Hallo zusammen, ich habe mir ein neues Projekt herausgesucht: Ich möchte ein Machine Learning System bauen, das Musikdateien analysiert und musikalische Größen ableitet, beispielsweise (polyphone) Tonhöhen, Akkorde, vllt. Genre oder auch den Puls/Takt der Musik. Der Stand der Technik scheint mir noch etwas enttäuschend, aber vielleicht ist das ja ein gutes Zeichen, und es gibt noch Dinge zu entwickeln. Ein paar erste Aufgaben zur Vorarbeit zeichnen sich schon ab – auch weil es dabei sicher viel zu lernen gibt. Beispielsweise möchte ich aus einer Audiodatei gerne mp4-Videos mit Audio und Spektrogrammen generieren, die möglichst viele der „relevanten“ Informationen enthalten. Aus meiner Sicht ist es „relevant“, Tonhöhen genau bestimmen zu können – davon gibt es laut midi-protokoll max. 127, aber eine deutlich größere Menge Obertöne kann wohl nicht schaden. Vielleicht helfen auch zwischen den wohltemperierten Frequenzen liegende Teilschritte um später einzelne Instrumente sauber zu identifizieren? Und es ist dummerweise gleichzeitig relevant, eine saubere zeitliche Auflösung, beispielsweise zur Erkennung von Notenanschlägen zu erreichen (<1ms als Hausnummer). Wenn man zum Vergleich über das Corti-Organ im menschlichen Innenohr liest, lernt man von ~15000 Haarzellen, von denen jede bis zu 100 einzelne Haare (Zilien) hat. Daher könnte es ja sein, dass hier ~15000 mechanische Resonanzschwinger eine ebenso große Anzahl von Frequenzen parallel analysieren... Das ist natürlich erstmal reine Spekulation. So was sind jetzt eigentlich die Fragen? 1. Wavelet-Analyse oder gefensterte DFT? Habt ihr Favoriten für Musik? Warum? Könnt ihr noch weitere Verfahren empfehlen? 2. Bei der DFT erhalte ich Phase und Amplitude. Glaubt ihr, in der Phase sind irgendwelche musikalisch relevanten Infos enthalten? Wohl eher nicht, oder? 3. meine Frequenzunterteilung wird logarithmisch (alle 12 Halbtonschritte verdoppelt sich die Frequenz). Gibt’s irgendwelche Besonderheiten bei den üblichen Verfahren, falls die Frequenzskala nichtlinear ist? 4. Das menschliche Lautstärkeempfinden ist ebenfalls logarithmisch skaliert – Stichwort: dB. Steckt da mehr dahinter als die Ausgangsamplituden in meinem Spektrogramm zu logarithmieren? Gerade wenn die Frequenzskala nichtlinear ist, bin ich unsicher, ob man bei der Berechnung nicht irgendwelche frequenzabhängige Faktoren entstehen, um beispielsweise Leistungsdichten oder Ähnliches sauber abzubilden? Die Frequenzabhängigkeit beim menschlichen Lautstärkeempfinden nach dB(A) und Phone darf erstmal ignoriert werden, finde ich. 5. „exakte Tonhöhe“ vs. „zeitliche Auflösung“ sind ja eher widersprüchliche Ziele. Kennt ihr Ansätze bei denen mehrere Spektrogramme parallel erzeugt werden, um das Problem in den Griff zu kriegen? Oder gibt’s dazu bessere Ideen? 6. Spricht etwas dagegen, die Wavelet- oder Fensterlänge grundsätzlich frequenzabhängig zu gestalten? Tiefe Töne scheinen mir oft in langsamerer Abfolge zu kommen. Außerdem „dauert“ bei 100Hz-Tönen das Integral über eine einzige Schwingung ja bereits 10ms. 7. Was wären vielversprechende Fensterformen für Audiosignale? https://www.inspiredacoustics.com/en/MIDI_note_numbers_and_center_frequencies https://de.wikipedia.org/wiki/Corti-Organ https://www.phonomigo.com/gehoer/haarzellen-im-ohr-sie-entscheiden-mit-wie-gut-wir-verstehen/ https://de.wikipedia.org/wiki/Lautst%C3%A4rke
A. S. schrieb: > Aus meiner Sicht ist es „relevant“, Tonhöhen genau bestimmen zu können – > davon gibt es laut midi-protokoll max. 127, aber eine deutlich größere > Menge Obertöne kann wohl nicht schaden. Damit liegst du schon einmal daneben! Es gibt wesentlich mehr Töne und Zwischentöne, also nur 127. Das ist lediglich eine Vereinfachung für das grobe MIDI. Und mit Obertönen hat es auch nichts zu tun. Die Obertöne verformen den Klang qualitativ. A. S. schrieb: > 3. meine Frequenzunterteilung wird logarithmisch (alle 12 > Halbtonschritte verdoppelt sich die Frequenz). Gibt’s irgendwelche > Besonderheiten bei den üblichen Verfahren, falls die Frequenzskala > nichtlinear ist? Welche Frequenzskala sollte da "nichtlinear" sein? Und welche sollte "Linear" sein? Du schreibst du selber, dass die Frequenzen logarithmisch verlaufen. Wo ist das denn nicht so? A. S. schrieb: > 5. „exakte Tonhöhe“ vs. „zeitliche Auflösung“ sind ja eher > widersprüchliche Ziele. Wieso? Heisenberg in der Musik?
A. S. schrieb: > 1. Wavelet-Analyse oder gefensterte DFT? Autoadaptiver Görtzel. Man muss in jedem Fall selektive Frequenzen erkennen und zerlegen. Eine reine FFT ist z.B. zu starr. > 2. Bei der DFT erhalte ich Phase und Amplitude. Glaubt ihr, in der Phase > sind irgendwelche musikalisch relevanten Infos enthalten? Ja sicher(?) Vergleiche mal das Spektrum eines Dreiecks und eines Rechtecks: Abgesehen von den Amplituden sind die Phasen verschoben und das ist relevant, wenn man z.B. die Amplituden bei einer iFFT belässt und nur die Phasen verschiebt. Siehe: Beitrag "Re: bandlimitierte Rechtecksignale zielgenau erzeugen" Wenn du da die Oberwellen jeweils um 90 Grad verschiebst, formt sich das Rechteck langsam in Richtung Dreieck. > 3. meine Frequenzunterteilung wird logarithmisch (alle 12 > Halbtonschritte verdoppelt sich die Frequenz). Theoretisch ja, praktisch hat das Gehör in den Höhen einen anderen Verlauf. Ab rund 600Hz knickt das etwas ab. Auch Instrumente haben das, siehe Klavierspreizung. > 4. Das menschliche Lautstärkeempfinden ist ebenfalls logarithmisch > skaliert Auch nur sehr im Groben. Es gibt Bereiche, da werden 6-8dB als Verdopplung wahrgenommen und Bereiche, wo es > 10dB braucht. Das muss auch frequenzspezifisch betrachtet werden. Siehe "Hörkurven" u.a. bei https://de.wikipedia.org/wiki/Frequenzbewertung > Die Frequenzabhängigkeit beim menschlichen Lautstärkeempfinden nach dB(A) > und Phone darf erstmal ignoriert werden, finde ich. Nö. Das ist relevant. Das ist vor allem relevant, wenn man Musik abmischen und analysieren will. Es gibt Verfahren, die das unterstützen und aufgrund spektraler Betrachtungen die Multibandkompressoren und die Gesamtlautstärke anpassen - Radiostationen und Masteringstudios nutzen das. Aber das ist eben nur so ugefähr. Letztlich muss man immer Quellspektrum und Hörkurven in Einklang bringen. Hinzu kommen Maskierungseffekte und vieles mehr. > 5. „exakte Tonhöhe“ vs. „zeitliche Auflösung“ sind ja eher > widersprüchliche Ziele. Nicht unbedingt: Man kann durchaus zu jedem Zeitpunkt die aktuelle Tonhöhe hinreichend genau angeben. Das erfordert aber immer mehr technischen Aufwand, der sich meistens nicht lohnt, weil er irgendwann keine Information bringt. > Kennt ihr Ansätze bei denen mehrere > Spektrogramme parallel erzeugt werden, um das Problem in den Griff zu > kriegen? Mehrere parallel laufenden Faltungen im FPGA: http://www.96khz.org/htm/spectrumanalyzer2.htm > 6. Spricht etwas dagegen, die Wavelet- oder Fensterlänge grundsätzlich > frequenzabhängig zu gestalten? Das ist nötig, ja. Schon wegen des Fensterns. > Tiefe Töne scheinen mir oft in langsamerer Abfolge zu kommen. Nicht unbedingt, wieso? > Außerdem „dauert“ bei 100Hz-Tönen das > Integral über eine einzige Schwingung ja bereits 10ms. Der Ton dauert auch länger (was nicht heißt, dass die Abfolge langsamer wärem, siehe Echos durch Reflektionen z.b.) aber hier muss man Ton von Frequenz unterscheiden: Ein musikalischer Ton hat Oberwellen und einen Lautstärkeverlauf. Abseits der Oberwellen wird auch der tiefe Basston durch die Lautstärke moduliert, siehe "gating", "compression" und "Hüllkurve" und das führt letztlich zu steileren Anstiegen, die man wieder in Frequenzen uminterpretieren kann. Die tauchen dann in deiner Spektralanalyse auf. Schau dir mal einen Technobass an, der mit Attack < 3ms arbeitet. > 7. Was wären vielversprechende Fensterformen für Audiosignale? Blackman-Harris-II oder das S2-Fenster von meiner Wenigkeit.
Audiomann schrieb: > A. S. schrieb: >> Aus meiner Sicht ist es „relevant“, Tonhöhen genau bestimmen zu können – >> davon gibt es laut midi-protokoll max. 127, aber eine deutlich größere >> Menge Obertöne kann wohl nicht schaden. > Damit liegst du schon einmal daneben! Es gibt wesentlich mehr Töne und > Zwischentöne, also nur 127. Zunächst muss mal die Frequenz gefunden werden. Welcher Ton das ist, hängt von der Tonleiter / Stimmung ab. Natürlich kann man das anhand einer Grundstimmung einteilen, muss dann aber einen Offset mit angeben, z.B. für das aktuelle Vibrato oder eine absichtlich verstimmte Tonhöhe, wie z.B. bei "blue notes" oder überstimmten Instrumenten: Manche Soloinstrumente werden absichtlich an der Hauptstimmung vorbeigestimmt, meistens etwas höher. Hinzu kommt, dass auch die Grundstimmung nicht eindeutig ist, weil nicht jeder auf 440Hz stimmt und dann auch in "A" spielt. Orchester spielen z.B. nicht auf 440Hz und auch akustische Musik, z.B. bei Gitarren tut das nicht: Es reicht, wenn jemand seine A-Seite elektronisch exakt auf 440Hz stimmt und danach per Gehör die anderen Seiten auf D und G in Null-Schwebung stimmt, weil er in reiner Stimmung spielen will oder es unbewusst tut. Dann haben die Nachbarseiten andere Frequenzen, als die gleichstufige Stimmung (12. Wurzel aus 2) vorgibt. Wenn das Stück dann in G-Dur oder gar C-Dur gespielt wird, kommen damit überwiegend Noten, die nicht exakt in der Mitte des dedizierten Bereichs liegen. Noch netter wird es, wenn man die Töne in Echtzeit bestimmen will, um damit weitere Geräte zu steuern. Nimm dir mal die Audio-2-MIDI-Converter, die z.B. ein Gitarrensignal in eine MIDI-Note wandeln. Die Tonhöhen ändern sich sehr schnell, wenn jemand über die Saiten slided oder ein Vibrato spielt. Auch wenn eine schwingende Saite gegriffen und losgelassen wird, ändert sich die Tonhöhe fließend. Mit MIDI-Noten-Nummern kommt man da nicht weit. Bei meinen Converter umgehe ich daher die MIDI-Nummerierung und spätere Wiederzuordnung (Midi-Note in Tabelle suchen und Frequenz ablesen + Vibrato addieren) und spiele die Frequenz direkt in den Synthesizer. Da die Analyse sehr schnell geht, fließt auch die Frequenz sehr gleichmäßig und es gibt keine unnötige Granularisierung. http://www.96khz.org/htm/audio2midifpga.htm > Obertönen hat es auch nichts zu tun. Die Obertöne > verformen den Klang qualitativ. Zu den Obertönen ist zu sagen, dass diese nicht immer exakt auf den erwarteten Frequenzen, also den Vielfachen liegen. Beim Klavier und anderen Saiteninstrumenten ist das z.B. der Fall, weil eine Saite nicht exakt mit der idealen Differentialgleichung schwingt, weil es aufhängungsbedingt Längenänderungen gibt und sie sich auch dehnt. Je kürzer die Saite überhaupt ist, desto stärker macht sich das bemerkbar. Siehe den Diskanten beim Klavier. https://de.wikipedia.org/wiki/Streckung_(Musik) Damit ist es im Übrigen auch möglich, Klaviertöne zu erkennen, wenn sie ein bestimmtes Obertonmuster zeigen. Zumindest ist das mal zu berücksichtigen, wenn man Musik analysieren will. Gerade da Obertonspektrum vom Klavier ist da besonders komplex. Das ist auch und vor allem davon abhängig, wie der Klavierstimmer das Instrument einstellt. Das wiederum ist eine Frage der Strategie, des persönlichen Geschmacks und auch der Stücke, die gespielt werden. Ich hatte da einst eine sehr aufschlussreiche Diskussion mit Ernst Kochsiek, die mir enorm weitergeholfen hat.
Angehängte Dateien:
-

musiscope_ASaw.jpg
35 KB
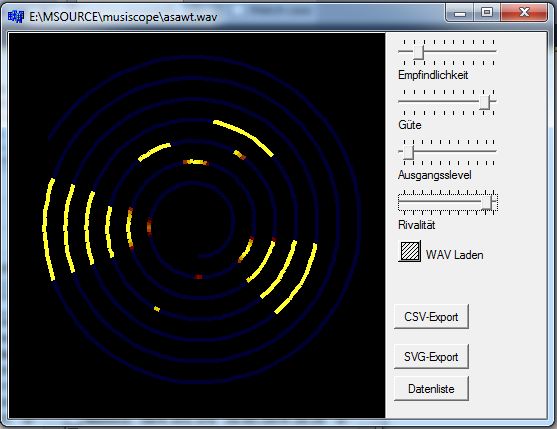
A. S. schrieb: > Beispielsweise möchte ich aus einer > Audiodatei gerne mp4-Videos mit Audio und Spektrogrammen generieren, die > möglichst viele der „relevanten“ Informationen enthalten. Ähnliches hat mich auch schon mal beschäftigt. Übliche Spektrogramme zeigen aber nicht unmittelbar musikalischen Zusammenhänge. Brauchbar ist da eine Spirale, bei der gleiche Töne unterschiedlicher Oktaven auf einer Linie liegen und Intervalle zu Winkeln werden. Das Programm, das ich dazu entwickelt hatte, detektiert die Töne mit simulierten Schwingkreisen. Das Beispiel-Bild zeigt einen Sägezahn-Ton von 440hz, die Obertöne sind deutlich erkennbar.
Danke für eure ausführlichen Antworten! Mir ist klar, dass ich nicht alle Aspekte von Musik abbilden kann. Ein typisches Beispiel wäre ein tool, dass aus einem Summenmix mehrere PianoRolls extrahiert - je eines pro (erkanntem) Instrument. Echtzeit soll erstmal kein Thema sein. Eine mp3 reinzuladen und 10min später die Piano Rolls herauszubekommen wäre immer noch ein brauchbarer use case. Dass da noch weitere Themen wie Drums, Vocals, Tuning, Slides, Effekte, Mixdown oder Mastering analysiert werden könnten ist klar. Aber man kann ja nicht alles auf einmal lösen. Meine Hoffnung ist, dass ein neuronales Netz diese Dinge für "für die Aufgabe unwichtig" einordnet und selbständig vom output fern hält. Das heißt natürlich nicht, dass man das Ding nicht durch sinnvolle Vorverarbeitung der Wellenform dabei unterstützen sollte. Daher suche ich ein schlau gestaltetes Spektrogramm. Oder mehrere. Jürgen S. schrieb: > Autoadaptiver Görtzel. Man muss in jedem Fall selektive Frequenzen > erkennen und zerlegen. Eine reine FFT ist z.B. zu starr. Nach meiner Recherche mit diesem Stichwort sehe ich ein, dass die DFT unterlegen ist: Der Vorteil des Görtzels ist wohl Flexibilität & Rechenzeit. Aber habe ich die Flexibilität mit wavelets nicht auch? Effektiv ist da ja das Fenster einfach in die Faltungsoperation eingepreist. Wavelets wären auf GPU mit den bekannten DeepLearning-Trainingstools nur deutlich einfacher zu implementieren als ein Görtzel. Aber was meinst du mit "autoadaptiv"? Dazu konnte ich nichts finden. Vielleicht fehlt mir noch ein gedanklicher Baustein. Sprichst du von selbst-tunenden Filtern, die sich auf gespielte Frequenzen einstellen? Und auf was sollten die sich im dreckigen Summenmix einstellen und in welcher Einschwingzeit? > Zu den Obertönen ist zu sagen, dass diese nicht immer exakt auf den > erwarteten Frequenzen, also den Vielfachen liegen. Das Thema stretch-tuning ist ein gutes Stichwort. Also sieht das Obertonspektrum der tiefen Töne eines Instruments nicht einfach so aus wie das verschobene Spektrum der höheren Töne. Und dass die Instrumente eher auf Obertonkonsonanz gestimmt werden als auf saubere Grundtöne, war mir auch neu. Welche Konsequenz ich daraus für das Spektrogramm des Summenmixes ziehen sollte ist mir aber noch nicht klar. Will ich eine so hohe Frequenzauflösung, dass man diese Effekte sehen kann? Oder will ich bewusst weniger Frequenzen darstellen, um diesen Effekt bereits in der Vorverarbeitung zu verbergen? Wenn ich so drüber nachdenke: eher nicht. Du deutest ja schon an, dass der menschliche Hörer z.B. das Klavier sehr gut erkennen kann, weil es eben nicht so sauber ins Muster passt. Ein solches Verhalten möchte ich eigentlich auch haben. Dann also ganz viele verschiedene Frequenzen zusammenkratzen? > Nicht unbedingt: Man kann durchaus zu jedem Zeitpunkt die aktuelle > Tonhöhe hinreichend genau angeben. Wie denn? Sprechen wir hier von polyphonem Material? Das wäre spannend Audiomann schrieb: > Wieso? Heisenberg in der Musik? genau. https://en.wikipedia.org/wiki/Uncertainty_principle#Signal_processing ""One cannot simultaneously sharply localize a signal (function f) in both the time domain and frequency domain" Jürgen S. schrieb > Ein musikalischer Ton hat Oberwellen und einen Lautstärkeverlauf. > Abseits der Oberwellen wird auch der tiefe Basston durch die Lautstärke > moduliert, siehe "gating", "compression" und "Hüllkurve" und das führt > letztlich zu steileren Anstiegen, die man wieder in Frequenzen > uminterpretieren kann. Genau, ich habe wohl nicht die richtigen Begriffe benutzt. Ein Sub-Bass wird nicht in schnellen 16teln spielen und falls doch, glaube ich kaum, dass man seine Grundschwingung im Spektrogramm entsprechend schnell auftauchen und verschwinden sieht. Die Anschläge werden wohl eher - so wie du es beschreibst - zu Obertönen, die man dann etwa als menschlicher Hörer stellvertretend als Pulse des tiefen Grundtons wahrnimmt. Jobst Q. schrieb: > Das Beispiel-Bild zeigt einen Sägezahn-Ton von 440hz Spannende Darstellung, vielleicht probiere ich das auch mal. Allerdings für die Weiterverarbeitung im neuronalen Netz ist da meiner Meinung nach zu viel "schwarz"
A. S. schrieb: > Sprichst du von > selbst-tunenden Filtern, die sich auf gespielte Frequenzen einstellen? Exakt. > Und auf was sollten die sich im dreckigen Summenmix auf die erkannten Frequenzen, die einen Zusammenhang bilden und damit in Bezug stehen könnten. Geht in Richtung Matcher. >Einschwingzeit? Variabel! A. S. schrieb: > Ein Sub-Bass > wird nicht in schnellen 16teln spielen Opening von "Kiss: I was made for loving you". > und falls doch, glaube ich kaum, > dass man seine Grundschwingung im Spektrogramm entsprechend schnell > auftauchen und verschwinden sieht. Der Basston hat eben eine Menge Oberwellen, die das "Auftauchen" und "Abtauchen" realisieren -> Transienten. Und das Ohr hört genau deshalb den Basston raus.
Jobst Q. schrieb: > Brauchbar ist > da eine Spirale, bei der gleiche Töne unterschiedlicher Oktaven auf > einer Linie liegen und Intervalle zu Winkeln werden. Finde ich sehr interessant. Ich habe was Ähnliches am Start - nur im Komplexen (siehe Riemannsche Spirale) - allerdings mit einem anderen Ziel. Kommt aus einer industriellen Anwendung und hat aktuell nur graphische / künstlerische Gründe. Die Idee, das als Marker für Oberwellen zu nehmen ist recht übersichtlich und macht auch eine sinnvolle Aussage. Ich nehme an, die Färbung ist der Betrag und der Winkel das Module der Frequenz (eine Oktave für 306°) ? Man könnte jetzt noch die Phase aus der FFT reinnehmen und färben oder den Kreis modulieren, z.B. in der Z-Achse , z.B. über den komplexen Winkel. Müsste recht lustig aussehen, das in Echtzeit zu machen.
Jürgen S. schrieb: >> Sprichst du von >> selbst-tunenden Filtern, die sich auf gespielte Frequenzen einstellen? > Exakt. okay spannend. Da ich dazu aber kaum etwas online finde - oder die falschen Begriffe verwende - bräuchte ich aber noch ein paar Infos, was man sich darunter genau vorstellen kann. Ich nehme an, es geht um einen Regelkreis, der die Frequenz des Filters anpasst. Aber basierend auf was? Wird versucht, die ausgebene Amplitude zu maximieren? Dann muss man vermutlich den Frequenzbereich limitieren oder ständig zurücksetzen, sonst driftet der ja davon. Ohne damit DSP-Erfahrung zu haben, hätte ich jetzt einen Ausschnitt von wenigen 100ms gewählt; den in ein paar Dutzend Blöcke zerlegt, die sich möglicherweise überlappen, und dann auf jedem Block eine Wavelet-Analyse laufen lassen. Leider liegt dann N irgendwo zwischen 100-1000, vielleicht sind da gar nicht genug Infos vorhanden für eine feine Analyse? Oder ist das der Hauptvorteil des Görtzels: man braucht gar keine "Blöcke" und kann zu jedem Frame im Ausschnitt einen Wert ausgeben? Bisher klangst du eher so als würde man sehrwohl mit kurzen "Blöcken" arbeiten, um ein Spektrogramm zu generieren. Ich glaube, ich muss das einfach mal ausrpobieren... Ganz nett zum Vergleich: hier wird N statisch auf eine fest vorgegebene Frequenz eingestellt. https://dsp.stackexchange.com/a/54527
Angehängte Dateien:
-

signal.png
30 KB -

omega3.png
55 KB -

omega4.png
51 KB -

omega6.png
50 KB -

omega10.png
49 KB -

omega15.png
46 KB -

omega20.png
43 KB -

omega30.png
41 KB -

omega50.png
39 KB
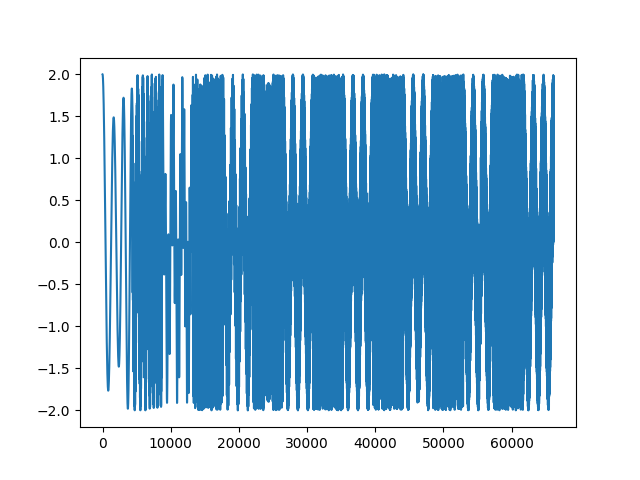
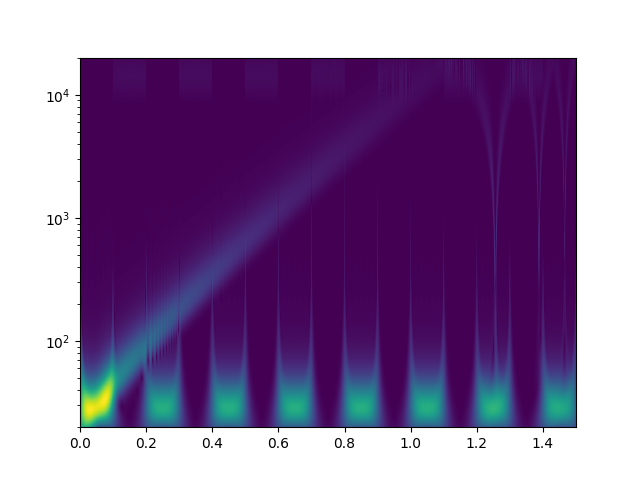
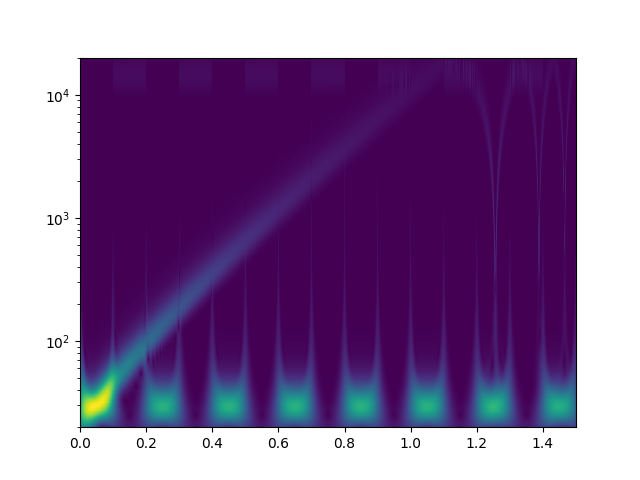
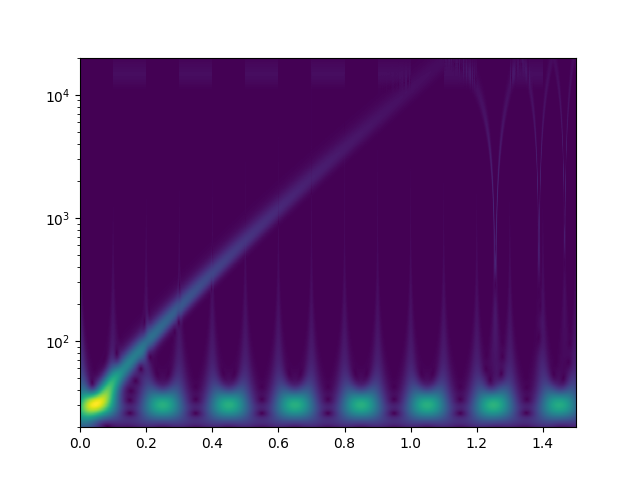
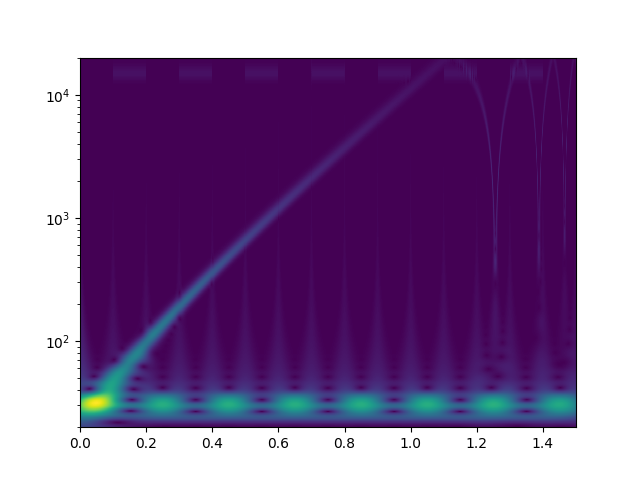
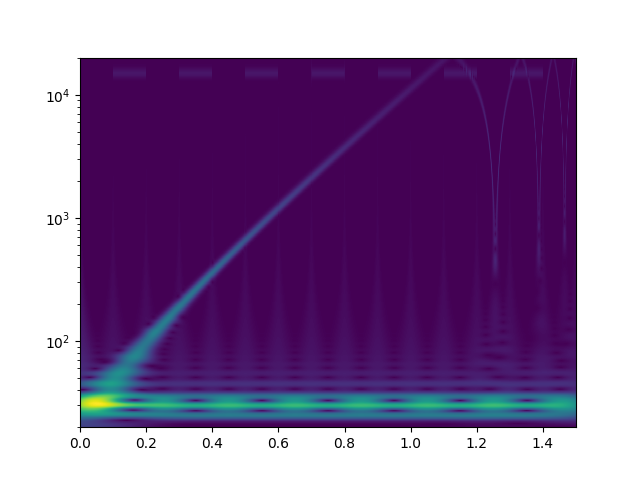
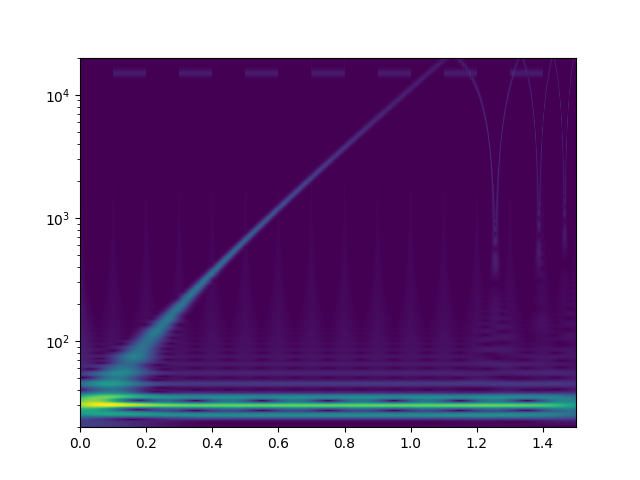
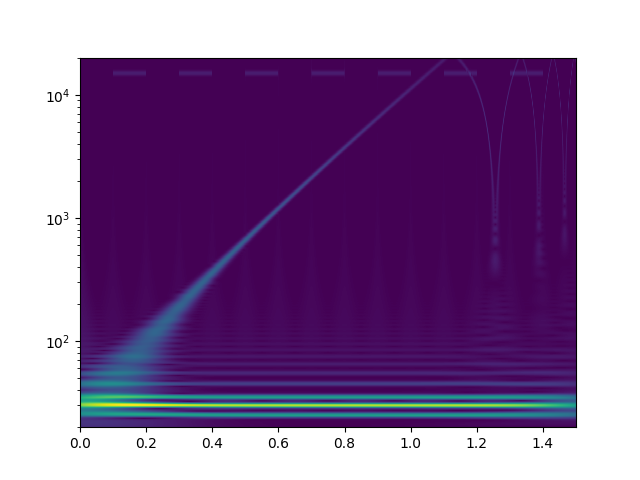
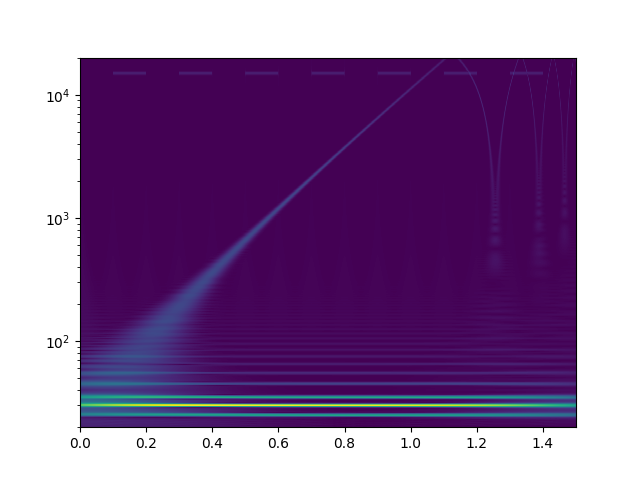
Ich habe mal zum Kennenlernen mit der continuous wavelet transform mit morlet kernels gespielt. Bei der cwt beantwortet sich die Frage nach den "Blöcken" von selbst. Das weiß ich jetzt. Zunächst definiere ich ein Signal, das einen sweep von 20Hz..20kHz enthält, sowie zwei zeitlich versetzte Tremolotöne mit 30Hz bzw. 15kHz
1 | t_end = 1.5 # a 1500msec sample |
2 | fs = 44100 # at 44.1kHz |
3 | dt = 1.0 / fs # sampling step size |
4 | t = np.arange(0, t_end, dt) # time vector |
5 | fB = np.geomspace(20, 20000, int(t_end * fs)) # sweep |
6 | sig = np.cos(2*np.pi*fB*t) |
7 | sig += np.where((t % 0.2) > 0.1, np.sin(2*np.pi*15000*t), 0.0) |
8 | sig += np.where((t % 0.2) < 0.1, np.cos(2*np.pi*30*t), 0.0) |
Das drehe ich dann durch die complex-float32 cwt von scipy mit einer großen Zahl an logarithmisch skalierter morlet wavelets und plotte den Betrag der komplexen Ergebnisse.
1 | freq = np.geomspace(20, 20000, 1024) # logarithmically spaced anchor freqs 20Hz .. 20kHz |
2 | widths = omega*fs / (2*freq*np.pi) # wavelet widths to yield desired fundamental freqs |
3 | # impl: https://github.com/scipy/scipy/blob/v1.8.1/scipy/signal/_wavelets.py#L309-L386 |
4 | cwtm = signal.cwt(sig, signal.morlet2, widths, w=omega, dtype=np.csingle) |
Als freier Parameter bleibt "omega", das für alle einzelwavelets identisch ist. Ich habe [3.0, 4.0, 6.0, 10.0, 15.0, 20.0, 30.0, 50.0] rad/s versucht. Bilder als Anhang. Eine solche cwt rechnet 150sek auf einem CPU Kern meines PCs. Ich würde das gerne optimieren, denn es sieht so aus als könnte man hohe Frequenzen bereits mit kürzeren Audioschnipseln sauber zeitlich auflösen. Für alles <100Hz werde ich aber vielleicht sogar zu noch größeren Zeiträumen gehen müssen. Habt ihr noch andere Ideen, wie man tiefe Frequenzen bei der wavelet-Analyse besser zeitlich auflösen könnte? Auch wenn das die lib API nicht zulässt, will ich später vielleicht nicht für alle Wavelets das gleiche Omega wählen? Was mir auch nicht klar ist: warum habe ich am Ende des Sweeps aliasing-effekte? 20kHz müssten doch laut shannon abbildbar sein, oder? Die plots sehen aber eher so aus, als versucht da jemand bis >100kHz zu rechnen. Wo ist mein zusätzlicher Faktor 2pi, der raus muss?
Angehängte Dateien:
-

full_abs.png
81 KB
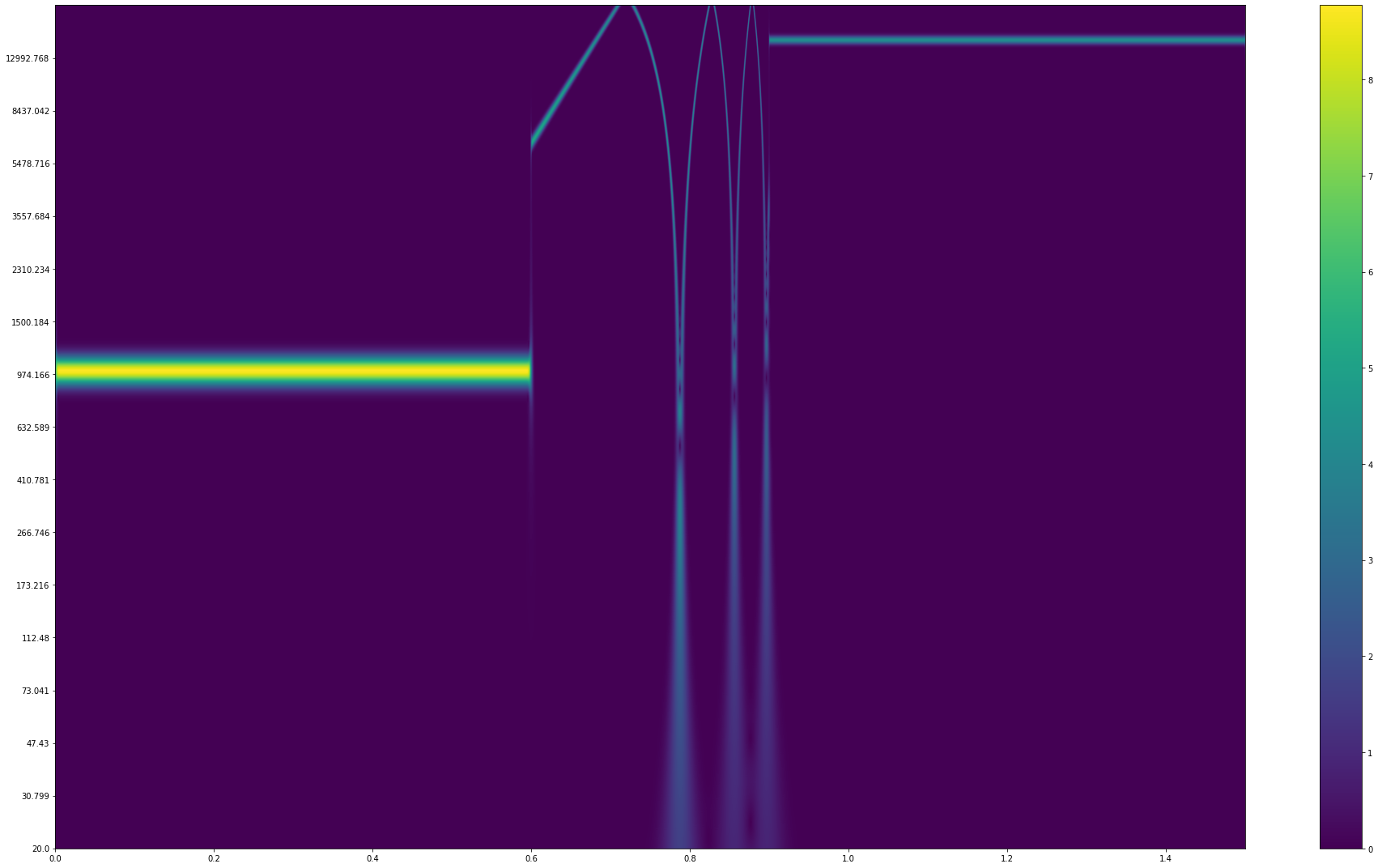
kleines update: A. S. schrieb: > Was mir auch nicht klar ist: warum habe ich am Ende des Sweeps > aliasing-effekte? 20kHz müssten doch laut shannon abbildbar sein, oder? > Die plots sehen aber eher so aus, als versucht da jemand bis >100kHz zu > rechnen. Wo ist mein zusätzlicher Faktor 2pi, der raus muss? Es hat sich herausgestellt, dass die Frequenz-Sweeps wirklich passen. Konstante Frequenzen werden mit demselben code wie gewünscht abgebildet. Bugrelevante Faktoren sind da keine drin. Als Erklärung bleibt wohl nur, dass so schnelle, logarithmisch skalierte Sweeps wohl weitere Frequenzanteile enthalten, die das Bild weit nach oben verzerren. Und genauso hört es sich auch an!
1 | T = t.shape[0] // 5 |
2 | fB = np.concatenate( |
3 | ( |
4 | np.ones(2*T) * 1000, |
5 | np.geomspace(1000, 15000, T), |
6 | np.ones(2*T) * 15000, |
7 | ), |
8 | axis=0 |
9 | ) |
10 | sig = np.cos(2*np.pi*fB*t) |
11 | save_signal(sig) |
Die Werte in fB sind korrekt eingetragen: * 600ms @ 1kHz * 300ms sweep nach oben * 600ms @ 15kHz Das Laufzeitproblem habe ich übrigens auch hinbekommen. Tatsächlich war der plot-code ziemlich langsam. Die Erzeugung des vollen 16384 x 66150 Spektrogramms dauert jetzt single core nur noch 90sek. Längere Sequenzen sind jetzt RAM-limitiert. Aber in 1.5sek "hört" man ja schon etwas.
Beitrag #7130664 wurde von einem Moderator gelöscht.
Sieht sehr interessant aus, aber wie möchte man das auswerten? Nur rein optisch?
A. S. schrieb: > Ich möchte ein Machine > Learning System bauen, Wie denn? Ich denke da eher an Mustererkennung und Ergänzen unvollständiger Muster, und denke dabei auch an Handschrift-Erkennungs-Programme, oder Spracherkenner die eine lange Entwicklungsgeschichte hinter sich haben. Außerdem besteht einfaches Lernen im Nachmachen. Per Nase reiben und schnippen, "ich habs" geht natürlich auch, ist aber schwieriger auf die Spur zu kommen bzw. zu unterscheiden, ob tatsächlich Lernen stattfinden, oder nur der Groschen fällt. Geht auch beides gleichzeitig, aber Nachmachen ist normalerweise die einfachere Technik (als Nachdenken). Nachmachen ist auch bei Musikern sehr beliebt, wie auch das Klauen aus Musikstücken..ein oft erfolgreiches Pokern auf Muster-Nichterkennung ;)
Angehängte Dateien:
-

full.png
74 KB
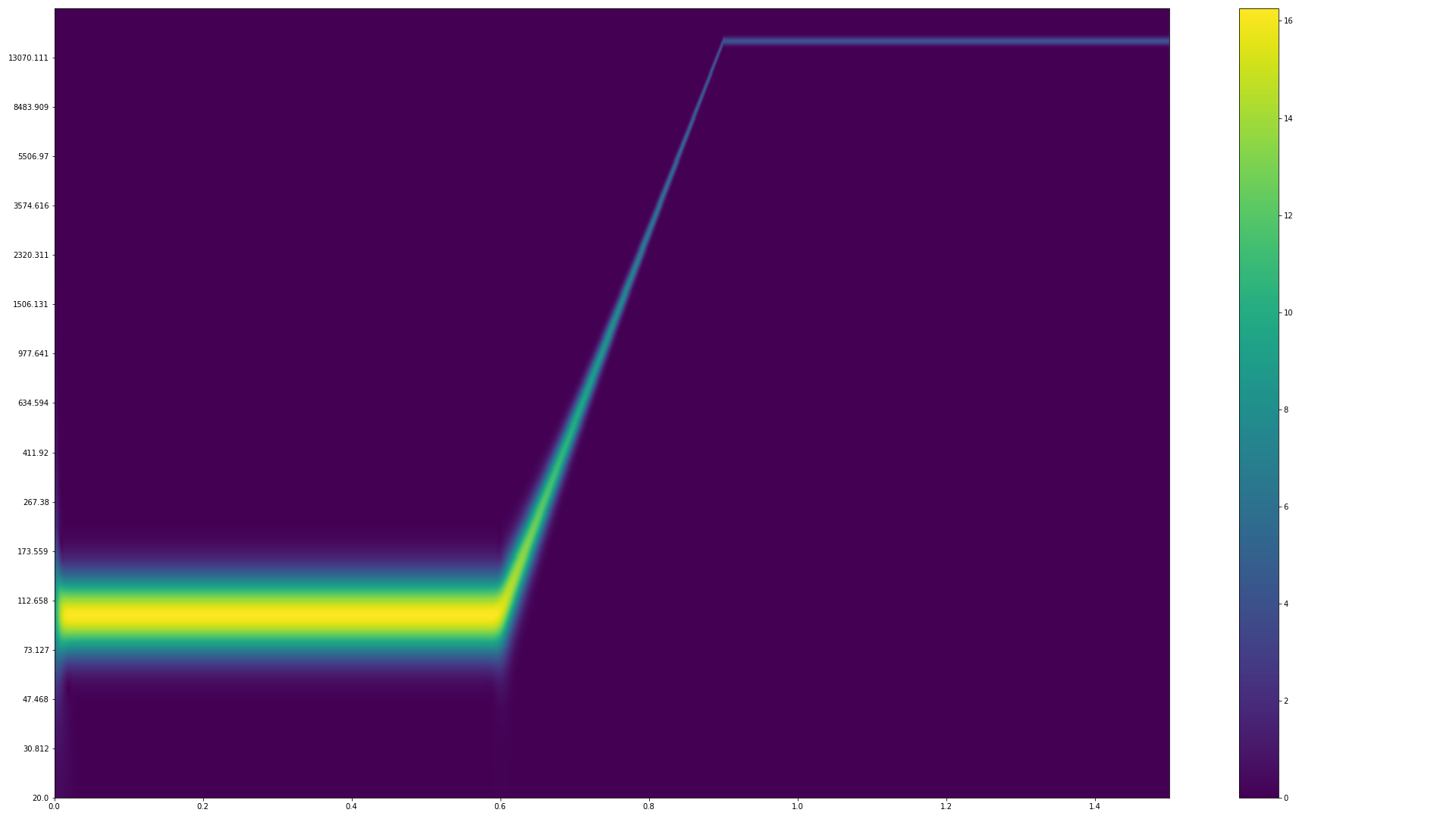
Mathe nicht verstanden. Man darf bei einer variablen Frequenz nicht einfach elementweise f * t rechnen um die Phase zu erhalten. Stattdessen:
1 | T = t.shape[0] // 5 |
2 | fB = np.concatenate( |
3 | ( |
4 | np.ones(2*T) * 100, |
5 | np.geomspace(100, 15000, T), |
6 | np.ones(2*T) * 15000, |
7 | ), |
8 | axis=0 |
9 | ) |
10 | phase = np.cumsum(2*np.pi*fB/fs) |
11 | sig = np.cos(phase) |
... eine schwere Geburt
rbx schrieb: > Wie denn? sollte funktionieren wie immer: Durch Trainieren mit einer großen Menge Audiodateien mit gewünschter Ausgabe. Die kann man zum Beispiel synthetisieren mit Samples aus VST-Instrumenten etc. Das wird definitiv die größte Baustelle des Ganzen. Aber damit kenne ich mich wenigstens aus :D Wie man die Eingangsdaten des Systems erzeugt, also in meinem Fall das Spektrogramm, ist die erste Hürde. Dazu gehört auch die Gewichtung der verschiedenen Frequenzen.
A. S. schrieb: > Dazu gehört auch die Gewichtung der > verschiedenen Frequenzen. Hast du schon mal versucht, Vogelgesang bzw. -gezwitscher zuzuordnen? Mit etwas Übung geht das ganz gut. Man braucht allerdings auch die passenden Kandidaten für schwierige Unterscheidungen, oder um Verwechselungen ausschließen zu üben. (Ganz abgesehen davon, einige Vogeltypen sieht (oder hört)man vielleicht einmal, aber dann nie wieder. Andere können völlig unbekannt sein, oder sind einfach nur sehr schwer einzuordnen.
rbx schrieb: > Hast du schon mal versucht, Vogelgesang bzw. -gezwitscher zuzuordnen? > Mit etwas Übung geht das ganz gut. Mit dem Gehör ist das Trivial, weil es mehrere Sekunden lang immer die gleiche Signatur ist. Aber Musikanalyse erfordert etwas ganz anderes, nämlich das modulare Zerlegen der Information in Teilinformationen und Klassifizierung derselben. Ansonsten wäre es nur "Musik" wiedererkennen und dazu braucht ein Musiker auch nur Sekunden.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.