Den Test könnte man in meine fpga Version oben wohl recht leicht einbauen. Problem mit dem + 3072 Rechnen pro Kern ist halt, dass wir eine Abbruchbedingung für alle GPU Kerne brauchen. Der einzelne Kern weiss nicht, was sein Nachbar tut. Also ob er fertig ist. D.h. regelmäßige Zwischenstopps machen schon Sinn?
Nein, alle GPUs laufen die gleiche Anzahl von Iterationen - die Anzahl der Iterationen muss man so auslegen, dass 99% oder 99,9% der GPUs (durch Simulationsläufe auf einem normalen PC) ihr "lower-limit-not-reached"-Bit gelöscht haben, wenn sie nicht das "upper-limit-reached"-Bit gesetzt haben. Sie übergeben dann ihr Ergebnis in ein globales Array, berechnen ihren nächsten Startwert, initialisieren ihre Flags neu un legen mit dem nächsten Zyklus los.
gonzens schrieb: > den entsprechenden "hart codierten" tests auf > record und stopwert, die jeweils durch überschreiten oder unterschreiten > bestimmter 2-er potenzen also entsprechender max und der min gesetzten > Bits hinausläuft :) ggf. bekommt man auf die art auch deutlich mehr > solcher "Collatz_Units" auf den FPGA :) das hatte ich nie anders geplant und ist eigentlich Voraussetzung für ein "kleines" Design!
matthias schrieb: > Nach vielen Versuchen mit den sog. SSE Extensions der neuesten Intel und > Xeon Prozessoren, glaub ich es geht damit nicht. Die Flags werden nicht > richtig gesetzt oder gar nicht.. @mattias: U.U. lassen sich die SSE Extensions nutzen, wenn Du statt einem INT128 oder einem INT192 einen INT112 oder INT160 (56 + 48 + 56) entsprechend meinem Beitrag "Re: 128 Bit Risc" bastelst - ich meine, der Code müsste ohne Flags funktionieren (entsprechende Tests stehen allerdings noch aus). Erfordert aber nat., dass man auf die einzelnen Bytes eines Registers zugreifen, und diese separat manipulieren kann!?
U.G. L. schrieb: > Vielleicht kann einer von den MP-lern bei Nallatech nachfragen, > ob die für mehrere nackte Boards und für so ein Projekt > gegebenenfalls die Doku und Software zur Verfügung stellen > (aber nicht den Link verraten - die Kaufen sonst bei dem Preis > die Boards glatt selber zurück :-). Hatte dann doch gleich selber mal nachgefragt und zur Antwort bekommen, dass es für ihre Boards keinen Support gibt, wenn sie über eine "3rd party" bezogen wurde. Die gebrauchten Boards kann man also ad acta legen und damit höchstwahrscheinlich auch eine FPGA-Lösung. Man wird sich wohl besser auf eine Grafikkarten/OpenCL-Variante konzentrieren.
U.G. L. schrieb: > @mattias: > U.U. lassen sich die SSE Extensions nutzen, wenn Du statt einem INT128 > oder einem INT192 einen INT112 oder INT160 (56 + 48 + 56) entsprechend > meinem Beitrag "Re: 128 Bit Risc" bastelst - ja nett aber was ist das für eine Sprache und mit int160 meinst du einen Datentyp? gnu c ist es nicht oder g++ Tnx merry xmax;)
matthias schrieb: > ja nett aber was ist das für eine Sprache und mit int160 meinst du einen > Datentyp? Na es sollte dann doch C++ sein :-) Aber wie schon oben geschrieben, noch nicht compiliert oder gar getestet, also nur eine Idee, noiert in C++. Und ja, int112 oder int160 wären, aus int64 gebastelte, eigene Typen, in denen Platz für Überläufe und zu shiftende Bits vorhanden ist - weswegen für eine Implementierung keine Operationen mit Carry-Bit notwendig sein sollten. Allerdings müsste man auf diverse, einzelne Bytes zugreifen und sie separat manipulieren können. Nutzbits würden beim einem int112 im low-Part nur die Bytes 0 bis 6 und im hgh-Part nur die Bytes 1-7 enthalten - low-Part-Byte7 und hgh-Part-Byte0 ersetzen sozusagen das Carry-Bit.
1 | hgh-Part low-Part |
2 | _______________________________ _______________________________ |
3 | |_7_|_6_|_5_|_4_|_3_|_2_|_1_|_0_| |_7_|_6_|_5_|_4_|_3_|_2_|_1_|_0_| |
4 | |
5 | ___________________________ ___ ___ ___________________________ |
6 | |_7_|_6_|_5_|_4_|_3_|_2_|_1_| |_0_| |_7_| |_6_|_5_|_4_|_3_|_2_|_1_|_0_| |
C++ geht auf GPU eigentlich nicht. Nur OpenCL (wenn es für ne grössere Auswahl an GPU Typen sein soll). Problem ist, dass es ziemlich bremsen dürfte, wenn man solch grosse Typen byteweise manipuliert. Wenn dem IP Problem, werd ja bei einem if else immer beide Zweige ausgeführt. Wird also nur 1 Kern ein Byte anfassen, müssen alle Kerne diesen Code ausführen. Also wird wohl jeder Kern jedes Byte anfassen müssen. Ganz schlecht. Es sollten idealerweise nur Datentypen benutzt werden, welche die GPU nativ unterstützt. Deshalb wäre halt long long cool, wenn eine GPU dann eine Addition z.B. mit einem einzigen Maschinenbefehl ausführen kann. Alternativ halt ein long2 Vektor, damit man nur 2 Elements anfassen muss, und nicht etwa 20 (160 Bit = 20 Byte). Hat jetzt schonmal jemand so ein Streaming SDK installiert, damit man mal praktisch was probieren kann? Theoretisch soll das ja jetzt auch in einer virtuellen Maschine gehen, aber das hab ich noch nicht probiert.
Andreas R. schrieb: > C++ geht auf GPU eigentlich nicht. Nur OpenCL (wenn es für ne grössere > Auswahl an GPU Typen sein soll). Es ist klar, dass das letztlich mit OpenCL gemacht werden muss. Wie schon erwähnt, ist der gepostet Code nur 'n Vorschlag/Idee niedergeschrieben in C++, vielleicht die Basis einer Simulation. > Problem ist, dass es ziemlich bremsen > dürfte, wenn man solch grosse Typen byteweise manipuliert. Wenn dem IP > Problem, werd ja bei einem if else immer beide Zweige ausgeführt. Wird > also nur 1 Kern ein Byte anfassen, müssen alle Kerne diesen Code > ausführen. Also wird wohl jeder Kern jedes Byte anfassen müssen. Ganz > schlecht. Es sollten idealerweise nur Datentypen benutzt werden, welche > die GPU nativ unterstützt. Deshalb wäre halt long long cool, wenn eine > GPU dann eine Addition z.B. mit einem einzigen Maschinenbefehl ausführen > kann. Alternativ halt ein long2 Vektor, damit man nur 2 Elements > anfassen muss, und nicht etwa 20 (160 Bit = 20 Byte). Erstmal - die 160 bit waren nur ein Einwurf, wie man die 112 Bit erweitern würde, wenn die mal nicht mehr reichen. Der aktuell interssante Bereich wird sich mit irgendwas zwischen 80 bis 128 bit erschlagen lassen. Leider gibt es, soweit ich das sehe, in aktuell verfügbaren Implementierungen von OpenCL keine 128bit Typ, sonst würde man sich ganz klar darauf stürtzen. Und ein long2 ist halt alles andere als ein 128bit Typ - es ist ein Vektor aus zwei 64bit Typen, die eigentlich nix miteinander zu tun haben, insbesondere gibt es nix, in was ein Überlaufe/Unterlauf am oberen Ende der ersten Komponente bzw. an am unteren Ende der zweiten Komponente reinfallen würde (Carrry) - es ist also notwendig, vor jeder Operation zu bestimmen, ob ein Überlauf/Unterlauf entstehen wird und diesen separat zu behandeln, womit wir bei etwas wären, was so wie in www.mikrocontroller.net/topic/413678#4835838 gezeigt funktionieren müsste. Die Idee hinter meinem Vorschlag war nun, dass bei einer GPU eigentlich Zugriffs-/Manipulationsmöglichkeiten auf einzelne Bytes vorhanden sein müssten, da Bytetypen nun ja alles andere als selten genutzte Datentypen auf einer Graka sind (8bit Pixel, 8bit Komponenten bei RGB und RGB32) und man dann jeweils ein Byte (unten oder oben) eines 64bit Integers als Raum für Uber- und Unterlauf verwenden könnte - und dann eben nicht nur für einen Uber-/Unterlauf, sondern gleich für mehrere, so dass z.B. die Überlaufbehandlung für eine 3 x + 1 Operation nur einmal, statt dreimal gemacht werden muss. Ob mein Vorschlag funktioniert, muss aber jemand sagen, der sich mit Graka-Programmierung auskennt.
Bei Cuda scheint es mit inline ASM zu gehen. http://stackoverflow.com/questions/6162140/128-bit-integer-on-cuda Bei OpenCL eher nicht. https://community.amd.com/thread/188702
Eukrott V. schrieb: > wir haben grad gemessen > auf einem core #53 in 4 min 44 > > dh wir sind mit reinem asm um etwa faktor 3 schneller > (beides läuft auf derselben maschine) Heute ist mir noch ein Gedanke gekommen, womit der höher als von mir erwartete Faktor zwischen der GMP- und der Assembler-Version kommen könnte - wie ich schon längere Zeit eruiert hatte und heute wieder von mir ausgebudelt wurde, unterscheidet sich der Typ "int" bei MinGW zwischen der 32Bit- und der 64bit-Version nicht! Ein unterschied findet sich nur beim Typ "long long", der auf 32bit immernoch 32bit breit ist, bei der 64bit Version dann aber doch 64bit!
1 | printf("\nsi=%u", sizeof(short int));
|
2 | printf("\ni=%u", sizeof(int));
|
3 | printf("\nli=%u", sizeof(long int));
|
4 | printf("\nlli=%u", sizeof(long long int));
|
5 | printf("\nf=%u", sizeof(float));
|
6 | printf("\nd=%u", sizeof(double));
|
7 | printf("\nld=%u", sizeof(long double));
|
8 | |
9 | mgw32: |
10 | si=2 |
11 | i=4 |
12 | li=4 |
13 | lli=8 |
14 | f=4 |
15 | d=8 |
16 | ld=12 |
17 | |
18 | mgw64: |
19 | si=2 |
20 | i=4 |
21 | li=4 |
22 | lli=8 |
23 | f=4 |
24 | d=8 |
25 | ld=16 |
Ich weiß jetzt nicht, wie das beim GCC unter Linux ausschaut, wenn der das aber ebenso handhabt, könnte ich mir vorstellen, dass GMP auch in einer 64bit Umgebung nut mit 32bit breiten "Stücken" arbeitet - man müsste feststellen, wie groß dort ein "limb" ist!? Falls die limbs nur 32 bit breit sind, würde das natürlich den Faktor 3 teilweise erklären.
Andreas R. schrieb: > Bei Cuda scheint es mit inline ASM zu gehen. > > http://stackoverflow.com/questions/6162140/128-bit-integer-on-cuda > > Bei OpenCL eher nicht. > > https://community.amd.com/thread/188702 Cuda und Assembler würde ich aus dem weg gehen wollen - sicher wird man damit schnelleren Code hinbekommen, der läuft dann aber halt nur auf einer bestimmten Karte. Mit OpenCL hat man den Vorteil, das der Code auf Grafikkarten von Nvidia, AMD und Intel laufen kann - entsprechend leichter sollte gegebenefalls es sein, Grafikkarten für das Projekt abzustellen. Interessant erscheint mir dafür auch die Webseite, auf die im geposteten Link verwiesen wird (https://devtalk.nvidia.com/default/topic/491349/cuda-programming-and-performance/larger-than-64bit-integer-i-want-to-count-with-very-big-integers-larger-than-64bit/) - eine Methode, wie man das fehlende Carry ersetzen kann. Ich habe mittlerweile zudem erkannt, dass bei einer 2x + x + 1 Operation nur zweimal ein Carry auftreten kann - für die Addition der 1 ist im low-Element immer Platz und eine Carry-Prüfung und Übertragung ist nicht notwendig.
U.G. L. schrieb: > Ein unterschied findet sich nur > beim Typ "long long", der auf 32bit immernoch 32bit breit ist, bei der > 64bit Version dann aber doch 64bit! Das widerspricht meiner Erfahrung und insbesondere auch Deinen Testergebnissen.
Hab' auf Basis meines letzten Beitrags mal eine prakisch reine C-Version geschrieben (GMP ist nur noch für die Ausgabe drinnen). Sie ist fast um den Faktor zwei schneller wie meine GMP-Version, obwohl sie ebenfalls mit 32bit arbeitet, d,h, mit 64bit wäre vermutlich noch mehr drin. Ich kann bei meiner Version weitere kanpp 8% gewinnen, wenn ich nach der "Rechenstufe" eine zweite, optionale Teilung einfüge, u.U. bringt das auch was bei Eurer Assemblerversion. Kann aber auch sein, dass das bei mir nur was bringt, weil ich noch vollkommen unnötige Vergleiche mit dem Startwert drin habe (immer, wenn ich zuvor ein 3x+1 Schritt hatte und schon gegen den Pfadrekord getestet habe). Das Urige - wenn ich diesen "Schönheitsfehler" beseitige, profitiert das Programm nicht etwas davon, sondern wird minimal langsamer - und die zweite, optionale Teilung verschlechtert das Ergebnis deutlich!? Keine Ahnung - vielleicht irgedwelche Cache-Effekte!? Oder meine CPU hat gerade Hitzewallungen :-) Hab' das aber nicht mehr weiter untersucht, weil ich eher in Richtung GPU arbeite. Dafür ist auch die weitere Variante im Code gedacht - die läuft auf der CPU zwar langsamer, könnte aber auf den GPUs von Vorteil sein, weil das Abprüfen gegen den Pfadrekord und gegen den Startwert nicht nacheinander passiert, stattdessen auf der einzelnen GPUs nur gegen den gerade aktuellen Vergleichswert geprüft wird - mit dem gleichen Code, aber ensprechend preparierten Daten.
1 | für #45 n=8528817511 r=18144594937356598024 |
2 | |
3 | GMP #if 1 #if 1 #if 1 |
4 | BSTAGE |
5 | 371sec 192sec 178sec 257sec |
6 | \_1,93_/ \_8%_/ |
1 | // g++ -Ofast c128.cpp -o c128 -I ..\..\gmp\include\ -L ..\..\gmp\lib\ -lgmp |
2 | |
3 | #include <ctime> |
4 | #include <stdio.h> |
5 | #include "..\..\gmp\include\gmp.h" |
6 | |
7 | //[ typedefs ---------------------------------------------------- |
8 | typedef unsigned int ui32; |
9 | typedef unsigned long long ui64; |
10 | typedef struct u128 {ui64 l; ui64 h;} u128;
|
11 | //] eof typedefs ------------------------------------------------ |
12 | |
13 | void u128_print(const char* str, u128* z) { //[
|
14 | mpz_t x; |
15 | ui32* u = (ui32*) z; |
16 | |
17 | mpz_init2(x, 128); |
18 | mpz_set_ui(x, u[3]); |
19 | mpz_mul_2exp(x, x, 32); |
20 | mpz_add_ui(x, x, u[2]); |
21 | mpz_mul_2exp(x, x, 32); |
22 | mpz_add_ui(x, x, u[1]); |
23 | mpz_mul_2exp(x, x, 32); |
24 | mpz_add_ui(x, x, u[0]); |
25 | gmp_printf(str, x); |
26 | }//] |
27 | |
28 | int main(int argc, char **argv) { //[
|
29 | static char timstr[10]; |
30 | static time_t stt, now; |
31 | static double sec; |
32 | static const ui32 step = 3072; |
33 | static const ui32 lend = 116; |
34 | static ui32 loop = 0; |
35 | static ui64 base = 0; |
36 | static const ui32 rest[] = {
|
37 | 27, 31, 63, 91, 103, 111, 127, 159, 207, 231, 255, 283, |
38 | 303, 319, 327, 411, 415, 447, 463, 487, 495, 511, 543, 559, |
39 | 603, 615, 639, 667, 679, 703, 751, 763, 795, 799, 831, 859, |
40 | 871, 879, 927, 1023, 1051, 1071, 1087, 1095, 1135, 1179, 1183, 1191, |
41 | 1215, 1231, 1255, 1263, 1275, 1279, 1327, 1351, 1383, 1435, 1471, 1519, |
42 | 1563, 1567, 1627, 1639, 1647, 1663, 1695, 1767, 1791, 1819, 1855, 1863, |
43 | 1903, 1951, 1959, 1983, 2031, 2043, 2047, 2079, 2095, 2119, 2139, 2151, |
44 | 2175, 2203, 2215, 2239, 2287, 2299, 2331, 2367, 2407, 2463, 2511, 2535, |
45 | 2559, 2587, 2607, 2671, 2715, 2719, 2727, 2751, 2791, 2799, 2811, 2815, |
46 | 2847, 2887, 2907, 2919, 2983, 3007, 3055, 3067}; |
47 | u128 r = {160 >> 1, 0};
|
48 | u128 n = {0, 0}, x, w;
|
49 | ui64 t64; |
50 | ui32 t32, flg, lim; |
51 | int cnt, c; |
52 | |
53 | stt = time(0); |
54 | while (1) {
|
55 | n.l = base + rest[loop++]; |
56 | if (loop >= lend) {
|
57 | loop = 0; |
58 | base += step; |
59 | } |
60 | x = n; |
61 | lim = 2; |
62 | cnt = 0; |
63 | c = 0; |
64 | do { // 32bit implementation
|
65 | cnt++; |
66 | flg = (*((ui32*) (&x.l))) & 1; |
67 | // w = x/2; |
68 | t32 = ((*((ui32*) (&x.h))) & 1) << 31; |
69 | w.h = x.h >> 1; |
70 | w.l = x.l >> 1; |
71 | (*(((ui32*) (&w.l)) + 1)) |= t32; |
72 | // if (even) x = {0, 0};
|
73 | t64 = -((signed long long) flg); |
74 | x.l &= t64; |
75 | x.h &= t64; |
76 | // x = x + w + flg; |
77 | x.h = x.h + w.h; |
78 | x.l = x.l + w.l; |
79 | x.h += (x.l < w.l); // carry |
80 | x.l += flg; |
81 | #if 1 |
82 | #define BSTAGE 0 |
83 | if (flg) { // cmp r
|
84 | t64 = x.h + (x.l > r.l); |
85 | // copy new record, if one found |
86 | if (t64 > r.h) {
|
87 | r = x; |
88 | c = cnt; |
89 | } |
90 | } |
91 | #if BSTAGE |
92 | //[ extra x = x/2 stage |
93 | if (!((*((ui32*) (&x.l))) & 1)) {
|
94 | // w = x/2; |
95 | t32 = ((*((ui32*) (&x.h))) & 1) << 31; |
96 | x.h >>= 1; |
97 | x.l >>= 1; |
98 | (*(((ui32*) (&x.l)) + 1)) |= t32; |
99 | }//] |
100 | #endif |
101 | } while (x.h || (x.l > n.l)); |
102 | #else |
103 | // copy u128 to compare with x |
104 | w = flg ? r : n; |
105 | // compare |
106 | t64 = x.h + (x.l > w.l); |
107 | t32 = (t64 > w.h); |
108 | // extract results |
109 | t32 |= (flg << 1); |
110 | lim &= 0x0000FFFD >> (t32 << 2); |
111 | lim |= 0x00001000 >> (t32 << 2); |
112 | // copy new record, if one found |
113 | if (flg & t32) { // cmp r
|
114 | r = x; |
115 | c = cnt; |
116 | } |
117 | } while (lim & 2); |
118 | #endif |
119 | if (c) {
|
120 | now = time(0); |
121 | sec = difftime(now, stt); |
122 | printf("\n%.f:", sec);
|
123 | w = n; |
124 | u128_print(" n=%Zd", &w);
|
125 | w.l = r.l << 1; |
126 | w.h = r.h << 1; |
127 | w.h |= ((signed long long) r.l) < 0 ? 1 : 0; |
128 | u128_print(" r=%Zd", &w);
|
129 | printf(" c=%u", c);
|
130 | } |
131 | } |
132 | return 0; |
133 | }//] |
U.G. L. schrieb: > Ein unterschied findet sich nur > beim Typ "long long", der auf 32bit immernoch 32bit breit ist, bei der > 64bit Version dann aber doch 64bit! Das ist so in Windows, weil MS sich nicht traute, DWORD=long aufzugeben. Das LLP64 Typenmodell. In Linux findest du LP64, also 64 Bit long.
Markus K. schrieb: > U.G. L. schrieb: >> Ein unterschied findet sich nur >> beim Typ "long long", der auf 32bit immernoch 32bit breit ist, bei der >> 64bit Version dann aber doch 64bit! > > Das widerspricht meiner Erfahrung und insbesondere auch Deinen > Testergebnissen. LOL - da hab' ich vielleicht einen Stuss zusammengeschrieben - da sind wohl ursprüngliche Annahmen, Messungen und Vergucker fröhlich durcheinander gewürfelt worden :-) Es gibt, zumindest bei den Integertypen gerade keine Unterschiede, insbesondere ist der "int", entgegen meiner Erwartung, auch in der 64bit Umgebung nur 32bit breit (bei MinGW). Und das könnte vielleicht dazu führen, dass eben auch bei der GMP in einer 64bit Umgebung ein "limb" nur 32bit breit ist (falls der GCC auf Linux sich wie MinGW auf Windows verhält) - und das war's, was ich eigentlich sagen wollte :-)
U.G. L. schrieb: > Cuda und Assembler würde ich aus dem weg gehen wollen - sicher wird man > damit schnelleren Code hinbekommen, der läuft dann aber halt nur auf > einer bestimmten Karte. > > Mit OpenCL hat man den Vorteil, das der Code auf Grafikkarten von > Nvidia, AMD und Intel laufen kann - entsprechend leichter sollte > gegebenefalls es sein, Grafikkarten für das Projekt abzustellen. Interessant ist, dass diese Inline Asm Lösung wohl nur mit NVidia Karten geht, welche aber nach meinen Erfahrungen im Integer Bereich immer langsamer als die AMD Karten waren (vielleicht bis auf die ganz neuen Karten). Deshalb wurde ja z.B. beim Bitcoin-Mining immer auf die AMD Karten gesetzt. Wenn ich mich recht entsinne, haben den NVidia 1,2 wichtige Befehle für diese Encryption-Geschichten gefehlt. Ich glaub, es ging um Schiebe-Befehle. Da steht was dazu: https://www.extremetech.com/computing/153467-amd-destroys-nvidia-bitcoin-mining Das hat jetzt wohl zur Folge, dass wir entweder guten Code auf ner schlechten Karte haben, oder schlechten Code auf ner guten Karte? ;-) D.h. die freie Wahl zwischen Pest oder Cholera. Ciao, Andreas
Gustl B. schrieb: > Dieses Gestochere im Nebel ... es gibt doch int64_t und uint64_t. Es geht nicht darum, was man nehmen könnte, sondern darum, wie C's Standard-Typen implementiert sind!
Angehängte Dateien:
-

CollatzMachine.png
14 KB
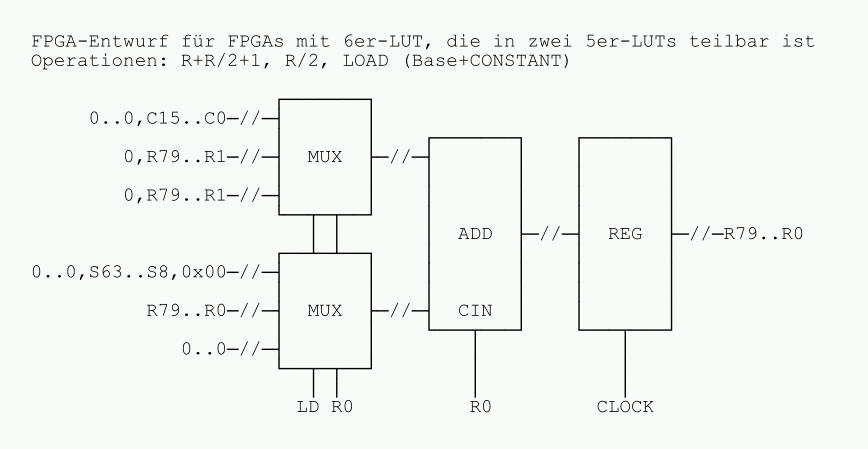
Markus W. schrieb: > Geht es hier eigentlich noch um 128 bit risc? Ich denke, die Diskussion hat schnell gezeigt, dass das zu bearbeitende Problem, wenn überhaupt mit einem FPGA, dann nicht mittels einer klassichen 128bit RISC CPU, sondern mittels möglichst vieler, parallel arbeitender, spezieller Collatz-Maschinen anzugehen wäre.
Wie ich gestern abend entdeckt habe, sollte man bei Verwendung der GMP-Library für jeden Aufruf von mpz_init2(...) einen korrespondierenden mpz_clear(...)-Aufruf spendieren :-) Wer also eines meiner Beispiele als Grundlage für eigene Programme benutzt, sollte auf die korrigierten Versionen im Anhang zurückgreifen. Beitrag "Re: 128 Bit Risc" collatz1.cpp collatz1.exe Beitrag "Re: 128 Bit Risc" collatz2.cpp collatz2.exe Beitrag "Re: 128 Bit Risc" collatz.cpp Beitrag "Re: 128 Bit Risc" collatz3.cpp collatz4.cpp Beitrag "Re: 128 Bit Risc" c128.cpp
Frohes neues Jaaa! Bei dem o.a. Collatz Algorithmus tritt der Effekt auf, dass man bei Zahlen kongruent 2 modulo also Zahlen die durch 3 geteilt 2 Rest bleiben, abbrechen kann. Also z.B. 2,5,8,11,.14,17,.....,254,257,250,,770,..3074,...,8192,.. 16385,,,32768,..,49154,, Beispiele bis ca, 2^16. Eine Lösung isr gefunden z.b., wenn die Quersumme im Dezimalsystem Rest 2 mod 3 ergibt. Aber wir arbeiten mit 128 Bit Binär Maschinen. Man müsste doch einen schnellen "modulo-3-Algorithus" in _86 Assembler oder mit LTU s implementieren können. Das Standardverfahren ist der euklidische Algorithmus, der erscheint mir hier zu aufwendig. Es gibt aber auch kein erkennbares Bitmuster in den unteren 16 bit. Das gute ist, dass nur modulo 3 interessiert, keine generelle modulo funktion für 128/64 Bit Integer ist benötigt. Ein mathematisches oder logistisches Problem /Lösung? Schnell muss sie sein.
Angehängte Dateien:
-

MOD3.png
5,4 KB

matthias schrieb: > Ein mathematisches oder logistisches Problem /Lösung? Auf den ersten Blick hin, eigentlich eine einfache Sache (vielleicht überseh' ich auf die Schnelle aber etwas?). Ein gesetztes Even-Bit trägz mit einem Rest 1 zum Gesamtergebnis bei, ein gesetztes Odd-Bit bringt einen Rest 2 ein. Das Bild zeigt eine Schaltung für 16Bit, pro Bitbreitenverdopplung käme rechts eine weitere "Redzierstufe" hinzu. Da 4er LUTs in FPGAs meist nur einen Ausgang haben, müsste man die LUTs aus der Schaltung mittels zweier FPGA-LUTs realisieren. Im Prinzip eine Schaltung ähnlich einem Parity-Generator (https://de.wikipedia.org/wiki/Parit%C3%A4tsgenerator).
Und als Software wären es halt 4 Zugriffe in ein 4GB-LUT oder 8 Zugriffe in eine 64kB LUT plus Ergebnisse shiften und oderieren, dann ein weiterer LUT-Zugriff in eine 256Byte oder 64kB-LUT.
Andere Ideee wäre, durch Maskieren Odd- und Even-Bits zu trennen, und einen Algo mittels eines CountBits-Algo (http://graphics.stanford.edu/~seander/bithacks.html#CountBitsSetNaive) stricken.
Aber vermutlich wir da die Modulo-3-Operation, jeweils angewandt auf die unteren und oberen 64Bit schneller sein!
U.G. L. schrieb: > plus Ergebnisse shiften und oderieren, dann ein > weiterer LUT-Zugriff in eine 256Byte oder 64kB-LUT. Einfaches Addieren plus Griff in eine kleine LUT reicht eigentlich.
Gerade sehe ich, dass es unter SSE4 gibt es die POPCNT instruction. Also wieder in odd- und even-bits trennen(maskieren) gesetzte Bits zählen und auswertem. Und falls es interessiert - wie popcnt in hardware realisiert wird: http://www.wseas.us/e-library/conferences/2006hangzhou/papers/531-262.pdf
Dein Bildchen ist nett, aber die modulo 3 Bitmuster wiederholen sich
nicht bei 2^16 leider:
65536 kongruent 1 mod 3
So lößt es gcc:
#include <stdio.h>
int main ()
{
// 998 mod 3 =2
unsigned int i= 998;
unsigned int j= i%3;
printf("\n i = %i",i);
printf("\n j = %i",j);
}
Auszug aus dem .S file, geht bis 32 bit denk ich...
Lade was Du willst in -8(%rbp)
Ergebnis in -4(%rbp)
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $998, -8(%rbp)
movl -8(%rbp), %ecx
movl $-1431655765, %edx
movl %ecx, %eax
mull %edx
shrl %edx
movl %edx, %eax
addl %eax, %eax
addl %edx, %eax
subl %eax, %ecx
movl %ecx, %eax
movl %eax, -4(%rbp)
998 mod 3 =2
Happy New Year anyway ;)
M.J.
Und wie kommt der Compiler auf das mysteriöse -1 431 655 765?? Also 2^32 = 4 294 967 296 -1 431 655 765 = 2 863 311 531. Aber wie entsteht dieses 1 431 655 765? Bei anderen modulo quotienten macht der gcc compiler andere Weter an der Stelle, ja kla. Main Ja Nuhr ;) ciao
matthias schrieb: > Also 2^32 = 4 294 967 296 -1 431 655 765 = 2 863 311 531. Aber wie > entsteht dieses 1 431 655 765? 10101010101010101010101010101011 ist 2863311531 als unsigned int und -1431655765 als signed int. Die Register selber sind nicht signed/unsigned, sondern die Befehle.
matthias schrieb: > Dein Bildchen ist nett, aber die modulo 3 Bitmuster wiederholen sich > nicht bei 2^16 leider: > > 65536 kongruent 1 mod 3 16 ist gerade, also ist 2^16 = 1 mod 3 - passt doch!!! 2^n = 1 mod 3, wenn n gerade 2^n = 2 mod 3, wenn n ungerade z.B.
1 | 0x5201700A: |
2 | |
3 | 0x5201700A |
4 | & 0xAAAAAAAA |
5 | = 0x0200200A ==> 4 gerade Bits gesetzt ==> 4 x 1 = 4 |
6 | |
7 | |
8 | 0x5201700A |
9 | & 0x55555555 |
10 | = 0x50015000 ==> 5 ungerade Bits gesetzt ==> 5 x 2 = 10 |
11 | -------------------------------------------------------- |
12 | Summe 14 |
13 | 14 = 2 mod 3 |
14 | |
15 | ergo: |
16 | 0x5201700A = 2 mod 3 |
oder 998 == 0x3E6:
1 | 0x000003E6 |
2 | & 0xAAAAAAAA |
3 | = 0x000002A2 ==> 5 gerade Bits gesetzt ==> 5 x 1 = 5 |
4 | |
5 | |
6 | 0x000003E6 |
7 | & 0x55555555 |
8 | = 0x00000144 ==> 3 ungerade Bits gesetzt ==> 3 x 2 = 6 |
9 | -------------------------------------------------------- |
10 | Summe 11 |
11 | 11 = 2 mod 3 |
12 | |
13 | ergo: |
14 | 0x000003E6 = 2 mod 3 |
matthias schrieb: > Also 2^32 = 4 294 967 296 -1 431 655 765 = 2 863 311 531. Aber wie > entsteht dieses 1 431 655 765? https://en.wikipedia.org/wiki/Division_algorithm#Division_by_a_constant
namt Mein Idee wäre auch eine Bruteforce Primzahlzerlegung von 128-Bit-Zahlen dadurch zu beschleunigen, dass man nicht wie üblich durch alle Primzahlen kleiner als die Wurzel der Zahl nacheinander teilt, etwa 988651 durch 2,3,5,7,11,...995. Sondern gleich durch die ersten 8 oder mehr auf einmal teilt, weil man z.B. eine 8 core AM3+ CPU hat. Wobei 988651 selbst Prim ist. Die ersten Primes bis 1000000 oder so könnte man vorbereitet halten und erst nachsehen ob sie in dieser LUT ist, wenn nicht, dann die ersten 8 Divisionen parallel stzarten. Wenn eine aufgeht deren Divisionsergebnis als neuen Startwert, oder so.. Mj
matthias schrieb: > Mein Idee wäre auch eine Bruteforce Primzahlzerlegung ... > dadurch zu beschleunigen, dass man ... > ... die ersten 8 oder mehr auf einmal teilt Wir haben das mal in den 90ern auf einem Linux-Cluster mit 256 und dann 512 Rechnern laufen lassen. Das lief auch so, daß alte, bereits gefundene Zahlen gespeichert blieben und über einen Hash-Algo gesucht wurden, um sie zu nutzen. Ich habe sowas mal für eine FPGA-Lösung auf einem anderen Gebiet gemacht. Das Problem: Die Chips heute sind schweineschnell, kriegen aber die Speicherbandbreite nicht hin, um alles zu speichern und zu laden. Selbst mit den schnellsten DDR4-Controllern ist mal limitiert, wenn es um den Vergleich mit FPGA-Applikationen geht, die auf Block-Rams arbeiten. Leider haben die FPGAs für solche APPs (noch) viel zu wenig Speicher. Markus W. schrieb: > Liesse sich so eine Division nicht auf einem FPGA durch Parallelisieren etwas beschleunigen? Sicher, man kann beim Prüfen auf Teilbarkeit mehrere Annahmen machen und sich dann für die übernächste Stufe das Ergebnis heraussuchen, das durch die Stufe zuvor bestätigt wurde. Ich habe z.B. eine Wurzel, die 4 Wege macht und damit 2 Bits in einem Schritt ermittelt.
Jürgen S. schrieb: > Markus W. schrieb: >> Liesse sich so eine Division nicht auf einem FPGA durch Parallelisieren etwas > beschleunigen? > Sicher, man kann beim Prüfen auf Teilbarkeit mehrere Annahmen machen und > sich dann für die übernächste Stufe das Ergebnis heraussuchen, das durch > die Stufe zuvor bestätigt wurde. Ich habe z.B. eine Wurzel, die 4 Wege > macht und damit 2 Bits in einem Schritt ermittelt. Was ich noch suche, ist ein Algorithmus bzw. einen schnelle asm x86 Methode, 128 Bit Zahlen zu multipliziern bis hin zu 256 bit Grösse also Ymm Register: sagen wir ymm1:= ymm2*ymm3 Leider rechnen auch die ymm Register nur mit den Quadwords soweit ich das sehen kann. Gute Seite ist http://www.felixcloutier.com/x86/ Vielleicht habe ich was übersehen.. Ich dachte an den Karazuba o.ä. Algorithmus. Passt jetzt nicht 100% in den Thread aber immer noch sehe ich da vielleicht zu optimistisch Möglichkeiten. Es gibt auch noch https://de.wikipedia.org/wiki/Sch%C3%B6nhage-Strassen-Algorithmus, und andere. Wie man eben 2 8 stellige Dezimalzahlen multipliziert: 12345678 * 75312452, Schulmethode, so müsste man halt ohne splitting der 256 grossen Register auf 32 oder auch 64 Bit Teile der ymm Register zugreifen und etwa 0x098712BF * 0x13FD01A1 intelligent berechnen. Jemand n Ansatz? M.J.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.