Jo danke, trotzdem komisch das run.sh auf wsl-debian bei mir diverse
Macken hat.
Ich konnte die Ausführungszeit beim zweiten IO Versuch via seek mit
einem 100MB Buffer halbieren. Jetzt schaue ich mal nach fread mit strtok
und nachträglicher newline Erkennung.
Ich möchte zu Bedenken geben, dass die Benchmarks evtl. unterschiedliche
Ladezeiten des Binaries nicht berücksichtigen. Vielleicht muss die
libstdc++ einen Haufen Sachen initialisieren, bevor die main aufgerufen
wird. Die Ausgabe von time ist daher vielleicht etwas mit Vorsicht zu
genießen. Eine Alternative wäre rdtsc vor/nach
Synchronisierungspunkten/barrier, damit die Operationen auch tatsächlich
abgeschlossen sind. Wenn man die Dateien aus einem tmpfs läd, sollte der
syscall overhead auch deutlich vernachlässigbar klein sein.
Einfach Klasse dieses Testdingens..
Der hans.exe fehlt noch ein arg für Spaltenzahl weil immer 45 oder habe
ich das falsche Paket erwischt?
Strtok war ja schonmal nicht schlecht, liefert nur falsche Ergebnisse
bei leeren Feldern aus.. lol
Ich versuche es mal mit strtok_r. Mit fread konnte ich mein Script von
10Sekunden auf 4Sekunden reduzieren. Aber halt nur mit der List.txt.
So da habe ich es auch mal geschafft.. eher ein Funproject so
umständlich wie das noch wurde..
mit strtok_r und fread.. einziger Nachteil da nicht automatisch gelöst
man muss je nach Filegrösse den Buffer der Datei anpassen..
Wenn ich mal Zeit finde mache ich das mit fwrite und buffer..
komischerweise habe ich auch ein Projekt mit 10000 Dateien a 45 Spalten
:D
Philipp K. schrieb:> So da habe ich es auch mal geschafft.. eher ein Funproject so> umständlich wie das noch wurde..
Kompiliert unter Windows leider nicht. Da gibt es keine strtok_r()
Funktion,
und der Code ist ein schlimmes Gemisch aus C und C++, das weder der C
noch
der C++ Compiler mag.
Aber Zeiger auf Zeiger auf FILE habe ich noch nie gesehen, dafür ein
Plus für Kreativität.
Unter WSL2 Ubuntu geht es durch den gcc Compiler.
Aber das Program macht nur eine Endlosschleife, und müllt die Festplatte
zu,
Nachdem das nodup.txt über 70 GB gross war, Abbruch.
Damit hast du erst mal den letzen Platz, mit Abstand!
udok schrieb:> Kompiliert unter Windows leider nicht. Da gibt es keine strtok_r()> Funktion
#if defined(_WIN32) || defined(_WIN64)
/* We are on Windows */
# define strtok_r strtok_s
#endif
Ok, danke, war schon etwas frustriert!
Mit dem define geht es durch den Compiler.
Das list.txt muss genau 100e3 Zeilen sein, ich hatte zum Testen kleinere
Daten genommen, und damit die Endlosschleife produziert.
Hier die Ergebnisse unter Win10, 100 Bytes / Feld:
Ja sorry, so kompiliert wohl alles überall anders..
ich wollte es halt nur mit strtok ausprobieren.. da scheint dann nur der
Dateizugriff die Rolle zu spielen.
So siehts bei mir aus.. mit 4MB buffer (anstatt 150 :D) und setvbuf mit
4MB.
Philipp K. schrieb:> Ja sorry, so kompiliert wohl alles überall anders..>> ich wollte es halt nur mit strtok ausprobieren.. da scheint dann nur der> Dateizugriff die Rolle zu spielen.
Danke jedenfalls für dein Programm!
Mir ist aufgefallen, dass die Ergebnisse für die foobar2 Version
heute deutlich schlechter waren, nur 136 MB/sec, die waren schon mal
bei über 200 MB/sec.
Lösung: Ich habe heute nur mit -O2 compiliert, und nicht mit "-O2 -Oi-
-GS-", wie zuletzt.
Der MS Compiler schaltet bei -O2 automatisch die intrinsic
Funktionen an, und die Compiler eigene memcpy/strcmp ist eine for
Schleife, und die ist deutlich langsamer, als die Funktion aus der C
Runtime.
Damit ist auch Phillips strtok Funktion auch um einiges schneller.
Hier also noch ein Update für Win10, 100 Zeichen/Feld, cl 2019, -O2 -Oi-
GS-:
Frank M. schrieb:> Profiler messen Dauer/Anzahl von Funktionsaufrufen. Der nützt Dir gar> nichts innerhalb der while-Schleife.
"Measure, don't guess." (Kirk Pepperdine)
"Premature optimization is the root of all evil." (Donald E. Knuth)
Können wir das Testpackage vielleicht bei GitHub oder so hochladen? :)
Und hat jemand eine Idee, wie man eine Julia Variante
(https://julialang.org/, fyi, das ist eine relativ neue Sprache, die so
einfach wie Python, aber so leistungsfähig wie C sein soll, speziell für
"scientific computing") benchmarken könnte? Das Problem ist, dass das
Skript bei jedem call in eine neue, frische Shell neu JIT kompiliert
wird, was ja irgendwie Quatsch ist. Es gibt ein benchmarking Paket
(https://github.com/JuliaCI/BenchmarkTools.jl), aber das läuft nur, wenn
man es aus der selben shell mehrfach startet.
Das Benchmarking shell skript hier callt das Skript oder die Binary
mehrfach und rechnet dann die Zeit aus, richtig?
Ja ist komisch.. ich habe trotz 2x Debian-WSL (einmal alter i5m-4Kern
und 6Kern neuer i5-9600) total unterschiedliche Rang-Ergebnisse.
Ich habe mal eine Datei mit Outputbuffer angehängt.. da kommt nochmal
1/3. (Jedenfalls bei mir).
Auf dem LAppy bekomme ich das ./run.sh mit Zeitmessung nicht hin, auf
dem Tower lief es sofort.
Jan K. schrieb:> Können wir das Testpackage vielleicht bei GitHub oder so hochladen? :)>
Von mir aus schon, aber die meisten Programme sind nicht von mir...
Ich stelle die nächsten Tage die aktuelle Version hier rein.
> Und hat jemand eine Idee, wie man eine Julia Variante> (https://julialang.org/, fyi, das ist eine relativ neue Sprache, die so> einfach wie Python, aber so leistungsfähig wie C sein soll, speziell für> "scientific computing") benchmarken könnte?
Sollte ja nicht so schwierig sein?
Mit Python, Perl, Lua und gawk gehts ja auch,
und die Ergebnisse sind sehr gut.
Wenn du ein Skript hast, stell es einfach hier rein.
> Das Benchmarking shell skript hier callt das Skript oder die Binary> mehrfach und rechnet dann die Zeit aus, richtig?
Richtig.
Philipp K. schrieb:> Ja ist komisch.. ich habe trotz 2x Debian-WSL (einmal alter i5m-4Kern> und 6Kern neuer i5-9600) total unterschiedliche Rang-Ergebnisse.>
Hast du eventuell noch die WSL Version 1? Die kannst du für grosse
Files vergessen. Eventuell sind auch die dynamischen Libs
unterschiedlich?
Ich trenne Windows und Linux immer strikt.
Die Ergebnisse sind eigentlich sehr gut reproduzierbar.
Versuche, mal unter Windows oder unter Linux reproduzierbar ordentliche
Performance zu bekommen.
Die Windows exe laufen bei mir unter Windows auf einem Cygwin/Msys2
Terminal,
und die Linux Programme laufen auf einem WSL2 bash Terminal.
Sonst hast du unerwartete Effekte, wenn etwa auf grosse Dateien
über die Grenze der virtuellen Maschine zugegriffen wird, oder wenn
ein Kompatibilitätslayer dazwischen ist.
Wenn du hier Ergebnisse postest, dann sortier sie bitte mit "run.sh
|sort -k5V", ansonsten kann das keiner Lesen. Und schreibe dazu, was du
genau auf welchem System gemacht hast, und wie du compiliert hast.
> Ich habe mal eine Datei mit Outputbuffer angehängt.. da kommt nochmal> 1/3. (Jedenfalls bei mir).
Wundert mich etwas, 64-512 kByte Buffer ist bei mir das Optimum,
drüber fällst du aus dem Cache raus.
Ich nicht schrieb:> Noch nicht alles gelesen... Hat schon jemand eine> multithreading-Variante mit getrenntem io- und processing-threads> skizziert?
Es gibt von Roger eine MT Variante.
Im Prinzip kannst du das ganze File aufteilen, und jeder Prozessor
übernimmt einen Teil.
Ich würde das Fass hier aber nicht aufmachen.
Das braucht viel Zeit, und so interessant ist das Problem ja dann doch
nicht.
Philipp K. schrieb:> Ich habe mal eine Datei mit Outputbuffer angehängt.. da kommt nochmal> 1/3. (Jedenfalls bei mir).
Sehe ich hier eher nicht, aber der Speicherverbrauch ist runtergegangen:
Python liest das ganze 909 MB File ein einen Rutsch in den Speicher,
alle anderen Programme brauchen deutlich weniger RAM.
Der Peak WorkingSet sind (glaube ich) shared DLL und privater RAM.
Ok.
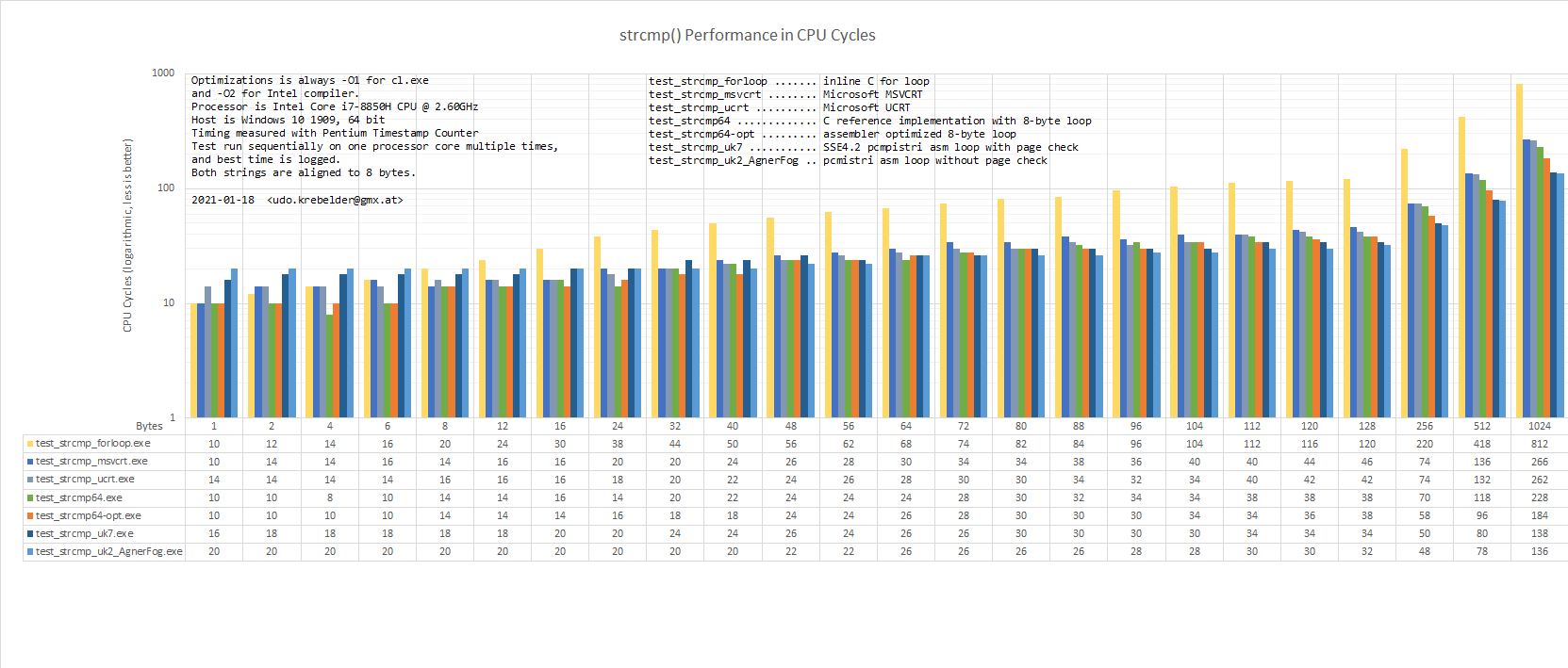
ich habe noch versucht zu optimieren aber strcmp scheint ja schon das
schnellste zu sein.
Ich wollte noch 3 checks einbauen um strcmp zu umgehen, das war aber
eher kontraproduktiv.
1. Doppelte Strings im Array direkt leeren damit strcmp früher
aussteigt.
2. Die Stringlängen anhand der vorhandene Pointer vergleichen.
3. Man hat ja einen Pointer für len+1 .. den direkt zum vergleich des
letzetn Zeichens nutzen (*Nextsep-1)..
Dauert aber alles länger als strcmp direkt durchlaufen zu lassen.. wäre
bei großen Feldern interessant.
Ich denke mal mit strtok lohnt da ausser vielleicht mmap nichts mehr.
udok schrieb:> Sehe ich hier eher nicht, aber der Speicherverbrauch ist runtergegangen:
Ich denke mal das lag am fprintf, wieso habe ich eigentlich c und c++
gemischt? Mein Code müsste ja eigentlich gnu99 Konform sein? (Habe davon
aber keine Ahnung.)
Ich habe jetzt mal fprintf mit fwrite und Buffer optimiert. Sieht
jedenfalls bei mir ganz gut aus.
Wie kann die Native Version eigentlich schneller sein als die
Festplatte, zeigt jedenfalls mein Laptop. Ich benutze nur WSL2 mit
aktuellen Updates.
Philipp K. schrieb:> Ich denke mal das lag am fprintf, wieso habe ich eigentlich c und c++> gemischt? Mein Code müsste ja eigentlich gnu99 Konform sein? (Habe davon> aber keine Ahnung.)
Dein Code ist GNU und Linux konform, compiliert aber nicht unter
Windows.
Ein älterer Compiler als VS2019 hat gleich aufgegeben...
Ist eigentlich schade, weil es immer nur Kleinigkeiten sind.
Um es nicht noch ein viertes Mal ausbessern zu müssen, habe ich dir die
Änderungen angehängt. Ich habe mir rausgenommen, die Einrückungen etwas
anzupassen, ich komme damit sonst nicht klar.
stpcpy() und strtok_r gibt es nicht, lässt sich aber leicht umgehen.
Hier die Ergebnisse unter Win10, compiliert mit vs2019 -O2 -GS-
Ich habe diesmal extra lange Felder mit 500 Bytes genommen,
weil das Ergebnis sehr interessant ist.
Der Gewinner ist Perl, abgesehen von den optimierten und deutlich
aufwendigeren native C Funktionen!
Perl dürfte die beste Hash Bibliothek haben, und der Overhead
der Skriptsprachen spielt bei so grossen Feldern keine Rolle.
Philipp K. schrieb:> Wie kann die Native Version eigentlich schneller sein als die> Festplatte, zeigt jedenfalls mein Laptop. Ich benutze nur WSL2 mit> aktuellen Updates.
Die Festplatte spielt da keine Rolle, weil die Files sowieso im RAM
sind. Drum bringt dein Ansatz mit dem supergrossen Buffer auch
nicht viel.
Achso okay, trotzdem witzig das bei mir das Ergebnis mit meinem Ziel
übereinstimmt (nativ angenähert). Habe nur den folder kopiert und mein
Script eingetragen.
Ja mit dem Buffer ist klar, das war nur noch so ein Test Überbleibsel
damit ich Blöcke und nicht einzelne Bytes schreibe. Für meine Anwendung
Spalten in tausenden Lines zu löschen reicht es allemal.
Wieder etwas dazugelernt. Danke.
In bash dauert es fast ne halbe Stunde ;)
Philippk_59 schrieb:> Achso okay, trotzdem witzig das bei mir das Ergebnis mit meinem Ziel> übereinstimmt (nativ angenähert). Habe nur den folder kopiert und mein> Script eingetragen.
Was anderes mache ich auch nicht, warum sind dein Werte sooo langsam?
Lass das ganze doch mal unter Windows laufen.
> In bash dauert es fast ne halbe Stunde ;)
Kannst du das Skript posten?
udok schrieb:>> In bash dauert es fast ne halbe Stunde ;)> Kannst du das Skript posten?
Gibt es so noch nicht, ich meinte nur mein Spalten Löschscript das noch
zeilen löscht, Daten konvertiert und Dateien umarrangiert.. das dürfte
in C schneller gehen. Ich kann es ja mal in Bash umsetzen.
udok schrieb:> warum sind dein Werte sooo langsam?
Ich finde es geht eigentlich, das ist ja vielleicht sogar AMD/INTEL
abhängig.. Mein Laptop ist halt nicht so schnell, der Tower schafft es
genau doppelt so schnell bei gleichem Endergebnis.
Ich habe noch nie auf Windows kompiliert.. mir ist das ganze zu
umständlich. bei Linux arbeite ich nur mit "Nano" und Shell ohne
Autoscripts.
Gcc, debuggen, und coden alles in der Bash ;)
p.s. Onlinegdb nutze ich auch nur wenn ich unterwegs bin um auf die
schnelle rumzuspielen.
EDIT: Der stpcpy Erstaz für Windows ist aber schon krass .. ein Strlen
auf den Buffer beim einfügen von nem Semikolon ist nicht sehr
performant. Ode rhabe ich da jetzt einen Denkfehler?
Philipp K. schrieb:> Ich habe noch nie auf Windows kompiliert.. mir ist das ganze zu> umständlich. bei Linux arbeite ich nur mit "Nano" und Shell ohne> Autoscripts.
Ist genau so einfach wie unter Linux. Statt gcc rufst du halt cl auf.
Du musst nur die Pfade richtig sethen, wie im Skript vs2019.env gezeigt.
Wenn die Pfade passen, kannst du auch einfach das Skript build.sh
aufrufen.
Als Shell verwende ich Mingw, Powershell oder das neue Windows Terminal
geht aber sicher genauso, oder auch die bash von WSL2.
Philipp K. schrieb:> EDIT: Der stpcpy Erstaz für Windows ist aber schon krass .. ein Strlen> auf den Buffer beim einfügen von nem Semikolon ist nicht sehr> performant. Ode rhabe ich da jetzt einen Denkfehler?char *> STPCPY (char *dest, const char *src)> {> size_t len = strlen (src);> return memcpy (dest, src, len + 1) + len;> }
Meine strpcpy war sowieso falsch, ich dachte die hängt Strings
zusammen...
Von der Performanceseite ist es egal, memcpy und strlen sind so gut
optimiert, das du das nicht merkst.
Und Funktionsaufrufe sind auf x64 praktisch gratis.
Mit cl -O2 optimiert der compiler das auch weg, nur der Code ist nur
mehr
halb so schnell, weil die compiler inline Version langsamer als der
Funktionsaufruf ist.
udok schrieb:> Ich habe noch mal bei FreeBSD geschaut, was die für eine stpcpy> Funktion> haben:> char *stpcpy(char * __restrict to, const char * __restrict from)> {> for (; (*to = *from); ++from, ++to);> return(to);> }>> Linux weiss ich nicht, mit den glibc Sourcen komme ich nicht klar.
Ich würde mit ziemlicher Sicherheit sagen, dass das der "allgemeine
Fallback" ist. Gängige Compiler ersetzen die Standardfunktionen durch
vektorisierte, handoptimierte Varianten für die ausgewählte CPU.
Das sieht dann irgendwie so aus
https://code.woboq.org/userspace/glibc/sysdeps/x86_64/multiarch/strcpy-avx2.S.html
oder so
https://code.woboq.org/userspace/glibc/sysdeps/arm/armv6/strcpy.S.html
Al Fine schrieb:> Gängige Compiler ersetzen die Standardfunktionen durch vektorisierte,> handoptimierte Varianten für die ausgewählte CPU
Oder wie ich bei strtok gesehen habe 64 Bit breite Verarbeitung.. mein
Denkfehler war das ich ja mit lastconcat den Anfang setze, daher ist das
strlen auf das source nicht so heikel.
Auf meinen Rechner lässt sich Fread und strtok auf unter 2 Sekunden
beschränken..450MB lesen und verarbeiten.
Ich habe dann nur das Schreiben optimiert wobei dann nochmal 2-3
Sekunden dazukommen. Also das mindeste müsste ja die Plattenperformance
sein. Damit sind meine Zeiten plausibel mit lesen,gebuffertem schreiben
beim verarbeiten.. das verarbeiten ohne schreiben könnte ich auf weit
unter 1 Sekunde berechnen.
udok schrieb:> Linux weiss ich nicht, mit den glibc Sourcen komme ich nicht klar.
Ich denke mal das es in Linux bestmöglich gelöst ist, während es Windows
einfacher hält.
Die ganzen Stringsachen sind in Windows Byteschubbserei, während diese
in der Glibc schon besser gelöst sind.
Wie z.B. stpcpy das einfach memcpy direkt ausführt.. wenn ich das
richtig gesehen habe, scheint die Verarbeitung wenn keine groben Fehler
gemacht werden nur wenig Zeit in Anspruch zu nehmen, das es dann eher
auf die IO Umsetzung ankommt.
Strtok benutzt in der Glibc strspn und strcspn die etwas anders
angesetzt sind.. bei Windows ist es vielleicht wieder nur
Byteschubbserei wenn man den Sources trauen kann.
https://code.woboq.org/userspace/glibc/sysdeps/x86_64/multiarch/strspn-c.c.html
Philipp K. schrieb:>> Linux weiss ich nicht, mit den glibc Sourcen komme ich nicht klar.>> Ich denke mal das es in Linux bestmöglich gelöst ist, während es Windows> einfacher hält.
Der Satz lässt ja alle Möglichkeiten offen, je nach Definition von
bestmöglich :-)
Das fängt schon damit an, das Windows einfach andere Ziele hat.
Das ist kein OS für Rechenzentren und hohen Datendurchsatz.
Für GUIs und Mausschubsen reicht es allemal.
Binäre Kompatibilität ist z.B wichtiger als Performance im MS Universum.
So hat der stdio File Layer nicht nur eine Schicht wie in Linux,
sondern 2-3 Schichten, wo auch die Unix open/read/write/close
Funktionen abgebildet werden und verschiedene Konvertierungen gemacht
werden. Das kostet halt immer etwas, in der Praxis ist das aber meist
nicht so wichtig.
> Die ganzen Stringsachen sind in Windows Byteschubbserei, während diese> in der Glibc schon besser gelöst sind.
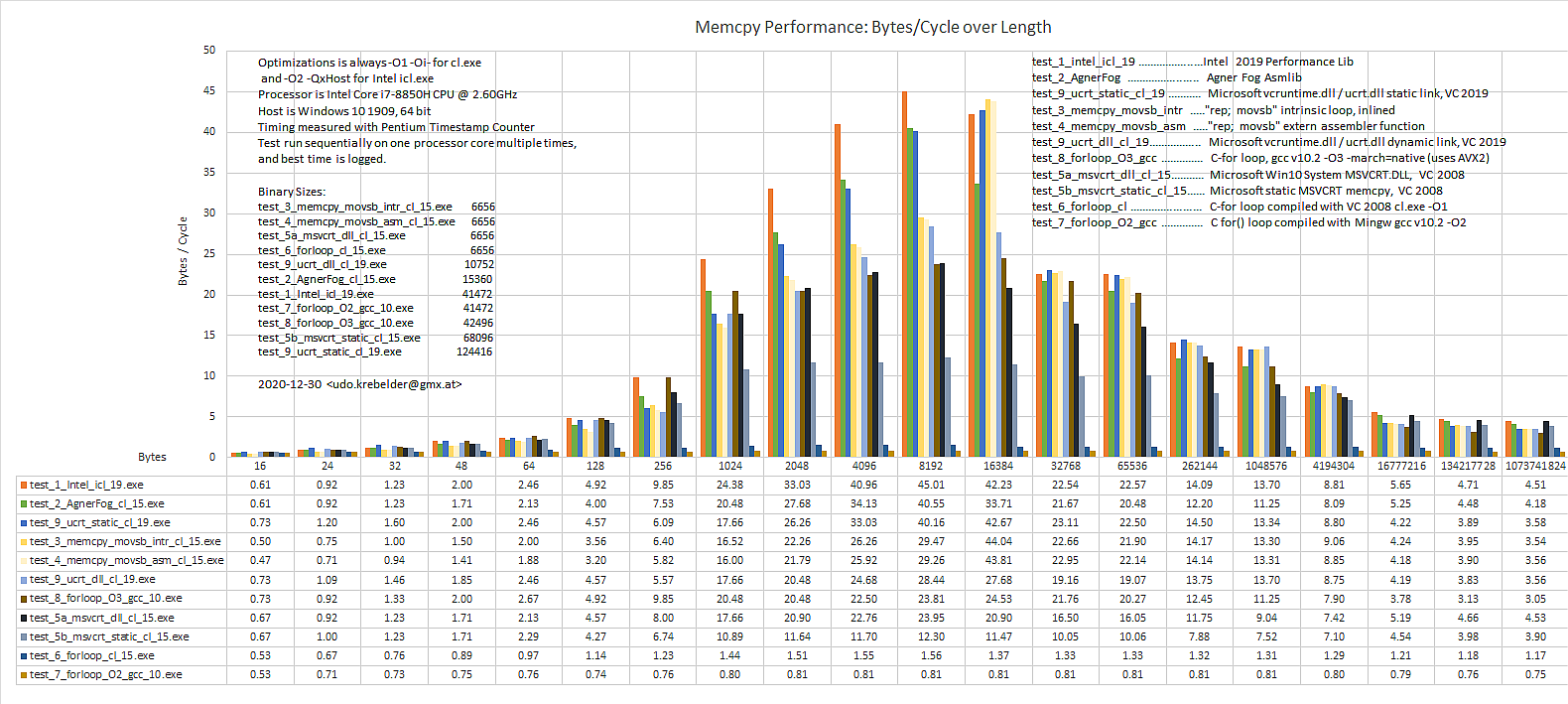
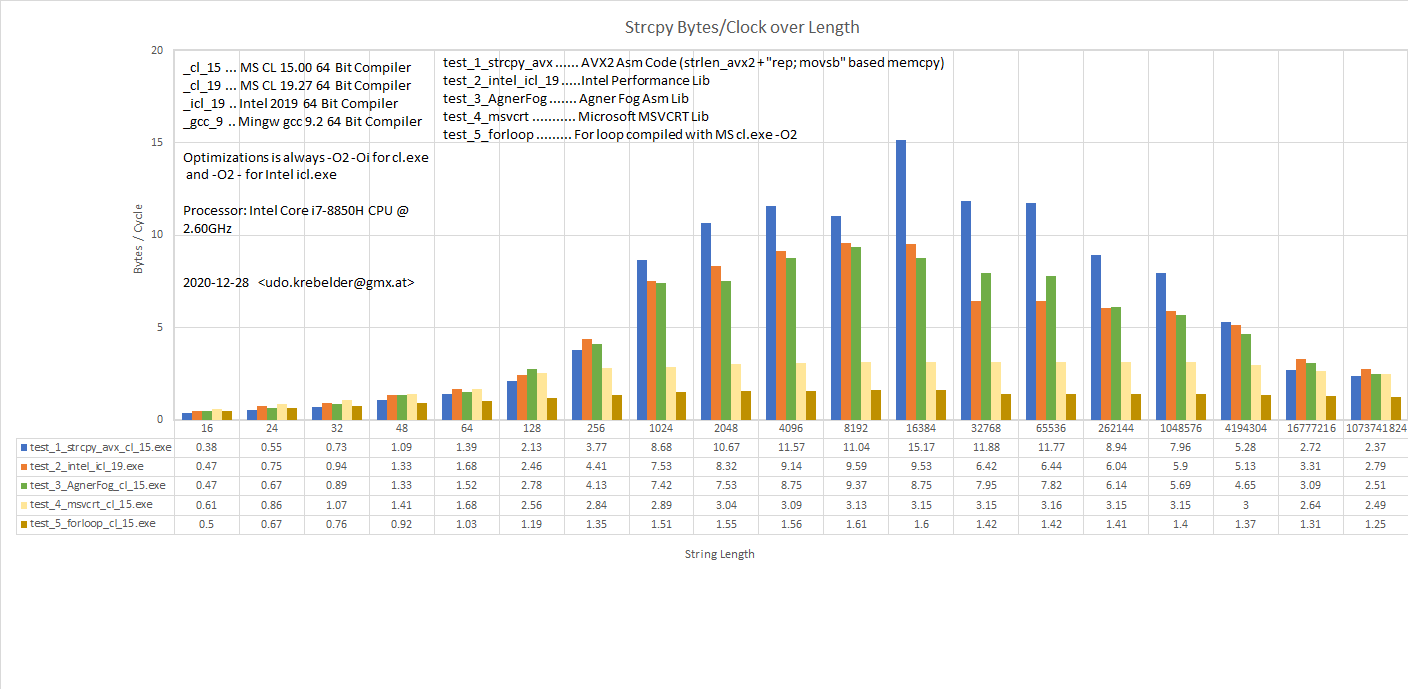
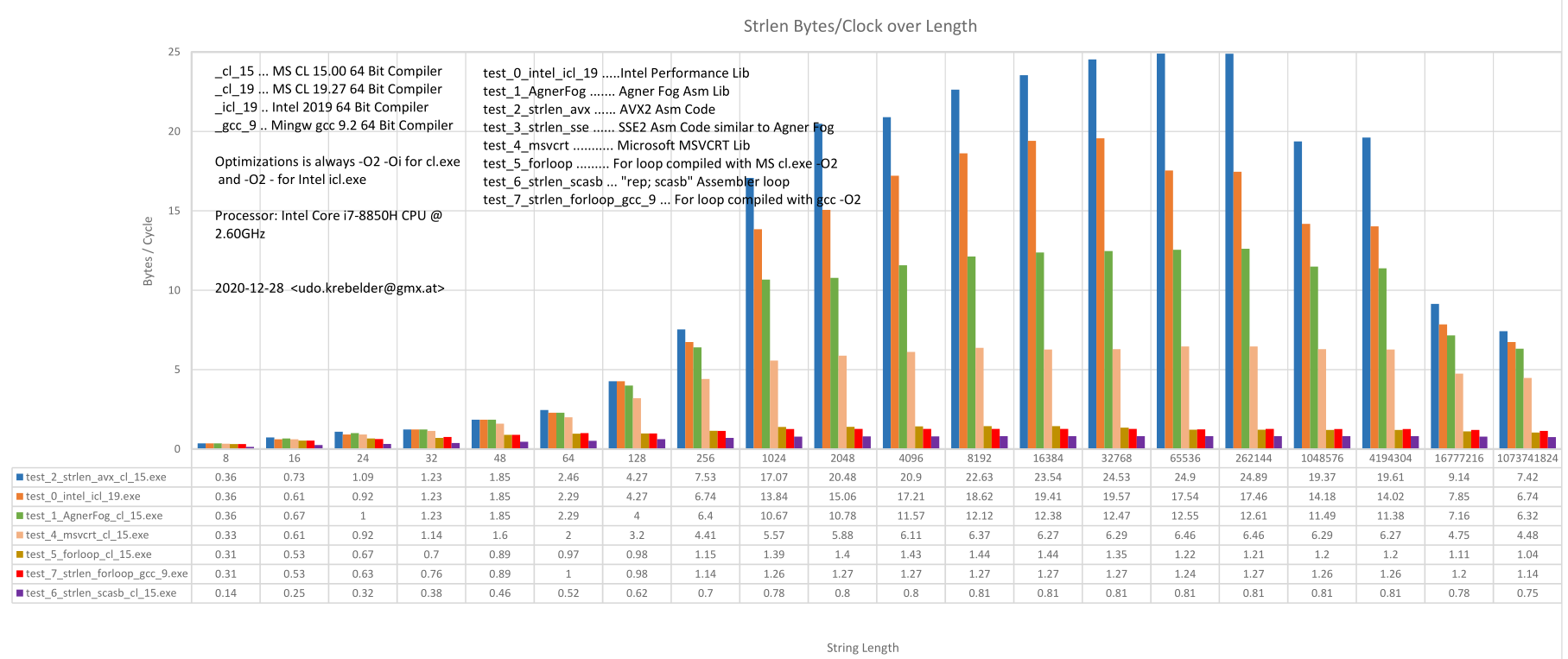
Ich habe dir ein paar Bilder angehängt mit Performance Tests.
Die neuere Ucrt hat ein paar ziemlich gut optimierte Funktionen
drinnnen. Besser geht fast immer, aber die Systeme nähern sich an.
Der MS compiler macht auch sehr kompakten und schnellen Code.
Aber fette Binaries und unlesbaren Code und kranke Benutzerkonzepte hast
du da wie dort.
Früher hattest du mal 5% der heutigen Rechenleistung, aber die Programme
waren trotzdem recht schnell.
Heute wird die Performance von riesen Ascii Files und Megaframeworks mit
superauflösenden Icons aufgefressen, davon hat der Anwender nichts.
Das Problem heute ist, das man mit PC Software kein Geld verdienen kann.
Es gibt vieles gratis, und daher kein kommerzielles Interesse an guten
Programmen.
Die SW Industrie sattelt um auf Dienste und/oder Werbung. Ein paar
Nischen halten sich noch, aber die werden fast alle in 10 Jahren
verschwunden sein.
> Wie z.B. stpcpy das einfach memcpy direkt ausführt.. wenn ich das> richtig gesehen habe, scheint die Verarbeitung wenn keine groben Fehler> gemacht werden nur wenig Zeit in Anspruch zu nehmen, das es dann eher> auf die IO Umsetzung ankommt.
Wenn die Daten erst mal im 1st Level Cache sind, spielt alles weitere
keine grosse Rolle.
Dann musst nur mehr schauen, das du möglichst mehrere Bytes auf
einmal anschaust (SSE/AVX oder 8-Byte Register), und das du keine
Abhängigkeiten zwischen den
Daten hast - Eine CPU kann dann bis zu 6 Operation gleichzeitig
ausführen.
Danke für die tolle Erklärung und den Benchmarks.
Irgendwie scheint man nur mit Glibc in Linux einen direkten Vergleich
machen zu können.
In MingW ist zum Beispiel strtok auch nur eine Hilfe nicht direkt mit
Bytes arbeiten zu müssen, dort wird mit Schleifen und Char ohne andere
Funktionen gearbeitet. Also im Prinzip kein Vergleich möglich.
Denke aber auch das es bei den heutigen Rechenleistungen und SSD
Performance irgendwie keine Rolle spielt für die Privaten Anwendungen.
Angenommen bei meinem Script habe ich in Glibc darauf geachtet das kein
Byte mehr als nötig gelesen und geschrieben wird..
Bei der MingW Version mit stpcpy, strtok etc. bestimmt 3 mal mehr. Das
macht dann bei 450MB auch ne Sekunde mit dem ganzen IO drum herum.