handelt, so> daß er diese elegant von dannen optimieren kann. ;-)
Mal 'ne Frage: Die Lösung ist nicht schlecht, aber wenn man "const"
Deklariert, müsste mit getrennten *.cpp Dateien das Gleiche bei raus
kommen, oder?
PS zu dieser Bitmaskenorgie: Ich finde MSP430 nicht undbedingt besser,
ist halt 'ne Alternative und Geschmackssache.
Ich finde Templates oder Inline-Funktionen am besten lesbar. Man müsste
sie halt mit "mehrere Bits auf einmal" umsetzen.
Karl Käfer schrieb:> der Optimizer des GCC arbeitet nun einmal> nur auf den einzelnen Übersetzungseinheiten.
Meines Wissens nach stimmt das nicht, GCC kann seit ca. 5 jahren LTO
(Link Time Optimization) und die macht genau das.
https://gcc.gnu.org/wiki/LinkTimeOptimization
Ob er es seit 5 Jahren kann, bezweifle ich. Aber heute kann er es sehr
gut. Kein Grund den Compiler zu wechsel. Schon gar nicht, wenn man
AVR-Code erzeugen will.
Nachdem ich hier eine ganze Zeit mitgelesen habe und eigentlich nichts
klares zu erkennen ist, finde ich das alles mittlerweile eher
abschreckend mit C++ auf einem µC zu arbeiten.
Nun, in zwei bis drei Jahren möchte ich dann auch mal mit C++ anfangen
und mal sehen, ob ich das dann anders sehe.
Ok, falsch formuliert: seit wann man darauf bauen kann, daß es
funktioniert. Nur um zu vermeiden, daß jemand mit einer Anno Tobak
Version testet und flucht. Aber sonst sind wir ja auf einer Linie: der
GCC kann das!
Michael Reinelt schrieb:> Meines Wissens nach stimmt das nicht, GCC kann seit ca. 5 jahren LTO
Es ist aber auch keine Wunderwaffe. En bisschen Mitarbeit ist gefragt.
Weil:
Ralf G. schrieb:> Für eine> ordentliche Code-Größe hat es sich dann mit 'AVR-Studio aufmachen -> Projekt anlegen - Dateien einfügen - Compilern' erledigt!
Karls Beispiel
Beitrag "Re: C++ auf einem MC, wie geht das?" in Module
verteilt, dem gcc mit LTO auf die Sprünge geholfen... und? ...
funktioniert!! Das muss aber nicht immer so sein.
Falls ich mir mit C++ eine Lib aufbaue, würde ich die gern mit
unterschiedlichen Compilern vernünftig nutzen können.
Es macht offenbar viel mehr Spaß, Stundenlang über Compiler-Optimierung
zu debattieren, statt einfach mit "const", "private" oder "final" dafür
zu sorgen, dass der Kompiler ohne Debatte ordentlich optimiert.
Zumindest nach meinem Verständnis, wie gesagt, so ähnlich wie bei
'ichbinmaldiesmaldas'^^.
F. Fo schrieb:> Nachdem ich hier eine ganze Zeit mitgelesen habe und eigentlich nichts> klares zu erkennen ist, finde ich das alles mittlerweile eher> abschreckend mit C++ auf einem µC zu arbeiten
Das liegt eher geringfügig an C++. Das sind typische
Designentscheidungen und jeder hat erst mal eine andere Vorstellung im
Kopf. Das dauert dann bis man sich auf eine Variante geeinigt hat, weil
man sich gegenseitig zu überzeugen versucht. Das man hier in Schriftform
kommuniziert (schnarch langsam) tut dann sein Übriges dazu.
TriHexagon schrieb:> Das dauert dann bis man sich auf eine Variante geeinigt hat, weil> man sich gegenseitig zu überzeugen versucht.
Guter Punkt: Noch ein Grund, warum ich Euch von 'const', 'private' oder
'final' überzeugen will:
Falls man durch seine Programmierung in anderen Modulen versucht,
'const'-Member zu verändern, meckert der Compiler und man merkt es!
Sonst merkt man sowas doch gar nicht und blickt gar nicht durch, was da
im Hintergrund passiert!
Der Optimizer gibt doch kein verlässliches 'warning' aus: "Wenn Sie das
hier anders programmiert hätten, hätte ich besser optimieren können."
Ein Entfernen eines 'const' oder 'final' oder eine Änderung 'private' ->
'protected' ist dann immer eine bewusste Design-Entscheidung.
Falls ich auf dem Holzweg sein sollte: Warum?
Torsten C. schrieb:> Noch ein Grund, warum ich Euch von 'const', 'private' oder> 'final' überzeugen will:
Also, wenn ich was zu sagen hätte, dann hättest du ab sofort
'const'-'private'-'final'-Schreibverbot.
Ralf G. schrieb:> Also, wenn ich was zu sagen hätte, dann hättest du ab sofort> 'const'-'private'-'final'-Schreibverbot.
Das ist wenig konstruktiv. Ich versuche mit den anderen hier die
(erweiterte) Frage 'C++ auf einem MC, wie geht das am besten?' im
Konsens zu beantworten.
Torsten C. schrieb:> Falls ich auf dem Holzweg sein sollte: Warum?
Darauf hat bisher niemand geantwortet. Was soll ich daraus schließen?
Ein Schreibverbot ist gar nicht nötig, das klappt auch ohne.
@Ralf G.: Ich versuche hier nicht wie Moby unbeirrbar den Sinn von C++
in Frage zu stellen. Merkst Du was?
Ralf G. schrieb:> Also, wenn ich was zu sagen hätte, dann hättest du ab sofort> 'const'-'private'-'final'-Schreibverbot.
Das ist eigentlich nur die Kurzfassung für:
Mach doch mal ein kleines Demoprogramm. Mal mit, mal ohne
'const'-'private'-'final'. Was könnte das Ergebnis sein? Entweder du
siehst, dass es nichts bringt, oder alle anderen staunen, was da für ein
exquisit optimierter Code entsteht, wenn man richtig Ahnung hat. Bis
dahin braucht man das doch nicht immer wiederholen. Oder?
Torsten C. schrieb:>> Ich versuche mit den anderen hier die> (erweiterte) Frage 'C++ auf einem MC, wie geht das am besten?' im> Konsens zu beantworten.>
Ich seh das mit meinem momentanen Kenntnisstand so :
Kann man MC mit C++ programmieren ?
Ja, aber .....
Kann man das auch effektiv ?
Ja, aber ...
Kann man das auch portabel auf andere MC Familien ?
Ja, aber ...
Wie geht das am besten ?
Kann ich nicht sagen ...
Kann man diese letze Frage online ausdiskutieren ?
Nein.
Hans-Georg Lehnard schrieb:> Ja, aber ...
Das ist doch mal 'ne klare Ansage.
Also, wer will, kann hier viele Ansätze finden, einen Port
AVR-unabhängig in eine Klasse zu packen, ohne dass es großartig aufträgt
(wenn überhaupt!). Das sollte für diesen Teil reichen. Falls jetzt noch
jemand Lust hat, könnte man als nächstes darüber diskutieren, inwiefern
es sinnvoll ist, den diversen Interruptroutinen eine Klasse zu
spendieren (Ich gehe mal ins Rennen: 'Nicht sinnvoll!'). Mit 'Timer'
geht's los. (Damit das hier auch schön 'on-topic' bleibt. Peter
Dannegger soll daran seine Freude haben!)
Hans-Georg Lehnard schrieb:> Ja, aber ...
Schade. Gemeint war das anders:
Gut: Der Compiler optimiert über mehrere Module, falls er das kann.
Besser: Der Compiler meckert, weil er nicht opimieren kann.
Im ersten Fall muss man immer wieder in die *.lss schauen, um sicher zu
gehen.
Im letzteren Fall muss man nur bei einer Fehlermeldung reagieren und
kann bewusst entscheiden, was zu tun ist, ohne wiederholt in die *.lss
schauen zu müssen, …
… wobei der Compiler genau genommen nicht meckert, 'weil er nicht
opimieren kann'^^, sondern, weil man in irgendeinem Modul was gemacht
hat, was dazu führt, dass ein Wert zur Laufzeit veränderbar sein muss.
Ralf G. schrieb:> Was könnte das Ergebnis sein?
Ich dachte, das wäre ohne Demoprogramm offensichtlich,
nachdem Hans-Georg Lehnard schrieb:> … das musst du verhindern …
Nun verstehe ich das Problem: Es ist gar nicht offensichtlich.
Danke für das konstruktive Feedback.
Hans-Georg Lehnard schrieb:> Kann ich nicht sagen ...
Wie meinst Du das? Das habe ich offenbar bereits zu oft gesagt:
=> "… doch nicht immer wiederholen. Oder?"^^
Hans-Georg Lehnard schrieb:> Kann man diese letze Frage online ausdiskutieren ?> Nein.
Der Wirkungsgrad ist wirklich mies, hast Recht!
Ich habe auch manchmal das Gefühl, dass es hier einigen darum geht, zu
zeigen, wer hier der schlaueste Programmierer ist, statt konstruktiv an
einem Konsens zu arbeiten.
Ralf G. schrieb:> Falls jetzt noch jemand Lust hat …
Was mich betrifft: Ich bin mir wegen des Wirkungsgrades^^ noch unsicher.
Ralf G. schrieb:> Mit 'Timer' geht's los.
Beim AVR stehen die ISR-Vektoren im Flash-ROM. Da wäre meine erste
Fragestellung: Wie programmiert man dann am besten? Bei einem
Zustandsautomaten wäre es effizient, wenn man mit einem 'member function
pointer' arbeitet:
1
ISR(…_vect){
2
// vectors are located in flash rom
3
(….*…_ISR)();
4
}
Normalerweise ist es jedoch effizienter, wenn die Funktion in der ISR
zur Laufzeit nicht veränderbar sein muss.
Aber für die Frage von Peter Dannegger benöttigt man ja einen
Zustandsautomaten. Den hatten wir ja schon mal andiskutiert.
Ich bin gedanklich daher ziemlich bei dem,
was Ralf G. schrieb:> Ich gehe mal ins Rennen: 'Nicht sinnvoll!'
So wird das nichts. Einfach so ins Blaue hinein, kommt nix bei raus.
Es müssen konkrete Rahmenbedingungen definiert werden. Soll eine
Abstraktion nur für die AVRs gelten? Soll sie nur für 8-Bitter mit ein
paar 100 Bytes RAM gelten? Oder ist das Ziel eine Plattform mit 32 Bit
und RAM in zweistelligen Kilobyte-Bereich oder noch mehr? Möchte man ein
Plattform-Übergreifende Abstraktion mit der man möglichst universell auf
"alle" Mikrocontroller zugreifen kann? Usw.
Ohne Vorgaben wird das nichts. Die müssen erst geklärt sein.
Ralf G. schrieb:> .... könnte man als nächstes darüber diskutieren, inwiefern> es sinnvoll ist, den diversen Interruptroutinen eine Klasse zu> spendieren (Ich gehe mal ins Rennen: 'Nicht sinnvoll!'). Mit 'Timer'> geht's los. (Damit das hier auch schön 'on-topic' bleibt. Peter> Dannegger soll daran seine Freude haben!)
Hallo Ralf,
Timer sind wieder so ein wunderbares Beispiel für Ja, aber ... ;)
Ja, du hast Recht es macht keinen Sinn irgendetwas in Klassen zu
verpacken nur damit es Klassen sind. ISR lassen sich auch nicht direkt
verpacken.
Dazu gibt es hier im Forum einen schönen Artikel:
http://www.mikrocontroller.net/articles/AVR_Interrupt_Routinen_mit_C%2B%2B
Aber, ich halte eine Klasse SystemTimer, die einen Hardware Timer
kapselt, für sinnvoll weil Timer in einem MC System üblicherweise
bergrenzt sind und ich kann nicht z.B. jedem Pin zur Entprellung einen
eigenen Timer spendieren.
@Torsten
Schau dir einfach mal Pedas Entprellroutine in C an. Was spricht dagegen
die 1:1 in eine (System)Timer Callback Methode deiner InputPin Klasse zu
übernehmen die alle 20ms aufgerufen wird.
Da gilt genau das gleiche:
Ja das kann man als "richtige" Statemachine verpacken - Aber man muss
das nicht ...
Wenn ich jetzt einen Eingang nicht einzel betrachte dann macht es
vielleicht Sinn eine Entprell Klasse zu haben die gleichzeitig mehrere
Pins verwaltet, darin wäre dann vieleicht auch eine "richtige"
Statemachine die bessere Lösung.
Wenn die Eingänge an einer externen Schieberegisterkette hängen wird man
das auf alle Fälle in einer Klasse kapseln.
Du hast immer die Entscheidung Aufwand gegen Nutzen.
Hans-Georg Lehnard schrieb:> Schau dir einfach mal Pedas Entprellroutine in C an. Was spricht dagegen> die 1:1 in eine (System)Timer Callback Methode deiner InputPin Klasse zu> übernehmen die alle 20ms aufgerufen wird.
Genau! Deshalb habe ich die von mir (mehr oder weniger sinnvollen)
vorgeschlagenen Pin-Klassen-Implementierungen immer für den ganzen Port
(bzw. für 1..8 Pins) gemacht.
Theoretiker schrieb:> So wird das nichts. Einfach so ins Blaue hinein, kommt nix bei raus.>> Es müssen konkrete Rahmenbedingungen definiert werden. Soll eine> Abstraktion nur für die AVRs gelten? Soll sie nur für 8-Bitter mit ein> paar 100 Bytes RAM gelten? Oder ist das Ziel eine Plattform mit 32 Bit> und RAM in zweistelligen Kilobyte-Bereich oder noch mehr? Möchte man ein> Plattform-Übergreifende Abstraktion mit der man möglichst universell auf> "alle" Mikrocontroller zugreifen kann? Usw.>> Ohne Vorgaben wird das nichts. Die müssen erst geklärt sein.
Die Vorgaben sind wie immer ...
Wir müssen schneller auf den Markt, es darf nichts kosten und es muss
in 2 Wochen fertig sein. ;)
Hans-Georg Lehnard schrieb:> Was spricht dagegen> die 1:1 in eine (System)Timer Callback Methode deiner InputPin Klasse zu> übernehmen die alle 20ms aufgerufen wird.
Da fragst Du den Richtigen: Den, der immer 'Ja aber ...' sagt. ;-)
Ich bin inzwischen auch fest davon überzeugt, dass eine uCpp ein Fass
ohne Boden ist, selbst falls man sich z.B. nur auf 8-Bit AVR
beschränken würde.
Der eine braucht 4 GPIOs 'am Stück' um ein Display anzusteuern, der
nächste einzelne GPIOs - irgendwo verteilt - als Slave-Select für SPI,
der übernächste … usw.
Beim Timer mit 2 Kanälen ist das noch schlimmer: Der eine Kanal macht
PWM, der andere IC (Input-Compare), oder beide machen PWM oder beide
machen IC.
Im STM32 sind's noch mehr Kanäle.
Wenn man alle Varianten annäherd so effizient umsetzen will, wie mit
ASM, dann gibt es eine Inflation von Klassen oder Templates die niemand
debuggen oder nach einem Jahr noch verstehen kann.
Vorschlag für einen Ausweg (um hier zerrissen zu werden): Man baut sich
für das eine oder andere wiederkehrende Problem ein Code-Snippet (für
den Manager, siehe Bild), so wie man es gerade braucht.
Um nach diesen Überlegungen Deine Frage zu beantworten: Es gibt
Projekte, bei denen die Rahmenbedingungen keinen 'Systick' (ich hätte
beinahe 'Sysfick' geschrieben) zulassen. Nichts spricht aus meiner
Sicht ansonsten dagegen.
Falls statt einer uCpp-Lib Interesse an einer Snippet-Sammlung besteht,
könnte man eine solche als Projekt starten.
Als einer der hier interessiert mitliest, habe ich eigentlich nur auf
die Erkenntnis von Torsten gewartet.
C++ ist sinnvoll für gewisse reine Software-Themen (PT1- Glieder oder
allgemein digitale Filter als gutes Beispiel) aber nicht für die
harware-nahen Sachen.
Torsten hat eh schon ein paar Beispiele genannt; immer dann wenn die
Ausnutzung der Hardware "kreativ" wird, ists Essig mit der schönen
schnöden Abstraktion in Klassen.
Anfangen könnte man schon bei ganz simplen Dingen wie Wired-And auf den
Pins: Hier wird der Pin nicht über das PORT-Register gesteuert, sondern
über DDR. Das könnte man ja noch hinkriegen...
Timer sind aus meiner Sicht ganz schwierig: Dynamisches Umschalten
zwischen den Modi, dynamisches Weiterschalten des Output-Compare, ...
Software-Interrupts? EEPROM-Write zweckentfremdet?
Kreative Verwendung von "artfremden" Dingern als Timer? (z.B. ADC
freerunning als Timer)
Genau diese kreativen (und genialen) Verwendungen der vielfältigen
Möglichkeiten der Hardware kriegst du nie in ein Objekt-Modell.
Willst du das alles C++-mäßig simplifizieren, bist du bei Arduino. Nett,
aber beschränkt. Sobald du mehr willst, wirfst du das über Bord.
Schlimmstenfalls hast du dann ein mischmasch, das keiner mehr lesen und
verstehen kann.
Peters Frage dürfte damit beantwortet sein.
Ralf G. schrieb:> Vor allen Dingen: Das ist nicht das, was ich mir unter effizient> vorgestellt habe. Vielleicht hat ein Profi 'ne bessere Idee.
O je, ihr habt diesen Unsinn ja noch immer nicht zu Grabe getragen.
Ja, ich hab ne bessere Idee - und ich hatte sie bereits viel weiter oben
geäußert: Laßt all diesen C++ Krimskram bleiben und kommt auf den
Teppich herunter. Vernünftige Peripherie-Treiber, die eine echte Arbeit
leisten und ne hardwareunabhängige Schnittstelle zur Applikation
herstellen, sind viel effektiver, viel verständlicher und machen die
Applikation viel eher portabel, sofern das überhaupt geht. Sowas wie
"LED1.toggle = KEY1.press" oder auch "LED1::setOutput(xpcc::Gpio::Low);"
sind Mumpitz und zu nichts nütze. Das ist nur digitale Onanie.
W.S.
Und ich habe darauf gewartet das jetzt wieder einer behauptet C++ sei
dafür grundsätzlich nicht geeignet.
Das jemand die Komplexität eines Problemes unterschätzt ist doch völlig
normal, das passiert jedem und vor allen Dingen wenn er neu auf dem
(embedded) Gebiet ist. Das ist aber überall so völlig unabhängig von der
Sprache.
Und wie entwerfe ich meine Klassen gehört nicht zu den leichtesten
Übungen bei objektorientierten Sprachen.
Es war doch nicht Tomas, sondern die lieben Assembler Programmierer, die
geschrieen haben das wär doch alles trivial.
Gegen Vorurteile kämpfen ist wie gegen Windmühlen.
Und bei den SOC wie zum Beispiel dem Zynq, das weisst du ja als
Softwerker nicht mal was dein Kollege dir für eine Hardware ins FPGA
bastelt. Das wird es erst richtig Hardwarenah und da möchte ich mal
sehen wer dann noch in Assembler programmieren will.
Hallo Michael,
Michael Reinelt schrieb:> Meines Wissens nach stimmt das nicht, GCC kann seit ca. 5 jahren LTO> (Link Time Optimization) und die macht genau das.
Wenn das korrekt funktionieren würde, dann würde die Kompilatgröße nicht
explodieren, sobald man den Quellcode auf mehrere Übersetzungseinheiten
aufteilt -- aber sie tut es. Das zeigt mir, daß die LTO in diesem Falle
offenbar nicht wie gewünscht funktioniert, ein oberflächlicher Blick ins
Mapfile scheint meinen Verdacht zu bestätigen. Schade.
Liebe Grüße,
Karl
Hallo F.,
F. Fo schrieb:> Karl Käfer schrieb:>> Dahinter verbirgt sich eine Art C++,>> Arduino language is based on C/C++. It links against AVR Libc and allows> the use of any of its functions; see its user manual for details.>> Wer es selber nachlesen will:> http://arduino.cc/en/pmwiki.php?n=Reference/HomePage
Der Sinn erschließt sich, wenn Du den ganzen Satz liest. Der geht
nämlich weiter mit: "die dafür gemacht und optimiert wurde, von
absoluten Anfängern und Nichttechnikern benutzt zu werden". Die "eine
Art" bezieht sich also auf den Teil "die dafür gemacht und optimiert
wurde".
Liebe Grüße,
Karl
Mein lieber Karl, mein Englisch ist zwar nicht (mehr) auf C Niveau, aber
du liest da was (oder an anderer Stelle?) was da nicht steht.
Es ist wohl schon 30 Jahre her, dass ich mich dort mal längere Zeit
aufgehalten hatte, aber aus dem Satz,
Karl Käfer schrieb:> Arduino language is based on C/C++.,
kann man nicht mehr raus lesen, als da steht.
Da steht, dass Arduino auf C/C++ basiert. Nicht mehr und nicht weniger.
Ob dir das nun gefällt oder nicht, so steht es da.
Ich hatte ja mit Arduino angefangen, aber ich habe mir natürlich nicht
die "Basis" dazu angesehen, noch fehlt mir bis heute das Wissen das gut
genug zu beurteilen.
Ich will ja nicht behaupten, dass du unrecht hast, aber dass das da
steht wie es steht, ist für jeden zu lesen.
Hi Ralf,
Ralf G. schrieb:> Karls Beispiel> Beitrag "Re: C++ auf einem MC, wie geht das?" in Module> verteilt, dem gcc mit LTO auf die Sprünge geholfen... und? ...> funktioniert!! Das muss aber nicht immer so sein.
Oh, das funktioniert doch? Ui. Dann nehme ich alles zurück und behaupte
das Gegenteil!
Liebe Grüße,
Karl
Hallo Hans-Georg,
Hans-Georg Lehnard schrieb:> Kann man diese letze Frage online ausdiskutieren ?>> Nein.
Daß wir in dieser Diskussion immer wieder festhängen, liegt primär an
ihrem rekursiven Charakter. Das betrifft vor allem Nebensächliches wie
"Templates oder nicht", aber auch "const"-, "private"- und
"final"-Deklarationen.
Ohne konkreten Code als Diskussionsgrundlage laufen diese Fragen aber
leider immer wieder ins Leere. Leider scheine ich hier aber derzeit der
Einzige zu sein, der aktiv an Code arbeitet und diesen wiederholt
gepostet hat.
Aus mir unerfindlichen Gründen wird über meinen Code aber kaum
diskutiert. Stattdessen verliert sich die Diskussion wiederholt in
Details, hängt aber mangels konkreten Codes als Diskussionsgrundlage
frei in der Luft.
Mir ist unklar, wie wir das lösen können. Aber vielleicht mag ja der
Eine oder andere einfach mal meinen Code lesen und eine fundierte Kritik
daran äußern. Vielen Dank.
Liebe Grüße,
Karl
Hallo Michael,
Michael Reinelt schrieb:> C++ ist sinnvoll für gewisse reine Software-Themen (PT1- Glieder oder> allgemein digitale Filter als gutes Beispiel) aber nicht für die> harware-nahen Sachen.
Hast Du mal einen Blick in den von mir geposteten Code geworfen? Wenn
ja, wüßte ich gerne, wie Du zu dieser Aussage kommst.
Liebe Grüße,
Karl
Hallo W.,
W.S. schrieb:> O je, ihr habt diesen Unsinn ja noch immer nicht zu Grabe getragen.>> Ja, ich hab ne bessere Idee - und ich hatte sie bereits viel weiter oben> geäußert: Laßt all diesen C++ Krimskram bleiben und kommt auf den> Teppich herunter. Vernünftige Peripherie-Treiber, die eine echte Arbeit> leisten und ne hardwareunabhängige Schnittstelle zur Applikation> herstellen, sind viel effektiver, viel verständlicher und machen die> Applikation viel eher portabel, sofern das überhaupt geht. Sowas wie> "LED1.toggle = KEY1.press" oder auch "LED1::setOutput(xpcc::Gpio::Low);"> sind Mumpitz und zu nichts nütze. Das ist nur digitale Onanie.
Ich bilde mir ein, mittlerweile ziemlich eindeutig bewiesen zu haben,
daß man mit C++ auch für Mikrocontroller elegante Programme schreiben
kann, die kein einziges Byte größer sind als ihr Äquivalent in C, dafür
aber sehr viel besser zu Lesen und zu Warten sind.
Weißt Du, labern und mosern kann jeder. Deswegen schlage ich vor, daß
wir uns die Sache hier ganz einfach machen. Wenn Du es schaffst, mit C
oder Assembler etwas zu implementieren, das a) genau so lesbar ist wie
meine angehängte "main.cpp" und b) zu nicht mehr als 146 Byte Code
kompiliert, dann laß uns einfach mal Deinen großartigen Code sehen. Wenn
Du das nicht schaffst, dann schlage ich vor, daß Du Dich irgendwoanders
konstruktiver einbringst und uns hier nicht weiter störst.
Jetzt bin ich aber wirklich mal gespannt, ob Du Manns genug bist, Dich
dieser einfachen Herausforderung zu stellen. Viel Erfolg!
Liebe Grüße,
Karl
Karl Käfer schrieb:> Hast Du mal einen Blick in den von mir geposteten Code geworfen?
Ja, habe ich.
> Wenn ja, wüßte ich gerne, wie Du zu dieser Aussage kommst.
Das bissi LED-einschalten ist aber noch lange nicht "kreative"
Verwendung von Hardware. mach mal Wired-And dazu, Entprellung, einen
Timer mit OCR-Leiter, dann schauen wir weiter.
Karl Käfer schrieb:> Leider scheine ich hier aber derzeit der> Einzige zu sein, der aktiv an Code arbeitet und diesen wiederholt> gepostet hat
Nicht wirklich der einzige! Oder meinst Du das ernst? Ich habe im Moment
den USART und einen Timer an der Backe und kann auch gern Beispiele
posten. Dadurch wird der Thread jedoch nicht übersichtlicher. Also
bleiben wir beim GPIO:
Karl Käfer schrieb:> Aus mir unerfindlichen Gründen wird über meinen Code aber kaum> diskutiert.
Schau doch bitte mal, ob bei Deiner 'class Pin' im *.lss wirklich immer
'sbi' und 'cbi' auftauchen. Ich habe da Bedenken.
Falls immer 'sbi' und 'cbi' compiliert wird, liegt der Mangel an Kritik
vielleicht daran, dass keiner was dran auszusetzen hat, das Kapitel also
abgeschlossen ist.
Hallo Michael,
Michael Reinelt schrieb:> Torsten hat eh schon ein paar Beispiele genannt; immer dann wenn die> Ausnutzung der Hardware "kreativ" wird, ists Essig mit der schönen> schnöden Abstraktion in Klassen.> [...]> Timer sind aus meiner Sicht ganz schwierig: Dynamisches Umschalten> zwischen den Modi, dynamisches Weiterschalten des Output-Compare, ...> [...]> Genau diese kreativen (und genialen) Verwendungen der vielfältigen> Möglichkeiten der Hardware kriegst du nie in ein Objekt-Modell.
Man muß nicht alles in Klassen und Objektmodelle stopfen. Und mit einer
C++-Bibliothek, die auf der AVR-Libc aufbaut, steht deren Funktionalität
auch weiterhin uneingeschränkt zur Verfügung.
> Willst du das alles C++-mäßig simplifizieren
Entschuldige, darum geht es doch gar nicht. Es reicht doch schon aus,
die vielen "normalen", "unkreativen" Dinge les- und wartbarer zu machen.
Wenn Du Deine Hardware voll ausreizen und kreativ nutzen willst, kein
Problem: dann kannst Du C und sogar Assembler innerhalb von C++-Code
nutzen.
Aber wenn Du nur "normale" Sachen machen, und zum Beispiel einen Pin
wackeln willst, was sicherlich 80 oder sogar 90% der Anwendungsfälle
abdeckt: dann hilft C++, den Code besser zu organisieren.
> Schlimmstenfalls hast du dann ein mischmasch, das keiner mehr lesen und> verstehen kann.
Was meinst Du? C ist (weitestgehend) eine Untermenge von C++. Wer C++
benutzt, muß zwangsläufig C können. Könntest Du Deinen Einwand anhand
eines Codebeispiels aufzeigen?
Liebe Grüße,
Karl
Karl Käfer schrieb:> einen Pin> wackeln willst, was sicherlich 80 oder sogar 90% der Anwendungsfälle> abdeckt
Also bei mir ist das signifikant kleiner 10%
Karl Käfer schrieb:>> Schlimmstenfalls hast du dann ein mischmasch, das keiner mehr lesen und>> verstehen kann.>> Was meinst Du? C ist (weitestgehend) eine Untermenge von C++. Wer C++> benutzt, muß zwangsläufig C können. Könntest Du Deinen Einwand anhand> eines Codebeispiels aufzeigen?
Nehmen wir mal an ich hätte eine Wunderwuzzi-Timer-Klasse. Dann hab ich
einen "kreativen" Anwendungsfall, den die Klasse überhaupt nicht
abdeckt, und ich muss erst wieder an TCCR "rummachen". Das meine ich mit
MischMasch.
Hallo,
Karl Käfer schrieb:> Wenn das korrekt funktionieren würde, dann würde die Kompilatgröße nicht> explodieren, sobald man den Quellcode auf mehrere Übersetzungseinheiten> aufteilt -- aber sie tut es.
Da Ralf festgestellt hat, daß das nicht der Fall ist, und ich dies
anhand meines Codes verifizieren konnte, ist diese Aussage widerlegt.
Liebe Grüße,
Karl
Michael Reinelt schrieb:> Nehmen wir mal an ich hätte eine Wunderwuzzi-Timer-Klasse. Dann hab ich> einen "kreativen" Anwendungsfall, den die Klasse überhaupt nicht> abdeckt, und ich muss erst wieder an TCCR "rummachen". Das meine ich mit> MischMasch.
Wieso. TCCR wird als protected definiert und die Klasse
WunderwuzziWurschtel wird von Wunderwuzzi abgeleitet. Wers braucht, kann
es doch machen.
Icn bin gerade am Timer mit zwei Kanälen und es geht mir wie dem
Beamten:
1
Ein Beamter macht Urlaub auf einem Bauernhof. Der Bauer gibt ihm
2
was zu tun: „Hier sind zwei Schüsseln, eine große und eine kleine
3
und dort hinten ist ein Sack Kartoffeln. Sortieren Sie bitte die
4
großen Kartoffeln in die große Schüssel und die kleinen Kartoffeln
5
in die kleine!“ Nach einer Stunde kommt der Bauer wieder. Da sitzt
6
der Beamte vor seinen zwei Schüsseln. In der kleinen ist eine
7
kleine Kartoffel, in der großen ist eine große Kartoffel und in
8
der Hand hält er eine mittelgroße und fragt den Bauern: „Ist die
9
jetzt groß oder klein?“
Die Methoden für Kanal A und für Kanal B müssen unterschiedlich sein.
Mache ich nun zwei Methoden mit unterschiedlichen Bezeichnungen oder
eine gemeinsame mit einem Parameter und if / else?
Man kann sich mit diesem c++-Kram ganz schön aufhalten.
'if/else' ist marginal ineffizienter aber schneller global geändert.
Bei unterschiedlichen Bezeichnungen müsste man mit 'suchen/ersetzen'
arbeiten oder doch wieder mit #define arbeiten.
Ich überlege schon länger als der Beamte. :-(
Torsten C. schrieb:> Die Methoden für Kanal A und für Kanal B müssen unterschiedlich sein.
Wiso? Was ist beim einen anders als beim anderen? Kann man es nicht per
Template parameter lösen?
Nur mal so nebenbei: ZX,Y und Z sind Pointer-Register. Wenn man sie
nicht als solche benutzt, sondern z.B. XL als 8-Bit Wert, wie hier oft
zu sehen, dann sollte man es R26 nennen. Andernfalls setzt man sich dem
Vorwurf aus, die Programmfunktion verschleiern zu wollen. Du hast da ein
tolles Beispiel geliefert für das, was viele an ASM-Programmen stört.
Ein Programm, nach meinem Verständnis, soll im Source-Code die
Problemlösung beschreiben. Das kann man mit den schon zu sehenden
Beispielen sehr gut. Wenn ich in C++
1
Led7.toggle();
schreibe, dann kann ich in der entsprechenden Klasse die HW-Detail,
alter/neuer AVR, mit PIN-Toggle HW oder ohne versteckt. Einmal getestet,
ist das gegessen. Und ob der Compiler dann 0 oder n temp. Register
braucht um das umzusetzen, darüber haben sich andere schon den Kopf
zerbrochen.
Wenn es also wirklich Bedarf nach ASM gibt (wegen Timing, etc) dann muß
da für mich deutlich mehr Kommentar als Code stehen.
Gratulation, Du hast meinen Vorurteil bestätigt. BTW, ich programmieren
kleine bis ganz große Kisten nun seit 35Jahren (und lebe gut davon), da
war viel Zeit aus Fehlern zu lernen.
chris_ schrieb:>>Led7.toggle();>> Hmm ... das hier vielleicht:>> http://playground.arduino.cc/Code/DigitalToggle
Ein schönes Beispiel wie man es nicht machen sollte ...
void digitalToggle(uint8_t P)
{
*portInputRegister(digitalPinToPort(P)) = digitalPinToBitMask(P);
}
Ich gehe jetzt mal davon aus, das wir einen Ausgang Toggeln wollen und
das der Code irgendwie funktioniert ...
portInputRegister(digitalPinToPort(P))
// das liefert uns die Adresse eines Ausganges ?
*portInputRegister(..) = digitalPinToBitMask(P) // das toggelt ?
void digitalToggle(uint8_t P)
// das funktioniert auf einem ARM ?
Hans-Georg Lehnard schrieb:> void digitalToggle(uint8_t P)> {> *portInputRegister(digitalPinToPort(P)) = digitalPinToBitMask(P);> }
Hmm. Könnte ich mir jetzt was darunter vorstellen. Schlimm finde ich das
nicht.
Außer:
PINx beschreiben zum Umschalten, ist jetzt eben 'die allerneueste Mode'
;-)
Funktioniert aber nicht immer. (Ich lass das erstmal.)
Ralf G. schrieb:> Hans-Georg Lehnard schrieb:>> void digitalToggle(uint8_t P)>> {>> *portInputRegister(digitalPinToPort(P)) = digitalPinToBitMask(P);>> }>> Hmm. Könnte ich mir jetzt was darunter vorstellen. Schlimm finde ich das> nicht.> Außer:> PINx beschreiben zum Umschalten, ist jetzt eben 'die allerneueste Mode'> ;-)> Funktioniert aber nicht immer. (Ich lass das erstmal.)
Für dich ist das völlig normal, das man eine Funktion, die einen Apfel
zurückliefern soll, "GibMirEineBirne" tauft und das das alles so oder so
nur Modeerscheinungen sind ?
Für mich ist der Thread damit auch erledigt ...
Hans-Georg Lehnard schrieb:> Ralf G. schrieb:>> Hans-Georg Lehnard schrieb:>>> void digitalToggle(uint8_t P)>>> {>>> *portInputRegister(digitalPinToPort(P)) = digitalPinToBitMask(P);>>> }>>>> Hmm. Könnte ich mir jetzt was darunter vorstellen. Schlimm finde ich das>> nicht.>> Außer:>> PINx beschreiben zum Umschalten, ist jetzt eben 'die allerneueste Mode'>> ;-)>> Funktioniert aber nicht immer. (Ich lass das erstmal.)>> Für dich ist das völlig normal, das man eine Funktion, die einen Apfel> zurückliefern soll, "GibMirEineBirne" tauft und das das alles so oder so> nur Modeerscheinungen sind ?
Hier wird doch nichts geliefert!?
Hier wird nur was gemacht.
'_void_ digitalToggle(uint8_t P)' heißt für mich: 'Digitales Umschalten
von...'
Wenn jetzt in 'P' Port und Pin codiert ist (Hi/Low im Byte) dann holt
sich
'digitalPinToPort(P)' die Portadresse, 'digitalPinToBitMask(P)' die
Pinmaske, ... '*portInputRegister' ..., hmm, hätte ich jetzt mit so
einer Konstruktion verglichen: '_SFR_MEM8(sfr_regs::_pin)'
Und zum Schluss wird sowas wie 'PORTB = 1 << 6' draus.
> Ralf G. schrieb:> PINx beschreiben zum Umschalten, ist jetzt eben 'die allerneueste Mode'> ;-)> Funktioniert aber nicht immer. (Ich lass das erstmal.)
Das würde ich dann noch mal hervorheben wollen:
->> Funktioniert aber nicht immer. <<-
Gerade weil das "nicht immer funktioniert", ist es gut eine Template
Klasse zu haben, die weiß, wann es geht und die der Compiler zu den 1..3
AVR-Opcodes reduziert, die jeweils gebraucht werden.
Ralf G. schrieb:> Hier wird doch nichts geliefert!?> Hier wird nur was gemacht.> '_void_ digitalToggle(uint8_t P)' heißt für mich: 'Digitales Umschalten> von...'> Wenn jetzt in 'P' Port und Pin codiert ist (Hi/Low im Byte) dann holt> sich> 'digitalPinToPort(P)' die Portadresse, 'digitalPinToBitMask(P)'
Kann man sich ja noch vorstellen
die
> Pinmaske, ... '*portInputRegister' ..., hmm, hätte ich jetzt mit so> einer Konstruktion verglichen: '_SFR_MEM8(sfr_regs::_pin)'>
*portInputRegister(..) ist eine Funktion und die hat einen Pointer als
Rückgabe der dereferenziert wird ... Mir ist schon klar was da gemacht
wird aber warum packe ich da das wort input in den Funktionsnamen.
> Und zum Schluss wird sowas wie 'PORTB = 1 << 6' draus.>>> Funktioniert aber nicht immer. (Ich lass das erstmal.)> Das würde ich dann noch mal hervorheben wollen:> ->> Funktioniert aber nicht immer. <<-
PORTB = 1 << 6' toggelt niemals einen Pin auch nicht manchmal
Das setzt bit6 auf 1 und alle anderen Bits auf 0.
Hans-Georg Lehnard schrieb:> *portInputRegister(..) ist eine Funktion und die hat einen Pointer als> Rückgabe der dereferenziert wird ... Mir ist schon klar was da gemacht> wird aber warum packe ich da das wort input in den Funktionsnamen.
Weil das Ding die Adresse von PINx liefert, nicht von PORTx.
Hans-Georg Lehnard schrieb:> PORTB = 1 << 6' toggelt niemals einen Pin auch nicht manchmal
Hat ja auch keiner behauptet.
Aber PINB = 1 << 6 toggelt auf neueren AVRs einen Pin.
Jörg Wunsch schrieb:> Hans-Georg Lehnard schrieb:>> PORTB = 1 << 6' toggelt niemals einen Pin auch nicht manchmal>> Hat ja auch keiner behauptet.>> Aber PINB = 1 << 6 toggelt auf neueren AVRs einen Pin.
Ok, danke das ist mir neu und bisher noch bei keinen anderen MC
begegnet.
Und ich dachte auch immer Arduino kennt nicht nur neue Avrs ...
Hmm ich spare bei dem Toggle Befehl mit dem Input Pin Register 2Byte im
Flash und 2 Takte während der Laufzeit dafür handle ich mir etwas nicht
portables in einer "portablen" Lib ein.
Kann man das wenigstens beim AVR mit
#if _AVR_ARCH_ >= XXX abfangen ?
Moby AVR schrieb im Beitrag #3995376:
> Um die geht es aber hier nicht, sondern um einfache Mikrocontroller.
Als wir angefangen haben, waren die Computer in der 10000 DM Klasse so
groß wie heutigen Mikrocontroller. Jede Sprache hat ihre Berechtigung.
Nur hier geht es nicht um AS sondern um C++.
Konrad S. schrieb:> Weil das Ding die Adresse von PINx liefert, nicht von PORTx.
Ja, verdammt. :-( ich meinte ja auch PINx (kleiner Schreibfehler...)
Ralf G. schrieb:> PINx beschreiben zum Umschalten, ist jetzt eben 'die allerneueste Mode'> ;-)
Hans-Georg Lehnard schrieb:> Hmm ich spare bei dem Toggle Befehl mit dem Input Pin Register 2Byte im> Flash und 2 Takte während der Laufzeit dafür handle ich mir etwas nicht> portables in einer "portablen" Lib ein.>> Kann man das wenigstens beim AVR mit> #if AVR_ARCH >= XXX abfangen ?
Also ich ignoriere das erstmal :-)
Ralf G. schrieb:> Ja, verdammt. :-( ich meinte ja auch PINx (kleiner Schreibfehler...)
Und auch das solltest du zurücknehmen ..
> Und zum Schluss wird sowas wie 'PORTB = 1 << 6' draus.
wenn du 'PINB = 1 << 6' meinst ...
Tu das nie wieder ich könnte es dir übel nehmen ;)
Hallo Jörg,
Jörg Wunsch schrieb:> Hans-Georg Lehnard schrieb:>> PORTB = 1 << 6' toggelt niemals einen Pin auch nicht manchmal>> Hat ja auch keiner behauptet.>> Aber PINB = 1 << 6 toggelt auf neueren AVRs einen Pin.
Was genau heißt in diesem Zusammenhang "neuere AVRs"?
Liebe Grüße,
Karl
Hallo Karl,
wenn du noch dabei bist eine Lib zu bauen würde ich solche
"Spezialitäten" ehrlich gesagt nicht berücksichtigen und den portablen
Weg wählen. Sonst hast du wirklich ein Fass ohne Boden. Ähnliches gilt
auch für den Pull up der hat mal ein eigenes Register (PUE) dann wird er
wieder über das PORTx Register eingeschaltet.
Das Problem dabei ist du musst nach jeweiligen Chip unterscheiden und
auch innerhalb eines Chips funtioniert das nur wenn der PIN als
digitaler Ausgang benutzt wird. Wenn der Pin z.B. als Timer Ausgang
konfiguriert ist funktioniert das nicht mehr.
Falls ich die Datenblätter falsch verstanden habe bitte korrigieren.
Die Logik von Atmel ist:
Ein "ReadOnlyRegister" ist ein Register, wenn man da was reinschreibt
ändert sich zwar nichts in diesem Register aber in einem anderen kann
das manchmal der Fall sein.
Wenn du eine Anwendung wie den Transistortester schreibts, der bei der
Kapazitätsmessung Ladungsimpulse definierter Länge auf den Kondensator
gibt, kann das Vorteile bringen weil es die Auflösung erhöht, aber für
eine LED blinken zu lassen ist das völlig egal ob die 2 Takte länger
braucht oder nicht.
Und LED blinken lassen werden die Hauptanwender deiner Lib sein.
Hans-Georg Lehnard schrieb:> Das Problem dabei ist du musst nach jeweiligen Chip unterscheiden und> auch innerhalb eines Chips funtioniert das nur wenn der PIN als> digitaler Ausgang benutzt wird. Wenn der Pin z.B. als Timer Ausgang> konfiguriert ist funktioniert das nicht mehr.
Man kann ja eine toogle Methode zur verfügung stellen mit einer
weitgehend allgemeinen Lösung. Und dann die Speziallösungen mit dem
Präprozessor zugänglich machen. Das ist ja das schöne an einer
Abstraktionsschicht im Vergleich mit dem direkten Registerhandling.
Hallo Hans-Georg,
Hans-Georg Lehnard schrieb:> Hmm ich spare bei dem Toggle Befehl mit dem Input Pin Register 2Byte im> Flash und 2 Takte während der Laufzeit dafür handle ich mir etwas nicht> portables in einer "portablen" Lib ein.
Was ist eine Abstraktionsschicht?
Liebe Grüße,
Karl
Hallo Konrad,
Konrad S. schrieb:> Hans-Georg Lehnard schrieb:>> Kann man das wenigstens beim AVR mit>> #if AVR_ARCH >= XXX abfangen ?>> Kaum, denn es kann immer wieder mal was Neues dazukommen.
Bitte korrigiere mich, wenn ich etwas Falsches sage, aber wenn mich
meine Erinnerung nicht trügt, macht man etwas mit solchen Bibliotheken,
das man "Pflege" nennt. ;-)
> Übrigens ... bei den ATxmega-Controllern sieht's nochmal anders aus.
Ja... äh, und?
Liebe Grüße,
Karl
@Karl Käfer
Mit der Abfrage von AVR_ARCH erfährt man etwas über den Befehlssatz,
nicht über Peripherie-Eigenschaften. Abfragen (speziell
Vergleichsoperatoren wie >= usw.) lassen sich zuverlässig nur für
diejenigen Eigenschaften auf ein Makro anwenden, für die das Makro
designt wurde. Mag sein, dass einige Peripherie-Eigenschaften mit
AVR_ARCH korrespondieren, aber ich halte das nicht für eine zugesicherte
Eigenschaft. Die Bibliotheks-Pflege müsste für jeden neu hinzukommenden
Controller untersuchen, ob die bisherigen Annahmen bezüglich AVR_ARCH
und Peripherie-Eigenschaften noch zutreffen. Apropos ... noch sehe ich
so eine Bibliothek in weiter Ferne - wenn dieses verschwommene Pünktchen
am Horizont überhaupt eine Bibliothek ist, kein Fatamorgähnchen. ;-)
Karl Käfer schrieb:> Ja... äh, und?
Nun, die ATxmega-Ports weisen erhebliche Unterschiede zu den
ATtinys/ATmegas auf, sowohl hinsichtlich Konfiguration als auch
bezüglich Benutzung. Die Ports lassen sich ausgehend von ihrer
jeweiligen Basisadresse über eine Struktur ansprechen, eine zugesicherte
Eigenschaft.
Hallo Hans-Georg,
Hans-Georg Lehnard schrieb:> wenn du noch dabei bist eine Lib zu bauen würde ich solche> "Spezialitäten" ehrlich gesagt nicht berücksichtigen und den portablen> Weg wählen. Sonst hast du wirklich ein Fass ohne Boden. Ähnliches gilt> auch für den Pull up der hat mal ein eigenes Register (PUE) dann wird er> wieder über das PORTx Register eingeschaltet.
In meinen Partdescription-XML-Dateien, 194 Stück an der Zahl, gibt es
139 ATtiny und ATmega, welche ich für mich zunächst einmal als
Zielplattform festgelegt habe. Von diesen 139 Tinys und Megas haben
insgesamt 7 ein PUE[ABC]-Register und insgesamt 29 können einen Pin
mittels Beschreibens des PIN-Registers umschalten. Dafür arbeite ich
derzeit an einem kleinen Codegenerator, der aus diesem XML dann
Präprozessor-Code generiert.
> Das Problem dabei ist du musst nach jeweiligen Chip unterscheiden und> auch innerhalb eines Chips funtioniert das nur wenn der PIN als> digitaler Ausgang benutzt wird. Wenn der Pin z.B. als Timer Ausgang> konfiguriert ist funktioniert das nicht mehr.
Wenn ich vor jedem "toggle()" testen will, daß der Pin nicht für Timer
konfiguriert ist, lande ich wieder bei Arduino. Die machen das IIRC so,
und für deren anvisierte Zielgruppe ist es auch absolut sinnvoll.
Wie oben schon einmal erwähnt, ist das aber eine philosophische Frage.
Nach meiner Auffassung ist es die wichtigste Aufgabe einer Bibliothek,
Dinge zu ermöglichen, und nicht, sie zu verhindern. Deswegen will ich
mögliche Fehler höchstens dann abfangen, wenn es nichts kostet. Damit
möchte ich maximale Effizienz und Flexibilität erreichen.
Wer es anders haben möchte, ist nicht meine Zielgruppe und hat mit
Arduino eine funktionierende, aber weniger flexible und effiziente
Alternative.
Liebe Grüße,
Karl
Karl Käfer schrieb:> Hallo Hans-Georg,> Was ist eine Abstraktionsschicht?
Das ist genau das, was dieser Diskussion fehlt ;)
Ich zittiere mal Wikipedia ...
Eine Abstraktion bezeichnet meist den induktiven Denkprozess des
Weglassens von Einzelheiten und des Überführens auf etwas Allgemeineres
oder Einfacheres.
Wir verzetteln uns hier immer wieder in Kleinigkeiten und in die Tiefen
der Avr Bitpopelei.
Dem Hobbyanwender ist diese Diskussion völlig wurscht, der bestellt sich
den passenden Chip, programmiert ihn in seine Lieblingssprache, und
damit ist das Problem erledigt.
Der gewerbliche Anwender, der mindestens 10 Jahre Ersatzteile liefern
muss kann das leider nicht so einfach tun ..
Karl Käfer schrieb:> Hallo Hans-Georg,
...
> Nach meiner Auffassung ist es die wichtigste Aufgabe einer Bibliothek,> Dinge zu ermöglichen, und nicht, sie zu verhindern.
Kann man so sehen ...
> Deswegen will ich mögliche Fehler höchstens dann abfangen, wenn es nichts >
kostet. Damit möchte ich maximale Effizienz und Flexibilität erreichen.
>> Wer es anders haben möchte, ist nicht meine Zielgruppe>
Genau so ist es du definierst dein Sytem (Lib) und entscheidest was es
kann und was nicht.
Über Geschmack lässt sich nicht streiten.
Hans-Georg Lehnard schrieb:> du definierst dein Sytem (Lib) und entscheidest was es> kann und was nicht.
… wobei ich Karl Käfers 'Geschmack' teile. Ich bin - wie gesagt - gerade
am Timer und komme auch nur viel langsamer voran als Karl (viele
Baustellen, pro Tag nur mal 1-2h Zeit, …).
Eine 'mikrocontroller.net-Lib' darf man das sicher nicht nennen, wenn es
keinen Konsens gibt. Ich versuche möglichst nach der gleichen
Philosophie wie Karl weiter zu machen. Wenn ich seine GPIOs nehme,
passt's wenigstens.
Karl Käfer schrieb:> Dafür arbeite ich> derzeit an einem kleinen Codegenerator, der aus diesem XML dann> Präprozessor-Code generiert.
Cool. :-)
Hallo Hans-Georg,
Hans-Georg Lehnard schrieb:> Karl Käfer schrieb:>> Hallo Hans-Georg,>> Was ist eine Abstraktionsschicht?>> Das ist genau das, was dieser Diskussion fehlt ;)
Was ich sagen wollte, ist: für spezifische Details wie PUE-Register oder
die Frage, wie genau die Controller-Hardware einen Pin toggeln kann, hat
der liebe Gott (oder jemand anderes) die Abstraktionsschicht erfunden.
Wenn der GPIO-Pin die Methoden "toggle()" und "setPullup()" anbietet,
ist es für den Benutzer der Bibliothek gleichgültig, wie sie intern
implementiert sind.
> Wir verzetteln uns hier immer wieder in Kleinigkeiten und in die Tiefen> der Avr Bitpopelei.
Gerade diese "Avr Bitpopelei" halte ich aber für extrem wichtig, da sie
die Grundlage für etliche andere Dinge ist. Wer diese nicht sauber
hinbekommt, wird sich schwer tun, damit einen performanten, effizienten
Treiber für zum Beispiel ein Display hinzubekommen.
Liebe Grüße,
Karl
Hallo Torsten,
Torsten C. schrieb:> Über Geschmack lässt sich nicht streiten.
Doch, natürlich kann man das. Es bringt nur nichts, weil man nie zu
einem Ergebnis kommt.
> Hans-Georg Lehnard schrieb:>> du definierst dein Sytem (Lib) und entscheidest was es>> kann und was nicht.>> … wobei ich Karl Käfers 'Geschmack' teile. Ich bin - wie gesagt - gerade> am Timer und komme auch nur viel langsamer voran als Karl (viele> Baustellen, pro Tag nur mal 1-2h Zeit, …).
Ehrlich gesagt habe ich nicht die geringste Idee, wie man die Timer der
AVRs in C++ abbilden könnte.
> Karl Käfer schrieb:>> Dafür arbeite ich>> derzeit an einem kleinen Codegenerator, der aus diesem XML dann>> Präprozessor-Code generiert.>> Cool. :-)
Die ersten beiden Generatoren habe ich hier einmal angehängt, aber der
Code für die USARTS gefällt mir noch nicht so richtig. Für Vorschläge
und Ideen werden bin ich gerne offen.
Liebe Grüße,
Karl
Hans-Georg Lehnard schrieb:> Hmm ich spare bei dem Toggle Befehl mit dem Input Pin Register 2Byte im> Flash und 2 Takte während der Laufzeit dafür handle ich mir etwas nicht> portables in einer "portablen" Lib ein.
Ganz so einfach ist das nicht, denn read-modify-write ist nicht atomar.
Hat man eine ISR, die einen anderen Pin an demselben Port ändert, geht
das irgendwann schief. Es sei denn, man denkt dran, das ganze mit
ATOMICBLOCK zu umschließen.
Zum eigentlichen Thema:
Ich programmiere seit einiger Zeit meine XMegas objektorientiert. Das
hat mehrere Gründe:
Erst einmal ist das für mich persönlich die Art, wie ich am besten
Programmieraufgaben löse. Das ist rein subjektiv und gilt natürlich
nicht allgemein.
Bei mehrfach vorhandener, identischer Hardware (z.B. bis zu 8 USARTs
beim XMega) stösst die herkömmliche Programmierung mit einer festen
Kodierung der Hardware definitiv an ihre Grenzen. Eine dynamische
Bindung der Hardware an jeweils eine Instanz einer Klasse zur Laufzeit
ist da deutlich einfacher und flexibler.
Ich programmiere auch häufiger Benutzerschnittstellen auf grafischen
LCDs. Mit Hilfe der Polymorphie und Objekten, die sich selbst zeichnen,
kann man da meiner Meinung nach viel übersichtlicher und flexibler seine
Schnittstelle aufbauen.
Insgesamt ist meine Erfahrung, dass einfache, aber dafür zeitkritische
Steueraufgaben meist besser klassisch funktional/prozedural gelöst
werden sollten. Bei zeitunkritischen Steueraufgaben mit
Benutzerschnittstelle hat dafür der objektorientierte Ansatz Vorteile.
Detlev T. schrieb:> Hans-Georg Lehnard schrieb:>> Hmm ich spare bei dem Toggle Befehl mit dem Input Pin Register 2Byte im>> Flash und 2 Takte während der Laufzeit dafür handle ich mir etwas nicht>> portables in einer "portablen" Lib ein.>> Ganz so einfach ist das nicht, denn read-modify-write ist nicht atomar.> Hat man eine ISR, die einen anderen Pin an demselben Port ändert, geht> das irgendwann schief. Es sei denn, man denkt dran, das ganze mit> ATOMICBLOCK zu umschließen.
Das ist natürlich richtig. Aber wie oft kommt es vor, daß ich auf ein
und denselben Pin in der Main-Loop und einer ISR zugreife?
> Zum eigentlichen Thema:>> Ich programmiere seit einiger Zeit meine XMegas objektorientiert. Das> hat mehrere Gründe:>> Erst einmal ist das für mich persönlich die Art, wie ich am besten> Programmieraufgaben löse. Das ist rein subjektiv und gilt natürlich> nicht allgemein.
Doch, eigentlich schon. Wer einmal den Komfort von objektorientierter
Programmierung kennengelernt hat, will ihn nicht mehr missen... ;-)
> Bei mehrfach vorhandener, identischer Hardware (z.B. bis zu 8 USARTs> beim XMega) stösst die herkömmliche Programmierung mit einer festen> Kodierung der Hardware definitiv an ihre Grenzen. Eine dynamische> Bindung der Hardware an jeweils eine Instanz einer Klasse zur Laufzeit> ist da deutlich einfacher und flexibler.>> Ich programmiere auch häufiger Benutzerschnittstellen auf grafischen> LCDs. Mit Hilfe der Polymorphie und Objekten, die sich selbst zeichnen,> kann man da meiner Meinung nach viel übersichtlicher und flexibler seine> Schnittstelle aufbauen.>> Insgesamt ist meine Erfahrung, dass einfache, aber dafür zeitkritische> Steueraufgaben meist besser klassisch funktional/prozedural gelöst> werden sollten. Bei zeitunkritischen Steueraufgaben mit> Benutzerschnittstelle hat dafür der objektorientierte Ansatz Vorteile.
Nunja... man kann auch in C sehr viele OO-Konzepte umsetzen, aber das
ist dann eben nicht so übersichtlich. Elecia White hat da in "Making
Embedded Systems" viele gute Anregungen und Tips. Auf Mikrocontrollern
kann man es ja machen. ;-)
Andererseits bin ich jedoch überzeugt, daß man mit einer guten
C++-Library ein Werkzeug haben und viele komfortable Konzepte nutzen
kann, ohne dabei an Effizienz gegenüber C einzubüßen. Natürlich kann man
kritische Dinge in Assembler machen -- aber da sind C und C++ doch kein
Hindernis?!
Liebe Grüße,
Karl
Karl Käfer schrieb:> Das ist natürlich richtig. Aber wie oft kommt es vor, daß ich auf ein> und denselben Pin in der Main-Loop und einer ISR zugreife?
Nee, nee, nicht den selben Pin. Es reich(t|en) schon ein/ mehrere
andere(r) Pin(s) am selben Port!
Detlev T. schrieb:> Bei mehrfach vorhandener, identischer Hardware (z.B. bis zu 8 USARTs> beim XMega) stösst die herkömmliche Programmierung mit einer festen> Kodierung der Hardware definitiv an ihre Grenzen.
Warum?
Detlev T. schrieb:> Bei mehrfach vorhandener, identischer Hardware (z.B. bis zu 8 USARTs> beim XMega) stösst die herkömmliche Programmierung mit einer festen> Kodierung der Hardware definitiv an ihre Grenzen. Eine dynamische> Bindung der Hardware an jeweils eine Instanz einer Klasse zur Laufzeit> ist da deutlich einfacher und flexibler.
Richtig ist sicherlich, dass die Bindung der Hardware an jeweils eine
Instanz einer Klasse besser lesbar ist:
1
serial1.print(constchar*str);
Aber bevor nun wieder 'mit ANSI C geht das auch' kommt:
Die herkömmliche Programmierung ist weniger 'schön' und Fehler des
Programmierers rutschen schneller mal durch.
chris_ schrieb:> Der Vorteil: bekannte Funktionsnamen, viele Codebeispiele
Man sollte sich m.E. daran orientieren, wenn man was effizientes neu
aufbauen möchte. Immer wird das sicher nicht gehen.
Torsten C. schrieb:> Richtig ist sicherlich, dass die Bindung der Hardware an jeweils eine> Instanz einer Klasse besser lesbar ist
Mit
ldi ZL,low(Var) ;Pointer auf Variable im SRAM
ldi ZH,high(Var)
rcall serial1out
ist auch alles ganz verständlich gesagt.
Ganz ohne zusätzlichen Bedarf an Klassen und deren Instanzen.
> Die herkömmliche Programmierung ist weniger 'schön' und Fehler des> Programmierers rutschen schneller mal durch
Asm formuliert klar, einfach, eindeutig.
Die schweren Fehler sind sprachunabhängig sowieso eher strategischer
bzw. systemarchitektonischer Natur oder durch Nichttesten aller
möglichen realen Inputs bedingt.
Weniger schön finde ich wiederum
> serial1.print(const char * str);
und man weiß ja, das Instruktionen und Ausdrücke in C noch ganz andere,
viel extremere Formen annehmen können.
Torsten C. schrieb:> Die herkömmliche Programmierung ist weniger 'schön' und Fehler des> Programmierers rutschen schneller mal durch.
Um das zu verfeinern:
Herkömmliche Programmierung (gilt für ANSI-C genau so wie für Assembler)
erlaubt es nicht, dass unerlaubte Parameter-Typen als Parameter
übergeben werden. Enums sind z.B. wie Integer.
Es geht nicht nur um 'Fehler des Programmierers'^^, sondern auch um
Bequemlichkeit: Die IDE schlägt nur Parameter, Methoden usw. vor, die
auch compilierbar sind, also z.B. möglichst keine 'private' Member
außerhalb der Klasse. Bei C# ist das z.B. so.
Um nochmal den 'Guru' zu zitieren:
"fundamental design goal: design violations should not compile".
Die Steigerung wäre:
"the IDE should warn at design violations".
Das gehört eher zum Thema:
"C++ auf einem MC, welche Vorteile hätte das?"
Ich hoffe, es passt trotzdem!
chris_ schrieb:> Das Serial.print ist polymorph
Du meinst wahrscheinlich das richtige.
Es geht Dir hier vermutlich nicht um Polymorphie mit der Bestimmung der
Klasse zur Laufzeit. Das würde VTables und Performance-Nachteile
bringen.
Funktionen und Methoden mit gleichen Bezeichnern im gleichen Namensraum
und unterschiedlichen Signaturen sind aber auch was, was die Lesbarkeit
des Codes m.E. deutlich verbessert. Das sehe ich auch so, Chris.
Der Vorteile von Namensräumen wurde ja auch schon genannt, wobei einige
IDEs diesen Aspekt m.E. noch nicht perfekt im Griff haben.
>Es geht Dir hier vermutlich nicht um Polymorphie mit der Bestimmung der>Klasse zur Laufzeit. Das würde VTables und Performance-Nachteile>bringen.
Leider weiß ich nicht, ob Polymorphismus in C++ immer VTables nach sich
zieht.
Poylmorphie wird im englischen Wikpedia-Artikel an einem Python Beispiel
gezeigt, indem es so etwas wie VTables vermutlich nicht gibt. Ich denke
das ist eine Implementierungsdetail von C++ was aber genauso gut zur vom
Compiler zur Compile-Time ohne VTables zu lösen wäre.
http://en.wikipedia.org/wiki/Polymorphism_%28computer_science%29
Moby schrieb:> Asm formuliert klar, einfach, eindeutig.
Bitte eröffne deinen eigenen Assembler-Evangelismus-Thread.
Deine diesbezüglichen Auslassungen sind in diesem Thread unerwünscht.
> Serial.print(78) gives "78"> Serial.print(1.23456) gives "1.23"> Serial.print('N') gives "N"> Serial.print("Hello world.") gives "Hello world.">Es geht Dir hier vermutlich nicht um Polymorphie mit der Bestimmung der>Klasse zur Laufzeit.
Nachdem ich mir den Wikipedia Artikel durchgelesen habe
http://de.wikipedia.org/wiki/Tabelle_virtueller_Methoden
bin ich der Meinung, dass für den obigen Code keine VTables gebraucht
werden, da alle Argumente zur Laufzeit bekannt sind. Der Compiler kann
z.B für
Serial.print(1.23456) gives "1.23"
gleich die passende Funktion
Serial.print(float f)
kompilieren.
Ich nehme mal an und hoffe, dass es der gcc auch so macht.
Hallo chris_,
chris_ schrieb:> bin ich der Meinung, dass für den obigen Code keine VTables gebraucht> werden, da alle Argumente zur Laufzeit bekannt sind. Der Compiler kann> z.B für>> Serial.print(1.23456) gives "1.23">> gleich die passende Funktion>> Serial.print(float f)>> kompilieren.> Ich nehme mal an und hoffe, dass es der gcc auch so macht.
Das ist korrekt. "Serial.print(float f)" hat eine andere
Funktionssignatur als "Serial.print(char c)", und darum weiß der
Compiler auch ohne VTables, was er aufrufen muß. Der Compiler ist
übrigens die C++-Version des gcc.
Liebe Grüße,
Karl
>Das ist korrekt.
Hallo Karl,
das freut mich zu hören. Ich habe mich bis gerade eben noch nie so
richtig mit dem Thema VTables befasst. Der Begriff wird aber immer gerne
mal wieder fallen gelassen wie eine Art "Mysterium". Das richtige
Verständnis dafür scheint für viele schwierig.
Das scheint mir auch für den Wikipedia-Artikel zu gelten. Da steht:
"Die Tabelle virtueller Methoden (engl.: virtual method table oder
virtual function table, kurz VMT, VFT, vtbl oder vtable) ist ein Ansatz
von Compilern objektorientierter Programmiersprachen um dynamisches
Binden umzusetzen. Das ist unter anderem Grundvoraussetzung für
Vererbung und Polymorphie."
Eigentlich müsste es präzisser heisen
Das ist unter anderem Grundvoraussetzung für Vererbung wenn die Objekte
zur Compile-Zeit noch nicht bekannt sind.
Karl Käfer schrieb:> "Serial.print(float f)" hat eine andere Funktionssignatur> als "Serial.print(char c)"
Genau. Das ist alles Richtig, danke. Ich wollte nur sagen, dass
unterschiedliche Funktionssignaturen auch ohne Klassen, Polymorphie und
VTables in C++ gehen, aber nicht in K&R-C, ASM, …
Dann sind wir uns mal wieder einig. :-)
Sorry, falls ich für Verwirrung gesorgt haben sollte.
chris_ schrieb:> bin ich der Meinung, dass für den obigen Code keine VTables gebraucht> werden, da alle Argumente zur Laufzeit bekannt sind.chris_ schrieb:> Leider weiß ich nicht, ob Polymorphismus in C++ immer VTables nach sich> zieht.
Ich habe mir in C ein Interface / Vtable selber geschrieben.
Da sieht man gut, wie der Compiler optimier kann und wann du Overhead
hast.
Was passiert:
a) Compiler inlined processDataId100
mehr Code, dafür ist der Funktionszeiger auf doStart bekannt und die
Vtable wird wegoptimiert. Der Code von doStart, etc. kann geinlined
werden.
b) Compiler lässt processDataId100 stehen
die Funktion kennt die Funktionszeiger nicht. Der Zeiter wird aus der
Vtable geladen. Statt einer Konstanten wird der Inhalt der Vtable als
Sprungadresse gelesen. Der Code von doStart, etc. ist unbekannt und kann
nicht optimiert werden.
Wie man sieht liegt der Nachteil von Polymorphismus zur Laufzeit in der
mangelnden Optimierungsmöglichkeit, wenn er nicht aufgelöst wird.
Trivialen Funktionsaufrufe wie doEnd(), können nicht
wegoptimiert/geinlined werden. Im Vergleich hat die Zeigerarithmetik
meist weniger Aufwand. Dafür entsteht weniger Code, falls doEnd(), etc
sowieso nicht geinlined werden (große Funktionen).
in C++ müsste das irgendwie so aussehen:
1
struct Base{
2
virtual void doStart(int ID)=0;
3
virtual void doData(const void * Data, int length)=0;
4
virtual void doEnd()=0;
5
}
6
7
struct sendData_t: public Base {/*Implementierung*/};
8
sendData_t sendData;
9
struct receiveData_t: public Base{/*Implementierung*/};
PS: Dieselbe Funktion nehmen zu können, um Datenpakete zu
zusammenzustellen und wieder aufzudröseln, habe ich von BOOST (ich
glaube serialize) geklaut.
PSS: Man sollte im C++ Beispiel auch nicht mehr C-Arrays nehmen, sondern
std::array
http://de.cppreference.com/w/cpp/container/array
Grüße Felix
FelixW schrieb:> Man sollte im C++ Beispiel auch nicht mehr C-Arrays nehmen, sondern> std::array
Guter Hinweis, danke. :-)
FelixW schrieb:> Wie man sieht liegt der Nachteil von Polymorphismus zur Laufzeit in der> mangelnden Optimierungsmöglichkeit, wenn er nicht aufgelöst wird.
Ich habe keine zig verschiedenen Toolketten im Betrieb, um die
Assembler-Dateien zu analysieren. Macht es Sinn, in einer C++-Lib
Polymorphismus zu verwenden, der sich zur Compiler-Zeit auflösen lässt,
oder ist das zu 'unsicher'?
Beim Begriff "Polymorphismus" scheint es auch ein unterschiedliches
Verständnis zu geben.
Bei den oben genannten Funktionenen
> Serial.print(78) gives "78"> Serial.print(1.23456) gives "1.23"> Serial.print('N') gives "N"> Serial.print("Hello world.") gives "Hello world."
geht es um den in der Wikipedia als "Ad hoc polymorphism" bezeichneten
Typ:
http://en.wikipedia.org/wiki/Polymorphism_%28computer_science%29
Felix, wenn ich Dein Beispiel richtig verstehe, geht es Dir um den als
"Subtyping" bezeichneten Typ.
Torsten C. schrieb:> FelixW schrieb:>> Man sollte im C++ Beispiel auch nicht mehr C-Arrays nehmen, sondern>> std::array> Guter Hinweis, danke. :-)
Das ist nur ein wrapper für c arrays, Der die Initialisierung, etc.
unnötig erschwert.
> Polymorphismus zu verwenden, der sich zur Compiler-Zeit auflösen lässt,> oder ist das zu 'unsicher'?
Einfach die Basisklasse ausschlieslich verwenden, um davon klassen
abzuleiten, und kein virtual verwenden. Dann kann nichts passieren.
Daniel A. schrieb:> Einfach die Basisklasse ausschlieslich verwenden, um davon klassen> abzuleiten, und kein virtual verwenden. Dann kann nichts passieren.
Häää? Und dann werden die Member der abgeleiteten Klassen verwendet?
Falls das geht, würde ich sehr gern lernen, wie das geht.
Torsten C. schrieb:> Daniel A. schrieb:>> Einfach die Basisklasse ausschlieslich verwenden, um davon klassen>> abzuleiten, und kein virtual verwenden. Dann kann nichts passieren.>> Häää? Und dann werden die Member der abgeleiteten Klassen verwendet?>> Falls das geht, würde ich sehr gern lernen, wie das geht.
Du gibst dem compiler einfach keinen grund für ne vtable
1
//ungetestet
2
classbase{
3
public:
4
inlineinttest(){
5
return0;
6
}
7
};
8
classderived:publicbase{
9
inlineinttest(){
10
return1;
11
}
12
};
13
14
voidprintDerived(derived*x){
15
std::cout<<x.test()<<std::endl;// muss derived::test sein, weil nicht virtual
16
}
17
18
// dashier vermeiden:
19
// die Basisklasse ausschlieslich verwenden, um davon klassen abzuleiten
20
voidprintBase(base*x){
21
std::cout<<x.test()<<std::endl;// muss base::test sein, weil nicht virtual
22
}
23
24
intmain(){
25
derivedx;
26
printDerived(x);// gibt 1 aus
27
printBase(x);// gibt 0 aus, weil nicht virtual
28
}
Die Polymorphie ist so leicht eingeschränkt, aber zur compiletime stehen
alle Funktionsaufrufe fest, der compiler kann nichts in eine vtable
packen. Die programmierung wird so aber anspruchsfoller.
chris_ schrieb:> Felix, wenn ich Dein Beispiel richtig verstehe, geht es Dir um den als> "Subtyping" bezeichneten Typ.
ja
Daniel A. schrieb:> Das ist nur ein wrapper für c arrays, Der die Initialisierung, etc.> unnötig erschwert.
warum? Was geht nicht/nur umständlicher (bei welcher C++ Version).
Daniel A. schrieb:>> Polymorphismus zu verwenden, der sich zur Compiler-Zeit auflösen lässt,>> oder ist das zu 'unsicher'?> Einfach die Basisklasse ausschlieslich verwenden, um davon klassen> abzuleiten, und kein virtual verwenden. Dann kann nichts passieren.
Wenn der Compiler den bekannten Typ optimieren kann macht es keinen
Unterschied. Wenn nicht, dass hast du nicht funktionierenden code.
Ich rate davon ab!
Irgendwo weiter vorne gab es ein PDF. Es gibt (subtyping) Polymorphismus
zu
a) Kompilierzeit (mit templates)
b) Linkerzeit (mit templates und Instanzen)
c) Laufzeit (virtual)
chris_ schrieb:> Beim Begriff "Polymorphismus" scheint es auch ein unterschiedliches> Verständnis zu geben.>> Bei den oben genannten Funktionenen>>> Serial.print(78) gives "78">> Serial.print(1.23456) gives "1.23">> Serial.print('N') gives "N">> Serial.print("Hello world.") gives "Hello world.">> geht es um den in der Wikipedia als "Ad hoc polymorphism" bezeichneten> Typ:>> http://en.wikipedia.org/wiki/Polymorphism_%28computer_science%29
Danke für die Klarstellung
Vielleicht hilft dem besseren Verständnis:
Ad-hoc Polymorphismus heißt nichts anderes, als das der Kompiler die
Typen in den Funktionsnamen aufnimmt und damit keinen extra code
generiert. (genauso wie namespace) Die genaue Namensgebung ist vom
compiler abhängig. Ist Serial.print() nicht als "static" deklariert
sieht das dann so aus:
_Serial_print_int( &Serial, 78)
_Serial_print_float( &Serial, 1.23456)
_Serial_print_char( &Serial, 'N')
_Serial_print_pointer_to_char( &Serial, "Hello world.")
Damit kann man dann auch C++ Memberfunktionen von C-Code aus aufrufen
(allerdings dann Kompilerabhängig).
Hallo FelixW,
FelixW schrieb:> Ad-hoc Polymorphismus heißt nichts anderes, als das der Kompiler die> Typen in den Funktionsnamen aufnimmt und damit keinen extra code> generiert.
Der Compiler übernimmt nur die Argument-Typen in die Signatur, nicht die
Rückgabe-Typen. Daher ist:
FelixW schrieb:> Wenn der Compiler den bekannten Typ optimieren kann macht es keinen> Unterschied.
Genau da liegt dass Problem: Wenn mann bei meinem Beispiel derived::test
virtual machen würde, kann der Compiler zur Compiletime nicht wissen, ob
in einer anderen Compilationsunit eine classe von derived abgeleitet
wird, die die methode test überschreibt. Dass ist erst zur linkerzeit
bekannt, wenn keine pointer auf die Classen bei dynamisch nachgeladenen
Library Funktionen als Parameter oder Rückgabewerte existieren, wobei
dass der Compiler nicht wissen kann. Derartige Compileroptimierungen
halte ich für unwarscheinlich.
> Wenn nicht, dass hast du nicht funktionierenden code.
Diese aussage ist falsch. Es verhält sich nicht so wie bei gewönlicher
polymorphie, aber es funktioniert, so wie es im standard definiert
wurde.
> Ich rate davon ab!
Wenn alle beteiligten die Funktionsweise von Code ohne virtual
verstehen, und wenn sie wissen, was sie tuhen, sehe ich keine Probleme.
Ich habe den Thread interessiert mitgelesen und im Netz eine Library von
KonstantinChizhov gefunden, die für meine Kenntnisse noch einigermassen
nachvollziehbar ist.
Alexandra
Mcucpp - is a C++ hardware abstraction library for microcontrollers.
************************************************************************
The aim of the project is to make a high level but extremly efficient
C++ hardware abstraction framework for different microcontroller
families.
For latest version visit https://github.com/KonstantinChizhov/Mcucpp
************************************************************************
Hallo zusammen,
im Rahmen meiner C++-Spielchen stehe ich vor zwei Herausforderungen.
Zunächst frage ich mich derzeit, wie man eine Timer-Abstraktion
entwerfen könnte. Das Problem ist, daß sich die
Hardware-Implementierungen von Timern auf verschiedenen AVRs recht stark
unterscheiden, einerseits danach, wie alt der AVR ist, andererseits
haben die Timer einiger AVRs zusätzliche Funktionen. Eine Strategie zum
Umgang mit dem Problem könnte sein, zunächst nur einfache Timer auf den
neueren AVRs zu implementieren und weitere später über eine Weiche wie
in "avr/io.h" mit "#ifdef __AVR_ATmega[X]__ (...)" nachzurüsten. Das
hätte den Vorteil, daß jeweils eine korrekte Timer-Implementierung wie
im Datenblatt nutzbar wäre. Andererseits widerspricht das der Idee, über
mehrere Plattformen hinweg arbeiten zu können. Hat jemand eine kluge
Idee dazu?
Die zweite Herausforderung betrifft den GCC-Optimizer. Wenn ich eine
Klasse außerhalb der "main()"-Funktion instanziiere, beispielsweise um
einen Pin in einer ISR und außerhalb zu benutzen, wird das Kompilat
plötzlich beinahe um den Faktor zwei größer. Das ließe sich umgehen,
indem die Variable einfach in der ISR und der main()-Funktion
instanziiert würde, aber natürlich wäre das nicht sonderlich elegant.
Meine Frage ist nun: kann man den Optimizer des GCC irgendwie dazu
überreden, die Instanziierung einer Klasse außerhalb der main()-Funktion
besser zu optimieren?
Über Ideen und Anregungen würde ich mich freuen, solange diese darauf
verzichten können, Assembler oder C zu empfehlen... ;-)
Lieben Dank,
Karl
Karl Käfer schrieb:> kann man den Optimizer des GCC irgendwie dazu überreden, die> Instanziierung einer Klasse außerhalb der main()-Funktion besser zu> optimieren?
Ich versuche immer code unabhängig vom verwendeten compiler zu
erstellen. Ich sehe 3 möglichkeiten:
1) die klassen nicht Instanzieren
2) als constexpr declarieren
3) Das memorylayout der Classe wird dem in den speicher gemapten abbild
der peripherie exakt angepast. Wenn sich PORTx an speicherstelle ab
befindet, hat die portklasse eine grösse von einem byte, der einzige
member geisst pins, und die "Instanzierung" sieht so aus:
Karl Käfer schrieb:> Zunächst frage ich mich derzeit, wie man eine Timer-Abstraktion> entwerfen könnte. Das Problem ist, daß sich die> Hardware-Implementierungen von Timern auf verschiedenen AVRs recht stark> unterscheiden,
Ich fange das auch gerade erst an zu verstehen:
Programmiere gegen ein Interface, nicht gegen eine Implementierung.
Interface steht dabei für eine FUNKTION: Was soll passieren?
Implementierung steht für die vorhandenen Möglichkeiten. Was kann ich
programmieren / was kann mein Timer? Beides ist Grundverschieden.
Deine Schnittstelle sollte nur das Verhalten zur Verfügung stellen, was
dein Projekt braucht. Dann kannst du es leicht portieren.
Brauchst du andere Funktionen? -> Definiere eine neue Schnittstelle und
implementiere diese dann bzw. ändere bestehende Implementierungen ab.
Mögliche Interfaces:
- Interrupt Callback aller xx us
- Impulszähler im Zeitfenster
- PWM-Generator, 1 Phase
- PWM-Generator, 3 Phasen
- Was du noch gerade brauchst
Karl Käfer schrieb:> Die zweite Herausforderung betrifft den GCC-Optimizer. Wenn ich eine> Klasse außerhalb der "main()"-Funktion instanziiere, beispielsweise um> einen Pin in einer ISR und außerhalb zu benutzen, wird das Kompilat> plötzlich beinahe um den Faktor zwei größer.
Gib uns mal konkrete Details, was alles dazukommt. Sonst gibt es
Glaskugelraten (vor allem da wir deinen Code nicht kennen).
Karl Käfer schrieb:> Zunächst frage ich mich derzeit, wie man eine Timer-Abstraktion> entwerfen könnte. Das Problem ist, daß sich die> Hardware-Implementierungen von Timern auf verschiedenen AVRs recht stark> unterscheiden, einerseits danach, wie alt der AVR ist, andererseits> haben die Timer einiger AVRs zusätzliche Funktionen. Eine Strategie zum> Umgang mit dem Problem könnte sein, zunächst nur einfache Timer auf den> neueren AVRs zu implementieren und weitere später über eine Weiche wie> in "avr/io.h" mit "#ifdef __AVR_ATmega[X]__ (...)" nachzurüsten. Das> hätte den Vorteil, daß jeweils eine korrekte Timer-Implementierung wie> im Datenblatt nutzbar wäre. Andererseits widerspricht das der Idee, über> mehrere Plattformen hinweg arbeiten zu können. Hat jemand eine kluge> Idee dazu?
Ich würde mich von dem "eine Lib (Datei) für alles" Gedanken Lösen und
eine Datei pro Controller Familie anlegen.
Auserdem würde ich verschiedene Featurelevel definieren, die dann
bestimmte Funktionen zur Verfügung stellen.
z.B.:
Timer_Base: Einfacher Systemtimer, Zeit Einstellbar, ruf bei Interrupt
eine bestimmte Funktion aus
Timer_Level2: Wie Base + PWM Ausgabe
...
Damit liesen sich einige Probleme lösen. Und bei falls man
Beispielsweise auf einem Timer_Base Prozessor ein PWM Ausgeben will,
bekommt man eben eine Fehlermeldung, dass es nicht unterstützt wird.
Dann hat man die Möglichkeit, es einzufügen, oder es mit Timer_Base und
Softpwm zu umgehen.
Ein weitere Vorteil wäre, dass man auch entsprechende Tests schreiben
könnte und so alle Funktionen Testen kann, da eben genau Festgelegt ist,
wie sich eine Funktion zu verhalten hat.
Hallo Daniel,
Daniel A. schrieb:> Karl Käfer schrieb:>> kann man den Optimizer des GCC irgendwie dazu überreden, die>> Instanziierung einer Klasse außerhalb der main()-Funktion besser zu>> optimieren?>> Ich versuche immer code unabhängig vom verwendeten compiler zu> erstellen.
Das ist grundsätzlich immer eine gute Idee. Aber in diesem speziellen
Fall möchte ich mich gerne vor allem auf den GCC konzentrieren, weil es
für AVR nicht gar so viele C/C++-Compiler gibt und GCC sowohl unter
Linux, sowie dank Atmel Studio unter Windows der am weitesten
verbreitete Compiler für AVRs ist. Natürlich möchte ich, daß mein Code
auch mit anderen Compilern funktioniert, aber mein Anspruch ist ja, daß
meine Bibliothek eine ebenso effiziente Programmierung ermöglicht wie C
mit dem GCC als Referenz. Daher konzentriere ich mich bei Feinheiten wie
der Optimierung auf den GCC.
> Ich sehe 3 möglichkeiten:> 1) die klassen nicht Instanzieren> 2) als constexpr declarieren> 3) Das memorylayout der Classe wird dem in den speicher gemapten abbild> der peripherie exakt angepast. Wenn sich PORTx an speicherstelle ab> befindet, hat die portklasse eine grösse von einem byte, der einzige> member geisst pins, und die "Instanzierung" sieht so aus:>
1
>constexprvolatilePortp=(volatilePort*)0xab;
2
>
Hm, da sind zwei gute Ideen dabei. 1) fällt hingegen für mich aus rein
ästhetischen Gründen aus, weil ich die "::"-Orgien, die manche da
machen, einfach nicht leiden kann. Das ist aber eine reine
Geschmackssache; wenn mich das nicht so stören würde, könnte ich auch
gleich eine der Libraries Mcucpp, savr oder xpcc v benutzen. ;-)
Bisher funktioniert meine Bibliothek so, daß ich zunächst einmal
einzelne Register in einem Template abstrahiert habe; im Prinzip ist
mein Register- Klasse nur ein "const volatile uint8_t *" (oder uint16_t
für 16-Bitter) mit ein paar Methoden zur Abfrage und Manipulationen des
Registers.
Ein GPIO besteht nun aus drei Registern (DDRn, PORTn, PINn) sowie einem
"uint8_t" für das betreffende Bit, zB. PB2. Im Prinzip ist das also
alles bereits konstant, und solange der Compiler das innerhalb der
"main()" oder einer anderen Funktion instanziiert, erkennt er das auch
und optimiert die Klassen weg. Ich habe nun mehrere Programme in C und
C++ geschrieben, die exakt genauso groß oder in einigen Fällen sogar ein
paar Byte kleiner sind als ein C-Programm mit derselben Funktionalität.
Die Idee, dem Compiler mit "const" und "constexpr" auf die Sprünge zu
helfen, erscheint mir aber vielversprechend, und ich werde ihn nochmal
ausführlich ausprobieren.
Lieben Dank und viele Grüße,
Karl
Hallo Felix,
FelixW schrieb:> Karl Käfer schrieb:>> Zunächst frage ich mich derzeit, wie man eine Timer-Abstraktion>> entwerfen könnte. Das Problem ist, daß sich die>> Hardware-Implementierungen von Timern auf verschiedenen AVRs recht stark>> unterscheiden,>> Ich fange das auch gerade erst an zu verstehen:> Programmiere gegen ein Interface, nicht gegen eine Implementierung.
So sieht ordentliches Programmierhandwerk aus, keine Frage. Aber hier in
diesem speziellen Fall erscheinen mir abstrakte Klassen problematisch,
da sie -- Stichwort: VMT (virtual method table) -- dazu neigen, das
Kompilat aufzublähen. Andererseits sehe ich abseits von Lehrmeinung und
Eleganz für Mikrocontroller-Umgebungen mit ihren begrenzten Ressourcen
und das daher meist überschaubaren Funktionalität keinen echten Nutzen
von Interfaces, denn die konkrete Implementierung jeder Schnittstelle
müßte dann wieder auf die verschiedenen Hardware-Implementierungen
portiert werden.
Dummerweise unterscheiden sich die Timer von ATtinys und ATmegas schon
beim Timer/Counter Control Register TCCRn: einige haben nur ein TCCR0,
andere TCCR0A und TCCR0B, wieder andere TCCR0{A,B,C} und wieder andere
TCCR0[A-F], manche haben gemeinsame TIMSK- und TIFR-Register, andere
wiederum für jeden Timer ein eigenes solches Register. Damit hätte ich
zwar am Ende eine abstrakte Klasse mit Methoden wie "setPWM(Prescaler)",
aber diese müßten für jede dieser Hardware-Implementierungen wiederum
einzeln implementiert werden.
> Deine Schnittstelle sollte nur das Verhalten zur Verfügung stellen, was> dein Projekt braucht.
Bei der Komplexität üblicher Mikrocontroller-Programme kann ich dann
aber auch gleich jeweils eine Timer-Klasse für den konkreten
Anwendungsfall und die konkrete Zielplattform schreiben. Kein Problem,
sowas läuft hier schon auf einem Atmega328P, aber eben nur für den
Timer0 auf diesem und allen registerkompatiblen AVRs...
> Karl Käfer schrieb:>> Die zweite Herausforderung betrifft den GCC-Optimizer. Wenn ich eine>> Klasse außerhalb der "main()"-Funktion instanziiere, beispielsweise um>> einen Pin in einer ISR und außerhalb zu benutzen, wird das Kompilat>> plötzlich beinahe um den Faktor zwei größer.>> Gib uns mal konkrete Details, was alles dazukommt. Sonst gibt es> Glaskugelraten (vor allem da wir deinen Code nicht kennen).
Weiter oben in diesem Thread findest Du einen Haufen Code von mir. In
den nächsten Tagen werde ich eine kleine Zip-Datei zusammenbauen und sie
hier einstellen. Im Prinzip geht es um Folgendes (Standardheader und
Gedöns mal weggelassen):
1
typedefvolatileuint8_t*constReg8;
2
typedefvolatileuint16_t*constReg16;
3
4
template<typenameT,typenameU>
5
classRegister{
6
protected:
7
constTreg;
8
public:
9
Register(Treg):reg(reg){}
10
11
/** set "bit" = 1 */
12
voidsbi(constUbit){*this->reg|=(1<<bit);}
13
14
/** clear (unset, set to 0) "bit" */
15
voidcbi(constUbit){*this->reg&=~(1<<bit);}
16
17
/** return true if "bit" is set */
18
boolgbi(constUbit){return*this->reg&(1<<bit);}
19
20
/** set bitmask "mask" */
21
voidsms(constUmask){*this->reg|=mask;}
22
23
/** clear bitmask "mask" */
24
voidcms(constUmask){*this->reg&=~mask;}
25
26
/** set all "bits" */
27
voidset(constUbits){*this->reg=bits;}
28
29
/** get register value */
30
Uget(void){return(U)*this->reg;}
31
32
/** EXPENSIVE! set bit list, eg.
33
* Register(&ADCSRA).sbiList(ADPS1, ADPS0)
34
* @params ... list of bits to set
35
*/
36
voidsbl(uint8_tn,...){
37
uint8_tval;
38
va_listvl;
39
va_start(vl,n);
40
for(uint8_ti=0;i<n;i++){
41
val=va_arg(vl,int);
42
this->sbi(val);
43
}
44
}
45
46
/** EXPENSIVE! clear bit list, eg.
47
* Register(&ADCSRA).sbiList(ADPS1, ADPS0)
48
* @params ... list of bits to clear
49
*/
50
voidcbl(uint8_tn,...){
51
uint8_tval;
52
va_listvl;
53
va_start(vl,n);
54
for(uint8_ti=0;i<n;i++){
55
val=va_arg(vl,int);
56
this->cbi(val);
57
}
58
}
59
};
60
61
typedefRegister<Reg8,uint8_t>Register8;
62
typedefRegister<Reg16,uint16_t>Register16;
63
64
classPin{/** base class for a pin */
65
protected:
66
Register8ddr;
67
Register8port;
68
Register8pin;
69
uint8_tnum;
70
71
public:
72
/** constructor
73
* @param ddr DDRn register address of pin (eg. &DDRB)
74
* @param port PORTn register '' (eg. &PORTB)
75
* @param pin PINn register (eg. &PINB)
76
* @param num pin number (eg. PB2)
77
*/
78
Pin(Reg8ddr,Reg8port,Reg8pin,uint8_tnum):
79
ddr(ddr),port(port),pin(pin),num(num)
80
{}
81
};
82
83
classOutputPin:publicPin{/** an output pin */
84
public:
85
OutputPin(Reg8ddr,
86
Reg8port,
87
Reg8pin,
88
uint8_tnum):
89
/** constructor @params see Pin::Pin() */
90
Pin(ddr,port,pin,num)
91
{this->ddr.sbi(this->num);}
92
93
/** set output high */
94
voidsetHigh(void){this->port.sbi(this->num);}
95
96
/** set output low */
97
voidsetLow(void){this->port.cbi(this->num);}
98
99
/** toggle output */
100
voidtoggle(void){
101
#if CAN_TOGGLE_PIN == 1
102
this->pin.sbi(this->num);
103
#else
104
if(this->pin.gbi(this->num)){
105
this->setLow();
106
}else{
107
this->setHigh();
108
}
109
#endif // CAN_TOGGLE_PIN
110
}
111
112
/** assignment operator
113
* @param parm if true: set pin high, else set pin low
114
*/
115
voidoperator=(bool&parm){
116
if(parm){
117
this->setHigh();
118
}else{
119
this->setLow();
120
}
121
}
122
};
123
124
125
// "HAL"
126
classAusgabe:publicOutputPin{
127
public:
128
Ausgabe(volatileuint8_t*ddr,
129
volatileuint8_t*port,
130
volatileuint8_t*pin,
131
uint8_tnum):
132
OutputPin(ddr,port,pin,num)
133
{}
134
};
135
136
137
intmain(void){/* ZeileA */
138
139
Ausgabeaus{&DDRD,&PORTD,&PIND,PD2};/* ZeileB */
140
141
while(1){
142
aus.toggle();
143
_delay_ms(50);
144
}
145
}
Wenn ich dieses Programm so übersetze, wie es da steht, ist das Kompilat
genau 156 Bytes groß, also exakt genauso groß wie das funktional gleiche
C-Programm. Wenn ich nun ZeileA und ZeileB vertausche, wird das Ergebnis
plötzlich 284 Bytes groß -- beinahe das Doppelte. Und jetzt würde ich zu
gerne verstehen, warum er das im zweiten Fall nicht genauso hinbekommt,
zumal sich an der Funktionalität des Programms gar nichts ändert.
Liebe Grüße und vielen Dank,
Karl
Hallo robin,
robin schrieb:> Karl Käfer schrieb:>> Zunächst frage ich mich derzeit, wie man eine Timer-Abstraktion>> entwerfen könnte.>> Ich würde mich von dem "eine Lib (Datei) für alles" Gedanken Lösen und> eine Datei pro Controller Familie anlegen.
Vermutlich habe ich mich falsch ausgedrückt, aber das war ganz und gar
nicht mein Gedanke.
Deswegen mache ich es bei USARTs schon so: es gibt eine Klasse BaseUsart
mit verschiedenen Funktionen wie "getc()", "puts(float)",
"puts(uint8_t)" usw., von der meine Usarts erben. Über einen kleinen
Codegenerator, der die XML-Partdescription-Datein von Atmel parst,
erstelle ich dann für jeden Controller die passenden Usarts: für den
tiny2313 nur eine Usart, für einen mega328P eine Usart0, und für einen
mega1284 eine Usart0 und eine Usart1 -- korrespondierend zum Datenblatt.
Der Entwicklungsprozeß sieht dann so aus: Du schaust ins Datenblatt des
Ziel-uC, und wenn da eine Usart1 definiert ist, kannst Du mit "Usart1
pc{}" eine Instanz davon erstellen und mit 'pc.puts("hallo\n")' direkt
eine freundliche Begrüßung darauf ausgeben.
> Auserdem würde ich verschiedene Featurelevel definieren, die dann> bestimmte Funktionen zur Verfügung stellen.> z.B.:> Timer_Base: Einfacher Systemtimer, Zeit Einstellbar, ruf bei Interrupt> eine bestimmte Funktion aus> Timer_Level2: Wie Base + PWM Ausgabe
Im Moment habe ich Partdescription-Dateien für 139 ATtinys und -megas...
egal, ob ich das mit einem Codegenerator machen oder von Hand schreiben
würde, dürfte das in ziemlich viel Arbeit ausarten.
Ich fürchte auch, Ihr setzt den angestrebten Abstraktionslayer viel
höher an als ich, oder, anders gesagt: Ihr scheint die Sache von einer
anderen Seite aus anzugehen als ich. In meinen Augen braucht es erst
eine saubere Abstraktion der Hardware, auf der dann (siehe "HAL" im oben
geposteten Codebeispiel) wiederum eine oder mehrere weitere
Abstraktionsschichten aufsetzen können. Mir geht es hier zunächst um
eine möglichst schlanke, effiziente und dennoch vielseitige Abstraktion
der Hardware.
So, ich geh' jetzt erstmal mein Repository aufräumen und möchte in den
nächsten Tagen eine Zip-Datei mit dem aktuellen Stand und ein wenig
Dokumentation dazu bereitstellen.
Liebe Grüße,
Karl
Karl Käfer schrieb:> Wenn ich dieses Programm so übersetze, wie es da steht, ist das Kompilat> genau 156 Bytes groß, also exakt genauso groß wie das funktional gleiche> C-Programm. Wenn ich nun ZeileA und ZeileB vertausche, wird das Ergebnis> plötzlich 284 Bytes groß -- beinahe das Doppelte.Glaskugel {
1. Vermutung
Wenn "aus" global ist, werden wohl alle definierten Funktionen als
solches vom Linker übernommen. Die Globale Variable könnte ja in anderen
Programmteilen verwendet werden ('extern Ausgabe aus;' im Header).
Details im lst-file.
2. Vermutung
keine Konstanten Memberfunktionen. Wenn sich *DDR, *PIN, etc. ändern
könnten muss der Code darauf angepasst sein.
}
PS: Kann hier gerade keine 700MB+ zum Nachschauen runterladen.
FelixW schrieb:> Wenn "aus" global ist,
Sollte sich ja eigentlich mit 'static' verhindern lassen. Macht es aber
nicht.
Ob die Variable(n) nur vor oder in 'main' stehen, ist zwar für den
Programmablauf egal. Außerhalb würde ich's aber auch schöner finden,
wegen der Übersicht über den Speicherverbrauch.
Karl Käfer schrieb:> o sieht ordentliches Programmierhandwerk aus, keine Frage. Aber hier in> diesem speziellen Fall erscheinen mir abstrakte Klassen problematisch,> da sie -- Stichwort: VMT (virtual method table)
VMT entsteht erst, wenn der Typ unbekannt ist. (s.o.)
Ich glaube da kommen wir mit dem Begriff Interface bzw. Schnittstelle
durcheinander.
Beispiel für die Sammlung von Schnittstellendefinitionen:
* Registerbeschreibung im Datenblatt -> Summe von Welche Bits kann ich
setzen und was passiert dann.
* Dokumentation der Header-Datei -> Summe von Welche Funktion macht was
und wie wird sie aufgerufen
Abstrakten Klassen bzgl. Schnittstellen: Sie zwingen dich dazu der
gleichen Notation zu folgen. Sie ermöglichen es zur Laufzeit die
Implementierung zu wechseln. Es gibt immer eine Verweis auf den
gemeinsamen Nenner (Basisklasse).
Karl Käfer schrieb:> Ich fürchte auch, Ihr setzt den angestrebten Abstraktionslayer viel> höher an als ich, oder, anders gesagt: Ihr scheint die Sache von einer> anderen Seite aus anzugehen als ich.
Ich glaube es gibt da 2 Ansätze.
Horizontal/Schichten indem du die Funktion der Geräte hinter Funktionen
versteckst und so lange Verhalten emulierst, bis sich alle uCs gleich
verhalten. Deine konkrete HAL kann sehr viel. Grundlage sind die
Möglichkeiten der Implementierung (Hardware)
Du arbeitest Vertikal/nach Aufgaben, du unterteilst ein Gerät in
verschiedene Aspekte, die jeweils eine Aufgabe umsetzen. Die Lösung des
Aspekts orientiert sich an der Hardware. Deine konkrete HAL kann sehr
wenig. Grundlage ist die benötigte Funktion. (Anforderung der Software)
Diese Variante bevorzuge ich, stehe erst am Anfang.
Karl Käfer schrieb:> warum er das im zweiten Fall nicht genauso hinbekommt,> zumal sich an der Funktionalität des Programms gar nichts ändert.
Da ändert sich eine ganze Menge an der Funktionalität und an der Art,
wie das Objekt gespeichert wird. Im zweite Fall könnte was in der Art
void ich_komme_von_extern() {
aus.toggle();
}
funktionieren.
Man muß sich aber das Ergebnis anschauen und was der Compiler macht.
Karl Käfer schrieb:>> Karl Käfer schrieb:>>> Die zweite Herausforderung betrifft den GCC-Optimizer. Wenn ich eine>>> Klasse außerhalb der "main()"-Funktion instanziiere, beispielsweise um>>> einen Pin in einer ISR und außerhalb zu benutzen, wird das Kompilat>>> plötzlich beinahe um den Faktor zwei größer.
Wenn der Kompiler nicht wirklich optimiert kein wunder :/
Er sollte doch zumindest mitbekommen, dass R25 immer 0 ist?
Hi Felix,
FelixW schrieb:> Karl Käfer schrieb:>>> Karl Käfer schrieb:>>>> Die zweite Herausforderung betrifft den GCC-Optimizer. Wenn ich eine>>>> Klasse außerhalb der "main()"-Funktion instanziiere, beispielsweise um>>>> einen Pin in einer ISR und außerhalb zu benutzen, wird das Kompilat>>>> plötzlich beinahe um den Faktor zwei größer.>> Wenn der Kompiler nicht wirklich optimiert kein wunder :/> Er sollte doch zumindest mitbekommen, dass R25 immer 0 ist?
Das sollte er wohl, ja. Aber vielleicht kann ich das Problem mit einem
Singleton lösen, das probiere ich jetzt mal aus. ;-)
Liebe Grüße,
Karl
Hallo Karl Käfer,
bereits Erfolg mit deinem Singleton gehabt?
Ich habe ne Lösung für dich und die heißt constexpr
Details im Anhang. Damit weiß der Kompiler, dass die Variablen
unveränderlich sind.
Hi Felix,
FelixW schrieb:> Hallo Karl Käfer,>> bereits Erfolg mit deinem Singleton gehabt?
Jaein -- das Singleton funktioniert, aber das Binary ist 292 Bytes und
damit um den Faktor 1,7 größer als das äquivalente C-Kompilat mit 176
Bytes.
> Ich habe ne Lösung für dich und die heißt constexpr> Details im Anhang. Damit weiß der Kompiler, dass die Variablen> unveränderlich sind.
constexpr habe ich auch schon ausprobiert, aber abgesehen von der
Kosmetik (das läßt nur einen leeren Konstruktor zu und benötigt darum
eine init()-Funktion) bläht es das Kompilat auf 278 Bytes auf, wenn man
die ISR() und den sei()-Aufruf hinzufügt. Das ist zwar schon besser,
aber noch weit von "gut" entfernt.
Liebe Grüße,
Karl
Thomas schrieb:> Vermutlich sind VMTs garnicht sooo bloaty...
Ich denke, was viel mehr stört, ist wenn sie auf dem Heap liegen. Oder
kann man die VMTs z.B. auch in Arrays zwingen?
Hier der Genauigkeit halbe einen kurzen Einwurf, was ARDUINO betrifft.
Das hier ist der Code für die Ansteuerung der Pins auf einem ARM Cortex
M0 ARDUINO:
https://github.com/arduino/ArduinoCore-samd/blob/master/cores/arduino/wiring_digital.c
Was man dabei sieht:
- Die Funktionen machen die Ansteuerung der ARM-Pins sehr einfach, ohne
die Funktionen ist es sehr komplex. Deutlich komplexer als auf einem AVR
- Die Funktionen sind unter dem Namen "wiring" zusammengefasst, nicht
ARDUINO.
- Die Funktionen sind in C geschrieben
Der Grund warum ich auf den Namen "wiring" wert lege, findet sich hier:
http://arduinohistory.github.io/
Das ist eine ziemlich spannende Geschichte über Wiring vom Programmierer
selbst beschrieben.
Der erste Absatz ist etwas langweilig aber dann geht die Erzählung
richtig ab.
Es ist eine Abhandlung darüber was mit der Anerkennung eines Entwicklers
passieren kann, wenn ein Projekt eine bestimmte Berümtheit erreicht.
Torsten C. schrieb:> Thomas schrieb:>> Vermutlich sind VMTs garnicht sooo bloaty...>> Ich denke, was viel mehr stört, ist wenn sie auf dem Heap liegen. Oder> kann man die VMTs z.B. auch in Arrays zwingen?
Die vTables gibt es ja einmal pro Klasse, nicht pro Objekt und sollten
eigentlich im Flash liegen.
Pro Instanz kommt meist nur ein Pointer auf eine vTable hinzu. Also wird
pro Instanz 16bit (AVR) oder 32bit (ARM) mehr benötigt. Ob das vom RAM
oder Flash abgeht hängt davon ab, wo der Compiler das Objekt hin tut.
Wenn das Objekt konstant ist, kann es ja auch im Flash landen.
Torsten C. schrieb:> Ich denke, was viel mehr stört, ist wenn sie auf dem Heap liegen.
Immer diese unbeschreibliche Angst vor malloc().
Aber: es steht dir bei der avr-libc völlig frei, dein eigenes malloc()
zu implementieren, wenn du denkst, dass du das unbedingt machen
müsstest. Dann hättest du wenigstens die Gewähr, statt eines recht
sauber debuggten malloc()s der Bibliothek deine eigenen, neuen Bugs
einzubauen. :-)
Edit: aller Wahrscheinlichkeit nach liegen die vtables aber nicht
im Heap, damit ist diese Diskussion sowieso hinfällig. Im Flash
liegen sie jedoch auch nicht, denn das würde im Compiler eine
Sonderbehandlung für den AVR erfordern. (Ich erinnere mich, dass ich
dafür mal einen Bugreport geschrieben habe.) Mithin werden sie wohl
zwar RAM brauchen, aber ganz normal zusammen mit .data aus dem Flash
initialisiert.
Jörg W. schrieb:> Immer diese unbeschreibliche Angst vor malloc().
Vor allem bei einem allokierten Block pro Klasse kann ein Programmierer
ja nicht abschätzen, weiviele neue Klassen zur Laufzeit dazukommen! :-)
Hallo,
ich habe mir grad dieses sehr interessante Thema durchgelesen. Momentan
arbeite ich im Controllerbereich nur mit C und etwas OOP. OOP wird dabei
über structs realisiert...
Hat jemand schon C++ Hardware Bibliotheken für einen Xmega bzw. Atmega
Controller erstellt und würde diese teilen? Bei den Xmegas macht OOP mit
C++ sogar richtig Sinn, da sich die verschiedenen Timer und
Schnittstellen (welche mehrfach zur Verfügung stehen) sich nur durch den
Port-Namen unterscheiden.
Bibliothek
- mit grundlegenden Funktionen
Mit Beispielen für
GPIO, Timer, USART, SPI, 7Seg, LCD, GLCD, RS485, ..
Ist keine vollständige Library,
- eher ein umfangreiches Beispiel und gutes Konzept in C++ mit
Templates.
Konzept passt für verschiedene Architekturen,
- bei mir AVR und STM32F3,F4,(F7):
Beitrag "Re: C++ auf einem MC, wie geht das?"
Beispiel für Timer mit AVR8,
anpassbar für alle Varianten:
Beitrag "Re: statische Memberfunktion als Interrupt-Handler?"

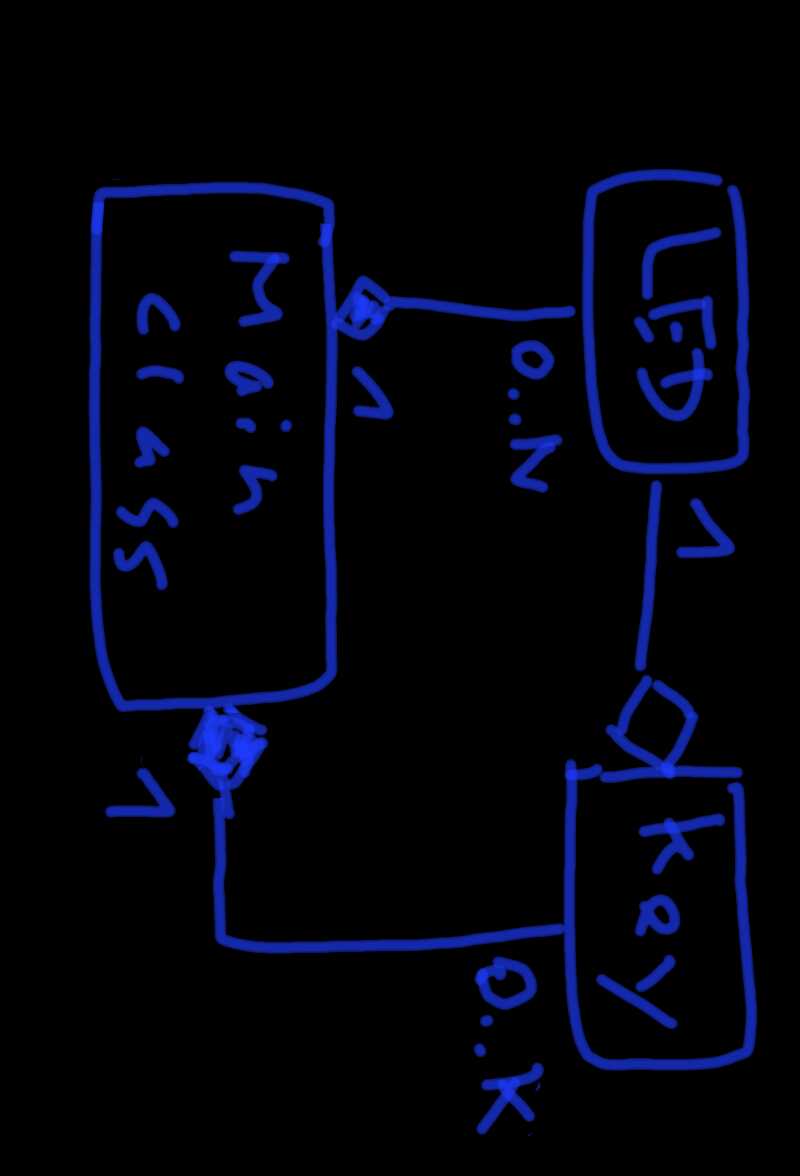
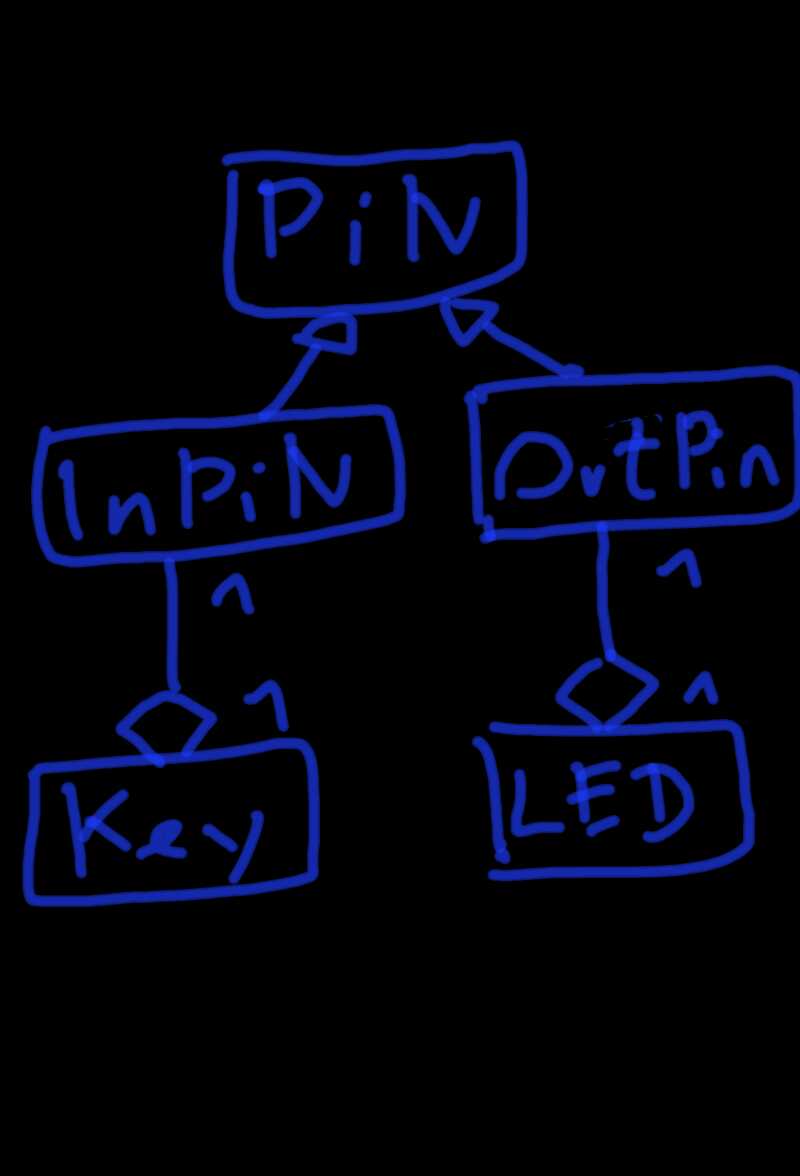

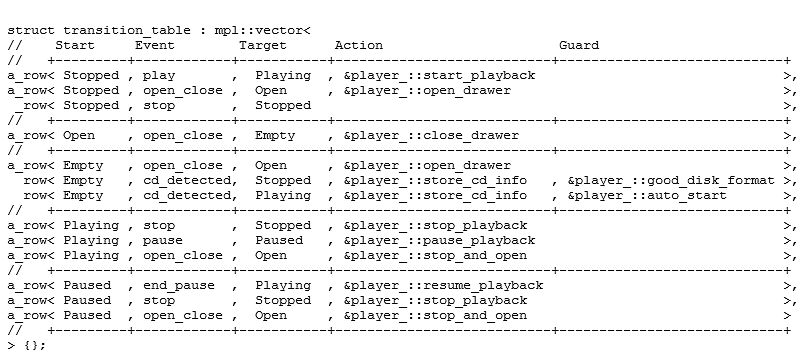

{kind=link}
{kind=link}
{kind=link}
{kind=link}