Hallo,
ich habe auf meine Bastelplatine auch einen RAM mit HyperBus Interface
gelötet.
https://www.mouser.de/datasheet/2/198/66-67WVH8M8ALL-BLL-938852.pdf
Das habe ich getan weil der nur wenige FPGA IOs benötigt und doch recht
groß und schnell ist.
Das ist jetzt der letzte Bausteion auf dem Board den ich in Betrieb
nehme und dazu habe ich ein paar Fragen zwecks Herangehensweise:
Der Stein kann ziemlich viel, lineare Bursts, wrapped Bursts, aber immer
Bursts, die Burstlänge ist einstellbar und wenn man nur einzelne
Bytes/Adressen schreiben will muss man eben während der restlichen
Adressen im Burst das Mask Bit RWDS setzen damit die Daten nicht
geschrieben werden.
Aber vieles brauche ich auch nicht. Ich will eigentlich nur linear lesen
und schreiben. Daten vom ADC in das RAM und dann wieder vom RAM um es
über USB zu schaufeln. Ich denke daher an ein Interface zu meinem zu
schreibenden Controller das gleich 32Byte breit ist, ein paar
Handshaking Signale hat und noch die Startadresse des Bursts/Pageadresse
übergibt.
Macht das Sinn oder vielleicht als generelle Frage:
Sollte man sehr breite Interfaces im FPGA vermeiden und die Daten lieber
seriell übertragen? Als Alternative könnte ich auch einen kleinen
Speicher einbauen. Dann wird immer gewartet bis der voll ist, dann wird
das in den RAM geschrieben und wieder gewartet.
Und dann ist mir die Speicherorganisation noch etwas unklar.
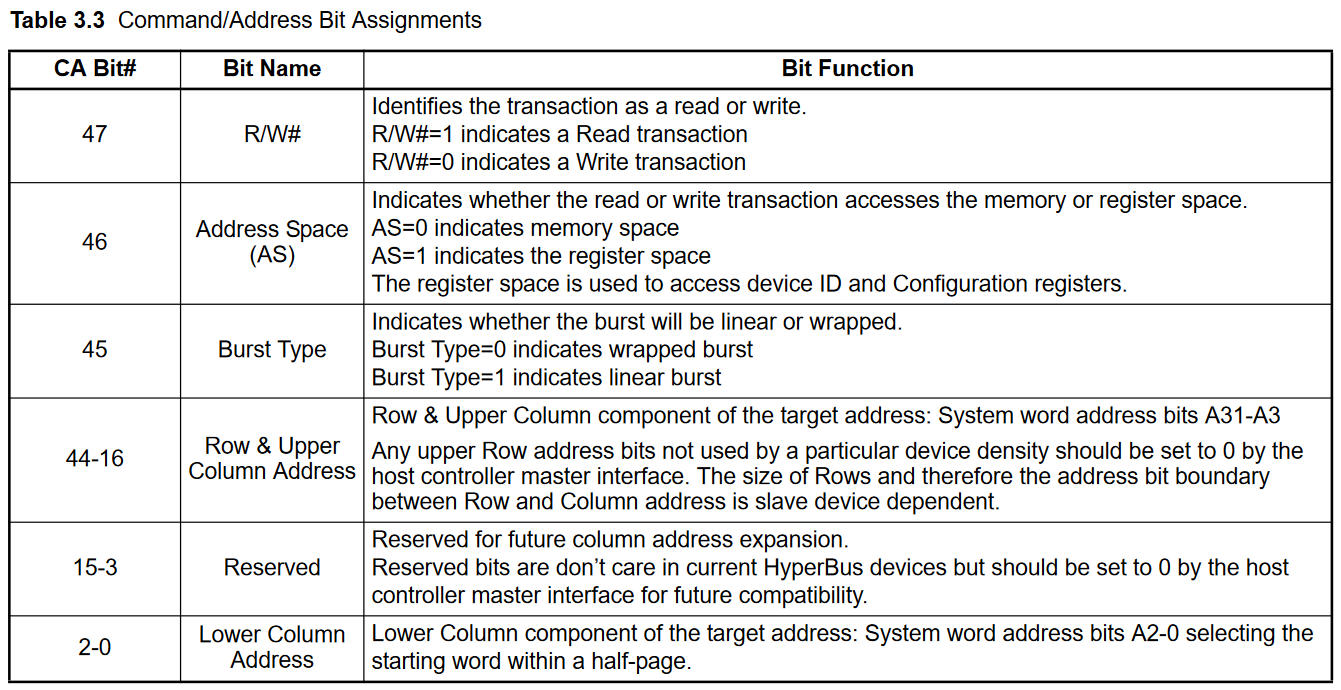
Es gibt die Bits 44-16 das ist Row & Upper Column Address.
Dann gibt es noch die Bits 2-0, Lower Column Address.
Lower Column component of the target address: System word address bits
A2-0 selecting the starting word within a half-page.
Und die Fußnoten:
1. A Row is a group of words relevant to the internal memory array
structure and additional latency may be inserted by RWDS when crossing
Row boundaries - this is device dependent behavior, refer to each
HyperBus device data sheet for additional information. Also, the number
of Rows may be used in the calculation of a distributed refresh interval
for HyperRAM memory.
2. A Page is a 16-word (32-byte) length and aligned unit of device
internal read or write access and additional latency may be inserted by
RWDS when crossing Page boundaries - this is device dependent behavior,
refer to each HyperBus device data sheet for additional information.
3. The Column address selects the burst transaction starting word
location within a Row. The Column address is split into an upper and
lower portion. The upper portion selects an 8-word (16-byte) Half-page
and the lower portion selects the word within a Half-page where a read
or write transaction burst starts.
4. The initial read access time starts when the Row and Upper Column
(Half-page) address bits are captured by a slave interface. Continuous
linear read burst is enabledby memory devices internally interleaving
access to 16 byte half-pages.
Wenn also ein Burst 32 Bytes lang ist, dann sind das 16 Words. Da hätte
ich jetzt 4 Bits erwartet als Adresse und nicht nur 3.
Ich würde gerne die LSBs immer auf 0000 lassen und so nur ganze Pages
schreiben. Macht das Sinn?
Und noch eine Frage:
Habt ihr so einen Stein schon mal verwendet?
Zusatz:
Ja, ich weiß dass es IP dazu gibt. Diese will ich aber nicht verwenden
weil ich das selber machen möchte und weil ich mir auch keinen Prozessor
oder sonst wie AXI ins System holen möchte.
Wie machen das eigentlich richtige Speichercontroller mit dem
Management? Ich stelle mir das schwierig vor wenn das System dem
Controller nur Adressen und Daten zum Schreiben oder Lesen gibt. Ich
stelle mir das so vor, dass der Controller Adressen und Daten zusammen
in eine Cue packt und dort dann so umsortiert, dass er möglichst viele
Daten zusammenhängend in Bursts lesen kann. Das hat dann aber das
Problem, dass der Controller ja nicht ewig warten kann. Wenn also noch
ein paar Adressen zu lesen sind die nicht zu einem Burst passen muss er
das trotzdem tun irgendwann. Und dann ist noch das Problem, dass das
System die Daten nicht in der Reihenfolge zurückbekommt in der es die
Leseanfragen an den Controller gegeben hat. Vermutlich ist das eine
ganze Wissenschaft für sich.
Danke!
Gustl B. schrieb:> Sollte man sehr breite Interfaces im FPGA vermeiden und die Daten lieber> seriell übertragen? Als Alternative könnte ich auch einen kleinen> Speicher einbauen. Dann wird immer gewartet bis der voll ist, dann wird> das in den RAM geschrieben und wieder gewartet.
Noe, da kannst du ruhig zulangen. Wenn du Speicher Controller hast, dann
hast du ziemlich oft breite Datenbusse (z.B. 320 bit sind da keine
Seltenheit). Wenn das einigermassen vernuenftig gemacht ist, kommt man
da auch auf ein paar 100 MHz Taktrate ohne Probleme zu bekommen.
Gustl B. schrieb:> Wie machen das eigentlich richtige Speichercontroller mit dem> Management? Ich stelle mir das schwierig vor wenn das System dem> Controller nur Adressen und Daten zum Schreiben oder Lesen gibt. Ich> stelle mir das so vor, dass der Controller Adressen und Daten zusammen> in eine Cue packt und dort dann so umsortiert, dass er möglichst viele> Daten zusammenhängend in Bursts lesen kann. Das hat dann aber das> Problem, dass der Controller ja nicht ewig warten kann. Wenn also noch> ein paar Adressen zu lesen sind die nicht zu einem Burst passen muss er> das trotzdem tun irgendwann. Und dann ist noch das Problem, dass das> System die Daten nicht in der Reihenfolge zurückbekommt in der es die> Leseanfragen an den Controller gegeben hat. Vermutlich ist das eine> ganze Wissenschaft für sich.
Gute Controller machen das auch. Kannst ja mal die Doku zum Xilinx MIG
durchlesen um dir Inspiration zu holen.
OK, ja mein Problem ist eher zu entscheiden welche Features alles rein
sollen und welche nicht. Wenn ich jetzt auch Zugriffe auf einzelne
Adressen, unterstützen möchte, dann muss ich die anderen Bytes im Burst
maskieren. Und dann muss ich entweder den Controller schlauer machen
(was ich nicht will) oder das System muss dem Controller sagen können ob
jetzt eine einzelne Adresse oder eine Page gelesen werden soll.
Edit:
Oder ist das vielleicht sogar üblich, dass das Betriebsystem sagt ob es
jetzt eine Adresse oder eine Page lesen möchte?
Die andere Frage hat sich geklärt:
During linear transactions, accesses start at a selected location and
continue in a sequential manner until the transaction is terminated when
CS# returns High.
Das ist schön, ich kann mir also eine Länge aussuchen. Eher zwei Längen.
Ich werde vermutlich das Lesen/Schreiben von einzelnen Words und von
Bursts mit 16 Words(=Page) bauen.
Dann habe ich noch den hier gefunden:
https://github.com/gtjennings1/HyperBUS
Der hat
input [31:0] i_mem_wdata,
output [31:0] o_mem_rdata,
32 Bit Daten.
Das macht an der Stelle vermutlich Sinn weil das für einen 32 Bit RiscV
gedacht ist, aber das ist auch recht langsam. Das sind nur zwei Takte
für die Datenübertragung, aber mindestens sechs Takte für Command und
Warten. Naja ... war vermutlich ein Kompromiss weil man sonst eben einen
schlaueren Controller bräuchte der Bursts kann und so.
Vancouver schrieb:> Willst du dir das wirklich antun, einen eigenen Hyperbuscontroller zu> schreiben? Da kann man eine ganze Menge Zeit drin versenken.
Ja schon, ist nur zu Lernzwecken.
Vancouver schrieb:> SystemVerilog
Das kann ich (noch) nicht. Und kann daher nicht beurteilen ob der
Controller Bursts unterstützt oder nur 32Bit Transaktionen. Ich brauche
auf jeden Fall Bursts wenn ich 100 MBytes/s wegschreiben können will.
Der Cypress IP, welchen Anschluss hat der intern? Ist das AXI? Kann man
den auch ohne CPU bedienen oder würde das extrem umständlich?
Ich habe mit dem Microblaze bisher nur sehr wenig gemacht. Zur
Rechenleistung gibt es schon Angaben im Netz, aber wie sieht es beim
Datendurchsatz aus? Schafft der es die 100 MBytes/s vom ADC zum RAM zu
schaufeln?
Gustl B. schrieb:> Ich habe mit dem Microblaze bisher nur sehr wenig gemacht. Zur> Rechenleistung gibt es schon Angaben im Netz, aber wie sieht es beim> Datendurchsatz aus? Schafft der es die 100 MBytes/s vom ADC zum RAM zu> schaufeln?
Unwahrscheinlich. Aber sowas würde ich eine DMA-Engine, die direkt am
Speichercontroller hängt machen lassen.
Duke
Duke Scarring schrieb:> DMA-Engine
Genau sowas gibt es. Das ist auch fein wenn immer neue Daten nachkommen,
aber ich habe da wieder so eine Angst die mich dann Dinge selbst
schreiben lässt:
Z. B. kann man ich ja bei Xilinx einen FIFO generieren lassen als IP.
Ich verwende den auch in manchen Projekten. Wie ist das wenn ich nur
eine Bestimmte endliche Datenmenge übertragen möchte, z. B. 16 Bytes.
Dann will ich am Ziel auch genau diese 16 Bytes haben - und zwar
vollständig. Der FIFO hat aber die Einstellung, dass der das Empty Flag
schon setzt wenn noch Daten drinnen sind.
Bei einem kontinuierlichen Datenstrom ist das OK, auch sonst könnte man
die Daten die man haben will durch zusätzliche Daten "durchspülen".
Das sind so Dinge die ich bei einem AXI System aus der Hand gebe. Wenn
ich so einem DMA IP dann eine Anzahl an Bytes gebe, landen die alle im
RAM auch wenn das kein kontinuierlicher Datenstrom ist?
Ich müsste mir das mal zusammenklicken und gucken ... habe ich noch
nicht gemacht.
Teilweise. Also ja, das ist ebenfalls pseudostatisch, aber du hast keine
getrennten Daten und Adressleitungen. Sondern man hat nur 8 Leitungen
(+Clock und so) und darüber wird zuerst in ein paar Takten ein Kommando
übertragen, dann folgt eine Wartephase und dann werden da die Daten
übertragen, DDR. Das ist also beim Burst schön schnell (333 MByte/s
maximal), aber wenn nur einzelne Bytes an zufällige Adressen geschrieben
werden sollen, dann bricht die Transferrate auch sehr stark ein. Das ist
eben ein DRAM und das Übertragen vom Kommando kostet bei
Einzelzugriffen schon mehr Zeit als die Datenübertragung selbst. Bei mir
ist das egal, ich will das nur als Samplespeicher verwenden. Da werden
in großen Bursts 100 MByte/s hingeschrieben bis das RAM voll ist oder
eben die Zahl der aufzunehmenden Samples, und dann wird langsam daraus
gelesen und zum PC übertragen. Oben hatte ich ein PDF verlinkt, da kann
man das Timing schön sehen. Das ist also eher ein serielles Interface
wie SPI, nur eben OctaSPI mit DDR und Wartephasen und bidirektionalen
Leitungen.
Gustl B. schrieb:> Ja schon, ist nur zu Lernzwecken.
Das ist ein Argument, aber wie gesagt, der Aufwand ist nicht zu
unterschätzen.
Gustl B. schrieb:> Der Cypress IP, welchen Anschluss hat der intern? Ist das AXI?
Ja, AXI3 und AXI4.
Gustl B. schrieb:> Kann man> den auch ohne CPU bedienen oder würde das extrem umständlich?
Der Controller hat einige interne Register, die gesetzt werden müssen.
Z.B, gibt es ein Setting, das ein Timing feingranular verschiebt, danmit
es passt. Das muss sogar im laufenden Betrieb hin und wieder gemacht
werden, wenn die Temperatur das Timing verändert. Du brauchst auf jeden
Fall einen Controller, der das alles macht. Ob der Aufand ohne CPU zu
groß ist, liegt in Deinem Ermessen. Wir betreiben den Controller an
einem DMA mit einem RISCV.
Gustl B. schrieb:> aber wie sieht es beim> Datendurchsatz aus? Schafft der es die 100 MBytes/s vom ADC zum RAM zu> schaufeln?
Ohne DMA wird das sportlich, zumindest, wenn der MB noch andere Dinge
tun soll.
Gustl B. schrieb:> Wenn> ich so einem DMA IP dann eine Anzahl an Bytes gebe, landen die alle im> RAM auch wenn das kein kontinuierlicher Datenstrom ist?
Aber natürlich. DMA hätte keinen Sinn, wenn die letzten Bytes irgendwo
hängen bleiben. Ein DMA-Controller erzeugt erst einen Interrupt, wenn
alle Daten übertragen wurden.
Gustl B. schrieb:>> SystemVerilog>> Das kann ich (noch) nicht. Und kann daher nicht beurteilen ob der> Controller Bursts unterstützt oder nur 32Bit Transaktionen.
Dazu müsste ich nochmal Kolleggah interviewen, aber soweit ich weiß,
haben wir den Controller ausgewählt, weil der die HB-Spec vollständig
umsetzt.
Wenn du VHDL kannst, sollte es aber kein allzu großes Problem sein, den
SV-Code zumindest in groben Zügen zu verstehen. Learning by reading :-)
Nach fast 15 Jahren VHDL habe ich SV ziemlich schnell gelernt, auch wenn
ich noch längst nicht alle Details kenne.
Vancouver schrieb:> unterschätzen
Kann ich, hab ich schon mal gemacht.
Vancouver schrieb:> AXI3 und AXI4.
Habe ich ebenfalls schon mal gemacht, ohne CPU. Da habe ich den XADC und
mal den UARTlite von Xilinx bedient. Quasi einen billigen AXI Master
gespielt. War nicht irre schwer.
Vancouver schrieb:> Der Controller hat einige interne Register, die gesetzt werden müssen.> Z.B, gibt es ein Setting, das ein Timing feingranular verschiebt, danmit> es passt.
Also dass ich im RAM vielleicht die Configregister beschreiben muss ist
OK, aber das Timing nachträglich korrigieren und die Temperatur
überwachen? Nein. Da gehe ich lieber mit dem Takt runter. Mir reichen ja
100 MBytes/s. Bei 1,8 V kann das RAM 166 MHz, ich betreibe den Rest im
FPGA großteils mit 100 MHz und wollte das auch mit dem RAM machen. Also
200 MHz DDR. Das sollte entspannt funktionieren.
Vancouver schrieb:> Aber natürlich. DMA hätte keinen Sinn, wenn die letzten Bytes irgendwo> hängen bleiben. Ein DMA-Controller erzeugt erst einen Interrupt, wenn> alle Daten übertragen wurden.
Danke!
Vancouver schrieb:> Learning by reading :-)
So mache ich das auch oft, ob man wirklich alle Details kennen sollte
weiß ich nicht. Ich komme auch ganz gut mit einem Teil aus VHDL zurecht.
Aber man kann immer was dazulernen.
So, ich laufe gerade in einige Fragen hinein:
Dieser HyperBus verlangt, dass bei der Übertragung vom FPGA zum RAM die
Daten so anliegen, dass die Taktflanke mittig in den Daten liegt.
Das muss ich also beim Übertragen der 6 Bytes für das Command und beim
Schreiben in das RAM einhalten.
Wenn ich aus dem RAM lese, dann treibt der RAM das RWDS Signal und legt
die Daten passend dazu an, und zwar wieder so, dass die RWDS Flanken
schön mittig in den Daten liegen.
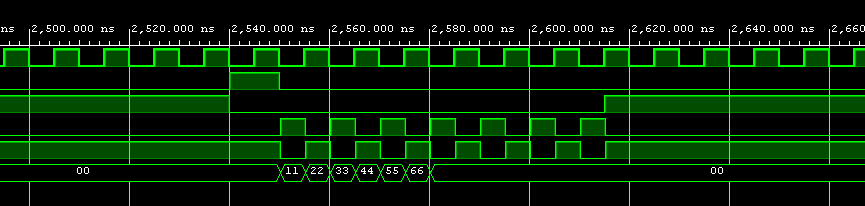
Meine Fragen sind jetzt welche Hardwareblöcke ich verwenden sollte.
Biesher habe ich jetzt den SelectIO Wizard verwendet, und ein
bidirektionales DDR Interface erzeugt. Da kann ich aber die ausgegebenen
Daten nicht gegenüber dem ausgegebenen Takt verzögern. Es kommt also
sowas raus wie in Screenshot, da liegt die Flanke nicht mittig in den
Daten.
Wäre es vernünftiger Datenausgabe, Dateneinlesen und Clock komplett
getrennt zu machen, also nicht über einen SelectIP IP?
Z. B. einen IP oder so zum einlesen der DDR Daten mit RWDS und einen IP
zur Datenausgabe und noch einen IP/ODDR zur Taktausgabe. Und noch einen
ODDR zur Taktausgabe für die phasenverschobene Clock PSC.
Das Tristate würde ich dann in der Toplevel VHDL machen.
Dann möchte ich das schön einfach halten und "nur" die 100 MHz verwenden
die synchron zum Rest des Systems sind. Ist das der richtige Weg, oder
wäre es sinnvoll da 200 MHz verwenden damit ich die Daten bei 100 MHz um
einen halben Takt verschoben ausgeben kann? Dann könnte ich auch den
Takt quasi manuell ausgeben.
So, ODELAY gibt es in HR Bänken nicht ... und der Spartan hier hat nur
HR Bänke. Naja, gut.
Ich könnte jetzt mit 4 Takten arbeiten:
1. Der 100 MHz Takt zu dem ich die Daten mit dem SelectIO IP als DDR
ausgebe.
2. Ein um 90° verschobener 100 MHz Takt den ich dann differentiell als
CK und CK# ausgebe.
3. Ein weiterer gegebüber 1. um 180° verschobener 100 MHz Takt den ich
als PSCK und PSCK# ausgebe.
4. Beim Lesen treibt der RAM Stein das Signal RWDS, das ist dann also
auch ein Takt mit dem ich die DDR Daten übernehme.
Würde man die Verschiebung von 2. und 3. mit Constraints lösen? Also
dass 2. um 2.5 ns nach 1. oder nach den Daten anliegt und dass 3. noch
mal 2.5 ns später ausgegeben wird?
Hast du mal die Setup und Hold Zeiten als Constraints in deiner XDc
angegeben? Jenachdem wie kritisch die sind, brauchst du da nicht von
Hand an der Phase rumfummeln.
Wie klein/gross sind den Setup & Hold?
Tobias B. schrieb:> Hast du mal die Setup und Hold Zeiten als Constraints in deiner XDc> angegeben?
Bisher noch nicht.
Tobias B. schrieb:> Jenachdem wie kritisch die sind, brauchst du da nicht von> Hand an der Phase rumfummeln.
Ja, was wird denn dann durch Routingdelay verschoben? Der Takt nach
hinten?
Tobias B. schrieb:> Wie klein/gross sind den Setup & Hold?
Bei 100 MHz ist das jeweils 1 ns. Im Datenblatt steht center aligned
drinnen, und daran wollte ich mich halten. Bei 100 MHz liegen die Daten
maximal 5 ns an. Davon müssen sie 2 na stabil sein, also 1 ns vor der
Taktflanke und 1 ns nach der Taktflanke. Ich finde das ist recht
entspannt.
Selbst bei maximalem Takt von 166 MHz sind Setup und Hold nur 0,6 ns. Da
ist also eine Periode 6 ns, eine halbe Periode also 3 ns die die Daten
maximal anliegen könnten und davon genügen 1,2 ns um die Taktflanke
herum.
So, da bin ich wieder ... meine Testbench macht schon den
Schreibevorgang wie im Datenblatt, aber ob das wirklich passt und um
auch aus dem RAM zu lesen brauche ich jetzt das RAM in der Simulation.
Und das gibt es auch, aber es verwendet Dinge die mein Vivado nicht
kennt:
1
LIBRARYIEEE;
2
USEIEEE.std_logic_1164.ALL;
3
USEIEEE.VITAL_timing.ALL;
4
USEIEEE.VITAL_primitives.ALL;
5
USESTD.textio.ALL;
6
7
LIBRARYFMF;
8
USEFMF.gen_utils.all;
9
USEFMF.conversions.all;
Tja was kann ich da machen? Wenn ich das nicht simulieren kann würde ich
mir selber eine Testbench schreiben die RAM spielt. Und wenn das passt
würde ich eben auf der Hardware testen.
In dem .zip hier https://www.cypress.com/verilog/s27kl0641-verilog ist
auch das VHDL Modell und eine Testbench drinnen.
Modelsim müsste die notwendigen VITAL2000-Libraries mitbringen.
Den Rest gibt's da, wo Du das model her hast.
[edit: nö, da: https://freemodelfoundry.com/packages.php]
Markus F. schrieb:> Modelsim müsste die notwendigen VITAL2000-Libraries mitbringen.
GHDL auch. Evtl. muss man da aber mit dem -frelaxed-rules Switch
arbeiten.
OK, danke. Für dieses Projekt würde ich schon gerne bei dem Vivado
Simulator bleiben.
Wie ist das "draußen", welcher Simulator hat da grob welche
Marktdurchdringung?
Gustl B. schrieb:> Wie ist das "draußen", welcher Simulator hat da grob welche> Marktdurchdringung?
Das kann man so pauschal nicht sagen. Haengt stark vom Projekt, der
Sicherheitsklasse, den Prozessen und letztendlich auch vom Budget ab.
Gustl B. schrieb:> OK, danke. Für dieses Projekt würde ich schon gerne bei dem Vivado> Simulator bleiben.
Hat keiner gesagt, dass Du den Simulator wechseln sollst...
@ Tobias B.: Es gibt also keinen "Industriestandard"?
Nun, die Tipps hier haben waren Modelsim und GHDL, das klingt für mich
danach, dass ich nicht den Vivado Simulator nutzen sollte.
Gustl B. schrieb:> Nun, die Tipps hier haben waren Modelsim und GHDL, das klingt für mich> danach, dass ich nicht den Vivado Simulator nutzen sollte.
Beide genannten Pakete enthalten die VITAL2000 Quellen
OK, ich habe noch nicht wirklich verstanden was die VITAL2000 Teile
sind. Ist das sowas wie das IEEE das ich in einen Ordner kopieren muss
damit es vom Simulator gefunden werden kann?
Gustl B. schrieb:> @ Tobias B.: Es gibt also keinen "Industriestandard"?>> Nun, die Tipps hier haben waren Modelsim und GHDL, das klingt für mich> danach, dass ich nicht den Vivado Simulator nutzen sollte.
Jeder nutzt das womit er glaubt seine Ziele zu den geringsten Kosten zu
erreichen. Ich kenne keinen Standard oder Norm welche vorschreibt dass
dieser oder jener Simulator verwendet werden muss.
Die Questa Produktfamilie von Mentor hat zum Beispiel eine ISO 26262
Zertifizierung, siehe z.B.:
https://www.mentor.com/company/news/mentor-achieves-iso-26262-cert-questa-product-tool-qualification-report
D.h. aber noch lange nicht, dass ich nur mit ISO 26262 zertifizierten
Tools entsprechend entwickeln darf. (Falls das falsch sein sollte, bitte
jemand korrigieren, ich komme aus der Medizin und hab mit Automotive
nicht viel am Hut.)
Eine Uebersicht findest du hier
https://en.wikipedia.org/wiki/List_of_HDL_simulators inkl. einer
MArkierung der "Big 3". Wobei auch die Big 3 relativ sind, stark
Branchen abhaengig und nicht wirklich auf empirischen Daten beruhend
(dazu kommt noch dass diese auch den ASIC Markt beherrschen). Was ma
jedoch ziemlich sicher sagen kann: Die Big 3 sind auch die Top 3 unter
den Preisen. ;-)
Danke! Ich habe mir aber jetzt selber einen RAM Baustein geschrieben für
die Simulation. Funktioniert auch schon alles wunderbar in der
Simulation.
Ich habe mich jetzt entschieden, dass ich einzelne 2 Byte (das ist ein
Takt und 1 Word) Transfers und lineare Bursts mit 64 Bytes unterstütze.
Beides lesend und schreibend.
Tja warum 64 Bytes? Nun wenn ich die Config Register im RAM nicht
anfasse, dann hat das 6 Takte Latenz und immer die zweifache Latenz
(RWDS = '1'). Wenn ich einen 32 Byte Burst mache, dann brauche ich dafür
1+2+2*6+16+1+1 = 33 Takte, Damit liege ich bei 100 MHz unter den
angepeilten 100 MBytes/s. In den Config Registern könnte ich die Latenz
auf 4 Takte runtersetzen bei 100 MHz, aber ... wenn ich das nicht muss
lass ich das.
Bei 64 Byte Bursts brauche ich 1+2+2*6+32+1+1 = 49 Takte, also 490 ns
bei 100 MHz. Das macht dann 64Bytes*1s/490ns macht 130,6 MBytes in einer
Sekunde.
Aber: Das sind jetzt echt viele Bits/Leitungen im FPGA. 512 hin und 512
zurück ... mal gucken ob das auch auf Hardware funktioniert.
So, ... es baut nicht.
[Route 35-54] Net: HyperRAM_RWDS_IOBUF_inst/O is not completely routed.
[Route 35-7] Design has 1 unroutable pin, potentially caused by
placement issues.
Ja was ist das? Nun, beim HyperBus ist es so, dass es ein RWDS Signal
gibt.
Wenn man in den RAM schreibt, dann kann man mit dem RWDS die Daten
maskieren.
Wenn man aus dem RAM liest, dann ist das RWDS der Takt mit dem man die
Daten vom RAM eintaktet.
Ich habe mir also mit dem SelectIO IP das bauen lassen:
RWDS ist natürlich ein inout, also habe ich den als Tristate
beschrieben:
1
RWDS<=RWDS_OUTwhenRWDS_tristate='0'else'Z';
2
RWDS_IN<=RWDS;
Weil ich nicht weiß wie ich das korrekt löse, wäre mein nächster Ansatz,
den RWDS nicht als inout, sondern nur noch als in zu beschreiben, aber
mit Pulldown. Ja, dann kann ich keine Bits maskieren, aber das habe ich
sowieso nicht vor.
Gibt es eine bessere Lösung?
Ja "Fehler" gefunden. Und zwar habe ich RWDS_IN nicht nur an den IP
Block gegeben, sondern auch zusätzlich noch an einer Stelle verwendet.
Aber das muss ich ja auch machen, denn am Anfang der Transaktion ist
RWDS noch keine Clock oder Maskierung, sondern zeigt an ob das RAM
einfache oder doppelte Latenz für die Daten benötigt.
Ich habe jetzt RWDS nur als in mit Pulldown beschrieben und das baut.
Edit:
Jetzt wieder als inout, aber bei dem IP habe ich nicht external sondern
internal Clock angegeben und verwende dort das RWDS_IN.
Tobias B. schrieb:> Jeder nutzt das womit er glaubt seine Ziele zu den geringsten Kosten zu> erreichen.
"Wir sparen, egal was es kostet" ist ein beliebtes Sprichwort hier unter
den Ingenieuren.
Nichts kaufen (Softwaretools, Schulungen, Bücher, Busanalyzer,
Messgeräte, Build-Server, Rapid-Prototyping Systeme...), dafür mehr
Personenstunden ist bei Schweizerlöhnen vielleicht nicht die Variante
mit den geringsten Kosten...
Ja, das ist nicht optimal. Wahrschenlich fallen entsprechende Firmen bei
noch mehr Punkten im Joel Test durch. ;-)
Aber zum Glueck arbeiten nicht alle so.
Tobias B. schrieb:> Ja, das ist nicht optimal. Wahrschenlich fallen entsprechende Firmen bei> noch mehr Punkten im Joel Test durch. ;-)
In einer früheren Firma hatte ich den Joel Test mal in der Kaffeeecke
aufgehängt (Die war gerade von 3 auf 4 Punkte raufgeklettert durch
einführen von Versionskontrolle). Leider keine Reaktion...
Was auch Spass macht, ist den Joel Test VOR einem Bewerbungsgespräch zur
Beantwortung einzusenden.
1. Do you use source control?
2. Can you make a build in one step?
3. Do you make daily builds?
4. Do you have a bug database?
5. Do you fix bugs before writing new code?
6. Do you have an up-to-date schedule?
7. Do you have a spec?
8. Do programmers have quiet working conditions?
9. Do you use the best tools money can buy?
10. Do you have testers?
11. Do new candidates write code during their interview?
12. Do you do hallway usability testing?
Bei 2.: Was ist denn überhaupt ein "build"? Man kann immer den letzten
Schritt einer langen vielschritten Kette als den "build" definieren und
der läuft dann auch in einem Schritt. Oder ist das Starten eines Skripts
ein Schritt?
Bei 3.: Was für ein Blödsinn, es reicht neu zu bauen wenn man auch was
am Code geändert hat.
Bei 5.: Einige Bugfixes SIND neuer Code.
Bei 6.: Es gibt nichts was immer aktuell ist. Die Frage ist wie schnell
es aktualisiert wird.
Bei 9.: Total sinnlos weil das oft eine Abwägung ist. Ja, eine kleine
Firma könnte sich das weltbeste Tool kaufen dass dann noch ein klein
wenig besser ist als das was sie derzeit nutzen, aber danach ist die
Firma eben pleite. Und wieso überhaupt kaufen? Da zählen also Clang und
GCC schon mal nicht zu Tools die verwendet werden dürfen.
Ja, sind gute Punkte dabei, aber wirkt wenig durchdacht.
Edit:
Mit wenig durchdacht meine ich vor allem die Formulierung. Bei 5. z. B.
hätte man schreiben können und auch sollen:
5. Do you fix bugs before implementing new features.
Christoph Z. schrieb:> In einer früheren Firma hatte ich den Joel Test mal in der Kaffeeecke> aufgehängt (Die war gerade von 3 auf 4 Punkte raufgeklettert durch> einführen von Versionskontrolle). Leider keine Reaktion...
Dann hilft nur das Weite zu suchen. Nix ist schlimmer als eine Firma die
ihre Probleme kennt, aber egal sind.
Christoph Z. schrieb:> Was auch Spass macht, ist den Joel Test VOR einem Bewerbungsgespräch zur> Beantwortung einzusenden.
Das haette ich mich damals nach der Uni nicht getraut und jetzt wo ich
selbststaendig bin gibts keine Gelegenheit mehr. Aber den Tipp geb ich
auf jedenfall weiter! :-)
@Gustl B.
Was der Joel Test beschreibt sind CI Prozesse in einfachen Fragen, diese
sollte man als Experte nicht allzu woertlich nehmen, wir verstehen aber
deren Kern sehr wohl. Da du noch sehr weit davon entfernt bist das zu
verstehen, solltest du eine Bewertung des Joel Tests eher vermeiden. Das
wuerde man dir als Mangel von Expertise auslegen und eher peinlich
enden.
Was man evtl. schon anmerken kann ist, dass der Test knapp 20 Jahre alt
ist, und seiner damaligen Zeit extrem vorraus war. Heute wuerde man den
Test vll. ein bisschen zeitgemaesser machen, was den natuerlich eher
strenger macht.
Kleiner Edit:
Hier
https://www.joelonsoftware.com/2000/08/09/the-joel-test-12-steps-to-better-code/
sidn auch die Anmerkungen vom Autor selbst. An sich ist die ganze Seite
sehr interessant und mit vielen inspirierenden Geschichten.
Natürlich verstehe ich den Hintergrund der Fragen, aber ich finde Fragen
sinnfrei die entweder schlecht gestellt sind oder nicht zu ernst
genommen werden sollen.
Was ist das eigentlich ausser Kompexitätsmanagement? Das läuft schon
lange so, dass die Komplexität immer weiter wächst und statt dass man
dann auf den UNIX Ansatz geht versucht man die Komplexität in den Griff
zu bekommen indem man aussen noch was dranbaut. Das macht dann jeder so
und plötzlich ist es "Industriestandard". Nur weil eine Mehrheit etwas
so macht bedeutet das nicht, dass es gut ist.
Man kann sich mal gut angucken wie die Größe von quasi allem gestiegen
ist. Irre fette Websites (https://player.vimeo.com/video/147806338 ),
fette "Apps", ... und was kann es? Nicht wirklich mehr als vor 20 Jahren
(2004 hatte ich ein Smartphone MPX200 mit Windows, Office, Browser,
Spielen, Paint, Explorer, Outlook, Telefon/SMS und Musikplayer - in 32
MByte Flash). Aber weil es jetzt so fett ist ist es schlechter wartbar.
Statt das zu beheben, also das Problem mal an der Wurzel zu packen hat
man oben noch ein wenig Komplexität draufgeworfen um die Komplexität
drunter besser verwalten zu können.
Und wenn das dann so irre komplex ist, dass das System nurnoch auf genau
dem System läuft auf dem es gebaut wurde dann ... packt man das einfach
in eine VM/Qube/Cabinet/Container und liefert es einfach komplett aus
(-:
Tolle Welt, aber nicht das was ich will. Sollte ich je nach einem Job in
der Wirtschaft suchen dann ganz bestimmt nicht als
Komplexitätsverwalter.
Gustl B. schrieb:> Bei 2.: Was ist denn überhaupt ein "build"? Man kann immer den letzten> Schritt einer langen vielschritten Kette als den "build" definieren und> der läuft dann auch in einem Schritt. Oder ist das Starten eines Skripts> ein Schritt?
1
git clone
2
make all
Mehr soll nicht nötig sein (natürlich sind andere build Systeme erlaubt)
Also das Gegenteil von (alles schon durchgemacht, nicht gerade alles so
auf einmal):
1 Code vom Server kopieren (weil keine Versionskontrolle)
2 Projekt in IDE erstellen oder alle Pfade korrigieren (weil IDE zu doof
und absolute Pfade benutzt)
3 Projekt Einstellungen setzen gemäss README (oder Word Dokument...)
4 Alle nötigen Schritte in der IDE/mehreren Tools ausführen bis eine
Datei da ist, die man aufs Target laden kann (oder Windows Installer,
Debian Packet, zip Datei mit Gerber Daten,...)
5 Programmiersoftware starten und gemäss Word Dokument alles richtig
anklicken
6 Nach Hause gehen, weil der Arbeitstag schon vorbei ist.
Punkt 4 ist z. B. mit Vivado und Vivado SDK besonders lustig für Leute
die das nur alle paar Wochen machen. Die verlieren bei uns jedesmal ein
paar Stunden bis es wieder klappt.
Gustl B. schrieb:> Bei 9.: Total sinnlos weil das oft eine Abwägung ist. Ja, eine kleine> Firma könnte sich das weltbeste Tool kaufen dass dann noch ein klein> wenig besser ist als das was sie derzeit nutzen, aber danach ist die> Firma eben pleite. Und wieso überhaupt kaufen? Da zählen also Clang und> GCC schon mal nicht zu Tools die verwendet werden dürfen.
Punkt 9 wird immer gerne kontrovers diskutiert. Ist auch provokativ
formuliert, wohl bewusst.
"A fool with a tool is still a fool", freie Software ist nicht Gratis.
Bücher, Schulungen, Support mit kurzen Reaktionszeiten kosten oder die
Firma zahlt mehr Einarbeitungszeit. Ist eine Abwägung.
Ach ja, aktuelle Firma läuft bei 5 Punkten...
Christoph Z. schrieb:> Punkt 9 wird immer gerne kontrovers diskutiert. Ist auch provokativ> formuliert, wohl bewusst.>> "A fool with a tool is still a fool", freie Software ist nicht Gratis.> Bücher, Schulungen, Support mit kurzen Reaktionszeiten kosten oder die> Firma zahlt mehr Einarbeitungszeit. Ist eine Abwägung.
Ich denke der Punkt war Anno 2000 schon noch korrekt. Heutzutage muesste
es wohl eher heissen:
Do you use the best tools available?
Wobei im FPGA Bereich es weiterhin keine Alternative zu den wirklich
teuren Flagschiffen gibt. Ich kenne z.B. kein Tool dass mir z.B.
Functional Coverage und Code Coverage (soviel Line als auch Branch
Coverage) bietet. Und da mittlerweile die Designs riesig sind, besteht
nicht nur Bedarf an Functional sondern auch an Formal Verification um
die Testzeiten endlich zu halten.
Wenn ich mir da z.B. anschaue was Mentor mit Questa Prime bietet, dann
finde ich da nicht ansatzweise in der freien Software Gemeinde etwas was
da ran kommt. Anderseits kann man mit GHDL in nemm Docker Container und
z.B. noch mit VUnit schon richtig viel erreichen. Ist halt alles eine
Frage der Anforderungen.
Tobias B. schrieb:> Und da mittlerweile die Designs riesig sind, ...[]
Für mich als Laie sieht das teilweise sehr so aus wie in der
Softwarebranche. Es soll möglichst schnell ein Produkt entstehen und
dann baut man das mit Methoden die genau das versprechen. Dabei ist
völlig egal ob das dann noch wartbar ist oder welche Abhängigkeiten von
sonstwo man sich ins Haus holt. Und weil man das dann so gemacht hat
braucht man auch mächtigere Werkzeuge die einem helfen irgendwie den
Überblick zu behalten.
Ja, ist schön, dass man heutzutage so entwickeln kann, aber das ist dann
nicht unbedingt robust. Bei FPGAs noch eher, da kann man immer das
verwenden was man schon hat (ausser die Lizenz einer Mietsoftware läuft
aus), aber im Webbereich wo gnadenlos externe Dinge eingebunden werden
funktioniert das auch nur so lange wie diese auch vorhanden sind.
Leftpad hätte eigentlich mal ein Umdenken lostreten können, hat es aber
nicht. Weil es den Kunden/Enduser nicht interessiert. Und Firmen die ein
Produkt verkaufen interessiert es im Consumerbereich auch immer weniger
ob das lange beim Kunden funktioniert. Die Halbwärtszeit von Fernsehern
z. B. ist krass gesunken und andere Geräte und auch Software "Apps"
haben von hause aus oft nur eine kurze Lebenszeit. Und dann kann man ja
heute fast überall nachpatchen. Wird ein Bug bekannt der kritisch ist
für den Verdienst der Firma, dann behebt man den nachträglich. Da kann
man schön abwägen ob es sich überhaupt rechnet einen Bug zu patchen oder
ob man dem Kunden lieber ein neues Produkt verkauft oder einem die
Kunden einfach egal sind.
Aber alles egal, jetzt gibt es Essen.
Hm, nun, der HyperRAM will nicht. Aus purer Dummheit habe ich mir aber
die Debuggingmöglichkeiten etwas stark eingeschränkt. Ich habe den RAM
IC direkt neben das FPGA gesetzt und komme so nur an manche Signale - an
die, die durch ein Via geführt werden. Die kann ich schön angucken denn
der dünne Fädeldraht passt ziemlich perfekt in ein Via. Sehen kann ich
so RWDS, CK, PSCK, und ein paar der Bits. #Reset und #CS kann ich nicht
angucken.
So, jedenfalls sehen CK und PSCK und die Daten (ich gucke mir DQ(0) an)
gut aus vom Timing her. Allerdings hapert es beim Lesen, da bekomme ich
einfach keine Daten. Für mich sieht das bisher nach einem Problem mit
RWDS aus. Wenn ich das im FPGA auf 'Z' lege, dann bekommt es einen High
Pegel - aber nie einen Low Pegel. Und zwar auch wenn ich im .xdc einen
Pulldown für den Pin einbauen. Das sieht also so aus als würde der RAM
RWDS immer treiben?! So recht kann ich das nicht glauben und dem Vivado
vertraue ich auch nicht mehr. Normalerweise kann man ja die Simulation
und so neu starten in der GUI und das verwendet dann die aktuellen
Quellcode Dateien. Aber das ist leider nicht immer der Fall. Manchmal
musste ich Vivado schließen, händisch die generierten Dateien löschen
und dann Vivado neu starten. Dann wurde alles neu gebaut und die
Simulation war wieder aktuell. Seltsam.
Daher die Frage:
Wenn ich einen Pin wie RWDS als Tristate mache UND da noch einen Pullup
hinhänge, wo hängt der Pullup?
Hängt der Pullup zwischen Pad und Tristate oder hängt der Pullup am
Ausgangstreiber, also zwischen FPGA Logik und Tristate?
Zusatzfrage 1:
Ich schaffe das nicht 4 Oszi Tastköpfe mit Massefeder gleichzeitig zu
halten. Gibt es dafür eine elegante Lösung?
Zusatzfrage 2:
Ich gebe die Daten DQ mit den Takten CK/#CK und PSCK/#PSCK aus. Der
Xilinx IP kann Clock forwarding. Das würde ich gerne nutzen und gleich
eine differentielle Clock ausgeben. Aber welchen IO-Standard sollte ich
da auswählen um den korrekten vollen 1,8 V Pegel zu bekommen?
Vielen Dank!
Duke Scarring schrieb:> In günstig, siehe Bild...
Ja, so etwas (oder PMK 2-Fuss) sollte jeder in der Nähe haben.
PMK hat noch mehr nette Sachen, SKID, modulares System um Sonden und
Leiterplatten beim Testen zusammen zu halten: http://www.pmk.de/de/skid
Zu teuer für zu Hause aber in einer Firma kann sich das schon rentieren.
Ein anderer Ansatz ist, sich bei den Chemikern mit Stativmaterial
einzudecken, da kann man sich dann beliebig komplizierte Messsetups
zusammenschrauben. Und das Chemikermaterial ist viel günstiger als das
überteuerte Messgerätezubehör.
Ich habe keine Verbindung mit dieser Firma, einfach der erstbeste Link
aus der Suchmaschine:
http://www.laborhandel24.de/allgemeiner-laborbedarf/stativmaterial.html?p=1
Es gibt auch Klammern mit Schwanenhals, die sind dann wieder eher teuer:
http://www.laborhandel24.de/allgemeiner-laborbedarf/stativmaterial/b08309658-de
OK, ja der Tipp mit den Stativen ist schon sinnvoll, sowas habe ich
hier. Aber das braucht dann doch recht viel Platz und ich muss die
Platine fixieren. Gibt es günstige Lötlösungen?
Vor einiger Zeit habe ich mal einen Oszi Tastkopf zerlegt. Da war nicht
viel drinnen, drei Widerstände und ein Kondensator. Das könnte man doch
auch in sehr klein und leicht bauen. Dann hinten ein dünnes Koax dran
oder noch besser eine Buchse für SMA/UF.L und vorne zwei dünne drähte
die ich direkt auf die Platine löten kann.
Ich habe mir das gebaut, aber eben nur mit billigen Tastköpfen. Die
teureren mit 300 MHz Bandbreite will ich ungerne schlachten.
Gibt es sowas vielleicht schon fertig zu kaufen?
Genau sowas suche ich. Nur eben reichen bis so grob 300 MHz. Aber egal,
ich habe jetzt die Platine mit Klebemand auf einer Platte befestigt, die
Tastköpfe drauf gelegt und ebenfalls festgeklebt und die Signale über
sehr kurzen Draht angelötet.
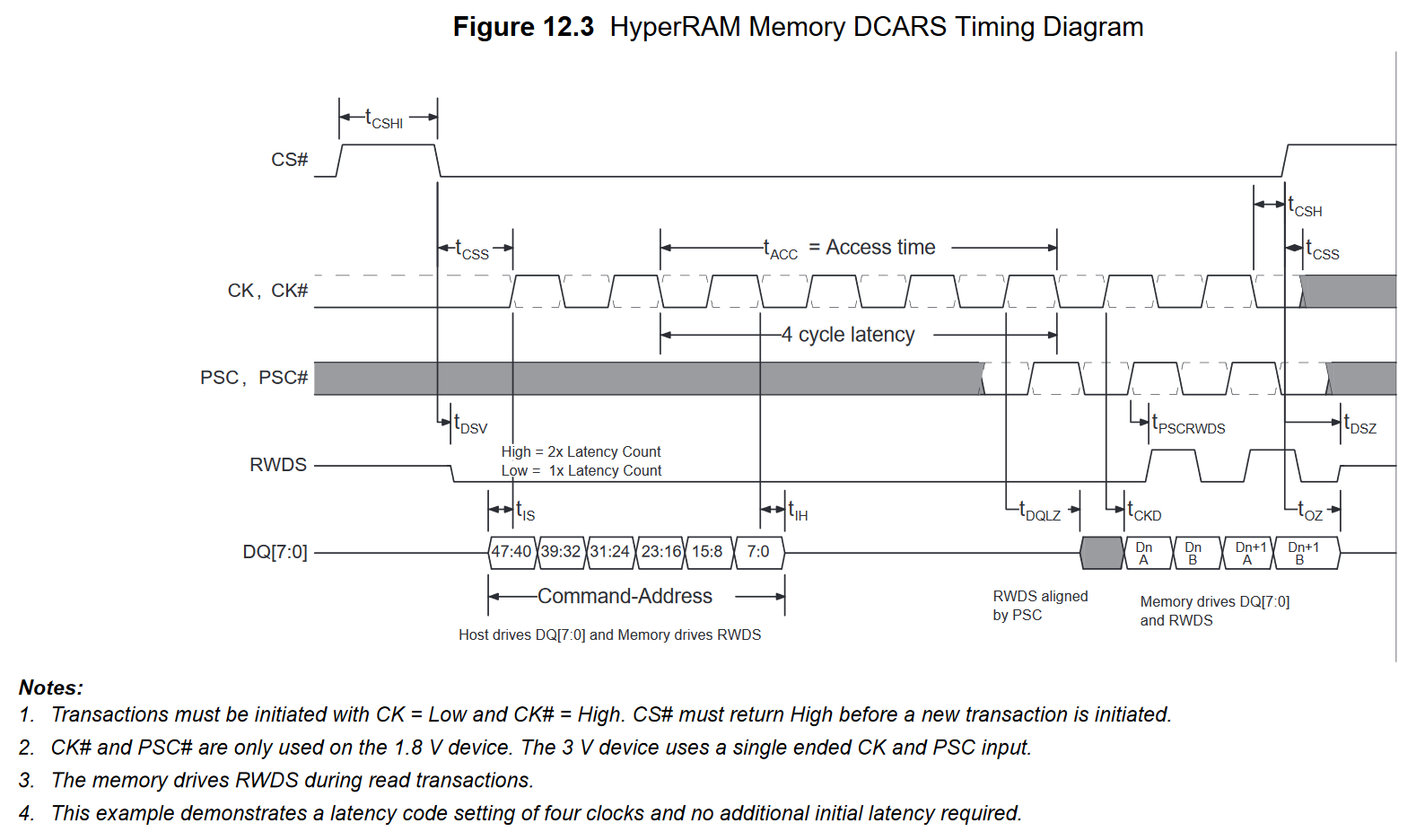
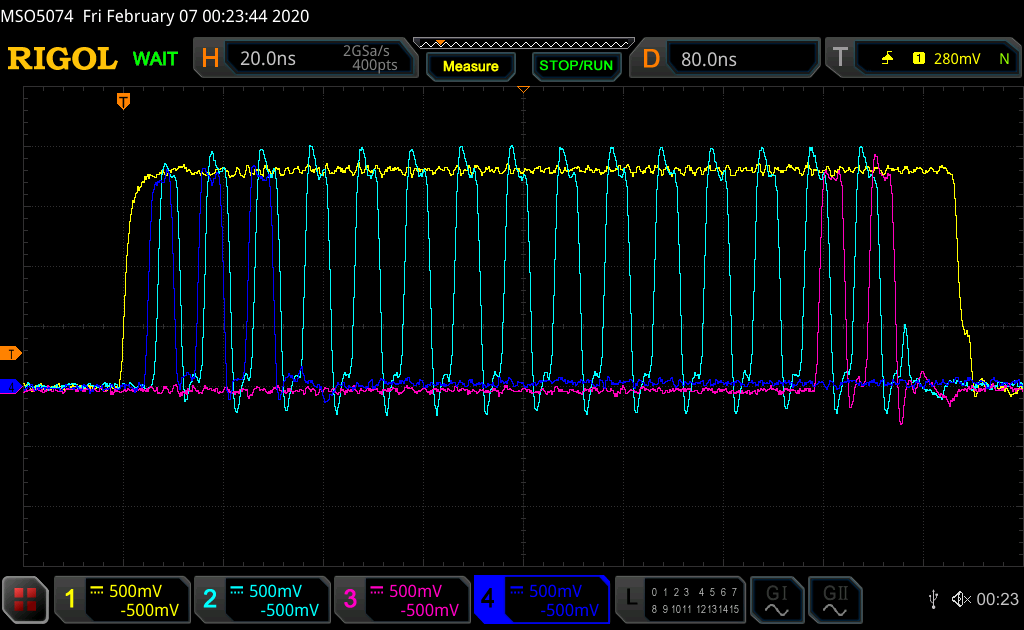
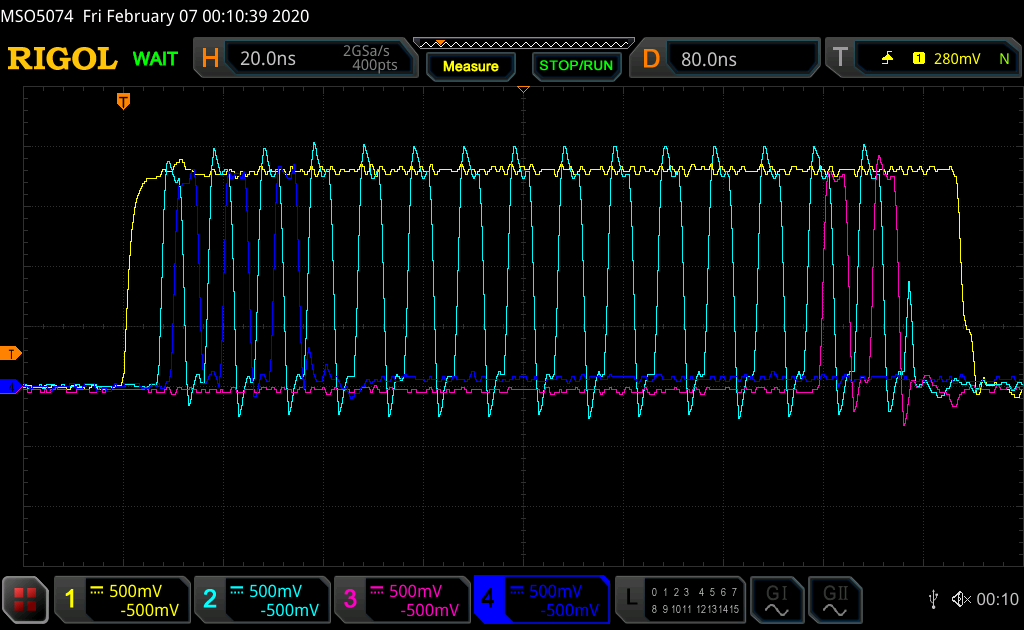
Im Anhang sind jetzt ein paar Bildchen, die zeigen wie folgt:
- Gelb: RWDS
- Cyan: CK
- Magenta: PSC
- Blau: DQ(0)
Hyper_LSB_XXX zeigen, wo die Bits beim Kommanto sitzen. Man kann sehen,
dass die zur jeweiligen Flanke anliegen.
Hyper_Write zeigt einen Schreibvorgang an die Adresse 9. Geschrieben
wird ein Wort.
Saltsam ist, dass der RAM IC scheinbar immer RWDS treibt. Beim Schreiben
geht das nicht ganz runter, da treibt der FPGA und vermutlich der RAM IC
das Signal obwohl beim Schreiben nach der Command Phase nurnoch der
Master RWDS treiben darf.
Dann habe ich noch nicht verstanden wozu ich PSC brauche. Ja,
anscheinend braucht das der RAM IC, aber wann genau? Laut Datenblatt
kann ich das beim Schreiben auch statisch high oder low setzten. Aber
beim Lesen brauche ich das wohl zwingend?! und muss da einen Takt mehr
ausgeben als ich lesen will?! Im Timingdiagramm
https://www.mouser.de/datasheet/2/198/66-67WVH8M8ALL-BLL-938852.pdf
Seite 43 werden 4 Bytes gelesen (2 Takte mehr auf CK und zwei Takte auf
RWDS) aber 6 Flanken über PSC ausgegeben.
Ja und dann ist noch minimal unklar wie viele Takte ich überhaupt warten
muss als Latency. Default besitzt der RAM IC immer doppelte Latenz und
die Latenz ist auf 6 Takte eingestellt (Config Register 0, Seite 20).
Das bedeutet, dass ich am Anfang zwei Takte von CK ausgebe und danach
die doppelte Latenz von 6 Takten, also 12 Takte habe bis ich tatsächlich
schreiben oder lesen darf.
Nach 14 Takten beginnt dann also der Burst.
In den Screenshots will ich nur ein Wort übertragen, also einen Takt.
Dann müsste das stimmen mit den insgesammt 15 Takten.
Und das kann ich mir nicht erklären:
Ich habe RWDS als inout.
Daran hängt ein Tristate.
RWDS <= RWDS_OUT when RWDS_tristate = '0' else 'Z';
RWDS_IN <= RWDS;
Und jetzt kann ich aber (warum auch immer) problemlos RWDS_IN im FPGA in
den Takteingang des DDR IPs geben und gleichzeitig noch in eine
Bedingung schreiben (if RWDS_IN = '1' then ...).
Und das obwohl ich für den Takteingang des IPs external Clock gewählt
habe.
Jetzt versuche ich den RWDS statt inout nur auf in umzubauen und einen
Pulldown im XDC einzubauen.
Also Tristate raus, und zwar nur die obere Zeile entfernt:
RWDS_IN <= RWDS;
RWDS_IN geht weiterhin an den Takteingang des IPs und in die if
Bedingung. Tja und da meckert die Implementation, dass ich das Signal
nicht an zwei verschiedenen Zielen verwenden darf.
[Synth 8-5535] port <HyperRAM_RWDS> has illegal connections. It is
illegal to have a port connected to an input buffer and other
components. The following are the port connections :
Input Buffer:
Port I of instance ibuf_clk_inst(IBUF) in module
<HyperBus_IN_selectio_wiz>
Other Components:
Port I3 of instance i_817(LUT6) in module Spartan7_revc_ram_test
Wieso ist das so, der Ausgang vom Tristate (also der Eingang in Richtung
FPGA) sollte doch äquivalent zu dem Signal ohne Tristate sein wenn
dieses ein in ist. Ich stelle mir das so vor, dass jetzt nur der
Tristate umgangen wird, aber das ist anscheinend nicht so.
Edit:
Ich muss RWDS am Anfang der Transaktion auswerten, und danach muss ich
mit RWDS die Daten übernehmen wenn gelesen wird, dann ist das also ein
Takt wenn ich das richtig sehe.
Wie gerade beschrieben kann ich beides gleichzeitig machen wenn ich da
ein Tristate an den Eingang setze. Wenn ich das weglasse und das nur als
Eingang verwende geht es nicht. Wie kann ich das denn sonst lösen?
Gut, weil ich die Default Einstellungen im RAM nutze, habe ich immer
doppelte Latenz und müsste RWDS am Anfang nicht auswerten. Aber
eigentlich will ich meine Beschreibung so bauen, dass ich später auch
von den Defaulteinstellungen abweichen kann um den Durchsatz zu erhöhen.
So, jetzt ist RWDS nur ein Eingang mit Pulldown.
Aber der ist wohl zu schwach? Selbst dann wenn der RAM IC RWDS nicht
treiben dürfte bleibt es high. Der Pulldown ist aber da, denn man kann
am Oszi schön sehen, dass RWDS "langsam" (ca. 500 ns) nach Masse geht
wenn #CS am Ende wieder High ist.
Hm, damit bin ich jedenfalls unzufrieden, aber das Problem ist wohl
nicht RWDS, sondern dass der IC das treibt, also nicht erkennt, dass ich
lesen oder schreiben will. Vielleicht hängt der ja in einem komischen
Zustand oder die Hardware hat einen Fehler. Versorgungsspannung ist da,
aber ob alle Lötbällchen Kontakt haben kann ich nicht sehen.
Guter Punkt!
Ich habe einen
IS66WVH8M8ALL-166B1LI
und laut Ordering Information braucht der kein PSC/#PSC. Gut, ich hatte
das Datenblatt
The PSC/PSC# differential clock is used only in HyperBus devices
with 1.8 V nominal core and I/O voltage. HyperBus devices with 3 V
nominal core and I/O voltage use only PSC as a single-ended clock.
So verstanden, dass alle 1.8 V Chips das haben. Aber ist wohl nicht so.
Gut, was habe ich jetzt gewonnen? Wenn ich mir die Pinbelegungen
angucke, dann sind die bis auf PSC/#PSC identisch. Es müsste also
genügen wenn ich PSC/#PSC abschalten und hochohmig mache. Aber ich
vermute, dass ich dann noch nicht weiter bin.
Vielen Dank Michael K. ich war aber auch tatsächlich doof. Ich hatte die
ganze Zeit versucht von Cypress die VHDL Datei zu verwenden, aber die
braucht diese VITAL 2000 Teile. Aber es gibt auch eine Verilog Datei
(Anhang) und die funktioniert ohne VITAL auch mit VIVADO. Aber ob die
fehlerfrei ist weiß ich nicht. Naja, jetzt kann ich jedenfalls versuchen
das Verilog zu verstehen (das ist gar nicht so schwer) und so meinen
Controller ans Laufen zu bringen. Immerhin habe ich in der Simulation
das gleiche Verhalten wie auf der Hardware. Ist zwar nicht schön, aber
ein Hardwarefehler wäre schlimmer.
Edit:
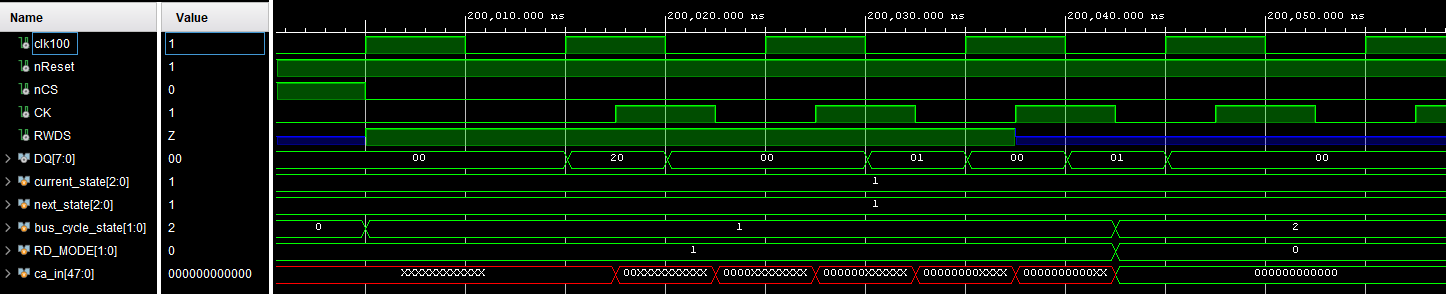
Ist irgendwie komisch. Manche Signale wie ca_in ändern sich schön mit
den ersten 6 Flanken von CK, aber es werden nur 00 übernommen. Obwohl
auf DQ ganz klar etwas anderes steht. Ja, da ist wieder ein Tristate,
aber das habe ich nicht so ganz verstanden wie man den in Verilog
schreibt oder wie der hier beschrieben ist.
Im Anhang ein Bildchen aus der Simulation und hier die Codestellen:
Die Ports wie eine Entity in VHDL:
1
modules27kl0641
2
(
3
DQ7,
4
DQ6,
5
DQ5,
6
DQ4,
7
DQ3,
8
DQ2,
9
DQ1,
10
DQ0,
11
RWDS,
12
13
CSNeg,
14
CK,
15
RESETNeg
16
);
Dann gibt es Wires:
1
wireDQ7_ipd;
2
wireDQ6_ipd;
3
wireDQ5_ipd;
4
wireDQ4_ipd;
5
wireDQ3_ipd;
6
wireDQ2_ipd;
7
wireDQ1_ipd;
8
wireDQ0_ipd;
Die werden dem Signal Din zugewiesen:
1
wire[7:0]Din;
2
assignDin={DQ7_ipd,
3
DQ6_ipd,
4
DQ5_ipd,
5
DQ4_ipd,
6
DQ3_ipd,
7
DQ2_ipd,
8
DQ1_ipd,
9
DQ0_ipd};
Und so sind die Wires DQX_ipd mit DQ verbunden:
1
buf(DQ7_ipd,DQ7);
2
buf(DQ6_ipd,DQ6);
3
buf(DQ5_ipd,DQ5);
4
buf(DQ4_ipd,DQ4);
5
buf(DQ3_ipd,DQ3);
6
buf(DQ2_ipd,DQ2);
7
buf(DQ1_ipd,DQ1);
8
buf(DQ0_ipd,DQ0);
Das bedeutet doch, dass Din direkt DQ entspricht oder?!
Und hier:
1
CA_BITS:
2
begin
3
if(!CSNeg&&
4
(rising_edge_CKDiff||falling_edge_CKDiff))
5
begin
6
for(i=1;i<=8;i=i+1)
7
ca_in[ca_cnt-i]=Din[8-i];
8
ca_cnt=ca_cnt-8;
Werden die Daten in ca_in geschrieben.
Habe ich das bis hierhin richtig verstanden?
OK, Sorry, das war ein Fehler von mir ...
Aber dadurch wird es noch nicht viel besser.
Die CA Daten werden korrekt übernommen, Adresse=9, RW=0 (Write),
Target=0 (Memory).
Aber was ist RD_MODE?
1
parameterLINEAR=4'd0;
2
parameterCONTINUOUS=4'd1;
3
reg[1:0]RD_MODE=CONTINUOUS;
Im Datenblatt gibt es nicht LINEAR und CONTINUOUS, sondern linear und
wrapped. Ist also CONTINUOUS = wrapped Burst?
Im Datenblatt bedeutet eine 1 linear, hier ist es genau umgekehrt.
Gibt es da irgendwelche Bedingungen dass ein Burst stattfinden darf? Ich
meine sowas wie die Adresse muss der Anfang einer Page sein oder so.
Seltsamerweise zählt data_cycle nicht. Jetzt mal nur den Code für die
steigende Flanke von CK:
1
DATA_BITS:
2
begin
3
if(rising_edge_CKDiff&&!CSNeg)
4
begin
5
if(Target==1'b1&&RW==1'b0)
6
begin
7
Data_in[15:8]=Din;
8
data_cycle=data_cycle+1;
9
end
10
else
11
if(BurstDelay==0&&!PO_in)
12
begin
13
RdWrStart=1'b0;
14
if(RW==1)//read
15
begin
16
glitch_rwds=1'b1;
17
glitch_rwdsR=1'b1;
18
RWDSout_zd_tmp=1'b1;
19
if(Target==0)//mem
20
begin
21
if(Mem[Address][15:8]==-1)
22
Dout_zd_tmp=8'bxxxxxxxx;
23
else
24
Dout_zd_tmp=Mem[Address][15:8];
25
end
26
else//reg
27
Dout_zd_tmp=Config_reg[15:8];
28
end
29
else//(RW==0)write
30
begin
31
Data_in[15:8]=Din;
32
data_cycle=data_cycle+1;
33
UByteMask=RWDS;
34
end
35
end
36
end
Ich schreibe (RW=0) in den Speicher (Target=0). Ich gehe also in den
ersten else Zeig und da wird auf BurstDelay=0 geprüft, was es aber nicht
ist. Das behält den Wert 6. BurstDelay wird aber nur verringert wenn
REFCOLL_ACTIV 0 ist. Und das wird nur dann 0 gesetzt wenn !REF_in
gegeben ist. Und das wiederum wird 0 gesetzt wenn rising_edge_REF_out
gegeben ist. Und das findet statt bei always @(posedge REF_out).
Das hängt dann aber wieder von REF_in ab?!
1
//RefreshCollisionTime
2
always@(posedgeREF_in)
3
begin:REFr
4
if(SPEED100)
5
#tdevice_REF100REF_out=REF_in;
6
end
7
always@(negedgeREF_in)
8
begin:REFf
9
#1REF_out=REF_in;
Kann das dann überhaupt jemals eintreten?
Ich hänge nochmal die Verilogdatei an ...
So, letztes Update für diese Nacht:
Ich habe ein Minimalprojekt geschrieben. Das macht nach 200 us einen
Reset und danach eine Schreibtransaktion auf Adresse 9 und darauf eine
Lesetransaktion von Adresse 9. Ja, das ist jetzt nur stumpf
hingeschrieben, aber es ist das gleiche Timing das mein
HyperBusController hat. Man kann also schön gucken was hier in dem RAM
IC abgeht und warum was nicht funktioniert - das ist genau die Stelle
die ich nicht verstehe.
Christoph Z. schrieb:> git clone> make all>> Mehr soll nicht nötig sein (natürlich sind andere build Systeme erlaubt)
Zählt das auch, wenn dieser Schritt zwischendurch Daten aus dem Netzwerk
nachlädt, diverse Debian-Pakete baut, durch ein systemspezifisches Tool
(nicht Teil des Buildsystems!) jagt, daraus einen Haufen Images baut,
diese dann wieder auseinandernimmt und neu zusammenknotet, um am Ende
eine ZIP-Datei auszuwerfen? :-)
In dem Test liegen wir bei 7~8, wobei einige grenzwertig sind (z.B.
"Gibt es eine Spec?" - "Darf man sie auch ignorieren/ständig
anpassen?").
Das war ein guter Tipp Michael.
Dann verstehe ich aber Seite 15 unten Fußnote 5 nicht.
https://www.mouser.de/datasheet/2/198/66-67WVH8M8ALL-BLL-938852.pdf
The figure shows RWDS masking byte A0 and byte B1 to perform an
unaligned word write to bytes B0 and A1.
Wenn da B0 und A1 geschrieben wird, dann wird doch genau das geschrieben
bei dem RWDS 0 ist.
Werde ich daheim ausprobieren, aber ich glaube mittlerweile, dass RWDS 0
sein muss damit die Daten geschrieben werden.
Noch ein Zitat zu RWDS beim Schreiben:
During the write data transfers, RWDS is driven by the host master
interface as a data mask. When data is being written and RWDS is
High the byte will be masked and the array will not be altered. When
data is being written and RWDS is Low the data will be placed
into the array.
Seite 14 im Datenblatt.
Hallo Gustl,
ja ist richtig RWDS muss low sein.
Das Simulation Problem ist in der Datei s27kl0641.v
parameter TimingModel = "DefaultTimingModel";
ändere das mal auf
parameter TimingModel = "S27KL0641DABHI020";
Gruss,
Michael
S. R. schrieb:> Christoph Z. schrieb:>> git clone>> make all>>>> Mehr soll nicht nötig sein (natürlich sind andere build Systeme erlaubt)>> Zählt das auch, wenn dieser Schritt zwischendurch Daten aus dem Netzwerk> nachlädt, diverse Debian-Pakete baut, durch ein systemspezifisches Tool> (nicht Teil des Buildsystems!) jagt, daraus einen Haufen Images baut,> diese dann wieder auseinandernimmt und neu zusammenknotet, um am Ende> eine ZIP-Datei auszuwerfen? :-)
Genau um solche Beispiele geht es! :-)
Ohne Build Automatisierung bekommt man von drei Ingenieuren vier
verschiedene Ergebnisse...
> In dem Test liegen wir bei 7~8, wobei einige grenzwertig sind (z.B.> "Gibt es eine Spec?" - "Darf man sie auch ignorieren/ständig> anpassen?").
Living Specs sind ja ein altes Problem. Genau aus dieser Erkenntnis
kommen ja die ganzen Agilen Methoden, weil Teile des V-Modells nicht mit
der Realität zusammenpassen.
Und genau da liegen auch viele Fehlinterpretationen. Agil bedeutet genau
gar nicht, das keine Spec da ist. Die Spec muss am Ende eines Sprints
mit dem Release zusammenpassen (Hat hier jemand Self-documenting code
oder executable Spec gesagt?), sonst ist der Sprint nicht abgeschlossen
und wie sollten dann auch die Tests geschrieben werden und der nächste
Sprint geplant werden.
So, Simulation funktioniert mit TimingModel = "S27KL0641DABHI020", aber
meine Hardware ist ja ein IS66WVH8M8ALL-166B1LI und mit dem funktioniert
es nicht (auf der Hardware).
Daher erstmal:
Das ist ja ein 166 MHz RAM, ist das trotzdem OK wenn ich den nur mit 100
MHz betreibe? Meine Vermutung ist, dass das baugleiche ICs sind die
selektiert werden. Die besseren werden als 166 verkauft, die
schlechteren als 100.
Sehe ich das richtig, dass dieser Verilog Code der TimingModel auswertet
nur darauf guckt ob in dem String ein "A" enthalten ist?
Ja und dann finde ich von ISSI leider keine (V)HDL Beschreibungen.
Müsste der ISSI Stein wie der Cypress Stein funktionieren weil ja
HyperBus oder könnte es trotzdem sein, dass ich irgendetwas ansers
machen muss?
Wäre zwar etwas Aufwand, aber ich könnte mir auch den S27KS0641DPBHI020
kaufen und damit den ISSI Stein ersetzen.
Danke! Auch damit funktioniert die Simulation wunderbar. Bei TimingModel
habe ich S27KS0641DPBHI020 geschrieben.
Nun ... ich werde auf meiner nächsten Platine dann einen
S27KS0641DPBHI020 verbauen und alle Signale auf Testpads routen.
So, ich habe bei Terasic sehr versteckt ein Modell für einen ISSI STein
gefunden. Ebenfalls in Verilog. Und zwar kann man da einige Dinge per
ifdef einstellen. Kommentar im Code:
1
*RunningOptions
2
*+S10:SetACtimingparameterfor-10(100MHz)
3
*+S75:SetACtimingparameterfor-75(133MHz)
4
*+S60:SetACtimingparameterfor-60(166MHz)
5
*+VERBOSE:Displayinternaloperationstatus
6
*+OFF_ST:PhaseShiftedClockenabled
7
*(default:PhaseShiftedClockdisable)
Und so sieht das Verilog mit den Ports und den Ifdefs aus:
Wie kann ich das in meine VHDL Testbench einbinden? Die Inputs sind mir
klar, aber die ifdefs, sind das Generics?
Bedeutet z. B.
`ifdef S10
dass es ein Generic mit dem Namen "S10" gibt und wenn das '1' ist ist
das gesetzt und bei '0' nicht gesetzt/erfüllt? Und welchen Typ hat das
Generic?
Edit:
Generics wie
1
componentIS66WVH16M8ALLis
2
generic(
3
S10:boolean;
4
S75:boolean;
5
S60:boolean;
6
SPEEDSIM:boolean;
7
VERBOSE:boolean;
8
OFF_ST:boolean);
9
port(
10
ck:instd_logic;
11
ckb:instd_logic;
12
psc:instd_logic;
13
pscb:instd_logic;
14
csb:instd_logic;
15
resetb:instd_logic;
16
dq:inoutstd_logic_vector(7downto0);
17
rwds:inoutstd_logic);
18
endcomponent;
funktionieren leider nicht.
Und noch ein Edit:
Ich habe jetzt das Verilog so editiert, dass die Parameter einfach fest
sind ohne Ifdefs. Und siehe da, die Simulation funktioniert auch hier
... hm ... sieht tatsächlich nach einem Hardwareproblem aus.
Im Anhang noch das Verilogmodell von Terasic, dort ist es in dem ZIP
https://www.terasic.com.tw/cgi-bin/page/archive.pl?Language=English&CategoryNo=253&No=1140&PartNo=3
enthalten.
Edit2:
Edit3: Edit2 entfernt^^ Simulation läuft problemlos ohne Fehlermeldung
im Verbose Modus mit den 166 MHz Timings im Verilogmodell aber nur 100
MHz CK/#CK.
Vielen Dank!
Es war die Hardware. Erhitzen hat nicht geholfen, also habe ich den IC
getauscht gegen einen baugleichen (ISSI). Jetzt funktioniert das
wunderhybsch.
Im Anhang das Projekt für die Simulation mit den Verilogmodellen die ich
finden konnte. Mit dabei ist mein "HyperBus Master". Den habe ich
möglichst einfach gehalten:
1
entityHyperBusisPort(
2
clk100:instd_logic;
3
start:instd_logic;
4
mem_regs:instd_logic;--0: Mem, 1: Regs
5
burstlength:instd_logic;--0: 2Bytes, 1:64Bytes
6
adr:instd_logic_vector(21downto0);-- 21 ... 9: 8192 Rows, 8 ... 0: 512 Words in 1 Row. (2 ... 0: 8 Words = 1 Half Page)
clk100 ist der Systemtakt,
start sagt dass es losgehen soll und Daten/Adresse anliegt.
mem_regs sagt ob aus dem RAM oder dessen Registern gelesen werden soll
(Schreiben der Register ist nicht unterstützt!).
burstlength sagt ob 1 Wort oder 32 Worte gelesen/geschrieben werden
sollen.
adr ist die adresse.
snd_rcv sagt ob geschrieben oder gelesen werden soll.
ready sagt ob die Komponente bereit ist.
data_snd sind die zu schreibenden Daten,
data_rcv_valid sagt ob die gelesenen Daten data_rcv aktuell sind. Dabei
ist aber data_rcv_valid nur für genau einen Takt lang '1' nach einem
Lesevorgang.
Die restlichen Anschlüsse betreffen die Hardware. Dabei wird PSC/nPSC
jetzt mit 'Z' belegt weil ich das angeschlossen habe. Aber der im
Projekt enthaltene MMCM erzeugt auch PSC. Man kann also mit der
Beschreibung auch HyperRAM Steine betreiben die PSC benötigen. In diesem
MMCM kann man auch schön CK/nCK gegenüber DQ verschieben (über die
Phase) damit die Taktflanke dann wirklich mittig in den Daten liegt.
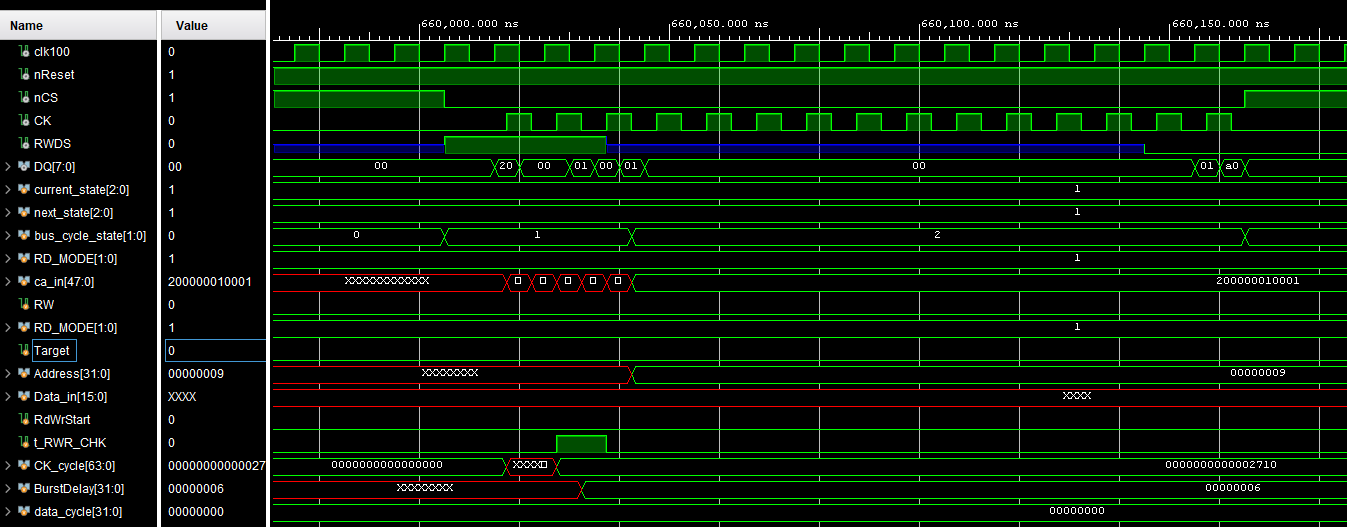
In der Simulation geschieht bei grob 650 us ein Reset (den mach mein
HyperBus Controller immer wenn er losläuft, kann man auch rauslöschen).
Dann bei 660 us gibt es einen 32 Wort Schreibvorgang und bei 662 us
einen 32 Wort Lesevorgang.
Ein 32 Wort Burst dauert 480 ns, dann muss nCS noch für mindestens einen
Takt '1' sein, macht zusammen 490 ns für 64 Bytes. Und (1/490ns)*64Bytes
= 130,6 MBytes/s. Damit liegt das jetzt knapp über meinem Ziel, ich
wollte auf jeden Fall die Daten meiner ADCs wegschreiben können (100
MByte/s) und als "nett zu haben" auch noch schneller sein als Gigabit
Ethernet falls ich das mal verwende mit dem FPGA.
Ja, sonst ... darf gerne verwendet und modifiziert werden. Bei Fragen
einfach fragen.
Gustl B. schrieb:> Theoretisch gehen 200 MByte/s und da würden mir> die 100 MHz am RAM nicht mehr ausreichen.
Du kannst auch zwei RAM-Chips nehmen und parallel ansteuern...
Das ist auch der Plan. Aber ich weiß noch nicht genau was sonst noch auf
die Platine soll. Ich würde gerne was mit SerDes machen. Da bieten sich
schnelle ADCs oder DACs an. HDMI ginge auch.
Aber da Laufe ich dann vermutlich in das Problem, dass HDMI ja LVDS out
ist und ich dafür die Bank am FPGA auf 2.5 V legen muss. Damit geht dann
an dieser Bank kein HyperRAM.
Schneller ADC ginge, aber da werde ich mehrere RAMs brauchen. Wenn ich 1
GByte/s in den Samplespeicher schreiben will reichen mir 4 RAMs mit je
250 MByte/s. Und die bekomme ich bei 166 MHz und mindestens 128 Byte
langen Bursts oder auch mit 200 MHz und 64 Byte Bursts.
Statt ADC könnte ich auch zwei weitere USB-C Buchsen verbauen. Das wären
dann 8 LVDS Pärchen. Mit einem LVDS fähigen schnellem Komparator am
anderen Ende des USB-C Kabels könnte ich so einen schnellen
Logikanalysator bauen.
Wenn du weiter Ideen für ein Bastel-lernprojekt hast immer her damit.
Hauptsächlich will ich einmal USB-C mit USB3 gemacht haben. Aber da
bleiben eben noch einige IOs übrig.
Leider sieht aktuell die Verfügbarkeit von ICs, z. B. dem HyperRAM echt
mies aus. Die 3 V Variante bekommt man gar nicht.
Und 1.8 V gehen nicht weil an der Bank auch das Konfigurationsflash
hängt und das mag 3.3 V.
Alles nicht so einfach, aber Luxusprobleme.
Aber wenn ich schon beim Planen bin, sollte ich lieber den 1.8 V oder
den 3.0 V RAM verwenden (beides 200 MHz RAMs)? Strom und Kosten sind mir
an der Stelle egal, mir geht es drum bei welcher Spannung ich
"problemloser" den höheren/maximal möglichen Takt erreiche.
Hm, eigentlich nicht wirklich, aber:
- Ich habe nur zwei halbe Bänke - geht das? Und welche Bankspannungen
sind erlaubt?
- Da muss ich wohl AXI verwenden?!
- Ich habe das jetzt mal mit dem MIG bauen lassen und zähle 36 IOs die
das braucht. Das ist weniger wie 4x HyperRAM. Wobei ... bei 4x Hyperram
könnte ich doch CK (die wohl lieber nicht), CS# und Reset# untereinander
verbinden und bin dann 39 IOs für alle 4. Hm ... Hm ...
- Das könnte vom Layout her ziemlich fies werden, wäre aber eine neue
Herausforderung nachdem HyperRAM jetzt abgehakt ist (-:
Edit:
Kann man einen DDR2/3 auch langsamer betreiben wenn das Layout nicht für
den hohen Takt gut genug ist? Beim HyperRAM geht das recht problemlos.
Ich habe gerne Dinge die zur Not zumindest noch ein bischen
funktionieren ...
Gustl B. schrieb:> Kann man einen DDR2/3 auch langsamer betreiben wenn das Layout nicht für> den hohen Takt gut genug ist? Beim HyperRAM geht das recht problemlos.> Ich habe gerne Dinge die zur Not zumindest noch ein bischen> funktionieren ...
Nicht mit dem Xilinx MIG. Der braucht einen Mindestakt damit er bei der
Kalibrierung zumindest ein komplettes Datenauge samplen kann.
Gustl B. schrieb:> - Ich habe nur zwei halbe Bänke - geht das? Und welche Bankspannungen> sind erlaubt?
Der MIG meckert bei zwei halben Bänken ... aber gut, dann muss ich eben
andere Dinge umplanen.
DDR3 braucht 1.5 V und wäre auch sonst recht schick. Aber was mache ich
dann mit den restlichen IOs an der Bank? Für 1.5 V gibt es leider kaum
ICs die ich noch verbauen könnte. DDR2 geht mit 1.8 V, das ist schon
feiner.
Gustl B. schrieb:> - Da muss ich wohl AXI verwenden?!
Muss man nicht. Auch schick! Hach ...
Tobias B. schrieb:> Nicht mit dem Xilinx MIG. Der braucht einen Mindestakt damit er bei der> Kalibrierung zumindest ein komplettes Datenauge samplen kann.
OK, aber kann ich da einen DDR2 800 verwenden und den MIG erstmal für
einen DDR2 400 konfigurieren und mich dann langsam an die 800 MHz
rantasten?
Und dann möchte ich noch die tatsächliche Datenrate abschätzen können.
Bei Wikipedia steht z. B. 3.2 GB/s für den DDR2 400 und 64 Bit Breite.
Ist klar, 8 Bytes * 400 M = 3.2 GByte.
Aber das ist doch dann nur die Maximaldatenrate während eines Bursts.
Was schafft denn der RAM im zeitlichen Mittel?
Bei 8 Bit Datenbus sind das dann 400 MByte/s beim Burst.
Beim HyperRAM mit 200 MHz werden auch die 400 MByte/s angegeben, aber
das ist leider auch nur Burst und nicht Durchschnitt. Beim HyperRAM geht
aber nicht mehr wie 200 MHz IO Takt, beim DDR2 schon, da geht es mit 200
MHz erst los und geht bis 533 MHz.
Gustl B. schrieb:> Aber das ist doch dann nur die Maximaldatenrate während eines Bursts.
Ja.
> Was schafft denn der RAM im zeitlichen Mittel?
Das hängt von Deinem Zugriffsmuster ab. Wenn aus jedem Burst nur ein
Byte rausgeholt wird, geht die Rate deutlich in den Keller.
Duke
Noch ein paar Überlegungen zur Datenrate je FPGA IO:
Der HyperRAM macht bei mir bei 100 MHz und 64 Byte Bursts 130.6 MByte/s.
Dafür werden 13 FPGA IOs benötigt. Macht also grob 10 MByte/IO.
Bei 200 MHz und 256 Byte langen Bursts macht der RAM 353.1 MByte/s im
Schnitt. Das sind grob 27 MByte/s im zeitlichen Mittel.
DDR2 mit 8 Bit Datenbus benötigt 35 IOs und schafft. Bei DDR2_400 400
MByte/s. Das sind dann 11.4 MByte/ IO. Bei DDR2_800 sind es also 22
MByte/IO. Und leider kann mein Spartan7 sogar nur DDR2 bis 667 MHz.
Und in diesem Vergleich haben wir die durchschnittliche Datenrate beim
HyperRAM und die Burst Datenrate vom DDR2 verglichen.
Mit 3 HyperRAM ICs komme ich bei den 200 MHz und den längeren Bursts im
Schnitt auf über 1 GByte/s, bei DDR2_800 nicht. Die 3 HyperRAMs breichen
39 IOs, der DDR2 35. Bei den HyperRAMs gibt es auch welche die nur eine
single-ended Clock haben, das ist dann 1 IO weniger je IC und ich könnte
auch die Resets untereinander verbinden.
Eigentlich reichen mir auch 2 HyperRAMs. Ich muss halt die 200 MByte vom
FT600 wegschreiben können und ich würde gerne HDMI machen. Da der
Spartan7 sowieso keine irre schnellen SerDes hat lange ich bei einer
Pixelclock vermutlich unter 100 MHz. Das sind dann 300 MByte/s bei RGB
maximal.
Ja, ich verwe jetzt nochmal HyperRAM verbauen und meinen Controller
umbauen dass der ein FIFO Interface hat und einen höheren Takt kann.
Vielleicht per Generic einstellbar welches HyperRAM Modell man bei
welchem Takt verwenden will.
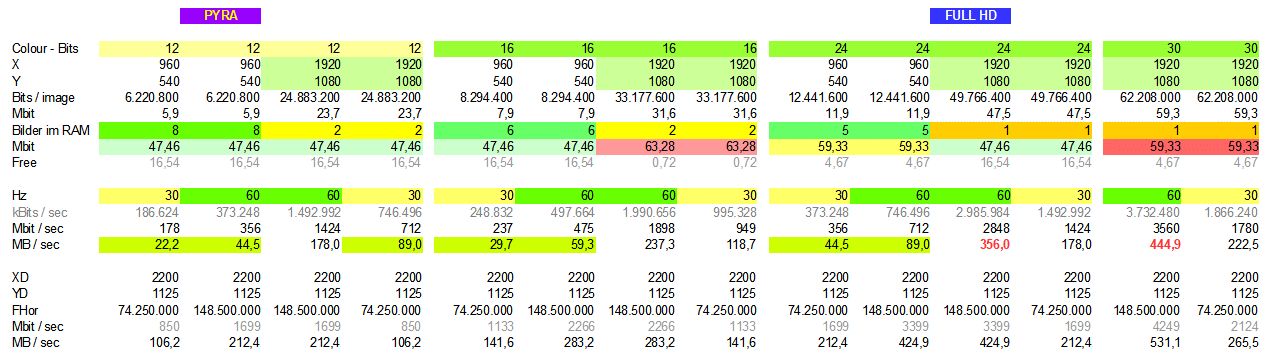
Gustl B. schrieb:> Bei 200 MHz und 256 Byte langen Bursts macht der RAM 353.1 MByte/s im> Schnitt. Das sind grob 27 MByte/s im zeitlichen Mittel.
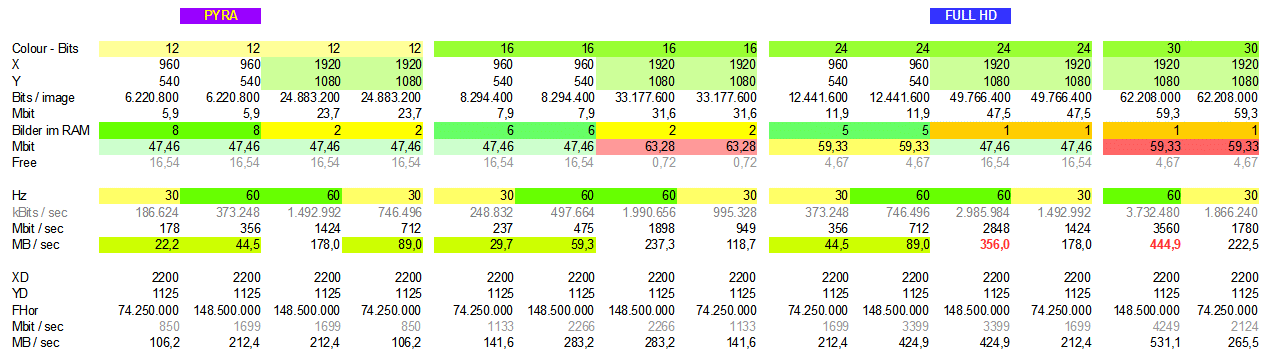
Geht noch etwas mehr??? Ich bin da bwegen meiner Workstation auch
gerade dran und hatte schon probiert full HD auszulesen, um einen echten
frame buffer zu haben, in den man auch offline zeichnen kann. Müssten
netto rund 356MB/s sein - siehe Tabelle.
Für den Audio-Betrieb wird es bei mir aber wohl nur die halbe Auflösung
bei 12 Bit werden, damit ich mehr Bilder reinbekomme. Mein RAM hat nur
64Mbit. Zudem werden es gfs nur 30Hz.
Der RAM-Baustein ist aber prima, für solche Anwendungen, weil er nicht
so arg viele PINs verschluckt.
Werde es demnächst mal wieder anpacken und schauen, ob es geht. Für den
Controller gibt es ein update. Mehr Pins geht nicht, da nicht vorhanden.
Das PCB ist fix designed. Mit einem Baustein.
















{kind=link}