Da ich am evaluieren von CH32V003 bin, habe ich im Zuge dessen jetzt
auch einmal die Ausführungszeiten für ein Apfelmännchen gemessen /
getestet. Hier bin ich jetzt erstaunt / verwundert und denke ich habe
irgendwo einen Denkfehler.
Zuerst einmal die Ausführungszeiten:
1
Ausfuehrzeiten fuer das Programm: Fraktal-Speedtest:
2
3
Display: 160x128 ST7735
4
Interface: Hardware-SPI
5
6
Controller | Zeit [Sekunden]
7
-------------------------------------------------
8
STM32F401 / 84MHz | 2.8
9
STM32F401 / 96MHz (uebertaktet) | 2.6
10
STM32F103 / 72MHz | 11.4
11
STM32F030 / 48MHz | 34.0
12
CH32V003 / 48MHz | 80.5
13
CH32V003 / 24MHz | 123.0
14
ATmega328 / 16Mhz | 63.0
Alle werden mit denselben Grafikroutinen betrieben, alle mit
Hardware-SPI (wobei im Falle von CH32V003 und dem Apfelmännchen relativ
unerheblich ist, ob das mittels Hardware-SPI oder Bitbanging betrieben
wird, Bitbanging braucht ca. 2 Sekunden länger).
Alle laufen mit einem Systemticker, im Falle vom ATmega generiert Timer1
einen 1 Millisekundenintervall in dem ein Zähler hochgezählt wird.
Dann traute ich meinen Systemtickern nicht so recht über den Weg und
habe das handgestoppt, die Zeiten stimmen.
Noch betreibe ich den CH32V003 über das Setup des Frameworks CH32FUN
(und ersetze nach und nach dessen Routinen durch eigene, bis ich das
Framework dann nicht mehr benötige).
Ist im CH32FUN im Clocksetup etwas grundsätzlich nicht richtig (ich bin
hier auf der Suche), oder ist der CH32V003 hier wirklich so lahm, dass
sogar ein ATmega das Apfelmännchen schneller zeichnet?
Compileroptimierungsschalter steht auf -Os (natürlich habe ich auch -O1
und -O2 ausprobiert, aber außer an der Codegröße hat sich nicht viel
geändert).
Compiler für den CH32V003 ist riscv-none-elf-gcc.
Im Anhang hier ist der Programmcode des Apfelmännchens enthalten.
Wie kompilierst du den Quelltext? Benutze mal float Konstanten, also
statt 2.0 2.0f oder benutze -fsingle-precision-constant.
1
ty= 2.0f*wx*wy+jy;
Diese Stelle müsste (ohne das ..f) beim STM32 (evtl. auch beim RISC-V)
in doubles berechnet werden. Die Kovertierung auf float findet erst beim
abspeichern in ty statt.
Ich denke, dass der Compiler bei den STM32 an bestimmten Stellen doubles
einbaut, evtl. auch beim CH32V003. Vermutlich hat dieser RISC-V Kern
(v2a) auch nur eine langsamere (keine Single Cycle) Integer
Multiplikation. Diese wird ja auch benötigt, um die Gleitkommabefehle
auzuführen.
Christoph M. schrieb:> Die STM32F4xx haben eine Fließkommaeinheit.
Das weiß ich!
Klaus R. schrieb:> Wie kompilierst du den Quelltext? Benutze mal float Konstanten, also> statt 2.0 2.0f oder benutze -fsingle-precision-constant.ty=> 2.0f*wx*wy+jy;
Es ging mir vor allen Dingen darum, wie schnell ein CH32V003 den Code im
Vergleich zu STM32F030 und ATmega ausführt.
Den Versuch mit 2.0f werde ich aber machen!
So, die Versuche für einfache Genauigkeit und 2.0f habe ich jetzt mal
gemacht:
STM32F401 / 84 MHz => 0.5 Sekunden
STM32F103 / 72 MHz => 9.2 Sekunden
STM32F030 / 48 MHz => 24.9 Sekunden
CH32V003 / 48 MHz => 62.9 Sekunden
ATmega328 / 16 MHz => 63 Sekunden
Dass ATmega nicht schneller wird war anzunehmen, da meines Wissens der
AVR-GCC Compiler bei Angabe 2.0 keine doubles berechnet.
Dennoch finde ich das Ergebnis für CH32V003 etwas enttäuschend:
Float-Berechnungen nicht schneller als auf einer alten 8-Bit MCU mit nur
16 MHz !!
Wenn ich das richtig nachgeschaut habe, hat der CH32V003 nur das
institution set "RV32EC". Somit hat der noch nichtmal für integer eine
Multiplikation bzw. Division und die dürften hier recht häufig genutzt
werden.
- "RV32E" Base integer instruction set (embedded), 32-bit, 16 registers
- "C" Standard extension for compressed instructions
- "M" = Standard extension for integer multiplication and division
- https://en.wikipedia.org/wiki/RISC-V#Standard_extensions
Irgend W. schrieb:> Somit hat der noch nichtmal für integer eine Multiplikation bzw.> Division und die dürften hier recht häufig genutzt werden.
Naja ein Cortex-M0 ist IMHO nicht so verschieden...
Abseits des Taktes bleibt noch die Frage ist, ob es für den Risc-V eine
optimierte float library gib...
Der F0 und der AVR sind auf den Takt normalisiert in etwa gleich auf.
Den CH32v003 würde ich in etwa in der gleichen Liga sehen...
73
Ralph S. (jjflash)
>Dennoch finde ich das Ergebnis für CH32V003 etwas enttäuschend:>Float-Berechnungen nicht schneller als auf einer alten 8-Bit MCU mit nur>16 MHz !!
Wie ist denn der CH32V003 implementiert? Es könnte ja sein, dass der
Kern aus Kostengründen eine Bit-Slice-Architektur wie ein Z80 früher
ist.
Dann bräuchte er einige Takte mehr pro Befehl.
Gibt es irgendwo Angaben, wie viele Takte er für ein Integer-Add
braucht?
Hans W. schrieb:> Stimmt der SPI clock (nicht, dass du unabsichtlich einen viel> langsameren clock verwendest)?
Der SPI-Clock ist garantiert nicht das "Problem", da die Zeiten nicht
viel schneller sind, wenn es gar keine Ausgabe auf dem Display gibt (und
man nur die Berechnungen durchführt).
Irgend W. schrieb:> Wenn ich das richtig nachgeschaut habe, hat der CH32V003 nur das> institution set "RV32EC". Somit hat der noch nichtmal für integer eine> Multiplikation bzw. Division und die dürften hier recht häufig genutzt> werden.
Das, glaube ich, wird des Pudels Kern sein !
Hans W. schrieb:> Der F0 und der AVR sind auf den Takt normalisiert in etwa gleich auf.> Den CH32v003 würde ich in etwa in der gleichen Liga sehen...
Im Moment sehe ich das eher nicht so!
Harald K. schrieb:> Das ist ein RISC-V, QingKe V2A core, RV32EC, Details finden sich im> Reference Manual:>> https://www.wch-ic.com/downloads/CH32V003RM_PDF.html> https://www.wch-ic.com/downloads/QingKeV2_Processor_Manual_PDF.html
... und das schaue ich mir jetzt einmal an, vielen Dank
Harald K. (kirnbichler)
14.04.2025 09:50
>Das ist ein RISC-V, QingKe V2A core, RV32EC, Details finden sich im>Reference Manual:
Siehst du da irgendwelche Angaben zu den Taktzyklen pro Befehl?
Christoph M. schrieb:> Siehst du da irgendwelche Angaben zu den Taktzyklen pro Befehl?
Nope.
Auf "reddit" gefunden:
CH32V003 fetches 4 bytes of instructions in 1 clock cycle at 24 MHz, or
2 clock cycles at 48 MHz. Then it executes whatever instructions are in
those 4 bytes (plus maybe the last 2 byte of the previous instruction
fetch, if it started a 4 byte instruction) at (usually) 1 clock cycle
per instruction.
So at 48 MHz you can execute one 4-byte instruction in 3 clock cycles,
or two 2-byte instructions in 4 clock cycles.
(in einer der Antworten auf
https://www.reddit.com/r/RISCV/comments/12qocw4/example_assembly_code_for_the_ch32v003/)
>CH32V003 fetches 4 bytes of instructions in 1 clock cycle at 24 MHz, or>2 clock cycles at 48 MHz.
Interessant: Bei doppeltem Clock gleich schnell beim Fetch. Liegt
wahrscheinlich am Flash.
Falls ein AVR-Assembler Experte mitliest: Wieviel Zyklen braucht ein
Atmega für ein 32Bit add ?
Christoph M. schrieb:> Interessant: Bei doppeltem Clock gleich schnell beim Fetch. Liegt> wahrscheinlich am Flash.
Nehm ich auch an. Ob sich das ändert, wenn man den Code aus dem RAM
ausführt? Viel hat er davon ja nicht, aber ...
Ralph S. schrieb:> Hans W. schrieb:>> Stimmt der SPI clock (nicht, dass du unabsichtlich einen viel>> langsameren clock verwendest)?>> Der SPI-Clock ist garantiert nicht das "Problem", da die Zeiten nicht> viel schneller sind, wenn es gar keine Ausgabe auf dem Display gibt (und> man nur die Berechnungen durchführt).
Ich meinte damit eigentlich: "Stimmen die 48MHz überhaupt"?
Also indirekte Messung über den SPI-CLK, da der ja aller
Wahrscheinlichkeit nach vom CPU CLK abgeleitet wird.
73
Ralph S. schrieb:> Dennoch finde ich das Ergebnis für CH32V003 etwas enttäuschend:> Float-Berechnungen nicht schneller als auf einer alten 8-Bit MCU mit nur> 16 MHz !!
Das sollte man aber ein wenig kontextualisieren:
Der ATMega ist eine extrem gut ausgestattete moderne 8-Bit-CPU, die
recht gut optimiert ist. Das lässt sich der Hersteller aber auch
bezahlen. Der CH32V003 ist ein absolutes Lowcost-Produkt. Der ATMega328
kostet so um die 1.50, der CH32V003 sagen wir mal so etwa 30 Cent. Da
kriegst du also für ein Fünftel des Preises halbwegs vergleichbare
Performance. Viele Anwendungen brauchen keine
Hochleistungs-Microcontroller, sondern müssen nur ein paar Sensoren
auswerten und Transistoren schalten, da wird sowas dann natürlich höchst
interessant.
In der Mounriver-Toolchain für die CH32-Controller wird die generische
soft-fp der glibc verwendet. Diese ist in C implementiert und in
keinster Weise an spezifische CPU-Typen angepasst. Die AVR-FP-Routinen
hingegen sind in Assembler speziell für diesen CPU-Typ geschrieben.
Das alleine macht schon einen Riesenunterschied. Dazu kommt dann noch
der fehlende Hardwaremultiplizierer im CH32V003. Immerhin ist ist die
Integermultiplikation beim CH32V003 in Assembler geschrieben.
Vielleicht erinnert sich noch jemand an die Zeiten, wo auch für den AVR
die soft-fp der glibc verwendet wurde. Da hat man um jeden Preis
versucht, auf FP-Arithmetik komplett zu verzichten.
Evtl. gibt es für den CH32V003 irgendwo eine optimierte FP-Bibliothek,
ich kenne aber keine.
PS: Vielleicht möchte sich mal jemand das da anschauen:
https://www.segger.com/news/risc-v-embedded-variant-rv32e-now-fully-supported-by-seggers-floating-point-library/
Hans W. schrieb:> Abseits des Taktes bleibt noch die Frage ist, ob es für den Risc-V eine> optimierte float library gib...Yalu X. schrieb:> CH32-Controller wird die generische> soft-fp der glibc verwendet.
Danke für die Antwort!
Das erklärt den Unterschied voll und ganz!
Gerade hat DHL mein 1. Design mit einem CH32V003 geliefert... hatte
schon Sorgen, dass ich bei der Komponentenauswahl für den Kunden
irgendwas übersehen habe :)
Ohne ASM-soft-fp und ohne Hardware Multiplier ist die Geschwindigkeit
aber eigentlich ok :)
73
Hans W. schrieb:> ch meinte damit eigentlich: "Stimmen die 48MHz überhaupt"?>> Also indirekte Messung über den SPI-CLK, da der ja aller> Wahrscheinlichkeit nach vom CPU CLK abgeleitet wird.
Das war die erste Überlegung, ob die 48MHz überhaupt stimmen. Erst im
Framework gesucht (war alles in Ordnung ... und ich habe wieder etwas
über die Register gelernt) und dann zusätzlich auf der SPI natürlich den
Klassiker 0x55 und 0xAA ausgegeben... kommt mit dem Clock-Prescaler so
hin. Das Teil läuft wirklich mit 48MHz!
F. schrieb:> Der ATMega ist eine extrem gut ausgestattete moderne 8-Bit-CPU, die> recht gut optimiert ist. Das lässt sich der Hersteller aber auch> bezahlen. Der CH32V003 ist ein absolutes Lowcost-Produkt. Der ATMega328> kostet so um die 1.50, der CH32V003 sagen wir mal so etwa 30 Cent. Da> kriegst du also für ein Fünftel des Preises halbwegs vergleichbare> Performance.
Na ja, es ging ja nicht darum (zumindest hier nicht) was das Teil
kostet. Ich beschäftige mich mit dem Dingelchen ja eigentlich nur aus
"sportlichem" Antrieb heraus weil das so billig ist. Allerdings hätte
ich angenommen, dass RISCV den ATmega um längen schlägt. Ob ATmega jetzt
als "extrem gut ausgestattet" und "modern" bezeichnet werden kann, lass
ich jetzt mal unkomentiert. Optimiert ist sie sicherlich. AVR sind
momentan - verglichen mit ihrer Leistung - sowieso relativ teuer:
günstigste Teile ATmega328 eher schon 2€, CH32V003 0,22€, allerdings
auch STM32F030 0,62€.
Aber wie gesagt sind das eher sportliche Gründe. Mir gefallen
mittlerweile die Gehäuseformen TSSOP20 und dann (für mehr Pins) LQFP48
und auch LQFP64.
Yalu X. schrieb:> In der Mounriver-Toolchain für die CH32-Controller wird die generische> soft-fp der glibc verwendet. Diese ist in C implementiert und in> keinster Weise an spezifische CPU-Typen angepasst. Die AVR-FP-Routinen> hingegen sind in Assembler speziell für diesen CPU-Typ geschrieben.
Das dürfte dann wohl die "Ursache" sein und vielen vielen Dank für die
Info (meine ich absolut ohne Ironie - schade, dass man das immer dazu
schreiben muß). Schön - auch wenn andere das anderst sehen - wenn hier
wieder gezeigt wird, wie kompetent die Moderatoren sind: Daumen sowas
von nach oben !
Yalu X. schrieb:> Vielleicht erinnert sich noch jemand an die Zeiten, wo auch für den AVR> die soft-fp der glibc verwendet wurde. Da hat man um jeden Preis> versucht, auf FP-Arithmetik komplett zu verzichten.
Die Zeiten kenne ich noch!
Hans W. schrieb:> Gerade hat DHL mein 1. Design mit einem CH32V003 geliefert... hatte> schon Sorgen, dass ich bei der Komponentenauswahl für den Kunden> irgendwas übersehen habe :)
Was wirst du damit anstellen ?
Ralph S. schrieb:> F. schrieb:>> Der ATMega ist eine extrem gut ausgestattete moderne 8-Bit-CPU, die>> recht gut optimiert ist. Das lässt sich der Hersteller aber auch>> bezahlen. Der CH32V003 ist ein absolutes Lowcost-Produkt. Der ATMega328>> kostet so um die 1.50, der CH32V003 sagen wir mal so etwa 30 Cent. Da>> kriegst du also für ein Fünftel des Preises halbwegs vergleichbare>> Performance.>> Na ja, es ging ja nicht darum (zumindest hier nicht) was das Teil> kostet. Ich beschäftige mich mit dem Dingelchen ja eigentlich nur aus> "sportlichem" Antrieb heraus weil das so billig ist.
Es geht nicht darum, was es kostet, du beschäftigst dich aber damit,
weil es billig ist?
Der CH32V003 ist ein sehr einfacher RISC-V, den der Hersteller extrem
kostengünstig produzieren kann. Dass man da keine großartige Leistung
erwarten kann, ist irgendwie klar. RISC-V ist nicht auf absurde
Performance optimiert, sondern darauf, eine möglichst einfache, aber
dennoch praktikable Architektur zu sein, die zudem auch frei ist.
> Allerdings hätte> ich angenommen, dass RISCV den ATmega um längen schlägt.
Warum? Der wirklich schnelle Hardware-Multiplier des ATMega macht ihn
sehr leistungsstark, dazu noch gute, optimierte Compiler und Libraries.
Der CH32V003 kann im Gegensatz dazu tatsächlich echt absolut gar nichts,
da er einen ziemlich basalen RISC-V implementiert. Muss er aber
natürlich auch nicht, das Teil überzeugt über den Preis. Ich begrüße das
tatsächlich, anstatt überall den gruseligen 80C51 einzubauen. Außerdem:
Der CH32V003 schlägt den ATMega, er kostet ca. 20% des Preises. Bei
anspruchsvollen Echtzeitanforderungen mit gleichzeitig viel
Gleitkommaarithmetik ist man selbstverständlich mit anderen Prozessoren
besser bedient, für solche Dinge wie langsame Auswertung von
Umweltsensoren eignet sich aber beides.
> Ob ATmega jetzt> als "extrem gut ausgestattet" und "modern" bezeichnet werden kann, lass> ich jetzt mal unkomentiert.
Ich nicht: Du hast nämlich den "8-Bit-Microcontroller" vergessen.
Natürlich gibt's Moderneres, unter den 8-Bittern ist er aber der
Modernste.
Denk nur mal an den grausigen 80C51 (schlimme, teure Compiler; wenig
Register; schwieriges instruction set) oder den PIC (ich sag nur: banked
memory!), da ist der AVR im Vergleich ja eine echte Wohltat.
> Optimiert ist sie sicherlich. AVR sind> momentan - verglichen mit ihrer Leistung - sowieso relativ teuer:> günstigste Teile ATmega328 eher schon 2€, CH32V003 0,22€, allerdings> auch STM32F030 0,62€.
Ich hatte bei Digikey und LCSC nachgeschaut, meine Preise sind etwa
aktuell. Bei deinen Preisen ist der CH32V003 ja sogar noch besser, da
kostet der nur etwas leistungsfähigere ATMega328 ja bereits das
Neunfache.
> Aber wie gesagt sind das eher sportliche Gründe. Mir gefallen> mittlerweile die Gehäuseformen TSSOP20 und dann (für mehr Pins) LQFP48> und auch LQFP64.
Das ist ja durchaus verständlich, aber der CH32V003 ist eben ein echtes
Lowcost-Produkt für Anwendungen, in denen man bisher wahrscheinlich
irgendeinen 80C51 verwendet hat. Dafür ist er definitiv deutlich besser.
Mich wundert ehrlich gesagt, dass er an den ATMega328 rankommt.
F. schrieb:> Der wirklich schnelle Hardware-Multiplier des ATMega
Naja... Der stm32f0 hat einen 1-cycle multiplier... Halb so viele Takte
wie der verhältnismäßig uralte AVR.
Aber gut, die AVRs laufen anscheinend in einem 320nm Prozess und der
stm32 in 180nm. Da bekommst du einfach viel mehr auf viel weniger Fläche
hin.
Beim CH32V... hab leider noch keine Referenzen zum Halbleiter Prozess
gefunden.
Mit einem alten AVR (also im Alter von m328) würde ich wirklich kein
neues Projekt mehr starten wollen.
Die ganzen F103, die es so gibt, sind z.B IMHO fast immer die bessere
Alternative.
Die Auswahl des Controllers ist halt immer ein trade-off...
F. schrieb:> Der CH32V003 ist ein sehr einfacher RISC-V, den der Hersteller extrem> kostengünstig produzieren kann.
Das stimmt. Im CH32v307 ist ein wesentlich potenterer Risc-V... Ca 1€
teurer als der mega328, dafür mit FPU, USB und Ethernet phy (10mbit
Ethernet, 480mbit USB) usw.
Risc-V und ARM gibt's halt von extrem einfach bis ultra performant... Da
muss man schon recht genau schauen welchen Befehlsatz der Core
tatsächlich implementiert.
Es wär' wirklich interessant wie sich die soft-fp lieb von segger
schlagen würde...
73
Die eine Sache ist der Floating-Point-Benchmark, der stark durch die
Implementierung bestimmt ist.
Die andere Sache ist die grundsätzliche Geschwindigkeit des Prozessors.
Wie oben beschrieben, erhöht sich die Geschwindigkeit
Kommando-Byte-Fetch nicht beim Umstellen von 24Mhz auf 48MHz.
Ich würde mal einen standardisierten Benchmark wie den
Drystone-Benchmark laufen lassen, um zu sehen, ob es nur an der
Floating-Point Implementierung liegt. Damit erhält man etwas bessere
Einblicke als die in diesem Thread beschriebenen Vermutungen.
https://github.com/oomlout/oomlout-BMAR
Christoph M. schrieb:> Wie oben beschrieben, erhöht sich die Geschwindigkeit> Kommando-Byte-Fetch nicht beim Umstellen von 24Mhz auf 48MHz.>> Ich würde mal einen standardisierten Benchmark wie den> Drystone-Benchmark laufen lassen, um zu sehen, ob es nur an der> Floating-Point Implementierung liegt.
Einen "standardisierten" Benchmark braucht's eigentlich nicht, da wir ja
(erstmal) nur sehen wollen, was der Unterschied zwischen 24 MHz und
einer 48 MHz Clock bei CH32V003 ausmacht. Da es ja keine FPU Hardware
gibt, würde auch das Apfelmännchen taugen. Evtl. wäre Ralph so nett und
lässt mal das Apfelmännchen mit nur 24 MHz auf dem CH32V003 laufen und
postet die Ergebnisse.
Der Dhrystone ist wohl dann sinnvoll, wenn wenn man die Performance von
verschiedenen µC im integer Bereich vergleichen will. Wobei ich nicht
weiß, was ein aktueller gcc (je nach Optimierungsstufe) aus dem
Dhrystone macht.
Mir würde erstmal sowas reichen:
CH32V003 / 48 MHz => 62.9 Sekunden
CH32V003 / 24 MHz => ? Sekunden
Fyi: mich hat das nicht ganz in Ruhe gelassen mit der float library und
etwas weiter gegoogelt.
Ans Tageslicht kam das hier: https://github.com/pulp-platform/RVfplib
Dazu gibt's auch ein paper von der ETH zürich...
https://www.research-collection.ethz.ch/bitstream/handle/20.500.11850/582612/rvfplib.pdf;jsessionid=1B9CB0AB1B260620F676C7FD38A2C5F9?sequence=1
Die scheint auch in der esp32-idf zum Einsatz zu kommen. So ich Zeit
habe, werde ich das in den nächsten Tagen Mal testen...
Wenn man dem Benchmarking im paper traut, dann sollten sich die
Ausführungszeit mit dieser lib im Vergleich zur glibc in etwa halbieren.
Interessant ist auch der Vergleich zur segger-lib...die dürften da
teilweise wirklich jeden taktzyklus rausgequetscht haben... Vor allem
bei den Divisionen...
73
Hans W. schrieb:> Der F0 und der AVR sind auf den Takt normalisiert in etwa gleich auf.
Ist das nicht auch erstaunlich? Ein 8-bitter muss doch vermutlich viele
Zwischenschritte berechnen um auf die volle Float-Bitbreite zu kommen.
Thorsten M. schrieb:> Ist das nicht auch erstaunlich?
Eigentlich überhaupt nicht.
Die ARM Cortex-M Architektur ist bei byteweisen Zugriffen auf den
Speicher nicht gerade für seine Effizienz bekannt.
Genau dieses Bit-Verdrehen brauchst du aber bei IEEE754 haufenweise.
Nebenbei ist gerad der Cortex M0 als billiger 8-bit Ersatz entwickelt
worden.
Daher hat er auch nur einen 32x32=32bit Multiplier verbaut.
Nachdem die 32bitter typischerweise in neueren Halbleitertechnologien
gefertigt werden, ist es auch klar, warum die chips tendenziell billiger
sind als alte 8-bitter.
Beim CH32V003 ist es wahrscheinlich so, dass der Großteil der Kosten im
Packaging und nicht im Chip liegen.
Im übrigen: Wer so kleine Chips verbaut, der hat einfach keine Ansprüche
an die Hardware. Selbst ein 32F103 von ST kostet ca 1,50 bei LCSC. Das
ist in etwa der Preis von einem ATMega328.
Was aber den CH32V003 so interessant macht: Er kann mit 5V betrieben
werden.
In meiner Anwendung "brauche" ich das, weil ich alles direkt von einem
Lipo versorge. Also 3...4,2V.
Übrigens: Ich habe mir so ein combi-devboard-angebot mit CH32V003 und
CH32V203 geholt. Damit werde ich mal versuchen, die Zahlen von oben zu
verifizieren.... Die SPI Ausgabe werde ich dabei aber auskommentieren...
es sei denn, ich bekomme das komplette Projekt vom TO :)
Der CH32V203 ist nämlich dem STM32F103/STM32F203 ähnlich... nur RISC-V.
Dort wäre auch eine FPU mit drinnen und er kann 144MHz. Preislich ist er
bei 60Cent. Damit sollte er in diesem "Benchmark" eigentlich die
Geschwindigkeit vom F401 erreichen.... Das ist eigentlich schon ein
Hammer um den Preis!
73
Hans W. schrieb:> Der CH32V203 ist nämlich dem STM32F103/STM32F203 ähnlich... nur RISC-V.> Dort wäre auch eine FPU mit drinnen und er kann 144MHz. Preislich ist er> bei 60Cent.
Nur hört dann der Spaß mit 5 V wieder auf ;-)
FP beim CH32V003 würde mich (eher als Ersatz für einen ATtiny) nur am
Rande interessieren. Augenscheinlich ist seine Stromaufnahme nicht
sonderlich klein und mehr Interruptprioritäten würden nicht schaden.
Mehr Details hatte ich mir noch nicht angesehen.
Der Preis ist aber sehr nett, wenn man größere Stückzahlen braucht ;-)
Klaus R. schrieb:> Mir würde erstmal sowas reichen:>> CH32V003 / 48 MHz => 62.9 Sekunden> CH32V003 / 24 MHz => ? Sekunden
Mit der Zeile
ty= 2.0f*wx*wy+jy;
für float-Berechnung (und nicht double) benötigt das Apfelmännchen mit
24 MHz dann 95.6 Sekunden! (für welche Betrachtungen auch immer).. :-)
Hans W. schrieb:> Übrigens: Ich habe mir so ein combi-devboard-angebot mit CH32V003 und> CH32V203 geholt. Damit werde ich mal versuchen, die Zahlen von oben zu> verifizieren.... Die SPI Ausgabe werde ich dabei aber auskommentieren...> es sei denn, ich bekomme das komplette Projekt vom TO :)
:-) :-) :-) ich bin noch am "evaluieren" und am für mich anpassen.
Natürlich kann ich das in ein ZIP-File einpacken und zur Verfügung
stellen (habe ich sowieso irgendwann vor, weil es aus meiner Sicht der
Dinge kein wirklich gutes "Getting started" gibt ... und schon überhaupt
nicht auf Deutsch).
In meinem "Paket" habe ich im ch32fun Framework herumgewerkelt, das
Grundgerüst des Makefiles für mich angepasst. Ich mag zum Bsp. nicht,
bei einem "make" oder "make all", dass der Code compiliert, gelinkt und
gleich noch upgeloadet wird. Meine Editoren und meine Toolchain sind so
ausgelegt, dass ein einfaches einfach nur ein "build" durchführt und ein
"make flash" das ganze hochlädt. Außerdem habe ich aus meinem Paket
Dateien entfernt, die nicht "ch32v003" heißen (irgendwann möchte ich
auch den #define-Wust aus den .c .h so säubern, dass es eben nur noch
ch32v003 heißt, einfach um besser bestimmte Dinge kontrollieren oder
ändern zu können).
Außerdem sind meine Funktionen nur in den Quellcodes dokumentiert (die
Funktionsschnittstelle). D.h. momentan muß man da dann eben in die
Sources schauen.
Uuuuund wenn es dann kein "Gemecker" über den Stil wie ich etwas
realisiere gibt, kannst du gerne mein "Paket" haben. Schmunzeln muß:
mein eigenes printf ist häufig Stein eines Anstoßes. Das Fun-Paket hat
ein printf automatisch integriert, welches Debug-Informationen auf der
seriellen Schnittstelle ausgibt. Allerdings nur TxD und kein RxD ... und
zu dem im Code auch größer als meiner. Also habe ich ein eigenes printf
und in der Main-Datei muß dann stehen: void my_putchar(char ch) ... und
in meiner my_printf.c Datei ist das dann als extern deklariert.
Wenn Dir das nichts ausmacht: gerne !
F. schrieb:> Denk nur mal an den grausigen 80C51
Die waren nicht grausig, ich habe die "geliebt". Zudem bin ich bis heute
dem Intel-Stil der Mnemonic verhaftet, egal ob das 8080, MCS-48 (jaja,
den habe ich auch noch gemacht), MCS-51 oder später am PC für 8086 und
dann 80286 gemacht habe. Ein MOV und ein JMP war mit immer lieber als
ein ld und ein br. Und die kleinen Dinger habe ich dann eh nicht mit
Hochsprache programmiert.
Hans W. schrieb:> Der CH32V203 ist nämlich dem STM32F103/STM32F203 ähnlich... nur RISC-V.> Dort wäre auch eine FPU mit drinnen und er kann 144MHz. Preislich ist er> bei 60Cent. Damit sollte er in diesem "Benchmark" eigentlich die> Geschwindigkeit vom F401 erreichen.... Das ist eigentlich schon ein> Hammer um den Preis!
Das werde ich dann mal später evaluieren, bei der letzten Bestellung
hatte ich mir aus diesen Gründen genau einen V203 mitbestellt.
Grundsätzlich funktioniert der zwar ähnlich dem V003, aber eben nur
ähnlich.
Im übrigem ist es so eine Sache mit dem STM32F401 ... aus blanker
Neugierde hatte ich mir bei lcsc.com einen STM32F402 mitbestellt, der
bei ST scheinbar gar nicht gelistet ist, es aber ein chinesisches
Datenblatt dafür gibt (von ST). Es scheint auch keine Fake-MCU zu sein
und so habe ich ein Board damit aufgebaut und darauf Programme laufen
lassen, die ansonsten auf einem F401 laufen. Es gab keine Unterschiede:
Ein Binärfile ließ sich einfach hochladen und die Programme laufen alle
(Kennung vom F402 ist auch die vom F401). Warum nun F402?
STM32F402RCT => 84MHz, Floatingpoint, 256 kB Flash, 64 kB Ram
Preis: 1,46€
(auf dem F402 läuft das Apfelmännchen im übrigen mit exakt derselben
Geschwindigkeit wie mit dem F401: 0,5 Sekunden ... und von dieser MCU
bin ich dann wirklich ein FAN)
>(auf dem F402 läuft das Apfelmännchen im übrigen mit exakt derselben>Geschwindigkeit wie mit dem F401: 0,5 Sekunden ... und von dieser MCU>bin ich dann wirklich ein FAN)
Da wäre jetzt noch der PiPico 2 mit dem Apfelmänchen auf 2 Kernen und
auf 200MHz übertaktet interessant.
>warum ?
Um zu sehen, ob er schneller ist. Die STM-Architekturen sind ja nicht so
schlecht und es könnte für den PiPico schwierig sein, die selben
Geschwindigkeiten zu erreichen.
Außerdem sind Apfelmännchen ideal für die Parallelverarbeitung.
So, :-) auf einfachen Wunsch einer einzelnen Person habe ich jetzt mal
das ganze Projektpaket zusammengefasst auf das nötigste.
Als Compiler benötigt man: riscv-none-elf-gcc (bei mir ist es die
Version 14.2.0-3
Dieser sollte im systemweit verfuegbar sein. Das schöne an diesem
Compiler ist (wie auch beim arm-none-eabi-gcc) dass er in "irgendein"
Verzeichnis gelegt werden kann (bei mir ist es /usr/local/) und in der
.bashrc nur der Pfad erweitert sein muss.
So, das Archiv enthält alle Dateien um das Apfelmännchen für einen
CH32V003 zu übersetzen, befindet sich im Order:
- fraktal_speedtest
Dem ganzen Paket habe ich Teile des CH32fun mit eingefügt und manche
Dinge daraus auch geändert. Allen voran das Makefile fraktal_speedtest
Aaaaber: für diejenigen (wie mich) die immer auch die Bastler sind
(heißt das heute Maker?) sind in dem ganzen CH32Fun Paket Dinge
versteckt, die nicht so wirklich richtig beschrieben sind. Die
Kurzfassung:
- es gibt eine Programmersoftware für Arduino-Uno / Nano, die in der
Lage ist, einen CH32V003 zu programmieren. Der ist zwar schnarchlangsam,
aber er kann es. Nennt sich ardulink. Bei näherem Hinsehen, läuft das
Programm auch auf ATmega88, ATmega168 und bei noch genauerem Hinsehen
sogar auf ATtiny2313. Dort habe ich Quellcode manipuliert und es kann im
Verzeichnis ./ardulink eine Firmware für AVR erstellt werden, die den
Programmer für einen CH32V003 darstellt
- das Uploadprogramm zu einem CH32V003 heißt minichlink und ist im
Ordner minichlink. Dieses Programm compilieren und im systemweit
verfügbar machen (bei mir im selben Ordner wie der Compiler
- in den Ordner bootloader ist ein wirkliches Schmankerl: Ein
Bootloader, der in einem CH32V003 installiert werden kann (nimmt noch
nicht einmal Programmflashspeicher weg) und fortan braucht es keinen
Programmer
- im Ordner rvswdio_programmer ist die Firmware für einen Programmer,
der in einem CH32V003 arbeitet und in der Lage ist, als Programmer eben
für diesen Chip zu dienen.
Die originale Zeichnung wie das zu beschalten ist, finde ich
"dahingerotzt" (Entschuldigung an die, die das CH32FUN Framework
aufgebaut haben) und aus diesem Grund habe ich einen saubereren
Schaltplan gezeichnet. Die Schaltung habe ich nach allerfeinster V-USB
Manier für AVR-Controller (also eher kein so gutes USB :-) ) erweitert,
so dass ein Programmer oder Bootloader mit 3.3V oder mit 5V laufen kann
und das ganze umschaltbar gemacht. Hier ist (wie bei diesem V-USB Sachen
immer) darauf zu achten, dass das Zenerdioden kleinerer Leistung sind,
da ich die Erfahrung gemacht habe, dass die Kurve in Sperrrichtung nicht
so senkrecht nach unten geht wie es wünschenswert wäre und von daher
sollten das kleine Z-Dioden mit 1/4W Leistung sein).
Interessanterweise kann man mit dem Bootloader eben die
Programmerfirmware flashen aber bei Bedarf auch andere Programme laufen
lassen.
-----------------------------------------
So, wer hier also gerne mitevaluieren möchte kann das hier gerne
herunterladen, außer einem Chip (wenn man den als Bootloader betreibt)
und einen AVR mit USB-Bridge (Arduino) braucht es nicht!
By the way: Wäre fast schon etwas für ein Projekt oder einen Artikel
Christoph M. schrieb:> Da wäre jetzt noch der PiPico 2 mit dem Apfelmänchen auf 2 Kernen und> auf 200MHz übertaktet interessant.
200 sind nach neuer Zeitrechnung (laut Raspberry ltd) nicht übertaktet.
Die 420MHz hier, die sind's allerdings. ;-)
Edit: Fipptehler
... eigentlich ging es mir ja nur um "float". Weil aber in der
Diskussion grundsätzlich über Geschwindigkeit diskutiert wurde habe ich
einen weiteren Test gemacht.
An sich wollte ich drystone oder whetstone implementieren, was daran
scheiterte, dass bei einbinden der Math-Bibliothek mit -lm schon alleine
die Berechnung eines einzelnen Sinus nicht in den Flashspeicher des
CH32V003 passt (produziert ein Compilat > 18 kByte).
Okay, aber für einen Test war ja das Apfelmännchen nicht gaaaanz so
schlecht.
Also wollte ich wissen wie es sich denn mit Integer-Berechnungen
verhält.
Damit die Ergebnisse vergleichbar sind, habe ich einen
Pseudozufallszahlengenerator implementiert, der seine Werte mittels 2
linear rückgekoppelten 32-Bit Schieberegister die miteinander
"ver-xoder-d" erzeugt.
Als Rechentest werden 2000 Linen und 2000 Kreise nach dem
Bresenham-Algorithmus berechnet, die mittels 16-Bit Integerberechnung
erfolgen.
So gibt es hier einen Mix an 32-Bit und 16-Bitberechnungen. Die
Programme, für die, die das wirklich interessiert habe ich hier
angefügt.
Die Ergebnisse sind:
ATmega328p / 16 MHz : 41,0 Sekunden
CH32V003 / 48 MHz: 8,1 Sekunden
CH32V003 / 24 MHz: 13,5 Sekunden
Kuriosität am Rande:
Compilat für ATmega328p (okay, alter Compiler) avr-gcc v. 7.3.0 : 8586
Bytes
Compilat für CH32V003 riscv-none-elf-gcc v. 14.2.0 : 3768 Bytes
Eigentlich hätte ich erwartet, dass der V003 mehr Speicher als der 328p
benötigt.
Andererseits ist mir positiver Weise mit dem V003 aufgefallen gewesen,
dass der Speicherbedarf für 2 der Spiele, die auf einem STM32F030 laufen
und dort beide knapp über 18 kByte benötigen für den CH32V003 hierfür
knapp unter den 16 kByte liegen (und auch ausführbar sind).
F. schrieb:> Das ist ja durchaus verständlich, aber der CH32V003 ist eben ein echtes> Lowcost-Produkt für Anwendungen, in denen man bisher wahrscheinlich> irgendeinen 80C51 verwendet hat. Dafür ist er definitiv deutlich besser.> Mich wundert ehrlich gesagt, dass er an den ATMega328 rankommt.
Hierzu --meine-- Meinung:
Der CH32V003 kommt nicht nur an den ATmega328 heran, unterm Strich
überholt er ihn auf fast allen Gebieten oder ist überlegen.
Vorteile für den ATmega328p:
+ 32kByte Flash (anstelle 16kByte beim V003)
+ internes EEProm
+ Geschwindigkeit bei float auf demselben Niveau wie V003
Vorteile für den CH32V003
+ für Integerberechnungen sehr viel schneller
+ SPI sehr viel schneller als AVR
+ extrem billig
+ relativ speicherplatzschonend
+ läuft mit 3,3V und mit 5,0V
+ voller Takt auch ohne Quarz
+ USART (hat mich überrascht) habe ich getestet bis 460800 Bd und das
funktionierte
problemlos
Beim vielen Testen des CH32V003 (ich bin da noch nicht fertig) ist
aufgefallen:
- I2C ist ähnlich doof wie bei STM32F0, der Controller will vorher schon
wissen, wieviel Bytes auf dem Bus transferiert werden (habe Codes vom
STM32F0 dann adaptiert, kommt aber meiner früheren Vorgehensweise nicht
so sehr entgegen, funktioniert aber)
- ADC hat leider nur 10-Bit Auflösung, die 12-Bit eines STM32 wären
schön. Bei konstant gehaltener Betriebsspannung und Eingangsspannung am
ADC-Pin nach Laufzeit 3 Stunden (Zimmertemperatur) Abweichung von 2
Digits
- wirklich schön ist Timer 2. Hier gibt es einen wirklich sehr
komfortablen Prescaler, der komplett mit 16-Bit beschreibbar ist. Hier
können wirklich "krumme" Taktvorteiler eingetragen werden. Eine
Kombination von Prescaler= 48000 und einem Compare auf 1000 ergibt hier
tatsächlich eine Sekunde mit der es dann möglich ist, den Timer 2
Interrupt wirklich nur jede Sekunde aufzurufen.
Summasumarum ist von daher der CH32V003 nicht nur eher ein Ersatz für
ATtiny sondern eher auch für ATmega, wenn die Pinanzahl und der
Speicherplatz ausreichend ist
--------------------------
Okay, ich wollte eigentlich gar nicht so viel schreiben, entschuldigung
!
--------------------------
PS: Nachtrag für obigen Post:
riscv - Compiler gibt es unter:
https://github.com/xpack-dev-tools/riscv-none-elf-gcc-xpack/releases/
Ralph S. schrieb:> ADC hat leider nur 10-Bit Auflösung, die 12-Bit eines STM32 wären> schön.> Summasumarum ist von daher der CH32V003 nicht nur eher ein Ersatz für> ATtiny sondern eher auch für ATmega, wenn die Pinanzahl und der> Speicherplatz ausreichend ist
Für etwa den doppelten Preis eines CH32V003 bekommst du den CH32V203.
Der hat den gewünschten 12-Bit-ADC, mehr Pins (37 GPIOs), mehr Flash (64
KiB), mehr RAM (20 KiB) sowie Hardwaremultiplikation und -division.
Darüberhinaus hat er im Vergleich zum CH32V003 doppelt so viele Timer,
I²C, SPI und OPAs. Die Taktfrequenz ist dreimal so hoch, USARTs hat er
sogar viermal so viele. Damit nicht genug: Es gibt auch noch 2×USB,
1×CAN und 10×TouchKey.
Für den Preis von etwa fünf CH32V003 (immer noch deutlich billiger als
der ATmega328P) bekommst du den CH32V303. Diese hat neben einer FPU noch
deutlich mehr Flash (256 KiB), RAM (64 KiB), Timer (10), USARTs (8),
GPIOs (80), OPAs (4), ADC-Kanäle (16) und ein zusätzliches SPI (3).
Hinzukommen 2×DAC (12 Bit), 2×I²S, SDIO, FSMC und ein TRNG.
Speziell für Lottogewinner (also etwa so teuer wir der ATmega328P) gibt
es den CH32V307, bei dem man noch Ethernet sowie Highspeed für eines der
beiden USB-Interfaces obendrauf bekommt.
Somit decken die CH32Vxxx neben der Apfelmännchenmalerei auch noch eine
recht große Palette weiterer Anwendungen ab ;-)
Yalu X. schrieb:> Für etwa den doppelten Preis eines CH32V003 bekommst du den CH32V203.> Der hat den gewünschten 12-Bit-ADC, mehr Pins (37 GPIOs), mehr Flash (64> KiB), mehr RAM (20 KiB) sowie Hardwaremultiplikation und -division.
Den V203 habe ich hier und nur mal superkurz darüber gesehen. Register
sind zwar ähnlich, aber eben nur ähnlich. Immerhin kann der 144 MHz und
die Hardwaremultiplikation/Division auch als Floatingpoint-Unit (FPU).
:-) :-) :-) vllt. male ich dann darauf ja auch Apfelmännchen (obschon es
sch ja auch zum Zeichnen von Linien und Kreisen eignet).
Aber irgendwie bin ich dann in dieser "Leistungsklasse" den STM32
verhaftet (hier sind dann mein "Lieblinge" STM32F402, STM32F407 und
STM32F429)
Spaß beiseite: Mir ging es eigentlich ursprünglich nur darum
herauszufinden, was denn an diesem V003 dran ist, weil der des öfteren
erwähnt wird. Für eine Anwendung sucht man sich den Controller heraus,
von dem man annimmt dass er den Ansprüchen die an ihn gestellt werden
gewachsen ist. Hier ist es dann vllt. nicht schlecht, mehrere zur
Auswahl zu haben.
Im Fall vom V003 im TSSOP20 Gehäuse ist super von Vorteil, dass er
Pinkompatibel zum STM3S003 / S103 ist. Hier habe ich spaßeshalber den
V003 (in besonderen Fall für Panelmeter für DS18B20 Temperatursensor) au
eine Platine gelötet, die eben für den STM8 entwickelt war. Das Programm
angepasst (eigentlich keine Änderung bis auf die Systeminitialisierung)
und die Schaltung lief sofort in der "fremden" Platine.
Von daher ist der (wie in irgendeinem Thread hier) erwähnt wurde der
V003 dann der Ersatz für STM8, wenn diese - wie schon einmal -
abgekündigt werden. Platinen wären weiter nutzbar.
>ATmega328p / 16 MHz : 41,0 Sekunden>CH32V003 / 24 MHz: 13,5 Sekunden
41Sec*16/24= 27.333 Sec // Atmega, wenn 24MHz
Interessant: Könnte der Atmega328 24MHz wäre er etwas halb so schnell
wie der CH32V003
Christoph M. schrieb:> Interessant: Könnte der Atmega328 24MHz wäre er etwas halb so schnell> wie der CH32V003
Um die generelle Leistung eines µC zu bewerten, sollte man eine größere
Applikation mit einer breiter aufgestellten Nutzung der Maschinenbefehle
vergleichen.
Es ist problemlos möglich, ein Programm zu schreiben, welches einen 6502
bei 1 MHz verdammt gut aussehen lässt. (Schneller als ein ATMega bei
16 MHz)
Dennoch käme niemand auf die Idee zu behaupten, dass ein oller 6502 auch
nur annähernd die Leistung eines Mega erreicht.
>Es ist problemlos möglich, ein Programm zu schreiben, welches einen 6502>bei 1 MHz verdammt gut aussehen lässt. (Schneller als ein ATMega bei>16 MHz)
Das musst du mir mal zeigen.
Christoph M. schrieb:> Das musst du mir mal zeigen.
Gerne. Später.
Aber ich lass' es erst einmal ein wenig so stehen.
Einige der Älteren werden sich gewiss schmunzelnd erinnern.
PS. Kleiner Tipp ist aber erlaubt.
Obwohl … Ach egal … Zum Beispiel Fibonacci.
Yalu X. schrieb:> Für etwa den doppelten Preis eines CH32V003 bekommst du den CH32V203.
Der läuft halt nicht mehr mit 5V, und 5V-tolerant sind seine I/Os wohl
auch nicht.
Oberhalb des CH32V003 aber gibt es auch noch den CH32V006 - mit 8 kB
RAM, 62 kB Flash-ROM, 12-Bit-ADC, 2 UARTs, Betriebsspannungsbereich 2 ..
5 V. Und im QFN32 hat er dann auch mehr gleichzeitig nutzbare I/O-Pins.
https://github.com/ch32-riscv-ug/CH32V006?tab=readme-ov-file
Ralph S. schrieb:> Den V203 habe ich hier und nur mal superkurz darüber gesehen. Register> sind zwar ähnlich, aber eben nur ähnlich. Immerhin kann der 144 MHz und> die Hardwaremultiplikation/Division auch als Floatingpoint-Unit (FPU).
Sicher, dass der eine FPU hat? Ich dachte, die gibt es erst beim V3xx.
Harald K. schrieb:>> Single cycle multiplication, hardware division,> hardware FPU
Das dürfte ein Fehler sein und ist wohl darauf zurückzuführen, dass in
dem Datenblatt Informationen zum CH32V203 (ohne FPU) und CH32V3xx (mit
FPU) vermischt sind.
Hmmm.. der CH32B203 hat einen Qingke V4B Kern.
Laut dem Qingke V4 Manual hat er tatsächlich keine FPU... Die hätte nur
der V4F...
Hmm... Guter Hinweis mit dem Datenblatt misch-masch
73
Yalu X. schrieb:> Das dürfte ein Fehler sein und ist wohl darauf zurückzuführen, dass in> dem Datenblatt Informationen zum CH32V203 (ohne FPU) und CH32V3xx (mit> FPU) vermischt sind.
Oh. Das spricht nicht für WCH, denn das steht gleich auf der ersten
Seite des Datenblatts in der Featureliste. Vermutlich sind die
chinesischen Unterlagen besser korrigiert, die wird man dann in solchen
Fällen mit einem Übersetzer à la Google Translate hinzuziehen müssen.
Hmpf.
Harald K. schrieb:> Vermutlich sind die chinesischen Unterlagen besser korrigiert,
Mit DeepL vom Chinesischen ins Englische übeersetzt:
Datenblatt CH32V203 (V2.8)
Kernel Core:
- Green Barley 32-bit RISC-V kernel with multiple instruction set
combinations
- Fast Programmable Interrupt Controller + Hardware Interrupt Stack
- Branch Prediction, Conflict Handling Mechanisms
- Single Cycle Multiplication, Hardware Dividing
- System Frequency 144MHz:
Datenblatt CH32V303/305/307/317 (V3.5)
Kernel Core:
- Green Barley 32-bit RISC-V4F kernel with multiple instruction set
combinations
- Fast Programmable Interrupt Controller + Hardware Interrupt Stack
- Branching Prediction, Conflict Handling Mechanisms
- Single Cycle Multiplication, Hardware Dividing, Hardware Floating
Point
- System Frequency 144 MHz, Zero-Waiting
Die englischen Datenblätter haben die gleichen Versionsnummern und sind
jeweils ein paar Tage jünger als die chinesischen. Die Abweichungen in
der englischen Version spricht damit immerhin dafür, dass die
Übersetzung nicht komplett automatisch erfolgt ist :)
Meine Wahl ch32x033/35, gibt es in tssop20, hat 62/20kB flash/ram,
12bit-adc, 14xtouch, pioc, 2xopa/pga, 3xcmp, usb/serial bootloader, den
besseren 4c core mit hw-mul und ist billig zu bekommen.
Besonder der pioc 2K/8bit-slave ermöglicht performante Interface
Realisierungen.
Zur Zeit mein Lieblingsspielzeug ...
Mehmet K. schrieb:> @majortom> Dem wäre noch der 3,3V/5V Spannungsbereich hinzuzufügen.
...und der integrierte vollständige Controller für USB-C PD.
Man kann mit den ch32x033/35 also einen vollständig programmierbares
USB-C PD Triggerboard bauen. Und das für insg. weniger Geld als die
Fertiglösungen.
Siehe hier:
https://github.com/wagiminator/CH32X035-USB-PD-Adapter
Sind schon nett die Dinger...
Ich glaube es wurde ja oben schon geschrieben
- der CH32V003 hat einen sehr einfachen RISC-V Core ohne
Multiplikationshardware. Außerdem ist die Ausfühung aus dem Flash nicht
sehr schnell, da kein Cache.
Schneller wird es mit:
- CH32V002 / CH32V006, denn die haben einen RISC-V core mit multiplier
- Du kannst mit ch32fun funktionen aus dem RAM ausführen lassen, was die
Flash-waitstates eliminiert. Dazu muss man bei der Funktiondeklaration
das attribut unten setzen.
1
2
void function (...) __attribute__((section(".srodata"))) __attribute__((used));
- Code optimieren, um die floating point operationen durch fixed point
zu ersetzen, bzw. einer eigenen floating-point implementierung. IEEE754
ist durch viele special cases langsam.
Noch schneller ist CH32V203 mit cache usw.
Christoph M. schrieb:> Laut Datenblatt hat der CH32V003 die> Erweiterung Zmmul und damit einen Hardwaremultiplizerer.
wo liest du das genau? Der CH32V003 besitzt den V2A core. Laut dem
QingKeV2 Prozessor Manual ist nur der V2C core mit ZMUL ausgestattet.
"2. The m-extension in V2C only includes hardware multiplication
instructions, i.e. Zmmul extension, the use of which needs to be based
on the MRS compiler or the toolchain it provides."
Thomas Z. (usbman)
>wo liest du das genau? Der CH32V003 besitzt den V2A core. Laut dem>QingKeV2 Prozessor Manual ist nur der V2C core mit ZMUL ausgestattet.
Du hast Recht. Ich habe übersehen, das es bei den V2 Cören eine Version
A und C gibt.
Christoph M. schrieb:> Falls ein AVR-Assembler Experte mitliest: Wieviel Zyklen braucht ein> Atmega für ein 32Bit add ?
Hallo,
mit Standard Arduino IDE die avr-gcc 7.3 verwendet mit C++11.
Ohne volatile d wäre alles Compilezeit berechnet.
1
intmain(void)
2
{
3
uint32_ta{888888};// a
4
uint32_tb{999999};// b
5
uint32_tc{a+b};// c=a+b
6
volatileuint32_td{a+b+c};// d=a+b+c
7
8
while(1){}
9
}
asm dump, Takte aus Manual in Klammern.
1
intmain(void)
2
{
3
100:cf93pushr28
4
102:df93pushr29
5
104:00d0rcall.+0;0x106<main+0x6>
6
106:1f92pushr1
7
108:cdb7inr28,0x3d;61
8
10a:deb7inr29,0x3e;62
9
uint32_ta{888888};// a
10
uint32_tb{999999};// b
11
uint32_tc{a+b};// c=a+b
12
volatileuint32_td{a+b+c};// d=a+b+c
13
10c:8eeeldir24,0xEE;238(1Takt)
14
10e:94ealdir25,0xA4;164(1Takt)
15
110:a9e3ldir26,0x39;57(1Takt)
16
112:b0e0ldir27,0x00;0(1Takt)
17
114:8983stdY+1,r24;0x01(2Takt)
18
116:9a83stdY+2,r25;0x02(2Takt)
19
118:ab83stdY+3,r26;0x03(2Takt)
20
11a:bc83stdY+4,r27;0x04(2Takt)
21
11c:ffcfrjmp.-2;0x11c<main+0x1c>
Ansonsten dauert ein ADD Befehl (Addition von 2 Registern) nur einen
Takt.
Christoph M. schrieb:> Wieviel Zyklen braucht ein Atmega für ein 32Bit add ?
Ich gehe mal davon aus, dass es um float geht.
Eine float Addition braucht 108 Cycles. Core avr2 braucht geringfügig
mehr, nämlich 113 Cycles.
Multiplikation kostet übrigens 138 Cycles (mit 8*8=16 MUL Instruktion
bzw. 375 ohne MUL.
https://avrdudes.github.io/avr-libc/avr-libc-user-manual/benchmarks.html
Die Funktionen stehen in Assembler, sind also unabhängig vom Compiler.
Skalare 32-Bit Integer Addition (ohne Saturierung) kostet 4 Cycles.
Für Anwendungen wie im Eröffnungsposting wird man natürlich keine
float-Arithmetik nahmen sondern Fixed-Point.
auch wenn das jetzt schon wieder fast ein halbes Jahr her ist, fasse ich
diesen Thread hier noch einmal an, weil es um die Geschwindigkeit von
CH32V003 und ATmega328p am Ende ging.
Ich wollte jetzt einmal wissen, wie sich das halbwegs in der Praxis
verhält und habe einen sehr einfachen (und wahrscheinlich nicht wirklich
präsentativen) Benchmark geschrieben, der unterschiedliche Integertypen
und Float-Typ zum Testen heranzieht und auch Zugriff auf Arrays
generiert um auch etwas von einem Speicherzugriff zu haben.
Der Benchmmark in der AVR-Version ist im Anhang, natürlich fehlt die
Toolchain um das zu compilieren (ich habe die Ausgaben mit einem eigenen
printf auf einem TFT-Display gemacht, der Benchmark selbst läuft auf so
ziemlich allen Controllern die ich habe mit Ausnahme von Padauk PFS154).
Ergebnis war:
ATmega328p / 16 MHz : 18 Sekunden
CH32V003 / 48 MHz : 6.2 Sekunden
Bei Bedarf kann ich das auch auf einem STM32F401 laufen lassen, für
STM32F411 und STM32F103 müßte ich das erst wieder zusammenstecken, da
weiß ich leider die Zeiten nicht mehr, aber zumindest beim F4 war das
dramatisch schneller)
Ralph S. schrieb:> ATmega328p / 16 MHz : 18 Sekunden> CH32V003 / 48 MHz : 6.2 Sekunden
d.h. der Atmega wäre bei 48MHz fast genauso schnell aber mit 8 statt 32
Bit.
Christoph M. schrieb:> Ralph S. schrieb:>> ATmega328p / 16 MHz : 18 Sekunden>> CH32V003 / 48 MHz : 6.2 Sekunden>> d.h. der Atmega wäre bei 48MHz fast genauso schnell aber mit 8 statt 32> Bit.
Das ist eine Milchmädchenrechnung. Ich kann die Loops der "Benchmarks"
so anpassen, dass da fast nur float gerechnet wird, dann wird der AVR in
Bezug zum V003 immer schneller. Laß ich nur 32 Bit-Operationen laufen,
Dann liegen zwischen AVR und V003 Welten. Deshalb ist die Verteilung der
Rechenoperationen wichtig. Ich kann nicht einfach sagen: 3 mal schneller
und ich kann auch nicht einfach die Taktfrequenz hochskalieren um zu
sagen: "eigentlich wäre ich genauso schnell wenn... " Das "wenn" ist
Konjunktiv, aber Fakt ist, der V003 kann mit höherem Takt yls AVR
betrieben werden und auch aus diesem Grund ist er schneller. Um wieviel
Prozent hängt von der Anwendung, vom Programm, der Sprache und vom
Programmierstil ab.
Ralph S. schrieb:> Christoph M. schrieb:>> Ralph S. schrieb:>>> ATmega328p / 16 MHz : 18 Sekunden>>> CH32V003 / 48 MHz : 6.2 Sekunden>>>> d.h. der Atmega wäre bei 48MHz fast genauso schnell aber mit 8 statt 32>> Bit.>> Das ist eine Milchmädchenrechnung. Ich kann die Loops der "Benchmarks"> so anpassen, dass da fast nur float gerechnet wird, dann wird der AVR in> Bezug zum V003 immer schneller. Laß ich nur 32 Bit-Operationen laufen,> Dann liegen zwischen AVR und V003 Welten.
Dann sind die angegebenen Laufzeiten auch 'Milchmädchenrechnung' und
nichtssagend.
Compilerflags sind beide mit Optiomierung auf Codegröße ( -Os) und
Optimierung im Zwischencode ( -flto ), die Debuginformationen ( -g )
dürften normalerweise keine Beeinträchtigung der Geschwindigkeit haben.
Außerdem wäre noch -march=native eine Option!
Grundsätzlich jedoch "mag" ich meine Standardeinstellung und so lange
ich da keine Geschwindigkeitsprobleme habe (da nehme ich dann
ehrlicherweise einen STM32), habe ich die Optimierungseinstellung -Os,
weil ich eher meistens Probleme mit dem verfügbaren Flashspeicher habe.
Harald K. schrieb:> Solange noch nicht mal klar ist, mit welchen Compilereinstellungen der> "Benchmark" erfolgt ist, ist das nur fettarme H-Milch, also weißes> Wasser.
Das ist grundsätzlich nur "fettarme H-Milch" (die mir übrigens nicht
schmeckt, du siehst hier die Analogie? :-) ), es ging mir hier nur ganz
grob darum "halbwegs" zu belegen, entgegen Aussagen ein paar weniger,
dass der CH32V003 grundsätzlich schneller als ein AVR ist.
Wie oben gesagt kann man den "Benchmark" über das Verhältnis der
einzelnen Loops in jede Richtung beeinflussen und ich gebe zu, dass ich
keine Informationen darüber habe, wie die statistisch gesehen die
Verteilung unterschiedlicher Rechenoperationen in "üblichen Programmen"
ist.
Schade, dass es keine standardisierten Benchmarkprogramme für kleine
Controller mit nur 2 KByte gibt (wie im Verlauf des Threads bereits
gesagt: Dhrystone und Whetstone sind nicht auf CH32V003 lauffähig).
Ralph S. schrieb:> Das ist grundsätzlich nur "fettarme H-Milch" (die mir übrigens nicht> schmeckt, du siehst hier die Analogie? :-) ),
Warum hab' ich sie wohl "weißes Wasser" genannt?
> es ging mir hier nur ganz grob darum "halbwegs" zu belegen,> entgegen Aussagen ein paar weniger, dass der CH32V003 grundsätzlich> schneller als ein AVR ist.
Magst Du den Test mal mit Optimierung auf Geschwindigkeit wiederholen?
Nicht, weil ich Deine Prämisse in Frage stellen wollte, sondern weils
vielleicht noch irgendwelche weiteren Erkenntnisse bringen könnte.
(Vielleicht ist einer der beiden Compiler beim Optimieren in der einen
Kategorie besser als in der anderen, oder umgekehrt, oder es macht
keinen Unterschied ...)
Wie groß sind denn die resultierenden Binaries?
Ralph S. schrieb:> Schade, dass es keine standardisierten Benchmarkprogramme für kleine> Controller mit nur 2 KByte gibt (wie im Verlauf des Threads bereits> gesagt: Dhrystone und Whetstone sind nicht auf CH32V003 lauffähig).
Ja, finde ich auch. Man müsste sie dann aber in int16, int32 und float
unterteilen.
Harald K. schrieb:> Magst Du den Test mal mit Optimierung auf Geschwindigkeit wiederholen?
Werde ich nach Feierabend mal tun, :-) im Moment kann ich hier nur
während der Raucherpause antworten.
Harald K. schrieb:> Wie groß sind denn die resultierenden Binaries?
die werden wohl "explodieren"!
Christoph M. schrieb:> Ja, finde ich auch. Man müsste sie dann aber in int16, int32 und float> unterteilen.
Na ja, das mache ich ja schon, nur stoppe ich die Zeit im Gesamtpaket
und nicht für jeden Teilbereich einzeln.
Außerdem werde ich das Testprogramm (so wirklich Benchmark ist es ja
nicht, auch wenn ich das im Dateinamen so benannt habe) umschreiben,
damit auch der Systemticker beim V003 sowie der Timerinterrupt beim
ATmega entfallen und stattdessen werde ich einen GPIO setzen / reseten
um damit eine Stopuhr zu bedienen um dann diese Einflüsse zu
eliminieren. Alles in allem: Spieltrieb
Ralph S. schrieb:> Na ja, das mache ich ja schon, nur stoppe ich die Zeit im Gesamtpaket> und nicht für jeden Teilbereich einzeln.
Oft gibt es z.B. in der Ct Benchmarks, die in einem Balkendiagram
dargestellt werden. Da sind dann meist für einen Prozessor oder eine
Graphikkarte mehrere Balken für die unterschiedlichen Kategorien.
Für mich wäre ein Benchmark für MAC-Operationen für Filteranwendungen
interessant.
Für ATmega hat die AVR-LibC ein paar Timings. Weil die float-Funktionen
nur aus der libm/libgcc hinzugelinkt werden, haben Optionen wie -O3
darauf keinen Einfluss. Das einzige was sich damit ändert, ist wie der
Compiler float-Werte hin-und-herschaufelt.
https://avrdudes.github.io/avr-libc/avr-libc-user-manual-2.3.0/benchmarks.html#bench_libm
Weil die Benchmarks keine Harware brauchen, kann man sie komfortabel auf
einem Simulator ausführen. Hat dann den Vorteil, dass man keine extra
Hardware braucht, und dass alles schneller wird. Auf meinem Rechner
entspriche ne AVR-Simulation einer AVR Hardware, die auf ca. 95 MHz
läuft :-)
Harald K. schrieb:> (Vielleicht ist einer der beiden Compiler beim Optimieren in der einen> Kategorie besser als in der anderen, oder umgekehrt, oder es macht> keinen Unterschied ...)>> Wie groß sind denn die resultierenden Binaries?
:-) Kirnbichler: wenn du mir mit deiner Anregung zeigen wolltest, dass
mein "Testprogramm" nichts taugt, dann ist dir das wirklich sehr
eindrucksvoll gelungen!!!! (das war jetzt eine ehrliche Aussage und
keine Verarsche oder negativ gemeint, oder wie auch immer).
Ich habe zwar meine Stopuhr noch nicht eingebaut (weil ich da mit einer
bereits vorhandenen Platine noch etwas mit der Bedienung kämpfe, damit
da auch noch andere Funktionen drin sind), aber die Ergebnisse über UART
ausgegeben sprechen dennoch für sich.
Verwendet man andere Compilereinstellungen bei der Optimierung, dann
kann man mit diesem Testprogramm nur sehen, wie aggressiv der Compiler
mit Flags -O3 zu Rande geht. Wahrscheinlich erkennt der Compiler, dass
die Ergebnisse der Rechnungen in den Benchmarks nirgendwo gebraucht
werden und optimiert die komplett weg.
Anderst ist auch nicht zu erklären, dass beim CH32V003 der Code mit
Option -O3 sogar kleiner als mit -Os ist.
Ich habe das zig mal überprüft. Hm, wenn ich einen wirklichen Vergleich
haben möchte, muß ich Array und Variable wohl volatile machen, für einen
direkten Geschwindigkeitsvergleich taugt da das Apfelmännchen wohl eher
(und da liegen beide gleich auf), sowie ein Linienzeichenprogramm, bei
dem der CH32V003 mehr als nur deutlich vorne liegt.
:-) :-) wenn mich das noch eine Weile weiter beschäftigen sollte, wird
vielleicht sogar mal ein brauchbares Testprogramm daraus werden.
Hier mal die Ergebnisse (und im Anhang als Textdatei):
[code]
Benchmark Ergebnisse CH32V003
Compiler: riscv-none-elf-gcc Version 14.2.0 / ch32v003fun Framework
| Zeit [s]
|
Optimierung | int8 | int16 | int32 | float | Codegroesse
|
------------------------------------------------------------------------
----
-Os | 7,8 | 7,7 | 28,8 | 2,52 | 5692
|
------------------------------------------------------------------------
----
-O3 | 0,33 | 0,35 | 0,18 | 0,13 | 5684
|
------------------------------------------------------------------------
----
Apfelmaennchen 160x128 Pixel
Optimierung -Os 62,9s / 6388 Byte
-O3 62,8s / 7664 Byte
Benchmark Ergebnisse ATmega328
Compiler: avr-gcc Version 7.3.0
| Zeit [s]
|
Optimierung | int8 | int16 | int32 | float | Codegroesse
|
------------------------------------------------------------------------
---
-Os | 15,0 | 46,0 | 58,0 | 6,0 | 5108
|
------------------------------------------------------------------------
---
-O3 | 0,1 | 1,0 | 2,0 | 0,1 | 13362
|
------------------------------------------------------------------------
----
Apfelmaennchen 160x128 Pixel
Optimierung -Os 63,0s / 8324 Byte
-O3 61,0s / 14770 Byte
[code]
So, jetzt habe ich die Testprogramme überarbeitet, damit der Compiler
nicht "zu leichtes Spiel" hat und das nicht komplett wegoptimieren (also
löschen) kann, sondern dass die Schleifen auch wirklich ausgeführt
werden.
Hier ergibt sich dann ein anderes Bild und weil mir dann die schiere
Menge an Schleifendurchläufen zu lange gedauert haben, habe ich die dann
dementsprechend reduziert um noch eine Aussage in der Zeit zu haben und
die Wartezeit auf das Ergebnis nicht zu dramatisch ist.
Verrückt, wie man seine Zeit mit eigentlich Unnötigem "verplempert",
aber grundsätzlich mag ich dann schon wirklich wissen, was eine MCU kann
und was nicht. Ich glaube ich werde das ganze am Wochenende oder
zumindest in zeitlicher Nähe auch auf STM32F0, -F1 und -F4 portieren. Da
bin ich dann gespannt (ganz gezielt hier dann auf -F4, die ja Gleitkomma
in Hardware können).
Programme für CH32V003 und ATmega328 im Anhang, sowie die Ergebnisse
hier und im Anhang:
[code]
Benchmark Ergebnisse CH32V003
Compiler: riscv-none-elf-gcc Version 14.2.0 / ch32v003fun Framework
| Zeit [s] |
Optimierung | int8 | int16 | int32 | float | Codegroesse |
-------------------------------------------------------------------
-Os | 6,75 | 7,43 | 6,98 | 5,1 | 5768 |
-------------------------------------------------------------------
-O3 | 5,9 | 6,74 | 0,62 | 4,37 | 11084 |
-------------------------------------------------------------------
Apfelmaennchen 160x128 Pixel
Optimierung -Os 62,9s / 6388 Byte
-O3 62,8s / 7664 Byte
Benchmark Ergebnisse ATmega328
Compiler: avr-gcc Version 7.3.0
| Zeit [s] |
Optimierung | int8 | int16 | int32 | float | Codegroesse |
---------------------------------------------------------------------
-Os | 16,81 | 48,2 | 60,61 | 6,52 | 5378 |
---------------------------------------------------------------------
-O3 | 15,77 | 0,86 | 48,65 | 5,54 | 23510 |
---------------------------------------------------------------------
Apfelmaennchen 160x128 Pixel
Optimierung -Os 63,0s / 8324 Byte
-O3 61,0s / 14770 Byte
[code]
Christoph M. schrieb:> Da sind dann meist für einen Prozessor oder eine> Graphikkarte mehrere Balken für die unterschiedlichen Kategorien.
... bitte sehr!
Ralph S. schrieb:> ... bitte sehr!
Danke schön :-)
Wirklich erstaunlich, dass sich der Unterschied bei Integer so stark
bemerkbar macht und bei float fast eingeebnet ist.
Vielleicht müsste man den Kehrwert im Diagramm darstellen (so was wie
Operationen/Sekunde), damit der RISC-V auch optisch schneller erscheint.
Ralph S. schrieb:> wenn du mir mit deiner Anregung zeigen wolltest, dass> mein "Testprogramm" nichts taugt, dann ist dir das wirklich sehr> eindrucksvoll gelungen!!!!
Oh, sorry, da hab' ich ja was losgetreten. So boshaft war meine Frage
gar nicht gemeint gewesen ...
Danke für den jetzt sehr, sehr ausführlichen Testbericht.
Ehrluch gesagt verstehe ich den "Banchmark" nicht. Da sind doch die
Zeiten enthalten, die printf braucht, um die Ergebnisse auszugeben?
Außerdem sind die Funktionen nicht gegen Inlining / Cloning geschützt.
Johann L. schrieb:> Ehrluch gesagt verstehe ich den "Banchmark" nicht. Da sind doch> die> Zeiten enthalten, die printf braucht, um die Ergebnisse auszugeben?
Das "messen" der Zeit erfolgt direkt vor und nach dem Benchmark-Start
und geht nicht in die Zeitmessung mit ein (tick_ms wird vom systemticker
hochgezählt).
Johann L. schrieb:> Außerdem sind die Funktionen nicht gegen Inlining / Cloning geschützt.
Es ging mir um einen ersten Vergleich, deshalb auch viele volatile.
Speziell habe ich den "Verdacht" bei int32, dass dort Inline / Cloning
gemacht wird (vor allem bei -O3) und das werde ich mir noch ansehen.
Zudem ist mir auch bewußt, das das nicht wirklich "repräsentativ" ist:
Traue keiner Statistik, die Du nicht selbst gefälscht hast.
Harald K. schrieb:> Oh, sorry, da hab' ich ja was losgetreten. So boshaft war meine Frage> gar nicht gemeint gewesen ...>> Danke für den jetzt sehr, sehr ausführlichen Testbericht.
Schmunzeln muß, du hast das bösartig gemeint? Das ist mir ehrlich gesagt
nicht aufgefallen, weil deine Anmerkungen ja gerechtfertigt waren /
sind. Berechtigte Aussagen Zweifel Anmerkungen sind nie bösärtig und
schon gar nicht, wenn sie nicht persönlich werden.
So, in diesem Sinne habe ich das Testprogramm auch für STM32 angepasst
und hier sind die Ergebnisse (immer auch vorbehaltlich der Aussage von
Johann):
1
Benchmark Ergebnisse CH32V003
2
3
Compiler: riscv-none-elf-gcc Version 14.2.0 / ch32v003fun Framework
Hier finde ich erstaunlich (und das untermauert die Aussage von Johann,
dass die Verarbeitung eines float auf einem STM32F030 länger dauert als
bei einem CH32V003, das Apfelmännchen aber in der hälfte der Zeit
aufgebaut ist).
Ich hab mal die Tests so gemacht, dass die Zeiten von printf nicht
migemessen werden.
Weil ich die hardware nicht hab, weder den Controller noch LCD oder was
auch immer, habe ich AVRtest als Simulator verwendet.
https://github.com/sprintersb/atest
Der Simulator implementiert unterschiedliche Syscalls z.B. zur
Zeitmessung, so dass keine I/O gebraucht wird.
verändern sich die Ausführungszeiten nur wirklich sehr minimal. Es
rentiert sich hier (fast) nicht, dafür die Werte neu aufzuschreiben
(werde ich aber, wenn ich Zeit habe, dennoch machen). Hast du weitere
Anmerkungen / Verbesserungsvorschläge?
(Eigentlich sollte das gar kein Benchmarktest geben, sondern nur
Geschwindigkeitsunterschiede aufzeigen)
Johann L. schrieb:> int_8 Benchmark... done> int_16 Benchmark... done> int_32 Benchmark... done> float Benchmark... done> F_CPU = 16000000> cycles int8 : 50400037 = 3.150 s> cycles int16: 74050028 = 4.628 s> cycles int32: 86620070 = 5.413 s> cycles float: 82622222 = 5.163 s
die Abweichungen sind hochinteressant und ich werde nächste Woche das
ganze nach deinen Vorgaben testen und jegliches printf weglassen und
lediglich einen gpio pin vor und nach dem Test togglen und das mittels
einer Hardwarestopuhr (nicht im Controller sondern schlicht eine externe
Uhr) stoppen um die Zeiten zu verifizieren.
Veit D. schrieb:> Christoph M. schrieb:>>> Falls ein AVR-Assembler Experte mitliest: Wieviel Zyklen braucht ein>> Atmega für ein 32Bit add ?>> Hallo,>> mit Standard Arduino IDE die avr-gcc 7.3 verwendet mit C++11.> Ohne volatile d wäre alles Compilezeit berechnet.
Auch wenns schon ein halbes Jahr her ist: in dem Assemblerprogramm wird
sehr offensichtlich gar nichts gerechnet, das macht auch mit volatile
alles der Compiler zur Compilezeit.
Oliver
> verändern sich die Ausführungszeiten nur wirklich sehr minimal.
Mag sein. Aber noinline, noclone oder auf neueren GCC noipa gehören
einfach dazu, ebenso andere Maßnahmen die sicherstellen, dass man das
misst bzw. betestet, was gemessen bzw. betestet werden soll.
p.s. Bei dem float Benchmark hatte ich noinline/noclone vergessen, und
mit einer avr-gcc Version war die Zeit dann 0 Sekunden :-)
> Hast du weitere Anmerkungen / Verbesserungsvorschläge?
Bei Bestimmung der Codegröße gehen die Größen der Ausgabefunktionen /
Hardwarekonfiguration etc. mit ein. nicht sooo sinnvoll. Wenn, dann als
separate Untersuchung zu printf etc.
Im ganzen Test hast du "\n\r". Das macht man komfortabler in der char
Ausgabe-Routine, so dann man in Code einfach "\n" schreiben kann wie in
C üblich.
Ralph S. schrieb:> Johann L. schrieb:>> F_CPU = 16000000>> cycles int8 : 50400037 = 3.150 s>> cycles int16: 74050028 = 4.628 s>> cycles int32: 86620070 = 5.413 s>> cycles float: 82622222 = 5.163 s>> die Abweichungen sind hochinteressant und ich werde nächste Woche das> ganze nach deinen Vorgaben testen und jegliches printf weglassen
Für die Zeit-/Cycles-Messung sollte das egal sein wenn man es denn
richtig macht. Und die Zeiten auf Hardware gemessen sollten mit denen
AVRtest Zeiten übereinstimmen. (Cum granum salis: Meine Messung
berücksichtigt nur den Code der Funktionen ohne CALL/RET). Das lässt
sich aber einfach anpassen:
So kann man dann per -include .../avrtest.h zwischen der
Hardware-Variante und der Simulator-Variante umschalten.
Ralph S. schrieb:> Johann L. schrieb:>> Ehrlich gesagt verstehe ich den "Banchmark" nicht. Da sind>> doch die Zeiten enthalten, die printf braucht, um die Ergebnisse>> auszugeben?
Gibt es da mehrere Versionen? Und wenn ja, auf welche beziehen sich die
Werte?
Dann noch: Bei Optimierung auf Geschwindigkeit ist -O2 zumindest auf AVR
wesentlich geeigneter als -O3. Alle Schleifen aufzurollen bringt ja
nix, schon gar nicht bei Schleifen, die nicht komplett aufgerollt werden
können (etwa weil zu groß, oder weil die Anzahl der Durchläufe nicht
bekannt ist). Dann führt -O3 nur zu Code Bloat ohne erkennbaren
Geschwindigkeitszuwachs.
Hier mal ein paar Ergebnisse für verschiedene avr-gcc Versionen, bench.c
siehe Anhang.. Zeiten in Sekunden.
1
Options: -Os -DF_CPU=16000000
2
Version | int8 | int16 | int32 | float
3
avr-gcc 4.8.1 | 2.943 | 4.528 | 5.273 | 4.892
4
avr-gcc 4.9.2 | 2.950 | 4.528 | 5.273 | 5.130
5
avr-gcc 5.4.0 | 2.850 | 4.478 | 5.273 | 5.130
6
avr-gcc 7.3.0 | 3.150 | 4.628 | 5.413 | 5.163
7
avr-gcc 8.5.1 | 3.150 | 4.628 | 5.413 | 5.163
8
avr-gcc 13.4.1 | 3.150 | 4.631 | 5.333 | 5.235
9
avr-gcc 14.3.1 | 2.950 | 4.531 | 5.253 | 6.081
10
avr-gcc 15.2.1 | 3.162 | 4.840 | 5.266 | 5.611
11
avr-gcc 16.0.0 | 3.050 | 4.731 | 5.435 | 5.164
1
Options: -O2 -DF_CPU=16000000
2
Version | int8 | int16 | int32 | float
3
avr-gcc 4.8.1 | 2.943 | 3.231 | 4.973 | 4.961
4
avr-gcc 4.9.2 | 3.043 | 3.234 | 4.973 | 5.200
5
avr-gcc 5.4.0 | 2.850 | 3.281 | 4.973 | 5.200
6
avr-gcc 7.3.0 | 3.150 | 3.340 | 5.113 | 5.227
7
avr-gcc 8.5.1 | 3.243 | 3.340 | 5.113 | 5.227
8
avr-gcc 13.4.1 | 3.343 | 3.334 | 5.033 | 5.235
9
avr-gcc 14.3.1 | 3.143 | 3.234 | 4.953 | 6.027
10
avr-gcc 15.2.1 | 3.143 | 3.384 | 4.953 | 5.323
11
avr-gcc 16.0.0 | 3.143 | 3.434 | 5.076 | 5.227
Was ich noch nicht verstehe sind die Schwankungen bei float. Die Zeiten
sollten i.W. durch die Laufzeiten der libm-Funktionen gegeben sein, die
unabhängig von der Compilerversion sind da in Asm implementiert.
Johann L. schrieb:> Was ich noch nicht verstehe sind die Schwankungen bei float. Die Zeiten> sollten i.W. durch die Laufzeiten der libm-Funktionen gegeben sein, die> unabhängig von der Compilerversion sind da in Asm implementiert.
"Sollten" - hier wäre es sicher interessant, sich den erzeugten
Binärcode mit einem Disassembler anzusehen, um zu vergleichen, was für
Code da wirklich generiert wurde.
am stärksten für die Zeiten (und die größte Verfälschung) ist schlicht
nicht das printf oder eine Ausgabefunktion, sondern (und das habe ich
radikal unterschätzt) ist der aufgesetzte Timerinterrupt, der die Zeiten
mißt!
Asche über mein Haupt.
Ich bin jetzt noch nicht dazu gekommen, meine Stopuhr selbst
aufzuarbeiten um das genauer zu sehen und am Stück. Fürs erste hat sich
gezeigt, dass die int8 und int16 Tests deutlich schneller laufen (weil
die häufigsten Loops), wenn sie nicht durch den Timerinterrupt zur
Zeitmessung unterbrochen werden!
Das wird sich dann zeigen, wenn mein "Stopuhrenprojekt" (welches auf der
Platine meines Picomons aus einem anderen Thread aufsetzt, dann so ist,
wie ich das haben möchte.
Allerdings wollte ich nicht wirklich ein Benchmarkprogramm erarbeiten,
das hatte sich (der ursprüngliche Thread) nur daraus ergeben gehabt,
weil ich darüber erstaunt war, wie langsam ein CH32V003 war.
Mit AVR mache ich fast nichts mehr, in den meisten Fällen dienen die mir
nur noch für Referenzzwecke und unter dem Strich ist es ja eigentlich
auch egal, was ein Benchmarktest ausgibt. Relevant ist, wie schnell eine
Firmware abgearbeitet wird.
Im besten Fall kann man vielleicht (aber auch nur vielleicht) eine
Erkenntnis daraus ziehen, wie man zukünftig Programme schreibt.
Beispiel: seit geraumer Zeit verwende ich auf einem 32-Bit Controller
lieber ein int32_t oder uint32_t auch dann, wenn ein uint8_t reichen
würde, weil dann keine Bereichsprüfung erfolgen muß.
Tatsächlich heißt das, dass es genügend Fälle gibt, bei denen dann ein
int32 schneller als ein int8 abgearbeitet wird.
Johann L. schrieb:> Gibt es da mehrere Versionen? Und wenn ja, auf welche beziehen sich die> Werte?
sorry, ja, es gibt da mittlerweile die dritte Version des Tests, guckst
du hier:
Beitrag "Re: CH32V003, float wirklich langsam?"
Manuel H. schrieb:> Johann L. schrieb:>> Was ich noch nicht verstehe sind die Schwankungen bei float. Die Zeiten>> sollten i.W. durch die Laufzeiten der libm-Funktionen gegeben sein, die>> unabhängig von der Compilerversion sind da in Asm implementiert.>> "Sollten" - hier wäre es sicher interessant, sich den erzeugten> Binärcode mit einem Disassembler anzusehen, um zu vergleichen, was für> Code da wirklich generiert wurde.
Hab ich ja gemacht. Und da ich die selbe AVR-LibC Version verwende bei
den avr-gcc ≥ v8 gibt's keine Unterschiede bei der Implementation von
__addsf3 oder __mulsf3. Und der Compiler erzeugt auch die gleichen
Aufrufe.
Ich bin aber bissl deppert weil ich auf der Benchmark Seite die Spalte
für Size (ca 380) mit der für Laufzeit (ca 110) verwechselt hab. Mit
den richtigen libm Laufzeiten fällt der Code in der Benchmarkfunktion
natürlich viel mehr ins Gewicht. avr-gcc-14 erzeugt zum Beispiel:
1
std Y+1,r22 ; 232 [c=4 l=1] movqi_insn/2
2
std Y+2,r23 ; 233 [c=4 l=1] movqi_insn/2
3
std Y+3,r24 ; 234 [c=4 l=1] movqi_insn/2
4
std Y+4,r25 ; 235 [c=4 l=1] movqi_insn/2
5
ldd r18,Y+1 ; 236 [c=16 l=4] *movsf/2
6
ldd r19,Y+2
7
ldd r20,Y+3
8
ldd r21,Y+4
und liest Y+1 noch nicht mal aus danach... Damit gewinnt man natürlich
keinen Blumentopf. Vermutlich https://gcc.gnu.org/PR110093 o.ä.
Ralph S. schrieb:> Ich bin jetzt noch nicht dazu gekommen, meine Stopuhr selbst> aufzuarbeiten um das genauer zu sehen und am Stück.
Es sollte möglich sein, einen freilaufenden Timer ohne Interrupt zu
verwenden, der einfach nur hochzählt.
Dessen Wert zu Anfang der Messung bestimmen und nach der Messung, dann
die Differenz betrachten. Wenn der Timer mit 1 kHz getaktet wird, kann
man mit 'nem 16-Bit-Timer Zeitdauern von über 'ner Minute damit
bestimmen.
Harald K. schrieb:> Ralph S. schrieb:>> Ich bin jetzt noch nicht dazu gekommen, meine Stopuhr selbst>> aufzuarbeiten um das genauer zu sehen und am Stück.>> Es sollte möglich sein, einen freilaufenden Timer ohne Interrupt zu> verwenden, der einfach nur hochzählt.>> Dessen Wert zu Anfang der Messung bestimmen und nach der Messung, dann> die Differenz betrachten. Wenn der Timer mit 1 kHz getaktet wird, kann> man mit 'nem 16-Bit-Timer Zeitdauern von über 'ner Minute damit> bestimmen.
... wir würden hier sagen:"2 doofe beim Training" , (nett gemeint), weil
ich auf der Fahrt zu einer Location genau das gedacht hatte. Allerdings
hatte ich mir überlegt gehabt, den Timer mit einem Prescale von 16000 zu
beaufschlagen, was zu einem Takt von 1 ms führt (wie du sagtest). Bei
einem 16-Bit Zähler reicht das dann für 65,535 Sekunden. Ein Test darf
dann nicht länger dauern. Aber wie gesxgt wollte ich mich mit AVR nicht
mehr so sehr kümmern.
Ralph S. schrieb:> Hierzu --meine-- Meinung:
Schreibe bitte fein weiter zu den Teilen. Mittlerweile hab ich sie hier
und würde gerne nächstes Jahr damit anfangen.
Deshalb bin ich (sicher auch andere) an allem interessiert, was es um
die Teile so gibt.
Frank O. schrieb:> Schreibe bitte fein weiter zu den Teilen. Mittlerweile hab ich sie hier> und würde gerne nächstes Jahr damit anfangen.> Deshalb bin ich (sicher auch andere) an allem interessiert, was es um> die Teile so gibt.
na ja :-) im Moment habe ich deutlich zu viele Baustellen gleichzeitig
offen und diese hier mit Geschwindigkeitstests ist die unnötigste. Es
ist vollkommen egal, wieviel schneller oder langsamer ein Controller im
Vergleich mit einem anderen ist: entweder er ist für die Anwendung in
der er laufen soll ausreichend oder eben nicht. Momentan könnte ich
diesen Geschwindigkeitstest hier gar nicht weiter programmieren, da ich
nicht alle von mir genutzten Controller dabei habe. Grundsätzlich, um
das Vergleichbar zu machen, möchte ich ein eigenes Setup für die 32-Bit
Controller haben, ohne HAL, ohne libopencm3, ohne cmsis. Hierfür ist
dann ein eigener Startupcode und ein Linkerscript von Nöten. Am We hatte
ich mich da für einen STM32F030 hingesetzt und ich habe Zeit
"verdummbeutelt", nur um den mit 48 MHz an's laufen zu bekommen und
einen Pin zu toggeln nur damit ich dann beim Setup des Uart gnadenlos
versage. Natürlich "pfupfert" es mich das hinzubekommen, einzig ist die
Frage: wozu. Hier sind dann andere Baustellen liegen geblieben,
namentlich meine Spielekonsole für STM32F4 und ein PCB hierfür, ein PCB
für Logicmachine mit CH32V003 und die Doku für den aktuellen Bootloader
des CH32V003 mit einem eigenen kleinen PCB und - für mich realtiv
ungewohnt - Beispieldatei für Arduino, weil in einem anderen Thread das
so geschrieben worden ist, dass das ja irgendwie nicht schlecht wäre.
Hier begebe ich mich dann wirklich zum ersten mal in das Muster von
Arduino um hierfür im Arduino-Style ( eigene Klassen in den
"Arduino-Libraries" ) Code zu erzeugen. an 2 oder 3 Stellen habe ich
mich hier dann auch verfranzt, bspw. um einen externen Interrupt
aufzusetzen: Arduinostyle attachinterrupt will ich da einfach nicht
hinbekommen und habe dann den Interrupt eben kurzerhand (okay eher
längerhand) global gemacht. Dann kommt der Kampf um das Hardware I2C
hinzu, das dann endlich läuft und hier muß das dann getrennt werden von
der Bitbanging I2C und die "Librarie" für ein SSD1306 Display neu zu
schreiben.
Viele Baustellen, und nicht nur alle CH32V003. Schlimm ist, dass es gute
Homepages und / oder github Repositories für den CH32V003 nicht so
wirklich viele gibt.
Wenn du also schreibst ich soll da schön weiter schreiben, dann mußt du
diejenigen besänftigen, denen ich grundsätzlich ein Dorn im Auge (mit
meinem Geschwafel) bin!
Ach so, ja: meine Homepage für den CH32V003 ist mittlerweile auch weit
entfernt von dem neuesten Stand den ich hier verwende und ich sollte das
ausmisten.
So, abschließender Satz: wenn du die Teile bereits bei dir liegen hast,
warum willst du bis nächstes Jahr warten um mit denen etwas anzufangen?
Wenn ich neue - mir unbekannte - Teile bekomme, bin ich gierig darauf,
mit denen etwas anzufangen und zu evaluieren, was ich mit denen
anstellen kann.
Bis die Tage,
Ralph
Hallo Ralph!
Ich fange dann mal von hinten an.
Im Moment gibt es noch ein paar wichtiger Dinge (Geld!) um die ich mich
kümmern muss, dann kommt schon Skiurlaub und Weihnachten und letztlich
das Jahresende.
Durch die vielen Einschläge kann ich mir leider nicht mehr so viel
merken wie früher und deshalb will ich gleich dran bleiben. Dazu kommt,
dass ich aus C komplett raus bin und damals erst angefangen hatte es zu
lernen. Das macht grundsätzlich nichts, da ich quasi immer im Quadrat
gelernt habe, also von allen Außenkanten nach innen und immer mehr oder
weniger gleichzeitig. Ich habe also eigentlich auch immer mehrere
Baustellen offen.
Manchmal sind genau diese Sachen, die du gerade machst und oft sogar
zufällig, genau die Sachen, die einen dann nach vorne bringen.
Ich finde Arduino recht nützlich um schnell zu Ergebnisen zu kommen.
Obwohl ich dort im Grunde lange raus war, wuchs der Bremsentester doch
recht schnell. Allerdings habe ich den, nach dem neuen Tumor nicht mehr
weiter gebaut. Aber vor allem, weil mir die große 80V Batterie fehlt.
Nur bin ich zwischenzeitlich auf die Speichergrenzen gestoßen. Die
hatte ich zwar zuletzt im Griff und trotzdem wurde mir klar, dass ich
nun doch langsam mit 32-Bittern anfangen muss und die Tiny10 doch so
langsam am Ende sind.
Deshalb würde ich gerne in diese Teile einsteigen, weil sie uns sicher
noch viel öfter begegnen. Und sie sind sehr günstig.
Geschwindigkeit war bisher nie ein Problem, könnte es aber bei d3m
Bremsentester noch geworden sein. Allein deshalb sind deine Erkenntnisse
für mich schon nützlich gewesen.
Ich muss nichts mehr entwickeln, weil ich jetzt Rentner bin und es war
auch nie meine Aufgabe. Deshalb brauche ich nur noch einen Nachfolger
für die 8-Bitter. Die STM waren mir viel zu umfangreich, vor allem ohne
HAL.
Hier sieht das alles so aus, als könnten die für mich passen.
Und da ich im Moment wieder etwas weiter von der Kiste entfernt bin und
vielleicht doch noch ein paar Jahre leben darf und es mir relativ gut
geht, ist es das was ich machen möchte.
Grüß Dich Frank,
das mit Deinen Einschlägen tut mir leid und ich weiß wovon ich spreche,
ich hatte dieses Jahr auch genügend davon (mit insgesamt 5
Krankenhausaufenthalten) und die COPD gefällt mir auch nicht.
:-) andere Aktivitäten als Mikrocontroller sind wichtiger (auch wenn ich
kein Ski fahre).
Frank O. schrieb:> Ich finde Arduino recht nützlich um schnell zu Ergebnisen zu kommen.
Oha, die Sache mit Arduino! Mit den Geschwindigkeittests habe ich mich
verzettelt und das hat mir Zeit gefressen, die ich nicht für andere
Projekte genutzt habe. Eines davon ist CH32V003 und Arduino.
Die Kombination CH32V003 und Arduino ist bei mir hier am Entstehen und
momentan beschäftige ich mich damit, obwohl ich Arduino nicht nutze,
gemacht wird das also für andere. Hier steige ich jetzt zum ersten mal
etwas tiefer in Arduino ein, weil ein Forenmitglied hier meinte, dass
man meinen Bootloader dafür verwenden kann und genau das mache ich
gerade im Moment. Die Hardware funktioniert und es ist so etwas
entstanden wie ein Arduino Nano allerdings mit CH32V003 Controller. USB
anstecken und über ein eigenes Hostprogramm den Controller flashen. Für
mich ist mein eigenes Board fast schon obsolet geworden, weil ich eine
für mich bessere Lösung für bspw. ein Steckbrett habe.
Aber das Spielen mit diesem Teil und mit Arduino macht irgendwie Spaß,
auch wenn manche Dinge, speziell Hardware I2C und externe Interrupts
irgendwie knifflig waren, bis die mit Arduino und CH32V003 laufen (geht
aber).
Grundsätzlich solltest du bedenken, dass CH32V003 und Arduino nicht so
wirklich zwingend gut ist: Von den schon wirklich mageren 16 kByte Flash
genehmigt sich Arduino schon einmal 4600 Byte fürs funktionieren. Dann
gibt es bspw. den Fallstrick, dass ein Aufruf von delayMicroseconds noch
einmal fast 5000 Byte benötigt (also die Mikrosekunden anderst lösen).
Momentan habe ich für CH32V003 "Libraries" geschrieben für:
- Software I2C (Bitbanging)
- Hardware I2C
- OLED Display 128x64 Pixel
- WS2812 Leuchtdioden
- HX1838 Infrarot Empfänger
- DS18B20 Temperatursensor (allerdings ohne Bus, nur ein Sensor möglich)
- 7-Segmentanzeige mit TM1650 / TM1637 Baustein
- Charlieplexing für 20 Leuchtdioden
Im Moment in Arbeit ist die Realtime-Clock DS3231. Ich sollte das
allerdings lassen und das, was ich habe Dokumenieren und veröffentlichen
Den CH32V003 als Ersatz für ATmega zu nehmen ist dann eine gute Wahl,
wenn der Flashspeicher reicht und die Anzahl der GPIO's ausreichend ist.
Wenn dem nicht so ist verwende ich tatsächlich STM32 und du solltest
deine Abneigung gegen STM32 noch einmal überdenken. Das Framework
libopencm3 hilft einem da sehr. Zudem habe ich über diesen
Hardwareabstraktionslayer noch einmal meinen eigenen Layer darüber
gelegt (wie bei allen von mir verwendeten Controllern), so dass man von
der Hardware - wenn man das möchte - nicht mehr viel sieht. Wenn du da
mehr Infos darüber haben möchtest, kannst du mir gerne eine PN schreiben
und wir tauschen uns über Mail aus.
By the way:
Frank O. schrieb:> und die Tiny10 doch so> langsam am Ende sind.
Du hast wirklich mit Tiny10 gearbeitet? Damit sind nun wirklich nur
rudimentäre Aufgaben zu machen und im Normalfall würde ich sagen den
programmiert man nur mit Maschinensprache. Arduino ist da komplett raus
Ralph S. schrieb:> Die Kombination CH32V003 und Arduino ist bei mir hier am Entstehen und> momentan beschäftige ich mich damit, obwohl ich Arduino nicht nutze,> gemacht wird das also für andere...
Ein großes Lob von mir :-)
Der Lohn dürfte sein, dass diese Software ziemlich viele Leute nutzen
werden. Und vor allen Dingen: Eine unendliche Anzahl Bibliotheken wird
plötzlich nutzbar.
Ralph S. schrieb:> Aber das Spielen mit diesem Teil und mit Arduino macht irgendwie Spaß,> auch wenn manche Dinge, speziell Hardware I2C und externe Interrupts> irgendwie knifflig waren, bis die mit Arduino und CH32V003 laufen (geht> aber).
Ich hatte mich auch vor längere Zeit damit beschäftigt. Der große Spaß
dabei ist eigentlich, wenn die Komponenten dann Schritt für Schritt
funktionieren. Außerdem ist es ja relatv anspruchsvoll, die Treiber
platzsparend und schnell implementiert.
Ralph S. schrieb:> Im Moment in Arbeit ist die Realtime-Clock DS3231. Ich sollte das> allerdings lassen und das, was ich habe Dokumenieren und veröffentlichen
Das ist wahrscheinlich eine gute Idee. Software ist ja nie zu 100%
fertig und deshalb müsste man die Veröffentlichung ja ewig hinaus
schieben.
Ralph S. schrieb:> Du hast wirklich mit Tiny10 gearbeitet?
Bis vor dem Bremsentester hatte ich nur wenige Aufgaben zu erfüllen.
Aber zunächst wünsche ich dir natürlich auch gute Besserung!
Ala ich mit der Elektronik anfing, da kamen von Anfang an viele Sachen
dazuwischen und nach dem Tod von meinem Sohn war ich für Jahre aus allem
raus.
Im Grunde fange ich (wenn nicht wieder noch mehr dazwischen kommt) jetzt
erst wieder an und wenig über Null.
Arduino hat schon Vorteile. Da musst du dir nicht irgendwelche Libs
schreiben und es gibt viele Beispiele die man gut zum Einstieg in das
gerade geforderte Thema nehmen kann und darauf aufbauen. Es ist
allerdings dann auch genau deswegen oft begrenzt. Das hatte ich so
richtig bei dem Bremsentester gemerkt, als mir der Speicher knapp wurde
und ich mich dann richtig mit der Libary von Uli Kraus auseinandersetzen
musste.
Hier will ich auch gerne wieder in C einsteigen. Ob das alles klappt,
das weiß ich noch nicht. Aber es ist ja nur Hobby und Spaß an der
Technik.
Geld muss ich nicht mehr verdienen, da ich jetzt die EM-Rente durch habe
und finanziell passt es auch, sodass ich keine Flaschen sammeln muss.:-)
Die Nacht über habe ich auch schon ein paar Dinge dazu gesammelt und die
geforderte IDE installiert. Wenn es heute geht, dann werde ich mich mit
der Hardware und der Einbindung in Arduino beschäftigen. Bis 1.0.3
konnte ich schon die Boards einbinden, 1.0.4 funktioniert nicht oder
noch nicht.
Den Bremsentester werde ich wohl versuchen mit diesem Teil und kleinen
Magneten doch noch zu bauen. Allein dafür brauche ich schon Arduino.
Heute will ich mal schauen, dass die Hardware läuft und ich eines der
Boards zum Blinken bringe.
Frank O. schrieb:> Bis 1.0.3> konnte ich schon die Boards einbinden, 1.0.4 funktioniert nicht oder> noch nicht.
1.0.4 hatte ich ausprobiert, weil dieser in einer Library das
attachinterrupt implementiert hatte (1.0.3 hatte das nicht), der Code
ist hier explodiert und von daher ist da eher 1.0.3 zu verwenden.
Frank O. schrieb:> Arduino hat schon Vorteile. Da musst du dir nicht irgendwelche Libs> schreiben und es gibt viele Beispiele die man gut zum Einstieg in das> gerade geforderte Thema nehmen kann und darauf aufbauen.
Das ist aber oft das Problem, wenn du mit Arduino werkeln möchtest, aber
dein Controller KEIN AVR ist. Viele Coreinstallationen für Controller,
namentlich STM32, CH32 oder sogar ein offizielles Arduino-Board mit
RA4M1 Controller von Renesas können mit den allermeisten Libs nichts
anfangen und funktionieren nicht. Auch die I2C Umsetzung von wire.h für
den CH32V003 des Arduino Pakets funkioniert nicht so recht.
Aus diesem Grunde bin ich jetzt mal an den Dingen dran, damit man das so
auch verwenden kann. Bevor ich ans dokumentieren gehe, werde ich die Lib
für die Echtzeituhr machen und eine Lib für Hardware SPI.
In der Liste oben hatte ich vergessen, dass es noch eine Lib für
Schieberegister SN74HC595 gibt.
Grundsätzlich habe ich das unter Linux geschrieben, aber die Libs
sollten auch unter Windows funktionieren. Eine Testmöglichkeit habe ich
mangels Windowssystem allerdings nicht
Ralph S. schrieb:> Das ist aber oft das Problem, wenn du mit Arduino werkeln möchtest, aber> dein Controller KEIN AVR ist.
Aber Lebenszeit ist knapp, insbesondere meine.
Ist schon alles richtig und wenn man was komplett selbst gemacht hat,
ist man natürlich auch richtig "im System drin".
Ein paar Anmerkungen zum Eröffnungspost
Ralph S. schrieb:> Im Anhang hier ist der Programmcode
1
r= wx*wx+wy+wy;
Das ist natülich ein Tippfehler, und man bekommt eine etwas zerschossene
Grafik (mandel-1.png). Zur Hervorhebung des Äußeren von M wechseln die
Farben immer zwischen schwarz und weiß. Der Fehler wirkt sich nicht auf
den Benchmark aus weil er in neueren Versionen enthalten ist.
Es sollte natürlich heißen:
1
r = wx*wx + wy*wy;
Mit der korrigierten Version bekommt man dann ein etwas vertrauteres
Ergebnis (mandel-2.png). Allerdings sind die Grenzen zwischen den
Farbbändern keine Äquipotentiallinien. Das liegt daran, dass als
Abbruchbedingung
gewählt wurde. Damit bekommt man zwar eine Visualisierung von M, aber
eben keine Feldlinien / Äquipotentiallinien. Das lässt sich beheben,
indem man einen größeren Schwellenwert nimmt wie
(mandel-3.png) Von der Performance her macht das keinen großen
Unterschied weil die Folge der Iterierten hyperexponentiell wächst wenn
|w| > 2.
Äquipotentiallinien sind auch Voraussetzung für einen glatten
Farbverlauf wie in mandel-4.png
Für einen Benchmark ist sowas m.E. nur mäßig geeignet, man bekommt i.W.
eine Kombination der Zeiten der libm / libgcc float-Implementierungen.
Direkte Zeitmessungen würden da einen besseren Überblick geben als in
einem Algorithmus verwurstet.
Weil ich kein Display habe, macht das Programm die Ausgabe per printf in
Form einer Anymap / ppm (Portable Pixmap)
https://de.wikipedia.org/wiki/Portable_Anymap
Die so erstellte Textdatei kann man dann in ein gänggigeres Format wie
PNG umwandeln, zum Beispiel mit convert aus ImageMagick:
1
convert mandel-1.ppm mandel-1.png
Da Optionen wie -Os nicht auf die eigentlichen float-Routinen wirken
(zumindest ohne FPU), misst man damit also nicht unterschiedliche
Implementierungen gegeneinander, sondern nur, wie effizient der Compiler
Werte hin- und herschaufelt. Etwas Performance bekommt man mit
-ffast-math, und imdem man ldexpf verwendet statt *2: Auf AVR dauert
float+float ca 100 Cycles, ldexpf kostet ca. 40.
Falls man wirklich entsprechende Grafiken möchte, würde man ohnehin auf
Fixed-Point gehen. Selbst mit FPU kann das schneller sein als float,
und vor allem kann man eine viel bessere Auflösung erreichen.
Auf einem PC wird man auch gerne parallelisieren, was mit GCC -fopenmp
nur eine einzige Zeile braucht:
Hatte gerade etwas Zeit und Lust und habe mich nochmal reingelesen und
eine Led zum blinken gebracht.
Zunächst habe ich das auf dem Board versucht und habe zuletzt, alle Pins
parallel, neben der zusätzlichen Led ausprobiert. Die auf dem Board
blinkt nicht.
Leider konnte ich auch keinen Schaltplan zu dem Board finden und
Durchgang hatte ich an PD1. Auch das Bord ohne Programmer an USB ließ
dort nichts blinken.
Aber zumindest blinkt es erstmal. Wenn jemand dazu einen Schaltplan hat,
gerne posten. Für heute ist erstmal Schluß.
Frank O. schrieb:> Durchgang hatte ich an PD1
Das ist auch so, aber der Pin müsste geändert werden, womit aber das
Programmieren nicht mehr möglich wird.
Hier wäre ein Auszug der Programmierung dazu:
Frank O. schrieb:> Christoph M. schrieb:>> Ist es eines von denen:>> CH32V003F4P6_DevBoard ist es.
Na ja, auf beiden Boards sitzt ein CH32V003F4P6, das war's aber schon
mit den Gemeinsamkeiten.
Wesentliche Unterschiede:
- Die Anzahl der Pins der Stiftleisten ist verschieden
- Die Pinbelegung an den Stiftleisten ist verschieden.
- Die Pinbelegung am Debug-Anschluss ist verschieden.
- Die rote LED ist an verschiedenen GPIOs angeschlossen.
- Das Wagiminator-Board hat einen 3,3V-Spannungsregler, so dass der µC
immer mit 3,3V läuft, auch wenn das Board über die USB-Buchse versorgt
wird.
Yalu X. schrieb:> Na ja, auf beiden Boards sitzt ein CH32V003F4P6, das war's aber schon> mit den Gemeinsamkeiten.
Dann würde ich sagen, denn nur so ist es überall angegeben, ist es ein
noname Board.
Zumindest kann ich es schon einmal zum Laufen bekommen.
Sollte jemand das nach dem Video von pixeledi Tech Hub aufgebaut haben
und auch RX an PD1 angeschlossen haben, so funktioniert der
SerialMonitor unter Arduino nicht. Natürlich muss man das an TX des
NoNameBoards anschließen, dann funktioniert auch der SerialMonitor.
Yalu X. schrieb:> Die Boards gibt es übrigens gerade günstig im 5er-Pack für 1,99€ (0,99€> für Neukunden) inkl. Versand:
Da ich kein Neukunde bin, musste ich noch Versand drauf bezahlen, aber
ich hatte tatsächlich vorher noch aus ähnlichem Angebot welche bestellt.
Als nächste Aktion werde ich mal ein größeres Arduino Projekt versuchen
auf diesen Controller zu portieren.
Yalu X. schrieb:> günstig im 5er-Pack für 1,99€
Jetzt sinds für Bestandskunden schon 3.49, zuzüglich Versand, wobei der
ab 10 Euro nix kostet.
70 Cent pro Platine ist immer noch lächerlich günstig.
Harald K. schrieb:> 70 Cent pro Platine ist immer noch lächerlich günstig.
Das stimmt!
Aber es ist auch nicht nur der Preis. Datenblatt, Software,
funktioniert auch in Arduino, das ist alles schon ganz gut. Und du weißt
ja, meistens setzt sich "noch billiger" gegen "günstig" durch. Und
deshalb erwarte ich da künftig noch mehr Unterstützung.
Eigentlich wollte ich eher auf Holtek gehen, weil die in Weißware und
vielen Haushaltsgeräten zu finden sind. Aber letztendlich muss ich die
nicht mehr reparieren.
Auch wenn ich bisher nur mit dem blanken Chip und meinem eigenen Board
hantiere, würde es mich interessieren, wie dieses Board aufgebaut ist.
Der Beschreibung nach, soll hier ja USB nicht nur als Power Supply
dienen, sondern hier sind dann wohl D+ und D- von USB auf dem Chip
aufgelegt, so dass darauf V-USB gemacht werden kann (wie auf dem Github
von Christian Lohr).
Allerdings sehe ich da keine Dioden und auch keinen Spannungsregler und
so wäre das nur für 3,3V nutzbar, sehe ich das richtig?
Prinzipiell wäre es hier dann möglich (wenn auch umständlich) darauf den
V-USB Bootloader (ebenfalls bei Christian Lohr) aufzuspielen.
Ich guck mir das mal
Yalu X. schrieb:> https://docs.zephyrproject.org/latest/boards/wch/ch32v003f4p6_dev_board/doc/index.html
an!
Ralph S. schrieb:> Allerdings sehe ich da keine Dioden und auch keinen Spannungsregler und> so wäre das nur für 3,3V nutzbar, sehe ich das richtig?
Wenn ich da USB-C dran anschließe, dann hatte der 5V und die kommen auch
so am Controller an (gemessen).
Was beim "zephyr"-Projekt nicht dabei ist, ist ein Schaltplan des Boards
(was auch irgendwie verständlich ist).
Unschön, wirklich unschön ist wohl diese Designentscheidung hier:
> SWIO pin is connected to PD1 and also to led on the board.
(https://docs.zephyrproject.org/latest/boards/wch/ch32v003f4p6_dev_board/doc/index.html#flashing)
Das macht Ärger. Von PD1 sollte man die Finger lassen, wenn es sich
irgendwie vermeiden lässt.
Wenn man z.B. beim 8-Pinner tatsächlich sechs GPIOs nutzen will, kann
man das nicht vermeiden, aber das ist eine Enscheidung, die man bewusst
trifft, und nicht als quasi "Gendefekt" einer Entwicklungsplatine
mitgeben muss.
Prinzipiell sehe ich den Sinn dieses Boards nicht, das sieht für mich
aus, wie ein TSSOP-20 PCB Adapter, der noch zusätzlich eine USB-Buchse
zur Stromversorgung hat.
Harald K. schrieb:> Unschön, wirklich unschön ist wohl diese Designentscheidung hier:>>> SWIO pin is connected to PD1 and also to led on the board.>>
(https://docs.zephyrproject.org/latest/boards/wch/ch32v003f4p6_dev_board/doc/index.html#flashing)
>> Das macht Ärger. Von PD1 sollte man die Finger lassen, wenn es sich> irgendwie vermeiden lässt.
:-) darauf bin ich schon hereingefallen: Finger weg vom SWIO-Pin
Harald K. schrieb:> Unschön, wirklich unschön ist wohl diese Designentscheidung hier:>>> SWIO pin is connected to PD1 and also to led on the board.
Viel schlimmer noch:
PD5 und PD6 sind direkt mit D+ und D- der USB-Buchse verbunden.
Schließt man das Board mit einem gewöhnlichen Datenkabel an einen PC
oder einen Hub an und konfiguriert PD5 und/oder PD6 als Ausgang,
gelangen fast 5V (Vbus minus Flussspannung der Schottkydiode auf dem
Board minus Spannungsabfall am I/O-Treiber) an die USB-Datenleitungen.
Viele USB-Controller vertragen nach Datenblatt aber nur 3,8V an diesen
Leitungen.
Speziell bei PD5 ist die Versuchung besonders groß, diesen Pin als
Ausgang zu benutzen, da er u.a. als UART-TX-Ausgang dient (praktisch für
printf-Debugging :)) und auf dem Board auch entsprechend beschriftet
ist.
Evtl. gibt es Revisionen des Boards, die dieses Problem nicht aufweisen.
Falls die Verbindung zu den USB-Datenleitungen aber tatsächlich besteht,
möchte man sie vielleicht sicherheitshalber auf der Unterseite des
Boards auftrennen.
Gemessen und scharf hingeschaut. Einen Schaltplan habe ich nicht, aber
arg komplex ist das Board ja ohnehin nicht.
Wenn man USB-Kommunikation mittels V-USB machen will, sollte das Board
ähnlich wie dieses vom Wagiminator aufgebaut sein:
https://github.com/wagiminator/Development-Boards/tree/main/CH32V003F4P6_DevBoard_VUSB
Dafür gibt es auch Schaltplan und Gerber.
Yalu X. schrieb:> https://github.com/wagiminator/Development-Boards/tree/main/CH32V003F4P6_DevBoard_VUSB>> Dafür gibt es auch Schaltplan und Gerber.
Sicher kann man die, wenn man mal alles kennt, als günstige Boards
benutzen.
Aber für den Anfang (wenn man denn vorher lesen würde), ist es immer
besser die empfohlenen Sachen zu nehmen.
Edit: Die Daten zum Board können meiner Meinung nach auch nicht stimmen.
Da ist kein Quarz zu erkennen, dann kann das Board doch eigentlich keine
48Mhz schaffen. Zumindest, wenn ich das richtig gelesen habe.
Frank O. schrieb:> Edit: Die Daten zum Board können meiner Meinung nach auch nicht stimmen.> Da ist kein Quarz zu erkennen, dann kann das Board doch eigentlich keine> 48Mhz schaffen. Zumindest, wenn ich das richtig gelesen habe.
Doch, interner Takt 24 MHz und PLL-Verdoppelung bringt 48 MHz, aber
natürlich nicht quarzgenau.
Hier hole ich das Thema nochmals vor, weil ich Messungen des Apfelmann
mit dem CH32V006 gemacht habe. Dieser hat ja, im Unterschied zum
CH32V003, die hardware Extension für Ganzzahl-Multiplikation. Bei 48 MHz
und fast Optimierung braucht der Apfelmann ohne Ausgabe nur 37 Sekunden.
Bei Deaktivierung der Ganzzahl-Multiplikation sind es jedoch 104
Sekunden, also langsamer als der CH32V003. Die mögliche Wegoptimierungen
im Apfelmann, habe ich durch volatile verhindert.
Den CH32V003 sollte man also nicht mehr verwenden. Das war ein
Testballon aus dem der Hersteller gelernt hat. Der ATmega328 läuft eine
Klasse darunter.
Ausfuehrzeiten fuer das Programm: Fraktal-Speedtest:
2
Display: 160x128 ST7735
3
Interface: Hardware-SPI
4
5
Controller | Zeit [Sekunden]
6
-------------------------------------------------
7
STM32F401 / 84MHz | 2.8
8
STM32F401 / 96MHz (uebertaktet) | 2.6
9
STM32F103 / 72MHz | 11.4
10
STM32F030 / 48MHz | 34.0
11
CH32V003 / 48MHz | 80.5
12
CH32V003 / 24MHz | 123.0
13
ATmega328 / 16Mhz | 63.0
Maximilian schrieb:> Hier hole ich das Thema nochmals vor, weil ich Messungen des Apfelmann> mit dem CH32V006 gemacht habe. Dieser hat ja, im Unterschied zum> CH32V003, die hardware Extension für Ganzzahl-Multiplikation. Bei 48 MHz> und fast Optimierung braucht der Apfelmann ohne Ausgabe nur 37 Sekunden.
Das ist ja nur knapp doppelt so schnell wie der CH32V003. Wenn ich mich
recht erinnere, hat der CH32V003 einen langsamen Speicherzugriff mit
Waitstates. Ich vermute den Geschwindigkeitsunterschied eher durch
schnelleren Speicherzugriff also durch einen Hardwaremultiplizierer
begründet.
Vielleicht hilft dieser Thread bei der Diskussion:
Beitrag "Multiplizierer Hardware Aufwand"
Christoph M. schrieb:> Das ist ja nur knapp doppelt so schnell wie der CH32V003. Wenn ich mich> recht erinnere, hat der CH32V003 einen langsamen Speicherzugriff mit> Waitstates. Ich vermute den Geschwindigkeitsunterschied eher durch> schnelleren Speicherzugriff also durch einen Hardwaremultiplizierer> begründet.
Das Gegenteil ist der Fall:
Der ch32v003 hat gemäß Datenblatt:
Number of FLASH wait states
00:0 wait (Recommended 0=<SYSCLK=<24MHz)
01:1 wait (Recommended 24=<SYSCLK=<48MHz)
Other: Invalid
Der ch32v006 dagegen:
FLASH wait status number.
00: 0 wait (Recommended 0<=SYSCLK<=15MHz);
01: 1 wait (Recommended 15<SYSCLK<=24MHz);
10: 2 wait (Recommended 24<SYSCLK<=48MHz);
11: Reserved.
float generell gilt bei standard.operationen schon immer als langsamer
als Integer, nicht nur wenn die FPU eher lahm angebunden ist wie weiland
bei den intel x87 Co-prozessoren. Also nimmt man nur float wenn man
wirklich float braucht und/oder die Teilzeit nicht ins Gewicht fällt.
Sollte man eigentlich in der ersten Stunde eine Numerik-Vorlesung
lernen. Gründe liegen in der notwendigen Normalisierung und nötige
Konvertierungen INT <> FLOAT. BTW, wie ist das eigentlichen mit den
Branch-relevante CPU-Flags bei den Vergleichen ?
https://www.agner.org/optimize/instruction_tables.pdf
Maximilian schrieb:> Den CH32V003 sollte man also nicht mehr verwenden.
Das ist natürlich Unfug - den kann man weiterhin gut für alles
verwenden, für das man ihn verwenden kann.
Wie schon dargelegt, ist bei dem das Flash-ROM schneller als bei
(einigen) Nachfolgemodellen, wie CH32vV002 oder CH32V006, die aber
können aus anderen Gründen (mehr RAM, mehr Flash, geänderte Peripherie,
erweiterter Betriebsspannungsbereich) interessant sein.
Aber für das, wofür der CH32V003 taugt, taugt er natürlich trotz der
Erkenntnisse.
Bradward B. schrieb:> float generell gilt bei standard.operationen schon immer als langsamer> als Integer
Sofern es nicht auf maximale Geschwindigkeit ankommt, ist es aber oft
sinnvoller, in float (oder double) zu rechnen, als sich zu verkrampfen
und zwanghaft jedes Problem mit Integer-Arithmetik zu lösen. Wenn
genügend Programmspeicher vorhanden ist, wenn nichts zeitkritisches
dadurch zu langsam wird, warum um alles in der Welt nicht?
Das ist eine ähnliche Monstranz wie die "bloß niemals printf
verwenden"-Monstranz.
Maximilian schrieb:> Den CH32V003 sollte man also nicht mehr verwenden. Das war ein> Testballon aus dem der Hersteller gelernt hat. Der ATmega328 läuft eine> Klasse darunter.
Der "beste" Mikrocontroller ist der preiswerteste, der die an ihn
gestellten Aufgaben komplett und zufriedenstellend lösen kann. Und
alleine deine Aussage, dass der ATmega328 eine Klasse darunter liegt
sagt doch, dass es, wenn Flash und GPIO-Pins ausreichend sind, ein
CH32V003 eher die bessere Wahl als ein ATmega328 ist!
Ralph S. schrieb:> Der "beste" Mikrocontroller ist der preiswerteste, der die an ihn> gestellten Aufgaben komplett und zufriedenstellend lösen kann.
Nö, da spielen noch ein paar Kriterien mehr mit rein. Z.B. ob die
Toolchain gut, zugänglich und bequem zu programmieren ist und ob Du Dich
mit dem Controller und der Serie bereits auskennst oder ob Du Dich da
erst neu einarbeiten musst.
Wenn wir in die Vergangenheit blicken und PIC vs. Atmega anschauen, dann
hätte so ein PIC12 oder PIC16 für vieles ausgereicht oder hätte sogar
bessere Peripherie als der vergleichbare Atmega gehabt. Dennoch taten
sich die PICs sehr schwer, einfach weil sie nicht für die Programmierung
in C gemacht waren und es keinen normalen GCC dafür gab.
Ist bei RISC-V vs. ARM definitiv nicht so extrem. Bei den ARM Cortex-M
gibt es weniger Varianten als bei RISC-V, was es einfacher macht dass
der Compiler direkt funktioniert und den optimalen Code generiert.
Gerd E. schrieb:> Dennoch taten> sich die PICs sehr schwer, einfach weil sie nicht für die Programmierung> in C gemacht waren und es keinen normalen GCC dafür gab.
Die Marktanteile gegenüber AVR sprechen dagegen und heute gehört AVR
Microship.
Auch draußen, ob es die Elektrolytanzeigeelektronik bei den Batterien
war oder andere Sachen, da waren immer eher PICs oder andere µC drin,
als AVR.
Für den Hobbybereich mag das ja stimmen.
Schau mal in Waschmaschinen (zumindest ältere), da ist fast überall
Holtek drin.
Benning hat in den Ladegeräten zumindest ein Zeit lang AVR gehabt. Das
ist der einzige Profi, bei dem ich überhaupt AVR gesehen habe.

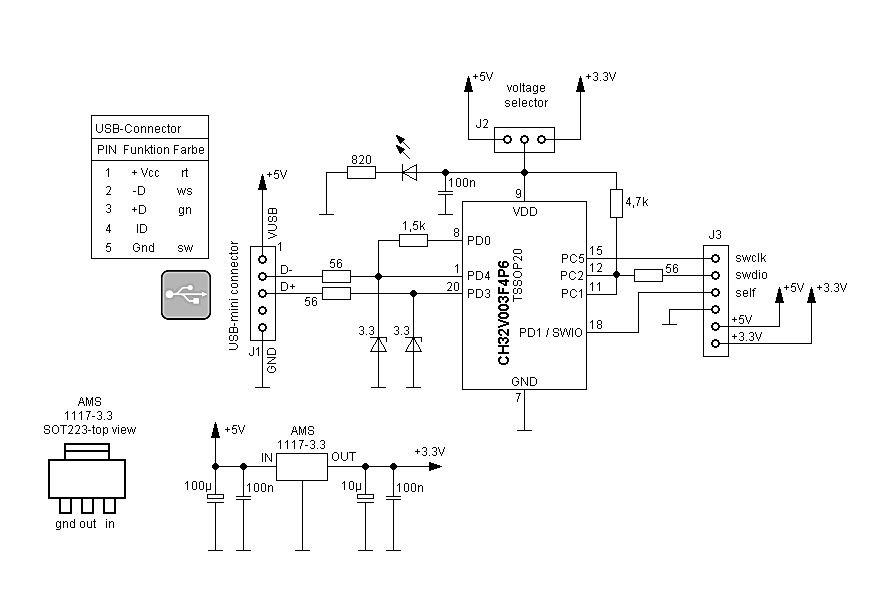








{kind=link}