Hallo,
ich denke, ich kann mein Pythonprogramm, für Keithley DMM6500 u.ä.
Messgeräte, auf die Menschheit loslassen. Ich habe mich bemüht es C++
ähnlich mit Klasse (Modul) aufzubauen, damit es leicht erweiterbar ist
bzw. für verwandte Messgeräte mit ähnlichen SCPI Syntax anpassbar
bleibt.
Das Modul 'KeithleyDMM6500SCPI.py' stellt die SCPI Klasse für Keithley
mit den nutzbaren Methoden dar .
Die '_FUNCTION_LIST' enthält derzeit Einträge die ich für mich aktuell
für wichtig halte um irgendwas messen zu können. Das wird sich je nach
Bedarf mit der Zeit erweitern. Die erste Spalte 'name' darin enthält den
Namen um an den eigentlich SCPI Syntax zu kommen ohne kryptische
Indexnummern verwenden zu müssen. Die 2. Spalte 'command' enthält den
eigentlichen SCPI Syntax laut Manual. Die Einträge kann man jederzeit
erweitern.
Derzeit am Ende des Moduls sind Methoden die diese Einträge in lesbarer
Form verwenden bzw. dem eigentlichen Programmaufruf außerhalb der Klasse
zur Verfügung stellen.
Die Methode '_getMode' übersetzt nur die Funktionsauswahl wie im Display
sichtbar was man messen möchte in einen Teil des SCPI Syntax, mit der
bei Notwendigkeit der Syntax zur Übertragung ans Messgerät
zusammengebaut wird.
Im Hauptprogramm 'SCPI Keithley DMM6500.py' beginnt es mit den üblichen
Zeilen. Ressourcen anlegen und Verbindung zum Messgerät herstellen.
2 Objekte anlegen in einer Struktur. Jeweils für den SCPI Syntax (obiges
Modul) Objekt-Member 'scpi' und einmal für die Verbindung zum Messgeräte
Objekt-Member 'line'. Beide sind über die Instanz 'keithley' definiert.
Hätte ich mehrere SCPI Messgeräte würden hiermit mehrere Instanzen der
Klasse Device angelegt werden.
Nach Start erfolgt zu Beginn ein Uhrenvergleich. Ist die Differenz
größer 1s wird das Messgerät frisch auf Systemzeit gesetzt. Theoretisch
müsste keine Batterie mehr gewechselt werden. Ich hatte festgestellt das
die interne RTC schon nach paar Wochen um sehr viele Sekunden falsch
geht.
Danach wird ein String zusammengebaut der aus dem aktuellen Datum und
Uhrzeit besteht um damit einen Dateinamen anzulegen der das Logfile ist.
Das heißt mit jedem Start des Programms wird, sofern eingestellt, ein
neues Logfile geschrieben mit aktuellen Zeitstempel im Dateinamen.
Danach folgen benötige Methoden die mittels SCPI Objekt Methoden
funktionieren.
Das eigentliche Programm beginnt mit:
- Logdatei anlegen
if SAVE_DATA:
Oder noch paar Systeminfos wenn gewünscht Zeilen darüber.
Danach folgen verschiedene Kombinationsbeispiele der Funktionen.
- 403 - Buffer im Messgerät löschen,
- 404 - Messungfunktion auf normale Widerstandsfunktion vorauswählen,
- 405 - Vorauswahl auch ans Messgerät übertragen und damit endgültig
einstellen
- 407 - da vorher nichts anderes eingestellt wurde, erfolgen mit
Sampling 30 Einzelmessungen nacheinander mit einer Pause von 0s.
- 408 - die erfolgten Messung werden aus dem Buffer gelesen und ins
Logfile geschrieben.
Erfolgt danach keine Löschung des Buffers, verbleiben diese im Buffer.
Es wird intern ein Index mitgeführt, damit immer nur die noch nicht
ausgelesenen Buffereinträge im Logfile landen und es damit keine
doppelte Auslesung gibt. Sieht man im Logfile wenn man das auslesen
zwischen den Messung macht oder erst am Ende von allen.
- 410 - der Average Mode 'Repeat' wird eingestellt mit Filterfaktor 20.
20 interne Messungen werden gemacht, um daraus einen gefilterten Wert
auszugeben bzw. in den Buffer zu schreiben.
- 411 - es werden 10 Average Messungen gemacht mit je 1s Pause
dazwischen
- 412 - Average Mode wird deaktiviert
- 413 - die bis dahin noch nicht gespeicherten Einträge werden aus dem
Buffer ins Logfile geschrieben
- 415 - Buffer wird noch nicht gelöscht
- 416 bis 418 - es werden wieder 3 normale Einzelmessungen gemacht
- 419 - die bis dahin noch nicht gespeicherten Einträge werden aus dem
Buffer ins Logfile geschrieben
- 422 - Änderung der Messfunktion auf 4 Draht Widerstandsmessung
- 423 - Übertragung der neuen Einstellung ans Messgerät
- 425 - Average Mode mit Filterfaktor 15 wird aktiviert
- 426 bis 428 - erneut 3 Einzelmessungen im Average Mode
- 429 - Average Mode wird abgeschalten
- 430 - die bis dahin noch nicht gespeicherten Einträge werden aus dem
Buffer ins Logfile geschrieben
Am Ende sauberen Endzustand herstellen. Vorsorglich Average Mode
ausschalten, falls man es vergisst und bei Bedarf Buffer löschen. Datei
vorsorglich nochmal schließen falls noch nicht automatisch geschehen.
Warten bis alle restlichen Kommandos verarbeitet sind, lokalen
kontinuierlichen Messmodus herstellen und Verbindung trennen.
Die Formatierungen für das Logfile war eine größere Baustelle, damit
Excel den Datenimport machen kann. Etwas Nachhilfe bleibt erhalten.
Bspw. erkennt Excel nicht das Datumsformat automatisch. Warum auch
immer. Beim Zeitstempel werden die Millisekunden abgeschnitten aber
bleiben zum Glück nur unsichtbar erhalten. Die ersten 10 Dummyeinträge
dienen dazu damit Excel die generelle Datenformatierung mit allen
Spalten erkennt. Die Dummyzeilen sind schnell gelöscht, wer mit Excel
die Messwerte weiter verarbeiten möchte. Im Logfile stehen auch weitere
Informationen drin. Damit kann man auch nachträglich herauslesen was wie
in welcher Reihenfolge gemessen wurde, auch wenn man den Buffer erst am
Ende nach allen Messungen ausliest.
Ob man die Funktionen changeFunction() und setFunction() zusammenführen
sollte, da bin ich mir bis heute unschlüssig.
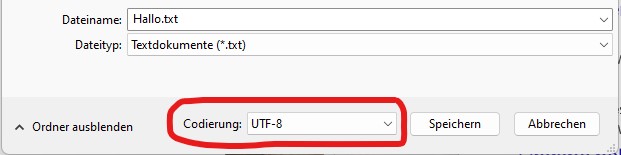
Was man im Excel während und nach dem Import machen?
Daten > Daten abrufen > Aus Datei > Aus Text/CSV importieren,
'65001:Unicode UTF-8' kontrollieren/auswählen,
Trennzeichen Tabstopp auswählen,
Daten transformieren auswählen (nicht sofort laden),
im sich öffnenden Power Query Editor die Datumsspalte auswählen,
Datentyp 'Datum' statt 'Ganze Zahl' auswählen und 'Aktuelle ersetzen'
anschließend 'schließen & laden'
zu guter Letzt Spalte vom Zeitstempel auswählen
und das Zellformat Benutzerdefiniert auf hh:mm:ss,000 ändern,
mehr als 3 Nachkommastellen funktioniert nicht,
die Messwertspalte je nach Bedarf einheitlich auf 2 oder 3 Kommastellen
Dürft ihr gern ausprobieren und Verbesserungen vorschlagen.
Danke.
Ich habe gerade keinen Zugang zum Keithley, werde es aber bei
Gelegenheit ausprobieren.
Ich bin nicht das grosse Programmiergenie und finde deine Skripte auf
den ersten Blick recht kompliziert.
Gefühlt macht der Initialisierungscode 75% aus, das verwirrt und sollte
in eine Bibliothek oder meinetwegen in eine Klasse in einem anderen File
rein.
Die uralten HP GPIB Programme mit dem eingebauten BASIC Interpreter sind
bei weitem leichter lesbar. Ok, damals war die Welt auch noch
einfacher.
Gruß, Udo
PS: Du hast noch Sonderzeichen 0x202f drinnen, die werden nicht richtig
angezeigt ohne passenden Font...
Hallo,
es stören die Funktionen oben im Hauptprogramm? Nimmt einem die
Übersicht? Die dort rauszunehmen wäre ein auslagern von Code. Kann man
machen, kann ich darüber nachdenken. Das wächst genauso mit wie die
_FUNCTION_LIST.
Wenn irgendwas zu kompliziert geschrieben ist, dann müsste ich wissen
wie es einfacher geht. Python ist für mich auch noch recht neu.
Wegen Sonderzeichen. Ich verwende zum programmieren VSC, hier werden
Sonderzeichen korrekt ausgegeben. Für das Logfile wird explizit
encoding="utf-8" angegeben. In der Logfile Textdatei sind alle
Sonderzeichen korrekt. Probiere es bitte aus und sage mir was wo schief
läuft. Ich sehe es aktuell nicht.
Danke.
Christian M. schrieb:> was nutzt ihr für Py für eine Umgebung?
Privat Emacs, was sonst? ;-)
Dienstlich inzwischen auch meist VScode, weil die Kollegen es nutzen und
so ein einheitlicher Workflow (insbesondere hinsichtlich des
integrierten Debuggers) entsteht.
Andere Kollegen mit Windows schwören auf Notepad++.
Veit D. schrieb:> [...] mein Pythonprogramm, [...]
Nunja, im Prinzip ist das ein C++-Programm, das in Python geschrieben
wurde. Anders gesagt wendest Du das, was Du aus Cpp kennst, auf Python
an. Dadurch verpaßt Du allerdings gerade das, was Python ausmacht: die
Lesbarkeit, die Eleganz, die Leichtigkeit, Verständlichkeit und
Wartbarkeit. ;-/
In Deiner Funktion _getMode() fällt mir auf, daß Du da einen Switch
benutzt, obwohl ein Dictionary adäquater und lesbarer wäre. Ähnliches
gilt auch für Deine _FUNCTION_MAP. Als Beispiel möchte ich Dir einmal
eine pythonischere Variante Deiner _getMode() zeigen:
1
from typing import Optional
2
3
class Kscpi:
4
modes: dict[str, list[Optional[str], str]] = {
5
"DCV": ["V", "VOLTage:DC"],
6
"DCI": ["A", "CURRent:DC"],
7
"ACV": ["V", "VOLTage:AC"],
8
"ACI": ["A", "CURRent:AC"],
9
"2W": ["Ω", "RESistance"],
10
"4W": ["Ω", "FRESistance"],
11
"Freq": [None, "FREQuency"],
12
"Period": [None, "PERiod"],
13
"Diode": ["V", "DIODe"],
14
"Temp": ["°C", "TEMPerature"],
15
"Cap": ["F", "CAPacitance"]
16
}
17
18
def get_mode(self, measure: str) -> str:
19
try:
20
self._unit, retval = self.modes[measure]
21
return retval
22
except KeyError as e:
23
self._unit = None
24
return "unknown"
Ja, man könnte natürlich zuerst abfragen, ob "measure" ein Schlüssel in
dem Dictionary "self.modes" ist, aber das würde unnötig Rechenzeit
kosten und es entspricht der Python-Philosophie eher, Dinge einfach
auszuprobieren und im Fehlerfall die Exception zu händeln. Ja, ich weiß,
für gestandene Cpp- und Java-Entwickler wirkt das auf den ersten Blick
oft nicht so schön... :-)
Ich finde es auch nicht so richtig schön, in einer Methode gleichzeitig
den internen Zustand eines Objekts zu verändern und da obendrein noch
einen Wert zurückzugeben. Solche Seiteneffekte können die Nutzer der
Methode verwirren. Python-Funtionen und Methoden können aber mehrere
Werte zurückgeben, und so würde ich das in meinen Programmen auch
machen.
Meine Implementierung hat neben der -- wie ich finde -- wesentlich
besseren Lesbarkeit im Übrigen noch einen weiteren Vorteil: es ist sehr
einfach, die Daten in self.modes in eine Konfigurationsdatei (YAML,
JSON, INI) zu legen, und die Klasse dadurch generischer zu machen.
Ähnliches gilt natürlich auch für die _FUNCTION_LIST, die ich von
vorneherein als Dictionary implementieren würde -- Du dagegen machst
erst eine Liste aus Dataclasses, und erzeugst im Konstruktor (Zeile 91)
dann ein Dictionary daraus. Äh, ja. :-)
Klassen, Funktionen und sogar Typen sind obendrein erstklassige Bürger
im Python-Universum. Man kann sie als Parameter benutzen, oder etwa auch
als Value in einem Dictionary, einer Liste, einem Tupel... you get the
idea. Deswegen ist sowas hier:
1
#!/usr/bin/env python
2
3
classEins:
4
deffoo(self):
5
return"Eins.foo()"
6
7
classZwei:
8
deffoo(self):
9
return"Zwei.foo()"
10
11
if__name__=='__main__':
12
bar={
13
"eins":Eins,
14
"zwei":Zwei
15
}
16
17
cls=bar['eins']
18
inst=cls()
19
print(inst.foo())
20
21
print(bar['zwei']().foo())
...absolut gültiger und funktionierender Python-Code -- auch wenn die
letzte Zeile natürlich nicht so schön zu lesen und deswegen eher etwas
für schnelle Hacks statt für langfristig zu wartende Programme ist. Aber
sie zeigt was so ein Python-Interpreter alles zuläßt und ausführt.
Weiterhin legst Du beinahe überall den Datentyp fest, auch wenn Du nur
eine globale Variable zuweist. Das ist sehr Cpp und in Python eher
ungewöhnlich. Zumal die Typen in Python gar nicht geprüft werden,
jedenfalls nicht wie in Cpp zur Kompilierzeit (Kunststück: die
Kompilation findet ja ohnehin erst zur Laufzeit statt). Beim Zugriff
achtet Python hingegen sehr wohl auf den Datentyp, weswegen 3 + '3'
natürlich, anders als etwa in PHP und Perl, eine Exception wirft. Aber
das passiert, wie gerade bereits erklärt, natürlich erst zur Laufzeit
(oder mit einem Typchecker wie mypy, aber das ist eine andere Geschichte
und soll ein andermal erzählt werden).
Außerdem arbeitest Du, ähnlich wie in Cpp, mit Zugriffsmodifikatoren...
oder, okay: den rudimentären Möglichkeiten, die Python Dir dazu bietet.
Das macht man in Python normalerweise nicht, zumal: einen echten Schutz
wie private und protected in Cpp bieten die Dir eh nicht. In Python
benutzt man sowas normalerweise nur, um einem anderen Entwicker zu
sagen: "Vorsicht, here be dragons, hier bitte nur herumfummeln wenn Du
wirklich verstanden hast, was Du da tun möchtest -- und warum".
Und dann sehe ich da noch so ein paar Dinge, wo Du offenbar noch nicht
sooo genau in die Standardbibliotheken von Python geschaut hast. Deine
Funktion setFunction() zum Beispiel öffnet bei jedem Aufruf eine Datei,
schreibt (in Abhängigkeit von der Variablen SAVE_DATA) die neu gesetzte
Funktion hinein, schließt die Datei wieder... in Deiner Anwendung spielt
es vermutlich keine Rolle, zumal Du direkt danach eine Sekunde schläfst,
aber für soche Zwecke enthält Pythons Standardlibrary das Modul
"logging".
Für Deine Variablen SAVE_DATA, OUTPUT_FORMAT und DEBUG würde ich
(unabhängig von den Schreibweisen in CAPS, schau bitte mal in PEP 8 [1]
und PEP 20) vorschlagen, den argparse.ArgumentParser zu benutzen:
Dadurch kannst Du die betreffenden Variablen nicht nur im Skript ändern,
sondern als Kommandozeilenparameter übergeben -- und bekommst obendrein
automagisch eine schicke Hilfe, wenn jemand das Programm mit "-h" oder
"--help" aufruft. Nice! :-)
Insofern sehe ich einerseits, daß Du aus der Welt der kompilierten,
typsicheren Sprachen kommst und versuchst, deren Konzepte auf Python zu
übertragen. Auf der anderen Seite sehe ich aber auch, daß Du ein
erfahrener Entwickler bist und nur entweder mehr Erfahrung oder ein paar
kleine Anstubser brauchst, um Deinen Code eleganter, pythonischer zu
machen.
[1] https://peps.python.org/pep-0008/
[2] https://peps.python.org/pep-0020/
Christian M. schrieb:> Frage eines Anwenders, der vor 20 Jahren das letzte mal im Quelltext> gewurschtelt hat, was nutzt ihr für Py für eine Umgebung?
Wie bei auch hier den GNU Emacs. Der ist allerdings, ähnlich wie der
vi(m), mit einer gewissen Eingangshürde verbunden... :-)
Hallo Udo,
ich fange erstmal mit Udo an, ist kürzer. :-)
Du sprichst vom Logfile? Ich habe auch Win11 und das Logfile kann ich
bspw. mit dem Texteditor und Notepad++ öffnen und alle Sonderzeichen
sind korrekt. Eine Bsp. Datei im Anhang. Du müsstest mir sagen was
geändert werden muss, damit es auch für dein vim funktioniert. Notepad++
funktioniert wie gesagt.
Veit D. schrieb:> Eine Bsp. Datei im Anhang. Du müsstest mir sagen was> geändert werden muss, damit es auch für dein vim funktioniert.
Ich hab's mir gerade im vim angesehen und nichts Fehlerhaftes
festgestellt bzw. gefunden. Wo soll das denn sein?
1
:se
2
--- Optionen ---
3
fileformat=dos
4
syntax=python
5
filetype=python
6
fileencoding=utf-8
7
fileencodings=ucs-bom,utf-8,default,latin1
Edit: Oh, im Logfile. Habe ich mangels Gerät nicht. Sollte aber per
default als utf-8 erstellt werden und dann keine Probleme verursachen.
Jörg W. schrieb:> Veit D. schrieb:>> Du sprichst vom Logfile?>> Ich denke, er meint das Omega.
Natürlich, ist ja ein Sonderzeichen. Nur womit ist unklar. Udo spricht
leider derzeit in Rätseln. Rätselraten vermutlich im Logfile? Oder
Terminalausgabe vom Programm? Win11 und Notepad++ kann ich nicht
bestätigen.
Veit D. schrieb:> Rätselraten vermutlich im Logfile?
Du hast es ja auch im Sourcecode stehen, und außerdem schrieb er ja nur,
dass man dafür einen entsprechenden Font da haben muss und der benutzte
Editor den auch verwenden muss.
Habe das Ding nicht auf Windows ausgepackt, nur auf FreeBSD, da gab's
natürlich keine Probleme mit der Darstellung.
Ein T. schrieb:> Veit D. schrieb:>> [...] mein Pythonprogramm, [...]>> Nunja, im Prinzip ist das ein C++-Programm, das in Python geschrieben> wurde. Anders gesagt wendest Du das, was Du aus Cpp kennst, auf Python> an. Dadurch verpaßt Du allerdings gerade das, was Python ausmacht: die> Lesbarkeit, die Eleganz, die Leichtigkeit, Verständlichkeit und> Wartbarkeit. ;-/> ...
Hallo Typ,
gut analysiert. Bin zwar kein Entwickler in dem Sinne, ich sage einmal
ambitionierter Hobby Mensch. ;-)
Und ja, ich habe das wie gesagt Cpp ähnlich aufgebaut. Datentypangabe
habe ich später sicherheitshalber hinzugefügt, weil ich Probleme mit dem
Datentyp bekam, wobei man unter Python einer Variablen alles und jeden
zuweisen können sollte. So ist wenigstens klar, dass meistens ein String
zurückkommt. Manchmal bin ich zum casten gezwungen und beim
zusammensetzen von Strings komischerweise in Teilstrings um mittendrin
auftretende Zeilenumbrüche entfernen zu können. Oft wird ein
Zeilenumbruch zu viel erzeugt, was nirgends steht. Dann hat man
plötzlich mittendrin eine Leerzeile, statt nur eine neue Zeile. Das am
Rande warum manche Funktionen so lang geworden sind als Entschuldigung.
;-)
Von Cpp bin ich Typsicherheit gewohnt. Damit tue ich mich ehrlich gesagt
unter Python noch schwer das es sowas nicht gibt. Deswegen auch der
Versuch Datentypen anzugeben. Ob das Sinn macht weiß ich noch nicht.
Beim Lesen der Funktion sollte jedoch jedem sofort ersichtlich sein, was
Eingabe und Ausgabe erwarten. Das war/ist die Motivation dahinter. :-)
Ich will damit nicht über Python meckern. Man muss sich daran gewöhnen.
Ansonsten ist deine Antwort das was ich an Kritik erwartet habe und mich
ran setzen kann. Vielen Dank.
Jörg W. schrieb:> Du hast es ja auch im Sourcecode stehen, und außerdem schrieb er ja nur,> dass man dafür einen entsprechenden Font da haben muss und der benutzte> Editor den auch verwenden muss.
Ich glaube Windows 3.1 oder 3.11 (aber ohne fW) konnte so etwas noch
nicht.
Aber ein halbwegs modernes System? Oder muss man für Deutsche Umlaute
auch ein spezielles Servicepack installieren?
Demnächst erklärt noch jemand, dass Windows kein großen ẞ kann.
Verlässt gram-gebeugten Hauptes die Bühne nach links. Kopfschüttelnd.
Veit D. schrieb:> gut analysiert. Bin zwar kein Entwickler in dem Sinne, ich sage einmal> ambitionierter Hobby Mensch. ;-)
Alles gut, ich bin auch aus dem C- und Cpp-Umfeld gekommen, als ich mit
meiner ersten Skriptsprache Perl angefangen habe. :-)
> Und ja, ich habe das wie gesagt Cpp ähnlich aufgebaut. Datentypangabe> habe ich später sicherheitshalber hinzugefügt, weil ich Probleme mit dem> Datentyp bekam, wobei man unter Python einer Variablen alles und jeden> zuweisen können sollte.> [...]> Von Cpp bin ich Typsicherheit gewohnt. Damit tue ich mich ehrlich gesagt> unter Python noch schwer das es sowas nicht gibt. Deswegen auch der> Versuch Datentypen anzugeben. Ob das Sinn macht weiß ich noch nicht.> [...]> Beim Lesen der Funktion sollte jedoch jedem sofort ersichtlich sein, was> Eingabe und Ausgabe erwarten. Das war/ist die Motivation dahinter. :-)
Genau DAS ist einer der Gründe, weswegen ich das bei größeren Projekten
auch mache. Einerseits dokumentiert das gleich die Parameter, so daß ich
das nicht mehr in extra pydoc-Kommentare schreiben muß. Aber es eröffnet
noch viel mehr Möglichkeiten, nämlich einerseits die Prüfung meines Code
mit dem statischen Typchecker Mypy [1,2], und andererseits kann ich
meinen Code bei Bedarf viel effizienter in ein Binary Executable
verwandeln. Da gibt es ein paar schicke Compiler, die für Type
Annotations sehr dankbar sind. :-)
Insofern: ja, Type Annotations haben mehrere Vorteile und für Code, den
man selbst länger nutzen und pflegen, oder anderen zur Verfügung stellen
möchte, sollte man sie deshalb auch benutzen. Andererseits machen sie
den Code nicht unbedingt lesbarer, bieten keinerlei echten Schutz und
kosten beim Schreiben natürlich ein bisschen Zeit.
Nebenbei bemerkt, ist Python -- im Gegensatz zu Perl und PHP --
tatsächlich typsicher. Anders als die meisten kompilierten Sprachen
bindet es Datentypen jedoch nicht an die Variable, sondern an ihren
Wert. Darum wirft Python eine Exception (TypeError), wenn Du 3 + '3'
auszuführen versuchst; Perl und PHP hingegen casten den String einfach
automatisch in eine Zahl und geben 6 aus.
[1] https://mypy-lang.org/
[2] https://mypy.readthedocs.io/en/stable/> Ich will damit nicht über Python meckern. Man muss sich daran gewöhnen.
Keine Sorge, wenn Du das öfter benutzt, wirst sicherlich auch Du an den
Punkt kommen, der Python den Beinamen "ausführbarer Pseudocode"
eingebracht hat.
> Manchmal bin ich zum casten gezwungen und beim> zusammensetzen von Strings komischerweise in Teilstrings um mittendrin> auftretende Zeilenumbrüche entfernen zu können.
Um Zeilenumbrüche und anderen Whitespace aus einem Text zu entfernen,
gibt es viele Möglichkeiten, von str.replace('\n', '') über
str.[lr]strip()... Und dann gibt es in Python die Builtin-Funktion
map(), die eine Funktion auf alle Elemente eines Iterable (Liste, Tupel,
Set, ...) anwendet und ein map-Objekt zurückgibt, also einen Generator
(think Cpp Streams). Und am Ende, wenn einem da wirklich gar nichts mehr
einfällt, hat Python natürlich ein Standardmodul namens regex für, was
für eine Überraschung: regular Expressions. :-)
> Ansonsten ist deine Antwort das was ich an Kritik erwartet habe und mich> ran setzen kann. Vielen Dank.
Sehr gerne... wenn Du magst, könntest Du ein öffentliches oder privates
Git-Repository zum Beispiel bei Codeberg.org (aus Berlin) anlegen oder
mich das machen lassen, und dann arbeiten wir gemeinsam daran.
Hallo,
also ich möchte jetzt nicht auf Udo und Sonderzeichen rumreiten, weil
Udo wie ich so mitbekomme ein netter Mensch ist. Nur sind mir seine
Aussagen zu schwammig zu unklar formuliert. Ich kann damit nichts
anfangen. Entweder gibt es ein Problem oder es gibt kein Problem. Damit
nichts durcheinanderkommt, pflege ich die genaue Abfolge einzuhalten was
wann geschrieben wurde.
> PS: Du hast noch Sonderzeichen 0x202f drinnen, die werden nicht richtig> angezeigt ohne passenden Font...
Kann man als Hinweis verstehen, habe ich so verstanden, dass bei Udo
Sonderzeichen nicht korrekt dargestellt werden.
> Die Probleme mit dem Sonderzeichen habe ich mit vim und notebook++ unter> Windows 11.
Hat sich damit bestätigt. Udo sieht keine Sonderzeichen. Genau das kann
eigentlich nicht sein. Ich gebe im Programm extra das UTF-8 Format an
für anlegen und speichern des Logfiles. Eben weil ich ohne diese Angabe
auch Probleme mit dem Sonderzeichen hatte. Da UTF-8 Format standardmäßig
vorhanden ist, lautet die Frage, warum kann Udos Rechner das nicht?
Speichere einmal bei dir zum Test mein Logfile mit "speichern unter"
nochmal ab und achte auf die Codierung unten rechts im Fenster. Das
sollte so schon eingestellt sein für diese Datei. Wenn nicht ändere es
ab und öffne erneut.
Veit D. schrieb:> Danke für die Links. Das ist irgendwie unfair. Da hat schon jemand meine> Arbeit gemacht. :-)
Ja sorry, ist wirklich unfair :-) Aber schaue es dir erst mal an.
Das Problemchen mit dem Sonderzeichen ist im Python File in Zeile 376
das 'NARROW NO-BREAK SPACE' statt dem Leerzeichen in "1 ms".
Wenn ein Windows Font ein Unicode Zeichen nicht enthält wird Font
Substitution verwendet. Die meisten Open Source Programme schalten Font
Substitution nicht ein, schon gar nicht wenn sie aus der Linux Ecke
kommen. Wenn vim oder Notepad++ einen (Konsolen) Font verwendet, der so
ein Zeichen nicht beinhaltet sieht man dann ein Rechteck. Das sticht
ins Auge, sonst passiert da nichts schlimmes. Das kannst du ignorieren.
Hallo Udo,
ich erahne langsam was du meinst. Es geht nicht um falsch dargestellte
Zeichen während der Ausgabe meiner gewollten Daten. Es geht rein um die
Darstellung des reinen Programmcodes. War für mich leider zu undeutlich
was du dir anschaust. ;-) Nun denn. Will mal nicht so streng sein.
Also wenn ich die Datei SCPI Keithley DMM6500 v0.1.0.py im Notepad++
öffne, dann sieht die Kommentarzeile 376 auch bei mir komisch aus was in
der Klammer steht. Geschrieben ist der Code in VSC. Ich habe folgendes
probiert.
Original steht in VSC geöffnet das drin in Zeile 376.
1
# Kurze Pause zur Stabilisierung (z. B. 1 ms)
In VSC geändert in
1
# Kurze Pause zur Stabilisierung (zum Bsp. 100 ms)
wird in Notepad++ wie folgt dargestellt.
1
# Kurze Pause zur Stabilisierung (zum Bsp. 100NNBSPms)
Also eine Korrektur hat so keine Wirkung auf fehlerhafte Zeichen.
In VSC Zeile gelöscht, gespeichert, beendet.
In VSC neu geöffnet und Zeile neu getippt, gespeichert, beendet.
In Notepad++ geöffnet. Alles korrekt.
Wer weiß was da beim tippen der Zeile bzw. speichern schief ging. Oder
es kam ungewollt ein unsichtbares Zeichen rein. Keine Ahnung. Scheint ja
eine Ausnahme zu sein. Noch mehr solchen Mist sehe ich im Notepad++
nicht wenn ich scrolle. Bei einem systematischen Fehler müssten noch
mehr Zeilen betroffen sein. Ist die Lösung damit zufriedenstellend?
Geändertes .zip hängt dran.
Veit D. schrieb:> Ist die Lösung damit zufriedenstellend?
War meiner Meinung nach auch vorher nicht falsch.
Ich bin nach wie vor verblüfft, dass Windows anscheinend noch nicht
einmal rudimentäre Fonts per Default mitliefert.
Ich habe gerade mal auf meinem System alle Fonts gelistet, welche ein
NNBSP (u202f) beinhalten.
Bin auf achtzig (80) Fonts/Varianten gekommen. Viele (die meisten) davon
gehören zur absoluten Basisausstattung
(DejaVu,Free,Lato,Liberation,Noto).
Da lohnt es sich wohl zwecks Datenaustausch mit Windows-Nutzern den
geschriebenen Text besser auf 7-Bit ASCII zu limitieren. Oder
Keilschrift.
Hallo Typ,
da tun sich Möglichkeiten auf. ;-) Mit Typsicherheit meinte ich folgende
ungewohnte Möglichkeit der wilden Zuweisungen.
1
var = "String"
2
print(var)
3
var = 1234
4
print(var)
5
6
oder
7
8
var:str = "String"
9
print(var)
10
var = 1234
11
print(var)
In allen Fällen erscheint:
1
String
2
1234
Nur wenn man String mit 1234 addieren möchte muss man casten. :-) :-)
Auch wenn die Links zu fertigen Bibliotheken und Programmen verlockend
sind, man hat ja dennoch eigene Vorstellungen in der Art der Verwendung.
Mein Endziel irgendwann soll sein, das ich das Messgerät Keithley
DMM6500 und Netzteil TTi QL355TP mittels SCPI steuern kann um bspw. eine
Diodenkennlinie automatisiert erstellen zu können. Also die Daten
aufnehme und meinetwegen in Excel daraus ein Diagramm erstelle. Dafür
ist noch eine Menge zu tun.
Um Zeilenumbrüche zu entfernen nutze ich bisher end="" oder .strip(). Es
wäre nur gut zu wissen warum da überhaupt Zeilenumbrüche drin sind. Wo
kommen die plötzlich her? Ich musste manche zusammengesetzte Strings
wieder zerlegen, um zu wissen an welcher Stelle ein .strip() notwendig
ist.
Codeberg.org ist ein Git-Repository Kopie aber ohne Microsoft Kontrolle?
Habe mich mit Git… noch nie so richtig befasst, ist mir bis jetzt alles
zu kompliziert in der Bedienung. Außer das ich auf Github einen Account
habe für Downloads etc. Aber ich wäre bereit es auszuprobieren und ein
Projekt anzulegen. Ich überlege mir das einmal. Danke schon einmal für
das Angebot. Es wäre schon gut jetzt ein Stopp einzulegen um den Code
aufzuräumen. Bevor dieser Python untypisch verwurstet. Ich kann ja schon
alles was nichts mit dem Messgerät zu hat rauswerfen.
Norbert schrieb:> Veit D. schrieb:>> Ist die Lösung damit zufriedenstellend?>> War meiner Meinung nach auch vorher nicht falsch.> Ich bin nach wie vor verblüfft, dass Windows anscheinend noch nicht> einmal rudimentäre Fonts per Default mitliefert.
Hallo Nobert,
das scheint kein Font Problem gewesen zu sein. Ich habe am Font nichts
geändert. Ich habe praktisch das scheinbar "komische" Leerzeichen vor ms
entfernt und alles neu getippt. Das scheint kein reines Leerzeichen wie
in anderen Hunderten Zeilen gewesen zu sein. Warum auch immer. Mit 7-Bit
ASCII hat man kein Omega o.ä. zur Verfügung.
Ja, aber das
> das scheinbar "komische" Leerzeichen
ist tatsächlich ein völlig normales und gültiges Zeichen (narrow non
breaking space) wie man es in der Textverarbeitung sehr oft findet.
Und es sollte im UTF-8 Umfeld keinesfalls ein Problem verursachen.
> Mit 7-Bit ASCII hat man kein Omega o.ä. zur Verfügung.
Das war natürlich eine leichte Überzeichnung um das Problem zu
verdeutlichen.
Norbert schrieb:>> das scheinbar "komische" Leerzeichen>> ist tatsächlich ein völlig normales und gültiges Zeichen (narrow non> breaking space) wie man es in der Textverarbeitung sehr oft findet.> Und es sollte im UTF-8 Umfeld keinesfalls ein Problem verursachen.
Andererseits gibt es eben jenseits der Textverarbeitung keinen richtigen
Grund, sowas in einem Programmtext zu verwenden.
Norbert schrieb:> Ich bin nach wie vor verblüfft, dass Windows anscheinend noch nicht> einmal rudimentäre Fonts per Default mitliefert.
Gerade Windows hat sich mit UTF-8 lange Zeit sehr schwer getan. Die
haben sehr früh mit UTF-16 angefangen, aber dann sehr lange daran
geklebt, obwohl es erstens für viele Texte Platz verschwendet,
andererseits aber eben trotzdem einen Teil der Sprachen der Welt nicht
abdeckt.
Scheint sich inzwischen aber so allmählich zu erledigen.
Jörg W. schrieb:> Andererseits gibt es eben jenseits der Textverarbeitung keinen richtigen> Grund, sowas in einem Programmtext zu verwenden.
Aber selbstverständlich. Gerade Python ist prädestiniert, den UTF8
Zeichensatz innerhalb von Strings zu nutzen. Teilweise sogar außerhalb,
aber das funktioniert dann wohl nur auf *X Systemen anstandslos.
Jörg W. schrieb:> Gerade Windows hat sich mit UTF-8 lange Zeit sehr schwer getan. Die> haben sehr früh mit UTF-16 angefangen,
Wobei die ersten ~ 65000 Zeichen aber doch gleich sind (Nicht in der
Kodierung, aber der erste Level ist komplett abgedeckt).
Und dazu gehört zB. auch ein NNBSP.
Norbert schrieb:> Ein bisschen präziser sollte man es schon versuchen:>
1
#!python
2
>var="1234"
3
>print(var,type(var))
4
>var1=1234
5
>print(var1,type(var1))
6
>var2=1234.0
7
>print(var2,type(var2))
8
>var3=var1==var2
9
>print(var3,type(var3))
10
>var4=var==var2
11
>print(var4,type(var4))
>
1
> 1234 <class 'str'>
2
> 1234 <class 'int'>
3
> 1234.0 <class 'float'>
4
> True <class 'bool'>
5
> False <class 'bool'>
6
>
Hallo,
ähmm. Das ändert alles nichts an den Möglichkeiten der bunten Mischung
an Zuweisungen, egal welchen Datentyp eine Variable hat(te). Der
Wildwuchs macht eben Python aus. Mit der nicht vorhandenen
Datentypsicherheit muss man umgehen lernen, wenn man anderes gewohnt
ist.
Norbert schrieb:>> Andererseits gibt es eben jenseits der Textverarbeitung keinen richtigen>> Grund, sowas in einem Programmtext zu verwenden.>> Aber selbstverständlich. Gerade Python ist prädestiniert, den UTF8> Zeichensatz innerhalb von Strings zu nutzen.
Es ging mir ganz speziell um den "narrow non breaking space", nicht um
UTF8 allgemein. Konkret: das "Ω" stelle ich gar nicht in Frage.
Non breaking space an sich ist schon eher was für eine Textverarbeitung,
in einem technischen Dokument (wie einem Logfile) sehe ich dafür keinen
Sinn. Der "normale" NBSP wäre ja aber noch im einfachen
8-Bit-Zeichensatz drin, wofür aber braucht man hier davon auch noch die
"narrow"-Variante?
Veit D. schrieb:> Das ändert alles nichts an den Möglichkeiten der bunten Mischung> an Zuweisungen, egal welchen Datentyp eine Variable hat(te). Der> Wildwuchs macht eben Python aus.
Ich würde es nicht als Wildwuchs bezeichnen, eher als kompletten
Kontrollverlust des Programmierers. ;-)
Veit D. schrieb:> Mit der nicht vorhandenen> Datentypsicherheit muss man umgehen lernen, wenn man anderes gewohnt> ist.
Das stimmt. Obschon auch Python Typüberprüfungen durchführen kann,
sollte es denn erforderlich erscheinen.
Hallo,
wir/ihr müssen uns jetzt nicht wegen dem NBSP oder NNBSP streiten. Das
stand auch nicht im Logfile, sondern in der .py Programmdatei in einer
Kommentarzeile. Das ist Udo "nur" beim anschauen des Programmcodes
aufgefallen. Das hätte keine Auswirkung auf das Programm gehabt. Wie
gesagt, wie das dort hinkam weiß ich nicht. Es ist korrigiert und gut
ist.
Veit D. schrieb:> da tun sich Möglichkeiten auf. ;-) Mit Typsicherheit meinte ich folgende> ungewohnte Möglichkeit der wilden Zuweisungen.>
1
> var = "String"
2
> print(var)
3
> var = 1234
4
> print(var)
5
>
6
> oder
7
>
8
> var:str = "String"
9
> print(var)
10
> var = 1234
11
> print(var)
12
>
>> In allen Fällen erscheint:>
1
> String
2
> 1234
>> Nur wenn man String mit 1234 addieren möchte muss man casten. :-) :-)
True, aber solche Casts sind häufig ein Hinweis auf ein verkorkstes
Design. Und
1
var = "String"
2
print(var + str(1234))
gibt "String1234" aus -- das "+" ist nämlich für Zahlen der Additions-
und für Strings der Konkatenationsoperator. Es gibt jedoch eine
(selbstverständlich dokumentierte) Ausnahme:
1
print(5 * '-')
gibt "-----" aus. Das kann zum Beispiel dann nützlich sein, wenn man
schicke Tabellen ausgeben möchte, wobei es auch dafür viel bessere
Fremdbibliotheken gibt.
Nebenbei bemerkt: mit den Builtin-Funktionen type() findest Du den Typ
des aktuellen Werts einer Variablen heraus und mit isinstance() kannst
Du prüfen, ob der aktuelle Wert einer Variablen einem (oder mehreren)
erwarteten Typen entspricht. Aber bitte tu' Dir und mir einen Gefallen:
ja, ich weiß, Du bist an Typsicherheit gewöhnt und darauf zu verzichten,
fühlt sich am Anfang echt merkwürdig an -- aber bitte fang' jetzt nicht
an und spicke alles in Deinen Programmen mit type()- und
isinstance()-Aufrufen. In meinen > 15 Jahren mit Python habe ich type()
bisher nur zu informativen Zwecken und isinstance() allenfalls drei oder
vier Mal benutzt.
Nebenbei bemerkt: das Modul "builtins" enthält eine Reihe von sehr
nützlichen Funktionen und Klassen, da sollte man mal hineingeschaut
haben. :-)
Was Type Hints angeht, gibt es einen lesenswerten Artikel bei
RealPython: [1]. Die Seite ist ohnehin (neben der offiziellen
Python-Website [2]) eine der mit Abstand besten Python-Seiten, die ich
kenne.
[1] https://realpython.com/python-type-checking/
[2] https://www.python.org/> Auch wenn die Links zu fertigen Bibliotheken und Programmen verlockend> sind, man hat ja dennoch eigene Vorstellungen in der Art der Verwendung.> Mein Endziel irgendwann soll sein, das ich das Messgerät Keithley> DMM6500 und Netzteil TTi QL355TP mittels SCPI steuern kann um bspw. eine> Diodenkennlinie automatisiert erstellen zu können. Also die Daten> aufnehme und meinetwegen in Excel daraus ein Diagramm erstelle. Dafür> ist noch eine Menge zu tun.
Ja, äh... also... Mit dem (externen) Modul "pandas" gibt es sehr
mächtige Werkzeuge zur Verarbeitung und Visualisierung von Daten, und
wer das einmal zusammen mit dem interaktiven Jupyter benutzt hat, der
möchte danach keine Tabellenkalkulationen mehr haben. :-)
> Um Zeilenumbrüche zu entfernen nutze ich bisher end="" oder .strip(). Es> wäre nur gut zu wissen warum da überhaupt Zeilenumbrüche drin sind. Wo> kommen die plötzlich her? Ich musste manche zusammengesetzte Strings> wieder zerlegen, um zu wissen an welcher Stelle ein .strip() notwendig> ist.
Die Builtin-Funktion print() hängt automatisch einen Zeilenumbruch an,
wenn "end=''" nicht übergeben wird.
Tipp: logging-Modul benutzen. Das ist sehr alt, was man an
Funktionsnamen wie basicConfig() sehen kann (PEP 8, der Styleguide für
Python, empfiehlt nämlich für Funktions- und Methodennamen snake case,
also würde die Funktion heute basic_config heißen).
1
# Importe
2
import sys
3
import logging
4
5
# Modul "logging" konfigurieren (da geht noch viel mehr!)
loggt auf sys.stdout (std::cout, STDOUT), wenn "stream=..." durch
"filename=" mit einem Dateinamen ersetzt wird, loggt es in die
betreffende Datei.
> Codeberg.org ist ein Git-Repository Kopie aber ohne Microsoft Kontrolle?
Ganz genau, der Verein ist in Berlin beheimatet und unterliegt deswegen
den europäischen und deutschen Vorschriften zum Datenschutz. Die
Oberfläche ist Forgejo und Gitlab sehr ähnlich.
> Habe mich mit Git… noch nie so richtig befasst, ist mir bis jetzt alles> zu kompliziert in der Bedienung.
Git möchte ich Dir wärmstens ans Herz legen, das benutze ich ausnahmslos
immer. Ja, es gibt eine Einstiegshürde, aber der Nutzen überwiegt die
Kosten sehr, sehr, sehr, sehr (you get the idea) schnell.
> Danke schon einmal für> das Angebot. Es wäre schon gut jetzt ein Stopp einzulegen um den Code> aufzuräumen. Bevor dieser Python untypisch verwurstet. Ich kann ja schon> alles was nichts mit dem Messgerät zu hat rauswerfen.
Ja, das wäre wohl ein guter Anfang. :-)
Hallo,
sehr viele Infos, schaue ich mir alle nacheinander an. Danke.
>> Um Zeilenumbrüche zu entfernen nutze ich bisher end="" oder .strip(). Es>> wäre nur gut zu wissen warum da überhaupt Zeilenumbrüche drin sind. Wo>> kommen die plötzlich her? Ich musste manche zusammengesetzte Strings>> wieder zerlegen, um zu wissen an welcher Stelle ein .strip() notwendig>> ist.>> Die Builtin-Funktion print() hängt automatisch einen Zeilenumbruch an,> wenn "end=''" nicht übergeben wird.
Darauf möchte ich gleich eingehen. Hier gibt es ein Missverständnis.
Das print einen Zeilenumbruch anhängt ist ja okay und soll es auch tun.
Mein Problem ist, dass ich mittendrin im zusammensetzen eines Strings
plötzlich Zeilenumbrüche in der Ausgabe hatte. Deswegen muss ich während
des Zusammensetzens diese entfernen. Genauso spielt es verrückt wenn ein
Komma mit rein kommt für den SCPI Syntax. Jetzt wollte ich die Zeilen
separieren zum Vorführen und das Problem ist weg. :-( Den .strip() muss
ich aber im eigentlichen Programm machen, sonst habe ich 2 Zeilen statt
einer und mit Komma 3 statt einer. Wie gesagt, so wie es jetzt einzeln
hier steht funktioniert es komischerweise ohne ungewollte
Zeilenumbrüche.
Christian M. schrieb:> Frage eines Anwenders, der vor 20 Jahren das letzte mal im Quelltext> gewurschtelt hat, was nutzt ihr für Py für eine Umgebung?
Das ist reine Geschmackssache, je nach persönlicher Präferenz.
Da ist von vi / emacs bis zu Exabyte-großen und oftmals entsprechend
lahmarschigen IDEs alles möglich. Jedem Tierchen sein Pläsierchen hieß
es schon damals.
Was ich persönlich allerdings für extrem hilfreich erachte, ist ein
kleiner lokaler Webserver und die komplette, vollständige Dokumentation
der genutzten Python Version. Einfacher geht's dann kaum noch.
Für alle installierten/verfügbare Module noch ein:
Veit D. schrieb:> ähmm. Das ändert alles nichts an den Möglichkeiten der bunten Mischung> an Zuweisungen, egal welchen Datentyp eine Variable hat(te). Der> Wildwuchs macht eben Python aus. Mit der nicht vorhandenen> Datentypsicherheit muss man umgehen lernen, wenn man anderes gewohnt> ist.
Wildwuchs ist, was Du daraus machst...
Mein Rat wäre, Dich daran nicht allzu sehr aufzuhängen, das ist nur eine
Gewohnheitssache.
Wenn Du in stark typisierten Sprachen wie Cpp, Java, oder meinetwegen
auch Golang unterwegs bist, dann denkst Du beim Design und beim Coden
ständig über Datentypen nach. Denn, na klar: bevor Du eine Variable
deklarierst, mußt Du natürlich wissen, welchen Typ sie hat.
Daß Python die Datentypen allenfalls als Hinweise (Hints) formuliert,
heißt aber nicht, daß Datentypen in Python gleichgültig wären oder nicht
verwendet würden. Sie werden durchaus benutzt und in gewissem Umfang
auch zur Laufzeit überprüft. Du mußt sie nur nicht zuerst anlegen. Und
indem ihr Typ nicht an den Variablennamen, sondern an den Variablenwert
gekoppelt ist, geschieht das erstens automatisch und bedeutet zweitens
eben auch, daß Du der Variablen -- also: ihrem Namen -- einen anderen
Wert mit anderem Typ zuweisen könntest. Am Ende habe ich aber im Laufe
der Jahre nur sehr, sehr wenig Pythoncode gesehen, in dem derselbe
Variablenname für Werte von unterschiedlichen Typen verwendet worden
wären. Und auch wenn man das machen kann, rate ich sehr dringend davon
ab, so etwas zu machen.
Veit D. schrieb:> Wie gesagt, so wie es jetzt einzeln> hier steht funktioniert es komischerweise ohne ungewollte> Zeilenumbrüche.
Zeig doch bitte mal ein Beispiel, das ungewollte Zeilenumbrüche erzeugt.
Das Problem ist sicherlich lösbar. :-)
Norbert schrieb:> Ein T. schrieb:>> pydoc builtins.isinstance>> same dance, another girl
Sorry, aber das ist "der offensichtlich richtige Weg" versus "geht".
Außerdem funktioniert isinstance() -- im Gegensatz zu Deiner Methode --
auch für Kind-Instanzen, was genau das ist, was benötigt, gewünscht, und
erwartet wird. Bitte beachte die Feinheiten:
1
#!/usr/bin/env python
2
3
classEins:pass
4
classZwei(Eins):pass
5
6
if__name__=='__main__':
7
z=Zwei()
8
print(isinstance(z,Eins))# True # True (1)
9
print(isinstance(z,Zwei))# True
10
print(isinstance(z,(Eins,Zwei)))# True
11
12
print(type(z)isEins)# False (2)
13
print(type(z)isZwei)# True
(1) Na klar, die Klasse Zwei erbt von der Klasse Eins und ist damit
auch eine Instanz der Klasse Eins...
(2) ...und das wird hier nicht erkannt.
Meine ganz persönliche Erfahrung ist: wer versucht, klüger als die
Entwickler einer Sprache zu sein, schießt sich damit meistens in den
eigenen Fuß. (a)
PEP 20 ("The Zen of Python") sagt: "There should be one-- and preferably
only one --obvious way to do it". Wenn es für etwas eine
Builtin-Funktion gibt, ist sie wahrscheinlich dieser "one obvious way".
(a) Gilt vielleicht nicht für PHP... ;-)
Ein T. schrieb:> Zeig doch bitte mal ein Beispiel, das ungewollte Zeilenumbrüche erzeugt.> Das Problem ist sicherlich lösbar. :-)
Ich kann das Problem was es gab nicht mehr nachvollziehen. Hat sich in
Luft aufgelöst. Der Code erzeugt einen zusammenhängenden String, wie
gewünscht, auch ohne .strip() und ohne end="". Dann kann ich die
.strip() und end="" aus dem Modulcode wieder rausnehmen. Ich hatte das
Modul nochmal umgebaut, am eigentlich verwendeten SCPI Syntax wurde
jedoch nichts geändert. Vielleicht habe ich doch etwas geändert. Wie
gesagt, kann es nicht mehr nachvollziehen wie das zu Stande kam.
Veit D. schrieb:> Ich kann das Problem was es gab nicht mehr nachvollziehen. Hat sich in> Luft aufgelöst. Der Code erzeugt einen zusammenhängenden String, wie> gewünscht, auch ohne .strip() und ohne end="". Dann kann ich die> .strip() und end="" aus dem Modulcode wieder rausnehmen. Ich hatte das> Modul nochmal umgebaut, am eigentlich verwendeten SCPI Syntax wurde> jedoch nichts geändert. Vielleicht habe ich doch etwas geändert. Wie> gesagt, kann es nicht mehr nachvollziehen wie das zu Stande kam.
In genau solchen Fällen ist eine Versionskontrolle wie Git wirklich Gold
wert... also, wenn man sie benutzt. Wirklich, wärmstens empfohlen! :-)
>
Hallo,
Danke. Es gibt scheinbar unendliche Möglichkeiten des Syntax bzw.
Formatierungen.
Ich hatte gestern vorm Test auch Python 3.14.0 installiert, vorher war
es 3.13.3.
Das hier ist demzufolge Python untypischer Syntax? Wenn man etwas
zusammensetzen möchte. Weswegen es vielleicht Probleme gab.
Untypisch daran wären höchstens die Klammern, wofür sollen die gut sein?
Ansonsten sind "f-Strings" mittlerweile sehr Python-typisch.
Aber du kannst auch wie in C++ Strings mit += zusammensetzen.
Veit D. schrieb:> Das hier ist demzufolge Python untypischer Syntax? Wenn man etwas> zusammensetzen möchte. Weswegen es vielleicht Probleme gab.> scpiCode = (f'{syntax} {start}, {end}, "{name}"')
Nö. Der ist OK. Es werden zur Laufzeit einfach nur die jeweils aktuellen
Werte der vier Variablen eingesetzt. Wenn die allerdings – wie evtl. im
Falle von name – newlines enthalten, werden die natürlich auch in den
resultierenden String eingefüttert.
könnte da helfen.
Wobei insgesamt gesehen die Klammern außen herum unnötig sind.
Was und wie man sonst noch alles formatieren kann, ist in der Sektion
›Format Specification Mini-Language‹ in den Python docs gut beschrieben.
Jörg W. schrieb:> Untypisch daran wären höchstens die Klammern, wofür sollen die gut sein?
Gute Frage. :-)
> Ansonsten sind "f-Strings" mittlerweile sehr Python-typisch.
Die Begeisterung vieler Python-Entwickler für F-Strings hat sich mir
bisher allerdings noch nicht erschlossen, zumal ich sie auch schon an
Stellen sehen mußte, wo sie Injection-Angriffe provoziert haben (think
Bobby Tables). Aber andererseits ist das vermutlich eine Geschmacks- und
Gewohnheitsfrage -- und selbst wenn man sie, wie ich, nicht im eigenen
Code benutzen will, wird man sie früher oder später in fremdem Code
begegnen und sollte also wissen, daß sie existieren und wie sie
funktionieren.
> Aber du kannst auch wie in C++ Strings mit += zusammensetzen.
Mitunter auch sehr nützlich sind str.join():
1
#!/usr/bin/env python
2
3
a=list()
4
a.append('eins')
5
a.append('zwei')
6
a.append('drei')
7
print(''.join(a))# "eins zwei drei"
und string.Template:
1
#!/usr/bin/env python
2
3
fromstringimportTemplate
4
t=Template('$eins ist $zwei')
5
print(t.substitute({'eins':'Das','zwei':'toll'}))# 'Das ist toll'
Die Syntax "${eins}" wird auch unterstützt, wie in verschiedenen Shells.
Wer eine komplette Template-Engine braucht, ist mit Jinja2 prima
bedient.
Ein T. schrieb:> Die Begeisterung vieler Python-Entwickler für F-Strings hat sich mir> bisher allerdings noch nicht erschlossen
Convenience. Man zwingt die Anwender nicht dazu, ständig neuen Versionen
zu installieren.
f-strings: ab 3.6
template strings: ab 3.14
Veit D. schrieb:> Hallo,>> ich möchte behaupten, dass die F String Methode (und +) der einzige> Syntax ist, der jedem sofort erschließt was wie zusammengesetzt wird.
Das wirkt zunächst sicherlich so.
Aber es gibt auch gute Gründe so etwas zu machen:
Veit D. schrieb:> Hallo,>> prinzipiell klar, coole Sache. Mir erschließt jedoch nicht das 123_123> als Integer durchgeht.
Gültige und gängige Python Syntax um sehr große Zahlen schnell und
eindeutig lesbar zu machen ohne mit Finger oder Cursor durch 10,20,30
Stellen zu rutschen. Arbeite mal des öfteren mit Milliardenwerten ohne
sci oder eng Formatierung und du wirst es zu schätzen lernen. ;-)
ad1: Geht übrigens auch mit Hex-Werten, zB. ein 32Bit WORD optisch in
zwei HALFWORDS zu splitten. Oder 32bit Bin-Werte in vier Gruppen à
8Bits.
Hallo,
also gültiger Syntax als Trenner. Okay.
Wegen der Methode _getMode().
Abgeschaut und etwas "Cpp struct" eingebaut. :-)
Was haltet ihr davon?
Dann hätte man sprechend mittels "unit" und "command" Zugriff auf die
Einträge. Wobei ich soeben sehe das noch eine Falle mit _unit vs. unit
lauern kann.
Veit D. schrieb:> Abgeschaut und etwas "Cpp struct" eingebaut. :-)
Mein erster Gedanke: Ein guter Programmierer kann ›C-Code‹ in jeder
beliebigen Programmiersprache schreiben.
Man darf aber dictionaries auch schachteln und sich das Leben einfach
machen.
Hallo,
ja gut, nur mir wäre das mit 'unit' und 'command' in der Liste zu viel
Wiederholung, das jedesmal hinschreiben zu müssen. Sieht einfach aus,
gefallen tut es mir nicht so richtig. Vielleicht auch Geschmackssache?
Nicht böse sein, Zugriff mit Indexnummern geht für gar nicht. :-) Hatte
schon das Bsp. vom Ein Typ drin. ;-)
Weiter gehts ...
Hallo,
nach Überlegung muss ich wieder in alte Muster verfallen. Ich möchte
nicht immer wieder mittels gewählter Funktion "DVI", "2W" usw. command
und unit abfragen. Die Messfunktion soll einmal ausgewählt und
eingestellt werden. Damit müssen alle internen Variablen für diese
Funktion mit Werten genau dafür zugewiesen werden bzw. sein. Sodass man
dann nur mittels getUnit o.ä. die Einheit von der aktuellen Einstellung
abfragt. Sonst stellt jemand DVI ein und fragt dummerweise von 2W ab.
Das möchte ich nicht.
Ich denke einmal darüber nach ... das war auch der Sinn der
Function_List.
Hallo,
ich glaube jetzt war ich in Gedanken zu schnell. get_mode bleibt intern.
Wird also nur einmal mit einer set_function Funktion ausgeführt womit
alles intern neu gesetzt wird.
Veit D. schrieb:> prinzipiell klar, coole Sache. Mir erschließt jedoch nicht das 123_123> als Integer durchgeht.
Seit C++14 gibt es das ähnlich in Cpp, nur mit dem "'" anstelle des "_":
Veit D. schrieb:> ja gut, nur mir wäre das mit 'unit' und 'command' in der Liste zu viel> Wiederholung, das jedesmal hinschreiben zu müssen.
Dann schreib das doch nur einmal:
1
#!/usr/bin/env python
2
3
deffm(unit:Optional[str],command:str)->dict{
4
return{'unit':unit,'command':command}
5
}
6
7
modes:dict[str,dict[Optional[str],str]]={
8
"DCV":fm("V","VOLTage:DC"),
9
# ...
10
}
Aber klar, Du kannst natürlich auch Deine Dataclass benutzen. Das ist
nicht flashc, es sieht nur ungewöhnlich aus.
Andererseits... Eine Lösung mit Dict-Values in einem Dict hätte wie bei
meiner Implementierung oben den Vorzug, die Daten einfach in eine Datei
auslagern zu können, etwa mit YAML. Schau' mal in den Anhang... :-)
Das würde Deine Klasse erstens generischer machen, zweitens die
Konfiguration ohne Programmierkenntnisse erlauben, drittens könnte die
Konfigurationsdatei womöglich sogar aus der Gerätedokumentation erzeugt
werden.
> Nicht böse sein, Zugriff mit Indexnummern geht für gar nicht. :-)
Die kannst Du auch als Enums definieren, dann hast Du was Sprechendes.
:-)
Edit: Anhang nachgetragen. 8-O
Ein T. schrieb:> Veit D. schrieb:>> Nicht böse sein, Zugriff mit Indexnummern geht für gar nicht. :-)>> Die kannst Du auch als Enums definieren, dann hast Du was Sprechendes.> :-)
Ach so, Nachtrag: mein Beispielcode benutzt gar keine Indexnummern,
sondern eine Mehrfachzuweisung ([1], erster Codeblock, Zeile 20).
[1] Beitrag "Re: Python SCPI - Keithley DMM6500 u.ä."
Ein T. schrieb:> Die Begeisterung vieler Python-Entwickler für F-Strings hat sich mir> bisher allerdings noch nicht erschlossen, zumal ich sie auch schon an> Stellen sehen mußte, wo sie Injection-Angriffe provoziert haben
Wenn du sicheren Code schreiben willst, musst du tperl benutzen. :-)
(Die "taint"-Checks von suidperl haben mir schon manche Stellen gezeigt,
die ich in einem setuid-C-Programm bestimmt übersehen hätte.)
Ein T. schrieb:> Seit C++14 gibt es das ähnlich in Cpp, nur mit dem "'" anstelle des "_":
Weil der Unterstrich halt ein gültiger Name dort ist, der sehr häufig
mit dem Präprozessor benutzt wird (beispielsweise zur
Internationalisierung von Strings). Das wollte man nicht kaputt machen.
Hatte die gleiche Diskussion in der WG14, auch dort hat man sich dann
für den Apostroph entschieden.
Andere Sprachen (VHDL, Verilog?) hatten den Unterstrich schon länger
dafür benutzt, weil es natürlich vor allem bei Binärzahlen nötig ist,
sie irgendwie gruppierbar zu machen.
Bis auf die Getter sieht das doch schon wie richtiger Python-Code aus.
Und was die Getter betrifft... schau mal hier [1] und hier [2] (bei
RealPython bekomme ich gerade eine Fehlermeldung von Cloudflare, aber
wenn Du das liest, ist die Seite womöglich schon wieder da). Viel Spaß!
[1] https://docs.python.org/3/library/functions.html#property
[2] https://realpython.com/python-property/
Jörg W. schrieb:> Wenn du sicheren Code schreiben willst, musst du tperl benutzen. :-)>> (Die "taint"-Checks von suidperl haben mir schon manche Stellen gezeigt,> die ich in einem setuid-C-Programm bestimmt übersehen hätte.)
Bevor ich Python für mich entdeckt habe, waren Perl4 und Perl5 15 Jahre
lang meine Go-To-Skriptsprache für alles, das kein C oder C++ gebraucht
hat. Seit ich allerdings Python habe, nutze ich Perl nurmehr als Filter
in der Shell, think 'perl -pe'... :-)
> Hatte die gleiche Diskussion in der WG14, auch dort hat man sich dann> für den Apostroph entschieden.
In der WG14 sitzt Du also auch noch... schläfst Du zwischendurch auch
mal, oder hast Du den magischen Tag mit 48 Stunden erfunden? 8-O
Hallo,
Danke. Ich glaube ich habe die @property Verwendung verstanden.
Nur ist das nicht andererseits ein Spiel mit dem Feuer?
Man kann Variablen/Elemente nicht von Methodenaufrufen unterscheiden.
Irgendwann hat man eine Methode und Element mit gleichen Namen und
wundert sich.
Ein T. schrieb:> Bevor ich Python für mich entdeckt habe, waren Perl4 und Perl5 15 Jahre> lang meine Go-To-Skriptsprache für alles, das kein C oder C++ gebraucht> hat. Seit ich allerdings Python habe, nutze ich Perl nurmehr als Filter> in der Shell, think 'perl -pe'... :-)
Aber etwas Vergleichbares wie die taint-Checks kenne ich dort nicht.
suidperl hat mir schon manches Mal geholfen.
Für reine Regexp-Verarbeitung finde ich Perl ansonsten nach wie vor
angenehmer. $foo =~ re und $x = $1 schreibt sich deutlich handlicher
als re.match(re, foo) und x = m.group(1).
>> Hatte die gleiche Diskussion in der WG14, auch dort hat man sich dann>> für den Apostroph entschieden.>> In der WG14 sitzt Du also auch noch...
Ich habe die 0b-Zahlen dort mal durchgezogen (nachdem so ziemlich jede
andere Sprache sie schon hatte :), in dem Zusammenhang kam dann das
Trennzeichen für die Strukturierung mit hoch.
Ansonsten bin ich da nur noch gelegentlicher interessierter Mitleser.
Der Datenstrom an Diskussionen ist einfach mal zu viel, um sich das
alles anzutun.
Veit D. schrieb:> Danke. Ich glaube ich habe die @property Verwendung verstanden.> Nur ist das nicht andererseits ein Spiel mit dem Feuer?
In der Praxis nicht, allerdings... ich würde die Eigenschaften "command"
und "unit" ohnehin, wenn schon, als normale Eigenschaften benutzen, also
ohne properties-Dekorator und ohne "_"-Präfix. Das verstecken zu wollen
ist der Gedanke eines Entwicklers, der Zugriffsmodifkatoren kennt. Aber
weil ich ja Deine Vorliebe für Zugriffsmodifikatoren gesehen habe,
wollte ich Dir einen Weg zeigen, wie Du die Eigenschaften zumindest
readonly machen kannst. ;-)
Davon abgesehen würde ich selbst "unit" und "command" aber ohnehin
niemals als Eigenschaften einer Instanz verwenden, sondern nur als
Rückgabewerte. Wenn Du
Eigenschaften benutzt, mußt Du immer beachten, daß jeder folgende Aufruf
der get_mode()-Methode diese Eigenschaften verändern könnte. Das wäre
eine Quelle von schwierig zu findenden, weil nicht offensichtlichen
Fehlern.
Zudem möchtest Du mit "unit" und "command" ja etwas tun, genauer: das,
was get_mode() aufruft, will das "command" ans DMM senden und dessen
Rückgabewert mit der "unit" ausgeben. Was läge da näher, als "unit" und
"command" einfach an den Aufrufer zu übergeben? Wenn der diese Variablen
in folgenden Zugriffen überschreibt, dann ist das wesentlich weniger
fehleranfällig beim Schreiben und sehr viel leichter zu finden, wenn es
trotzdem geschieht.
Insofern würde ich das zunächst als einfache Funktion gestalten:
1
#!/usr/bin/env python
2
3
defget_mode(measure:str):
4
modes:dict[str,dict[Optional[str],str]]={...}
5
try:
6
returnmodes[measure]
7
exceptKeyErrorase:
8
raise
Ein weiterer Vorteil ist die Sache mit der Zuständigkeit. Diese Funktion
ist nur für eine einzige Sache zuständig. Muß das zu Deiner Hauptklasse
gehören, die die SCPI-Verbindung herstellt, Kommandos darüber sendet und
die Rückgabe darüber empfängt? Ich finde, nein, das muß es nicht, und
meiner Meinung nach sollte es das auch nicht.
Exkurs: Ich würde die Verantwortungen trennen: n Klassen, die
ausschließlich für die Verbindung, das Senden und Empfangen zuständig
ist und eine Klasse, die sich nur um Konfigurationsdaten kümmert. Am
Ende eine Klasse, die diese vorgenannten übergeben bekommt und sie
benutzt, um die Meßwerte zu erhalten und sie mit den entsprechenden
Einheiten auszugeben. Die Verbindungsklassen würden dann alle von einer
abstrakten Basisklasse (BaseConnection) erben und das würde
sicherstellen, daß sie alle exakt dieselbe API haben... Abstrakte
Klassen kennst Du ja vermutlich auch schon von Cpp, und in Python geht
das syntaktisch und technisch etwas anders, aber im Prinzip durchaus
ähnlich.
Okay, weiter im Text: nun möchte ich das Ding doch mit
Konfigurationsdateien benuzten -- und bin aber zu faul, meinen ganzen
Code zu ändern. Enter Magic Methods (auch Dundermethods für "double
under" genannt):
Dank "__call__()" werden die Instanzen von GetMode aufrufbar wie eine
Funktion oder Methode, "self.get_mode = GetMode(...)" erzeugt eine neue
Methode in der Keithley-Klasse, und das namedtuple läßt sich wahlweise
wie ein Tupel oder mit den benannten Feldern wie eine Instanz benutzen.
Python ist sehr flexibel und bietet viele Möglichkeiten, die andere
Sprachen nicht kennen. :-)
> Man kann Variablen/Elemente nicht von Methodenaufrufen unterscheiden.
Aber ja doch, Methodenaufrufe enden mit "(...)". :-)
> Irgendwann hat man eine Methode und Element mit gleichen Namen und> wundert sich.
Die Entwicklung von Software ist nicht trivial, und ein paar Sachen muß
man sich schon merken... ansonsten kommt beim Testen eine Exception. :-)
Hallo,
muss ich da erst reindenken wohin das jetzt geht.
Möchte noch eins äußern. Die SCPI Klasse war schon vorher nur für den
Syntax zuständig. Die hat nichts ans Gerät gesendet oder so. Der
komplette Syntax muss vorher noch vervollständigt zusammengebaut werden.
Das ist mein geringstes Problem.
Die get_mode Methode muss den Syntax ändern. Damit legt man die
Messfunktion fest. Damit werden alle anderen SCPI Syntax Codes die man
zum messen benötigt automatisch für diese Messfunktion abgeändert. In
der Function_List gibt es dafür einen Platzhalter "MESSMODE". Der wird
mit dem rausgefischten Funktionssyntax von get_mode ersetzt. Danach kann
man alle eingepflegten SCPI Befehle ans Gerät senden wie man lustig ist.
Das war mein Trick bzw. Idee alle Aufrufe zum messen praktisch zu
halten. Wenn man sich den Firlefanz von meinem Hauptprogramm wegdenkt,
waren das nur paar wenige Funktionsaufrufe und man konnte messen. Das
hat sich nur leider nie jemand so angeschaut.
Ansonsten haste schon recht. Da es in Python keine Kapselung gibt, kann
man sich ein paar der gedachten privaten _ "Dinge" sparen. Dagegen darf
von der Function_List nur mit einer Kopie gearbeitet werden. Sonst ist
der Platzhalter "MESSMODE" zum suchen und ersetzen futsch.
Veit D. schrieb:> Da es in Python keine Kapselung gibt, kann> man sich ein paar der gedachten privaten _ "Dinge" sparen.
Ich hielt es bis jetzt immer für recht schwer möglich, mit seinen
unegalen Wurstfingern von außen an Variablen innerhalb einer Klasse
herum zu spielen, wenn diese self.__xxxxx (double underscore) genannt
werden.
Die modifiziert man mit einer Methode oder liest sie über @property.
Aber man manipuliert sie nicht so einfach unkontrolliert von außen.
Hallo,
ich möchte mich jetzt nicht weiter über das Thema Kapselung C++ vs.
Python unterhalten. Ich weiß nicht wie das enden würde. Danke für das
Verständnis. Ich möchte mich in Python reindenken.
Es ging hier und jetzt darum das "Ein T" vorgeschlagen hat, alle
"privaten" _ Variablen wegzulassen, weil es fast keine gibt. Sie demnach
sowieso fast alle von außen geändert werden. Bis auf wenige Ausnahmen,
diese verbleiben mit _ "privat". Mit Doppel _ fang nicht nun nicht an.
Die allgemeine Konvention ist 1x _.
Veit D. schrieb:> Ich möchte mich in Python reindenken.Veit D. schrieb:> Mit Doppel _ fang nicht nun nicht an.
Vielleicht hilft die Dokumentation dabei, sich vernünftig rein zu
denken:
9.6. Private Variables
Norbert schrieb:> Wobei insgesamt gesehen die Klammern außen herum unnötig sind.
Ganz am Rande möchte ich anmerken, daß runde Klammern () einem
Entwickler in seltenen Momenten ganz schön ins Gesäß beißen können. Denn
sie erzeugen nach Kontext ein Tupel oder einen Generator:
1
>>> a = ('a', 'b', 'c')
2
>>> print(type(a), a)
3
<class 'tuple'> ('a', 'b', 'c')
4
>>> b = (f'prefix_{item}' for item in a)
5
>>> print(type(b), b)
6
<class 'generator'> <generator object <genexpr> at 0x7c0610551ff0>
Norbert schrieb:> Ein T. schrieb:>> Die Begeisterung vieler Python-Entwickler für F-Strings hat sich mir>> bisher allerdings noch nicht erschlossen>> Convenience. Man zwingt die Anwender nicht dazu, ständig neuen Versionen> zu installieren.
Man zwingt die Nutzer stattdessen dazu, ständig neue Möglichkeiten für
die Formatierung von Zeichenketten zu erlernen. Aktuell gibt es dazu
doch, wenn ich nichts vergessen habe: str.% (str.__mod__),
string.Template, str.format, f-Strings und neuerdings t-Strings, die im
Prinzip ja so etwas wie f-Strings auf Steroiden sind. Und dann gibt es
natürlich Concatenations mit "+". f- und t-Strings finde ich auch nicht
so richtig elegant, weil sie von den aktuellen globals() und locals()
abhängen.
Aber diese Nebendiskussion weiterzuführen, wäre dem Thread abträglich.
Das fände ich bedauerlich, weil Ihr schon so weit gekommen seid.
Veit D. schrieb:> Danke. Ich glaube ich habe die @property Verwendung verstanden.> Nur ist das nicht andererseits ein Spiel mit dem Feuer?
Nicht wirklich, wie bei Variablen gilt die letzte Zuweisung.
> Man kann Variablen/Elemente nicht von Methodenaufrufen unterscheiden.
Wenn aus Dir mal ein fortgeschrittener und erfahrener Python-Entwickler
geworden ist (was womöglich nicht mehr allzu lange dauern wird, Du
machst beeindruckend schnelle Fortschritte) und Dir Deskriptoren [1,2]
oder die magischen Methoden [3,4] begegnen, wirst Du sehen: intern sind
das alles Aufrufe von Funktionen (oder, na klar, Methoden).
[1] https://docs.python.org/3/howto/descriptor.html
[2] https://realpython.com/python-descriptors/
[3] https://rszalski.github.io/magicmethods/
[4] https://realpython.com/python-magic-methods/> Irgendwann hat man eine Methode und Element mit gleichen Namen und> wundert sich.
Wie gesagt, Python ist da leidenschaftslos: die letzte Zuweisung gilt.
Das ist bei Variablen ja genauso. Warum sollte es bei Eigenschaften
anders sein?
Veit D. schrieb:> Es ging hier und jetzt darum das "Ein T" vorgeschlagen hat, alle> "privaten" _ Variablen wegzulassen, weil es fast keine gibt.
Wenn ich ihn richtig verstanden habe, schlägt er das nicht deswegen vor,
weil es keine gibt. Sein Vorschlag ist die beiden Variablen command und
unit nicht als Eigenschaften, und somit als Zustand, sondern lediglich
als Rückgabewerte zu verwenden. (Bitte korrigiert mich, wenn ich falsch
liege.) :)
In Python gibt es außerdem keine privaten oder sonstwie geschützten
Variablen. Dieses ganze Konzept gehört zu einer kommerziellen
Entwicklung in der Software als Binärcode ausgeliefert wird. Und nur mit
den passenden Headern verwendet werden kann, die eine öffentliche (==
"public") API definieren.
Python ist keine solche Sprache.
> Die allgemeine Konvention ist 1x _.
Die allgemeine Konvention ist 0x _. 1x _ benutzt man nur dann, wenn man
dem Benutzer seines Codes signalisieren will "hey, fummel da mal nicht
rum, das wird für interne Sachen benutzt und damit solltest Du echt nur
rumhantieren, wenn Du wirklich haargenau weißt, was Du da tust und
warum. Finger weg!".
Diesen ganzen Unfug mit Kapselung und dem Schützen von Variablen sparen
wir uns in Python einfach mal. Wenn Du nicht merkst, daß Du Deine
Variablen aus Versehen überschreibst, dann ist Programmieren vielleicht
nicht Dein Ding.
Das heißt: wir machen keine Unterstriche, weder vor Eigenschaften, noch
vor Methoden. Alles ist öffentlich ("public"), und wenn Dir mal eine der
wenigen Ausnahmen begegnet, dann wirst Du es merken. :)
Hallo,
ich gebe mir Mühe. Nachdem ich viele kleine Tests gemacht habe muss ich
das große Ganze neu anschauen. Ich muss überdenken was ich an Aufteilung
behalte und was nicht. Ob ich im SCPI Modul mehrere Klassen anlege usw.
Dann können wir erneut darüber reden. Danke @ all.
Udo K. schrieb:> Wenn du das ganze linear in C runterprogrammiert hättest, wärest du> jetzt schon 2x fertig 😉
Mit USB und allem? Du beliebst zu scherzen. Zumal es hier ja auch um das
Erlernen einer neuen und sehr mächtigen Sprache geht...
Ein T. schrieb:> Mit USB und allem? Du beliebst zu scherzen. Zumal es hier ja auch um das> Erlernen einer neuen und sehr mächtigen Sprache geht...
Das ist einfach in C, Keithley hat dafür fertige Libs. Ich dachte es
geht darum Messungen zu automatisieren. Ob Python mächtig ist? Ich
würde sagen, es ist Alleskleber.
Udo K. schrieb:> Ein T. schrieb:>> Mit USB und allem? Du beliebst zu scherzen. Zumal es hier ja auch um das>> Erlernen einer neuen und sehr mächtigen Sprache geht...>> Das ist einfach in C, Keithley hat dafür fertige Libs.
Python auch -- und es kann natürlich auch einfach die Keithley-Libs
nutzen, denn es wurde ja von Anfang an auch als Glue-Sprache entwickelt.
> Ich dachte es geht darum Messungen zu automatisieren.
Wenn ich das richtig sehe, geht es auch darum, Python zu lernen. Aber
das weiß unser TO natürlich am Besten, allerdings hat er aber
ausdrücklich nach Python gefragt -- das steht sogar im Titel dieses
Threads.
> Ob Python mächtig ist? Ich> würde sagen, es ist Alleskleber.
Ja, zu diesem Schluß könnte man kommen, wenn man Python nicht oder nur
wenig kennt. Die Mächtigkeit erschließt sich erst mit der Erfahrung --
allerdings kannst bei Interesse Du diesem Text [1] von Eric S. Raymond
einen kleinen Vorgeschmack entnehmen. Viel Vergnügen! :-)
Nebenbei bemerkt habe ich Aussagen wie "in der Sprache X wärst Du
schneller fertig" nicht nur hier im Forum schon tausendmal gelesen und
gehört, für X als beliebige typsichere, kompilierte Sprache. Leider
warte ich bis heute darauf, daß sich solche vollmundigen Aussagen auch
praktisch belegen lassen. Das fände ich wirklich spannend, denn ich
spreche und benutze nicht nur Skriptsprachen, sondern auch mehrere
typsichere und kompilierte Sprachen, und halte das aus meinen eigenen
Erfahrungen heraus für ausgeschlossen. Und alle mir bekannten halbwegs
seriösen Untersuchungen scheinen meine Meinung zu belegen.
Wenn Du magst, können wir das gerne ausdiskutieren, allerdings schlage
ich vor, daß Du dann einen eigenen Thread dafür eröffnest. Wir wollen
diesen Thread hier doch bitte nicht kaputt machen, oder?
[1] https://www.linuxjournal.com/article/3882
Ein T. schrieb:>>> Ob Python mächtig ist? Ich>> würde sagen, es ist Alleskleber.>> Ja, zu diesem Schluß könnte man kommen, wenn man Python nicht oder nur> wenig kennt. Die Mächtigkeit erschließt sich erst mit der Erfahrung --> allerdings kannst bei Interesse Du diesem Text [1] von Eric S. Raymond> einen kleinen Vorgeschmack entnehmen. Viel Vergnügen! :-)
Ich übersetze Mächtigkeit erstmal mit Kompliziertheit :-)
In dem Problem geht es doch nur um Senden und Empfangen von ein paar
ASCII Strings. 1-2 Seiten linearer C Code.
Ok, wenn man will, kann man das auch in eine Klasse packen, aber die
Python Klassen Syntax ist schon ziemlich grauslich. Da hilft auch kein
seitenlanger Style Guide.
Aber ich lese hier weiter mit und freue mich über neue Erkenntnisse.
Udo K. schrieb:> In dem Problem geht es doch nur um Senden und Empfangen von ein paar> ASCII Strings. 1-2 Seiten linearer C Code.
Es ist nicht bei Strafe verboten, einfach hundert völlig unwartbare
Einzelfunktionen zu schreiben. Da wünsche ich genauso viel Spaß wie bei
jeder anderen Programmiersprache.
Udo K. schrieb:> Ok, wenn man will, kann man das auch in eine Klasse packen, aber die> Python Klassen Syntax ist schon ziemlich grauslich.
Das mag dem Uninitiierten durchaus so erscheinen.
Man sollte aber das Erlernen einer Programmiersprache nicht dem Benutzen
einer anderen, bereits erlernten gegenüber stellen.
Wichtig ist, dass die Programmerstellung nicht am Monitor mit bereits
geöffneten Editor stattfindet, sondern der Denkprozess viel früher auf
der Couch, im Café oder auf einer Bank am Waldrand beginnt.
Wenn die Struktur klar ist und der Ablauf im Kopf funktioniert, dann
wird zum ersten Mal ein Computer gebraucht.
Udo K. schrieb:> Ich übersetze Mächtigkeit erstmal mit Kompliziertheit :-)
Wenn man komplizierte Probleme löst, kann sogar Python kompliziert
werden.
> Ok, wenn man will, kann man das auch in eine Klasse packen, aber die> Python Klassen Syntax ist schon ziemlich grauslich.
Schau, meinetwegen kannst Du gerne gegen Python stänkern, wenn es Dir
ein unwiderstehliches Bedürfnis ist. Aber kannst Du dafür bitte einen
eigenen Thread eröffnen, anstatt diesen hier zu beschädigen? Danke.
Hallo,
ich würde auch darum bitten das es hier weiter um Python geht und um
nichts anderes. Wer denkt er kann es in einer anderen Sprache besser und
schneller der darf das tun, macht dafür einen eigenen Thread auf und
wartet auf die sachliche Diskussion. Hier bitte nur Python. Danke fürs
Verständnis.
Hallo,
Das wäre mein aktuelles Grundgerüst. KeithleySCPI.py
Bevor ich weitermache stehe ich vor einem Problem. Parameterfehler
werden zwar in setFunction() und scpiCommandSyntax() sauber abgefangen,
dabei haben _unit und _function den Wert None, jedoch führt das zu einem
Rattenschwanz von Problemen. Wenn man sich vertippt hat, statt "2W" nur
"W" o.ä. oder später bei den nachgelagerten Messfunktionen, kann ich ja
nicht in jeder Funktion abfragen ob _function == None ist. Damit
verschleppe ich nur eine Sache durch den gesamten Code und einen SCPI
Syntax den ich nie ans Gerät senden möchte. Das gesamte Programm muss
abbrechen. Ansonsten passiert sowas.
1
function found → 2W
2
RESistance
3
Ω
4
:MEASure:RESistance?
5
function unknown → Tzemp
6
None
7
None
8
:MEASure:RESistance?
"2W" ist korrekt und alles damit wird ausgeführt.
"Tzemp" hat einen Tippfehler, dass wird erkannt und _function bekommt
None.
_syntaxTable wird nicht aktualisiert, was auch richtig ist.
Bedeutet alle weiter ausgeführten Methoden/Funktionen arbeiten noch mit
der "2W" Einstellung.
Das kann fatal enden. Es macht für mich keinen Sinn eine
Sicherheitsabfrage _function == None durch das gesamte Programm zu
schleppen.
Wäre es korrekt, bei Fehlererkennung mit
except KeyError:
ein
Veit D. schrieb:> Das wäre mein aktuelles Grundgerüst. KeithleySCPI.py
Du machst ja immer noch das Zeug mit den Unterstrichen... :-)
> Bevor ich weitermache stehe ich vor einem Problem. Parameterfehler> werden zwar in setFunction() und scpiCommandSyntax() sauber abgefangen,> dabei haben _unit und _function den Wert None, jedoch führt das zu einem> Rattenschwanz von Problemen. Wenn man sich vertippt hat, statt "2W" nur> "W" o.ä. oder später bei den nachgelagerten Messfunktionen, kann ich ja> nicht in jeder Funktion abfragen ob _function == None ist. Damit> verschleppe ich nur eine Sache durch den gesamten Code und einen SCPI> Syntax den ich nie ans Gerät senden möchte. Das gesamte Programm muss> abbrechen. Ansonsten passiert sowas.
Das ist das Verhalten, vor dem jemand weiter oben gewarnt hat: wenn unit
und command Eigenschaften Deiner Klasse sind, mußt Du die Methoden immer
in der korrekten Reihenfolge aufrufen, wenn nicht, erhälst Du solche
Fehler.
Meiner Meinung nach wäre es einfacher, nur eine Tabelle zu benutzen, die
als Schlüssel den gewünschten Funktionsnamen hat und als Werte jeweils:
Einheit (unit), Funktion (function), und Syntax (syntax).
Bei den Ersetzungen würde ich im Übrigen
1
tmpl = 'FOO:{messmode}:Bar'
2
tmpl.format(messmode='baz')
oder strings.Template benutzen, um eindeutig zu machen, was da passiert.
Auf der anderen Seite verstehe ich zwar, daß _updateTable() Dir
Tipparbeit spart, aber durch die damit verbundene Indirektion wird IMHO
nicht besonders klar, wie Deine Tabellen am Ende aussehen. ;-)
> Wäre es korrekt, bei Fehlererkennung mit> except KeyError:> ein
1
sys.exit()
aufzurufen?
Das kannst Du machen, aber eleganter wäre es, eine eigene Exception zu
werfen, mit einer verständlichen Fehlermeldung. Wenn die Exception nicht
gehändelt wird, beendet sie das Programm.
sys.exit() ist im Übrigen mit Vorsicht zu genießen. Ohne Parameter
aufgerufen, nimmt der Parameter "status" den Default-Wert None an, und
das Programm wird mit dem Status 0 beendet. Status 0 bedeutet, die
Ausführung des Programms war erfolgreich, und das willst Du an dieser
Stelle vermutlich nicht. Du kannst sys.exit() jedoch mit einem Integer
aufrufen, der der zurückgegebene Status des Programms wird, alles außer
der 0 signalisiert einen Fehler. Du kannst sys.exit() aber auch etwas
mitgeben, das keine Integer ist, dann wird das ausgegeben und das
Programm mit einem Status ungleich beendet. Kurz gesagt:
1
# Status 0, Programm erfolgreich beendet
2
sys.exit()
3
sys.exit(0)
4
5
# Status ungleich 0, Programm hatte Fehler
6
sys.exit(1)
7
sys.exit(-1)
8
sys.exit(255)
9
10
# Status ungleich 0, Programm hatte Fehler, zudem Ausgabe: "a"
Hallo,
_ ... steht in alle Python Dokus für Privates. :-)
Ih denke es gibt ein Verständnisproblem wie das genutzt werden wird. Mit
setFunction("x") wird die Messfunktion festgelegt. Widerstandsmessung,
Spannungsmessung etc., was weiß ich. Alle anderen Funktionsaufrufe
danach sind in der Reihenfolge egal, es muss nur für den Benutzer Sinn
machen was er wie misst.
Wenn self._function allerdings den Wert None hat oder anderen Unsinn,
ist alles danach für den Benutzer sinnlos. Die Abarbeitung muss gestoppt
werden. Anstatt irgendeinen Fehler mit Abbruch vom Interpreter zu
erhalten, möchte ich das eleganter beenden.
Okay ich kann demnach folgendes machen.
1
def setFunction(self, measure: str) -> str:
2
try:
3
mode = self._modes[measure]
4
self._unit = mode["unit"]
5
self._function = mode["function"]
6
self._updateTable(self._function)
7
return f'function found → {measure}'
8
except KeyError:
9
self._unit = None
10
self._function = None
11
print (f'function unknown → {measure}')
12
sys.exit("Abbruch")
Was für einen Unterschied macht es ob sys.exit() erfolgreich oder nicht
erfolgreich abbricht? Ist doch nur ein Interpreterablaufprogramm.
Hallo,
gut, man kann und sollte noch mit bspw.
finally:
data.close()
für eine nicht Datenzerstörung etc. sorgen. Wäre auch in meinem
Interesse, würde die Messdatendatei betreffen. Nur wie sys.exit()
ausgeht ist laut aktueller Kenntnis doch egal? Ende ist doch Ende. Oder
nicht? Wem wird es gemeldet oder wer hat etwas davon ob sys.exit()
erfolgreich oder nicht erfolgreich war?
Veit D. schrieb:> Was für einen Unterschied macht es ob sys.exit() erfolgreich oder nicht> erfolgreich abbricht? Ist doch nur ein Interpreterablaufprogramm.
Das ist nur in der aufrufenden Umgebung relevant, aber es hat Sinn, es
sich richtig anzugewöhnen. Wenn ein Script von dir beispielsweise von
einem "make" mal aufgerufen wird, dann führt ein exit mit Fehlerstatus
dazu, dass die Kommandokette an dieser Stelle beendet wird, andernfalls
läuft sie fröhlich weiter.
Aber statt des try … except … sys.exit siehe oben, gewöhn dich lieber
dran, deiner Klasse eigene Exceptions beizubringen. Ganz rudimentär
genügt es für den Anfang auch, sowas zu machen:
1
def setFunction(self, measure: str) -> str:
2
try:
3
mode = self._modes[measure]
4
self._unit = mode["unit"]
5
self._function = mode["function"]
6
self._updateTable(self._function)
7
return f'function found → {measure}'
8
9
except KeyError:
10
raise Exception(f'function unknown → {measure}')
zu schreiben.
Der Vorteil: wenn deine Klasse bspw. von einem GUI-Kontext aus mal
gerufen werden sollte, zerstört sich nicht gleich die ganze GUI, sofern
in der GUI pauschal noch ein Exception-Handler installiert ist. Der kann
dann zumindest mal den String aus deiner Exception in einem GUI-Popup
zeigen und danach immer noch den geordneten Rückzug antreten (d.h. sein
"OK"-Button beendet das Programm).
Hallo,
habe mir das Logging Modul angeschaut. Das dient, was ich lese, dazu
Fehler des Programmablaufes zu protokolieren mit verschiedenen Levels.
Das kann ich nicht zum Messdaten schreiben verwenden.
Ich würde aktuell das .json Format (import json) bevorzugen. Wäre das
eine Basis um später daraus eine Diagramm aus Python heraus erstellen zu
lassen?
Jörg W. schrieb:> Aber statt des try … except … sys.exit siehe oben, gewöhn dich lieber> dran, deiner Klasse eigene Exceptions beizubringen. Ganz rudimentär> genügt es für den Anfang auch, sowas zu machen:> ...
Das macht Sinn. Danke.
Veit D. schrieb:> Ih denke es gibt ein Verständnisproblem wie das genutzt werden wird. Mit> setFunction("x") wird die Messfunktion festgelegt. Widerstandsmessung,> Spannungsmessung etc., was weiß ich. Alle anderen Funktionsaufrufe> danach sind in der Reihenfolge egal, es muss nur für den Benutzer Sinn> machen was er wie misst.
"Alle anderen Funktionsaufrufe" heißt: zuerst muß ein foo() erzeugt
werden.
Danach (!!1!11!!) muß ein setFunction() (PEP 8: set_function())
ausgeführt werden, damit die richtige "Funktion" ausgewählt ist.
Danach (!!1!11!!) fragst Du Eigenschaften des Objekts (der Instanz
Deiner Klasse) ab (obj.unit und obj.command).
Und danach (!!1!11!!) setzt Du mit scpiCommandSyntax wieder einen
Zustand Deines Objekts.
Jedes dieser [dD]anach ist vom vorhergehenden abhängig. Mist.
> Wenn self._function allerdings den Wert None hat oder anderen Unsinn,> ist alles danach für den Benutzer sinnlos.
Es ist möglich ein neues foo() zu erzeugen. Vorhandene zu resetten. Oder
das ganze Design nicht so, sorry, zu verkacken.
> Die Abarbeitung muss gestoppt werden.
... oder neu gestartet...
> Anstatt irgendeinen Fehler mit Abbruch vom Interpreter zu> erhalten, möchte ich das eleganter beenden.
Einen Python-Entwickler würde ich fragen, ob er noch ganz bei Trost ist.
Hier auch: Du packst Deinen Wert erst mit "{'syntax': syntax}" ein, um
ihn sofort wieder auszupacken?
Hallo Sheeva,
Deine jetzige Beschreibung trifft so nicht zu.
> "Alle anderen Funktionsaufrufe" heißt: zuerst muß ein foo() erzeugt werden.
Verstehe nicht was du damit meinst.
Nur mit setFunction() wird die gewünschte Messfunktion festgelegt.
_modes:
ist der Übersetzer von Displayanzeige zu SCPI Syntax der Messfunktion.
_syntaxTable:
ist die jederzeit erweiterbare Auswahl wie gemessen werden soll. Dazu
muss der Platzhalter "MESSMODE" für die eingestellte Messfunktion
einmalig in der Tabelle ersetzt werden. Solange bis man eine andere
Messfunktion mit setFunction() eingestellt hat. Um den Platzhalter zu
ändern benötige ich _updateTable().
scpiCommandSyntax() gibt nur einen String zurück, es verändert nichts.
_syntaxTable: dict ist das original und bleibt unverändert
_syntax: dict ist die Kopie mit der gearbeitet wird
Das Replacement ist anders wie vorher. Weil jetzt eine Liste mit einem
Dictionary verschachtelt ist. Ob das einfacher geht weiß ich jetzt
nicht.
Hallo,
ich weiß nicht was daran falsch sein soll. Der Eintrag "syntax" wird aus
dem Dictionary rausgezogen und ggf. "MESSMODE" ersetzt. Das Ergebnis
wird ins Dictionary self._syntax geschrieben, damit eine geänderte Kopie
angelegt. Den Namen self._syntax kann man noch ändern.
Veit D. schrieb:> _ ... steht in alle Python Dokus für Privates. :-)
Es gibt in Python keine Privates.
> Ih denke es gibt ein Verständnisproblem wie das genutzt werden wird.
Du denkst an die auszuführenden Schritte und erhälst dann eine API wie:
1
k = KeithleySCPI("Keithley DMM6500")
2
print(k.setFunction("2W"))
3
print(k.function)
4
print(k.unit)
5
print(k.scpiCommandSyntax("measure"))
Ich hingegen denke an eine saubere API und erhalte so etwas wie:
1
k = KeithleySCPI(...)
2
function, unit, value = k.get("2W")
Keine Zustände (außer der Konfiguration), keine Reihenfolge...
> Was für einen Unterschied macht es ob sys.exit() erfolgreich oder nicht> erfolgreich abbricht? Ist doch nur ein Interpreterablaufprogramm.
Das ist der Rückgabecode, den die aufrufende Shell erhält. Es ist
sinnvoll, das korrekt zu machen, also im Erfolgsfall 0 und in allen
andere Fällen etwas ungleich 0 zurückzugeben. Dadurch kann das Ergebnis
des letzten Aufrufs in der Shell abgefragt werden (bash: $?) oder es
können Befehle mit einem logischen UND oder ODER verknüpft werden. Bei
einem C- oder Cpp-Programm schreibst Du ja am Ende auch ein "return 0"
hin, nicht nur um die Warnung zu vermeiden, daß main() den Rückgabetyp
int hat...
Ein T. schrieb:> Veit D. schrieb:>> _ ... steht in alle Python Dokus für Privates. :-)>> Es gibt in Python keine Privates.
Ich verstehe euch nicht, weil das regt mich jetzt schon etwas auf. Ihr
wollt das ich Python konform programmiere. Okay, will ich auch, also
mache ich das. In allen Python Dokus steht drin, man soll _ verwenden
für "private" Dinge. Also nicht öffentliche Dinge, bedeutet private
Dinge. Warum schreibt ihr laufend man soll kein _ verwenden wenn es doch
in jeder Doku steht auf die ihr selbst immer verweist. Klar ist das nur
eine Konvention, aber es ist eine dokumentierte Konvention wie man es
machen soll.
API usw. kommt dran wenn ich Listen gemischt mit Dictionary, Zugriffen
usw. besser verstanden habe. Da bin ich zu schnell drüber hinweg
gegangen.
Edit:
API ganz kurz.
> Ich hingegen denke an eine saubere API und erhalte so etwas wie:
[/code]
k = KeithleySCPI(...)
function, unit, value = k.get("2W")
[/code]
k.get("2W") soll nichts messen. Das kann nur die Funktion
auswählen/einstellen. Es ist damit nicht klar wie überhaupt gemessen
werden soll. Darüber können wir später noch reden. Eine wichtige Frage
dazu. Kennst du dich mit dem Messgerät und SCPI Syntax aus? Nicht das
wir ggf. aneinander vorbeireden. Was wie mit dem Syntax möglich ist, wie
das funktioniert usw.
Hallo,
neues Grundgerüst vom Modul. Das sollte jetzt Python konform sein.
Die Testaufrufe am Ende gehören wie kommentiert nicht ins Modul. Dient
nur für den unkomplizierten Test.
Wenn das grundlegend okay, können wir uns über die beste Methode
unterhalten um dem Messgerät zu sagen wie es messen soll und wie man die
Werte erhält bzw. in eine Datei schreibt.
Ob man das Keithley SCPI Modul so lässt und alle Funktionen die man mit
der _syntax_table zur Verfügung hat und dafür Funktionen schreiben muss
in ein weiteres Modul verlagert. Was ich nicht möchte ist, im
Hauptprogramm mit den str Namen der _syntax_table operieren. Das sollten
gleichnamige Funktionen sein die der User verwendet.
Ein T. schrieb:>> Ich denke es gibt ein Verständnisproblem wie das genutzt werden wird.>> Du denkst an die auszuführenden Schritte und erhälst dann eine API wie:>>
1
> k = KeithleySCPI("Keithley DMM6500")
2
> print(k.setFunction("2W"))
3
> print(k.function)
4
> print(k.unit)
5
> print(k.scpiCommandSyntax("measure"))
6
>
>> Ich hingegen denke an eine saubere API und erhalte so etwas wie:>>
1
> k = KeithleySCPI(...)
2
> function, unit, value = k.get("2W")
3
>
Hier gibt es wirklich ein Missverständnis.
1
k.function
2
k.unit
3
k.scpiCommandSyntax("measure")
sind nur für Tests "rausgezogen" wurden. Das bleibt alles intern.
k.get() bleibt auch intern.
Das sind die alten Aufrufer vom Benutzer.
Wie man dann am Dümmsten die Messwerte abfragt um sie im Terminal
auszugeben und/oder in eine Datei zu schreiben, dafür bin ich offen.
Das auslesen vom Buffer und speichern in eine Datei hatte bspw.
saveBufferWithTimestamp(keithley) übernommen.
Veit D. schrieb:> Ein T. schrieb:>> Ich verstehe euch nicht, weil das regt mich jetzt schon etwas auf.
Bitte nicht aufregen, wir schaffen das.
> Ihr> wollt das ich Python konform programmiere. Okay, will ich auch, also> mache ich das. In allen Python Dokus steht drin, man soll _ verwenden> für "private" Dinge.
In den mir bekannten Dokumentationen steht, daß das für "internal",
mithin interne Dinge gedacht sei. Das hat nichts mit "private" oder den
anderen Zugriffsmodifikatoren aus Cpp, Java und Co. zu tun, aber Du
versuchst, es genau dafür zu benutzen. PEP 8 [1] sagt dazu:
_single_leading_underscore: weak “internal use” indicator. E.g. from M
import does not import objects whose names start with an underscore
Außerdem werden solche Variablen nicht in die Dokumentation (.__doc__)
der Klasse und ihrer Instanzen aufgenommen. Sie sind also nicht
"private", sondern nur nicht öffentlich.
Wie schon anfangs erwähnt: Du versuchst, die Dir aus Cpp bereits
bekannten Zugriffsmodifikatoren in Python nachzuempfinden.
[1] https://peps.python.org/pep-0008/#descriptive-naming-styles> API usw. kommt dran wenn ich Listen gemischt mit Dictionary, Zugriffen> usw. besser verstanden habe. Da bin ich zu schnell drüber hinweg> gegangen.
Das ist allerdings leider ein ziemlich wichtiger Aspekt, den Python auch
intern fast überall benutzt. Außerdem gibt es noch Tupel, die im Prinzip
unveränderbare Listen sind, und Sets, um eindeutige Werte zu erzwingen.
> k.get("2W") soll nichts messen. Das kann nur die Funktion> auswählen/einstellen. Es ist damit nicht klar wie überhaupt gemessen> werden soll. Darüber können wir später noch reden. Eine wichtige Frage> dazu. Kennst du dich mit dem Messgerät und SCPI Syntax aus? Nicht das> wir ggf. aneinander vorbeireden. Was wie mit dem Syntax möglich ist, wie> das funktioniert usw.
Nein, kenne ich nicht. Bitte korrigiere mich, wenn ich flashc liege,
aber normalerweise wird zuerst eine Verbindung zum Gerät hergestellt
(über USB, TCP, you get the idea), dann werden 1 bis n Kommandos ans
Gerät gesendet, dessen Antworten auf die Kommandos empfangen, eventuell
weitere Kommandos gesendet und empfangen, und am Ende wird die
Verbindung geschlossen.
Ist das ungefähr richtig so?
Veit D. schrieb:> neues Grundgerüst vom Modul. Das sollte jetzt Python konform sein.
Ich verstehe _fs(), _updateTable() und _syntaxTable leider immer noch
nicht. In der Methode _fs() packst Du den übergebenen Wert zuerst in ein
Dictionary {'syntax': wert}, nur um ihn in _updateTable() wieder heraus
zu holen. Dort könntest Du _fs() und dessen Aufrufe einfach weglassen,
und anstelle von
benutzen. Das Ein- und Auspacken in das Dictionary ist völlig
überflüssig -- und eigentlich auch bei _modes weder notwendig, noch
elegant. (Das hatte ich selbst als nur als Beispiel gebracht, wie man so
etwas machen könnte, jedoch wäre ein namedtuple hier IMHO trotzdem
schöner -- wenn man unbedingt will, grundsätzlich würde sogar ein
einfaches Tupel funktionieren.)
Außerdem kannst Du anstelle Deiner zu ersetzenden Variablen "MESSMODE"
einen Format-String benutzen:
An einer Stelle ist mir gerade aufgefallen, daß Dein Kommando am Ende
ein Leerzeichen enthält, das habe ich mit einem Kommentar markiert. Ist
das gewollt oder womöglich ein Tippfehler?
> Die Testaufrufe am Ende gehören wie kommentiert nicht ins Modul. Dient> nur für den unkomplizierten Test.
Dafür hat Python einen ganz besonderen Trick:
1
# hier wird alles ausgeführt
2
if __name__ == '__main__':
3
# das hier nur bei direktem Aufruf ausführen
Alles, was innerhalb der Verzweigung steht, wird nur ausgeführt, wenn
die Datei als Programm aufgerufen wurde (./datei.py), aber nicht, wenn
es als Bibliothek geladen wurde (import datei).
> measureSampling(keithley, 5, 0) # 5 Einzelmesssungen mit 0sec Pause
4
> dazwischen
5
> saveBufferWithTimestamp(keithley)
6
>
>> Der Rest wurde/wird intern behandelt.
Ah, verstehe. Also könnte man die Schritte "Änderung vorbereiten" und
"Einstellung übertragen" sowie "5 Einzelmessungen..." und das Speichern
möglicherweise zu jeweils einem Schritt zusammenfassen?
> Wie man dann am Dümmsten die Messwerte abfragt um sie im Terminal> auszugeben und/oder in eine Datei zu schreiben, dafür bin ich offen.
Naja, wie und womit möchtest Du die Daten denn weiterverarbeiten? Oder
möchtest Du sie nur sehen?
> Das auslesen vom Buffer und speichern in eine Datei hatte bspw.> saveBufferWithTimestamp(keithley) übernommen.
;-)
Veit D. schrieb:> habe mir das Logging Modul angeschaut. Das dient, was ich lese, dazu> Fehler des Programmablaufes zu protokolieren mit verschiedenen Levels.
Das ist die Idee, aber...
> Das kann ich nicht zum Messdaten schreiben verwenden.
... man kann es auch dafür "mißbrauchen".
> Ich würde aktuell das .json Format (import json) bevorzugen. Wäre das> eine Basis um später daraus eine Diagramm aus Python heraus erstellen zu> lassen?
Ja, unbedingt -- und Du kannst sogar JSON loggen.
Allerdings ist JSON recht gesprächig, und das erfordert dann natürlich
einerseits Speicherplatz und andererseits auch ausreichende Kapazitäten
beim Schreiben und Lesen. Mein Mittel der Wahl sind daher bei so etwas
die guten alten CSV-Dateien. Dafür besitzt Python ein Standardmodul mit
einem DictWriter:
1
d = DictWriter(sys.stdout, fieldnames=['a', 'b', 'c'])
2
d.writeheader()
3
d.writerow({'a': 1, 'b': 2, 'c': 3})
4
d.writerow({'a': 1, 'b': 2, 'c': 3})
Im Beispiel schreibe ich einfach auf sys.stdout, aber da kann man
natürlich auch eine Datei benutzen. Bei sehr großen Datenmengen und
genügend Zeit zum Komprimieren kann man die Datei auch zum Beispiel mit
gzip öffnen, dann ist die Datei beim Schreiben gleich auch komprimiert.
Veit D. schrieb:> Ein T. schrieb:>> Veit D. schrieb:>>> _ ... steht in alle Python Dokus für Privates. :-)>>>> Es gibt in Python keine Privates.>> Ich verstehe euch nicht, weil das regt mich jetzt schon etwas auf.
Mensch, ärgere Dich nicht. [1]
[1] Beitrag "Hobbybastler gibt sein Projekt Open Source"> Ihr wollt das ich Python konform programmiere. Okay, will ich auch, also> mache ich das.
Wir versuchen, Dir Python etwas näher zu bringen.
> In allen Python Dokus steht drin, man soll _ verwenden> für "private" Dinge. Also nicht öffentliche Dinge, bedeutet private> Dinge.
Also in den Python-Dokus, die ich gelesen habe wurde meistens versucht
die Begriffe "private" und "protected" zu vermeiden. Weil sie bei
Entwicklern aus anderen OO-Sprachen oft zu genau diesen
Mistverständnissen führen. Und die mir bekannten Python-Dokumentationen
erwähnen das zwar der Vollständigkeit halber, aber in der Praxis ist der
Gebrauch eher selten.
> Warum schreibt ihr laufend man soll kein _ verwenden wenn es doch> in jeder Doku steht auf die ihr selbst immer verweist. Klar ist das nur> eine Konvention, aber es ist eine dokumentierte Konvention wie man es> machen soll.
Die Konvention ist: "alles was mit einem Unterstrich beginnt ist mit
größter Vorsicht zu genießen. Faß das nur dann an wenn Du meinen Code
verstanden hast und genau weißt was Du tust". Nicht mehr, nicht weniger.
> API usw. kommt dran wenn ich Listen gemischt mit Dictionary, Zugriffen> usw. besser verstanden habe. Da bin ich zu schnell drüber hinweg> gegangen.
Das ist in Python aus Sicht von Entwicklern aus klassischen OO-Sprachen
erst einmal ein Mysterium. Zumal diese Geschichte mit dem "der Datentyp
hängt am Wert anstatt am Variablennamen" zum Beispiel dazu führt daß in
Python die Listen und Tupel und sogar die Keys von Dictionaries immer
Werte verschiedener Typen haben können:
1
a = ["dings", 1, "bums", 2] # list()
2
a = ("dings", 1, "bums", 2) # tuple()
3
a = {"dings": 1, "bums": "zwei", 3: "vier"} # dict()
Gerade das letzte Ding finde ich nach > 10 Jahren Erfahrung vollkommen
irre und in der Praxis würde ich aus der 3 eine "3" machen.
Auch verschachtelte Datenstrukturen sind kein Thema. Denk an JSON oder
YAML.
> k.get("2W") soll nichts messen. Das kann nur die Funktion> auswählen/einstellen.
Die Funktion des Gerätes, nehme ich an?
> Kennst du dich mit dem Messgerät und SCPI Syntax aus?
Das Gerät übersteigt mein Budget leider allzu deutlich und mit SCPI
kenne ich mich leider auch nicht aus.
Veit D. schrieb:> ich antworte euch später.
Da ich am Freitag auf Geschäftsreise gehe und bis dahin vermutlich mit
den Vorbereitungen beschäftigt bin, könnte das für mich schwierig
werden. Aber hier sind viele fachlich sehr gute Leute wie Jörg Wunsch
oder Ein Typ, die mindestens genauso gut helfen können.
> Ist ja einiges zusammengekommen von euch.
Und um das Zusammengekommene noch ein bisschen größer zu machen, habe
ich Deine Implementierung aus Deinem Beitrag vom 27.10., 19:43 Uhr, mal
etwas umgebaut und hier angehängt. Meine großen Änderungen an internen
Tabellen erkennst Du sicherlich selbst, an anderen Stellen habe ich
Kommentare mit '###' markiert, damit Du sie leichter finden kannst.
Die Ausgaben Deiner und meiner Varianten sind exakt gleich; meine
Variante ist wegen der Konfiguration von logging und der eigenen
Exception mit Kommentar zu "pass" zwar in summa etwas länger, obwohl ich
Deine Funktionen _fm() und _fs() entfernt und auch sonst ein wenig
eingespart habe. Oh, und ich sehe gerade daß ich das "from enum import
Enum" nicht wieder herausgenommen habe, das ist aber überflüssig, weil
ich in Zeile 88 meines Code eine Mehrfachzuweisung verwendet habe
anstelle des Zugriffs über Indizes.
Diese ganzen Dictionaries {'syntax': value} habe ich entfernt und
stattdessen entweder direkt die Werte benutzt, oder für die
_modes-Tabelle den Datentypus "Tupel". Das ist im Prinzip so etwas wie
eine Liste, nur unveränderbar:
1
>>> mylist = [1, 2, 3]
2
>>> mylist
3
[1, 2, 3]
4
>>> mylist[1]
5
2
6
>>> mylist[1] = 5
7
>>> mylist
8
[1, 5, 3]
9
>>> mytuple = (1, 2, 3)
10
>>> mytuple
11
(1, 2, 3)
12
>>> mytuple[1] = 5
13
Traceback (most recent call last):
14
File "<stdin>", line 1, in <module>
15
TypeError: 'tuple' object does not support item assignment
16
>>> mytuple
17
(1, 2, 3)
Auch Methoden wie list.append() etc. kennen Tupel nicht. Daraus ergibt
sich nebenbei erwähnt auch noch eine andere spannende Eigenschaft: Tupel
sind im Gegensatz zu Listen und Sets ein "hashable type", und können
darum auch als Schlüssel eines Dictionary benutzt werden (Fortsetzung):
1
>>> d = {}
2
>>> d[mylist] = 111
3
Traceback (most recent call last):
4
File "<stdin>", line 1, in <module>
5
TypeError: unhashable type: 'list'
6
>>> d[mytuple] = 111
7
>>> d
8
{(1, 2, 3): 111}
Am Ende habe ich mir noch einmal die Verwendung von Unterstrichen für
_unit und _function angeschaut und bemerkt: was Du da machst, ist
absolut korrekt. Ein Benutzer Deiner Bibliothek soll da gar nicht
manuell dran herum fummeln. Das Zeugs wird nur intern verwendet und
gesetzt und Markierungen als intern, die die Unterstriche signalisieren,
sind also absolut richtig. Ebenso ist es sauber, den Zugriff darauf
"read-only" über Properties zu machen. Jedenfalls so, wie das aktuell
implementiert ist.
Nichtsdestotrotz solltest Du es damit nicht übertreiben. Ich habe gerade
mal in die Webframeworks Django und Flask geschaut: in Django sind keine
5%, und in Flask nicht einmal 3% der Methoden als "internal" markiert.
Der Erfahrung nach ist es häufig ein Indiz für ein schlechtes Design,
wenn man solch viele Dinge als internal markieren muß.
Insgesamt habe ich leider auch noch nicht ganz verstanden, wie Dein
Modul funktioniert. In Deinem Beitrag vom 27.10., 20:05 Uhr, beschreibst
Du unter "die alten Aufrufe vom Benutzer" eine API, die für mich doch
sehr nach einer Objektorientierung in C aussieht: der erste Parameter
ist ein Zeiger auf die Instanz einer struct. So funktionieren
objektorientierte Sprachen wie C++ und Java übrigens heute noch, auch
Python. Nur das Python das, was in C++ "this" ist, in seinen Methoden
explizit mit "self" sichtbar macht.
Nebenbei bemerkt ist "self" nur eine Konvention. Du kannst auch andere
Namen benutzen, wenn Du von den Usern Deiner Bibliothek gesteinigt
werden willst. Das hier ist lauffähiger Python-Code:
1
class Ei:
2
def __init__(ei, eieiei):
3
ei.ei = eieiei
4
5
def printme(hans):
6
print(hans.ei)
7
8
if __name__ == '__main__':
9
Ei('ach').printme()
Das ist ein Quatsch-Beispiel und würde niemand in der realen Welt so
machen. Aber es zeigt einerseits wie flexibel und mächtig Python ist und
andererseits wie sehr die Python-Welt auf Konventionen anstelle von
Zwang setzt. Und dabei habe ich noch nicht mit interneren Schweinereien
wie __new__(), Deskriptoren, Speichermanagement oder solchen Dingen
angefangen. Python ist so einfach wie ein Fahrrad, aber intern mächtiger
als ein modernes Flugzeug.
Okay, am Ende noch ein paar Fragen: wozu ist _update_table() eigentlich
da? Dort wird etwas in _syntax_table_modified geschrieben (Glückwunsch
übrigens dazu, daß Du lange und sprechende Variablennamen benutzt: sehr
gut!) und es danach in scpi_command_syntax() wieder abgefragt. Könnte
man diese Methoden nicht womöglich in eine zusammenfassen? Ist das eine
Besonderheit von SCPI, oder Deines Multimeters?
(Edit: code tags korrigiert - Mod.)
Hallo,
> ... wird zuerst eine Verbindung zum Gerät hergestellt> (über USB, TCP, you get the idea), dann werden 1 bis n Kommandos ans> Gerät gesendet, dessen Antworten auf die Kommandos empfangen, eventuell> weitere Kommandos gesendet und empfangen, und am Ende wird die> Verbindung geschlossen.> Ist das ungefähr richtig so?
Ja schon richtig, Funktionen zusammenlegen macht dennoch keinen Sinn.
Das was ihr in der _syntax_table() seht, ist nur ein Bruchteil aus dem
SCPI Reference Manual. Mit dem funktionieren erstmal "nur" grundlegende
Messfunktionen. Alle benötigten Messeinstellungen, die ich oder
irgendwer für wichtig hält, sollten einzeln zur Verfügung stehen. Damit
man sich seinen eigenen Messablauf im Hauptprogramm zusammenstellen
kann. Deswegen kann man keine Funktionen zusammenlegen.
Wegen _fs(), _updateTable() und _syntaxTable und einpacken auspacken.
Ich dachte das macht eben Sinn, damit es gleich json kompatibel ist mit
Bezeichner wie 'snytax:''unit:', 'function:' usw.
Das hat sich jetzt sowieso geändert, mit der Codeänderung von Sheeva.
Auch wenn damit die "Bezeichner" snytax:''unit:', 'function:' für
spätere json Verarbeitung erstmal wegfallen. Kann man jedoch dann an
benötigter Stelle einbauen und schleppt es nicht durch den gesamten
Code. Okay.
Mittels _modes wird der SCPI Syntax intern im Modul vorbereitet für die
Messfunktion. Spannung, Widerstand, Strom etc. _modes bleibt
unverändert. Das spiegelt nur die Displaybedienbutton wieder.
'function' ersetzt in der _syntax_table Kopie "MESSMODE". Ab da
werden/sollen durch glasklare Einzelfunktionen fertig bereitliegende
SCPI Kommandos an das Keithley gesendet.
Diese Auftrennung finde ich genial, weil das die SCPI Pflege
erleichtert. Das Keithley SCPI Reference Manual ist mit dem was ihr hier
seht noch nicht einmal Ansatzweise abgebildet. Das ist der Einstieg mit
grundlegenden Messfunktionen. Die Auftrennung und Zugriff mittels
lesbaren Bezeichner möchte ich beibehalten.
Das Leerzeichen muss an manchen SCPI Code am Ende sein, weil da noch ein
"Integer" angehangen wird beim zusammenbauen. "Integer" für einen Count
bswp. Das erspart mir an anderen Stellen beim zusammensetzen des SCPI
Syntax Ärger. Der SCPI Syntax ist auch an manchen Stellen nicht 100%
logisch, da muss gewisse Dinge lieber vorher anpassen und erspart sich
Nacharbeit.
> changeFunction(keithley, "2W") # Änderung vorbereiten> setFunction(keithley) # Einstellung übertragen/setzen> measureSampling(keithley, 5, 0) # 5 Einzelmesssungen mit 0sec Pause> dazwischen> saveBufferWithTimestamp(keithley)>>> Der Rest wurde/wird intern behandelt.> Ah, verstehe. Also könnte man die Schritte "Änderung vorbereiten" und> "Einstellung übertragen" sowie "5 Einzelmessungen..." und das Speichern> möglicherweise zu jeweils einem Schritt zusammenfassen?
Nein, möchte ich nicht zusammenfassen. changeFunction und setFunction
kann man meinetwegen zusammenfassen. Den Rest auf keinen Fall. Das
Keithley hat gefühlt tausende Möglichkeiten wie es messen soll. Das kann
man nicht in eine Funktion werfen. Ich möchte auch nicht jedesmal die
Funktion als Parameter mitgeben. Einmal ausgewählt soll es bei der
Funktion Spannung oder Widerstand usw. messen bleiben bis zur gewollten
Änderung. Ansonsten hat man viel zu viele Parameter die man einer
Funktion mitgeben muss. Das würde im Kaos enden. Viele klare
Einzelfunktionen haben auch den Vorteil in der Bedienung, entspricht dem
was man auf dem Display drücken könnte und könnte später einer GUI
Bedienung dienlich sein. GUI ist aber in ferner Zukunft.
Lieber glasklare Einzelfunktionen anstatt zu viele Parameter einer
Multikultifunktion. Das erspart auch das ständige auswerten der
eigentlichen Messfunktion (Spannung, Widerstand, Strom) die ja sowieso
gleich bleibt bis zur expliziten Änderung.
Datenverarbeitung.
Alles im Terminal ausgeben ist gut. Zusätzlich in einer Datei speichern
noch besser. Ob ich die Auswertung in Excel mache oder nicht ist davon
erstmal unabhängig.
Wegen .json speichern und loggen etc.
Sollte auf meinen recht modernen Rechner alles kein Problem sein.
Rechenleistung und Speicher satt vorhanden. Außerdem ist das kein
Messplatz in einer Firma sondern zu Hause Hobby. Ich messe nicht jede
Woche irgendwas. Das Keithley konnte ich hier im Forum günstig erwerben,
nur deswegen ist sowas in meinem Besitz.
> Okay, am Ende noch ein paar Fragen: wozu ist _update_table() eigentlich> da? Dort wird etwas in _syntax_table_modified geschrieben (Glückwunsch> übrigens dazu, daß Du lange und sprechende Variablennamen benutzt: sehr> gut!) und es danach in scpi_command_syntax() wieder abgefragt. Könnte> man diese Methoden nicht womöglich in eine zusammenfassen? Ist das eine> Besonderheit von SCPI, oder Deines Multimeters?
Der Sinn ist, dass ich ein in den meisten Fällen fertig modifiziertes
SCPI Kommando bereitliegen habe und nur abrufe, um es dann zu senden.
aus dem Hauptprogramm:
Mit measureOnce(keithley) bspw. hole ich aus dem Modul den in der
Tabellenkopie bereitliegenden Syntax für das SCPI Kommando.
1
scpiCode: str = device.scpi.getMeasureOnce()
ruft auf:
1
def getMeasureOnce (self) -> str:
2
return self._getSCPIcommandByName("measure")
zeigt auf Eintrag:
1
_FunctionItem("measure", ":MEASure:MESSMODE?"),
welcher dann bspw. ":MEASure:VOLTage:DC?" lautet in der Tabellenkopie.
Das bereitlegen und nur abrufen spart Zeit. Jetzt habe ich darüber
nachgedacht, also wie immer ;-), die Gedanken dazu kommen natürlich aus
meiner kleinen AVR Welt. Womit man den vorhandenen Speicher nutzen
sollte um dafür Rechenzeit einzusparen. Gut, ein PC hat genügend
Rechenleistung um paar zusätzliche Methodenaufrufe zu erledigen, auch
wenn diese immer wieder gleich sind und überflüssig wären. Das sollte
nicht stören. Das würde bedeuten die Tabellenkopie fliegt raus und jeder
Funktionsaufruf wie bspw.
1
measureOnce(keithley)
welches
1
def getMeasureOnce (self) -> str:
2
return self._getSCPIcommandByName("measure")
aufruft, modifiziert {messmode} live vor der Rückgabe.
Das müsste man dann in jede Methode schreiben, was ich mir wie erwähnt
ersparen wollte, den immer gleichen Aufruf in allen Methoden. Wenn ich
so darüber nachdenke, also wie immer ;-), finde ich die modifizierte
Tabellenkopie nicht schlecht. ;-)
Wenn der Ablauf noch nicht verständlich ist, dann belassen wir es
erstmal dabei und reden nur darüber ob Tabellenkopie oder live
Modifizierung sinnvoll ist. Dann baue ich alles um.
Veit D. schrieb:> Das hat sich jetzt sowieso geändert, mit der Codeänderung von Sheeva.> Auch wenn damit die "Bezeichner" snytax:''unit:', 'function:' für> spätere json Verarbeitung erstmal wegfallen. Kann man jedoch dann an> benötigter Stelle einbauen
Puh, das war jetzt ein recht langer Beitrag von Dir, den ich mir morgen
und am Montag noch einmal gepflegt zu Gemüte führen möchte. Aber wenn
ich mir so die Ersetzungen anschaue, die Dir vorschweben... da kann man
ja die Möglichkeiten, die Python zum Ersetzen / Einsetzen von
Zeichenketten bietet, recht geschickt miteinander kombinieren. Schau mal
in den Anhang: da wird zunächst der {modus} per str.format ersetzt, dann
ein string.Template aus dem Ergebnis gemacht, die gegebenen Parameter
und mit jenen dieses Template abgeglichen... und alles mit einer
sauberen Fehlerbehandlung durch eigene Exceptions. Ist ein Spielbeispiel
und vielleicht noch nicht bis ins letzte Detail durchdacht, aber es
zeigt den Weg, wie das mit mehreren Ersetzungen und Prüfung der
Parameter ginge...
Besonders elegant finde ich dabei, daß sich die Parameter (im Beispiel a
und b) mit string.Template.get_identifiers() extrahieren und gegen die
dynamischen Keyword-Arguments von fill() prüfen lassen. :-)
müsste ich dann in allen weiteren Methoden aufrufen, damit ich live den
Rückgabe String modifiziere und damit ohne Tabellenkopie auskomme. Ich
denke mit Einzeltests habe ich genug gemacht, es wird komplett umgebaut,
dann sieht man das große Ganze besser.
Veit D. schrieb:> ersetze, kann ich damit folgendes machen :-) :-)
Klar, das kannst Du so machen:
>
1
> from string import Template
2
>
3
> t = Template(k.scpi_command_syntax("measure"))
4
> result = t.substitute(messmode=k.function)
5
> print(result)
6
>
> müsste ich dann in allen weiteren Methoden aufrufen, damit ich live den> Rückgabe String modifiziere und damit ohne Tabellenkopie auskomme. Ich> denke mit Einzeltests habe ich genug gemacht, es wird komplett umgebaut,> dann sieht man das große Ganze besser.
Ja, natürlich. Du kannst Deine Ersetzungen aber auch im Konstruktor
machen und dadurch eine große Tabelle mit allen Messmodi erzeugen, wenn
Du magst...
Meine Idee bezog sich aber auf den netten Nebeneffekt von
strings.Template, daß man dort mit der Methode get_identifiers() die vom
Template erwarteten Variablennamen herausziehen kann, sowie auf die
Verarbytung von dynamischen Keyword-Argumenten ("**kwargs", wobei der
Bezeichner "kwargs" nur Konvention ist, auch "**kwds" sieht man hie und
da), die sich dann gegen die erwarteten Namen des Templates überprüfen
lassen. Denn im Endeffekt möchtest Du ja zwei Ersetzungen: einmal die
von "measure", und dann jene eventueller Parameter, die diese Messung
erwartet. Fangen wir mit *args und **kwargs an:
Du siehst: *args bezeichnet eine variable Liste von Argumenten (okay, in
der Funktion ist es dann ein Tupel, also eine unveränderliche Liste),
sowas kennt man in anderen Sprachen als "variadische Argumente" oder
"varargs". **kwargs erweitert dieses Konzept auf Schlüsselwort-Argumente
(keyword arguments), die mit "name=wert" übergeben werden.
Durch die Kombination dieser Features, string.Template.get_identifiers()
und **kwargs, lassen sich die der Funktion übergebenen
Schlüsselwort-Argumente gegen die vom string.Template erwarteten
Bezeichner abgleichen. Natürlich ist es aber auch möglich, das mehrfach
zu machen (allerdings wird das ab einer gewissen Anzahl dann etwas
unübersichtlich mit dem $-Zeichen:
1
#!/usr/bin/env python
2
fromstringimportTemplate
3
4
if__name__=='__main__':
5
s='eins:$measure:zwei $$a $$b'
6
tpl1=Template(s)
7
res1=tpl1.substitute(measure='DINGS')
8
tpl2=Template(res1)
9
res2=tpl2.substitute(a=1,b=2)
10
print(res1)# eins:DINGS:zwei $a $b
11
print(res2)# eins:DINGS:zwei 1 2
Übrigens, wie oben schon erwähnt: wie in einer Shell läßt sich eine
Variable wie $measure auch als ${measure} schreiben. Das ist wichtig,
wenn nach dem Variablennamen eine Zeichenkette stehen soll, die
ansonsten selbst Teil des Variablennamens sein könnte:
Und um ein Dollarzeichen zurückzuerhalten kann einfach $$ benutzt
werden, das verwende ich im zweiten Beispiel dieses Beispiel für die
Variablen $a und $b in der zweiten Stufe.
HTH und viel Vergnügen! :-)
Hallo,
vielen Dank an alle für die vielen Informationen, Erklärungen, Code
usw.. Ich muss jetzt jedoch erstmal die Bremse reinhauen. Leider. Die
Informationsflut ist doch schon ganz schön hoch. Ich ändere mein
Programm nach besten neuen Wissen.
Ich möchte zusätzlich bis Weihnachten noch einen Umbau an der
Modelleisenbahn machen, inkl. C++ Programmänderung. Sodass ich langsam
in zeitliches Gedrängel gerate.
Wenn ich den Pythoncode für mich zufriedenstellend geändert habe, melde
ich mich wieder. Messdaten speichern ist ja auch noch Thema. Ich will
das jetzt ungern abwürgen, muss es jedoch irgendwie tun. Bitte versteht
mich. Ich bleib ja dran. Ist nur verschoben. Vielleicht finde ich auch
zwischendurch dafür Zeit. Aufgeschoben ist nicht aufgehoben. :-)
Wir hören uns!
Veit D. schrieb:> Ich möchte zusätzlich bis Weihnachten noch einen Umbau an der> Modelleisenbahn machen, inkl. C++ Programmänderung. Sodass ich langsam> in zeitliches Gedrängel gerate.
Alles gut, nur keinen Streß. Vielleicht magst Du Dir dabei schon einmal
ein Versionsmanagement wie Git oder Mercurial aneignen, das ist auch in
C++ sehr hilfreich und nützlich... :-)
> Wenn ich den Pythoncode für mich zufriedenstellend geändert habe, melde> ich mich wieder.
Ich freu' mich drauf, viel Spaß und Erfolg!
Hallo,
ich versuche mich wieder reinzudenken was ich damals ändern wollte. Habe
die Listenkopie entfernt und ersetze Parameter beim Syntax anfordern
live. Dafür nehme ich nun doch die Template Ersetzung. Auf den Stand
würde ich nun alle vorherigen in der Testphase entfernten Methoden
wieder im Modul hinzufügen.
Hallo,
habe jetzt das Hauptprogramm auf das geänderte Modul angepasst. Damit
funktioniert das Programm wie im Eingangsthread. Zusätzlich habe ich
eine virtuelle Umgebung damit erstellt, ist alles im .zip drin.
Wie würdet ihr sinnvolle Namen vergeben für aktuell
Hauptprogramm: SCPI Keithley DMM6500.py
Modul: KeithleyDMM6500SCPI.py
Das ist mir irgendwie zu ähnlich. Hat da jemand eine Idee das sinnvoll
zu benennen?
Jetzt könnte man die Datenausgabe modernisieren, also mein Logfile der
Messdaten. Es wurde einmal etwas von json geschrieben. Das wäre für mich
Neuland. Wir muss ich Schritt für Schritt vorgehen?
Veit D. schrieb:> Wie würdet ihr sinnvolle Namen vergeben für aktuell> Hauptprogramm: SCPI Keithley DMM6500.py> Modul: KeithleyDMM6500SCPI.py
Wenn noch andere Geräte dazukommen, wäre es für mich offensichtlich so:
SCPI
KeithleyDMM6500SCPI
In SCPI kannst Du dann aus einer Liste vorhandener Module (gefunden im
Unterverzeichnis "Module") das Passende auswählen.
Somit darf dann im Programm SCPI nichts Modul-spezifisches mehr
vorhanden sein.
Konzeptionelle Anregung dazu:
MVC -> Model View Controller ->
https://de.wikipedia.org/wiki/Model_View_Controller
Hallo,
okay, die Beschreibung ist mir dann doch leider zu technisch. Die
Funktionen im Modul sind laut meiner Meinung gut abgegrenzt nur im
Modul. Wird sich bei Erweiterungen zeigen ob ich etwas übersehen habe.
Habe die virtuelle Umgebung nochmal umgestaltet mit .venv. Dein scpi
Namensvorschlag hat mich angestupst, dass Hauptprogramm in main.py
umzubenennen. Danke. Es liegt ja alles abgegrenzt im Projektordner. ;-)
Später soll noch ein Modul für das Aim TTi Netzteil dazukommen.
Der Ursprungsgedanke für alles ist, dass ich zusammen mit Netzteil und
Messgerät eine automatisierte Diodenkennlinie aufnehme, so zum Spass.
Netzteil bekommt bspw. 1mA Schritte vorgegeben und das Messgerät misst
die abfallende Flussspannung. Das treibt mich an. ;-)
Veit D. schrieb:> Die Funktionen im Modul sind laut meiner Meinung gut abgegrenzt nur im> Modul.
Das ist dann schon gut angelegt.
> Wird sich bei Erweiterungen zeigen ob ich etwas übersehen habe.
Das passiert sicherlich. Wichtig ist es dann halt, sich zu bemühen
Verflechtungen aufzubrechen, auch wenn es etwas mühsam ist.
Veit D. schrieb:> dass Hauptprogramm in main.py umzubenennen.
Das ist halt kein besonders origineller Programmname. :-)
Ich stell mir vor alle Programme heißen main.exe :-))
Wenn es rein um den Filenamen geht ist main natürlich üblich und gut.
Hallo,
einigen wir uns auf main_scpi.py? ;-)
Das 'main' sticht eben gleich ins Auge um was es sich handelt.
Ansonsten ja, die Welt ist im stetigen Wandel. Anpassungen an alten
Stellen werden sicherlich nicht ausbleiben.
Hallo,
ist zwar irgendwie blöd zu sagen, aber ich komme aktuell nicht dazu am
Thema weiterzumachen. Ich hab ehrlich gesagt derzeit andere Flausen im
Kopf die ich fertig machen möchte. Deswegen erstmal Danke für alles
Geschriebene. Man hört sich.