Hallo allerseits, Ich möchte demnächst lernen mit asm für den Microkontroller zu programmieren. Dabei strebe ich aber nur Berechnungen an. Kann mir dafür jemand eine gute Quelle nennen? Ich habe keine Grundkenntnisse und möchte ein paar in C selbstgeschriebene Funktionen on ASM schreiben und ggf dadurch optimieren. Viele Grüße und vielen Dank
Warum kein C? Es gibt Compiler, die übersetzen das für Dich in Maschinencode.
Pete K. schrieb: > Warum kein C? Es gibt Compiler, die übersetzen das für Dich in > Maschinencode. Weil es teilweise hilfreich ist ASM zu können? Gerade wenn man Fehler sucht oder zeitkritische Aufgaben hat ist eine optimieren ab und zu hilfreich. Heist ja nicht, dass man das komplette Programm in ASM schreiben muss
Uhoh, heikles Thema. ASM auf dem Cortex M4 ist schon ne Hausnummer. Ich sage nicht, dass es nicht möglich ist, aber es ist komplex, einfach weil die Initialisierung des Kerns und der Peripherie nicht so einfach ist wie beispielsweise beim AVR und die Teile insgesamt viel mehr können. Was für Berechnungen willst du durchführen? Ggf. kommt dann noch die floating point unit dazu, da muss man auch eine Reihe an Sachen beachten. Ohne Erfahrung wird das schwierig!
Pete K. schrieb: > Warum kein C? Es gibt Compiler, die übersetzen das für Dich in > Maschinencode. Abgesehen von der Tatsache, das sich "c" nicht für seriöse und ernsthafte Programmprojekte eignet: Hast Du die Frage nicht verstanden? Wenn Dich jemand nach einem Friseur fragt, antwortest Du dann auch mit der Adresse eines Schlachters?
Christopher S. schrieb: > Hallo allerseits, > > Ich möchte demnächst lernen mit asm für den Microkontroller zu > programmieren. Dabei strebe ich aber nur Berechnungen an. Kann mir dafür > jemand eine gute Quelle nennen? > Ich habe keine Grundkenntnisse und möchte ein paar in C > selbstgeschriebene Funktionen on ASM schreiben und ggf dadurch Nimm dir einen Debugger und schaue dir den Code an den der Compiler generiert. Dazu dann noch das ARM Machine Instruction Manual zum verstehen. Programmieren würde ich mit GCC Inline Assembler anfangen, da gibt es diverse Tutorials im Netz zu > optimieren. Christian R. schrieb: > Weil es teilweise hilfreich ist ASM zu können? Gerade wenn man Fehler > sucht oder zeitkritische Aufgaben hat ist eine optimieren ab und zu > hilfreich. Auf jeden Fall hilfreich beim Debuggen von kniffligen Problemen. Optimieren, naja falls man zusätzliches Hintergrundwissen über die mathematische Operation hat, also etwas was der Compiler nicht weis, dann kann man da manchmal was machen. Auch bei den DSP Instruktionen kann man manchmal was rausholen, für die hat der GCC aber builtin Funktionen und spezielle Datentypen, Assembler also eigentlich unnötig. Die Pipepline der CPU kennt der Compiler aber meist besser, da gewinnt der Mensch nur schwerlich gegen den Compiler. Bei AVR8 sieht das etwas anders aus.
egbert schrieb: > Abgesehen von der Tatsache, das sich "c" nicht für seriöse und > ernsthafte Programmprojekte eignet: Blödsinn. (siehe z.B. Linux Kernelentwicklung)
> GCC Inline Assembler
Das ist ja nun die absolute Hilfskruecke.
Der GNU-Assembler heisst gas.
(º°)·´¯`·.¸¸.·´¯`·.¸¸.·´¯`·.¸¸.·´¯`·.¸¸.·´¯`·.¸¸.· schrieb im Beitrag #5125132: >> GCC Inline Assembler > > Das ist ja nun die absolute Hilfskruecke. > Der GNU-Assembler heisst gas. Was kann der Inline Assembler denn nicht, was der gas kann? Beim Inline Assembler ists sehr praktisch dass man sich (oft) nicht mit Calling Conventions / ABI's herumplagen muss, und sich vom Compiler alles schön zurecht legen lassen kann. Die Syntax ist aber etwas fummelig und nicht gut dokumentiert...
Mein Ziel ist die endliche Körperarithmetik über einen Galoiskörper. Ich muss auch generell sagen, dass ich Mathematiker bin, der einen kleinen Ausflug in die µC Welt macht und ein Projekt darin realisieren muss. Da mir die Performance wichtig ist, bin ich der Meinung, dass man da doch "einiges" durch ASM rausholen kann. Mein Plan war auch erst den durch C-generierten ASM heranzuziehen und daran zu "entwickeln". Als Compiler nehme ich den ARM-NONE-EABI-gcc Compiler. Aktuell habe ich nur eine Lib für die Ausgabe über USART erzeugt und taste mich langsam an den Prozessor ran (Interpretierung und Speicherung von Werten.) Dabei ist mir Aufgefallen, dass 2^31 als -2^31 ausgegeben und ab da an gegen 0 "runtergezählt" wird, im Datentyp long long. Intern werden die Werte wohl weiterhin als >0 behandelt. Entwicklungs Plattform ist Windows-10, Notepad ++ und Makefile. Ausgabe lese ich in einer VM mit Ubuntu aus. Im übrigen werde ich mit Zahlen rechnen, die aus 11*32-Bit bestehen. Ich weiß nur nicht welcher Datentyp hierfür intelligent gewählt ist: short[22*16-Bit] oder int[11*32-Bit]. In jedem Fall muss ich das Ergebnis im größeren (int resp. long long) Casten und den Übertrag im Carry nutzen und im nächsten Berechnungsschritt aufsummieren. (Alle Datentypen als unsigned.)
Du musst in der Assemblerprogrammierung schon ziemlich gut sein, um den GCC zu schlagen. Das heißt nicht, dass der vom GCC erzeugte Code nicht weiter optimierbar ist, aber wenn du frisch mit Assembler beginnst, wirst du wirst einige Zeit dafür investieren müssen. Evtl. gelingt es dir in weniger Zeit, deinen C-Code besser zu schreiben und damit einen ähnlichen Geschwindigkeitszuwachs zu erzielen. Shalec#Guest schrieb: > Dabei ist mir Aufgefallen, dass 2^31 als -2^31 ausgegeben und ab da an > gegen 0 "runtergezählt" wird, im Datentyp long long. Intern werden die > Werte wohl weiterhin als >0 behandelt. Es gibt in C sowohl signed als auch unsigned Integer-Typen. Ein (signed) int hat auf dem ARM den Wertebereich [-2^31, 2^31-1], ein unsigned int hingegen [0, 2^32-1]. Shalec#Guest schrieb: > Im übrigen werde ich mit Zahlen rechnen, die aus 11*32-Bit bestehen. Ich > weiß nur nicht welcher Datentyp hierfür intelligent gewählt ist: > short[22*16-Bit] oder int[11*32-Bit]. Es gibt diverse Big-Integer-Bibliotheken (bspw. GNU MP), so dass du das Rad nicht unbedingt neu erfinden musst.
egbert schrieb: > Abgesehen von der Tatsache, das sich "c" nicht für seriöse und > ernsthafte Programmprojekte eignet: Unfug. > Wenn Dich jemand nach einem Friseur fragt, antwortest Du dann auch mit > der Adresse eines Schlachters? Wenn er nach Schnitzeln fragt, ja. Shalec#Guest schrieb: > Ich muss auch generell sagen, dass ich Mathematiker bin, der einen > kleinen Ausflug in die µC Welt macht und ein Projekt darin realisieren > muss. Das heißt, dass du von Mikroarchitektur eher wenig Ahnung hast... > Da mir die Performance wichtig ist, bin ich der Meinung, dass man > da doch "einiges" durch ASM rausholen kann. ...und das wiederum heißt, dass du gegen den Compiler verlierst. Optimiere deine Algorithmen, schmeiße dem Compiler keine Steine in den Weg (prüfe also den generierten Code) und du wirst ein besseres Ergebnis erhalten, als du es mit Asm selbst hättest erzeugen können. Shalec#Guest schrieb: > Dabei ist mir Aufgefallen, dass 2^31 als -2^31 ausgegeben und > ab da an gegen 0 "runtergezählt" wird, im Datentyp long long. Dann hast du bei printf() den falschen Formatspezifier benutzt. "int" und "unsigned long" und "long long" sind verschiedene Typen. Baue deinen Code mit "-Wall -Wextra" und achte auf Compilerwarnungen. Bedenke, dass "long long" ein anderer Typ ist als "unsigned long long". Shalec#Guest schrieb: > Entwicklungs Plattform ist Windows-10, Notepad ++ und Makefile. Ausgabe > lese ich in einer VM mit Ubuntu aus. B'scheuert. Du kannst Entwicklung mit beidem machen, du kannst die Werte auch mit beidem auslesen. Shalec#Guest schrieb: > Im übrigen werde ich mit Zahlen rechnen, die aus 11*32-Bit bestehen. Ich > weiß nur nicht welcher Datentyp hierfür intelligent gewählt ist: > short[22*16-Bit] oder int[11*32-Bit]. Der richtige Typ ist:
1 | uint32_t val[11]; |
Und wenn du ordentlich arbeiten möchtest, besorgst du dir eine Bibliothek, mit der du arbitrary precision machen willst. Wenn der Code läuft und korrekt arbeitet, und dann noch zu langsam ist, fängst du mit der Optimierung an. Vorher nicht. Das Carry-Flag macht der Compiler bzw. die Library für dich.
Sind diese auch optimiert auf den M4? Oder wäre das eine generische Übersetzung? Das Nutzen einer solchen Lib wäre mir deutlich lieber. (Rad neu erfinden und so ist natürlich unnötig. Ich möchte aber gerne die Lib-Funktionen "nachvollziehen" können.) Ich habe durchgehend nur unsigned verwendet. Also Initialisierung war:
1 | unsigned int a,b; |
2 | unsigned long long c; |
3 | |
4 | c= (unsigned long long) a*b; |
5 | |
6 | print_int(c); //nicht von "int" durcheinander bringen lassen. |
7 | // Dieser wird mittels sprintf in einen Char gewandelt und dann ausgegeben. |
Ausgabe war dann selbst bei
1 | a= pow(2,31); |
2 | print_int(a); // -> -pow(2,31) |
3 | |
4 | a=pow(2,32)-1; //Eingabe nicht berechnen lassen, sondern als Zahl gespeichert |
5 | print_int(a); // -> -1 |
Shalec#Guest schrieb: > Mein Ziel ist die endliche Körperarithmetik über einen Galoiskörper. Würd ich in C anfangen, da kannst du dann auch in Assembler implementierte Funktionen aufrufen.
1 | extern int asmfunc (int a, int b); |
und du hast ein Framework, das den µC initialisert, die Funktion mit Werten versorgt, einfach Rückhabewerte anzeigen / testen kann etc. Dazu musst du natürlich das vom Compiler verwendete ABI kennen und beachten, also wie Datentypen aufgebaut sind, wo wie welche Werte übergeben werden, welche Register eine Funktion zerstören darf und welche nicht, etc. Selbst wenn es ein reines Asm-Projekt wird oder werden muss, kann es vorausschauend sein, C-ABI zu verwenden um später die hoffentlich schnellen Routinen übergangslos von C(++) aus verwenden zu können: Alles was du dort dann noch brauchst sind Prototypen für die Funktionen. Wenn du mit Arithmetik über GF anfängst dann interessiert dich vermutlich entweder der Fall GF(2^n) oder große Primzahlen. In Charakteristik 2 kannst du am ehesten einen (spürbaren) Vorteil durch Asm erwarten, allerdings kann C keine Asm-Funktionen inlinen. Wenn du also z.B. auf einem ARM Arithmetik über GF(2^32) in packed Darstellung implementierst, dann ist eine Addition a+b einfach a XOR b. Dafür eine (nicht-inlinebare) Funktion zu verwenden ist nicht sinnvoll, wenn's um Performance geht. > dass 2^31 als -2^31 ausgegeben Dann fehlt irgendwo ein unsigned oder ein %u anstatt %d bei der Ausgabe, > Ich weiß nur nicht welcher Datentyp hierfür intelligent gewählt ist: > short[22*16-Bit] oder int[11*32-Bit]. Weder noch. Auf jeden fall ein unsigned Typ wie uint32_t, kein signed. Welche Operationen sollen es werden? Auch kompliziertere Sachen wie diskrete Wurzel und Log?
Shalec#Guest schrieb: > Sind diese auch optimiert auf den M4? In der GNU-MP-Bibliothek sind die Grundfunktionen (Addition, Multiplikation, Division usw.) für eine Vielzahl von Prozessoren, u.a. für ARM in Assembler implementiert und dürften damit deutlich schneller als entsprechende C-Funktionen sein. Aus dem Readme in gmp-6.1.2/mpn/arm:
1 | This directory contains mpn functions for ARM processors. It has been |
2 | optimised mainly for Cortex-A9 and Cortex-A15, but the code in the |
3 | top-level directory should run on all ARM processors at architecture |
4 | level v4 or later. |
Ich kenne mich mit ARM-Prozessoren nicht so gut aus, deswegen kann ich nicht sagen, wie gut die Routinen auf einem M4 laufen. A9 und A15 haben die Architektur ARMv7-A, der M4 ARMv7-M. Der für reine Berechnungen relevante Hauptunterschied scheint zu sein, dass ARMv7-M nur den Thumb- Instruktionsatz unterstützt, der aber m.W. aus demselben Assembler- Quellcode generiert wird. Ich würde die Bibliothek einfach mal ausprobieren (geht schneller als Assembler zu lernen) und schauen, wie groß der Geschwindigkeitszuwachs gegenüber deinen handgeschriebenen Funktionen ist.
Insgesamt wird am Ende ein kryptographisches Pairing stehen. Die Primzahl p hat 339-Bit und ich arbeite in GF(p^16). Wobei die Elemente als Array über GF(p) aufgefasst werden mit 16 Einträgen. Dadurch habe ich dann auch Homomorphismen in einer super schnellen Form für die p-Potenzierung (also den p-Frobenius) zur Verfügung stehen. Einzelne Elemente sollen dann entsprechend in ASM (falls möglich) geschrieben werden. D.h. egtl. nur die Multiplikation, Addition, Subtraktion und co. :) Das einzige, was ich noch brauche, sind schnelle Quadrierung und Inversion. Wobei eine Inversion in einigen Fällen ja auch eine Konjugation ist. Das gibt aber meine Primzahl nicht her. (p = 5 mod 8, = 13 mod 32) Ich werde mir definitiv die Lib anschauen. Wegen %u und %d, das wird sehr wahrscheinlich der Fehler sein. :) Ich bin aber auch noch ein Frischling in C. Das sind quasi meine ersten Gehversuche :D Ich habe bislang nur ein Buch dazu gelesen und die FourQlib für ARM (Cortex-M4) von Microsoft durchforstet. Dadurch konnte ich einiges lernen. Bzgl ASM lernen: Mein Arbeitgeber beauftragt mich auch zeitgleich mit einem Projekt, bei dem ich ebenfalls ASM lernen soll ;) Da er das "mitbekommen" hat, dass ich in 2-3 Wochen anfangen wollte, dies für meine Masterarbeit zu lernen. Bzgl. Performance werde ich sowieso erstmal alles mit C schreiben und dann, wenn das Produkt fertig ist, optimieren, was das Zeug hält. (Nach einer Dokumentation des Codes) Gibt es irgendwelche Benchmark-Tools? Gibt es noch irgendwo einen sehr günstigen Anbieter für das Discoveryboard mit einem F417 draufgelötet? (Möglichst ohne Bildschirm, da ich sonst meine USART-Lib-Config ändern müsste) Ich entwickle auf einem CJMCU Board mit dem STM32F407VGT6. (Preis ca. 11€ aus China)
Christopher S. schrieb: > Insgesamt wird am Ende ein kryptographisches Pairing stehen. Die > Primzahl p hat 339-Bit und ich arbeite in GF(p^16). Wobei die Elemente > als Array über GF(p) aufgefasst werden mit 16 Einträgen. Dadurch habe > ich dann auch Homomorphismen in einer super schnellen Form für die > p-Potenzierung (also den p-Frobenius) zur Verfügung stehen. > > Einzelne Elemente sollen dann entsprechend in ASM (falls möglich) > geschrieben werden. D.h. egtl. nur die Multiplikation, Addition, > Subtraktion und co. :) Das einzige, was ich noch brauche, sind schnelle > Quadrierung und Inversion. Wobei eine Inversion in einigen Fällen ja > auch eine Konjugation ist. Das gibt aber meine Primzahl nicht her. (p = > 5 mod 8, = 13 mod 32) Kann es sein, daß Du Dir einfach den falschen Prozessor ausgesucht hast? Die STM32 sind µCs, bei denen Berechnungen je nach Typ und bezogen auf ihre Controller-Hardware recht schnell ablaufen. Wenn aber nur mit Zahlen 'gewürfelt' werden soll, wären doch Prozessoren mit Taktfrequenzen im GHz-Bereich nebst leistungsfähiger FPU angesagt. Christopher S. schrieb: > Gibt es noch irgendwo einen sehr günstigen Anbieter Die Kosten sollten erst einmal nicht das Problem sein, solange nicht klar ist, ob die erwartete Lösung/Leistung erreicht wird.
Der Prozessor war vorgegeben :) Wegen des Anbieters hatte ich gefragt, da ich absolut keine Quelle für solche Boards mit dem Prozessor fand. Ein Pairing ist ist eine bilineare Funktion, die auf der einen Seite elliptische Kurven Arithmetik und auf der anderen Seite endliche Körper Arithmetik nutzt. Die sog. Miller loop stellt das Herz der OP und die sog. Final Exponentiation den "Rattenschwanz" dar.
Shalec#Guest schrieb: > Sind diese auch optimiert auf den M4? Für die Architektur (ARM) definitiv, für die Mikroarchitektur vermutlich nicht. Es wird trotzdem schneller sein, als dein handgeklöppeltes Zeugs. > (Ich möchte aber gerne die > Lib-Funktionen "nachvollziehen" können.) Die sind im Quelltext verfügbar. Ob sie gut lesbar sind, weiß ich nicht. Christopher S. schrieb: > Einzelne Elemente sollen dann entsprechend in ASM (falls möglich) > geschrieben werden. D.h. egtl. nur die Multiplikation, Addition, > Subtraktion und co. :) Schreibe deinen Quelltext so, dass sämtliche mathematischen Operationen als Funktionen ausgeführt sind und achte darauf, dass der Compiler diese grundsätzlich inlined (also im Ergebnis kein Funktionsaufruf mehr stattfindet). Das ist einer der wenigen Fälle, wo man Code (Funktionen als "static inline", vielleicht auch mit "__attribute__((always_inline))") in einem Header haben sollte. Diese Funktionen kannst du später mit inline-Assembler umschreiben, wenn dir die Standardfunktion / Bibliotheksfunktion nicht ausreichen sollte. Christopher S. schrieb: > Gibt es irgendwelche Benchmark-Tools? Für deinen Anwendungsfall auf deinem Prozessor wird das eher auf Mikrobenchmarks hinauslaufen, die du dir sinnvollerweise selbst schreibst (nur du weißt, welche Werte relevant sind). Ein frei laufender Timer ist auf solchen Controllern dafür optimal geeignet. Christopher S. schrieb: > Der Prozessor war vorgegeben :) Ich habe irgendwie das Gefühl, dass du die Mathematik hinter einer Art "Bluetooth-Pairing" implementieren sollst oder soetwas in der Art. Könnte das hinkommen? Reicht für die Entwicklung nicht auch ein ähnlicher Prozessor (quasi ein beliebiger STM32F4)? Ein Energiesparwunder ist das Ding eh nicht, und die Chips unterscheiden sich ja nicht in der Performance, sondern in der verfügbaren Peripherie usw.
Jan K. schrieb: > ASM auf dem Cortex M4 ist schon ne Hausnummer ARM Assembler lernen geht schon einfacher auf einem Pi mit RTOS. Da gibt es haufenweise Seiten mit Beispielen und sogar ein Buch. Das lässt sich dann alles weitgehend auf den M4 übertragen, auch DSP und FPU. Aber man kann sich eben z.B. einfach eine Grafik plotten und nicht über UART gehen. https://www.amazon.de/Raspberry-Assembly-Language-Beginners-2014-02-06/dp/B01FIYK7F0/ref=asap_bc?ie=UTF8 Beim uC ist erstmal das Problem, dass es umständlich ist, jedesmal neu zu assemblieren und zu flashen / debuggen. Dann noch der Unterschied Ausführung im Flash / RAM. Von Waitstates, Modi, MPU erst gar nicht zu reden. Ein M0 wäre zum Einstieg einfacher z.B. LPC810 gibt es sogar als DIL. Da braucht es erstmal keinen Startup-Code.
Soweit ich das mitbekommen habe, benutzt die C-Umgebung den Stack um ständig benutzte Register (in Schleifen etc.) zu retten und wiederherzustellen. Wenn du da ein Assembler-Programm reinfunzeln willst musst du bestimmt aufpassen dass du nicht dem restlichen Programm dazwischenfunkst, also den Stack und vielleicht andere Register am Ende so lassen wie er war.
hänschen schrieb: > Wenn du da ein Assembler-Programm reinfunzeln willst musst du bestimmt > aufpassen dass du nicht dem restlichen Programm dazwischenfunkst, also > den Stack und vielleicht andere Register am Ende so lassen wie er war. Das Stichwort nennt sich ABI und ist in der Regel Teil der Compiler-Dokumentation.
Ein Bluetooth-Pairing wird das nicht. Insgesamt sieht es so aus, dass ich über eine for-Schleife ein bisschen EC und FF Arithmetik aufrufe (Punktmultiplikation, Addition, Sekante/Tangente an Punkt auswerten; Multiplikation, Quadrierung, Inversion) und das Ergebnis am Ende der Funktion wird nochmal mit (p^16-1)/r potenziert. p hat 339 Bits r etwas weniger. Diese Zahl, die am Ende dabei rauskommt, ist dann das sog. Pairing und kann für eine Vielzahl (ID-basierte Verschlüsselung, Signaturen, ...) kryptographischer Mechanismen verwendet werden.
Btw. der STM32F417 war nur noch von Interesse wegen der verbauten Cryptounit. Laut STM haben der F407 und der F417 jeweils einen TRNG an board. Den würde ich ebenfalls gerne nutzen. Soll ich für diese Hardwarebzeugsfrage einen neuen Thread machen? Welche Rubrik wäre das?
Shalec#Guest schrieb: > Ein Bluetooth-Pairing wird das nicht. > > Insgesamt sieht es so aus, dass ich über eine for-Schleife ein bisschen > EC und FF Arithmetik aufrufe (Punktmultiplikation, Addition, > Sekante/Tangente an Punkt auswerten; Multiplikation, Quadrierung, > Inversion) und das Ergebnis am Ende der Funktion wird nochmal mit > (p^16-1)/r potenziert. p hat 339 Bits r etwas weniger. > > Diese Zahl, die am Ende dabei rauskommt, ist dann das sog. Pairing und > kann für eine Vielzahl (ID-basierte Verschlüsselung, Signaturen, ...) > kryptographischer Mechanismen verwendet werden. Erstmal zum ursprünglichen Thema: Kurzreferenz der ASM-Befehle gibt im Technical Reference Manual: http://infocenter.arm.com/help/topic/com.arm.doc.100166_0001_00_en/arm_cortexm4_processor_trm_100166_0001_00_en.pdf zusätzlich werden da einige grundlegende Dinge beschrieben wie Bit Bending, NVIC, FPU oder MPU. Gibt's auch etwas aufgeräumter von ST: "STM32F3, STM32F4 and STM32L4 Series Cortex®-M4 programming manual" http://www.st.com/content/ccc/resource/technical/document/programming_manual/6c/3a/cb/e7/e4/ea/44/9b/DM00046982.pdf/files/DM00046982.pdf/jcr:content/translations/en.DM00046982.pdf Kryptoalgorithmen selbst implementieren? Kann man zum Spaß machen. Wenn's in die freie Wildbahn gehen soll, sollte man aber sehr gut wissen was man tut. Für den Einsteig: Side Channel Cryptanalysis Lounge https://www.emsec.rub.de/research/projects/sclounge/ (ist zwar nicht mehr ganz up to date, liefert aber aber genügend für weitergehende Recherchen)
Jungs, könnt ihr erst am Samstag mit dem Thema weiter machen. Da habe ich dann Bier und Popcorn hier. Und dann sind auch die C++ler dabei. SCNR
Tjo. Manche brauchen Jahre um sich in so komplexe Dinge wie die ARM-Architektur, Kryptographie-Algorithmen, Assembler, ABI's, Mikrocontroller-Programmierung/Debugging einzuarbeiten und dabei besser als ein Compiler und bestehende Libraries zu sein. Andere machen das mal eben für ein Projekt ohne auch nur mal vom 2er-Komplement gehört zu haben ;-)
hänschen schrieb: > Soweit ich das mitbekommen habe, benutzt die C-Umgebung den Stack um > ständig benutzte Register (in Schleifen etc.) zu retten und > wiederherzustellen Auf einem Cortex A/R ist das so. Der Cortex M nutzt Hardware-Autostacking. Jeder Stackfehler führt sofort zum Hardfault: http://www.keil.com/forum/59365/stacking-and-interrupts/
Na ja ... Dr. Sommer schrieb: > Andere machen das mal eben für ein Projekt ohne auch nur mal vom > 2er-Komplement gehört zu haben ;-)
Lothar schrieb: > Auf einem Cortex A/R ist das so. Der Cortex M nutzt > Hardware-Autostacking. Jeder Stackfehler führt sofort zum Hardfault: Hä? Der C-Compiler legt auch auf einem Cortex-M den Frame auf den Stack (und nutzt dann SP-relative Adressierung, um an die lokalen Variablen zu kommen). Stackfehler führen nicht automatisch zu einem Hardfault - woher auch?
S. R. schrieb: > Stackfehler führen nicht automatisch zu einem Hardfault - woher auch? Auf einem Cortex A/R wird z.B. bei einem Interrupt oder SVC die Registerbank (teilweise) gewechselt, dafür braucht es keinen Stack. Der Cortex M hat keine Registerbänke und muss bestimmte Register auf einen Stack schieben. Das hat mit dem C Compiler nichts zu tun, es ist Hardware-Autostacking. Und wenn der Stack dafür nicht reicht, gibt es Hardfault: http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0337e/Babedgea.html
Lothar schrieb: > Und wenn der Stack dafür nicht reicht, gibt es Hardfault: Der Stack wächst aber in aller Regel von oben nach unten... und damit reicht der Stack eigentlich immer, um die Register zu pushen. Eher gehen deine Daten (Heap, .bss und .data - meist in dieser Reihenfolge) kaputt, und der Hardfault ist eine Konsequenz dessen. Zuviel poppen führt schon eher zum Tilt, aber eben auch nicht immer.
Dr. Sommer schrieb: > Tjo. Manche brauchen Jahre um sich in so komplexe Dinge wie die > ARM-Architektur, Kryptographie-Algorithmen, Assembler, ABI's, > Mikrocontroller-Programmierung/Debugging einzuarbeiten und dabei besser > als ein Compiler und bestehende Libraries zu sein. Andere machen das mal > eben für ein Projekt ohne auch nur mal vom 2er-Komplement gehört zu > haben ;-) Ich bin halt Mathematiker mit Vertiefung in der Crypto und schreibe meine MA in der Informatik/Mathematik ohne Vorkenntnisse bzgl. Programmierung und co. (PHP und CAS zählen da nicht :D ) Das mit den Compilern und Makefile musste ich auch erstmal lernen, genauso C. Wie der Prozessor exakt läuft weiß ich noch nicht, kommt aber langsam. (Learning by doing) Wie lässt sich denn USART in Win auslesen? Ich habe die libopencm3 genutzt und die monitor.sh des FourQ builds von Patrick Longa bei Github.
Ich würde auch empfehlen, dass Du in C codierst und mit Optimierungsstufen des Compilers experimentierst. Der Cortex Kern ist nicht unbedingt intuitiv, was Performanz angeht. Eine der wesentlichen Eigenarten des Kernels ist z.B. dass Operationen rein im Kernel um Grössenordnungen schneller sind als auf dem Bus operierende, und auf den internen Bussen (iCode und dCode) operierende wesentlich schneller sind als die, die auf dem externen Bus operieren. Du wirst z.B. merken, dass ein auf Geschwindigkeit optimerter Compiler ein Schleife durch "unfolding" auflöst. Er wird also z.B. eine Schleife mit n Iterationen in n/4 Durchläufe derselben Schleife übersetzen, wobei jede Iteration vier mal denselben Code enthält,dabei aber mit vier verschiedenen Registersätzen seine Zwischenvariablen vorhält. Dadurch werden Datenbuszyklen minimiert. Der Geschwindigkeitsgewinn kann gigantisch sein (ich diskutiere das ansatzweise in Kapitel 2 meines Buches). Die Zahl 4 ist dabei variabel; je nachdem, wieviel Register frei sind, werden mehr oder weniger Iteration aufgefaltet. Eine andere "Falle" ist z.B., dass der Cortex M7 Kern auf Parallelität optimiert ist, d.h. die Anordnung der Maschinenbefehle macht einen Riesenunterschied - zwei aufeinanderfolgende, voneinander unabhängige Operationen können durch die 5 stage pipeline im selben Zyklus abgearbeitet werden. All diese Dinge weiss ein fähiger Compiler, aber Du musst es lernen und kannst dabei mglw. Mehr Zeit im Verständnis der Architektur verbringen als Du brauchst, um dein Problem zu lösen.
> Schreibe deinen Quelltext so, dass sämtliche mathematischen Operationen > als Funktionen ausgeführt sind So mache ich das auch, dass ich möglichst wenig in einer Funktion verarbeite und diese Teilfunktionen dann in einer Hauptfunktion aufrufe. > und achte darauf, dass der Compiler diese > grundsätzlich inlined (also im Ergebnis kein Funktionsaufruf mehr > stattfindet). Das mit dem Inlinen habe ich nicht ganz nachvollziehen können. Das Buch, das ich zum Lernen von C las, hat sowas nicht behandelt, wenn ich mich recht erinnere. > Das ist einer der wenigen Fälle, wo man Code (Funktionen als "static > inline", vielleicht auch mit "__attribute__((always_inline))") in einem > Header haben sollte. > > Diese Funktionen kannst du später mit inline-Assembler umschreiben, wenn > dir die Standardfunktion / Bibliotheksfunktion nicht ausreichen sollte. d.h. ich habe dann z.B. in einer Lib die Funktion "void add(unsigned int a, unsigned b, long long *c)" Diese macht zum Beispiel: a+b und speichert das Ergebnis im Speicherort von c. Hier sehe ich keine Zerspaltungsmöglichkeit. Aber nehme ich z.B.
1 | #typedef int gf_t[11] |
2 | #typedef gf_t gf16_t[16] |
3 | void add_gf16(gf16_t a, gf16_t b, gf16_t c) |
Diese macht das Gleiche, wie zuvor, aber diesmal mit Arrays. (Nennt man die überhaupt so an dieser Stelle?) Hier würde ich per for-Schleife über jeden Eintrag iterieren. Nach Speed optimiert, wäre noch ein Test a_i == 0 || b_i == 0 dabei. Constant-Time nicht. (Kann man in C auch, wie in PHP, a_i || b_i == 0 schreiben? Oder äquivalentes?) Innerhalb der for-Schleife würde ich dann
1 | static inline add_gf(gf_t a, gf_t b, gf_t c_i) |
aufrufen (habe mal meiner Vermutung nach "static inline" einfach davor gestellt.) Diese Funktion wäre wieder eine For-Schleife, die ich dann über obiges "static inline add(int,int,long long)" definiert hätte. Wäre das eine korrekte/vorgestellte Anwendung?
@Ruediger Asche Da gebe ich Dir recht. Ich habe hier auch ein buch "The definitive guide to ARM Cortex-M3 and [...] M4 Processors". Meine Erwartungen an das Buch waren ursprünglich, dass ich auf Programmierebene durch die Eigenheiten des Prozessor geleitet werde, aber von Programmierung ist darin kaum eine Spur. :) Insgesamt habe ich einen groben Plan, wie der Code auf einer 32-Bit Basis erzeugt werden muss, damit er läuft. Die Performance versuche ich durch Vorüberlegungen zu erzeugen. Mein Plan ist sowieso erstmal alles in C soweit zu schreiben, dass es darin für mein (auf den Zeitpunkt bezogen) Verständnis nicht weiter in C optimiert werden kann. Danach würde ich einige Elemente in ASM versuchen zu schreiben. Orientiert an den Compilerausgaben. Dazu gehört für mich erstmal zu verstehen (ganz im Allgemeinen natürlich immer ;) ) wie die ASM-Befehle Arbeiten und abgearbeitet werden. Erst wenn ich weiß wie der vorliegende Code überhaupt arbeitet, kann ich ja erst in der Lage sein seine Schwach-/Verbesserungsstellen zu entdecken. Am liebsten wäre mir zum Verständnis erlernen erstmal ein Buch, dass auf Basis des M4 (oder wenigstens im Kern anwendbar auf den M4 ist) den ASM-Code einführt, vorstellt und vervollständigt. Ist der Befehlssatz egtl. für alle Prozessoren der Architektur STMv7-M identisch? (Ich hoffe ich schreibe die Architektur richtig..ist halt die des M4 und anderen, ohne Vectoring)
Christopher S. schrieb: > @Ruediger Asche > > > Am liebsten wäre mir zum Verständnis erlernen erstmal ein Buch, dass auf > Basis des M4 (oder wenigstens im Kern anwendbar auf den M4 ist) den > ASM-Code einführt, vorstellt und vervollständigt. Ich kenne so ein Buch nicht und würde es auch nicht selber schreiben (dazu ist die daran interessierte Ziegruppe zu klein). > Ist der Befehlssatz > egtl. für alle Prozessoren der Architektur STMv7-M identisch? (Ich hoffe > ich schreibe die Architektur richtig..ist halt die des M4 und anderen, > ohne Vectoring) Du meinst, ob M4 und M7 Befehlssätze identisch sind? Jein. M7 hat Double Precision FPU Befehlssätze, die auf dem M4 mit FPU nicht zur Verfügung stehen, aber solange Du Dich auf den M4 Befehlssatz beschränkst, kannst Du kompatible Befehle verwenden. Wie sie sich verhalten, ist aber wie gesagt durch die 6 stage Pipeline nicht unbedingt identisch. Ein hilfreicher Vergleich zwischen den Architekturen findet sich hier: http://chipdesignmag.com/sld/blog/2014/10/24/this-is-not-your-father%E2%80%99s-mcu/
Christopher S. schrieb: > Ich möchte demnächst lernen mit asm für den Microkontroller zu > programmieren. vs. > Dabei strebe ich aber nur Berechnungen an. beißt sich schon mal erheblich. Mach die Berechnungen in C, dafür ist das optimal. Den Aufwand erst Asm zu lernen und hinterher zeitintensiv damit zu codieren rentieren eventuelle, keineswegs sichere Effizienzgewinne in den seltensten Fällen. Und dann Asm auch noch für komplexe Architekturen wie ARM... Assembler zu verwenden macht höchstens auf einfachen 8Bittern Sinn.
Schau mal in den Technical Reference Manuals nach... Cortex M3: http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0337h/index.html Von dort aus kommst du auch zu den anderen manual. Nachdem der instruction dispacher im compiler die ganzen timings kennt, glaube ich nicht, dass du wesentlich schnelleren code bauen kannst. viel wichtiger als die instruktionen sind z.b. die berücksichtigung der cache-line größen und vor allem der algorithmen. im aller besten fall bekommst du duch reine ASM implementierungen geschwindigkeitszuwächste im niedrigen einstelligen prozentbereich (wenn du den compiler entsprechend optimieren lässt.. Stichword LTO, loop-unrolling,...). 73
Ruediger A. schrieb: > Christopher S. schrieb: >> @Ruediger Asche >> >> >> Am liebsten wäre mir zum Verständnis erlernen erstmal ein Buch, dass auf >> Basis des M4 (oder wenigstens im Kern anwendbar auf den M4 ist) den >> ASM-Code einführt, vorstellt und vervollständigt. > > Ich kenne so ein Buch nicht und würde es auch nicht selber schreiben > (dazu ist die daran interessierte Ziegruppe zu klein). > >> Ist der Befehlssatz >> egtl. für alle Prozessoren der Architektur STMv7-M identisch? (Ich hoffe >> ich schreibe die Architektur richtig..ist halt die des M4 und anderen, >> ohne Vectoring) > > Du meinst, ob M4 und M7 Befehlssätze identisch sind? Jein. M7 hat Double > Precision FPU Befehlssätze, die auf dem M4 mit FPU nicht zur Verfügung > stehen, Ja und nein... das ist mal wieder ein optionales Feature http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0489d/CACHBAHH.html Bspw. haben die STM32F7x3 und STM32F7x2 oder der F745 und die F7x6 nur Single Precision, die anderen aus der Reihe (F7x7, 7x8 und 7x9 ebenso der 765) dagegen Double Precision. Spielt bei dem Projekt aber keine Rolle, da nur Integer-Arithmetik verwendet werden dürfte und die Befehlssätze ansonsten afaik identisch sind. Unterschiede ansonsten u.a. Bit Band, dass es nur auf M4s gibt (außer der Hersteller hat für den M7 selber was gebastelt) und beim M4 kann man zw. 32- und 64-Bit Stack Alignment wählen, beim M7 ist es immer 64-Bit
Für sehr viel Mathematik gibt es in der CMSIS DSP lib passende Funktionen: http://arm-software.github.io/CMSIS_5/DSP/html/index.html Das Zeug ist von ARM geschrieben und in Assembler handoptimiert. Den Aufruf dieser Funktionen würde ich getrost dem C-Compiler überlassen, schneller als der bekommt man das wohl kaum hin. Viele Grüße, Stefan
Markus schrieb: > Christopher S. schrieb: >> Ich möchte demnächst lernen mit asm für den Microkontroller zu >> programmieren. > > vs. > >> Dabei strebe ich aber nur Berechnungen an. > > beißt sich schon mal erheblich. Mach die Berechnungen in C, dafür ist > das optimal. Den Aufwand erst Asm zu lernen und hinterher zeitintensiv > damit zu codieren rentieren eventuelle, keineswegs sichere > Effizienzgewinne in den seltensten Fällen. Und dann Asm auch noch für > komplexe Architekturen wie ARM... Seit wann ist ARM komplex? ;) > Assembler zu verwenden macht höchstens > auf einfachen 8Bittern Sinn. Bei den meisten Sachen heute würde ich zustimmen, aber nicht bei dem speziellen Fall hier... siehe oben > Side Channel Cryptanalysis Lounge > https://www.emsec.rub.de/research/projects/sclounge/ Einige der nötigen Gegenmaßnahmen machen es u.U. erforderlich, die Algorithmen in Assembler zu implementieren oder zumindest dem Compiler/Optimizer sehr, sehr genau auf die Finger zu schauen. Mal eben den Lehrbuch-Algorithmus in C runterschreiben ist bei kryptographischen Algorithmen/Protokollen eher keine gute Idee. Stefan K. schrieb: > Für sehr viel Mathematik gibt es in der CMSIS DSP lib passende > Funktionen: > > http://arm-software.github.io/CMSIS_5/DSP/html/index.html > > Das Zeug ist von ARM geschrieben und in Assembler handoptimiert. Die Lib rechnet nicht mit großen Integern wie sie bei den Verfahren hier nötig sind.
Angehängte Dateien:
-

assembly-vs-c.png
110 KB -

assembly-vs-c2.png
98 KB
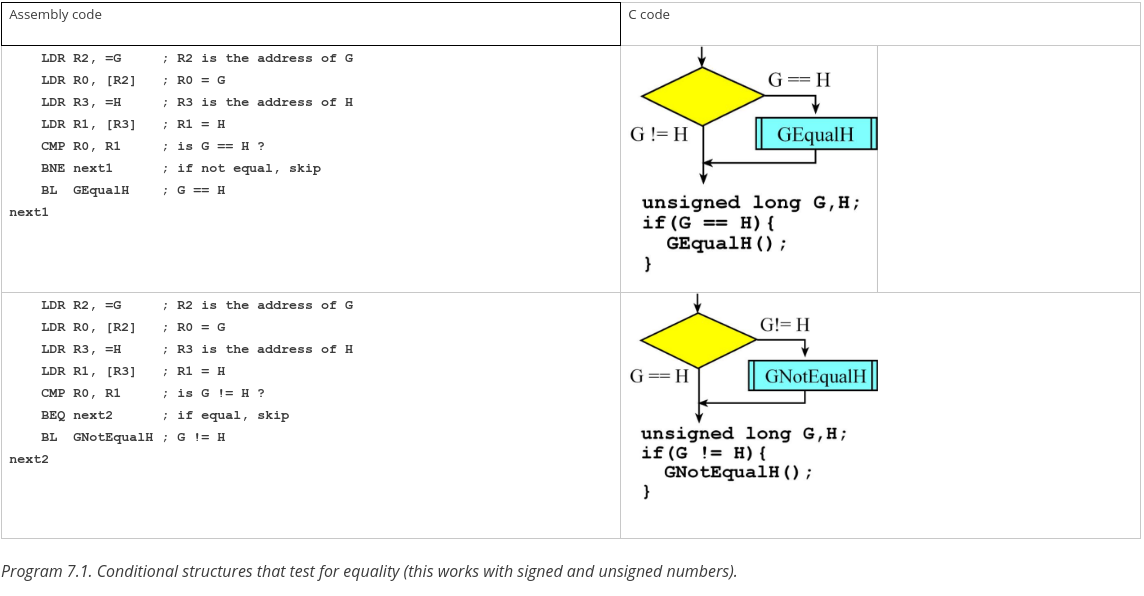
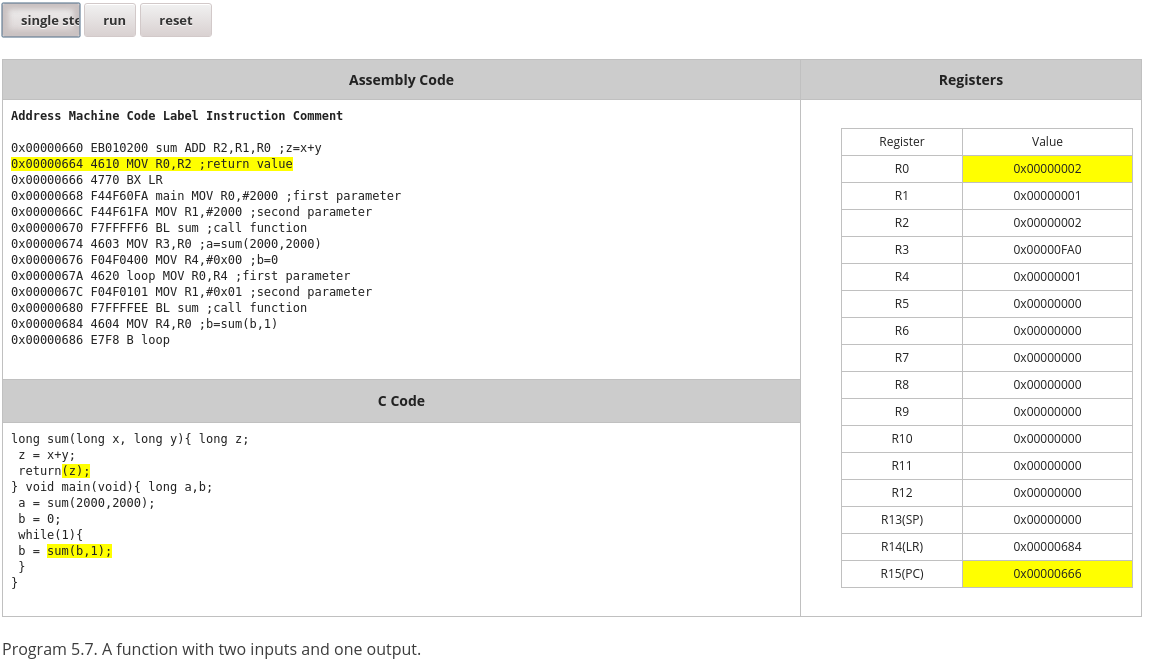
Ich finde den MOOC "Embedded Systems Shape the World" bei edx.org gar nicht so schlecht. Genau genommen gibt es zwei Stück, wobei der eine auf dem anderen aufbaut. Hier mal ein paar Auszüge, die dich vielleicht etwas weiterbringen: Registers: https://youtu.be/VB8iLtfy3Cc Assembly Language: https://youtu.be/F9HZfJWdV-A Interrupt Processing: https://youtu.be/Kt_pVkFPj3c Auch ansonsten werden im Kurs sehr gut die Zusammenhänge zwischen C und Assembler verdeutlicht, siehe Screenshots. Der Autor des Kurses hat auch ein Buch geschrieben, was Cortex-M4 in der Tiefe behandelt: https://www.amazon.de/Embedded-Systems-Introduction-CortexTM-M-Microcontrollers/dp/1477508996/ref=sr_1_3?ie=UTF8&qid=1504099591&sr=8-3&keywords=Jonathan+Valvano Sehr hilfreich fand ich persönlich auch http://www.davespace.co.uk/arm/introduction-to-arm/ bzw. http://www.davespace.co.uk/arm/efficient-c-for-arm/ Ansonsten unbedingt empfehlenswert finde ich das oben schon genannte "The Definitive Guide to ARM Cortex-M3 and Cortex-M4 Processors". Da wird das komplette Kapitel 5 für Assembler verwendet ("Instruction set"), wobei das eher als Referenz zu sehen ist. Wenn man vorher noch nichts mit Assembler gemacht hat wird man daraus vielleicht nicht unbedingt schlau. Als Student kannst du das Buch eventuell kostenlos herunterladen. Schlussendlich muss ich aber meinen Vorrednern zustimmen, dass es sehr sehr schwer sein wird, den Compiler zu schlagen. Viel Erfolg dabei.
Arc N. schrieb: > Bei den meisten Sachen heute würde ich zustimmen, aber nicht bei dem > speziellen Fall hier... siehe oben >> Side Channel Cryptanalysis Lounge >> https://www.emsec.rub.de/research/projects/sclounge/ > > Einige der nötigen Gegenmaßnahmen machen es u.U. erforderlich, die > Algorithmen in Assembler zu implementieren oder zumindest dem > Compiler/Optimizer sehr, sehr genau auf die Finger zu schauen. > Mal eben den Lehrbuch-Algorithmus in C runterschreiben ist bei > kryptographischen Algorithmen/Protokollen eher keine gute Idee. Ähm... Side Channel Attacks haben zu 99.99% nichts mit der Programmiersprache zu tun! Timing-Analysen kann man z.B so unmöglich machen, dass du einen Timer startest wenn die Anfrage kommt und das ergebnis erst beim Ablauf zurück gibst => immer idente Laufzeit. Gegen Angriffe über Stromaufnahme und/oder Abstrahlung hilft die möglichst alles im Chip dauerhaft zu beschäftigen (oder eben ein Chip der auf sowas hin optimiert wurde). Zusätzlich könnte man ja den Algorithmus in zufälligen Abständen einfach unterbrechen und z.B. nebenbei Pi berechnen.... Wenn überhaupt würde ich für einige teile eine funktionale sprache verwenden um implementierungsfehler zu verringern... angeblich sei mit denen bei der implementierung von algorithmen die häufigkeit von fehlern geringer... kann ich aber für mich nicht bestätigen :o) was ich sagen will: Die Sprache ist wurscht für Geschwindigkeit, Side-Channel-Attacks,... Wichtiger ist das Design vom Gesamtsystem - und das ist total unabhängig davon. 73
Markus schrieb: > Christopher S. schrieb: >> Ich möchte demnächst lernen mit asm für den Microkontroller zu >> programmieren. > > vs. > >> Dabei strebe ich aber nur Berechnungen an. > > beißt sich schon mal erheblich. Mach die Berechnungen in C, dafür ist > das optimal. Den Aufwand erst Asm zu lernen und hinterher zeitintensiv > damit zu codieren rentieren eventuelle, keineswegs sichere > Effizienzgewinne in den seltensten Fällen. Und dann Asm auch noch für > komplexe Architekturen wie ARM... Assembler zu verwenden macht höchstens > auf einfachen 8Bittern Sinn. Leider gehts aber auch um µs Zeitgewinn. :)
Markus schrieb: > Und dann Asm auch noch für komplexe Architekturen wie ARM... > Assembler zu verwenden macht höchstens auf einfachen 8Bittern Sinn Also die Komplexität ist erstmal 8051 < ARM < PIC < AVR :-) ARM Assembler kommt schliesslich vom 6502 da ist gar nichts komplex. Was beim STM32 komplex ist, ist nicht der ARM Kern, sondern die merkwürdige Peripherie, dabei ist DMA oder ART noch gar nicht gemeint.
Lothar schrieb: > Also die Komplexität ist erstmal 8051 < ARM < PIC < AVR :-) Äh... Also ich konnte den AVR-Instruction Set nach einiger Nutzung schnell auswendig, bei ARM muss ich immer noch nachschlagen...
Christopher S. schrieb: > Leider gehts aber auch um µs Zeitgewinn. :) Nur um dich ein wenig auf den Arbeitsaufwand vorzubereiten... Ich hab letztes Jahr ein paar kleine Assembler Funktionen geschrieben um Audio-Daten verschiedener Bitbreiten und Abtastraten linear(!!!) interpoliert auf verschiedene Zielformate aufzublasen. Selbst jener absurd simple Code hatte am Ende 2200 Zeilen. Der Aufwand war einzig und allein dadurch zu rechtfertigen, dass der Code in jener Form für das kommende Jahrzehnt wiederverwendet werden soll und auf teilweise sehr schwachbrüstigen Prozessoren laufen muss, wo ein paar µs tatsächlich weh tun. Bei deinen Posts weiter oben versteh ich teilweise nicht einmal die Ausdrücke, also möcht ich mir gar nicht erst ausmalen wie komplex die Berechnungen teilweise sein werden... Bei einem derart "Algorithmen"-lastigen Projekt würde ich mir vermutlich sogar überlegen nicht gleich in Python oder was ähnlich "hohem" anzufangen.
Hans schrieb: > Timing-Analysen kann man z.B so unmöglich machen, dass du einen Timer > startest wenn die Anfrage kommt und das ergebnis erst beim Ablauf zurück > gibst => immer idente Laufzeit. Problem sind da aber kombinierte Angriffe. Timing-Attacks sind ja schon leicht abzuwehren, wenn man dann noch Power-Analysis fährt hilft nur > Gegen Angriffe über Stromaufnahme und/oder Abstrahlung hilft die > möglichst alles im Chip dauerhaft zu beschäftigen (oder eben ein Chip > der auf sowas hin optimiert wurde). Zusätzlich könnte man ja den > Algorithmus in zufälligen Abständen einfach unterbrechen und z.B. > nebenbei Pi berechnen.... Sinnlose oder weitere Berechnungen. Die Frage ist dann ob nicht interne Mechanismen Additionen/Multiplikationen mit 0 ohnehin ohne Berechnungen unter den Tisch fallen lassen würden. Dafür müsste man aber vorher tiefer in die Sets gucken :( > Wenn überhaupt würde ich für einige teile eine funktionale sprache > verwenden um implementierungsfehler zu verringern... angeblich sei mit > denen bei der implementierung von algorithmen die häufigkeit von fehlern > geringer... kann ich aber für mich nicht bestätigen :o) Da kenne ich jetzt nur Haskell. Schöne Sprache, wird mir aber bei meinem Projekt zu viel :D > was ich sagen will: Die Sprache ist wurscht für Geschwindigkeit, > Side-Channel-Attacks,... Wichtiger ist das Design vom Gesamtsystem - und > das ist total unabhängig davon. + EMS Messungen lassen sich ja auch auf einer bestimmten Distanz erfolgreich durchführen. Dagegen hilft nur eine Hardwarehärtung -> Farradayscher Käfig/Blei... :D Oder entsprechend Cryptounits. Der BSI gibt hierfür ja auch Hardware frei.
Vielen Dank für die Ausführungen. Helfen werden sie gewiss. Christopher J. schrieb: > Ansonsten unbedingt empfehlenswert finde ich das oben schon genannte > "The Definitive Guide to ARM Cortex-M3 and Cortex-M4 Processors". Da > wird das komplette Kapitel 5 für Assembler verwendet ("Instruction > set"), wobei das eher als Referenz zu sehen ist. Wenn man vorher noch > nichts mit Assembler gemacht hat wird man daraus vielleicht nicht > unbedingt schlau. Als Student kannst du das Buch eventuell kostenlos > herunterladen. Das Buch habe ich hier im Regal stehen, ist allerdings für einen blutigen Anfänger mit Systemen, Programmieren und co. echt ne Hausnummer zu hoch und viel zu speziell. Die Version ausschließlich für M3 lässt sich übrigens auch als Direkdownload über Google finden ;)
Das Buch von Joseph Yiu ist auch mehr ein Nachschlagewerk als etwas, was man von Anfang bis Ende durcharbeitet. Für letzteres wäre wohl eher das Buch von Jonathan Valvano geeignet. Das steigt auf einem sehr tiefen Level ein. Die Kapitel über GPIO und co kannst du ja erstmal überspringen. Da es dir eigentlich nur um die Berechnungen geht kannst du die ja mit jedem CM4 durchführen, egal ob der jetzt von TI oder STM kommt. Ich denke aber nach wie vor, das du erstmal den Kram in C implementieren solltest und erst danach die Sache in ASM angehen solltest. Was nutzt dir denn eine ASM-Implementierung wenn du keine Messlatte hast? PS: Ich würde sogar soweit gehen, den Algorithmus erstmal nur auf dem PC zu implementieren. Wenn du dir bei den Datentypen ein bisschen Mühe gibst, dann ist der C-Code 1:1 portabel. Entwickeln und debuggen direkt am PC ist aber erstmal deutlich einfacher als auf einem Mikrocontroller.
Christopher J. schrieb: > Das Buch von Joseph Yiu ist auch mehr ein Nachschlagewerk als etwas, was > man von Anfang bis Ende durcharbeitet. Für letzteres wäre wohl eher das > Buch von Jonathan Valvano geeignet. Das steigt auf einem sehr tiefen > Level ein. Die Kapitel über GPIO und co kannst du ja erstmal > überspringen. Da es dir eigentlich nur um die Berechnungen geht kannst > du die ja mit jedem CM4 durchführen, egal ob der jetzt von TI oder STM > kommt. Ich denke aber nach wie vor, das du erstmal den Kram in C > implementieren solltest und erst danach die Sache in ASM angehen > solltest. Was nutzt dir denn eine ASM-Implementierung wenn du keine > Messlatte hast? So mache ich es sowieso. Es sollte erstmal ein Produkt stehen, erst danach macht es Sinn an "Optimierung" zu denken ;) > PS: Ich würde sogar soweit gehen, den Algorithmus erstmal nur auf dem PC > zu implementieren. Wenn du dir bei den Datentypen ein bisschen Mühe > gibst, dann ist der C-Code 1:1 portabel. Entwickeln und debuggen direkt > am PC ist aber erstmal deutlich einfacher als auf einem Mikrocontroller. So viel einfacher wird es nicht unbedingt, der Aufwand reduziert sich um eine Kommandozeileneingabe erhöht sich aber auf zwei Makefiles :) Ich habe das Board über einen STlink-v2 und einem PL2303 (mit altem Treiber, der neue hatte das Ding unbrauchbar gemacht) mit Windows und einer VM mit Ubuntu 16.04 LTS verbunden. Über Windows kompiliere ich zur *.bin (mein gcc in Ubuntu läuft nicht, anstelle der Zeitaufbringung zum Fixen habe ich es lieber so gelassen und einen Shared-Ordner eingerichtet. Läuft auch Prima. :) ) Über Ubuntu flashe ich mit "st-flash write <dir/file.bin> 0x8000000" wobei ich nicht weiß, warum ich genau 0x80000000. Ich wusste es aber mal ganz genau :( Hatte irgendwas mit dem reservierten nicht-beschreibbaren Speicher zu tun, wenn ich mich richtig erinnere. Habe hier übrigens auch ein grünes Script, das von TI und Cortex M4 handelt. Btw. das Buch "The Definitive Guide..." hatte ~23€ + Versand gekostet.
Hans schrieb: > Arc N. schrieb: >> Bei den meisten Sachen heute würde ich zustimmen, aber nicht bei dem >> speziellen Fall hier... siehe oben >>> Side Channel Cryptanalysis Lounge >>> https://www.emsec.rub.de/research/projects/sclounge/ >> >> Einige der nötigen Gegenmaßnahmen machen es u.U. erforderlich, die >> Algorithmen in Assembler zu implementieren oder zumindest dem >> Compiler/Optimizer sehr, sehr genau auf die Finger zu schauen. >> Mal eben den Lehrbuch-Algorithmus in C runterschreiben ist bei >> kryptographischen Algorithmen/Protokollen eher keine gute Idee. > > Ähm... Side Channel Attacks haben zu 99.99% nichts mit der > Programmiersprache zu tun! > > Timing-Analysen kann man z.B so unmöglich machen, dass du einen Timer > startest wenn die Anfrage kommt und das ergebnis erst beim Ablauf zurück > gibst => immer idente Laufzeit. Wäre eine Möglichkeit, führt aber je nach Häufigkeit zu erheblicher unnützer Systemlast und schlechtem Durchsatz... "Efficient Cache Attacks on AES, and Countermeasures" https://www.tau.ac.il/~tromer/papers/cache-joc-20090619.pdf > Gegen Angriffe über Stromaufnahme und/oder Abstrahlung hilft die > möglichst alles im Chip dauerhaft zu beschäftigen (oder eben ein Chip > der auf sowas hin optimiert wurde). Alles beschäftigen reicht nicht, erhöht zwar das Rauschen und damit die Dauer des Angriffs unterbindet den aber nicht (ausreichend). > Zusätzlich könnte man ja den > Algorithmus in zufälligen Abständen einfach unterbrechen und z.B. > nebenbei Pi berechnen.... Kann reichen, muss nicht, kann es sogar verschlimmern > Wenn überhaupt würde ich für einige teile eine funktionale sprache > verwenden um implementierungsfehler zu verringern... angeblich sei mit > denen bei der implementierung von algorithmen die häufigkeit von fehlern > geringer... kann ich aber für mich nicht bestätigen :o) Es geht bei diesen Seitenkanalangriffen darum, eine formal korrekte Implementation anzugreifen... Ansonsten wird das Thema funktionale Sprachen hier "etwas" zu sehr OT ;) > was ich sagen will: Die Sprache ist wurscht für Geschwindigkeit, > Side-Channel-Attacks,... Wichtiger ist das Design vom Gesamtsystem - und > das ist total unabhängig davon. Unabhängig würde ich nicht sagen, denn bei einigen Sprachen besteht gerade keine Möglichkeit ausreichend auf den generierten Code (zur Not eben durch Einsatz von handgeschriebenem Assemblercode) Einfluss zu nehmen, um einige der Angriffe unterbinden zu können. Ansonsten ist das Design natürlich das wichtigste bspw. um erst mal überhaupt zu sehen/festzulegen, gegen welche Angriffe das System abgesichert werden muss/soll.
Dr. Sommer schrieb: > Was kann der Inline Assembler denn nicht, was der gas kann? Das geht ja schon los mit ".syntax unified" um dem SUB / SUBS Schleifen Crash bei gemeinsamem Code für M0 und M4 entgegen zu wirken. > bei ARM muss ich immer noch nachschlagen Ich meinte Cortex A/R bzw. klassische ARM sind einfach. Beim Cortex M muss ich auch nachschlagen bzw. nutze halt viele Befehle nicht, wenn ich mich grade nicht dran erinnern kann.
Lothar schrieb: > Was beim STM32 komplex ist, ist nicht der ARM Kern, sondern die > merkwürdige Peripherie, dabei ist DMA oder ART noch gar nicht gemeint. Zu dumm daß das eine nicht ohne das andere zu bekommen ist.
D.Sperber schrieb: > Lothar schrieb: >> Was beim STM32 komplex ist, ist nicht der ARM Kern, sondern die >> merkwürdige Peripherie, dabei ist DMA oder ART noch gar nicht gemeint. > > Zu dumm daß das eine nicht ohne das andere zu bekommen ist. Deshalb sind auch einige Hersteller auf die Idee gekommen Software zu schreiben, die einem, zumindest am Anfang, diese ganze Konfigurationsorgien abnehmen... CubeMX von ST halte ich da immer noch für eine der besten Lösungen (Diskussionen über die Libs besser in einem anderen Thread...). Umschreiben und optimieren und sich in die Details der div. Peripherie einarbeiten kann man dann immer noch bzw. überlässt am Anfang eben dem generierten Code die Arbeit und macht nur das, was man sich gerade aneignen will.
D.Sperber schrieb: >> Was beim STM32 komplex ist, ist nicht der ARM Kern, sondern die >> merkwürdige Peripherie, dabei ist DMA oder ART noch gar nicht gemeint. > > Zu dumm daß das eine nicht ohne das andere zu bekommen ist. Die NXP LPC hatten mal einen 8051 Kern und jetzt haben sie einen ARM Kern. Die Peripherie ist gleich einfach geblieben. Es gibt sogar bitaddressierbaren Speicher ganz ohne Bitbanding.
Beitrag #5128913 wurde von einem Moderator gelöscht.
Norbert schrieb im Beitrag #5128913: > Arc N. schrieb: >> Deshalb sind auch einige Hersteller auf die Idee gekommen Software zu >> schreiben, die einem, zumindest am Anfang, diese ganze >> Konfigurationsorgien abnehmen > > Da ersetzt das eine nur das andere. Hier noch eine zusätzliche Software, > da noch eine Hochsprache. Framworks, Tools wohin das Auge blickt. Alles > will richtig beherrscht und konfiguriert werden. Statt immer mehr > bürokratischen vereinfachungsvortäuschendem Wasserkopf lieber das Übel > an der Wurzel packen und gleich möglichst einfache Hard-und Software > verwenden! Aufgrund der Andeutungen des TO zu den eigentlichen Berechnungen/Algorithmen kann man zumindest schließen, dass sich AVRs etc. dazu heute nicht mehr eignen (außer man will schauen wie sich so was auf Smartcards etc. macht)... > Asm auf STM32 fällt jedenfalls nicht in diese Kategorie. Warum nicht? Alles was nicht extrem optimiert werden muss wird wie üblich in einer Hochsprache gemacht. Die kritischen Algorithmen erst mal ebenso und wenn das nicht reicht oder um zu sehen was machbar ist, dann u.U. die Optimierung mit handgeschriebenem Assembler. Komplizierter als AVR-Assembler ist Assembler auf Cortex-M ebenso nicht. Eher einfacher
Beitrag #5129743 wurde von einem Moderator gelöscht.
Zum Glück muss ich mich mit der Hardware nicht sonderlich rumschlagen :D Selbst die LED's sind mir egal. :-) So lange USART läuft, läufts. Ich werde wohl noch einen F429_USART schreiben, damit mein zweiter Mikrocontroller auch die Ausgaben auswerfen kann. :) Es liegt vermutlich nur an Adressen, die der STM32F429 für das on-Board-Display verbraucht hat. Apropos On-Board-Display: Gibt es dafür eine Lib, sodass ich darauf einfach (Ohne viel Aufwand meinerseits) Text schicken kann, der mir dann dargestellt wird? <- Neuer Thread?
Pete K. schrieb: > egbert schrieb: >> Abgesehen von der Tatsache, das sich "c" nicht für seriöse und >> ernsthafte Programmprojekte eignet: > > Blödsinn. (siehe z.B. Linux Kernelentwicklung) Welcher Teil von "ernsthafte Programmprojekte" ist unverständlich?
egbert schrieb: > Welcher Teil von "ernsthafte Programmprojekte" ist unverständlich? Dann hau doch mal einen raus und nenne uns einmal eines deiner ernsthaften Projekte, wenn dir Linux schon zu trivial ist!
Christopher S. schrieb: > Die Primzahl p hat 339-Bit und ich arbeite in GF(p^16). Woher kommen eigentlich p und GF und die elliptische Kurve? Ist das alles hausbacken oder implementiert das ein bekanntes, beschriebenes System? M.W. Nicht alle Darstellungen von GF (vermutlich per Adjunktion einer formalen Nullstelle eines irr. Polynoms vom Grade 16 über GF(p)) sind kryptographisch gleichwertig. Wenn es um Performace geht und GF "frei" gewählt werden kann, dann wäre auch über GF(2^n) nachzudenken — EC über GF(2^n) sind ja kein Hexenwerk (und wenn bist du der Hexer). Über den Daumen gepeilt wäre n > 5000, ziemlich viel für ein auf EC basierenden System... > Einzelne Elemente sollen dann entsprechend in ASM (falls möglich) > geschrieben werden. D.h. egtl. nur die Multiplikation, Addition, > Subtraktion und co. Die meiste Laufzeit werden Multiplikation und Division verschlingen, + und + sind da Pillepalle ;-) Wichtig ist auf jeden fall, kritische Daten in schnellen Speicher zu lokatieren; lahmer Speicher kann Algorithmen mehr ausbremsen als suboptimaler Code. Zu bedenken ist auch, dass Asm-Code, der schnell "aussieht", nicht unbedingt schnell ist. Wenn du dich nicht genau mit Pipelining, Caching, Scheduling etc. auskennst, kann es gut sein, dass ein "schlecht" aussehender, von einem Compiler erzeugter Code deinem "optimierten" Asm-Code aussticht...
Beitrag #5130176 wurde von einem Moderator gelöscht.
Beitrag #5130195 wurde von einem Moderator gelöscht.
Beitrag #5130202 wurde von einem Moderator gelöscht.
Beitrag #5130207 wurde von einem Moderator gelöscht.
Johann L. schrieb: > Christopher S. schrieb: >> Die Primzahl p hat 339-Bit und ich arbeite in GF(p^16). > > Woher kommen eigentlich p und GF und die elliptische Kurve? https://eprint.iacr.org/2017/334 KSS16 mit der 35-Bit Primzahl. Btw. mein "Bit-Zähl-Algorithmus" hat das LSB ausgelassen. p hat tatsächlich 340 Bit, was aber keinen Unterschied macht. > Ist das alles hausbacken oder implementiert das ein bekanntes, > beschriebenes System? Kommt drauf an. KSS16 Kurven waren kaum bis kein Gegenstand der Forschung. Das "optimal Ate-Pairing" hingegen schon. Auch sind die verwendeten Methoden bis zum Ende ausgereizt, laut Experten aus dem Bereich. Es gibt keine Sicht auf mathematischen Fortschritt in dieser Richtung. > M.W. Nicht alle Darstellungen von GF (vermutlich per Adjunktion einer > formalen Nullstelle eines irr. Polynoms vom Grade 16 über GF(p)) sind > kryptographisch gleichwertig. Ich betrachte F_p[x]/(X^16 -2). Auch habe ich dafür bereits den Frobenius-Endomorphismus ausgerechnet. Nun bin ich dabei erstmal die Operationen für GF(p^16) zu schreiben, die dann auf GF(p) koeffizientenweise basieren. Bei der Multiplikation bin ich mir derzeit noch nicht sicher, wie ich das angehe. Dazu gibt es ja einige Paper. Auch weiß ich noch nicht, ob ich Montgomery oder Karatsuba verwenden werde. Für beide Algos fehlen mir noch Informationen bzw. eine Gegenüberstellung. Aktuell würde ich Karatsuba verwenden, wobei ich weiß, dass Montgomery in den letzten Jahren immer mehr implementiert wurde. > Wenn es um Performace geht und GF "frei" gewählt werden kann, dann wäre > auch über GF(2^n) nachzudenken — EC über GF(2^n) sind ja kein Hexenwerk > (und wenn bist du der Hexer). Über den Daumen gepeilt wäre n > 5000, > ziemlich viel für ein auf EC basierenden System... Ja, zur Charakteristik 2 würden sich einige Berechnung wirklich beschleunigen lassen, da es da (Fallabhängig) nur Bitschupsen wäre. Leider ist es vorgeschrieben. >> Einzelne Elemente sollen dann entsprechend in ASM (falls möglich) >> geschrieben werden. D.h. egtl. nur die Multiplikation, Addition, >> Subtraktion und co. > > Die meiste Laufzeit werden Multiplikation und Division verschlingen, + > und - sind da Pillepalle ;-) Wichtig ist auf jeden fall, kritische > Daten in schnellen Speicher zu lokatieren; lahmer Speicher kann > Algorithmen mehr ausbremsen als suboptimaler Code. Ich kenne mich mit den Speichertypen gar nicht aus, habe quasi kein Wissen aus der Informatik. Ich versuche nur mein einwöchiges C-Buchlesen, etwas Mathematik und Lesen von Algorithmen zu verbinden und daraus eine Abgabe zu erschaffen, die wenigistens von den Überlegungen her valide erscheint ;) Mit Vorwissen in C und Architekturen/Speicherarten und entsprechendes mathematisch vertieftes Vorwissen wäre die Arbeit wirklich ein 2 Wochenprojekt. Mein (mathematischer) Background liegt bei ca. 60 Seiten bestehend aus für mich zu 90% neuem Inhalt. Als Prozessor habe ich ja den STM32F407VGT6 auf einem CJMCU Board. (Bilder hatte ich mal in einem anderen Thread gepostet, den ich auch angefangen hatte, um eine LED auf dem Board blinken zu lassen. Was übrigens bis heute nicht funktioniert aber auch egal ist, seitdem ich USART auslesen kann.) > Zu bedenken ist auch, dass Asm-Code, der schnell "aussieht", nicht > unbedingt schnell ist. Wenn du dich nicht genau mit Pipelining, Caching, > Scheduling etc. auskennst, kann es gut sein, dass ein "schlecht" > aussehender, von einem Compiler erzeugter Code deinem "optimierten" > Asm-Code aussticht... Ja, gute Punkte. Ich werde mich mit ASM auch erst auseinander setzen, wenn ich wirklich nichts mehr in C machen kann. Ich hoffe noch im September fertig zu werden. Ich nutze auch viel das Buch von Mrabet "Guide to Pairing-Based Cryptography" und eine Vielzahl aktuellerer Paper.
Christopher S. schrieb: > Ich kenne mich mit den Speichertypen gar nicht aus, habe quasi kein > Wissen aus der Informatik. Gibt hier * https://www.mikrocontroller.net/articles/Speicher einen guten Artikel für dem Bereich embedded - mit Vergleich - dazu. mfg Olaf
egbert schrieb: > Welcher Teil von "ernsthafte Programmprojekte" ist unverständlich? Wie wäre es mit Windows? Ist größtenteils in C geschrieben, ebenso wie MS Office. Arc N. schrieb: > Aufgrund der Andeutungen des TO zu den eigentlichen > Berechnungen/Algorithmen kann man zumindest schließen, dass sich AVRs > etc. dazu heute nicht mehr eignen (außer man will schauen wie sich so > was auf Smartcards etc. macht)... Da habe ich mal einem Vortrag von NordicSemi (zu IoT) beiwohnen dürfen, wo es u.a. darum ging, was man braucht, um erträgliche Zeiten für Bluetooth (Pairing und Verbindung herstellen) bei minimalem Energieverbrauch zu erreichen. Das war schon ziemlich beeindruckend, und definitiv nix mehr für einen AVR.
Statt ASM sollten die Hersteller der gesamten µC sich darauf konzentrieren, dass das Programmieren viel einfacher wird und somit eine viel breitere Masse diese Teile nutzen kann. Erstmal würden dann vielleicht viele neue und wichtige Errungenschaften aufkommen (da nicht jeder brillante Kopf ASM auf einem Cortex lernen will), die so nie das Licht der Welt erblicken. Und diese ganzen "man muss das von der Picke auf lernen" Typen, sind doch auch nur Heuchler. Sie haben auch nicht das Erz ausgegraben, eingeschmolzen und aus dem Stahl ein Messer geschmiedet, nur damit sie morgens ihr Brötchen scheiden und mit Butter bestreichen können. Wie viele von diesen Typen können ihr Auto komplett zerlegen, instand setzen und dann wieder zusammen bauen. Bin mir sicher, dass die meisten nicht mal alle Flüssigkeiten kontrollieren könnten.
F. F. schrieb: > egbert schrieb: >> Welcher Teil von "ernsthafte Programmprojekte" ist unverständlich? > > Dann hau doch mal einen raus und nenne uns einmal eines deiner > ernsthaften Projekte, wenn dir Linux schon zu trivial ist! Wo bleiben jetzt deine "ernsthaften Projekte"?
F. F. schrieb: > Statt ASM sollten die Hersteller der gesamten µC sich darauf > konzentrieren, dass das Programmieren viel einfacher wird und somit eine > viel breitere Masse diese Teile nutzen kann. hust Arduino hust
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.