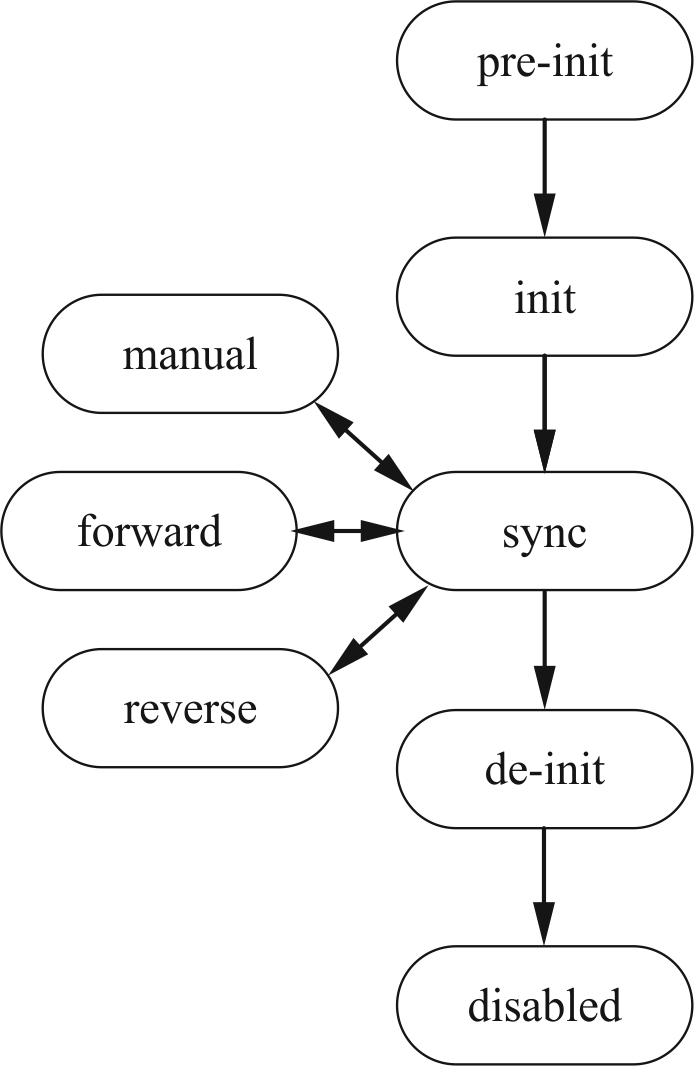
Guten Tag, ich will eine Zustandsmaschine implementieren, die sich von einem beliebigen IST-Zustand über eine Reihe von erlaubten Zustandswecheln auf einen Soll-Zustand zubewegt. Bislang ist das eine riesige geschachtelte switch-case-Orgie. Ich habe zwar insgesamt nur 12 Zustände, aber die kombinatorische Explosion macht das extrem unübersichtlich. Andererseits gibt es ohnehin nur eine überschaubare Anzahl an erlaubten Zustandsübergängen. Der Informatiker wird das wohl als eine Ansammlung gerichteter Graphen verstehen. Mir fehlt nur gerade die Vorstellungkraft, wie da die passende Datenstruktur aussehen mag, um den passenden Pfad vom aktuellen Zustand zum Zielzustand effizient zu finden.
Angehängte Dateien:
Ich bin nicht sicher, ob ich dir Frage verstehe. Du bist in beliebigen Zustand X und möchtest wissen, über welche Übergänge man in Zustand Y kommt, oder? Dafür brauchst du erstmal keine Datenstruktur, sondern einen Algorithmus. Das Ergebnis kannst du dann speichern und auslesen. Dafür würde ich wahrscheinlich eine einfache Liste für jeden Knoten mit möglichen Zielknoten nehmen. Als Algorithmen bieten sich Graphsuchalgorithmen an, zum Beispiel zu finden unter https://de.wikipedia.org/wiki/Kategorie:Graphsuchalgorithmus Leider kann ich auf die Schnelle nicht sagen, welcher davon auf gerichteten Graphen funktioniert.
1. Versuch Es ist tatsächlich schwer vorstellen, was du willst. Bestimmt lege ich falsch. Trotzdem ich versuche es Was du hier gezeigt hast, ist nur der Lifecycle für eventuell einen Knoten. Eventuel existieren viele solche Knoten, die zu einander bestimmte Relationen haben und Regeln. Zb. von einem kann man zu dem anderen nur dann übergehen, wenn ein Knoten in einem Zustand und der andere in dem anderen. Daher es ist tatsächlich ein graph, jedoch die Kanten sind entweder dynamisch, ob es sie gibt oder eventuell mit Gewichten rumspielen. 2. Versuch Ein Knoten soll eine Klassentität sein. Eine relation auch. Danach gibt es konfiguration der Welt, und Logik, die alle Kanten auf die einheitliche Art und Weise durchläuft, wenn ein neuer Zustand übermittelt wird, in welchem sich die Maschine gerade befindett oder befinden wird. Mit Graphen ist es einfach zu realisieren. Ich hoffe, ein wenig zu helfen.
Walter T. schrieb: > Bislang ist das eine riesige geschachtelte > switch-case-Orgie. Ich habe zwar insgesamt nur 12 Zustände, aber die > kombinatorische Explosion macht das extrem unübersichtlich. Variante 1: Split das ganze und nutze je Zustand jeweils eine Funktion die den Übergang zu den 11 anderen Zuständen prüft/steuert. Dadurch wird es übersichtlicher. Varinante2: Mach eine Zustandsübergangstabelle 12x12. Jeder erlaubte Übergang enthält einen Zeiger auf eine Funktion die eine Übergangsaktion ausführen kann. Ein Funktionspointer NULL signalisiert, dass der Übergang nicht erlaubt ist. Variante3: Nutz ein Tool, das aus Zustandsdiagrammen Sourcecode erzeugt oder die Tabelle aus Variante2 erzeugt. Was unklar ist: Sind die Zustandsübergänge fix? Oder können sie sich unter Bedingungen verändern?
Dussel schrieb: > Du bist in beliebigen > Zustand X und möchtest wissen, über welche Übergänge man in Zustand Y > kommt, oder? Genau. Ich bin im Zustand A, will in Zustand B. Zu welchem Zustand muss ich als nächstes? (Beispiel: Ich bin in "pre-init", will nach "manual" -> "init" ist der nächste Schritt.) Bevor ich einen Algorithmus suchen kann, brauche ich doch erst einmal eine Datenstruktur für die Daten. Aber wahrscheinlich reicht ein einfaches zweifach indiziertes Array mit den Kantenlisten. Ungerichtete Kanten haben dann einfach zwei Einträge. Wobei ich mittlerweile gemerkt habe, dass der Algorithmus auch gar nicht so effizient sein muss. 12 Zustände gehen in 4 Bit, d.h. ein komplettes Lookup-Table passt in 216 Byte. Damit kann man leben. Klaus H. schrieb: > Was unklar ist: Sind die Zustandsübergänge fix? Oder können sie sich > unter Bedingungen verändern? Sie können sich ändern, es können Verbindungen verboten werden. Aber alle erlaubten Bedingungen sind beim Programmstart bekannt.
Walter T. schrieb: > Mir fehlt nur gerade die Vorstellungkraft, wie da die passende > Datenstruktur aussehen mag, um den passenden Pfad vom aktuellen Zustand > zum Zielzustand effizient zu finden. Datenstruktur egal, und der Algorithmus eher auch. Weil's nur 12 Zustände sind. https://de.wikipedia.org/wiki/Breitensuche drüber, fertig sobald du am Zielknoten angekommen bist. Etwas komplizierter wirds, wenn du den Zustandsübergängen/Kanten noch Kosten zuweisen willst, also mehrere Wege zum Ziel führen können, aber der Kürzeste nicht unbedingt der Beste ist. Aber auch da: Breitensuche mit etwas modifizierter Abbruchbedingung wird wohl reichen.
Walter T. schrieb: > Zu welchem Zustand muss ich als nächstes? Hier ist noch zu klären was bedeutet 'muss'? Denn, wenn du sagen würdest 'kann', dann ist die Logik der Kanten die Grundlage, aber mit dem muss ist gemeint, dass ein 'höheres' Ziel vorhanden ist und fie Anzahl der Schritte klein wie möglich sein soll...
Und die Ergänzung dazu. Walter T. schrieb: Zu welchem Zustand muss ich als nächstes? Im Schach gibt es sehr viele Züge, die möglich sind, aber zum Gewinn bringen nur bestimmte.
Walter T. schrieb: > ich will eine Zustandsmaschine implementieren, die sich von einem > beliebigen IST-Zustand über eine Reihe von erlaubten Zustandswecheln auf > einen Soll-Zustand zubewegt. Hört sich eher nicht nach einem Zustandsautomaten an, wenn du dich auf einen "Sollzustand zubewegst". https://en.wikipedia.org/wiki/Finite-state_machine > Andererseits gibt es ohnehin nur eine überschaubare Anzahl an erlaubten > Zustandsübergängen. Der Informatiker wird das wohl als eine Ansammlung > gerichteter Graphen verstehen. > Mir fehlt nur gerade die Vorstellungkraft, wie da die passende > Datenstruktur aussehen mag, um den passenden Pfad vom aktuellen Zustand > zum Zielzustand effizient zu finden. Für Datenstrukturen siehe: https://en.wikipedia.org/wiki/Sparse_matrix Für eine Suche wurde ja oben schon die Breitensuche erwähnt: https://en.wikipedia.org/wiki/Breadth-first_search
Walter T. schrieb: > Bevor ich einen Algorithmus suchen kann, brauche ich doch erst einmal > eine Datenstruktur für die Daten. Aber wahrscheinlich reicht ein > einfaches zweifach indiziertes Array mit den Kantenlisten. Ungerichtete > Kanten haben dann einfach zwei Einträge. Da es anscheinend auf einem Mikrocontroller laufen soll, muss man sehen, wie viel Platz vorhanden ist. Ist viel Platz übrig, würde ich mir um die Struktur nicht so viele Gedanken machen. Eine Liste aller (Start-)Knoten, wovon jeder dieser Knoten eine Liste der potentiellen Zielknoten enthält und davon jeder eine Liste des besten Wegs zu diesem Knoten. Ansonsten könnte man das sicher auch deutlich sparsamer beschreiben, wenn man den Weg über Verweise auf andere Wege speichert. Man speichert zum Beispiel den Pfad von B nach E über C und D (B->C->D->E). Wenn man jetzt von A nach D möchte und A und B benachbart sind, muss man nur den Weg von A nach B (A->B) speichern und ab da auf den schon gespeicherten Pfad von B nach E verweisen. Mikro 7. schrieb: > Walter T. schrieb: >> ich will eine Zustandsmaschine implementieren, die sich von einem >> beliebigen IST-Zustand über eine Reihe von erlaubten Zustandswecheln auf >> einen Soll-Zustand zubewegt. > > Hört sich eher nicht nach einem Zustandsautomaten an, wenn du dich auf > einen "Sollzustand zubewegst". Warum nicht? Das kann schon sein. Als einfaches Beispiel eine Ampelschaltung. Nord-Süd-Richtung hat grün und jetzt soll auf Ost-West-Richtung grün geschaltet werden. Das geht nicht direkt, sondern man über über N-S gelb, alle rot, O-W gelb-rot zu O-W grün gehen. Das ist jetzt natürlich ein sehr einfaches Beispiel, aber auch in einem Zustandsautomaten kann der kürzeste Weg zu einem Zielzustand gesucht sein.
Klaus H. schrieb: > Variante 1: Split das ganze und nutze je Zustand jeweils eine Funktion > die den Übergang zu den 11 anderen Zuständen prüft/steuert. Dadurch > wird es übersichtlicher. Das war mein erster Versuch. Ergebnis war eine Schar einander sehr ähnlicher Funktionen. Deswegen will ich jetzt den datenbasierten Ansatz versuchen. Mikro 7. schrieb: > Für Datenstrukturen siehe: > https://en.wikipedia.org/wiki/Sparse_matrix Hmja, an eine Art Adjazenzmatrix anstelle einer Kantenliste habe ich auch schon gedacht. Mikro 7. schrieb: > Hört sich eher nicht nach einem Zustandsautomaten an, wenn du dich auf > einen "Sollzustand zubewegst". Bitte nicht den Anwendungsfall (Zustandsautomat) mit dem Mittel dazu (Pfadsuche) verwechseln. Mir geht es um letzteres. Mikro 7. schrieb: > Für eine Suche wurde ja oben schon die Breitensuche erwähnt: Nach allem, was ich heute gelesen und probiert habe, ist Breitensuche wohl nicht so der Renner auf einem Mikrocontroller (pun intended), weil doch recht dynamisch mit dem Speicher umgegangen wird (Warteschlange), und weil ich sie auch mit viel Mühe nicht von rekursiv auf iterativ umgestellt bekomme. Aber kommt Zeit kommt Rat. Der freie Samstag ist jetzt vorbei, und vielleicht fällt im Laufe der Woche noch der Groschen.
Nachtrag: Über die Adjazenzmatrix geht es doch ganz angenehm, direkt die Breitensuche aus dem Wikipedia-Artikel zu implementieren. Ein wenig knifflig war es noch, den Suchpfad mitzuloggen. Ein wenig unsicher bin ich mir noch, ob die Länge der Warteschlange beschränkt ist (und wie lang). Ich werde das also sicherheitshalber nur dazu nutzen, auf dem PC lookup-Tables zu erzeugen.
Walter T. schrieb: > Nach allem, was ich heute gelesen und probiert habe, ist Breitensuche > wohl nicht so der Renner auf einem Mikrocontroller (pun intended), weil > doch recht dynamisch mit dem Speicher umgegangen wird (Warteschlange), Musst du nicht dynamisch machen. Du hast 12 Knoten, wie groß kann also eine "Warteschlange" von noch-nicht-besuchten knoten maximal werden? Wenn du Speicher sparen willst: sowohl die Kanten von jedem Knoten weg als auch die Queue, und sogar die Wegbeschreibung passen in je einen uint16_t, als einzelne Bits kodiert. Ist sogar noch Platz übrig, um auf 16 Knoten zu erweitern. Viele Aktionen auf dem Graph werden dann zu einfachen Logik-Operationen.
https://de.m.wikipedia.org/wiki/Dijkstra-Algorithmus
1 | Der Algorithmus von Dijkstra (nach seinem Erfinder Edsger W. Dijkstra) ist ein Algorithmus aus der Klasse der Greedy-Algorithmen[1] und löst das Problem der kürzesten Pfade für einen gegebenen Startknoten. |
Εrnst B. schrieb: > Du hast 12 Knoten, wie groß kann also > eine "Warteschlange" von noch-nicht-besuchten knoten maximal werden? Das ist die Frage. Dafür bin ich zu wenig Informatiker. 8191 Knoten?
Walter T. schrieb: > Das ist die Frage. Dafür bin ich zu wenig Informatiker. 8191 Knoten? Es macht keinen Sinn in die Queue Knoten einzufügen, für die bereits ein kürzerer Weg gefunden wurde. Neuer Versuch? Vielleicht über die Mengenlehre? Du bildest die Teilmenge der Knoten die vom aktuellen Knoten erreichbar und noch unbesucht sind. Kann diese Teilmenge größer sein als die Menge "aller Knoten" oder größer als die Menge "unbesuchter Knoten"? Warum "Mengenlehre"? Wenn alle Kanten (ungewichtet) gleichlang sind, passt das schön zur µC-tauglichen Implementierung über Bitfelder. Schnittmenge ist Bitweises AND usw. Einzig aus dem Bitmuster wieder eine Knotennummer zu generieren ist etwas ungünstig. Der GCC bringt ein ffs / __builtin_ffs mit, was zwar "schnell" ist, aber trotzdem O(n) …—… für n ≤ 12.
Εrnst B. schrieb: > Kann diese Teilmenge größer sein als die Menge "aller Knoten" oder > größer als die Menge "unbesuchter Knoten"? Wenn ich das richtig sehe ja. Jeder Knoten wird ja pro Verzweigung und einmal mehr besucht. Und die Reihenfolge ist wichtig, weil daraus später der Pfad generiert wird. Also braucht die Warteschlange mindestens 4 Bit pro Element.
Walter T. schrieb: > Jeder Knoten wird ja pro Verzweigung und > einmal mehr besucht. Muss er nicht, ist ja Breitensuche. Falls du einen Knoten zur Queue hinzufügen willst, der schon drinnen ist: Einfach nicht machen. Der vorhandene Eintrag wurde über einen kürzeren Pfad erreicht, und bei ungewichteten Kanten (insb. keine negativen Gewichte) macht es keinen Sinn, längere Pfade und Schleifen zu verfolgen. Walter T. schrieb: > Und die Reihenfolge ist wichtig, weil daraus später der Pfad generiert > wird. Der Pfad braucht die Reihenfolge nicht (wieder unter der Annahme: "Ungewichtete Kanten"), die ergibt sich beim "Abarbeiten" des Pfades wieder automatisch, der ganze Pfad passt also auch in ein uint16_t (wenn der Startknoten bekannt ist) Aktueller Knoten X, Pfad P: Nächster Knoten X' ist dann ffs(kanten[X]&P)-1, nächster Pfad P' ist P&~(1<<X) Ziel erreicht bei !P...
Εrnst B. schrieb: > der ganze Pfad passt also auch in ein uint16_t (wenn > der Startknoten bekannt ist Das verstehe ich nicht. Wie passt der ganze Pfad dort hinein, dass ich die Reihenfolge rekonstruieren kann, ohne die ganze Suche wieder zu durchlaufen?
Walter T. schrieb: > Das verstehe ich nicht. Wie passt der ganze Pfad dort hinein, dass ich > die Reihenfolge rekonstruieren kann, ohne die ganze Suche wieder zu > durchlaufen? Weil du nicht neu suchen musst, sondern die Schnittmenge bildest zwischen denen von der aktuellen Position direkt erreichbaren Knoten und den Knoten, die in deinem Pfad vorkommen. Schnittmenge: "Bitweises AND", "kanten[X] & P" im Pseudocode oben. Diese Schnittmenge ist dann einelementig (bei einem eindeutigen Pfad), kann aber, wenn mehrere gleichwertige Pfade existieren, auch mehrelementig sein. Du wählst einfach einen Knoten aus der Schnittmenge aus (ich nahm den mit der niedrigsten Nummer), und machst von dem aus weiter, im Pseudocode oben "ffs(...)-1" Also keine Suche, einfaches Ablaufen der Knotenmenge.... Das Aufbauen des "Pfad"-Bitsets, dafür ist die Suche nötig. Wenn's grad nicht so schön sonnig wäre, würd ich das mal in C runtertippen. Vielleicht am Nachmittag...
Hier ist es diesig. Es funktioniert wirklich. Die Warteschlange darf wirklich eine Bitmaske sein, weil die Reihenfolge der Abarbeitung der Warteschlange egal ist. Damit wird die Sache erstaunlich effizient, zumal der µC auch CLZ() eingebaut hat. Nicht effizient genug, um in der Hauptschleife immer mitzulaufen, aber effizient genug, um die Lookup-Tables auf der Zielplattform zu berechnen. Momentan ist mein Quelltext definitiv noch zu häßlich zum zeigen, und auch noch nicht alle Grenzfälle abgetestet. Danke für die hilfreichen Beiträge und Tipps!
Beitrag #7223336 wurde von einem Moderator gelöscht.
Beitrag #7223340 wurde von einem Moderator gelöscht.
Es scheint alles zu funktionieren und ich bin zufrieden. Im Anhang noch mein Quelltext, falls jemand in eine ähnliche Problemstellung läuft und ein abschreckendes Beispiel sucht. Das Testbeispiel entspricht dem Diagramm im Eröffnungspost. Danke für die Hilfe und die Anregungen!
Funktioniert der Code? Hast Du da später was verändert? * alut? * lut als funktion und als parametername? seltsam...
1 | void lut(void *lut, uint32_t Adj[], uint8_t nNode) |
2 | {
|
3 | uint8_t (*alut)[nNode][nNode] = (uint8_t (*)[nNode][nNode]) lut; |
4 | //...
|
Klaus H. schrieb: > Hast Du da später was verändert? Ja, damit das Beispiel zum Eröffnungsbeitrag passt. Klaus H. schrieb: > Funktioniert der Code? Leider nein, in TEST(statemachine, findPath) ist ein Tippfehler (forwrd anstelle forward), aber ich wollte meinen Beitrag nicht ein drittes Mal löschen, weil sich der Anhang nicht bearbeiten lässt. Klaus H. schrieb: > lut als funktion und als parametername? Gibt es eine Regel, die das verbietet?
Ah, jetzt hab ich’s kapiert. Zu schnell überflogen. alut passt. >>lut als funktion und als parametername? >Gibt es eine Regel, die das verbietet? Nein, der Parameter lut wird als lokale Variable betrachtet und überdeckt damit den globalen Namen der Funktion. Ich würde es trotzdem nicht machen. Änderst Du den Parameternamen könnte das Programm weiterhin compilieren, da du dann den Funktionspointer (über den cast) speicherst. Na ja, das wird natürlich beim Test aufgedeckt. Aber ich versuche solche Konstruktionen zu vermeiden. Seltsam dass der Compiler nicht meckert? Welchen Compiler nutzt Du? Was passiert wenn du '-Wshadow' o.ä. aktivierst?
Klaus H. schrieb: > Welchen Compiler nutzt Du? Einen gut abgelagerten GCC 5.1.0 (MinGW). Mit -Wshadow ändert sich nichts. Aber die mir bekannte Beschreibung lautet "Warn whenever a local variable shadows another local variable", was ja auch nicht zutrifft. Klaus H. schrieb: > Aber ich versuche solche Konstruktionen zu vermeiden. Es wird wohl auch nicht so bleiben. Das war jetzt Zufall - geschuldet einem ausprobieren zwischen Tür und Angel (Respektive zwischen Mittagessen und Kuchen). Meinen "Prototypen" für die Breitensuche hatte ich gestern in Matlab geschrieben, und heute wollte ich in C ausprobieren, ob es wirklich so einfach ist und die Reihenfolge der Warteschlange wirklich keine Rolle spielt. Und plötzlich hatte ich eine funktionierende Pfadsuche und habe den LUT auch noch schnell nachgeschoben. (Den Wechsel zwischen Matlab und C sieht man leider auch recht deutlich daran, dass ich an etlichen Stellen vergessen habe, dass ich Umlaute nutzen darf.)
Ich habe die Kommentare bisher nur überflogen, falls das schon mal angesprochen wurde habe ich es übersehen. Aber solche Zustandsautomaten wie die in der Aufgabenstellung oben beschrieben sind, lassen sich sehr kompakt in C++ mit hilfe von enum class und den passenden Operator beschreiben. Bis auf den Übergang in den Abzweig ist das komplett im ++operator machbar 🙄
Walter T. schrieb: > Einen gut abgelagerten GCC 5.1.0 (MinGW). Mit -Wshadow ändert sich > nichts. Aber die mir bekannte Beschreibung lautet "Warn whenever a local > variable shadows another local variable", was ja auch nicht zutrifft Stimmt. Hab's mit aktuellem gcc und clang probiert, meckert nicht. Ich orientiere mich meist an den CppCoreGuidelines: "ES.12: Do not reuse names in nested scopes".
Generell: Ich muss eingestehen, aus deiner Aufgabe und dem Code nicht viel verstanden zu haben. Denn. Es sind nur Zustände und die erlaubte Übergänge angegeben, jedoch nicht - was bedeutet ein IST- und dazu ein SOLL-Zustand. Dazu noch. Es sind z.B. Zyklen vorgeben wie z.B. manual<->sync. Daher, nehme ich an wenn der Automat sich in einem IST-Zustand wie pre-init befindet, was würde bedeuten - würde er in den Zustand manual jemals reingehen können, wenn der SOLL-Zustand z.B. disabled ist? Und wenn ja, dann - wie viele Male? Überhaupt - wie kann man sich vorstellen den SOLL-Zustand? Ist der SOLL-Zustand immer "disabled"? Wenn man das nicht beachtet, dann ist die Bedeutung von Richtungen wie sync->manual, sync->forward, sync->reverse gar nicht nötig, denn solche bei der Berechnung des kürzeren Weges niemals "betreten" werden sollen. Weil sie als Zyklus erkannt und als unnötig "ignoriert" werden müssen. Wie gesagt, sind solche Relationen dafür da, bestimmen zu können, welche nächster Schritt überhaupt erlaubt ist. Jedoch nicht, wie der richtige Weg durch die Zustände aussehen kann. Dafür sind weitere Logiken nötig, die über den Übergang mehr Informationen liefern, ob ein Übergang einen Sinn ergibt. Min. mögliche Lösung: Ohne deine Aufgabe-Stellung so richtig verstanden zu haben, lässt sich auch nicht dein Code nachzuvollziehen. Erlaube mir aber doch zu sagen, dass es auf den ersten Blick zu komplex aussieht. Manchmal kann man auch genau das lösen, was gefordert ist und nicht eine "allgemein-galaktische-Lösung" erfinden. Für genau diese Anzahl (8) der erlaubten Kombinationen würde ich z.B. mit 8 Bytes lösen können, wo jedem Knoten ein Bit zugewiesen werden kann:
1 | [disabled] [de-init] [sync] [reverse] [forward] [manual] [init] [pre-init] |
2 | state[0] = b00000010; // pre_init |
3 | state[1] = b00100000; // init |
4 | state[2] = b00100000; // manual |
5 | state[3] = b00100000; // forward |
6 | state[4] = b00100000; // reverse |
7 | state[5] = b01011100; // sync |
8 | state[6] = b10000000; // de_init |
9 | state[7] = b00000000; // disabled |
wie man sieht, sind die Werte für state[1] state[2], state[3] und state[4] gleich, weil sie alle nur auf sync verweisen. Und wenn ein weiterer Zustand ermittelt werden will, dann aus den Bit-Stellen, die für diesen Zustand auf Eins stehen - ableiten, ob es möglich ist. Z.B. aus state[0] = b00000010; // pre_init ist "sichtbar" dass disabled, also 7. Stelle nicht erreichbar ist, weil sie auf Null steht. Aber das ist nur als Beispiel zum Nachdenken - nicht als Lösung. Da ich nach wie vor nicht verstanden habe, was SOLL-Zustand bedeutet?
VD schrieb: > Ich muss eingestehen, aus deiner Aufgabe und dem Code nicht viel > verstanden zu haben. > [Viel weiterer Text] Das ist in Ordnung. Nicht jeder muß zu allem eine Meinung haben. Also warum der Beitrag?
Walter T. schrieb: > Es funktioniert wirklich. Die Warteschlange darf wirklich eine Bitmaske > sein, weil die Reihenfolge der Abarbeitung der Warteschlange egal ist. Freut mich, dass mein inkohärentes Gebrabbel dich irgendwie zu funktionierenden Code leiten konnte :) > Damit wird die Sache erstaunlich effizient, zumal der µC auch CLZ() > eingebaut hat. Rein interessehalber: ist auf deiner Zielplattform ffs / __builtin_ffs entsprechend optimiert, dass es auch CLZ verwendet?
Walter T. schrieb: > Nicht jeder muß zu allem eine Meinung haben. Also warum der Beitrag? Eine Aufgabestellung hat mit unterschiedlichen Meinungen nichts zu tun. Die Beiträge schreibt man, um eventuell Menschen zu unterstützen. Da du aber frech bist, stellte ich fest, dass es tatsächlich Mühe umsonst war.
Εrnst B. schrieb: > Rein interessehalber: > ist auf deiner Zielplattform ffs / __builtin_ffs entsprechend optimiert, > dass es auch CLZ verwendet? Danke für den Hinweis. Es hätte natürlich __builtin_clz() und nicht __builtin_clzl() heißen müssen. Praktischerweise hat der Optimizer aber gemerkt, dass nur 32 Bit geprüft werden müssen. Falls das nicht als wink mit dem Zaunpfahl gemeint war: Das weiß ich nicht. ffs() habe ich noch nie verwendet. __builtin_clz() und __builtin_clzl() führen im Assembler-Listing zu einem (bzw. zwei) CLZx.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.