Für ein Projekt muss ich u.a. die Werte eines 24Bit-ADCs mit 62kSPS
filtern.
Um eine ausreichende Filtersteilheit zu erreichen, brauche ich
wahrscheinlich zwei Bi-Quads hintereinander.
Würde da da der SAM4(E) grob reichen?
Welche praktischen Nachteile hat der SAM7x gegenüber SAM4E?
Alexxx schrieb:> Werte eines 24Bit-ADCs
Wieviele Kanäle? Welchen ADC verwendest du?
Alexxx schrieb:> 62kSPS
Das bedeutet du hättest jede 16,129µs einen neuen Datensatz.
Egal ob du nun 1 oder 8 Kanäle hast, alle Berechnungen müssen unter 16µs
liegen, jedoch braucht dein µC (Firmware) ja auch noch Ausführungszeit.
Alexxx schrieb:> SAM7x
Meinst du damit die SAMS7x/SAME7x/SAMV7x?
Edit:
Ich muss mal kurz neue Zeitmessungen machen, die vorherigen waren
falsch.
@Adam P.
Danke für die Messungen.
D.h. Float ist viel schneller als uint32-Mul?
40ns kann das wirklich sein? ~5 Zyklen @ 120MHz
Dann müsste das ja locker für 2 Biquads reichen.
Hoffe nur, dass single precision dafür reicht und keine Überraschungen
produziert.
Aber dass 1.) und 2.) trotz unterschiedlicher umfangreicher Berechnungen
gleich lange brauchen???
>> Meinst du damit die *SAMS7x/SAME7x/SAMV7x*?
Ja genau, wegen der double-precision FPU.
Hat diese SAMs schon mal einer benutzt??
Alexxx schrieb:> Aber dass 1.) und 2.) trotz unterschiedlicher umfangreicher Berechnungen> gleich lange brauchen???
Hat mich auch gewundert, aber der LogicAnalyser liefert diese
Zeitangaben.
Habe die Berechnungen extra im SysTick Handler durchgeführt,
dass die Berechnung nicht von anderen Interrupts unterbrochen wird.
Alexxx schrieb:> Hat diese SAMs schon mal einer benutzt??
Wir haben den SAMV71Q21B noch im Einsatz, aber da kann ich dir jetzt
sponatan keine Zeitangaben sagen.
Könnte dir morgen mal Messungen machen.
Was die Peripherie und den Umgang damit betrifft, kann ich dir leider
nicht sagen, da nicht meine Baustelle.
Alexxx schrieb:>>> Meinst du damit die *SAMS7x/SAME7x/SAMV7x*?> Ja genau, wegen der double-precision FPU.> Hat diese SAMs schon mal einer benutzt??
Wir haben sie im Einsatz, funktionieren gut, wenngleich die Appnote für
den Übergang von SAM4E auf SAME70 einiges zu wünschen übrig lässt.
Ärgerlichstes Detail: es gibt wieder nur 16-bit-Timer, obwohl der SAM4E
32-bittige hatte. Muss man dann wieder verketten wie anno dunnemals beim
SAM4S.
Wie viel die 64-bit-FPU wirklich bringt, kann ich dir nicht sagen. Weiß
nur, dass sie vorhanden ist. :) Ärgerlich für uns ist, dass die CMSIS
DSP library nach wie vor nur für float32 existiert, nicht für float64.
Die hätte uns sonst wirklich interessiert, so rechnen wir unseren
DSP-Krams nach wie vor mit 32-bit-Floats.
Der CPU-Takt ist doppelter Systemtakt, insofern arbeitet die CPU
volldampf nur aus dem Cache, oder du spendierst ihr einen Teil des RAMs
als tightly coupled memory (TCM). Da muss man aber dann zu gleichen
Teilen RAM sowohl für Daten als auch Befehle opfern. Haben wir bislang
noch nicht.
Alexxx schrieb:> @Adam P.> Meinst du damit die *SAMS7x/SAME7x/SAMV7x*?>> Ja genau, wegen der double-precision FPU.> Hat diese SAMs schon mal einer benutzt??
Da läuft mein CAN-LAN-Gateway drauf. Ich hatte auch mal zusätzlich eine
FFT mit float und 1024 ausprobiert. Ich mein ich war die FFT war
schneller als 22 ms, bin mir aber nicht sicher.
Board war das SAM E70 XPLD.
Gruß JackFrost
@Jörg W.
>> ...dass die CMSIS DSP library nach wie vor nur für float32 existiert...
Na toll. Das bedeutet dann aber, dass die FPU64 eigentlich nicht nutzbar
ist, traurig, traurig.
Unterstützt GCC / Atmel Studio eigentlich "Float64" oder double?
Alexxx schrieb:> Na toll. Das bedeutet dann aber, dass die FPU64 eigentlich nicht nutzbar> ist, traurig, traurig.
Für die DSP-Library nicht.
> Unterstützt GCC / Atmel Studio eigentlich "Float64" oder double?
Ja, sicher, also ganz normales "double". Hat er auch bei der 32-bit-FPU,
dort dann halt als Software-Lib.
Gerade mal schnell in eine C-Datei hier ein
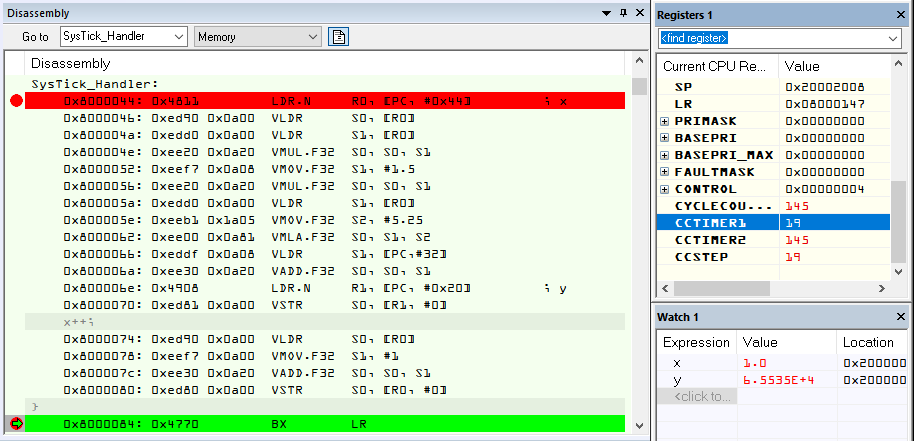
Adam P. schrieb:> SAM4E mit 120MHz.>> 1)> x & y: uint32_t> y = (x*x) + x + 0xFFFF;> Dauer: 0,1µs>> 2)> x & y: uint32_t> y = (x*x*x*x) + (x*x*x) + (x*x) + x + 0xFFFF;> Dauer: 0,1µs>> 3)> x & y: float> y = (1.5 * (x*x)) + (5.25 * x) + 0xFFFF;> Dauer: 40ns (Dank der FPU)
Die (Zeit-)Werte kannst du alle in die Tonne treten.
Da hat der Compiler doch zum Schluss nur das Ergebnis
in das Register geladen, aber nichts ausgerechnet!
Rudolph schrieb:> Um noch was dazwischen in den Ring zu werfen das neuer ist: SAMD51
Ist aber eine völlig andere Liga.
Hier wurde über 32- und 64-bit-FPUs geredet, da kann der kleine
Cortex-M0+ nun wirklich nicht mitreden.
Allerdings halte ich die Peripherie der kleinen SAMD & Co. insgesamt für
eleganter, nicht so dinosaurierhaft.
Oh, sorry, dann habe ich mich durch das SAMD täuschen lassen. :) Man
lernt nie aus.
Ist mit 120 MHz nicht ganz so flink wie die großen Boliden, aber die
Peripherie klingt interessant.
Tonne schrieb:> Die (Zeit-)Werte kannst du alle in die Tonne treten.> Da hat der Compiler doch zum Schluss nur das Ergebnis> in das Register geladen, aber nichts ausgerechnet!
Dann erkläre mir mal bitte wie & wo sich der Compiler ALLE Ergebnisse
die zur Laufzeit auftretten können, speichert? :-/
Vllt. solltest du erstmal alles lesen, bevor du so einen sinnlosen
Beitrag verfasst:
Adam P. schrieb:> Habe die Berechnungen extra im SysTick Handler durchgeführt
Und du meinst ernsthaft der Compiler ist so blöd sich ein Ergebnis zu
berechnen, auf den Stack zu schaufeln und dann zu verwerfen weil es
niemand braucht?
Mach mal aus deinem y eine globale volatile Variable, dann sieht die
Welt sicher anders aus.
temp schrieb:> Mach mal aus deinem y eine globale volatile Variable, dann sieht die> Welt sicher anders aus.
Ja...ansich hast du recht, nobody is perfect, es dauert länger, was
bei mir falsch war sind auf jeden fall die Werte für float, bei uint32_t
gehts eigentlich.
Tonne schrieb:> Da hat der Compiler doch zum Schluss nur das Ergebnis> in das Register geladen, aber nichts ausgerechnet!
War durch diese Formulierung verwirrt...Da es ja ohne rechnen kein
Ergebnis geben kann.
Also hier die neuen Werte:
1
//volatile uint32_t y;
2
//uint32_t x;
3
4
volatilefloaty;
5
floatx;
6
7
voidSysTick_Handler(void)
8
{
9
ioport_set_pin_level(PIN_DBG_0,1);
10
// y = (x*x) + x + 0xFFFF;
11
y=(1.5*(x*x))+(5.25*x)+0xFFFF;
12
x++;
13
ioport_set_pin_level(PIN_DBG_0,0);
14
}
Für uint32_t:
Anstatt 0,1µs sinds nun 0,25µs.
Für float:
Anstatt 40ns sinds nun 7,18µs.
>> Für float: Anstatt 40ns sinds nun 7,18µs.
Das kann doch auch nicht sein (ist OHNE FPU?)!!!
FPU würde 840 Clocks @120MHz brauchen.
"Wer misst, misst Mist!"
Ja der SAM D51 ist auch interessant.
Was sind denn jetzt die wirklich entscheidenden Unterschiede zwischen
D51 und E4, wenn man CAN, Ethernet nicht braucht?
Der SAMS70J scheint mir zu vollgepackt mit Peripherie, die ich nicht
brauche.
Auch zur "Bare-Metal"-Programmierung scheit er noch viel komplizierter
als D21 und sogar D51.
Die 300MHz wären interessant, wenn der Flash und die Peripherie auch so
schnell wäre.
Alexxx schrieb:> Das kann doch auch nicht sein (ist OHNE FPU?)!!!
Ist mit FPU.
Was mich jedoch wundert:
- In der Debug Config. kann ich "-mfloat-abi=hard -mfpu=fpv4-sp-d16"
nutzen.
- In der Release Config. bekomme ich da jedeoch 1000 Fehler, da
funktioniert nur "-mfloat-abi=softfp -mfpu=fpv4-sp-d16".
Wobei laut GCC ist es ja mit HW-Unterstützung:
"Use -mfloat-abi=softfp with the appropriate -mfpu option to allow the
compiler to generate code that makes use of the hardware floating-point
capabilities for these CPUs."
Alexxx schrieb:> Die 300MHz wären interessant, wenn der Flash und die Peripherie auch so> schnell wäre.
Naja, was heißt schon schnell. Flash ist eigentlich nicht das Problem,
weil das Ding Cache hat und zur Not gibt es die konfigurierbaren TCMs.
Was ist an der Peripherie falsch?
Adam P. schrieb:> Ist mit FPU.
Aha. Aber auf einem SAM4 sicher nicht alles, oder?
Die Multiplikation x*x vielleicht, der Rest ist nach der ersten
Berührung mit einer double-Konstanten ebenfalls double und muss dann in
SW gemacht werden.
Hast Du mal den erzeugten Code zur Hand, ob auch wirklich die richtigen
Instruktionen erzeugt werden?
@Adam P. "Ist mit FPU"
Meiomei, was ist DAS denn für eine FPU? Single-Cycle jedenfalls nicht.
Bähhh.
Deine Berechnungsformel ist ja Nenner oder Zähler eines Bi-Quads
Dh. ein Filter-Durchlauf: 2x 7,2µs + 1x Division ??µs + ??µs
Zusätzliches.
Das reicht bei 62,5 kSPS nichtmal für einen einzigen Bi-Quad - trotz
FPU!
Dann kommt also doch nur Integer-Arithmetik in Frage...
Somit waren deine Messungen wichtig, wenn auch nicht befriedigend.
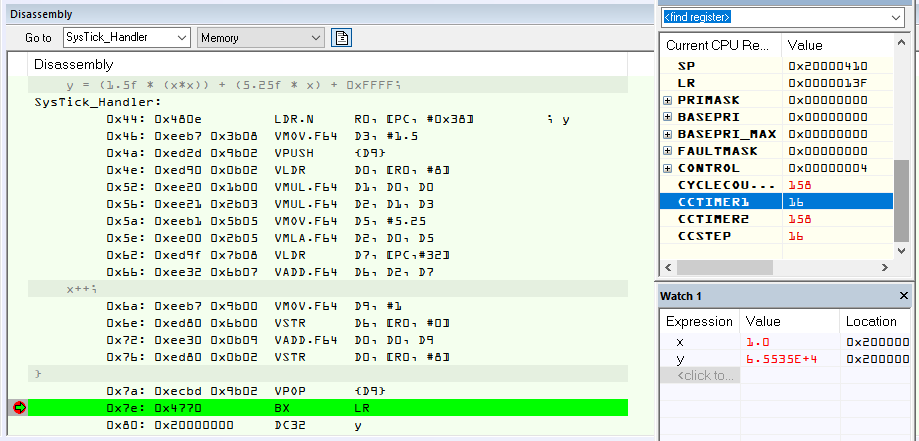
Adam P. schrieb:> Im Anhang ist das *.lss für folgendes:
Danke und q.e.d. Außer x*x und x++ wird hier nichts von der FPU gemacht.
Die 64 bit Rechnungen laufen in SW und sind dementsprechend gähnend
langsam. Wenn Du nicht die Muße hast, an die Konstanten ein "f"
anzuhängen, gibts auch einen Compilerschalter dafür
(--single-precision-constant oder so)
Du meinst es sicher gut, aber ich denke Du bist (noch?) nicht der
richtige um zu Performance-Fragen aussagekräftige Messungen zu machen
und einen anderen hilflosen zu beraten. Damit erweißt Du ihm einen
Bärendienst.
Adam P. schrieb:> bekomme ich da jedeoch 1000 Fehler
Dann linkst du gegen die falsche(n) Bibliothek(en). Soft-FP und Hard-FP
muss für alle gemeinsam zu linkenden Objekte gleich sein, wenn du die
FPU nutzen willst, müssen folglich auch all deine Libs so compiliert
worden sein.
Hatten wir auch mal.
Im Hausfrauenforum werden Fragen kompetenter beantwortet!
"Meine Waschmaschine braucht nur 40 Sekunden für den Hauptwaschgang!"
"Komisch, meine braucht 7,5 Stunden?"
"Ja der Trick ist, die Wäsche wird gar nicht gewaschen. Da steckt
der Lieferbote blos die Pakete rein."
Ich biete mal ca. 113 ns auf einem STM32F407 bei 168 MHz
(ohne Flashwaitstates, ohne Ruecksprung und mit floats).
19 Cycles * 5.95 ns.
Details siehe Bild.
> sone komische Schrift
Die Schrift ist nicht komisch, sondern vorzueglich lesbar.
Tipp: Kann man einstellen!
8402-22891 hab ich noch nicht installiert.
Mach ich aber demnaechst.
> Geschmackssache
Dem aufmerksamen Betrachter wird nicht entgangen sein, dass die
die verwendete Schrift eine OCRA ist. Die ist bzgl. ihrer
eindeutigen Lesbarkeit schon auf Grund ihres Einsatzzwecks
mit Sicherheit besser als jede Courier, Andale oder Consolas.
Das ist also keine Geschmackssache, allenfalls eine Gewoehnungsfrage.
Larry schrieb:> Die ist bzgl. ihrer> eindeutigen Lesbarkeit schon auf Grund ihres Einsatzzwecks> mit Sicherheit besser als jede Courier, Andale oder Consolas.
Eindeutige Lesbarkeit ist das eine, aber danach bewerte ich die Optik
meines Editors nicht so sehr. Da spielen schon auch ästhetische
Gesichtspunkte eine Rolle.
Die Schrift in meinem Editor ist auch eindeutig lesbar (bspw. werden
Null und O gut unterschieden), auch wenn es keine OCR-Schrift ist.
Wenn du damit zufrieden bist, ist es ja aber OK.
Jörg W. schrieb:> Dann linkst du gegen die falsche(n) Bibliothek(en). Soft-FP und Hard-FP> muss für alle gemeinsam zu linkenden Objekte gleich sein, wenn du die> FPU nutzen willst, müssen folglich auch all deine Libs so compiliert> worden sein.
OK, ich bin echt davon ausgegangen, dass ich die FPU nutze.
Aber man lernt ja zum Glück nie aus.
Was mich jedoch wundert, ich habe mir mal die FFT und FIR Besipiele im
AtmelStudio angeschaut, dort wird auch nur "softfp" benutzt und bei
"hard" scheint es wirklich so zu sein wie du sagtest:
(Ein Fehler von vielen)
Aber wie bekomme ich es nun richtig hin?
In der Appnote steht auch nur das wie ich es auch habe:
http://ww1.microchip.com/downloads/en/AppNotes/Atmel-42144-SAM4E-FPU-and-CMSIS-DSP-Library_AP-Note_AT03157.pdf
Wäre toll, wenn mir das jmnd erklären könnte, da ich die FPU ebenfalls
für Filter nutze (bzw. nutzen möchte) - würde ich es auch gern richtig
machen (dazulernen).
Edit:
Vllt. hat ja jmnd ein Mini-Projekt (3 Zeiler) welches richtig für SAM4E
mit FPU konfiguriert ist, dann könnte ich mir da die Unterschiede
heraussuchen.
Möglicherweise ist da noch etwas „Voodoo“ drin, bspw. bin ich mir nicht
sicher, ob man __FPU_PRESENT tatsächlich selbst definieren muss, oder ob
-mlong-calls wirklich sinnvoll ist. Manches an diesem Projekt ist
einfach nur „historisch gewachsen“.
Kalle schrieb:> Du meinst es sicher gut, aber ich denke Du bist (noch?) nicht der> richtige um zu Performance-Fragen aussagekräftige Messungen zu machen> und einen anderen hilflosen zu beraten.
Naja...es lag einfach nur an mehreren Dingen die dafür gesorgt haben,
dass so komische Zeiten entstanden sind.
Danke für den Tipp mit dem Suffix!
Nun sollte ich es haben.
1)
Hab es nun auch mit "hard" kompiliert bekommen, aber wie Atmel und GCC
sagt:
"softfp" und "hard" nutzen die "Hardware floating-point instructions".
Da ist kein Unterschied messbar.
2)
Der fehlende Suffix "f", hat dafür gesorgt, dass er double angenommen
hat,
somit hat man in der *.lss...
Adam P. schrieb:> Im Anhang ist das *.lss
...keine HW-Float Befehle gesehen.
3)
y = (1.5f * (x*x)) + (5.25f * x) + 65535.0f;
x += (x * 1.25f);
Laufzeit nun 0,26µs, entspricht bei 120MHz - 32 Clocks
Und im *.lss ist es nun wie zu erwarten war auch richtig:
Adam P. schrieb:> Der fehlende Suffix "f", hat dafür gesorgt, dass er double angenommen> hat,
Ja, da muss man beim SAM4E bisschen aufpassen.
Beim SAME70 darf man da schlampiger sein. ;-)
Jörg W. schrieb:> powf() statt pow()?
Werde ich mal ausprobieren...
pow() hat ja nämlich double parameter.
Gibt es ein Grund warum mir aber die Funktion pow() rot unterstrichen
wird, also nicht definiert, aber trotzdem kein Fehler beim compile
entsteht und es auch funktioniert.
Da macht es auch kein unterschied, ob ich
math.h oder arm_math.h einbinde.
Adam P. schrieb:> Gibt es ein Grund warum mir aber die Funktion pow() rot unterstrichen> wird, also nicht definiert
Das musst du die IDE deines geringsten Misstrauens fragen. Die macht das
schließlich.
Adam P. schrieb:> Da ist kein Unterschied messbar.
Noch nicht ;-) sobald Parameter übergeben werden wird es interessanter,
weil dann alles über die normalen Register muss und nicht über die der
fpu.
Du meinst die Berechnung in ner Funktion machen?
Mh... Gute Idee, werde ich mal ausprobieren, klingt interessant ?
Wobei, wenn ich so drüber nachdenke... Sollte es kein unterschied
machen.
Da man ja eh nur 32bit Register hat und float nur interpretation ist.
Bei einer normalen Berechnung, nutzt man auch die Register, der
Umterschied
wäre, das man den stack nicht benutzt...
Oder meinst du was anderes?
Der Punkt ist, dass der Registerdruck erhöht wird und die Parameter
zuerst in die s-register kopiert werden müssen.
Eine Funktion die z.b. c=a+b rechnet wobei a und b float Parameter sind
und c zurückgibt hätte bei softfp mehr Overhead durch das Verschieben
der Werte in die richtigen Register als für die Berechnung notwendig
ist. Wie praxisrelevant das ist hängt natürlich vom Anwendungsfall ab,
aber es gibt auf einem Controller wenige Gründe für softfp.