Hallo,
ich bin gerade dabei, mir die #define für die Register
zusammenzuschreiben.
Nun stehe ich vor dem Problem, dass ich aus dem Reference Manual nicht
erkennen kann, welche (zum Beispiel) 3 von den 5 USARTs in meinem µC
(STM32F103C8T6) nun benutzt werden. Dementsprechend müsste ich dann ja
auch die Speicheradressen setzen.
Sind das einfach die ersten 3 oder gibt es dafür irgendwo eine
Übersicht/Dokument?
Grüße
Leopold
Leopold N. schrieb:> ich bin gerade dabei, mir die #define für die Register> zusammenzuschreiben.
Warum das denn? Lade Dir doch das Cube HAL Firmware Paket für STM32F1
herunter und extrahiere davon das CMSIS Verzeichnis. Da hast du alle
Includes drin, in der von ARM spezifizierten Schreibweise.
Oder nimm sie aus meinem Beispielprojekt:
http://stefanfrings.de/stm32/index.html#cmsis
Da hast du dann auch gleich ein passendes Linkerscript und Startup-Code.
Im Datenblatt zum IC steht dann drinne welche Peripherie wirklich
vorhanden ist.
https://www.st.com/resource/en/datasheet/cd00161566.pdf
zB auf Seite 11 in der Übersicht.
Aber warum defines?
Die Registerdefinitionen packet man eigentlich in structs welche man
dann auf die Basiadresse "legt".
Für die Bits empfehlen sich enums.
Ja ich weiß, dass habe ich alles schon durchgelesen.
Ich finde es mit den Structs aber nicht sonderlich schön, und HAL hat ja
auch noch so einige Bugs hab ich gehört :)
Außerdem will ich den Controller verstehen, damit ich nachher weiß wovon
ich rede. Und wenn ich sowas wie HAL oder die Standard Lib benutze,
verstehe ich das Ganze nicht mal im Ansatz.
Grüße
Dann musst du aber für jeden SPI jedes Register 3 mal definieren:
SPI1_CR1
SPI2_CR1
SPI3_CR1
Das is doch Murks.
Vor allem kannste dann nicht mal eben die Funktionalität von SPI1 nach
SPI3 schieben, weils für das Layout besser passt, sondern musste dann
alle Namen ändern.
Nachdem du hier bereits kläglich gescheitert bist,
Beitrag "ST Link V2 Atollic TrueStudio"
glaubst du ernsthaft, das selber besser und -vor allem- fehlerfreier als
die ARM-Leute bei ST & Co zu können???
Ich lach mich schlapp!!!
Leopold N. schrieb:> Und wenn ich sowas wie HAL oder die Standard Lib benutze,> verstehe ich das Ganze nicht mal im Ansatz.
Die CMSIS enthält nur wenige Zeilen Code. Sie besteht zu 99% lediglich
aus den Defines, die du Dir gerade selbst erstellt.
Lass das doch bleiben, das ist Quatsch! Es führt nur zu Problemen, wenn
du später Hilfe anforderst und deine Defines und Makros anders heißen,
als der ARM Standard festlegt.
stefanus schrieb:> Leopold N. schrieb:>> Und wenn ich sowas wie HAL oder die Standard Lib benutze,>> verstehe ich das Ganze nicht mal im Ansatz.>> Die CMSIS enthält nur wenige Zeilen Code. Sie besteht zu 99% lediglich> aus den Defines, die du Dir gerade selbst erstellt.>> Lass das doch bleiben, das ist Quatsch! Es führt nur zu Problemen, wenn> du später Hilfe anforderst und deine Defines und Makros anders heißen,> als der ARM Standard festlegt.
Ich kann später ja immer noch umsteigen, aber für den Anfang geht es mir
erstmal darum, mir eine eigene Lib aufzubauen, um das Ganze von Grund
auf zu verstehen.
Grüße
Leopold
Leopold N. schrieb:> Kann ich uint_32 so definieren (ohne irgendeine Standard Lib vorher)?
Warum willst du das?
uint8_t und Konsorten sind seit fast 20 Jahren (in Worten: seit _zwanzig
Jahren_) im C-Standard enthalten!
Das ist wie eine Seuche, dass jeder meint, sich seinen uint8, uint_8,
u8, unsigned8, byte selbst definieren zu müssen.
Sven P. schrieb:> Leopold N. schrieb:>> Kann ich uint_32 so definieren (ohne irgendeine Standard Lib vorher)?>> Warum willst du das?> uint8_t und Konsorten sind seit fast 20 Jahren (in Worten: seit _zwanzig> Jahren_) im C-Standard enthalten!>> Das ist wie eine Seuche, dass jeder meint, sich seinen uint8, uint_8,> u8, unsigned8, byte selbst definieren zu müssen.
Verstehe ich, aber ich möchte so etwas mal wirklich von Grund auf bauen,
und alle Libs selber geschrieben haben (natürlich nicht so was gestörtes
wie USB oder so, aber zumindest die kleinen Dinge)
Also geht das so oder muss ich das anders machen?
Grüße
Leopold N. schrieb:> Ich kann später ja immer noch umsteigen, aber für den Anfang geht es mir> erstmal darum, mir eine eigene Lib aufzubauen, um das Ganze von Grund> auf zu verstehen.
Nein eben nicht. Verwende besser die eine Datei:
stm32f10x.h
Da steht alles drin was der µC so alles hat. Und baue genau auf der
einen Datei Deine eigene Lib auf und fange bitte nicht an alles neu zu
definieren was der µC kann.
Diese eine Datei ist NICHT die HAL von ST, sonder nur die
Register-Definition und Deklarationen. Es sind einige tausend Codezeilen
und mehrere 100KB, das willst Du nicht nochmal selbst erfinden, glaub
mir.
Um das ganze von Grund auf zu verstehen zu lernen, befasse dich besser
ein paar Tage mit dieser einen Datei - das wird dich weiter bringen.
Leopold N. schrieb:> Ich kann später ja immer noch umsteigen, aber für den Anfang geht es mir> erstmal darum, mir eine eigene Lib aufzubauen, um das Ganze von Grund> auf zu verstehen.
Da gibt's doch nichts zu verstehen. Die Defines sind eine laaaange Liste
von Register-Adressen. Was lernt man denn dabei, wenn man diese komplett
neu schreibt?
Hast du deinen Klassenlehrer angezickt und musst das nun als Strafarbeit
machen?
Verwende deine Zeit doch lieber damit, den Startup-Code aus meinem
Beispielprojekt zu analysieren. Der ist bereits auf ein vernünftiges
Minimum reduziert.
Leopold N. schrieb:> Könnt ihr mir nicht einfach meine Frage beantworten?
Guck doch in die CMSIS rein, oder ins Datenblatt. Wie viele Antworten
brauchst du denn noch?
Noch eine Frage:
Im Reference Manual steht für CAN zwei CANs drinne, obwohl ich nur einen
habe.
In dem anderen Dokument steht nur CAN drinne, nicht CAN1 oder CAN2.
An welcher Adresse starten denn nun die Register?
Grüße
Leopold N. schrieb:> Könnt ihr mir nicht einfach meine Frage beantworten?
Guck doch in die CMSIS rein, oder ins Datenblatt. Wie viele Antworten
brauchst du denn noch?
> Kann ich uint_32 so definieren
Kannst du, aber auch das ist Quatsch. Willst du jetzt im Ernst auch noch
die stdint.h neu erfinden? Warum schreibst du Dir nicht gleich einen
eigenen Compiler?
Wenn du unbedingt mal einen µC so von ganz unten programmieren willst,
dann mache das in Assembler mit einem 89C2051 - der ist wesentlich
simpler. Dein Vorhaben mit dem STM32 ist nur 50x Arbeitsintensiver aber
lernen tust du dabei fast nichts zusätzliches - ausser vielleicht Übung
im Tippen.
Stefanus F. schrieb:> Guck doch in die CMSIS rein, oder ins Datenblatt. Wie viele Antworten> brauchst du denn noch?
Du beantwortest damit immer noch nicht meine Frage.
Ich habe es im CMSIS Header File stm32f10x.h versucht und bin auf den
oben angehängten Ansatz gekommen.
Stimmt der so?
Leopold N. schrieb:> Stefanus F. schrieb:>> Guck doch in die CMSIS rein, oder ins Datenblatt. Wie viele Antworten>> brauchst du denn noch?>> Du beantwortest damit immer noch nicht meine Frage.> Ich habe es im CMSIS Header File stm32f10x.h versucht und bin auf den> oben angehängten Ansatz gekommen.> Stimmt der so?
Fehler: Hab das falsche Header File geschrieben.
Hab im stdint.h nachgeguckt.
Arduinator schrieb:> Beratungsresistenz ist eine Zier, doch weiter kommt man ohne Ihr.
Wenn du meine Frage nicht beantworten möchtest, dann schreib doch bitte
einfach gar nichts.
Leopold N. schrieb:> An welcher Adresse starten denn nun die Register?
Der STM32 hat 2 Datenblätter:
1) Reference Manual - da steht alles übergriefend für die ganze
Produktlinie drin
2) Datasheet - für jeden µC das Datenblatt mit den den Details und
Pin-Belegung.
Die Adressen stehen in 1) beim jeweiligen Peripheriemodul als
Basis-Adresse und die Register als Adressoffset zu der jeweiligen
Basisadresse.
Leopold N. schrieb:> Fehler: Hab das falsche Header File geschrieben.> Hab im stdint.h nachgeguckt.
Dann guck doch mal im richtigen Header-File:
stm32F10x.h
und lerne wie es die Profis machen, die viele Jahre Erfahrung haben.
Markus M. schrieb:> Leopold N. schrieb:>> An welcher Adresse starten denn nun die Register?>> Der STM32 hat 2 Datenblätter:>> 1) Reference Manual - da steht alles übergriefend für die ganze> Produktlinie drin>> 2) Datasheet - für jeden µC das Datenblatt mit den den Details und> Pin-Belegung.>> Die Adressen stehen in 1) beim jeweiligen Peripheriemodul als> Basis-Adresse und die Register als Adressoffset zu der jeweiligen> Basisadresse.
Ja, das habe ich auch bisher so gemacht, aber beim Peripherimodul steht
nur ein Verweis auf die Basisadresse. Der Verweis beim CAN ist ungültig
(falsches Kapitel angegeben, hat wohl jemand bei ST vergessen zu ändern)
und in der Memory Map steht CAN1 und CAN2 drin. Es gibt aber nur CAN
(ohne 1 oder 2). Ist das jetzt CAN1 oder CAN2 oder was ganz anderes
(adresstechnisch)?
Markus M. schrieb:> Dann guck doch mal im richtigen Header-File:>> stm32F10x.h>> und lerne wie es die Profis machen, die viele Jahre Erfahrung haben.
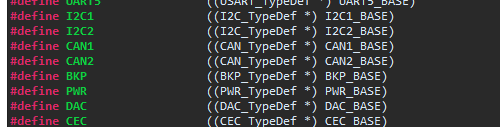
Da war ich bereits unterwegs, und die definieren 2 CANs (CAN1 und CAN2).
Für beide wird ein struct erstellt. Da es aber nur einen CAN gibt weiß
ich jetzt nicht welcher das ist.
Markus M. schrieb im Beitrag #5724555:
> Leopold N. schrieb:>> Ist das jetzt CAN1 oder CAN2 oder was ganz anderes>> (adresstechnisch)?>> Markus M. schrieb:>> Dann guck doch mal im richtigen Header-File:>>>> stm32F10x.h
Da du mir wohl nicht glaubst, hier der entsprechende Ausschnitt
(Anhang).
als Vorlage zum Abschauen, lernen, lade dich einfach mal dem Mikroe
Compiler runter.
Dort ist es, wenn ich richtig verstanden habe, genau so gemacht, wie Du
es vorhast.
Die Datei wäre also perfekt zum abschauen
Kim P. schrieb:> als Vorlage zum Abschauen, lernen, lade dich einfach mal dem> Mikroe> Compiler runter.> Dort ist es, wenn ich richtig verstanden habe, genau so gemacht, wie Du> es vorhast.> Die Datei wäre also perfekt zum abschauen
Grad gegoogelt, der kostet 300$ richtig?
Markus M. schrieb:> Im Datenblatt vom STM32F103 steht ja auch wie viele CAN's der hat.> Dann> wird das wohl oder übel ein einzelner der erste sein.
Aber du schätzst es auch nur oder steht das irgendwo?
Weil reintheoretisch könnte man ja - sofern man die Lib benutzt - CAN2
benutzen und somit irgendwo im RAM rumschreiben oder?
Grüße
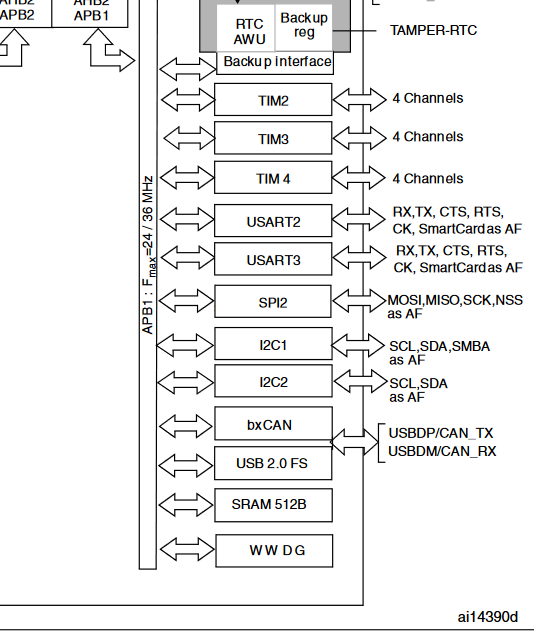
Leopold N. schrieb:> Sind das einfach die ersten 3 oder gibt es dafür irgendwo eine> Übersicht/Dokument?
Steht im Datenblatt. Ansonsten: spar dir das Abtippen, ich hatte das
schon vor langer Zeit erledigt:
https://www.mikrocontroller.net/attachment/316790/STM32F103C8T6.ZIP
Und von all dem Cube, ST-lib, ST-HAL und dessen Brüdern halte ich
relativ wenig. Man wird nur dazu ermuntert, den inneren Schweinehund
walten zu lassen und nicht zu lernen, was man da für ein Pferd zu reiten
beabsichtigt.
W.S.
Leopold N. schrieb:> Markus M. schrieb:>> Im Datenblatt vom STM32F103 steht ja auch wie viele CAN's der hat.>> Dann>> wird das wohl oder übel ein einzelner der erste sein.>> Aber du schätzst es auch nur oder steht das irgendwo?> Weil reintheoretisch könnte man ja - sofern man die Lib benutzt - CAN2> benutzen und somit irgendwo im RAM rumschreiben oder?>> Grüße
Nix RAM, bestenfalls ins Leere des IO-Bereichs, eventuell aber
BusFault/HardFault.
W.S. schrieb:> Leopold N. schrieb:>> Sind das einfach die ersten 3 oder gibt es dafür irgendwo eine>> Übersicht/Dokument?>> Steht im Datenblatt. Ansonsten: spar dir das Abtippen, ich hatte das> schon vor langer Zeit erledigt:>> https://www.mikrocontroller.net/attachment/316790/STM32F103C8T6.ZIP>> Und von all dem Cube, ST-lib, ST-HAL und dessen Brüdern halte ich> relativ wenig. Man wird nur dazu ermuntert, den inneren Schweinehund> walten zu lassen und nicht zu lernen, was man da für ein Pferd zu reiten> beabsichtigt.>> W.S.
Endlich mal jemand, der ähnlich denkt.
Das Abtippen würde ich jetzt trotzdem gerne nochmal machen, einfach um
auch einen Überblick zu bekommen, was der alles für Register und Module
hat, die man dann auch verwalten muss.
Mich interessiert einfach, wie das alles funktioniert.
Danke für deine Datei, an der werde ich mich orientieren.
Du hast beim CAN aber auch 2 CANs reingenommen, obwohl der nur einen
hat.
Grüße
Carl D. schrieb:> Nix RAM, bestenfalls ins Leere des IO-Bereichs, eventuell aber> BusFault/HardFault.
Mit der genauen Lokalisation der Register habe ich mich noch nicht
beschäftigt.
Also stehen die ganzen Peripherie Register in einfachem Speicher
getrennt vom SRAM?
Da ich gerne wie in Atmel Studio einfach durch (zum Beispiel)
PORTA = 0x13;
oder
sbi(PORTA, 3);
auf Register zugreifen möchte, habe ich überlegt, dass das doch so gehen
müsste (Beispiel):
#define CAN_TSR ((uint_32*) (BASE_ADDRESS_CAN + 0x08))
Damit habe ich doch einen Pointer auf die Adresse xxx.
Ein Zugriff ala
CAN_TSR = 0x00
würde doch eine 0 an die Adresse xxx schreiben, oder?
Oder muss noch ein Sternchen vor uint_32?
Grüße
So geht das bei STM32 mit den Definitionen der CMSIS:
1
GPIOA->ODR = 0x13; // Auf Port A den Wert 0x13 ausgeben
oder
1
GPIOA->BSRR=GPIO_BSRR_BS3; // Pin PA3 auf High setzen
2
GPIOA->BSRR=GPIO_BSRR_BR3; // Pin PA3 auf Low setzen
Wie gesagt braucht man dafür die CMSIS, keine hand-gedengelten
Register-Definitionen. Beim AVR schreibst du dir doch auch nicht die
ganzen Register-Definitionen und die libc selbst neu.
Stefanus F. schrieb:> Wie gesagt braucht man dafür die CMSIS, keine hand-gedengelten> Register-Definitionen.
Nich ganz, es kommt drauf an wie man Selbstdengelt.
Bei meinen Definitionen geht das ja auch in dieser Schreibweise.
Aber mal ne kurze Frage zu deinem F103 Tutorial:
Wieso hast du da Funktionen gebaut zum Register lesen/schreiben?
Leopold N. schrieb:> Carl D. schrieb:>> Nix RAM, bestenfalls ins Leere des IO-Bereichs, eventuell aber>> BusFault/HardFault.>> Mit der genauen Lokalisation der Register habe ich mich noch nicht> beschäftigt.> Also stehen die ganzen Peripherie Register in einfachem Speicher> getrennt
RAM: 0x20000000...$+20k
IO: 0x40000000...0x5fffffff (mit großen Lücken)
Es gibt das "Referenz Manual", das die ganze STM32F1-Serie im Detail
beschreibt und das "Datasheet", das Speicherlayout, Pinout und konkrete
Peripherie-Ausstattung einzelner Chips beschreibt. In ersterem steht
dann z.B. wie ein Advanced Timer zu bedienen ist und in letzterem
wieviele davon ein konkreter Chip besitzt, wo die "Device-Base"-Adressen
liegen und an welchen Pins man die einzelnen Signale abgreifen
kann/einspeisen muß.
Allzu unbedarft sollte man für Baremetall-Programmierung auf STM32 aber
nicht sein und mir hat ein ST/Link-Debugger(-Clone) geholfen, z.B Timer
und DMA-Zusammenspiel live zu testen. Wenn man eine IDE hat, die da
mitspielt.
Mw E. schrieb:> Wieso hast du da Funktionen gebaut zum Register lesen/schreiben?
Hab ich nicht. Das sind Markos aus der CMSIS und ich habe sie dort
hingeschrieben, damit man sie kennen lernt.
Die avr libc stellt ähnliche Makros bereit, zum Beispiel das von Dir
genannte sbi(). Dieses ist übrigens als "obsolete/deprecated"
gekennzeichnet - nur so nebenbei bemerkt.
Leopold N. schrieb:> Da ich gerne wie in Atmel Studio einfach durch (zum Beispiel)>> PORTA = 0x13;>> oder>> sbi(PORTA, 3);>> auf Register zugreifen möchte, habe ich überlegt, dass das doch so gehen> müsste (Beispiel):>> #define CAN_TSR ((uint_32*) (BASE_ADDRESS_CAN + 0x08))>> Damit habe ich doch einen Pointer auf die Adresse xxx.> Ein Zugriff ala>> CAN_TSR = 0x00
Im Prinzip schon, aber wenn dem Compiler bekannt gemacht wird, das die
Register in einer Struktur organisiert sind (bekannte Offsets zu einer
Basisadresse), dann erzeugt er deutlich kompakteren Code. Jedem Register
eine eigene Adresse zu geben verschleiert die "Nachbarschaft" der
Register.
Außerdem: es existieren meist mehrere Devices mit gleicher
Registerstruktur, die sich nur in der Basisadresse unterscheiden. Also
nur einmal hinschreiben.
Ich muss mal für stefanus aka Stefan Frings eine Lanze brechen: Er hat
wirklich eine gute Anleitung geschrieben, wie man den STM32F103 ohne das
ganze ST HAL Zeugs programmiert, genau so wie Leopold das eigentlich
will.
Unter http://stefanfrings.de/stm32/index.html ist dies alles zu finden.
Am Ende findet man dann auch W.S. wirklich brauchbaren USB Code. Stefan
hat sogar noch Zeit gefunden, dass ganze in Buchform zu schreiben:
http://stefanfrings.de/mikrocontroller_buch2/Einblick%20in%20die%20moderne%20Elektronik.pdf
Die verwendeten "Funktionen" WRITE_REG usw. sind eigentlich Makros und
stammen aus der stm32f10x.h Header Datei
Stefanus F. schrieb:> So geht das bei STM32 mit den Definitionen der CMSIS:> GPIOA->ODR = 0x13; // Auf Port A den Wert 0x13 ausgeben>> oder> GPIOA->BSRR=GPIO_BSRR_BS3; // Pin PA3 auf High setzen> GPIOA->BSRR=GPIO_BSRR_BR3; // Pin PA3 auf Low setzen>> Wie gesagt braucht man dafür die CMSIS, keine hand-gedengelten> Register-Definitionen. Beim AVR schreibst du dir doch auch nicht die> ganzen Register-Definitionen und die libc selbst neu.
Wie das mit CMSIS geht habe ich schon begriffen, aber ich wollte es ja
selber mal gemacht haben. Drum werd ich solche Beiträge in Zukunft
einfach ignorieren.
Stefanus F. schrieb:> Die avr libc stellt ähnliche Makros bereit, zum Beispiel das von Dir> genannte sbi(). Dieses ist übrigens als "obsolete/deprecated"> gekennzeichnet - nur so nebenbei bemerkt.
Das weiß ich, aber es sind nützliche Makros, an die ich mich gewöhnt
habe.
Deshalb möchte ich sie auch weiterhin nutzen.
Carl D. schrieb:> Außerdem: es existieren meist mehrere Devices mit gleicher> Registerstruktur, die sich nur in der Basisadresse unterscheiden. Also> nur einmal hinschreiben.
Das mit den Basisadressen behalte ich auch bei.
Nur die structs möchte ich loswerden.
Leopold N. schrieb:> Danke für deine Datei, an der werde ich mich orientieren.
Mach es nicht, so programmiert heute niemand ernsthaft mehr C.
Das ist Masochismus, was W.S. da treibt.
Ich krieg schon Zahnfleischbluten, wenn ich den ganzen Mist mit wilder
Bitfrickelei da sehe. Und die Konsequenz ist, dass alles dreifach
kopiert wird, weil es z.B. drei UARTs gibt. Mit CMSIS wäre das nicht
passiert.
Das hat schon einen Sinn, warum die CMSIS Bitnamen definiert und mit
Peripherie-Offsets arbeitet.
Leopold N. schrieb:> Das weiß ich, aber es sind nützliche Makros, an die ich mich gewöhnt> habe.> Deshalb möchte ich sie auch weiterhin nutzen.
Und warum?
Sie helfen dir exakt garnicht.
Viel schlimmer noch, sie verhindern, dass du mal verstehst, wie Zugriffe
über den AHB laufen. Viel Spaß beim Fehlersuchen.
Achso, CAN1 und CAN2 sind Instanzen von CAN, falls das noch hilft.
Sven P. schrieb:> Sie helfen dir exakt garnicht.> Viel schlimmer noch, sie verhindern, dass du mal verstehst, wie Zugriffe> über den AHB laufen. Viel Spaß beim Fehlersuchen.>> Achso, CAN1 und CAN2 sind Instanzen von CAN, falls das noch hilft.
Das weiß ich schon alles, schließlich habe ich mir das CMSIS File
durchgelesen.
Aber dennoch hat jeder CAN Controller eine eigene Hardware mit einer
eigenen Adresse, die hier nicht eindeutig ist, da es nur einen CAN
Controller gibt aber zwei Adressen.
Leopold N. schrieb:> Aber dennoch hat jeder CAN Controller eine eigene Hardware mit einer> eigenen Adresse, die hier nicht eindeutig ist, da es nur einen CAN> Controller gibt aber zwei Adressen.
Dieser Satz widerspricht sich selbst zweifach doppelt gemoppelt.
> Das weiß ich schon alles, schließlich habe ich mir das> CMSIS File durchgelesen.
Ach so, und warum fragst du dann nach den Adressen?
den mikroe Comipiler kannst du KOSTENLOSS runterladen!!!
Er hat halt nru eine KB Grenze beim erstellen von Progrmmane..aber Du
solslt ja auch keien programme damit erstellen sondenr nur die
Definitionsdaei füde n Controler rauskopieren aus dem Ordner...
Leopold N. schrieb:> Markus M. schrieb:>> Dann guck doch mal im richtigen Header-File:>>>> stm32F10x.h>>>> und lerne wie es die Profis machen, die viele Jahre Erfahrung haben.>> Da war ich bereits unterwegs, und die definieren 2 CANs (CAN1 und CAN2).> Für beide wird ein struct erstellt. Da es aber nur einen CAN gibt weiß> ich jetzt nicht welcher das ist.
Siehe dieser Post, solltest vllcht mal den ganzen Thread lesen...
Kim P. schrieb:> den mikroe Comipiler kannst du KOSTENLOSS runterladen!!!> Er hat halt nru eine KB Grenze beim erstellen von Progrmmane..aber Du> solslt ja auch keien programme damit erstellen sondenr nur die> Definitionsdaei füde n Controler rauskopieren aus dem Ordner...
Ah ok,
ja werde ich mal probieren.
Danke
Leopold N. schrieb:> Die Frage mit dem typedef vom uint_32 ist noch offen...
ja, sollte mit dem GCC so gehen, da beim GCC "__UINT32_TYPE__" ein
vordefiniertes Macro ist.
Ich empfehle aber trotzdem die Vorschläge meiner Vorredner zu beherzigen
und dafür stdint.h zu nutzen, weil das eben einfach standard ist.
Was die Register angeht schließe ich mich auch meinen Vorrednern an und
empfehle dir die vordefinierten #defines und structs zu nutzen. Die
Bezeichner decken sich 1:1 mit den Bezeichnungen im Reference Manual und
man kann wunderbar damit arbeiten. Da nochmal für nix alles neu zu
schreiben halte ich für groben Unfug, es sei denn du möchtest einen
obfuscated code contest gewinnen und/oder du möchtest dadurch deinen
Arbeitsplatz langfristig sichern, weil wirklich außer dir niemand mehr
durchblickt. Bei letzterem besteht das Risiko, dass du aus genau diesem
Grund deinen Job verlierst aber ymmv.
Wenn du tatsächlich was über den Controller lernen willst, schnapp dir
den "Definitive Guide to Arm Cortex" von Joseph Yiu, das Reference
Manual und die CMSIS-Header und leg los. Abgesehen von der Peripherie
gibt es noch andere Dinge, wie z.B. das Interrupt-System oder etwa
Startup-Code und Linker-Scripte die verstanden werden wollen, vor allem
wenn du z.B. gedenkst mal einen eigenen Bootloader zu schreiben.
Leopold N. schrieb:> Carl D. schrieb:>> Außerdem: es existieren meist mehrere Devices mit gleicher>> Registerstruktur, die sich nur in der Basisadresse unterscheiden. Also>> nur einmal hinschreiben.>> Das mit den Basisadressen behalte ich auch bei.> Nur die structs möchte ich loswerden.
Also kurz: hoffnungslos.
Carl D. schrieb:> Also kurz: hoffnungslos.
... ja und umfänglich ahnungslos + grob beratungsresistenz, sprich -
halt das übliche und weitverbreitete mittelmaß - bäh!
mt
Mw E. schrieb:> Für die Bits empfehlen sich enums.
Für Bitmasken nimmt man keine enums, sondern defines. Wie sinnfrei enums
an der Stelle sind, merkt man schon daran, daß Du die enums nicht
benennst und die Register auch nicht von dem Typ des jeweiligen enums
nutzt.
Leopold N. schrieb:> Die Frage mit dem typedef vom uint_32 ist noch offen...
Warum soll die denn noch offen sein?
Hab nicht mitgezählt, aber es waren mehr wie 3 Antworten.
So wie du es in deinem Code-Ausschnitt gemacht hast...kann man machen,
ist halt kacke!
1) Hat deine *.h keinen Include-Guard
2) Kein Schutz vor Mehrfach-Define deiner uint32_t
Nimm die stdint.h und falls du was wissen willst, lies es dort nach!
...
Wenn ich Backen lernen möchte, dann fang ich doch auch nicht an und
lerne wie man Mehl herstellt :-/
Bei den ADCs habe ich das Problem, das die Register alle ADC_xxx heißen,
es aber 2 ADCs gibt.
Teilen sich beide ADCs diese Register oder hat jeder ADC einen eigenen
Satz dieser Register.
Bei den GPIOx_ mit x=A...G war das eindeutig, ist das bei den ADCs
genauso?
Betrifft auch die SPIs und die USARTs.
#define BASE_PERIPHERAL ((uint32_t) 0x40000000)
#define OFFSET_APB2 ((uint32_t) (BASE_PERIPHERAL + 0x00010000))
#define BASE_ADDRESS_GPIO_A ((uint32_t) (OFFSET_APB2 + 0x00000800))
#define GPIO_A_ODR *((uint32_t*) (BASE_ADDRESS_GPIO_A + 0x0C))
Wenn ich ein Register so definiere, dann kann ich einen uint32_t x
folgendermaßen in das Register schreiben oder?
GPIO_A_ODR = x;
Lesen natürlich analog dazu:
uint32_t x = GPIO_A_ODR;
Oder mache ich da jetzt einen Fehler?
Leopold N. schrieb:> Bei den ADCs habe ich das Problem, das die Register alle ADC_xxx heißen,> es aber 2 ADCs gibt.>> Teilen sich beide ADCs diese Register oder hat jeder ADC einen eigenen> Satz dieser Register.> Bei den GPIOx_ mit x=A...G war das eindeutig, ist das bei den ADCs> genauso?>> Betrifft auch die SPIs und die USARTs.
Ich würde mir doch mal überlegen, ob die Leute mit der
Struktur/Basisadresse wirklich so falsch liegen. Die kennen nämlich des
Rätsels Lösung.
Carl D. schrieb:> Ich würde mir doch mal überlegen, ob die Leute mit der> Struktur/Basisadresse wirklich so falsch liegen. Die kennen nämlich des> Rätsels Lösung.
Nun, ich hätte mir überlegt, dass aufgrund der Tatsache, dass für ADC1
und ADC2 jeweils eine eigene Basisadresse definiert ist im RM, dass
jeder ADC einen eigenen Registersatz hat.
Explizit steht das aber nicht im RM wie bei den GPIOx_ oder den TIMERx_
Registern.
Wäre nett, wenn "diese Leute" mir mal des Rätsels Lösung mitteilen
könnten, dann müsste ich denen nämlich nicht alles aus der Nase ziehen.
Außerdem habe ich ja die Struktur mit den Basisadressen beibehalten, nur
halt ohne die Structs. Und wenn du ein Problem damit hast, dass ich Bock
hab meinen eigenen Code zu schreiben, dann antworte doch einfach nicht
mehr.
Leopold N. schrieb:> Wenn ich ein Register so definiere, dann kann ich einen uint32_t x> folgendermaßen in das Register schreiben oder?>> GPIO_A_ODR = x;
ja, sollte gehen, die Offsets habe ich aber nicht überprüft.
Mit dem Standard-Header:
GPIOA->ODR = x;
oder analog für GPIOB:
GPIOB->ODR = x;
Leopold N. schrieb:> Lesen natürlich analog dazu:>> uint32_t x = GPIO_A_ODR;
Bei Open-Drain Ausgängen kann man eine 1 "schreiben" obwohl das Signal
in Wirklichkeit low ist aber ansonsten ginge das auch so, ja.
analog
x = GPIOA->ODR;
Leopold N. schrieb:> Teilen sich beide ADCs diese Register oder hat jeder ADC einen eigenen> Satz dieser Register.
Jeder ADC hat seine eigenen Register (abgesehen vom Multimode, wo der
ADC2 ein paar Register vom ADC1 nutzt aber das ist eine Besonderheit bei
den ADC und gibt es so nicht bei UART, SPI oder Timern).
ADC1->CR1 = y; // schreibt ins CR1 von ADC1
ADC2->CR1 = z; // schreibt ins CR1 von ADC2
Leopold N. schrieb:> Explizit steht das aber nicht im RM wie bei den GPIOx_ oder den TIMERx_> Registern.
Ich bin mir ziemlich sicher das es irgendwo steht.
Danke für die Antwort.
Das hat mir schonmal sehr geholfen.
Ich habe den entsprechenden Abschnitt im RM wohl noch nicht gefunden
(kein Wunder, ist ja nur 1132 Seiten lang).
Nächste Frage:
Ich habe meinen Code minimiert, unter anderem alle Std_Peripheral Libs
rausgeschmissen und nur das CMSIS Zeug dringelassen (auch die stdint.h,
damit dürfen ein paar Leute hoffentlich beruhigt sein).
Wenn ich diesen Minimalcode (Anhang) nun compiliere, kommt eine Warnung
(Anhang).
Hätte hier jemand eine Liste für mich, was (neben dem Reset Handler)
noch alles mindestens gemacht werden muss?
PS: In General Defines stehen nur ein paar sbi und cbi Makros.
Leopold N. schrieb:> Hätte hier jemand eine Liste für mich, was (neben dem Reset Handler)> noch alles mindestens gemacht werden muss?
Der restliche Kram der im Startup-Code gemacht wird, d.h. RAM nullen,
.data aus dem Flash ins RAM kopieren und die Interrupt-Vektoren anlegen,
sofern man denn Interrupts nutzen möchte.
Ich würde aber erstmal den vorhandenen Startup-Code nehmen und versuchen
den zu verstehen.
Irgendwelche Fehlermeldungen bitte immer als Text und nicht als Bild und
erst recht nicht mit schwarzer Schrift auf grauem Grund!
Christopher J. schrieb:> Leopold N. schrieb:>> Hätte hier jemand eine Liste für mich, was (neben dem Reset Handler)>> noch alles mindestens gemacht werden muss?>> Der restliche Kram der im Startup-Code gemacht wird, d.h. RAM nullen,> .data aus dem Flash ins RAM kopieren und die Interrupt-Vektoren anlegen,> sofern man denn Interrupts nutzen möchte.>> Ich würde aber erstmal den vorhandenen Startup-Code nehmen und versuchen> den zu verstehen.>> Irgendwelche Fehlermeldungen bitte immer als Text und nicht als Bild und> erst recht nicht mit schwarzer Schrift auf grauem Grund!
Ja, ich wollte mich an dem Startup-Code von ST orientieren.
Sry wegen der Farben...habe ich nicht dran gedacht.
Werde mich morgen weiter damit beschäftigen, für heute reichts.
Gute Nacht
du kannst den Startup-Code auch in C schreiben, auch wenn das ein paar
Fallstricke bietet. Ich hatte vor ein paar Jahren mal was von Bernd K.
aus dem Forum auf den F103C8 angepasst, inklusive PLL-Setup:
https://github.com/ChristianRinn/bare_metal_stm32f103c8/blob/master/src/STM32F103C8/gcc_startup_system.c
In dem Repo sind auch noch ein paar Minimalbeispiele für Timer, GPIO und
ADC drin.
PS: Wenn du wissen willst was die Welt im innersten zusammenhält dann
hol dir den "Definitive Guide to ARM Cortex-M3 and M4" von Joseph Yiu.
Damit hast du die Chance zu verstehen was der Controller ab dem ersten
Takt macht.
Leopold N. schrieb:> Wäre nett, wenn "diese Leute" mir mal des Rätsels Lösung mitteilen> könnten
Wie gesagt kannst du das dem Referenzhandbuch und den CMSIS Dateien
entnehmen. Die Struktur der CMSIS Dateien ist von ARM Spezifiziert und
kann daher als Teil der offiziellen Dokumentation betrachtet werden.
Du brauchst dort auch keine Bugs zu befürchten. Die Bugs die hier
diskutiert werden, beziehen sich auf Codeschnipsel der HAL und was der
CubeMx Generator erzeugt. Die CMSIS ist hingegen ziemlich statisch.
Übrigens bauen auch HAL und die ältere SPL auf CMSIS auf. Warum auch
nicht? Wirklich alle ARM Controller von allen Herstellern werden mit
einer CMSIS ausgeliefert, darauf kannst du dich verlassen.
Ein ältere Ausgabe von dem hier so oft genannten YUI Buch findest du
hier kostenlos:
https://www.eecs.umich.edu/courses/eecs373/labs/refs/M3%20Guide.pdf
Was den STM32F103 angeht ist dieses noch aktuell. Die aktuelle Fassung
hat zusätzliche Infos für den Cortex M4, der STM32F103 ist aber ein
Cortex M3.
Leopold N. schrieb:> (natürlich nicht so was gestörtes> wie USB oder so, aber zumindest die kleinen Dinge)
Geht aber sogar: USB-Tutorial mit STM32
Hat hier eigentlich noch keiner die SVD-Files erwähnt? Das ist eine
Sammlung maschinenlesbarer XML-Dateien mit allen Registerdefinitionen.
Daraus kann man sich dann seine eigenen Header bauen. Die können dann
genau so wie die stm32f103xx.h aussehen ohne die Tastatur komplett
abzunutzen.
Die sind m.W. in den Device Packs enthalten:
https://www.keil.com/dd2/pack/https://www.keil.com/cmsis/svd
Wenn man es schon selbst macht wäre es etwas innovativer die Adressen
per Linkerscript anzugeben:
1
externuint32_tGPIOA_BSRR;
2
3
intmain(){
4
GPIOA_BSRR=0x1;
5
}
und im LD-Script:
1
GPIOA_BSRR = 0x40010810;
Dadurch hätte man sauberen standardkonformen C-Code ohne die hässlichen
Casts und Makros. Besser natürlich per struct statt einzelnen Registern.
Leopold N. schrieb:> Nächste Frage:
Du hast Leerzeichen in den Dateinamen der Code-Files? Mutig...
Niklas G. schrieb:> Wenn man es schon selbst macht wäre es etwas innovativer die Adressen> per Linkerscript anzugeben:>> extern uint32_t GPIOA_BSRR;>> int main () {> GPIOA_BSRR = 0x1;> }>> und im LD-Script:> GPIOA_BSRR = 0x40010810;
Dann musst Du aber trotzdem noch einen riesen Header pflegen und um die
ganzen externs zu beinhalten, am Ende pflegst Du die
Registerdefinitionen dann in 2 gleich großen Dateien, pro Definition in
jedem der beiden je eine Zeile, unterm Strich also nichts gewonnen, nur
maximal exzentrisch gelöst und ein herzhaftes "WTF??" bei jedem Leser
wäre vorprogrammiert.
Im andern Fall (wie man es normalerweise macht) kann alles in einer
einzigen Headerdatei gepflegt werden ohne alle Namen doppelt
hinschreiben zu müssen.
> standardkonformen C-Code ohne die hässlichen Casts und Makros.
Casts und Makros sind standardkonform. Und hässlich müssen die auch
nicht sein, die kann man sauber und geradeaus hinschreiben (so wie in
den CMSIS-Headern bereits geschehen) ohne irgendwelche obskuren
Verrenkungen zu machen. Die CMSIS-Header sind absolut sauber und gut
lesbar, die haben absolut nichts hässliches an sich.
Über die verkrampfte STM32 HAL und deren (Un)Nützlichkeit und
(Un)Eleganz kann man trefflich streiten aber an den CMSIS Headern ist
eingentlich absolut nichts auszusetzen, die verwende ich gerne.
Bernd K. schrieb:> Dann musst Du aber trotzdem noch einen riesen Header pflegen und um die> ganzen externs zu beinhalten,
Ja, das muss man dann automatisieren.
Bernd K. schrieb:> unterm Strich also nichts gewonnen
"Möglichst kompakt" war sowieso nie das Ziel...
Bernd K. schrieb:> Casts und Makros sind standardkonform.
Das Casten von beliebigen Zahlen auf Zeiger aber nicht. Durch die
Auslagerung ins Linkerscript wird dies vor C versteckt. Dadurch kann man
die Register-Zeiger auch an C++-templates übergeben, was bei Makros mit
Casts nicht geht!
Bernd K. schrieb:> Die CMSIS-Header sind absolut sauber und gut> lesbar, die haben absolut nichts hässliches an sich.
Ich finde mehrfach verschachtelte Textersetzungen grundsätzlich
hässlich.
Bernd K. schrieb:> maximal exzentrisch gelöst
Wenn man das Rad schon zum 100. Mal neu erfindet kann man wenigstens mal
was neues probieren...
Niklas G. schrieb:> Das Casten von beliebigen Zahlen auf Zeiger aber nicht.
Das ist wahrscheinlich Implementation-defined. Und die Untermenge der
Implementierungen auf denen Adressen als Zahlen ausgedrückt werden
können umfasst alle Implementierungen auf denen die betreffenden
Register die hier definiert werden überhaupt existieren. Es handelt sich
hier also um ein rein akademisches Nicht-Problem das sich bei genauerem
Hinsehen in Luft auflöst.
Bernd K. schrieb:> Es handelt sich> hier also um ein rein akademisches Nicht-Problem das sich bei genauerem> Hinsehen in Luft auflöst.
Kannst du dieses Problem dann bitte mal durch Hinsehen auflösen:
Florain schrieb:> Steht im Datenblatt.> Aber warum machst Du das? Das gibt es doch schon fix und fertig von ST.
Es ist im professionellen Umfeld durchaus üblich das Zeug selbst zu
schreiben, weil ST einem nicht garantiert, dass die Werte stimmen. Die
sollten zwar generiert sein , aber ich habe schon einige male (nicht bei
ST) erlebt, dass Bits verrutscht waren.
Stefanus F. schrieb:> Lade Dir doch das Cube HAL Firmware Paket für STM32F1> herunter
Jeder, der auf Cube verweist hat wohl selbst noch nie in den Code von
Cube geschaut. Ein gravierender Fehler zum Beispiel: Es wird RAM
benutzt, den es laut Datenblatt nicht gibt. Das funktioniert nur, weil
STM den nicht hinaus-fused und jeder Controller immer den maximal
verfügbaren seiner Familie enthält. STM sagt aber, dass sie die, nicht
im Datenblatt angegebenen, Speicherbereiche nicht testen. Somit läuft
fast jeder Code auf STM Controllern mit nicht getestetem RAM.
Link zum Thema: Beitrag "SRAM Lücke STM32Fxxx, Linkerskripte falsch"
Meines Wissens ist das bis heute nicht repariert.
M. H. schrieb:> aber ich habe schon einige male (nicht bei> ST) erlebt, dass Bits verrutscht waren.
Beim STM32F373 war (ist?) das Conversion Done Bit des SD-ADC falsch
definiert (als Overrun Bit) sodass man das erste Ergebnis verpasst und
ggf. einen Zeitversatz erhält... Ob das allerdings auch in der SVD
falsch ist weiß ich nicht.
> Stefanus F. schrieb:> Lade Dir doch das Cube HAL Firmware Paket für STM32F1 herunterM. H. schrieb:> Jeder, der auf Cube verweist hat wohl selbst noch nie in den Code von> Cube geschaut.
Ich habe nicht auf Cube HAL verwiesen, sondern auf die CMSIS. Die kann
man bei ST nicht mehr einzeln downloaden.
Stefanus F. schrieb:> M. H. schrieb:>> Es ist im professionellen Umfeld durchaus üblich das Zeug selbst zu>> schreiben>> Das übersteigt meine Vorstellungkraft.
gerade, wenn deine software TÜV oder ander Sachen bekommen soll, musst
du nachweisen, dass alles "prozesskonform" gemacht wurde. Das geht mit
vordefinierten Files nicht. Deshalb müssen in so einem Fall die
Entwickler selber ran.
Niklas G. schrieb:> Kannst du dieses Problem dann bitte mal durch Hinsehen auflösen:> #include <cstdint>>> #define GPIOA_BSRR (*((volatile uint32_t*) 0x40010810))
So (also mit eingebautem Dereferenzier-Operator) definiert man das
üblicherweise auch nicht sondern man macht das sauber so wie das in den
CMSIS Headern gelöst ist, dann bekommst Du einen sauberen Pointer und
keinen Fetzen C mit einem Pointer zwischendrin.
M. H. schrieb:> gerade, wenn deine software TÜV oder ander Sachen bekommen soll, musst> du nachweisen, dass alles "prozesskonform" gemacht wurde. Das geht mit> vordefinierten Files nicht. Deshalb müssen in so einem Fall die> Entwickler selber ran.
Schreiben die sich auch ihren einene Compiler? Wie soll man sonst
nachweisen, dass alles "konform" ist?
Stefanus F. schrieb:> Schreiben die sich auch ihren einene Compiler? Wie soll man sonst> nachweisen, dass alles "konform" ist?
Das ist ein Knackpunkt an der Sache. Für STM verwendet man zum Beispiel
nen Keil Compiler, der zugelassen ist.
Gibt auch Hersteller, die gewisse geprüfte GCCs (natürlich für viel
Geld) verkaufen.
Generell gilt:
Der Compiler ist aber auch nicht komplett zugelassen. Ein Klassiker ist,
dass der Code -O0 kompiliert werden muss.
M. H. schrieb:> Das ist ein Knackpunkt an der Sache. Für STM verwendet man zum Beispiel> nen Keil Compiler, der zugelassen ist.
Ja schön, sowit ich weiss liefert Keil aber auch einen Satz CMSIS Files
dazu. Wenn man dem Compiler vertraut, dann kann man sicher auch den
CMSIS Headern der selben Firma vertrauen, oder nicht?
Siehe http://www2.keil.com/mdk5/cmsis/driver
Stefanus F. schrieb:> M. H. schrieb:>> Das ist ein Knackpunkt an der Sache. Für STM verwendet man zum Beispiel>> nen Keil Compiler, der zugelassen ist.>> Ja schön, sowit ich weiss liefert Kein aber auch einen Satz CMSIS Files> dazu. Wenn man dem Compiler vertraut, dann kann man sicher auch den> CMSIS Headern der selben Firma vertrauen, oder nicht?
Kommt drauf an, ob die da eben die selben Zulassungen erfüllen. Wie
gesagt: Es kann schon soweit gehen, dass nur ein einziger Aufruf eine
Compilers zugelassen ist. Die einzige Variable ist dann das C-File.
M. H. schrieb:> Stefanus F. schrieb:>> M. H. schrieb:>>> Das ist ein Knackpunkt an der Sache. Für STM verwendet man zum Beispiel>>> nen Keil Compiler, der zugelassen ist.>>>> Ja schön, sowit ich weiss liefert Kein aber auch einen Satz CMSIS Files>> dazu. Wenn man dem Compiler vertraut, dann kann man sicher auch den>> CMSIS Headern der selben Firma vertrauen, oder nicht?>> Kommt drauf an, ob die da eben die selben Zulassungen erfüllen. Wie> gesagt: Es kann schon soweit gehen, dass nur ein einziger Aufruf eine> Compilers zugelassen ist. Die einzige Variable ist dann das C-File.
Das sind ja echt schränge Anforderungen. Gut dass ich mich mit so etwas
nicht herumschlagen muss.
Stefanus F. schrieb:> Das sind ja echt schränge Anforderungen. Gut dass ich mich mit so etwas> nicht herumschlagen muss.
Ja. Aber in manchen Bereichen (Luftfahrt, Automobil, Bahn etc...) ist
sowas üblich. Stell dir vor, du willst eine sichere Software
(Brandmeldeanlage, Schinenleitsysteme, o.ä.) entwickeln und nutzt
CubeMX. Das tut zwar irgendwie. Wenn man aber genau hinschaut, verwendet
deine SW dann RAM, der nicht von ST getestet wurde, und den es laut
Datenblatt nicht gibt. Das ist schon schwierig zu begründen, warum man
das so macht. Und wenn du Pech hast, kommt das Ganze durch den
TÜV/andere Kontrollinstanz und wird freigegeben und DANN merkst du, dass
es falsch ist. Dann geht der Spaß erst richtig los. Dann darfst du das
ändern und musst Auswirkungsanaysen etc machen. Das können dann mehrere
Monate werden, bis da wieder alles im Lot ist. Und du hast natürlich das
Problem, dass dein Prozess dann offenbar Murks ist.
Ansich ist es ja nicht wichtig, dass du nachweist, dass es richtig
gemacht wurde, sondern, dass es nach dem Prozess gemacht wurde. Bisschen
schräg ist das schon manchmal.
M. H. schrieb:> Stefanus F. schrieb:>> M. H. schrieb:>>> Das ist ein Knackpunkt an der Sache. Für STM verwendet man zum Beispiel>>> nen Keil Compiler, der zugelassen ist.>>>> Ja schön, sowit ich weiss liefert Kein aber auch einen Satz CMSIS Files>> dazu. Wenn man dem Compiler vertraut, dann kann man sicher auch den>> CMSIS Headern der selben Firma vertrauen, oder nicht?>> Kommt drauf an, ob die da eben die selben Zulassungen erfüllen. Wie> gesagt: Es kann schon soweit gehen, dass nur ein einziger Aufruf eine> Compilers zugelassen ist. Die einzige Variable ist dann das C-File.
Das ist ja lächerlich. So tief bücke ich mich nicht. Das sollen
meinetwegen andere machen denen das eigene Ich nichts mehr wert ist, die
haben doch nicht mehr alle Tassen im Schrank, wie kann man so tief
sinken sowas freiwillig mitzumachen? Vollkommen lächerlich!
Bernd K. schrieb:> So (also mit eingebautem Dereferenzier-Operator) definiert man das> üblicherweise auch nicht sondern man macht das sauber so wie das in den> CMSIS Headern gelöst ist
Stimmt; wenn man einen Pointer statt Referenz verwendet
test.cc:10:26: error: '(volatile uint32_t*)1073809424' is not a valid template argument for 'volatile uint32_t* {aka volatile long unsigned int*}' because it is not the address of a variable
16
writeReg<GPIOA_BSRR> (42);
Bernd K. schrieb:> wie kann man so tief> sinken sowas freiwillig mitzumachen? Vollkommen lächerlich!
Gibt wahrscheinlich gutes (Schmerzens-)Geld. Und wenn man nie vom süßen
Nektar der modernen Programmierung gekostet hat, weiß man auch nicht was
man verpasst...
Niklas G. schrieb:> Und wenn man nie vom süßen> Nektar der modernen Programmierung gekostet hat, weiß man auch nicht was> man verpasst...
Was ist das? Etwa so: Hurra, mein Matlab Script funktioniert, wie bekomm
ich die 2MB generierten Code jetzt auf den kleinen Cortex M0 auf der
Schaltung die mitsamt Stecker in eine 30mm lange M8 Hülse passen muss
und nicht mehr als 5mA ziehen darf? Geht nicht? OK - Ablage Rund.
Undurchführbar. Nächtes Projekt! So modern ungefähr?
Bernd K. schrieb:> Hurra, mein Matlab Script funktioniert, wie bekomm ich die 2MB> generierten Code
Der Witz an C++ ist ja, dass es mindestens genauso effizient wie C ist
(in Sachen Größe und Geschwindigkeit) und man dennoch sauberer
abstrahieren und strukturieren kann.
Hallo,
zum Thema sicherheitsrelevante Software:
Entweder man verwendet eine zertifizierte Toolkette (und dann gibt es
tatsächlich Einschränkungen, die aber inzwischen bei weitem nicht mehr
so drastisch sind), oder man gestaltet die Toolkette so, dass z.B.
Compiler und Linker nicht im kritischen Pfad sind (was mehr Teste des
Compilats bedeutet).
Selber Headerfiles schreiben kommt aber zumindest in der
Automobilindustrie nicht (mehr) vor. Aerospace mag anders sein, hier
wird dann aber der wirklich sicherheitsrelevante Code von verschiedenen
Teams auf verschiedenen Architekturen mehrfach redundant implementiert
und eine einzelne Zeile kann auch mal in die 5-Stelligen Euro-Regionen
kommen (also z.B. Lageregler mit 100 Zeilen Code = 1 Mio Euro).
Schöne Grüße,
Martin
Bernd K. schrieb:> Das ist ja lächerlich. So tief bücke ich mich nicht. Das sollen> meinetwegen andere machen denen das eigene Ich nichts mehr wert ist, die> haben doch nicht mehr alle Tassen im Schrank, wie kann man so tief> sinken sowas freiwillig mitzumachen? Vollkommen lächerlich!
Beispiel: du baust für einen Zug ein Schienenleitsystem. Du debugst das.
Alles tut. Jetzt schaltest du den Compiler auf release. Alles tut
weiterhin. Drei Jahre später verunglückt ein Zug mit mehreren Toten.
Dann kommt raus, dass die SW aufgrund eines Compilerfehlers nicht
richtig funktioniert hat.
Da will ich als Entwickler lieber nicht Schuld sein. Deswegen der
Aufwand. Ich sitze selbst häufiger in Verkehrsmittlen, in denen Code
läuft, mit dem ich zumindest zu tun hatte. Teilweise ist das sehr
beunruhigend. Wobei man sagen muss, dass es in der Luftfahrt eigentlich
geht. Da läuft halt alles weiter, auch wenn's nen Fehler gab, weil
ausgehen ist meist keine gute Option.
Bernd K. schrieb:> Niklas G. schrieb:>> Kannst du dieses Problem dann bitte mal durch Hinsehen auflösen:>> #include <cstdint>>>>> #define GPIOA_BSRR (*((volatile uint32_t*) 0x40010810))>> So (also mit eingebautem Dereferenzier-Operator) definiert man das> üblicherweise auch nicht sondern man macht das sauber so wie das in den> CMSIS Headern gelöst ist, dann bekommst Du einen sauberen Pointer und> keinen Fetzen C mit einem Pointer zwischendrin.
Aber genau so macht es doch das CMSIS, außer das anstatt dem uint32_t
z.b. eine Struktur verwendet wird:
[c]
typedef struct
{
...
} NVIC_Type;
#define SCS_BASE (0xE000E000UL)
#define NVIC_BASE (SCS_BASE + 0x0100UL)
#define NVIC ((NVIC_Type *) NVIC_BASE)
[c]
oder wie meinst du wäre es richtig?
M. H. schrieb:> Da will ich als Entwickler lieber nicht Schuld sein.
So eine lustige Zertifizierung macht die Toten nicht lebendiger.
Wie kommt man überhaupt auf die Idee, einen sicherheitsrelevanten Build
nicht zu testen? Unterschiede zwischen Optimierungsstufen sind nun
wirklich überhaupt keine Neuheit.
Adam P. schrieb:> Aber genau so macht es doch das CMSIS, außer das anstatt dem uint32_t> z.b. eine Struktur verwendet wird:
Das CMSIS-makro ergibt einen Zeiger. Der andere Stil der mir nicht
gefällt ergibt einen Zeiger an dem links gleich noch das
Dereferenzier-Sternchen dran klebt. Ist Geschmackssache. Den CMSIS-Stil
find ich weitaus eleganter.
Jemand schrieb:> Unterschiede zwischen Optimierungsstufen sind nun> wirklich überhaupt keine Neuheit.
Unterschiede zwischen Optimierungsstufen werden von falschem Code
ausgelöst.
Anstatt aber die Ursache genau dort zu suchen und zu verhindern schreibt
man lieber dem Compiler die Schuld zu oder tut so als ob der Code in
Ordnung wäre nur weil er mit diesem einen zertifizierten Compiler mit
genau diesen zertifizierten Einstellungen rein zufällig das gewünschte
Ergebnis liefert. Dieses Verhaltensmuster ist tatsächlich keine Neuheit.
Solche Trial-and-error Programmierer kennen wir alle zur Genüge. Und es
ist daher ein trauriges Armutszeugnis für alle Zertifizierhanseln und
für alle die davon überzeugt sind daß diese bizarre Ausgeburt der
Lächerlichkeit der richtige Weg ist und dieses hilflose Herumgestochere
im Nebel und Festklammern an bedeutungslosen Strohhalmen angesichts des
offensichtlich bereits erfolgten Totalverlusts der Kontrolle auch noch
irgendwie mit "professionell" assoziieren.
Der richtige Weg beginnt mit einem vollständigen Konzept, dass nicht nur
die geradeaus-Fälle beschreibt, sondern auch alle möglichen Fehler und
Schwachpunkte.
Es darf im Quelltext kein einziger "if" oder "case" ohne spezifiziertem
Verhalten existieren. Man muss die Spezifikation also während der
Entwicklung ergänzen. Denn nur dann kann man vollständig testen.
Spezifizierte Arbeitsmittel können vollständige Tests nicht ersetzen.
Bernd K. schrieb:> Unterschiede zwischen Optimierungsstufen werden von falschem Code> ausgelöst.
Nicht unbedingt! Rechnungen mit Gleitkommazahlen sind geradezu
berüchtigt dafür, und das ist im Allgemeinen kein Fehler. Falsche
Annahmen über die Rechnungen dagegen schon.
Bernd K. schrieb:> Unterschiede zwischen Optimierungsstufen werden von falschem Code> ausgelöst.
Bei normalen Optimierungsstufen (-O2, -O3, usw.) stimmt das durchaus,
allerdings gibt es einen interessanten Bug im arm-none-eabi-gcc, wodurch
-flto redefinitionen von weak symbols ignoriert, wenn das weak symbol
zuerst gelinkt wird (also die .o Datei in der das weak symbol definiert
ist in der Kommandozeile vor der .o Datei steht, in der das symbol
strong neu deklariert wird)
Alex D. schrieb:> Bei normalen Optimierungsstufen (-O2, -O3, usw.) stimmt das durchaus,> allerdings gibt es einen interessanten Bug im arm-none-eabi-gcc, wodurch> -flto redefinitionen von weak symbols ignoriert, wenn das weak symbol> zuerst gelinkt wird
Ja, ich weiß, den hab ich damals gefunden und den zugehörigen Workaround
veröffentlicht und die drei Bugreports bei Arm und Gcc und Launchpad
miteinander verlinkt. Den meisten Nutzern von Standard-IDEs fiel das
scheinbar nie auf, nur Leuten wie mir die sich für bestimmte Zwecke
eigene Makefiles gestrickt haben. Und das ist ein offensichtlicher Bug
und die knabbern anscheinend immer noch dran rum. Aber wenn er zuschlägt
dann gleich so daß man es gar nicht übersehen kann. Und das geschieht
übrigens nur wenn die .o-Datei mit den weak-Symbolen aus einer
Assemblerdatei generiert wurde (im dem Fall typischerweise der
Startup-Code). Weak-Symbole aus C-Kompilat kannst Du linken wie Du
lustig bist.
Bernd K. schrieb:> Den meisten Nutzern von Standard-IDEs fiel das> scheinbar nie auf, nur Leuten wie mir die sich für bestimmte Zwecke> eigene Makefiles gestrickt haben
Mir fiel es in SystemWorkbench4STM32 auf, weil ich mir dachte, dass ich
mal probiere, wie viel kleiner Code wird wenn man -flto noch
einschaltet. Der ist dann auch deutlich kleiner geworden, hauptsächlich
aber weil die Interrupt Handler nicht mehr im Programm waren.
Bernd K. schrieb:> Und das ist ein offensichtlicher Bug> und die knabbern anscheinend immer noch dran rum
Ja den Bug gibts ja schon ne ganze Zeit, da bin ich auch drauf gekommen.
Bernd K. schrieb:> Und das geschieht> übrigens nur wenn die .o-Datei mit den weak-Symbolen aus einer> Assemblerdatei generiert wurde (im dem Fall typischerweise der> Startup-Code). Weak-Symbole aus C-Kompilat kannst Du linken wie Du> lustig bist.
Das habe ich gar nicht bemerkt, habe weak symbols eigentlich nur
wirklich für die Interrupt Handler im assembler startup file benutzt.
Niklas G. schrieb:> Hat hier eigentlich noch keiner die SVD-Files erwähnt? Das ist eine> Sammlung maschinenlesbarer XML-Dateien mit allen Registerdefinitionen.> Daraus kann man sich dann seine eigenen Header bauen. Die können dann> genau so wie die stm32f103xx.h aussehen ohne die Tastatur komplett> abzunutzen.
Das ist definitiv ein vernünftiger Vorschlag und manche Frameworks
arbeiten ja auch genau mit diesen SVDs, z.B. mit SVD2Rust. Ich hatte mir
selber mal ein kleines Programm geschrieben was die Register als reine
#defines erzeugt, damit man auch in Assembler damit Spaß haben kann ohne
sich die Finger wund zu tippen. Komme leider heute Abend nicht mehr an
den Rechner aber vielleicht lade ich es morgen mal bei Github hoch und
verlinke das hier. Für C würde ich aber definitiv immer die CMSIS-Header
nutzen.
Die Problematik mit den Casts bei C++ Templates kannte ich so noch
nicht. Fände ich mal interessant wie hier eine saubere und typsichere
Lösung aussieht. Wären hier für die Bitdefinitionen nicht C++-Enums
prädestiniert?
Christopher J. schrieb:> Fände ich mal interessant wie hier eine saubere und typsichere> Lösung aussieht.
Hab ich doch gezeigt - mit "extern" und Adressdefinition im
Linkerscript.
Christopher J. schrieb:> Wären hier für die Bitdefinitionen nicht C++-Enums> prädestiniert?
Enum class vielleicht, zwecks Typsicherheit. Oder eigene
Klassentemplates, die die entsprechenden Operatoren typsicher überladen.
Der CubeMX Code ist so geil, dass er beim USB Host im IRQ an der
Statemachine des RTOS Task was ändert und DANN ein Signal an den RTOS
Task schickt.
Das Signal dient nur zum task aufwachen, nicht zum message übertragen.
Wenn der dann aber wegen was anderem schlief und dann mit einer
vermurksten Statemachine aufwacht tut dieser interessante Dinge.
zB wird dann beim Abziehen eines USB Sticks gleich wieder ein anstecken
erkannt trotz leerer Buchse. Wenn man dann einen Stick wieder ansteckt
hängt der USB Host.
Ich nutz den ST HAL bzz deren Middlewars sehr ungerne genau wegen sowas.
Aber einen USB Host wollt ich jetzt nicht selber schreiben und genau da
ist dann son Kracher drinne ...
Niklas G. schrieb:> Enum class vielleicht, zwecks Typsicherheit. Oder eigene> Klassentemplates, die die entsprechenden Operatoren typsicher überladen.
Ja genau das meinte ich. Es sollte durch den Compiler möglichst
sichergestellt sein, dass ich keinen Müll in die Register schreibe, z.B.
eine Bitdefinition des CR ins SR, etwa
TIM1->SR = TIM_CR_CEN;
sollte einen Fehler geben, funktioniert aber in C wunderbar.
Das gleiche gilt für Libraries wie STs HAL:
HAL_GPIO_TogglePin(GPIOA, 4);
funktioniert wunderbar, toggelt aber nicht PA4, sondern PA3.
Alex D. schrieb:> Das habe ich gar nicht bemerkt, habe weak symbols eigentlich nur> wirklich für die Interrupt Handler im assembler startup file benutzt.
Ich benutze das gerne für optionale Hook-Funktionen von Treibern. Zum
Beispiel kann ich nem USB-Treiber beibringen bei USB-Traffic
Blinkenlights blinken zu lassen indem ich ne Hook-Funktion
implementiere die vom Treiber aufgerufen wird wenn geblinkt werden soll
ohne daß der Treiber wissen muss wo und wie die LEDs angeschlossen sind
oder wie man die ansteuert. Wenn ich sie nicht implementiere wird
stattdessen eine leere weak Funktion aufgerufen die nichts tut und
komplett samt Aufruf wegoptimiert wird und dann blinkt halt eben nichts.
Den Mechanismus nutze ich für vieles. Manche hooks sind mandatory, dann
gibts keinen weak default, manche sind optional, da existiert dann je
eine leere weak default Implementierung.
Die STM32-HAL nutzt solche weak hooks übrigens auch an vielen Stellen.
Wenn man das so macht und somit die Hooks schon zur Compilezeit
verdrahtet werden anstatt zur Laufzeit einen Funktionszeiger zu
übergeben schrumpft das auch modulübergreifend so schön zusammen daß
manchmal nur noch ein kleiner Fetzen Inline-Code im Aufrufer
übrigbleibt.
Die Vorwärtsdeklarationen für meine ganzen Hooks schreib ich alle in den
jeweiligen Header des Moduls das sie aufruft in nem separaten Abschnitt,
alle mit "modulname_hook_" im Namen und ein paar Worten Dokumentation
dazu daß man sofort sieht was Sache ist.
Bernd K. schrieb:> Ich benutze das gerne für optionale Hook-Funktionen von Treibern. Zum> Beispiel kann ich nem USB-Treiber beibringen bei USB-Traffic> Blinkenlights blinken zu lassen indem ich ne Hook-Funktion> implementiere die vom Treiber aufgerufen wird wenn geblinkt werden soll> ohne daß der Treiber wissen muss wo und wie die LEDs angeschlossen sind> oder wie man die ansteuert
Das ist definitiv eine echt gute Anwendung
Bernd K. schrieb:> Die STM32-HAL nutzt solche weak hooks übrigens auch an vielen Stellen.
Die HAL benutze ich nicht, habe es einmal probiert und hab es gleich
gelassen. Da bin ich bei den meisten Sachen wirklich schneller, wenn ich
das auf Register Level schreibe, vor allem ist es dann weniger Doku zum
Lesen, das Reference Manual ist ja schon genug.
Die Idee den Umstieg zwischen unterschiedlichen Serien zu vereinfachen
ist ja gut, nur leider ist es die Umsetzung mit STM32-Cube HAL meiner
Meinung nach leider nicht.
Niklas G. schrieb:> Christopher J. schrieb:>> Ja genau das meinte ich.>> Da gibt's alle möglichen Varianten und auch vorhandene Ansätze, z.B.:> https://github.com/kvasir-io/Kvasir
Genau diese Variante kenne ich schon, bin aber leider kein C++-Guru und
blicke bei der ganzen Template-Magie nicht so wirklich durch. Außerdem
finde ich die Syntax, naja, etwas aufgebläht. Elegant ist es jedenfalls
in meinen Augen nicht und damit meine ich nicht den (ebenfalls per SVD)
generierten Code für die Library an sich (der darf meinetwegen auch
Ecken und Kanten haben), sondern den Code um diese Library dann
schlussendlich zu nutzen.
Mein Wunsch wäre etwas kompakterer und dafür verständlicherer Code, der
trotzdem eine gewisse Typsicherheit bietet, also frei nach Pareto 80%
des Nutzens mit 20% Aufwand ;)
Christopher J. schrieb:> Der restliche Kram der im Startup-Code gemacht wird, d.h. RAM nullen,> .data aus dem Flash ins RAM kopieren und die Interrupt-Vektoren anlegen,> sofern man denn Interrupts nutzen möchte.
Wie geht das genau?
Da brauche ich ja Assembler dafür, also muss ich eine .s Datei
einbinden.
Mach ich das mit #include oder brauch der Atollic Linker das irgendwie
irgendwo anders?
Grüße
Leopold N. schrieb:> Wie geht das genau?
Schau Dir einfach mal einen Startup Code an. Ich habe Dir weiter oben
bereits ein Beispielprojekt
(http://stefanfrings.de/stm32/index.html#cmsis) empfohlen, wo du das
schön sehen kannst.
Dass du deine eigene Basis aufbauen willst habe ich inzwischen
akzeptiert (meine meinung dazu kennst du). Aber deine Vorgehensweise
halte ich für falsch. Du versuchst hier als Anfänger eine Basis
aufzubauen, noch bevor das nötige Know-How vorhanden ist.
Meine Empfehlung: Arbeite erstmal mit meinem eispielprojekt und schau
Dir an, wie dieses funktioniert. Und dann nutze das für einige reale
Aufbauten, bevor du das Rad neu erfindest.
Das Projekt ist übrigens nichtmal mein eigenes Werk, sondern es wird
genau so von der System Workbench generiert. Ich habe lediglich die
CMSIS (aus einem HAL Firmware-Paket für die STM32F1 Serie extrahiert
und) dazu kopiert, sowie die Namen in der Interrupt-Vektor
vervollständigt. Also alles kein Hexenwerk.
Leopold N. schrieb:> Christopher J. schrieb:>> Der restliche Kram der im Startup-Code gemacht wird, d.h. RAM nullen,>> .data aus dem Flash ins RAM kopieren und die Interrupt-Vektoren anlegen,>> sofern man denn Interrupts nutzen möchte.>> Wie geht das genau?> Da brauche ich ja Assembler dafür, also muss ich eine .s Datei> einbinden.> Mach ich das mit #include oder brauch der Atollic Linker das irgendwie> irgendwo anders?
Das geht in Assembler oder auch in C. Ein Beispiel wie das in C geht
hatte ich bereits verlinkt, sogar für deinen Controller. Ein Beispiel
wie es in Assembler geht bekommst du vom Hersteller (siehe Beschreibung
von Stefan). Linkerscript und Startup-Code müssen zusammenpassen, da im
Linker Symbole definiert werden (Start und Ende des RAM) auf die der
Startup-Code Zugriff haben muss. Machst du das in C, wird die Datei
kompiliert, machst du es in Assembler wird sie assembliert. In jedem
Fall hast du am Ende eine .o-Datei, die der Linker dann in das fertige
Binary packen kann.
Christopher J. schrieb:> du kannst den Startup-Code auch in C schreiben, auch wenn das ein paar> Fallstricke bietet. Ich hatte vor ein paar Jahren mal was von Bernd K.> aus dem Forum auf den F103C8 angepasst, inklusive PLL-Setup:> https://github.com/ChristianRinn/bare_metal_stm32f103c8/blob/master/src/STM32F103C8/gcc_startup_system.c
Habe ich mir mal angesehen.
Frage: Das erste was ausgeführt wird bei einem Reset ist doch der
ResetHandler.
Du nullst dann den RAM, kopierst die .data ins RAM und dann erst wartest
du, dass HSI sich stabilisert hat.
Aber der Prozessor braucht doch eine stabile Clock, um überhaupt erst
die ersten beiden Aktionen durchführen zu können.
Leopold N. schrieb:> Aber der Prozessor braucht doch eine stabile Clock, um überhaupt erst> die ersten beiden Aktionen durchführen zu können.
Darum muss sich wohl die Hardware selbst kümmern. Wie sonst soll er den
Reset-Vektor ordentlich ausführen?
Was du übersehen hast: Er aktiviert die Vervielfachung des Taktes
mittels PLL, und das ist der Part, auf den er warten muss. Die PLL
braucht eine Weile, um sich einzuschwingen, nicht der HSI Oszillator.
WEAK void SystemInit(void) {
/* Enable Power Control clock -> see section 7.3.8 in the manual */
RCC->APB1ENR |= RCC_APB1ENR_PWREN;
/* Wait for HSI to become ready */
while ((RCC->CR & RCC_CR_HSIRDY) == 0);
/* Disable main PLL */
RCC->CR &= ~(RCC_CR_PLLON);
/* Enable HSE */
RCC->CR |= RCC_CR_HSEON;
/* Wait until PLL unlocked (disabled) */
while ((RCC->CR & RCC_CR_PLLRDY) != 0);
/* Wait for HSE to become ready */
while ((RCC->CR & RCC_CR_HSERDY) == 0);
Also bei mir wartet er darauf, dass HSI stabil wird.
Wenn sich die HW drum kümmern würde, müsste er doch nicht warten oder?
Leopold N. schrieb:> Aber der Prozessor braucht doch eine stabile Clock, um überhaupt erst> die ersten beiden Aktionen durchführen zu können.
Nein, prinzipiell kann man die Clock-Konfiguration komplett weglassen,
auch dann funktioniert der Controller korrekt. Der HSI ist von Anfang an
ohne PLL aktiv. Durch Takt-Konfiguration kann man den Takt erhöhen (PLL)
und genauer machen (HSE mit Quarz o.ä.). Das ist für manche Peripherien
erforderlich welche einen hohen/stabilen Takt benötigen. Der RAM und
Prozessor funktionieren aber auch ohne. Rein technisch ist es unnötig
auf "HSIRDY" zu warten - nach dem Reset ist das immer an. Das wird nur
gebraucht wenn man den HSI aus- und wieder einschaltet; schaden tut es
aber nicht.
Man könnte auch die PLL-Konfiguration ganz zu Anfang vom ResetHandler
anstoßen und parallel dazu den RAM initialisieren; kurz vor Aufruf der
main() wartet man noch aufs Einschwingen. Dadurch würde man etwas Zeit
sparen.
Leopold N. schrieb:> Also bei mir wartet er darauf, dass HSI stabil wird.
Der HSI ist nach dem Reset immer ready, weil das ein simpler R/C
Oszillator ist. Auf ihn per Software zu warten wäre auch sinnlos, weil
er ja gerade diese Software taktet.
Niklas G. schrieb:> Rein technisch ist es unnötig> auf "HSIRDY" zu warten - nach dem Reset ist das immer an. Das wird nur> gebraucht wenn man den HSI aus- und wieder einschaltet; schaden tut es> aber nicht.
Ja, das stimmt. Ich war vielleicht ein bisschen übervorsichtig und habe
deshalb die Lösung mit Gürtel und Hosenträger gewählt ;)
Leopold N. schrieb:> /* Wait for HSI to become ready */> while ((RCC->CR & RCC_CR_HSIRDY) == 0);
Den Part kann man bedenkenlos rauslöschen.
Nächste Frage:
Du deklarierst ein paar extern Variablen, die im Linker definiert sind.
Sind diese Variablen im Linker Pointer oder nur Integer?
Das hier generiert bei mir nämlich einen Fehler:
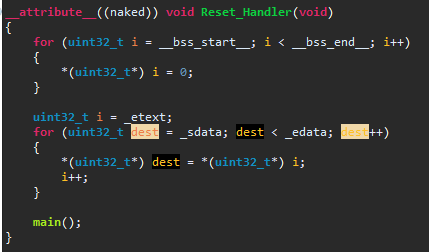
for (uint32_t *i = _bss_start_; i < _bss_end_; i++)
{
...
}
Fehler: Warning: Comparison between pointer and integer.
Außerdem: warum inkrementierst du (bei dir "dest") i vor dem Durchlauf
der for-Schleife?
Würde dieser Code zum RAM nullen und Variablen kopieren passen?
PS: Erstes Bild ignorieren, da hatte Atollic TrueStudio die eine
Variable so übel markiert...
Leopold N. schrieb:> Würde dieser Code zum RAM nullen und Variablen kopieren passen?
Der Code knallt - aber heftig. Du greifst mit Deiner Variablen i, die Du
in einen uint32_t-Pointer castest, auf ungerade Adressen zu.
Hättest Du den Code nicht als Bild, sondern als ASCII-Code gepostet,
hätte ich diejenigen Stellen, die Du falsch gemacht hast, korrigieren
können.
Aber soll ich Dein Bild erst abtippen? Nee.
Leopold N. schrieb:> Würde dieser Code zum RAM nullen und Variablen kopieren passen?>> PS: Erstes Bild ignorieren, da hatte Atollic TrueStudio die eine> Variable so übel markiert...
Wie wäre es denn einfach mal mit Text statt Bildern?
Die Forensoftware wirkt zwar von Anno Tobak aber die kann sogar
Syntaxhighlighting (mit den richtigen Tags)!
Leopold N. schrieb:> Außerdem: warum inkrementierst du (bei dir "dest") i vor dem Durchlauf> der for-Schleife?
Das wird nicht vor der Schleife inkrementiert. In diesem Fall ist ++dest
gleich mit dest++ !
Im übrigen bin ich mir ganz sicher, dass der Code macht was er soll.
Leopold N. schrieb:> Fehler: Warning: Comparison between pointer and integer.
Dann caste doch den Pointer zu einem Integer wenn du die vergleichst.
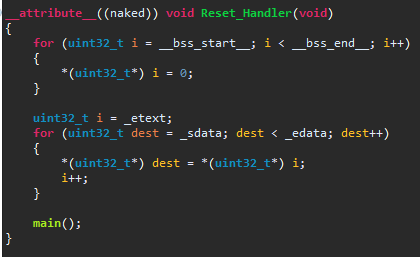
Leopold N. schrieb:> Also, hier nochmal als .c
Hallelujah...
Mach mal aus
uint32_t i = _etext;
besser
uint32_t *i = _etext;
und dann entsprechend
*(uint32_t*) dest = *(uint32_t*) i;
zu
*(uint32_t*) dest = *i;
Dann sollte es passen.
Zur Erklärung:
Wenn man ein uint32_t inkrementiert steigt der Wert der Variablen um
eins.
Wenn man einen Pointer auf uint32_t inkrementiert, erhöht sich die
Adresse auf die der Pointer zeigt um vier.
Damit zeigt der Pointer dann auf den nächsten uint32_t und eben nicht
auf das nächste Byte!
Christopher J. schrieb:> Mach mal aus>> uint32_t i = _etext;>> besser>> uint32_t *i = _etext;
Hatte ich vorher...gibtn error wegen conversion without a cast.
Leopold N. schrieb:> Hatte ich vorher...gibtn error wegen conversion without a cast.
Stimmt, den hatte ich vergessen.
Leopold N. schrieb:> Ich habs mittlerweile so.> Aber jetzt krieg ich diesen Fehler:
Da du ja TrueStudio zu nutzen scheinst, tippe ich mal darauf, dass
irgendwo noch der originale Startup-Code von ST rumgeistert und der hat
natürlich ebenfalls einen Reset_Handler
Junge Junge Junge, genau deswegen hasse ich IDEs.
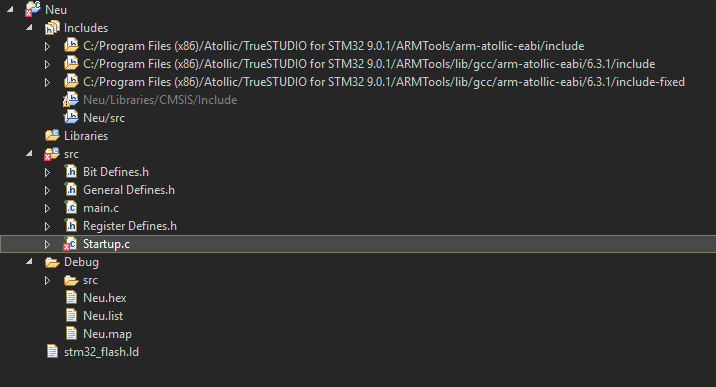
Anbei mal mein Project Explorer.
Wo kann ich da denn die alte Startup Datei rausnehmen?
Die startup.c ist meine.
Schon wieder so ein doofer Screenshot!
Es ist doch offensichtlich, dass die Antwort nicht dort zu sehen ist.
Also lade doch einfach dein ganzes Projekt als *.zip hier hoch und dann
können wir es uns anschauen anstatt um den heissen Brei herum zu raten.
<option id="com.atollic.truestudio.ld.general.nostartfiles.531802630" name="Do not use standard start files" superClass="com.atollic.truestudio.ld.general.nostartfiles" useByScannerDiscovery="false" value="false" valueType="boolean"/>
Deswegen bindet die IDE automatisch eigenen Startup-Code ein. Diese
Einstellung ist sicher irgendwo in den Projekteinstellungen grafisch
aufbereitet wieder zu finden. Oder du musst es beim Anlegen eines neuen
Projektes einstellen. Eventuell einen anderen Projekt-Typ verwenden.
Bei meinem bereits 2x empfohlenen System Workbench Beispielprojekt liegt
der Startup Code als Assembler Quelltext (startup/startup_stm32.s) vor,
wo du ihn leicht editieren kannst.
Vielleicht bis du mit der System Workbench besser bedient, als mit
TrueStudio.
Leopold N. schrieb:> Junge Junge Junge, genau deswegen hasse ich IDEs.
Es zwingt dich niemand dazu TrueStudio zu nutzen. Da du ja sowieso alles
zu Fuß machen willst, kannst du dir auch genauso gut ein Makefile
schnappen und mit dem Editor deiner Wahl kombinieren. Ich habe ganz gute
Erfahrungen mit QT-Creator gemacht (eigentlich ja auch eine IDE).
Jedenfalls kann man damit auch debuggen und den restlichen Kram wie
Syntaxhighlighting, Autovervollständigung, linting, usw. hat der auch
und meiner Meinung nach alles ein bisschen besser als bei
Eclipse-basierten IDEs, nur halt ohne klickibunti Projektassistent für
STM32 aber das brauchst du ja sowieso nicht.
Durchsuche doch mal die Projekteinstellungen nach "Do not use standard
start files".
Das ist natürlich schon ein fieses Ding, wenn da MaschinenCode aus
Quelltexten erzeugt wird, die nicht Bestandteil deines Projektes sind.
Wie will man damit reproduzierbare Ergebnisse erreichen? So muss man
nach jedem Upgrade fürchten, dass irgend etwas in den eigenen Projekten
kaputt geht.
Finde ich nicht gut, wie TrueStudio das handhabt.
Kann dir nicht sagen wo sie liegt aber vermutlich heißt sie
"startup_stm32f103xb.s". Die Dateiendung ist jedenfalls ziemlich sicher
.s oder .S. Warum folgst du nicht dem Vorschlag von Stefan und schmeißt
sie aus dem Projekt raus? Dann ist es doch völlig Wurst wo die Datei
liegt. Wenn nicht, dann nutze sie doch einfach wie sie ist.
Stefanus F. schrieb:> Das ist natürlich schon ein fieses Ding, wenn da MaschinenCode aus> Quelltexten erzeugt wird, die nicht Bestandteil deines Projektes sind.> Wie will man damit reproduzierbare Ergebnisse erreichen? So muss man> nach jedem Upgrade fürchten, dass irgend etwas in den eigenen Projekten> kaputt geht.
Im Prinzip ist das aber bei der avr-gcc toolchain ganz genauso.
Natürlich brauchen auch die AVR einen Startup-Code und ein Linker-Script
haben sie auch aber es ist halt alles Bestandteil des avr-gcc und der
sucht sich dann die passenden Dateien anhand des angegebenen Controllers
raus.
Nichtsdestotrotz gebe ich dir aber recht. Es vernebelt die Sache
unnötig.
Christopher J. schrieb:> Leopold N. schrieb:>> Junge Junge Junge, genau deswegen hasse ich IDEs.>> Es zwingt dich niemand dazu TrueStudio zu nutzen. Da du ja sowieso alles> zu Fuß machen willst, kannst du dir auch genauso gut ein Makefile> schnappen und mit dem Editor deiner Wahl kombinieren. Ich habe ganz gute> Erfahrungen mit QT-Creator gemacht (eigentlich ja auch eine IDE).> Jedenfalls kann man damit auch debuggen und den restlichen Kram wie> Syntaxhighlighting, Autovervollständigung, linting, usw. hat der auch> und meiner Meinung nach alles ein bisschen besser als bei> Eclipse-basierten IDEs, nur halt ohne klickibunti Projektassistent für> STM32 aber das brauchst du ja sowieso nicht.
Klingt gut.
Christopher J. schrieb:> Kann dir nicht sagen wo sie liegt aber vermutlich heißt sie> "startup_stm32f103xb.s". Die Dateiendung ist jedenfalls ziemlich sicher> .s oder .S. Warum folgst du nicht dem Vorschlag von Stefan und schmeißt> sie aus dem Projekt raus? Dann ist es doch völlig Wurst wo die Datei> liegt. Wenn nicht, dann nutze sie doch einfach wie sie ist.
Habe ich bereits.
Aber scheinbar ist sie irgendwie immer noch drin.
Ich werde jetzt mal QT ausprobieren denke ich.
Atollic ist einfach zu viel undurchsichtiger Schnickschnack meiner
Ansicht nach.
Christopher J. schrieb:> Im Prinzip ist das aber bei der avr-gcc toolchain ganz genauso.
Ganz Recht, und deswegen habe ich in meine Kommerziellen Projekt-ZIP
Files immer gleiche die ganze Toolchain mit eingepackt.
> Ich werde jetzt mal QT ausprobieren denke ich.
Ich empfehle Dir erneut die System Workbench, die erzeugt ein sichtbares
Startup File, dass du ändern und löschen kannst.
Stefanus F. schrieb:> Ich empfehle Dir erneut die System Workbench, die erzeugt ein sichtbares> Startup File, dass du ändern und löschen kannst.
Das wäre auf jeden Fall die einfachere Variante ;)
Stefanus F. schrieb:> Ich empfehle Dir erneut die System Workbench, die erzeugt ein sichtbares> Startup File, dass du ändern und löschen kannst.
Da du mir ja wohl nie Ruhe lassen wirst mit deiner Empfehlung,
installiere ich mir nebenbei noch SW4STM32 und vergleiche
Lösch das Projekt aus Eclipse und füge es als makefile projekt wieder
hinzu. Dann wird da kein Hokuspokus mehr automatisch heimlich im
Hintergrund hinzugelinkt sondern es ruft einfach nur make auf und Du
hast volle Kontrolle.
Alex D. schrieb:> Bernd K. schrieb:>> Unterschiede zwischen Optimierungsstufen werden von falschem Code>> ausgelöst.>> Bei normalen Optimierungsstufen (-O2, -O3, usw.) stimmt das durchaus,> allerdings gibt es einen interessanten Bug im arm-none-eabi-gcc, wodurch> -flto redefinitionen von weak symbols ignoriert, wenn das weak symbol> zuerst gelinkt wird (also die .o Datei in der das weak symbol definiert> ist in der Kommandozeile vor der .o Datei steht, in der das symbol> strong neu deklariert wird)
Offenbar bin ich Jahre später noch in dasselbe Problem gerannt. Wo sind
die URLs dazu, gibt's Lösungen dazu?
Ich verwende CubeMX auf stm32f7 und wollte die UART ISR mit dem LL API
überschreiben ...
startup_stm32f722xxs:
Du definierst USART3_IRQHandler() zwei mal.
Ein mal in stm32f7xx it.c und ein mal in der serial.cpp. Da ist es kein
Wunder, wenn der Linker sich beschwert.
Wenn du die IRQ Funktion tatsächlich selber schreiben willst, dann musst
du die automatische Generierung in der _it abschalten und die Funktion
dort löschen (die ist nämlich nicht weak).
Mike R. schrieb:> Du definierst USART3_IRQHandler() zwei mal.>> Ein mal in stm32f7xx it.c und ein mal in der serial.cpp. Da ist es kein> Wunder, wenn der Linker sich beschwert.
Unter normalen (nicht weak) Umständen ist das richtig.
> Wenn du die IRQ Funktion tatsächlich selber schreiben willst, dann musst> du die automatische Generierung in der _it abschalten und die Funktion> dort löschen (die ist nämlich nicht weak).
Hier werde ich unsicher, das asm Startup File definiert das ja als weak
Symbol; unabhängig davon, ob das Symbol in stm32f7xx it.c als 'waek'
(__weak oder GCC attribute) oder nicht deklariert wird. Soweit mein
Verständnis - so tief bin ich aber auch nicht in Mixing Asm/C
vorgedrungen.
Olaf .. schrieb:> Hier werde ich unsicher, das asm Startup File definiert das ja als weak> Symbol; unabhängig davon, ob das Symbol in stm32f7xx it.c als 'waek'> (__weak oder GCC attribute) oder nicht deklariert wird.
Das heißt aber nur, dass die Definition aus dem startup File "weak" ist.
Die beiden Definitionen in stm32f7xx it.c und serial.cpp sind "strong".
Wenn du nur eine strong Definition hättest, würde diese die "weak"
Definition überschreiben. Aber du hast 2.
Was ist überhaupt das Ziel? Warum hast du 2 Definitionen der Funktion?
Welche soll davon ausgeführt werden?
Olaf .. schrieb:> so tief bin ich aber auch nicht in Mixing Asm/C> vorgedrungen.
Damit hat das übrigens nichts zu tun, die Logik mit weak/strong ist
Sache des Linkers, das funktioniert zwischen C, C++ und ASM äquivalent.
Niklas G. schrieb:> Olaf .. schrieb:>> Hier werde ich unsicher, das asm Startup File definiert das ja als weak>> Symbol; unabhängig davon, ob das Symbol in stm32f7xx it.c als 'waek'>> (__weak oder GCC attribute) oder nicht deklariert wird.>> Das heißt aber nur, dass die Definition aus dem startup File "weak" ist.> Die beiden Definitionen in stm32f7xx it.c und serial.cpp sind "strong".> Wenn du nur eine strong Definition hättest, würde diese die "weak"> Definition überschreiben. Aber du hast 2
das sehe ich ein.
> Was ist überhaupt das Ziel? Warum hast du 2 Definitionen der Funktion?> Welche soll davon ausgeführt werden?
Ziel ist es möglichst wenig vom STM's CubeMX generierten Source
anzufassen und auf meine eigene Quellen zu verwenden. Mit den LowLevel
(LL) API von CubeMX werden einige Stubs generiert, manche sind sinnvoll,
andere nicht für mich hier.
> Olaf .. schrieb:>> so tief bin ich aber auch nicht in Mixing Asm/C>> vorgedrungen.>> Damit hat das übrigens nichts zu tun, die Logik mit weak/strong ist> Sache des Linkers, das funktioniert zwischen C, C++ und ASM äquivalent.
Genau, daher dachte ich ursprünglich, ich habe den Bug getroffen :)
Olaf .. schrieb:> Ziel ist es möglichst wenig vom STM's CubeMX generierten Source> anzufassen und auf meine eigene Quellen zu verwenden.
Dann verwende den Code-Generator doch einfach überhaupt nicht und
schreibe alles selber?