Moin,
da meine Assembler Projekte langsam umfangreicher werden, suche ich nach
Möglichkeiten den Quellcode besser zu strukturieren.
Dabei stört mich besonders, dass jede Label Bezeichnung nur ein mal
vergeben werden kann.
Z.B. kommen dann schon mal solche Namen heraus:
1
twi_send_byte:
2
...
3
twi_send_byte_loop_0:
4
...
5
ret
Das ist nicht schön, schlecht lesbar und man kann wie bereits genannt
jeden Namen nur 1 mal vergeben.
Besser wäre doch so etwas
1
twi_send_byte:
2
loop_1:
3
...
4
loop_2:
5
ret
6
7
twi_get_byte:
8
loop_1:
9
...
10
loop_2:
11
ret
Ist das irgendwie machbar?
Desweiteren frage ich mich, ob man bestimmte Routinen (z.B. Loops) über
Makros ersetzen könnte.
Vielleicht hat jemand noch weitere Tipps oder nützliche Referenzen für
mich :D
Na ja, als Ende der 60er dieses Problem auftauchte, setzte sich die
Lösung von Ken Thompson und Dennis Ritchie durch.
In den 40 Jahren hat niemand eine bessere Lösung gefunden.
int 21h schrieb:> Moin,>> da meine Assembler Projekte langsam umfangreicher werden,
Welcher Assembler für welche CPU?
> Möglichkeiten den Quellcode besser zu strukturieren.> Dabei stört mich besonders, dass jede Label Bezeichnung nur ein mal> vergeben werden kann.
Das ist der Sinn von eindeutigen Labels.
> retDas ist nicht schön,
Es ist brauchbar. Wenn du was schönes haben willst, werde Künstler.
> Besser wäre doch so etwastwi_send_byte:> loop_1:> ...> loop_2:> ret
Das wären lokale Labels, die gibt es bei einigen Assemblern, aber ich
glaube nur in Macros.
Hallo,
ich nutze Viele Macros, die Funktionalitäten ähnlich wie Inline C-
Funktionen generieren können.
Auch Label und deren Referenzierung werden dabei eineindeutig generiert.
Sonst schreibe ich das Einsprung-Label <label> durch anfügen von
weiteren Bezeichnern weiter.
Bsp.: <label>_Exit, <label>_loop0, <label>_if0, <label>_else0,
<label>_endif0, <label>_return.
Hi
Vielleicht hat jemand noch weitere Tipps
Bei mir bekommt ein Unterprogramm einen Namem:
xyz
Alle Labels innerhalb des Unterprogramms heißen dann
xyz10
...
xyz20
...
xyz30
...
Sichtbar machen von Schleifen kannst du durch Code-Einrücken.
MfG Spess
> Welcher Assembler für welche CPU?
Steht in der Überschrift, schönen guten Morgen!
Ich verwende für meine Labels beschreibende Namen und versuche,
allgemeine zu vermeiden.
Also als Beispiel im Hauptprogramm "Loop_Count1" oder was auch immer,
und in einer Funktion "Read" dann z.B. "_Read_Loop_Count1" und wieder
"Read_Loop_Count1" wenn ich das Label im Hauptprogramm brauche.
Der Assembler-Quellcode von meiner AlarmSau sind inzwischen 247kB, 8700
Zeilen, keine Probleme mit Label-Kollisionen.
int 21h schrieb:> Z.B. kommen dann schon mal solche Namen heraus:> ...> twi_send_byte_loop_0:> ...> ret> Das ist nicht schön, schlecht lesbar
Warum? Nur das loop würde ich mir sparen, statt dessen einfach nur
eine laufende Nummer, am besten mit etwas Abstand. Man muss übrigens
nicht alles in der Sprungmarke als solches bezeichnen was es ist (Loop)
wenn es ohnehin aus dem gesamten Kontext hervorgeht. Außerdem lässt sich
sowas wie twi_send_byte bei den Folgemarken auch locker abkürzen wenn
der Zweck der Routine sowieso schon entweder aus der Startmarke oder
einer Kommentarzeile hervorgeht.
Ben B. schrieb:> Der Assembler-Quellcode von meiner AlarmSau sind inzwischen 247kB, 8700> Zeilen, keine Probleme mit Label-Kollisionen.
247KB in 8700 Zeilen in Assembler?
Sure.
Davon sind 230KB unbenutzt, oder vielleicht Tabellen
(fragt sich nur wofür).
Marc V. schrieb:> 247KB in 8700 Zeilen in Assembler?
Er (Ben B.) redet vom Quelltext, nicht vom Code selber.
Ben B. schrieb:> keine Probleme mit Label-Kollisionen
Die sind eigentlich auch selten wenn man auf sowas wie loop oder
ähnliche Allgemeinbezeichner verzichtet. Wenn Kollisionen doch mal
auftreten korrigiert man halt die paar Namen. Der Assembler sagt ja
bequemerweise wo sie auftreten. Grundsätzlich sollte man wichtige
Informationen eher im Kommentar als in der Sprungmarke unterbringen.
Die meisten Assembler die ich kenne bieten Proc EndP zur Kennzeichnung
von Assembler Funktionen. Beim Borland TASM kann man auch lokale Labels
generieren (@label). Ansonsten sind Labels auf Dateiebene global.
Wenn man also mit einem Linker die Dateien zusammenkommt, kann ein
Label1 in jedem Object File existieren. Allgemein verfügbar sind nur
Symbole die public deklariert sind.
Macros würde ich nur in speziellen Fällen benutzen das kann ziemlich
fehleranfällig sein. Ich würde deshalb immer den Source in verschiedene
Files aufteilen und dann dem linker die Arbeit über lassen. Duplikate
Labels werden nur zum Problem wenn man Sourcecode mit include zum
Programm zusammen baut.
Das ist übrigens genau das Gleiche wie wenn man h Files mit code in c
includen würde.
Thomas
> Grundsätzlich sollte man wichtige Informationen eher im> Kommentar als in der Sprungmarke unterbringen.
Deswegen ist eine Datei Assembler-Quellcode
mit 8700 Zeilen bei mir 247kB groß.
Lokale Labels sind natürlich auch eine gute Möglichkeit wenn der
Assembler das unterstützt, schützt aber nicht gegen Kollisionen im
Hauptprogramm. Da könnte man dann probieren, das Hauptprogramm so kurz
wie möglich zu machen und alles in Funktionen zu packen.
Letzteres mache ich meistens wegen der Übersichtlichkeit bei größeren
Programmen sowieso. Da besteht die Hauptschleife nur aus einer Serie von
Funktionsaufrufen. Das erleichtert auch das Debugging weil man relativ
schnell herausbekommt, welche Funktion Probleme verursacht (solange man
sich nicht in den Interruptsroutinen irgendwas zerschießt).
Ben B. schrieb:>> Grundsätzlich sollte man wichtige Informationen eher im>> Kommentar als in der Sprungmarke unterbringen.> Deswegen ist eine Datei Assembler-Quellcode> mit 8700 Zeilen bei mir 247kB groß.
Macht im Mittel 29 Zeichen/Zeile.
Aber im Ernst, was glaubt du, mit so einem ASM-Projekt zu erreichen?
Held der Arbeit? Ist die Leitungsfähigkeit des Mikrocontroller dermaßen
ausgereitzt, daß du ASM unbedingt brauchst?
Thomas schrieb:> Duplikate> Labels werden nur zum Problem wenn man Sourcecode mit include zum> Programm zusammen baut.
Mit ein paar Grundregeln bei der Namensvergabe (s.o.) sind sie keines.
Ob mit oder ohne include.
Falk B. schrieb:> Aber im Ernst, was glaubt du, mit so einem ASM-Projekt zu erreichen?> Held der Arbeit? Ist die Leitungsfähigkeit des Mikrocontroller dermaßen> ausgereitzt, daß du ASM unbedingt brauchst?
Nicht jeder sieht in höheren Sprachen eine lernenswerte Investition.
Auf dem Boden der Hardware-Tatsachen zu bleiben kann durchaus reizvoll
sein.
Das mMn wichtigste Element (nach sinnvollen white space), um
Assemblercode lesbar zu halten, sind lokale numerische Labels (0:, 1:
etc zum Definieren und 0b, 0f, 1b, 1f etc zum Referenzieren). Die
Definitionen sind kurz genug, dass sie nicht stören, die
Referenzierungen zeigen direkt an, ob es nach vorne oder hinten geht und
man muß nicht lange suchen, da die erste passende Nummer das Ziel ist.
Lange Labels (wie z.B "twi_send_byte_loop_0") sind Kontraproduktiv. Der
längeste Teil davon ist unnötiger Ballast, man braucht viel zu lange, um
sie zu lesen und zu vergleichen. Das einzig Wichtige ist doch die "0".
Und nach Murphy sucht man immer zuerst in die falsche Richtung ...
Geht aber nichts über nen guten Macroassembler, wie z.B. C ;-)
Falk B. schrieb:> Aber im Ernst, was glaubt du, mit so einem ASM-Projekt zu erreichen?> Held der Arbeit? Ist die Leitungsfähigkeit des Mikrocontroller dermaßen> ausgereitzt, daß du ASM unbedingt brauchst?
Eigentlich halte ich mich aus solchen "C vs ASM" Diskussionen immer
raus, weil jedes Wort verschenkte Liebesmüh ist. Aber bei solchen
Sprüchen muss ich doch mal was sagen.
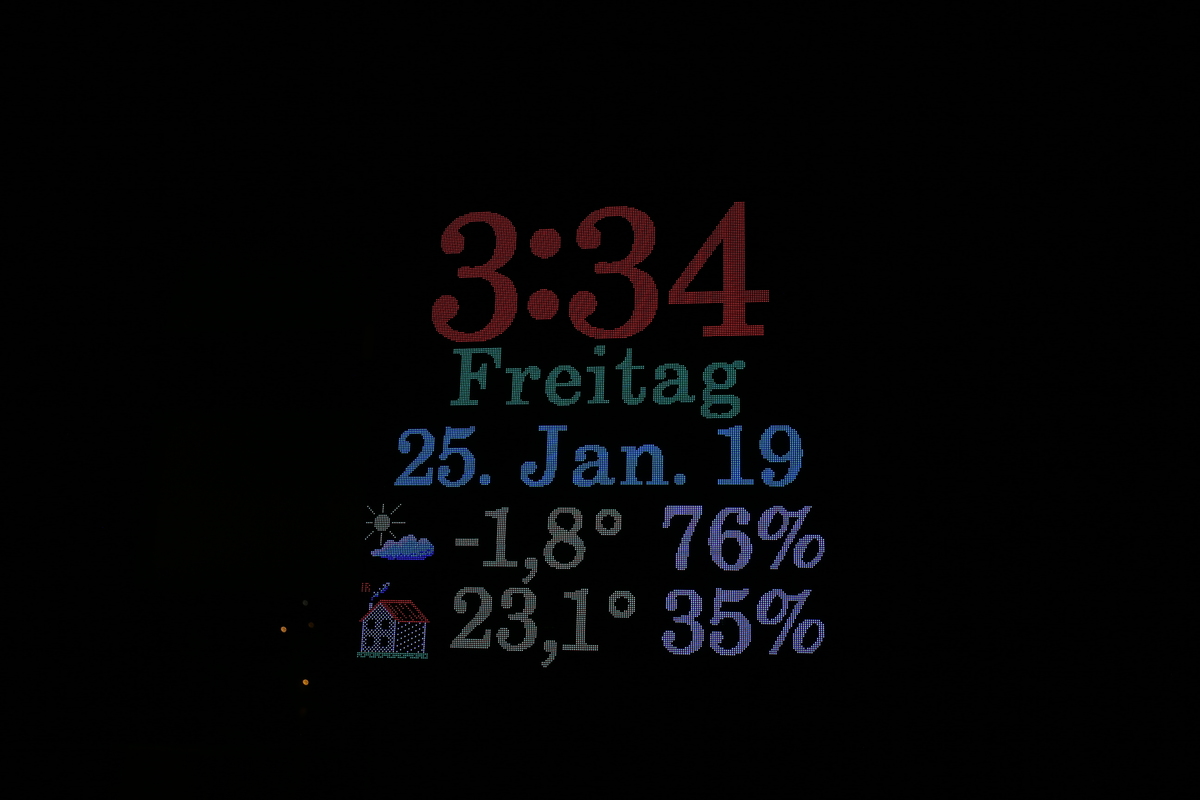
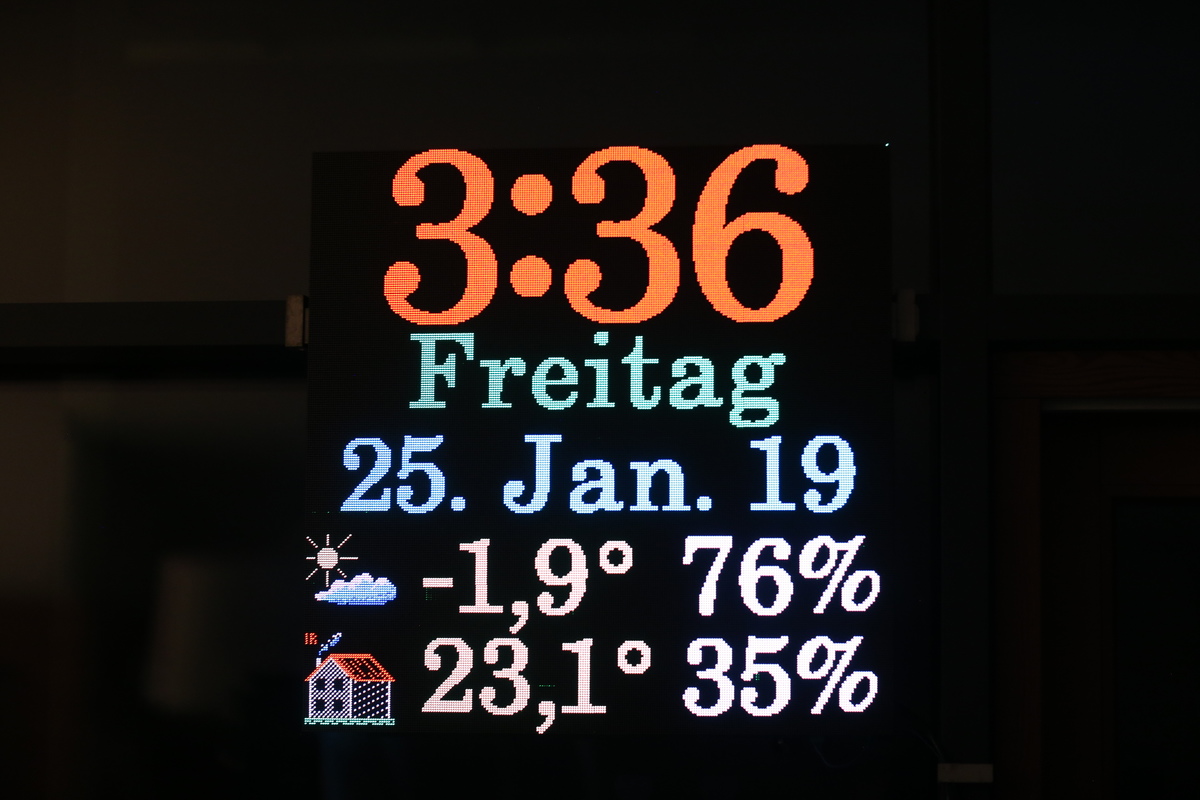
Angehängt sind einige Schnappschüsse meines neuesten Projekts.
Normalerweise treibt man solche LED Displays mit einem FPGA, aber hier
tut es ein xmega auf 32 MHz.
Es sind insgesamt 4*4 Panels mit 64*64 LEDs, also 65536 Pixel. Die
Refreshrate liegt bei 250 Hz. 100 gehen zwar auch, aber bei schnellen
Augenbewegungen hat man die Zeilen gesehen, was ein bissl genervt hat.
Die Helligkeit passt sich stufenlos an die Umgebungslichtstärke an.
Komplette Duty-Range von 0-100% ohne Totzeit.
Und jetzt mal ein bissl rechnen: 65536*250=16 381 500 Bytes pro Sekunde
an Daten, die an die Panels geschickt werden. Die CPU Last ist 70%. Die
restlichen 30% Idle werden für die Uhr selber (also das Zeichnen)
verwendet. Weitere externe Hardware wird nicht verwendet. Der interne
DMA wird nicht verwendet, da er tatsächlich langsamer(!) als die ASM
Lösung war. (Das liegt an dem internen Aufbau des DMA. Stichwort BUS
Polling.)
Irgendwann stelle ich das Projekt mal im Detail vor und klatsche es
nicht so lieblos hier hin. Aber das musste jetzt mal raus ;)
Rödel schrieb:> Irgendwann stelle ich das Projekt mal im Detail vor und klatsche es> nicht so lieblos hier hin. Aber das musste jetzt mal raus ;)
Wo ist der Luftdruck?
Rödel schrieb:> Falk B. schrieb:>> Aber im Ernst, was glaubt du, mit so einem ASM-Projekt zu erreichen?>> Held der Arbeit? Ist die Leitungsfähigkeit des Mikrocontroller dermaßen>> ausgereitzt, daß du ASM unbedingt brauchst?>> Eigentlich halte ich mich aus solchen "C vs ASM" Diskussionen immer> raus, weil jedes Wort verschenkte Liebesmüh ist.
Jain. Es ist eine sachliche Frage.
> Angehängt sind einige Schnappschüsse meines neuesten Projekts.> Normalerweise treibt man solche LED Displays mit einem FPGA, aber hier> tut es ein xmega auf 32 MHz.
Hmmm.
> Es sind insgesamt 4*4 Panels mit 64*64 LEDs, also 65536 Pixel. Die> Refreshrate liegt bei 250 Hz. 100 gehen zwar auch, aber bei schnellen> Augenbewegungen hat man die Zeilen gesehen, was ein bissl genervt hat.
Ganz schön viel.
> Die Helligkeit passt sich stufenlos an die Umgebungslichtstärke an.> Komplette Duty-Range von 0-100% ohne Totzeit.>> Und jetzt mal ein bissl rechnen: 65536*250=16 381 500 Bytes pro Sekunde
Da habe ich so meine Zweifel. Auch ein Xmega schaufelt mal sicher KEINE
16MB/s aus seinen IOs. Zumindest macht das die CPU nicht allein,
vermutlich nutzt du clevererweise DMA. Denn 16MB/s wären ein Byte pro 2
Takte. Glaub ich eher nicht.
> an Daten, die an die Panels geschickt werden. Die CPU Last ist 70%. Die> restlichen 30% Idle werden für die Uhr selber (also das Zeichnen)> verwendet. Weitere externe Hardware wird nicht verwendet. Der interne> DMA wird nicht verwendet, da er tatsächlich langsamer(!) als die ASM> Lösung war.
Kann ich mir schwer vorstellen.
> (Das liegt an dem internen Aufbau des DMA. Stichwort BUS> Polling.)
???
> Irgendwann stelle ich das Projekt mal im Detail vor und klatsche es> nicht so lieblos hier hin. Aber das musste jetzt mal raus ;)
Wenn es dir jetzt besser geht, nur zu. Und ich sagte bereits.
"Ist die Leitungsfähigkeit des Mikrocontroller dermaßen ausgereitzt, daß
du ASM unbedingt brauchst?"
Es gibt sicher Projekte, so wie dieses, wo man nur durch ASM die volle
Leistung ausreizen kann, muss und will. Da ist das auch OK. Aber im
Allgemeinen ist das nicht so, die meisten Anwendungen haben da deutlich
mehr Luft, sodaß man sich den geringfügigen Overhead von C problemlos
leisten kann. Und selbst wenn nicht, sind es meistens nur wenige, eher
kleine Kernfunktionen, welche WIRKLICH in ASM handoptimiert sein müssen.
Dann greift man sinnvollerweise zu ASM-Funktionen, welche in ein
C-Projekt eingebunden sind. Inline-ASM geht zwar auch, ist bei längeren
Funktionen aber eher ein Graus.
Beitrag "Re: Frage zu IR-Remote+LED-Strips an AVR"
foobar schrieb:> Das mMn wichtigste Element (nach sinnvollen white space), um> Assemblercode lesbar zu halten, sind lokale numerische Labels (0:, 1:> etc zum Definieren und 0b, 0f, 1b, 1f etc zum Referenzieren). Die> Definitionen sind kurz genug, dass sie nicht stören, die> Referenzierungen zeigen direkt an, ob es nach vorne oder hinten geht und> man muß nicht lange suchen, da die erste passende Nummer das Ziel ist.>> Lange Labels (wie z.B "twi_send_byte_loop_0") sind Kontraproduktiv. Der> längeste Teil davon ist unnötiger Ballast, man braucht viel zu lange, um> sie zu lesen und zu vergleichen. Das einzig Wichtige ist doch die "0".> Und nach Murphy sucht man immer zuerst in die falsche Richtung ...>> Geht aber nichts über nen guten Macroassembler, wie z.B. C ;-)
Das ist zu 100% auch meine Meinung zu dem Thema.
Man kann sich dazu für typische Kontrollstrukturen wie if, if-else,
if-elif-else, while-do, do-while, switch-case usw. jeweils ein festes
Schema zurechtlegen. Bei verschachtelten Kontrollstrukturen werden die
Labelnummern einfach vergößert, so dass keine Konflikte zwischen den
einzelnen Verschachtelungsebenen entstehen.
Damit kann man das Prinzip der strukturierten Programmierung auch sehr
gut in Assembler umsetzen. Am besten schreibt man an die Sprungbefehle
und die Labels noch einen Pseudocodekommentar wie bspw, "if
<Bedingung>", "else", "endif", "while <Bedingung>", "endwhile" usw. und
rückt den Code wie in einer Hochsprache ein, so dass man beim Lesen die
Struktur auch ohne Vergleich der Labelnummern leicht erfassen kann.
Dann sind lange, aussagekräftige Labelnamen nur noch für Unterprogramme
und eventuelle "Querfeldeinsprünge" (die man in einer Hochsprache per
Goto implementieren würde), erforderlich. Man muss sich somit auch in
Assembler nur für diejenigen Dinge einen Namen ausdenken, für die man
dies auch in einer Hochsprache tun müsste.
Allerdings bin auch ich der Meinung, dass es kaum noch einen Grund gibt,
Assembler-Only-Programme zu schreiben. Aber wenn jemand seine Freude
daran hat, warum nicht?
Wilhelm M. schrieb:> Falk B. schrieb:>> Lerne C ;-)>> Es geht um Struktur!>> Lerne C++!
Was bietet C++ an Kontrollstrukturen (um die es hier geht) mehr als C?
Yalu X. schrieb:> Wilhelm M. schrieb:>> Falk B. schrieb:>>> Lerne C ;-)>>>> Es geht um Struktur!>>>> Lerne C++!>> Was bietet C++ an Kontrollstrukturen (um die es hier geht) mehr als C?
Nein, es geht nicht nur um Kontrollstrukturen.
Der TO sprach zuerst generell vom Strukturieren seines Codes. Als
Beispiel brachte er dann etwas für ihn besonders Nerviges: das Nachbauen
von Iterationen.
Yalu X. schrieb:> Was bietet C++ an Kontrollstrukturen (um die es hier geht) mehr als C?
try-catch, "constexpr if" und die Range-Based for Loop gibt's nur in
C++. Und man kann sich eigene Kontrollstrukturen bauen mit Lambdas,
z.B.:
Niklas G. schrieb:> Yalu X. schrieb:>> Was bietet C++ an Kontrollstrukturen (um die es hier geht) mehr als C?>> "constexpr if" und die Range-Based for Loop gibt's nur in C++. Und man> kann sich eigene Kontrollstrukturen bauen mit Lambdas, z.B.
Na ob DAS dem OP weiterhilft und ob DAS C++ den "normalen" Leuten
schmackhaft macht?
Falk B. schrieb:> Na ob DAS dem OP weiterhilft und ob DAS C++ den "normalen" Leuten> schmackhaft macht?
Insbesondere die Vorteile der Range-Based for loop sollten sofort jedem
ersichtlich sein:
1
for(auto&elem:container){...
Kann jeden Container-Typ aus der Standard-Library (und auch viele
andere) iterieren. Wenn ich "container" zwischen einem C-Array,
std::vector oder std::list ändere, muss ich an dieser Iteration nichts
anpassen. Und gut lesbar ist sie auch.
Manche Anwendungen von Lambdas sind auch eingängig:
Sortiert den Container rückwärts. Funktioniert auch mit allen
Container-Typen.
try-catch sollte Programmierern aus anderen Sprachen bekannt sein;
besser ist aber die konsequente Anwendung von RAII.
constexpr-if ist eher für "low level" template-Libraries und hat eher
indirekten Nutzen. Eine Anwendung ist z.B.:
Führt den Code-Block nur aus, wenn im Container vorzeichenbehaftete
Zahlen sind, wobei der Code nur syntaktisch, aber nicht semantisch
korrekt sein muss, wenn die Bedingung nicht erfüllt ist.
Rödel schrieb:> Falk B. schrieb:>> Aber im Ernst, was glaubt du, mit so einem ASM-Projekt zu erreichen?>> Held der Arbeit? Ist die Leitungsfähigkeit des Mikrocontroller dermaßen>> ausgereitzt, daß du ASM unbedingt brauchst?>> Eigentlich halte ich mich aus solchen "C vs ASM" Diskussionen immer> raus, weil jedes Wort verschenkte Liebesmüh ist. Aber bei solchen> Sprüchen muss ich doch mal was sagen.
Ja, schön daß du Falk bestätigst. Denn in deinem Fall ist es
anscheinend wirklich so, daß du
> die Leitungsfähigkeit des Mikrocontroller dermaßen ausreitzt
daß es nur mit Assembler geht. Das ist aber nun nicht der Normalfall.
Und während der zusätzliche Zeitaufwand für ein Hobby ok ist (der Weg
ist das Ziel) wäre man bei einem kommerziellen Produkt einfach auf einen
schnelleren µC umgestiegen und hätte C benutzt. Die Hardware wäre am
Ende wahrscheinlich nichtmal teurer, ein STM32F1 z.B. kostet kaum mehr
als dein XMega, ist aber deutlich flotter. Und man wäre deutlich
schneller fertig gewesen.
Niklas G. schrieb:> Falk B. schrieb:>> Na ob DAS dem OP weiterhilft und ob DAS C++ den "normalen" Leuten>> schmackhaft macht?>> Insbesondere die Vorteile der Range-Based for loop sollten sofort jedem> ersichtlich sein:>
1
for(auto&elem:container){...
> Kann jeden Container-Typ aus der Standard-Library (und auch viele> andere) iterieren. Wenn ich "container" zwischen einem C-Array,> std::vector oder std::list ändere, muss ich an dieser Iteration nichts> anpassen. Und gut lesbar ist sie auch.> ...
Niklas: genau diese Diskussion habe ich hier schon so oft geführt, und
es kommen immer wieder die gleichen Leute mit den gleichen scheinbaren
Argumenten. Dieses Unterforum ist für derartige Abstraktionsgrade
ungeeignet ;-)
Hm, es wurde direkt nach C++-Kontrollstrukturen gefragt, da habe ich
doch nur drauf geantwortet.
In Assembler-Code benutze ich auch lokale Labels für Sprünge innerhalb
von Funktionen und "richtige" Labels für Funktionen selbst. Nur Code bei
dem es wirklich nötig ist (z.B. Kontextwechsel oder Exceptions je nach
Prozessor) oder in einem der seltenen Fälle wenn der Compiler einen
kritischen Abschnitt wirklich nicht gut optimiert bekommt benutze ich
für einzelne Funktionen Assembler. Die werden dann aus C++ aufgerufen,
welches somit diese Komponenten strukturiert.
int 21h schrieb:> Moin,>> da meine Assembler Projekte langsam umfangreicher werden, suche ich nach> Möglichkeiten den Quellcode besser zu strukturieren.> Dabei stört mich besonders, dass jede Label Bezeichnung nur ein mal> vergeben werden kann.
Was spricht gegen einen Precompiler, der ein übersichtliches und
pflegeleichtes strukturiertes Assembler-Programm mit so gut wie keinen
Labels* in ein flaches (strukturloses) Assembler-Programm übersetzt
(dann je nach Komplexität der Strukturen mit vielen automatisch
erzeugten Labels), das man normalerweise nicht einmal anschauen, sondern
nur assemblieren muss?
Hast du schon einmal mit einem solchen Precompiler gearbeitet und
schlechte Erfahrungen damit gemacht? Oder warum willst du keinen (laut
Betreff)?
Ein Precompiler für strukturierte Sprachelemente würde das
Assembler-Programmieren ziemlich erleichtern und du könntest dich auf
das eigentliche Programm konzentrieren anstatt über viele Labels
nachzudenken.
* Im Normalfall sind Labels nur eimal für jedes Unterprogramm nötig.
int 21h schrieb:> Z.B. kommen dann schon mal solche Namen heraus:
twi_send_byte:
> ...> twi_send_byte_loop_0:> ...> retDas ist nicht schön, schlecht lesbar und man kann wie bereits genannt> jeden Namen nur 1 mal vergeben.
Mein Aufbau wäre so:
twi_send_byte: 'der einzige Eingang
... 'Falls notwendig PUSH, Register auf Stack sichern
twi_send_byte_10:
...
twi_send_byte_20:
...
twi_send_byte_30:
twi_send_byte_99: 'Der einzige Ausgang der ASM-Subroutine
... 'Hier alle POP , Register wieder herstellen
Return
Wo wir gerade dabei sind hab ich auch mal eine Frage:
Beim Assembler-Programmieren hat man eine Menge Freiheitsgrade
insbesondere zur Reihenfolge der Instruktionen, z.B. ob man in einer
Schleife die Bedingung am Ende prüft und ggf. zurück an den Anfang
springt, oder am Anfang prüft und ggf. hinter die Schleife springt, ob
man zu ladende Daten am Ende der Schleife für den nächsten Durchlauf
lädt oder am Anfang der Schleife, ob man Pointer inkrementiert und mit
den Ende vergleicht oder einen Zähler Richtung 0 dekrementiert, ob man
bedingte Sprünge oder bedingte Anweisungen (ARM) verwendet, ob man
mehrere einzelne Load/Store-Instruktionen verwendet oder solche die
mehrere Register laden/sichern können, allgemein die Reihenfolge bei
Instruktions-Sequenzen mit teilweisen Abhängigkeiten untereinander usw.
Je nach Pipeline- und Cache-Struktur/Zustand wirken sich diese
Entscheidungen (oft nichttrivial) auf die Performance aus. Wie wählt ihr
die beste Variante aus? Alle Möglichkeiten durchprobieren und messen?
Nach Gefühl?
Das hängt von zu vielen Faktoren ab als dass man eine allgemeingültige
Antwort geben kann. Meiner Erfahrung nach ist es z.B. sinnvoll, häufig
benutzte Codeteile so zu alignen, dass sie immer am Anfang einer
Cache-Page landen. Selbst wenn dadurch Lücken entstehen, die Flashes
sind meist groß genug. Bei Controllern mit MMU (z.B. SPC56EL.., SPC58)
kann man z.B. auch nur einen kleinen Teil des Flashes cachen, in dem
dann die kritischen Routinen stehen. Oder kritische Teile des Codes in
das RAM auslagern.
Weitaus schwieriger wird es, ein deterministisches Zeitverhalten ohne
Timer/Interrupts hinzubekommen. Das geht bei den AVR einfacher...
Jörg
Yalu X. schrieb:> Damit kann man das Prinzip der strukturierten Programmierung auch sehr> gut in Assembler umsetzen. Am besten schreibt man an die Sprungbefehle> und die Labels noch einen Pseudocodekommentar wie bspw, "if> <Bedingung>", "else", "endif", "while <Bedingung>", "endwhile" usw. und> rückt den Code wie in einer Hochsprache ein, so dass man beim Lesen die> Struktur auch ohne Vergleich der Labelnummern leicht erfassen kann.
Ich finde: Je weniger zu lesen desto lesbarer- weil desto schneller
finden wirklich relevante Infos (in Kommentaren) das Auge des
Betrachters. Man muss nicht alles langwierig beschreiben oder gar dem
Leser zeitgleich noch einen Asm-Kurs aufs Auge drücken wollen.
Strukturieren lässt auch allein mit der Leertaste hervorragend. Und
natürlich: Man muß nicht so viel schreiben. Das geht alles schön knapp,
im Wesentlichen sinds ja bloß die paar Asm-Codes.
> Allerdings bin auch ich der Meinung, dass es kaum noch einen Grund gibt,> Assembler-Only-Programme zu schreiben. Aber wenn jemand seine Freude> daran hat, warum nicht?
Eben. Nicht jeder mags abstrakt und immer abstrakter. Das kann man alles
je nach Vorkenntnissen auch schnell als intransparent empfinden. Vor
allem aber gehts um den Overhead von Hochsprachen. Der besteht weniger
im Mehrverbrauch an Code und Verlust an Speed (der AVR hat die nötigen
Reserven für viele Zwecke) als vielmehr im Lernaufwand, der sich in
dicken Lehrbüchern manifestiert. Die Freude besteht auch in dem Gefühl,
alles selber in der Hand zu haben. Zugegebenermaßen sind das aber alles
keine Argumente um schnell ans Ziel zu kommen.
Anton M. schrieb:> Ich finde: Je weniger zu lesen desto lesbarer- weil desto schneller> finden wirklich relevante Infos (in Kommentaren) das Auge des> Betrachters.
Das ist so absolut Unsinn, denn dann kannst du gleich zur Bome-Notation
übergehen . . .
> Man muss nicht alles langwierig beschreiben oder gar dem> Leser zeitgleich noch einen Asm-Kurs aufs Auge drücken wollen.
Falsch. Man muss kurze, prägnante Namen finden, welche NICHT aus
tonnenweise Abkürzungen und Codes bestehen. Loop ist ein kurzes Wort,
ebenso ret oder return etc.
Das Optimum liegt selten beim Mini- oder Maximum!
> Strukturieren lässt auch allein mit der Leertaste hervorragend. Und> natürlich: Man muß nicht so viel schreiben.
Vollkommen nebensächlich. Denn Code wird praktisch nur einmal
geschrieben, dafür aber vielfach gelesen.
> Das geht alles schön knapp,> im Wesentlichen sinds ja bloß die paar Asm-Codes.
Jaja, die dann bei einigen auf 20kB++ und 5000 Zeilen++ anwachsen.
Man kann auch c-code so verunstalten/missbrauchen, dass man irgendwie
keinen Schritt vorwärts kommt oder eher Satire abliefert.
Was u.a. hilft ist, wenn man sich gute Programme anschaut und dem
Programmierstil - zumindest ansatzweise - nacheifert.
Seine Unterprogramme "loopxyz" zu nennen ist schon mal nicht so toll.
besser vielleicht: "printf n"
Die Standardisierung könnte z.B. sein CX = Zählregister
push cx
mov cx, Zähler
call Printer
loop
Wobei der letzte Befehl kein Label ist, sondern ein direkter
Assemblerbefehl.
Wenn man in Haskell ein Funktion wie "meinef (x:xs) =" erstellt, dann
ist das auch nur eine recht bewährte Strategie des Variableneinsatzes
innerhalb des Sprachjargons.
Man lernt sie mit der Zeit auswendig.
Und je mehr man sich mit solchen Sachen beschäftigt, desto eher hat man
ein Gefühl dafür, wie man mit den guten Eigenschaften oder den
Begrenzungen beim Problemlösen (o.ä.) klarkommt.
Falk B. schrieb:>> Und jetzt mal ein bissl rechnen: 65536*250=16 381 500 Bytes pro Sekunde>> Da habe ich so meine Zweifel. Auch ein Xmega schaufelt mal sicher KEINE> 16MB/s aus seinen IOs. Zumindest macht das die CPU nicht allein,> vermutlich nutzt du clevererweise DMA. Denn 16MB/s wären ein Byte pro 2> Takte. Glaub ich eher nicht.
Ich formuliere es mal genauer: Es sind RGB LEDs, also drei LEDs pro
Pixel. Es sind 65536 Pixel, die mit 250 Hz aktualisiert werden. Es
werden pro Sekunde also 49 152 000 Pixelwerte an die Panels
rausgesendet. So ist es rechtlich sicher formuliert ;)
> Kann ich mir schwer vorstellen.>>> (Das liegt an dem internen Aufbau des DMA. Stichwort BUS>> Polling.)>> ???
Ist halt so. Nimm ein Oszi und mess es nach. Oder glaub es einfach
nicht.
Rödel schrieb:> Und jetzt mal ein bissl rechnen: 65536*250=16 381 500 Bytes pro Sekunde> an Daten, die an die Panels geschickt werden. Die CPU Last ist 70%.
Wäre es nicht einfacher gewesen, einen Prozessor mit LCD-"RGB"-Interface
zu verwenden (z.B. TI Sitara oder manche STM32)? Diese können ein
2D-Array aus Pixeln auf bis zu 24 Leitungen parallel ausgeben (3x8=RGB)
bei 0% CPU-Last. Ob da jetzt ein LCD oder LEDs dran hängen ist auch
relativ egal...
Rödel schrieb:> Es> werden pro Sekunde also 49 152 000 Pixelwerte an die Panels> rausgesendet
Wie geht das denn auf einem 32MHz-Prozessor? Kann der mehrere Bytes pro
Takt aus dem RAM laden und ausgeben? Wenn das Timing so knapp ist,
braucht man ja eine sehr schnell laufende Schleife für die Ausgabe. Wo
packt man dann die Bildberechnung hin?
Rödel schrieb:> Falk B. schrieb:>>> Und jetzt mal ein bissl rechnen: 65536*250=16 381 500 Bytes pro Sekunde>>>> Da habe ich so meine Zweifel. Auch ein Xmega schaufelt mal sicher KEINE>> 16MB/s aus seinen IOs. Zumindest macht das die CPU nicht allein,>> vermutlich nutzt du clevererweise DMA. Denn 16MB/s wären ein Byte pro 2>> Takte. Glaub ich eher nicht.>> Ich formuliere es mal genauer: Es sind RGB LEDs, also drei LEDs pro> Pixel. Es sind 65536 Pixel, die mit 250 Hz aktualisiert werden. Es> werden pro Sekunde also 49 152 000 Pixelwerte an die Panels> rausgesendet. So ist es rechtlich sicher formuliert ;)
Das wird ja immer mehr! Jetzt schon die dreifache Menge! 49 MB
(MEGABYTE) pro Sekunde! Niemals! Oder du hast einen ECHT cleveren
Algorithmus gefunden. Das glaube ich aber erst dann, wenn ich ihn sehe.
Willst du deinen Superalgorithmus mit uns teilen?
>> Kann ich mir schwer vorstellen.
Kann ich mir erst recht nicht vorstellen.
> Ist halt so. Nimm ein Oszi und mess es nach. Oder glaub es einfach> nicht.
Du bist ja ein echter Sportsgeist! Andere Forumsteilnehmer würden sich
bemühen, das Problem für Andere verständlich darzulegen.
Niklas G. schrieb:> Rödel schrieb:>> Und jetzt mal ein bissl rechnen: 65536*250=16 381 500 Bytes pro Sekunde>> an Daten, die an die Panels geschickt werden. Die CPU Last ist 70%.>> Wäre es nicht einfacher gewesen, einen Prozessor mit LCD-"RGB"-Interface> zu verwenden (z.B. TI Sitara oder manche STM32)? Diese können ein> 2D-Array aus Pixeln auf bis zu 24 Leitungen parallel ausgeben (3x8=RGB)> bei 0% CPU-Last. Ob da jetzt ein LCD oder LEDs dran hängen ist auch> relativ egal...
Ich weiss nicht, ob das Interface vom HUB75E mit solchen Controllern
kompatibel ist. Die scheinen mir recht eigen zu sein. Falls ja, hätten
die Chinesen aber auch keine FPGAs nehmen müssen.
> Rödel schrieb:>> Es>> werden pro Sekunde also 49 152 000 Pixelwerte an die Panels>> rausgesendet>> Wie geht das denn auf einem 32MHz-Prozessor? Kann der mehrere Bytes pro> Takt aus dem RAM laden und ausgeben? Wenn das Timing so knapp ist,> braucht man ja eine sehr schnell laufende Schleife für die Ausgabe. Wo> packt man dann die Bildberechnung hin?
Die mir bekannte schnellste Lösung, Bytes vom SRAM auf einen PORT zu
schieben ist
ld r24,Z+
out ADDR,r24
Das sind drei Takte pro Byte. Die Clock muss man aber auch noch treiben
und die Abbruchbedingung muss auch noch irgendwo hin.
Ich habe ein VRAM auf 4 BPP Basis programmiert. Der grösste xmega ohne
EBI hat ja nur 32 KB RAM.
Den Displaytreiber alleine in Assembler zu schreiben ist auch nur die
halbe Miete. Die Zeichenfunktionen (z.B. dynamische Schriftgrösse mit
Ausrichtiungsfunktionen links, mittig, rechts) und Einfärbeoptionen
wären in C sicher auch wesentlich langsamer als in Assembler. Das sind
halt einfach verdammt viele Pixel mit Farbwerten für einen 8-Bitter.
Falk B. schrieb:>> Ist halt so. Nimm ein Oszi und mess es nach. Oder glaub es einfach>> nicht.>> Du bist ja ein echter Sportsgeist! Andere Forumsteilnehmer würden sich> bemühen, das Problem für Andere verständlich darzulegen.
Das eine Problem habe ich dir schon mit einem Wort erklärt. Der
DMA-Controller hat ab und zu einige Takte Pause, wenn etwas anderes den
Bus blockiert. Das muss nichtmal ein Interrupt sein.
Das zweite Problem ist, dass auch der DMA nicht schneller läuft als der
Kerntakt. Wenn er also nach jedem Byte einen Counter dekrementieren muss
um auf Abbruch zu Testen, muss er zwangsläufig mehr als drei Takte pro
Byte brauchen. Ich brauche auf Abbruchbedingung nicht prüfen und komme
deshalb mit 3 Takten pro Byte aus.
Rödel schrieb:> Das eine Problem habe ich dir schon mit einem Wort erklärt.
Jaja, welche eindeutige Erklärung.
[ ] Du kennst den Unterschied zwischen einem Stichwort und einer
Erklärung.
> Der> DMA-Controller hat ab und zu einige Takte Pause, wenn etwas anderes den> Bus blockiert. Das muss nichtmal ein Interrupt sein.
Kann sein, hab ich im Detail noch nie getestet.
> Das zweite Problem ist, dass auch der DMA nicht schneller läuft als der> Kerntakt.
Reicht doch.
> Wenn er also nach jedem Byte einen Counter dekrementieren muss> um auf Abbruch zu Testen, muss er zwangsläufig mehr als drei Takte pro> Byte brauchen.
Blödsinn. DMA ist eine Statemachine in Hardware, da läuft alles parallel
und er kann problemlos mit jedem Takt ein Datum übertragen.
> Ich brauche auf Abbruchbedingung nicht prüfen und komme> deshalb mit 3 Takten pro Byte aus.
Hmm, das macht aber bei 32 MHz CPU-Takt bestenfalls ~10MB/s und nicht
mal ansatzweise 49MB/s.
int 21h schrieb:> Moin,>> Z.B. kommen dann schon mal solche Namen heraus:>
1
twi_send_byte:
2
> ...
3
> twi_send_byte_loop_0:
4
> ...
5
> ret
ich kürze dann in der Funktion immer ab
1
twi_send_byte:
2
...
3
twi_sb_l00: ;für Schleifen
4
twi_sb_m00: ;für allgemeine Sachen
5
twi_sb_end: ;für spezielle Punkte
6
...
7
ret
> Desweiteren frage ich mich, ob man bestimmte Routinen (z.B. Loops) über> Makros ersetzen könnte.
Was soll bei einer Loop in das Makro rein? Da würde ja dann der Code
(immer gleich, oder x-Makros) mit drin stehen, da kannst du dann besser
ein Unterprogramm draus machen.
Sascha
Falk B. schrieb:> Blödsinn.
Mess es halt selber nach.
>> Ich brauche auf Abbruchbedingung nicht prüfen und komme>> deshalb mit 3 Takten pro Byte aus.>> Hmm, das macht aber bei 32 MHz CPU-Takt bestenfalls ~10MB/s und nicht> mal ansatzweise 49MB/s.
Ich habe nirgendwo 49 MB/s geschrieben. Auf MB umgerechnet sind es in
der Tat nur lächerlicher 10 MB/s. Ich koche auch nur mit Wasser. Das
Gewürz macht den Geschmack.
Rödel schrieb:> Ich habe nirgendwo 49 MB/s geschrieben. Auf MB umgerechnet sind es in> der Tat nur lächerlicher 10 MB/s.Rödel schrieb:> Und jetzt mal ein bissl rechnen: 65536*250=16 381 500 Bytes pro Sekunde> an Daten, die an die Panels geschickt werden. Die CPU Last ist 70%.
Ohne Rechenfehler wären es 1638400 Bytes/s und bei voller Ausnutzung der
CPU sogar 23405714 Bytes/s. Das sind zwar noch keine 49 MB/s, entspräche
bei 3 Zyklen/Byte immerhin einer Taktfrequenz von über 70 MHz.
Yalu X. schrieb:> Rödel schrieb:>> Ich habe nirgendwo 49 MB/s geschrieben. Auf MB umgerechnet sind es in>> der Tat nur lächerlicher 10 MB/s.>> Rödel schrieb:>> Und jetzt mal ein bissl rechnen: 65536*250=16 381 500 Bytes pro Sekunde>> an Daten, die an die Panels geschickt werden. Die CPU Last ist 70%.>> Ohne Rechenfehler wären es 1638400 Bytes/s und bei voller Ausnutzung der> CPU sogar 23405714 Bytes/s. Das sind zwar noch keine 49 MB/s, entspräche> bei 3 Zyklen/Byte immerhin einer Taktfrequenz von über 70 MHz.
Es war spät. Da kann man statt 65536 auch schonmal aus Versehen 65526 in
den Taschenrechner eintippen. Die Angabe "Bytes" war dennoch falsch.
Deshalb der spätere Nachtrag:
> Ich formuliere es mal genauer: Es sind RGB LEDs, also drei LEDs pro> Pixel. Es sind 65536 Pixel, die mit 250 Hz aktualisiert werden. Es> werden pro Sekunde also 49 152 000 Pixelwerte an die Panels> rausgesendet. So ist es rechtlich sicher formuliert ;)
Geht es um solche Panels?
https://bikerglen.com/projects/lighting/led-panel-1up/
Also drei Bit pro Pixel. Wird jetzt bei dir für jeden
Scan(komplette Bild) die Zeile einmal ausgegeben,
damit dann 3bit/Pixel.
Oder tatsächlich jede Zeile mehrfach pro Scan
zur Modulation um die Farbauflösung zu erhöhen?
Andere Vorgehensweise?
Ich denke Mal ersteres ? Ist aber immer noch
eine ziemlich hohe Datenrate bei 250hz
Falk B. schrieb:> Anton M. schrieb:>>> Ich finde: Je weniger zu lesen desto lesbarer- weil desto schneller>> finden wirklich relevante Infos (in Kommentaren) das Auge des>> Betrachters.>> Das ist so absolut Unsinn, denn dann kannst du gleich zur Bome-Notation> übergehen . . .
Du solltest nichts als absoluten Unsinn bezeichnen wenn es mindestens
einen gibt der das definitiv so empfindet. Und wo es den einen gibt
gibts sicher auch andere. Relevante Information ist bei Assembler sehr
gut im Kommentar aufgehoben, auf elend lange Bezeichner (und noch
kompliziertere Ausdrücke) verzichte ich sehr gerne. Allen denkbaren
Ansprüchen, Kenntnissen und Motivationen eines externen Betrachters wird
man sowieso nie gerecht. Zuallererst gehts mal darum dass die
Funktionalität nachvollziehbar ist. Im Bedarfsfall bei Asm sofort,
unmittelbar und vollständig bis zur letzten Instruktion. Ich bin sehr
dafür dass man alles sofort sieht und nicht auf Umwegen über allerlei
Hilfskonstrukte oder Makros. Das nenne ich lesbar. Den Code möglichst
einfach halten, mit dem nötigen Minimum an Mitteln lautet die Devise.
>> im Wesentlichen sinds ja bloß die paar Asm-Codes.>> Jaja, die dann bei einigen auf 20kB++ und 5000 Zeilen++ anwachsen.
Ohne weiteres. Die können aber genauso gut dokumentiert und funktionell
strukturiert sein wie in Hochsprache. In aller Regel sind es aber
kleinere Programme für einfachere Controller die in Asm verfasst sind.
Rödel schrieb:> Falk B. schrieb:>> Blödsinn.>> Mess es halt selber nach.>>>> Ich brauche auf Abbruchbedingung nicht prüfen und komme>>> deshalb mit 3 Takten pro Byte aus.>>>> Hmm, das macht aber bei 32 MHz CPU-Takt bestenfalls ~10MB/s und nicht>> mal ansatzweise 49MB/s.>> Ich habe nirgendwo 49 MB/s geschrieben.
Soso. Dein Kurzzeitgedächtni scheint nicht das Beste zu sein.
Beitrag "Re: AVR Assembler besser strukturieren (ohne Precompiler)"
"Und jetzt mal ein bissl rechnen: 65536*250=16 381 500 Bytes pro Sekunde
an Daten, die an die Panels geschickt werden. Die CPU Last ist 70%."
Beitrag "Re: AVR Assembler besser strukturieren (ohne Precompiler)"
"Ich formuliere es mal genauer: Es sind RGB LEDs, also drei LEDs pro
Pixel. Es sind 65536 Pixel, die mit 250 Hz aktualisiert werden. Es
werden pro Sekunde also 49 152 000 Pixelwerte an die Panels
rausgesendet. So ist es rechtlich sicher formuliert ;)"
Und jetzt willst du mir bestimmt erzählen, daß deine Pixelwerte kleiner
als 1 Byte sind.
> Auf MB umgerechnet sind es in> der Tat nur lächerlicher 10 MB/s. Ich koche auch nur mit Wasser. Das> Gewürz macht den Geschmack.
Und vor allem das Geschwätz drum herum, nicht wahr?
Anton M. schrieb:> Falk B. schrieb:>> Anton M. schrieb:>>>>> Ich finde: Je weniger zu lesen desto lesbarer- weil desto schneller>>> finden wirklich relevante Infos (in Kommentaren) das Auge des>>> Betrachters.>>>> Das ist so absolut Unsinn, denn dann kannst du gleich zur Bome-Notation>> übergehen . . .>> Du solltest nichts als absoluten Unsinn bezeichnen wenn es mindestens> einen gibt der das definitiv so empfindet.
Klar, das meint der gute Josef G. auch.
> Und wo es den einen gibt> gibts sicher auch andere.
Ein bestechendes Argument . . .
> Relevante Information ist bei Assembler sehr> gut im Kommentar aufgehoben, auf elend lange Bezeichner (und noch> kompliziertere Ausdrücke) verzichte ich sehr gerne. Allen denkbaren> Ansprüchen, Kenntnissen und Motivationen eines externen Betrachters wird> man sowieso nie gerecht. Zuallererst gehts mal darum dass die> Funktionalität nachvollziehbar ist.> Im Bedarfsfall bei Asm sofort,> unmittelbar und vollständig bis zur letzten Instruktion.
Blödsinn^3. Gerde ASM mit seiner "Krümelauflösung" erschließt kein
komplexen Zusammenhänge, weil man immer wie Aschenputtel mit den kleinen
Erbsen beschäftigt ist.
> Ich bin sehr> dafür dass man alles sofort sieht und nicht auf Umwegen über allerlei> Hilfskonstrukte oder Makros. Das nenne ich lesbar.
Na dann tu dich mit Bome zusammen, der ist ähnlich schräg drauf.
@Falk B: Soweit mir bekannt beschäftigt sich der angesprochene Josef G
mit einer völlig eigenen und ziemlich kryptischen Lösung. Wir sind
hier aber bei allbekanntem AVR Assembler. Das scheint Dir irgendwie
entgangen zu sein. Ansonsten kannst Du Dein Unverständnis gerne weiter
mit dem albernen Ruf "Blödsinn" kaschieren- allein, irgendwie
beeindruckend ist das kaum.
int 21h schrieb:> twi_send_byte:> ...> twi_send_byte_loop_0:> ...> twi_send_byte:> loop_1:> ...> loop_2:> ret>> twi_get_byte:> loop_1:> ...> loop_2:> ret
Hallo, ich denke, dass du es dir einfach unnötig schwer machen willst!
Ich unterstelle jetzt mal, dass das Unterprogramm "twi_send_byte:" keine
200 Zeilen lang und entsprechend unübersichtlich ist...also machst du
Label der Form "twi_s_1, twi_s_2, twi_g_1" usw. Da diese mehr oder
weniger nahe am Programmnamen stehen, ist doch klar, was die machen. Und
wenn du tatsächlich oft Schachteln mußt, dann ist für mich der klarste
Weg, das über Einrückungen zu zeigen. Ich halte mich grundsätzlich an
den Spruch, wenn es unübersichtlich wird, dann hast du zu viele
Funktionen in ein (Unter)Programm gepackt. Also brech den Haufen
auf...in viele kleine Häppchen :-)
Gruß Rainer
int 21h schrieb:> Ist das irgendwie machbar?
irgendwie (mit AVR macro assembler 2.1.12) ginge bspw:
1
#define cName() unique_a
2
#define l(@1) cName() ## local_ ## @1
3
#define L(@1) cName() ## local_ ## @1:
4
brne l(0)
5
....
6
L(0)
7
L(1)
8
;_____new namespace____
9
#undef cName
10
#define cName() unique_b
11
brne l(0)
12
....
13
L(0)
14
L(1)
grundsätzlich hat der AVR macro assembler 2 Arten von Makros:
a) asm-Makros, die - wie Thomas weiter oben geschrieben hat - lokale
Labels, bedingte Kompilierung u.ä. unterstützen, aber nur sehr bedingt
für 'komprimierte' Schreibweisen (mehrere Befehle in einer Zeile )
tauglich sind und
b) (etwas eingeschränkt) C-Makros, die zum einen nur aus einer Zeile
bestehen (lassen sich optisch mit "\" in mehere Zeilen aufteilen) und
praktisch '_nur_' Textersetzungen erledigen.
Für verschachtelte Blockstrukturierung fehlt beiden ein Stack der im
Beispiel am Ende von "new namespace" wieder cName=last(cName) definieren
könnte.
Mit etwas Murks lässt sich die interne 64bit Berechnung als 4-fach Stack
missbrauchen, um 'echte' Schleifen (mind. 1 Durchlauf; Abbruchbedingung
'unten') ohne sichtbare Labels zu schreiben:
(mit etwas mehr Murks ließen sich auch 2*64bit->max.8 oder mehr
verwenden)
> Möglichkeiten den Quellcode besser zu strukturieren.
Neben der asm-Makro Auslagerung lassen sich durch Textersetzungen bspw.
Befehle 'einheitlicher' bzw. je nachdem was im Kontext passender ist
umformulieren:
1
;#define c_i s
2
;#define s_i c
3
;#define inv_cs(@cs)@cs##_i
4
#define if(@s,R,N,cs) sb ## @s ## inv_cs(cs) R,N
5
/* A */ if(r,r16,7,s) ldi r17,-1
6
/* B */ if(i,UCSRA,RXC,s) rjmp rec_data
7
; oder zusätzlich/alternativ
8
#define br(@s,R,N,cs)if(@s,R,N,cs) rjmp
9
/* B */ br(i,UCSRA,RXC,s) rec_data
10
; bei der Gelegenheit noch "until" aus dem obigen Beispiel:
11
#define until(@s,R,N,cs) sb ## @s ## cs R,N wend
etwas problematisch sind 'vorwärts' Label, aber mit etwas Vorsicht
über den Umweg mit Textersetzungen lassen sich auch brXX in das Schema
integrieren (z.B.:res=Ergebnis der letzten
Operation;Leerfeld=Statusflags)
1
if(,,t,s) ldi r16,timereg; t-flag
2
if(res,,,eq) ldi r16,equal_val; nach cp r0,r0
kurz: für verschachtelte Konstrukte ist ein Precompiler u.U. etwas
einfacher, aber nicht völlig alternativlos.
> Vielleicht hat jemand noch weitere Tipps oder nützliche Referenzen für> mich :D
- grundsätzlich sind AVR recyclebar d.h. falls du einmal versehentlich
einen AVR in der falschen Sprache programmiert hast dann kannst du den
löschen und mit einer richtigen Sprache neuprogrammieren
- für eigene Projekte: ausprobieren was dir ('Referenz') am besten
gefällt, ansonsten mit den anderen Beteiligten absprechen
- falls du bei dir erste Versuche bemerkst in ASM eine
Typprüfung/Typabhängigkeiten o.ä. zu implementieren, dann evtl. doch
über eine 'richtige' Sprache nachdenken (das obige Beispiel könnte nicht
automatisch ein Flagregister (r).equ flag=r16 von (i).equ flag=GPIOR0
unterscheiden)
Hm, wieso schreibe ich sowas wie die AlarmSau in Assembler...
gute Frage.
Ich denke zum einen bin ich recht gut mit Assembler unterwegs, C(++)
müsste ich definitiv erst lernen um würde dabei in jede Anfängerfalle
reinrennen, die es dabei gibt. Mit C(++) lernen wäre ich
höchstwahrscheinlich nicht schneller gewesen, es wäre nur mehr debuggen
als Quelltext schreiben geworden. Und viel nachfragen müssen hier im
Forum, mir (nicht nur) Falks gequälte Kommentare antun müssen, wieso ich
irgendeine vermeintlich einfache Noob-Antwort nicht selbst gefunden
habe.
Zweitens war das interessante die GSM-Funktionen zu schreiben bzw.
überhaupt mit diesem GSM-Modul klarzukommen wenn man sowas noch nie in
der Hand hatte. Der Rest danach war easy und evtl. lässt sich der Output
des Projekts nun auch einfach in weitere Projekte einbauen.
Drittens wenn man ein gutes Grundgerüst an Funktionen hat, werden selbst
komplexe Abläufe einfach zu programmieren. Z.B. um eine Zeile an's
LCD-Display zu senden reicht bei meinen Assembler-Funktionen
1
ldi R16,1 ;Zeile 1 oder 2
2
ldi R31,high(LCD_Text_Label) ;Anfang vom Text im Flash
3
ldi R30,low (LCD_Text_Label)
4
rcall TERMINAL_SendLine ;Funktionsaufruf
Um den ganzen Rest, daß der Text dann auch irgendwie über die beiden
USARTs beim Display ankommt, kümmern sich andere Programmteile und die
Hardware, da brauche ich gar nicht mehr dran denken.
Ließe sich in C bestimmt mit etwas wie
1
TERMINAL_SendLine(LCD_Text_Label);
erschlagen, aber ich bin nicht wesentlich langsamer beim Tippen und kann
beides gleich gut lesen. Wo Hochsprachen schneller sind, sind z.B.
komplexere Verschachtelungen von irgendwas, da lässt sich in einer
Programmzeile manchmal sehr viel mehr Inhalt unterbringen und es ist
auch einfacher zu lesen als wenn man es in Assembler konstruiert hat.
Aber sonst... für mich kein Unterschied.
Also nur beispielsweise im übertragenen Sinne sowas wie
1
if ((user_input<5) or (user_input>100)) {
2
TERMINAL_SendLine("Gib keinen Scheiß ein!!");
3
} else {
4
if ((user_input="blah") or (user_input="blub")) {
5
TERMINAL_SendLine("Na also, geht doch!");
6
}
7
}
wird in Assembler wesentlich länger.
Ich denke auch sehr gerne auf Hardware-Ebene, also ich weiß gerne genau,
was der µC macht. Ich glaube das hilft beim Debugging, wenn mal
irgendwas nicht so funktioniert wie erwartet.
Ich mag es auch nicht, wenn man sich seine Programme aus vorgefertigten
Lösungen einfach zusammenklickt. Als Arduino-Version wäre die AlarmSau
vielleicht in 500 Zeilen Quellcode und ein paar Tagen fertig gewesen.
Einen Arduino und ein paar Shields bezahlt und gestapelt, Hardware
fertig. Aber weiß ich dann wie's funktioniert? Macht das Spaß? Also mir
nicht, ich kann diesen Zweig "Programmierer" nicht wirklich gut
ausstehen. Das sind größtenteils fremde Lorbeeren, auf denen man sich da
ausruht. Sowas kann jeder, das ist langweilig. Und spätestens wenn eine
Library mal nicht so funktioniert wie ich es erwarte, stehe ich vor
einem Problem - eben weil ich nicht weiß wie es funktioniert. Dann
brauche ich die Zeit, die ich vorher gespart habe, hinterher für's
Debugging - toll. Da ist mir eigener Code wesentlich lieber, da weiß ich
wo ich suchen muß wenn etwas nicht wie gedacht funktioniert.
Wobei... die AlarmSau ist da vielleicht ein schlechtes Beispiel, die
macht einige nicht gleich so offen wahrgenommene Funktionen um z.B.
Fehlalarme zu unterdrücken usw. wodurch das noch einige Zeilen mehr
Quellcode werden. Aber das Terminal davon wäre ein gutes Beispiel. Wenn
man nicht wissen will wie es funktioniert, Ardunio plus LCD-Shield, alle
Daten vom USART an das Display und schon sind 40% davon fertig. Gibt
bestimmt auch ein Tastatur-Shield mit entsprechender Lib, alle Ausgaben
dieser Lib in den USART gedumpt, 80% fertig. Der Rest sind dann ein paar
Zusatzfunktionen, daß die bunte LED so blinkt wie man möchte, das lässt
sich wohl nicht so extrem verkürzen. Diese Funktionen habe ich ins
Terminal verlegt, damit ich mich später im Control-Modul nicht mehr
darum kümmern brauche und das funktioniert auch richtig gut. Also das
Terminal ließe sich jetzt problemlos für eine ganze Reihe an Projekten
nutzen, die ein LCD-Display mit kleinem Tastenfeld brauchen.
Ben B. schrieb:> rcall TERMINAL_SendLine ;Funktionsaufruf> Um den ganzen Rest, daß der Text dann auch irgendwie über die beiden> USARTs beim Display ankommt, kümmern sich andere Programmteile und die> Hardware, da brauche ich gar nicht mehr dran denken.
...genau! Und vermutlich hast du in allen deinen Unterprogrammen auch
nicht pausenlos loop1, loop1, loop1...
Je länger ich über die Frage des TO nachdenke, um so unverständlicher
(um es mal höflich auszudrücken) wird sie mir! Zumindest fragt da wohl
kein "gestandener" ASM-Programmierer :-)
Gruß Rainer