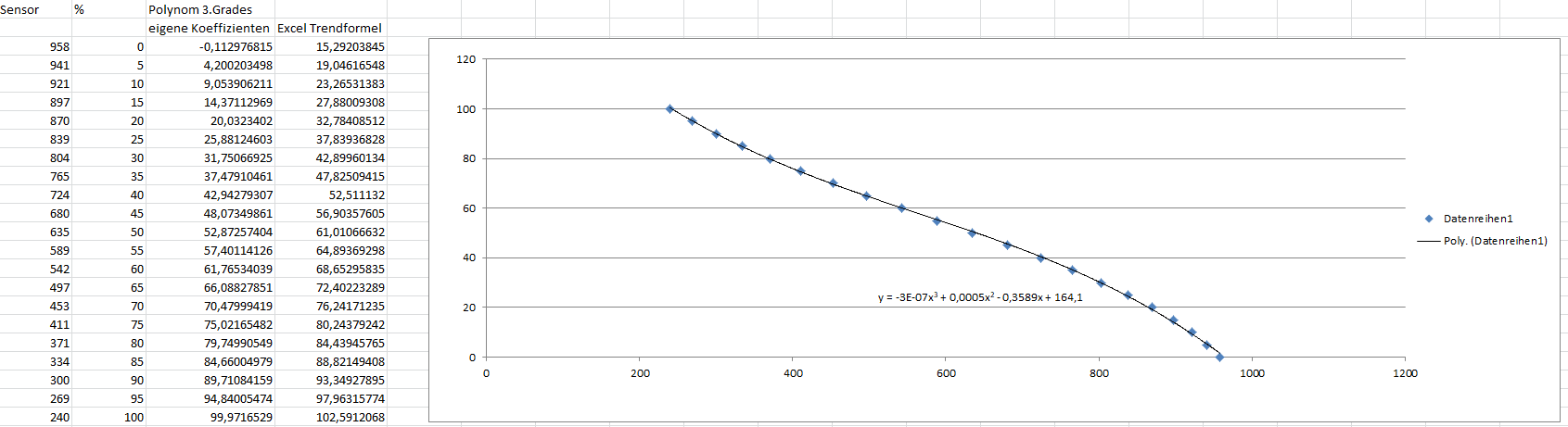
Ein blöder Sensor sollte auf 0-100% skaliert werden. Da ich mal genug Rechenleistung habe (Raspberry) dachte ich mir: Polynom statt Tabelle erstellen. Wertepaare in Excel eingetippt, Trendlinie Polynom 3.Grades, die Kurve passte auch ganz gut und ausreichend genau. Formel hergenommen da habe ich mich schon über die glatten a und b gewundert, aber gut - kann ja sein) und dann kam das böse Erwachen, stimmte hinten und vorne nicht. Bisher war ich immer der Meinung, Excel kann (ausser Diagrammen, das ist nicht toll) so ziemlich alles numerische gut. Inzwischen habe ich gelesen, dass die Trendlinie ziemlich miese Ergebnisse liefert - warum auch immer. Wieso legt der ne passende Kurve da hin, liefert aber ne ziemlich falsche Gleichung ab? Selbst ermittelte Koeffizienten: a: -3,31882660411389E-07 b: 0,000546655625451365 c: -0,394156344836167 d: 167,698104632209
Angehängte Dateien:
-

Excel_polynom.PNG
22 KB
H.Joachim S. schrieb: > Bisher war ich immer der Meinung, Excel kann (ausser Diagrammen, das ist > nicht toll) so ziemlich alles numerische gut. Ist es nicht eher umgekehrt? Der typische Excel-User will keine Mathematik, sondern bunte Tortendiagramme. Demzufolge hat MS die gesamte Entwickler-Power auf diesen Diagrammtyp fokussiert. Dinge wie Approximationen versteht ein BWLer sowieso nicht, deswegen fällt es niemandem auf, wenn hier die Ergebnisse ungenau sind ;-) Hier gibt es eine Erklärung und auch eine Lösung für das Problem: https://support.microsoft.com/en-us/help/211967/chart-trendline-formula-is-inaccurate-in-excel
sowas würd ich sowieso von Anfang an mit python/numpy/matplotlib machen, ist doch auch viel besser zu handhaben und nachzuvollziehen als das elende rumgeklicke in Excel.
Danke, das klingt gut, werde ich gleich mal ausprobieren. Ich habe zwar jetzt eine ausreichende Lösung, aber vielleicht kommt ja was ähnliches mal wieder. Die Vorgehnsweise von Microsoft sollte eigentlich andersherum sein. Erstmal max. Genauigkeit verwenden und wem das zuviel ist kann dann ungenauer einstellen. Mit ner Tabelle wäre ich schon lange fertig gewesen :-) Witzigerweise liefert die lineare Trendfunktion (y=f(x)=-0,1277x+129,27) an jedem einzelnen Wertepaarstelle einen deutlich kleineren Fehler als das Excel-Polynom-Konstrukt. Zu Tortendiagrammen kann ich nichts sagen, die habe ich noch nie für irgendwas gebraucht :-)
Hallo H.Joachim Seifert, wie bist Du schlussendlich an die besseren Koeffizienten gekommen? Ich hätte die Koeffizientensuche als Optimierungsproblem im Solver formuliert.
Magst du gerade noch einmal schnell darlegen, warum du meckerst, wenn Excel die Darstellung (IM BILD) auf etwa vier Stellen rundet und damit berechnete Ergebnisse verglichen mit ~16 Stellen (die Excel bei der Berechnung der DARGESTELLTEN Punkte natürlich auch verwendet) Mist sind? Anwenderfehler sind keine Programmfehler. Auch wenn ich Excel nicht mag: Diesmals ist eher der TE doof.
@Peter M. 4 Wertepaare -> 4 Gleichungen -> Matritzenrechnung -> fertig Wertepaar 1: 0=a*958^3 + b* 958^2 + c*958 + d . . 100=a*240^3 + b*240^2 +c*240 +d Lukas: Mist ist die von Excel ausgeworfene Gleichung (im Diagramm ersichtlich). Mir scheint eher, dass du doof bist als ich, wenn wir schon auf dieses Niveau herabsinken.
H.Joachim S. schrieb: > @Peter M. > 4 Wertepaare -> 4 Gleichungen -> Matritzenrechnung -> fertig > Wertepaar 1: > 0=a*958^3 + b* 958^2 + c*958 + d > . > . > 100=a*240^3 + b*240^2 +c*240 +d Ah ja! Wenn Du das in Excel via Solver formulierst, kannst Du anstelle Deiner vier Stützstellen gleich alle 20 verwenden: Du minimierst einen Fehlerterm. Der ergibt sich aus der Summe aller Einzelfehlerterme. Ein Einzelfehlerterm ist dann z.B. die quadrierte Differenz zwischen den gegebenen Funktionswerten und den interpolierten Werten. Die Zellen, an denen der Solver rumspielen darf, sind dann die, in denen die Koeffizienten a,b,c und d stehen.
H.Joachim S. schrieb: > Bisher war ich immer der Meinung, Excel kann (ausser Diagrammen, das ist > nicht toll) so ziemlich alles numerische gut. Inzwischen habe ich > gelesen, dass die Trendlinie ziemlich miese Ergebnisse liefert - warum > auch immer. Wieso legt der ne passende Kurve da hin, liefert aber ne > ziemlich falsche Gleichung ab? Die Darstellung der Funktion im Plot ist nicht falsch, sondern großzügig gerundet. Ist ärgerlich, aber wohl nicht zu ändern. > Selbst ermittelte Koeffizienten: > a: -3,31882660411389E-07 > b: 0,000546655625451365 > c: -0,394156344836167 > d: 167,698104632209 Die Koeffizienten nimmt man auch nicht aus der Grafik, sondern benutzt die Rechenfunktionen von Excel (IMHO RGP(), TREND() ). Versuche es, Du wirst Dich wundern...
Mit der Darstellung war ich völlig zufrieden, auch mit den Fehlern, die sich aus nur 3.Grades ergeben. Ärgerlich war, dass die angezeigte Funktionsgleichung nur wenig mit der dargestellten (ausreichend passenden) zu tun hat. edit: Ja, geht alles. Ich bin halt drüber gestolpert, dass das, was da steht schlicht falsch ist (bzw. so grosszügig gerundet, dass es keinen Sinn mehr macht. Warum bei c und d 4 Dezimalstellen, aber bei a und b nur eine?)
H.Joachim S. schrieb: > Inzwischen habe ich gelesen, dass die Trendlinie ziemlich miese > Ergebnisse liefert - warum auch immer. Welche Koeffizienten hast du denn verwendet, um die Zahlen in der Spalte "Excel Trendformel" zu berechnen? Doch nicht etwa die grob gerundeten Werte aus der Formel, die in der Graphik eingeblendet ist, oder? Falls letzteres der Fall ist, liegen die miesen Ergebnisse nicht an der Trendlinieberechnung, sondern an der kräftigen Rundung der Koeffizienten durch die gewählte Zahlenformatierung bei der Anzeige der Trendlinienformel. Lass dir dort mal ein paar mehr Nachkommastellen anzeigen oder rechne die Koeffizienten über die entsprechende Funktion aus. ;-)
Wolfgang schrieb: > Doch nicht etwa die grob gerundeten > Werte aus der Formel, die in der Graphik eingeblendet ist, oder? Doch, erst mal ja. Ist ja heutzutage kein Problem mehr, mehr Stellen anzuzeigen. Ist ja erst mal nicht ersichtlich dass die massiv (bis zur Unkenntlichkeit/Unverwendbarkeit) gerundet sind. Dann schreib ich doch lieber gar nichts hin als so einen Mist. Noch dazu, da das nicht durchgehend so ist - c und d lassen vermuten, dass eine höhere Genauigkeit verwendet wird. Mit durchgehend 4 Deziamlstellen wäre das brauchbar gewesen. So aber nicht.
H.Joachim S. schrieb: > Ist ja heutzutage kein Problem mehr, mehr Stellen anzuzeigen. Der bessere Weg ist - wie vorgeschlagen -, die Parameter der Kurve direkt berechnen zu lassen und nicht aus in der Graphik eingeblendeten Formel abzuschreiben. > Ist ja erst mal nicht ersichtlich dass die massiv (bis zur > Unkenntlichkeit/Unverwendbarkeit) gerundet sind. Eine einzige gültige Ziffer sollte einem aber sofort verdächtig vorkommen und der erste Schritt ist dann doch wohl, sich das Zahlenformat für die Formeldarstellung anzugucken.
Alles richtig, und es hat mich ja auch direkt stutzig gemacht, dass a und b nur so einfach dargestellt werden. Die eigentliche Frage: warum suggeriert man mit c und d, dass eine höhere Genauigkeit vorhanden wäre? Warum rundet man a und b anders als c und d? Entweder durchgehend massiv gerundet (dann wäre es wirklich direkt ersichtlich) oder durchgehend mit gleicher Genauigkeit. Dieser Mischmasch macht keinerlei Sinn.
Weil vermutlich irgendjemand das Zahlenformat mal so festgelegt hat, dass pro Koeffizient maximal fünf Zeichen oder vier signifikante Stellen angezeigt werden sollen. 3e-07 sind fünf Zeichen. 0,0005 sind fünf Zeichen (plus Komma). 0,3589 sind fünf Zeichen (plus Komma). 164,1 sind vier signifikante Stellen. Soll ja nicht genau sein, sondern nur einen groben Eindruck über die Art der Kurve geben. Wenn die Koeffizienten sehr unterschiedlich groß sind, kann man auch überlegen, ob die sehr kleinen Koeffizienten überhaupt sinnvoll/nötig sind oder ob eine quadratische/lineare Näherung nicht ausreicht, das zeigt die Formel noch. Keine Ahnung, ob und wo die Anzeige konfigurierbar ist. MfG, Arno
H.Joachim S. schrieb: > Die eigentliche Frage: warum suggeriert man mit c und d, dass eine > höhere Genauigkeit vorhanden wäre? Warum rundet man a und b anders als c > und d? Da stecken wohl etwa 30 Jahre Erfahrung mit Tabellenkalkulationssoftware von einer großen Softwarefirma hinter. :-(
Arno schrieb: > Weil vermutlich irgendjemand das Zahlenformat mal so festgelegt hat, > dass pro Koeffizient maximal fünf Zeichen oder vier signifikante Stellen > angezeigt werden sollen. Warum auch immer hier gerade 5 Nachkommastellen als Default eingestellt sind, ist es in solchen Fällen doch die erste Tat, das Zahlenformat für die Darstellung in der Formel zu ändern,
Angehängte Dateien:
-

fehler.png
23 KB
Bernd K. schrieb: > sowas würd ich sowieso von Anfang an mit python/numpy/matplotlib machen
1 | import numpy as np |
2 | |
3 | xs = np.array([ 958, 941, 921, 897, 870, 839, 804, |
4 | 765, 724, 680, 635, 589, 542, 497, |
5 | 453, 411, 371, 334, 300, 269, 240 ]) |
6 | |
7 | ys = np.linspace(0, 100, 21) |
8 | |
9 | cs = np.polyfit(xs, ys, 3) |
10 | |
11 | print(cs) |
Ergebnis:
1 | [-2.68906282e-07 4.57026132e-04 -3.61151868e-01 1.64458578e+02] |
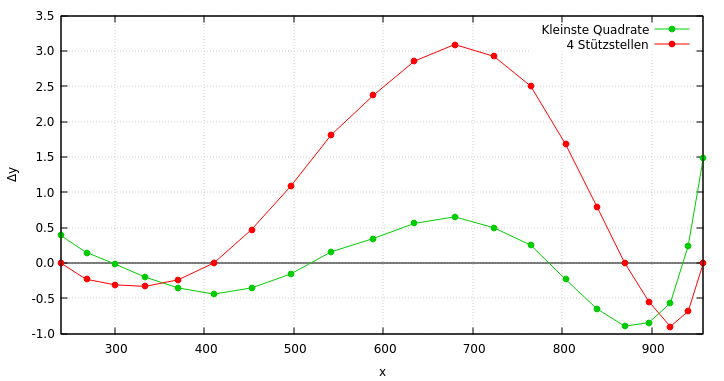
H.Joachim S. schrieb: > 4 Wertepaare -> 4 Gleichungen -> Matritzenrechnung -> fertig Im Anhang gibt's den Fehlerplot für beide Verfahren.
Angehängte Dateien:
-

Excel_polynom2.PNG
11 KB
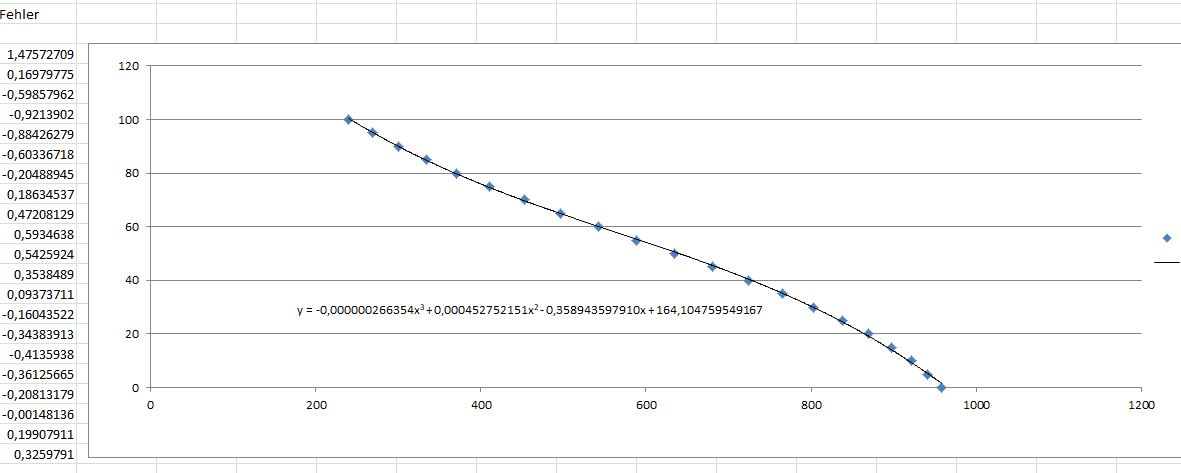
Super, Danke. Excel kann es auch ganz gut, mit fast identischem Fehlerverlauf. xyz schrieb: > Rechtsklick in die angezeigte Formel, dann Formatierung? so gehts.
Der echte Elektroniker hätte seinen Sharp PC-1403 aus der Schublade geholt und damit die Lösungen des minimierenden Gleichungssystems bestimmt. Aber doch nicht mit so einem Mist wie Exel. Ihr seid alle unfähig!
Weshalb sollte man irgendwelche Werte in einem Sharp eintippen, wenn man alles auf dem PC hin und her copy pasten kann.
Nebeltroll schrieb: > Weshalb sollte man irgendwelche Werte in einem Sharp eintippen, > wenn man > alles auf dem PC hin und her copy pasten kann. Warum soll man umständlich Copy-Pasten wenn man es von einem Script direkt aus einer Datei einlesen lassen kann?
Hatten wir 2011 schon mal: Beitrag "PT100: Mathematisches Problem" Suchbegriffe waren "excel trendlinie formel" mit 5 Treffern.
H.Joachim S. schrieb: > Excel kann es auch ganz gut, mit fast identischem Fehlerverlauf. Auch wenn sowohl die Numpy- als auch die Excel-Ergebnisse für den vorliegenden Anwendungsfall mehr als ausreichend genau sind, hat es mich jetzt doch interessiert, welches der beiden Tools näher am theoretisch richtigen Ergebnis liegt. Dazu habe ich die Polynomkoeffizienten mit einem weiteren Tool, nämlich wxMaxima nach der Methode der kleinsten Quadrate exakt berechnen lassen. Ergebnisse:
1 | a = -8536676654970643591975 / 31745917575274522495028685848 |
2 | b = 522313700937540573913048415 / 1142853032709882809821032690528 |
3 | c = -137581169182481693004239233135 / 380951010903294269940344230176 |
4 | d = 46987996036471179121783722044275 / 285713258177470702455258172632 |
Die drei Tools im Genauigkeitsvergleich:
1 | a: |
2 | wxMAxima: -2.689062817204402e-07 auf 16 Stellen gerundet |
3 | Numpy: -2.689062817204375e-07 Genauigkeit: 14 Stellen |
4 | Excel: -2.66354 e-07 Genauigkeit: 2 Stellen |
5 | |
6 | b: |
7 | wxMAxima: +4.570261319594640e-04 auf 16 Stellen gerundet |
8 | Numpy: +4.570261319594604e-04 Genauigkeit: 14 Stellen |
9 | Excel: +4.52752151 e-04 Genauigkeit: 2 Stellen |
10 | |
11 | c: |
12 | wxMAxima: -3.611518679429549e-01 auf 16 Stellen gerundet |
13 | Numpy: -3.611518679429534e-01 Genauigkeit: 14 Stellen |
14 | Excel: -3.58943597910 e-01 Genauigkeit: 2 Stellen |
15 | |
16 | d: |
17 | wxMAxima: +1.644585775829997e+02 auf 16 Stellen gerundet |
18 | Numpy: +1.644585775829994e+02 Genauigkeit: 15 Stellen |
19 | Excel: +1.64104759549167 e+02 Genauigkeit: 3 Stellen |
Wie man sieht, liegt die Genauigkeit der Koeffizienten bei Numpy fast schon im Bereich der Auflösung von Double-FP-Zahlen (ca. 16 Stellen). Im Vergleich dazu muten die Ergebnisse von Excel eher wie eine grobe Schätzung an. Betrachtet man allerdings den mittleren quadratischen Fehler der resultierenden Approximation, ist der Unterschied nur marginal:
1 | wxMAxima: 0.55536 |
2 | Numpy: 0.55536 |
3 | Excel: 0.55619 |
Trotzdem stellt sich natürlich die Frage, warum MS hier mal wieder das Rad neu erfindet und nicht einfach einen der öffentlich zugänglichen und nachweislich besseren Algorithmen verwendet. Generell würde ich bei solchen numerischen Anwendungen Numpy/Scipy oder Matlab weit mehr als Excel vertrauen. Numpy und Matlab basieren beide auf der LAPACK-Bibliothek, die den Industriestandard in diesem Bereich darstellt und nach einem Vierteljahrhundert¹ Entwicklungszeit und intensiver Nutzung (auch außerhalb von Numpy und Matlab) als absolut ausgereift betrachtet werden kann. ————————— ¹) Rechnet man die Vorgänger LINPACK und EISPACK mit ein, sind es noch einmal zwei Jahrzehnte mehr.
Vielleicht hat sich ja inzwischen da auch was geändert - ich verwende Excel 2010. Aber wie schon gesagt - für mich mehr als ausreichend gut.
Der Vollständigkeit halber noch Gnuplot (GP) und LibreOffice Calc (LO, hier mit übertrieben vielen Stellen formatiert, um nichts zu übersehen) im Vergleich zu den richtigen Werten aus wxMaxima (wx)
1 | a: |
2 | wx -2.689062817204402e-07 |
3 | LO -2.6890628172044000000E-07 |
4 | GP -2.68906281719567e-07 |
5 | |
6 | b: |
7 | wx 4.570261319594640e-04 |
8 | LO 4.5702613195946400000E-04 |
9 | GP 4.57026131957835E-04 |
10 | |
11 | c: |
12 | wx -3.611518679429549e-01 |
13 | LO -3.6115186794295400000E-01 |
14 | GP -3.361151867942018E-01 |
15 | |
16 | d: |
17 | wx 1.644585775829997e+02 |
18 | LO 1.6445857758299900000E+02 |
19 | GP 1.64458577582838e+02 |
Yalu X. schrieb: > warum MS hier mal wieder das > Rad neu erfindet und nicht einfach einen der öffentlich zugänglichen und > nachweislich besseren Algorithmen verwendet. Weil sie das immer so machen. Wenn es für irgendein Problem eine Standardlösung gibt, die der Rest der Welt seit Jahrzehnten verwendet und die kompatibel, problemlos und korrekt funktioniert, verwendet MS irgendwas halbgares selbstgebasteltes, das dank ewiger Rückwärtskompatibilität nie repariert wird.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.