Hallo zusammen, meine Frage wäre, ob sich ein Bash Datei , die auch unter einem Subsystem auf Windows läuft sich grundsätzlich auch in ein ausführbares Programm unter Python umsetzen lässt. Der Hintergrund ist der, nicht auf allen Windows Rechnern ist ein Subsystem installiert und die BASH Routine sollte gerne unter Windows als ausführbares Programm laufen. Es ist gedacht, um eine Registrierungs-Datei aus, einen Roland V-Akkordeon in seine einzelnen Blöcke zu zerlegen. Wäre schön, wenn hierauf einmal jemand antworten könnte Gruß Christian aus NF
Christian P. schrieb: > Hallo zusammen, meine Frage wäre, ob sich ein Bash Datei , die auch > unter einem Subsystem auf Windows läuft sich grundsätzlich auch in ein > ausführbares Programm unter Python umsetzen lässt. Ja. > Der Hintergrund ist der, nicht auf allen Windows Rechnern ist ein > Subsystem installiert und die BASH Routine sollte gerne unter Windows > als ausführbares Programm laufen. Es heißt "Windows Subsystem for Linux", auch wenn es eigentlich ein Linux-Subsystem für Windows ist. Davon abgesehen benötigt so ein Python-Programm natürlich einen Python-Interpreter, ist der auf den Systemen installiert? > Es ist gedacht, um eine Registrierungs-Datei > aus, einen Roland V-Akkordeon in seine einzelnen Blöcke zu zerlegen. > Wäre schön, wenn hierauf einmal jemand antworten könnte Was auch immer so eine "Registrierungs-Datei" ist... vielleicht lädst Du die "Registrierungs-Datei" und das Shellskript einfach einmal hier als Anhang an, dann hast Du sicherlich bessere Chancen.
Es gibt auch (mehr als eine) bash für Windows. Mir fallen spontan MinGw und CygWin ein. Da bash Dateien typischerweise von Programmen abhängen, die sie aufrufen, wird die Verfügbarkeit dieser Programme wohl eher der Knackpunkt sein.
Hallo Christian, Versuch doch mal das bash script ChatGPT oder Github Cpilot zu geben, mit der Anweisung das von bash nach python(3?) zu konvertieren unter der Angabe der Rahmenbedingungen im original Post. Das Konvertieren von Scripten in Sprache A nach Sprache B können die mittlerweile ganz gut. Dennoch solltest Du das Ergebnis ausführlich testen um sicher zu stellen dass das neue Script auch das macht was Du haben willst.
Ich habe hier mal die Bash Routine vom Greg hochgeladen, genau so wie
die
Datei mit der Endung UPA die kleine Datei ist für den Roland Fr4x und
zerlegt den Registrierungsfile (musische Einstellungen in 98 einzelne
Daten
das sind 7 Blöcke mit je 14 Registrierungen.
Eine Datei mit der Endung heißt User Programm All wird dann zerlegt in
UPB = user Programm Bank, das sind 8 Stück, ein UPB beinhaltet
UPG = user Programm , das sind 14 einzelne Dateien, also zusammen 98
Für das größere Roland Modell den FR8X ist die Datei größer und
beinhaltet
98 Blöcke mit insgesamt 1400 Datenblöcken.
Es gibt von Roland keine Software zum Zerlegen, damit man die einzeln
bearbeiten kann. Daher hat mein Bekannter in den Staaten, der Gree V.
eine Routine in einer Bash Datei geschrieben, er ist eingefleischter
Linux Schreiber und somit haben alle Anwender hier das Problem, dass sie
entweder Linux auf einem Rechner haben oder nichts geht. Daher habe ich
mal die
Software angefügt. Wäre echt super , wenn sich ein toller Programmierer
oder rin das mal anschaut.
Ich füge mal den Text zum File von Greg an
***********************************************************************
Updated Version 8.8
Please use/test this version and let me know if there are any issues.
Release notes:
[Corrected typo on help screen]
[Corrected index error in processing 4x UPG's from UPB's.]
This utility will convert UPA files to UPB's or UPG's or UPB's to UPGs.
download and unzip the file
This is a bash script.
the file runs natively on MAC and Linux computers. ( nothing needed).
on windows computers you will need to add the WSL 2 ubuntu from the
microsoft store or elsewhere - you need to have the bash interpreter
installed.
You will open a bash terminal window and from the command line run one
of the commands below.
Here is the help screen.
Definitions:
UPG = User Program ( 1 UPG = just one User Program)
UPB = User Program Bank ( 1 UPB = 14 User Programs)
UPA = User Program ALL ( 1 UPA = 1400 User Programs or 100 banks each
containing 14 User Programs)
This program extracts user programs or user banks from a UPA file or
user programs from a UPB file
Usage:
./makeupgs.sh -u UPG_ALL.UPA
The above line will create all user programs (UPG's) from the .UPA file
./makeupgs.sh -b UPG_ALL.UPA
The above line will create all the user banks (UPB's) from the .UPA file
./makeupgs.sh -u UPG_ALL.UPB
The above line will create all user user programs (UPG's) from the .UPB
file
./makeupgs.sh -h
The above line will display this help screen
Remember the....
8x/Evo contain 1400 User Programs / 100 Banks
4x contains 98 User Programs / 7 banks
This program will autodetect whether the input file is a 4x or 8x/Evo
The output files are put in a sub folder containing the date the program
was run. You can run from a USB drive or internal dirve.
Remember the -u option generates user programs (UPA or UPB files)
Remember the -b option generates user banks (UPA files
Have fun
************************************************************************
ich danke euch für eure freundliche Hilfe
Christian
Angehängte Dateien:
-

Convert.png
70 KB
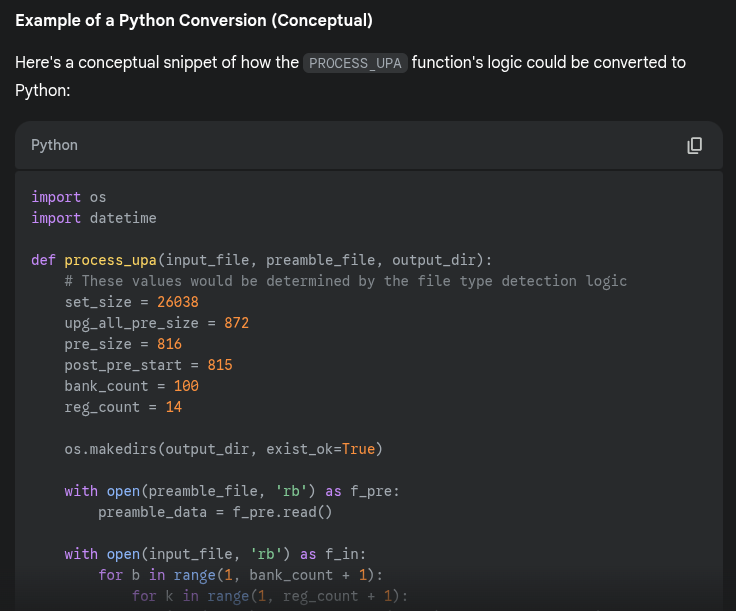
Ich würd das auch mal mit KI versuchen.
Klar, wenn du ein bischen Bash und Python kannst, kriegst du das selber
besser hin, aber selbst das allerkleinste, kostenlose,
nicht-Coding-Optimierte KI-Model kriegt da was hingefrickelt, auch wenn
man das File Stückchen/Funktionsweise reinfüttern und explizit
Anweisungen ("ersetze den 'sed' Aufruf durch nativen Code") geben muss.
Händisch weiteroptimieren kann man danach immer noch.
Christian P. schrieb: > Ich habe hier mal die Bash Routine vom Greg hochgeladen, genau so wie > die Das ist ja nur ein bisschen print und dd plus Stringverarbeitung. Das solltest Du schnell in Python konvertieren können.
Guten Morgen. Ob die Bash Routine nun in PYTHON oder einer anderen Sprache läuft ist im Prinzip egal, schön wäre es wenn man die Routine unter Windows laufen lassen könnte. Es gibt ein ganzes Reihe von Kollegen aus dem Bereich der Musik, die benutzen eben Windows und da wäre es sehr hilfreich wenn man es direkt davon als kleines Programm starten könnte. ich selbst bin eher der Elektroniker und HF-Techniker als der Programmierer Und habe dort doch Recht grosse Schwierigkeiten mich mühsam in Programmiersprachen durch zu beißen. wäre schön wenn dort jemand evlteinwenig Hilfe leisten könnte. danke Gruss Christian
In diesem Thread [1] von 2023 geht es um dasselbe Thema, dort finden
sich auch eine Beschreibungen und weitere Beispieldateien.
Wenn ich das richtig sehe, bestehen diese UPA und UPD-Dateien jeweils
aus einem Header-String ("ef bb bf 00 00 03 5e" für UPG_ALL.UPA, "ef bb
bf 00 00 03 33" für vom_8_UPG_ALL.UPA). Danach folgt ein XML-Teil,
vermutlich ist das ein Header zur Beschreibung der danach folgenden
binären Daten. Ich werd mal die vorhandenen Beschreibungen lesen, dann
sehen wir weiter. :-)
Grundsätzlich kann man das natürlich mit Python machen, allerdings
möchte ich aus verschiedenen Gründen lieber Go(lang) eine Chance geben.
:-)
[1] Beitrag "BASH -Code auf Linux Mint ausführen, brauche bitte Hilfe"
@ Ein T.
>möchte ich aus verschiedenen Gründen lieber Go(lang) eine Chance geben.
Die da wären?
Kannst Du das bitte etwas erläutern.
Danke
Es wäre vielleicht zielführender wenn man genau beschreibt was das Programm mit den Daten machen soll. Dann könnte man vielleicht ein Phyton Programm schreiben das das viel besser oder einfacher macht. Das gewünschte Vorgehen ist irgendwie als wenn man jetzt statt eines Hammers einen Schraubendreher nehmen will, damit aber versucht den Nagel einzuschlagen, statt eine Schraube zu benutzen.
Markus W. schrieb: > Die da wären? > > Kannst Du das bitte etwas erläutern. Gerne. Erstens lassen sich mit Golang leicht statisch gelinkte Executables erzeugen, also Programme, die keine (dynamisch gelinkten) Libraries benötigen. Wer also diese eine Datei für sein Betriebssystem hat, kann sie direkt ausführen. Zweitens lassen sich in Golang mit dem Package "embed" ganz besonders einfach Dateien und sogar Dateisysteme in das Executable einbetten. Das erscheint mir für die Byte- und XML-Header sinnvoll. Drittens macht es Golang sehr einfach, Programme für andere Betriebssysteme zu erzeugen, indem zwei Umgebungsvariablen für Betriebssystem und CPU-Architektur des Zielsystems gesetzt werden. Eine weitere Idee wäre viertens, Golangs "Build Tags" zu benutzen, um zwei verschiedene Versionen zu erzeugen: eines für die Kommandozeile und eines mit einem eingebauten Webserver für Leute, die sich mit Kommandozeilen nicht wohl fühlen -- oder die diese Software lieber auf ihrem NAS oder in einem Docker Container mit ihrem Webbrowser benutzen wollen. Mal schauen. :-)
Warum nicht einfach die für das Bash Skript erforderlichen Programme bzw. DLLs aus z.B. Cygwin nehmen? Das werden wohl so um die 20 Dateien sein, die vermutlich ohne Installation laufen und das Bash Skript ausführen könnten.
Udo S. schrieb: > Es wäre vielleicht zielführender wenn man genau beschreibt was das > Programm mit den Daten machen soll. Wenn ich das [1] bisher richtig verstanden habe, geht es darum, die Binärdaten von den Byte- und XML-Headern zu befreien. Außerdem geht es anscheinend darum, diese Binärdaten danach anhand definierter Offsets zu splitten. @TO: - Ist das korrekt? - Gibt es eine Möglichkeit, die erzeugten Dateien auf Korrektheit zu prüfen, ohne sie in ein Roland-Gerät zu laden und es damit womöglich zu beschädigen? [1] https://www.mikrocontroller.net/attachment/588400/Roland_FR4x_file_beschreibung_bitte_lesen.txt
@Ein T. Danke für Deine Erlaeuterung. >Erstens lassen sich mit Golang leicht statisch gelinkte Executables >erzeugen, also Programme, die keine (dynamisch gelinkten) Libraries >benötigen. Wer also diese eine Datei für sein Betriebssystem hat, kann >sie direkt ausführen. Das war mir bekannt uns sehe ich auch als Vorteil, einfach ein Binary weiter geben. So ist es z.B. mit dem Backup-Programm restic, welches ich schon seit Jahren so verwende. >Zweitens lassen sich in Golang mit dem Package "embed" ganz besonders >einfach Dateien und sogar Dateisysteme in das Executable einbetten. Das >erscheint mir für die Byte- und XML-Header sinnvoll. Wusste ich nicht, da ich in der Go-Materie nicht so drin bin. >Drittens macht es Golang sehr einfach, Programme für andere >Betriebssysteme zu erzeugen, indem zwei Umgebungsvariablen für >Betriebssystem und CPU-Architektur des Zielsystems gesetzt werden. War auch bekannt, aber noch nie in Anspruch genommen. >Eine weitere Idee wäre viertens, Golangs "Build Tags" zu benutzen, um >zwei verschiedene Versionen zu erzeugen: eines für die Kommandozeile und >eines mit einem eingebauten Webserver für Leute, die sich mit >Kommandozeilen nicht wohl fühlen -- oder die diese Software lieber auf >ihrem NAS oder in einem Docker Container mit ihrem Webbrowser benutzen >wollen. Mal schauen. :-) Hört sich auch interessant an. Gruß Markus
>Wenn ich das [1] bisher richtig verstanden habe, geht es darum, die >Binärdaten von den Byte- und XML-Headern zu befreien. Außerdem geht es >anscheinend darum, diese Binärdaten danach anhand definierter Offsets zu >splitten. So habe ich das auch verstanden. Splitten an den jeweiligen Stellen und Header voranstellen und mit entsprechendem Namen (Prefix + Bank-Idx+Reg-Idx) in bestimmten Verzeichnis ablegen. Markus
Wenn ich das hier [1] richtig sehe, gibt es insgesamt fünf Dateitypen mit jeweils spezifischen Byte-Headern (die ersten sieben Byte der Dateien): UPS: 0xef 0xbb 0xbf 0x0 0x0 0x3 0x28 UPB: 0xef 0xbb 0xbf 0x0 0x0 0x3 0x29 UPA: 0xef 0xbb 0xbf 0x0 0x0 0x3 0x5e SET: 0xef 0xbb 0xbf 0x0 0x0 0x3 0x28 ALL: 0xef 0xbb 0xbf 0x0 0x0 0x8 0x2f Nun bin ich ein wenig verwirrt hinsichtlich der Angabe, daß die Byte-Header von UPS- und SET-Dateien dieselben sein sollen. Kann mich jemand erhellen? Außerdem wäre es schön, für jeden der Dateitypen eine Beispieldatei und -- wo möglich -- eine kleine Beschreibung dazu zu haben. Lieber TO, kannst Du dabei vielleicht behilflich sein? Dankeschön! [1] https://www.mikrocontroller.net/attachment/588400/Roland_FR4x_file_beschreibung_bitte_lesen.txt
Guten Tag ich versuche dort noch einmal einzugreifen Also Fakt ist mein bekannter in den Vereinigten Staaten hat eine Routine in erstellt als sogenannten bash script Dieser bestritt kann auch unter Windows ausgeführt werden wenn dort ein Windows Subsystem Linux mit eingebunden wird. Diese best Datei führt folgendes aus es nimmt eine Datei mit der Endung UPA oder UPG die von einem Roland musikinstrument erstellt wird und zerlegt die in kleinere Blöcke und speichert sie dann in einem Verzeichnis wieder ab. Das ist eigentlich alles Es wäre allerdings schön wenn diese Skript Datei auch direkt unter Windows ausführbar wäre ohne dass dort irgendetwas anderes geladen werden muss das heißt also ein Programm das direkt von Windows ausgestattet werden kann ohne dass man erst Linux hinzufügen muss dazu sind die meisten Anwender die auch Musiker sind nicht in der Lage. Ich selber bin nicht der Programmierer sondern eher in dem Bereich nachrichtentechnik und Elektronik angesiedelt und kann dieses leider nicht machen. Meine Frage war ob jemand in der Lage ist diese beschdatei einfach in ein Windows ausführbares Programm umzusetzen oder zu kompilieren oder übersetzen wie immer auch. Ich füge dieser Message hier noch mal eine Datei bei die von meinem Roland Instrument stammt die lässt sich dann mit der skript-datei von dem Gregor zerlegen , dazu muss ich nachher aber erst einmal kurz an meinen PC gehen weil das von dem Smartphone aus hier per spracheingabe nicht möglich ist Wäre echt toll wenn da etwas positives mit eurer Hilfe bei rauskommt danke schön Gruß Christian
Hallo Markus Diese Skript Datei von meinem Kollegen aus den Staaten ist nur dazu da die Dateien vom Roland erfr acht mit der Endung UPA in einzelne Blöcke zu zerlegen und dann wieder abzuspeichern diese Blöcke sind dann einzeln in dem Instrument ladbar sonst kommst du an die Sachen nicht ran bei dem großen Instrument dem FR8 besteht eine User Programm all Datei aus 1400 Eintragungen wenn jemand die alle von Hand bearbeiten will sitzt der ewigs dabei dieses Skript Datei zerlegt die dann einfach in einzelne Blöcke so dass jeder sich das dann rauspicken kann und ich wollte eigentlich nur dass dieser bash script unter Windows ausführbar ist das war erstmal das Anliegen Gruß Christian
Das sind da in dem Script doch Linux Standardprogramme. echo, mkdir, read, sleep, printf, dd, for .. do Bei dd bin ich mir unsicher (gleich beim installieren im Setup kontrollieren) aber der Rest wird normal direkt über die Bash, hier Cygwin, zur Verfügung gestellt. Ob da nun Python oder etwas anderes installiert werden muss, sollte doch egal sein. Wird etwas geändert, müsstest du das in deinem Code nachpflegen. Windows Subsystem for Linux wurde schon genannt und ist eigentlich ein Overkill. Die Antwort gab es doch gleich ganz oben. Nemopuk schrieb: > Es gibt auch (mehr als eine) bash für Windows. Mir fallen spontan MinGw > und CygWin ein. Hier der Link: https://www.cygwin.com/install.html Cygwin startet eine Shell und kann auch auf die normalen Windows-Ordner zugreifen. Script und Daten in den Ordner kopieren. Sollte ein Programm fehlen. Setup starten und das Programm da noch zusätzlich installieren. Für andere dann dokumentieren. Mit "wget <Internetpfad>" kann man sich das Skript auch direkt herunterladen. Das umzuschreiben ist wahrscheinlich mehr Aufwand. Ich habe jetzt keine Zeit das selber zu testen. Der einzige Aufwand ist zu schauen wo der Standard-Cygwin-Ordner ist.
Christian P. schrieb: > Diese Skript Datei von meinem Kollegen aus den Staaten ist nur dazu da > die Dateien vom Roland erfr acht mit der Endung UPA in einzelne Blöcke > zu zerlegen und dann wieder abzuspeichern diese Blöcke sind dann einzeln > in dem Instrument ladbar sonst kommst du an die Sachen nicht ran bei dem > großen Instrument dem FR8 besteht eine User Programm all Datei aus 1400 > Eintragungen wenn jemand die alle von Hand bearbeiten will sitzt der > ewigs dabei dieses Skript Datei zerlegt die dann einfach in einzelne > Blöcke so dass jeder sich das dann rauspicken kann und ich wollte > eigentlich nur dass dieser bash script unter Windows ausführbar ist das > war erstmal das Anliegen Gruß Christian Okay, ich bin jetzt soweit, daß ich eine UPA-Datei lesen, den XML-Header sauber heraus pflücken und alles sauber in eine Datenstruktur parsen kann. Der nächste Schritt wird sein, die Blöcke aus dem Inhalt zu extrahieren. Dazu werde ich mir morgen zunächst einmal die Offsets anschauen. Schauen wir mal. Wenn Du, lieber TO, Dir bitte ein wenig mehr Mühe mit Deinen Beiträgen geben (Satzzeichen wie Punkte und Kommata existieren, und dürfen sie ohne Aufpreis benutzt werden ;-)) und womöglich sogar meine Fragen beantworten könntest, dann wäre sicherlich schon viel gewonnen. Bekommen wir das hin? Danke.
Ist das nicht genau derselbe Quark wie hier? Beitrag "Wer kann helfen und weiss wie die Compilierung geht"
Harald K. schrieb: > Ist das nicht genau derselbe Quark wie hier? > Beitrag "Wer kann helfen und weiss wie die Compilierung geht" Nein. Ähnlicher Kontext, aber andere Frage.
Christian P. schrieb: > Wäre schön, wenn hierauf einmal jemand antworten könnte Ich habe das Bash Skript in ein Windows Konsolen Programm kompiliert. Mit deinem UPG_ALL.UPA File als Eingabe erzeugt es UPG und UPB Files, die binär identisch sind. Schreib mal ob das so passt. Ich kann das nicht testen, ich habe kein Roland Akkordeon und auch keine Ahnung davon. Ich glaube aber das das Bash Skript noch Fehler hat. Wenn eine Bank von Programmen aus dem UPA File extrahiert wird (ein UPB Files), und im zweiten Schritt UPG Files aus dem UPB extrahiert werden, dann stimmen die UPG Files NICHT mit denen überein, die man erhält, wenn man in einem Schritt die UPG Files erzeugt. Ich habe das in meinem Programm geändert. Gruss Udo
:
Bearbeitet durch User
Ein T. schrieb: > Wenn Du, lieber TO, Dir bitte ein wenig mehr Mühe mit Deinen Beiträgen > geben (Satzzeichen wie Punkte und Kommata existieren, und dürfen sie > ohne Aufpreis benutzt werden ;-)) und womöglich sogar meine Fragen > beantworten könntest, dann wäre sicherlich schon viel gewonnen. Bekommen > wir das hin? Danke. Okay, der TO scheint sich nicht mehr zu melden, aber ich möchte das kleine Projektlein trotzdem noch nicht aufgeben. Deswegen habe ich jetzt Greg Vee und Steve Palm angeschrieben und um Informationen zu den Dateiformaten gebeten. Schauen wir mal, ob da vielleicht etwas zurück kommt.
Udo K. schrieb: > Ich habe das Bash Skript in ein Windows Konsolen Programm kompiliert. Wow, cool. Darf ich fragen, wie Du das gemacht hast?
Ein T. schrieb: > Deswegen habe ich jetzt Greg Vee und Steve Palm angeschrieben und um > Informationen zu den Dateiformaten gebeten. Da steht doch schon fast alles wichtige: https://github.com/hyphz/fr8x-editor/wiki/FR8x-set-file https://github.com/hyphz/fr8x-editor/wiki/FR8X-User-Program-File-(.UPG) Und das dekompilierte Java des Roland-Editors gibt ebenfalls Einblicke.
:
Bearbeitet durch User
Ein T. schrieb: > Udo K. schrieb: >> Ich habe das Bash Skript in ein Windows Konsolen Programm kompiliert. > > Wow, cool. Darf ich fragen, wie Du das gemacht hast? Mit meiner natürlichen Intelligenz und einem kleinen C Programm :-) Ich habe die XML Struktur ignoriert, und stupide Blöcke mit fixer Größe aus dem UPA File extrahiert, genauso wie es das Bash Skript macht. Das Eingangsfile wird erstmal in den Speicher gemappt, in das Ausgansgsfile wird als erstes der XML Header geschrieben, dann werden in einer Schleife die Blöcke aus dem Eingangsfile mit memcpy statt dd kopiert und an das Ausgabefile drangehängt. Am Anfang gibt es noch eine Überprüfung des Dateiformats. Bei den Kommandozeilenoptionen habe ich noch vorgesehen, dass man die Nummer der Bank oder des Programms angeben kann, damit man nicht immer alles extrahieren muss (bis zu 1400 Files). Wobei da auch noch was nicht stimmt, das FR-8X Beispielfile "vom_8_UPG_ALL.UPA" vom TE ist etwa zu klein, es gehen nur maximal 99 Blöcke, nicht 100.
:
Bearbeitet durch User
Hallo Udo schönen guten Tag. Ich habe deine Datei die du erstellt hast und die im Windows powerstrip Fenster ausgeführt wird die letzte Woche recht gut getestet das funktioniert einwandfrei tolle Arbeit danke schön hast du richtig toll gemacht. So gut sind meine Programmierkenntnisse dann nur doch nicht ich habe zwar mit Hilfe einer kleinen KI auch eine Konvertierung zurecht bekommen aber das war doch recht wackelig und holperig. Frage von mir wäre noch einmal ich suche immer noch in jeder User program Datei die extrahiert worden ist den eigentlichen dateinamen der wird so ungefähr bei 39B Hex abgelegt Soviel ich herauszubekommen habe ist der dateiname ungefähr 20 weit lang könnte auch ein wenig länger sein noch. Der Text der da drinne steht ist wohl 7 Bit ascii komprimiert. Der muss also erst entpackt werden wenn man den dateinamen lesen will das ist mir nicht gelungen da dort meine Programmierkenntnisse nicht ausreichen Ich habe in der vergangenen Woche den Greg Vilovic in den Staaten noch einmal angeschrieben das ist der Mann der die best Routine erstellt hat, Er hat mir aber mitgeteilt dass er dort nicht mehr weitermachen möchte weil er sich jetzt neuerdings mit dem Kork syprema, das brandaktuelle elektronische Akkordeon der Firma Korg auseinandersetzt. Dort dürfte also nichts mehr zu erwarten sein. Vielleicht hast ja du oder jemand anders hier im Forum noch eine Idee wie man die dateinamen aus den einzelnen zerlegten Blöcken in eine Datei ausliest. Wenn das möglich ist ist das richtig echt hilfreich Gruß Christian
Nemopuk schrieb: > Da bash Dateien typischerweise von Programmen abhängen, die sie > aufrufen, wird die Verfügbarkeit dieser Programme wohl eher der > Knackpunkt sein. Und deswegen lautet die Antwort erstmal Nein. Um ein Bash-Skript auf Windows umzumünzen braucht es andere Shell Builtins und die benutzten Coreutils (dd.exe, sed.exe usw.) ob diese dann von einem Batch Skript oder einem Python Skript aufgerufen werden ist dann auch egal. In diesem Fall verwendet:
1 | rm -> del |
2 | mkdir -> md |
3 | echo -> echo |
4 | for -> for |
5 | while -> goto |
6 | if -> if |
7 | read: bash builtin |
8 | printf: bash builtin |
9 | getopts: bash builtin |
10 | case: bash builtin |
11 | date: linux coreutils |
12 | sleep: linux coreutils |
13 | dd: linux coreutils |
14 | cat: linux coreutils |
15 | sed: linux coreutils |
16 | cut: linux coreutils |
Selbstverständlich alle mit eigener Syntax, dauert ewig und drei Tage den Ablauf des Skripts 1:1 abzubilden. Natürlich besteht immer die Möglichkeit die Funktionalität der Coreutils in Python nachzubilden, hat dann aber nichts mit der Portierung eines Bash-Skripts zu tun. besser: neu schreiben
:
Bearbeitet durch User
Christian P. schrieb: > Frage von mir wäre noch einmal ich suche immer noch in jeder User > program Datei die extrahiert worden ist den eigentlichen dateinamen der > wird so ungefähr bei 39B Hex abgelegt > Soviel ich herauszubekommen habe ist der dateiname ungefähr 20 weit lang > könnte auch ein wenig länger sein noch. > Der Text der da drinne steht ist wohl 7 Bit ascii komprimiert. An der Position 039B sehe ich im Hexeditor keinen String. Was genau meinst du mit 7 Bit Ascii komprimiert? Speicher doch mal ein File mit einem bekannten Dateinamen ab, und stelle es hier rein. Was möchtest du mit dem Dateinamen machen?
Ich finde bei den 1400 Dateien da auch bei Position 039B (923 dez.) keinen String mit 20 Bytes Länge. Irgendwas stimmt da noch nicht. Udo K. schrieb: > Was möchtest du mit dem Dateinamen machen? Ich nehme mal an, daß er die Registrierungen (Namen) archivieren will, damit er auch später was findet. Das sind ja bei 1400 Dateien bei dem FRX8 eine Menge. So kann er später mal einzelne Registrierungen (.upg) zusammenstellen und an sein Akkordeon schicken bzw. an andere Musiker weiter geben.
:
Bearbeitet durch User
Moin, Hallo Udo und auch Heinz. Jede Datei mit der Endung UPG, die aus der großen Datei UPA extrahiert wurde beinhaltet divers Einstellungen und verschiedene Parameter von dem Instrument. Also nochmal beim Roland Fr4x sind in der UPA Datei 98 Userprogramme drin und beim Roland Fr8x sind in der UPA 1400 Userprogramme drin. Dank dir Udo gibt es ja jetzt durch deine Hilfe ein kleines Programm das diese Zerlegung macht. Der Aufbau einer solchen Userprogrammdatei ist ungefähr wie folgt am Anfang steht ein wenig Binärcode, der angibt um welches Gerät und welche Datei es sich handelt. Dann kommt ein XML Block einer bestimmten Länge. Dann, so um 39B Hex fängt der Dateiname eines Userprogrammes an. Beim Roland FR8, der hat ein Farbdisplay, da wird der Dateiname auch angezeigt. Genau so beim Roland Editor, ein Programm vom PC, auch dort wird in diese, Datenblock der Dateiname angezeigt. Soviel ich herausbekommen habe , einerseits vom Greg in den Staaten als auch durch eigene Versuche, wir vom Instrument ab 39B der Dateiname der Registrierung vom Instrument abgespeichert.. Der Greg hat mir erzählt, dass Roland die Daten dort in ASCII komprimiert ablegt, um Speicherplatz zu sparen. Das sollen so um die 20 Byte sein, die dort für den Dateinamen reserviert sind. Der Rest der Datei ist dann wieder ein Hex Block mit Systemparametern und Einstellungen. Wenn die Zerleger-Routine läuft, dann werden als Dateinamen ja nur Nummern vergeben. Genau das ist das Problem, diese Nummern sagen zwar um welchen Datenblock es sich handelt, aber wenn ich auf dem Instrument als Beispiel, Kneipe, Capri, oder griechischer 2 auf dem Display in meinem Instrument sehe, dann wird das bei Zerlegen der UPA Datei als UPG1, UPG2 usw. abgelegt. Da hat der Heinz schon recht, wenn ich diese Abkürzungen in Nummernfolge auf dem PC habe, kann ich die nicht zuordnen, geschweige eine Liste mit den Dateinamen erstellen. Ich habe mal 4 Beispieldateien hier mit angefügt , damit ihr mal die richtigen Dateinamen seht. Danke für eure Hilfe und Unterstützung Gruß Christian
Hallo Herr Petersen,
du sprichst doch jetzt von den zerlegten .upg - Dateien ? Du hast ja mal
vorher einen Ordner mit 1400 Dateien hier gepostet. Dort finde ich aber
keine XML - Daten, zumindest nicht im Klartext, wie er in den .UPA
Dateien steht. Sind das wieder andere .upg Dateien von einem anderen
Programm ? Könnte ja jetzt sein, daß hier der Offset 39B Hex den
XML-Anteil mitrechnet. Da kann man dann lange suchen und nichts finden.
Also schaffe da mal Klarheit.
Was die 7Bit Ascii - Kodierung betrifft, habe ich das so verstanden :
Man hat ein kodiertes Zeichen, das binär so z.b. aussieht :
"1000001"
Nun ordnet man von rechts ausgehend, für jedes Bit eine Zahl zu :
2^0(1), 2^1(2), 2^2(4), 2^3(8), 2^4(16), 2^5(32), 2^6(64)
Das entspricht dann
64 + 0 + 0 + 0 + 0 + 0 + 1
Das ergibt dann 65.
Schaut man dann in der ASCII-Tabelle nach, entspricht das dann dem
großen A. Ascii - und ASNI Tabellen haben ja identische Positionen, was
Zahlen und Buchstaben betrifft.
In BASIC auch mit Chr$(65) zu erreichen. Das Gegenstück in BASIC ist
auch das ASC("Zeichen"), das ein 7Bit Zeichen in einen ANSI - Code
verwandelt.
Soweit mal meine Kenntnisse darüber.
:
Bearbeitet durch User
Diese Dateien sind ein Bitstream, in dem die ASCII Zeichen für den Namen aber nur 7 Bits belegen. Man muss halt an der passenden Stelle im Bitstream nach den 7-Bit ASCII Zeichen suchen. Beispiel Datei "kneipe_2.UPG" von weiter oben ab Offset 0x39B:
1 | 0000039B 65 CE 8B 26 ¦ 84 54 08 10 ¦ 20 40 81 02 ¦ 04 08 10 20 |
2 | 000003AB 40 82 01 80 ¦ AD 52 BA 04 ¦ 08 10 20 40 ¦ 81 02 00 00 |
3 | |
4 | 65 CE 8B 26 84 54 08 |
5 | |
6 | 01100101 11001110 10001011 00100110 10000100 01010100 00001000 |
7 | |
8 | 01 1001011 1001110 1000101 1001001 1010000 1000101 0100000 |
9 | |
10 | 01001011 01001110 01000101 01001001 01010000 01000101 00100000 |
11 | |
12 | 0x4B 0x4E 0x45 0x49 0x50 0x45 0x20 |
13 | K N E I P E <SPACE> |
Das passt so auch bei den anderen Beispieldateien, wie lang der Name
maximal sein kann muss man schauen (20 kommt aber wohl gut hin).
Nachtrag: wer es genauer wissen will schaut in die "acc_prmtbl.h" Datei
aus der Java .jar Datei des Roland Editor.
Bei ACC_SC_USER_PRG_NAME1 beginnt der Name, der ist Bestandteil der "Set
Common Parameters", die fangen direkt nach dem XML Header an ("Set
Common Parameters" ist der "SC" Eintrag im XML Header).
:
Bearbeitet durch User
Das wird dann wohl schwieriger als gedacht und die acc_prmtbl.h Datei hat wohl auch kaum jemand. Zusätzlich müßte man sich auch in JAVA auskennen. Ich kann ja nur byteweise (1 Byte = 8 Bit) einlesen. Also hat man ja 1 Bit zuviel eingelesen, was ja eigentlich schon zum nächsten 7Bit-Ascii gehört. Vielleicht könnte man auch die 20 gelesenen Bytes in eine lange Bit-Sequenz (z.b. in Basic mit BIN$) umwandlen, dann Stückchenweise (immer 7 Bit) wieder rausnehmen und wieder in einen Buchstaben oder Zahl umwandeln. Oder denke ich jetzt falsch ?
:
Bearbeitet durch User
Hallo Dieter,
Klasse, du hast das aufgezeigt, dass ich richtig lag mit meiner
Vermutung.
Wie machst du das, dass du die ASCII-Zeichen ab Speicherzelle 0x39B
wieder sichtbar machst. Hast du eine Idee, oder eine kleine Routine in
Windows PowerShell, damit ich den Dateinamen wieder sichtbar machen
kann.
Bist du so freundlich und versuchst mir zu erklären, wie du dort
hingekommen bist.
Ich bin nicht der große Programmierer, sondern muss mich mühselig
dadurch beißen.
Du hast dort etwas aufgezeigt, schön in Reihe und Glied,
---------------------------------------------------------------------
Beispiel Datei "kneipe_2.UPG" von weiter oben ab Offset 0x39B:
0000039B 65 CE 8B 26 ¦ 84 54 08 10 ¦ 20 40 81 02 ¦ 04 08 10 20
000003AB 40 82 01 80 ¦ AD 52 BA 04 ¦ 08 10 20 40 ¦ 81 02 00 00
65 CE 8B 26 84 54 08
01100101 11001110 10001011 00100110 10000100 01010100 00001000
01 1001011 1001110 1000101 1001001 1010000 1000101 0100000
01001011 01001110 01000101 01001001 01010000 01000101 00100000
0x4B 0x4E 0x45 0x49 0x50 0x45 0x20
K N E I P E <SPACE>
----------------------------------------------------------------------
Aber wie mache ich die wieder sichtbar. Ist das eine einfache
Bitmaskierung , oder wie geht das?.
Mir reichte schon ein Skript, um eine 'UPA oder auch UPG Datei zu
öffnen, den Titel der Datei zu lesen und in eine einfache Textdatei
zurückzuschreiben.
Am Ende deines Artikels ist eine Anmerkung auf den Roland Editor
----------------------------------------------------------------------
Nachtrag: wer es genauer wissen will schaut in die "acc_prmtbl.h" Datei
aus der Java .jar Datei des Roland Editor
----------------------------------------------------------------------
hast du die Info aus einer dekompilierten Editor Datei, oder wie komme
ich daran, um die Eintragung zu lesen ??
Danke für eure Hilfe
Gruß Christian
Sorry, aber ich habe nicht vor hier die Grundlagen zu erklären. Ich bin mir relativ sicher dass Udo K. (udok), der Autor des RolandFrxSettings EXE, das beschriebene umsetzen kann falls er Lust dazu hat es in sein Programm einzubauen. Das extrahieren der 7-Bit ASCII Zeichen ist mit ein paar Zeilen Code erledigt und dass eine Java .jar Datei nur ein ZIP Archiv ist stellt ebenfalls kein Geheimnis dar, genauso wenig wie das Dekompilieren von nicht obfuskierten Java Klassen.
:
Bearbeitet durch User
Kurzer Test damit man sieht was so als Name vorkommt: Im Anhang sind die Namen in den einzelnen UPG Dateien aus der Datei "UPG_ALL.UPA" von weiter oben.
Hallo Dieter, danke für deine Antwort.- Ich wollte auch keinen Grundlagenkurs von dir. So war das nicht gemeint. Mit welchem Programm oder welcher Routine hast du die Namen extrahiert. Vielleicht bist du ja so freundlich und stellt das evtl. zur Verfügung, das reicht doch schon. Danke für deine Mühe Gruß´Christian
Anbei ein Update. Die Ausgabe Files werden jetzt nach dem internen Namen benannt. Mit dem Fr-8x Beispiel funktioniert das aber nicht. Da stimmt der Offset 39B nicht oder die Bits werden anders verwurschtelt. Gruß Udo
Und noch ein Update. Die Dateien werden jetzt auch mit dem Fr-8x Beispiel vom_8_UPG_ALL.UPA nach dem internen Namen benannt. Im bash Skript sind die Konstanten für Fr-8x Header falsch. Das dürfte noch nie jemand getestet haben... Ich kann da auch nur im Blindflug UPG Dateien draus machen.
Die richtigen Angaben zu den Datenstrukturen holt man sich am besten direkt aus den UPA Dateien und nicht aus der Skript Datei. Der Aufbau einer UPA Datei ist relativ einfach:
1 | EF BB BF : Magic |
2 | 4 Bytes : Länge des XML Header (Big-Endian) |
3 | XML Header : XML mit weiteren Angaben zu den Daten |
4 | die einzelnen Sets : Anzahl und Größe entsprechend dem XML Header |
5 | "UPLIST" : Bedeutung unklar, für die Sets wohl nicht relevant |
Die einzelnen Sets fangen also ab Offset "7 + Länge des XML Header" an, die Anzahl und Größe ergibt sich aus dem XML Header. Zum XML Header, der ist eigentlich selbsterklärend, es wird der Aufbau der Daten beschrieben, die relevanten Teile:
1 | für den Fr: <SET size="26038" number="98" offset="0"> |
2 | |
3 | -> 98 Sets mit je 26038 Bytes |
4 | |
5 | für den Fr-8x: <SET size="25752" number="1400" offset="0"> |
6 | |
7 | -> 1400 Sets mit je 25752 Bytes |
Der Unterschied in der Setgröße zwischen Fr und Fr-8x ergibt sich aus dem fehlenden "SC2" Eintrag beim Fr-8x. Der Aufbau eines Sets wird ebenfalls im XML Header beschrieben, hier für den Fr:
1 | <SC size="128" number="1" offset="0"/> |
2 | <O_R size="86" number="26" offset="128"/> |
3 | <OB_R size="66" number="7" offset="2364"/> |
4 | <OBC_R size="72" number="8" offset="2826"/> |
5 | <OFB_R size="72" number="8" offset="3402"/> |
6 | <TR size="304" number="16" offset="3978"/> |
7 | <BR size="84" number="16" offset="8842"/> |
8 | <BCR size="96" number="16" offset="10186"/> |
9 | <ORR size="64" number="26" offset="11722"/> |
10 | <OBR size="42" number="7" offset="13386"/> |
11 | <OBCR size="124" number="8" offset="13680"/> |
12 | <OFBR size="118" number="8" offset="14672"/> |
13 | <ORCH1 size="210" number="28" offset="15616"/> |
14 | <ORCH2 size="152" number="28" offset="21496"/> |
15 | <SC2 size="286" number="1" offset="25752"/> |
Der Offset ergibt sich aus der Länge der davor liegenden Daten, der Aufbau des Sets ist aber wohl für das Zerlegen der UPA Dateien nicht relevant. Inwieweit der fehlende "SC2" Eintrag beim Fr-8x wichtig ist und eventuell beim Zerlegen neu erzeugt werden muss ist unklar. Und dann gibt es am Ende der UPA Dateien noch die "UPLIST", die steht auch im XML Header, hier wieder für den Fr:
1 | <UPLIST size="131072" number="1" offset="2551724"/> |
Der Offset ergibt sich aus den davor liegenden Sets. In der Beispiel Datei "UPG_ALL.UPA" steht dort nichts, in der Datei "vom_8_UPG_ALL.UPA" für den Fr-8x steht dort etwas, die Bedeutung ist unklar.
:
Bearbeitet durch User
Dieter S. schrieb: > Die richtigen Angaben zu den Datenstrukturen holt man sich am besten > direkt aus den UPA Dateien und nicht aus der Skript Datei. Danke für die Info. Ich habe mir die Header dann auch direkt aus den UPA Dateien geholt. Das Ergebnis müsste aber jemand mit einem Fr-8x testen. Ich habe keine Fr-8x UPG Dateien für einzelne Programme, da habe ich nur das UPA File. Für Fr-4x gibt es ja ein paar Beispiele.
Ich habe mal ein paar von den von Deinem Program erzeugen UPG Dateien mit dem Roland Editor geladen (dazu muss man etwas tricksen wenn man das Instrument nicht hat und den Development Mode auf "eingeschalten" patchen). Das hat funktioniert, auch mit Dateien von der Fr-8x UPA Datei. Ich denke dass aber die 4 Bytes "Länge des XML Header" in den Fr-8x UPG Dateien nicht stimmt, dem Roland Editor ist das aber scheinbar egal, er ignoriert diese 4 Bytes.
Hallo und guten Tag, ich stelle hier mal eine aktuelle UPG_ALL.UPA Datei vom Roland meinem Roland FR8 erzeugt zu Testzwecken ins Forum. Für den Dieter nochmal würdest du die gepatchte Version vom Editor evtl. mir via PM-zur Verfügung stellen, ich habe hier nämlich genau das Problem, das du da beschreibst. Wenn der Editor gestartet wird, dann verlangt er eben, dass der Roland FR8 angeschlossen wird, sonst kann der Anwender das Programm nicht weiter nutzen. Dazu muss eben jedes Mal die große Kiste zu PC geschleppt und via USB Kabel angeschlossen werden, obwohl ich eben nur meinetwegen einige Stellen in einer Registrierung ändern möchte. Wenns bei dir läuft, wäre das eine gute Hilfe. Danke. Dem Udo schreibe ich noch ein PM und versuche das zu klären mir der Ausgabe der Daten der Dateitexte, die du ja schon gestern sehr deutlich dargestellt hast. Gruß aus NF Christian
Hier die aktuelle Version der UserprogrammAll. Upa Datei von meinem Roland FR8x
Dieter S. schrieb: > für den Fr: <SET size="26038" number="98" offset="0"> > -> 98 Sets mit je 26038 Bytes > für den Fr-8x: <SET size="25752" number="1400" offset="0"> > -> 1400 Sets mit je 25752 Bytes Also, die .UPA vom FRX8 Dateien scheinen wohl unterschiedliche Größen bei den Registrierungen zu haben. Bei deiner hier : 26038 mit 1400 Registrierungen Ich habe aber von dir auch eine mit 25752 mit 1400 Registrierungen Also ist es besser, das erst im XML auszulesen, um keine falschen Einzeldateien beim Auslesen und Neuschreiben zu bekommen.
Hallo Dieter,würdest du mir den "Patch" zukommen lassen. Das wäre sehr freundlich. Gruß Christian
Heinz B. schrieb: > Also ist es besser, das erst im XML auszulesen, um keine falschen > Einzeldateien beim Auslesen und Neuschreiben zu bekommen. Ja, das ist viel besser, und nach der x-ten Iteration habe ich es jetzt so gemacht. Damit lassen sich die Sets aus den UPA, UPB, ST4 und FR4/FR8 Files ohne Spezialbehandlung extrahieren. Dank Dieter sind die Strukturen in den Roland Files auch viel klarer. Alle Testfiles - die erst nach und nach eingetrudelt sind - laufen zumindest durch. Wieder was gelernt: Wenn man schnelle Hacks macht, ohne Doku und ohne saubere Datenstrukturen und Planung, rächst sich das früher als man glaubt. Trotzdem ist das Kommandozeilen Programm noch recht kompakt, 17 kB exe im Vergleich zu 14 kB Shell Skript. Die Quellcode Zeilen sind von ca. 250 für die erste Version auf ca. 600 angestiegen. Das Shell Skript hat ca. 500 Zeilen. Das RolandFrxSettings.exe kann aber deutlich mehr und macht das 1500 mal schneller (0.3 Sekunden zu 8 Minuten für das UPG_ALL-Fr8x.UPA auf Cygwin). Das Programm legt die Dateien jetzt in einem Unterverzeichnis ab, und gibt optional auch eine Liste der internen UPG Namen als Excel Liste aus. Ein praktisches Feature: Wenn man im Windows Explorer UPA Dateien immer mit RolandFrxSettings.exe öffnet, dann braucht man nur auf das UPA File doppelt drauf klicken, und es wird ein Unterordner mit den einzelnen Programmen erzeugt. Ich hoffe das den Roland Akkordionisten damit geholfen ist 😅.
Udo K. schrieb: > > Das RolandFrxSettings.exe kann aber deutlich mehr und macht das 1500 mal > schneller (0.3 Sekunden zu 8 Minuten für das UPG_ALL-Fr8x.UPA auf > Cygwin). Das Hauptproblem für das langsame Skript dürfte der "bs=1" (Blocksize) Parameter für dd sein, eventuell hätte hier schon das Tauschen der "count" und "bs" Parameter eine Verbesserung gebracht. Der nächste Wunsch wird bestimmt sein dass man auch gleich einige Funktionen des Roland Editor mit Deinem Programm auf die Dateien anwenden kann ;-)
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.