hi
ich wollte in c++ eine Routine schreiben um in einem (einige Millionen
Zeilen langem) csv in jeder Zeile (ab Spalte 3) Duplikate zu löschen.
Der Code ist folgender
Hansi schrieb:>ich wollte in c++ eine Routine schreiben um in einem (einige Millionen>Zeilen langem) csv in jeder Zeile (ab Spalte 3) Duplikate zu löschen.
ich würde das ganze in SQLite lösen...
dann hätte man mit einem optimierten insert Befehl Duplikatfreie
Inserts.
Philipp K. schrieb:> ich würde das ganze in SQLite lösen...
ja ich weißt, es gibt bereits fertige Lsungen die wesentlich schneller
wären. Ich möchte es aber in c++ bewerkstelligen, da ich noch andere,
wesentlich komplexere File Manipulationen vorhabe. Zuerst möchte ich
aber diesen relative simplen Code optimieren...
Hansi schrieb:> einige Millionen> Zeilen langem) csv
Dein Code liest Zeilenweise ein, da wird wohl viel Zeit fuer
unoptimierten IO verschwendet.
Hansi schrieb:> Zuerst möchte ich> aber diesen relative simplen Code optimieren...
Da kann ich Python mit Dataframes und/oder Numpy empfehlen.
CSV liest man schneller mit dataframes ein (inkl. memory mapping oder
nicht), bei binaeren Dateien ist numpy schneller.
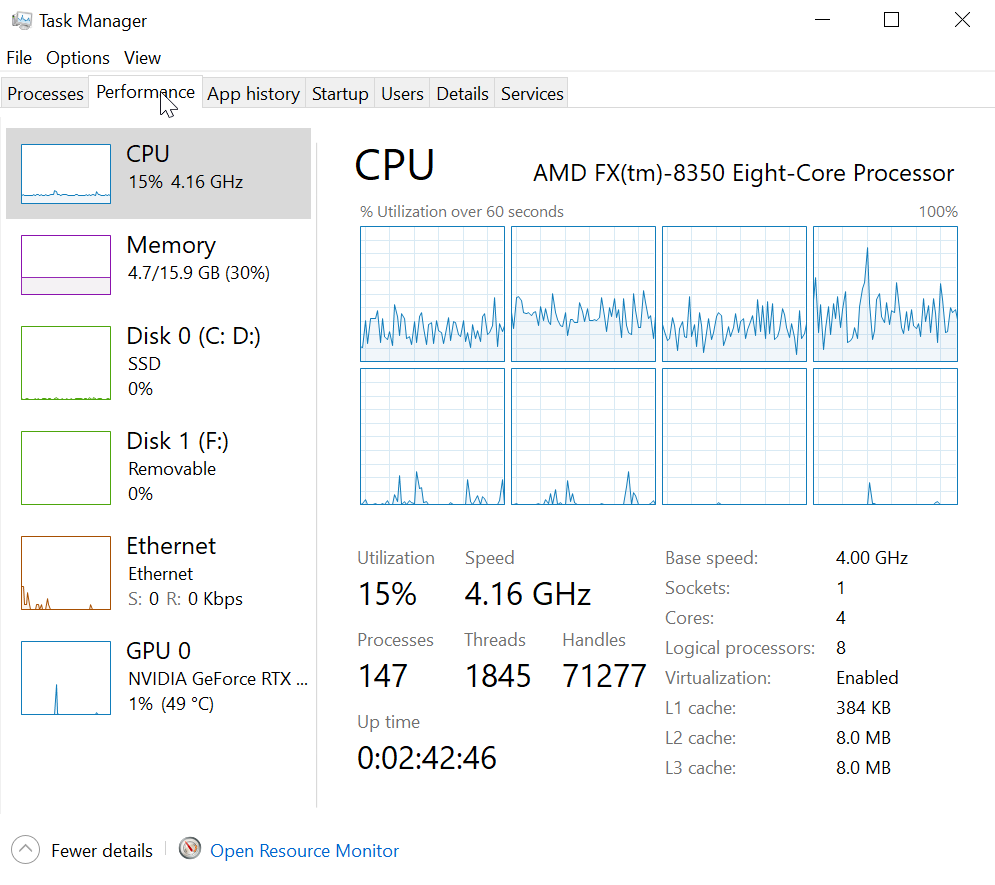
Hansi schrieb:> Es wird gerade mal 10%> der PC Leistung verwendet.
Was ist denn das für ein PC?
Wenn der 8 Kerne hat, läuft das Programm maximal mit 12,5%
Systemleistung.
Das ist der theoretische Wert.
Dazu kommt dann das ganze File I/O - und das ist langsam (im Vergleich
zum Rest)
Dein Code verwendet zwei verschachtelte for-Schleifen und benötigt ~n²/2
Vergleiche, wobei n=csv_len ist. Bei n = 10^6 benötigt dein Verfahren
5*10^11 Schritte.
Sinnvoller wäre z.B. die Datensätze z.B. mit Quicksort zu sortieren
(n*lg(n) Vergleiche), danach die Liste durchlaufen und Duplikate
entfernen (n Schritte) und gegebenenfalls nach ursprünglichen
Zeilennummern zurück zu sortieren (n*lg(n)). Insgesamt also 2*n*lg(n) +
n Schritte.
Bei n=10^6 sind das ~41*10^6 Schritte
Hansi schrieb:> ja ich weißt, es gibt bereits fertige Lsungen die wesentlich schneller> wären.
Fakt ist, die Tabellen müssen in den Ram, dann kannst du mit mehreren
Parallelen Aufgaben X mal schneller arbeiten.
Durch das Read Line by line und output kannst du technisch nicht
parallel arbeiten. Wieviel Datenmasse ist das?
Vielleicht beim einlesen einen MD5 oder so speichern und dann beim
nächsten einlesen im Ram als Variable vergleichen.
So wird das nichts. Wenigstens 1000 Zeilen vorladen oder am besten nen
ganzes Megabyte oder so erhöht es schön um das x fache.
CSV Datei in ein tmpfs (RAM) kopieren oder SSD einsetzen.
Wenn CPU Auslastung <100%, dann ist die Festplatte der bottleneck (CPU
könnte schneller, muss aber auf die Daten warten)...
Abgesehen davon ist der Algorithmus natürlich auch langsamer als nötig.
Maik Hauguth schrieb:> Sinnvoller wäre z.B. die Datensätze z.B. mit Quicksort zu sortieren> (nlg(n) Vergleiche), danach die Liste durchlaufen und Duplikate> entfernen (n Schritte) und gegebenenfalls nach ursprünglichen> Zeilennummern zurück zu sortieren (nlg(n)).
Genau das Sortieren nach dem Einlesen ist der richtige Ansatz. Dann
liegen identische Datensätze nämlich hintereinander.
In der UNIX-Shell gibt man einfach ein:
1
sort <infile | uniq >outfile
oder noch kürzer, weils beide Schritte kombiniert:
1
sort -u <infile >outfile
P.S.
Die beiden Unix-Dienstprogramme sort und uniq sind trivial. Das kann man
auch in C/C++ einfachst nachbauen.
Es gibt da viele möglichkeiten.. z.B. 2 oder mehr Threads.. der lesende
eilt dem schreibenden 100MB vorweg, so hab ich etwas ähnliches in Java
um das 200 fache optimiert.
Dazu noch einen Hash bei MD5 z.B 8 Byte bei 1.000.000 Zeilen 8Megabyte
Ram, bei gleichem Hash erst nochmal Inhalt vergleichen um Fehler
auszuschließen.
Also Threads und nur eine MD5 Tabelle mit nem 128Bit Integer anlegen.
Das würde ich so ausprobieren... Ob MD5 dann etwas langsamer macht
keinen Plan, da kommt es auf die Länge des Inhalts der Zeilen an.
Die Datei wird zeilenweise gelesen. Da puffern OS und std::stream in der
Regel ausreichend.
Dann geht es um ein Array mit 45 Einträgen (aus der Zeile, halt CSV).
Das sollte alles im CPU Cache sein. Imho bringt da auch ein Sort nicht
viel.
Soweit keine weiteren Infos vom TS kommen, denke ich, dass der Prozess
einfach nur idlet weil er auf Daten von der Platte wartet.
Hansi schrieb:> Es funktioniert soweit, ist aber relativ langsam. Es wird gerade mal 10%> der PC Leistung verwendet. Kann ich den Code irgendwie beschleunigen?
Ist es relevant, die ursprüngliche Sortierung zu behalten (soweit nicht
gelöscht wird)?
Falls nein: man kann alle Zeilen einlesen und mit einem passenden
Vergleichskriterium in einem std::set speichern (elimiert automatisch
alle Duplikate), danach das set wieder ausgeben.
Falls ja: Stattdessen einen std::vector nehmen, darin alle aufzuhebenden
Zeilen speichern.
Um Duplikate zu erkennen, parallel dazu von jeder Zeile einen Hash-Wert
berechnen und alle Hashwerte in einem std::set speichern. Vor dem
Einfügen einer Zeile den zugehörigen Hashwert im set suchen und ggf. die
Zeile ignorieren.
PS: im zweiten Fall kann man den vector natürlich auch weglassen und
gleich ausgeben...
laut CPU Auslastungs Grafik scheint es, als ob 4 Kerne an der Aufgabe
schuften, kann das sein? Die Runtime verwendet insg. etwa 11-12% von den
angezeigten 15%.
Der PC hat eine SSD, also kein Flaschenhals dort.
Hansi schrieb:> Der PC hat eine SSD, also kein Flaschenhals dort.
Das hängt dann doch noch etwas von der SSD ab. Hast du mal den
Datendurchsatz (Größe Input + Größe Output) / Zeit abgeschätzt? Den Wert
vergleichst du dann mit den theoretischen Maximalwerten von SSD und RAM.
Danach kannst du dann entscheiden, ob dein Programm langsam ist.
Hansi schrieb:> laut CPU Auslastungs Grafik scheint es, als ob 4 Kerne an der Aufgabe> schuften, kann das sein? Die Runtime verwendet insg. etwa 11-12% von den> angezeigten 15%.>> Der PC hat eine SSD, also kein Flaschenhals dort.
Da wird nur aus Termischen gründen zwichen vier Kernen gewechselt. Von
der auslastung her ist es aber nur ein Kern der mit maximalleistun
läuft. Das passt ja auch zu deinem Programmcode. Du hast ja dort nichts
drin um die Arbeit auf mehrere Threads zu verteilen.
Such z.B. mal nach "multithreaded sorting c++"
https://www.heise.de/select/ix/2017/5/1492877730281965https://www.boost.org/doc/libs/1_67_0/libs/sort/doc/html/sort/parallel.html
"openmp" ist auch so ein Stichwort dazu:
https://en.wikipedia.org/wiki/OpenMP
IO dauert immer seine Zeit, gerade wenn man gemütlich eine Zeile nach
der anderen liest. Da ist auch eine SSD keine Rakete.
Probiere einfach mal wie lange es alleine dauert die Datei einzulesen
ohne was mit den ganze for zu verarbeiten.
Die moderne Variante C++ zu parallelisieren ist Intels TBB
(https://github.com/oneapi-src/oneTBB) bzw die parallel Algorithms der
STD (hoffentlich irgendwann mal).
Aber wie bereits hundert mal erwähnt hier sicher nicht das "Bottleneck".
Dirk B. schrieb:> Was steht denn bei deinem Programm unter dem Reiter „Processes“ bei CPU> Auslastung?
ist doch völlig egal. Das Programm ist, wie oben schön vorgerechnet
wurde, aufgrund des ungeeigneten O(n²)-Algorithmus um einen
Faktor >10000 langsamer als es sein müsste.
-> Sinnvolle Datenstrukturen verwenden (STL-Container können helfen),
und schon verpasst du das Teil im Taskmanager komplett, wenn du im
falschen Moment blinzelst.
Was einige wohl übersehen: es werden nicht doppelte Zeilen entfernt
sondern nur doppelte Felder innerhalb einer Zeile. Es existieren genau
45 Felder in jeder Zeile, die Erkennung läuft daher (trotz des
suboptimalen Algorithmus) mit konstanter Zeit ab - die Laufzeit des
Programms ist also O(AnzahlZeilen).
Wenn man das parallelisieren will, geht das relativ einfach, indem man
die Datei vorher in N Teile splittet, dann N-mal das Programm parallel
auf die Einzeldateien loslässt, und anschließen die Ergebnisse wieder
zusammenführt.
foobar schrieb:> Was einige wohl übersehen: es werden nicht doppelte Zeilen entfernt> sondern nur doppelte Felder innerhalb einer Zeile.
Ups. Stimmt, mein Fehler, so macht mein Post weiter oben natürlich
keinen Sinn.
Hab mich da auf Maik verlassen...
> Kann ich den Code irgendwie beschleunigen?
Versuch die String-Klasse zu vermeiden, insb auch den stringstream für
jede Zeile. In einfachem C bekommst du das ohne Speicherallozierung hin
und dürfte dann um einiges schneller sein.
foobar schrieb:> In einfachem C bekommst du das ohne Speicherallozierung hin> und dürfte dann um einiges schneller sein.
Und warum sollte es um "einiges" schneller sein? Und wieviel ist
"einiges"?
foobar schrieb:> Untested:
Und bist du sicher, dass man das nicht noch etwas unleserlicher und
unflexibler schreiben kann?
Εrnst B. schrieb:> Dirk B. schrieb:>> Was steht denn bei deinem Programm unter dem Reiter „Processes“ bei CPU>> Auslastung?>> ist doch völlig egal. Das Programm ist, wie oben schön vorgerechnet> wurde, aufgrund des ungeeigneten O(n²)-Algorithmus um einen> Faktor >10000 langsamer als es sein müsste.> -> Sinnvolle Datenstrukturen verwenden (STL-Container können helfen),> und schon verpasst du das Teil im Taskmanager komplett, wenn du im> falschen Moment blinzelst.
Es ging darum, dass das Programm den Prozessor nicht zu 100% auslastet -
da wäre ungünstiger Code (sofern kein IO benutzt wird) ja vorteilhaft.
Das Programm kann - da ohne Threads - auf einem 8 Kern Rechner ja nur
maximal 12,5% CPU Auslastung machen.
Wenn es 10% macht ist es ja auch ok.
Frank M. schrieb:> Genau das Sortieren nach dem Einlesen ist der richtige Ansatz. Dann> liegen identische Datensätze nämlich hintereinander.>> In der UNIX-Shell gibt man einfach ein:> sort <infile | uniq >outfile> oder noch kürzer, weils beide Schritte kombiniert:sort -u <infile>>outfile
Das entfernt aber Zeilen, die komplett gleich sind. Er will aber nicht
duplizierte Zeilen löschen, sondern innerhalb jeder Zeile duplizierte
Spalten, und das auch nur ab Spalte 3.
Zumindest ist das die Aussage aus dem Initialposting und passt auch zu
dem Code.
Rolf M. schrieb:> Er will aber nicht duplizierte Zeilen löschen, sondern innerhalb jeder> Zeile duplizierte Spalten, und das auch nur ab Spalte 3.
Ja, sorry, das hatte ich missverstanden.
Was mir hier auffällt:
Er startet die zweite for-Schleife unabhängig davon, ob csv_entries[n]
leer ist oder nicht, um dies dann zigmal in der zweiten Schleife zu
prüfen. Zieht man die erste Bedingung
1
csv_entries[n]!=""
vor die zweite Schleife, wird diese erst gar nicht (unnötigerweise)
durchlaufen. Denn die Variable n ändert sich im zweiten
Schleifendurchlauf gar nicht.
Also:
1
for(intn=3;n<csv_len-1;n++){
2
if(csv_entries[n]!="")
3
{
4
for(intm=n+1;m<csv_len;m++){
5
if(csv_entries[n]==csv_entries[m]){
6
csv_entries[m]="";
7
}
8
}
9
}
10
}
Dieses sollte einen spürbaren Geschwindigkeitsvorteil bringen.
Was mich irritiert: Da ist kein "break" in der zweiten Schleife, wenn
die beiden zu vergleichenden Spalten ungleich sind. Will der TO
tatsächlich auch Dubletten rauswerfen, die erst viel später wieder
erscheinen, also:
1
irgendwas ... eins zwei drei eins
soll tatsächlich transferiert werden in
1
irgendwas ... eins zwei drei
? Oder will er nur hintereinanderliegende Dubletten rauswerfen?
Letzteres ist entscheidend für die Optimierung. Ein korrekt platziertes
"break" würde nämlich die Verarbeitungsdauer nochmals verringern:
1
for(intn=3;n<csv_len-1;n++){
2
if(csv_entries[n]!="")
3
{
4
for(intm=n+1;m<csv_len;m++){
5
if(csv_entries[n]==csv_entries[m]){
6
csv_entries[m]="";
7
}
8
else
9
{
10
break;
11
}
12
}
13
}
14
}
Das ist aber noch nicht alles: Wenn tatsächlich nur gleiche Spalten
hintereinander geleert werden sollen, kann man unmittelbar vor dem
break noch einfügen:
Sven B. schrieb:> Wie immer gilt: nicht herumraten, erstmal einen Profiler> verwenden.
Profiler messen Dauer/Anzahl von Funktionsaufrufen. Der nützt Dir gar
nichts innerhalb der while-Schleife.
Außer es wird jeder Stringvergleich in C++ in eine externe Funktion
ähnlich zu strcmp() münden. Das bezweifele ich aber hier.
Frank M. schrieb:> Dieses sollte einen spürbaren Geschwindigkeitsvorteil bringen.
Wenn das die Stelle ist, die die Geschwindigkeit begrenzt.
Frank M. schrieb:> Letzteres ist entscheidend für die Optimierung.
Ist es nicht. Entscheident ist erstmal festzustellen, ob das Programm
"zu langsam" ist. Dazu muss gemessen werden. Danach sucht man die
Ursache. Dann sucht man nach Lösungen. Man fängt nicht mit dem letzten
Schritt an.
Frank M. schrieb:> Sven B. schrieb:>> Wie immer gilt: nicht herumraten, erstmal einen Profiler>> verwenden.>> Profiler messen Dauer/Anzahl von Funktionsaufrufen. Der nützt Dir gar> nichts innerhalb der while-Schleife.
Also z.B. perf annotiert einzelne Assembly-Instructions mit einem
geschätzten Gewicht. Mag sein, dass das nicht jeder Profiler kann, aber
möglich ist es definitiv.
mh schrieb:> Entscheident ist erstmal festzustellen, ob das Programm "zu langsam"> ist. Dazu muss gemessen werden. Danach sucht man die Ursache
Sehe ich anders.
Erstmal definiert man eine konkrete Aufgabenstellung, dann entwirft man
einen Algorithmus dafür.
Leider hat der TO verschwiegen, ob er nur hintereinanderliegende
Dubletten rauswerfen will oder alle. Und das ist entscheidend für den
Algorithmus.
Ein Algorithmus, der zigmal denselben Stringvergleich macht, obwohl man
mit einem pro Spalte auskommt, kann nicht optimal sein.
Frank M. schrieb:> Außer es wird jeder Stringvergleich in C++ in eine externe Funktion> ähnlich zu strcmp() münden. Das bezweifele ich aber hier.
Das wird zusätzlich auch noch passieren, das ist
std::string::operator==. ;)
> Ein Algorithmus, der zigmal denselben Stringvergleich macht, obwohl man> mit einem pro Spalte auskommt, kann nicht optimal sein.
Sicher, aber kein Algorithmus ist ideal. Man kann immer etwas besser
machen, praktisch gesprochen. Es ist schon wichtig, zu wissen, was
eigentlich das Problem ist.
Ich habe das mal schnell compiliert, und dazu ein cvs File mit 100e3
Zeilen
hergenommen:
Hans CPP (liest list.txt und generiert nodup.txt):
time ./test_hans.exe
real 0m6.766s
user 0m0.015s
sys 0m0.000s
foobar C:
time ./test_foobar.exe < list.txt > nodup2.txt
real 0m2.008s
user 0m0.000s
sys 0m0.015s
diff nodup.txt und nodup2.txt: Files sind identisch
Frank M. schrieb:> Ein Algorithmus, der zigmal denselben Stringvergleich macht, obwohl man> mit einem pro Spalte auskommt, kann nicht optimal sein.
Es muss nicht optimal sein. Es muss den Anforderungen entsprechen. Und
deine Optimierung liefert vermutlich sowas wie 0.1% Verbesserung, wenn
das Programm nur auf die SSD wartet.
Noch ein kurzes Update:
Ich habe den Spass mit Visual Studio compiliert.
Bei so einem modernen C sind alle Funktionen aus der libc
auf multithreaded ausgelegt, mit entsprechendem Overhead.
Gerade beim lesen einzelner Zeichen mit getchar() bricht die
Performance ziemlich ein.
Mit dem Macro
#define _CRT_DISABLE_PERFCRIT_LOCKS 1
lassen sich diese unnötigen Locks ausschalten.
Damit läuft die C Variante in 0.8 Sekunden durch.
Noch mal ein Faktor 2.5 :-)
Die C++ Variante braucht 4.5 Sekunden.
TotoMitHarry schrieb:> Rein Dateitechnisch sind 10 Millionen Lines einlesen was anderes als> 100MB in den Ram holen :D
Weil die Zeilen nicht 10 Byte lang sind?
mh schrieb:> Frank M. schrieb:>> Letzteres ist entscheidend für die Optimierung.> Ist es nicht. Entscheident ist erstmal festzustellen, ob das Programm> "zu langsam" ist.
Das ist ja die Ausgangsbasis für die ganze Diskussion. Das steht bereits
in der Überschrift.
> Dazu muss gemessen werden.
Wenn es dem TE zu langsam ist, ist es ihm zu langsam. Wie willst du das
messen?
> Danach sucht man die Ursache.
Aber genau das macht Frank doch.
mh schrieb:> Frank M. schrieb:>> Ein Algorithmus, der zigmal denselben Stringvergleich macht, obwohl man>> mit einem pro Spalte auskommt, kann nicht optimal sein.>> Es muss nicht optimal sein. Es muss den Anforderungen entsprechen.
Die Anforderung hier ist: "Soll schneller werden, wenn möglich".
> Und deine Optimierung liefert vermutlich sowas wie 0.1% Verbesserung, wenn> das Programm nur auf die SSD wartet.
Ja, wenn… bei Optimierung sind pauschale Annahmen keine gute Idee.
Rolf M. schrieb:> mh schrieb:>> Frank M. schrieb:>>> Letzteres ist entscheidend für die Optimierung.>> Ist es nicht. Entscheident ist erstmal festzustellen, ob das Programm>> "zu langsam" ist.>> Das ist ja die Ausgangsbasis für die ganze Diskussion. Das steht bereits> in der Überschrift.>>> Dazu muss gemessen werden.>> Wenn es dem TE zu langsam ist, ist es ihm zu langsam. Wie willst du das> messen?
Wenn du dir die Beiträge des TO nochmal anguckst, beruht seine
Einschätzung "zu langsam" auf einer niedrigen CPU Auslastung. Weitere
Infos, was dieses "zu langsam" bedeutet, fehlen.
Rolf M. schrieb:>> Danach sucht man die Ursache.> Aber genau das macht Frank doch.
Also hat er das Problem schon gefunden? Wie?
> mh schrieb:>> Frank M. schrieb:>>> Ein Algorithmus, der zigmal denselben Stringvergleich macht, obwohl man>>> mit einem pro Spalte auskommt, kann nicht optimal sein.>>>> Es muss nicht optimal sein. Es muss den Anforderungen entsprechen.> Die Anforderung hier ist: "Soll schneller werden, wenn möglich".
Dafür muss man erstmal wiessen, warum es aktuell nicht schnell genug
ist.
Rolf M. schrieb:>> Und deine Optimierung liefert vermutlich sowas wie 0.1% Verbesserung, wenn>> das Programm nur auf die SSD wartet.>> Ja, wenn… bei Optimierung sind pauschale Annahmen keine gute Idee.
Deswegen bin ich dafür erst zu messen bevor ich Annahmen mache.
Die Info die es bis jetzt gibt ist effektiv "Ich glaube mein Programm
ist zu langsam, weil sich die CPU langweilt."
Gibt es hier wirklich jemanden der ernsthaft der Meinung ist, dass der
beste nächste Schritt die Reduktion der CPU Last ist?
Rolf M. schrieb:>> Und deine Optimierung liefert vermutlich sowas wie 0.1% Verbesserung, wenn>> das Programm nur auf die SSD wartet.>> Ja, wenn… bei Optimierung sind pauschale Annahmen keine gute Idee.
Genau, deshalb muss man mit einem Profiler messen, und nicht annehmen,
dass das Problem vielleicht eine bestimmte Operation ist. ;)
Sven B. schrieb:> Genau, deshalb muss man mit einem Profiler messen
Ja eben nicht, es gab hier ja genug Verbesserungen die jedem der das
schon umgesetzt hat aufgefallen sind.
mmap -> muss man zwar selber auf Zeilenende testen aber liest dann ohne
Overhead direkt.
Sort -> ich glaube bis so eine Datei sortiert ist, ist dann Weihnachten.
nicht Zeilenweise -> in größeren Häppchen einlesen (Overhead beim lesen
begrenzen)
Multithreaded -> gekonnt an der richtigen Stelle ist das ganz anders als
automatisches Multithreading.
Richtiger Ansatz -> Skippen anstatt Leer rechnen lassen.
etc.. etc. etc.. Wer messen will braucht einen Vergleich.
mh schrieb:>> Wenn es dem TE zu langsam ist, ist es ihm zu langsam. Wie willst du das>> messen?> Wenn du dir die Beiträge des TO nochmal anguckst, beruht seine> Einschätzung "zu langsam" auf einer niedrigen CPU Auslastung. Weitere> Infos, was dieses "zu langsam" bedeutet, fehlen.
Was soll es schon bedeuten? Er will, dass es weniger Zeit braucht. Nicht
hinter allem, was ein Bastler macht, steckt ein hartes Requirement.
> Rolf M. schrieb:>>> Danach sucht man die Ursache.>> Aber genau das macht Frank doch.> Also hat er das Problem schon gefunden?
Wenn man etwas sucht, bedeutet das nicht, dass man es automatisch auch
gefunden hat, auch wenn in Software der Button "Suchen" heute gerne
durch "Finden" ersetzt wird, weil das so schön positiv klingt. Er hat
Tipps gegeben, was man ändern könnte, und dann kann man das einfach mal
ausprobieren. Ist es schneller - Ziel erreicht. Ist es nicht schneller -
wieder was gelernt.
>>> Es muss nicht optimal sein. Es muss den Anforderungen entsprechen.>> Die Anforderung hier ist: "Soll schneller werden, wenn möglich".> Dafür muss man erstmal wiessen, warum es aktuell nicht schnell genug> ist.
Ja, und das kann man entweder durch eine hochkomplexe Analyse im
tiefsten Detail erreichen, bevor man überhaupt erwägt, etwas zu ändern,
oder bei einem so trivialen Programm auch einfach durch ausprobieren.
> Rolf M. schrieb:>>> Und deine Optimierung liefert vermutlich sowas wie 0.1% Verbesserung, wenn>>> das Programm nur auf die SSD wartet.>>>> Ja, wenn… bei Optimierung sind pauschale Annahmen keine gute Idee.> Deswegen bin ich dafür erst zu messen bevor ich Annahmen mache.>> Die Info die es bis jetzt gibt ist effektiv "Ich glaube mein Programm> ist zu langsam, weil sich die CPU langweilt."
Die CPU langweilt sich offenbar nur deshalb, weil sie aus vielen Kernen
besteht, von denen nur einer genutzt werden kann und die anderen
Däumchen drehen.
> Gibt es hier wirklich jemanden der ernsthaft der Meinung ist, dass der> beste nächste Schritt die Reduktion der CPU Last ist?
Sieht so aus. Und die geposteten Werte scheinen dieser Meinung recht zu
geben.
Philipp K. schrieb:> mmap -> muss man zwar selber auf Zeilenende testen aber liest dann ohne> Overhead direkt.
mmap war in meinen Versuchen immer etwas langsamer als read/write.
Dazu ist die Fehlerbehandlung schwierig, und die Performance hängt stark
vom RAM ab. Ist nur empfehlenswert, wenn man viel im File herumhüpft.
Philipp K. schrieb:> Sven B. schrieb:>> Genau, deshalb muss man mit einem Profiler messen>> Ja eben nicht, es gab hier ja genug Verbesserungen die jedem der das> schon umgesetzt hat aufgefallen sind.
Keine Ahnung, ich sehe das anders. Wenn du alle Vorschläge umsetzt, ist
es vermutlich schnell, ja. Aber 50-70% davon werden vermutlich kein
Prozent Performance bringen, weil sie einfach etwas optimieren, was
überhaupt nicht das Bottleneck ist.
Warum Zeit mit Optimieren verschwenden an Stellen, wo es nichts bringt?
Sven B. schrieb:> Warum Zeit mit Optimieren verschwenden an Stellen, wo es nichts bringt?
Weil man noch nix von Knuth und "Premature optimisation is the root of
all evil" gehoert hat? ;)
Menschen sind erstaunlich schlecht darin vorherzusagen was an einem
Program am langsamsten ist, genau dafuer nimmt man Profiler, die 80/20
Regel ist eben meist die 95/5 Regel.
Ansonsten denke ich immer noch dass man einfacheren und schnelleren Code
fuer diese Aufgabe mit Python/pandas/numpy hinbekommt (Vectorization!),
ist quasi dafuer gemacht.
C++ mit so einem naiven Ansatz ist weder schneller, noch einfacher
umzusetzen.
Mladen G. schrieb:> Ansonsten denke ich immer noch dass man einfacheren und schnelleren Code> fuer diese Aufgabe mit Python/pandas/numpy hinbekommt (Vectorization!),> ist quasi dafuer gemacht.
Da würde ich nicht drauf wetten und man müsste dafür Python, pandas und
numpy beherschen.
mh schrieb:> Da würde ich nicht drauf wetten und man müsste dafür Python, pandas und> numpy beherschen.
Wie gesagt, ich wuerde darauf Wetten, ist ein triviales Problem dafuer,
und man kann noch viel komplexere Dinge sehr einfach damit umsetzten.
"drop_duplicates" ist sogar schon implementiert, da kann man auch die
Spalten angeben welche ein Duplikat ausmachen:
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop_duplicates.html
Mladen G. schrieb:> mh schrieb:>> Da würde ich nicht drauf wetten und man müsste dafür Python, pandas und>> numpy beherschen.>> Wie gesagt, ich wuerde darauf Wetten, ist ein triviales Problem dafuer,> und man kann noch viel komplexere Dinge sehr einfach damit umsetzten.>> "drop_duplicates" ist sogar schon implementiert, da kann man auch die> Spalten angeben welche ein Duplikat ausmachen:> https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop_duplicates.html
Zu dumm, dass die Funktion nicht das gleiche macht, wie das hier
gezeigte Programm.
Mladen G. schrieb:> Weil man noch nix von Knuth und "Premature optimisation is the root of> all evil" gehoert hat? ;)>
Blos weil du es 100 x gehört hat, wird es auch nicht wahrer.
Was machst du denn, wenn das Program zu langsam ist?
Blöde Sprüche klopfen, wie 9 von 10 es hier machen, löst das Problem
nicht.
> Menschen sind erstaunlich schlecht darin vorherzusagen was an einem> Program am langsamsten ist, genau dafuer nimmt man Profiler, die 80/20> Regel ist eben meist die 95/5 Regel.
Ich würde sagen, Menschen, die sich keine Gedanken machen
sind erstaunlich schlecht darin irgendwas sinnvolles vorherzusagen...
Mich hat es gerade mal 10 Minuten gekostet, das Program um
einen Faktor 5 schneller zu machen.
Es würde mich noch mal 20 Minuten kosten, einen weiteren
Faktor 4 herauszuholen.
Und das ohne irgendwas an dem simplen Algorithmus zu ändern.
Kauf dir doch mal einen PC, der statt 4 GHz, 80 GHz schnell ist...
mh schrieb:> Zu dumm, dass die Funktion nicht das gleiche macht, wie das hier> gezeigte Programm.
Naja, da koennte man sich fragen ob das hier gezeigte Programm zur
Problemstellung passt, "Duplikate loeschen", das Programm interessiert
sich ja nur fuer aufeinanderfolgende Duplikate.
Dass C++ "mit Schleifen" nicht schneller sein kann bei grossen
Datenmengen als "vektorisierte" Verarbeitung in Python/pandas ist IMO
schon gegeben.
Mladen G. schrieb:> Dass C++ "mit Schleifen" nicht schneller sein kann bei grossen> Datenmengen als "vektorisierte" Verarbeitung in Python/pandas ist IMO> schon gegeben.
Hängt von den Daten ab. Wenn die Einträge grad mal 1-30 Zeichen lang
sind,
würde ich nicht drauf wetten. Da ist der Overhead der Parallelisierung
viel zu hoch.
udok schrieb:> Mladen G. schrieb:>> Weil man noch nix von Knuth und "Premature optimisation is the root of>> all evil" gehoert hat? ;)>>> Blos weil du es 100 x gehört hat, wird es auch nicht wahrer.>> Was machst du denn, wenn das Program zu langsam ist?
Herausfinden warum es langsam ist.
udok schrieb:> Mich hat es gerade mal 10 Minuten gekostet, das Program um> einen Faktor 5 schneller zu machen.> Es würde mich noch mal 20 Minuten kosten, einen weiteren> Faktor 4 herauszuholen.> Und das ohne irgendwas an dem simplen Algorithmus zu ändern.
Schön, dass du die korrekten Daten und den korrekten Rechner hast, um
das "relativ langsam" des TO zu reproduzieren.
mh schrieb:> Schön, dass du die korrekten Daten und den korrekten Rechner hast, um> das "relativ langsam" des TO zu reproduzieren.
Das war jetzt der leichtest Teil, ich gebe zu ich habe
einen nicht wissenschaftlichen Ansatz gewählt :-)
Mladen G. schrieb:> Naja, da koennte man sich fragen ob das hier gezeigte Programm zur> Problemstellung passt, "Duplikate loeschen", das Programm interessiert> sich ja nur fuer aufeinanderfolgende Duplikate.
Man kann sich viel fragen, so z.B. warum der TE (der mal wieder den
Kopf in den Sand steckt), überhaupt so grossse cvs Files braucht,
und was da drinnen steht.
udok schrieb:> Blos weil du es 100 x gehört hat, wird es auch nicht wahrer.>> Was machst du denn, wenn das Program zu langsam ist?> Blöde Sprüche klopfen, wie 9 von 10 es hier machen, löst das Problem> nicht.
Soweit bist du der einzige mit bloeden Spruechen hier.
Was ich mache hab ich doch schon gesagt: Profiler nutzten
udok schrieb:> Mich hat es gerade mal 10 Minuten gekostet, das Program um> einen Faktor 5 schneller zu machen.> Es würde mich noch mal 20 Minuten kosten, einen weiteren> Faktor 4 herauszuholen.> Und das ohne irgendwas an dem simplen Algorithmus zu ändern.>> Kauf dir doch mal einen PC, der statt 4 GHz, 80 GHz schnell ist...
Das Problem in diesem Thread sollte sich in weniger als 15 Minuten
komplett loesen lassen (weniger wenn man Erfahrung hat), ist ja wirklich
trivial, und zwar so, dass da auch sehr schell laeuft.
Mladen G. schrieb:> Soweit bist du der einzige mit bloeden Spruechen hier.
Ah ha.
> Was ich mache hab ich doch schon gesagt: Profiler nutzten
Und was soll dir das bringen?
> Das Problem in diesem Thread sollte sich in weniger als 15 Minuten> komplett loesen lassen (weniger wenn man Erfahrung hat), ist ja wirklich> trivial, und zwar so, dass da auch sehr schell laeuft.
Wieder mal ein blöder Spruch ohne Nutzen.
udok schrieb:> mh schrieb:>> Schön, dass du die korrekten Daten und den korrekten Rechner hast, um>> das "relativ langsam" des TO zu reproduzieren.>> Das war jetzt der leichtest Teil, ich gebe zu ich habe> einen nicht wissenschaftlichen Ansatz gewählt :-)
Ich hätte nicht so positive Worte gewählt, um dein Vorgehen zu
beschreiben. Deine Zahlen sind vermutlich richtig auf deinem Rechner,
haben aber vermutlich nichts mit dem Problem des TO zu tun.
udok schrieb:> Hängt von den Daten ab. Wenn die Einträge grad mal 1-30 Zeichen lang> sind,> würde ich nicht drauf wetten. Da ist der Overhead der Parallelisierung> viel zu hoch.
Ich verarbeite hier "zum Spass" Daten (time series) gerne CSV bzw.
Binaerdaten von mehreren GB, da kommt man mit selbstgemachtem "Zeug"
nicht hin.
Vektorisierung ist nicht wirklich Parallelisierung im Sinne von mehreren
Threads.
Anstatt die Daten iterativ zu verarbeiten, macht man das "alles auf
einmal", sehr vereinfacht ausgedrueckt.
Mladen G. schrieb:> Anstatt die Daten iterativ zu verarbeiten, macht man das "alles auf> einmal", sehr vereinfacht ausgedrueckt.
Davon träumen wir alle, wenn der Tag lang ist...
Mladen G. schrieb:> udok schrieb:>> Davon träumen wir alle, wenn der Tag lang ist...>> SIMD in den Desktopprozessoren traeumt auch davon oefter benutzt zu> werden..
Und du glaubst, dass der C++ Compiler nicht in der Lage ist SIMD zu
nutzen?
mh schrieb:> Und du glaubst, dass der C++ Compiler nicht in der Lage ist SIMD zu> nutzen?
Den Trick moechte ich sehen bei dem der C++ Compiler eine Schleife
einfach so vektorisiert.
Mladen G. schrieb:> mh schrieb:>> Und du glaubst, dass der C++ Compiler nicht in der Lage ist SIMD zu>> nutzen?>> Den Trick moechte ich sehen bei dem der C++ Compiler eine Schleife> einfach so vektorisiert.https://godbolt.org/z/GMjdx5nWd
Heinzel schrieb:> Mladen G. schrieb:>> mh schrieb:>>> Und du glaubst, dass der C++ Compiler nicht in der Lage ist SIMD zu>>> nutzen?>>>> Den Trick moechte ich sehen bei dem der C++ Compiler eine Schleife>> einfach so vektorisiert.>> "autovectorization">> Folie 17ff:> http://hpac.cs.umu.se/teaching/sem-accg-16/slides/08.Schmitz-GGC_Autovec.pdf
Ja danke fuer den Link, aber da sieht man doch schon warum zB. der Code
oben in diesem Thread nicht vektorisiert werden kann.
> Loop to be vectorized must be innermost loop if nested
Wenn man das selber explizit macht, wird es eben doch besser.
Geht natuerlich auch mit C++, gibt ja SIMD Bibliotheken dafuer, aber
dafuer muss man sich erstmal die Schleifen abgewoehnen bzw. das
iterative Denken.
Aber das mit C++ zu machen zu wollen uebersteigt ja wohl die
Faehigkeiten der meisten, und ich bezweifle stark das es dann messbar
schneller waere..
Das mit Python/Pandas/Numpy zu machen is dagegen trivial, wie gesagt
sind dafuer gemacht.
Mladen G. schrieb:> Das mit Python/Pandas/Numpy zu machen is dagegen trivial, wie gesagt> sind dafuer gemacht.
Dann zeig mal her. Sollte ja kein großer Aufwand sein, da trivial.
mh schrieb:> Dann zeig mal her. Sollte ja kein großer Aufwand sein, da trivial.
Guter Vorschlag!
Mal so als einfachsten Fall fuer den Anfang, verstehe die Aufgabe so,
dass man Duplikate entfernen soll, anders als im Ausgangspost, muessen
diese aber nciht zusammenhaengen
Ist ungetestet, aber sobald mir jemand Testdaten zuer Verfuegung stellt
aendert sich das, dann kann man schon mal vergleichen zwischen
verschiedenen Implementierungen.
Mladen G. schrieb:> Mal so als einfachsten Fall fuer den Anfang, verstehe die Aufgabe so,> dass man Duplikate entfernen soll, anders als im Ausgangspost, muessen> diese aber nciht zusammenhaengen
Zum zweiten Mal, drop_duplicates hilft hier nicht.
Es geht hier doch einzig und alleine um Duplikate einer Zeile oder
nicht?
Ich hätte es so übersetzt
"Gucke, ob in aktueller Zeile ein oder mehrere Einträge identisch sind.
Setze diese zu "". Fange ab Spalte/Eintrag 4 (warum steht da 3?) an."
Nicht korrekt?
Gibt's Beispiel Daten?
Mladen G. schrieb:> mh schrieb:>> Zum zweiten Mal, drop_duplicates hilft hier nicht.>> Schieb mal lieber Testdaten rueber anstatt hier von oben herab zu reden.
Das mache ich, nachdem du erklärt hast was das Programm des TO macht und
was drop_duplicates macht.
Mladen G. schrieb:> mh schrieb:>> Dann zeig mal her. Sollte ja kein großer Aufwand sein, da trivial.>> Guter Vorschlag!>> Mal so als einfachsten Fall fuer den Anfang, verstehe die Aufgabe so,> dass man Duplikate entfernen soll, anders als im Ausgangspost, muessen> diese aber nciht zusammenhaengen> import pandas as pd>> df = pd.read_csv("list.txt")> df = df.drop_duplicates(subset=["alle", "spalten", "die", "duplikate",> "definieren"])> df.to_csv("no_dup.txt")
Um nochmal auf den SIMD Teil zurückzukommen auf den sich meine
Aufforderung bezogen hat. Wo genau setzt drop_duplicates SIMD ein, das
nicht automatisch vom C Compiler erzeugt wurde?
Anbei Testdaten mit 100e3 Zeilen.
Hans CPP Program braucht auf meinem Lappi 3.8 Sekunden,
Die Foobar C Implementierung mit ein paar Optimierunen 0.46 Sekunden.
Zeig mal, was du kannst :-)
Wie oben bereits korrekt angemerkt ist kommt der größte Teil des
Performance-Verlustes durch Verwendung der klasse "string" um den Wert
der einzelnen Felder zu speichern. Viel zu umständlich.
Für diese Aufgabe wäre es besser die Zeilen "on-the-fly" in Felder zu
zerlegen und direkt wieder in den Ausgabestream zu schreiben. Schon
geschriebene Feldewerte merkt man sich in einem extra Array (sinnvoll
wenn der selbe Werte mehrfach vorkommt) oder sucht einfach immer wieder
vom begin des ersten relevanten Feldes (wenn Duplikate eher vereinzelt
auftreten). Letzteres kann man auch noch ein bisl optimieren, in dem man
den Suchanfang nachzieht wenn man ein Duplikat findet.
Jan K. schrieb:> Es geht hier doch einzig und alleine um Duplikate einer Zeile oder> nicht?>> Ich hätte es so übersetzt>> "Gucke, ob in aktueller Zeile ein oder mehrere Einträge identisch sind.> Setze diese zu "". Fange ab Spalte/Eintrag 4 (warum steht da 3?) an.">> Nicht korrekt?> Gibt's Beispiel Daten?
Ja, so ist es. 4 weil C++ von 0 wegzählt. Daten sind im vorherigen Post.
udok schrieb:> Jan K. schrieb:>> Es geht hier doch einzig und alleine um Duplikate einer Zeile oder>> nicht?>>>> Ich hätte es so übersetzt>>>> "Gucke, ob in aktueller Zeile ein oder mehrere Einträge identisch sind.>> Setze diese zu "". Fange ab Spalte/Eintrag 4 (warum steht da 3?) an.">>>> Nicht korrekt?>> Gibt's Beispiel Daten?>> Ja, so ist es. 4 weil C++ von 0 wegzählt. Daten sind im vorherigen Post.
Ich weiß, dass C ab 0 beginnt ;) der OP schrieb aber "ab dem dritten
Eintrag". Nicht, dass da schon ein Bug vorliegt. Ich probiere es Mal mit
Matlab und Julia 😁
udok schrieb:> Anbei Testdaten mit 100e3 Zeilen.
Solch rege Beteiligung und erst ein alternativer Vorschlag?!
Wer weitere Testdaten braucht...
1
awk 'BEGIN { OFS=";" ; srand(0) ; while (1) { for (i=1;i<=45;++i) $i=int(10 * rand()) ; print }}'
Minimalösung mit awk:
1
dd if=data status=progress | awk -F ';' '{ OFS=FS ; for (i=4 ; i<NF ; ++i) if ($i != "") for (j=i+1 ; j<=NF ; ++j) if ($i==$j) $j="" ; print }' >/dev/null
Läuft mit ca. 1 MB/s.
Das Program des TS mit ca. 6 MB/s.
Das Programm foobar mit ca. 28 MB/s.
Im "Leerlauf" ca. 360 MB/s.
Alles auf einem alten i3 und Ubuntu.
Was ich hier mitnehme: Der C++ i/ostream ist um Größenordnungen
langsamer als der FILE stream (zumindest bei meiner Gcc Version).
Mikro 7. schrieb:> Was ich hier mitnehme: Der C++ i/ostream ist um Größenordnungen> langsamer als der FILE stream (zumindest bei meiner Gcc Version).
Vergleichst du das Programm des TO mit dem von foobar?
udok schrieb:> Anbei Testdaten mit 100e3 Zeilen.>> Hans CPP Program braucht auf meinem Lappi 3.8 Sekunden,> Die Foobar C Implementierung mit ein paar Optimierunen 0.46 Sekunden.>> Zeig mal, was du kannst :-)
Danke, damit kann man schon ich mehr anfangen.
Anscheinend hast du nur ints und floats, also keine Strings, die Datei
ist im Textformat.
Was mir jetzt noch fehlt ist die Datei mit der Ausgabe, vielleicht noch
dein Code, oder zumindest die Aussage was da denn alles mitreingerechnet
wird an Zeit, lesen, verarbeiten und schreiben?
Das finden der Duplikate dauert mit
1
df.duplicated(subset= df.columns[4:])
bei auf meiner Maschine 0.18799471855163574 Sekunden, aber das heisst
natuerlich nix weil du wohl andere HW hast.
Mladen G. schrieb:> bei auf meiner Maschine 0.18799471855163574 Sekunden, aber das heisst> natuerlich nix weil du wohl andere HW hast.
und das pro Zeile? Kommt mir reichlich langsam vor.
Bin ich weiter oben auch darauf reingefallen:
Eingabgedatei und Ausgabedatei haben gleichviel Zeilen. Nur werden
manche Zeilen kürzer.
Ich glaube dein Code macht was Anderes.
Εrnst B. schrieb:> und das pro Zeile? Kommt mir reichlich langsam vor.
Fuer alle Daten ohne einlesen, schreiben etc. pp.
Nur die Duplikate finden/markieren.
Εrnst B. schrieb:> Eingabgedatei und Ausgabedatei haben gleichviel Zeilen. Nur werden> manche Zeilen kürzer.
Danke!
Εrnst B. schrieb:> Ich glaube dein Code macht was Anderes.
Bestimmt, bin ja auch von etwas anderem ausgegangen.
Mladen G. schrieb:> Εrnst B. schrieb:>> Ich glaube dein Code macht was Anderes.>> Bestimmt, bin ja auch von etwas anderem ausgegangen.
Ich hab dich schon 2 Mal darauf hingewiesen, dass drop_duplicates was
anderes macht als das Programm des TO...
Im ursprünglichen Code wird eine Menge an std::strings unnötig angelegt
und wieder zerstört, das kostet eine Menge Zeit. Umrüstung auf aktuelles
C++ und std::string_view sollte einiges an Laufzeit einsparen.
rµ schrieb:> Im ursprünglichen Code wird eine Menge an std::strings unnötig angelegt> und wieder zerstört, das kostet eine Menge Zeit. Umrüstung auf aktuelles> C++ und std::string_view sollte einiges an Laufzeit einsparen.
Schaut so aus, als wäre C++ noch immer eine ewige Baustelle.
In den letzen Jahren hat sich viel positives getan,
aber der Speed von C ist noch in weiter Ferne, zumindest wenn
man in C++ nicht C programmieren will.
Unter Visual Studio bringt std::ios_base::sync_with_stdio(false)
gar nichts...
Ergebnisse ohne "std::ios_base::sync_with_stdio(false)",
ohne Multithreading Locks, und meinem zuvor gepostetem list.txt,
compiliert mit VS 19 (gelinkt mit ucrt.dll):
Ergebnisse mit "std::ios_base::sync_with_stdio(false)",
ohne Multithreading Locks, und meinem zuvor gepostetem list.txt,
compiliert mit VS 19 (gelinkt mit ucrt.dll):
test_hans.exe ist um 0.1 sec langsamer geworden.
Ergebnisse ohne "std::ios_base::sync_with_stdio(false)",
ohne Multithreading Locks, und meinem zuvor gepostetem list.txt,
compiliert mit VS 15 (gelinkt mit msvcrt.dll):
rµ schrieb:> Im ursprünglichen Code wird eine Menge an std::strings unnötig angelegt> und wieder zerstört, das kostet eine Menge Zeit. Umrüstung auf aktuelles> C++ und std::string_view sollte einiges an Laufzeit einsparen.
PS: Wenn ich list.txt mit nodup.txt vergleiche, dann entfernt das
originale Programm vom TO gar keine Felder, außer in der allerersten
Zeile. Wirkt recht sinnlos auf mich.
Heinzel schrieb:> PS: Wenn ich list.txt mit nodup.txt vergleiche, dann entfernt das> originale Programm vom TO gar keine Felder, außer in der allerersten> Zeile. Wirkt recht sinnlos auf mich.
Das ist richtig, ist aber bei dem Algorithmus
egal, da sowieso nicht vorher abgebrochen wird.
Du kannst das awk Skript von mikro77 verwenden, das verwendet
Zufallsdaten.
Ich habe versucht dein C++ zu übersetzen, ging leider weder unter
VS15, noch unter VS19:
test_heinzel.cpp(4): fatal error C1083: Cannot open include file:
'string_view': No such file or directory
udok schrieb:> Ich habe versucht dein C++ zu übersetzen, ging leider weder unter> VS15, noch unter VS19:>> test_heinzel.cpp(4): fatal error C1083: Cannot open include file:> 'string_view': No such file or directory
benötigt C++17 für string_view
Hier, unter Windows mit MinGW g++.exe (x86_64-posix-seh-rev0, Built by
MinGW-W64 project) 8.1.0 sieht das alles etwas anders aus.
Alles mit g++, O3 und std c++17 kompiliert.
foobars c Version, ich schätze, da ist aber einfach Get-Content auch
lahmarschig...
Das ist irgendwie alles etwas langsamer als bei euch ;) Aber auch hier
gewinnt die moderne C++ Variante. Gibt's die C Version auch mit fopen()
oder so? Denke, der stdin in der Powershell ist der Flaschenhals.
Ich habe dir die foobar Version mit fopen() ins 7zip kopiert.
Es ist auch ein bash Skript run.sh und build.sh dabei,
dass die Programme ausführt, und die MB/sec berechnet.
Jetzt brauchen wir noch einen Python Experten :-)
udok schrieb:> Jetzt brauchen wir noch einen Python Experten :-)
Hier eine Python Version von einem
SolangeEsNurEinigeSekundenBrauchtIstEsVermutlichSchnellGenug-Experten.
Braucht bei mir ungefähr 3 Mal so lange wie die Orginal C++ Variante,
also < 1 Sekunde auf meinem Rechner.
1
import csv
2
3
def main():
4
with open('list.txt', mode='r') as fin, open('nodup.py.txt', mode='w') as fout:
MaWin schrieb:> mh schrieb:>> Braucht bei mir ungefähr 3 Mal so lange wie die Orginal C++ Variante,>> also < 1 Sekunde auf meinem Rechner.>> Das läuft bei mir nicht?
Wenn du Hilfe willst, musst du schon nen paar Infos rausrücken. Sowas
wie eine genaue Beschreibung was "läuft nicht" bedeutet.
> Was ich hier mitnehme: Der C++ i/ostream ist um Größenordnungen> langsamer als der FILE stream
Ich denke nicht - std:string dürften den größten Unterschied ausmachen.
> Somit ist der C++ Code schneller :-)
;-) Nun ja, das war eine Quick'n'Dirty Trivialimplementation. Das
Einzelzeichenlesen dürfte einiges kosten. Umstellen auf zeilenweisen
I/O sollte schon einiges bringen:
1
#include<stdio.h>
2
#include<string.h>
3
4
intmain(intargc,char**argv)
5
{
6
charbuf[32768];
7
8
// if (!freopen("list.txt", "r", stdin)) return 1;
9
// if (!freopen("nodup.txt", "w", stdout)) return 1;
10
11
while(fgets(buf,sizeof(buf),stdin))
12
{
13
char*field[64],*p;
14
inti;
15
16
for(field[i=0]=p=buf;(p=strchr(p,';'));p++)
17
if(i<sizeof(field)/sizeof(*field)-1)
18
*p=0,field[++i]=p+1;
19
20
for(intn=3;n<i-1;n++)
21
if(field[n][0])
22
for(intm=n+1;m<i;m++)
23
if(strcmp(field[n],field[m])==0)
24
field[m][0]=0;
25
26
p=buf;
27
for(intn=0;n<i;n++)
28
{
29
char*s=field[n];
30
while(*s)
31
*p++=*s++;
32
*p++=';';
33
}
34
*p++='\n';
35
*p=0;
36
fputs(buf,stdout);
37
}
38
return0;
39
}
Das ist die Krux mit C++: benutzt man es wie eine High-Level-Sprache,
bekommt man auch die Performance einer High-Level-Sprache. Man kann nur
gewinnen, wenn man entweder auf C-Niveau programiert oder komplexe
Konstrukte ausnutzen kann (wie z.B. unten im Lua-Kode Patternmatching
oder Assoziativarrays).
> Jetzt brauchen wir noch einen Python Experten :-)
Wie wär's mit Lua oder LuaJIT? ;-)
foobar schrieb:> ;-) Nun ja, das war eine Quick'n'Dirty Trivialimplementation. Das> Einzelzeichenlesen dürfte einiges kosten. Umstellen auf zeilenweisen> I/O sollte schon einiges bringen:
Anscheinend bringt das gar nicht mal so viel:
1
[cvs_fun]$ cat test_hans.timing
2
user 0m1,997s
3
user 0m1,968s
4
user 0m1,972s
5
user 0m1,976s
6
user 0m2,011s
7
[cvs_fun]$ cat test_foobar2.timing
8
user 0m1,705s
9
user 0m1,788s
10
user 0m1,776s
11
user 0m1,753s
12
user 0m1,742s
13
[cvs_fun]$ cat test_foobar3.timing
14
user 0m1,500s
15
user 0m1,478s
16
user 0m1,552s
17
user 0m1,510s
18
user 0m1,528s
19
[cvs_fun]$ cat test_heinzel.timing
20
user 0m1,000s
21
user 0m1,014s
22
user 0m0,994s
23
user 0m1,023s
24
user 0m1,010s
25
[cvs_fun]$ cat test_heinzel2.timing
26
user 0m1,002s
27
user 0m0,982s
28
user 0m0,989s
29
user 0m0,997s
30
user 0m1,020s
Diesmal auf einem anderen (alten) Rechner ausgeführt: Intel Core2 T7200,
2.00GHz. Deinen neuen Code bezeichne ich als "test_foobar3.c".
Kompiliert (gcc 8) und in einem tmpfs/RAM ausgeführt mit:
for i in `seq 5`; do time ./test_foobar2; done 2>&1 | grep user > test_foobar2.timing
Die angehängte test_heinzel2.cpp enthält einen fix: Die Überprüfung auf
ein leeres Feld war unnötig (dead code), weil die extrahierten CSV
Felder immer den ; beinhalten und deshalb nie leer sein können. Sie ist
nochmal geringfügig schneller als die ursprüngliche Implementierung.
Seltsamerweise wird sie langsamer, wenn man statt
bzw. ganz ohne die "a" Variable und mit remove_prefix:
1
for(std::size_tb,i=0;
2
(b=line_view.find(';'))!=std::string_view::npos;
3
)
4
{
5
csv_entries[i++]=line_view.substr(0,b+1);
6
line_view.remove_prefix(b+1);
7
}
Bei foobars C Implementierung hätte ich mir eigentlich etwas mit strtok
vorgestellt. IMO sollte es möglich sein, dass die C und C++
Implementierungen am Ende gleich schnell sind.
mh schrieb:> Hier eine Python Version von einem> SolangeEsNurEinigeSekundenBrauchtIstEsVermutlichSchnellGenug-Experten.> Braucht bei mir ungefähr 3 Mal so lange wie die Orginal C++ Variante,> also < 1 Sekunde auf meinem Rechner.
Super :-)
Nur macht es nicht, was die anderen Programme machen...
Im Anhanng ein 10 Zeilen Input mit soll und ist Ausgabe.
foobar schrieb:> Das ist die Krux mit C++: benutzt man es wie eine High-Level-Sprache,> bekommt man auch die Performance einer High-Level-Sprache.
Das stimmt nicht. Der Trick ist, dass man es wie eine High-Level-Sprache
benutzen muss, während man trotzdem noch versteht was intern daraus
wird. Dann ist C++ trotz hohem Abstraktionsniveau (z.B. für den Leser
des Codes) schneller als viele andere vergleichbar abstrakte Sprachen.
Ausserdem wird hier immer noch wild herumgeraten. Das langsame an dem
heinz-Programm ist das Vergleichen der Strings, hier muss man
optimieren, wenn man es schneller haben will. Evtl. helfen eine
sortierte liste oder eine std::map.
Heinzel schrieb:> Bei foobars C Implementierung hätte ich mir eigentlich etwas mit strtok> vorgestellt. IMO sollte es möglich sein, dass die C und C++> Implementierungen am Ende gleich schnell sind.
Sollte möglich sein, nur schaut dann das C++ Program so aus wie das C
Program.
Aktuelle Daten mit VS 2019 unter Win10 kompiliert (-O2):
Die Performance der C++ Programme hängt ziemlich stark von
der jeweiligen Version des Compilers und der Runtime ab (Faktor 3),
wenn es überhaupt compiliert...
C ist viel gutmütiger, compiliert immer, und liefert immer dieselbe gute
Performance.
Einzelne Zeichen lesen ist kein Performance Problem,
solange die Funktion ein Makro ist.
strcmp ist ebenfalls kein grosses Performanceproblem in C.
Python fehlt noch :-/
Sven B. schrieb:> Ausserdem wird hier immer noch wild herumgeraten. Das langsame an dem> heinz-Programm ist das Vergleichen der Strings, hier muss man> optimieren, wenn man es schneller haben will. Evtl. helfen eine> sortierte liste oder eine std::map.
Vorsicht! Auf deinem Rechner ist das Vergleichen der Strings der
Flaschenhals. Das mag auf einem Rechner mit DDR3 und unbekannter SSD
anders aussehen...
udok schrieb:> mh schrieb:>> Hier eine Python Version von einem>> SolangeEsNurEinigeSekundenBrauchtIstEsVermutlichSchnellGenug-Experten.>> Braucht bei mir ungefähr 3 Mal so lange wie die Orginal C++ Variante,>> also < 1 Sekunde auf meinem Rechner.>> Super :-)>> Nur macht es nicht, was die anderen Programme machen...>> Im Anhanng ein 10 Zeilen Input mit soll und ist Ausgabe.
Bei mir liefert das Skript eine Ausgabe, die identisch zu deiner
nodup_soll.txt ist. Bist du dir sicher, dass du das Skript richtig
kopiert hast? Also auf die Leerzeichen geachtet? Ich wüsste auch nicht,
wie die nodup_ist.txt heruskommen soll.
udok schrieb:> Nur macht es nicht, was die anderen Programme machen...
Das print ist bei dir zwei Stufen zu weit eingerückt. Es sollte die
gleiche Einrückung wie das darüberliegende for haben.
Im Python Skript war ein Leerzeichen falsch, jetzt läuft es durch,
und mit einer super Performance.
Ich habe noch mit dem Mingw Compiler experimentiert, das
bringt aber nix gutes.
Letztendlich ist die Qualität der Runtime der entscheidende Faktor bei
der Performance.
mh schrieb:> Vorsicht! Auf deinem Rechner ist das Vergleichen der Strings der> Flaschenhals. Das mag auf einem Rechner mit DDR3 und unbekannter SSD> anders aussehen...
Denkbar. An der rohen I/O-Performance der Platte kannst du allerdings eh
nicht viel schrauben, und das CPU-Profile wird auf den meisten Rechnern
relativ aehnlich aussehen.
udok schrieb:
> C ist viel gutmütiger, compiliert immer, und liefert immer dieselbe gute> Performance.
Wir haetten einfach alle bei F77 bleiben sollen. Exception Handling und
Resource Management mit goto ist sicherlich der Weisheit letzter
Schluss; der Versuch, aehnlich effiziente Sprachen zu entwickeln, die
dafuer bessere Loesungen haben, ist ein Irrweg. /s
Sven B. schrieb:> Denkbar. An der rohen I/O-Performance der Platte kannst du allerdings eh> nicht viel schrauben, und das CPU-Profile wird auf den meisten Rechnern> relativ aehnlich aussehen.
In den Tests sind die Daten nach dem 2. Durchlauf eh im RAM.
Die Festplatte/SSD ist da wurscht.
Sven B. schrieb:> Wir haetten einfach alle bei F77 bleiben sollen. Exception Handling und> Resource Management mit goto ist sicherlich der Weisheit letzter> Schluss; der Versuch, aehnlich effiziente Sprachen zu entwickeln, die> dafuer bessere Loesungen haben, ist ein Irrweg. /s
Vielleicht kannst du ja ein Fortran Program herzeigen?
Dann können wir ja drüber nachdenken.
Sven B. schrieb:> mh schrieb:>> Vorsicht! Auf deinem Rechner ist das Vergleichen der Strings der>> Flaschenhals. Das mag auf einem Rechner mit DDR3 und unbekannter SSD>> anders aussehen...>> Denkbar. An der rohen I/O-Performance der Platte kannst du allerdings eh> nicht viel schrauben, und das CPU-Profile wird auf den meisten Rechnern> relativ aehnlich aussehen.
Wenn das OS im Hintergrund die Datei langsam in den RAM lädt, kann die
CPU machen was sie will, solange sie ihre Arbeit erledigt bevor der
nächste Block im Filecache ist (abgesehen von Randeffekten für die
letzte Zeile).
udok schrieb:> Python fehlt noch :-/
Hi,
wie ich feststellen musste, laesst sich das nicht vektorisieren mit
Pandas/Numpy, da die Verarbeitung innhalb der einzelnen Zeilen
stattfindet, anstatt dass alle Zeilen auf einmal verarbeitet werden
koennen.
Damit bleibt nix anderes uebrig, als da wieder zu iterieren, bzw. ich
finde da keinen anderen Weg.
Das laeuft so sehr langsam (insgesamt ca. 14 Sekunden bei mir), da eben
keine Vektorisierung moeglich ist bei finden der Duplikate in einer
Zeile, das ersetzten dagegen laeuft wiederum vektorisiert.
diese Zeile dauert ca. 12 Sekunden, laueft iterativ (apply(..)) ueber
alle Zeilen:
udok schrieb:> Ich habe dir die foobar Version mit fopen() ins 7zip kopiert.>> Es ist auch ein bash Skript run.sh und build.sh dabei,> dass die Programme ausführt, und die MB/sec berechnet.>> Jetzt brauchen wir noch einen Python Experten :-)
Vielen Dank! Wie lässt du die sh file bei dir laufen unter Windows?
Cygwin oder Git Bash oder im WSL?
edit: in beidem läuft dein run.sh nicht (nachdem es Probleme mit dem
Zeilenumbruch gab, kann aber auch an GIT gelegen haben)
WSL2, Ubuntu
1
find-duplicates-benchmark/cvs_fun$ ./run.sh
2
gawk: cmd. line:1: BEGIN { print - ; }
3
gawk: cmd. line:1: ^ syntax error
edit: ich muss erstmal bash v5 installieren... sonst gibts
$EPOCHREALTIME nicht. Gehe ich also davon aus, dass du in der WSL
unterwegs bist?
Jan K. schrieb:> Vielen Dank! Wie lässt du die sh file bei dir laufen unter Windows?> Cygwin oder Git Bash oder im WSL?
Ich verwende https://www.msys2.org - wenn die bash aktuell ist, laufen
die Skripts auch mit Cygwin, WSL2 und Linux.
Die aktuellen Source Files mit den compilierten Programmen
für Win10 und den Skripten run.sh und build.sh sind angehängt.
> edit: in beidem läuft dein run.sh nicht (nachdem es Probleme mit dem> Zeilenumbruch gab, kann aber auch an GIT gelegen haben)
Sollten Unix Zeilenumbrüche sein, sonst gibt es nur Ärger.
@mgira
> wie ich feststellen musste, laesst sich das nicht vektorisieren mit> Pandas/Numpy, da die Verarbeitung innhalb der einzelnen Zeilen> stattfindet, anstatt dass alle Zeilen auf einmal verarbeitet werden> koennen.
Die Python Variante läuft eigentlich schon sehr schnell,
da ist nicht viel Unterschied zu C++ ohne string_view,
was es erst in C++17 gibt.
Ich habe noch ein Windows Native Program angehängt, das ganz
ohne C Runtime auskommt, alle Programme sind dynamisch mit der MS
Runtime
gelinkt, hier die Ergebnisse:
Das schnellste Program schafft 110 MB/sec, und hat gerade mal 1844 Bytes
und belegt einen 4k Sektor auf der SSD.
Die SSD schafft über 1GB/sec, die Programme sind zumindest
bei den relativ kleinen Files nicht IO limitiert.
Hab auch nochmal mit Matlab rumgespielt. High level Sprache, also auch
nicht zu viel auf low level rumfrickeln, sondern vektorisieren wo geht.
Das Kernproblem ist, dass ML column major die Daten im Speicher ablegt.
Man kann also wunderbar eine gesamte Spalte oder ein Subset daraus lesen
und bearbeiten, manuell dadurch zu iterieren, um alle Spalten und eine
Zeile zu bekommen ist ein Graus. Da hab' ich nach einigen Minuten mal
abgebrochen bei der Trivial Lösung mit `table` Datentyp.
Da wir hier aber ja keine Fancy Operationen auf coolen Datentypen machen
wollen, sondern eine String Matrix vollkommen reicht, kann man auch
`readmatrix` nehmen.
Interessanterweise spielt es dann doch keine Rolle, ob man über Zeilen
oder Spalten iteriert.
Es findet alles im RAM statt, also wird die Lösung irgendwann abkacken,
wenn die Dateien zu groß sind...
Ich bin mit den selben Voraussetzungen dran gegangen, was delimiter,
#Variables und so weiter angeht, ein automatisches Erkennen dauert ein
paar hundert Millisekunden mehr.
1
function T = mat()
2
opts = delimitedTextImportOptions('NumVariables',45,"Delimiter",";","VariableTypes",repmat("string",45,1)); % kommentieren, um floats zu bekommen
@mgira, bei dir fehlt noch, dass alles ab der 4. Spalte geprüft werden
muss. Und bringt es evtl. was, den Datensatz zu transponieren?
Quintessenz für mich:
1) Meine Güte, ist table lahmarschig... egal ob rowfun oder manuelle
Iteration. Habe beim selben Test nach 200 Sekunden abgebrochen
2) Matlab ist auf Augenhöhe mit Pandas, wenn man einen primiveren
Datentyp (string matrix) verwendet
3) Strings in ML sind gar nicht mehr so langsam wie sie mal waren
4) Output Variablen werden berechnet, obwohl sie nicht gebraucht werden
(~), wtf...
5) row vs col major ist wohl doch nicht so wichtig
6) der Profiler ist wichtig
7) arrayfun ist langsamer als manuelles loopen :(
Hier noch eine Idee grob skizziert:
File mit readahead in Speicher mappen (mmap)
Sich zum n-ten Separator via Pointer ranrobben.
Nach dem n-ten Seperator Hash bis zum Zeilenende bilden.
Den Hash in der Hash-Tabelle suchen und ggf. Hashinput vergleichen.
Falls gefunden
weiter
Falls nicht
Hash in Tabelle speichern und den Hashinput als Pointer in die
gemappte Datei speichern
Zeile ausgeben (vorher den Pointer auf den aktuellen Zeilenanfang
sichern)
nächste Zeile
Die Anzahl der Hashbuckets in der Hashtabelle ist kritisch, dafür bietet
sich eine Heuristik über die Dateigrösse an.
Richtig implementiert sollte man mit wenig speicherkopieren und wenig
zusätzlichen Speicher und funktionsaufrufen auskommen.
Evtl. lässt sich das auf mehrere CPUs verteilen wenn man den Input auf
die CPUs aufteilt und die Hashsuche nur in einer Instanz laufen lässt.
udok schrieb:> Die Python Variante läuft eigentlich schon sehr schnell,> da ist nicht viel Unterschied zu C++ ohne string_view,> was es erst in C++17 gibt.
Ich hatte eigentlich vor den Unterschied zwischen Iteration in C++ und
Vektorisierung in Python/Pandas darzustellen, denn damit haette
Python/pandas eine echte Chance schneller zu sein, theoretisch.
Jan K. schrieb:> @mgira, bei dir fehlt noch, dass alles ab der 4. Spalte geprüft werden> muss. Und bringt es evtl. was, den Datensatz zu transponieren?
Ja das fehlt noch.
transform ist eine sehr gute Idee! :)
Den dataframe "kippen", dann koennte man spaltenweise vektorisiert
arbeiten und muss nur ueber die 44 Spalten iterieren, anstatt ueber alle
Zeilen zu iterieren.
Ich probier das mal.
Mladen G. schrieb:> Ich hatte eigentlich vor den Unterschied zwischen Iteration in C++ und> Vektorisierung in Python/Pandas darzustellen, denn damit haette> Python/pandas eine echte Chance schneller zu sein, theoretisch.
Kannst du mal genau erklären, was deiner Meinung nach der Unterschied
zwischen Iteration in C++ und Vektorisierung in Python ist?
Mladen G. schrieb:> Ja das fehlt noch.> transform ist eine sehr gute Idee! :)> Den dataframe "kippen", dann koennte man spaltenweise vektorisiert> arbeiten und muss nur ueber die 44 Spalten iterieren, anstatt ueber alle> Zeilen zu iterieren.
Welche Operationen können dann deiner Meinung nach vektorisiert
ausgeführt werden?
mh schrieb:> Kannst du mal genau erklären, was deiner Meinung nach der Unterschied> zwischen Iteration in C++ und Vektorisierung in Python ist?
Ich gehe davon aus dass die Vektorisierung der Iteration ueberlegen ist,
egal in welcher Sprache.
Mein naiver Ansatz war wohl zu naiv um das zu zeigen, kann auch sein
dass ich da komplett falsch liege.
mh schrieb:> Welche Operationen können dann deiner Meinung nach vektorisiert> ausgeführt werden?
Das suchen nach Duplikaten pro Zeile, aber da Pandas da nicht mitmacht,
muss ich das wohl erst in ein Format bringen bei dem Pandas das macht,
da kam der Vorschlag mit transform, also den "dataframe zur Seite
kippen", Zeilen zu Spalten, dann sollte es auch mit der Vektorisierung
klappen, iterieren muesste man dann nur noch ueber die Spalten.
Ob das dann mit dem ganzen umwandeln des DF schneller ist, muesste ich
dann mal sehen.
mh schrieb:> Welche Operationen können dann deiner Meinung nach vektorisiert> ausgeführt werden?
Bei Matlab und Python heißt vektorisieren eher, auf kompletten Spalten
(also allen Zeilen gleichzeitig) zu operieren. Das meinte ich oben mit
column Major. Dann kann es sehr schnell werden, weil die Bereiche im
Speicher hintereinander liegen. Man kann z.b. sowas machen
1
A = rand (1000, 1000); % 1000x1000 matrix
2
Col1 = A(:,1) + 200;
Man muss also nicht explizit über alle Elemente iterieren, sondern
operiert direkt auf Vektoren (oder auch Matrizen, geht aber im TO
Beispiel nicht). I
In meinem Beispiel wird 200 auf alle Elemente der ersten Spalte addiert.
Und das ist zig Fach schneller, als das in einem Loop zu machen. Es wird
dann direkt die richtige BLAS Funktion aufgerufen und teilweise kann das
auch über SIMD wirklich in der CPU vektorisiert werden afaik. Aber ich
weiß nicht, wann das kickt und wann eben nicht.
Jedenfalls sollte man in beiden Sprachen so wenig wie möglich iterativ
auf einzelnen Elementen machen und eher "größer" denken. Ist mehr
mathematisch angehaucht finde ich. Am Ende muss man das allerdings auch
so machen, weil beide Sprachen als interpretierte Sprachen keine Chance
haben gegen C und co
Mladen G. schrieb:> Das suchen nach Duplikaten pro Zeile, aber da Pandas da nicht mitmacht,> muss ich das wohl erst in ein Format bringen bei dem Pandas das macht,> da kam der Vorschlag mit transform, also den "dataframe zur Seite> kippen", Zeilen zu Spalten, dann sollte es auch mit der Vektorisierung> klappen, iterieren muesste man dann nur noch ueber die Spalten.> Ob das dann mit dem ganzen umwandeln des DF schneller ist, muesste ich> dann mal sehen.
In Matlab ist es das jedenfalls nicht :( aber das heißt nix. Fand die
Idee gut :P
Mladen G. schrieb:> Ich gehe davon aus dass die Vektorisierung der Iteration ueberlegen ist,> egal in welcher Sprache.> Mein naiver Ansatz war wohl zu naiv um das zu zeigen, kann auch sein> dass ich da komplett falsch liege.
Davon ging ich zuerst auch aus. Bei näherem Nachdenken bin ich mir nicht
mehr so sicher. Die Low Level libs, BLAS und Co könnten das auch wieder
nur in eine iterative Form bringen. Und damit ist das alles
syntaktischer Zucker. Ich suche Mal, ob es dazu Infos gibt. Noch denke
ich auch, dass vektorisiert schneller ist. Bin gespannt
Mladen G. schrieb:> mh schrieb:>> Kannst du mal genau erklären, was deiner Meinung nach der Unterschied>> zwischen Iteration in C++ und Vektorisierung in Python ist?>> Ich gehe davon aus dass die Vektorisierung der Iteration ueberlegen ist,> egal in welcher Sprache.
Du gehst also davon aus, ohne beschreiben zu können, was es überhaupt
ist.
Jan K. schrieb:> Man muss also nicht explizit über alle Elemente iterieren, sondern> operiert direkt auf Vektoren (oder auch Matrizen, geht aber im TO> Beispiel nicht).
Du glaubst also, dass da im Hintergrund nicht iteriert wird? Ich
verstehe das Argument nicht.
mh schrieb:> Du glaubst also, dass da im Hintergrund nicht iteriert wird? Ich> verstehe das Argument nicht.
Aus Anwenderperspektive nicht. Im Hintergrund hängt es von der konkreten
Implementierung ab, wie ich in dem anderen Post schrieb, gehe ich aber
durchaus davon aus, dass da auch Vektor Instruktionen der CPU zu trage
kommen. Weiß aber noch nicht wann und in welchem Ausmaß.
Als Hinweis für dich, ich glaube, dass vektorisieren je nach Kontext
unterschiedlich interpretiert wird. Und hier möglicherweise zwei Welten
aufeinander prallen. Im Falle von Matlab und Python (beide kommen aus
dem wissenschaftlichen Rechnen) ist es so wie ich oben schrieb. Und es
wird so auch in gängiger Literatur zu den Programmen propagiert. Was Low
level passiert steht auf nem anderen Blatt.
Jan K. schrieb:> Als Hinweis für dich
Ich hätte es vielleicht dazuschreiben sollen, ich bin mir bewusst, wie
numpy (ich gehe davon aus wenn du python schreibst meinst du numpy oder
pandas) funktioniert. Ich arbeite jeden Tag damit. Was ich nicht
verstehe ist die angegebene Begründung, warum diese Vektorisierung numpy
oder matlab schneller machen soll als C oder C++.
mh schrieb:> Was ich nicht> verstehe ist die angegebene Begründung, warum diese Vektorisierung numpy> oder matlab schneller machen soll als C oder C++.
Schneller nicht, aber unter Umständen "nicht langsamer".
Sven B. schrieb:> mh schrieb:>> Was ich nicht>> verstehe ist die angegebene Begründung, warum diese Vektorisierung numpy>> oder matlab schneller machen soll als C oder C++.>> Schneller nicht, aber unter Umständen "nicht langsamer".
Das ist immer noch sehr optimistisch ;-). Ich habe es bis jetzt noch
nicht erlebt, dass für realistische Aufgaben numpy an C oder C++
herankommt. Mladen G. glaubt aber, dass pandas schneller sein kann:
Mladen G. schrieb:> Ich hatte eigentlich vor den Unterschied zwischen Iteration in C++ und> Vektorisierung in Python/Pandas darzustellen, denn damit haette> Python/pandas eine echte Chance schneller zu sein, theoretisch.
mh schrieb:> Jan K. schrieb:>> Als Hinweis für dich> Ich hätte es vielleicht dazuschreiben sollen, ich bin mir bewusst, wie> numpy (ich gehe davon aus wenn du python schreibst meinst du numpy oder> pandas) funktioniert. Ich arbeite jeden Tag damit. Was ich nicht> verstehe ist die angegebene Begründung, warum diese Vektorisierung numpy> oder matlab schneller machen soll als C oder C++.
Okay :) ja ich meine numpy/Pandas.
Gibt es echt keine Fälle, wo das sein kann? Optimieren Standard C (GCC,
clang) compiler z.B. enge Schleifen, Skalarprodukte, Linearkombination
und so direkt zu SIMD Instruktionen?
Zumindest ML (und numpy mit Sicherheit auch) tun das wohl
https://stackoverflow.com/questions/45770057/how-does-vectorization-in-matlab-work
Jan K. schrieb:> Gibt es echt keine Fälle, wo das sein kann?
Keine Fälle würde ich nicht sagen. Aber wenn in numpy und in C++ die
gleiche Arbeit verrichtet wird, ist C++ sehr sehr sehr Wahrscheinlich
schneller. Wenn in numpy weniger Arbeit verrichtet wird, weil ein besser
Algo verwendet wird, ist es kein fairer Vergleich. An dieser Stelle
liegt der Vorteil von numpy. Es ist wahrscheinlich, dass man einen
akzeptabel optimierten Algo in numpy oder scipy findet.
> Optimieren Standard C (GCC,> clang) compiler z.B. enge Schleifen, Skalarprodukte, Linearkombination> und so direkt zu SIMD Instruktionen?
Das kommt drauf an. Schleifen ja, das ist allerdings nicht perfekt.
Skalarprodukte, Linearkombinationen und ähnliches wird bei numpy und
vermutlich Matlab von BLAS erledigt, einer Lib, die in C oder Fortran
geschrieben ist.
Jan K. schrieb:> Gibt es echt keine Fälle, wo das sein kann?
numpy ist ja in C/Fortran geschrieben. Klar kannst du C-Code schreiben,
der langsamer ist, aber es wird offensichtlich für jeden Anwendungsfall
möglich sein, C-Code zu schreiben, der gleich schnell oder schneller
ist.
Sven B. schrieb:> numpy ist ja in C/Fortran geschrieben.
Darum verstehe ich nicht wie hier C mit "Python" verglichen wird ;-)
Genauso wie bei Rust: Rust ist mindestens genauso schnell wie C/C++ bla,
bla, bla!
Tja, wenn Rust LLVM (also die gleichen Optimierungen) benutzt....
OK, angebissen. Hat jemand eine Erklärung dafür, dass der Python code
(s.o.) im Gegensatz zu den obigen Ergebnissen bei mir nahezu *doppelt so
schnell* ist wie der originale C++ code (0.42s vs 0.82s)? (Linux Mint
20.1, Python 3.8.5, gcc 9.3.0). Kann das jemand unter Linux bestätigen?
Die Ausgabe habe ich natürlich verglichen.
Marcus H. schrieb:> OK, angebissen. Hat jemand eine Erklärung dafür, dass der Python code> (s.o.) im Gegensatz zu den obigen Ergebnissen bei mir nahezu *doppelt so> schnell* ist wie der originale C++ code (0.42s vs 0.82s)? (Linux Mint> 20.1, Python 3.8.5, gcc 9.3.0). Kann das jemand unter Linux bestätigen?>> Die Ausgabe habe ich natürlich verglichen.
Bei Python habe ich das nicht gesehen.
Aber ähnliches Verhalten gibt es bei gawk, unter WSL2 ist gawk 4.1.4 ca.
3x langsamer als die msys2 gawk 5.1.0 version.
Schon komisch, das eine so alte Sprache noch solche Sprünge macht.
Ich habe run.sh angepasst, sodass sie auch mit der bash 4.x unter
Ubuntu WSL2 out of the box funktioniert.
Es gibt auch ein build_linux.sh, das die Programme unter Linux baut.
Die C++ Runtime ist unter Linux sehr viel näher an der C Runtime dran.
Allerdings kackt die C Runtime beim lesen einzelner Zeichen ab
(test_foobar2.exe), da die getchar() Funktion kein Makro mehr ist,
schade.
Auch braucht es -O3, um eine brauchbare Performance zu bekommen,
sonst werden anscheinend inline/template/was-auch-immer Konstrukte
nicht gut optimiert.
Hier die Ergebnisse (Linux Ubuntu unter WSL2, gcc 7.5.0, x64):
udok schrieb:> Hier die Ergebnisse (Linux Ubuntu unter WSL2, gcc 7.5.0, x64):
Lässt du jedes Programm einmal laufen? Kein Best-Of oder Median aus 5
Durchläufen oder etwas ähnliches?
mh schrieb:> Lässt du jedes Programm einmal laufen? Kein Best-Of oder Median aus 5> Durchläufen oder etwas ähnliches?
Läuft nur einmal durch. Ich habe eine neue Version angehängt,
die 3x durchläuft.
Anbei noch ein paar Werte. Alles in MB/s. Werte um die 300 MB/s sind mit
Vorsicht zu bewerten da nahe am Durchsatzlimit.
1
100 10 1
2
-------------------------
3
heinzel 344 64,8 12,8
4
foobar 155 94,8 28,6
5
n2.awk 21,1 5,9 1,2
6
n2.pl 68,6 7,8 1,7
7
n2 40,5 33,7 20,5
8
hash.awk 36,8 22,8 7,9
9
hash.pl 177 31,0 6,2
10
hash 324 107 29,2
11
sort 287 88,4 18,8
Spalten 2-4 geben die Feldlaengen wieder: 100 Zeichen, 10 Zeichen, 1
Zeichen.
Felder sind Zufallszahlen (0..9) mit Padding bei den 10/100 Zeichen.
n2: quadratischer Ansatz (alle Felder vergleichen)
Da das Programm von foobar bereits eine Pointertabelle
nutzt habe ich es in meinem n2-Ansatz mal ohne probiert
(C++)... mit sehr maessigen Erfolg. ;-)
sort: Duplikate werden durch Sortierung gefunden (C++).
Die *.pl-Programme sind in Perl. Ohne Endung in C/++.
Source Code kann ich bei Interesse posten.
Am besten gefaellt mir die AWK/Hash Implementierung (ist natuerlich sehr
subjektiv).
Die Awk Variante ist super schnell, vergleichbar mit der python Version
:-)
Bitte poste den Source Code, mich interessiert die Perl Version,
die fehlt in bei den Vergleichen ja noch.
Grüsse,
Udo
Ich habe das Python-Programm von mh ein wenig optimiert, ohne aber am
grundsätzlichen Verfahren etwas zu ändern:
- Den CSV-Parser habe ich – wie alle anderen hier – weggelassen und
durch einen wesentlich schnelleren split(';') ersetzt. Da das auch der
TE getan hat, ist davon auszugehen, dass in den einzelnen Elementen
keine Semikola vorkommen, so dass diese Vereinfachung IMHO zulässig
ist.
- Das inkrementelle Zusammensetzen von Strings aus Teilstrings mittels
+= ist in Python langsam, da Strings immutable sind und deswegen bei
jedem Anhängen eine Teilstrings komplett neu angelegt und kopiert
werden müssen. Ich habe das dahingehend geändert, dass der
Ausgabestring erst am Ende der Zeilenbearbeitung in einem Rutsch mit
join erzeugt wird.
Auf meinem Laptop mit i5-6267U CPU @ 2.90GHz und Arch Linux sehen die
Ergebnisse so aus:
Yalu X. schrieb:> Ich habe das Python-Programm von mh ein wenig optimiert, ohne aber am> grundsätzlichen Verfahren etwas zu ändern:
Lustig, fast den selben Text habe ich heute Nachmittag auch verfasst und
eben vor dem Abschicken noch mal die Seite aktualisiert :-)
> - Das inkrementelle Zusammensetzen von Strings aus Teilstrings mittels> += ist in Python langsam, [...] Ich habe das dahingehend geändert, dass der> Ausgabestring erst am Ende der Zeilenbearbeitung in einem Rutsch mit> join erzeugt wird.
Habe ich auch gemacht, hat bei mir aber keinen nennenswerten Vorteil
erbracht. Ich hoffte dass ich im nächsten Schritt die Listenelemente der
Zeile effizienter in-place modifizieren könnte (Schleife mit
enumerate()). War aber nicht der Fall -- im Gegenteil.
Man kann auch pypy, statt cpython, verwenden. Dann läuft das noch mal
doppelt so schnell. Dazu muss allerdings das print() durch fout.write()
ersetzt werden.
Yalu X. schrieb:> Ich habe das Python-Programm von mh ein wenig optimiert, ohne aber am> grundsätzlichen Verfahren etwas zu ändern:
Der Python code ist damit schneller als der C++ Code vom TE...
Soviel zu den Vorurteilen gegenüber Skriptsprachen.
Irgendwann vor zig Jahren habe ich mal CVS verwendet, ist anscheinend
hängen geblieben.. habe es in CSV geändert.
Ich habe noch eine Linux Native Version angehängt (open/read/write).
Das ist etwas lieblos gemacht, und die Benschmarks sind nicht
berauschend.
udok schrieb:> Der Python code ist damit schneller als der C++ Code vom TE...
Das ist ja auch der falsche ansatz..
Wenn Python davon ein mmap und Pointerarithmetik macht ist das doch kein
Wunder.. mach das doch mal in C..
ach war hier ja schon ->
Beitrag "Re: c++ Code langsam"
Da ist halt durch den GetLine-Overhead und das die Verarbeitung auf
GetLine warten muss und umgekehrt schon ein Bottleneck.
Philipp K. schrieb:> Wenn Python davon ein mmap und Pointerarithmetik macht ist das doch kein> Wunder.. mach das doch mal in C..
Warum sollte python mmap und Pointerarithmetik machen?
> ach war hier ja schon ->> Beitrag "Re: c++ Code langsam">> Da ist halt durch den GetLine-Overhead und das die Verarbeitung auf> GetLine warten muss und umgekehrt schon ein Bottleneck.
Hast du dafür einen Beleg?
mh schrieb:> Warum sollte python mmap und Pointerarithmetik machen?
Weil Der Pyrhon Sourcecode auch nur in C geschrieben ist.. also wenn da
für Fopen csv ein Bytestream gelesen wird.. steht im Quelltext
memchar(Fin) (Wohl das schnellste ByteIO in C) Musst du selbst suchen
und nachlesen.. ich habe kurz mal reingeschaut.
mh schrieb:> Hast du dafür einen Beleg?
weil getline noch nicht die schnellste Version ist und beim TO
Verarbeitung auf Eingabe und Ausgabe auf Verarbeitung warten muss. der
Rest sind nur Nice To Have Unterschiede.
@Philipp:
Das Einlesen der Datei fällt bei der vorliegenden Anwendung kaum ins
Gewicht. Außerdem hat Python dabei keinen Vorteil gegenüber C++. Ich
habe mal die Zeiten für dass bloße zeilenweise Einlesen der Datei
gemessen:
C++:
1
#include<fstream>
2
#include<string>
3
4
intmain(){
5
std::ifstreaminFile("list.txt");
6
std::stringline;
7
while(std::getline(inFile,line));
8
}
Python:
1
for line in open('list.txt'): pass
Gemessene Zeiten in ms:
1
von SSD aus Cache
2
────────────────────────────
3
Python 107 47
4
C++ 87 15
5
────────────────────────────
Da udok in seinem aktuellen run.sh jeden Benchmark dreimal ausführt und
das Minimum der gemessenen Zeiten nimmt, ist die Spalte "aus Cache"
relevant.
Philipp K. schrieb:> mh schrieb:>> Warum sollte python mmap und Pointerarithmetik machen?>> Weil Der Pyrhon Sourcecode auch nur in C geschrieben ist..
Willst du mit dem Satz aussagen, dass ein Teil der Python-Bibliothek in
C geschrieben ist?
Philipp K. schrieb:> also wenn da> für Fopen csv ein Bytestream gelesen wird.. steht im Quelltext> memchar(Fin) (Wohl das schnellste ByteIO in C) Musst du selbst suchen> und nachlesen.. ich habe kurz mal reingeschaut.
Was genau ist memchar? Wo wird das im csv Modul genutzt? Und wo genau
wird ein mmap durchgeführt?
Philipp K. schrieb:> mh schrieb:>> Hast du dafür einen Beleg?>> weil getline noch nicht die schnellste Version ist und beim TO> Verarbeitung auf Eingabe und Ausgabe auf Verarbeitung warten muss. der> Rest sind nur Nice To Have Unterschiede.
Ich warte immer noch auf Belege. Vermutungen haben wir genug.
mh schrieb:> Ich warte immer noch auf Belege. Vermutungen haben wir genug.
Google die Basics doch selbst, ich mach nur Elektroinstallation.
Dann holste dir von deinem Linux repo die source für python3 und suchst
nach iofile und libcsv.
Irgendwann findest du das vielleicht auch.
Philipp K. schrieb:> mh schrieb:>> Ich warte immer noch auf Belege. Vermutungen haben wir genug.>> Google die Basics doch selbst, ich mach nur Elektroinstallation.
Ok, damit gehe ich davon aus, dass du keine Ahnung vom Thema hast.
> Dann holste dir von deinem Linux repo die source für python3 und suchst> nach iofile und libcsv.>> Irgendwann findest du das vielleicht auch.
Habe auf github in source geguckt und gegoogelt und nichts gefunden.
Ich hab noch etwas mit C++ getestet:
Mikro 7. schrieb:> Was ich hier mitnehme: Der C++ i/ostream ist um Größenordnungen> langsamer als der FILE stream (zumindest bei meiner Gcc Version).Heinzel schrieb:> https://en.cppreference.com/w/cpp/io/ios_base/sync_with_stdio
Ich dachte ja, damit wäre mein i/ostream Problem gelöst [->UNSYNC]. Ist
es aber nicht.
Zum einen ist cin "tied" to cout. D.h., bei jedem getline wird cout
geflushed was zu vielen system calls führt (strace). [->UNTIE]
Dann ist auch der ostream< operator für char sehr gemütlich. Besser ist
put(), wie auch mh oben benutzt. [->PUTCHAR] (Dagegen hatte write() bei
mir keine spürbaren Effekte.)
Aber selbst wenn man beides fixed, bleibt der FILE Stream noch immer
schneller. [->FSTREAM]
1
awk 'BEGIN { OFS=";" ; srand(0) ; while (1) { for (i=1;i<=45;++i) $i=sprintf("%d",int(10 * rand())) ; print }}' | head -1000000 > 1mx1
2
3
g++ -O3 -Wall -o h hash_test.cc
4
/usr/bin/time -f %E ./h <1mx1 >/dev/null
5
0:04.95
6
7
g++ -DUNSYNC -O3 -Wall -o h hash_test.cc
8
/usr/bin/time -f %E ./h <1mx1 >/dev/null
9
0:03.04
10
11
g++ -DUNTIE -O3 -Wall -o h hash_test.cc
12
/usr/bin/time -f %E ./h <1mx1 >/dev/null
13
0:04.43
14
15
g++ -DPUTCHAR -O3 -Wall -o h hash_test.cc
16
/usr/bin/time -f %E ./h <1mx1 >/dev/null
17
0:04.17
18
19
g++ -O3 -Wall -o h hash_test.cc
20
/usr/bin/time -f %E ./h <1mx1 >/dev/null
21
0:04.95
22
23
g++ -DUNSYNC -DUNTIE -DPUTCHAR -O3 -Wall -o h hash_test.cc
24
/usr/bin/time -f %E ./h <1mx1 >/dev/null
25
0:01.92
26
27
g++ -DUNSYNC -DFSTREAM -O3 -Wall -o h hash_test.cc
28
/usr/bin/time -f %E ./h <1mx1 >/dev/null
29
0:01.55
Ich habe hash_test.cc angehangen.
Nach der Anpassung meiner drei Programme führt das zu entsprechend
höheren Durchsätzen.
Vorher (UNSYNC only):
Hier eine C# implementation, liegt mit dem csv_fun testset zwischen
foobar2 und foobar3.
Jagt man was durch das Dubletten auch in Linien neben der ersten hat,
dann schlaegt die C# Implementation sogar test_win_native.
Cheers, Roger
mh schrieb:> Habe auf github in source geguckt und gegoogelt und nichts gefunden.
Mmap wird da auch nicht genutzt, das war eher als Beispiel.. wieso sucht
man den schnellsten Weg nicht in C obwohl der Interpreter oder das
benutzte Tool sowieso in C geschrieben sind. Ohne C ists klar, da nimmt
man den Interpreter oder das Tool bei dem es nur ein paar Zeilen sind.
Habe auch schon etwas ähnliches mit 10000 CSVs mit Tausenden Zeilen in
Bash mit dem Openoffice Kommandozeilen tool und anderen verdächtigen wie
sed und MCP umgesetzt. Das waren hinterher nur 20 Zeilen. Die
eigentliche Zeit spielte allerdings keine Rolle.
Philipp K. schrieb:> mh schrieb:>> Habe auf github in source geguckt und gegoogelt und nichts gefunden.>> Mmap wird da auch nicht genutzt, das war eher als Beispiel.. wieso sucht> man den schnellsten Weg nicht in C obwohl der Interpreter oder das> benutzte Tool sowieso in C geschrieben sind.
Ok, dann bleibt noch die Freage wo diese memchar genutzt wird und was es
ist.
Da das Programm für die Testdatei außer in der ersten Zeile anscheinend
keine Duplikate erzeugt, halte ich den Benchmark zwar für ziemlich
witzlos, immerhin komme ich mit meinem zusammengebastelten Rust-Programm
auf ganz gute Performance, trotz Optimierungspotential.
Würde ja vermuten, dass da irgendwo ein grober Schnitzer ist, aber der
einzige Test gibt den korrekten Hash ¯\\\_(ツ)_/¯.
list.txt wurde mit 300000 Zeilen erzeugt, CPU ist ein AMD EPYC 7702P,
GCC 10.3.1, rustc 1.54.0-nightly, Python 3.9.4.
Den Python Code mithilfe von Cython nativ zu übersetzen führt zu nochmal
etwas schnellerer Ausführung als durch den pypy JIT Compiler. Wir
bewegen uns aber mit dem Testdatensatz, selbst auf nicht ganz aktueller
Hardware, im Rahmen der Messungenauigkeit.
@mh: Kannst du mal die Kommandozeile zum Übersetzen deines Codes
angeben? Ich bekomme hier Fehlermeldungen. (g++ -O3 -march=native
-std=c++17 test_mh.cpp -o test_mh)
Das SNR einer high-level Sprache ist unschlagbar.
Marcus H. schrieb:> Wir> bewegen uns aber mit dem Testdatensatz, selbst auf nicht ganz aktueller> Hardware, im Rahmen der Messungenauigkeit.
Die Wiederholgenauigkeit auf meinem Rechner ist 0.003 Sekunden, wenn die
Dateien im RAM sind.
Marcus H. schrieb:> @mh: Kannst du mal die Kommandozeile zum Übersetzen deines Codes> angeben? Ich bekomme hier Fehlermeldungen. (g++ -O3 -march=native> -std=c++17 test_mh.cpp -o test_mh)
c++20, string_view hat sonst keinen Konstruktor mit zwei Iteratoren.
Wenn das ein Problem ist müsste die Zeile
mh schrieb:> Marcus H. schrieb:>> Wir bewegen uns aber mit dem Testdatensatz, selbst auf nicht ganz aktueller>> Hardware, im Rahmen der Messungenauigkeit.>> Die Wiederholgenauigkeit auf meinem Rechner ist 0.003 Sekunden, wenn die> Dateien im RAM sind.
Interessant, hier schwankt schon die hundertstel Sekunde deutlich. Wenn
ich mir die Ergebnisse weiter oben ansehe, scheint es anderen ähnlich zu
gehen. Eigentlich spielte ich aber auf die Relevanz einer Schwankung im
einstelligen Prozent Bereich an. Das muss dann für die spezielle
Anwendung bewertet werden.
> Sonst müsste alles c++17 sein.
Der quick-fix ging leider nicht. Irgendein Typecast sitzt schief. Mit
g++-10 und -std=c++20 lässt sich das aber übersetzen. Default war bei
mir g++-9.
Yalu X. schrieb:> Außerdem hat Python dabei keinen Vorteil gegenüber C++.
Ja irgendwie schon und irgendwie nicht..
Einerseits muss es gleich schnell sein wenn bei Python die schnellste
Variante implementiert wurde, andererseits ist es ja auch etwas
speziell.
Ich habe hier mal etwas anderes gefunden, also so habe ich mir das
vorgestellt.
Beispiel: https://codereview.stackexchange.com/a/235445
mh schrieb:> Was genau hast du dir "so" vorgestellt?
Wie man es nicht macht, aber das thema ist das gleiche.
Aber zum Compare hätte ich noch eine Optimierungsidee. Kommt halt drauf
an wie lang die Spalten bzw. dessen Inhalt sind.. Die Lösung von 42
Spalten INTs unterscheidet sich von 20x BLOB Strings und INTs oder 40
Spalten Strings unter 8 Byte.
Man könnte anstatt strcomp eine Pointer Arithmetrik verwenden um nur die
Anfangsbuchstaben und dann jeden weiteren Buchstaben jeder Spalte zu
vergleichen, oder sogar beides nach Spaltenlänge mischen.. quasi
Bubblesort als ArrayString Compare. Lohnt halt beim Int oder unter 8
Zeichen nicht.
Auf jedenfall spart man sich da das erstellen eines Arrays. Mal sehen
wenn ich mal ne Stunde Zeit habe probier ich meine Ansätze einfach mal
aus.
Philipp K. schrieb:> mh schrieb:>> Was genau hast du dir "so" vorgestellt?>> Wie man es nicht macht, aber das thema ist das gleiche.
Wie man was nicht macht?
Philipp K. schrieb:> Auf jedenfall spart man sich da das erstellen eines Arrays.
Welches Array?
Philipp K. schrieb:> Mal sehen> wenn ich mal ne Stunde Zeit habe probier ich meine Ansätze einfach mal> aus.
Ich bin gespannt.
Philipp K. schrieb im Beitrag #6689455:
> mh schrieb:>> Welches Array?> Das Array csv_entries.
Warum willst du das Array einsparen?
Philipp K. schrieb im Beitrag #6689455:
> Nicht lauffähig und theoretisch Unsinn, aber die Idee auf dem Blatt..> hab's nicht so mit Pointern.
Wenn man mal über die ganzen Fehler (nicht nur Pointer) hinwegsieht, ist
von der Idee nichts zu sehen. Wie dieses first berechnet wird, könnte
interessant sein.
1
>if(first)//erstes vorkommen in den ausgabepuffer kopieren
Allerdings wird es nie berechnet. Ich gehe einfach mal davon aus, dass
du nen Kasten Bier getrunken hat, bevor du das hier gepostet hast.
Noch ein Benchmark Update.
Ich habe versucht, die inzwischen geposteten Programme einzubauen.
Leider haben nicht alle compiliert (VS 2019).
Perl und Python schlagen sich gut, und Rust ist ganz vorne dabei.
Lua ist etwas abgeschlagen.
Ich bin eigentlich ziemlich Baff, wie schlecht sich C++ schlägt.
Mag sein, dass die IO Lib unter Win10 schlecht ist...
Damit die Skriptsprachen und die Hash/Sort Algorithmen
gegenüber den Brute-Force N^2/2 Algorithmen
eine bessere Change haben, verwende ich jetzt längere Felder mit 10 und
100 Zeichen. Damit steigen die Kosten pro Vergleich.
Die Felder werden jetzt auch zufällig generiert,
daher gibt es viel mehr doppelte Werte und kleinere Ausgabefiles.
Der Windows Native Code verwendet jetzt AVX2 optimierte
Blockoperationen, und hat noch mal zugelegt.
Es gibt auch eine Version, die Hashes verwendet,
das bringt besonders bei kurzen Keys viel.
Bei längeren Keys kostet die Hash Berechnung viel Zeit.
Allerdings ist der Hash Key sehr einfach.
Als Lua-Fan stößt es mir doch etwas auf, dass Perl und Python schneller
sein sollen ;-) Ok, Lua ist jetzt nicht unbedingt auf
String-Bearbeitung ausgelegt, aber 6 mal langsamer ist doch etwas viel.
Hier also noch eine etwas optimierte Version. Die erste war QnD direkt
in den Browser eingetippt. Diese ist etwas trickreicher, wird aber erst
deutlich schneller, wenn viele Duplikate vorhanden sind.
Was mir aufgefallen ist: die awk-Versionen sind bei mir immer langsamer
(sowohl gawk als auch mawk) als die Lua-Version, bei dir immer deutlich
schneller. Irgendwas ist merkwürdig ...
1
io.input "list.txt"
2
io.output "nodup.txt"
3
4
local meta = { __index = function(t,k) t[k] = ";" return k end }
5
6
for l in io.lines() do
7
local seen = setmetatable({}, meta)
8
local a,b = l:match"(.-;.-;.-;)(.*)"
9
io.write(a, b:gsub(".-;", seen), "\n")
10
end
LuaJIT bringt leider nicht allzu viel (~20%), da string.match NYI ist
und das Compilieren unterbricht. Der Speed-Up kommt also hauptsächlich
durch die handoptimierte VM.
foobar schrieb:> Was mir aufgefallen ist: die awk-Versionen sind bei mir immer langsamer> (sowohl gawk als auch mawk) als die Lua-Version, bei dir immer deutlich> schneller. Irgendwas ist merkwürdig ...
Ist mir auch schon aufgefallen, da ist die Version wichtig,
vielleicht auch Unterschiede zwischen Win10/Linux.
udok schrieb:> mh schrieb:>> Ich hab noch etwas mit C++ getestet:>> Compiliert leider nicht (VS 2019):
siehe:
mh schrieb:> Marcus H. schrieb:>> @mh: Kannst du mal die Kommandozeile zum Übersetzen deines Codes>> angeben? Ich bekomme hier Fehlermeldungen. (g++ -O3 -march=native>> -std=c++17 test_mh.cpp -o test_mh)> c++20, string_view hat sonst keinen Konstruktor mit zwei Iteratoren.> Wenn das ein Problem ist müsste die ZeileEntry(It it, End end):> value(it, end), hash(makeHash(value)) {}> DurchEntry(It it, End end): value(it, end - it), hash(makeHash(value))> {}> ersetzt werden (ungetestet). Sonst müsste alles c++17 sein.
Mark B. schrieb:> Ist eigentlich niemandem aufgefallen, dass der Themenersteller schon> seit ner Woche nicht mehr da ist?
Ist doch normal hier, vielleicht liest er ja noch mit.
udok schrieb:> Noch ein Benchmark Update.> Ich habe versucht, die inzwischen geposteten Programme einzubauen.> Leider haben nicht alle compiliert (VS 2019).
udok schrieb:> Ich bin eigentlich ziemlich Baff, wie schlecht sich C++ schlägt.
Auf meinem Rechner nehmen sich die C++, C und rust Versionen nicht viel.
Die Laufzeit liegt bei 0.42s bis 0.48s bei meinem aktuellen Test.
Ausnahmen sind der orginal C++ Code mit 0.86s und meine C++ Variante mit
0.28s.
udok schrieb:> Mark B. schrieb:>>> Ist eigentlich niemandem aufgefallen, dass der Themenersteller schon>> seit ner Woche nicht mehr da ist?>> Ist doch normal hier, vielleicht liest er ja noch mit.
Finde ich hier gar nicht schlimm, die entstandene Diskussion finde ich
sehr interessant. Vllt sollte man die Testsuite Mal nach GitHub packen?
Dann kann man sie besser erweitern 😁
Hallo udok,
ist das mein "altes" Programm in deinen Tests oder das "neue" (mit ein
paar #ifdefs zur Analyse des iostream Bottlenecks):
Beitrag "Re: c++ Code langsam"
1
g++ -DUNSYNC -DFSTREAM -O3 -Wall -o h hash_test.cc
Ich mag ja die stdin/stdout Verarbeitung; und da schlug das cout als
Bottleneck zu (gcc 7.5.0 auf Ubuntu 18.04).
Viele Grüße, mikro
Aus spass noch meine C++ Variante so wie ich das implementieren wuerde.
Ist einen tick schneller als heinzel2 aber die nehmen sich da nicht
viel, da eigentlich dasselbe Prinzip.
Mein testset generator etwas angepasst so dass groessere nummern
rausploppen, mit 1e6 zeilen, etwa 422MB, ist nun auch bei mir nun
win_native deutlich schneller, dann .NET, dann C mit rust(!),
abgeschlagen C++ mit der OP version als schlusslicht - die yalu python
variante is ein hauch schneller.
@udok, kannst du die native AVX variante posten?
Cheers, Roger
Mikro 7. schrieb:> ist das mein "altes" Programm in deinen Tests oder das "neue" (mit ein> paar #ifdefs zur Analyse des iostream Bottlenecks):>> Beitrag "Re: c++ Code langsam"> g++ -DUNSYNC -DFSTREAM -O3 -Wall -o h hash_test.cc>> Ich mag ja die stdin/stdout Verarbeitung; und da schlug das cout als> Bottleneck zu (gcc 7.5.0 auf Ubuntu 18.04).>> Viele Grüße, mikro
Ist dein neues mit -DUNSYNC und -DUNTIE, aber ohne -DFSTREAM (sonst wäre
es ja fast schon C :-))
Roger S. schrieb:> Aus spass noch meine C++ Variante so wie ich das implementieren wuerde.> Ist einen tick schneller als heinzel2 aber die nehmen sich da nicht> viel, da eigentlich dasselbe Prinzip.>> Mein testset generator etwas angepasst so dass groessere nummern> rausploppen, mit 1e6 zeilen, etwa 422MB, ist nun auch bei mir nun> win_native deutlich schneller, dann .NET, dann C mit rust(!),> abgeschlagen C++ mit der OP version als schlusslicht - die yalu python> variante is ein hauch schneller.>> @udok, kannst du die native AVX variante posten?>> Cheers, Roger
Ich habe 2 Stunden mit deiner C# Version herumgespielt,
aber das Ding kompiliert bei mir einfach nicht...
Selbst nachdem ich VS neu installiert habe, mit dem .NET 5 von
deinem Link.
Es kann aber sein, dass ich da irgendwo ein Problem mit dem Rechner
habe.
Kannst du da ein exe posten, oder ein Skript?
Mit deiner C++ Version komme ich leider auch nicht klar...
Unter Win10 gehts, aber WSL2 Ubuntu hat nur g++ 7.5.0,
und da gibt es nur -std=c++17, das scheint nicht zu reichen.
Ich poste den Source Code in Kürze, die AVX magic findet aber nur
in den strchr, memcpy, memset und memcmp Funktionen statt, und
die sind unter Linux sowieso top.
Der Trick besteht darin, nicht einzelne Bytes anzuschauen, sondern
immer Blöcke mit den optimierten Funktionen zu verarbeiten,
so wie im zweiten C Code von foobar.
udok schrieb:> Ich habe 2 Stunden mit deiner C# Version herumgespielt,> aber das Ding kompiliert bei mir einfach nicht...
wow.. dedication 👍
hier ein 'Wohlfuehlpaket', da sind alle C# und C++ projekte drin, sogar
precompiled 🤞
> Mit deiner C++ Version komme ich leider auch nicht klar...> Unter Win10 gehts, aber WSL2 Ubuntu hat nur g++ 7.5.0,> und da gibt es nur -std=c++17, das scheint nicht zu reichen.
Vermutlich das problem mit dem string_view constructor, ist eine
refactored version mit drinn.
Dem OP war ja aufgefallen dass die genutzte 'PC Leistung' etwas schwach
war, drum hier mit dabei eine multi-threaded .NET Variante.
Cheers, Roger
Roger S. schrieb:> hier ein 'Wohlfuehlpaket', da sind alle C# und C++ projekte drin, sogar> precompiled 🤞
Danke für die Mühe, funkt jetzt :-)
C# ist ganz vorne dabei. MT bringt etwas, aber nicht so viel wie
erwartet.
Ich würde aber das Fass nicht weiter aufmachen, da kann man viel Zeit
verbraten.
Ich poste noch mal die letzten Ergebnisse mit Quellcode für alle
Interessierten.
test_native_hash.exe verwendet unter Linux die libc Runtime (memcpy,
memset, memcmp, strchr).
Unter Windows wird die libc Runtime nicht verwendet (diese Funktionen
sind aber nicht alle schlechter).
Toll, dass du dir die Arbeit gemacht hast und danke für die Ergebnisse!
Bei den (45-3) Feldern macht sich tatsächlich O=n2 bemerkbar. Ich hatte
ursprünglich angenommen, dass die n2-Suche die ge-map-pten Ansätze
schlägt.
Die Hash-Table schlägt sich (umso) besser, je länger die Felder sind.
Zudem performen dann auch optimierte Blockoperationen (strcmp, strchr,
strcpy, etc.) besser als eigene Character Zugriffe.
Dein Hash-Key ist aber ein bisschen zu einfach, oder? ;-) Der
funktioniert auf den Testdaten, im Real-Life entartet deine Hash-Table
aber schnell zur Liste.
Es wäre noch interessant zu schauen, wie gut/schlecht sich die GNU/C++
Hash-Table gegen eine Eigenimplementierung (wie deine schlägt). Selbst
wenn man die "Optimierung" deiner Key-Funktion rausnimmt, scheint sich
dein Hash besser zu schlagen. -- Ich hatte bereits einmal festgestellt,
dass der Hash aus der Boost Lib besser als der GNU Hash performed.
Ansonsten muss man halt in C++ ein bisschen bei den I/Ostreams
aufpassen, dass die nicht zum Bottleneck werden.
mh schrieb:> Warum willst du das Array einsparen?
Ich hatte da noch einen Denkfehler drin, daher habe ich den Beitrag
gelöscht.
Du brauchst den ja garnicht, das ist ja auch schon ein nicht optimaler
Ansatz. dort nimmt man jede spalte dreimal in die Hand, das kann man ja
reduzieren.
Ich habe mir auch erst als ich Zeit hatte die Native Version angeschaut,
da ist ja schon alles wie ich das meinte drin. Quasi soweit Perfekt für
den normalen Gebrauch.
Witzig wäre es halt jetzt nur inwieweit kann man sich
Stnadard-Funktionen zu nutze machen die einem diese Arbeit abnehmen..
mir ist schon klar wie die nativ funktioniert, habe ich auch schon auf
mikrocontrollern so gemacht weil jeder Tick zählt. Aber ich bin Faul und
würde mir überlegen welche Funktionen nähern sich da an. Zum Beispiel
strtok.
Bei der nativen Version wird halt kaum ein Byte zweimal in die Hand
genommen oder kopiert (eigentlich schon, aber nicht mehr als nötig,
Sprichwörtlich).
Im Endeffekt muss man sich das anpassen.. wenn 40 Spalten 0 oder 1
enthalten braucht sich da keiner einen Gedanken machen. Diese Infos
fehlen halt.
Beispiel:
Man könnte den String mit strok durchgehen, jeden Pointer speichern und
wenn die nächste Stelle/Spalte gefunden ist mit den letzten
gespeicherten Pointern die Strings Charweise vergleichen. Das könnte das
einfachste mit den Standard bereitgestellten Funktionen sein. Das sind
keine 10 Zeilen aber man macht es sich nicht zu einfach und es könnte
sich an die native Funktion annähern.
Philipp K. schrieb:> Beispiel:> [snip]
Könnte, könnte, kõnnte... warum lieferst du nicht die Implementation
statt all dem Geschwurbel? Wenns denn nur 10 Zeilen sind. Diesmal
vielleicht eine die kompilliert.
Cheers, Roger
Mikro 7. schrieb:> Toll, dass du dir die Arbeit gemacht hast und danke für die Ergebnisse!
Mich hat schon immer interessiert, was man aus einem PC heute rausholen
kann :-)
> Bei den (45-3) Feldern macht sich tatsächlich O=n2 bemerkbar. Ich hatte> ursprünglich angenommen, dass die n2-Suche die ge-map-pten Ansätze> schlägt.
Eigentlich wundert es mich, dass es so knapp ist:
(45-3)^2/2 = 880 String Vergleiche pro Zeile im Falle von N2,
Im Falle von Hash: (45-3) Lookup Operationen.
Das Lesen und Splitten der Zeilen macht natürlich viel aus.
Habe ich da noch was übersehen?
> Dein Hash-Key ist aber ein bisschen zu einfach, oder? ;-) Der> funktioniert auf den Testdaten, im Real-Life entartet deine Hash-Table> aber schnell zur Liste.
Ja, das ist so ziemlich der optimale Hash für den Testfall ;-)
Ich habe aber noch mit anderen Hash Funktionen experimentiert,
und die Ergebnisse angehängt.
Die Intel Hardware CRC32 Funktion kommt ziemlich nahe an
den Simple-Hash heran. Meine einfachen HW-CRC32 Hash
kann man eventuell noch schneller machen (asm?).
> Es wäre noch interessant zu schauen, wie gut/schlecht sich die GNU/C++> Hash-Table gegen eine Eigenimplementierung (wie deine schlägt). Selbst> wenn man die "Optimierung" deiner Key-Funktion rausnimmt, scheint sich> dein Hash besser zu schlagen. -- Ich hatte bereits einmal festgestellt,> dass der Hash aus der Boost Lib besser als der GNU Hash performed.
Hast du einen Link, eventuell kann ich das einfach testen.
> Ansonsten muss man halt in C++ ein bisschen bei den I/Ostreams> aufpassen, dass die nicht zum Bottleneck werden.
Die I/O Libs sind wahrscheinlich kein arger Bottleneck,
die fread/fwrite kann in bestimmten Fällen z.B.
direkt die System Read/Write Funktion aufrufen,
ohne Umgweg über den Stream Buffer.
Das Problem mit den System Libs ist, dass die Qualität stark schwankt,
und das man sehr genau wissen muss, wie die Funktionen implementiert
sind,
um die gute Performance zu erreichen.
Das sieht man schön in den Tests Windows/Linux, wo die Performance
bei den C++ und auch bei den C Programmen stark schwankt.
Damit ist man eigentlich wieder nicht systemunabhängig.
Sobald man mehr als ein paar duzend Bytes/Feld hat,
wird C++ unter Windows von den Skriptsprachen und moderen
Sprachen abgehängt, das fand ich schon ernüchternd.
C lebt halt noch von den sehr guten Libs aus den 90'ern.
Das Rust, C# und Python/Perl so schnell sind, hätte ich auch nicht
erwartet.
Unter Linux ist C++ wesentlich besser unterstützt.
Hier noch die Ergebnisse mit unterschiedlichen Hash Funktionen.
Die Agner Fog Asm Lib ist etwas schneller als meine auf Grösse
optimierten Funktionen.
Die MS UCRT schlägt sich auch sehr gut, und
hängt die ältere MSVCRT um einen Faktor 2 ab.
Philipp K. schrieb:> Witzig wäre es halt jetzt nur inwieweit kann man sich> Stnadard-Funktionen zu nutze machen die einem diese Arbeit abnehmen..> mir ist schon klar wie die nativ funktioniert, habe ich auch schon auf> mikrocontrollern so gemacht weil jeder Tick zählt. Aber ich bin Faul und> würde mir überlegen welche Funktionen nähern sich da an. Zum Beispiel> strtok.
Die native Version verwendet eh die Standard memcpy, memcmp, memset und
strstr oder strchr Funktionen.
Ob die strtok was bringt, weiss ich nicht, das müsste man (du) testen.
Roger S. schrieb:> Könnte, könnte, kõnnte... warum lieferst du nicht die Implementation> statt all dem Geschwurbel?
weil ich es kann :D (Spaß)
So habe ich mir das vorgestellt.. ist noch nicht ganz fertig oder
getestet (onlinegdb grüsst) und IO das erste aus google genommen.
fprintf war auch nur als improvisorium.
Ich muss erstmal Zeit dafür haben.
udok schrieb:> Ob die strtok was bringt, weiss ich nicht, das müsste man (du) testen.
Ja, kommt Zeit kommt Rat. Bin ja witzigerweise an etwas ähnlichem dran.
udok schrieb:> Philipp K. schrieb:>> weil ich es kann :D (Spaß)>> Anbei ein einfacher Testcase mit nur 5 Zeilen und 10 Feldern.> Schau mal, ob der durchläuft ;-)
Aber bitte mindestens 3 Mal durchlaufen lassen, damit die Laufzeit
zuverlässig bestimmt werden kann.
udok schrieb:> Anbei ein einfacher Testcase mit nur 5 Zeilen und 10 Feldern.> Schau mal, ob der durchläuft ;-)
Ja, ich musste noch etwas optimieren..
Variable Spalten und irgendwie eine Zeile zuviel..
Das Output war identisch.
mh schrieb:> Aber bitte mindestens 3 Mal durchlaufen lassen, damit die Laufzeit> zuverlässig bestimmt werden kann.
im Vergleichstest irgendwann gerne wenn ich wieder am DEV-Rechner bin..
ich bin bei onlinegdb mit 300Zeilen, jeweils 43 Spalten je 3 Ziffern und
90% Dupletten bei 2ms. Sagt ja nichts aus. Bei OnlineGDB springt das
Beispiel zwischen 20 und 60 Micros.
https://onlinegdb.com/hFUrM_y-u
hm.. wenn ich auf Debian-WSL2 das csv_fun run.sh Script starte bekomme
ich eine Gawk Syntax Fehler..
gawk: cmd. line:1: BEGIN { if (1e99 < run.sh:) print 1e99; else print
run.sh:; }
EDIT: Okay gerade gefunden, in WSL nimmt man Hochkomma anstatt
Anführungsstriche..
Nur die Zeitberechnungen klappen nicht.. ich schaue weiter. Kein Systick
ist meine Vermutung, daher funzt die Zeitmessung von meinem Script in
WSL auch nicht.
Du musst nur dein Programm in die Liste der Programme (ganz am Anfang)
in run.sh eintragen, sonst brauchst du nichts ändern:
1
# List of test programs
2
proglist=(
3
#test_foobar_lua.sh:Lua # Auskommentiert
4
#test_foobar_lua2.sh:Lua
5
#test_mikro77_n2.gawk:Gawk
6
test_hans.exe:CPP
7
test_PHILIPP.exe:CPP
8
...
Zusätzlich muss das Program gen_cvs.exe und test_hans.exe
zum Erzeugen der Testdaten Im Verzeichnis sein.
Diese Programme kannst du mit ./build_linux.sh compilieren.
Zur Zeitmessung wird /usr/bin/time verwendet (nicht das bash eigene time
Kommando).
udok schrieb:> Zur Zeitmessung wird /usr/bin/time verwendet (nicht das bash eigene time> Kommando).
Ja, das habe ich alles schon herausgefunden.. komischerweise hatte ich
einen Hochkamma,Gänsefüsschen Fail, das kann in Bash Scripten
passieren(Ubuntu/Debian Implementierung, wird witzig bei Find+rm), ich
musste die für GAWK tauschen, time nachinstallieren und habe alles
auskommentiert:
Bi allen aktivierten Scripten steht:
test_test.exe C Bytes=14480 Seconds=0.00
MB/sec=0.0
Die Zeitmessfunktion im Test-Programm funktioniert auf OnlineGDB, aber
nicht in WSL-Debian.. "0S"