Hallo zusammen, hat jemand von euch schon einmal Erfahrung mit der Programmiersprache Rust im Embedded Umfeld (primär Cortex-M) gemacht? Gerade im Vergleich zu C oder C++ scheint es einige Vorteile zu geben. Ich habe mir mit C und C++ schon öfters effizient in den Fuß geschossen, was gerade auf µCs oft nicht direkt auffällt, das es keinen SegFault wie auf dem PC gibt (Bitte keine Belehrungen dazu. Ich bin mir sicher, dass solche Dinge jedem schon einmal passiert sind... :-) ). Rust vermeidet anscheinend ja effektiv Dangling Ponters und es gibt auch keine NULL-Pointer. Array-Bounds werden auch gecheckt. Das nimmt ja schon mal das meiste Gefahren-Potential. Was ich mich noch frage: was passiert standardmäßig im Falle eines panic!()-Aufrufs? Wie sieht es mit der Effizienz des erzeugtem Maschienencodes aus? Es wird ja LLVM benutzt, was ja schon einiges erwarten lässt (clang ist mWn auch ein LLVM-Frontend). Ich gehe stark davon aus, dass pure C/C++ eine kleinere Runtime hat (und damit erst einmal ein kleineres Binary), aber bei größeren Projekten sieht das evtl. anders aus (kann ich mangels einem solchen Projekt nicht testen). Über Antworten freue ich mich. Grüße, nga
Schau mal hier: Rust your ARM microcontroller! http://blog.japaric.io/quickstart/ Vielleicht ist da ja was hilfreiches bei. nga schrieb: > Rust vermeidet anscheinend Nicht nur anscheinend: es tut es. Der Preis dafuer ist halt eine laengere Compilierzeit. Man bekommt praktisch fuer alles einen Error, wo es in C/C++ noch nicht mal eine Warnung gibt bzw. nur, wenn man sie einschaltet. Ausserdem muss man sich an ein paar Stellen eine neue Art der Programmierung angewoehnen, da man z.B. nicht mehrer Zeiger mit Schreibzugriff haben kann (ausser in unsafe {}), und das Borrowing erfordert auch ein umdenken. Ich arbeite mich gerade selber in Rust ein, allerdings erstmal auf dem Desktop unter Linux. Ich will es dann aber auch auf ARM und AVR nutzen.
Kaj schrieb: > wo es in C/C++ noch nicht mal eine Warnung gibt bzw. nur, wenn man sie > einschaltet. Ja, genau: für die allermeisten C-Probleme gibt es Warnungen, die man einschalten kann.... Und notfalls gibt es lint und Mists. Und Warnung als Error gibt's auch.
Beitrag #5513351 wurde von einem Moderator gelöscht.
Karl K. schrieb im Beitrag #5513351: > Behalte Deinen C-Mist, hat keiner danach gefragt. man man man, Turett-Syndrom, oder was? Hat er wohl nach gefragt: wer schreibt: > Gerade im Vergleich > zu C oder C++ scheint es einige Vorteile zu geben. fragt nach genau sowas. Wobei, in so einem Fall C und C++ in einem Atemzug zu nennen, da ist schon klar, warum es beim programmieren zu Schüssen ins Bein kommt. Und, mal ehrlich, wer wegen > Array-Bounds werden auch gecheckt. Meint eine neue Sprache lernen zu müssen ... Man könnte dann auch einfach (C++) gecheckte Zugriffe nehmen und fertig? C und C++ hier in einem Atemzug zu nennen, klingt auch schon verdächtig. C++ und C haben eigentlich was Pointer angeht, nicht mehr viel gemeinsam. C++ mit Raw Pointern ist das selbe wie Rust mit Raw Pointern. Und null-Referenzen gibt es in C++ nicht. Hat wirklich schonmal jemand mit -Wall und smart-Pointern Probleme mit dangling Pointers oder nullpointern gehabt? Das klingt für mich extrem exotisch. Unabhängig davon macht Rust wirklich einen netten Eindruck und warum nicht, wenns Freude macht. Aber die vom TO vorgeschobenen C++ Probleme sind Quark. vlg Timm
Timm R. schrieb: > Meint eine neue Sprache lernen zu müssen ... Man könnte dann auch > einfach (C++) gecheckte Zugriffe nehmen und fertig? Es ist schon auffällig, dass hier im Forum in so ziemlich jedem Thread in dem eine andere Programmiersprache erwähnt wird die C-Freaks aufschlagen und erklären, wie toll ihr C ist und dass man das ja auch mit C könnte. Ihr nervt!
Karl K. schrieb: > Timm R. schrieb: >> Meint eine neue Sprache lernen zu müssen ... Man könnte dann auch >> einfach (C++) gecheckte Zugriffe nehmen und fertig? > > Es ist schon auffällig, dass hier im Forum in so ziemlich jedem Thread > in dem eine andere Programmiersprache erwähnt wird die C-Freaks > aufschlagen und erklären, wie toll ihr C ist und dass man das ja auch > mit C könnte. > > Ihr nervt! Timm sprach aber von C++ nicht von C
Marian M. schrieb: >> Es ist schon auffällig, dass hier im Forum in so ziemlich jedem Thread >> in dem eine andere Programmiersprache erwähnt wird die C-Freaks >> aufschlagen und erklären, wie toll ihr C ist und dass man das ja auch >> mit C könnte. >> >> Ihr nervt! > > Timm sprach aber von C++ nicht von C Nur mal so nebenbei als kleiner Seitenhieb: Egal ob er von C oder C++ sprach, war DAS nicht genau das, was einigen von euch immer so an Moby aufgestoßen ist, wenn er sein Assembler unerwartet in den Ring warf? Und warum stört euch der gleiche Vorgang plötzlich viel weniger oder gar nicht, wenn anstatt mit Assembler nun mit C oder C++ in eine Rust-Diskussion hineingegrätscht wird? Kann es sein, dass hier gewisse verbreitete C, C++ Vorlieben zu einer deutlich höheren Toleranzschwelle gegenüber Störenfrieden führen? Pharisäertum hier?
völlig egal schrieb: > Marian M. schrieb: >>> Es ist schon auffällig, dass hier im Forum in so ziemlich jedem Thread >>> in dem eine andere Programmiersprache erwähnt wird die C-Freaks >>> aufschlagen und erklären, wie toll ihr C ist und dass man das ja auch >>> mit C könnte. >>> >>> Ihr nervt! >> >> Timm sprach aber von C++ nicht von C > > Nur mal so nebenbei als kleiner Seitenhieb: Egal ob er von C oder C++ > sprach, war DAS nicht genau das, was einigen von euch immer so an Moby > aufgestoßen ist, wenn er sein Assembler unerwartet in den Ring warf? Und > warum stört euch der gleiche Vorgang plötzlich viel weniger oder gar > nicht, wenn anstatt mit Assembler nun mit C oder C++ in eine > Rust-Diskussion hineingegrätscht wird? > > Kann es sein, dass hier gewisse verbreitete C, C++ Vorlieben zu einer > deutlich höheren Toleranzschwelle gegenüber Störenfrieden führen? > > Pharisäertum hier? Ich verstehe worauf du hinaus willst, nur war es nicht meine Absicht C oder C++ besser als Rust darzustellen, ich hatte nur angemerkt, dass Timm von C++ und nicht von C gesprochen hat. Persönlich empfinde ich es durchaus als Bereicherung eine weitere Sprache auf Controllern lauffähig zuhaben, nur sehe ich die Schwierigkeiten bei Rust darin wie bisheriger Code, welcher in C oder C++ geschrieben wurde, wiederverwendet werden kann. Bisher dachte ich, dass dazu dieser Teil des Projektes (zB eine Bibliothek) als unsafe eingebunden werden muss, was ja nicht der Weisheit letzter Schluss sein kann. Sollte ich mich hier irren, könnten diejenigen bitte ein paar Beispiele verlinken, ich lerne durchaus gerne dazu ;) Aber wenn man überlegt wie lange es gedauert hat bis sich C++ überhaupt in die Köpfe mancher embedded Entwickler eingeschlichen hatte, kann es gerade bei Rust noch Jahre dauern bis es zu einer nennenswerten Verbreitung kommt, aber eventuell gibt es ja dann doch ein paar Einflüsse die das beschleunigen könnten.
Kaj schrieb: > Schau mal hier: > > Rust your ARM microcontroller! > http://blog.japaric.io/quickstart/ > > Vielleicht ist da ja was hilfreiches bei. Besser hier: https://rust-embedded.github.io/discovery/ Vom selben Autor, aber neuer, und damit auf dem aktuellen Stand... Xargo wird z. B. nicht mehr benötigt: https://users.rust-lang.org/t/cortex-m-library-development-now-possible-on-beta-and-the-path-towards-stable-embedded-rust/17420
hier ist noch ein kleiner fanboy von Rust im embedded Bereich :) denke es hat sehr großes Potential. Timm R. schrieb: > Meint eine neue Sprache lernen zu müssen ... Man könnte dann auch > einfach (C++) gecheckte Zugriffe nehmen und fertig? korrigiere mich wenn ich falsch liege aber smartpointers etc. werden zur Laufzeit überprüft, während Rust versucht das ganze noch zur Compilezeit aufzulösen, was einen minimalistischeren Code ergeben sollte. wenn man sich die Beispiele auf japarics blog anschaut, ist der generierte Assembler schon wirklich sehr effizient. Klar kann ich sowas auch mit C und C++ erreichen aber mit wesentlich mehr Aufwand. Für mich ist es eine einfache Kosten Nutzen Rechnung. Ich persönlich kann eher Rust lernen als C und/oder C++ so gut beherrschen um das gleiche zu erreichen. Auf der embedded world 2018 habe ich den ersten Stand mit Dienstleistungen für Rust im embedded Bereich gesehen :) für manche sachen wird wohl noch der nightly build vom Rust compiler benötigt, mit dem Rust 2018 release (erwartet im Dezember) soll embedded targets out of the box unterstützt werden nga schrieb: > Was ich mich noch frage: was passiert standardmäßig im Falle eines > panic!()-Aufrufs? die cortex-rt crate kümmert sich darum. Default ist (glaube ich) es wird ein Fehler über semihosting oder SWO ausgegeben und anschließend eine endlosschleife betreten. Lässt sich aber auch umleiten auf z.B. einen UART oder so ...
Ben W. schrieb: > korrigiere mich wenn ich falsch liege aber smartpointers etc. werden zur > Laufzeit überprüft, während Rust versucht das ganze noch zur Compilezeit > aufzulösen, was einen minimalistischeren Code ergeben sollte. Ich kann dich korrigieren :). C++ macht das bei std::array z.B. auch zur Compilezeit. Im Endeffekt wird auch in den aktuellen C++ Standards (11,14,17,21 ... ) viel auf solche Themen eingegangen. Der Punkt ist aber dass man sich es auch angewöhnen muss die STL in C++ Projekten zu nutzen und man sich sehr mit der Toolchain beschäftigen muss, weil es immer mal wieder Desktop Funktionalitäten gibt die man für embedded deaktivieren muss. (z.B. Exceptions, RTTI ...). Daher kann ich es schon verstehen das einige hier den Weg über eine andere Sprache, die verspricht einem diese Fallstricke abzunehmen, gehen wollen. Deshalb weiter so! Ich wollte nur diese Diskussion "C++ kann das nicht aber Rust" entkräften. Das zeigt eigentlich schon was modernes C++ falsch macht. Die Leute wissen einfach nicht mehr was C++ alles kann und wie die Ganzen neuen Konstrukte funktionieren. Deshalb ist Rust vllt. wirklich die einfachere Alternative. Gruß Alex
Lieber Karl, Karl K. schrieb: > Es ist schon auffällig, dass hier im Forum in so ziemlich jedem Thread > in dem eine andere Programmiersprache erwähnt wird die C-Freaks > aufschlagen und erklären, wie toll ihr C ist und dass man das ja auch > mit C könnte. Das Problem ist vielleicht auch, dass Du, weil du so genervt bist, einfach nicht liest? Der Ursprungs-Post ist – auch – ein C, C++ vs. Rust Post. Wenn der OP das nicht will, muss er einfach die Schlüsselwörter weglassen. Zumal C++ vs. besonders "ansprechend" gestaltet ist, weil der OP nahelegt, dass er gar kein C++ kann, was das Ganze etwas grotesk macht. Ich bin auch kein C Freak, noch nicht mal ein C++ Freak, du wirst auch von mir keinen einzigen Beitrag finden können, der die von Dir behaupteten Eigenschaften zeigt. Programmiersprachen sind Werkzeuge und keine Religionen. Das C++ für embedded eine sehr heikle Sache sein kann, weil es schwierig ist, den Überblick zu behalten welche Features den Code blähen, ist bekannt und unbestritten. Ich habe auch nicht das geringste gegen Rust einzuwenden, warum auch? Ich habe schonmal angefangen Rust zu lernen, zu der Zeit war aber noch nicht so viel los damit, ist aber auch schon was her. Könnte sich denn vielleicht einer der Rust-kundigen und C++-kundigen erbarmen, mal ein minimales Beispiel mit c++ Pointer-Katastrophe zu zeigen und wie es in Rust besser läuft? Das wäre doch sicher für mehrere Rist-Unkundige interessant und erhellend? Mir fehlt da einfach die Vorstellungskraft. vlg Timm
Hi Ben, Ben W. schrieb: > Timm R. schrieb: >> Meint eine neue Sprache lernen zu müssen ... Man könnte dann auch >> einfach (C++) gecheckte Zugriffe nehmen und fertig? > > korrigiere mich wenn ich falsch liege aber smartpointers etc. werden zur > Laufzeit überprüft, während Rust versucht das ganze noch zur Compilezeit > aufzulösen, was einen minimalistischeren Code ergeben sollte. smart Pointer werden AFAIK gar nicht geprüft. Wenn ein smart Pointer null ist, gibts zur Laufzeit einen Knall. Sie verhindern nur böse Sachen wie:
1 | char* dp = NULL; |
2 | {
|
3 | char c; |
4 | dp = &c; |
5 | } |
6 | *dp = 42; |
Was ja vermutlich so Szenarien sind, mit denen sich Anfänger in den Fuß schießen? Bounds werden natürlich (ich weiße es nicht) in Rust genau so zur Laufzeit gecheckt, wie auch in C++. Das kann ja gar nicht anders gehen. vlg Timm
Timm R. schrieb: > Könnte sich denn vielleicht einer der Rust-kundigen und C++-kundigen > erbarmen, mal ein minimales Beispiel mit c++ Pointer-Katastrophe zu > zeigen und wie es in Rust besser läuft? Das wäre doch sicher für mehrere > Rist-Unkundige interessant und erhellend? Ja, das fände ich konstruktiv! Gerne auch in C. Und mit Angabe der Warnungen, die man dafür ausblenden muss oder nicht einschalten darf.
Für Rust benötigt man meines Wissens nach LLVM, die Auswahl an Backends ist dort aber noch überschaubar. Momentan setze ich (je nach Verfügbarkeit) auf GCC und SDCC, was wegen dem SDCC schon C++ ausschließt. Es gibt zwar genügend Anleitungen, um eigene Backends für LLVM zu schreiben, aber das ist ein Aufwand, den ich mir nicht antun möchte.
Also ich weiß nicht, geht das hier nicht 'schöner'?:
1 | // Send a single character
|
2 | usart1.tdr.write(|w| w.tdr().bits(u16::from(b'X'))); |
Ich habe mich bisher nur wenig mit Rust beschäftigt, halte es aber für eine der interessantesten Programmiersprachen aus jüngerer Zeit. Rust verfolgt ähnliche Ziele wie C++, nämlich relativ hohe Abstraktion mit minimalem bis gar keinem Laufzeit-Overhead. Mein Eindruck ist, dass alle wesentlichen Features von C++ in Rust ebenso verfügbar sind oder aber durch mindestens gleichwertige andere Features ersetzt wurden. Da diese Features bereits frühzeitig in das Sprachkonzept eingeflossen sind und nicht, wie in C++, über viele Jahre verteilt, ist Rust (zumindest derzeit noch) trotz seiner Mächtigkeit eine recht schlanke Sprache ohne Kompatibilitätsaltlasten. Wenn ich demnächst etwas mehr Zeit habe, werde ich versuchen, meine Rust-Kenntnisse etwas zu vertiefen und in kleineren Hobbyprojekten anstelle von C oder C++ zu nutzen. Timm R. schrieb: > Könnte sich denn vielleicht einer der Rust-kundigen und C++-kundigen > erbarmen, mal ein minimales Beispiel mit c++ Pointer-Katastrophe zu > zeigen und wie es in Rust besser läuft? Hier ist ein kleines Beispiel von Steve Klabnik: https://github.com/steveklabnik/uniq_ptr_problem
Ich habe keine Ahnung von rust und habe daher nichts zum eigentlich Thema zu sagen. Aber zu diesem Link kann ich etwas sagen. Yalu X. schrieb: > Hier ist ein kleines Beispiel von Steve Klabnik: > > https://github.com/steveklabnik/uniq_ptr_problem Eine ganze Seite "Seite", die mit dem Ziel:
1 | While it's true that C++'s smart pointers are a huge leap forward, they aren't actually safe in all cases. I always forget what the exact cases are, so I made this page to remind myself. |
erstellt wurde, enhält genau ein Beispiel und dieses eine Beispiel ist trivial und sollte für jeden offensichtlich sein, der verstanden hat was ein unique_ptr und was move-Semantik ist. Es ist kein Beispiel für Probleme mit smart-Pointern in c++, sondern eher für Probleme mit der move-Semantik. Probleme die rust anscheinend auch hat, wie man der gleichen Seite entnehmen kann. Ok bei rust gibt der Compiler eine Meldung aus, die man aber auch in c++ bekommt, wenn man clang-tidy benutzt.
Hallo Yalu, ja, ich denke, das Beispiel ist gültig. Danke! Der Claim ist ja gerade, dass Rust sich wie ein erfahrener Ratgeber verhält und verhindert, dass man (aus versehen) blöde Dinge tut. Die Move Semantik ist scheinbar so eindeutig, dass der Compiler diesen Fehler verhindern kann, das ist ein Beleg für den Claim. Natürlich kommt das zu einem Preis, natürlich kann man sagen, dass das echt ein saublöder Fehler ist, den erfahrene Programmierer nie machen würden, aber darum geht es ja gerade. Unfälle passieren, weil man unachtsam blöde Dinge tut. Vermutlich warnt der C++ Compiler nicht, weil std::move ja nicht move heißt, sondern nur move versuchen und was genau passiert, weiß man nicht. Bei einem anderen Typ könnte das Beispielprogramm problemlos laufen. Andererseits ist bei std::unique_ptr klar, dass das Programm fehlerhaft ist und er könnte sehr wohl warnen, wenn er wollte. Wie auch immer: Wenn die Priorität auf dangling Pointer um jeden Preis vermeiden liegt, hat Rust hier einen Punkt gemacht. Finde ich. vlg Timm P.S. Ich glaube mich persönlich holt das Beispiel jetzt nicht so ab, denn es zeigt ja nichts unerwartetes oder spezielles, genau so wie in dem Beispiel soll es ja sein, trotzdem ist der Rest-flavour des Themas natürlich einsteigerfreundlicher, eindeutiger und sicherer.
nga schrieb: > Ich habe mir mit C und C++ schon öfters effizient in den Fuß geschossen, > was gerade auf µCs oft nicht direkt auffällt, das es keinen SegFault wie > auf dem PC gibt Den gibt es schon, heißt nur HardFault und führt normalerweise zu einem Reset. Unterbindet man das (z.B. durch einen eigenen HardFault-Handler), dann unterscheidet er sich nicht besonders von seinem PC-Pendanten. Weglaufende Pointer fängt man damit relativ gut ein. nga schrieb: > Rust vermeidet anscheinend ja effektiv Dangling Ponters und es gibt auch > keine NULL-Pointer. Array-Bounds werden auch gecheckt. Das nimmt ja > schon mal das meiste Gefahren-Potential. Die meisten Gefahren kann man auch in C++ relativ zuverlässig verhindern, wenn man ein Stück weit von C weggeht. Referenzen sind z.B. oft eine gute Alternative zu Pointern und niemals NULL. Mit range-based for-loops lässt sich gut über Container iterieren, ohne dabei Arraygrenzen zu überschreiten (reduziert für mich einiges an Gefahrenpotential). Viele (aber nicht alle) Array-Bounds lassen sich auch zur Compilezeit prüfen, und wenn man die überschreitet, gibt es nette Warnungen. Das ist alles nicht mehr so schlimm wie vor einigen Jahren. Ansonsten haben die meisten modernen Sprachen ähnliche Features, z.B. muss man in Kotlin alle Variablen, die NULL sein können, entsprechend annotieren und den NULL-Fall auch durchgängig abfangen. nga schrieb: > Wie sieht es mit der Effizienz des erzeugtem Maschienencodes aus? Es > wird ja LLVM benutzt, was ja schon einiges erwarten lässt (clang ist mWn > auch ein LLVM-Frontend). Die LLVM-Backends für x86 und ARM sind relativ gut, davon abgesehen wird es eher dünn. Clang ist das C/C++-Frontend für LLVM, es gibt aber noch sehr viele andere - wie eben z.B. für Rust. Kaj schrieb: > Man bekommt praktisch fuer alles einen Error, wo es in C/C++ noch > nicht mal eine Warnung gibt bzw. nur, wenn man sie einschaltet. Wer C/C++ mit weniger als "-Wall" benutzt, hat sämtliche daraus resultierenden Fehler selbst zu verantworten. Es sei denn, man gehört auch sonst zu denjenigen, die sich überall die Ohren zuhalten, um ja nicht ihre Realität hinterfragen zu müssen. :-) Kaj schrieb: > Ich arbeite mich gerade selber in Rust ein, allerdings erstmal auf dem > Desktop unter Linux. Ich will es dann aber auch auf ARM und AVR nutzen. Für ARM ist das vermutlich kein Problem, aber auf dem AVR kannst du das Thema vergessen. Selbst, wenn du es einigermaßen zum Laufen bekommst, so ist der LLVM-Support dafür eher mäßig.
mh schrieb: > Es ist kein Beispiel für Probleme mit smart-Pointern in c++, sondern > eher für Probleme mit der move-Semantik. Es ist ein Beispiel dafür, dass nach einem Move das betreffende Objekt fehlerhafterweise weiter benutzt wird. Der Rust-Compiler erkennt diesen Fehler garantiert, ein C++-Compiler nicht unbedingt. > Ok bei rust gibt der Compiler eine Meldung aus, die man aber auch in > c++ bekommt, wenn man clang-tidy benutzt. Ist das bei clang-tidy wirklich garantiert, auch in verzwickteren Fällen? Mit welchen Optionen muss ich clang-tidy aufrufen, damit in folgendem Beispiel der Fehler erkannt wird:
1 | #include <iostream> |
2 | #include <memory> |
3 | |
4 | void sub(std::unique_ptr<int> *up) { |
5 | auto stolen = std::move(*up); |
6 | }
|
7 | |
8 | int main () { |
9 | std::unique_ptr<int> orig(new int(5)); |
10 | std::cout << *orig << '\n'; |
11 | sub(&orig); |
12 | std::cout << *orig << '\n'; |
13 | }
|
Hallo Yalu, guter Punkt! Wobei ich da doch eine Referenz bevorzugt hätte, als die altmodische C Variante, aber das ändert natürlich rein garnichts. vlg Timm
Timm R. schrieb: > Wobei ich da doch eine Referenz bevorzugt hätte, als die altmodische C > Variante, aber das ändert natürlich rein garnichts. Ich hatte ursprünglich eine Referenz verwendet, diese wurde aber von clang-tidy angemeckert, weil ich mit -checks=* einfach mal blind alle verfügbaren Prüfungen – und damit auch "google-runtime-references" – aktiviert hatte: https://google.github.io/styleguide/cppguide.html#Reference_Arguments > Eine Nachfrage: Kann ich in Rust das Äquivalent zu std::move auf Objekte > anwenden, die nicht bewegbar sind? Wie gesagt, ich bin noch sehr grün in Sachen Rust, weswegen ich diese Frage nicht beantworten kann. Ich habe sie möglicherweise aber auch gar nicht verstanden, oder warum sollte ein nicht bewegbares Objekt gemovet (also bwegt) werden können? Das wäre doch ein Widerspruch in sich?
Yalu X. schrieb: > mh schrieb: >> Es ist kein Beispiel für Probleme mit smart-Pointern in c++, sondern >> eher für Probleme mit der move-Semantik. Die Seite selbst behauptet aber, dass es ein Beispiel ist für "c++ smart-Pointer sind unsicher". Yalu X. schrieb: > ...folgendem Beispiel... Ein raw-Pointer auf einen unique_ptr ... zum Glück ist es nur ein Beispiel. Wer sowas macht hat keine Warnung vom Compiler verdient ;-) . Yalu X. schrieb: > Ist das bei clang-tidy wirklich garantiert, auch in verzwickteren > Fällen? Nein. Ist es in rust garantiert? Wie würde die folgende Funktion (zum Glück auch nur ein Beispiel) in rust aussehen und was sagt der Compiler, wenn er f1 und f2 nicht zur Compilezeit kennt?
1 | std::unique_ptr<int> func(bool f1, bool f2, std::unique_ptr<int> &up) { |
2 | std::unique_ptr<int> tmp; |
3 | if(f1) { |
4 | tmp = std::move(up); |
5 | } else { |
6 | tmp = std::unique_ptr<int>(new int(6)); |
7 | }
|
8 | if(f2) { |
9 | std::cout << *up << std::endl; |
10 | }
|
11 | |
12 | return tmp; |
13 | }
|
Verbietet er die Funtkion, gibt er eine Warnung aus (clang-tidy bugprone*) oder macht er etwas anderes?
mh schrieb: > Verbietet er die Funtkion, gibt er eine Warnung aus (clang-tidy > bugprone*) oder macht er etwas anderes? also ich habe keinen Schimmer von Rust, möchte aber gern eine Wette abgeben: Er verbietet es. Sonst würde imho das ganze Gezeter keinen Sinn ergeben. Die Idee ist doch gerade, nur zuzulassen, was auch klappt, wenn der Entwickler nicht das falsche Gras geraucht hat. Dein Code kann aber in die Hose gehen. Also wette ich auf: Error. Was ich dann auch nur folgerichtig und gut fände. vlg Timm
Hallo, kann hier jemand Rust? Könnte mir zufällig mal schnell jemand dies hier rosten? Die Definition von measure<> habe ich weggelassen, die wird man eh nicht 1:1 rosten können, ist aber auch egal. Ich würde gern mal damit in Tust experimentieren. Ich würde es selbst versuchen, aber diese borrow mut Referenzen Geschichte, wäre nur trial & error. vlg Timm
1 | void mv2(std::vector<size_t>& a, std::vector<size_t>& b) {
|
2 | for(size_t i=0; i<100000; i++) |
3 | {
|
4 | a = std::move(b); |
5 | a[i]=42; |
6 | b = std::move(a); |
7 | } |
8 | } |
9 | |
10 | |
11 | int main(int argc, const char * argv[]) {
|
12 | std::vector<size_t> a{33, 100000};
|
13 | std::vector<size_t> b{34, 100000};
|
14 | auto timing = measure<std::chrono::microseconds>::execution(mv2, a, b); |
15 | std::cout << b[100000-1] << " Zeit: " << timing << " µs" << std::endl; |
16 | return 0; |
17 | } |
mh schrieb: > Yalu X. schrieb: >> Ist das bei clang-tidy wirklich garantiert, auch in verzwickteren >> Fällen? > Nein. Ist es in rust garantiert? Selbstverständlich. Es ist Teil der Sprachdefinition, ein Verstoß gegen die Ownership-Regeln könnte nicht kompiliert werden, es wäre ungültiger Code und der Compiler würde mit Fehler abbrechen.
Bernd K. schrieb: > mh schrieb: >> Yalu X. schrieb: >>> Ist das bei clang-tidy wirklich garantiert, auch in verzwickteren >>> Fällen? >> Nein. Ist es in rust garantiert? > > Selbstverständlich. Es ist Teil der Sprachdefinition, ein Verstoß gegen > die Ownership-Regeln könnte nicht kompiliert werden, es wäre ungültiger > Code und der Compiler würde mit Fehler abbrechen. In c++ gibt es nur im Fall f1=true f2=true ein Problem. Die drei anderen Fälle sind in Ordnung. Für rust ist das egal und es ist verboten? Wo in der "Sprachdefinition" sind diese Ownership-Regeln definiert? Das was unter https://doc.rust-lang.org/stable/reference/memory-ownership.html steht ist nun wirklich nicht hilfreich.
1 | fn func(f1: bool, f2: bool, up: Box<i32>) -> Box<i32> {
|
2 | let mut tmp = Box::new(0); |
3 | if f1 {
|
4 | tmp = up; |
5 | } |
6 | if f2 {
|
7 | println!("{}", up)
|
8 | } |
9 | tmp |
10 | } |
11 | |
12 | fn main() {
|
13 | let x = Box::new(42); |
14 | func(true, true, x); |
15 | } |
1 | error[E0382]: use of moved value: `up` |
2 | --> src/main.rs:7:24 |
3 | | |
4 | 4 | tmp = up; |
5 | | -- value moved here |
6 | ... |
7 | 7 | println!("{}", up)
|
8 | | ^^ value used here after move |
9 | | |
10 | = note: move occurs because `up` has type `std::boxed::Box<i32>`, which does not implement the `Copy` trait |
11 | |
12 | error: aborting due to previous error |
13 | |
14 | For more information about this error, try `rustc --explain E0382`. |
15 | error: Could not compile `untitled2`. |
16 | |
17 | To learn more, run the command again with --verbose. |
18 | |
19 | Process finished with exit code 101 |
mh schrieb: > Wo in der "Sprachdefinition" sind diese Ownership-Regeln definiert? Da: https://doc.rust-lang.org/book/second-edition/ch04-01-what-is-ownership.html#what-is-ownership
1 | Ownership Rules |
2 | |
3 | First, let’s take a look at the ownership rules. Keep these rules in mind |
4 | as we work through the examples that illustrate them: |
5 | |
6 | Each value in Rust has a variable that’s called its owner. |
7 | There can only be one owner at a time. |
8 | When the owner goes out of scope, the value will be dropped. |
S. R. schrieb: > aber auf dem AVR kannst du das Thema vergessen. Warum? An dem Projekt wird aktiv gearbeitet: https://github.com/avr-rust/
Kaj schrieb: > mh schrieb: >> Wo in der "Sprachdefinition" sind diese Ownership-Regeln definiert? > Da: > https://doc.rust-lang.org/book/second-edition/ch04... Interessant, dass die Regeln nicht in der "The Rust Reference" stehen, sonder unter "Learning Rust". Bernd K. schrieb: > func(true, true, x); Bei false false sagt er leider das gleiche. Kaj schrieb: > Ownership Rules > > First, let’s take a look at the ownership rules. Keep these rules in > mind > as we work through the examples that illustrate them: > > Each value in Rust has a variable that’s called its owner. > There can only be one owner at a time. > When the owner goes out of scope, the value will be dropped. Also für den false false Fall ist nach den Regeln alles in Ordnung. Hat nen Owner. Es gibt nur einen Owner. Ist im Scope.
mh schrieb: > Also für den false false Fall ist nach den Regeln alles in Ordnung. > Hat nen Owner. Aber es könnte zur Laufzeit beide Fälle geben und deshalb ist der Code in dieser Form ungültig und kann nicht kompiliert werden.
Bernd K. schrieb: > mh schrieb: >> Also für den false false Fall ist nach den Regeln alles in Ordnung. >> Hat nen Owner. > > Aber es könnte zur Laufzeit beide Fälle geben und deshalb ist der Code > in dieser Form ungültig und kann nicht kompiliert werden. Ok, es sollte also gehen, wenn man den Fall true true verhindert:
1 | if f2 & (f1 == false) {
|
2 | println!("{}", up)
|
3 | } |
Leider immer noch die gleiche Meldung.
mh schrieb: > Bernd K. schrieb: >> mh schrieb: >>> Also für den false false Fall ist nach den Regeln alles in Ordnung. >>> Hat nen Owner. >> >> Aber es könnte zur Laufzeit beide Fälle geben und deshalb ist der Code >> in dieser Form ungültig und kann nicht kompiliert werden. > > Ok, es sollte also gehen, wenn man den Fall true true verhindert: if > f2 & (f1 == false) { > println!("{}", up) > } > Leider immer noch die gleiche Meldung. Habe keine Ahnung von Rust, aber ich vermute es wird wie in anderen Sprachen auch behandelt: Wenn der Ausdruck nicht garantiert (unabhängig vom tatsächlichen Ausdruck!) während des Kompilierens ausgewertet werden kann, ist er so zu behandeln, als wäre das Ergebnis nur zur Laufzeit bekannt. Das vereinfacht die Implementation und sorgt für konsistentes Verhalten. Für mich ist das überhaupt nicht überraschend.
mh schrieb: > Leider immer noch die gleiche Meldung. Man kann den Code auch so schreiben daß sich das Problem gar nicht erst stellt.
1 | fn func(f1: bool, f2: bool, up: Box<i32>) -> Box<i32> {
|
2 | if f2 {
|
3 | println!("{}", up)
|
4 | } |
5 | |
6 | if f1 {
|
7 | up |
8 | } else {
|
9 | Box::new(0) |
10 | } |
11 | } |
mh schrieb: > Wo in der "Sprachdefinition" sind diese Ownership-Regeln definiert? Das > was unter > https://doc.rust-lang.org/stable/reference/memory-ownership.html steht > ist nun wirklich nicht hilfreich. Das Reference-Dokument ist leider noch sehr unvollständig, was den Autoren aber bewusst ist:
1 | For now, this reference is a best-effort document. We strive for |
2 | validity and completeness, but are not yet there. In the future, the |
3 | docs and lang teams will work together to figure out how best to do |
4 | this. Until then, this is a best-effort attempt. If you find something |
5 | wrong or missing, file an issue or send in a pull request. |
Zudem scheint die Sprachdefinition in einigen Punkten ohnehin noch im Fluss zu sein. Was die Regeln zur Überprüfung des Verlusts der Ownership betrifft, ist der Compiler eher pessimistisch. Selbst in diesem Fall
1 | let a = Box::new(123); |
2 | if false { |
3 | let b = a; |
4 | }
|
5 | print!("{}\n", a); |
meckert der Compiler, obwohl es offensichtlich ist, dass der if-Zweig nie ausgeführt wird. Bei der Prüfung wird also wohl davon ausgegangen, dass jede if/while- Bedingung unabhängig von dem tatsächlichen Ausdruck und unabhängig von allen anderen if/while-Bedingungen einen beliebigen Wahrheitswert annehmen kann. Wenn es unter dieser Annahme einen Pfad gibt, der zum Zugriff auf ein nicht geowntes Objekt führt, wird ein Fehler ausgegeben. Diese Regel erscheint auf den ersten Blick unnötig pessimistisch. Wenn aber etwas darüber nachdenkt, kann man die Entscheidung durchaus verstehen: - Der Compiler sollte eher zu pessimistisch als zu optimistisch sein, so dass auf keinen Fall eine Verletzung der Ownership akzeptiert wird. Denn das würde das ganze schöne Konzept über den Haufen schmeißen. - Ein perfekter Algorithmus zum Aufspüren von Verletzungen in beliebig komplizierten Code existiert nicht, da dieses Problem ebenso wenig entscheidbar ist wie das Halteproblem. Das Regelwerk muss also zu einem gewissen Grad pessimistisch sein. - Es stellt sich nun die Frage, ob man - ein nahezu optimales, dafür aber sehr komplexes, oder - ein weniger optimales, dafür aber einfaches Regelwerk bevorzugt. Die Rust-Entwickler haben sich offensichtlich für die zweite Option entschieden. Das ist IMHO auch gut so, denn die Koplexität des Regelwerks betrifft ja nicht nur die Compilerbauer, sondern jeden Rust-Programmierer. Ich vermute, dass in realem Code die Fälle, wo der Compiler einen Fehler meldet, obwohl bei genauerer Analyse keine Verletzung der Ownership vorliegt, sehr selten sind. Sollte dieser Fall dennoch einmal auftreten, kann das Problem sicher durch eine leichte Umstrukturierung des Codes behoben werden, was den angenehmen Nebeneffekt hat, dass der Code etwas entworren wird.
Yalu X. schrieb: > Ich habe mich bisher nur wenig mit Rust beschäftigt, halte es aber für > eine der interessantesten Programmiersprachen aus jüngerer Zeit. Ebenso. Es erscheinen regelmäßig neue Sprachen auf der Bildfläche die einen nicht wirklich vom Hocker reißen und keine wirklich neuen Konzepte einführen und verschwinden bald wieder in der Versenkung aber nur alle paar Schaltjahre taucht mal ein Stern am Programmiersprachenhimmel auf der sich wirklich von der Masse abhebt. Und dann auch noch eine Sprache deren Kompilat ohne Runtime auskommt und damit in direkte Konkurrenz mit C(++) tritt und somit auch für kleinste µC interessant ist, solche Sprachen kann man fast an einer Hand abzählen. Rust steht mittlerweile auch bei mir ganz oben auf meiner Liste der Sprachen in die ich gerne etwas tiefer einsteigen will.
Bernd K. schrieb: > > Und dann auch noch eine Sprache deren Kompilat ohne Runtime auskommt Hallo, sorry, kann mir jemand erklären, was das bedeutet? Heißt das, man kann Rust nicht dynamisch linken? Warum ist das gut? Viele liebe Grüße timm
Timm R. schrieb: > Bernd K. schrieb: >> >> Und dann auch noch eine Sprache deren Kompilat ohne Runtime auskommt > > Hallo, > > sorry, kann mir jemand erklären, was das bedeutet? Bernd mein vermutlich so etwas wie bei Java oder C#, wo man ein Riesenpaket an Bibliotheken und sonstigem Gedöns installieren muss, bevor man die erste kleine Anwendung starten kann. > Heißt das, man kann Rust nicht dynamisch linken? Doch, das geht schon. Auf Plattformen ohne Betriebssystem gibt es aber meist weder einen dynamischen Linker noch ein Filesystem, vom dem die dynamischen Bibliotheken geladen werden können. Da möchte man die komplette Anwendung mit allem, was dazugehört, statisch in ein einziges Executable linken.
Yalu X. schrieb: > Timm R. schrieb: >> Bernd K. schrieb: >>> >>> Und dann auch noch eine Sprache deren Kompilat ohne Runtime auskommt >> >> Hallo, >> >> sorry, kann mir jemand erklären, was das bedeutet? > > Bernd mein vermutlich so etwas wie bei Java oder C#, wo man ein > Riesenpaket an Bibliotheken und sonstigem Gedöns installieren muss, > bevor man die erste kleine Anwendung starten kann. ach soo! Alles klar, danke. Ich dachte, das ginge gegen c/c++ und das ist ja wirklich mal eine Stelle, wo bei c/c++ alles proper ist. vlg und danke Timm
Timm R. schrieb: > Hallo, > > sorry, kann mir jemand erklären, was das bedeutet? Nein, das bedeutet daß Rust (genau wie C oder C++ auch) sich gut für bare metal eignet, weil es zu nativem Code kompiliert der läuft ohne viel mehr als nur sich selbst zu benötigen, man kann große Teile der Standard Library welche dynamische Speicherallokation benutzen einfach weglassen und die Sprache mit dem was übrig bleibt immer noch benutzen (und die wichtigen Sprachfeatures immer noch funktionieren) und braucht dann nur noch die üblichen paar hundert Byte Startupcode (wie bei C++ auch) um den Prozessor zu initialisieren und den nackten kompilierten Rust-Code. Runtime wäre sowas wie zum Beispiel ein immer zwingend vorhandener Garbage-Collector (das gibts nicht in Rust) oder gar eine riesige VM (wie in Java oder C#) die gleich mal mit vergleichsweise riesigem Overhead daherkommen selbst beim kleinsten Hello World. Bei Rust kann man es so einrichten daß man genau wie bei C oder C++ wirklich nur noch die selbst geschriebenen Funktionen im Kompilat hat und sonst praktisch so gut wie nichts mehr (nicht mehr als man auch hätte wenn man es in C++ gemacht hätte) und die laufen so wie sie sind direkt auf dem blanken Silizium. > Heißt das, man kann > Rust nicht dynamisch linken? Warum ist das gut? Das hat damit gar nichts zu tun. Eher im Gegenteil ist es so daß man bei den oben genannten "gemanageten" Sprachen die innerhalb einer VM ablaufen arge Klimmzüge machen muß oder umständliche Wrapper braucht um sie in die eine oder andere Richtung mit C Kompilaten zu linken (falls überhaupt möglich). Mit Rust kann man selbstverständlich Code erzeugen der sich mit C oder C++ problemlos und ganz direkt dynamisch oder statisch linken lässt. Darauf hat man absichtlich Wert gelegt. Rust ist in dieser Hinsicht wie C, nur die eigentliche Sprache ist komplett anders und besser.
Bernd K. schrieb: > Mit Rust kann man selbstverständlich Code erzeugen der sich mit C oder > C++ problemlos... .. zusammenlinken läßt. Naja, eben. Rust ist ganz offensichtlich nur ein weiterer Vorbrenner für C. Sieht ja auch fast genauso aus, ist nur noch ein wenig unübersichtlicher. W.S.
Genau, schließlich wissen wir ja alle dass die Optik bei einer Programmiersprache am Wichtigsten ist. Deswegen ist ja z.B. auch die Shakespeare Programming Language eine der Beliebtesten.
W.S. schrieb: > weiterer Vorbrenner für C. Sieht ja > auch fast genauso aus, Nur daß es eigentlich komplett anders aussieht. Und nein, es wird nicht in irgendeinem Zwischenschritt nach C kompiliert, C kommt überhaupt nicht vor, das verwechselst Du wahrscheinlich mit irgendeiner anderen Sprache. Der Compiler verwendet LLVM und spuckt direkt das native Binary aus.
W.S. schrieb: > Rust ist ganz offensichtlich nur ein weiterer Vorbrenner für C. Sieht ja > auch fast genauso aus, ist nur noch ein wenig unübersichtlicher. man merkt gleich, dass Du dich ganz genau informiert hast.
Markus F. schrieb: > W.S. schrieb: >> Rust ist ganz offensichtlich nur ein weiterer Vorbrenner für C. Sieht ja >> auch fast genauso aus, ist nur noch ein wenig unübersichtlicher. > > man merkt gleich, dass Du dich ganz genau informiert hast. Für W.S. ist alles C, was nicht Pascal ist ;-) Versuchen wir aber trotzdem, die Diskussion auf das vom TE vorgegebene Thema, nämlich Rust (im Vergleich zu C und C++) zu beschränken!
Timm R. schrieb: > Könnte mir zufällig mal schnell jemand dies hier rosten? Ich hab's mal versucht. Allerdings habe ich das da nicht ganz verstanden:
1 | std::vector<size_t> a{33, 100000}; |
2 | std::vector<size_t> b{34, 100000}; |
Damit werden zwei Vektoren mit je zwei Elementen angelegt, was hier
1 | for(size_t i=0; i<100000; i++) |
2 | {
|
3 | a = std::move(b); |
4 | a[i]=42; |
5 | b = std::move(a); |
6 | }
|
unweigerlich zum Crash führt. Ich nehme an, es sollte
1 | std::vector<size_t> a(100000, 33); |
2 | std::vector<size_t> b(100000, 34); |
heißen (jeweils 100000 Elemente mit dem Wert 33 bzw. 34). movetest1.rs wäre die 1:1-Umsetzung deines Codes. Das kompiliert aber nicht, weil in mv2 versucht wird, die mittels Referenzen geborgten Objekte zu moven. Das ist genauso, als würdest du dein Auto einem Freund leihen und dieser es an einen Dritten verschenken oder es gleich auf den Schrottplatz bringen :) In C++ ist das zwar prinzipiell erlaubt, und sogar clang-tidy akzeptiert das, trotzdem muss man beachten, dass nach dem Aufruf von mv2 der Vektor a weggemovet worden ist und keine sinnvollen Daten mehr enthält. Rust hat bzgl. geborgter Objekte (d.h. Referenzen auf Objekte) strengere Regeln. Alternativ zu Referenzen könnte man a und b per move an mv2 übergeben, allerdings hat man dann hinterher keinen Zugriff mehr darauf, so dass die Ausgabe des Elements von b angemeckert wird. Man könnte a und b auch klonen, nur bekommt dann das Hauptprogramm die in mv2 vorgenommenen Änderungen nicht mehr mit. Wenn man die Argumentübergabe umgeht, indem man die Schleife ins Hauptprogramm verlagert, gibt es keine Probleme. So habe ich es in movetest2.rs schließlich gemacht. movetest.cpp ist dein leicht modifizierter C++-Code. Damit bei der Zeitmessung der Aufruf-Overhead von mv2 nicht mitgemessen wird, habe ich sie in die Funktion mit hinein gepackt. Die Compileraufrufe:
1 | clang++ -Wall -std=c++17 -O3 -o movetestc movetest.cpp |
2 | g++ -Wall -std=c++17 -O3 -o movetestg movetest.cpp |
3 | rustc -C opt-level=3 movetest.rs |
Die gemessenen Zeiten auf zwei Laptops mit unterschiedlichen CPUs:
1 | i7-4910MQ i5-6267U |
2 | ——————————————————————————————— |
3 | Clang 512.8 ms 611.8 ms |
4 | GCC 513.2 ms 611.8 ms |
5 | Rust 526.4 ms 526.4 ms |
6 | ——————————————————————————————— |
Noch ein Hinweis: Wenn du mit dem C++-Code herumspielst und feststellst, dass der Clang-Code plötzlich um den Faktor 6 schneller als der GCC-Code ist, liegt das daran, dass der Clang die Funktion mv2 inlinet und dabei einen Großteils des Codes wegoptimiert. Mit __attribute__(noinline)) kann das ggf. vermieden werden.
Hallo Yalu, ja hatte das auf dem handy hingetippert. Wie blöd. War wohl dann schonmal eine kleine Werbung für Rust :-) Vielen Dank! Sehr nett von dir! Viele liebe Grüße timm
Hey Yalu, du hast da einen kleinen Fehler in deinem Code. In movetest1.rs hast du:
1 | for i in 0..N {
|
2 | *a = *b; |
3 | b[i] = 42; // !!! |
4 | *b = *a; |
5 | } |
Und in movetest2.rs hast du aber:
1 | for i in 0..N {
|
2 | a = b; |
3 | a[i] = 42; // !!! |
4 | b = a; |
5 | } |
Aendert man in movetest2.rs das a[i] zu b[i], dann compiliert es auch nicht mehr.
1 | warning: value assigned to `a` is never read |
2 | --> src/main.rs:6:11 |
3 | | |
4 | 6 | let mut a = vec![33usize; N]; |
5 | | ^ |
6 | | |
7 | = note: #[warn(unused_assignments)] on by default |
8 | |
9 | error[E0382]: use of moved value: `b` |
10 | --> src/main.rs:13:5 |
11 | | |
12 | 12 | a = b; |
13 | | - value moved here |
14 | 13 | b[i] = 42; |
15 | | ^ value used here after move |
16 | | |
17 | = note: move occurs because `b` has type `std::vec::Vec<usize>`, which does not implement the `Copy` trait |
18 | |
19 | error: aborting due to previous error |
20 | |
21 | For more information about this error, try `rustc --explain E0382`. |
22 | error: Could not compile `test_prog`. |
Kurz: Egal wie du es machst, es geht nicht. :D Yalu X. schrieb: > Man könnte a und b auch klonen, nur bekommt dann das Hauptprogramm die > in mv2 vorgenommenen Änderungen nicht mehr mit. Da sich das Beispiel anscheinend nicht 1:1 in Rust umsetzen laesst, warum a und b nicht einfach als Tuple (oder sonstwas) zurueck geben? Gruesse
Hallo Yalu, Yalu X. schrieb: > Die gemessenen Zeiten auf zwei Laptops mit unterschiedlichen CPUs: > i7-4910MQ i5-6267U > ——————————————————————————————— > Clang 512.8 ms 611.8 ms > GCC 513.2 ms 611.8 ms > Rust 526.4 ms 526.4 ms > ——————————————————————————————— hmhm, da stellt sich doch die Frage, warum das mit Clang und GCC auf meinem i7-6700K CPU @ 4.00GHz 10 ms langsamer ist, als auf Deinem i5-6267U. Das ist irgendwie ungerecht :-) Danke, genau so, wie du es programmiert hast, war es gedacht. 1. Mein Fehler mit den {} ist ein Punkt für Rust 2. Habe ich die Timings zum Anlass genommen, die Behauptung des OP, Zugriffe seien Range-checked zu überprüfen: Das stimmt nicht, Zugriffe sind nicht range-checked. 3. Diese move-Sache interessiert mich. Hätte man nicht erwartet, dass Rust viel schneller ist? Ich dachte, ich hätte gelesen, dass Rust den Speicher als Block kopiert. C++ geht ja über alle Elemente und ruft den Move Konstruktor auf, was bei szie_t natürlich nichts bringt? Mit String statt size_t ist dann bei mir der C++ move vermutlich im Vorteil. Rust braucht 5.28s, Clang 1.62s vlg Timm
Timm R. schrieb: > Hätte man nicht erwartet, dass > Rust viel schneller ist? Ich dachte, ich hätte gelesen, dass Rust den > Speicher als Block kopiert. Rust muß doch beim Eigentümerwechsel zur Laufzeit gar nichts mehr machen. Das Objekt liegt irgendwo im Speicher und der Compiler hat schon zur Compilezeit sichergestellt daß die Eigentumsverhältnisse überall korrekt sind, es geht ja nur darum daß der Compiler keinen Code erzeugen kann bei dem ein Teil des Programms dem anderen unerwartet die Variablen unter den Füßen wegziehen kann. Sobald der Code so geschrieben ist daß das niemals geschehen kann muß beim eigentlchen move zur Laufzeit gar nichts mehr geschehen.
Timm R. schrieb: > 1. Mein Fehler mit den {} ist ein Punkt für Rust Wieso ist dein Fehler ein Punkt für rust? In rust ist auch relevant was man genau schreibt:
1 | let v = vec![10, 5]; |
2 | let w = vec![10; 5]; |
Timm R. schrieb: > 3. Diese move-Sache interessiert mich. Hätte man nicht erwartet, dass > Rust viel schneller ist? Ich dachte, ich hätte gelesen, dass Rust den > Speicher als Block kopiert. C++ geht ja über alle Elemente und ruft den > Move Konstruktor auf, was bei szie_t natürlich nichts bringt? In dem Beispiel wird ein std::vector gemoved. Es wird nicht jedes Element gemoved. Einen std::vector zu moven bedeutet 3 Pointer zu kopieren.
Yalu X. schrieb: > Für W.S. ist alles C, was nicht Pascal ist ;-) OK, ich revidiere das mal dahingehend, daß Rust sowohl wie C als auch wie Basic aussieht:
1 | fn main() { |
2 | let mut a = vec![33usize; N]; |
3 | let mut b = vec![34usize; N]; |
4 | let start = Instant::now(); |
Es fehlen bloß die Zeilennummern und 'dim'. 100 let a = 123 101 gosub 200 oder so ähnlich. Ist mir schon zu lange her. Also was soll sowas bloß? Offenbar schmeißt Rust mit noch mehr Interpunktionszeichen um sich als C - und das will schon was heißen. Aber mit dem Vorbrenner für C hatte ich schon Recht. Zitat: "On Windows, Rust additionally requires the C++ build tools for Visual Studio 2013 or later." W.S.
W.S. schrieb: > OK, ich revidiere das mal dahingehend, daß Rust sowohl wie C als auch > wie Basic aussieht: Alter Schwede, was für ein saublödes Geschwätz. W.S. wie er leibt und lebt wieder mal. Echt original.
Kaj schrieb: > du hast da einen kleinen Fehler in deinem Code. > > In movetest1.rs hast du: for i in 0..N { > *a = *b; > b[i] = 42; // !!! > *b = *a; > } Du hast recht, da sollte
1 | a[i] = 42; |
stehen wie von Timm hier vorgegeben: Timm R. schrieb: > a[i]=42; Die Fehlermeldungen bleiben aber die gleichen und beziehen sich auf das *a = *b und *b = *a. In movetest2.rs ist die entsprechende Zeile richtig. Kaj schrieb: > Yalu X. schrieb: >> Man könnte a und b auch klonen, nur bekommt dann das Hauptprogramm die >> in mv2 vorgenommenen Änderungen nicht mehr mit. > Da sich das Beispiel anscheinend nicht 1:1 in Rust umsetzen laesst, > warum a und b nicht einfach als Tuple (oder sonstwas) zurueck geben? Stimmt. Es würde sogar reichen, b zurückzugeben, da a ja sowieso zermovet ist (auch im Original-C++-Code von Timm) und auch gar nicht mehr benötigt wird. Ich habe das mal in movetest3.rs so umgesetzt.
Hallo Bernd, Bernd K. schrieb: > Timm R. schrieb: >> Hätte man nicht erwartet, dass >> Rust viel schneller ist? Ich dachte, ich hätte gelesen, dass Rust den >> Speicher als Block kopiert. > > Rust muß doch beim Eigentümerwechsel zur Laufzeit gar nichts mehr > machen. meine Worte, bzw.: um so erstaunlicher. 500-600 ms ist eine lange Zeit für "nichts" ... (Siehe Yalus Timings) vlg Timm
Timm R. schrieb: > hmhm, da stellt sich doch die Frage, warum das mit Clang und GCC auf > meinem i7-6700K CPU @ 4.00GHz 10 ms langsamer ist, als auf Deinem > i5-6267U. Das ist irgendwie ungerecht :-) Da sich die Prozessoren im Pipelining und in der Branch-Prediction stark unterscheiden, kann es schon passieren, dass der eigentlich schnellere Prozessor in bestimmten Fällen langsamer ist. Als ich einmal mit einem Stückchen Code die Geschwindigkeit von C und Haskell vergleichen wollte, stellte ich überrascht fest, dass der Haskell-Code etwa 50% schneller war. Noch überraschter war, als ich den vom C-Compiler generierten Assemblercode analysierte, der nach meinem Dafürhalten nicht weiter optimierbar war, höchstens mit einem mir unbekannten Programmiertrick. Also habe ich im vom Haskell-Compiler generierten Assemblercode nach diesem Programmiertrick gesucht, musste aber feststellen, dass dieser Code zwar nicht schlecht, aber dennoch umständlicher war das der vom C-Compiler generierte. Ich vermute deswegen, dass der Haskell-Code einfach besser mit dem Piplining des Prozessors harmoniert hat. Auf einem anderen Prozessor war der C-Code schneller.
mh schrieb: > In dem Beispiel wird ein std::vector gemoved. Es wird nicht jedes > Element gemoved. Einen std::vector zu moven bedeutet 3 Pointer zu > kopieren. und dafür braucht c++ 500 ms? Dann sollte man sich tatsächlich ernsthaft überlegen, die Sprache zu wechseln. vlg Timm
Bernd K. schrieb: > Rust muß doch beim Eigentümerwechsel zur Laufzeit gar nichts mehr > machen. Da bin ich mir nicht so sicher, bin aber noch nicht weit genug in die Tiefen von Rust abgestiegen, um das sicher beurteilen zu können. Im konkreten Beispiel hätte der Compiler das Kopieren vermutlich wegoptimieren können, aber das geht nicht immer: In folgendem Beispiel
1 | let a = ...; |
2 | let b = ...; |
3 | if ... { |
4 | b = a; |
5 | }
|
6 | machwasmit(b); |
ist b beim Aufruf von machwasmit entweder das ursprüngliche b oder das ursprüngliche a, jenachdem, ob die if-Bedingung falsch oder wahr ist. Deswegen muss bei b = a mindestens eine Shallow-Copy gemacht werden. Immerhin kann durch das Moven auf eine Deep-Copy verzichtet werden, und durch die Prüfung der Ownership zur Compilezeit ist der Code auch ohne Overhead durch Laufzeitprüfungen sicher.
Timm R. schrieb: > meine Worte, bzw.: um so erstaunlicher. 500-600 ms ist eine lange Zeit > für "nichts" ... (Siehe Yalus Timings) Der "Eigentümer" muss immer noch gewechselt werden, was etwas mehr als "nichts" ist. Wenn a[i] (oder b[i]) einen Seiteneffekt hat, wie z.b. Rangecheck mit evtl. panic (k.a. was da genau im Hintergrund passiert), kann die Schleife auch nicht wirklich optimiert werden. Timm R. schrieb: > mh schrieb: > >> In dem Beispiel wird ein std::vector gemoved. Es wird nicht jedes >> Element gemoved. Einen std::vector zu moven bedeutet 3 Pointer zu >> kopieren. > > und dafür braucht c++ 500 ms? Nein, die 800e6 Bytes wollen auch kopiert werden. Timm R. schrieb: > Dann sollte man sich tatsächlich ernsthaft > überlegen, die Sprache zu wechseln. Oder eine der Sprachen richtig lernen, damit du verstehst was alles im Hintergrund passiert?!
W.S. schrieb: > OK, ich revidiere das mal dahingehend, daß Rust sowohl wie C als auch > wie Basic aussieht:fn main() { > let mut a = vec![33usize; N]; > let mut b = vec![34usize; N]; > let start = Instant::now(); > > Es fehlen bloß die Zeilennummern und 'dim'. > 100 let a = 123 > 101 gosub 200 Ja, dein scharfes Auge hat in beiden Beispielen das Schlüsselwort "let" entdeckt. Herzlichen Glückwunsch dafür ;-) Ist dir schon einmal in den Sinn gekommen, dass dieses "let" in Rust eine gänzlich andere Bedeutung haben könnte als in Basic?
Beitrag #5516440 wurde von einem Moderator gelöscht.
Angehängte Dateien:
-

Watch-1.gif
23 KB -

Watch-2.gif
23 KB
{kind=link}
{kind=link}
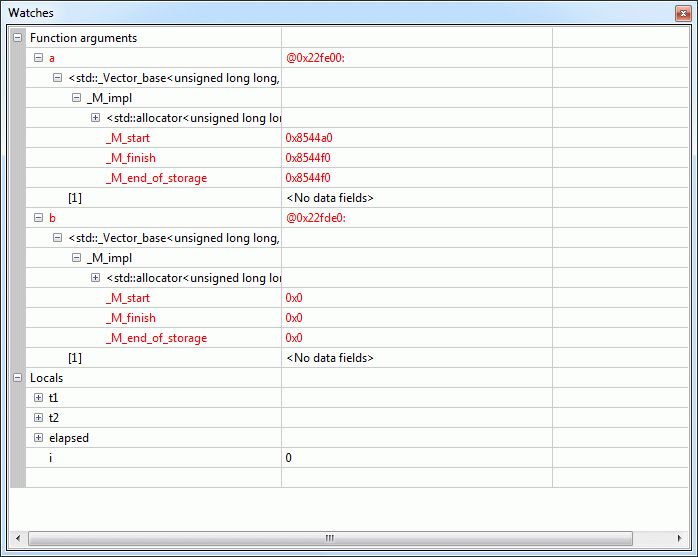
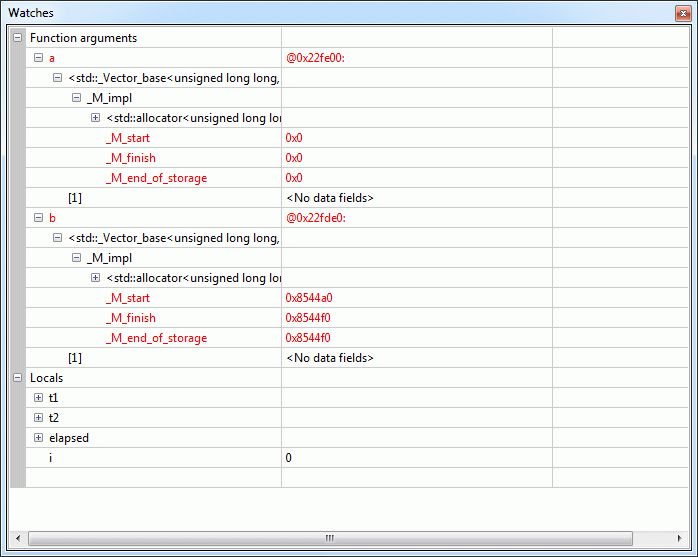
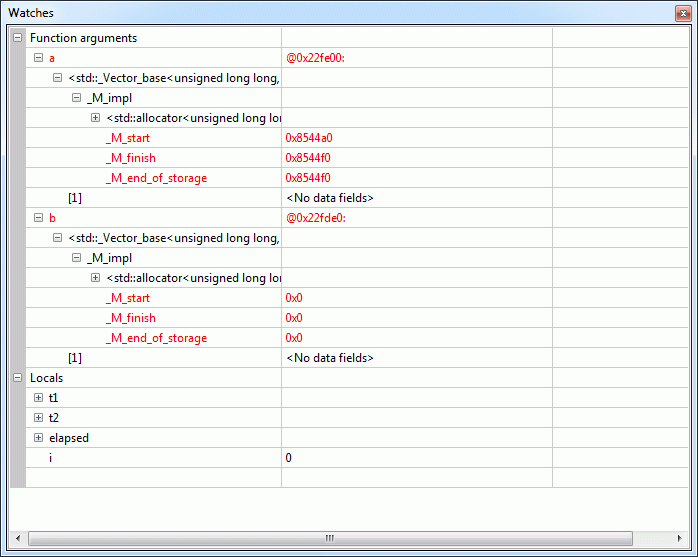
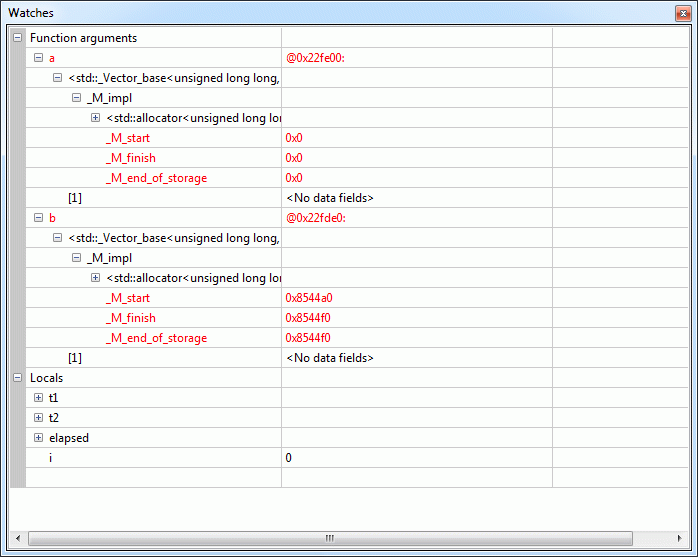
Mir fehlt ein wenig die Einsicht was euer Code hier eigentlich soll??? Im Endeffekt lasst ihr 3 Pointer zwischen a und b immer sinnlos hin- und herpendeln (siehe Anhang!). Wenn der Compiler schlau genug wäre könnte er eigentlich über eine genauere "Laufzeit-Vorab-Analyse" nach ein paar Durchläufen erkennen, dass hier sinnlos im Kreis gepointert wird (Ringelrein mit Adressen) und den Code dazu anstatt Millionen mal schlicht zweimal ausführen a[] -> b[] -> a[] und gut ist.
Timm R. schrieb: > meine Worte, bzw.: um so erstaunlicher. 500-600 ms ist eine lange Zeit > für "nichts" ... (Siehe Yalus Timings) Das sind 5-6 ns pro Schleifendurchlauf, d.h 2 Moves, 1 Zuweisung des Array-Elements und Schleifenoverhead.
mh schrieb: >>> In dem Beispiel wird ein std::vector gemoved. Es wird nicht jedes >>> Element gemoved. Einen std::vector zu moven bedeutet 3 Pointer zu >>> kopieren. >> >> und dafür braucht c++ 500 ms? > Nein, die 800e6 Bytes wollen auch kopiert werden. Du wolltest also schreiben: Einen std::vector zu moven bedeutet 3 Pointer und den gesamten Speicherbereich der Elemente zu kopieren? Das ist aber nicht genau das selbe. >Oder eine der Sprachen richtig lernen Deutsch zum Beispiel? vlg Timm
Timm R. schrieb: > Du wolltest also schreiben: > > Einen std::vector zu moven bedeutet 3 Pointer und den gesamten > Speicherbereich der Elemente zu kopieren? Nein!
1 | //ein vector mit 1000 ints
|
2 | std::vector<int> foo(1000); |
3 | |
4 | //hier werden 3 Pointer kopiert
|
5 | auto baa = std::move(foo); |
6 | |
7 | // in dieser Schleife werden 6000 Pointer werden kopiert und 1000 ints werden geschrieben
|
8 | for(int i=0; i<1000; ++i) { |
9 | foo = std::move(baa); // 3 Pointer werden kopiert |
10 | foo[i] = 42; // ein int wird in den Speicher geschrieben |
11 | baa = std::move(foo); // 3 Pointer werden kopiert |
12 | }
|
Hallo, diese move-Thema interessiert mich weiterhin. Und danach, wie rüde und selbstsicher die Antworten formuliert sind zu gehen, bin ich wohl der Einzige, dem sich kein einheitliches Bild ergibt. 1. Warum genau ist die Move-Operation bei Rust so viel schneller, als bei clang c++? 2. Warum bricht die Performance so stark ein, wenn es sich nicht um einen vector von size_t sondern von string handelt? std::string clang: 1452 ms rust: 5275 ms size_t clang: 831 ms rust: 488 ms rustc 1.28.0 LLVM version 9.1.0 Vielen Dank Timm
mh schrieb: > Timm R. schrieb: >> Du wolltest also schreiben: >> >> Einen std::vector zu moven bedeutet 3 Pointer und den gesamten >> Speicherbereich der Elemente zu kopieren? > Nein! Ich bitte um Entschuldigung und danke für die Klarstellung. Da hatte ich wohl Tomaten auf den Ohren! vlg Timm
nga schrieb: > > Was ich mich noch frage: was passiert standardmäßig im Falle eines > panic!()-Aufrufs? Mikrokontroller programmiert man normalerweise ohne die Standardbibliothek, die sonst das Panik-Handling macht (Direktive #[no_std]). Darum muss es irgendwo einen Panik-Handler geben, für den Anfang reicht eine Endlosschleife:
1 | use core::panic::PanicInfo; |
2 | |
3 | #[panic_implementation] |
4 | fn panic(_info: &PanicInfo) -> ! {
|
5 | loop {}
|
6 | } |
Es gibt auch fertige Handler, die wohl per cortex-m-rt eingebunden werden sollen (panic-semihosting, panic-abort), hab ich aber noch nicht ausprobiert.
Timm R. schrieb: > 1. Warum genau ist die Move-Operation bei Rust so viel schneller, als > bei clang c++? > 2. Warum bricht die Performance so stark ein, wenn es sich nicht um > einen vector von size_t sondern von string handelt? > std::string > clang: 1452 ms > rust: 5275 ms > size_t > clang: 831 ms > rust: 488 ms Was genau vergleichst du? Am besten du zeigst den Quelltext der beiden Programme mit denen du testest.
Timm R. schrieb: > Könnte sich denn vielleicht einer der Rust-kundigen und C++-kundigen > erbarmen, mal ein minimales Beispiel mit c++ Pointer-Katastrophe zu > zeigen und wie es in Rust besser läuft? Das wäre doch sicher für mehrere > Rist-Unkundige interessant und erhellend? Mir fehlt da einfach die > Vorstellungskraft. Hmm, du hättest bei meinem Vortrag vor ein paar Wochen über Rust dabei sein sollen. Dafür habe ich den Heartbleed Bug in C++ nachprogrammiert - und dann versucht ihn auch unter Rust zu programmieren (ohne Unsafe). Letzteres war nicht möglich. In der angehängten Datei sind zwei Versionen drin - eine die zur Compilezeit schon Error wirft und eine die die falsche Array-Längenangabe garnicht nutzen kann.
Alex G. schrieb: > Hmm, du hättest bei meinem Vortrag vor ein paar Wochen über Rust dabei > sein sollen. Wo hast du diesen Vortrag gehalten? Alex G. schrieb: > Dafür habe ich den Heartbleed Bug in C++ nachprogrammiert Du hast den "Bug" in c programmiert und dann iostream benutzt, damit du es c++ nennen darfst. Für ein echtes c++ Beispiel hättest du zumindest std::string und/oder std::vector nutzen müssen. Der eigentliche Bug in deinem Programm ist übrigens ein memory leak. Wo in deiner HeartbleedDemo.cpp ist eigentlich die
1 | template <typename T> |
2 | void return(T) |
deklariert/definiert? ;-)
Bernd K. schrieb: > mh schrieb: >> Yalu X. schrieb: >>> Ist das bei clang-tidy wirklich garantiert, auch in verzwickteren >>> Fällen? >> Nein. Ist es in rust garantiert? > > Selbstverständlich. Es ist Teil der Sprachdefinition, ein Verstoß gegen > die Ownership-Regeln könnte nicht kompiliert werden, es wäre ungültiger > Code und der Compiler würde mit Fehler abbrechen. Selbst wenn es Teil der Sprachdefinition ist, ist das keine Garantie für irgendwas. Das gilt im übrigen auch für alle anderen Garantien die Rust geben will. Formale Beweise kommen so langsam, zumindest für eine gute Untermenge von Rust, https://people.mpi-sws.org/~dreyer/papers/rustbelt/paper.pdf Appendix und weiteres gibt's unter https://plv.mpi-sws.org/rustbelt/popl18/ Weniger formal erklärt inkl. der noch fehlenden Teile https://blog.acolyer.org/2018/01/18/rustbelt-securing-the-foundations-of-the-rust-programming-language/
mh schrieb: > Alex G. schrieb: >> Hmm, du hättest bei meinem Vortrag vor ein paar Wochen über Rust dabei >> sein sollen. > Wo hast du diesen Vortrag gehalten? Hochschule Master in einem Kurs über "Secure Systems". Haupthema war allerdings eher "Rust Belt"; ein mathematischer Ansatz der die Sicherheit von Rust's Standard library nachweist obwohl diese intern "unsafe" benutzt. EDIT: Sehe grade, Arc. N hat genau darauf Bezug genommen! Mag vielleicht noch nicht vollständig sein, aber ist noch immer erheblich mehr als was es für jede andere brauchbare Sprache gibt. "Besseres" gibt es nur in Sprachen die umgekehrt entwickelt wurden: Erst sicheres mathematisches Konstrukt, dann darauf eine Art von Sprache. Nur will man das Zeug als Programmierer der sein Geld durch einigermaßen effizientes Arbeiten verdienen muss, nicht mal mit der Kneifzange anfassen... > Alex G. schrieb: >> Dafür habe ich den Heartbleed Bug in C++ nachprogrammiert > Du hast den "Bug" in c programmiert und dann iostream benutzt, damit du > es c++ nennen darfst. Für ein echtes c++ Beispiel hättest du zumindest > std::string und/oder std::vector nutzen müssen. Der eigentliche Bug in > deinem Programm ist übrigens ein memory leak. Der Heartbleed war doch im Grunde ein Memoryleak. Halt über die Systemgrenze hinweg. Gut, das ist C. Sollte eben so leicht lesbar wie möglich sein. In dem Fall brauchte es auch eher keine Objektorientierung ;) > Wo in deiner HeartbleedDemo.cpp ist eigentlich die >
1 | > template <typename T> |
2 | > void return(T) |
3 | >
|
> deklariert/definiert? ;-)
Das verstehe ich jetzt aber nicht so ganz. Wofür wäre ein Template gut
gewesen?
Achso, damit es mehr nach C++ klingt? :P
Alex G. schrieb: > Der Heartbleed war doch im Grunde ein Memoryleak. Halt über die > Systemgrenze hinweg. Nein! Bei Heartbleed kann man Speicher lesen, den man nicht lesen können sollte. Ein Programm hat ein memory leak, wenn es Speicher allokiert hat, auf den niemand mehr zugreifen kann. Und welche Systemgrenze meinst du? Alex G. schrieb: > Gut, das ist C. Sollte eben so leicht lesbar wie möglich sein. Warum hast du es dann c++ genannt? Hättest du strings/vectoren genommen, könntest du testAliveA und testAliveB analog zu deinen rust Versionen schreiben und das es existiert nicht. Alex G. schrieb: > In dem Fall brauchte es auch eher keine Objektorientierung Aber jemanden, der c++ als c mit Objekten sieht, hat die Sprache nicht verstanden. Bleibt die Frage: Warum vergleicht man c++ mit rust, wenn man kein c++ kann? Alex G. schrieb: > Das verstehe ich jetzt aber nicht so ganz. Wofür wäre ein Template gut > gewesen? > > Achso, damit es mehr nach C++ klingt? :P Nein, aber ich habe auch nicht erwartet, dass du die Frage verstehst.
Echt jetzt, muss diese Überheblichkeit sein? Bin Praktiker und kein Theoretiker den es interessiert die Sprache "zu verstehen". Dafür habe ich meine Bachelor Thesis mit Softwareprojekt in richtigem C++ geschrieben.
Alex G. schrieb: > Echt jetzt, muss diese Überheblichkeit sein? ist doch eigentlich nicht wichtig. Die Leute, die sich mit Rust befassen und es bewerben wollen, schaffen es ja nicht einmal, eine saubere Sprachdefinition hinzukriegen. Siehe z.B. dort: https://rust-lang-de.github.io/rustbook-de/ Da wird zuerst die Werbetrommel gerührt, was für hehre Ziele Rust denn so hat, Zitat: "Willkommen! Dieses Buch wird dir die Programmiersprache Rust beibringen. Rust ist eine Systemprogrammiersprache mit dem Fokus auf drei Ziele: Sicherheit, Geschwindigkeit und Nebenläufigkeit (Safety, Speed, Concurrency). Sie erreicht diese Ziele ohne Garbage Collector, was sie zu einer nützlichen Sprache für eine Reihe von Anwendungsfällen macht, in denen andere Sprachen nicht so gut sind..." und dann kommt nicht das Allerwichtigste, nämlich eine Sprachdefinition (vorzugsweise Backus-Naur), sondern sowas: (wieder ein Zitat) Erste Schritte - Richte deinen Computer ... ein. Lerne Rust - Lerne Rust-Programmierung durch kleine Projekte. Effektives Rust - Fortgeschrittene Konzepte, um ausgezeichneten Rust-Code zu schreiben. Syntax und Semantik - Jedes Stück Rust auf kleine Stücke heruntergebrochen. Nightly Rust - Cutting-edge features, die noch nicht im stabilen Compiler verfügbar sind. Glossar - Erklärungen von Begriffen, die in diesem Buch verwendet werden. Akademische Forschung - Literatur, die Rust beeinflusst hat. Was soll das? Das ist ja schlimmer als die Leute, die eurer Oma ne Wolldecke mit Magneten drin verhökern wollen. Hier liegt ein Sprach-Gewurschtel vor und keine sauber konstruierte Programmiersprache. Die Fans fummeln an tausend kleinen Details herum, ohne daß es eine saubere logische Gesamtdefinition gäbe - und das macht eben keine gute Programmiersprache aus. Und ihr wollt hier diskutieren, ob sich DAS als Programmiersprache für einen PIC32 oder einen Cortex eignet? Nur zu, wer es sich in den Kopf gesetzt hat, partout Rust für die Firmware seines BluePill-Brettl's oder seines AVR nehmen zu wollen, der muß es halt tun - wenngleich ich das Ganze für eine ausgemachte .. naja, sagen wir mal Theoretisiererei.. halte. Ich bin mir sicher, daß in den nächten 10 Jahren weitere 30 derartige Sprachen der staunenden Fachwelt vorgestellt werden, die allesamt und jede für sich alles bisher Dagewesene in den Schatten stellt. OK, um hier im Forum ein bissel zu diskutieren, mag Rust ja geeignet sein. W.S.
Glaube du zählst zu den wenigen Personen welche sich beim Befassen mit einer neuen Sprache, als erstes die Backus Naur Form sehen wollen... Btw. hat es mich nur eine Google Query gekostet, zu finden was du scheinbar suchst: https://doc.rust-lang.org/grammar.html Dass immer wieder revolutionäre Sprachen auftauchen die sich nie so richtig durchsetzen ist leider wahr. Damit hat auch Rust zu kämpfen, denn die Millionen C Entwickler kriegt man schlicht nicht umgeschult. Trotzdem ist die Sprache sehr förderungswert - zu unser aller Sicherheit! Beliebt ist die Sprache jedenfalls. Schon seit drei Jahren an der Spitze: https://insights.stackoverflow.com/survey/2018/#most-loved-dreaded-and-wanted
Alex G. schrieb: > Damit hat auch Rust zu kämpfen, > denn die Millionen C Entwickler kriegt man schlicht nicht umgeschult. Da kann man nur auf die Plancksche Lösung warten. Leider wachsen immer wieder welche nach... Alex G. schrieb: > Beliebt ist die Sprache jedenfalls. Schon seit drei Jahren an der > Spitze: Naja, Python steht da auch auf Platz drei, während Pascal nichtmal vorkommt. Beliebtheit ist offenbar kein Qualitätskriterium. ;-)
Gute Nutzbarkeit ist natürlich ausschlaggebend und da ist Python kaum geschlagen. Klar, in der Umfrage da werden alle Entwickler-Arten von Embedded bis AI zusammengenommen. Wobei Rust eigentlich auch nicht unbedingt in erster Linie für Embedded ist. Die aktuellen Vorzeigeprojekte sind im Bereich Server und Desktop.
Alex G. schrieb: > Beliebt ist die Sprache jedenfalls. Wobei man hinzufügen sollte, dass Rust keine nennenswerte Verbreitung hat (unter 4.2% in der gleichen Umfrage, d.h. taucht unter den Top 25 nicht auf). Daraus lässt sich schließen, dass die hohe Beliebtheit von einer kleinen, sehr loyalen Anhängerschaft stammt. Im Technologiegraph taucht Rust ebenfalls nicht auf, vermutlich wird Rust zu selten professionell eingesetzt. Schade eigentlich, denn dort hätte man die Anwendungsfälle sehen können. Nachtrag: Delphi/Object Pascal taucht in der Liste der unbeliebtesten Sprachen auf Platz 12 auf, gleich neben C. C++ steht auf beiden Listen, polarisiert also offensichtlich sehr stark. Überhaupt finde ich die Liste der beliebtesten Sprachen interessant.
S. R. schrieb: > Alex G. schrieb: >> Beliebt ist die Sprache jedenfalls. > > Wobei man hinzufügen sollte, dass Rust keine nennenswerte Verbreitung > hat (unter 4.2% in der gleichen Umfrage, d.h. taucht unter den Top 25 > nicht auf). Daraus lässt sich schließen, dass die hohe Beliebtheit von > einer kleinen, sehr loyalen Anhängerschaft stammt. Würde eher sagen die Beliebtheit stammt von Leuten die von der Sprache gehört haben und sie "interessant" finden, aber sie trotzdem nicht selber einsetzen (im Privaten hat man selten Projekte wo die Sprache Sinn macht und professionell ist sie leider eher rar wie du schon sagst). Die Umfrage betrachtet nicht nur die tatsächlichen Nutzer der Sprache. > Im Technologiegraph taucht Rust ebenfalls nicht auf, vermutlich wird > Rust zu selten professionell eingesetzt. Schade eigentlich, denn dort > hätte man die Anwendungsfälle sehen können. Leider wahr. Der englische Wiki Artikel nennt ein paar Programme bzw. Projekte welche die Sprache einsetzen. Zwei davon sind allerdings von Mozilla selbst. > Überhaupt finde ich die Liste der beliebtesten Sprachen interessant. Was haben eigentlich alle gegen Visual Basic? o.O
Alex G. schrieb: > Die Umfrage betrachtet nicht nur die tatsächlichen Nutzer der Sprache. Ich glaube, dass Rust hauptsächlich von Leuten angekreuzt wird, die es auch nutzen. Sonst hat ja niemand dazu einen Grund (bzw. wenn ich mich recht entsinne, stand das auch dabei). Und da es kaum professionelle Projekte in Rust gibt, sind das alles Hobbyisten - und die würden kein Rust verwenden, wenn sie es nicht toll fänden. Alex G. schrieb: >> Überhaupt finde ich die Liste der beliebtesten Sprachen interessant. > Was haben eigentlich alle gegen Visual Basic? o.O Naja, ich hab damit (und QBasic) angefangen, vor ziemlich vielen Jahren. Letztes Jahr habe ich aus nostalgischen Gründen (und weil ich bei meinen Eltern war) mal mein altes, dickes Fachbuch* rausgekramt und mich speziell in die Details reingelesen, die ich als Kind damals nicht verstanden habe. *konkret "Visual Basic 6 Kompendium" von Peter Monadjemi Nee, ich hab nicht das Gefühl bekommen, nochmal mit VB6 arbeiten zu wollen.
Alex G. schrieb: > Wobei Rust eigentlich auch nicht unbedingt in erster Linie für Embedded > ist. Das ist richtig, aber gerade da koennte Rust, m.M.n., punkten. Besonders da, wo hohe Anforderungen an Fehlerfreiheit gestellt werden. Da man viele Fehler in Rust, verglichen mit C und C++, gar nicht erst machen kann, beschraenken sich die Fehler fast ausschliesslich auf Logikfehler. Alex G. schrieb: > und professionell ist sie leider eher rar wie du schon sagst Sehe ich nicht so. Siehe hier: https://www.rust-lang.org/en-US/friends.html Mit Cloudflare, Dropbox, Threema, Mozilla (die es ja entwickelt haben), Samsung, etc. sind schon ein paar grosse/bekannte Namen dabei, die Rust aktiv nutzen. Und auch dieses 5 Seiten PDF, wie Rust bei einem Spielestudio seine Vorteile ausspielt, finde ich sehr interessant: Rust Case Study: Chucklefish Taps Rust to Bring Safe Concurrency to Video Games https://www.rust-lang.org/pdfs/Rust-Chucklefish-Whitepaper.pdf Es gibt praktisch kaum einen Grund, nicht auf Rust zu setzten (ausser im Embedded Bereich, wobei ARM schon recht gut unterstuetzt wird). Das Oekosystem ist sehr durchdacht, man muss keine Angst haben, dass man z.B. eine bestimmte Version eines Crates nicht mehr bekommt (ausser Github explodiert), man muss sich Abhaengigkeiten nicht von Hand zusammensuchen, etc. Zum veroeffentlichen eines Crates braucht man zwar einen GitHub-Account, aber den Code selbst kann man Hosten wo man will. Auch das Unittesting finde ich sehr gut, da man praktisch alle Funktionen testen kann, was in C++ mit privaten Methoden schon schwer wird. Auch das Benchmarking finde ich klasse, wobei das, je nach Funktion, etwas tricky werden kann. Insgesamt wirkt die Sprache und das gesamte Oekosystem sehr durchdacht. Ob die eigentliche Toolchain wirklich durchdacht ist, darueber koennte man bestimmt streiten. Gerade fuer den Embedded Bereich wuerde ich es schoener finden, wenn aus Rust nur Zwischencode erzeugt wird, den man dann an einen beliebigen Compiler z.B. an den AVR-GCC verfuettert. So schlage ich mich immernoch damit herum, avr-rust zu bauen, was praktisch immer an LLVM scheitert... Aber gut, es ist wie es ist, und abgesehen von Embedded, bin ich mit Rust sehr zufrieden.
Kaj schrieb: > .... Gerade fuer den Embedded Bereich wuerde ich es > schoener finden, wenn aus Rust nur Zwischencode erzeugt wird, den man > dann an einen beliebigen Compiler z.B. an den AVR-GCC verfuettert. So > schlage ich mich immernoch damit herum, avr-rust zu bauen, was praktisch > immer an LLVM scheitert... Es gibt ein C-Backend für LLVM, das genau für den Usecase gedacht ist. rust -(rustc)-> C -(GCC)-> AVR8 Sicher nicht ideal, aber besser als nichts.
S. R. schrieb: > Naja, ich hab damit (und QBasic) angefangen, vor ziemlich vielen Jahren. > Letztes Jahr habe ich aus nostalgischen Gründen (und weil ich bei meinen > Eltern war) mal mein altes, dickes Fachbuch* rausgekramt und mich > speziell in die Details reingelesen, die ich als Kind damals nicht > verstanden habe. Dann sei froh, dass du damals nicht an Rust geraten bist. Denn mit so einer Einführung hier https://rust-lang-de.github.io/rustbook-de/ Erst hüh "Es ist ebenfalls beachtenswert, dass hier keine Typangaben notwendig waren: Obwohl Rust statisch typisiert ist, mussten wir den Typ nicht ausdrücklich angeben. Rust hat type inference [engl.: Typinferenz, Typableitung], um die Stärke statischer Typen und der Ausführlichkeit des Angebens von Typen auszubalancieren." dann hott "Anders als bei let, musst du die Typen von Funktionsargumenten angeben. Das hier funktioniert nicht: # #![allow(unused_variables)] #fn main() { fn print_sum(x, y) { println!("sum is: {}", x + y); } " Aha! Manchmal ist es eine Stärke von Rust KEINE Typangaben machen zu müssen und manchmal ist eine Stärke von Rust DOCH Typangaben machen zu müssen oder wie? Der Autor bekennt und lobt in der "Wir" Form: "Das ist eine bewusste Designentscheidung. Obwohl das Herleiten der Typen eines kompletten Programmes möglich ist, wie zum Beispiel in Sprachen wie Haskell, wird dennoch häufig dazu geraten die Typen ausdrücklich zu dokumentieren. Wir stimmen zu, dass ausdrückliche Typvermerke in Funktionssignaturen und Typherleitung innerhalb von Funktionskörpern wundervoller Mittelweg ist." Dann solche Schwurbelsätze wie "Referenzen interagieren mit dem ownership-System durch das ‚Ausleihen‘ (borrowing) dessen, worauf sie zeigen. Der Unterschied ist, dass sie nicht den zugrunde liegenden Speicher freigibt, wenn die Referenz den Scope verlässt. Falls sie das täte, dann würden wir zweimal freigeben, was schlecht wäre." Der Abschnitt beginnt mit "Referenzen interagieren mit dem ownership-System .." Klingt für mich ähnlich wie Der Programmierer interagiert mit seinem Quellcode oder Der Programmierer interagiert mit seinem Algorithmus so lange, bis der Mist endlich fehlerfrei läuft. Dann heißt es "push ist eine Methode auf Vektoren, die ein weiteres Element an das Ende des Vektors anhängt." Mit Vektor soll hier das Stückchen String "Hallo Welt" gemeint sein. Aus "let mut x = vec!["Hallo", "Welt"];" Und was versteht der Autor unter einer Referenz y wenn er schreibt "let y = &x[0];" y sei nun das erste Element des Vektors x ? doch nicht etwa Erstes Element vec(x) = 'H' ??? Warum wird eine schnöde Zeichenkette hier in Schwurbelpädagogik umschrieben, die nichts weiter als eine Ansammlung von Einzelelementen vom Typ Char ist, so aufgeplustert, als etwas völlig Artfremdes dargestellt, was es in anderen Sprachen doch schon seit umme gibt? Dazu heißt es "Wir haben eine weitere Variablenbindung y hinzugefügt. In diesem Fall ist y eine ‚Referenz‘ auf das erste Element des Vektors. Rusts Referenzen sind ähnlich wie Zeiger in anderen Sprachen, aber mit zusätzlichen Überprüfungen zur Kompilierzeit. Referenzen interagieren mit dem ownership-System durch das ‚Ausleihen‘ (borrowing) dessen, worauf sie zeigen." Und? Hab ich jetzt mit "let z = &x[1];" mir hemmungslos das ZWEITE Element des Vektors x ausgeborgt? Frau Gilzer, ich hätte gerne ein 'a'. Was muss ich da wohl tun? Ach das ist einfach Herr Kandidat. Sie müssen lediglich per borrow sich eine Referenz von ihrem mutable-baren Vektor x ausleihen und dann einer neuen Variablen, z.B. z zuweisen, aber ohne mutable. Welches Element hättens denn gerne? Ach Frau Gilzer, geben Sie mir mal ein 'o'. Dann lieber Kandidat, wäre das so zu schreiben "let z = &x[4];" Nun haben Sie ein 'o' geborgt von ihrem Vektor x. Aber lieber Kandidat, passen Sie auf, dass ihr x dabei nicht gerade den Scope verlässt. Sonst borgen Sie von etwas was ihnen gar nicht mehr gehört! Aber keine Sorge, da schreitet der Kompiler schon ein (hoffentlich). Bei uns fangen Sie sich jedenfalls keine Nebenläufigkeit ein. Das haben wir alles im Griff. Frau Gilzer, was ist denn eine Nebenläufigkeit? Ach Herr Kandidat, wenn ich ihnen das jetzt alles erklären müsste ... Hauptsache Sie haben keinem hängenden Zeiger! Ich bitte Sie, Frau Gilzer! Bei mir hängt gar nix! Darauf können Sie sich verlassen. Frau Gilzer: Und da wäre ja auch noch die iterator Invalidation. DIE ist erst speziell ...
Privatfrickler schrieb: > Dann sei froh, dass du damals nicht an Rust geraten bist. Das wäre mir damals auch egal gewesen. Verstanden hätte ich es sowieso nicht. Ich hatte die "Visual Basic 6 Einsteiger Edition" und ein Buch von "DATA BECKER". Absolute Qualitätslektüre, ich weiß, aber für einen 14-Jährigen, der sich da ganz allein ohne Hilfe durchboxen muss (bzw. will), sind solch bebilderte Anleitungen verdammt nützlich. Habe ich damit "programmieren" gelernt? Sicherlich nicht. Aber aus der Zeit stammt ein kleines Programm, was bei meinem Vater noch immer täglich im Einsatz ist. Und darauf bin ich ein kleines bisschen stolz. ;-)
S. R. schrieb: > Privatfrickler schrieb: >> Dann sei froh, dass du damals nicht an Rust geraten bist. > > Das wäre mir damals auch egal gewesen. > Verstanden hätte ich es sowieso nicht. Das meinte ich damit. Da war PASCAL doch geradezu eine Wohltat gegen. > Ich hatte die "Visual Basic 6 Einsteiger Edition" und ein Buch von "DATA > BECKER". Absolute Qualitätslektüre, Du wirst es nicht glauben, ich habe noch PC intern 4 - Systemprogrammierung. Ein fast 1400 Seiten Wälzer mit CD mit zig Assembler, C und PASCAL Listings. Kein schlechtes Buch! > ich weiß, aber für einen > 14-Jährigen, der sich da ganz allein ohne Hilfe durchboxen muss (bzw. > will), sind solch bebilderte Anleitungen verdammt nützlich. > > Habe ich damit "programmieren" gelernt? Sicherlich nicht. > Aber aus der Zeit stammt ein kleines Programm, was bei meinem Vater noch > immer täglich im Einsatz ist. Und darauf bin ich ein kleines bisschen > stolz. ;-) Mit GFA BASIC auf dem AMIGA hab ich damals viele kleinere Progrämmchen geschafft. GFA BASIC fand ich damals schon sehr angenehm. Ich meine aus der Erinnerung, es ließ sich sogar kompilieren und lief dann flott.
PC intern 4 - Systemprogrammierung war ein DATA Becker Buch vom Autor Michael Tischer Erstauflage 1994.
S. R. schrieb: > Ich hatte die "Visual Basic 6 Einsteiger Edition" und ein Buch von "DATA > BECKER". Absolute Qualitätslektüre, ich weiß, aber für einen > 14-Jährigen, der sich da ganz allein ohne Hilfe durchboxen muss (bzw. > will), sind solch bebilderte Anleitungen verdammt nützlich. > > Habe ich damit "programmieren" gelernt? Sicherlich nicht. Gerade nochmal recherchiert. Data Becker musste 2014 dicht machen. https://www.heise.de/newsticker/meldung/Data-Becker-wird-geschlossen-1975472.html Hier Jürgen Kuri dazu https://plus.google.com/+J%C3%BCrgenKuri/posts/BCszMPpX9RS
Alex G. schrieb: > Glaube du zählst zu den wenigen Personen welche sich beim Befassen mit > einer neuen Sprache, als erstes die Backus Naur Form sehen wollen... > > Btw. hat es mich nur eine Google Query gekostet, zu finden was du > scheinbar suchst Du hast den Sinn nicht erfasst. Wenn ich unbedingt wollte, könnte ich mich selber auf die Suche machen, aber hier geht es nicht darum, was ich will, sondern darum, was die Rust-Leute ihren eventuellen Interessenten anbieten, also wie sich Rust dem Publikum präsentiert. Da wäre eine straffe Definition der Sprache - eben per BNF - an allererster Stelle extrem hilfreich, um eine neue Sprache sachgerecht einzuführen und sie auf saubere Logik (oder eben deren Fehlen) abzuklopfen. Was man dort jedoch sieht, ist Gelaber und Geschwurbel. Die PR-Leute von Rust schaffen es nicht, dem Leser einen sachlichen Überblick zu geben (weil sie den wohl selber nicht haben) und stochern stattdessen in Details herum. Nochmal: die Sprache per BNF darzustellen ist ein Prüfstein für die Sprache selbst. Dort kommt es nämlich ganz schnell heraus, wenn es an innerer Logik fehlt und stattdessen mit Sonderfällen und "hier ist das eben so" gearbeitet wird. W.S.
Denke schon die Tatsache dass es Rust Belt gibt zeigt dass es nicht grade schlecht um die Logik steht. Und nochmal, für diese Sache interessieren sich theoretische Informatiker, aber kaum Programmierer und letztere sind es die Rust braucht und anlocken muss um erfolgreich zu sein! Btw. wenn ich auf Java.com gehe finde ich sowas dazu auch nicht. Was ist die Referenzseite zu C oder C++ wo die Theorie angeblich an erster Stelle steht?
Beitrag #5517631 wurde von einem Moderator gelöscht.
Nichteinmal die Logik Sprache schlechthin, Matlab stellt die Grammatik in ihrer Doku an erster Stelle! https://de.mathworks.com/help/matlab/
S. R. schrieb: > Ich hatte die "Visual Basic 6 Einsteiger Edition" und ein Buch von "DATA > BECKER". Siehste, andere hatten nur "Programmieren mit dem Mikrocomputer KC85" oder so. Das war aber nur ein dünnes Heftchen. Aber es kam ganz viel GOTO darin vor. ;-)
W.S. schrieb: > Da wäre eine straffe Definition der Sprache - eben per BNF - an > allererster Stelle extrem hilfreich Bei allem Geschwurbel, was Du hier abgibst, aber: Das fehlt mir bisher auch, um mal einen Überblick über die Sprache zu bekommen.
Karl K. schrieb: > Siehste, andere hatten nur "Programmieren mit dem Mikrocomputer KC85" > oder so. Och, auf dem hab ich auch ein bisschen BASIC gemacht. Hauptsächlich aber DIGGER gespielt. :-) Das war aber alles lange nach der Wende, die Bücher existieren schon lange nicht mehr und die KCs sind mit dem Tod der Station Junger Techniker alle entsorgt worden. Leider, ich hätte gerne einen davon gehabt.
Karl K. schrieb: > W.S. schrieb: >> Da wäre eine straffe Definition der Sprache - eben per BNF - an >> allererster Stelle extrem hilfreich > > Bei allem Geschwurbel, was Du hier abgibst, aber: Das fehlt mir bisher > auch, um mal einen Überblick über die Sprache zu bekommen. Ehrlich gesagt halte ich es persönlich anhand meiner Erfahrungen aus dem Grundstudium, für nahezu unmöglich daraus einnechtes Gefühl dafür zu bekommen wie man mit der Sprache tatsächlich programmiert und ist es nicht das was zählt? Es gab eine Reihe von Versuchen hochsichere Sprachen mathematisch zu bauen. Die sahen in solchen normierten Formen auch sehr schön aus. Den Bekanntheitsgrad von Rust konnte davon aber nichts erlangen weil sie einfach nicht wirklich praxistauglich sind. Wie auch immer - enthält dieser Link nicht die Information die du brauchst? https://doc.rust-lang.org/grammar.html
Alex G. schrieb: > Btw. wenn ich auf Java.com gehe finde ich sowas dazu auch nicht. > Was ist die Referenzseite zu C oder C++ wo die Theorie angeblich an > erster Stelle steht? Du missverstehst da etwas absichtlich. Erstens sind C, C++ und Java etablierte Sprachen, die müssen sich mit anderen Sprachen nicht mehr messen lassen. Deren Vor- und Nachteile sind bekannt. Zweitens sind all diese Sprachen in einer Zeit entstanden, als eine vollständige, lückenlose Definition nicht notwendig war. Daraus folgen ziemlich hässliche Altlasten und komplexe formale Definitionen. Neue Sprachen müssen mehr Anforderungen erfüllen als alte Sprachen, denn die Welt hat sich geändert. Sonderlocken im Parser drehen zu müssen ist nicht mehr akzeptabel, eine klare BNF macht das deutlich. Nebenläufigkeit und Speichermodelle sind ordentlich und klar in einer Weise zu definieren, die effiziente Implementationen ermöglicht. Undefiniertes Verhalten ist inakzeptabel. Wenn man das hinkriegt, dann kann man seine Nische gründlich besetzen. Kotlin hat das für Android bereits getan. Rust nicht. Btw: https://kotlinlang.org/docs/reference/grammar.html
Nagut, wenn du meinst dass die potentielle Nutzerschaft wirklich darauf achtet bzw. sich das durchlesen würde... EDIT: Willst du mich verarschen oder so? Dein Kotlin hat "grammar" exakt genau so wenig an erster Stelle der Doku wie Rust!
Alex G. schrieb: > EDIT: Willst du mich verarschen oder so? Nein, ich habe zum Vergleich auf die BNF von Kotlin verlinkt. Da sind keine FIXMEs und längliche Erläuterungen drin. Wenn du aber so angepisst reagierst, naja... schlaf dich erstmal aus.
Ich pick mir mal noch einen Absatz aus dem rustbook heraus. https://rust-lang-de.github.io/rustbook-de/Variablenbindung.html "Fast jedes nicht-triviale Rust-Programm verwendet Variablenbindungen. Sie sehen so aus: fn main() { let x = 5; } fn main() { in jedes Beispiel zu schreiben ist ein wenig mühsam, also werden wir es in Zukunft weglassen. Falls du diese Beispiele ausprobierst, stelle sicher, dass du deinen Code in einer main() Methode schreibst (und nicht wie wir weglässt). Ansonsten bekommst du einen Fehler. In vielen Sprachen wird das eine Variable genannt, aber Rusts Variablenbindungen haben ein paar Tricks im Ärmel. Zum Beispiel ist die linke Seite der let Anweisung ein ‘Muster’ und nicht einfach nur ein Variablenname. Das bedeutet, dass wir solche Sachen tun können: # #![allow(unused_variables)] #fn main() { let (x, y) = (1, 2); " Was um alles in der Welt denkt sich dieser Schreiberling hier bei seinen Ausführungen? Anstatt mal den Begriff "Variablenbindung" vor dessen Verwendung zu definieren, haut er mir gleich mal ein Beispiel um die Ohren, nämlich dieses hier fn main() { let x = 5; } und geht anschließend überhaupt nicht mehr darauf ein. Statt dessen macht er einen auf "ich bin ein fauler Schreiber" und lässt gleich mal ein wichtiges Bestandteil zum NEULERNEN einer Programmiersprache weg. In C wäre das dann in etwa so: Hier mal ein C-Programm für euch printf("Hallo Welt") Das Unwichtige mit dem main() und so hab ich mal weggelassen, weil ich (euer Tutor) bin ja schreibfaul (hihihi). Wenn ihr (Dooflinge) also mein Programm compilieren wollt, vergesst doch bitte nicht alles hinzuzufügen, was es bei einem ORDENTLICHEN C-Programm eben so braucht. Da fällt mir wirklich die Hutkrempe herunter. Dann der Halbsatz "In vielen Sprachen wird das eine Variable genannt, ..." " ... aber Rusts Variablenbindungen haben ein paar Tricks im Ärmel." Was ist denn das für ein Schwafler, der so schreibt? Klingt als Leser wie "Hey! Hier is uns're supergoile Proggersprache mit den affengeilen Tricks im Ärmel" Dann dieses tendenziöse "ich kann's euch nich erklären, darum bringe ich lieber ein Beispiel". Da isses wieder: "Zum Beispiel ist die linke Seite der let Anweisung ein ‘Muster’ und nicht einfach nur ein Variablenname. Das bedeutet, dass wir solche Sachen tun können:" Jetzt müsste man ihn gleich löchern und fragen, erklären Sie doch mal genau, was ein Muster ist. "Das bedeutet, dass wir solche Sachen tun können:" Das bedeutet, DU lieber Schreiberling kannst NICHT erklären! DAS bedeutet das! Das jenes hier let x = 5; so gar nicht ausschaut wie das Geklammerte hier (eben wegen dieser Klammern) let (x, y) = (1, 2); lässt er natürlich unter den Tisch fallen. Weil er das erste Beispiel unter den Tisch fallen lies und nix dazu erklärte. Vielleicht gab es auch gar nix dazu zu erklären, weil es einfach eine Variablendeklaration ist und sonst gar nix. Aber nein, er schrieb ja "In vielen Sprachen wird das eine Variable genannt, " legt den Schluss nahe, bei Rust ist das eben NICHT so oder vielleicht doch und der Autor weiß es einfach selber nicht so genau. --- Und so gehen diese Erklärungen, d.h. dieses Geschwurbel weiter und weiter. Ich komm da keine paar Zeilen weit, ohne dass mir der Widerspruch in den Fingern juckt. Vielleicht liegt es auch an diesem elendigen auf DU-und-DU gemache ICH-KENN-DICH-PERSÖNLICH Schreibstil, der immer öfter um sich greift, siehe "Wenn du die zwei geschweiften Klammern ({}, manche nennen sie Schnurrbärte..) in deinem auszugebenden String einfügst, " Sorry, aber ich möchte als Leser NICHT so angesprochen werden! Das stört mich auch oftmals an diesen YouTube-Vorträgen, in denen Studies gerne auf Kumpel machen, um mir was zu vermitteln. Gute Vorträge werden so nicht gesprochen. Dieser ASTA-Speech nervt mich total ab. Ich bekomme Wutstarre. Korrekt heißt das so Ein auszugebender String wird in geschweifte Klammern gesetzt. Rust interpretiert die Klammern als Anweisung, an dieser Stelle einen Wert einzufügen. Nix "wenn DU die" ... und "Schnurrbärte" Dödel!
Beitrag #5517735 wurde von einem Moderator gelöscht.
Beitrag #5517752 wurde von einem Moderator gelöscht.
Alex G. schrieb: > Karl K. schrieb: >> W.S. schrieb: >>> Da wäre eine straffe Definition der Sprache - eben per BNF - an >>> allererster Stelle extrem hilfreich >> >> Bei allem Geschwurbel, was Du hier abgibst, aber: Das fehlt mir bisher >> auch, um mal einen Überblick über die Sprache zu bekommen. > > Ehrlich gesagt halte ich es persönlich anhand meiner Erfahrungen aus dem > Grundstudium, für nahezu unmöglich daraus einnechtes Gefühl dafür zu > bekommen wie man mit der Sprache tatsächlich programmiert und ist es > nicht das was zählt? Mir geht es bzgl. der BNF ähnlich wie Alex: Um mir einen ersten Eindruck über die Syntax einer Sprache zu verschaffen, möchte ich ein paar aussagekräftige Codebeispiele und keine formale Syntaxbeschreibung per BNF. Diese steht in Lehrbüchern – wenn überhaupt vorhanden – üblicherweise ganz am Ende. Ich habe diese noch nie komplett durchgelesen, sondern nutze sie allenfalls dann, wenn ich eine konkrete Frage zu irgend einem syntaktischen Detail habe. Um einen ersten Eindruck über die Semantik der Sprache zu bekommen, möchte ich eine kurze Erläuterung der wichtigsten Eigenschaften in Prosa und keine Semantikbeschreibung mittels abstrakter mathematischer Modelle. Eine solche Beschreibung gibt es sowieso nur für die wenigsten Programmiersprachen. S. R. schrieb: > Nein, ich habe zum Vergleich auf die BNF von Kotlin verlinkt. Da sind > keine FIXMEs und längliche Erläuterungen drin. Im Anhang findest du entsprechendes für Rust, ebenfalls ohne FIXMEs und längliche Erläuterungen.
Beitrag #5517760 wurde von einem Moderator gelöscht.
Beitrag #5517761 wurde von einem Moderator gelöscht.
Beitrag #5517762 wurde von einem Moderator gelöscht.
Beitrag #5517763 wurde von einem Moderator gelöscht.
Beitrag #5517764 wurde von einem Moderator gelöscht.
Beitrag #5517765 wurde von einem Moderator gelöscht.
Beitrag #5517766 wurde von einem Moderator gelöscht.
Beitrag #5517767 wurde von einem Moderator gelöscht.
Beitrag #5517768 wurde von einem Moderator gelöscht.
Beitrag #5517771 wurde von einem Moderator gelöscht.
Beitrag #5517772 wurde von einem Moderator gelöscht.
Beitrag #5517773 wurde von einem Moderator gelöscht.
Beitrag #5517774 wurde von einem Moderator gelöscht.
Beitrag #5517778 wurde von einem Moderator gelöscht.
Beitrag #5517780 wurde von einem Moderator gelöscht.
Beitrag #5517782 wurde von einem Moderator gelöscht.
Beitrag #5517784 wurde von einem Moderator gelöscht.
Beitrag #5517785 wurde von einem Moderator gelöscht.
Beitrag #5517786 wurde von einem Moderator gelöscht.
Beitrag #5517787 wurde von einem Moderator gelöscht.
Beitrag #5517788 wurde von einem Moderator gelöscht.
Beitrag #5517789 wurde von einem Moderator gelöscht.
Beitrag #5517792 wurde von einem Moderator gelöscht.
Beitrag #5517794 wurde von einem Moderator gelöscht.
Beitrag #5517795 wurde von einem Moderator gelöscht.
Beitrag #5517799 wurde von einem Moderator gelöscht.
Beitrag #5517801 wurde von einem Moderator gelöscht.
Beitrag #5517804 wurde von einem Moderator gelöscht.
Beitrag #5517805 wurde von einem Moderator gelöscht.
Beitrag #5517806 wurde von einem Moderator gelöscht.
Beitrag #5517807 wurde von einem Moderator gelöscht.
Beitrag #5517808 wurde von einem Moderator gelöscht.
Beitrag #5517809 wurde von einem Moderator gelöscht.
Beitrag #5517810 wurde von einem Moderator gelöscht.
Beitrag #5517811 wurde von einem Moderator gelöscht.
Beitrag #5517813 wurde von einem Moderator gelöscht.
Beitrag #5517814 wurde von einem Moderator gelöscht.
Beitrag #5517815 wurde von einem Moderator gelöscht.
Beitrag #5517816 wurde von einem Moderator gelöscht.
Beitrag #5517817 wurde von einem Moderator gelöscht.
Beitrag #5517819 wurde von einem Moderator gelöscht.
Beitrag #5517820 wurde von einem Moderator gelöscht.
Beitrag #5517821 wurde von einem Moderator gelöscht.
@privatfrickler: Die deutsche Übersetzung des Rust-Handbuchs ist uralt. Nimm besser dieses hier https://doc.rust-lang.org/book/2018-edition/ oder – falls dir das ebenfalls nicht zusagt – such dir eins von hier aus, das besser deinem Geschmack entspricht: https://hackr.io/tutorials/learn-rust
Beitrag #5517823 wurde von einem Moderator gelöscht.
Beitrag #5517824 wurde von einem Moderator gelöscht.
Beitrag #5517825 wurde von einem Moderator gelöscht.
Beitrag #5517826 wurde von einem Moderator gelöscht.
Beitrag #5517827 wurde von einem Moderator gelöscht.
Beitrag #5517828 wurde von einem Moderator gelöscht.
Beitrag #5517829 wurde von einem Moderator gelöscht.
Beitrag #5517830 wurde von einem Moderator gelöscht.
Beitrag #5517831 wurde von einem Moderator gelöscht.
Beitrag #5517832 wurde von einem Moderator gelöscht.
Beitrag #5517833 wurde von einem Moderator gelöscht.
Beitrag #5517834 wurde von einem Moderator gelöscht.
Beitrag #5517836 wurde von einem Moderator gelöscht.
Beitrag #5517837 wurde von einem Moderator gelöscht.
Beitrag #5517838 wurde von einem Moderator gelöscht.
Beitrag #5517839 wurde von einem Moderator gelöscht.
Beitrag #5517840 wurde von einem Moderator gelöscht.
Beitrag #5517842 wurde von einem Moderator gelöscht.
Beitrag #5517843 wurde von einem Moderator gelöscht.
Beitrag #5517844 wurde von einem Moderator gelöscht.
Beitrag #5517845 wurde von einem Moderator gelöscht.
Beitrag #5517847 wurde von einem Moderator gelöscht.
Beitrag #5517848 wurde von einem Moderator gelöscht.
Beitrag #5517850 wurde von einem Moderator gelöscht.
Beitrag #5517851 wurde von einem Moderator gelöscht.
Beitrag #5517852 wurde von einem Moderator gelöscht.
Beitrag #5517853 wurde von einem Moderator gelöscht.
Beitrag #5517855 wurde von einem Moderator gelöscht.
Beitrag #5517857 wurde von einem Moderator gelöscht.
Beitrag #5517858 wurde von einem Moderator gelöscht.
Beitrag #5517859 wurde von einem Moderator gelöscht.
Beitrag #5517860 wurde von einem Moderator gelöscht.
Beitrag #5517862 wurde von einem Moderator gelöscht.
Beitrag #5517863 wurde von einem Moderator gelöscht.
Beitrag #5517864 wurde von einem Moderator gelöscht.
Beitrag #5517865 wurde von einem Moderator gelöscht.
Beitrag #5517867 wurde von einem Moderator gelöscht.
Beitrag #5517868 wurde von einem Moderator gelöscht.
Beitrag #5517869 wurde von einem Moderator gelöscht.
Beitrag #5517870 wurde von einem Moderator gelöscht.
Beitrag #5517871 wurde von einem Moderator gelöscht.
Beitrag #5517872 wurde von einem Moderator gelöscht.
Beitrag #5517873 wurde von einem Moderator gelöscht.
Beitrag #5517874 wurde von einem Moderator gelöscht.
Beitrag #5517875 wurde von einem Moderator gelöscht.
Beitrag #5517876 wurde von einem Moderator gelöscht.
Beitrag #5517877 wurde von einem Moderator gelöscht.
Beitrag #5517878 wurde von einem Moderator gelöscht.
Dieser Beitrag ist gesperrt und kann nicht beantwortet werden.