Ich würde gerne eine kleine CPU (ohne Interrupt, nur Befehle abarbeiten)
in VHDL auf einem FPGA (Cyclone II) erstellen, dazu hätte ich ein paar
Fragen:
1. Ich hab hier ein ganz gutes Dokument
(http://users.etech.haw-hamburg.de/users/Schwarz/En/Publications/Sample/Chap8.pdf)
gefunden, dass den Aufbau einer CPU in VHDL beschreibt, auf Seite 10 &
11 wird der Aufbau der ALU verdeutlicht, da gibt es ein
1
generic(DEL:time:=10ns);
später bei der architecture-Definition befindet sich hinter den
Verarbeitungsschritten ein
1
afterDEL;
Warum macht man das bzw. benötigt man das zwingend?
2. Wenn ich einen Befehl "Lade Wert von Adresse xyz" mit einer
Befehlswortbreite von 8-Bit (4-Bit Opcode und 4-Bit Daten), ich aber
einen 8-bit breiten Adressbus habe (weil ich 256Byte adressieren können
möchte), wie kann ich dann in 4-bit Daten trotzdem 8-bit Adressen
adressieren?
Oder macht es mehr Sinn, die Befehlsbreite auf 12-Bit zu erhöhen (also
4-Bit Opcode und 8-bit Daten)?
Max M. schrieb:> auf Seite 10 &> 11 wird der Aufbau der ALU verdeutlicht, da gibt es ein> generic (DEL: time:=10ns);>> später bei der architecture-Definition befindet sich hinter den> Verarbeitungsschritten ein> after DEL;>> Warum macht man das bzw. benötigt man das zwingend?
Ohne Gewähr: Das ist nur für die Simulation. Wird unter 8.3.2 näher
erklärt.
Max M. schrieb:> Warum macht man das bzw. benötigt man das zwingend?
Die Zuweisung erfolgt dann halt erst nach einer gewissen Zeit. Wo das
synthesefähig sein soll ist mir ein Rätsel.
Max M. schrieb:> 2. Wenn ich einen Befehl "Lade Wert von Adresse xyz" mit einer> Befehlswortbreite von 8-Bit (4-Bit Opcode und 4-Bit Daten), ich aber> einen 8-bit breiten Adressbus habe (weil ich 256Byte adressieren können> möchte), wie kann ich dann in 4-bit Daten trotzdem 8-bit Adressen> adressieren?
Zum Beispiel indem du mit den 4 Bit nur ein Register adressierst in dem
die eigentliche Adresse steht. Sinnvoll wäre es trotzdem, längere
Instruktionen zuzulassen. Muss ja auch nicht jede Instruktion gleich
lang sein.
Max M. schrieb:> Warum macht man das bzw. benötigt man das zwingend?>
Wurde ja schon erklärt, aber der Gag daran ist wohl, dass für den
Anfänger die Wellenformen etwas expliziter (im Sinne der Abtaktung von
Signalen) werden. Aber daran gewöhnen sollte man sich nicht :-)
> 2. Wenn ich einen Befehl "Lade Wert von Adresse xyz" mit einer> Befehlswortbreite von 8-Bit (4-Bit Opcode und 4-Bit Daten), ich aber> einen 8-bit breiten Adressbus habe (weil ich 256Byte adressieren können> möchte), wie kann ich dann in 4-bit Daten trotzdem 8-bit Adressen> adressieren?
Na mit einem H/L-Bit, d.h. sowas wie
1
0x94 ; lade high nibble mit 0x4
2
0x1c ; lade low nibble mit 0xc
12Bit-Opcodes? Denk mal drüber nach, wie das im Speicher organisiert
werden müsste (Stichwörter: effektive Speicherzellen-Grösse versus
Pack-Logik-Aufwand).
Max M. schrieb:> Oder macht es mehr Sinn, die Befehlsbreite auf 12-Bit zu erhöhen (also> 4-Bit Opcode und 8-bit Daten)?
Ein Befehlswort sieht bei Load store maschinen gern so aus:
Instruction - SRC-Addr - Dest-Addr
Nur eine Addresse zu verwenden impliziert einen Akkumulator als
Standard-Dest, das will keiner mehr.
Schau mal hier im Forum nach piBla - das ist ein VHDL Nachbau der 8bit
CPU picoblaze, da ist das instruction word 16bit lang und wie folgt
eingeteilt:
1
84--parts within instructionword
2
85--the coded operation (sometimes 6, sometimes 8 bit long, seldom longer
C. A. Rotwang schrieb:> Nur eine Addresse zu verwenden impliziert einen Akkumulator als> Standard-Dest, das will keiner mehr.
Ja so hatte ich das eigentlich vor, habs so auch im Studium gelernt. Mir
ist klar, dass die CPU keiner braucht, soll ja nur für mich zum Spielen
sein.
Mir erscheint das irgendwie simpler, es mit einem Akkumulator zu machen.
Es sollte wirklich sehr einfach sein für den Anfang, da ich mich nicht
mit VHDL auskenne und mit CPU Design auch nicht wirklich.
Ich hab mir 16 Befehle ausgedacht die imho erstmal reichen, von daher
würde ich den Opcode 4-bit lang machen
C. A. Rotwang schrieb:> da ist das instruction word 16bit lang und wie folgt> eingeteilt:
Ich hab leider auch keinen Plan, wie ich die Größe des Operanden mit
VHDL dynamisch einteilen kann, also z.B. dass der Befehl
1
LD0xAF;ladeDatenvonAdresse0xAFindenAkkumulator
2-Bit groß ist und ich dann den vollen Adressraum ansprechen kann, dann
reichen 10-bit Wortbreite, oder?
Das Problem ist nur, dass ich aktuell 5 Befehle habe, die als Operanden
eine Adresse haben (Jump wenn Carry, Jump wenn Zero, Jump wenn Equal,
Jump zu Adresse), die passen nicht in 2-bit rein :(
Irgendwie komplizierter als ich dachte.
Max M. schrieb:> Das Problem ist nur, dass ich aktuell 5 Befehle habe, die als Operanden> eine Adresse haben (Jump wenn Carry, Jump wenn Zero, Jump wenn Equal,> Jump zu Adresse), die passen nicht in 2-bit rein :(
Jetzt weißt du, wieso üblicherweise OPCodes mehr als 2 Bit haben...
Ist doch eigentlich ganz simpel. Entweder nimmst du eine fixe länge und
lebst damit, am besten sowas wie 16 Bit. Oder du definierst OPCode
Gruppen, lässt dann zB. die ersten 4 Bit die erste Gruppenhierarchie
bestimmen, gehst dann zur nächsten usw. Dann kannst du verschiedene
längen haben, je nach dem in welcher Gruppe ein Befehl ist eben. Dafür
wird halt der Decoder aufwändiger.
Korrektur das Picoblaze Intructionword ist 18bit breit, beim AVR sind es
16.
Die Arbeit mit Registerfile statt akku ist nicht viel anders, für das
Registerfile baut man sich einen Dual Port RAM aus distributed Mem, legt
die addressbits aus dem Instruction word an den adressbus des dualPort
rams und muxt dann nur noch den Datenbus abhängig vom Instructionword
(Scratchpad-Ram, IO, Register). Der Speicher den der Pibla addressieren
kann ist aber sehr klein 1k glaube ich.
Am besten du mals erst mal ein Blockbild der Datenpfade mit
Multiplexern, dann erklärt sich das fast von selbst. Und schau mal in
die Doku von Picoblaze und dessen Vürgänger KCPSM:
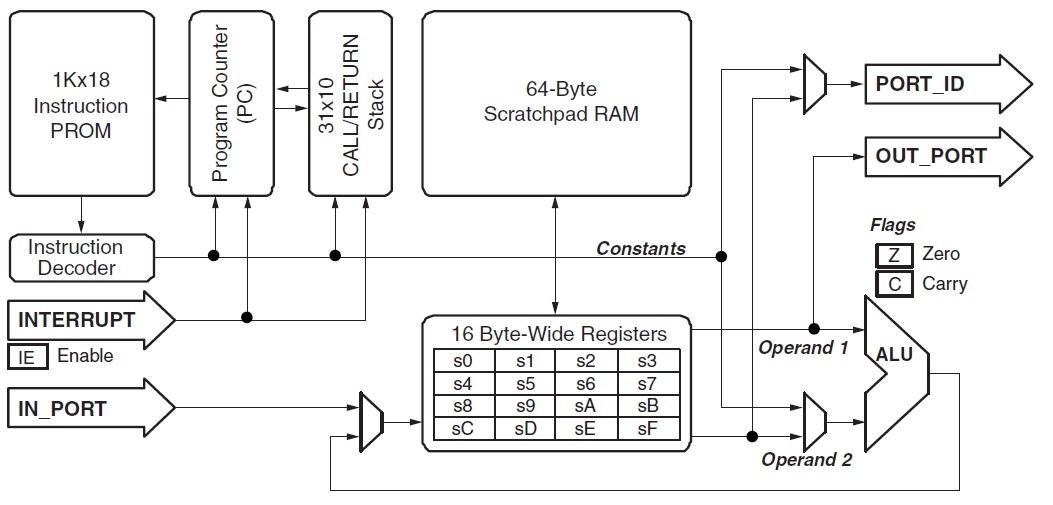
http://www.mcu-turkey.com/wp-content/uploads/2012/12/picoblaze_Architec.jpghttp://3.bp.blogspot.com/-tL-oQJMDhQI/UXMt4lGYtxI/AAAAAAAAATc/pSKvyAKdWhw/s1600/core.jpghttps://www.xilinx.com/support/documentation/ip_documentation/ug129.pdf
Im Anhang D ab S. 115 ist gezeigt welche bedeutung die einzelnen bits
des Instruction words haben.
Naja, diese 8bit CPU ist vielleicht ein wenig schlecht handhabbar für
jemanden, der nach einer einfachen Implementierung sucht.
Wer es etwa dicker mag, kann sich mal Renes MAIS anschauen:
Beitrag "Mais-CPU veröffentlicht 32bit Softcore"
Ich hatte mit dem Entwickler schon Kontakt und mir das auch angesehen,
ist allerdings für meine privaten Zwecke etwas zu speziell, wenn auch
beachtenswert.
Guest schrieb:> Oder du definierst OPCode> Gruppen, lässt dann zB. die ersten 4 Bit die erste Gruppenhierarchie> bestimmen, gehst dann zur nächsten usw. Dann kannst du verschiedene> längen haben, je nach dem in welcher Gruppe ein Befehl ist eben. Dafür> wird halt der Decoder aufwändiger.
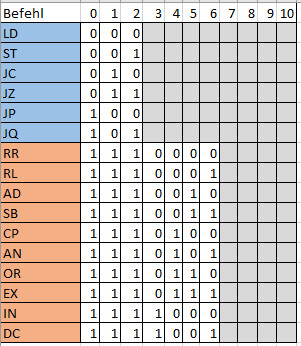
Macht das Sinn, was ich hier gemacht habe (siehe Anhang)?
C. A. Rotwang schrieb:> Am besten du mals erst mal ein Blockbild der Datenpfade mit> Multiplexern, dann erklärt sich das fast von selbst.
Das werde ich machen, danke.
Max M. schrieb:> Macht das Sinn, was ich hier gemacht habe (siehe Anhang)?
Hm, da fehlt meines Erachtens das wesentliche -> die Unterteilung in
Befehl (Operation) und Daten (Operanden), siehe Wikipedia
https://en.wikipedia.org/wiki/Instruction_set_architecture#Parts_of_an_instruction
Das Ganze als Single-word instruction set aufzuziehen ist m.E. sehr
Sinnvoll, und im FPGA wenn man die interne RAM-Blöcke nutz die sich zu
unterschiedliche Busbreiten konfigurieren lassen (16/18/20/24 bit)
einfach realisierbar. Bei Nutzung externer Speicher wird man bei
"krummen Werten" (abseits von 8+n bits) schnell ein paar bits
verschenken.
Es gibt ein paar Klassiker zum Thema CPU entwerfen, die finden sich in
besseren Bibliotheken in der Abteilung Computer-Architektur. Meine
Empfehlung: ISBN: 348659190 auch die älteren Auflagen aus dem vorherigen
Jahrtausend sind m.E. recht brauchbar.
Bücher , die direkt mit der FPGA-Implementierung beginnen halte ich eher
ungeeignet - bevor die erste Codezeile geschrieben wird, sollte man sich
einige Gedanken zu Realisierung und Architektur machen. Beispielsweise
sollte klar sein wie man den/die Arbeitsspeicher verschaltet wenn man
sich für Hatvard und gegen v. Neumann entscheidet.
C. A. Rotwang schrieb:> Hm, da fehlt meines Erachtens das wesentliche -> die Unterteilung in> Befehl (Operation) und Daten (Operanden), siehe Wikipedia
Der graue Bereich sollte die Daten sein :)
C. A. Rotwang schrieb:> bevor die erste Codezeile geschrieben wird, sollte man sich> einige Gedanken zu Realisierung und Architektur machen. Beispielsweise> sollte klar sein wie man den/die Arbeitsspeicher verschaltet wenn man> sich für Hatvard und gegen v. Neumann entscheidet.
Das sehe ich auch so
C. A. Rotwang schrieb:> Bei Nutzung externer Speicher wird man bei> "krummen Werten" (abseits von 8+n bits) schnell ein paar bits> verschenken.
Also sind 11-Bit eher ungeeignet als Wortbreite?
C. A. Rotwang schrieb:> Sorry, Fehler in der ISBN, gemeint ist das:
Danke für den Tipp
Moin,
wenn du keinen Systemprozessor bauen willst und mit wenig Resourcen
auskommen musst, i.e. Distributed RAM nutzt, spricht nix gegen höhere
Bitbreite, und beim BlockRAM sind die Breiten typischerweise in
9-Bit-Einheiten organisiert.
Fang doch einfach mal an. Es ist ja zum Lernen, da musst du dir sowieso
die Nase blutig rennen.
Zum Studium sollte man sich sicher mal den 8051, PDP11 und MIPS
reinziehen. So richtig kompakt wäre dann noch die ZPU (8 bit opcodes, 32
bit Datenbreite) oder gar die J1 (pure Stack-Maschine). Zu MIPS findet
man an amerikanischen Unis ne Menge, z.B.
http://db.cs.duke.edu/courses/cps104/spring10/lectures/6up-lecture05.pdf
Bisschen mehr advanced ist das RISC-V Zeug.
Zu erwähnen letztlich noch: Um nicht von Anfang an zuviel verpropfende
Logik zu entwerfen, kann man anfangs die ganze State-Machine mit
Pseudo-Opcodes einer deutlich höheren Breite designen und anschliessend
einen Interpreter für die 8 bit opcodes vorschalten. Vorsehen muss man
nur einen "Wait/Stall"-Zustand. Und dann tut man sich dasselbe ev.
nochmal mit Pipelining an.
Und wenn du dann DOCH mal noch Exception/IRQ Handling einbauen willst,
musst du allenfalls nur die interne FSM aufbohren oder neu machen.
VHDL ist allerdings beim CPU-Design eine rechte Bremse. Wenn du Python
kannst, sparst du mit MyHDL massiv Zeit in der funktionalen Entwicklung,
der Schritt zur Synthese ist dann klein. Die Risc-V-Dinger sind in
Chisel entworfen, aber ob man sich das antun will...
Strubi schrieb:> Wenn du Python> kannst, sparst du mit MyHDL massiv Zeit in der funktionalen Entwicklung
Ich kann zwar (etwas) Python, aber ich hab mir gedacht, ich arbeite mich
in die Standard-Tools ein, und die bieten eben (zumindest Quartus II)
nur VHDL und Verilog, außerdem mach ich das zwar aus Spaß aber ich
wollte das auch in meine Bewerbung für eine eventuelle
Werkstudentenstelle einbauen (falls ich da nicht zu optimistisch bin),
ich weiß nicht, wie weit MyHDL verbreitet ist.
Strubi schrieb:> Fang doch einfach mal an. Es ist ja zum Lernen, da musst du dir sowieso> die Nase blutig rennen.
Ja, mach ich jetzt auch. Ich hab das FPGA hier liegen und Quartus II
offen aber in meinem Kopf herrscht noch rechtes Wirrwarr, ich mach
erstmal so einen Blockplan.
Die kleinstmögliche CPU, die ich kenne findet man bei GitHub hier:
https://github.com/cpldcpu/MCPU . Die ist nicht nur in VHDL und Verilog
beschrieben, sondern ein Simulator und ein Assembler in C werden auch
mitgeliefert.
>Die kleinstmögliche CPU, die ich kenne
Sehr schön, nur 4 Instructionen.
Ich hatte vor einiger Zeit mal mit dem Nibbler ein wenig herumprobiert:
https://www.bigmessowires.com/nibbler/
Dabei ist mir aufgefallen, dass das größte Hindernis für eine bestimmte
Klasse von Programmen ( z.B. ein Forth Interpreter ) das fehlen von
relative Adressierungen ist. Die braucht man unbedingt, wenn man
Software-Stacks programmieren will.
Hab ich dann einen Flash mit 256 x 11 Program Memory und einen RAM oder
sind Befehle und RAM in einem Speicher?
Also was lässt sich einfacher auf einem FPGA implementieren?
Max M. schrieb:> Also was lässt sich einfacher auf einem FPGA implementieren?
Lass hören, wenn dus geschafft hast, Flash in FPGA Fabric zu
implementieren. Moderne CPUs sind harvard Architekturen, deren Cache
Controller auf einen gemeinsamen Speicherbus zugreifen. Sprich, der Kern
sieht getrennte Programm- und Datenspeicher, in Wirklichkeit liegt aber
alles in einem großen RAM.
Was für deine Anwendung (welche ist das überhaupt?) sinnvoll ist musst
du selber wissen.
Max M. schrieb:> Strubi schrieb:>> Fang doch einfach mal an. Es ist ja zum Lernen, da musst du dir sowieso>> die Nase blutig rennen.>> Ja, mach ich jetzt auch. Ich hab das FPGA hier liegen und Quartus II> offen aber in meinem Kopf herrscht noch rechtes Wirrwarr, ich mach> erstmal so einen Blockplan.
Du hast sicher nicht nur den nackten FPGA sondern ein Board mit FPGA und
anderen Chips. Leg mal fest was deine erste CPU von dem Board mit nutzen
soll. Soll der Speicher auf dem Board (wahrscheinlich DDR-RAM, SRAM
und7oderFlash) der Arbeitsspeicher für die CPU sein? IMHO ist es für den
Start einfacher, den Board Speicher nicht einzubinden, sondern allein
die Speicher-blöcke auf dem FPGA als Programm und Arbeitsspeicher zu
nutzen.
> Fang doch einfach mal an. Es ist ja zum Lernen, da musst du dir sowieso> die Nase blutig rennen.
Anfangen ja , losstürzen nein. Halt Dich nicht zu lang mit dem Entwurf
des Instruction sets auf, es sollte schon lang genug sein um einen 8 bit
Directoperanden mitaufzunehem oder eine längere (?10bit?)
direkt-Sprungaddresse (dann kannst du problemlos 1024 Zeilen Code
benutzen). Falls dir Registerbank zu kompliziert ist dann bau fürs erste
ne Akku-Maschine.
Aufbohren würde ich die erste CPU später nicht, sondern eine zweite
from the scratch beginnen. So ne einfache CPU ist nicht übermäßig viel
in VHDL (ca. 500 zeilen), man muss sich auch nicht viel mit
paramtrisierbaren/skalierbaren Eigenschaften (Generics für Größe
Arbeits-Befehlsspreicher) oder Re-Use rumschlagen. Das kann mensch bei
CPU Nr. 3 machen. Und die gegen CPU #1 um die Wette laufen lassen um
Optimierungsbedarf für CPU #4 zu erkennen.
> Also sind 11-Bit eher ungeeignet als Wortbreite?
Sie werden einfach nicht ausreichen für Op-code und Directoperanden. Ich
würde auf mindestens 16 bit gehen. Wenns 15,17,18 bit sinds ists fürs
erste auch egal, da verschwendet mal halt ein paar bits. Wenn du den
fpga-externen Speicher nutzen willst solltest du dich natürlich an
dessen Busbreite orientieren. Aber das würde ich eher nicht für CPU #1
vorsehen.
Mich wundert es ja immer, dass so viele Leute eine CPU auf dem FPGA
implementieren wollen. Mich interessiert das zwar selber, aber weniger,
weil ich es so verwenden will, sondern eher aus akademischem Interesse.
Ansonsten gibt es FPGAs mit integrierter CPU wie das Zynq oder die
Möglichkeit, eine MCU mit einer FPGA zu kombinieren.
Das BlackIce MyStorm finde ich ganz interessant:
http://hamsterworks.co.nz/mediawiki/index.php/MyStorm_Blackice
Max M. schrieb:> später bei der architecture-Definition befindet sich hinter den> Verarbeitungsschritten einafter DEL;> Warum macht man das
Damit der Lehrer dem Schüler schön das vorher und nachher zeigen kann.
> bzw. benötigt man das zwingend?
Meine Empfehlung: niemals symbolische Delays. Die dort angenommen Zeiten
passen eh' nicht zur Hardware und können seltsame Effekte hervorrufen.
Siehe den Beitrag "Re: Simulation - Bei Abtastung anliegendes Signal übernehmen" und die
darin enthaltenen Links.
Zum Thema CPU auf dem FPGA: die Arbeit führt letztlich in eine
Sackgasse, weil du für deine CPU sowieso keinen Assembler oder Compiler
hast.
Ich habe auch noch nie eine gebaut, aber stattdessen schon einige
"schlaue" Peripheriemodule, die auch programmierbar sind, und ihre
Prozessabarbeitung selber steuern. Man könnte diese Blöcke
"Coprozessoren" nennen.
Lothar M. schrieb:> weil du für deine CPU sowieso keinen Assembler oder Compiler> hast.
Ich hab vor, einen Assembler dafür zu schreiben, der dann VHDL-Code
erzeugt und ich das nur per Copy-Paste in Cyclone II übernehme,
wahrscheinlich stelle ich mir das gerade zu einfach vor.
C. A. Rotwang schrieb:> sondern allein> die Speicher-blöcke auf dem FPGA als Programm und Arbeitsspeicher zu> nutzen.
Okay, dann mache ich das.
C. A. Rotwang schrieb:> Sie werden einfach nicht ausreichen für Op-code und Directoperanden.
Wenn es sich um einen 4-Bit Prozessor handelt? Also der Akku hat 4-bit
und die ALU kann 4-bit Operationen verarbeiten.
C. A. Rotwang schrieb:> Du hast sicher nicht nur den nackten FPGA sondern ein Board mit FPGA und> anderen Chips.
Ja, das stimmt. Es ist ein Altera DE1 mit externem SRAM, SDRAM und
Flash.
Guest schrieb:> (welche ist das überhaupt?)
Einfach rumprobieren :D
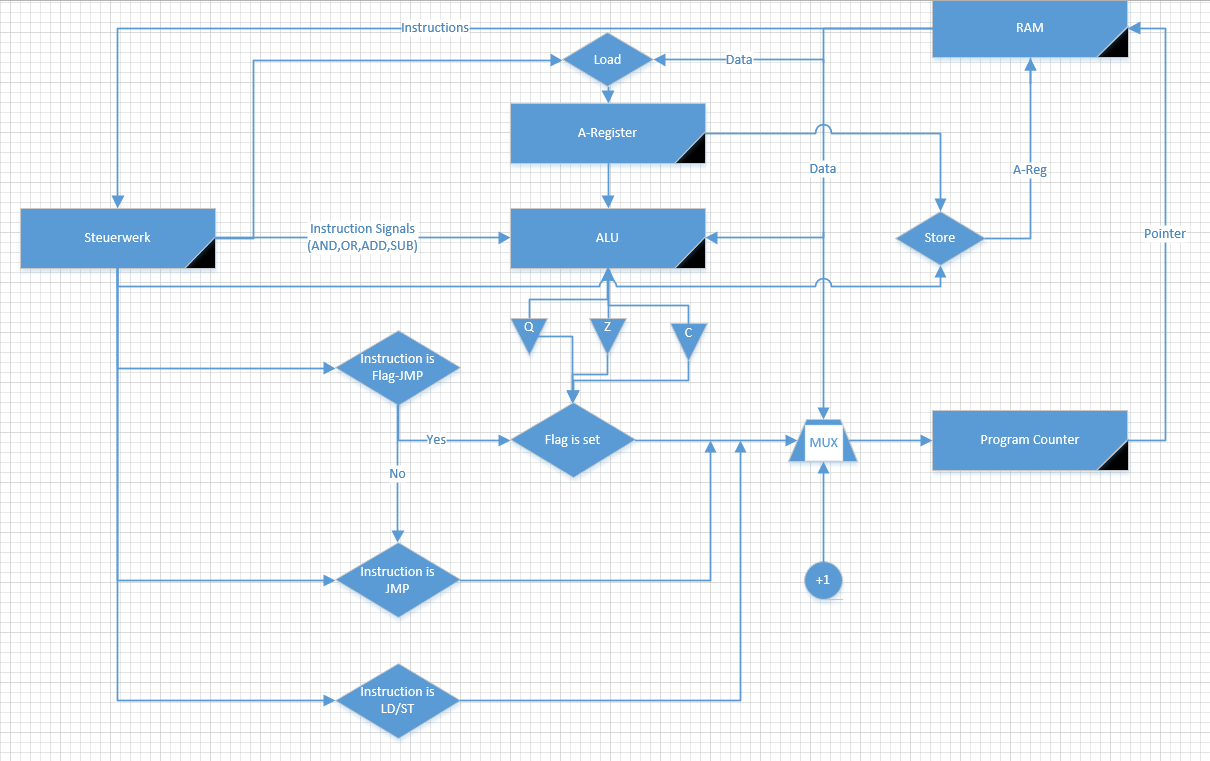
Ich hab mal versuch, ein Blockbild zu malen, wie ich mir das ungefähr
vorstelle.
Was ich nicht ganz verstehe:
Bei einem Load-Befehl (also Daten aus dem RAM in das A-Register laden),
muss in einem Takt der Program Counter auf den Wert der Instruktion
gestellt und das Flag im Steuerwerk für "Es ist ein Load Befehl" gesetzt
werden. Dann muss der RAM aber noch mit der neuen PC-Adresse
aktualisiert werden, so dass er die Daten richtig an das A-Register
weitergibt, und schließlich muss das A-Register die Daten noch
übernehmen - klappt das überhaupt?
Edit: Okay das ist kompletter Blödsinn, bei einem Load/Store sollte der
PC gar nichts machen -.-
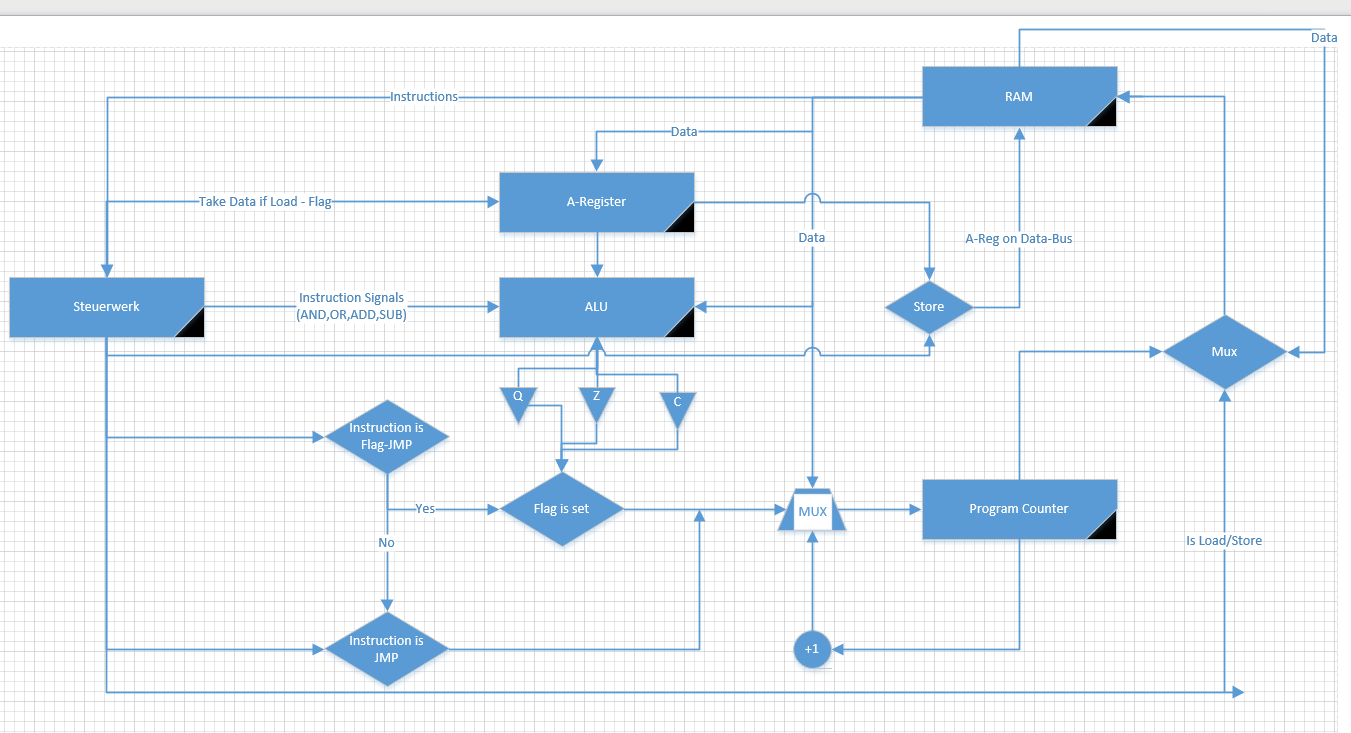
Edit_2: Eher so?
Um das zusammenzufassen: Deine Cpu enthält den Akkumulator AC, den
Befehlszähler PC und das Befehlsregister IR. Die Register sind jeweils
16 Bit lang und beim Befehlsregister werden 4 Bits als Opcode verwendet
und 12 Bits als Adresse. Zum Speicher geht der Adressbus und der
Datenbus
Die Ausführung des Load-Befehls geht dann so:
1
PC auf den Adressbus geben
2
Datenbus vom Speicher in das IR übertragen
3
Funktion im IR dekodieren
4
...
5
Wenn Load-Befehl
6
12 Bits aus dem IR auf den Adressbus geben
7
Datenbus vom Speicher in den AC übertragen
8
zum Anfang
9
Wenn Store-Befehl
10
12 Bits aus dem IR auf den Adressbus geben
11
AC auf den Datenbus zum Speicher geben
12
zum Anfang
13
Wenn Add-Befehl
14
12 Bits aus dem IR auf den Adressbus geben
15
AC auf AC + Datenbus vom Speicher setzen
16
...
Einen fertigen Befehlssatz für eine ähnliche Cpu findest Du bei
https://www.pcengines.ch/toy2.htm
Dort wird auf einen Artikel in der Byte 01/87 verwiesen, den kann man
bei archive.org herunterladen.
Alexander D. schrieb:> Datenbus vom Speicher in das IR übertragen> Funktion im IR dekodieren
Warum geht das nicht in einem Schritt? Also die Instruktionen direkt
dekodieren?
Max M. schrieb:> Warum geht das nicht in einem Schritt? Also die Instruktionen direkt> dekodieren?
Das Dekodieren des Befehls kann natürlich nur mit einigen Logikgattern
geschehen und nicht in einem eigenen Zustand. Trotzdem wird ein
Load-Befehl in zwei Schritten ausgeführt, weil man zwei Speicherzugriffe
benötigt. Mit dem ersten Speicherzugriff holt man den Befehl und die
Adresse für den Load-Befehl. Diese Adresse muss man zwischenspeichern,
da sie beim zweiten Speicherzugriff für die Daten des Load-Befehls
benötigt werden.
Das sieht man schön bei der im ersten Beitrag von mir erwähnten MCPU in
der Datei "tb02cpu2.vhd". Die Ausführung erfolgt dort auch in zwei
Schritten und gesteuert wird das über einen endlichen Automaten, der für
jeden Schritt und jeden Befehl einen eigenen Zustand hat.
Das alles lässt sich natürlich mit Pipelining und einer
Harvard-Architektur beschleunigen.
Alexander D. schrieb:> Das alles lässt sich natürlich mit Pipelining und einer> Harvard-Architektur beschleunigen.
Zu dem Thema würden mich Beispiele oder Literaturtipss interessieren.
Alexander D. schrieb:> Max M. schrieb:>> Warum geht das nicht in einem Schritt? Also die Instruktionen direkt>> dekodieren?>> Das Dekodieren des Befehls kann natürlich nur mit einigen Logikgattern> geschehen und nicht in einem eigenen Zustand. Trotzdem wird ein> Load-Befehl in zwei Schritten ausgeführt, weil man zwei Speicherzugriffe> benötigt. Mit dem ersten Speicherzugriff holt man den Befehl und die> Adresse für den Load-Befehl. Diese Adresse muss man zwischenspeichern,> da sie beim zweiten Speicherzugriff für die Daten des Load-Befehls> benötigt werden.> Das alles lässt sich natürlich mit Pipelining und einer> Harvard-Architektur beschleunigen.
Nicht ganz , Havard beschleunigt nicht diesen doppelten Speicherzugriff
sondern überführt ihn in zwei einzelne Zugriffe, weil es zwei getrennte
Speicher für Befehle und Daten hat.
Man kann auch auf einen Datenspeicher komplett verzichten und dafür mit
einem großen Register-file arbeiten, da gabs mal von Atmel vor
Jahrzehnten was. Für Kaffemaschine reicht das.
Direktes Dekodieren funktioniert, siehe
https://www.mikrocontroller.net/articles/PiBla
Cyberpunk schrieb:> Hat jemand hier schon mal versucht ein LLVM Backend zu schreiben?
Es gibt auch weitere Ansätze um die Erstellung der Hardware und Software
zu beschleunigen. ArchC http://www.archc.org/doc.html versucht das zu
automatisieren. Aus der Beschreibung des Prozessors werden ein
angepasster GCC mit Assembler und Simulator erzeugt. So wie ich das
verstanden habe, sind die Zielarchitekturen begrenzt.
Wenn ich eine CPU in VHDL erstelle, ist das dann am Besten, wenn man für
jede Komponente (ALU, Instruktionsregister, Program Counter ...) eine
eigene Datei erstellt und die dann in einer Datei ("Entity" in Quartus
II) alles verknüpft?
Wie erstelle ich in VHDL einen Bus, der 2 oder mehr Komponenten
verbindet, es gibt die signal Bezeichnung, aber wie mache ich
deutlich, dass es sich um das selbe Signal in zwei Komponenten handelt?
Cyberpunk schrieb:> Hat jemand hier schon mal versucht ein LLVM Backend zu schreiben? Ich> hab mal ein paar Tutorials und Anleitungen dazu angeschaut, sieht> eigentlich machbar aus, auch wenns natürlich viel Arbeit ist.
Ja, hab ich. Für ein Community-Projekt macht es auch Sinn, aber wenn man
als einzelner produktiv sein möchte, ist der Aufwand des Unterhalts doch
zu gross. Für einfache DSP-Pipelines braucht/will man kein C und für
Systemprozessoren greift man doch aus pragmatischen Gründen zu den
GNU-Tools. Auf dem FPGA lässt sich alles wunderbar kombinieren.
Am elegantesten geht es IMHO in Python/MyHDL, da kann man aus dem
grossen Regresstest-Skript alle benötigten Module (Hardware-Design,
Assembler, usw) per import aufrufen und seine Testcases integrieren.
Natürlich kann man da auch GCC/LLVM aufrufen.
C. A. Rotwang schrieb:> Nicht ganz , Havard beschleunigt nicht diesen doppelten Speicherzugriff> sondern überführt ihn in zwei einzelne Zugriffe, weil es zwei getrennte> Speicher für Befehle und Daten hat.
Das liest sich etwas missverständlich. Es sind ja typischerweise
parallel ablaufende Zugriffe, insofern schon schneller, wenn die
Archtektur es kann (wie ein m56k).
Max M. schrieb:> Wie erstelle ich in VHDL einen Bus, der 2 oder mehr Komponenten> verbindet, es gibt die signal Bezeichnung, aber wie mache ich> deutlich, dass es sich um das selbe Signal in zwei Komponenten handelt?
Du verbindest deine Komponenten einfach eine Ebene höher mit dem
eindeutig benannten Signal, mehr deutlichermachen tust du da nicht. Hast
du dir Wishbone schon mal angesehen?
E. M. schrieb:> Alexander D. schrieb:>> Das alles lässt sich natürlich mit Pipelining und einer>> Harvard-Architektur beschleunigen.>> Zu dem Thema würden mich Beispiele oder Literaturtipss interessieren.
Wie wärs mit "Rechneraufbau und Rechnerarchitektur" von Axel Böttcher
aus dem Springer Verlag? Hab mich ein bisschen eingelesen und mein
Wissen wieder aufgefrischt vom Studium. Finde es eigentlich ganz gut als
Grundlage.
Alexander D. schrieb:> Cyberpunk schrieb:>> Hat jemand hier schon mal versucht ein LLVM Backend zu schreiben?>> Es gibt auch weitere Ansätze um die Erstellung der Hardware und Software> zu beschleunigen. ArchC http://www.archc.org/doc.html versucht das zu> automatisieren. Aus der Beschreibung des Prozessors werden ein> angepasster GCC mit Assembler und Simulator erzeugt. So wie ich das> verstanden habe, sind die Zielarchitekturen begrenzt.
Interessanter Ansatz, werde ich mir demnächst mal genauer anschauen.
Vielen Dank.
Martin S. schrieb:> Cyberpunk schrieb:>> Hat jemand hier schon mal versucht ein LLVM Backend zu schreiben? Ich>> hab mal ein paar Tutorials und Anleitungen dazu angeschaut, sieht>> eigentlich machbar aus, auch wenns natürlich viel Arbeit ist.>> Ja, hab ich. Für ein Community-Projekt macht es auch Sinn, aber wenn man> als einzelner produktiv sein möchte, ist der Aufwand des Unterhalts doch> zu gross. Für einfache DSP-Pipelines braucht/will man kein C und für> Systemprozessoren greift man doch aus pragmatischen Gründen zu den> GNU-Tools. Auf dem FPGA lässt sich alles wunderbar kombinieren.
Ja klar, interessant ist das ganze wirklich nur fürs Hobby. Ansonsten
nimmt man lieber was fertiges und klatscht seine eigene Peripherie dran.
Wie meinst du das mit den GNU-Tools? An binutils kommt man tatsächlich
nicht drumrum (ld, gasm, objcopy...), aber so wie ich es mitbekommen
habe ist ein LLVM-Backend einfacher Umzusetzen als so ein GCC-Backend
und LLVM/Clang steht dem GCC kaum noch in etwas nach.
Ich kapiers leider immer noch nicht, ich hab nun gestern mal versuch
alle Komponenten zu erstellen.
Wie definiere ich denn einen Daten- bzw. Instruktionsbus in VHDL? Wie
gesagt, ich hab mir das nun so überlegt, dass bei einem Load, Store oder
Jump die ersten 8-Bit der Instruktion als Daten (Adresse) benutzt werden
und ansonsten die ersten 4-Bit (da 4-Bit CPU).
Ich bin mir ebenfalls unsicher, wie ich den einzelnen Komponenten klar
mache, ob es sich nun um einen Jump handelt bzw. wenn ja, um welchen?
Ich glaube, ich hab viel zu viele Flags.
Außerdem bin ich verwirrt von den Datentypen in VHDL, ich wollte einen
Shift-Left und Shift-Right Befehl implementieren, aber jetzt lese ich,
dass das mit einem STD_LOGIC_VECTOR gar nicht geht sondern man einen
bit_vector benötigt - was sind da die Unterschiede? Wenn ich den
Datenbus als STD_LOGIC_VECTOR definiere (?), kann ich dan einen
bit_vector überhaupt auf diesen Datenbus geben da es zwei
unterschiedliche Datentypen sind?
Ich erwarte nicht, dass sich jemand den VHDL-Code ansieht, aber wäre
nett wenn mir jemand Feedback dazu geben könnte.
Moin,
kurzes Feedback:
Schmeiss weg: 'use ieee.std_logic_arith.all;', das sollte man nur noch
in Legacy-Compat-Modulen verwenden. Vielbehandelter Klassiker, nimm
'ieee.numeric_std.all'.
'buffer' auch besser vermeiden, spendier lieber nen extra Output.
Vergiss auch bit_vector, wenn du beliebige shifts (nicht fix) machen
willst, musst du einen Barrel-Shifter implementieren. Oder emulieren,
wie es die kleine ZPU macht.
Womit simulierst du? Ich will ja nicht nerven, aber wenn du noch in den
VHDL-Anfängen steckst, würde ich dir nochmals einen Anfang in MyHDL
nahelegen. Wenn dann dein funktionales Modell sich selbst verifiziert
hat (und damit musst du gleich als erstes parallel anfangen), ist der
Schritt zur Ausgabe [toVHDL(entity, sig1, sig2)] nicht mehr so gross,
und insgesamt sind deine Iterations-Zyklen deutlich kleiner als in pur
VHDL und du kannst dich ganz auf deine Aufgabe fokussieren.
Max M. schrieb:> ich hab nun gestern mal versuch alle Komponenten zu erstellen.
Wenn du jede Kombinatorik jedesmal in jedem Prozess taktest, dann wirst
du bald Bekanntschaft mit dem Begriff "Latency" machen...
1
process(CLK,IsJC,IsJZ,IsJP,IsJQ,QALU,ZALU,CALU)
2
begin
3
if(CLK'EventandCLK='0')then
In getakteten Prozessen hat nur der Takt etwas in der Senstivliste
verloren. Denn nur nach einer Taktflanke muss der Prozess vom Simulator
neu berechnet werden.
1
process
2
begin
3
if(CLK'EventandCLK='0')then
Prozesse brauchen entweder eine Sensitivliste oder z.B. ein "wait until
rising_edge(clk);"
Das wird dir der Synthesizer aber noch mitteilen.
1
process
2
begin
3
if(CLK'EventandCLK='0')then
4
if(CMD=b"0000")then--Shift Right through Carry
5
if(CONTENT(0)='1')then
6
CALU<='1';
7
else
8
CALU<='0';
9
CONTENT<=CONTENTsrl1;
10
endif;
11
elsif(CMD=b"0001")then--Shift Left through Carry
12
if(CONTENT(3)='1')then
13
CALU<='1';
14
else
15
CALU<='0';
16
endif;
17
CONTENT<=CONTENTsll1;
18
elsif(CMD=b"0010")then--Add
19
if(CONTENT+DATA)>b"1111"then
20
CALU<='1';
21
else
22
CALU<='0';
23
endif;
Offenbar gefallen dir Prozesse und das if-elsif-endif, weil du sowas
Ähnliches von prozeduralen Programmiersprachen her kennst. Es gibt aber
gerade in VHDL hübsche nebenläufige Konstrukte (auf Englisch: concurrent
assignments), die ganz ohne Prozess und Sensitivliste eine Kombinatorik
beschreiben können.
Martin S. schrieb:> 'buffer' auch besser vermeiden
Buffer sind eigentlich ein Kündigungsgrund, wenn sie lediglich zur
Unterstützung der Schreibfaulheit im Stil von "Überaus praktisch, denn
dann kann ich den Ausgang einlesen und spare mir lokale Signale!"
verwendet werden.
Okay, ich seh schon - ich bin noch sehr am Anfang.
Martin S. schrieb:> Ich will ja nicht nerven, aber wenn du noch in den> VHDL-Anfängen steckst, würde ich dir nochmals einen Anfang in MyHDL> nahelegen.
Wie schwer fällt dann später der Umstieg auf VHDL?
Also ich hatte von VHDL zu MyHDL eine gewisse Lernkurve zu durchlaufen
(bzw. durchlaufe sie immernoch), und umgekehrt gilt sicher dasselbe.
Beide Sprachen verwenden das gleiche Konzept der Modellierung auf
RTL-Ebene, aber mit deutlich unterschiedlicher Syntax.
Wenn Du mit VHDL arbeiten willst, dann fang jetzt damit an. MyHDL
erleichert die Simulation und die funktionale Verifikation, aber nicht
das Design, und wenn Du Richtung FPGA-Design gehen willst, kommst Du an
VHDL oder Verilog eh nicht vorbei.
Was ist eigentlich jetzt Sache mit MyHDL? Die letzte offizielle Versions
gabs 2015 und auch die 1.0dev aus dem GIT-Repo ist nicht mehr ganz
taufrisch. Ich will nicht hoffen, dass das Projekt einschläft, das wäre
wirklich sehr schade.
Max M. schrieb:> Okay, ich seh schon - ich bin noch sehr am Anfang.>> Martin S. schrieb:>> Ich will ja nicht nerven, aber wenn du noch in den>> VHDL-Anfängen steckst, würde ich dir nochmals einen Anfang in MyHDL>> nahelegen.>> Wie schwer fällt dann später der Umstieg auf VHDL?
Ich würde nicht in "später" denken, der Workflow kann auch parallel
verlaufen: Wenn alles im Simulator läuft, musst du u.U. für die Synthese
nochmal von vorne loslegen. DAS nimmt dir MyHDL nicht ab. Ich habe mir
anfangs die ausgegebene HDL immer noch mal separat angesehen, die muss
man auch lesen können (oder nochmals simulieren). VHDL/Verilog nimmt
dann die Rolle einer Transfersprache ein, du musst aber passenden
Python-Code schreiben, der nah am VHDL-Paradigma ist.
Das mag scary klingen, aber unterm Strich spart die "doppelte Arbeit"
Zeit.
Vancouver schrieb:> Was ist eigentlich jetzt Sache mit MyHDL? Die letzte offizielle Versions> gabs 2015 und auch die 1.0dev aus dem GIT-Repo ist nicht mehr ganz> taufrisch. Ich will nicht hoffen, dass das Projekt einschläft, das wäre> wirklich sehr schade.
Da schläft gar nix ein...MyHDL wird in seiner Community aktiv genutzt.
Eigentlich ein gutes Zeichen, wenn nicht zuviele Aenderungen
stattfinden. In den letzten Jahren tauchte hier grade mal ein Bug
auf...der Rest sind Erweiterungen.
Ist nicht ganz so advokatisch wie bei VHDL, aber trotzdem genug
konservativ..
Meine Meinung: Die Diskussion hier läuft schief.
Grund ist der Titel: CPU in VHDL designen.
CPU designen ist die eine Sache. Da geht es um Dinge
wie Festlegung der Breite des externen Adressbusses
und des externen Datenbusses, Festlegung der für den
Programmierer sichtbaren Register, Festlegung des
kompletten Befehlssatzes einschließlich der Dauer
der Befehle. Dann überlegt man sich einen Ringzähler,
welcher die Phasen der Befehlsausführung bereitstellt.
Man überlegt, welche zusätzlichen Register, welche
Datenpfade, welche Multiplexer, welche Funktionsnetze
(Addierer, Inkrementierer, ...) man braucht, um den
Befehlssatz mit dem angestrebten Zeitverhalten zu
realisieren. Schließlich erstellt man die Logikterme
für die Erzeugung der Steuersignale (Select-Signale
der Multiplexer, Write-Signale der Register, ...)
aus den Befehlscodes.
Die ganze Architektur dann in VHDL zu beschreiben,
ist eine andere Sache und kommt erst ganz am Schluss.
Jedenfalls hab ich es so gemacht. Ich wüsste
nicht, wie es anders gehen könnte.
@MartinS
"...MyHDL wird in seiner Community aktiv genutzt. "
Genutzt ja, aber auch weiterentwickelt? Zumindest Jan Decaluwe scheint
momentan inaktiv zu sein. Abseits von Bugfixes gäbe es da noch Einiges
zu verbessern, z.B. bei der Erzeugung von HDL-Code: hierachischer
VHDL-Code mit einem Modul pro File, gleicher Funktionsumfang bei Verilog
und VHDL, SystemVerilog-Backend usw. Und die Klimmzüge zur Konkatenation
und Segmentierung von Bitvektoren verursachen auch erst mal
Kopfschütteln (bis man verstanden hat, was dahinter steckt). Und noch
einiges andere.
Leider muss man sagen, was nicht weiterentwickelt wird, stirbt
irgendwann, da gibts ja genug Beispiele in der OpenSource-Community. Im
Falle von MyHDL wäre das ein echter Verlust.
Wenn ich so darüber nachdenke, wäre es vielleicht gut, bei diesem
Projekt mitzuarbeiten. Muss ich mal drüber meditieren.
Vancouver schrieb:> Leider muss man sagen, was nicht weiterentwickelt wird, stirbt> irgendwann, da gibts ja genug Beispiele in der OpenSource-Community. Im> Falle von MyHDL wäre das ein echter Verlust.>> Wenn ich so darüber nachdenke, wäre es vielleicht gut, bei diesem> Projekt mitzuarbeiten. Muss ich mal drüber meditieren.
Wenn keine bessere Alternative hinterm Horizont vorkommt, stirbt das
Konzept für die damit produktiv arbeitenden sicher nicht.
MyHDL mag schon seine Quirks haben, und nicht alles ist elegant, aber es
ist immerhin kein wüster Hack wie der Migen-Ansatz (der quasi schon tot
ist).
MyHDL hat die kritische Masse schon erreicht und wird sicher so alt
werden wie VHDL93.
Die Umsetzung von Hierarchien, wenn gewünscht, kann man sich leicht
selber stricken. Dauert weniger lang als sich auf der MyHDL-Mailingliste
die Diskussionen zu liefern..
Martin S. schrieb:> Die Umsetzung von Hierarchien, wenn gewünscht, kann man sich leicht> selber stricken. Dauert weniger lang als sich auf der MyHDL-Mailingliste> die Diskussionen zu liefern.
Wichtig ist, sowas auch beizutragen, um ein Projekt in die richtige
Richtung zu schieben. Ansonsten verselbständigen sich die Leute in
diesen Listendiskussionen und schieben es irgendwo hin, wo die
Mittelmässigen es sehen und gerne hätten, denn die sind es, die in den
Listen am Lautesten schreien.
Also am Besten Funktion bauen, unterlegen, convenience rein und dann
raus damit als unumgängliches Paket, das Standards setzt. So habe Ich
das beim embedded linux immer mal gemacht.
Dann übernehmen das Viele und es setzt sich automatisch durch.
Natürlich ist es das Problem Nummer 1, dass die wirklich Befähigten
immer dick mit Arbeit zu sind und ihren hauptsächlichen output tagsüber
in der Firma haben und meistens nichts davon herausgeben dürfen.
Thomas U. schrieb:> Also am Besten Funktion bauen, unterlegen, convenience rein und dann> raus damit als unumgängliches Paket, das Standards setzt. So habe Ich> das beim embedded linux immer mal gemacht.
Gerade bei (embedded) linux habe ich es schon lange aufgegeben,
irgendwelche Patches oder Verbesserungen einzureichen, da der Overhead
der Diskussionen mit teils wenig pragmatisch denkenden Coder-Egos
einfach zu gross ist.
Solange es nur Patches sind und keine feindlichen Forks finde ich es
ausreichend, sich einfach an die OpenSourciquette zu halten und den
angepassten (L)GPL-Code irgendwo zu veröffentlichen oder die ganze
Problematik so zu umgehen, dass keine Lizenzverletzungen vorliegen.
Martin S. schrieb:> Gerade bei (embedded) linux habe ich es schon lange aufgegeben,
...irgendwo geistert von mir noch ein Patch rum, der auf nem Router das
WLAN aktiviert. War im Prinzip nur eine Liste, die auf bestimmten
Geräten einen anders verdrahteten Pin fixt und wurde deswegen abgelehnt.
War mir dann aber auch egal, weil es auf meinem Gerät lief und m.W.
sonst keiner Interesse hatte.
{kind=link}
{kind=link}