Hallo, Da ich gerade selber das Problem habe, eine .hex zerlegen zu wollen, da aber selber nicht weiterkomme, und auch keinen finde, der dazu bereit wäre, sich das mal näher anzusehen, frage ich mich, warum es eigentlich so schwer möglich ist, Maschinencode zurück zu C zu Decompilieren. Immerhin folgt ja der Maschinencode auch nur einem bestimmten Katalog an Instructionen die ein entsprechnder Prozessor beherrscht. Warum also ist es so einfach den Code zu compilieren, aber extrem schwer die Software wieder zurück zu Source Code zu bekommen? Und warum kann man dann als Mensch der davor hockt das was der Disassembler rauswirft doch irgednwie lesen und verstehen, warum kann das nur ein Mensch? Ich meine klar, die Kommentare usw. werden nicht mit kompilliert, sind also in dem Maschinencode nicht mehr da, aber der Source Code ist ja danach in einer anderen Form noch da nur eben nicht mehr in dem was Menschen (Ohne gewaltig Aufwand) lesen können, sondern eben in Maschinencode. Gibt es Programme die aus einer .hex wieder eine .C oder .C++ Datei machen können, und die sind uns einfach nur nicht zugänglich und z.B. Regierungen (Und vielleicht einigen Chinesen) vorbehalten, oder ist das wirklich so unmöglich? Und warum schaut eigentlich der C Code den IDA z.B. rausschmeißt so anders aus als echter Source Code, warum ist dieser Pseudo C Code so anders?
Oh man... Aus einem Hamburger kann man auch nicht wieder eine Kuh machen! Lern einfach mal C und Assembler und du versteht es.
Ganz einfach, weil 95% der "alten"/ notwendigen Informationen fehlen. Es wird ja nur der Machinencode gespeichert, nicht der Umstand des Wieso man etwas so macht. Ich nutze die Macroerweiterung eines Compilers, um mir eine "Hochsprache" zu implementieren. Oder Funktionale Macros, erklären werde ich das nun nicht weiter.
Anders ausgedrückt: Warum ist es schwerer, Zahnpasta zurück in die Tube zu drücken, als raus? ;-) Compilierung ist ein teilweise irreversibler Prozess, es dabei geht viel Information verloren. Ein Decompiler kann diese verlorene Information zu erraten versuchen, oder frei erfinden, aber nicht originalgetreu wiederherstellen.
Codeoptimierung und fehlende symbolsche Adressen machen die Rückübersetzung nicht leicht.
Bastler schrieb: > nd die sind uns einfach nur nicht zugänglich und z.B. > Regierungen (Und vielleicht einigen Chinesen) vorbehalten Genau, wenn man nicht verstanden hat, warum etwas nicht geht, ist die Regierung schuld, weil sie verschweigt, daß sie es doch kann.
Hauptproblematik ist dass der Kompilierprozess stark verlustbehaftet ist. Da verschwinden nicht nur Kommentare, sondern durch Optimierungen und Umorganisationen des Codes ne Menge zusätzlicher Informationen. Ob du für deine Schleife ein for, while oder gar goto verwendet hast, ist im Maschinencode nicht mehr erkenntlich. Eventuell verschwindet deine Schleife auch komplett und der Code wird einfach direkt 4 Mal ausgeführt. Menschen haben gegenüber der Software dann einen entscheidenen Vorteil: Jeder der sich mit Reverse Engineering auseinandersetzt wird selbst auch Programmieren. Somit kann man sich Konstrukte in der Disassembly (bzw. auch im Dekompilat) manuell in sinnvollen Code zurückdenken. Weiterhin kann der Mensch viel eher die Funktionsweise des Codes analysieren. Hierbei helfen auch z.B. Fehlermeldungen. Wenn in einer Funktion ein call zu print mit "[ERROR] SetVoltage: Voltage is negative" als Argument steht, kann ich davon ausgehen, dass die Funktion SetVoltage heißt und irgendeine Spannung setzt. Übrigens: Ghidra hat auch nen recht brauchbaren Decompiler.
Bastler schrieb: > [...] Und warum schaut eigentlich der C Code den IDA > z.B. rausschmeißt so anders aus als echter Source Code, warum ist dieser > Pseudo C Code so anders? Das wäre vielleicht ein guter Ansatzpunkt für Dich, die Sache mal näher zu untersuchen. Was sind die Unterschiede? Wie würdest Du sie beschreiben? Falls Du schon in der Lage bist, nicht-trivialen Code zu schreiben, empfehle ich Dir solch ein Programm mal zu compilieren und mit IDA wieder zurück zu übersetzen. Variiere beim compilieren auch mal die Optimierungsoptionen.
Besonders lustig ist's wenn man ein Programm analysiert, das größtenteils furchtbar ineffizient ist, aber stellenweise ein paar enorm clevere Optimierungen hat (z.B. binäre Suche bei einem großen switch-case). Da ahnt man was der Compiler produziert hat und was "original" ist!
Hallo, Das ist ja das Problem ich interessiere mich schon lange fürs Programmieren, weiß aber nicht wo ich anfangen soll, dazu war ich in Sprachen (Englisch) Noch nie eine Leuchte, so gut wie alles übers Programmieren ist aber in Englisch. Daran ist es bisher immer gescheitert. Warum kann man denn nicht einfach einen Prozessor simulieren, dann den Code auf dem simulierten Prozessor ausführen lassen, dabei beobachten was passiert, und anhand von dem zurückrechnen, wie der Code lautet? Sicherlich wirst du keinen sofort wieder kompilierungsfähigen Code bekommen aber was du vielleicht hinkriegst wäre was lesbares? Ich meine ich kenne jemanden, der früher bei einer großen Firma war die beutellose Sauger baut. Chinesen haben Geräte dieser Firma kopiert. Darauf befand sich die selbe Software wie auf den original Geräten. Aber ein ganz anderer Prozessor der nicht programmkompatibel ist. Den Unkompillierten Code hat nur die Firma des Originalgerätes, und trotzdem lief auf den Fälschungen später der Code der Originalfirma. Nun frage ich mich, wie wurde der Code da drauf zum laufen bekommen, woher weiß die Originalfirma dass es ihr Code ist (Derjenige sagte mir, dass es eine art stempel in der .hex gibt, der ihnen das verifizieren ermöglichte) und wie haben die den Code überhaupt bekommen? Ich denke nicht dass sie den unkompiliert gekriegt haben, also können sie ihn nur aus einem verkauften Gerät auf irgendeine Weise am Lockbit vorbei gelesen haben, dann wie auch immer reverse engineert haben, und anschließend auf einen anderen Prozessor kompiliert haben. Dabei blieb der Stempel der Originalfirma der zum Verifizieren diente aber erhalten?!?
Bastler schrieb: > Warum kann man denn nicht einfach einen Prozessor simulieren, dann den > Code auf dem simulierten Prozessor ausführen lassen, dabei beobachten > was passiert Kann man, ist nur eine unendliche Fummelei. Wie ein millionenteiliges Puzzle aus sich verändernden dreidimensionalen Teilen! > und anhand von dem zurückrechnen, wie der Code laute Wie stellst du dir diese "Berechnung" vor?! Bastler schrieb: > weiß aber nicht wo ich anfangen sol Ausrede, es gibt Mengen an Einsteiger Informationen. Auch auf Deutsch. Und Englisch lernt sich dabei fast von selbst.
Ohne Englisch kein programmieren. Punkt. > Warum kann man denn nicht einfach einen Prozessor > simulieren, dann den Code auf dem simulierten Prozessor ausführen > lassen, dabei beobachten was passiert Kann man doch, macht man auch. Nur ist ein simulierter Prozessor noch kein komplettes Systems. Hier ist zum Beispiel ein besonders schicker Simulator für den 6502 Prozessor: http://www.visual6502.org/JSSim/ Da kannst du jedes einzelne Signal bei der Ausführung des kleinen Programms mitverfolgen. Damit kannst du üben. Das Programm ist nur wenige Bytes groß. Der Befehlssatz des Prozessors ist mit Google leicht zu finden. Vielleicht bekommst du so ein Gefühl dafür, was es bedeutet, ein 1000 mal größeres Programm nachzuvollziehen. > und anhand von dem zurückrechnen, wie der Code lautet? Das wurde bereits beantwortet. Lerne Programmieren, dann wirst du es verstehen. > Sicherlich wirst du keinen sofort wieder kompilierungsfähigen Code > bekommen aber was du vielleicht hinkriegst wäre was lesbares? Das Problem ist, dass sämtliche Labels fehlen. Eine Ansammlung von mehreren zig-tausend Befehlen ohne Beschriftung durchblickt kein normaler Mensch. Gleiches gilt für die Ansammlungen von Daten. Ohne Markierungen, was wozu dient, ist das einfach nur ein großer Hausen Zahlen, du hast das doch selbst gesehen! > Darauf befand sich die selbe Software wie auf den > original Geräten. Aber ein ganz anderer Prozessor der nicht > programmkompatibel ist. Das kann unmöglich sein. Die selbe Software ist nur auf einem kompatiblen Prozessor lauffähig. > und wie haben die den Code überhaupt bekommen? Da fragst du die falschen Leute. Woher sollen ausgerechnet wir das wissen? Wir waren nicht dabei. > Ich denke zu viel über Sachen nach, von denen du keinen blassen Schimmer hast. > weiß aber nicht wo ich anfangen soll Fange hiermit an http://stefanfrings.de/avr_workshop/index.html und arbeite dich dann durch die weiteren Infos auf der Seite durch.
Wieso kann ich aus einem Essen das Rezept nicht rekonstruieren?
Um es einfacher auszudrücken, weil es keine eineindeutige Beziehung zwischen Maschinencode und Hochsprachen-Code gibt. Verschiedene C-Codeabschnitte können einen identischen Codeschnipsel ergeben. So lassen sich ganze Programmteile beliebig "umformulieren" und haben trotzdem den gleichen Maschinencode. Beispielsweise kann die Zahl 5 in Variablen des Typs Byte, Word, Shortinteger, Integer oder auch als Gleitkommazahl gespeichert werden. Dadurch wird es bei Datenstrukturen schwierig zu erkennen, wie sie aufgebaut sind. Hinzu kommt, daß die Hochsprachen mit Hilfe einiger weniger Grundfunktionen komplexere Funktionen in Standardbibliotheken abbilden, d.h. diese werden wieder und wieder in den Maschinencode eingebettet oder als Unterprogramme aufgerufen. Das zu entwirren, ist extrem schwierig, weil die aussagekräftigen Labels für Sprungmarken und Variablen fehlen.
Ganz einfach: Die chinesische und amerikanische Regierung haben sich gegen dich verschworen. Ist doch logisch. Warum auch sonst?!
Stefanus F. schrieb: > Ohne Englisch kein programmieren. Punkt. Wieso Punkt? Man muss die Bedeutung der Befehle kennen. Punkt Natürlich ist es hilfreich, wenn man auch noch etwas Englisch kann. Man stelle sich nur vor, die Japaner verwenden Japanisch, die Russen verwenden Russisch oder andere Arabisch, usw. Früher gab es sogar problemlos Arbeitsspeicher, Programmspeicher, Kellerspeicher usw alles ohne Englisch und leicht verständlich.
Das Problem an der Sache ist einfch dass ich noch niemanden gefunden habe, den ich dahingehend ausquetschen kann. Ich kenne jemanden der früher bei Renault in der Entwicklung war, seitdem kenne ich jeden Motorkennbuchstaben den Renault je verwendet hat auswendig, du kannst mich am Telefon nach einem Fehler fragen, und ich weiß was es ist, und ich kann dir sagen, wie du aus einem d7f Twingomotor 5 Ps und eine Menge Drehmoment mehr rausholst indem du die Nockenwelle um eine definierte Gradzahl verdrehst und einen Sensor tauschst. So jemanden gibt es aber im Bereich Programmieren nicht, der den ich bei Renault da kenne ist in Rente hat Zeit, den kann man gut ausfragen, wenn ich jetzt noch jemanden finden würde der sowas im Bereich Programmieren ist... Aber das gibts nicht, die haben alle was anderes zu tun, ich weiß ja noch nicht mal mit welcher Sprache ich anfangen soll, C C++ (Schwer, sagen alle) Java (Gibts für St Dinger schon garkeine Compiler...) oder sonst noch irgendwas anders? Kotlin, hab ich mal gehört, gibts für STm, PIC usw auch keinen Compiler, usw. Dann sagt der eine schon wieder Englisch braucht man unbedingt, der andere sagt braucht man nicht ubedingt, der nächste sagt sollte man können. Ein bisschen englisch kann ich, ich kann mich auch gut mit jemandem auf Englisch unterhalten, auch in einem amerikanischen Forum halbwegs verständlich auf Englisch schreiben, was ich aber nicht kann ist eine Englische Anleitung zum Programmieren lernen lernen was die ganzen befehle machen und gleichzeitig noch raten was englische Begriffe bedeuten von denen ich noch nie gehört habe, ich sehe schon hoffnungsloser Fall.
Wie wäre es, wenn du das tust was alle anderen auch tun... einfach mal anfangen und dabei langsam lernen. Und dafür braucht man nix, einfach irgendeine freie Entwicklungsumgebung auf den PC packen und anfangen. Und dann nicht bei jedem Problemchen sofort jemanden Fragen. Einfach mal selbst die Lösung suchen, auch wenns zwei Wochen dauert. Nur so lernt man Probleme selbständig zu lösen.
Angehängte Dateien:
-

PD7.png
500 KB

Bastler schrieb: > frage ich mich, warum es eigentlich so schwer möglich ist, Maschinencode > zurück zu C zu Decompilieren. Beim Compilieren wird die Bedieneroberfläche der Programmiersprache entfernt. Das ist so als wenn Du einen Blick in Deinen aufgeschraubten Computer wirfst und Dich fragst was das Alles darstellen soll. Ich geh Bettkarte stempeln.
Was möchtest Du eigentlich? Programmieren? Fange auf dem PC an, installiere Dir die Sprache, die Dir als erstes in den Sinn kommt, und lege los. Egal ob C, JAVA, Logo oder irgendwas grafisches für 4-jährige. µController LEDs blinken lassen? kaufe Dir irgendeinen fertigen Bausatz, der Dir vor die Tastatur fällt und in Stückzahlen umworben wird. Wenn Du dann erste Erfahrungen hast, dann kannst Du Dir noch immer eine geeignete Sprache oder eine geeignete Architektur auswählen, die ersten paar Wochen ist es egal, hauptsache Du springst in kalte Wasser.
Decompilieren im Sinne aus einer Binärdatei Source code zu machen kannst du vergessen. Es gibt Tools die dir einen Assembler code generieren und den du mit einem eingebauten Debugger durchsteppen kannst. Das funktioniert aber nicht immer fehlerfrei und Datenbereiche versucht er auch zu dekompilieren. Ich habe das mal für C++ code und Windows mit x32dbg bzw x64dbg gemacht. Das kannst du nicht aus einem Buch lernen das musst du selber ausprobieren. Wenn dein Binärcode im debug mode erstellt wurde und noch die Symboltabellen enthält bekommst du sogar noch sinnvolle Namen sonst ist alles einfach durchnummeriert.
Bastler schrieb: > ich interessiere mich schon lange fürs > Programmieren, weiß aber nicht wo ich anfangen soll Fang einfach überhaupt an. > Warum kann man denn nicht einfach einen Prozessor > simulieren, dann den Code auf dem simulierten Prozessor ausführen > lassen, dabei beobachten was passiert, und anhand von dem zurückrechnen, > wie der Code lautet? Genau das macht ein Disassembler ja. OK, außer daß er den Prozessor nicht simuliert, das ist vollkommen unnötig. Man kann den Maschinencode 1:1 in Assemblercode zurück übersetzen. Nur ist Assembler eben nicht C. Oder C++. Oder Pascal. Rust. Java. $YOU_NAME_IT Denn da geht es doch schon los: aus welcher Hochsprache resultiert denn der betrachtete Maschinencode? Oft kann man das erraten, manchmal aber auch nicht. Z.B. sind C und C++ so nah beieinander, daß es schon schwierig wird. > Sicherlich wirst du keinen sofort wieder > kompilierungsfähigen Code bekommen aber was du vielleicht hinkriegst > wäre was lesbares? Ernsthafte Programmierer können Assembler ihrer Zielplattform lesen. Insofern ist diese Anforderung trivial erfüllbar. Nur hilft das bei der eigentlichen Fragestellung kein bißchen weiter. Das Beispiel wurde doch schon genannt: ein Decompiler gleicht dem Versuch, aus einer Portion eines Gerichts das Rezept zu rekonstruieren. Der Disassembler entspricht dann dem Chemiker, der den Gehalt verschiedener Nährstoffe bestimmen kann. Damit kannst du zwar eine enährungstechnisch gleichwertige Pampe produzieren, aber dem Rezept bist du damit kein Stückchen näher gekommen. Das Reverse-Engineering von Kochrezepten ist dem Reverse-Engineering von Software dahingehend vergleichbar, daß die erforderlichen Kenntnisse und Erfahrungen sehr hoch sind. Sie sind nicht wesentlich von denen verschieden, die benötigt werden, um das entsprechende "Rezept" von Grund auf neu zu erfinden. Da du (nach eigener Aussage) nie gelernt hast, zu programmieren, wirst du auch an der Aufgabe des Reverse-Engineerings scheitern. Und die Leute, die es könnten, haben weiß Gott besseres zu tun, als einem Skript-Kiddie beim Tunen seines E-Scooters zu helfen. Du hast verloren. Trag es mit Würde!
Nur mal so als Hinweis: IDA ist kein Decompiler sondern ein Disassembler. Für diese Disassembler gibt es ein Plugin genannt HexRays was versucht erkannte Funktionen in einer C ähnlichen Pseudo Sprache anzeigen zu lassen. Das funktioniert erstaunlich gut und man kann Variablen sogar sprechende Namen geben die dann wieder im Disassembler auftauchen. Das Plugin erzeugt aber manchmal auch kompletten Unsinn. Dann liegt es am Betrachter dem Decompiler auf die Sprünge zu helfen. Dieses Decompiler Plugin ist als nur dann hilfreich wenn du wirklich gut programmieren kannst und wird für etwa 2500 Euro netto verkauft. Was natürlich die Frage aufwirft woher deine Version wohl stammt..... Der Hersteller sagt zu diesem Plugin: Es funktioniert manchmal ist aber besser als garnichts. Decompiler gibt es zumindest für native Compiler nicht. Auch das HexRays Plugin ist relativ neu 8..10 Jahre. Übrigens haben ernsthaft Anwender Signatur Files für die gängigen Libs der Compiler auf der Platte. Dann sieht der Disassembler Output gleich mal viel besser aus. Thomas
Bastler schrieb: > Das Problem an der Sache ist einfch dass ich noch niemanden gefunden > habe, den ich dahingehend ausquetschen kann. Da gibt es etwas, das nennt sich "Google". Und noch etwas namens "Amazon", das kann dir sogenannte "Bücher" bis an die Haustür schicken. Programmieren lernt man besser mit einem gut durchdachten Lehrplan, und nicht indem man kreuz und quer Fragen stellt. Bastler schrieb: > weiß ja noch nicht mal mit welcher Sprache ich anfangen soll Da du Controller programmieren und reverse engineeren willst: C.
Axel S. schrieb: > Ernsthafte Programmierer können Assembler ihrer Zielplattform lesen. Sicher nicht. Von dem Programmierer, der die Lohnbuchhaltung geschrieben hat, erwarte ich daß er sich mit Steuern, Renten und Krankenversicherung auskennt und mein Gehalt richtig berechnet. Auf welchem Rechner das dann ausgeführt wird, ist ihm (und auch mir) egal. Und das Gehalt ist für mich jedenfalls "ernsthaft". MfG Klaus
Bastler schrieb: > Warum also ist es so einfach den Code zu compilieren, aber extrem schwer > die Software wieder zurück zu Source Code zu bekommen? Warum also ist es so einfach die Zutaten zusammen zu rühren, aber extrem schwer den Kuchen wieder zurück zu getrennten Zutaten zu zerlegen? Denk 'mal darüber nach, welche Informationen im Source Code enthalten sind, die dann im Hex File fehlen. mfg mf
M. K. schrieb: > Ist schon Freitag? Wenn du den Brückentag frei hast, ja. Also sowas ähnliches wie Freitag... mfg mf
Bastler schrieb: > ich weiß ja noch nicht mal mit welcher Sprache ich anfangen soll Ich habe Dir etwas empfohlen. Du musst das lesen und ausprobieren, um weiter zu kommen. Oder lies irgendeine andere Anleitung, die dir besser gefällt. Irgendwo musst du anfangen.
Du wirst den Roller nicht so einfach umbauen können. Beitrag "BLDC Controller mit STM32F103C8T6 Geschwindigkeitsbegrenzer in der .hex"
Bastler schrieb: > Warum also ist > es so einfach den Code zu compilieren, aber extrem schwer die Software > wieder zurück zu Source Code zu bekommen? Naja Source-code ist nicht gleich Source-Code insbesonders bei Hochsprachen wie C, weil eben eine Hochsprache - Kompilierung keine bijektive Abbildung ist. Und statt was scheinbar falsches aka anders als erwartet auszugeben (bspw. while-loop statt ädequate foor-loop) macht der de-compiler lieber keine ausgabe anstatt Prügel zu beziehen dafür, daß er was sinngemäß richtig wiedergegeben hat, aber eben nicht auf den (überflüssigen) I-Punkt genau. De-compiler sind auch nur Menschen, die scheuen sich auch ihren "Cheffe" dämlich ausschauen zu lassen - auch wenn er es verdient hat.
Du kannst den Maschinencode mit einer Auflistung der Bauteile eines Hauses vergleichen. Für jeden Stein, Schraube, Rohrstück, usw. ist ganz genau beschrieben, welche Abmessungen es hat und wo es positioniert ist. Mit so einer Liste wäre man theoretisch imstande, das gleiche Haus erneut zu bauen. Aber du als Mensch kannst an so einer Liste nicht mehr das große Ganze erkennen. Dementsprechend schwierig sind Änderungen. Welche Steine müssten in der Liste geändert werden, damit ein anderes Rohr verlegt werden kann? Bei tausenden Steinen ist das schwer herauszufinden. Dazu kommt, das in sicherheitsrelevanten Anwendungen oft ein Selbst-Schutz gegen Veränderungen integriert ist. Damit werden gefährliche Fehlfunktionen verhindert. Diesen Algorithmus müsste man dann auch noch knacken, falls vorhanden.
Bastler schrieb: > C++ (Schwer, sagen alle) Ja, C++ ist schwer zu lernen. Alleine schon, weil es eine Multiparadigmensprache ist. Dennoch rate ich dir dazu. Einen großen Teil der C Grundlagen lernst du automatisch mit. Wer zuerst C lernt, und dann C++ hat größere (innere) Hürden zu überwinden, als anders rum. Zeitfenster: Wenn du dir Mühe gibst.... Dann benötigst du für das lernen der µC Grundfunktionen (fast egal welcher µC) und die erste Sprache (auch recht egal, welche), ca 3 Jahre. Plus ca 1/2 Jahr für jede weitere µC Familie und weitere Sprache. Nach ca 10 Jahren kannst du dann auf diesem Gebiet recht fit sein. Wenn du ein Überflieger bist, mag es schneller gehen.
Disassembler für Kuchen nennt sich Rosinenpicker. Das Rezept wird er so kaum herausbekommen. C3 2000 ist z.B. bei Z80 ein absoluter Spung nach 2000. Aber was ist irgendwo 44C3 eine Adresse oder ein Stück des Befehls oder ein Wert? Das nur der Erzeuger, für andere wird es mühsam.
Angehängte Dateien:
-

x32dbg.PNG
190 KB
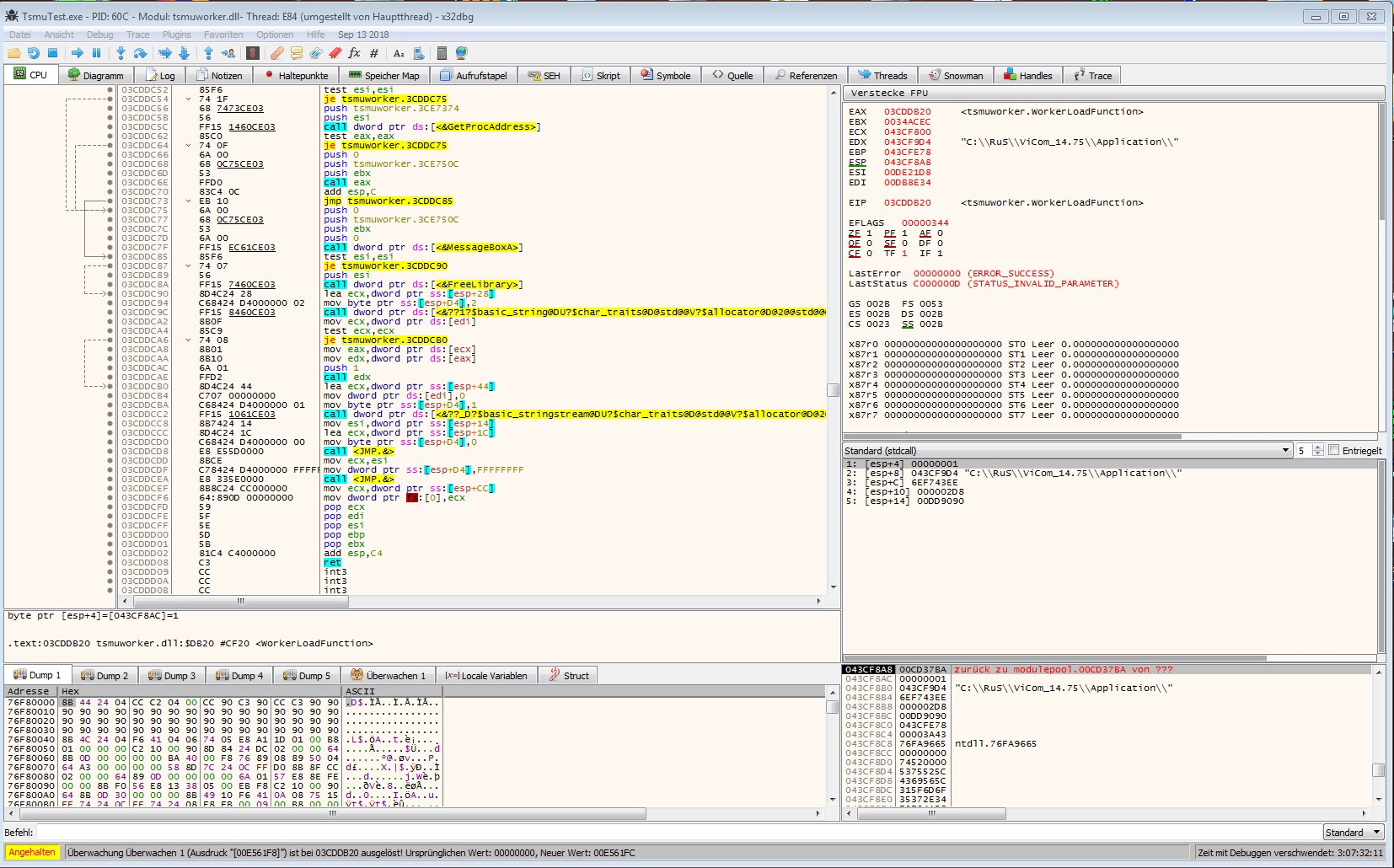
Im Anhang ein Beispiel wie so etwas aussieht. Das ist allerdings x86 Assembler und Windows mit einem selbstgeschrieben Programm mit dem ich versucht habe proprietäre DLLs zu Analysieren. @Thomas Z. Es gibt für Windows eine freie Sparversion von IDA, hat mich allerdings nicht überzeugt. Damit lassen sich keine Plugins laden.
Wenn schon die Hochsprache (von mir aus C) so leicht zu verstehen ist, dann versuch dich mal an "Obfuscated C". https://ioccc.org/ Vieleicht verstehst du dann, warum Maschinencode nur schwer zu verstehen ist. Obwohl das doch "eigentlich das Gleiche ist". Nick
Hallo, Dr. Sommer schrieb: > Und noch etwas namens "Amazon", das kann dir sogenannte "Bücher" > bis an die Haustür schicken. Und es gibt auch den örtlichen Buchhändler, bei dem man auch alle Bücher kaufen kann und der dazu noch deutlich schneller ist (außerdem unterstützt man dadurch die heimische Wirtschaft). > Da du Controller programmieren und reverse engineeren willst: C. Und da empfehle ich immer noch (trotz des Alters) "Programmieren in C" von Kernighan & Ritchie. Zum verstehen der C-Grundlagen für mich immer noch der Maßstab. rhf
Bastler schrieb: > Warum kann man denn nicht einfach einen Prozessor > simulieren, dann den Code auf dem simulierten Prozessor ausführen > lassen, dabei beobachten was passiert, und anhand von dem zurückrechnen, > wie der Code lautet? Z.B. weil der Programmablauf von den jeweiligen Eingaben abhängt. Das ist ja gerade der Sinn und Zweck von EDV. Dass man heutzutage schon Computer programmiert, um eine LED im Takt blinken zu lassen, täuscht vielleicht etwas über diesen eigentlichen Zweck hinweg.
Hallo, Arduino Fanboy D. schrieb: > Zeitfenster: ... > ...3 Jahre. > ...1/2 Jahr > ...10 Jahren Ich hoffe, du arbeitest nicht als Motivationstrainer. :-) rhf
Roland F. schrieb: > Motivationstrainer. Mit dem Wissen wächst die Verzweiflung :-) Einige Studenten wie Claus W. haben im letzten Jahrtausend in 8 Wochen ein Betriebssystem mit Papier, Bleistift und Befehlstabelle komplett auseinandergenommen. Heute sind es nur ein paar GB mehr... :-)
Roland F. schrieb: > Ich hoffe, du arbeitest nicht als Motivationstrainer. Ja, das ist keine meiner Kernkompetenzen! Andererseits neige ich dazu Leute in ihren vorgefassten Meinungen zu bestärken, wenn sie mir richtig erscheinen. Der Bastler kann englisch lesen und schreiben. Dagegen fehlt es ihm an fachlicher Kompetenz/Vokabular. Das sind ganz normale Voraussetzungen, fast schon gute, für einen "EDV" Anfänger. Nicht so prickelnd, ist die Verweigerung anzufangen. > Tausend mal schaut der Wille durch das Fenster, > bis die Tat durch die Tür schreitet. Das stimmt mich hier, in der Tat, etwas pessimistisch. Und diesen Pessimismus zeigt auch Bastler. Also muss ich ihn da bestätigen. Auch der Versuch sich irgendwo anzuhängen "dass ich noch niemanden gefunden habe, den ich dahingehend ausquetschen kann" mündet in gegenseitigem Frust, erfahrungsgemäß. Bastler muss lernen, sich die Information selber zu beschaffen, und die Zeit kommt oben drauf. > Wir lernen, in dem wir es tun. Klar, könnte ich den Arduino Priester machen, und sagen: So kommst du schnell zu ersten Erfolgserlebnissen! Aber für die "Tiefe" ist dann auch die Zeit nötig. Aus meiner Sicht: 1. Egal wo 2. Hauptsache, anfangen Irgendwo werden einen die Aufgaben und Interessen dann schon hin führen. Also ruhig, fremde *.hex Dateien analysieren. Ist auch ein Startpunkt. (dass ich ihn für suboptimal halte, ist dabei zweitrangig)
Beitrag #5990959 wurde von einem Moderator gelöscht.
Gebt euch keine Mühe, eure Vorschläge und Erfahrungen nimmt er doch nicht an, er sucht immer noch einen Dummen, der die Arbeit für ihn macht. Genau das zeigen seine Beiträge zum Thema und die fehlenden Antworten auf eure Fragen. Blackbird PS: Interessant sind eure Beiträge trotzdem.
Bastler schrieb: > seitdem kenne ich jeden > Motorkennbuchstaben den Renault je verwendet hat auswendig, Ganz fein. Toll gemacht!
Arduino Fanboy D. schrieb: > Zeitfenster: > Wenn du dir Mühe gibst.... > Dann benötigst du für das lernen der µC Grundfunktionen (fast egal > welcher µC) und die erste Sprache (auch recht egal, welche), ca 3 Jahre. > Plus ca 1/2 Jahr für jede weitere µC Familie und weitere Sprache. > > Nach ca 10 Jahren kannst du dann auf diesem Gebiet recht fit sein. > Wenn du ein Überflieger bist, mag es schneller gehen. Bei mir im Studium waren für das erlernen der beiden Sprachen C und C++ 15CP (also 450h) vorgesehen. Waren insgesamt 3 Klausuren im 1. und 2. Semester (Grundlagen, OOP, Datenstrukturen und Algorithmen). Wobei es da natürlich nicht nur um die Programmiersprachen ging. Insgesamt waren es 5 Semester zu je 4 Monaten (2 Monate Semesterferien pro Semester), 1 Praxissemester und 1 Semester Bachelorarbeit und Wahlfächer. Und das war nur auf der FH - also auf Sparflamme.
Bastler schrieb: > Das Problem an der Sache ist einfch dass ich noch niemanden gefunden > habe, > den ich dahingehend ausquetschen kann. [...] Mit etwas Geduld, wird Dich jemand finden. Das ist wie mit der Liebe. :-) Naja. Das ist schon nützlich, so jemanden zu haben, aber auch, selbst anzufangen. > ... ich weiß ja noch nicht mal mit > welcher Sprache ich anfangen soll, {...] Super. Du weisst schon mehr als ich: "Kotlin" lese ich zum erstenmal. :-) Wie das so ist. 3 Fachleute und 4 Meinungen. :-) Im Grunde ist es egal, welche Sprache Du als erstes lernst. Schau Dir einfach mal drei oder vier verschiedene an und nimm die, welche Dir intuitiv geeignet erscheint. Das kann auch BASIC sein, oder Python. Das wesentliche ist für einen Anfänger nicht, eine Sprache zu wählen, die für einen bestimmten Zweck geeignet ist oder für eine bestimtme Plattform, meine ich. Das wesentliche ist vielmehr, mit einer Denkweise Erfahrungen zu machen, die darauf hinauslääuft, 1. sich in einer sehr detailliert definierten Sprache auszudrücken und 2. Vorgänge in extrem kleine Schritte zu zerlegen, wie man das im täglichen Leben eigentlich nicht gewohnt ist, weil man schon vergessen hat, welche präzise und vorausschauende Planung allein das Gehen erfordert (OK. So bewusst lernen wir das nicht, aber nimm etwa das Autofahren als Vergleich, falls Du einen Führerschein hast). > Dann sagt der eine schon wieder Englisch [...] Naja. Das war früher, so in den 80er Jahren, noch wesentlich bedeutender als heute. (Denk dran, dass hier viele alte Säcke rumlungern). Es gibt schon recht viel deutsche Literatur. Allerdings wirst Du langfristig nicht darum herum kommen, Engslisch zu lernen. > was > ich aber nicht kann ist eine Englische Anleitung zum Programmieren > lernen lernen was die ganzen befehle machen und gleichzeitig noch raten > was englische Begriffe bedeuten von denen ich noch nie gehört habe, ich > sehe schon hoffnungsloser Fall. Da empfehle ich mal https://www.youtube.com/watch?v=0HxnyY0cS3M Ich habe diesen Vortrag auch erst vor einigen Monaten entdeckt. Habe aber festgestellt, dass ich damals (ich war in Fremdpsprachen auch keine Leuchte), als ich wirklich Programmieren und Elektronik lernen wollte, faktisch genau so vorgegangen bin. Schritt für Schritt, Wort für Wort. Ohne Anleitung und nicht so wie in der Schule. Im Laufe der Zeit merkt man sich immer mehr. Das geht schon, wenn man die Sache nur stark genug verstehen will. Also: Viel Erfolg.
Bastler schrieb: > warum es eigentlich > so schwer möglich ist, Maschinencode zurück zu C zu Decompilieren. Ein Compiler ist wie eine Traubenpresse, um Traubensaft herzustellen: Trauben kommen in die Presse, zudrücken, Saft kommt raus, Trester (die zerquetschten Trauben) bleiben übrig und kommen auf den Kompost. Aus dem Saft kannst Du auch keine Trauben mehr bauen, obwohl Du exakt weißt, wie der Saft hergestellt wurde. Ein Teil wurde vernichtet (verrottet auf dem Kompost) und nur der Saft wurde aufgehoben. Trauben <==> C-Code Presse <==> Compiler Saft <==> Maschinencode
Darum auch: Du programmierst nicht für den Compiler, sondern für den Programmierer der Deinen Code lesen und verstehen muss (oft ist man das selbst, nach einiger Zeit).
oszi40 schrieb: > Einige Studenten wie Claus W. > haben im letzten Jahrtausend in 8 Wochen ein Betriebssystem mit Papier, > Bleistift und Befehlstabelle komplett auseinandergenommen. Ich habe möglicherweise noch einen kommentierten Ausdruck des kompletten Quellcodes eines Unix-Kernels rumliegen. Den gabs damals in Buchformat, und nicht sonderlich dick. Hat sehr zum Verständnis der Innereien von Betriebssystemen beigetragen. "You are not expected to understand this" https://en.wikipedia.org/wiki/Lions%27_Commentary_on_UNIX_6th_Edition,_with_Source_Code
A. K. schrieb: > Ich habe möglicherweise noch einen Ausdruck des kompletten Quellcodes > eines Unix-Kernels rumliegen. Den gabs damals in Buchformat, und nicht > sonderlich dick. ;-) Das Kommentierte ROM Listing des Commodore 64 gab es auch mal als Buch. Das war ein dicker schmöker. Dessen Code dürfte vom Umfang her dem Roller ähnlich sein. Das bring mich auf folgende Idee: Bastler, schau Dir mal diese Seite an: https://www.pagetable.com/c64disasm/ Das ist der Disassemblierte Code des Commodore 64. Rechts daneben die Kommentare aus dem originalen Quelltext. Noch weiter rechts die Kommentare von unterschiedlichen sehr erfahrenen Spezialisten, die das Gerät in und auswendig kannten. Kannst du mit solchen Kommentaren etwas anfangen? Dazu eine Testfrage: Wie lautet die Bildschirmmeldung nach dem Einschalten, die Betriebsbereitschaft signalisiert? Kannst du sie im Code finden? Zweite Testfrage: Was müsstest du ändern, um die standard Hintergrundfarbe vom Bildschirm zu ändern. Findest du die Stelle? Versuch mal kurz, diese Fragen zu beantworten. Achte auch mal darauf, wie wertvoll die fett hervorgehobenen Kommentare im Originalquelltext sind, welcher den anderen Kommentatoren damals nicht zur Verfügung stand. Dann wird dir vielleicht ein bisschen klar, wie schwer fremder Assembler Code zu analysieren ist.
Es gäbe auch noch die Möglichkeit - die wird hier aber vermutlich nicht zutreffen! -, daß das Programm in Assembler geschrieben wurde UND der Programmierer ein Disassemblieren erschweren wollte. In solchen Programmen findet sich oft "toter Code", der unsinne Loops erzeugt, oder selbstmodifizierenden Code -> auch sehr schön, um den Disassembler zu verwirren. Warum hat man das gemacht? µP haben im Gegensatz zum µC i.d.R. keinen Schutz gegen das Auslesen. Und wer sein Programm schützen wollte... Heute schützt man ein Produkt oft besser durch die Software im µC als durch Patente. Hochwertige µP-Software wird häufig durch Dongles geschützt, wobei es auch da extrem schwierig ist, die passenden Zeilen im Code zu finden, um die Abfrage zu deaktivieren oder das Ergebnis als okay zu liefern.
Bastler schrieb: > woher weiß die Originalfirma dass es ihr Code ist An der Benutzeroberfläche, dem Hardwareinterface und vor allem an den Fehlern.
Mische einen Kuchenteig. Nehme anschließend 150g Zucker wieder heraus. Klaus.
Besonders schwer zu durchschauen sind Programmaufrufe oder Sprünge über Zeigervariable, denn deren Inhalt ist nur zur Laufzeit verfügbar.
Bastler schrieb: > Da ich gerade selber das Problem habe, eine .hex zerlegen zu wollen, da > aber selber nicht weiterkomme, und auch keinen finde, der dazu bereit > wäre, sich das mal näher anzusehen, frage ich mich, warum es eigentlich > so schwer möglich ist, Maschinencode zurück zu C zu Decompilieren. Also erstens, wenn du schon daran scheiterst, eine Hexdatei fachgerecht zu zerlegen - wobei deren Format ja nun wirklich seit gefühlten 100 Jahren in allen Einzelheiten dokumentiert ist - dann solltest du zuvörderst darüber dich belesen, bis du es kapiert hast. OK, die Programmierer des GCC waren bislang auch zu blöd, zu kapieren, wozu das CS:IP-Format und der dazugehörige Blocktyp im .hex eigentlich gedacht ist. Sonst hätten sie für die 32 Bit Controller gleich zum dafür gedachten Blocktyp gegriffen. Und als nächstes solltest du dich fragen, wie du zu der sachlich unbegründbaren Annahme kommst, daß das Ausgangsmaterial für eine Hexdatei nur ein C-Quellcode sein könnte. Tip: Es gibt noch andere Programmiersprachen außer C. W.S.
GEKU schrieb: > Besonders schwer zu durchschauen sind Programmaufrufe oder Sprünge über > Zeigervariable, denn deren Inhalt ist nur zur Laufzeit verfügbar. Jein, der Code, zeigt einem doch die Ladevorgänge in die 16-Bit Register, wenn dann etwas nach indirekten Zugriffen aussieht, ist es ein einfaches den realen Ort zu berechnen.
W.S. schrieb: > OK, die Programmierer des GCC waren bislang auch zu blöd, zu kapieren, > wozu das CS:IP-Format und der dazugehörige Blocktyp im .hex eigentlich > gedacht ist Der GCC arbeitet überhaupt nicht mit dem Hex Format. Wenn schon, dann binutils und objcopy.
Ich habe vor einer Weile mal den Code aus einem dieser $10-LCD-„Scopes“ mit einem ATmega64 nach C zurückübersetzt. Das ging, weil der ohne Optimierung übersetzt war. Da war es tatsächlich möglich, mit etwas trial und error einen C-Code zu schreiben, der zu identischem Assembler-Code kompilierte. gcc erzeugt ohne Optimierung ganz gut erkennbare Pattern. Solche Details wie Variablen- oder Funktionsnamen spukte das Verfahren natürlich nicht aus. Oliver
Bastler schrieb: > Maschinencode zurück zu C zu Decompilieren Was bringt dir das denn, wenn du kein C verstehst? Bastler schrieb: > Und warum schaut eigentlich der C Code den IDA z.B. rausschmeißt so > anders aus als echter Source Code, warum ist dieser Pseudo C Code so > anders? Wenn du warmes und kaltes Wasser vermischst und hinterher lauwarmes Wasser hast, kannst du daraus ohne weiteres auch nicht wieder warmes und kaltes Wasser machen. Das ganze nennt sich Entropie. "You can not unscrumble the eggs!"
wolle g. schrieb: > Stefanus F. schrieb: >> Ohne Englisch kein programmieren. Punkt. > > Wieso Punkt? Das ist ergonomischer.
Seit dem Transistor ist Englisch die Sprache der Elektronik. Das hat sich auch mit dem Computer nicht geändert. Im Gegensatz zur Elektronik hat die Sprache hier logische und physikalische Spuren hinterlassen. Für einen Linguisten mag das vielleicht interessant sein, der Praktiker bleibt einfach beim Englisch und macht nichts lieber als einen Punkt.
Antoni Stolenkov schrieb: > Das hat sich auch mit dem Computer nicht geändert. Zunehmend gibt es Datenblätter nur noch auf Chinesisch.
Arduino Fanboy D. schrieb: > Antoni Stolenkov schrieb: >> Das hat sich auch mit dem Computer nicht geändert. > Zunehmend gibt es Datenblätter nur noch auf Chinesisch. Wenn man wirklich will, kann man schon finden.. https://www.ccc.de/hackabike/ https://www.bussgeldkatalog.org/roller-entdrosseln/ Das mit dem Asm-Code kann man ja mal selber machen. Viele kleine Codeschnipsel von Hex/Asm nach C, C++ oder Pascal o.ä. übersetzen und schauen wie gut das geht. Es kann aber unbekanntes Know How im Code sein, z.B. ein bestimmter, besonders ausgefeilter Algorithmus, denn man selber - und das Übersetzungsprg auch nicht - gar nicht kennt. Das Übersetzerprg könnte zumindest skippen (aber an welcher Stelle?) oder einen Ersatz vorschlagen (aus welcher Bibliothek?). Die beste Übung ist wohl, viele kleine Programme von Asm nach C und C++ (und von mir aus Java) übersetzen und umgekehrt. Das geht nicht immer astrein. Wenn man aber nach einer gewissen Zeit ein gewisses Gefühl dafür bekommt, warum das wohl so ist, dann wäre man eigentlich schon einen Schritt weiter.
Gibt's eigentlich schon eine Programmiersprache, die ausschliesslich in Chinesisch formuliert ist? APL mag manchen so erscheinen, ist aber mathematisch inspiriert.
A. K. schrieb: > Gibt's eigentlich schon eine Programmiersprache, die ausschliesslich in > Chinesisch formuliert ist? https://de.wikipedia.org/wiki/Chinese_BASIC
A. K. schrieb: > Gibt's eigentlich schon eine Programmiersprache, die ausschliesslich in > Chinesisch formuliert ist? Das würde die chinesischen Programmierer vom Weltvorrat an vorhandener Software ausschliessen - so blöd sind die nicht. Auch teutsche Programmiersprachen sind ausgestorben, sogar bei Siemens. Georg
A. K. schrieb: > APL mag manchen so erscheinen Ok, Asm nach J kann man auch versuchen ;) https://code.jsoftware.com/mediawiki/images/d/d9/J_fuer_c.pdf https://de.wikipedia.org/wiki/J_(Programmiersprache)
Georg schrieb: > Auch teutsche Programmiersprachen sind ausgestorben, sogar bei Siemens. Gemäß eines bloggenden Insiders hat man sich in den 70ern sehr wohl die Frage gestellt, ob die Programmiersprachen eingedeutscht werden sollten. Das Killerargument dagegen: bessere Unterscheidbarkeit Schlüsselwörter und eigene Token
A. S. schrieb: > Gemäß eines bloggenden Insiders hat man sich in den 70ern sehr wohl die > Frage gestellt, ob die Programmiersprachen eingedeutscht werden sollten. Schlimmer noch: bei Microsoft hat man sich in VBA dafür entschieden, das zu tun!
Hallo, Ja das sind Hacker rbx schrieb: > Arduino Fanboy D. schrieb: >> Antoni Stolenkov schrieb: >>> Das hat sich auch mit dem Computer nicht geändert. >> Zunehmend gibt es Datenblätter nur noch auf Chinesisch. > > Wenn man wirklich will, kann man schon finden.. > https://www.ccc.de/hackabike/ > https://www.bussgeldkatalog.org/roller-entdrosseln/ Ja, das sind richtige Hacker, aber sowas kann ich bei weitem nicht und werde ich auch nie können. Die Deutsche Polizei braucht mich in Österreich nicht zu interessieren ich darf da 25 mitm E Scooter... Ich denke aber dieses Verfahren der Polizei Fahrzeuge einzuziehen und dann durch Sachverständige zu prüfen wird bald am Ende sein, wenn ich jetzt programmieren könnte würde mir schon so einiges einfallen um denen das Leben beim begutachten so richtig schwer zu machen (Lockbits, selbstlöschender Code, Prüfstandserkennung, Geofencing, Sperrsysteme die erkennen wenn das Fahrzeug von der Polizei mitgenommen wurde usw, usf) Das wird für die Ordnungshüter noch ganz schön schwierig in der Zukunft, einfach mal aufschrauben und sagen "Da is jan Tuning Vergaser drin!" wird dann nichtmehr gehen, die haben dann das gleiche Problem wie ich jetzt mit meinem Scooter, entweder kriegen sie die Daten aus dem Prozessor garnicht erst raus, oder aber sie stehen davor und sagen "OH, tuning Einsen und Nullen, nur wo sind die in dem 128kb großen hex File?"
A. S. schrieb: > Gemäß eines bloggenden Insiders hat man sich in den 70ern sehr wohl die > Frage gestellt, ob die Programmiersprachen eingedeutscht werden sollten. Yep. Eine deutsche Assembler-Sprache gab es beispielsweise beim Telefunken Grossrechner TR-440. BRINGE statt MOVE. Der Rest vom Umgang war ähnlich, es wurde nicht gelinkt, sondern montiert.
Bastler schrieb: > Die Deutsche Polizei braucht mich in > Österreich nicht zu interessieren ich darf da 25 mitm E Scooter. Dann kauf Dir doch bitte einen der das kann - und gut ist es.
A. S. schrieb: > Das Killerargument dagegen: bessere Unterscheidbarkeit Schlüsselwörter > und eigene Token Hmm, damit können die Engländer, und Amerikaner leider nicht viel anfangen. Demnach müssten die doch eine andere Sprache bevorzugen, oder nicht?
Nop schrieb: > Schlimmer noch: bei Microsoft hat man sich in VBA dafür entschieden, das > zu tun! Und damit reichlich Ärger gestiftet beim internationalen Austausch von Excel Makros gestiftet.
Arduino Fanboy D. schrieb: > Antoni Stolenkov schrieb: >> Das hat sich auch mit dem Computer nicht geändert. > Zunehmend gibt es Datenblätter nur noch auf Chinesisch. Die haben sich aber ... Georg schrieb: > A. K. schrieb: >> Gibt's eigentlich schon eine Programmiersprache, die ausschliesslich in >> Chinesisch formuliert ist? > > Das würde die chinesischen Programmierer vom Weltvorrat an vorhandener > Software ausschliessen - so blöd sind die nicht. ... ins gemachte Bett gelegt.
Hi Bastler Wie so oft im Leben gibt es auch beim Programmieren zwei Seiten. Die Programmiersprache, die kann man lernen. Tja, und dann kommt noch das "Talent", wenn ich es mal so ausdrücken darf. Und das ist m. E. nicht erlernbar. Glaub mir, ich hab schon so einige "talentlose" Programme gesehen und mit einigen mußte ich auch arbeiten. Diese Programme erfüllten zwar die Anforderungen, waren aber null bedienerfreundlich. OK, du willst programmieren lernen, dann fange an. Hast du schon eine Idee? Nein, dann kennst du jemanden, der eine hat? Auch nicht? Nun, dann wird es schwer, denn ohne Ziel einen Weg zu finden ist meist planloses Hin-und Hergelaufe. Ohne ein Ziel wirst du den Weg nicht finden. Trotzdem, nimm dir die hier von Stefanus vorgeschlagene Lektüre vor. Stefanus F. schrieb: > Fange hiermit an http://stefanfrings.de/avr_workshop/index.html und > arbeite dich dann durch die weiteren Infos auf der Seite durch. Vielleicht hilft dir auch dieses: https://www.makerconnect.de/media/user/oldmax/PC%20und%20Mikrocontroller%20Teil%201%20und%202%20Stand%2026.07.2019.pdf Ist ein wenig als Leitfaden zur Programmerstellung gedacht. Ach ja, Programme zu disassembleren macht nur in ganz seltenen Fällen Sinn. Die Vorstellung, man könnte sich in professionelle Programme hacken, ist für einen Anfänger völlig illusorisch. Selbst Spezialisten fällt das nicht leicht, und bevor die sowas anfangen, schreiben sie lieber ein eigenes Programm. Da haben sie dann auch das, was sie haben wollen. Zum Schluß noch eine Bemerkung zur Sprache "Englisch". Ja, das ist die Sprache der Elektronik und Software, aber mit Grundkenntnissen kommt man schon ganz gut zurecht. Ein Hindernis in einer Programmiersprache ist englisch sicher nicht. Gruß oldmax
A. K. schrieb: > A. S. schrieb: >> Gemäß eines bloggenden Insiders hat man sich in den 70ern sehr wohl die >> Frage gestellt, ob die Programmiersprachen eingedeutscht werden sollten. > > Yep. Eine deutsche Assembler-Sprache gab es beispielsweise beim > Telefunken Grossrechner TR-440. BRINGE statt MOVE. Der Rest vom Umgang > war ähnlich, es wurde nicht gelinkt, sondern montiert. Schön mal vom T eakholz R echner 440 zu hören. Wieviel gab es davon? Es ist doch kein Problem, weder im Assembler noch in C für jeden englischen Ausdruck ein deutsches Makro vorzuschalten.
Martin V. schrieb: > Ein Hindernis in einer Programmiersprache ist > englisch sicher nicht. Die paar Schlüsselwörter kann man auswendig lernen und Programmieranleitungen gibt es genug in jeder beliebigen Sprache. Der Knackpunkt sind hier eher die 3rd party Bibliotheken und Datenblätter.
Hi Stefanus F. schrieb: > Der Knackpunkt sind hier eher die 3rd party Bibliotheken und > Datenblätter. So kompliziert ist das nun auch wieder nicht. Ein Anfänger liest sich, wenn er will, da hinein. Und wenn es um die Frage geht, "versteht er es dann auch?" kommen wir wieder zum Punkt "Talent". Gruß oldmax
klausb schrieb: > Schön mal vom T eakholz R echner 440 zu hören. Wieviel gab es davon? 46-60, je nach Quelle. Wohl hauptsächlich an Hochschulen. Es gibt natürlich auch einen Emulator dafür: http://www.tr440.info/
Bastler schrieb: > Ich denke aber dieses Verfahren der Polizei Fahrzeuge einzuziehen > und dann durch Sachverständige zu prüfen wird bald am Ende sein, Wieso? Die behalten die einfach ein, bis die Prüfung vollumfänglich abgeschlossen ist. Du machst es denen schwer? Dann dauert das eben 25 Jahre. Stefanus F. schrieb: >> Das Killerargument dagegen: bessere Unterscheidbarkeit Schlüsselwörter >> und eigene Token > > Hmm, damit können die Engländer, und Amerikaner leider nicht viel > anfangen. Demnach müssten die doch eine andere Sprache bevorzugen, > oder nicht? War das nicht OpenOffice/LibreOffice, die daran teilweise noch immer kranken? Schließlich haben die den Code von StarOffice übernommen und da wurde deutsch programmiert (benamt) und kommentiert... Und ja, die sprachabhängigen Schlüsselworte in Excel sind ein kräftig leuchtendes Lowlight in der realen Welt. Genauso nervig ist die Stringumwandlung von "1.23" in eine Zahl, was ebenfalls nur sprachabhängig ist.
S. R. schrieb: >Genauso nervig ist die > Stringumwandlung von "1.23" in eine Zahl, was ebenfalls nur > sprachabhängig ist. "1.23" sollte eigentlich kein Problem bringen, da intern mit us-amerikanischen Format gerechnet wird. Man muss halt darauf achten, dass der String ins us-amerikanischen Format umgewandelt wird, also vorher ein replace des Application.International(xlDecimalSeparator) mit einem "." vornimmt - vorher natürlich Tausendertrennzeichen entfernen. Klingt blöde - ist es aber nicht, wenn man sich klar macht, dass eine Anzeige (also ein ganz normaler String) jeder Zahl bzw. Datums immer länderspezifischen Ursprungs ist oder sein kann. Das "weiß" der String natürlich nicht und kann es daher auch nicht verraten - insbesondere wenn sich Ursprung und Istzustand der Ländereinstellung unterscheiden.
Bastler schrieb: > wenn ich jetzt > programmieren könnte würde mir schon so einiges einfallen um denen das > Leben beim begutachten so richtig schwer zu machen (Lockbits, > selbstlöschender Code, Prüfstandserkennung, Geofencing, Sperrsysteme die > erkennen wenn das Fahrzeug von der Polizei mitgenommen wurde usw, usf) Spinner :-)
Hugo H. schrieb: > A. K. schrieb: >> Gibt's eigentlich schon eine Programmiersprache, die ausschliesslich in >> Chinesisch formuliert ist? > > https://de.wikipedia.org/wiki/Chinese_BASIC Da spart man sich sicher die interne Umsetzung der Schlüsselworte in Token-Werte. Jeder Befehl ein 16bit-Unicode-Buchstabe.
Hugo H. schrieb: > Carl D. schrieb: >> Jeder Befehl ein 16bit-Unicode-Buchstabe. > > Das halte ich für ein Gerücht. Das war keine Tatsachenbeschreibung, sondern eine mir in den Sinn gekommene Option, die sich aus der Wortgewaltigkeit chinesischer Schriftzeichen ergeben könnte. Mein ZX81 vor fast 40 Jahren hat seine Basic-Tokens jedenfalls als 8-Bit Wert in den Speicher gelegt.
MeierKurt schrieb: > S. R. schrieb: >> Genauso nervig ist die Stringumwandlung von "1.23" in eine Zahl, >> was ebenfalls nur sprachabhängig ist. > > "1.23" sollte eigentlich kein Problem bringen, da intern mit > us-amerikanischen Format gerechnet wird. Sagen wir's mal so... ich habe bei uns ein paarmal gut nach dem Fehler gesucht, weil die eine oder andere Tool-Versionsnummernverwaltung bei uns genau darauf basiert. Und es nicht funktioniert hat, weil Schweden wie Deutschland ein Dezimalkomma benutzt, die ursprünglichen Entwickler aber nicht. > Das "weiß" der String natürlich nicht und kann es daher auch nicht > verraten - insbesondere wenn sich Ursprung und Istzustand der > Ländereinstellung unterscheiden. Eben. Spaßig ist auch, wenn der Build immer montags kaputtgeht, weil dann "mån" im Datumsfeld steht... aber daran ist nicht Excel schuld.
Georg schrieb: > Auch teutsche Programmiersprachen sind ausgestorben, sogar bei Siemens. Auch ansonsten war die Siemens-Dokumentation in erstaunlich sperriger Form geschrieben. Ich erinnere mich noch an den Begriff Prozeßsignalformersteuerung im (natürlich auf Microfiche gelieferten) Handbuch einer R10VH. Es hat ewige Zeit gedauert, bis ich verstand, was der Begriff bedeuten sollte...
Georg schrieb: > Auch teutsche Programmiersprachen sind ausgestorben, sogar bei Siemens. In der Lehre werden gelegentlich noch so Gräuel wie "Logo" (hat nichts mit Siemens Logo zu tun) verwendet, welches eine deutsche Variante hat. Das hat den Vorteil, dass auch Seiteneinsteiger-Informatik-Lehrer, welche kein Englisch können, damit klar kommen.
A. K. schrieb: > Yep. Eine deutsche Assembler-Sprache gab es beispielsweise beim > Telefunken Grossrechner TR-440. BRINGE statt MOVE. Der Rest vom Umgang > war ähnlich, es wurde nicht gelinkt, sondern montiert. In meiner Jugend(tm) war in vielen Büchern noch die Sprache von "binden und laden". Statisches Linken wurde mit Hilfe des sog. "Bindeladers" durchgeführt. Auch im Jahr 2009 wurden diese Begriffe noch in Vorlesungen verwendet: https://www.informatik.uni-kiel.de/~wg/Lehre/Vorlesung-SS2009/Folien_20090420.pdf
Dr. Sommer schrieb: > In der Lehre werden gelegentlich noch so Gräuel wie "Logo" (hat nichts > mit Siemens Logo zu tun) verwendet, welches eine deutsche Variante hat. > Das hat den Vorteil, dass auch Seiteneinsteiger-Informatik-Lehrer, > welche kein Englisch können, damit klar kommen. Naja, ersetzen wir lieber "klar kommen" durch "klar kommen sollten". Es gab etliche Versuche, im Schulunterricht deutschsprachige Programmiersprachen einzuführen, die aber glücklicherweise allesamt gescheitert sind, da es außer den paar Schulbüchern keinerlei weitere Literatur dazu gab und das ganze keinerlei Relevanz außer der Schule hatte. Bei vielen derartigen Versuchen steckt aber einfach auch ein gewisser politischer Klüngel dahinter. Ich erinnere mich noch an die Einführung einer völlig exotischen Programmiersprache an Schleswig-Holsteiner Schule, so gegen Mitte/Ende der 1980er Jahre. Wie sich mittlerweile herausstellte, war der entsprechende Entscheidungsträger im Kultusministerium verwandt mit dem Geschäftsführer des Unternehmens, das den entsprechenden Compiler oder Interpreter herstellte.
Dr. Sommer schrieb: > Das hat den Vorteil, dass auch Seiteneinsteiger-Informatik-Lehrer, > welche kein Englisch können, damit klar kommen. Och, das war schon bei APL der Fall. Dessen Quellcode verstehen englische Muttersprachler genauso wenig wie Deutsche, und der Lehrer, der sich damals (unabhängig von 3 Schülern) an meiner Schule damit befasste, war unvermeidlich Seiteneinsteiger.
A. K. schrieb: >> Schön mal vom T eakholz R echner 440 zu hören. Wieviel gab es davon? > > 46-60, je nach Quelle. Wohl hauptsächlich an Hochschulen. Ich kann mich dunkel erinnern, dass der Uni Tübingen so ein Rechner fürs Rechenzentrum politisch aufs Auge gedrückt wurde. Die Zentraleinheit war aber so schwer (nicht nur Teakholz), dass der Kran umstürzte und das Dach des Rechenzentrums durchschlug. Das löste bei den Verantwortlichen zunächst Jubel aus, weil man dachte, jetzt wäre man den ungeliebten Rechner los, aber das war ein Irrtum - es wurde von den gleichen Stellen beschlossen alles zu reparieren. Alles Geschichte, meines Wissens war das sowieso der letzte Telefunken-Rechner. Georg
Nachtrag: Jetzt ist mir der Name der Programmiersprache wieder eingefallen: COMAL. https://de.wikipedia.org/wiki/COMAL https://www.booklooker.de/B%C3%BCcher/Borge-Christensen+COMAL-0-14-Handbuch-Herausgegeben-vom-Landesinstitut-Schleswig-Holstein-f%C3%BCr-Praxis/id/A02fE9pj01ZZJ Aus inhaltlicher Sicht war die Einführung von COMAL kein völliger Unsinn, da es gegen Ende der achtziger Jahre einen großen Umbruch in den Schulen gab. Auf der einen Seite waren (schulabhängig) sehr viele Commodore PET/CBM oder Apple II(-Nachbauten) vorhanden, auf der anderen Seite wurden schon neue PCs mit MS-DOS beschafft. COMAL konnte auf allen Systemen genutzt werden. Trotzdem gab es hier in S-H eben das "Gschmäckle", weil der deutsche Hersteller/Händler eben eng mit den Entscheidungsträgern liiert war. Nun die Frage: Kennt hier jemand COMAL noch aus der eigenen Schulzeit? In welchem Bundesland war das?
Georg schrieb: > Ich kann mich dunkel erinnern, dass der Uni Tübingen so ein Rechner fürs > Rechenzentrum politisch aufs Auge gedrückt wurde. Während meiner Studienzeit wurde für das Physikzentrum ein neuer zentraler Server ausgeschrieben. Dabei musste es sich gemäß politischer Vorgabe aber um ein deutsches Produkt handeln. Daraufhin wurde ein "AEG SPARCserver 1000" statt des "Sun SPARCserver 1000" beschafft...
Andreas S. schrieb: > Dabei musste es sich gemäß politischer > Vorgabe aber um ein deutsches Produkt handeln. Sicher dass nicht nur der Händler deutsch sein musste? Das gibt's immer noch, Forschungsprojekte an Hochschulen dürfen nur bei europäischen Zwischenhändlern statt direkt in China bestellen. Der Zwischenhändler freut sich über die Marge... Georg schrieb: > Ich kann mich dunkel erinnern, dass der Uni Tübingen so ein Rechner fürs > Rechenzentrum politisch aufs Auge gedrückt wurde. Oh Graus... Behörden-Bürokratie am Werk... Andreas S. schrieb: > , da es außer den paar Schulbüchern keinerlei weitere > Literatur dazu gab und das ganze keinerlei Relevanz außer der Schule > hatte. Seit wann interessiert irgendjemanden die Relevanz von Schulstoff? An meiner Ex-Schule gab es den Informatikunterricht auch schon seit den 80ern. 20 Jahre später waren die Konzepte anscheinend noch die gleichen, man hat wohl nichts dazugelernt. Das Beklagen von miserablem Informatikunterricht könnte Bibliotheken füllen - lassen wir das :-)
Georg schrieb: > Die Zentraleinheit war aber so schwer (nicht nur Teakholz), Ich hatte jahrelang ein recht kompaktes Netzteil der TR-440 im Keller rumliegen. Ein Drehstrom-Linearnetzteil für -5,2V ECL. Das war richtig schön schwer. Zig Stück davon... Siehe obere Reihe in http://www.vaxman.de/historic_computers/telefunken/tr440/tr440.jpg
{kind=link}
Dr. Sommer schrieb: > Andreas S. schrieb: >> Dabei musste es sich gemäß politischer >> Vorgabe aber um ein deutsches Produkt handeln. > > Sicher dass nicht nur der Händler deutsch sein musste? Ja, da bin ich ganz sicher. Das Teil wurde mit AEG-Beschriftung geliefert, und beim Login erschien auch irgendwo ein "AEG SunOS" statt "Sun SunOS". Natürlich war allen Beteiligten klar, dass es sich nur um ein umgelabeltes Sun-Produkt handelte, denn schließlich sollte das System auch so kompatibel wie möglich sein. Ich weiß aber nicht, ob auch jede Seite in der Schrankwand voll Handbücher entsprechend umetikettiert war.
Das Problem nennt sich 'semantische Lücke' und beschreibt i.w. den Verlust von Informationen zwischen den verschiedenen Darstellungsebenen (die meisten Daten gehen beim Optimieren und kompilieren verloren,z.b. Typinformationen). Aus llvm bytecode könnte man z.B. auch Dinge in andere Sprachen übersetzen, da dort noch nahezu alle Typinformationen vorhanden sind.
Martin K. schrieb: > Das Problem nennt sich 'semantische Lücke' und beschreibt i.w. den > Verlust von Informationen zwischen den verschiedenen Darstellungsebenen > (die meisten Daten gehen beim Optimieren und kompilieren verloren,z.b. > Typinformationen). Der Witz ist: Es geht eigentlich überhaupt keine (nützliche) Information verloren, es wird nur (unnütze) Redundanz entfernt. Schließlich läuft das Binary ja und tut, was es soll (im Idealfall). Sprich: all das entfernte Zeug ist für den Endzweck nicht nötig, ja es stört sogar. Es würde die Sache ganz sicher größer als nötig machen und (sehr wahrscheinlich) auch langsamer als möglich. Alles eine Frage des Zwecks. Normalerweise ist der Zweck eines Programms, seine Aufgabe zu erledigen und dabei möglichst wenige Resourcen zu verbrauchen. Dass es so viel redundantes Zeug zu entfernen gibt, zeigt eigentlich nur eins: Die Beschreibungssprache für das Problem taugt nicht sehr viel, jedenfalls nicht unter dem Aspekt, das Problem für das Zielsystem effizient zu beschreiben. Allerdings taugt sie dazu, es menschenverständlich zu beschreiben (Hardcore -C/C++ mal ausgenommen, das dient auch eher nur dazu, die Intentionen des Programmierers zu verdunkeln). > Aus llvm bytecode könnte man z.B. auch Dinge in > andere Sprachen übersetzen, da dort noch nahezu alle Typinformationen > vorhanden sind. Es gibt in praktisch jeder Sprache und mit jeder Toolchain viele Möglichkeiten, menschenverwertbare Information mit in das Binary zu füllen, wenn man das will. Nur bläht das halt mit Sicherheit den Code auf und macht ihn i.d.R. auch langsam. Deswegen klemmt man sich das normalerweise, außer zu Debug-Zwecken.
c-hater schrieb: > Der Witz ist: Es geht eigentlich überhaupt keine (nützliche) Information > verloren, es wird nur (unnütze) Redundanz entfernt. Du siehst Kommentare im Quelltext also als völlig nutzlos an.
A. K. schrieb: > Du siehst Kommentare im Quelltext also als völlig nutzlos an. Für den Endzweck des Programms sind sie ganz offensichtlich nutzlos, da der ja ganz offensichtlich auch ohne diese Information erfüllt werden kann.
c-hater schrieb: > Es geht eigentlich überhaupt keine (nützliche) Information > verloren, es wird nur (unnütze) Redundanz entfernt. Ist eine Frage der Sichtweise. Ich brauche diese Informationen, um den Code zu verstehen. Also sind sie nicht unnütz. > Dass es so viel redundantes Zeug zu entfernen gibt, zeigt eigentlich > nur eins: Die Beschreibungssprache für das Problem taugt nicht sehr > viel, jedenfalls nicht unter dem Aspekt, das Problem für das > Zielsystem effizient zu beschreiben. Du musst ein Roboter sein, wenn du das ernst meinst.
Stefanus F. schrieb: > Ist eine Frage der Sichtweise. Ganz genau. Ich formulierte es so: >> Alles eine Frage des Zwecks > Ich brauche diese Informationen, um den > Code zu verstehen. Du vergißt: es nicht nicht der Endzweck des Codes, von dir verstanden zu werden. Der ist: möglichst effizient zu laufen.
c-hater schrieb: > Du vergißt: es nicht nicht der Endzweck des Codes, von dir verstanden zu > werden. Doch. Code der nicht gepflegt werden kann, ist Einweg-Müll - fast nichts wert. > Der ist: möglichst effizient zu laufen. Effizienz rangiert in den allermeisten Anwendungen nicht auf Platz 1, nicht auf Platz2 , auch nicht auf Platz 3, sondern irgendwo ganz weit hinten. Aber dass deine Ansichten ziemlich weit weg von der Realität heutiger Softwareentwickler entfernt ist, das wissen wir ja schon länger. Denke mal wirtschaftlich, dann bekommst du vielleicht auch mal wieder einen richtigen Job.
Stefanus F. schrieb: > Effizienz rangiert in den allermeisten Anwendungen nicht auf Platz 1, > nicht auf Platz, auch nicht auf Platz 3 sondern irgendwo ganz weit > hinten. Weil es so viele Idioten gibt, die das so sehen, haben wir heute halt die Software, die wir eben haben. All die Fortschritte der Leistungsfähigkeit der Hardware wurden unverzüglich dadurch aufgezehrt, dass er dazu verwendet wurde, es dummen und faulen Programmierern leichter zu machen, anstatt dazu, den Anwendern schnellere Programme zu Verfügung zu stellen. > Aber dass deine Ansichten ziemlich weit weg von der Realität > heutiger Softwareentwickler entfernt ist, das wissen wir ja schon > länger. > > Denke mal wirtschaftlich, dann bekommst du vielleicht auch mal wieder > einen richtigen Job. Ich habe einen richtigen Job. Ich brauche mich nicht so zu prostituieren, wie du das tust...
c-hater schrieb: > Weil es so viele Idioten gibt, die das so sehen, haben wir heute halt > die Software, die wir eben haben. Das sind nicht Idioten, sondern Softwareentwickler die damit ihren Lebensunterhalt verdienen (müssen). Im Hobby dürfen gerne andere Maßstäbe gelten und sicher gibt es in der kommerziellen Softwareentwicklung auch zahlreiche kleine Ecken, wo auf Performance optimiert werden sollte. Das gilt jedoch nicht für die große Masse der Software. > All die Fortschritte der Leistungsfähigkeit der Hardware wurden > unverzüglich dadurch aufgezehrt, dass er dazu verwendet wurde, es dummen > und faulen Programmierern leichter zu machen Ich korrigiere: geschäftstüchtige Programmierer > anstatt dazu, den Anwendern schnellere Programme zu Verfügung zu stellen. Dafür ist Software sehr viel billiger geworden. Ich erinnere mich an den ersten IBM PC, den mein Vater für seine Firma anschaffte. Der Rechner kostete ein Monatsgehalt, das Textverarbeitungsprogramm drei Monatsgehälter und das Schach-Spiel ein viertel Monatsgehalt. Wer würde heute für einen PC mit Textverarbeitung und Schachspiel (sonst nichts weiter) rund 18000 Euro ausgeben? Du nicht, habe ich Recht? Abgesehen davon hast du maßlos übertrieben. Mein erster PC keine Musik in CD Qualität abspielen - geschweige denn erzeugen. Mein jetziger PC ist Pi mal Daumen 500x so schnell. Dafür stellt er Videospiele in damaliger Kino-Qualität samt Musik die zur Szene passen generiert wird ohne das geringste Ruckeln. So viel zum Thema, dass die ganze Leistung vergeudet wird.
Solange die Experten hier meinen, das ein Compiler aus Eiern ein Rührei macht und man das nicht trennen kann ist mein Job ja sicher.
Andreas S. schrieb: > Auch ansonsten war die Siemens-Dokumentation in erstaunlich > sperriger Form geschrieben. IBM kann das aber auch... "Leitwegeinrichtung" in OS/2.
Wieso ist es so schwer, aus einer Tüte Paniermehl ein Brötchen zusammen zu setzen.??
Stefanus F. schrieb: > Der Rechner > kostete ein Monatsgehalt, das Textverarbeitungsprogramm drei > Monatsgehälter und das Schach-Spiel ein viertel Monatsgehalt. Na, wer genügend Zeit und Geld hat auch noch Spiele zu kaufen, für den ist es wohl nicht teuer! Ich nie weder Zeit noch Geld in Spiele investiert. Gruss Chregu
Hi Ich bin schon erstaunt, welche Vorstellung hier auch von Fachleuten verbreitet werden. Ich muß c-heater Recht geben, wozu braucht ein Prozessor symbolische Adressen und Kommentare? Er liest Befehlscode, also Maschinencode,und führt einen nach dem anderen aus.Was interessiert ihn der Programmierer mit seiner Denkweise, alles noch Mal mit Kommentaren erklären zu müssen, was sowieso klar ist und eine Adresse symbolisch zu zu verwalten ist für den Prozessor genauso unsinnig. Wenn ein Programmierer meint, einen Maschinencode deassemblieren zu müssen, dann soll er doch Mal denken wie ein Prozessor! Gruß oldmax
Irgendwie haben ja alle recht. Die Lösung des Problems wären interpretierende Programmiersprachen (gibt es die für µC überhaupt?), hier kann jederzeit der Quellcode samt Kommentaren geändert werden. Leider erkauft man sich das für einen Performanceverlust um den Faktor 100. Allerdings ist es nahezu unmöglich, geistiges Eigentum bei interpretierenden Sprachen zu schützen.
c-hater schrieb: > Martin K. schrieb: > >> Das Problem nennt sich 'semantische Lücke' und beschreibt i.w. den >> Verlust von Informationen zwischen den verschiedenen Darstellungsebenen >> (die meisten Daten gehen beim Optimieren und kompilieren verloren,z.b. >> Typinformationen). > > Der Witz ist: Es geht eigentlich überhaupt keine (nützliche) Information > verloren, es wird nur (unnütze) Redundanz entfernt. Schließlich läuft > das Binary ja und tut, was es soll (im Idealfall). Sprich: all das > entfernte Zeug ist für den Endzweck nicht nötig, ja es stört sogar. Es > würde die Sache ganz sicher größer als nötig machen und (sehr > wahrscheinlich) auch langsamer als möglich. Widerspruch: es geht das Entscheidendste verloren, was der Compiler benutzt und der Programmierer kreiert bzw. einsetzt, und das sind Datentypen. Datentypen sind dafür verantwortlich, dass der später Maschinencode so aussieht, wie er aussieht. Zweitens die Struktur des Codes in der Hochsprache, wie Klassen, Funktionen, Kontrollstrukturen, etc. . Beides benutzt der Compiler nicht einfach nur, um irgendwelchen 1:1 Maschinencode daraus zu erzeugen, sondern ist auch zusammen mit dem abstrakten Maschinenmodell der Hochsprache Grundlage für alle Optimierungen. Natürlich kann das niemand verstehen, für den 1) alles ein "int" ist, und 2) sollte 1) nicht zutreffen, dann eben ein String
Wilhelm M. schrieb: > Natürlich kann das niemand verstehen, für den ... Ach, der c-hater mag eine neurotische Fehlanpassung haben... Aber wie ein Kompiler in etwa funktioniert, wird er schon wissen. Und dass man aus einer *.hex kein hübsches/wartbares C oder C++ Programm generieren kann, auch. Sein Interesse, vermute ich mal, liegt eher im Bereich Zwietracht sähen, polemisieren usw.
Nils schrieb: > Solange die Experten hier meinen, das ein Compiler aus Eiern ein Rührei > macht und man das nicht trennen kann ist mein Job ja sicher. Leider sind die Jobs nicht sicher vor solchen "Experten", wie man an manchen Produkten erkennt.
Es gehen nicht nur Kommentare und benamung verloren, sondern auch alles HW- und Projektspezifische. Der Code ist ggf. portabel, z.B. bezüglich endianess. Das ist nicht mehr rekonstruierbar. Anderes Beispiel: mit einem Rezept im Backbuch kannst Du einen Kuchen backen. Durch Analyse des Kuchens aber nicht diese Rezeptseite rekonstruieren.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.