Hi!
Ich suche eine Möglichkeit, mit sehr großen Zahlen ca 2 ^128 einfache
Rechnungen durchzuführen.
An sich brauche ich nur Integer-Operationen: Shl Shr, Rrc, Rlc und or,
xor, and, Compare und add.
Das Bit 128 kann das sign bit sein. Muss nicht.
Multiplikationen und Divisionen kann ich wenn nötig selber schreiben bin
Mathematiker. Kein Floating Point benötigt. Ich kann auch aus 32 bit
words 128 bit Operationen simulieren. Das wäre aber nicht optimal.
Nach vielen Versuchen mit den sog. SSE Extensions der neuesten Intel und
Xeon Prozessoren, glaub ich es geht damit nicht. Die Flags werden nicht
richtig gesetzt oder gar nicht..
Kann man so was mit FPGA realisieren? evtl mehreren?
Gibt es einen default Befehlssatz?
Ich weiss auch nicht ob und wie ich z.b. dieses Gerät "easyFpga" s.u. an
ein normalen PC anbinde und ins ddr3 ram schreibe und ob es Assembler
gibt, die ja den Mikrocode erzeugen sollen.
Und wie realisiert man Ein und Ausgabe Routinen der Hex Zahlen?
Also an sich suche ich einen schnellen RisC Prozessor mit hoher interner
Registerbreite.
Wer sich für mathe interessiert dem kann ich gern erzählen worauf ich
hinaus will:)
Ist easyFpga zu empfehlen: recht preiswert.
https://www.os-cillation.de/easyfpga-kaufen-landing/?gclid=CjwKEAiA94nCBRDxismumrL83icSJAAeeETQtLfFeBenuLyPksiJ_tLtEiplCq2_lxIuQ3O1HLeYzxoCeVrw_wcB
Danke für jeden Hinweis
MM.
Das hängt sehr von der Anwendung ab ob sich das überhaupt lohnt. Zum
einen wird so eine riesige ALU im FPGA langsam sein im Vergleich zu
einer 64- Bit ALU in einem aktuellen PC-Prozessors. Zum anderen wird
die Übertragung der Daten zwischen PC und FPGA schnell ein Flaschenhals.
Schau dir lieber Mal GMP an, ist eine Bibliothek für beliebig große
Zahlen.
> Ich weiss auch nicht ob und wie ich z.b. dieses Gerät "easyFpga" s.u. an> ein normalen PC anbinde
Das sieht nach einem (sehr) kleinen Spartan aus.
Nur die gaaanz kleinen gibt es in diesem Package.
Und mehr als freie IOs entdecke ich da auch nicht.
Gegenueber den internen SSE-Befehlen, die du schon entdeckt hast,
wird jede Anbindung an den PC(-Bus) grottenlangsam sein.
Wenn Mann nicht am PCIe-Bus herumfuhrwerken will,
wofuer der gezeigte FPGA auch nicht in der Lage waere,
bliebe eine parallele Anbindug z.B. ueber den USB-Bus
und z.B. einen CY7C68013A. Den muesstest du an dieses
Board dann noch anschliessen.
126 Eu fuer so ein Board ist auch nicht annaehernd preiswert.
Vergleichbares, mit etwas aelteren FPGA (Cyclone 2),
bekommst du aus Chine fuer < 15 Eu.
Wenn es schnell sein soll, such dir ein Board was per
PCIe an den Host anschliessbar ist.
Das wirst du fuer 126 Eu wohl nicht bekommen.
Die Instanziierung ueber ein Java-Interface ist auf
lange Sicht auch eher hinderlich, weil sie alles
was optimierbar waere hinter dem eigenen Mechanismus
verbirgt. Da kommt Mann um VHDL/Verilog nicht herum.
Fuer die Einbindung wirst du dann auch noch IPs fuer
die PCIe-Komponente erwerben wollen muessen, falls
du die nicht selber machen willst...
Wenn Geld keine Rollt spielt, gibt es bei Intel/Altera
sowas sicher auch fertig zu kaufen.
matthias schrieb:> Ich kann auch aus 32 bit words 128 bit Operationen simulieren. Das wäre> aber nicht optimal.
Nicht optimal inwiefern? Dann nimm zwei Mal 64 Bit. Ich sehe nicht wie
du mit einer fpga Lösung schneller oder sonst was werden könntest.
Was du willst ist klar nur verstehe ich das Problem mit der
offensichtlichen Lösung nicht.
Er schreibt von Flags. Traditioneller Umgang mit Flags ist tatsächlich
ein schwacher Punkt bei SSE. Aber das liegt massgeblich an Arbeitsweise
und Ziel dieser Befehle, denn auch wenn sich SSE-128 vereinzelt auf eine
geschlossene 128-Bit Operation bezieht geht es doch meist um mehrere
parallel arbeitende Operationen auf kleinere Operanden. Und was könnte
man dabei mit klassischen Flags schon viel anfangen?
SSE Optimierung arbeitet deshalb wenn möglich anders. Nicht mit massiv
von bedingten Sprüngen durchsetztem Code, dessen Pipeline-Ausnutzung bei
aller Qualität von Sprungvorhersage doch immer wieder auch klassischen
Schweizer Käse an Löchern schlägt. Sondern indem weitestmöglich
alternative Datenpfade durch bedingte Operationen (conditional move:
results über and/or mit masks rekombiniert, ...) statt bedingten
Programmablauf ersetzt werden. Die auch bei einfachen Operationen
tieferen Pipelines von SSE Operationen werden es danken.
Seine Schilderung hingegen zielt auf klassische Integer-Befehle ab, nur
dummerweise eben mit 128-Bit Operanden. Mit klassischem von bedingten
Sprüngen dominiertem Code. In klassischem Integer-Code findet man oft
eine bedingten Sprung auf 3-5 Befehle. Wenn es ihm nicht gelingt, seine
Algorithmen auf eher Datenfluss-orientierte Arbeitsweise umzustellen,
dann hilft ihm SSE nicht viel.
Immer sehr interessant deine Beiträge. Respekt.
Kenne mich mit sse jetzt nicht in dem Detail aus. Meine Frage nach dem
Problem mit der offensichtlichen Lösung bezieht sich darauf, was gegen
die ganz normalen integer Befehle spricht inkl carry etc.
Ich wage einfach zu bezweifeln dass ein fpga eine aktuelle cpu bei solch
einfachen Operationen schlagen kann, insbesondere wenn man den Overhead
berücksichtigt. (Von massiv parallel verarbeiteten Daten im fpga
abgesehen)
Vielleicht kann der OP etwas Licht ins Dunkel bringen.
Ich sage mal, daß die Operationen in einem FPGA sehr leicht
implementierbar sind, wenngleich da bei den Auflösungen die Datenraten
doch gewaltig nach unten gehen. Die Problematik ist dann zudem, die
Daten ein und raus zu bekommen. Wenn dort nur zu einem gewissen
Prozentsatz gerechnet werden muss, ist eine manuelle Emulation in einem
Intel-Core wohl zielführender.
matthias schrieb:> Also an sich suche ich einen schnellen RisC Prozessor mit hoher interner> Registerbreite.
Definiere "schnell".
Denn schnell wird ein FPGA nur, wenn du parallel arbeiten kannst.
Ansonsten ist jeder "kreuzlahme" 600Mhz Rechner schneller als ein
(Anfänger-)FPGA-Design. Und vor Allem: den kannst du fertig kaufen. Bis
das mit dem FPGA läuft, dauert das sicher 1-2 Mannjahre...
matthias schrieb:> Multiplikationen und Divisionen kann ich wenn nötig selber schreiben bin> Mathematiker.
Bwahaha.
Seltsame Anforderungen hast du da.
Ich rechne z.Zt. aus anderen Gründen mit 1024 Bit (Mantisse) breiten
Gleitkommazahlen.
Auf einem 8-Bit-AVR.
Nase schrieb:> Ich rechne z.Zt. aus anderen Gründen mit 1024 Bit (Mantisse) breiten> Gleitkommazahlen. Auf einem 8-Bit-AVR.
Alles eine Frage der Zeit. ;-)
Du kannst auch einen High-Performance-Cluster durch einen SC/MP
ersetzen, wenn du extern genug RAM dran hängst.
Moin,
>> Nach vielen Versuchen mit den sog. SSE Extensions der neuesten Intel und> Xeon Prozessoren, glaub ich es geht damit nicht. Die Flags werden nicht> richtig gesetzt oder gar nicht..> Kann man so was mit FPGA realisieren? evtl mehreren?
Schon. Die Frage stellt sich nach dem Durchsatz, und wo die Daten
herkommen, wo sie hinsollen...
> Gibt es einen default Befehlssatz?
Den musst du selber definieren. Das FPGA ist ja von Haus aus wie
"neugeboren" (ich hüte mich, zu sagen "dumm").
> Ich weiss auch nicht ob und wie ich z.b. dieses Gerät "easyFpga" s.u. an> ein normalen PC anbinde und ins ddr3 ram schreibe und ob es Assembler> gibt, die ja den Mikrocode erzeugen sollen.
Ich sehe da kein DDR-RAM. Da müsstest Du eher zum ähnlichen Papilio Pro
greifen. Die Cores, die da per Hochsprache instanziert werden, lösen
dein Problem sicher nicht.
Prinzipiell ist schon der LX9 ist etwas schwach für solche Bitbreiten:
Die RAM-Primitiven sind gerade mal 18 Bit breit und über das Die
verteilt. Da ergibt sich schon der erste Flaschenhals, wenn die Sache
auf Geschwindigkeit optimiert werden soll und gleichzeitig Daten rein
und raus müssen.
Genannter PCIe-Ansatz ist sicher flott, aber aufwendiger als eine
klassische USB-FIFO-Lösung...
> Und wie realisiert man Ein und Ausgabe Routinen der Hex Zahlen?> Also an sich suche ich einen schnellen RisC Prozessor mit hoher interner> Registerbreite.> Wer sich für mathe interessiert dem kann ich gern erzählen worauf ich> hinaus will:)
Ich nehme mal an, dass es um Zahlentheorie geht...
Punkten kannst du mit dem FPGA gegenüber einer 2 GHz-CPU nur dort, wo du
eine ALU-Pipeline bauen kannst, die eine aufwendige Operation per
Taktzyklus durchspult oder Parallelisierung erlaubt.
Also was z.B. gut geht sind Matrizenmultiplikationen und entsprechende
Transformationen (DCT, FFT, Wavelet...)
Ansonsten versuchen sich da immer alle Jahre wieder mal Leute daran, das
Rad in 64 oder 128 bit neu zu erfinden, aber schlussendlich bleibt doch
alles beim Alten: Du bist auf dich selbst gestellt, um deine
Spezialanwendung effektiv zu erschlagen. So richtig generisch gibts kaum
was, da fällt mir höchstens noch der HiCoVec ein (pfiffiges Konzept,
aber nur 32 bit).
Ansonsten gibt es da ein paar HLS-Ansätze, aber das Fass will ich grade
nicht aufmachen..
Aber zum Stichwort Mikrocode: das kannst du durchaus ohne Assembler
sogar in VHDL direkt runterschreiben. Der Ansatz ist natürlich sehr
mächtig, aber du musst deine parallelisierenden SIMD-Befehle
entsprechend designen. Dafür kannst du relativ wilde Sachen machen, wie
zur Laufzeit aus einer Host-CPU das Programm ändern.
Gruss,
- Strubi
Ich hatte mir sowas ähnliches schon mal für Java BigDecimal Zahlen
überlegt, aber das scheitert wohl am IO, was zu langsam ist.
Einfache Operationen mit grossen Zahlen findest Du z.B. in Cryptocoin
Minern. Da gibt es ja inzwischen auch Opensource Code, in den Du mal
schauen könntest. Musst aber hält eher den kompletten Algorithmus im
fpga laufen haben, um IO zu minimieren.
> Du kannst auch einen High-Performance-Cluster durch einen SC/MP> ersetzen, wenn du extern genug RAM dran hängst.
Du darfst gerne mal eine Genomanalyse auf einem SC/MP
mit 1 TB RAM implementieren.
Bis der fertig ist, wirst du dich mindestens 3x im Grab umdrehen.
Weltbester FPGA-Pongo schrieb im Beitrag #4818635:
> Eine einfache Multiplikation in einem Artix 7 mit 128 Bit läuft mit> gerade mal noch 43MHz. Wer's braucht.
Wer es ernst meint, der macht es anders als du vermutlich getan hast.
Aktuelle CPUs versuchen nicht erst, das in einem Takt zu erledigen.
Sondern brauchen schon bei 64bit um die 4 Takte bis zum Ergebnis, dafür
aber gepipelined.
matthias schrieb:> Ich suche eine Möglichkeit, mit sehr großen Zahlen ca 2 ^128 einfache> Rechnungen durchzuführen.
kannst du etwas mehr über die Berechnung sagen? Wenn du die Aufgabe
vollständig erklären kannst, finden sich eventuell Leute die es als
Herausforderung sehen.
Ich hatte jetzt spontan an GPGPU gedacht, die dafür nötige
Speicherbandbreite wäre ja gegeben.
In OpenCL sind sogar 128 Bit variabeln in Planung. Die wirst du aber
jetzt noch selbst implementieren müssen, sofern dies möglich ist.
https://de.wikipedia.org/wiki/OpenCL> Folgende Datentypen wurden zudem für spätere Versionen von OpenCL> reserviert:> long long, long longn: Vorzeichenbehaftete 128-Bit-Ganzzahlen und> -vektoren.> unsigned long long, unsigned long longn: Vorzeichenlose 128-Bit> Ganzzahlen und -vektoren.
Bei der Konkurrenz von Nvidia sieht das schon schlechter aus:
https://de.wikipedia.org/wiki/CUDA> ... daher kennen GPUs eher exotische Datentypen wie 9 Bit oder 12 Bit mit> Festkommastelle, verzichten hingegen aber häufig auf die für> Allzweck-CPUs und NPUs üblichen Registerbreiten von 32, 48, 64 oder 80> Bit (usw.). Somit sind Berechnungen, beispielsweise mit den Genauigkeiten> nach IEEE 754 (64 Bit für double precision), häufig nicht im Befehlssatz> der GPU vorgesehen und müssen relativ aufwendig per Software emuliert> werden.
Dies ist jedoch sehr generisch geschrieben. Ob dies nun alle GPU
Lösungen betrifft, oder lediglich auf CUDA bezug nimmt, ist mir nicht
ganz klar.
Peter II schrieb:> matthias schrieb:>> Ich suche eine Möglichkeit, mit sehr großen Zahlen ca 2 ^128 einfache>> Rechnungen durchzuführen.>> kannst du etwas mehr über die Berechnung sagen? Wenn du die Aufgabe> vollständig erklären kannst, finden sich eventuell Leute die es als> Herausforderung sehen.
also es geht um die sogenannte Collatz Folge:
1 ) nimm irgendeine Zahl n
2 ) wenn ungerade multipliziere sie mit 3 und addiere 1.
3 ) wenn gerade halbiere sie.
Schleife 2-3-2-3-3-3-2-3... bis 1 rauskommt oder eine andere schleife
oder n gegen unendlich geht.
Die sog. Collatz Vermutung lautet nun:
Für alle startenden n endet die Kette IMMER mit 1, bzw 4,2,1,4,2,1..
siehe z.B.:
5,16,8,4,2,1
11,34,17,52,26,13,40,20,10,5,16,8,4,2,1
27,82..........9232,..........1.
Bei gewissen Startwerten wie hier 27 laufen die Ketten sehr hoch.
Diese "Hochwerte" nennt man pathrecords.
Der pathrecord von 8528817511 ist 18,144594,937356,598024 was die
höchste in 64 bit darstellbare unsigned integer ist.
Und da scheitern z.b. Vpaddq xmm1,xmm2,xmm3 oder vpmuludq xmm1,xmm2,xmm3
bzw. machen was anderes als erwünscht und setzen keine Flags.
Der Intel Prozessor muss über sse2 verfügen. besser sse4 wie manche
Xeon.
Trotzdem failed ein shift left logical einer xmm128 Zahl an der 64 bit
Grenze.
z.B. 6,345,568,321,109,753,349 shl 1 geht noch.
= 12,691,136,642,219,506,698 aber + 6,345,568,321,109,753,349 müsste
19,036,704,963,329,260,047 ergeben, was mehr als 2^64 ist.
Tuts aber nicht.
Was aus der doku auch klar wird.
z.B.
http://www.felixcloutier.com/x86/PADDQ.html
Ausserdem ist der AVR-gcc assembler ziemlich ungeeignet für etwa
mov edi, [ebp+16] oder umgekehrt.
oder
mov rax, qword ptr [rbp+rdx*4]
Wenn ich wüsste, wie man masm code in gcc einbindet, wäre ich schon
weiter.
Bei Interesse kann ich den ganzen gcc mit eingebundenem asm () posten.
bis Startzahl 8528,817511.
siehe
http://www.ericr.nl/wondrous/pathrecs.html
Und der neueste Xeon kann sogar angeblich ymm register bis 2^256, das
wäre sehr interessant, wenn ich wüsste wie man es richtig einsetzt!
M
Also die Collatz Folge ließe sich als Statemachine in einen FPGA
einbauen. Da brauchts dann keine CPU mehr.
Ist nur die Frage ob das nur den Rekord ausgeben soll oder auch alle
Zwischenwerte?
Wenn ich das Recht verstehe ist dein Problem nicht die Performance
sondern überhaupt korrekte Ergebnisse zu erhalten?
Klingt ehrlich gesagt nach einem Fall für gmp. Falls das nicht schnell
genug ist kann man immer noch weiter schauen. Das rechnen an einer Zahl
scheint ja nicht sonderlich parallelisierbar zu sein, aber immerhin
durch bitshift und Addition darstellbar.
Eine gpu könnte viele viele folgen parallel berechnen. Ein fpga ist
denke ich im bezahlbaren Rahmen weder aus Performance sicht noch aus
Aufwandssicht die beste Lösung.
Natürlich lässt sich das auch in einem fpga umsetzen aber wozu, wenn ein
"dreizeiler" auf dem PC das gleiche macht.
Ok, Statemachine in ein FPGA ist wohl die naheliegendste Option.
Aber: was bringt das? Nimmt man ein 128 Bit Input Register und schaltet
einen Counter vor, der alle Zahlen bis 128 Bit hochzählt und abbricht,
wenn entweder die Statemachine bei 4 (oder 1) ankommt. Dann wird das
Eingaberegister um 1 erhöht, Statemachine-Reset und der Test startet für
die neue Zahl.
Im anderen Fall würde es wohl einen Overflow geben, oder kann die
Statemachine in eine Endlosschleife geraten?
Aber sogar wenn das Ergebnis wäre, dass alle 128 Bit Zahlen irgendwann
bei 1 ankommen, dann wäre ja noch nichts über 129 Bit Zahlen ausgesagt?
Also die Vermutung wäre weder bewiesen noch widerlegt?
Die höchste berechnete Startzahl ist momentan 1,980976,057694,848447
also unter 64 bit.
Der zugehörige pathrecord p(#88) ist
64,024667,322193,133530,165877,294264,738020 also unter 2^126.
2^128 ist ca. 340,282366,920938,463463,374607,431770,000000.
Die nächste zu berechnende Startzahl, die einen höheren pathrecord als
p(#88) liefert ist unbekannt.
Dieser könnte auch über 2^128 liegen.
Dazu bräuchte ich eine schnelle 2^128 Berechnung.
Bei overflow über 128 Bit müsste man sich was überlegen.
Schön wäre auch, wenn man auf Wunsch die korrekten präzisen
Zwischenwerte der Collatz folge zur späteren Abfrage zwischenspeichern
könnte.
Zum schnellrechnen diese Option halt abschalten.
Oder man lässt optional abbrechen nach n Schritten, oder bei overflow.
Ein 256 Bit-Rechner wäre genial, der nur shr, shl, add und inc $1,reg256
kann, also eine echte 256 Bit Risc Maschine.
Nicht nur für dieses spezielle Problem.
Thx
M.
Sag mal, liest du die Antworten?
Hast du die gmp Bibliothek ausprobiert?
Wo liegt konkret dein Problem? Ist eine pc basierte Lösung zu langsam
oder schaffst du nicht dass sie korrekt rechnet?
In der momentanen Implementation in 64 Bit avr-gcc Assembler dauern
Startwerte von z.B.
start=23035,537407 record==68,838156,641548,227040 ca. 2 Minuten.
der letzte bekannte P(#88) mit
k = 1,980976,057694,848447 und (bekannte) P(k) =
64,024667,322193,133530,165877,294264,738020 läuft seit einigen Wochen.
Ich glaube nicht, dass eine Implementierung mit der gmp library
schneller sein kann als reine Assembler codierung, habs noch nicht
probiert.
Das verilog DHL erscheint mir vielversprechend..
Ich habe aber noch zu wenig Ahnung ehrlich gar keine ;) von VDHL und wie
man da überhaupt rangeht..
Wie ich schon sagte: ich strebe einen 256 Bit-Risc-Rechner an, also eine
echte 256 Bit Risc Maschine.
Nicht nur für dieses spezielle Problem.
Von GPU und CUDA wurde mir abgeraten wg abweichender Registerbreiten
etc.
486 Assembler behersche ich recht gut.
Auf welchen Prozessoren läuft denn VDHL? sorry microcode ist alles
Neuland für mich, aber reizt mich zu lernen
M
Es gibt Verilog und VHDL. 2 konkurrierende Sprachen.
Sie laufen u.a. auf CPLDs, FPGAs und ggf kann man sie sogar in ein Asic
giessen. Hängt von Deinem Budget und Deinen Anforderungen ab.
https://www.mikrocontroller.net/articles/Verilog
Du kannst auch mit freien Tools wie Altera Quartus oder Xilinx ISE
anfangen und alles komplett im Simulator machen. Günstige FPGAs bekommst
schon für unter 15,- .
matthias schrieb:> In der momentanen Implementation in 64 Bit avr-gcc
Ist das ein Tippfehler? Avr?
Die gmp lib ist für die Performance kritischen Sachen in Assembler. Viel
schneller wird es nicht.
Das Problem mit dem fpga ist, dass er keinen deut schneller rechnet als
ein moderner Prozessor, solange du keinen Weg findest die Berechnungen
zu parallelisieren. Wenn du dazu einen Ansatz hast: Go for it. Falls
nicht kannst dir das sparen. Außer du willst was zum Spaß lernen.
matthias schrieb:> Wie ich schon sagte: ich strebe einen 256 Bit-Risc-Rechner an, also eine> echte 256 Bit Risc Maschine.
Ich dachte es sollte 128 Bit sein?
Wie dem auch sei, ich verstehe nicht warum du auf unterstem Level in
Assembler rumdödeln möchstest, wenn dir geeignete Tools zur Verfügung
stehen.
matthias schrieb:> 486 Assembler behersche ich recht gut.
Um damit was zu machen? Auf einem 8 Kern, 16 Thread Prozessor parallel
deinen Algorithmus laufen zu lassen, weil dir alles andere zu lange
dauert?
Mit Python hättest du dies vermutlich schneller geschrieben und
ausgerechnet, als dir ein Konstrukt überlegt um von 64Bit Registern auf
128 (oder doch 256?) Bit in Assembler zu kommen.
GMP gibts auch für Python, die Zeit zum Ausrechnen ist nicht viel
länger: https://jasonstitt.com/c-extension-n-choose-k
Operator S. schrieb:> Wie dem auch sei, ich verstehe nicht warum du auf unterstem Level in> Assembler rumdödeln möchstest, wenn dir geeignete Tools zur Verfügung> stehen.
ich denke schon das der Ansatz mit ASM richtig ist. Er hat ein korrektes
Problem was er optimieren will. Die Berechnung ist so überschaubar das
man es auch noch in ASM mache kann.
Wenn es nicht gerade eine fertige Bibliothek für genau diesen Problem
gibt hilft das alles nicht weiter. Klar kann man mit jeder Sprache mit
128bit rechnen - die Frage ist nur wie schnell.
Wenn ich es richtig verstehe, kann man das auch nicht wirklich
Parallelisieren damit dürften auch Grafikkarten zu langsam für das
Problem sein.
Ich würde auch versuchen, mit geschickter ASM programmieren das Problem
auf einem PC zu lösen.
Moin,
würde mich auch Vorpostern anschliessend und mal die Aussage treffen,
dass die libgmp dem FPGA vorzuziehen wäre.
Der Rechenschritt ist sonst ansich einfach und dürfte auf einem FPGA
direkt ohne Schmerzen als 1-cycle-pipeline bei min 150MHz z.B. auf einem
Spartan6 ticken. Nur scheint die Folge nicht gerade per "divide et
impera" zu beschleunigen, also müsstest du parallel mehrere Folgen in
separaten Recheneinheiten durchnudeln. Da stellt sich dann die Frage, ob
du die Startwerte und Iterationswerte im Vergleich zu einer schnellen
CPU mit riesigem Speicher schnell genug rein bzw. rausbekommst. Dann
kommt dazu, dass die parallelen Pipelines alle zu unterschiedlichen
Zeiten fertig sind, wenn ich die Sache richtig kapiert habe. Das schreit
nach Multithreading.. Und am Schluss willst Du noch alles in einer
Datenbank... Freude herrscht, da kann man schon eine Diplo..ach nee,
heute heisst das ja Bachelor.
Aber spannend wäre die Übung schon.
matthias schrieb:> Auf welchen Prozessoren läuft denn VDHL? sorry microcode ist alles> Neuland für mich, aber reizt mich zu lernen
Da müssen wir die Begriffe nochmal klären:
- VHDL: Die Sprache, in der du deinen "Prozessor" definierst/designst.
- Microcode: typischerweise für den User nicht sichtbare SIMD-Applets,
die z.B. Berechnungen einer Pipeline-Stufen-Folge kontrollieren
- VHDL-Simulator: läuft auf nahezu jeder Plattform
- VHDL-Synthese: x86(-64) Linux/Windows only
Der Microcode-Ansatz macht nur Sinn, wenn du eine flexible Pipeline
designen musst, die mehrere Arten von Rechnungen durchführt. Bestes
Beispiel sind die nvidia shader units, die parallel Skalarprodukte, usw.
rechnen. Intel nutzt ausgiebig Microcode-Tricks, um kompatibel zu sich
selbst zu bleiben (d.h. den uralt-i86-opcodes) und trotzdem eine
effiziente Architektur hinzukriegen...
Mal ne andere Frage: Wofür ist die Collatz-Folge gut? Kann man damit
Primzahlen finden?
- Strubi
Hallo Matthias,
FPGAs sind Logikbausteine, d.h. da hat man zB UND- und ODER-Gatter mit
denen man Digitalschaltungen bauen kann, z.B. eine CPU. Da ist aber
keine CPU auf der das läuft, sondern die muss man sich halt (falls
nötig) selber schreiben. Man muss da aber nicht mit den einzelnen
Gattern hantieren, sondern kann da in einer Hochsprache (VHDL oder
Verilog) zB eine Addition hinschreiben und der Compiler macht dann die
konkrete Hardwarebeschreibung daraus. Meistens hat man im FPGA aber
keine CPU.
Wie hier schon mehrfach erwähnt wurde sind FPGAs was den Takt angeht den
modernen PC-CPUs deutlich unterlegen. Der Vorteil von FPGAs ist ihre
Parallelität. Dazu fallen mir spontan zwei Lösungen ein:
1) Du rechnest einfach die Folgen für viele verschiedene Startwerte (zB
100 oder 1000) parallel. Dann sind zwar die einzelnen Folgen langsamer
als auf dem PC, aber Du kannst viel mehr Startwerte in der gleichen Zeit
untersuchen.
2) Du rechnest mehrere potentielle Pfade parallel. Angenommen die
aktuelle Zahl n sei gerade, dann rechnest Du parallel a) n/2, b)
(3(n/2)+1) und c) n/4. Danach entscheidest Du anhand des Ergebnisses von
a), ob b) oder c) der richtige Weg ist. Du musst für die Berechnung von
b) und c) nicht auf das Ergebnis von a) warten. Das lässt sich dann auch
beliebig kaskadieren.
>> Auf welchen Prozessoren läuft denn VDHL? sorry Microsoft ist alles>> Neuland für mich, aber reizt mich zu lernen> Da müssen wir die Begriffe nochmal klären:> - VHDL: Die Sprache, in der du deinen "Prozessor" definierst/designst.> - Mikrocode: typischerweise für den User nicht sichtbare SIMD-Applets,> die z.B. Berechnungen einer Pipeline-Stufen-Folge kontrollieren> - VHDL-Simulator: läuft auf nahezu jeder Plattform> - VHDL-Synthese: x86(-64) Linux/Windows only>> Der Microcode-Ansatz macht nur Sinn, wenn du eine flexible Pipeline> designen musst, die mehrere Arten von Rechnungen durchführt. Bestes> Beispiel sind die nvidia shader units, die parallel Skalarprodukte, usw.> rechnen. Intel nutzt ausgiebig Microcode-Tricks, um kompatibel zu sich> selbst zu bleiben (d.h. den uralt-i86-opcodes) und trotzdem eine> effiziente Architektur hinzukriegen...> Mal ne andere Frage: Wofür ist die Collatz-Folge gut? Kann man damit> Primzahlen finden?
Anm..: Der inline Assembler in gcc heißt tatsächlich AVR-gcc AFAIK.
Zur letzteren Frage:
Es gibt die mehr oder weniger bekannte Collatz Vermutung von 1920.
Eben dass alle Folgen startend mit n > 0 gefolgt von den Schritten
n->3n+1 bei n Odd, n->n/2 be n Even alle irgendwann bei 1 enden.
Es wurde noch kein Gegenbeispiel gefunden.
Ob das für wirklich alle N gilt und Warum das so ist ist unbewiesen.
So entstehen Folgen der Art, wie ich sie im Beitrag vom 10.12. 16:13
(warum haben die keine Nummern) andeutete, wie lange die werden wissen
wir vorher nicht.
Nach Collatz endlich lang.
Die, die mit P(#5) = 27 anfängt und mit 1 endet ist ca. 70 Schritte
lang, und hat als höchsten Zwischenwert M(#5) 9232 das nennt man den
pathrecord von 27.
Mehr unter Wikipedia.de. Collatz-Vermutung
Die nächsten höheren Startwerte die höhere pathreords erzeugen sind
255,447,639,...
Der höchste bis heute bekannte Startwert der einen höchstmöglichen
pathrecord erzeugt ist p(#88) = 1,980976,057694,848447 und
endet nachgerechnet mit 1, bei einem pathrecord von M(#88) = 64 024667
322193 133530 165877 294264 738020.
Nach erreichen dieses Wertes geht er runter auf 1. Das ist ja gerade die
C Vermutung.
Vermutlich hörten Oliviera und Silva da auf weiter zu rechnen, eben weil
die 2^128 Bit Grenze erreicht wird.
Schlicht und ergreifend suche/n ich (wir) die nächste höhere
Collatz-Startzahl. P(#89) und den pathrecord M(#89)
siehe auch http://www.ericr.nl/wondrous/pathrecs.html
Also starte bei der nächsten ungeraden n = 1,980976,057694,848449, bilde
die Collatz-Folge bis 1 und schaue nach,
ob irgendwo mittendrin ein höherer Wert als 64 024667 322193 133530
165877 294264 738020 auftaucht.
Dafür bietet sich natürlich multithreading an, also starte nicht
nacheinander mit einer Zahl z.B. 1,980976,057694,848449 sondern gleich
mit
sagen wir 12 aueinanderfolgenden ungeraden der Art von Rest 3 modulo 4,
z.B.
60979,60983,60987,60991,60995,60999,61003,61007,61011,61015,61019,61023
und wenn eine fertig nimm die nächste 61027
Und die shift und add Befehle möchte ich auf einer schnellen Hardware
mit einer "intelligenten" multithreading fähigen Sprache schreiben.
Welche Hardware brauche ich präzise?
Welche Software brauche ich präzise?
VDHL Simulator hört sich gut an.
Ist das eine Hard- oder Software?
Ich habe ein funktionierendes w7/64 System zu Hause, was brauche ich?
Eine PCI Karte mit Prozessor oder ALU? Ein FPGA Programmiergerät?
Ich bräuchte mal ein Starter Kit oder so was ;)
Sorry ich hab echt keine Ahnung was worauf läuft und was ich alles
brauche. Wie baue ich das zusammen? und programmiere es.
Mit einer geeigneten HW also eine Art 128 oder 256 Bit RISC prozessor
könnte ich mir noch ganz andere wunderbare Dinge vorstellen,
wie parallelisierte Prime factorization.
Thx
M.
matthias schrieb:> So entstehen Folgen der Art, wie ich sie im Beitrag vom 10.12. 16:13> (warum haben die keine Nummern) andeutete
Die haben Nummern. Die Überschrift des Beitrages ist ein Link auf den
Beitrag. Das da ist der Link zu Deinem Beitrag
Beitrag "Re: 128 Bit Risc"> Welche Hardware brauche ich präzise?
Etwas vereinfacht: Das größte FPGA-Board, das Du Dir leisten
kannst/willst. Ab einer bestimmten Größe kostet allerdings die Software
dazu auch noch Geld.
> Welche Software brauche ich präzise?
Die Hersteller haben IDEs für ihre FPGAs, bei Xilinx zB heißt die zZt
Vivado. Bei den kleineren FPGAs ist die kostenlos, bei den größeren
Modellen wollen sie Geld dafür.
> VDHL Simulator hört sich gut an.> Ist das eine Hard- oder Software?
Eine Software.
Man baut im FPGA ja eine Digitalschaltung zusammen und da das ja kein
Programm ist, in das man einfach reindebuggen kann simuliert man das
vorher am PC.
Du könntest also durchaus das ganze erst mal NUR am PC simulieren und
erst wenn Du weißt wie viele Ressourcen Du brauchst Dich für einen
konkreten FPGA entscheiden.
> Ich habe ein funktionierendes w7/64 System zu Hause, was brauche ich?> Eine PCI Karte mit Prozessor oder ALU? Ein FPGA Programmiergerät?> Ich bräuchte mal ein Starter Kit oder so was ;)FPGAs die auf einer PCIe-Karte sitzen sind eher teuer.
Bei vielen Demo-Boards sind bereits Programmieradapter drauf, da reicht
dann ein USB-Kabel.
> Sorry ich hab echt keine Ahnung was worauf läuft und was ich alles> brauche. Wie baue ich das zusammen? und programmiere es.
Vielleicht solltest Du Dich einfach mal in VHDL einarbeiten, damit Du
ein Gefühl dafür bekommst.
matthias schrieb:> Vermutlich hörten Oliviera und Silva da auf weiter zu rechnen, eben weil> die 2^128 Bit Grenze erreicht wird.
Glaube ich nicht. Eher haben sie noch nichts gefunden.
> Schlicht und ergreifend suche/n ich (wir) die nächste höhere> Collatz-Startzahl. P(#89) und den pathrecord M(#89)>> siehe auch http://www.ericr.nl/wondrous/pathrecs.html>> Also starte bei der nächsten ungeraden n = 1,980976,057694,848449, bilde> die Collatz-Folge bis 1 und schaue nach,> ob irgendwo mittendrin ein höherer Wert als 64 024667 322193 133530> 165877 294264 738020 auftaucht.>
Das ist im Prinzip brute force. Hast du dir schon mal gedanken gemacht
wie gross diese Zahlen sind und wieviel du testen musst?
Schreib mal ein Programm was von 2^63 bis auf 2^64-1 hochzählt und sonst
nichts macht, und messe wie lange dein bester Rechner braucht.
Ich hab erst mal das Programm vivado von xilinx installiert und hoffe da
ein paar einfache Aplikationen zu schreiben, zu finden und oder
auszuprobieren.
Eine 8 bit addier maschine wäre schon was;)
Ich glaube fast, dass das was ich also will einen 128 Bit risc rechner
auf FPGA Basis gibt es schon...
Hier ist übrigens das bestehende collatz-folgen-programm in gcc und dem
eingebauten assembler.
Das ist sicher verbeseerungswürdig, wenn man an das pipelining beim xeon
denkt, kann man sicher die vielen zeitfressenden conditional jumps
irgendwie "intelligent" übergehen, da ja so wie ich das verstand die
Befehle vor-abgearbeitet werden, die mit oder ohne carry als nächstes
dran sind.
Wer Lust hat mag etwas daran herumverbessern
Bei Startwerten um 10^12 dauert es etwa 70 Minuten, bis die 1 ereicht
wird.
Wir arbeiten mit den 64 bit Registern r9,r13, bzw r10,r14
Danke
#include <stdio.h>
unsigned __int128 start;
unsigned __int128 start_base;
unsigned __int128 record;
unsigned __int128 merkrecord;
int roosendaal_number;
unsigned long starttime;
#define base_step 3072
unsigned int reste[] =
{27,31, 63, 91, 103, 111, 127, 159, 207, 231, 255, 283, 303, 319, 327,
411, 415, 447, 463, 487, 495, 511, 543, 559, 603, 615, 639, 667, 679,
703, 751, 763, 795, 799, 831, 859, 871, 879, 927, 1023, 1051, 1071,
1087, 1095, 1135, 1179, 1183, 1191, 1215, 1231, 1255, 1263, 1275, 1279,
1327, 1351, 1383, 1435, 1471, 1519, 1563, 1567, 1627, 1639, 1647, 1663,
1695, 1767
, 1791, 1819, 1855, 1863, 1903, 1951, 1959, 1983, 2031, 2043, 2047,
2079, 2095, 2119, 2139, 2151, 2175, 2203, 2215, 2239, 2287, 2299, 2331,
2367, 2407, 2463, 2511, 2535, 2559, 2587, 2607, 2671, 2715, 2719, 2727,
2751, 2791, 2799, 2811, 2815, 2847, 2887, 2907, 2919, 2983, 3007, 3055,
3067};
#define reste_amount 116
unsigned int reste_loop = 0;
void printf_128(__int128 path) {
// Ausgabe int128 im Dezimalformat
// jeweils 6 Ziffern durch Kommata getrennt
int ziffer[42];
int cnt = 0;
int loops;
while (path > 0)
{
ziffer[cnt]=path%10;
path=path/10;
cnt++;
}
for (loops = cnt-1; loops >= 0; loops--)
{
printf("%i",ziffer[loops]);
if ( (loops%6==0) && (loops > 0) )
printf(",");
}
}
void printf_time() {
long nowtime = time(NULL)-starttime;
int now_min = nowtime/60;
int now_sec = nowtime%60;
if (now_min<1) printf("%is",now_sec);
else printf("%i:%02is",now_min,now_sec);
}
// und hier beginnt das hauptprogramm :)
int main () {
printf("\nCollatz meets assembler - Version 1.0 by gonz\n");
starttime = (unsigned)time(NULL);
start_base = 0;
// da wir (3x+1)/2 schritte durchführen, sind die records halb so gross
wie die bei Roosendaal gelisteten
record = 8;
roosendaal_number = 2;
while (1) {
// wir betrachten nur spezielle reste
start=start_base+reste[reste_loop];
reste_loop++;
if (reste_loop>=reste_amount) {
reste_loop=0;start_base=start_base+base_step; }
// und los gehts :)
merkrecord = record;
asm(
// Vorab die Registerbelegung in der Assembler Routine:
// r8 : startwert (bleibt erhalten fuer stopp pruefung)
// r9,r13 : aktueller Folgewert (niederwertig...hoeherwertig)
// r10,r14 : dessen haelfte fuer (3x+1)/2 schritt
// r11,r15 : record (wird mitgefuehrt, ursprungs-record wert geht
verloren)
// Startwert und bisherigen Record aus RAM in Register kopieren
"MOV start(%rip),%r8 \n\t"
"MOV %r8,%r9 \n\t"
"MOV record(%rip),%r11 \n\t"
"MOV $0,%r13 \n\t"
"MOV record+8(%rip),%r15 \n\t"
// Register fuer aktuellen Wert auf Startwert setzen
// und hier beginnt die Rundreise
"collatz_start: \n\t"
"TEST $1,%r9 \n\t"
"JZ gerade \n\t"
"MOV %r13,%r14 \n\t"
"MOV %r9,%r10 \n\t"
// hier: ungerade. fuehre den (3x+1)/2 Schritt durch.
"SHR $1,%r14 \n\t" // hoeherwertig - und ins carry
"RCR $1,%r10 \n\t" // niederwertiges uebernimmt carry
// beim addieren kann hier die 64bit Grenze erreicht werden.
"STC \n\t"
"ADC %r10,%r9 \n\t" // niederwertig - und ins carry
"ADC %r14,%r13 \n\t" // hoeherwert uebernimmt carry
// nach einem (3x+1)/2 Schritt koennte ein neuer Pass Record erreicht
sein
"CMP %r13,%r15 \n\t"
"JA collatz_start \n\t"
"JB do_record \n\t"
"CMP %r9,%r11 \n\t"
"JA collatz_start \n\t"
// wenn ja diesen aufs passende Register uebertragen
"do_record: \n\t"
"MOV %r9,%r11 \n\t"
"MOV %r13,%r15 \n\t"
"JMP collatz_start \n\t"
// hier: gerade. fuehre den x/2 Schritt durch
"gerade: \n\t"
"SHR $1,%r13 \n\t"
"RCR $1,%r9 \n\t"
// so und damit... schauen, ob Stoppwert erreicht. Wenn nicht: naechste
runde :)
"CMP $0,%r13 \n\t"
"JNZ collatz_start \n\t"
"CMP %r8,%r9 \n\t"
"JA collatz_start \n\t"
// habe fertig: Register wieder ins RAM kopieren.
"fertig: \n\t"
"MOV %r11, record(%rip) \n\t"
"MOV %r15, record+8(%rip) \n\t"
);
if (record>merkrecord) {
printf_time();
roosendaal_number++;
printf(" #%i start=",roosendaal_number);
printf_128(start);
printf(" record==");
printf_128(record*2);
printf("\n");
}
}
}
Da ist noch gut Luft nach oben. Die datenabhängigen gerade/ungerade
Zweige führen zu erbärmlicher Sprungvorhersage. Statt dessen solltest du
beide Varianten ineinander verzahnt berechnen und anschliessend per CMOV
das Resultat abholen. Deine CPU kann 4 Befehle pro Takt ausführen, das
macht die also nebenher. Aber ein falsch vorhergesagter Sprung frisst
2stellige Takte.
Ich wäre übrigens nicht erstaunt, wenn so ein Code, mit CMOV optimiert,
auf AMD CPUs viel schneller rennt als auf Intel. Intel tut sich mit
ADC/RCR erheblich schwerer als AMD (z.B. stc/adc/adc 3 Takte, statt 5
bei Haswell).
Damit es nicht gar so abstrakt bleibt, hab ich mal schnell was mit
verilog zusammengetippt. Es compiliert in einer älteren Quartus Version
und braucht so 569 Logikelemente. Allerdings komplett unoptimiert,
ungetestet und überhaupt. Es fehlt auch die Speicherung des max Wertes,
der Sequenz usw.
Hab als Ziel so ein cyclone 2 minimum dev board genommen, wie man es für
unter 15,- bei ebay bekommt.
matthias schrieb:> In der momentanen Implementation in 64 Bit avr-gcc Assembler dauern> Startwerte von z.B.> start=23035,537407 record==68,838156,641548,227040 ca. 2 Minuten.
Also ich hab' das mal mit GMP implementiert.
Da das Programm mit dem "start"-Wert den "record" reproduziert, meine
ich, den Algorithmus korrekt implementiert zu haben.
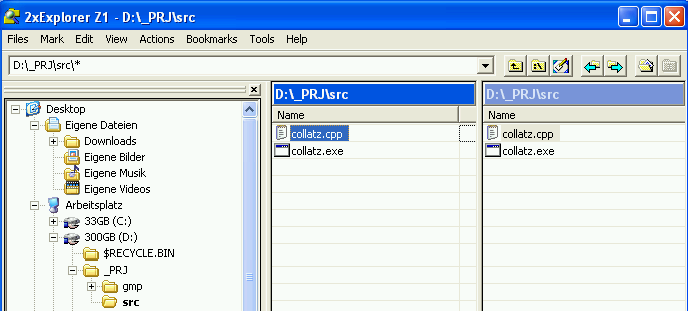
1
D:\_PRJ\src>collatz
2
3
n=23035537407
4
r=68838156641548227040
5
c=196
6
D:\_PRJ\src>
Auf einer popeligen logischen CPU eines i5 M540 dauert das unter
Verwendung von 256bit-Werten - ääähhhmmmmmm - so ungefähr 0,nix Sekunden
(bei gerade einmal 196 "Auf und Ab's" eigentlich auch kein Wunder)!!!
????????????? Irgendwas hab' ich da wohl missverstabden ?????????????
Ich bin mit den gmp Funktionen nicht so vertraut, aber
mir scheint, daß die Implementierung von U.G.L. nur für
ungerade Startwerte richtig funktioniert. Oder habe ich da
was übersehen?
Joe S. schrieb:> Ich bin mit den gmp Funktionen nicht so vertraut, aber> mir scheint, daß die Implementierung von U.G.L. nur für> ungerade Startwerte richtig funktioniert.
gerade macht auch keinen sinn. Denn dann wird gleich halbiert und man
ist bei einem "anderen" startwert.
tztztz "nur" -Ofast ;)
zumindest -march=native sollts schon sein... immerhin will man ja die
ganzen schönen extentions nutzen :P
Btw in dem Zusammenhang ist der Artikel lesenswert...
https://en.wikipedia.org/wiki/Intel_ADX
73
Ich denke, ich weiß nun, wie die 2 Minuten zu interpretieren sind.
Ich habe das Programm jetzt so geändert, dass eine Liste bis zu z.B.
P(#47) generieren werden kann. Die Berechnung einer Liste bis P(#47)
dauert auf einer logischen CPU meinems "Couch"-Laptops (i5 M540) knapp
1000 Sekunden, damit gut 8 mal länger als die angegebenen 2 Minuten.
Ich vermute mal, dass sich dieser Faktor weitestgehend mit einer
schnelleren CPU und einer 64bit Implemetierung ausgleichen läßt und die
GMP-Implemetierung kaum langsamer sein wird als eine
Assembler-Implemetierung, die auch 256bit unterstützt. Dabei unterstützt
die GMP-Implementierung letztlich nicht nur 256bit, sondern passt sich
gegebenenfalls auftauchenden Anforderungen an, weitet die 256bit also,
wenn es sein muss, auch auf 1000bit, 10000bit oder noch mehr Bits aus!
Hans schrieb:> tztztz "nur" -Ofast ;)>> zumindest -march=native sollts schon sein... immerhin will man ja die> ganzen schönen extentions nutzen :P
Die Geschwindigkeit dürfte primär davon abhängen, wie GMP übersetzt
wurde.
Ich verwende
http://cs.nyu.edu/~exact/core/gmp/gmp-static-mingw-4.1.tar.gz -
dieses Compilat setzt einen Pentium III voraus.
Ein, auf einen aktuellen Prozessor beschränktes Compilat wird natürlich
schneller sein, so dass sich auch hier noch Optimierungen auftun.
Ob der Rest mittels -Ofast oder etwas anderem übersetzt wird, dürfte
unerheblich bleiben.
Servus,
hätte natürlich ein "nativ" optimiertes gpm vorausgesetzt... bin nämlich
über die ADX diskussionen auf der gpm mailinglist auf den wiki artikel
gestoßen :)
nachdems anscheinend ums suchen/testen der nächst höheren geht, lässt
sich das auf einer moderen cpu locker locker parallelisieren... also
mehrere startwerte parallel meine ich damit....
Jedenfalls befürchte ich, dass das auf einem FPGA nicht schneller wird
da zumindest einige intel CPUs genau für diese anwendung (riesige bzw
beliebig große integer) eine befehlssatzerweiterung haben.
damit hat man hoch optimiertes silizium mit optimiertem befehlssatz und
richtig böser speicheranbindung gegen einen fpga... ziemlich unfair aus
meiner sicht...
73
Sehr interessant die Disskussion hier.
Sorry, die Frage ist etwas OT: Was ist die Anwendung dafür? Habe mir mal
den Wiki-Artikel durchgelesen, sehe aber nicht was man damit "machen"
kann. Oder geht es hier um das rein akademische rund um das
Collartz-Problem?
Hab' über Nacht das Programm mal mit einer anfänglichen Variablenbreite
von 32bit laufen lassen - die Variation der Zeiten dürften vermutlich
darauf zurückzuführen sein, was man mit der Mühle sonst noch gerade
macht und wie heiß sie sich gerade fühlt - die GMP-Implementierung
dürfte fast vollkommen unabhängig von der verwendeten Breite der
Variablen sein.
Hans schrieb:> hätte natürlich ein "nativ" optimiertes gpm vorausgesetzt...
Meine Erfahrungen bei derartigen Untersuchungen, zuletzt mit
http://matheplanet.com/matheplanet/nuke/html/viewtopic.php?rd2&topic=182808&start=80#p1538578
haben immer gezeigt, das eine Investition in die Auswahl der zu
testenden Fälle und in den Grund-Algorithmus jedwede Investition in die
Laufzeitoptimierung um Längen schlägt - von daher juckt es mich nicht
die Bohne, hier mit einer Pentium III Library zu arbeiten.
Hans schrieb:> nachdems anscheinend ums suchen/testen der nächst höheren geht, lässt> sich das auf einer moderen cpu locker locker parallelisieren... also> mehrere startwerte parallel meine ich damit....
ganz so einfach wird das nicht, da die Untersuchung für den
Startwert(n+1) den Rekord(n) benötigt - das läßt sich aber mittels der
Annahme Rekord(n) = Startwert(n+1) und einer "Nachbehandlung" der
Resultate beheben.
Es wird aber vorallen Dingen nur gelingen, eine Parallelisierung auf
Threadebene zu erreichen - eine Vektorisierung wird wohl nicht mögkich
sein.
Hans schrieb:> Jedenfalls befürchte ich, dass das auf einem FPGA nicht schneller wird
So vermute ich das auch, zumindest, wenn man das unter ökonomischen
Gesichtspunkten betrachtet - eine 100-Thread-Lösung mit sauteuren
MegaFPGAs wird wohl von einer 10-Maschine-i7-Lösung unter diesem
Gesichtspunkt geschlagen. Bestenfalls bei der energieeffizientesten
Lösung sehe ich ein Chance für die FPGAs.
U.G. L. schrieb:> Hans schrieb:>> nachdems anscheinend ums suchen/testen der nächst höheren geht, lässt>> sich das auf einer moderen cpu locker locker parallelisieren... also>> mehrere startwerte parallel meine ich damit....>> ganz so einfach wird das nicht, da die Untersuchung für den> Startwert(n+1) den Rekord(n) benötigt - das läßt sich aber mittels der> Annahme Rekord(n) = Startwert(n+1) und einer "Nachbehandlung" der> Resultate beheben.>> Es wird aber vorallen Dingen nur gelingen, eine Parallelisierung auf> Threadebene zu erreichen - eine Vektorisierung wird wohl nicht mögkich> sein.
Im threading liegt ja der witz... ohne jetzt die interna genauer
studiert zu haben nehme ich an, dass jede integer einheit eigene logik
für ADX hat.
Nachdem anscheinend die Zyklenanzahl groß werden kann müsste man mit
prediction und "nachbearbeitung" was machen können (so fakor 2)...
U.G. L. schrieb:> Hans schrieb:>> hätte natürlich ein "nativ" optimiertes gpm vorausgesetzt...>> Meine Erfahrungen bei derartigen Untersuchungen, zuletzt mit> http://matheplanet.com/matheplanet/nuke/html/viewtopic.php?rd2&topic=182808&start=80#p1538578> haben immer gezeigt, das eine Investition in die Auswahl der zu> testenden Fälle und in den Grund-Algorithmus jedwede Investition in die> Laufzeitoptimierung um Längen schlägt - von daher juckt es mich nicht> die Bohne, hier mit einer Pentium III Library zu arbeiten.
ja schon, aber... :)
hab auf die schnelle jetzt nichts zu gmp direkt und den unterschied
MMX+SSE (kann der P3) zu AVX2/... gefunden aber interessant ists schon
http://www.numberworld.org/ymp/v1.0/benchmarks.html
SSE4.1 zu AVX2 macht im durchsatz einen faktor 2 bei riesigen
multiplikationen ...
ein "normales" windows compilat nutzt normalerweise nichtmal mmx...
ich habe mal sowas wie spice für die uni nachgebaut für ein spezielles
problem... am schluss war per compiler switch ein faktor 10 drinnen...
hängt halt davon ab was man macht... bei mir waren eben multiplikationen
von doubles mit AVX (+ auto-vectorizing) einfach um eine größenordnung
schneller.
aber dafür gibt es ja diese befehlsatzerweiterungen.
natürlich muss der algorithmus (+implementierung des selben!) auch
passen... da habe ich mir nochmal einen faktor 10 geholt...
da es aber um die umsetzung des oben mit inline-asm gespickten code in
einem fpga geht, sehe ich das als optimal an ... zu fragen der optimalen
(=schnellsten) lösung von problemen der theorethischen elektrotechnik
habe ich eine meinung, zu sowas.... ähhhh nein :)
ich werd' am abend mal meine arbeitsbox (i5 6600k) mit dem gmp code
füttern... auf der rechne ich normal gekoppelte 3d-fem probleme... mal
schaun was sie zur abwechslung zu integer arithmetik sagt :)
73
Hans schrieb:> SSE4.1 zu AVX2 macht im durchsatz einen faktor 2 bei riesigen> multiplikationen ...
Klar, AVX2 hat insgesamt 256Bit und SSE 128Bit. Man kann also doppelt so
viele Multiplikationen in der gleichen Zeit machen.
> ein "normales" windows compilat nutzt normalerweise nichtmal mmx...
Was auch immer "normal" ist. So haben zB alle CPUs mit x86-64 auch
mindestens Unterstützung für SSE2.
Markus K. schrieb:> Klar, AVX2 hat insgesamt 256Bit und SSE 128Bit. Man kann also doppelt so> viele Multiplikationen in der gleichen Zeit machen.
Ab Haswell. In Sandy/Ivy Bridge waren zwar die Befehle für 256 Bits
schon drin, die Execution Units waren aber noch 128 Bits breit.
Hans schrieb:> Also ich habe da nur folgendes gefunden:>> https://www.microsoft.com/en-us/windows/windows-10-specifications-To> install a 64-bit OS on a 64-bit PC, your processor needs to support> CMPXCHG16b, PrefetchW, and LAHF/SAHF.
Das wird von Microsoft genau deswegen so angegeben, weil es CPUs mit
x86-64 und ohne diese Befehle gab. Hingegen gab es keine CPUs mit x86-64
und ohne SSE2 - selbst der VIA Nano kann das.
Namt,
Freut mich dass das Thema Interesse weckt!
Zur Info habe meine obigen Code
Beitrag "Re: 128 Bit Risc"
an ener Stelle mit condional moves aufgepeppt.
aus
"collatz_start: \n\t"
"TEST $1,%r9 \n\t"
// wenn bit 1 von r9 gesetzt ist, ist r9 ungerade.
"JZ gerade \n\t"
"MOV %r13,%r14 \n\t"
"MOV %r9,%r10 \n\t"
// hier: ungerade. fuehre den (3x+1)/2 Schritt durch.
"ungerade: \n\t"
"SHR $1,%r14 \n\t" // hoeherwertig - und ins carry
"RCR $1,%r10 \n\t" // niederwertiges uebernimmt carry
Habe ich
"collatz_start: \n\t"
"TEST $1,%r9 \n\t"
// if bit 1 von r9 gesetzt ist, ist r9 ungerade.
"cmovnz %r13,%r14 \n\t"
"cmovnz %r9,%r10 \n\t"
"JZ gerade \n\t"
// hier: ungerade. fuehre den (3x+1)/2 Schritt durch.
"ungerade: \n\t"
"SHR $1,%r14 \n\t" // hoeherwertig - und ins carry
"RCR $1,%r10 \n\t" // niederwertiges uebernimmt carry
gemacht was ca 20% speed bringt.
Damit erreiche ich den (PR #61):
start=2,674309,547647 record==770419,949849,742373,052272 in 156:45s
also in reinem GCC inline assembler auf 1 core des xeon.
Sicher kann man die anderen CMP, mit anschliessendem JA, JB auch noch
optimieren.
das Werk :
http://www.agner.org/optimize/ gibt noch mehr Tricks her, danke guter
Tip!
Wie nutzt man das prefetching aus um dies Jmp entscheidungen zu
minimieren. Also lässt die cpu einfach 2 Zweige oder mehr weiterechnen,
egal ob above oder below? Sie macht das doch wowieso oder?
Und entscheidet später, was plausibel ist.
Der Wert (#88) von eric.nl ist noch nicht offiziell verifiziert!! er
erscheint mir auch zu hoch.
Thx!
matthias schrieb:> Wie nutzt man das prefetching aus um dies Jmp entscheidungen zu> minimieren. Also lässt die cpu einfach 2 Zweige oder mehr weiterechnen,> egal ob above oder below? Sie macht das doch wowieso oder?> Und entscheidet später, was plausibel ist.
Wenn Du an einen bedingten Sprung kommst, dann entscheidet sich die CPU
anhand statistischer Daten für einen Zweig und macht mit dem Prefetching
usw. dort weiter. Falls die Vorhersage falsch war, dann verwirft sie
diese Ergebnisse und macht mit dem richtigen Zweig weiter. Das ist aber
teuer. Die CPU führt aber nicht die beiden möglichen Pfade parallel aus.
Deine CPU hat wahrscheinlich 2 Integereinheiten, die sie auch parallel
benutzen kann, aber natürlich nur, wenn es keine Abhängigkeiten gibt.
Man kann 3n+1 also nicht parallel rechnen lassen, weil man für das +1 ja
das Ergebnis vom 3n braucht. Man könnte vielleicht zwei Folgen (von
verschiedenen Startwerten) parallel berechnen. Die wären dann ja in
verschiedenen Registern und hätten damit keine Abhängigkeiten.
Hans schrieb:> 283: n=23035537407 r=68838156641548227040 c=196
ok - das sind knapp 10% mehr, als man durch den Sprung von i5 M540 auf
i5-6600K erwarten durfte.
matthias schrieb:> Der Wert (#88) von eric.nl ist noch nicht offiziell verifiziert!! er> erscheint mir auch zu hoch.
Also das r für das n von #88 passt auf jeden Fall mal schon (siehe meine
zweite Nachricht in diesem Thread). Es kann also höchstens noch sein,
dass ein kleinerer Startwert ein höheres r erzielt!
matthias schrieb:> Sicher kann man die anderen CMP, mit anschliessendem JA, JB auch noch> optimieren.
Entscheidend wäre für diese Art der Optimierung, sowohl die gerade als
auch die ungerade Version zu berechnen und dann das Ergebnis mit CMOV
auszuwählen. Völlig ohne bedingtem Sprung für diese Abfrage.
Also sinngemäss statt:
if (gerade)
n = <A>;
else
n = <B>;
ohne Sprung:
t1 = <A>;
t2 = <B>;
n = gerade ? t1 : t2; // mit CMOV statt Jxx
Durch die zusätzlich in den Datenpfad eingebrachten CMOV Befehle wächst
zwar die Länge des Datenpfades, und damit die Mindestausführungszeit
einer Iteration, aber die Laufzeit von CMOV ist konstant gering, weil
keine Misprediction erfolgt.
Wieviel das bringt, oder ob überhaupt, hängt völlig davon ab, ob die
Sprungvorhersage irgendwelche Muster findet, oder ob das weitgehend
zufällig ist. Die ADC/RCR Befehle sind nicht zueinander
parallelisierbar, da nur eine der Units dazu in der Lage ist. Der
Datenpfad wächst also zunächst deutlich an, es entfallen aber mögliche
Pipeline Flushes durch Misprediction.
Ablauftechnisch betrachtet ist ein CMOV kein bedingt ausgeführter MOV,
sondern ein Auswahlbefehl. Also nicht
if (condition)
dst = src;
sondern
dst = condition ? src : dst;
Bei bedingten Sprüngen, die meistens in die gleiche Richtung gehen, wird
sich das jedoch nicht unbedingt lohnen.
A. K. schrieb:> Entscheidend wäre für diese Art der Optimierung, sowohl die gerade als> auch die ungerade Version zu berechnen und dann das Ergebnis mit CMOV> auszuwählen. Völlig ohne bedingtem Sprung für diese Abfrage.
Noch besser wäre meines Erachtens, die Entscheidung gerade/ungerade
komplett zu eliminieren, so wie das bei meiner Implementierung geschehen
ist - den Code-Part immer mit ungeradem n anlaufen, dann einmal UP (3 x
n + 1) und anschließend alle DOWNs in einem Aufwasch erledigen.
Die DOWNs erledige ich unter Verwendung einer
COUNT_TRAILING_ZEROS-Funktion und shifte danach den Wert entsprechend.
Unter Visual sieht das so aus:
1
uint CountTrailingZeros(ui64 mod64) { //[
2
uint ctz = mod64 ? 0 : 64;
3
4
if (ctz) {
5
return ctz;
6
} else {
7
ui32* pui32 = (ui32*) &mod64;
8
if (pui32[0]) {
9
_BitScanForward((DWORD*) &ctz, pui32[0]);
10
} else if (pui32[1]) {
11
_BitScanForward((DWORD*) &ctz, pui32[1]);
12
ctz += 32;
13
}
14
return ctz;
15
}
16
}//]
Wie das unter GCC/MINGW ausschaut, hab' ich noch nicht eruiert.
Unter GMP gibt's dafür mpz_scan1(...).
U.G. L. schrieb:> Noch besser wäre meines Erachtens, die Entscheidung gerade/ungerade> komplett zu eliminieren,
Ein besserer Algorithmus schlägt meist jede Optimierung auf
Befehlsebene.
U.G. L. schrieb:> matthias schrieb:>>> Der Wert (#88) von eric.nl ist noch nicht offiziell verifiziert!! er>> erscheint mir auch zu hoch.>> Also das r für das n von #88 passt auf jeden Fall mal schon (siehe meine> zweite Nachricht in diesem Thread). Es kann also höchstens noch sein,> dass ein kleinerer Startwert ein höheres r erzielt!
Womit dann #88 ungültig wäre.
Genau darum geht es ja beim verifizieren.
Dazu muss man alle ungeraden Werte zwischen 1038743969413717663 und
1980976057694848447 erst gegen den Sieb und was da durchfällt gegen die
aktuelle Folge testen. Das sind 471116044140565391 Werte.
Wenn man es schafft 1000000000 Werte/Sekunde (d.h. alle 4 CPU Takte
einer 4GHz Maschine) zu testen braucht man fast 15 Jahre.
#89 zu finden braucht vorrausichtlich bis zum doppelten der Zeit.
Empirisch habe ich gesehen dass der Abstand zwischen 2 Rekorden ausser
am Anfang durch 4 teilbar ist (#2-#72 nachgeprüft). Das halbiert die
Dauer der Suche.
Gibt es eigentlich eine sinnvoll Anwendung für 128 Bit Auflösung? Ausser
jetzt mal mathematischen Spielchen.
Ich habe den Eindruck, dass wir hier in Regionen vorstossen, die mher in
Richtung Esotherik gehen und sich von dem Notwendigen entfernen.
Vielleicht passt das 128 Bit Rechensystem ja auch zu den 128 Bit ADCs
mit denen neuerdings Audiosamples abgespielt werden:
http://ewms.scidata.eu/Typ-I
Man beachte den letzten Satz auf der Seite. Der ist aber kein
Tippfehler. Der Autor erklärt das auf den weiteren Seiten sehr genau,
wie das patentierte Verfahren funktioniert.
Hier gibt es mehr zu dem System:
https://www.musiker-board.de/threads/sehr-interessante-neue-workstation-keyboard-in-entwicklung.640227/
Andreas R. schrieb:> Verschlüsselung fällt mir als erstes ein.
Nur ungewöhnliche Verfahren. Normale macht man heute oft mit spezieller
Hardwareunterstützung.
Das schnellerte Finden immer grösserer Werte die bis zu einen pathrecord
hoch und dann runterlaufen, ist an sich eher eine
Programmier-Herausforderung.
Die Herausforderung der Mathematik ist Ob und Warum enden wirklich alle
Folgen auf 1?
Und das seit 2009 keine grösseren Werte als o.a. p(#87) gefunden wurden,
ist merkwürdig, bei den heute verfügbaren Ressourcen.
Wohl auch deswegen weil ein Finden solcher bessern Werte noch kein
Beweis der Collatz-vermutung darstellt.
Jedoch neben Oliveira, Silva und Rosendaal in der Hall of fame zu landen
ist doch nett oder?
Und einen wirklich guten schnellen bezahlbaren universell verwendbaren
128- oder 256 Bit Risc Integer Rechner, sei es mit fpga, asics oder wie
auch immer zu "bauen", fände sicher Interessenten. (Jedenfalls 2 kenne
ich gg)
U.G. L. schrieb:
> Hans schrieb:>> nachdems anscheinend ums suchen/testen der nächst höheren geht, lässt>> sich das auf einer moderen cpu locker locker parallelisieren... also>> mehrere startwerte parallel meine ich damit....>> ganz so einfach wird das nicht, da die Untersuchung für den> Startwert(n+1) den Rekord(n) benötigt - das läßt sich aber mittels der> Annahme Rekord(n) = Startwert(n+1) und einer "Nachbehandlung" der> Resultate beheben.>> Es wird aber vorallen Dingen nur gelingen, eine Parallelisierung auf> Threadebene zu erreichen - eine Vektorisierung wird wohl nicht mögkich> sein.
Hallo miteinander :)
Doch, das geht sehr gut, zB einfach unter linux mit fork auf mehrere
Kerne oder indem man einfach nur bestimmte Reste auf einzelnen Maschinen
betrachtet. Die Abhängigkeit von den vorhergehenden Records wird dabei
erst einmal nicht berücksichtigt, dh jeder Kern / jede Maschine wirft
auch "Candidate Records" aus, die von anderen getoppt werden die von
anderen Kernen/Maschinen gefunden wurden. Die sind aber vergleichsweise
einfach auszusortieren, entweder durch manuelles "drübergucken" oder
indem sie an einen zentralen thread weitergegeben werden, der dann
vergleicht und nur die "echten" Records durchlässt. Da es
vergleichsweise wenige (Candiate) Records gibt im Vergleich zur Anzahl
der zu untersuchenden Folgen fällt das bezüglich der laufzeit kaum ins
gewicht. Wir haben aktuell knapp 50 Kerne am Start, was natürlich einen
sehr erwünschten Faktor zur Laufzeit beiträgt, und eine Überlegung wäre
tatsächlich es mit verteiltem Rechnen weiter anzugehen und dazu eine
Schnittstelle anzubieten, über die man ungenutzte Maschinen/Kerne an das
System anbinden kann.
have fun!
gonzens
matthias schrieb:> Und einen wirklich guten schnellen bezahlbaren universell verwendbaren> 128- oder 256 Bit Risc Integer Rechner, sei es mit fpga, asics oder wie> auch immer zu "bauen", fände sicher Interessenten. (Jedenfalls 2 kenne> ich gg)
Das ist aber etwas völlig anderes und ein viel aufwändigeres Projekt
als nur die Collatz-Folge zu berechnen. Wenn Du auch noch schneller als
eine aktuelle Intel-CPU sein möchtest, die sich ihre 256bit
zusammenstückeln muss, dann wird das auch noch richtig teuer.
Eukrott V. schrieb:>> Es wird aber vorallen Dingen nur gelingen, eine Parallelisierung auf>> Threadebene zu erreichen - eine Vektorisierung wird wohl nicht mögkich>> sein.> Doch, das geht sehr gut, zB einfach unter linux mit fork auf mehrere> Kerne oder indem man einfach nur bestimmte Reste auf einzelnen Maschinen> betrachtet.
Das ist aber keine Vektorisierung. Mit Vektorisierung ist gemeint, dass
man die SIMD-Befehle der CPU benutzt um die Berechnungen zu machen. Aber
wie Matthias schon ganz am Anfang geschrieben hat, fehlt den
SIMD-Befehlen das Carry-Flag, d.h. man kann sich aus einer
64Bit-Addition keine 256Bit Addition zusammenbasteln.
ich habe gpp mit apt-get installiert, aber wie installiere ich die gmp
library, so dass:
g++ -Ofast collatz.cpp -o collatz -I ..\gmp\include\ -L ..\gmp\lib\
-lgmp
nicht den Fehler "g++: error: ..gmplib -lgmp: Datei oder Verzeichnis
nicht gefunden"
meldet?
Damke
Markus K. schrieb:> Das ist aber keine Vektorisierung. Mit Vektorisierung ist gemeint, dass> man die SIMD-Befehle der CPU benutzt um die Berechnungen zu machen. Aber> wie Matthias schon ganz am Anfang geschrieben hat, fehlt den> SIMD-Befehlen das Carry-Flag, d.h. man kann sich aus einer> 64Bit-Addition keine 256Bit Addition zusammenbasteln.
Ja klar, deshalb sprach ich auch erstmal von Parallelisierung. Die
Vektoriesierung ist ein anderes Ding, klar, und da besteht bei mir auch
erheblicher "Nachholbedarf"...
Mit den Registern R8..R15 bekommt man es hin, dort wird das Carry in
klassischer Weise bedient, nx64 Werte "zusammenzubasteln", siehe den
Code oben. Dort hab ich es mit 2x64 Bit Registern gemacht, es auf 3x64
zu erweitern wäre kein Ding und damit auch alles abgedeckt was man
brauchen wird. Welchen Laufzeitunterschied eine 64bit zu einer 128bit
oder 192bit Version macht würde ich einfach nochmal austesten.
Ich poste dann einfach auch bei Gelegenheit nochmal die aktuellen Werte
die wir mit einer auf dieser Basis zubereiteten x86-version erreichen.
Entweder indem Du die Pfade "..\gmp\include\" und "..\gmp\lib\" an Deine
Gegebenheiten anpasst oder indem Du meine Verzeichnisstruktur verwendest
:-)
Vermutlich kannst Du "-I ..\gmp\include\ -L ..\gmp\lib\" auch weglassen
und entsprechende Enviroment-Variablen setzen.
U.G. L. schrieb:> Vermutlich kannst Du "-I ..\gmp\include\ -L ..\gmp\lib\" auch weglassen> und entsprechende Enviroment-Variablen setzen.
Also "Hans" hat auf seinem Linux lt.
Beitrag "Re: 128 Bit Risc"
"g++ -Ofast collatz.cpp -o collatz -lgmp" zum Compilieren benutzt -
u.U. wird der Include-Suchpfad und der Library-Suchpfad schon bei der
Installation von GMP korrekt ergänzt!?
Um mal ein paar Benchmarks zu haben...
Wir benutzen ein Programm nach einem Algorithmus, den "cyrix" vom MP
optimiert hat, und das in C geschrieben ist. Der Algo besorgt im
wesentlichen das Begrenzen auf einzelne Reste nach Zweierpotenzen und
führt mehrere Schritte in einem durch, indem die Ergebnisse vorberechnet
werden und die Faktoren/Summanden die zu verwenden sind aus einer
Tabelle abgegriffen werden. Wir haben das auf ca. 50 Kernen laufen, die
auf "handelsübliche" Server unter Linux verteilt sind. 12 davon habe ich
beigesteuert. Wir erreichen damit
path #63 in ca. 1 min 20 sek und damit auf etwa 1 Stunde bezogen auf
einen Kern.
Das ist ein 42 bit Startwert, dh die Maschinerie verarbeitet insgesamt
etwas bei 5*10^43 pro Stunde oder 10^42 / (Kern*Stunde). Das Ganze läuft
jetzt seit etwa 3 Wochen und wir sind damit bei #83 (immer nach dem
Listing bei Roosendaal) angekommen. Spannend wird es also erst, wenn wir
nach aktuellem stand die vierfache laufzeit erreichen, was leider dann
schon in monaten rechnet und eigentlich keinen spass macht zu warten. dh
es werden noch verbesserungen gesucht :)
Wir arbeiten parallel an einem Programm in x86 asembler (code oben von
mathias gepostet), ziel war zu schauen ob man damit überhaupt eine
merkliche verbesserung gegenüber dem c code erreicht. dieses erreicht
auf einem kern und mit einem eher "brute force" vorgehen
#47 in 1 min 24s das ist bei 35 bit startwert
Dh unser Assembler Programm "Hinkt" um einen faktor von geschätzt < 4
hinter der algorithmisch verbesserten, in C codierten Lösung her (was
oben ja auch schon angedeutet wurde, dass man sich eher auf den
algorithmus konzentrieren sollte).
(trotzdem hat es mich da erfasst und ich würde gerne hier noch
optimierungspotiential ausschöpfen wo es sich anbietet, dh mehr darüber
lernen, wie man assembler für aktuelle prozessoren optimiert).
Eukrott V. schrieb:> Wir benutzen ein Programm nach einem Algorithmus, den "cyrix" vom MP> optimiert hat, und das in C geschrieben ist.
Ah ja - der cyrix vom MP - der wird dann die in meiner Implementierung
gemachten Optimierungen (Eliminierung der gerade/ungerade Entscheidung,
Zusammenfassung der DOWNs, Abbruch der Berechung für einen Startwert,
wenn ein vorhergehnerder Rekordwert erreicht wurde), vermutlich alle
schon eingebaut haben!
Eukrott V. schrieb:> Das Ganze läuft> jetzt seit etwa 3 Wochen und wir sind damit bei #83 (immer nach dem> Listing bei Roosendaal) angekommen. Spannend wird es also erst, wenn wir> nach aktuellem stand die vierfache laufzeit erreichen, was leider dann> schon in monaten rechnet und eigentlich keinen spass macht zu warten. dh> es werden noch verbesserungen gesucht :)
Wieso setzt Ihr eigentlich nicht direkt in der Gegend von #87 auf (bis
dahin scheinen die Ergebnisse doch verifiziert zu sein)?
was dort gemacht wurde läuft (als eigentlich zentrale verbesserung)
darauf hinaus, a) schritte zusammenzufassen und b) mit zwei werten zu
rechnen, einem ungefähren der die grössenordnung angibt und der zum
prüfen des Erreichen von path-record oder startwert benutzt wird, und
dann den letzten stellen, also dem rest bzgl. irgendeiner 2^x basis, die
genau berechnet werden, um eben die nächsten sprünge zu bestimmen.
http://matheplanet.de/matheplanet/nuke/html/viewtopic.php?topic=223140&post_id=1633918
hier um den post herum wird das da beschrieben.
warum wir uns die roosendaal liste entlangarbeiten ist glaube ich
einfach historisch bedingt. natürlich könnte man auch bei #87 anfangen.
das macht aber eigentlich erst sinn wenn man schnell genug ist dort auch
nennenswerte bereiche abzugrasen. und wenn man schnell genug ist.. kann
man auch bei eins anfangen * feix
U.G. L. schrieb:> U.G. L. schrieb:>> Vermutlich kannst Du "-I ..\gmp\include\ -L ..\gmp\lib\" auch weglassen>> und entsprechende Enviroment-Variablen setzen.>> Also "Hans" hat auf seinem Linux lt.> Beitrag "Re: 128 Bit Risc"> "g++ -Ofast collatz.cpp -o collatz -lgmp" zum Compilieren benutzt -> u.U. wird der Include-Suchpfad und der Library-Suchpfad schon bei der> Installation von GMP korrekt ergänzt!?
unter linux braucht man weniger denken... wenn die lib sauber
installiert wurde, dann weiß der gcc wo sie ist (für gewöhnlich /usr/lib
bzw /usr/lib64).
bei dem kurzen code bekomme ich ca +-10% unterschiedliche laufzeiten je
nach compilereinstellungen auf meiner x86-64 maschine.
ob gmp mit assembler optimierungen compiliert wurde oder nicht ist da
schon drinnen.
ich habe jetzt aber (noch) nicht gegen die Intel MKL gelinkt... gut
möglich, dass da einiges drinnen ist... bei BLAS machts jedenfalls einen
gewaltigen unterschied.
73
Moin,
Ich wollte die gmp library auf einem ubuntu Derivat installieren.
sudo apt-get install libgmp3-dev
Finde aber nicht das Verzeichnis gmp/lib/" oder gmp/include/" ...
die library müsste doch unter usr sein? oder sbin?
Aufruf von "find -name libgmp3-dev"
findet eine Datei ./usr/share/doc/libgmp3-dev.gz wohl eine doku.
Sry ich hab wenig Erfahrung mit linux, wie ruf ich gpp bzw g++ richtig
auf?
Das collatz.cpp hab ich unter home/matthias
also bei
"g++ -Ofast collatz.cpp -o collatz -I ..\gmp\include\ -L ..\gmp\lib\
-lgmp"
stimmen die Pfade natürlich nicht.
Thx
M.
matthias schrieb:> Moin,> Ich wollte die gmp library auf einem ubuntu Derivat installieren.>> sudo apt-get install libgmp3-dev>> Finde aber nicht das Verzeichnis gmp/lib/" oder gmp/include/" ...> die library müsste doch unter usr sein? oder sbin?> Aufruf von "find -name libgmp3-dev"> findet eine Datei ./usr/share/doc/libgmp3-dev.gz wohl eine doku.> Sry ich hab wenig Erfahrung mit linux, wie ruf ich gpp bzw g++ richtig> auf?>> Das collatz.cpp hab ich unter home/matthias> also bei> "g++ -Ofast collatz.cpp -o collatz -I ..\gmp\include\ -L ..\gmp\lib\> -lgmp"> stimmen die Pfade natürlich nicht.> Thx> M.
* \ ist ein "escape"-zeichen, nicht als pfad-trenner verwenden
* / als pfad-trenner verwenden
* dpkg -L libgmp3-dev bzw. dpkg -s libgmp3-dev
* libgmp3-dev ist vermutlich eh das falsche paket --> apt-get install
libgmp-dev
* man find
bei mir unter ubuntu 16.04 braucht die libgmp kein zusätzliches -I oder
-L
#87 0e6a 5c22 fd7b de9f : 003d 8335 83fc b4f4 a0aa 0247 bd70 f498
#88 1b7d d73a 9374 85bf : 302a b3d0 52fb 87c0 6228 d249 581b e0e4
Mal angedacht - eine FPGA-Lösung mit reste_amount Maschinen.
Jede Maschine bearbeitet einen Startwert und liefert nur 1bit
Information (=> wenig Outoutdaten) der Form
uninteressanter/interessanter-Startwert. Uniteressant ist ein Startwert,
wenn innerhalb einer gewissen Anzahl von Takten (250 oder 500 oder 1000
/ noch zu bestimmen) keines der Bits X59 bis X117 gestetzt ist (die
Maschine wird dann gestoppt, damit sie sich nicht zum falschen Zeitpunkt
vielleicht doch noch kurz für interessant hält :-). "Interessant" wären
alle anderen (und mit einer richtigen CPU zu überprüfen), also die, bei
denen eines dieser Bits nach x-Takten gesetzt ist. Wenn der bisherige
Rekord "angekratzt" wird, also X116 oder X117 gesetzt wird, wird die
Maschine angehalten - sie (also derm entsprechende Startwert) ist auf
jeden Fall interessant. Verzichten würden wir also auf
Startwert-Register und Rekordwert-Register und zwei Vergleicher, sowie
die ganze Logik darum herum, was den Aufwand pro Maschine grob
verdoppeln, die Anzahl der Maschinen halbieren würde.
117 LUTs/FFs 117bit Arbeitsreg. X mit Input Multiplexer
(ALU/Shifter/Load?)
118-? LUTs 118bit ALU zur Berechnung von UP (2X + X + Carry(1)) / 2
117-? LUTs 117bit Shifter zur Generierung der DOWNs X/2 (& ev.
Load-Daten?)
10-50 LUTs Uninteressant/Interessant- und Ausgabe-Logik
Die Maschinen sind nur für das "Abgrasen" eines bestimmten Bereichs
konfiguriert - ist der abgearbeitet oder ein neuer Rekordwert gefunden,
muss das Design angepasst und neu compiliert werden!
Schön wäre es, wenn der Algorithmus dahingehend geändert werden könnte,
dass base_step eine Potenz von 2 ist (also z.B. 2048 oder 4096), dann
könnte start_base von einem einfachen Counter kommen und reste[Maschine]
wäre fix.für jede Maschine. Falls das nicht möglich ist, müsste
start_base von einer weiteren Register/ALU-Kombination kommen, der
Startwert von jeder Maschine selbst berechnet werden - dazu müsste in
den X-Operand-Pfad ein weiterer Multiplexer eingebaut werden (was die
erreichbare Taktfrequenz senkt), mittels dem man 2 * reste[Maschine] an
den X-Operand anlegen kann - außerdem für diese Berechnung Carry(0).
Wir haben also keine Inputdaten!
Die Fähigkeiten des Shifters würde man zunächst mal so wählen, dass er
die erreichbare Taktfrequenz nicht verringert, seine Durchlaufzeit also
kleiner/gleich der der ALU ist, in zweiter Linie, wieviele LUTs man
dafür investieren möchte.
Insgesamt könnte man pro Maschine mit 500-1000 LUTs hinkommen, die
gesamte FPGA-Lösung erforert also 100k LUTs aufwärts - lt. Mouser
erfordert das FPGAs für 150 EUR aufwärts!
Fragen an die Mathematiker:
- hilft Euch das weiter?
- base_step == 2048?
- ???
Fragen an die FPGAler:
- wieviele LUTs für 128bit ALU?
- erreichbare Takt-Frequenz?
- verfügbare Boards mit PCIe-, USB- oder Ethernetanbindug zum PC?
- ???
Hans schrieb:> ob gmp mit assembler optimierungen compiliert wurde oder nicht ist da> schon drinnen.>> ich habe jetzt aber (noch) nicht gegen die Intel MKL gelinkt... gut> möglich, dass da einiges drinnen ist... bei BLAS machts jedenfalls einen> gewaltigen unterschied.
Ich denke, entscheident ist, für welche Targets GMP speziellen Code zur
Verfügung stellt!
https://gmplib.org/manual/Build-Options.html => CPU types => x86 family
@U.G. L. : man braucht ja keine komplette 128 Bit ALU. Die wenigen
Funktionen (halbieren und *3+1) haben auf dem cyclone 2 ja nur paar
hundert LEs belegt. Man sollte halt ein Array mit solchen Collatz
Filtern haben, aber auch das ginge auf einem < 50,- FPGA vielleicht
noch.
Ja, das hilft weiter :)
ich fang mal mit den einfachen dingen an...
der wahl der "basis" von 3*2^n erlaubt es, etwa ein drittel der reste
auszusondern, da man auch Zahlen der Form 3*x+2 nicht prüfen braucht
(Grund wird gerne nachgeliefert). So dies natürlich einen Faktor von 3/2
oder mehr durch probleme in der konkreten implementierung erzeugt, macht
es keinen sinn und man kann stattdessen "basen" der form 2^n nutzen. Es
erschien effizienter, die Zahl der Basen um Faktor 3 zu erhöhen und die
entsprechenden Reste auszulassen, als zur laufzeit den rest mod 3 zu
bestimmen. astrid schlug vor, den rest mod 3 mitlaufend zu berechnen,
vielleicht geht das effizient zu programmieren, da habe ich mir keinen
genaueren kopf drüber gemacht.
das sieb bzgl. der 2-er potenzen kann man simpel berechnen, ich mache es
aktuell mit einem PHP Programm (igittttt) das mir eine datei reste.h
erzeugt, die ich in den c code einbinde. Die Tabelle könnte man
theoretisch beliebt erweitern, allerdings bringt es dann keine so
riesigen faktoren mehr (klaro). Auch dazu ggf. gerne mehr oder mal auf
dem mp gucken.
schön dass der thread hier auf dem mp verlinkt wurde :) das macht es
ggf. einfacher. ich bin dort gonz (klar).
Den Rest des Beitrages Autor: U.G. L. (dlchnr) Datum: 16.12.2016 13:24
muss ich erstmal schritt für schritt verdauen, aber das scheint genau
die richtung zu sein, die mir da im kopf herumschwebte. Das entspricht
meinen vorstellungen das parallel zu bearbeiten, und ggf. kann eben so
ein prozess auch einfach "kandidaten" herausfiltern, die man dann
anderswo konkret einzeln prüft. zB könnte man das vergleichen mit dem
Record erheblich vereinfachen, indem man auf das überschreibten
bestimmter "höchsten bits" prüft und dann das ergebis auswirft, auf dass
zB pc-seitig dann genau berechenet wird, ob das nun passt oder nicht.
ich werd mich da am we mal genauer mit beschäftigen - heute muss ich
leider erstmal noch arbeitstechnisch was erledigen * feix
PS.: Cool wäre es zB, jedem FPGA genau einen (oder eine Anzahl von)
Resten beizubringen, und dann eine Maschine zu haben, die zB Folgen der
Form 4096*x+127 durchrechnet (nur um ein Beispiel zu geben). Wenn man
von diesen 100 (oder whatever) auf einem FPGA unterbringt, könnte man
dort dann entsprechend eben 100 Reste hinterlegen und, wenn das FPGA
Array grösser wird, eben die 2-er Basis erhöhen.
daybyter schrieb:> @U.G. L. : man braucht ja keine komplette 128 Bit ALU. Die wenigen> Funktionen (halbieren und *3+1) haben auf dem cyclone 2 ja nur paar> hundert LEs belegt. Man sollte halt ein Array mit solchen Collatz> Filtern haben, aber auch das ginge auf einem < 50,- FPGA vielleicht> noch.
OK - mit dem Begriff ALU hab' ich mich vertan, es genügt natürlich ein
128Bit Adder - bei geschätzten Aufwand LUTs/LEs mit ein paar Hundert für
Register und Adder stimmen wir ja überein. Für mehr als 100 solcher
Maschinen kommen wir dann aber doch in den 100k LUT/LE-Bereich.
U.G. L. schrieb:> Jede Maschine bearbeitet einen Startwert und liefert nur 1bit> Information (=> wenig Outoutdaten) der Form> uninteressanter/interessanter-Startwert. Uniteressant ist ein Startwert,> wenn innerhalb einer gewissen Anzahl von Takten (250 oder 500 oder 1000> / noch zu bestimmen) keines der Bits X59 bis X117 gestetzt ist (die> Maschine wird dann gestoppt,
wäre es möglich sich zusätzlich zum pathrecord auch die zyklen anzahl zu
merken bei dem er erreicht wurde und in den folgenden berechnungen
einfach abzubrechen wenn der höchstwert für den aktuellen startwert bei
der gleichen zyklen anzahl noch unter dem bisherigen rekord liegt?
unter den 1. 10 gibt's 2 ausreißer.. die frage ist nun ob das nicht als
"sieb" schon herhalten würde..
Sprich auf die Art die nächst höhere bestimmen und dann von oben nach
unten genau runter suchen.
wenn man die bisher höchste zyklenzahl zum erreichen des Rekords
heranzieht würden die 1. 10 problemlos funktionieren...
73
zu Basis 3*2^n:
Ich hab' den Thread mal auf MP überflogen, aber eigentlich keine Zeit,
mich da einzuarbeiten, da ich eigentlich endlich mal mein
VHDL-LErn-Projekt angehen will :-)
Ich vermute dann aber mal, das man das zusätzliche Register + Adder (da
genügen 64bit) und einen gewissen Taktfrequenzverlust in Kauf nehmen
wird (z.B. statt 150MHz nur 125MHz), wenn der Algorithmus dafür
entsprechend effizienter wird.
ansonsten:
"kandidaten" ==> "Interessant"
überschreibten bestimmter "höchsten bits" ==> X116 oder X117 gesetzt
wird
> Cool wäre es zB, jedem FPGA genau einen (oder eine Anzahl von)> Resten beizubringen
ich gehe eigentlich davon aus, dass das FPGA wenigstens reste_amount ==
116 Einheiten enthält!
1
die erste berechent pro Interval (z.B. 500 Takte)
2
3
start_base+3072*T+tab[0], im Interval T1 start_base+3072*1+ tab[0]
4
im Interval T2 start_base+3072*2+ tab[0]
5
:
6
die zweite entsprechend
7
8
start_base+3072*T+tab[1], im Interval T1 start_base+3072*1+ tab[1]
9
im Interval T2 start_base+3072*2+ tab[1]
10
:
11
:
12
:
13
:
14
15
die letzte
16
start_base+3072*T+tab[115], im Interval T1 start_base+3072*1+ tab[115]
Hans schrieb:
> wäre es möglich sich zusätzlich zum pathrecord auch die zyklen anzahl zu> merken
Ich würde mir keinen pathrecord merken wollen, sonder nur durch gesetzte
Bits auf X116 und X117 feststellen wollen, das der pathrecord
"angekratzt" wurde, schon gar nicht weitere Sachen merken, weil das in
einem FPGA zu teuer ist.
Ich seh' das so - eine LUT / ein LE ist gut ausgeben, wenn's dort
richtig "klappert" - wenn das LE nur alle 100000 oder 1000000 Takte
schaltet, sollte man es vermutlich für was anderes verwenden - hier für
eine weitere Maschinen.
Es könnte von daher durchaus sinnvoll sein, sich z.B. auf 80bit zu
beschränken und den Startwert als "Interessant" zu markieren, wenn X78
oder X79 gesetzt werden.
Wichtiger erscheint mir momentan die untere Grenze zu sein - wieviele
Takte sind notwendig, um den Startwert in 99% oder 99m9% der Fälle unter
0x0800.0000.0000.0000 zu bringen - oder dauert das zu lange und es musss
doch in ein 64Bit-Startwert-Register und in einen 64plus-Vergleicher
investiert werden (plus ==> sind X64 bis X117 müssen zusätzlich 0 sein).
Solche Fragen müssen von den MPlern mittels Simulationen/Runs im
fraglichen Zahlenbereich klären.
Auf der anderen Seite müsste sich dann ein versierte VHDLler oder
VERILOGer finden, der die Erkenntnisse umsetzt - ich kann dazu derzeit
nichts betragen.
> ich gehe eigentlich davon aus, dass das FPGA wenigstens reste_amount ==> 116 Einheiten enthält!
In mindestens dieser Größenordnung müssen wir uns bewegen!
Denn eine einzelne Kette berechnet der Syklake viel schneller.
Wenn nicht wenigstens diese Anzahl von Einheiten bei einer ordentliche
Taktfrequnez (mindestens 100MHz) erreichbar ist, kaufst Du statt dem
FPGA besser einen 1/8 Skylake :-)
Ich bin mit diesen Pfaden in Linux nicht so vertraut..
Ich gebe an: g++ -Ofast collatz.cpp -o collatz -lgmp
Vorher hatte ich
apt-get install g++ und dann
apt-get install libgmp3-dev erfolgreich installiert.
Oder ist das das falsche gmp?
Wenn ich in meinem home/ich Verzeichnis angebe: g++ -Ofast collatz.cpp
-o collatz -lgmp, dann kommt:
collatz.cpp:4:32: fatal error: ..\gmp\include\gmp.h: Datei oder
Verzeichnis nicht gefunden
#include "..\gmp\include\gmp.h"
compilation terminated.
In line 4 des collatz.cpp steht #include "..\gmp\include\gmp.h"
Kann ja gar nich gehen, denn das waere ja unter \home\gmp und das gibts
nicht.
Wenn ich das #include "..\gmp\include\gmp.h" rauslasse kommt :
collatz.cpp:6:14: error: variable or field ‘collatz’ declared void
void collatz(mpz_t n, mpz_t r) { //[
^
collatz.cpp:6:14: error: ‘mpz_t’ was not declared in this scope
collatz.cpp:6:23: error: ‘mpz_t’ was not declared in this scope
void collatz(mpz_t n, mpz_t r) { //[
k.A was da nicht stimmt oder fehlt?
Thx
^
matthias schrieb:> In line 4 des collatz.cpp steht #include "..\gmp\include\gmp.h"> Kann ja gar nich gehen, denn das waere ja unter \home\gmp und das gibts> nicht.
dass #include "..\gmp\include\gmp.h" anzupassen ist, hab' ich schon viel
weiter oben angemerkt. Wo das apt-get die GMP hinplaziert, kann ich Dir
nicht sagen - ich arbeite noch nicht auf Linux, sondern in diesem Fall
mit MinGW/TDM-GCC.
Vermutlich kann Dir Hans
Beitrag "Re: 128 Bit Risc"
sagen, wie das #include abzuändern ist.
ohne das #include kennt der Compiler nat. schon mal den Typ mpz_t nicht!
Zu libgmp3-dev / libgmp-dev hatte sich rmu
Beitrag "Re: 128 Bit Risc"
geäußert - ich kann dazu, ohne Recherche nichts sagen.
Zusatz:
Ich sehe hier leider keine Möglichkeit, einen abgeschickten Thread zu
ändern, oder habs übersehen.
Was ich hinzufügen wollte ist, dass ich gern Masm Befehle unter gcc
verwenden würde, so dann man
mov rsi,ebp
mov rax,[rsi+rax*8] oder umgekehrt
mov qword ptr [rsi+rax*8],rdx etc. einfügen kann zum lesen
schreiben/schreiben der Zwischenwerte in ein array of __int128.
M
matthias schrieb:> Zusatz:> Ich sehe hier leider keine Möglichkeit, einen abgeschickten Thread zu> ändern, oder habs übersehen.
Würd' ich auch oft gerne machen, um meine Schreibfehler, die ich gerne
erst eine halbe Stunde später sehe, zu beseitigen.
Das Bearbeiten klapp aber leider nur für ein gewisse Zeit (halbe Stunde
oder Stunde) und nur solange noch kein weiterer Beitrag ergänzt wurde.
> Was ich hinzufügen wollte ist, dass ich gern Masm Befehle unter gcc> verwenden würde, so dann man> mov rsi,ebp> mov rax,[rsi+rax*8] oder umgekehrt> mov qword ptr [rsi+rax*8],rdx etc. einfügen kann zum lesen> schreiben/schreiben der Zwischenwerte in ein array of __int128.
Vermutlich wirst Du diebezüglich am Inlie-Asssembler nichts drehen
können.
Mit separten Assembler-Dateien und GAS könne vielleicht was gehen:
https://en.wikibooks.org/wiki/X86_Assembly/GAS_Syntax
"The AT&T syntax is the standard on Unix-like systems but some
assemblers use the Intel syntax, or can, like GAS itself, accept both."
Hans schrieb:> für den skylake ist gibts ein extra target in 6.1.0 ...>> https://gmplib.org/list-archives/gmp-devel/2015-August/004101.html>> möglicherweise wäre es sinnvoll statt mpz-funktionen die mpn varianten> zu probieren.
Wenn ich das ichtig verstehe, wurde dieMP aber nicht speziell fpr den
skylake getunt, der Code funktioniert auf syklake nur gut.
Wenn ich mir die unterstützen x86 CPU-Typen anschaue, scheint mit AMD64
das "schärfste zu sein, was man zum Optimieren einsetzen kann.
OK,
Das korrekte include war #include <../../../usr/include/gmpxx.h> ;)
mit der Version aus
Beitrag "Re: 128 Bit Risc"
habe ich in 18 minuten PR #52 erreicht!
Und der Ansatz mit dem verteilen auf mehrere cores/threads ist noch gar
nicht eingesetzt.
An sich würde ich gern mit freepascal und masm arbeiten.
Dieses gas schau ich mal an.
thx
matthias schrieb:> OK,> Das korrekte include war #include <../../../usr/include/gmpxx.h> ;)> mit der Version aus> Beitrag "Re: 128 Bit Risc"> habe ich in 18 minuten PR #52 erreicht!> Und der Ansatz mit dem verteilen auf mehrere cores/threads ist noch gar> nicht eingesetzt.>> An sich würde ich gern mit freepascal und masm arbeiten.> Dieses gas schau ich mal an.> thx
was spricht gegen #include <gmpxx.h> ?
U.G. L. schrieb:> matthias schrieb:>> In line 4 des collatz.cpp steht #include "..\gmp\include\gmp.h">> Kann ja gar nich gehen, denn das waere ja unter \home\gmp und das gibts>> nicht.>> dass #include "..\gmp\include\gmp.h" anzupassen ist, hab' ich schon viel> weiter oben angemerkt. Wo das apt-get die GMP hinplaziert, kann ich Dir> nicht sagen - ich arbeite noch nicht auf Linux, sondern in diesem Fall> mit MinGW/TDM-GCC.
der include ist schlicht
1
#include<gmp.h>
debian ist nicht so mein, aber das packet das du da installiert hast
sollte schon passen..
U.G. L. schrieb:> Faktor 2,7 gegenüber meiner Mühle - war zu erwarten.> Wie schaut's im Vergleich zur Assembler-Version aus?
nicht ganz ein faktor 2 wenn ich mich richtig erinnere...
wobei das gegen deine 1. version war...
73
matthias schrieb:> An sich würde ich gern mit freepascal und masm arbeiten.> Dieses gas schau ich mal an.> thx
unter linux ist sonst noch nasm weit verbreitet...
ich würde bei c bleiben... der gcc mit allem drumrum ist drauf getrimmt
c und asm zu mischen... (inline sowie externe asm files)
73
ich nehme an, dass das der overhead gegenüber den low-level funktion in
der gmp ist von denen die docu spricht...
immerhin müssen die gmp funktionen das vorzeichen beachten... das ist in
der asm version nicht so oder?
73
ich habs aktuell so, dass ich den startwert auf 64bit gegrenze und die
folgen bis 128bit laufen können genau wie die path records. ich werd mal
sehen dass ich mal auf 3x64bit raufgehe und gucke was das bzgl. der
lauftzeit ausmacht. mehr werden wir dann nicht brauchen denk ich.
Markus K. schrieb:> Das ist aber keine Vektorisierung. Mit Vektorisierung ist gemeint, dass> man die SIMD-Befehle der CPU benutzt um die Berechnungen zu machen. Aber> wie Matthias schon ganz am Anfang geschrieben hat, fehlt den> SIMD-Befehlen das Carry-Flag, d.h. man kann sich aus einer> 64Bit-Addition keine 256Bit Addition zusammenbasteln.
Man kann den 64 bit overflow bei addition ohne carry bit erkennen, wenn
(unsigned) vpaddq a,b,c < max(a,b) ist. (add c,2^64 if c below a or b).
Wenn man nun weiter xmm register betrachten/benutzen will, die Simd
funtionaltät ignorierend.
matthias schrieb:> Markus K. schrieb:>> Das ist aber keine Vektorisierung. Mit Vektorisierung ist gemeint, dass>> man die SIMD-Befehle der CPU benutzt um die Berechnungen zu machen. Aber>> wie Matthias schon ganz am Anfang geschrieben hat, fehlt den>> SIMD-Befehlen das Carry-Flag, d.h. man kann sich aus einer>> 64Bit-Addition keine 256Bit Addition zusammenbasteln.>> Man kann den 64 bit overflow bei addition ohne carry bit erkennen, wenn> (unsigned) vpaddq a,b,c < max(a,b) ist. (add c,2^64 if c below a or b).
Das kannte ich sogar, aber ich hatte es ignoriert, weil nicht glaube,
dass das schneller ist. Man braucht dann ja zusätzlich zwei Vergleiche
und die SSE/AVX-Vergleiche liefern als Ergebnis entweder alle Bits 1
oder 0. Man muss dann noch jeweils ein AND 1 machen um daraus eine 1
oder 0 zu machen. Dann die beiden Carry-Bits Verodern und dann als extra
Addition zu den oben 64Bit dazuzählen. Sind 6 zusätzliche Befehle, damit
man 4 Additionen parallel machen kann.
U.G. L. schrieb:> Ich würde mir keinen pathrecord merken wollen, sonder nur durch gesetzte> Bits auf X116 und X117 feststellen wollen, das der pathrecord> "angekratzt" wurde, schon gar nicht weitere Sachen merken, weil das in> einem FPGA zu teuer ist.
Das denke ich ist der richtige Ansatz. Man baut eine FPGA Maschine, die
Kandidaten ausspuckt, und sortiert mit einer CPU nach bzw. kann es sich
dort dann leisten, die kandidaten ganz klassisch durchzurechnen. Wenn
man spezielle Versionen für spezielle Bereiche macht, weiss man vorher,
auf die Überschreitung welcher bitgrenze man triggern muss und kann dann
aufhören.
Das würde sogar sinn machen für die jetztige ASM version, es würde dort
die kaskaden von vergleichen sparen. ggf. kann man also einen Prototyp
dessen auch für die CPU in assembler schreiben. vielleicht würde es auch
sinn machen, den verleich mit dem stoppwert ähnlich simpel zu stricken,
lieber mal ein paar folgeglieder mehr berechnen und erst stoppen, wenn
eine bestimmte bitzahl unterschritten wird.
viel stoff zum nachdenken :)
einen schönen weg ins WE wünscht
gonz
U.G. L. schrieb:> ich gehe eigentlich davon aus, dass das FPGA wenigstens reste_amount ==> 116 Einheiten enthält!
Ok, und das geht (ich kann die zahlen nicht beurteilen) in die richtung.
Wir haben aktuell also mit CPU einen Faktor von gefühlt 20-30 mehr in
der Taktrate, und schaffen einen parallelisierung auf 50 kerne (mehr
wäre natürlich möglich, aber dazu müsste man ein projekt zum verteilten
rechnen starten und dürfte nicht nur die server nehmen die wir eben so
über haben). das würde heissen, dass das etwa der Rechenleistung von 10
FPGA entspräche. Der Vorteil einer FPGA Lösung wäre dann nur, dass man
diese einfacher und preisgünstiger clustern kann als ganze CPUs mit
ihrem drumherum. Denkt man an ein Array von zB 64 FPGA (dh wir bräuchten
einen Sponsor und es wäre ein Projekt das in Hardware aufzubauen) hätten
wir mit Glück eine 10er Potenz gegenüber der CPU basierten Lösung
gewonnen.
Liege ich da richtig? ich vergreife mich immer mal gerne bei so zahlen *
schmunzel
Es würde aber m.E. dies rechtfertigen, mal genauer zu gucken wie weit
man da kommt, also die zahlen in obiger abschätzung genauer zu wissen.
Andreas R. schrieb:> Hab als Ziel so ein cyclone 2 minimum dev board genommen, wie man es für> unter 15,- bei ebay bekommt.
ich fand das bei ebay:
http://www.ebay.de/itm/Altera-Cyclone-II-EP2C5T144-FPGA-CPLD-Entwicklungs-board-DevelI2Copment-IO-SPI-/172328261937?hash=item281f909931:g:UAMAAOSwMgdXyhsU
Hast du mit diesem oder so einem ähnlichen da echt deine collatz.v Code
implementiert? Wie wird das angeschlossenen, mit parallel
Schnittstelle?, usb sehe ich da nicht.
Ist es nur zum Programmieren oder läuft das auch als Simulation?
Und die Sprache ist Vdhl in deinem collatz.v? Sorry Anfänger Fragen,
aber wenn das so preiswert ist lege ich s mir zu.
Ist so ein Board für Anfänger nicht so geeignet sondern ein sog.
eval-board besser? Welches?
Thx
M
matthias schrieb:> Wie wird das angeschlossenen, mit parallel> Schnittstelle?,
wenn es sowas komfortables wie usb etc nicht gibt, wäre es vielleicht
sinnig, ne art konzentrator zwischenzuschalten, also einfach nen board
nach wahl zu nehmen, das auf der einen seite ethernet oder usb oder...
unterstützt und am pc hängt, und auf der anderen seite via IO mit den
FPGAs kommuniziert. Im Prinzip könnte man die Werte ja problemlos über
sowas wie nen I2C morsen oder ne parallele schnittstelle und für jeden
FPGA ne select leitung spendieren... an der stelle müssen wir ja nicht
wirklich schnell sein. (wobei ich mich da an gute alte
hardware-architekturen erinnere ggg)
Eukrott V. schrieb:> vielleicht würde es auch> sinn machen, den verleich mit dem stoppwert ähnlich simpel zu stricken,> lieber mal ein paar folgeglieder mehr berechnen und erst stoppen, wenn> eine bestimmte bitzahl unterschritten wird.
Das war das, was ich mit "keines der Bits X59 bis X117 gestetzt ist"
gemient habe
Beitrag "Re: 128 Bit Risc"
Man müsste den Folgewert dann auf 0x0800.0000.0000.0000 bringen.
Man müsste mit einem C-Porgramm ermitteln, wieviele Takte im
Durchschnitt mehr invesiert werden müssen - verdoppelt sich die
Taktzahl, wird man besser doch den "64plus-Vergleicher"
Beitrag "Re: 128 Bit Risc"
einbauen, da der dann doch weniger kostet wie eine weitere Maschine
Ok, hier noch ein paar zahlen. verzichten wir auf den faktor 3 in der
basis
bekommen wir:
58 aus 1024 gleich 5.664% (basis 2^10)
113 aus 2048 gleich 5.518%(basis 2^11)
195 aus 4096 gleich 4.761% (basis 2^12)
313 aus 8192 gleich 3.821% (basis 2^13)
619 aus 16384 gleich 3.778% (basis 2^14)
1086 aus 32768 gleich 3.314% (basis 2^15)
natürlich könnte man die Reste auch auf mehrere FPGA verteilen.
U.G. L. schrieb:> Man müsste mit einem C-Porgramm ermitteln, wieviele Takte im> Durchschnitt mehr invesiert werden müssen - verdoppelt sich die
ok das kann ich mir mal auf die fahnen schreiben. ich hab eh vor mal ne
version zu schreiben die nen paar statische werte aufsummier (und
entsprechend langsamer läuft - egal) damit könnte man sowas austesten.
wenn jemand anders mag gerne - ich komme wahrscheinlich erst in den
nächsten tagen dazu....
Eukrott V. schrieb:> hätten> wir mit Glück eine 10er Potenz gegenüber der CPU basierten Lösung> gewonnen.
Faktor 10 war da auch das, was ich als machbar angesehen habe.
Angesichts der tollen Beiträge von cyrix ist das aber verdammt
ambitioniert!
Wenn man so ein Projekt angeht, muss man durchaus einkalkulieren, dass
vielleicht nur ein Faktor von eins, zwei oder drei rauskommt!
Der einzige Vorteil wäre, dass man know-how und hardware hätte, die man
prinzipiell an verbesserte algos anpassen könnte und die auch für andere
zahlentheoretisch orientiere aufgabenstellungen brauchbar wäre. (ok, in
begrenztem maße). also im prinzip müsste man damit rechnen, dass man es
eigentlich macht, um es mal gemacht zu haben grins
matthias schrieb:> http://www.ebay.de/itm/Altera-Cyclone-II-EP2C5T144-FPGA-CPLD-Entwicklungs-board-DevelI2Copment-IO-SPI-/172328261937?hash=item281f909931:g:UAMAAOSwMgdXyhsU
Das Board hat eine USB-Entwicklungsschnittstelle, vermutlich wird die
aber keinen Kanal für die "Anwenderkommunikation" zur Verfügung stellen.
Die Anzahl der LUTs/LEs wird nur für ca. 10 Maschaschinen reichen.
Ich gehe davon aus, dass damit keine 100MHz zu erreichen sind, denn die
300MHz werden wohl erreicht, wenn der Registerausgang direkt auf die
eigene LUT zurückgeführt wird - bei dem anvisierten Design werden aber
doch einige Stufen in der Loop mehr vorhanden sein.
Die LEs des Bausteins haben aber auf jeden Fall mal eine "Carry-Chain",
ohne die das Erreichen einer brauchbaren Taktfrequenz bei einem
80-128bittigem Adder wohl ilusorisch ist. Ob so eine "Carry-Chain" aber
ausreicht, um eine brauchbare Taktfrequenz zu erreichen, kann ich Euch
nicht sagen - dazu müssen sich andere FPGAler äußern, die Erfahrungen
mit aktuellen Bausteinen haben (meine Erfahrungen mit FPGAs liegen lange
zurück).
In meinen Augen braucht Ihr aber jetzt kein Board.
Man müsste nur wissen, welches Board man letztendlich einsetzen könnte,
falls das "Spielen" mit der zugehörigen Entwicklungsumgebung
"ermunternd"
ist (der Zeit- und Kostenaufwand einer Eigenentwicklung kann man sich,
glaub'ich, abschminken - da kauft ihr besser Skylakes und lasst sie
sofort rechnen!).
Vielleicht findet Ihr ja kostengünstig auf ebay sowas
https://www.enterpoint.co.uk/shop/home/106-merrick-6.htmlhttps://www.enterpoint.co.uk/shop/home/98-merrick-3.html
oder gar sowas :-)
https://www.enterpoint.co.uk/shop/home/13-merrick1.html
(wobei ich jetzt noch nicht geprüft habe, ob die verwendeten FPGAs für
diese Anwendung tauglich sind)
U.G. L. schrieb:> Man müsste nur wissen, welches Board man letztendlich einsetzen könnte,> falls das "Spielen" mit der zugehörigen Entwicklungsumgebung> "ermunternd" ist
nochmal an die mitlesend FPGAler - hat jemand ein passendes Board im
Sinn, dass geeignet wäre - PCIe/USB/oder Ethernetanschluss, ein oder
besser mehrere FPGAs mit 100k+ LUTs/LEs und Bausteinen mit
"Carry-Chain"?
Ach ja - jetzt kommt mir noch ein wichtiger Gedanke - gerade für die für
Euch interessanten größeren FPGAs gibt es nicht umgedingt auch
kostenlose Entwicklungsumgebungen!!!
Erste Ergebnisse aus der Statistik:
die werte konvergieren recht fix, es ist das verhältniss
(3x+1)/2 Schritte zu /2 Schritte: 1,45
Schritte insgesamt pro Folge im Mittel : 24,02
Das lohnt vielleicht, mal näher betrachtet zu werden:
http://www.ebay.de/itm/PCIe-280-8-lane-PCI-Express-2-0-FPGA-accelerator-card-/272417191446?hash=item3f6d547616:g:J7gAAOSwU-pXrDtb
mit PCIe-Anschluss!
Leider nicht im Text beschrieben, ob mit XC5VLX220T oder XC5VLX330T
bestückt,
entsprechend wären knapp 35000 oder gut 50000 "Slices" verfügbar.
Ein Slice enthält "Four function generators, Four storage elements,
Arithmetic logic gates, Large multiplexers, Fast carry look-ahead
chain".
U.U. können auch die 128/196 DSP slices eingebaut werden.
Ein komplexes Teil (so wie es aussieht mit eigenem Stromanschluss!!!) -
ein Teil, mit dem man gut 100 "Maschinen" u.U. realisieren kann!?
Und eigentlich müssen wir nicht die durchschnittliche Schrittzahl
wissen,
sondern die Schrittzahl, bei der 99% und 99,9% unter Startwert bzw.
0x0800.0000.0000.0000 gelangen?
Also ich hahe es geschafft, eine 3x+1 Operationn über die 64 bit Grenze
zu schreiben durch 2 additionen dann noch +1.
Leider gelingt es nicht, ein shift right eines ganzen 128 bit words um 1
bit zu machen.
oder weiss jemnand wie man die das umgehen könnte?
VPSRLDQ xmm1, xmm2, imm8 denkt man würde das machen abert tuts nicht
shifted nur quadwords.
also etwa 0x00.00.00.01.B2.A0.C1.00 1 oder 2 bit nach rechts shiften?
Hat herr intel nicht vorgesehn. Man kann höchstens das 128 bit xmm word
splitten und die qword getrennt betrachten. dann wären wir aber bei der
64 bit implementation von gonz.
Die xmm bzw ymm256 Bit sind nicht geeignet für was ich/wir wollen.
Wie gesagt eine simple 128 bit addier machine würde reichen, wobei es
mir anfänglich gar nicht so um Zeit geht.
M
Mittlerweile gibts auch schon FPGAs in der Wolke:
https://aws.amazon.com/de/ec2/instance-types/f1/
Von den Daten her sind es Xilinx Virtex Ultrascale+ XCVU9P (2.5 Mio
System Logic Cells, 6840 DSP Slices, 345Mb RAM)
Also das cyclone 2 Board hab ich hier (bekommst auch für die Hälfte vom
obigen ebay Link) und dann noch ein de0 Nano Board:
http://www.terasic.com.tw/cgi-bin/page/archive.pl?Language=English&No=593
Leider sind wir bei beiden recht weit weg von 100k+ LEs... ;-(
Wenn ihr Speicher zum Beschleunigen braucht, fallen mir noch die Mimas
Boards ein:
http://numato.com/mimas-v2-spartan-6-fpga-development-board-with-ddr-sdram/
Das nehmen ja die J-Core Leute um den Linux Kernel drauf laufen zu
lassen.
Aber braucht ihr echt 100k+ LEs? Wäre es ggf nicht günstiger z.B. 4
Boards mit je 25k LEs zu verwenden und die Aufgaben auf diese Boards zu
verteilen?
unabhängig von der zu beschreitenden Lernkurve würde ich für diese
Problemstellung das ZYBO-Board von Digilent vorschlagen: dort ist ein
Xilinx Zynq verbaut. Dabei handelt es sich um einen dual-core ARM
Prozessor mit "angebautem" FPGA-Teil.
So wie ich die Problematik verstanden habe, spielen bei der
Datenübertragung Latenz und Bandbreite eine Rolle. Genau hier kann eine
Zynq-basierte Lösung punkten. Das vorgeschlagene Konzept wäre also:
Auf dem ARM-Teil des Zynq läuft unter Linux ein Hauptprogramm von dem
aus die 128-bit/256-bit-Operanden und -Ergebnisse ultraschnell (denn es
läuft ja alles auf EINEM Chip) mit einem 128-bit/256-bit Co-Prozessor im
FPGA-Teil ausgetauscht werden. Das Board hat Ethernet, so dass man von
einem PC aus remote arbeiten kann.
Das ist alles nicht so einfach zu erlernen aber ich denke, das wäre die
passende Plattform.
Gruss
Peter Schulz
Andreas R. schrieb:> Aber braucht ihr echt 100k+ LEs? Wäre es ggf nicht günstiger z.B. 4> Boards mit je 25k LEs zu verwenden und die Aufgaben auf diese Boards zu> verteilen?
Wenn man es als Kosten-Nutzen-Rechnung betrachtet, und wir eh mehr als
einen FPGA einsetzen würden (zumindest perspektivisch), dann wäre das
natürlich ein Rechenexemple. Wenn man nur die Kosten der Bauteile
betrachtet wäre dann wahrscheinlich eine 4x25k Lösung günstiger als eine
1x100k. Tatsächlich muss das dann aber auch jemand zusammenbauen etc...
Es gab ja auch schon den Vorschlag, einfach eine Farm an möglichst
günstigen CPU Boards per Ethernet zusammenzuschalten. Wenn man nicht auf
die Stromrechnung guckt wäre das wohl die günstigste Variante um an
Rechenleistung zu kommen...
Peter Schulz schrieb:> ZYBO-Board von Digilent
Dann könnte man dort mal anfragen was denn für eine "produktiv-version"
16 solcher boards in "nackt" ohne das development kit drumrum kosten
würden :) und einen Sponsor suchen (ernstgemeint). Wobei - wenn man die
über ethernet koppelt, könnte man sie auch über WWW koppeln. Dh man
könnte sich auch vorstellen, lauter kleine Boxen auf der Basis zu bauen,
für die dann "Stellplätze" mit Strom- und Webanschluss gesucht werden *
schmunzel
Was man ja dann auch für andere Berechnungen gut verwenden könnte (ich
denke da immer noch an vormalige Aufgaben aus den Al-Zimmerman
Contests...
und - das sind LUTs mit 6 Eingängen (statt der ältern LUTs mit nur
4 Eingängen)!!! statt einer LUT mit 6 Eingängen und einem Ausgang
kann man die LUT auch als zwei LUTs mit 5 Eingängen und 2 Ausgängen
konfigurieren!!!
Damit ließe sich z.B. eine Maschine mit den Operationen (3X+1)/2,
SHR1, SHR2 und LOAD realisieren, ohne extra LUTs für den Shifter
auszugeben, der könnte in Multiplexer mit intergriert werden!
Da ergibt sich dann schon wieder eine Aufgabe für die MPler - wie
oft haben wir den Fall, das nach einer (3X+1)/2-Operation ein Shift1,
ein Shift2, ein Shift3, ein Shift4, ...ausgeführt wird - u.U. lohnt
es gar nicht, mehr als eine SHR2-Operation zu integrieren, weil
SHR3, SHR4 ... zu selten benötugt werden.
Eukrott V. schrieb:> wir haben grad gemessen> auf einem core #53 in 4 min 44
ok also - nachdem ich verstanden habe dass gar nicht das rumrechnen
"kostet" sondern das springen - hier eine version bei der (3x+1)/2 und
/2 in demselben konstrukt behandelt werden:
// r9,r13 : aktueller Folgewert (niederwertig...hoeherwertig)
// r10,r14 : dessen haelfte fuer (3x+1)/2 schritt
// r11,r15 : record (wird mitgefuehrt, ursprungswert geht verloren)
// rax : null (da komischerweise cmovnc nicht mit konstante geht)
// auf gehts! lets do the collatz ...
"collatz_start: \n\t"
// wir erzeugen auf r10,14 eine kopie des aktuellen wertes
"MOV %r13,%r14 \n\t"
"MOV %r9,%r10 \n\t"
// und halbieren diese schon einmal (brauchen wir fuer beide faelle)
"SHR $1,%r14 \n\t" // shr+rcr rotiert ueber und in das carry
"RCR $1,%r10 \n\t"
// aus dem Carry kann man jetzt entnehmen ob gerade oder ungerade
// wenn der gerade fall loeschen wir den bisherigen Folgenwert
"CMOVNC %rax,%r13 \n\t"
"CMOVNC %rax,%r9 \n\t"
// fuer "ungerade": carry is set, auf r9,13 der bisherige wert
// fuer "gerade": carry clear und r9/13 geloescht :)
"ADC %r10,%r9 \n\t" addieren uebers/mit dem carry
"ADC %r14,%r13 \n\t"
// habe fertig: auf 9,13 steht jetzt der neue folgewert.
das bringt ungefaehr 30%, ich komme jetzt auf einem kern zur #53 in 3
min 21 und kann auf der 12-kern maschine das Leavens&Vermeulen Programm
(bis #63 bei Roosendaal) in einer Stunde erledigen * smile
have fun!
gonz
Anfrage beim ebay-Verkäufer, ob das Board XC5VLX220T oder XC5VLX330T
enthält, läuft - und auch, ob die Boards nackt kommen oder mit der
ursprünglich mitgelieferten Doku und Software (z.B: dem notwendigen
PCIe-Core für den XC5VFX100T) geliefert werden.
Vielleicht kann einer von den MP-lern bei Nallatech nachfragen,
ob die für mehrere nackte Boards und für so ein Projekt
gegebenenfalls die Doku und Software zur Verfügung stellen
(aber nicht den Link verraten - die Kaufen sonst bei dem Preis
die Boards glatt selber zurück :-).
Als Sponsoren kommen sicherlich nur Intel/Altera, Xilinx
Lattice, also die Anbieter von solchen FPGAs und deren
Distributoren infrage - dort könnt Ihr mal diesbezüglich
nachfragen.
U.U. stellen die sogar ein wenig Manpower/Knowhox für
die Implementierung der Maschinen zur Verfügung!?
Eukrott V. schrieb:> ok also - nachdem ich verstanden habe dass gar nicht das rumrechnen> "kostet" sondern das springen - hier eine version bei der (3x+1)/2 und> /2 in demselben konstrukt behandelt werden:
Schon über die Realisierungsmöglichkeit einer Version
nachgedacht, die ohne diesbezügliche Entscheidungen
auskommt?
Also immer abwechselnd eine (3X+1)-Operation, dann ein
Count_Trailing_Zeros (bzw.BitScanForward1) und einem
entsprechenden ShiftRight um n Stellen (man kann wohl
darauf verzichten, hier mehr als 64 trailing zeros
einzukalkulieren).
Dann könnte man noch darüber nachdenken, ob sich ein
Unfold der Loop machen läßt - also in einer Schleife
gleiche mehrere UP/DOWNs realisiert.
Und berechnet Ihr eigentlich für jede Kette deren eigenen
Rekordwert und verfolgt sie bis zu einem Wert kleiner dem
Startwert oder vergleicht ihr wie bei meiner GMP-Implementierung
den aktuellen Wert auch mit dem aktuellen "globalen" Rekordwert?
Wenn eine Kette den bisherigen Rekordwert erreicht hat,
kann abgebrochen werden - das brachte, wenn ich mich recht
entsinne, auch wieder 25% - klar, die Kette muss dann
erst gar nicht mehr wieder bis unter den Startwert
verfolgt werden.
U.U. rechnet es sich sogar, zusätzlich auch auf den alten Rekordwert zu
prüfen und ebenfalls abzubrechen?
Das Down bis zum Startwert dauert in diesen Fällen zwar nicht solange,
der alte Rekordwert wird dafür aber vermutlich wesentlich häufiger
erreicht.
Eukrott V. schrieb:> Peter Schulz schrieb:>> ZYBO-Board von Digilent>> Dann könnte man dort mal anfragen was denn für eine "produktiv-version"> 16 solcher boards in "nackt" ohne das development kit drumrum kosten> würden :)
mit "4,400 logic slices, each with four 6-input LUTs and 8 flip-flops"
kommt Ihr halt nicht weit!
Da dürften allein die kleinen 4 gebrauchten Boards
(http://www.ebay.de/itm/272337657073?clk_rvr_id=1141516663638&rmvSB=true),
grob zum Preis eines ZYBO-Boards, wesentlich mehr bringen!
Wenn sich nicht ein Sponsor unter den FPGA-Herstellern/Distributoren
auftut und sichergestellt werden kann, dass neben den nackten Boards
auch die nowendige Doku und Software zu bekommen ist, sehe ich
eigentlich die neun gebrauchen Boards als "alternativlos" an :-)
Auf den Boards sind FPGAs verbaut, die vor fünf Jahren vermutlich
mehr als 3000/4000EUR, u.U. sogar teilweise mehr als 10000EUR
gekostet haben!!!
U.G. L. schrieb:> Und berechnet Ihr eigentlich für jede Kette deren eigenen> Rekordwert und verfolgt sie bis zu einem Wert kleiner dem> Startwert oder vergleicht ihr wie bei meiner GMP-Implementierung> den aktuellen Wert auch mit dem aktuellen "globalen" Rekordwert?
ich mach es so dass ich den globalen recordwert beim einstieg in die
collatz routine, die eine Kette durchrechnet, mitgebe, und mit diesem
nach jedem (up-schritt) vergleiche. Wenn man beim überschreiten gleich
abbricht, dann muss man nachträglich prüfen, ob die folge nicht im
weiteren verlauf noch einen höheren wert erzeugt, deshalb lasse ich sie
weiterlaufen bis zum stopwert und überschreibe den globalen record ggf.
mehrmals mit einem jeweils höheren wert. dass abbrechen hier 25% bringt
glaube ich nicht, ggf. kann die folge ja auch erstmal wieder sinken,
aber vor erreichen des stopwertes dann wieder ansteigen bis zu einem
höheren wert, sodass man sie zumindest soweit durchrechnen muss bis sie
auf einen schon betrachteten Startwert anlandet.
U.G. L. schrieb:> Dann könnte man noch darüber nachdenken, ob sich ein> Unfold der Loop machen läßt - also in einer Schleife> gleiche mehrere UP/DOWNs realisiert.
das habe ich nicht, es wurde aber in C gemacht. man kann dann für eine
bestimmte anzahl von schritten vorab berechnen, welchen faktor/summanden
man erhält für jede mögliche folge von up/dn, und diese dann aus einer
tabelle abgreifen. zu beachten ist dabei natürlich auch, dass ggf. in
einem zwischenschritt der record überschritten und danach wieder
unterschritten wird genauso mit dem stopwert, dh. man muss entsprechende
"Sicherheitsabstände" einbauen, oder eben zB "Candidate Records"
auswerfen, wenn man hinreichend dicht (aber weniger als der mögliche
Überschwung in einem multistep) an den record herangekommen ist.
ich weiss noch nicht, ob es sinn macht, den algo der da in C realisiert
wurde, in asm nachzubauen.
U.G. L. schrieb:> Schon über die Realisierungsmöglichkeit einer Version> nachgedacht, die ohne diesbezügliche Entscheidungen> auskommt?
nachdenken ständig, siehe mein erster anlauf beide zweige ineinander zu
verschachteln. das ist aber sicher noch nicht das optimum was ich da
herausgeholt habe...
Andreas R. schrieb:> Das könnte man auf trailing Zeros umbauen und im nächsten Schritt alle> Nullen am Ende entfernen.
alle Nullen am Ende kannst Du nie in einem Takt entfernen, da das sehr
viele werden können - um 50 Nullen entfernen zu können, muss der
Multiplexer am Arbeitsregisterbiteingang 50 Eingänge breit sein - und
dieses Features würde so gut wie nie benutzt - selbst ein 10bit Shift
wird sehr, sehr selten sein. U.U. ist mit den, mit einer 6erLUT
möglichen (und geschenkten) ShiftRight1- und ShiftRright2-Operationen
schon das Optimum gefunden.
Eukrott V. schrieb:> Wenn man beim überschreiten gleich> abbricht, dann muss man nachträglich prüfen, ob die folge nicht im> weiteren verlauf noch einen höheren wert erzeugt
Ich prüfe, ob aktuellerWert >= bisherigerRekortwert ist, dann
nachgeschaltet, ob aktuellerWert == bisherigerRekortwert - wenn dem
so ist, kann ich abbrechen (aus der Loop springen), weil ein bisheriger
Rekord keinen neuen Rekord ergeben kann - ist das nicht der Fall
(aktuellerWert != bisherigerRekortwert), dann haben wir definitiv einen
neuen Rekord und können sofort den bisherigen überschreiben.
Eukrott V. schrieb:> dass abbrechen hier 25% bringt glaube ich nicht
ich bin mir ziemlich sicher, dass ich n=23035537407 dann statt in 913
Sekunden erst nach mehr als 1300 Sekunden erreicht habe!
Der Laufzeitgewinn entsteht nicht bei der Berechnung der aktuellen
Folge, sondern bei der Berechnung der Folgen von weiteren, höheren
Startwerten,
die den neuen Rekord einstellen, aber nicht überbieten! Denn die alle
müssen dann nicht zurück auf den jeweiligen Startwert iteriert werden.
Im Prinzip kann auf Gleichheit zu jedem bisher aufgetretenen Wert
geprüft und abgebrochen werden, doch jeder Vergleich kostet natürlich
auch und drum vermute ich schon, dass ein zusätzliches Prüfen auf den
letzten Rekordwert sich nicht rechnet.
Der Vergleich aktuellerWert >= bisherigerRekortwert mit nachgeschaltetem
aktuellerWert == bisherigerRekortwert statt
aktuellerWert > bisherigerRekortwert rechnet sich aber immer,
da der ">="-Vergleich nicht länger dauert als der ">"-Vergleich und der
nachgeschaltete Vergleich ja nur im Trefferfall Zeit kostet!
U.G. L. schrieb:> Im Prinzip kann auf Gleichheit zu jedem bisher aufgetretenen Wert> geprüft und abgebrochen werden, doch jeder Vergleich kostet natürlich> auch und drum vermute ich schon, dass ein zusätzliches Prüfen auf den> letzten Rekordwert sich nicht rechnet.
aber man könnte es natürlich mal überprüfen.
Und man könnte darüber nachdenken, ob es Werte gibt, bei denen sich
Folgen gehäuft vereinigen und auf die dann eher ein zusätzliches
Abprüfen sinnvoll ist.
Hab' nämlich den Eindruck, dass Silva damals nicht nur weitere Pfeile im
Köcher hatte, sondern eine weitere Axt!
Substanzielle Verbesserung erscheinen mir nur möglich mit Techniken, die
viele Folgen/Startwerte auf einmal tilgen.
U.G. L. schrieb:> ich bin mir ziemlich sicher, dass ich n=23035537407 dann statt in 913> Sekunden erst nach mehr als 1300 Sekunden erreicht habe!
ich habe folgendes probiert: ich zähle die fälle, in denen der bisherige
pathrecord nochmal erreicht wird. das sind jedoch vergleichsweise sehr
wenige fälle, zB. 6x zwischen Roosendaal #42 und #43. in diesem bereich
werden jedoch mehrere millionen folgen durchgespielt. damit kann es
eigentlich den von dir beschriebenen faktor durch diese prüfung nicht
geben, kannst du das nochmal überprüfen?
Eukrott V. schrieb:> ich habe folgendes probiert: ich zähle die fälle, in denen der bisherige> pathrecord nochmal erreicht wird. das sind jedoch vergleichsweise sehr> wenige fälle, zB. 6x zwischen Roosendaal #42 und #43. in diesem bereich> werden jedoch mehrere millionen folgen durchgespielt. damit kann es> eigentlich den von dir beschriebenen faktor durch diese prüfung nicht> geben, kannst du das nochmal überprüfen?
Ich hab' das Programm, im Prinzip eine inline-Version des Programms
von Beitrag "Re: 128 Bit Risc"
mit einer äußeren Loop, nochmal laufen lassen und es benötigt
tatsächlich wesentlich länger.
Du hast dennoch recht!!!
Denn für die Beschleunigung bei der nächsten Version war nicht
die Idee mit dem ">=" verantwortlich, sondern das Rausschmeißen
der lokalen Varianlen l, wie ein Gegentest beweißt.
Ich rechnete die Beschleunigung dem ">=" zu, weil mir das Umkopieren
von l auf r nach der while-Schleife als zu wenig auswendig vorkam -
das gleichzeitig nicht ständig x nach l umkopiert wird, hatte ich
übersehen :-)
Vermutlich ist aber zumindest die Differenz von 952 auf 913 Sekunden
zum größten Teil dem ">=" zuzuschreiben und nur zu einem kleineren Teil
den auch schon beobachteten temperaturanhängige
Geschwindigkeitsunterschieden der CPU.
Weltbester FPGA-Pongo schrieb im Beitrag #4834192:
> Ist das hier noch das Unterforum FPGA?
Es ist durchaus üblich, dass man Algorithmen erst mal auf dem PC testet,
bevor man sie auf einem FPGA implementiert. Das Thema FPGA ist ja auch
noch nicht durch.
Nachdem ihr nun so doll optimiert habt, frag ich mich ob da nicht noch
was mit OpenCL ginge.
Also viele Folgen parallel auf jeweils einem GPU Kern rechnen.
Diese Schiene wurde bisher ja etwas stiefmütterlich behandelt.
Also die neun gebrauchten ebay-Boards kämen "nackt".
Etwas seltsam die Meldung "the item is not coming with any equiped
items".
Kann mir nicht vorstellen, dass die die FPGAs unter dem Kühlkörper
entfernt haben - vermute vielmehr, dass die glauben, es gehe um
Teile, die für die Steckplätzen vorgesehen sind. Die haben wohl
keine Ahnung, was sie da verscherbeln - eine entsprechende Rückfrage
läuft.
Falls Ihr Euch bei Nallatech keine Unterstützung sichern könnt
(Doku, Software), sind die Boards aber sowieso uninteressant.
sry das ist ein doppelpost auch in stackoverflow, deswegen denglisch:)
Split xmm128 register:
How to I split Intel xmm128 Bit register into 2 64 bit qwords?
If have a very large number in xmm1 and want to get the higher quadword
to r9 and lower quadword to r10, or RAx and RDx.
Whats the correct instruction?
and other way around compose an xmm register from 2 quadwords?
movlpd or movhpd only works with reg to mem or vice versa.
Thx
M.
Weltbester FPGA-Pongo schrieb im Beitrag #4834192:
> Ist das hier noch das Unterforum FPGA?
Klar. Ich denke zur Veranschaulichung dessen was in dem Projekt
gebraucht wird reicht das massig.
daybyter schrieb:> Nachdem ihr nun so doll optimiert habt, frag ich mich ob da nicht noch> was mit OpenCL ginge.
Yep. Das ist eine der Richtungen in die man schauen sollte. Nach dem was
ich bisher herausbekommen habe gibt es dort nicht von Haus aus breite
Integertypen, dh man müsste dort irgendeine art von bigint-lib (wie auch
immer es dann dort heisst) oder verkettete schmale register verwenden.
Der Faktor, der nach Ansicht von Leuten, die sich eventuell auskennen,
zu erreichen ist, liegt bei 100. Das würde man natürlich gerne
mitnehmen. Aber auch das gehört nicht hierher * schmunzel
ich schreib nachher mal für den mp ne zusammenfassung wo meiner einer da
stecken geblieben ist :)
Les gerade opencl specs. Darin wird der Datentyp long long erwähnt. Ein
128 bit long Typ. Wenn man ein sdk hätte, welches das unterstützt, würde
es die Sache doch erstmal vereinfachen.
Bei den Vector Typen gibt es zwar die Shift und Add Operationen, aber
sie funktionieren nur für die einzelnen Komponenten. Wenn also x ein
long4 ist, dann werden bei x >> 1 die 4 longs nach rechts geschoben,
aber der Übertrag dazwischen fehlt. Bit 0 von long 1 wird nicht in das
msb von long 0 geschoben usw. Das muss man dann von Hand machen. Erst
die 3 0 Bits der oberen longs mit & maskieren, dann wohl um 63 Bit nach
links schieben, mit shuffle um eine Komponente verschieben und mit |
wieder hinzufügen.
Beim Addieren müsste man analog den Übertrag von Hand hinzufügen.
Andreas R. schrieb:> Bei den Vector Typen gibt es zwar die Shift und Add Operationen, aber> sie funktionieren nur für die einzelnen Komponenten. Wenn also x ein> long4 ist, dann werden bei x >> 1 die 4 longs nach rechts geschoben,> aber der Übertrag dazwischen fehlt. Bit 0 von long 1 wird nicht in das> msb von long 0 geschoben usw. Das muss man dann von Hand machen. Erst> die 3 0 Bits der oberen longs mit & maskieren, dann wohl um 63 Bit nach> links schieben, mit shuffle um eine Komponente verschieben und mit |> wieder hinzufügen.
Meine Idee wäre, sich auf einen INT112 zu beschränken und das
obere Byte des low-int64, sowie das unter Byte des hgh-int64
als Carry-Area zu verwenden.
Uncompiliert und ungetestet, nur mal so als Idee und als
C++ - Klasse, ausgeführt für den gerade interessanten Bereich!
Hab den Vorteil dieser Lösung nicht ganz verstanden, aber ok.
Was anderes: nicht jede GPU unterstützt ja jeden Datentyp. Welche GPUs
habt ihr denn zum Rechnen?
Andreas R. schrieb:> Hab den Vorteil dieser Lösung nicht ganz verstanden, aber ok.
Das war zumächst einmal nur eine Idee - ob sie sich vorteilhaft umsetzen
läßt, müssen die entscheiden, die das implementieren können. Mein
Vorschlag setzt voraus, dass auf die einzelnen Bytes eines INT64
zugegriffen werden kann, mehr wird eigentlich nicht benötigt.
Er ermöglicht, das Überträge "gesammelt" werden können (andernfalls muss
für eine (2 x + x + 1)-Operation dies drei mal geschehen!) und kann auch
mehrere Überträge gleichzeitig von einem INT64-Teil zum anderen bewegen,
so also auch bis zu 8 Bits auf einmal nach rechts shiften (und mehr
dürften seltenst gebraucht werden).
Der Vorschlag minimiert Entscheidungen und Sprünge und realisiert eine
sehr einfache Upper- und Lower-Limit-Erkennung.
Ich weiß jetzt nicht, ob OpenCL ein Carry-Bit in die Schnittstelle
exportiert, wenn nicht, müsste die (2 x + x + 1)-Operation in etwa
so realisiert werden.
1
hgh <<= 1;
2
tmp = low >> 63;
3
hgh |= tmp;
4
tmp = low << 1;
5
if ((tmp & 0x80000000) && (low & 0x80000000)) {
6
hgh += 1;
7
}
8
low += tmp;
9
if (low == 0xFFFFFFFF) {
10
hgh += 1;
11
}
12
low +=1;
Statt einem fünf-Zeiler ein zehn-Zeiler, inklusive zweier
Entscheidungen/Sprünge - und ich sehe nicht, wie man das auf einen
fünf-Zeiler eindampfen könnte, schon gar nicht, wie die
Entscheidungen/Sprünge zu eliminieren wären?
Ich schmeiss mal zuerst ein Tutorial in den Raum für die Lesewilligen...
http://amd-dev.wpengine.netdna-cdn.com/wordpress/media/2013/01/Introduction_to_OpenCL_Programming-Training_Guide-201005.pdf
Die ganze Sache muss noch ein bischen umgebaut werden, weil u.a. das
Problem besteht, dass alle GPU Kerne nur 1 Instructionpointer haben.
D.h. alle Kerne laufen immer gleich lange. Man kann nicht einfach einen
Kern anhalten, wenn er fertig ist, sich die Daten von ihm holen und ihm
neue Daten geben und ihn neu starten.
Ich hab mir überlegt, dass das Programm immer x Iterationen machen
müsste (sagen wir 100 oder auch 1000, je nachdem wie lange so ne
durchschnittliche Folge ist). Dann stoppen alle Kerne. Jetzt wird
abgefragt, welche Kerne fertig sind, und diese Kerne bekommen neue
Daten. Dann wird das Programm weiterlaufen gelassen.
Wobei die Schleife in dem Sinn gar nicht erkennen muss, ob sie fertig
ist. Man testet einfach, ob der aktuelle Wert 4,2 oder 1 ist?
Das mit den Sprüngen ist so ne Sache.
Zu dem Carry Flag: sowas hab ich auch schon gesucht, aber nicht
gefunden.
Mit den Conditionals musst aufpassen U.G. L., da alle GPU Kerne immer
den ganzen Code durchlaufen müssen. Ein einzelner GPU Kern kann nicht
einfach springen, sondern er durchläuft auch den Code, wenn eine
Bedingung nicht erfüllt ist, ignoriert aber die Befehle darin. Kostet
aber Leistung.
https://community.amd.com/thread/180106
Andreas R. schrieb:> Ich schmeiss mal zuerst ein Tutorial in den Raum für die> Lesewilligen...>> http://amd-dev.wpengine.netdna-cdn.com/wordpress/m...>> weil u.a. das> Problem besteht, dass alle GPU Kerne nur 1 Instructionpointer haben.
Das is' nat. schon mal übel - ich hab' mit GPU-Programmierung noch keine
Erfahrungen gemacht, drum war mir das nicht klar, es leuchtet aber
schnell ein, wenn man sich daran erinnert, dass man in Verbindung mit
GPUs eigentlich (fast) immer auch von SIMD liest.
> Ich hab mir überlegt, dass das Programm immer x Iterationen machen> müsste (sagen wir 100 oder auch 1000, je nachdem wie lange so ne> durchschnittliche Folge ist). Dann stoppen alle Kerne. Jetzt wird> abgefragt, welche Kerne fertig sind, und diese Kerne bekommen neue> Daten. Dann wird das Programm weiterlaufen gelassen.> Wobei die Schleife in dem Sinn gar nicht erkennen muss, ob sie fertig> ist. Man testet einfach, ob der aktuelle Wert 4,2 oder 1 ist?> Das mit den Sprüngen ist so ne Sache.
Auf eine Erkennung der Uberschreitung eines Upper-Limits wird man nicht
verzichten können, denn man will ja pathrecords finden - es muss also
wenigstens ein Upper-Flag gegebenenfalls gesetzt werden.
Auf eine Erkennung der Unterschreitung eines Lower-Limits wird man nicht
verzichten wollen, weil das die Zahl der notwendigen Iterationen
beträchtlich verringert - man wird also auch da gegebenenfalls ein
Lower-Flag setzen wollen.
Wenn man die Right-Shifts bündeln kann, werden dann vermutlich 50
Iterationen ausreichen. Die Haupt-CPU wird dann all die Startwerte
genauer berechnen müssen, bei denen das Upper-Flag gesetzt ist und
all die, bei denen das Lower-Flag nicht gesetzt ist.
> Mit den Conditionals musst aufpassen U.G. L., da alle GPU Kerne immer> den ganzen Code durchlaufen müssen.
Mit ein Grund, weshalb ich Entscheidungen/Sprünge schon mal so weit als
möglich tilgen wollte.
Ein Problem stellen vermutlich dann auch alle Folgen dar, bei denen
StiftRigth-Operation um mehr als sieben oder acht Stellen notwendig sind
- die kann man aber vermutlich einfach aussortieren (indem man z.B. das
Upper-Flag setzt) und von der Haupt-CPU berechnen lassen.
Bei meiner einfachen Implementierung betrachte ich das obere Limit als
erreicht, wenn eins der Bits von hgh.c[7] gesetzt ist - so wie ich Dich
verstanden habe, müssen die GPUs parallel laufen, eine einzelne GPU kann
nicht angehalten werden - und da hgh..low einen sehr dynamischen Wert
enthält, nützt es nichts, wenn ich in hgh.c[7] etwas "überschreibe" -
nach wenigen Iterationen und insbesondere zu dem Zeitpunkt, an dem alle
GPUs angehalten werden, könnte jedwede Information in hgh.c[7] verloren
gegangen sein?
Ein Lower-Flag könnte man sich zwar sparen, wenn man hgh..low in die
4-2-1-Schleife schickt, ein schnelles Abfragen der Ergebnisse
erleichtert das aber auch nicht?
Ich würde einfach jedem Kern eine Variable fürs obere Limit geben und
wenn der aktuelle Wert größer ist, den Wert überschreiben. Diesen Wert
zusammen mit dem aktuellen Wert vom Host nach jedem Durchgang auslesen.
Ich denke, die einfachste Möglichkeit ginge wohl so:
Die Host-cpu erzeugt mit clCreateBuffer 2 Arrays. Das 1. ist für den
aktuellen Wert der Folge, das 2. für das obere Limit. Die Host CPU
initialisiert jetzt beide Arrays mit den Startwerten der Folgen, da ja
der maximal Wert am Anfang der Startwert ist.
Also könnten die Arrays z.B. die Werte 3,5,7,9,... enthalten.
Jeder GPU Kern kennt seine ID, was der Index der Array Elemente ist.
GPU Kern 11 nimmt also den 11. Wert des 1. Array, errechnet das
Folge-Element und speichert es wieder in das 11. Element des 1. Array.
Ist es grösser wie das 11. Element des 2. Array, wird dieses ersetzt.
Stoppt der Durchgang kann die Host CPU durch die 2 Arrays gehen und
beide Werte checken. Ist Wert im 1. Array 1,2 oder 4 kann dieses Element
entfernt werden. Dabei wird auch gleich der Path Record entfernt und
gecheckt, ob wir ihn aufheben. Dann wird der jeweilige Wert in den 2
Arrays neu gesetzt, bevor neu gestartet wird.
Die Host CPU erzeugt dafür jeweils die neuen Startwerte, bis der
Wertebereich abgesucht ist.
@daybyter:
eine vereinfachung hierzu: man kann einfach folgen aussortieren, die die
bitlänge des vorgegebenen records erreichen. dann werden zwar 3-4 mal so
viele folgen ausgeworfen, aber die kann die cpu ja aussortieren. damit
vereinfacht sich die übergabe (ziel-bitlänge) und die prüfung ob der
record erreicht ist erheblich.
Es gilt eigentlich zunächst mal den Bereich zwischen #87 und #88 zu
verifizieren, gegebenenfalls darin neue Rekordpfade zu finden.
D.h., ein sinnvoller Startwert, wenn man mal "ernstlich" zu rechnen
anfängt, wird z.B. #87 - #87 % 3072 sein.
Für die nächsten Jahre und auch für die nächste Grafikkarten-Generation
werden Folgen "interessant" sein, wenn der Pfad einen Wert erreicht, bei
dem ein Bit im Bereich ## gesetzt ist (bei meiner Art, den BigInt zu
realisieren, wäre das hgh.c[7]). Wir können dann ein Flag
"upper-limit-reached" (vermutlich in einem Array) setzten, das zu Beginn
eines Zykluses gelöscht wurde. Wir brauchen also kein Array mit
Rekordwerten.
Bei derart großen Flogewerten dauert es viel zu lange, die Folge auf die
Loop 4-2-1 zu iterieren. Wir begnügen uns damit, wenn der Pfad einen
Wert erreicht, bei dem kein Bit im Bereich $$ aufwärts (oder besser noch
xxxxxx$$ & 0xFFFFFFFE) gesetzt ist (bei meiner Art, den BigInt zu
realisieren, wäre das hgh.i oder hgh.i & 0xFFFFFFFE ). Wir können dann
ein Flag "lower-limit-not-reached" (vermutlich in einem Array) löschen,
das zu Beginn eines Zykluses gesetzt wurde.
Die richtigen Kerne müssen dann alle Folgen überprüfen, bei denen
"upper-limit-reached" gesetzt wurde und alle Folgen, bei denen
"lower-limit-not-reached" immer noch gesetzt ist.
Wenn möglich, würde man die beiden Falgs so plazieren, dass sie sich mit
einem Zugriff abgefragen lassen (und auch zu Beginn eines Zykluses
gemeinsam initialsieren lassen).
Wir müssen auch nicht laufend ein Array mit Startwerten übergeben, denn
jede GPU kann sich den nächsten Startwert selber berechnen.
nächsterStartwert = alterStartwert + 3072
Falls die Zahl der GPUs für mehre 3072er-Sätze reicht würde sich der
nächste Startwert entsprechend zu
nächsterStartwert = alterStartwert + (sets * 3072)
berechnen. Und mit etwas Gehirnschmaltz lassen sich sicherlich auch dann
immer noch unbeschäftigte GPUs beschäftigen (andere Siebweiten als 3072
oder das unterschiedliche Reste-Sätze auf unterschiedliche
Grafikkarten/Maschinen verteilt werden.
Die GPU-Maschinerie hat also nur Initialisierungsdaten (Array mit
Startwert), keine Inputdaten und pro GPU nur zwei Flags Outputdaten.
yep das klingt sehr schlüssig.
das passt übrigens sowohl zu FPGA als auch GPU, denn auch auf dem FPGA
brauchen wir eigentlich ja gar keine komplette ALU, sondern etwas was /2
und (*3+1)/2 kann (was ggf. ohne zusätzliches register geht wenn man
x+x>>1+1 betrachtet) und den entsprechenden "hart codierten" tests auf
record und stopwert, die jeweils durch überschreiten oder unterschreiten
bestimmter 2-er potenzen also entsprechender max und der min gesetzten
Bits hinausläuft :) ggf. bekommt man auf die art auch deutlich mehr
solcher "Collatz_Units" auf den FPGA :)
ich bin dabei, das aktuell auch schonmal in meine x86-asm version
aufzunehmen :) aber das ist ein anderes thema :)