Hallo,
neues Projekt Abrechnung Stromverbrauch für diverse Mieteinheiten.
Erfasst werden sollen jeweils drei Daten:
- Mieteinheit
- Datum
- Zählerstand
Das Programm soll daraus dann für die jeweiligen Mieteinheiten den
Verbrauch und die Kosten errechnen.
Ich würde die Ablesedaten jetzt an eine Textdatei anhängen und per
streamreader auslesen und verarbeiten.
Funktioniert - ist aber sicher nicht Stand der Technik. Wie macht man es
besser?
Danke für Unterstützung
grundschüler schrieb:> Wie macht man es> besser?
Wo denn - Handy, PC, Microprozessorsystem? Oder gleich in der Cloud? Auf
US-Servern sind die Daten technisch gesehen absolut sicher, da hat der
Staat immer Kopien davon.
Welche Programmiersprache wäre auch nicht so ganz uninteressant, aber
das kannst du für die nächste Salamischeibe aufheben, dann wird das hier
wieder so ein schöner Endlos-Thread. Bei 100 Posts schaue ich vielleicht
mal wieder rein.
Georg
Sqlite installieren falls nicht vorhanden.
Datenbank mit " SQLiteStudio " erstellen. <- Kostenlos use Google.
Daten in die Datenbank schreiben
Sich freuen.
Die Datenbank kann man 1:1 auf ein Android-Handy kopieren und dort mit
der passenden Software abfragen.
Mache ich übrigens genau so.
Programmiersprache ist relativ unwichtig. C++ + VB geht jedenfalls
prima. ;)
Bei VB muss ich aber ins Projekt die Sqlite DLL's anmelden + importieren
grundschüler schrieb:> Wie macht man es besser?
Bin jetzt nicht der C#- Experte, aber leg eine Klasse an und schreibe
die Objekte in eine der Aufzählungsklassen. Alternativ externe DB
(MariaDB fällt mir als erstes ein). Deine Anwendung wird aber erstmal
ohne auskommen. Die Berechnungen kannst du als Klassenmethoden
definieren. Viel Spaß!
Datenbank ist viel Besser.
2 Tabellen
1 mit Grunddaten des Hauses und des Verbrauch des Jahres. Und wenn man
das richtig macht gehört auch z.b. die Müllabfuhr dazu.
1 mit den Mietern ink. Wohneinheit, anz der Mieter in der Wohnung und
Größe der Wohnung.
Wenn man dann es richtig macht, kann das Programm die Nebenkosten
komplett berechnen.
Ist echt kein Hexenwerk wenn man keine Felder in der Datenbank vergisst.
Und weil das anlegen der Felder eine einmalige Sache ist, habe ich den
Sql-Manager empfohlen. Das spart ne Menge an Zeit.
Damit die Datenbanken einmal anlegen, und dann mit der Software füttern.
Fertig.
grundschüler schrieb:> Funktioniert - ist aber sicher nicht Stand der Technik. Wie macht man es> besser?
Als allererstes: Vergiss das mit C# gleich mal wieder und benutz was
sinnvolles wie Python.
Zweitens: Solche Daten gehören in einen vernünftige Datenbank wie
MariaDB. Dann kannst du die gewünschten auch ganz leicht gleich
berechnen.
IT-Abteilung schrieb:> grundschüler schrieb:>> Funktioniert - ist aber sicher nicht Stand der Technik. Wie macht man es>> besser?>> Als allererstes: Vergiss das mit C# gleich mal wieder und benutz was> sinnvolles wie Python.> Zweitens: Solche Daten gehören in einen vernünftige Datenbank wie> MariaDB. Dann kannst du die gewünschten auch ganz leicht gleich> berechnen.
Humbug, als ob die verwendete Programmiersprache irgendwie maßgeblich
wäre. Jede moderne Programmiersprache bietet heute Schnittstellen zu
DBMS (z.B. MariaDB, Postgres, Filemaker, Oracle, Ocelot ...)
Maßgeblich bzw. wirklich wichtig sind dagegen das Systemkonzept, das
Datenmodell und die Sicherheit gegen Datenverlust und Manipulation.
Schlaumaier schrieb:> Die Datenbank kann man 1:1 auf ein Android-Handy kopieren und dort mit> der passenden Software abfragen.
Warum sollte man eine Datenbak kopieren**, anstatt übers Netz darauf
zuzugreifen? Wie schräg ist das denn?
(** ausser zu Backup-Zwecken)
Frank E. schrieb:> Warum sollte man eine Datenbak kopieren**, anstatt übers Netz darauf> zuzugreifen? Wie schräg ist das denn?
In der heutigen Zeit (und auch sonst) spare ich gerne Strom. Also ist
ein Zugriff von extern auf meinen PC (auch aus Sicherheitsgründen) nicht
möglich.
Bei 2 meiner Programme habe ich eine Abgespeckte Version der Datenbank
auf den Handy. Wird von der PC-Software automatisch erzeugt.
Ansonsten kopiere ich einfach die DB aufs Handy.
Der Nebeneffekt ist, das ich ein extra Backup habe.
Aber Wölkchen sind ja soooo fein. Mal sehen wann wir uns mit den Amis
anlegen, und dann als "Dankeschön" die uns die Wölkchen genau so
abschalten wie sie gerade Huaweii aus den Markt schmeißen. Bis anfang
des Jahres war Gas auch nur ein Billig-Produkt ;)
DESHALB kopiere ich eine Datenbank aufs Handy. Da bin ich dann auch
NIEMANDEN angewiesen wenn ich auf die Datenbank zugreifen will.
Schlaumaier schrieb:> Frank E. schrieb:>> Warum sollte man eine Datenbak kopieren**, anstatt übers Netz darauf>> zuzugreifen? Wie schräg ist das denn?> In der heutigen Zeit (und auch sonst) spare ich gerne Strom. Also ist> ein Zugriff von extern auf meinen PC (auch aus Sicherheitsgründen) nicht> möglich.> Bei 2 meiner Programme habe ich eine Abgespeckte Version der Datenbank> auf den Handy. Wird von der PC-Software automatisch erzeugt.> Ansonsten kopiere ich einfach die DB aufs Handy.> Der Nebeneffekt ist, das ich ein extra Backup habe.> Aber Wölkchen sind ja soooo fein. Mal sehen wann wir uns mit den Amis> anlegen, und dann als "Dankeschön" die uns die Wölkchen genau so> abschalten wie sie gerade Huaweii aus den Markt schmeißen. Bis anfang> des Jahres war Gas auch nur ein Billig-Produkt ;)> DESHALB kopiere ich eine Datenbank aufs Handy. Da bin ich dann auch> NIEMANDEN angewiesen wenn ich auf die Datenbank zugreifen will.
Wenn du das gleichzeitig als Backup betrachtest, ok, ist ein Argument.
Ansonsten sehe ich das anders:
- Original und Kopie driften inhaltlch zwangsläufig auseinander
- Sicherheit: Ich auch nix Cloud, aber wozu gibt es schließlich VPN?
- für eine (kleine) Datenbank nimmt man auch keinen "PC", sondern z.B.
ein NAS oder einen Raspi
Für ne Handvoll daten nimmt man csv und excel, maximal SQLITE womit man
jede andere SQL Query sicher auch nachbilden/benutzen kann.
IT-Abteilung schrieb:> Zweitens: Solche Daten gehören in einen vernünftige Datenbank wie> MariaDB.
Mit Panzeranonen auf Spatzen geschossen, SQLite ist auch vernünftig ;)
grundschüler schrieb:> Erfasst werden sollen jeweils drei Daten:> - Mieteinheit> - Datum> - Zählerstand
Das reicht bei weitem nicht für die neue Informationspflicht.
https://www.energie-experten.org/news/neue-heizkostenv-mieter-muessen-jetzt-monatlich-informiert-werden
Auch wieder so ein Schuss ins eigene Knie. Bei unseren 4 Einheiten kann
jeder selbst in den Keller und sich die Verbräuche anschauen.
Wenn ich das jetzt den Mietern zur Verfügung stellen muss, dann ist es
für mich deutlich einfacher und vor allem rechtssicherer das ein
Abrechnungsunternehmen machen zu lassen und die zusätzlichen Kosten
dafür auf die Mieter umzulegen.
Wenn nur ein Programm zur Zeit dran muss, reicht XML völlig aus.
Bau ne sinnvolle Objektstruktur aus Datenobjekten, und lese über
serializable und xml serializer.
Bekommt man in .net einfach so, kostenlos und quasi ohne Aufwand.
Vorteil ist : die Visualisierung ist einfach, wenn man schon Objekte
hat.
Frank E. schrieb:> Humbug, als ob die verwendete Programmiersprache irgendwie maßgeblich> wäre.
Natürlich ist die Programmiersprache wichtig. Python ist eine schlanke
schnelle Sprache und C# ist, naja, als wenn du mit gezogener Handbremse
ein Rennen fahren willst.
IT-Abteilung schrieb:> Natürlich ist die Programmiersprache wichtig. Python ist eine schlanke> schnelle Sprache und C# ist, naja, als wenn du mit gezogener Handbremse> ein Rennen fahren willst.
Kannst Du mir ein Beispiel nennen, wo Du die schlanke schnelle Python
einsetzen musstest, weil C# dazu zu langsam ist?
IT-Abteilung schrieb:> Natürlich ist die Programmiersprache wichtig. Python ist eine schlanke> schnelle Sprache und C# ist, naja, als wenn du mit gezogener Handbremse> ein Rennen fahren willst.
So ein Schwachsinn. Python ist eine interpretierte Sprache. C# nicht.
Damit ist eigentlich bereits entschieden, was von beidem schneller sein
MUSS.
Zwar gibt aus auch für Python Compiler, aber damit ist ja der Vorteil
einer interpretierten Sprache weg und es bleibt nur diese unsäglich
dämliche Python-Syntax, die nur Leute gut finden, die nix anderes
können...
Ozvald K. schrieb:> IT-Abteilung schrieb:>> Natürlich ist die Programmiersprache wichtig. Python ist eine schlanke>> schnelle Sprache und C# ist, naja, als wenn du mit gezogener Handbremse>> ein Rennen fahren willst.>> Kannst Du mir ein Beispiel nennen, wo Du die schlanke schnelle Python> einsetzen musstest, weil C# dazu zu langsam ist?
Nö, das kann er nicht, weil seine Aussage jeglicher Grundlage entbehrt.
Wahrscheinlich kann er nur Python
Wenn's schnell sein soll, dann muß es eine Programmiersprache sein, die
ein natives ausführbares Programm, unter Win also eine EXE, erzeugt. Das
wären z.B. C, C++, Objekt Pascal oder auch VB um mal 4 Beispiele zu
nennen. C# Programme werden erst mal in eine Zwischensprache übersetzt
und erst zur Laufzeit wird das ausführbare Programm erzeugt. Zumindest
beim erstmaligen Laden sind umfangreiche C# Programme meist langsamer
als native Programme. Wenn sie einmal im Speicher bestehen bemerkt man
kaum noch einen Unterschied. Bei Java ist es ähnlich, da wird ein
Bytecode erzeugt der ebenfalls erst zur Laufzeit in das ausführbare
Programm übersetzt wird. Alle interpretierten Sprachen wie Basic,
Python, Perl etc. werden erst durch den Interpreter zur Laufzeit
übersetzt und sind damit am langsamsten. Ja auch für diese Sprachen gibt
es Compiler die ausführbare Programme daraus machen können, aber dann
gehen halt wie Vorteile, wie z.B. Plattformunabhängigkeit, die ein
interpretriertes Programm prinzipiell bietet, verloren - aber das hat ja
der c-hater auch schon geschrieben.
Das ist ein Thema wo jeder nach Lust und Laune zeigen kann was'n toller
IT-Hecht er ist.
Wer kennt die geilste Programmiersprache, wer die hipste Datenbank.
Ist Python schnell genug? C#, C oder doch lieber Assembler?
Backup auf dem Handy nicht vergessen.
Ganz ehrlich: auch wenns langweilig klingt, die Aufgabenstellung schreit
förmlich nach 'ner 90er-Jahre Exceltabelle.
grundschüler schrieb:> Funktioniert - ist aber sicher nicht Stand der Technik. Wie macht man es> besser?
Wenn du jetzt Yello-Strom wärst, mit 1 Mio Kunden, der Verpflichtung die
Rechnungsdaten revisionssicher abzulegen, dann hättest du sicher eine
Datenbank, und zusätzlich eine gestreamte Textdatei (read only, nur
append) zum Wiederaufsetzen bei korrupter Datenbank.
Aber deine paar Daten, die landen im RAM Hauptspeicher, da ist eine
(relationale oder objekt-) Datenbank so was von Overkill als wolltest du
mit Atombomben auf Fischfang gehen.
Udo S. schrieb:> Das reicht bei weitem nicht für die neue Informationspflicht.> https://www.energie-experten.org/news/neue-heizkostenv-mieter-muessen-jetzt-monatlich-informiert-werden
Allerdings ging es um Strom.
Und dazu kommen Teilabrechnungen weil sich Tarife ändern, da gibt es
komplexe Tagestabellen weil nicht einfach 1/365 pro Tag anzusetzen ist.
Die Tabelle der Tageszahlen ist grösser als seine ganzen erfassten
Zählerstände. Aber auch bloss eine Spalte mit 365 Zeilen.
Le X. schrieb:> die Aufgabenstellung schreit förmlich nach 'ner 90er-Jahre Exceltabelle.
Ja, aber wieso 90er Jahre ? Auch heute ist Excel Excel.
Mit Excel muss man nichts programmieren, kann aber auf jede erdenkliche
Art auswerten, z.B. Graphiken.
Wenn er unbedingt programmieren will, tun es die Daten im Hauptspeicher.
Und zwar egal ob er 2 Mieter oder 2000 hat, das ist alles nur ein
Klacks.
Michael B. schrieb:> Und dazu kommen Teilabrechnungen weil sich Tarife ändern, da gibt es> komplexe Tagestabellen weil nicht einfach 1/365 pro Tag anzusetzen ist.
Klor kann man das. Gibt es sogar eine Gesetzliche Vorschrift drüber.
Macht mein Strom-/Gasanbieter sehr oft. Der schickt doch nicht bei jeder
Änderung ein Raus zum Ablesen. Wer soll das den Zahlen.
Also ganz klar ist: Konventionelle Programmiersprachen sind viel zu
langsam. Sowas muss definitiv in Assembler umgesetzt werden. Hier geht
es darum, aus zwei Zahlen den nächsten Verbrauchswert zu berechnen!
Textdatei? Das ist gefährlich langsam, weil das dort im Ascii-Format
steht. Das muss also erstmal umgerechnet werden. Sowas muss als
Binärdaten hinterlegt werden. Damit das ausfallsicher ist, braucht das
minimum ein S3 Bucket. Wichtig ist auch hier, einen Tarif mit möglichst
viel Bandbreite zu wählen (mindestens 1 Gbit/s garantierter Upload am
Server), um den Geschwindigkeitsvorteil von Assembler nicht zu
verlieren.
Lokal würde ich die Daten in eine HCL Notes Domino DB packen. Das ist
auch gar nicht so teuer (wichtig: Hier muss die Perpetual License inkl.
12 Month Maintenance (SW S&S) gewählt werden).
Nicht zu vergessen ist, dass auch das System, dass die Daten erfasst,
absolut ausfallsicher sein muss. Hier braucht es in jedem Falle ein PC
mit Raid 5, zusätzlich zum S3 würde ich auf jeden Fall noch ein
Offsite-Backup auf einem NAS (hier auch mit Raid 5) packen. Zusätlich
dazu würde ich die Daten einmal die Woche ausdrucken, und zu einem Notar
senden lassen. Man müsste gucken, ob hier ein Dienstleister günstiger
ist - sonst eine studentische Hilfskraft oder jemand auf 520 Euro Basis.
Man man man was sind hier wieder für Knalltüten unterwegs!
Pack deine Daten in eine Textdatei oder XML (wenn's Dir damit besser
geht) und den Rest googel Dir zusammen. Dieses Micro-Tool, das Du
möchtest, ist in einer Stunde geschrieben. Für eine Quereinsteiger, der
vorher Bäckereifachverkäufer war.
Martin S. schrieb:> Man man man was sind hier wieder für Knalltüten unterwegs!
Cooler Text. Gefällt mir.
Die meisten Leute die ich kenne hätte/haben !!! das Problem mit Excel
gelöst. Genau wie mein ehemaliger Chef. Der macht es nämlich mit Excel.
Schlaumaier schrieb:> Sqlite installieren falls nicht vorhanden.
Kannst Du BITTE aufhören, Anfängern dieses kaputte Spielzeug zu
empehlen? Die werden ihres Lebens nivht mehr froh!
IT-Abteilung schrieb:> Als allererstes: Vergiss das mit C# gleich mal wieder und benutz was> sinnvolles wie Python.
Daß Python eine großartige Sprache ist, spricht nicht gegen C#. Gegen C#
spricht, daß die damit entwickelte Software plattformabhängig ist, aber
ob dieser Umstand ein Problem für den TO ist, entscheidet er, nicht Du.
> Zweitens: Solche Daten gehören in einen vernünftige Datenbank wie> MariaDB. Dann kannst du die gewünschten auch ganz leicht gleich> berechnen.
MySQL ist zweifellos besser geeignet als SQLite, aber eigentlich will
der TO ja Zeitreihen speichern. Er braucht auch keine einzige der
Garantien, die SQL-Datenbanken so aufwändig und teuer machen. Insofern
ist für seine Workload zweifellos eine Zeitseriendatenbank besser
geeignet. Da gibt es, angefangen beim guten alten RRDTool über InfluxDB
und OpenSearch bis hin zut TimescaleDB, einer auf solche Daten
spezialisierten Erweiterung für PostgreSQL. Nach meinen Erfahrungen
gehören TimescaleDB und OpenSearch zu dem performantesten Lösungen in
diesem Bereich und sind meistens schneller als spezialisierte Werkzeuge
wie InfluxDB, aber das sollte man besser für den konkreten
Anwendungsfall ausmessen und dann entscheiden.
Ein T. schrieb:> TotoMitHarry schrieb:>> Mit Panzeranonen auf Spatzen geschossen, SQLite ist auch vernünftig ;)>> NEIN, ist es NICHT!
Was kann man nehmen, wenn man keinen Server aufsetzen will?
c-hater schrieb:> IT-Abteilung schrieb:>> Natürlich ist die Programmiersprache wichtig. Python ist eine schlanke>> schnelle Sprache und C# ist, naja, als wenn du mit gezogener Handbremse>> ein Rennen fahren willst.>> So ein Schwachsinn. Python ist eine interpretierte Sprache. C# nicht.
So ein Schwachsinn. Python ist KEINE rein interpretierte Sprache, viele
Teile der Sprache selbst, der Standardbibliotheken und externer
Libraries sind in C, C++ und Fortran geschrieben, welche in nativen
Maschinencode übersetzt und daher direkt auf der CPU ausgeführt werden.
C# wird zwar kompiliert, aber nicht in Maschinencode, sondern in einen
Bytecode, der zur Laufzeit interpretiert wird.
> Damit ist eigentlich bereits entschieden, was von beidem schneller sein> MUSS.
Nö, das hängt sehr vom Anwendungsfall ab. Große Datenmengen können mit
darauf spezialisierten Python-Bibliotheken wie numpy, NumExpr, Pandas
und pandarallel zweifellos schneller verarbeitet werden.
> Zwar gibt aus auch für Python Compiler, aber damit ist ja der Vorteil> einer interpretierten Sprache weg
Nein. Du kannst genauso schnell entwickeln, wie das für interpretierte
Sprachen typisch ist, und bekommst trotzdem am Ende Maschinencode
heraus, der nativ und direkt auf der CPU ausgeführt wird.
> und es bleibt nur diese unsäglich> dämliche Python-Syntax, die nur Leute gut finden, die nix anderes> können...
Das ist wohl Geschmackssache. Ich habe im Laufe der Jahre etliche
Sprachen benutzt, von VC20-Basic über Assembler, C, Pascal, C++, Perl,
Ruby, Java und PHP bis hin zu PL/SQL und verschiedenen UNIX-Shells, und
dazu noch einen Haufen Zeug, den ich gerade vergessen oder verdrängt
habe. Trotzdem mag ich Pythons Syntax am Liebsten: sie ist einfach,
lesbar, und steht mir niemals im Weg. Nicht zuletzt auch wegen seiner
klaren, verständlichen Syntax muß ich mich nicht mit der Formulierung
meiner Ideen beschäftigen, sondern kann mich auf die Umsetzung
konzentrieren -- nicht umsonst wird Python ja auch oft als "ausführbarer
Pseudocode" bezeichnet.
Le X. schrieb:> Ganz ehrlich: auch wenns langweilig klingt, die Aufgabenstellung schreit> förmlich nach 'ner 90er-Jahre Exceltabelle.
Oder einer 70er-Jahre CSV-Datei... ;-)
Dirk B. schrieb:> Ein T. schrieb:>> TotoMitHarry schrieb:>>> Mit Panzeranonen auf Spatzen geschossen, SQLite ist auch vernünftig ;)>>>> NEIN, ist es NICHT!>> Was kann man nehmen, wenn man keinen Server aufsetzen will?
Wenn Du es richtig machen willst, kommst Du meines Wissens aktuell
leider nicht um einen Server oder eine eigene Implementierung herum.
Aber einen PostgreSQL- oder TimescaleDB-Server (zum Beispiel)
aufzusetzen ist jetzt auch nicht besonders schwierig. ;-)
Ein T. schrieb:> TotoMitHarry schrieb:>> Mit Panzeranonen auf Spatzen geschossen, SQLite ist auch vernünftig ;)>> NEIN, ist es NICHT!
DOCH ist es. Wenn man keine Super-Sicherheitstechnik in der Datenbank
braucht ist es Ideal. Es läuft auf Windows + Android. Das Backup
erledigt man einfach mit den üblichen Festplatten-Backup.
Und ich habe Datenbanken mit Sqlite mit fast 5 Mio. Datensätze und es
funktioniert unter VB-2010 sogar hervorragend. Die DLL ist kostenlos
(k.a. ob auch vertrieben werden darf).
Also WAS zu Hölle spricht dagegen. !?!?!?
Ich setze das Zeug auf meinen Handy für meine selbst geschriebene
Einkaufsliste ein, und auch für meine Comic-Sammlung. Ist prima auf den
Flohmarkt.
Klor ich könnte auch mein Serverchen auf meiner Domain nutzen. Aber das
kostet mich Traffic (von den ich eh zu wenig habe) und der Empfang ist
nicht an allen Stellen 100% gewährleistet. Davon abgesehen dauert der
Zugriff zu lange.
Und wie bereits erwähnt, ich würde als TO mit einer Excel-Tabelle
anfangen.
Die Daten kann man hinterher ja in eine Software übernehmen. Meine erste
Comic-Tabelle war auch unter Excel. Dann die erste Software (ohne
Bilder) für mein Atari-Portfolio geschrieben, dann eine für mein
Pocket-PC von HP, und dann für mein Android-Handy. Nur für die paar
Jahre als ich ein Ei-fon hatte, habe ich wegen der lausigen Politik von
Apple dafür nix geschrieben.
Was auch ein Grund ist, wieso ich zu Android gegangen bin.
Was ich dir damit versuche zu erklären ist. Ich entscheide mich für das
was aktuell SINNVOLL + BEZAHLBAR (besser Kostenlos) ist. Und je freier
die Software ist, und je verbreiteter die ist, desto höher ist die
Wahrscheinlichkeit das ich sie einsetzt.
Ach ja, meine ersten Datenbank habe ich mit DBase gemacht. Das erste
richtige Programm dazu mit DBase-IV-Clipper.
IT-Abteilung schrieb:> Natürlich ist die Programmiersprache wichtig. Python ist eine schlanke> schnelle Sprache und C# ist, naja, als wenn du mit gezogener Handbremse> ein Rennen fahren willst.
Sorry, aber das ist für die beschriebene Anwendung doch völlig egal!
Das kannst Du auch problemlos mit GW-Basic(*) bewerkstelligen. ;-)
Ich brauch ja zum einkaufen um die Ecke auch keinen Ferrari.
(*) Basicinterpreter in frühen MS-DOS-Versionen
IT-Abteilung schrieb:> Als allererstes: Vergiss das mit C# gleich mal wieder und benutz was> sinnvolles wie Python.
Kannst Du diese Aussage bitte mal ein wenig erläutern?
Ein T. schrieb:> C# wird zwar kompiliert, aber nicht in Maschinencode, sondern in
die CLI, also eine Zwischensprache (intermediate), die dann
interpretiert wird. Und das ist so schnell, dass die Ausführung einer
nativen Exe kaum schneller ist. Allerdings mit allen Vorteilen.
Hi c-hater
c-hater schrieb:> Zwar gibt aus auch für Python Compiler, aber damit ist ja der Vorteil> einer interpretierten Sprache weg und es bleibt nur diese unsäglich> dämliche Python-Syntax, die nur Leute gut finden, die nix anderes> können...
also ich hab bis vor Kurzem so ähnlich gedacht! Ich wollte auch nix mit
Python machen. Dann hab ich mal MicroPython für uC-Boards ausprobiert.
Und jetzt hab ich meine Meinung doch ein wenig revidiert: Die Syntax ist
nicht so C-like wie Java oder C#, aber sie ist schnell gelernt.
Richtig nett ist die unkomplizierte Möglichkeit, Module mit pip zu
installieren. Und insgesamt finde ich die Komplexität der
"Infrastruktur" doch relativ überschaubar.
Was allerdings z.B. echt Mist ist, ist das fehlen bestimmter Konzepte.
Ich vermisse z.B. aktuell die Möglichkeit, lokale statische Variablen zu
definieren! OK, soll man mit Klassen machen. Ist aber auch nicht in
jedem Fall die einfachste Lösung.
Also für überschaubare Sachen, zur Inhouse-Verwendung etc. find ich
Python inzwischen gar nicht mehr so schlecht. Das einzige, was mich noch
nervt, ist der Hype um Python.
Gruß
Marcus
DenkenMachtSpaß schrieb:> Das kannst Du auch problemlos mit GW-Basic(*) bewerkstelligen. ;-)
Hm.
In GW-Basic müsste er dann eine Index-relational-Datenbank aufbauen.
Wobei bei seinen paar Daten auch eine Sequenzielle Datenbank reicht.
Habe ich übrigens beides schon gemacht. Und könnte ich heute noch wie im
Schlaf ;)
Er kann auch zum Anfangen das hier nehmen :
http://xprofan.de/start.htm
Unter download die kostenlose Version 11.a.
Da ist dBase integriert und es können bis zu 15 Tabellen gleichzeitig
bearbeitet werden. Indizies werden auch unterstützt.
Für kleine Sachen (bis 1 Mio. Datensätze) reicht das vollkommen.
Und es ist ganz leicht, eine GUI drumherum zu erstellen. Da braucht
man nicht mit Kanonen auf Spatzen zu schießen.
Reicht mir bis heute immer noch, um kleine Tools zu erstellen bzw.
kleine DBs zu erstellen/verwalten.
Schlaumaier schrieb:> Ein T. schrieb:>> TotoMitHarry schrieb:>>> Mit Panzeranonen auf Spatzen geschossen, SQLite ist auch vernünftig ;)>>>> NEIN, ist es NICHT!>> DOCH ist es.
NEIN, ist es NICHT.
> Wenn man keine Super-Sicherheitstechnik in der Datenbank> braucht ist es Ideal. Es läuft auf Windows + Android. Das Backup> erledigt man einfach mit den üblichen Festplatten-Backup.
Es spielt keine Rolle, was Du damit machen kannst -- entscheidend ist,
was es nicht kann. Nämlich, die Einhaltung der ACID-Kriterien zu
garantieren.
> Und ich habe Datenbanken mit Sqlite mit fast 5 Mio. Datensätze und es> funktioniert unter VB-2010 sogar hervorragend. Die DLL ist kostenlos> (k.a. ob auch vertrieben werden darf).
5 Millionen Datensätze... da reicht ja eine CSV-Datei.
> Also WAS zu Hölle spricht dagegen. !?!?!?
Daß der Mist einerseits kein ACID garantieren kann, andererseits jedoch
die ACID-Kriterien zu den wichtigsten Garantien von Datenbanken gehören.
SQLite ist deswegen keine Datenbank, sondern allenfalls ein
Festplattentreiber mit SQL-ähnlichem Interface.
Ein T. schrieb:> 5 Millionen Datensätze... da reicht ja eine CSV-Datei.
Wenn man Zeit hat, etwas zu warten, ja.
Das Problem ist auch, 5 Mio. Datensätze in einer Liste zu halten,
damit der Zugriff etwas schneller wird. Bei ein paar tausend DS
geht das schon eher. Ich kann mich noch an die XT / AT Zeiten um
1980 erinnern. Da mußte ich zum Einlesen von etwa 10.000 Zeilen
6-8 Sekunden warten. Heutzutage, mit den modernen Prozessoren, ist
sowas unerheblich.
Martin S. schrieb:> Ein T. schrieb:>> C# wird zwar kompiliert, aber nicht in Maschinencode, sondern in>> die CLI, also eine Zwischensprache (intermediate), die dann> interpretiert wird.
Also doch interpretiert, as I say. Weißt Du übrigens, was Python an
dieser Stelle macht? Genau: es kompiliert den Quellcode in Bytecode,
also so eine Zwischensprache, die dann interpretiert wird. Merkste was?
Nebenbei bemerkt, kann man Python natürlich auch in Dateien mit Bytecode
übersetzen. Dafür enthält die Standarddistribution das Modul
"compileall", und beim Deployment muß man auch nur den Bytecode
ausliefern. Und in der Regel übersetzt der Python-Interpreter den Code
von Modulen beim ersten Ausführen in Bytecode und legt ihn in
__pycache__-Verzeichnissen ab. Für weitere Ausführungen des Programms
wird dann nur der Bytecode geladen und ausgeführt, solange der Quellcode
unverändert ist.
Übrigens machen das meines Wissens alle modernen Skriptsprachen so, wie
ich das oben beschrieben habe. Für PHP war es lange Zeit eine
kostenpflichtige Erweiterung, Perl macht das mit dem Bytecode schon seit
deutlich mehr als zwanzig Jahren, Ruby macht es auch. Insofern
unterscheiden sich technisch betrachtet die Ausführungsmodelle von
Microsofts "Common Intermediate Language" (CIL) und modernen
Skriptsprachen nur darin, daß bei der CIL ein separater
Kompilationsschritt manuell angestoßen werden muß, während das bei
Skriptsprachen unnötig ist, weil sie sich automatisch darum kümmern. Am
Ende steht aber immer ein Bytecode, der zur Laufzeit interpretiert wird.
> Und das ist so schnell, dass die Ausführung einer> nativen Exe kaum schneller ist. Allerdings mit allen Vorteilen.
Ja, das habe ich schon vor Jahren im Zusammenhang mit Java gelesen und
gehört. Trotzdem ist es bis heute so, daß Java-Programme beim Ausführen
ungefähr so schnell sind wie C++ im Debug-Modus. Angesichts der Leistung
moderner Hardware spielt das zwar eine untergeordnete Rolle, keine
Frage. Aber ganz so einfach, wie mein hassender Vorredner es dargestellt
hat, ist die ganze Sachen in der Realität eben trotzdem nicht.
DenkenMachtSpaß schrieb:> Was allerdings z.B. echt Mist ist, ist das fehlen bestimmter Konzepte.> Ich vermisse z.B. aktuell die Möglichkeit, lokale statische Variablen zu> definieren! OK, soll man mit Klassen machen. Ist aber auch nicht in> jedem Fall die einfachste Lösung.
Was genau möchtest Du denn machen? Vielleicht gibt es eine elegante
Möglichkeit, die Du nur noch nicht kennst.
Heinz B. schrieb:> Ein T. schrieb:>> 5 Millionen Datensätze... da reicht ja eine CSV-Datei.>> Wenn man Zeit hat, etwas zu warten, ja.> Das Problem ist auch, 5 Mio. Datensätze in einer Liste zu halten,> damit der Zugriff etwas schneller wird. Bei ein paar tausend DS> geht das schon eher. Ich kann mich noch an die XT / AT Zeiten um> 1980 erinnern. Da mußte ich zum Einlesen von etwa 10.000 Zeilen> 6-8 Sekunden warten. Heutzutage, mit den modernen Prozessoren, ist> sowas unerheblich.
Wenn Du Daten benutzen willst, die in einer Datei gespeichert sind,
wirst Du kaum darum herum kommen, diese Datei zu lesen und zu parsen. In
diesem Punkt unterscheiden sich SQLite und CSV-Dateien eher wenig. ;-)
Ein T. schrieb:> In> diesem Punkt unterscheiden sich SQLite und CSV-Dateien eher wenig. ;-)
Ja. z.b. in den ich ca. 10-12 Befehle tippe unter VB und dann die Daten
wunderschön aufbereitet in einer Tabelle habe. ;-P
Ein T. schrieb:> Also doch interpretiert,
Muss mich korrigieren. Da wird scheinbar gar nichts interpretiert:
"Dieser Code wird auf dem Ausführungsrechner in einem Laufzeitsystem
(der Common Language Runtime) zu nativem Maschinencode übersetzt
(sogenannte JIT-Kompilierung) und ausgeführt."
Also sind C#-Kompilate durch die JIT kompilierung ausgeführter
Maschinencode. Da wird also rein gar nichts interpretiert.
Ein T. schrieb:> Es spielt keine Rolle, was Du damit machen kannst -- entscheidend ist,> was es nicht kann. Nämlich, die Einhaltung der ACID-Kriterien zu> garantieren.
FYI: https://www.sqlite.org/transactional.html
Sqlite garantiert acid!
Concurrency, also mehrere, parallele schreibenden Zugriffe sind aber
meist ein Problem. Das ist aber in sehr vielen Fällen kein Thema (1
thread/prozess handelt die datenbank exklusiv).
Übrigens würde ich für sowas auch sqlite anwerfen... SQL Statements für
alle möglichen und unmöglichen Abfragen sind einfach schneller
zusammengebastelt (selbst für mich, der das alle paar Jahre braucht),
als irgendwelche Filterfunktionen per Hand zu programmieren.
Z.b Verbrauch per Mieter pro monat/quartal/jahr/gesamt ist in sql mit
SUM und GROUP ein einziges SELECT Statement...
Das user-frontend machst du in der Sprache deiner Wahl...
73
Ein T. schrieb:> Wenn Du Daten benutzen willst, die in einer Datei gespeichert sind,> wirst Du kaum darum herum kommen, diese Datei zu lesen und zu parsen. In> diesem Punkt unterscheiden sich SQLite und CSV-Dateien eher wenig. ;-)
Bei mehreren tausend Datensätzen kann man im Gegensatz zur einer
csv-Datei bei dBase und SQL u. a. einen Index auf ein Feld oder mehrere
drauflegen. Das macht sich schon bemerkbar. Wir hatten damals in den
80er
Jahren bei der VHS mal eine Indexierung mit Turbo Pascal realisiert.
Das Pflegen und Erstellen einer solchen Indexdatei macht da schon
Aufwand.
Schon beim alten dBase ging das alles automatisch.
Und das Lesen bei SQL geht ja mittels SELECT und WHERE automatisch
von der DB-Engine aus. Da braucht man sich nicht eigenhändig
durchzuhangeln.
Ich kann bei meiner Sprache sogar eine Liste z.b. ein Gridboxhandle
angeben, in der die Ergebnisse der SQL-Abfrage landen. Einfacher
gehts doch gar nicht mehr.
PS:
Außerdem hat der TO noch nicht verraten, wie aufwändig er es haben
will. Braucht er nur die Differenz zum Vormonat oder will er gar
eine Statistik fürs ganze Jahr. Eine DB wird er wohl nicht unbedingt
brauchen, es sei denn er hat mehrere Hunderte von Mieteinheiten zu
verwalten, was ich aber eher nicht annehme. Da reicht eher Exel oder
eine .csv mit einem Programm drumherum.
Schlaumaier schrieb:> Ja. z.b. in den ich ca. 10-12 Befehle tippe unter VB und dann die Daten> wunderschön aufbereitet in einer Tabelle habe. ;-P
Beeindru... ach, nee, stimmt.
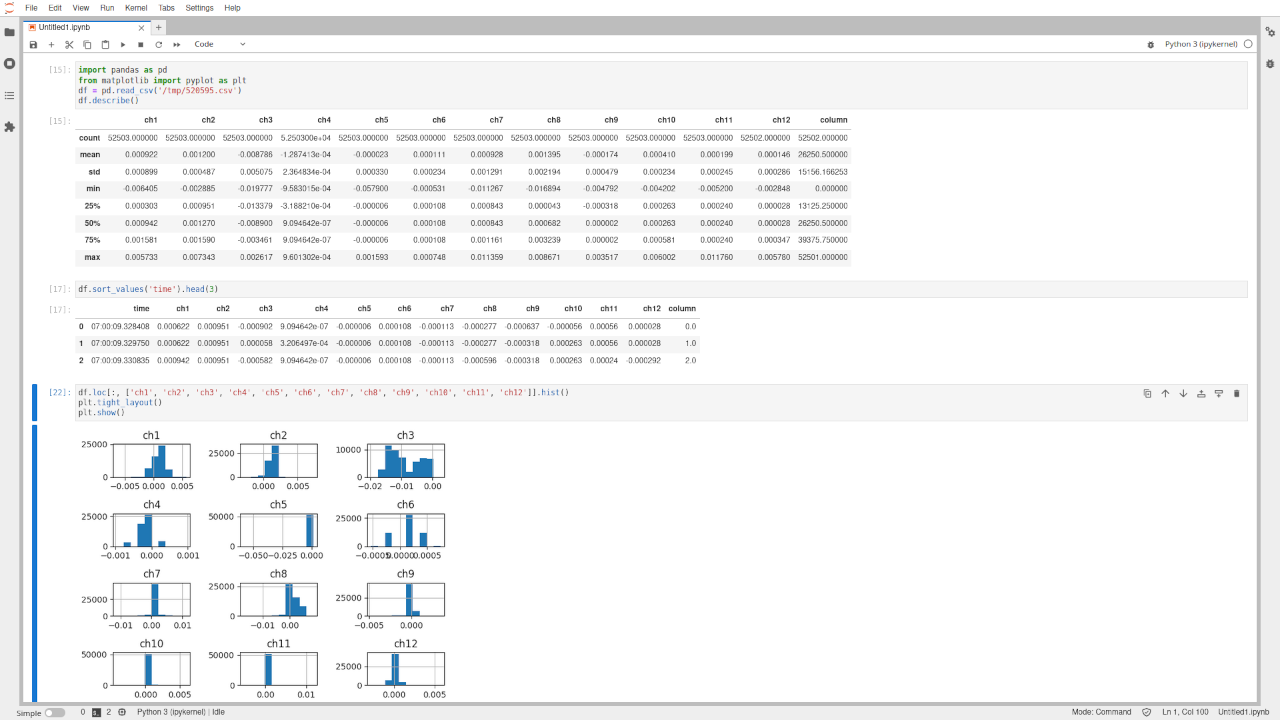
Ich hab' mir mal die Sensordaten aus diesem Thread [1] genommen, und
siehe da: ein bisschen Pandas-Python reicht, schon gibt es
a) einen Überblick über die Spalten jeweils mit den Durchschnittswerten,
Standardabweichungen, Minima, Maxima und Quartilen,
b) eine schicke tabellarische Ausgabe der Daten, hier allerdings aus
Gründen des Platzes auf drei Zeilen gekürzt, und
c) ein kleines grafisches Histogramm für jede Spalte.
52503 Zeilen mit je 14 Spalten in einer Datei mit 12402688 Bytes (12
MB), drei Minuten Coding, 1,6 Sekunden Gesamtlaufzeit, von der ca. 1,3
Sekunden für die Erzeugung und Ausgabe der Grafik für die Histogramme
anfällt.
[1] Beitrag "Anwendung des Filters funktioniert nicht"
Edit: Link eingefügt.
Ein T. schrieb:> NEIN, ist es NICHT.>> Es spielt keine Rolle, was Du damit machen kannst -- entscheidend ist,> was es nicht kann. Nämlich, die Einhaltung der ACID-Kriterien zu> garantieren.>> Daß der Mist einerseits kein ACID garantieren kann, andererseits jedoch> die ACID-Kriterien zu den wichtigsten Garantien von Datenbanken gehören.> SQLite ist deswegen keine Datenbank, sondern allenfalls ein> Festplattentreiber mit SQL-ähnlichem Interface.
Ey Alter komm mal runter von deinem Trip. Einen Datenbank-Server
aufsetzen für eine Anwendung, die vielleicht 2 Tabellen braucht, von
denen keine in ihrer Lebenszeit mehr als 1000 Datensätze aufnehmen wird?
ACID bei einem Client? Die paar Daten des TO könnte man locker in ein
CSV schreiben, SQLite bietet aber das deutlich bessere Interface zum
Zugriff auf die Daten.
Nur weil man mal eine Enterprise-Anwendung gesehen hat, ist das nicht
die Lösung für alle Probleme.
merciless
Vielen Dank für alle Beiträge - insbesondere für diesen:
Martin S. schrieb:> Nicht zu vergessen ist, dass auch das System, dass die Daten erfasst,> absolut ausfallsicher sein muss.
Phyton werde ich mir sicher nicht mehr antun. Ich bin nach vielen
anderen Programmiersprachen bei c# gelandet. Alternativlos hinsichtlich
der Interoptionalität zu ms-Produkten.
ms-word ist für mich Alternativlos, weil mein Diktiersystem Dragon nur
mit word richtig funktioniert.
Selbst wenn eine andere Programmiersprache besser sein sollte - mir ist
schon der Umfang von c# zu viel. Die Möglichkeiten von c# kann ich
allenfalls erahnen - aber nicht ausschöpfen. Wichtig ist mir die
einheitliche c-Syntax damit ich mich bei der UC-Programmierung nicht auf
eine andere Syntax umstellen muss.
Programmierung in Excel - habe ich lange Jahre gemacht VBA ist aber
inzwischen unter meinem programmiererischen Niveau. Alles, was mit VBA
geht geht auch mit c# + interop. Da bleib ich dann lieber bei der
einheitlichen c-Syntax.
Mir gings eigentlich darum, ob die Umstellung auf dbf-Files sinnvoll
ist. Den Beiträgen etnehme ich zusammenfassend, dass dies bei meiner
Anwendung gegenüber txt-files keinen großen Vorteil bietet. Muss ich
mich also nicht mit befassen.
Dirk K. schrieb:> Ey Alter
Ich fürchte, Du verwechselst mich. Ich bin weder "Alter", noch "Ey".
> komm mal runter von deinem Trip. Einen Datenbank-Server> aufsetzen für eine Anwendung, die vielleicht 2 Tabellen braucht, von> denen keine in ihrer Lebenszeit mehr als 1000 Datensätze aufnehmen wird?
Für die Datenintegrität ist die Anzahl der Datensätze unerheblich.
> ACID bei einem Client?
Ja. Vor allem das "I".
> Die paar Daten des TO könnte man locker in ein> CSV schreiben,
Das hatte ich vorgeschlagen, schon vergessen?
> SQLite bietet aber das deutlich bessere Interface zum> Zugriff auf die Daten.
Das halte ich für ein Gerücht.
> Nur weil man mal eine Enterprise-Anwendung gesehen hat, ist das nicht> die Lösung für alle Probleme.
Das stimmt, spielt hier aber keine Rolle. Ein kleiner Datenbankserver
ist nun wirklich kein Hexenwerk und in wenigen Minuten aufgesetzt.
PostgreSQL hat sogar einen grafischen Windows-Installer, den man -- wie
bei derlei Werkzeugen üblich -- nur starten und einige Male auf "Weiter"
klicken muß.
Ein T. schrieb:> Huch.
It's not a bug - It's a feature!
von der Homepage:
1
1. Datatypes In SQLite
2
Most SQL database engines (every SQL database engine other than SQLite, as far as we know) uses static, rigid typing. With static typing, the datatype of a value is determined by its container - the particular column in which the value is stored.
3
4
SQLite uses a more general dynamic type system. In SQLite, the datatype of a value is associated with the value itself, not with its container. The dynamic type system of SQLite is backwards compatible with the more common static type systems of other database engines in the sense that SQL statements that work on statically typed databases work the same way in SQLite. However, the dynamic typing in SQLite allows it to do things which are not possible in traditional rigidly typed databases. Flexible typing is a feature of SQLite, not a bug.
5
6
Update: As of version 3.37.0 (2021-11-27), SQLite provides STRICT tables that do rigid type enforcement, for developers who prefer that kind of thing.
Wenn der insert schief gehen soll, dann musst du eben deine Tabelle
richtig definieren!
73
grundschüler schrieb:> Alles, was mit VBA> geht geht auch mit c# + interop. Da bleib ich dann lieber bei der> einheitlichen c-Syntax.
Sehe ich absolut genau so. Bloß das ich Visual-Basic nutze.
Hier ist eine prima Anleitung wie das in C gemacht wird mit SQLite.
https://www.codeguru.com/dotnet/using-sqlite-in-a-c-application/
Wie oft gesagt. Einige Befehle und das war es.
Für ein einfaches Programm brauch man den ganzen Mist nicht den die
Großen SQL-Sprachen haben. Weshalb es ja auch SQL-LITE <- Leicht heißt =
SQL vereinfacht.
Dirk K. schrieb:> Ein T. schrieb:>> Huch.>> Lol, und wer hindert den Programmierer daran, in ein CSV an die Stelle,> an der ein Integer erwartet wird, einen String zu schreiben?
Nichts, aber das ist ja auch nicht der Punkt. CSVs sind nun einmal immer
Zeichenketten, das liegt in ihrer Natur. Wer CSV-Dateien liest, weiß das
und erwartet demzufolge natürlich, daß er Zeichenketten erhält.
In SQL erwartet der Entwickler dieses Verhalten dagegen nicht. Das
verletzt also nicht nur das ACID-Kriterium der Integrität, sondern auch
das Prinzip der geringsten Überraschung (principle of least
astonishment, POLA).
Noch übler ist, daß SQLite bei Anfragen auf dieselbe Spalte die Werte im
ResultSet mit unterschiedlichen Datentypen zurückgibt. Wenn der
Entwickler also über das Ergebnis eines Query iteriert und für eine
Integer-Spalte richtigerweise annimmt, darin Integers zu finden, kann
das für die ersten drölf Ergebnisse gut gehen -- und beim drölf+1ten
Datensatz fliegt ihm die Angelegenheit um die Ohren, weil plötzlich ein
String drinsteht. Yay!
Und als wäre das alles nicht schon schrecklich genug, konvertiert SQLite
Daten einfach ungefragt, ähnlich wie PHP, Lua und Perl es tun, wofür sie
zurecht regelmäßig harsch kritisiert werden: wenn man einen String "2"
in eine Integer-Spalte einträgt, steht am Ende (tadaaa!) ein Integer
darin.
An diesen inkonsistenten und verwirrenden Verhaltensweisen ändert auch
der Kommandozeilenparameter "-safe" nichts. Oh... schade.
Kurz gesagt: in Bezug auf Datentypen veranstaltet SQLite ein Verhalten,
welches für SQL-erfahrene Entwickler vollkommen unerwartet, chaotisch
und erratisch ist, das die Grundprinzipien von SQL verletzt und dem
Entwickler im Zweifelsfall spätestens dann auf die Füße fällt, wenn das
Projekt auf eine richtige Datenbank migriert werden soll.
Bevor jetzt der nächste kluge Mensch mich auf die Möglichkeiten
hinweist, die SQLite mit der STRICT-Option für Tabellen bietet: ich
weiß, aber das müßte das Standardverhalten und nicht optional sein.
> Huch.
Ja, genau: Huch, Du hattest das Problem nicht richtig verstanden. Aber
Du bist hier anscheinend in bester Gesellschaft. Deshalb macht doch, was
Ihr wollt -- es sind ja Eure Daten und nicht meine. Aber bitte empfehlt
das Zeug keinem Anfänger, ohne ihn ausdrücklich zu warnen. ;-)
Ein T. schrieb:> Bevor jetzt der nächste kluge Mensch mich auf die Möglichkeiten> hinweist, die SQLite mit der STRICT-Option für Tabellen bietet: ich> weiß, aber das müßte das Standardverhalten und nicht optional sein.
Noch einmal für dich.
Wenn ich eine LITE-Version benutze erwarte ich das alles ein bisschen
lockerer ist. Das ist genau wie bei der Marmelade im LITE-Variante wo
sie statt Zucker WASSER rein tun.
Und was deine Argumentation angeht. So beißt du dir selbst in den
Schwanz.
Wenn ich "konvertiere" dann gibt es 2 Möglichkeiten. Entweder ich mache
das mit einer Software ODER und da kommst du ins Spiel :-) Ich
exportiere die alte Datenbank (egal welches Format) in CSV. Und lese
diese "nackten Texte" in meine neue Datenbank ein.
So habe ich das schon immer gemacht und so werde ich das immer machen.
Dann weiß ich wenigstens das alles da ist wo es hin gehört und mir NIX
auf die Füße fällt.
Hans W. schrieb:> Ein T. schrieb:>> Huch.>> It's not a bug - It's a feature!
Auch mit meinem größtmöglichen Wohlwollen schaffe ich es nicht, diesen
Unsinn als "Feature" anzusehen.
> von der Homepage:>>
1
> 1. Datatypes In SQLite
2
> Most SQL database engines (every SQL database engine other than SQLite,
3
> as far as we know) uses static, rigid typing. [...]
Genau: alle anderen machen es anders, nur wir sind die Erleuchteten und
wissen es besser... oder so.
>
1
> Update: As of version 3.37.0 (2021-11-27), SQLite provides STRICT tables
2
> that do rigid type enforcement, for developers who prefer that kind of
3
> thing.
>> Wenn der insert schief gehen soll, dann musst du eben deine Tabelle> richtig definieren!
Als hätte ich nicht schon geahnt, daß mir einer mit STRICT kommt... ;-)
Ein T. schrieb:> Als hätte ich nicht schon geahnt, daß mir einer mit STRICT kommt... ;-)
Sorry, das ist dokumentiertes Verhalten.
Damit habe ich echt kein Problem... vor allem, wenn du mit einer Sprache
arbeitest die ohnehin dynamisch typisiert ist...
Übrigends steht für mich als Informatik Laien (komme aus der
Elektrotechnik) ACID für "atomicity, consistency, isolation, durability"
(siehe https://en.wikipedia.org/wiki/ACID oder
https://mariadb.com/kb/en/acid-concurrency-control-with-transactions/)
Damit haben deine Kritikpunkte eigentlich keinen Bezug auf ACID...
73
Ein T. schrieb:> Wer CSV-Dateien liest, weiß das> und erwartet demzufolge natürlich, daß er Zeichenketten erhält.
In meinen txt-Dateien - ist wohl das gleiche wie csv? - stehen immer
strings, die beim Lesen dann mit parse in Date oder integer oder decimal
umgewandelt werden. Wenn das nicht geht, gibt es eine Fehlermeldung weil
irgendwas nicht stimmt. Muss auch so sein da Mist nicht verarbeitet
werden soll.
Was ist jetz der Unterschied/Vorteil bei sql?
Hans W. schrieb:> Ein T. schrieb:>> Als hätte ich nicht schon geahnt, daß mir einer mit STRICT kommt... ;-)>> Sorry, das ist dokumentiertes Verhalten.
Das stimmt immerhin. Aber bei etwas, das "SQL" schon im Namen wie eine
Monstranz vor sich her trägt, halte ich das trotzdem für bescheuert.
Nebenbei bemerkt beweist gerade die nachträgliche Einführung von STRICT,
daß das Problem offensichtlich sogar von den SQLite-Entwicklern endlich
erkannt und verstanden wurde. Dummerweise hat man die Gelegenheit einer
neuen Major-Version verpaßt, STRICT als Default zu setzen...
> Übrigends steht für mich als Informatik Laien (komme aus der> Elektrotechnik) ACID für "atomicity, consistency, isolation, durability"> (siehe https://en.wikipedia.org/wiki/ACID oder> https://mariadb.com/kb/en/acid-concurrency-control-with-transactions/)>> Damit haben deine Kritikpunkte eigentlich keinen Bezug auf ACID...
Hups, stimmt, trotzdem wird ACID verletzt: das "C" steht für
Consistency, also Konsistenz. Ein String in einer Integer-Spalte sind
aber offenbar nicht konsistent, sondern ein Fehler. Anderer Buchstabe,
selbes Resultat.
Das Ärgerliche ist halt, daß dieses bescheuerte Verhalten von SQLite
immer wieder zu mitunter teuren und immer ärgerlichen Problemen führt.
Egal, ob es bei der Analyse und Verarbeitung, oder bei der Übernahme von
Daten in richtige Datenbanksysteme geht, muß man dieses bescheuerte
Verhalten von SQLite berücksichtigen, und die Daten oft sogar manuell
bereinigen. Sowas nervt dann ungemein, insbesondere auch weil das
Problem leicht vermeidbar gewesen wäre, wenn die SQLite-Entwickler
darauf verzichtet hätten, alles besser zu wissen und anders zu machen
als der Rest der zivilisierten Welt.
grundschüler schrieb:> Was ist jetz der Unterschied/Vorteil bei sql?
In deinem Fall wäre der Vorteil, dass du die Abfragen selbst nicht mehr
ausprogrammieren musst.
z.B. select sum(Verbrauch) where Mieter="Mieter 123" and Jahr=2021
Das würde dir den gesamtverbrauch von "Mieter 123" für das Jahr 2021
ausspucken.
select sum(Verbrauch) where Mieter="Mieter 123" group by Jahr
Würde dir den Gesamtverbrauch für jedes Jahr ausgeben.
Zusätzlich fällt das Parsen/Schreiben und vor allem das Testen von dem
Zeug weg.
Allein Gleitkommazahlen=>String ist ein Horror, wenn du auf "." und ","
aufpassen musst (siehe M$ Excel).
73
grundschüler schrieb:> Was ist jetz der Unterschied/Vorteil bei sql?
Das man eine CSV-Datei komplett lesen muss, einen Filter erstellen muss,
dann die Felder vergleichen muss und das Ergebnis in ein Array am PC
einlesen muss.
Wie oben geschrieben, habe ich unter VB/VC mit ca. 12-14 Zeilen ein
perfekt in ein Gitterelement aufgebaute Tabelle. Und das schneller als
du mit deiner großen Textdatei.
CSV ist hervorragend zum übertragen von Daten von System/DB a in
System/DB b
Es ist ergo ein NORM-Datenaustauschformat unabhängig von der Plattform.
Bei lausigen 100 Datensätzen ist das alles Wurst. Sowas ziehe ich auch
heute noch in ein Speicher-Array wenn es schnell gehen muss.
Aber lese mal ne Textdatei mit 5 Mio. Datensätze ein. Da ist dein PC
locker 20 Min beschäftigt. Mit SQLite bekomme ich auf meiner Kiste eine
LIK-Abfrage in ca. 20 Sekunden auf ein NICHT indexierten Feld hin.
DAS ist der Unterschied.
Und DAFÜR ist SQLite auch entwickelt worden. Schnelle Abfragen von Daten
auf den heimischen PC und weniger Stress für den Programmierer.
PS. Firefox nutzt auch SQL (vermutlich SQLite) für seine Datenbanken.
Jedenfalls kann man SQLite-Manager und die SQLlite-DLL die einwandfrei
lesen. ;)
Ein T. schrieb:> Major-Version
SQLite4 wurde anscheinend vor Jahren begraben.
Ich nehme an, die wollen schlicht innerhalb von SQLite3 das
Default-Verhalten nicht ändern. Finde ich gut.
Ein T. schrieb:> Sowas nervt dann ungemein, insbesondere auch weil das> Problem leicht vermeidbar gewesen wäre, wenn die SQLite-Entwickler> darauf verzichtet hätten, alles besser zu wissen und anders zu machen> als der Rest der zivilisierten Welt.
Soweit ich das verstehe, geht das auf die Implementierungsdetails des
Backends zurück. Das hat nix mit Besserwisserei zu tun.
Wenn du wirklich immer INTEGER haben willst, musst du eben einen
CHECK(typeof(mycol) = 'integer')-Constraint einbauen... wie gesagt, das
ist dokumentiertes Verhalten.
Ich gebe dir aber Recht, dass es durchaus nerven kann...
Aber ich würde SQLite nicht notwendigerweise als Ersatz für eine
"richtige" Datenbank sehen. Eher als Option, wenn ich eine Datenbank
will, aber mir die typischen Datenbankserver zu aufwändig sind.
Die Zusammenfassung auf https://www.sqlite.org/whentouse.html finde ich
zumindest schon sehr, sehr zutreffend.
Ein T. schrieb:> Hups, stimmt, trotzdem wird ACID verletzt: das "C" steht für> Consistency, also Konsistenz. Ein String in einer Integer-Spalte sind> aber offenbar nicht konsistent, sondern ein Fehler. Anderer Buchstabe,> selbes Resultat.
1
Consistency ensures that a transaction can only bring the database from one consistent state to another, preserving database invariants: any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof. This prevents database corruption by an illegal transaction. Referential integrity guarantees the primary key–foreign key relationship.
Wenn "1" für die Datenbank gleichbedeutend einer 1 ist, dann ist das so!
Die Daten in der Datenbank bleiben trotzdem konsistent und eine illegale
Transaktion macht die Daten nicht kaputt.
Da ist keine Verletzung von ACID.
73
grundschüler schrieb:> Ein T. schrieb:>> Wer CSV-Dateien liest, weiß das>> und erwartet demzufolge natürlich, daß er Zeichenketten erhält.>> In meinen txt-Dateien - ist wohl das gleiche wie csv? - stehen immer> strings, die beim Lesen dann mit parse in Date oder integer oder decimal> umgewandelt werden. Wenn das nicht geht, gibt es eine Fehlermeldung weil> irgendwas nicht stimmt. Muss auch so sein da Mist nicht verarbeitet> werden soll.>> Was ist jetz der Unterschied/Vorteil bei sql?
Bei richtigem SQL -- also nicht SQLite -- steht genau der Datentyp in
einer Spalte, mit dem sie deklariert ist. Wenn ich in einer Tabelle eine
Spalte habe, die als INTEGER deklariert ist, dann stehen dort Ganzzahlen
drin. Wenn Du die Daten wieder abfragst, kannst Du Dich felsenfest
darauf verlassen, Ganzzahlen zurückzubekommen, mit denen Du dann zum
Beispiel rechnen oder die Du grafisch visualisieren kannst.
Dasselbe gilt auch für andere Datentypen, beispielsweise Datums- und
Zeitangaben: wenn Deine Spalte in der Datenbank als DATETIME deklariert
wurde, dann stehen dort Datums- und Zeitangaben drin, und Du mußt sie
bei der Abfrage auch nicht parsen oder konvertieren. Richtige
Datenbanken können mit solchen Spalten sogar rechnen, zum Beispiel wird
ein WHERE spalte BETWEEN <datum1> AND <datum2> alle Zeilen zurückgeben,
die in "spalte" einen Wert haben, der zwischen <datum1> und <datum2>
liegt.
Außer bei SQLite. Das kennt nicht einmal Datentypen für Datum oder Zeit.
Ein T. schrieb:> Außer bei SQLite. Das kennt nicht einmal Datentypen für Datum oder Zeit.
Hm. Jetzt bin ich verwirrt.
Ich lege die DB's mit den "SQLiteStudio 3.3.3" an, weil ich kein Bock
habe dafür extra Code zu schreiben.
Da habe ich die Feldtypen DATE + DATETIME drin. Genau wie die anderen
"üblichen" Feldtypen.
Also was kenne SQLite nicht und warum kann/muss ich die Typen angeben.
Die Frage ist ernst gemeint. Weil wenn ich in VB ein Feld abfrage
bekomme ich typ-Fehler wenn ich die Antwort einer falschen Variable(TYP)
zuweise.
Ein T. schrieb:> Das verletzt also nicht nur das ACID-Kriterium der Integrität,
Das "I" in ACID steht allerdings nicht für "Integrität", sondern für
"Isolation". Gray, Reuter und Härder haben das 1983 für Transaktionen
so definiert. Das hat nichts mit Typsicherheit zu tun. Gar nichts.
Hans W. schrieb:> Ich nehme an, die wollen schlicht innerhalb von SQLite3 das> Default-Verhalten nicht ändern. Finde ich gut.
WIMRE wurde STRICT mit Version 3 eingeführt, und es zum
Standardverhalten zu machen, hätte außerdem eine neue Major-Version
rechtfertigt. Innerhalb einer Minor-Version wäre das genauso unschön wie
das von mir kritisierte Verhalten selbst, das sehe ich genauso wie Du
wohl auch.
> Soweit ich das verstehe, geht das auf die Implementierungsdetails des> Backends zurück. Das hat nix mit Besserwisserei zu tun.
Daß das Backend das zuläßt, ist offensichtlich, denn STRICT existiert ja
und macht haargenau das. Außerdem handelt es sich um
OpenSource-Software, die keinen übergeordneten Sachzwängen unterliegt.
Man hätte ein anderes Backend wählen, oder das gewählte entsprechend
erweitern können.
Beides hat man aber nicht gemacht, sondern schreibt stattdessen auf
seine Webseite, daß man sich nicht an Standards und Garantien hält, die
überall sonst in der SQL-Welt gelten. Diese Leute gehen sogar so weit,
auf ihrer Seite zu behaupten, daß die Inkompatibilität mit dem Rest der
Welt kein Fehler, sondern ein Feature sei, welches angeblich
Möglichkeiten eröffnen würde, die mit anderen Datenbanken nicht möglich
seien... Möglichkeiten, soso, welche sollten das denn sein?
> Ich gebe dir aber Recht, dass es durchaus nerven kann...> Aber ich würde SQLite nicht notwendigerweise als Ersatz für eine> "richtige" Datenbank sehen. Eher als Option, wenn ich eine Datenbank> will, aber mir die typischen Datenbankserver zu aufwändig sind.>> Die Zusammenfassung auf https://www.sqlite.org/whentouse.html finde ich> zumindest schon sehr, sehr zutreffend.
Naja, es wird hier immerhin als Ersatz für ein richtiges RDBMS
gepriesen. Dabei -- das muß man sich mal auf der Zunge zergehen lassen
-- möchte der TO dort sogar finanzrelevante Daten ablegen, die sogar für
eine gesetzlich streng regulierte Abrechnung (IIRC 556 BGB) genutzt
werden sollen.
>
1
> Consistency ensures that a transaction can only bring the database from
2
> one consistent state to another, preserving database invariants: any
3
> data written to the database must be valid according to all defined
4
> rules, including constraints, cascades, triggers, and any combination
5
> thereof. This prevents database corruption by an illegal transaction.
6
> Referential integrity guarantees the primary key–foreign key
7
> relationship.
8
>
Weiter unten steht:
1
Consistency is a very general term, which demands that the data must meet all validation rules.
Der gegebene Datentyp einer Spalte ist nach meinem Verständnis natürlich
auch solch eine "validation rule".
> Wenn "1" für die Datenbank gleichbedeutend einer 1 ist, dann ist das so!
...und eine prima Quelle für logische Fehler. Manche Entwickler, die mit
Sprachen wie PHP, Lua und Perl arbeiten, können davon ein Lied singen...
> Da ist keine Verletzung von ACID.
Wie gesagt, das sehe ich anders. Und daß es dokumentiert ist, macht die
Sache zwar ein winzig kleines bisschen besser, aber trotzdem nicht gut.
Ein T. schrieb:> Der gegebene Datentyp einer Spalte ist nach meinem Verständnis natürlich> auch solch eine "validation rule".
Der Standard sieht das anders, da wird zwischen Types und Constraints
unterschieden. Sonst dürfte PostgreSQL auch keine automatischen
assignment casts machen, denn ich kann durchaus einen String in einen
Integer INSERTen, FALLS dieser automatisch gecastet werden kann.
https://www.postgresql.org/docs/current/typeconv-query.html
Das ist natürlich allemal besser als ein laxes typing wie bei SQLite,
aber unter einer Definition wie o.g. auch nicht zulässig. Das ganze
Kapitel 10 der PostgreSQL Doku ist sowieso ganz interessant zu lesen.
Schlaumaier schrieb:> Ein T. schrieb:>> Außer bei SQLite. Das kennt nicht einmal Datentypen für Datum oder Zeit.>> Hm. Jetzt bin ich verwirrt.>> Ich lege die DB's mit den "SQLiteStudio 3.3.3" an, weil ich kein Bock> habe dafür extra Code zu schreiben.>> Da habe ich die Feldtypen DATE + DATETIME drin. Genau wie die anderen> "üblichen" Feldtypen.>> Also was kenne SQLite nicht und warum kann/muss ich die Typen angeben.>> Die Frage ist ernst gemeint. Weil wenn ich in VB ein Feld abfrage> bekomme ich typ-Fehler wenn ich die Antwort einer falschen Variable(TYP)> zuweise.
Schau mal in die Dokumentation [1]. Für Datums- und Zeitangaben
empfehlen die SQLite-Entwickler die Typen TEXT, REAL oder INTEGER.
PostgreSQL kennt hingegen drei (mit Zeitzonen fünf) Datentypen dafür und
zusätzlich einen Datentyp für Datums- und Zeitabstände [2]. Demzufolge
bietet SQLite auch lediglich sechs Datums- und Zeitfunktionen an [3],
während PostgreSQL... ach, sieh einfach selbst: [4].
[1] https://www.sqlite.org/datatype3.html
[2] https://www.postgresql.org/docs/current/datatype-datetime.html
[3] https://www.sqlite.org/lang_datefunc.html
[4] https://www.postgresql.org/docs/current/functions-datetime.html
Ergo70 schrieb:> Ein T. schrieb:>> Das verletzt also nicht nur das ACID-Kriterium der Integrität,>> Das "I" in ACID steht allerdings nicht für "Integrität", sondern für> "Isolation". Gray, Reuter und Härder haben das 1983 für _Transaktionen_> so definiert. Das hat nichts mit Typsicherheit zu tun. Gar nichts.
Guten Morgen und vielen Dank für Deinen Beitrag, wenngleich uns das
schon aufgefallen ist. Mein Fehler, ich bitte um Verzeihung. Die
Typsicherheit gehört natürlich zur "Consistency", dem "C" in ACID.
Schlaumaier schrieb:> das Datum> sicherheitshalber als TEXT-Falschrum im Format "yyyy-mm-dd" abspeichere.
Das mache ich auch so. Ist ja praktisch auch das dBase-Format.
Vor allem läßt es sich damit leichter rechnen und auch wenn man
nach Datum sortieren will. Die automatische Sortierung bei den
Controls (list,-Gridboxen usw.) funktionieren bei Zahlen ja nicht
wie gewünscht. Da kommt eben nach 1 : 10 11 12 usw. statt 1, 2, 3 ...
weil eben von MS streng nach ASCII sortiert wird.
Ergo70 schrieb:> Der Standard sieht das anders, da wird zwischen Types und Constraints> unterschieden. Sonst dürfte PostgreSQL auch keine automatischen> assignment casts machen, denn ich kann durchaus einen String in einen> Integer INSERTen, FALLS dieser automatisch gecastet werden kann.> https://www.postgresql.org/docs/current/typeconv-query.html> Das ist natürlich allemal besser als ein laxes typing wie bei SQLite,> aber unter einer Definition wie o.g. auch nicht zulässig. Das ganze> Kapitel 10 der PostgreSQL Doku ist sowieso ganz interessant zu lesen.
Das sind zwar aus akademischer Sicht absolut korrekte Einwände, für
diese eher praktisch orientierte Diskussion aber nicht sehr relevant.
;-)
Heinz B. schrieb:> Schlaumaier schrieb:>> das Datum>> sicherheitshalber als TEXT-Falschrum im Format "yyyy-mm-dd" abspeichere.>> Das mache ich auch so. Ist ja praktisch auch das dBase-Format.
Praktischerweise entspricht das Format auch dem ISO-Standard.
Tim T. schrieb:> Was für ein Schwachsinn, da kommen Timestamps rein und sonst garnix.> Aber wenn sich die Spezialisten mal wieder mit sich selbst> beschäftigen...
Und wenn du Datums vor 1582 speichern musst. ???
Dann kommst du mit deinen Time-Stamps nicht weit.
Sogar vor 1900 + vor 1970 sind so magische Grenzen.
Mit meiner Textmethode kann ich sogar vor-Christi speichern einfach ein
minus davor und es geht runter wie bei einen Thermometer.
Schlaumaier schrieb:> Tim T. schrieb:>> Was für ein Schwachsinn, da kommen Timestamps rein und sonst garnix.>> Aber wenn sich die Spezialisten mal wieder mit sich selbst>> beschäftigen...>> Und wenn du Datums vor 1582 speichern musst. ???> Dann kommst du mit deinen Time-Stamps nicht weit.>> Sogar vor 1900 + vor 1970 sind so magische Grenzen.>> Mit meiner Textmethode kann ich sogar vor-Christi speichern einfach ein> minus davor und es geht runter wie bei einen Thermometer.
Wie gesagt, wenn die Schwachköpfe wieder texten...
Ein T. schrieb:> In SQL erwartet der Entwickler dieses Verhalten dagegen nicht. Das> verletzt also nicht nur das ACID-Kriterium der Integrität, sondern auch> das Prinzip der geringsten Überraschung (principle of least> astonishment, POLA).>> Noch übler ist, daß SQLite bei Anfragen auf dieselbe Spalte die Werte im> ResultSet mit unterschiedlichen Datentypen zurückgibt. Wenn der> Entwickler also über das Ergebnis eines Query iteriert und für eine> Integer-Spalte richtigerweise annimmt, darin Integers zu finden, kann> das für die ersten drölf Ergebnisse gut gehen -- und beim drölf+1ten> Datensatz fliegt ihm die Angelegenheit um die Ohren, weil plötzlich ein> String drinsteht. Yay!>> Und als wäre das alles nicht schon schrecklich genug, konvertiert SQLite> Daten einfach ungefragt, ähnlich wie PHP, Lua und Perl es tun, wofür sie> zurecht regelmäßig harsch kritisiert werden: wenn man einen String "2"> in eine Integer-Spalte einträgt, steht am Ende (tadaaa!) ein Integer> darin.>> An diesen inkonsistenten und verwirrenden Verhaltensweisen ändert auch> der Kommandozeilenparameter "-safe" nichts. Oh... schade.>> Kurz gesagt: in Bezug auf Datentypen veranstaltet SQLite ein Verhalten,> welches für SQL-erfahrene Entwickler vollkommen unerwartet, chaotisch> und erratisch ist, das die Grundprinzipien von SQL verletzt und dem> Entwickler im Zweifelsfall spätestens dann auf die Füße fällt, wenn das> Projekt auf eine richtige Datenbank migriert werden soll.
Du lässt hier die Anforderungen komplett außer acht: Die Anwendung
benötigt keine Datenbank, die hunderte Benutzer gleichzeitig bedienen
muss, sondern 1 Client, der die Daten reinschreibt und wieder
herausliest. Alles komplett unter Kontrolle in einer Hand. Da kommt kein
String aus einer Integer-Spalte, wenn der auch nicht reingeschrieben
wird.
Du empfiehlst die Installation eines Datenbank-Servers. Der muss aber
dann ständig laufen. Die SQLite-DB ist ein File, kann mit der Exe auf
einen USB-Stick geschoben werden und die Anwendung funktioniert an jedem
Windows-PC, kein Netzwerk ist notwendig.
Wenn man die Daten in ein CSV schreibt, muss beim Lesen jede Zeile
geparst und konvertiert werden, im Falle von SQLite spart man sich das.
Ich bin auch als Software-Architekt tätig, und das was du hier predigst,
ist Over-Engineering par excellence. KISS - Keep it simple, stupid.
merciless
Dirk K. schrieb:> Ich bin auch als Software-Architekt tätig, und das was du hier predigst,> ist Over-Engineering par excellence. KISS - Keep it simple, stupid.
Ich bin zwar nicht so was edeles ;) aber ich stimme dir zu 100 % zu.
Genau deshalb setze ich das SQLite in MEINEN Datenbanken ein. Da ich die
Rechtsgrundlage nicht kenne (Anwalt bin ich auch nicht) setzt ich in VB
das Pedant via Access-DB ein.
Der Befehlssatz + Programmiercode ist absolut das gleiche. Nur der
Connect-String muss angepasst werden auf den Provider.
Dürfte in VC ähnlich sein.
Der Grund warum ich gewechselt habe ist, das 2 GB Speicherplatz für 2
Anwendungen bei mir lächerlich sind. Und ich habe mir extra ein Script
geschrieben was die Daten von Access nach meiner neuen DB zieht. Und so
nebenbei einige "macken" ausgebügelt ;)
Dirk K. schrieb:> Du lässt hier die Anforderungen komplett außer acht: Die Anwendung> benötigt keine Datenbank, die hunderte Benutzer gleichzeitig bedienen> muss, sondern 1 Client, der die Daten reinschreibt und wieder> herausliest.
Das ist doch bezüglich der beschriebenen Typsicherheit (bzw. des
eklatanten Mangels selbiger) sowas von vollkommen irrelevant, dass man
schon garnicht mehr ausdrücken könnte WIE irrelevant das ist.
> Alles komplett unter Kontrolle in einer Hand. Da kommt kein> String aus einer Integer-Spalte, wenn der auch nicht reingeschrieben> wird.
Das ist ein ziemlich idiotisches Konzept. Typsicherheit ist die
(zumindest eine) Grundlage für stabile Programme.
> Du empfiehlst die Installation eines Datenbank-Servers. Der muss aber> dann ständig laufen. Die SQLite-DB ist ein File, kann mit der Exe auf> einen USB-Stick geschoben werden und die Anwendung funktioniert an jedem> Windows-PC, kein Netzwerk ist notwendig.
Du wirst lachen: wenn es nur um Windows geht, gibt es typsichere
Altenativen zu diesem unsäglichen SQlite-Scheiß. Sogar mehrere,
mindestens zwei:
1) eine lokale Instanz eine MS-"SQL-Server". In der Extremform als
"lokaldb". Die gibt's aber wohl nur für Server.
2) Die gute alte *.mdb-Datei. Also das, was Access intern benutzt, was
man aber auch ohne eine Access-Installation in vollem Umfang benutzen
kann, wenn man die (kostenlose) MDAC installiert.
> Ich bin auch als Software-Architekt tätig
Das glaube ich nicht. Wäre es so, könntest du die Bedeutung von
Typsicherheit sinnvoll einschätzen.
Dirk K. schrieb:> Du lässt hier die Anforderungen komplett außer acht: Die Anwendung> benötigt keine Datenbank, die hunderte Benutzer gleichzeitig bedienen> muss, sondern 1 Client, der die Daten reinschreibt und wieder> herausliest.
Davon redet ja auch keiner. Okay, außer Dir natürlich.
> Wenn man die Daten in ein CSV schreibt, muss beim Lesen jede Zeile> geparst und konvertiert werden, im Falle von SQLite spart man sich das.
Deine Sprache hat keinen CSV-Parser? Das tut mir leid. Und
SQLite-Dateien müssen nicht gelesen und geparst werden, oder wie muß ich
das verstehen?
> Ich bin auch als Software-Architekt tätig, und das was du hier predigst,> ist Over-Engineering par excellence. KISS - Keep it simple, stupid.
Ich warne nur vor den problematischen und unerwarteten Eigenarten einer
bestimmten Software und verdeutliche diese hie und da anhand einer
anderen Software, die sich standardkonform und wie erwartet verhält.
Anstatt aber nun dem TO das Einzig Richtige (tm) zu raten -- nämlich:
"achte unbedingt darauf, Deine Tabellen mit STRICT zu deklarieren, sonst
ist SQLite nämlich leider nicht typsicher" -- werden die Probleme immer
wieder kleingeredet, negiert, geleugnet und davon abgelenkt. Pardon,
aber besonders von einem Softwarearchitekten erwarte ich, daß er die
Risiken und Probleme seiner Lösungsvorschläge kennt, sie gegeneinander
abwogen hat und erklärt, warum er sich für diese oder jene Empfehlung
entschieden hat.
Ein T. schrieb:> Ich warne nur vor den problematischen und unerwarteten Eigenarten einer> bestimmten Software
Sorry, aber wenn Sqlite sooooo mies, unbeherrschbar und problematisch
wäre, dann würde sie nicht so massiv eingesetzt werden!
Ein T. schrieb:> "achte unbedingt darauf, Deine Tabellen mit STRICT zu deklarieren, sonst> ist SQLite nämlich leider nicht typsicher" -- werden die Probleme immer> wieder kleingeredet
Ich sehe das eher umgekehrt. Du versteifst dich auf ein Problem, das in
der Realität oft überhaupt keine Relevanz hat.
Wenn ich z.B in Qt IRGENDEINE sql engine verwende, bekome ich von einem
SELECT einen QVariant zurückt. Damit bekomme ich einen schönen Integeger
raus, selbst wenn die Datenbank mir einen String gibt. Von der
Umwandlung merke ich gar nichts!
Und bitte lies dir mal die About SQLite Seite durch:
1
Think of SQLite not as a replacement for Oracle but as a replacement for fopen()
Genau das war und ist der Grund, warum hier viele sagen: Nimm doch
sqlite
73
Dieser Thread ist ein perfektes Beispiel dafür, warum ich Vertreter so
wenig ausstehen kann. Man geht zu ihnen, mit einem expliziten Problem,
aber bekommen tue ich hinterher ein rundum sorglos paket mit 10 Jahren
Cloud-Lizenz, Messhardware für Messaufgaben, die ich nie hatte, einen
persönlichen Berater, einen Chauffeur - allerdings ohne dass ich ein
Auto habe, einen 5-Jahres Fitnessstudiovertrag, und eine wöchentliche
Lieferung von Durstexpress und der rollenden Gemüsekiste.
Diese Diskussion hier ist so dermaßen weit weg von der Problemstellung
des TO, dass es schon vor 76 Beiträgen sinnvoller gewesen wäre, einen
eigenen Thread aufzumachen, damit sich die pro/contra SQLlite Fraktion
dort die Köpfe einschlagen kann. Hier werden Anforderungen
hinzugedichtet, die aus einem simplen 50-Zeiler-Programm ein Roundup
über Datenbanken, Datenbankauswertung, Datenbankparsing machen.
Dinge, die hier aktuell noch nicht diskutiert wurden: Kommen vom Zähler
mal aus irgendeinem Grund keine Zählerwerte - was dann? Wie wird der TO
informiert? LTE Modul verbauen? Wie an die SQLlite Datenbank
anschließen? Was ist, wenn der TO im Urlaub ist? Da brauchts definitiv
noch ein System, das automatisch ein Rückflugticket bucht, damit er
schnellstens nach hause fliegen kann...
Hans W. schrieb:> Ein T. schrieb:>> Ich warne nur vor den problematischen und unerwarteten Eigenarten einer>> bestimmten Software>> Sorry, aber wenn Sqlite sooooo mies, unbeherrschbar und problematisch> wäre, dann würde sie nicht so massiv eingesetzt werden!
Schick, ein argumentum ad populum hatten wir schon lange nicht mehr. ;-)
> Ein T. schrieb:>> "achte unbedingt darauf, Deine Tabellen mit STRICT zu deklarieren, sonst>> ist SQLite nämlich leider nicht typsicher" -- werden die Probleme immer>> wieder kleingeredet>> Ich sehe das eher umgekehrt. Du versteifst dich auf ein Problem, das in> der Realität oft überhaupt keine Relevanz hat.
Genau diese "keine Relevanz" habe ich leider viel zu oft selbst und bei
Kollegen und Freunden erlebt, und zwar in der Realität. Gerade deswegen
weise ich ja auf die Unzulänglichkeiten von SQLite hin.
> Wenn ich z.B in Qt IRGENDEINE sql engine verwende, bekome ich von einem> SELECT einen QVariant zurückt. Damit bekomme ich einen schönen Integeger> raus, selbst wenn die Datenbank mir einen String gibt. Von der> Umwandlung merke ich gar nichts!
Ja, wenn. Aber wenn Du das machst, gibt es überhaupt gar keinen
Grund, nicht den eingebetteten MySQL-Server zu benutzen, den das
Qt-Framework ja meines Wissens auch anbietet.
Überraschenderweise gibt es auf der Welt nicht nur Qt SQL, sondern einen
riesigen Haufen anderer Frameworks, die keine QVariants zurückgeben. Und
selbst Deine QVariant wird Dir auf die Füße fallen, wenn Deine Datenbank
Dir zum Beispiel "eins" zurückgibt und Du .toTint() darauf aufrufst.
Zudem ist es ja hin und wieder so, daß Entwickler und ihre Programme
etwas mit den Daten machen, die sie aus einer Datenbank bekommen. Bei
Daten aus einer Integer- oder Float-Spalte zum Beispiel soll es hin und
wieder sogar vorkommen, daß jemand mathematische Operationen darauf
ausführen will. Und wenn dieser Jemand dann zum Beispiel Differenzen aus
Zählerständen ziehen möchte -- wie, nebenbei bemerkt, der TO -- und die
Datenbank gibt anstelle eines Integer den String "1337" zurückgibt, dann
explodiert die Sache nur dann nicht, wenn unser Jemand eine typunsichere
Sprache wie PHP, Lua, oder Perl benutzt. Aber sogar mit diesen Sprachen
wird die Software etwas tun, das die Fachliteratur oft euphemistisch
"undefiniertes Verhalten" nennt, wen anstelle von "1337" etwa "dreizehn"
aus der DB kommt.
> Und bitte lies dir mal die About SQLite Seite durch:>>
1
> Think of SQLite not as a replacement for Oracle but as a replacement for
2
> fopen()
3
>
>> Genau das war und ist der Grund, warum hier viele sagen: Nimm doch> sqlite
Dann könnte man ja auch gleich fopen() empfehlen, oder? Dann muß der
Frager keine Bibliothek installieren -- zumal Installationen ja, wie ich
in diesem Thread gelernt habe, unzumutbar aufwändig und kompliziert sind
-- und kann sofort loslegen. Yeah, cool! ;-)
Das Problem ist, daß SQLite von seinen Fanboys gerne als genau das
verkauft wird: als Ersatz für eine richtige Datenbank. Es ist aber keine
richtige Datenbank, wie seine Enwickler höchstselbst ausdrücklich
einräumen -- auch wenn sie bei der Namensgebung ihres Projekts an
richtige SQL-Datenbanken anknüpfen. Wenn man so etwas empfiehlt, dann
sollte man fairerweise auf diesen Umstand hinweisen, insbesondere
Anfänger. Ist es wirklich zu viel verlangt, Anfänger nicht gleich in die
Falle tappen zu lassen?
Egal, ob nun DB, SQL oder CSV.
Prinzipiell ist der Programmierer erstmal selber dafür verantwortlich,
welche Daten sein User über ein Eingabefeld o.ä. eingibt, die dann
in die DB sollen. Da muß schon erstmal geprüft werden, ob es z.b. ein
Integer oder Datum ist, bevor das in die DB kann. Oft muß man den
eingegeben String mal zuerst in eine Zahl umwandeln bzw. Datum über-
prüfen. Wenn nicht, wird halt eine Meldung per Messagebox o.ä.
angezeigt, die den User anweist, daß er nicht das richtige eingegeben
hat. Das macht man schon generell, ob nun DB oder sonstige Verarbeitung.
Es gibt ja z.b. nicht umsonst die Message ~ES_NUMBER für Editfelder,
die schon mal Buchstaben verhindert.
Auch wenn der Aufwand im Detail übertrieben zu sein scheint - der TO hat
doch sicher eine Domain mit Webspace? Die überwiegende Anzahl der
Domainhoster bietet gleichzeitig auch eine oder mehrere MySQL-Instanzen
kostenlos oder für ganz kleines Geld.
Einem geschenken Barsch guckt man schließlich nicht in den ...
Frank E. schrieb:> Einem geschenken Barsch guckt man schließlich nicht in den ...
Lies mal deren AGB. Lies sich nochmal und versuch sie zu verstehen.
Und ich mag nicht gerne Abhängig sein. Und mit so Sachen ist mal
abhängig.
Ist wie Putin-Gas. Er dreht die Leitung zu und du bekommst nix mehr. Der
Provider macht Klick und du bekommst "Zugang verweigert".
Meine Festplatte, mein Backup, MEINE Daten , mein Risiko.