Im Xilinx XST Guide gibt es viele Beispiele, wie man Multiplizierer instanziert, insbesondere pipelined. Ich brauche allerdings einen, der in einem Takt fertig ist. Ist es dazu besser den eingang registered zu machen oder den Ausgang?
Lars S. schrieb: > Im Xilinx XST Guide gibt es viele Beispiele, wie man Multiplizierer > instanziert, insbesondere pipelined. Ich brauche allerdings einen, der > in einem Takt fertig ist. Ist es dazu besser den eingang registered zu > machen oder den Ausgang? Mach Beides. Das tolle daran, es bleibt beim Durchlauf durch den Multiplizierer in einem Takt. Du solltest mal konkret werden, welchen FPGA-typfamilie du einsetzt, und um welche Multiplikation es sich handelt (Opernadenbreite, signed/unsigned, konstant). Und von welchem Takt du sprichst, auch einen Systemtakt könnte man in mehrer subtakte auf beide Flanken zerlegen. Und wie schaut der Datenpfad aus, kommen die Faktoren aus Blockrams oder aus einer Registerbank. BRAMS bringen u.U. FF-Stufen mit, die näher/weiter vom DSP-slice wegliegen als fabric-FF. Und schau dir mal den Hardware-Multiplizieren an: https://docs.xilinx.com/v/u/en-US/ug479_7Series_DSP48E1
Fpgakuechle K. schrieb: > Mach Beides. Das tolle daran, es bleibt beim Durchlauf durch den > Multiplizierer in einem Takt. Er hat aber nach einem Takt gefragt und wenn dann Register vor und nach dem Multiplizierer sitzen kann das Ergebnis nicht in einem Takt am Ausgang anliegen. Das ist ausgeschlossen.
Gustav G. schrieb: > Fpgakuechle K. schrieb: >> Mach Beides. Das tolle daran, es bleibt beim Durchlauf durch den >> Multiplizierer in einem Takt. > > Er hat aber nach einem Takt gefragt und wenn dann Register vor und nach > dem Multiplizierer sitzen kann das Ergebnis nicht in einem Takt am > Ausgang anliegen. Der Multiplizier soll nach einen Takt fertig sein, und das schafft er, weil die Daten innerhalb eines Taktes vom Q der Stufe 1 durch den (kombinatorischen) Multiplizierer zum D der Stufe 2 laufen. Anderes wäre es, wenn innerhalb des Mzlriplizieres eine Pipelinestufe sitzen würde. Es ist halt die Frage, wo man die Grenzen des Multiplizieres zieht, ob beispielsweise die 1.Stufe gleichzeitig die Ausgangsstufe des Faktorenspeichers ist. Deshalb die Frage nach dem Gesamtdatenpfad. Kommen bspw. die Faktoren direkt aus einem Register (bspw. Deserializer vom ADU) dann ist der Eingang des Mult quasi registered und ein weitere FF-stage verändert das timing nicht wesentlich. Natürlich sollte das synthese tool auch auf "optimize across hierarchy" gestellt sein. Dasselbe gilt für die Ausgangsstufe, warum extra eine FF-Stufe in den Mul hineingenerieren, wenn der Ausgang ohnehing mit einem Register im design verbunden ist? (Bspw, Serializer UART). Erst mit den Infos wie das im kompletten Datenpfad ausschaut kann man sagen, wo FF sinnvoll wären um den kritischen Pfad zu kürzen.
Angehängte Dateien:
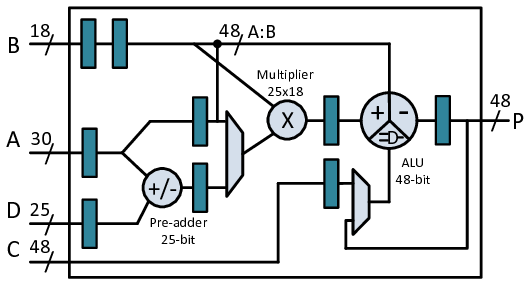
Jürgen S. schrieb: > Siehe auch: Beitrag "Re: Spartan 3 32x32 Multiplier" Passender Beitrag insbesonders der Hinweis: " Man muss in deinem Fall noch die Funktion "Multiplikation" von dem Chipelement "Multiplizier" trennen, " der IMHO immer gilt, nicht nur in diesem Speziellen Fall. Allerdings scheint in dem Beitrag "dahinter" und "davor" gelegentlich verwechselt worden zu sein. Wie ich es verstehe, wird zuerst "FF hinter MULT" (also Ausgang, Produkt) empfohlen, beschrieben werden aber Details in der Implementierung mit xtra FF-Stufe davor (vor Eingang, Faktoren). Am besten ist natürlich, man probiert alle vier Varianten (Extra FF: Keine, Faktoren, Produkt, beide) aus, das kann man auch in VHDL per generic und GENERATE sozusagen für jeden Implementierungslauf einstellbar machen. Und entscheidet sich dann für die Variante ohne timingfehler. Aus dem Bauch heraus vermute ich die größere Verbesserungen bei FF vor dem Multiplizier, statt danach. Im DSP-Slice sind wohl beide Varianten vorgesehen (siehe Anhang aus https://www.researchgate.net/publication/282398023_Mapping_for_maximum_performance_on_FPGA_DSP_blocks)
Solche Dinge habe ich breit ausprobiert. War früher allerdings wichtiger, asl heute, weil verbesserte Chiptechnologie. Was ich gefunden habe, ist dass es kaum noch einen Unterschied macht - auch weil die Tools heute mehr oder weniger automatisch balancieren. Zudem ist es so, daß der Synthesizer bei MULs, die etwas größer sind, als das MUL-slice (also 25, 18) einen Teil der Terme mit Kombi baut. Diese wird dann timingtechnisch mit anderer Kombilogik aus den Berechnungen davor oder dahinter verbacken, wodurch sich wieder andere Strukturen ergeben. Entsprechend sind die FFs mal da oder mal da besser wirksam. Praktisch werden wohl oft genug Mischformen entstehen.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.