Ist jemandem bekannt, welche Tests mit einem neu produzierten FPGA gefahren werden, wenn sie aus der Fabrik kommen? Ich nehme an, die Hersteller spielen zumindest ein image drauf und probieren die Funktionen durch. Es geht dabei sowohl im reine FPGAs, als auch um SoC-Bausteine. Mit welcher Sicherheit kann man davon ausgehen, dass die Chips 100% funktionieren?
Hein schrieb: > Mit welcher Sicherheit kann man davon ausgehen, dass die Chips 100% > funktionieren? Mit keiner, schau dir einfach mal die Eratasheets an, die die Hersteller im laufe der Produktzyklen rausballern, beispiel Block-RM probleme: https://forums.xilinx.com/t5/Spartan-Family-FPGAs-Archived/Spartan-6-Block-RAM-errata/td-p/256208
Ruck-Zuck Fresse dick schrieb: > Mit keiner, schau dir einfach mal die Eratasheets an, die die Hersteller > im laufe der Produktzyklen rausballern, beispiel Block-RM probleme: Ein Erratum betr. Designmangel/Anomalie hat so rein gar nichts mit einem Funktionstest zu tun. @Hein: Du wirst darüber vermutlich keine Details von den Herstellern erhalten, aber typischerweise durchlaufen die Chips mehrere Tests: - Wafer Probe (Funktionstest auf der Siliziumscheibe) - Boundary-Scan-Tests der einzelnen Funktionszellen - Finaler Burn-In nach Bonding/Packaging (Testofen) Damit kann man dann so statistisch gesehen schon eine 100%ige Funktionsfähigkeit (minus Epsilon) des Silizium bei Temperatur X, Frequenz Y, Strahlung Z, usw. garantieren, für wie lange und bei welcher MTBF ist halt sehr variabel. Die Testdauer ist hier ein Kostenfaktor, gerade Boundary-Scan ist nicht sonderlich schnell. Könnte mir schon vorstellen, dass es spezielle BIST-Images gibt dafür, die zumindest die Tests nach dem Packaging beschleunigen. Und je nach Industrial oder MIL-Variante sind die Tests und Preise dann auch recht unterschiedlich.
Hein schrieb: > Ich nehme an, die Hersteller spielen zumindest ein image drauf und > probieren die Funktionen durch. Nein, das wird aus Kostengründen eher selten gemacht, die übergeordnetetn Testverfahren sind Prozessüberwachung (durch BIST u.ä.) und Stichproben zur Ermittlung Chargen-Qualität und ATPG (Automatic Test Pattern Generation). > Mit welcher Sicherheit kann man davon ausgehen, dass die Chips 100% > funktionieren? Geh davon aus, daß die Chips nicht zu 100% funktionieren, das Dir das aber entweder nicht auffällt oder es einen Workaround gibt, der die defekten Bereiche "ausblendet". Dieser Workarounds kann dir offiiziel mitgeteilt werden (bspw. "benutzen sie die Blockrams an den Bereichen XxYy nicht in Mode z, die BRAM's in den anderen Bereichen sind OK" oder durch ein Softwareupdate der Toolchain "heimlich" eingespielt. Es gibt aber auch Fälle insbesonders bei neuen Typen, wo der Hersteller eben schulterzuckend einräumt, das eben die PLL o.ä. im IC es in diesem Temperaturbereich nicht tut oder eben der IC doch 50% mehr Leistung verbrät und es dem Kunden nicht anderes übrigbleibt als die PCB's neu zu designen. Während der Wafer-prozessierung wird der gesamte Wafer unabhängig der Chipdetails überwacht, ob die Prozessschritte (Belichtung, Etch, etc.) auch ordentlich ausgeführt werden. Dazu gibt es "Teststrukturen" auf dem Wafer (gern in den Bereichen wo abschliessend die Diamantsäge drüber geht) oder es werden spezielle Testwafer denen man ähnlich der Layer-kontrollmarken auf PCB's ansieht ob alles i.O. lief. Bspw kann man dank Dünnschichtinterferenz dem Wafer an der Farbe ansehen wie dick die (Passivierungsschicht) geraten ist, "dazwischen gemischt". Ist der Wafer OK nach jedem geprüften Prozessschritt OK, geht man davon aus, das die Chips OK sind. In den Chips befinden sich auch gerne BIST-Schaltungen die eine "Signatur" ermitteln und diese mit einer Referenz vergleichen https://de.wikipedia.org/wiki/Signaturanalyse_(Digitaltechnik) https://de.wikipedia.org/wiki/Built-in_self-test Damit wird aber eher selten eine 100% Testabdeckung erreicht, was man aus Zeitgründen auch nicht unbedingt erreichen will. Bei Hundert Millionen Transistoren braucht es halt Ewigkeiten jeden einzelnen zu überprüfen, Zeit die man in der Ära der Massenproduktion ohnehin nicht hat. Eine Zeitlang hat man sich mit "cleverer" Testpatterngenerierung beholfen, Hat also überlegt, welche Herstellungsfehler auftreten könnten (bspw. stuck-at-Zero) und hat entsprechende Input-muster ermittelt bei denen der Fehler an den Ausgängen sichtbar wird. https://en.wikipedia.org/wiki/Automatic_test_pattern_generation Und eben Stichprobenermittlung, da wird eben nur einer von hundert und bei reiferen Produkten, einer von tausenden geprüft. Da kann es gut sein, das trotzdem die gesamte Charge madig ist (deshalb gibt ja beispielsweise Xilinx in den Erratas an, welche Foundry in welchen Produktionswochen betroffen sein könnte und bittet um Rücklieferung) oder das doch einzelne Blindgänger in dieser Charge hocken.
Auf den Seiten der Hersteller hatte ich schon nachgesehen. Allerdings scheinen das sehr subjektive Darstellungen. Nett wären unabhängige Quellen. Irgendwelche sonstigen konkreten Links? Hat irgendwer sich schon damit befasst FPGAs in der eigenen Fertigung zu prüfen? Oder erfolgt das nur im Zusammenhang des Gesamtsystems?
> Hat irgendwer sich schon damit befasst FPGAs in der eigenen Fertigung zu > prüfen? Nein, das ist sinnlos, weil im FPGA allerseltens alle Bereiche benutzt werden. Warum sollte man das Teil aufwendig aussortieren, wenn die matschigen Stellen dann ohnehin nicht benutzt werden? > Oder erfolgt das nur im Zusammenhang des Gesamtsystems? Ja, bei der Geräteendprüfung. Bisher hatte ich fast keine Probleme; 1 x Lattice bei ca 20 k Stück. Mülleimer auf, Baugruppe rein.
Hein schrieb: > Mit welcher Sicherheit kann man davon ausgehen, dass die Chips 100% > funktionieren? Die werden nur auf Waver Ebene getestet, die Bonding und Packaging Prozesse werden ebenfalls überwacht und evtl noch ein E-Test durchgeführt. eine 100% Sicherheit hat man nie, jedoch kann ich empfehlen keine FPGA's von irgendwelchen Resalern aus China zu kaufen...
Fitzebutze schrieb: > Ruck-Zuck Fresse dick schrieb: Hein schrieb: > Mit welcher Sicherheit kann man davon ausgehen, dass die Chips 100% > funktionieren? >> Mit keiner, schau dir einfach mal die Eratasheets an, die die Hersteller >> im laufe der Produktzyklen rausballern, beispiel Block-RM probleme: > > Ein Erratum betr. Designmangel/Anomalie hat so rein gar nichts mit einem > Funktionstest zu tun. Ein erratum sagt sehr wohl aus, welche Funktionen der Hersteller nicht garantiert. Einfach mal in eins schauen: https://www.xilinx.com/support/documentation/errata/en247.pdf > Auf den Seiten der Hersteller hatte ich schon nachgesehen. aber nur flüchtig, xilinx macht sehr wohl Angaben zur Reliability. https://www.xilinx.com/support/documentation/user_guides/ug116.pdf Wenn ich micht recht erinnere gibt es auch Reports für aktuelle gefundenen Probleme, für die man sich allerdings anmelden muss. Einfach mal den zuständigen FAE fragen
Bürovorsteher schrieb: > Nein, das ist sinnlos, weil im FPGA allerseltens alle Bereiche benutzt > werden. Warum sollte man das Teil aufwendig aussortieren, wenn die > matschigen Stellen dann ohnehin nicht benutzt werden? ... weil es vermieden werden soll, eine Baugruppe voll zu bestücken, wenn der FPGA nicht funktioniert. FPGA ist billig, Baugruppe teuer. Ruck-Zuck Fresse dick schrieb: > Einfach mal den zuständigen FAE fragen die erzählen einem viel, wenn der Tag lang ist ...
Hein schrieb: > Ruck-Zuck Fresse dick schrieb: >> Einfach mal den zuständigen FAE fragen > die erzählen einem viel, wenn der Tag lang ist ... Mit dieser Einstellung solltest Du mal zum Psychologen und nicht in eine Entwicklungsabteilung gehen. >Bürovorsteher schrieb: >> Nein, das ist sinnlos, weil im FPGA allerseltens alle Bereiche benutzt >> werden. Warum sollte man das Teil aufwendig aussortieren, wenn die >> matschigen Stellen dann ohnehin nicht benutzt werden? >... weil es vermieden werden soll, eine Baugruppe voll zu bestücken, >wenn der FPGA nicht funktioniert. FPGA ist billig, Baugruppe teuer. Der FPGA funktioniert aber genau dort, wo es die Baugruppe resp. deren Funktion als Baugruppe verlangt ... Wie schon geschrieben, es ist sinnlos Bauteile nach kriterien auszusortieren, die für die Funktion irrelevant sind. Oder geht es hier um den WAF? https://en.wikipedia.org/wiki/Wife_acceptance_factor , da ist natürlich jede Vernunft hinderlich.
> ... weil es vermieden werden soll, eine Baugruppe voll zu bestücken, > wenn der FPGA nicht funktioniert. FPGA ist billig, Baugruppe teuer. Das vorherige Aussortieren ist wesentlich teurer (Zeit für eine komplette Prüfung, Erstellung der Testpattern, Kosten für den Prüfplatz - und wenn es nur ein DSO ist, Verschleiß an Testfassungen, Bauteilverluste duch das Handling z.B. verbogene Beine) als aller Jubeljahre mal eine komplette Baugruppe zu verschrotten. Bei mir beläuft sich der Verlust durch defekte FPGA in über zehn Jahren auf weit unter 100 EUR bei einer Warenproduktion mit FPGA von ca. 2 Mio EUR. Das sollte man in den meisten Fällen verschmerzen können.
Ich habe keinen Durchsatz an FPGAs, kann daher auch nicht mit Stückzahlen argumentieren, aber bei mir gar es bisher nur zwei defekte FPGAs, und die hab ich selbst zersemmelt. Ich könnte mir vorstellen, das bei der Produktion über JTAG ein Test gefahren wird um anschließend defekte Reihen oder Spalten per Fuse zu deaktivieren. Mit einer solchen Maßnahme dürfte man die Ausbeute drastisch steigern. So ähnlich wird es doch bei den CPUs auch gemacht: Wenn was nicht geht, wird der Core deaktiviert und der Chip als Dualcore verkauft, oder mit kleinerem Cache... Duke
Duke Scarring schrieb: > Ich könnte mir vorstellen, das bei der Produktion über JTAG ein Test > gefahren wird um anschließend defekte Reihen oder Spalten per Fuse zu > deaktivieren. Mit einer solchen Maßnahme dürfte man die Ausbeute > drastisch steigern. Ich kann mir nicht vorstellen wie das gehen soll ohne dass das Timing völlig unvorhersehbar wird. Ich gehe eher davon aus das der hohe Testaufwand einer der Gründe für die hohen Preise ist. Ein anderer sind natürlich die großen Dies und dadurch niedrige Ausbeute. Von Xilinx gab es früher ab gewissen Stückzahlen die günstigeren Easypath Varianten. Das war im Prinzip der Ausschuss der nicht vollständig funktioniert aber für die Xilinx garantiert dass sie mit genau dem einen Bitstream des Kunden funktionieren.
Hein schrieb: > ... weil es vermieden werden soll, eine Baugruppe voll zu bestücken, > wenn der FPGA nicht funktioniert. FPGA ist billig, Baugruppe teuer. Das hängt sehr vom FPGA ab. Die derzeit teuersten Bausteine liegen bei ca. $80.000 pro Stück. Bei einer Baugruppe, auf der solche FPGAs ist natürlich auch nicht nur Vogelfutter für drei Euro drauf, aber die Kosten für das FPGA können schon deutlich höher sein als der Rest.
Blechbieger schrieb: > Von Xilinx gab es früher ab gewissen Stückzahlen die günstigeren > Easypath Varianten. Das war im Prinzip der Ausschuss der nicht > vollständig funktioniert aber für die Xilinx garantiert dass sie mit > genau dem einen Bitstream des Kunden funktionieren. Nope, xilinx garantierte für zwei Bitstreams: der für die eigentliche (productive) Anwendung und einen zweiten bspw für die Wartung, Board-diagnose. Und der Rest war nicht zwangsläufig Ausschuss, der von den beiden Designs nicht genutzte Bereich wurde einfach nicht geprüft. Xilinx leitete aus den bistreams verkürzte Testpattern ab und sparte so Testkosten (-zeit, verschleiss) das ist nochmals eine weitere Effizienzsteigerung neben dem verbesserten yield. Für die Erstellung dieser kundenspez. Testprocedure verlangt xilix aber auch so um die 10000 US$ und der preisnachlass, bewegte sich so um 16.00$ statt 16.50$/stück, da lohnt sich das Ganze erst in 100k Stückzahlen und kostet die Möglichkeit Bugfixes und neue Features nachzuliefern.
Andreas S. schrieb: > Hein schrieb: >> ... weil es vermieden werden soll, eine Baugruppe voll zu bestücken, >> wenn der FPGA nicht funktioniert. FPGA ist billig, Baugruppe teuer. > > Das hängt sehr vom FPGA ab. Die derzeit teuersten Bausteine liegen bei > ca. $80.000 pro Stück. In diesem Falle wäre es ja kein Problem, bei welchen die Baugruppe durch das FPGA getestet werden müsste. In dem von mir skizzierten Fall ist es aber in der Tat so, dass der FPGA dreistellig und der Rest fünfstellig ist. Leider ist der FPGA so ziemlich das erste Bauteil das montiert wird und kriegt durch den Lötprozess hintendrein nochmal kräftig was ab.
Hein schrieb: > Mit welcher Sicherheit kann man davon ausgehen, dass die Chips 100% > funktionieren? Mit welcher Sicherheit kannst Du sagen das Dein Code und Deine Schaltung in allen möglichen Betriebszuständen zu 100% funktionieren? Was ist wenn das FPGA zu 100% funzt, der Spannungsregler aber nicht? Ich habe schon viele 100 Fehlfunktionen, Defekte, dramatische Abbrände etc. gesehen. Schnell war da oft die Rede von gefälschten Bauteilen, schlechten Chargen etc. Hat man sich das genau angeschaut, stieß man eigentlich immer auf eine Schwäche im Design, die die betreffenden Bauteile oft weit über die max Ratings belastet hat. Die Bauteile sind meist besser als im DS. Sicherheitskritische Designs sind ohnehin 3fach redundant ausgelegt. Wenn Dir also auf 100K Bauteile mal ein Defektes geliefert wird, ist das wohl zu verschmerzen. Es gibt umfangreiche Unterlagen zur MTBF Berechnung, in denen viele Erfahrungswerte stehen. Mich hat diese Papierorgie nie so richtig angesprochen weil ich das für realitätsfern halte, aber wenn Du da Bock drauf hast, nur zu.
Ich hoffe der TO will kein Atomkraftwerk damit steuern ^^ Scherz bei Seite: Es gibt durchaus sehr teure FPGAs, welche dann auch für Weltraumanwendungen qualifiziert sind. Die kosten aber schnell mal 100K das Stück. Dort werden genau definierte Tests gefahren + Screening und alles was dazu gehört. Jedes FF ist dann auch noch 3 Fach redundant ausgeführt und die Technologie besonders sicher gegen Einflüsse von ionisierenden Teilchen...
Besorgter schrieb: > Jedes FF ist dann auch noch 3 Fach redundant > ausgeführt Dazu interessieren mich Quellen, wie das gebaut und verwendet wird. Wie wird eine konträre Information wieder zusammengeführt? Mehrheitsentscheider hinter jedem FF? Eigentlich baut man ja größere Schaltungszzweige redundant auf, sodass eine elementare Funktion aus der SPEC abgeschlossen behandelt wird (encapsulated requiremenent fullfillment)
Angehängte Dateien:
-

TMR.jpg
37 KB
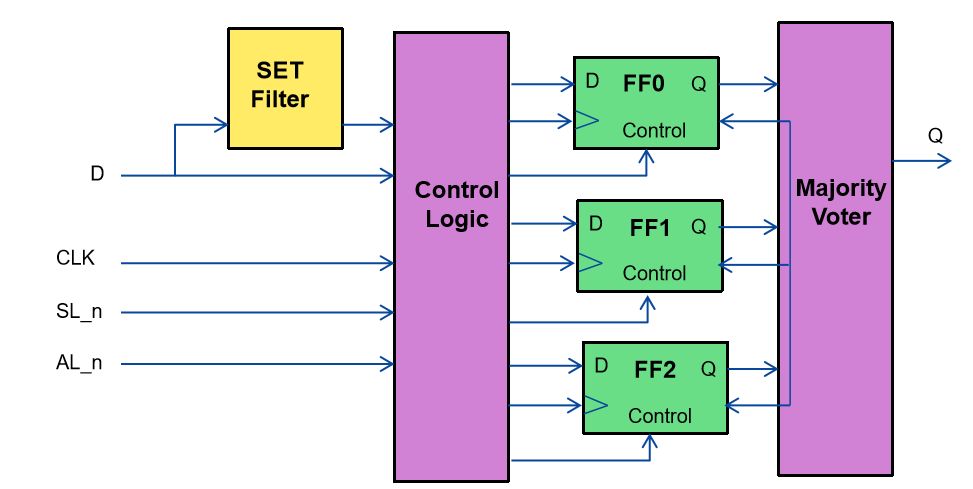
Jürgen S. schrieb: > Besorgter schrieb: >> Jedes FF ist dann auch noch 3 Fach redundant >> ausgeführt > > Dazu interessieren mich Quellen, wie das gebaut und verwendet wird. Wie > wird eine konträre Information wieder zusammengeführt? > Mehrheitsentscheider hinter jedem FF? > > Eigentlich baut man ja größere Schaltungszzweige redundant auf, sodass > eine elementare Funktion aus der SPEC abgeschlossen behandelt wird > (encapsulated requiremenent fullfillment) Ja genau. Es wird hierbei ein Mehrheitsentscheid herangezogen. Das Schlüsselwort ist hierbei TMR (triple-module redundancy). Microsemi hat entsprechende FPGAs im Angebot. Der RTG4 wurde speziell für die Anwendung im All entwickelt.
Jürgen S. schrieb: > Eigentlich baut man ja größere Schaltungszzweige redundant auf, sodass > eine elementare Funktion aus der SPEC abgeschlossen behandelt wird > (encapsulated requiremenent fullfillment) Das sind zwei Varianten um an das selbe Ziel zu kommen. Entweder man nutzt einen FPGA mit TMR in jeder Logikzelle und baut klassisch ohne weitere Redundanz. Oder man nutzt einen günstigeren FPGA ohne TMR und baut die Redundanz selber ein und zahlt das durch die zusätzlich verbrauchten Logikzellen. Die zweite Variante ist üblicher wenn keine Strahlungstoleranz nötig ist, da hier übliche Industrie-FPGA eingesetzt werden können. Synopsis verkauft auch ein Tool um eine vorhandene Beschreibung in eine TMR gesicherte Variante zu konvertieren. Besorgter schrieb: > Microsemi hat > entsprechende FPGAs im Angebot. Der RTG4 wurde speziell für die > Anwendung im All entwickelt. Wenn es nicht gleich ein RTG4 big iron sein muss (der wirklich so um die 100k kostet) gibt es noch die RTAX (TMR auf Zellebene) und RTPro (TMR durch Synthesetool) Serien. Beachte: Die stehen alle unter ITAR mit entsprechendem Papierkram beim Im-/Export.
Christophz schrieb: > Synopsis verkauft auch ein Tool um eine vorhandene Beschreibung in eine > TMR gesicherte Variante zu konvertieren. Geht das komplett automatisch?
J. S. schrieb: > Christophz schrieb: >> Synopsis verkauft auch ein Tool um eine vorhandene Beschreibung in eine >> TMR gesicherte Variante zu konvertieren. > > Geht das komplett automatisch? Falsche Frage, richtige Frage: ?Taugt das was? Ich bezweifle das, denn mit in ein Module wie ein FPGA eingebaute Redundanz macht man das Modul selbst nicht redundant, sondern nur Subsystem innerhalb des Modules. Es verbleibt mind. ein single Point of Failure bspw. die Stromversorgung. https://de.wikipedia.org/wiki/Single_Point_of_Failure Prominentes Beispiel: https://www.handelsblatt.com/politik/deutschland/g20-reise-die-bundeswehr-hat-wohl-keine-schuld-an-merkels-pannen-flug/23801934.html?ticket=ST-61840717-zeMOQGijG4XTMxHW5zwD-ap1
C. A. Rotwang schrieb: > Es verbleibt mind. ein single Point of > Failure bspw. die Stromversorgung. Die Stromversorung hat nichts mit der funktionalen Sicherheit im FPGA zu tun und lässt sich grundsätzlich nicht gleich behandeln. Damit ist der Rotwangsche Einwurf wieder einmal von der gleichen Qualität wie sonst auch. Selbstredend kann ein FPGA durch ausreichende Massnahmen bei der Versorgung unabhängig von der Schaltung gesichert werden. Praktisch je Spannung auf heutigen PCBs ist überwacht.
Michael K. schrieb: > Mit welcher Sicherheit kannst Du sagen das Dein Code und Deine Schaltung > in allen möglichen Betriebszuständen zu 100% funktionieren? > Was ist wenn das FPGA zu 100% funzt, der Spannungsregler aber nicht? Solche Ausfälle sind leicht zu erkennen, zu protokollieren und nachzuweisen, um sie entsprechend zu behandeln / bekämpfen. Bei der Funktionssicherheit geht es um das zufällig Nichtfunktionieren, infolg von (kleinen Spannungseinbrüchen gfs) aber vor allem Störungen auf Informationsleitungen von Außen, Timingproblemen die nicht erkannt wurden und Temperaturschwankungen, die nicht ausreichend berücksichtigt wurden oder werden konnten. Der FPGA kann sich theoretisch jederzeit irgendwo vertakten und verrechnen, besonders bei EMI und Strahlung, sobald irgendwelche Block-RAMs oder gar externe RAMs im Spiel sind und ECC nicht geholfen hat. Solche Fehler müssen rechentechnisch erkannt werden, daher werden solche Schaltungen entsprechend überwacht und ausgelegt. TMR ist dabei nur eine von mehreren Waffen.
Thomas U. schrieb: > zufällig Nichtfunktionieren, > infolg von Ich leihe dir zwei "e" für das zufällig-e- und infolg-e- aber ansonsten find ich den Beitrag intressant. Wie wahrscheinlich sind solche Strahlenfehler? Welche sonstigen Einflussfaktoren gäbe es denn noch, die solche Redundanz erfordern würde?
Thomas U. schrieb: > C. A. Rotwang schrieb: >> Es verbleibt mind. ein single Point of >> Failure bspw. die Stromversorgung. > > Die Stromversorung hat nichts mit der funktionalen Sicherheit im FPGA zu > tun und lässt sich grundsätzlich nicht gleich behandeln. Doch die Ermittlung der Single Point of Failures ist Bestandteil der Analyse im Rahmen der funktionalen Sicherheit. Deshalb beschreibt die ISO 26262 auch die Aufstellung der Single Point Fault Metric. > Damit ist der > Rotwangsche Einwurf wieder einmal von der gleichen Qualität wie sonst > auch. Tolle Argumentation, Bravo; Dir würde ich auf jeden Fall die Konstruktions eines Herzschrittmachers oder eines Augenlasers anvertrauen, Du weisst, worauf es ankommt .... >Solche Ausfälle sind leicht zu erkennen, zu protokollieren und >nachzuweisen, um sie entsprechend zu behandeln / bekämpfen. Klar, wie erkennt man beispielsweise, das durch einen Spannungseinbruch verursacht durch Kriechströme an den V_AUX-Pins die SRAM-Konfigurationsbits kippen, die den Redundanz-Comperator auf "always on" umfallen lassen?? Und was nützt ein Protokolleintrag in dem in etwa steht "das Kind ist in den Brunnen gefallen" ???
>>> Synopsis verkauft auch ein Tool um eine vorhandene Beschreibung in eine >>> TMR gesicherte Variante zu konvertieren. >> >> Geht das komplett automatisch? > > Falsche Frage, richtige Frage: ?Taugt das was? Ja, eines unserer Designs ist auf dem Weg zum Mars. Noch ein Nachtrag dazu: Ich habe inzwischen erfahren, dass auch Mentor zu seinen Synthesetools eine TMR Option anbietet. Thomas U. schrieb: > Die Stromversorung hat nichts mit der funktionalen Sicherheit im FPGA zu > tun und lässt sich grundsätzlich nicht gleich behandeln. Damit ist der > Rotwangsche Einwurf wieder einmal von der gleichen Qualität wie sonst > auch. Wenn die Stromversorgung komplett weg ist, hat es nichts mehr mit der Funktionalen Sicherheit im FPGA zu tun, weil der ja nix mehr tun kann. Die Stromversorgung ist aber natürlich zentraler Bestandteil der Betrachtung der funktionalen Sicherheit des Gesammtsystems. Also haben Thomas UND C. A. recht :-) Ich lege aber nach: Strahlung, Vibration, Alterungseffekte können die Spannungsregler bzw. Schaltregler beeinflussen und so zu erhöhtem Spannungsripple, Peaks oder Glitches führen. Diese können einen direkten Einfluss auf die funktionale Sicherheit des FPGA haben, wenn z. B. die Stützkondensatoren zu knapp bemessen sind für den Worst-case (Worst-case Temperatur, Worst-case Toleranz, Worst-case Alter). Im Security Bereich sieht man gut, was so alles schiefgeht, wenn plötzlich die Spannungsversorgung im blödsten Moment plötzlich kurz zu tief ist... (Power-glitching, eine übliche Side-channel Attacke). Thomas U. schrieb: > Der FPGA kann sich theoretisch jederzeit irgendwo vertakten und > verrechnen, besonders bei EMI und Strahlung, sobald irgendwelche > Block-RAMs oder gar externe RAMs im Spiel sind und ECC nicht geholfen > hat. Solche Fehler müssen rechentechnisch erkannt werden, daher werden > solche Schaltungen entsprechend überwacht und ausgelegt. TMR ist dabei > nur eine von mehreren Waffen. Genau, egal ob Block-RAM oder extern, hat alles bei uns ECC drauf und die Statusbits werden gespeichert, damit darauf reagiert werden kann (Also irgendeine Art Safe-Mode). C. A. Rotwang schrieb: > Klar, wie erkennt man beispielsweise, das durch einen Spannungseinbruch > verursacht durch Kriechströme an den V_AUX-Pins die > SRAM-Konfigurationsbits kippen, die den Redundanz-Comperator auf "always > on" umfallen lassen?? Das ist ein wichtiger Punkt, der gar nicht so einfach zum Lösen ist: - Lösung 1: Keine SRAM FPGAs verwenden (Microsemi Antifuse oder Flash). Nachteile: Teuer, keine modernen Chips mit >10 Gbit/S Serdes, Embedded CPU, eher hoher Stromverbrauch da eher grössere Chipstrukturen. - Lösung 2: Bitstream zurücklesen, vergleichen, reagieren (benötigt wieder eine dazugehörige Risiko- und Fehlerbetrachtung) - Lösung 3: Je nach Design kann man den Bitstream schneller neu laden, als die möglichen auftretenden Fehler ihre Auswirkung zeigen. Ist ein Trick den ich bei Cubesats schon angetroffen hatte. Da wird einfach jede Minute der FPGA neu konfiguriert und davon ausgegangen, dass dazwischen nichts kaputt gehen kann und höchstens ein paar Messwerte (erkennbar) kaputt sind. Es gibt wohl noch andere kreative Lösungen oder Kombinationen davon, die mir noch nicht geläufig sind. C. A. Rotwang schrieb: > Und was nützt ein Protokolleintrag in dem in etwa steht "das Kind ist in > den Brunnen gefallen" ??? In der FMEA steht ja nicht nur drin, dass ein Protokolleintrag gemacht wird, sondern was zu tun ist, damit das Kind doch nicht reinfällt oder z. B. das automatisch ein Rettungsring dem Kind nachgeworfen wird. (Der oben erwähnte Safe-Mode)
Hans schrieb: > Welche sonstigen Einflussfaktoren gäbe es denn noch, die solche > Redundanz erfordern würde? Miese Leiterbahnen und Lötverbindungen. Diese ändern die Signalform. Auch bei der Alterung. Was im Test in der FAB ging, geht oft nach Jahren nicht mehr.
Christoph Z. schrieb: > Je nach Design kann man den Bitstream schneller neu laden, > als die möglichen auftretenden Fehler ihre Auswirkung zeigen. Ist ein > Trick den ich bei Cubesats schon angetroffen hatte. Da wird einfach jede > Minute der FPGA neu konfiguriert und davon ausgegangen, dass dazwischen > nichts kaputt gehen kann und höchstens ein paar Messwerte (erkennbar) > kaputt sind. Das erfordert aber dann sicher jeweils einer weiteren redundanten FPGA, der die komplette Funktion während der Ladepause übernimmt?
Markus W. schrieb: > Das erfordert aber dann sicher jeweils einer weiteren redundanten FPGA, > der die komplette Funktion während der Ladepause übernimmt? Kommt darauf an, ob der FPGA systemkritische Aufgaben erledigt (z. B. Lageregelung, Powermanagement), dann ist ein zweiter redundanter FPGA nötig. Das Umschalten dazwischen erfordert nochmals zusätzliche Komponenten, was die Analyse wieder komplexer macht. Diese Komponenten sollten möglichst simple und robust sein. Das Cubesat Beispiel war mehr aus dem Bereich Bilddatenauswertung. Der FPGA ist nicht systemkritisch also nicht redundant aber missionskritisch. Der Mission ist es aber egal wenn sie z. B. 1 min falsche Bilddaten bekommt. Kommt natürlich auf die Mission drauf an (Das gehört zur FMEA, die Bewertung wie stark gewichtet ein Fehler ist, aufgrund seiner Auswirkungen).
Hans schrieb: > Thomas U. schrieb: >> zufällig Nichtfunktionieren, > infolg von > > Ich leihe dir zwei "e" für das zufällig-e- und infolg-e- aber ansonsten > find ich den Beitrag intressant. Wie wahrscheinlich sind solche > Strahlenfehler? Für Systeme, die in Stahlungsgefährdeten Bereichen eingesetzt werden, sehr hoch und sehr wahrscheilich. Ohne Behandlung sind Fehlfunktionen mehr oder weniger garantiert. Für normale Anwendungen sind RAMs gegenüber der Strahlung aus dem Weltraum und dem Boden resisent genug. Das geht alles im Rauschen unter. Etwas anderes wären Attacken a la NEMP. Daran arbeiten wir gerade.
Thomas U. schrieb: > Etwas anderes wären Attacken a la NEMP. Daran arbeiten wir gerade. Könntest du uns dann ein paar Tage vorher warnen? ;-)
Thomas U. schrieb: > Hans schrieb: >> Thomas U. schrieb: >>> zufällig Nichtfunktionieren, > infolg von >> >> Ich leihe dir zwei "e" für das zufällig-e- und infolg-e- aber ansonsten >> find ich den Beitrag intressant. Wie wahrscheinlich sind solche >> Strahlenfehler? > > Für Systeme, die in Stahlungsgefährdeten Bereichen eingesetzt werden, > sehr hoch und sehr wahrscheilich. Ohne Behandlung sind Fehlfunktionen > mehr oder weniger garantiert. > > Für normale Anwendungen sind RAMs gegenüber der Strahlung aus dem > Weltraum und dem Boden resisent genug. Das geht alles im Rauschen unter. Naja ist ne Frage was normal ist und welche Fehlerrate akzeptabel. Untersuchungen von google haben gezeigt, das RAM-Fehler eher häufig auftreten (0.1-1/Monat). Die Daten wurden anhand des ECC-RAMS in den google Server Farmen ermittelt. Eine solch hohe Fehlerrate ist schon bei der Fliegerrei inakzeptabel: https://www.zdnet.de/41515463/studie-dram-fehler-sind-weit-haeufiger-als-bisher-bekannt/ Und wir sprechen hier von rechner in klimatisierten und überwachten Räumen. Unterhaltungspause: ein Ausschnitt aus der Tschernobyl-TV-Serie bezüglich Strahlenfehler: https://www.youtube.com/watch?v=J7UcYtLq3zk https://www.youtube.com/watch?v=gOUVLJvbqys
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.