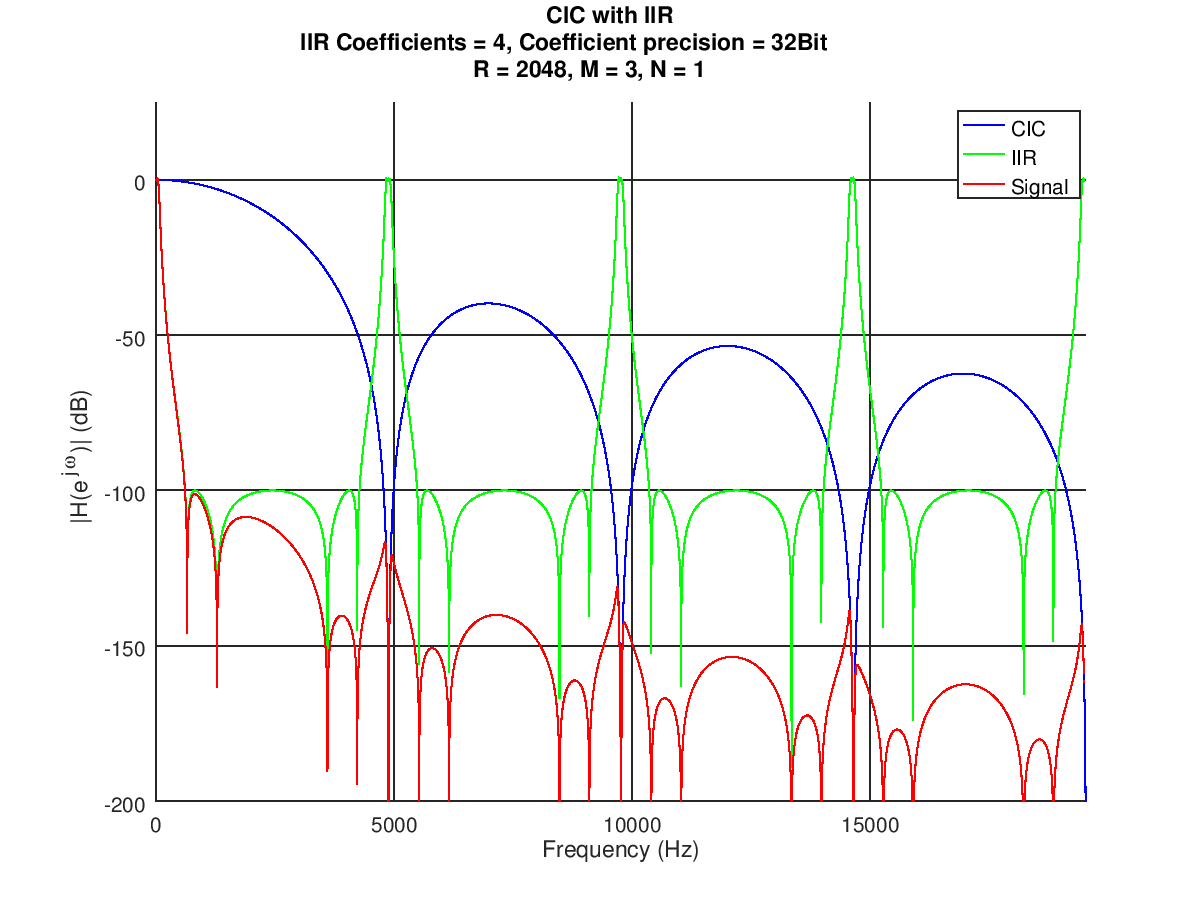
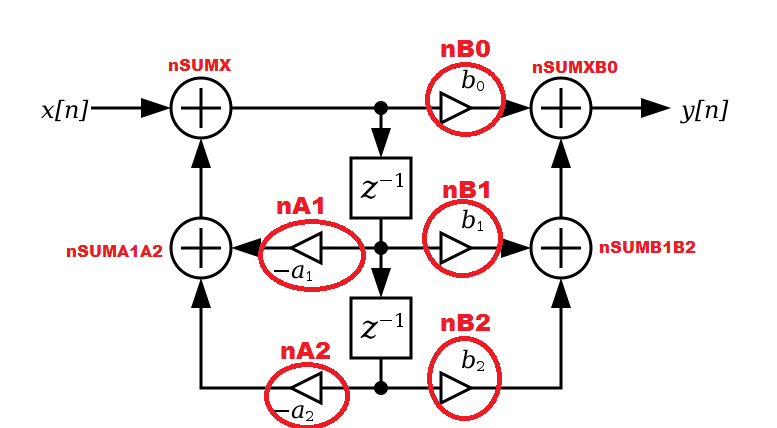
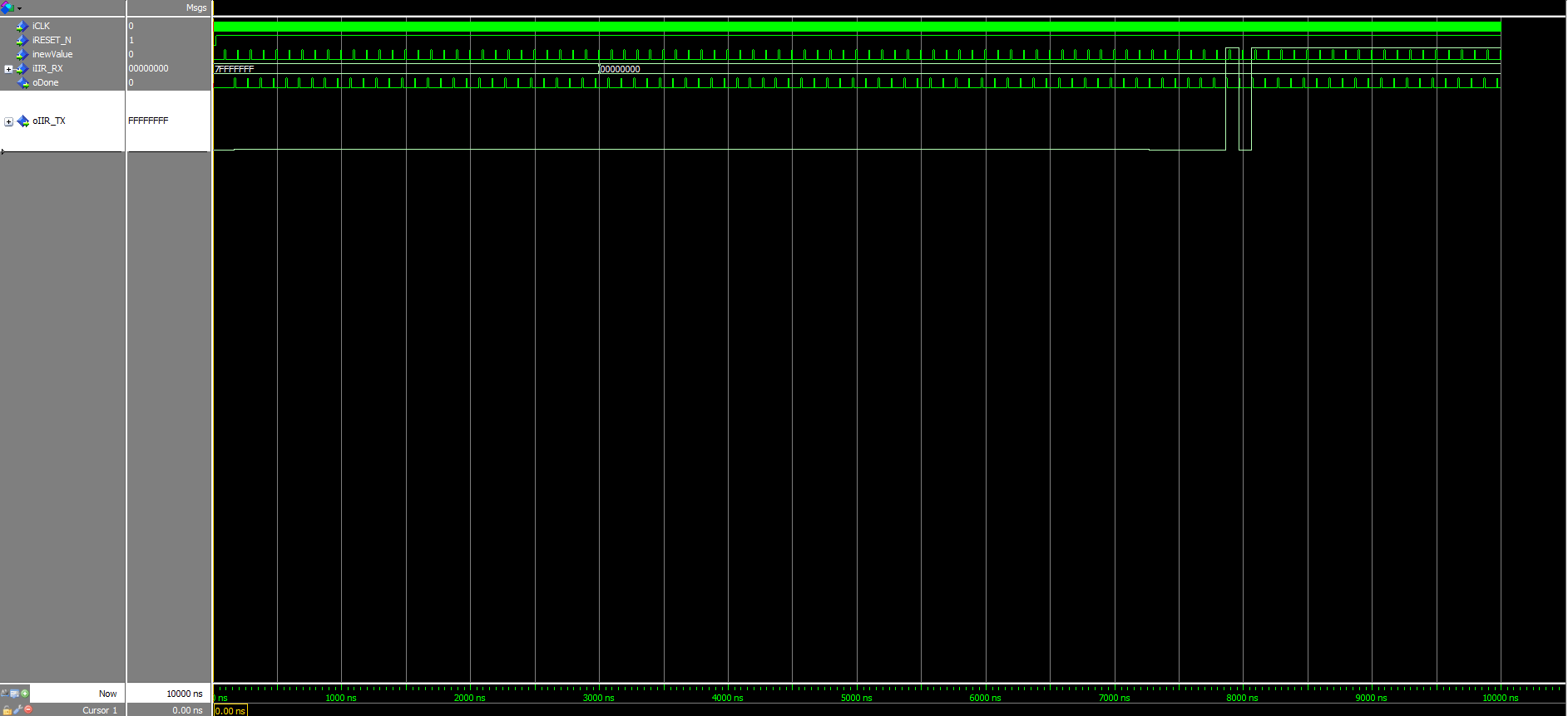
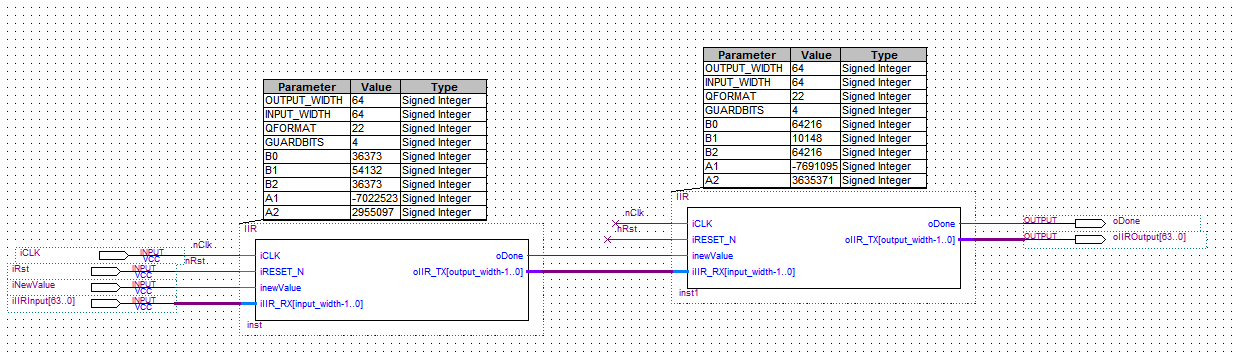
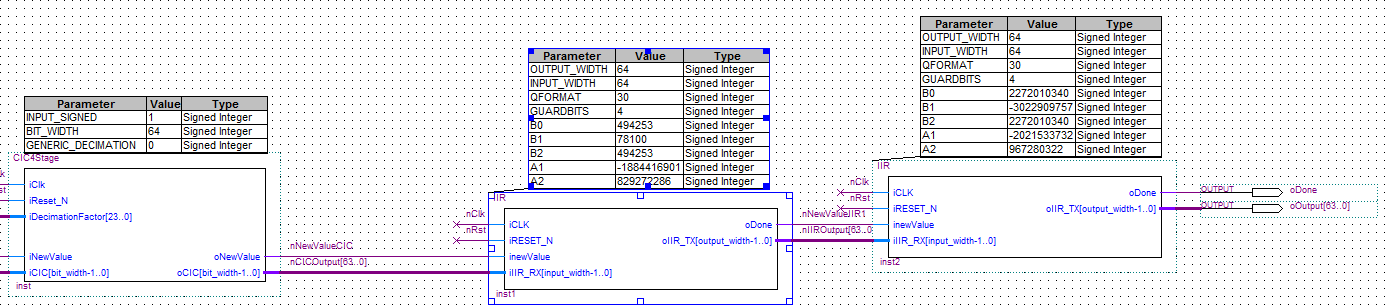
Hi Leutz! Nachdem ich erfolgreich ein FIR Filter in den FPGA gebracht habe, wollte ich nun schauen, ob ich mit einem IIR Filter Platz spare. Dazu habe ich mir ein IIR Filter mit Chebyshev 2 Eigenschaften in Matlab erstellt, Zähler/Nennerpolynom mithilfe der tf2sos-Funktion in ein SOS Filter überführt, der den Gain direkt zu den Koeffizienten multipliziert. Zur Implementierung auf dem FPGA in einem getakteten Prozess habe ich mir nun überlegt, zuerst die Signale mit den Koeffizienten zu multiplizieren (nA1,nA2,nB1,nB2), diese dann zu summieren (nSUMA1A2,nSUMB1B2), die Summe mit dem Eingangssignal zu bilden (nSUMX), die beiden Speicherregister zu aktualisieren und das Produkt aus Eingangssumme und Koeffizient B0 zu berechnen sowie letztlich das Ausgangssignal aus der Summe von nB0 und nSUMB1B2 zu erhalten (siehe Bild). Da ich Samples mit höchstens 1MHz bekomme und mein FPGA mit 100MHz läuft, habe ich also genügend Zeit alles in einem getakteten Prozess zu verarbeiten. Nur leider sieht die Simulation kein bisschen nach einem IIR Filter aus, gebe ich einen Sprung ins System, erhalte ich nicht das für ein IIR Filter typische(?) Einschwingen. Wahrscheinlich ist schon mein Ansatz falsch gewählt? Momentan nutze ich zwei Koeffizienten, später soll das Design es eigentlich ermöglichen auch ein Filter 4. oder 6. Ordnung durch Kaskadierung zu erreichen (SOS Filter halt).
Angehängte Dateien:
-

CIC_IIR.png
21 KB -

Biquad_filter_DF-II.png
25 KB -

Simulation.png
19 KB -

CIC_IIR.png
20 KB
Zeig mal deinen Code zusammen mit den Koeffizienten. Bei IIR Filtern ist es wichtig die "internen Werte" passend zu skalieren, damit alles klappt.
Stehen in der angehängten IIR.vhd inklusive der Umrechnung in 32Bit signed Werte als Kommentar.
1 | B0 : integer := 14419; -- = ((2^31)/1,995) * 0,000013396 |
2 | B1 : integer := -14105; -- = ((2^31)/1,995) * -0,000013103 |
3 | B2 : integer := 14419; -- = ((2^31)/1,995) * 0,000013396 |
4 | A1 : integer := -2147268361; -- = ((2^31)/1,995) * -1,9948 |
5 | A2 : integer := 1070803162 -- = ((2^31)/1,995) * 0,99477 |
Die Koeffizienten sind in der Matlab/Octave Datei erzeugbar und können aus der Variable SOS herausgelesen werden.
Hier mal ein Filter (in LUA) das gut für Debugging Zwecke geeignet ist, weil bei den ersten 20 Werten noch kein Fehler durch die Rundung passiert. Alle Werte kann man leicht durch Handrechnung nachvollziehen.
1 | scale=65536 |
2 | B0=1.0*scale |
3 | B1=1.0*scale |
4 | B2=-0.5*scale |
5 | A1=-1.0*scale |
6 | A2=0.5*scale |
7 | |
8 | x1=0 |
9 | x2=0 |
10 | y1=0 |
11 | y2=0 |
12 | |
13 | for k=0,20 do |
14 | if(k==2) then IIRinput=6400 else IIRinput=0 end |
15 | x0=IIRinput |
16 | |
17 | yNew=(B0*x0+B1*x1+B2*x2-A1*y1-A2*y2)/scale |
18 | x2=x1 ; x1=x0 ; y2=y1 ; y1=yNew |
19 | |
20 | print(k,IIRinput,yNew) |
21 | end
|
22 | |
23 | |
24 | k input output |
25 | 0 0 0 |
26 | 1 0 0 |
27 | 2 6400 6400 |
28 | 3 0 12800 |
29 | 4 0 6400 |
30 | 5 0 0 |
31 | 6 0 -3200 |
32 | 7 0 -3200 |
33 | 8 0 -1600 |
34 | 9 0 0 |
35 | 10 0 800 |
36 | 11 0 800 |
37 | 12 0 400 |
38 | 13 0 0 |
39 | 14 0 -200 |
40 | 15 0 -200 |
41 | 16 0 -100 |
42 | 17 0 0 |
43 | 18 0 50 |
44 | 19 0 50 |
45 | 20 0 25 |
Wozu benötigt, das das / 1,995? Um den Faktor 2 und einen Überlauf zu meiden?
Meister E. schrieb: > Wozu benötigt, das das / 1,995? Um den Faktor 2 und einen Überlauf zu > meiden? Um den Wertebereich auf 32 Bit (31 wegen signed) abzubilden und nicht mit Floats auf dem FPGA rechnen zu müssen. Ich normalisiere mehr oder weniger, heißt ich setze die 1,95 (nahe am höchsten Wert) als 2^31 fest und bekomme so einen Multiplikator, den ich auf alle Zahlen anwende.
Du skalierst die Koeffizienten durch Multiplikation mit (2^31)/1,995. Dann dividierst Du bei nA2(nA2'left downto INPUT_WIDTH) aber durch 2^32. Das passt nicht zueinander. Ich vermute aber, dass eventuell noch andere Fehler im Code sind. Du könntest den Code eventull mal nach C oder JAVA portieren und dort testen, das finde ich immer viel einfacher als HDL Code zu debuggen.
Das Filter ist instabil. So funzt das nich.
>> roots([1 -1.9948 0.99477 ])
ans =
1.0035
0.9913
Cheers
Detlef
Wenn du mit matlab schon deinen Filter erstellt hast, kannst du ihn auch problemlos mit dem HDL Coder inkl. Testbench als VHDL Datei speichern. Wenn es dir um die Übung an sich geht, dann immer weiter.
Mit pyFDA https://github.com/chipmuenk/pyFDA/blob/master/README.md kann man sich auch sehr viel schön einfach berechnen lassen. Vor allem auch die Koeffizienten in verschiedenen Wertebereichen.
Angehängte Dateien:
-

PN.png
16 KB
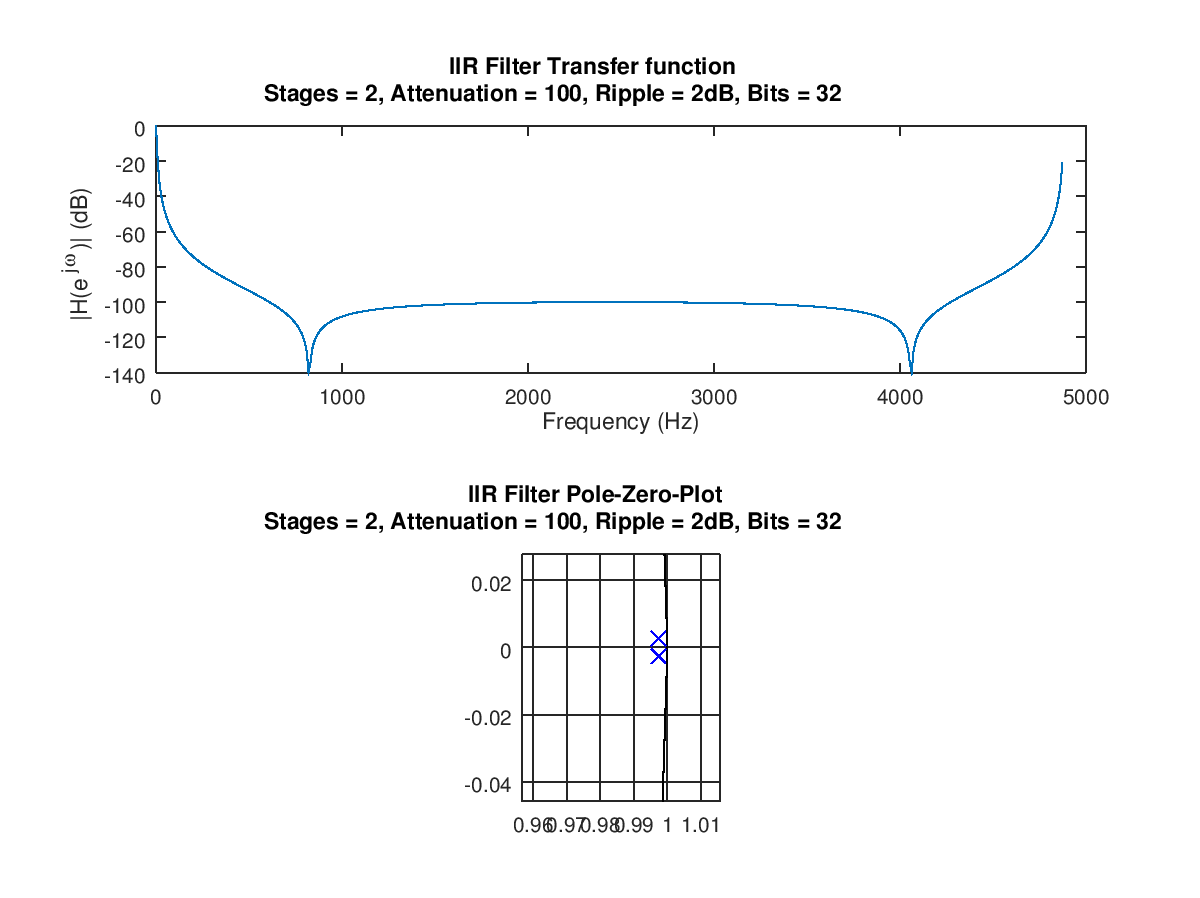
Gerald M. schrieb: > Wenn du mit matlab schon deinen Filter erstellt hast, kannst du ihn auch > problemlos mit dem HDL Coder inkl. Testbench als VHDL Datei speichern. Ist in Octave geschrieben, glaube nicht, dass es dafür ein Plugin für sowas gibt? Detlef _. schrieb: > Das Filter ist instabil. So funzt das nich. Laut PN-Plan liegen meine Pole innerhalb des Einheitskreises (siehe Anhang), soweit ich mich ans Studium erinnere, ist das Filter doch dann stabil oder nicht?
Ich erhalte das gleiche Ergebnis wie Detlef _a für Deine Koeffizienen, nämlich dass das Filter instabil ist. Aber vermutlich ist das nicht das einzige Problem.
Marcel D. schrieb: > Gerald M. schrieb: >> Wenn du mit matlab schon deinen Filter erstellt hast, kannst du ihn auch >> problemlos mit dem HDL Coder inkl. Testbench als VHDL Datei speichern. > Ist in Octave geschrieben, glaube nicht, dass es dafür ein Plugin für > sowas gibt? > > Detlef _. schrieb: >> Das Filter ist instabil. So funzt das nich. > > Laut PN-Plan liegen meine Pole innerhalb des Einheitskreises (siehe > Anhang), Nein soweit ich mich ans Studium erinnere, ist das Filter doch dann > stabil oder nicht? Ja. z^2 -1.9948*z + 0.99477 = 0 Davon die Nullstellen berechnen. Das geht ohne Programm mit der pq-Formel. math rulez! schönen Tach Cheers Detlef
Detlef _. schrieb: > z^2 -1.9948*z + 0.99477 = 0 > > Davon die Nullstellen berechnen. Das geht ohne Programm mit der > pq-Formel. > In meinem PN-Plan wird mit genaueren Werten gerechnet als es die SOS Struktur widerspiegelt, daher wohl die Instabilität. >>> disp (sos); >> sos = >> 1.3396e-005 -1.3103e-005 1.3396e-005 1.0000e+000 -1.9948e+000 9.9477e-001 >> a >> a = >> 1.00000 -1.99476 0.99477 Aber dennoch bekomme ich mein Filter nicht zum laufen, ist meine VHDL Implementierung prinzipbedingt falsch? Ich glaube, der Hund liegt im shiften/cutten der Bits begraben -_-
>>>>> In meinem PN-Plan wird mit genaueren Werten gerechnet als es die SOS Struktur widerspiegelt, daher wohl die Instabilität. Ja, durch die Normierung z.B. auf 32Bit wandern die Pole und das Ding kann instabil werden. Das ist das Hauptproblem bei 'scharfen' IIR deren Pole nahe am Einheitskreis liegen. Man braucht hohe Genauigkeit der Koeffizienten und damit zusammenhängend eine hohe Rechendynamik, 64Bit reicht da vllt. nicht. Du trennst die Probleme des Entwurfs von den Problemen der Implementierung: Erst in Octave oder Scilab oder Matlab das Filter zum Fliegen bringen mit allen Koeffizientenrundungen und Bitbreitenbeschränkungen, dann die Migration aufs FPGA. Schöne Aufgabe, viel Spass. Cheers Detlef
Mit den Filterkoeffizienten von meinem oben gezeigten IIR Filter ist das Debugging wegen der einfachen Zahlen einfacher. Manchmal hilft es auch, wenn man zuerst in C das ganze so laufen lässt, wie es später in VHDL laufen soll. In C ist das Debuggen viel einfacher.
Angehängte Dateien:
-

butter.PNG
8,1 KB -

example.PNG
9,8 KB


Detlef _. schrieb: > Du trennst die Probleme des Entwurfs von den Problemen der > Implementierung: Erst in Octave oder Scilab oder Matlab das Filter zum > Fliegen bringen mit allen Koeffizientenrundungen und > Bitbreitenbeschränkungen, dann die Migration aufs FPGA. > Da ich ja nicht an ein gewisses Filterverhalten gebunden bin, hab ich mir mal ein stabiles Butterworth-Filter mit 2 Koeffizienten gebastelt: SOS : 0.097631 0.195262 0.097631 1.000000 -0.942809 0.333333 roots([1.000000 -0.942809 0.333333]) => 0.47140 + 0.33333i => 0.47140 - 0.33333i Zudem habe ich mich doch mal an eine Implementierung mit asynchronem Verhalten getraut (nach transponierter DF2). Mit Filterkoeffizienten aus einem Buch sieht das ganze schon nach einem normalen Filterverhalten aus - zumindest übersteuert es nicht wie blöde. Meine errechneten Koeffizienten bringen das Teil aber anscheinend wieder durcheinander. Irgendwo ist noch der Wurm drin...
Ich finde FPGA-Code, der komplizierte Rechnungen macht, immer schwer zu debuggen. Ich mache dann oft erstmal eine "Simulation" des Codes in einer passenden Sprache. Das hab ich mit Deinem VHDL Code gemacht. Als LUA Code sieht das ganze dann so aus
1 | scale=65536 |
2 | |
3 | cB0= 1.0*scale |
4 | cB1=-2.0*scale |
5 | cB2= 3.0*scale |
6 | cA1=-1.0*scale |
7 | cA2= 0.5*scale |
8 | |
9 | nZ1=0 |
10 | nZ2=0 |
11 | |
12 | for k=0,10 do |
13 | if(k==1) then IIRinput=800 else IIRinput=0 end |
14 | nX=IIRinput |
15 | print("nX=",nX) |
16 | --mul |
17 | nA1 = nZ1 * cA1; |
18 | nA2 = nZ2 * cA2; |
19 | nB1 = nZ1 * cB1; |
20 | nB2 = nZ2 * cB2; |
21 | print("nA1=",nA1/scale," nA2=",nA2/scale) |
22 | --s1 |
23 | nSUMA1A2 = nA1/scale + nA2/scale; |
24 | nSUMB1B2 = nB1/scale + nB2/scale; |
25 | print("nSUMA1A2=",nSUMA1A2," nSUMB1B2=",nSUMB1B2 ) |
26 | --s2 |
27 | nSUMX = nX - nSUMA1A2; |
28 | print("nSUMX=",nSUMX) |
29 | --s3; |
30 | nZ1help = nSUMX; |
31 | nZ2help = nZ1; |
32 | nZ1=nZ1help |
33 | nZ2=nZ2help |
34 | nB0 = nSUMX * cB0; |
35 | --s4; |
36 | nSUMXB0 = nB0/scale + nSUMB1B2; |
37 | print("nSUMXB0 ==============================================================",nSUMXB0 ) ; |
38 | --convert |
39 | --nY <= std_logic_vector(nSUMXB0(nSUMXB0'left downto nSUMXB0'left-INPUT_WIDTH+1)); |
40 | --finished |
41 | --oIIR_TX <= nY(nY'left downto (nY'left - OUTPUT_WIDTH+1)); |
42 | end
|
Der Code ist ziemlich nahe am Original. Die Bitshifts hab ich durch Divisionen durch den Skalierungsfaktor ersetzt. Ich rechne ein einfaches Filter, das man besser von Hand nachrechnen kann. Damit habe ich Deinen Code analysiert und folgenden Fehler gefunden: Die Zeile nSUMA1A2 <= nA1(nA1'left downto INPUT_WIDTH) - nA2(nA2'left downto INPUT_WIDTH); muss ersetzt werden durch: nSUMA1A2 <= nA1(nA1'left downto INPUT_WIDTH) + nA2(nA2'left downto INPUT_WIDTH); Dann ist, glaube ich, die Skalierung des Ausgangssignals unnötig (vgl. LUA Code). Weiter musst Du aufpassen (hatte ich oben schon gesagt): Dein Code verwendet nach den Multiplikationen eine Division durch 2 ^ Input_Width, damit musst Du auch deine Koeffzienten skalieren (nicht mit 1.95....) Zur Simulation Deines Filters kannst Du ja den LUA Code nehmen.
Martin O. schrieb: > Weiter musst Du aufpassen (hatte ich oben schon gesagt): Dein > Code verwendet nach den Multiplikationen eine Division durch 2 ^ > Input_Width, damit musst Du auch deine Koeffzienten skalieren (nicht mit > 1.95....) > > Zur Simulation Deines Filters kannst Du ja den LUA Code nehmen. Wow, vielen Dank für die Mühe! Es hat den Anschein, als habe ich die Umrechnung der Koeffizienten noch nicht ganz verstanden und genau dort vermute ich gerade den Fehler, nachdem meine weiteren Versuche einen Filter zu basteln ähnlich scheitern wie mit diesem Code hier. Wäre super wenn mich da jemand erleuchten könnte, wie ich mein 48Bit Eingangssignal mit den Matlab-Koeffizienten verrechnen muss :)
Ja, das glaube ich auch. Mit den Koeffizienten ist definitiv was faul!
Ein paar Bemerkungen zur Skalierung etc. Zum Üben kann man das folgende Filter nehmen:
1 | scale=65536 |
2 | gain=0.075 |
3 | B0=1.0*gain*scale |
4 | B1=2.0*gain*scale |
5 | B2=1.0*gain*scale |
6 | A1=-1.4*scale |
7 | A2= 0.7*scale |
8 | |
9 | x1=0 |
10 | x2=0 |
11 | y1=0 |
12 | y2=0 |
13 | |
14 | for k=0,28 do |
15 | if(k>=2) then IIRinput=5000 else IIRinput=0 end |
16 | x0=IIRinput |
17 | |
18 | yNew=(B0*x0+B1*x1+B2*x2-A1*y1-A2*y2)/scale |
19 | x2=x1 ; x1=x0 ; y2=y1 ; y1=math.floor(yNew) |
20 | |
21 | print(k,IIRinput,y1) |
22 | end
|
23 | |
24 | k Input y1 |
25 | 00 0 |
26 | 1 0 0 |
27 | 2 5000 375 |
28 | 3 5000 1650 |
29 | 4 5000 3547 |
30 | 5 5000 5310 |
31 | 6 5000 6451 |
32 | 7 5000 6814 |
33 | 8 5000 6523 |
34 | 9 5000 5862 |
35 | 10 5000 5140 |
36 | 11 5000 4592 |
37 | 12 5000 4330 |
38 | 13 5000 4347 |
39 | 14 5000 4554 |
40 | 15 5000 4832 |
41 | 16 5000 5077 |
42 | 17 5000 5225 |
Es ist ein Tiefpassfilter mit näherungsweise Tschebyscheff Charakteristik. Gestartet wurde das Design mit den Filterkoeffizienten b0=1 ; b1=2 ; b2=-1 ; a1=-1.4 ; a2=0.7 Diese ergeben sich aus den Pol- und Nullstellen. Dieses Filter hat für Frequenz 0 allerdings eine Verstärkung von A=13.3333=1/0.075. Um ein Filter zu erhalten das bei f=0 die Verstärkung 1 hat, multipliziert man die b-Koeffizienten mit 0.075=1/A. Nun sollen die Koeffizienten skaliert werden. Es werden alle Koeffizienten mit S=65536=2^16 multipliziert. Hinter den Multilizierern wird dann durch S dividiert, indem die Resultate um 16 nach rechts schiebt. Soweit ist es noch simpel. Der kompliziertere Teil kommt danach: Jetzt muss man festlegen, mit welchen Wortbreiten man addiert und multipliziert. Die Bitbreiten muss man so bestimmen, dass kein Überlauf stattfinden kann. Die Bitbreite des Eingangssignals ist meist bekannt. Die Bitbreite des Ausgangssignals meist auch. Schwierig sind die Bitbreiten der internen Größen. Da IIR Filter resonantes Verhalten zeigen können, können diese internen Signale wesentlich größer werden, als die Eingangs- uind Ausgangssignale. Die "interne Verstärkung" kann man, glaube ich, anhand der Polstellen näherungsweise bestimmen. Ich nehme aber oft einfach 4 Bits mehr als unbedingt nötig, und mache dann Tests mit verschiedensten Eingangssignalen. Vielleicht kennt hier jemand ein besseres Vorgehen.
Angehängte Dateien:
-

64Bit_IIR.PNG
11 KB
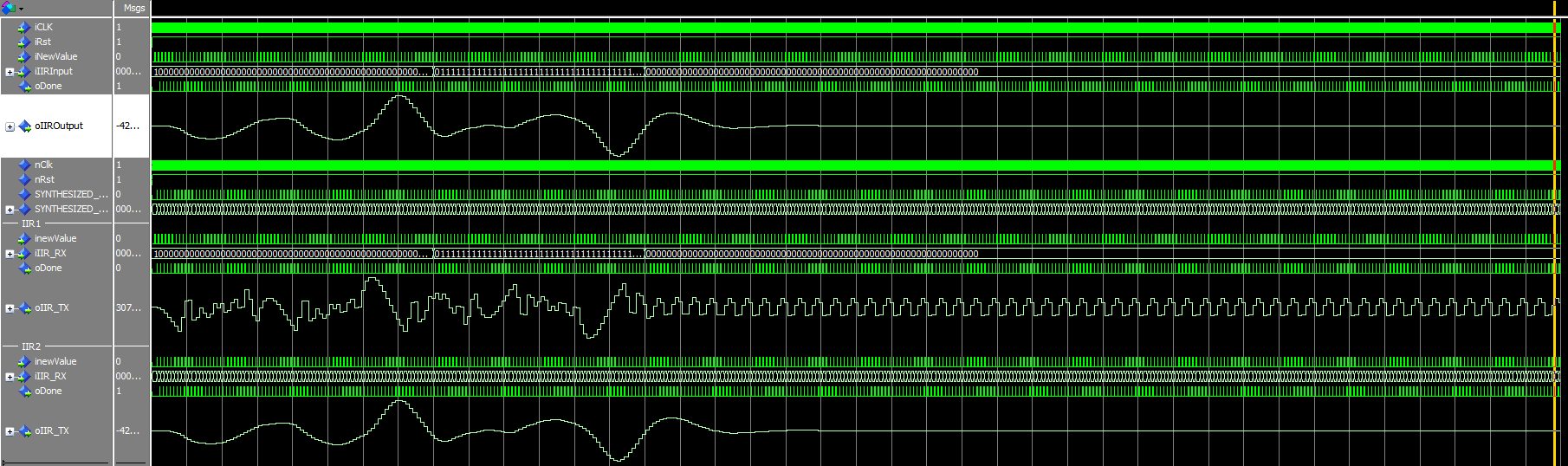
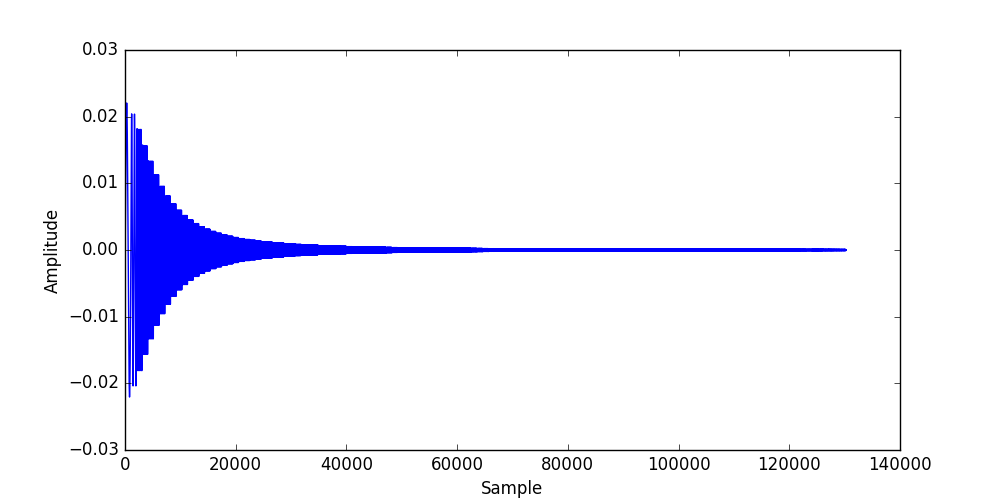
Danke für die ausführliche Erklärung :) Ich habe anscheinend einen laufenden IIR auf dem FPGA implementiert, werde ihn heute noch versuchen zu testen aber die Simulation schaut vernünftig aus. Nur klappt das mit der Verstärkung von 1 nicht genau, was aber wohl an Quantisierungseffekten liegen dürfte. Meine Ergebnisse und den Sourcecode/Testbench lasse ich hier mal für andere stehen, eventuell hilft es ja jemand anderem Ratlosen weiter.
Was für ein Filter soll das denn sein? Woher stammt das Design? Wie lauten die Filterkoeffizienten unskaliert?
Beitrag #5118654 wurde von einem Moderator gelöscht.
Angehängte Dateien:
-

FPGA_messung.png
290 KB
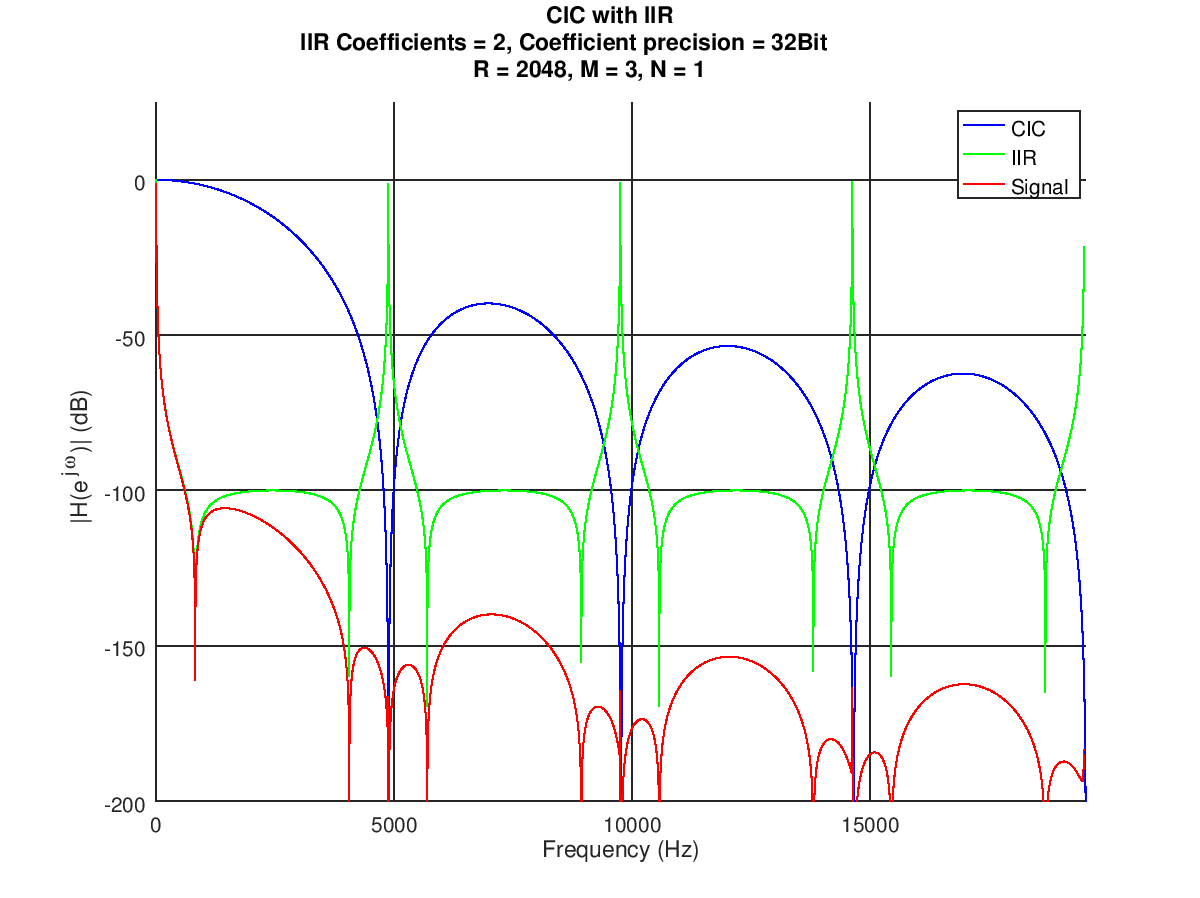
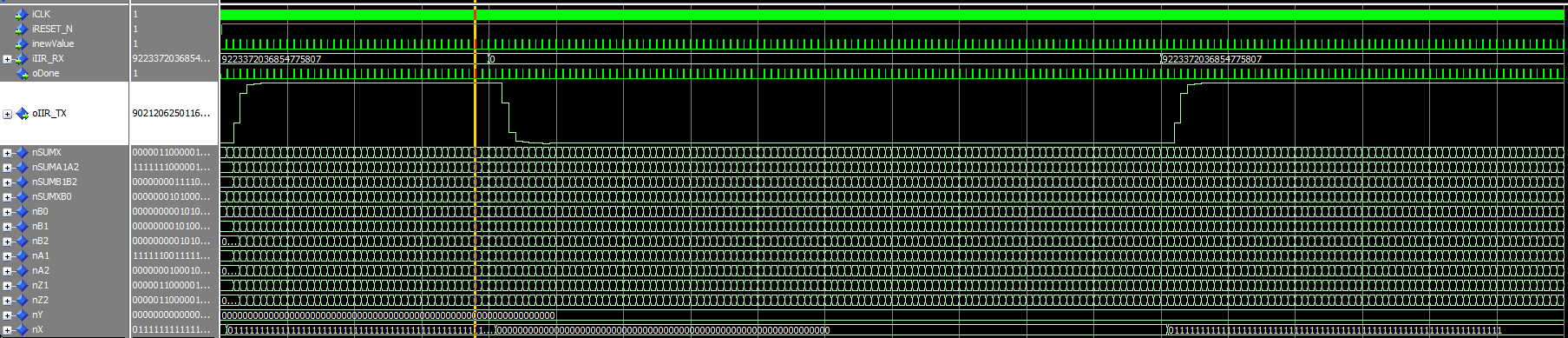
Ein einfacher 2-Stage Butterworth Filter zum testen des SOS-Designs. Ich habe ihn im FPGA hinter ein 4 Stage CIC Filter verbaut. Die Koeffizienten für das SOS-Design sind > b0 = 0.097631 > b1 = 0.195262 > b2 = 0.097631 > a0 = 1.000000 > a1 = -0.942809 > a2 = 0.333333 Die Koeffizienten habe ich mit (2^31/0,943)*Wert skaliert, der Gain müsste bei 1,00000085270047 liegen, wenn ich mich nicht verrechnet habe. Simulation und FPGA-Test zeigen in etwa das gleiche Bild, somit sollte es geklappt haben.
Ich glaube in Deiner aktuellen Version steckt wieder ein Fehler Statt nSUMX <= nX + nSUMA1A2(67 downto 0); muss es heissen nSUMX <= nX - nSUMA1A2(67 downto 0); damit die Berechnung mit dem Blockplan aus dem allerersten Posting übereinstimmt. Weiter kannst Du nicht die Koeffizienten mit (2^31/0,943) skalieren, und die Multiplikationsergebnisse durch 2^31 dividieren. Die beiden Skalenfaktoren müssen gleich sein, falls nicht, änderst Du die Filtercharakteristik. Du solltest mal ein Filter laufen lassen, bei dem Du jedes Bit genau nachvollziehen kannst. Ich habe ja Beispiele dazu gegeben. Alles andere ist ein Stochern im Nebel......
Beitrag #5118838 wurde von einem Moderator gelöscht.
Beitrag #5118871 wurde von einem Moderator gelöscht.
Hi, deine Eingangsdaten sind 64 Bit breit, scale macht 17Bit, gain verliert wieder 4Bit, 4 Additionen je 1 Bit, engineering margin 4Bit, macht 85 Bit nötige Wortbreite. So breit rechnest Du nicht?! Cheers Detlef ? Jetzt ist der Beitrag weg, auf den ich mich bezog. Schade.
Angehängte Dateien:
-

Lua_Simu.PNG
14 KB
Martin O. schrieb: > Statt > nSUMX <= nX + nSUMA1A2(67 downto 0); > muss es heissen > nSUMX <= nX - nSUMA1A2(67 downto 0); Ich glaube das + ist schon richtig, da der Wert von A1 negativ ist. Ich habe meine Implementierung mal auf 16Bit Koeffizienten minimiert und gebe Werte aus dem LUA-Skript ein. Dennoch verhalten sie sich nicht gleich, wenn ich das + durch ein - ersetze wird alles nur noch schlimmer. Hoffe die Kommentare geben Aufschluss über die Implementierung, ich multipliziere meine Koeffizienten mit 2^16 und right shifte um 2^16 nach der Multiplikation.
1 | scale=65535 |
2 | gB0=1 |
3 | gB1=2*gB0 |
4 | gB2=1 |
5 | gA1=-1.4 |
6 | gA2=0.7 |
7 | gain = 1/((gB0+gB1+gB2)/(1+gA1+gA2)) |
8 | B0=gB0*gain*scale |
9 | B1=gB1*gain*scale |
10 | B2=gB2*gain*scale |
11 | A1=gA1*scale |
12 | A2= gA2*scale |
13 | print(B0,B1,B2,A1,A2,gain) |
14 | x1=0 |
15 | x2=0 |
16 | y1=0 |
17 | y2=0 |
18 | -- Input 64Bit signed |
19 | for k=0,60 do |
20 | if(k<=20 or k>=40) then IIRinput=9223372036854775807 else IIRinput=0 end |
21 | x0=IIRinput |
22 | |
23 | yNew=(B0*x0+B1*x1+B2*x2-A1*y1-A2*y2)/scale |
24 | x2=x1 ; x1=x0 ; y2=y1 ; y1=math.floor(yNew) |
25 | |
26 | print(k,IIRinput,y1) |
27 | end |
Detlef _. schrieb: > ? Jetzt ist der Beitrag weg, auf den ich mich bezog. Schade. Hab was editiert, aber man kann hier ja leider keine Anhänge tauschen ^^ Detlef _. schrieb: > Hi, deine Eingangsdaten sind 64 Bit breit, scale macht 17Bit, gain > verliert wieder 4Bit, 4 Additionen je 1 Bit, engineering margin 4Bit, > macht 85 Bit nötige Wortbreite. > > So breit rechnest Du nicht?!
1 | signal nB0 : signed(83 downto 0) := (others => '0'); -- 64 + 4 Guard + 16 Bit |
2 | signal nB1 : signed(83 downto 0) := (others => '0'); -- 64 + 4 Guard + 16 Bit |
3 | signal nB2 : signed(83 downto 0) := (others => '0'); -- 64 + 4 Guard + 16 Bit |
4 | signal nA1 : signed(84 downto 0) := (others => '0'); -- 64 + 4 Guard + 17 Bit |
5 | signal nA2 : signed(83 downto 0) := (others => '0'); -- 64 + 4 Guard + 16 Bit |
Sind doch 85/84 Bit für die Multiplikationen. Die Addierer können ja kleiner sein, weil ich vorher eh shifte?
Ok, hatte ich nicht wahrgenommen. Dein oIIR_Tx sieht erwartungskonform
aus, 6.28/angle(roots([1 -1.4 0.7])) ~ 11, dh. dein Filter schwingt
gedämpft mit Periodendauer 11 Abtastwerte. Das passt doch, die
Vorzeichen sind richtig.
>>>Dennoch verhalten sie sich nicht gleich,
Was verhält sich nicht gleich. Sieht alles gut aus. Was geht jetzt
nicht?
Cheers
Detlef
Ich wette um 10 cent dass hier das Minuszeichen hinmus nSUMX <= nX - nSUMA1A2(67 downto 0); genauso wie hier vor den A Produkten jeweils Minuszeichen sind.... yNew=(B0*x0+B1*x1+B2*x2-A1*y1-A2*y2)/scale
Angehängte Dateien:
-

Signal-.PNG
11 KB

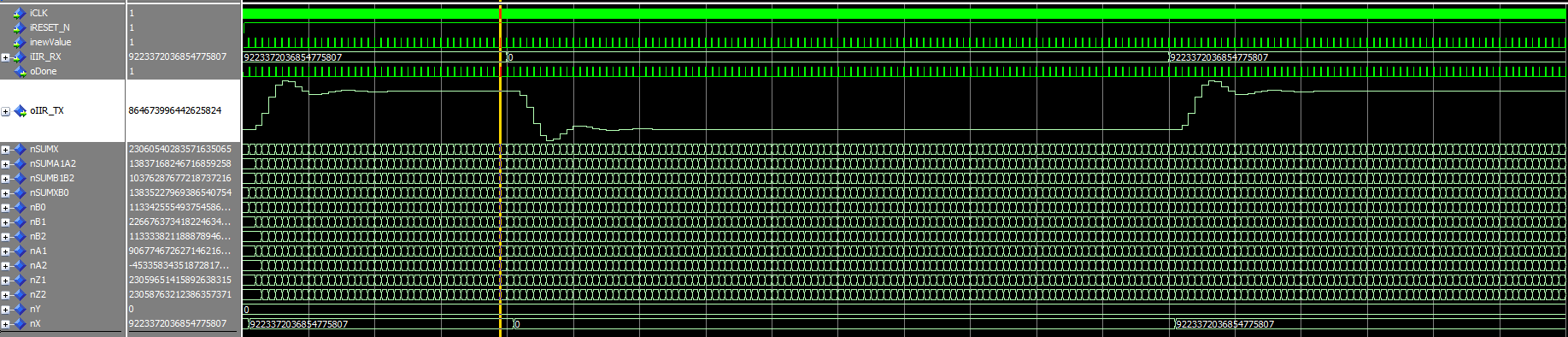
Detlef _. schrieb: > Ok, hatte ich nicht wahrgenommen. Dein oIIR_Tx sieht erwartungskonform > aus, 6.28/angle(roots([1 -1.4 0.7])) ~ 11, dh. dein Filter schwingt > gedämpft mit Periodendauer 11 Abtastwerte. Das passt doch, die > Vorzeichen sind richtig. Kannst du das genauer erklären? :D > Was verhält sich nicht gleich. Sieht alles gut aus. Was geht jetzt > nicht? Müsste ich durch meine Skalierung mit dem Verstärkungsfaktor bei f0 nicht das selbe Ausgangs- wie Eingangssignal haben? Zudem sind die Ausgangswerte nicht identisch mit dem Lua-Skript... Martin O. schrieb: > Ich wette um 10 cent dass hier das Minuszeichen hinmus > > nSUMX <= nX - nSUMA1A2(67 downto 0); > Dann pendelt sich der Wert jedenfalls nicht wieder bei 0 ein in der Simulation (Siehe Bild). Hab meinen Testbench ja mit beigelegt, könnt simulieren wenn ihr wollt :)
In deinem letzten post sieht das Ausgangssignal aber anders aus als in dem von 12:03, auf das ich mich bezogen hatte. Marcel D. schrieb: > Detlef _. schrieb: >> Ok, hatte ich nicht wahrgenommen. Dein oIIR_Tx sieht erwartungskonform >> aus, 6.28/angle(roots([1 -1.4 0.7])) ~ 11, dh. dein Filter schwingt >> gedämpft mit Periodendauer 11 Abtastwerte. Das passt doch, die >> Vorzeichen sind richtig. > Kannst du das genauer erklären? :D > Die Pole des Filters sind bei roots([1 -1.4 0.7]) ~0.7+-j0.46. Die Zahlen haben den Winkel +-0.57rad, 2*pi rad ist die Abtastfrequenz, das ist ~1/11 davon. >> Was verhält sich nicht gleich. Sieht alles gut aus. Was geht jetzt >> nicht? > > Müsste ich durch meine Skalierung mit dem Verstärkungsfaktor bei f0 > nicht das selbe Ausgangs- wie Eingangssignal haben? Du gehst rein mit einem Sprung, dann siehst du die Sprungantwort des Filters, und die sieht qualitativ richtig aus, auf die Amplitude habe ich nicht geschaut. Das Vorzeichen stimmt, die Wette halte ich, siehe z.B. slide 23: http://public.beuth-hochschule.de/~purat/lehre/dsv2/slides/Realisierung.pdf Cheers Detlef
Detlef _. schrieb: > In deinem letzten post sieht das Ausgangssignal aber anders aus als in > dem von 12:03, auf das ich mich bezogen hatte. > Das war auch der Versuch mit Ossis Minus :) > Du gehst rein mit einem Sprung, dann siehst du die Sprungantwort des > Filters, und die sieht qualitativ richtig aus, auf die Amplitude habe > ich nicht geschaut. Genau das macht mir halt noch Bauchschmerzen, von dem was ich hier gelernt habe, müsste die Amplitude meinem Eingangssprung entsprechen, wenn ich bei der Skalierung alles richtig gemacht habe. Die Summe aus B1+B2+B3 dividiert durch A1+A2+A3 ergibt für mich 13,33 und mein Faktor für B1 bis B3 also 0,0075 (siehe Lua skript). > Das Vorzeichen stimmt, die Wette halte ich, siehe z.B. slide 23: > http://public.beuth-hochschule.de/~purat/lehre/dsv2/slides/Realisierung.pdf > Nice, was zum schmöckern :)
Das Vorzeichen stimmt, die Wette halte ich, siehe z.B. slide 23: http://public.beuth-hochschule.de/~purat/lehre/dsv... Da haben die A-Koeffizienten genau ein Minuszeichen, genau wie ichs meine.
Was sagt denn die Simulation? Vielleicht hast Du es in VHDL nur nicht richtig hingeschrieben, eine Klammer vergessen, einen Datentypen falsch bezeichnet oder eine Konstante negiert.
Weltbester FPGA-Pongo schrieb im Beitrag #5119151: > Was sagt denn die Simulation? Vielleicht hast Du es in VHDL nur nicht > richtig hingeschrieben, eine Klammer vergessen, einen Datentypen falsch > bezeichnet oder eine Konstante negiert. Sollte soweit alles stimmen, der Code und die Simulation habe ich ja inklusive Screenshots gepostet :)
Martin O. schrieb: > Das Vorzeichen stimmt, die Wette halte ich, siehe z.B. slide 23: > http://public.beuth-hochschule.de/~purat/lehre/dsv... > > Da haben die A-Koeffizienten genau ein Minuszeichen, > genau wie ichs meine. >>>>>>>>yNew=(B0*x0+B1*x1+B2*x2-A1*y1-A2*y2)/scale hamse doch. Cheers Detlef
Ok, wobei man an der Schreibweise noch feilen könnte.
Angehängte Dateien:
-

Own_Coeff_Plus.PNG
14 KB -

Own_Coeff_Minus.PNG
13 KB -

Random_Coeff_Plus.PNG
14 KB -

Random_Coeff_Minus.PNG
14 KB

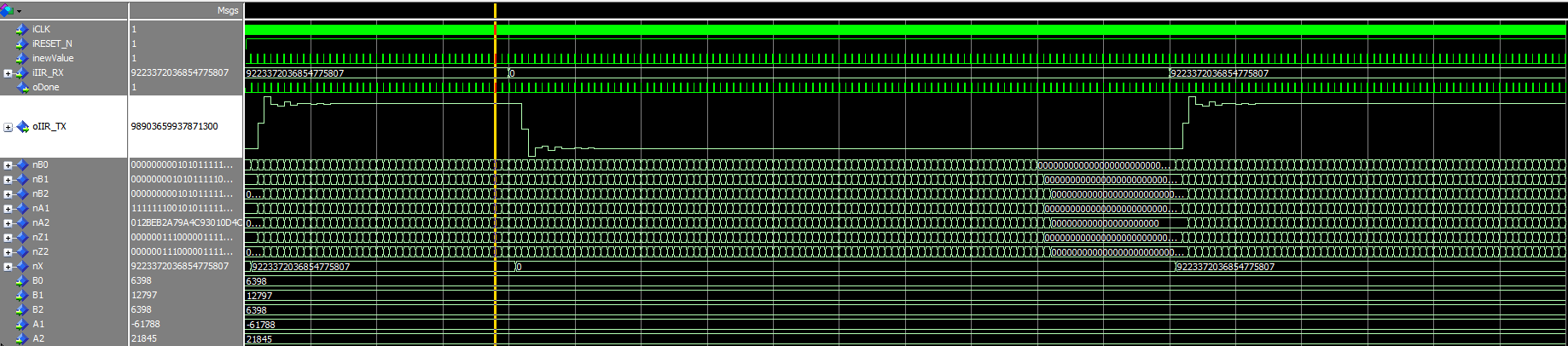
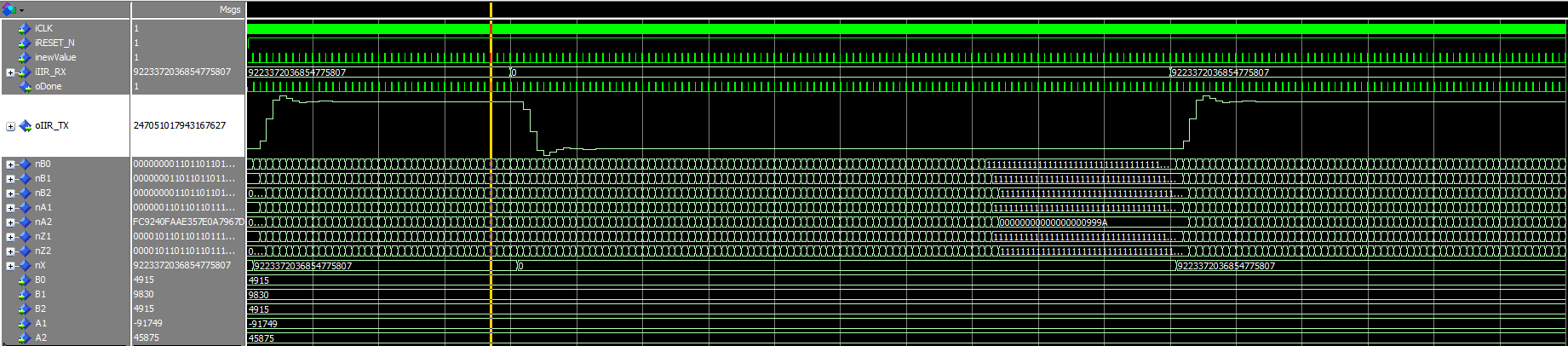
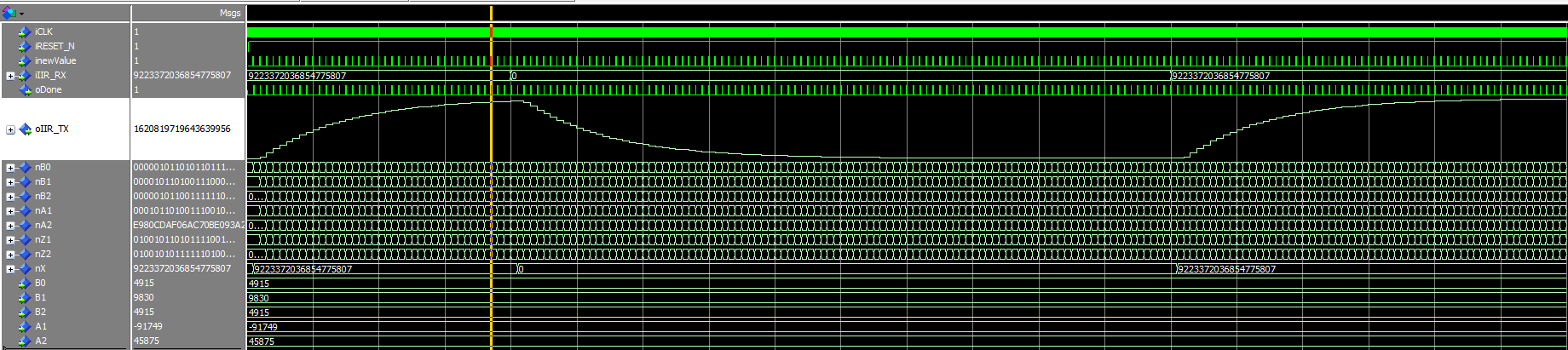
Weltbester FPGA-Pongo schrieb im Beitrag #5119187: > Wo ist dann das Problem? Das Problem ist, dass ich kein konsistentes Verhalten bei meiner Implementierung finden kann. Je nachdem, ob ich ein Minus
1 | nSUMA1A2 <= nA1(84 downto 16) - nA2(83 downto 16); |
oder Plus
1 | nSUMA1A2 <= nA1(84 downto 16) + nA2(83 downto 16); |
an dieser Stelle implementiere, bekomme ich ein unterschiedliches Verhalten von meinen Filterkoeffizienten > b0 = 0.097626 > b1 = 0.195251 > b2 = 0.097626 > a1 = -0.942810 > a2 = 0.333328 > Gain = 1.00003841199684 > siehe Own Coeff Minus/Plus und den Koeffizienten von Ossi > b0 = 1 > b1 = 2 > b2 = 1 > a1 = -1.4 > a2 = 0.7 > Gain = 0.0075 > siehe Random Coeff Minus/Plus Alle B-Koeffizienten sind dabei mit dem Gain multipliziert. Wenn ich mich richtig an meine Vorlesung erinnere, müssen alle rückgekoppelten Signale subtrahiert werden, also wäre doch eher folgende Implementierung richtig
1 | nSUMA1A2 <= nA1(84 downto 16) - nA2(83 downto 16); -- divide by 2^16 |
2 | nSUMB1B2 <= nB1(83 downto 16) + nB2(83 downto 16); -- divide by 2^16 |
3 | nSUMXB0 <= nB0(83 downto 16) + nSUMB1B2; -- divide by 2^16 |
4 | nSUMX <= nX - nSUMA1A2(67 downto 0); |
Dabei sehen die Kurven in "Own Coeff Minus" und "Random Coeff Plus" für mich qualitativ richtig aus, zumindest pendeln sie sich um einen Wert ein und finden auch wieder zur 0 zurück. Dabei muss aber eine Implementierung falsch sein und ich blicke langsam echt nicht mehr durch. Detlef _. schrieb: >> Da haben die A-Koeffizienten genau ein Minuszeichen, >> genau wie ichs meine. > >>>>>>>>>yNew=(B0*x0+B1*x1+B2*x2-A1*y1-A2*y2)/scale > > hamse doch. > Cheers > Detlef Mein A2 ist aber kein negativer Koeffizient ^^
Damit es mit den Vorzeichen keine Verwirrung gibt gehe ich üblicherweise in meinen Programmen wie folgt vor. Die Übertragungsfunktion des biquads ist
Und diese Bezeichnungen gelten, egal ob die einzelnen Koeffizienten positiv oder negativ sind. In meinen Programmen stehen dann die Variablen B0,B1,... für genau diese Koeffizienten und sie können im einzelnen wieder positiv und negativ sein. Mit diesen Variablen gilt dann die Rekursion yNew=(B0*x0+B1*x1+B2*x2-A1*y1-A2*y2) wobei vor den As jetzt Minuszeichen auftauchen. Das Filter programmiert man dann ohne dass man weiss, ob die einzelnen Koeffizienten positiv oder negativ sind.
1 | nSUMA1A2 <= nA1(84 downto 16) - nA2(83 downto 16); -- divide by 2^16 |
2 | nSUMB1B2 <= nB1(83 downto 16) + nB2(83 downto 16); -- divide by 2^16 |
3 | nSUMXB0 <= nB0(83 downto 16) + nSUMB1B2; -- divide by 2^16 |
4 | nSUMX <= nX - nSUMA1A2(67 downto 0); |
Dieser Block ist dann falsch, weil A1 und A2 mit unterschiedlichen Vorzeichen verrechnet werden. Meiner Meinung nach kannst Du schreiben:
1 | nSUMA1A2 <= nA1(84 downto 16) + nA2(83 downto 16); -- divide by 2^16 |
2 | nSUMB1B2 <= nB1(83 downto 16) + nB2(83 downto 16); -- divide by 2^16 |
3 | nSUMXB0 <= nB0(83 downto 16) + nSUMB1B2; -- divide by 2^16 |
4 | nSUMX <= nX - nSUMA1A2(67 downto 0); |
oder
1 | nSUMA1A2 <= -nA1(84 downto 16) - nA2(83 downto 16); -- divide by 2^16 |
2 | nSUMB1B2 <= nB1(83 downto 16) + nB2(83 downto 16); -- divide by 2^16 |
3 | nSUMXB0 <= nB0(83 downto 16) + nSUMB1B2; -- divide by 2^16 |
4 | nSUMX <= nX + nSUMA1A2(67 downto 0); |
Alle Klarheiten beseitigt?
Martin O. schrieb: > Womit simuliert Ihr VHDL Code ? Gibt es kostenlose VHDL Simulatoren? Der ModelSIM von Altera ist frei.
Ich habe jetzt nicht alles angesehen, aber dafür, dass Du mit bis zu 64 Bits rechnest, ist das Ergebnis von der ModelSIM-Grafik her "bescheiden". Sicher, dass das vom VHDL her passt? Z.B. sollte man darüber ... >nSUMA1A2 <= nA1(99 downto 32) + nA2(99 downto 32); ... nochmal nachdenken und auch generell über die Themen "Rundung" und "Fehlerfortplanzung". Simuliere Dir das mal in Real und dann in INT. Wenn es in Real läuft, ist es entweder ein Rundungs- oder Timingproblem, also eine Frage der Zuordnung von Ergebnissen.
Martin O. schrieb: > Womit simuliert Ihr VHDL Code ? Gibt es kostenlose VHDL Simulatoren? GHDL + gtkwave Ist zwar nur mit 'Fachwissen' zu benutzen, aber kostenlos & open source...
Angehängte Dateien:
-

IIR_Filter.PNG
13 KB

So, meine neueste Implementierung. Getaktet und funktionierend, inklusive 1er Gain und Überlaufschutz. Mein Problem war wohl, dass ich nach der Multiplikation direkt dividierte und somit ein so großer Teil der Auflösung flöten ging, dass augenscheinlich nur Murks heraus kam. Sobald ich anfing, die Koeffizienten nur um 2^7 zu dividieren, mit dem genaueren Signal zu rechnen und den Rest der 2^11 erst vor den Koeffizienten wieder zu dividieren, hat die Implementierung funktioniert. Ossi hatte auch recht was die Vorzeichen angeht, danke dafür nochmal! Bis auf die Zeile
1 | nX <= signed(iIIR_RX) & "0000000000000000000000"; |
sollte die Implementierung für jedes Q-Format und jede Bitweite funktionieren. Jedenfalls scheint meine Simulation soweit zu klappen :) Zur Simulation nutze ich die kostenlose ModelSIM Version. Etwas umständlich, aber das ist in der FPGA Welt eh fast alles. Kann Xilinx mit ISE/Vivado aber empfehlen, hat mir persönlich mehr Spaß gemacht als Altera :)
Wenn man die States Idle und Mul editiert:
1 | when idle => |
2 | oDone <= '0'; |
3 | if(iNewValue = '1') then |
4 | state <= mul; |
5 | nX(INPUT_WIDTH-1 downto 0) <= signed(iIIR_RX); |
6 | |
7 | end if; |
8 | when mul => -- Multiply signals for sums |
9 | nA1 <= nZ1(nZ1'left downto QFORMAT) * cA1; |
10 | nA2 <= nZ2(nZ2'left downto QFORMAT) * cA2; |
11 | nB1 <= nZ1(nZ1'left downto QFORMAT) * cB1; |
12 | nB2 <= nZ2(nZ2'left downto QFORMAT) * cB2; |
13 | nX <= shift_left(signed(nX),QFORMAT); |
14 | state <= s1; |
Sollte das gesamte Design leicht editierbar sein. Bin schon gespannt, wie sich das Filter im FPGA nun verhält und ob man es kaskadieren kann. Dann gehts ans optimieren ^^
Angehängte Dateien:
-

CIC_IIR.png
20 KB -

FPGA_messung.png
310 KB
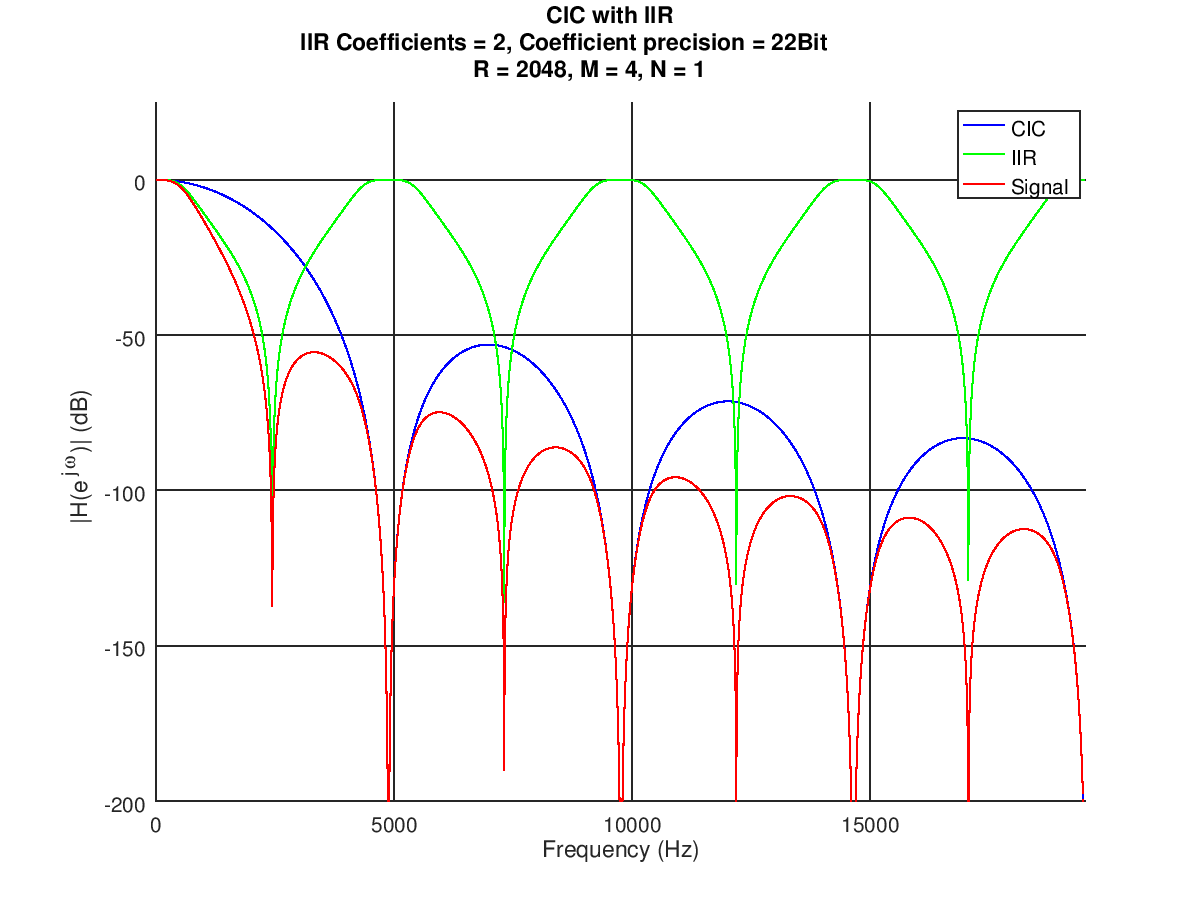
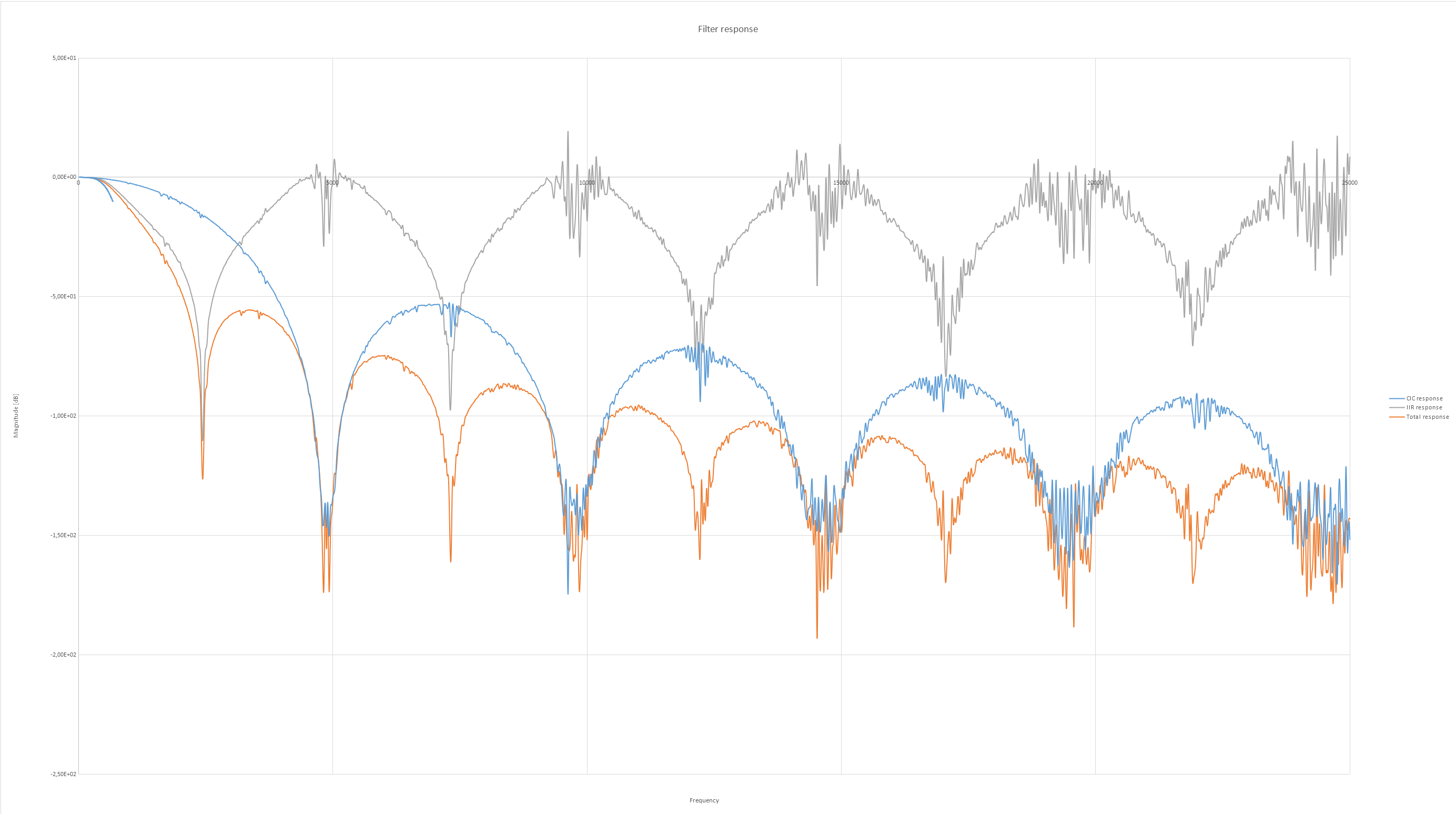
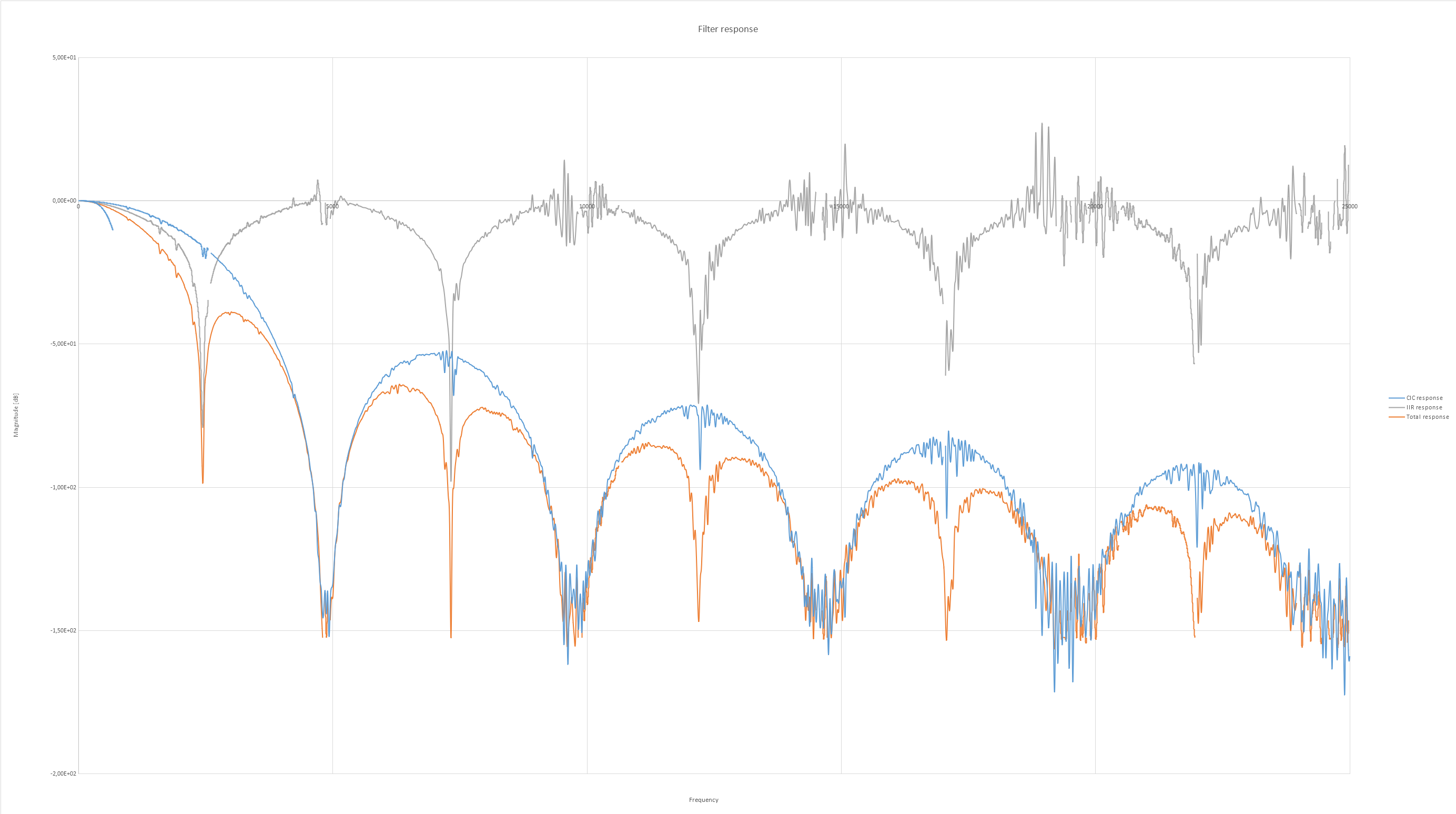
Nochmal ein Vergleich Matlab vs. FPGA Scheint nun endlich zu funktionieren, ein dickes Danke nochmal an alle! Habe mal ein paar Fehler aus der VHDL Datei behoben und alles etwas verschlankt, hoffe das einige Leute damit was anfangen können! :)
Die zerissenen 'Kuppen' des IIR und des CIC schmecken nach overflow. Du hast die Bitbreiten ja ganz prima parametrisiert, zieht die nen bißchen hoch und schaue, ob der Effekt weg ist. Ist zwar sowieso egal, weil das ja im Stopband liegt, sieht aber aus wie 'übertünchter Pfusch', hätte ich kein gutes Gefühl bei. Cheers Detlef
Detlef _. schrieb: > Die zerissenen 'Kuppen' des IIR und des CIC schmecken nach overflow. Eigentlich habe ich einen Overflow-Schutz implementiert:
1 | if((nSUMXB0(nSUMXB0'left downto nSUMXB0'left-5) = "000000") OR (nSUMXB0(nSUMXB0'left downto nSUMXB0'left-5) = "111111")) then |
2 | oIIR_TX <= std_logic_vector(nSUMXB0(nSUMXB0'left-4 downto 22)); |
3 | else
|
4 | if(nSUMXB0(nSUMXB0'left) = '1') then |
5 | oIIR_TX <= (others=>'0'); |
6 | oIIR_TX(oIIR_TX'left) <= '1'; |
7 | else
|
8 | oIIR_TX <= (others=>'1'); |
9 | oIIR_TX(oIIR_TX'left) <= '0'; |
10 | end if; |
11 | end if; |
Die "Kuppen" scheinen auch eher vom vorgeschalteten CIC Filter zu kommen, da dieser genau dieses Muster aufweist. Die Kurve vom IIR ist nur errechnet aus dem Ausgangssignal - Signal nach CIC.
Ich hätte einen Verbesserungsvorschlag: Momentan benutzt Du den Wert QFORMAT für zwei (verschiedene) Zwecke: a) Anzahl der Bits zur Koeffizientenspeicherung b) Anzahl der Bits zun Schieben nach der Multiplikation Diese beiden Werte müssen aber nicht unbedingt gleich sein. Könntest Du eine Version erstellen, bei der man für die beiden Zwecke getrennte Parameter (z.B. QSIZE und QSHIFT) hat. Leider reichen meine VHDL Kenntnisse nicht aus, das selbst zu machen. Mit der Modifikation kann man auch Koeffizienten B0,B1,B2 benutzen, die grösser als 1 sind.
Martin O. schrieb: > Könntest Du eine Version erstellen, bei der man für die beiden Zwecke > getrennte Parameter (z.B. QSIZE und QSHIFT) hat. Leider reichen > meine VHDL Kenntnisse nicht aus, das selbst zu machen. > > Mit der Modifikation kann man auch Koeffizienten B0,B1,B2 benutzen, > die grösser als 1 sind. Der Shift muss identisch zum Q-Format sein, weil das Inputsignal und die Multiplikationsdaten die selbe Zehnerpotenz haben müssen,sonst haut das mit dem dividieren bei
1 | nZ1 <= nSUMX(nSUMX'left downto QFORMAT); |
nicht hin. Was du möchtest ist das, was ich für nA1 gemacht habe. Soweit ich das sehe, musst du dafür "einfach" nur den Bitbereich für die anderen Multiplikationen und Konstanten erweitern.
1 | constant cA1 : signed(QFORMAT+1 downto 0) := to_signed(A1,QFORMAT+2); |
und
1 | signal nA1 : signed(INPUT_WIDTH-1+GUARDBITS+QFORMAT+2 downto 0); |
sollten dafür die Blaupause sein. Du müsstest also die ganze Deklaration wie folgt ändern:
1 | constant cA1 : signed(QFORMAT+1 downto 0) := to_signed(A1,QFORMAT+2);-- A1 |
2 | constant cA2 : signed(QFORMAT+1 downto 0) := to_signed(A2,QFORMAT+2);-- A2 |
3 | constant cB0 : signed(QFORMAT+1 downto 0) := to_signed(B0,QFORMAT+2);-- B1 |
4 | constant cB1 : signed(QFORMAT+1 downto 0) := to_signed(B1,QFORMAT+2);-- B1 |
5 | constant cB2 : signed(QFORMAT+1 downto 0) := to_signed(B2,QFORMAT+2);-- B1 |
6 | |
7 | signal nSUMX : signed(INPUT_WIDTH-1+GUARDBITS+QFORMAT downto 0); -- Sum of shifted Input and recursive sum |
8 | signal nSUMA1A2 : signed(INPUT_WIDTH-1+GUARDBITS+QFORMAT+1 downto 0); -- Sum of recursive multiplication |
9 | signal nSUMB1B2 : signed(INPUT_WIDTH-1+GUARDBITS+QFORMAT+1 downto 0); -- Sum of forward multiplication |
10 | signal nSUMXB0 : signed(INPUT_WIDTH-1+GUARDBITS+QFORMAT+1 downto 0); -- Sum before Output |
11 | signal nB0 : signed(INPUT_WIDTH-1+GUARDBITS+QFORMAT+2 downto 0); -- Multiplication of B0 |
12 | signal nB1 : signed(INPUT_WIDTH-1+GUARDBITS+QFORMAT+2 downto 0); -- Multiplication of B1 |
13 | signal nB2 : signed(INPUT_WIDTH-1+GUARDBITS+QFORMAT+2 downto 0); -- Multiplication of B2 |
14 | signal nA1 : signed(INPUT_WIDTH-1+GUARDBITS+QFORMAT+2 downto 0); -- Multiplication of A1 |
15 | signal nA2 : signed(INPUT_WIDTH-1+GUARDBITS+QFORMAT+2 downto 0); -- Multiplication of A2 |
und den Abgriff der Daten um ein "zusätzliches" Guardbit erweitern
1 | |
2 | if((nSUMXB0(nSUMXB0'left downto nSUMXB0'left-(GUARDBITS+2)) = "0000000") OR (nSUMXB0(nSUMXB0'left downto nSUMXB0'left-(GUARDBITS+2)) = "1111111")) then |
3 | oIIR_TX <= std_logic_vector(nSUMXB0(nSUMXB0'left-GUARDBITS-1 downto QFORMAT)); |
Meine Simulation funktioniert damit noch einwandfrei, ob das nun mit größeren Werten als 1 funktioniert, konnte ich leider noch nicht testen.
Angehängte Dateien:
-

BDF.PNG
12 KB -

4Stage-Simulation.PNG
15 KB
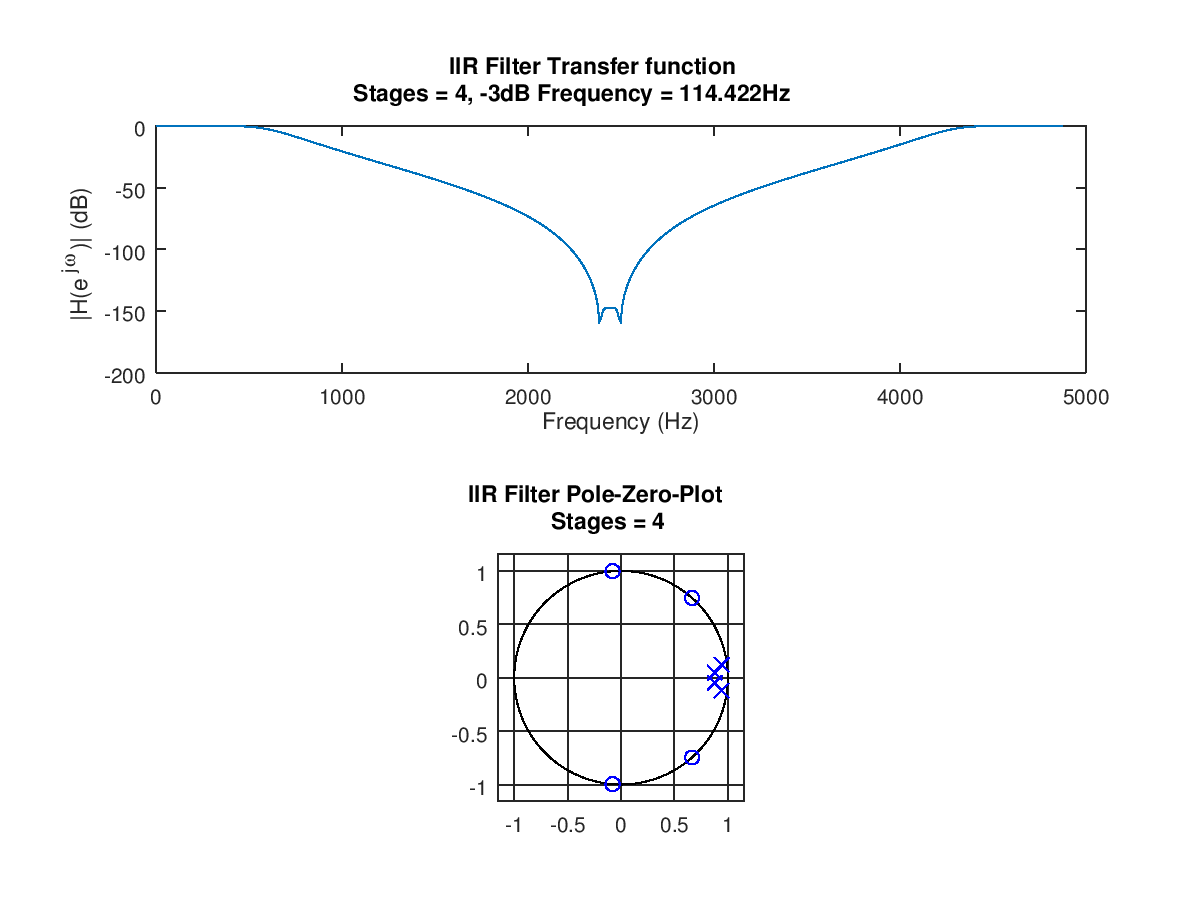
Nun habe ich versucht, beide Filter hintereinander zu kaskadieren, leider ohne Erfolg. Meine MATLAB-Simulation scheint dabei stabil, auch die einzelnen A's der beiden Filter sind laut PN-Plan stabil. Was habe ich übersehen? Meine Koeffizienten für den Filter 4. Ordnung laut tf2sos sind: SOS1: a1= -1,67E+00 a2 = 7,05E-01 b0 = 1,33E-04 b1 = 1,98E-04 b2 = 1,33E-04 SOS2: a1 = -1,83E+00 a2 = 8,67E-01 b0 = 1 b1 = 1,58E-01 b2 = 1 B-Gain = 0,029321379760263
Angehängte Dateien:
-

wave_in.png
15 KB -

wave_out.png
19 KB
Jo, die Koeffizienten sehen gut aus, funktioniert. Hab das mal in Python geschrieben und werde das nachher mal in VHDL übersetzen. Für die Simulation bietet sich ein Sweep an der also schön linear die Frequenz vom Sinus als Eingangssignal erhöht, kann man auch prima in VHDL schreiben und simulieren.
So, ich habe jetzt ne Version erstellt, bei der man die Parameter: a) QSIZE: Anzahl der Bits zur Koeffizientenspeicherung b) QSHIFT: Anzahl der Bits zun Schieben nach der Multiplikation getrennt einstellen kann. Dann habe ich die testbench so modifiziert, dass Testausgaben erzeugt werden, mit denen man die Werte innerhelb des Filters nachkontrollieren kann. Ausgabe sieht wie folgt aus:
1 | # nValue= 0 nOUT= 0 help 1..4 /65536= 0 0 0 0 at time 100 ns
|
2 | # nValue= 0 nOUT= 0 help 1..4 /65536= 0 0 0 0 at time 200 ns
|
3 | # nValue= 1000 nOUT= 0 help 1..4 /65536= 0 0 0 0 at time 300 ns
|
4 | # nValue= 0 nOUT= 1000 help 1..4 /65536= 0 0 0 0 at time 400 ns
|
5 | # nValue= 0 nOUT= 3000 help 1..4 /65536= -1000 0 2000 0 at time 500 ns
|
6 | # nValue= 0 nOUT= 5500 help 1..4 /65536= -1000 500 2000 3000 at time 600 ns
|
7 | # nValue= 0 nOUT= 4000 help 1..4 /65536= -500 500 1000 3000 at time 700 ns
|
"signed", für real gibt es da keine Notwendigkeit. "überlaufschutz" braucht es auch keinen, wenn die Dynamik stimmt da muss man eben passend zwischen skalieren
Wie macht man das dann mit den Koeffizienten? #SOS1: IIR_0_a1= -1.67E+00 IIR_0_a2 = 7.05E-01 IIR_0_b0 = 1.33E-04 IIR_0_b1 = 1.98E-04 IIR_0_b2 = 1.33E-04 #SOS2: IIR_1_a1 = -1.83E+00 IIR_1_a2 = 8.67E-01 IIR_1_b0 = 1.0 IIR_1_b1 = 1.58E-01 IIR_1_b2 = 1.0 B_Gain = 0.029321379760263 Also wenn ich das mit signed(15 downto 0) mache, kann ich das einfach so skalieren, dass -1.67E+00 dann -2**15 ist? Oder eben +2=2**15-1 und -2=-2**15. Oder muss ich bei Koefizienten <1 tatsächlich eine Division einbauen?
Das hängt jetzt ein wenig an den Gleichungen und dem Wert der Koeffizienten - ganz optimal, also schnell UND klein wird es wenn man sich für jeden Schritt die optimale Breite des Vektors rechnet, unter Berücksichtigung der Rundung. Ich verwende für Filter gerne auch statistische Rundung durch Rauschen, um Artefakte zu meiden. Um die Betrachtung des Rundens kommt man eh nicht herum, weil aufgrund der Rückkopplungen im IIR immer scheinbar wachsende Vektoren entstehen mit man Abschneiden muss. Ich frage mich nur immer noch, ob das bei dem CIC, der auch summiert oben korrekt gemacht ist.
An welchen Stellen darf man denn bei einem IIR Filter abscheiden? Also wie im Eingangspost oben in dem Bildchen. Nur am Ausgang? Auch vor den einzelnen Registern? Wie ist das wenn man zwei dieser Biquads verbindet zu einer Kette, darf man dann zwischen diesen Beiden auch abschneiden? Edit: Das müsste sogar egal sein weil bei so einer Kette keine Rückkopplung stattfindet. FIR Filter sind mir irgendwie lieber ... oder eben real Zahlen.
Angehängte Dateien:
-

4Stage_Butter.PNG
13 KB

Jürgen S. schrieb: > Ich frage mich nur immer noch, ob das bei dem CIC, > der auch summiert oben korrekt gemacht ist. Simulation und Test meiner Einheit im FPGA passen fast aufs Hz genau und der CIC sieht mir auch aus wie die normalen CIC Kurven. Denke, das sollte alles seine Richtigkeit haben. Ich hab mir mein SOS-Filter nochmal mit anderen Koeffizienten gebastelt, dessen Polstellen nicht so nahe am Einheitskreis liegen und mit einem Butterworth-Verhalten klappt die Kaskadierung.
In dem anderen Bild weiter oben sah das etwas grob aus. Bei mir sehen Filter meistens so aus: http://96khz.org/doc/vasynthesisvhdl (Bild ganz unten).
Angehängte Dateien:
-

IIR_Response.PNG
9,8 KB

Mal noch eine Frage, da ich momentan Probleme mit dem DC Gain habe: Bei einem Filter 4. Ordnung errechne ich den DC Gain für die SOS-Struktur ebenfalls mit dem Kehrwert der Division der Summe aller B-Koeffizienten durch die Summe aller A-Koeffizienten? Oder betrachte ich jeden Filter mit seinen Koeffizienten einzeln? SOS-Filter 1 >b0=b2 = 1,2159e-004 >b1 = -1,3970e-004 >a1 = -1,8807e+000 >a2 = 8,8481e-001 SOS-Filter 2 >b0=b2 = 1,0000e+000 >b1 = -1,8295e+000 >a1 = -1,9450e+000 >a2 = 9,4941e-001 Wenn ich die Filter einzeln betrachte und den Gain-Faktor auf die einzelnen Filter anwende, kommt mein Ausgangssignal dem Eingangssignal zumindest nahe, aber so richtig zufrieden bin ich mit dem Ergebnis noch nicht.
Gain(Hintereinanderschaltung)=Gain(Filter1) * Gain(Filter2) gilt auch für DC, also Filter einzeln betrachten und DC-Verstärkungen multiplizieren. Bei guter Skalierung und nicht zu kleinem Eingangssignal sollte sich der Gain=1 ziemlich genau ergeben. Dein Filter1 hat ziemlich kleine bk Koeffizienten. Eventuell verlierst Du da schon an Genauigkeit. Ich habe bei solchen Filtern oft den DC-Gain sozusagen gleichmässig auf alle Stufen verteilt. Das war gar nicht schlecht.
Ja, sehe ich so wie mein Vorredner. Die b des SOS1 zwei Zehnerpotenzen größer, die vom SOS2 2 Zehnerpotenzen kleiner. Ist aber nicht ungefährlich, weil SOS2 dann ein hundertmal größeres Eingangssignal sieht. Cheers Detlef
Beitrag #5134500 wurde von einem Moderator gelöscht.
Angehängte Dateien:
-

IIR_CIC_BDF.PNG
15 KB -

IIR_CIC_Response.PNG
9,9 KB -

IIR_CIC_simulation.png
14 KB

Dann bin ich wohl zu blöd zum rechnen ^^ Ich habe mir jetzt ein neues Filter designed, die Koeffizienten sind: SOS-Filter 1 >b0=b2 = 2,1754e-004 >b1 = 3,4375e-005 >a1 = -1,7550 >a2 = 7,7232e-001 > (b0+b1+b2)/(1+a1+a2) = 0,012811961189376 > Gain1 = 1/0,012811961189376 = 78,052062851174 SOS-Filter 2 >b0=b2 = 1,0000e+000 >b1 = -1,3305e+000 >a1 = -1,8827 >a2 = 9,0085e-001 > (b0+b1+b2)/(1+a1+a2) = 36,8870523415978 > Gain2 = 1/36,8870523415978 = 0,027109783420463 Wenn ich euch richtig verstanden habe, muss ich nun beide Gains multiplizieren > Gges = Gain1 * Gain2 = 2,1159745194157 Alle B-Koeffizienten müssen nun mit diesem Gain multipliziert werden? Das Filter ist laut PN-Plan stabil, ich habe die Bitbreite der Koeffizienten auf 30Bit erhöht. Leider bekomme ich bei meinem Sprung einen negativen Ausgangswert. Irgendwas kann da nicht stimmen, entweder ist meine Implementierung noch immer buggy (obwohl bei anderen Filtern die Filterkurve im FPGA stimmt) oder ich habe einen Denkfehler.
Nein, die a's spielen überhaupt keine Rolle, an denen kannst Du überhaupt nicht drehen. Es geht nur um die b's. Aus denen kannst Du einen beliebigen Koeffizienten rausziehen. Die b's von SOS1 sind grob 4 Zehnerpotenzen kleiner als die von SOS2. Das haut auf die Rechengenauigkeit und die Festigkeit gegen Overflows. Also den einen Koeffezientensatz der b's 2 Zehnerpotenzen kleiner, den anderen 2 Zehnerpotenzen grösser, hinten kommt dasgleiche raus. Cheers Detlef
Angehängte Dateien:
-

IIR_CIC_BDF.PNG
15 KB -

IIR_CIC_Response.PNG
10 KB -

IIR_8Guardbits.PNG
9,8 KB


Detlef _. schrieb: > Nein, die a's spielen überhaupt keine Rolle, an denen kannst Du > überhaupt nicht drehen. Es geht nur um die b's. An den a's habe ich auch nichts geändert ;) Habe nun die B-Koeffizienten um 2 Bit verschoben, das zerhaut mir aber mein ganzes Filter. Mal die Guard Bits höher schrauben? EDIT: Habe die Guardbits auf 8 hoch geschraubt, es verhält sich wieder wie ein Filter, aber mein Ausgangssignal ist noch immer 4x so hoch wie das Eingangssignal :-/
Allerhand schief: - Wie kommst Du denn auf den b von 2.1754e-004? Das ist ungleich 494253/(2^31) aus dem .png - Skaliert QFORMAT 30 auf 2^30 oder aus 2^31 ? Vermutlich letzteres, weil sonst die a's keinen Sinn machen. Dann passen die b's aber überhaupt nicht. - Die b's skalieren nur die Sprungantwort, die Form ändert sich nicht. Die simulierte Sprungantwort ist nicht richtig, zumindest nicht die, die Matlab richtig findet. Overflow ist nach wie vor mein Tipp. Die Bitbreite hochziehen: 64+31 ~ 100, zur Simulation mit intern 100Bit rechnen. Wenns denn geht kann man immer noch runterziehen. Der DC gain ist Dein kleinstes Problem, da kann man wenn alles fertig ist die b's skalieren. Das Ding klippt. Cheers Detlef clear fb1a=[2.1754e-004 3.4375e-005 2.1754e-004]; fa1a=[1 -1.7550 7.7232e-001]; fb2a=[1 -1.3305e+000 1 ]; fa2a=[1 -1.8827 9.0085e-001]; fb1=[494253/(2^31) 78100/(2^31) 494253/(2^31)]; fa1=[1 -1884416901/(2^30) 829272286/(2^30)]; fb2=[2272010340/(2^31) -3022909757/(2^31) 2272010340/(2^31)]; fa2=[1 -2021533732/(2^30) 967280322/(2^30)]; y=filter(fb1,fa1,ones(1,1000)); y=filter(fb2,fa2,y); plot(y) return
>>>>>>>>>>
EDIT: Habe die Guardbits auf 8 hoch geschraubt, es verhält sich wieder
wie ein Filter, aber mein Ausgangssignal ist noch immer 4x so hoch wie
das Eingangssignal :-/
Yo, weil Du die b's zweimal Faktor 2 falsch skalierst. Aber die
Sprungantwort sieht ganz richtig aus.
Cheers
Detlef
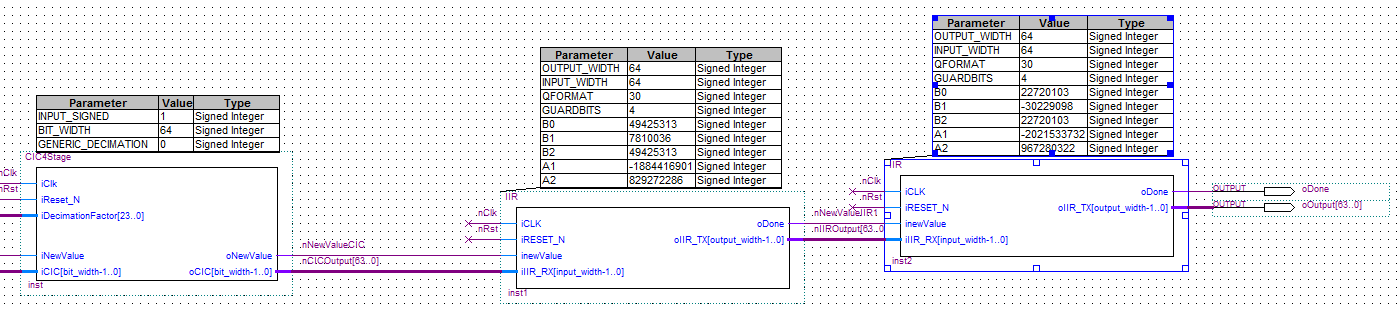
Detlef _. schrieb: > Allerhand schief: > > - Wie kommst Du denn auf den b von 2.1754e-004? Das ist ungleich > 494253/(2^31) aus dem .png (494253/((2^30)*Gges)) = 0,00021753994310336215479880413673356 (78100/((2^30)*Gges)) = 0,000034374843564677572599026415780766 (2272010340/((2^30)*Gges)) = 1 (-3022909757/((2^30)*Gges)) = 1,3305000000897886654119436743203 Oder habe ich das mit dem Gesamt-Gain falsch verstanden? > - Skaliert QFORMAT 30 auf 2^30 oder aus 2^31 ? Vermutlich letzteres, > weil sonst die a's keinen Sinn machen. Passt doch? => -1,755 * 2^30 = -1884416901,12 Ohne meine Gain-Korrektur lande ich ebenfalls bei 1 clear fb1a=[2.1754e-004 3.4375e-005 2.1754e-004]; fa1a=[1 -1.7550 7.7232e-001]; fb2a=[1 -1.3305e+000 1 ]; fa2a=[1 -1.8827 9.0085e-001]; fb1=[233582/(2^30) 36910/(2^30) 233582/(2^30)]; fa1=[1 -1884416901/(2^30) 829272286/(2^30)]; fb2=[1073741824/(2^30) -1428613497/(2^30) 1073741824/(2^30)]; fa2=[1 -2021533732/(2^30) 967280322/(2^30)]; y=filter(fb1,fa1,ones(1,1000)); y=filter(fb2,fa2,y); plot(y) ya=filter(fb1a,fa1a,ones(1,1000)); ya=filter(fb2a,fa2a,ya); plot(ya)
Am besten erstmal unskaliertes und skaliertes Filter in C,Lua,Python oder weiss Gott was simulieren und kontrollieren ob der DC-Gain dann tatsächlich 1 ist.
Ja, die a's passen, die b's nicht. Gges ist die Gesamtverstärkung? Die verwurstest Du da nicht. Das ist ganz schlicht: Ist der Output Faktor 4 zu hoch machst Du alle b's in SOS1 und SOS2 Faktor 2 kleiner. Der Output geht linear mit den b's mit. Passt doch. Das zweite Filter hat auch noch eine Resonanzüberhöhung von ca. 3dB, entsprechend Faktor ~1.5. Dort muss Du auf jeden Fall noch prüfen ob er klippt, oder ohne auf die Resourcen zu achten die Guardbits noch eins hochziehen. funzt. Cheers Detlef
Angehängte Dateien:
-

IIR_Gain.png
12 KB -

IIR_CIC_BDF.PNG
14 KB -

IIR_CIC_Response.PNG
9,7 KB
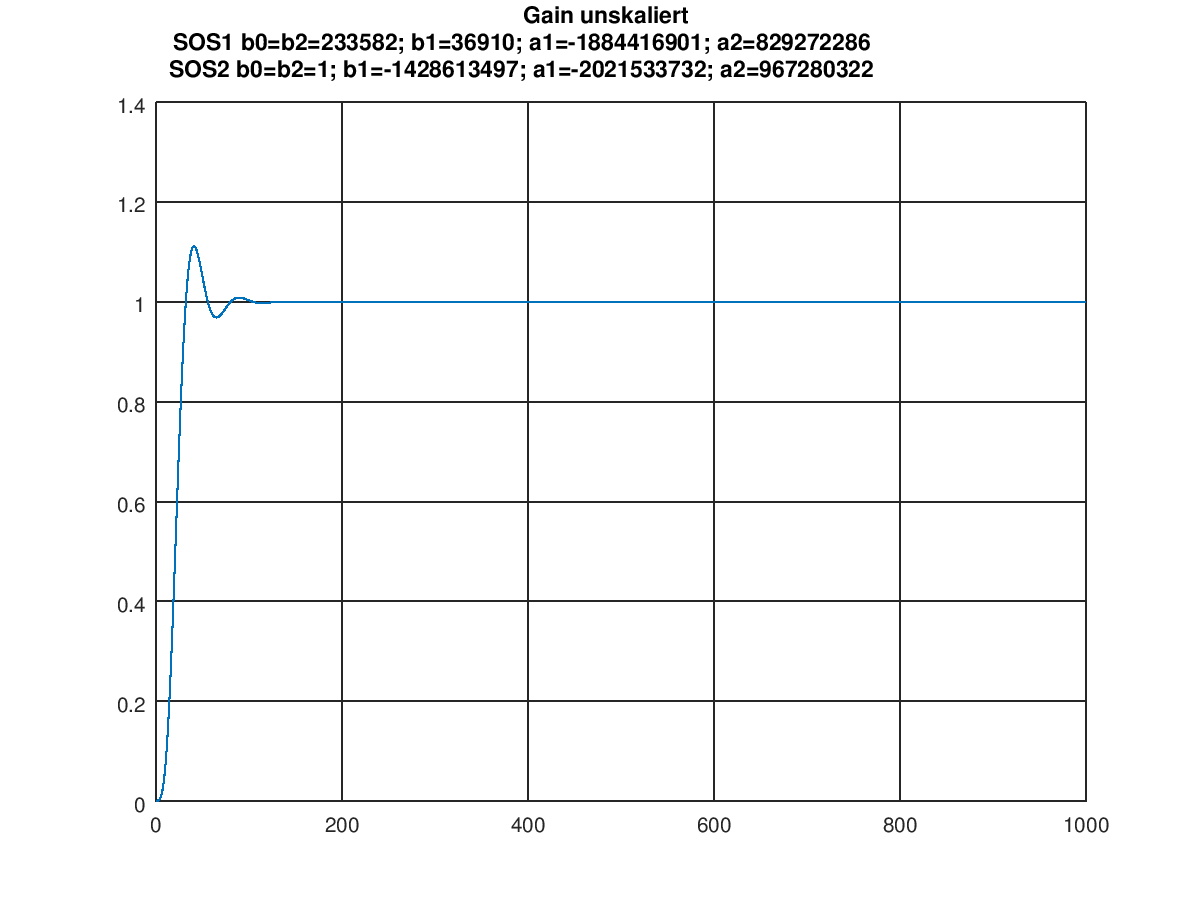


Martin O. schrieb: > Am besten erstmal unskaliertes und skaliertes Filter in C,Lua,Python > oder > weiss Gott was simulieren und kontrollieren ob der DC-Gain dann > tatsächlich 1 ist. In Matlab geht es auf die 1 ohne Gain-Skalierung Detlef _. schrieb: >Ja, die a's passen, die b's nicht. Gges ist die Gesamtverstärkung? Die >verwurstest Du da nicht. Habe nun die Koeffizienten so genommen, wie ich sie aus MATLAB bekomme und nur mit 2^30 multipliziert. Gges besteht bei mir aus folgender Rechnung, habe ich aber in der jetzigen Simulation außen vor gelassen um jeden Rechenfehler auszuschließen: SOS-Filter 1 >b0=b2 = 2,1754e-004 >b1 = 3,4375e-005 >a1 = -1,7550 >a2 = 7,7232e-001 > (b0+b1+b2)/(1+a1+a2) = 0,012811961189376 > Gain1 = 1/0,012811961189376 = 78,052062851174 SOS-Filter 2 >b0=b2 = 1,0000e+000 >b1 = -1,3305e+000 >a1 = -1,8827 >a2 = 9,0085e-001 > (b0+b1+b2)/(1+a1+a2) = 36,8870523415978 > Gain2 = 1/36,8870523415978 = 0,027109783420463 > Gges = Gain1 * Gain2 = 2,1159745194157 => Jetzt alle b's mit dem Gges multiplizieren? Nun bekomme ich aber mit den blanken Koeffizienten einen negativen Ausgang. EDIT: In der Matlab Simulation waren die B's nicht 1 sondern 1073741824, falsche Beschriftung aber Simulation lief mit den richtigen Werten :D
>>In Matlab geht es auf die 1 ohne Gain-Skalierung Wenn Du in Matlab und VHDL die gleichen Koeffizienten mit den gleichen Skalierungen verwendest sollte eigentlich bei beiden auch der gleiche Gain rauskommen.
@ Marcel D. Ich würde an Deiner Stelle in Deine VHDL Simulation mal numerische Testausgaben einbauen, damit Du genau nachvollziehen kannst, was passiert. Und dann wird solange nach Fehlern gesucht, bis Matlab und VHDL aufs letzte Bit übereinstimmen. Alles andere ist Fischen und Vermuten im Trüben.
Marcel, machs nicht so umständlich. Es war Faktor 4 zu gross, dann machs zweimal Faktor 2 kleiner und fertig ist die Laube. Bei Deinen neuen Versuchen hast Du vllt. wieder nen klipping bei den b's eingebaut. Wenn die signed sind und der Wert zu gross wird kriegst Du einen negativen Ausgang. Cheers Detlef
Angehängte Dateien:
-

IIR_CIC_Response.PNG
8,6 KB -

3FFFFFFFFFFFFFFF.PNG
8,4 KB


Detlef _. schrieb: > Marcel, machs nicht so umständlich. Es war Faktor 4 zu gross, dann machs > zweimal Faktor 2 kleiner und fertig ist die Laube. > So, es ist vollbracht, habe die Koeffizienten um jeweils zwei Zehnerpotenzen nach links/rechts verschoben, meine neuen Koeffizienten sehen nun wie folgt aus: SOS-Filter 1 >b0=b2 = 0,021754 >b1 = 0,0034375 >a1 = -1,7550 >a2 = 7,7232e-001 SOS-Filter 2 >b0=b2 = 0,01 >b1 = -0,013305 >a1 = -1,8827 >a2 = 9,0085e-001 Auf 2^30 skaliert, bekomme ich ein annähernd ähnliches Ausgangs- wie Eingangssignal (siehe Simulation). Jedoch fangen die Werte ab einem Eingangswert über 0FFFFFFFFFFFFFFF wieder an, auseinander zu driften (Ausgang < Eingang). Dabei spielt die Anzahl der Guard Bits keine Rolle, selbst auf 16 ändert sich nichts am Verhalten.
und ein weiteres Aufdrehen der Bits willst Du nicht? was tut sich da?
Die Eingangs/Ausgangs Bitbreiten aufdrehen, sehe ich auch so, das ist sicher Eingangs/Ausgangsclipping. Wenn Du mit 60Bit Werten reingehst hast Du noch 3Bit Luft, das ist nicht viel. Die DC gains des SOS1 und SOS2 sind Faktor ~2 unterschiedlich, da ist eines der Bits schon weg. Cheers Detlef Und ach ja: Bei einem des SOS hatte ich ja den Faktor 1.5 als Resonanzüberhöhung berechnet, da ist das zweite Bit perdu. Das ist alles sehr auf Kante genäht, da darf man nicht viele Fehler machen. Jetzt mal bißchen Großzügigkeit zeigen ;) ( ausserdem brauchst du keine 64Bit)
Detlef _. schrieb: > Wenn Du mit 60Bit Werten reingehst dann hat er aber was falsch gemacht. Kein Mensch brauch irgendwo 60 Bit-Auflösung.
Edi M. schrieb: > Detlef _. schrieb: >> Wenn Du mit 60Bit Werten reingehst > > dann hat er aber was falsch gemacht. Kein Mensch brauch irgendwo 60 > Bit-Auflösung. Ich hab das Teil nicht designed, ich soll es nur bauen ^^ Soweit ich es sehe, sollte meine FPGA Implementierung auch richtig sein. Zumindest verhält sich das Filter als einzelnes Filter 2. Ordnung so, wie es soll. Eventuell ist meine Filterkurve zu sehr auf Kante genäht und bei Werten über 60Bit wird es halt instabil? EDIT: Ich habe mir mal einen Butterworth Filter 4. Ordnung designed und die Koeffizienten übertragen. Das Filter scheint wunderbar zu funktionieren, zumindest wenn ich Sprünge drauf gebe ist der Ausgangswert nahezu identisch mit dem Eingangswert. Liegt also wirklich eher an den Filterkoeffizienten wie es scheint.
>>Liegt also wirklich eher an den Filterkoeffizienten wie es scheint. Ja, das liegt an den Filtereigenschaften. Die Sprungantwort des Filters schwingt über, also hast Du auf jeden Fall clipping wenn Du mit deinem Maximalsignal reingehst. Wieviel kleiner als das Maximalsignal das Eingangssignal sein darf, ohne dass es zu clipping kommt hängt von der Höhe des Überschwingens ab. >>> Soweit ich es sehe, sollte meine FPGA Implementierung auch richtig sein. Ja, das Filter ist ok, sehe ich auch so. >>> Eventuell ist meine Filterkurve zu sehr auf Kante genäht und bei Werten über 60Bit wird es halt instabil? Nein, Stabilität ist eine Eigenschaft des Filters und hat mit dem Eingangssignal nix zum tun. Das Ding clippt, weil die Ausgangsbitbreiten bei hoch ausgesteuertem Eingang zu klein sind, der Ausgang braucht 'Platz zum Überschwingen'. Mit genau dieser Argumentation erzählst Du Deinem 'Auftraggeber', dass er nicht mit 64 voll ausgesteuerten Bit reingehen kann. Wenn er das will, muss die Eingangs/Ausgangsbitbreite grösser werden. Wenn Du Lust und die Möglichkeit zum bashen hast, kannst Du deinem Auftraggeber gleich auch noch erzählen, dass die vorgegebene Spec. im wesentlichen sein eigenes technisches Unverständnis dokumentiert. Schönes W'ende. Cheers Detlef
@ Marcel D. Könntest Du Deinen aktuellen VHDL Code nochmal hier reinstellen (inkl. aktueller Koeffizienten)? Ich würde da gerne nochmal was ausprobieren.
Martin O. schrieb: > @ Marcel D. > Könntest Du Deinen aktuellen VHDL Code nochmal hier reinstellen > (inkl. aktueller Koeffizienten)? Ich würde da gerne nochmal was > ausprobieren. Hausaufgaben saugen?
Ich habe jetzt JAVA-Routinen geschrieben, mit denen man die Arithmetik solcher Filter simulieren kann. Dabei wird auch automatisch überwacht, ob irgendwo ein Überlauf stattfindet. Gleichzeitig wird für jeden Wert der maximal aufgetretene Wert ermittelt. @ Marcel D Damit könnte ich Dein Filter mal analysieren. @ elektrowagi78 Bevor Du solche Unterstellungen loslässt, lies Dir lieber mal den Thread durch, und entscheide dann, ob ich eher Geber oder Nehmer in diesem Thread bin.
Marcel D. schrieb: > Ich hab das Teil nicht designed, ich soll es nur bauen ^^ Dann frage Ich doch mal anders herum: Wer hat es womit DESIGNED? Und mit welcher Methode und Richtlinie wurde es (automatisch) übersetzt? Martin O. schrieb: > Gleichzeitig wird für jeden Wert der maximal aufgetretene Wert > ermittelt. Ich nehme ab, für jede Veriable wird der maximale Wert ermittelt. Wie testest Du das Szenatio? Wie ermittelst Du den testvector für den worst case, den Du auf den Filter loslassen musst, damit Du den worst case auch erzeugst?
Angehängte Dateien:
-

IIR_CIC_Response.PNG
11 KB
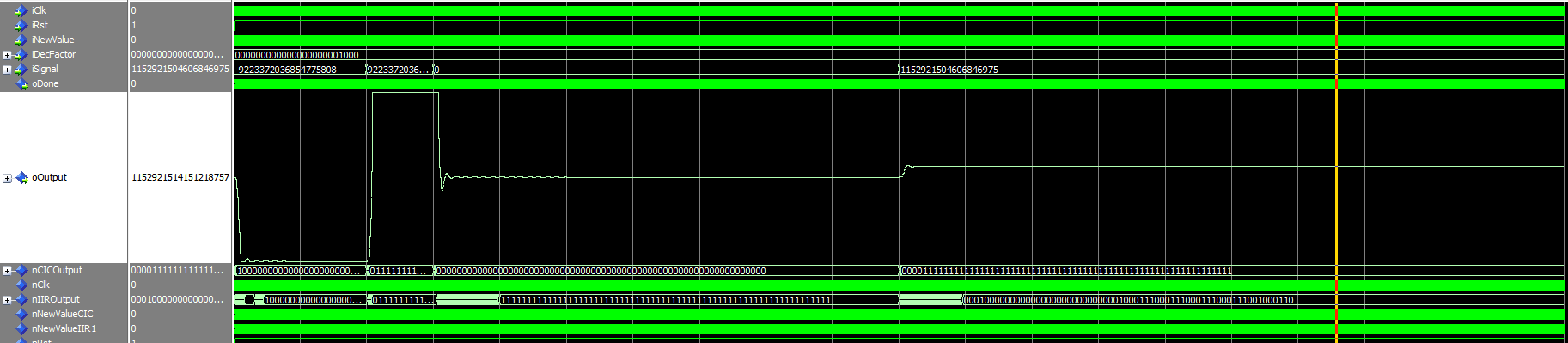
Martin O. schrieb: > @ Marcel D. > Könntest Du Deinen aktuellen VHDL Code nochmal hier reinstellen > (inkl. aktueller Koeffizienten)? Ich würde da gerne nochmal was > ausprobieren. Koeffizienten für das erste Filter der Kaskade: >A1 => -1465764964, >A2 => 512819095, >B0 => 30199151, >B1 => 60397654, >B2 => 30199151, >GUARDBITS => 4, >INPUT_WIDTH => 64, >OUTPUT_WIDTH => 64, >QFORMAT => 30 Koeffizienten für das zweite Filter der Kaskade: >A1 => -1730549698, >A2 => 799411525, >B0 => 35648239, >B1 => 71307173, >B2 => 35648239, >GUARDBITS => 4, >INPUT_WIDTH => 64, >OUTPUT_WIDTH => 64, >QFORMAT => 30 @Edi: Die Designvorgaben waren, möglichst steiles Filterverhalten bei möglichst wenig Platz auf dem FPGA und 64Bit Datenbreite. Habe mich nun in Matlab eingearbeitet und ein paar Filter durchprobiert, bis ich auf Koeffizienten gestoßen bin, die meiner vagen Aufgabenbeschreibung entsprechen. Mit den aktuellen Koeffizienten habe ich laut Simulation auch eine Verstärkung von 1, leider weicht das ganze in der Realität nun extrem davon ab. Ersetze ich das Filter durch ein FIR-Design, stimmt die Amplitude wieder.
@ Marcel D Kannst Du mir auch noch die Fliesspunktwerte der Filterkoeffizienten geben?
Martin O. schrieb: > @ Marcel D > Kannst Du mir auch noch die Fliesspunktwerte der Filterkoeffizienten > geben? Filter1: A1 = -1,37E+00 A2 = 4,78E-01 B0 = 9,33E-04 B1 = 1,87E-03 B2 = 9,33E-04 Filter2: A1 = -1,61E+00 A2 = 7,45E-01 B0 = 1 B1 = 2,00E+00 B2 = 1 Die Koeffizienten für die FPGA Implementierung sind korrigiert, um einen DCGain von 1 zu erhalten. Also nicht wundern, wenn du mit 2^30 multiplizierst auf andere Werte kommst ;)
Ok, ich weiss ich nerve..... Kannst Du mir die Fliespunkt-Koeffizienten mal mit mindestens 6 Stellen Genauigkeit geben. Genauso die Normalöieesierungskoeffzzienten, die Du nimmst, um im FPGA gain=1 zu erreichen.
Martin O. schrieb: > Kannst Du mir die Fliespunkt-Koeffizienten mal mit mindestens 6 Stellen > Genauigkeit geben. Gibt mir MATLAB genau so aus, genauer kann ich sie dir nicht liefern > Genauso die Normalöieesierungskoeffzzienten, die > Du nimmst, um im FPGA gain=1 zu erreichen. Ich addiere alle B's pro Stufe und dividiere sie durch die Summe aller A's. Komme für die erste Stufe auf 1/0,033187733 und für die Zweite auf 1/30,12047286. Damit multipliziere ich die einzelnen Koeffizienten des jeweiligen Filters und erhalte in der Simulation (fast genau) die gleiche Amplitude wie am Eingang.
Die Werte von Filter1 kann ich jetzt nachvollziehen, aber bei Filter2 geht was schief: A1=-1.61 A1*2^30=-1.61*1073741824=-1728724337 Du gibst für VHDL aber >A1 => -1730549698,
Martin O. schrieb: > A1=-1.61 > A1*2^30=-1.61*1073741824=-1728724337 > Du gibst für VHDL aber >A1 => -1730549698, Hab doch genauere Werte bekommen xD Filter1: A1 = -1,3651 A2 = 0,4776 B0 = 0,00093341 B1 = 0,0018668 B0 = 0,00093341 Gain = 30,1316148938564 Filter2: A1 = -1,6117 A2 = 0,74451 B0 = 1 B1 = 2,0003 B0 = 1 Gain = 0,03320000999925
1 | So, eine erste Version von Routinen zur Simulation von FPGA Arithmetik/Filtern in Java ist fertig. |
2 | |
3 | Werte werden in "Variablen" vom Typ "DSPvalue" gespeichert. In "DSPvalue"-Werten steht nicht |
4 | nur der eigentliche Variablenwert (als Java "BigInteger"), sondern auch Skalierungsfaktor, |
5 | Anzahl der Bits zur Speicherung und einiges mehr. Man kann für jede "DSPvalue" Variable |
6 | ein "logging" einschalten, dann wird jede Zuweisung protokolliert. |
7 | Eine Variable mit "varWidth" Bits, skaliert mit "scale", Anfangswert=0 und Namen "IIRoutput1" |
8 | erzeugt man mittels: |
9 | |
10 | DSPvalue IIRoutput1=new DSPvalue( 0 ,varWidth ,scale1,"IIRoutput1" ) ; |
11 | |
12 | Zum Rechnen gibt es ein "DSP"-Objekt, damit kann man die Standardoperationen auf Variablen |
13 | vom Typ "DSPvalue" ausführen. Dabei wird überwacht, ob ein Überlauf stattfindet. Weiter |
14 | kann man eine Protokollierung einschalten, dann werden alle Operationen ausgegeben. |
15 | |
16 | Der Code, der das IIR Filter von Marcel D. simuliert, sieht wie folgt aus (vergleiche VHDL Code von Marcel): |
17 | |
18 | |
19 | void step(long IIRinput, DSPvalue IIRout){ |
20 | nX.valueSet(IIRinput) ; |
21 | |
22 | //VHDL: nA1 <= nZ1 * cA1;
|
23 | DSP.mul(nZ1,cA1,nA1) ; |
24 | //VHDL: nA2 <= nZ2 * cA2;
|
25 | DSP.mul(nZ2,cA2,nA2) ; |
26 | //VHDL: nB1 <= nZ1 * cB1;
|
27 | DSP.mul(nZ1,cB1,nB1) ; |
28 | //VHDL: nB2 <= nZ2 * cB2;
|
29 | DSP.mul(nZ2,cB2,nB2) ; |
30 | //VHDL: nX <= shift_left(signed(nX),QFORMAT);
|
31 | DSP.shl(nX,scaleShift,nXhelp) ; |
32 | //VHDL: nSUMA1A2 <= nA1(nA1'left-1 downto 0) + nA2(nA2'left-1 downto 0);
|
33 | DSP.add(nA1,nA2,nSUMA1A2) ; |
34 | DSP.add(nB1,nB2,nSUMB1B2) ; |
35 | DSP.sub(nXhelp,nSUMA1A2,nSUMx) ; |
36 | |
37 | DSP.shr(nSUMx,scaleShift,nSUMxHelp) ; |
38 | |
39 | DSP.copy(nSUMxHelp,nZ1help) ; |
40 | DSP.copy(nZ1,nZ2help ) ; |
41 | DSP.mul(nSUMxHelp,cB0,nB0) ; |
42 | |
43 | DSP.copy(nZ1help,nZ1 ) ; |
44 | DSP.copy(nZ2help,nZ2 ) ; |
45 | |
46 | DSP.add(nB0,nSUMB1B2,nSUMxB0) ; |
47 | |
48 | DSP.shr(nSUMxB0,scaleShift,IIRout) ; |
49 | }
|
50 | |
51 | Der Code zur Simulation zweier IIR Filters hintereinander sieht dann wie folgt aus |
52 | (Eingangssprung von 0 auf 10000, Filter2 schwingt etwas über): |
53 | |
54 | nSamples=100 ; |
55 | for(int k=0 ; k<nSamples ; k++){ |
56 | if(k>=10) { IIRinput=10000 ; } else { IIRinput=0 ; } |
57 | IIRfil1.step(IIRinput,IIRoutput1) ; |
58 | IIRfil2.step(IIRoutput1.asBigInt.longValue(),IIRoutput2) ; |
59 | }
|
60 | |
61 | Die Ausgabe ergibt sich dann als : |
62 | |
63 | Fil1.nX := 0 IIRoutput1 := 0 IIRoutput2 := 0 |
64 | Fil1.nX := 0 IIRoutput1 := 0 IIRoutput2 := 0 |
65 | Fil1.nX := 10000 IIRoutput1 := 281 IIRoutput2 := 9 |
66 | Fil1.nX := 10000 IIRoutput1 := 1227 IIRoutput2 := 74 |
67 | Fil1.nX := 10000 IIRoutput1 := 2666 IIRoutput2 := 292 |
68 | Fil1.nX := 10000 IIRoutput1 := 4178 IIRoutput2 := 771 |
69 | Fil1.nX := 10000 IIRoutput1 := 5555 IIRoutput2 := 1576 |
70 | Fil1.nX := 10000 IIRoutput1 := 6713 IIRoutput2 := 2697 |
71 | Fil1.nX := 10000 IIRoutput1 := 7635 IIRoutput2 := 4056 |
72 | Fil1.nX := 10000 IIRoutput1 := 8342 IIRoutput2 := 5536 |
73 | Fil1.nX := 10000 IIRoutput1 := 8866 IIRoutput2 := 7005 |
74 | Fil1.nX := 10000 IIRoutput1 := 9243 IIRoutput2 := 8340 |
75 | Fil1.nX := 10000 IIRoutput1 := 9509 IIRoutput2 := 9451 |
76 | Fil1.nX := 10000 IIRoutput1 := 9691 IIRoutput2 := 10282 |
77 | Fil1.nX := 10000 IIRoutput1 := 9812 IIRoutput2 := 10821 |
78 | Fil1.nX := 10000 IIRoutput1 := 9891 IIRoutput2 := 11086 |
79 | Fil1.nX := 10000 IIRoutput1 := 9941 IIRoutput2 := 11124 |
80 | Fil1.nX := 10000 IIRoutput1 := 9972 IIRoutput2 := 10994 |
81 | Fil1.nX := 10000 IIRoutput1 := 9989 IIRoutput2 := 10761 |
82 | ......
|
83 | Fil1.nX := 10000 IIRoutput1 := 9999 IIRoutput2 := 9998 |
84 | Fil1.nX := 10000 IIRoutput1 := 9999 IIRoutput2 := 9998 |
85 | Fil1.nX := 10000 IIRoutput1 := 9999 IIRoutput2 := 9998 |
86 | |
87 | Name= Fil1.nA1 absMax/scale= 121411.99392 absMax= 130365135809220.00 [ 46.9 Bits] of [48] Bits |
88 | Name= Fil1.nA2 absMax/scale= 42477.74399 absMax= 45610130309300.00 [ 45.4 Bits] of [48] Bits |
89 | Name= Fil1.nB0 absMax/scale= 2501.45085 absMax= 2685912401000.00 [ 41.3 Bits] of [48] Bits |
90 | Name= Fil1.nB1 absMax/scale= 5002.84820 absMax= 5371767346760.00 [ 42.3 Bits] of [48] Bits |
91 | Name= Fil1.nB2 absMax/scale= 2501.45085 absMax= 2685912401000.00 [ 41.3 Bits] of [48] Bits |
92 | Name= Fil1.nZ1 absMax/scale= 88940.00000 absMax= 88940.00 [ 16.4 Bits] of [48] Bits |
93 | Name= Fil1.nZ2 absMax/scale= 88940.00000 absMax= 88940.00 [ 16.4 Bits] of [48] Bits |
94 | Name= Fil1.nSUMA1A2 absMax/scale= 78940.79353 absMax= 84762031636924.00 [ 46.3 Bits] of [48] Bits |
95 | Name= Fil1.nSUMB1B2 absMax/scale= 7504.24280 absMax= 8057619350106.00 [ 42.9 Bits] of [48] Bits |
96 | Name= Fil1.nSUMx absMax/scale= 88940.79353 absMax= 95499449876924.00 [ 46.4 Bits] of [48] Bits |
97 | Name= Fil1.nSUMxHelp absMax/scale= 88940.00000 absMax= 88940.00 [ 16.4 Bits] of [48] Bits |
98 | Name= Fil1.nSUMxB0 absMax/scale= 10005.46865 absMax= 10743290157906.00 [ 43.3 Bits] of [48] Bits |
99 | Name= Fil1.nZ1help absMax/scale= 88940.00000 absMax= 88940.00 [ 16.4 Bits] of [48] Bits |
100 | Name= Fil1.nZ2help absMax/scale= 88940.00000 absMax= 88940.00 [ 16.4 Bits] of [48] Bits |
101 | Name= Fil1.nX absMax/scale= 10000.00000 absMax= 10000.00 [ 13.3 Bits] of [48] Bits |
102 | Name= Fil1.nXhelp absMax/scale= 10000.00000 absMax= 10737418240000.00 [ 43.3 Bits] of [48] Bits |
103 | Name= Fil1-cB0 absMax/scale= 0.02813 absMax= 30199150.00 [ 24.8 Bits] of [32] Bits |
104 | Name= Fil1-cB1 absMax/scale= 0.05625 absMax= 60397654.00 [ 25.8 Bits] of [32] Bits |
105 | Name= Fil1-cB2 absMax/scale= 0.02813 absMax= 30199150.00 [ 24.8 Bits] of [32] Bits |
106 | Name= Fil1-cA1 absMax/scale= -1.36510 absMax= -1465764963.00 [ 30.4 Bits] of [32] Bits |
107 | Name= Fil1-cA2 absMax/scale= 0.47760 absMax= 512819095.00 [ 28.9 Bits] of [32] Bits |
108 | Name= IIRoutput1 absMax/scale= 10005.00000 absMax= 10005.00 [ 13.3 Bits] of [48] Bits |
109 | Name= Fil2.nA1 absMax/scale= 135510.12424 absMax= 145502887974063.00 [ 47.0 Bits] of [48] Bits |
110 | Name= Fil2.nA2 absMax/scale= 62597.65626 absMax= 67213721610475.00 [ 45.9 Bits] of [48] Bits |
111 | Name= Fil2.nB0 absMax/scale= 2791.42362 absMax= 2997268286881.00 [ 41.4 Bits] of [48] Bits |
112 | Name= Fil2.nB1 absMax/scale= 5583.68470 absMax= 5995435798667.00 [ 42.4 Bits] of [48] Bits |
113 | Name= Fil2.nB2 absMax/scale= 2791.42362 absMax= 2997268286881.00 [ 41.4 Bits] of [48] Bits |
114 | Name= Fil2.nZ1 absMax/scale= 84079.00000 absMax= 84079.00 [ 16.4 Bits] of [48] Bits |
115 | Name= Fil2.nZ2 absMax/scale= 84079.00000 absMax= 84079.00 [ 16.4 Bits] of [48] Bits |
116 | Name= Fil2.nSUMA1A2 absMax/scale= 74188.17233 absMax= 79658943478564.00 [ 46.2 Bits] of [48] Bits |
117 | Name= Fil2.nSUMB1B2 absMax/scale= 8369.56392 absMax= 8986750829635.00 [ 43.0 Bits] of [48] Bits |
118 | Name= Fil2.nSUMx absMax/scale= 84079.17233 absMax= 90279323859748.00 [ 46.4 Bits] of [48] Bits |
119 | Name= Fil2.nSUMxHelp absMax/scale= 84079.00000 absMax= 84079.00 [ 16.4 Bits] of [48] Bits |
120 | Name= Fil2.nSUMxB0 absMax/scale= 11124.40113 absMax= 11944734757138.00 [ 43.4 Bits] of [48] Bits |
121 | Name= Fil2.nZ1help absMax/scale= 84079.00000 absMax= 84079.00 [ 16.4 Bits] of [48] Bits |
122 | Name= Fil2.nZ2help absMax/scale= 84079.00000 absMax= 84079.00 [ 16.4 Bits] of [48] Bits |
123 | Name= Fil2.nX absMax/scale= 10005.00000 absMax= 10005.00 [ 13.3 Bits] of [48] Bits |
124 | Name= Fil2.nXhelp absMax/scale= 10005.00000 absMax= 10742786949120.00 [ 43.3 Bits] of [48] Bits |
125 | Name= Fil2-cB0 absMax/scale= 0.03320 absMax= 35648239.00 [ 25.1 Bits] of [32] Bits |
126 | Name= Fil2-cB1 absMax/scale= 0.06641 absMax= 71307173.00 [ 26.1 Bits] of [32] Bits |
127 | Name= Fil2-cB2 absMax/scale= 0.03320 absMax= 35648239.00 [ 25.1 Bits] of [32] Bits |
128 | Name= Fil2-cA1 absMax/scale= -1.61170 absMax= -1730549697.00 [ 30.7 Bits] of [32] Bits |
129 | Name= Fil2-cA2 absMax/scale= 0.74451 absMax= 799411525.00 [ 29.6 Bits] of [32] Bits |
130 | Name= IIRoutput2 absMax/scale= 11124.00000 absMax= 11124.00 [ 13.4 Bits] of [48] Bits |
131 | |
132 | Man erkennt, das in beiden Filtern der nA1 Wert am grössten ist, un d deshalb am ehesten einen Überlauf |
133 | verursachen wird. Hier reichen die vorgesehenen Bits (48) gertade aus, um die nötigen Bits (46.9) zu speichern. |
134 | Viel Luft ist da nicht mehr, was man bei einem größeren Eingangssignal auch merkt: |
135 | |
136 | |
137 | Bei einem Sprung von 0 auf 20000 am Eingang ergibt sich ein Überlauf bei Wert Fil2.nA1: |
138 | |
139 | Error: MUL overflow 2 |
140 | Fil2.nA1 =mul(Fil2.nZ1=164017 * Fil2-cA1=-1730549697 ) |
141 | Name= Fil2.nA1 nBits= 48 Value=-269957099983515 [ 47.9 Bits] value/scale=-251417.141392375340 |
142 | asDouble=-269966856015344.06000 range is -140737488355328 .. 140737488355327 [ 47.0 Bits] |
143 | |
144 | Statt eines Eingangssprungs kann man natürlich auch einen Frequenzsweep oder andere Eingangssignale |
145 | simulieren. Wie man sieht kann man mit diesen Routinen gut untersuchen, was eine Filterimplementation so macht. |
Hab vergessen: Diese Tabelle gibt Auskunft darüber, wie gross die entsprechende Variable maximal wurde, wievuiel Bits sie dann braucht, und wieviele Bits reserviert sind
1 | Name= Fil1.nA1 absMax/scale= 121411.99392 absMax= 130365135809220.00 [ 46.9 Bits] of [48] Bits |
2 | Name= Fil1.nA2 absMax/scale= 42477.74399 absMax= 45610130309300.00 [ 45.4 Bits] of [48] Bits |
Die Variable Fil1.nA1 ist kurz davor (46.9 Bits von 48 Bits) einen Überlauf zu verursachen.
Hier mal ein "vollständiges" Beispiel. Zuerst der JAVA Code:
1 | package allClasses; |
2 | |
3 | public class Demo1v01 { |
4 | /* A1=-1.0*scale
|
5 | A2= 0.5*scale
|
6 | B0= 1.0*scale
|
7 | yNew=(B0*x0-A1*y1-A2*y2)/scale
|
8 | y2=y1 ;
|
9 | y1=yNew
|
10 | */
|
11 | static void demo(){ |
12 | int scaleShift=16 ; |
13 | long scale=1L<<scaleShift ; |
14 | int scale1=1 ; |
15 | int coeffWidth=17 ; |
16 | int varWidth=16 ; |
17 | int productWidth=32 ; |
18 | |
19 | DSPvalue B0=new DSPvalue( (long)( 1.0*scale) ,coeffWidth ,scale,"B0" ) ; |
20 | DSPvalue A1=new DSPvalue( (long)(-1.0*scale) ,coeffWidth ,scale,"A1" ) ; |
21 | DSPvalue A2=new DSPvalue( (long)( 0.5*scale) ,coeffWidth ,scale,"A2" ) ; |
22 | |
23 | DSPvalue x0=new DSPvalue( 0 ,varWidth ,scale1,"x0" ) ; |
24 | DSPvalue y1=new DSPvalue( 0 ,varWidth ,scale1,"y1" ) ; |
25 | DSPvalue y2=new DSPvalue( 0 ,varWidth ,scale1,"y2" ) ; |
26 | DSPvalue yNew=new DSPvalue( 0 ,varWidth ,scale1,"yNew" ) ; |
27 | |
28 | DSPvalue pB0=new DSPvalue( 0 ,productWidth ,scale,"pB0" ) ; |
29 | DSPvalue pA1=new DSPvalue( 0 ,productWidth ,scale,"pA1" ) ; |
30 | DSPvalue pA2=new DSPvalue( 0 ,productWidth ,scale,"pA2" ) ; |
31 | DSPvalue sum=new DSPvalue( 0 ,productWidth ,scale,"sum" ) ; |
32 | |
33 | yNew.valueProt=true ; |
34 | x0.valueProt=true ; |
35 | pA1.valueProt=true ; |
36 | pA2.valueProt=true ; |
37 | |
38 | int nSamples=10 ; |
39 | int IIRinput ; |
40 | for(int k=0 ; k<nSamples ; k++){ |
41 | if(k==2) { IIRinput=10000 ; } else { IIRinput=0 ; } |
42 | x0.valueSet(IIRinput) ; |
43 | DSP.mul(x0, B0, pB0) ; // pB0 = x0 * B0 |
44 | DSP.mul(y1, A1, pA1) ; // pA1 = y1 * A1 |
45 | DSP.mul(y2, A2, pA2) ; // pA2 = y2 * A2 |
46 | DSP.copy(pB0,sum) ; // sum = pB0 |
47 | DSP.sub(sum,pA1,sum) ; // sum=pB0-pA1 |
48 | DSP.sub(sum,pA2,sum) ; // sum=pB0-pA1-pA2 |
49 | DSP.shr(sum,scaleShift,yNew) ; // yNew=sum>>scaleShift |
50 | DSP.copy(y1,y2) ; // y2 = y1 |
51 | DSP.copy(yNew,y1) ; // y1=yNew |
52 | System.out.println() ; |
53 | }
|
54 | DSPvalue.maxListShow() ; |
55 | }
|
56 | }
|
Das Programm erzeugt die folgende Ausgabe:
1 | x0 := 0 pA1 := 0 pA2 := 0 yNew := 0 |
2 | x0 := 0 pA1 := 0 pA2 := 0 yNew := 0 |
3 | x0 := 10000 pA1 := 0 pA2 := 0 yNew := 10000 |
4 | x0 := 0 pA1 :=-655360000 pA2 := 0 yNew := 10000 |
5 | x0 := 0 pA1 :=-655360000 pA2 := 327680000 yNew := 5000 |
6 | x0 := 0 pA1 :=-327680000 pA2 := 327680000 yNew := 0 |
7 | x0 := 0 pA1 := 0 pA2 := 163840000 yNew := -2500 |
8 | x0 := 0 pA1 := 163840000 pA2 := 0 yNew := -2500 |
9 | x0 := 0 pA1 := 163840000 pA2 := -81920000 yNew := -1250 |
10 | x0 := 0 pA1 := 81920000 pA2 := -81920000 yNew := 0 |
Das sind die Daten der Filtersimulation. Danach wird die folgende Tabelle ausgegeben, die für jede Variable den Maximalwert ausgibt
1 | Name= B0 absMax/scale= 1.00000 absMax= 65536.00 [ 16.0 Bits] of [17] Bits |
2 | Name= A1 absMax/scale= -1.00000 absMax= -65536.00 [ 16.0 Bits] of [17] Bits |
3 | Name= A2 absMax/scale= 0.50000 absMax= 32768.00 [ 15.0 Bits] of [17] Bits |
4 | Name= x0 absMax/scale= 10000.00000 absMax= 10000.00 [ 13.3 Bits] of [16] Bits |
5 | Name= y1 absMax/scale= 10000.00000 absMax= 10000.00 [ 13.3 Bits] of [16] Bits |
6 | Name= y2 absMax/scale= 10000.00000 absMax= 10000.00 [ 13.3 Bits] of [16] Bits |
7 | Name= yNew absMax/scale= 10000.00000 absMax= 10000.00 [ 13.3 Bits] of [16] Bits |
8 | Name= pB0 absMax/scale= 10000.00000 absMax= 655360000.00 [ 29.3 Bits] of [32] Bits |
9 | Name= pA1 absMax/scale= 10000.00000 absMax= 655360000.00 [ 29.3 Bits] of [32] Bits |
10 | Name= pA2 absMax/scale= 5000.00000 absMax= 327680000.00 [ 28.3 Bits] of [32] Bits |
11 | Name= sum absMax/scale= 10000.00000 absMax= 655360000.00 [ 29.3 Bits] of [32] Bits |
12 | Stop :JavaTestBed1v01 |
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.