avr schrieb:> Arduino-C gibt es übrigens nicht
'tschuldigung. C für Arduino meine ich.
avr schrieb:> Mit sizeof findest du die Größe heraus.
Könntest du dir vorstellen, dass ich die Variable erst anlegen will?
Roth schrieb:> Könntest du dir vorstellen, dass ich die Variable erst anlegen will?
ähm es kann sich keiner vorstellen ... :(
Ich erkläre dann mal. Also ich will Pointer in Variablen speichern.
Genau genommen Funktionspointer, also Pointer auf Funktionen.
Zu Arduino-C: Könntze mir vorstellen, dass die Größe von Variablen mit
der (max)Größe des Speichers/EEPROMS korreliert. Daher müsste es keinen
Sinn machen, Pointern in einer relativ kleinen Welt 32 Bit zu
spendieren.
Aber meine Frage signalisiert mein Unwissen. Ich weiß nicht, wie groß
der C-Compiler Pointer für die Arduino-Plattform macht. Daher die Frage.
Arduino Fanboy D. schrieb:> Roth schrieb:>> Könntest du dir vorstellen, dass ich die Variable erst anlegen will?>> Was hält dich ab?
My Unwisse. long oder int, das ist die Frag, my Boy
@Roth (Gast)
>Ich erkläre dann mal. Also ich will Pointer in Variablen speichern.>Genau genommen Funktionspointer, also Pointer auf Funktionen.
Dazu muss man aber deren Größe nicht kennen. Man definiert einfach einen
Funktionspointer, den Rest macht der Compiler.
>Zu Arduino-C: Könntze mir vorstellen, dass die Größe von Variablen mit>der (max)Größe des Speichers/EEPROMS korreliert.
Nö, der korrelliert mit der CPU.
> Daher müsste es keinen>Sinn machen, Pointern in einer relativ kleinen Welt 32 Bit zu>spendieren.>Aber meine Frage signalisiert mein Unwissen. Ich weiß nicht, wie groß>der C-Compiler Pointer für die Arduino-Plattform macht. Daher die Frage.
Das Problem ist einfach, daß die Arduino-Plattform mehrere, recht
verschiedene CPUs beinhaltet. Angefangen vom AVR mit 16 Bit Pointern,
über dem SAM??? vom Arduino Due mit wahrscheinlich 32 Bit Pointern bis
hin zu ESP & Co.
Soweit ich weiß gibt's Arduino inzwischen für 8, 16 und 32 Bitter mit
stark unterschiedlichen Adressräumen. Da werden dann wohl auch die
Pointergrößen, die C++ für die entsprechende Zielplattform generiert,
unterschiedlich sein. Mit der Menge Info, mit der du aufwartest, lässt
sich das also offensichtlich nicht entscheiden.
Gerhard
Roth schrieb:> Arduino Fanboy D. schrieb:>> Roth schrieb:>>> Könntest du dir vorstellen, dass ich die Variable erst anlegen will?>>>> Was hält dich ab?>> My Unwisse. long oder int, das ist die Frag, my Boy
Wenn du einen Pointer anlegen willst, dann solltest du das auch tun!
Roth schrieb:> Wieso geht ein byte als Pointer mit durch?
Da doch eine Funktion einen Rückgabewert hat.
Und dessen Type bestimmst du damit.
Roth schrieb:> Oder macht der Compiler was er will?
Der Compiler hält sich an die jeweils geltenden Standards.
Mache dich über Pointer kundig.
Ich rate dir dringend zu einem ca 1000 seitigen C++ Buch.
Die Konstruktion mit dem '[]' kannte ich z.B. überhaupt noch nicht.
Vielen Dank an alle. Insbesondere an meine lieben Freund den Arduino
Fanboy :D (das meine ich jetzt ernst, hat mich gefreut)
Arduino Fanboy D. schrieb:> Ich rate dir dringend zu einem ca 1000 seitigen C++ Buch.
So lange lebe ich am ende gar nicht mehr ;)
Ach so, den Pointer habe ich mit void angelegt. Comiler macht also was
er will, wie meine Angestellten ... irgendwas mache ich falsch
Allerdings gehts bei dem Parameter 'mitPointerparameter(int p)' nur mit
int oder long . byte gibt nur 'Ha' aus, das 'llo' wird verschluckt.
Verstehe das wer will ...
Roth schrieb:> So lange lebe ich am ende gar nicht mehr ;)
Du verplemperst mehr Lebenszeit mit "im Nebel stochern".
Naja, wenn es dir Spass macht?
Roth schrieb:> Verstehe das wer will ...
Du schlägst die Warnungen deines Compilers in den Wind, und beschwerst
dich dann, dass er Mist baut?
Seltsame Vorstellungen du hast...
Arduino Fanboy D. schrieb:> Du schlägst die Warnungen deines Compilers in den Wind, und beschwerst> dich dann, dass er Mist baut?
Quatsch. Da kommen keine Warnungen. Ich bin blauäugig aber nicht blöd.
Außerdem gehts schon lange. Eine Interrupt-Routine, die zeitgesteuert
beliebige Funktionen aufrufen können soll. Am meisten ärgert mich ja,
dass Arduino Fanboy zur Lösung beigetragen hat ;) aber das Skript mit
Using ist gut. Bin ja noch C-Anfänger, aber habe ich glatt in mein
Repertoire übernommen. thx
> aber das Skript mit Using ist gut.
Exakt das gleiche bekommst du mit "typedef void (*FunktionPointer)();"
und im Gegensatz zu dem Using-Statement (ein C++11-Feature) funktioniert
das mit allen C und C++ Compilern.
Btw, was du anstellst nenn ich Voodoo-Programmierung - ohne Verständnis
irgendwelche Codefragmente zusammenpappen und hoffen, dass irgendwas
Lauffähiges bei rauskommt.
> Außerdem gehts schon lange. Eine Interrupt-Routine, die zeitgesteuert> beliebige Funktionen aufrufen können soll.
Du hast nur noch nicht die Fehler gefunden ;-) An dem Problem haben sich
schon gestandene C-Programmierer die Zähne ausgebissen.
Roth schrieb:> Aber meine Frage signalisiert mein Unwissen. Ich weiß nicht, wie groß> der C-Compiler Pointer für die Arduino-Plattform macht. Daher die Frage.
Die Größe brauchst du gar nicht zu wissen, um einen solchen Zeiger zu
erstellen. Die weiß der Compiler auch ohne dich.
Roth schrieb:> Allerdings gehts bei dem Parameter 'mitPointerparameter(int p)' nur mit> int oder long . byte gibt nur 'Ha' aus, das 'llo' wird verschluckt.> Verstehe das wer will ...Roth schrieb:> Nur völlig suspekt ist das hier:byte (*pDerPointer)();> Wieso geht ein byte als Pointer mit durch? Oder macht der Compiler was> er will?Roth schrieb:> OK. Verstehen tue ich es nicht, aber es geht.Roth schrieb:> Arduino Fanboy D. schrieb:>> Ich rate dir dringend zu einem ca 1000 seitigen C++ Buch.>> So lange lebe ich am ende gar nicht mehr ;)
Deine Aussagen zeigen, dass du keinerlei Idee hast, wie oder warum der
Code funktioniert. Das ist ja erstmal nicht schlimm - letztendlich fängt
ja jeder mal so an. Aber glaube mir: Mit einem Buch wirst du schneller
sein, als mit deiner aktuellen Lernmethode. Das weiß ich aus eigener
Erfahrung.
Roth schrieb:> aber das Skript mit Using ist gut. Bin ja noch C-Anfänger, aber habe ich> glatt in mein Repertoire übernommen. thx
Das ist kein C, sondern C++.
Roth schrieb:> Arduino Fanboy D. schrieb:>> Du schlägst die Warnungen deines Compilers in den Wind, und beschwerst>> dich dann, dass er Mist baut?>> Quatsch. Da kommen keine Warnungen. Ich bin blauäugig aber nicht blöd.
Da müssten eigentlich viele Warnungen kommen, denn da passen überall die
Typen nicht zusammen. Mich wundert, dass der Compiler das überhaupt
akzeptiert. C++ ist da normalerweise ziemlich restriktiv.
Klaus schrieb:> avr schrieb:>> Mit sizeof findest du die Größe heraus.>> Was hilft es einem, wenn man das weiß?
Man muß dann keine dummen[*] Fragen mehr in ein Forum rotzen
[*] ok, vielleicht nicht direkt "dumm". Aber man kann die Antwort mit
minimalem Aufwand selber herausfinden.
Roth schrieb:> Arduino Fanboy D. schrieb:>> Du schlägst die Warnungen deines Compilers in den Wind, und beschwerst>> dich dann, dass er Mist baut?>> Quatsch. Da kommen keine Warnungen. Ich bin blauäugig aber nicht blöd.
Du bist unglaublich borniert, wenn ich das mal so sagen darf.
Ich finde, lernende haben die Informationen aufzusaugen, wie ein
Schwamm. So sollte es sein. Aber du bis wie Lotus. Alles was dir nicht
schmeckt perlt einfach ab.
Siehe Anhang.
Dazu würde ich sagen, ein Pointer ist so groß, wie es dem Programmierer
des Compilers in den Kram passte. Was noch nicht mal bedeutet, dass er
seine Meinung zu dem Thema nicht auch mal ändern könnte.
Und wenn jetzt der große Aufschrei kommt, dass er die Größe an die
Zielarchitektur anpasst, gebe ich folgendes zu bedenken :
Wenn man es genau nimmt haben AVRs 3 Adressräume :
- Programmspeicher (Flash)
- RAM
- Daten EEPROM
Wobei ich gerade Teile mit bis zu 384k Programmspeicher und 32k Ram
sehe. Also braucht es geschätzte 19 Bit, um eine Speicheradresse
eindeutig zu adressieren. 24 Bit wären also eine ganz nette Größe.
AVR-GCC benutzt meines Wissens nach nur 16 Bit. Das kommt bestimmt auch
daher, dass die AVRs mal mit 8k Programmspeicher angefangen haben.
Ausserdem hat man versäumt die Adressbereiche sauber in den Pointern
abzulegen, sondern hat seltsame Konstrukte gewählt, um beim Zugriff den
Adressraum anzugeben.
Was also, wenn die Entwickler von AVR-GCC irgendwann mal einen Rappel
kriegen und sagen, jetzt machen wir das mal richtig und ändern die Größe
eines Pointers ?
Oder wenn Du Deinem Projekt WLAN bescheren möchtest und vom AVR zum ESP
wechselst ?
Da gibt es nur eins : Schreibe am Besten keinen Code, der davon abhängig
ist, wie der Compiler die Daten ablegt !
Ich sehe auch in dem Code, den der Fragesteller als Lösung akzeptiert
hat keinen Zugriff, der die Länge eines Pointers kennen müsste, ausser
dass die Länge in Bytes ausgegeben wird.
Rolf M. schrieb:> Die Größe brauchst du gar nicht zu wissen, um einen solchen Zeiger zu> erstellen. Die weiß der Compiler auch ohne dich.
Normal muss man schon wissen, wie groß eine Variable sein soll, wenn man
sie anlegt (long, int, ...). Woher soll ich wissen, dass bei Pointern
der Comiler den Datentyp ignoriert und selbst festlegt? Sogar ein void
ging ja. Ich komme aus einer anderen Programmierecke (VB, Assembler,
SQL). Mit C/C++ habe ich keine praktische Erfahrung, man mann ja nicht
alles gleichzeitig tun.
foobar schrieb:> Exakt das gleiche bekommst du mit "typedef void (*FunktionPointer)();"> und im Gegensatz zu dem Using-Statement (ein C++11-Feature) funktioniert> das mit allen C und C++ Compilern.
Danke. Hier in diesem Forum kann man viel lernen.
foobar schrieb:> Btw, was du anstellst nenn ich Voodoo-Programmierung - ohne Verständnis> irgendwelche Codefragmente zusammenpappen und hoffen, dass irgendwas> Lauffähiges bei rauskommt.
Ich versuche plumpes abschreiben zu vermeiden. Aber manchmal ist es eben
so, wenn man in einem drin Projekt ist, da fehlt die Zeit für die Basics
und dann muss learning by doing her. OK, ich habe noch ein paar Löcher
in C, aber die werden sich schließen, wenn ich öfter in C arbeite.
Aktuell bin ich am allerersten Programm.
foobar schrieb:> Du hast nur noch nicht die Fehler gefunden ;-) An dem Problem haben sich> schon gestandene C-Programmierer die Zähne ausgebissen.
hähä. Ich habe ja selbst nicht geglaubt, aber es funktionierte sogar auf
Anhieb. Natürlich nur wegen eurer tollen Hilfe.
Die Größe des Pointers hängt ausschließlich mit der Architektur
zusammen.
Beim AVR oder ARM kann man von 16bit bzw. 32Bit ausgehen. Auf einem PC
wird die Sache schon schwieriger, Long, Long Long ... usw..32bit oder
64bit Architektur..
Marco H. schrieb:> Die Größe des Pointers hängt ausschließlich mit der Architektur> zusammen.
Nein. Das wurde hier erläutert:
fop schrieb:> Dazu würde ich sagen, ein Pointer ist so groß, wie es dem Programmierer> des Compilers in den Kram passte. Was noch nicht mal bedeutet, dass er> seine Meinung zu dem Thema nicht auch mal ändern könnte.
Der Programmierer des Compilers kennt ja in der Regel die Architektur
und macht dann was sinnvolles. Aber ob es im Grenzfall 2,3 oder 4 Byte
sind, und ob noch ein paar Bits zwischen Flash und RAM unterscheiden
oder auch EEPROM mit berücksichtigen, ... das macht er, wie er will.
Das ist das schöne an z.B. ARM: Da sind Flash, EEPROM, RAM, Peripherie,
externes RAM, usw. alle in einem großen 32bit-Adressraum. Dadurch kann
man alles einheitlich mit einem 32bit-Zeiger adressieren, welche von der
32bit-Architektur natürlich effizient verarbeitet werden.
Dr. Sommer schrieb:> Das ist das schöne an z.B. ARM: Da sind Flash, EEPROM, RAM, Peripherie,> externes RAM, usw. alle in einem großen 32bit-Adressraum. Dadurch kann> man alles einheitlich mit einem 32bit-Zeiger adressieren, welche von der> 32bit-Architektur natürlich effizient verarbeitet werden.
Du vergleichst Äpfel mit Birnen - bzw. Harvard- mit von
Neumann-Architektur.
Den Unterschied sollte man schon verstehen.
Bei Harvard-Architektur gibt es physikalisch getrennte Adressräume für
Code und Daten.
* AVR-8bit ist Harvard-Architektur.
* ARM ist von Neumann-Architektur
Roth schrieb:> Normal muss man schon wissen, wie groß eine Variable sein soll, wenn man> sie anlegt (long, int, ...).
Nein. Wenn du einen long definierst, ist das eine Variable vom Typ long,
und fertig. Eine Größe gibt man da nicht an.
> Woher soll ich wissen, dass bei Pointern der Comiler den Datentyp> ignoriert und selbst festlegt?
Er ignoriert gar nichts. Du hast nur nicht verstanden, wie Pointer
funktionieren. Und genau solche Grundlagen lassen sich am besten einem
Buch oder Tutorial entnehmen. Das alles durch trial & error und
Interpretation dessen, wie der Compiler reagiert, zu erlernen, ist
ziemlich aussichtslos.
> Sogar ein void ging ja.
Ja, weil das void überhaupt nichts mit der Größe des Zeigers zu tun hat.
Wenn du einen long* definierst, ist das ein Zeiger auf einen long.
Welche Größe der Zeiger selber hat, ist davon unabhängig. Ein void* ist
ein Zeiger auf etwas, das an dieser Stelle nicht weiter definiert ist.
Auch hier hat das nichts mit der Größe des Zeigers zu tun.
> foobar schrieb:>> Btw, was du anstellst nenn ich Voodoo-Programmierung - ohne Verständnis>> irgendwelche Codefragmente zusammenpappen und hoffen, dass irgendwas>> Lauffähiges bei rauskommt.>> Ich versuche plumpes abschreiben zu vermeiden. Aber manchmal ist es eben> so, wenn man in einem drin Projekt ist, da fehlt die Zeit für die Basics> und dann muss learning by doing her. OK, ich habe noch ein paar Löcher> in C, aber die werden sich schließen, wenn ich öfter in C arbeite.
Ich fürchte, das sind ein paar ziemlich große Löcher. Wenn du das lernen
willst, indem du einfach in C arbeitest, könnten die schlimmsten dieser
Löcher sich in einigen Jahren verkleinert haben. Wie schon oben
geschrieben: Ich kenne das aus persönlicher Erfahrung und würde
niemandem empfehlen, das genauso ineffizient zu machen wie ich damals.
Roth schrieb:> Das erste Wort meine ich. Hier long> long (*pDerPointer)();
Das long ist nicht die Größe des Pointers, sondern die Angabe, welchen
Typ die Funktion, wenn Du sie über den Pointer aufrufst,
zurückliefert.
Schreibe also statt long den Typ hin, welchen die Funktion
zurückliefert. Wenn sie keinen zurückliefert, dann void.
Hauptsache, das passt zusammen. Sonst erlebst Du mit etwaigen
Rückgabewerten Dein blaues Wunder.
Roth schrieb:> Normal muss man schon wissen, wie groß eine Variable sein soll, wenn man> sie anlegt (long, int, ...). Woher soll ich wissen, dass bei Pointern> der Comiler den Datentyp ignoriert und selbst festlegt?
Ich denke, ich habe Dein Verständnisproblem verstanden. ;)
Es geht hier nicht um Pointer im allgemeinen, sondern speziell um
Funktionspointer. Der Datentyp, von dem Du meinst, er werde ignoriert,
gibt nicht die Größe des Pointers an, sondern das ist der Datentyp, den
die Funktion zurückgibt, auf die der Pointer zeigen kann.
1
void (*funcptr1)(void)
Ist ein Zeiger auf eine Funktion, die keinen Aufrufparameter und keinen
Rückgabewert hat.
1
char (*funcptr2)(int)
Ist ein Zeiger auf eine Funktion, die mit einem int-Parameter aufgerufen
wird und einen char-Wert zurückgibt.
Die Größe des Pointers selbst (also die Größe Adresse der aufzurufenden
Funktion) ist in beiden Fällen gleich.
Versuchst Du, die Adresse einer Funktion einem Pointer mit anderer
Signatur (Aufruf- und Rückgabetypen) zuzuweisen, bekommst Du eine
Compilerwarnung (vorausgesetzt Warnungen sind aktiviert).
Ergänzung: Auch bei Daten-Pointern ist es so, dass der angegebene Typ
nicht die Pointergröße ist, sondern die Größe des Datentyps auf den der
Pointer zeigen kann.
Hier gehen jetzt zwei Dinge durcheinander. Die Größe eines Pointers und
die Größe dessen, auf was er zeigt.
Für das zweite gibst Du ja den Typ an, auf den der Pointer zeigt. Wenn
Du dafür jetzt noch die Typen aus der stdint.h nutzt, weißt Du es
ziemlich genau.
fop schrieb:> AVR-GCC benutzt meines Wissens nach nur 16 Bit.
und dann klemmte es als der ATmega2560 und ATmega 1284p kam, es wurd
flugs ein drittes Adressbyte nachbestellt!
Ich wunderte mich in den Anfangszeiten über keinen Zugriff oberhalb 64K
beim m2560, mit dem m1284p lernte ich dann dazu.
Vielleicht hilft es: Seit C99 kann es in stdint.h die optionalen
typedefs intptr_t und/oder uintptr_t geben, die einem Integer-Typ
entsprechen, der einen void* Pointer aufnehmen kann.
fop schrieb:> Und wenn jetzt der große Aufschrei kommt, dass er die Größe an die> Zielarchitektur anpasst, gebe ich folgendes zu bedenken :> Wenn man es genau nimmt haben AVRs 3 Adressräume :> - Programmspeicher (Flash)> - RAM> - Daten EEPROM
Nö, entweder man legt es "eng" aus, dann haben die AVR8 vier
Adressräume, nämlich Flash, RAM, REGS und SFR. Der EEPROM hat bei dieser
Betrachtungsweise allerdings überhaupt keinen eigenen Adressraum, der
ist eine reine Fiktion des C-Compilers. Außerdem zerfällt der
SFR-Bereich, genau genommen, auch noch in zwei Teile...
Oder man legt es "weit" aus, dann gibt zwar den EEPROM-Raum, aber auch
noch sehr viel mehr Adressräume beim AVR8 (als Subräume der o.g.), mit
deren vollem Umfang allerdings jeder existierende C-Compiler
hoffnungslos überfordert ist. Der Nutzer hat viele Aspekte dieses Zeugs
selber zu kontrollieren, typischerweise über Linker-Scripts.
Und zusätzlich: egal ob weit oder eng: Die Adressierung kann mehrdeutig
sein. Schon in der "engen" Betrachtung überlappen REGS/RAM (allerdings
nicht bei den ATXmega) und SFR/RAM. Besonders schlechte Voraussetzungen
für die Grundkonzepte eines C-Compilers, der kommt ja schon ganz
grundsätzlich mit mit mehreren Adressräumen nicht wirklich klar...
> Da gibt es nur eins : Schreibe am Besten keinen Code, der davon abhängig> ist, wie der Compiler die Daten ablegt !
Noch besser: mach' dich erst garnicht von den Furzen eines Compilers
abhängig, sondern rede mit dem Device in der einzigen Sprache, die es
ganz sicher immer korrekt versteht! Asm rules...
Bei Zeigern auf Funktionen gibt es ja noch mehr Größen :
- Größe des Zeigers
- Größe des Programmcodes der Funktion
- Größe des Rückgabewertes
- Größen der Aufrufparameter
Punkt 2 ist wieder vom Umfang Deiner Funktion, dem Compiler und diversen
Optimierungsoptionen sowie der Zielhardware abhängig. Das gute daran :
so lange noch genug Platz im Programmspeicher vorhanden ist, braucht
Dich diese Angabe nicht kümmern.
Die letzten beiden Punkte gibst Du wieder an, wenn Du den Typ des
Zeigers festlegst.
Jetzt mal ungetestet einfach so hingetippt :
sollte einen Zeiger auf eine Funktion anlegen, die 8 Bit zurück gibt,
die genau 2 Parameter erwartet, deren erster Parameter 16 Bit groß ist
und deren 2. Parameter 32 Bit groß ist.
Du solltest peinlich genau darauf achten, dass alle Funktionen, deren
Verweis Du in diesen Pointer lädst, diese Bedingungen erfüllen !
Wenn Du jetzt sagst, ich mag aber ganz unterschiedliche Funktionen mit
ganz unterschiedlichen Parametern über so einen / so ein Array von
Pointer(n) referenzieren sage ich : Ja - Nee - is klar...
Weil bei mir ist nur angekommen : Jetzt will ich das Chaos auf die
Spitze treiben.
Als Anfänger würde ich Dir vorschlagen, nur die gemeinsamen Werte als
Parameter zu übergeben, und die unterschiedlichen Dir innerhalb der über
Pointer aufgerufenen Funktionen per Aufruf von Funktionen besorgen zu
lassen.
c-hater schrieb:> Noch besser: mach' dich erst garnicht von den Furzen eines Compilers> abhängig, sondern rede mit dem Device in der einzigen Sprache, die es> ganz sicher immer korrekt versteht! Asm rules...
Was es aber mitnichten einfacher macht die Prozessorarchitektur zu
wechseln.
fop schrieb:> c-hater schrieb:>> Noch besser: mach' dich erst garnicht von den Furzen eines Compilers>> abhängig, sondern rede mit dem Device in der einzigen Sprache, die es>> ganz sicher immer korrekt versteht! Asm rules...>> Was es aber mitnichten einfacher macht die Prozessorarchitektur zu> wechseln.
Natürlich nicht.
Der Punkt ist: es macht es aber auch nicht schwerer. Solange man
nämlich direkt mit der Hardware hakelt, sind alle C-Versprechen zur
"Portabilität" sowieso nur eins: reine Lügen.
Rolf M. schrieb:> Ich fürchte, das sind ein paar ziemlich große Löcher. Wenn du das lernen> willst, indem du einfach in C arbeitest, könnten die schlimmsten dieser> Löcher sich in einigen Jahren verkleinert haben. Wie schon oben> geschrieben: Ich kenne das aus persönlicher Erfahrung und würde> niemandem empfehlen, das genauso ineffizient zu machen wie ich damals.
Ja meinetwegen sieht das so aus. Allerdings lassen sich mit großen
Defiziten auch keine großen Sprünge machen. Das Quereinsteigertum
(betrachte mich als solchen) bringt es so mit sich, Lücken auch schon
mal in Basics zu haben. Es fehlt ja die fundierte Ausbildung, und das
ist eben so.
> Ja, weil das void überhaupt nichts mit der Größe des Zeigers zu tun hat.> Wenn du einen long* definierst, ist das ein Zeiger auf einen long.> Welche Größe der Zeiger selber hat, ist davon unabhängig. Ein void* ist> ein Zeiger auf etwas, das an dieser Stelle nicht weiter definiert ist.> Auch hier hat das nichts mit der Größe des Zeigers zu tun.
So siehste, genau das war es jetzt. Unabhängig vom Datentyp wird IMMER
ein Pointer gespeichert. Ich habe mich offenbar nicht deutlich
ausgedrückt. In VB/VBA z.B. stellen sich solche Fragen gar nicht, und in
SQL schon gar nicht. Aber reden wir mal von Assembler. Für eine Variable
reserviere ich Platz. Für ein Byte 1 Byte, für ein Integer 2 Byte usw.
Und daher habe ich gefragt, wieviel Platz ein Pointer benötigt, weil ich
den als long oder int anlegen wollte. Für mich ist ein Pointer einfach
nur ein 16- oder 32-Bit Wert, der in einer entsprechend großen
Speicherstelle abgelegt werden muss. Dazu dachte ich an die Variable und
übersah, dass C/C++ Variablen eh nur als Pointer referenziert und es
daher egal ist, wie groß der Datentyp ist und warum auch void
funktioniert. Das sind Eigenarten der Softwarearchitektur, die ich
leider erst kapieren muss, und die ich noch nicht mal in Assembler so
hatte. Feste Zeigeradressen waren in ASM letztendlich nur Präprozessor-
oder Parserangelegenheiten, die dann irgendwann hardcodiert im Code
standen.
Sehr gut, wieder was dazugelernt.
So, jetzt habe ich alles durchgelesen. Ihr habt euch alle mächtig ins
Zeug gelegt, danke danke danke :-) Ich mus es nochmal sagen, ein
wirklich tolles Forum mit genau so qalifizierten wie hilfsbereiten
Mitgliedern. Sowas ist heute selten und es freut mich, dass es das noch
gibt.
LG
Ich empfehle, alle Compiler Warnung mit der Compiler-Option -Wall zu
aktivieren. Als Editor/IDE empfehle ich QT-Creator, weil dieses eine
große Menge zusätzliche Kontrollen durchführt und auf mögliche Probleme
hinweist.
Roth schrieb:> Und daher habe ich gefragt, wieviel Platz ein Pointer benötigt, weil ich> den als long oder int anlegen wollte.
Dafür lassen sich besagte (u)intptr_t Typen gebrauchen.
Roth schrieb:> Woher soll ich wissen, dass bei Pointern> der Comiler den Datentyp ignoriert und selbst festlegt?
Ein Pointer zeigt auf eine Speicherstelle, an der eine Variable steht.
Welchen Typ diese Variable hat, ist für die Größe des Pointers völlig
egal.
Wolfgang schrieb:> Ein Pointer zeigt auf eine Speicherstelle, an der eine Variable steht.> Welchen Typ diese Variable hat, ist für die Größe des Pointers völlig> egal.
den Satz verstehe ich nicht mal, für mich war ein Pointer ein Zeiger auf
eine Variable, also eine Adresse im Speicher.
Wenn die Adresse mit 16-bit erreicht werden kann dann sind das 2 Byte a
8 Bit, aber wenn die Adresse den 64K Adressraum übersteigt braucht mein
Pointer 3 Byte oder gar 4 Byte oder in 64-Bit Versionen sogar 8 Byte,
also verstehe ich nur das Pointer zwischen 16-64 Bit lang sein können.
Joachim B. schrieb:> Wenn die Adresse mit 16-bit erreicht werden kann dann sind das 2 Byte a> 8 Bit, aber wenn die Adresse den 64K Adressraum übersteigt braucht mein> Pointer 3 Byte oder gar 4 Byte oder in 64-Bit Versopnen sogar 8 Byte,
Naja...
Ganz so einfach ist es nicht.
Der ATMega2560 hat auch nur 2 Byte breite function pointer.
Trotz 256k Flash
Stichwort: trampolines
Arduino Fanboy D. schrieb:> Ganz so einfach ist es nicht.> Der ATMega2560 hat auch nur 2 Byte breite function pointer.
und was war mit der Adresserweiterung aufs dritte Byte, ich bekomme es
gerade nicht zusammen war das ES Register?
gefunden
Beitrag "Re: ATmega2560 Adressraum Pages"
und folgende
Stefanus F. schrieb:> Das wäre theoretisch denkbar. Ich kenne aber keine CPU und keinen> Compiler, die das so flexibel handhaben.
Fairchilds F9445: Der Speicher umfasste in einem seiner beiden Modi 64k
16-Bit Worte. Worte wurden mit 16-Bit Wortadressen angesprochen, Bytes
indes mit 17-Bit Byteadressen.
Weniger altertümlich: Maxims MaxQ2000 Microcontroller. Worte werden mit
Wortadressen, Bytes mit Byteadressen adressiert. Gleiches Problem,
andere Lösung: An die obere Hälfte eines 64kW Adressraums kommt man nur
wortweise ran.
Bei den Renesas M16C Mikrocontrollern gibt es einen 64kB
Datenadressraum, der in einem 1MB Adressraum eingebettet ist. Es handelt
sich also nicht um getrennte Adressräume. Konstanten im ROM lassen sich
nur mit 20-Bit Adressen ansprechen, für Variablen im RAM jedoch reichen
16-Bit Adressen. Wer immer sowas erfindet, an C kann er dabei nicht
gedacht haben.
Joachim B. schrieb:> und was war mit der Adresserweiterung aufs dritte Byte, ich bekomme es> gerade nicht zusammen war das ES Register?>> gefunden> Beitrag "Re: ATmega2560 Adressraum Pages">> und folgende
Hier dreht es sich um Function Pointer, da sieht die Sache noch etwas
anders aus. Da wird noch eine verborgene Extrarunde gedreht.
Suche mal nach "avr trampolin section"
ich werfe mal noch was in die Runde. In AVR oder ARM Code sieht man
häufig das int pointer auf Funktionen zeigen... Genau um solche
Konstrukte ging es hier... Deshalb die Frage nach der Größe.. Die Frage
lässt sich vermeiden wenn man es richtig macht ;)
@ Marco H. (damarco)
>Konstrukte ging es hier... Deshalb die Frage nach der Größe.. Die Frage>lässt sich vermeiden wenn man es richtig macht ;)
Oder wie es immer heißt.
Es kommt nicht auf die Größe an. ;-)
(Wer's glaubt, wird seelig)
Arduino Fanboy D. schrieb:> Hier dreht es sich um Function Pointer
ähm, ich verstehe deinen Einwand nicht Function Pointer sind auch nur
Zeiger oder Adressen und da sie ja auch ausserhalb von 16 Bit liegen
können müssen mehr als 2 Byte mitspielen.
Als ich die Arduino fastLED LIB zum ersten Mal auf dem 1284p statt 328p
nutze klappte nichts mehr, im Oszi sah ich das die Zugriffslänge von
einem Farbklecks statt 30µs nun 10% länger dauerte dauerte, das dritte
Adressbyte war wohl Schuld
Beitrag "Arduino FastLED LIB vs. WS28xx LIB"https://www.mikrocontroller.net/attachment/244099/m1284p_timing.jpg
Marco H. schrieb:> In AVR oder ARM Code sieht man häufig das int pointer auf Funktionen> zeigen...
Das sieht man nur in sehr, sehr grindigem Code, der aus steinalten
K&R-Zeiten stammt.
So etwas wird seit Beginn der 90er Jahre nicht mehr geschrieben; könnte
es sein, daß Du da einfach etwas missverstehst?
Zeig' doch mal so ein Stück "AVR oder ARM Code", der solch einen
int-Pointer enthalten soll.
Joachim B. schrieb:> Arduino Fanboy D. schrieb:>> Hier dreht es sich um Function Pointer>> ähm, ich verstehe deinen Einwand nicht Function Pointer sind auch nur> Zeiger oder Adressen und da sie ja auch ausserhalb von 16 Bit liegen> können müssen mehr als 2 Byte mitspielen.>> Als ich die Arduino fastLED LIB zum ersten Mal auf dem 1284p statt 328p> nutze klappte nichts mehr, im Oszi sah ich das die Zugriffslänge von> einem Farbklecks statt 30µs nun 10% länger dauerte dauerte, das dritte> Adressbyte war wohl Schuld>> Beitrag "Arduino FastLED LIB vs. WS28xx LIB"> https://www.mikrocontroller.net/attachment/244099/m1284p_timing.jpg
Die Function Pointer sind beim AVR immer 16bit lang. Damit erreicht man
entweder Funktionen innerhalb der erste 64k Worte, oder speziell dafür
erzeugte Sprungbefehle in den Bereich >64k Worte, die "Trampoline"
genannt werden und ganz vorne im Code angesiedelt werden. Sie sind mit
16bit-Function-Pointern immer erreichbar (nur dauert der extra Sprung
etwas).
Roth schrieb:> Rolf M. schrieb:>> Ja, weil das void überhaupt nichts mit der Größe des Zeigers zu tun hat.>> Wenn du einen long* definierst, ist das ein Zeiger auf einen long.>> Welche Größe der Zeiger selber hat, ist davon unabhängig. Ein void* ist>> ein Zeiger auf etwas, das an dieser Stelle nicht weiter definiert ist.>> Auch hier hat das nichts mit der Größe des Zeigers zu tun.>> So siehste, genau das war es jetzt. Unabhängig vom Datentyp wird IMMER> ein Pointer gespeichert.
Meine Güte, wie merkbefreit kann man sein? "Pointer" allein ist kein
Datentyp. "Pointer auf long" ist das. Und ein Pointer auf long ist etwas
anderes als ein Pointer auf char oder Pointer auf float oder auch ein
void Pointer. Der Compiler "vergißt" hier gar nichts. Er legt einen
Pointer von eben jenem Typ an, den du per Programm verlangt hast.
> Ich habe mich offenbar nicht deutlich ausgedrückt.
Du hast vor allem keine Ahnung. Und - was schlimmer ist - scheinbar auch
keine Absicht, daran etwas zu ändern. Sonst hättest du all das, was wir
dir schreiben, schon in einem Buch über C gelesen.
> Aber reden wir mal von Assembler. Für eine Variable> reserviere ich Platz. Für ein Byte 1 Byte, für ein Integer 2 Byte usw.
Und schon wieder falsch. Integer ist kein Konzept von Assembler. Das ist
ein Konzept von C. Und auch in C ist ein Integer nicht zwangsweise 2
Byte lang. Da ist noch nicht mal ein Byte immer 8 Bits lang.
> Und daher habe ich gefragt, wieviel Platz ein Pointer benötigt
Pointer sind auch kein Konzept von Assembler. Das äquivalente Konzept in
Assembler heißt Adresse. Es ist aber viel weniger abstrakt als ein
Pointer. Bspw. kannst du eine Adresse in Assembler immer nur in
Einerschritten inkrementieren. Der Inkrement-Operator in C hingegen
erhöht den "Wert" des Pointers um die Größe des Datentyps, auf den der
Pointer zeigt.
> Für mich ist ein Pointer einfach nur ein 16- oder 32-Bit Wert
Und das ist im Kontext von C schlicht falsch> übersah, dass C/C++ Variablen eh nur als Pointer referenziert
Häh?
> und es> daher egal ist, wie groß der Datentyp ist und warum auch void> funktioniert.
Ich glaube du hast nichts davon begriffen.
> Das sind Eigenarten der Softwarearchitektur, die ich> leider erst kapieren muss
Das ist eine schöne Einsicht. Es wäre toll wenn du daraus auch mal
Schlußfolgerungen ziehen würdest. C ist nicht Assembler.
Stefanus F. schrieb:> Das wäre theoretisch denkbar. Ich kenne aber keine CPU und keinen> Compiler, die das so flexibel handhaben.
Das würde auch die Idee, dem Nutzer Memory-Management durch pointer zu
ermöglichen, ad absurdum führen, denn du könntest dann pointer nicht
mehr sinnvoll inkrementieren weil der nächste Pointer könnte ja mehr Bit
brauchen...
Theoretisch könnte man das aber für die binary einer höheren
Programmiersprache (die keine direkten pointer anbietet) machen. Z.B.
für Go oder Rust. Mit letzterem wird ja immerhin auf uCs experimentiert.
Joachim B. schrieb:> ähm, ich verstehe deinen Einwand nicht Function Pointer sind auch nur> Zeiger oder Adressen und da sie ja auch ausserhalb von 16 Bit liegen> können müssen mehr als 2 Byte mitspielen.
Ich sehe, dass du das nicht verstehst...
Das kommt noch...
Die Adresse ist übrigens bis zu 22 Bit breit beim (x)AVR
ATMega2560: (z.B. Arduino Mega)
16Bit breite Funkionszeiger für einen 128kWort(256kByte)
Adressbereich/Flash.
Das ist Fakt.
Unabwendbar.
Der Widerspruch wird mit Hilfe von trampolines aufgelöst.
Teste es...
Schau dir den generierten ASM Code an.
Suche die Trampolin Section.
Und dann wird es dir wie Schuppen in die Augen fallen.
Die Breite verschiedenartiger Pointer ist nicht ausschliesslich von
Maschine oder Sprache beeinflusst, sondern kann auch auf Einschränkungen
des Compilers zurück gehen.
Joachim B. schrieb:> Arduino Fanboy D. schrieb:>> Hier dreht es sich um Function Pointer>> ähm, ich verstehe deinen Einwand nicht Function Pointer sind auch nur> Zeiger oder Adressen und da sie ja auch ausserhalb von 16 Bit liegen> können müssen mehr als 2 Byte mitspielen.
Nicht zwingend. Es wurde schon mehrfach auf Trampolines hingewiesen.
Alex G. schrieb:> Stefanus F. schrieb:>> Das wäre theoretisch denkbar. Ich kenne aber keine CPU und keinen>> Compiler, die das so flexibel handhaben.> Das würde auch die Idee, dem Nutzer Memory-Management durch pointer zu> ermöglichen, ad absurdum führen, denn du könntest dann pointer nicht> mehr sinnvoll inkrementieren weil der nächste Pointer könnte ja mehr Bit> brauchen...
Und man bräuchte dann für jede Größe einen anderen Zeigertypen. Gegeben
hat es was derartiges mal unter DOS. Da gab es je nach genutztem
Memory-Modell einen near-Pointer, der nur innerhalb eines 64k-Segments
zugreifen konnte und einen far-Pointer, der an den ganzen Speicher ran
kam.
Axel S. schrieb:> Meine Güte, wie merkbefreit kann man sein? "Pointer" allein ist kein> Datentyp. "Pointer auf long" ist das. Und ein Pointer auf long ist etwas> anderes als ein Pointer auf char oder Pointer auf float oder auch ein> void Pointer.
Es ging um die Größe eines Pointers und die ist unabhängig davon, auf
was für einen Variablentyp der Pointer zeigt.
Bei Pointer auf <Irgendwas> bekommt der Compiler eine Zusatzinformation
über die Variable, z.B. um beim Inkrement die entsprechende Schrittweite
zu kennen.
Rolf M. schrieb:> Nicht zwingend. Es wurde schon mehrfach auf Trampolines hingewiesen.
habe gerade mal geschaut:
"A little more on the issue: GCC pointers - of all types - are only
16-bits in length. That means you can address up to 128KB of FLASH
memory directly with them, since FLASH is addressed as a number of
16-bit words and not bytes like SRAM."
However, that means that they cannot address data or functions located
above 128KB of FLASH space. A few 8-bit AVRs have 256KB of FLASH, so
this means we need a way to address the higher flash segment when we
perform an indirect function call. The solution is this automatically
generated "trampoline" section which contains code needed to call the
higher addresses. When your code needs to get above the 128KB barrier
via an indirect function call, it instead "bounces" up to the desired
location via the code in the trampoline section."
nun hat aber ein ATmega 1284p genau 128K flash nicht mehr! also hätte
ich den Zugriff genau wie beim m328p erwartet und nicht langsamer.
Beim m2560 verstehe ich das.
my2ct schrieb:> Axel S. schrieb:>> Meine Güte, wie merkbefreit kann man sein? "Pointer" allein ist kein>> Datentyp. "Pointer auf long" ist das. Und ein Pointer auf long ist etwas>> anderes als ein Pointer auf char oder Pointer auf float oder auch ein>> void Pointer.>> Es ging um die Größe eines Pointers und die ist unabhängig davon, auf> was für einen Variablentyp der Pointer zeigt.
Es dürfte dir schwer werden, das allgemeingültig zu beweisen. Zumindest
der C-Standard gibt das nicht her. Du machst hier den gleichen Fehler
wie der TE, das Konzept "Pointer" in C mit dem Konzept "Adresse" auf
Maschinenebene gleichzusetzen. Aber das ist falsch. Es sind weitgehend
äquivalente Konzepte. Aber eben nicht das Gleiche.
> Bei Pointer auf <Irgendwas> bekommt der Compiler eine Zusatzinformation> über die Variable, z.B. um beim Inkrement die entsprechende Schrittweite> zu kennen.
Das ist nur ein Punkt, in dem ein Pointer mehr Information enthält als
eine Adresse. Ein anderer Punkt wäre der Adreßraum, in dem der Pointer
gilt. Schon avr-gcc kennt neben Pointern auf RAM auch Pointer auf Flash
und Pointer auf EEPROM. Auf anderen Architekturen mag es noch weitere
Adreßräume geben, durchaus auch mit sehr unterschiedlicher Größe. Es
gibt genau gar keinen Grund, warum der C-Compiler dann Pointer auf
unterschiedliche Adreßräume nicht auch mit unterschiedlicher Größe
codieren dürfte.
In der Praxis wird es in 99% der Fälle so sein, daß alle Pointer gleich
groß sind. Aber es gibt keine Garantie dafür.
Joachim B. schrieb:> habe gerade mal geschaut:> "A little more on the issue: GCC pointers - of all types - are only> 16-bits in length. ..."
Aufpassen! Das ist eine Aussage über diese eine Implementierung mit
dem Namen avr-gcc. Es ist keine allgemeingültige Aussage über gcc (den
gibts auch für viele weitere Architekturen) oder gar über noch andere
C-Compiler.
Axel S. schrieb:> Das ist nur ein Punkt, in dem ein Pointer mehr Information enthält als> eine Adresse. Ein anderer Punkt wäre der Adreßraum, in dem der Pointer> gilt. Schon avr-gcc kennt neben Pointern auf RAM auch Pointer auf Flash> und Pointer auf EEPROM. Auf anderen Architekturen mag es noch weitere> Adreßräume geben, durchaus auch mit sehr unterschiedlicher Größe. Es> gibt genau gar keinen Grund, warum der C-Compiler dann Pointer auf> unterschiedliche Adreßräume nicht auch mit unterschiedlicher Größe> codieren dürfte.
Doch, den gibt es. Schließlich weiß C nichts von Adressräumen. Und ein
int* hat eine statisch zur Compilezeit festgelegte Größe. Es gibt keine
Zeiger auf "int in Adressraum X" oder sowsas.
Der Compiler könnte also höchstens verschiedene Datentypen in getrennten
Adressräumen unterbringen (also einer für short, einer für int u.s.w.).
Das wäre aber eher ungewöhnlich. Und es muss dennoch möglich sein, jeden
beliebigen Datenzeiger verlustlos in einen void* und zurück zu
konvertieren, und diesen void* z.B. zu verwenden, um per memcpy die
Daten umher zu kopieren.
Einzig die Unterscheidung zwischen Code und Daten gibt es. In C sind
Funktionszeiger nicht kompatibel zu Datenzeigern und können nicht in die
eine oder die andere Richtung konvertiert werden (auch wenn es die
meisten C-Compiler trotzdem zulassen). Somit könnte ein Funktionszeiger
völlig anders aufgebaut sein als ein Datenzeiger und auch auf einen
eigenen Adressraum nutzen.
Axel S. schrieb:> Aufpassen! Das ist eine Aussage über diese eine Implementierung mit> dem Namen avr-gcc.
OK ist aber keine Antwort warum der m1284p trotz NICHTÜBERSCHREITEN der
128KB langsamer zugreift als der m328p bei gleich großen
überstreichendem Adressraum
Rolf M. schrieb:> Axel S. schrieb:>> Das ist nur ein Punkt, in dem ein Pointer mehr Information enthält als>> eine Adresse. Ein anderer Punkt wäre der Adreßraum, in dem der Pointer>> gilt. Schon avr-gcc kennt neben Pointern auf RAM auch Pointer auf Flash>> und Pointer auf EEPROM. Auf anderen Architekturen mag es noch weitere>> Adreßräume geben, durchaus auch mit sehr unterschiedlicher Größe. Es>> gibt genau gar keinen Grund, warum der C-Compiler dann Pointer auf>> unterschiedliche Adreßräume nicht auch mit unterschiedlicher Größe>> codieren dürfte.>> Doch, den gibt es. Schließlich weiß C nichts von Adressräumen. Und ein> int* hat eine statisch zur Compilezeit festgelegte Größe. Es gibt keine> Zeiger auf "int in Adressraum X" oder sowsas.
Du haust hier zwei Dinge durcheinander. Das was du als C-Programmierer
siehst und das, was der Compiler sieht. Bzw. sogar sehen muß. Schon
avr-gcc muß für die Dereferenzierung eines char* unterschiedlichen Code
generieren, je nachdem ob der auf einen String im RAM oder auf einen
String im Flash zeigt. Rein durch einen Blick auf das C-Programm kann
man jedenfalls nicht feststellen, ob der Compiler für
1
constchar*msg="foobar";
einen Pointer in den Flash oder in das RAM anlegt.
> Der Compiler könnte also höchstens verschiedene Datentypen in getrennten> Adressräumen unterbringen (also einer für short, einer für int u.s.w.).> Das wäre aber eher ungewöhnlich.
Nimm noch Funktionszeiger dazu und schon ist es gar nicht mehr
ungewöhnlich. Beim AVR liegt Code ausschließlich im Flash, Variablen
hingegen ausschließlich im RAM.
> Und es muss dennoch möglich sein, jeden> beliebigen Datenzeiger verlustlos in einen void* und zurück zu> konvertieren, und diesen void* z.B. zu verwenden, um per memcpy die> Daten umher zu kopieren.
Da ist kein Widerspruch. Ein void* muß einfach nur groß genug für jeden
anderen Pointertyp sein. Wie die Konvertierung zwischen verschiedenen
Pointertypen im Detail abläuft, kann Betriebsgeheimnis des Compilers
bleiben. Die Pointertypen stehen zur Compilezeit fest.
Axel S. schrieb:> Rein durch einen Blick auf das C-Programm kann> man jedenfalls nicht feststellen, ob der Compiler für>> const char* msg="foobar";>> einen Pointer in den Flash oder in das RAM anlegt.
Bei ARM spielt es keine Rolle, aber bei AVR zeigt dieser Pointer in den
Datenadressraum und der String liegt auch dort. Nur bei AVR-Versionen,
die neben dem RAM noch anderen Speicher in den Datenadressraum mappen,
kann dieser String ausserhalb des RAMs liegen.
Will man das anders haben, muss man es anders schreiben.
Harry L. schrieb:> * AVR-8bit ist Harvard-Architektur.> * ARM ist von Neumann-Architektur
Die meisten (alle?) ARM-Prozessoren sind Harvard Architekturen, da sie
(mindestens) 2 Busse für Daten und Instruktionen haben. Echte
Von-Neumann-Architekturen gibt es kaum (gar nicht?) mehr. Moderne
Prozessoren wie ARM und x86 kombinieren die Vorteile von Harvard und
Neumann: Flexibilität des einheitlichen Adressraums, die Effizienz von
Harvard dank 2 Bussen, und die Sicherheit von Harvard mittels MMU oder
MPU (XN-Bits). Bei AVR muss der Compiler ggf die Neumannsche
Flexibilität simulieren...
Harry L. schrieb:> AVR-8bit ist Harvard-Architektur.> ARM ist von Neumann-Architektur
Bitte tut nicht so, als ob es nur diese beiden Architekturen gäbe. Es
gibt viele weitere die der einen oder anderen oder gar beiden ähnlich
sind.
Man sollte bedenken, dass die Technik seit etwa 100 Jahren schneller
verändert wird, als die Schulbuchverlage und Lehrer mithalten können.
Deswegen lehren sie oft noch uralte Sachen, die zwar nicht falsch aber
unvollständig sind.
Dr. Sommer schrieb:> Die meisten (alle?) ARM-Prozessoren sind Harvard Architekturen, da sie> (mindestens) 2 Busse für Daten und Instruktionen haben.
Wie du selbst feststellst, ergibt der Begriff nur einen Sinn, wenn man
ihn auf Adressräume bezieht, nicht auf Busse. Anno Harvard Mk I war das
noch nicht ganz so kompliziert wie heute, da war das kein Unterschied.
Die ARM Cores bis einschliesslich der 7er haben keine getrennten Busse.
Joachim B. schrieb:> OK ist aber keine Antwort warum der m1284p trotz NICHTÜBERSCHREITEN der> 128KB langsamer zugreift als der m328p bei gleich großen> überstreichendem Adressraum
Auf Function Pointer trifft das "so" nicht zu.
Denn der Compiler/Linker wird bei dem "kleinen" Flash keine tampolines
nutzen.
Im Glaskugel Modus:
Davon ab, ist der m128p im Kern dem m2560 ähnlicher als dem m328p
Könnte mir vorstellen, dass die den Adressbus dort auch auf 22 Bit
aufgeblasen haben, obwohl es faktisch nicht nötig wäre.
Es muss dann bei jedem Funktionsaufruf 1 Byte mehr auf dem Stack
gelagert werden, da der Rücksprung 24Bit breit gehändelt/gespeichert
wird.
Dr. Sommer schrieb:> Die meisten (alle?) ARM-Prozessoren sind Harvard Architekturen, da sie> (mindestens) 2 Busse für Daten und Instruktionen haben. Echte> Von-Neumann-Architekturen gibt es kaum (gar nicht?) mehr.
Blödsinn!
Das ist reinrassige von Neumann-Architektur.
Mit der Hardware-Umsetzung hat das gar nix zu tun.
Stefanus F. schrieb:> Harry L. schrieb:>> AVR-8bit ist Harvard-Architektur.>> ARM ist von Neumann-Architektur>> Bitte tut nicht so, als ob es nur diese beiden Architekturen gäbe. Es> gibt viele weitere die der einen oder anderen oder gar beiden ähnlich> sind.
Du solltest dich erstmal informieren, bevor du sowas von dir gibts!
Arduino Fanboy D. schrieb:> Könnte mir vorstellen, dass die den Adressbus dort auch auf 22 Bit> aufgeblasen haben, obwohl es faktisch nicht nötig wäre.
Der ATmega128(P)(A) ist ziemlich alt und verwendet einen 16-Bit PC.
A. K. schrieb:> Die ARM Cores bis einschliesslich der 7er haben keine getrennten Busse.
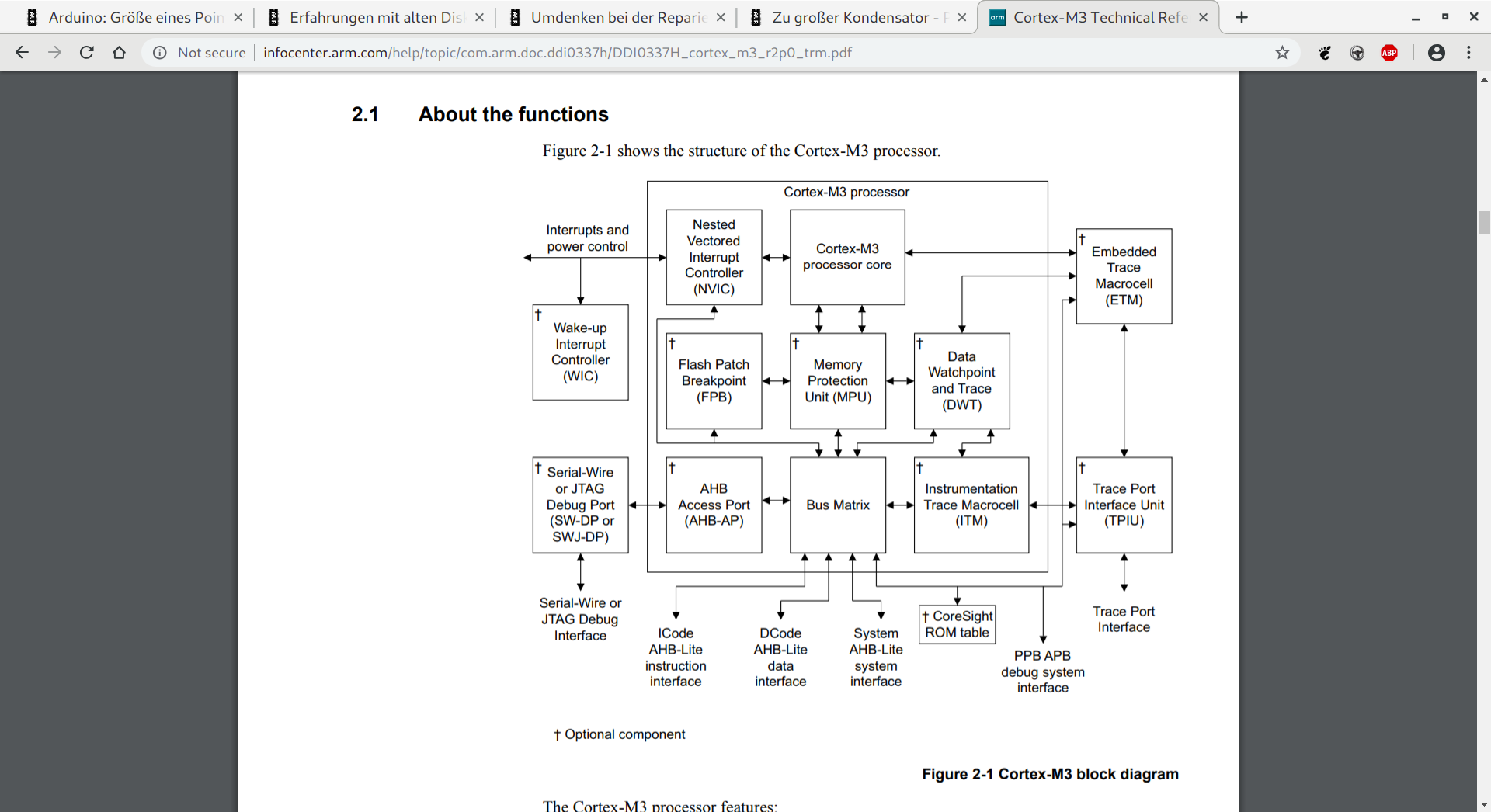
Dann schau Dir mal das angehängte Bild an. Es stammt aus dem "Cortex-M3
Technical Reference Manual" von ARM.
http://infocenter.arm.com/help/topic/com.arm.doc.ddi0337h/DDI0337H_cortex_m3_r2p0_trm.pdf
Ich sehe da zahlreiche Busse, die teilweise über eine "Bus Matrix"
miteinander verbunden sind. Die Taktfrequenzen der Busse sind nach
meinem Kenntnisstand unterschiedlich einstellbar und wenn man
Bus-Übergreifend (also durch die Matrix) auf sie zugreift entfallen
unter Umständen Verzögerungen durch die Synchronisation der Takte an.
Stefanus F. schrieb:>> Die ARM Cores bis einschliesslich der 7er haben keine getrennten Busse.>> Dann schau Dir mal das angehängte Bild an. Es stammt aus dem "Cortex-M3> Technical Reference Manual" von ARM.
Wie hatten zwar gestern schon jemanden, der den Unterschied zwischen 7
und 8 nicht recht verinnerlicht hatte, aber die ARM7* Cores haben mit
den diversen Cortexen noch deutlich weniger gemein. Meine "7" bezog sich
auf die frühere Nummerierung der Cores seitens ARM. Mit den ARM9 Cores
trennten sich Befehle von Daten.
Arduino Fanboy D. schrieb:> Im Glaskugel Modus:> Davon ab, ist der m128p im Kern dem m2560 ähnlicher als dem m328p> Könnte mir vorstellen, dass die den Adressbus dort auch auf 22 Bit> aufgeblasen haben, obwohl es faktisch nicht nötig wäre.> Es muss dann bei jedem Funktionsaufruf 1 Byte mehr auf dem Stack> gelagert werden, da der Rücksprung 24Bit breit gehändelt/gespeichert> wird.
Das Datenblatt scheint dazu etwas inkonsistent zu sein.
Einerseits steht in Kapitel 5.7.1:
"A return from an interrupt handling routine takes five clock cycles.
During these five clock cycles, the Program Counter (three bytes) is
popped back from the Stack, the Stack Pointer is incremented by three,
and the I-bit in SREG is set."
Andererseits steht in Kapitel 6.2:
"The ATmega1284P Program Counter (PC) is 16 bits wide, thus addressing
the 64K program memory locations."
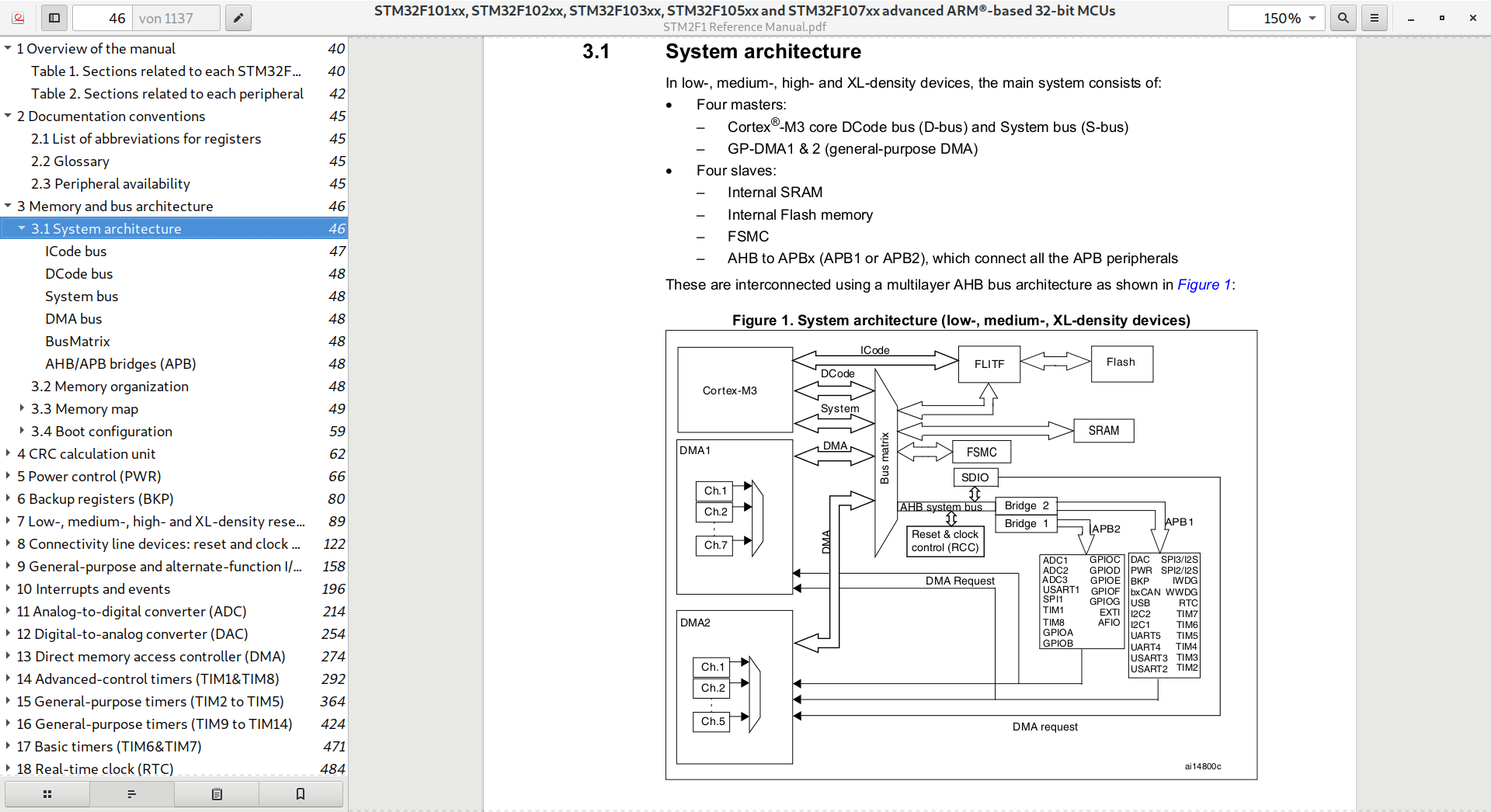
Stefanus F. schrieb:> Auch im STM32F1 Reference Manual sind die Busse sehr deutlich getrennt> gezeichnet. Siehe Anhang.
Die Cortexe implementieren zwar eine ARMv7-M Befehlssatz-Architektur,
aber der ARM7TDMI implementierte ARMv4T. Die Cores nummerierten
unabhängig von der Befehlssatz-Architektur, was man aber nur am dem "v"
unterscheiden kann.
Rolf M. schrieb:> "The ATmega1284P Program Counter (PC) is 16 bits wide, thus addressing> the 64K program memory locations."
Das ist auch richtig. Der Programmspeicher ist nämlich nicht 8bit Breit,
sondern 16bit.
Im Gegensatz zum Datenspeicher kannst du den Programmspeicher des AVR
nicht Byteweise adressieren.
Arduino Fanboy D. schrieb:> Im Glaskugel Modus:> Davon ab, ist der m128p im Kern dem m2560 ähnlicher als dem m328p> Könnte mir vorstellen, dass die den Adressbus dort auch auf 22 Bit> aufgeblasen haben, obwohl es faktisch nicht nötig wäre.> Es muss dann bei jedem Funktionsaufruf 1 Byte mehr auf dem Stack> gelagert werden, da der Rücksprung 24Bit breit gehändelt/gespeichert> wird.
das war meine Vermutung als ich vom 64K Adressraum ausging, deswegen
verwirrt mich das ja so mit den 10% langsameren Zugriffen.
Joachim B. schrieb:> deswegen> verwirrt mich das ja so mit den 10% langsameren Zugriffen.
Du sprichst immer noch von Datenzugriffen, oder?
Wir sprechen über Funktion Pointer und Adressen auf dem Bus.
Joachim B. schrieb:> erkläre es du mir, das jedenfalls half
Bahnhof!
Verstehe nicht, was du mir damit sagen/zeigen willst.
Du spricht über Datenzugriffe?
Die sind natürlich Byteweise adressierbar.
Darum wird man auf dem m1284p (über 64kByte Flash) mit
pgm_read_byte_far() also mit den far Varianten arbeiten müssen.
Der Programmspeicher ist allerdings Word weise organisiert.
Darum braucht man die tampolines erst ab 128kByte Flash
A. K. schrieb:> Rolf M. schrieb:>> Das Datenblatt scheint dazu etwas inkonsistent zu sein.>> Welches genau?
Das des ATmega1284P.
http://ww1.microchip.com/downloads/en/DeviceDoc/doc8059.pdfStefanus F. schrieb:> Rolf M. schrieb:>> "The ATmega1284P Program Counter (PC) is 16 bits wide, thus addressing>> the 64K program memory locations.">> Das ist auch richtig.
Nein.
> Der Programmspeicher ist nämlich nicht 8bit Breit, sondern 16bit.
Es geht nicht um den Programmspeicher, sondern um den Program Counter,
also das Register, das die aktuelle Position der Code-Ausführung
enthält. An der einen Stelle steht, das sei 3 Bytes groß, an der anderen
16 Bits.
Dass der Programmspeicher 16 Bit breit ist, steht nicht in Frage.
Arduino Fanboy D. schrieb:> Joachim B. schrieb:>> deswegen>> verwirrt mich das ja so mit den 10% langsameren Zugriffen.>> Du sprichst immer noch von Datenzugriffen, oder?> Wir sprechen über Funktion Pointer und Adressen auf dem Bus.
Bei Datenzugriffen sieht es natürlich ggf. auch nochmal anders aus. Denn
dort braucht man ja eine Adresse auf Bytes, die für 128k Flash in 16 Bit
nicht mehr reinpasst. Deshalb braucht man für Datenzugriffe auf den
Flash mehr Bits. Dafür wird das Register RAMPZ verwendet.
Rolf M. schrieb:> Es geht nicht um den Programmspeicher, sondern um den Program Counter,> also das Register, das die aktuelle Position der Code-Ausführung> enthält. An der einen Stelle steht, das sei 3 Bytes groß
Steht so auch in meinem älteren Datenblatt von 2015. Komisch.
Der PC des ATmega1284 ist 2 bytes groß. Ganz sicher. Im Kapitel
"In-System Reprogrammable Flash Program Memory" steht es an anderer
Stelle klar drin:
1
The ATmega164A/164PA/324A/324PA/644A/644PA/1284/1284P Program Counter (PC) is 15/16 bits wide, thus addressing the 32/64K program memory locations.
Rolf M. schrieb:> Das des ATmega1284P.
In 7.5 fischt der RETI nur 2 vom Stack. Doku-Fehler - aber wo?
Beim ATmega128 tut er es auch in der Beschreibung vom Interrupt.
A. K. schrieb:> Jetzt bräuchten wir nur noch den Code, auf den sich diese Rechnerei> bezieht.
arduino fastLED Lib
https://github.com/FastLED/FastLEDRolf M. schrieb:> Dazu kommt, dass laut Datenblatt CALL und RET 5 Taktzyklen brauchen, was> eigentlich nur gilt, wenn's 3 Byte sind.
so sehe ich das auch, deswegen ist der Code auf dem m1284p ja langsamer
Joachim B. schrieb:> A. K. schrieb:>> Und wo dort?>> ich habe eine ältere Version>> in delay.h liegt meine Änderung, nach 1284 suchen
Da stehen irgendwelche Makros, die irgendwelche Zahlen umrechnen.
Interessant ist aber der Code, in dem diese Makros genutzt werden.
Harry L. schrieb:> Stefanus F. schrieb:>> Auch im STM32F1 Reference Manual sind die Busse sehr deutlich getrennt>> gezeichnet. Siehe Anhang.>> Was genau an>> Harry L. schrieb:>> Mit der Hardware-Umsetzung hat das gar nix zu tun.>> hast du nicht verstanden?>> https://de.wikipedia.org/wiki/Harvard-Architektur> https://de.wikipedia.org/wiki/Von-Neumann-Architektur
Ich empfehle mal im "von Neumann"-Link etwas runterzublättern und die
Abgrenzung zu "Harvard" durchzulesen. Nicht gemeinsamer oder getrennter
Adressraum (aus Programmierersich) macht den Unterschied, sondern
getrennte Busse für Befehls- und Datenzugriff (die dann überlappend
passieren können).
In so fern bezeichnet die Firma ARMzurecht große Teile ihrer heutigen
Produkte als "Harvard-Architektur".
Carl D. schrieb:> Nicht gemeinsamer oder getrennter> Adressraum (aus Programmierersich) macht den Unterschied, sondern> getrennte Busse für Befehls- und Datenzugriff (die dann überlappend> passieren können).
Es gibt beide Interpretationen, die orthodoxe und die sinnvolle.
Eine nützliche Aussage ergibt sich heute nur, wenn man sich dabei auf
getrennte Adressräume bezieht. In der orthodoxen Interpretationen ist
die Verwendung der Begriffe Harvard/Neumann heute sinnlos.
Andernfalls landet man bei ARM9 als Harvard und 8051 als von Neumann,
weil der ARM9 getrennte Busse hat, während Intels 8051 zumindest im
üblichen Blockbild nur einen Bus zeigt.
A. K. schrieb:> Es gibt beide Interpretationen, die orthodoxe und die sinnvolle.
Verstehe ich nicht.
1
Orthodoxie bezeichnet in der Grundbedeutung die Richtigkeit einer Lehrmeinung bzw. die Anhängerschaft der richtigen Lehrmeinung, im Gegensatz zu davon abweichenden Lehrmeinungen, die entsprechend für falsch erachtet und abgelehnt werden (Heterodoxie). Grundsätzlich betrachtet sich jede Lehrmeinung selbst als orthodox, so dass die Zuschreibung der Orthodoxie eine Frage des Standpunktes ist.
A. K. schrieb:> Carl D. schrieb:>> Nicht gemeinsamer oder getrennter>> Adressraum (aus Programmierersich) macht den Unterschied, sondern>> getrennte Busse für Befehls- und Datenzugriff (die dann überlappend>> passieren können).>> Es gibt beide Interpretationen, die orthodoxe und die sinnvolle.>> Eine nützliche Aussage ergibt sich heute nur, wenn man sich dabei auf> getrennte Adressräume bezieht.
Sehe ich nicht so. Für mich sind die hardwaremäßig getrennten
Speicher-Busse für Daten und für Code das wesentliche Element. Der
Vorteil von Harvard ist vor allem, dass dadurch ein Code- und ein
Datenzugriff zeitgleich erfolgen kann.
Getrennte Adressräume hat man auch auf dem PC auch, sobald man
virtuellen Speicher benutzt - nur sind diese bei gängigen
Betriebssystemen immer auf den selben physischen Speicher gemappt. Ich
würde den PC dennoch eher Richtung von-Neumann sehen als Richtung
Harvard.
Generell ist eine harte Trennung aber kaum mehr möglich. Oft sind z.B.
Caches für Code und Daten getrennt vorhanden, aber der Haupstspeicher
nicht.
Der Unteschied Harvard vs. von Neumann hat aber ganz konkrete
Auswirkungen auf die Programmierung. (zumindest bei AVR 8bit)
Genau wegen dieser Harvard-Architektur bedarf es solcher Konstruktionen
wie PROGMEM und pgm_read_xx().
Das ist bei von Neumann absolut nicht erforderlich, und die Anzahl der
internen Busse ist vollkommen irrelevant.
Die werden dabei nämlich nur noch durch ihre Adressen in einem großen
gemeinsamen Adressraum unterschieden.
Bei Harvard gibt es 2 logisch getrennte Adressräume.
Rolf M. schrieb:> Vorteil von Harvard ist vor allem, dass dadurch ein Code- und ein> Datenzugriff zeitgleich erfolgen kann.
Solange man sich auf dem Level des Harvard Mk I bewegt, also in der
ersten Vorlesungsstunde von Rechnerarchitektur, passt das. In der
heutigen Realität passt das weder hinten noch vorne.
Ob diese Zugriffe gleichzeitig stattfinden oder nicht, interessiert
heute lediglich ein paar Dutzend Leute in der Entwicklung von
Prozessorchips. Der Rest der Welt interessiert sich für die erzielbare
Leistung, und da ist das ein kleiner Aspekt von sehr vielen.
> Getrennte Adressräume hat man auch auf dem PC auch, sobald man> virtuellen Speicher benutzt - nur sind diese bei gängigen> Betriebssystemen immer auf den selben physischen Speicher gemappt.
Von Neumann kann man leidlich sauber als Klassifikation nutzen, indem
man das auf einen gemeinsamen Adressraum von Code und Daten innerhalb
eines Programms bezieht. In dem der Unterschied dazwischen nur in der
Interpretation der Daten durch den Prozessor besteht, also Code auch vom
Programm geschrieben werden kann (etwa durch einen Java JIT-Compiler).
Das ist bei Trennung von Code und Daten unmöglich. In der orthodoxen
Literatur rettet sich daraus über dem Begriff der modifizierten
Harvard-Architektur. Auf getrennten Wegen an das gemeinsame Ziel
gelangen.
Die Interpretation über getrennte Code/Datenräume enthält eine weiterhin
nützliche Information, und zwar für den Programmierer. Die
Interpretation über Busse enthält ausserhalb der Riege der Chipdesigner
praktisch keine nützliche Information mehr.
Wobei das über Memory Mapping komplizierter werden kann, das stimmt.
Einige PDP11 Versionen konnten mit 64kB I-Space und 64kB D-Space
arbeiten. Mussten aber nicht. In diesem Sinn hat ein solcher Prozessor
das Zeug zu beidem, je nachdem, wie der Prozess läuft. Der Maschine ist
das folglich egal, aber nicht dem Programmierer. Für den ist dieser
Unterschied von grosser Bedeutung.
> Generell ist eine harte Trennung aber kaum mehr möglich. Oft sind z.B.> Caches für Code und Daten getrennt vorhanden, aber der Haupstspeicher> nicht.
In den leistungsfähigeren Varianten gibt es den einen Speicherbus
sowieso nicht mehr. Gruppen von Speichermodulen werden unabhängig über
getrennte Wege angesprochen. Einerseits über 2-4 Speicherkanäle. Sind
mehrere Prozessor-Dies vorhanden sind, hängt es überdies von der Adresse
ab, ob der Speicher am eigenen Die hängt, oder an einem Kollegen, der
vielleicht über Point-to-Point erreichbar ist, vielleicht über Crossbar.
Und das geschieht so nicht nur zwischen Sockeln, sondern bei MCMs auch
innerhalb davon (bei x86 z.B. AMD).
In physikalischer Sicht noch irgendwas über Busse zu klassifizieren, ist
völlig sinnlos geworden. Es gibt davon zu viele.
Harry L. schrieb:> Genau wegen dieser Harvard-Architektur bedarf es solcher Konstruktionen> wie PROGMEM und pgm_read_xx().
Moment mal. Die STM32F1 sind auch Harvard-Architektur. Aber bei denen
brauchst du keine PROGMEM Konstrukte, weil es zwischen den Bussen noch
eine Brücke gibt.
> Bei Harvard gibt es 2 logisch getrennte Adressräume.
Wie gesagt ist die Welt nicht so schwarz/weiss wie es manche gerne immer
noch lehren würden.
Die Vorstellung, dass jeder Mikrocontroller entweder der Harvard oder
der von Neumann Architektur entsprechen muss, ist obsolet. Gerade die
STM32 und viele andere zeigen, dass beides gleichzeitig zutreffen kann.
Sicher gibt es auch Mikrocontroller die weder der einen noch der anderen
Architektur entsprechen - also eine dritte Kategorie. Dieses Duale
Schubladen-Denken beschränkt nur eure Kreativität unnötig.
Ihr würdet wahrscheinlich völlig verrückt werden, wenn ich euch eine CPU
mit 13 Bit Registern, einer 17 Bit ALU und 29 Bit Programmzähler
präsentieren würde. Mit einem gemeinsamen Datenbus für RAM und ROM, aber
separaten Adressleitungen. Mit einer analogen Recheneinheit und einem
sechseckigen Gehäuse aus Kartoffel-Stärke. Na wie wäre das? In welche
Schublade würdet ihr diese CPU stecken?
...jetzt wundert es mich nicht mehr, daß man in mehr als 100 Beiträgen
über das Verständnis von sowas Grundlegendem wie Pointer diskutieren
kann....
Da bin ich direkt wieder raus...
Stefanus F. schrieb:>> Es gibt beide Interpretationen, die orthodoxe und die sinnvolle.>> Verstehe ich nicht.
Ich verwendete "orthodox" im Sinn von "althergebracht", der alten Lehre
folgend. Ich sehe diese nach wie vor oft vorgebrachte alte Lehre über
die Busse schlicht als veraltet an.
Harry L. schrieb:> ...jetzt wundert es mich nicht mehr, daß man in mehr als 100 Beiträgen> über das Verständnis von sowas Grundlegendem wie Pointer diskutieren> kann....
Wer sagt denn, dass grundlegende Dinge einfach sein müssen? Die Welt
wird nicht nur im realen Leben immer komplizierter, sondern auch im
virtuellen.
In fast allen Fällen in denen etwas mit den Begriffen von-Neuman oder
Harvard beschrieben wird, wird diese Beschreibung mehr Fragen auf als
sie beantwortet. Vllt. sollte man gleich von Anfang an genau beschreiben
was man meint.
Rolf M. schrieb:> ... Für mich sind die hardwaremäßig getrennten> Speicher-Busse für Daten und für Code das wesentliche Element. Der> Vorteil von Harvard ist vor allem, dass dadurch ein Code- und ein> Datenzugriff zeitgleich erfolgen kann.> Getrennte Adressräume hat man auch auf dem PC auch, sobald man> virtuellen Speicher benutzt - nur sind diese bei gängigen> Betriebssystemen immer auf den selben physischen Speicher gemappt. Ich> würde den PC dennoch eher Richtung von-Neumann sehen als Richtung> Harvard. ...
Wo genau fängt denn der Speicher-Bus an, vor oder nach "dem" Cache? Wie
werden Adressräume gewertet, die getrennt sind, aber nicht nach
code/daten sondern z.B. nach code+schnelle daten/langsame daten? Was
zählt als gleichzeitiger Zugriff im Zeitalter von SIMD, SIMT, OoO und
speculative execution? Fragen über Fragen.
Harry L. schrieb:> Der Unteschied Harvard vs. von Neumann hat aber ganz konkrete> Auswirkungen auf die Programmierung. (zumindest bei AVR 8bit)>> Genau wegen dieser Harvard-Architektur bedarf es solcher Konstruktionen> wie PROGMEM und pgm_read_xx().
Das stimmt nicht so ganz. Das Problem ergibt sich eigentlich nur, weil
der AVR eben keine reine Harvard-Architektur ist. Harvard heißt Trennung
zwischen Code und Daten, und man liest keine Daten aus dem Codespeicher.
AVR hat stattdessen eine Trennung zwischen RAM und Flash. PROGMEM und
pgm_read_xx() brauche ich nur, wenn ich Daten aus dem Flash statt dem
RAM lesen will.
A. K. schrieb:> Ob diese Zugriffe gleichzeitig stattfinden oder nicht, interessiert> heute lediglich ein paar Dutzend Leute in der Entwicklung von> Prozessorchips. Der Rest der Welt interessiert sich für die erzielbare> Leistung, und da ist das ein kleiner Aspekt von sehr vielen.
Harvard würde ich aber nicht über die Leistung, sondern eben über die
Busse definieren.
>> Getrennte Adressräume hat man auch auf dem PC auch, sobald man>> virtuellen Speicher benutzt - nur sind diese bei gängigen>> Betriebssystemen immer auf den selben physischen Speicher gemappt.>> Von Neumann kann man leidlich sauber als Klassifikation nutzen, indem> man das auf einen gemeinsamen Adressraum von Code und Daten innerhalb> eines Programms bezieht. In dem der Unterschied dazwischen nur in der> Interpretation der Daten durch den Prozessor besteht, also Code auch vom> Programm geschrieben werden kann (etwa durch einen Java JIT-Compiler).> Das ist bei Trennung von Code und Daten unmöglich.
Beim PC ist das ja eigentlich auch unmöglich und wird nur durch den
Trick der Betriebssysteme erzielt, dass sie eben Code- und Datenspeicher
auf den selben physischen Speicher mappen. Eigentlich sind es aber
getrennte Adressräume, weil man für Code und Daten separate
Segmentdeskriptoren braucht. Und Daten in ein für Codeausführung
vorgesehenes Segment zu schreiben, ist nicht möglich.
>> Generell ist eine harte Trennung aber kaum mehr möglich. Oft sind z.B.>> Caches für Code und Daten getrennt vorhanden, aber der Hauptspeicher>> nicht.>> In den leistungsfähigeren Varianten gibt es den einen Speicherbus> sowieso nicht mehr. Gruppen von Speichermodulen werden unabhängig über> getrennte Wege angesprochen.
Das hat aber nichts damit zu tun, ob da Code oder Daten drin stehen.
Harvard heißt ja nicht einfach nur, dass es mehr als einen Speicherbus
gibt.
> In physikalischer Sicht noch irgendwas über Busse zu klassifizieren, ist> völlig sinnlos geworden. Es gibt davon zu viele.
Das gilt für Adressräume genauso. Ich schrieb ja schon, dass bei
modernen Prozessoren eine strenge Einteilung in Harvard und von Neumann
recht sinnlos ist.
Rolf M. schrieb:> Und Daten in ein für Codeausführung> vorgesehenes Segment zu schreiben, ist nicht möglich
Und wie kommt der Code dann da zur Laufzeit rein? Oder meinst Du
geflashtes BIOS oder sowas?
Achim S. schrieb:> Und wie kommt der Code dann da zur Laufzeit rein?
In dem man (das OS) einen Deskriptor erzeugt, welcher das Schreiben
erlaubt.
Versehentliche Code Änderungen sollen unterbunden werden.
Prozesse/Tasks dürfen/können sich nicht gegenseitig stören.
Rolf M. schrieb:> Beim PC ist das ja eigentlich auch unmöglich und wird nur durch den> Trick der Betriebssysteme erzielt, dass sie eben Code- und Datenspeicher> auf den selben physischen Speicher mappen. Eigentlich sind es aber> getrennte Adressräume, weil man für Code und Daten separate> Segmentdeskriptoren braucht. Und Daten in ein für Codeausführung> vorgesehenes Segment zu schreiben, ist nicht möglich.
Wobei die Segmente mittlerweile weitgehend Makulatur sind. Code- wie
Datensegment existieren nur noch pro forma und mappen nicht nur auf
denselben physikalischen Speicher, sondern auch auf denselben virtuellen
Speicher (linearer Speicher in Intel Nomenklatur). Ob ausführbar
und/oder schreibbar ist daher eine Entscheidung auf der Ebene des
Pagings, nicht der Segmentierung.
Einzig für thread local storage wird noch Segmentierung verwendet. Die
kostet dann beim Zugriff 1 Takt extra.
Rolf M. schrieb:>> Es gibt genau gar keinen Grund, warum der C-Compiler>> dann Pointer auf unterschiedliche Adreßräume nicht>> auch mit unterschiedlicher Größe codieren dürfte.>> Doch, den gibt es. Schließlich weiß C nichts von Adressräumen.
Richtig, aber C kennt "Zeiger auf Dinge", und im Gegensatz zu C kennt
der C-Compiler sowohl die Adressräume als auch die Dinge.
Und es steht ihm frei, die Zeiger beliebig zu definieren, solange er die
restlichen Bedingungen nicht verletzt. Im Rahmen der Optimierung ist das
auf manchen Architekturen sinnvoll.
> Und ein int* hat eine statisch zur Compilezeit festgelegte Größe.> Es gibt keine Zeiger auf "int in Adressraum X" oder sowsas.
Als übliche Compiler-Erweiterung mit ganz aktuellen C (also sowas wie
__flash) schon.
> Und es muss dennoch möglich sein, jeden beliebigen Datenzeiger> verlustlos in einen void* und zurück zu konvertieren, und diesen> void* z.B. zu verwenden, um per memcpy die Daten umher zu kopieren.
Richtig, ich muss nach void* und zurück wandeln können. Das heißt aber
nicht, dass alle Zeiger unterschiedlich breit sind, sondern nur, dass
ein void* alle Zeigertypen in sich aufnehmen kann.
Ein 24 Bit-Typ für "void*" und ein 16 Bit-Typ für alles andere wäre
dementsprechend vollkommen ausreichend. :-)
S. R. schrieb:> Ein 24 Bit-Typ
22 Bit ist ausreichend für alle AVR, auch für die mit dem X da dran.
Aber das passt nicht schön in 8 Bittige Bytes, und dann fängt wieder ein
Geschrei an.
c-hater schrieb im Beitrag #5611185:
> unsäglichen dumm
Wer es sagt, der ist es auch!
Oder, wie die Kinder sagen: Spiegel!
S. R. schrieb:> Rolf M. schrieb:>> Und ein int* hat eine statisch zur Compilezeit festgelegte Größe.>> Es gibt keine Zeiger auf "int in Adressraum X" oder sowsas.>> Als übliche Compiler-Erweiterung mit ganz aktuellen C (also sowas wie> __flash) schon.
Und in "N1275 draft of ISO/IEC DTR 18037" spezifiziert, d.h. keine
GCC-Eigenheit, sondern mit Aussicht auf Aufnahme in den Standard.
S. R. schrieb:> Richtig, ich muss nach void* und zurück wandeln können. Das heißt aber> nicht, dass alle Zeiger unterschiedlich breit sind, sondern nur, dass> ein void* alle Zeigertypen in sich aufnehmen kann.>> Ein 24 Bit-Typ für "void*" und ein 16 Bit-Typ für alles andere wäre> dementsprechend vollkommen ausreichend. :-)
Nicht ganz. Ein char* muss die gleiche Darstellung haben wie ein void*.

{kind=link}