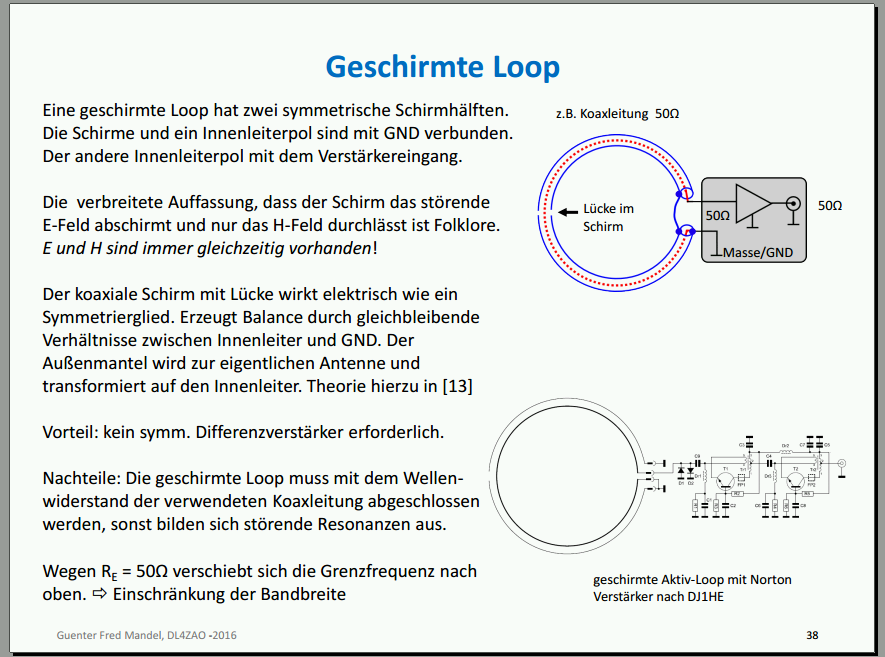
Hallo, wenn ich hier auf der Seite png-Bilder unter Ubuntu und Modzilla FF speichern möchte, geht das mit den aktuellen Einstellungen anscheinend nur im webp-Format (auf anderen Seiten noch nicht probiert). z.B. das hier kann nach Rechtsklick ins Bild -> "Grafik speichern als ..." https://www.mikrocontroller.net/attachment/527778/geschirmteLoop.png nur als webp-Datei gespeichert werden. Weiß jemand, was man machen muss, um Bilddateien im orginalen png-Format zu speichern?
{kind=link}
Hmm, problemlos hier (78.13.0esr)
Das Problem mit dem genannten Bild: es ist, trotz seines Suffixes, ein Web/P-Bild:
1 | \`> file geschirmteLoop.png |
2 | geschirmteLoop.png: RIFF (little-endian) data, Web/P image |
Wenn du ein natives PNG auf die Art speicherst, wird dir korrekt das Speichern als *.png angeboten.
Die Bilder unter Beitrag "Unscharfer Werbetext" sind laut Endung png, werden aber als webp gespeichert. Haben es drei Leute mit falscher Endung hochgeladen oder passiert doch irgendwo eine automatische Konvertierung?
Wenn man es über den Link speichert, ist es ebenfalls ein PNG. Nur, wenn man das Bild über den Link aufruft, und es dann direkt speichern will, ist’s kein PNG. Liegt nicht am FF, die Forensoftware konvertiert’s offensichtlich vor dem Ausliefern.
> Liegt nicht am FF
Ein Haarspalter könnte antworten, diese Aussage ist nicht korrekt.
Der FF sendet den Header "Accept: ...,image/webp,...".
Du kannst im F12 den Header editieren und erneut senden. Dann bekommst
du ein PNG.
Jack V. schrieb: > Wenn man es über den Link speichert, ist es ebenfalls ein PNG. Ah, Danke für den Tipp! :) Der Opa aus der Muppet Show schrieb: > Du kannst im F12 den Header editieren und erneut senden. Dann bekommst > du ein PNG. Auch interessant, Danke!
Man kann webp-Support auch generell im FF deaktivieren (via "about:config" nach "image.webp.enabled" suchen) Es gibt auch Browserweiterungen um webp im Accept-Header wegzulassen. Dauerhaft würde ich es allerdings nicht deaktivieren - Das Format spart schon teils gut ein gegenüber den "klassischen" Formaten...
bluppdidupp schrieb: > Man kann webp-Support auch generell im FF deaktivieren (via > "about:config" nach "image.webp.enabled" suchen) > Es gibt auch Browserweiterungen um webp im Accept-Header wegzulassen. > Dauerhaft würde ich es allerdings nicht deaktivieren - Das Format spart > schon teils gut ein gegenüber den "klassischen" Formaten... Wobei, damit es wirklich spart, das Bild halt noch einmal durch einen verlustbehafteten Schredder gedreht wird. Merke: HTTP ist offensichtlich ungeeignet, um Daten unverfälscht zu transportieren oder aber hat jedenfalls jede Menge Fallstricke. Man denke an nicht mehr stimmende Datei-Signaturen usw. "GET asd.png" -> "Joah, kriegste n webp, näh"
Erstmal hat das nichts mit Ubuntu zu tun. Kann es sein, dass es ein MC.NET Problem ist? Ich glaube, es ist erst seit einiger Zeit so. Kann auch am FF liegen. Ich nehme so ein Bild in die Zwischenablage (WIN) und füge es dann in meinen Bildbtrachter (IrvanView) ein. Dort dann ordentlich abspeichern.
> HTTP ist offensichtlich ungeeignet, um Daten unverfälscht zu transportieren
Stimmt. Das Cern wollte mit dem HTTP keine Daten übertragen. Dafür
hatten die ja FTP.
Die wollten Inhalte, Dokumente mit Hyperlinks übertragen. Auf NeXT
Workstations und DOS PCs wurden diese Inhalte sowieso unterschiedlich
dargestellt.
LiberNicht schrieb: > Man > denke an nicht mehr stimmende Datei-Signaturen usw. "GET asd.png" -> > "Joah, kriegste n webp, näh" Auf Dateiendungen sollte man sich nie verlassen, die sind nur reine Konvention und dienen als Indikator. Man könnte auch jede andere Verwenden oder gar keine. Das Format wird allein durch den Dateiinhalt bestimmt.
LiberNicht schrieb: > Wobei, damit es wirklich spart, das Bild halt noch einmal durch einen > verlustbehafteten Schredder gedreht wird. WebP muss nicht verlustbehaftet sein. Insofern stellt sich mir hier die Frage: wurde das PNG denn wirklich nochmal verlustbehaftet komprimiert, so dass Informationen des Bildes verlorengegangen werden, oder stört man sich nur an der ungewohnten Endung (und dem Problem, dass veraltete Systeme mit dem Format nichts anfangen können)? Interessanterweise wird mir oben nun in jedem Fall ein PNG zum Download angeboten, so dass ich das auch auf die Schnelle nicht selbst nachgucken kann. LiberNicht schrieb: > Merke: HTTP ist offensichtlich ungeeignet, um Daten unverfälscht zu > transportieren oder aber hat jedenfalls jede Menge Fallstricke. Man > denke an nicht mehr stimmende Datei-Signaturen usw. "GET asd.png" -> > "Joah, kriegste n webp, näh" Vielleicht möchtest du nochmal nachgucken, wie HTTP funktioniert und ob es überhaupt was damit zu tun haben könnte, und ob es einen Unterschied zwischen Signatur (hier war wohl eher MIME-Typ gemeint) und Dateinamen geben könnte? Dann müsstest du nämlich nicht so einen Blödsinn zum Besten geben.
Jack V. schrieb: > Dann müsstest du nämlich nicht so einen Blödsinn zum > Besten geben. Ach so... Das ist eine Sache, die man auf dem Server konfigurieren kann. HTTP räumt die Möglichkeit ein, eine "passende" Repräsentation eines Dokumentes auszuliefern statt dem originalem Dokument. Das ist das, was da oben mit der Grafik passiert. Und es gibt keinerlei Möglichkeit Seitens des Clients, zu sagen "Ich will genau das Original". Soviel dazu.
LiberNicht schrieb: > HTTP räumt die Möglichkeit ein […] HTTP ist ein Transportprotokoll. Der Webserver liefert die Datei darüber aus, aber welche Datei es ist, darauf hat das verwendete Protokoll keinen Einfluss. Und das ist bei jedem Protokoll so, nicht nur beim HTTP.
Jack V. schrieb: > LiberNicht schrieb: >> HTTP räumt die Möglichkeit ein […] > > HTTP ist ein Transportprotokoll. Der Webserver liefert die Datei darüber > aus, aber welche Datei es ist, darauf hat das verwendete Protokoll > keinen Einfluss. Und das ist bei jedem Protokoll so, nicht nur beim > HTTP. Nein, HTTP definiert einen Satz an Standard-Headern usw.und wie diese zu interpretieren sind. Magste hier gucken: https://developer.mozilla.org/de/docs/Web/HTTP
In diesem Fall war der Aufruf etwa GET /Pfad/zur/Datei.png, und der Server hat aus Clientsicht genau /Pfad/zur/Datei.png zurückgegeben. Dass da nun WebP drin war, lag nicht am Protokoll. Deine Behauptung war, dass HTTP nicht geeignet wäre, Daten unverfälscht zu übertragen – und das ist nunmal Stuss.
Jack V. schrieb: > In diesem Fall war der Aufruf etwa GET /Pfad/zur/Datei.png, und der > Server hat aus Clientsicht genau /Pfad/zur/Datei.png zurückgegeben. Dass > da nun WebP drin war, lag nicht am Protokoll. Oh, doch - tut es. Auf dem Server liegt ein png. Das ist halt die Freiheit eines HTTP-konformen Servers, das lieber als webp auszuliefern. > Deine Behauptung war, dass HTTP nicht geeignet wäre, Daten unverfälscht > zu übertragen – und das ist nunmal Stuss. Ja, lies es nach. Es gibt keine client-seitige Möglichkeit den Server zu zwingen, genau die Datei auszuliefern, die er selbst ausliest. Und das ist ein HTTP-Feature: Es kann irgendetwas ausgeliefert werden, was dem angefragten Inhalt entspricht.
Können wir uns auf die Behauptung einigen, HTTP ist nicht dafür konzipiert, Daten unverfälscht zu übertragen. Vom ersten Tag an hatten die Server unterschiedliche Daten für Lynx und Mosaik ausgeliefert. Dann kamen die Javascript Hacks für Navigator oder IE. Danach die kompaktere Darstellung für die alten Smartphones. Das große Feature das Opera: Deren Proxies komprimierten die Bilder soweit, dass es auch mit den damaligen Datenübertragungsraten halbwegs flüssig lief... Problem ist eher, die alten Protokolle, die Daten unverfälscht übertrugen, sind verschwunden.
Der Opa aus der Muppet Show schrieb: > Können wir uns auf die Behauptung einigen, HTTP ist nicht dafür > konzipiert, Daten unverfälscht zu übertragen. Nope. In dem Fall wäre die Integrität von allem anzuzweifeln, und das Netz wäre nicht nutzbar. Kein Download würde vertrauenswürdig sein, sämtliche „Cloud“-Daten wären wertlos. Wir können uns aber darauf einigen, dass der Server etwas anderes liefern kann – das ist allerdings kein Problem des Protokolls, sondern der Serverkonfiguration. Das Protokoll verfälscht keine Daten auf dem Transportweg.
Jack V. schrieb: > In dem Fall wäre die Integrität von allem anzuzweifeln, und das > Netz wäre nicht nutzbar. Wieso das? Das ist genau für Webbrowser ausgelegt und konzipiert. Dafür ist der Mechanismus ja auch gut. Man hat eine Resource (die naütrlich irgendeinen intrinsischen Typ de-facto hat) und man hat einen Client, der bestimmte Inhaltstypen beherrscht. Der Server liefert dann einen für den Client geeigneten Inhalt, welcher die Resource repräsentiert, oder einen Fehler "Die kannst du leider nicht verarbeiten." Um Dateien zu übertragen gibt es andere (Anwendungs-)Protokolle. Jack V. schrieb: > Das Protokoll verfälscht keine Daten auf dem > Transportweg. Für den low-level Transport ist ja auch TCP zuständig. Soweit es HTTP betrifft: Auch hier kann die Kodierung für den Transport nach belieben angepasst werden.
Kommt halt drauf an, ob du den "Accept:" Header als Teil des Protokoll betrachtest. Aber das eigentliche Problem: HTTP war gar nicht für Downloads oder Cloud-Storrage gedacht. Dafür gab es ja FTP. Was damals fehlte, war ein Protokoll, das Inhalte von Hypertext Dokumenten so auslieferte, dass es auf Workstations und Ascii Terminals dargestellt werden konnte. Download über HTTP ist ein Missbrauch des Protokolls. Die Probleme entstehen, weil wir dieses Protokoll für Sachen benutzen, für das es gar nicht gedacht war.
Anfangs gab es ja URLs für unterschiedliche Protokolle. Aber die anderen werden nicht mehr benutzt.
1 | http://server/datei |
2 | ftp://server/datei |
https://www.w3.org/Addressing/URL/4.1_Schemes.html Theoretisch könnten wir auch ein cloudspace://server/datei in den Standard aufnehmen.
Beitrag #6794417 wurde von einem Moderator gelöscht.
Jack V. schrieb: > Interessanterweise wird mir oben nun in jedem Fall ein PNG zum Download > angeboten, so dass ich das auch auf die Schnelle nicht selbst nachgucken > kann. Bei mit (mit Firefox 91.0) ist es ein verlustloses WebP. JPEGs werden mitunter ebenfalls als WebP gespeichert, dann aber im verlustbehafteten Modus. Sowohl die verlustfreie also auch die verlustbehaftete WebP-Variante ist meiner Erfahrung nach oft nur etwa halb so groß wie das entsprechende PNG bzw. JPEG, zudem ist im zweiten Fall trotz der geringeren Dateigröße i. Allg. die Qualität besser. Insofern ist dieses WebP-Format eine gute Sache. Auch dass es im Web als Alternativformat zu JPEG und PNG genutzt wird, um den Traffic zu reduzieren, finde ich prinzipiell in Ordnung. Etwas blöd ist halt nur, dass noch nicht alle Programme dieses Format importieren können.
Yalu X. schrieb: > Insofern ist dieses WebP-Format eine gute > Sache. Auch dass es im Web als Alternativformat zu JPEG und PNG genutzt > wird, um den Traffic zu reduzieren, finde ich prinzipiell in Ordnung. > Etwas blöd ist halt nur, dass noch nicht alle Programme dieses Format > importieren können. Ja, für den typischen Browser-Usecase ist das schon sinnvoll. Problematisch ist nur, dass zumindest die Referenz-Implementierung von WebP zum Dekodieren wirklich das gesamte Bild im Speicher halten muss. JPEG braucht für die Dekodierung nur Bildbreite*"kleines X" Bytes an Arbeitsspeicher und kann also direkt auf Storage gestreamed werden. Ob das jetzt ein implementierungsspezifisches Merkmal ist oder direkt am Algorithmus liegt, kann ich nicht sagen. Problem ist, dass der Client den MIME-Type der Resource nicht kennen kann, also ggf. eben webp mit angeben muss, um nicht zu riskieren, dass der Server einfach nur einen Fehler zurück liefert. Und wenn der dann eben im Zweifel alles in WebP konvertiert, hat man unnötigen Resourcen-Verbrauch in speziellen Use-Cases.
LiberNicht schrieb: > Wieso das? Das ist genau für Webbrowser ausgelegt und konzipiert. Dafür > ist der Mechanismus ja auch gut. Vielleicht sollte man an dieser Stelle differenzieren: ich argumentiere nicht gegen die Tatsache, dass man einen Webserver so konfigurieren und einen Aufruf so gestalten kann, dass der Browser nicht von vorneherein weiß, was genau er bekommt – aber das kann ich halt jedem anderen Protokoll auf diesem Layer im Stack genauso machen. Ich argumentiere gegen die Behauptung, dass HTTP für eine bitgenaue Datenübertragung per se ungeeignet, bzw. eine solche über dieses Protokoll nicht möglich wäre. Konkret beziehe ich mich dabei auf: LiberNicht schrieb: > Merke: HTTP ist offensichtlich ungeeignet, um Daten unverfälscht zu > transportieren … und das ist halt in dieser Absolutheit Unsinn.
Jack V. schrieb: > Vielleicht sollte man an dieser Stelle differenzieren: ich argumentiere > nicht gegen die Tatsache, dass man einen Webserver so konfigurieren und > einen Aufruf so gestalten kann, dass der Browser nicht von vorneherein > weiß, was genau er bekommt – aber das kann ich halt jedem anderen > Protokoll auf diesem Layer im Stack genauso machen. Das Problem ist aber schon vielschichtiger. Es könnte auch eine dazwischengeschaltete nginx ihre Senf dazu geben, was beim Client ankommt. Oder vllt. ein HTTP-Proxy? Das sind alles Möglichkeiten, die sich genau aus der Nutzung von HTTP ergeben. HTTP spricht von Resourcen, deren Repräsentation beim Client ankommen muss. Da wirst du nirgendwo lesen, dass die Resource unverfälscht wiedergegeben werden muss. TCP andererseits stellt als Transportprotokoll sicher, dass das, was gesendet wird auch genau das ist, was Empfangen wird. Egal über wie viele Hops das Paket gelaufen ist. Jack V. schrieb: > LiberNicht schrieb: >> Merke: HTTP ist offensichtlich ungeeignet, um Daten unverfälscht zu >> transportieren > > … und das ist halt in dieser Absolutheit Unsinn. Um so dumm zu kommen, weiß jeder, der Lesen kann, sofort, dass HTTP für Datentransfer völlig ungeeignet ist, weil es eben kein Transportprotokoll ist. Punkt.
LiberNicht schrieb: > Um so dumm zu kommen, weiß jeder, der Lesen kann, sofort, dass HTTP für > Datentransfer völlig ungeeignet ist, > weil es eben kein Transportprotokoll ist. Punkt. Na hoffentlich wissen das die beiden letzten Buchstaben des ›HTTP‹ auch. Fassungslos…
Wenn schon Haarspalterei, dann aber richtig zitiert. Der vorletzte Buchstabe in "Hypertext Transfer Protocol" steht nicht für Transport.
Western Union bietet einen Geldtransfer an. Du legst Euroscheine auf den Tresen und in Somalia zahlen sie Schilling aus. Bei einem Geldtransport müssten sie deine Scheine im Koffer nach Somalia transportieren und dort genau deine Scheine dem Empfänger aushändigen.
Der Opa aus der Muppet Show schrieb: > Western Union bietet einen Geldtransfer an. Du legst Euroscheine > auf den > Tresen und in Somalia zahlen sie Schilling aus. > > Bei einem Geldtransport müssten sie deine Scheine im Koffer nach Somalia > transportieren und dort genau deine Scheine dem Empfänger aushändigen. Schön, spalten wir ein wenig ;-) Bei einem Transfer ›Du legst Euroscheine auf den Tresen und in Somalia zahlen sie Schilling aus‹ kommt also gar nicht das an was man auf die Reise geschickt hat. Bei einem Transport ›deine Scheine im Koffer nach Somalia … und dort genau deine Scheine dem Empfänger‹ hingegen doch. Also, mir ist ein Transport von Daten lieber als ein Transfer mit unvorhersehbaren Wandlungen und Modifikationen. ;-) Wenn der Transfer jedoch in der Realität einem Transport gleichkommt (wie in den RFCs vorgesehen), das ist dann OK.
Norbert schrieb: > Also, mir ist ein Transport von Daten lieber als ein Transfer mit > unvorhersehbaren Wandlungen und Modifikationen. ;-) Im Falle des Webhostings sollte man, wenn man eine Seite gestaltet, vermutlich die Resourcen in der Tat selbst in webp konvertieren, wenn man das Datenvolumen reduzieren will. Das spart Rechenzeit - nicht, dass die Konvertierungsarbeit bei jedem Request im gesamten Internet hochgerechnet noch dem Bitcoin-Mining den Rang an Energieverschwendung abläuft...
LiberNicht schrieb: > Es könnte auch eine > dazwischengeschaltete nginx ihre Senf dazu geben, was beim Client > ankommt. Oder vllt. ein HTTP-Proxy? Nginx ist ein Webserver, der auch als Proxy konfiguriert werden kann. Möchtest du wirklich nicht nochmal selbst gucken, wie das alles zusammenhängt, und nicht nur ’n paar Stichworte irgendwo raussuchen, die dich zu bestätigen scheinen, solange man den Kontext nicht beachtet?
Jack V. schrieb: > Nginx ist ein Webserver, der auch als Proxy konfiguriert werden kann. > Möchtest du wirklich nicht nochmal selbst gucken, wie das alles > zusammenhängt, und nicht nur ’n paar Stichworte irgendwo raussuchen, die > dich zu bestätigen scheinen, solange man den Kontext nicht beachtet? Wie was zusammenhangt? HTTP und umgewandelte Resourcen?
Al Fine schrieb: > Wie was zusammenhangt? Was ein Webserver ist, was ein Proxy ist, was ein Protokoll ist, … solche Sachen halt. Du erinnerst dich: er sprach dem HTTP die Eigenschaft ab, Daten darüber unverfälscht zu übertragen zu können („… ist ungeeignet“) – was ganz offensichtlich Unsinn ist, denn wenn das nicht ginge, würde kein Hash einer heruntergeladenen Datei stimmen, kein heruntergeladenes Image eines Datenträgers booten, kein heruntergeladenes Programm laufen, etc. Darum ging’s in diesem Nebenfaden der Diskussion.
Jack V. schrieb: > Du erinnerst dich: er sprach dem HTTP die > Eigenschaft ab, Daten darüber unverfälscht zu übertragen zu können („… > ist ungeeignet“) Wenn Ihre Hoheit sich daran zu erinnern beliebt, dass der Satz dort keineswegs sein Ende fand? Wie Ihre Hoheit einerseits als Web-Enwickler sicherstellen wollen, dass nicht ein Proxy-Server des Kunden den Inhalt vermurkst oder als Kunde, ein Reverse-Proxy des Anbieters, der ggf. noch hinter Cloudflare sitzt, unter Benutzung des HTTP-Protokolls vermag sich nicht zu erschließen. Funktioniert es doch so, wie intendiert, auch wenn das geschieht?
> Also, mir ist ein Transport von Daten lieber als ein Transfer mit > unvorhersehbaren Wandlungen und Modifikationen. Der Rest der Welt ist zu einer anderen Einschätzung gekommen. Und benutzt mehr oder weniger das 7-Schichten Modell der OSI. Layer 4, der Transport Layer überträgt Daten unverändert. Darüber liegt ein Presentation Layer, der die Daten in irgend etwas umwandelt, was für Computer und Benutzer lesbar ist. Früher hatte der Presentation Layer zwischen EBCDIC und Ascii konvertiert, heute zwischen Jpeg und Webm. Oder zwischen Quicktime und H264. Alle außer dir sind der Ansicht, Youtube sollte die Videos in dem Format ausliefert, das der Rechner abspielen kann. Nicht das Format was der Ersteller hochgeladen hat. Problem ist, wir benutzen einen für Webbrowser optimierten Presentation Layer für alles mögliche. Und packen dann noch einen Layer 8 oben drauf, der einen Presentation Layer als Transport Layer missbraucht.
Aha, alle außer mir erwarten WEBM wenn sie Portable Network Graphic laden. Alle außer mir erwarten - ja was eigentlich? - wenn sie ein ISO Image herunter laden. Alle außer mir erwarten konvertierten Gibberish wenn sie sich zB. eine Firmware herunter laden. Cool, wusste ich noch nicht. Aber was lernt man nicht alles im Netz.
LiberNicht schrieb: > Wie Ihre Hoheit einerseits als Web-Enwickler > sicherstellen wollen, dass nicht ein Proxy-Server des Kunden den Inhalt > vermurkst oder als Kunde, ein Reverse-Proxy des Anbieters, der ggf. noch > hinter Cloudflare sitzt, unter Benutzung des HTTP-Protokolls vermag sich > nicht zu erschließen. Es ging darum, dass der Narr davon geschwafelt hat, dass das Protokoll grundsätzlich ungeeignet zum unverfälschten Übertragen von Daten wäre. Will er nun etwas anderes behaupten? Dass die Daten auf dem Transportweg von jeder Maschine auf dem Weg manipuliert werden können, ist weder ein Geheimnis, noch exklusiv beim HT-Transfer-Protocol so – das Problem betrifft alle unverschlüsselten Protokolle. Das ist allerdings nicht der Punkt gewesen, wie der Narr sich erinnern möge: der Punkt war, dass man über das HTTP sehr wohl Daten unverfälscht übertragen kann.
Jack V. schrieb: > der Punkt war, dass man > über das HTTP sehr wohl Daten unverfälscht übertragen kann. Nein, der Punkt war, dass das Protokoll dafür nicht geeignet ist und allerlei Mechanismen hat, die eben dieser Nutzung zuwiederlaufen. Man sehe und lerne. Im Gegensatz zu vielen anderen Protokollen widerspricht es bei HTTP nicht der inhärenten Zielsetzung, wenn ein Proxy nochmal ein wenig was an den Daten herumdreht. Schließlich sagt der Client nur: "Gib mir mal irgendeine Darstellung der Resource X, von der du meinst, dass sie passen könnte."
Der Opa aus der Muppet Show schrieb: > Was damals fehlte, war ein > Protokoll, das Inhalte von Hypertext Dokumenten so auslieferte, dass es > auf Workstations und Ascii Terminals dargestellt werden konnte. > > Download über HTTP ist ein Missbrauch des Protokolls. In den Zeiten, von denen du da oben schreibst, wurde der Hypertext aber noch größtenteils nicht dynamisch erstellt. Die Webseiten waren einfach Dateien, die der Browser sich runtergeladen hat. Heute wird das ja alles dynamisch erzeugt, so dass ein Großteil der übertragenen Daten auf dem Server gar nicht als Datei rumliegen. Man hat es also streng genommen mehr zum Download von Dateien benutzt als heute. > Die Probleme entstehen, weil wir dieses Protokoll für Sachen benutzen, für > das es gar nicht gedacht war. Ja. Wobei das ja nur der Anfang ist. Man schaue sich Websockets und sowas an. Da werden quasi ganze Netzwerkverbindungen durch einen http-Stream getunnelt, weil das das einzige Protokoll ist, das fast überall durchkommt (z.B. Proxies). Also setzt man eben alles auf http drauf, statt es einfach direkt zu übertragen.
LiberNicht schrieb: > Nein, der Punkt war, dass das Protokoll dafür nicht geeignet ist und > allerlei Mechanismen hat, die eben dieser Nutzung zuwiederlaufen. Es hat auch Mechanismen, welche die integere Übertragung binärer Daten sicherstellen kann – was es sehr wohl auch dafür geeignet macht. Zum ursprünglichen Zweck:
1 | HTTP has been in use by the World-Wide Web global |
2 | information initiative since 1990. The first version of HTTP, |
3 | referred to as HTTP/0.9, was a simple protocol for raw data transfer |
4 | across the Internet. |
So sehe und lerne.
Jack V. schrieb: > Zum ursprünglichen Zweck:HTTP has been in use by the World-Wide Web > global > information initiative since 1990. The first version of HTTP, > referred to as HTTP/0.9, was a simple protocol for raw data transfer > across the Internet. Also gut - vor 30 Jahren hättest du vielleicht Recht gehabt.
Ich sag’s mal so: man kann dafür sorgen, dass der Client die Daten 1:1 so bekommt, wie er sie angefragt hat. Damit ist das Protokoll aus meiner Sicht grundsätzlich geeignet, Daten unverfälscht zu übertragen, und das wird auch milliardenfach gemacht – jeden Tag. Deine gegenteilige Behauptung ist also falsch. Soweit ich das verstanden habe, war einer deiner Punkte, dass der Client keinen Einfluss darauf hätte, was der Server tatsächlich liefert. Ja, das ist so – bei jedem Protokoll. Ein Weiterer war, dass auf dem Transportweg Manipulationen stattfinden könnten. Ja, das ist so – bei jedem unverschlüsselten Protokoll ohne Integritätsprüfung auf anderem Weg. Was macht also das HTTP ungeeigneter zum Übertragen von Dateien, als jedes andere Protokoll mit diesen Einschränkungen (etwa FTP)? Der zweite Punkt könnte dabei auch wegfallen, da es im Grunde um HTTPS ging (zur Erinnerung: Ausgangspunkt war das Bild, welches falsch ausgeliefert wurde – und das erfolgte via HTTPS).
Die Annahme, FTP übertrage stets unverfälscht, ist übrigens falsch. Von Haus aus nimmt eine im ursprünglichen Stil gestartete FTP Session gerne an, dass es sich um Textdateien handelt und konvertiert zwischen verschiedenen Konventionen der beteiligten Systeme. Will man das nicht riskieren, sollte im Kommandoprotokoll auf rein binäre Übertragung hingewiesen werden.
SvenS schrieb: > z.B. das hier kann nach Rechtsklick ins Bild -> "Grafik speichern als > ..." > https://www.mikrocontroller.net/attachment/527778/geschirmteLoop.png > nur als webp-Datei gespeichert werden. wenn man den Link hat, kann man noch "Ziel speichern unter" auswählen, dann kommt das auch als png
Image resizing and conversion ist ein Feature von CloudFlare und bei Microcontroller.net aktiviert. Ob und wie konvertiert wird entscheidet CloudFlare dynamisch, unter anderem Anhand des Accept- und User-Agent-Headers. HTTP erlaubt das und wird z.B. bei User-Agent-spezifischen Seiten oft benutzt (unterschiedliches HTML für Desktop, Handy oder TV). Es gibt auch Header (z.B. Accept oder Accept-Language), mit denen man gezielt Varianten anfordern kann. Ob und wie das genutzt wird entscheidet der Seitenbetreiber. Bei Benutzung von Proxys noch der Proxybetreiber. Allerdings braucht es seit der starken Verbreitung von HTTPS schon MITM-Proxys wie CloudFlare, um da noch zwischenfunken zu können.
Screenshot...
● Des I. schrieb: > auswählen, dann kommt das auch als png Zumindest heisst es so. ;-) Auf diese Art kriegt man aber u.U. PNGs auf die Disk, die keine sind. Ich hatte schon gelegentlich Files, die sich beim Öffnen als anderer Typ herausstellten. Mancher Bildbetrachter ist dann so freundlich, es umzubenennen. Das ist ja das hier skizzierte Szenario. Aus dem HTML ergibt sich der Name samt Endung. Was der Browser aber tatsächlich kriegt, ist eine andere Baustelle. Siehe vorhin zu Cloudflare.
(prx) A. K. schrieb: > Die Annahme, FTP übertrage stets unverfälscht, ist übrigens falsch. Von > Haus aus nimmt eine im ursprünglichen Stil gestartete FTP Session gerne > an, dass es sich um Textdateien handelt und konvertiert zwischen > verschiedenen Konventionen der beteiligten Systeme. Sie nimmt es nicht nur gerne an, sondern es ist spezifiziert, dass ASCII mit CR/LF der Default ist (es gibt in FTP mehr als nur "Text" und "Daten"). Wer keine Umwandlung will, muss die erst explizit abschalten. Kann man alles in RFC959 nachlesen: https://datatracker.ietf.org/doc/html/rfc959 Man muss bedenken, dass FTP aus einer Zeit stammt, als noch so Dinge wie 36-Bit-Datenwörter oder EBCDIC nicht unüblich waren. Da konnte man ohne eine Konvertierung mit den Daten oft nix anfangen oder sie gar nicht erst übertragen. (prx) A. K. schrieb: > Das ist ja das hier skizzierte Szenario. Aus dem HTML ergibt sich der > Name samt Endung. Was der Browser aber tatsächlich kriegt, ist eine > andere Baustelle. Siehe vorhin zu Cloudflare. Wobei das dem Browser prinzipiell egal ist. Der geht halt nach dem Mimetype. Das Problem ergibt sich erst beim abspeichern, sofern man ein System hat, das dabei den mimetype verwirft und später nur noch anhand des Namens entscheidet, was das für eine Datei ist.
LiberNicht schrieb: > Jack V. schrieb: >> Das Protokoll verfälscht keine Daten auf dem >> Transportweg. > > Für den low-level Transport ist ja auch TCP zuständig. Soweit es HTTP > betrifft: Auch hier kann die Kodierung für den Transport nach belieben > angepasst werden. HTTP ist eigentlich für alles nutzbar. Das hat zwar das nette Feature der Presentation, aber das kann man ja steuern, bzw. muß es eigentlich gar nicht nutzen. Wenn ich etwas binär 1:1 rübergereicht haben will, dann gebe ich den Mediatype application/octet-stream an, und gut is. Da ist dem System dann klar, daß da nix anderweitig präsentiert werden soll. application/octet-stream wird wohl der Typ sein, der allgemein zum Download von binären Daten genutzt wird, die nicht näher spezifiziert werden können.
Jens G. schrieb: > application/octet-stream wird wohl der Typ sein, der allgemein zum > Download von binären Daten genutzt wird, die nicht näher spezifiziert > werden können. Ja, das ist naheliegend. Jedoch keine Garantie, dass das es dir Originaldatei ist.
1 | The recommended action for an implementation that receives an |
2 | "application/octet-stream" entity is to simply offer to put the data |
3 | in a file, with any Content-Transfer-Encoding undone, or perhaps to |
4 | use it as input to a user-specified process. |
https://www.iana.org/assignments/media-types/application/octet-stream Ein tar.gz zu tar.xz umzukonvertieren wäre doch eine Idee...
Rolf M. schrieb: > Wobei das dem Browser prinzipiell egal ist. Der geht halt nach dem > Mimetype. Das Problem ergibt sich erst beim abspeichern, sofern man ein > System hat, das dabei den mimetype verwirft und später nur noch anhand > des Namens entscheidet, was das für eine Datei ist. Dafür gab/gibt es zB den "interpreter" Zusatz im Content-Type. Ist aber wohl etwas in Verruf geraten:
1 | To reduce the danger of transmitting rogue programs, it is strongly |
2 | recommended that implementations NOT implement a path-search |
3 | mechanism whereby an arbitrary program named in the Content-Type |
4 | parameter (e.g., an "interpreter=" parameter) is found and executed |
5 | using the message body as input. |
https://www.iana.org/assignments/media-types/application/octet-stream Haha. Hahahaha...
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.