Da kann doch nur die Arduino-IDE einen Bug haben oder ?
C kann doch direkt ein 16-Bit-Register, wie es dass OCR3A ist
beschreiben.
Auch der Versuch OCR3AL & OCR3AH einzeln zu beschreiben funktioniert
nicht.
Hatten wir das nicht letztens schon?
Arduino bereitet alle Timer Für eine 8 Bit PWM vor.
Hatten wir das nicht letztens schon?
Setze, bevor du irgendwas anderes mit dem Timer tust, die
Controllregister auf Null.
Hatten wir das nicht letztens schon?
Bernd S. schrieb:> Programmierung von AVR8-Mikrocontrollern in C
Das ist C++, mein Lieber!
C++! Nix C!
Mein Lieber.
Bernd S. schrieb:> Da kann doch nur die Arduino-IDE einen Bug haben oder ?
Was soll die denn Schuld sein, wenn du unmögliches versucht....
Bernd S. schrieb:> Da kann doch nur die Arduino-IDE einen Bug haben oder ?
Auch wenn man das ab und zu denkt. Meist ist es nicht so und das Problem
sitzt vor dem Bildschirm.
Mampf F. schrieb:> Gabs da nicht mal was, dass man erst L und dann H beschreiben muss,> damit das mit dem Beschreiben von H dann als 16Bit Wert aktiv wird?
ja. Auch beim Auslesen (z.B. des ADC-Werteregisters).
Arduino F. schrieb:> Arduino bereitet alle Timer Für eine 8 Bit PWM vor.
Ich dachte immer das Arduino-Framwork lässt alle Hardware
in Ruhe bis auf die die es wirklich braucht. Im Fall der
Timer wäre das beim Arduino Timer0 und sonst nichts. Also
nicht alle Timer.
Georg M. schrieb:> C ist C, und Arduino ist Arduino.
Arduino verwendet einen GCC Compiler.
https://gcc.gnu.org/
Durch welche IDE der aufgerufen wird, ist doch egal.
Rainer W. schrieb:> Du kannst nicht erst das H-Byte und dann das L-Byte lesen. Dann holst du> einen alten Wert aus dem TEMP-Register, der nicht zu deinem L-Byte> gehört.
Richtig, genau anders herum funktioniert es.
N. M. schrieb:> Bernd S. schrieb:>> Da kann doch nur die Arduino-IDE einen Bug haben oder ?>> Auch wenn man das ab und zu denkt. Meist ist es nicht so und das Problem> sitzt vor dem Bildschirm.
Im Studium habe ich mal mit Betreuern des Uni-RZ gesprochen. Die haben
mir erzählt, sie hätten bei der Nutzerbetreuung mal Erbsen gezählt und
dabei herausgefunden, dass von 1000 Reklamationen der Art "Der Compiler
X arbeitet falsch" nur eine einzige berechtigt gewesen war.
Später dann, in meiner ersten Arbeitsstelle fing ich zusammen mit einem
Computer-Anfänger an (Mathematik-Studium abgebrochen) an, der manchmal
nervlich fast zusammengebrochen ist, weil seine FORTRAN-Programme nicht
liefen. Waren aber immer seine Fehler, die ich oder jemand anders ihm
zeigen musste.
Arduino F. schrieb:> Arduino bereitet alle Timer Für eine 8 Bit PWM vor.> Hatten wir das nicht letztens schon?>
Jo das wars, danke. Habe wohl ein schlechtes Gedächnis, es kommt mir
aber bekannt vor. Habe TCCR3A bis C auf null gesetzt.
Rahul D. schrieb:> auch ein Achtbitter darf 16-Bit-Register haben...
Ja, hatte schon der 8-Bitter Z80 vor fast 50 Jahren.
Wenn man aber Hardware-Komponenten programmiert, dann studiert man IMMER
das Datenblatt des Prozessors. Ganz gleich, was die Programmiersprache
kann/könnte.
Bernd S. schrieb:> kann doch direkt ein 16-Bit-Register, wie es dass OCR3A ist beschreiben
Du hast da einen sehr interessanten Fall konstruiert. Die
OCR-Doppelregister des AVR müssen byteweise in einer bestimmten
Reihenfolge geschrieben und auch gelesen werden. Der gcc-Compiler tut
das bei direkten 16-Bit-Zugriffen auf solche Doppelregister auch schön.
Allerdings übergibst du in deinem Code das OCR3A-Doppelregister an
println(). Und ich vermute stark, dass innerhalb von println() das
Wissen über diese Spezialbehandlung verloren gegangen ist. Ich werde mal
versuchen, das nachzuvollziehen.
LG, Sebastian
Wastl schrieb:> Ich dachte immer das Arduino-Framwork lässt alle Hardware> in Ruhe bis auf die die es wirklich braucht. Im Fall der> Timer wäre das beim Arduino Timer0 und sonst nichts. Also> nicht alle Timer.ALLE Timer.
Sebastian W. schrieb:> Und ich vermute stark, dass innerhalb von println() das> Wissen über diese Spezialbehandlung verloren gegangen ist.
Nein!
println() bekommt nur den Wert zu sehen, das Makro wird vorher
ausgewertet, bevor Print überhaupt was tut.
Sebastian W. schrieb:> Du hast da einen sehr interessanten Fall konstruiert.
Das hat ihm wirklich!
Arduino macht den Timer zu einem 8 Bit PWM Timer und ihm versucht dort
16 Bit in ein Register zu schreiben, welches aufgrund der vorher
erfolgten Konfiguration nur 8 Bit aufnehmen kann.
Bernd S. schrieb:> Jo das wars, danke.
Fein!
Arduino F. schrieb:> Sebastian W. schrieb:>> Und ich vermute stark, dass innerhalb von println() das>> Wissen über diese Spezialbehandlung verloren gegangen ist.> Nein!>> println() bekommt nur den Wert zu sehen, das Makro wird vorher> ausgewertet, bevor Print überhaupt was tut.
Ok, ich hab mit das Datenblatt des Atmega2560P und den Arduino-Code noch
einmal vorgenommen:
1. "Reading the OCRnA/B/C 16-bit registers does not involve using the
Temporary Register." und "The Timer/Counter does not update this
register automatically"
2. wiring.c::init():
1
sbi(TCCR3B,CS31);// set timer 3 prescale factor to 64
2
sbi(TCCR3B,CS30);
3
sbi(TCCR3A,WGM30);// put timer 3 in 8-bit phase correct pwm mode
3. WGMn3:0=1, PWM, Phase Correct, 8-bit, TOP=0x00FF
4. "Note that when using fixed TOP values the unused bits are
masked to zero when any of the OCRnx Registers are written."
5. OCR3A ist definiert als _SFR_MEM16(0xnn). _SFR_MEM16 ist definiert
als _MMIO_WORD. _MMIO_WORD ist definiert als * (volatile uint16_t * ).
@arduinof, du hast also recht. An println wird keine Referenz auf eine
Variable übergeben, sondern ein Wert. Und in OCR3A steht tatsächlich
nach der Zuweisung von 500 der Wert 244, weil die oberen 8 Bit durch den
in init() eingestellten PWM-Modus schon bei der Zuweisung maskiert
werden.
Wieder was gelernt.
LG, Sebastian
Mampf F. schrieb:> Gabs da nicht mal was, dass man erst L und dann H beschreiben> muss,> damit das mit dem Beschreiben von H dann als 16Bit Wert aktiv wird?
Ja. Der gcc weiß das aber und macht es bei 16-Bit Zugiffen automatisch.
Sebastian W. schrieb:> 1. "Reading the OCRnA/B/C 16-bit registers does not involve using the> Temporary Register." und "The Timer/Counter does not update this> register automatically"
Eben. Wegen letzterem ist ersteres nicht notwendig. ATMEL hat das
temp-Register nur dort implementiert, wo es notwendig ist.
Sebastian W. schrieb:> @arduinof, du hast also recht.
Nicht immer, aber in Sachen Arduino und drum rum doch schon recht
häufig.
Und: Danke für die Überprüfung/Klärung.
Interessant, dass du der Erste bist, der das in diesem Thread öffentlich
getan hat. Eigentlich erwarte ich das von einem Threadersteller, bevor
die Frage gestellt wird.
Denn die nötige Information liegt ja öffentlich aus.
Sebastian W. schrieb:> Wieder was gelernt.
Einer der Gründe, warum auch ich hier bin. Man muss nur ein wenig
aufpassen, dass man hier das richtige lernt.
Schlussendlich:
Man kann von der Arduino IDE halten, was man will....
Aber hier, in diesem konkreten Fall, ist sie vollständig von jeder
Schuld freizusprechen.
Jetzt was Anderes.
Hat jemand eine elegantere bzw. in der Programmabarbeitung schnellere
Idee ?
Es soll immer zwischen den MIN,- und MAX-Wert mit der SCHRITTWEITE hin
und hergependelt werden ( siehe Anhang ).
Bernd_Stein
Bernd S. schrieb:> Es soll immer zwischen den MIN,- und MAX-Wert mit der SCHRITTWEITE hin> und hergependelt werden ( siehe Anhang ).
Schon mal was von einer for() Schleife gehört? Nicht zu verwechseln mit
der imaginären if()-Schleife.
http://www.if-schleife.de/
Arduino F. schrieb:> Schlussendlich:> Man kann von der Arduino IDE halten, was man will....> Aber hier, in diesem konkreten Fall, ist sie vollständig von jeder> Schuld freizusprechen.
Ähem, nö. Erstens ging es nicht um die IDE (die ist vergleichsweise
sowieso ziemlich grottig), sondern eher um das Framework.
Und auch das ist grottig. Und das zeigt sich sogar am konkreten Fall
besonders deutlich. Es kann doch nicht sein, dass es ungefragt einen
Timer aquiriert, dessen Funktionalität in der gebotenen Form dann aber
garnicht genutzt wird und damit letztlich den Programmierer dabei
behindert, den Timer für das zu nutzen, was er tatsächlich tun will.
Ja OK, dieses Fehlverhalten ist wenigstens dokumentiert. Wäre ja auch
noch viel schlimmer, wenn nichtmal das der Fall wäre. Das wäre dann
vorsätzliche Sabotage. Aber auch der gegenwärtige Sachverhalt ist meiner
Meinung nach nicht sehr weit weg davon.
Denn technisch gäbe es durchaus die Möglichkeit, bereits zur Compilezeit
(!) festzustellen, ob die vom Framework gebotene Timer-Funktionalität
vom Anwenderprogramm überhaupt genutzt wird und, wenn das nicht der Fall
ist, den Timer einfach mal in Ruhe zu lassen.
Ob S. schrieb:> Denn technisch gäbe es durchaus die Möglichkeit, bereits zur Compilezeit> (!) festzustellen, ob die vom Framework gebotene Timer-Funktionalität> vom Anwenderprogramm überhaupt genutzt wird und, wenn das nicht der Fall> ist, den Timer einfach mal in Ruhe zu lassen.
Man könnte auch einfach aufhören zu plappern und zu heulen und den Timer
VOLLSTÄNDIG und RICHTIG initialisieren. Dann klappt das auch.
Falk B. schrieb:> Ob S. schrieb:>> Denn technisch gäbe es durchaus die Möglichkeit, bereits zur Compilezeit>> (!) festzustellen, ob die vom Framework gebotene Timer-Funktionalität>> vom Anwenderprogramm überhaupt genutzt wird und, wenn das nicht der Fall>> ist, den Timer einfach mal in Ruhe zu lassen.>> Man könnte auch einfach aufhören zu plappern und zu heulen und den Timer> VOLLSTÄNDIG und RICHTIG initialisieren. Dann klappt das auch.
Vollständig heißt aber in jeder anderen Umgebung: ausgehend vom im DB
dokumentierten Reset-State.
Bei der Arduino-Gülle aber eben nicht. Und das, obwohl es technisch
möglich wäre, die unnütze Doppelinitialisierung, auf die es ansonsten
hinausläuft, einfach mal einzusparen. Das wäre im Minimum gut für die
Codegröße. Aber natürlich auch gut zur Vermeidung derartiger
Überraschungen.
Bernd S. schrieb:> Jetzt was Anderes.
Dann wäre es jetzt auch an der Zeit, für etwas anderes einen neuen
Thread zu eröffnen - nur um die Dinge ein bisschen sortiert zu halten.
Ob S. schrieb:> Vollständig heißt aber in jeder anderen Umgebung: ausgehend vom im DB> dokumentierten Reset-State.
Ja und? Im ZWEIFELSFALL muss man halt ALLE Register setzen. So what!
> Bei der Arduino-Gülle aber eben nicht. Und das, obwohl es technisch> möglich wäre, die unnütze Doppelinitialisierung, auf die es ansonsten> hinausläuft, einfach mal einzusparen.
Ach du Ärmster, die Doppelinitialisierung! Das ist so wie Doppel-Wums!
Oder Doppelpass!
> Das wäre im Minimum gut für die> Codegröße.
Schon wieder Weltrettungsphantasien? Musst du deinen Flash-Verbrauch
minimieren, so wie auch deine CO2 Erzeugung? Wie Klimaschädlich ist
Flash-Speicher in CO2 Äquivalenten? ;-)
Ob S. schrieb:> Vollständig heißt aber in jeder anderen Umgebung: ausgehend vom im DB> dokumentierten Reset-State.>> Bei der Arduino-Gülle aber eben nicht. Und das, obwohl es technisch> möglich wäre, die unnütze Doppelinitialisierung,
Da Du ja offensichtlich der Programmiergott bist, koenntest Du Dich
bei Arduino einbringen und die Issues (die es gibt) zum Teil loesen.
si tacuisses, philosophus mansisses. Oder Machen: Das ist naemlich wie
wollen, nur krasser.
Vax W. schrieb:> Da Du ja offensichtlich der Programmiergott bist, koenntest Du Dich> bei Arduino einbringen und die Issues (die es gibt) zum Teil loesen.
1) Das sind keine "issues", jedenfalls nicht in dem Sinne, wie man das
üblicherweise versteht. Das sind grundlegende Fehler im Konzept des
Frameworks.
2) Ich habe mit meiner verbleibenden Lebenszeit sicher Besseres vor, als
dieses grottige Framework nochmals von Grund auf neu zu schreiben.
Falk B. schrieb:> Ob S. schrieb:>> Vollständig heißt aber in jeder anderen Umgebung: ausgehend vom im DB>> dokumentierten Reset-State.>> Wie Klimaschädlich ist> Flash-Speicher in CO2 Äquivalenten? ;-)
Bitte nehmt Euch ein Separée.
Ob S. schrieb:> 1) Das sind keine "issues", jedenfalls nicht in dem Sinne, wie man das> üblicherweise versteht. Das sind grundlegende Fehler im Konzept des> Frameworks.
Das ist deine Beurteilung!
Wenn du nicht willst, dass das Framework die Dinge initialisiert, dann
solltest du auf die Initialisierung verzichten. Arduino Jünger wissen
meist wie das geht. Du offensichtlich nicht.
Tipp:
Eine eigene main() anlegen, dann werden die Timer (und einiges andere)
nicht angefasst.
Arduino F. schrieb:> Wenn du nicht willst, dass das Framework die Dinge initialisiert, dann> solltest> du auf die Initialisierung verzichten. Arduino Jünger wissen meist wie> das geht. Du offensichtlich nicht.
Ich löse das Problem viel einfacher: Ich benutze das Framework (und auch
die IDE) generell nicht.
Funktioniert nämlich alles wunderbar auch ohne diesen Mist!
delay(1000);// nur, damit es nicht zu schnell durchhuscht
44
}
Ob S. schrieb:> Erstens ging es nicht um die IDE
Doch um genau die ging es im Eröffnungsposting.
Hast du scheinbar auch übersehen...
Sicherlich wegen zuviel Schaum vorm Mund.
Falk B. schrieb:> Je ne parle pas français!
Dann unterlass' doch einfach den Versuch. Von dir angedeutete oder
behauptete Kompetenz (in irgendeiner Hinsicht) nimmt dir eh' niemand ab,
der wirklich weiß, wie der Laden läuft...
Ob S. schrieb:> Ich löse das Problem viel einfacher: Ich benutze das Framework (und auch> die IDE) generell nicht.
Darf ich dich als "Windbeutel" bezeichnen?
Warum buddelst du auf Baustellen, die dich nix angehen?
Arduino F. schrieb:> Ob S. schrieb:>> Erstens ging es nicht um die IDE> Doch um genau die ging es im Eröffnungsposting.
Nicht wirklich.
Das war nur das, wo Bernd S. das Problem lokalisiert zu haben glaubte...
Aber der Typ kann nach >10 Jahren Praxis immer noch nicht kompetent mit
AVR8-Assembler umgehen. Ist also eher nicht dazu geeignet,
einzuschätzen, wo ein Problem beheimatet ist.
Ob S. schrieb:> Dann unterlass' doch einfach den Versuch. Von dir angedeutete oder> behauptete Kompetenz (in irgendeiner Hinsicht) nimmt dir eh' niemand ab,> der wirklich weiß, wie der Laden läuft...
Geh mal besser hier hin
-> Humorbefreite Zone!
Gehe sofort dort hin.
Ziehe keine 4000 Euro ein!
Arduino F. schrieb:> Darf ich dich als "Windbeutel" bezeichnen?
Nein. Das würde ich als Beleidigung auffassen.
> Warum buddelst du auf Baustellen, die dich nix angehen?
Man muss immer auch mal über den Tellerrand schauen. Genau dies kannst
du und deinesgleichen scheinbar nicht.
Na ihr Streithammel, könnt ihr auch mal wieder produktiv sein und mir
erklären, warum ich das Output Compare A3 Match-Flag nicht löschen kann.
Das niederwertige Nibble bleibt immer gleich ( alles Einsen ).
1
// Flag auswerten um guenstigen Moment zu erwischen
2
if(TIFR3&OCF3A){
3
4
Serial.print("TIFR3 = ");
5
Serial.print(TIFR3,BIN);
6
Serial.println();
7
8
OCR3A=rampeArray[rampeArrayZeiger];
9
TIFR3=1<<OCF3A;// Flag durch schreiben einer 1 loeschen
Bernd S. schrieb:> TIFR3 = 1<< OCF3A; // Flag durch schreiben einer 1 loeschen
vielleicht weil du nicht das machst was im Kommentar steht...
TIFR3 |= 1<< OCF3A; // Flag durch schreiben einer 1 loeschen
Thomas Z. schrieb:> vielleicht weil du nicht das machst was im Kommentar steht...>> TIFR3 |= 1<< OCF3A; // Flag durch schreiben einer 1 loeschen>
Mit deiner Schreibweise, lasse ich ja nur die anderen Bits in dem
Register unberührt. Ich habe das Register komplett neu beschrieben, d.h.
die anderen Bits bleiben trotzem unberührt, da sie ja nur durch
Schreiben einer 1 gelöscht werden können.
Da bin ja wiedermal gespannt, was nun die Ursache für das Phänomen ist.
Bernd_Stein
Thomas Z. schrieb:> Bernd S. schrieb:>> TIFR3 = 1<< OCF3A; // Flag durch schreiben einer 1 loeschen>> vielleicht weil du nicht das machst was im Kommentar steht...
Ausnahmsweise doch. Denn die Bits in DEM Register verhalten sich anders
als normale Speicherzellen. Siehe Datenblatt.
> TIFR3 |= 1<< OCF3A; // Flag durch schreiben einer 1 loeschen
Nein.
Bernd S. schrieb:> Da bin ja wiedermal gespannt, was nun die Ursache für das Phänomen ist.
Vermutlich die Verzögerung vom Löschen zur Ausgabe durch die
print-Anweisung. Denn deine PWM läuft vermutlich mit sehr hoher Frequenz
und print ist bei 9600 Baud schnarchlangsam. Eher so.
1
OCR3A=rampeArray[rampeArrayZeiger];
2
TIFR3=1<<OCF3A;// Flag durch schreiben einer 1 loeschen
Falk B. schrieb:> Vermutlich die Verzögerung vom Löschen zur Ausgabe durch die> print-Anweisung. Denn deine PWM läuft vermutlich mit sehr hoher Frequenz> und print ist bei 9600 Baud schnarchlangsam.>
Wiedermal Danke, genau das war es.
Bernd_Stein
Falk B. schrieb:> Ausnahmsweise doch. Denn die Bits in DEM Register verhalten sich anders> als normale Speicherzellen. Siehe Datenblatt.
Nicht nur in dem Register: man achte auf den Namen: Flag-Register. Davon
gibt es viele. Da man an einem schnellen (atomaren) Löschen der Flags
interessiert ist, hilft uns hier die HW.
Leider sind die Datenblätter von Atmel/MicroChip sehr schlecht. In
dieser Hinsicht sind bspw. die DB von STM besser: hier steht es ganz
klar bei jedem Flag dabei, ob es rc_w0, rc_w1 oder rc_w, rc_r, rs_r ist.
Wilhelm M. schrieb:> Leider sind die Datenblätter von Atmel/MicroChip sehr schlecht.
So ein Unsinn! Nur weil die hier vielleicht nicht ganz so gut wie andere
sind, sind sie nicht generall schlecht!
Falk B. schrieb:> Wilhelm M. schrieb:>> Leider sind die Datenblätter von Atmel/MicroChip sehr schlecht.>> So ein Unsinn! Nur weil die hier vielleicht nicht ganz so gut wie andere> sind, sind sie nicht generall schlecht!
Das stimmt. Sie sind nicht generell schlecht!
In meinem obigen Satz fehlte ein "in dieser Hinsicht". Sorry, das habe
ich zu später Stunde falsch formuliert. Und es hätte eigentlich Atmel
heißen müssen, denn die der neuen AVRs (DA, DB, DD, EA, ... tiny1,
tiny2, ...) sind nicht nur in dieser Hinsicht viel besser geworden.
Georg M. schrieb:> Wilhelm M. schrieb:>> Leider sind die Datenblätter von Atmel/MicroChip sehr schlecht.>> Was genau ist unverständlich?
Ich spreche nicht von unverständlich: es geht mir um Übersichtlichkeit
und einfaches Erkennen.
Wie gesagt: der obiger Satz sollte heißen: " ... sind in dieser Hinsicht
schlecht".
Die DB von MicroChip/Atmel (eigentlich Atmel) für die alten AVRs
verwenden (mindestens) drei verschiedene Formulierungen:
- writing a '1'
- writing a logic one
- writing a one
Das ist schlecht für die Suche im Dokument.
Bei STM gibt es in der Registerübersicht unter den Bits noch die Zusätze
wie rc_w0, ...
Natürlich könnte man auch sagen, dass das Problem an der Definition der
Register in C liegt. In C++ (ja, ihr wisst schon) kann man das viel
besser machen. Aber um eine sinnvolle C++-Schnittstelle zu den Registern
zu liefern, sind die Hersteller zu faul, obwohl man das aus ihren
eigenen XML-Beschreibungen recht einfach erzeugen könnte.
Wilhelm M. schrieb:> Natürlich könnte man auch sagen, dass das Problem an der Definition der> Register in C liegt. In C++ (ja, ihr wisst schon) kann man das viel> besser machen. Aber um eine sinnvolle C++-Schnittstelle zu den Registern> zu liefern, sind die Hersteller zu faul, obwohl man das aus ihren> eigenen XML-Beschreibungen recht einfach erzeugen könnte.
Hast du dazu bitte ein Beispiel?!
Wilhelm M. schrieb:> Aber um eine sinnvolle C++-Schnittstelle zu den Registern> zu liefern, sind die Hersteller zu faul
Wohl auch, weil jeder C++ Entwickler eine eigene Vorstellung davon hat,
was sinnvoll ist. Viele Möglichkeiten bringen viele unterschiedliche
Lösungsansätze. Und in OOP kann man wunderbar akademisch aufgeblasene
Gebäude konstruieren, die nur wenige Menschen durchblicken, aber
akademisch super elegant aussehen.
Bernd S. schrieb:> if( TIFR3 & OCF3A ) {
Die Zeile kommt mir verdächtig vor. Soll die das OCF3A Bit (Bit 1 im
TIFR3, Atmega2560) abfragen oder das TOV3 im Bit 0?
Stefan F. schrieb:> Und in OOP kann man wunderbar akademisch aufgeblasene> Gebäude konstruieren, die nur wenige Menschen durchblicken, aber> akademisch super elegant aussehen.
In der Tat. Das sind dann die Chuck Norris der Softwareentwicklung!
https://youtu.be/YRccr0Wmwtk?si=Bh4dhtjyp5FGRW2-
Stefan F. schrieb:> Wilhelm M. schrieb:>> Aber um eine sinnvolle C++-Schnittstelle zu den Registern>> zu liefern, sind die Hersteller zu faul>> Wohl auch, weil jeder C++ Entwickler eine eigene Vorstellung davon hat,> was sinnvoll ist.
Wenn es gut gemacht ist, so denke ich, dass das schon konvergiert.
> Viele Möglichkeiten bringen viele unterschiedliche> Lösungsansätze.
Klar, und das ist auch gut ... und hoffentlich ist dann mindestens eine
guter Ansatz dabei ;-)
> Und in OOP kann man wunderbar akademisch aufgeblasene> Gebäude konstruieren, die nur wenige Menschen durchblicken, aber> akademisch super elegant aussehen.
Was ich meine, hat so gar nichts mit OOP im klassischen Sinn zu tun.
Es geht darum, dass ich einfach
1
TIFR3=1<<OCF3A;
oder
1
TIFR3|=1<<OCF3A;
gar nicht erst schreiben kann. Eine der Möglichkeiten von C++ ist es
eben, eigene DT zu definieren, die nur die sinnvollen Operationen
enthalten. Und ein "|=" ist bei den Flag-Registern nicht sinnvoll.
Arduino F. schrieb:> Unser Wilhelm kapert mal wieder einen Thread um zu zeigen was für ein> toller Hecht er doch ist.
Der einzige, der hier "abenteuerlichen" Code präsentiert hat, bis Du!
Wahrscheinlich um zu zeigen, dass Du templates in C++ verstanden hast.
Wilhelm M. schrieb:> dass Du templates in C++ verstanden hast
Ich danke dir herzlich für die Blumen.
Deine Anerkennung und Lobpreisungen, gehen mir runter wie Öl.
Falk B. schrieb:> ...
Im nörgeln ist ist er ganz prächtig!
Im "zeigen" hapert es ganz derbe. Da kommt wenig und wenn, dann meist
unvollständiges Zeugs.
In diesem Thread bisher noch gar nix.
Und eine verständliche, gut strukturierte Doku, habe ich noch nie von
ihm gesehen.
Arduino F. schrieb:> Falk B. schrieb:>> ...> Im nörgeln ist ist er ganz prächtig!
Na, das hatten wir schon mal: wenn man darauf hinweist, das wie hier
z.B. die DBer der Hersteller in einigen Punkten verbesserungsfähig sind,
ist das für Dich "nörgeln". Gut: dazu stehe ich.
> Im "zeigen" hapert es ganz derbe. Da kommt wenig und wenn, dann meist> unvollständiges Zeugs.
Ich habe sogar ein Beispiel gebracht, wie es besser geht.
> In diesem Thread bisher noch gar nix.> Und eine verständliche, gut strukturierte Doku, habe ich noch nie von> ihm gesehen.
Wie sieht denn Deine aus?
Harald K. schrieb:> Wilhelm M. schrieb:>> Ich habe sogar ein Beispiel gebracht, wie es besser geht.>> Besser? Einigen wir uns auf anders.
Nö: wenn man es schafft, die Operation |= unmöglich zu machen in Fällen,
in den sie definitv falsch ist, ist das in meinen Augen eine starke
Verbesserung.
Wilhelm M. schrieb:> Ich habe sogar ein Beispiel gebracht, wie es besser geht.
1. Wo?
2. Das würde ich mal als klassische Lüge bezeichnen.
Und ja, ich weiß schon was jetzt folgt!
Wie so häufig, wenn es dir mal wieder gelungen ist einen Thread zu
kapern.
Das übliche für blöd erklären.
Da scheinst du ja irgendwie drauf angewiesen zu sein.
Bitte erfülle meine Erwartungen.
Wilhelm M. schrieb:> Der TO hat sein Thread selbst gekapert
Hmmm.....
So wie du eine eigene Bedeutung von "Beispiel" zu haben scheinst, willst
du auch "kapern" mit einer eigenen versehen.
Hier mal die Bedeutung von "kapern":
> übertragen: etwas übernehmen, sich in Besitz eines (fremden) Guts setzenWilhelm M. schrieb:> Der TO
Dem TO gehört der Thread schon, seit er ihn angelegt hat.
TO == Thread Owner
Owner == Eigentümer/Besitzer
Dass man dir sowas erklären muss, ist ganz schön verblüffend für mich.
Arduino F. schrieb:> Dem TO gehört der Thread schon, seit er ihn angelegt hat.> TO == Thread Owner> Owner == Eigentümer/Besitzer>> Dass man dir sowas erklären muss, ist ganz schön verblüffend für mich.
Ach, das Leben hält auch für Dich einige Überraschungen bereit.
An welcher Stelle hat denn die Übernahme statt gefunden?
Fenton G. schrieb:> Bernd S. schrieb:>> if( TIFR3 & OCF3A ) {>> Die Zeile kommt mir verdächtig vor. Soll die das OCF3A Bit (Bit 1 im> TIFR3, Atmega2560) abfragen oder das TOV3 im Bit 0?>
Bei dem von mir gewähltem CTC-Mode 4, wird kein Overflow Flag gesetzt,
da ich nicht bis MAX ( 0xFFFF ) hochzähle. Bzw. dieses Flag wird
wahrscheinlich einmalig gesetzt.
Bernd_Stein
Hi
>Bei dem von mir gewähltem CTC-Mode 4, wird kein Overflow Flag gesetzt,
Wie kommst du auf das schmale Brett?
Lies dir mal (S.145-!46) "17.9.2 Clear Timer on Compare Match (CTC)
Mode" durch.
Da steht genau drin wann der Overflow-Flag gesetzt wird.
Kleiner Tip: OCRnA (mit n= 1, 3, 4, oder 5) bestimmt den MAX-Wert und
damit die CTC-Frequenz.
MfG Spess
Bernd S. schrieb:> Fenton G. schrieb:>> Bernd S. schrieb:>>> if( TIFR3 & OCF3A ) {Bernd S. schrieb:> Bei dem von mir gewähltem CTC-Mode 4, wird kein Overflow Flag gesetzt,
Ich wollte eher darauf hinaus, ob es nicht statt:
if( TIFR3 & OCF3A ) {
besser
if( TIFR3 & (1<<OCF3A) ) {
heißen sollte?
Fenton G. schrieb:> Ich wollte eher darauf hinaus, ob es nicht statt:> if( TIFR3 & OCF3A ) {> besser> if( TIFR3 & (1<<OCF3A) ) {> heißen sollte?
Mit Sicherheit, denn die Bitmanipulation funktioniert nur so beim
avr gcc / Arduino.
Falk B. schrieb:> Fenton G. schrieb:>> Ich wollte eher darauf hinaus, ob es nicht statt:>> if( TIFR3 & OCF3A ) {>> besser>> if( TIFR3 & (1<<OCF3A) ) {>> heißen sollte?>> Mit Sicherheit, denn die Bitmanipulation funktioniert nur so beim> avr gcc / Arduino.
Und so hat er tatsächlich TOV3 getestet ;-)
Und schon wieder ein Argument aus der Praxis, dass man die Operationen
"&" oder auch "&=" bzw. "|" und "|=" für (solche) Register nicht möglich
sein sollten.
S.a.
Beitrag "Re: Bitte um Hilfe bei der Programmierung von AVR8-Mikrocontrollern in C"
Moin,
Wilhelm M. schrieb:> Und so hat er tatsächlich TOV3 getestet ;-)>> Und schon wieder ein Argument aus der Praxis, dass man die Operationen> "&" oder auch "&=" bzw. "|" und "|=" für (solche) Register nicht möglich> sein sollten.
Gute Idee! Noch eine gute Idee: Mit Besteck kann man auch jede Menge
gefaehrliche Operationen vollführen: Messer sind toedliche Stichwaffen,
mit Gabeln kann man sehr schmerzhaft pieksen, sogar mit Loeffeln kann
man sich die Augen ausloeffeln.
Also mal wieder ein Argument dafuer, Nahrung nur aus einem Trog, ohne
weitere Hilfsmittel, zu sich zu nehmen und Besteck abzuschaffen.
Ich weiss schon, warum ich im 3. Post schrub, dass der TO da nix machen
kann...
Gruss
WK
Wilhelm M. schrieb:> Und schon wieder ein Argument aus der Praxis, dass man die Operationen> "&" oder auch "&=" bzw. "|" und "|=" für (solche) Register nicht möglich> sein sollten.
Deinen Gedankengang kann ich nicht nachvollziehen. Ich halte es eher für
einen strategischen Fehler, dass Atmel (bzw. Microchip) diese Flags wie
OCF3A als Bitnummer statt als Bitmaske definiert. Dann könnte man sich
diese Shifterei wie (1 << OCF3A) von vornherein sparen.
Beim STM32 ist das anders. Die hier vorzufindenden Konstanten (CMSIS,
StdLib, HAL) für die Register sind in der Regel Bitmasken und nicht
Bitnummern. Da zieht Dein Argument erst gar nicht bzw. wirkt es eher
deplaziert.
Hall,
Wilhelm M. schrieb:> Und schon wieder ein Argument aus der Praxis, dass man die Operationen> "&" oder auch "&=" bzw. "|" und "|=" für (solche) Register nicht möglich> sein sollten.
Es ist eher ein Argument dafür, das sich Bernd endlich mal ein
C-Lehrbuch kauft und es von vorn bis hinten durcharbeitet. So lange er
nicht weiß was er eigentlich tut, ist jede zusätzliche Abstraktion von
letztlich grundlegenden Befehlen völlig sinnlos.
rhf
Frank M. schrieb:> Ich halte es eher für> einen strategischen Fehler, dass Atmel (bzw. Microchip) diese Flags wie> OCF3A als Bitnummer statt als Bitmaske definiert.
Das Argument, warum das gemacht wird, ist eine aus der vorderen
Altsteinzeit. So kann man nämlich in Assembler die gleichen
Definitionsdateien wie in C verwenden, wenn man die Bitoperationen SBI
und CBI benutzt, die es nur für die ersten 32 Adressen im Adressraum
gibt.
Deswegen werden ewiglange Shiftketten hingeschrieben. Überall. Nur
deswegen.
(Und gerne wird auch eine 0 geshiftet, weil das ja "übersichtlicher"
ist)
/semirant
Frank M. schrieb:> Deinen Gedankengang kann ich nicht nachvollziehen. Ich halte es eher für> einen strategischen Fehler, dass Atmel (bzw. Microchip) diese Flags wie> OCF3A als Bitnummer statt als Bitmaske definiert. Dann könnte man sich> diese Shifterei wie (1 << OCF3A) von vornherein sparen.
Ist halt Konvention bei Atmel.
Wenn man es nicht weiß, muss man es halt lernen.
Wilhelm M. schrieb:> Und schon wieder ein Argument aus der Praxis, dass man die Operationen> "&" oder auch "&=" bzw. "|" und "|=" für (solche) Register nicht möglich> sein sollten.
Stimmt. Aber C war schon immer ein Rasiermesser, das in fähige Hände
gehört.
Frank M. schrieb:> Deinen Gedankengang kann ich nicht nachvollziehen. Ich halte es eher für> einen strategischen Fehler, dass Atmel (bzw. Microchip) diese Flags wie> OCF3A als Bitnummer statt als Bitmaske definiert.
Ist historisch so gewachsen, weil die Header auch für Assembler nutzbar
sind bzw. waren. Und der AVR Assembler braucht für seine Bitoperationen
halt die Nummer.
> Dann könnte man sich> diese Shifterei wie (1 << OCF3A) von vornherein sparen.
Stimmt.
Beitrag "Re: XC8 compiler - Register schreiben wie bei Atmel"
Falk B. schrieb:> Stimmt.> Beitrag "Re: XC8 compiler - Register schreiben wie bei Atmel"
Ich hatte da bereits 2014 mal einen Konzept-Vorstoß gemacht, wie man die
AVR-Register-Bits fest an die zugehörigen Register bindet, um die
Anwendung von falschen Bits in falschen Registern direkt auszuschließen:
Beitrag "AVR-Register als Bitfields"
Leider wäre das für micht allein zuviel Arbeit gewesen, für alle AVRs
die entsprechenden Header-Dateien zu erzeugen. Deshalb habe ich das
Konzept nicht weiter verfolgt.
Falk B. schrieb:> Ist historisch so gewachsen, weil die Header auch für Assembler nutzbar> sind bzw. waren. Und der AVR Assembler braucht für seine Bitoperationen> halt die Nummer.
Also, ganz so ist das nicht.
Erstens wäre es problemlos möglich gewesen, die Header so zu generieren,
dass sowohl Bitnummer als auch Bitmaske darin sind, so wird es
schließlich heute für die neueren AVR8 auch durchgängig getan
(Symbol-Suffix _bp bzw. _bm).
Und zweitens käme der AVR-Assembler auch allein mit der Maske zurecht.
Er bietet nämlich u.a. die Builtin-Funktion Log2.
Also: woran es auch immer lag: der AVR-Assembler jedenfalls war nicht
schuld.
Harald K. schrieb:> Ob S. schrieb:>> Und zweitens käme der AVR-Assembler auch allein mit der Maske zurecht.>> Er bietet nämlich u.a. die Builtin-Funktion Log2.>> Schon immer?
Keine Ahnung, ob das "schon immer" so war, auf jeden Fall schon sehr
lange, ganz sicher vor der Einführung des AVR Assembler 2 . Siehe
angehängten Auszug aus der Hilfe zum Studio4.
Harald K. schrieb:> (Und gerne wird auch eine 0 geshiftet, weil das ja "übersichtlicher"> ist)
Also dass man eine 1 der Konsistenz wegen um 0 binäre Stellen shiftet,
ok. Aber eine 0 shiften?
LG, Sebastian
Sebastian W. schrieb:> Aber eine 0 shiften?
Ja, das sieht man öfters in diversen Quellcodes. Es soll ausdrücken,
dass das genannte Bit eben nicht gesetzt werden soll.
Beispiel:
1
TCCR0A|=(1<<COM0A1)|(0<<COM0A0);
Diese Methode ist daher eher für den geneigten Leser und nicht als
Anweisung für den Compiler gedacht.
Frank M. schrieb:> Ja, das sieht man öfters in diversen Quellcodes. Es soll ausdrücken,> dass das genannte Bit eben nicht gesetzt werden soll.
Stimmt, so was hab ich auch schon gesehen.
LG, Sebastian
Sebastian W. schrieb:> Frank M. schrieb:>> Ja, das sieht man öfters in diversen Quellcodes. Es soll ausdrücken,>> dass das genannte Bit eben nicht gesetzt werden soll.>> Stimmt, so was hab ich auch schon gesehen.
Ich mach soetwas zu dokumentationszwecken auch des öfteren - und werde
prompt von Lintern angemotzt, weil ich sinnlosen Code schreibe 🙈😂
Mampf F. schrieb:> und werde> prompt von Lintern angemotzt, weil ich sinnlosen Code schreibe
Womit ihm auch recht hat!
Das ist eine der Angelegenheiten, wo es (min.) 2 Wahrheiten gibt, die
beide ihre begründbare Berechtigung haben, aber sich doch widersprechen.
Frank M. schrieb:> Ich hatte da bereits 2014 mal einen Konzept-Vorstoß gemacht, wie man die> AVR-Register-Bits fest an die zugehörigen Register bindet, um die> Anwendung von falschen Bits in falschen Registern direkt auszuschließen:>> Beitrag "AVR-Register als Bitfields">> Leider wäre das für micht allein zuviel Arbeit gewesen, für alle AVRs> die entsprechenden Header-Dateien zu erzeugen. Deshalb habe ich das> Konzept nicht weiter verfolgt.
WOW! Gerade in meiner Mittagspause gelesen - schade dass die gute Idee
im Sande verlaufen ist.
Frank M. schrieb:> Ich hatte da bereits 2014 mal einen Konzept-Vorstoß gemacht, wie man die> AVR-Register-Bits fest an die zugehörigen Register bindet, um die> Anwendung von falschen Bits in falschen Registern direkt auszuschließen
Soweit mir bekannt erfolgt bei Bitfields ein read-modify-write Zugriff.
Das ist bei Flag und PINX Registern eher nicht gewünscht, bzw. gar
problematisch. Ein einfaches write ist angemessener.
Arduino F. schrieb:> Frank M. schrieb:>> Ich hatte da bereits 2014 mal einen Konzept-Vorstoß gemacht, wie man die>> AVR-Register-Bits fest an die zugehörigen Register bindet, um die>> Anwendung von falschen Bits in falschen Registern direkt auszuschließen>> Soweit mir bekannt erfolgt bei Bitfields ein read-modify-write Zugriff.
Genau. Also Blödsinn, dass so zu machen.
Beim AVR gibt es nur rc_w1 flag register.
Bei rc_w0 wäre es zudem vollkommen falsch, weil noch ein AND im rmw
versteckt ist.
Ähnlich einem "|= oder &=" bei einem Flag-Register.
Deswegen: bit-fields sind für Register-Abstraktion vollkommen
ungeeignet.
Arduino F. schrieb:> Soweit mir bekannt erfolgt bei Bitfields ein read-modify-write Zugriff.
Das mag ja allgemein so stimmen, beim AVR-gcc (und nur dafür war das
Konzept angedacht!) stimmt es jedenfalls nicht.
Assembler-Outputs sind im verlinkten Thread durchaus angegeben, die das
Gegenteil belegen, z.B. hier:
Beitrag "Re: AVR-Register als Bitfields"
Auszug:
1
BFM_PORTB5=1;// BFM-Version
ergibt:
1
sbi 0x05, 5
Und:
1
BFM_PORTB5=0;// BFM-Version
ergibt:
1
cbi 0x05, 5
Ich sehe da keinen read-modify-write-Zugriff.
Wilhelm M. schrieb:> Deswegen: bit-fields sind für Register-Abstraktion vollkommen> ungeeignet.
Bit-fields sind für so ziemlich alles ungeeignet, da sie grundsätzlich
nicht portabel sein können. Das habe ich schon oft in einigen Threads
ausdrücklich betont - auch in Threads, wo Du ebenso tätig warst. Ich
benutze sie daher grundsätzlich nicht, da ich immer möglichst portabel
(und auch Prozessor-Familien-übergreifend) programmiere.
Betrachte den verlinkten Thread bitte lediglich als Demonstration, wie
man es konkret für AVR und avr-gcc hätte machen können. Ich habe dann
schließlich davon abgesehen, es durchzuziehen: einmal aus Zeitgründen,
zum anderen wegen zu vielen speziellen Voraussetzungen über die
Verhaltensweise des avr-gcc. Das geht viel zu schnell in die Hose,
sobald sich da etwas beim avr-gcc geändert hätte.
Bestimmt kannst Du mit C++ einen registersicheren Zugriff auf die
AVR-Register konstruieren. Leider kommt in dieser Richtung nix von Dir.
Es wäre doch ganz toll, wenn man das Thema ein für allemal erschlagen
könnte. Ich kenne nämlich allzuviele Threads, wo der TO mit den falschen
Konstanten auf die falschen AVR-Register zugegriffen hat - einfach, weil
ein und dieselben Bits bei verschiedenen AVRs teilweise auch in
verschiedenen Registern gehalten werden.
Frank M. schrieb:> Leider kommt in dieser Richtung nix von Dir.
Ja, das ist schade...
Dabei gibts doch hier ein so schönes Wiki wo man das gut unterbringen
könnte, damit da jeder was von hat.
Frank M. schrieb:> Ich sehe da keinen read-modify-write-Zugriff.
Oh ha. Dachte Du kennst Dich aus?
Probiere das mal mit einem SFR mit einer Adresse >= 0x32. Da geht doch
sbi/cbi nicht mehr.
Frank M. schrieb:> Assembler-Outputs sind im verlinkten Thread durchaus angegeben, die das> Gegenteil belegen,
Ist es denn wirklich so, dass alle Flag und PINX Register im Bereich bis
zu Adresse 0x1F zu finden sind?
Bei allen betreffenden AVR?
Frank M. schrieb:> Bit-fields sind für so ziemlich alles ungeeignet, da sie grundsätzlich> nicht portabel sein können.
Portable müssten sie auch gar nicht sein, weil sie eh
compiler/mcu-spezifisch sind. Sie müssten nur so funktionieren, wie man
sich das wünscht. Und das tun sie auch ganz abseits von
Portabilitätsaspekten nicht.
Und falls jemand sogar
1
BF_TCCR0A.wgm0&=1;
statt
1
BF_TCCR0A.wgm0=1;
schreibt, kommt gar doppelter Bullshit dabei heraus.
Also, mit Bitfields machst Du alles nur noch schlimmer.
Wilhelm M. schrieb:> Frank M. schrieb:>> Ich sehe da keinen read-modify-write-Zugriff.>> Oh ha. Dachte Du kennst Dich aus?> Probiere das mal mit einem SFR mit einer Adresse >= 0x32. Da geht doch> sbi/cbi nicht mehr.
Sorry, muss natürlich 0x20 heißen.
Frank M. schrieb:> Bestimmt kannst Du mit C++ einen registersicheren Zugriff auf die> AVR-Register konstruieren.
Ja, das kann man.
> Leider kommt in dieser Richtung nix von Dir.
Das habe ich mittlerweile in diesem Forum aufgegeben.
Letztlich benutzen wir einen kompletten rewrite der AVR-Header in C++.
Darin finden sich für Register der internen Peripherie Klassen, die auf
die passenden Adressen gemappt werden. Die Elemente der Klassen sind im
wesentlichen eines Typs der drei templates FlagRegister<>,
ControlRegister<> und DataRegister<>. Parametriert sind diese templates
mit den scoped-enums der möglichen Bits bzw. Bit-Kombinationen.
Damit kommen dann Konstrukte wie
zustande.
Da diese etwas geschwätzige Art der Notation hier kaum jemanden gefällt,
ist es müßig, dass hier zu präsentieren.
Jedoch: der Vorteil ist ganz klar: alles hier gezeigten Fehler werden
vermieden.
Die einzige "Fehlerquelle", die bleibt, ist, falls man
1
mcu_adc()->ctrla.add<ctrla_t::freerun>();
meint, aber dann
1
mcu_adc()->ctrla.add<ctrla_t::leftadj>();
schreibt. Aber gegen semantische Fehler (WYMIWYG) ist keine Kraut
gewachsen.
Wilhelm M. schrieb:> mcu_adc()->intflags.testAndReset<intFlags_t::isReady>([&]{> f();> });
Schreibe das mal in eine Stellenausschreibung. Wir suchen Sie als C++
Programmierer, wenn sie diesen Code verstehen und pflegen können.
So kommt man dann zum "Fachkräftemangel".
Stefan F. schrieb:> Wilhelm M. schrieb:>> mcu_adc()->intflags.testAndReset<intFlags_t::isReady>([&]{>> f();>> });>> Schreibe das mal in eine Stellenausschreibung. Wir suchen Sie als C++> Programmierer, wenn sie diesen Code verstehen und pflegen können.>> So kommt man dann zum "Fachkräftemangel".
Es würde tatsächlich funktionieren: es kommen nur noch die fähigen ;-)
Wilhelm M. schrieb:> Es würde tatsächlich funktionieren: es kommen nur noch die fähigen ;-)
Ach ja?
Jeder dritte Neuntklässler erfüllt nicht die minimalen Anforderungen ans
Leseverständnis. Jeder zweite Fällt in der Theoretischen Fahrprüfung
durch.
Fällt dir was auf?
Wer denkt, dass die Menschen immer intelligenter werden und immer
komplexere Dinge beherrschen, der irrt gewaltig. Tatsächlich passiert
gerade das Gegenteil. Wer das ignoriert hat bald kein Personal mehr.
Schau dir mal den Film Idiocracy an. Das sollte mal eine Komödie sein,
heute wirkt er jedoch gar nicht mehr belustigend.
Stefan F. schrieb:> Wilhelm M. schrieb:>> Es würde tatsächlich funktionieren: es kommen nur noch die fähigen ;-)>> Ach ja?>> Jeder dritte Neuntklässler erfüllt nicht die minimalen Anforderungen ans> Leseverständnis.
Woran das wohl liegt . . . ?
> Jeder zweite Fällt in der Theoretischen Fahrprüfung> durch.
Ist doch nur Theorie! Wer braucht die schon in der Praxis! ;-)
> Wer denkt, dass die Menschen immer intelligenter werden und immer> komplexere Dinge beherrschen, der irrt gewaltig. Tatsächlich passiert> gerade das Gegenteil. Wer das ignoriert hat bald kein Personal mehr.
Spätrömische Dekandenz. Wie amüsieren und konsumieren uns dumm und
dämlich, im wahrsten Sinne des Wortes. Aldous Huxley hatte Recht! Orwell
nur zum Teil.
Wilhelm M. schrieb:> Da diese etwas geschwätzige Art der Notation hier kaum jemanden gefällt,> ist es müßig, dass hier zu präsentieren.
Geschwätzig sind sie, das ist unübersehbar. Darüber hinaus aber auf
unangenehme Art geschwätzig. Trotz ihrer Geschwätzigkeit ist nämlich für
den geneigten Leser nicht gerade schnell zu erkennen, was der Kram
eigentlich tut.
Sprich: die typischen Auswüchse einer akademisch gedunsenen
WO-Programmiersprache. Macht es nur für den Compiler einfach. Aber ja:
der kann dann auch semantische Fehler finden. Mit ein wenig Glück, wenn
wenigstens alles syntaktisch richtig eingetippt ist.
Ein Zeichen versehentlich falsch eingetippt oder vergessen oder zuviel
und der Programmierer wird mit Fehlermeldungen geradezu geflutet, die
aber überwiegend absolut nicht hilfreich sind.
Oder es gibt mal wieder eine neuer Version dieser Sprache. Na dann wird
es u.U. richtig lustig den "alten" (vielleicht drei Jahre oder so) Code
zu kompilieren. Da braucht man schon ein ordentliches Storage-System mit
Fiber-Channel-Anbindung, um auch nur die Fehlermeldungen in akzeptabler
Zeit wegzuschreiben.
Nö, das kann nicht die Zukunft des Programmierens sein.
Also, ganz kann ich die ganze Theoretisiererei wie sie hier im Forum oft
vorkommt, nicht nachvollziehen.
Ich beschäftige mich schon seit einigen Jahrzehnten mit uC und wußte
nicht, daß die Art der Manipulierung der SFRs in 2023 einen
krisenartigen Charakter annehmen würde.
Damals, sah man sich die entsprechenden Header Files an und wußte im
Zusammenhang mit dem Datenblatt vollkommen Bescheid. Und jetzt wird das
alles so aufgebauscht um zu Zeigen wie man unverständlichen Code baut.
Da komme ich jedenfalls nicht mehr mit. Die Welt der uC Programmierung
war damals für mich auf diesen Gebiet vollkommen in Ordnung. Wenn ich
mir die für Uneingeweihte oft vollkommen unleserlich und verständliche
C++ Konstrukte ansehe, da finde ich die alte C Schreibweisen wesentlich
klarer im Ausdruck.
In Fakt, C Konstrukte sind oft wesentlich klarer zu verstehen, als die
abstrakten C++ Konstrukte, die nur nach extensiver Recherche von
Nichtversierten nachvollziehbar sind.
Es gibt viele kompetente Fachleute, die nur gelegentlich,
projekt-orientiert programmieren, um irgend etwas Notwendiges am Laufen
zu haben. Solche Leute tun sich da mit klarer, einfacherer
Ausdrucksweise wesentlich leichter, ihren eigenen Code nach langer
Abwesenheit zu verstehen. Sicher, wer sich mit C++ tagtäglich befasst
und sich damit seine Brötchen verdient, kommt damit klar und ist damit
zu Hause. Aber nicht jeder ist ein toller Programmierhecht. Ich wage
aber zu behaupten, daß 90% der Forumleserschaft sich nicht in dieser
Kategorie befindet und für sie eine klare, verständliche
Programmier-Ausdrucksweise besser dienlich ist. Für diejenigen, die auch
ein anderes Technikleben haben, als 10 Stunden pro Tag zu programmieren,
werden meine Ansicht wahrscheinlich besser verstehen.
Wie kommt es, daß ich mir z.B. CodeVisionAVR, CCS oder Keil zulegen
kann, gute Referenzdokus bekomme und damit alleine alles Notwendige in
einem gut strukturierten Referenzbuch finden zu können? Auch ein
Anfänger könnte damit klarkommen, wenn er sich dort durcharbeitet. Mit
GCC muß man tief tauchen, um Ordnung in den Dokus zu finden. GCC mag ja
sehr fähig sein, ist aber umständlich zu lernen und die notwendigen und
klaren Dokus zu finden, ist umständlich. Oft sind auch deren Dokus nur
schwer verdaulich und bedürfen viel Kreuzsuche und Recherche. Und gute
Bücher findet man auch nicht immer leicht.
Ich verstehe ohne große Recherche C, Pascal, Fortran, BASIC, also
Sprachen der früheren Generation. Aber wenn man sich viele esoterische
C++ Programme anschaue, die sich auf die aktuellen C++ Standards
stützen, da ist Vieles dabei, daß man als nicht-Fachmann recherchieren
muß, weil die gewünschte Funktion nicht länger aus ihrem Konstrukt noch
direkt lesbar ist. Das ist der große Unterschied zu früher, wo K&R
ausreichte.
Früher konnte man sich eine Programmiersprache mit vollständiger,
gebundener Dokus zulegen und die Eigenschaften des Produkts lernen ohne
umständlich im Internet herumsuchen zu müssen oder Bücher kaufen zu
müssen.
C++ hat Vieles was nützlich ist, aber auch dort sollte es möglich sein,
einigermassen lesbaren Sourcecode zu erstellen.
Viele uC Anwendungen lassen sich durchaus noch klar und sauber in frühen
C-Stil realisieren.
Ohne Grund zügelt z.B. MISRA auch nicht die Freiheiten im Gebrauch der
Sprachen.
Zum Glück kann man sich meistens die Programmiersprache noch selber
aussuchen. Ich bin froh, daß ich in diesem Rennen nicht mehr mitmachen
muß. Das Design und Programmieren von uC soll doch eigentlich ansprechen
und Freude machen und keine Zäsur sein.
Ist nur meine Ansicht.
Gerhard
Stefan F. schrieb:> Wilhelm M. schrieb:>> Es würde tatsächlich funktionieren: es kommen nur noch die fähigen ;-)>> Ach ja?>> Jeder dritte Neuntklässler erfüllt nicht die minimalen Anforderungen ans> Leseverständnis. Jeder zweite Fällt in der Theoretischen Fahrprüfung> durch.>> Fällt dir was auf?
Ja. Und zwar, dass ich noch nie irgendwelche unterdurchschnittlichen
Neuntklässler einstellen wollte.
> Wer denkt, dass die Menschen immer intelligenter werden und immer> komplexere Dinge beherrschen, der irrt gewaltig.
Sie werden aber auch nicht dümmer.
> Tatsächlich passiert> gerade das Gegenteil. Wer das ignoriert hat bald kein Personal mehr.
Probleme habe nur die, die tradierten Vorstellungen von Firmenkultur
oder Exzellenz anhaften, oder eben glauben, mit irgendwelchen
langweiligen Stellenanzeigen der Besten Aufmerksamkeit zu erregen.
Aber echt jetzt: Du musst aufpassen, dass Dich hier nicht Arduino F.
wegen Thread-Kaperns anmacht ;-)
Gerhard O. schrieb:> Das ist der große Unterschied zu früher, wo K&R> ausreichte.>> Früher konnte man sich eine Programmiersprache mit vollständiger,> gebundener Dokus zulegen und die Eigenschaften des Produkts lernen ohne> umständlich im Internet herumsuchen zu müssen oder Bücher kaufen zu> müssen.
Oh man, schon wieder so ein Beitrag nach dem Motto: alte Herren erzählen
von guten alten Sandkastenzeit.
TLDR
Gerhard O. schrieb:> C++ hat Vieles was nützlich ist, aber auch dort sollte es möglich sein,> einigermassen lesbaren Sourcecode zu erstellen.>> Viele uC Anwendungen lassen sich durchaus noch klar und sauber in frühen> C-Stil realisieren.
Das kann man auch gut kombinieren.
Arduino F. schrieb:> Das kann man auch gut kombinieren.
Hallo,
ja. Danke für das Beispiel. Mit dieser Vorgehensweise habe auch ich kein
Problem und sieht sehr sauber aus.
Ist die ADC Lib ein Eigenbau oder Github Public?
Gerhard
Arduino F. schrieb:> Gerhard O. schrieb:>> Eigenbau>> Eigenbau> Ist im inneren etwas unaufgeräumt, deckt aber die meisten AVR der> Arduinowelt ab.
OK. Sieht im Inneren doch ganz ordentlich aus.
(Kommt mir zumindest so vor:-) )
In den meisten meiner Programme lasse ich den ADC im Hintergrund als
Multikanal ISR mit Mittlung laufen und habe den ADC immer anhand des
DaBlas mit den SFRs konfiguriert.
Schön einstellen, lässt sich alles mit Deiner Lösung auf alle Fälle und
ist sehr übersichtlich.
Gerhard
Arduino F. schrieb:> Gerhard O. schrieb:>> Eigenbau>> Eigenbau> Ist im inneren etwas unaufgeräumt, deckt aber die meisten AVR der> Arduinowelt ab.
Was machst Du mit µC, die mehr als einen ADC haben, z.B. die
tiny1-Serie?
Hallo,
ich verstehe immer nicht was die ganze Diskussion um C und C++ immer
soll. Gerhard schwelgt in alten Erinnerungen die niemanden vorwärts
bringen. C ist stehen geblieben, es sollte auch für C einmal einer neuer
Sprachstandard kommen von dem ich bis heute nichts gelesen habe. Im
Gegensatz dazu entwickelt sich C++ ständig weiter. Man muss sich
entscheiden ob man stehen bleiben möchte oder die nützlichen Dinge einer
sich fortlaufenden Sprache wie C++ anzunehmen. Man muss ja nicht den
unleserlichsten Code schreiben, aber Vorteile bringt C++ schon. Man kann
das nutzen was einem Vorteile bringt.
Wie letztens erst festgestellt sind #defines zum Bsp. großer Mist.
Leider kommt man davon wohl auf lange Sicht nicht los, weil das in den
Headerfiles drin steckt. Außer man schreibt Eigene. C++ ist nun einmal
auf Datentypsicherheit ausgelegt. Das ist die Grundlage. Das muss man
einfach verstehen wollen.
Wer immer wieder von früher erzählt, da weiß ich nicht was ich dazu
sagen soll. Fakt ist doch:
Wer C programmieren möchte der soll es machen.
Wer C++ programmieren möchte der soll es machen.
Wer Assembler programmieren möchte der soll es machen.
Wer ... programmieren möchte der soll es machen.
Aber lasst doch bitte diese sinnfreie Diskussion das genau die Sprache
die einem nicht gefällt ausgerechnet Teufelszeug sein soll.
Wilhelm M. schrieb:> Du
Mach dir mal keine unnützen Sorgen....
Du könntest, anstatt zu nörgeln, auch mal zeigen wie du ALLEAVR
abdeckst.
Merksatz:
Nörgeln ist einfach, Nörgler vom nörgeln abzubringen eher nicht.
Einen zufriedengestellten Nörgler?
Das riecht nach "Paradoxie"
Veit D. schrieb:> ich verstehe immer nicht was die ganze Diskussion um C und C++ immer> soll.
Ich schon.
> Gerhard schwelgt in alten Erinnerungen die niemanden vorwärts> bringen.
Nein, das allein ist es nicht. Es geht darum, daß man es mit der
"Moderne" und Abstraktion gerade bei C++ GEWALTIG übertreiben KANN! Und
genau DAS wird kritisiert.
> C ist stehen geblieben,
Ausgereift. Irgendwann ist ein Konzept erschöpft. Ist aber auch OK. Die
ISS ist auch ausgereift und wird in absehbarer Zeit verschrottet. Oder
doch nicht? Schau mer mal.
> es sollte auch für C einmal einer neuer> Sprachstandard kommen von dem ich bis heute nichts gelesen habe.
Wenn gleich natürlich in der IT Dinge, welche sich nicht erneuern,
relativ schnell veralten und irgendwann mal weg vom Fenster sind, so ist
es andererseits auch eine Seuche, an bewährten Dingen dauernd
rumzuschrauben.
> Im> Gegensatz dazu entwickelt sich C++ ständig weiter.
Mit allen Vor- und Nachteilen, allein voran, daß es immer komplexer und
umfangreicher wird. Wer kann das WIRKLICH VOLLSTÄNDIG überblicken und in
der Praxis auch gewinnbringend umsetzen? Ich fürchte, nur eine
Minderheit. Das Schweizer Taschenmesser mit 100 Funktionen, das jedes
Jahr um 10% wächst, ist sinnlos!
KISS sollte viel öfter berücksichtigt werden! Oder auf gut Deutsch.
So einfach wie möglich, so komplex wie nötig.
> Man muss sich> entscheiden ob man stehen bleiben möchte oder die nützlichen Dinge einer> sich fortlaufenden Sprache wie C++ anzunehmen.
Jain. Siehe oben.
> Man muss ja nicht den> unleserlichsten Code schreiben, aber Vorteile bringt C++ schon.
Das ist glaube ich für die meisten Leute unbestritten, selbst für mich,
der von C++ keine Ahnung hat ;-)
> Man kann> das nutzen was einem Vorteile bringt.
Ja, aber! Siehe oben!
> Wer immer wieder von früher erzählt, da weiß ich nicht was ich dazu> sagen soll. Fakt ist doch:> Wer C programmieren möchte der soll es machen.> Wer C++ programmieren möchte der soll es machen.> Wer Assembler programmieren möchte der soll es machen.> Wer ... programmieren möchte der soll es machen.
Alles Ok, aber nicht der Punkt. Der Punkt ist die kritische Diskussion
um die Komplexität einer Lösung sowie deren Fehlersicherheit.
> Aber lasst doch bitte diese sinnfreie Diskussion das genau die Sprache> die einem nicht gefällt ausgerechnet Teufelszeug sein soll.
Das hat keiner behauptet.
Veit D. schrieb:> C ist stehen geblieben, es sollte auch für C einmal einer neuer> Sprachstandard kommen von dem ich bis heute nichts gelesen habe.
Mmh ... C11, C17, C23
also, stehengeblieben ist anders.
Hier sind doch einige "verwöhnte Bürschchen" :-)
Erwartet ihr wirklich, dass der Compiler alle logischen und sachlichen
Fehler findet und ggf. sogar noch ausbügelt?
Ich (O.K. ich nutze C nur im Hobby-Bereich) finde die Bit-Manipulationen
für Register ganz O.K. - ich öffne parallel sowieso immer das Datenblatt
um zu wissen, was ich tue.
Bei den XMegas (mit denen ich schon gearbeitet habe) und scheinbar auch
neueren Tinys ist/scheint das etwas eleganter zu sein, aber mir
zumindest erspart es nicht den Blick in das DB.
Logische Fehler erkennt wohl kaum ein Compiler sicher - zumindest keiner
der mir bekannt ist.
Für mich. als Nicht-Experte liest und schreibt sich
TIFR3 |= 1<< OCF3A;
leichter als
mcu_adc()->intflags.testAndReset<intFlags_t::isReady>([&]{
f();
Inhaltlich nicht vergleichbar, klar, aber die 2. Schreibweise erinnert
mich irgendwie leicht an "Brainfuck" :-) . Wer es kann prima, für den
der es nicht kann und warten muss weniger prima.
Hugo H. schrieb:> Hier sind doch einige "verwöhnte Bürschchen" :-)>> Erwartet ihr wirklich, dass der Compiler alle logischen und sachlichen> Fehler findet und ggf. sogar noch ausbügelt?
Compiler und Hochsprachen sind dazu da, große Datenmengen und
Komplexitäten zu verwalten und soweit möglich, Fehler zu verhindern.
Solche Fehler sind prinzipiell vom Compiler verhinderbar, wenn man es
richtig macht.
> Ich (O.K. ich nutze C nur im Hobby-Bereich) finde die Bit-Manipulationen> für Register ganz O.K. - ich öffne parallel sowieso immer das Datenblatt> um zu wissen, was ich tue.
Das ist nicht der Punkt.
> Logische Fehler erkennt wohl kaum ein Compiler sicher - zumindest keiner> der mir bekannt ist.
Darum geht es nicht! Es geht um die recht lockere Definition der
Bitnamen. Ein Bit in einem Register per Namen anzusprechen, das gar
nicht existiert, sollte nicht möglich sein! Die Steigerungsform davon
ist, bestimmte Bits nur auf bestimmte Weise anzusprechen.
> Für mich. als Nicht-Experte liest und schreibt sich>> TIFR3 |= 1<< OCF3A;
Ist sachlich falsch. Die Interrupts werden so gelöscht.
TIFR3 = 1<< OCF3A;
Ja, alles wird mit Null "beschrieben", was aber in diesem Register nur
das eine, gesetzt Bit löscht! Klingt komisch, ist aber so!
> leichter als>> mcu_adc()->intflags.testAndReset<intFlags_t::isReady>([&]{> f();
Naja, das Beispiel ist auch nicht sonderlich gut, eher dazu da zu
zeigen, wie man es nicht "besser" machen sollte.
> Inhaltlich nicht vergleichbar, klar, aber die 2. Schreibweise erinnert> mich irgendwie leicht an "Brainfuck" :-) . Wer es kann prima, für den> der es nicht kann und warten muss weniger prima.
Moin,
Gegen Nichtlesen des Datenblatts bzw. Nichtverstehen der Eigenschaften
der Hardware hilft eine Hochsprache mit Wahnsinnsfeatures ungefaehr so
sinnvoll, wie Fritzboxeinstellungen gegen pubertierende
Social-Media-Bratzen.
scnr,
WK
Falk B. schrieb:
einmal auf den Kern reduziert zitiert, hoffe das ist nicht zu kurz.
> Nein, das allein ist es nicht. Es geht darum, daß man es mit der> "Moderne" und Abstraktion gerade bei C++ GEWALTIG übertreiben KANN! Und> genau DAS wird kritisiert.> Alles Ok, aber nicht der Punkt. Der Punkt ist die kritische Diskussion> um die Komplexität einer Lösung sowie deren Fehlersicherheit.
Okay, dann habe ich den Threadverlauf falsch eingeschätzt falsch
verstanden. Bezüglich C++ stimmt was du schreibst. Die Komplexität der
Möglichkeiten ist extrem. Das in aller Fülle zu beherrschen ist nur noch
was für Vollblutprogrammierer. Ich kann davon nur einen Bruchteil nutzen
den ich verstanden habe. Paar erlernte Annehmlichkeiten möchte ich
jedoch nicht missen.
1
"Wir leben von Möglichkeiten und sterben an Wirklichkeiten."
Falk B. schrieb:>>>> mcu_adc()->intflags.testAndReset<intFlags_t::isReady>([&]{>> f();>> Naja, das Beispiel ist auch nicht sonderlich gut, eher dazu da zu> zeigen, wie man es nicht "besser" machen sollte.
Dass das Beispiel nicht äquivalent zu
Falk B. schrieb:> TIFR3 = 1<< OCF3A;
ist, dürfte klar sein.
Hierfür würde man
1
timer()->intflags.reset<intflags_t::ocfb>();
schreiben. Und hierbei ist es dann egal, ob das ein rc_w0 oder rc_w1
ist.
Dergute W. schrieb:> Gegen Nichtlesen des Datenblatts
Genau: und hier (flag-register) bleiben die Datenblätter von
Atmel/MicroChip hinter denen von STM zurück (wobei sie wieder in anderer
Hinsicht besser sind).
Wie gesagt, das alles ließe sich vermeiden (mit Ausnahme, dass man ggf.
OutputCompare3 mit OutputCompare2 desselben Timers verwechselt, aber das
ist eine andere Geschichte), wenn man verhindert, dass solche Konstrukte
wie
1
TIFR3|=1<<OCF3A;
überhaupt kompilieren. Das geht mit C aber nicht.
Wenn man auf C++ umschwenkt, dann sollte man (wie in meinem Fall) die
ganzen Header für AVR umschreiben. Dann werden solche Fehler zur
Compilezeit ausgedeckt. Ob man dabei die "geschwätzige" Form wie in
meinem Fall verwendet, bliebe dann dem Hersteller überlassen. Jedoch ist
auch das nicht das Problem, weil ja die IDE das mit autocomplete
vervollständigt.
Hugo H. schrieb:> Erwartet ihr wirklich, dass der Compiler alle logischen und sachlichen> Fehler findet und ggf. sogar noch ausbügelt?
Ich erwarte (in diesem Fall nicht vom Compiler, sondern hier von der
gewählten software-technischen Abstraktion der HW), dass möglichst viele
falsche Konstrukte nicht compilieren. Denn ich habe nicht wirklich Bock
auf Laufzeit-Debugging. D.h. der "|=" oder "&=" Operator für rc_w1 oder
rc_w0 Flag-Register darf nicht möglich sein.
Arduino F. schrieb:> Wilhelm M. schrieb:>> Du> Mach dir mal keine unnützen Sorgen....
Um Dich mache ich mir schon lange keine Sorgen mehr ;-)
> Du könntest, anstatt zu nörgeln, auch mal zeigen wie du ALLEAVR> abdeckst.
Ich habe eine Frage gestellt. Ist das für Dich auch schon nörgeln?
Du hast einen Monostate-Ansatz für Deine Klasse Adc gewählt. Wenn Du das
erweitern möchtest, könntest Du in etwa
1
Adcadc{1,AT_TINY_1614};
verwenden.
Ich denke allerdings, dass das zu wenig effizientem Code führen wird.
Zudem wird es schwierig, Fehler wie
Wilhelm M. schrieb:> Jedoch ist> auch das nicht das Problem, weil ja die IDE das mit autocomplete> vervollständigt.
Aber selbst dieser Luxus bleibt vielen verwehrt weil sie noch an ihrer
Arduino IDE 1.x festhalten. Dabei hat sich gerade bei Intellisense
soviel getan in den letzten Jahren.
J. S. schrieb:> Wilhelm M. schrieb:>>> Jedoch ist>> auch das nicht das Problem, weil ja die IDE das mit autocomplete>> vervollständigt.>> Aber selbst dieser Luxus bleibt vielen verwehrt weil sie noch an ihrer> Arduino IDE 1.x festhalten.
Es soll Leute geben, die immer noch ed(1) verwenden ;-)
> Dabei hat sich gerade bei Intellisense> soviel getan in den letzten Jahren.
Vim, VSCode, ....
Falk B. schrieb:>> Erwartet ihr wirklich, dass der Compiler alle logischen und sachlichen>> Fehler findet und ggf. sogar noch ausbügelt?>> Compiler und Hochsprachen sind dazu da, große Datenmengen und> Komplexitäten zu verwalten und soweit möglich, Fehler zu verhindern.> Solche Fehler sind prinzipiell vom Compiler verhinderbar, wenn man es> richtig macht.
Nicht richtig - der Compiler wird nicht willkürlich sein Verhalten
ändern, nur weil es für 8Bit AVR irgendwie besser - oder gar logischer -
wäre.
Ihr müsst es halt lernen, wie es richtig geht.
Mampf F. schrieb:> der Compiler wird nicht willkürlich sein Verhalten> ändern, nur weil es für 8Bit AVR irgendwie besser - oder gar logischer -> wäre.
Wer hat das denn behauptet?
Moin,
Jetzt möchte ich mich mal die Frage aufwerfen, ob es nicht im Interesse
der Klarheit und Unzweideutigkeiten besser wäre, immer mit der
Hersteller Datenblatt Register Namenskonvention zu arbeiten.
Um beim Beispiel zu bleiben, TIFR3 ist meiner Ansicht nach eindeutiger
als z.B. (Verzeih Wilhelm)
1
timer()->intflags.reset<intflags_t::ocfb>();
Beim Beispiel ist es nur durch Nachschauen in den Header Files
erkenntlich, ob sich es eindeutig auf TIFR3 und OCF3A bezieht.
Jetzt würde Wilhelm argumentieren, daß sein Konstrukt damit alle
vorhandenen Timer unterstützt. Allerdings soll das jetzt keine Kritik
sein, weil ich mich ohne Recherche nicht gut genug auskenne, inwieweit
GCC Header files bereitstellt. Z.b. ist "ocfb" schon definiert oder eine
eigene Bezeichnung? Ich vermute auch, daß man tief eintauchen muß, um
alles eindeutig nachvollziehen zu können. Ist das wichtig, wird
wahrscheinlich gefragt werden. Nun, Wer es wirklich bestätigt wissen
muß, tut sich bei TIFR3 leichter, weil es selbstdokumentierend ist, was
bei der Abstraktion verloren geht.
Ich habe von Anfang an immer die direkte Hersteller Datenblatt Benamung
der Register bevorzugt, weil es eindeutig selbstdokumentierend aufs
Datenblatt zurückführbar ist und deshalb von mir bevorzugt wird.
Da das uC Programmieren am Ende sich immer mit seiner Hardware befasst,
ist einfach und eindeutige, Datenblatt konforme Benamung eigentlich
fehlervermeidend, weil nur in Zusammenarbeit mit dem Datenblatt die HW
genau erfasst und programmiert werden kann. Die Benamung alleine ist
dann wegen der betroffenen HW selbstdokumentierend.
Früher konnte ohnehin nur so gearbeitet werden. Da ich in der Regel
meine HW selber entwickle, sind die Datenblätter meine
Referenzdokumentation und nicht unmittelbar die Compilermöglichkeiten.
Deshalb könnte man auch gegenargumentieren, daß unnötige Abstraktion die
tatsächliche HW Bezogenheit verschleiert, die dann nur durch Studium der
relevanten Header Dateien geklärt werden können.
Die Verfechter der Abstraktion fahren dann bestimmt mit gewichtigen
Gegenargumenten auf, warum deren Konventionen besser sind. Und sofort
haben wir einen Glaubenskrieg:-)
Wilhelm, ich will Dich nicht (böswillig) angreifen. Es ist nur meine
Ansicht, warum mir die traditionelle Form der datenblattgerechten SFR
Manipulierung lieber ist, auch wenn die neuen Sprachenstandards all
diese Abstraktionen unterstützen, die Dir gefallen.
Für mich ist uC Projekt Erstellung eine HW bezogene Aktivität, wo die
Programmierung dieser HW eben (auch noch) notwendig ist. Dieser
Sachverhalt kontrastiert gewaltig mit generellem Computer Programmieren,
wo die HW nur in anderen Hinsichten relevant ist. Vielleicht kommt
dieser Hang zur Abstraktion von daher. Meiner Ansicht nach sollte man es
aber im uC Kontext vielleicht, im Interesse der Eindeutigkeit, nicht zu
übertreiben.
Vielleicht bin ich wirklich um Jahrzehnte hinter den aktuellen Methoden
die man heutzutage anwendet. Aber andrerseits habe auch ich meine
(guten) Gründe aufgeführt warum ich das nicht unbedingt für gut finde
und man es besser nicht so machen sollte.
Gruß,
Gerhard, der Ketzer:-)
Gerhard O. schrieb:> Moin,>> Jetzt möchte ich mich mal die Frage aufwerfen, ob es nicht im Interesse> der Klarheit und Unzweideutigkeiten besser wäre, immer mit der> Hersteller Datenblatt Register Namenskonvention zu arbeiten.
Das ist mehr als nur empfehlenswert, es ist fast alternativlos. Denn wer
will schon für all die Register und Bits neue Namen erfinden und
verwalten? Das ist Wahnsinn, erst recht auf größeren Controllern! Wie
man die Namen dann in Konstrukten verwendet, ist eine andere Frage.
Gerhard O. schrieb:> Um beim Beispiel zu bleiben, TIFR3 ist meiner Ansicht nach eindeutiger> als z.B. (Verzeih Wilhelm)timer()->intflags.reset<intflags_t::ocfb>();> Beim Beispiel ist es nur durch Nachschauen in den Header Files> erkenntlich, ob sich es eindeutig auf TIFR3 und OCF3A bezieht.
Deine Betrachtung ist sehr zentriert auf die alten AVRs: nur dort heißt
das Interrupt-Flag-Register des TC3 dann TIFR3, und die Bezeichnung der
Bitnummer OCF3A für den OCA dieses Timers.
Also: wenn man sich eine sinnvolle Nomenklatur dafür überlegen würde
seitens Atmel, dann müsste das Register TC3IF oder TC3IFR heißen und die
Bitnummer OCA oder OCFA; die Nummer 3 ist redundant. Oder TOV statt
TOV3.
Bei den neueren AVRs (DA, DB, ... du weißt schon) heißt das Register
tatsächlich INTFLAGS und das Flag TCA_SINGLE_OVF (oder TCA_SPLIT_OVF) in
den Headern, im Datenblatt dann nur OVF. Das Flag könnte auch OVF in den
Headern heißen, wenn, ja, wenn die Timer tatsächlich so regulär
aufgebaut wären wie bei den STM32-Familien, dann bräuchte man kein
TCB_OVF oder TCD_OVF.
Bei den STMs wiederum heißt das entsprechende Flag-Register SR und das
Flag immer TIM_SR_UIF, egal welcher Timer.
Also, wenn Du Dein Blick etwas weitest, erkennst Du, dass es auch
bessere Namensschemata gibt.
Und: ich sprach davon, dass man sinnvollerweise die Header-Files der
Hersteller ersetzt. Wenn das der Hersteller machen würde, könnte man
auch alle Namen vereinheitlichen. Da das die Hersteller nicht tun bzw.
es noch nicht einmal schaffen, sinnvolle C-Header-Files zu erzeugen oder
wie bei den DA, ... reguläre Peripherie-Strukturen herzustellen, geht es
nur mit eigenem Aufwand.
Gerhard O. schrieb:> Wilhelm, ich will Dich nicht (böswillig) angreifen. Es ist nur meine> Ansicht, warum mir die traditionelle Form der datenblattgerechten SFR> Manipulierung lieber ist, auch wenn die neuen Sprachenstandards all> diese Abstraktionen unterstützen, die Dir gefallen.
Alles perfekt: wenn Du damit zufrieden bist, ist ja alles ok.
Gerhard O. schrieb:> Deshalb könnte man auch gegenargumentieren, daß unnötige Abstraktion die> tatsächliche HW Bezogenheit verschleiert, die dann nur durch Studium der> relevanten Header Dateien geklärt werden können.
Dann müssten wir bits schnitzen.
Du siehst aber schon an der Diskussion um den Mist mit dem falschen
Statement
1
TIFR3|=1<<OCF3A;
das auch hier bei simplem C die Zusammenhänge nicht verstanden werden,
obwohl jemand behauptet, ins DB zu schauen.
Also: C ist eine viel zu hohe Abstraktionsebene.
Noch schlimmer ist es nur mit dem abstrusen Vorschlag der Bit-Fields in
C für SFR.
Falk B. schrieb:
>ist mehr als nur empfehlenswert, es ist fast alternativlos.
Damit verewigt man die Ungeschicktheiten von Atmel, Microchip, STM ...
in den Headern oder in den IDE's für alle Ewigkeit.
Alternative:
TIFR3=1<<OCF3A;// Flag durch schreiben einer 1 loeschen
Damit hab ich ja wieder eine Lawine losgetreten und der wichtige Fehler
den ich vorher gemacht habe ist fast untergegangen. Danke für deine
sorgfältige Code-Analyse.
Fenton G. schrieb:> Ich wollte eher darauf hinaus, ob es nicht statt:> if( TIFR3 & OCF3A ) {> besser> if( TIFR3 & (1<<OCF3A) ) {> heißen sollte?>
Besser - ist gut. Richtig wäre dies !
Hatte da also tatsächlich dass TOV3 abgefragt, aber dass OCF3A gelöscht.
1
iomxx_0_1.h
2
3
#define TIFR3 _SFR_IO8(0x18)
4
#define ICF3 5
5
#define OCF3C 3
6
#define OCF3B 2
7
#define OCF3A 1
8
#define TOV3 0
Spess53 .. schrieb:> Hi>>>Bei dem von mir gewähltem CTC-Mode 4, wird kein Overflow Flag gesetzt,>> Wie kommst du auf das schmale Brett?>
Bitte richtig zitieren und nicht dass Wichtigste weglassen.
Es wird ja nicht ohne Grund zwischen TOP = OCR3A und MAX = 0xFFFF
unterschieden und ich bleib dabei :
Bei dem von mir gewähltem CTC-Mode 4, wird kein Overflow Flag gesetzt,
da ich nicht bis MAX ( 0xFFFF ) hochzähle. Bzw. dieses Flag wird
wahrscheinlich einmalig doch gesetzt.
Es gibt ja nicht umsonst dass TOV und dass OCFnA Flag.
Bernd_Stein
Falk B. schrieb:> Schon mal was von einer for() Schleife gehört? Nicht zu verwechseln mit> der imaginären if()-Schleife.>
Da ich dies nur schrittweise bei jedem Interrupt tue, ist eine
FOR-Schleife nicht dass Richtige.
Bernd S. schrieb:> Pendeln anders realisieren> Hat jemand eine elegantere bzw. in der Programmabarbeitung schnellere> Idee ?
Wilhelm M. schrieb:> Du siehst aber schon an der Diskussion um den Mist mit dem falschen> Statement> TIFR3 |= 1<< OCF3A;>> das auch hier bei simplem C die Zusammenhänge nicht verstanden werden,> obwohl jemand behauptet, ins DB zu schauen.
Ja - ich schon.
Hi
>Bei dem von mir gewähltem CTC-Mode 4, wird kein Overflow Flag gesetzt,>da ich nicht bis MAX ( 0xFFFF ) hochzähle. Bzw. dieses Flag wird>wahrscheinlich einmalig doch gesetzt.
Du irrst;
Figure 17-6. CTC Mode, Timing Diagram (ATMega2560)
Dort findest du folgenden Satz
"OCnA Interrupt Flag Set or ICFn Interrupt Flag Set (Interrupt on TOP)"
TOP bezieht sich hier auf den Inhalt von OCnA- oder ICFn-Register und
nicht auf 0xFFFF
MfG Spess
Hugo H. schrieb:> Wilhelm M. schrieb:>> Du siehst aber schon an der Diskussion um den Mist mit dem falschen>> Statement>> TIFR3 |= 1<< OCF3A;>>>> das auch hier bei simplem C die Zusammenhänge nicht verstanden werden,>> obwohl jemand behauptet, ins DB zu schauen.>> Ja - ich schon.
Glück gehabt. Da ich schon lange nichts mehr mit den alten Dingen mache,
ist mir der Spezialfall entfallen.
Versuchst Du da bei einem neueren AVR oder irgendetwas anderem, wirst Du
auf die Nase fallen.
Spess53 .. schrieb:> TOP bezieht sich hier auf den Inhalt von OCnA- oder ICFn-Register und> nicht auf 0xFFFF>
Genau, deshalb kommt es ja nicht zu einem Überlauf.
Ich hatte es mal getestet und daher weiß ich dass es so stimmt.
Es wird nämlich nur einmal die Timer Overflow ISR aufgerufen, danach nur
noch die Output Compare Match ISR.
Bernd_Stein
Wilhelm M. schrieb:> Spezialfall
Gilt merkwürdiger Weise auch für den beliebten ATMega328P etc.
Aber klar, die "alten" AVR sind ja nur (noch) Spezialfälle ;-)
A. B. schrieb:>>ist mehr als nur empfehlenswert, es ist fast alternativlos.>> Damit verewigt man die Ungeschicktheiten von Atmel, Microchip, STM ...> in den Headern oder in den IDE's für alle Ewigkeit.
Willst du ALLE Register und Bits NEU definieren? Viel SPaß! Klar kann
man EINIGE zusammenfassen und den Zugriff vereinfachen, aber der Rest?
" However, changing the TOP to a value close to BOTTOM when
the counter is running with none or a low prescaler value must be done
with care since the CTC mode does not have the double buffering feature.
If the new value written to OCRnA or ICRn is lower than the current
value of
TCNTn, the counter will miss the compare match. The counter will then
have to count to its maximum value (0xFFFF) and wrap around starting at
0x0000 before the compare match can occur. "
Ich vermute, damit kann man dann diesen Fehlerfall erkennen, wenn der
Timer dann bis MAX ( 0xFFFF ) gezählt hat.
Bernd_Stein
Falk B. schrieb:> Willst du ALLE Register und Bits NEU definieren?
Das macht man ja nur einmal und das funktioniert ja nach einem
definierten Schema. Der Aufwand hält sich in Grenzen.
A. B. schrieb:>> Willst du ALLE Register und Bits NEU definieren?>> Das macht man ja nur einmal und das funktioniert ja nach einem> definierten Schema. Der Aufwand hält sich in Grenzen.
Willst du micht verarschen? Das ist schon grenzwertig bei einem kleinen
ATtiny. Von größeren AVRs oder ausgewachsenen 32 Bittern mit fetter
PEripherie ganz zu schweigen! Und wie übersetzt du dann die Namen in der
Doku in deine eigenen Namen? Mit der selbstgedruckten Bibel?
Und wie arbeitest ud damit, wenn du die Namen in der Doku liest und dann
in deine "geweihte" Sprache übersetzt?
A. B. schrieb:> Das macht man ja nur einmal und das funktioniert ja nach einem> definierten Schema. Der Aufwand hält sich in Grenzen.
Sowas lässt man Chatti (aka GPT4) in Python in 5 Minuten programmieren
und verschwendet selbst keine Minute damit^^
Ansonsten ist die Idee doof ...^^
Wenn der Bedarf bestände, würden die Hersteller sicher auch andere
Programmiersprachen als C mit Hardwaredefinitionen beglücken. Oder diese
Definitionen in XML oder JSON veröffentlichen. Dann könnte Wilhelm z.B.
daraus automatisch ein C++-API generieren.
Tun sie aber nicht. Warum wohl?
LG, Sebastian
Sebastian W. schrieb:> Wenn der Bedarf bestände, würden die Hersteller sicher auch andere> Programmiersprachen als C mit Hardwaredefinitionen beglücken. Oder diese> Definitionen in XML oder JSON veröffentlichen. Dann könnte Wilhelm z.B.> daraus automatisch ein C++-API generieren.>> Tun sie aber nicht. Warum wohl?
Tun sie doch?
In den "Device Packs" gibt's nen Ordner "atdf", der .atdf files enthält,
welche wiederum XML sind. Die AVR-LibC generiert sogar ihre Header
daraus, zumindest für die Devices, für die es solche XML-Beschreibungen
gibt. (Für alte Devices wie zB ATmega103 etwa gibt es keine XMLs).
Spaßig wirs das ganze erst dann, denn sich in eine solche Datei der
Tippteufel eingeschlichen hat.
Johann L. schrieb:> Sebastian W. schrieb:>> Wenn der Bedarf bestände, würden die Hersteller sicher auch andere>> Programmiersprachen als C mit Hardwaredefinitionen beglücken. Oder diese>> Definitionen in XML oder JSON veröffentlichen. Dann könnte Wilhelm z.B.>> daraus automatisch ein C++-API generieren.>>>> Tun sie aber nicht. Warum wohl?>> Tun sie doch?>> In den "Device Packs" gibt's nen Ordner "atdf", der .atdf files enthält,> welche wiederum XML sind.
Ja, die sind ganz brauchbar. Daraus habe ich meine erste Version
generiert.
STM liefert die svd-Files (XML), die sind ebenfalls gut, aber auch
leider hier und da fehlerbehaftet. Das modm-Projekt beschäftigt sich mit
der Verbesserung der Datenqualität.
Wilhelm M. schrieb:> Ja, die sind ganz brauchbar. Daraus habe ich meine erste Version> generiert.
Das klingt nun allerdings schon viel weniger nach einem
Wartungsalbtraum!
LG, Sebastian
Johann L. schrieb:> In den "Device Packs" gibt's nen Ordner "atdf", der .atdf files enthält,> welche wiederum XML sind.
Da drin fehlt die "fast toggle" Fähigkeit der PINX Register.
Im 4er Studio gabs die Info noch.
Arduino F. schrieb:> Johann L. schrieb:>> In den "Device Packs" gibt's nen Ordner "atdf", der .atdf files enthält,>> welche wiederum XML sind.>> Da drin fehlt die "fast toggle" Fähigkeit der PINX Register.
In den alten XML-Files fehlt noch mehr ;-) Und ich bezweifle, dass die
tatsächliche Semantik eines Bits da irgendwie mal drin gestanden hat.
Die neueren XML-Files sind da schon etwas besser, weil hier bspw. der
erlaubte Zugriff ("R", "RW") enthalten ist. Was allerdings immer noch
fehlt, ist die Info, ob die Bits nun rc_w1 ist (oder rc_w0) sind.
Insofern kann man hier nur intelligent raten beim Auswerten der XMLs.
Die XMLs von STM sind noch etwas besser: hier ist die Beschreibung der
Bits enthalten (wobei bei mehrfachem Vorkommen im Text(!) auf die
Beschreibung eines anderen Bits verwiesen wird). Aber auch hier fehlt
die Info zu rc_w1, etc. Obwohl das im DB drin steht. Daher: auch diese
XMLs sind nur die halbe Wahrheit.
Arduino F. schrieb im Beitrag #7518663:
> Schwachmat!Wilhelm M. schrieb:> Arduino F. schrieb:>> Gerhard O. schrieb:>>> Eigenbau>>>> Eigenbau>> Ist im inneren etwas unaufgeräumt, deckt aber die meisten AVR der>> Arduinowelt ab.>> Was machst Du mit µC, die mehr als einen ADC haben, z.B. die> tiny1-Serie?
Wie war jetzt Deine Antwort darauf? Meine konntest Du ja oben schon
lesen.
Moin,
Ich unterbreche die Verbalinjurien ja nur ungerne - aber
ihaettamolafrooch:
Welche Sprache/n ist geeignet, um aus so XML-Zeugs dann die Headerfiles
zu generieren?
Hat da wer ein Simpelbeispiel?
Gruss
WK
Dergute W. schrieb:> Welche Sprache/n ist geeignet, um aus so XML-Zeugs dann die Headerfiles> zu generieren?
Ich verwende PHP um solche Dateien zu lesen.
Es gibt für jede halbwegs moderne/brauchbare Sprache irgendeine DOM
Implementierung.
A. B. schrieb:> Das macht man ja nur einmal und das funktioniert ja nach einem> definierten Schema. Der Aufwand hält sich in Grenzen.
Bei dem Tempo, mit dem neue Modelle veröffentlicht werden, wäre ich mir
da nicht so sicher. Es gibt schließlich noch andere Dinge, mit denen man
sich im Leben beschäftigen möchte.
Dieser Programmabschnitt kann doch keine 5µs, bei 16MHz ( 62,5ns )
CPU-Takt dauern.
Erlaubt diese Arduino-Klamotte, dass ein Interrupt durch einen anderen
unterbrochen werden darf ?
Bernd S. schrieb:> Erlaubt diese Arduino-Klamotte, dass ein Interrupt durch einen anderen> unterbrochen werden darf ?
Nein. Wenn also gerade ein anderer Interrupt behandelt wird, muss
TIMER3_COMPA_vect auf dessen Beendigung warten. Spezialfälle wie die
explizite Freigabe neuer Interrupts in einem Interrupthandler mal
ausgenommen.
Bernd S. schrieb:> Dieser Programmabschnitt kann doch keine 5µs, bei 16MHz ( 62,5ns )> CPU-Takt dauern.
Zeig mal das Assemblat.
LG, Sebastian
Bernd S. schrieb:> Erlaubt diese Arduino-Klamotte, dass ein Interrupt durch einen anderen> unterbrochen werden darf ?
Da hat/nimmt es keinen Einfluss drauf.
Du bist der Programmierer/Gott deines µC, nicht Arduino.
Bernd S. schrieb:> Dieser Programmabschnitt kann doch keine 5µs, bei 16MHz ( 62,5ns )> CPU-Takt dauern.
Schau dir einfach das Assemblerlisting an, da kannst du die Takte leicht
auszählen, die der Code benötigt.
Caches oder Pipelines kennt der AVR8 nicht, das Takte-Auszählen ist also
wirklich eine reine Fleißarbeit, die sogar so jemand wie du (mit dem
entsprechenden Fleißeinsatz) problemlos leisten könnte.
Nur zu faul dazu?
Sebastian W. schrieb:> Bernd S. schrieb:>> Dieser Programmabschnitt kann doch keine 5µs, bei 16MHz ( 62,5ns )>> CPU-Takt dauern.> Zeig mal das Assemblat.
Um den Assemblercode zu erzeugen, musst du folgendes tun:
1. Aktiviere in den Arduino-Einstellungen "Ausführliche Ausgabe
während:" "Kompilierung"
2. Übersetze deinen Sketch
3. Notiere dir das in den letzten Zeilen der Ausgabe genannte
Arduino-Installationsverzeichnis (bei mir zum Beispiel
C:\\Users\\Hobbyraum\\AppData\\Local\\Arduino15\\packages\\arduino\\tool
s\\avr-gcc\\7.3.0-atmel3.6.1-arduino7/bin) und das temporäre
Sketchverzeichnis (bei mir zum Beispiel
C:\\Users\\HOBBYR~1\\AppData\\Local\\Temp\\arduino_build_174782).
4. Öffne ein Windows Eingabeaufforderung
5. Wechsle in der Eingabeaufforderung mit "cd
C:\\Users\\HOBBYR~1\\AppData\\Local\\Temp\\arduino_build_174782" (oder
wie auch immer es bei dir gerade heißt) in das temporäre
Sketchverzeichnis.
6. Führe in der Eingabeaufforderung "dir" aus. Eine der Dateien dort
sollte die Endung ".elf" haben (bei mir zum Beispiel "gen1mhz.ino.elf").
7. Führe in der Eingabeaufforderung auf der .elf-Datei das Kommando
avr-objdump mit den Optionen -d (disassemblieren) und -S (mit Sourcecode
verschränken) aus, und leite die Ausgabe in eine neue Datei um (bei mit
zum Beispiel
"C:\\Users\\Hobbyraum\\AppData\\Local\\Arduino15\\packages\\arduino\\too
ls\\avr-gcc\\7.3.0-atmel3.6.1-arduino7/bin/avr-objdump" -dS
gen1mhz.ino.elf >gen1mhz.ino.elf.lst)
8. Öffne das temporäre Sketchverzeichnis in einem Windows
Dateiexplorer-Fenster
9. Öffne dort die entstandene Datei mit der Endung ".lst" mit einem
Editor deiner Wahl. Dort findest du den erzeugten Assemblercode.
LG, Sebastian
Hallo,
ich würde einen Pin ein- und ausschalten lassen und am Oszi oder mit
Logic Analyzer messen. Nur muss man den Pin direkt mit PORT Bit
Manipulation schalten. Wenn das Bernd mit digitalWrite gemacht haben
sollte ist das eine Fehlmessung.
Veit D. schrieb:> Hallo,>> ich würde einen Pin ein- und ausschalten lassen und am Oszi oder mit> Logic Analyzer messen.>
Genau so habe ich es gemacht.
Wer gut im C-Programme lesen ist, hätte gesehen dass ich in dem Programm
einen negativen Impuls erzeuge, der halt ca. 5µs dauert. Er ist
natürlich nicht negativ ( nur für die Korintenkacker hier ), aber ich
weiß nicht wie ich es sonst erklären soll.
Ob S. schrieb:> Schau dir einfach das Assemblerlisting an, da kannst du die Takte leicht> auszählen, die der Code benötigt.>
Bei 16MHz dauert ein Befehlstakt 62,5ns.
Der größte Teil der AVR8-Befehle wird in einem Taktzyklus verarbeitet.
5000ns / 62,5ns = 80. Also hätte ich etwas weniger wie 80
Assembler-Befehle auszuwerten.
Ich habe 15 C-Befehle verwendet. Wenn ich pro Befehl ca. 5 CPU-Takte
rechne
kommt das schon hin.
Danke für diesen Denkanstoss, hatte vorher immer im Kopf von ns zu µs
ist es der Faktor 1000, dabei sind es aller höchstens 80 ASM-Befehle.
Bernd_Stein
Bernd S. schrieb:> Er ist natürlich nicht negativ..., aber ich> weiß nicht wie ich es sonst erklären soll.
Ich denke, du hast dich verständlich ausgedrückt. Man könnte es auch
einen LOW-Impuls nennen.
Habe ein schwer zu findenden Fehler in meinem Code.
Die PAUSE sollte jeweils nur einmal stattfinden.
Dachte erst, dass dies mit einer Regelmäßigkeit auftritt, da dies beim
errorZaehler-Stand 3, 8, 13, 18 auftrat.
Dann aber bei 26, 31, 36, 41, 46, 51, 59, 64, 72, 74, 79 und
noch mehr Stellen. Es gibt also keine erkennbare Regelmäßigkeit, auch
wenn es oft im 5er Abstand aufkommt.
Im Anhang mein Kot ;-)
Bernd_Stein
Beim Arduino Framework ist serielle Ausgabe innerhalb einer ISR
problematisch. Denn während die ISR läuft, sind alle anderen Interrupts
gesperrt. Die Serielle Ausgabe braucht aber ebenfalls Interrupts.
Deswegen sollte man solche Konstrukte besser vermeiden.
Schau dir mal genau den Code unter dem Kommentar "Sofortigen Interrupt
verhindern" an. Tut er wirklich sicher das, was der Kommentar sagt? Die
Abarbeitung dieser Zeilen braucht einige CPU Takte. Innerhalb dieser
Zeit könnte der Interrupt kommen.
Außerdem hast du den Zugriff "stepCount = SM_SCHRITTANZAHL" auf die 32
Bit Variable nicht geschützt. Dein AVR braucht auch dafür einige CPU
Takte. Während dessen kann ein Interrupt dazwischen stören und die halb
gesetzte Variable verändern. Packe da mal eine Interruptsperre drum
herum:
1
cli();
2
3
stepCount=SM_SCHRITTANZAHL;// Variable wird in ISR runtergezaehlt
4
5
// Sofortigen Interrupt verhindern
6
TCNT3=0;// Timer ruecksetzen
7
TIFR3=1<<OCF3A;// Output Compare Interrupt Flag loeschen
Stefan F. schrieb:> Beim Arduino Framework ist serielle Ausgabe innerhalb einer ISR> problematisch. Denn während die ISR läuft, sind alle anderen Interrupts> gesperrt. Die Serielle Ausgabe braucht aber ebenfalls Interrupts.> Deswegen sollte man solche Konstrukte besser vermeiden.>
Hm - so kenne ich das auch, dass man eigentlich innerhalb einer ISR
andere ISR freigeben muss, damit die laufende ISR dann durch die Andere
unterbrochen werden kann.
Ah - dann werden die Print-Befehle gar nicht an dieser Stelle der OC-ISR
ausgeführt, sondern erst nach verlassen dieser, wobei erst ein Befehl in
der Loop ausgeführt wird und dann die ISR für die anstehenden
Print-Befehle
ausgeführt wird.
Stefan F. schrieb:> Schau dir mal genau den Code unter dem Kommentar "Sofortigen Interrupt> verhindern" an. Tut er wirklich sicher das, was der Kommentar sagt? Die> Abarbeitung dieser Zeilen braucht einige CPU Takte. Innerhalb dieser> Zeit könnte der Interrupt kommen.>
Irgend einer schon, aber nicht mein OC-IRQ, da ich ihn ja vorher mit
sperre.
Stefan F. schrieb:> Außerdem hast du den Zugriff "stepCount = SM_SCHRITTANZAHL" auf die 32> Bit Variable nicht geschützt. Dein AVR braucht auch dafür einige CPU> Takte. Während dessen kann ein Interrupt dazwischen stören und die halb> gesetzte Variable verändern. Packe da mal eine Interruptsperre drum> herum:>
Stimmt generell.
Aber in meinem Fall sperre ich ja als aller erstes in der Loop den
OC-IRQ, der stepCount verändert. Ob irgend eine andere ISR beim Arduino
Framework zufällig auch stepCount benutzt weiß ich nicht.
Ich verstehe einfach nicht, was sich da in die Quere kommt, denn ich
habe in der Loop nur drei weitere Print-Befehle ( Neu ) eingefügt und
255 Error Zählungen sind ohne Fehler von statten gegangen.
Bernd S. schrieb:> dann werden die Print-Befehle gar nicht an dieser Stelle der OC-ISR> ausgeführt, sondern erst nach verlassen dieser
Genau. Die Strings werden in einen Puffer geschrieben. Das Programm wird
sich wohl an dieser Stelle aufhängen, wenn der Puffer voll läuft. Deine
Ausgaben sind offenbar kurz genug, dass das nicht passiert.
> Irgend einer schon, aber nicht mein OC-IRQ, da ich ihn ja vorher> mit ... sperre.
Guter Hinweis, das hatte ich übersehen.
> Ich verstehe einfach nicht, was sich da in die Quere kommt
Bin da jetzt auch ein bisschen überfordert. Ein Debugger wäre jetzt
nicht schlecht.
Bernd S. schrieb:> Ah - dann werden die Print-Befehle gar nicht an dieser Stelle der OC-ISR> ausgeführt, sondern erst nach verlassen dieser, wobei erst ein Befehl in> der Loop ausgeführt wird und dann die ISR für die anstehenden> Print-Befehle> ausgeführt wird.
Das hört sich unsinnig an!
Natürlich gibt es keine Warteschlange für Print Methoden.
Die Print::print() werden sofort ausgeführt.
Es wird ein char/uint8_t Ringbuffer mit den Ausgaben gefüllt.
Die Probleme/Blockaden entstehen, wenn der Ringbuffer voll ist.
Bernd S. schrieb:> Im Anhang mein Kot ;-)
In der Tat. So eine Scheiße kriegen nur die ganz großen Experten wie du
hin. Die Meister der Unlogik und der maximal verkorksten Lösung. Bravo!
Wie schon mehrfach gesagt, ist eine Serielle Ausgabe im Interrupt bei
der Arduinoumgebung nicht möglich. Sinnvoll ist si so oder so nicht. Die
kann man PROBLEMLOS im Hauptprogramm machen, wenn man weiß was man tut.
Ach so, du bist es ja!
Falk B. schrieb:> Sinnvoll ist si so oder so nicht.
Das hat er doch nur mangels Debugger gemacht, um den Ablauf des
Programmes zu kontrollieren. Für den Zwecks reicht der Puffer ja auch
offenbar.
Falk B. schrieb:> Wie schon mehrfach gesagt, ist eine Serielle Ausgabe im Interrupt bei> der Arduinoumgebung nicht möglich.
Doch, ist sie!
Solange noch Platz im Ringbuffer ist.
Solange kann man man die Print Methoden ohne Hemmung aufrufen.
Die UART Interrupts kommen allerdings erst nach einem sei(), bzw. ISR
Ende wieder durch.
Es ist also nur die Leerung des Buffers, der von der Print::print()
aufrufenden ISR aufgehalten wird.
Falk B. schrieb:> Sinnvoll ist si so oder so nicht.
Sinnvoll?
Auf jeden Fall sollte man Vorsichtig sein!
Auch da sich Ausgaben des Hauptprogramms und Ausgaben in der ISR
vermischen können/werden.
Die Endergebnisse werden also, ohne Vorkehrungen(Semaphore?), vermutlich
wenig zufriedenstellend ausfallen.
Threadsafe, ist vielleicht nicht ganz der richtige Begriff, aber trifft
es schon ganz gut. Die Print Methoden (Ringbuffer Verwaltung) sind nicht
Wiedereintritts fähig.
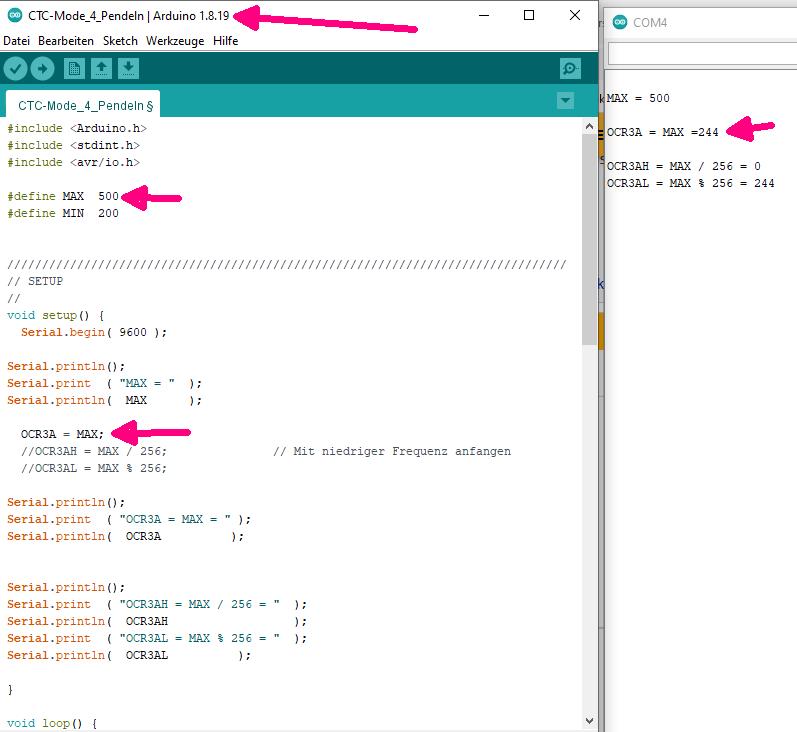
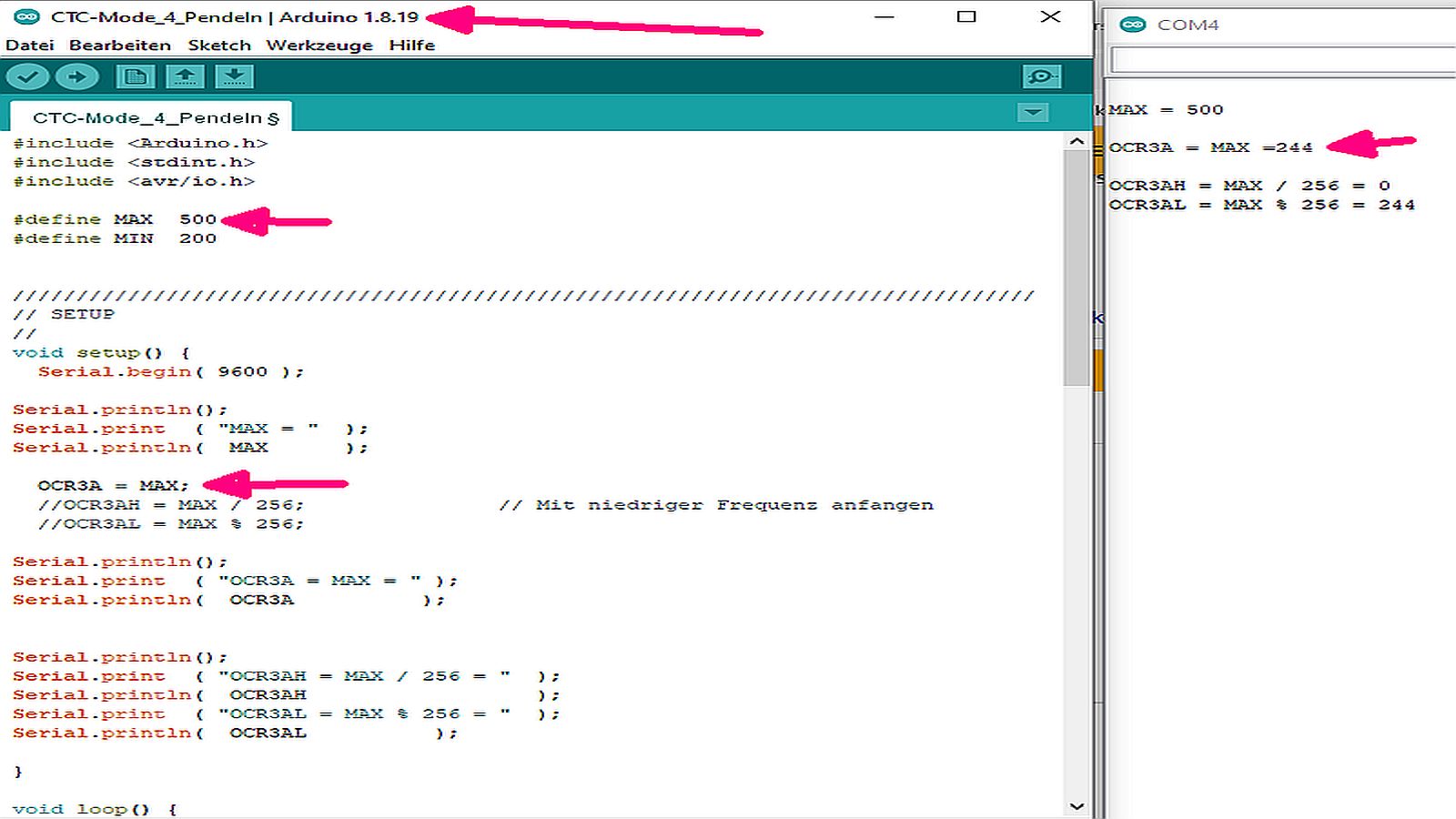

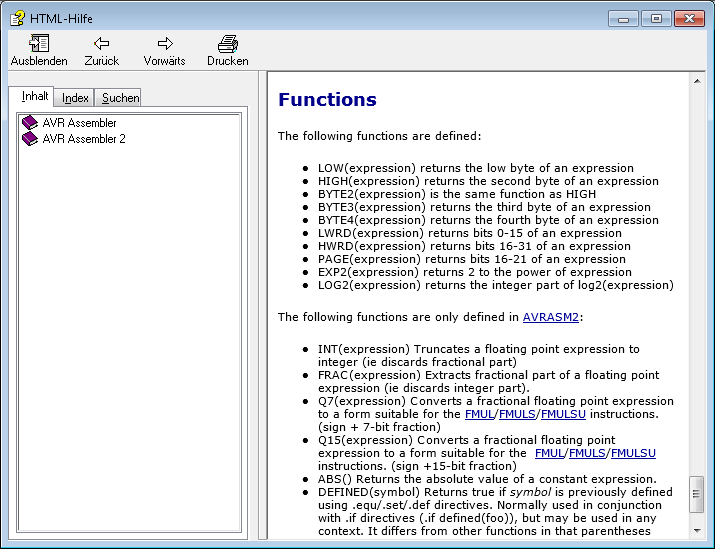

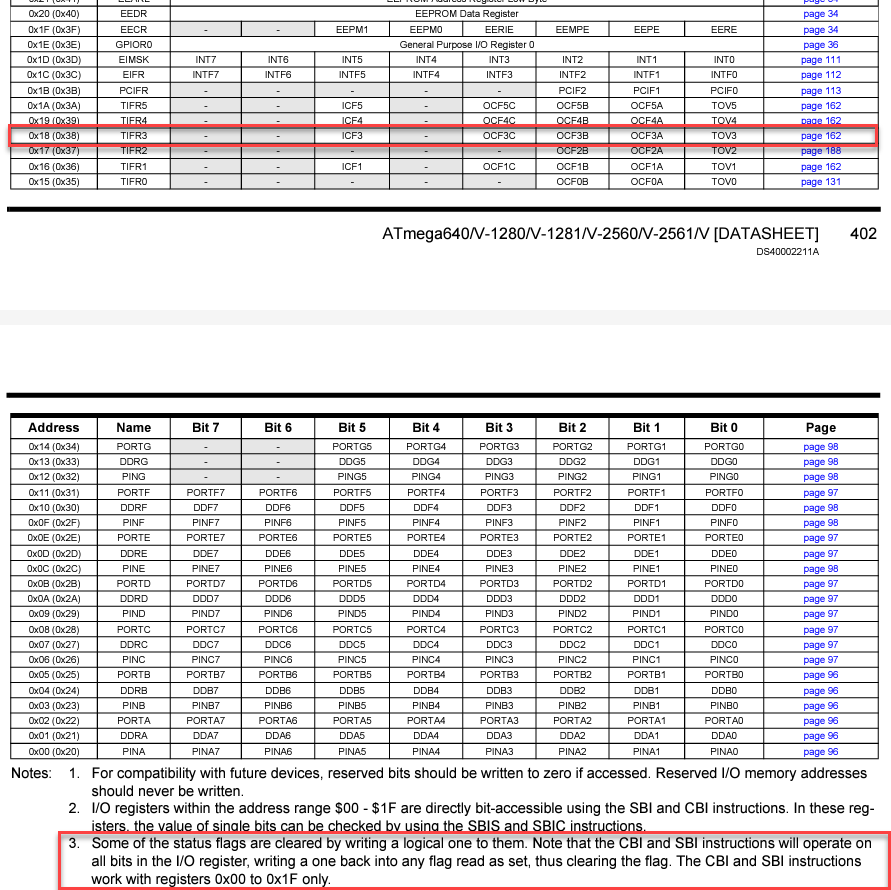
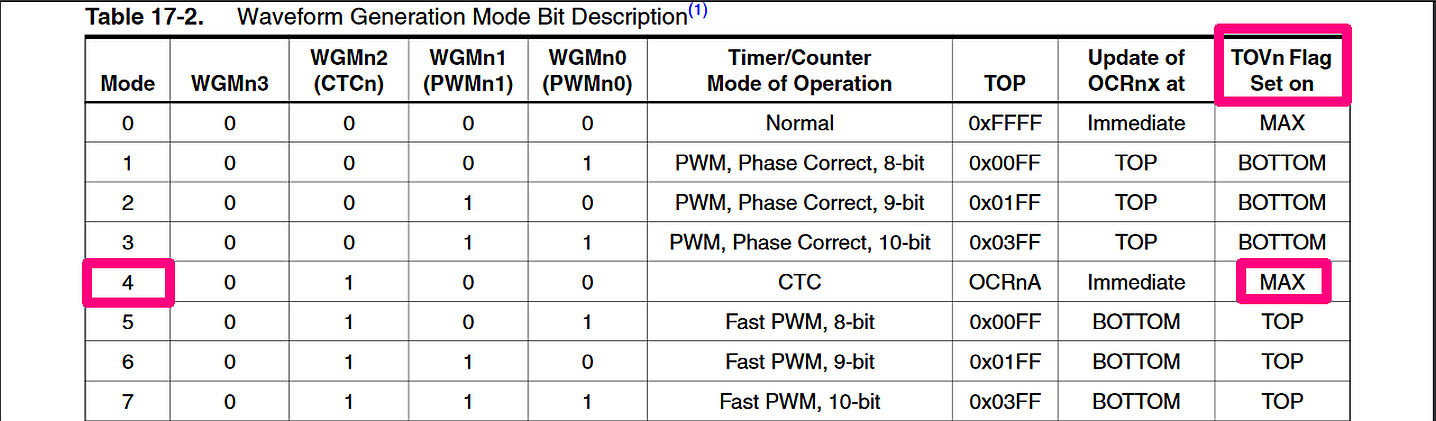
{kind=link}
{kind=link}