Hallo, ich würde gerne Zufallszahlen erzeugen, die einer gewissen Verteilung folgen. Den Wikipedia Artikel zur Inversionsmethode habe ich gelesen. Das wäre ja auch eigentlich alles ganz simpel, wenn die Verteilung einen monotonen Verlauf hätte. Das Ganze sieht aber so aus wie dies hier: http://www.dieter-heidorn.de/Physik/VS/StrukturMaterie/K11_Kerne/sv250274.gif Man kann also nicht so einfach die Zufallszahl in eine Umkehrfunktion stecken, weil diese Funktion nicht eindeutig ist. Gibt es für so etwas einen einfachen Trick?
Steffen schrieb: > ich würde gerne Zufallszahlen erzeugen, die einer gewissen Verteilung > folgen Wenn sie auf einer bestimmten Kurve liegen sollen, sind es natürlich keine Zufallszahlen. Georg
Den Wikipedia Artikel zuende lesen. Dort wird am Ende auf die Probleme hingewiesen und auf https://de.wikipedia.org/wiki/Verwerfungsmethode verwiesen.
Steffen schrieb: > Das wäre ja auch eigentlich alles ganz simpel, wenn die Verteilung einen > monotonen Verlauf hätte. Das Ganze sieht aber so aus wie dies hier: > > http://www.dieter-heidorn.de/Physik/VS/StrukturMaterie/K11_Kerne/sv250274.gif > > Man kann also nicht so einfach die Zufallszahl in eine Umkehrfunktion > stecken, weil diese Funktion nicht eindeutig ist. > > Gibt es für so etwas einen einfachen Trick? Du hast das falsch verstanden -- das geht immer. Invertieren musst du die kumulative Wahrscheinlichkeitsverteilungsfunktion, nicht die Wahrscheinlichkeitsdichtefunktion (die in deinem Diagramm gezeieichnet ist). Die kumulative Verteilungsfunktion ist das Integral über die Wahrscheinlichkeitsdichte und die ist immer monoton -- sogar streng, wenn deine Wahrscheinlichkeitsdichte keine Nullstellen hat.
Ja gibt einen einfachen Trick. Du befüllst einen Zahlenpool (fettes Array) so wie du es willst und ziehst dann daraus mit einem normalen Zufallszahlengeneratoren die Zahlen. Also als Beispiel musst du deine Funktion als Wertetabelle sampeln. Z. B.: Häufigkeit 0 8 4 3 4 9 2 5 X-Achse ... 0 1 2 3 4 5 6 7 ... Im Beispiel soll also die 1 doppelt so wahrscheinlich sein wie die 2. Jetzt füllt man den Zahlenpool und schreibt da jede Zahl so oft rein wie ihre Häufigkeit: Pool: 1 1 1 1 1 1 1 1 2 2 2 2 3 3 3 4 4 4 4 5 5 5 5 5 5 5 5 5 6 6 7 7 7 7 7 Und jetzt kann man mit einem normalen Zufallszahlengeneratoren aus dem Array Zahlen ziehen. Man verwendet also den normalen Zufallszahlengeneratoren um den Index zu erzeugen den man zieht. Je feiner man seine Wertetabelle am Anfang baut und je mehr Zahlen am Ende im Array landen desto feiner kann man dann die Wahrscheinlichsverteilung nachbilden. Viel Spaß!
Gustl B. schrieb: > Du befüllst einen Zahlenpool (fettes Array) so wie du es willst und > ziehst dann daraus mit einem normalen Zufallszahlengeneratoren die > Zahlen. Das Problem ist, dass man das Rejection Sampling genau dann nicht machen will, wenn man Verteilungsfunktionen mit großer Dynamik hat -- also die Verteilung über weite Bereiche einen sehr kleinen Wert hat. Dann funktioniert auch diese Methode nicht mehr -- wenn ich zum Beispiel reelle Zahlen größer 1 haben will, die gemäß 1/x^2 verteilt sind, was schreibe ich dann in mein Array rein um die großen Werte abzudecken? 10^5 oder 10^5+0.1? So oder so werde ich für sinnvolle Array-Größen von den großen Zahlen immer nur dieselben drei kriegen ... Das ist gerade die Stärke vom inverse transform sampling, da geht das trotzdem noch mit sinnvollem Ressourcenaufwand.
Ich kenne mich da nicht aus, fand das aber eine nette Idee die für vieles doch funktioniert. Klar hat die ihre Grenzen. "inverse transform sampling" kenne ich garnicht.
Angehängte Dateien:
-

sinus_verteilung.png
43 KB
{kind=link}
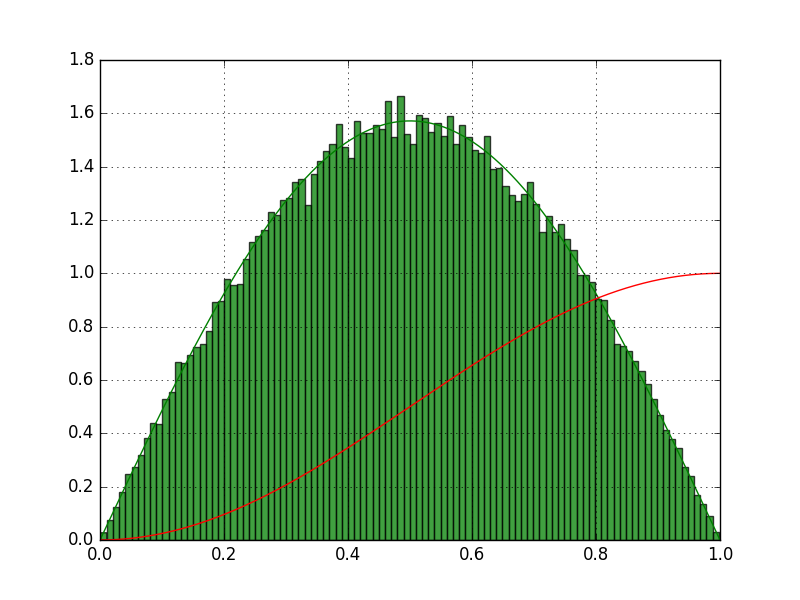
Hallo, zunächst vielen Dank an alle für die super Unterstützung! Dank eurer Hilfe habe ich meine Verteilung nun. Sicherlich nicht die performanteste Lösung, aber ich verstehe sie zumindest ;). Der entscheidende Hinweis war die Verteilungsdichte zunächst zu integrieren. Danach konnte man die Inverse dann ja auch eindeutig zuordnen. Hier der Python Code, der die angehängte Grafik mit der Sinusverteilung erzeugt. Bin noch recht neu in Python und da gibt es sicher allerhand zu optimieren. Gerade was das Integral und das finden der Inversen angeht..
1 | import numpy as np |
2 | import matplotlib.pyplot as plt |
3 | |
4 | |
5 | points = 2000 |
6 | t = np.linspace(0, 1, points) |
7 | |
8 | #Wahrscheinlichkeitsdichtefunktion |
9 | sinus = np.sin(np.pi*t) |
10 | |
11 | #Dichtefunktion auf Fläche=1 normieren |
12 | sinus = sinus / sum(sinus) |
13 | |
14 | #gleichverteile Zufallszahlen erzeugen |
15 | x_values = np.random.rand(100000) |
16 | |
17 | |
18 | #Dichtefunktion integrieren |
19 | i=0 |
20 | integral = [] |
21 | s_alt=0 |
22 | for s in sinus: |
23 | integral.append(s+s_alt) |
24 | s_alt += s |
25 | i +=1 |
26 | |
27 | |
28 | #Zufallszahlen mit Hilfe des inversen Integrals verteilen |
29 | histo = [] |
30 | for x in x_values: |
31 | i=0 |
32 | while integral[i] <= x: |
33 | i += 1 |
34 | histo.append(i/points) |
35 | |
36 | |
37 | #alles plotten |
38 | plt.hist(histo, 100, normed=1, facecolor='green', alpha=0.75) |
39 | plt.plot(t, sinus*points) |
40 | plt.plot(t, integral) |
41 | plt.grid() |
42 | |
43 | plt.show() |
Steffen schrieb: > Bin noch recht neu in Python und da gibt es sicher allerhand zu > optimieren. Gerade was das Integral und das finden der Inversen angeht.. Hihi ja ;) > sinus = sinus / sum(sinus) sum -> np.sum, ist viel schneller > #Dichtefunktion integrieren > i=0 > integral = [] > s_alt=0 > for s in sinus: > integral.append(s+s_alt) > s_alt += s > i +=1 integral = np.cumsum(sinus) > #Zufallszahlen mit Hilfe des inversen Integrals verteilen > histo = [] > for x in x_values: > i=0 > while integral[i] <= x: > i += 1 > histo.append(i/points) histo = np.interp(x_values, integral, t) Damit ist auch die Ausführungszeit quasi 0 statt ewig lang.
Sven B. schrieb: > Damit ist auch die Ausführungszeit quasi 0 statt ewig lang. Vielen Dank! Das ist tatsächlich unvergleichbar viel schneller :)
Bin mal so frech und verlinke den Blogpost, den ich vor einer Weile über genau sowas geschrieben habe: http://blog.svenbrauch.de/2016/04/13/processing-scientific-data-in-python-and-numpy-but-doing-it-fast/
Diesen Digitaler Rauschgenerator im FPGA kann man zu einem dedizierten Generator umbauen. Die auszugebenden Werte kommen in ein Array zusammen mit der echten Zufallszahl und dann wird sortiert zugegriffen.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.