tutuTUTU schrieb:> Hat die Funktion von euch hier mal einer benutzt und kann sagen, ob das> wie erwartet funktioniert?
Was erwartest Du denn. Der Code sieht gut aus, hat witzige Konstrukte um
Zeichen zu sparen (warum auch immer) und hat die Tests mit an Bord.
Den Umfang (resp. die Einschränkungen) kannst Du schnell im Code sehen.
Hallo,
ich buddle den Beitrag nochmal aus, weil ich bei meinem ATmega8 Projekt
so langsam über die 90% .text Grenze kam, da ich die standard printf()
Funktion verwendete.
Ich habe die Sourcen von Snafu verwendet und 3 bugs korrigiert.
Jetzt funktionieren sie einwandfrei und es ist wieder genügend Platz im
.text Segment.
Grüße Manni
tutuTUTU schrieb:> Oder gibt es Korrekturen/Hinweise dazu?tutuTUTU schrieb:> Oder gibt es Korrekturen/Hinweise dazu?
Nö, nur nachträglich eine eher generelle Frage:
Wozu eigentlich?
Beim PC mit gigabytegroßem RAM ist sowas heutzutage eher nebensächlich,
aber wenn man Ausgaben in der Firmware für einen kleinen µC plant und
knapp bei Speicherplatz ist, wozu dann so einen Umweg über einen
Formatstring? Im Grunde weiß man ja bereits bei der Planung der
Firmware, was man auszugeben beabsichtigt. Also wäre es wesentlich
folgerichtiger, wenn man dann die Ausgabe-Konvertierungen direkt
aufruft. Ohne die Rudimente des bei printf üblichen Text-Parsers, die
hier nur unnütz Speicher und Rechenzeit kosten.
W.S.
W.S. schrieb:> Also wäre es wesentlich> folgerichtiger, wenn man dann die Ausgabe-Konvertierungen direkt> aufruft.
Vom Prinzip her stimme ich Dir zu.
Aber ich brauche es nur zum Debuggen im Terminal Window vom Atmel Studio
7.
Für diese Zwecke ist so ein Tool ein echter Segenbringer !
Manni
Manfred L. schrieb:> Aber ich brauche es nur zum Debuggen im Terminal Window vom Atmel Studio> Für diese Zwecke ist so ein Tool ein echter Segenbringer !
Wie genau meinst/machst du das?
Nutzt du das mit dem Simulator zusammen?
Gib mal bitte Hinweise wie as geht oder was dazu benötigt wird.
Prinzipiell ist es bekannt, aber wie geht das in AS7.
W.S. schrieb:> Wozu eigentlich?
Gute Frage, ich mache so etwas i.A. mit itoa und seinen Verwandten. Bei
einem 8-Bitter war mir printf schon immer etwas overkill.
Andreas B. schrieb:> W.S. schrieb:>> Wozu eigentlich?>> Gute Frage, ich mache so etwas i.A. mit itoa und seinen Verwandten. Bei> einem 8-Bitter war mir printf schon immer etwas overkill.
Nunja, scheinbar ist das auch bei 32Bittern mit 133MHz noch ein Problem.
Siehe RaspiPico-SDK und den dort fehlenden (adäquaten) Support für
double...
littleBoy schrieb:> Gib mal bitte Hinweise wie das geht oder was dazu benötigt wird.
Ganz einfach:
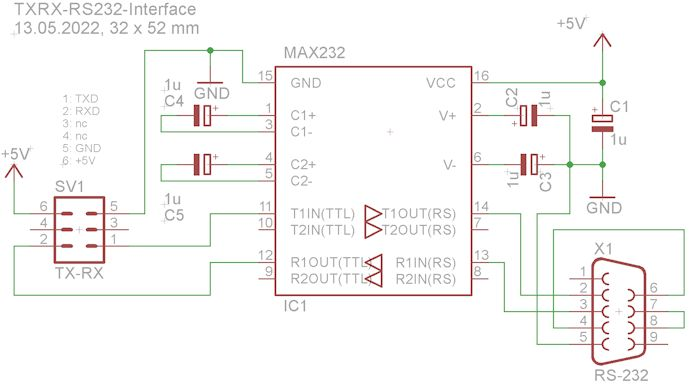
- man nehme einen MAX232, siehe Bild und schließe den TX Ausgang vom
uController an Pin 1 von SV1 an
- man nehme ein USB/RS232 Converter und verbinde ihn mit dem D-SUB-9
Stecker und einem freien USB Eingang am Laptop/PC
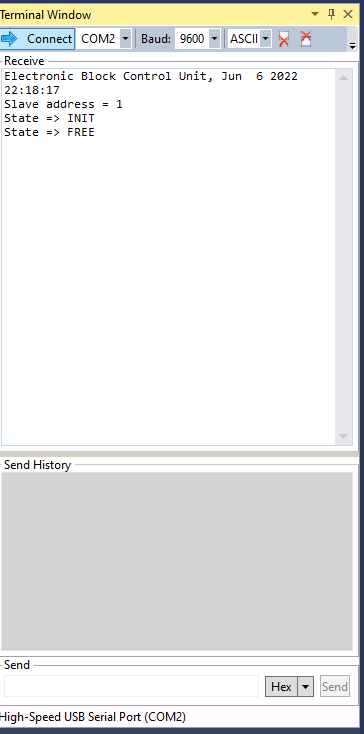
- man öffne im Atmel Studio 7 das Terminal-Window (ggf. noch als Tool
nachladen), siehe Bild, wähle das COM Port und die Datenrate aus, bei
mir sind 9600 Baud in der Firmware fest definiert
Wenn meine neu zu entwickelnde Firmware dann nicht macht, was ich will,
ist der Fehler mit ein paar printf() Anweisungen im Nu gefunden.
Manni
c-hater schrieb:> Nunja, scheinbar ist das auch bei 32Bittern mit 133MHz noch ein Problem.
Es ist generell ein Problem.
Es ist ja nicht nur der Formatstring, der zunächst gespeichert werden
muß, es ist auch der Umstand, daß selbiger auch noch zur Laufzeit
interpretiert werden muß.
Obendrein ist es ein Problem, daß man für printf auch noch mit einer
variablen Anzahl von Argumenten hantieren muß und diese obendrein auch
noch von unterschiedlichem Datentyp sind. Sowas bringt Komplikationen
bei der Gestaltung der tatsächlichen Aufruf-Schnittstelle mit sich.
Ein Beispiel: Beim ARM werden standardmäßig die ersten Argumente in
Registern übergeben und nicht auf dem Stack. So hatten es K&R nicht
vorgesehen.
Kurzum: Sowas wie printf verlagert Übersetzungsarbeit vom
Übersetzungszeitpunkt in die Laufzeit, benötigt dazu auch noch
Speicherplatz und bringt Schwierigkeiten bei der binären Gestaltung von
Funktionsaufrufen mit sich, die es den Compilerbauern schwerer macht,
als es sachlich nötig gewesen wäre.
Das Einzige, was all diesen Kritikpunkten gegenübersteht, ist die
Möglichkeit, einen Formatstring zur Laufzeit zu generieren. Aber die
Notwendigkeit für so etwas ist mir bislang nicht untergekommen.
W.S.
schön das es mittlerwiele viele viele µC gibt die so ein bisschen parsen
nicht juckt und auch genug Speicher haben.
Wenn man nicht alles in zig Zeilen zusammenstückeln muss ist das ein
Gewinn an Komfort und Übersichtlichtkeit. Es ermöglicht nette debug und
trace Makros sowie ordentlich formattierte Tabellen. Alleine die
Fummelei mit dem Alignment und fixen Nachkommastellen soll zu Fuss
machen wer will. Oder sich tot optimieren und ewig Fehler suchen wenn
das Programm einen Tick verändert wird.
W.S. schrieb:> und bringt Schwierigkeiten bei der binären Gestaltung von> Funktionsaufrufen mit sich, die es den Compilerbauern schwerer macht,> als es sachlich nötig gewesen wäre.
Da die Compilerbauer aber nicht gerade erst mit ihrer Arbeit angefangen
haben, und va_arg in praktisch jedem existierenden Compiler genau das
tut, was es soll, nämlich funktionieren, sind Deine Betrachtungen
reichlich sinnlos.
Lieber einmal den Code für ein printf in sein System reinhängen und dann
einfache printf-Aufrufe nutzen als für jede Ausgabe mühsam aus den von
Dir bevorzugten Einzelfunktionen etwas zusammenzustoppeln.
Manfred L. schrieb:> Wenn meine neu zu entwickelnde Firmware dann nicht macht, was ich will,> ist der Fehler mit ein paar printf() Anweisungen im Nu gefunden.
Naja, wenn man nur zeitunkritische Sachen hat. ;-)
Mit pinwackeln und Logikanalyzer kommt man erheblich weiter.
DerEinzigeBernd schrieb:> Lieber einmal den Code für ein printf in sein System reinhängen und dann> einfache printf-Aufrufe nutzen als für jede Ausgabe mühsam aus den von> Dir bevorzugten Einzelfunktionen etwas zusammenzustoppeln.
Das zeigt eigentlich, daß man <10% der uC Leistung wirklich benötigt
(wenn sich diese Aussage auf einen 8-Bitter bezieht).
Eine ganze Latte individueller Ausgabefunktionen aufzurufen ist
gegenüber einem Aufruf einer geeigneten printf-Implementierung kein
großer Performancegewinn. Hier tun manche so, als wäre printf der
schlimmste aller möglichen Performancefresser.
Sofern die primäre Funktion eines µC nicht darin besteht, ständig printf
aufzurufen, ist es ziemlich scheißegal, wie viel Performance das
"frisst".
Und wenn printf (oder die Wunderausgabefunktionen) an mehr als ein, zwei
Stellen im Programm aufgerufen wird, dann ist auch der ach so riesige
Codeverbrauch einfach kein Thema.
Klar, wenn man auf einem Tiny13 einen Wert ausgeben will, dann ist
printf nicht das Mittel der Wahl. Aber sonst?
Andreas B. schrieb:> Das zeigt eigentlich, daß man <10% der uC Leistung wirklich benötigt
Bekommt man Geld für ungenutzte Leistung zurück? Die wenigsten, vom
einen oder anderen Assemblerfreund vielleicht mal abgesehen, optimieren
ihre Anwendungen auf den langsamsten und mit am wenigsten Speicher
ausgestatteten µC.
DerEinzigeBernd schrieb:> Bekommt man Geld für ungenutzte Leistung zurück?
Nein, aber braucht man auch keinen Raspi, um mal eine LED blinken zu
lassen (jetzt nur leicht uebertrieben, aber so aehnlich sehe ich das
oefter).
> Die wenigsten, vom> einen oder anderen Assemblerfreund vielleicht mal abgesehen, optimieren> ihre Anwendungen auf den langsamsten und mit am wenigsten Speicher> ausgestatteten µC.
Das nicht gerade, aber ich suche schon den Controller nach der
benoetigten Aufgabe aus.
Du wirst aber eingestehen können, daß der da oben gepostete Code
wirklich kein Brot frisst und mal von so Winzlingen wie einem Tiny13 auf
sehr vielen µCs problemlos unterkommen kann.
Und auch ein vollwertigeres printf (mit Formatierung, aber ohne float)
ist nicht so gigantisch, daß das statt eines Mega328 einen Raspberry Pi
erforderlich macht.
DerEinzigeBernd schrieb:> vollwertigeres printf (mit Formatierung, aber ohne float)
Das gehört für mich zu den großen Rätseln: Warum printf() unbedingt auf
double geht. Ich kann mir keinen Anwendungsfall vorstellen, wo die
Stellen von float nicht ausreichen. Und wenn ist es auch kein Hexenwerk,
die Stellen manuell darzustellen.
Walter Tarpan schrieb:> Das gehört für mich zu den großen Rätseln: Warum printf() unbedingt auf> double geht.
Tut es ja nicht unbedingt. Z.B. eben beim Pico-SDK nicht. Da ist im
Gegenteil float der Standard, und, mehr noch: auch wenn tatsächlich
double benötigt wird, ist das nicht leicht änderbar.
> Ich kann mir keinen Anwendungsfall vorstellen, wo die> Stellen von float nicht ausreichen.
Nun ja, genau solche Leute wie du haben wohl das Pico-SDK verbrochen...
Ich wünschte, es gäbe mehr Intelligenz. Und vor allem ein schöneres,
richtig durchdachtes API. Denn wenn nicht der Schwachsinn des
Grundkonzepts von printf mit dem "Aufblasen" wäre, dann wären es solche
zwangskastrierten Krüppel-Implementierungen auch überhaupt nicht nötig.
Der ursächliche Fehler liegt also im Grundkonzept. Wie so oft bei C.
c-hater schrieb:> Denn wenn nicht der Schwachsinn des> Grundkonzepts von printf mit dem "Aufblasen" wäre, dann wären es solche> zwangskastrierten Krüppel-Implementierungen auch überhaupt nicht nötig.
Geh mal nicht so harsch mit C um, schließlich lag dieser Sprache
eigentlich überhaupt kein Grundkonzept zugrunde, wenn man mal davon
absieht, aus sowas wie BCPL etwas benutzbares zu machen, und das unter
der Beschränkung der damaligen Rechentechnik. Eben deshalb gibt es
seitdem auch das Prinzip des Preprozessors, eben um die Übersetzung
eines Programmes aufzuteilen. Daß da sowas wie lesbare Ausgaben bei der
Kompilierung nicht berücksichtigt wurden und deshalb vom Programm selber
zur Laufzeit erledigt werden müssen, ist nur ein Teil der Misere. In
Pascal hat man mit 'write' das komplette Gegenteil. Da wird der ganze
Schmonzes zur Übersetzungszeit zerlegt und dann nur die tatsächliche
Ausführung in den erzeugten Maschinencode gepackt. Eben deshalb braucht
da kein Programm variable Argumentanzahlen usw. An sowas sieht man eben
den Unterschied zwischen einer überlegt konzipierten Programmiersprache
und C.
Aber das sind eben allgemeine Überlegungen.
Das was unsereiner bei dem hier vorgestellten Projekt sieht, ist eine
Art Halbherzigkeit: Platz sparen - ja, aber konsequent - nein.
Und die Frage ist wozu ? da das gesamte Anliegen ja die Ausgabe bei
kleinen Plattformen mit ganz wenig Ressourcen ist. Entweder ist das
printf als solches dem Autor derart wichtig, daß er es nicht über's Herz
bringt, es dem Projektziel zu opfern oder er kann sich einfach nichts
anderes vorstellen.
W.S.
W.S. schrieb:> Das was unsereiner bei dem hier vorgestellten Projekt sieht, ist eine> Art Halbherzigkeit: Platz sparen - ja, aber konsequent - nein.
Lieber W.S. (Gast),
da ich mein Projekt bisher halbherzig und nicht konsequent angehe, habe
ich mein Projekt hier mal als Zip-Datei angehängt.
Ich bitte Dich deshalb ganz herzlich, mir ein paar Vorschläge zu
unterbreiten, wie ich dieses Projekt konsequenter testen kann als mit
den "verhaßten" printf() Anweisungen, denn für neue Ideen habe ich immer
ein offenes Ohr.
Zur Info: Ich habe kein firmenmäßgig ausgerüstetes Elektronik-Meßlabor,
sondern ich bin nur Bastler mit einem Lötkolben, einem Diamex Programmer
und einem PC.
Beste Grüße
Manni
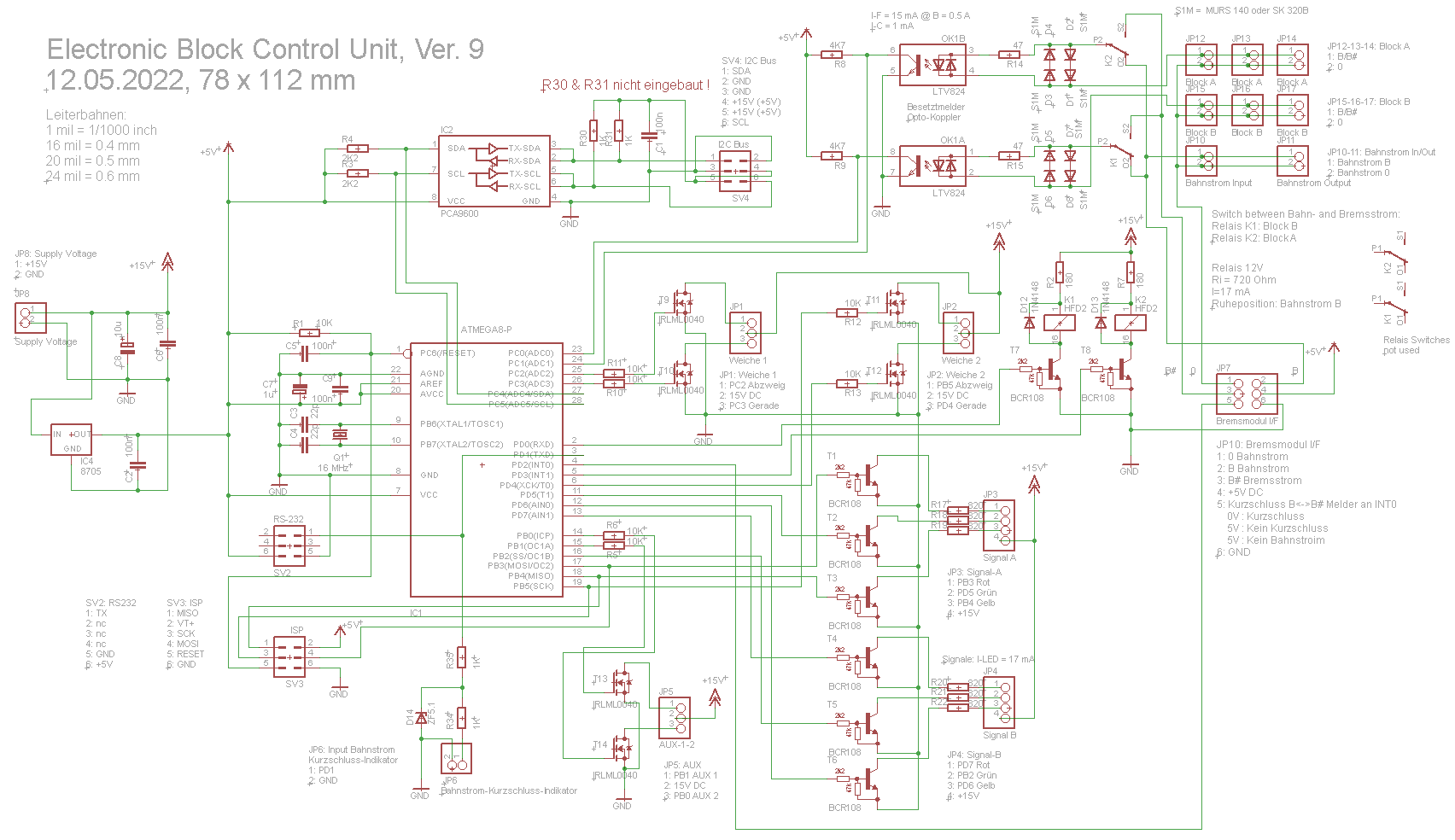
Manfred L. schrieb:> ElectronicBlockControlUnit-Schematics.png
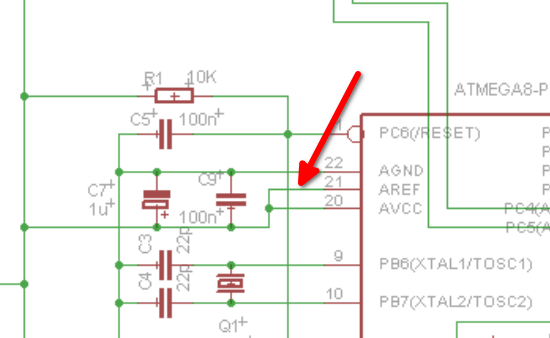
Offtopic, aber da ist ein potentieller Kurzschluss. Nicht tragisch.
Aref offen lassen, wenn der ADC nicht verwendet wird.
Kondensator Aref -> GND, wenn er verwendet wird.
Wenn Aref=VCC gelten soll, kann man das per Software auswählen.
Ich würde da immer den Kondensator an Aref mit einplanen, und ggfs.
unbestückt lassen.
Εrnst B. schrieb:> aber da ist ein potentieller Kurzschluss. Nicht tragisch.
Oh Mann,
Du hast ja so recht ! Denn in Atmel Doku in Kapitel:
"Bit 7:6 – REFS1:0: Reference Selection Bits" steht ja mehr als
eindeutig:
"The internal voltage reference options may not be used if an external
reference voltage is being applied to the AREF pin."
Diesen Satz habe ich bisher einfach überlesen, weil ich die interne Vref
noch nicht verwendet hatte. Ich danke Dir jedefalls für diesen wichtigen
Hinweis !
Grüße Manni
Manfred L. schrieb:> wie ich dieses Projekt konsequenter testen kann als mit> den "verhaßten" printf() Anweisungen
Bin zwar nicht WS, aber such Dir was aus:
1
voidPrintc(charc){
2
inttemp_Statusreg;
3
temp_Statusreg=SREG;
4
while(!(UCSR0A&(1<<UDRE0)));// wait until UDR ready
5
UDR0=c;// send character
6
SREG=temp_Statusreg;
7
}
8
9
voidPrints(char*s){// loop until *s != NULL
10
while(*s){
11
Printc(*s);
12
s++;
13
}
14
}
15
16
voidPrintsP(constunsignedchar*s){// loop until *s != NULL
Manfred L. schrieb:> Ich bitte Dich deshalb ganz herzlich, mir ein paar Vorschläge zu> unterbreiten, wie ich dieses Projekt konsequenter testen kann als mit> den "verhaßten" printf() Anweisungen, denn für neue Ideen habe ich immer> ein offenes Ohr.
Also erstens: für sowas wie 'verhaßt' sollte man als Techniker und
Programmierer keinen Platz in seinem Sinn haben. Hier geht es um
sachliche Abwägungen.
Und zweitens: ich hatte hier schon vor Zeiten verschiedene Quellcodes
gepostet, wo u.a. auch dieses Thema eine Rolle spielt. Angefangen mit
der Lernbetty, wo man bereits vor so etwa 6..7 Jahren sowas nachlesen
konnte. Heutzutage sehe ich jedoch noch immer, daß die Leute, die hier
ihre Probleme posten, nichts dazugelernt haben. Siehe der vorherige
Beitrag (mit diversen Quellstücken, die lustig blockierende
Ausgaberoutinen mit Konvertierungen vermengen.
Gerade für die Grundstruktur einer Firmware für einem µC ist es wichtig,
diese in sinnvolle Level zu teilen.
Ich gebe dir mal ein Beispiel:
serial.c der/die Lowlevel-Handler zur Zeichenein/ausgabe
gio.c Zwischenschicht für vereinheitlichte Aufrufe verschiedener
serieller Kanäle. Kann man bei Platznot weglassen
conv.c die E/A-Konvertierungen. Ich häng dir mal die aus
der Lernbetty dran. Nicht wundern, dort hat man
relativ viel Platz im Flash und deshalb ist das Projekt
in ein Basisprogramm und Apps geteilt und die Konversionen
sind reichlich: Stellenanzahlen, Nachkommastellen,
führende Nullen usw.
Dabei ist es so, daß nur serial.c wirklich hardwareabhängig ist. Bereits
gio.h ist selbst nur teilabhängig, weil es je nach Plattform UART0..x
oder UART1..x gibt und der VCP via USB nicht überall existiert. Alles
andere ist plattformunabhängig, auch conv.c ist plattformunabhängig,
solange man nur einen Kommunikationskanal hat. Hat man mehrere, dann muß
ein Handle zum Kennzeichnen des gewünschten Kanals mit durchgeschleift
werden. Ist aber bei der Lernbetty noch nicht dabei.
Der in diesem Thread aber wichtige Knackpunkt ist, daß man bei Platznot
nur die Konvertierungen einbauen kann, die man auch tatsächlich
benötigt. Wer eine Toolchain hat, die das von selbst beim Linken tut,
der braucht sich nichtmal selbst darum zu kümmern. Eben das ist
anders, als bei deinem ganz oben gezeigten Ansatz, der ja das Parsen des
Formatstrings enthält und folglich alle enthaltenen Konvertierungen
benötigt, egal welche nun tatsächlich benötigt werden.
W.S.
W.S. schrieb:> die lustig blockierende> Ausgaberoutinen mit Konvertierungen vermengen.
Wo blockiert da was?
Edit: Du meinst vermutlich die IRQ lose Ausgabe. Das war damals dem
Speichermangel geschuldet. Ja, das kann man auch genauso gut ueber den
TX IRQ und Buffer machen wenn es stoert. Mir ging es auch nur um die
Kuerze des Codes, der fuer sinnvolle Ausgaben notwendig ist.
Andreas B. schrieb:> Bin zwar nicht WS, aber such Dir was aus:
Nee, zu viel Redundanz - jede Funktion kann übersichtlicher/kürzer
geschrieben.
W.S. schrieb:> Also erstens: für sowas wie 'verhaßt' sollte man als Techniker und> Programmierer keinen Platz in seinem Sinn haben. Hier geht es um> sachliche Abwägungen.
Da bin bei dir!
W.S. schrieb:> Ich häng dir mal die aus der Lernbetty dran.
Ja, mach mal - fehlt noch.
... und so kann die Funktion printBin() für byte, word, dword aussehen,
hier mit printf zum schnell mal ausprobieren!
Wenn ich zum Code Review komme, dann könnte es "kitzlig" werden ... :-)
Was ist nicht verstehe: Die selbstgebastetelten printf()s geben ja nur
einzelne Variablen aus. Habt ihr keine längeren Zeichenketten, bei denen
die Variablen nur ein Teil sind und auch noch irgendwie ausgerichtet
werden müssen?
Apollo M. schrieb:> hier mit printf zum schnell mal ausprobieren!
Soll das 'ne Persiflage sein? Deine printf()-Aufrufe in Zeile 4 und 5
lassen sich durch putc() ersetzen.
Walter T. schrieb:> Habt ihr keine längeren Zeichenketten
Was ich meine: Irgendwie sehen die Geschichten bei mir immer
komplizierter aus. Ich habe gerade mal in meinem zuletzt geöffneten
µC-Projekt den ersten Xprintf()-Aufruf herauskopiert, den ich mit Strg-F
finden konnte:
DerEinzigeBernd schrieb:> Soll das 'ne Persiflage sein? Deine printf()-Aufrufe in Zeile 4 und 5> lassen sich durch putc() ersetzen.
klar, selbsterklärend!
https://ideone.com wollte mir kein putc spendieren.
DerEinzigeBernd schrieb:> Andreas B. schrieb:>> Bin zwar nicht WS, aber such Dir was aus:>> Und welchen Vorteil soll das bitte haben?
Die brauchen weniger Speicher. Ich kommentiere auch nur die Funktionen
ein, die ich gerade brauche.
Wie gesagt, es geht hier ums debuggen bei kleinen Controllern.
Apollo M. schrieb:> ... und so kann die Funktion printBin() für byte, word, dword aussehen,> hier mit printf zum schnell mal ausprobieren!
Ja schön. Das printf sollte ja eben gerade vermieden werden. Diese lib
zieht einige kB in den Flash rein.
Apollo M. schrieb:> Die Funktions-/Variablennamen sind oft> grausam z.B. Printc -> printChar/putc oder PrintByteBinaer - auha! ...
Printc: Print character
Prints: Print String
PrintByteBinaer: Druckt ein Byte in binärer Form aus.
Was ist daran jetzt so schlimm?
Walter T. schrieb:> Habt ihr keine längeren Zeichenketten, bei denen> die Variablen nur ein Teil sind und auch noch irgendwie ausgerichtet> werden müssen?
Beim debuggen nicht und darum gehts hier ja. Das ist auch der Grund
warum ich das nicht mit IRQs gemacht hatte. Diese Ausgaben laufen
normalerweise in der Hauptschleife und produzieren jede Menge Traffic.
Irgendwelche Buffer sind da im Nu übergelaufen. Da lasse ich pro
Schleifendurchgangg nur wenige Zeichen ausgeben.
Ist halt alles eine Krücke, das debuggen mit diesen AVRs. Mittlerweile
mache ich viel mit LPC-ARMs und bin glücklich über diese
Debugmöglichkeiten die ich da via BMP/SWP habe.
Apollo M. schrieb:> Ja, mach mal - fehlt noch.
Ähem... naja, so im Nachhinein sag ich mir, daß eigentlich die .h für
das aufzuzeigende Grundprinzip zum Diskutieren ausreicht und daß man das
ganze Lernbetty-Projekt sich auch komplett hier herunterladen kann. Es
fehlt also nicht wirklich, sondern wird bloß nicht nochmal auf dem
Silbertablett dargereicht.
Siehe auch da:
Beitrag "Die Lernbetty: Die SwissBetty von Pollin als ARM-Evalboard"
W.S.
W.S. schrieb:> Es> fehlt also nicht wirklich, sondern wird bloß nicht nochmal auf dem> Silbertablett dargereicht.
Ich habe vor ein paar Tagen nochmal hereingeschaut. Ein paar Sachen sind
ja gut gelungen, beispielsweise die Implementierung des Font-Systems.
Aber ich habe die Implementierung des Menü-Systems (gibt es eins?), was
mich am meisten interessiert hat, nicht gefunden. Ich finde nirgendwo
umfangreiche Navigation.
Walter T. schrieb:> Aber ich habe die Implementierung des Menü-Systems (gibt es eins?),
Naja, mal ganz kurz (wir wollen diesn Thread ja nicht gar so sehr aus
dem Ruder laufen lassen):
Ja, es gibt ein Menüsystem. Guck dir mal menu.c und die *.inc an.
Zum Verstehen:
Jedes "Ding" im Menu ist so etwas ähnliches wie ein Objekt (was es in C
ja nicht gibt) und es hat:
- jemanden, dem es gehört (bis auf das jeweilige Menü selber, das gehört
niemandem), das ist der "owner".
- andere Dinge, die ihm gehören, das sind die "members".
- Koordinaten, jeweils relativ zum Owner
- einen Zeiger, der auf variables Zeugs im RAM zeigt. Je nachdem, ob und
was für Zeugs das jeweiligen "Objekt" grad braucht.
- verschiedene Flags und anderes konstantes Zeugs, je nach Bedarf des
konkreten "Objekts".
- eine "Methode", also eine Funktion, die zum Reagieren auf Tastendrücke
dient
- eine "Methode", die zum Reagieren auf sonstige Ereignisse dient
- eine "Methode", mit der sich das Ding selbst zeichnet.
Das ist ein zwar primitives, aber recht generisches System, denn was so
ein Ding macht, wie es aussieht, ob es ein Rahmen oder ein Knopf oder
eine Liste oder sonstwas ist, das ist nicht festgelegt, sondern wird
durch die Methoden, die Koordinaten, Flags und Variablen im RAM
bestimmt. Dabei steht alles andere im Flash und belegt deshalb nur das
allernotwendigste an RAM.
Wie man sieht, kann man auch in C und auf einem µC sowas ähnliches wie
objektorientierte Programmierung betreiben.
W.S.
W.S. schrieb:> Guck dir mal menu.c und die *.inc an.
Ah, die *.inc habe ich durchgehend übersehen.
Wenn ich das richtig interpretiere, ist das gesamte Menüsystem eine
double linked list und jedes einzelne Element hat eine eigene
Darstellungsfunktion?
(Und dann gibt es ein paar wiederverwendete Callback-Funktionen für
Events.)
Müsste ich Punkte verteilen, gäbe es Bonuspunkte für maximale
Flexibilität und Punktabzug, weil damit ein Menüsystem mit nur wenigen
zig Einträgen maximal schnell aus dem Ruder läuft.
Ich würde behaupten, dass der Verzicht auf ein printf() und damit
formatierte Strings einen zu hohen Preis kostet.
Ich will nicht behaupten, es besser zu können, aber Du kochst auch nur
mit Wasser. Es scheint nur der eine Suppe und der andere Brei zu
bevorzugen.
Wenn Du Material zum Gegenlästern brauchst, kannst Du Dich gerne an
meiner total verkorksten Menü-Implementierung auslassen:
http://dl1dow.de/artikel/myStepCounter/index.htm
Im Ordner .zip/bin/Mockup findest Du das Menü zum Herumspielen am PC.
Enter ist ein kurzer Tastendruck, Shift-Enter ein langer.
Hier gibt es das Gegenteil-Problem: Insgesamt nur 7 Menü-Einträge, aber
die volle Last eines Menüsystems für größere Systeme.
Walter T. schrieb:> Wenn ich das richtig interpretiere, ist das gesamte Menüsystem eine> double linked list und jedes einzelne Element hat eine eigene> Darstellungsfunktion?
Ähem... nein.
Nur gleichrangige Elemente sind in einer Liste. Wenn ein Element einige
Members hat, dann sind die in einer jeweiligen eigenen Liste.
Und nur Elemente, die etwas anderes sind, als die üblichen Elemente,
haben eine eigene Darstellungsfunktion. Gleichartige Elemente haben
dieselbe Darstellungsfunktion, aber verschiedene Koordinaten, Flags usw.
Aber was soll das alles mit Konvertier-Routinen, Platz sparen und printf
zu tun haben?
W.S.
Walter T. schrieb:> Wenn Du Material zum Gegenlästern brauchst, kannst Du Dich gerne an> meiner total verkorksten Menü-Implementierung auslassen:
Ich nehme dich beim Wort, aber eher um zu lernen! Ich lese gerade wieder
intensiv Source Code und finde immer was nützliches - was ich dann in
meine Schatztruhe übernehme.
Die Vielfalt/Menge deiner Projekte ist beachtlich - hat dein Tag mehr
als 24 Stunden?!
Die Mechanik sieht zum Fingerlecken aus - verdammt gut. Dein
Machinenpark muss beachtlich sein.
Apollo M. schrieb:> Die Vielfalt/Menge deiner Projekte ist beachtlich - hat dein Tag mehr> als 24 Stunden?!
Nö, die Seite ist nur mittlerweile volljährig. Es läppert sich über die
Zeit.
Apollo M. schrieb:> Dein Machinenpark muss beachtlich sein.
Hält sich in Grenzen - ist aber auch beschrieben.
Apollo M. schrieb:> Die Mechanik sieht zum Fingerlecken aus
Eine vernünftig aussehende Mechanik ist ja auch einfacher als vernünftig
aussehende Firmware. Beim Programmieren finde ich es unheimlich
schwierig, mich über die Jahre hinweg zu verbessern. Es gibt zwar viel
Material - aber es ist sehr schwer, Menschen zum Erfahrungsaustausch zu
finden.
Apollo M. schrieb:> Ich nehme dich beim Wort, aber eher um zu lernen!
Betrachte es als abschreckendes Beispiel. Es funktioniert alles, aber
elegant geht anders.
Walter T. schrieb:> Wenn Du Material zum Gegenlästern brauchst, kannst Du Dich gerne an> meiner total verkorksten Menü-Implementierung auslassen
Ach nö, mir ist nicht danach, in einem rund 13 MB großen Zipfile
herumzustochern, zumal es dort keinerlei Manual zum Projekt gibt. Und
obendrein hat das keinen Bezug zu diesem Thread.
Ich sag's nochmal: Wenn man Ausgaben von Zahlen machen will und zugleich
Platz sparen muß, dann ist es das Allererste, sämtliche
Übersetzungsarbeiten zur übersetzungszeit zu erledigen oder bereits
erledigt zu haben und dann nur noch die eigentlichen
Konvertierungsroutinen und zwar nur diejenigen, welche gebraucht werden,
in die erzeugte Firmware eingehen zu lassen.
Und das ist komplett unabhängig von anderen Aspekten wie Menüsystem,
Display usw.
W.S.
{kind=link}