Hallo und schöne Feiertage,
ich habe zwei Prozesse geschrieben, die genau das selbe tun: Einer
Ziffer die jeweiligen Segmente einer 7-Segment-Anzeige zuordnen.
Für die erste Variante habe ich für jedes Segment aussagenlogische
Formeln mittels KV-Diagramm entwickelt und für die zweite Variante habe
ich stur mittels des case-Konstrukts die entsprechenden Bits zugewiesen.
Hier der Code beider Varianten:
Variante 1:
1
showSegments : process (number)
2
begin
3
segments(0) <= not(number(3) or number(1) or (number(2) and number(0)) or (not number(2) and not number(0)));
4
segments(1) <= not(not number(2) or (number(1) and number(0)) or (not number(1) and not(number(0))));
5
segments(2) <= not(number(2) or number(0) or (not number(1) and not number(0)));
6
segments(3) <= not(number(3) or (not number(2) and not number(0)) or (not number(2) and number(1)) or (number(2) and not number(1) and number(0)) or (number(1) and not number(0)));
7
segments(4) <= not((not number(2) and not number(0)) or (number(1) and not number(0)));
8
segments(5) <= not(number(3) or (not number(1) and not number(0)) or (number(2) and not number(1)) or (number(2) and not number(0)));
9
segments(6) <= not(number(3) or (not number(2) and number(1)) or (not number(1) and number(2)) or (number(2) and not number(0)));
10
segments(7) <= '1';
11
12
end process showSegments;
Variante 2:
1
showSegments : process (number)
2
begin
3
case number is
4
when "0000" => segments <= "11000000"; -- "0"
5
when "0001" => segments <= "11111001"; -- "1"
6
when "0010" => segments <= "10100100"; -- "2"
7
when "0011" => segments <= "10110000"; -- "3"
8
when "0100" => segments <= "10011001"; -- "4"
9
when "0101" => segments <= "10010010"; -- "5"
10
when "0110" => segments <= "10000010"; -- "6"
11
when "0111" => segments <= "11111000"; -- "7"
12
when "1000" => segments <= "10000000"; -- "8"
13
when "1001" => segments <= "10010000"; -- "9"
14
when others => segments <= "11111111"; -- "Error"
15
end case;
16
end process showSegments;
Beide Code-Schnipsel funktionieren genauso gut.
Der Lesbarkeit nach hat Variante 2 auf jeden Fall die Nase vorn. Das
führt mich zu meiner Frage: Welche Variante würde man praktisch der
anderen vorziehen? Ist eine sparsamer oder wird das ohnehin alles
optimiert von der Synthese?
Gruß und frohes Fest.
Auf einem FPGA würde ich davon ausgehen, dass die erste Variante in die
zweite umgewandelt wird, da ja ein FPGA aus LUTs besteht. Für
synthetisierte Logik aus einzelnen Gattern hingegen würde ich vermuten,
dass die erste Variante näher am Endergebnis liegt.
Lesbarer ist aber auf jeden Fall die zweite - und ein Tool, welches es
nicht schafft, daraus die jeweils bessere Variante zu erzeugen, ist sein
Geld wohl nicht wert.
Deine Variante 1 beruecksichtigt ueberhaupt nicht, was denn in
"Transistoren" gemessen die beste Implementierung waere. Bsp.: Ein
4-fach NAND ist schneller als ein 4-fach NOR (in heutiger CMOS
Implementierung), das hat zu tun mit der Ladungstraegerbeweglichkeit und
anderen physikalischen Effekten. Auch koennte bei Variante 1 evtl. ein
XOR oder XNOR Transistoren und damit Flaeche/Laufzeit sparen...
Variante 2 sollte ein halbwegs normaler Synthesizer optimieren koennen,
ein danach folgender Mapper (auf die Zieltechnologie) macht den Rest.
Beim FPGA halt typischerweise eine 4/5/6-Bit LUT (SRAM 1Bitx16/32/64).
Also wirst du eigentlich immer Variante 2 hinschreiben wollen, weil:
Besser lesbar!
Es ist aber durchaus interessant, wenn man sich mal so manche High-Level
Statements auf Gatterebene runterbricht. Es hilft auch, die Komplexitaet
eines Designs abschaetzen zu koennen. Und falls du nicht FPGA, sondern
ASIC mit Standard-Zell machst, kommst du um solche Ueberlegungen eh'
nicht rum...
Ein Klassiker ist das n-fach AND-OR, der Multiplexer. Dass der in
Wirklichkeit im ASIC immer auf NAND runtergebrochen wird sollte man mal
gesehen & verstanden haben.
Die Logiksynthese wird beide Varianten zu einer Netzliste synthetisieren
und diese anschließend optimieren. Dabei wird jeweils eine Architektur
herauskommen, die für die Zieltechnologie am besten geeignet ist (außer
du verbietest der Synthese ausdrücklich, etwas zu optimieren). Von
deinen mühevoll hergeleiteten ORs und NOTs wird dabei vermutlich nichts
übrig bleiben.
Insofern ist Variante 2 die weitaus bessere, weil sie einfacher zu
verstehen und zu warten ist. Es macht überhaupt keinen Sinn, den Tools
irgendwelche Optimierungsaufgaben anbnehmen zu wollen - die können das
besser als du. Also schreib deinen Code auf die einfachste Art und Weise
und lass die Synthese etwas Brauchbares draus backen. Nur wenn das nicht
klappt (was manchmal vorkommt), musst du ihr unter die Arme greifen.
Derek C. schrieb:> ich habe zwei Prozesse geschrieben, die genau das selbe tun
Nein, das tun sie nicht.
Siehe Screenshots der Waveform von Variante1.png und Variante2.png.
Vancouver schrieb:> Von deinen mühevoll hergeleiteten ORs und NOTs wird dabei vermutlich> nichts übrig bleiben.> Insofern ist Variante 2 die weitaus bessere,
Besser wäre "im Prinzip" die Variante 1, bei der ganz offensichtlich die
"others" Bedingung wegfällt. Somit kann der Synthesizer in den
undefinierten Zuständen "1010"..."1111" beliebige Bitmuster erzeugen,
statt dort definierte "1111111" im "Error"-Fall ausgeben zu müssen.
Deshalb hat der Synthesizer bei Variante 1 "im Prinzip" mehr
Freiheitsgrade zur Optimierung.
Allerdings ist das hier schnurzegal: weil jedes einzelne Segment nur 4
Eingänge hat und diese 4 Eingänge exakt auf eine 4er-LUT passt, werden
in beiden Fällen für 8 Ausgänge in beiden Fällen genau 8 LUTs gebraucht.
> weil sie einfacher zu verstehen und zu warten ist.
Dann würde ich gleich auf die Variante mit einem "segment" Array und
"number" als Index gehen. Damit kann ich mir das ganze unnötig
ausschweifende Process-Gehampel sparen:
Diese Variante braucht wie zu erwarten ebenfalls 8 LUTs, die Waveform
habe ich als VarianteArray.png angehängt.
Das kann man übrigens einfach selber mal ausprobieren und sich dabei die
Synthesizer-Logs und den RTL-Schaltplan mal genauer anschauen. Den dann
auftretenden Effekt nennt man "Lernen"... ;-)
Lothar M. schrieb:> Diese Variante braucht wie zu erwarten ebenfalls 8 LUTs
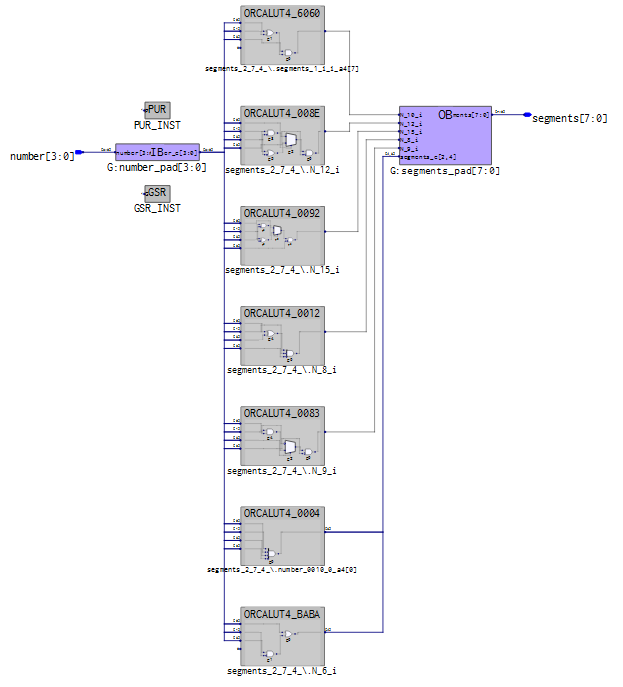
Hmm, bei mir sind es immer 7 LUTs (MSB ist immer '1').
Lothar M. schrieb:> Variante 1, bei der ganz offensichtlich die> "others" Bedingung wegfällt.
Alternativ könnte man in der Array-Variante die "11111111" Einträge mit
"--------" modellieren (falls wirklich nur 10 Einträge genutzt werden).
Xilinx zumindest nutzt es tatsächlich als "Don't Care" und setzt ein,
was ihm optimal erscheint. Und, die Simulation sieht besser aus. Man
erkennt sofort, wenn doch ungültige Nummern kommen.
daniel__m schrieb:> Hmm, bei mir sind es immer 7 LUTs (MSB ist immer '1').
Ich habs mit Lattice Diamond auf einem MachXO2 ausprobiert.
svedisk ficklampa schrieb:> Ein Wunder das der aus dem Array keinen ROM instanziiert hat!
Eine LUT ist ein 16x1-ROM. Acht LUTs ergeben ein 16x8 ROM. Dafür einen
vorbelegten RAM-Block mit x kBit zu nehmen, wäre offensichtlicher
Overkill. Und zudem bräuchte ein zu einem ROM umfunktionierter RAM-Block
noch einen Takt.
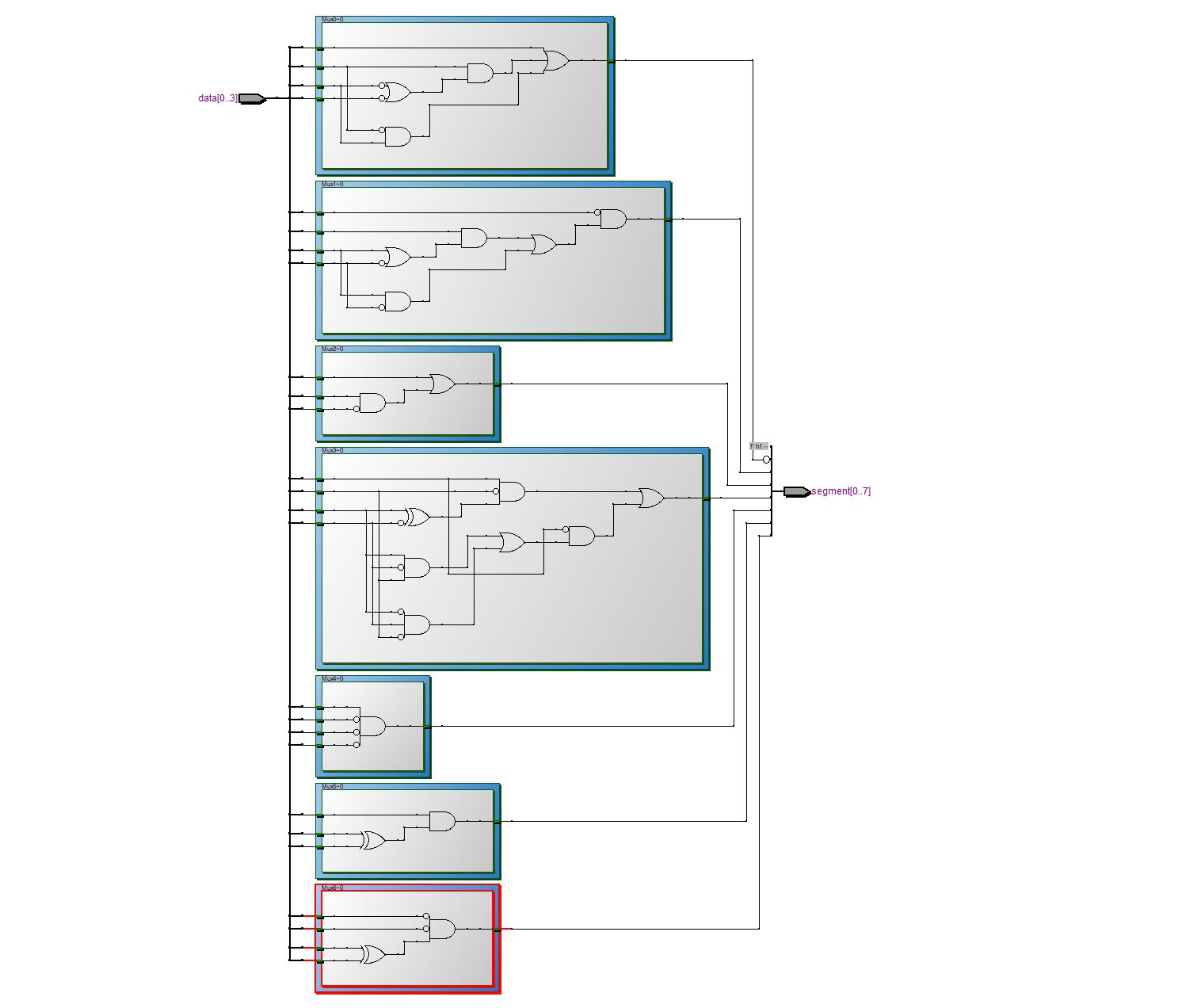
Hast du das gemalt oder wurde das automatisch erzeugt? Diese 3-Input
LUTs finde ich etwas seltsam. Nach dem Place und Route sieht das
bestimmt anders aus.
svedisk ficklampa schrieb:> Ja, ein Grund mehr bei Altera zu bleiben.
Ich sehe da kein ROM...
> Ja, ein Grund mehr bei Altera zu bleiben.
Oder doch ein Grund weniger, bei Altera zu bleiben, denn wie vermutet
bleiben auch bei Diamond zum Schluss in der Technology Schematic nur 7
LUTs übrig.
> automatisch erzeugt?
[x]
> Diese 3-Input LUTs finde ich etwas seltsam.
Jo mei, wenn der Term halt nur von 3 abhaengt.
Er zeigt ja die zugehoerige Kombinatorik im Kasterl.
Derek C. schrieb:> Welche Variante würde man praktisch der> anderen vorziehen?
Ich bevorzuge die (maximal) lesbare Form. Optimieren kann man immer
noch, wenn es tatsächlich nötig werden sollte.
Außerdem versuche ich im Design alle Signale als high-Aktiv zu behandeln
(1 = AN). Erst an der Schnittstelle nach außen wird ggf. invertiert, um
- wie hier - low-Aktive LED-Segmente anzusteuern.
Duke

{kind=link}
{kind=link}
{kind=link}