Hallo, ich habe ein paar generelle Fragen/Überlegungen zu einem Speichercontroller. Mir geht es hier um das Anliefern und Abholen der Daten. Ich habe einen Controller geschrieben der 64 Bytes in den RAM schreibt oder daraus liest. Dazu habe ich zwei 512 Bit std_logic_vector verwendet. Und das sind eben sehr viele Leitungen, vor allem für kleine FPGAs. Meine Frage ist jetzt: Wird das draussen in der Industrie auch anders gelöst? Ich könnte mir da zwei Methoden vorstellen: 1. Der Controller hat zwei FIFO Interfaces, eines zum Schreiben und eines zum Lesen. Beim Schreiben läuft das so: Man schreibt von FPGA Seite Werte der Reihe nach in den FIFO. Wenn da dann genug Werte für einen Burst drinnen liegen, dann sagt man dem Controller "start" und eine Adresse an der der Burst beginnen soll und eine Burstlänge, also die Anzahl der zu schreibenden Werte. Der Controller sieht das "start", beginnt den Burst und liest dabei dann aus dem FIFO und schreibt in das RAM. 2. Ein DualPort BRAM zum Übergabe. Will man schreiben, so schreibt man Werte in das BRAM, beginnend bei Adresse 0. Wenn geniug Werte drinnen stehen für einen Burst sagt man dem Controller wieder "start" und eine Adresse an der der Burst beginnen soll und eine Burstlänge. Der Controller liest dann aus dem BRAM beginnend bei Adresse 0 und schreibt das ins RAM. Weil man aber nicht genau weiß wo der Controller gerade ins BRAM schreibt oder daraus liest, kann man zwei BRAMs verwenden um so immer von beiden Seiten schreiben und lesen zu können. Macht das irgendwie Sinn? Gibt es noch weitere Methoden? Oder sind sehr breite Interfaces der Normalfall? Vielen Dank!
Man benutzt sowohl Fifos für Daten und Befehle als daa auch ein schlauer Controller zusammenhängende Speicherbereiche der angeforderten Daten erkennt und als Burst vom RAM liest/schreibt.
Gustl B. schrieb: > Mir geht es hier um das Anliefern und Abholen der Daten. > Ich habe einen Controller geschrieben der 64 Bytes in den RAM schreibt > oder daraus liest. Dazu habe ich zwei 512 Bit std_logic_vector > verwendet. Und das sind eben sehr viele Leitungen, vor allem für kleine > FPGAs. Nein, siehe dazu auch mein Beitrag in Beitrag "Re: HyperBus Ideen" Modernen Speicher haben irrsinnig hohe Bandbreiten. Um die auszunutzen bist du bei entsprechend niedrigen FPGA Taktraten nunmal auf breite Datenbusse angewiesen.
Deinen Beitrag hatte ich schon gelesen. Ich hab das dann auch so gebaut, eben mit breitem Interface. Ja, stimmt, in meinem Fall ist es aber nicht so. Vermutlich ist das mit meinem HyperRAM so ein Spezialfall, denn der ist ja nicht so wirklich schnell, ich könnte also die Daten nacheinander mit einem vergleichsweise schmalen (16 Bit breiten) FIFO anliefern und abholen. Gibt es im Vivado irgendwo eine Ansicht die die Auslastung der Routingverbindungen im FPGA zeigt? Ich hätte da gerne eine Art Heatmap die mir schön anzeigt wo es vom Routing her eng wird. Aber wird es vermutlich nicht geben.
Angehängte Dateien:
-

data_rcv.png
290 KB
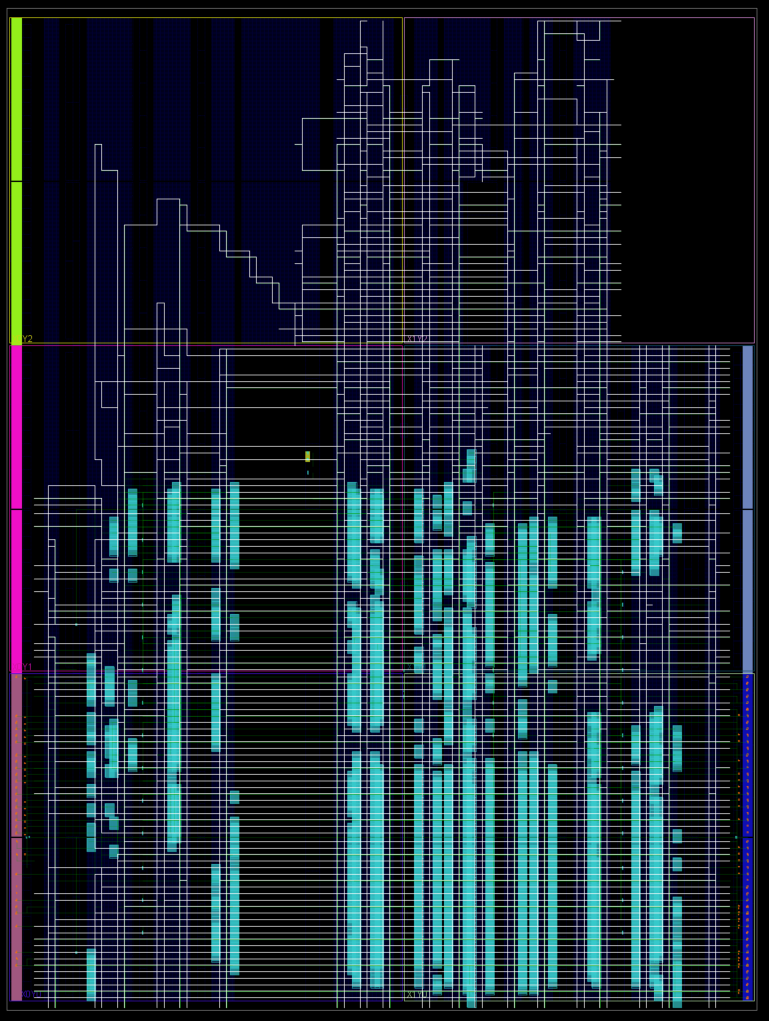
Hier mal ein Bildchen vin den Innereien. Gehighlighted ist eine der 512 Bit Verbindungen/Register. Wie man schön sehen kann werden auch weit abseits von angeschlossener Logik (oben im Bild) Verbindungen geroutet. Ich vermute daher, dass der untere Teil vom Routing her schon (fast) vollständig genutzt wird und kaum noch Verbindungen frei sind. Da wäre in meinem speziellen Fall ein FIFO für das Routing einfacher. Andererseits ... der FPGA hat die Verbindungen sowieso eingebaut, warum sollte man sie dann nicht auch nutzen?
Angehängte Dateien:
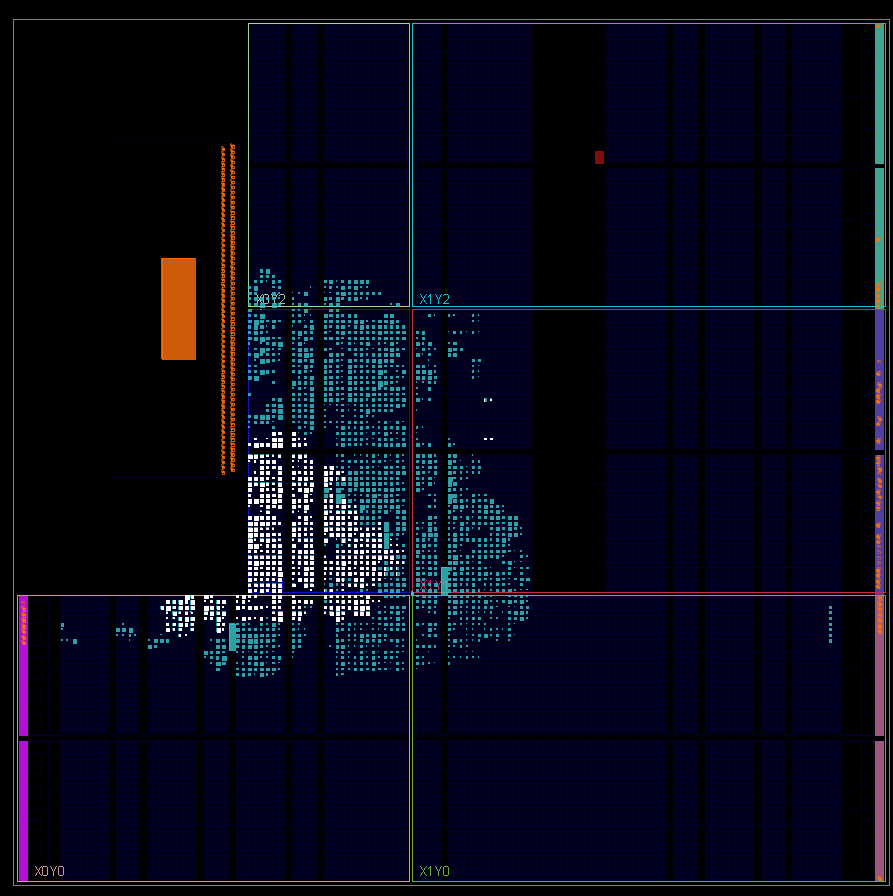
Ich nutze solche Bildchen nur für Vorträge und Poster :-) Relevant sind die genutzten Einheiten (LUT/FF, BRAM, etc.). Bei einem Zynq mit ein paar Devices im FPGA-Teil (PL) geht für den AXI-Interconnect auch ein erschrekend großer Haufen Logic drauf... Solange für alle gewünschten Funktionen genug Platz ist, würde ich mir da keine großen Gedanken machen. Duke
Ich habe da eigentlich nur aus Interesse hingeguckt um mal zu sehen wie die beiden breiten Interfaces aussehen. Duke Scarring schrieb: > Relevant sind die genutzten Einheiten (LUT/FF, BRAM, etc.). Siehe Anhang. Ist eher wenig. Unter anderem deswegen würde mich auch so eine Angabe zu den Routingressourcen interessieren. Es könnte ja vielleicht sein, dass nur wenige FFs/LUTs verwendet werden, das Design aber trotzdem nicht routbar wird. Oder durch eine Änderung von z. B. einem breiten Speicherinterface hin zu einem schmaleren FIFO dann ein deutlich besseres Timing schafft. Duke Scarring schrieb: > geht für den > AXI-Interconnect auch ein erschrekend großer Haufen Logic drauf... Das ist einer der Gründe wieso ich einen uBlaze und AXI nur dann verwende wenn es wirklich nicht anders geht. In diesem Design mit UART/DAC/ADC/RAM/Samplespeicher/SPI komme ich noch ganz gut ohne AXI und CPU aus. Duke Scarring schrieb: > Solange für alle gewünschten Funktionen genug Platz ist, würde ich mir > da keine großen Gedanken machen. So sehe ich das jetzt auch und werde alles lassen wie es ist. Wobei ... bei meiner nächsten Platine werde ich USB3 verwendet. Das ist schneller als mein HyperRAM. ABer so ein HyperRAM braucht ja nur wenige IOs. Ich könnte also mehrere (z. B. 4 Stück) an das FPGA anschließen und da dann parallel schreiben und lesen. Das wären im FPGA dann aber deutlich mehr Leitungen, das könnte Probleme geben. Zum Glück kann man das ja ausprobieren ohne eine Hardware bauen zu müssen.
Quartus gibt im Log an, wieviel % der Routing-Ressourcen verbraucht sind und wo auf dem Chip es am engsten zugeht. Würde mich wundern, wenn Xilinx das nicht auch könnte?
Tatsache, da steht was in einem Report: Router Utilization Summary Global Vertical Routing Utilization = 12.0193 % Global Horizontal Routing Utilization = 7.48959 %
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.