Die PiPico-Reihe hat ja mehrere Kerne, die man eher selten nutzt.
Hier will ich mal ein wenig damit experimentieren um die Schwierigkeiten
und Untiefen auszuloten. Hat jemand Erfahrung damit?
Hier mein erstes Experiment: 1 |
| 2 | /*
| 3 | * Pipico Multicore Programming
| 4 | *
| 5 | * based on Early Hill Power PiPico Framework
| 6 | * https://github.com/earlephilhower/arduino-pico/blob/master/libraries/rp2040/examples/Multicore/Multicore.ino
| 7 | *
| 8 | * 2025-03-26 mchris
| 9 | *
| 10 | */
| 11 | #define SPEAKERPIN 14
| 12 |
| 13 | uint32_t DelayTime_us = 1000;
| 14 |
| 15 | // ################# CORE 0 #############################
| 16 |
| 17 | void setup() {
| 18 | Serial.begin(115200);
| 19 | delay(5000);
| 20 | Serial.printf("core 0 started\n");
| 21 | }
| 22 |
| 23 | void loop() {
| 24 | uint16_t val = analogRead(A0);
| 25 | float frequency = val;
| 26 | DelayTime_us = 1 / frequency * 1e6;
| 27 | if(DelayTime_us>100000)DelayTime_us=100000;
| 28 | delay(100);
| 29 | Serial.println(DelayTime_us);
| 30 | }
| 31 |
| 32 | // ################# CORE 1#############################
| 33 |
| 34 | void setup1() {
| 35 | pinMode(SPEAKERPIN, OUTPUT);
| 36 | }
| 37 |
| 38 | void loop1() {
| 39 | digitalWrite(SPEAKERPIN, HIGH);
| 40 | delayMicroseconds(DelayTime_us);
| 41 | digitalWrite(SPEAKERPIN, LOW);
| 42 | delayMicroseconds(DelayTime_us);
| 43 | }
|
Was soll es da für Schwierigkeiten geben? Das ist das Gleiche wie
mehrere Threads auf dem PC zu verwenden. Man muss sich halt im Klaren
sein, das gemeinsam benutzte Ressourcen entsprechend gegen
konkurrierende Zugriffe abgesichert werden. Und ja ich benutze den
zweiten Kern, regelmäßig.
Christoph M. schrieb:
> uint16_t val = analogRead(A0);
> float frequency = val;
> DelayTime_us = 1 / frequency * 1e6;
Was macht die IEEE754 Implementation wenn val == 0 ist?
Und warum uint -> float -> uint?
Wichtiger aber, der Zugriff auf DelayTime_us von beiden Kernen aus ist —
da 32Bit noch atomar gehandhabt werden – zwar möglich. Wenn du aber
später ernsthafte Anwendungen schreiben möchtest, dann brauchst du einen
Semaphore Mechanismus. Davon bringt der Pico praktischerweise gleich
mehrere Hände voll in Hardware mit sich. Ebenso Pipelines für
Interprozess-Kommunikation.
Andreas M. schrieb:
> Was soll es da für Schwierigkeiten geben? Das ist das Gleiche wie
> mehrere Threads auf dem PC zu verwenden
Wie implementierst du _Atomic auf dem PiPico damit man wie auf dem PC
mit Threads arbeiten kann?
Aber grundsätzlich ist es sogar einfacher als auf dem PC, weil der
Cortex-M0 ja keinen Cache und keine keine OoO-Execution hat und man
keine Cache Maintenance Operations braucht.
Niklas G. schrieb:
> Wie implementierst du _Atomic auf dem PiPico damit man wie auf dem PC
> mit Threads arbeiten kann?
Das hab ich auch auf dem PC noch nie genutzt. Threads gabs schon vor
2011. Zugriffe auf "int" sind übrigens immer atomar, auch über Core
Grenzen hinweg... Das reicht vollkommen für Synchronisationsprimitive.
>Zugriffe auf "int" sind übrigens immer atomar
sicher? => AVR-gcc, Interrupt?
Andreas M. schrieb:
> Threads gabs schon vor
> 2011.
Ja, und meines Wissens basierte die Implementation von Threads & Mutexen
auf Kernel-Ebene auf x86 SMP schon immer auf Atomics. Da wurde dann
natürlich nicht das viel später definierte C-Sprachkonstrukt _Atomic
genutzt sondern (Inline) Assembler für die Instruktionen XADD und
CMPXCHG, aber das Ergebnis ist das Selbe.
Atomics direkt im Code selber zu nutzen hat in diversen Situationen
große Performance-Vorteile, als immer gleich einen Mutex zu nutzen
und/oder Interrupts zu sperren.
Andreas M. schrieb:
> Zugriffe auf "int" sind übrigens immer atomar, auch über Core
> Grenzen hinweg...
Wo ist das definiert? Meines Wissens nach garantiert C da überhaupt
nichts. Bei allen (?) ARM-Compilern ist int aber 32bit, und einzelne
(!!) 32bit-Zugriffe sind bei ARM atomisch, wenn sie korrekt aligned
sind. Damit kann man aber z.B. noch keinen Lock-Counter atomisch
inkrementieren, denn dafür braucht man eben atomische read-modify-Write
Mechanismen.
x86 macht das mit XADD und dem "LOCK" Prefix etc., und ARMv7 und drüber
macht dies über die STREX/LDREX Instruktionen. Der Cortex-M0 ist aber
ARMv6M und hat diese nicht, und auch kein Äquivalent.
Daher die Frage: Wie geht das beim PiPico mit Cortex-M0 (beim -M33 ist's
klar, der hat STREX etc)?
Andreas M. schrieb:
> Zugriffe auf "int" sind übrigens immer atomar, auch über Core
> Grenzen hinweg
Für den rp2350 stimme ich im Großen und Ganzen zu.
Aber beim rp2040 wird explizit geraten die Spinlocks zu benutzen.
»…which can** be used to manage mutually-exclusive access to shared
software
resources…«
und
»…If both cores try to claim the same lock on the same clock cycle, core
0 succeeds…«
** Wenn man sich die Sektion durchliest wird klar, dass das deutlich
mehr als nur ein Vorschlag ist.
Niklas G. schrieb:
> Wie geht das beim PiPico mit Cortex-M0
Spinlocks!
Christoph M. schrieb:
> AVR-gcc, Interrupt?
So ein Pico ist da Busbreitentechnisch schon deutlich weiter als ein
armer AVR.
Norbert schrieb:
> Spinlocks!
Okay, leider nicht so besonders effizient, und dann halt auch nicht
"genau so wie auf dem PC".
Niklas G. schrieb:
> Okay, leider nicht so besonders effizient,
Das stimmt, die Nutzung dauert mehrere Nanosekunden.
> und dann halt auch nicht "genau so wie auf dem PC".
Stimmt auch. Ich bin allerdings bis jetzt nicht auf die Idee gekommen
einen Pico mit einem PC zu vergleichen. ;-)
Norbert schrieb:
> die Nutzung dauert mehrere Nanosekunden.
Und man braucht extra Speicherplatz für den Spinlock.
Norbert schrieb:
> bin allerdings bis jetzt nicht auf die Idee gekommen einen Pico mit
> einem PC zu vergleichen. ;-)
Andreas schon...
Niklas G. schrieb:
> Und man braucht extra Speicherplatz für den Spinlock.
Ähm, das sind Register.
Die liest man zum acquire und beschreibt sie zum release
Norbert schrieb:
> Ähm, das sind Register
Okay, bisschen ungünstig dass die dann PiPico-spezifisch und nicht
portabel sind. Kann man Mithilfe dieser Register beliebig viele
Spinlocks implementieren, oder begrenzt die Hardware das? Bei ARMv7 und
x86 kann ja jedes einzelne Byte im Speicher ein eigener Atomic sein.
>Christoph M. schrieb:
>> AVR-gcc, Interrupt?
Norbert:
>So ein Pico ist da Busbreitentechnisch schon deutlich weiter als ein
>armer AVR.
Upps, ich vergesse immer ein paar Sachen zu erwähnen: Normalerweise
mache ich meine Programme so, dass sie auch auf dem kleinen AVR laufen.
Im Falle der zwei Kerne des Picos ist das natürlich schwierig. Ich
versuche das aber quasi zu "emulieren" indem der zweite Kern durch eine
schnelle Interruptsteuerung emuliert wird. Schnelle Sounderzeugung im
Interrupt, langsame Tonsteuerung sonst.
Christoph M. schrieb:
> Im Falle der zwei Kerne des Picos ist das natürlich schwierig. Ich
> versuche das aber quasi zu "emulieren
Die klassische Methode dafür ist es ein RTOS zu nutzen, dann ist es egal
ob Single- oder Multicore, aber für den AVR ist das eher nix.
Wenn Du einen Lock verwendet, dann bekommst Du immer Verzögerungen. Dass
liegt in der Sache der Natur, ganz unabhängig davon wie das
implementiert ist
Mein Ansatz ist es, die Software möglichst so zu struktieren, dass ich
gar keine Locks oder dergleichen brauche. D.h die Ressourcen werden auf
die Threads/Cores aufgeteilt. Dazwischen nutze ich gerne FIFOs, oder
einfach nur zwei Zähler für Ping/Pong.
Wer Locks braucht, aber kein Atomic hat kommt z.B. hiermit weiter:
https://en.m.wikipedia.org/wiki/Lamport%27s_bakery_algorithm
Andreas M. schrieb:
> Dazwischen nutze ich gerne FIFOs, oder
> einfach nur zwei Zähler für Ping/Pong.
Und die sind ohne Locks implementiert?
Christoph M. schrieb:
>> Zugriffe auf "int" sind übrigens immer atomar
> sicher? => AVR-gcc, Interrupt?
Ja, 8 Bitter sind die Ausnahme :). Da muss man sich halt auf uint8_t
beschränken.
Niklas G. schrieb:
> Andreas M. schrieb:
>> Dazwischen nutze ich gerne FIFOs, oder
>> einfach nur zwei Zähler für Ping/Pong.
>
> Und die sind ohne Locks implementiert?
Ja klar. Bei Fifos inkrementiert der Schreiber den Schreibzähler und der
Leser den Lesezähler.
Niklas G. schrieb:
> Kann man Mithilfe dieser Register beliebig viele
> Spinlocks implementieren, oder begrenzt die Hardware das?
32. Aber da wir über einen Nano- bis Mikrosekunden-Bereich der Benutzung
reden.
TEST: Zwei Kerne, jeder durchläuft 100.000 Schleifen und führt fünf mal
ein Inkrement einer globalen Variable aus. Der Zähler sollte zum Schluss
also bei 1.000.000 stehen.
Mit vorhersehbarem Misserfolg ohne die Nutzung von Spinlocks:
elapsed time: 175.0 ms (1.7 µs/loop)
Counter: 599997 <<< stark variabel
Unter Zuhilfenahme eines Spinlocks:
elapsed time: 258.7 ms (2.6 µs/loop)
Counter: 1000000
Ach ja, falls es interessiert, µPy. Mit C oder Thumb-Assembler geht's
dann noch etwas flinker.
Andreas M. schrieb:
> Bei Fifos inkrementiert der Schreiber den Schreibzähler und der
> Leser den Lesezähler.
Nutzt du dann die Methode, immer min. 1 Platz freizulassen, um die
Uneindeutigkeit im Fall Lesezähler=Schreinzähler zu vermeiden? Wenn
nicht, und du einen separaten Zähler/Flag zur Unterscheidung dieser
Fälle nutzt, wie synchronisierst du den Zugriff darauf? Du nutzt dann
aber schon DMB zwischen den Zugriffen (bei _Atomic ja impliziert)?
Das funktioniert dann nur wenn man nur genau 1 Consumer und 1 Producer
hat, was ja bei Dual-Core genau hinhaut.
Norbert schrieb:
> elapsed time: 258.7 ms (2.6 µs/loop)
Schon ein gewisser Unterschied. Aber eigentlich müsste man das mit
_Atomic vergleichen auf dem M33.
Norbert schrieb:
> 32.
Das skaliert dann nicht ganz so toll über eine komplexe Datenstruktur.
Niklas G. schrieb:
> Schon ein gewisser Unterschied.
Ja. Aber da die beiden Kerne ja nur sehr triviale Aufgaben erfüllen (ein
wenig Inkrementieren) verbringen sie per Definition einen substanziellen
Teil mit gegenseitigem warten. Das wäre bei jedweder Synchronisation,
egal über welchen Mechanismus) gleich.
Und wenn man in einem realen Programm mehrere hunderttausend Mal pro
Sekunde aus mehreren Ecken auf die selbe Resource lesend und schreibend
hämmert, dann wäre es ein guter Zeitpunkt das Konzept zu überdenken.
Im Normalfall ist eine Resource ja nahezu immer verfügbar und Spinlocks
dienen halt der Absicherung.
Der reine Acquire/Release Zyklus braucht übrigens nur 130ns. µPy!
Niklas G. schrieb:
> Das skaliert dann nicht ganz so toll über eine komplexe Datenstruktur.
Wir reden aber schon noch über einen Microcontroller, oder?
Niklas G. schrieb:
> Nutzt du dann die Methode, immer min. 1 Platz freizulassen, um die
> Uneindeutigkeit im Fall Lesezähler=Schreinzähler zu vermeiden?
Nein, ich lasse die Zähler einfach weiterlaufen. Füllstand ist die
Differenz. Bei 2er Potenzen in der FIFO Tiefe braucht man dann nur noch
Modulo machen um den Zugriffsindex zu bekommen. Andere Tiefen lassen
sich aber auch abbilden, man lässt den Zähler bis 2xTiefe-1 laufen und
bricht dann auf 0 um. Braucht dann ein paar IF's für die Füllstände und
Zugriffsindizes, ist aber immer noch schneller als Modulodivision durch
nicht 2er Potenzen.
Andreas M. schrieb:
> Nein, ich lasse die Zähler einfach weiterlaufen. Füllstand ist die
> Differenz.
Wenn Lesepointer=0 und Schreibpointer=0, ist der Fifo dann komplett
voll oder komplett leer?
Niklas G. schrieb:
> Andreas M. schrieb:
>> Nein, ich lasse die Zähler einfach weiterlaufen. Füllstand ist die
>> Differenz.
>
> Wenn Lesepointer=0 und Schreibpointer=0, ist der Fifo dann komplett
> voll oder komplett leer?
Leer.
Andreas M. schrieb:
> Leer.
Was machst du dann wenn Lesepointer=0, Schreibpointer=N-1 und was neues
geschrieben werden soll?
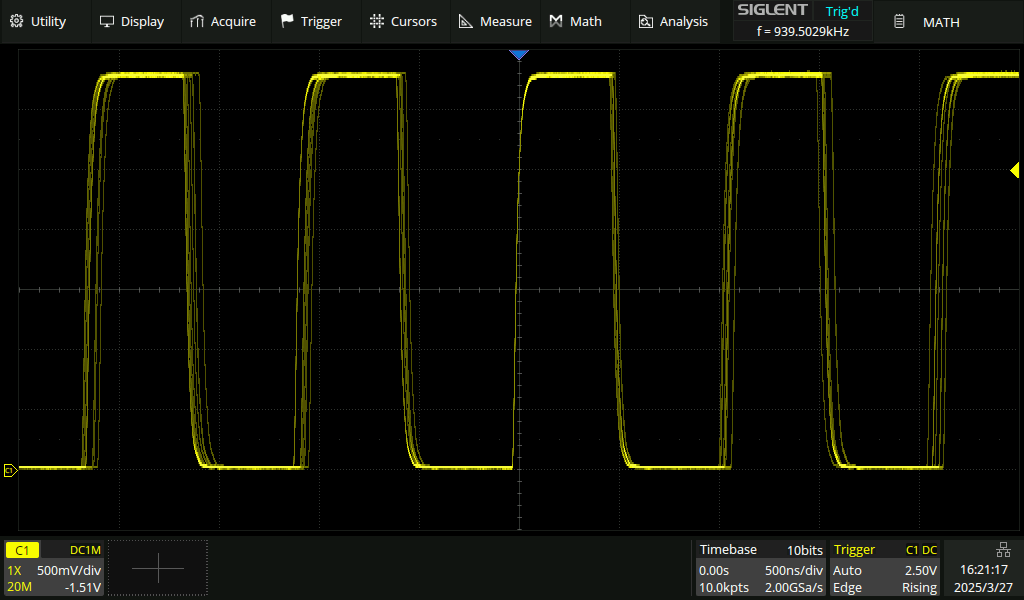
Da es mir um Geschwindigkeit geht, hier mal ein Test, bei dem ein Pin
auf Core1 getoggled wird.
Erwartung: Frequenz im Megahertzbereich, absolut stabiles Signal weil
der ganze Kern nur für das Toggling verwendet wird.
Beobachtung: ~2MHz, aber leichter Jitter auf Rechtecksignal
1 | // simple multicore example
| 2 | // core pin toggle test
| 3 |
| 4 | /*
| 5 | * Pipico Multicore Programming
| 6 | *
| 7 | * based on Early Hill Power PiPico Framework
| 8 | * https://github.com/earlephilhower/arduino-pico/blob/master/libraries/rp2040/examples/Multicore/Multicore.ino
| 9 | *
| 10 | * 2025-03-27 mchris
| 11 | *
| 12 | */
| 13 | #define TESTPIN 16
| 14 |
| 15 | uint32_t DelayTime_us = 1000;
| 16 |
| 17 | // ################# CORE 0 #############################
| 18 |
| 19 | void setup() {
| 20 | pinMode(LED_BUILTIN, OUTPUT);
| 21 | delay(1000);
| 22 | Serial.begin(115200);
| 23 |
| 24 | Serial.printf("core 0 started\n");
| 25 | }
| 26 | uint16_t Counter=0;
| 27 | void loop() {
| 28 | digitalWrite(LED_BUILTIN, HIGH);
| 29 | delay(500);
| 30 | digitalWrite(LED_BUILTIN, LOW);
| 31 | delay(500);
| 32 | Serial.println(Counter++);
| 33 | }
| 34 |
| 35 | // ################# CORE 1#############################
| 36 |
| 37 | void setup1() {
| 38 | pinMode(TESTPIN, OUTPUT);
| 39 | }
| 40 |
| 41 | void loop1() {
| 42 | digitalWrite(TESTPIN, HIGH);
| 43 | digitalWrite(TESTPIN, LOW);
| 44 | }
|
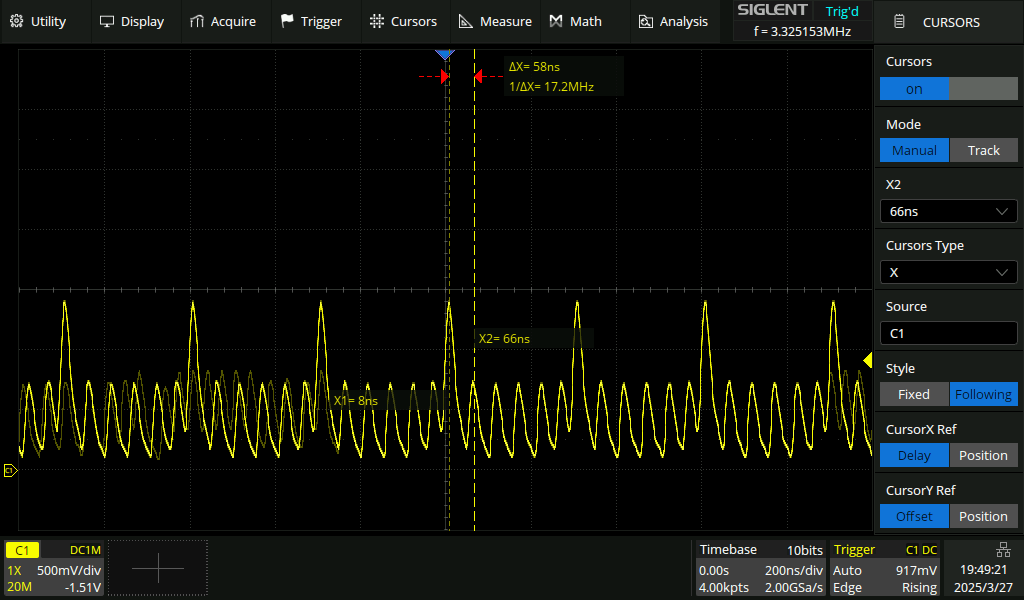
Christoph M. schrieb:
> Beobachtung: ~2MHz, aber leichter Jitter auf Rechtecksignal
Und was willst du uns damit sagen?
>Und was willst du uns damit sagen?
Der Jitter erscheint mir für die 150MHz des Pico2 zu groß.
Christoph M. schrieb:
> Der Jitter erscheint mir für die 150MHz des Pico2 zu groß.
Ein Jitter wird bei ARM Controllern immer auftreten da jede
I/O-Operation mit den Ports gepuffert wird und damit jede
Aktion erst mit dem I/O Clock auf den Core-Clock
synchronisiert werden muss. Absolute Core-Clock-synchrone
Ausgaben gibt es nicht, sondern nur Jitter-behaftet.
Das Arduino Framework funkt auch noch mit Interrupt dazwischen.
Christoph M. schrieb:
> Der Jitter erscheint mir für die 150MHz des Pico2 zu groß.
Welchen Jitter erwartest du, und wieviel misst du?
>Das Arduino Framework funkt auch noch mit Interrupt dazwischen.
Ich meine, das sollte nur auf Core0 funken.
>Welchen Jitter erwartest du, und wieviel misst du?
Weniger. 150MHz liegt Faktor 75 über 2MHz, das sollte man fast nichts
sehen.
Mach mal im Vergleich: 1 | void setup1() {
| 2 | gpio_init(TESTPIN);
| 3 | gpio_set_dir(TESTPIN, GPIO_OUT);
| 4 | }
| 5 | void loop1() {
| 6 | gpio_put(TESTPIN, true);
| 7 | gpio_put(TESTPIN, false);
| 8 | }
|
>Mach mal im Vergleich:
Danke, eine sehr gute Idee.
Das Signal scheint so schnell, dass der Ausgangspin nicht mehr mitkommt.
Die Störungen im mitlaufenden UKW-Radio sind je nach Initialisierung
völlig unterschiedlich sowie mit- und ohne while-Loop Kapselung.
Wenn ich mit pinMode statt mit gpio_init / set initialisiere, kann ich
den UKW-Sender im Radio vollständig blockieren.
1 | void setup1() {
| 2 | gpio_init(TESTPIN);
| 3 | gpio_set_dir(TESTPIN, GPIO_OUT);
| 4 | //pinMode(TESTPIN, OUTPUT);
| 5 | }
| 6 |
| 7 | void loop1() {
| 8 | while (1)
| 9 | {
| 10 | gpio_put(TESTPIN, true);
| 11 | //delayMicroseconds(1);
| 12 | gpio_put(TESTPIN, false);
| 13 | //delayMicroseconds(1);
| 14 | }
| 15 | }
|
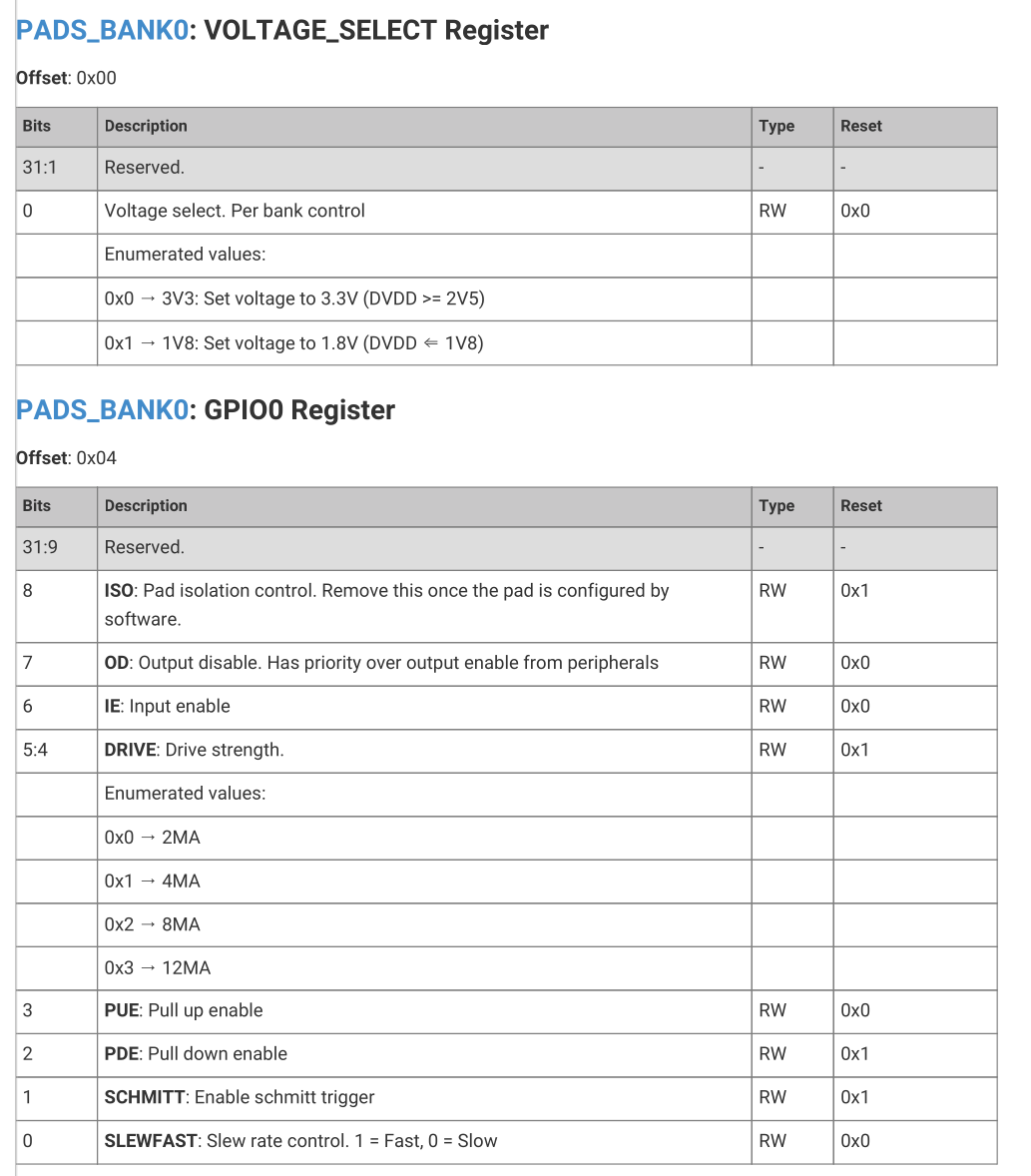
Mach mal noch im Setup: 1 | gpio_set_slew_rate(TESTPIN, GPIO_SLEW_RATE_FAST);
| 2 | gpio_set_drive_strength(TESTPIN, GPIO_DRIVE_STRENGTH_12MA);
|
>Mach mal noch im Setup:
Danke :-)
Unglaublich, was man bei den MCU-Pads alles einstellen kann (Screenshot
aus dem Datenblatt).
Ich werde vermutlich das Standardmässige "pinMode" verwenden.
https://github.com/earlephilhower/arduino-pico/blob/master/cores/rp2040/wiring_digital.cpp
Niklas G. schrieb:
> Andreas M. schrieb:
>> Leer.
>
> Was machst du dann wenn Lesepointer=0, Schreibpointer=N-1 und was neues
> geschrieben werden soll?
Das neue reinschreiben und den Schreibpointer auf N setzen.
Andreas M. schrieb:
> Das neue reinschreiben und den Schreibpointer auf N setzen.
Ah okay, und was machst du bei
Lesepointer=7
Schreibpointer=6
Gesamtgröße=10
wenn geschrieben werden soll?
Was machst du wenn
Lesepointer=6
Schreibpointer=7
Beim Lesen?
Lesepointer 7 und Schreibpointer 6 ist kein gültiger Zustand bei meinem
Algo. Ich schrieb ja, das ich die "Pointer" - das ist der Falsche
Begriff, es sind bei mir Zähler, bei 2xTiefe-1 Umbreche. D.h in für den
Fall hier dass neun Elemente in der FIFO sind wäre der Lesezähler 7 und
der Schreibzähler 16. Die jeweiligen Pointer für den Zugriff erhält man
durch "x >= 10 ? (x-10) : x". Bei 2er Potenzen wirds noch einfacher, da
reicht dann z.B. "x%16" was einfach nur ein "and" ist und man braucht
nix umbrechen sondern inkrementiert die Zähler einfach nur.
Andreas M. schrieb:
> Ich schrieb ja, das ich die "Pointer" - das ist der Falsche Begriff, es
> sind bei mir Zähler, bei 2xTiefe-1 Umbreche.
Ups, hab ich überlesen, weil ich dachte da kommt jetzt was triviales 🤣
So ganz überzeugt bin ich nicht, kannst du den Schreib-und
Lesealgorithmus zeigen?
Wenn ich wieder zu Hause bin, ja.
N. M. (mani)
27.03.2025 20:12
>void setup1() {
> gpio_init(TESTPIN);
> gpio_set_dir(TESTPIN, GPIO_OUT);
>}
Zu welchen Framework gehören die gpio-Funktionen? Laufen die auch auf
einem STM32 oder ESP32?
Christoph M. schrieb:
> Zu welchen Framework gehören die gpio-Funktionen?
RP2040/RP2350 (Raspberry Pi Pico)
https://www.raspberrypi.com/documentation/pico-sdk/hardware.html#group_hardware_gpio
Christoph M. schrieb:
> Laufen die auch auf einem STM32 oder ESP32?
Nein, das ist die nackte HAL für die Rasp Picos.
Ich finde die weiter oben dargestellten Resultate ein wenig befremdlich.
Und das ist noch stark euphemistisch formuliert.
Hier für die Interessierten mal eine Darstellung der real erzielbaren
Werte.
Entschuldigt die Textdarstellung, für solchen Kleinkram reicht das
jedoch allemal aus.
Auf Core 0 wird gemessen, auf Core 1 werden vier verschiedene Routinen
gestartet, zweimal Python, zweimal Assembler. Jeweils für die schnellste
symmetrische und die schnellste asymmetrische Wellenform.
Selbstverständlich jeweils von einem Hardware Reset eingeleitet.
CPU ist auf 100 MHz gebremst um die Skalierung angenehmer zu gestalten.
Gemessen wird an Pin 16, der war gerade so schön nahe. 1 | ===== Micropython 1.24.1 =====
| 2 |
| 3 | _thread.start_new_thread(python_toggle_symmetric,…)
| 4 | CPU @ 100.000 MHz
| 5 | Cycle 10.000 ns
| 6 | │╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│1000ns (100ns/div – 10ns/tick)
| 7 | ███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁
| 8 |
| 9 | ▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁███▁▁▁██
| 10 | │╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│1000ns (100ns/div – 10ns/tick)
| 11 |
| 12 |
| 13 | _thread.start_new_thread(python_toggle_asymmetric,…)
| 14 | CPU @ 100.000 MHz
| 15 | Cycle 10.000 ns
| 16 | │╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│1000ns (100ns/div – 10ns/tick)
| 17 | █▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█
| 18 |
| 19 | ▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁
| 20 | │╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│1000ns (100ns/div – 10ns/tick)
| 21 |
| 22 |
| 23 | _thread.start_new_thread(asm_toggle_symmetric,…)
| 24 | CPU @ 100.000 MHz
| 25 | Cycle 10.000 ns
| 26 | │╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│1000ns (100ns/div – 10ns/tick)
| 27 | ██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁
| 28 |
| 29 | ██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁██▁▁
| 30 | │╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│1000ns (100ns/div – 10ns/tick)
| 31 |
| 32 |
| 33 | _thread.start_new_thread(asm_toggle_asymmetric,…)
| 34 | CPU @ 100.000 MHz
| 35 | Cycle 10.000 ns
| 36 | │╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│╵╵╵╵╵╵╵╵╵│1000ns (100ns/div – 10ns/tick)
| 37 | █▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█
| 38 |
| 39 | ▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁▁█▁
| 40 | │╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│╷╷╷╷╷╷╷╷╷│1000ns (100ns/div – 10ns/tick)
|
Für die beiden Python Schleifen und die beiden Assembler Schleifen
kommen wir
mit ein wenig zählen auf 6, 3, 4, 3 Taktzyklen pro Wellenform.
und mit ein wenig rechnen auf 16.667, 33.333, 25.000, 33.333 Mehahertz.
Insofern finde ich die 2 MHz mit Arduino gar nicht mal so schlecht.
Man sollte es vielleicht nur vermeiden, wenn man etwas präziser arbeiten
möchte. ;-)
Und nein, bei Messung zwei und vier ist kein Fehler unterlaufen.
Python und Assembler sind dort vom Ergebnis tatsächlich identisch.
>Hier für die Interessierten mal eine Darstellung der real erzielbaren
Werte.
Mir ist unklar, was du da zeigst. Könntest du den Code dazu posten?
Christoph M. schrieb:
> Mir ist unklar, was du da zeigst.
Hmmm, dachte ich hätte es genau genug dargelegt.
Im Grunde genommen lasse ich auf einem Pi Pico bzw. auch einem Pi Pico2
vier mal verschiedene Endlosschleifen laufen (auf Core 1) und messe das
sich per Pin toggling ergebende Signal am Pin 16 mittels eines weiteren
Programmes auf Core 0.
Es laufen:
1. Eine Schleife in Python welche ein symmetrisches (50:50)
Ausgangssignal erzeugt. Damit erreicht man 16.667 MHz.
2. Eine Schleife in Python welche ein asymmetrisches (33:67)
Ausgangssignal erzeugt, dafür jedoch nochmals schneller ist. Damit
erreicht man 33.333 MHz.
3. Eine Schleife in Thumb-Assembler (innerhalb Python) welche ein
symmetrisches (50:50) Ausgangssignal erzeugt. Damit erreicht man 25.000
MHz.
4. Eine Schleife in Thumb-Assembler (innerhalb Python) welche das
schnellstmögliche, asymmetrisches (33:67) Ausgangssignal erzeugt. Damit
erreicht man ebenfalls 33.333 MHz.
Christoph M. schrieb:
> Könntest du den Code dazu posten?
Zum Programm: Nein. Bei der hier im Forum nicht nur latent vorhandenen,
sondern offen zur Schau gestellten Aggressivität und Feindseligkeit
gegenüber Python (und auch allem anderen was nicht mit ›C‹ anfängt und
am besten mit dem selben ›C‹ oder ›+‹ gleich wieder aufhört), habe ich
für mich entschieden — wenn es erforderlich erscheint — bestenfalls nur
noch kleinere Snippets zu zeigen.
Letzten Endes ging es darum zu zeigen, dass die vormals genannten 2 MHz
mit Arduino noch nicht einmal annähernd in den Bereich des Möglichen
reichen. Und ganz zweifellos können die Port Pins diese hohe
Geschwindigkeit problemlos mitgehen.
Das ganze hat aber selbstverständlich keinerlei Bezug zu Bedürfnissen in
der realen Welt. Da nutzt man für solche Dinge natürlich die eingebaute
Hardware und erreicht damit 50 MHz.
Alle Angaben bezogen auf eine CPU welche mit 100 MHz getaktet ist.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
|