Ich bin gerade dabei, eine utility library in C zu erstellen, in der ich
nützlich Funktionen für andere Projekte zusammenfasse
(https://github.com/Daniel-Abrecht/dpa-utils). Ist aber alles noch
unfertig.
Eine Sache, die ich einbaue, ist eine Art Interning für Buffer Objekte,
wie z.B. Strings. Wenn die Daten kleiner sind, als mein Buffer Objekt,
speichere ich die direkt dort drin. Andernfalls enthält das Buffer
Objekt (momentan) einen Pointer auf einen Eintrag in einem Hash Map. Der
Sinn der Sache ist es, Vergleiche von häufig verwendeten Strings schnell
& trivial zu machen, und die eventuell dann auch in anderen Hash Maps
oder Sets usw. einsetzen zu können.
Dieses Hash Map, das ist der Punkt, an dem ich gerade bin.
Es gibt da einige erschwerende Faktoren. Das HashMap soll Thread Safe
sein. Momentan habe ich dafür einfach ein paar Mutex Locks. Ich nutze
den Hash, um einen Lock zu wählen, um eine Gruppe an Buckets zu locken,
bevor ich sie modifiziere. (mtx_t ist auf meinem System 40 Bytes gross!
Darum spendiere ich nicht jedem Bucket seinen eigenen Lock).
Und die Einträge des Hash Map haben einen Reference Counter. Das
momentane Design sieht vor, dass der Eintrag und dessen Reference
Counter mit einem Pointer referenziert werden können. Das
vereinheitlicht das Referencecounting und das Freigeben der Objekte,
aber bedeutet auch, das der Eintrag nicht verschoben werden kann.
Bei Hash Maps gibt es ja den Open Addressing und den Closed Addressing
Ansatz. Momentan tendiere ich zu letzterem Ansatz, denn wenn die
Einträge separat mit malloc allociiert sind, ist es trivial diese nicht
zu verschieben.
Was mich nun aber wunder nimmt, man hört ja immer, linked lists (und
damit Closed Addressing) seien so schlimm für die CPU Caches, das sei
wahnsinnig ineffizient. Und die locks sind ja auch nicht so toll für
Performance.
Und damit zur eigentlichen Frage. Wie "schlimm" ist dieser Ansatz
tatsächlich? Gibt es da bessere Ansätze?
Ist zwar völlig OT, aber trotzdem:
Wenn du irgendwann mal mit all deinen zugegebenermaßen durchaus
beeindruckenden C-Zauberkunststücken fertig bist, hast du endlich dein
eigenes C++, oder auch Rust. Warum nimmst du nicht das Original?
Oliver
Daniel A. schrieb:> ....
Zu kompliziert, solange du nicht weißt ob du es wirklich brauchst.
>> Do the simplest thing that could possibly work. Not the most>> stupid thing.> Und damit zur eigentlichen Frage. Wie "schlimm" ist dieser Ansatz> tatsächlich?
Kann man nicht sagen. Du musst das für deine Daten, in deiner Umgebung
und für deine Anwendung messen wenn du es optimieren willst. Aber, dass
heißt dann noch nicht dass deine hochgezüchtete Implementierung im
Einsatz robust gegenüber kleinen Veränderungen in deinen Eingangsdaten
ist.
> Gibt es da bessere Ansätze?
Einfache, robuste Standardimplementierungen nehmen. Erst dann
hochzüchten wenn es für deine Anwendung wirklich nötig ist. Das heißt
wenn du gemessen hast, nicht Bauchi-Bauchi-Gefühl dass dich deine
Hashmap zu viel Resourcen kostet.
So würde ich zum Beispiel für das Multithreading am Anfang einen
einzigen Lock nehmen und erst mal brutal die ganze Hashmap locken.
Vielleicht reicht das in der Anwendung. Wenn's nicht reicht fängst du an
zu optimieren. Es gibt auch lock-free Algorithmen für Hashmaps auf die
man mal einen Blick werfen könnte.
Daniel A. schrieb:> Was mich nun aber wunder nimmt, man hört ja immer, linked lists (und> damit Closed Addressing) seien so schlimm für die CPU Caches, das sei> wahnsinnig ineffizient. Und die locks sind ja auch nicht so toll für> Performance.
Generell stimmt das, jedoch hängt das wieder vom System (CPU+Cache+RAM)
ab.
Teste doch einfach mal std::vector<> gegen std::list<>, oder schau Dir
die entsprechenden Tests an.
Mutex-Locking ist tatsächlich langsam: schau die
lockfree-Datenstrukturen an.
Daniel A. schrieb:> Das HashMap soll Thread Safe> sein.
Threadsafe Datenstruktren / Container sind relativ unüblich, weil sie
kompliziert, ineffizient und Deadlock-anfällig sind. Nebenläufigkeit /
Multithreading implementiert man am Besten auf der obersten
Anwendungsebene, die Ebenen darunter (inkl. normalen Datenstrukturen)
wissen nichts davon. Klar gibt es so etwas wie thread-safe queues, die
sind aber genau für diese Anwendungsebene gedacht (und werden bei
Single-Thread-Anwendungen überhaupt nicht genutzt).
Diese ganze Funktionalität "in einem" zu implementieren klingt nach "The
Blob"-Antipattern und ziemlich unflexibel. Die meisten Sprachen (außer
C) bieten die einzelnen Elemente, die du umsetzen willst, als Bausteine
fertig an (Hash-Maps, Strings mit SSO, Speicherverwaltung mit
Referenzzählung) sodass man sie nach Bedarf kombinieren oder einzeln
nutzen kann. Vielleicht wäre das für dich sinnvoller?
Daniel A. schrieb:> Der> Sinn der Sache ist es, Vergleiche von häufig verwendeten Strings schnell> & trivial zu machen
Strings, welche nicht allzu lang sind, zu vergleichen, ist gar nicht
so langsam. Hashes zu berechnen, eine Hash-Map entlangzuhangeln,
Mutexe zu locken hingegen schon - insbesondere eben auch wegen der
Cache-Misses.
Strings als Key in einer Hashmap zu nutzen passiert auch nicht zu oft;
meistens beim Einlesen von ASCII-Formaten, wo Bezeichner einer Bedeutung
zugewiesen werden (z.B. "red" nach 0xFF0000 o.ä.). Das bedeutet aber
auch, dass man diesen String als Hash-Key auch nur an genau dieser einen
Stelle braucht und dann nie wieder. Da macht es dann sehr wenig Sinn
dieses "red" irgendwie zu cachen, weil man intern dann doch nur mit
0xFF0000 rechnet; sollte das nicht der Fall sein, stimmt wahrscheinlich
etwas an der Architektur nicht.
Ja, in dynamischen Sprachen (ruby, Python, JS...) ist praktisch "alles"
eine HashMap und Zugriffe auf Objekt-Attribute sind oft Hash-Zugriffe.
In kompilierten Sprachen aber eben nicht.
Daniel A. schrieb:> Vergleiche von häufig verwendeten Strings
Meistens ist ja eine Seite des Vergleichs fest / bekannt. Die braucht
man also nicht in eine flexible / threadsichere HashMap stecken, sondern
kann den Hash "direkt" nutzen. Oder die HashMap readonly nutzen, dann
entfällt das Locking.
Hannes J. schrieb:> Einfache, robuste Standardimplementierungen nehmen. Erst dann> hochzüchten wenn es für deine Anwendung wirklich nötig ist. Das heißt> wenn du gemessen hast, nicht Bauchi-Bauchi-Gefühl dass dich deine> Hashmap zu viel Resourcen kostet.
Naja, bei C gibt es ja nicht "die" Standardimplementierungen. Und nicht
jede ist für meine Zwecke geeignet.
Eine bekannte, die ich gesehen habe, ist z.B. uthash. Sieht ebenfalls
sehr nach doubly linked list aus. Und so wie es verwendet wird, kann der
Eintrag, der dran hängt, ebenfalls nicht verschoben werden. Soweit
ähnlich wie bei mir.
Aber UT_hash_handle enthält 6 Pointer und 2 integer, auf einem 64bit PC
sind das Mindestend 56 bytes, das ist schon recht viel.
Thread Safe scheint es auch nicht zu sein.
Und der hash ist immer ein unsigned integer, auf meinem PC ist das 4
bytes. Bei einem hash map sollte der load factor ja nicht zu hoch
werden, sind da maximal 2^32 buckets auf einem System, das bis zu 2^48
Addressen hat, nicht etwas wenig?
Andere Implementierungen kenne ich noch nicht. Diese zu evaluieren, ob
sie geeignet sind, was Vor / Nachteile sind, ist auch Aufwand. Und ich
hole mir damit eine weitere Abhängigkeit rein, um die ich mich dann
kümmern muss.
Wilhelm M. schrieb:> Mutex-Locking ist tatsächlich langsam: schau die> lockfree-Datenstrukturen an.
Diese reizen mich schon. Sind aber sehr schwierig & aufwendig richtig
hin zu kriegen. Vielleicht versuche ich das später nochmal.
Niklas G. schrieb:> Diese ganze Funktionalität "in einem" zu implementieren klingt nach "The> Blob"-Antipattern und ziemlich unflexibel. Die meisten Sprachen (außer> C) bieten die einzelnen Elemente, die du umsetzen willst, als Bausteine> fertig an (Hash-Maps, Strings mit SSO, Speicherverwaltung mit> Referenzzählung) sodass man sie nach Bedarf kombinieren oder einzeln> nutzen kann. Vielleicht wäre das für dich sinnvoller?
Was ich hier mache ist genau so eine Library, die solche Bausteine
anbietet, eine Utility library halt, für C17. Und nein, ich bleibe bei
C, das ist nicht verhandelbar.
Herbert B. schrieb:> not invented here-syndron. das muss ich alles selber machen.
Bei C ist das durchaus üblich. So ziemlich jedes grosse Projekt
implementiert seine eigenen Memory Management Primitive und
Datenstrukturen, mit seinen eigenen Versionen von allerhand üblichen
Sachen.
Ich realisierte gerade noch etwas.
Momentan nutze ich size_t für meine hashs. Die Überlegung war, der load
factor der hash map sollte gering sein, man hat also effektiv etwa
gleich viele buckets wie Elemente vielleicht auch halb oder doppelt so
viele, aber nichts dramatischeres. Also sollte mein hash gleich viele
indexe adressieren können wie das System. (ok, mit der logik sollte ich
eigentlich intptr_t nehmen, kommt aber normalerweise mehr oder weniger
auf selbe raus).
Bei meinen Refcountern nutze ich 64bit. Der Grund ist recht simpel,
angenommen, ich würde es darauf anlegen, den überlaufen zu lassen mit
"while(++refcount);", effektiv dauert das länger, als der PC halten
wird. Nehmen wir an ein increment dauert 1us, also 1/1'000'000s, dan
bräuchte es 2**64 1000000 (356*24*60*60) = ~599'730 Jahre bis zum
überlauf. (Wobei, eigentlich nutze ich 4 bits noch für was anderes, also
hab ich "nur" 37'483 Jahre bis zum überlauf).
Jetzt ist auf meinem PC ein size_t auch 64bit gross. Und damit meine
hashs, die ja effektive indeces in ein Array sind auch. Aber aus dem
selben Grund, wie bei den Refcountern, dürfte es ja gar zeitlich nicht
möglich sein, die alle auszunutzen, und ein malloc ist ja nochmal um
einiges langsamer, als einen Pointer zu inkrementieren.
Ich frage mich jetzt also, rein zeitlich betrachtet, was ist eigentlich
die Limite an kleinen Allokationen, die hier überhaupt realistisch sind?
Angenommen eine Allokation dauert 25us, und ich mache nichts anderes 1
Jahr lang, dann hätte ich ja (10*356*24*60*60) * (1000000 / 25) =
~2^43.5 Einträge. Bei 50us ~2^42.5, 100us ~2^41.5. 100us und 1 Jahr
wären ~2^38.
Passt das so ungefär? Wie lange braucht malloc heutzutage normalerweise?
Und zusammen mit Locking & Hashing usw., wie schnell könnte mein hash
map "schlimmstenfalls" überhaupt werden?
Ab 1 Jahr, mit 7.2ms pro Eintag, bräuchte ich höchstens noch 32bit für
meinen Hash. Macht es überhaupt Sinn mehr als 2^32 Einträge zu
erlaubten, oder nutzt das sowieso nie jemand aus?
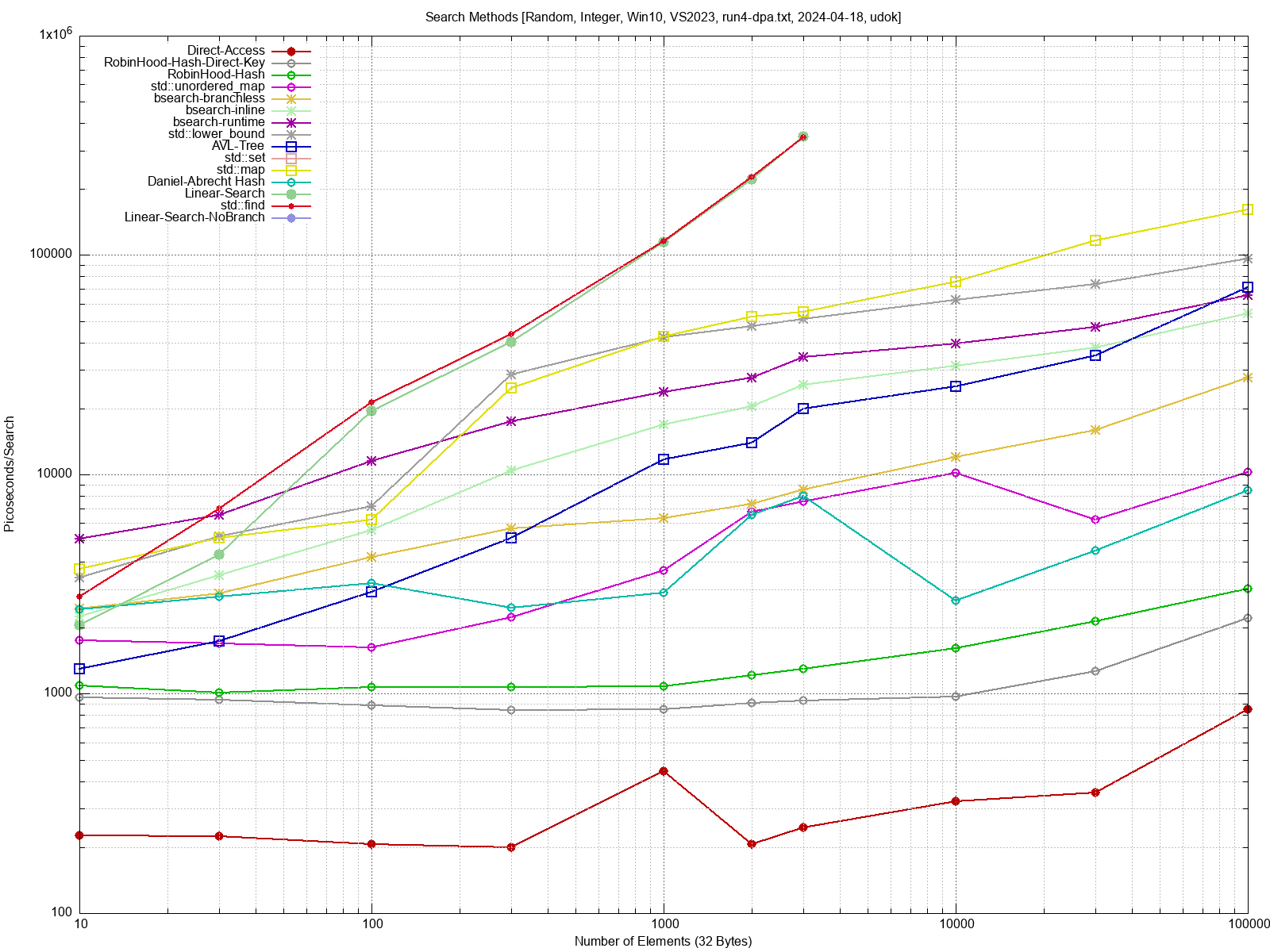
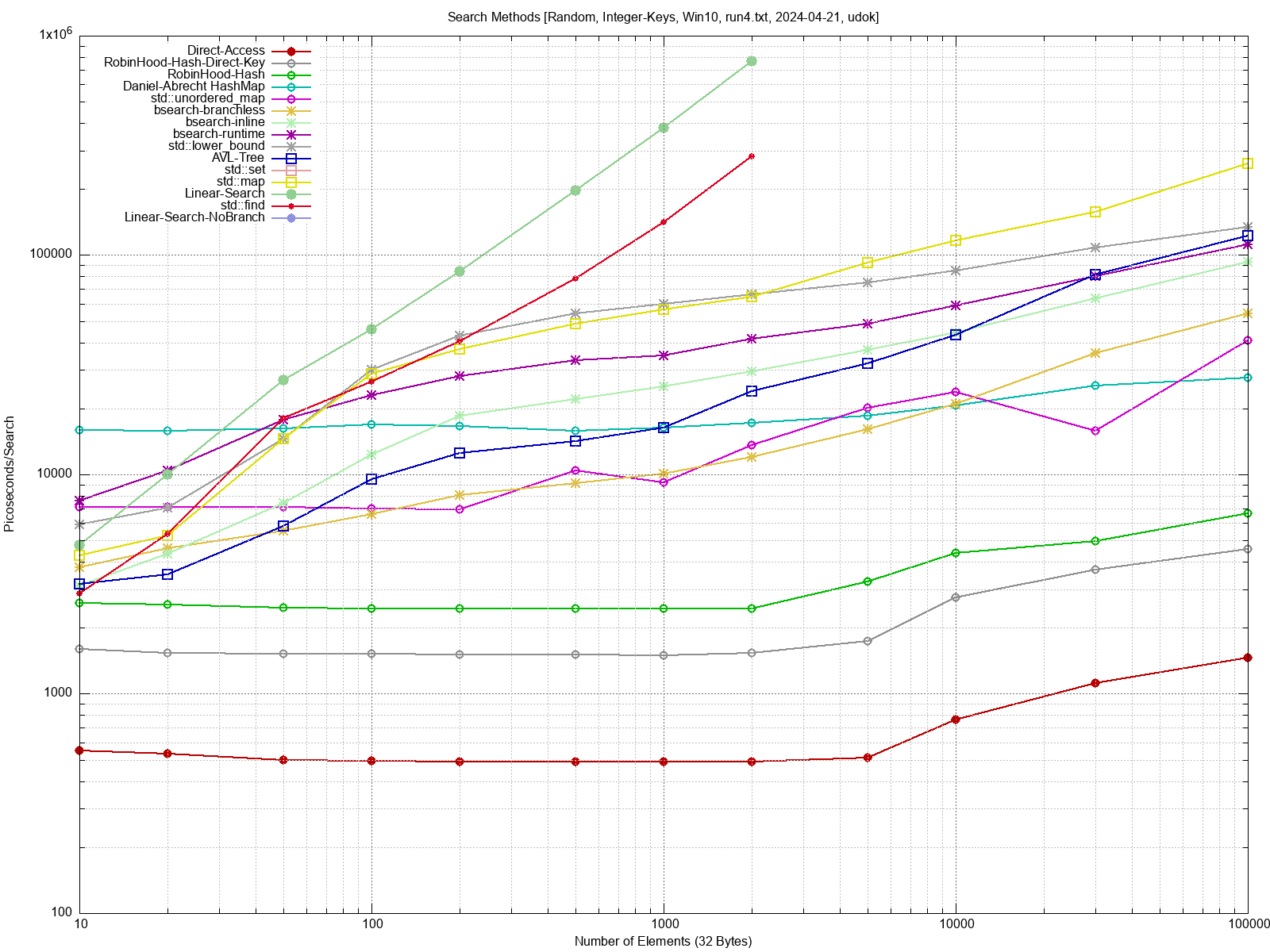
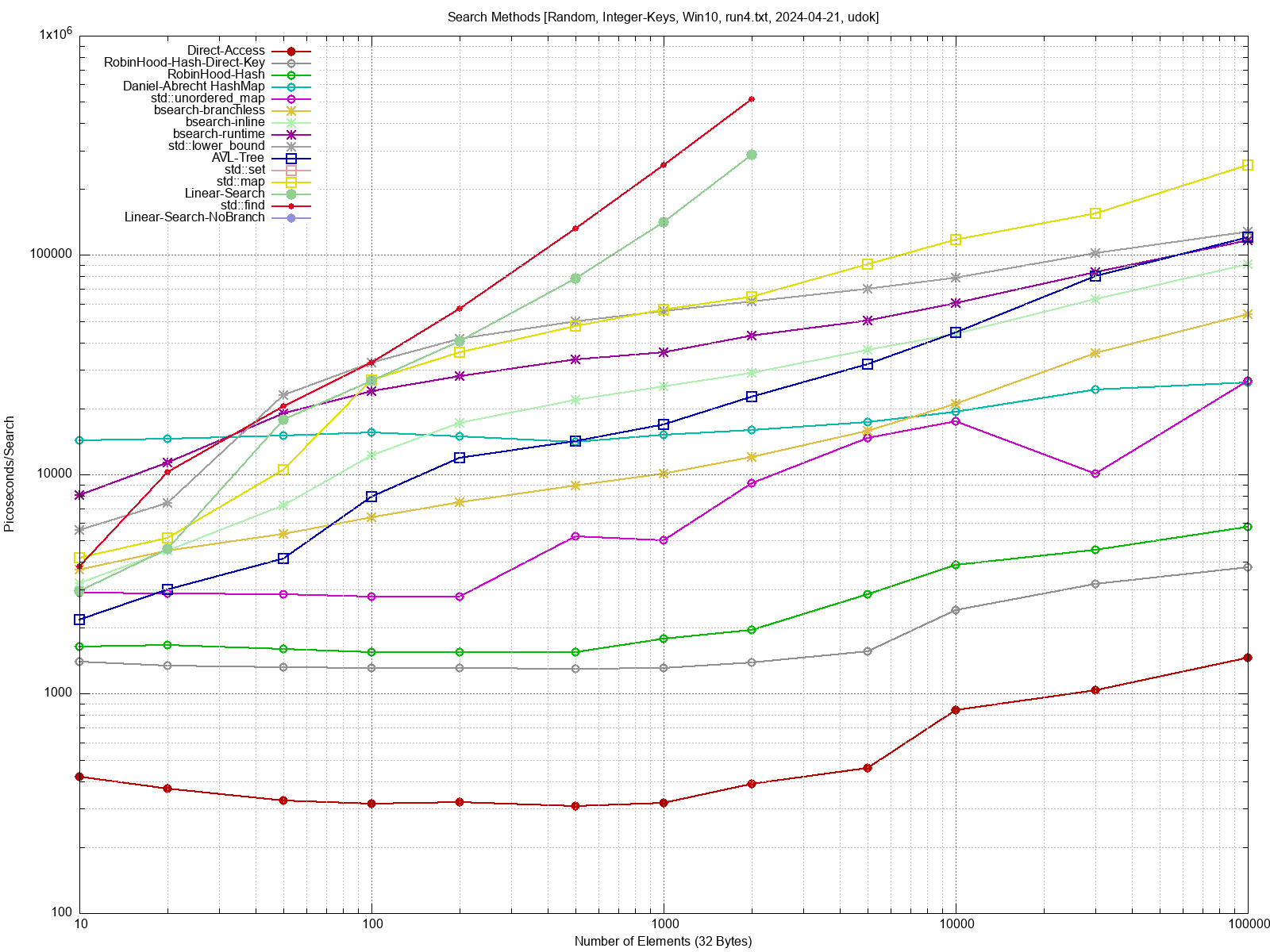
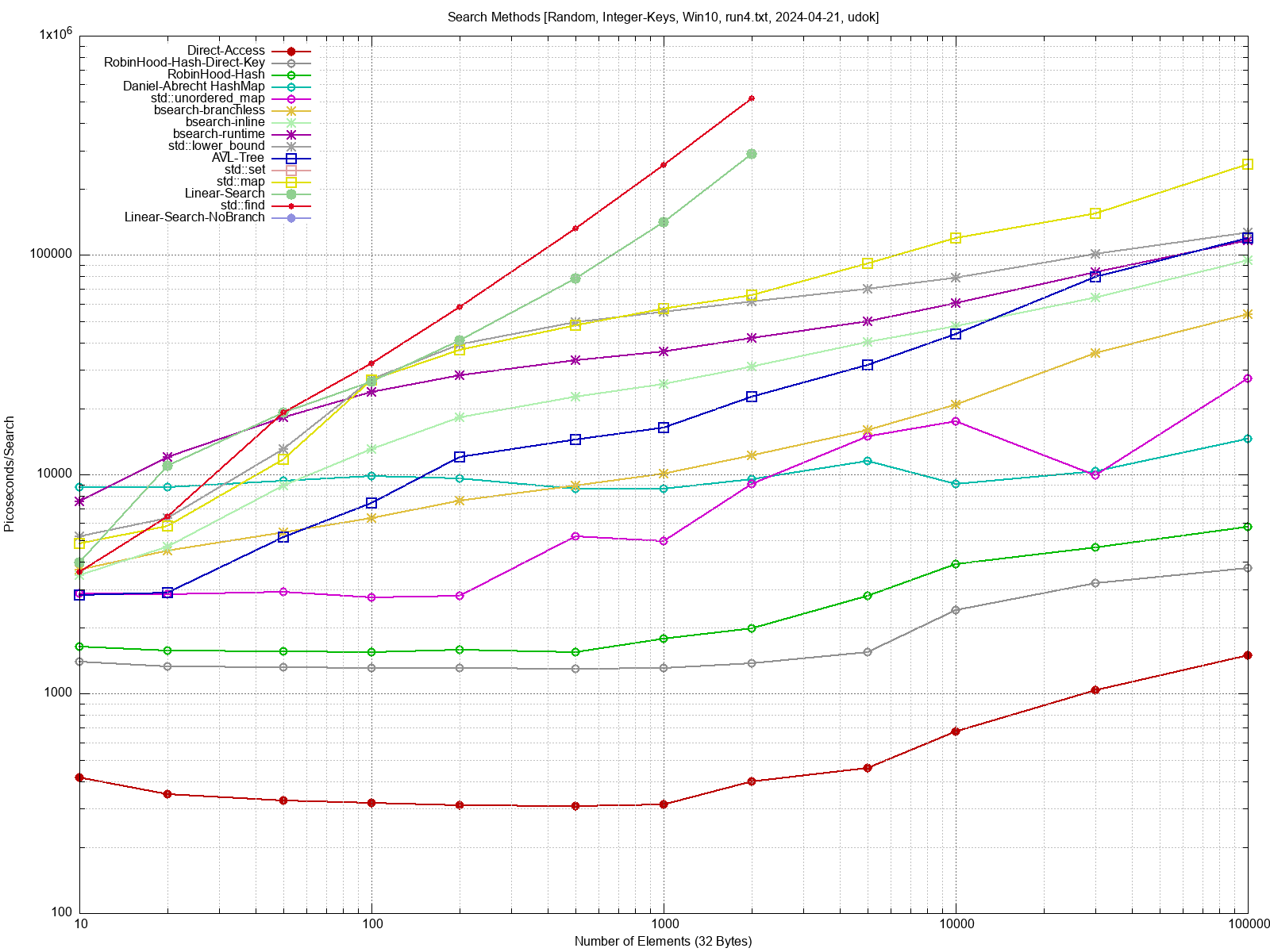
Ich habe mich vor einiger Zeit mit verschiedenen Suchmethoden
beschäftig,
und einige Antworten gefunden. Siehe hier:
Beitrag "Benchmark: C/C++ Effiziente Methoden zum Suchen"
Heutige Prozessoren sind abartig schnell, und im Vergleich dazu ist der
DRAM so langsam, dass die Grösse deiner Datenstrukturen die maximale
Geschwindigkeit deiner Suche bestimmt. Wenn du also alles in den
L1/L2/L3 Cache reinbekommst ist deine Suche um ein Vielfaches schneller.
Wenn du zufällig rumhüpfst, und die Daten gross sind, dann ist die
Geschwindigkeit deiner Suche durch das RAM limitiert, der Cache ist dann
ja praktisch ausgeschaltet. Das gilt natürlich nur, wenn deine Hash
Funktion oder deine Vergleichs-Funktion nicht der Bottleneck sind (wie
es in der Praxis oft der Fall seiin dürfte).
Wenn du eine brauchbare Hash-Map ausprogrammiert hast, dann kann ich
eventuell den Benchmark mit deiner Hash-Map noch mal durchlaufen lassen.
Gruss,
Udo
Daniel A. schrieb:> Und damit zur eigentlichen Frage. Wie "schlimm" ist dieser Ansatz> tatsächlich? Gibt es da bessere Ansätze?
Du möchtest reference counting strings, die um noch einmal Duplikate zu
vermeiden, alle strings im system in einer hash map halten? Und das in
C?
Ja, Du kannst eine hash map haben, die die Strings und ihre counter
enthält. Die string Typen müssten dann nur noch einen Zeiger auf die
Strings selbst enthalten (evtl. als Optimierung den hash). Eine zweite
hash map könnte dann Mutexe enthalten. Könnte auch eine sehr triviale
hash map sein, die eine fixe Größe hätte und bei der sich der bucket
z.B. einfach durch Modulo aus dem string hash ermitteln läßt. Dann
brauchst Du keinen mutex für die string hash map und auch keinen mutex
für die mutex hash map.
Ich würde das erst einmal vom Interface her designen. Wie sieht das aus
der Sicht der Nutzer dieser Strings aus. Dann würde ich das trivialste
implementieren, dass dieses Design erfüllt.
Die ersten C++ string Klassen hatten auch reference counting / copy on
write implementiert. Die Praxis hat aber später gezeigt, dass sich der
Aufwand nicht lohnt. Daher der Ansatz, das Interface zu erst zu
gestalten, dann könnte man diese Implementierung auch später noch
einführen, wenn Messungen zeigen, dass dort Handlungsbedarf besteht.
Und ja, in C++ ist das sicher 10mal einfacher umzusetzen ;-)
Viel Erfolg!
Mittlerweile habe ich meine Hashmap schon fast fertig, ein paar Bugs
muss ich noch beheben. Ich melde mich dann nochmal, sobald sie voll
funktionsfähig ist.
Mein erster Versuch hatte ich erst getestet, als er schon praktisch
fertig war, und da hatte ich noch einen ziemlich groben Fehler drin,
beim Vergrössern der Hashmap
https://github.com/Daniel-Abrecht/dpa-utils/blob/f7c64c1db30488bc8bf175624531e4a3482cacd7/src/bo-unique.c#L110
Ich habe bei Kollisionen eine simple Linked List der Einträge. Diese
Sortiere ich nach dem Hash Wert.
Ich habe ein Array von Pointern auf Arrays von Buckets, die Buckets
beinhalten einen Pointer auf den ersten Eintrag. Die Arrays von Buckets
nenne ich Bucket Listen. Jedes Bucket Liste ist 2^N gross, und die
nächste Bucket Liste ist doppelt doppelt do gross wie die vorherige.
Ausser bei den ersten 2, die sind gleich gross.
Beim Einfügen der Einträge verwendete ich einfach die hintersten N bits
des Hashs. Mittels log2 bekam ich die Bucket Liste heraus, und die
restlichen Bits waren einfach der Index, des Buckets in der Bucket
Liste.
Beim Vergrössern hatte ich einfach die neue Bucket Liste mit calloc
alloziiert, und dann bei allen bestehenden Buckets das n-te Bit bei den
Hashs der Einträge geprüft. Sobald ich den ersten gefunden katte, habe
ich diesen, mit dem Rest der Linked List der Einträge, einfach in die
neue Bucket List in den passenden Bucket umgehängt. Reihenfolge bei
beiden Bucket Lists gleich, die hintersten N bits des Hash.
Eventuell realisiert ihr schon, was ich da falsch gemacht hatte. Das
Problem war, welche Bits des Hashs sind bei der Sortierung wichtiger?
Mit einem simplen > und < Vergleich, natürlich die oberen / linken
Bits.Aber der Index meiner Buckets nutzte die unteren Bits...
Ich habe 2 Möglichkeiten, das zu lösen.
1) Entweder, Ich nehme die Oberen statt die Unteren Bits als Index in
die Buckets und Bucket Listen (die Variante habe ich mittlerweile fast
fertig, statt log2/__builtin_clzll kann ich __builtin_ctzll nehmen (die
0 bits von rechts statt links zählen>). Nachteil ist, dass die
Reihenfolge sich bei den Grössenänderungen zwischen den Bucket Lists
verändert, weil von rechts statt links ein Bit zum Index dazu kommt. Die
Berechnung ist dadurch auch etwas komplexer. Ich glaube das macht noch
recht viel aus.
2) Die andere Möglichkeit ist, beim Sortieren, bei den Hashs, vor dem
vergleich, alle Bits der Hashs umzukehren. Gibt es einen einfachen &
schnellen Weg, so einen verkehrten Vergleich durchzuführen? Bits
umdrehen ist ja nicht unbedingt eine schnelle Aktion...
Ich muss noch schauen, was in der Praxis tatsächlich schneller ist / ob
es überhaupt eine Rolle spielt.
Daniel A. schrieb:> Ich habe bei Kollisionen eine simple Linked List der Einträge. Diese> Sortiere ich nach dem Hash Wert.
Du sortierst die Elemente einer verketteten Liste? Wozu?
Torsten R. schrieb:> Du sortierst die Elemente einer verketteten Liste? Wozu?
Die Liste ist von allen Einträgen im gleichen Bucket. Also von den
Einträgen, die Kollisionen haben. Beim Einfügen eines Eintrag muss ich
sie sowieso vergleichen. Wenn ich es dann gleich sortiert einfüge, muss
ich nicht die ganze Liste vergleichen, das spart Zeit. Und aufgrund
meiner Vergrösserungsstrategie (nennt man wohl normalerweise
"rehashing"), muss ich dabei auch nicht jeden einzelnen Eintrag
betrachten.
Daniel A. schrieb:> Die Liste ist von allen Einträgen im gleichen Bucket. Also von den> Einträgen, die Kollisionen haben.
Es macht Sinn, gefundene Einträge ganz vorne in die Liste einzutragen.
Wenn öfters nach dem selben Wert gesucht wird, dann findest du ihn
schneller.
Manchmal wird auch ein binärer Baum anstatt einer Liste verwendet. Damit
entschärft man das Problem, dass die ganze Hash Map zu einer sau
langsamen Liste entarten kann.
Udo K. schrieb:> Manchmal wird auch ein binärer Baum anstatt einer Liste verwendet. Damit> entschärft man das Problem, dass die ganze Hash Map zu einer sau> langsamen Liste entarten kann.
Baum und verlinkte Liste sind beide mies, was Zugriffszeit ins RAM
angeht. Die ist nämlich sequentiell sehr viel besser als vogelwild. Dann
schon eher B-Baum statt binär.
Daniel A. schrieb:> Torsten R. schrieb:>> Du sortierst die Elemente einer verketteten Liste? Wozu?
Du willst ja eigentlich nur sehr wenige Elemente in der Liste haben. Du
kannst auch nicht binär nach Einträgen suchen, also must Du eh mit O(n)
suchen.
(prx) A. K. schrieb:> Baum und verlinkte Liste sind beide mies, was Zugriffszeit ins RAM> angeht. Die ist nämlich sequentiell sehr viel besser als vogelwild. Dann> schon eher B-Baum statt binär.
Das Problem hat aber praktisch jede Hash Map. Da wird ja auch mehr oder
minder zufällig auf die Elemente zugegriffen. Und wenn du öfters auf
die selben Elemente zugreifst, sind sie hoffentlich im Cache. Darum
auch der Tipp, ein gefundenes Element vorne in der Liste einzutragen.
Wenn das Element dann noch einmal gesucht wird, muss man nicht die ganze
Liste in den Cache holen. Andererseits soll eine Hashmap ja gar nicht
so voll werden soll, das das eine Rolle spielt.
Im Benchmark Link weiter oben von mir sieht man den Effekt recht schön.
Bei heutigen Cache Grössen ist das aber nur für richtig aufwendige
Simulationen und Serveranwendungen wichtig. Wer hat schon eine Hashmap
mit > 100000 Elementen?
Udo K. schrieb:> Das Problem hat aber praktisch jede Hash Map. Da wird ja auch mehr oder> minder zufällig auf die Elemente zugegriffen.
Der erste Zugriff geht nicht anders. Wenn dann schon Ende ist, man
seinen Eintrag gefunden hat, ist alles OK. Sitzt dort aber der Anfang
einer Liste, dann kann sinnvoll sein, darüber nachzudenken, wie man ab
dieser Stelle mindestens auf kurz sequentiell weiter macht, statt gleich
Pointer hinter Pointer zu setzen.
Allerdings habe ich das Gefühl, dass hier das Rad neu erfunden werden
soll. Darüber sollten eigentlich längst Horden von Informatikern
nachgedacht und es experimentell untersucht haben. Aber bitte nicht
Knuth - der schrieb in einer Zeit uniformen RAMs, während heute eher
gilt, dass der L1-Cache das ist was damals RAM war, und das heutige DRAM
mehr seinen Bändern ähnelt.
> Andererseits soll eine Hashmap ja gar nicht> so voll werden soll, das das eine Rolle spielt.
Yep. Ich hatte mich auch nur zur Idee von Bäumen geäussert. Nicht zu
einer Hash-Tabelle mit wenig Konflikten.
Mittlerweile funktioniert meine hash map. Ein Beispiel, wie sie
verwendet wird, ist hier:
https://github.com/Daniel-Abrecht/dpa-utils/blob/master/src/main/intern-example.c
Und hier:
https://github.com/Daniel-Abrecht/dpa-utils/blob/master/src/main/bo-example.c
Die Funktion dpa_u_bo_intern speichert die Einträge in der Hash Map.
Naja, eigentlich speichert die Funktion dpa__u_bo_do_intern einen
Eintrag im Hash Map, dpa_u_bo_intern tut das nur, wenn das Wort grösser
als das Buffer Object ist, bei 64bit Systemen normalerweise ab >15 Bytes
Länge.
Von den 234937 Wörtern in /usr/share/dict/words, die ich im Beispiel
oben verende, sind das gerade mal 6803.
An der Library habe ich noch einiges zu tun, bis sie fertig ist. Aber
den Hash Map teil könnt ihr schon mal ausprobieren, wenn ihr wollt.
Der Hash ist momentan noch ein lahmer FNV-1a Hash. Und die Schwellwerte,
wann die Grösse des Hashmap verdoppelt / halbiert wird, ist vermutlich
noch zu hoch
(https://github.com/Daniel-Abrecht/dpa-utils/blob/master/src/bo-unique.c#L16-L17).
Aber das kann ich später noch optimieren.
Im Branch "hm-test" habe ich noch versucht die unteren statt die oberen
Bits vom Hash zu nehmen, um zu sehen, ob das schneller ist. In dem
Branch ist noch irgendwo ein Bug, aber es scheint sowieso nicht
nennenswert schneller zu sein. Vielleicht schau ich mir das später
nochmal an.
Daniel A. schrieb:> Bei C ist das durchaus üblich. So ziemlich jedes grosse Projekt> implementiert seine eigenen Memory Management Primitive und> Datenstrukturen, mit seinen eigenen Versionen von allerhand üblichen> Sachen.
Es gibt heute noch große Projekte die C verwenden, irgendwann gemerkt
haben, dass ihr Problem nicht zur Programmiersprache passt und dann
lieber das Rad neu erfinden, anstatt die getroffene Entscheidung zur
Programmiersprache zu korrigieren?
Erstaunlich.
Ich habe mal versucht, den Code mit MS cl zu übersetzen. Das hat leider
nicht funktioniert... clang-cl liefert auch seitenweise
Fehlermeldungen...
Kompatibilität ist eigentlich das wichtigste Argument für "C". Die
Präprozessor Orgien und gcc Spezialitäten sind doch für eine einfache
Hash Tabelle nicht nötig? Und wenn ich schon am Jammern bin: Ein paar
Leerzeichen, Zeilenumbrüche und lesbare Funktionsnahmen würden sicher
nicht schaden.
Gruss,
Udo
Nun hab ich den Fehler im Branch "hm-test" gefunden, war nur ein
off-by-one Fehler.
Ich hab dann das "intern-example" von oben mit beiden Varianten nochmal
laufen lassen, mit etwas mehr Einträgen als sonst (4096000 davon, mit
"pwgen -1 16 4096000" generiert). Die Variante im "hm-test" Branch war
doch etwas schneller. Normalerweise um die 2.4s statt 2.8s. Ich hab das
jetzt in den master branch gemerged, und die alte Version in den
"hm-test2" branch getan. Diff ist relativ klein:
https://github.com/Daniel-Abrecht/dpa-utils/commit/22b08b576a3e09e82aa6982acde6649917fc3be1Udo K. schrieb:> Kompatibilität ist eigentlich das wichtigste Argument für "C". Die> Präprozessor Orgien und gcc Spezialitäten sind doch für eine einfache> Hash Tabelle nicht nötig?
Es verwendet ein paar Attribute:
* __attribute__((always_inline)) - Weil es teil simple Funktionen die
nur ein Feld zurückgaben nicht geinlined hat. Ok, das könnte ich noch
weg lassen.
* __attribute__((packed)) - Ohne das ist das Layout meiner Buffer
Objekte nicht umsetzbar. Da gibt es keinen weg darum rum.
* __attribute__((visibility("default"))) - Weile es eine library ist,
und nur die Symbole exportiert werden sollen.
* __attribute__((weak)) - Brauch ich für optionale setup / teardown
Funktion für ein simples test utility.
Davon abgesehen ist es alles komplett Standard konformes c17. Lässt sich
also mit jedem vernünftigen, c17 konformen, Compiler kompilieren. Ich
hab es mit gcc und mit clang getestet. Ich kompilere das Ding bei mir
mit "--std=c17 -Wall -Wextra -pedantic -Werror
-Wno-missing-field-initializers -Wno-missing-braces".
Zu diesem "cl" habe ich nur das hier gefunden:
https://clang.llvm.org/docs/MSVCCompatibility.html
Falls "cl" den MS Compiler meint, MSVC implementiert C nicht
vollständig, das kann man vergessen. Und falls du versuchst, die Header
mit C++ zu kompilieren, das kann man auch vergessen. Das ist eine C
Library, keine C++ Library, und das soll es auch nicht werden.
Die Macros und Generics sind teil eines Konzepts, mit der man
verschiedene Arten von Buffer Objekten an Funktionen übergeben kann, und
mit der Selben API auf alle zugreifen kann. Dafür muss ich an die
grenzen dessen gehen, was in C möglich ist.
Auf Windows wird es auch nicht laufen. Ich glaube, dort implementiert
kein Compiler die C17 Thread Library. Ausserdem brauche ich die
getrandom() Funktion meiner libc (die wederum /dev/urandom ausliest), um
die Hash Funktion richtig zufällig zu initialisieren (um gegen
vorausberechnete hash collisions zu schützen). Windows Support ist für
mich aber auch keine Priorität, weil proprietär.
Wichtig ist für mich hauptsächlich Linux. Und vermutlich geht die
Library auch auf anderen unixoiden Systemen. Mehr interessiert mich
ehrlich gesagt eh nicht.
Ich habe jetzt noch eingebaut, dass wenn man es mit -DDPA_U_NO_THREADS
baut, alles was mit Multithreading zu tun hat ausgeschaltet wird. Das
ist nützlich für Plattformen & Programme, die das sowieso nicht
unterstützen.
Ohne das locking usw. braucht es für die 4096000 Einträge nur 2.0s statt
2.4s.
Ich hatte einen Fehler in dem Macro mit dem ich das
__attribute__((always_inline)) gesetzt habe. Statt es nur bei gcc und
clang zu setzen, hatte ich es versehentlich nur gesetzt, wenn es nicht
gcc oder clang ist.
Mit dem korrigiert braucht das "intern-example" Program bei meinem PC
für 4096000 Einträge nur noch 2.1s statt 2.4s. Und mit
-DDPA_U_NO_THREADS gesetzt sind es 1.7s statt 2.0s.
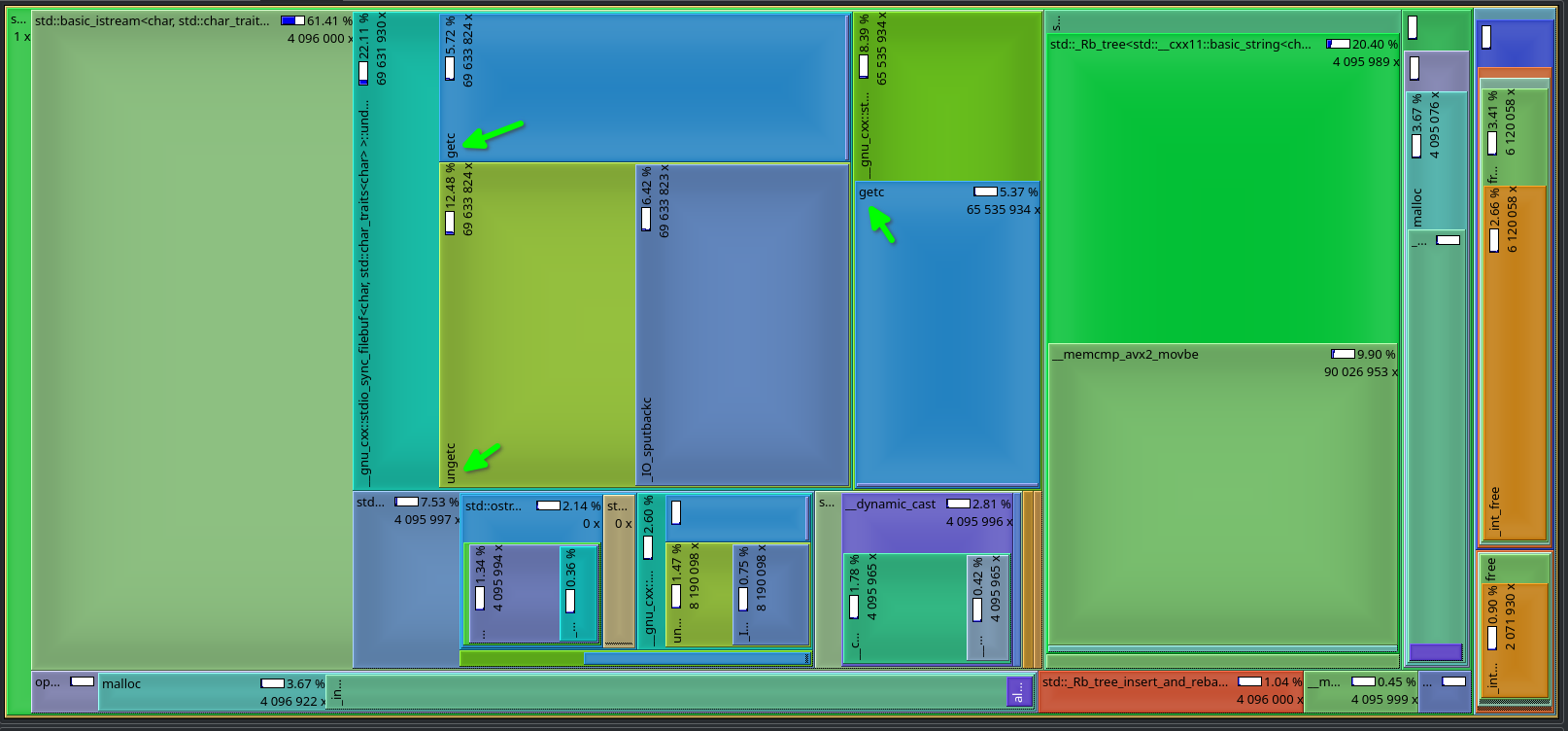
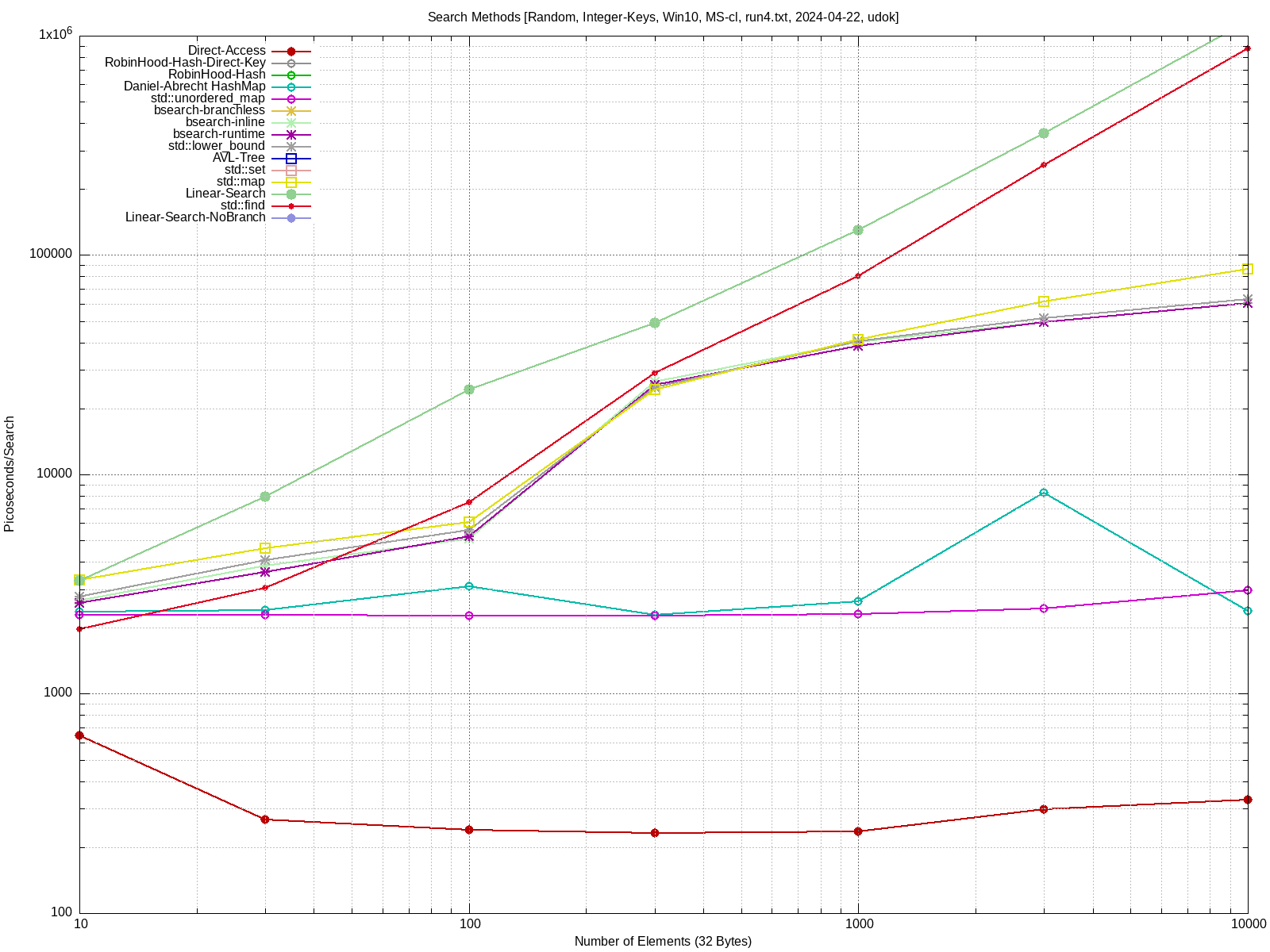
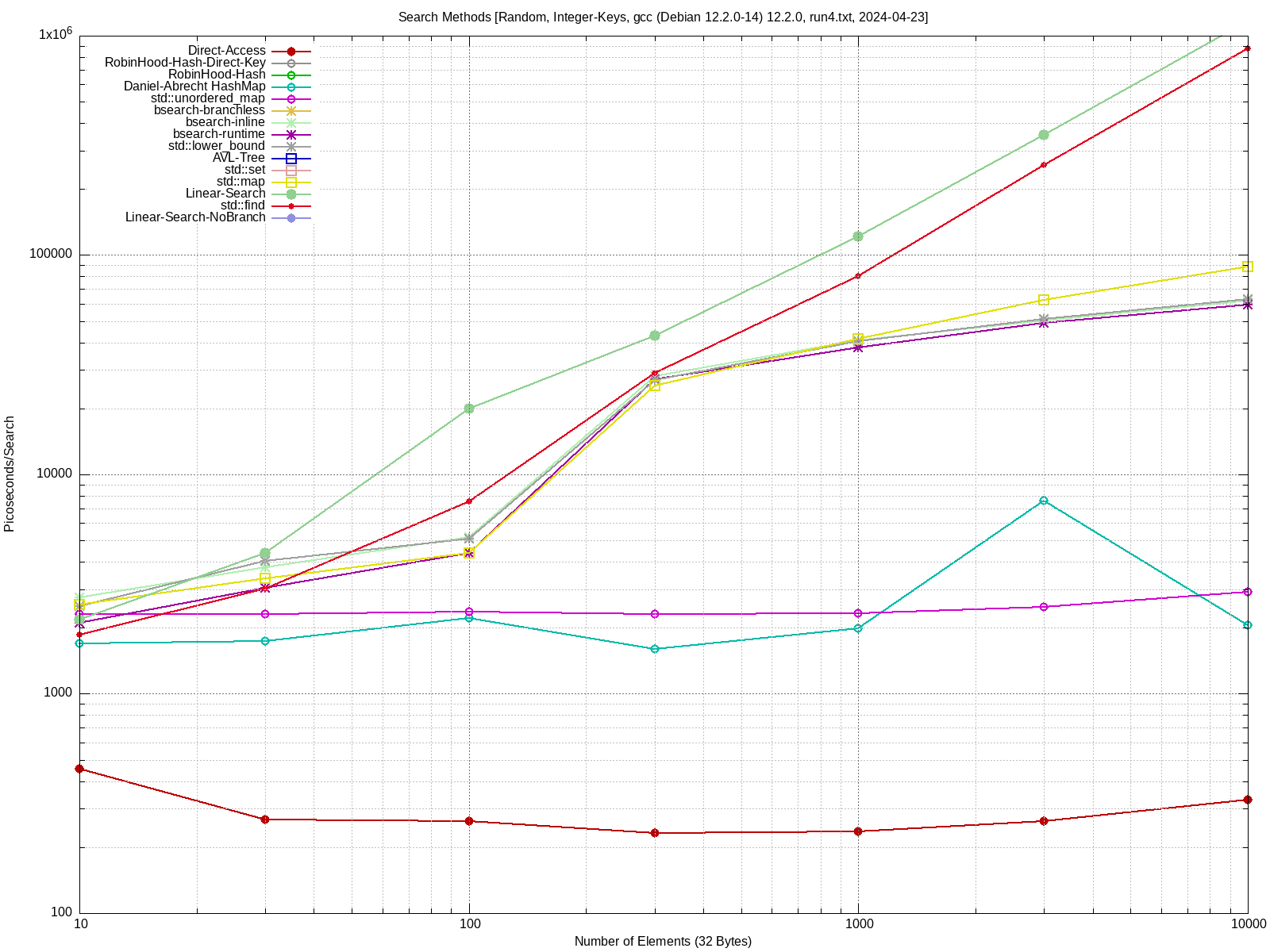
kommt bei mir mit dem 67MB "pwgen"-Testfile auf 6,77 Sekunden, davon
entfallen laut Profiler 21,7% (≈1.5 Sekunden) auf die set, der Rest wird
im std::istream vertrödelt.
Εrnst B. schrieb:> Rein interessehalber: kannst du das mal auf deiner Hardware gegen eine> C++/STL-Version testen?
Ergebnisse sind im Anhang. Getestet unter Devuan Linux (vergleichbar mit
Debian).
Bei mir kommen mit gcc auch etwa 6s heraus. Mit clang sogar etwa 7s
(dort musste ich noch ein paar () einfügen, damit clang den Code
akzeptiert hat).
In test2.cc habe ich noch eine Version die näher an dem ist, was das
"intern-example" Programm macht. Das kopiert den string jeweils 1mal
unnötig, ist aber trotzdem schneller (5.4s)!
Ich vermute, dass da noch irgendwo etwas kopiert wird, und
std::istream_iterator<std::string>(std::cin) noch irgendwo sonstige
ineffizienzen hat.
Hat mich ehrlich gesagt überrascht, ich hätte nicht erwartet, dass mein
Programm schneller ist. War auch nie meine Absicht. Aber das muss auch
nicht unbedingt viel heissen.
Könnte zwar alles mögliche sein. Vielleicht sind einfach die
Eingangsdaten zufällig für mein Set besser geeignet. Oder vielleicht ist
das Vergrössern / Rehashing, in der STL ineffizienter (falls es das
macht). Mein Set fängt auch mit 512 Buckets an, da es nur 1 globales
gibt, vielleicht ist die STL dafür bei kleineren Sets effizienter?
Und der Test ist ja auch nicht unbedingt besonders realistisch,
normalerweise fügt man ja nicht nur Strings ein, die es noch nicht im
set gibt.
Daniel A. schrieb:> Ich vermute, dass da noch irgendwo etwas kopiert wird, und> std::istream_iterator<std::string>(std::cin) noch irgendwo sonstige> ineffizienzen hat.
ja, das scheint die Eingabe recht unglücklich zu verarbeiten, laut
valgrind/callgrind byteweise mit sehr vielen getc / ungetc aus der libc.
Daniel A. schrieb:> Könnte zwar alles mögliche sein.
die std::set benutzt kein hashing, sondern einen Binärbaum. Insofern ist
das eh ein Äpfel/Birnen-Vergleich, auch wenn man am Ende die
Datenstruktur für ähnliches verwenden kann.
die meiste Zeit verbringt die Set mit (AVX2-Optimierten)
String-Vergleichen, etwas malloc/free usw. das Tree-Rebalance fällt mit
1% nicht weiter ins Gewicht, was aber an der Zufalls-Verteilung der
Eingabedaten liegen kann.
Interessanterweise ist das Set-Test-Programm jedoch mit einem sortierten
Eingabefile schneller als mit dem unsortierten. Hätte das eher
andersherum erwartet.
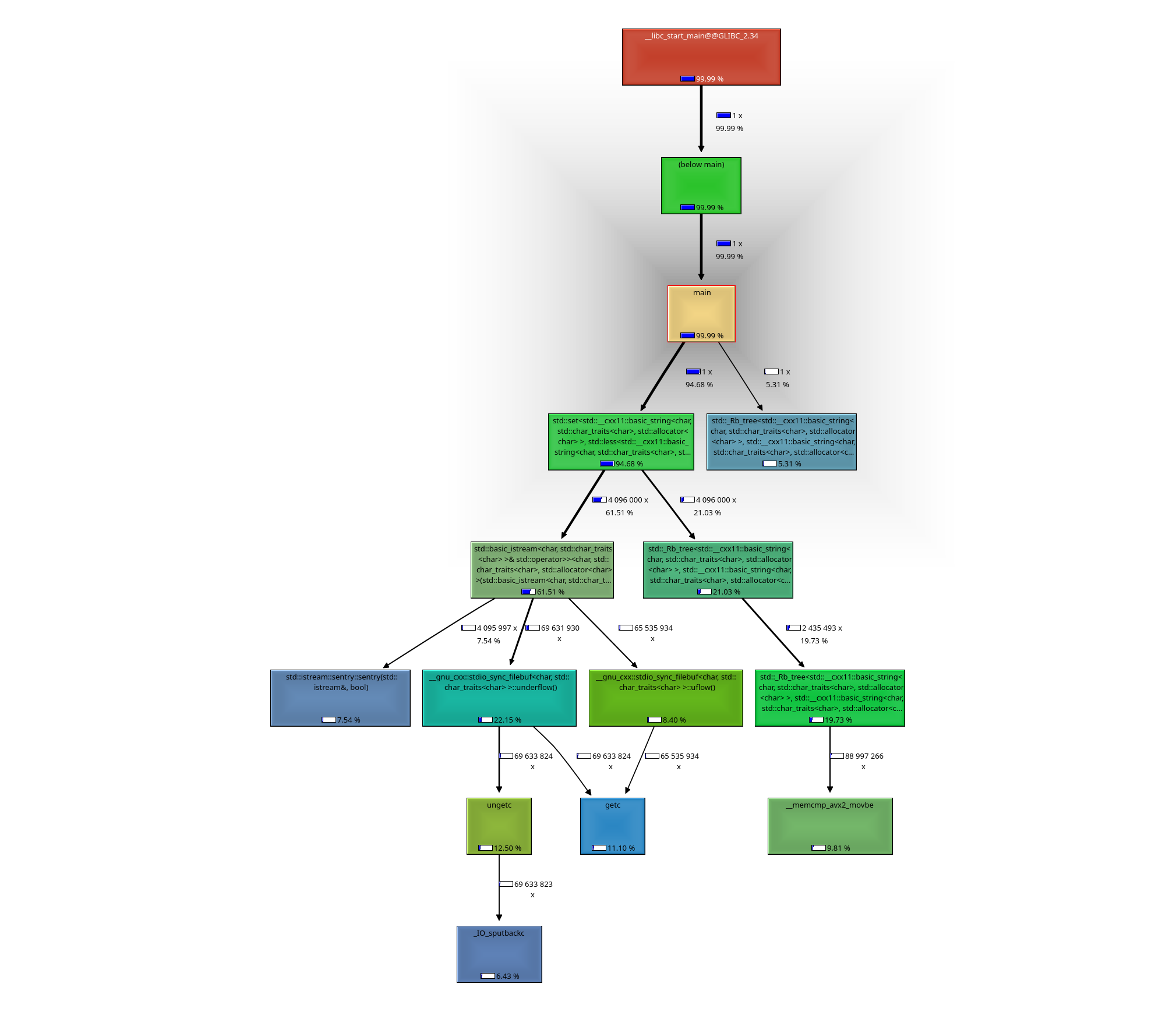
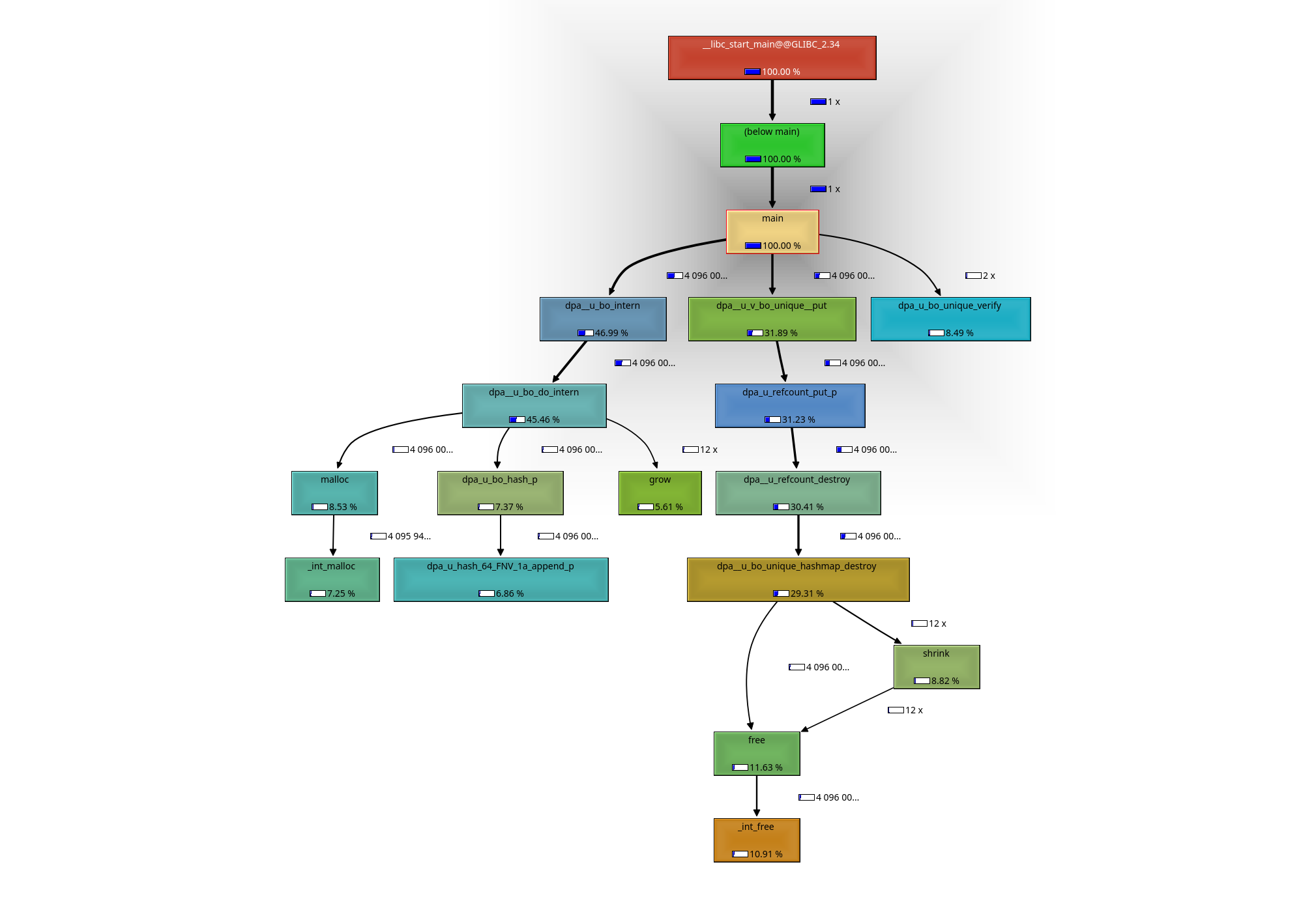
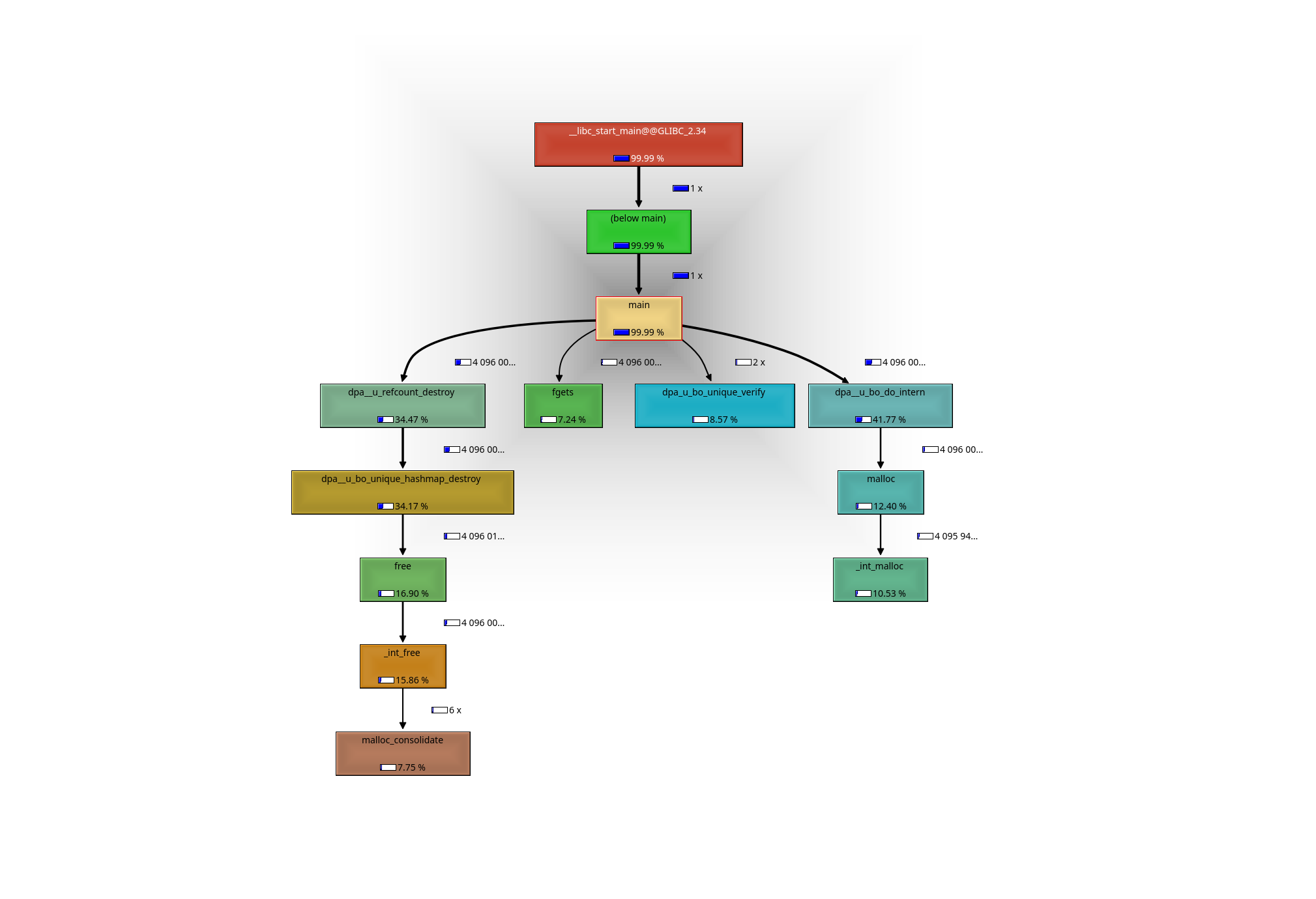
Ich habe jetzt auch mal noch so einen call graph erstellt. Das ist doch
recht nützlich, um zu sehen, wo es am längsten braucht.
Wenn ich im "intern-example" Programm den Teil nach dem einfügen der
Einträge auskommentiere (also das Validieren des Set und das wieder
Entfernen aus dem Set jedes einzelnen Eintrags), kommt mein Programm
auch auf 1.2s.
Jetzt kompiliert es sogar auch mit avr-gcc!
(Bei älteren Versionen muss man im makefile -std=c17 statt -std=c11
setzen, und dass -Werror raus nehmen, aber dann geht es mit
`CFLAGS="-DDPA_U_CONFIG='\"$PWD/example-config/avr-gcc.h\"'" make
CC=avr-gcc notest=1 clean all`).
Ist zwar nicht wirklich sinnvoll auf Chips mit so wenig ram. War aber
gut um noch ein paar Platformabhängige Annahmen zu finden und
auszumerzen.
Daniel A. schrieb:> Jetzt kompiliert es sogar auch mit avr-gcc!
Der Code ist nicht Standard-C konform. Siehe etwa hier:
https://stackoverflow.com/questions/60772586/sizeof-of-packed-structure-with-bit-fields.
Hier ein Beispiel, wie man es konform machen kann (wobei es meiner
Meinung nach gescheiter ist ganz auf Bitfields zu verzichten):
https://stackoverflow.com/questions/71227275/merge-bit-fields-across-anonymous-structs-in-c
Ich habe schon einiges an Code gesehen, aber deine Makro und Typedef
Orgien in Kombination mit unlesbaren Funktionsnahmen und ohne Kommentare
schlagen so ziemlich alles auf der Negativskala... inklusive der C++ STL
Lib - ok die STL liegt noch knapp vorne.
Aus deinem Source Code werde ich also nicht schlau, das kann aber auch
an mir liegen.
Abgesehen davon bin ich gerne bereit anzunehmen, dass der Code genial
ist...
Aber wie bitte verwende ich die Hash Map in der Praxis?
Annahme:
Ich habe ein Feld mit User-Strukturen MyData.
Die will ich in die Hash-Map einfügen, mehrmals suchen, und später
wieder rauslöschen.
Der Key soll etwa ein Integer sein. Kannst du da ein funktionierendes
Beipiel posten?
Hier meine Vorstellung:
1
#define N 1000
2
3
staticstructMyData
4
{
5
charm_data[32];// Private Daten - gehen keinen was an.
6
intm_key;// Der Key zum Einfügen und Suchen in die Hash-Map.
Udo K. schrieb:> Daniel A. schrieb:>> Jetzt kompiliert es sogar auch mit avr-gcc!>> Der Code ist nicht Standard-C konform. Siehe etwa hier:> https://stackoverflow.com/questions/60772586/sizeof-of-packed-structure-with-bit-fields.
Wie ich bereits sagte:
Daniel A. schrieb:> Es verwendet ein paar Attribute:> * __attribute__((always_inline)) - Weil es teil simple Funktionen die> nur ein Feld zurückgaben nicht geinlined hat. Ok, das könnte ich noch> weg lassen.> * __attribute__((packed)) - Ohne das ist das Layout meiner Buffer> Objekte nicht umsetzbar. Da gibt es keinen weg darum rum.> * __attribute__((visibility("default"))) - Weile es eine library ist,> und nur die Symbole exportiert werden sollen.> * __attribute__((weak)) - Brauch ich für optionale setup / teardown> Funktion für ein simples test utility.>> Davon abgesehen ist es alles komplett Standard konformes c17.
Dass das alles vom Layout und Grösse her passt stelle ich mit einigen
static_assert() sicher.
Udo K. schrieb:> Hier ein Beispiel, wie man es konform machen kann (wobei es meiner> Meinung nach gescheiter ist ganz auf Bitfields zu verzichten):> https://stackoverflow.com/questions/71227275/merge-bit-fields-across-anonymous-structs-in-c
Das ist ein guter Weg, sich selbst in den Fuss zu schiessen. Sobald man
da auf e zugreift, sind die Einträge die von reserved geschützt hätten
werden sollen eventuell trotzdem futsch. (Zudem ist die Reihenfolge der
Bitfelder ja implementation defined).
Zugegeben, das __attribute__((packed)) in meinen buffer typen ist etwas
unschön. Aber eine bessere Lösung hab ich momentan einfach nicht. Die 3
Haupt buffer struct typen sind absichtlich so gestaltet, dass es so
gross wie ein size_t + ein pointer ist (und die sind meistens gleich
gross). Das macht es recht Effizient, viele davon zu haben, oder sie an
Funktionen als Argument zu übergeben. Im Grunde sind es eine Art fat
pointer mit ein par Bits für die typ info. Darum mache ich meinen size_t
typ in den meisten buffern 1 byte kleiner. Nur beim dpa_u_inline_bo_t
Typ packe ich die Grösse ins erste Byte, weil es da halt noch Platz hat,
und ich dann ein byte mehr darin speichern kann. Und die Bitfelder sind
da, damit man das alles schön mit designated initializern initialisieren
kann.
Vielleicht versuche ich das später nochmal zu überarbeiten, aber im
moment bekomme ich das nicht besser hin.
Udo K. schrieb:> Aus deinem Source Code werde ich also nicht schlau, das kann aber auch> an mir liegen.> Abgesehen davon bin ich gerne bereit anzunehmen, dass der Code genial> ist...> Aber wie bitte verwende ich die Hash Map in der Praxis?
Das HashMap ist eigentlich nur ein Implementationsdetail des
dpa_u_bo_unique_hashmap_t und des dpa_u_bo_unique_t typs, den man von
dpa_u_bo_intern(bo) bekommt. Es ist nicht als general purpose HashMap
gedacht.
Es geht da nur darum, dass das vergleichen von 2 dpa_u_bo_unique_t
typen, und das Abfragen des Hash, in O(1) möglich ist.
(Das erstmalige Hashen beim Einfügen von längeren Strings in die
HashMap, damit man den eindeutigen dpa_u_bo_unique_t bekommt, ist
natürlich trotzdem O(n), aber die ganzen buffer typen sind speziell
dafür da, unnötiges Kopieren, Hashen, oder suchen im HashMap, wann immer
möglich zu vermeiden).
Daniel A. schrieb:> Udo K. schrieb:>> Daniel A. schrieb:> Zugegeben, das __attribute__((packed)) in meinen buffer typen ist etwas> unschön. Aber eine bessere Lösung hab ich momentan einfach nicht.
Das ist nich nur unschön, sondern nicht definiertes Verhalten. Es ist
nicht garantiert,
das Bitfelder, die grösser als der zugrundeliegende Integer Typ sind,
zusammengefasst werden.
Dein Code setzt sogar voraus, das die Bitfelder in angrenzenden structs
zusammengefasst werden.
Dazu trickst du wild mit packed herum, und hoffst, dass der Compiler das
schon richten wird.
Der gcc unter Cygwin z.B. macht es z.B. nicht, auch nicht der Windows
clang oder Microsoft cl
(der nebenbei bemerkt C17 und C++20 konform ist). Der Code wird
wahrscheinlich nicht mal auf älteren
Prozessoren laufen, die davon ausgehen, dass ein size_t 4 oder 8 Byte
aligned im Speicher liegt.
Schaue dir doch mal an wie es die Hash-Maps in den letzen 20 Jahren
gelöst haben.
Abgesehen davon kosten die Bitfelder Laufzeit und bringen nur eine
marginale Ersparnis an Speicher,
der oft vom grösseren Code aufgefressen wird. Ältere Compiler
optimieren Bitfelder relativ schlecht.
> Das HashMap ist eigentlich nur ein Implementationsdetail des> dpa_u_bo_unique_hashmap_t und des dpa_u_bo_unique_t typs, den man von> dpa_u_bo_intern(bo) bekommt. Es ist nicht als general purpose HashMap> gedacht.
Wozu ist das Ding dann da? Irgendwie steige ich da langsam aus...
Kann ich damit mein einfaches Problem von weiter oben mit dem struct
MyData lösen,
und deine Lib als Ersatz für std::unordered_map verwenden oder geht das
nicht?
Gruss,
Udo
Udo K. schrieb:> Dazu trickst du wild mit packed herum, und hoffst, dass der Compiler das> schon richten wird.
Ich hoffe nicht nur, ich prüfe es mit static_assert nach.
Udo K. schrieb:> Prozessoren laufen, die davon ausgehen, dass ein size_t 4 oder 8 Byte> aligned im Speicher liegt.
Nur einige der inneren Structs sind packed, und es gibt keine Referenzen
zu den packed Feldern. Und es sind auch nicht alle Felder in einem
packed struct.
Deshalb ist das kein Problem, und wegen dem Alignment des Haupt struct
kann der Compiler trotzdem annahmen zum alignment machen, selbst bei den
enthaltenen packed structs.
> Schaue dir doch mal an wie es die Hash-Maps in den letzen 20 Jahren> gelöst haben.
Wie schon mehrfach gesagt, das HashMap ist ein Implementations Detail,
um diese buffer typen zu implementieren, und nicht umgekehrt. Dem
HashMap code selbst ist das layout der Structs sogar egal.
> Abgesehen davon kosten die Bitfelder Laufzeit und bringen nur eine> marginale Ersparnis an Speicher,
In der Praxis macht das hier nicht viel aus. Ausserdem kann der Compiler
das oft ganz wegoptimieren, da das struct oft per value übergeben wird,
dessen Wert oft schon zur Compile zeit bekannt ist, und er bei einigen
typen überhaupt nicht abgefragt wird. Wobei, gcc kommt damit nicht so
gut klar wie clang, und macht beim dpa_u_inline_bo_t ein paar sinnlose
moves: https://godbolt.org/z/bqcaejEzf
Aber in der Praxis macht es nicht viel aus, da haben adere Faktoren
grösseren Einfluss. (Ironischerweise sehen die movs von GCC sehr nach
einem missglückten Versuch der Optimierung mit AVX aus. Auf dem Stack
alignt der gcc unter amd64 die Structs normalerweise auf 16bytes, und
die passen mit 16bytes auch ins 128bit grosse xmm0 register). Wobei, der
Code von GCC ist trotzdem nur 2 Instruktionen länger, wenn man sich den
Inhalt von main() ansieht.
> der oft vom grösseren Code aufgefressen wird. Ältere Compiler> optimieren Bitfelder relativ schlecht.
Compiler, die derart alt sind, unterstützen meist auch kein C11 und
_Generic, und Kompilieren es sowieso erst gar nicht.
Udo K. schrieb:> Der Code wird> wahrscheinlich nicht mal auf älteren> Prozessoren laufen, die davon ausgehen, dass ein size_t 4 oder 8 Byte> aligned im Speicher liegt.
Wenn die Compiler Möglichkeiten haben, Strukturen ohne padding zu
erzeugen, dann erzeugen die für solche Strukturen auch Code, der nicht
vom natürlichen Alignment ausgeht. Das ist dann entsprechend größerer
und langsamerer Code.
Udo K. schrieb:> Schaue dir doch mal an wie es die Hash-Maps in den letzen 20 Jahren> gelöst haben.
Würde ich an seiner Stelle nicht machen. Es ist frustrierend, wenn man
glaubt, ein neues Rad erfunden zu haben und dann feststellt, dass andere
schneller waren.
Ich habe mir andere Implementierungen doch schon längst angesehen, und
bin mit den Ergebnissen bisher mehr als zufrieden. Es tut was es soll,
es ist doch recht schnell, und auch mit dem Platzverbrauch bin ich ganz
zufrieden.
Wollt ihr einfach nicht wahr haben, das man auch heute noch gute
Programme schreiben kann?
Daniel A. schrieb:> Ich habe mir andere Implementierungen doch schon längst angesehen, und> bin mit den Ergebnissen bisher mehr als zufrieden. Es tut was es soll,> es ist doch recht schnell, und auch mit dem Platzverbrauch bin ich ganz> zufrieden.> Wollt ihr einfach nicht wahr haben, das man auch heute noch gute> Programme schreiben kann?
Ok, mit den Innereien kann ich leben, wenn ich das irgendwie übersetzt
bekomme. Geht nur leider nicht. Solchen empfindlichen Code kenne ich
nur von C++ Projekten.
Und wie kann ich die Hash Map verwenden, um Datenblöcke wie in meinem
Beispiel oben in einer Schleife einzufügen und zu suchen? Das muss ja
wohl irgendwie einfach gehen?
Udo K. schrieb:> Und wie kann ich die Hash Map verwenden, um Datenblöcke wie in meinem> Beispiel oben in einer Schleife einzufügen und zu suchen? Das muss ja> wohl irgendwie einfach gehen?
Man kann das hashmap in meiner utility library mit 2 minimalen
anpassungen schon dafür missbrauchen, aber vorgesehen ist es nicht. Im
"struct dpa__u_bo_unique_hashmap_entry" brauchte man einen Pointer auf
die assoziierten Daten. Und dpa__u_bo_do_intern ist eine
suche-und-füge-ein-falls nicht-vorhanden funktion, da müsste man den
Suchen teil (hier markiert
https://github.com/Daniel-Abrecht/dpa-utils/blob/0eec4fd282e2494fc86611ed864a39264dc06c2f/src/bo-unique.c#L305-L333)
erst in eine andere Funktion auslagern. Der Insert Funktion könnte man
dann den Key übergeben, und im zurückgegebenen struct
dpa__u_bo_unique_hashmap_entry* könnte man den Pointer auf seine Daten
setzen. Aber eben, vorgesehen ist das so nicht.
Vorgesehen sind da komplett andere Anwendungszwecke:
Man hat einen String oder sonstige Daten als key in einem buffer objekt,
und ruft dpa__u_bo_do_intern auf. Dann bekommt man das eindeutige
dpa_u_bo_unique_t Objekt zurück. Danach geht den Hash abzufragen, sowie
2 dpa_u_bo_unique_t zu vergleichen, extrem Schnell, in O(1). Ist also
ideal geeignet als Key in einem weiteren HashMap, dort müsste dann kein
Hash mehr berechnet werden, und keine langen Strings mehr verglichen
werden.
Und so ein dpa_u_bo_unique_t ist auch gut geeignet, wenn man sich die
Namen von Tags und Attributen einer XML Struktur oder so speichern will.
Die kurzen Namen passen meistens direkt in die dpa_u_bo_unique_t. Die
langen kommen halt ins globale HashMap, und verbrauchen nur 1mal
Speicher.
Das ist, wofür es eigentlich gedacht ist. Eventuell füge ich auch
irgendwann mal noch ein general purpose HashMap zu meiner Library hinzu,
aber da würde ich sicher einiges anderes machen, weil man da andere
Anforderungen an sowas hätte.
Daniel A. schrieb:> Bei C ist das durchaus üblich. So ziemlich jedes grosse Projekt> implementiert seine eigenen Memory Management Primitive und> Datenstrukturen, mit seinen eigenen Versionen von allerhand üblichen> Sachen.
Ich muss nochmal darauf zurückkommen. Hast du da ein Beispiel für ein
größeres Projekt in C?
Ich habe testweise das ganze trotz allem mal mit MSVC Kompiliert, in der
WSL. Geht jetzt einfach mit `make use=msvc clean all`.
Das Inkludiert das Makefile unter mk/msvc.mk, in dem ein paar config
Optionen gesetzt sind, und CC auf script/msvc-cc setzt, ein Wrapper
Script von mir, das die Optionen für CC übersetzt und dann cl.exe
aufruft.
Momentan setze ich in der msvc.mk "noshared=1", damit stelle ich das
bauen einer dll in meinem Makefile ab. Es baut & nutzt nur die static
library (das funktioniert).
Ohne die Option baut mein Makefile eine DLL von der static library, aber
ich kriege die EXEs nicht dazu die Variablen aus der DLL zu nehmen. Mit
ein paar dllimport kriege ich die EXEs dann zwar auch mit DLL gebaut,
aber dann wollen sie nicht starten. Keine Ahnung, warum.
Ein anderes Problem sind die dllexport / dllimport statements selbst.
Mit den dllexport Statements bekommt die exe, wenn man mit der
statischen library linkt, auch ein .lib file, weil es Symbole
exportiert, und dllimport .geht nur, wenn ein Symbol tatsächlich in
einer DLL drin ist. Damit kann man also nicht die gleichen .obj Dateien
für static und shared library verwenden. Eventuell könnte man da was mit
.def Dateien statt dllimport/dllexport in den .c Files machen, aber das
ist mir zu kompliziert / aufwändig.
Sachen die ich für MSVC anpassen musste waren unter anderem, 2 VM Typen,
die ich ersetzen musste, und die Position 2er Funktionsdeklarationen,
die msvc nicht Passten. Ein Makro switch, um die Buffer Structs ohne
Packing oder Bitfields auszulegen (sind dann 24 statt 16 Bytes gross),
und um MT / Atomic Sachen zu deaktivieren, hatte ich eh schon eingebaut,
und da auch gebraucht.
Und mein Testframework habe ich für MSVC auch deaktiviert, weil das
funktioniert mit file descriptor inheritance unter Testprogrammen um die
Ergebnisse zurück zu melden, und das hat man unter Windows nicht.
Und das dpa_u_init Macro habe ich in MSVC noch nicht implementiert, das
Initialisieren des Zufallsseed für das Hash Map geht darum dort noch
nicht.
Das Struct Packing scheint keinen grossen Einfluss auf die
Geschwindigkeit zu haben, zumindest nicht in meinen 2
Beispielprogrammen. Deaktiviert man es, sind die buffer Objekte halt
grösser / verschwenden mehr platz. Dafür passen in den dpa_u_bo_inline_t
Type aber mehr Daten rein. Daher musste ich beim Testen längere
Datensätze nehmen, ich habe die mit "pwgen -1 24 4096000" erzeugt.
Das "intern-example" Programm, kompiliert mit MSVC cl, braucht dabei
etwa 8s. Was wäre etwa 3x langsamer als unter linux mit gcc / llvm. Ich
weiss aber nicht, wie viel davon effektiv die runtime war, und wie lange
es einfach dauerte, bis Windows die exe gestartet hatte, vermutlich wäre
es eigentlich nicht ganz so extrem. Meine utility library setzt aber
extrem auf kleine Hilfsfunktionen und inlining, ich vertraue da voll
drauf, dass der Optimizer alles weg optimiert, und ich glaube nicht,
dass MSVC das besonders gut hinbekommt. Die inline Funktionen scheint es
auch in jedes Objektfile nochmal rein zu packen, statt nur in denen
objects mit den exports derselben, das ist dabei sicher auch nicht
hilfreich.
Was mir noch aufgefallen ist, es gibt eine stdatomic.h, aber msvc cl
scheint die nicht kompilieren zu können, weil es die _Atomic()
Statements darin nicht kann, und setzt auch die Macros, um das
anzuzeigen. Ich frag mich, wofür es die Datei überhaupt hat.
Insgesamt ist sicher nicht alles ideal, aber als PoC, dass es selbst mit
dem MSVC cl gehen würde, reicht es erst mal.
Ich habe auch mal mit der Dokumentation angefangen:
https://daniel-abrecht.github.io/dpa-utils/bo.html
Aber sowohl die Doku, als auch die Implementation, sind noch lange nicht
vollständig. Und dazu, Testcases zu schreiben, bin ich auch noch nicht
gekommen. Da werde ich noch länger dran sein.
Super, freut mich, dass du deinen Sourcecode mit MSVC compiliert
bekommen hast :-)
Wenn es dich interessiert, wo die Zeit verbraten wird, dann kannst du
mit Profiling compilieren. Starte dazu den MSVC Kommandoprompt, wo die
Umgebungsvariablen PATH, INLUDE und LIB richtig gesetzt sind:
Dann lässt du Test.exe laufen, und es wird ein File mit der Info erzeugt, welche Funktionen wie oft aufgerufen werden.
8
9
pgomerge.exe -merge *.pgd
10
11
und
12
13
pgomgr.exe -summary *.pgd
14
15
erzeugen dann ein lesbares Textfile mit der relevanten Info, wo die Zeit verbraten wird.
Wenn Dein Code 3x langsamer unter Windows läuft, zeigt das ein Problem
auf. So ein Hash Map Test muss OS unabhängig sein - du willst da DEINE
Routinen testen...
Wenn du Zeit hast, dann implementiere bitte mein Minimalbeispiel von
weiter oben.
Damit wird dein Hashcode für viele Anwendungen sinnvoll einsetzbar.
Gruss,
Udo
Daniel A. schrieb:> Meine utility library setzt aber> extrem auf kleine Hilfsfunktionen und inlining, ich vertraue da voll> drauf, dass der Optimizer alles weg optimiert, und ich glaube nicht,> dass MSVC das besonders gut hinbekommt.
Dann schau dir doch die Linker map an. Da siehst du schnell welche
Funktionen in deinem Program drinnen stehen (cl.exe ... -link -map)
> Die inline Funktionen scheint es> auch in jedes Objektfile nochmal rein zu packen, statt nur in denen> objects mit den exports derselben, das ist dabei sicher auch nicht> hilfreich.
Die stehen in den Objects drinnen, damit der Linker mehrere gleiche
Funktionen zusammenfassen kann. Wenn sie nicht gebraucht werden fallen
sie später raus.
"inline" ist mit einem modernen MSVC Compiler völlig unnötig, der macht
das automatisch beim Linken wo der gesamte Code vorliegt mit LTCG.
Ich bin gerade dabei, noch ein HashMap und ein HashSet zu
implementieren.
Also diesmal kein globales für String Interning, sondern ein
klassisches. Man kann dann da Nummern, die geinternten Strings, oder
Pointer hinzufügen, entfernen, Checken ob sie drin sind, und darüber
iterieren, das übliche eben.
Ich habe vor, Robin Hood Hashing zu verwenden:
https://programming.guide/robin-hood-hashing.html
Ich verdopple halbiere den Speicher von dem Set Map wieder je nach
bedarf. Ich nehme die oberen paar Bits des Hash zum einfügen / Sortieren
der Einträge.
Die Idee dahinter ist, unter anderem, dass dadurch beim vergrössern /
verkleinern, die Signifikanten Bits sich nicht ändern, und deshalb die
Reihenfolge, wann auch nicht die Position, der Einträge, gleich bleibt.
Beim Vergrössern und Verkleinern hänge ich nun etwas fest. Ich würde es
eigentlich gerne inplace machen, nach/vor einem realloc, und ich würde
idealerweise jeden Eintrag gerne nur einmal umsortieren. Nur leider ist
mir dafür noch keine gute Methode eingefallen. Eines der Schwierigkeiten
ist, dass wenn ein paar Einträge auf den letzten Eintrag Hashen, dann
wird der Anfang der Liste nach vorne geschoben. Es erinnert fast ein
bisschen an einen Ring Buffer. Es gibt also nicht wirklich einen Anfang
/ Ende. Bei meinen Überlegungen laufe ich da dann immer rein, was, wenn
wegen dem vorherigen Eintrag ich den etwas weiter hinten platzieren
müsste? Einen Ort zum Anfangen hab ich ja nicht, das könnte an jeder
Position passieren...
Wie würdet ihr das lösen?
Baue die Hash Map komplett neu auf, trage jeden Einträge aus der alten
Hash Map in die neue Hash Map ein. Die Kollisionen sind ja auch von der
Grösse der Hash Map abhängig. Der Overhead für den Neuaufbau ist meist
klein.
Aufpassen, dass du keine ungünstige Reihenfolge nimmst. Sonst kann die
neue Hash Map zu einer Liste entarten (weiss jetzt nicht genau wie das
geht, aber es gibt da böse Spezialfälle).
Udo K. schrieb:> Baue die Hash Map komplett neu auf, trage jeden Einträge aus der alten> Hash Map in die neue Hash Map ein.
Ok, das ist vermutlich der bessere weg. Löst aber mein Problem auch
nicht so ganz. Aber Ich denke ich bin nun dahinter gekommen, wie ich das
am besten mache, zumindest beim vergrössern.
Ich muss nur einen Eintrag mit PSL (Probe Sequence Length) 0 finden. So
einen müsste es immer geben. Nach dem vergrössern hat der dann immer
noch einen PSL von 0, das heisst, er ist effektiv an der Position, wo
der hash hin zeigt. Von dort weg kann ich dann einfach jeden Eintrag der
reihe nach kopieren. Bei ungeraden hashs mit PSL 0 muss ich ein Feld im
Ziel überspringen, ansonsten müsste alles gleich bleiben.
Für die leeren Einträge verwende ich einfach den Index-1. Das ergibt den
höchsten berechenbaren PSL (Anzahl buckets - 1). Mit dem Trick kann ich
nochmal etwas speicher sparen.
Das funktioniert nur, wenn der Platz in der vergrösserten HM noch frei
ist, was wegen Kollisionen nicht der Fall sein muss. Wenn du das mit
einer entarteten HM durchspielst, kann es sein, dass die Einträge in der
oberen Hälfte wieder in die untere Hälfte wandern. Du darfst also durch
Verschieben eines Eintrags in die obere Hälfte keine ungültige HM
zurücklassen. Dazu kommt, dass es neben freien Einträgen auch gelöschte
Einträge gibt, die nicht übernommen werden sollen. Ist ziemlich
aufwändig und bringt nur einen kleinen Speichervorteil. RH Hashing
funktioniert auch noch mit einer 3/4 vollen HM, und hat sowieso schon
einen Speichervorteil. Ich würde den Aufwand in ein effizienteres
Abspeichern der Einträge stecken, das geht direkt in einen
Geschwindigkeitsvorteil über. Z.B. würde ich den Hashwert nicht
mitabspeichern, der braucht 4-8 Bytes, die meist nutzlos sind und den
Cache zumüllen. Der ganze HM Eintrag lässt sich auf 8 Bytes
zusammenstampfen.
Udo K. schrieb:> Das funktioniert nur, wenn der Platz in der vergrösserten HM noch frei> ist, was wegen Kollisionen nicht der Fall sein muss.
Normalerweise schon, aber bei diesem Hashmap sind die Einträge sortiert,
und auch nach dem verdoppeln der Grösse ist es noch gleich sortiert. Ich
habe da einige Ideen, wofür ich die Eigenschaft ausnutzen kann.
Udo K. schrieb:> Z.B. würde ich den> Hashwert nicht mitabspeichern, der braucht 4-8 Bytes, die meist nutzlos> sind und den Cache zumüllen.
Ich mache das umgekehrt. Ich speichere nur den hash. Da es sich nicht
um einen kryptographischen Hash handelt, kann ich eine Funktion nehmen,
die sich umkehren lässt. Ich brauche den Hash, um den PSL eines Eintrags
zu berechnen, und neue Einträge einzusortieren. Daher nützt mir der Hash
mehr als der Wert, ich muss den dann nie neu berechnen.
Daniel A. schrieb:> Ich mache das umgekehrt. Ich speichere nur den hash. Da es sich nicht> um einen kryptographischen Hash handelt, kann ich eine Funktion nehmen,> die sich umkehren lässt. Ich brauche den Hash, um den PSL eines Eintrags> zu berechnen, und neue Einträge einzusortieren. Daher nützt mir der Hash
Ok, da bin ich ausgestiegen. Wozu musst du den Hash umkehren, und geht
das mit allen möglichen Hash Funktionen?
Für die PSL (DIB = Distance to Initial Bucket) reichen ein paar Bits
aus. Normalerweise ist die DIB << 16, darüber entartet das zu einer
unsortierten Liste wie in einer klassischen HM. Pass auf, das die vielen
Spezialfälle nicht die Performance in den wichtigen Fällen
zusammenhauen. Die HM Einträge mit Zeiger auf die Daten sollten
idealerweise <= 8 Bytes sein.
Udo K. schrieb:> Wozu musst du den Hash umkehren, und geht> das mit allen möglichen Hash Funktionen?
Nein, nicht alle Hash Funktionen sind umkehrbar. Ich versuche es
zunächst mal mit folgender:
Ich verwende die obersten Bits, also schaue ich einfach, dass diese von
möglichst allen Bits abhängig sind. Die Funktion ist nicht ideal wenn
die Bits des Keys im vornherein schon nicht unabhängig sind, aber
andererseits lässt sich theoretisch immer ein Fall konstruieren, wo eine
Hash Funktion nicht ideal performt. Ich muss mal schauen, ob die hier
gut genug funktioniert.
Auf jeden Fall kann ich damit hash -> key und key -> hash berechnen
(DPA__U_SM_KEY_TYPE und DPA__U_SM_KEY_ENTRY_TYPE sind hier gleich gross,
und DPA__U_SM_KEY_ENTRY_TYPE ist ein positiver integer).
Die PSL zu berechnen geht mit dem Hash ja schnell. Ich brauche nur eine
Shift operation, und dann muss ich das vom Index des Eintrags abziehen.
Kannst du deine Hash Funktion so wie die HashBernstein Funktion
schreiben?
Also mit einer allgemeinen Länge (gerne auch begrenzt auf 32 Bytes)?
1
// Bernstein's hash
2
UINTHashBernstein(PCSTRkey,SIZE_Tlen)
3
{
4
SIZE_Ti;
5
UINThash=5381;
6
7
for(i=0;i<len;i++)
8
hash=33*hash+key[i];
9
returnhash^(hash>>16);
10
}
Ich schicke sie dann durch meinen Kollisionschecker durch.
Da sollte ein Ergebnis wie in der Tabelle unten rauskommen.
Da sieht man, dass etwa die CRC32C_HW die niedrigste Kollisonsrate hat
und recht schnell ist.
Wobei das dafür gedacht ist, wenn man die oberen Bits nutzt.
Für die unteren bits müsste man es auf die andere Seite Shiften:
https://godbolt.org/z/oWbzr37Yn
Die Ergebnisse mit den Wörtern aus den Werken von Shakespeare sind nicht
gut.
Das memcpy wird nicht wegoptimiert, und die Kollisionen sind
unterirdisch.
Udo K. schrieb:> Die Ergebnisse mit den Wörtern aus den Werken von Shakespeare sind nicht> gut.
Ok, muss ich mir eine bessere Funktion überlegen. Eigentlich nicht
überraschend. (Die Funktion war übrigens von der Pointer Hash Funktion
in Mesa inspiriert).
Vielleicht versuche ich es als nächstes mit Knuth's integer hash
Funktion. Eine simple Multiplikation, aber manche Werte sind umkehrbar
(wie man hier sehen kann https://github.com/jenssegers/optimus)
Aber zuerst kümmere ich mich um den restlichen Kram. Um die
Optimierungen kann ich mich kümmern, wen das Ding erst mal läuft.
> Das memcpy wird nicht wegoptimiert, und die Kollisionen sind> unterirdisch.
Naja, die ursprüngliche Funktion war für integer Hashes gedacht, von
genau einem Integer fester Grösse. Dort brauche ich dann auch das memcpy
nicht. Dass das äquivalent für variable Längen nicht effizient ist, ist
wenig überraschend, dafür war es ja auch nicht designt.
PS: Vermutlich ist das immer noch besser als in Python. Dort ist der
Hash eines Integer wieder der selbe integer:
1
dpa@dragonfly:~$ python3 -c 'print(hash(12345))'
2
12345
3
dpa@dragonfly:~$ python3 -c 'print(hash(12345))'
Was aber auch nicht schlimm sein muss. Es kommt immer darauf an, wofür
man es verwendet, und das ist auch eine perfekte hash funktion (jeder
eindeutige Input hat einen eindeutigen Output und umgekehrt).
Ich würde eine allgemeine und austauschbare Hash Funktion verwenden,
sonst verbaust du dir zu viel.
Es gibt nicht die beste Hash Funktion, der Hash hängt ja auch von der
Anwendung ab.
Die Hash Map muss mit Zeigern auf die User-Daten zurechtkommen, und auch
mit dem Fall, dass die User-Daten einen Zeiger auf den Key enthalten,
oder der Key irgendwo in den User-Daten eingebettet ist. Meist sind die
User-Daten in einer weiteren Datenstruktur drinnen (Array, Liste), und
die HM wird nur zur schnellen Suche verwendet.
Für 64 Bit Zeiger bringt deine Funktion auch einen Haufen Kollisionen,
vielleicht ist da noch ein Bug drinnen.
Eine leicht modifizierte CRC32C Funktion mit einer zusätzlichen Rotation
(mit x64 Hardware Instruction) ist für den Fall ziemlich unschlagbar:
Daniel A. schrieb:> PS: Vermutlich ist das immer noch besser als in Python. Dort ist der> Hash eines Integer wieder der selbe integer:dpa@dragonfly:~$ python3 -c> 'print(hash(12345))'> 12345> dpa@dragonfly:~$ python3 -c 'print(hash(12345))'
Die Identity Funktion kann in Spezialfällen sehr gut funktionieren,
versagt aber völlig in anderen, vor allem wenn die HM eine 2'er Potenz
ist.
Das ist merkwürdig. Immerhin beinhalten die ursprünglichen Daten, und
die von meiner Funktion gehashten Daten, die gleiche Menge an
Informationen, also gleich viel Entropie.
Vermutlich kommt der Unterschied daher, dass einerseits nur ein Teil des
Hashs verwendet wird, und andererseits am Anfang / Ende der Daten noch
ein paar Nullen padding angehängt werden, wenn die Daten kein vielfaches
von sizeof(UINT) sind. Von dem Teil wird auch der Teilhash genommen. Im
schlimmsten Fall hat man in dem Fall nur 10 sich unabhängig ändernde
Bits.
Würde man die Identity Funktion auf gleiche weise mit Radding Bytes
versehen, hätte man im schlimmsten Fall sogar nur 8 sich ändernde bits.
Aber ich kann ja nicht davon ausgehen, dass ich bei meiner hash Funktion
mit Integern fester Grösse nur grosse Zahlen erhalte, daher hätte ich
das Problem in der Praxis auch, insbesondere auch, weil ich ja
signifikanten Bits des Hash bevorzuge.
Der Hash mag ja noch viel Information enthalten, aber spätestens bei der
Abbildung des Hashes auf die Hash Map wird Information weggeschmissen,
besonders im Fall das die Hash Map Grösse eine 2-er Potenz ist - da
werden die oberen Bits einfach weggeschnitten.
Die Idee mit der umkehrbaren Hash Funktion ist ganz interessant,
schränkt aber die Hash Funktion zu sehr ein. Aus den geposteten Tabellen
kannst du dir ja eine brauchbare Hash Funktionen heraussuchen. Die
einfachen Hash Funktionen wie Identity versagen in vielen
Anwendungsfällen, wenn etwa Zeiger aus mehreren Speicherbereichen
vorkommen. Die CRC Funktionen sind ziemlich gut und mit HW
Unterstützung schnell. Die FNV Funktion ist für kurze Keys gut, für
lange aber langsam. Die SBOX, Murmur2 und Paul Hsieh Funktionen sind
auch gut (In der Tabelle oben stimmen die Cycles manchmal nicht, wenn
ein Taskswitch passiert).
Ich habe jetzt eine neue umkehrbare hash Funktion. Ein xor mit einer
Zufallszahl, und eine Multiplikation (wie bei Knuth multiplikativer Hash
Funktion). Durch wählen einer geeigneten Primzahl, und dessen
multiplikativem Invers, ist sie umkehrbar.
1
Thash(Tx){
2
return(x^r)*choose_prime(T);
3
}
4
5
Tunhash(Tx){
6
return(x*choose_prime_inverse(T))^r;
7
}
Das xor mit der Zufallszahl habe ich drin, in der Hoffnung, dass bei
unterschiedlichen Zufallszahlen nicht die selben Hashs kollidieren, aber
ob das effektiv funktioniert, habe ich noch nicht getestet. Falls nicht
nehme ich es wieder raus, der Hash selbst wird dadurch ja nicht besser.
Ich habe mir, je nachdem wie gross der Positive Integer Datetyp ist,
unterschiedliche Primzahlen rausgesucht. Für alles von 1 bis und mit 256
bits hab ich eine. Die sind mehr oder weniger zufällig, ich habe welche
genommen, die möglichst gross sind, aber trotzdem einigermassen zufällig
wirken. Also nicht sowas wie 0x10001.
Naja, zumindest hoffe ich die Nummern sind Primzahlen, bei den grossen
kann ich das nicht wirklich zweifelsfrei sagen. Wird schon passen...
Der ganze code ist hier: https://godbolt.org/z/6Wo15qs98
Nicht von den grossen _Generic abschrecken lassen, da wird nur die
Primzahl zur compile time ausgesucht. Zumindest bei de paar Grössen, die
ich ausprobiert habe, hat das funktioniert.
Alles über 64bit (also was ein PC nicht direkt kann) wird aber recht
ineffizient. Vielleicht werde ich da dass dann in der Praxis stattdessen
als ein paar 64bit Werte behandeln, und die dann XORen.
Ich muss nachher mal noch eine Variante für variable Datenlängen machen,
um das hier etwas zu testen. Eventuell sollte ich auch mal noch was
hinzufügen, um die Bitreihenfolge umzukehren. Das bringt ja wenig, wenn
wir die unteren Bits testen, aber ich die oberen verwende...
Daniel A. schrieb:> Der ganze code ist hier: https://godbolt.org/z/6Wo15qs98> Nicht von den grossen _Generic abschrecken lassen, da wird nur die> Primzahl zur compile time ausgesucht. Zumindest bei de paar Grössen, die> ich ausprobiert habe, hat das funktioniert.
Knapp 1000 Zeilen für eine Multiplikation mit einer Konstanten.. Ich
hätte nicht gedacht, das das in C überhaupt möglich ist.
Ich habe mir den ASM Code angeschaut, der ist einfacher lesbar 😉.
Die Hash Funktion sollte so sein, dass sie zur Runtime mit beliebigen
Daten umgehen kann. Sonst baust du endlose Spezialfälle, und die Hash
Map wird langsam, da der Instruction-Cache zugemüllt wird.
Ich habe deine Funktion für 64 Bit eingestampft mit r = 0:
1
INLINEUINTDaniel_hash64(UINT64x)
2
{
3
returnx*0xFD2D84CA00000225;
4
}
5
6
UINTDaniel_hash3(PCSTRkey,SIZE_Tlen)
7
{
8
returnDaniel_hash64(*(UINT64*)key);
9
}
> (wie bei Knuth multiplikativer Hash Funktion).
Die Idee bei den multiplikativen Hash Funktionen ist, dass die Bits nach
oben wandern und dabei durchgemischt werden, bei langen Keys haben die
ersten Bytes aber keinen Einfluss mehr auf den Hashwert.
Das hast du bei deiner Hash Funktion nicht, du schiebst durch die
Multiplikation die relevanten Bits nach oben, vermischt sie aber nicht.
Je nachdem wo die wichtigen Bits im Zeiger stehen, sind sie für die
Hash-Map relevant oder nicht.
Das ist der grosse Vorteil der CRC Funktionen: Da wird eine pseudo
Zufallszahl durch ein Schieberegister mit Feedback generiert, Bits die
oben rauswandern, werden unten wieder reingestopft. Auch bei sehr langen
Keys hat das erste Byte noch einen Einfluss auf den Hashwert.
Hier die Ergebnisse:
Udo K. schrieb:> Knapp 1000 Zeilen für eine Multiplikation mit einer Konstanten.. Ich> hätte nicht gedacht, das das in C überhaupt möglich ist.Daniel A. schrieb:>> It seems that perfection is attained not when there is nothing more to add,>> but when there is nothing more to remove>> — Antoine de Saint Exupéry
Das selbst gesteckte Ziel ist weiter weg denn je...
Udo K. schrieb:> Die Idee bei den multiplikativen Hash Funktionen ist, dass die Bits nach> oben wandern und dabei durchgemischt werden, bei langen Keys haben die> ersten Bytes aber keinen Einfluss mehr auf den Hashwert.> Das hast du bei deiner Hash Funktion nicht, du schiebst durch die> Multiplikation die relevanten Bits nach oben, vermischt sie aber nicht.> Je nachdem wo die wichtigen Bits im Zeiger stehen, sind sie für die> Hash-Map relevant oder nicht.
In meinem Fall macht es keinen Sinn, die Bits von Oben wieder nach Unten
zu mischen, denn ich verwende die oberen Bits.
Die meisten Hashmaps machen ja `index = hash % size`, wenn size eine 2er
Potenz ist, entspricht das `index = hash & (size-1)`. Ich speichere die
Grösse meines Hashmap gleich als log2 ab, den ich verdopple / halbiere
dessen Grösse ja immer nur. Ich verwende dann effektiv `index = hash >>
(sizeof(hash)*CHAR_BIT-lbsize)`.
Das ist der Grund, warum es bei mir keine rolle spielt, wenn die unteren
Bits nicht so gut gemischt sind. Und auch wenn mehr der unteren Bits
verwendet werden / das hash map grösser wird, spielt es keine rolle. Der
Extremfall wäre ja wenn alle Bits verwendet würden, in dem Fall hätte es
sogar gar keine Kollisionen mehr.
Wenn man das in dem test da umdreht, wird das Ergebnis sicher besser.
1
uint64_thash(uint64_tx){
2
uint64_ta=x*0xFD2D84CA00000225ull;
3
uint64_tr=0;
4
for(inti=0;i<64;i++)
5
r|=((uint64_t)!!(a&(1ull<<i)))<<(63-i);
6
returnr;
7
}
Udo K. schrieb:> Knapp 1000 Zeilen für eine Multiplikation mit einer Konstanten.. Ich> hätte nicht gedacht, das das in C überhaupt möglich ist.> Ich habe mir den ASM Code angeschaut, der ist einfacher lesbar 😉.
Ich habe eine Art Template, wo ich die Funktion für viele verschiedene
Integer Typen definiere. Bei einigen Typen weiss man nicht, wie gross
sie sind. 16bit, 32bit, 64bit, oder gar ein vielfaches von 9 statt 8bit?
Wäre alles möglich.
Also schaue ich einfach, wie viele Bits hat der Typ, und suche zur
Compile Time eine passende Konstante aus.
> Die Hash Funktion sollte so sein, dass sie zur Runtime mit beliebigen> Daten umgehen kann.
Das kann sie auch. Am Ende ist immer noch eine einfache Multiplikation
einer Variable mit einer Konstante. Ist nur jenachdem, ob das jetzt ein
short oder ein long ist, eine andere.
> Sonst baust du endlose Spezialfälle, und die Hash> Map wird langsam, da der Instruction-Cache zugemüllt wird.
Naja, dort habe ich auch einen HashMap und HashSet Typ pro key Typ. Ein
wenig wie bei C++ Templates.
Daniel A. schrieb:> Udo K. schrieb:>> Die Hash Funktion sollte so sein, dass sie zur Runtime mit beliebigen>> Daten umgehen kann.>> Das kann sie auch.
Nur halt nicht so gut wie etablierte Funktionen, wie Udo's Ergebnisse
zeigen.
Klaus schrieb:> Nur halt nicht so gut wie etablierte Funktionen, wie Udo's Ergebnisse> zeigen.
Wie schon gesagt, da ich die oberen Bits verwende, und der hash
Algorithmus auch darauf ausgelegt ist, und das unbekannte Test Programm
vermutlich die unteren verwendet, kann man das so momentan noch nicht
beurteilen.
Udo K. schrieb:> Schaut besser aus: Coll-Rate ist überschaubar, an der Geschwindigkeit> musst du noch was machen:
Naja, das kommt von der Umkehrung der Bitreihenfolge. In der Praxi muss
ich das ja nicht machen, weil ich dort die oberen Bits per Shift
verwende, statt die Unteren per And.
Daniel A. schrieb:> Naja, das kommt von der Umkehrung der Bitreihenfolge
Ich verstehs noch nicht. Willst du eine Hash-Funktion schreiben, die nur
dann halbwegs ok funktioniert, wenn bestimmte Teile der Daten gut
verteilt sind?
Klaus schrieb:> Daniel A. schrieb:>> Naja, das kommt von der Umkehrung der Bitreihenfolge>> Ich verstehs noch nicht. Willst du eine Hash-Funktion schreiben, die nur> dann halbwegs ok funktioniert, wenn bestimmte Teile der Daten gut> verteilt sind?
Nein, die Verteilung der Daten vor dem Hashen spielt keine rolle. Es ist
nur so, dass die oberen Bits des Hash bessere Avalanche Eigenschaften
als die unteren haben.
Die Hash Funktion werde ich nur für mein neues HashMap verwenden. Dieses
bevorzugt die oberen Bits des Hash. Und darauf ist die Hash Funktion
ausgelegt. Wie man ja gerade gesehen hat, funktioniert sie gut, wenn man
sie so verwendet, wie ich es vor habe. Works as designed.
Ok, dann freue ich mich schon mal auf deine Hash Table.
Hier ein Vorschlag für ein C Interface.
Ich nehme an, dass der Key in den User-Daten an einem fixen Offset
abgespeichert ist. Die speziellen HT Funktionen rufen die allgemeinen
HT Funktionen mit den passenden Funktionszeigern auf.
1
#ifndef HASHTBL_H
2
#define HASHTBL_H
3
4
#include<windows.h>
5
6
7
typedefINT(*HT_CMP)(PVOID,PVOID);/* return 0 if the arguments are equal */
8
typedefUINT(*HT_HASH)(PVOID);/* return hash value of the argument */
Daniel A. schrieb:> Works as designed.
Zeiger die auf aufeinanderfolgende 16 MB Bereiche zeigen, sind nicht so
optimal.
Selbst bei minimalem Fill Faktor von 0.02 versagt die Funktion.
Daniel A. schrieb:> (Ich weiss> auch nicht wirklich, was eine gute / schlechte Konstante aus macht).
Warum versuchst Du dann das Rad neu zu erfinden und nicht auf Bewährtes
zurückzugreifen?
Klaus schrieb:> Daniel A. schrieb:>> (Ich weiss>> auch nicht wirklich, was eine gute / schlechte Konstante aus macht).>> Warum versuchst Du dann das Rad neu zu erfinden und nicht auf Bewährtes> zurückzugreifen?
Eine Multiplikation als Hash Funktion nun wirklich nichts neues, das hat
sogar einen Namen.
Und warum ich gerade diese Methode nehme, steht weiter oben. Weil die
Funktion so umkehrbar ist.
Du kannst auch einfach einen Zeiger auf die Daten abspeichern. Der Hash
kann schnell neu berechnet werden. Das ist einfach und umkehrbar.
Mit 32 Bit Hash Werten und beliebigen Daten funktioniert Umkehrbarkeit
nicht. Die Daten sind auch nicht immer gleich lang.
Udo K. schrieb:> Ich nehme an, dass der Key in den User-Daten an einem fixen Offset> abgespeichert ist.
Eine Version, bei der das so gelöst wird, kann ich später auch noch
hinzufügen. Bei der Variante an der ich gerade Arbeite, wird es nicht
nötig sein, den Key noch zusätzlich zu speichern. Das bietet gewisse
Vorteile, aber auch gewisse Nachteile.
Udo K. schrieb:> Du kannst auch einfach einen Zeiger auf die Daten abspeichern.
Ja, beim HashMap werde ich so oder so einen Pointer als Wert speichern.
Aber nicht unbedingt im HashSet.
> Der Hash kann schnell neu berechnet werden.
Das kommt ganz auf die Hash Funktion an. Eine simple Multiplikation
würde tatsächlich nicht ins Gewicht fallen.
> Das ist einfach und umkehrbar.> Mit 32 Bit Hash Werten und beliebigen Daten funktioniert Umkehrbarkeit> nicht. Die Daten sind auch nicht immer gleich lang.
Wenn die Daten beliebig lang sein können, kann das Hashen schon recht
langsam werden. Deshalb funktioniert das HashMap, an dem ich gerade
arbeite, anders.
Mein Key ist ein Integer, ein Pointer, oder ein bereits eindeutiges
String Objekt (wobei das Objekt eine feste Grösse hat, bei kleinen
Strings der String selbst, anderenfalls einen eindeutigen Pointer auf
den String (d.h. es kann keine unterschiedlichen Pointer auf die selben
Werte geben)).
Damit habe ich immer eine fixe Grösse der zu hashenden Daten.
Solange der Hash mindestens so gross ist wie die Daten, kann ich den
auch umkehrbar machen. Dann sind Hash und Daten gleichwertig.
Eine Version für beliebige andere Arten von Daten, mit eigener Hash /
Vergleichsfunktion, kann ich später auch noch hinzufügen. Aber zuerst
will ich mal diese Version fertig bekommen.
----
Die Primzahlen oben wurden übrigens mit einem Python Skript generiert.
Ich hatte einfach die erste vor `(i**2 * 9779516207054258 + i**2 *
110241896472871) // (10**16)` genommen.
Ich versuche mal 2 andere.
Vielleicht geht eine richtig zufällige besser:
0x4E7184CB320E45E9llu / 0xEA5E24FD2782E259llu (inverse)
Oder vielleicht eine wo ungefähr jedes 5te Bit gesetzt ist:
0x108421084210841Fllu / 0xF7DF7DF7DF7DF7DFllu (inverse)
1
fromsympyimportprevprime,nextprime
2
fromosimporturandom
3
4
defgen_c_const(x):
5
s=''
6
i=0
7
whilex:
8
r=x%2**64
9
x=x// 2**64
10
r='((T)0x%Xllu)'%r
11
ifi:r='(%s<<%d)'%(r,i)
12
i+=64
13
s=r+s
14
ifx:s='|'+s
15
returns
16
17
a=''
18
b=''
19
20
foriinrange(8,289):
21
j=2**i
22
#s = (j * 9779516207054258 + j * 110241896472871) // (10**16) # This wasn't good enough
Daniel A. schrieb:> Vielleicht geht eine richtig zufällige besser:> 0x4E7184CB320E45E9llu / 0xEA5E24FD2782E259llu (inverse)
Die ist ziemlich gut. Ich habe einen Fall gefunden, wo sie abkackt.
Zeiger aus drei Speicherbereichen, einer im Addressraum um die 28 Bit,
einer um die 56 Bit,
und ein Bereich mit zufälligen Addressen.
Da versagen auch etliche alte Standard-Hash, die wohl nie für Zeiger
gebaut wurden.
Die CRC ist aber immer ganz vorne dabei - meine Empfehlung.
Ich schaue in der Tabelle auf Collision-Rate und Max-Collisions.
Die Instruction Cycles sind nicht immer zuverlässig.
Ich würde es jetzt damit belassen. Wenn du das ernsthaft
weiterverfolgen willst, musst du
dir eine Hash Tabelle nach deinen Vorstellungen bauen, und mit Statistik
Code testen.
Der Code den ich verwenden ist von https://www.strchr.com/hash_functions
abgekupfert
(eine der besten Hash Seiten im Web).
Udo K. schrieb:> Der Code den ich verwenden ist von https://www.strchr.com/hash_functions> abgekupfert
Danke, ich werde mir das mal ansehen.
Noch eine Frage zu den Statistiken, eine Sache verstehe ich da noch
nicht. "# Lines read: 1500" ist doch die Anzahl Werte, oder? Wie kann es
zu 17462 Kollisionen kommen, wenn es nur 1500 Einträge gibt?
Daniel A. schrieb:> Danke, ich werde mir das mal ansehen.>> Noch eine Frage zu den Statistiken, eine Sache verstehe ich da noch> nicht. "# Lines read: 1500" ist doch die Anzahl Werte, oder? Wie kann es> zu 17462 Kollisionen kommen, wenn es nur 1500 Einträge gibt?
Es werden alle 1500 Einträge gesucht, und die Kollisionen aller Einträge
aufaddiert. Wenn also jeder Eintrag 10 Kollisionen hat, kommt 15000
raus.
In dem Fall oben hat jeder Eintrag im Mittel 11.6 Kollisionen, und
mindestens 1 Eintrag hat 910 Kollisionen.
Zur Info: Die Hash Tabelle verwendet in den Tests Open Addressing und
keine Linked List.
In der Tabelle oben sieht man auch schön, dass die moderneren Hash
Funktionen gut mit 64-Bit Zeigern zurechtkommen, während die klassischen
Funktionen - die für Text entworfen sind - damit Probleme haben. Die
schlimmsten Hash Funktionen wie die Fletcher Checksum oder Weinberger
sind der Tabelle schon draussen.
Böse sind auch Testdaten mit langen identischen Prefixen. Da kann man
gleich weitere Funktionen für eine allgemeine Hash-Lib aussortieren.
FNV1A hat hier zwar eine halbwegs passable Kollisionsrate, ist aber
wegen der langen Strings langsam.
Wenn die Zeilen richtig lang werden, kacken alle Funktionen ab, die
Strings Byte für Byte abarbeiten.
Die CRC32C HW Funktionen arbeiten mit 8 Bytes auf einmal, und ziehen
davon.
Ich muss noch etwas mehr testen. Vermutlich kann man auch noch einiges
optimieren. Ich habe noch nicht nachgesehen, wie schnell es ist.
Und ich will später noch Funktionen hinzufügen, um über die Sets / Maps
zu iterieren, und um Schnittmengen zu bilden. Da dürfte die Sortierung
der Maps / Sets dann nützlich werden.
Aber die Basics, Hinzufügen und Löschen von Einträgen, scheint schon mal
zu gehen.
Microsoft (R) C/C++ Optimizing Compiler Version 15.00.30729.207 for x64
3
Copyright (C) Microsoft Corporation. All rights reserved.
4
5
set-and-map.c
6
../include\dpa/utils/common.h(7) : fatal error C1083: Cannot open include file: 'stdnoreturn.h': No such file or di
7
rectory
Und Clang-cl
1
[0]$ clang-cl -I ../include -c set-and-map.c
2
In file included from set-and-map.c:26:
3
In file included from ../include/dpa/utils/set.h:6:
4
In file included from ../include/dpa/utils/_set-and-map.generator:1:
5
In file included from ../include/dpa/utils/bo.h:4:
6
../include/dpa/utils/common.h(20,9): warning: DANGER: C atomic or threads support missing, library will not be threadsafe! [-W#pragma-messages]
7
#pragma message ("DANGER: C atomic or threads support missing, library will not be threadsafe!")
8
^
9
In file included from set-and-map.c:26:
10
In file included from ../include/dpa/utils/set.h:6:
11
In file included from ../include/dpa/utils/_set-and-map.generator:1:
12
In file included from ../include/dpa/utils/bo.h:5:
13
In file included from ../include/dpa/utils/refcount.h:10:
14
C:/WinDDK/7600.16385.1/inc/crt/stdlib.h(393,20): error: __declspec attributes must be an identifier or string literal
15
_CRTIMP __declspec(noreturn) void __cdecl exit(__in int _Code);
16
^
17
C:/msys64/mingw64/lib/clang/16/include/stdnoreturn.h(13,18): note: expanded from macro 'noreturn'
18
#define noreturn _Noreturn
19
^
20
In file included from set-and-map.c:26:
21
In file included from ../include/dpa/utils/set.h:6:
22
In file included from ../include/dpa/utils/_set-and-map.generator:1:
23
In file included from ../include/dpa/utils/bo.h:5:
24
In file included from ../include/dpa/utils/refcount.h:10:
25
C:/WinDDK/7600.16385.1/inc/crt/stdlib.h(394,20): error: __declspec attributes must be an identifier or string literal
26
_CRTIMP __declspec(noreturn) void __cdecl _exit(__in int _Code);
27
^
28
C:/msys64/mingw64/lib/clang/16/include/stdnoreturn.h(13,18): note: expanded from macro 'noreturn'
29
#define noreturn _Noreturn
30
^
31
In file included from set-and-map.c:81:
32
In file included from ../include/dpa/utils/_set-and-map.generator:9:
33
../include/dpa/utils/_set-and-map.common.h(40,10): fatal error: 'src/set-and-map.c' file not found
34
#include DPA__U_SM_TEMPLATE
35
^~~~~~~~~~~~~~~~~~
36
set-and-map.c(79,28): note: expanded from macro 'DPA__U_SM_TEMPLATE'
37
#define DPA__U_SM_TEMPLATE <src/set-and-map.c>
38
^~~~~~~~~~~~~~~~~~~
39
<scratch space>(126,1): note: expanded from here
40
<src/set-and-map.c>
41
^~~~~~~~~~~~~~~~~~~
42
1 warning and 3 errors generated.
Ich will bitte ein Header File und ein Lib File oder ein C File. Das
muss mit jedem der 3 grossen Compiler durchlaufen. Über das Makefile und
den Source Code traue ich mich nicht drüber. Das geht über meinen
Horizont.
Udo K. schrieb:> Das geht über meinen Horizont.
Nicht nur über deinen.
Ich wage mal die Prognose, die Anzahl der User dieser Library wird "1"
nie überschreiten.
Aber egal, gibt wesentlich unvernünftigere Hobbies...
Udo K. schrieb:> Ich habe mal versucht das unter Windows zu compilieren:
Ich habe (zuhause) halt leider keinen Windows PC, das macht das Testen
etwas schwieriger.
Die gcc Fehlermeldung sieht sehr nach dem hier aus:
https://stackoverflow.com/questions/7789668/why-would-the-size-of-a-packed-structure-be-different-on-linux-and-windows-when
Insbesondere `-mno-ms-bitfields`. Aber gut zu wissen, was der Windows
GCC das macht, das habe ich noch nicht getestet. Es gibt da wohl ein
Attribut, welches das selbe macht `__attribute__((gcc_struct))` bzw.
`gnu::gcc struct` in c23. Ich muss mal schauen, das ich das bei gcc
bei dem Struct anwende.
Bei msvc hat man das selbe Problem auch, aber dort setze ich automatisch
`-DDPA_U_BO_NOT_PACKED`, das stellt das struct packing aus. Mach das
`dpa_u_bo_unique_t` Objekt aber grösser, was in einem open addressing
hash map, wo es ja kopiert werden muss, nicht ideal ist.
Für msvc habe ich vorhin noch einen kleinen Fix ins repo gepusht, dort
wird max_align_t nicht definiert. Ist hallt immer noch nicht ganz C11
Konform...
Ich kompiliere das zum Testen in der WSL, mit gnu make, mit `make
use=msvc`. Log ist im Anhang, da sieht man, mit welchen Parametern der
Compiler aufgerufen wird, da braucht es noch ein paar.
Und was bei all deinen Aufrufen fehlt, ist noch `-I.` Das
`src/set-and-map.c` ist ein Template, das Inkludiert sich indirekt
selbst ein paar mal, das findet sich selbst sonst nicht. Und eventuell
noch --std=c17 btw. /std:c17 , das ist immerhin c11/c17 code.
Udo K. schrieb:> Ich will bitte ein Header File und ein Lib File oder ein C File. Das> muss mit jedem der 3 grossen Compiler durchlaufen.
Kann ich machen, ich Kopiere das nachher mal zusammen.
So, nach einigen Präprozessor Tricks und herum kopieren, ist jetzt alles
in einem File. Hat länger gedauert und war aufwendiger als ich dachte,
ich hoffe, ich habe dabei keine Fehler gemacht.
Die Funktionen, die einen dpa_u_bo_unique_t nehmen, hab ich weg
gelassen, und einige Präprozessor Checks auch.
Auf Windows hab ich das jetzt nicht ausprobiert, aber sollte eigentlich
passen.
Ein kleines Benchmark zum kurz ausprobieren habe ich auch noch angehängt
(Da füge ich einfach 2**28 = 268435456 ein):
Jetzt muss ich das nur noch mit irgendwas vergleichen, keine Ahnung ob
das gut ist oder nicht. Ist aber interessant, wie viel die Grösse des
Keys ausmacht.
H:\Udo\Projekte\UKEagle\SourceCode\TestAVLTree\current\dpa\set-and-map.h(4): error C2054: expected '(' to follow 'dpa_u_unsequenced'
4
H:\Udo\Projekte\UKEagle\SourceCode\TestAVLTree\current\dpa\set-and-map.h(47): error C2085: 'dpa_u_count_bits': not in formal parameter list
5
H:\Udo\Projekte\UKEagle\SourceCode\TestAVLTree\current\dpa\set-and-map.h(47): error C2143: syntax error: missing ';' before '{'
Inzwischen habe ich den github Code mit MS cl zum compilieren bekommen.
- /std:c17 geht, std:clatest geht aber nicht, die C Versionsabfrage geht
nicht richig
- Die Warnungen bekomme ich nur mit /W0 weg
- Die Funktionen haben alle __declspec(dllimport) oder
__declspec(dllexport) davor - das ist nur für DLLs gedacht
- clang liefert immer noch seitenweise Fehler
Wenn ich den C Code als C++ kompiliere kracht es gleich wieder. Sorry,
aber das geht so nicht.
Udo K. schrieb:> dpa_u_unsequenced ist nirgends definiert?
Da habe ich übersehen, das es in set-and-map.h noch an einer stelle
verwendet wird, und habe es in die .c gepackt. Wenn __builtin_popcountg
oder __builtin_popcountll vorhanden ist (wie bei GCC), nimmt es das,
ansonsten definiert es eine fallback Funktion und die verwendet
dpa_u_unsequenced. dpa_u_unsequenced selbst ist nur ein optionaler
Hinweis an den Compiler, dass die Funktion keine Seiteneffekte hat. Ich
korrigiere das schnell mal... (Anhang)
Udo K. schrieb:> Inzwischen habe ich den github Code mit MS cl zum compilieren bekommen.> - /std:c17 geht, std:clatest geht aber nicht, die C Versionsabfrage geht> nicht richig
Doch, die geht einwandfrei. In clang und gcc habe ich --std=c2x /
--std=c23 getestet, ohne Probleme. Die Library macht dann auch Gebrauch
von den neuen Features. Native Attribute, typeof, usw. Gut möglich, dass
msvc halt mal wieder unvollständig ist.
> - Die Warnungen bekomme ich nur mit /W0 weg
Ja, bei msvc gibt es an manchen stellen viele false positives.
> - Die Funktionen haben alle __declspec(dllimport) oder> __declspec(dllexport) davor - das ist nur für DLLs gedacht
Ursprünglich wollte ich auch das eine DLL, zusätzlich zur statischen
lib, erstellt wird. Nur habe ich die nie zum laufen gebracht.
Ausserdem ist das Konzept unter Windows ziemlich kaputt.
Unter linux sage ich mit __attribute__((visibility(default))), das ein
Symbol sichtbar sein soll. Die Objekt Files packe ich in eine statische
Library. Und aus der lasse ich den Linker dann auch noch eine shared
library (.so) erstellen. Das geht dort wunderbar.
Aber unter Windows? Dort müsste ich bei der statischen Library ohne
dllexport, aber bei der DLL mit. Also müsste ich das doppelt
kompilieren. Und dann gibt es noch weitere Einschränkungen, wenn es um
das Exportieren / Importieren von Variablen statt Funktionen geht, unter
anderem. So ein scheiss.
> - clang liefert immer noch seitenweise Fehler
Da wird er sicher gute Gründe haben.
> Wenn ich den C Code als C++ kompiliere kracht es gleich wieder. Sorry,> aber das geht so nicht.
Es ist halt nun mal kein C++ Code, sondern C. Sorry, da bist du selber
schuld.
Daniel A. schrieb:>>> - clang liefert immer noch seitenweise Fehler>> Da wird er sicher gute Gründe haben.>>> Wenn ich den C Code als C++ kompiliere kracht es gleich wieder. Sorry,>> aber das geht so nicht.>> Es ist halt nun mal kein C++ Code, sondern C. Sorry, da bist du selber> schuld.
Du bist ganz schön weltfremd. Wie soll ich deine Hash Map und die C++
std::map gemeinsam testen? In der guten alten Zeit wäre das kein
Problem. Da hätte man ein 30 Zeilen Header File mit der Deklaration der
5 Funktionen, dazu "extern C" und etwas Doku und gut ist es. Die
Implementierung lebt in einer Lib oder einem C99 Source File. Ich als
Anwender muss davon nichts wissen, das kann jeder 0815 C Compiler auch
noch in 10 Jahren übersetzen.
Dein Header File hat aber über 1000 Zeilen und reizt alle möglichen
schlecht unterstützen C Konstrukte aus;
von den meisten habe ich vor diesem Thread noch nicht mal was gehört und
fast alles kommt mir unnötig kompliziert vor. Warum programmierst du
nicht C++? Bei deinem Programmierstil wäre das kompatibler, stabiler und
lesbarer. Die MS und Windows Jammerei ignoriere ich mal. Mir wird immer
ein Rätsel bleiben warum Informatiker mit aller Kraft die wenigen
Arbeitgeber die noch 6-stellig zahlen schlecht reden.
Ich kann mit allem möglichen Code gut leben, solange ich als Anwender
damit nicht in Berührung komme,
und solange das Ding compiliert und tut was es soll und das gut.
Und meine Hochachtung vor deinem Programmierwissen. Nur versuche dich
mal in Leute reinzudenken, die nicht so gut aufgestellt sind oder das
als Hobby machen, und die deinen Code verstehen wollen. Meiner Erfahrung
nach ist verständlicher Code auch wartbarer und performanter.
Ich habe nach etlichen unnötigen Hacks deine Hash Map mit MS CL
compiliert und mit anderen Suchverfahren verglichen. Die Ergebnisse
sind gut, rechtfertigen aber meiner Meinung nach nicht die Beschränkung
der Hashfunktion und den Code Bloat. Aber das ist ja noch eine 0-er
Version und da ist sicher Potential nach oben.
Zur Info: Die rote "Direct-Access" Kurve ganz unten ist der reine
Speicherzugriff auf die Daten. Die graue RobinHood-Hash-Direct-Key
Kurve ist Robin Hood mit perfekter Hash Funktion ohne Kollisionen. Die
grüne RobinHood-Hash Kurve verwendet einen CRC32C Hash. Dann kommt
deine Funktion, die etwa gleichauf std::unordered Hash ist. Im Bereich
um die 3000 Einträge gibt es zu viele Kollisionen, im Bereich unter 100
Einträge ist der Overhead relativ gross, da ist sogar die AVL Suche
schneller.
Gruss,
Udo
Udo K. schrieb:> In der guten alten Zeit wäre das kein> Problem.
In der guten alten Zeit gab es noch gar keine hash maps. Da gab es
Lochkarten. Oder welche Zeit meinst du?
C und C++ sind (und waren schon immer) verschiedene Sprachen, mit
verschiedenen Compilern.
Udo K. schrieb:> Du bist ganz schön weltfremd.
Oh ja...
Oliver
Oliver S. schrieb:> In der guten alten Zeit gab es noch gar keine hash maps. Da gab es> Lochkarten. Oder welche Zeit meinst du?
Hash Maps gibts schon länger als C. Aber der Wildwuchs an
Programmiersprachen Features ist seit 10-20 Jahren schon extrem.
Programmieren ist für mich ein Hobby, und die vielen Features sind für
mich nicht nützlich und verursachen unnötigen Schreibaufwand. Im ASM
Output sieht man dann meist auch gar keinen Unterschied, der Compiler
optimiert besser als der Anwender.
Erstmal, danke für das angehängter Benchmark. Das sieht doch recht gut
aus.
Udo K. schrieb:> Warum programmierst du> nicht C++? Bei deinem Programmierstil wäre das kompatibler, stabiler und> lesbarer.
Bevor ich zu C gewechselt bin, hatte ich C++ genutzt. Du hast ja
gesehen, was ich mit C anstellen kann, nun stell dir mal vor, was ich
mit all den Features von C++ machen würde.
Udo K. schrieb:> Nur versuche dich> mal in Leute reinzudenken, die nicht so gut aufgestellt sind oder das> als Hobby machen, und die deinen Code verstehen wollen.
Das Projekt von mir war auch nur ein Hobby. Da mache ich es so, wie ich
gerade Lust habe.
Udo K. schrieb:> Ich habe nach etlichen unnötigen Hacks deine Hash Map mit MS CL> compiliert und mit anderen Suchverfahren verglichen. Die Ergebnisse> sind gut, rechtfertigen aber meiner Meinung nach nicht die Beschränkung> der Hashfunktion und den Code Bloat.
Nochmal danke dafür. Um den Code Bloat zu reduzieren, und nichts doppelt
zu schreiben, inkludiere ich die Dateien eben mehrfach. Damit habe ich
dann 110 statt 1200 Zeilen beim Header File. Also ich finde das
übersichtlicher, als wenn ich nichts unterteilen und alles in ein File
packen würde.
---
Ich habe das selbe benchmark wie vorher mal mit den C++ set / map
Klassen nachgebaut, als Verglich.
gcc, C++ set / map:
1
$g++-O2-Wall-Wextra-pedanticbench.cpp-obench
2
$./bench.cpp
3
set<uc>add|10.525s
4
set<us>add|29.794s
5
set<u>add|87.840s
6
set<lu>add|81.112s
7
set<llu>add|99.008s
8
set<z>add|85.098s
9
set<u8>add|11.795s
10
set<u16>add|29.618s
11
set<u32>add|81.833s
12
set<u64>add|81.999s
13
set<p>add|80.658s
14
set<__int128_t>add|114.183s
15
16
map<uc>add|9.220s
17
map<us>add|28.469s
18
map<u>add|107.741s
19
map<lu>add|95.344s
20
map<llu>add|101.766s
21
map<z>add|95.376s
22
map<u8>add|10.369s
23
map<u16>add|30.314s
24
map<u32>add|102.433s
25
map<u64>add|93.427s
26
map<p>add|104.723s
27
map<__int128_t>add|88.617s
clang, C++ set / map:
1
set<uc>add|11.323s
2
set<us>add|27.782s
3
set<u>add|117.430s
4
set<lu>add|110.283s
5
set<llu>add|111.867s
6
set<z>add|112.654s
7
set<u8>add|12.415s
8
set<u16>add|27.915s
9
set<u32>add|109.823s
10
set<u64>add|111.677s
11
set<p>add|112.676s
12
set<__int128_t>add|133.795s
13
14
map<uc>add|13.560s
15
map<us>add|36.143s
16
map<u>add|118.259s
17
map<lu>add|120.783s
18
map<llu>add|120.638s
19
map<z>add|121.839s
20
map<u8>add|13.491s
21
map<u16>add|38.620s
22
map<u32>add|119.589s
23
map<u64>add|120.836s
24
map<p>add|114.451s
25
map<__int128_t>add|135.914s
gcc, Mein set / map (selber PC, aber ein anderer als gestern abend):
1
Function|total|work|resize
2
dpa_u_set_uc_add|0.864s|0.864s|0.000s
3
dpa_u_set_us_add|0.956s|0.921s|0.035s
4
dpa_u_set_u_add|7.135s|6.784s|0.351s
5
dpa_u_set_lu_add|21.386s|18.767s|2.619s
6
dpa_u_set_llu_add|24.449s|21.062s|3.387s
7
dpa_u_set_z_add|24.034s|21.085s|2.950s
8
dpa_u_set_u8_add|1.428s|1.428s|0.000s
9
dpa_u_set_u16_add|1.533s|1.476s|0.057s
10
dpa_u_set_u32_add|11.239s|10.534s|0.705s
11
dpa_u_set_u64_add|19.974s|17.449s|2.526s
12
dpa_u_set_u128_add|46.393s|40.270s|6.123s
13
dpa_u_set_pointer_add|29.691s|25.702s|3.989s
14
15
Function|total|work|resize
16
dpa_u_map_uc_set|7.148s|4.891s|2.257s
17
dpa_u_map_us_set|5.566s|4.613s|0.953s
18
dpa_u_map_u_set|37.319s|34.401s|3.918s
19
dpa_u_map_lu_set|40.535s|35.293s|5.242s
20
dpa_u_map_llu_set|38.812s|32.829s|5.983s
21
dpa_u_map_z_set|39.403s|33.734s|5.669s
22
dpa_u_map_u8_set|7.576s|5.140s|2.436s
23
dpa_u_map_u16_set|5.917s|4.898s|1.019s
24
dpa_u_map_u32_set|37.992s|34.297s|3.694s
25
dpa_u_map_u64_set|36.835s|31.862s|4.973s
26
dpa_u_map_u128_set|60.030s|52.256s|7.774s
27
dpa_u_map_pointer_set|43.443s|36.785s|6.659s
Das war auf Debian mit g++. Meine Implementierung ist rund 2-12x
schneller! Zumindest beim Hinzufügen, und bei grossen Datenmengen.
Was mich beim std::set und std::map erstaunt, ist, dass die Grösse des
Keys nicht so starken Einfluss auf die Performance hat, wie bei meinem
Hash Set / Hash Map. Und auch der Unterschied zwischen der Performance
des Maps und des Sets ist bei der STL geringer. Ich frage mich, woran
das liegen könnte. Vielleicht hätte ich key & value ins selbe Array
packen sollen, statt in separate?
Wie dem auch sei, an den kleinen Datentypen (unsigned char short
uint16_t, usw.), sieht man, dass sich die Spezialisierung da durchaus
gelohnt hat, nicht nur zum sparen von Speicherplatz, auch
Geschwindigkeitsmässig.
Daniel A. schrieb:> Wie dem auch sei, an den kleinen Datentypen (unsigned char short> uint16_t, usw.), sieht man, dass sich die Spezialisierung da durchaus> gelohnt hat, nicht nur zum sparen von Speicherplatz, auch> Geschwindigkeitsmässig.
Hast du in deiner Anwendung denn so harte Anforderungen bzgl.
Speicherplatz und Geschwindigkeit?
Momentan schreibe ich mir eine Utility Library. Ich packe da alles rein,
was bei anderen / zukünftigen Projekten nützlich sein könnte.
Früher habe ich immer mal wieder Code zwischen Projekten herum kopiert.
Jetzt mach ich das einmal richtig, so dass ich all den Kram an einem Ort
zentral habe.
Memory Management primitive, Refcounting, Mathe Funktionen, UTF-8
Hilfsfunktionen, diverse Hash Maps & Sets für diverse unterschiedliche
use-cases, übliche Macros (z.B. container_of), etc.
Es ist nicht so, das ich es für eine konkrete Anwendung brauchen würde.
Es muss eigentlich auch nicht besser sein als bestehendes, auch wenn es
erfreulich ist, wenn es gut performt.
Das wird quasi meine kleine persönliche Bastelkiste. Eine kleine Welt,
wo alles so läuft, wie mir das gefällt, und wo alles drin ist, was ich
so brauche.
Momentan fehlt noch so einiges, aber ich komme doch recht gut voran.
Daniel A. schrieb:> Was mich beim std::set und std::map erstaunt, ist, dass die Grösse des> Keys nicht so starken Einfluss auf die Performance hat, wie bei meinem> Hash Set / Hash Map. Und auch der Unterschied zwischen der Performance> des Maps und des Sets ist bei der STL geringer. Ich frage mich, woran> das liegen könnte. Vielleicht hätte ich key & value ins selbe Array> packen sollen, statt in separate?
Hier unter Windows 10 ist bei deinem Test map schneller als set -
interessant. Alles ist ziemlich unabhängig von der Grösse der Keys.
Der Test ist aber ziemlich uninteressant. Er testet ja nur das
Einfügen. In praktisch allen Fällen ist die Geschwindigkeit beim Suchen
interessant.
Gibt es einen Grund dass du das nicht testest? Ein realistisches
Szenario addiert immer wieder "Sets" von einigen 100-1000 Einträgen,
sucht dann wiederholt, entfernt Sets etc. etc. Und das über zumindest
15-60 Minuten. Da kann es zu Fragmentierung und lokalen Anhäufungen in
der Map kommen. Sieht man im angehängten Bild: Über die Zeit ändern
sich die Kollisionen, und die Zugriffszeiten. Eine mittelmässige Hash
Map degeneriert da mit der Zeit, eine gute hält die Performance.
Das es kaum Unterschiede bei der Grösse der Keys gibt klingt erst mal
vernünftig, da die Zeit vom Lesen einer Cache Line (32 Byte) bestimmt
wird. Die Einträge liegen ja zufällig im Speicher. Der hohe
Speicherverbrauch der C++ Container dürfte auch an der mittelmässigen
Performance in meinen Test weiter oben Schuld sein.
PS: Beim Testen sollte in der inneren Schleife kein Funktionsaufruf
drinnen sein, das verhindert Optimierungen, und hier geht es um
Nanosekunden.
Udo K. schrieb:> Er testet ja nur das> Einfügen. In praktisch allen Fällen ist die Geschwindigkeit beim Suchen> interessant.> Gibt es einen Grund dass du das nicht testest?
Das Einfügen zu testen war am einfachsten. Und wenn das Einfügen schnell
ist, sollte es auch der Lookup sein, denn ich mache beim Einfügen immer
zuerst einen Lookup, um die Position raus zu kriegen, wo der Eintrag ist
oder hin soll.
Udo K. schrieb:> Ich habe nach etlichen unnötigen Hacks deine Hash Map mit MS CL> compiliert und mit anderen Suchverfahren verglichen.
Eine Frage habe ich dazu noch. War das mit Optimierungen ( /O2 ) oder
ohne?
Ich weiss nicht, wie das bei MS CL ist, aber bei GCC & Clang macht das
massive Unterschiede (ungefähr 2x).
Ich konnte set-and-map.c nicht als C++ Source compilieren wegen zig
kleiner Fehler (z.B. Rückgabewert von malloc muss immer gecasted werden
und das "restrict" keyword geht nicht).
Ich habe daher set-and-map.c als C File mit -O2 und Codegenerierung zur
Linkzeit compiliert (-GL), und dann das obj File mit dem C++ Testprogram
gelinkt. Meiner Erfahrung nach geht das verdammt gut, und macht inline
Funktionen überflüssig.
Ich verwenden in den Tests eine Tabelle mit LINE Strukturen von 32
Bytes:
1
typedefstructline
2
{
3
AVLNODEnode;/* 16 Bytes */
4
#if STRING_KEYS
5
charid[DATA_SIZE-16];/* string key */
6
#else
7
key_tid;/* integer key */
8
#endif
9
#if FILL_DATA > 0
10
BYTEfill_data[FILL_DATA];
11
#endif
12
}LINE;
Kann ich deine DPA set (nicht map) Funktionen mit dem integer key in den
Strukturen verwenden (mit offset=16)? So wie ich das verstehe wird bei
den set Funktionen kein separater key abgespeichert, da der key in den
Daten enthalten ist, die set Funktion könnte damit schneller sein.
Ich weiss jetzt nicht genau, was du vor hast. Den Key selbst kannst du
schon zum Set hinzufügen | Abfragen | Löschen.
Du kannst auch einen Pointer auf die Struktur darin speichern. Der wird
dann aber nicht dereferenziert, der Pointer selbst wäre dann der Key,
nicht das, auf das er zeigt.
Daniel A. schrieb:> Ich weiss jetzt nicht genau, was du vor hast. Den Key selbst kannst du> schon zum Set hinzufügen | Abfragen | Löschen.> Du kannst auch einen Pointer auf die Struktur darin speichern. Der wird> dann aber nicht dereferenziert, der Pointer selbst wäre dann der Key,> nicht das, auf das er zeigt.
Der Key ist in den Daten enthalten. Die Hash Map soll einen Zeiger auf
die Daten speichern, und muss wissen dass der Key an einem Offset in den
Daten drinnen steht. Damit entfällt das getrennte Speichern von Key und
Daten.
Das habe ich noch nicht implementiert. Habe ich eigentlich auch nicht
vor.
Das würde sicher etwas Speicherplatz sparen, aber ich bezweifle, dass
das schneller wäre. Der Lookup ist momentan (für die meisten Datentypen)
2 Vergleiche:
1
while(1){
2
constTekey=that->key_list[i];
3
Tpsl_b=ekey-((T)i<<shift);
4
if(psl_b==psl_a)
5
return(structlookup_result){i,true};
6
if(psl_a<=(T)(psl_b-1))// Das -1 ist ein hack, psl_b == 0 wäre ein leerer Eintrag.
7
return(structlookup_result){i,false};
8
psl_a-=I;
9
i=(i+1)&mask;
10
}
Wobei, eigentlich könnte ich den Vergleich `psl_b == psl_a` aus der
Schleife raus nehmen. Muss ich später mal machen.
Jedenfalls, momentan sind das ein paar simple Vergleiche
aufeinanderfolgender Einträge. Ich hab die Hashs, und vergleiche sie.
Würde ich stattdessen einen Pointer auf den Key Speichern, müsste ich
zusätzlich den Pointer dereferenzieren, und den key Hashen, bevor ich
den Vergleich machen kann. Das sind mehr Operationen, und den Cash würde
es vermutlich auch nicht freuen.
Daniel A. schrieb:> Das habe ich noch nicht implementiert. Habe ich eigentlich auch nicht> vor.
Schade, das ist ein ziemlich häufiger Anwendungsfall.
Mir ist aufgefallen das der Rückgabewert ein struct ist
(dpa_u_optional_pointer_t).
Das ist suboptimal. Erstens schmeisst du ein wertvolles Register weg
(rax ist unbenutzt, struct werden in rcx als Zeiger übergeben), zweitens
kostet der Aufruf der Suchfunktion Performance, weil erst die
Rückgabewerte auf den Stack kopiert werden muss. Ich kann nicht einfach
den Rückgabewert auf NULL vergleichen, sondern muss den "present" des
dpa_u_optional_pointer_t Eintrag auf dem Stack abfragen, und wenn der
true ist, muss ich mir den Zeiger Wert vom Stack holen.
Deine Funktion ist damit auch die einzige aller Suchfunktionen, die
Optimierung des Programms zur Link Zeit braucht, um auf eine
passable Performance zu kommen. Ich nehme an, dass der Optimizer diese
komplizierten Rückgabewerte zur Linkzeit auflöst. Im Anhang die
Performance mit O1, O2 und O2 mit globaler Link-Zeit Optimierung.
Udo K. schrieb:> Mir ist aufgefallen das der Rückgabewert ein struct ist> (dpa_u_optional_pointer_t). Das ist suboptimal.
Oh. Das das etwas ausmachen könnte, daran hatte ich noch überhaupt nicht
gedacht.
Der Grund für das dpa_u_optional_pointer_t war eigentlich nur, dass die
Funktion dann als [[`reproducible`]], also ohne Seiteneffekte, markiert
werden kann.
Wobei, das einzige was das bringt, ist das wenn man sowas macht:
1
if(dpa_u_map_u_get(&map,123).present)
2
puts(dpa_u_map_u_get(&map,123).value);
Dann können, zumindest gcc und clang, den zweiten Aufruf von
dpa_u_map_u_get weg optimieren.
Muss ich mir mal genauer ansehen, ist ja einfach anzupassen. Vielleicht
könnte ich auch eine inline Wrapper Funktion machen, um das beste beider
Welten zu bekommen. Der Compiler könnte die dann weg optimieren, und ich
könnte ihm immer noch mitteilen, das es keine Seiteneffekte gibt. (Wenn
ich den Wert per Pointer zurückgebe, ist das ein Seiteneffekt, und mit
`reproducible` würde der Compiler dann annehmen, dass der Wert nicht
geändert wurde, daher kann ich nicht beides direkt machen).
https://en.cppreference.com/w/c/language/attributes/unsequenced
Ich frage mich aber, macht das wirklich etwas aus?
https://godbolt.org/z/TWv6saz5e
Ich bin nicht so der Assembler Typ, daher kann ich das nicht so gut
einschätzen, aber so wild sieht das, zumindest beim gcc, doch eigentlich
gar nicht aus. Vielleicht ein pop mehr, wenn überhaupt, aber ansonsten
ziemlich das selbe.
Ich habe dein set-and-map.c mit einem aktuellen msys2 gcc compiliert und
zum Testprogram gelinkt. Die Laufzeit ist marginal schlechter, die Exe
ist aber von 30k auf 120k gewachsen, bringt also nichts. Was du
probieren kannst, ist deine Funktionen C++ kompatibel zu machen. Dann
kann ich das ganze set-and-map File in das Testprogram inkludieren, oder
du packst alles mit inline in den Header. Meiner Meinung nach ist die
Aufrufkonvention aber nicht ganz optimal, sonst würde das Link-Time
optimieren nichts mehr bringen.
Ohne die Link-Time Optimierung ist eine einfache binäre Suche mit 21
Zeilen Sourceode bis 10000 Elemente schneller als deine Hashtabelle.
Unter 30 Elemente hast du das langsamste Suchverfahren erfunden. Das
nenne ich suboptimal. Die neueren Tests liefen auf einem Laptop, die
ersten Tests mit besseren Ergebnissen auf einem schnelleren Rechner mit
Core i9 und sehr schnellem RAM.
Udo K. schrieb:> Unter 30 Elemente hast du das langsamste Suchverfahren erfunden.
Es ist immer noch normales Robin Hood Hashing, der Algorithmus ist nicht
das Problem. Ich muss nur die Implementierung noch etwas verbessern.
Daniel A. schrieb:>> Unter 30 Elemente hast du das langsamste Suchverfahren erfunden.>> Es ist immer noch normales Robin Hood Hashing, der Algorithmus ist nicht> das Problem. Ich muss nur die Implementierung noch etwas verbessern.
Das ist halt der Unterschied zwischen Theorie und Praxis 😇
Wenn du neue Ideen hast, probiere ich es gerne aus. Die Sourcen vom
Testprogram kann ich bei Bedarf rausrücken, aber das läuft nur unter
Windows und war ein schneller Wochenend-Hack, der mit der Zeit noch
aufgebohrt worden ist.
Gruss & gutes Gelingen,
Udo
Udo K. schrieb:> Die Sourcen vom> Testprogram kann ich bei Bedarf rausrücken, aber das läuft nur unter> Windows und war ein schneller Wochenend-Hack, der mit der Zeit noch> aufgebohrt worden ist.
Das wäre sehr praktisch. Eventuell könnte ich dann auch versuchen, das
auf Linux zu portieren.
Im Anhang die Sourcen. Ich habe mal versucht den Win spezifischen Teil
rauszunehmen. Da musst du sicher noch was anpassen damit der gcc
glücklich ist. Für die Zeitmessung verwende ich den NT Performance
Counter, da müsstest du clock() oder was unter Linux für genaue
Zeitmessung verwendet wird, einsetzen. Wenn du Zeiten unter 1ns messen
willst, dann spielt auch Alignment und Layout der Funktionen eine Rolle.
Da musst du probieren, falls dir das wichtig ist. Aufrufen geht mit:
build.sh -> run4.sh -> run4.png
Danke, mittlerweile habe ich es kompiliert bekommen. Für die
PerfCountStamp muss ich mir vermutlich noch was anderes suchen als
clock(), das ist vermutlich nicht genau genug, aber ich habe schon mal
einen Output. Im Anhang noch die Dateien, die ich verändert habe, und
das Diagramm.
Edit: Ich sehe gerade, die Bezeichnungen im Diagramm muss ich noch
anpassen. War mit "gcc (Debian 12.2.0-14) 12.2.0", auf einem "12th Gen
Intel(R) Core(TM) i5-1235U", Optionen -O2.
Zur Zeitmessung verwende ich nun
`clock_gettime(CLOCK_PROCESS_CPUTIME_ID,...)`.
Ich konnte es nun auch noch ein wenig Optimieren, indem ich einen
Vergleich in der Lookup Funktion aus der Schleife raus nahm, die Lookup
Funktion geinlined habe, und noch an einer Stelle mit der Branch
Prediction nachgeholfen habe. Vermutlich lässt sich da noch mehr raus
holen, ich könnte z.B. bei `(that->key_list[i>>shift])-i-1` das -i-1
schon beim Insert machen, dann wäre in der Schleife nur noch ein
Vergleich, und der shift würde auch noch wegfallen.
Ich weiss nicht, warum es bei dir im Vergleich bei msvc so viel
schlechter abschliesst. Vielleicht ist das Windows ABI da einfach
ineffizienter oder so.
PS: -flto macht bei mir keinen unterschied. Wird hier sogar eher
schlechter damit.