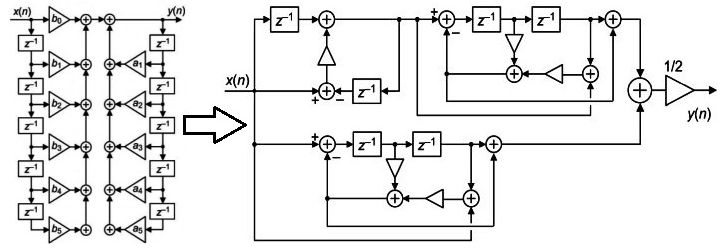
Da (unter anderem hier Beitrag "Re: FPGAs in der Lehre") wieder mal die Effizienz des Codes aus MATLAB diskutiert wird: Hier ein kleines Beispiel eines Polyphasenfilters auf der Basis eines Artikels in der DSP-Gruppe von Rick Lyons, welches auf den Vorschlag von Fred Harris der San Diego State zurückgeht. Es formt ein typisches IIR-Filter auf parallele Strukturen um, um mit weniger Multiplikationen auszukommen. Im Beispiel ist es eines 5-ter Ordnung. Der Artikel ist hier zu finden: https://www.dsprelated.com/showarticle/1269.php Der Filter im Beispiel wurde als Demonstrator vom MATLAB-Coder für einen Artix 7 umgesetzt und mit Vivado 2019 synthetisiert. Ein solches Filter dieser Art braucht bei einem Eingangssignal mit 24 Bit insgesamt 9 Multiplizierer, weil aufgrund der Auflösung von 24x24 jeweils 2 benötigt werden. Das Original, benötigt aufgrund der 2x5 Multiplikationen maximal 21 Multiplizierer - auch wegen z.B. rescaling. Schränkt man den Eingang auf 16 Bit ein, reichen theoretisch 5 bzw 11. Das hat MATLAB auch hinbekommen und eine Gegenprobe mit HLS unter Verwendung des geposteten Algos in C war bei entsprechenden constraints der gleichen "Meinung", bzw kommt in die gleiche Größenordnung. Soweit, so schön! Weniger schön ist die erreichte Taktfrequenz von unter 60MHz in der standardisierten Synthese, die sich mit Mühen und FFs-Ausgießen zusammen mit der Physical Resynthesis auf gut 140 steigern ließ, was irgendwie trotzdem ein 50%-Resulat darstellt, weil man Artixe miit etwas Quetschen auf über 300 MHz takten und auch kompliziert rechnen lassen kann, wenn man tunded. Ganz und gar nicht nett wird es, wenn man mehrere dieser Filter benötigt: Einfach mal 8 Stück zu instanziieren führte über den HDL-Coder zum erwarteten Ergebnis mit 72 Multiplizierern, was den verwendeten FPGA praktisch schon erschöpft. Die Resynthese hat dann irgendwo 7 Stück geklaut - ich nehme an, es ist der erste, der gemultiplext wurde. Habe das nicht weiter untersucht. Wenn man probierte, die Schaltung zu pipelinen, entsteht ein FF-Wald mit immerhin noch 18 Multiplizieren, der aber auch mit zusätzlichen FFs allein fürs timing nicht schneller wird, als 100 MHz. Er klebt bei rund 90MHz fest. Will man schneller prozessieren, braucht es 2 Einheiten parallel. ******************************************************* Jetzt die Preisfrage an die Experten: Wie klein (Anzahl der MULs) und wie schnell wird das design, wenn man es per Hand baut, dabei die Ähnlichkeit der Zweige berücksichtigt, diese geschickt multiplext, partiell rotierend pipelined, mit oversamling rundet und FFs nur nach timing-Bedarf gezielt im Design setzt und dies aber an der idealen pipeline-Länge orientiert? ******************************************************** Mit Bezug zu diesem Beitrag: Beitrag "Re: Ganzzahlprobleme mit MATLAB" sei vorausgeschickt, dass auch in diesem erzeugten HDL wieder mehrere Stellen mit sehr hohen Auflösungen zu finden waren, die man rundungstechnisch und konzeptionell anders hätte lösen können. Die Ergebnisse meiner Lösung poste ich dann etwas später. Möchte mal sehen, wie die Tipps ausfallen :-) Es geht jedenfalls erheblich kleiner und schneller, wenn man richtig baut und vor allem richtig denkt, wobei nicht unerwähnt bleiben darf, dass das Denken schon damit beginnt, nicht einfach nur einen Standardfilter, wie den ursprünglich erdachten einzusetzen, sondern zu prüfen, ob die Aufgabenstellung eine Vereinfachung verträgt. Das kann MATLAB nicht leisten. MATLAB kann auch nicht die Aufgabe analysieren und im Netz nachgucken, ob es etwas gibt, was man verwenden kann. Das muss der Ingenieur nach wie vor selber tun :-)
Angehängte Dateien:
Jürgen S. schrieb: > Das kann MATLAB nicht leisten. Und damit wird der Vergleich deiner Lösung mit der aus Matlab sinnfrei. Formuliere deine Lösung als C und lasse die mit HLS bauen, dann kannst du was vergleichen.
Dazu gehört auch der Zeitaufwand für die handgeschriebene Lösung, inklusive Verifikation. Je nach Anforderungen, Stückzahlen, Stundenlöhnen und Personalverfügbarkeit kann es trotzdem Sinn machen die suboptimale, automatisierte Lösung zu nutzen. Ich würde auch gerne alles selber entwickeln aber aus kommerzieller Sicht macht es oft Sinn fertige IP-Cores zu kaufen oder, wo nicht verfügbar, Code-Generierung zu nutzen.
Blechbieger schrieb: > Stundenlöhnen Stundensatz wäre richtiger gewesen. Es kommen noch Sachen wie Lohnnebenkosten, Büromiete und Managmentoverhead dazu. Da ist man schnell bei über 100 Euro die Stunde.
Jürgen S. schrieb: > Jetzt die Preisfrage an die Experten: > ... Das schreit bisschen nach einer Antwort 'Kuck mal, was ich kann'. Ich lasse das mal im Detail aus, viel erreichen kann man da mit relativ generisch designten MAC-Baenken/Delays und Multiplexern, die ueber ein n-stufiges Mikrocode-Programm gesteuert werden. Da gibt man quasi die Resourcen/f_max vor und dreht nur noch an den VLIW-Opcodes (u.U. zur Laufzeit), die man schliesslich hart verdrahtet. Die 'HLS' nimmt hier, wenn man so will, a priori eine optimale Auslastung der Resourcen aufs Korn. Das groebste Manko an obiger Art HLS deucht mich, dass kaum Routing-Constraints oder Layout-Einschraenkungen in den ersten Schritt der Synthese (Inference/Mapping) eingehen und jegliche Kontrolle ueber die Inferenz dem Hersteller ueberlassen ist. Unterm Strich ist mein Fazit: Man implementiert es immer zweimal. Das ist auch meist ok so. Der PhD mit der tollen Idee darf mit Matlab rumspielen, der Praktikant kloppt's durch's die HLS und soll's trial&error-testen, und wenn's Richtung Produkt geht, wird's nochmal von einem/r, der/die die Materie wirklich versteht, von Anfang an neu designt, weil das FPGA sonst zu heiss/teuer/gross wird. -gb- schrieb: > Formuliere deine Lösung als C und lasse die mit HLS bauen, dann kannst > du was vergleichen. Siehe oben, wurde ja offenbar gemacht. Die Frage stellt sich bloss immer wieder, warum man in einer Sprache, die fuer sowas nicht designt wurde, mit Ach und Krach eine Loesung hinfrickeln sollte. (NB, ich mag C, aber nur in Software-Kernels). Die Frage kann man offenbar so beantworten: Mit fortschreitend-fehlendem Verstaendnis der Interna (ein Bildungsproblem) dirigiert man die Loesung des Problems in Richtung Tools. Das ist auch ok, bis zu einem gewissen Punkt. Wenn sich nur die Exekutive in der hoeheren Etage damit nicht regelmaessig arduino-Style komplett verschaetzen wuerde, und fuer die Reimplementierung kein Budget mehr kalkuliert hat...
Martin S. schrieb: > -gb- schrieb: >> Formuliere deine Lösung als C und lasse die mit HLS bauen, dann kannst >> du was vergleichen. > > Siehe oben, wurde ja offenbar gemacht. Wurde das in C ähnlich formuliert wie deine handoptimierte HDL Lösung? Mit C kann man Dinge auch so formulieren, dass sie zwar für den Programmierer einfach und elegant aussehen, auf einer CPU auch gut laufen, aber vielleicht schlecht auf Hardware abzubilden sind. Martin S. schrieb: > Die Frage stellt sich bloss immer wieder, warum man in einer Sprache, > die fuer sowas nicht designt wurde, mit Ach und Krach eine Loesung > hinfrickeln sollte. Das wurde schon beantwortet und läuft auf ein "ist in einigen vielen Fällen gut genug" heraus. Das ist eine Wirtschaftlichkeitsrechnung. Martin S. schrieb: > Mit fortschreitend-fehlendem > Verstaendnis der Interna (ein Bildungsproblem) Die Interna werden verstanden - aber von wenigen Menschen. So ist das doch überall, die Technik schreitet voran, wird dabei komplexer, und die Grundlagen wie diese Technik funktioniert verstehen immer weniger Leute. Muss man nicht gut finden, weil wir uns von etwas abhängig machen was wir nicht verstehen, aber scheint ganz gut zu funktionieren diese Herangehensweise. Gleichzeitig ist das aber auch so komplex, dass wir nicht alles wissen können und auch gar nicht brauchen. Ist das schlecht? Es ist praktisch! Dadurch haben wir Zeit und Denkleistung frei um andere Dinge zu lösen. Wir sind umgeben von magischen Zauberkästen (Handy/Computer/...) [Zauberkästen weil sie für die allermeisten Menschen nicht von Zauberei zu unterscheiden sind*] benutzen sie täglich und ohne sie wäre das heutige Leben nicht möglich. *Arthur C. Clarke: “Any sufficiently advanced technology is indistinguishable from magic”.
-gb- schrieb: > Jürgen S. schrieb: >> Das kann MATLAB nicht leisten. > Und damit wird der Vergleich deiner Lösung mit der aus Matlab sinnfrei. Das ist gemacht worden. Der MATLAB Code ist ja anbei im paper vorgegeben. Des weiteren kann man das mit embedded MATLAB in Simulink einbetten, kommt aber auf auch nichts anderes raus, weil die Struktur ja nicht modifiziert ist. > Formuliere deine Lösung als C und lasse die mit HLS bauen, dann kannst > du was vergleichen. Wenn, würde man das schon "objektorientiert" formulieren müssen und dem HLS die optimierte Struktur anbieten. Das hilft aber alles nichts, weil es anders als beim C im HDL eben die Option gibt, von der rein sequenziellen Abarbeitung von threads (auch in C++ und Mehrkern-CPUs sind es in letzter Konsequenz durch das pipen sequenzielle Abläufe) zu unterschiedlichen teilparallelen Sttrukturen überzugehen und die kann ein Auto-Coder sich nicht ausdenken sondern müsste sie kennen und auswählen, was aber auch das Setzen von Randbedinungen erfordert. Selbst ich, der ich eine Lösung habe, wüsste nicht, wie man ein System aufbauen könnte, das solche Constraints entgegennehmen und verwerten könnte und wie die Schnittstelle dafür aussieht. Das, was HDL und auch Catapult fressen, sind C++ Objekte mit sequenziellen Abläufen. Die lassen sich stringent vorwäerts in Hardware umsetzen, aber nicht alles, was in Hardware zu bauen ist, lässt sich in C auch formulieren. Das ist das Problem.
Angehängte Dateien:
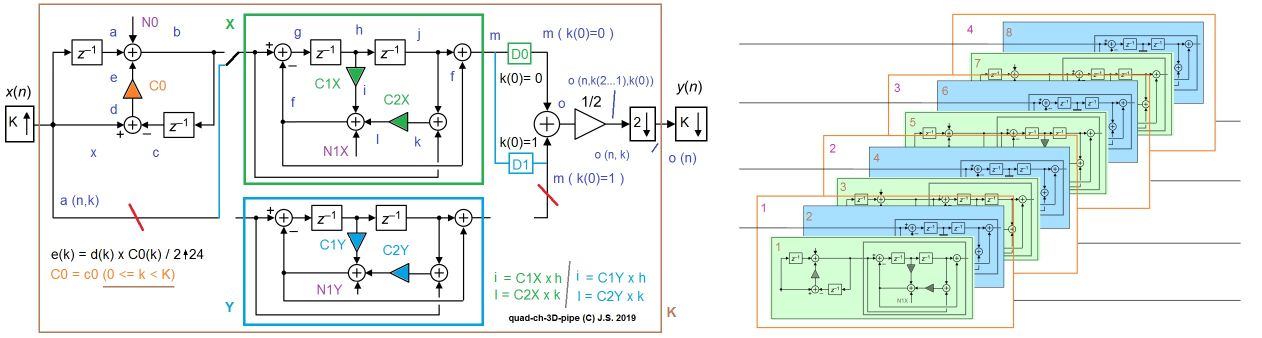
Also dann hier mein Vorschlag zur Umsetzung mit Variationen (die schon mal verdeutlichen, dass es die unterschiedlichsten Umsetzungen gibt, welche man nur formulieren kann, wenn die Aufgabe funktionell bekannt ist. Im Ablauf des Filters steckt das nicht drin und ist auch nicht zu entnehmen). Wenn man das design umstellt und richtig flipflopisiert, dass es AN ALLEN STELLEN mit einer 8-fach rotierenden pipeline arbeitet, kommt man zu fast 200MHz (mit jeweils einem Doppel-FF hinter den Multiplizierern). Die Hälfte aller time slots steht dann zur Verfügung, um die beiden ähnlichen Schaltungsteile zu multiplexen. Damit gibt es schaltungslogisch nur den oberen Pfad und es sind 3 Multiplikationen nötig, die im Vollausbau 5 Multiplizierer erfordern. Die anderen 4 timeslots entsprechen zur Hälfte den im Schritt 2 oben gewünschten 8 Pfade. Da die Schaltung mehr als doppelt so schnell arbeitet, wie die HLS-Lösung, ist sie funktionell gleichwertig. Alternative: Braucht man nur 2 Kanäle oder weniger, kann man mit den time slots die Rechnung oversampeln, um die Auflösung zu steigern und gfs die Multiplizierer auf jeweils einen einzudampfen. Spätestens mit intelligentem Rauschen ist die Schaltung auch mit jeweils einem Multiplier genauer, als die Koeffizienten es vorgeben und damit genau genug. In der Schaltung sind das die 3 Noiseeinspeisepunkte. Wir hätten also 3 ... 5 MULs mit der vollen Frequenz gegenüber 9 ... 18 MULs bei der halben Frequenz. Ausgehend von 160 MHz, können so 4 Kanäle jeweils mit 20 MHz Datenfrequenz prozessiert werden. Von der Zahl der Multiplier / der Module/FF-Zahl (je nachdem, was in der Synthese des Gesamtdesigns mal klemmt) passt durch die händische Lösung die 2-4 fache Schaltungsmenge in den FPGA. Nimmt man die Vorteile durch die Umsetzung aus dem paper noch hinzu, ist die Lösung je nach Genauigkeitsanforderung um Faktor 5-10 kleiner, als die Standardimplementierung, wenn sie von MATLAB gecoded wird. Das Teil läuft in 24Bit in meinem Synth in leicht reduzierter Form ohne Rauschen als Core in einem MAX10 eines Kunden.
Martin S. schrieb: > Das groebste Manko an obiger Art HLS deucht mich, dass kaum > Routing-Constraints oder Layout-Einschraenkungen in den ersten Schritt > der Synthese (Inference/Mapping) eingehen und jegliche Kontrolle ueber > die Inferenz dem Hersteller ueberlassen ist. So ist es und diese constraints wären auch nur ein Teil der Wahrheit. Wie oben erwähnt, ist der Punkt bei der Umsetzung die Auswahl der richtigen pipeline-Konstellation mit 4:2. Wie will man das wo einspeisen? Wenn die zu bauende Filterschaltung minimal anders wäre, könnte man den längsten Pfad nicht mit 5 sondern 4 Delays bauen, wodurch man bei einem sehr schnellen Chip, der keine FFs fürs timing closure braucht, auch eine 2:2 bauen könnte, was noch etwas kleiner wäre. Dasselbe gilt für eine Anforderung mit sehr niedrigerer Taktfrequenz und die MULs in einem Takt arbeiten. Umgekehrt könnte man das auch mit einem alten Cyclone bauen, der mehr FFs braucht, um zu timen und auf eine 12-er pipe gehen. Das alles muss man im Blick haben und ich sehe nicht, wie ein tool das ohne Einspeisung von requirements tun sollte. Es bleibt über dies der Punkt um das Wissen bezüglich spezieller Lösungen, die in einem paper stehen und eine Standardschaltung ersetzen können.
Gustl B. schrieb: > Das wurde schon beantwortet und läuft auf ein "ist in einigen vielen > Fällen gut genug" heraus. Das ist eine Wirtschaftlichkeitsrechnung. Wirtschaftlich ist das leider nicht, und in Faellen, die ueber die einfachen SDR-Problemstellungen hinausgehen, auch nicht gut genug (sic). Diese Antwort kann ich geben :-) C ist schlicht dafuer nicht geeignet. C++ wuerde schon Formalismen ermoeglichen, ist aber als reine Compilersprache denkbar schwerfaellig, geschwaetzig, und langsam, taugt als Beschreibungssprache also gerade mal fuer Code-Generatoren. Die Sprachen, die grundsaetzlich eine sinnvolle Moeglichkeit der HLS mit voller Kontrolle bei gleichzeitig kompakter Syntax erlauben, gehen in Richtung funktionale Programmierung (scala basierte HDL wie SpinalHDL) oder Python. Wurde hier aber schon genug dazu verraten und auch schon zum zigten mal durchgekaut (taeglich gruesst das Murmeltier).
Blechbieger schrieb: > Dazu gehört auch der Zeitaufwand für die handgeschriebene Lösung, > inklusive Verifikation. Je nach Anforderungen, Stückzahlen, > Stundenlöhnen und Personalverfügbarkeit kann es trotzdem Sinn machen die > suboptimale, automatisierte Lösung zu nutzen. Die Frage ist doch im Kern, wie viel Zeit sich durch die Automatismen sparen lässt. So eine Schaltung wie die im Beispiel angeführte, sollte sich in einigen Stunden codieren lassen. Sagen wir maximal ein halber Tag. Hinzu kommt der Aufwand für die Testbench, die Stimuli-Vektoren und die Parameter für die Filter. Insgesamt ein Tag. Der Hauptaufwand ist später ohnehin der Test. Nur diese paar Stunden kannst du in Matlab durch die Codierung wegsparen, weil der Rest auch benötigt wird. Sind mit allem drum und dran 500,- mehr an Entwicklungskosten. Bei einem durchschnittlichen FPGA spart das z.B. 3,- Euro ein, braucht also 200 Einheiten im Verkauf, dass es lohnt. Macht das an mehreren Stellen, spart es noch mehr und es braucht trotzdem immer noch 200 Einheiten, dass es sich rechnet. Auch zu erwähnen: 1) Für die Entwicklung und die Änderungen wird keine Matlablizenz belegt und es ergibt sich nativer Code, der überall läuft und leicht anpassbar ist. Bei mehreren Optimierungsschleifen wegen der zu findenden Parameter kann sich das weiter verengen, weil nicht dauernd Matlab angeworfen und graphisch geändert werden muss. Ich verweise dazu auf den regelmäßigen Installations- und Aktualisierungsbedarf von Matlab und seinen vielen Extensions. Andauernd passt irgend etwas nicht und erzeugt Zusatzarbeit. 2) Wenn es gelingt, eine kleine Baugruppe um 20,- HSK zu senken, sind das im Endprodukt 50,- und damit ein Kostenvorteil, der zu mehr Verkäufen führt. Es kann also sein, dass die Firma nicht nur überhaupt genug Einheiten absetzt, dass die Investition in intelligentere Lösungen lohnt, sondern dadurch auch noch mehr verkauft. Dann spielt die Verbesserung sogar noch weiteres Geld ein! Meine Kunden feilschen bei Größenordnungen von 180,- pro fertiger Elektronikplatine um jeden einzelnen Euro, obwohl es nur 500 Einheiten p.a. sind. Wenn sich da ein paar Euro sparen lassen, GERNE! Aber es gibt ja auch Spezialisten die absichtlich alles mit Matlab und eigenen Scripten bauen, damit der Abnehmer aus der eigenen Abteilung oder der Kunde gezwungen ist, bei jedem Fizzelchen wieder gekrochen zu kommen und man wichtig genug bleibt. :D
Thomas U. schrieb: > Aber es gibt ja auch Spezialisten die absichtlich alles mit Matlab und > eigenen Scripten bauen, damit der Abnehmer aus der eigenen Abteilung > oder der Kunde gezwungen ist, bei jedem Fizzelchen wieder gekrochen zu > kommen und man wichtig genug bleibt. :D Genau darin stecken massive Folgekosten und unkalkulierbarer Aufwand, wenn das eine für min. 10 Jahre nachhaltige Entwicklung sein muß. Dreckiger ausgedrückt: wir lassen uns nicht erpressen.
Frage an die Experten: Angenommen, ich benutze eine Schleife in C, um die Lösung für eine Gleichung zu finden, oder eine Näherungslösung für den Sinus oder die Wurzel. Wie wird das übersetzt? Ich nehme an, es wird eine Schaltung gebaut, die diese Schleife durchführt und die Rechenschritte in ähnlicher Weise abarbeitet. Richtig? Das Ergebnis kommt dann wahrscheinlich heraus, wenn es durchgelooped wurde. Können Zwischenergebnisse durch von anderen Teilen des Programmes genutzt werden? Was passiert, wenn eine solche Funktion von mehreren Stellen im Programm aus aufgerufen wird? Und was, wenn dies dynamisch geschieht? Was wird erzeugt, wenn die Schleife als Rekursion läuft? Wie wird das übersetzt? Kann sich die Schaltung dann selbst aufrufen? Wie wird das stack management gelöst? Wie wird ein dynamisches Abbruchkriterium gebildet und überwacht? Was wird erzeugt, wenn Prozesse vererbt und virtuell dupliziert werden? Was wird erzeugt, wenn Prozesse auf unterschiedlichen Cores laufen und sich synchronisieren? Gibt es dann Schaltungsduplikate? Können die in gleicher Weise miteinander kommunizieren und sich die Arbeit austauschen?
Ich bin Neuling im Bereich FPGA, aber was ist eine "rotierende Pipeline"? Google hat für "rotating pipeline" irgendwie nicht brauchbares ausgespuckt, nach was müsste ich da suchen und wozu ist das gut?
Halbbrücke schrieb: > Ich bin Neuling im Bereich FPGA, aber was ist eine "rotierende > Pipeline"? Google hat für "rotating pipeline" irgendwie nicht > brauchbares ausgespuckt, Da steht nicht "pipeline" sondern "pipelined", korrekt wäre wohl "pipelining". Pipelining steht für die Methode einen langen Kombinatorik-Pfad durch hineingestreute FF im Sinne der STA (Statische Timing Analyse) zu verkürzen und so die maximale Taktfrequenz zum Preis einer Latenz von mehreren Takten zu erhöhen. https://de.wikipedia.org/wiki/Pipeline_(Prozessor) https://www.allaboutcircuits.com/technical-articles/why-how-pipelining-in-fpga/ Mit rotation könnte nun eine Form des zyklischen Zugriffs gemeint sein, wie beim Register-Windowing (konnten die SPARC-Prozessoren um Zeit/Takte beim Context switch zu sparen). https://en.wikipedia.org/wiki/Register_window Oder irgendwas anderes wie Rotation scheduling: https://ieeexplore.ieee.org/abstract/document/594829 Das Ganze ist nicht FPGA-Spezifisch, ein gutes Buch zur Computerarchitektur wie ISBN: 978-3-528-05173-0 sollte deinem Verständnis besser auf die Sprünge helfen als unsinspiriertes Rum-googeln. Dazu sollte man aber die mehreren Hundert Seiten tatsächlich lesen. Und verstehen.
Softi schrieb: > Frage an die Experten: > Wie wird das übersetzt? Ich nehme an, es wird eine Schaltung > gebaut, die diese Schleife durchführt und die Rechenschritte in > ähnlicher Weise abarbeitet. Richtig? Können > Zwischenergebnisse durch von anderen Teilen des Programmes genutzt > werden? > Was passiert, wenn eine solche Funktion von mehreren Stellen im Programm > aus aufgerufen wird? Und was, wenn dies dynamisch geschieht? > Was wird erzeugt, wenn die Schleife als Rekursion läuft? Wie wird das > übersetzt? Kann sich die Schaltung dann selbst aufrufen? Wie wird das > stack management gelöst? Wie wird ein dynamisches Abbruchkriterium > gebildet und überwacht? > Was wird erzeugt, wenn Prozesse vererbt und virtuell dupliziert werden? > Was wird erzeugt, wenn Prozesse auf unterschiedlichen Cores laufen und > sich synchronisieren? Gibt es dann Schaltungsduplikate? Können die in > gleicher Weise miteinander kommunizieren und sich die Arbeit > austauschen? Genau das ist das Problem, du versuchst die Hardwarewelt allein mit den Begriffen aus Deiner beschränkten Softwarewelt zu verstehen. Schlimmer noch, du versuchst nicht mal Deine Software-Komfortzone zu verlassen, um es selber zu verstehen, sondern glaubst durch einen Schwall an billig formulierten Fragen "an die Experten" in ein kostenloses Forum Deine Lernlücken unentgeltlich auffüllen zu lassen.
Softi schrieb: > Angenommen, ich benutze eine Schleife in C, um die Lösung für eine > Gleichung zu finden, oder eine Näherungslösung für den Sinus oder die > Wurzel. Wie wird das übersetzt? In der Regel durch parallele Hardware. Das ist dann eine der ersten Stellen, wo der Softwerker stolpert, weil vielleicht der Synthesizer nicht mit einer dynamischen Abbruchbedingung klarkommt. Duke
Halbbrücke schrieb: > Ich bin Neuling im Bereich FPGA, aber was ist eine "rotierende > Pipeline"? Stell Dir eine Fabrik mit einem Fließband vor. Wenn zu viele Teile reinkommen, gibt es einen großen Haufen vor dem Werktor. Um den Durchsatz zu erhöhen, stellst Du mehrere Fließbänder auf. Die Wareneingangskontrolle legt die zu bearbeitenden Teile reihum auf die jeweiligen Fließbänder. Voila, schon hast Du eine 'rotierende Pipeline'... Duke
Duke Scarring schrieb: > Softi schrieb: >> Angenommen, ich benutze eine Schleife in C, um die Lösung für eine >> Gleichung zu finden, > In der Regel durch parallele Hardware. Das ist dann eine der ersten > Stellen, wo der Softwerker stolpert, weil vielleicht der Synthesizer > nicht mit einer dynamischen Abbruchbedingung klarkommt. Es ist zu hoffen, das der Softwerker dabei richtig stolpert und mglw . nach dem Sturz anfängt darüber nachzudenken, was eigentlich der Kern der Implementierung ist: Nicht irgendwelche Sprachkonstrukte wie Schleifen, Vererbung, Funktionsauruf, sonder der Algorithmus, also die Rechenvorschrift resp. Steueranweisung. Und diesen Algo aus dem Programmiersprachengeschiss drumherum zu extrahieren und auf die entsprechenden Resourcen (ALU, DSP-Slices) abzubilden. Dann kann es also bedeudeten das die 'Schleiferei' des µC bei der sinusberechnung zu einem Tabellen(ROM)-lookup mit Interpolation umgesetzt wird. Oder zur CORDIC-Hardware, die dann auch gleich für ander Funktionen benutzt werden kann. Beim FPGA-Design sind also nicht nur Grundkenntnisse in Computerarchituktur essential sondern auch Know-How aus der Numerik. Eigentlich ist Numerik (Mathematische hergeleitete Lösungsverfahren für Nicht-Mathematiker i.e. Ingenieure) die Grunddisziplin der Informatik. Aber anwendbare Erfahrung darin schein den Informatikabsolventen durch die C-Herumhackerei und Software-Engineering-Scrum-Gackerei abhanden gekommen zu sein. ISBN: 9783343005802 https://en.wikibooks.org/wiki/File:CORDIC_(Bit-Parallel,_Unrolled,_Circular_Rotation).svg https://en.wikibooks.org/wiki/Digital_Circuits/CORDIC https://www.allaboutcircuits.com/technical-articles/an-introduction-to-the-cordic-algorithm/ BTW auch hier steht R für Rotation ...
Halbbrücke schrieb: > Ich bin Neuling im Bereich FPGA, aber was ist eine "rotierende > Pipeline"? Da ich das eingeworfen habe, muss ich wohl auch erklären, was ich damit meine ;-) Konkret geht es darum, dass man: a) unterschiedliche und von einander unabhängige Pfade mit derselben Schaltung zu prozessieren, z.B. mehrere Kanäle einer Messkette, Variationsrechnungen bei Simulationen oder Annahmen bei Matchern b) innerhalb derselben gfs. einen oder mehr Mikrozyklen aufzuziehen, wie bei einem IIR-Filter, das auf alte Zustände zurückgreifen muss, aber die Rechnung nicht in einem Takt schafft oder auch explizite Iterationen, deren Rechnungen auf allerlei Zwischenergebnisse aus mehreren Zeiten zurückgreifen. Wenn man solche Strukturen nutzt, verwindet man quasi Rechnungen ineinander mit jeweils orthogonal verschränkten Kanälen und Samples. Bei einer einfachen pipeline wird entweder immer nur auf ein sample zurückgegriffen, bei längeren FF-Ketten und Latenzen Zeiten ausgelassen bzw. mit enables gearbeitet oder überhaupt nur strikt vorwärts gerechnet, wie z.B. bei einem binomische Multiplizier mit Akkumulator, bei dem keine Zwischenergebnisse angefasst werden. Abseits dieser funktionellen Gründe gäbe es noch: Mcn schrieb: > Pipelining steht für die Methode einen langen Kombinatorik-Pfad durch > hineingestreute FF im Sinne der STA (Statische Timing Analyse) zu > verkürzen und so die maximale Taktfrequenz zum Preis einer Latenz von > mehreren Takten zu erhöhen. ... aus Zeitoptimierungsgründen.
Mcn schrieb: > Mit rotation könnte nun eine Form des zyklischen Zugriffs gemeint sein, > wie beim Register-Windowing Das wäre ein Beispiel für so eine Anwendung. Zu allererst ist es mal einfach eine an 1,2 oder 3 Stellen rückgekoppeltes System, das in jedem Takt eins weiter dreht, wobei entweder ein Kanal, oder ein Sample, oder nur die virtuelle Zeit vorgeschoben wird. Da innerhalb immer mehrere Zustände von Signalen zu unterschiedlichen Zeiten existieren, kann man sie elegant verrechnen. Das, was ich konkret 3D-pipeline nenne, kann man sich wie 3 Zahnräder vorstellen, die zueinander senkrecht stehen und ineinander greifen, wobei die Mechanik klemmen würde - was in VHDL nicht passiert, weil die Richtung variabel ist und auch mehrere unterschiedlich große Zahnräder im Tempo "passend gemacht" werden können, indem zwei kleine parallel drehen und damit genug voranschauffeln, dass es abgenommen werden kann. Vor allem kann der aus der pipe herausfallende "Zahn" aktualisiert und vorn oder an einem anderen Punkt wieder reingeschmissen werden, was hochinteressante Bearbeitungsmöglichkeiten schafft. So läuft z.B. die Stimmverteilung über die Samples, der Kanäle und der Instrumente in meinem Synth. Auch viele Filter arbeiten so, d.h. zu jedem Zeitpunkt macht jedes Schaltungselement einer VHDL-Zeile in jedem Codeteil "ihr Ding". Da gibt es keine Steuerung oder enables und es wird nichts angehalten. Ich habe da Konzepte für FSMs, die mehrere Kanäle mit ihren Zuständen "gleichzeitig" verarbeiten können. Mcn schrieb: > Das Ganze ist nicht FPGA-Spezifisch, ein gutes Buch zur > Computerarchitektur Guter Einwurf! In der Tat gibt es starke Parallelen zu der Art und Weise, wie in CPUs parallel gleichartige Prozesse gefahren werden, vorhandene parallele CPUs arbeiten und mit look-ahead-Architekturen mehrere Annahmen gleichzeitig bearbeitet werden, was in Summe auch schon 3-dimensional ist. Wir haben solche Dinge im Studium beim Prozessorentwurf gelernt und als ich mit FPGAs angefangen hatte, habe ich das unbewusst übernommen und vereinzelt rennt das so auch in Kundendesigns. Vor etwa 10 Jahren kam es dann mal auf einem Treff zu einem Gespräch mit einem Designer von Micron, dem ich meine Synthi-Architektur vorgestellt hatte und der dann viele Parallelen zu den Multicore- und Multithreading-Architekturen aufzeigte und darlegte, dass so in etwa auch vorausschauende Zugriffe auf RAMs laufen, wenn mehre Annahmen, was demnächst gefragt werden könnte, auf Halde gelegt- und dann sukzessive bestätigt und sortiert wird, bevor entschieden wird, was abgesendet wird. Der Grund ist auch da dass die Schaltung als pipeline läuft und viele unabhängige Anfragen (von den CPUs) verwursten kann, bevor die Daten und Zustände verarbeitet sind und man sich wieder um ein neues Datum desselben Kanals kümmern kann.
Softi schrieb: > Ich nehme an, es wird eine Schaltung gebaut, die diese Schleife > durchführt und die Rechenschritte in ähnlicher Weise abarbeitet. Das ist eine Lösung, z.B. realisiert durch einen Zähler, der den Datenfluss so steuert, wie die Variablenzuweisungen in C erfolgen. Der Code für diesen Rechenblock sieht in HDL praktisch genau so aus wie in C. Es kann aber auch als statische pipeline gebaut werden, indem der Konstrukt ausgerollt wird. Dann sieht jedes Teilmodul so aus, wie das Rechenblöckchen, es gibt aber mehrere davon, die hinter einander geschaltet sind. Das ist dann ein statisches Rechenwerk, das pro Datentakt mehrere Rechnungen machen kann und pro Systemtakt eine Stufe einer Rechnung. In Simulink habe ich das mit embedded-MATLAB schon gebaut, in HLS müsste es ähnlich sein. Wäre nur zu definieren, wie man es steuert. C ist da nicht eindeutig: An der Stelle muss wieder herausgestrichen werden, dass explizite Schleifen in VHDL nur von der Simulation und der Synthese ausgeführt werden. Im Ergebnis looped die Synthesesoftware und nicht etwa eine Schaltung im FPGA. Die wird lustigerweise durch eine implizite Schleife definiert, wie sie bei einer FSM vorliegt. Ich denke, dass ist das, was Softwareentwickler am Meisten irritiert. Der Grund ist einfach, dass VHDL diese beiden Ebenen Verhalten und Struktur nicht wirklich von einander trennt und der Code am Ende immer beides enthält. In jedem Fall finde ich die Formulierung mit FOR und GENERATE in VHDL einleuchtender und ist definitiv besser steuerbar. Mit diesen Werkzeugen und etwas Hirnschmalz kann auch eine zweidimensionale statische pipeline gebaut werden, die tatsächlich eine Schleife hat und trotzdem gepipelined ist. Das ist etwa das, was eingangs mit dem Filter beschrieben wurde (allerdings ohne dessen Doppelpfadnutzung, die noch eine Dimension aufmacht). Ich wüsste nicht, wie das in HLS oder gar MATLAB automatisch gehen sollte, ohne es ausdrücklich aufzumalen oder zu formulieren. Softi schrieb: > Zwischenergebnisse von anderen Teilen des Programmes genutzt werden? Klar, sogar zeitlich vom Ablauf entkoppelt, je nachdem wann welches Ergebnis vorliegt. Das ist sogar ein großer Vorteil in FPGAs und teilparalleler Realisation. Das müsste natürlich auch genau formuliert werden, eventuell durch das Schreiben von Speichern oder FIFOs und es müsste bei einer pipe so in zeitlichen Zusammenhang gesetzt werden, dass die Daten auch zeitlich zueinander passen - siehe Zahnräder. In VHDL ist das direkt formulierbar, weil bekannt ist, wie die (zeitverzögerten) Signale ihrer Quellen heißen und auch, wann sie den relevanten Wert tragen, den man haben will. Die dafür nötigen Speicherfunktionen gehen auch ausschließlich in die Größe und belasten nicht die Zeit. Bei einigen Formen der FFT-Implementierung in FPGAs wird das z.B. genutzt.
Softi schrieb: > Was passiert, wenn eine solche Funktion von mehreren Stellen im Programm > aus aufgerufen wird? Und was, wenn dies dynamisch geschieht? Da müsste man sicher mehrere Fälle untersuchen und formulieren, dafür gibt es sicher keine eindeutige Lösung. Das einfachste ist wie in C, eine Schaltung alternativ zu nutzen oder sie "inlining" einfach reinzukopieren, was dazu führt, dass sie mehrfach da ist. Das z.B. macht HLS ja in dem oben angeführten Beispiel. Grundsätzlich ist das ohne Weiteres zu lösen, wenn man Daten auf Systemtaktebene sequenzialisiert. Ausgehend von dem, was man in FPGAs bauen kann, kommt es wieder drauf an, wie das gedacht ist: Bei einen Einzelmodul als Endprodukt müssten Rechenanfragen in FIFOs geleitet werden, um sie abzuarbeiten. Das muss vor allem dann passieren, wenn wenn mehrere Stellen wirklich "gleichzeitig" im selben Takt arbeiten. Klassischer Fall: Mehrere VHDL-Einheiten schicken Stati raus, die zum Prozessor sollen. Die brauchen alle eine FIFO-pipe, ähnlich einer pipe in Unix. Bei einer in geloopten pipeline gibt es mehr Optionen: Es steht je nach Latenz eine Anzahl von time slots zur Verfügung, die von unterschiedlichen Quellen genutzt werden kann, wenn deren Anzahl kleiner ist. Da würde ein handshake reichen. Ansonsten muss dynamisch verwaltet werden. Das kann man tun, kommt aber schnell dahin, dass die Verwaltung für solche Mechanismen zu aufwändig wird und die Effizienz des FPGAs tötet. Wo es klappt ist die dynamische MIDI-Verwaltung und Stimmverwaltung bei (m)einem Synthesizer: Die MIDI-Noten (=Prozesse) belegen konvergierend über FIFOs mehrere Instrumente gleichzeitig (= Verteiler, beim Computer der Scheduler im OS) und diese wiederum belegen divergierend die Stimmen (= Prozessoren). Es funktioniert deshalb effektiv, weil ich im Gegensatz zu einem echten Multithreading-System gezielte Annahmen über die maximale Zahl der Kanäle und der Prozesse mache und zudem die auszuführenden Prozesse abbrechen kann: MIDI-Noten, die zu alt sind und zu leise, werden "gestohlen", wie man sagt. Die maximale Zahl der "Prozesse" ist damit konstant. Nichtnutzung von Prozessen stellt anderen aber nicht mehr Zeit oder Resourcen zu Verfügung. Die "Prozessoren" im FPGA sind dabei virtuell, also eine große Schaltung gepiped, daher ist nicht determiniert, welche Note wo landet und gespielt wird, was im Übrigen den "-kill Befehl" bei Prozessen (hier das MIDI-off) ziemlich kompliziert macht, besonders, wenn noch "vererbt" wird - also die MIDI-Noten noch wegen Echos vervielfacht werden :-) Es gibt derzeit meines Wissens kein System außer meinem, das dafür eine Lösung hat. Alle Hersteller von "FPGA-Synths", die dazu Stellung genommen haben, prozessieren die Notenverwaltung in diesem Punkt mit einem CPU-ähnlichen System oder gleich einer Soft-CPU, bzw einem Zynq. Bei den anderen Fragestellungen dürfte es um so mehr darauf ankommen, wie es formuliert ist und was man dem Tool noch mit auf den Weg gibt. Du kannst schlicht nicht alles steuern, was im FPGA ausdrücklich aufgebaut werden kann.
Mcn schrieb: > Schleifen, Vererbung, Funktionsauruf Das sind alles virtuelle Strukturen die die gegenteilige Richtung gehen. Es ging eigentlich um die Frage, ob und welche Vorteile z.B. C oder C++ bei der Formulierung einer FPGA-Lösung haben kann und wie zielsicher sich das Parallelisieren steuern lässt, das ja DER Vorteil der FPGAs ist. Bei C++ ist da ja besonders kompliziert, weil es einen Dualismus der Parallelität gibt: Es gibt eine P. der Strukturen im Code und eine P. bei duplizierten Prozessen. Beides kann (und muss) unabhängig voneinander durch entweder echte parallele Strukturen oder sequenzielles Arbeiten im FPGA oder Kombinationen daraus ersetzt werden und das geht definitiv nicht ohne weitere Vorschriften. Hier kommen wir jetzt zu Dingen, die in C formulierbar sind aber sich im FPGA ohne Weiteres nicht sinnvoll bauen lassen, oder einen ordentlichen Mehraufwand erzeugen, wenn es um Spezialitäten wie Pointer und mehrdimensionale Datenstrukturen geht. Ganz generell müssen ja alle Funktionen, die das C liefert oder die der Compiler in den Code einsetzt, auch im FPGA gebaut werden - was theoretisch immer geht - aber eben Aufwand macht. Verkettete Listen mit Pointern z.B. lassen sich in den RAMs schon verwalten, das Umsortieren ist aber nicht effektiver, es sei denn es werden mehrere unabhängige Systeme gefahren. Es gibt da eigentlich wenige Fälle, in denen man da etwas Besseres bauen kann, als eine sequentielle Steuerung auf der Basis eines Prozessors und dazu nimmt man eben am Besten gleich einen solchen. Da im Weiteren speziell C++ sehr viel mitbringt, was in C schon umständlich ist, wenn es nachgebaut werden soll, gilt das für FPGAs umsomehr.
>Das hat MATLAB auch >hinbekommen und eine Gegenprobe mit HLS unter Verwendung des geposteten >Algos in C war bei entsprechenden constraints der gleichen "Meinung", >bzw kommt in die gleiche Größenordnung. Welches Tool bezeichnest du konkret als HLS? HLS ist ein ziemlich allgemeiner Begriff: https://www.elektronikpraxis.de/fpgas-mit-cc-programmieren-herausforderungen-bei-hls-design-flows-a-826858/
Angehängte Dateien:

.svg){kind=link}
Christoph M. schrieb: > Welches Tool bezeichnest du konkret als HLS? In dem Fall primär Xilinx HLS. > HLS ist ein ziemlich allgemeiner Begriff: Stimmt. Xilinx hat den Begriff sozusagen gekapert und verwendet ihn direkt für ihr internes Übersetzungswerkzeug bzw. die gesamte Kette / Methode. Ist ähnlich wie bei "Synthese". Wenn du mit einem Xilinx-Vertreter sprichst, wirst du gerne mal korrigiert, was du unter dem Begriff Synthese zu verstehen hast. Als Ergänzung noch dieses Beispiel, dass ich auch an anderer Stelle bereits einmal gepostet hatte: Als das mit dem Catapult und später Xilinx HLS hochkam, hatte ich meinen ersten in C verfassten Synth für meinen DSP geschnappt und durchlaufen lassen. Da gab es die gleichen Effekte: Es wurde kräftig dupliziert und Schleifen liefen zwar mitunter als pipeline, aber alles gegated und eindimensional.
Quarkteilchen-Beschleuniger schrieb: > Genau darin stecken massive Folgekosten und unkalkulierbarer Aufwand, > wenn das eine für min. 10 Jahre nachhaltige Entwicklung sein muß. > Dreckiger ausgedrückt: wir lassen uns nicht erpressen. Heißt was? Ihr nehmt keine externen Dienstleister oder ihr nehmt keine Code-Generatoren? Mcn schrieb: > https://en.wikibooks.org/wiki/Digital_Circuits/CORDIC Solche CORDIC-Funktionen sind heute elementarer Bestandteil von FPGAs. Allerdings werden sie einfach reingeworfen und angeschlossen.
Blechbieger schrieb: > ertige IP-Cores zu kaufen Für so etwas wie hier wirst du kaum einen fertigen Core kaufen können, weil die Verschaltung der verwendeten Multiplizier und Addierer höchst individuall ist. Da ließen sich Millionen von Core erdenken. Martin S. schrieb: > Das groebste Manko an obiger Art HLS deucht mich, dass kaum > Routing-Constraints oder Layout-Einschraenkungen in den ersten Schritt > der Synthese (Inference/Mapping) eingehen Das ist das Problem, an dem ich auch gerade dran bin. Wie ließen sich solche Vorgaben machen? Ich habe im Code Generator praktisch nur die option "pipeline" oder "nicht pipeline". Weitere Randbedingungen gibt es nicht.
T.U.Darmstadt schrieb: > Quarkteilchen-Beschleuniger schrieb: >> Genau darin stecken massive Folgekosten und unkalkulierbarer Aufwand, >> wenn das eine für min. 10 Jahre nachhaltige Entwicklung sein muß. >> Dreckiger ausgedrückt: wir lassen uns nicht erpressen. > Heißt was? Ihr nehmt keine externen Dienstleister oder ihr nehmt keine > Code-Generatoren? Ich beantworte mal die Frage aus meiner Sicht: MATHWORKS versucht massivst, durch Convenience die Entwickler dazu zu bewegen, möglichst alles mit Matlab zu entwerfen und dazu die zahlreichen toolboxen zu nutzen. Für die Umsetzung in C und VHDL soll dann aus einem grafischen Ansatz heraus in Simulink der FPGA gebaut werden. Mag für einige Entwickler und Anwednungsfälle angemessen sein. Sobald es aber in Richtung Mehrdimensionalität geht, versagt das 2-dimensionale Malen. Auch die im Eingangspost dargestellte Lösung ist ja nicht in 2D hinzuzeichnen. Es bleibt also aus meiner Sicht dabei, dass solche Lösungsansätze in VHDL direkt verfasst werden müssen. Damit (und nur damit) lassen sich mit Generate solche breiten und tiefen Funktionen aufziehen. Als Beispiel hätten wir in meinem Anwendungsfall eine kubische FFT, die mehrere Kanäle und Samples gleichzeitig verarbeitet. Auch da werden viele Zwischenergebnisse aus anderen Berechnungen kreuz und quer mit einander verrechnet. Ich sehe keine Möglichkeit, wie MATLAB das erzeugen könnte, wenn es nur Randvorgaben hat. So etwas muss man sich ausdenken, es validieren und dann händisch eintragen. In C geht das insofern schnell, weil es dann direkt als Protyp in einem Programm benutzbar und testbar wird. Automatisch in VHDL zu übersetzen, geht aber nicht, weil es dann zu einem Schleifenprogramm wird und schrecklich langsam. Es muss neu aufgezogen werden. Martin S. schrieb: > Unterm Strich ist mein Fazit: Man implementiert es immer zweimal. D'accord! > Der PhD mit der tollen Idee darf mit Matlab rumspielen > der Praktikant kloppt's durch's die HLS und soll's trial&error-testen Haha! Du scheinst unsere Firma zu kennen. > wenn's Richtung Produkt geht, wird's nochmal von > einem/r, der/die die Materie wirklich versteht, von Anfang an neu > designt, weil das FPGA sonst zu heiss/teuer/gross wird. und wer macht es? Die Schweizer :-)
Rolf schrieb: > Das ist das Problem, an dem ich auch gerade dran bin. > > Wie ließen sich solche Vorgaben machen? > > Ich habe im Code Generator praktisch nur die option "pipeline" oder > "nicht pipeline". Weitere Randbedingungen gibt es nicht. Muesste man wohl einen neuen Thread fuer aufmachen. Ich nutze hier eine Python-Notation fuer Pipelines, siehe auch hier: https://gist.github.com/hackfin/f25373db56485b4aa576f863d5c4787c Der Einstieg ist aber etwas aufwendiger. Die Notation war eigentlich als Zwischenschicht gedacht. Mit den genannten `stages` und `slots` laesst sich aber relativ feinkoernig kontrollieren, wie die Pipeline zwischen voll-pipe und voll-fsm ausgerollt wird, plus Latency-Check beim Zusammensetzen. Grund fuer die Zwischenform mit den slots und gemultiplexter Betrieb von Resourcen ist ja typischerweise, dass man zwei Kanaele gleichzeitig durch eine Recheneinheit schleust, wie gern bei der DCT gemacht. Das kriegen offenbar die Matlab-Coder-Tools so nicht optimiert.
:
Bearbeitet durch User
>> Das groebste Manko an obiger Art HLS deucht mich, dass kaum >> Routing-Constraints oder Layout-Einschraenkungen in den ersten Schritt >> der Synthese (Inference/Mapping) eingehen > Das ist das Problem, an dem ich auch gerade dran bin. > > Wie ließen sich solche Vorgaben machen? > > Ich habe im Code Generator praktisch nur die option "pipeline" oder > "nicht pipeline". Weitere Randbedingungen gibt es nicht. Das ist so nicht korrekt, neben dem VHDL-Code kann auch ein constraint-file für andere elemente der toolchain erzeugt werden. Oder man schreibt constraintsfile resp. attribute für architektur-details selbst. Dazu kommen je nach HLS-Provider Pragmas oder directiven wie in https://www.xilinx.com/support/documents/sw_manuals/xilinx2020_1/ug902-vivado-high-level-synthesis.pdf p. 118 genannt. Das Problem damit ist gerne, das der HLS Nutzer keinen Schimmer hat wAuswirkungen diese bzgl. der Implementierung hat und auch nichts willens ist, das einfach mal spielerisch zu erkunden. IMHO hat sich an der Situation seit 20 Jahren kaum was geändert, der Algoritmus wird von Personen entwickelt die mangels Erfahrung kaum bis garnicht optimal für die Hardware entwickeln und auch gerne mal auf Zielwerte hin optimieren, die in der Praxis eher irrelevant sind. Und diese Erfahrungslücke wird oft durch geringe time-to-market begründet. "Früher" war es selbstverständlich, das man das ganze ohnehin "zweimal entwickelt". Zuerst entwickelt/simuliert man den Algo in eine Hochsprache, Evalboard - und für das Endprodukt nimmt man die Ergebnisse der Algo-entwicklung in die Spec mitauf und entwickelt von diesen "neu".
Bradward B. schrieb: > Das Problem damit ist gerne, das der HLS Nutzer keinen Schimmer hat > wAuswirkungen diese bzgl. der Implementierung hat und auch nichts > willens ist, das einfach mal spielerisch zu erkunden. Das ist der springende Punkt, trial & error engineering kostet schlicht zuviel. Dann ist es noch nicht mal portabel, geschweige hat man die feinkoernige Kontrolle ueber die Arithmetik, oder harte ALU-Bloecke, die man allenfalls nutzen muss. Und dann die Fehlersuche, spaetestens wenn man formale Verifikationsmethoden auf die "Blackbox" loslaesst. Bradward B. schrieb: > "Früher" war es selbstverständlich, das man das ganze ohnehin "zweimal > entwickelt". Zuerst entwickelt/simuliert man den Algo in eine > Hochsprache, Evalboard - und für das Endprodukt nimmt man die Ergebnisse > der Algo-entwicklung in die Spec mitauf und entwickelt von diesen "neu". Das Zweimal-Entwickeln ist ja grundsaetzlich ok, Firmen die sowas nicht einplanen, verbraten ihr Geld typischerweise in sinnlosen Meetings. Aber dann kommt immer noch die Frage nach der Verifikation: was im Prototyp z.B. mit double (float) gut rechnet, muss im FPGA doch schnell mal in Fixpoint aus Resourcengruenden. Wie erledigt man dann die Co-Verifikation einer HW-Pipeline mit eleganten Formalismen gegen den originalen Prototypen? Oder der Klassiker mit den Zaehlern, der HLS-Ing schreibt "c += 1", im FPGA werden zig Binaerzaehler instanziiert und einer darf am Schluss alle auf Gray oder LFSR hindrehen, damit die Security und Stromverbrauch stimmen. Vielleicht ist das ja inzwischen besser abstrahiert.
Bradward B. schrieb: > IMHO hat sich an der Situation seit 20 Jahren kaum was geändert, Das ist auch mein Eindruck. Ich kann mich noch an eine Diskussion mit Mathworks zu dem Thema CC++ -> VHDL erinnern. Das war so um 2007. Damals wurde Catapult C(++) gehyped. Wurde bei meinem damaligen Kunden auch eingesetzt. So überzeugende Ergebnisse habe ich nie gesehen. Im Weiteren ging es um den HDL-Coder. Der ist mir immer wieder begegnet und ich sehe da keine grundlegenden Änderungen - wie auch, man müsste ja Eingabemethoden entwicklen und vorhandenes ändern. Die Grundprobleme bleiben ohnehin: Der Aufwand, ein System zu beschreiben, damit es automatisch in die Niesche generiert werden kann, ist ab einer gewissen Komplexität einfach zu hoch. Es ist dann einfacher, es direkt hinzuschreiben. Mit Programmiersprachen wie C++, auch wenn sie objektorientierte Strukturen bieten, kann man nicht alles beschreiben. Soweit man es kann, ist die Beschreibung auch nicht wirklich einfacher oder kürzer. Viele der komplexen Lösungen sind eine Vereinigungsmenge aus paralleler und sequenzieller Nutzung von Modulen. So ja auch die von mir vorgestellte oben. Soetwas erfordert dann einfach das richtige Instanziieren der MOdule selber und deren Verschaltung. Das ist im VHDL ein Hintereinanderhängen, ein paralleles Generate oder eben das sequenzielle Zuführen von Daten - gfs mit Zeitsteuerung durch einen Zähler. Das ist sehr überschaubarer Aufwand.
Martin S. schrieb: > Aber dann kommt immer noch die Frage nach der Verifikation: was im > Prototyp z.B. mit double (float) gut rechnet, muss im FPGA doch schnell > mal in Fixpoint aus Resourcengruenden. Wie erledigt man dann die > Co-Verifikation einer HW-Pipeline mit eleganten Formalismen gegen den > originalen Prototypen? Nun ja, du musst in C eben auch in Integer Codieren. Das ist erstmal mit aufwand verbunden, aber nötig, um die Soll-Ergebnisse zu liefern, wenn du eine solche formale Verifikation brauchst. In double zu rechnen taugt halt zunächst mal für Regelungen, um überhaupt zu testen, ob die Idee funzt. Die Frage ist, ob das schon "doppeltes" Entwickeln ist. Es ist in jedem Fall ein Zusatzschritt, allerdings einen, den auch ich gehe: Wenn ich mir eine Synthesefunktion überlege oder einen Prozessor, dann schreibe ich die Funktionen in der Tat erst einmal als normale Berechnung hin, z.B. in ein Excel. Wenn es dann funktioniert, die Breiche stimmen und die Parameter klar sind, z.B. von -1 ... +1 , dann übersetze ich das per Skalierung in ein Ganzzahlsystem. Der Schritt dient mir dann dazu, ob die Ganzzahlgeschichte überhaupt stimmt und welchen Fehler sie produziert. Habe ich das am Laufen, geht es in das pipelinen, d.h. ich schiebe mir die Zeilen so hin, dass ich das Zeitverhalten mit Registern sehe. Ab da ist es dann Copy&Paste. > Oder der Klassiker mit den Zaehlern, der HLS-Ing schreibt "c += 1", im > FPGA werden zig Binaerzaehler instanziiert und einer darf am Schluss > alle auf Gray oder LFSR hindrehen, damit die Security und Stromverbrauch > stimmen. Vielleicht ist das ja inzwischen besser abstrahiert. Auch da muss man eben die richtigen Datentypen nehmen. Ein Binärregister kann man auch in C rotieren und instanziieren. Problem: Es geht nicht schneller oder kleiner, als das direkt in VHDL hinzuschreiben. Will man es automatisch generieren lassen (man kann durchaus in MATLAB einiges parametrisch steuern) muss man es eben wieder ausdrücklich sagen.
J. S. schrieb: > Auch da muss man eben die richtigen Datentypen nehmen. Ein Binärregister > kann man auch in C rotieren und instanziieren. Problem: Es geht nicht > schneller oder kleiner, als das direkt in VHDL hinzuschreiben. Will man > es automatisch generieren lassen (man kann durchaus in MATLAB einiges > parametrisch steuern) muss man es eben wieder ausdrücklich sagen. Dank Meta-Programmierung kann man durchaus "c +=1" in manchen Frameworks hinschreiben und aendert "nur" noch die Zaehlerklasse. Nur geht das mit C leider nicht... Fixpoint in C hinzunudeln ist ein Graus fuer eine automatisierte Verifikation. Aber wahrscheinlich meinst du C++. Ja, kann man ja in SystemC machen. Nur liegen seltenst die Algorithmen in Fixpunkt vor. Die eigentliche (rhetorische) Frage zielt darauf ab, wie man den C++-Algo gegen das HDL-transferierte Konstrukt automatisch und einigermassen elegant ohne massiven Coding-Einsatz co-verifiziert, ohne am Prototypen viel zu aendern. Technisch gesehen geht das natuerlich prinzipiell mit jedem Simulator, der es irgendwie erlaubt, puren ausfuehrbaren Code gegen die Hardware-Simulation zu linken. Der Coding-Aufwand ist allerdings erheblich, und um eine Pipeline (formal) zu verifizieren reicht's eben nur unter Vorbehalt, naemlich, dass das C++-Framework bereits eine Pipeline-Notation mitbringt. Geht halt in Python dank seiner quasi "eingebauten" Transpilationsfaehigkeiten schon mit sehr viel weniger Overhead. Um das kurz auszufuehren: das gleiche "Programm" soll im quasi-Ursprungszustand (wie es derjenige mit der guten Idee geprototyped hat) gegen die vom HDL-Verifikator hinzugefuegte Dekoration (Designregeln) co-simulieren. Es wird also einerseits direkt ausgefuehrt, waehrend es in einer anderen Domaene RTL erzeugt, die wiederum vom Simulator-FW in ausfuehrbaren, taktsensitiven Code uebersetzt wird. Einzelne Pipe-Stages koennen dann so automatisch formal verifiziert werden, oder man laesst den ganzen Kram parallel mit realistischen Daten in der Loop zappeln. Die Python-Hauptschleife ist natuerlich nicht sonderlich schnell, fuer eine CPU-Emulation reicht's nicht. Eine urspruenglich vor zig Jahren noch in VHDL entwickelte Encoder-Pipeline habe ich aus Dollerei per Rueckkonversion nach Python/cyhdl so nochmal nachverifiziert, und siehe da, es wurde etwas gefunden, wo die Verifikation des Kunden noch gruen durchgelaufen war. Dasselbe Ding mit den Zaehlern, Binaer/Ripple-Counting ist einfach in den meisten Faellen Unfug, erzeugt ADC-Artefakte, ermoeglicht Seitenkanalattacken, usw. - aber jeder notiert sie erst mal so. Also aendert man in der HLS-Notation typischerweise nur noch die Zaehlerklasse und belaesst die eigentliche Funktion wie sie ist. Ja, man koennte auch hier theoretisch Operator Overloading und spezifische Datentypen in der HDL (ausser Verilog 2005) nutzen. Aber ist das dann portabel? Als Coder will man einerseits die klare Notation, aber auch sehen koennen, was genau passiert. Da nimmt die HDL besser die Rolle einer (synthesefaehigen) Transfersprache ein.
Bradward B. schrieb: > Das ist so nicht korrekt, neben dem VHDL-Code kann auch ein > constraint-file für andere elemente der toolchain erzeugt werden. Oder > man schreibt constraintsfile resp. attribute für architektur-details > selbst. Ja, richtig, die ändern aber nicht die Struktur der Schaltung und das wäre nötig. Wenn die voll oder nicht gepipelined ist, bleibt die so. Die Constraints modizieren dann nur noch Teile der Umsetzung wie ich testen konnte. Da werden z.B. mehr FFs ausgegossen und eine höhere Taktfrequenz erreicht. Auch werden Teile der Controller für mehrere identische FSMs zusammengefasst, z.b. Statuszähler etc, aber das betrifft dann auch nur das Thema FF-Resourcen die sich ändern, soweit er mit dem Platzieren hinkommt oder auch nicht.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.