Hallo zusammen, ich arbeite mich gerade in FPGAs ein. Dazu habe ich ein Board gemacht mit einem Xmega und einem Spartan 6 LX9. Das ist rein für mein Hobby und auch nicht meine Abschlussarbeit. Die ist schon länger her. :-) Ich möchte das FPGA als Coprozessor für den Xmega verwenden. Hier sollen Berechnungen in 8,16,32 und 64bit laufen. Jeweils signed und unsigend. Später auch noch float. Je nachdem wie schnell das FPGA voll ist. Angebunden ist das FPGA über den EBI des Xmega. Zusätzlich ist noch ein externes SRAM angebunden. Der Zugriff darauf funktioniert auch. Also die Schaltung und das Board ist ok. Jetzt habe ich angefangen eine ALU zu bauen, die die Berechnungen durchführen soll. Das Problem ist jetzt, dass alle Unterblöcke weg optimiert werden. Ich habe auch schon gesucht und es könnte sein, dass es daran liegt, dass die Daten für die Berechnungen über ein Dual-Port-Ram übergeben werden. Die Signale gehen eben nicht auf einen FPGA Pin direkt. Ich finde aber leider nichts dazu wie man das Problem umgehen kann. Kann mir da bitte jemand von euch auf die Sprünge helfen? Wie macht man das richtig? Vielen Dank! Grüße, Jens
Hab leider kein ISE hier drauf, deswegen kann ich jetzt nicht das Projekt bauen. Prinzipiell wird das wegoptimiert was du eh nicht benutzt hättest. Das kann an nicht angeschlossenen Pins liegen oder aber auch an Bedingungen die nicht eintreten können, z.b. ein Vergleich mit unterschiedlichen Bitbreiten. Oft kann man was in den Reports finden. So auch hier in der Datei xst.xmsg im _xmsg Unterordner: ALU_CTRL.vhd: line 73 "All outputs of instance My_ALU_CONSTANTS are unconnected - Underlying logic will be removed." Das Gleiche gilt für alle andere ALU_SX Blöcke genauso. Der Grund dafür liegt mMn in Zeile 168: internal_ALU_INPUTS(135-i*8 downto 136-i*8-8) <= di_ram after 5ns; Du nimmst hier das 8 Bit di_ram und schreibst es 17 mal in einen breiteren Vektor und zwar als Kopie, nicht etwa zu Unterschiedlichen Zeiten. (Das "after" dort ist eh eine schlechte Idee, weil es in der Logik dort keine Verzögerung gibt solange du das hinterher wieder eintaktest, deine Simulation wird sich damit eventuell anders Verhalten wie die Hardware, die das "after" einfach ignoriert) Dadurch das dort z.b. Bit 0-7 und 128-135 immer den gleichen Inhalt haben, lässt sich warscheinlich jede Menge wegoptimieren. Das ist aber jetzt erstmal nur eine Vermutung, könnte auch woanders liegen. Allgemein ist der komplette "next_state_proc" sehr ungünstig formuliert, weil du dort viel zu viel ungetaktet machst, u.a. Pins für das Dualport ram treiben. Mein Tip für sowas: Simulation. Die Logik ist doch nun wirklich komplex genug um dort Fehler einzubauen, die man nicht aufwändig mit Logikanalyzer oder Scope finden will, d.h. es lohnt sich in jedem Fall. Und um Anderen vorzukommen: verwende nicht STD_LOGIC_UNSIGNED und STD_LOGIC_ARITH und NUMERIC_STD. Wirf einfach die ersten beiden raus, die brauchst du nicht wenn du richtig castest/konvertierst.
Hallo, vielen Dank schonmal. Da scheint noch mehr im Argen zu liegen. Macht es dann wirklich Sinn schon zu schauen, warum das weg optimiert wird, oder sollte ich nicht nochmal über die Architektur nachdenken. Du schreibst ja, dass auch bei dem Zustandsautomat wenig getaktet ist und das zu Problemen führen kann/wird. Das ist genau das was ich eigentlich verstehen und lernen will, wie man so etwas richtig macht. Ich lade heute Abend das Blockschaltbild hoch und schreib ein bisschen mehr, was ich mir dabei gedacht habe. Ich bin auf deine Meinung gespannt. Grüße, Jens
Jens W. schrieb: > Die Signale gehen eben nicht auf einen FPGA Pin direkt. > Ich finde aber leider nichts dazu wie man das Problem umgehen kann. Alle Ausgänge die nicht verwendet werden, werden von der Synthese wegoptimiert. Ein großes AND, OR oder XOR und dann alles auf einen unbenutzten Ausgangspin gegeben hilft hier erstmal weiter. Ich hätte übrigens nicht mit der ALU angefangen, sondern mit der Kommunikation über das EIB-Interface: schreiben und zurücklesen. Duke
Hallo Duke, das habe ich auch so gemacht. Das Schreiben und Lesen über EBI in externe Ram und auf die eine Seite des Dual Port Rams funktioniert. Das habe ich schon getestet. Und da ist das Problem. Ich kann die Werte, die ich übergebe, nicht auf Pins legen. Die Schnittstelle ist ja das RAM. Unter dem Strich wird das ein speichergekoppeltes System werden. Dual Port Rams sind ja auch Standard in Designs. Es muss also einen Weg geben, das auch dem Synthesewerkzeug beizubringen. Da hänge ich halt gerade dran. Wie gesagt, ich lade heute Abend noch ein paar Infos mehr hoch, damit sich jeder ein genaueres Bild machen kann. Sonst macht die Diskussion keinen Sinn. Und vermutlich bleibt mir dann nichts anderes übrig, als wieder ein paar Schritte zurück zu gehen und das System in der Architektur nochmal zu überdenken. Wahrscheinlich habe ich mich da schon verrannt. Aber da freue ich mich drauf. Schließlich will ich das ja verstehen und lernen wie das richtig gemacht wird. Grüße, Jens
Wenn du ins Dual Port Ram schreiben und wieder lesen kannst, dann ist es die andere Seite die keine Funktion hat. Mal ein Beispiel bei dir: In state decode_op wird internal_ALU_RESULT etwas zugewiesen und zwar rein ungetaktet. Einen Takt später benutzt du es aber bei execute_op um do_ram zu füllen. Weil internal_ALU_RESULT nie getaktet wird baut er daraus im "besten" Fall ein Latch, kann aber auch sein das es ganz wegoptimiert wird. In diesem State gibt es einfach keinen Treiber für das Signal. Versuche mal als erstes jede nichttriviale Zuweisung getaktet zu machen und nur jede triviale Zuweisung ungetaktet, dann aber auch stetig. In dem Beispiel würden bei mir alle Zuweisungen zu internal_ALU_RESULT getaktet stattfinden. Die Zuweisung zu do_ram wiederrum wäre gar nicht in dem process sondern als dauerhafte Zuweisung die immer aktiv ist zu finden. Lediglich das we_ram wäre wiederrum getaktet.
Jens W. schrieb: > Das Schreiben und Lesen über EBI in > externe Ram und auf die eine Seite des Dual Port Rams funktioniert. Das > habe ich schon getestet. wie genau hast du das getestet? Eine Adresse geschrieben und dann zurueck gelesen? Oder das ganze RAM geschrieben und dann das ganze RAM wieder zurueck gelesen? Ich frage fuer einen Freund... Spaessle. Wie ist denn dein EBI Timing eingestellt beim lesen? Passt das, wenn du ein BRAM verwendest? Hast du das mal simuliert? So mit realistischen Timings?
Angehängte Dateien:
-

Top_Entity.JPG
240 KB
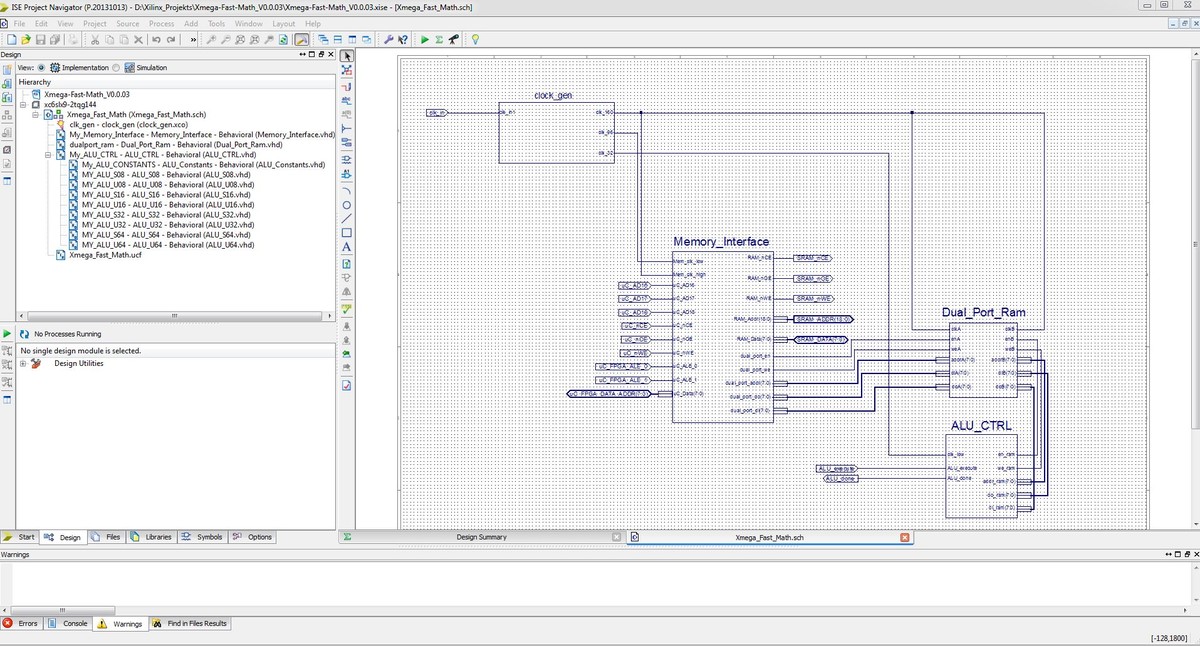
@Berndl: Ich habe eine RAM Test Funktion, die das gesamte externe RAM (SRAM) mit Daten füllt. Und zwar rechne ich mit den Laufvariablen, den aktuellen Ergebnissen und so weiter eine CRC Prüfsumme und schreibe diese. Das gibt ganz gut "zufällige" Werte. Ich schreibe das gesamte RAM voll und dann lese ich zurück und berechne nochmal die gleichen Werte, die ich beim Schreiben schon gerechnet habe. Diese vergleiche ich. Wenn die gleich sind, dann ist das RAM richtig geschrieben und gelesen. Zusätzlich habe ich die Möglichkeit über den JTAG Debugger mir die Werte anzuschauen, die ich Schreibe und Lese. Das ist also im echten System getestet. Mit dem EBI Timing hat das nichts zu tun. Das hat mich auch schon Nerven gekostet. Aber das habe ich hin bekommen. ;-) Ich habe mal ein Screenshot von der Top Entity angehängt. Auf der linken Seite sieht man wie die einzelnen Module zusammen gehören. Im Schematic wird klar, wie ich mir das gedacht habe. Memory Interface ist der Block, der das Timing für den EBI inne hat. Daran ist die Schnittstelle zum externen RAM dran (das geht direkt auf die Pins des FPGA über Adresse, Daten, CE, OE und WE). Wenn man nun in die ersten 256 Byte der Speichermap schreibt gelangen die Daten nicht ins externe RAM, sondern ins Dual Port RAM. Und das ist auch die einzige Schnittstelle für ALU_CTRL. Hier sollen die Berechnungen laufen und das Ergebnis wieder über das Dual Port Ram ausgetauscht werden. Ich hoffe so wird klar, wie ich mir das gedacht hatte. @FPGAzumSpass: Wenn ich die Zuweisung der Signale getaktet machen soll, das verstehe ich. Aber wenn ich versuche das in den Zustandsautomaten zu integrieren wird es wohl doch sehr unübersichtlich. Wie trennt man das denn sinnvoll auf? Gibt es da was ähnliches wo ich mir das vorher mal anschauen kann wie das aussehen muss? Hast du da eine Quelle? Vielen Dank euch schonmal! Grüße, Jens
Ob das übersichtlicher ist oder nicht, da scheiden sich wohl die Geister. Ich persönlich bevorzuge die 1-Prozess schreibweise, manche benutzen aber sogar die 3-Prozess Schreibweise. Hier mal eine sehr gute Erklärung von Lothar: http://www.lothar-miller.de/s9y/archives/43-Ein-oder-Zwei-Prozess-Schreibweise-fuer-FSM.html Habe mal dein Modul umgeschrieben und angehangen. Ohne Anspruch auf Korrektheit, aber sollte zumindest zeigen wie ich mir das vorstellen würde. Habe mir erlaubt die Abfolge der Signale in der FSM umzustellen, so wie ich glaube das es richtig(er) ist und eine Anmerkungen an die Steps geschrieben, die aktuell nicht funktionieren können. Überleg dir unbedingt wie dein DualPort Ram Zugriff aussehen soll. An deiner Stelle würde ich den Zugriff auch nicht mit 8 Bit machen, weil das sehr lange dauern wird. Wenn du genug Blockrams hast bietet sich ein 136 Bit Zugriff an. Das braucht dann zwar 4 Blockrams, gibt dir aber einen Request mit einem Zugriff statt mit 17! Blockrams können beide Seiten mit unterschiedlicher Bitbreite behandeln und auch ein Byteenable ist möglich. Wenn das übrigens so aussieht wie ich es im Moment vermute, nämlich das du immer nur die gleichen 136 Bit benutzen willst, dann würde ich überhaupt kein Blockram dafür verwenden, sondern gleich 136 Flipflops, also ein getaktetes Signal. Das macht es nicht nur viel einfacher, sondern auch schneller und braucht weniger Ressourcen!
Hallo, vielen Dank für die Infos soweit. Das schaue ich mir an. Die Seite von Lothar hilft mir sehr denke ich. Auch den Zugriff über das RAM werden ich anders gestalten. Die Implementierung für das Dual Port Ram ist aus dem XST User Guide. Da ist kann ich die Seite B ohne Problem mit einem breiten Vector machen. Ich werde zuerst versuchen hier die Daten richtig austauschen zu können und dann weiter in die einzelnen ALU Blöcke gehen. Ich halte euch auf dem Laufenden. Aber ich werde sicher ein paar Tage brauchen. Grüße, Jens
Hallo, ich gebe euch ein kurzes Update. Die Tipps haben mir schon sehr weiter geholfen! Vielen Dank! Ich habe nun erstmal alle Unterblöcke raus genommen und konzentriere mich auf den Zustandsautomat und den Datenaustausch. Ich rechne im ersten Schritt nur Operant_A + Operant_B. Beim synthetisieren sieht man auch, dass jetzt deutlich Ressourcen verbraucht werden. Da tut sich also was. Ich mach am Wochenende eine Testbench dazu und kontrolliere die Ergebnisse. Erst wenn das richtig tut, gehe ich einen Schritt tiefer in die einzelnen Blöcke. Vermutlich komme ich da auch mit weniger aus. Das sieht zumindest für mich danach aus. Aber das wird sich zeigen. Eine Frage habe ich nun jetzt schon. Ich will eine Multiplikation machen. Da kann man einfach a * b schreiben und da kommt auch irgendwas raus, aber sollte man das auch so machen? Bei der Division habe ich schon gesehen, dass es besser ist, dass richtig zu machen so wie von der Seite von Lothar Miller. Aber wie sieht es bei der Multiplikation aus? Sollte man das auch "zu Fuß" machen? Grüße, Jens
Multiplikation kannst du ruhig mit * machen. Wenn die Operation das Timing nicht schafft, dann musst du eventuell einen Multicycle Path daraus machen. Immer noch besser als die Multiplikation per Code in mehrere Cycles zu zerteilen. Die Frage die du dir eher stellen musst, ist was du mit den Ergebnisbits machst. Bsp: 32bit * 32Bit sind 64Bit. Möglichkeiten das Umzusetzen sind: - volle 64 Bit als Ergebnis -> muss deine Architektur hergeben - 2*32 Bit als Ergebnis -> 2 verschiedene Opcodes für High und Low - nur die unteren 32 Bit als Ergebnis, eventuell mit Überlaufcheck Bisher hattest du die dritte Variante ohne Überlaufcheck.
So ein kleines Update von mir: Ich habe das Design überarbeitet. Das läuft auch soweit. Die einzelnen ALU-Blöcke für die verschiedenen Rechenoperationen funktionieren für sich. Ich verwende aber den Core Generator. Ich erhoffe mir dadurch, dass die Blöcke effizienter sind als meine, da die Entwickler von Xilinx das sicher besser drauf haben als ich. Ergänzt habe ich auch Float, sin, cos und so weiter. Das FPGA ist damit auch gut zur Hälfte gefüllt und das Mapping dauert jetzt schon eine Stunde. Der einzige Core der Probleme macht ist der integer Dividierer. Hier verwende ich den div_gen_3.0 aus dem IP Catalogue. Den kann ich nicht über my_xxx: entity work.xxx instanziieren. Da muss ich vorher die componente mit definieren. Im Verzeichnisbaum erscheint der Core richtig, aber ich kann dafür keine Test bench erstellen. Da bleibt im File ein "?". Ich habe keine Ahnung woran das liegt. Es scheint aber Cores zu geben, die buggy sind. Diese Baustelle bleibt erstmal. Was mir jetzt Probleme bereitet ist die Testbench für die ALU. Nachdem ich die Daten über ein Dual Port Ram übergebe, habe ich keine Ahnung, wie ich die Daten aus dem RAM für die Simulation übergeben kann. Am Port habe ich ja nur Adresse, Data_in und Data_out. Da wird zyklisch gelesen. Einfach einen Wert an Data_in anlegen geht zwar, aber ich bekomme keine Infos was intern läuft. Es werden in der Simulation nur die Signale aus der Port map angezeigt. Wie komme ich an die internen Signale ran? Wie macht man das richtig? Da finde ich auch nichts im Netz. Kann mir jemand von euch da auf die Sprünge helfen? Grüße, Jens
Angehängte Dateien:
-

modelsim.png
43 KB
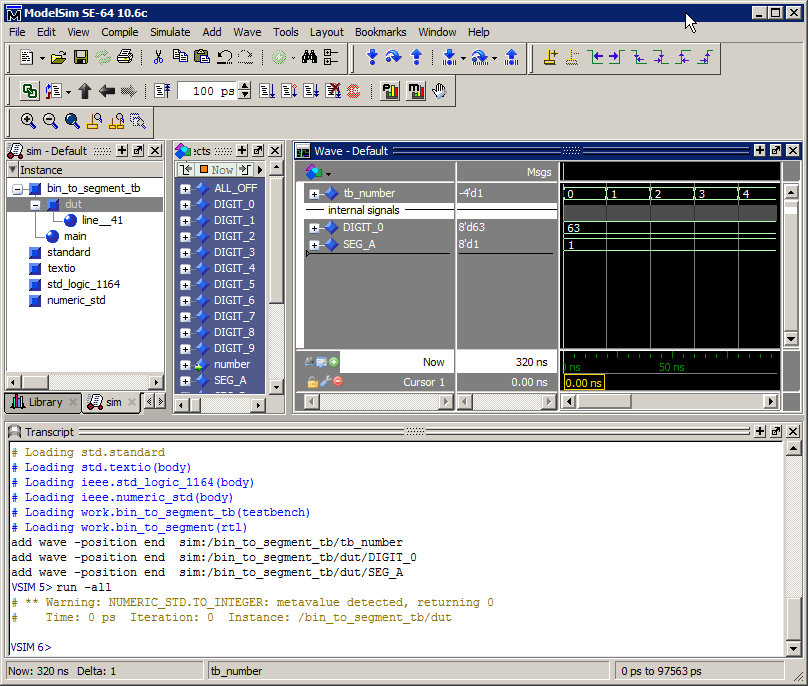
Jens W. schrieb: > Ich verwende aber den Core Generator. Ich erhoffe mir dadurch, dass die > Blöcke effizienter sind als meine, da die Entwickler von Xilinx das > sicher besser drauf haben als ich. Naja. Meine Erfahrung sind da etwas anders. Zum Einen sind einige Cores recht flexibel in der Parametrierung und benötigen dann auch im FPGA etwas mehr Fläche. Zum Anderen, warum sollte Xilinx die Cores optimieren, wenn man doch so ggf. ein größeres FPGA (mit mehr Marge) verkaufen kann. Was mich aber regelmäßig stört, ist das Xilinx die Interfaces von Version zu Version ändert und das sie auf Xilinx limitiert sind. Jens W. schrieb: > Es werden in der Simulation nur > die Signale aus der Port map angezeigt. Welchen Simulator verwendest Du? > Wie komme ich an die internen > Signale ran? > Wie macht man das richtig? Da finde ich auch nichts im Netz. > Kann mir jemand von euch da auf die Sprünge helfen? Üblicherweise kann man sich die im Simulator einfach reinziehen. Siehe Anhang. Duke
Hallo Duke, mit der Fläche habe ich leider noch keine Erfahrung. Das glaube ich dir einfach mal. Das mit den Interfaces habe ich auch schon gemerkt. Nachdem der IP Core div_gen V3 Probleme macht, habe ich gedacht, ach, dann nimm den neueren Core, da wird das dann sicher besser sein. Von wegen! Das Interface ist anders und ich müsste alle anderen Cores drauf anpassen, damit es in der gesamten Struktur wieder passt. Der Plan ist nun, dass wenn überhaupt mal was geht und die Anwendung mit dem Controller erstmal funktioniert, dass man dann schaut was man optimieren kann. Und wie. Ich will ja eigentlich in erster Linie die Architektur von meiner Elektronik anschauen und lernen, wie das geht. Das Problem mit dem div_gen IP Core werde ich wohl so lösen, dass ich den komplett raus schmeiße und die Division von Lothars Seite verwende. Die muss ich nur so erweitern, dass sie auch mit signed Variablen umgehen kann. Ich will das so machen, dass man sich das Vorzeichen merkt, dann die Werte in unsigned wandle, die Division durchführe und dann, je nach Vorzeichen, das Ergebnis wieder nach unsigned wandeln und ausgeben. Ich verwende ISIM. Das mit den Signalen habe ich gefunden. Funktioniert. Da kann ich sehen, was ich gesucht habe. Eine Frage habe ich noch (und ich werde es auch gleich ausprobieren): Ich übergebe Daten über ein Dual Port Ram. In der Simulation wäre es gut, wenn das Ram schon mit den Daten gefüllt wäre, die im richtigen Betrieb der Mikrocontroller an das FPGA übergibt. Kann ich für die Simulation einfach ein RAM in der Test Bench instanziieren und hier die Werte, mit denen ich arbeiten will, als Default Wert reinschreiben? Die Idee kam mir heute morgen. Macht man das so, oder gibt es da einen eleganteren Weg? Weil direkt über den Port geht nicht. Da gibt es kein Signal mit dem ich neue Daten lese. Daher kann ich darüber die Werte auch nicht zur richtigen Zeit übergeben. Vielen Dank dir! Bleibt gesund! Grüße, Jens
Jens W. schrieb: > Ich will das so machen, dass man sich das Vorzeichen > merkt, dann die Werte in unsigned wandle, die Division durchführe und > dann, je nach Vorzeichen, das Ergebnis wieder nach unsigned wandeln und > ausgeben. Genau so habe ich das auch schon gemacht. > Ich übergebe Daten über ein Dual Port Ram. In der Simulation wäre es > gut, wenn das Ram schon mit den Daten gefüllt wäre, die im richtigen > Betrieb der Mikrocontroller an das FPGA übergibt. Ja, der RAM kann schon mit initialen Werten gefüllt sein. Bei FPGA (im Gegensatz zu ASIC) klappt das zum Großteil sogar für die Synthese, da beim Startup auch die (Block)RAM-Zellen mit initialisiert werden. Beispiele wie man das in VHDL hinschreibt finden sich im XST user guide U627 bzw. UG687. Duke
wenn dein FPGA-RAM vom µC aus befüllt wird, wäre es m.E. sinnvoll, das auch in der Testbench entsprechend nachzuvollziehen (dabei kann auch einiges schief gehen)?
Hallo Duke: Danke für die Dokumente. Die schau ich mir an. @Markus: Das stimmt. Habe ich auch schon gemacht. Das ist sogar schon auf der HW getestet. An der Stelle hängt es jetzt. Das RAM wird befüllt und das FPGA muss mit den Daten was machen. Jetzt will ich den Teil simulieren, was als Rechenoperation ausgeführt werden soll (mit einem simulierten RAM in der Test Bench) und danach versuche ich das gesamte Design auf der HW zum Laufen zu kriegen. Das dauert leider alles etwas, da ich das ja nur nebenbei mache. Und ich arbeite mich auch erst in die Materie ein. Ich habe schon gemerkt, dass das deutlich länger dauert, als wenn ich für einen Controller in C einfach eine Funktion hin stelle und das laufen lasse (zumindest ist das bei mir so). Danke euch allen! Grüße, Jens
Jens W. schrieb: > Ich habe schon gemerkt, dass das deutlich länger dauert, als wenn ich > für einen Controller in C einfach eine Funktion hin stelle und das > laufen lasse (zumindest ist das bei mir so). Das ist so (und wird sich auch nur unwesentlich ändern). Ist halt ein Unterschied, ob man Hardware macht oder nur fertige Hardware nutzt.
Ich würds so machen: - Controller Code, sofern tatsächlich nur C, direkt für den PC übersetzen. - Per Define die Schreibroutine zum FPGA ersetzen durch Schreiben in eine Datei - In der Testbench die Datei parsen auf neue Requests und dann mit dem normalen Protokoll über die Pins ins FPGA geben - Berechnen lassen und auf normalem Weg über Pins in die Testbench zurück - Ergebnis in eine andere Datei schreiben - im C Programm diese Datei parsen und normal den Controller Code weiter ausführen Wenn das Controller Programm auf dem PC nicht oder nur mit immensem Aufwand lauffähig ist, dann das gleiche Konzept benutzen, aber die Dateien mit einem Script füllen/prüfen. Eine statische Testbench zu benutzen geht auch, aber spätestens wenn man die 5 mal geändert hat, weil man das Nächste probieren will oder die Testbench immer komplizierter wird, hat sich der Aufwand locker gelohnt. Mal ganz davon abgesehen, das sich so ein File-IO Interface für das nächste Projekt recyclen lässt.
Hallo, das klingt ein bisschen kompliziert. Also zumindest für mich. Ich komme aus der HW Ecke. Skripte schreiben und in Files die Ergebnisse und so weiter. Das klingt gut. Aber das tu ich mir im Moment noch nicht an. Da versenke ich zu viel Zeit. Da sind meine Lücken zu groß. @Duke: Zurück zum Dividieren. Du hast geschrieben du hast das schon gemacht. Gibt es da einen Trick sich das Vorzeichen zu merken? Damit man nicht zu viel Zeit verliert. Ich hätte da den Zustandsautomat erweitert um einen oder zwei Zustände. Kann man da einen Trick anwenden und sich das erweitern des Zustandsautomaten sparen? Zur Simulation: Da komme ich weiter! Lasst mich euch an dieser Stelle danken! Ich bin so begeistert! Ich habe heute früh die ersten Durchläufe laufen lassen. Ein paar Fehler waren tatsächlich drin. Klar, hätte mich gewundert wenn nicht. ;-) Addition, Subtraktion und Multiplikation funktionieren. Dividieren noch nicht. Aber das ist sicher der Punkt, den ich schon geschrieben hatte, dass der IP Core irgendwie Probleme macht. Und da will ich den Code von Lothar verwenden. Float, Sinus und Cosinus fehlen noch. Ich mache erst die Integer Operationen fertig. Aber es geht gut voran! Grüße, Jens
Hallo zusammen, kleines Update von mir. Es funktioniert! Ich habe heute auf der finalen Hardware getestet und es funktioniert. Zumindest der Teil, den ich getestet habe. Es sind noch nicht alle Rechenoperationen für den Mikrocontroller implementiert. Aber das wird schon. Ich bin so begeistert! Danke an euch alle! Grüße und bleibt gesund, Jens
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.