Hallo. Bekannterweise besteht die Möglichkeit Pseudozufallszahlen per LFSRs zu erzeugen. Kann man auch pseudozufällige Primzahlen hardwareseitig erzeugen? Wenn ja, würde ich mich über kurze Erklärungen oder Lesetipps freuen.
Im Elektronikkompendium steht dazu dass es die Möglichkeit gibt, Pseudozufallszahlen zu generieren und anschließend zu testen, ob es sich bei der Zahl um eine Primzahl handelt. Wenn nicht, erzeuge neue Zufallszahl, so lange bis eine Primzahl erzeugt wurde. Da stellt sich mir die andere Frage: Wie überprüfe ich hardwareseitig ob es sich bei einer Zahl um eine Primzahl handelt? Das erscheint mir extrem ineffizient.
highfrequency schrieb: > Da stellt sich mir die andere Frage: Wie überprüfe ich hardwareseitig ob > es sich bei einer Zahl um eine Primzahl handelt? Das macht die elektronische Hardware genauso wie die biologische: man versucht die Zahl durch alle kleineren Zahlen zu teilen. Wenn dabei bei jedem Versuch ein Rest bleibt, ist die Zahl eine Primzahl. highfrequency schrieb: > Das erscheint mir extrem ineffizient. Ineffizient? Es gibt keinen anderen Weg, keine Abkürzung für die Primfaktorzerlegung. Gerade das macht Primzahlen ja für die Kryptographie so interessant.
highfrequency schrieb: > Hallo. > Bekannterweise besteht die Möglichkeit Pseudozufallszahlen per LFSRs zu > erzeugen. > Kann man auch pseudozufällige Primzahlen hardwareseitig erzeugen? > Wenn ja, würde ich mich über kurze Erklärungen oder Lesetipps freuen. Gegenfrage: Warum sollten sich bspw. die Algorithmen z.B. aus OpenSSL 1) nicht in Hardware gießen lassen? 1) Mal in den Quelltexten unter https://github.com/openssl/openssl suchen
Markus F. schrieb: > Das macht die elektronische Hardware genauso wie die biologische: man > versucht die Zahl durch alle kleineren Zahlen zu teilen. Wenn dabei bei > jedem Versuch ein Rest bleibt, ist die Zahl eine Primzahl. Naja ... es fallen schon mal alle Zahlen mit der letzten Ziffer von 0 und 2 und 4 und 5 und 6 und 8 durch den Filter, somit sind 60% außen vor Dh es bleiben nur die Zahlen mit der Endziffer 1, 3, 7 und 9 als Primzahlkanditaten Diese Menge reduzieren wir noch um alle die Zahlen deren Quersumme 3 oder ein Vielfaches von 3 ergibt - und um die deren letzte 2 Ziffern eine Quersumme von 3 oder ganzzahliges Vielfaches davon ergeben ...
Das Thema ist hier schon mehrfach in unterschiedlichsten threads diskutiert worden: LSFR erzeugen bedingt gute Zufallsfolgen. Die nimmt man nur, wenn es auf Gleichverteilung ankommt wie beim Rauschspektrum. Zufallszahlen, bei denen auch einzelne Werte mehrfach kommen sollen, bevor andere kommen und trotzdem balancierte Verteilung haben, erzeugt man mit Vertauschern, also "zufällig" durchlaufend abgefragten Tabellen. Damit lässt sich das Auftreten regeln und bestimmen, so nötig. In eine solche Tabelle könnte man Primzahlen ein bauen. Dann muss nichts geprüft werden. Es gibt dazu eine Reihe von unterschiedlichen Verfahren, implizite Zahlenfolgen mit "Verdrehung" zu generieren, die deterministisch sind, scheinbar auch nicht voraussagbar, aber trotzdem eine gute Verteilung liefern, wie Mersenne, Marsaglia oder z.B. PCG. Richtigen Zufall gibt es nur mit zufälligem Rauschen wie hier: Digitaler Rauschgenerator im FPGA Gfs auch mit Zugriff auf Tabellenwerte und damit einem definierten Wertebereich, aber in der Auftrittswahrscheinlichkeit nicht mehr vorhersehbar und nicht balanciert. Es kann dann also sein, dass einige Werte dauernd kommen und andere nie und nach jedem Einschalten ist das Verhalten anders.
Markus F. schrieb: > highfrequency schrieb: > >> Das erscheint mir extrem ineffizient. > > Ineffizient? Es gibt keinen anderen Weg, keine Abkürzung für die > Primfaktorzerlegung. Gerade das macht Primzahlen ja für die > Kryptographie so interessant. Irgendwie fühle ich mich jetzt ertappt, so viel Lerntransfer sollte man halt haben :) Arc N. schrieb: > 1) Mal in den Quelltexten unter https://github.com/openssl/openssl > suchen Ich bevorzuge Algorithmen in Pseudocode, aber trotzdem danke :) Zu deiner Gegenfrage: Ja klar, das lässt sich natürlich in Hardware gießen. Walter K. schrieb: > Naja ... es fallen schon mal alle Zahlen mit der letzten Ziffer von 0 > und 2 und 4 und 5 und 6 und 8 durch den Filter, somit sind 60% außen vor > > Dh es bleiben nur die Zahlen mit der Endziffer 1, 3, 7 und 9 als > Primzahlkanditaten > > Diese Menge reduzieren wir noch um alle die Zahlen deren Quersumme 3 > oder ein Vielfaches von 3 ergibt - und um die deren letzte 2 Ziffern > eine Quersumme von 3 oder ganzzahliges Vielfaches davon ergeben ... Danke für den Tipp.
Wieviel Bit sollen die generierten Zahlen haben? Ich würde die Primzahlen in einer Tabelle hinterlegen, in einem ROM. Und da dann beliebig drauf zugreifen und quasi eine Primzahl "ziehen". Bei 16 Bits sind das 6542 Zahlen, also 13,084 kBytes. Das finde ich relativ wenig und man kann wirklich sehr schnell und ohne weitere Überprüfung Zahlen generieren.
Markus F. schrieb: > man > versucht die Zahl durch alle kleineren Zahlen zu teilen. Wenn dabei bei > jedem Versuch ein Rest bleibt, ist die Zahl eine Primzahl. Es reicht bis zur der Quadratwurzel der Zahl (einschließlich) zu testen. Wenn man bis dahin keinen Faktor gefunden hat findet man auch keinen mehr.
highfrequency schrieb: > Walter K. schrieb: >> Naja ... es fallen schon mal alle Zahlen mit der letzten Ziffer von 0 >> und 2 und 4 und 5 und 6 und 8 durch den Filter, somit sind 60% außen vor >> >> Dh es bleiben nur die Zahlen mit der Endziffer 1, 3, 7 und 9 als >> Primzahlkanditaten >> >> Diese Menge reduzieren wir noch um alle die Zahlen deren Quersumme 3 >> oder ein Vielfaches von 3 ergibt - und um die deren letzte 2 Ziffern >> eine Quersumme von 3 oder ganzzahliges Vielfaches davon ergeben ... Das ließe sich auch leicht generisch formulieren, indem man ausser der 2 gerade Zahlen gar nicht erzeugt und einen parallelen Generator die Vielfachen der elementaren Primzahlen wie eben 3,5,7,11,13 etc ausblenden lässt. Das Problem der subtraktiven Synthese, wie sie oben vorgestellt wird, dass auch eine Menge Datenmüll erzeugt wird, der weggefiltert werden muss. Das wird dann bei höheren Ordnungen recht langsam und in der Praxis unbrauchbar. In den Anwendungen, die mir bisher begegnet sind, in denen dedizierte Werte wie eben Primzahlen benötigt wurden, sind die offline erzeugt, validiert und dann hinterlegt worden. Das gilt für gemischte und getauschte AES-Codes etc... Es reicht ja nicht, die Zahl zu erzeugen, sie muss auch plausibilisiert werden und das ist bei Primzahlen nicht Echtzeit problematisch. Also muss ich alles in der design phase checken und dann HABE ich alle Lösungen parat.
Gustl B. schrieb: > Wieviel Bit sollen die generierten Zahlen haben? 1024. Jürgen S. schrieb: > Es gibt dazu eine Reihe von unterschiedlichen Verfahren, implizite > Zahlenfolgen mit "Verdrehung" zu generieren, die deterministisch sind, > scheinbar auch nicht voraussagbar, aber trotzdem eine gute Verteilung > liefern, wie Mersenne, Marsaglia oder z.B. PCG. Danke, das sagt mir bisher noch nichts aber darüber werde ich mich informieren.
Walter K. schrieb: > Markus F. schrieb: >> Das macht die elektronische Hardware genauso wie die biologische: man >> versucht die Zahl durch alle kleineren Zahlen zu teilen. Wenn dabei bei >> jedem Versuch ein Rest bleibt, ist die Zahl eine Primzahl. > > Naja ... es fallen schon mal alle Zahlen mit der letzten Ziffer von 0 > und 2 und 4 und 5 und 6 und 8 durch den Filter, somit sind 60% außen vor > > Dh es bleiben nur die Zahlen mit der Endziffer 1, 3, 7 und 9 als > Primzahlkanditaten > > Diese Menge reduzieren wir noch um alle die Zahlen deren Quersumme 3 > oder ein Vielfaches von 3 ergibt - und um die deren letzte 2 Ziffern > eine Quersumme von 3 oder ganzzahliges Vielfaches davon ergeben ... Das klingt zwar irgendwie schlüssig, ist aber Unsinn. Diese Dinge sind Eigenschaften der gewählten Darstellung der Zahl, nicht der Zahl selbst. Dadurch kann man nichts sparen. Interessant ist vermutlich eher dieses Verfahren: https://en.wikipedia.org/wiki/Fermat_primality_test
Jürgen S. schrieb: > Das Problem der subtraktiven Synthese, wie sie oben vorgestellt wird, > dass auch eine Menge Datenmüll erzeugt wird, der weggefiltert werden > muss. Das wird dann bei höheren Ordnungen recht langsam und in der > Praxis unbrauchbar. Da es bislang keine Alternative zu der "Subtraktiven Synthese" gibt wird uns wohl nichts weiters übrig bleiben als weiterhin Zufallszahlen zu generieren und die durch den Miller-Rabin Test zu schicken.
Sven B. schrieb: > Walter K. schrieb > Naja ... es fallen schon mal alle Zahlen mit der letzten Ziffer von 0 > und 2 und 4 und 5 und 6 und 8 durch den Filter, somit sind 60% außen vor > Dh es bleiben nur die Zahlen mit der Endziffer 1, 3, 7 und 9 als > Primzahlkanditaten > Diese Menge reduzieren wir noch um alle die Zahlen deren Quersumme 3 > oder ein Vielfaches von 3 ergibt - und um die deren letzte 2 Ziffern > eine Quersumme von 3 oder ganzzahliges Vielfaches davon ergeben ... >>...... > Das klingt zwar irgendwie schlüssig, ist aber Unsinn. Diese Dinge sind > Eigenschaften der gewählten Darstellung der Zahl, nicht der Zahl selbst. > Dadurch kann man nichts sparen. > Wenn das Unsinn ist, dann teste halt alle ungeraden Zahlen - lach
Nils P. schrieb: > Da es bislang keine Alternative zu der "Subtraktiven Synthese" gibt wird > uns wohl nichts weiters übrig bleiben als weiterhin Zufallszahlen zu > generieren und die durch den Miller-Rabin Test zu schicken. Die Frage ist, wie und man man die Wertemenge erzeugt. Das in Echtzeit zu machen (so lese Ich den o.g. Ansatz) ist für mich nicht zielführend.
highfrequency schrieb: > Gustl B. schrieb: >> Wieviel Bit sollen die generierten Zahlen haben? > > 1024. Sorry, aber das ist grober Unsinn. Das ist eine Dezimalzahl von über 300 Stellen. Oder meinst du Primzahlen bis 1024? Also 10 Bits?
Jürgen S. schrieb: > Nils P. schrieb: >> Da es bislang keine Alternative zu der "Subtraktiven Synthese" gibt wird >> uns wohl nichts weiters übrig bleiben als weiterhin Zufallszahlen zu >> generieren und die durch den Miller-Rabin Test zu schicken. > > Die Frage ist, wie und man man die Wertemenge erzeugt. Das in Echtzeit > zu machen (so lese Ich den o.g. Ansatz) ist für mich nicht zielführend. Sobald jemand rausbekommt, wie man Primzahlen vorhersagen kann ist er ganz klarer Kandidat für die Field Medallie (Der Nobelpreis für Mathematiker). Bis dahin bleibt nur der Weg Zufallszahlen zu generieren und so lange auf Prime zu prüfen bis man glück hat. Klingt doof und ineffizient, ist aber so.
Gustl B. schrieb: > highfrequency schrieb: >> Gustl B. schrieb: >>> Wieviel Bit sollen die generierten Zahlen haben? >> >> 1024. > > Sorry, aber das ist grober Unsinn. Das ist eine Dezimalzahl von über 300 > Stellen. Oder meinst du Primzahlen bis 1024? Also 10 Bits? Nein ich meinte schon 1024 Bit, also eine Dezimalzahl von 309 Stellen. Es geht um RSA-2048.
Ok, aber will man das dann wirklich auf einem FPGA machen? Wieviele Primzahlen gibt es bis 2^1024? Kann man das sinnvoll irgendwo speichern?
Gustl B. schrieb: > Ok, aber will man das dann wirklich auf einem FPGA machen? Ich bin mir noch nicht sicher, würde sowas zum ersten mal machen und versuche mir daher gerade ein Bild von der Komplexität zu machen. Das Projekt wäre privater Natur. Würde es aber schon gerne in die Tat umsetzen. Gustl B. schrieb: > Wieviele Primzahlen gibt es bis 2^1024? Kann man das sinnvoll irgendwo > speichern? Gute Frage, das weiß ich leider auch nicht.
Gustl B. schrieb: > Ok, aber will man das dann wirklich auf einem FPGA machen? > > Wieviele Primzahlen gibt es bis 2^1024? Kann man das sinnvoll irgendwo > speichern? Etwa 2,53*10^305, also nein.
Nils P. schrieb: > Sobald jemand rausbekommt, wie man Primzahlen vorhersagen kann ist er > ganz klarer Kandidat für die Field Medallie (Der Nobelpreis für > Mathematiker). Wenn diese Person weniger als 40 Jahre auf dem Buckel hat ;) > Bis dahin bleibt nur der Weg Zufallszahlen zu generieren und so lange > auf Prime zu prüfen bis man glück hat. > > Klingt doof und ineffizient, ist aber so. Richtig, nur muss man u.U. nicht, wie oben im Thread vorgeschlagen, die ineffizienteste Variante nehmen (Probedivision), sondern darf das ruhig den Anforderungen angepasst auch schneller testen. Imo guter Einstieg (und ein paar kurze Hinweise zur Parallelisierbarkeit) in https://cs.stackexchange.com/questions/23260/when-is-the-aks-primality-test-actually-faster-than-other-tests Wer tatsächlich bessere Ansätze hat als in den dort aufgeführten Algorithmen verwendet, dürfte sehr wahrscheinlich nicht hier solche Fragen stellen ;)
Ja krass sind das viele Zahlen, habe mir das gerade mal angeguckt und zuerst selber zahlen mit Python erzeugt und konnte nicht glauben, dass es bis 100.000.000 ca. jede 20. Zahl ist die prim ist. http://www.michael-holzapfel.de/themen/primzahlen/pz-anzahl.htm hat mir dann weitergeholfen. Ich dachte das nimmt deutlich stärker ab mit Größe der Zahlen. Dann bleibt wirklich nur erzeugen und testen. Aber gab es nicht mal diese Rainbow-Tables? Da wurde das doch auch irgendwie gespeichert? Gingen die nicht bis 2^1024? Gut, da wurden keine Primzahlen gespeichert ...
Ich weiß nicht, warum meine Antwort ignoriert wurde, aber sie ist immer noch dieselbe: der Fermat-Primzahltest. Davon abgesehen lohnt es auch, sich mal elliptische Kurven anzuschauen -- dafür braucht man keine großen Primzahlen.
Nils P. schrieb: > Sobald jemand rausbekommt, wie man Primzahlen vorhersagen kann ist er > ganz klarer Kandidat für die Field Medallie (Der Nobelpreis für > Mathematiker). Du hast gelesen, dass ich den Unterschied nicht zwischen einerseits "Vorhersagen" und andererseits "Schätzen+Prüfen" - sondern an anderer Stelle gemacht habe, nämlich bei entweder "FPGA berechnet in Echtzeit Primzahlen" oder "FPGA gibt vorberechnete Primzahlen aus"? Nochmal: Wie man zu den Primzahlen kommt, ist eine Sache. Die entscheidende Aufgabe scheint mir aber hier, das zufällige Erzeugen, also gesteuerte Ausgeben derselben und zwar in einem gewissen Zeitrahmen, darf man annehmen. So habe ich die Aufgabe gelesen und so macht sie für die einschlägigen Anwendungen auch Sinn. Da bleibe ich bei "Tabelle offline füllen und mit Zufallsadressen zugreifen". Jemand schrieb: >> Wieviele Primzahlen gibt es bis 2^1024? Kann man das sinnvoll irgendwo >> speichern? > > Etwa 2,53*10^305, also nein. Ich glaube, man müsste genauer fragen, wieviele Zahlen es gibt, die genau die geforderten 1024 bit haben. Ich weiß nicht auswändig, wie weit die Primzahlen aufgedeckt wurden, aber es sollte rauszufinden sein, ob und wieviele diese Forderung erfüllen. In jedem Fall halte ich es für unzweckmäßig die Aufgabe im FPGA zu machen. Die Prüfung auf "Prim" oder "nicht Prim" ist eher eine Mathematische und daher etwas für C++ und GPU. Besonders die komplexeren Testverfahren sollten damit einfacher zu realisieren sein.
Jürgen S. schrieb: > Ich glaube, man müsste genauer fragen, wieviele Zahlen es gibt, die > genau die geforderten 1024 bit haben. Ich weiß nicht auswändig, wie weit > die Primzahlen aufgedeckt wurden, aber es sollte rauszufinden sein, ob > und wieviele diese Forderung erfüllen. Damit halbierst du in etwa die Anzahl an Primzahlen und sorgst dafür, dass der Zustand eines weiteren Bits bedingungslos bekannt ist. Der informationsgehalt dieser ganzen Primzahlen übersteigt übrigens Schätzungen über den Informationsgehalt des gesamten Universums bei weitem.
Ich verstehe, was Du meinst. Du möchtest auf den Wegfall der unteren Hälfte der 1024 Bit hinaus. Ich bin aber nicht sicher, ob damit nur ein Bit eingeschränkt wird. Ich denke eher, dass im unteren Bereich erheblich mehr Primzahlen stecken. Gefühlte 90%! Ich kann das so nicht beweisen, aber zwischen 0 und 127 gibt es auch erheblich mehr, als zwischen 128 und 255, oder? Jede unten existierende PZ blendet alle Zahlen ihres Vielfachen weiter oben aus. Damit wird die Dichte immer geringer und eine Verdopplung der Zahlenmenge bringt schon rein optisch bei Weitem keine Verdopplung der Wertemenge mehr. Weiter oben dürfte der Effekt eher noch geringer sein. Ich stelle mal die Behauptung auf, dass die Dichte sogar zunehmend geringer wird, also die Zahl der zusätzlichen PZ mit einer immer weiteren Verdopplung des Zahlenbereiches nicht nur geringer, sondern stärker geringer wird. Dieses Verhalten müsste sich anhand der bekannten PZ nachprüfen lassen. Für die Wertegruppe von a) 0 ... 63 b) 64 ... 127 und c) 128 ... 255 stimmt es schon mal. Die Abweichung der Anzahl der PZ in den höheren Gruppen vom Doppelten (was die Vermutung wäre) wird nach oben größer. Wahrscheinlich steigt die Zahl der PZ irgendwann mal mit jeder Verdopplung nur noch etwas mehr, als linear an.
Angehängte Dateien:
-

Plot.gif
20 KB
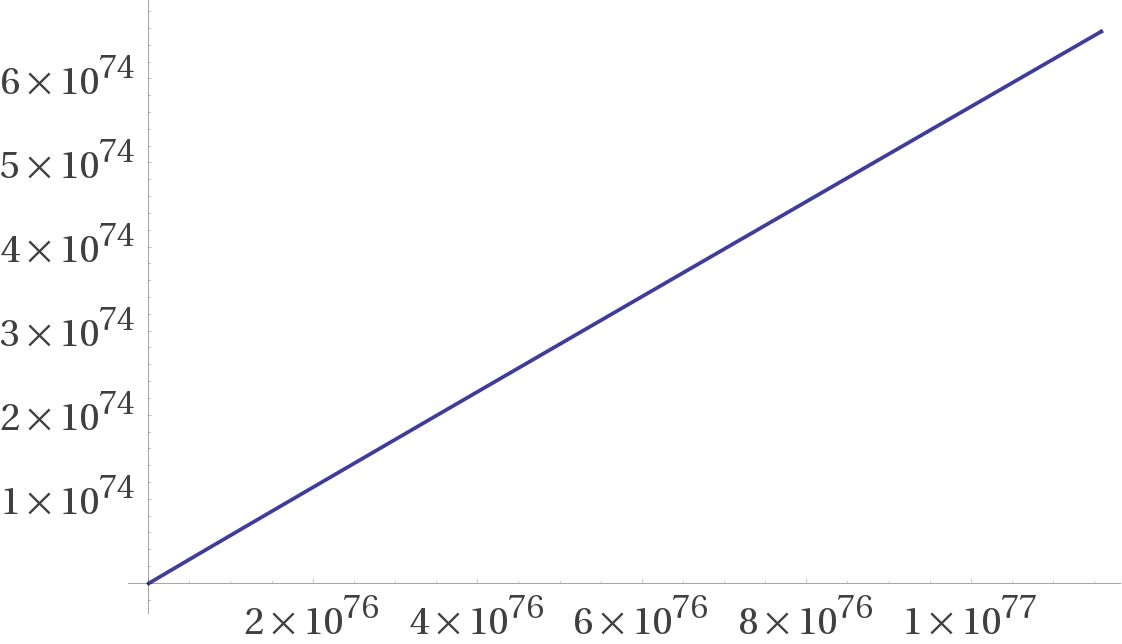
Jürgen S. schrieb: > Jede unten existierende PZ blendet alle Zahlen ihres Vielfachen weiter > oben aus. Damit wird die Dichte immer geringer und eine Verdopplung der > Zahlenmenge bringt schon rein optisch bei Weitem keine Verdopplung der > Wertemenge mehr. Weiter oben dürfte der Effekt eher noch geringer sein. Die Dichte sinkt schon, allerdings fällt das nur im kleinen Zahlenbereich wirklich auf. Im großen Zahlenbereich linearisiert sich das Wachstum weitgehend. Im Bild die Näherung der Anzahl von 0 bis 2^256.
Walter K. schrieb: > Markus F. schrieb: >> Das macht die elektronische Hardware genauso wie die biologische: man >> versucht die Zahl durch alle kleineren Zahlen zu teilen. Wenn dabei bei >> jedem Versuch ein Rest bleibt, ist die Zahl eine Primzahl. > > Naja ... es fallen schon mal alle Zahlen mit der letzten Ziffer von 0 > und 2 und 4 und 5 und 6 und 8 durch den Filter, somit sind 60% außen vor > > Dh es bleiben nur die Zahlen mit der Endziffer 1, 3, 7 und 9 als > Primzahlkanditaten > > Diese Menge reduzieren wir noch um alle die Zahlen deren Quersumme 3 > oder ein Vielfaches von 3 ergibt - und um die deren letzte 2 Ziffern > eine Quersumme von 3 oder ganzzahliges Vielfaches davon ergeben ... Widerspricht sich doch nicht. Das ist nichts anderes als ein vereinfachter Test auf Teilbarkeit ohne Rest.
Sven B. schrieb: > Ich weiß nicht, warum meine Antwort ignoriert wurde, aber sie ist immer > noch dieselbe: der Fermat-Primzahltest. Der ist nicht eindeutig für diese Aufgabe. Wieviele Basen willst du nehmen und wie häufig akzeptierst du ein false-Positive? Entweder naiv durch Durchprobieren, oder: Seit 2002 (Publikation von AKS) wissen wir, dass Prime in P liegt. Ein AKS Test ist schnell implementiert. Jedoch könnte das für relativ kleine Primzahlen im Zeitaufwand nachteilig gegenüber dem naiven Test sein. je größer die Primzahl allerdings, desto besser.
Markus F. schrieb: >> Naja ... es fallen schon mal alle Zahlen mit der letzten Ziffer von 0 >> und 2 und 4 und 5 und 6 und 8 durch den Filter, somit sind 60% außen vor >> >> Dh es bleiben nur die Zahlen mit der Endziffer 1, 3, 7 und 9 als >> Primzahlkanditaten >> >> Diese Menge reduzieren wir noch um alle die Zahlen deren Quersumme 3 >> oder ein Vielfaches von 3 ergibt - und um die deren letzte 2 Ziffern >> eine Quersumme von 3 oder ganzzahliges Vielfaches davon ergeben ... > > Widerspricht sich doch nicht. Das ist nichts anderes als ein > vereinfachter Test auf Teilbarkeit ohne Rest. ja natürlich --- er reduziert schlicht und einfach die Menge der mit einem passenden Algorithmus zu testenden Zahlen. so wie man solchen einem Algorithmus keine geraden Zahlen zum testen anbieten wird, wird man natürlich auch keine ungerade Zahl, die z.B. auf 5 endet durchlaufen lassen ..oder eben eine, die die anderen Quersummenregeln erfüllt
Der Hocko schrieb: > WasWeissIch schrieb: >> dass Prime in P liegt. > Was heisst hier "in P"? Das Problem "Prime" liegt in der Komplexitätsklasse "P". Es gibt also einen Algorithmus (den AKS Test), mit dem in polynomieller Zeit (abhängig von der Größe des Problems, in diesem Fall log(N)) festgestellt werden kann, ob N eine Primzahl ist.
WasWeissIch schrieb: > Sven B. schrieb: >> Ich weiß nicht, warum meine Antwort ignoriert wurde, aber sie ist immer >> noch dieselbe: der Fermat-Primzahltest. > > Der ist nicht eindeutig für diese Aufgabe. Wieviele Basen willst du > nehmen und wie häufig akzeptierst du ein false-Positive? > > > Entweder naiv durch Durchprobieren, oder: > Seit 2002 (Publikation von AKS) wissen wir, dass Prime in P liegt. Ein > AKS Test ist schnell implementiert. Jedoch könnte das für relativ kleine > Primzahlen im Zeitaufwand nachteilig gegenüber dem naiven Test sein. je > größer die Primzahl allerdings, desto besser. Der TO möchte Primzahlen für RSA haben, wenn ich das richtig verstehe. Die haben mindestens 1024 Bit. Die exakten Methoden funktionieren dafür quasi "per definitionem" nicht, sonst wäre das Verfahren nicht sicher. Primzahlen dieser Größe generiert man mit dem Fermat-Primzahltest. 100% sicher, dass es eine Primzahl ist bist du dann nicht, das ist richtig; du kannst die Parameter des Tests aber so wählen, dass die Fehler-Wahrscheinlichkeit z.B. < 10^-20 ist. Das ist praktisch gesehen dasselbe.
>ja natürlich --- er reduziert schlicht und einfach die Menge der mit >einem passenden Algorithmus zu testenden Zahlen. ne eben nicht, da er doch die prüfung ob gerade oder ungerade auch beim ERZEUGEN machen muss - du gewinnst gar nix...
meister schrieb: >>ja natürlich --- er reduziert schlicht und einfach die Menge der mit >>einem passenden Algorithmus zu testenden Zahlen. > > ne eben nicht, da er doch die prüfung ob gerade oder ungerade auch beim > ERZEUGEN machen muss - du gewinnst gar nix... Das ist sowieso alles völlig irrelevant. Wenn du drei viertel der zu überprüfenden Zahlen sparst, sind das gerade mal 2 Bit weniger, also 1022 statt 1024 Bits. Meinst du, das macht irgendeinen Unterschied bei Betrachtung der Frage, ob das mit einem bestimmten Algorithmus zeittechnisch machbar ist oder nicht? Nein.
Jemand schrieb: > Die Dichte sinkt schon, allerdings fällt das nur im kleinen > Zahlenbereich wirklich auf. Im großen Zahlenbereich linearisiert sich > das Wachstum weitgehend. Stimmt. Da war ich wohl zu pessimistisch. Ich habe mir mal etwas Literatur dazu angesehen und gefunden, dass man PZ schon in den 1950ern im Bereich 1024 Bit gefundenen hat. Siehe die Rekordzahlen im Wiki. Damit dürften die gesuchten Werte eigentlich offen liegen. Oder kann man unterstellen, dass in dem Bereich noch nicht alle gefunden wurden?
Jürgen S. schrieb: > Oder kann man unterstellen, dass in dem Bereich noch nicht alle > gefunden wurden? Natürlich nicht. Überleg doch mal, wieviele das wären. Wenn jede hunderste Zahl eine Primzahl ist, sind das 2^1017. Wenn jede Zahl ein Byte brauchen würde zum Auflisten, würdest du für 2^32 Zahlen 4 GB Speicher benötigen. Klingt das realistisch, dass man die "alle gefunden" hat? Dazu wäre ja dann RSA-1024 auch völlig kaputt ...
Jürgen S. schrieb: > Oder kann man unterstellen, dass in dem Bereich noch nicht alle > gefunden wurden? Die Anzahl der Primzahlen in einem Intervall lässt sich abschätzen: https://en.wikipedia.org/wiki/Prime-counting_function#Inequalities Für das Intervall von 2^1023 bis 2^1024 ergibt das 1.5e305 Primzahlen. Im Vergleich dazu gibt es im gesamten Universum weniger als 10^100 Elementarteilchen.
Sven B. schrieb: > Der TO möchte Primzahlen für RSA haben, wenn ich das richtig verstehe. > Die haben mindestens 1024 Bit. Die exakten Methoden funktionieren dafür > quasi "per definitionem" nicht, sonst wäre das Verfahren nicht sicher. > Primzahlen dieser Größe generiert man mit dem Fermat-Primzahltest. > > 100% sicher, dass es eine Primzahl ist bist du dann nicht, das ist > richtig; du kannst die Parameter des Tests aber so wählen, dass die > Fehler-Wahrscheinlichkeit z.B. < 10^-20 ist. Das ist praktisch gesehen > dasselbe. Ja das hast du richtig verstanden. Wäre eine Implementierung des Fermat-Primzahltests deiner Meinung nach auf einem FPGA in dieser Größenordnung implementierbar, wenn die Generierung der Primzahl unter 60 s dauern sollte? Es geht mir bei dem Projekt nicht um die bestmögliche Effizienz, es sollte einfach funktionieren.
Kann ich nicht einschätzen, sorry. Kommt sicherlich auch auf das FPGA an. RSA-Keys generieren ist aber traditionell relativ langsam und wie schnell du einen findest ist auch ein bisschen Glückssache. Wir haben hier so eine 400 MHz ARM-Embedded-CPU, die braucht für einen 4096 Bit-Key zwischen 20 Sekunden und mehreren Minuten. Das kommt aber auch darauf an, wieviel Zufall da ist, glaube ich. Wenn du irgendwie die Wahl hast, nimm elliptische Kurven. Die Schlüssel lassen sich super schnell generieren (du brauchst nur Zufallszahlen, keine Zufalls-Primzahlen) und sind bei vergleichbarer Sicherheit dazu nur weniger als ein fünftel so groß. Noch ein Hinweis: "pseudozufällig" ist für diese Anwendung nicht was du willst! Zum Schlüssel generieren brauchst du echten Zufall.
Ich stimme Sven zu. Wenn du die Wahl hast nimm Elliptische Kurven in GF(2^x) und kryptographische Funktionen die auf dem Logarithmus Problem basieren. Das hat gleich mehrer Vorteile gegenüber RSA und Konsorten. 1.) wenn man beim RSA keine 100%'tige Kontrolle über den Schlüsselerzeugungsprozess hat dann ist es als unsicher einzustufen. Man kann nämlich mit modifizierten Schlüsselerzeugungsprozess einen sogennannten verdeckten Kanal einbauen über den der Schlüsselerzeuger faqst mit Null Aufwand jeden Schlüssel und die damit verschlüsselten nachrichten brechen kann. Das Problem mit solchen Verfahren ist es das die gleichen mathematischen Bedingungen die RSA erst sicher machen auch für diesen verdeckten Kanal gelten und ihn vor Entdeckung schützen. Mit anderen Worten: ich würde niemals einem TrustCenter trauen das für mich meine RSA Schlüssel erzeugt hat. Dieses Problem hat man mit Verfahren die auf den Logarithmusproblem basieren grundsätzlich nicht. 2.) Den Zufallsschlüssel/Private Key kann man notfalls auch mit dem Würfel händisch ermitteln. 3.) Die benutzten Primzahlen sind öffentlich und können mit Hilfe spezieller Verfahren ein mathematisch beweisbares und überprüfbares Zertifikat erhalten. Somit sind alle sicherheitsrelevanten Informationen dem DL öffentlich verifizierbar. 4.) Die benutzten Primzahlen und Elliptischen Kurven werden einmalig offline erzeugt. 5.) die Berechnungsoperationen in der GF(2^x) Domain sind für FPGAs ideal umsetzbar und hoch parallelisierbar. 6.) diese Berechnungen kommen meist ohne komplexere Operationen aus, wie zb. die nötigen Divisionen/Multiplikation in N. Gruß hagen
Sven B. schrieb: > Klingt das realistisch, dass man die "alle gefunden" > hat? So langsam verstehe ich, was der TE möchte: Wie sollen ihm ein System konstruieren, womit er dann fehlende Primes finden und Meriten abstauben kann :-) Die höchste derzeit bekannte scheint irgendwas mit 70000 Stellen zu sein. Dann behaupte ich mal frech, das (2!111111111 - 1) eine Prime ist. Wie prüfe ich es nun nach? Gibt es überhaupt einen Rechner, der das kann?
Alexander F. schrieb: > Die Anzahl der Primzahlen in einem Intervall lässt sich abschätzen: > https://en.wikipedia.org/wiki/Prime-counting_function#Inequalities Das habe ich inzwischen auch gefunden. Die Frage wäre jetzt, ob es Tabellen mit Besetzungsstatistiken gibt, welche angeben, wo man suchen könnte und wie groß die Abdeckung ist. Und wie die Finder zu den neuen, viel größeren PZ gelangen. Dort werden offenbar Bereiche übersprungen. Besonders die einschlägigen Binärpotenzen-1 scheinen mir Zufallsfunde. Die testen mit immer höheren Potenzen, bis sie was haben.
Jürgen S. schrieb: > Alexander F. schrieb: >> Die Anzahl der Primzahlen in einem Intervall lässt sich abschätzen: >> https://en.wikipedia.org/wiki/Prime-counting_function#Inequalities > > Das habe ich inzwischen auch gefunden. Die Frage wäre jetzt, ob es > Tabellen mit Besetzungsstatistiken gibt, welche angeben, wo man suchen > könnte und wie groß die Abdeckung ist. Deine Vorstellung davon, wieviele Primzahlen es gibt, ist falsch. Es gibt unfassbar viele davon und sie sind sehr gleichmäßig verteilt. So eine Tabelle macht keinerlei Sinn. > Und wie die Finder zu den neuen, viel größeren PZ gelangen. Dort werden > offenbar Bereiche übersprungen. Besonders die einschlägigen > Binärpotenzen-1 scheinen mir Zufallsfunde. Die testen mit immer höheren > Potenzen, bis sie was haben. Ja, natürlich. Die 2^n-1 Primzahlen heißen Mersenne-Primzahlen, und es gibt m.W. sogar spezielle Algorithmen, die eine Zahl genau dieser Form auf Primalität überprüfen.
Sven B. schrieb: > Deine Vorstellung davon, wieviele Primzahlen es gibt, ist falsch. Es > gibt unfassbar viele davon und sie sind sehr gleichmäßig verteilt. So > eine Tabelle macht keinerlei Sinn. Ich meinte das anders herum: Eine Tabelle, die angibt, welche Zahlen schon gefunden wurden. Diese würde in Verbindung mit der Annahme der Gleichverteilung ja gerade offenlegen, wo man noch suchen könnte.
Jürgen S. schrieb: > Eine Tabelle, die angibt, welche Zahlen > schon gefunden wurden. Auch diese Tabelle ist potentiell beliebig groß. Manche Primzahlen folgen bestimmten Regeln (wie z.B. die Mersenne-Primzahlen), aber dazwischen gibt es immer wieder welche, die keinen Regeln folgen (oder für die wir zumindest keine Regeln kennen). Übrigens verwendet man in der Realität für Krypto keine Primzahlen, sondern nur Zahlen, die mit sehr hoher Wahrscheinlichkeit prim sind. Der exakte Nachweis würde ja eine Primfaktorzerlegung erfordern, die nachvollziehbarerweise schwierig sein soll. :-)
Jürgen S. schrieb: > Sven B. schrieb: >> Deine Vorstellung davon, wieviele Primzahlen es gibt, ist falsch. Es >> gibt unfassbar viele davon und sie sind sehr gleichmäßig verteilt. So >> eine Tabelle macht keinerlei Sinn. > > Ich meinte das anders herum: Eine Tabelle, die angibt, welche Zahlen > schon gefunden wurden. Diese würde in Verbindung mit der Annahme der > Gleichverteilung ja gerade offenlegen, wo man noch suchen könnte. Das hat dasselbe Problem. Stell dir vor, du willst in der Sahara Sandkörnchen finden, die einen bestimmten Farbton haben. Nicht alle haben diesen Farbton, aber sagen wir mal 1% davon. Und jetzt überleg mal, wie hilfreich bei diesem Unterfangen eine Tabelle wäre, die für jeden Kubikzentimeter Sand auflistet, wieviele solche Sandkörnchen du schon gefunden hast ... > Der exakte Nachweis würde ja eine Primfaktorzerlegung erfordern, die > nachvollziehbarerweise schwierig sein soll. :-) Das stimmt übrigens nicht: der Nachweis, dass eine Zahl prim ist, ist mit anderen Algorithmen und geringerem Aufwand lösbar als die konkrete Zerlegung.
Scon mal jemandem aufgefallen, dass der "Hochfrequenz" seit wenigstens einer Woche nicht mehr mitliest? Ich werfe diesbezüglich kurz in die Diskussion ein, wie ein FPGA mit seinem begrenzten Speicher und Rechenmöglichkeiten diese großen Zahlen handhaben soll.
FPGA-Mann schrieb im Beitrag #5500180: > Scon mal jemandem aufgefallen, dass der "Hochfrequenz" seit wenigstens > einer Woche nicht mehr mitliest? Wie stellt man das fest? Das er nicht mehr antwortet sieht man, aber wie erkennt man ausbleibende Lesezugriffe? Außerdem ist es auch völlig unerheblich, ob es den TO noch gibt: Solange wie im Thread geschrieben wird, ist eine gewisse Resonanz vorhanden... Duke
Angehängte Dateien:
-

setipro_stat_kle.gif
3,1 KB
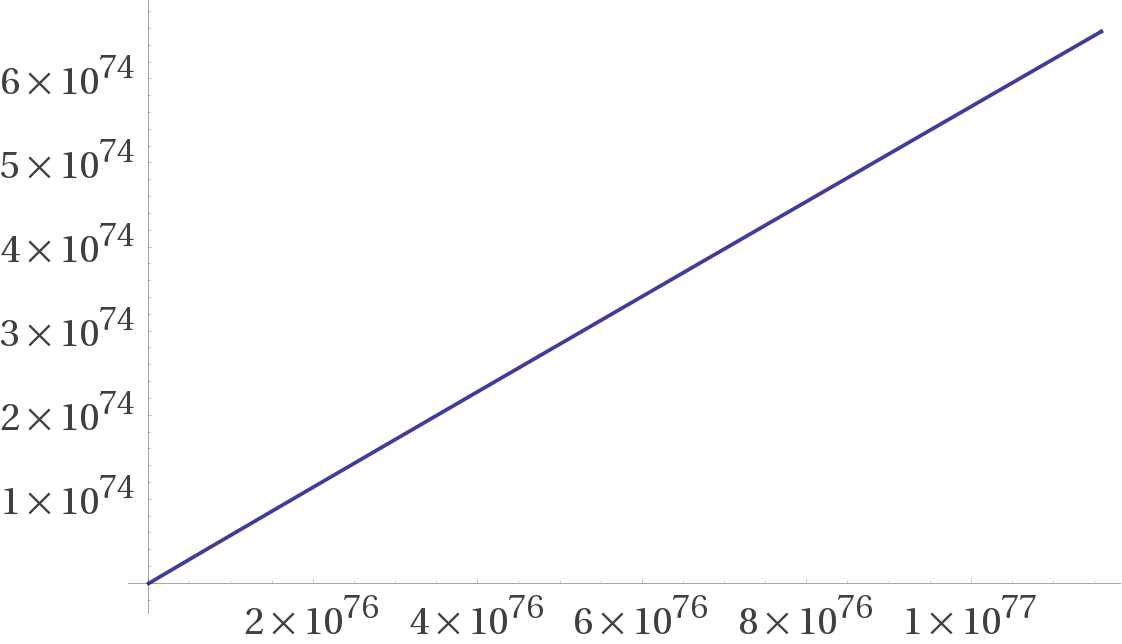{kind=link}
{kind=link}
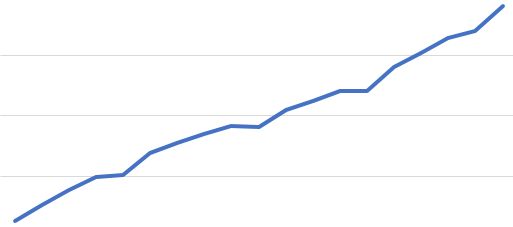
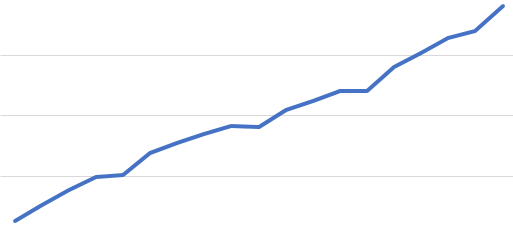
Sven B. schrieb: > überleg > mal, wie hilfreich bei diesem Unterfangen eine Tabelle wäre, die für > jeden Kubikzentimeter Sand auflistet, wieviele solche Sandkörnchen du > schon gefunden hast ... Sie wäre dann hilfreich, wenn sie offenbarte, dass es in Region 1,2,3 und 5 jeweils 10% rote Sandkörner gibt und in Region 4 nur 3%. Ich würde dann die Region 4 absuchen. Sagt die Tabelle aber sowas wie 4%,3%,20%, 17%, könnte man unterstellen dass 20% so eine Art Limit ist, die Region 4 ziemlich abgegrast ist und es sich in den ersten beiden lohnt. Das ist das klassische Goldsucherproblem. Anhand der Umgebung schätzen was lokal zu vermuten ist und plausibilisieren, wie vollständig der Wertemenge ist. Ich möchte doch mal wetten, dass die Tabelle noch nicht konsistent ist, also sicher nicht der vermuteten Verlaufsform folgt. Sie wird Lücken aufweisen. Solche Besetzungsstatistiken sehen - egal wie der Verlauf ist - immer irgendwie so aus wie im Bild. Selbst in völliger Unkenntnis des Prinzipverlaufs (hier sinx +x) sieht man, wo man suchen muss.
Jürgen S. schrieb: > Sven B. schrieb: >> überleg >> mal, wie hilfreich bei diesem Unterfangen eine Tabelle wäre, die für >> jeden Kubikzentimeter Sand auflistet, wieviele solche Sandkörnchen du >> schon gefunden hast ... > > Sie wäre dann hilfreich, wenn sie offenbarte, dass es in Region 1,2,3 > und 5 jeweils 10% rote Sandkörner gibt und in Region 4 nur 3%. > Ich würde dann die Region 4 absuchen. Das ist aber schlicht nicht so. Die Sandkörner sind extrem viele und extrem gleichmäßig verteilt.
Sven B. schrieb: > Das ist aber schlicht nicht so. Die Sandkörner sind extrem viele und > extrem gleichmäßig verteilt. Das Sandkornbeispiel war nicht von mir, bleiben wir mal bei der Frage nach den Primzahlen. Gibt es eine Tabelle, die aufzeigt, inwieweit die Anzahl der gefundenen Zahlen diejenige erreicht, die durch die Abschätzung weiter oben angeführt würde? Wenn da durchschnittlich nur 1% aufgeführt wären, so wäre das in der Tat ohne Information. Aber ist das so?
Walter K. schrieb: > ... > Dh es bleiben nur die Zahlen mit der Endziffer 1, 3, 7 und 9 als > Primzahlkanditaten > > Diese Menge reduzieren wir noch um alle die Zahlen deren Quersumme 3 > oder ein Vielfaches von 3 ergibt - und um die deren letzte 2 Ziffern > eine Quersumme von 3 oder ganzzahliges Vielfaches davon ergeben ... "deren letzte 2 Ziffern eine Quersumme von 3 oder ganzzahliges Vielfaches davon ergeben"? 127? 139? 151?
Jürgen S. schrieb: > Sven B. schrieb: >> Das ist aber schlicht nicht so. Die Sandkörner sind extrem viele und >> extrem gleichmäßig verteilt. > > Das Sandkornbeispiel war nicht von mir, bleiben wir mal bei der Frage > nach den Primzahlen. Gibt es eine Tabelle, die aufzeigt, inwieweit die > Anzahl der gefundenen Zahlen diejenige erreicht, die durch die > Abschätzung weiter oben angeführt würde? > > Wenn da durchschnittlich nur 1% aufgeführt wären, so wäre das in der Tat > ohne Information. Aber ist das so? Hm, ich glaube irgendwie ist mein Punkt nicht klar. Ich mache mal ein Zahlenbeispiel für die Primzahlen. Wir katalogisieren mal nur Primzahlen, die so grob zwischen 2**4095 und 2**4096 liegen, im Bereich von RSA 4096-Keys. Jetzt nehmen wir mal an, unsere Tabelle hat großzügige 2**64=18446744073709551616 Bereiche, die katalogisiert sind. Dazu nehmen wir an, in jedem einzelnen dieser Bereiche würden wir soviele Primzahlen kennen, wie wir im kompletten der Menscheit zur Verfügung stehenden Speicher abspeichern könnten. Das werden so ganz grob 10**18 Stück sein. Von den genannten Primzahlen (unter der Annahme, dass jede tausendste Zahl eine Primzahl ist, aber das ist relativ egal) haben wir dann sowas wie 10**18 * 2**64 / (2**4096 / 1000) = tja, ich kann's gar nicht ausrechnen, passt nicht in die Floating-Point-Genauigkeit, Moment ... 10**-1189% katalogisiert. Das sind, äh, 0.0000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000 0000000000000000000000000000000000000001%, ungefähr. Für den Prozentsatz in jedem einzelnen Tabellenbereich gilt dasselbe.
oder anders ausgedrückt: Primzahlen der höhren Ränge sind so gut wie gar nicht erforscht und bekannt. Man kann praktisch überall welche finden.
Beitrag #5511486 wurde von einem Moderator gelöscht.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.