Ich plane ein Bildverarbeitungssystem für Videoüberwachung und muss Bilder zur späteren Weiterverarbeitung im PC im Grabber zwischenspeichern. Wir haben eine Hardware, die etwas Ähnliches leistet, welche auf einem Spartan 3E basiert und auf einen aktuellen Baustein übersetzt werden soll. Geplant ist Artix oder Kintex. Nun ist das Problem aufgetreten, dass bei der Designportierung ein neuer DDR-Controller fabriziert werden muss und der MIG den gleichzeitigen Zugriff von Schreiben und Leser nicht unterstützt. Zumindest finde ich nichts. Ich habe so eine Schaltung vor einiger Zeit auf einem Spartan 6 aufgesetzt und da ging es noch. Dies war damals noch mit ISE, aber weder in der ISE noch im Vivado wird ein Multiport angeboten. Im Netz wird beschrieben, wie das manuell gestaltet werden kann, also einen händischen Arbitter zu schreiben, der die Ports multiplext. Leider sind erste Versuche ziemlich in die Hose gegangen. Schon bei einem Port klappt es nicht. Kann es sein, dass der Artix Controller anders arbeitet und anzusprechen ist, als bei Spartan? Er scheint einzelne Zugriffe nicht zu verstehen, jedenfalls werden Daten nicht übernommen, oder nicht rückgelesen.
hi, der MIG hat "nur" einen Port. Wenn er Nativ verwendet werden soll, muss manuell ein Arbiter gebaut werden. Haben wir für ein Virtex6 mal gemacht (recht identisch zum jetzigen Artix/Kintex). Inzwischen würde ich nur noch das AXI System empfehlen. Das Öko System ist deutlich größer und man findet deutlich mehr. Auch kann man Vivado HLS Module einfach dran hängen. Für die o.g. Anwendung sind die AXI VDMAs von Xilinx gedacht. Einfach per AXI Interconnect (auch kaskadierbar) an den MIG anbinden. Viel Spass beim Lesen der paar hundert Seiten User Guides ;)
Wenn ich es richtig verstehe, bietet der AXI-Controller dann mehrere Ports? Wie machen die das? Eigentlich kann das doch so umfangreich nicht sein. Ich habe in dem bestehenden Design kein AXI-System und möchte auch nur ungern alles daraufhin umstellen. Was ich eigentlich nur wissen möchte, ist, ob es ein grundsätzliches Problem gibt. Ich meine, es ist ja letztenendes dem MIG-Core egal, woher ich meine Daten herbekomme, die ich reinschreibe. Es ist nur etwas verwunderlich, dass es die Portstruktur, die beim Spartan lief, beim Artix nicht geht. Jedenfalls nicht zu 100%. Es sehe nochmal nach, ob ich gfs einen Config-Fehler im MIG habe.
Klaus L. schrieb: > bietet der AXI-Controller dann mehrere > Ports? Nein, nur "einen" AXI Memory Mapped Port. Der AXI Interconnect ist der Arbiter, welcher dann pro Stufe bis zu 16 Ports bereit stellt. Der Nativ-Mode ist aber auch nicht weiter kompliziert. app_addr ist die Adresse. Je nach Anzahl und Breite der Speicherbausteine ist das eine Word, DWord, QWord oder noch höhere Adresse (selten eine Byteadresse). Es werden üblicherweise immer 8*Speicherbreite (in Bits) pro Request geschrieben bzw. gelesen (DDR3). Daher ist es besser, wenn die Adressen immer aligned sind, so dass die unteren 3 Bits Null sind. Ansonsten müssten die gelesenen Daten "sortiert" werden. Weiterhin werden Adressen und Kommandos via Ready (app_rdy) / Valid (app_en) an den MIG übergeben. Auch beim Schreiben werden die Daten (und Mask) via Ready (app_wdf_rdy) / Valid (app_wdf_wren) an den MIG übergeben. Die gelesenen Daten kommen mit einem Valid in der Reihenfolge der Requests zurück. Whats all. grüße
Klaus L. schrieb: > Ich habe in dem bestehenden Design kein AXI-System und möchte auch nur > ungern alles daraufhin umstellen. AXI ist Stand der Technik und es ist falsch auf alten Standards (MIG-IF) stehen zu bleiben. Um deine vorhandenen Funktionen weiterhin nutzen zu können, kannst du dir einen Protokoll-Konverter schreiben, der von deinem MIG-IF auf AXI umsetzt. Eventuell gibt es so etwas schon. Du bist schließlich nicht der erste der dieses Problem hat. Frage mal euren Xilinx-FAE. Neue Komponenten kannst du dann mit AXI ausstatten. Und mit HLS bekommst du ein AXI-Interface geschenkt. Tom
Thomas R. schrieb: > Neue Komponenten kannst du dann mit AXI ausstatten. Und mit HLS bekommst > du ein AXI-Interface geschenkt. Das bedeutet aber ein stückweises Abrücken von nativen Interfaces und damit auch von der Möglichkeit, Lösungen effektiv zu implementieren. Und es bedeutet auch eine Festlegung auf den jeweiligen Hersteller. Nicht jeder sieht in HLS die Zukunft seiner Produktentwicklung. Es gibt gute Gründe den Ball flach zu halten, um das mal so zu formulieren.
Ich finde man sollte ab einer bestimmten Größe des Systems schon ein grundlegendes AXI-Repertoire (Interconnect, Width-Converter, Bridges, DMA, Datamover, TB-Funktionen/BFMs) besitzen oder etwas vergleichbares. Es geht einfach um die Systematik, wesentlich verringerte Fehleranfälligkeit und geringere Debug-Zeit im Endsystem. Manchmal muss man auch die Verdrahtung groß umbauen, da will man nicht über jede Interface-Anpassung stöhnen. Eine bestimmte Größe ist meiner Meinung nach schon mit einem DDR+CPU oder DDR+Highspeed Anschluss gegeben. Seine eigenen Cores muss man nicht ein volles AXI4 geben, je nachdem sind AXI-Stream, AXI-lite oder APBs sehr einfache Interfaces für die es Anschlussmöglichkeiten gibt.
Weltbester FPGA-Pongo schrieb im Beitrag #4784837: > Thomas R. schrieb: >> Neue Komponenten kannst du dann mit AXI ausstatten. Und mit HLS bekommst >> du ein AXI-Interface geschenkt. > > Das bedeutet aber ein stückweises Abrücken von nativen Interfaces und > damit auch von der Möglichkeit, Lösungen effektiv zu implementieren. Was ist an MIG effektiver als an AXI? Beweise deine Behauptung. > es bedeutet auch eine Festlegung auf den jeweiligen Hersteller. Ach so mit dem MIG-Interface legt man sich nicht auf einen Hersteller fest. Eher ist doch AXI portabler weil es von ARMs-AMBA abstammt. > Nicht > jeder sieht in HLS die Zukunft seiner Produktentwicklung. Es gibt gute > Gründe den Ball flach zu halten, um das mal so zu formulieren. Wie alle anderen System werden auch FPGA-Design immer komplexer. Um diese steigende Komplexität effektiv handhaben zu können, braucht man neue Methoden. Wer ewig gestrig weitermacht, den wird der Markt aussortieren. Tom
Das (sowohl AXI als auch HLS) ist die gleiche Diskussion die schon seit Jahrzehnten für Assembler/C/C++/Java/... und die zugehörigen Libs geführt wird. Ist heute nur noch selten sinnvoll in Assembler zu programmieren und alle Libs selbst zu schreiben.
Zoom Zoom schrieb: > Das (sowohl AXI als auch HLS) ist die gleiche Diskussion die schon > seit > Jahrzehnten für Assembler/C/C++/Java/... und die zugehörigen Libs > geführt wird. > Ist heute nur noch selten sinnvoll in Assembler zu programmieren und > alle Libs selbst zu schreiben. und das ist auch der Grund, warum die CPUs, Speicher, Chipsätze und alles immer effizienter und schneller wird, aber das Betriebssystem merklich nur kaum schneller arbeitet. Zurück zum TO: Was ist so schlimm daran einen eigenen Arbiter für seinen MIG zu bauen. Sowas ist doch wirklich kein Hexenwerk und ich bin mir sicher, dass das schneller geht, als sich in die ganze AXI Thematik einzuarbeiten. AXI will zwar für manche Sachen bequem sein, aber man kann nicht alles machen was man will. Wenn alles auf AXI aufbaut, kann man kann sich von der Funktionalität vom Markt nicht sonderlich abheben - auch diese Leute werden aussortiert! Man wird auch in was reingezwengt, was man vielleicht gar nicht will. Es gibt auch gute Gründe AXI bei Seite zu lassen.
Thomas R. schrieb: > Wie alle anderen System werden auch FPGA-Design immer komplexer. Um > diese steigende Komplexität effektiv handhaben zu können, braucht man > neue Methoden. Das ist aber jetzt ein wenig arg weit ausgeholt, um zu begründen, sich auf neue Designprinzipien einzulassen, zumal schon ein design existiert. Nicht alle FPGA-designs haben einen Prozessor drin, oder brauchen einen. Dafür gibt es viele Designs, wo es auf Effizienz ankommt. Es gibt immer mehr Anfragen für effektive resourcenschonenen Implementierungen. > Wer ewig gestrig weitermacht, den wird der Markt > aussortieren. Und wer ständig vorwärts rennt und ohne Not und Grund, seine toolchains umändert, ehemals vorhandene Interfaces oder features rausschmeisst, ohne die alten Kunden mitzunehmen, wird auch aussortiert. Das ist schon schon mehrfach passiert. Lattice freut sich über neue Kunden. Viele sind die Politik von Xilinx reichlich satt.
Ich habe einen Arbitter, der jetzt für jeden Port einmal liest und schreibt. Damit komme ich mit Faktor 1/4 auf das DDR, was eigentlich reichen sollte. Der Arbitter holt sich selber die Daten aus zwei Zwischen-RAMs auf die die Prozesse schreiben. Von der Seite gibt es also erst einmal kein Problem. >Der Nativ-Mode ist aber auch nicht weiter kompliziert. Ich beziehe mich auf die MIG-Doku, die ein timing dafür hat, was mir auch plausibel ist und so schon implementiert wurde. Es gibt jetzt eine Unklarheit: >Je nach Anzahl und Breite der Speicherbausteine ist das eine >Word, DWord, QWord oder noch höhere Adresse Ich habe einen Baustein mit 8 Bit und will eigentlich immer 8 Bytes auf einmal schreiben. Damit passt das genau zu DDR3. Der Port ist 64 Bit breit, kommt schon so vom CoreGen und ich hänge die 8 bytes einfach aneinander. Das Höchste ist dabei das letzte, wegen der Bytereihenfolge. Die Adressen zähle ich immer um 8 weiter, überspringe also wie gehabt die unteren 3 Bits. Das müsste so funzen und scheint auch zu stimmen, wenn ich die zurückgelesenen Daten heranziehe. Aber leider stimmen die nicht immer. Ich habe auch noch nicht rausfinden können, ob es am Lesen oder Schreiben liegt. Die Reproduzierbarkeit an bestimmten Stellen scheint eher dafür zu sprechen, dass das Schreiben schief gegangen ist. Ich denke, es hat was mit dem APP_READY zu tun. Der vorhandene Code läuft so, daß gewartet wird, bis data_ready und app_ready der Fall sind und dann erfolgt ein Schreibbefehl, bzw Lesebefehl mit zunächst einem app_ena und data_ena. Laut Doku muss ich so lange warten, bis beide noch im nächsten Takt der Fall ist. Ich springe also erst nach Prüfung beider Signale wieder aus dem state heraus. Bei einzelnen Daten scheint das zu klappen, aber wenn ich mehr, als ein Datum senden will, bekommt er manche nicht mit. Nun habe ich in der Doku gesehen, daß es ein Problem mit dem data_end gibt. Angeblich soll man das beim letzen Datenwort mit setzen. Da ich immer 64 Bit schreibe setze ich immer data_end auf 1, weil das letzte Byte ja in der Gruppe enthalten ist. Ich beziehe mich da auf ein Diagramm in der Doku. An anderer Stelle wird davon gesprochen, dass das data ena egal sei.(???) Da geht gfs was schief. Dann gibt es noch einen Verdacht: Ich überfahre gfs den Fifo, weil Daten-ENA und APP_ENA nicht passen oder stimmig ausgewertet werden. Dazu gibt es in der Doku einen Hinweis, dass das APP_ENA maximal 2 Takte nach dem DATA_ENA kommen darf. Was ist, wenn ich das nicht einhalten kann? Was passiert mit dem Datum im FiFo? Das wird ja sicher nicht vernichtet. Ich habe es ausprobiert und finde, dass man ruhig mehrere Takte warten kann und es wird dennoch gelesen. Es kann aber auch eine Fehlinterpretation sein, weil ich ja dauernd schreibe und lese und gfs die falschen ENAs zusammensortiert werden. Ich habe den Verdacht, dass manche APP_ENAs ins Leere gehen und den internen MIG-FiFo aufblähen und da was daneben geht. Dazu passend wäre noch die umgekehrte Frage zu stellen: Wie nahe darf APP_ENA dem DATA_ENA sein? Eigentlich möchte ich mehrere Datenworte mit einem APP_ENA erschlagen, momentan reicht es mir aber, wenn es wenigstens Stück für Stück ginge. Daher habe ich es im Moment so, dass ich erst ein Datum in den FiFo schicke, dann warte ob es mit dem ready geklappt hat und dann erst dazu übergehe, einmal APP_ENA mit Write anzuwenden, wobei Ich auch da gfs warte, falls es nicht geklappt hat. Trotzdem kommen Fehler...
Angehängte Dateien:
-

ddr3_fsm_write.gif
28 KB
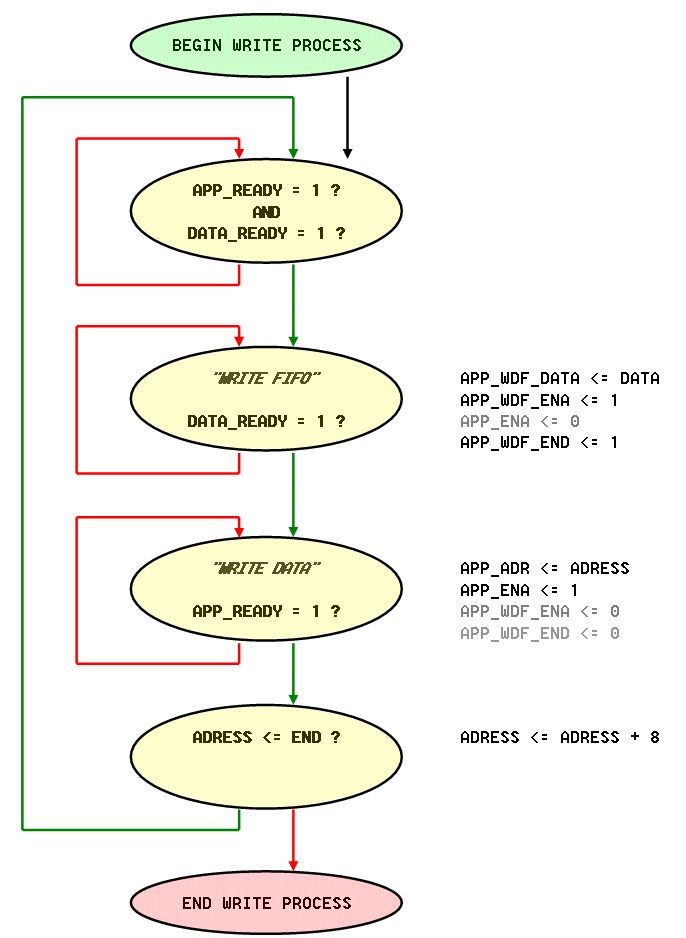
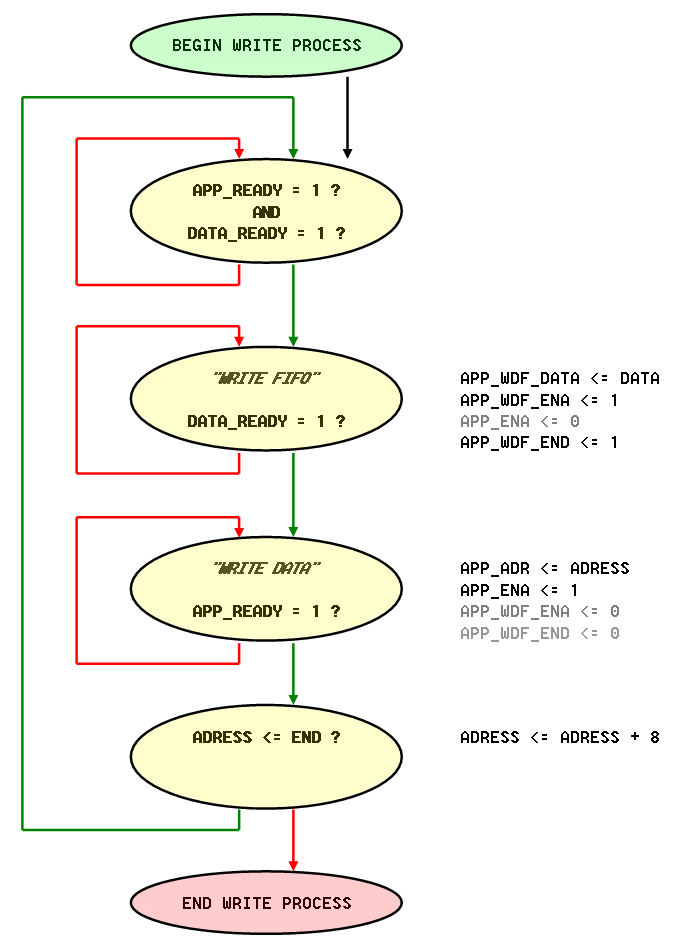{kind=link}
Das Testboard ist das Nexys DDR und der Ablauf an der Stelle ist dargestellte. Was könnte da schief gehen? Wie bediene ich das Data End korrekt?
Klaus L. schrieb: > Die Adressen zähle ich immer um 8 weiter, überspringe > also wie gehabt die unteren 3 Bits. Die unteren 3 Bit sollten dringend immer 0 null sein, d.h. das Speicheralignment muss bei dir 8 Bytes betragen. Ansonsten sollten die Adressen passen. Das APP_WDF_END sieht mir auch richtig aus. Wie es verwendet wird, hängt von der Interfacebreite ab. Wir haben z.b. 400MHz DDR mit 4x16 Bits = 64 Bits => 64 Bits * 8 Cycles = 512 Bits per Transfer. Jetzt verwenden wir nicht 100 Mhz * 512 Bit sondern 200 Mhz * 256 Bit, so dass ein Transfer aus 2 "beats" besteht (um den AXI Terminus zu verwenden). Dabei muss der 2. (=letzte) Beat mit APP_WDF_END markiert sein. Genauso beim Lesen, da ist der Letzte der beiden Beats auch vom MIG markiert. Bei dir mit 8 Bits * 8 Cycles = 64 Bits und 64 Bit Interfacebreite sollte also 1 Transfer immer aus genau einem Takt bestehen und somit ist APP_WDF_END immer zu setzten. Welches Timing vorgeschrieben ist, wenn erst die Daten und dann das Kommando kommen, weiß ich nicht. Bei uns läuft es so: Wenn Lesen, dann wird APP_ENA gesetzt und gewartet, bis die Übernahme durch APP_ENA und APP_RDY high erfolgt. Dabei können die Kommandos "back-to-back" also ohne Lücke erfolgen, der MIG bremst ggf. durch das APP_RDY. Beim Schreiben (kann auch direkt ohne Lücke erfolgen) ist es im Prinzip identisch. Beide ENAs werden bei uns gleichzeitig gesetzt. Dann wird gewartet bis beide Channels die Daten übergeben haben, wobei das jeweilige ENA auf low geht, sobald der Channel übergeben hat. Auch hier bremst bremst ggf. der MIG durch APP_RDY und APP_WDF_RDY. Ein Überfahren ist eigentlich nicht möglich. Klaus L. schrieb: > Laut Doku muss ich > so lange warten, bis beide noch im nächsten Takt der Fall ist. Ich > springe also erst nach Prüfung beider Signale wieder aus dem state > heraus. Ich denke hier ist ein Fehler. UG586 Seite 166ff (Fig. 1-74, 1-75 und 1-77) beschreibt eigentlich die Fälle, wobei die Anmerkung zu app_rdy in 1-74 auch für app_wdf_rdy in 1-75 gilt (siehe Text zu "Write Path"). viel Erfolg
Ich mache eigentlich alles so, wie Du es beschreibst, allerdings verstehe ich eines nicht: Einerseits sagst Du: > Beim Schreiben (kann auch direkt ohne Lücke erfolgen) > Beide ENAs werden bei uns gleichzeitig gesetzt. > Dann wird gewartet bis beide Channels die Daten übergeben haben > wobei das jeweilige ENA auf low geht, sobald der Channel übergeben > hat. Auch hier bremst bremst ggf. der MIG durch APP_RDY und APP_WDF_RDY. Das heisst doch, daß Du jeweils auch wartest und das ENA high hälst, bis das ready 1 ist, bzw wieder wird, falls es 0 war. Ich prüfe halt vorher noch, ob sie schon 1 sind, was sicher kein Problem sein dürfte. Es gibt also zwei Fälle: 1) Ich appliziere das ENA und das Ready bleibt im nächsten Takt 1. Dann nehme ich das ena weg. 2) Ich appliziere das ENA und das Ready geht im nächsten Takt auf 0. Dann halte ich es. Damit ist das ENA in dem Fall eben 2 Takte an. (Nach meiner Beobachtung gibt es keinen längeren Ausfall von ready).
Klaus L. schrieb: > im nächsten Takt Ich weiss jetzt nicht, wass du damit meinst. Folgende sind mögliche Kombinationen für 1x Kommando:
1 | ENA ___--------______ |
2 | RDY __________-______ |
3 | oder |
4 | ENA ___-_________ |
5 | RDY ___-_________ |
6 | oder |
7 | ENA _____-_______ |
8 | RDY __--------___ |
9 | oder |
10 | ENA _____----____ |
11 | RDY -----___----_ |
12 | oder |
13 | ENA _____--______ |
14 | RDY __---_-______ |
15 | |
16 | mit den Daten könnte es so aussehen für 1x Kommando + 1x Daten |
17 | oder |
18 | ENA _____----______ |
19 | RDY __---___-_____ |
20 | WDF_ENA _____------____ |
21 | WDF_RDY __________-____ |
22 | oder |
23 | ENA _____-------___ |
24 | RDY __---______-___ |
25 | WDF_ENA _____--____ |
26 | WDF_RDY ______-____ |
Die Diagramme scheinen mir alle richtig, aber sie gehen davon aus, daß das ready (das des Ports, wie das des Datenfifos) ... a) meistens aus ist b) nachdem es (als acknowledge) einen Takt an ist und wieder verlischt Beides ist nicht der Fall, soweit ich das kenne. Im Gegenteil: Die readys sind meistens an, signalisieren Bereitschaft. Verlöschen tun die nur, bei sehr vielen Daten / Kommandos auf einmal oder wenn gerade ein Refresh behindert.
Sodele: Wir hatten eine Supportanfrage an Xilinx: Der FAE hat empfohlen, es mit AXI zu machen, weil die Funktion mit dem nativen Interface nicht mehr garantiert wird, da es nicht unterstürtzt wird, wie auch immer das technisch sein kann und welche Gründe es dafür gibt.
Als kleinen Nachtrag zu dem Thema, weil ich es wieder habe aufgreifen müssen: daniel__m schrieb: > Auch kann man Vivado HLS Module einfach dran > hängen. Für die o.g. Anwendung sind die AXI VDMAs von Xilinx gedacht. So wurde das in einem Projekt gelöst und funktioniert (nach Lesen von Tausend und nicht nur Hundert Seiten :-) Es ist allerdings so, dass die AXI-Zugriffsseite über VDMA recht delay-lastig arbeitet, recht viel Logik verschlingt und dennoch nicht an die Bandbreite herankommt, die sich mit einem nativen Interface machen lässt. Ganz offenbar steckt da sehr viel Allgemeines drin, um für alle erdenklichen Fälle gewannet zu sein, was zu sehr hohem Siliziumverbrauch und Strombedarf führt. Scheint auch nicht viel von der Synthese verworden zu werden, was nicht benötigt wird.
Hi, tja das sind die Nachteile von vielen Xilinx Cores. Die werden mit vielen Funktionen "vollgestopft", um jeden einen Einstieg zu ermöglichen und alles mögliche demonstrieren zu können. GGf. lassen sich Funktionen bei der Instanziierung tailorn, jedoch sind die Cores troztdem selten genügsam. Warum auch, so werden größere FPGAs / ZYNQs verkauft ;). Wir verwenden Xilinx Cores nur sehr sparsam und nutzen oft Eigenentwicklungen. Ist zwar im ersten Moment mehr Aufwand, aber es zahlt sich oft aus: kleiner, schneller und vor allem "white-box". grüße
daniel__m schrieb: > Warum auch, so werden größere FPGAs / ZYNQs verkauft ;). Den Eindruck habe ich auch immer mehr. Was eigentlich Mutmaßung war, nämlich nicht nur die Kunden durch die Cores überhaupt auf die eigenen Produkte (zunächst das design tool, dann die Chips) einzuschwören, sondern eben auch den Absatz nebenbei zu steigern, scheint mir das Hauptziel geworden zu sein. Es werden unzählige Demoprojekte ausgeliefert, die einen Pfad vorzeigen und den Eindruck erwecken, man könne alles mal eben im Vorbeigehen erledigen, aber wehe, man möchte etwas mehr tun, als der Demoentwickler zusammengeschraubt hat. Dann hakt es oft an kleinen Details wie einer Interface-Inkompatibilität, einen mislungenen Core-Update oder irgend einem anderen Pfurz. Und versuche mal etwas von den verpackten HLS-Teilen für eigene Dinge zu nutzen. Keine Chance. Die Cores, die man vom großen X bekommt, sind auch nicht so wirklich nützlich. Das meiste, was frei ist, ist in Sachen SV durch CORDIC gelöst, was oft ineffektiv ist und richtige SV wie Viterbi, Kalman oder Markov gibt es nur in simpel, von Drittfirmen oder gar nicht. Um die FPGA-Entwicklung ist ein großer Core IP Hype entbrannt. Fehlt eigentlich nur noch der Google-Core-Store.
Signalverarbeiter schrieb: > Es werden unzählige Demoprojekte ausgeliefert, die einen Pfad vorzeigen > und den Eindruck erwecken, man könne alles mal eben im Vorbeigehen > erledigen, aber wehe, man möchte etwas mehr tun, als der Demoentwickler > zusammengeschraubt hat. Sehe ich auch so. Und das geht schon bei den Tutorials los, wo man fast scheitert, weil eine Kleinigkeit anders ist und die Fallstricke oder Hintergründe bzw. der Link zu den Hintergründen nicht erwähnt werden. Aber mit 'fastest time to market' werben. Denkste. Duke
Dieses Blockbausystem passt aber in unsere Zeit: Schnell zusammengestöpselt macht Eindruck. Und dann ab damit auf Youtube. Mein Teamleiter kam letzterdings an und hat auf einen Studenten verwiesen, der ein solches Video als Bewerbung eingereicht hat (also den link auf sein Werk). Er hat binnen 3 Tagen ein vollständiges SOC-System zusammengeklickt und einen Kleincomputer gebaut. Dieses System sollte sich unser 8-Bit-CPU-Freund aus dem parallelen Thema mal antun :-) Beitrag "Re: 8bit-Computing mit FPGA" Bevor es aber falsch rüber kommt: Das ist kaum vergleichbar. Ich habe mich auch schon öfters am Blockdesign aufgehängt, weil irgendwo etwas nicht gestimmt hat. Man kriegt da sehr rasch 99% der Aufgabe gelöst. Aber das letzte Prozent dauert dann Wochen ...
daniel__m schrieb: > GGf. lassen sich Funktionen > bei der Instanziierung tailorn, jedoch sind die Cores troztdem selten > genügsam Kaum! Es ist auch nicht möglich, den Core konfigurierbar zu halten und Funktionen bei der Synthese wegzulassen. Was mich stört, ist momentan weniger die zusätzliche Schaltungsmasse an sich, sondern der Stromverbrauch. Sobald man im nächst größeren FPGA-Baustein hängt, steigen nicht nur die Kosten, sondern auch der Besaftungsanspruch. Und dann stopfst du gleich 10% mehr Blockkondensatoren rein und nimmst 30% mehr Stromreserve bei den Reglern. Ich hatte schon mehrfach das Problem, dass ich in die kritische Wärmezone geraten bin und mehr Kühlung vorsehen musste.
>Und versuche mal etwas von den verpackten HLS-Teilen für eigene Dinge zu >nutzen. Keine Chance. Das geht. Irgendein Fuchs hier im Forum hat mal die passenden Schlüssel zum entschlüsseln der Ipcores gepostet inkl. Anleitung wo welche Teile zu finden sind. Finde es leider auf die schnelle nicht, aber es existiert definitiv und funktioniert recht "einfach".
jibi schrieb: > funktioniert recht "einfach". Ich würde es nicht als "einfach" hinstellen, wenn man die aus guten Gründen angewandte Versteck-Taktik eines Herstellers erst knacken muss, um vollen Profit aus seinen Demos ziehen zu können. Die Frage, die sich sicher dazu stellt, ist auch: Ist das auch 100% legal? Ich kann mir vorstellen, dass es sich um eine Art des reenginerings handelt, welches regelmäßig im Rahmen des Klickens des Licens-Agreements untersagt ist. In jedem Fall finde ich es aber interessant. Hätte jemand einen Link?
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.