Bevor jemand fragt: Es geht um bunte LEDs am Arduino.
Mit fft (Elm-Chan)funktioniert das problemlos, aber benötigt zu lange.
Nicht wirklich fürchterlich lange (15 Hz),aber es hat Totzeiten, in
denen einzelne Rhythmus-Drums übersprungen werden.
Der Gedanke ist, man könnte es mit digitale Filtern probieren, und die
Allgemeinbildung ein wenig zu erweitern.
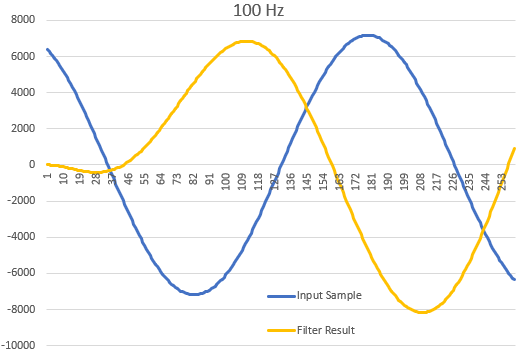
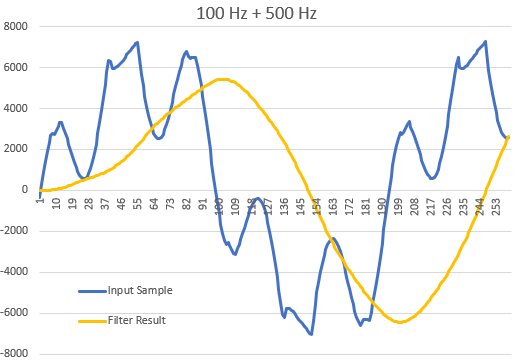
Um zu testen, ob ich das im Grundsatz verstanden habe, hab ich eine IIR,
100 Hz, schön mit Arduino-Float, ohne jede Optimierung programmiert.
Die Koeffizienten habe ich aus dem Nigel Redmon's Biqad-Calculator
https://www.earlevel.com/main/2021/09/02/biquad-calculator-v3/.
Bedenkt man die Genauigkeit (die Floats im Arduino sind nicht ewig
lang): Das tut viel besser tun als gedacht - Siehe Bilder.
So weit alles gut.
Folgende Fragen:
1) Wie bekomme die Koeffizienten
1
floata0=0.000264105.7214119353f;
2
....
3
floatb1=-1.9720443900665618f;
4
...
Sinnvoll ganzzahlig (uint64_t)? Alles mal 10 hoch 9? Dann hätte ich
zumindest 6 Stellen vor dem Komma.
Wenn ich die Idee mit dem Biquad Calculator prüfe, sieht das managebar
aus.
Ich vermute trotzdem, man macht es anders.
2) Wie bestimmt man nach der Filterung, das man die Zielfrequenz
gefunden hat?
Mein Verständnis ist, man integriert (Summiert) den Filteroutput.
Wie viele Perioden (0.25, 0.5, 1.0)?
Wo legt man sich den Schwellwert hin?
Danke!
Störend wird der Rundungsfehler wenn ein IIR deshalb schwingt.
In pyfda sehe ich nicht, ob es auf FIR beschränkt ist, aber die Aussage:
"Filter coefficients and poles / zeroes can be displayed, edited and
quantized in various formats"
würde mit "poles" auch IIR bedeuten. Da steht noch quantized, das wäre
ja die Rundung. "tested for overflow and quantization behaviour" bringt
auch noch den Überlauf ins Spiel, der stört natürlich auch.
"chipmuenk...from Murmele" niedlich. Wobei Streifenhörnchen und
Murmeltier nicht dasselbe sind.
Moin,
Ibram G. schrieb:> Dann hätte ich> zumindest 6 Stellen vor dem Komma.
Wenn's ein vernuenftiges Filterdesign ist, dann geht das auch mit
deutlich ungenaueren Koeffizienten.
Ibram G. schrieb:> 2) Wie bestimmt man nach der Filterung, das man die Zielfrequenz> gefunden hat?
Das Ding halt mal mit den entsprechend gerundeten Koeffizienten in z.b.
Octave laufen lassen, Frequenzgang angucken und sich dann ueberlegen, ob
man damit leben kann.
Gruss
WK
Vielen Dank - was die Tools angeht, ist für den Fortschritt meiner
Bildung gesorgt :-)
Zu meiner zweiten Frage,
Wie bestimmt man nach der Filterung, das man die Zielfrequenz
gefunden hat?
Mein Verständnis ist, man bildet den Durchschnitt des Filteroutput über
eine Periode. Wenn man dann Werte in der Nähe von "Amplitude/SQRT(2)"
hat, ist die gesuchte Frequenz sicher und "reinrassig" im Spektrum
enthalten.
Kommt das hin? Kommt mir etwas hölzern vor. Geht das nicht besser?
Ibram
Ibram G. schrieb:> Sinnvoll ganzzahlig (uint64_t)? Alles mal 10 hoch 9?
Theoretisch ja, man muss aber betrachten, ob es an allen Stellen passt,
wegen Minimalauflösung und Überläufen. Außerdem gibt es oft
Quadrierungen in den Algos, die es erfordern, danach richtig
runterzuskalieren, bevor man weiterrechnet. Der Faktor geht ja auch im
Quadrat. Demzufolge müssen oft die Koeffizienten des Filters angepasst
werden. Z.B. bei a0 + a1*x + a2*x2 das a2 anders als das a1. Deren
Auflösung muss mit zwei Randbedingungen angepasst werden. Dazu empfiehlt
sich eine Fehlerfortpflanzungsbetrachung.
Man wird des Weiteren überlegen, die Skalierung so zu wählen, dass
einfache Divisionen und Wurzelbildungen ermöglicht werden, falls
erforderlich. Manchmal ist es zweckmäßig die Wurzel eines optimalen
Divisionsfaktors als Skalierung zu nehmen und im Nachbarterm den vollen
Faktor.
Christoph db1uq K. schrieb:> Störend wird der Rundungsfehler wenn ein IIR deshalb schwingt.
Da muss man aber schon ziemlich schlecht runden :-) , dass es DESHALB
schwingt (und vorher nicht). Der Regelfall bei solchen
Filter-Resonatorsystemen ist erst einmal, dass man sich durch die
Rundung noch weiter vom Ideal entfernt, als es durch die Diskretisierung
an sich schon der Fall ist, siehe Differenzenquotient <->
Differentialquotient und das Problem der hohen Frequenzen. Viele
vergessen bei den numerischen Integrationen das Restglied und dessen
Abschätzung.
Dergute W. schrieb:> Ibram G. schrieb:>> Dann hätte ich zumindest 6 Stellen vor dem Komma.> Wenn's ein vernuenftiges Filterdesign ist, dann geht das auch mit> deutlich ungenaueren Koeffizienten.
"vor dem Komma" hat bei Ganzzahlrechnungen eigentlich wenig
Aussagekraft.
Die Frage ist, wie genau das insgesamt ist und wie die Rechnung skaliert
wurde. Mit Blick auf die Fehlerfortplanzung ist die Genauigkeit durchaus
sehr schnell dahin. Bei reinen Filtern, deren Historie nur bedingt
wirksam ist und für die eine vollständige analytische Lösung bekannt
ist, ist das weniger ein Problem. Aber z.B. das Durchstimmen eines
Resonators im Zeitbereich mit Ganzzahltechnik erfordert schon etwas
Schmalz bei Genauigkeit und Rundung, wenn er auch oberhalb 1-2% der
Abtastrate noch genau arbeiten- und die exakte Frequenz liefern soll. In
jedem Fall muss geschaut werden, dass die Rundungen nicht mehr Fehler
diesbezüglich aufwerfen, als es durch die Diskretisierung schon
passiert.
Es ist aber ein Leichtes, sich eine Ganzzahlrechnung neben einer
Real-Berechnung aufzubauen und dann bei beiden die Abtastfrequenz
hochzudrehen und parallel dazu bei der Ganzzahlrechnung die Auflösung zu
variieren, wenn man kein Gefühl dafür hat. Dann bekommt man aufeinander
zustrebende Lösungen und sieht schon rein optisch, ab wann man genau
(genug) ist und welche Komponenten den Limiter darstellt.
Dazu folgende Übungsaufgabe: Man formuliere ein Resonanzfilter gemäß DGL
2. Ordnung und lasse die gleiche und eine ähnliche Frequenz drauf los,
die man nach einer Zeit wegnimmt. Man beobachte die sich jeweils
bildenden Oberwellen während der Anregungsphase und dann vor allem das
Verhalten des Ausschwingen des Resonators- speziell wenn die Amplitude
unterhalb der letzten 10 Bits geht. Hier schlägt die Rundungsstrategie
voll zu.
Zum Runden noch folgende Anekdote:
Ich hatte dazu mal ein sehr sehr negatives Erlebnis mit dem output des
MATLAB HDL-Coders. Den bachelor-Entwicklern, die diese Komponente
programmiert haben, kennen diesbezüglich offenbar nichts oder gehen
davon aus, dass der Entwickler alles selber formuliert. Die meisten
Entwickler kennen das offenbar aber auch nicht und gehen daher davon
aus, dass MATLAB das schon richten wird, wenn sie ein Real-Modell
auscodieren lassen. Im HDL finden sich dann aber interessante
Umsetzungen, wie z.B. Quadrierungen ohne jegliche Rundungsvorbehandlung,
bei denen einfach ein MUL drinsteckt und hinten kräftig abgeschnitten
wird.
Als Beispiel ergaben sich bei den letzen Bits aus den Vorwerten 7,48 *
3,47 nicht etwa 26,25 aus denen 26 werden und damit dem Wert
entsprechen, den man aus dem Real 25,6 durch Aufrunden bekäme - sondern
nur 21. Mit einem Bit mehr, das ich hinzugefügt habe, sind es 23 und mit
2 Bits immerhin 25. Noch heißer war 7,64 x 3,52, wo meine statistische
Rundung auch mit 26 arbeitet, was der realen 27 nahekommt, während
MATLAB schon auf 32 springt. Das sind im schlimmsten Fall 9 digit
Rauschen!
Man muss daher mit wenigstens 2-3 Bits mehr Auflösung in die Rechnung,
hat im Quadrat 4-8 Bit mehr Bedarf oder muss generell höher aufgelöst
weiterrechnen. Der MATHWORKS FAE hatte dazu die Ansicht, dass "bei eh
schon 32 Bit Auflösung nochmal 4 Bits nichts machen". Wenn man aber
Datensicherheit 2 Bits für CRC und Bitkorrektur braucht, macht es für
die RAMs einen gewaltigen Unterschied, ob man unterhalb 36 bleibt oder
38 benutzen muss, wie jeder VHDL-Entwickler weis.
Solche Sachen sind der Grund, warum automatisch erzeugte HDL-Designs
scheinbar grundlos langsamer, größer und träger sind und vor allem mehr
RAMs brauchen.
Ich bin nicht im DSP/VHDL Geschäft, habe aber ähnliche Erfahrungen:
Was zählt, ist "Time to Market", möglichst billig.
Es ist schön wenn etwas sinnvoll funktioniert, jedoch reicht es völlig
aus, wenn die Testcases abgearbeitet werden, also wenn bei 4*4 etwa 16
herauskommt, super. Mann muss nicht mit 7,48 * 3,47 testen.
Falls Kunden unerwarteterweise mit Zahlen, welche keinen Potenzen von 2
entsprechen, rechnen, kann man es mit einem Folge - Release klären.
Im Ergebnis ergibt sich Meskimens Gesetz:
"Man hat nie genug Zeit, um etwas richtig zu machen, jedoch man hat
immer Zeit, etwas nochmal zu machen"
Ibram G. schrieb:> "Man hat nie genug Zeit, um etwas richtig zu machen, jedoch man hat> immer Zeit, etwas nochmal zu machen"
Klar, denn dann hat der Kunde ja bereits gezahlt. Und mit der ganzen
Unverfrorenheit der BWLer kann man ihn vielleicht sogar auch noch für
die Bugfixes erneut zahlen lassen...
So funktioniert Kapitalismus nunmal: Als institutionalisierter Betrug
(meint: nur die allerschlimmsten Auswüchse des Systems werden manchmal
gekappt).
Ibram G. schrieb:> Mann muss nicht mit 7,48 * 3,47 testen.
Nee, nee das kam schon aus Real-Variablen in Simulink und die
Erwartungshaltung war, dass der generierte Code die Auflösungen richtig
abbildet. Das VHDL arbeitete in dem Fall wie üblich mit Ganzzahlen. Die
Repäsentation der Zahlen wäre z.B. mit 2 Bit mehr x.25, x.50, x.75 oder
mit 3 Bit mehr x.125 ,x.250, x.375 etc. Wo der MATLAB-Coder den
INT-Punkt setzt, ist ja ihm überlassen, wenn er einen setzt. Es scheint
nur keine Strategie zur Findung der richtigen Auflösung zu geben.
Jedenfalls ist mir nicht mbekannt, dass es eine hätte (und auch dem
MATWORKS FAE nicht.:- )
Das ist aber die Aufgabe, die es zu leisten gilt. So richtig auffallen
tut es halt nicht wenn ich nicht auch mit geringen Aussteuerungen teste,
sondern am Bereichsende arbeite. Allerdings sind ja die kleinen Werte
regelmäßig die Problemverursacher, wie jeder weiß.
Nutzt man MATLAB, muss man das schätzen, passend bauen, wie man es denkt
und dann per Simulation prüfen. Ich muss also MATLAB beim Rechen
helfen,was aber nicht sein müsste:
Der richtige Weg wäre meines Erachtens eine phyiskalische SPEC für jeden
Eingang, wie U_ADC = -150mV ... 2750mv Input +/- 0,05 % acc. 12 Bit in
Simulink, die dann vom MATLAB ausgewertet wird.
Ab da hat ja auch der Ingenieur alles beieinander, um die Auflösung
durch die Rechnung hindurch zu ziehen. In dem Fall min 0,08 mV ... max
1,38 mV Fehler von der Messung des DAC + 0,67 mV absolut durch die 12
Bit -> 0,75mV ... 2,1mV Fehler. Ab dann bei jeder Stufe genau
ausrechnen, wie hoch aufgelöst die Vektoren sein müssen, damit die
digitale Rundung nichts ausmacht, also z.B. Faktor 10 kleiner bleibt und
einen Fehler von nur 0,1mV beisteuert. Mache ich in Excel ja auch.
Solche Ganzzahlrundungsgeschichten sind meines Erachtens ein absolutes
Target für ein simulierendes Mathematikprogramm und wenn Mathworks
möchte, dass mehr Ingenieure das Tool zum Auslegen von Messtechnik und
Signalverarbeitung nutzen, dann muss es auch die Werkzeuge und die
Auslegungsstrategien dafür anbieten und unterstützen.
Genau das Thema habe ich schon vor 10 Jahren mit einem
Mathworksvertreter diskutiert, der eine Vorführung bei meinem damaligen
Kunden gemacht hat und ihm vorgehalten, dass ich das schon an Mathworks
herangetragen hatte. Er gab dann mehr oder weniger zu, dass das noch in
den Kinderschuhen stecke und insbesondere der HDL-Coder da noch
Baustellen hat, man aber dran sei, da was zu machen.
Seither hat sich nichts getan.
Wie man sowas macht, lernt aber eigentlich jeder im ersten Semester der
Messtechnik, wenn er eine Messkette auslegt, berechnet, die Fehler
abschätzt und z.B. OP-Verstärkungen anpasst, bevor es in den Wandler
geht. Da gibt es ja einige Freiheitsgrade und Randbedingungen die an
unterschiedlichen Stellen einsetzen. Das gleiche Fortpflanzungsthema
kommt dann nochmal in der digitalen Signalverarbeitung und ist -
zumindest bei uns - Gegenstand von Seminaren und Laboren für die
Studenten. Man sollte eigentlich meinen, dass das geklärt ist. Dennoch
findet man bisweilen abenteuerliche Umsetzungen.
So... Zurück zum Thema.
Der Filter solle ja möglich schnell rechnen, und mit float ist das
gemeinhin nicht so einfach. Ein einfacher 8 Bit ATMEGA hat einen 8 Bit
Integer Kern.
16 und 32 bit macht der Compiler in Software - Wie bei float auch.
Nun, was läuft schneller?
Messen wir es doch mal.
Der Timer ist abgeschaltet, mit millis() würde man nicht weit kommen.
Man kann an einen Pin mit digital write jeweils high/low ausgeben und
mit dem Oszi messen.
Alle beteiligten Variablen waren jeweils "Datentyp".
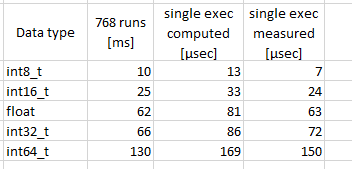
Tabelle angehängt. 2 Messungen:
Einmal in einer Loop 768 Durchläufe, mit etwas Overhead, wie Sichern der
Vorgängerwerte, und als Einzelmessung des
"y(n) = a0x(n) + a1x(n-1) + a2x(n-2) – b1y(n-1) – b2y(n-2)); "
Also .. float ist gar nicht so schlecht.
Bedenkt man, das int64 notwendig wäre, um den Wertebereich vollständig
abzudecken, bleibe ich besser bei float.
Im gegenwärtigen Programm,
mit Berechnung des Durchschnittes .................... 130 µsec / 7.5
kHz,
mit Vorbereitung der Ausgabe auf die LEDS etc., 675 µsec / 1.5 kHz.
Notwendig ist 5-kanalig. Also die Zeiten mal 5.
Mit anderen Worte, die zeitnahe Ausgabe für jedes Sample wird nix, denn
das reduziert die Sample Rate auf Infraschall - Niveau.
Man kann blockweise arbeiten, muss nicht das Ergebnis jedes einzeln
Samples ausgeben.
In wiefern etwas heraus kommt, was besser läuft als ElmChans FFT ... man
wird sehen.
Jürgen S. schrieb:> Solche Ganzzahlrundungsgeschichten sind meines Erachtens ein absolutes> Target für ein simulierendes Mathematikprogramm und wenn Mathworks> möchte, dass mehr Ingenieure das Tool zum Auslegen von Messtechnik und> Signalverarbeitung nutzen, dann muss es auch die Werkzeuge und die> Auslegungsstrategien dafür anbieten und unterstützen.
Ist https://de.mathworks.com/products/fixed-point-designer.html nicht
genau das?
Blechbieger schrieb:> Ist https://de.mathworks.com/products/fixed-point-designer.html nicht> genau das?
Leider nein, weil man das erstens doch per Hand machen muss und das Tool
einem nur die Umsetzung abnimmt, statt es eben von übergeordneten
Randbedingungen her abzuleiten. Auch da muss selber auswählen, was man
wo optimiert, weil das Tool einem nicht das Denken abnimmt.
Ehrlich gesagt ist an der Umsetzung eines float Wertes in einen Integer
auch nicht so derart viel dran, dass man dazu einen tool Box bräuchte.
Auf den ersten Blick ist das je einfach mal ein Multiplizieren mit einem
Binärwert.
Hier haben wir aber das erste Problem: ES gibt Fälle wo die Skalierung
mit Binär nicht optimal ist, sondern eine mit 360, 400
(Winkelberechnungen) oder mit PI (Rechnen mit Kreiswinkeln). Bei der
Amplitude kann das geschickte Mitschleppen von Mehrbits sinvoll sein,
wenn es zum Thema Runden kommt. MATLAB und auch die beste tool box
können nicht entscheiden, was besser ist, weil es nicht alle
Randbedingungen kennt. Es kann nur durchspielen, was rauskommt, wenn man
verschiedene Ansätze ausprobiert und sich die Ergebnisse ausrechnen
lässt - also z.B. die Fehler / Abweichungen.
Wenn man das aber aus Erfahrung schon weis, hilft einem das nicht.
Dann kommt das zweite Problem: Die Fehlerfortpflanzung bei iterativen
Prozessen. Ein ungenauer Skalierungsfaktor wird bei einer
rückgekoppelten Schleife immer wieder seine Ungenauigkeiten verstärken
und damit potenziert sich der Fehler in einigen Fällen, in anderen
regelt sich das weg. Das könnte man jetzt auch wieder durch Simulationen
lösen, um zu schauen, ob:
a) es konvergiert oder divergiert (also behandlungspflichtig ist)
b) wie stark sich der Fehler pro Iteration auswirkt
c) wieviele Iterationen es überhaupt gibt (endlich bei z.B. forward
Newton oder unendlich bei einem IIR-Filter).
All diese Dinge kann der Filterdesigner oder Fixed-Point-Designer gar
nicht wissen, sondern müsste man durch mehrere Ansätze ausprobieren und
durchsimulieren.
Oder aber: Man kann denken und hat die Fälle vor Augen und schreibt die
richtige Lösung hin. Für den Extremfall einer unendlichen Iteration
potenziert sich der Fehler gemäß einer - sagen wir gewichteten
Zinsformel - und damit konvergiert der Fehler relativ gegenüber dem der
Werteunsicherheit mit 1+a*k+a2*k2+a3*k3 ...
Damit kann man direkt abschätzen, wieviele Stellen der Skalierungsfaktor
haben muss. Für eine Dämpfung / Rückkopplung von 1:10 läuft es also auf
1+0,1*k+0,01*k2 +0,001*k3 . Macht 1min Arbeit statt 1h
MATLAB-Simulation.
Ab da weis ich dann, dass die Skalierung mit 65536 dauerhaft zu einer
maximalen Abweichung von x% führt, aber dann ...
... kommt Punkt 3: Man man muss noch das tun, was man nach jeder
Simulation auch noch tun muss, nämlich, das Ergebnis bewerten: Reicht
dieser Fehler an die Grundgenauigkeit heran, ist er dominant oder
irrelevant. Das ist das, was der Ingenieur tun muss. Das ist aber
aufgabenstellungabhängig und kann MATLAB nicht lösen, d.h. es nimmt
einem maximal nur wieder einen Teil der Arbeit ab und wandelt fehlendes
Wissen in Arbeitszeitbedarf um.
Der Vorteil ist natürlich, dass es hoffentlich richtig rechnet, wenn man
es schon durchsimulieren muss. Dabei darf man aber nicht vergessen, dass
bei jeder Simulation auch die Problemfälle komplett definiert werden
müssen, was am Eingang und am Ausgang die Chance auf
Interpretationsfehler öffnet.
Was mich beim Simulink diesbezüglich stört ist der Umstand, dass man
nach wie vor für Vergleiche bei Komparatoren die Datentypen vorgeben
muss, weil sie sonst nicht funktionieren und das es immer noch ein nötig
ist einen Devider richtig zu constrainen, so als sei nicht klar, was bei
einer FP-DIV rauskommen kann.
Ich nehme da lieber mein Excel, stecke die Werte oben rein sowie die
maximal zulässigen Abweichungen und lasse mir die Werte, die
Auflösungen, das benötigte Runden und den resultierenden VHDL-Code
direkt ausdrucken. Dauert 10 Sekunden.
Ab da ist es COPY & PASTE.
MATLAB braucht man eigentlich für andere Dinge, wenn es um komplizierte
Berechnungen geht, wo die Struktur des designs erst ausprobiert und
öfters geändert werden muss oder man mit einem Mausklick ganze
Filterblöcke oder vorhandene Designs mit angepassten Modellen einkopiert
und rechnen lässt. Für sowas macht auch ein Coder Sinn, wenn er eine
Regelschleife ins HDL bringt, damit es auf einer Simulationsplattform
schneller rechnen kann. Das ist zwar ineffizientes HDL, stört aber
nicht, wenn es ohne viel eigenes Zutun gebaut und genutzt werden kann.
BTDT, z.B. bei Bildverarbeitung wo man alle paar Nase lang neue Daten
aus der Testabteilung bekommt und die Modelle der binären Beobachter
ändern muss. Die Iteration ist dann 1h umändern, 3h compilen und
synthetisieren und über Nacht rechnen lassen. Das ist super effizient,
man muss allerdings auch erstmal investieren, um den flow erstmalig
aufzusetzen.
Ibram G. schrieb:> Falls Kunden unerwarteterweise mit Zahlen, welche keinen Potenzen von 2> entsprechen, rechnen, kann man es mit einem Folge - Release klären.
Dort kann dann auch gleich die Optimierung pi=4 eingebaut werden:
Im Jahr 1897 sollte im US-Bundesstaat Indiana mit dem Indiana Pi Bill
die Kreiszahl gesetzlich auf einen der von Hobbymathematiker Edwin J.
Goodwin gefundenen Werte festgelegt werden, der sich auf übernatürliche
Eingebungen berief. Aus seinen Arbeiten lassen sich unterschiedliche
Werte für die Kreiszahl ableiten, unter anderem 4 oder 16⁄5. Nachdem er
eine gebührenfreie Nutzung seiner Entdeckungen anbot, verabschiedete das
Repräsentantenhaus diesen Gesetzentwurf einstimmig. Als Clarence A.
Waldo, Mathematikprofessor der Purdue University, davon zufällig bei
einem Besuch des Parlaments erfuhr und Einspruch erhob, vertagte die
zweite Kammer des Parlaments den Entwurf auf unbestimmte Zeit
(https://de.wikipedia.org/wiki/Kreiszahl#Kuriosit%C3%A4ten)
Hp M. schrieb:> Dort kann dann auch gleich die Optimierung pi=4 eingebaut werden:> Im Jahr 1897 sollte im US-Bundesstaat Indiana mit dem Indiana Pi Bill> die Kreiszahl gesetzlich auf einen der von Hobbymathematiker Edwin J.> Goodwin gefundenen Werte festgelegt werden, der sich auf übernatürliche> Eingebungen berief.
Meine übernatürlichen Eingebungen tendieren leicht zur 3. Ich werde das
mal im Bundestag einbringen.
Mathematikus schrieb:> Hp M. schrieb:>> Dort kann dann auch gleich die Optimierung pi=4 eingebaut werden:> Meine übernatürlichen Eingebungen tendieren leicht zur 3.
Dann aber doch lieber die 3217/1024.
Moin,
Jaja, aber fuer die zukuenftigen Absolvierenden der integrativen
RonaldMcDonald-Gesamthochschulen wird 3 als Wert fuer PI gleichermaßen
ausreichend genau genug und mathematisch fordernd sein ;-)
Gruss
WK
>McDonald-Gesamthochschule
ein naher Verwandter der REAL-Schule und des ALDI-Gymnasiums
>3217/1024
= 3,141601562 ist schon ziemlich nah dran (3,141601562−π = 8,9 * 10E-6)
Christoph db1uq K. schrieb:> Und wer hats gefunden? Die Schweizer.
Es ist genau genommen ein in den USA geborener Chinese, der in der
Schweiz am Institut war, der die SW geschrieben hat, also eine Art
Entwicklungshilfe für Käseproduzenten im Heidi-Kanton. Gerechnet wurde
es auf einem Computer, den bekanntlich u.a. der Deutsche Konrad Zuse
erfunden hat, ausgestattet mit AMD-Prozessoren und Speichern von Micron
aus den USA und einem Motherboard aus Taiwan, sowie Flash-SDs aus
Malysia.
Was war daran jetzt wirklich CH? :-)
Der Rekord ist auch inzwischen schon wieder weg und liegt in Japan.
Christoph db1uq K. schrieb:>>3217/1024> = 3,141601562 ist schon ziemlich nah dran (3,141601562−π = 8,9 * 10E-6)
Sag ich doch :-)
Hab' ich als Jugendlicher beim Basteln am C64 mit Grafiken gefunden, die
mit Simons Basic liefen. Ich habe die Sinus-Funktionen immer aus dem
Assembler heraus aufgerufen und mit diesem Wert skaliert, weil ich
damals keine Idee hatte, wie ich im Assembler einen Sinus rechnen kann.
Ich hatte noch einen genaueren Wert mit etwa 35xx/ irgendwas, um die
Zahl parat zu haben, kann mich aber nicht erinnern.
Ibram G. schrieb:> in denen einzelne Rhythmus-Drums übersprungen werden.
Möchte da jemand eine Lichtorgel bauen?
>IIR Filterkoeffizienten Ganz-Zahlig?
Solche Filter haben wir im Bezug auch Mechaniksimulation und wenn diese
in Echtzeit laufen soll, wird die Auflösung immer an dem Term
orientiert, der die höchste Potenz / den größten Beitrag zum Ergebnis
liefert. Die Formel wird nach den Informationsspeichern abgeleitet um
den Zusammenhang zwischen Variation und Ergebnis als Funktion der
Parameteränderungen zu erhalten und dann die jeweiligen Extrma gesucht.
Danach das gleiche für die Parameter, um die Maxima der IS zu finden.
Beides liefert dann die Maximalabschätzung für den größtmöglichen
Fehler. Den festgelegt, lassen sich alle Abweichungen in ppm angeben und
ausrechnen, wie genau jeder Koeffizient skaliert werden muss.
Kai D. schrieb:> Möchte da jemand eine Lichtorgel bauen?
Ja. Diese ist schon fertig, funktioniert sogar gut ... Was kaum mein
Verdienst ist, sonder der von ElmChan.
Nur manchmal, wenn sie so am schön am nachdenken ist, und der Titel
schnell, fällt ein Rhytmus-Drum unter den Teppich :-(.
Wenn ich mit float auf dem Arduino rechne, benötigt ein Bandpass für 256
Samples 54 ms. Klar, des wird so nix. Schon gar nicht mit 5 Frequenz
Bändern.
Kai D. schrieb:> wenn diese> in Echtzeit laufen soll, wird die Auflösung immer an dem Term> orientiert, der die höchste Potenz / den größten Beitrag zum Ergebnis> liefert
In der Tat.
Die erste Stelle der IIR Koeffizienten unterschiedet sich um ~Faktor 19:
Kleinster: 0.0988
Größter: -1.86
Wenn es schnell gehe soll, brauch ich das in 8 Bit.
Dazu die Samples 8 Bit signed, macht 15 für den Akkumulator.
Ich würde die IIR Koeffizienten per Multiplikation mit 60 skalieren, die
-1.86 wird zu -112, die
0.0988 zur 6 (Die 6 stelligen Genauigkeiten sind damit dahin gegangen).
Das ist vermutlich nicht ganz das, was Du meinst wenn Du vom größten
Beitrag zu Ergebnis sprichst, aber ein Modell, welche Rundung welchen
Beitrag zu Fehler liefert ... Hm.
Würde das so funktionieren? Muss man den "b0" der typisch immer 1 ist,
noch anpassen?
Ibram
Ibram G. schrieb:> Muss man den "b0" der typisch immer 1 ist,> noch anpassen?
Sicher, weil er in die Summe einfließt und man später durchdividiert
werden soll. Das heißt man muss ihn immer in der erhöhten Auflösug
mitführen. Kann sein, dass das 65536/65536stel sind.
Kai D. schrieb:> Die Formel wird nach den Informationsspeichern abgeleitet um> den Zusammenhang zwischen Variation und Ergebnis als Funktion der> Parameteränderungen zu erhalten und dann die jeweiligen Extrma gesucht.
Per Hand oder mit MATLAB? Oder mit einem anderen Werkzeug?
Habe ein wenig experimentiert. Erkenntnis: So wird das nix.
Zunächst die Koeffizient ganzzahlig gemacht, der kleinste ist 101, der
größte 1885. Mit dem Datentyp "float" funktioniert es.
Mit int16 nicht.
Was nicht ernsthaft wundert: 1885 multipliziert mit einem Wert aus der
ADD von 100 ... Schon sind wir 'raus aus dem int16 Zahlenbereich.
Ausweg wäre
Die Eingangswerte zu limitieren auf z.B. -10 ... +10. Oder
Die Faktoren zu reduzieren auf 10 (Kleinster) bis 188 (Grösster)
Geht, aber dann filtert es nicht mehr wirklich.
Zahlenbereich vergößern auf int32 geht auch, aber dann ist es langsam
wie mit float.
Im Ergebnis:
Ziel 1: Eine Menge über digitale Filter gelernt. Ziel erreicht.
Ziel 2: Mit IIR und Arduino Language bekomme ich es nicht hin. Selbst
wenn man die Abtastrate reduziert. Also vorläufig ein fail.
Vermutlich ist die Lösung von "derguteweka"
> Beitrag ""LED-Spectrumanalyzer"software ohne Fouriertransformation"
die am meisten praktikable.
Werde versuchen, das zum laufen zu bringen.
Ibram
Für Leut' mit nur ein wenig mehr als Abiturkenntnissen es intuitiv
schwer nachzuvollziehen, warum, wenn man vom aktuelle Wert 80% des
Vorgänger abzieht, ein Tiefpass bestimmter Frequenz herauskommen soll,
nicht nur Misch-Masch.
Kein Zweifel natürlich an Ha(Omega), Z-Transfomiert in die S-Ebene ...
oder so.
Den für mich eingängigsten intuitiven Einstieg hat
"Real-Time Software Implementation of Analog Filters - Phil's Lab #20"
https://www.youtube.com/watch?v=MrbffdimDts
Gut sortiert und didaktisch (für mich) eingängig die DSP Serie hier:
https://www.linkedin.com/pulse/digital-filter-design-analog-prototypes-iir-filters-william-fehlhaber?trk=pulse-article
Es möge anderen Einsteigern nützen!
Ibram
Ibram G. schrieb:> Ziel 1: Eine Menge über digitale Filter gelernt. Ziel erreicht.
Geht mir auch so - gerade eben hatte ich das exakt selbe Problem und bin
tatsächlich nur rein zufällig über diesen Thread gestolpert - nicht mal
ergoogelt oder so ...
Filter-Koeffizienten eines IIR-BiQuad Filters in Fixed-Point
konvertieren und kucken, dass der Kram danach noch 1. filtert und 2.
stabil ist.
Nette Auffrischung mit Pole im Einheitskreis und so^^
Allerdings nicht auf 8Bit AVR ... Brauch das für FPGAs und da bau ich
mir meine Festpunk-"Datentypen", wie ich sie brauche 😁
Mampf F. schrieb:> Filter-Koeffizienten eines IIR-BiQuad Filters in Fixed-Point> konvertieren und kucken, dass der Kram danach noch 1. filtert und 2.> stabil ist.
... wobei trotzdem Kriterien für beides zu definieren wären. Gerade IIR
sind praktisch immer ein Kompromiss und das schon in Real.
Mampf F. schrieb:> Nette Auffrischung mit Pole im Einheitskreis und so^^
Das wäre ja bei den theoretisch optimalen Koeffizienten zu erledigen.
Die eigentliche Frage ist aber, ab welcher Genauigkeit / Auflösung die
Koeffizientendarstellung taugt.
Meiner Erfahrung nach braucht man für die Filterkoeffizienten
minmdestens 4 Bit mehr, dann benötigt man aber schon für 12 Bit Samples
auf dem Controller Longs, da die Koeffizienten (Betrag) auch größer als
1 sein können. Dabei bietet es sich dann gleich an, bei
Zwischenergebnissen ein paar Bits mehr stehen zu lassen. Im Beispiel auf
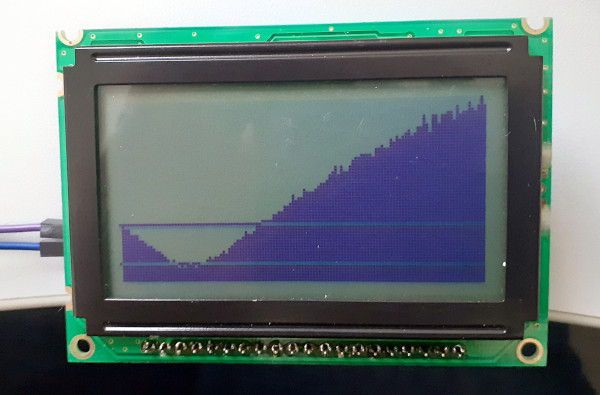
dem Bild erzeuge ich ein Signal aus vielen übereinandergelagerten
Sinuskurven, schicke das durch ein Butterwort-Hochpassfilter 1.Grades
mit f=fa/4 und zeige dann die Ergebnisse einer 256-Sützstellen FFT an.
Die Linien liegen ungefähr bei -10 und -20dB.
Die Koeffizienten lasse ich mir in Octave berechnen und als C-Source
ausgeben (siehe Anhang), das Filter selbst ist für die meisten
Plattformen in ASM geschrieben. Bei der FFT hatte ich auch ein paar
Tests in puncto Geschwindigkeit gemacht, allerdings nicht mit 8-Bittern.
Wie zu erwarten, ist Float mit einer FPU (soweit vorhanden) am
schnellsten, ansonsten 32 Bit (long) auf 32-Bittern und 16 Bot (short)
auf 16-Bittern.
Jörg
Joerg W. schrieb:> Meiner Erfahrung nach braucht man für die Filterkoeffizienten> minmdestens 4 Bit mehr,
4 Bit "mehr" als was? Als in direkter Ganzzahlrundung oder im Verhältnis
zu den zu verrechnenden Daten?
Und wieso das?
Theoretisch ist es so, je genauer die Koeffizienten, desto besser. Wenn
man sich Infomationen im Internet sucht, findet man oft, dass die
Koeffizienten eine größere Bitbreite benötigen als die eigentlichen
Samples. Genauer hinterfragt habe ich das aber nicht. Auf der anderen
Seite gilt es, Überläufe sicher zu vermeiden.
Filter höherer Ordnung als 2 splitte ich mit tf2sos auf, so dass die
einzelnen Filter nur maximal 2.Ordnung sind. Und die lassen sich mit
Integer-Werten scheinbar noch recht gut beherrschen.
Jörgb
Joerg W. schrieb:> dass die Koeffizienten eine größere Bitbreite benötigen als> die eigentlichen Samples.
Man möchte halt durch die Koeffizienten nicht noch weitere Fehler
hineinbringen. Wenn die in der gleichen Größenordnung sind,
multipliziert sich (A + a) * (B + b), womit sich nicht nur das
gewünschte A*B sondern auch die anderen Produkte ergeben. Also will man
B möglichst exakt. Von daher wäre bei einer Multiplikation z.B. ein
Faktor 10 .. 100 anzusetzen - macht 4-7 bits. Bei FIR-Filtern werden
viele Werte summiert, sodass sich die Fehler statistisch minimieren. Bei
IIR wirken Rückkopplungen bei denen man aufpassen muss.
*a,b sind die Abweichungen durch Rundungsfehler, die in der Ganzzahl
drinstecken.
Eine selten genutzte Möglichkeit, Berechungen genau zu bekommen, ist
eine Ausgleichsrechnung, bei der 2x gerechnet wird. So wird zunächst der
abgerundete und dann der aufgerundete Wert in Anschlag gebracht. Bei
einer Berechnung von Funktionswerten mit 3 Variablen, ergibt das 8
Berechnungen, bei denen man z.B. den Mittelwert der mittleren 4 benutzen
kann. Das ist erstaunlich genau am Endwert, wenn man es vergleicht.
-gb- schrieb:> Eine selten genutzte Möglichkeit
So selten ist die nicht :-)
Praktisch jede Form der Überabtastung mit Filterung und downsampling
arbeitet indirekt so, weil sie das Rauschen im System nutzt, um die
Genauigkeit zu erhöhen.